Всем привет! В этой статье пойдет речь о том, как написать простые UI-тесты на языке Java. Это будет интересно тем, кто давно хотел попробовать себя в автоматизации или добавить новенького в свой текущий проект.
В этой статье не будет большой остановки на теории, а также на том, как настроить рабочую среду. Эти темы я упомяну кратко и дам ссылки, которые помогут разобраться в них самостоятельно.
Основная часть статьи будет посвящена практическому разбору теста и нюансам их написания.
Собирайте с собой друзей, хорошее настроение и поехали!
Что такое UI-тесты? Плюсы и минусы.
UI-тестирование – это тестирование пользовательского интерфейса программы/сайта/приложения и др.
Звучит легко, а чем такие автотесты полезны?
1) Такие тесты используются, чтобы автоматизировать рутинные задачи и однотипные действия, например, проверку товаров в каталогах.
2) Чтобы ускорить или упростить проверку сложных пользовательских путей. Например, в кейсе, где есть очень много тестовых данных и переходов или для прохождения которого нужна сильная концентрация.
3) Чтобы снять часть работы с сотрудников, если их мало на проекте, часть проверок можно перенести на автотесты.

Какие инструменты нужны?
Для написания таких тестов нужны специальные программы и инструменты. Некоторые из них требуют установки и настройки, некоторые нет. Сейчас все будет расписано по порядку.
-
DevTools — это инструмент разработчика, он встроен практически во все современные браузеры и включается по кнопке F12. Здесь потребуется вкладка Elements (Элементы).
-
ChroPath – это плагин для браузера, позволяющий быстро сформировать локатор для элемента страницы. Подробнее об это будет написано дальше. Скачать можно по ссылке: ChroPath.
-
IntelliJ IDEA by JetBrains — интегрированная среда разработки программного обеспечения. С помощью нее будут написаны тесты. Бесплатную версию этой программы можно скачать с официального сайта: Community Edition.
-
JDK Java Development Kit — «комплект для разработки на Java». Это, простыми словами, сам язык Java, без которого мы не сможем написать никакой код. Скачать его можно здесь: Сайт с Amazon Corretto. А как установить быстро и понятно можно посмотреть здесь: Как скачать и установить Amazon Corretto. Также кроме Amazon Corretto можно установить другие JDK, вот например: Инструкция.
-
Maven — инструмент для управления и сборки проектов на Java. Он очень облегчает работу с проектами, так что этот пункт не стоит пропускать. Установка Maven.
Создаем проект и добавляем туда нужные плюшки.
1. Открываем IntelliJ IDEA.
2. Нажимаем File – New – Project.
3. Выбираем тип проекта Maven (на этом моменте убедитесь, что в Project SDK стоит как раз Amazon Corretto).
4. Нажимаем Next.
5. В блокe Name задаем название проекта, а в Location папку, где он будет лежать.
6. Нажимаем Finish. Проект создан.
Настройка зависимостей
Теперь, чтобы использовать инструменты для автоматизации (Selenium, Selenide), а также пользоваться другими фреймворками и библиотеками, нужно будет импортировать зависимости. Для этого:
1. Развернуть папку с названием проекта в левом баре.

-
Открыть файл pom.xml (когда проект только-только создан файл открыт по умолчанию).
pom.xml — это XML-файл, который содержит информацию о деталях проекта, и конфигурации используемых для создания проекта на Maven. -
Добавить в project новые зависимости из списка:
<dependencies>
<dependency>
<groupId>com.codeborne</groupId>
<artifactId>selenide</artifactId>
<version>5.23.2</version>
</dependency><dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
</dependencies> -
Затем обязательно нужно нажать кнопку Load Maven Changes, чтобы изменения сохранились.

Другие зависимости можно найти и самостоятельно добавить в проект на сайте: https://mvnrepository.com.
Как работать в IntelliJ IDEA
Прежде, чем переходить к самой интересной части и начинать писать тест, я предлагаю (настоятельно ! 😊) ознакомиться с этим блоком, особенно, если вы еще не работали в IntelliJ IDEA. Иначе дальше будет сложновато сходу разобраться в интерфейсе программы.
Как создавать классы
1. В папке main-java создаем package и называем его POM (page object model).
-
Далее таким же образом создаем класс, только выбираем не package, а Java Class. Назовем класс MainPage.

3. Таким же образом создаются классы, где будут лежать тесты, только из другой папки.
Как запускать тесты
Далее, когда вы уже напишите свои первые тесты их нужно будет запустить, чтобы получить результат. Это можно сделать двумя способами.
1. Запуск теста из интерфейса. Для этого в тестовом классе нажмите кнопку play. Тест запуститься самостоятельно.

-
Запуск теста с помощью Maven. Для этого в правом блоке меню выберите команду verify и тесты запустятся точно также.

А еще это можно сделать через командную строку прямо в программе. В нижнем меню откройте вкладку Terminal и введите команду «mvn verify».
Как отладить тесты.
1. Внутри теста поставьте брекпоинты (для этого нажмите на строку рядом с нужным фрагментом кода) на моменты теста, которые хотите тщательнее проверить (это может быть нажатие на кнопки, открытие разных страниц, проверки).

2. Далее нажмите кнопку Debug.

3. Управляйте шагами теста с помощью меню.

Структура проекта
Описание POM и методов
Обычно проект состоит из нескольких классов package, в котором находятся классы POM (page object model) «объектная модель страницы». Эти классы содержат в себе описание элементов со страниц и методы для взаимодействия с ними.
//ссылка на package, в котором находится класс package POM;
//взаимосвязь с нужными библиотеками и фреймворками
import com.codeborne.selenide.SelenideElement;
import org.openqa.selenium.support.FindBy;
import org.openqa.selenium.support.How;
//взаимосвязь с нужными библиотеками и фреймворками название класса
public class TestClassPage {
//описание SelenideElement (элемент со страницы)
@FindBy(how = How.XPATH (CLASS_NAME, NAME, ID и др) using = "локатор xpath или название класса (другого атрибута) элемента")
private SelenideElement elementName;
//метод для взаимодействия с вышеописанным элементом
public TestClass testMethodName() {
elementName.click();
return this;
}
}
В классах добавляются конструкции для описания SelenideElement. Таким образом элемент описывается как переменная. Благодаря этому с ним удобнее будет взаимодействовать и поменять локатор, если понадобится.
В How прописываем атрибут элемента, в этом случает это имя класса, а в using значение класса, которые находим в elements. Атрибутом может быть Xpath, Class_NAME, NAME и много других.

Теперь напишем метод для взаимодействия с элементом. Почему нельзя просто взять элемент и с ним делать всякие вещи в тесте? Можно, но так возможно получить различные ошибки как при написании кода, так при воспроизведении теста, так как не будет соблюдаться принцип инкапсуляции (об этом можно прочитать на досуге 😊).

Чтобы написать метод добавляем в код такую конструкцию.
public MainPage goToTheEnterAccountButton() {
enterToAccountButton.click();
return this;
}
Когда написали внутри метода имя переменной с кнопкой «Войти», поставьте рядом с ним точку. Вы увидите все доступные взаимодействия для этого элемента.
Так как нужно нажать на кнопку, чтобы перейти на страницу авторизации, выберем функцию click.
Метод готов, теперь его можно будет вызвать в тесте.
Как еще можно взаимодействовать с элементом.
Также можно обратиться к элементу на странице без описания его как отдельной переменной. Для этого можно не описывать переменную, а искать элемент с помощью локатора сразу в методе.
Подбор атрибута и локатора аналогичен тому, как это делается в SelenideElement.
$(byText("Тест элемент")).shouldBe(Condition.visible).click();
$(byClassName("test_element_class")).shouldBe(Condition.visible).click();
$(byId("test_element_id")).shouldBe(Condition.visible).click();
$(byName("element_name")).shouldBe(Condition.visible).click();
Описание тестового класса.
Из чего состоит тестовый класс показано ниже. Эту структуру можно использовать в своих проектах.
import POM.TestClassPage;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import static com.codeborne.selenide.Selenide.*;
import static com.codeborne.selenide.Selenide.closeWebDriver;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertTrue;
//название тестового класса
public class TestClass {
//обращение к классу из POM, чтобы взаимодействовать с его элементами
private TestClassPage testClassPage;
//переменные, которые могут быть нужны в тесте
private final String number = "12121212";
//аннотация Before - внутри прописывается то, что нужно сделать ДО теста
@Before
public void setUp() {
//открытие страницы веб-сайта с привязкой его к классу из POM; делается с
//помощью инструментов Selenide (WebDriver)
testClassPage = open("https://testSite.ru/", TestClassPage.class);
}
//аннотация After, содержит то, что нужно сделать ПОСЛЕ теста
@After
public void tearDown() {
//эти методы очищают куки и закрывают браузер
clearBrowserCookies();
clearBrowserLocalStorage();
closeWebDriver();
}
//аннотация Test, здесь содержится сам тест и проверки
@Test
//название теста
public void testName() {
//вызов класса из POM, а затем вызов меетода, относящегося к этому классу
testClassPage.clickToEnterButton();
//проверка с помощью Assert (бывают разные типы проверок) - здесь проверяется условие
//на истинность - в скобках указывается условие, которое нужно проверить.
assertTrue(testClassPage.openAuthPage());
}
}
Начнем писать автотесты
Первый тест
Работа в POM
Чтобы написать первый тест разберем небольшой тест-кейс.
1. Открываем сайт https://rostov.rt.ru/
2. Нажимаем на кнопку «Войти».
3. На странице авторизации проверяем заголовок. Нужно убедиться, что открылась именно страница авторизации.
Что мы видим из этого тест-кейса? За один маленький тест открывается 2 страницы, а также идет взаимодействие с двумя элементами. Это нужно будет описать в коде. Начнем с описания кнопки и заголовка.
Для этого пойдем по следующему алгоритму:
1. Создайте package и назовите его POM.
2. В package создайте класс и назовите его MainPage.
3. Так как нужно описать кнопку «Войти» идем в DevTools, открываем вкладку Elements. Выберите инструмент для просмотра элементов.

4. В коде страницы видим следующую конструкцию, которая подсвечивается при наведении на кнопку «Войти»:
![]()
5. Создаем Selenide Element с этим классом.
@FindBy(how = How.XPATH, using = "sp-l-0-2")
private SelenideElement enterToAccountButton;
6. Создаем метод для взаимодействия с кнопкой «Войти». В реальности мы бы кликнули на нее левой кнопкой мыши. Здесь за такое же действие отвечает функция click().
public MainPage goToTheEnterAccountButton() {
enterToAccountButton.click();
return this;
}
Дальше нужно описать вторую страницу, используемую в тесте.
1. В POM создаем класс AuthPage. Дальше описываем заголовок страницы как SelenideElement.
2. Написать локатор к титулу можно и с по CLASS_NAME, и по Xpath. На этом этапе советую использовать ChroPath.

3. Если использовать Xpath, то локатор можно просто скопировать из расширения и вставить в код.
@FindBy(how = How.XPATH, using = "//h1[contains(text(),'Авторизация по коду')]")
private SelenideElement authPageTittle;
4. Теперь напишем метод для проверки текста заголовка.
Используем ту же конструкцию, что дана в части «Структура проекта». Только тип возвращаемых данных меняем на Boolean. Это нужно потому, что мы будем проверять истинность условия (действительно ли заголовок содержит текст «Авторизация по коду»).
public boolean openAuthPage() {
//вызываем переменную с заголовком
//дальше пишем условие - переменая должна содержать текст и в скобках пишем необходимый текст
authPageTittle.shouldHave(Condition.exactText("Авторизация по коду"));
//если условие указанное выше выполняется, то метод должен вернуть true - правда
return true;
}
Дальше этот метод тоже можно будет использовать в тесте.
Написание теста
Тестом считается именно часть кода, написанная внутри метода под аннотацией @Test. Но нужно учитывать и то, что нужно будет сделать до и после теста.
На подготовительном этапе можно открыть страницу, перейти к нужному разделу сайта.
А после теста нужно провести «уборку», например, удалить пользователей или другие данные, которые были созданы в процессе.
1. Создадим тестовый класс EnterTest.
2. И сразу обращаемся к классам, с которыми будем взаимодействовать.
private MainPage mainPage;
private AuthPage authPage;
3. В этом случае перед тестом нужно открыть главную страницу сайта. Этот этап пойдет в аннотацию Before.
@Before
public void setUp() {
mainPage = open("https://voronezh.rt.ru/", MainPage.class);
}
4. Дальше (уже внутри теста) происходит нажатие на кнопку «Войти». Тест нужно будет назвать. Название должно передавать смысл проверки и содержать слово Test.
@Test
public void openAuthorizationTest() {
mainPage.goToTheEnterAccountButton();
}
5. Затем открывается уже другая страница, связанная с классом AuthPage. Ее нужно открыть точно также, как MainPage в начале теста, иначе программа не поймет с какой страницы она должна брать данные.
@Test
public void openAuthorizationTest() {
mainPage.goToTheEnterAccountButton();
authPage = open("https://b2c.passport.rt.ru/auth/realms/b2c/protocol/openid-connect/" +
"auth?client_id=lk_decosystems&redirect_uri=https://rostov.rt.ru/&response_type=" +
"code&scope=openid&_gl=1*1chzy0a*_ga*Mjk0OTYxOTY2LjE2NjQyNzU1MTY.*" +
"_ga_9G5GWSHJG0*MTY3MTcyODk1NS4xOS4xLjE2NzE3MjkwMzcuNTEuMC4w", AuthPage.class);
6. А затем по тесту мы должны провести проверку – правильный ли на странице заголовок. Последний шаг теста можно добавить сразу же в Assert.
@Test
public void openAuthorizationTest() {
mainPage.goToTheEnterAccountButton();
authPage = open("https://b2c.passport.rt.ru/auth/realms/b2c/protocol/openid-connect/" +
"auth?client_id=lk_decosystems&redirect_uri=https://rostov.rt.ru/&response_type=" +
"code&scope=openid&_gl=1*1chzy0a*_ga*Mjk0OTYxOTY2LjE2NjQyNzU1MTY.*" +
"_ga_9G5GWSHJG0*MTY3MTcyODk1NS4xOS4xLjE2NzE3MjkwMzcuNTEuMC4w", AuthPage.class);
assertTrue(authPage.openAuthPage());
}
Первый тест готов. Теперь его можно запускать. При запуске программа сама запустит тест в браузере Google Chrome.
После успешно пройденного теста вы увидите внизу экрана такое изображение:

В случае, если тест завершился неудачно или с ошибками нужно провести дебаг и выяснить, на каком этапе теста падает ошибка.
Второй тест
Теперь возьмем за основу первый тест и немного усложним его. Будем вводить в поле на странице авторизации несуществующий номер телефона и нажимать на кнопку «Получить код». А потом проверим, что на экране появилось сообщение об ошибке.
POM
Для этого нужно будет дописать элементы и методы в классе AuthPage.
1. Бокс для номера телефона или email опишем через Xpath. Но также можно это сделать через How.ID.

Получается такая переменная:
@FindBy(how = How.XPATH, using = "//input[@id='address']")
private SelenideElement setNumberOrEmail;
2. Сразу напишем метод с этим боксом. В нем будет возвращаться содержимое страницы, так что тип данных напишем AuthPage. Еще в методе нужно будет передать переменную, в которой будет содержаться номер телефона или email.
Для этого в скобках у названия пишем String (тип передаваемых данных, в этому случае – строка) и название переменной.
public AuthPage setNumberOrEmail(String number) {
return this;
}
Дальше нужно описать действие, имитирующее заполнение бокса. Вызываем переменную setNumberOrEmail и функцию setValue. В скобках функции передаем переменную (их может быть несколько).
public AuthPage setNumberOrEmail(String number) {
setNumberOrEmail.setValue(number);
return this;
}
3. Опишем кнопку «Получить код». Описать локатор также можно через Xpath, попробуйте найти его самостоятельно на сайте.
@FindBy(how = How.XPATH, using = "//button[@id='otp_get_code']")
private SelenideElement getCodeButton;
4. Дальше пишем метод, который нажимает на кнопку «Получить код». Он не будет возвращать true или false, не будет содержать переменных. Поэтому этот метод можно сделать по аналогии с тем, что был дан в первом тесте.
public AuthPage getCode() {
getCodeButton.click();
return this;
}
5. Опишем переменную с текстом ошибки. Это можно сделать как с помощью CLASS_NAME, так и с Xpath.
@FindBy(how = How.CLASS_NAME, using = "rt-input-container")
private SelenideElement errorText;
6. Напишем метод с проверкой текста сообщения об ошибке. Он будет аналогичен методу из первого теста.
public boolean getErrorText() {
errorText.shouldHave(Condition.exactText("<div class="rt-input-container rt-input-container--error email-or-phone otp-form__address">E-mail или мобильный телефонn" +
"Введите телефон в формате +7ХХХХХХХХХХ или +375XXXXXXXXX, или email в формате example@email.ru</div>"));
return true;
}
Тест
Этот тест можно будет написать в том же тестовом классе, так как происходит проверка функциональности из одного блока.
1. В тестовом классе описываем переменную. В ней будет содержаться условный номер телефона.
private final String number = "12121212";
2. Создаем новый тест и называем его по-другому. Нажатие на кнопку «Войти» и открытие страницы авторизации остается также, как и в прошлом тесте.
3. Чтобы написать номер телефона на странице вызовем 2 метода с authPage. Это можно сделать так:
authPage.setNumberOrEmail(number);
authPage.getCode();
А можно таким образом. Этот способ предпочтительнее, так как тест выглядит лаконичнее.
authPage.setNumberOrEmail(number)
.getCode();
4. Делаем проверку, которая тоже аналогична проверке из первого теста.
assertTrue(authPage.getErrorText());
Третий тест
В третьем тесте нужно будет открыть вкладку «Интернет» на главной странице. Затем из выпадающего меню выберем вкладку «Домашний интернет». После этого совершится переход на новую страницу и там нужно будет выбрать тариф «Облачный». После выбора тарифа будет открыта страница с подробностями о нем и нужно будет убедиться, что открыта правильная страница.
POM
1. В классе MainPage описываем кнопку «Интернет» и метод для взаимодействия с ней.
@FindBy(how = How.XPATH, using = ".//span[contains(text(),'Интернет')]")
private SelenideElement internetButton;
Метод строится также по стандартному типу.
public MainPage clickToInternetButton() {
internetButton.click();
return this;
}
2. Чтобы описать кнопку «Домашний интернет» будем использовать команду Find. Здесь проще всего искать ее по тексту.
public MainPage clickToHomeInternetButton() {
$(byText("Домашний интернет")).shouldBe(Condition.visible).click();
return this;
}
3. Дальше откроется страница с выбором тарифов. Для нее создадим новый класс. Назовем его HomeInternetPage.
На странице нужно будет нажать на стрелку, чтобы прокрутить бары с выбором тарифов, а затем нажать на карточку с тарифом «Облачный».
4. Описать кнопку-стрелку можно с помощью CLASS_NAME.

Получается так:
@FindBy(how = How.CLASS_NAME, using = "rt-carousel-v3-arrow")
private SelenideElement arrowButton;
5. Чтобы описать нажатие на карточку тарифа будем нажимать на заголовок. Описать его лучше всего через Xpath, так как class name не уникальный в данном случае для разных тарифов.
@FindBy(how = How.XPATH, using = "//div[contains(text(),'Облачный')]")
private SelenideElement oblachInternetButton;
6. В этот раз можно объединить действия в общем методе под названием chooseTariff.
public HomeInternetPage chooseTariff() {
arrowButton.shouldBe(Condition.visible).click();
oblachInternetButton.click();
return this;
}
7. Теперь опишем класс для страницы с подробным описанием тарифа. Я заранее называю его CreateOrderPage, так как дальше он будет использоваться еще и в другом тесте.
Для этого теста достаточно описать заголовок страницы и метод с ним.
@FindBy(how = How.XPATH, using = "//h2[contains(text(),'Облачный')]")
private SelenideElement tariffTitle;
public boolean textFromTitleOrder() {
tariffTitle.shouldHave(Condition.text("Облачный"));
return true;
}
Дополнения к тесту
А еще на этом этапе усложним часть, описанную в @Before.
Каждый раз, когда в браузере открывается домашняя страница сайта в самом начале теста мы видим всплывающее окно – с выбором города. Добавим сюда метод с нажатием на кнопку «Продолжить».
Для этого в MainPage добавим кнопку:
@FindBy(how = How.CLASS_NAME, using = "rt-button-small");
private SelenideElement continueButton
И метод:
public MainPage clickToContinueButton() {
continueButton.click();
return this;
}
Теперь этот метод можно вызывать перед тестом.
Тест
1. Создадим тестовый класс InternetTariffTest. В нем сразу нужно будет обратиться к трем страницам.
private MainPage mainPage;
private HomeInternetPage homeInternetPage;
private CreateOrderPage createOrderPage;
2. В @Before теперь добавляем еще один метод с подтверждением региона.
@Before
public void setUp() {
mainPage = open("https://voronezh.rt.ru/", MainPage.class);
mainPage.clickToContinueButton();
}
3. В самом тесте сначала вызываем методы с открытием страницы «Домашний интернет».
@Test
public void chooseInternetTariffTest() {
mainPage.clickToInternetButton()
.clickToHomeInternetButton();
4. Затем открываем страницу с выбором тарифов и вызываем метод.
@Test
public void chooseInternetTariffTest() {
mainPage.clickToInternetButton()
.clickToHomeInternetButton();
homeInternetPage = open("https://voronezh.rt.ru/homeinternet", HomeInternetPage.class);
homeInternetPage.chooseTariff();
5. После этого переходим на страницу с подробной информацией о тарифе и делаем проверку.
@Test
public void chooseInternetTariffTest() {
mainPage.clickToInternetButton()
.clickToHomeInternetButton();
homeInternetPage = open("https://voronezh.rt.ru/homeinternet", HomeInternetPage.class);
homeInternetPage.chooseTariff();
createOrderPage = open("https://voronezh.rt.ru/about_offer?offer=418923262504&cardId" +
"=3ee2ecc6&lcs=active&pr7=" +
"POSTPAIDUNLIM&ref=%2Fhomeinternet&tech=" +
"2&speed=100&tech=2&speed=100&tech=2&speed=100&cardPos=5",
CreateOrderPage.class);
assertTrue(createOrderPage.textFromTitleOrder());
}
Четвертый тест
В этом тесте нужно будет оформить заявку на подключение тарифа, выбранного на прошлом этапе. Но при этом заявку нужно оформить с некорректными данными. А потом проверить, что на странице появились сообщения об ошибке.
POM
Для оформления заявки нужно заполнить поля с адресом, именем и номером телефона. Потом нажать кнопку отправить. Но если адрес и номер некорректные, то на странице появятся 2 сообщения. Все эти элементы и нужно описать.

