Создайте средство проверки на плагиат с помощью машинного обучения
Время на прочтение
9 мин
Количество просмотров 4.7K
Используя машинное обучение, мы можем создать нашу собственную программу проверки на плагиат, которая выполняет поиск украденного контента в огромной базе данных. В этой статье мы сделаем демонстрационное приложение для этой цели.
Плагиат широко распространен в Интернете и в процессе обучения. При большом количестве контента иногда трудно определить, когда что-то стало плагиатом.
Авторы, пишущие сообщения в блогах, могут захотеть проверить, не украл ли кто-то их работу и не разместил ли ее в другом месте. Учителя могут захотеть сравнить работы студентов с другими научными статьями на предмет скопированных работ. Новостные агентства могут захотеть проверить, не украла ли контент-ферма их новостные статьи и не презентовала ли на это содержание как на свое.
Итак, как нам защититься от плагиата? Разве не было бы хорошо, если бы у нас было программное обеспечение, которое делало бы за нас всю тяжелую работу? Используя машинное обучение, мы можем создать нашу собственную программу проверки на плагиат, которая выполняет поиск украденного контента в огромной базе данных. В этой статье мы сделаем именно это.
Мы создадим Python Flask приложение, которое использует Pinecone — службу поиска сходства — для поиска возможного плагиата.
Обзор демонстрационного приложения
Давайте посмотрим на демонстрационное приложение, которое мы создадим сегодня. Ниже вы можете увидеть краткую анимацию приложения в действии.
Пользовательский интерфейс имеет простое текстовое поле для ввода, в которое пользователь может вставить текст из статьи. Когда пользователь нажимает кнопку «Отправить», этот ввод используется для запроса в базе данных статей. Затем пользователю отображаются результаты поиска и их проценты совпадения. Чтобы уменьшить количество шума, приложение также включает ползунок, в котором пользователь может указать порог схожести, чтобы показывать только очень сильные совпадения.

Как видите, когда исходный контент используется в качестве входных данных для поиска, оценки совпадений для статей, возможно, являющихся плагиатом, относительно низкие. Однако, если бы мы скопировали и вставили текст из одной из статей в нашей базе данных, результаты для статьи с плагиатом вернутся с совпадением 99,99%!
Итак, как мы это сделали?
При создании приложения мы начинаем с набора данных новостных статей от Kaggle. Этот набор данных содержит 143 000 новостных статей из 15 крупных публикаций, но мы используем только первые 20 000. (Полный набор данных, из которого создан этот, содержит более двух миллионов статей!)
Затем мы очищаем набор данных, переименовав пару столбцов и удалив несколько ненужных. Затем мы пропускаем статьи через модель вложения для создания vector embeddings (сопоставлений векторов) — это метаданные для алгоритмов машинного обучения для определения сходства между различными входными данными.
Подробнее см. статью на Хабре: «Чудесный мир Word Embeddings: какие они бывают и зачем нужны?»
Мы используем модель Average Word Embeddings Model (модель среднего количества сопоставлений слов). Наконец, мы вставляем эти сопоставления векторов в векторную базу данных, управляемую Pinecone.
Когда векторные сопоставления добавлены в базу данных и проиндексированы, мы готовы начать поиск аналогичного контента. Когда пользователи отправляют текст своей статьи в качестве входных данных, делается запрос к конечной точке API, использующей SDK Pinecone для запроса индекса сопоставлений векторов. Конечная точка API возвращает 10 похожих статей, которые, возможно, были плагиатом, и отображает их в пользовательском интерфейсе приложения. Вот и все! Достаточно просто, правда?
Если вы хотите попробовать это сами, вы можете найти код этого приложения на GitHub. README содержит инструкции по локальному запуску приложения на вашем компьютере.
Пошаговое ревью кода демонстрационного приложения
Мы рассмотрели внутреннюю работу приложения, но как мы на самом деле его создали? Как отмечалось ранее, это Python Flask приложение, которое использует Pinecone SDK. HTML использует файл шаблона, а остальная часть интерфейса создается с использованием статических ресурсов CSS и JS. Для простоты весь внутренний код находится в файле app.py, который мы полностью воспроизвели ниже:
from dotenv import load_dotenv
from flask import Flask
from flask import render_template
from flask import request
from flask import url_for
import json
import os
import pandas as pd
import pinecone
import re
import requests
from sentence_transformers import SentenceTransformer
from statistics import mean
import swifter
app = Flask(__name__)
PINECONE_INDEX_NAME = "plagiarism-checker"
DATA_FILE = "articles.csv"
NROWS = 20000
def initialize_pinecone():
load_dotenv()
PINECONE_API_KEY = os.environ["PINECONE_API_KEY"]
pinecone.init(api_key=PINECONE_API_KEY)
def delete_existing_pinecone_index():
if PINECONE_INDEX_NAME in pinecone.list_indexes():
pinecone.delete_index(PINECONE_INDEX_NAME)
def create_pinecone_index():
pinecone.create_index(name=PINECONE_INDEX_NAME, metric="cosine", shards=1)
pinecone_index = pinecone.Index(name=PINECONE_INDEX_NAME)
return pinecone_index
def create_model():
model = SentenceTransformer('average_word_embeddings_komninos')
return model
def prepare_data(data):
# rename id column and remove unnecessary columns
data.rename(columns={"Unnamed: 0": "article_id"}, inplace = True)
data.drop(columns=['date'], inplace = True)
# combine the article title and content into a single field
data['content'] = data['content'].fillna('')
data['content'] = data.content.swifter.apply(lambda x: ' '.join(re.split(r'(?<=[.:;])s', x)))
data['title_and_content'] = data['title'] + ' ' + data['content']
# create a vector embedding based on title and article content
encoded_articles = model.encode(data['title_and_content'], show_progress_bar=True)
data['article_vector'] = pd.Series(encoded_articles.tolist())
return data
def upload_items(data):
items_to_upload = [(row.id, row.article_vector) for i, row in data.iterrows()]
pinecone_index.upsert(items=items_to_upload)
def process_file(filename):
data = pd.read_csv(filename, nrows=NROWS)
data = prepare_data(data)
upload_items(data)
pinecone_index.info()
return data
def map_titles(data):
return dict(zip(uploaded_data.id, uploaded_data.title))
def map_publications(data):
return dict(zip(uploaded_data.id, uploaded_data.publication))
def query_pinecone(originalContent):
query_content = str(originalContent)
query_vectors = [model.encode(query_content)]
query_results = pinecone_index.query(queries=query_vectors, top_k=10)
res = query_results[0]
results_list = []
for idx, _id in enumerate(res.ids):
results_list.append({
"id": _id,
"title": titles_mapped[int(_id)],
"publication": publications_mapped[int(_id)],
"score": res.scores[idx],
})
return json.dumps(results_list)
initialize_pinecone()
delete_existing_pinecone_index()
pinecone_index = create_pinecone_index()
model = create_model()
uploaded_data = process_file(filename=DATA_FILE)
titles_mapped = map_titles(uploaded_data)
publications_mapped = map_publications(uploaded_data)
@app.route("/")
def index():
return render_template("index.html")
@app.route("/api/search", methods=["POST", "GET"])
def search():
if request.method == "POST":
return query_pinecone(request.form.get("originalContent", ""))
if request.method == "GET":
return query_pinecone(request.args.get("originalContent", ""))
return "Only GET and POST methods are allowed for this endpoint"Давайте пройдемся по важным частям файла app.py, чтобы понять его.
В строках 1–14 мы импортируем зависимости нашего приложения. Наше приложение использует следующее зависимости:
-
dotenvдля чтения переменных среды из файла .env -
flaskдля настройки веб-приложения -
jsonдля работы с JSON -
osтакже для получения переменных среды -
pandasдля работы с набором данных -
pineconeдля работы с Pinecone SDK -
reдля работы с регулярными выражениями (RegEx) -
requestsдля выполнения запросов API для загрузки нашего набора данных -
statisticsдля некоторых удобных методов статистики -
sentence_transformersдля нашей модели встраивания -
swifterдля работы с фреймом данных pandas
В строке 16 мы предоставляем шаблонный код, чтобы сообщить Flask имя нашего приложения.
В строках 18-20 мы определяем некоторые константы, которые будут использоваться в приложении. К ним относятся имя нашего индекса Pinecone, имя файла набора данных и количество строк для чтения из файла CSV.
В строках 22-25, метод initialize_pinecone получает наш ключ API из файла .env и использует его для инициализации Pinecone.
В строках 27-29, наш метод delete_existing_pinecone_indexищет в нашем экземпляре Pinecone индексы с тем же именем, что и тот, который мы используем («проверка на плагиат»). Если найден существующий индекс, мы его удаляем.
В строках 31-35, наш метод create_pinecone_index создает новый индекс, используя выбранное нами имя («проверка на плагиат»), метрику близости «косинус» и только одну shard.
В строках 37-40, наш метод create_model использует библиотеку offer_transformers для работы с моделью среднего количества сопоставлений слов. Позже мы закодируем наши сопоставлений векторов, используя эту модель.
В строках 62-68, наш метод process_file считывает CSV файл и затем вызывает методы prepare_data и upload_items. Эти два метода описаны ниже.
В строках 42-56 наш метод prepare_data корректирует набор данных, переименовывая первый столбец «id» и удаляя столбец «date». Затем он объединяет заголовок статьи с содержанием статьи в одно поле. Мы будем использовать это комбинированное поле при создании сопоставлений векторов.
В строках 58-60 наш upload_itemsметод создает сопоставление векторов для каждой статьи, кодируя его с помощью нашей модели. Затем мы вставляем сопоставления векторов в индекс Pinecone.
В строках 70-74, наши методы map_titlesи map_publications создают некоторые словари названий и имен публикаций, чтобы позже легче найти статьи по их идентификаторам.
Каждый из описанных методов вызывается в строках 95-101 при запуске серверной части приложения. Ее работа подготавливает нас к последнему этапу фактического запроса индекса Pinecone на основе пользовательского ввода.
В строках 103–113 мы определяем два маршрута для нашего приложения: один для домашней страницы и один для конечной точки API. Домашняя страница обслуживает файл шаблона index.html вместе с активами JS и CSS, а конечная точка API предоставляет функции поиска для запроса индекса Pinecone.
Наконец, в строках 76-93 наш метод query_pinecone принимает вводимое пользователем содержимое статьи, преобразует его в сопоставления векторов, а затем запрашивает индекс Pinecone, чтобы найти похожие статьи. Этот метод вызывается при переходе на конечную точку /api/search, что происходит каждый раз, когда пользователь отправляет новый поисковый запрос.
Для визуализации процесса, вот схема, показывающая, как работает приложение:

Примеры сценариев
Итак, суммируя сказанное, как выглядит пользовательский сценарий? Давайте рассмотрим три сценария: оригинальный контент, точная копия плагиата и контент с «исправлением написанного».
Когда отправляется оригинальный контент, приложение отвечает некоторыми, возможно, связанными статьями, но оценки соответствия довольно низкие. Это хороший знак, поскольку контент не является плагиатом, поэтому мы ожидаем низких оценок соответствия.
Когда отправляется точная копия плагиата, приложение выдает почти идеальную оценку совпадения для одной статьи. Это потому, что контент идентичен. Хорошая проверка на плагиат!
Теперь, для третьего сценария, мы должны определить, что мы подразумеваем под «исправлением написанного». Исправление написанного — это форма плагиата, при которой кто-то копирует и вставляет украденный контент, но затем пытается замаскировать факт плагиата, изменяя некоторые слова здесь и там. Если в предложении из исходной статьи говорится: «Он был вне себя от радости найдя свою потерянную собаку», кто-то может написать исправление, чтобы вместо этого сказать: «Он был счастлив вернуть свою пропавшую собаку». Это несколько отличается от перефразирования, потому что основная структура предложения содержания часто остается неизменной на протяжении всей статьи, подвергшейся плагиату.
Вот что самое интересное: наша программа проверки на плагиат действительно хорошо распознает контент с «исправлением написанного»! Если вы скопируете и вставите одну из статей в базе данных, а затем измените несколько слов здесь и там, и, возможно, даже удалите несколько предложений или абзацев, оценка совпадения все равно вернется как почти идеальное совпадение! Когда я попытался сделать это со скопированной и вставленной статьей, у которой была оценка совпадения 99,99%, содержание «записанного исправления» по-прежнему давало оценку совпадения 99,88% после моих изменений!
Не слишком испорчена оценка! Похоже, наша программа проверки на плагиат работает нормально.
Заключение и следующие шаги
Мы создали простое приложение Python для решения реальной проблемы. Подражание может быть высшей формой лести, но никому не нравится, когда его работы крадут. В мире растущего контента подобная программа для проверки плагиата будет очень полезна как авторам, так и учителям.
У этого демонстрационного приложения есть некоторые ограничения, так как это всего лишь демонстрация. База данных статей, загруженных в наш индекс, содержит всего 20 000 статей из 15 крупных новостных изданий. Однако существуют миллионы или даже миллиарды статей и сообщений в блогах. Подобная программа проверки на плагиат полезна только в том случае, если она проверяет ваш ввод на предмет всех мест, где ваша работа могла быть плагиатом. Это приложение было бы лучше, если бы в нашем индексе было больше статей и если бы мы постоянно добавляли в него.
Тем не менее, на данный момент мы продемонстрировали важное подтверждение концепции. Pinecone, как сервис поиска сходства, сделала за нас тяжелую работу, когда дело дошло до аспекта машинного обучения. С его помощью мы смогли создать полезное приложение, которое довольно легко использует обработку естественного языка и семантический поиск, и теперь мы можем быть спокойны, зная, что наша работа не является плагиатом.
Работая при университете, недавно столкнулся с интересной задачей, связанной с поиском академического плагиата во внутренней системе контестов по программированию, ставшей основой для преподавания основ алгоритмики студентам первого курса. Позже, начав поиск русскоязычных материалов, я был очень расстроен отсутствием каких-либо обобщающих статей на эту тему, поэтому незамедлительно решил восполнить этот пробел и рассказать о своем опыте создания модуля антиплагиата.
Введение
Академический плагиат — это очень распространенное явление, особенно если дать студентам много свободы в создании своих программ. По некоторым источникам, больше половины студентов технических специальностей хотя бы раз нечестно сдавали задания по программированию. Разумеется, с такой проблемой столкнулся и мой институт. Преподаватели и их ассистенты для большей части решений, прошедших проверку в системе автоматического тестирования, вынуждены открывать последние сданные исходники других студентов в рамках этой же задачи с целью выявить потенциальное наличие в них плагиата. Когда на потоке мало студентов и преподаватель условно знает «кто с кем дружит», то эта проверка не занимает длительного времени, но если на первый курс приходит более сотни студентов, то данную проблему быстро решить уже не получится. К счастью, этот процесс можно автоматизировать.
Начнём с того, что уже существует великое множество открытых и проприетарных решений, так или иначе решающих данную задачу: из опенсурсных популярны, например, MOSS и JPlag. Однако ни одно из них не удовлетворяет нашим требованиям: одни из них работают с лимитированным количеством языков программирования, другие сканируют половину интернета на наличие похожестей частей кода и прочее. Вот же краткий список требований к модулю, составленный нашей командой разработки:
-
Поддержка языков программирования платформы для контестов (C++, Python, Java, C# и Pascal);
-
Скоринг решений учеников, прошедших автоматическую проверку, в рамках одной задачи (то есть должна быть реализована push- или pull-модель взаимодействия с платформой);
-
Выдача преподавателю списка решений, наиболее похожих на целевое, для дальнейшего вынесения собственного вердикта о наличии списывания.
Как можно заметить, система просто должна автоматически выполнять ту работу, которую на данный момент вручную проделывает преподаватель. Остаётся лишь главный вопрос: как будет проходить непосредственно сам скоринг решений? И это уже детали реализации, которые мы сейчас разберем.
Типы заимствований исходного кода
Для начала стоит определиться, а что вообще считается академическим плагиатом? Существует прекрасная монография под названием A Survey on Software Clone Detection Research*, написанная ещё в 2007 году, и в дальнейшем повествовании я буду практически полностью опираться на неё, потому что она покрывает все необходимые нам темы. В ней описывается 4 основных типа заимствования исходного кода:
-
Программный код скопирован без каких-либо изменений (иными словами, идентичен оригиналу с точностью до комментариев);
-
Код скопирован с «косметическими» заменами идентификаторов (имен функций и переменных, типов данных, строковых литералов);
-
Код может включать заимствования второго типа, а также модификации скопированного оригинала путем добавления, редактирования или удаления его фрагментов или изменение порядка их исполнения, не влияющие на логику самой программы;
-
Программа некоторым образом переписана с общим сохранением логики работы и функциональности, однако синтаксически она может абсолютно отличаться от оригинала.
Качественная система антиплагиата должна хорошо определять первые три типа плагиата из классификации выше. Заимствования четвертого типа крайне затруднительны для выявления (см. статью) и часто представляют собой копирование самого алгоритма, а не частей кода оригинальной программы, что не является плагиатом как таковым.
Другой проблемой является то, что любой алгоритм антиплагиата будет давать ложноположительный результат на коротких и простых задачах (например, алгоритм Евклида или сортировка пузырьком), ведь если студент в здравом уме, то он явно не напишет что-то оригинальное и отличное от других решений. С этим недоразумением можно справиться несколькими способами: либо не запускать алгоритм на коротких задачах в принципе, либо использовать какой-то алгоритм «с пенальти» на короткие программы, либо вообще не решать данную проблему: преподаватель сам понимает, что задача простая, поэтому, вероятнее всего, сразу проставит ей нужную оценку.
Методы сравнения исходных кодов
В литературе встречается множество способов сравнения программ. Вот пять наиболее универсальных и распространенных подходов, которые в дальнейшем были успешно применены в нашей системе:
-
Text-based метод заключается в сравнении текстовых представлений программ на основе некоторой метрики, например, расстояния Левенштейна или Джаро-Виклера. Данный способ отличается своей скоростью и простотой, но результативность быстро снижается даже на простейших «косметических» модификациях.
-
Token-based метод основан на преобразовании ключевых слов программы в последовательность лексем языка программирования (далее просто токенов). Полученные токены сравниваются любым доступным способом. Этот алгоритм гораздо точнее предыдущего, так как игнорирует все изменения второго типа, однако он всё ещё не справляется со структурными изменениями.
-
Metric-based метод определяет на полученных в предыдущем методе токенах некоторые метрики (например, кол-во используемых циклов и условных конструкций), а далее считает схожесть программ на основе количества совпадающих метрик. В целом, алгоритм отлично дополняет другие методы антиплагиата, однако он часто даёт ошибочный результат (в частности, метод успешно отрабатывает на программах с переименованием переменных и изменением условий и циклов, но моментально деградирует при добавлении в код NO-OPов по типу объявления пустого цикла или инициализации неиспользуемых значений).
-
Tree-based подход требует представления кода в виде абстрактного синтаксического дерева (далее просто AST, Abstract Syntax Tree). В таком формате программы сравниваются любым доступным способом: от «наивного» подсчёта совпадающих узлов до продвинутых методов на основе расстояния Zhang-Shasha. Часто данный способ считается наиболее эффективным, но в то же время его сложнее внедрить: помимо построения самих AST, нужна реализация алгоритма для их сравнения.
-
Binary-based метод требует прохождения кодом этапа компиляции (или интерпретации). Полученное бинарное представление (ассемблерный листинг или байткод) служит основой для дальнейшего сравнения программ. Помимо высокой точности на заимствованиях 1-2 типа (мелкие структурные изменения часто оптимизируются компилятором, а разные реализации одного функционала, дают одинаковый ассемблерный листинг), алгоритм может дать неплохой результат на модификациях третьего типа, но в то же время может и легко ломаться. Было выявлено, что банальное изменение типов данные может уронить коэф. схожести на несколько десятков процентов.
Конечно же, это не все существующие алгоритмы. Есть множественные модификации каждого из методов, так или иначе повышающие эффективность скоринга (в этом плане может быть интересен метод Шинглов), а также совершенно другие подходы, которые могут основываться, например, на поведении программы во время исполнения (behavior-based метод) ини на графе её зависимостей (PDG-based метод). Кстати, упомянутая выше монография наполнена сравнительными таблицами как самих методов, так и их модификаций, что очень интересно для изучения.
В дополнении приведу ещё один интересный подход: если вы знаете специфику действий своего пользователя (например, с каким среднем промежутком времени сдаются задачи на платформе или сколько попыток нужно потратить для успешной сдачи), то сможете выделить ряд метрик, на основе которых можно будет определять подозрительность поведения конкретного пользователя. Например, если студент сдаёт к ряду несколько задач и они проходят все тесты, то это отличный триггер на жульничество с его стороны. К сожалению, такой подход не является универсальным, а результат зависит от выделенных для использования метрик.
Очевидно, что каждый из рассмотренных выше методов имеет свои преимущества и недостатки и некоторые из них могут быть эффективнее на определенных модификациях условного кода. Так что же мешает нам использовать лучшие стороны каждого из них? Алгоритм антиплагиата на основе нескольких подходов называется гибридным, и данный подход действительно значительнее устойчивее каждого из методов по отдельности. Для вынесения итогового вердикта можно использовать либо максимальный, либо средний скоринг для каждого из примененных алгоритмов. Второй вариант как раз таки и был применен в нашей дальнейшей реализации модуля антиплагиата.
Разработка алгоритма антиплагиата
Гибридный алгоритм антиплагита может быть реализован следующими простыми шагами:
-
Форматирование и нормализация (в т.ч. удаление комментариев) исходного кода для повышения точности текстовых сравнений;
-
Получение промежуточных представлений программы, а именно её токенов, AST и ассемблерного листинга;
-
Непосредственно сравнение полученных форматов вышеперечисленными методами;
-
Вынесение вердикта на основе полученных коэффициентов схожести;
-
(Опционально) Вычисление дополнительных полезных статистик, например, дисперсии и квантилей распределения этих коэффициентов для всей выборки решений.
С первым шагом особых проблем не возникает: нормализация может быть выполнена средствами языка программирования (в т.ч. регулярными выражениями), а для форматирования можно использовать сторонний инструмент (обратите внимание на clang-format), однако данный шаг опционален. Но вот с получением промежуточных представлений программы, а именно списка лексем и AST, могут возникнуть проблемы. Конечно, никто не мешает вам написать собственный лексер и парсер для каждой необходимой вам грамматики (так, например, сделали разработчики JPlag), но если у вас сжатые сроки и ленивые руки, то есть одно менее элегантное, но эффективное решение: использование парсера с открытым исходным кодом ANTLR.
ANTLR отлично зарекомендовал себя среди разработчиков различных грамматик и утилит для работы с ними, а сообщество уже добавило поддержку более двух сотен популярных языков программирования. Данный парсер сможет без проблем превратить вашу программу в список токенов, а также построить (и визуализировать!) абстрактное синтаксическое дерево на их основе. Небольшой платой за готовый синтаксический разбор будет долгое обращение к самой утилите (занимает порядка секунды для небольшой программы).
Итак, мы имеем все промежуточные представления на руках: ассемблерный листинг (или байткод) нам выдал компилятор/интерператор, токены и AST мы получили из ANTLR, а текстовое представление мы имеем по умолчанию. Исходники мы даже немного улучшили посредством нормализации, нечто подобное желательно сделать и с бинарным представлением, а именно удалить offsetы пямяти, оставив только исполняемые инструкции (тут достаточно задействовать утилиту grep).
Дальше нас ждет третий шаг, а именно скоринг полученных представлений. Со сравнением текстов и бинарного формата проблем не выходит: мы берем любую доступную метрику и сравниваем два набора символов. По моим наблюдениям, лучше всего показала себя комбинация расстояния Дамерау-Левенштейша и LCS. Со скорингом AST возникают некоторые трудности: если нужно это сделать эффективно, то в любом случае придётся считать редакторское расстояние для деревьев (кстати, есть одна каноническая реализация алгоритма на питоне), а если мы хотим сделать это быстро, то сойдёт и наивная стратегия, основывающаяся либо на прохождении по ветвям дерева до первого несовпадения элементов, либо на подсчете отношения количества совпавших узлов ко всем узлам (данная стратегия и легла в основу нашей реализации).
Полученный результат скоринга со всех методов, лежащий в промежутке от 0 до 1, фактически показывает, насколько два решения похожи друг на друга по некоторой метрике. Это можно усреднить и делать предположение по полученному значению: если коэффициент схожести программ выше 95%, то они практически идентичны. Дополнительные статистики, подсчитанные по выборке сданных на задачу решений, могут быть тоже очень полезны. К примеру, медианное значение схожести близкое к максимальному и низкая дисперсия говорят о простоте задачи — в этом случае можно уверенно давать отрицательный вердикт на наличие в решении заимствований.
Полученные результаты
Для тестирования полученного гибридного алгоритма была использована небольшая синтетическая выборка, включающая некоторые модификации программ на языках Java и C++ (~750 символов) для всех четырех типов заимствований. И вот как показали себя примененные методы по отдельности (коэф. схожести усреднен и округлен):
|
Модификация / процент схожести программ |
Text-based |
Token-based |
Metric-based |
Tree-based |
Binary-based |
|
Изменение комментариев (тип 1) |
100% |
100% |
100% |
100% |
99% |
|
Реформатирование кода (тип 2) |
97% |
97% |
92% |
93% |
100% |
|
Добавление неиспользуемых зависимостей (тип 2) |
89% |
92% |
85% |
91% |
99% |
|
Переименование идентификаторов (тип 2) |
85% |
100% |
100% |
96% |
98% |
|
Изменение типов данных (тип 2-3) |
97% |
99% |
100% |
98% |
85% |
|
Изменение порядка исполнения кода (тип 3) |
78% |
86% |
95% |
91% |
81% |
|
Выделение частей кода в функции (тип 3-4) |
65% |
74% |
72% |
51% |
67% |
В прошлой таблице важны не цифры, а сама динамика поведения различных методов. По результатам итогового тестирования, алгоритм в среднем выдавал следующие проценты схожести программ с заимствованиями различных типов (в зависимости от силы изменений):
-
Заимствования типа 1: 99-100%
-
Заимствования типа 2: 94-98%
-
Заимствования типа 3: 87-96%
-
Заимствования типа 4: 65-82%
Кэширование промежуточных представлений
Основным узким местом стало получение промежуточных форматов данных: обращение к ANTLR для каждой программы занимало примерно секунду, в то время как алгоритмическая часть работала почти моментально. Решением проблемы стало использование кэширования представлений посредством общеизвестного Redis, позволившее получать результат антиплагиата примерно за 1-2 секунды для выборки из 50 решений с «прогретым» кэшем. Это примерно соответствует среднему количеству решений для задачи на нашей платформе в пределах одной группы студентов.
Существующая проблема «холодного старта» решается использованием очередей и брокера сообщений, например, RabbitMQ: в рамках контестов можно спокойно дать алгоритму возможность поработать пару минут на первых решениях, чтобы затем доставать нужные представления из кэша на последующих программах. Скорость в нашем случае не имеет значение, ведь сданная задача может быть проверена как через пару минут, так и к концу месяца: всё зависит от загрузки преподавателя.
Заключение
Гибридная методика поиска академического плагиата показывает неплохие результаты для детектирования многочисленных кодовых модификаций и довольно устойчива ко многим маскирующим преобразованиям.
Стоит отметить огромный потенциал использования ANTLR: он предоставляет все необходимые промежуточные представления программ, для сравнения которых можно внедрить любую желаемую стратегию, а также позволяет без труда можно добавить поддержку многих языков программирования (спасибо за то большому комьюнити). Важно заметить, что использование кэширования обращений к ANTLR может ускорить процессинг исходников в десятки раз!
Цель данной статьи: дать небольшой обзор популярных методик, а также поделиться своим опытом внедрения модуля антиплагиата. Искренне надеюсь, что я этого достиг. Не вижу смысла оставлять здесь большой список литературы: всем заинтересованным в данном направлении я настоятельно советую обратиться к упомянутой выше монографии, а прочие источники я добавил в местах использования.
На текущий момент система антиплагиата на стадии интеграции с университетской платформой. Если после успешного внедрения появятся интересные результаты, то я обязательно ими поделюсь, а пока предлагаю вам поделиться в комментариях своими мыслями и наработками в данной области, если таковые имеются, а также задать интересующие вопросы. Мне очень интересно узнать ваше мнение и помочь вам в создании проектов смежной тематики.
Практики «Антиплагиат» и «Diff Tool»
Репозиторий содержит решения этой и этой задачи с ulearn.me.
Задачи прошли код-ревью у преподавателя (баллы: 50/50, 100/100). Все решения курса на максимальный балл также выложены в других репозиториях.
Ветка unsolved содержит изначальный проект.
Конечное приложение — приложение для сравнения схожести документов. Как и серии предыдущих примеров, демонстрируется реализация алгоритмов.
Практика «Антиплагиат»
ИТ-компания К. приглашает студентов на летнюю стажировку. Чтобы попасть на стажировку, претенденты решают тестовое задание — задачу на программирование вроде тех, что есть в этом курсе, только сложнее.
Из года в год претенденты присылают несколько сотен решений. Можно ли как-то автоматически найти среди них «списанные» решения, то есть такие, которые слишком сильно похожи друг на друга?
Оказывается расстояние Левенштейна можно использовать для того, чтобы сравнивать листинги программ (или вообще любые документы) друг с другом и находить самые похожие пары. Этим вам и предстоит заняться в данной задаче.
В этой задаче вам необходимо реализовать класс LevenshteinCalculator, который получает на вход список документов и возвращает список попарных сравнений каждого документа с каждым другим.
Мы хотим, чтобы разница в пробелах, пустых строках или небольшом переименовании переменных не сбивала наш алгоритм. Поэтому вам нужно реализовать модифицированный алгоритм Левенштейна:
-
Он должен анализировать не последовательности символов, а последовательности токенов — лексических единиц. Например, в коде
force = mass * acceleration5 токенов:force,=,mass,*,acceleration. Код разбиения на токены уже реализован и на вход вашему алгоритму поступает список токенов. Один документ представляется типомDocumentTokens(который объявлен, как синонимList<string>). -
Если два токена различаются, то будем учитывать ещё степень различия. Стоимость замены одного токена на другой в алгоритме Левенштейна будем вычислять с помощью формулы коэффициента Жаккара. Она тоже реализована за вас в методе
GetTokenDistanceклассаTokenDistanceCalculator. Стоимость удаления/добавления токена равна единице, как и в оригинальном алгоритме.
Корректность работы проверяйте с помощью имеющихся в проекте модульных тестов.
Практика «Diff Tool»
Алгоритм из предыдущей задачи находит похожие пары документов. В этой задаче вам предстоит проанализировать два документа и найти в них повторяющиеся части. Подобную задачу решают так называемые Diff Tools — инструменты для сравнения текстовых файлов.
Для этого вам нужен алгоритм, который будет по двум последовательностям токенов возвращать их наибольшую общую подпоследовательность. Она должна состоять из токенов первой последовательности, которые в том же порядке присутствуют и во второй последовательности (токены не обязательно должны идти подряд). И из всех таких последовательностей вернуть нужно самую длинную. Если самых длинных несколько, можно вернуть любую.
Например, у документов a1 b2 ab1 b21 b2 и b2 b2 a1 (токены разделены пробелом) наибольшая общая подпоследовательность — это b2 b2 и имеет длину 2 токена.
Реализуйте это в методе Calculate в классе LongestCommonSubsequenceCalculator и отладьте реализацию на тестах LongestCommonSubsequenceCalculator_Tests. Как и в прошлой задаче документы приходят в ваш метод уже разбитые на токены, вам этого делать не нужно.
Подсказки по алгоритму
Поиск длины наибольшей общей подпоследовательности — ещё одна классическая задача динамического программирования. Она решается, как и расстояние Левенштейна, с помощью построчного заполнения двумерного массива, назовём его opt, с таким инвариантом:
opt[i1, i2] — это длина наибольшей общей подпоследовательности префикса первого документа длины i1 и префикса второго документа длины i2.
В частности opt[0, 0] = 0 (оба префикса пустые). А opt[first.Length, second.Length] — это длина искомой подпоследовательности для документов first и second. Начните с того, что напишите формулу для расчёта значения очередной ячейки opt[i1, i2] через уже известные ячейки opt.
Саму подпоследовательность можно найти по заполненной матрице, начав с opt[first.Length, second.Length].
Запуск проекта
В папке SuspiciousSources лежат документы, которые нужно проверить на плагиат. После того, как вы отладите ваше решение на тестах, запустите проект на исполнение. На консоль выведется расстояние Левенштейна между каждой парой документов, а в директории с exe-файлом появится html-файл с отчётом, где у двух решений будет выделена общая часть. Откройте этот отчёт в браузере и изучите результат!
Обсуждение скорости работы алгоритмов
Оба алгоритма из этой серии задач имеют квадратичную сложность относительно размера документа. Кроме того, для сравнение каждого документа с каждым — тоже квадратичная операция относительно количества документов. Из-за этого, как вы могли заметить, поиск похожих пар документов работает не особенно быстро. А значит для анализа тысяч решений, размером в килобайт, нужно искать другой более быстрый алгоритм.
Программа антиплагиат
29.01.2017, 20:16. Показов 7020. Ответов 2

