Содержание
- 1 Русский
- 1.1 Морфологические и синтаксические свойства
- 1.2 Произношение
- 1.3 Семантические свойства
- 1.3.1 Значение
- 1.3.2 Синонимы
- 1.3.3 Антонимы
- 1.3.4 Гиперонимы
- 1.3.5 Гипонимы
- 1.4 Родственные слова
- 1.5 Этимология
- 1.6 Фразеологизмы и устойчивые сочетания
- 1.7 Перевод
- 1.8 Библиография
Русский[править]
| В Викиданных есть лексема датасет (L103480). |
Морфологические и синтаксические свойства[править]
| падеж | ед. ч. | мн. ч. |
|---|---|---|
| Им. | датасе́т | датасе́ты |
| Р. | датасе́та | датасе́тов |
| Д. | датасе́ту | датасе́там |
| В. | датасе́т | датасе́ты |
| Тв. | датасе́том | датасе́тами |
| Пр. | датасе́те | датасе́тах |
да—та—се́т
Существительное, неодушевлённое, мужской род, 2-е склонение (тип склонения 1a по классификации А. А. Зализняка).
Корень: -датасет-.
Произношение[править]
- МФА: [dətɐˈsɛt]
Семантические свойства[править]
Значение[править]
- информ. в файловой системе мейнфреймов от ‘IBM — коллекция из логических записей, хранящихся в виде кортежа ◆ Отсутствует пример употребления (см. рекомендации).
- прогр. логически неделимый набор данных ◆ Отсутствует пример употребления (см. рекомендации).
Синонимы[править]
Антонимы[править]
Гиперонимы[править]
Гипонимы[править]
Родственные слова[править]
| Ближайшее родство | |
Этимология[править]
От англ. dataset.
Фразеологизмы и устойчивые сочетания[править]
Перевод[править]
| Список переводов | |
Библиография[править]
|
|
Для улучшения этой статьи желательно:
|
Правильно
И так далее — единственно правильное написание устойчивого выражения, все слова в нем пишутся раздельно. Часто сочетается с выражением «и тому подобное», может сокращаться как «и т.д.».
Каждый день мы встаем, работаем, спим, опять встаем, работаем, спим и так далее.
Мы были на уроках, парах, собраниях, встречах и так далее.
Сперва вперед, потом назад, опять вперед, назад и так далее.
В школе мы учили алгебру, геометрию, физику, географию и так далее.
Неправильно
И тогдалие, и такдалее, итакдалее, и такдалие
Читайте также:
Каждый глагол описывает какое-либо действие. «Рассыпется» и «рассыплется» – это разные глаголы? А если они описывают одно и то же действие, то какое написание правильное?
Как правильно
В русском языке используются оба глагола: и «рассыпется», и «рассыплется». Первый вариант привычнее, чаще употребляется, но слово «рассыплется» фонетически более грамотное.
Какими правилами объясняется написание
Рассыпется – от слова рассыпать. Пример: книга скоро рассыпется.
В литературной речи используется вариант «рассыплется». Появление буквы «л» объясняется не орфографией, а правилами фонетики. «Л» добавляется после букв «б, п, м», если окончание слова начинается на «е».
Рассыпется: окончание «ет», после буквы «п». Значит, добавляется буква «л» -рассыплется. Тот же процесс наблюдаем в словах трепать – треплет, объять -объемлет.
Примеры предложений
- К утру мелкой крупой рассыплется снег – и неожиданно придет зима.
- Если упаковать получше, то ничего не рассыпется.
Проверь себя: «Гореть» или «гареть» как пишется?
Как неправильно писать
Допустимы оба варианта написания: рассыпется и рассыплется.
( 2 оценки, среднее 5 из 5 )
датагра́мма
датагра́мма, -ы (то же, что дейтагра́мма)
Источник: Орфографический
академический ресурс «Академос» Института русского языка им. В.В. Виноградова РАН (словарная база
2020)
Делаем Карту слов лучше вместе