1. В данном случае все боксы для данных удобно описать с помощью атрибута Name.
@FindBy(how = How.NAME, using = "address")
private SelenideElement addressBox;
@FindBy(how = How.NAME, using = "fullName")
private SelenideElement nameBox;
@FindBy(how = How.NAME, using = "phoneNumber")
private SelenideElement numberBox;
2. Сообщения об ошибке можно описать по Xpath, а можно найти в методе с помощью find.
@FindBy(how = How.XPATH, using = "//span[contains(text(),'Выберите дом из справочника')]")
private SelenideElement errorAddress;
@FindBy(how = How.XPATH, using = "//span[contains(text(),'Введите существующий номер телефона')]")
private SelenideElement errorPhone;
3. Чтобы заполнить заявку можно сделать метод, который будет получать 3 переменные String и заполнять соответствующие поля.
public CreateOrderPage fillOrder(String address, String name, String phoneNumber) {
addressBox.setValue(address);
nameBox.setValue(name);
numberBox.setValue(phoneNumber);
return this;
}
4. А далее нужно написать метод, который будет проверять, что сообщения об ошибках отображаются на странице. В предыдущих методах мы проверяли, содержит ли элемент текст. Теперь будет проверяться то, существует ли элемент на странице.
public boolean errorMessagesIsVisible() {
errorAddress.shouldBe(Condition.visible);
errorPhone.shouldBe(Condition.visible);
return true;
}
Тест
В этом тесте нужно будет заполнить заказ и проверить, отобразились ли ошибки. В @Before будет практически полностью содержаться предыдущий тест.
1. Создадим тестовый класс CreateInternetOrderTest. Обратимся к страницам, которые будут использоваться в тесте.
private MainPage mainPage;
private HomeInternetPage homeInternetPage;
private CreateOrderPage createOrderPage;
2. Дальше нужно создать переменные.
private final String address = "г Воронеж, ул Минская, д 100000";;
private final String name = "Иванов Иван Иваныч";
private final String phone = "7900000000"
3. В @Before прописывается полный путь вплоть до открытия страницы с подробностями о тарифе.
@Before
public void setUp() {
mainPage = open("https://voronezh.rt.ru/", MainPage.class);
mainPage.clickToInternetButton()
.clickToHomeInternetButton();
homeInternetPage = open("https://voronezh.rt.ru/homeinternet", HomeInternetPage.class);
homeInternetPage.chooseTariff();
createOrderPage = open("https://voronezh.rt.ru/about_offer?offer=418923262504&cardId=3ee2ecc6&lcs=active&pr7=" +
"POSTPAIDUNLIM&ref=%2Fhomeinternet&tech=" +
"2&speed=100&tech=2&speed=100&tech=2&speed=100&cardPos=5", CreateOrderPage.class);
}
4. А сам тест выглядит очень лаконично. Вызывается страница с созданием заявки, а потом идет проверка.
@Test
public void creatingInternetOrderWithoutFieldsTest() {
createOrderPage.fillOrder(address, name, phone);
assertTrue(createOrderPage.errorMessagesIsVisible());
}
Подведем итоги
Теперь вы умеете писать самые простые UI-тесты на Java с помощью фреймворка Selenide. Возможности автоматизированного тестирования только начинаются на этом этапе. Существуют юнит-тесты, API-тесты, которые могут выполнять другие задачи тестирования.
Но даже эти простые тесты можно улучшить. Например, с помощью фреймворка Allure или за счет комбинации UI-тестирования с другими типами тестов.
Файл с тестами, которые разобраны здесь будет приложен к статье. Можно попробовать на их основе сделать своей проект. А также внутри содержится еще один бонусный тест, его тоже можно разобрать самостоятельно в качестве маленького челленджа.
Всем удачи и спасибо за внимание!
Проект можно найти здесь: https://github.com/nadezdabokareva/RTK-demo-selenide
Продолжаем погружаться в работу тестировщика, он же — QA, quality assurance engineer. Его задача — проверить код на наличие ошибок и работу программы в разных условиях.
Мы уже писали о том, что ещё делают тестировщики и какие инструменты для этого используют:
- Кто такой инженер по тестированию и стоит ли на него учиться
- Зарплата 113 тысяч за то, чтобы ломать программы
- Тестируем и исправляем калькулятор на JavaScript
- Словарь тестировщика: автотесты, юнит-тесты и другие важные слова
- Какой софт нужен, чтобы стать тестировщиком
Сегодня мы попробуем написать автотесты — чаще всего именно этим занимаются тестировщики на работе.
Что такое автотесты
Автотесты — это когда одна программа проверяет работу другой программы. Работает это примерно так:
- У нас есть код программы с нужными функциями.
- Мы пишем новую программу, которая вызывает наши функции и смотрит на результат.
- Если результат совпадает с тем, что должно быть, — тест считается пройденным.
- Если результат не совпадает — тест не пройден и нужно разбираться.
Чтобы всё было наглядно, покажем работу автотестов на реальном коде.
Исходная программа
Допустим, мы пишем интерактивную текстовую игру — в ней всё оформляется текстом, и развитие игры зависит от ответов пользователя. Мы сделали отдельный модуль, который делает четыре вещи:
- получает имя игрока;
- принудительно делает в имени большую букву (вдруг кто-то случайно ввёл с маленькой);
- добавляет к нему приветствие;
- сформированную строку отправляет как результат работы функции.
# Собираем приветствие
def hello(name):
# делаем первую букву имени большой
out = name.title()
# формируем приветствие
out = 'Привет, ' + out + '.'
# возвращаем его как результат работы функции
return outЭта функция хранится в файле hello_function.py — так мы разбиваем программу на модули, каждый из которых делает что-то своё.
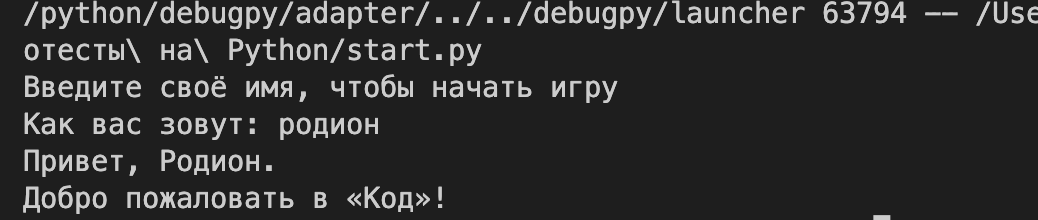
Напишем начало основной программы, которая запрашивает имя, формирует приветствие и добавляет к нему стартовую фразу:
# импортируем функцию из другого файла
from hello_function import hello
# объясняем, что нужно сделать пользователю
print("Введите имя, чтобы начать игру")
# спрашиваем имя
name = input("Как вас зовут: ")
# обрабатываем имя и формируем приветствие
result = hello(name)
# добавляем вторую строку
print(result + " nДобро пожаловать в «Код»!")Сохраним это в новом файле start.py и запустим его:
Вроде работает, но хорошо бы проверить, а всегда ли приветствие будет формироваться правильно? Можно сделать вручную, а можно написать автотест.
Пишем автотест
Первое, что нам нужно сделать, — подключить стандартный модуль для автотестов unittest. Есть модули покруче, но для наших проектов стандартного хватит с запасом. Также получаем доступ к функции hello() из файла hello_function.py — работу именно этой функции мы будем проверять автотестом.
# подключаем модуль для автотестов
import unittest
# импортируем функцию из другого файла
from hello_function import hello
А теперь самое важное: нам нужно объявить класс и функцию, внутри которой и будет находиться наш тест. Причём название функции должно начинаться с test_, чтобы она выполнялась автоматически.
Внутри функции делаем такое:
- формируем данные, которые мы отправляем в тестируемую функцию;
- прописываем ожидаемый результат.
Этими действиями мы как будто вызываем ту функцию и смотрим, получилось ли то, что нам нужно, или нет. При этом нам не нужно обрабатывать результаты тестов — за нас это сделает модуль unittest.
Для запуска тестов добавляем в конец кода стандартный вызов. Читайте комментарии, чтобы лучше вникнуть в код:
# подключаем модуль для автотестов
import unittest
# импортируем функцию из другого файла
from hello_function import hello
# объявляем класс с тестом
class HelloTestCase(unittest.TestCase):
# функция, которая проверит, как формируется приветствие
def test_hello(self):
# отправляем тестовую строку в функцию
result = hello("миша")
# задаём ожидаемый результат
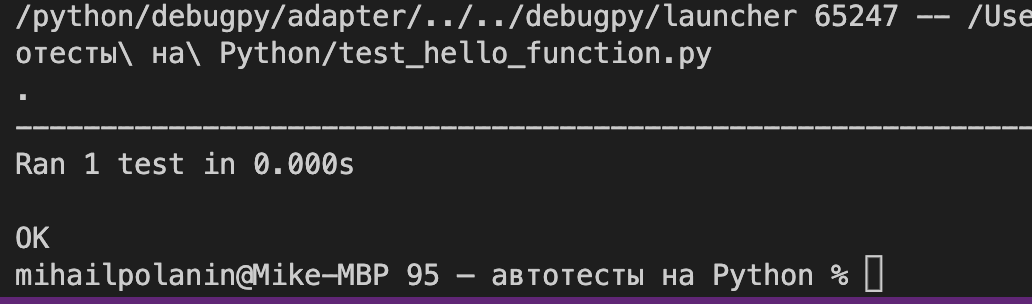
self.assertEqual(result, "Привет, Миша.")
# запускаем тестирование
if __name__ == '__main__':
unittest.main() После запуска мы увидим такое. Ответ «OK» означает, что наш тест сработал и завершился без ошибок:
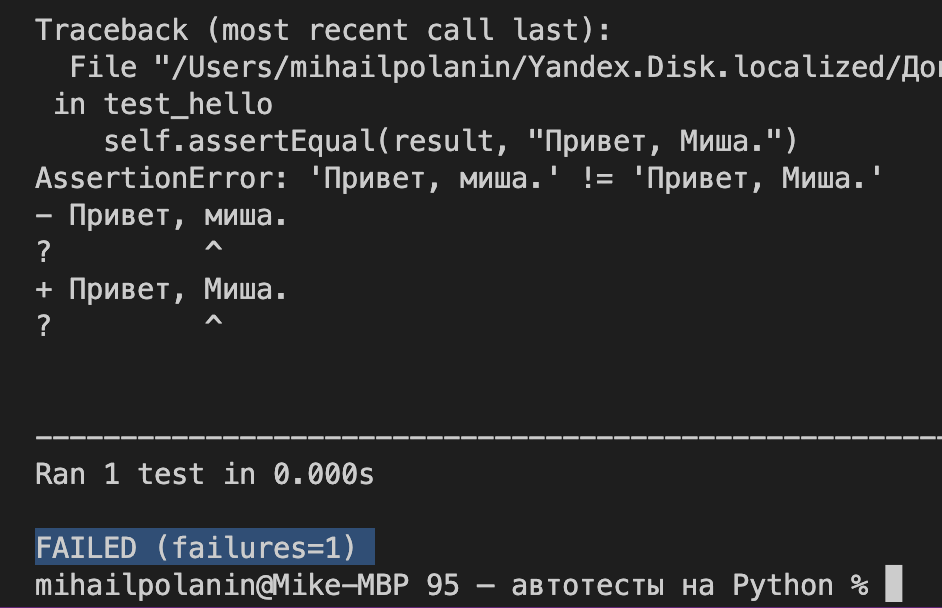
Ещё такие тесты позволяют найти ошибки в самом коде. Допустим, разработчик забыл добавить принудительный перевод большой буквы в имени, и тогда тест не пройдёт. Если получится, система даже подсветит, что именно не совпало в результате, — в нашем случае это первая буква имени.
Что дальше
Мы написали самый простой тест и всего с одним условием. При этом мы не проверили тестами работу основной программы — в реальном проекте это тоже нужно было бы сделать. Чтобы попрактиковаться, мы сделаем тесты для одного из наших старых проектов на Python. Заодно проверим, нет ли там каких ошибок, которые мы не заметили.
Вёрстка:
Кирилл Климентьев