Здравствуйте,сразу к делу.Задача написать программу антиплагиат на С++. суть антиплагиата, в базу данных вбиваются программы(допустим лабораторные работы какой-то группы 25 работ) и нужно найти идентичные работы.Сижу без идей как это реализовать(форму уже сделал все сделал осталось только сам алгоритм антиплагиата написать)
__________________
Помощь в написании контрольных, курсовых и дипломных работ, диссертаций здесь
0
Чтобы быть во всеоружии, недостаточно только читать наш телеграм-канал. Хотя информация там действительно полезная и поможет написать любую работу без труда. А если хотите экономить, заходите в группу.
Но что делать, если хочется не писать, а просто взять откуда-то готовую информацию и выдать ее за свою?
Сегодня каждый преподаватель использует интернет для поиска «злостных нарушителей» – тех, кто выполнял задание (реферат, контрольную, курсовую) не самостоятельно, а скачивал его из интернета. Чаще всего для повышения оригинальности текста используют программу «Антиплагиат вуз».
Что такое антиплагиат? Это краткий отчет, который позволяет быстро определить подлинность и покажет кусок заимствованного текста.
У многих вузов своя база учебных работ или они пользуются расширенной версией программы. Все это усложняет процесс подготовки работы.
Как же студенты пишут курсовые, дипломные, диссертации, если эти труды обычно на 70% состоят из заимствований (терминов, цитат, теорем, формул и т.д.)?
Давайте начистоту: если писать работу полностью самостоятельно, то и процент уникальности будет высоким. Но такой труд отнимает много времени и сил, поэтому студенты идут на хитрость и «копипастят».
Перечисленные ниже методы повышения уникальности текста лучше не использовать! Мы лишь приводим примеры, как с этой задачей справляются другие. Вам же настоятельно рекомендуем вручную перерабатывать всю информацию.
Актуальность и уникальность работы: как обойти антиплагиат?
Чем более популярна тема, тем сложнее написать уникальную работу. Большинство трудов состоит из уже написанного ранее: цитат, терминов, формул и т.д. Студент добавляет лишь собственную точку зрения и выводы, к которым пришел в ходе выполнения.

