Привет, меня зовут Александр Васин, я бэкенд-разработчик в Едадиле. Идея этого материала началась с того, что я хотел разобрать вступительное задание (Я.Диск) в Школу бэкенд-разработки Яндекса. Я начал описывать все тонкости выбора тех или иных технологий, методику тестирования… Получался совсем не разбор, а очень подробный гайд по тому, как писать бэкенды на Python. От первоначальной идеи остались только требования к сервису, на примере которых удобно разбирать инструменты и технологии. В итоге я очнулся на сотне тысяч символов. Ровно столько потребовалось, чтобы рассмотреть всё в мельчайших подробностях. Итак, программа на следующие 100 килобайт: как строить бэкенд сервиса, начиная от выбора инструментов и заканчивая деплоем.

TL;DR: Вот репка на GitHub с приложением, а кто любит (настоящие) лонгриды — прошу под кат.
Мы разработаем и протестируем REST API-сервис на Python, упакуем его в легкий Docker-контейнер и развернем с помощью Ansible.
Реализовать REST API-сервис можно по-разному, с помощью разных инструментов. Описанное решение не единственно верное, реализацию и инструменты я выбирал исходя из своего личного опыта и предпочтений.
- Что будем делать?
- Какие инструменты выбрать?
- Разработка
- Почему нужно начать с setup.py?
- Как указать версии зависимостей?
- База данных
- Проектируем схему
- Описываем схему в SQLAlchemy
- Настраиваем Alembic
- Генерируем миграции
- Приложение
- Сериализация данных
- Обработчики
- POST /imports
- GET /imports/$import_id/citizens
- PATCH /imports/$import_id/citizens/$citizen_id
- GET /imports/$import_id/citizens/birthdays
- GET /imports/$import_id/towns/stat/percentile/age
- Тестирование
- Обработчики
- GET /imports/$import_id/citizens
- POST /imports
- PATCH /imports/$import_id/citizens/$citizen_id
- GET /imports/$import_id/citizens/birthdays
- GET /imports/$import_id/towns/stat/percentile/age
- Миграции
- Обработчики
- Сборка
- CI
- Деплой
- Нагрузочное тестирование
- Что еще можно сделать?
- В заключение
Что будем делать?
Представим, что интернет-магазин подарков планирует запустить акцию в разных регионах. Чтобы стратегия продаж была эффективной, необходим анализ рынка. У магазина есть поставщик, регулярно присылающий (например, на почту) выгрузки данных с информацией о жителях.
Давайте разработаем REST API-сервис на Python, который будет анализировать предоставленные данные и выявлять спрос на подарки у жителей разных возрастных групп в разных городах по месяцам.
В сервисе реализуем следующие обработчики:
-
POST /imports
Добавляет новую выгрузку с данными; -
GET /imports/$import_id/citizens
Возвращает жителей указанной выгрузки; -
PATCH /imports/$import_id/citizens/$citizen_id
Изменяет информацию о жителе (и его родственниках) в указанной выгрузке; -
GET /imports/$import_id/citizens/birthdays
Вычисляет число подарков, которое приобретет каждый житель выгрузки своим родственникам (первого порядка), сгруппированное по месяцам; -
GET /imports/$import_id/towns/stat/percentile/age
Вычисляет 50-й, 75-й и 99-й перцентили возрастов (полных лет) жителей по городам в указанной выборке.
Какие инструменты выбрать?
Итак, пишем сервис на Python, используя знакомые фреймворки, библиотеки и СУБД.
В 4 лекции видеокурса рассказывается о различных СУБД и их особенностях. Для моей реализации я выбрал СУБД PostgreSQL, зарекомендовавшую себя как надежное решение c отличной документацией на русском языке, сильным русским сообществом (всегда можно найти ответ на вопрос на русском языке) и даже бесплатными курсами. Реляционная модель достаточно универсальна и хорошо понятна многим разработчикам. Хотя то же самое можно было сделать на любой NoSQL СУБД, в этой статье будем рассматривать именно PostgreSQL.
Основная задача сервиса — передача данных по сети между БД и клиентами — не предполагает большой нагрузки на процессор, но требует возможности обрабатывать несколько запросов в один момент времени. В 10 лекции рассматривается асинхронный подход. Он позволяет эффективно обслуживать нескольких клиентов в рамках одного процесса ОС (в отличие, например, от используемой во Flask/Django pre-fork-модели, которая создает несколько процессов для обработки запросов от пользователей, каждый из них потребляет память, но простаивает большую часть времени). Поэтому в качестве библиотеки для написания сервиса я выбрал асинхронный aiohttp.

В 5 лекции видеокурса рассказывается, что SQLAlchemy позволяет декомпозировать сложные запросы на части, переиспользовать их, генерировать запросы с динамическим набором полей (например, PATCH-обработчик позволяет частичное обновление жителя с произвольными полями) и сосредоточиться непосредственно на бизнес-логике. С выполнением этих запросов и передачей данных быстрее всех справится драйвер asyncpg, а подружить их поможет asyncpgsa.
Мой любимый инструмент для управления состоянием БД и работы с миграциями — Alembic. Кстати, я недавно рассказывал о нем на Moscow Python.
Логику валидации получилось лаконично описать схемами Marshmallow (включая проверки на родственные связи). С помощью модуля aiohttp-spec я связал aiohttp-обработчики и схемы для валидации данных, а бонусом получилось сгенерировать документацию в формате Swagger и отобразить ее в графическом интерфейсе.
Для написания тестов я выбрал pytest, подробнее о нем — в 3 лекции.
Для отладки и профилирования этого проекта я использовал отладчик PyCharm (лекция 9).
В 7 лекции рассказывается, как на любом компьютере с Docker (и даже на разных ОС) можно запускать упакованное приложение без необходимости настраивать окружение для запуска и легко устанавливать/обновлять/удалять приложение на сервере.
Для деплоя я выбрал Ansible. Он позволяет декларативно описывать желаемое состояние сервера и его сервисов, работает по ssh и не требует специального софта.
Разработка
Я решил дать Python-пакету название analyzer и использовать следующую структуру:

В файле analyzer/__init__.py я разместил общую информацию о пакете: описание (docstring), версию, лицензию, контакты разработчиков.
Ее можно посмотреть встроенной командой help
$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
Сервис с REST API, анализирующий рынок для промоакций.
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
Пакет имеет две входных точки — REST API-сервис (analyzer/api/__main__.py) и утилита управления состоянием БД (analyzer/db/__main__.py). Файлы называются __main__.py неспроста — во-первых, такое название привлекает внимание, по нему понятно, что файл является входной точкой.
Во-вторых, благодаря этому подходу к входным точкам можно обращаться с помощью команды python -m:
# REST API
$ python -m analyzer.api --help
# Утилита управления состоянием БД
$ python -m analyzer.db --helpПочему нужно начать с setup.py?
Забегая вперед, подумаем, как можно распространять приложение: оно может быть упаковано в zip- (а также wheel/egg-) архив, rpm-пакет, pkg-файл для macOS и установлено на удаленный компьютер, в виртуальную машину, MacBook или Docker-контейнер.
Главная цель файла setup.py — описать пакет с приложением для distutils/setuptools.
В файле необходимо указать общую информацию о пакете (название, версию, автора и т. д.), но также в нем можно указать требуемые для работы модули, «экстра»-зависимости (например для тестирования), точки входа (например, исполняемые команды) и требования к интерпретатору.
Плагины setuptools позволяют собирать из описанного пакета артефакт. Есть встроенные плагины: zip, egg, rpm, macOS pkg. Остальные плагины распространяются через PyPI: wheel, xar, pex.
В сухом остатке, описав один файл, мы получаем огромные возможности. Именно поэтому разработку нового проекта нужно начинать с setup.py.
В функции setup() зависимые модули указываются списком:
setup(..., install_requires=["aiohttp", "SQLAlchemy"])
Но я описал зависимости в отдельных файлах requirements.txt и requirements.dev.txt, содержимое которых используется в setup.py. Мне это кажется более гибким, плюс тут есть секрет: впоследствии это позволит собирать Docker-образ быстрее. Зависимости будут ставиться отдельным шагом до установки самого приложения, а при пересборке Docker-контейнера попадать в кеш.
Чтобы setup.py смог прочитать зависимости из файлов requirements.txt и requirements.dev.txt, написана функция:
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
Стоит отметить, что setuptools при сборке source distribution по умолчанию включает в сборку только файлы .py, .c, .cpp и .h. Чтобы файлы с зависимостями requirements.txt и requirements.dev.txt попали в пакет, их необходимо явно указать в файле MANIFEST.in.
setup.py целиком
import os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
# Возможно, модуль еще не установлен (или установлена другая версия), поэтому
# необходимо загружать __init__.py с помощью machinery.
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
# f-strings в setup.py не используются из-за соображений
# совместимости.
# Несмотря на то, что этот пакет требует Python 3.8, технически
# source distribution для него может собираться с помощью более
# ранних версий Python. Не стоит лишать пользователей этой
# возможности.
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
Установить проект в режиме разработки можно следующей командой (в editable-режиме Python не установит пакет целиком в папку site-packages, а только создаст ссылки, поэтому любые изменения, вносимые в файлы пакета, будут видны сразу):
# Установить пакет с обычными и extra-зависимостями "dev"
pip install -e '.[dev]'
# Установить пакет только с обычными зависимостями
pip install -e .Как указать версии зависимостей?
Здорово, когда разработчики активно занимаются своими пакетами — в них активнее исправляются ошибки, появляется новая функциональность и можно быстрее получить обратную связь. Но иногда изменения в зависимых библиотеках не имеют обратной совместимости и могут привести к ошибкам в вашем приложении, если не подумать об этом заранее.
Для каждого зависимого пакета можно указать определенную версию, например aiohttp==3.6.2. Тогда приложение будет гарантированно собираться именно с теми версиями зависимых библиотек, с которыми оно было протестировано. Но у этого подхода есть и недостаток — если разработчики исправят критичный баг в зависимом пакете, не влияющий на обратную совместимость, в приложение это исправление не попадет.
Существует подход к версионированию Semantic Versioning, который предлагает представлять версию в формате MAJOR.MINOR.PATCH:
MAJOR— увеличивается при добавлении обратно несовместимых изменений;MINOR— увеличивается при добавлении новой функциональности с поддержкой обратной совместимости;PATCH— увеличивается при добавлении исправлений багов с поддержкой обратной совместимости.
Если зависимый пакет следует этому подходу (о чем авторы обычно сообщают в файлах README или CHANGELOG), то достаточно зафиксировать значения MAJOR, MINOR и ограничить минимальное значение для PATCH-версии: >= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*.
Такое требование можно реализовать с помощью оператора ~=. Например, aiohttp~=3.6.2 позволит PIP установить для aiohttp версию 3.6.3, но не 3.7.
Если указать интервал версий зависимостей, это даст еще одно преимущество — не будет конфликтов версий между зависимыми библиотеками.
Если вы разрабатываете библиотеку, которая требует другой пакет-зависимость, то разрешите для него не одну определенную версию, а интервал. Тогда потребителям вашей библиотеки будет намного легче ее использовать (вдруг их приложение требует этот же пакет-зависимость, но уже другой версии).
Semantic Versioning — лишь соглашение между авторами и потребителями пакетов. Оно не гарантирует, что авторы пишут код без багов и не могут допустить ошибку в новой версии своего пакета.
База данных
Проектируем схему
В описании обработчика POST /imports приведен пример выгрузки с информацией о жителях:
Пример выгрузки
{
"citizens": [
{
"citizen_id": 1,
"town": "Москва",
"street": "Льва Толстого",
"building": "16к7стр5",
"apartment": 7,
"name": "Иванов Иван Иванович",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "Москва",
"street": "Льва Толстого",
"building": "16к7стр5",
"apartment": 7,
"name": "Иванов Сергей Иванович",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "Керчь",
"street": "Иосифа Бродского",
"building": "2",
"apartment": 11,
"name": "Романова Мария Леонидовна",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
Первой мыслью было хранить всю информацию о жителе в одной таблице citizens, где родственные связи были бы представлены полем relatives в виде списка целых чисел.
Но у этого способа есть ряд недостатков
- В обработчике
GET /imports/$import_id/citizens/birthdaysдля получения месяцев, на которые приходятся дни рождения родственников, потребуется выполнить слияние таблицыcitizensс самой собой. Для этого будет необходимо развернуть список с идентификаторами родственниковrelativesс помощью фунцииUNNEST.Такой запрос будет выполняться сравнительно медленно, и обработчик не уложится в 10-секундный таймаут:
SELECT relations.citizen_id, relations.relative_id, date_part('month', relatives.birth_date) as relative_birth_month FROM ( SELECT citizens.import_id, citizens.citizen_id, UNNEST(citizens.relatives) as relative_id FROM citizens WHERE import_id = 1 ) as relations INNER JOIN citizens as relatives ON relations.import_id = relatives.import_id AND relations.relative_id = relatives.citizen_id - В таком подходе целостность данных в поле
relativesне обеспечивается PostgreSQL, а контролируется приложением: технически в списокrelativesможно добавить любое целое число, в том числе идентификатор несуществующего жителя. Ошибка в коде или человеческий фактор (редактирование записей напрямую в БД администратором) обязательно рано или поздно приведут к несогласованному состоянию данных.
Далее, я решил привести все требуемые для работы данные к третьей нормальной форме, и получилась следующая структура:

- Таблица imports состоит из автоматически инкрементируемого столбца
import_id. Он нужен для создания проверки по внешнему ключу в таблицеcitizens. - В таблице citizens хранятся скалярные данные о жителе (все поля за исключением информации о родственных связях).
В качестве первичного ключа используется пара (
import_id,citizen_id), гарантирующая уникальность жителейcitizen_idв рамкахimport_id.Внешний ключ
citizens.import_id -> imports.import_idгарантирует, что полеcitizens.import_idбудет содержать только существующие выгрузки. - Таблица relations содержит информацию о родственных связях.
Одна родственная связь представлена двумя записями (от жителя к родственнику и обратно): эта избыточность позволяет использовать более простое условие при слиянии таблиц
citizensиrelationsи получать информацию более эффективно.
Первичный ключ состоит из столбцов (import_id,citizen_id,relative_id) и гарантирует, что в рамках одной выгрузкиimport_idу жителяcitizen_idбудут родственники c уникальнымиrelative_id.Также в таблице используются два составных внешних ключа:
(relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id)и(relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), гарантирующие, что в таблице будут указаны существующие жительcitizen_idи родственникrelative_idиз одной выгрузки.
Такая структура обеспечивает целостность данных средствами PostgreSQL, позволяет эффективно получать жителей с родственниками из базы данных, но подвержена состоянию гонки во время обновления информации о жителях конкурентными запросами (подробнее рассмотрим при реализации обработчика PATCH).
Описываем схему в SQLAlchemy
В лекции 5 я рассказывал, что для создания запросов с помощью SQLAlchemy необходимо описать схему базы данных с помощью специальных объектов: таблицы описываются с помощью sqlalchemy.Table и привязываются к реестру sqlalchemy.MetaData, который хранит всю метаинформацию о базе данных. К слову, реестр MetaData способен не только хранить описанную в Python метаинформацию, но и представлять реальное состояние базы данных в виде объектов SQLAlchemy.
Эта возможность в том числе позволяет Alembic сравнивать состояния и генерировать код миграций автоматически.
Кстати, у каждой базы данных своя схема именования constraints по умолчанию. Чтобы вы не тратили время на именование новых constraints или на воспоминания/поиски того, как назван constraint, который вы собираетесь удалить, SQLAlchemy предлагает использовать шаблоны именования naming conventions. Их можно определить в реестре MetaData.
Создаем реестр MetaData и передаем в него шаблоны именования
# analyzer/db/schema.py
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
# Именование индексов
'ix': 'ix__%(table_name)s__%(all_column_names)s',
# Именование уникальных индексов
'uq': 'uq__%(table_name)s__%(all_column_names)s',
# Именование CHECK-constraint-ов
'ck': 'ck__%(table_name)s__%(constraint_name)s',
# Именование внешних ключей
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
# Именование первичных ключей
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
Если указать шаблоны именования, Alembic воспользуется ими во время автоматической генерации миграций и будет называть все constraints в соответствии с ними. В дальнейшем cозданный реестр MetaData потребуется для описания таблиц:
Описываем схему базы данных объектами SQLAlchemy
# analyzer/db/schema.py
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
Настраиваем Alembic
Когда схема базы данных описана, необходимо сгенерировать миграции, но для этого сначала нужно настроить Alembic, об этом тоже рассказывается в лекции 5.
Чтобы воспользоваться командой alembic, необходимо выполнить следующие шаги:
- Установить пакет:
pip install alembic - Инициализировать Alembic:
cd analyzer && alembic init db/alembic.Эта команда создаст файл конфигурации
analyzer/alembic.iniи папкуanalyzer/db/alembicсо следующим содержимым:-
env.py— вызывается каждый раз при запуске Alembic. Подключает в Alembic реестрsqlalchemy.MetaDataс описанием желаемого состояния БД и содержит инструкции по запуску миграций. script.py.mako— шаблон, на основе которого генерируются миграции.versions— папка, в которой Alembic будет искать (и генерировать) миграции.
-
- Указать адрес базы данных в файле alembic.ini:
; analyzer/alembic.ini [alembic] sqlalchemy.url = postgresql://user:hackme@localhost/analyzer - Указать описание желаемого состояния базы данных (реестр
sqlalchemy.MetaData), чтобы Alembic мог генерировать миграции автоматически:# analyzer/db/alembic/env.py from analyzer.db import schema target_metadata = schema.metadata
Alembic настроен и им уже можно пользоваться, но в нашем случае такая конфигурация имеет ряд недостатков:
- Утилита
alembicищетalembic.iniв текущей рабочей директории. Путь кalembic.iniможно указать аргументом командной строки, но это неудобно: хочется иметь возможность вызывать команду из любой папки без дополнительных параметров. - Чтобы настроить Alembic на работу с определенной базой данных, требуется менять файл
alembic.ini. Гораздо удобнее было бы указать настройки БД переменной окружения и/или аргументом командной строки, например--pg-url. - Название утилиты
alembicне очень хорошо коррелирует с названием нашего сервиса (а пользователь фактически может вообще не владеть Python и ничего не знать об Alembic). Конечному пользователю было бы намного удобнее, если бы все исполняемые команды сервиса имели общий префикс, напримерanalyzer-*.
Эти проблемы решаются с помощью небольшой обертки analyzer/db/__main__.py:
- Для обработки аргументов командной строки Alembic использует стандартный модуль
argparse. Он позволяет добавить необязательный аргумент--pg-urlсо значением по умолчанию из переменной окруженияANALYZER_PG_URL.Код
import os from alembic.config import CommandLine, Config from analyzer.utils.pg import DEFAULT_PG_URL def main(): alembic = CommandLine() alembic.parser.add_argument( '--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL), help='Database URL [env var: ANALYZER_PG_URL]' ) options = alembic.parser.parse_args() # Создаем объект конфигурации Alembic config = Config(file_=options.config, ini_section=options.name, cmd_opts=options) # Меняем значение sqlalchemy.url из конфига Alembic config.set_main_option('sqlalchemy.url', options.pg_url) # Запускаем команду alembic exit(alembic.run_cmd(config, options)) if __name__ == '__main__': main() - Путь до файла
alembic.iniможно рассчитывать относительно расположения исполняемого файла, а не текущей рабочей директории пользователя.Код
import os from alembic.config import CommandLine, Config from pathlib import Path PROJECT_PATH = Path(__file__).parent.parent.resolve() def main(): alembic = CommandLine() options = alembic.parser.parse_args() # Если указан относительный путь (alembic.ini), добавляем в начало # абсолютный путь до приложения if not os.path.isabs(options.config): options.config = os.path.join(PROJECT_PATH, options.config) # Создаем объект конфигурации Alembic config = Config(file_=options.config, ini_section=options.name, cmd_opts=options) # Подменяем путь до папки с alembic на абсолютный (требуется, чтобы alembic # мог найти env.py, шаблон для генерации миграций и сами миграции) alembic_location = config.get_main_option('script_location') if not os.path.isabs(alembic_location): config.set_main_option('script_location', os.path.join(PROJECT_PATH, alembic_location)) # Запускаем команду alembic exit(alembic.run_cmd(config, options)) if __name__ == '__main__': main()
Когда утилита для управления состоянием БД готова, ее можно зарегистрировать в setup.py как исполняемую команду с понятным конечному пользователю названием, например analyzer-db:
Регистрация исполняемой команды в setup.py
from setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
После переустановки модуля будет сгенерирован файл env/bin/analyzer-db и команда analyzer-db станет доступной:
$ pip install -e '.[dev]'Генерируем миграции
Чтобы сгенерировать миграции, требуется два состояния: желаемое (которое мы описали объектами SQLAlchemy) и реальное (база данных, в нашем случае пустая).
