одина
Мы приступаем к одному из очень важных разделов программирования на Java — работа с базами данных. Данные являются наверно наиглавнейшей составляющей программирования и вопрос их хранения крайне актуален. Не буду больше говорить о важности этого вопроса — тут можно писать много-много-много разных интересных слов.
Сервер баз данных
Сама идея сервера баз данных и СУБД в виде отдельной программы появилось по совершенно очевидным причинам. Базы данных мгновенно стали МНОГОПОЛЬЗОВАТЕЛЬСКИМИ. Данные нужны всем и возможность одновременного доступа к ним является очевидной. Проблема базы данных в виде обычного файла заключается в том, что к этому файлу будет обращаться сарзу много программ, каждая из которых захочет внести изменения или получить данные. Организовать такой доступ на уровне файловой системы — по сути, невыполнимая задача.
Во-первых — файл должен быть доступен всем пользователям, что требует перекачку данных по сети и хранение этого файла где-то на сетевом диске. Большие объемы данных по сети (пусть даже с высокой скоростью) — кроме слова “отвратительно” у меня ничего не приходит на ум.
Во-вторых — попытка одновременной записи в файл несколькими программами обречена на провал. Для организации такого доступа обычной файловой системы явно не достаточно.
В-третьих — организация прав доступа к тем или иным данным тоже становится непосильной задачей.
В-четвертых — надо “разруливать” конфликты при одновременном доступе к одним и тем же данным.
После небольшого анализа, кроме этих вопросов, можно увидеть еще немалое количество проблем, которые надо решить при мультипользовательском доступе к данным.
В итоге было принято (и реализовано) вполне здравое решение — написать специальную программу, которая имеет несколько названий — Система Управления Базами Данных (СУБД), сервер баз данных и т.д. Я буду называть ее СУБД.
Суть и цель этой программы — организовать централизованный доступ к данным. Т.е. все запросы на получение или изменение данных от клиентских приложений (клинетов) посылаются (обычно по сети и по протоколу TCP/IP) именно в эту программу. И уже эта программа будет заниматься всеми вышеупомянутыми проблемами:
- СУБД будет иметь некоторый набор команд, который позволит записывать и получать данные
- СУБД будет сама работать с файловой системой (нередко у нее бывает своя собственная файловая система для скорости)
- СУБД предоставит механизмы разграничения доступа к разным данным
- СУБД будет решать задачи одновременного доступа к данным
В итоге мы получаем достаточно ясную архитектуру — есть СУБД, которая сосредоточена на работе с данными и есть клиенты, которые могут посылать запросы к СУБД.
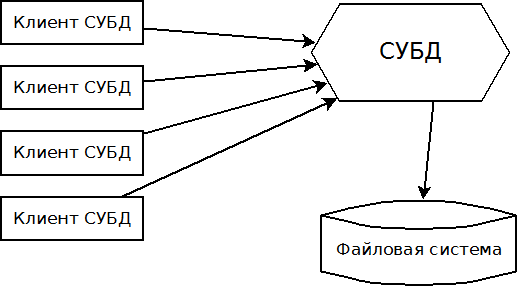
При работе с СУБД клиенты должны решить достаточно четкие задачи:
- Клиент должен соединиться с СУБД. Как я уже упоминал, чаще всего для общения используется сетевой протокол TCP/IP. В момент подключения клиент также передает свой логин/пароль, чтобы СУБД могла его идентифицировать и в дальнейшем позволить (или не позволить) производить те или иные действия над данными
- Клиент может посылать команды для изменения/получения данных в СУБД
- Данные внутри СУБД хранятся в определенных структурах и к этим структурам можно обратиться через команды
SQL базы данных
Могу предположить,что вышеупомянутые задачи и породили именно SQL-базы данных. В них есть удобные и понятные структуры для хранения данных — таблицы. Эти таблицы можно связывать в виде отношений и тем самым дается возможность хранить достаточно сложно организованные данные. Был придуман специальный язык — SQL (Structured Query Language — структурированный язык запросов). Этот язык хоть и имеет всего 4 команды для манипулирования данными, позволяет создавать очень сложные и заковыристые запросы.