Можно выбрать современную и актуальную тематику работы. Но в таком случае часто непонятно, где брать качественную информацию для курсовой или реферата. Да и преподаватели не всегда успевают за стремительно развивающимся миром и не могут проверить правильность расчетов и результатов.
Со старыми и стандартными темами все как-то спокойнее. Найти нужный материал гораздо легче, но дотянуть его уникальность будет сложнее.
Есть еще одна причина, которая может превратить работу с антиплагиатом в настоящий кошмар: неадекватные или очень строгие требования преподавателя. Если при написании курсовой или диплома обычно хватает 70-80% уникальности текста, то иногда особо требовательные преподаватели могут повысить планку до 90%.
Но как тогда написать реферат или курсовую без плагиата? Мы провели тщательное расследование и спешим поделиться с вами своими результатами, как с этим справляются другие.
6 стадий уникализации текста
Перед тем как изучить эффективные способы антиплагиата и повысить оригинальность реферата или любой другой работы, предстоит выполнить простой алгоритм действий, чтобы избежать коварных ловушек преподавателя:
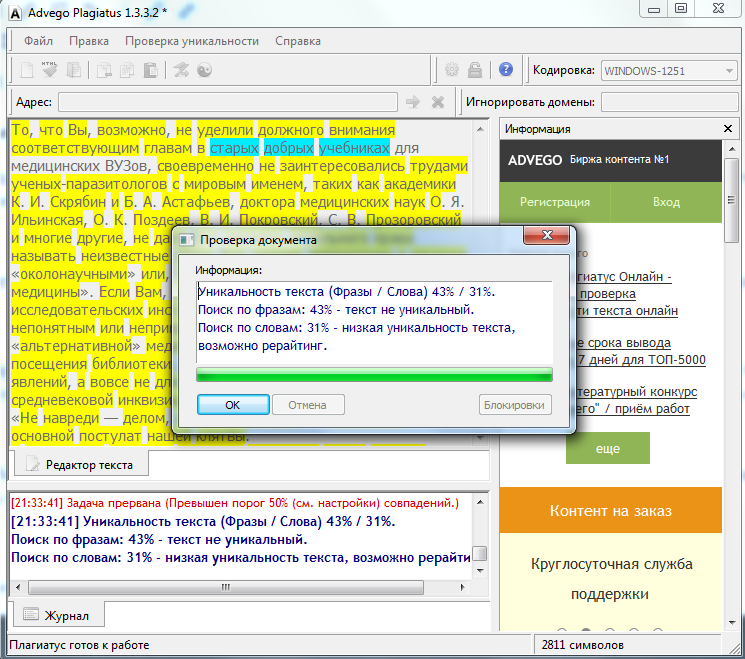
- Выбор сервиса проверки уникальности. Старайтесь выбрать популярный и максимально строгий сервис с обширным функционалом. В университете вашу работу будут проверять серьезными платными программами. И выбор заведомо мощного ресурса поможет избежать проблем с уникальностью. Особенно строгими среди студентов числятся следующие сервисы проверки текста на антиплагиат: ETXT, Advego Plagiatus, ресурсы Text.ru, Findcopy и Antiplagiat ру.
- Проверка уникальности. С помощью специальной программы или сервиса запустите проверку текста на уникальность. Интересно то, что разные программы/сервисы могут показывать разный процент уникальности текста (например, в программе Advego Plagiatus – 95%, а в ETXT – 60%). Хитрость в разных алгоритмах работы. Так, одни программы работают по методу шингла (определенного количества последовательных слов), другие – по оценке всего текста.
- Сохранение изначального варианта. Обязательно делайте резервную копию начального текста, даже если у него зафиксирован низкий процент уникальности. Так вы всегда можете вернуться к началу, если уже обработанный текст покажется перенасыщенным, бессмысленным и невосстанавливаемым.
- Выбор способа обхода антиплагиата. Сразу после создания резервной копии выберите оптимальный метод обхода системы проверки уникальности. Их будет много, и более предметно обсудим их далее в статье.
- Повышаем итоговую уникальность на 5-10% больше необходимого. Дело в том, что вузовские или любые другие платные программы, которыми может воспользоваться преподаватель, работают с продвинутыми инструментами. В итоге они почти всегда сильно занижают процент уникальности.
- Сохранение готового варианта. Как только работа сделана, несите ее на проверку! Самое время узнать, как вы справились с задачей.
Итак, мы определили примерную последовательность действий для повышения уникальности текста. Самое время рассмотреть действующие методики, как пройти антиплагиат диплома, курсовой, реферата или другой работы в 2023 году бесплатно. Советы собраны от опытных специалистов и прошаренных студентов из просторов всемирной паутины.
13 способов обойти систему антиплагиат и повысить оригинальность диплома/курсовой/реферата бесплатно
Остановимся на самых популярных и проверенных бесплатных способах обхода системы антиплагиат в 2023 году.
Глубокий рерайт
Самый честный и проверенный способ, как обхитрить систему и повысить оригинальность текста в антиплагиате самостоятельно – это написать то же самое, но своими словами. Это и есть глубокий рерайт. По крайней мере, отзывы об этом методе самые лучшие (даже у преподавателей). Да и обманом системы, если уж на то пошло, этот способ назвать нельзя.
Просто берете неуникальные куски текста, которые сервис считает плагиатом, и перерабатываете их, переписывая ту же мысль своими словами. Старайтесь опустить излишние детали, выделить тезисы и главные мысли.

Добавление синонимов и эпитетов
Часто используемые слова старайтесь заменить близкими по значению понятиями. При этом не обязательно должен меняться порядок слов в предложении.
Эпитеты также помогают преобразить исходный текст, делая его красочным и ярким. Но вот для сухого научного труда такой прием вряд ли подойдет.
Гораздо сложнее иметь дело с таблицами и формулами. Тут уж никакие эпитеты и синонимы не помогут.
Откроем секрет: вставляйте таблицы и формулы в работу картинками (делайте скриншоты, например).
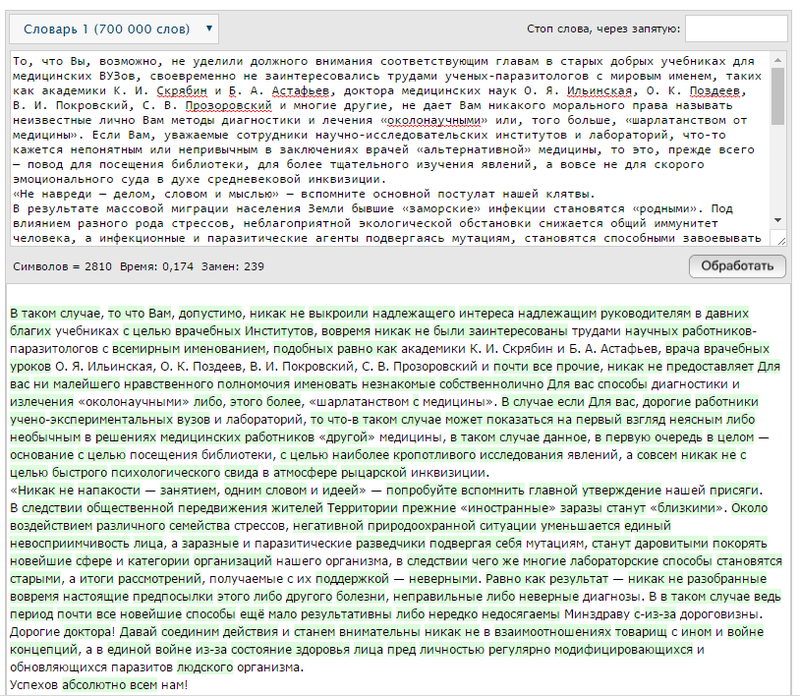
Если этого не сделать, сервисы проверки будут расценивать информацию в таблицах как дубли с других ресурсов. А вот распознавать текст на картинке они еще не научились.
Синонимайзеры
Этот способ настоятельно не рекомендуется использовать для крупных кусков текста, потому что получится откровенная ерунда. А вот для подъема уникальности всего на пару процентов может быть достаточным.
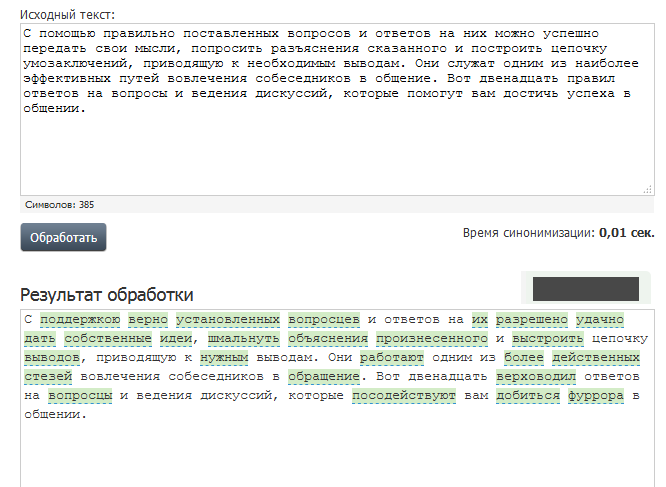
Итак, находите на просторах всемирной паутины подходящую программку, вводите отрывок текста и получаете обработанный кусок, который и поднимет его уникальность на заветные несколько процентов!
Использование автоматических переносов
Этот способ поможет поднять оригинальность текста лишь в малой степени. Но это хороший прием, если нужно лишь «подмарафетить» курсовую или диплом.
Итак, в документе MS WORD выставляете автоматический перенос слов. Как это сделать, посмотрите на картинке ниже:
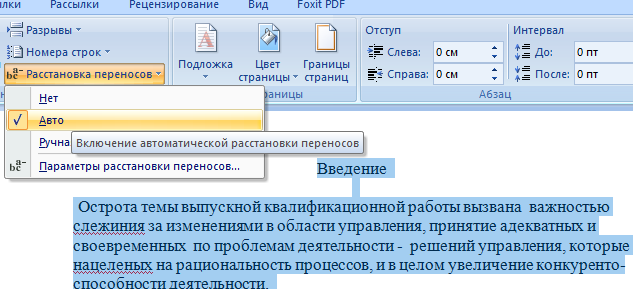
Как это поможет обойти программу «Антиплагиат вуз»? Дело в том, что при копировании такого текста в другие сервисы часть слов как бы обрезается, что позволяет программе воспринимать их как уникальные.
Метод шингла
Шингл – это определенное количество слов в определенной последовательности в тексте. На основе метода шинглов работает большинство программ проверки уникальности.
Изменяя одно слово из этой цепочки, вы меняете процент оригинальности текста.
Помните, что каждое последующее слово может начинать новый шингл или быть частью предыдущего. Так образуются своеобразные цепочки из фраз.
Если программа показывает, что не уникален целый абзац, попробуйте изменять каждые 2-3 слова. Так вы поменяете практически все шинглы, существенно повысив уникальность.
Иногда для повышения оригинальности изменяют каждое первое и последнее слово шингла. Но это не всегда легко, так как неясно, где он начинается и заканчивается.
Перевод текста на другие языки и обратно
При переводе текста на другой язык изменяется его структура. А при обратном переводе с иностранного новая структура сохраняется. Кроме того, автоматические переводчики часто заменяют оригинальные слова текста синонимами.
В качестве достойной альтернативы постарайтесь найти источник информации на зарубежных сайтах, так как большинство антиплагиат-сервисов занимается поиском совпадений на русскоязычном пространстве.
Замена русских букв на греческие
Многие модернизированные системы проверки видят замены латинскими буквами и обходят их стороной. Хотя со старыми системами и этот фокус может получиться.
А вот до греческого языка «дошли» немногие. Некоторые умельцы заменяют отдельные буквы в русском тексте на аналогичные буквы греческого алфавита.
Изменение часто повторяющихся слов
В тексте могут часто встречаться одни и те же слова. Просто замените их синонимами, фразами, местоимениями и другими подходящими по смыслу словами. Так вы повысите оригинальность.
Изменение предложения с конца
Речь идет о сложносочиненных и сложноподчиненных предложениях. Достаточно грамотно поменять две части местами, как автоматически повышается и уникальность документа.
Проследите, чтобы не менялся смысл текста.
Использование слов-паразитов
Например, слово «непосредственно» можно использовать практически в любом предложении, так как оно обязательно подойдет по смыслу хоть к какому-то слову.
В словарном запасе активного читателя обязательно найдется с десяток таких слов, которые можно чередовать и использовать во всем тексте. Но не переборщите! Лишняя вода в тексте не сыграет на руку при проверке. Перегруженный словами текст доносит основную мысль менее эффективно. Если же мыслей нет, лейте воду.
Помощь со стороны
Если есть хороший знакомый, можно доверить ему доработать ваш текст. Пусть перескажет работу своими словами, а вы перепишете.
Кстати! Если знакомых нет, можно обратиться в специальный студенческий сервис, где за чисто символическую сумму повысят уникальность или вовсе создадут работу с нуля. К тому же, для всех наших читателей сейчас действует скидка 10% на любой вид работы.