Я решил, что проще всего поднять Postgres с помощью Docker и для удобства добавил команду make postgres, запускающую в фоновом режиме контейнер с PostgreSQL на 5432 порту:
Поднимаем PostgreSQL и генерируем миграцию
$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... doneAlembic в целом хорошо справляется с рутинной работой генерации миграций, но я хотел бы обратить внимание на следующее:
- Пользовательские типы данных, указанные в создаваемых таблицах, создаются автоматически (в нашем случае —
gender), но код для их удаления вdowngradeне генерируется. Если применить, откатить и потом еще раз применить миграцию, это вызовет ошибку, так как указанный тип данных уже существует.Удаляем тип данных gender в методе downgrade
from alembic import op from sqlalchemy import Column, Enum GenderType = Enum('female', 'male', name='gender') def upgrade(): ... # При создании таблицы тип данных GenderType будет создан автоматически op.create_table('citizens', ..., Column('gender', GenderType, nullable=False)) ... def downgrade(): op.drop_table('citizens') # После удаления таблицы тип данных необходимо удалить GenderType.drop(op.get_bind()) - В методе
downgradeнекоторые действия иногда можно убрать (если мы удаляем таблицу целиком, можно не удалять ее индексы отдельно):Например
def downgrade(): op.drop_table('relations') # Следующим шагом мы удаляем таблицу citizens, индекс будет удален автоматически # эту строчку можно удалить op.drop_index(op.f('ix__citizens__town'), table_name='citizens') op.drop_table('citizens') op.drop_table('imports')
Когда миграция исправлена и готова, применим ее:
$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, InitialПриложение
Прежде чем приступить к созданию обработчиков, необходимо сконфигурировать приложение aiohttp.
Если посмотреть aiohttp quickstart, можно написать приблизительно такой код
import logging
from aiohttp import web
def main():
# Настраиваем логирование
logging.basicConfig(level=logging.DEBUG)
# Создаем приложение
app = web.Application()
# Регистрируем обработчики
app.router.add_route(...)
# Запускаем приложение
web.run_app(app)
Этот код вызывает ряд вопросов и имеет ряд недостатков:
- Как конфигурировать приложение? Как минимум, необходимо указать хост и порт для подключения клиентов, а также информацию для подключения к базе данных.
Мне очень нравится решать эту задачу с помощью модуля
ConfigArgParse: он расширяет стандартныйargparseи позволяет использовать для конфигурации аргументы командной строки, переменные окружения (незаменимые для конфигурации Docker-контейнеров) и даже файлы конфигурации (а также совмещать эти способы). C помощьюConfigArgParseтакже можно валидировать значения параметров конфигурации приложения.Пример обработки параметров с помощью ConfigArgParse
from aiohttp import web from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter from analyzer.utils.argparse import positive_int parser = ArgumentParser( # Парсер будет искать переменные окружения с префиксом ANALYZER_, # например ANALYZER_API_ADDRESS и ANALYZER_API_PORT auto_env_var_prefix='ANALYZER_', # Покажет значения параметров по умолчанию formatter_class=ArgumentDefaultsHelpFormatter ) parser.add_argument('--api-address', default='0.0.0.0', help='IPv4/IPv6 address API server would listen on') # Разрешает только целые числа больше нуля parser.add_argument('--api-port', type=positive_int, default=8081, help='TCP port API server would listen on') def main(): # Получаем параметры конфигурации, которые можно передать как аргументами # командной строки, так и переменными окружения args = parser.parse_args() # Запускаем приложение на указанном порту и адресе app = web.Application() web.run_app(app, host=args.api_address, port=args.api_port) if __name__ == '__main__': main()Кстати,
ConfigArgParse, как иargparse, умеет генерировать подсказку по запуску команды с описанием всех аргументов (необходимо позвать команду с аргументом-hили--help). Это невероятно облегчает жизнь пользователям вашего ПО:Например
$ python __main__.py --help usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT] If an arg is specified in more than one place, then commandline values override environment variables which override defaults. optional arguments: -h, --help show this help message and exit --api-address API_ADDRESS IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0) --api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081) - После получения переменные окружения больше не нужны и даже могут представлять опасность — например, они могут случайно «утечь» с отображением информации об ошибке. Злоумышленники в первую очередь будут пытаться получить информацию об окружении, поэтому очистка переменных окружения считается хорошим тоном.
Можно было бы воспользоваться
os.environ.clear(), но Python позволяет управлять поведением модулей стандартной библиотеки с помощью многочисленных переменных окружения (например, вдруг потребуется включить режим отладкиasyncio?), поэтому разумнее очищать переменные окружения по префиксу приложения, указанного вConfigArgParser.Пример
import os from typing import Callable from configargparse import ArgumentParser from yarl import URL from analyzer.api.app import create_app from analyzer.utils.pg import DEFAULT_PG_URL ENV_VAR_PREFIX = 'ANALYZER_' parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX) parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL), help='URL to use to connect to the database') def clear_environ(rule: Callable): """ Очищает переменные окружения, переменные для очистки определяет переданная функция rule """ # Ключи из os.environ копируются в новый tuple, чтобы не менять объект # os.environ во время итерации for name in filter(rule, tuple(os.environ)): os.environ.pop(name) def main(): # Получаем аргументы args = parser.parse_args() # Очищаем переменные окружения по префиксу ANALYZER_ clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX)) # Запускаем приложение app = create_app(args) ... if __name__ == '__main__': main() - Запись логов в stderr/файл в основном потоке блокирует цикл событий.
В лекции 9 рассказывается, что по умолчанию
logging.basicConfig()настраиваетзапись логов в stderr.Чтобы логирование не мешало эффективной работе асинхронного приложения, необходимо выполнять запись логов в отдельном потоке. Для этого можно воспользоваться готовым методом из модуля aiomisc.
Настраиваем логирование с помощью aiomisc
import logging from aiomisc.log import basic_config basic_config(logging.DEBUG, buffered=True) - Как масштабировать приложение, если одного процесса станет недостаточно для обслуживания входящего трафика? Можно сначала аллоцировать сокет, затем с помощью
forkсоздать несколько новых отдельных процессов, и соединения на сокете будут распределяться между ними механизмами ядра (конечно, под Windows это не работает).Пример
import os from sys import argv import forklib from aiohttp.web import Application, run_app from aiomisc import bind_socket from setproctitle import setproctitle def main(): sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http') setproctitle(f'[Master] {os.path.basename(argv[0])}') def worker(): setproctitle(f'[Worker] {os.path.basename(argv[0])}') app = Application() run_app(app, sock=sock) forklib.fork(os.cpu_count(), worker, auto_restart=True) if __name__ == '__main__': main() - Требуется ли приложению обращаться или аллоцировать какие-либо ресурсы во время работы? Если нет, по соображениям безопасности все ресурсы (в нашем случае — сокет для подключения клиентов) можно аллоцировать на старте, а затем сменить пользователя на
nobody. Он обладает ограниченным набором привиллегий — это здорово усложнит жизнь злоумышленникам.Пример
import os import pwd from aiohttp.web import run_app from aiomisc import bind_socket from analyzer.api.app import create_app def main(): # Аллоцируем сокет sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http') user = pwd.getpwnam('nobody') os.setgid(user.pw_gid) os.setuid(user.pw_uid) app = create_app(...) run_app(app, sock=sock) if __name__ == '__main__': main() - В конце концов я решил вынести создание приложения в отдельную параметризуемую функцию
create_app, чтобы можно было легко создавать идентичные приложения для тестирования.
Сериализация данных
Все успешные ответы обработчиков будем возвращать в формате JSON. Информацию об ошибках клиентам тоже было бы удобно получать в сериализованном виде (например, чтобы увидеть, какие поля не прошли валидацию).
Документация aiohttp предлагает метод json_response, который принимает объект, сериализует его в JSON и возвращает новый объект aiohttp.web.Response с заголовком Content-Type: application/json и сериализованными данными внутри.
Как сериализовать данные с помощью json_response
from aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Но существует и другой способ: aiohttp позволяет зарегистрировать произвольный сериализатор для определенного типа данных ответа в реестре aiohttp.PAYLOAD_REGISTRY. Например, можно указать сериализатор aiohttp.JsonPayload для объектов типа Mapping.
В этом случае обработчику будет достаточно вернуть объект Response с данными ответа в параметре body. aiohttp найдет сериализатор, соответствующий типу данных и сериализует ответ.
Помимо того, что сериализация объектов описана в одном месте, этот подход еще и более гибкий — он позволяет реализовывать очень интересные решения (мы рассмотрим один из вариантов использования в обработчике GET /imports/$import_id/citizens).
Как сериализовать данные с помощью aiohttp.PAYLOAD_REGISTRY
from types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Важно понимать, что метод json_response, как и aiohttp.JsonPayload, используют стандартный json.dumps, который не умеет сериализовать сложные типы данных, например datetime.date или asyncpg.Record (asyncpg возвращает записи из БД в виде экземпляров этого класса). Более того, одни сложные объекты могут содержать другие: в одной записи из БД может быть поле типа datetime.date.
Разработчики Python предусмотрели эту проблему: метод json.dumps позволяет с помощью аргумента default указать функцию, которая вызывается, когда необходимо сериализовать незнакомый объект. Ожидается, что функция приведет незнакомый объект к типу, который умеет сериализовать модуль json.
Как расширить JsonPayload для сериализации произвольных объектов
import json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
Позволяет автоматически сериализовать результаты запроса, возвращаемые
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(value: date):
"""
В проекте объект date возвращается только в одном случае — если необходимо
отобразить дату рождения. Для отображения даты рождения должен
использоваться формат ДД.ММ.ГГГГ
"""
return value.strftime('%d.%m.%Y')
dumps = partial(json.dumps, default=convert)
class JsonPayload(BaseJsonPayload):
def __init__(self,
value: Any,
encoding: str = 'utf-8',
content_type: str = 'application/json',
dumps: JSONEncoder = dumps,
*args: Any,
**kwargs: Any) -> None:
super().__init__(value, encoding, content_type, dumps, *args, **kwargs)Обработчики
aiohttp позволяет реализовать обработчики асинхронными функциями и классами. Классы более расширяемы: во-первых, код, относящийся к одному обработчику, можно разместить в одном месте, а во вторых, классы позволяют использовать наследование для избавления от дублирования кода (например, каждому обработчику требуется соединение с базой данных).
Базовый класс обработчика
from aiohttp.web_urldispatcher import View
from asyncpgsa import PG
class BaseView(View):
URL_PATH: str
@property
def pg(self) -> PG:
return self.request.app['pg']
Так как один большой файл читать сложно, я решил разнести обработчики по файлам. Маленькие файлы поощряют слабую связность, а если, например, есть кольцевые импорты внутри хэндлеров — значит, возможно, что-то не так с композицией сущностей.
POST /imports
На вход обработчик получает json с данными о жителях. Максимально допустимый размер запроса в aiohttp регулируется опцией client_max_size и по умолчанию равен 2 МБ. При превышении лимита aiohttp вернет HTTP-ответ со статусом 413: Request Entity Too Large Error.
В то же время корректный json c максимально длинными строчками и цифрами будет весить ~63 мегабайта, поэтому ограничения на размер запроса необходимо расширить.
Далее, необходимо проверить и десериализовать данные. Если они некорректные, нужно вернуть HTTP-ответ 400: Bad Request.
Мне потребовались две схемы Marhsmallow. Первая, CitizenSchema, проверяет данные каждого отдельного жителя, а также десериализует строку с днем рождения в объект datetime.date:
- Тип данных, формат и наличие всех обязательных полей;
- Отсутствие незнакомых полей;
- Дата рождения должна быть указана в формате
DD.MM.YYYYи не может иметь значения из будущего; - Список родственников каждого жителя должен содержать уникальные существующие в этой выгрузке идентификаторы жителей.
Вторая схема, ImportSchema, проверяет выгрузку в целом:
citizen_idкаждого жителя в рамках выгрузки должен быть уникален;- Родственные связи должны быть двусторонними (если у жителя #1 в списке родственников указан житель #2, то и у жителя #2 должен быть родственник #1).
Если данные корректные, их необходимо добавить в БД с новым уникальным import_id.
Для добавления данных потребуется выполнить несколько запросов в разные таблицы. Чтобы в БД не осталось частично добавленных данных в случае возникновения ошибки или исключения (например, при отключении клиента, который не получил ответ полностью, aiohttp бросит исколючение CancelledError), необходимо использовать транзакцию.
Добавлять данные в таблицы необходимо частями, так как в одном запросе к PostgreSQL может быть не более 32 767 аргументов. В таблице citizens 9 полей. Соответственно, за 1 запрос в эту таблицу можно вставить только 32 767 / 9 = 3640 строк, а в одной выгрузке может быть до 10 000 жителей.
GET /imports/$import_id/citizens
Обработчик возвращает всех жителей для выгрузки с указанным import_id. Если указанная выгрузка не существует, необходимо вернуть HTTP-ответ 404: Not Found. Это поведение выглядит общим для обработчиков, которым требуется существующая выгрузка, поэтому я вынес код проверки в отдельный класс.
Базовый класс для обработчиков с выгрузками
from aiohttp.web_exceptions import HTTPNotFound
from sqlalchemy import select, exists
from analyzer.db.schema import imports_table
class BaseImportView(BaseView):
@property
def import_id(self):
return int(self.request.match_info.get('import_id'))
async def check_import_exists(self):
query = select([
exists().where(imports_table.c.import_id == self.import_id)
])
if not await self.pg.fetchval(query):
raise HTTPNotFound()
Чтобы получить список родственников для каждого жителя, потребуется выполнить LEFT JOIN из таблицы citizens в таблицу relations, агрегируя поле relations.relative_id с группировкой по import_id и citizen_id.
Если у жителя нет родственников, то LEFT JOIN вернет для него в поле relations.relative_id значение NULL и в результате агрегации список родственников будет выглядеть как [NULL].
Чтобы исправить это некорректное значение, я воспользовался функцией array_remove.
БД хранит дату в формате YYYY-MM-DD, а нам нужен формат DD.MM.YYYY.
Технически форматировать дату можно либо SQL-запросом, либо на стороне Python в момент сериализации ответа с json.dumps (asyncpg возвращает значение поля birth_date как экземпляр класса datetime.date).
Я выбрал сериализацию на стороне Python, учитывая, что birth_date — единственный объект datetime.date в проекте с единым форматом (см. раздел «Сериализация данных»).
Несмотря на то, что в обработчике выполняется два запроса (проверка на существование выгрузки и запрос на получение списка жителей), использовать транзакцию необязательно. По умолчанию PostgreSQL использует уровень изоляции READ COMMITTED и даже в рамках одной транзакции будут видны все изменения других, успешно завершенных транзакций (добавление новых строк, изменение существующих).
Самая большая выгрузка в текстовом представлении может занимать ~63 мегабайта — это достаточно много, особенно учитывая, что одновременно может прийти несколько запросов на получение данных. Есть достаточно интересный способ получать данные из БД с помощью курсора и отправлять их клиенту по частям.
Для этого нам потребуется реализовать два объекта:
- Объект
SelectQueryтипаAsyncIterable, возвращающий записи из базы данных. При первом обращении подключается к базе, открывает транзакцию и создает курсор, при дальнейшей итерации возвращает записи из БД. Возвращается обработчиком.Код SelectQuery
from collections import AsyncIterable from asyncpgsa.transactionmanager import ConnectionTransactionContextManager from sqlalchemy.sql import Select class SelectQuery(AsyncIterable): """ Используется, чтобы отправлять данные из PostgreSQL клиенту сразу после получения, по частям, без буфферизации всех данных """ PREFETCH = 500 __slots__ = ( 'query', 'transaction_ctx', 'prefetch', 'timeout' ) def __init__(self, query: Select, transaction_ctx: ConnectionTransactionContextManager, prefetch: int = None, timeout: float = None): self.query = query self.transaction_ctx = transaction_ctx self.prefetch = prefetch or self.PREFETCH self.timeout = timeout async def __aiter__(self): async with self.transaction_ctx as conn: cursor = conn.cursor(self.query, prefetch=self.prefetch, timeout=self.timeout) async for row in cursor: yield row - Сериализатор
AsyncGenJSONListPayload, который умеет итерироваться по асинхронным генераторам, сериализовать данные из асинхронного генератора в JSON и отправлять данные клиентам по частям. Регистрируется вaiohttp.PAYLOAD_REGISTRYкак сериализатор объектовAsyncIterable.Код AsyncGenJSONListPayload
import json from functools import partial from aiohttp import Payload # Функция, умеющая сериализовать в JSON объекты asyncpg.Record и datetime.date dumps = partial(json.dumps, default=convert, ensure_ascii=False) class AsyncGenJSONListPayload(Payload): """ Итерируется по объектам AsyncIterable, частями сериализует данные из них в JSON и отправляет клиенту """ def __init__(self, value, encoding: str = 'utf-8', content_type: str = 'application/json', root_object: str = 'data', *args, **kwargs): self.root_object = root_object super().__init__(value, content_type=content_type, encoding=encoding, *args, **kwargs) async def write(self, writer): # Начало объекта await writer.write( ('{"%s":[' % self.root_object).encode(self._encoding) ) first = True async for row in self._value: # Перед первой строчкой запятая не нужнаа if not first: await writer.write(b',') else: first = False await writer.write(dumps(row).encode(self._encoding)) # Конец объекта await writer.write(b']}')
Далее, в обработчике можно будет создать объект SelectQuery, передать ему SQL запрос и функцию для открытия транзакции и вернуть его в Response body:
Код обработчика
# analyzer/api/handlers/citizens.py
from aiohttp.web_response import Response
from aiohttp_apispec import docs, response_schema
from analyzer.api.schema import CitizensResponseSchema
from analyzer.db.schema import citizens_table as citizens_t
from analyzer.utils.pg import SelectQuery
from .query import CITIZENS_QUERY
from .base import BaseImportView
class CitizensView(BaseImportView):
URL_PATH = r'/imports/{import_id:d+}/citizens'
@docs(summary='Отобразить жителей для указанной выгрузки')
@response_schema(CitizensResponseSchema())
async def get(self):
await self.check_import_exists()
query = CITIZENS_QUERY.where(
citizens_t.c.import_id == self.import_id
)
body = SelectQuery(query, self.pg.transaction())
return Response(body=body)
aiohttp обнаружит в реестре aiohttp.PAYLOAD_REGISTRY зарегистрированный сериализатор AsyncGenJSONListPayload для объектов типа AsyncIterable. Затем сериализатор будет итерироваться по объекту SelectQuery и отправлять данные клиенту. При первом обращении объект SelectQuery получает соединение к БД, открывает транзакцию и создает курсор, при дальнейшей итерации будет получать данные из БД курсором и возвращать их построчно.