На сегодняшний день SQL-базы данных являются самыми распространенными. В последние годы наметилась тенденция к использованию баз данных, основанные на других способах хранения и обработки данных, но пока их применение достаточно узконаправлено, хотя в некоторых случаях они действительно помогают решать важные задачи более эффективно, но все-таки пока SQL — самое главное направление баз данных. Почему я про это упоминаю ? Потому, что все наше знакомство с технологией работы с базами данных из Java будет сконцентрировано на SQL базах данных. С основными командами SQL вы можете познакомиться в различных учебниках. Их сейчас достаточно много и в большинстве своем они вполне понятны.
Возможно, что я тоже когда-нибудь внесу свою лепту в рассказы про SQL, но в данном разделе предполагается, что вы уже знакомы с основными идеями построения реляционных баз данных и с самим языком SQL.
JDBC — Java Database Connectivity — архитектура
Если попробовать определить JDBC простыми словами, то JDBC представляет собой описание интерфейсов и некоторых классов, которые позволяют работать с базами данных из Java. Еще раз: JDBC — это набор интерфейсов (и классов), которые позволяют работать с базами данных.
И вот с этого момента я попробую написать более сложное и в тоже время более четкое описание архитектуры JDBC. Главным принципом архитектуры является унифицированный (универсальный, стандартный) способ общения с разными базами данных. Т.е. с точки зрения приложения на Java общение с Oracle или PostgreSQL не должно отличаться. По возможности совсем не должно отличаться.
Сами SQL-запросы могут отличаться за счет разного набора функций для дат, строк и других. Но это уже строка запроса другая, а алгоритм и набор команд для доставки запроса на SQL-сервер и получение данных от SQL-сервера отличаться не должны.
Наше приложение не должно думать над тем, с какой базе оно работает — все базы должны выглядеть одинаково. Но при всем желании внутреннее устройство передачи данных для разных СУБД разное. Правила передачи байтов для Oracle отличается от правил передачи байтов для MySQL и PostgreSQL. В итоге имеем — с одной стороны все выглядят одинаково, но с другой реализации будут разные. Ничего не приходит в голову ?
Еще раз — разные реализации, но одинаковый набор функциональности.
Думаю, что вы уже догадались — типичный полиморфизм через интерфейсы. Именно на этом и строится архитектура JDBC. Смотрим рисунок.
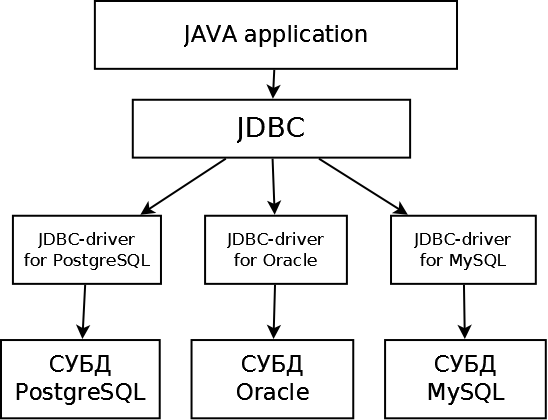
Как следует из рисунка, приложение работает с абстракцией JDBC в виде набора интерфейсов. А вот реализация для каждого типа СУБД используется своя. Эта реализация называется “JDBC-драйвер”. Для каждого типа СУБД используется свой JDBC-драйвер — для Oracle свой, для MySQL — свой. Как приложение выбирает, какой надо использовать, мы увидим чуть позже.
Что важно понять сейчас — система JDBC позволяет загрузить JDBC-драйвер для конкретной СУБД и единообразно использовать компоненты этого драйвера за счет того, что мы к этим компонентам обращаемся не напрямую, а через интерфейсы.