Маленькая хитрость: если не хотите заморачиваться с повышением уникальности текста, а работу сдать надо, отнесите ее преподавателю не в электронном виде, а распечатанную. Вряд ли у него хватит терпения и сил на сканирование, распознавание текста и последующее исправление ошибок, чтобы выявить плагиат.
Хотите удивить его еще больше? Напишите работу от руки. Конечно, такой способ больше подойдет для подготовки реферата, а не такого объемного труда, как дипломная или курсовая работа. Иначе вы рискуете остаться без руки. Руководитель явно будет шокирован, но и придираться будет меньше. Даже если он уверен, что содержимое скопировано, студент хотя бы приложил усилия, чтобы прочитать, а потом еще и переписать текст. Значит, все же что-то в его голове отложилось.
Методы уникализации текста, которые не работают
Не используйте для повышения уникальности старые способы обхода антиплагиата, такие как:
- замена букв кириллицы латинскими буквами;
- вставка большого количества вводных слов, эпитетов;
- синонимайзинг крупного отрезка или всего текста.
Умные программы уже давно могут определить, где в тексте присутствует неуместная латинская буква. Это делается путем прогона информации через проверку орфографии.
Эпитеты и вводные слова не подходят для текстов узкоспециализированной и научной направленности.
Синонимайзинг больших отрезков текста – отличный способ и самому вдоволь насмеяться, и преподавателя рассмешить.
Не стоит использовать и следующие приемы:
- Перестановка членов предложения местами. Так программу не обманешь: разработчики уже давно настроили инструменты на поиск переставленных слов.
- Перестановка абзацев или предложений. То же самое работает по отношению изменения мест предложений и абзацев. Вспомните про шинглы, повторяющиеся последовательные слова и т.д. Программе важна не последовательность предложений, а их содержание.
- Склейка или разбивка предложений. Некоторые пытаются искусственно соединить отдельные предложения или разбить сложное предложение на простые. Говорим сразу: не пройдет!
- Изменение знаков препинания. Запятые, точки, тире, двоеточия – программе все равно, какие знаки препинания стоят в тексте. Она учитывает только слова.
- Изменение фона текста. Некоторые «умельцы» дополняют основной текст разной ерундой, которую потом просто закрашивают белым цветом (меняют цвет шрифта, поэтому текст не виден). Эта попытка сразу обречена на провал, так как при копировании и вставке всего текста в область для проверки на антиплагиате отображается весь текст, даже невидимый. И если преподаватель увидит эту хитрость, кому-то не поздоровится.
- Применение программ для повышения уникальности текста. В сети можно найти массу сервисов по изменению уникальности текста. Но скажем сразу: все они основаны на тех принципах, перечисленных в пункте «Методы уникализации текста, которые НЕ РАБОТАЮТ». И воспользовавшись их помощью, вы рискуете получить в своем тексте сразу все запрещенные приемы, которые непременно будут обнаружены.
3 причины, почему не стоит обманывать антиплагиат
Есть несколько причин, почему лучше действительно поработать над курсовой или дипломом, а не искать надежные способы, как можно обойти антиплагиат и поднять оригинальность текста самостоятельно:
- вы рискуете попасться и провалиться;
- вы рискуете попасться и быть отправленным на повторную доработку;
- вы рискуете попасть на устаревшую программу.
В первом случае преподаватель просто отправит восвояси и не захочет больше иметь с вами дело. Не у каждого хватит терпения и сил простить того, кто пытался обмануть программу антиплагиат и препода.
Во втором случае у преподавателя хватит сил и мудрости вас простить, но он отправит вас доделывать работу по-человечески. То есть фактически потеряете время, которое было потрачено на переработку текста и повышение уникальности. При этом все равно нужно будет пойти и выполнить то, чего вы так усердно пытались избежать. А испорченная репутация теперь будет преследовать всегда.
В третьем случае есть вероятность использовать допотопную версию программы, в то время как у преподавателя будет полный набор модернизированных инструментов для «поимки преступников».
Помните: с каждым днем программы и сервисы становятся все умнее. То, что вы использовали неделю назад, сегодня уже может не прокатить.
Как проверить реферат/курсовую/дипломную на плагиат онлайн
Допустим, вы подготовили материал и хотите проверить работу на плагиат бесплатно, чтобы идти на проверку во всеоружии. Для начала узнайте, каким сервисом пользуются преподаватели в вашем вузе.
Разные системы проверки текста на плагиат используют разные алгоритмы и дают разный результат.
Вот топ популярных сервисов, позволяющих проверить оригинальность реферата, курсовой или диплома на плагиат онлайн и бесплатно.
- Антиплагиат.ру;
- Text.ru;
- Etxt.ru;
- Advego.ru.
Не переживайте, если с первого раза ничего не получается. Если вы отчаялись и не знаете, как сделать, чтобы курсовая, дипломная, реферат или любой другой текст прошли антиплагиат, обратитесь в студенческий сервис. Мы помогаем решать любые вопросы, связанные с обучением.
Вопрос/ответ
Как проверить курсовую/дипломную онлайн?
- Антиплагиат.ру;
- Text.ru;
- Etxt.ru;
- Advego.ru.
Как повысить оригинальность текста в антиплагиате самостоятельно?
- Глубокий рерайт – тщательно переписываем работу своими словами.
- Добавление синонимов и эпитетов – заменяйте слова синонимами, а к существительным добавляйте прилагательные. Только не переборщите. Это же дипломная всё-таки.
- Синонимайзеры – используйте их только для небольших отрывков текста.
- Перевод текста на другие языки и обратно – когда переводишь с одного языка на другой, меняется структура предложения. Это нам и надо, чтобы повысить уникальность на пару процентов.
- Изменение предложения с конца – достаточно грамотно поменять две части местами, как автоматически повышается и уникальность документа.
- Использование слов-паразитов – например, слово «непосредственно» можно использовать практически в любом предложении, так как оно обязательно подойдет по смыслу хоть к какому-то слову.
Как не стоит уникализировать текст?
- Менять слова местами.
- Менять предложения и абзацы местами.
- Склеивать и разбивать предложения.
- Менять знаки препинания
- Изменять фон или цвет текста.
- Использовать устаревшие программы для проверки работы на плагиат.
Каждому студенту рано или поздно придется столкнуться с проверкой антиплагиат. Обычно на плагиат проверяют только курсовые, дипломные и диссертационные работы. Чтобы получить хорошую оценку, нужно показать высокий результат оригинальности текста. Однако, многие учащиеся используют текст из интернета, который обязательно обнаружится при проверке работы. В этой статье мы расскажем, как обмануть антиплагиат в 2023 году. Опишем 12 методов, которые помогут скрыть любые заимствования и получить 80-90% уникальности работы. Читайте статью до конца, и вы узнаете, как проверить свою работу самостоятельно.
Содержание
- Что такое антиплагиат
- Как обмануть антиплагиат в 2023 году — 12 секретов
- Рерайт своими руками
- Заказной рерайт
- Шаг шингла
- Пересказ
- Зарубежные сайты
- Поиск уникального контента
- Цитирование
- Сокращение плагиата
- Антиплагиат Киллер
- Скриншот текста
- Синонимайзер
- Написать текст самому
- Какие способы не помогут обмануть антиплагиат в 2023 году
- Как самому проверить текст на антиплагиат
- Антиплагиат ру
- Антиплагиат ВУЗ
01 Что такое антиплагиат

Антиплагиат – это система поиска плагиата в любом тексте. Каждый студент, который хочет обмануть антиплагиат, должен знать, как работает антиплагиат. Сейчас мы постараемся кратко объяснить принцип действия.
Любая студенческая работа проверяется за несколько минут. Проверка текста проводится через миллионы текстов в открытых и закрытых ресурсах интернета. Поэтому не стоит надеяться, что скаченная работа пройдет проверку на оригинальность.
Программа антиплагиата загружает весь текст и разделяет его на небольшие отрезки, примерно по 3-5 слов. Дальше система ищет повторы этих комбинаций. И если находит, то подсвечивает их красным цветом. Таким образом, даже если было скопировано всего лишь 1 предложение, то оно будет найдено.
После того, как обработка завершится, проверяющий сможет увидеть процентное соотношение оригинального текста, заимствованного из интернета и правильного цитирования.
Если показатель оригинальности будет ниже допустимого порога, то студент не сможет пройти проверку антиплагиат. Каждому студенту нужно знать, какой процент уникальности должен быть, чтобы пройти Антиплагиат. Обычно минимальный порог уникальности составляет 60-70%.
Таким образом, если вы хотите получить хорошую оценку без особых усилий, то читайте дальше, как обмануть антиплагиат самостоятельно.
Лайфхак
Если вам нужно срочно поднять процент оригинальности, то рекомендуем заказать помощь профессионалов. На нашем сервисе Анти-антиплагиат.рф предоставляется услуга кодирования документа. Ваш текст никак не изменится, зато процент поднимется до 80-90%. Понадобится всего лишь пара минут. Мы гарантируем качество работы и предоставляем обработанный текст без предоплаты, чтобы вы смогли убедиться в повышении уникальности.
02 Как обмануть антиплагиат в 2023 году — 12 секретов
Мы подготовили для вас 12 суперспособов, как обмануть антиплагиат быстро и легко. Большинство методов можно использовать самостоятельно. Например, рерайт и пересказ. Однако они потребуют некоторых усилий. А есть совершенно простые приемы, которые выполняются за пару минут, например, обработка через Антиплагиат Киллер или скриншот текста.
Давайте разберемся подробно, что из себя представляет каждый прием. Читайте полную инструкцию по применению всех средств для обмана антиплагиата.