Этот подход позволяет не выделять память на весь объем данных при каждом запросе, но у него есть особенность: приложение не сможет вернуть клиенту соответствующий HTTP-статус, если возникнет ошибка (ведь клиенту уже был отправлен HTTP-статус, заголовки, и пишутся данные).
При возникновении исключения не остается ничего, кроме как разорвать соединение. Исключение, конечно, можно залогировать, но клиент не сможет понять, какая именно ошибка произошла.
С другой стороны, похожая ситуация может возникнуть, даже если обработчик получит все данные из БД, но при передаче данных клиенту моргнет сеть — от этого никто не застрахован.
PATCH /imports/$import_id/citizens/$citizen_id
Обработчик получает на вход идентификатор выгрузки import_id, жителя citizen_id, а также json с новыми данными о жителе. В случае обращения к несуществующей выгрузке или жителю необходимо вернуть HTTP-ответ 404: Not Found.
Переданные клиентом данные требуется проверить и десериализовать. Если они некорректные — необходимо вернуть HTTP-ответ 400: Bad Request. Я реализовал Marshmallow-схему PatchCitizenSchema, которая проверяет:
- Тип и формат данных для указанных полей.
- Дату рождения. Она должна быть указана в формате
DD.MM.YYYYи не может иметь значения из будущего. - Список родственников каждого жителя. Он должен иметь уникальные идентификаторы жителей
Существование родственников, указанных в поле relatives, можно отдельно не проверять: при добавлении в таблицу relations несуществующего жителя PostgreSQL вернет ошибку ForeignKeyViolationError, которую можно обработать и вернуть HTTP-статус 400: Bad Request.
Какой статус возвращать, если клиент прислал некорректные данные для несуществующего жителя или выгрузки? Семантически правильнее проверять сначала существование выгрузки и жителя (если такого нет — возвращать 404: Not Found) и только потом —корректные ли данные прислал клиент (если нет — возвращать 400: Bad Request). На практике часто бывает дешевле сначала проверить данные, и только если они корректные, обращаться к базе.
Оба варианта приемлемы, но я решил выбрать более дешевый второй вариант, так как в любом случае результат операции — ошибка, которая ни на что не влияет (клиент исправит данные и потом так же узнает, что житель не существует).
Если данные корректные, необходимо обновить информацию о жителе в БД. В обработчике потребуется сделать несколько запросов к разным таблицам. Если возникнет ошибка или исключение, изменения в базе данных должны быть отменены, поэтому запросы необходимо выполнять в транзакции.
Метод PATCH позволяет передавать лишь некоторые поля для изменяемого жителя.
Обработчик необходимо написать таким образом, чтобы он не падал при обращении к данным, которые не указал клиент, а также не выполнял запросы к таблицам, данные в которых не изменились.
Если клиент указал поле relatives, необходимо получить список существующих родственников. Если он изменился — определить, какие записи из таблицы relatives необходимо удалить, а какие добавить, чтобы привести базу данных в соответствие с запросом клиента. По умолчанию в PostgreSQL для изоляции транзакций используется уровень READ COMMITTED. Это означает, что в рамках текущей транзакции будут видны изменения существующих (а также добавления новых) записей других завершенных транзакций. Это может привести к состоянию гонки между конкурентными запросами.
Предположим, существует выгрузка с жителями #1, #2, #3, без родственных связей. Сервис получает два одновременных запроса на изменение жителя #1: {"relatives": [2]} и {"relatives": [3]}. aiohttp создаст два обработчика, которые одновременно получат текущее состояние жителя из PostgreSQL.
Каждый обработчик не обнаружит ни одной родственной связи и примет решение добавить новую связь с указанным родственником. В результате у жителя #1 поле relatives равно [2,3].
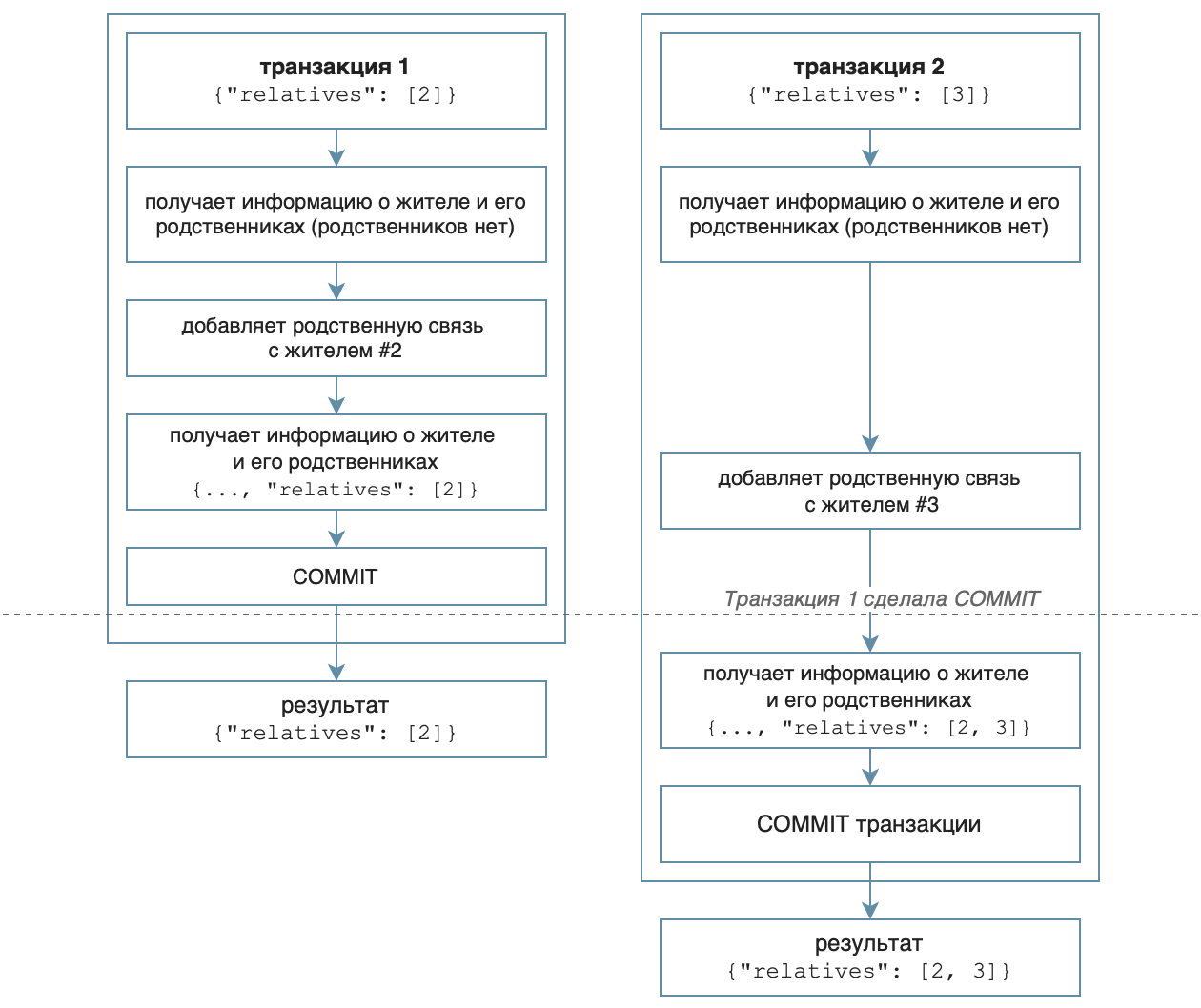
Такое поведение нельзя назвать очевидным. Есть два варианта ожидаемо решить исход гонки: выполнить только первый запрос, а для второго вернуть HTTP-ответ
409: Conflict (чтобы клиент повторил запрос), либо выполнить запросы по очереди (второй запрос будет обработан только после завершения первого).
Первый вариант можно реализовать, включив режим изоляции SERIALIZABLE. Если во время обработки запроса кто-то уже успел изменить и закоммитить данные, будет брошено исключение, которое можно обработать и вернуть соответствующий HTTP-статус.
Минус такого решения — большое число блокировок в PostgreSQL, SERIALIZABLE будет вызывать исключение, даже если конкурентные запросы меняют записи жителей из разных выгрузок.
Также можно воспользоваться механизмом рекомендательных блокировок. Если получить такую блокировку по import_id, конкурентные запросы для разных выгрузок смогут выполняться параллельно.
Для обработки конкурентных запросов в одной выгрузке можно реализовать поведение любого из вариантов: функция pg_try_advisory_xact_lock пытается получить блокировку и
возвращает результат boolean немедленно (если блокировку получить не удалось — можно бросить исключение), а pg_advisory_xact_lock ожидает, пока
ресурс не станет доступен для блокировки (в этом случае запросы выполнятся последовательно, я остановился на этом варианте).
В итоге обработчик должен вернуть актуальную информацию об обновленном жителе. Можно было ограничиться возвращением клиенту данных из его же запроса (раз мы возвращаем ответ клиенту, значит, исключений не было и все запросы успешно выполнены). Или — воспользоваться ключевым словом RETURNING в запросах, изменяющих БД, и сформировать ответ из полученных результатов. Но оба этих подхода не позволили бы увидеть и протестировать случай с гонкой состояний.
К сервису не предъявлялись требования по высокой нагрузке, поэтому я решил запрашивать все данные о жителе заново и возвращать клиенту честный результат из БД.
GET /imports/$import_id/citizens/birthdays
Обработчик вычисляет число подарков, которое приобретет каждый житель выгрузки своим родственникам (первого порядка). Число сгруппировано по месяцам для выгрузки с указанным import_id. В случае обращения к несуществующей выгрузке необходимо вернуть HTTP-ответ 404: Not Found.
Есть два варианта реализации:
- Получить данные для жителей с родственниками из базы, а на стороне Python агрегировать данные по месяцам и сгенерировать списки для тех месяцев, для которых нет данных в БД.
- Cоставить json-запрос в базу и дописать для отсутствующих месяцев заглушки.
Я остановился на первом варианте — визуально он выглядит более понятным и поддерживаемым. Число дней рождений в определенном месяце можно получить, сделав JOIN из таблицы с родственными связями (relations.citizen_id — житель, для которого мы считаем дни рождения родственников) в таблицу citizens (содержит дату рождения, из которой требуется получить месяц).
Значения месяцев не должны содержать ведущих нулей. Месяц, получаемый из поля birth_date c помощью функции date_part, может содержать ведущий ноль. Чтобы убрать его, я выполнил cast к integer в SQL-запросе.
Несмотря на то, что в обработчике требуется выполнить два запроса (проверить существование выгрузки и получить информации о днях рождения и подарках), транзакция не требуется.
По умолчанию PostgreSQL использует режим READ COMMITTED, при котором в текущей транзакции видны все новые (добавляемые другими транзакциями) и существующие (изменяемые другими транзакциями) записи после их успешного завершения.
Например, если в момент получения данных будет добавлена новая выгрузка — она никак не повлияет на существующие. Если в момент получения данных будет выполнен запрос на изменение жителя — то либо данные еще не будут видны (если транзакция, меняющая данные, не завершилась), либо транзакция полностью завершится и станут видны сразу все изменения. Целостность получаемых из базы данных не нарушится.
GET /imports/$import_id/towns/stat/percentile/age
Обработчик вычисляет 50-й, 75-й и 99-й перцентили возрастов (полных лет) жителей по городам в выборке с указанным import_id. В случае обращения к несуществующей выгрузке необходимо вернуть HTTP-ответ 404: Not Found.
Несмотря на то, что в обработчике выполняется два запроса (проверка на существование выгрузки и получение списка жителей), использовать транзакцию необязательно.
Есть два варианта реализации:
- Получить из БД возраста жителей, сгруппированные по городам, а затем на стороне Python вычислить перцентили с помощью numpy (который в задании указан как эталонный) и округлить до двух знаков после запятой.
- Сделать всю работу на стороне PostgreSQL: функция percentile_cont вычисляет перцентиль с линейной интерполяцией, затем округляем полученные значения до двух знаков после запятой в рамках одного SQL-запроса, а numpy используем для тестирования.
Второй вариант требует передавать меньше данных между приложением и PostgreSQL, но у него есть не очень очевидный подводный камень: в PostgreSQL округление математическое, (SELECT ROUND(2.5) вернет 3), а в Python — бухгалтерское, к ближайшему целому (round(2.5) вернет 2).
Чтобы тестировать обработчик, реализация должна быть одинаковой и в PostgreSQL, и в Python (реализовать функцию с математическим округлением в Python выглядит проще). Стоит отметить, что при вычислении перцентилей numpy и PostgreSQL могут возвращать немного отличающиеся числа, но с учетом округления эта разница будет незаметна.
Тестирование
Что нужно проверить в этом приложении? Во-первых, что обработчики отвечают требованиям и выполняют требуемую работу в окружении, максимально близком к боевому. Во-вторых, что миграции, которые изменяют состояние базы данных, работают без ошибок. В-третьих, есть ряд вспомогательных функций, которые тоже было бы правильно покрыть тестами.
Я решил воспользоваться фреймворком pytest из-за его гибкости и простоты в использовании. Он предлагает мощный механизм подготовки окружения для тестов — фикстуры, то есть функции с декоратором pytest.mark.fixture, названия которых можно указать параметром в тесте. Если pytest обнаружит в аннотации теста параметр с названием фикстуры, он выполнит эту фикстуру и передаст результат в значении этого параметра. А если фикстура является генератором, то параметр теста примет значение, возвращаемое yield, и после окончания теста выполнится вторая часть фикстуры, которая может очистить ресурсы или закрыть соединения.
Для большинства тестов нам потребуется база данных PostgreSQL. Чтобы изолировать тесты друг от друга, можно перед выполнением каждого теста создавать отдельную базу данных, а после выполнения — удалять ее.
Создаем базу данных фикстурой для каждого теста
import os
import uuid
import pytest
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, drop_database
from yarl import URL
from analyzer.utils.pg import DEFAULT_PG_URL
PG_URL = os.getenv('CI_ANALYZER_PG_URL', DEFAULT_PG_URL)
@pytest.fixture
def postgres():
tmp_name = '.'.join([uuid.uuid4().hex, 'pytest'])
tmp_url = str(URL(PG_URL).with_path(tmp_name))
create_database(tmp_url)
try:
# Это значение будет иметь параметр postgres в функции-тесте
yield tmp_url
finally:
drop_database(tmp_url)
def test_db(postgres):
"""
Пример теста, использующего PostgreSQL
"""
engine = create_engine(postgres)
assert engine.execute('SELECT 1').scalar() == 1
engine.dispose()
C этой задачей здорово справился модуль sqlalchemy_utils, учитывающий особенности разных баз данных и драйверов. Например, PostgreSQL не разрешает выполнение CREATE DATABASE в блоке транзакции. При создании БД sqlalchemy_utils переводит psycopg2 (который обычно выполняет все запросы в транзакции) в режим autocommit.
Другая важная особенность: если к PostgreSQL подключен хотя бы один клиент — базу данных нельзя удалить, а sqlalchemy_utils отключает всех клиентов перед удалением базы. БД будет успешно удалена, даже если зависнет какой-нибудь тест, имеющий активные подключения к ней.
PostgreSQL потребуется нам в разных состояниях: для тестирования миграций необходима чистая база данных, в то время как обработчики требуют, чтобы все миграции были применены. Изменять состояние базы данных можно программно с помощью команд Alembic, для их вызова требуется объект конфигурации Alembic.
Создаем фикстурой объект конфигурации Alembic
from types import SimpleNamespace
import pytest
from analyzer.utils.pg import make_alembic_config
@pytest.fixture()
def alembic_config(postgres):
cmd_options = SimpleNamespace(config='alembic.ini', name='alembic',
pg_url=postgres, raiseerr=False, x=None)
return make_alembic_config(cmd_options)
Обратите внимание, что у фикстуры alembic_config есть параметр postgres — pytest позволяет не только указывать зависимость теста от фикстур, но и зависимости между фикстурами.
Этот механизм позволяет гибко разделять логику и писать очень краткий и переиспользуемый код.
Обработчики
Для тестирования обработчиков требуется база данных с созданными таблицами и типами данных. Чтобы применить миграции, необходимо программно вызвать команду upgrade Alembic. Для ее вызова потребуется объект с конфигурацией Alembic, который мы уже определили фикстурой alembic_config. База данных с миграциями выглядит как вполне самостоятельная сущность, и ее можно представить в виде фикстуры:
from alembic.command import upgrade
@pytest.fixture
async def migrated_postgres(alembic_config, postgres):
upgrade(alembic_config, 'head')
# Возвращаем DSN базы данных, которая была смигрирована
return postgresКогда миграций в проекте становится много, их применение для каждого теста может занимать слишком много времени. Чтобы ускорить процесс, можно один раз создать базу данных с миграциями и затем использовать ее в качестве шаблона.
Помимо базы данных для тестирования обработчиков, потребуется запущенное приложение, а также клиент, настроенный на работу с этим приложением. Чтобы приложение было легко тестировать, я вынес его создание в функцию create_app, которая принимает параметры для запуска: базу данных, порт для REST API и другие.
Аргументы для запуска приложения можно также представить в виде отдельной фикстуры. Для их создания потребуется определить свободный порт для запуска тестируемого приложения и адрес до смигрированной временной базы данных.
Для определения свободного порта я воспользовался фикстурой aiomisc_unused_port из пакета aiomisc.
Стандартная фикстура aiohttp_unused_port тоже вполне бы подошла, но она возвращает функцию для определения свободых портов, в то время как aiomisc_unused_port возвращает сразу номер порта. Для нашего приложения требуется определить только один свободный порт, поэтому я решил не писать лишнюю строчку кода с вызовом aiohttp_unused_port.
@pytest.fixture
def arguments(aiomisc_unused_port, migrated_postgres):
return parser.parse_args(
[
'--log-level=debug',
'--api-address=127.0.0.1',
f'--api-port={aiomisc_unused_port}',
f'--pg-url={migrated_postgres}'
]
)
Все тесты с обработчиками подразумевают запросы к REST API, работа напрямую с приложением aiohttp не требуется. Поэтому я сделал одну фикстуру, которая запускает приложение и с помощью фабрики aiohttp_client создает и возвращает подключенный к приложению стандартный тестовый клиент aiohttp.test_utils.TestClient.
from analyzer.api.app import create_app
@pytest.fixture
async def api_client(aiohttp_client, arguments):
app = create_app(arguments)
client = await aiohttp_client(app, server_kwargs={
'port': arguments.api_port
})
try:
yield client
finally:
await client.close()
Теперь, если в параметрах теста указать фикстуру api_client, произойдет следующее:
- Фикстура
postgresсоздаст базу данных (зависимость дляmigrated_postgres). - Фикстура
alembic_configсоздаст объект конфигурации Alembic, подключенный к временной базе данных (зависимость дляmigrated_postgres). - Фикстура
migrated_postgresприменит миграции (зависимость дляarguments). - Фикстура
aiomisc_unused_portобнаружит свободный порт (зависимость дляarguments). - Фикстура
argumentsсоздаст аргументы для запуска (зависимость дляapi_client). - Фикстура
api_clientсоздаст и запустит приложение и вернет клиента для выполнения запросов. - Выполнится тест.
- Фикстура
api_clientотключит клиента и остановит приложение. - Фикстура
postgresудалит базу данных.