Написать автотест на Java не сложно. Даже без навыков программирования автоматизировать смоук небольшого проекта можно вооружившись знаниями с какого-нибудь мастер-класса.
Трудности начнут появляться по мере роста проекта. Увеличение числа автотестов заставит задуматься об оптимизации скорости их выполнения, организации кода, паттернах проектирования. Сложные кейсы и дальнейшее развитие тестового фреймворка уже потребуют уверенных знаний языка программирования и использования различных библиотек. Чем глубже будет проходить погружение тем с большим количеством технологий придется взаимодействовать, что одновременно и сложно и увлекательно.
Свои первые шаги в автотестах я делал в Яндексе, откуда затем проделал долгий путь до руководителя команды автоматизации тестирования во ВКонтакте, где на момент написания статьи вместе с коллегами развиваю тестовые фреймворки и инструменты для экосистемных проектов VK.
Меня периодически спрашивают «какими знаниями нужно обладать, чтобы начать писать автотесты на Java». В данной статье собрал список того, что считаю полезным со ссылками на материалы для изучения.
Определиться с языком программирования
В 2023 году Java всё ещё один из самых популярных языков программирования, в том числе для автоматизации тестирования. Но прежде чем погрузиться в мир Java, убедитесь, что именно она подходит вам и вашему проекту.
Автотесты можно писать почти на любом языке. Возможно, вы уже знаете какой-либо язык программирования или даже целый стек технологий для автоматизации. Если команда поддержит его и есть уверенность, что в долгосрочной перспективе ваше решение хорошо себя зарекомендует – используйте его.
Однако, при выборе языка для написания автотестов в первую очередь стоит обратить внимание на тот, который используется в вашем проекте. Преимущества очивидны: единая кодовая база, тесты можно катить одновременно с фичами, экспертиза и помощь разработчиков пишущих с тестировщиками на одном языке.
Если у вас уже есть команда автоматизации, и она использует язык отличный от того, на котором написан проект, то возможные проблемы если и имели место быть, то скорее всего решены до вас. Смело выбирайте язык, который использует команда. Преимущества: готовый фреймворк и инфраструктура, наличие экспертов в команде.
Если у вас нет проекта, и вы не знаете какой язык выбрать для изучения, попробуйте обратиться к трендам:
- TIOBE – рейтинг основан на количестве инженеров работающих с языком, курсов и поисковых запросов из Google, Bing, Yahoo!, Wikipedia, Amazon, YouTube и Baidu.
- PYPL (PopularitY of Programming Language) – индекс ориентируется на то, как часто в Google ищут учебные материалы по определенному языку.
- StackOverflow – рейтинг на основе самого популярного форума программистов.
- Octoverse – рейтинг крупнейшего сервиса для хостинга IT-проектов и совместной разработки.
- IEEE – рейтинг института инженеров электротехники и электроники.
Вместе с Java в автоматизации тестирования уверенно лидируют Python, JavaScript и С#.
Научиться программировать
Первые автотесты можно написать не имея опыта разработки. Но чтобы писать хороший код, научиться программировать придётся.
Ниже представлены ссылки на курсы и книги, которые будут полезны как для изучения Java так и программирования в целом.
Курсы по Java
- Официальный онлайн учебник по Java от Oracle
- JavaRush. Один из лучших онлайн-курсов по программированию на Java
- CodeGym – клон JavaRush на английском языке
- Java Basics (и другие курсы по Java) от Epam
- Интерактивный курс по Java от Sololearn
- Курс Java for Beginners от Hyperskill и JetBrains
- JavaBegin – fullstack обучение Java/Kotlin для новичков и профессионалов
- Вопросы для собеседования на Java Developer
Книги по Java
- Изучаем Java. Бэйтс Берт, Сьерра Кэти
- Java. Руководство для начинающих. Герберт Шилдт
- Java для чайников. Барри Бёрд
- Java. Библиотека профессионала, Кей С. Хорстманн
- Java. Методы программирования. Романчик Валерий, Блинов Игорь
- Effective Java. Джошуа Блох
- Философия Java. Брюс Эккель
Алгоритмы, паттерны и рефакторинг
- Гарвардский курс «CS50. Основы программирования»
- leetcode.com – онлайн сервис, где можно практиковаться в решении задач по программированию
- Грокаем алгоритмы. Иллюстрированное пособие для программистов и любопытствующих
- Head First. Паттерны проектирования. Эрик Фримен, Берт Бейтс, Кэти Сьерра, Элизабет Робсон
- Чистый код: создание, анализ и рефакторинг. Роберт Мартин
- Рефакторинг: улучшение проекта существующего кода. Мартин Фаулер
- Код. Тайный язык информатики. Чарльз Петцольд
- Алгоритмы на Java. Роберт Сэджвик, Кэвин Уэйн
- Книга Погружение в паттерны проектирования, курс Погружение в Рефакторинг и примеры паттернов на GitHub от Александра Швеца, автора сайта Рефакторинг.Гуру. К сожалению сайт заблокирован в России, но доступен под VPN.
- Статьи на Хабре Пожалуй, лучшая архитектура для UI тестов и Паттерны проектирования в автоматизации тестирования
Познать среду разработки
Писать код можно хоть в блокноте, но лучше использовать IDE (Integrated Development Environment) – интегрированную среду разработки.
Кроме текстового редактора и подсветки синтаксиса, IDE включает в себя инструменты автодополнения команд (autocomplete), предупреждения ошибок, рефакторинга, горячих клавиш (shortcut) и поиска. Встроены компилятор, средства автоматизации сборки, отладчик, терминал, система управления версиями.
IntelliJ IDEA
Несколько лет назад Eclipse и NetBeans довольно часто встречались в качестве рекомендуемых IDE для написания кода на Java. Сейчас их полностью вытеснила IntelliJ IDEA от JetBrains. Бесплатная Community Edition версия работает с Java и Android, которая покрывает потребности для написания автотестов.
В неумелых руках продвинутый инструмент пользы не принесёт. Чтобы использовать IntelliJ IDEA максимально эффективно, изучите её возможности, посмотрите курсы, и важно – выучите шоткаты!
- Бесплатный курс по IntelliJ IDEA от Хайнца Кабуца
- Официальное руководство и туториалы по IntelliJ IDEA
- Канал IntelliJ IDEA от JetBrains на YouTube со множеством полезных гайдов
- Несколько полезных роликов с Heisenbug про работу в IntelliJ IDEA от Юрия Артамонова: раз, два, три
- Крутой плагин для изучения шоткатов
- IntelliJ IDEA Course на YouTube
- Создание проекта с нуля в IntelliJ IDE
- IntelliJ IDEA. Профессиональное программирование на Java – книжка аж 2005 года, часть информации устарело, тем не менее пользу извлечь можно, и это единственная книга из известных мне на русском языке.
VS Code
Ещё одна популярная IDE Visual Studio Code так же предоставляет возможности для работы с Java. Если привычнее использовать её, рекомендую изучить официальный java туториал: Getting Started with Java in VS Code и Testing Java with Visual Studio Code.
Прокачать GIT
Работа с кодом, тем более в команде предполагает совместную работу с ним, поэтому умение работать с Git, а вместе с ним GitHub и GitLab – очевидный скилл не только для разработчика, но и любого айтишника, в том числе тестировщика.
Хорошая новость в том, что и IntelliJ IDEA и Visual Studio Code, как и большинство IDE умеют работать с Git через графический интерфейс. Однако, понимание того, что происходит «под капотом», позволит избежать возможных ошибок.
Материалы для изучения Git
Ниже несколько ресурсов для прокачки.
- Pro Git book – самый популярный учебник по Git
- Git How To – интерактивный курс
- Git: наглядная справка – справочник по Git в картинках
- Git: курс от JavaScript.ru на YouTube – аккуратный, необходимый, слегка «продвинутый»
- Онлайн-курс «Введение в Git» от Хекслет
- Learn Git Branching – интерактивный сервис для изучения Git.
Топ 10 команд Git
В повседневной работе с Git используется не так много команд.
Например, команда из примера ниже клонирует репозиторий проекта в текущую папку на компьютере.
git clone https://github.com/адрес-вашего-репозиторияСледующая команда переключится на master – главную ветку проекта.
git checkout masterКоманда ниже подтянет из репозитория свежие изменения.
git pull origin master && git fetchКоманда ниже создаст новую ветку в локальном репозитории и переключится, например для новых тестов.
git checkout -b имя-веткиТакая же команда, но без ключа -b, позволяет переключаться между существующими ветками.
git checkout имя-веткиСледующая команда добавит все созданные и изменённые файлы в новый коммит.
git commit -a -m имя-коммитаДобавить все созданные и изменённые файлы к отслеживанию Git в текущей ветке, без создания коммита.
git add .Добавить текщие изменения к текущему, ранее созданному коммиту.
git commit --amendИ последняя команда отправит вашу ветку с текущими коммитами в удалённый репозиторий.
git push --set-upstream origin название-удаленной-веткиЕсли обнаружили ошибку, что-то поправили в локальной ветке и нужно по новой сделать пуш следом за отправленным, используйте ключ -f.
git push --set-upstream origin название-удаленной-ветки -fРазобраться со стеком технологий
Итак, вы умеете программировать (хотя бы немного), как ниндзя применяете шоткаты в IntelliJ IDEA и можете запустить программу на выполнение, а ещё без особых трудностей пушите свой код в удаленный репозиторий и знаете как разрешить конфликты в Git. Если нет – ничего страшного, этому ещё предстоит научиться, но можно двигаться дальше.
Сборщики проектов Gradle и Maven
Современная программа состоит из множества файлов и подключенных библиотек. Если вы уже знакомы с Java то знаете, что прежде чем запустить программу на исполнение, сначала её нужно скомпилировать, превратив в байт код или как говорят «собрать». Ручная сборка проектов на Java – трудоёмкий процесс, чтобы его упростить и автоматизировать, существуют так называемые сборщики проектов.
Помимо непосредственно компиляции проекта, сборщики могут выполнять и другие задачи: запускать тесты, строить отчеты, выполнять очистку временных файлов и другое.
Кроме того, программы редко пишутся с нуля и чаще всего используют сторонние наработки подключаемые в виде пакетов (библиотек) – зависимостей, которые могут хранится локально или располагаться в публичных репозиториях (как у npm в JS или Composer в PHP). Сборщики в том числе умеют управлять этими зависимостями, по-простому – подключать их к проекту. Для этого нужно лишь указать зависимость в конфигурационном файле.
Поиск пакетов для Maven и Gradle от JetBrains
Самые популярные сборщики для Java – Gradle и Maven. В ближайшее время постараюсь сделать небольшую статью по ним. А пока стоит запомнить, что:
- Функционал Gradle и Maven схож, при выборе сборщика для проекта руководствуйтесь тем что уже используется командой.
- Gradle популярнее Maven. Однако существует огромное количество проектов на Maven, и популярность не всегда играет решающую роль.
- Конифг сборки Gradle на Groovy (файл build.gradle), короче XML, используемого в Maven (файл pom.xml).
- У Gradle нет собственного репозитория, зависимости он загружает из репозитория Maven.
- Gradle работает быстрее.
Полезные ресурсы по Gradle:
- Официальный сайт Gradle
- Документация Gradle
- Онлайн события и тренинги по Gradle
- Поиск зависимостей для Gradle
Полезные ресурсы по Maven:
- Официальный сайт Maven
- Maven репозиторий
Тестовые фреймворки JUnit и TestNG
Тестовые фреймворки нужны для того, чтобы уметь отделять код автотестов от кода программы (которого может и не быть если проект содержит только тесты), размечать, группировать в сьюты и запускать автотетсы.
Два самых популярных тестовых фреймворка для Java – JUnit и TestNG. Оба сильно схожи по функциональности. Подробное сравнение фреймворков и как подключить их к проекту можно почитать в моей статье JUnit vs TestNG.
JUnit сильно популярнее TestNG, однако как и в случае с Gradle / Maven популярность не всегда играет решающую роль, исходите из своих потребностей и того, что использует команда.
На своем основном проекте во ВКонтакте я использую связку TestNG / Gradle (так исторически сложилось и прекрасно работает), но для новых проектов чаще выбираю стек JUnit / Gradle, если не знаете что использовать, рекомендую попробовать последнее.
- Официальный сайт JUnit 5
- Официальный сайт TestNG
Selenium для автотестов в браузерах
Когда упоминают Selenium, часто подразумевают ним инструмент для автоматизации UI тестов выполняемых в браузере. Однако Selenium это целое семейство продуктов:
- Selenium WebDriver – библиотека для управления браузерами, основной продукт, разрабатываемый в рамках проекта.
- Selenium Server – сервер для управления браузером с удалённой машины по сети.
- Selenium Grid – ПО для объединения нескольких Selenium-серверов в кластер.
- Selenium RC – устаревшая библиотека для управления браузерами.
- Selenium IDE – плагин для Chrome и Firefoх для записи и последующего воспроизведения действий пользователя в браузере. В контексте автоматизации тестирования на Java полностью бесполезен. Ради интереса можно «потыкать», но не более.
В контексте автоматизации тестирования интерес представляет Selenium WebDriver и в некоторой степени Selenium Server и Grid, но последние два чаще заменяют альтернативными инструментами.
Для управления Selenium WebDriver из Java, используется библиотека selenium-java. Ниже приведен пример её подключения для Gradle.
implementation('org.seleniumhq.selenium:selenium-java') {
version {
strictly seleniumVersion
}
}Как это работает:
- библиотека selenium-java позволяет обращаться из Java кода к Selenium WebDriver;
- WebDriver должен быть скачан на машину, с которой будет происходить запуск тестов;
- путь к WebDriver указывается в проекте с автотестами при инициализации драйвера в коде;
- для каждого браузера и даже каждой версии браузера нужна соответствующая версия WebDriver. Логика выбора версии драйвера для тестов реализуется в коде самостоятельно или через сторонние библиотеки, например WebDriverManager (ссылка на Maven Repository);
- на машине (локально или на сервере) на которой будут выполняться тесты должен быть установлен браузер той же версии, что и WebDriver.
- инженер по автоматизации пишет автотесты используя команды selenium-java, а «под капотом» общение selenium-java и WebDriver осуществляются по REST-протоколу;
- если тесты будут гоняться удалённо, потребуется Selenium Server.
Полезные ресурсы по Selenium:
- Официальный сайт проекта Selenium
- Онлайн учебники по Selenium Webdriver от kreisfahrer и COMAQA
- Много полезного материала с конференции Selenium Camp
- WebDriverManager (ссылка на Maven Repository) – библиотека упрощающая управление веб-драйвером (загрузка, настройка, обслуживание)
- Курс Алексея Баранцева Selenium WebDriver: полное руководство
- Полезный ролик на YouTube от Simple Automation по работе с Selenium Webdriver
- Статья по Selenium от BrowserStack
- Подготовка к собеседованию по Selenium – 30 вопросов
Selenide – прокачанный Selenium
Selenide – фреймворк, надстройка над Selenium WebDriver, но более простая и удобная в использовании.
Чтобы оценить всю мощь и прелесть Selenide, попробуйте написать десяток тестов на Selenium, а затем повторите тоже самое на Selenide.
Вот тут вместе с примерами собраны основные преимущества Selenide против Selenium, рекомендую ознакомиться, но если кратко:
- инициализация браузера 1 строкой кода вместо 5;
- не нужно выполнять закрытие браузера, Selenide сделает это самостоятельно;
- простые конструкции для поиска элементов;
- простые ассерты;
- умные ожидания – если элемент не отобразился на странице, потому что еще не загрузился, Selenide подождёт 4 секунды (по-умолчанию);
- поиск элемента по тексту;
- создание скриншотов одной командой;
- и много других «плюшек».
Полезные ресурсы по Selenide:
- Быстрый старт по Selenide (как подключить к проекту и написать первый тест)
- Selenide wiki
- Как написать UI тест за 10 минут на Selenide
- Эффективные UI-тесты на Selenide – статья с обзором возможностей Selenide от его создателя Андрея Солнцева
- Примеры использования Selenide на GitHub
- Подборка сниппетов демонстрирующих функционал Selenide
Selenoid – прокачанный Selenium Server
Если Selenide – это Selenium «на стероидах», то аналогичное можно сказать про Selenoid представляющегося лучшей альтернативой в отношении Selenium Server.
Selenium Server сложен в установке и поддержке. Все компоненты (Java, браузеры, бинарники WebDriver-ов, Selenium Server) необходимо устанавливать и конфигурировать вручную, что скорее всего вызовет затруднения если вы не продвинутый системный администратор или DevOps. Решения на Selenium Server часто не всегда стабильны. Зависшие браузеры, а часто и сервер приходится перезапускать.
В противовес Selenium Server установка Selenoid выполняется в несколько команд. Есть готовые образы для облачных серверов, в том числе для Yandex Cloud. Его отличает простой понятный интерфейс и простота в обслуживании. Зависшие браузеры автоматически перезапускаются. Имеется поддержка очередей и записи видео прохождения тестов.
Selenoid запускает браузеры изолированно в Docker-контейнерах, и это не дань моде, а полезная фича – если потребуется новый браузер, просто скачивается и подключается новый контейнер.
Если вы уже используете Selenium Server, но хотите перейти на Selenoid, кроме адреса сервера в существующем проекте ничего не придется менять.
Полезные ресурсы по Selenoid:
- Официальный сайт Selenoid
- Документация по Selenoid
- Selenoid на GitHub
Так же рекомендую посмотреть доклад Ивана Крутого, одного из создателей Selenoid и видео с Heisenbug Павла Сенина.
Тестирование API: REST Assured и Retrofit
Для API автотестов не нужны ни Selenium, ни Selenide, ни Selenoid. Чтобы отправлять запросы и получать ответы используя REST понадобятся другие инструменты: REST Assured или Retrofit. Однако кроме API тестов они могут быть полезны и при тестировании UI, например если необходимо сконфигурировать сущность участвующую в тесте, тестируемый сервис и/или проверить результат теста, когда по API это сделать проще чем через UI.
Пример простого автотеста с использованием REST Assured.
Отчеты с Allure Report
Когда количество тестов перевалит за десяток, скорее всего понадобится анализировать результаты их выполнения. Консоль IntelliJ IDEA хоть и мощный инструмент, но все же не совсем для этого подходящий.
В TestNG функционал генерации отчетов работает «из коробки». JUnit не генерирует отчет, но сохраняет результат прогона автотестов, который можно привести к удобочитаемому с помощью плагинов. Однако есть инструмент, который превосходит по функционалу любое другое решение для построения отчётов – это Allure Report.
Функционал:
- Группирует результаты веб и API-тестов, десктопных, мобильных в одном отчете.
- Удобный интерфейс.
- Тесты отображаются с подробным сценарием выполнения, включая. Если у теста есть вложения (логи, скриншоты, видео) Allure прилинкует их к тесту.
- Гибкий фильтр, группировка, поиск.
- Аналитика запуска тестов.
- Поддержка не только Java, но и других языков программирования.
- Интеграции с CI/CD системами.
Подробнее можно ознакомиться в докладе Артёма Ерошенко создателя Allure или почитать в статье на Хабре.
Полезные ресурсы по Allure Report:
- Официальный сайт Allure Report
- Как подключить к Java проекту
- Документация Allure Report
- Allure Report на GitHub
Continuous Integration
Настраивать CI прерогатива специалистов DevOps и тема для отдельной статьи. Однако, и автоматизатору данный скилл и понимание процессов несомненно полезны, особенно, если DevOps на проекте отсутствует.
Если не углубляться в подробности, то для тестирования важно уметь запускать автотесты при поставке новых фич в тестинг, релиз или продакшн и получать отчёт о результатах их прохождения. Указанное является лишь небольшой частью процесса непрерывной интеграции.
Самыми популярными CI/CD системами являются Jenkins, TeamCity, GitHub Actions, GitLab CI.
Полезные ресурсы по Jenkins:
- Официальный сайт Jenkins
- Мини руководство по Jenkins от Reg.ru
- CI/CD на примере Jenkins. Автоматизация запуска тестов
- Jenkins Pipeline. Что это и как использовать в тестировании
- Jenkins 2. Приступаем к работе. Брент Ластер
Полезные ресурсы по TeamCity:
- Официальный сайт TeamCity
- Руководство по CI/CD в TeamCity
- Пошаговые руководства TeamCity
Полезные ресурсы по GitHub Actions:
- GitHub Actions
- Автоматизируем все с Github Actions
Полезные ресурсы по GitLab CI:
- GitLab CI/CD
- GitLab CI для тестировщика (вебинар на YouTube)
Прочие полезные инструменты и библиотеки
Lombok – избавляет от необходимости написания шаблонного кода для геттеров, сеттеров, toString() и прочих, улучшая удобств и читаемость кода.
Gson – библиотека сериализации / десериализации для преобразования объектов Java в JSON и обратно.
Log4j – библиотека логирования и SLF4J – обёртка для различных библиотек логирования.
Сопутствующие технологии
Инженеру по автоматизированному тестированию недостаточно знаний одной лишь Java. В зависимости от тестируемого приложения или сервиса, придётся столкнуться со множеством других технологий.
Чтобы найти элемент на странице – нужно уметь строить локаторы, чтобы выполнить скрипт или поменять из кода значения в LocalStorage браузера – придется познакомиться с JavaScript, захотите обратиться к базе данных – пригодится SQL, понадобится определить действительно ли пользователь ввёл в поле адрес электронной почты добро пожаловать в мир регулярных выражений, а тестирование API подразумевает хорошее знание компьютерных сетей.
CSS и XPath локаторы
Автотесты для web-приложений постоянно взаимодействуют с web-элементами на странице. Нужно уметь строить их, используя локаторы.
Локатор (или селектор) – это выражение, которое идентифицирует элемент или группу элементов в DOM-дереве. Наиболее распространёнными являются CSS и XPath локаторы.
CSS локаторы включают в себя набор атрибутов web-элемента, в XPath – это путь до элемента в DOM-дереве.
Обычно на проекте используют один из видов локаторов, комбинировать их без понятной причины не рекомендуется. Выбор CSS или XPath зависит от личных предпочтений и договорённостей в команде.
- Как писать CSS/XPath локаторы в Selenium WebDriver
- Про типы локаторов и CSS, XPath, jQuery
- Шпаргалка по локаторам
- Мануал по XPath
- И немного практических примеров в статье Эффективные UI-тесты на Selenide
HTML, CSS и JavaScript
- HTML Academy: интерактивные онлай-курсы по HTML, CSS и JavaScript
- HTMLBook.RU – онлайн самоучитель и справочник посвященный HTML и CSS
- Онлайн курс по Веб-программированию от университета ИТМО
- W3Schools – интерактивный учебник по web технологиям
- Sololearn – интерактивный учебник по HTML, CSS, JS, JQuery, PHP, SQL, Java и другим языкам
- Самый популярный онлайн учебник по JavaScript на русском языке
- Справочник по JavaScript на Mozilla Developer Network
- Учебник: Выразительный Javascript
Регулярные выражения
- Регулярные выражения (Regexp) от Хекслет
- Регулярные выражения. Джеффри Фридл
- Регулярные выражения. Сборник рецептов. Ян Гойвертс, Стивен Левитан
Работа в консоли
- Основы командной строки. Курс на Хекслет
- Введение в Linux
Компьютерные сети
- Онлайн курс Основы DevOps от Epam
- Учебный курс Андрея Созыкина «Компьютерные сети» (на YouTube)
- Компьютерные сети. Принципы, технологии, протоколы Виктор Олифер, Наталья Олифер
Для любителей курсов
- Автоматизатор тестирования на Java от Яндекс Практикум
- Школа инженеров по автоматизации тестирования QA.Guru
- Инженер по тестированию: с нуля до middle от Нетологии
- Тестировщик на Java
- Тренинги Алексея Баранцева
Что еще
Научиться методу слепой печати
Советы новичкам:
- Нажимайте клавиши только правильными пальцами и всегда возвращайте пальцы в исходную позицию «ФЫВА – ОЛДЖ», это основа метода слепого набора.
- Не смотрите на клавиатуру.
- Уделите внимание развитию безымянных пальцев и мизинцев обеих рук – их моторика хуже остальных, но они не меньше остальных пальцев участвуют в наборе текста.
- На первых порах фокусируйтесь на качестве, а не на скорости, и постепенно доводите до автоматизма.
Сервисы для тренировки метода слепой печати:
- Клавогонки
- СОЛО на клавиатуре (только для WIndows)
- Klava.org
- Keybr
Подтянуть английский
- Английский от Яндекс Практикума
- Puzzle English
- Puzzle Movies – английский по фильмам и сериалам
- Duolingo
- Lingualeo
Чек-лист автоматизатора
Прочтение этой статьи занимает 20 минут, но чтобы освоить приведенные в ней технологии, понадобится по меньшей мере год.
Если желание писать автотесты не угасло, надеюсь, что минимум – появилось понимание стека технологий для автоматизации тестирования, максимум – сложился некий «roadmap», из которого понятно, над чем стоит стоит подумать и какие скилы нужно подтянуть.
Чек-лист инженера по автоматизации тестирования на Java выглядит примерно так:
- определился с языком программирования, в идеале – это язык, на котором пишут разработчики в команде, если это Java – есть понимание почему именно она;
- может рассказать про ООП, его принципы (абстракция, инкапсуляция, наследование, полиморфизм) и объяснить что такое класс, интерфейс, объект;
- знает чем различаются JRE, JVM и JDK;
- знает, что такое переменные, каких типов они бывают, сколько места в памяти занимают и какие существуют модификаторы доступа;
- умеет работать с условиями, циклами, массивами, коллекциями;
- понимает, что такое PageObject, представляет, что такое паттерны и может применять некоторые из них;
- чтобы запустить программу не использует мышь или тач-бар и знает ещё c десяток шоткатов;
- может клонировать проект, отвести от него ветку, внести свои изменения, сделать коммит, запушить обратно в общий репозиторий и не боится конфликтов и ребейзов;
- не путается в названиях Gradle, Maven, JUnit, TestNG, понимает их назначение и может использовать в проекте;
- знает что такое Selenium, Selenide, Selenoid и использует две из трёх технологий;
- без шпаргалок составляет CSS и XPath локаторы;
- умеет использовать REST Assured или Retrofit для API-тестов;
- любит или не любит Lombok;
- каждый день заглядывает в Allure Report;
- уже настроил несколько пайплайнов в Jenkins или поигрался Selenoid в GitHub Actions;
- … большой молодец раз осилил так много технологий.
На этом всё. Но вы можете поддержать проект. Даже небольшая сумма поможет нам писать больше полезных статей.
Если статья помогла или понравилась, пожалуйста поделитесь ей в соцсетях.
Мы будем использовать Selenium совместно с Python версий 3.x.x. Цель статьи – не дать фундаментальные знания по теории программирования и написания автотестов, а заинтересовать в этой области и показать, как они пишутся в целом.
1. Установка необходимых компонентов
Для начала работы нам потребуется установить Python на рабочую машину.
Переходим на официальный сайт Python и качаем установщик для вашей ОС (мы будем использовать Windows). В процессе инсталляции поставьте галочки на добавлении компонентов в системные переменные PATH. Дождитесь завершения процесса, и если программа попросит перезагрузки, перезагрузитесь. Если у вас Linux, интерпретатор может уже присутствовать в системе, в противном случае стоит установить его из репозитория пакетов вашего дистрибутива.
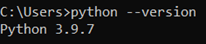
Проверьте корректность установки, перейдите в терминал (в Windows нажмите Win+R и запустите cmd или Alt+Ctrl+T в графической среде Linux). Выполните следующую команду:
python --version
Далее нам понадобится сам Selenium:
pip install selenium
Дождитесь завершения установки. Поскольку мы будем писать тест, воспользуемся популярной библиотекой pytest. Устанавливается она аналогично:
pip install pytest
Для создания приложений нужна интегрированная среда разработки или IDE (integrated development environment), но можно писать код и в обычном текстовом редакторе. Я выбрал самую популярную и удобную среду PyCharm от компании JetBrains.
Чтобы работать с браузером, помимо Selenium потребуется веб-драйвер: в нашем случае ChromeDriver – по сути это связующее звено в цепочке. Обратите внимание, что версия драйвера должна соответствовать версии браузера и вперед – к созданию проекта и написанию первого скрипта.
2. Первый скрипт с использованием драйвера
Все компоненты готовы, давайте создадим новый проект. Для
этого запускаем PyCharm и в открывшимся окне выбираем New Project.
Указываем
имя проекта и нажимаем Create.
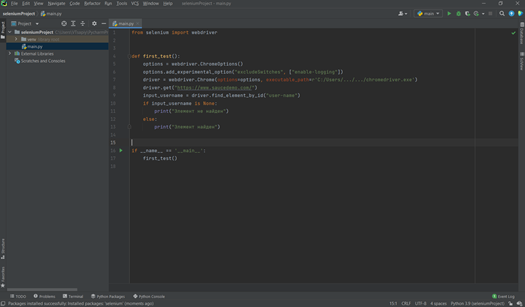
Напишем первый тест, чтобы проверить работоспособность драйвера.
В качестве примера ресурса для тестирования возьмем
популярный сайт для практики автоматизированного тестирования: https://www.saucedemo.com.
Кейс:
- Зайти на страницу.
- Найти элемент по id.
- Вывести в консоль сообщение с результатом поиска.
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options=options, executable_path=r'C:/Users/.../.../chromedriver.exe')
driver.get("https://www.saucedemo.com/")
input_username = driver.find_element_by_id("user-name")
if input_username is None:
print("Элемент не найден")
else:
print("Элемент найден")
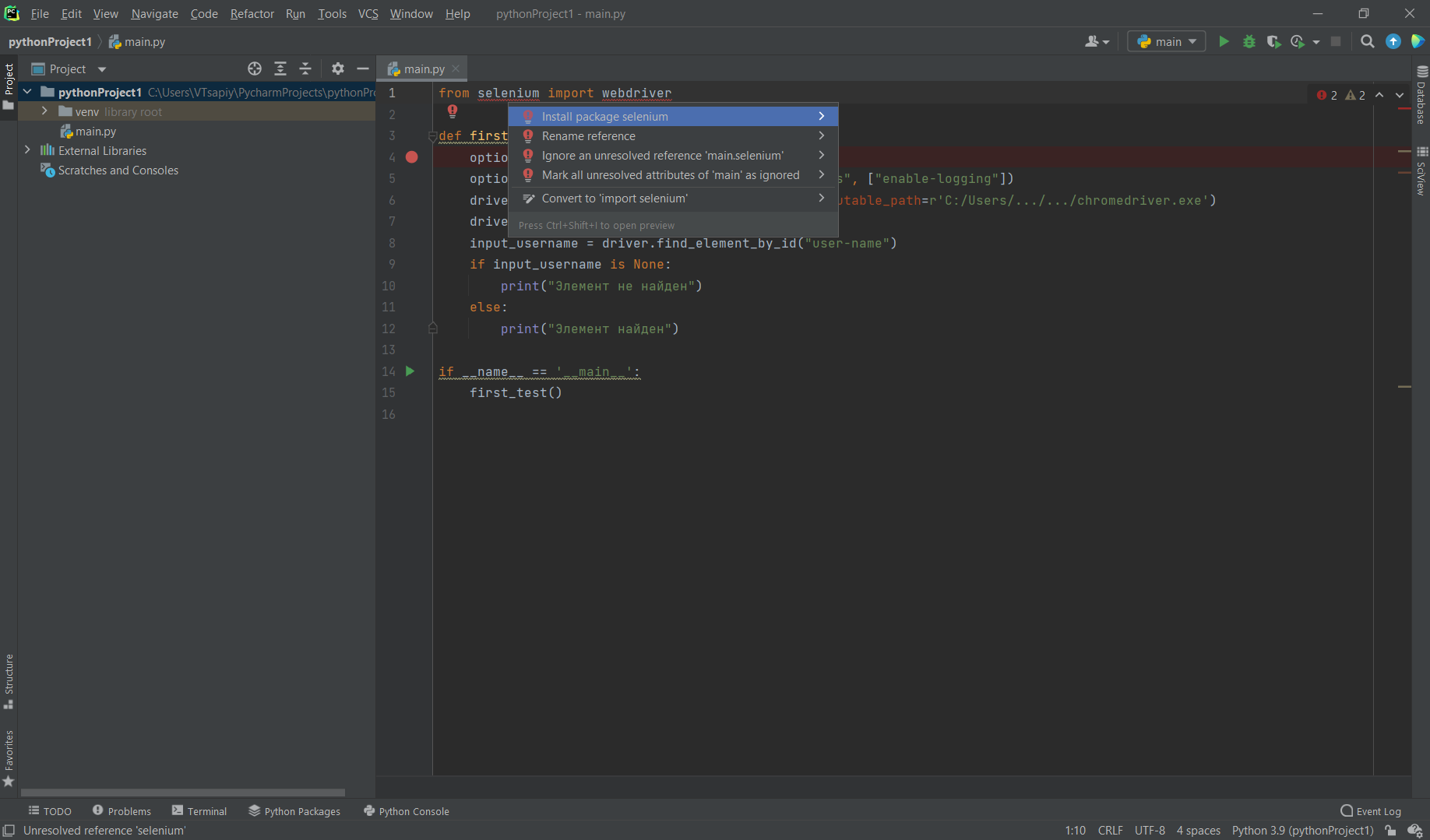
После
ввода кода необходимо установить библиотеку Selenium в наш проект.
Для
этого нажмите на подсвеченный текст в редакторе, нажмите Alt + Enter и далее
выберите Install package selenium. Это нужно делать для
каждого неустановленного пакета.
Запустить сценарий можно во встроенном эмуляторе терминала IDE или в любом другом:
python main.py
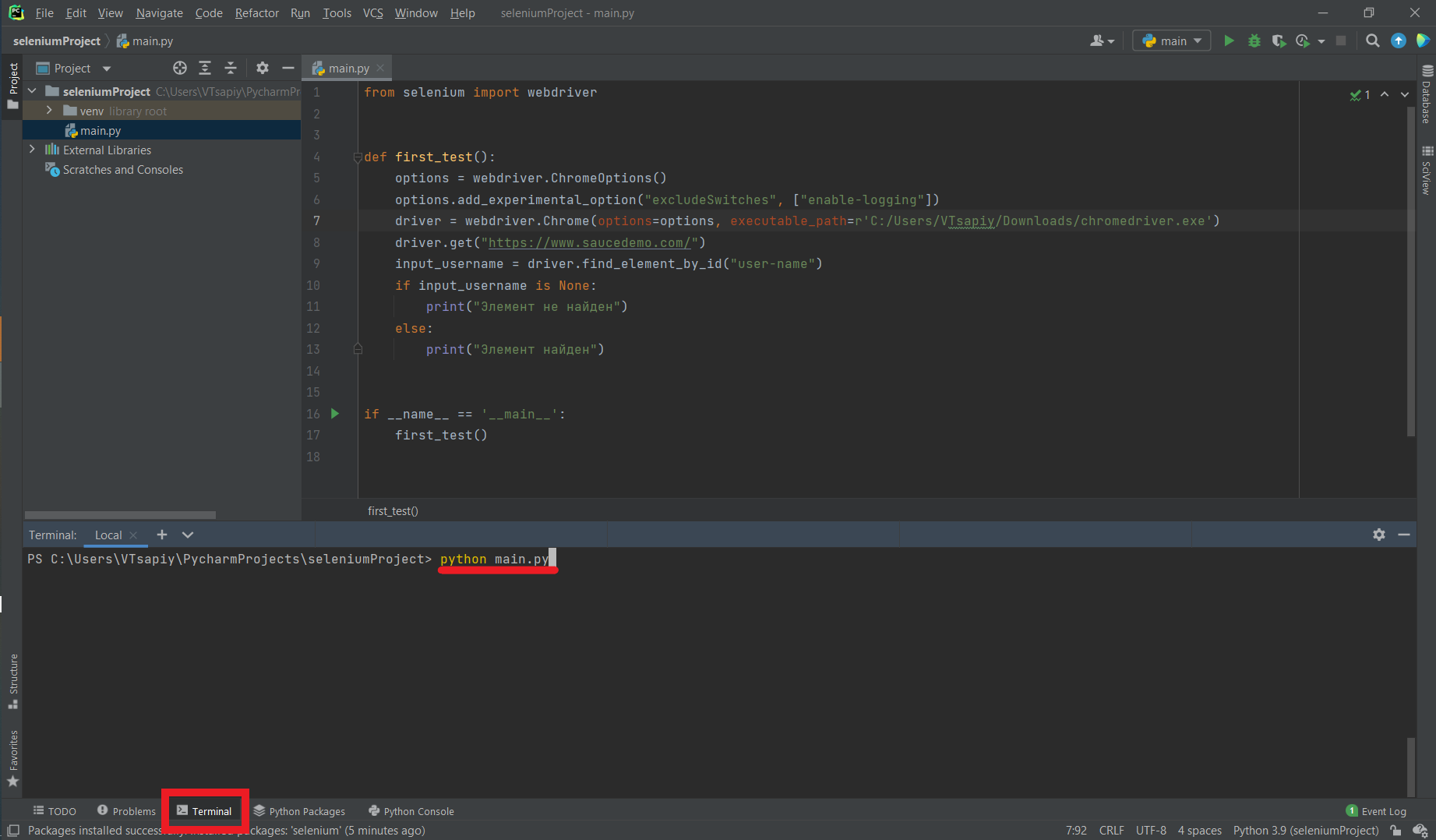
запуска скрипта из IDE
Если все установлено правильно, должен запуститься браузер,
который откроет страницу. Результатом запуска нашего сценария на Python, будет
сообщение: “Элемент найден”.