- Рерайт своими руками
Рерайт – это такой способ повышения уникальности, который используют все: студенты, копирайтеры, писатели, редакторы и т.д. Все, кто работают с текстом, конечно же, пользуются чужими текстами. Однако рерайт позволяет заимствовать чужие труды так, чтобы они казались оригинальными. Для этого проводится большая пошаговая работа. Перечислим все этапы рерайтинга:
- Нужно изменить структуру текста, поменять местами абзацы или большие фрагменты.
- Посмотрите, какие слова часто употребляются, найдите им синонимы и замените.
- Перефразируйте большую часть плагиата.
Итак, давайте разберем теперь каждый шаг отдельно.
- Изменять местами абзацы, фрагменты, большие части текста нужно. Это поможет запутать антиплагиат, чтобы он не нашел больших совпадений с чужими работами. Однако только перестановка мест не поможет вам обмануть антиплагиат. Обязательно нужно использовать следующие 2 шага.
- Чаще всего в студенческих работах встречаются одни и те же термины. Заменить их на синонимы бывает трудно, поэтому нужно стараться использовать более распространенные понятия, либо самостоятельно придумывать синонимы. Обычно это не занимает много времени. В остальных случаях вы можете использовать онлайн словарь синонимов. Он абсолютно бесплатный. Чтобы воспользоваться им, нужно ввести в поисковую строку заменяемое слово и нажать на кнопку «поиск». После этого словарь выдаст от 2 до нескольких десятков подходящих замен. Воспользуйтесь ими и вставляйте по всему тексту. Чем больше будет разнообразных слов, тем лучше. Ведь комбинация слов для антиплагиата изменится, и он не сможет найти соответствие в других ресурсах.
- Перефразировать текст нужно аккуратно. Лучше всего изменять те предложения, которые вы точно понимаете. Если какие-то фразы для вас непонятны, то их лучше оставить нетронутыми или превратить в цитату, как это сделать расскажем дальше.
Рерайт может занять много времени. Однако переделывание текста с опытом начнет получаться лучше и быстрее. Поэтому если вы хотите получить ценный навык на будущее, то начните рерайтить текст как можно раньше. Так вы сможете обмануть антиплагиат без чьей-либо помощи.

- Заказной рерайт
Чтобы обмануть антиплагиат, можно заказать рерайт. Вам не придется ничего делать самостоятельно. За вас работу по изменению текста выполнит программа или специалист.
Обычно принято заказывать рерайт у исполнителей. Их можно найти на сайтах копирайтинга и рерайтинга, а также на ресурсах для фрилансеров. На нашем сервисе вы также сможете заказать ручной рерайт от профессионала.
В чем заключается работа рерайтера? Он выполняет то же преобразование документа, старается изменить текст, не поменяв смысла работы. Заказчику остается только указать условия исполнения:
- Дату сдачи работы
- Цену
- Нужный процент уникальности
Скупиться на оплате работы, не советуем. Ведь исполнитель, который получает слишком мало за работу, не будет стараться. Он может не сдать работу в срок или просто проведет весь текст через бесплатный синонимайзер и отдаст вам готовый документ уже в «грязном» виде. Если прочитать такой текст, то можно найти грамматические, логические, орфографические ошибки. Поэтому будьте внимательны и проверяйте выполненный заказ.
Вы можете вообще не доверять людям, а довериться программе рерайта. На нашем сервисе представлена уникальная услуга – автоматический рерайт. Он позволяет за несколько минут получить полностью измененный текст. С помощью специального алгоритма нейросети и современного процессора программа может выполнить почти ту же работу, что и человек. Однако допускаются некоторые погрешности в стыковке слов в предложениях, т.е. в окончаниях. Поэтому пользователю придется пока еще раз самостоятельно перечитывать текст и при необходимости исправлять ошибки.
Тем не менее автоматический рерайт подходит тем, кто не хочет тратить много времени и денег на изменение документа.
Итак, если вам обязательно нужно преобразовать текст, но самостоятельно сделать это не получается, то закажите услугу рерайтера или программы для рерайта. Обмануть антиплагиат таким способом получится без особых проблем и трудностей.
- Шаг шингла
Шаг шингла – это и есть алгоритм поиска плагиата в тексте. Он поможет обмануть антиплагиат самостоятельно. Нужно лишь нарушить алгоритм.
Как он работает? Шингл – это комбинация из 3-4 слов, которую проверяют на соответствие в базе антиплагиат. Шаг – это выборка связки слов. Сначала проверяется первая связка из 3-4 слов, затем вторая. Однако они идут внахлест, а не в стык. То есть вторая комбинация слов начинается со второго слова предыдущей связки.
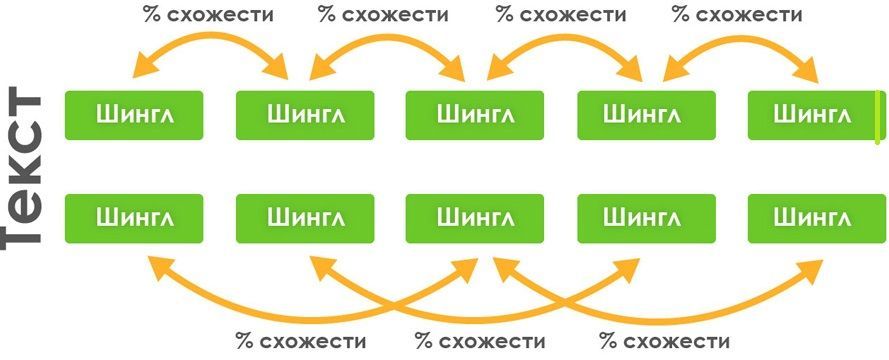
Например, предложение «Я сегодня ел манную кашку с медом» будет проверяться так:
- 1 связка – «я сегодня ел манную»
- 2 связка – «сегодня ел манную кашку»
- 3 связка – «ел манную кашку с медом» и т.д.
Чтобы пройти антиплагиат, нужно разбить эти комбинации. Проще всего вставлять между 2-3 словами новые. Нужно лишь подобрать подходящие по смыслу. Например, возьмем то же предложение «Я сегодня ел манную кашку с медом». Теперь разбавим его новыми словами.
Получается «Я сегодня, как и всегда, ел манную кашку с изюмом и медом».
Как вы видите, предложение совершенно изменилось. Именно так многие копирайтеры получают 100% уникальности. Чем чаще вы будете добавлять новые слова, тем выше будет процент оригинальности текста. Если вы не хотите изменять текст полностью, чтобы обмануть антиплагиат, то можете всего лишь добавить несколько новых слов.
- Пересказ
Мы рассказали, что в рерайте используется прием перефразирования. Он позволяет обмануть антиплагиат путем изменения предложений. Пересказ во многом совпадает с ним. Однако отличается по масштабу.
Пересказ – это изложение своими словами прочитанного текста. Сначала обязательно нужно прочитать большую часть или весь текст, а потом переписать его по своему пониманию и по памяти. Таким образом в вашей работе будет минимум повтора и максимум оригинального воспроизведения. Антиплагиат не сможет найти соответствий.
Не рекомендуем использовать данный способ, если вы не совсем понимаете тему работы. Иначе можно только испортить текст и потерять много времени. Обмануть антиплагиат с помощью пересказа достаточно тяжело. Но если перечитывать источник несколько раз, то можно легко усвоить информацию и изложить ее.
- Зарубежные сайты
Найти источники, которые отсутствуют в базе данных антиплагиата можно в зарубежных сайтах. Как обмануть антиплагиат и увеличить объем работы? Конечно же, воспользоваться поисковиком Гугл и найти уникальный контент.
Введите в поисковую строку название темы работы или ключевого слова на иностранном языке. Чаще всего используют английский язык. Также можно перевести на любые другие языки: немецкий, японский, китайский, украинский или белорусский и т.д.
Затем найти наиболее подходящий материал. Перевести страницы можно автоматически с помощью сервиса перевод от Гугл. Прочитайте текст и скопируйте те части, которые вам больше подходят. Таким образом, вы сможете заимствовать практически уникальный контент, который не будет обнаружен сервисом проверки.
- Поиск уникального контента

Найти подходящий контент, чтобы обмануть антиплагиат, можно и среди отечественных ресурсов. Антиплагиат обычно использует материалы, которые были индексированы в течение 3 месяцев. Совершенно новые публикации остаются в невидимом поле для антиплагиата.
Мы рекомендуем использовать поисковик Яндекс. Нужно лишь найти кнопку «инструменты» справа от поисковой строки, нажать на нее и выбрать сортировку по дате. Идеально подойдут сроки «за 2 недели», «за месяц». В этот период можно найти те тексты, которых нет в базе антиплагиата.
Таким образом, вы сможете без страха использовать заимствования. Однако есть минус у данного метода. Подходящего материала может быть найдено очень мало. Все-таки 2 недели и даже месяц – это небольшой период для пополнения контента.
- Цитирование
Цитирование – это отличный метод, чтобы не обманывать антиплагиат, а пройти его легально. Все, что нужно сделать: все заимствования заключить в кавычки. Конечно, если вся ваша работа является сплошным плагиатом, то вам не подойдет этот способ. Он помогает в том случае, если вы заимствовали от 1 предложения до абзаца.
Кстати, антиплагиат обнаруживает цитаты только по 2 парам кавычек. Если в начале цитаты будет кавычка, а в конце нет, то цитирование не будет засчитано. При этом ссылки на источники нужно указывать только для проверки преподавателя. По требованиям оформления ГОСТ все цитаты и ссылки должны указывать на литературный источник. Если у вас возникают трудности с оформлением, мы можем вам помочь. Заказывайте оформление ГОСТ на нашем сервисе, и мы выполним заказ к указанному сроку.
- Сокращение плагиата