Фикстуры позволяют избежать дублирования кода, но помимо подготовки окружения в тестах есть еще одно потенциальное место, в котором будет очень много одинакового кода — запросы к приложению.
Во-первых, сделав запрос, мы ожидаем получить определенный HTTP-статус. Во-вторых, если статус совпадает с ожидаемым, то перед работой с данными необходимо убедиться, что они имеют правильный формат. Здесь легко ошибиться и написать обработчик, который делает правильные вычисления и возвращает правильный результат, но не проходит автоматическую валидацию из-за неправильного формата ответа (например, забыть обернуть ответ в словарь с ключом data). Все эти проверки можно было бы сделать в одном месте.
В модуле analyzer.testing я подготовил для каждого обработчика функцию-помощник, которая проверяет статус HTTP, а также формат ответа с помощью Marshmallow.
GET /imports/$import_id/citizens
Я решил начать с обработчика, возвращающего жителей, потому что он очень полезен для проверки результатов работы других обработчиков, изменяющих состояние базы данных.
Я намеренно не использовал код, добавляющий данные в базу из обработчика POST /imports, хотя вынести его в отдельную функцию несложно. Код обработчиков имеет свойство меняться, а если в коде, добавляющем в базу, будет какая-либо ошибка, есть вероятность, что тест перестанет работать как задумано и неявно для разработчиков перестанет показывать ошибки.
Для этого теста я определил следующие наборы данных для тестирования:
- Выгрузка с несколькими родственниками. Проверяет, что для каждого жителя будет правильно сформирован список с идентификаторами родственников.
- Выгрузка с одним жителем без родственников. Проверяет, что поле
relatives— пустой список (из-заLEFT JOINв SQL-запросе список родственников может быть равен[None]). - Выгрузка с жителем, который сам себе родственник.
- Пустая выгрузка. Проверяет, что обработчик разрешает добавить пустую выгрузку и не падает с ошибкой.
Чтобы запустить один и тот же тест отдельно на каждой выгрузке, я воспользовался еще одним очень мощным механизмом pytest — параметризацией. Этот механизм позволяет обернуть функцию-тест в декоратор pytest.mark.parametrize и описать в нем, какие параметры должна принимать функция-тест для каждого отдельного тестируемого случая.
Как параметризовать тест
import pytest
from analyzer.utils.testing import generate_citizen
datasets = [
# Житель с несколькими родственниками
[
generate_citizen(citizen_id=1, relatives=[2, 3]),
generate_citizen(citizen_id=2, relatives=[1]),
generate_citizen(citizen_id=3, relatives=[1])
],
# Житель без родственников
[
generate_citizen(relatives=[])
],
# Выгрузка с жителем, который сам себе родственник
[
generate_citizen(citizen_id=1, name='Джейн', gender='male',
birth_date='17.02.2020', relatives=[1])
],
# Пустая выгрузка
[],
]
@pytest.mark.parametrize('dataset', datasets)
async def test_get_citizens(api_client, dataset):
"""
Этот тест будет вызван 4 раза, отдельно для каждого датасета
"""Итак, тест добавит выгрузку в базу данных, затем с помощью запроса к обработчику получит информацию о жителях и сравнит эталонную выгрузку с полученной. Но как сравнить жителей?
Каждый житель состоит из скалярных полей и поля relatives — списка идентификаторов родственников. Список в Python — упорядоченный тип, и при сравнении порядок элементов каждого списка имеет значение, но при сравнении списков с родственниками порядок не должен иметь значение.
Если привести relatives к множеству перед сравнением, то при сравнении не получится обнаружить ситуацию, когда у одного из жителей в поле relatives есть дубли. Если отсортировать список с идентификаторами родственников, это позволит обойти проблему разного порядка идентификаторов родственников, но при этом обнаружить дубли.
При сравнении двух списков с жителями можно столкнуться с похожей проблемой: технически, порядок жителей в выгрузке не важен, но важно обнаружить, если в одной выгрузке будет два жителя с одинаковыми идентификаторами, а в другой нет. Так что помимо упорядочивания списка с родственниками relatives для каждого жителя необходимо упорядочить жителей в каждой выгрузке.
Так как задача сравнения жителей возникнет еще не раз, я реализовал две функции: одну для сравнения двух жителей, а вторую для сравнения двух списков с жителями:
Сравниваем жителей
from typing import Iterable, Mapping
def normalize_citizen(citizen):
"""
Возвращает жителя с упорядоченным списком родственников
"""
return {**citizen, 'relatives': sorted(citizen['relatives'])}
def compare_citizens(left: Mapping, right: Mapping) -> bool:
"""
Сравнивает двух жителей
"""
return normalize_citizen(left) == normalize_citizen(right)
def compare_citizen_groups(left: Iterable, right: Iterable) -> bool:
"""
Упорядочивает списки с родственниками для каждого жителя, списки с жителями
и сравнивает их
"""
left = [normalize_citizen(citizen) for citizen in left]
left.sort(key=lambda citizen: citizen['citizen_id'])
right = [normalize_citizen(citizen) for citizen in right]
right.sort(key=lambda citizen: citizen['citizen_id'])
return left == right
Чтобы убедиться, что этот обработчик не возвращает жителей других выгрузок, я решил перед каждым тестом добавлять дополнительную выгрузку с одним жителем.
POST /imports
Я определил следующие наборы данных для тестирования обработчика:
- Корректные данные, ожидается успешное добавление в БД.
- Житель без родственников (самый простой).
Обработчику необходимо добавить данные в две таблицы. Если не обрабатывается ситуация, когда у жителя нет родственников, будет выполнен пустой insert в таблицу родственных связей, что приведет к ошибке.
- Житель с родственниками (более сложный, обычный).
Проверяет, что обработчик корректно сохраняет данные и о жителе и его родственных связях.
- Житель сам себе родственник.
Про этот случай было много вопросов, поэтому в шутку решил добавить и его.

- Выгрузка с максимального размера
Проверяет, что aiohttp позволяет загружать такие объемы данных и что при большом количестве данных в PostgreSQL не отправляется больше 32 767 аргументов (обработчик должен выполнить несколько запросов).
- Пустая выгрузка
Обработчик должен учитывать такой случай и не падать, пытаясь выполнить пустой insert в таблицу с жителями.
- Житель без родственников (самый простой).
- Данные с ошибками, ожидаем HTTP-ответ 400: Bad Request.
- Дата рождения некорректная (будущее время).
- citizen_id в рамках выгрузки не уникален.
- Родственная связь указана неверно (есть только от одного жителя к другому, но нет обратной).
- У жителя указан несуществующий в выгрузке родственник.
- Родственные связи не уникальны.

Если обработчик отработал успешно и данные были добавлены, необходимо получить добавленных в БД жителей и сравнить их с эталонной выгрузки. Для получения жителей я воспользовался уже протестированным обработчиком GET /imports/$import_id/citizens, а для сравнения — функцией compare_citizen_groups.
PATCH /imports/$import_id/citizens/$citizen_id
Валидация данных во многом похожа на описанную в обработчике POST /imports с небольшими исключениями: есть только один житель и клиент может передать только те поля, которые пожелает.
Я решил использовать следующие наборы с некорректными данными, чтобы проверить, что обработчик вернет HTTP-ответ 400: Bad request:
- Поле указано, но имеет некорректный тип и/или формат данных
- Указана некорректная дата рождения (будущее время).
- Поле
relativesсодержит несуществующего в выгрузке родственника.
Также необходимо проверить, что обработчик корректно обновляет информацию о жителе и его родственниках.
Для этого создадим выгрузку с тремя жителями, два из которых — родственники, и отправим запрос с новыми значениями всех скалярных полей и новым идентификатором родственника в поле relatives.
Чтобы убедиться, что обработчик различает жителей разных выгрузок перед тестом (и, например, не изменит жителей с одинаковыми идентификаторами из другой выгрузки), я создал дополнительную выгрузку с тремя жителями, которые имеют такие же идентификаторы.
Обработчик должен сохранить новые значения скалярных полей, добавить нового указанного родственника и удалить связь со старым, не указанным родственником. Все изменения родственных связей должны быть двусторонними. Изменений в других выгрузках быть не должно.
Поскольку такой обработчик может быть подвержен состоянию гонки (это рассматривалось в разделе «Разработка»), я добавил два дополнительных теста. Один воспроизводит проблему с состоянием гонки (расширяет класс обработчика и убирает блокировку), второй доказывает, что проблема с состоянием гонки не воспроизводится.
GET /imports/$import_id/citizens/birthdays
Для тестирования этого обработчика я выбрал следующие наборы данных:
- Выгрузка, в которой у жителя есть один родственник в одном месяце и два родственника в другом.
- Выгрузка с одним жителем без родственников. Проверяет, что обработчик не учитывает его при расчетах.
- Пустая выгрузка. Проверяет, что обработчик не упадет с ошибкой и вернет в ответе корректный словарь с 12 месяцами.
- Выгрузка с жителем, который сам себе родственник. Проверяет, что житель купит себе подарок в месяц своего рождения.
Обработчик должен возвращать в ответе все месяцы, даже если в эти месяцы нет дней рождений. Чтобы избежать дублирования, я сделал функцию, которой можно передать словарь, чтобы она дополнила его значениями для отсутствующих месяцев.
Чтобы убедиться, что обработчик различает жителей разных выгрузок, я добавил дополнительную выгрузку с двумя родственниками. Если обработчик по ошибке использует их при расчетах, то результаты будут некорректными и обработчик упадет с ошибкой.
GET /imports/$import_id/towns/stat/percentile/age
Особенность этого теста в том, что результаты его работы зависят от текущего времени: возраст жителей вычисляется исходя из текущей даты. Чтобы результаты тестирования не менялись с течением времени, текущую дату, даты рождения жителей и ожидаемые результаты необходимо зафиксировать. Это позволит легко воспроизвести любые, даже краевые случаи.
Как лучше зафиксировать дату? В обработчике для вычисления возраста жителей используется PostgreSQL-функция AGE, принимающая первым параметром дату, для которой необходимо рассчитать возраст, а вторым — базовую дату (определена константой TownAgeStatView.CURRENT_DATE).
Подменяем базовую дату в обработчике на время теста
from unittest.mock import patch
import pytz
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
@patch('analyzer.api.handlers.TownAgeStatView.CURRENT_DATE', new=CURRENT_DATE)
async def test_get_ages(...):
...Для тестирования обработчика я выбрал следующие наборы данных (для всех жителей указывал один город, потому что обработчик агрегирует результаты по городам):
- Выгрузка с несколькими жителями, у которых завтра день рождения (возраст — несколько лет и 364 дня). Проверяет, что обработчик использует в расчетах только количество полных лет.
- Выгрузка с жителем, у которого сегодня день рождения (возраст — ровно несколько лет). Проверяет краевой случай — возраст жителя, у которого сегодня день рождения, не должен рассчитаться как уменьшенный на 1 год.
- Пустая выгрузка. Обработчик не должен на ней падать.
Эталон для расчета перцентилей — numpy с линейной интерполяцией, и эталонные результаты для тестирования я рассчитал именно им.
Также нужно округлять дробные значения перцентилей до двух знаков после запятой. Если вы использовали в обработчике для округления PostgreSQL, а для расчета эталонных данных — Python, то могли заметить, что округление в Python 3 и PostgreSQL может давать разные результаты.
Например
# Python 3
round(2.5)
> 2
-- PostgreSQL
SELECT ROUND(2.5)
> 3
Дело в том, что Python использует банковское округление до ближайшего четного, а PostgreSQL — математическое (half-up). В случае, если расчеты и округление производятся в PostgreSQL, было бы правильным в тестах также использовать математическое округление.
Сначала я описал наборы данных с датами рождения в текстовом формате, но читать тест в таком формате было неудобно: приходилось каждый раз вычислять в уме возраст каждого жителя, чтобы вспомнить, что проверяет тот или иной набор данных. Конечно, можно было обойтись комментариями в коде, но я решил пойти чуть дальше и написал функцию age2date, которая позволяет описать дату рождения в виде возраста: количества лет и дней.
Например, вот так
import pytz
from analyzer.utils.testing import generate_citizen
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
def age2date(years: int, days: int = 0, base_date=CURRENT_DATE) -> str:
birth_date = copy(base_date).replace(year=base_date.year - years)
birth_date -= timedelta(days=days)
return birth_date.strftime(BIRTH_DATE_FORMAT)
# Сколько лет этому жителю? Посчитать несложно, но если их будет много?
generate_citizen(birth_date='17.02.2009')
# Жителю ровно 11 лет и у него сегодня день рождения
generate_citizen(birth_date=age2date(years=11))
Чтобы убедиться, что обработчик различает жителей разных выгрузок, я добавил дополнительную выгрузку с одним жителем из другого города: если обработчик по ошибке использует его, в результатах появится лишний город и тест сломается.
Интересный факт: когда я писал этот тест 29 февраля 2020 года, у меня внезапно перестали генерироваться выгрузки с жителями из-за бага в Faker (2020-й — високосный год, а другие годы, которые выбирал Faker, не всегда были високосными и в них не было 29 февраля). Не забывайте фиксировать даты и тестировать краевые случаи!
Миграции
Код миграций на первый взгляд кажется очевидным и наименее подверженным ошибкам, зачем его тестировать? Это очень опасное заблуждение: самые коварные ошибки миграций могут проявить себя в самый неподходящий момент. Даже если они не испортят данные, то могут стать причиной лишнего даунтайма.
Существующая в проекте initial миграция изменяет структуру базы данных, но не изменяет данные. От каких типовых ошибок можно защититься в подобных миграциях?
- Метод
downgradeне реализован или не удалены все созданные в миграции сущности (особенно это касается пользовательских типов данных, которые создаются автоматически при создании таблицы, я про них уже упоминал).Это приведет к тому, что миграцию нельзя будет применить два раза (применить-откатить-применить): при откате не будут удалены все созданные миграцией сущности, при повторном создании миграция пройдет с ошибкой — тип данных уже существует.
- Cинтаксические ошибки и опечатки.
- Ошибки в связях миграций (цепочка нарушена).
Большинство этих ошибок обнаружит stairway-тест. Его идея — применять миграции по одной, последовательно выполняя методы upgrade, downgrade, upgrade для каждой миграции. Такой тест достаточно один раз добавить в проект, он не требует поддержки и будет служить верой и правдой.
А вот если миграция, помимо структуры, изменяла бы данные, то потребовалось бы написать хотя бы один отдельный тест, проверяющий, что данные корректно изменяются в методе upgrade и возвращаются к изначальному состоянию в downgrade. На всякий случай: проект с примерами тестирования разных миграций, который я подготовил для доклада про Alembic на Moscow Python.
Сборка
Конечный артефакт, который мы собираемся разворачивать и который хотим получить в результате сборки, — Docker-образ. Для сборки необходимо выбрать базовый образ c Python. Официальный образ python:latest весит ~1 ГБ и, если его использовать в качестве базового, образ с приложением будет огромным. Существуют образы на основе ОС Alpine, размер которых намного меньше. Но с растущим количеством устанавливаемых пакетов размер конечного образа вырастет, и в итоге даже образ, собранный на основе Alpine, будет не таким уж и маленьким. Я выбрал в качестве базового образа snakepacker/python — он весит немного больше Alpine-образов, но основан на Ubuntu, которая предлагает огромный выбор пакетов и библиотек.
Еще один способ уменьшить размер образа с приложением — не включать в итоговый образ компилятор, библиотеки и файлы с заголовками для сборки, которые не потребуются для работы приложения.
Для этого можно воспользоваться многоступенчатой сборкой Docker:
- С помощью «тяжелого» образа
snakepacker/python:all(~1 ГБ, в сжатом виде ~500 МБ) создаем виртуальное окружение, устанавливаем в него все зависимости и пакет с приложением. Этот образ нужен исключительно для сборки, он может содержать компилятор, все необходимые библиотеки и файлы с заголовками.FROM snakepacker/python:all as builder # Создаем виртуальное окружение RUN python3.8 -m venv /usr/share/python3/app # Копируем source distribution в контейнер и устанавливаем его COPY dist/ /mnt/dist/ RUN /usr/share/python3/app/bin/pip install /mnt/dist/* - Готовое виртуальное окружение копируем в «легкий» образ
snakepacker/python:3.8(~100 МБ, в сжатом виде ~50 МБ), который содержит только интерпретатор требуемой версии Python.Важно: в виртуальном окружении используются абсолютные пути, поэтому его необходимо скопировать по тому же адресу, по которому оно было собрано в контейнере-сборщике.
FROM snakepacker/python:3.8 as api # Копируем готовое виртуальное окружение из контейнера builder COPY --from=builder /usr/share/python3/app /usr/share/python3/app # Устанавливаем ссылки, чтобы можно было воспользоваться командами # приложения RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/ # Устанавливаем выполняемую при запуске контейнера команду по умолчанию CMD ["analyzer-api"]
Чтобы сократить время на сборку образа, зависимые модули приложения можно установить до его установки в виртуальное окружение. Тогда Docker закеширует их и не будет устанавливать заново, если они не менялись.
Dockerfile целиком
############### Образ для сборки виртуального окружения ################
# Основа — «тяжелый» (~1 ГБ, в сжатом виде ~500 ГБ) образ со всеми необходимыми
# библиотеками для сборки модулей
FROM snakepacker/python:all as builder
# Создаем виртуальное окружение и обновляем pip
RUN python3.8 -m venv /usr/share/python3/app
RUN /usr/share/python3/app/bin/pip install -U pip
# Устанавливаем зависимости отдельно, чтобы закешировать. При последующей сборке
# Docker пропустит этот шаг, если requirements.txt не изменится
COPY requirements.txt /mnt/
RUN /usr/share/python3/app/bin/pip install -Ur /mnt/requirements.txt
# Копируем source distribution в контейнер и устанавливаем его
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/*
&& /usr/share/python3/app/bin/pip check
########################### Финальный образ ############################
# За основу берем «легкий» (~100 МБ, в сжатом виде ~50 МБ) образ с Python
FROM snakepacker/python:3.8 as api
# Копируем в него готовое виртуальное окружение из контейнера builder
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
# Устанавливаем ссылки, чтобы можно было воспользоваться командами
# приложения
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
# Устанавливаем выполняемую при запуске контейнера команду по умолчанию
CMD ["analyzer-api"]
Для удобства сборки я добавил команду make upload, которая собирает Docker-образ и загружает его на hub.docker.com.
CI
Теперь, когда код покрыт тестами и мы умеем собирать Docker-образ, самое время автоматизировать эти процессы. Первое, что приходит в голову: запускать тесты на создание пул-реквестов, а при добавлении изменений в master-ветку собирать новый Docker-образ и загружать его на Docker Hub (или GitHub Packages, если вы не собираетесь распространять образ публично).
Я решил эту задачу с помощью GitHub Actions. Для этого потребовалось создать YAML-файл в папке .github/workflows и описать в нем workflow (c двумя задачами: test и publish), которое я назвал CI.
Задача test выполняется при каждом запуске workflow CI, с помощью services поднимает контейнер с PostgreSQL, ожидает, когда он станет доступен, и запускает pytest в контейнере snakepacker/python:all.
Задача publish выполняется, только если изменения были добавлены в ветку master и если задача test была выполнена успешно. Она собирает source distribution контейнером snakepacker/python:all, затем собирает и загружает Docker-образ с помощью docker/build-push-action@v1.