3. Поиск элементов
В нашем скрипте присутствует следующая строка:
input_username = driver.find_element_by_id("user-name")
Метод find_element_by_id позволяет процессу найти элемент в разметке HTML по наименованию атрибута id. В реализации драйвера есть несколько способов поиска элементов на странице: по name, xpath, css, id. Поиск по css и xpath являются более универсальным, но он сложнее для начинающих. Использование поиска по name и id намного удобнее, но в практической разработке используется редко. Далее я буду использовать только xpath.
Теперь
давайте напишем кейс аутентификации пользователя на странице входа:
- Шаг 1: пользователь вводит корректный
usernameиpassword. - Шаг 2: нажимает кнопку ввода.
- Ожидаемый результат: пользователь попадает на главную страницу магазина. Проверка заголовка на соответствие “PRODUCTS”.
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
def first_test():
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options=options, executable_path=r'C:/Users/.../.../chromedriver.exe')
driver.get("https://www.saucedemo.com/")
# Поиск элементов и присваивание к переменным.
input_username = driver.find_element_by_xpath("//*[@id="user-name"]")
input_password = driver.find_element_by_xpath("//*[@id="password"]")
login_button = driver.find_element_by_xpath("//*[@id="login-button"]")
# Действия с формами
input_username.send_keys("standard_user")
input_password.send_keys("secret_sauce")
login_button.send_keys(Keys.RETURN)
# Поиск и проверка попадания на главную страницу
title_text = driver.find_element_by_xpath("//*[@id="header_container"]/div[2]/span")
if title_text.text == "PRODUCTS":
print("Мы попали на главную страницу")
else:
print("Ошибка поиска элемента")
time.sleep(5)
if __name__ == '__main__':
first_test()
Разберем
пример пошагово:
- Для работы с формой найдем и присвоим элементы переменным
input_username,input_passwordиlogin_buttonс помощьюxpath. - Далее вызовем для элемента метод
send_keysс данными, которые хотим передать в текстовое поле. В нашем случае вusernameотправляем «standart_user», вpassword– «secret_sauce». Проецируя поведение пользователя нажимаемEnterдля ввода данных, используя методsend_keysдля найденной кнопки с переданным аргументомKeys.RETURN. Этот аргумент позволяет работать с действиями клавиатуры в Selenium, аналогично нажатию наEnterна клавиатуре. - На главном экране нам необходимо найти и присвоить переменной элемент текста
Products. Как я говорил раннее, не всегда есть возможность найти элемент поid– здесь как раз тот случай.
title_text = driver.find_element_by_xpath("//*[@id="header_container"]/div[2]/span")
- Путь
xpathдо элемента://*[@id="header_container"]/div[2]/span. - Чтобы найти путь
xpath, зайдите на https://www.saucedemo.com и нажмите F12, чтобы открыть инструменты разработчика. Затем выберите стрелку-указатель и кликните по элементу до которого хотите найти путь. В нашем случае доProducts.
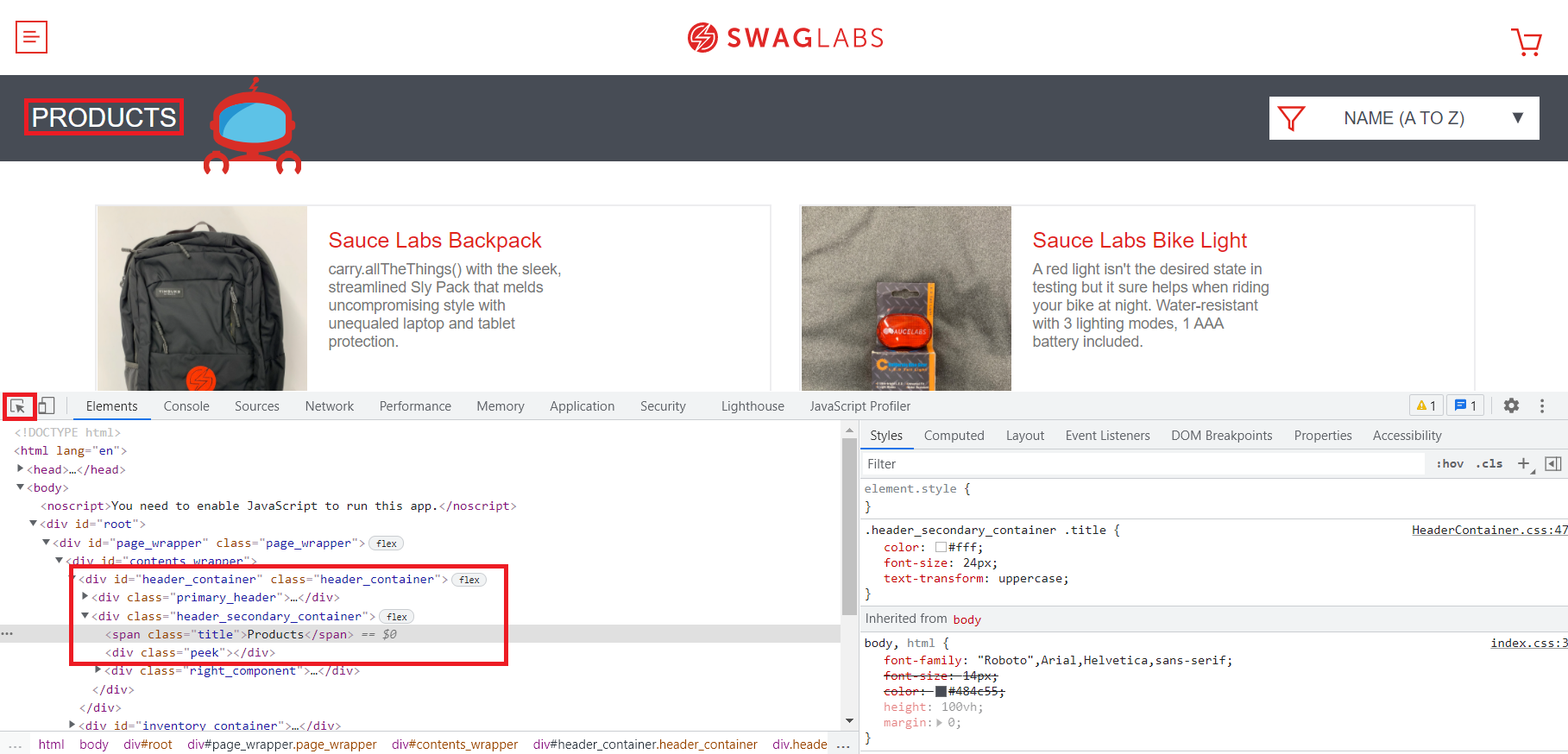
- Откроется код элемента в дереве HTML, далее нужно открыть контекстное меню выделенной строки и скопировать
xpath.
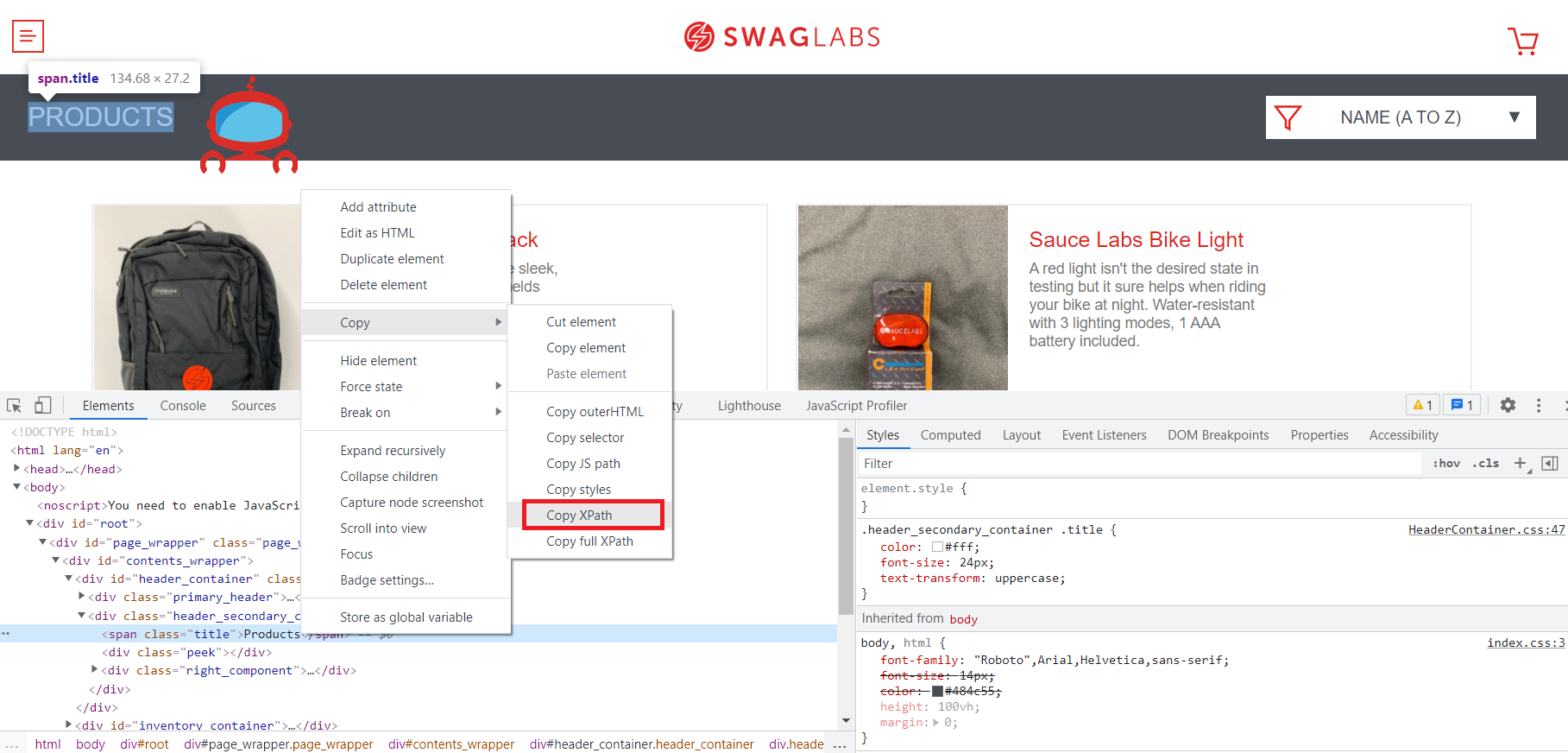
Если кратко рассматривать путь, то //* обозначает, что будут найдены все элементы на странице, а [@id="header_container"] обозначает условие поиска (будут найдены все элементы на странице с тэгом id = "header_container").И далее /div[2]/span – спускаемся на второй дочерний элемент div и далее на дочерний элемент span. Сравните полученный xpath с деревом элемента в инструментах разработчика – сразу станет понятно что к чему.
- Тут мы просто сравниваем текст найденного элемента с ожидаемым значением и выводим в консоль сообщение.
if title_text.text == "PRODUCTS":
print("Мы попали на главную страницу")
else:
print("Ошибка поиска элемента")
При выполнении скрипта получили следующий результат:

4. Первый тест с поиском и переходом по странице
Кейс:
- Введем логин и пароль пользователя и зайдем на главную страницу.
- Найдем позицию с названием «Sauce Labs Fleece Jacket».
- Перейдем на страницу товара и нажмем кнопку добавления в корзину.
- Перейдем в корзину и проверим что там присутствует 1 позиция с названием «Sauce Labs Fleece Jacket».
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
def first_test():
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options=options, executable_path=r'C:/Users/…/…/chromedriver.exe')
driver.get("https://www.saucedemo.com/")
# Поиск элементов и присваивание к переменным.
input_username = driver.find_element_by_xpath("//*[@id="user-name"]")
input_password = driver.find_element_by_xpath("//*[@id="password"]")
login_button = driver.find_element_by_xpath("//*[@id="login-button"]")
# Действия с формами
input_username.send_keys("standard_user")
input_password.send_keys("secret_sauce")
login_button.send_keys(Keys.RETURN)
# Поиск ссылки элемента позиции магазина и клик по ссылке
item_name = driver.find_element_by_xpath("//*[@id="item_5_title_link"]/div")
item_name.click()
# Поиск кнопки добавления товара и клик по этой кнопке
item_add_button = driver.find_element_by_xpath("//*[@id="add-to-cart-sauce-labs-fleece-jacket"]")
item_add_button.click()
# Поиск кнопки коризины и клик по этой кнопке
shopping_cart = driver.find_element_by_xpath("//*[@id="shopping_cart_container"]/a")
shopping_cart.click()
# Еще один поиск ссылки элемента позиции магазина
item_name = driver.find_element_by_xpath("//*[@id="item_5_title_link"]/div")
if item_name.text == "Sauce Labs Fleece Jacket":
print("Товар пристутствует в корзине")
else:
print("Товар отсутствует")
time.sleep(5)
if __name__ == '__main__':
first_test()
Из
нового тут добавился только метод click(), который просто кликает по
найденному элементу.
После прохождения всех шагов в консоль выводится результат, что в
корзине имеется товар.
Ожидания в selenium: что нужно знать?
В предыдущем кейсе с большой вероятностью можно столкнуться с проблемой, когда при нажатии на позицию мы сразу кликаем на корзину. При медленном интернете или долгом ответе от сервера в корзину может ничего не добавиться. Для таких случаев предусмотрены ожидания.
Selenium driver поддерживает два вида ожиданий: явное (explicit) и неявное (implicity). Для явных ожиданий есть специальные методы, которые помогут рационально использовать время выполнения теста: например, можно установить минимальное время ожидания и возвращать элемент, если он прогрузился раньше предполагаемого времени.
Пример явного ожидания:
element = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(
(By.XPATH, '//*[@id="page_wrapper"]/footer/ul/li[2]/a')
)
)
Процесс ждет 10 секунд пока элемент станет доступным, чтобы по
нему можно было кликнуть. Если элемент так и не прогрузился и недоступен для
клика, генерируется исключение TimeoutException.
Неявные ожидания в свою очередь устанавливаются один раз для
драйвера, а не для каждого элемента. Включается неявное ожидание, когда Selenium не может найти элемент: он ждет установленное время и если не дождется, тоже возвращает TimeoutException. В отличии от явного ожидания, этот тип менее гибок и может оказать плохое влияние на общее время прогона
тестов.
Пример неявного ожидания:
driver.implicitly_wait(10)
Ожидать действия можно и с помощью time.sleep(5). У нас в
примерах есть использование этого метода, но оно считается плохой практикой и обычно применяется только для дебага.
5. Рефакторинг теста, добавление ожиданий
Чтобы
pytest понял, что перед ним именно тестовая, а не обычная функция, сама тестовая функция
должна начинаться с test_.
Обновим наш тест, добавим необходимые ожидания для
стабильности тестовых функций.
Также я вынес отдельную функцию под ожидания, куда мы просто
передаем xpath и driver в виде аргументов.
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# Функция ожидания элементов
def wait_of_element_located(xpath, driver):
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located(
(By.XPATH, xpath)
)
)
return element
def test_add_jacket_to_the_shopcart():
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options=options, executable_path=r'C:/Users/…/…/chromedriver.exe')
driver.get("https://www.saucedemo.com/")
# Поиск и ожидание элементов и присваивание к переменным.
input_username = wait_of_element_located(xpath='//*[@id="user-name"]', driver=driver)
input_password = wait_of_element_located(xpath='//*[@id="password"]', driver=driver)
login_button = wait_of_element_located(xpath='//*[@id="login-button"]', driver=driver)
# Действия с формами
input_username.send_keys("standard_user")
input_password.send_keys("secret_sauce")
login_button.send_keys(Keys.RETURN)
# Поиск и ождиание прогрузки ссылки элемента товара магазина и клик по ссылке
item_name = wait_of_element_located(xpath='//*[@id="item_5_title_link"]/div', driver=driver)
item_name.click()
# Поиск и ожидание кнопки добавления товара и клик по этой кнопке
item_add_button = wait_of_element_located(xpath='//*[@id="add-to-cart-sauce-labs-fleece-jacket"]', driver=driver)
item_add_button.click()
# Ждем пока товар добавится в корзину, появится span(кол-во позиций в корзине) и кликаем по корзине чтобы перейти
wait_of_element_located(xpath='//*[@id="shopping_cart_container"]/a/span', driver=driver).click()
# Еще один поиск ссылки элемента позиции магазина
item_name = wait_of_element_located(xpath='//*[@id="item_5_title_link"]/div', driver=driver)
if item_name.text == "Sauce Labs Fleece Jacket":
print("Товар пристутствует в корзине")
else:
print("Товар отсутствует")
time.sleep(5)
if __name__ == '__main__':
test_add_jacket_to_the_shopcart()
Для запуска теста с помощью pytest в терминале введите
pytest main.py. После прохождения всех этапов должен отобразиться результат
прохождения.
6. Проверки, проверки, проверки
Мы плавно перешли к заключительному этапу написания теста – проверке вывода по известному ответу. Хотя тест выполняется успешно, он ничего
не проверяет и является бессмысленным. Будем использовать
стандартные инструкции assert или утверждения. Суть инструмента – проверить, что результат соответствует наши ожиданиям. Если соответствует, наш тест будет
считаться пройденным, а в противном случае – проваленным.
Добавим в тест проверки. Будем проверять, что название
куртки «Sauce Labs Fleece Jacket» и описание как в магазине.
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# Функция ожидания элементов
def wait_of_element_located(xpath, driver):
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located(
(By.XPATH, xpath)
)
)
return element
def test_add_jacket_to_the_shopcart():
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options=options, executable_path=r'C:/Users/…/…/chromedriver.exe')
driver.get("https://www.saucedemo.com/")
# Поиск и ожидание элементов и присваивание к переменным.
input_username = wait_of_element_located(xpath='//*[@id="user-name"]', driver=driver)
input_password = wait_of_element_located(xpath='//*[@id="password"]', driver=driver)
login_button = wait_of_element_located(xpath='//*[@id="login-button"]', driver=driver)
# Действия с формами
input_username.send_keys("standard_user")
input_password.send_keys("secret_sauce")
login_button.send_keys(Keys.RETURN)
# Поиск и ождиание прогрузки ссылки элемента товара магазина и клик по ссылке
item_name = wait_of_element_located(xpath='//*[@id="item_5_title_link"]/div', driver=driver)
item_name.click()
# Поиск и ожидание кнопки добавления товара и клик по этой кнопке
item_add_button = wait_of_element_located(xpath='//*[@id="add-to-cart-sauce-labs-fleece-jacket"]', driver=driver)
item_add_button.click()
# Ждем пока товар добавится в корзину, появится span(кол-во позиций в корзине) и кликаем по корзине чтобы перейти
wait_of_element_located(xpath='//*[@id="shopping_cart_container"]/a/span', driver=driver).click()
# Еще один поиск ссылки элемента позиции магазина
item_name = wait_of_element_located(xpath='//*[@id="item_5_title_link"]/div', driver=driver)
item_description = wait_of_element_located(
xpath='//*[@id="cart_contents_container"]/div/div[1]/div[3]/div[2]/div[1]',
driver=driver
)
assert item_name.text == "Sauce Labs Fleece Jacket"
assert item_description.text == "It's not every day that you come across a midweight quarter-zip fleece jacket capable of handling everything from a relaxing day outdoors to a busy day at the office."
driver.close()
if __name__ == '__main__':
test_add_jacket_to_the_shopcart()
Теперь при расхождении результата и ожидаемого
условия будет возвращена ошибка прохождения. Укажем название куртки «Sauce Labs Fleece Jacket1». Результат выполнения скрипта будет следующим:
Теперь причешем код, распределив логику по
методам, как, например, было с wait_of_element_located. Разбивать логику необходимо
для написания множества тестов.
import pytest
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# Функция ожидания элементов
def wait_of_element_located(xpath, driver_init):
element = WebDriverWait(driver_init, 10).until(
EC.presence_of_element_located(
(By.XPATH, xpath)
)
)
return element
# Вынесем инициализцию драйвера в отдельную фикстуру pytest
@pytest.fixture
def driver_init():
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options=options, executable_path=r'C:/Users/…/…/chromedriver.exe')
driver.get("https://www.saucedemo.com/")
yield driver
driver.close()
# Вынесем аутентификацию юзера в отдельную функцию
def auth_user(user_name, password, driver_init):
# Поиск и ожидание элементов и присваивание к переменным.
input_username = wait_of_element_located(xpath='//*[@id="user-name"]', driver_init=driver_init)
input_password = wait_of_element_located(xpath='//*[@id="password"]', driver_init=driver_init)
login_button = wait_of_element_located(xpath='//*[@id="login-button"]', driver_init=driver_init)
# Действия с формами
input_username.send_keys(user_name)
input_password.send_keys(password)
login_button.send_keys(Keys.RETURN)
def add_item_to_cart(xpath_item, driver_init):
# Поиск и ождиание прогрузки ссылки элемента товара магазина и клик по ссылке
item_name = wait_of_element_located(
xpath=xpath_item,
driver_init=driver_init)
item_name.click()
# Поиск и ожидание кнопки добавления товара и клик по этой кнопке
item_add_button = wait_of_element_located(
xpath='//*[@id="add-to-cart-sauce-labs-fleece-jacket"]',
driver_init=driver_init)
item_add_button.click()
# Ждем пока товар добавится в корзину, появится span(кол-во позиций в корзине)
# Возвращаем True или False в зависимости добавлися товар или нет
shop_cart_with_item = wait_of_element_located(
xpath='//*[@id="shopping_cart_container"]/a/span',
driver_init=driver_init)
return shop_cart_with_item
def test_add_jacket_to_the_shopcart(driver_init):
# Аутентификация пользователя
auth_user("standard_user", "secret_sauce", driver_init=driver_init)
# Добавление товара в корзину и если товар добавлен переход в корзину
add_item_to_cart(xpath_item='//*[@id="item_5_title_link"]/div',
driver_init=driver_init).click()
# Поиск корзины и клик
wait_of_element_located(xpath='//*[@id="shopping_cart_container"]/a',
driver_init=driver_init).click()
# Поиск ссылки элемента позиции магазина
item_name = wait_of_element_located(xpath='//*[@id="item_5_title_link"]/div',
driver_init=driver_init)
# Поиск описания товара
item_description = wait_of_element_located(xpath='//*[@id="cart_contents_container"]/div/div[1]/div[3]/div[2]/div[1]',
driver_init=driver_init)
assert item_name.text == "Sauce Labs Fleece Jacket"
assert item_description.text == "It's not every day that you come across a midweight quarter-zip fleece jacket"
" capable of handling everything from a relaxing day outdoors to a busy day at "
"the office."
if __name__ == '__main__':
test_add_jacket_to_the_shopcart(driver_init=driver_init)
В этом примере логика поделилась на функциональные компоненты (фикстуры). Теперь аутентификация пользователя будет происходить в отдельной функции, что позволит не производить одни и те же действия и дублировать код при каждом тесте, в котором нужно проходить аутентификацию. В качестве примера использования фикстур сделана инициализация драйвера, что позволит использовать инстанс драйвера во всех тестах, не пересоздавая его. Логика добавления товара в корзину тоже была вынесена в отдельный функциональный компонент для дальнейшего использования.
Суть разнесения логики заключается в принципе конструктора: собирать тесты из отдельных частей, подставляя только необходимые данные при переиспользовании функций в разных тестах.
При желании можно и дальше проводить рефакторинг кода.
Рекомендации по архитектуре
- Очевидно, что в одном файле хранить все вспомогательные функции и тесты неудобно. После добавления еще нескольких тестов даже с распределенной логикой скрипт будет похож на полотно с трудночитаемым кодом. К тому же если вы разрабатываете тесты с коллегами, без конфликтов в коде не обойтись. Для начала нужно разделить проект на модули: в одном будут находиться файлы с тестами, в другом частичная логика, в третьем – ресурсы, в четвертом – утилиты и т.д.
- Далее следует переходить на разработку автотестов с использованием объектно-ориентированного программирования. Это сэкономит массу времени и поможет в написании сложного и лаконичного кода.
- Стоит также обратить внимание на паттерны проектирования, особенно на PageObject и PageFactoroy. В эффективном тестировании UI они играют большую роль.
- Все тестовые данные лучше хранить в неизменяемых классах, константах или в отдельных файлах (json, csv).
Заключение
На этом создание первого автотеста закончено. Некоторые
моменты были рассмотрены поверхностно, что дает возможность пытливым умам
поглотить информацию из других источников. Удачи!
Привет! Меня зовут Сергей Иванов, я ведущий разработчик Android в Redmadrobot. С 2016 использую автотесты различных категорий и успел в этом набить немало шишек. Именно поэтому решил поделиться опытом. Возможно, что кому-то статья поможет систематизировать знания или начать применять эту практику в работе.
Автоматизированное тестирование — одна из самых сложных и холиварных тем в сфере разработки ПО. По моим наблюдениям, немногие в сообществе пишут автотесты, а те, кто это делают, не всегда получают реальную пользу. Кроме того, подступиться к теме не так-то просто: материалы в основном разрозненные, не всегда актуальны для нужной платформы, а в чем-то и противоречивы. В общем, чтобы начать нормально писать тесты, нужно очень много искать и разбираться.
В статье подсвечу основные аспекты автоматизированного тестирования, его специфику на Android, дам рекомендации для решения популярных вопросов и эффективного внедрения практики на проекте — то, к чему я сам пришел на текущий момент.
Подробнее расскажу про тесты на JVM, а не про UI-тесты, о которых в последнее время пишут часто. Материал будет хорошей отправной точкой для изучения темы, а также поможет дополнить уже имеющиеся знания.
Дисклеймер: статья получилась большой, поэтому указал основные темы, которые рассмотрю.
- Базовые понятия автоматизированного тестирования.
- Категории тестов и их специфика на Android.
- Основные инструменты для тестирования.
- Как писать тестируемый код.
- Дизайн тестов.
- Снижение хрупкости non-UI тестов.
- Тестирование асинхронного кода с RxJava.
- JVM integration testing.
- Как и когда применять методологию Test Driven Development.
При производстве приложений автотесты помогают:
- Находить баги на раннем этапе разработки. Это позволяет раньше устранять проблемы, при этом расходуя меньше ресурсов.
- Локализовать проблему. Чем более низкоуровневым является тест, тем более точно он способен указать на причину ошибки.
- Ускорить разработку. Это вытекает из предыдущих пунктов и из того, что благодаря автотестам разработка разных частей фичи может быть оперативно разделена на несколько разработчиков. Установив контракты между компонентами приложения, разработчик может разработать свой компонент и проверить его корректность при отсутствии остальных (например, при полном отсутствии UI).
- Служат документацией. При правильном оформлении тестов и поддержке их в актуальном состоянии покрытый тестами код всегда будет иметь последовательную документацию. Это упростит его понимание новым разработчикам, а также поможет автору, забредшему в забытый уголок проекта спустя несколько месяцев.
Но есть и проблемы:
- Нужно время на внедрение, написание и поддержку.
- При некорректном внедрении практики могут принести больше вреда, чем пользы.
Важные базовые понятия автоматизированного тестирования
System Under Test (SUT) — тестируемая система. В зависимости от типа теста системой могут быть разные сущности (о них подробнее написал в разделе «категории тестов»).
Для различия уровня тестирования по использованию знаний о SUT существуют понятия:
Black box testing — тестирование SUT без знания о деталях его внутреннего устройства.
White box testing — тестирование SUT с учётом деталей его внутреннего устройства.
Выделяют также Gray box testing, комбинацию подходов, но ради упрощения он будет опущен.
Для обеспечения базового качества автотестов важно соблюдать некоторые правила написания. Роберт Мартин сформулировал в книге «Clean Code» глобальные принципы F.I.R.S.T.
Fast — тесты должны выполняться быстро.
Independent — тесты не должны зависеть друг от друга и должны иметь возможность выполняться в любом порядке.
Repeatable — тесты должны выполняться с одинаковым результатом независимо от среды выполнения.
Self-validating — тесты должны однозначно сообщать о том, успешно их прохождение или нет.
Timely — тесты должны создаваться своевременно. Unit-тесты пишутся непосредственно перед кодом продукта.
Структура теста состоит как минимум из двух логических блоков:
- cовершение действия над SUT,
- проверка результата действия.
Проверка результата заключается в оценке:
- состояния SUT или выданного ею результата,
- cостояний взаимодействующих с SUT объектов,
- поведения (набор и порядок вызовов функций других объектов, которые должен совершить SUT, переданные в них аргументы).
При необходимости также добавляются блоки подготовки и сброса тестового окружения, отчасти связанные с первыми тремя принципам F.I.R.S.T.
Подготовка окружения заключается в создании SUT, установке исходных данных, состояний, поведения и др., необходимых для имитации ситуации, которую будет проверять тест.
На этапе сброса окружения может осуществляться очистка среды после выполнения теста для экономии ресурсов и исключения влияния одного теста на другой.
Зачастую для настройки окружения применяются тестовые дублеры.
Test doubles (Тестовые дублёры) — фиктивные объекты, заменяющие реальные объекты, от которых зависит SUT, для достижения целей теста.
Тестовые дублеры позволяют:
- зафиксировать тестовое окружение, имитируя неважные, нереализованные, нестабильные или медленные внешние объекты (например, БД или сервер),
- совершать проверки своих вызовов (обращений к функциям, свойствам).
Самая популярная классификация включает 5 видов тестовых дублеров, различных по своим свойствам: Dummy, Fake, Stub, Spy, Mock.
Stub — объект, который при вызовах его функций или свойств возвращает предустановленные (hardcoded) результаты, а не выполняет код реального объекта. Если же функция не имеет возвращаемого значения, то вызов просто игнорируется.
Mock — объект, позволяющий проверять поведение SUT путём отслеживания обращений к функциям и свойствам объекта: были ли в ходе теста вызваны функции мока, в правильном ли порядке, ожидаемые ли аргументы были в них переданы и т.д. Может также включать функциональность Stub.
Почитать об этих и остальных видах дублеров можно в первоисточнике.
Эта классификация не является стандартом, и в фреймворках для создания тестовых дублёров часто ради удобства API несколько типов обобщают термином Mock. А вот чем они на самом деле будут являться, зависит от их последующей конфигурации и применения в тесте. Например, при использовании фреймворка Mockito, экземпляр тестового дублера может быть создан как Dummy, а потом превращен в Stub и в Mock.
При именовании созданных с помощью фреймворка дублеров уместно использовать именования, продиктованные фреймворком. Вообще, в мировом сообществе многие оперируют термином Mock и вне кода, подразумевая на самом деле дублёры разных типов. Бывает, что это путает. Но, в большинстве случаев в тестах используются стабы, а вовсе не моки.
В русскоязычной среде встречается мнение, что разница между Stub-ом и Mock-ом заключается в том, что первый — это дублер, написанный вручную, а второй — созданный с помощью специального фреймворка. Но это заблуждение.
Различия полезно знать, чтобы не путаться в общении с коллегами, когда в контексте обсуждения тип дублера важен.
Категории тестов
Есть разные версии категоризации тестов, по разным характеристикам, поэтому существует некоторая путаница.
Покажу основные категории уровней тестов, на которых тестируется система, на примере одного из самых распространенных вариантов пирамиды тестирования:
Unit-тесты проверяют корректность работы отдельного unit-а (модуля). Unit-ом (то есть SUT данного типа тестирования) может быть класс, функция или совокупность классов.
Integration-тесты (в приложении) проверяют корректность взаимодействия модулей или наборов этих модулей (компонентов). Определение SUT данной категории является еще более расплывчатым, т.к. в свою очередь зависит от того, что считается модулем.
Грань между Unit- и Integration-тестированием довольно тонкая. Интеграционными тестами, в зависимости от масштаба и контекста, в принципе могут называть тесты, проверяющие взаимодействие чего-либо с чем-либо с определенной долей абстракции: приложение(клиент)-сервер, приложение-приложение, приложение-ОС и др. Но в дальнейшем я буду говорить об интеграционном тестировании в рамках приложения.
End-to-end-тесты (E2E) — интеграционные тесты, которые воздействуют на приложение и проверяют результат его работы через самый высокоуровневый интерфейс (UI), то есть на уровне пользователя. Использование тестовых дублеров на этом уровне исключено, а значит обязательно используются именно реальные сервер, БД и т.д.
Кстати, визуализация автоматизированных тестов в виде пирамиды говорит о том, что тесты более низкого уровня — основа более высокоуровневых, а также о рекомендуемом количественном соотношении тестов того или иного уровня в проекте.
Вернёмся к категориям. В Android сложность категоризации автотестов усугубляется еще и тем, что они могут работать на JVM или в Instrumentation-среде (эмулятор или реальное устройство). Последние называют инструментальными.
Чтобы было удобнее ориентироваться в видах тестов, не путаясь в терминологии, предлагаю такую категоризацию для мобильного приложения на Android:
JVM Integration tests — интеграционные тесты, проверяющие взаимодействие модулей или совокупностей модулей без использования Instrumentation. Характеризуются они высокой скоростью исполнения, сравнимой с Unit-тестами, также выполняющимися на JVM.
Instrumentation Integration non-UI tests — интеграционные тесты, исполняемые уже в реальной Android-среде, но без UI.
Component UI tests — интеграционные инструментальные тесты с использованием UI и фиктивных сервера и БД, если таковые требуются. Тест может состоять как из одного экрана, запущенного в изоляции, так и из нескольких экранов с соблюдением их реального флоу.
E2E UI tests — интеграционные инструментальные UI-тесты без тестовых дублеров только с реальным флоу экранов. Максимально приближены к ручным тестам.
Если Unit-тесты являются сильно завязанными на детали реализации, очень быстро выполняются, относительно легко пишутся и наиболее точно при поломке указывают на причину ошибки, то в случае E2E UI ситуация противоположная. Изменение этих характеристик происходит постепенно от низа к верху пирамиды.
При переходе от тестов на JVM к тестам на Instrumentation из-за использования настоящей Android-среды происходит резкое падение скорости выполнения этих тестов. Это становится серьезным ограничением. Особенно когда тесты необходимо запускать часто и много раз подряд. Поэтому к написанию инструментальных тестов следует прибегать лишь в случаях, когда использование настоящих Android-зависимостей действительно необходимо.
UI-тесты
Несмотря на малую зависимость от низкоуровневых деталей реализации SUT, UI-тесты являются самыми хрупкими. Вызвано это их зависимостью от самого UI. Изменение разметки, реализации отображения, анимации и т.д. могут потребовать длительных манипуляций для обеспечения работоспособности теста.
Часто они оказываются нестабильны в своём поведении и могут то выполняться, то падать, даже если не вносилось никаких изменений в реализацию (нестабильные тесты называют Flaky). Мало того, UI-тесты могут совершенно по-разному себя вести на разных устройствах, эмуляторах и версиях Android. Когда же UI-тесты являются еще и E2E, добавляется хрупкость и снижается скорость выполнения из-за реальных внешних зависимостей. Причем в случае ошибки найти её причину бывает затруднительно, поскольку проверки в таких тестах осуществляются на уровне состояния UI. В таких ситуациях выгоднее обойтись силами QA-инженеров.
Конечно, UI-тесты способны приносить и весьма существенную пользу. Мобильные приложения имеют свойство разрастаться, и в какой-то момент их ручное регрессионное тестирование выходит за адекватные временные рамки. Тогда часть проверок может быть делегирована E2E UI-тестам, что при удачном исполнении может здорово сократить время тестирования.
Поэтому, для написания UI-тестов желательно иметь разработчиков или QA-инженеров-автоматизаторов, которые будут заниматься именно ими бÓльшую часть времени.
Unit-тесты
Unit-тесты тоже в определенной мере хрупкие, но уже из-за того, что они больше связаны с деталями реализации, которым свойственно периодически меняться. При сильном изменении реализации SUT и связанных с нею сущностей может потребоваться почти полностью переписать unit-тест. Но unit-тесты стабильны.
Степень хрупкости же можно снизить за счет использования black box-стиля написания даже на этом уровне, когда возможно. Но не следует злоупотреблять применением тестовых дублеров: если уже реализованная сущность имеет тривиальную логику или наличие логики не подразумевается, стоит использовать ее настоящую реализацию.
А заменять дублером следует только то, что действительно необходимо для приемлемой изоляции SUT в конкретном случае. Иногда (но далеко не всегда!) бывает оптимальнее сделать переиспользуемый рукописный дублер, чем конфигурировать его фреймворком для создания дублеров в множестве мест.
Хочу отметить, что какими бы хорошими не были автотесты, полностью отказываться от ручного тестирования нельзя. Человеческий глаз и смекалка пока что незаменимы.
Подытожим
- Как я отметил несколько пунктов назад: тесты более низкого уровня — основа тестов более высокого уровня. Проверять высокоуровневыми тестами всё то, что спокойно проверяется низкоуровневыми, может быть слишком сложно, долго и невыгодно. Каждая категория тестов должна решать свою задачу и применяться на соответствующем этапе создания приложения — чем выше уровень, тем позже.
- Ручные тесты — самые достоверные и важные тесты. Unit-тесты, имеющие меньше всего общего с ручными, могут позволить проверить такие ситуации, краевые кейсы, которые проверять вручную будет чрезвычайно дорого. Unit-тесты являются наиболее важными среди автоматизированных.
- Лучше делать акцент на быстро выполняющиеся тесты. Так, после Unit-тестов рекомендую проверять JVM Integration-тестами интеграцию в том масштабе, который можно комфортно обеспечить без использования Instrumentation — от ViewModel до слоя данных.
Дальше я буду говорить преимущественно о тестах на JVM. Но некоторые моменты актуальны и для остальных категорий.
Инструментарий
Раньше для написания JVM-тестов наши разработчики использовали фреймворки Junit 4 и Junit 5, но потом переключились на молодой перспективный Spek 2. Junit 4 нужен для инструментальных тестов — с другими фреймворками они не работают.
Для проверок (assert) используем AssertJ — отличную библиотеку с богатым набором читабельных ассертов и удобных дополнительных функций.
Для создания тестовых дублеров применяем Mockito-Kotlin 2 — Mockito 2, адаптированный для Kotlin.
Для стаббинга и мокирования сервера — MockWebServer — библиотеку от Square, рассчитанную на работу с OkHttp.
Фреймворки PowerMock и Robolectric не используем из соображений скорости выполнения тестов и их надёжности. Кроме того, эти фреймворки поощряют «плохо пахнущий код» — это дополнительные зависимости, без которых вполне можно обойтись. Для этого код должен быть тестируемым.
Дизайн кода
Признаки нетестируемого кода:
- Наличие неявных зависимостей, сильная связанность. Это затрудняет изолированное unit-тестирование, тестирование на раннем этапе развития фичи, распараллеливание разработки. Использование статических функций, создание сложных объектов внутри класса, ServiceLocator исключают возможность использования тестовых дублеров.
- Обилие Android-зависимостей. Они требуют Instrumentation или объемную подготовку среды на JVM с тестовыми дублерами, если их использование вообще возможно (см. прошлый пункт).
- Наличие явного управления асинхронным и многопоточным поведением. Если результат работы SUT зависит от выполнения асинхронной работы, особенно порученной другому потоку (или нескольким), то не получится просто так гарантировать правильность и стабильность выполнения тестов. Тест может совершить проверки и завершиться раньше, чем асинхронная работа будет выполнена, и результат не будет соответствовать желаемому. При этом принудительное ожидание в тестах (в первую очередь на JVM) — плохая практика, поскольку нарушается принцип Fast.
class ExampleViewModel constructor(val context: Context) : BaseViewModel() {
private lateinit var timer: CountDownTimer
fun onTimeAccepted(seconds: Long) {
val milliseconds = MILLISECONDS.convert(seconds, SECONDS)
// Неявная зависимость, Android-зависимость, запуск асинхронной работы
timer = object : CountDownTimer(milliseconds, 1000L) {
override fun onTick(millisUntilFinished: Long) {
showTimeLeft(millisUntilFinished)
}
override fun onFinish() {
// Неявная зависимость. Вызов статической функции с Android-зависимостью
WorkManager.getInstance(context)
.cancelUniqueWork(SeriousWorker.NAME)
}
}
timer.start()
}
Как сделать код тестируемым
Следовать принципам SOLID, использовать слоистую архитектуру. Грамотное разделение и реализация сущностей позволит писать изолированные тесты именно на интересующую часть функционала, не допускать чрезмерного разрастания тестового файла и, при необходимости, осуществлять распараллеливание разработки. DI позволит подменять настоящие реализации тестовыми дублёрами.
Стремиться к чистоте функций. Это функции, которые:
- При одинаковом наборе входных данных возвращают одинаковый результат.
- Не имеют побочных эффектов, т.е. не модифицируют внешние переменные (класса, глобальные) и переданные в качестве входных данных параметры.
Пример теста такой функции:
val result = formatter.toUppercase(«адвокат»)
assertThat(result).isEqualTo(«АДВОКАТ»)
Минимизировать количество Android-зависимостей. Часто прямое использование Android-зависимостей в SUT не является необходимым. Тогда их следует выносить вовне, оперируя в SUT типами, поддерживающимися на JVM.
Самая распространенная Android-зависимость в потенциально тестируемых классах — ресурсы, и их выносить из, скажем, ViewModel, ну, совсем не хочется. В таком случае можно внедрить Resources во ViewModel, чтобы стаббить конкретные ресурсы (их id актуальны на JVM) и проверять конкретные значения:
mock<Resources> { on { getString(R.string.error_no_internet) } doReturn «Нет интернета» }
Но лучше поместить Resources во Wrapper, предоставляющий только необходимый функционал работы с ресурсами, и сделать его тестовую реализацию. Это избавит SUT от прямой зависимости от фреймворка и упростит подготовку окружения в тестах:
interface ResourceProvider {
fun getString(@StringRes res: Int, vararg args: Any): String
}
class ApplicationResourceProvider(private val resources: Resources) : ResourceProvider {
override fun getString(res: Int, vararg args: Any): String {
return resources.getString(res, *args)
}
}
class TestResourceProvider : ResourceProvider {
override fun getString(res: Int, vararg args: Any): String = «$res»
}
При таком поведении TestResourceProvider по умолчанию правильность строки в ожидаемом результате можно сверять по id ресурса:
val string = TestResourceProvider().getString(R.string.error_no_internet)
assertThat(string).isEqualTo(R.string.error_no_internet.toString())