Привет! Меня зовут Лампобот, я компьютерная программа, которая помогает делать
Карту слов. Я отлично
умею считать, но пока плохо понимаю, как устроен ваш мир. Помоги мне разобраться!
Спасибо! Я обязательно научусь отличать широко распространённые слова от узкоспециальных.
Насколько понятно значение слова ионизационный (прилагательное):
Синонимы к слову «датаграмма»
Предложения со словом «датаграмма»
- После этого пакет данных (датаграмма) с добавленной информацией об адресе получателя и отправителя идёт по выбранному маршруту.
- (все предложения)
Значение слова «датаграмма»
-
1. комп. блок информации, передаваемый протоколом без предварительного установления соединения и создания виртуального канала (Викисловарь)
Все значения слова ДАТАГРАММА
Определение и разбор слова
Данное слово является глаголом, который употребляется в значении “прекращая движение, занимать определённое положение, а также приобретать или усиливать в себе какие-то свойства”.
Несмотря на частое употребление этого слова, при написании возникают сложности.
Давайте с этим разберёмся.
Существует два варианта правописания анализируемого слова:
- “становиться”, где перед “-ся” пишется “-ть-“,
- “становится”, где перед “-ся” пишется “-т-“.
Как правильно пишется: “становиться” или “становится”?
Согласно орфографической норме русского языка оба варианта являются правильными.
становиться
Когда пишем с мягким знаком?
Слово “становиться” пишется с мягким знаком, если в предложении оно является инфинитивом. В данном случае “становиться” отвечает на вопрос “что делать?”.
Что делать? – становиться
В вопросе есть мягкий знак, поэтому и в глаголе он присутствует.
становится
Когда пишем без мягкого знака?
Слово “становится” пишется без мягкого знака, если оно стоит в форме 3-го лица настоящего времени.
В этом случае глагол будет отвечать на вопрос “что делает?”.
Что делает? – становится
Таким образом, “становиться” – это начальная форма глагола (инфинитив), а “становится” – форма 3-го лица настоящего времени глагола “становиться”.
Примеры для закрепления
- Он становится все спокойнее и уравновешеннее.
- Я буду становиться тем, кем хочу.
- Ему становится дурно при виде крови.
Типизированный DataSet- это DataSet в котором заведомо известны все DataTable и обращаться к ним можно по имени. В свою очередь DataTable тоже известны и можно получать доступ к полям без литералов и без приведения к конкретному типу. Т.е работа становится похоже на работу с классом у которого есть поля.
Подскажите, как правильно это делается? Какие возможны подводные камни(Нет ли особенностей наполнения через DataAdapter.Fill? или десериализации)? Что лучше переопределять в своих расширенных классах?
Если такое возможно, то не помешал бы примерчик с типизированным DataSet, где имеется 2 таблицы, которые имеют отношение по какому-то полю.
Хочется что-то типа такого сделать:
https://msdn.microsoft.com/en-us/library/mt710792.aspx
Но опять же, там не пишут про подводные камни и про то, что лучше переопределить в расширенных классах.
В статье рассказывается:
- Понятие и задачи датасета
- Виды датасетов
- Характеристики датасета
- Выборка для датасета
- Лучшие датасеты для анализа и машинного обучения
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Датасет представляет собой набор данных, которые используются в различных видах анализа и машинного обучения. Причем успешность последнего напрямую зависит от объема исходной информации: чем ее больше, тем качественней будет развиваться ИИ.
Очевидно, что собирать большой объем данных вручную сложно и не всегда целесообразно. В нашей статье мы расскажем, какие бывают датасеты, как они формируются, и предложим набор из лучших вариантов в различных областях.
Понятие и задачи датасета
Обработанная и структурированная информация, представленная в табличном виде, называется Dataset. В такой таблице объектами называются строки, а признаками – столбцы. Совокупность этой информации называется размеченными данными, которые являются основой для машинного обучения.

Формат представленной информации может быть разнообразным. Например, если есть необходимость добавить в приложение голосовой поиск, то достаточно предоставить нейронной сети данные, в которых имеется живая речь. Для облегчения распознавания запросов искусственным интеллектом нужно использовать как можно больше примеров. Под примером понимается фрагмент записи речи в аудио-формате, отмеченные в ней части и их перевод.
Под любые задачи имеется определенный вид разметки данных:
- выделение 2D и 3D объектов;
- сегментация объектов;
- сортировка изображений по категориям;
- классификация текстов;
- транскрипция рукописного текста;
- анализ тональности текстов;
- распознавание сущностей в тексте;
- транскрибация речи.
Скачать файл
Разметка данных является довольно утомительным и рутинным процессом. Например, нужно сделать так, чтобы приложение могло по фотографии распознать домашних животных. Для решения этой задачи следует произвести выделение кошек на нескольких тысячах изображений. В результате этих действий сеть определяет, присутствует ли на фотографии изображение кошки или нет.
Но в случае, если на картинке запечатлены собаки, обезьянки, хомячки или любые другие животные, то искусственный интеллект никак на них не отреагирует. Это указывает на необходимость проделать еще очень большой объем работы, результатом которого станет размещение всех животных, интересующих нас.

Решение этой же задачи усложнится в несколько раз в том случае, если потребуется определить не только вид животного, но и его породу. Тогда кроме определения классификации по виду, необходимо произвести подразделение их по породам, что влечет за собой огромное количество размеченных изображений.
Виды датасетов
С научной точки зрения существует три категории датасетов:
Простая запись
Это самая простая категория, при которой не прослеживается явная связь между строками-Наблюдениями или столбцами-Признаками, при этом для каждой строки характерен одинаковый набор характеристик. Как правило, такие записи сохраняются или в файлах формата .csv, .parquet, или в реляционных базах данных.
Простые записи имеют несколько подвидов:
- Транзакционные данные
Примером могут служить покупки в магазине. Наиболее часто встречаются двоичные признаки, по которым можно узнать была ли совершена покупка какого-либо предмета или нет.
- Матрица данных
В случае, если каждый объект коллекции имеет одинаковый фиксированный набор признаков в числовом выражении, то последние допустимо рассматривать как Векторы в многомерном пространстве. Определенное количество таких записей можно рассматривать как Матрицу m х n, в которой есть m строк, для каждого объекта по одной, и n столбцов, для каждого признака по одному.
Исходя из этого напрашивается вывод, что преобразование данных и осуществление управления ими, допустимо производить с помощью стандартных матричных операций. Для большего количества статистических данных матрица является стандартным форматом.
- Матрица разреженных данных (встречается матрица данных документа)
Характеризуется тем, что в отличие от матрицы данных, имеет ассиметричные признаки, то есть важное значение придают только ненулевым значениям.
Графы
Представляют собой данные, имеющие связь между объектами. Графы структурируются, узловые компоненты имеют определенную взаимосвязь между собой.

Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Уже скачали 19860 ![]()
Упорядоченные записи
Часть данных упорядочена в пространстве или во времени. Они бывают следующими:
- Последовательными. Эти данные образованы наборами отдельных объектов – словами или буквами, не имеют временных меток, но обладают позициями в упорядоченной последовательности.
- Временной ряд. Разновидность данных последовательного типа, где любая запись представлена в виде временного ряда, т.е. серии изменений.
- Пространственными. Эти данные характеризуются наличием координат.
Характеристики датасета
Основные параметры датасетов:
- Размерность – показывает, сколько признаков имеет набор данных. Если размерность высокая, то осуществить анализ такого набора данных будет затруднительно.
- Разреженность – показатель, характеризующийся заполненностью датасета, т.е. те ячейки, которые заполнены ненулевыми значениями. Для некоторого количества наборов данных, имеющих асимметричные функции, большое число признаков показывают нулевое значение, и только не более 1 % записей встречается с ненулевым значением.
- Разрешение. Характеризуется возможностью обнаруживать какое-либо явление, при условии, что данные подробны ровно настолько, насколько это соответствует решению задачи. Пример, перемещение циклона можно отразить по часовому изменению давления, но в масштабе нескольких месяцев это явление незначительно.

Выборка для датасета
Генеральная совокупность – это первоначальный комплект исходных данных. Процесс образования выборок из генеральной совокупности является порождением данных. Конечное подмножество элементов генеральной совокупности называется выборкой.
Внимательно изучив конечное подмножество, становится понятно поведение исходного множества. В качестве примера можно привести пример, в котором генеральная совокупность сформирована из 200 тысяч посетителей сайта, но в выборке из них оказались всего 300.
Ожидаемая модель порождения данных предполагает, что выборка из генеральной совокупности генерируется случайным образом. В случае, когда все множество ее элементов одинаково случайно и независимо друг от друга распределяются по исходному множеству, то такую выборку называют простой.
Данный тип выборки представлен математической моделью серии независимых опытов, и по статистике, чаще всего применяется для обучения машинного вида. Следует иметь в виду, что на каждый этап такого образовательного процесса требуется определенный набор данных:
- Обучающая выборка необходима для непосредственного обучения модели. По ней производят настройку и оптимизацию параметров модели.
- Контрольная или тестовая выборка применяется в случае, когда требуется оценить качество модели. В идеале эта выборка должна быть независимой от обучающей.
- Валидационная или проверочная выборка используется при выборе лучшей модели для машинного обучения. Также как и предыдущая выработка, эта не должна перекликаться с обучающей.
- Интеллектуальный анализ информации, выборка, датасет, Data Peperation.
Методы, по которым формируются обучающие и оценочные выборки, зависят от класса задачи, чье решение происходит при помощи машинного обучения:
- Для определения задач классификации, весь объем данных необходимо разделить таким образом, чтобы в образованных наборах соотношение численности объектов различных классов было аналогично исходной генеральной совокупности.
- Для решения задачи при регрессивном анализе следует одинаково распределить целевую переменную в полученных наборах, которые в будущем применяются для обучения и контроля качества.

После формирования выборки приходит последовательность следующих процессов CRISP-DM: очистка данных и действия с признаками:
- генерация;
- трансформация;
- нормализация и отбрасывание лишней переменной.


Читайте также
Все эти действия направлены на исключение мультиколлинеарности факторов и понижения размерности модели машинного обучения.
Лучшие датасеты для анализа и машинного обучения
Датасеты общего назначения
Государственные датасеты:
- Data.gov. Тут находится информация от различных организаций США. Данные могут быть абсолютно разными, от государственного бюджета до отметок в школьном табеле.
- Food Environment Atlas. Включает в себя сведения влиянии многообразия факторов на критерии выбора питания в США и его качества. Из показателей следует отметить расстояние до магазина или ресторана, стоимость продуктов, производителя и другие.
- School system finances. Информация о финансовом состоянии школьной системы в США.
- Chronic disease data. Этот датасет содержит сведения о хронических заболеваниях в США.
- The US National Center for Education Statistics. Содержит данные об образовательных заведениях и демографии не только в США, но и по всей планете.
- The UK Data Service. Наиболее крупное хранилище информации социальной, экономической и демографической направленности в Великобритании.
- Data USA. Подробная визуализация данных общего доступа в США.
![]()
Точный инструмент «Колесо компетенций»
Для детального самоанализа по выбору IT-профессии
![]()
Список грубых ошибок в IT, из-за которых сразу увольняют
Об этом мало кто рассказывает, но это должен знать каждый
![]()
Мини-тест из 11 вопросов от нашего личного психолога
Вы сразу поймете, что в данный момент тормозит ваш успех
Регистрируйтесь на бесплатный интенсив, чтобы за 3 часа начать разбираться в IT лучше 90% новичков.
Только до 6 марта
Осталось 17 мест
Данные о жилье:
- Boston Housing Dataset. Здесь можно увидеть сведения о жилом фонде в Бостоне, которые собрало бюро, осуществляющее перепись населения США.
Экономика и финансы:
- Quandi. Является неплохим источником информации экономической и финансовой направленности. Используется для строительства прогнозных моделей различных данных экономики или котировок акций.
- Word Bank Open Data. Включает определенные информационные комплексы, в которых отражается демографическая ситуация, разнообразные экономические показатели и индикаторы развития по всему миру.
- IMF Data. Содержит сведения международного валютного фонда о мировых финансах, долговых критериях, резервах валют, инвестиционные рекомендации и стоимость основных сырьевых товарах.
- Financial Times Market Data. Наиболее точная информация о финансовом рынке по всему миру, в том числе индексы стоимости акций, товаров и валют.
- Google Trends. Здесь можно узнать и проанализировать сведения по активности поисковых систем в сети.
- American Economic Association. Неплохое место для поиска информации о макроэкономических показателях США.