Т.е. наше приложение в принципе не различает, обращается оно к Oracle или PostgreSQL — все обращения идут через стандартные интерфейсы, за которыми “прячется” реализация.
Пока я предлагаю отметить несколько важных интерфейсов, которые мы будем рассматривать позже, но мне бы хотелось, чтобы у вас этот список уже был, чтобы вы могли по мере прочтения отмечать — “да, вот он важный интерфейс/класс и я теперь знаю, куда он встраивается”. Вот они:
- java.sql.DriverManager
- java.sql.Driver
- java.sql.Connection
- java.sql.Statement
- java.sql.PreparedStatement
- java.sql.CallableStatement
- java.sql.ResultSet
Теперь давайте рассмотрим несложный пример и поймем, как работает JDBC.
JDBC — пример соединения и простого вызова
Попробуем посмотреть на несложном примере, как используется JDBC-драйвер. В нем же мы познакомимся с некоторыми важными интерфейсами и классами.
Предварительно нам необходимо загрузить JDBC-драйвер для PostgreSQL. На данный момент это можно сделать со страницы PostgreSQL JDBC Download
Если вы не нашли эту страницу, то просто наберите в поисковике “PostgreSQL JDBC download” и в первых же строках найдете нужную страницу.
Т.к. я пишу эти статьи для JDK 1.7 и 1.8, то я выбрал строку “JDBC41 Postgresql Driver, Version 9.4-1208” — может через пару-тройку лет это будет уже не так.
Если вы выполнили SQL-скрипт из раздела Установка PostgreSQL, который создавал таблицу JC_CONTACT и вставил туда пару строк, то эта программа позволит вам “вытащить” эти данные и показать их на экране. Это конечно же очень простая программа, но на ней мы сможем посмотреть очень важные моменты. Итак, вот код:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
package edu.javacourse.database; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; public class SimpleDb { public static void main(String[] args) { SimpleDb m = new SimpleDb(); m.testDatabase(); } private void testDatabase() { try { Class.forName(«org.postgresql.Driver»); String url = «jdbc:postgresql://localhost:5432/contactdb»; String login = «postgres»; String password = «postgres»; Connection con = DriverManager.getConnection(url, login, password); try { Statement stmt = con.createStatement(); ResultSet rs = stmt.executeQuery(«SELECT * FROM JC_CONTACT»); while (rs.next()) { String str = rs.getString(«contact_id») + «:» + rs.getString(2); System.out.println(«Contact:» + str); } rs.close(); stmt.close(); } finally { con.close(); } } catch (Exception e) { e.printStackTrace(); } } } |
Для запуска этой програмы необходимо подключить JDBC-драйвер для PostgreSQL. Прочитайте раздел Что такое JAR-файлы для того, чтобы подключить нужный JAR с JDBC-драйвером к проекту в NetBeans.
Для запуска нашей программы из командной строки достаточно собрать этот код (причем здесь не надо подключать JAR на этапе компиляции — только на момент запуска).
Итак, команда для сборки:
|
javac edu/javacourse/database/SimpleDb.java |
И теперь команда для запуска:
|
java —cp .;postgresql—9.4.1208.jre7.jar edu.javacourse.database.SimpleDb |
Для запуска проекта в NetBeans предлагаю вам самостоятельно разобраться, как подключить JAR-файл — пример этого указан в статье Что такое JAR-файлы
Начнем разбор нашей программы с самого начала. Итак, в чем же заключается набор вызовов для создания соединения с базой
|
Class.forName(«org.postgresql.Driver»); String url = «jdbc:postgresql://localhost:5432/contactdb»; String login = «postgres»; String password = «postgres»; Connection con con = DriverManager.getConnection(url, login, password); |
Вызов Class.forName() мы уже встречали, когда разговаривали о рефлексии. Если вы этого не сделали — обязательно прочитайте, иначе многое будет непонятно. Так вот наш вызов загружает один из ключевых классов JDBC, который реализует очень важный интерфейс java.sql.Driver. Почему этот класс так важен, мы разберем чуть ниже.