В общем случае лучше вообще не заменять дублерами типы, принадлежащие сторонним библиотекам и фреймворкам. Это может привести к проблемам при обновлении их API. Обезопасить себя можно также с помощью Wrapper. Подробнее ситуация разобрана в статье “Don’t Mock Types You Don’t Own”.
Использовать Wrapper-ы для статических функций, управления асинхронным и многопоточным поведением. Существует немало стандартных статических функций или Android-зависимостей в виде таких функций. Если нужно иметь с ними дело, то следует помещать их во Wrapper-ы и внедрять в SUT для последующей подмены.
Это поможет и при работе с асинхронностью и многопоточностью: инкапсулирующий управление ими Wrapper можно заменить тестовым дублером, который позволит проверяемому коду выполняться в одном потоке и синхронно вызвать асинхронный код. Для RxJava и Kotlin Coroutines есть стандартные решения от их авторов.
Дизайн тестов
Важно оформлять тесты качественно. Иначе они помогут в момент написания, но в будущем будет уходить много времени на их понимание и поддержку.
Например, при падении теста, который сложно сходу понять и исправить, есть шанс, что его пометят как «игнорируемый» или удалят. Особенно если таких тестов много, ведь они тормозят продолжение разработки. Вот старый пример не самого удачного теста из опенсорса:
public void testSubClassSerializerInvokedForBaseClassFieldsHoldingArrayOfSubClassInstances() {
Gson gson = new GsonBuilder()
.registerTypeAdapter(Base.class, new BaseSerializer())
.registerTypeAdapter(Sub.class, new SubSerializer())
.create();
ClassWithBaseArrayField target = new ClassWithBaseArrayField(new Base[] {new Sub(), new Sub()});
JsonObject json = (JsonObject) gson.toJsonTree(target);
JsonArray array = json.get(«base»).getAsJsonArray();
for (JsonElement element : array) {
JsonElement serializerKey = element.getAsJsonObject().get(Base.SERIALIZER_KEY);
assertEquals(SubSerializer.NAME, serializerKey.getAsString());
}
}
Чтобы достичь желаемого эффекта от тестов, необходимо уделить внимание качеству их дизайна.
Наименование теста и разделение на блоки
Чтобы сделать содержимое теста более читабельным, его следует разделять на блоки соответствующих этапов. Я выбрал BDD-стиль, где есть этапы:
- Given — настройка SUT и среды;
- When — действие, инициирующее работу SUT, результат работы которой нужно проверить;
- Then — проверка результатов на соответствие ожиданиям.
Пример разделения тела теста:
@Test
fun `when create — while has 1 interval from beginning of day and ending not in end of day — should return enabled and disabled items`() {
// given
val intervalStart = createDateTime(BEGINNING_OF_DAY)
val intervalEnd = createDateTime(«2019-01-01T18:00:00Z»)
val intervals = listOf(
ArchiveInterval(startDate = intervalStart, endDate = intervalEnd)
)
// when
val result = progressItemsfactory.createItemsForIntervalsWithinDay(intervals)
// then
val expected = listOf(
SeekBarProgressItem.createEnabled(intervalStart, intervalEnd),
SeekBarProgressItem.createDisabled(intervalEnd, createDateTime(END_OF_DAY))
)
assertThat(result).isEqualTo(expected)
}
«Лицо» теста — его название. Оно должно быть читабельным и ёмко передавать информацию о содержимом, чтобы для ориентации не приходилось каждый раз анализировать это самое содержимое.
В тестах на JVM Kotlin позволяет использовать пробел и дефис при обрамлении названия функции обратными кавычками. Это здорово повышает читабельность. В инструментальных тестах это не работает, поэтому текст пишется в CamelCase, а вместо дефисов используются нижние подчеркивания.
Для тестов на Junit применим следующий паттерн именования в простых случаях:
- when … should …
- when — аналогично блоку When;
- should — аналогично блоку Then.
В более сложных случаях, когда есть дополнительные условия:
- when … — while/and … — should …, где
- while — предусловие до вызова целевой функции SUT;
- and — условие после вызова функции SUT.
Пример:
@Test
fun `when doesValueSatisfyRegex — while value is incorrect — should return false`() {
Так имя теста написано в виде требования, и в случае падения будет сразу видно, какой сценарий отработал некорректно:
Фреймворк Spek 2 выводит всё это на новый уровень. Он предоставляет «из коробки» DSL в стиле Gherkin (BDD).
object GetCameraGroupsInteractorTest : Spek({
Feature(«Transform cached cameras to groups of cameras») {
…
Scenario(«subscribe while has non-grouped camera and unsorted by groups order cameras») {
…
Given(«non-grouped camera and unsorted by groups order cameras») {
…
}
When(«subscribe») {
…
}
Then(«should return four groups») {
…
}
…
}
}
})
Блоки Given, When, Then — подтесты глобального теста, описанного с помощью блока Scenario. Теперь нет необходимости ставить всё описание в названии, можно просто расположить все части в соответствующих блоках.
Результат выполнения имеет иерархический вид:
Эти блоки могут присутствовать внутри Scenario в любом количестве, а для придания еще более «человекочитаемого» вида можно использовать блок And. Теперь насыщенный сценарий можно оформить, не растянув при этом название теста далеко за границу экрана:
Благодаря блокам типа Feature можно удобно разделять тесты для разных фич, если в одном тестовом файле их несколько.
Чтобы добиться схожего разделения и отображения результатов с помощью Junit 5, понадобилось бы написать в тестах много бойлерплейта с аннотациями.
Устранение лишнего кода
Чтобы сделать содержимое тестов читабельнее, нужно следовать нескольким правилам:
1. Если проверки результатов выполнения одного действия над SUT тесно связаны, допустимо иметь несколько проверок в тесте. В противном случае это должны быть отдельные тесты. Основная проблема в том, что если в тесте несколько проверок и одна из них фейлится, то последующие проверки осуществлены не будут.
В Spek 2 вместо создания полностью отдельных тестов, если они концептуально относятся к одному сценарию, разделение проверок можно сделать с помощью блоков Then/And внутри Scenario:
…
Then(«should return four groups») {…}
And(«they should be alphabetically sorted») {…}
And(«other group should contain one camera») {…}
And(«other group should be the last») {…}
…
В Junit 4 такой возможности нет. На помощь приходит механизм SoftAssertions из AssertJ, который гарантирует выполнение всех assert в тесте. Например:
// then
assertSoftly {
it.assertThat(capabilityState)
.describedAs(«Capability state»)
.isInstanceOf(Available::class.java)
it.assertThat((capabilityState as Available).disclaimer)
.describedAs(«Disclaimer»)
.isNull()
}
2. Если проверки объемные, нежелательные к разделению и повторяющиеся, следует выносить их в отдельную функцию с говорящим названием.
3. Использовать обобщающие конструкции тестового фреймворка для одинаковой настройки окружения, если настройка повторяется для большого количества тестов, находящихся на одном уровне иерархии (например, beforeEachScenario и afterEachScenario в случае Spek 2). Если настройка одинакова для нескольких тестовых файлов, можно использовать Extension для Junit 5, Rule для Junit 4, а для Spek 2 подобного механизма «из коробки» нет, поэтому нужно обходиться конструкциями before…/after….
4. Объемные схожие настройки тестового окружения следует также выносить в отдельную функцию.
5. Использовать статические импорты для повсеместно применяемых функций вроде функций проверок AssertJ и Mockito.
6. Если создание вспомогательных объектов объемное, используется в разных тестовых файлах и с разными параметрами, следует завести генератор с дефолтными значениями:
object DeviceGenerator {
fun createDevice(
description: String? = null,
deviceGroups: List<String> = emptyList(),
deviceType: DeviceType = DeviceType.CAMERA,
offset: Int = 0,
id: String = «»,
photoUrl: String? = null,
isActive: Boolean = false,
isFavorite: Boolean = false,
isPublic: Boolean = false,
model: String? = null,
vendor: String? = null,
title: String = «»,
serialNumber: String = «»,
streamData: StreamData? = null
): Device {
return Device(
description = description,
deviceGroups = deviceGroups,
deviceType = deviceType,
offset = offset,
id = id,
photoUrl = photoUrl,
isActive = isActive,
isFavorite = isFavorite,
isPublic = isPublic,
model = model,
vendor = vendor,
title = title,
serialNumber = serialNumber,
streamData = streamData
)
}
}
Given(«initial favorite camera») {
val devices = listOf(
createDevice(id = deviceId, isFavorite = true)
)
…
}
Очень важно не переборщить с созданием вспомогательных функций и архитектурных изысков, поскольку KISS и единообразие в автотестах важнее, чем DRY. Когда все тесты в проекте написаны однотипно и прозрачно, они гораздо лучше воспринимаются.
Тесты как документация
Когда предыдущие пункты соблюдены, тесты уже можно применять как документацию, свернув тестовые функции в IDE.
Для сворачивания и разворачивания всех блоков кода в файле в случае Mac используются комбинации клавиш “Shift” + “⌘” + “-” и “Shift” + “⌘” + “+”, для управления конкретным блоком — “⌘” + “-” и “⌘” + “+” соответственно.
В тестах на Junit 4 можно сделать еще лучше, сгруппировав тесты по регионам, ведь их тоже можно сворачивать.
В тестах на Spek 2 нет нужды делать разделение тестов по регионам, поскольку их можно хорошо сгруппировать с помощью блоков Scenario и Feature.
Если в файле с тестами присутствуют некоторые вспомогательные свойства или функции, их также стоит поместить в регион. Это поспособствует улучшению фокусировки внимания на названиях тестовых функций.
Так тесты сформированы в виде последовательных требований к SUT, в которых удобно ориентироваться. Теперь они отличная документация для ваших коллег и вас самих, которая поможет быстро разобраться или вспомнить, что делает SUT.
Она лучше обычной текстовой, поскольку в отличие от тестов, обычную документацию можно забыть актуализировать. Чем тесты более высокоуровневые, тем более близкими к составленным аналитиком функциональным требованиям будут их названия. Это будет заметно в разделе «JVM Integration Testing».
Параметрические тесты
Если нужно протестировать корректность работы SUT с разнообразным набором входных данных, но при этом основная реализация тестов меняться не должна, можно использовать параметрический тест.
Он может быть запущен много раз, каждый раз принимая разные аргументы. Поэтому отпадает надобность писать множество одинаковых тестов, у которых отличаются только входные данные и ожидаемый результат. Достаточно написать один тест и указать набор данных, которые будут поочередно в него передаваться. Часто параметрические тесты оказываются подходящим выбором для тестирования валидаторов, форматтеров, конвертеров и т.д.
В документации Spek 2 не написано о возможности написания параметрических тестов, хотя она есть, и писать их проще, чем в Junit 4 и Junit 5. Для этих целей удобно использовать стиль тестов Specification.
class OrientationTypeTest : Spek({
describe(«Orientation type») {
mapOf(
-1 to Unknown,
-239 to Unknown,
361 to Unknown,
2048 to Unknown,
340 to Portrait,
350 to Portrait,
360 to Portrait,
0 to Portrait,
…
).forEach { (tiltAngle, expectedOrientation) ->
describe(«get orientation by tilt angle $tiltAngle») {
val result = OrientationType.getOrientation(tiltAngle)
it(«return $expectedOrientation type») {
assertThat(result).isEqualTo(expectedOrientation)
}
}
}
}
})
Результат выполнения:
Снижение хрупкости non-UI тестов
Я писал, что степень хрупкости unit-тестов при изменениях исходного кода, обусловленную их привязкой к деталям реализации модуля, можно снизить. Это применимо для всех non-UI тестов.
Написание тестов в стиле White box искушает расширять видимость функций/свойств SUT для проверок или установки состояний. Это простой путь, который влечет за собой не только увеличение хрупкости тестов, но и нарушение инкапсуляции SUT.
Избежать этого помогут правила. Можно сказать, что взаимодействие с SUT будет в стиле Black box.
- Тестировать следует только публичные функции. Если SUT имеет приватную функцию, логику которой нужно протестировать, делать это следует через связанную с ней публичную функцию. Если сделать это проблематично, то, возможно, код приватной функции так сложен, что должен быть вынесен в отдельный класс и протестирован напрямую.
- Нужно стараться делать функции чистыми. Об этом я говорил выше.
- Проверки в тесте следует осуществлять по возвращаемому значению вызываемой публичной функции, публичным свойствам или, в крайнем случае, по взаимодействию с mock-объектами (с помощью функции verify() и механизма ArgumentCaptor в Mockito)
- Делать только необходимые проверки в рамках теста. Например, если в тесте проверяется, что при вызове функции “A” у SUT происходит вызов функции “X” у другого класса, то не следует до кучи проверять значения её публичных полей, особо не имеющих отношения к делу, и что у SUT не будет более никаких взаимодействий с другими функциями связанного класса (функция verifyNoMoreInteractions() в Mockito).
- Если для проведения определенного теста невозможно привести SUT в требуемое предварительное состояние с помощью аргументов целевой функции, моков/стабов или изменения полей, то следует вызвать другие публичные функции, вызов которых приводит SUT в интересующее состояние в условиях реальной работы приложения. Например, вызвать функции onLoginInputChanged и onPasswordInputChanged для подготовки теста onEnterButtonClick во ViewModel
Существует аннотация-маркер @VisibleForTesting для выделения функций/свойств, модификатор доступа которых расширили для тестирования. Благодаря этому маркеру Lint подскажет разработчику, обратившемуся к функции/свойству в таком месте исходного кода, в котором они на самом деле не должны быть доступны, что видимость функции расширена только для тестирования. Несмотря на возможность использования такого маркера, прибегать к расширению видимости всё равно не рекомендуется.
Тестирование асинхронного кода с RxJava
Лучше избегать прямого управления асинхронным и многопоточным поведением в SUT. Для тестирования же кода, использующего RxJava или Coroutines, применяются специфичные решения. Сейчас в большинстве наших проектов используется RxJava, поэтому расскажу именно про нее.
Для тестирования SUT, осуществляющей планирование Rx-операций, нужно произвести замену реализаций Scheduler-ов так, чтобы весь код выполнялся в одном потоке. Также важно иметь в виду, что на JVM нельзя использовать AndroidSchedulers.mainThread().
В большинстве случаев все Scheduler-ы достаточно заменить на Schedulers.trampoline(). В случаях, когда нужен больший контроль над временем события, лучше использовать io.reactivex.schedulers.TestScheduler с его функциями triggerActions(), advanceTimeBy(), advanceTimeTo().
Замену реализаций можно совершить двумя способами:
- RxPlugins (RxJavaPlugins & RxAndroidPlugins);
- Подход Schedulers Injection.
Первый способ — официальный и может быть применен независимо от того, как спроектирована SUT. Он имеет не самое удачное API и неприятные нюансы работы, усложняющие применение в некоторых ситуациях (например, когда внутри тестового файла в одних тестах нужно использовать Schedulers.trampoline(), а в других — TestScheduler).
Суть подхода Schedulers Injection заключается в следующем: экземпляры Scheduler-ов попадают в SUT через конструктор, благодаря чему в тесте они могут быть заменены на иные реализации. Этот подход является очень прозрачным и гибким. Также он останется неизменным независимо от выбранного тестового фреймворка (Junit 4, Junit 5, Spek 2…) — чего нельзя сказать об RxPlugins, которыми придется в каждом управлять по-своему.
Из минусов Shedulers Injection можно выделить необходимость внедрения дополнительного аргумента в SUT и необходимость использования вместо rx-операторов с Sheduler по умолчанию (таких как delay()) их перегруженные варианты с явным указанием Scheduler.
Есть две неплохие статьи на тему обоих подходов: раз, два. Но там упомянуты не все нюансы RxPlugins.
Я предпочитаю второй подход. Чтобы упростить внедрение и подмену реализаций в тесте, я написал SchedulersProvider:
interface SchedulersProvider {
fun ui(): Scheduler
fun io(): Scheduler
fun computation(): Scheduler
}
class SchedulersProviderImpl @Inject constructor() : SchedulersProvider {
override fun ui(): Scheduler = AndroidSchedulers.mainThread()
override fun io(): Scheduler = Schedulers.io()
override fun computation(): Scheduler = Schedulers.computation()
}
fun <T> Single<T>.scheduleIoToUi(schedulers: SchedulersProvider): Single<T> {
return subscribeOn(schedulers.io()).observeOn(schedulers.ui())
}
// другие необходимые функции-расширения…
Его применение в коде:
class AuthViewModel(
…
private val schedulers: SchedulersProvider
) : BaseViewModel() {
…
loginInteractor
.invoke(login, password)
.scheduleIoToUi(schedulers)
…
А вот и его тестовая реализация с Scheduler-ами по умолчанию, вместо которых при надобности можно передать TestScheduler:
class TestSchedulersProvider(
private val backgroundScheduler: Scheduler = Schedulers.trampoline(),
private val uiScheduler: Scheduler = Schedulers.trampoline()
) : SchedulersProvider {
override fun ui(): Scheduler = uiScheduler
override fun io(): Scheduler = backgroundScheduler
override fun computation(): Scheduler = backgroundScheduler
}
Применение в тесте:
authViewModel = AuthViewModel(
…
router = mock(),
schedulers = TestSchedulersProvider(),
loginInteractor = loginInteractor,
…
)
Вообще, RxJava «из коробки» имеет и другие полезные инструменты для тестирования (TestObserver, TestSubscriber), но они не входят в рамки статьи.
JVM integration testing
JVM Integration-тесты проверяют взаимодействие модулей или совокупностей модулей на JVM. Какие именно связки стоит тестировать, зависит от конкретных случаев.
В самых масштабных тестах этого типа проверяется взаимодействие всей цепочки модулей от ViewModel до Http-клиента, поскольку в этом промежутке обычно располагается основная логика, требующая проверки. Обеспечивать работу View на JVM обычно накладно и не имеет большого смысла.
Тест взаимодействует с SUT через ViewModel, инициируя действия и проверяя результат.
Чтобы достичь максимальной степени проверки SUT в данном случае следует заменять тестовыми реализациями только те сущности, которые действительно в этом нуждаются. Типичный набор таких сущностей:
- android.content.res.Resources или собственный Wrapper. Обычно достаточно стаба, обеспечивающего исправный возврат строк из ресурсов.
- androidx.arch.core.executor.TaskExecutor. Требуется в любых тестах на JVM, у которых SUT использует LiveData, поскольку стандартная реализация имеет Android-зависимость. Подробнее можно почитать в этой статье. Google предлагает готовое решение этой проблемы в форме Rule лишь для Junit 4, поэтому для Spek 2 и Junit 5 использую рукописный класс, содержащий код из того самого решения:
object TestLiveDataExecutionController {
fun enableTestMode() {
ArchTaskExecutor.getInstance()
.setDelegate(object : TaskExecutor() {
override fun executeOnDiskIO(runnable: Runnable) = runnable.run()
override fun postToMainThread(runnable: Runnable) = runnable.run()
override fun isMainThread(): Boolean = true
})
}
fun disableTestMode() {
ArchTaskExecutor.getInstance().setDelegate(null)
}
}
Соответствующие функции достаточно вызывать перед первым и после последнего теста в тестовом файле. Пример применения в Spek 2:
object DeviceDetailViewModelIntegrationTest : Spek({
beforeGroup { TestLiveDataExecutionController.enableTestMode() }
afterGroup { TestLiveDataExecutionController.disableTestMode() }
…
- Сервер. Для имитации сервера используется MockWebServer от создателей OkHttp. Он позволяет предустанавливать ответы на конкретные запросы, проверять состав запросов, факты их вызова и др.
- Interceptors с Android-зависимостями. Не следует пренебрегать добавлением интерцепторов в тестовую конфигурацию клиента OkHttp, соблюдая тот же порядок, что и в настоящем клиенте, чтобы серверные запросы и ответы правильно обрабатывались. Однако некоторые интерцепторы могут иметь Android-зависимости — их следует подменить. Например, это могут быть интерцепторы логирования. Интерцепторы последовательно передают данные друг другу и эту цепочку нельзя прерывать, поэтому фиктивный интерцептор должен выполнять это минимальное требование:
// StubInterceptor
Interceptor { chain ->
[email protected] chain.proceed(chain.request().newBuilder().build())
}
-
Персистентные хранилища данных (SharedPreferences, Room и т.д.)
Базовая логика управления тестовым сетевым окружением сконцентрирована в классе BaseTestNetworkEnvironment. Он используется на JVM и в Instrumentation. За специфическую конфигурацию под каждую из сред отвечают его классы-наследники: JvmTestNetworkEnvironment и InstrumentationTestNetworkEnvironment.
Сервер запускается при создании экземпляра *NetworkEnvironment до запуска теста и отключается функцией shutdownServer() после завершения теста (в случае Gherkin-стиля Spek 2 — до и после Scenario соответственно).
Для удобной настройки ответов на конкретные запросы используется функция dispatchResponses. При необходимости к mockServer можно обратиться напрямую.
abstract class BaseTestNetworkEnvironment {
companion object {
private const val BASE_URL = «/»
private const val ENDPOINT_TITLE = «Mock server»
}
val mockServer: MockWebServer = MockWebServer().also {
it.startSilently()
}
// класс, специфичный для инфраструктуры проекта
protected val mockNetworkConfig: NetworkConfig
init {
val mockWebServerUrl = mockServer.url(BASE_URL).toString()
mockNetworkConfig = TestNetworkConfigFactory.create(mockWebServerUrl, BASE_URL)
}
/**
* Используется для предустановки фиктивных ответов на конкретные запросы к [MockWebServer].
*
* [pathAndResponsePairs] пара путь запроса — ответ на запрос.
*
* Если [MockWebServer] получит запрос по пути, которого нет среди ключей [pathAndResponsePairs],
* то будет возвращена ошибка [HttpURLConnection.HTTP_NOT_FOUND].
*/
fun dispatchResponses(vararg pathAndResponsePairs: Pair<String, MockResponse>) {
val pathAndResponseMap = pathAndResponsePairs.toMap()
val dispatcher = object : Dispatcher() {
override fun dispatch(request: RecordedRequest): MockResponse {
val mockResponse = request.path?.let {
pathAndResponseMap[it]
}
return mockResponse ?: mockResponse(HttpURLConnection.HTTP_NOT_FOUND)
}
}
mockServer.dispatcher = dispatcher
}
fun shutdownServer() {
mockServer.shutdown()
}
/**
* Запуск сервера с отключенными логами
*/
private fun MockWebServer.startSilently() {
Logger.getLogger(this::class.java.name).level = Level.WARNING
start()
}
}
Содержимое JvmTestNetworkEnvironment уже сильно зависит от специфики конкретного проекта, но цель его неизменна — заменить некоторые сущности локального сетевого окружения тестовыми дублерами, чтобы код работал на JVM.
// Если не передавать в конструктор класса специфические экземпляры тестовых дублеров, то будут использоваться
// стабы с минимальным предустановленным поведением, необходимым для функционирования сетевого флоу.
class JvmTestNetworkEnvironment(
val mockPersistentStorage: PersistentStorage = mockPersistentStorageWithMockedAccessToken(),
val mockResources: ResourceProvider = TestResourceProvider()
) : BaseTestNetworkEnvironment() {
private val nonAuthZoneApiHolderProvider: NonAuthZoneApiHolderProvider
private val authZoneApiHolderProvider: AuthZoneApiHolderProvider
init {
val moshiFactory = MoshiFactory()
val serverErrorConverter = ServerErrorConverter(moshiFactory, mockResources)
val stubInterceptorProvider = StubInterceptorProvider()
val interceptorFactory = InterceptorFactory(
ErrorInterceptorProvider(serverErrorConverter).get(),
AuthInterceptorProvider(mockPersistentStorage).get(),
stubInterceptorProvider.get(),
stubInterceptorProvider.get()
)
nonAuthZoneApiHolderProvider = NonAuthZoneApiHolderProvider(
interceptorFactory,
moshiFactory,
mockNetworkConfig
)
authZoneApiHolderProvider = AuthZoneApiHolderProvider(
interceptorFactory,
moshiFactory,
UserAuthenticator(),
mockNetworkConfig
)
}
fun provideNonAuthZoneApiHolder() = nonAuthZoneApiHolderProvider.get()
fun provideAuthZoneApiHolder() = authZoneApiHolderProvider.get()
}
Функции для упрощения создания серверных ответов:
fun mockResponse(code: Int, body: String): MockResponse = MockResponse().setResponseCode(code).setBody(body)
fun mockResponse(code: Int): MockResponse = MockResponse().setResponseCode(code)
fun mockSuccessResponse(body: String): MockResponse = MockResponse().setBody(body)
Тела фиктивных серверных ответов сгруппированы по object-ам, соответствующим разным запросам. Это делает тестовые файлы чище и позволяет переиспользовать ответы и значения их полей в разных тестах. Одни и те же ответы используются тестами на JVM и Instrumentation (в том числе UI).
После добавления комментария «language=JSON» IDE подсвечивает синтаксис JSON. Подробнее о Language injections можно почитать тут.
С помощью выноса значений интересующих полей ответов в константы, можно использовать их при проверках в тестах, не дублируя строки. Например, убедиться, что описание ошибки из серверного ответа корректно передано в Snackbar. Тело ответа получается посредством вызова функции с параметрами, которые при надобности позволяют конфигурировать ответ из теста.
object LoginResponses {
const val INVALID_CREDENTIALS_ERROR_DESCRIPTION = «Неверный логин или пароль»
fun invalidCredentialsErrorJson(
errorDescription: String = INVALID_CREDENTIALS_ERROR_DESCRIPTION
): String {
// language=JSON
return «»»
{
«error»: {
«code»: «invalid_credentials»,
«description»: «$errorDescription»,
«title»: «Введены неверные данные»
}
}
«»».trimIndent()
}
…
}
Схожим образом вынесены и пути запросов:
const val LOGIN_REQUEST_PATH = «/auth/login»
object GetCameraRequest {
const val DEVICE_ID = «1337»
const val GET_CAMERA_REQUEST_PATH = «/devices/camera/$DEVICE_ID»
}
…
Общие для JVM и Instrumentation файлы должны находиться в директории, доступной обоим окружениям. Доступ настраивается в build.gradle:
android {
sourceSets {
// Instrumentation
androidTest {
java.srcDirs += ‘src/androidTest/kotlin’
java.srcDirs += ‘src/commonTest/kotlin’
}
// JVM
test {
java.srcDirs += ‘src/test/kotlin’
java.srcDirs += ‘src/commonTest/kotlin’
}
}
}
Взаимодействие View и ViewModel построено особым способом, благодаря которому очень удобно писать unit-тесты ViewModel и integration-тесты. Публичные функции ViewModel представляют события со стороны View (обычно они соответствуют действиям со стороны пользователя) и именуются в событийном стиле:
ViewModel воздействует на View посредством двух LiveData:
- state — описание состояния View
- events — однократные события, не сохраняющиеся в state
Пример организации ViewModel, ViewState и ViewEvents:
class AuthViewModel(…) {
val state = MutableLiveData<AuthViewState>()
val events = EventsQueue<ViewEvent>()
…
}
sealed class AuthViewState {
object Loading : AuthViewState()
data class Content(
val login: String = «»,
val password: String = «»,
val loginFieldState: InputFieldState = Default,
val passwordFieldState: InputFieldState = Default,
val enterButtonState: EnterButtonState = Disabled
) : AuthViewState() {
sealed class InputFieldState {
object Default : InputFieldState()
object Error : InputFieldState()
object Blocked : InputFieldState()
}
…
}
}
class EventsQueue<T> : MutableLiveData<Queue<T>>() {
fun onNext(value: T) {
val events = getValue() ?: LinkedList()
events.add(value)
setValue(events)
}
}
// ViewEvents:
interface ViewEvent
data class ShowSnackbarError(val message: String) : ViewEvent
class OpenPlayStoreApp : ViewEvent
…
Наконец, пример JVM Integration-теста:
object AuthViewModelIntegrationTest : Spek({
Feature(«Login») {
// region Fields and functions
lateinit var authViewModel: AuthViewModel
lateinit var networkEnvironment: JvmTestNetworkEnvironment
val login = «log»
val password = «pass»
fun setUpServerScenario() {
networkEnvironment = JvmTestNetworkEnvironment()
val authRepository = networkEnvironment.let {
AuthRepositoryImpl(
nonAuthApi = it.provideNonAuthZoneApiHolder(),
authApi = it.provideAuthZoneApiHolder(),
persistentStorage = it.mockPersistentStorage,
inMemoryStorage = InMemoryStorage()
)
}
val clientInfo = ClientInfo(…)
val loginInteractor = LoginInteractor(authRepository, clientInfo)
authViewModel = AuthViewModel(
resources = networkEnvironment.mockResources,
schedulers = TestSchedulersProvider(),
loginInteractor = loginInteractor
analytics = mock()
)
}
beforeFeature { TestLiveDataExecutionController.enableTestMode() }
afterFeature { TestLiveDataExecutionController.disableTestMode() }
beforeEachScenario { setUpServerScenario() }
afterEachScenario { networkEnvironment.shutdownServer() }
// endregion
Scenario(«input credentials») {…}
Scenario(«click enter button and receive invalid_credentials error from server») {
Given(«invalid_credentials error on server») {
networkEnvironment.dispatchResponses(
LOGIN_REQUEST_PATH to mockResponse(HTTP_UNAUTHORIZED, invalidCredentialsErrorJson())
)
}
When(«enter not blank credentials») {
authViewModel.onCredentialsChanged(login, password)
}
And(«click enter button») {
authViewModel.onEnterButtonClick(login, password)
}
Then(«reset password, mark login and password input fields as invalid and disable enter button») {
val state = authViewModel.state.value
val expectedState = Content(
login = login,
password = «»,
loginFieldState = Content.InputFieldState.Error,
passwordFieldState = Content.InputFieldState.Error,
enterButtonState = Content.EnterButtonState.Disabled
)
assertThat(state).isEqualTo(expectedState)
}
And(«create snackbar error event with message from server») {
val expectedEvent = authViewModel.events.value!!.peek()
assertThat(expectedEvent).isEqualTo(ShowSnackbarError(INVALID_CREDENTIALS_ERROR_DESCRIPTION))
}
}
…
}
…
})
Так тестируется основная логика пользовательских сценариев. Эти сценарии с теми же данными затем могут быть проверены в UI-тестах.
Что в итоге нужно тестировать?
Не нужно тестировать чужие библиотеки — это ответственность разработчиков библиотек (исследовательское тестирование — исключение). Тестировать нужно свой код.
Unit-тесты следует писать на логику, в которой есть реальная вероятность совершения ошибки. Это могут быть ViewModel, Interactor, Repository, функции форматирования (денег, дат и т.д.) и другие стандартные и нестандартные сущности. Тривиальную логику тестировать не стоит. Но нужно следить за изменением непокрытой тестами логики, если она при очередном изменении перестанет быть тривиальной, то тогда её нужно протестировать.
100%-е покрытие кода тестами несёт с собой вред: трата лишнего времени на написание бесполезных тестов, боль при изменении реализации, при поддержке бесполезных тестов, иллюзия хорошо протестированной системы. Процент покрытия не отражает реальной картины того, насколько хорошо система протестирована.
Я предпочитаю не устанавливать минимальный порог тестового покрытия для нового кода. Однако для разработчика всё же может быть полезной точечная проверка покрытия SUT, над которой он работает.
Тестами нужно проверять не только основные сценарии, но и краевые. Обычно там кроется наибольшее число багов.
При исправлении бага в коде, который не покрыт тестами, следует его ими покрыть.
JVM Integration-тесты от ViewModel до слоя данных следует писать для каждого экрана. Менее масштабные JVM Integration — при надобности. Возможны случаи, когда большинство модулей, включая ViewModel, сами по себе являются слишком простыми, чтобы их стоило покрывать unit-тестами. Однако создание масштабного JVM integration-теста на всю цепочку будет очень кстати, тем более что пишутся такие тесты достаточно просто и однотипно.
Нужно стараться не проверять в тестах более высокоуровневых категорий то, что проверено в более низкоуровневых, но повторы проверок основных сценариев во всё большей интеграции — это нормально.
Тесты Instrumentation Integration non-UI — только когда нужно проверить что-то, что нельзя адекватно проверить на JVM.
E2E UI- и Component UI-тесты нужны для замены части ручных тестов при регрессионном тестировании. Разумно доверить их написание QA-инженерам. В настоящее время мы с коллегами ищем оптимальный подход к тому, как организовывать UI-тесты, в каком количестве их писать и как сочетать с более низкоуровневыми тестами.
Test Driven Development
Можно подумать, что о написании тестов уже известно достаточно и пора идти в бой, но есть еще один момент… Вы, вероятно, собрались написать очередную фичу и затем покрыть её тестами? Замечательная идея. Именно так и стоит делать, пока навык написания тестов не будет более менее отработан. Такой подход называют Test Last. Конечно же, среди пишущих тесты разработчиков он наиболее распространен. Но он имеет серьезные недостатки:
- несмотря на знания о том, каким должен быть тестируемый код, всё равно может получиться реализация, протестировать которую сходу не получится. Может понадобиться рефакторинг, чтобы появилась возможность написать тесты и сделать их «не корявыми»