Датасеты для машинного обучения
Компьютерное зрение:
- xView. Является самым крупным из всех наборов воздушных снимков земли общего доступа. Здесь содержатся картинки разных сцен со всех уголков нашей планеты, которые аннотированы при помощи различных ограничений.
- Labelme. Включает большое количество аннотированных картинок.
- ImageNet. Датасет, где можно найти изображения для вновь созданных алгоритмов.
- LSUN. Массив картинок, отсортированных по различным критериям.
- MS COCO. Здесь можно найти все, что потребуется для обнаружения и сегментации объектов.
- Visual Genome. Размеры датасета с подробно аннотированными изображениями являются самыми крупными.
- Google’s Open Images. Включает коллекцию из более чем 9 миллионов URL-адресов, имеющих метки и охватывающих большое количество категорий под лицензией Creative Commons.
- Labelled Faces in the Wild. Включает изображения более 10000 человеческих лиц для применения приложений, в основе которых лежит распознавание лиц.
- Stanford Dogs Dataset. Анализ датасета позволит распознать изображения из определенных пород собак.
- Indoor Scene Recognition. Один из наиболее больших датасетов в плане узнавания интерьеров. В нем содержится 67 категорий включающих 15 620 картинок.
Анализ тональности текста:
- Multidomain sentiment analysis dataset. Достаточно возрастной проект, в котором содержится информация о товарах, купленных на Amazon.
- IMDB reviews. Маленький ресурс с тематикой «отзовик к фильмам».
- Stanford Sentiment Treebank. Проект Стенфортского университета, где анализируют тональность.
- Sentiment140. Модный портал, в котором можно найти множество твитов с удалёнными смайликами.
- Twitter US Airline Sentiment. Здесь находятся данные из Twitter обо всех компаниях авиаперевозчиках США.
Обработка естественного языка:
- HotspotQA Dataset. Ресурс, в котором содержатся вопросы и ответы. С его помощью можно создать систему стандартных ответов.
- Amazon Reviews. Здесь накопилось огромное количество отзывов с одноименного ресурса за восемнадцатилетний период. В них можно найти различные сведения и статистические данные о товаре.
- Google Books Ngrams. Включает коллекцию слов из книги Google.
- Wikipedia Links data. Этот проект построен из веб-страниц, причем на каждой имеется одна ссылка на Википедию и ее якорный текст аналогичен заголовку страницы.
- Gutenberg eBooks List. Датасет с аннотированным списком электронных книг проекта «Гутенберг».
- Jeopardy. Содержит архивные данные одноименной телевизионной викторины.
- Rotten Tomatoes Reviews. Здесь находятся рецензии в количестве 480 тысяч штук с Rotten Tomatoes.
- Yelp Reviews. Сведения, содержащие около 5 млн отзывов от Yelp.
- UCI’s Spambase. Крупный датасет, в котором находятся спам-письма.

Автопилоты:
- Berkeley DeepDrive BDD100k. В настоящий момент является самым большим датасетом для автопилотов. В нем содержится множество видеозаписей вождения, при разнообразных ситуациях.
- Baidu Apolloscapes. Ресурс с функцией распознавания 26 семантически разных объектов. Это могут быть машины, велосипеды, пешеходы, здания, уличные фонари и т. д.
- Comma.ai. Здесь содержится информация об основных параметрах машины, находящейся в движении.
- Oxford’s Robotic Car. Проект включает около 100 повторения одного и того же маршрута, которые были запечатлены за один год в Оксфорде. На маршруте явно прослеживаются разные условия: трафик, погода, пешеходы, ремонт дороги и т.д.
- Cityscape Dataset. Скачав этот датасет, можно найти сто записей с уличных камер из 50 городов.
- KUL Belgium Traffic Sign Dataset. Информация, содержащая аннотации к тысячам бельгийских светофоров.
Медицинские данные:
- MIMIC-III. Датасет содержащий обезличенную информацию о состоянии здоровья около 40 тысяч больных, которые подвергаются интенсивной терапии. Он включает карту пациента, показатели жизненной активности, принимаемые лекарства, прогноз лечения и т.д.