Полное описание workflow
name: CI
# Workflow должен выполняться при добавлении изменений
# или новом пул-реквесте в master
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
# Тесты должны выполняться при каждом запуске workflow
test:
runs-on: ubuntu-latest
services:
postgres:
image: docker://postgres
ports:
- 5432:5432
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: hackme
POSTGRES_DB: analyzer
steps:
- uses: actions/checkout@v2
- name: test
uses: docker://snakepacker/python:all
env:
CI_ANALYZER_PG_URL: postgresql://user:hackme@postgres/analyzer
with:
args: /bin/bash -c "pip install -U '.[dev]' && pylama && wait-for-port postgres:5432 && pytest -vv --cov=analyzer --cov-report=term-missing tests"
# Сборка и загрузка Docker-образа с приложением
publish:
# Выполняется только если изменения попали в ветку master
if: github.event_name == 'push' && github.ref == 'refs/heads/master'
# Требует, чтобы задача test была выполнена успешно
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: sdist
uses: docker://snakepacker/python:all
with:
args: make sdist
- name: build-push
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_LOGIN }}
password: ${{ secrets.REGISTRY_TOKEN }}
repository: alvassin/backendschool2019
target: api
tags: 0.0.1, latest
Теперь при добавлении изменений в master во вкладке Actions на GitHub можно увидеть запуск тестов, сборку и загрузку Docker-образа:

А при создании пул-реквеста в master-ветку в нем также будут отображаться результаты выполнения задачи test:

Деплой
Чтобы развернуть приложение на предоставленном сервере, нужно установить Docker, Docker Compose, запустить контейнеры с приложением и PostgreSQL и применить миграции.
Эти шаги можно автоматизировать с помощью системы управления конфигурациями Ansible. Она написана на Python, не требует специальных агентов (подключается прямо по ssh), использует jinja-шаблоны и позволяет декларативно описывать желаемое состояние в YAML-файлах. Декларативный подход позволяет не задумываться о текущем состоянии системы и действиях, необходимых, чтобы привести систему к желаемому состоянию. Вся эта работа ложится на плечи модулей Ansible.
Ansible позволяет сгруппировать логически связанные задачи в роли и затем переиспользовать. Нам потребуются две роли: docker (устанавливает и настраивает Docker) и analyzer (устанавливает и настраивает приложение).
Роль docker добавляет в систему репозиторий с Docker, устанавливает и настраивает пакеты docker-ce и docker-compose.
Опционально можно наладить автоматическое возобновление работы REST API после перезагрузки сервера. Ubuntu позволяет решить эту задачу силами системы инициализации systemd. Она управляет юнитами, представляющими собой различные ресурсы (демоны, сокеты, точки монтирования и другие). Чтобы добавить новый юнит в systemd, необходимо описать его конфигурацию в отдельном файле .service и разместить этот файл в одной из специальных папок, например в /etc/systemd/system. Затем юнит можно запустить, а также включить для него автозагрузку.
Пакет docker-ce при установке автоматически создаст файл с конфигурацией юнита — необходимо только убедиться, что он запущен и включается при запуске системы. Для Docker Compose файл конфигурации docker-compose@.service будет создан силами Ansible. Символ @ в названии указывает systemd, что юнит является шаблоном. Это позволяет запускать сервис docker-compose с параметром — например, с названием нашего сервиса, который будет подставлен вместо %i в файле конфигурации юнита:
[Unit]
Description=%i service with docker compose
Requires=docker.service
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=true
WorkingDirectory=/etc/docker/compose/%i
ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans
ExecStop=/usr/local/bin/docker-compose down
[Install]
WantedBy=multi-user.targetРоль analyzer сгенерирует из шаблона файл docker-compose.yml по адресу /etc/docker/compose/analyzer, зарегистрирует приложение как автоматически запускаемый сервис в systemd и применит миграции. Когда роли готовы, необходимо описать playbook.
---
- name: Gathering facts
hosts: all
become: yes
gather_facts: yes
- name: Install docker
hosts: docker
become: yes
gather_facts: no
roles:
- docker
- name: Install analyzer
hosts: api
become: yes
gather_facts: no
roles:
- analyzer
Список хостов, а также переменные, использованные в ролях, можно указать в inventory-файле hosts.ini.
[api]
# Хосты, на которые Ansible задеплоит проект.
# Необходимо поменять на свои.
1.2.3.4
[docker:children]
api
[api:vars]
analyzer_image = alvassin/backendschool2019
analyzer_pg_user = user
analyzer_pg_password = hackme
analyzer_pg_dbname = analyzerПосле того, как все файлы Ansible будут готовы, запустим его:
$ ansible-playbook -i hosts.ini deploy.ymlПро нагрузочное тестирование
Итак, приложение покрыто тестами, развернуто и готово к эксплуатации. Для полноты картины на минутку вспомним, что поводом для построения сервиса когда-то было техническое задание. В нем были указаны ограничения: на выгрузке с десятью тысячами жителей, из которых тысяча — родственники первого порядка, каждый обработчик должен обрабатывать запрос менее чем за 10 секунд. Безусловно, такое тестирование целесообразно производить именно на конечном сервере (а, скажем, не на CI-сервере): результаты тестирования напрямую зависят от конфигурации сервера и количества доступных ресурсов.
Допустим, мы сгенерировали выгрузку с жителями, вызвали друг за другом все обработчики, каждый из них отработал менее чем за 10 секунд. Достаточно ли этого? Можно предположить, что скорость обработки данных будет деградировать при увеличении количества данных, загружаемых в сервис. Важно понимать, сколько выгрузок сможет обработать сервис, прежде чем обработчики перестанут укладываться в ограничения.
Хоть для тестирования данного сервиса и не требуется генерировать высокий RPS, его нагрузочное тестирование имеет свою особенность: использовать статический набор запросов не получится. Например, чтобы получить список жителей, необходимо иметь идентификатор выгрузки import_id, который возвращается обработчиком POST /imports и может оказаться любым целым числом. Этот подход называется тестированием по сценарию.
Учитывая, что генерация данных уже реализована на Python 3, я решил воспользоваться фреймворком Locust.
Чтобы выполнить нагрузочное тестирование, необходимо описать сценарий в файле locustfile.py и запустить модуль командой locust. Затем результаты тестирования можно наблюдать на графиках в веб-интерфейсе или таблице результатов в консоли.
Графики Locust показывают общую информацию. Мне было интересно узнать, на каком раунде сервис не уложится в таймаут. Я добавил переменную с номером текущей
итерации self.round и логивание каждого запроса с указанием итерации тестирования и времени выполнения.
Описываем сценарий в файле locustfile.py
# locustfile.py
import logging
from http import HTTPStatus
from locust import HttpLocust, constant, task, TaskSet
from locust.exception import RescheduleTask
from analyzer.api.handlers import (
CitizenBirthdaysView, CitizensView, CitizenView, TownAgeStatView
)
from analyzer.utils.testing import generate_citizen, generate_citizens, url_for
class AnalyzerTaskSet(TaskSet):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.round = 0
def make_dataset(self):
citizens = [
# Первого жителя создаем с родственником. В запросе к
# PATCH-обработчику список relatives будет содержать только другого
# жителя, что потребует выполнения максимального кол-ва запросов
# (как на добавление новой родственной связи, так и на удаление
# существующей).
generate_citizen(citizen_id=1, relatives=[2]),
generate_citizen(citizen_id=2, relatives=[1]),
*generate_citizens(citizens_num=9998, relations_num=1000,
start_citizen_id=3)
]
return {citizen['citizen_id']: citizen for citizen in citizens}
def request(self, method, path, expected_status, **kwargs):
with self.client.request(
method, path, catch_response=True, **kwargs
) as resp:
if resp.status_code != expected_status:
resp.failure(f'expected status {expected_status}, '
f'got {resp.status_code}')
logging.info(
'round %r: %s %s, http status %d (expected %d), took %rs',
self.round, method, path, resp.status_code, expected_status,
resp.elapsed.total_seconds()
)
return resp
def create_import(self, dataset):
resp = self.request('POST', '/imports', HTTPStatus.CREATED,
json={'citizens': list(dataset.values())})
if resp.status_code != HTTPStatus.CREATED:
raise RescheduleTask
return resp.json()['data']['import_id']
def get_citizens(self, import_id):
url = url_for(CitizensView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens')
def update_citizen(self, import_id):
url = url_for(CitizenView.URL_PATH, import_id=import_id, citizen_id=1)
self.request('PATCH', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/{citizen_id}',
json={'relatives': [i for i in range(3, 10)]})
def get_birthdays(self, import_id):
url = url_for(CitizenBirthdaysView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/birthdays')
def get_town_stats(self, import_id):
url = url_for(TownAgeStatView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/towns/stat/percentile/age')
@task
def workflow(self):
self.round += 1
dataset = self.make_dataset()
import_id = self.create_import(dataset)
self.get_citizens(import_id)
self.update_citizen(import_id)
self.get_birthdays(import_id)
self.get_town_stats(import_id)
class WebsiteUser(HttpLocust):
task_set = AnalyzerTaskSet
wait_time = constant(1)Выполнив 100 итераций c максимальными выгрузками, я убедился, что время работы всех обработчиков укладывается в ограничения:

Как видно на графике распределения времени ответов обработчиков, скорость обработки запросов почти не деградирует с ростом количества данных (желтый — 95 перцентиль, зеленый — медиана). Даже со ста выгрузками сервис будет работать эффективно.

На графиках потребления ресурсов виден всплеск — установка приложения с помощью Ansible и далее ровное потребление ресурсов с ~20.15 до ~20.30 под нагрузкой от Locust.
Что еще можно сделать?
Профилирование приложения показало, что около четверти всего времени выполнения запросов уходит на сериализацию и десериализацию JSON: данных, отправляемых и получаемых из сервиса, достаточно много. Эти процессы можно существенно ускорить с помощью библиотеки orjson, но сервис придется немного подготовить — orjson не является drop-in-заменой для стандартного модуля json
Обычно для продакшена требуется несколько копий сервиса, чтобы обеспечить отказоустойчивость и справиться с нагрузкой. Для управления группой сервисов нужен инструмент, показывающий, «жива» ли копия сервиса. Решить эту задачу можно обработчиком /health, который опрашивает все требуемые для работы ресурсы, в нашем случае — базу данных. Если SELECT 1 выполняется меньше чем за секунду, то сервис жив. Если нет — нужно обратить на него внимание.
Когда приложение очень интенсивно работает с сетью, uvloop может здорово увеличить производительность.
Немаловажным фактором является и читабельность кода. Один мой коллега, Юрий Шиканов, написал объединяющий несколько инструментов модуль gray для автоматической проверки и оформления кода, который легко добавить в pre-commit Git-хук, настроить одним файлом конфигурации или переменными окружения. Gray позволяет сортировать импорты (isort), оптимизирует выражения python в соответствии с новыми версиями языка (pyupgrade), добавляет запятые в конце вызовов функций, импортов, списков и т. д. (add-trailing-comma), а также приводит кавычки к единому виду (unify).
* * *
На этом у меня все: мы разработали, покрыли тестами, собрали и развернули сервис, а также провели нагрузочное тестирование.
Благодарности
Я хотел бы выразить огромную благодарность ребятам, которые нашли время принять участие в написании этой статьи, поревьювить код, внести свои идеи и замечания: Марии Зеленовой zelma, Владимиру Соломатину leenr, Анастасии Семёновой morkov, Юрию Шиканову dizballanze, Михаилу Шушпанову mishush, Павлу Мосеину pavkazzz и особенно Дмитрию Орлову orlovdl.
Рассказывает Эмит Ирэндол, full-stack разработчик
В этой статье перечислены ключевые аспекты, которые нужно учитывать при создании бэкенда в контексте full-stack веб-разработки. Новичков она познакомит с основами, а более продвинутым программистам может быть полезна в качестве чек-листа.
1. Аутентификация
Большинство приложений стремится обрести новых пользователей, поэтому необходимо разработать механизм, позволяющий пользователям регистрироваться, аутентифицироваться и менять свои учётные данные.
Можно выделить два основных типа аутентификации:
- Запоминающая предыдущее состояние — реализуется с помощью сессий. Пользователь авторизуется один раз, а затем получает возможность свободно передвигаться по приложению и доступ к защищенным ресурсам (таким, как банковские транзакции или селфи в Snapchat), не отправляя данные, которые подтверждают его вход повторно.
- Не запоминающая предыдущее состояние — реализуется с помощью токенов. Пользователи делают все то же самое, но при выполнении каждого HTTP-запроса пользователю нужно отправлять идентификационные данные. Так обычно поступают с REST API. Сейчас золотой стандарт, не запоминающей состояние аутентификации с токенами, — JWT.
Есть и более продвинутый сценарий — многофакторная аутентификация. Она повышает безопасность приложения, добавляя дополнительные уровни защиты к логину и паролю. Хорошие примеры реализации есть у Google и Amazon.
Прим. перев. А у нас есть разъясняющая статья про двухфакторную аутентификацию и протокол FIDO U2F.
OAuth — другой широко распространенный сценарий. Он дает пользователям вашего приложения возможность зарегистрироваться и войти в него одним кликом, используя аккаунт одной из социальных сетей. Аутентификация происходит за счет того, что пользователи предоставляют вашему приложению некоторые свои данные из социальной сети, но при этом не вводят их вручную.
2. Роли, разрешения и контроль доступа
Многие путают авторизацию с аутентификацией, не понимая, что это разные понятия. Аутентификация определяет то, как пользователь входит в приложение. Авторизация же определяет то, что пользователь имеет право делать после входа.
Запутались? Объясню подробнее. Смысл слоя, отвечающего за авторизацию, — это выдача разрешений, поддержание безопасности личной информации, отказ в доступе к конкретным действиям и, где требуется, аннулирование привилегий, чтобы одни пользователи не пробирались в аккаунты других и не смотрели их личные фотографии. Логика разрешений проста:
Пользователь x может сделать действие y с объектом z.
Применим это в конкретной ситуации: Шэрон — редактор и может редактировать посты. Тогда надо определить:
- роль Шэрон — редактор;
- ее действие — редактирование;
- объекты, с которыми она может это делать, — посты.
Как это работает? Просто: булевы переменные. Вы возвращаете True/False в зависимости от того, что и кому разрешено делать с конкретным объектом. Итак, может ли Шэрон редактировать какой-то конкретный пост? Вернуть True, если она редактор, вернуть False и закрыть доступ к посту, если нет.
3. CRUD — Create, Read, Update, Delete
Вы не можете создавать пользователей или выдавать разрешения, не зная, как работать с ресурсами: создавать, читать, редактировать и удалять их. Это значит, что надо научиться управлять ресурсами приложения, и чаще всего для этого используют базы данных.
Но что такое ресурс? Если вы создаете книжный магазин, то книги — это ресурсы. Если вы создаете группу, она сама и есть ресурс и ее участники тоже ресурсы. А также каждая запись или аккаунт, который они используют. Например, это может быть официальное письмо к правительству, открытка или фильм, который они пытаются купить.
Здесь и появляется модель структуры ваших данных. Вам нужно будет понимать, как решить следующие задачи:
- как создавать новые данные;
- как их редактировать;
- как их обновлять и удалять.
Так выглядит CRUD при работе с фреймворком Ruby on Rail, который предоставляет слой объектно-реляционного сопоставления (Object Relational Mapping — ORM):
# создаем новую запись о студенте
student = Student.new(:first_name => ‘Ann’, :last_name => ‘Smith’, :birthday => ‘1986–08–11’)
# сохраняем созданную выше запись
student.saveТакже ваши ресурсы редко существуют в изоляции. Чаще всего они связаны какими-то отношениями или ассоциациями с другими ресурсами. Давайте взглянем на сценарий, где вы хотите сохранить информацию о парах, которые есть у студента. Вы можете создать дочерний ресурс в student и сохранить его:
student.classes.new(:name => ‘Geometry’).saveНе правда ли, это выглядит и читается, как обычный английский? Но учиться все равно придется, ведь в реальности задачи очень быстро обрастают трудностями! Поэтому вам нужно научиться работать с базами данных, выбрав для себя подходящую модель: реляционную или NoSQL.
Заметьте, что для задач CRUD вам также нужно будет научиться проверять входящие данные и сверяться с разрешениями, прежде чем вы сделаете что-то с этими данными.
4. REST
Чтобы обеспечить управление ресурсами в вашем приложении (такими, как книги или аккаунты), нужно реализовать программный слой, принимающий запросы и формирующий ответы. Здесь вам доведется поработать с маршрутами (routes) и контроллерами (controllers). Они обеспечивают соблюдение ограничений, накладываемых REST — стилем архитектуры программного обеспечения для распределенных систем.
В типичном приложении на Ruby маршрут выглядит так:
get '/photos/:id', to: 'photos#show'Что в это время происходит в системе:
- Приходит запрос на фото с этим маршрутом и передается контроллеру с помощью метода
show. - Этот метод, обращаясь к ресурсу из базы данных или к другому API, формирует и передает ответ в формате HTML или JSON.
- Клиент (в данном случае браузер компьютера) получает ответ и выводит фото на экран.
Запросы могут приходить из многих источников (их называют клиентами). Чаще всего запросы для веб-приложения формируются в форме ввода браузера. Но, если вы пишете бэкенд для мобильного приложения, то клиент — это API приложения, и он посылает запросы GET, POST, PUT, DELETE из приложения.
Вы можете разработать отвечающую на запросы систему, создав API с учетом REST. Такой API называется RESTful, читайте подробнее о нем в подробной статье.
Прим. перев. Также предлагаем ознакомиться с нашим материалом по этой теме.
5. Формы и состояния
Формы — это самый распространенный способ общения пользователей с приложением. В основном через них пользователи и вводят все данные.
Вам надо создать формы для взаимодействия с бэкендом: если пользователь заказывает билет на концерт, то форма должна выглядеть, как сетка мест:
Когда пользователь начинает взаимодействовать с формой, вам надо сделать следующее:
- Основываясь на правилах приложения, проверить введенную пользователем информацию и показать ошибки или сообщение об успешной проверке.
- Изменить название состояния или формы в зависимости от того, кто и что пытается сделать.
- Разрешить передачу данных, введенных проверенным пользователем с достаточными правами, в бэкенд для обработки.
6. API
Чтобы ваше приложение стало по-настоящему популярным, вам надо начать делиться данными с другими приложениями. Например, вы — музыкальная компания, и вы хотите, чтобы стриминговые сервисы типа SoundCloud поставляли ваш контент, а пользователи могли покупать вашу музыку напрямую из их приложения. Здесь и нужен API.
Термин API — аббревиатура от Application Programming Interface (интерфейс программирования приложений) — применяется к инфраструктуре, которая позволяет другим приложениям взаимодействовать с вашим.  На картинке выше вы видите пример применения API для обслуживания сети из многих мобильных и настольных клиентов.
На картинке выше вы видите пример применения API для обслуживания сети из многих мобильных и настольных клиентов.
Основные этапы написания API:
- Создать API-сервер. Этап подразумевает обеспечение защищенного доступа к ресурсам, которые вы хотите передавать клиентам. Если у вас книжный магазин, то ваш API будет предоставлять названия книг, цены и информацию об издателе другим сайтам и перекупщикам.
- Защитить сервер, используя идентификаторы приложений и секретные ключи.
- Сделать понятную интерактивную документацию, которая позволит другим разработчикам просматривать ее и взаимодействовать между собой и с вами.
7. Уведомления по Email, SMS и Webhooks
Когда пользователь совершает в вашем приложении важное действие, например, подписывается на обновления, создает новый аккаунт или проект, он должен знать, удалось это действие или нет.
Уведомления — это способ сообщить вашему пользователю о статусе выполнения действия и помочь ему организовать рабочий процесс в вашем приложении.
Для разных случаев вы можете использовать разные уведомления:
- оповещения на экране приложения;
- электронные письма (верификация почты или подтверждение покупки);
- SMS (авторизация или завершение транзакции);
- webhook-уведомления в реальном времени для обратившихся к вашему приложению чат-ботов на разных платформах, например Telegram или Slack;
- регулярные письма со счетами за покупки и информацией об оплате подписки.