Если вы не хотите обманывать антиплагиат, то рекомендуем просто убрать все заимствования из текста. Если вы не уверены, где именно будет обнаружен плагиат, то рекомендуем заказать полный отчет.
Отчет – это показ всех найденных соответствий, которые будут выделены прямо в тексте. Также можно узнать ресурсы, где были найдены дубли. Есть два выхода – удалить плагиат полностью, либо перефразировать его.
Чем меньше плагиата, тем выше будет процент оригинальности. Помните об этом.
- Антиплагиат Киллер
Антиплагиат Киллер – это метод, который поможет не только обмануть антиплагиат, но и получить помощь в самом экстренном случае. Он помогает оставить текст без изменений, но при этом получить 80-90% самостоятельности.
Если у вас осталось всего лишь пара минут до проверки, то лучше всего обратиться за помощью к специалистам. Наш сервис работает круглосуточно, поэтому вы можете заказать повышение уникальности даже ночью.
Как это работает? Вы заказываете повышение оригинальности на сервисе Анти-антиплагиат.рф. К заказу прикрепляете свою работу и ждете пару минут. За это время специалист обрабатывает ваш документ через программу Антиплагиат Киллер. Затем присылает вам на проверку готовый текст, чтобы вы смогли проверить повышение. Вы можете использовать любой сервис для поиска плагиата.
Только после того, как вы убедитесь в выполнении услуги, мы пришлем чек для оплаты. Все это займет не более 5 минут. Поэтому рекомендуем данный способ для обмана антиплагиата в 2023 году.
- Скриншот текста
Скриншот текста подходит тем, кто разбирается в инструментах операционной системы. Как это поможет обмануть антиплагиат? Дело в том, что система для поиска плагиата может обрабатывать только текстовые форматы электронных документов. Изображения пропускаются сервисом проверки, если они имеются в виде приложений.
Поэтому если изменить текстовый формат на изображение, то можно пройти антиплагиат без особых сложностей. Для этого нам понадобится клавиша Print Screen (prt sc) на клавиатуре, либо инструмент «Ножницы».
Ножницы можно найти, открыв «Пуск» и дальше открыв папку «Стандартные». Этот способ удобнее, ведь можно сразу выделить тот участок текста, который нужно «скрыть» от антиплагиата. Достаточно только выделить – и он сам превратиться в изображение. Остается только скопировать его, а затем вставить на место текстового исходника.
Не забудьте удалить данный фрагмент в текстовом формате, иначе весь метод будет выполнен в пустую. Скриншот – это самый быстрый способ, как обмануть антиплагиат. Однако нужно быть осторожным, ведь если преподаватель захочет прочитать вашу работу, то он сможет увидеть, что вы заменили текст на скриншот.
Поэтому сохраните отдельную копию с изображениями, чтобы отдать ее только на проверку плагиата в университете.
- Синонимайзер
Не каждый синонимайзер поможет вам обмануть антиплагиат. Бесплатные сервисы замены слов на синонимы работают очень плохо. Зачастую они делают еще хуже – после обработки появляются лишние слова, несвязность в предложениях, ошибки и т.д. В общем, приходится переделывать работу заново.
Однако существует синонимайзер «Умного поколения». Он помогает в ручную выбирать синонимы. Сама программа встраивается в ваш Ворд и становится помощником. Она предоставляет выбор, когда вам нужно заменить как можно больше слов по тексту. Вы сможете сами выбирать, нужно ли ставить такую замену для слова или нет.
Эта программа стоит 999 рублей. Однако она пригодится вам в будущем при написании рефератов, курсовых.
- Написать текст самому
Самый трудный, но лучший способ, как обмануть антиплагиат – это написать текст абсолютно самостоятельно. Он самый длительный и тяжелый, но при этом у вас не возникнут проблемы ни с сервисом проверки, ни с преподавателем. Таким образом, вы сможете сдать абсолютно оригинальную работу.
Итак, мы рассказали о 12 секретных методах, как пройти проверку антиплагиат. Мы рекомендуем посмотреть также видео, в котором рассказываем о дополнительных 18 способах, а также показываем, как они все работают.
03 Какие способы не помогут обмануть антиплагиат в 2023 году
Существуют способы, которые не помогут обмануть антиплагиат. С каждый годом их становится больше, ведь разработчики Антиплагиата придумывают больше роботов и технологий обнаружения обходов системы. Давайте перечислим то, что уже не сработает.
- Замена русских букв на английские не поможет пройти проверку. Уже давно был разработан алгоритм, который обнаруживает этот метод обхода.
- Замена русских букв на греческие также будет обнаружена. Студент увидит только знак обхода и получит либо выговор, либо отчисление из вуза.
- Скрытые символы – это уже устаревший метод, который также не работает и выводит знак обхода.
- Синонимайзер в бесплатном доступе также испортит ваш текст. При этом он не поможет повысить уникальность даже на 10%.
- Сервис перевода Гугл и Яндекс также устарел для прохождения проверки на антиплагиат в 2023 году. Их перевод с языка на язык стал почти безупречным. Поэтому после перевода текста с русского на английский, с английского на французский, с французского на русский, можно получить тот же текст, что и раньше. Так вы не поднимите уровень оригинальности.
Таким образом, не стоит полагаться на данные методы для обмана антиплагиата. Они вам ничем не помогут, а только сделают хуже.
04 Как самому проверить текст на антиплагиат
Каждому, кто сдает текст на проверку антиплагиата, нужно заранее проверять свой процент оригинальности. Для студентов отлично подходят два сервиса: Антиплагиат ру и Антиплагиат ВУЗ. Первый предоставляет бесплатный доступ к проверке документа. А второй используется почти во всех университетах страны, поэтому покажет точный результат.
- Антиплагиат ру
Чтобы проверить свою работу в Антиплагиат ру, нужно зайти на официальный сайт и зарегистрироваться. Затем добавить свой документ и начать проверку. Уже через несколько секунд или через пару минут будет известен результат.
Бесплатная проверка помогает узнать процентное соотношение оригинальности, плагиата и цитирования. А также 3 ссылки на найденные источники.
Антиплагиат ру в бесплатной версии не дает гарантии в точности результата. Поэтому рекомендуем вам использовать либо платный пакет на АП ру, который стоит 270 рублей. Либо заказать проверку в Антиплагиат ВУЗ за 249 рублей.
- Антиплагиат ВУЗ
Антиплагиат ВУЗ – это закрытый расширенный пакет Антиплагиата, который предназначен только для учебных заведений. Приобретать этот пакет могут только университеты. В открытом доступе найти этот сервис и доступ к нему нельзя.
Мы предоставляем услугу для проверки текста онлайн. Вам нужно лишь заказать проверку через преподавательский сервис на Анти-антиплагиат.рф, и вы сможете получить показатель оригинальности, полный отчет и справку на фирменном бланке Антиплагиат.
Таким образом, вы тщательно подготовитесь к финальной проверке в вузе, и будете предупреждены о своем показателе оригинальности.
Итак, в этой статье мы рассказали, как обмануть антиплагиат в 2023 году. Эти способы работают не только для работ студентов, но и для копирайтеров, рерайтеров, а также других специалистов, которые связаны с текстом. Вы можете выбрать один из этих методов повышения уникальности или использовать комплекс приемов. Тогда вы сможете точно получить 80-90% оригинальности антиплагиата.
Полезные ссылки:
Проверить документ на плагиат онлайн – бесплатно
Что такое курсовая работа и как ее быстро написать?
Как оформить цитаты в дипломной работе — ГОСТ 2023
Что такое Эссе, как его написать самому – примеры
Поднять уникальность текста онлайн – АНТИПЛАГИАТ
Как написать дипломную работу самостоятельно: советы
Модули в Антиплагиат ВУЗ: что это и какие они бывают

Каждому студенту нужно знать, как обойти антиплагиат самому. Это поможет вам быстрее и легче сдавать свои курсовые, дипломную работы. Благодаря этим способам вам не придется бояться проверки текста на плагиат.
В этой статье мы собрали лучшие методы и готовы ими поделиться с вами. Читайте полную инструкцию, как обойти антиплагиат самому онлайн.
Содержание
Что такое антиплагиат
Для чего нужно обойти антиплагиат
Как обойти антиплагиат самому онлайн: лучшие способы
— Обойти антиплагиат самому с помощью рерайта
— Как повысить антиплагиат с шагом шингла
— Поднять антиплагиат онлайн с Антиплагиат-ВУЗ.рф
— Как обойти антиплагиат самому с переводом иностранных статей
— Повысить антиплагиат с помощью цитирования
Как проверить работу в Антиплагиат ВУЗ самому
Что такое антиплагиат
В первую очередь вам нужно понять, что такое антиплагиат.
Это такой сервис, который помогает в поиске плагиата преподавателю. Студенты часто пользуются заимствованными текстами из открытых источников интернета. Это факт. Но как бороться с этим? Только с помощью антиплагиата.
Он позволяет найти в работе студента скопированные части и фрагменты текста, которые были опубликованы в сети раньше. С помощью сверки загруженного документа с миллиардом других текстовых материалов, он находит соответствия и показывает их в результате обработки. Так, проверяющие понимают, какой процент от всего текста является плагиатом, а какая часть все-таки была написана самостоятельно.
Существует несколько видов таких сервисов. Вообще Антиплагиат – это название одной системы, которая появилась благодаря российским разработчикам в 2005 году. Конечно, есть и другие разработки, которые были созданы в России и в других странах. Однако именно Антиплагиат стал популярен в России и в странах СНГ. Более того одним из самых усовершенствованных пакетов этой программы Антиплагиат ВУЗ пользуются более 90% высших учебных заведений в России.
Каким антиплагиатом пользуются преподаватели еще, рассказали в предыдущей статье.

Дальше рассмотрим, как обойти антиплагиат самому.
Для чего нужно обойти антиплагиат
Обойти антиплагиат самому достаточно сложно, однако это необходимо.
Сервис поиска плагиата в настоящее время обязателен для всех университетов. Но проверяют в основном только выпускные работы: ВКР и диссертации. Курсовые проверяются редко. Преподаватели используют сервис, когда не хотят тратить свое время на чтение всей работы. Поэтому можно сказать, что результатов антиплагиата зависит, какую оценку вы получите.
Для того, чтобы обойти антиплагиат, вам нужно узнать, какой допустимый порог возможен. На каждом факультете и в разных вузах свои значения. Например, студентам филологического факультета нужно набрать максимальный процент оригинальности при проверке. А вот студентам юридического факультета нужно написать оригинальный текст хотя бы больше половины, чтобы пройти проверку.
Мы назовем вам средние значения, которые были приняты в большинстве университетов:
Оригинальность курсовой работы должна быть выше 60%, чтобы получить оценку удовлетворительно. Если хотите получить хорошо, то придется постараться и набрать более 70% оригинальности, а на отлично сдать работу можно с уникальностью выше 75%.
Инструкцию, как написать курсовую без плагиата, вы можете увидеть в нашей предыдущей статье.
Антиплагиат дипломной и диссертационной работы должен быть выше 70%. Только тогда можно получить допуск к зачету. Если у вас будет показатель оригинальности выше 90%, то вашу работу уже будут оценивать по-другому. Участники аттестационной комиссии постараются оценить высоко ваше защитное слово и могут даже завысить отметку.
Таким образом, теперь вы знаете, для чего нужно обойти проверку на антиплагиат.
Как обойти антиплагиат самому онлайн: лучшие способы