Читайте также
В настоящее время заинтересованные участники рынка принимают участие в работе различных структур по разработке и внедрению новых регуляторных норм для создания датасетов. Планируется, что это приведет к облегчению доступа к данным, которые необходимы для обучения искусственного интеллекта, а также разработке ML-сервисов на объединенных наборах данных из разнообразных источников в режиме «песочниц».
Задача аналитика — искать закономерности, но есть данные неопределенные и неструктурированные, которые нельзя обработать инструментами анализа и с их помощью невозможно обучать нейронные сети. По этой причине специалисту требуются подготовленные данные — датасет.
Что означает датасет и как он помогает в анализе
Датасет — это структурированная информация в табличном виде, где у каждого объекта прописаны определенные свойства: характеристики, связи или конкретные места. Этот механизм применяют для построения гипотез, анализа результатов или обучения нейросети на основе данных.
Приведем пример: представьте набор карточек с рисунками разных собак. Эти карточки по отдельности — просто необработанные данные, их нельзя использовать для анализа или машинного обучения. Для того чтобы из этого набора сделать датасет, нужно прописать, какие именно собаки нарисованы на карточках и какое между ними отличие.
Из каких компонентов состоит датасет:
- объект: изображение, фотография, аудиозапись, болезнь, номер дома;
- характеристики: определенные признаки, связи между другими объектами или их место в таблице.
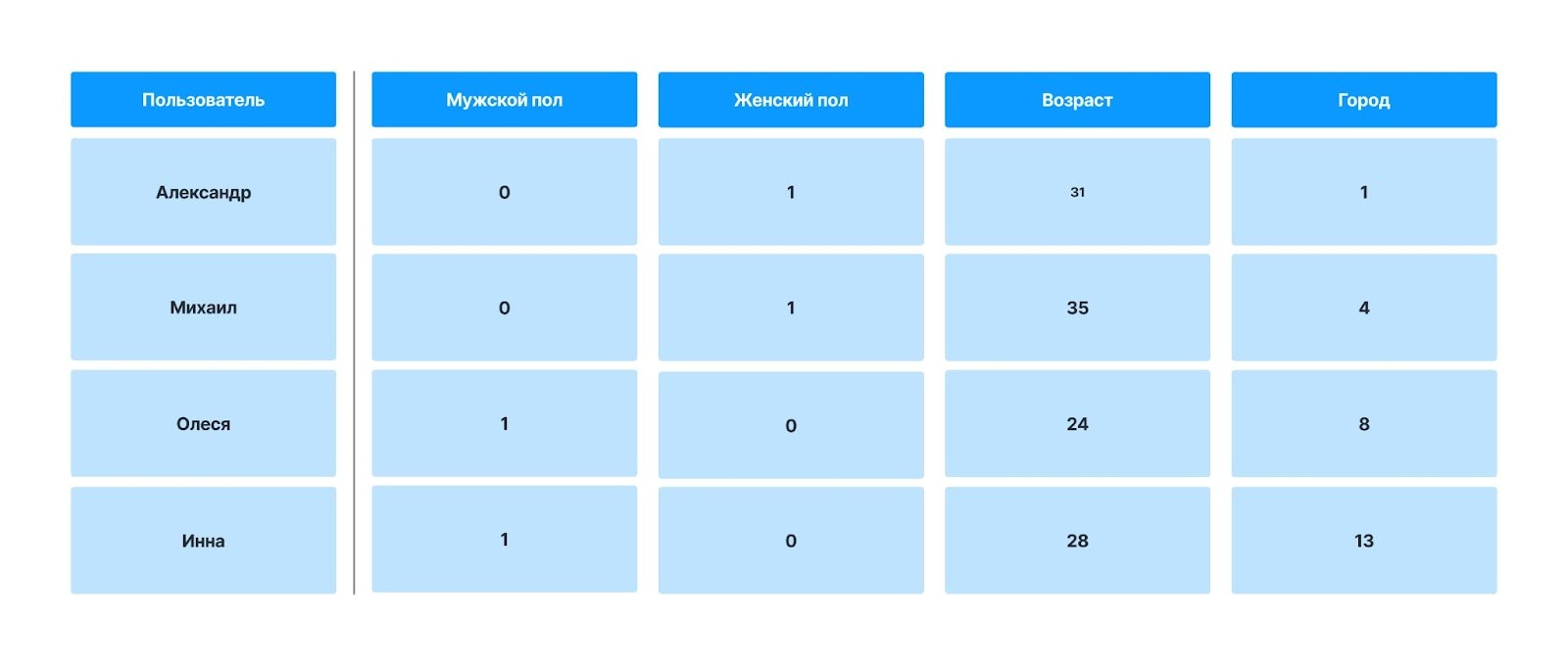
Как правило, свойства объекта описываются не фразами, а числами. Например, необходимо указать пол пользователя. Отмечать будут не привычными буквами «М» и «Ж», а обозначать каждый признак цифрами «Мужской» — 0, «Женский» — 1.
Какие виды датасетов бывают
- Простая запись
Это таблица, в строках которой размещены объекты, а в колонках — свойства. Конкретных связей между данными нет, признаки просто совпадают с определенными объектами. Обычно многие датасеты строятся именно таким образом.
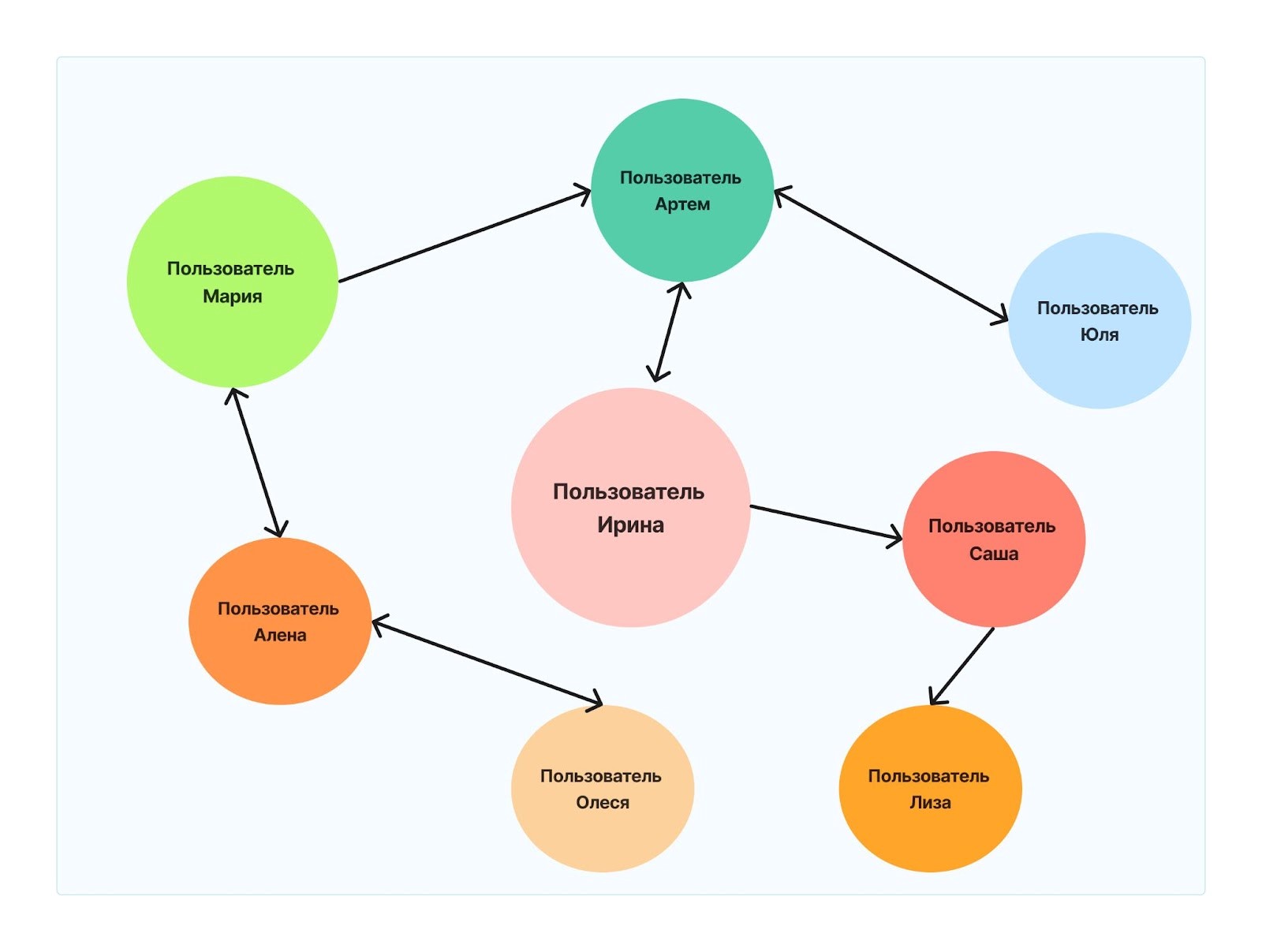
- Граф
Данные и их связи сгруппированы в виде схемы, объекты которой соединены стрелками. Граф бывает разных видов: структурированный и неструктурированный. У структурированных объекты соотносятся между собой. У неструктурированных эти связи направленные — например, один объект соотносится со вторым, а у второго с первым уже нет связи. Кроме того, у таких соотношений может быть еще и разный вес.
- Упорядоченные записи
Здесь соотношение объектов не так важно, главное — какое конкретное место объект занимает в таблице с данными.
Если вы интересуетесь AI, ML, Big Data или Data Science и хотите пройти обучение, а также поучаствовать в создании продуктов с искусственным интеллектом вместе с другими разработчиками, то вам точно нужно подать заявку в наш проекте «Цифровой прорыв. Сезон: искусственный интеллект».
Датасет – 1. Набор исследуемых данных, располагаемый на нескольких компьютерах одновременно ввиду большого объема. 2. Выборка из такого массивного объема данных, созданная с целью продемонстрировать тот или иной принцип или концепцию Машинного обучения (ML):