8. Подписка и тарифные планы
Продумывание тарифов только кажется маловажным, но на деле часто является необходимым. Вам придется научиться создавать многоуровневые тарифные планы и присваивать определенные роли, разрешения и привилегии пользователям, подписавшимся на конкретный план. Также хорошая идея научиться предоставлять динамическое ценообразование, основанное на свойствах, формирующих каждый тарифный план. Например, покупка нового сервера на AWS или DigitalOcean дает пользователям право выбирать память, процессор и т.д.
Полезные советы по проектированию тарифных планов:
- выделяйте рекомендуемый вариант;
- разрешите пользователям выбирать валюту (€/$/₽) и период оплаты (месяц/год);
- предоставьте первый месяц бесплатно для успешного вовлечения пользователей;
- особо выделите отзывы;
- продавайте преимущества вместо характеристик;
- дайте пользователям понять, что они могут отказаться в любой момент;
- разрешите пользователям выбирать интересующие характеристики и конфигурировать тарифные планы.
9. Взаимодействие с платежным шлюзом
Вам понадобится обрабатывать информацию о кредитных картах с помощью форм, которые обычно выглядят, как интерфейс интернет-магазина.
Во время транзакции нужно:
- убедиться, что информация о кредитной карте не сохраняется, не передается в другие части приложения и безопасно отправляется на платежный шлюз для обработки;
- принять оплату, если транзакция прошла успешно, и отправить уведомление о том, что оплата удалась; иначе — отправить уведомление о неудаче и предложить пользователю попробовать оплатить в другой раз.
Вы также можете использовать сторонние сервисы, такие, как Paypal, которые позволяют интегрировать их интерфейс в виде формы (или кнопки) в ваше приложение, и тогда транзакции будут частично управляться этим сервисом.
Не забывайте про счета — людям нужны документы о транзакциях для уплаты налогов и т. д.:
- создайте раздел со счетами, который является частью профиля пользователя;
- сделайте удобную сортировку и экспорт данных по транзакциям в виде счет-фактур в формате PDF;
- убедитесь, что пользователи могут отправлять эти счета себе на электронную почту.
Как работает платежный шлюз:
- Ваши кассовые формы отправляют детали покупки на платежный шлюз для обработки.
- Платежный шлюз передает данные транзакции банку продавца.
- Банк продавца передает эту информацию о транзакции банку, который выпустил карту покупателя, для авторизации транзакции.
- Банк, который выпустил карту покупателя, либо одобряет, либо отклоняет транзакцию и отправляет информацию банку продавца.
- Если транзакция одобрена, то банк переводит средства на ваш счет.
- После одобрения сторонний платежный шлюз отправляет детали транзакции и ответ вашему приложению.
- И, наконец, вы отправляете уведомление покупателю, сообщая, одобрена ли транзакция.
Если остались вопросы, посмотрите это видео:
10. Загрузка файлов
Очень вероятно, что когда пользователи начнут работать в вашем приложении, они будут хранить в нем свои данные, которые представляют из себя не только информацию в вашей базе, но и картинки, видео и PDF. Так что вам надо будет:
- Разрешить загружать только файлы определенных форматов.
- Проверять файлы на превышение разрешенного размера и отклонять загрузку слишком больших.
- Показывать пользователю процесс загрузки.
- Убедиться, что загрузка происходит асинхронно и не нарушает работу фронтенда.
- Разрешить пользователю помечать файлы как личные/общедоступные.
- Разрешить пользователю экспортировать загруженные данные.
- Создать медиа-библиотеку, чтобы фильтровать файлы и управлять ими (опционально).
11. Сторонние API, фреймворки и пакеты
Ruby, Elixir, PHP и JavaScript уже имеют тысячи пакетов, которые могут быть настроены и применены к вашему приложению. Их легко встроить с помощью команды в одну строку в терминале:
# аутентификация в Rails:
gem install devise
# отладка и профилирование в Laravel:
composer install clockwork
# аутентификация в Express:
npm install passportЕсли вы не будете включать сторонний код в вашу экосистему, то вам придется разбираться с такими низкоуровневыми проблемами, как создание сессий, хэширование и защита от атак CSRF и тому подобное вместо того, чтобы фокусироваться на высокоуровневых задачах, которые делают ваше приложение уникальным.
Чаще всего фреймворки составлены из отдельных пакетов, которые при желании можно заменять на более подходящие под ваши задачи. Вы можете оценить качество исходного кода пакета по следующим пунктам:
- бейджи репозитория;
- дата последнего обновления;
- пройденные тесты;
- популярность, например, по оценке пользователей в звездах;
- количество решенных проблем и открытых пулл реквестов.
12. Работа с Open Source
Вы столкнетесь с тем, что уже существующие пакеты не выполняют необходимые задачи или делают это некорректно. Тем не менее, всегда есть возможность подстроить под себя их функционал, поэтому учитесь работать с чужим исходным кодом. Полезные советы:
- читайте документацию и ищите ответы в ней, прежде чем задавать вопросы;
- посетите официальную страницу пакета на GitHub или Bitbucket, просмотрите открытые и решенные проблемы, и, возможно, вы найдете пулл реквест, в котором будет необходимая функциональность;
- также вы можете сами реализовать необходимую функциональность и отправить ее авторам, внеся свой вклад в развитие Open Source. Если ваш код не приняли, просто используйте свою версию вместо исходного пакета;
- если вы все-таки вынуждены писать свои функции с нуля, то убедитесь, что вы создаете их для универсального применения, чтобы другие тоже могли их использовать.
13. Интерфейс для управления
Как только вы выпустите приложение, пользователи захотят управлять им, настраивать и персонализировать его. Чтобы они ничего не сломали, стоит ограничить им доступ, предоставив приятную и простую в использовании панель управления. Создать её не так сложно, как кажется, да и большинство написанных для нее функций вы сможете использовать где-то еще.
Хорошая панель управления должна обладать следующими свойствами:
- защищенность от внешних атак;
- корректное отображение для пользователей с разными уровнями доступа;
- приятный дизайн и простота в использовании;
- фокус на самых частых задачах;
- возможность добавления внешних компонентов;
- возможность заменить неиспользуемые функции новыми.
14. Кэширование
Красивый и удобный фронтенд часто состоит из сложные многоуровневых данных, отображение которых может быть медленным и ресурсозатратным. Без кэширования ваша база данных будет вынуждена многократно выполнять почти одинаковые запросы, что приведет к ее перегрузкам.
Представьте промежуточный слой в стэке вашего приложения, который хранит статические данные и предоставляет их по запросу, не обращаясь к базе данных. Это и есть кэш.
Как работает кэширование в веб-приложениях? Можно выделить следующие типы механизмов:
- кэширование контента. Если контент веб-страницы не изменяется постоянно, то нет нужды каждый раз заново его генерировать. Целая HTML-страница может быть сохранена в кэше;
- кэширование фрагментов. Иногда целая страница не может быть закэширована, потому что на ней есть контент, который постоянно изменяется, но есть и части, которые изменяются медленно. HTML для этих статичных частей генерируется только при первом запросе, а при повторных извлекается из кэша;
- кэширование данных. Часто в основе веб-приложения лежит база данных, но каждый раз извлекать из нее информацию достаточно накладно, поэтому часто используемые данные кэшируются в памяти приложения или в других хранилищах, например, Redis, Varnish и Memcached.
15. Компоненты
Это больше относится к фронтенду, но так как вы full-stack разработчик, вам нужно разделить ваш код — и шаблоны страниц, и службы бэкенда — на модульные компоненты, если вы не хотите запутаться. В моем любимом проекте фронтенд организован следующим образом:
{% include '_components/global/_header' %}
{% include '_components/services/_masthead' %}
{% include '_components/services/_svc-stats_blok' %}
{% include '_components/services/_client-list' %}
{% include '_components/services/_sol-portfolio' with { 'brandColor': BrCore } %}
{% include '_components/services/_customers-blok' with { 'brandColor': BrCore, 'topConnector': true } %}
{% include '_components/services/_why-aranca-c' %}
{% include '_components/services/_svc_box_grid' with {'data': entry.experienceRichtext, 'brandColor': BrCore } %}
{% include '_components/services/_featured-case-study' %}
{% if entry.tfilterRichtext|length %}
{% include '_components/services/_table-filter' %}
{% endif %}
{% include '_components/services/_full-cta-a' %}
{% include '_components/services/_kc-content' %}
{% include '_components/global/_footer' %}Приведенный выше код взят из шаблона Twig, который можно легко менять. Кроме того, при выходе из строя одного из компонентов работа всей страницы не нарушается. Например, если ваш код для аутентификации находится в слое управления, будет гораздо лучше убрать его оттуда и сформировать в виде отдельного компонента.
16. Системы управления версиями
Речь, конечно, идет об использовании Git и GitHub. Новичкам использование Git кажется излишним, а его преимущества — неочевидными, поэтому предлагаю подумать о ситуациях, с которыми вы можете столкнуться в процессе написания кода:
- Если вы собираетесь работать с другими разработчиками над одним и тем же проектом, то вы будете пользоваться общим набором файлов. Как именно вы планируете избежать противоречий при изменениях в коде?
- Что, если вы захотите вернуть старую версию и посмотреть, как вы реализовали ту или иную задачу перед тем, как продолжите разработку?
- Что, если вы захотите откатить проект к последней версии, в которой еще не было сбоя?
- Что, если вы захотите поделиться своим исходным кодом? Вы будете его архивировать и рассылать по e-mail при добавлении каждой новой фичи?
- Как вы будете следить за тем, какие файлы были изменены, а какие — нет?
Научиться пользоваться GitHub поможет эта статья.
Прим. перев. А чтобы разобраться в основах Git, читайте наше руководство.
17. Командная строка
В интерфейсе, доступном пользователю, есть ограниченное количество кнопок, которых недостаточно для полноценного управления приложением на всех уровнях. Но для этого есть командная строка, которая поможет вам добавлять модули в инфраструктуру вашего приложения, тестировать его и выкладывать на удаленный сервер.
Для освоения командной строки советую эту книгу.
Прим. перев. Знакомство с командной строкой также можно начать с нашей шпаргалки по Bash.
18. Вопросы на Stack Overflow
Если вы не можете разобраться сами, то спросите на Stack Overflow. А чтобы не показаться смешным в глазах опытных пользователей и получить исчерпывающий ответ, задавайте вопросы по инструкции.
Перевод статьи «Part uh: what does it take to be a full stack developer?»
Рассказываем об основах создания простого бэкенда для сайта на обычном шаред-хостинге с помощью языка C++ и библиотеки cgicc.
Серверное окружение
Если вы думаете, что бэк на C++ возможен только на выделенном сервере, это не так: большинство шаред-хостингов имеют такую возможность. Любой веб-хост, который поддерживает CGI, поддерживает и C++ скрипты.
В зависимости от провайдера вы можете иметь или не иметь возможность компилировать сайт локально. Если вы собираетесь редактировать и компилировать скрипты через SSH, заранее об этом узнайте.
Простой пример
В примере будет рассматриваться шаред-хостинг с панелью на cPanel, но описание легко адаптируется под любой другой. cPanel предоставляет отдельный каталог cgi-bin, но использовать именно его не обязательно.
Любой файл с расширением .cgi будет автоматически обработан, если имеет корректные права доступа (обычно 0755). Ниже описаны необходимые файлы (убедитесь что используете табуляцию для отступов в Makefile).
Makefile:
all:
g++ -O3 -s hello.cpp -o hello.cgi
clean:
rm -f hello.cgi
hello.cpp:
#include <iostream>
#include <string>
#include <stdlib.h>
using namespace std;
void set_content_type(string content_type) {
cout << “Content-type: “ << content_type << “rnrn”;
}
void set_page_title(string title) {
cout << “<title>” << title << “</title>n”;
}
void h1_text(string text) {
cout << text << “n”;
}
int main() {
set_content_type(“text/html”);
cout << “<!doctype html>n”;
cout << “<html lang=”en”>n”;
cout << “<head>n”;
set_page_title(“Hello, World!”);
cout << “</head>n”;
cout << “<body>n”;
h1_text(“Hello, World!”);
cout << “</body>n”;
cout << “</html>”;
return 0;
}
Если на вашем аккаунте доступен компилятор (можно уточнить в техподдержке хостера), просто подключитесь к серверу по SSH переместите файлы в каталог public_html (можно и по FTP) и запустите в консоли:
make
Теперь попробуйте открыть файл в браузере:
http://your-test-site.com/hello.cgi
Вы должны увидеть на экране «Hello World».
Прежде, чем начать разбираться с кодом, давайте выясним, что происходит на сервере. Когда Apache получает запрос, он первым делом проверяет встроенный обработчик или RewriteRule, затем проверяет наличие запрашиваемого файла на диске. В нашем случае, он найдет hello.cgi и исполнит его: программа не принимает никаких данных, а просто возвращает строку. Apache возвращает строку в виде корректного ответа для браузера.
Что касается кода в текущем виде, то он написан не лучшим образом. Все, что он может делать, – отдавать строку текста, и при этом никак не структурирован. Чтобы обработка тегов выглядела опрятней и была более расширяемой, можно добавить функции для выдачи тегов, например:
void p(string text) {
cout << “<p>” << text << “</p>n”;
}
Таким образом, получается аккуратная обертка для параграфа:
p(“This would be paragraph text.”);
Входные данные
Обрабатывая запросы, веб-сервер передает огромное количество информации, которая хранится в переменных окружения. Чтобы получить к ней доступ, можно воспользоваться функцией getenv() из стандартной библиотеки C (не забудьте про #include <stdlib.h> в шапке файла).
К примеру, если нужно узнать запрашиваемый URI целиком, можно использовать:
string request_uri = getenv(“REQUEST_URI”);
Вот еще несколько полезных примеров:
- REMOTE_ADDR – получить IP адрес посетителя.
- REQUEST_METHOD – вернет метод запроса (GET, POST и так далее).
- DOCUMENT_ROOT – получить путь к корневому каталогу.
- QUERY_STRING – можно использовать для получения переменных из GET.
Разбираться с переменными из GET и POST-запросами, конечно, можно и вручную, но это утомительное занятие. Нужно либо писать собственные обертки, либо использовать существующую библиотеку (в нашем примере – cgicc), которая поможет работать с HTML и обрабатывать данные форм. Использование библиотек для крупных проектов позволит сохранить уйму времени.
На Debian и Ubuntu можно устанавливать библиотеки из консоли, используя утилиту apt:
apt install libcgicc5 libcgicc5-dev
На CentOS/RHEL с установкой пакетов сложнее, так что придется использовать:
cd /usr/local/src wget ftp://ftp.gnu.org/gnu/cgicc/cgicc-3.2.19.tar.gz tar xfz cgicc*.tar.gz cd cgicc* ./configure — prefix=/usr make make install
Обратите внимание, что версия 3.2.19 актуальна на момент написания заметки. Актуальную версию можно найти в ftp://ftp.gnu.org/gnu/cgicc/ (подключитесь по через ваш FTP-клиент).
Как только библиотека установлена, можно использовать ее в проекте. Рассмотрим пример, который принимает и обрабатывает пользовательский ввод в браузере.
Makefile:
all:
g++ -O3 -s hello.cpp -o hello.cgi
g++ -O3 -s cgicc.cpp -o cgicc.cgi /usr/lib/libcgicc.a
clean:
rm -f hello.cgi cgicc.cgi
cgicc.html:
<!doctype html>
<html lang="en">
<head>
<title>cgicc Test</title>
</head>
<body>
<form method="POST" action="cgicc.cgi">
<label for="name">Name</label>
<input name="name" type="text" value="">
<input name="submit" type="submit" value="Submit">
</form>
</body>
</html>
cgicc.cpp:
#include <iostream>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
void set_content_type(string content_type) {
cout << “Content-type: “ << content_type << “rnrn”;
}
void set_page_title(string title) {
cout << “<title>” << title << “</title>n”;
}
void h1_text(string text) {
cout << text << “n”;
}
int main() {
Cgicc cgi;
string name;
set_content_type(“text/html”);
cout << “<!doctype html>n”;
cout << “<html lang=”en”>n”;
cout << “<head>n”;
set_page_title(“cgicc Test”);
cout << “</head>n”;
cout << “<body>n”;
cout << “<p>”;
name = cgi(“name”);
if (!name.empty()) {
cout << “Name is “ << name << “n”;
} else {
cout << “Name was not provided.”;
}
cout << “</p>n”;
cout << “</body>n”;
cout << “</html>”;
return 0;
}
В этом примере cgicc помогает нам парсить POST и возвращает поле name. Этот пример упрощен и данные поле при попадании на сервер не проходят дополнительную обработку, что необходимо сделать на рабочем сайте, особенно, если будет взаимодействовать с базой данных.
Производительность
C++ известен своей быстротой, но это справедливо, если вы умеете писать на нем хороший код. Интерфейс CGI также несколько замедляет скорость работы приложения, но вы все равно получаете преимущество в скорости над интерпретируемыми языками, вроде PHP.
Вас также могут заинтересовать другие статьи по теме:
- 10 особенностей С++, о которых знают лишь опытные программисты
- Программирование на Си-плюс-плюс: ТОП-10 трюков
- 13 материалов для «продолжающих» С++ разработчиков
- С15 популярных вопросов с IT-собеседований по языку C++
Любой сайт состоит из пользовательской и серверной частей. На странице в интернете вы видите текст, кнопки, панели, изображения и видео. Можете перемещаться по сайту, свободно изучать контент. Перед вами — пользовательская часть сайта и результат труда frontend-разработчика: визуализация, интерактивность и понятность интерфейса. Вы видите красивый дизайн, подсвеченные кнопки и интересную типографику, сайтом удобно пользоваться. Но как всё это выглядит изнутри?
За логику, работоспособность и правильное функционирование сайта отвечает серверная часть, которая скрыта от пользователя. Её созданием занимается backend-разработчик, а управлять может только администратор сайта через специальный интерфейс.
Любой запрос, который делает пользователь, передаётся на сервер. Здесь всё и происходит: запрос обрабатывается, фильтруется, а ответ отправляется обратно. Backend-разработка отвечает за правильное выполнение этого процесса.
Возьмём в качестве примера обычный компьютер. Вы свободно перемещаетесь по файлам и папкам, можете удалять и изменять информацию, добавлять новую, делать всё, что хотите. Но в серверную часть для вас доступ закрыт. Компьютер скрывает папки с системными файлами, чтобы пользователь не наделал глупостей и не повлиял на его правильную работу. Примерно то же самое происходит с сайтом — вам доступны только те части, которые не влияют на его функционирование. То есть вы можете пользоваться продуктом, но не менять его код.
Серверная и пользовательская части взаимосвязаны. И могут дать хороший результат (то есть понятный и функциональный сайт), только когда работают слаженно.
Представьте, что мы говорим о человеке, а не о программном обеспечении. Взаимодействие frontend- и backend-разработки похоже на слаженную работу человеческого тела и нервной системы. Кожные рецепторы посылают информацию в мозг. Он анализирует полученные данные и отправляет ответный импульс, заставляя тело реагировать.

Frontend отвечает за то, как выглядит продукт.
Есть несколько клиентов — ими могут быть обычные браузеры на ПК или мобильном устройстве. Один из клиентов — браузер вашего компьютера. Вы хотите получить информацию из интернета. Делаете запрос — вводите фразу в поисковик Yandex или Google. Сразу же открывается страница с необходимой вам информацией.