Мы подобрали лучше способы, как обойти антиплагиат самому. Не секрет, что многие методы уже устарели, т.к. разработчики антиплагиата каждый год стараются усовершенствовать свою систему и проследить попытки обойти ее.
Конечно, они не могут раскрыть сразу все карты и сделать ее абсолютно неуязвимой, ведь тогда у них не будет постоянной работы. Поэтому мы стараемся придумывать постоянно новые способы обхода. Не только потому, что студенты хотят скрыть плагиат. Дело в том, что сервис поиска заимствований часто по ошибке увеличивает процент плагиата за счет правильных ссылок. Как это происходит?
Допустим, вы заимствовали какой-то фрагмент из чужой статьи. Однако после этого сразу указали в ссылке или в сноске автора и название источника, но не добавили кавычки. Антиплагиат же читать не умеет, он не разбирает, были указаны ссылки или нет. Поэтому такой фрагмент рассматривается как плагиат. Конечно, каждая проверка подлежит повторной экспертизе преподавателя. К тому же у студента есть не одна попытка сдать работу на антиплагиат. Об этом рассказали в статье: Диплом не прошел Антиплагиат вуз – что делать?
Тем не менее они редко идут на уступки и проводят самостоятельную проверку вашего документа, слепо доверяя программе.
Поэтому прочитайте дальше все эффективные способы, как обойти антиплагиат самому онлайн, и выберите для себя наиболее подходящий.
Обойти антиплагиат самому с помощью рерайта

Самый распространенный способ обойти антиплагиат – это сделать рерайт. Далеко не каждый знает это слово, но каждый хоть раз пользовался этим методом.
По-другому его можно назвать перефразированием. Именно этот метод позволит вам переделать скопированный текст из интернета и сделать его абсолютно оригинальным. Для этого вам понадобится только воображение и начитанность. Если вы легко можете пересказывать чужие тексты, умеете быстро подбирать синонимы к словам, то сможете легко сделать рерайт своей работы, но не за короткое время.
Рерайт курсовой работы может занять у вас около 3-4 дней. Если нужно переписать дипломную работу, то придется упорно сидеть и работать неделю и больше. Поэтому этот метод вам подойдет, только если у вас есть еще свободное время.
Если вы уверены, что не справитесь, что не сможете сделать самостоятельно новый текст на основе старого, то обратитесь к профессионалам. В настоящее время много рерайтеров сидят на бирже Текст ру, Адвего и т.д. Конечно, обращаться лучше к тем исполнителям, которые уже получили положительные отзывы.
Если вы доверитесь «ноунейму», то есть начинающему рерайтеру, то можете попасть впросак. За маской исполнителя может скрываться безответственный человек, который пришлет вам плохую работу. Он может воспользоваться бесплатным синонимайзером, за несколько секунд обработать ваш текст, заменив все слова на синонимы автоматически, и сдать вам работу. В итоге связность текста будет нулевая, и вам придется все переделывать заново.
Либо вы можете обратиться на сервис профессионалов, где вам помогут за более высокую цену с гарантией. Тогда вы точно сможете сдать работу с первого раза на отлично.
Таким образом, обойти антиплагиат можно с помощью рерайта. Однако нужно либо делать его самому, либо искать профессионалов.
Если вы хотите успешно пройти проверку на плагиат, вы можете воспользоваться услугами нашего сервиса Антиплагиат-вуз.рф. С его помощью вы сможете повысить уникальность текста до 80-90% всего за пару минут. Применяемые технологии позволяют скрыть все заимствования без изменения текста. Кроме того, у вас есть возможность проверить текст в системе Антиплагиат ВУЗ. В кратчайшие сроки вы получите отчет и справку о прохождении проверки. Так вы узнаете точный процент уникальности своего текста
Как повысить антиплагиат с шагом шингла
Повысить антиплагиат и обойти его с первого раза поможет такой метод, как шаг шингла. Он заключается в том, что вам необходимо изменить текст под алгоритм работы.
Шаг шингла – это алгоритм антиплагиата, который и позволяет программе находить заимствования в тексте очень четко. Естественно, что система не может сравнивать один текст с другим, как человек, и не может сверять их по каждому слову.
Поэтому берется небольшой фрагмент в тексте из 3-4 слов, который называют шинглом. Его проверяет на совпадение в миллиарде других текстовых материалов. Если будет найдено соответствие, то антиплагиат скажет, что это плагиат.

Другой шингл берется не с конца предыдущего, а со второго слова. Продемонстрируем на примере предложения: «Я приехал из дальнего странствия за тобой, любовь моя». Теперь посмотрим на возможные шинглы.
1 шингл. Я приехал дальнего странствия
2 шингл. Приехал дальнего странствия тобой
3 шингл. Дальнего странствия тобой любовь
Как вы видите, антиплагиат определяет только самостоятельные части речи, частицы и союзы ему не интересны.
Что нужно делать вам? Расставить через каждые 2-3 слова как можно больше словосочетаний и новых слов. Давайте посмотрим, что может получиться на том же примере:
«Я снова, как и прежде, приехал из дальнего и опасного, одинокого и отважного странствия за тобой, единственная и восхваляемая всеми поэтами, любовь моя».
Как вы видите, наш текст немного изменился, но при этом увеличился объем. Поэтому если вы не хотите увеличивать размер работы, то можете переходить к другому способу. Однако большинству студентов этот способ придется по душе. Это легко, просто и помогает добавить несколько страничек к общей работе.
Опять же нужно оставить для работы больше времени, тогда у вас все получится на отлично. Шаг шингл поможет вам обойти антиплагиат самому.
Поднять антиплагиат онлайн с Антиплагиат-ВУЗ.рф
Кто лучше поможет вам обойти антиплагиат онлайн, если не профессионалы? Наш сервис является таким. Мы уже больше 5 лет помогаем студентам проверить свою работу в Антиплагиат ВУЗ, т.е. в закрытом сервисе для преподавателей.
Также мы помогаем студентам повысить уникальность текста для того, чтобы обойти проверку в университете с первого раза. Мы, как никто другой, знаем устройство системы Антиплагиата, быстро реагируем на введение новых технологий разработчиков. Поэтому всегда остаемся на шаг впереди.
Наш сервис позволяет вам поднять уровень оригинальности до 80-90%. Мы поможем вам перекодировать внутреннюю часть документа без изменений в тексте. При этом вам не придется ничего делать самостоятельно, т.к. мы все сделаем за вас. Остается только заполнить форму для заказа услуги, а также прислать нам свою работу.
Наш сервис работает круглосуточно, поэтому техподдержка сразу же вам поможет и ответит немедленно. Перед тем, как прислать вам результат работы, мы его обязательно проверим в Антиплагиат ВУЗ. Пока мы сами не убедимся в прохождении документа, вы не получите результат. Практически всегда мы присылаем готовый результат в течение 5-10 минут. Поэтому вы можете не переживать из-за времени. Мы точно поможем вам даже в самых критических ситуациях.
Таким образом, если вам нужно обойти антиплагиат, обращайтесь к нам. Ответим в любое время суток.
Как обойти антиплагиат самому с переводом иностранных статей
Если вам нужно обойти антиплагиат, но у вас еще ничего не готово, то рекомендуем вам воспользоваться этим методом. Вы сможете написать дипломную работу за месяц, причем сделать текст оригинальным, если будете переводить зарубежные тексты.
В первую очередь вам нужно найти подходящие научные статьи или монографии на иностранном языке. Вам нужно воспользоваться Гуглом. Для начала переведите в онлайн переводчике название своей работы.
Затем скопируйте его и добавьте в поисковую строку браузера и загуглите.
После этого выберите сайты, включите автоматический переводчик, чтобы прочитать текст на русском языке.
Дальше вы можете просто скопировать эти статьи и вставить в свою работу.

Конечно, такой плагиат может быть опасен. Поэтому многие знающие студенты выбирают публикации не из интернета, а из книг и монографий. В Антиплагиат ВУЗ есть модуль поиска плагиата, который называет Интернет плюс. Он индексирует зарубежные сайты и позволяет использовать тексты при проверке.
Таким образом, если вы будете пользоваться этим методом, настоятельно вам рекомендуем выбирать не первые ссылки, а последние. Лучше смотреть на сайты со второй и третьей страницы. Тогда вы сможете обойти антиплагиат самостоятельность.
Повысить антиплагиат с помощью цитирования
Самый простой и одновременно сложный метод, как обойти антиплагиат самому – это сделать вместо плагиата цитирование. Здесь нужно быть аккуратным, потому что в антиплагиате допустимо только 25% цитат от всего текста.
Цитирование – это отдельный параметр вычислений при проверке текста на уникальность. Его система определяет так: если текст заключен в кавычки, значит он является цитированием.
Неважно, поставите вы за этим фрагментом указание на источник или нет. Антиплагиат этого не увидит. Такое оформление необходимо преподавателям и проверяющим, которые смотрят соблюдение требований ГОСТ при оформлении. Если вы сдаете текст только на проверку плагиата, то можете его даже не оформлять. Позже можно заказать оформление на сайте, и за вас сделают всю сложную работу.
Итак, способ с цитированием реально работает. Однако прежде, чем вы начнете им пользоваться, вам нужно получить полный отчет навряд ли студент сможет вспомнить, какие части текста он скопировал из интернета. Поэтому важно сразу обратить внимание на то, где антиплагиат нашел заимствования.
После того, как вы переведете плагиат в официальное цитирование, вы сможете успокоиться. Так, вы точно сможете обойти антиплагиат с первого раза.

Как проверить работу в Антиплагиат ВУЗ самому
Мы уже рассказывали, что большинство вузов используют сервис Антиплагиат ВУЗ. Это закрытая система, доступ к которой может получить только тот вуз, который купил лицензию у компании. Обычно учетной записью обладает только 2-3 человека на факультете. Передавать эту информацию никому нельзя. Также проверяющим запрещено помогать студентам и проверять их работы до официальной даты.
Поэтому у студента есть 3 варианта:
- Обратиться на сервис Антиплагиат ру, где вы сможете получить приблизительный результат оригинальности. Антиплагиат ру занижает процент
- Вы можете попытаться найти человека, у которого есть доступ, и уговорить его помочь вам
- Можно заказать проверку работы в Антиплагиат ВУЗ на сервисе
Наш сервис Антиплагиат-ВУЗ.рф в любое время суток поможет вам узнать точные показатели уникальности, плагиата и цитирования. Причем за 249 рублей вы получаете полный и справку Антиплагиат.
Вы можете выбрать абсолютно любой вариант, который вам больше нравится.
Итак, в этой статье мы рассмотрели, как пройти антиплагиат самому. Теперь вы знаете, что для этого есть несколько способов, которые различают по сложности, времени исполнению. Выбирайте любой метод, который вам понравился и пользуйтесь им. А мы желаем вам удачи и успехов.
Вам также будет интересно:

Как получить и скачать отчет Антиплагиат ВУЗ?
Если ваш научный руководитель сказал: «Принеси мне отчет после проверки в Антиплагиат ВУЗ», то вам срочно нужно узнать, где его искать. В нашей статье мы не только подскажем, что это за отчет, но и подскажем места, откуда его берут. Также вы узнаете, как он выглядит и как можно его улучшить за несколько минут, […]

Рамки для диплома: скачать шаблон, как сделать самому
Для студентов некоторых направлений обучения бывают нужны рамки для диплома. Это своеобразный формат оформления выпускной квалификационной работы. Он основывается на создании полей и таблиц на определенных страницах исследования. Сделать их можно самостоятельно. А мы в нашей статье предоставим для этого пошаговую инструкцию. С ее помощью вы сможете правильно оформить рамки в дипломной в текстовом […]

Где публикуется научная работа студентов — все места
Каждому студенту перед защитой диплома начинают говорить, что не плохо бы опубликовать хоть одну научную работу. Несерьезно студенту получить квалификацию без научных исследований. Будущим журналистам и филологам задают задания на семестр, сколько научных статей они должны опубликовать перед сессией. Если не выполнить план, то можно и не получить зачет. В общем каждому студенту […]