Датасеты – основа Науки о данных (Data Science), материал, на котором основаны все исследования. В контексте науки принято рассматривать два их типа: традиционные и Большие данные (Big Data).
Традиционные и Большие данные
Традиционные данные структурированы и хранятся в базах, управляемых с одного компьютера; это табличное представление, содержащее числовые или текстовые значения. На самом деле, эпитет «традиционный» мы вводим для ясности: это помогает подчеркнуть различия.
Большие данные, в свою очередь, массивнее, чем традиционные, как в контексте разнообразия (числа, текст, изображения, аудио, видео и проч.), так и скорости извлечения и вычисления в реальном времени, и объема (тера-, пета-, эксабайты и проч.). Большие данные обычно распределяются по компьютерной сети. Так что учебные, «игрушечные» датасеты, с помощью которых мы осваиваем модели и окололежащие особенности Машинного обучения, это метонимия (перенос наименования с одного предмета или явления на другой на основе смежности).
Виды датасетов
Наука разделяет датасеты на три категории:
Простая запись
Это самая простая форма не имеет явной связи между строками-Наблюдениями (Observation) или столбцами-Признаками (Feature), и каждая строка имеет одинаковый набор характеристик. Данные записи обычно хранятся либо в файлах (форматы .csv, .parquet), либо в реляционных базах данных:

Существует несколько подвидов простых записей:
- Транзакционные данные: например, покупки в супермаркете. Чаще всего это двоичные признаки, указывающие, был ли предмет куплен или нет:

- Матрица данных: если все объекты в коллекции имеют один и тот же фиксированный набор числовых признаков, то последние можно рассматривать как Векторы (Vector) в многомерном пространстве. Набор таких записей можно интерпретировать как Матрицу (Matrix) m × n, где имеется m строк, по одной для каждого объекта, и n столбцов, по одной для каждого признака. Следовательно, мы можем применять стандартные матричные операции для преобразования данных и управления ими. Матрица является стандартным форматом для большинства статистических данных:

- Матрица разреженных данных (иногда также матрицей данных документа): особая разновидность матрицы данных, в которой признаки одного типа и асимметричны; т.е. важны только ненулевые значения:

Графы
- Данные со связями между объектами: отношения между объектами фиксируются связями:

- Структурированные графы: узловые компоненты взаимосвязаны друг с другом определенным образом:

Упорядоченные записи
Некоторые данные упорядочены во времени или пространстве. Их можно разделить на следующие типы:
- Последовательные данные состоят из набора отдельных объектов, таких как слова или буквы. Здесь нет временных меток; вместо этого есть позиции в упорядоченной последовательности:

- Временной ряд (Time Series) – это особый тип последовательных данных, в которых каждая запись представляет собой временной ряд, то есть серию измерений, выполненных во времени:

- Пространственные данные имеют координаты:

Атрибуты датасета
Выделяют три основные характеристики датасета:
- Размерность (Dimensionality) – это количество признаков в наборе данных. Если таковых много (т.н. «высокая размерность»), тогда проанализировать такой набор данных будет сложнее. Эту проблему называют Проклятием размерности (Curse of Dimensionality).
- Разреженность (Sparsity) – черта, характеризующая заполненность датасета, т.е. доля ячеек, заполненных ненулевыми значениями. Для некоторых наборов данных с асимметричными функциями, большинство признаков имеют значения 0; во многих случаях менее 1% записей не равны нулю:

- Разрешение (Resolution) – это возможность обнаружить то или иное явление в случае, если данные подробны ровно настолько, сколько этого требует задача. Например, изменение атмосферного давления по часам отражает перемещение циклона, причем в масштабе месяцев такие явления незаметны. В статистике это называют Парадоксом Симпсона (Simpson Paradox).
Специальные методы датасетов
Для образовательных целей, как правило, достаточно игрушечных, небольших датасетов, и некоторые библиотеки подготавливают свои наборы данных для ускорения.
Встроенный метод библиотеки Pandas read_csv() позволяет преобразовать файл в Датафрейм (Dataframe), и это один из самых распространенных способов подгрузки данных в код:
df = pd.read_csv('https://www.dropbox.com/s/j04e6thkqmk02z1/LPL.csv?dl=1')Метод позволяет также указать тип разделителя (sep = ':'), кодировку (encoding = 'utf-8') и многие другие параметры загрузки.
У некоторых обширных библиотек вроде Scikit-learn также встречаются собственные методы, позволяющие быстро импортировать встроенные датасеты, прекрасно подходящие для демонстрации работы классов, функций, интерфейсов и других своих объектов.
from sklearn.datasets import load_digits
digits = load_digits()Помимо таких встроенных датасетов, данные для обучения нейросетей предоставляет еще и сайт kaggle.com.
С перечнем других встроенных наборов данных в Scikit-learn можно ознакомиться по ссылке.
Фото: @conscious_design
- data set
-
- устройство для преобразования сигналов терминала в форму, пригодную для передачи, и наоборот (компьют.)
- набор данных
набор данных
Идентифицированная совокупность физических записей, организованная одним из установленных в системе обработки данных способов и представляющая файлы или части файлов в среде хранения.
[ГОСТ 20886-85]набор данных
Множество элементов данных, объединенных в отдельное целое для решения определенной задачи.
Чаще всего набор данных представляется в виде файла, сообщения либо блока данных.
[Гипертекстовый энциклопедический словарь по информатике Э. Якубайтиса]
[http://www.morepc.ru/dict/]набор данных
НД
—
[ГОСТ Р МЭК 61850-7-2-2009]НАБОР ДАННЫХ (НД)
НД представляет собой набор ссылок на данные внутри информационной модели устройства. В НД могут быть включены как отдельные атрибуты данных (например, запись PTOC1.Str.general будет соответствовать одному логическому сигналу пуска защиты), так и логические узлы целиком (например PTOC1).
Устройства могут поддерживать различное количество наборов данных. Кроме того, устройства могут иметь фиксированные (то есть когда набор данных нельзя изменить) либо конфигурируемые наборы данных. Также возможны различные степени свободы конфигурации наборов данных: изменение данных, изменение наименования и т.п.
Использование наборов данных проиллюстрировано на рис. 3. При рассмотрении контроллера присоединения, на который заведены сигналы о положении всех разъединителей и заземлителей рассматриваемого присоединения, в устройстве должны присутствовать логические узлы, соответствующие каждому из аппаратов (в нашем случае – XSWI1…5). Примером набора данных может служить DATASET с наименованием SwitchPositions, включающий в себя элементы данных Pos каждого из указанных логических узлов. В дальнейшем составленный набор данных может использоваться, например, для сохранения событий в журнале при каждом изменении положения коммутационного аппарата (с использованием сервиса Log), отправки отчета о событии (с использованием сервиса Report) либо быстрого сообщения о событии (с использованием сервиса GOOSE).
Рис. 3. Использование наборов данных