- по моим наблюдениям, при покрытии кода тестами, разработчику свойственно подстраивать тесты под существующую реализацию, которая уже «засела у него в голове». Поэтому вероятность упустить какой-то кейс возрастает. И это чревато пропущенными багами.
- тесты остаются на последнюю очередь и на них зачастую не остается времени.
Решить эти проблемы можно, используя принцип Test First, придуманным Кентом Беком. Он основан на идее: «Never write a single line of code unless you have a failing automated test» (не стоит писать код реализации, пока для него не написан падающий тест).
На базе этого принципа Кент Бек создал методологию Test Driven Development (TDD, разработка через тестирование). Согласно ей, разработка должна вестись итеративно, путем цикличного повторения шагов Red-Green-Refactor (микро-цикл):
- написать тест на логику, которую предстоит реализовать, и убедиться, что он падает;
- написать простейшую реализацию, чтобы тест выполнился успешно;
- провести рефакторинг реализации, не сломав тесты.
Подразумевается, что в итерации падающий тест должен быть только один.
Позже Роберт Мартин развил TDD, сформулировав Three Laws of TDD (нано-цикл):
- перед написанием какого-либо кода реализации необходимо написать падающий тест;
- тест не должен содержать больше, чем нужно для его падения или провала компиляции;
- не нужно писать больше кода реализации, чем достаточно для того, чтобы падающий тест прошел.
Из-за второго правила работа сводится к поочерёдному написанию строчки реализации SUT за строчкой теста. Нано-циклы заставляют фокусироваться на очень маленькой подзадаче. Это также помогает, когда не знаешь, с чего начать реализацию.
Со временем Робертом были сформулированы еще два более масштабных цикла. Про всех них можно почитать в его статье.
Технику применения нано-циклов я использую далеко не всегда. Частые перескакивания в сложной задаче приводят к потере фокуса и снижают продуктивность. Несмотря на то, что более крупные циклы должны помогать этого избегать. Считаю, что эту технику лучше применять точечно и комфортный размер шага следует выбирать каждому самостоятельно. Жесткое следование всем правилам на практике не всегда идёт на пользу, но полезно при обучении.
Я несколько отступился от канонов и нашел эффективным такой алгоритм работы при реализации новой фичи:
1. Вникнуть в задачу, спроектировать связи между модулями, определить их ответственность.
2. Создать SUT, описать его интерфейс.
- Если функции должны возвращать какой-то результат, можно писать в их теле TODO(), чтобы код мог скомпилироваться, тогда при вызове функции тест будет прерван эксепшеном. Другой вариант — хардкодить возврат простого объекта или null. Так тесты смогут совершить проверки после вызова функции, но тут лучше быть поаккуратнее.
fun doSomething(): Boolean { TODO() }
3. Создать тестовый файл для SUT, объявить тесты-требования.
- Описать столько кейсов, сколько получится. Нормально, если в ходе написания реализации на ум придут еще какие-то кейсы.В пустые тесты/блоки можно добавлять вызов функции fail() (из Junit или AssertJ), чтобы не забыть реализовать какой-то из тестов, поскольку пустой тест при запуске выдает положительный результат.
@Test
fun `when invoke — should do something`() {
fail { «not implemented» }
}
4. Реализовать тест(ы)
- Методология подразумевает написание только одного теста и необходимой реализации SUT для его прохождения за микроцикл, но это может быть не продуктивно, если несколько тестов-требований тесно связаны. Вполне нормально написать несколько тестов и потом перейти к реализации. Если же тестов у SUT получается много и они направлены на проверку разных аспектов её работы, то написание всех тестов перед началом реализации будет приводить к потере фокуса с подзадач, которые предстоит в ходе реализации решить. Как именно поступать, стоит определять в зависимости от конкретного случая и от того, как получается комфортнее.
5. Реализовать SUT, чтобы реализованные тесты успешно выполнились.
- По умолчанию в момент времени стоит фокусироваться на прохождении одного конкретного теста.
6. Отрефакторить SUT, сохранив успешность выполнения реализованных тестов.
7. Если остались нереализованные тесты, перейти к пункту #4.
Алгоритм доработки SUT, которая уже покрыта тестами:
- Объявить новые тесты согласно новым требованиям,
- Реализовать новые тесты,
- Реализовать доработку в SUT, чтобы новые тесты выполнились успешно
- Если старые тесты упали:Они актуальны при новых требованиях — исправить реализацию SUT и/или эти тесты,Они неактуальны — удалить.
- Отрефакторить SUT, сохранив успешность выполнения реализованных тестов,
- Если остались нереализованные тесты, перейти к пункту 2.
Но если к началу работы над задачей невозможно получить достаточного представления о том, какие будут модули, их ответственность и связи, и для формирования представления требуется начать писать реализацию, экспериментировать, то TDD применять не стоит. В противном случае может быть потеряно много времени на переписывание тестов.
Приступаем к реализации по принципу Test Last, но как только достаточное представление сформируется, делаем паузу и переходим к тестам, продолжая дальнейшую разработку уже по TDD. Незачем также применять TDD для реализации тривиальной логики, если вы не собираетесь покрывать её тестами.
По итогу получаем от подхода следующие преимущества:
- Предварительное написание тестов вынуждает реализовывать SUT заведомо тестируемой. Тесты оказываются слабо связанными с деталями реализации.
- Тесты являются спецификацией SUT (если при этом соблюдать правила их именования). Часто они вытекают напрямую из функциональных требований к задаче. Сфокусированное перечисление тестов-требований до начала реализации помогает лучше понять и запомнить требования, лучше продумать детали интерфейса SUT. Увеличивается вероятность заблаговременного выявления всех необходимых краевых кейсов. Это само по себе уже помогает допускать меньше ошибок в будущей реализации, а возможность запуска готовых тестов в любой момент дает уверенность в том, что реализация осуществляется правильно.
- Наличие тестов делает рефакторинг реализации безопасным. После каждого изменения реализации можно быстро прогнать все тесты SUT и в случае обнаружения поломки сразу же её устранить. Время, затрачиваемое на отладку, очень сильно сокращается.
- На тесты хватает времени, ведь они неотъемлемая часть процесса разработки
- Все эти факторы в совокупности сокращают время, затрачиваемое на разработку и на развитие приложения в будущем.
- Приятно видеть, как красные тесты один за другим превращаются в зелёные
TDD — это в первую очередь подход к разработке. Методология замечательно показывает себя при реализации SUT с unit- и JVM integration-тестами, поскольку их можно быстро и часто запускать. С Instrumentation non-UI-тестами применять её можно, но из-за длительности запуска придется запускать тесты реже. Применять же TDD с UI-тестами крайне не рекомендуется.
Порог входа в TDD высок. Сперва следует закрепить базовые навыки написания тестов. Применять методологию в повседневности или нет — личное дело каждого, но не стоит отказываться, не попробовав. На моей практике встречались фичи со столь сложной логикой, требования к которой много раз менялись, что благополучную реализацию этих фич без TDD я себе не представляю.
Заключение
Применение автоматизированного тестирования способно вывести разработку ПО на качественно новый уровень. Главное — подходить к делу осознанно.
Разработчикам рекомендуется делать акцент на написании тестов на JVM. Чтобы поддержка тестов и изменения в кодовой базе не становились болью, следует писать только те тесты, которые действительно представляют ценность. Важно внимательно отнестись к дизайну продуктового и тестового кода, соблюдать ряд правил, стандартизировать подходы среди всех разработчиков проекта.
Можно извлекать существенную пользу за счет применения TDD с тестами на JVM. Применять его следует не всегда. Разработчику нужно самостоятельно подобрать комфортный размер шага в цикле разработки по TDD.
Полезные материалы
- Воркшоп с объяснением основ написания unit-тестов на практике в Junit 4;
- Доклад «Эффективное автоматизированное тестирование Android-приложений. Тестирование на JVM»;
- xUnit Patterns: Test Double;
- Mocks Aren’t Stubs;
- GivenWhenThen;
- «Следует ли тестировать приватные функции?»;
- Google: Testing On The Toilet — блог Google с заметками-рекомендациями по написанию автотестов;
- The Three Laws of TDD — Robert C. Martin;
- The Cycles Of TDD — Robert C. Martin;
- История развития идеи Test First;
- Доклад «Test Last, Test First, TDD: когда применять тот или иной подход».
Содержание
- Что такое автотесты
- Документация
- Инструменты
- Паттерны проектирования
- Что можно автоматизировать
- Советы для разработки автотестов
- Общий код стоит выносить
- Писать переиспользуемый код
- Тесты должны быть удобными
- Тесты должны быть простыми
- Разделение на модули
- Интеграции
- Главное кратко
Когда проект становится очень большим, а ручные тесты отнимают все больше времени и средств, требуется автоматизация тестирования. Тестировщик Даниил Шатухин рассказывает, как выстроить архитектуру автотестов на Java, чтобы потом не пришлось все срочно переделывать и оптимизировать.
Что такое автотесты
Под автоматизацией тестирования понимают написание скриптов, которые выполняют тесты за мануальных тестировщиков. Такие системы состоят из сложных сценариев проверки функциональности проектов, сбора статистики, фиксирования багов и генерации отчетности. Может показаться, что если однажды автоматизировать базу тестов, то можно навсегда забыть про долгий процесс тестирования каждого билда. Но автотесты надо постоянно актуализировать и поддерживать. Это первое, о чем стоит задуматься до внедрения автотестов в проект.
Написание автотестов занимает много времени. В итоге мы получаем отлаженную систему, которая запускается по одному клику или даже по расписанию. Но сам процесс займет некоторое время. Понадобятся специалисты в команде. Перед автоматизацией нужно оценить силы команды и финансовые возможности проекта. Иногда можно отказаться от идеи и разработать детальные чек-листы, которые сэкономят время и деньги компании.
Важно понимать, что не надо автоматизировать все подряд. Некоторые инструменты не меняются годами или занимают малую часть от всего проекта. Поэтому затраченные время и силы не окупятся. В этих случаях подойдут ручные тесты. Нужно помнить, что на поддержку и актуализацию большой базы тестов уходит много времени. Нельзя написать автотесты один раз и забыть про них.
Документация
Подумайте, что именно предстоит автоматизировать.
Составьте тест-план. Он поможет понять, что нужно тестировать и какие состояния можно считать успешным завершением тестов. В тест-плане кратко описывают тестируемый продукт, платформы и операционные системы, на которых предстоит работать. Здесь указывают критерии завершения тестов.
Подготовьте тест-кейсы. Это подробное текстовое описание прохождения каждого тестового сценария. Такой подготовительный этап можно назвать самым ответственным. Необходимо не просто собрать коллекцию тест-кейсов и начать писать код — надо понять, какие части проекта нужно автоматизировать в первую очередь. Обычно автотесты начинают писать, чтобы сократить время, которое уходит на ручное тестирование. Поэтому в приоритете:
- рутинные тесты, которые занимают много времени, часто запускаются и требуют постоянного воспроизведения. Например, в проекте есть анкета для обратной связи с большим количеством полей и входных данных. Ручное заполнение может занимать 5–10 минут, а запуск автоматизированного теста — несколько секунд. Автоматизация позволит освободить время на более приоритетные и интересные задачи;
- места с заведомо большим количеством багов. На каждом проекте они разные, но к ним, например, может относиться и часто обновляемый код.
Тест-кейсы следует описывать максимально детально и подробно; обязательно указывать состояние, которое можно считать успешным для завершения теста. Некоторые действия сложно автоматизировать. Например, с помощью скрипта можно проверить наличие картинки на сайте, но не ее содержимое. В этом случае задачу проще оставить для ручного тестирования.
Инструменты
Выбор инструментов напрямую зависит от стека технологий проекта. В этой статье рассмотрим, что обычно используется для разработки автотестов на Java.
При выборе фреймворка стоит обращать внимание на наличие подробной документации, его популярность и актуальность. Если последний раз фреймворк обновляли несколько лет назад, то его выбирать не стоит. Также необходимо хранить историю версий кода автотестов, генерировать подробные отчеты и выполнять интеграцию CI/CD.
Обычно стек инструментов и технологий для автоматизации на Java выглядит так:
- Selenide — популярный фреймворк для автоматизации тестирования веба на базе Selenium WebDriver;
- Allure Testops — инструмент для простого создания подробных отчетов. Поддерживает скриншоты, скринкасты и снапшоты состояния страниц во время выполнения теста. Все это позволяет не только увидеть наличие ошибок, но и посмотреть на сами ошибки визуально;