Как это работает на самом деле? Ваш клиент, он же браузер, отправляет запрос на сервер. Сначала на сервер пользователя — frontend. Frontend-сервер (компьютер) обрабатывает запрос, выбирает backend-сервер, который в данный момент свободен, и отправляет ему запрос из браузера. Backend-сервер обрабатывает запрос, обращается к базе данных и посылает ответ обратно frontend-серверу. А frontend, так как он отвечает за удобство пользователя, уже отображает ответ на запрос в виде HTML-страницы.
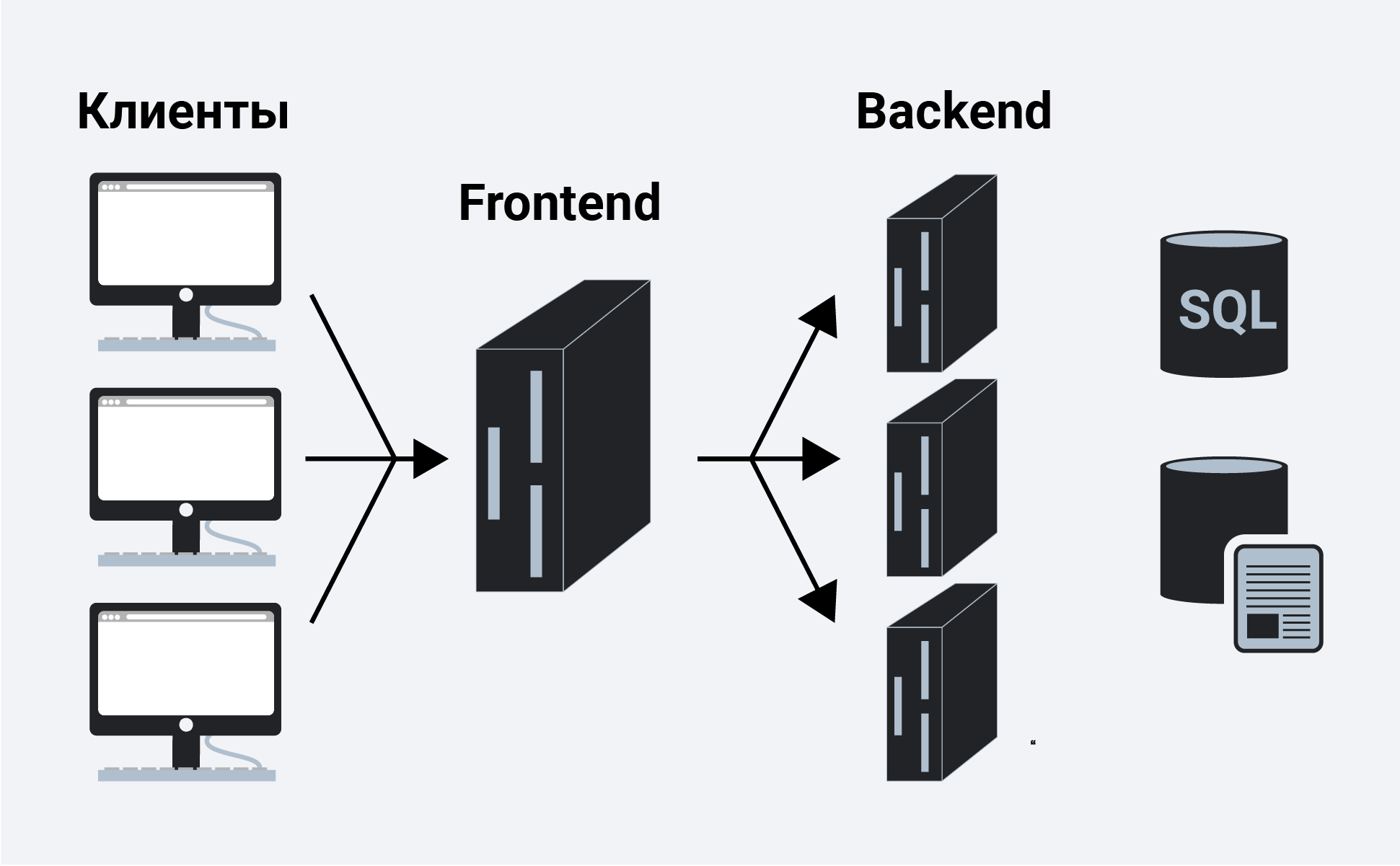
Теперь вы знаете, что за пользовательскую часть сайта отвечает frontend-разработка. Главная задача разработчика — создать понятный интерфейс, с которым будет легко взаимодействовать. Frontend — это не только дизайн, но и код, который помогает взаимодействовать с пользователем.
HTML — содержание сайта
За содержание сайта отвечает язык гипертекстовой разметки HTML. Это не язык программирования, но он поможет наполнить сайт необходимой информацией и расположить её в нужных частях страницы. Всё, что вы видите на сайте, — это HTML-файл. Но просто HTML-страница без оформления выглядела бы очень скучно и непривлекательно. Поэтому, чтобы оформить сайт, сделать его приятным для восприятия, нужен инструментарий CSS. Самые широкие возможности, включая адаптивности дизайна и анимацию, предоставляет версия HTML5, на которую сегодня и стоит ориентироваться.
CSS — оформление сайта
Этот язык отвечает за отображение HTML-документа. С его помощью вёрстка визуальной части сайта упрощается, у него появляется определённый стиль. А чтобы добавить интерактивность и динамику, например мигающие кнопки, можно использовать JavaScript.
JavaScript — интерактивность сайта
Это полноценный язык программирования, который в веб-разработке используется для оживления сайта.
jQuery — фреймворк языка JavaScript
Библиотека с набором готовых функций, которые упрощают написание JavaScript-кода. Фреймворк позволяет не писать код заново, а подобрать подходящую часть из готового набора.
Для создания серверной части сайта необходимо освоить полноценный язык программирования. Он может быть практически любым, но сейчас в веб-разработке чаще всего используют PHP. Это язык общего назначения, но для создания сайтов он подходит в большинстве случаев. Для разработки серверной части нужно разобраться с базами данных. Подойдёт система управления базами данных MySQL.
Теперь вы знаете, из чего состоит веб-сайт, чем бэкенд отличается от фронтенда, умеете различать пользовательскую и серверную части, получили общее представление о базовых инструментах веб-разработки и необходимых навыках.
Пишем сервер для мобильного приложения на Node.js без необходимости настройки Apache или Nginx.
Node.js — это платформа, которая позволяет выполнять JavaScript вне браузера и предоставляет API для операций ввода-вывода. По сути, Node превращает JS в язык общего назначения, позволяя писать на нем практически любые приложения. Тем не менее, наиболее часто эта технология применяется для написания серверной части или разнообразных утилит.
Одной из отличительных черт данной технологии является ее подход к работе с вводом-выводом и отсутствие многопоточности — упоминание неблокирующего, асинхронного API ввода-вывода можно найти чуть ли не в каждом определении. Чтобы понять, о чем речь, приведу простой пример — выполнение HTTP-запроса:
- С традиционным подходом вы вызываете функцию/метод, совершающую запрос, и выполнение потока блокируется до тех пор, пока не придет ответ или не произойдет ошибка. Если нужно выполнять какие-то действия во время выполнения запроса, то нужно использовать еще один поток.
- В Node вы вызываете функцию/метод, и помимо параметров запроса, передаете ей еще один аргумент — функцию, которая будет вызвана по завершению запроса. Вызов не блокирует выполнение, и код продолжает выполняться.
На этом принципе в Node построено все взаимодействие с сетью, базами данных и файловой системой. API для многопоточности не предусмотрено, и это убирает целый класс ошибок, связанных с синхронизацией потоков и race condition’ами. «Плата» за это — сложности с распараллеливанием вычислений.
Пару слов об npm
npm — это пакетный менеджер для Node, важная часть экосистемы. Собственно, так и расшифровывается — Node Package Manager (хотя на их сайте есть много забавных альтернативных расшифровок). На момент написания статьи количество пакетов в npm превышает 400 тысяч. Любые библиотеки и фреймворки для Node следует ставить через npm. Как правило, пакеты ставятся локально, т. е. только для данного проекта. Однако, некоторые утилиты, имеющие интерфейс командной строки (CLI), предпочтительно ставить глобально, на уровне системы. Пакеты, которые вы ставите из npm локально, должны быть перечислены в файле package.json, находящемся в корне проекта. Это нужно для того, чтобы вместе с проектом была информация обо всех пакетах, которые ему необходимы (можно считать этот файл аналогом Podfile).
Итак, начнем
Собственно, никаких особых требований к системе и ПО тут нет, открывайте терминал, свой любимый текстовый редактор, и вперед!
Установите Node при помощи Homebrew:
$ brew install nodeАльтернативный вариант — можно скачать установщик с официального сайта.
Убедимся, что Node установилась:
$ node --versionЕсли в ответ вы увидели версию, то этап установки завершен, и можно переходить к созданию приложения.
Создаем проект
Для примера, в данной статье мы рассмотрим простое чат-приложение. Оно будет поддерживать создание чат-комнат, поиск чат-комнат по имени, чтение и отправку сообщений в произвольные комнаты. Чтобы не перегружать статью подробностями, все данные будут храниться в памяти сервера без применения базы данных. Общение между клиентом и сервером будет организовано при помощи протокола HTTP.
Создайте директорию для проекта и перейдите в нее в терминале. Чтобы создать проект, воспользуемся пакетным менеджером npm:
$ npm initnpm попросит ввести несколько значений, но это можно пропустить, нажимая Enter. На работоспособность проекта это не повлияет. Данной командой мы сгенерировали файл package.json, в котором содержится информация о приложении. Любые поля в нем можно поменять позднее.
Установим зависимости
Для написания простого сервера нам понадобится всего два внешних пакета — это фреймворк Express и модуль body-parser к нему, который разбирает JSON-тело POST-запросов. Несмотря на то, что Express гордо называется фреймворком, никаких сложностей с его освоением не возникнет — во всяком случае, он точно проще, чем использование встроенного в Node HTTP-сервера в чистом виде. Express, по сути, является оберткой над ним.
Установим зависимости следующей командой:
$ npm install --save --exact express body-parserДанная команда ставит пакеты локально, в каталог node_modules, куда ставятся все зависимости. Также, после выполнения команды, в файле package.json добавятся следующие строки:
"dependencies": {
"body-parser": "1.15.2",
"express": "4.14.0"
}Можно было бы просто выполнить «npm install express», и это бы сработало, но в package.json не записалась бы информация о новых зависимостях. Поэтому в этой команде добавлены флаги —save и —exact.
- —save указывает сохранить зависимость в package.json, что и произошло.
- —exact заставит npm указать точную версию зависимости. Без этого флага будет указана минимальная допустимая версия, т. е. возможны обновления пакета без изменения версии в package.json. К сожалению, в модулях из npm, как и в любом ПО, встречаются баги. Можно потратить довольно много времени из-за поломки проекта при обновлении пакета, поэтому я советую использовать —exact.
Пишем код приложения
По возможности я постарался прокомментировать код, но если вы никогда не имели дела с JavaScript, то имеет смысл ознакомиться с основами языка, благо он довольно прост, если не рассматривать тонкие моменты вроде замыканий: Основы JavaScript.
Создадим четыре файла:
- index.js — точка входа в программу;
- app.js — задание обработчиков для разных URL;
- models.js — описание классов, которые будут хранить наши данные;
- config.json — JSON-файл с конфигурацией приложения.
Начнем с файла models.js, т. е. с определения модели данных нашего приложения. В современном JavaScript можно использовать «традиционный» синтаксис для классов, чем мы и воспользуемся. Однако стоит помнить, что ввиду динамической природы языка, поля явно нигде не определяются, а просто им присваивается значение в конструкторе.
Строго говоря, несмотря на более-менее привычный синтаксис, реализация ООП «под капотом» в JS отличается от большинства языков, здесь класс определяется функцией-конструктором со свойством prototype, в котором описаны его методы. Поэтому класс — это функция, вызов которой с оператором new приводит к созданию нового объекта. Подробности реализации — тема, достойная отдельной статьи, поэтому я просто приведу ссылку на материал по теме: ООП в JavaScript.
Модель данных довольно простая:
- Существует множество чат-комнат, которыми управляет ChatRoomManager.
- Каждая чат-комната хранит множество сообщений.

Содержимое файла models.js будет таким:
class ChatRoomManager {
constructor () {
// Задаем поля класса в его конструкторе.
// Словарь чат-комнат - позволяет получить чат-комнату по ее id.
this.chatRooms = {};
// Счетчик, который хранит id, который бдет присвоен следующей комнате
this._nextRoomId = 0;
}
createRoom (name) {
// Создаем объект новой комнаты
let room = new ChatRoom(this._nextRoomId++, name);
// Заносим его в словарь
this.chatRooms[room.id] = room;
return room;
}
// Регистронезависимый поиск по имени комнаты
findByName (searchSubstring) {
// Переведем поисковый запрос в нижний регистр
let lowerSearchSubstring = searchSubstring.toLowerCase();
// Получим массив комнат. Для этого, получим все ключи словаря в виде
// массива, и для каждого ключа вытащим соответствующий ему элемент
// Если вы используете Node 7.2 или выше, то можно сделать так:
// let rooms = Object.values(this.chatRooms);
let rooms = Object.keys(this.chatRooms).map(id => this.chatRooms[id]);
// Отфильтруем из массива только те комнаты, в названии которых есть
// заданная подстрока
return rooms.filter(room =>
room.name.toLowerCase().indexOf(lowerSearchSubstring) !== -1
);
}
// Получаем комнату по ее id
getById (id) {
return this.chatRooms[id];
}
}
class ChatRoom {
constructor (id, name) {
this.id = id;
// В отличие от чат-комнат, сообщения хранятся в массиве, а не в словаре,
// так как не стоит задачи получения сообщения по его id
this.messages = [];
this.name = name;
// По аналогии с ChatRoomManager - счетчик хранит id следующего объекта
this._nextMessageId = 0;
}
postMessage (body, username) {
// Создадим новый объект сообщения и поместим его в массив
// Дату намеренно не передаем - см. конструктор Message
let message = new Message(this._nextMessageId++, body, username);
this.messages.push(message);
return message;
}
toJson () {
// Приведем объект к тому JSON-представлению, которое отдается клиенту
return {
id: this.id,
name: this.name
};
}
}
class Message {
constructor (id, body, username, datetime) {
this.id = id;
this.body = body;
this.username = username;
// Если дата не задана явно, то используются текущие дата и время сервера
// new Date() без аргументов примет значение текущих даты/времени
this.datetime = datetime || new Date();
}
toJson () {
return {
id: this.id,
body: this.body,
username: this.username,
// Объект даты сериализуем в строку
datetime: this.datetime.toUTCString()
};
}
}
// Определим объекты, которые будут экспортироваться модулем как внешнее API:
module.exports = { ChatRoomManager, ChatRoom, Message };
Теперь перейдем к обработке клиентских запросов. Данные между клиентом и сервером будем передавать в формате JSON. Наш сервер будет поддерживать 4 разных запроса:
- GET /rooms — получение списка комнат, опционально — с фильтрацией по имени. Чтобы фильтровать комнаты по имени, нужно будет передать query-параметр searchString. Отдает список комнат в JSON.
- POST /rooms — создание комнаты. Принимает JSON-тело с единственным параметром name. Возвращает созданную комнату в JSON.
- GET /rooms/<roomId>/messages — получение сообщений из комнаты roomId. Отдает список сообщений в виде JSON.
- POST /rooms/<roomId>/messages — отправка сообщения в комнату roomId. Отдает отправленное сообщение в виде JSON.
Вот как будет выглядеть код для обработки этих запросов (app.js):
// Подключим внешние зависимости из node_modules.
// Каждая библиотека возвращает некоторый объект через module.exports, точно так
// же, как мы это сделали в models.js. Функция require динамически находит
// модуль, исполняет его код и возвращает его module.exports нам.
const express = require('express');
const bodyParser = require('body-parser');
// Подключаем наш модуль models.js
const models = require('./models');
class Application {
constructor () {
// Создаем наше Express-приложение.
this.expressApp = express();
// Создаем ChatRoomManager, экспортированный из models.js
this.manager = new models.ChatRoomManager();
this.attachRoutes();
}
attachRoutes () {
let app = this.expressApp;
// Создадим middleware для обработки JSON-тел запросов, т. е. функцию,
// которая будет вызываться перед нашими обработчиками и обрабатывать
// JSON в теле запроса, чтобы наш обработчик получил готовый объект.
let jsonParser = bodyParser.json();
// Назначаем функции-обработчики для GET/POST разных URL. При запросе на
// указанный первым аргументом адрес, будут вызваны все функции,
// которые переданы начиная со второго аргумента (их может быть сколько
// угодно).
// Важно обратить внимание на .bind - тут мы назначаем в качестве
// обработчиков методы, а не функции. По сути, метод - это функция,
// привязанная к объекту, что мы и делаем методом bind. Без него мы
// получим неопределенный this, так как метод будет вызван как обычная
// функция. Так следует делать всегда при передаче метода как аргумента.
// Каждый обработчик принимает два аргумента - объекты запроса и ответа,
// обозначаемые как req и res.
app.get('/rooms', this.roomSearchHandler.bind(this));
app.post('/rooms', jsonParser, this.createRoomHandler.bind(this));
// Имя после двоеточия - параметр, принимающий произвольное значение.
// Такие параметры доступны в req.params
app.get('/rooms/:roomId/messages', this.getMessagesHandler.bind(this));
app.post('/rooms/:roomId/messages', jsonParser, this.postMessageHandler.bind(this));
}
// Обработчик создания комнаты
createRoomHandler (req, res) {
// Если нет обязательного поля name в JSON-теле - вернем 400 Bad Request
if (!req.body.name) {
res.status(400).json({});
} else {
// Создаем комнату в manager'e и вернем ее в виде JSON
let room = this.manager.createRoom(req.body.name);
let response = {
room: room.toJson()
};
// Отправим ответ клиенту. Объект будет автоматически сериализован
// в строку. Если явно не задано иного, HTTP-статус будет 200 OK.
res.json(response);
}
}
getMessagesHandler (req, res) {
// Получаем комнату по ID. Если комнаты нет - вернется undefined
let room = this.manager.getById(req.params.roomId);
// Проверка на то, нашлась ли такая комната
if (!room) {
// Если нет - 404 Not Found и до свидания
res.status(404).json({});
} else {
// Преобразуем все сообщения в JSON
let messagesJson = room.messages.map(message => message.toJson());
let response = {
messages: messagesJson
};
// Отправим ответ клиенту
res.json(response);
}
}
postMessageHandler (req, res) {
// Получаем комнату по ID
let room = this.manager.getById(req.params.roomId);
if (!room) {
res.status(404).json({});
} else if (!req.body.body || !req.body.username) {
// Если формат JSON-сообщения некорректный - вернем 400 Bad Request
res.status(400).json({});
} else {
// Создаем сообщение и возвращаем его клиенту
let message = room.postMessage(req.body.body, req.body.username);
let response = {
message: message.toJson()
};
res.json(response);
}
}
roomSearchHandler (req, res) {
// Получаем строку-фильтр из query-параметра searchString.
// Если параметр не задан, то используем пустую строку, т. е.
// будут найдены все комнаты
let searchString = req.query.searchString || '';
// Ищем комнаты и представляем их в виде JSON
let rooms = this.manager.findByName(searchString);
let roomsJson = rooms.map(room => room.toJson());
let response = {
rooms: roomsJson
};
// Отдаем найденное клиенту
res.json(response);
}
}
// Экспортируем наш класс наружу
module.exports = Application;
Почти готово! Теперь осталось написать модуль, который будет точкой входа и запустить из него HTTP-сервер. Файл index.js:
const Application = require('./app');
// JSON-файлы тоже можно подгружать через require!
const config = require('./config.json');
let app = new Application();
// Возьмем express-приложение и запустим HTTP-сервер. Настройки возьмем из
// конфига приложения. После того, как приложение начнет слушать порт,
// будет выполнена функция, переданная в качестве аргумента.
app.expressApp.listen(config.port, config.host, function() {
console.log(`App listening at port ${config.port}`);
});
И создадим конфиг (config.json):
{
"host": "0.0.0.0",
"port": 8000
}Готово!