При описании информационной модели устройства в нотации МЭК 61850-6 для размещения описаний наборов данных используется системный логический узел LLN0. Наличие логического узла LLN0 является обязательным для каждого логического устройства. При этом не в каждом логическом устройстве могут размещаться наборы данных, поэтому при проектировании и наладке коммуникаций по МЭК 61850 требуется внимательно проверять размещение наборов данных в логических устройствах. Информацию о том, в каком логическом устройстве должны размещаться наборы данных,обычно предоставляет производитель в сопроводительной документации. Подробнее информация об этом будет рассмотрена в будущих публикациях, затрагивающих язык конфигурирования SCL, описанный шестой главой стандарта.
[http://www.news.elteh.ru/arh/2012/77/04.php]
Тематики
- организация данных в сист. обраб. данных
- релейная защита
EN
- data set
- DATA-SET
- DS

Англо-русский словарь нормативно-технической терминологии.
.
2015.
Полезное
Смотреть что такое «data set» в других словарях:
-
data set — data ,set noun count COMPUTING an amount of information stored as a file on a computer … Usage of the words and phrases in modern English
-
Data set — For IBM mainframe term for a file, see Data set (IBM mainframe). A data set (or dataset) is a collection of data, usually presented in tabular form. Each column represents a particular variable. Each row corresponds to a given member of the data… … Wikipedia
-
data set — UK / US noun [countable] Word forms data set : singular data set plural data sets computing an amount of information stored as a file on a computer … English dictionary
-
Data Set — I Data Set [engl.], Datenverwaltung: Dateneinheit. II Data Set [dt. »Datenübertragungseinrichtung«], Datenübertragung: DCE … Universal-Lexikon
-
Data Set Ready — [Abk. DSR, dt. »Betriebsbereitschaft«], Bezeichnung für eine Steuerleitung der seriellen Schnittstelle, mit der die Datenübertragungseinrichtung (z. B. Modem) der Datenendeinrichtung (z. B. PC) anzeigt, dass sie betriebsbereit ist … Universal-Lexikon
-
data set — data and accompanying documentation which relate to a specific theme, e.g. catches by vessel type for a certain year, counts and measurements used in describing a fish species … Dictionary of ichthyology
-
Data set (IBM mainframe) — This article is about mainframe computer file. For a general meaning in computing field, see Data set. data set (archaic), dataset (preferred), is a computer file having a record organization. The term pertains to the IBM mainframe operating… … Wikipedia
-
data set trailer label — baigiamoji žymė statusas T sritis automatika atitikmenys: angl. data set trailer label; trailer label vok. Dateiendeetikett, n; Dateiendekennsatz, m; Nachsatz, m rus. концевая метка, f pranc. label de fin, m … Automatikos terminų žodynas
-
Data set — Ein Dataset bezeichnet eine größere, zusammenhängende Datenmenge, nicht zu verwechseln mit einem Datensatz einer Datenbanktabelle. Im Detail hat der Begriff aber je nach Kontext unterschiedliche Bedeutungen: Dataset, IBM Großrechner Hier ist… … Deutsch Wikipedia
-
data set — Computers. 1. a collection of data records for computer processing. 2. modem. [1970 75] * * * … Universalium
-
data set — 1. AT&T name for modem. 2. A collection of related data … IT glossary of terms, acronyms and abbreviations
Что Такое датасет- Значение Слова датасет
Русский
Морфологические и синтаксические свойства
| падеж | ед. ч. | мн. ч. |
|---|---|---|
| Им. | датасе́т | датасе́ты |
| Р. | датасе́та | датасе́тов |
| Д. | датасе́ту | датасе́там |
| В. | датасе́т | датасе́ты |
| Тв. | датасе́том | датасе́тами |
| Пр. | датасе́те | датасе́тах |
да—та—се́т
Существительное, неодушевлённое, мужской род, 2-е склонение (тип склонения 1a по классификации А. А. Зализняка).
Корень: -датасет-.
Произношение
- МФА: [dətɐˈsɛt]
Семантические свойства
Значение
- информ. в файловой системе мейнфреймов от ‘IBM — коллекция из логических записей, хранящихся в виде кортежа ◆ Отсутствует пример употребления (см. рекомендации).
-
Антонимы
Гиперонимы
Гипонимы
Родственные слова
Ближайшее родство Этимология
От англ. .
Фразеологизмы и устойчивые сочетания
Перевод
Список переводов Библиография