- JUnit — инструмент для модульного тестирования ПО на Java;
- Rest Assured — библиотека для работы с REST-службами и тестирования API;
- Jenkins — открытая система для непрерывной интеграции ПО;

- Git — распределенная система управления версиями. Можно использовать любой удобный сервис, к примеру GitHub, GitLab или Bitbucket. При желании можно поднять собственный git-сервер.
Наверняка во время работы над автотестами появится необходимость в сторонних библиотеках, которые упрощают и ускоряют разработку. Со временем в проект можно установить несколько десятков библиотек, которые не используются в полном объеме. Все это замедляет сборку, так как каждая библиотека порождает зависимости. К примеру, популярная библиотека построена на вспомогательных инструментах от других разработчиков, и при ее установке в нашем проекте оказывается вся коллекция этих инструментов. Все это замедляет время сборки тестов и нагружает систему.
В этом случае важно понимать, что делает каждая установленная библиотека. Не надо устанавливать большой и тяжелый модуль из-за пары методов. Также накапливайте опыт, запоминайте, какие инструменты эффективнее, а какие только усложняют архитектуру. Это позволит на новом проекте сразу понять, от каких библиотек можно отказаться.
Паттерны проектирования
Автоматизация тестирования — уже сложившаяся сфера со своими правилами и подходами. Для упрощения разработки существует набор паттернов проектирования:
- Для структурирования кода существует понятие Page Object. Принцип заключается в объединении элементов страниц в свойства класса. Важно, что для каждой страницы создается ровно один класс, который содержит элементы в качестве свойств. В одном модуле мы храним локаторы, а в другом — взаимодействуем с ними. Это помогает повторно использовать локаторы и давать им понятные названия.
- Для запуска одних и тех же тестов с разными данными обычно используется подход Data Providers. Буквально представьте, что в вашем проекте есть отдельный модуль, поставляющий данные для тестов. Вам не надо самостоятельно генерировать данные, а достаточно просто вызвать ранее написанный модуль. Это упростит работу и поможет сэкономить время, ведь можно будет просто обратиться к «поставщику».
- Также следует использовать декораторы и дополнительные методы фреймворков, к которым можно отнести аннотации JUnit. Например, с помощью аннотации Issue, Story, CsvSource и Feature можно указать версию тестируемого приложения, кратко описать тестовый сценарии, добавить ссылку на тест в трекинговую систему или указать список тестовых данных.
Что можно автоматизировать
Практически каждый крупный проект состоит из фронтенда, бэкенда и мобильных приложений. В редких случаях на проекте могут быть какие-то уникальные гаджеты, разработанные командой.
Мобильные приложения и «железо» обычно тестируют отдельные QA-команды. Связано это с тем, что в тестировании приложений есть свои особенности и сценарии, которые практически не встречаются в веб-приложениях, а для тестирования «железа» необходимы специальные навыки. Фронтенд- и бэкенд-тестировщики обычно работают вместе и часто общаются с разработчиками этих систем.
Из всех тест-кейсов надо выбрать наиболее приоритетные. Если проект находится на стадии разработки, то надо начинать с тестирования бэкенда. Дело в том, что клиентская часть еще может поменяться, и тогда QA-команде придется переписывать тесты. А вот серверную часть вряд ли переделают перед самым запуском. Но и это не все, эти тестовые сценарии тоже надо рассортировать по приоритету.
Цель компании — получать прибыль; добиться ее можно с помощью веб-приложения. Поэтому в первую очередь следует покрывать тестами те части проекта, которые отвечают за продажи и аналитику. К примеру, на сайте есть форма оплаты и обратной связи. В первую очередь стоит обратить внимание на тестирование части, которая отвечает за получение денег. Ведь если никто не сможет купить продукт, то и обратная связь не понадобится.
Этой логикой следует пользоваться при выборе автоматизации каждого тест-кейса. В приоритете должны быть те системы, которые приносят прибыль и отвечают за обработку всего, что с ней связано. Конечно, это не всегда формы оплаты и перевода денег. К примеру, если тестируется стриминговый сервис с видеороликами, то в приоритете будет показ видео и рекламных вставок, но суть одна — именно эти части влияют на прибыль.
Советы для разработки автотестов
Советы ниже помогут с самого начала выстроить грамотную архитектуру и работу в QA-команде. Также работодатели чаще обращают внимание на соискателей, которые уже переняли лучшие практики индустрии и умеют ими пользоваться.
Общий код стоит выносить
Если какой-то метод или часть кода используется в коде несколько раз, то это можно вынести в общую часть. Тогда получится упростить чтение кода и уменьшить количество строк, которых со временем в файле будет становиться все больше.
Писать переиспользуемый код
Надо стараться писать универсальные методы и конструкции, которые можно будет использовать повторно. Это экономит время на разработке и ускоряет процесс автоматизации. Куда быстрее дополнить уже готовый метод, чем писать его с нуля.
Тесты должны быть удобными
Архитектуру автотестов следует планировать таким образом, чтобы на модификацию или обновление уходило минимум времени. В первую очередь это забота о себе и своем времени. Также важно помнить про удобство других членов команды. Есть вероятность, что со временем ваши тесты отдадут кому-то другому. Важно позаботиться о том, чтобы человек мог сам без подсказок разобраться с устройством кода.
Тесты должны быть простыми
Перед написанием каждого автотеста стоит проанализировать несколько реализаций и выбрать самую простую. Использование редких методов и множества библиотек хоть и покажет вашу экспертность, но усложнит работу для тех, кто с такими инструментами не сталкивался. Важно, чтобы тест был предельно понятен разработчику и другим членам команды даже спустя длительное время.
Разделение на модули
Хорошей практикой считается разделение автотестов на отдельные модули. Такой подход позволит быстрее искать ошибки в коде и вносить изменения. Не надо будет каждый раз переписывать весь тест, достаточно будет внести правки только в один из модулей.
Интеграции
Над автоматизацией тестирования обычно работает целая команда QA-отдела. И код надо писать таким образом, чтобы его можно было использовать внутри проекта. К примеру, разработчику необходимо протестировать систему, которая требует создания нового пользователя при каждой проверке. В этом случае можно самому написать модуль регистрации и потратить время, а можно обратить внимание, что коллеги уже успели это сделать, и использовать их модуль. Если каждый член команды будет думать о переиспользовании его кода внутри отдела, то работа будет идти быстрее.
Главное кратко
- Автоматизация тестирования — сложный процесс, требующий времени на внедрение и ресурсов на поддержание. Нельзя написать код один раз и оставить его без присмотра.
- Автотесты принесут пользу только при грамотном подходе и выборе инструментов. Иначе они просто заберут силы и время.
- Не надо автоматизировать всё подряд. Важно в первую очередь заняться теми частями проекта, которые имеют наибольшую значимость.
- Тесты должны быть «человечными». Зеленая галочка в терминале после прогона не даст никакой полезной информации менеджерам и другим участникам команды. Поэтому следует уделить время генерации подробной и понятной отчетности, из которой каждый сможет получить необходимые для себя данные.
- Код автотестов должен быть простым и понятным. Сложные конструкции и низкоуровневые вставки сделают только хуже.
- Использование большого количества сторонних библиотек чаще несет больше вреда, чем пользы. Библиотеки тянут за собой зависимости, которые замедляют сборку. Некоторые вещи уже могут быть реализованы в стандартной библиотеке Java.

Меня зовут дядя Вова, я ведущий инженер по автоматизации тестирования и, как писал уже несколько раз, неизменный фанат Robot Framework. Даже когда-то контрибьютил в его исходный код и иногда помогаю новичкам в официальном slack-чате этого инструмента.
Но, как я уже упоминал в одной из статей, есть у него один пробел по сравнению с pytest — это отсутствие адекватной параметризации тестов. Справедливости ради, у Robot Framework есть надстройка, которая позволяет генерировать тесты на основе внешней таблицы. Но это не совсем то, что нам подходит.
После прошлой статьи многие спрашивали меня, как именно делается параметрическая генерация автотестов. В этой статье отвечу на вопрос.
Проект-иллюстрация
Предположим, что в нашем проекте есть класс, который зависит от других входящих в него классов. Для простоты возьмем школьный курс генетики, кейс про горошек.
Горох может иметь цвет (Color) и тип (Kind):
from colors import Color
from kinds import Kind
class Peas:
color: Color
kind: Kind
def __init__(self, color: Color, kind: Kind):
self.color = color
self.kind = kind
def __str__(self):
return f"{self.color.name().capitalize()} {self.kind.name()} горошек." Не будем усложнять: класс переопределяет метод __str__() и выводит полную информацию о свойствах этого сорта гороха. Для иллюстрации этого будет вполне достаточно.
Добавим базовый класс «Цвет» (Color) и унаследуем от него основные — Зеленый и Желтый:
class Color:
color_name: str = "неизвестный цвет"
def name(self) -> str:
return self.color_name
class Green(Color):
color_name = "зелёный"
class Yellow(Color):
color_name = "жёлтый"Теперь опишем базовый тип и унаследуем от него основные — Гладкий и Сморщенный (он же — Мозговой):
class Kind:
kind_name: str = "неизвестная форма"
def name(self) -> str:
return self.kind_name
class Smooth(Kind):
kind_name = "гладкий"
class Brain(Kind):
kind_name = "мозговой"Базовый тест
Сфокусируемся на методе вывода информации о сорте. Чтобы покрыть все варианты, мы можем написать четыре простых теста:
from colors import Green, Yellow
from kinds import Smooth, Brain
from peas import Peas
def test_green_smooth_peas():
peas = Peas(Green(), Smooth())
assert str(peas) == "Зелёный гладкий горошек."
def test_yellow_smooth_peas():
peas = Peas(Yellow(), Smooth())
assert str(peas) == "Жёлтый гладкий горошек."
def test_green_brain_peas():
peas = Peas(Green(), Brain())
assert str(peas) == "Зелёный мозговой горошек."
def test_yellow_brain_peas():
peas = Peas(Yellow(), Brain())
assert str(peas) == "Жёлтый мозговой горошек."Это все замечательно работает, но я живу по принципу: «Если пишешь что-то дважды — значит, делаешь что-то не так!»
Параметризация тестов
Вынесем цвет и тип в параметры и напишем генерацию параметров через умножение (product()) списков:
from itertools import product
from typing import Tuple
from pytest import mark
from colors import Color, Yellow, Green
from kinds import Kind, Smooth, Brain
from peas import Peas
colors = [(Yellow(), "Жёлтый"), (Green(), "Зелёный")]
kind = [(Smooth(), "гладкий"), (Brain(), "мозговой")]
peas_word = "горошек"
sets = list(product(colors, kind))
@mark.parametrize("color_info,kind_info", sets)
def test_peas_str(color_info: Tuple[Color, str], kind_info: Tuple[Kind, str]):
color, color_str = color_info
kind, kind_str = kind_info
peas = Peas(color, kind)
assert str(peas) == f"{color_str} {kind_str} {peas_word}."Теперь мы ничего не дублируем и имеем те же четыре теста.
И в случае расширения функциональности (например, добавим новый — черный — цвет) нам не придется писать еще много кода. Напоминаю, что мы очень сильно упрощаем реальные тесты реальных продуктов.
Добавим черный цвет:
class Black(Color):
color_name = "чёрный"Теперь, чтобы тестов стало шесть, достаточно просто изменить список цветов в модуле тестов:
colors = [(Yellow(), "Жёлтый"), (Green(), "Зелёный"), (Black(), "Чёрный")]Надеюсь, идея ясна: класс может расширяться во всех направлениях, и тесты не нужно будет руками добавлять сотнями.
Названия кейсов
Возможно, первое, что бросилось в глаза при запуске таких тестов, — это не совсем приятное описание кейсов:

Для исправления этого недоразумения нужно для каждого кейса сгенерировать название и передать в параметризацию. Очень жаль, но русские буквы оно не любит, а наш метод возвращает только их. Поэтому будем обращаться к названию тестируемого класса:
test_names = [
f"{params[0][0].__class__.__qualname__} - {params[1][0].__class__.__qualname__}"
for params in sets
]Теперь пропишем их имена в параметризацию:
@mark.parametrize("color_info,kind_info", sets, ids=test_names)Совсем другое дело:

Расширенная генерация тестов
Лучшее — враг хорошего. Именно поэтому я страдаю от применения кортежей в качестве костылей. Кстати, это хороший повод рассказать о расширенной отдельным методом генерации тестов.
Сейчас мы избавимся от кортежей в параметрах самого теста и вынесем строки в отдельные параметры.
Есть в pytest зарезервированное название метода — pytest_generate_tests. Этот метод будет вызываться для каждого теста в модуле:
def pytest_generate_tests(metafunc):
args = []
names = []
for color_info, kind_info in product(colors, kinds):
color, color_str = color_info
kind, kind_str = kind_info
args.append([color, color_str, kind, kind_str])
names.append(f"{color.__class__.__qualname__} - {kind.__class__.__qualname__}")
metafunc.parametrize("color,color_str,kind,kind_str", args, ids=names)
def test_peas_str(color: Color, color_str: str, kind: Kind, kind_str: str):
peas = Peas(color, kind)
assert str(peas) == f"{color_str} {kind_str} {peas_word}."По сути, это синоним того, что было выше, но чуть более удобочитаемый. Уверен, что в вашей практике найдутся случаи, когда без этого подхода обойтись не получится.
Когда расширенная генерация тестов необходима
Иногда разработчики, уставшие от тонны issue, которые валятся как из рога изобилия в процессе написания автотестов, просят меня отключить какие-то кейсы. Чтобы не валить билд, зная заранее, что некоторые проблемы пока существуют.
Откровенно говоря, это не самая правильная практика и не стоит перенимать такой опыт. Но это хороший повод показать, почему иногда подход «расширенной» генерации незаменим и не может быть выполнен обычным @mark.parametrize.
Если вы еще не сталкивались с тем, как сделать тест при падении серым вместо красного (это не валит билд, но отмечает проблему), то это очень просто. Нужно использовать @mark.xfail. При необходимости в качестве параметра reason можно передать идентификатор issue в вашем баг-трекере.
Итак, представим, что по ТЗ у нас должен быть еще фиолетовый цвет горошка. Но разработчики с ним что-то напортачили, и тесты по нему падают. Разработчики просят нас сделать так, чтобы тесты фиолетового цвета проходили, но не валили билд.

Нужно лишь добавить условие, по которому будет определяться, нужно ли сделать кейс серым. Изменим код генерации аргументов:
params = [color, color_str, kind, kind_str]
args.append(
params if not isinstance(color, Purple) else pytest.param(*params, marks=pytest.mark.xfail(
reason="Not implemented yet."))
)Весь метод будет выглядеть так:
def pytest_generate_tests(metafunc):
args = []
names = []
for color_info, kind_info in product(colors, kinds):
color, color_str = color_info
kind, kind_str = kind_info
params = [color, color_str, kind, kind_str]
args.append(params if not isinstance(color, Purple) else pytest.param(*params, marks=pytest.mark.xfail(
reason="Not implemented yet.")))
names.append(f"{color.__class__.__qualname__} - {kind.__class__.__qualname__}")
metafunc.parametrize("color,color_str,kind,kind_str", args, ids=names)А результаты выполнения будут отмечены серым и не будут валить билд в CI:

Когда еще необходима расширенная генерация тестов
Когда необходимо написать базовый класс, использующий параметрические тесты, может случиться так, что в параметры нужно будет передать свойства этого класса.
Привычный всем подход @mark.parametrize("param", self.params) не будет работать, потому что на момент параметризации он еще не знает, что такое self. И тут мы снова возвращаемся к pytest_generate_tests, добавив его в класс:
def pytest_generate_tests(self, metafunc):
metafunc.parametrize("param", self.params)Такой подход уже будет работать.
И еще небольшая хитрость. Если вам нужно выполнить генерацию только для конкретного теста или по-разному организовать генерацию для разных тестов внутри pytest_generate_tests (напомню, он выполняется для каждого метода, начинающегося с test_ отдельно), можно обратиться к его параметру metafunc и получить свойство metafunc.function.__name__ — там и будет имя теста. Например,
class TestExample:
params: List[str] = [“I”, “like”, “python”]
def pytest_generate_tests(self, metafunc):
if metafunc.function.__name__ == “test_for_generate”:
metafunc.parametrize("param", self.params)
def test_for_generate(self, param: str):
print(param)
def test_not_for_generate(self, param: str):
print(param)…сгенерирует тесты для test_for_generate, но не сделает этого для test_not_for_generate.
Заключение
На моем текущем проекте есть сервис, который сочетает разные фильтры и сегменты, каждый из которых является отдельным классом, и использование pair-wise может дать размытый результат. Вследствие чего не будет понятно, в каком именно классе ошибка. Генерируя тесты, я могу добиться 100%-го покрытия тестами, которые будут давать четкие результаты.
Всего в этом сервисе на данный момент почти 11 тысяч тестов. Не представляю, как бы я это все покрывал без такой генерации.
Всем зеленых тестов и стопроцентного покрытия!