Тестируем
Для начала, запустим наше приложение:
$ node index.js
В консоль должно напечататься следующее сообщение:
App listening at port 8000Остановить сервер можно, нажав Ctrl-C.
Теперь откройте еще одно окно терминала. Для тестирования воспользуемся утилитой curl, которая позволяет слать произвольные HTTP-запросы. Для начала, создадим две чат-комнаты двумя POST-запросами:
$ curl -X POST -H "Content-Type: application/json" -d '{"name": "Test room 1"}' http://localhost:8000/rooms
$ curl -X POST -H "Content-Type: application/json" -d '{"name": "Test room 2"}' http://localhost:8000/rooms
Попробуем получить комнаты, в названии которых есть единица:
$ curl 'http://localhost:8000/rooms?searchString=1'Такой запрос должен вернуть следующий ответ:
{"rooms":[{"id":0,"name":"Test room 1"}]}Теперь попробуем написать пару сообщений и тут же получить их из беседы:
$ curl -X POST -H "Content-Type: application/json" -d '{"body": "Test message", "username": "test_user"}' http://localhost:8000/rooms/0/messages
$ curl -X POST -H "Content-Type: application/json" -d '{"body": "Еще одно сообщение!", "username": "TheOwl"}' http://localhost:8000/rooms/0/messages
$ curl 'http://localhost:8000/rooms/0/messages'
Последний запрос должен вернуть такой ответ:
{"messages":[{"id":0,"body":"Test message","username":"test_user","datetime":"Wed,28 Dec 2016 22:49:16 GMT"},{"id":1,"body":"Еще одно сообщение!","username":"TheOwl","datetime":"Wed, 28 Dec 2016 22:49:30 GMT"}]}Таким образом можно тестировать любые HTTP-запросы, если у вас нет приложения или иного фронтенда к серверу. Но не забывайте, что вся информация хранится в памяти сервера, и после перезапуска будет утеряна.
Заключение
Выше мы рассмотрели создание максимально простого сервера. Конечно же, в реальности все будет несколько сложнее — как минимум, добавится база данных и более сложная логика. Для базы данных можно использовать ORM Sequelize — так вам не придется писать чистый SQL и код будет более читаемым.
Исходники сервера можно взять из нашего репозитория на GitHub. После клонирования репозитория, вам нужно будет выполнить в каталоге сервера команду npm install (без аргументов), так как каталог node_modules в Git не отслеживается (добавлен в .gitignore).
Как и с любой технологией, главное — это практика!
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
3 месяца назад·3 мин. на чтение
Необходимые инструменты
Перед началом нужно убедиться, что на компьютере установлены все необходимые библиотеки, IDE и ПО, а именно:
- NodeJS и npm. Их можно скачать с официального сайта nodejs.org. npm установится автоматически вместе с NodeJS.
- Предпочитаемый IDE, например, Visual Studio Code.
- Опционально, установить git для удобной работы с кодом.
О приложении
В этой статье напишем приложение, которое будет получать и отображать список дел.
Структура папок будет выглядеть следующим образом.
app/ frontend/ backend/Создание бэкэнда на NodeJS
Запустим команду в папке
app/backendдля инициализации проекта:npm init -yЭта команда создаст файл
package.json. Этот файл содержит как общую информацию о проекте (название, версия, описание и т.д.), так и информацию о зависимостях, скрипты для запуска, сборки и тестирования.
Для создания сервера будем использовать express. Установим его с помощью команды:npm i expressСоздадим файл
index.js, который будет содержать код для запуска сервера. Этот код запускает веб сервер на порту3010, если он не задан в переменных среды.// backend/index.js const express = require('express'); const PORT = process.env.PORT || 3010; const app = express(); app.use((req, res, next) => { res.setHeader('Access-Control-Allow-Origin', '*'); next(); }); app.listen(PORT, () => { console.log(`Server listening on ${PORT}`); });
Добавим команду для запуска сервера вpackage.json. В результате сможем запускать наш сервер с помощью командыnpm start.// backend/package.json ... "scripts": { "start": "node ./index.js" }, ...Из директории
app/backendзапустим командуnpm start. Если ошибок нет, получим сообщение, что сервер прослушивает порт 3010.PS C:tutorials-codingnodejs-react-appbackend> npm start > backend@1.0.0 start > node ./index.js Server listening on 3010Создание API
API это интерфейс, с помощью которого React приложение будет общаться с веб-сервером, т.е. запрашивать, изменять или удалять данные.
В нашем случае мы создадим API для получения списка дел в формате JSON.
Создадим файлtodo-items.jsonc объектами todo. Этот массив будем отдавать по запросу/api/todo-items.[ { "id": 1, "text": "Изучить NodeJS", "done": true }, { "id": 2, "text": "Изучить ReactJS", "done": true }, { "id": 3, "text": "Написать приложение", "done": false } ]
Следующий код создает эндпоинт/api/todo-items. React приложение будет отправлятьGETзапрос на этот эндпоинт.// backend/index.js // ... const todoItems = require('./todo-items.json'); app.get('/api/todo-items', (req, res) => { res.json({ data: todoItems }); }); app.listen(PORT, () => { console.log(`Server listening on ${PORT}`); });Для того чтобы изменения вступили в силу, нужно перезапустить NodeJS сервер. Для остановки скрипта — в терминале, в котором запущен
npm start, нужно нажатьCtrl + C(Command + C). Далее снова запускаемnpm start.
Для проверки эндпоинта, в браузере перейдем по адресуhttp://localhost:3010/api/todo-items. В результате получим, такой ответ.
Создание фронтенда на React
В папке
app/откроем новый терминал и запустим команду для создания React приложения, гдеfrontendимя нашего приложения.npx create-react-app@latest frontendДождемся установки всех зависимостей. В терминале перейдем в папку
frontend.cd ./frontendУстановим библиотеку bootstrap для дальнейшего использования готовых компонентов.
npm install react-bootstrap bootstrapЗаимпортируем
bootstrap.min.cssв файлеfrontend/src/index.js.import 'bootstrap/dist/css/bootstrap.min.css';Запустим приложение командой
npm start.npm startПолучим следующее сообщение. Перейдем по указанному адресу в браузере.
Compiled successfully! You can now view frontend in the browser. Local: http://localhost:3003 On Your Network: http://192.168.99.1:3003 Note that the development build is not optimized. To create a production build, use npm run build.Отправка HTTP запроса из React в NodeJS
К этому моменту у нас уже есть рабочий сервер, который умеет принимать запросы и отдавать данные.
Сделаем запрос на/api/todo-itemsиз React приложения. Для этого вызовем функциюfetchиз хукаuseEffectв файлеApp.js.// frontend/src/App.js import { useState, useEffect } from 'react'; import Form from 'react-bootstrap/Form'; import './App.css'; function App() { const [todoItems, setTodoItems] = useState([]); useEffect(() => { fetch('http://localhost:3010/api/todo-items') .then((res) => res.json()) .then((result) => setTodoItems(result.data)); }, []); return ( <div> {todoItems.map((item) => ( <Form.Group key={item.id} className="app__todo-item"> <Form.Check type="checkbox" checked={item.done} /> <Form.Control type="text" value={item.text} /> </Form.Group> ))} </div> ); } export default App;Открыв приложение в браузере, получим такой результат.
Исходный код
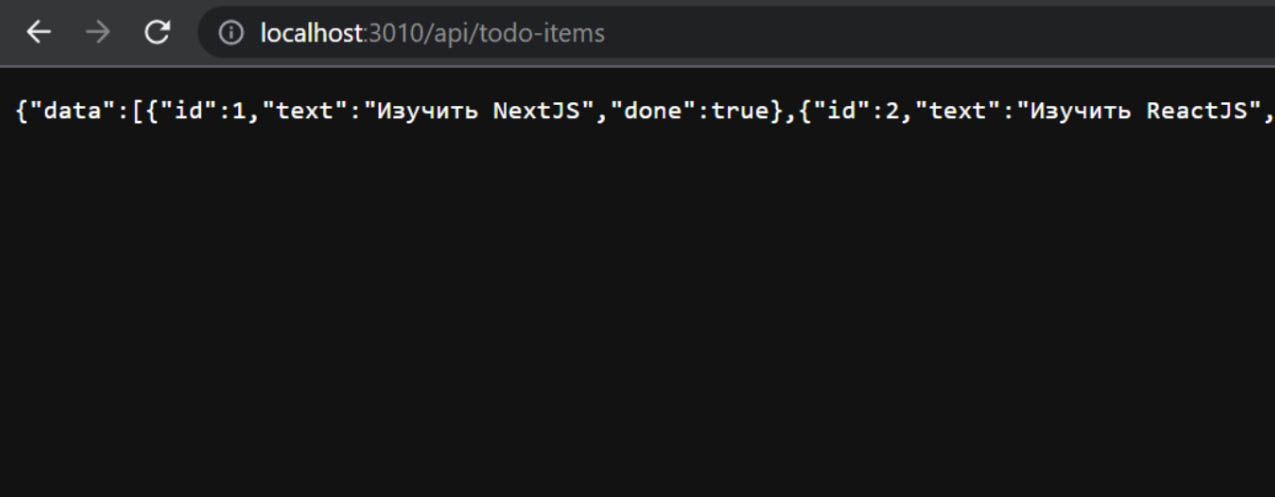
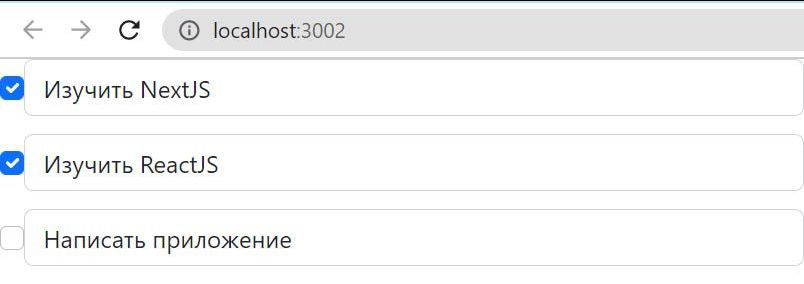
1. Domain Driven Design
First, let’s talk about architecture!
There is a lot to learn from architecture design when you want to build real world applications. When you look at most of the code examples provided by Flask or FastAPI you get a very simple application with a REST API with only a simple handler per endpoint. In real applications you want to separate your business logic from the API calls so you can interact with the app via other canals such as GraphQL API, or RabbitMQ messages. You also need to deal with one or more storage systems, a database, a caching layer, an object storage service, a secret store, and more complex systems like cloud providers APIs, Kubernetes, etc.
To properly implement separation of concerns and abstract interactions with other systems, Domain Driven Design (DDD) concepts provide a nice toolbox to look into. The Architecture Patterns with Python Book (available online here), is a gold mine for understanding how to implement the DDD architecture in Python. It provides tons of step by step examples for every concept so you can understand why you should or shouldn’t apply them. This is a must read, and most of what is presented here is based on this book.
So we’ll walk you through an architecture composed of 3 layers: Domain, Application, and Infrastructure. The Domain layer defines the Data structures in plain Python objects: the business objects. The Application layer holds the brain of the App: the business logic. Finally, the Infrastructure layer is the «arms and legs» of our App: the part that interacts with the external world (HTTP API, database, file system, servomotors, etc).
So let’s create our application’s skeleton with the wonderful poetry:
mkdir myapp cd myapp pip install poetry poetry init mkdir -p myapp/application mkdir myapp/domain mkdir myapp/infrastructure
You should have something like:
├── myapp │ ├── application │ ├── domain │ └── infrastructure └── pyproject.toml
1.1 Domain
The Domain layer is a model representation of the services. It really is the core of our services and it must be able to evolve fast. This layer doesn’t depends on any other layer (following the dependency inversion principle) and imports no external libraries (unless for justified exceptions, it only consists in raw python code).
A domain is a dataclass defining a business object. Most of the methods of these dataclasses consist of helpers manipulating the dataclass’ state. Some of these classes are abstract classes, implemented by other classes from the infrastructure layer.
Methods of these classes can return Domain objects, states («something went wrong», «no problem here», «only steps 1 and 3 worked»…), or nothing.
The general rule is to put as much stuff as possible there.
For example, here is an object that represents an entry in our todo app. And yes, our example will be a todo app! (as we all do ^^).
import uuid
from datetime import datetime
from dataclasses import dataclass, field
@dataclass
class TodoEntry:
id: str
created_at: datetime
content: str
tags: set[str] = field(default_factory=set)
@classmethod
def create_from_dict(cls, content:str) -> "TodoEntry":
return cls(id=str(uuid.uuid4()), created_at=datetime.utcnow(), content=content)
def set_tag(self, tag: str) -> None:
self.tags.add(tag)
Did you notice that we heavily use Python types? This is really a good way to get something working quick and with confidence. We strongly advise you to use them and enforce it in the CI so you won’t have surprises at execution time.
1.2 Infrastructure
To manage all the interactions with external systems like database, file system, network, API, etc.
These services act as «wrappers» around external dependencies so that they can be used within the Application layer.
1.2.1 The repository pattern
This is also a place where we can find Repositories. The repository pattern is simply a class abstracting an object persistency. It provides at least add and get functions, providing a single way to store and retrieve data from storage systems. We can start with a Pickle file storage until we reach performance limitations signifying us to switch to an SQL database or something else. This process spares us having to change any line of code in our Application or Domain layer.
For example, here is a ‘Todo entries’ repository using the Pickle library to serialize objects into files:
import pickle
from dataclasses import dataclass
from pathlib import Path
from myapp.domain.todo import TodoEntry
from myapp.domain.todo_entry_repository import ITodoEntryRepository
class TodoEntryNotFound(Exception):
pass
@dataclass
class TodoEntryPickleRepository(ITodoEntryRepository):
storage_dir: str
def get(self, entry_id: str) -> TodoEntry:
try:
entry: TodoEntry
with open(Path(self.storage_dir) / entry_id) as entry_file:
entry = pickle.load(entry_file)
return entry
except Exception:
raise TodoEntryNotFound()
def add(self, entry: TodoEntry) -> None:
with open(Path(self.storage_dir) / entry.id) as entry_file:
pickle.dump(entry, entry_file
Note that we implement an abstract class in the Domain layer. This allows us to import the repository interface from the Application layer without knowing what the actual implementation is.
1.3 Application
Now that we have the Domain that contains the business object as well as our Repository to manage persistence of this object in the Infrastructure layer, we need to glue them together with our business logic.
The Application layer contains all the services provided by the application, using the Domain structures and the Infrastructure as a backend.
These Application services «orchestrate» the Domain’s structures and the Infrastructure services so that they work together harmoniously.
Application data should not be modified here ; it is the job of the classes’ methods of the Domain layer. As mentioned before, no data is directly modified here. However, we catch exceptions and use object methods to apply the right business rules.
For example we can have a TodoService like this one:
from dataclasses import dataclass
from typing import Optional
from myapp.domain.todo import TodoEntry
from myapp.domain.todo_entry_repository import ITodoEntryRepository
@dataclass
class TodoService:
todo_repository: ITodoEntryRepository
def add_entry(self, content: str) -> str:
entry = TodoEntry.create_from_content(content)
self.todo_repository.add(entry)
return entry.id
def add_tag(self, entry_id: str, tag: str) -> None:
entry = self.todo_repository.get(entry_id)
entry.set_tag(tag)
def get_all(self, search: Optional[str] = None) -> list[TodoEntry]:
return self.todo_repository.get_all(search)
Wait! When was this todo_repository created and by who? It’s now time to talk about Dependencies Injection.
Want to speed up
backend development ?
1.4 Dependencies injection
The goal of dependency injection is to avoid creating objects everywhere or passing them in all functions in some kind of Context melting pot. To do so we’ll define where all Infrastructure services are created, in one single place. We can then easily inject these services as dependencies of Application services using a default value as a singleton (e.g. for a database connection) or a one-time object from a factory (e.g. for an HTTP request handler).
The Dependency Injector library is well designed and provides everything you need to define all your services, inject them and even load configurations.
Let’s install it:
poetry add dependency_injector
Explain configuration and dependency in the container.py code:
from dependency_injector import providers, containers
from myapp.application.todo_service import TodoService
from myapp.infrastructure.database.todo_entry_repository import TodoEntryPickleRepository
class ApplicationContainer(containers.DeclarativeContainer):
configuration = providers.Configuration()
todo_entry_repository = providers.Singleton(
TodoEntryPickleRepository,
storage_dir=configuration.storage_dir
)
todo_service = providers.Factory(
TodoService,
todo_entry_repository
)
2. Web API
Now that we have our base application, we need to create an API. FastAPI is a really nice library that helps you create your API endpoints, route them, serialize and deserialize the API objects (called models), and even generate interactive documentation pages.
Let’s add it to our dependencies with:
poetry add fastapi
A proper way to add your API is to separate them by controllers, one by group of endpoints. So let’s create a centralized setup file to aggregate common configuration and dependency injection for all controllers in infrastructure/api/setup.py.
from fastapi import FastAPI
from myapp.container import ApplicationContainer
from myapp.infrastructure.api import todo_controller
def setup(app: FastAPI, container: ApplicationContainer) -> None:
# Add other controllers here
app.include_router(todo_controller.router)
# Inject dependencies
container.wire(
modules=[
todo_controller,
]
)
And the controller for the /todo endpoints:
from dataclasses import asdict
from typing import Optional
from dependency_injector.wiring import Provide
from fastapi import APIRouter
from myapp.application.todo_service import TodoService
from myapp.container import ApplicationContainer
from myapp.infrastructure.api.todo_schema import TodoEntrySchema
todo_service: TodoService = Provide[ApplicationContainer.todo_service]
router = APIRouter(
prefix="/todo",
tags=["Todo"],
responses={404: {"description": "Not found"}},
)
@router.get("/", response_model=list[TodoEntrySchema])
async def list_todos(search: Optional[str] = None) -> list[TodoEntrySchema]:
todo_entries = todo_service.get_all(search)
return [TodoEntrySchema(**asdict(todo_entry)) for todo_entry in todo_entries]
@router.post("/")
async def add_todo(content: str) -> str:
return todo_service.add_entry(content)
Here is the todo schema used for the serialization. Note that we use a different object than the internal TodoEntry from the domain because we want to decorellate it from the external API. Thus, you can change your API wordings and hide internal values that are not useful for users. The schema is based on the Pydantic model that uses Python built-in typing. As advertised in the FastAPI documentation, it comes with plenty of advantages like static analysis with Mypy, useful IDE autocomplete, easy debugging and so on.
from pydantic import BaseModel
class TodoEntrySchema(BaseModel):
id: str
content: str
tags: list[str]
3. Test it!
Note that for the sake of simplicity, we kept the testing part out of the way so far… shame on us! This is one of the main reasons we split all of our code this way! Keep in mind that all the components can be easily tested both separately or in-context. Let me give you an example. Our API calls the application service which then calls the repository and then returns a todo list converted from the domain object.
Here is a simple test for our repository in myapp/infrastructure/database/test_todo_entry_repository.py:
…
>> Next page >>

Michael Mercier
Lead Software Engineer at Ryax Technologies. Michael is a Computer Science PhD and R&D engineer, with a wide IT infrastructure expertise in multiple contexts: Cloud, High Performance Computing, and Big Data.