Следующим важным вызовом явлется DriverManager.getConnection(url, login, password);.
Думаю, что параметры login и password достаточно оччевидны — это логин и пароль для подключения к СУБД. А вот первый параметр — url надо рассмотреть подробно.
Параметр url является строкой и я люблю его разбивать на две части. Первая часть jdbc:postgresql: позволяет идентифицировать, к какому типу СУБД вы подключаетесь — Oracle, MySQL, PostgreSQL, IBM DB2, MS SQL Server. В нашем случае тип базы данных — PostgreSQL.
Вторая часть — //localhost:5432/contactdb — определяет конкретный экземпляр выбранной базы данных. Т.е. если первая часть url указывает, что мы хотим работать с PostgreSQL, то вторая часть указывает на каком хосте и на каком порту (опять вспоминаем основы TCP/IP) работает конкретный экземпляр PostgreSQL. Еще раз — первая часть поределяет только тип, вторая часть — параметры оединения с конкретным экземпляром СУБД.
Как вы можете видеть, вторая часть включает помимо IP-адреса и порта (localhost:3306) включает имя базы данных, с которой вы будете соединяться.
И вот теперь возвращаемся к интерфейсу java.sql.Driver. Достаточно очевидно, что сложное приложение на Java может работать с несколькими типами СУБД и одновременно в приложнении участвуют несколько JDBC-драйверов для разных типов СУБД. Так как же класс DriverManager определяет, какой тип СУБД вы собираетесь использовать ?
Придется нам вернуться к моменту загрузки класса — Class.forName(). Большинство классов в момент своей загрузки выполняют очень важный шаг — они РЕГИСТРИРУЮТСЯ у класса DriverManager. Как они это делают ? Посмотрите документацию на класс DriverManager — например здесь:
DriverManager
Среди методов мы можете найти этот: registerDriver(Driver driver). Причем метод статический и создавать экземпляр DriverManager не надо. Таким образом драйвер под конкретный тип СУБД регистрируется у DriverManager. У этого класса (можно глянуть в исходники) создается список драйверов, каждый из которых реализует интерфейс java.sql.Driver. Что же происходить дальше ? Зайдем в документацию java.sql.Driver. Там есть два очень интересных метода:
- boolean acceptsURL(String url)
- Connection connect(String url, Properties info)
Первый метод как раз и позволяет классу DriverManager пройти по всему списку зарегистрированных у него драйверов и у каждого спросить — “ты умеешь работать с этим URL”. Отметим, что драйвер под конкретный тип СУБД работает с уникальным набором — MySQL принимает строку “jdbc:mysql:”, PostgreSQL — “jdbc:postgresql:” и т.д. Т.е. первая часть параметра url, о которой мы говорили немного раньше, как раз и позволяет классу DriverManager выбрать драйвер для определенного типа СУБД. Первый шаг сделан — мы выбрали нужный драйвер.
И вот тут приходит очередь второго метода — именно он позволяет создать соединение — возвращает экземпляр класса, который реализует еще один важный интерфейс — java.sql.Connection. Второй метод использует вторую часть url с адресом, портом и именем базы, а также используется логин и пароль. Снова обращаю ваше внимание на тот факт, что реальный класс будет какой-то специальный, под конкретный тип СУБД, но он обязательно должен реализовать интерфейс java.sql.Connection.
java.sql.Connection — это реальное соединение с конкретным экземпляром СУБД определенного типа. Наше соединение готово. Можем продолжать.
Следущий фрагмент кода уже будет проще:
|
Statement stmt = con.createStatement(); ResultSet rs = stmt.executeQuery(«SELECT * FROM JC_CONTACT»); |
Первая строка создает еще один важный элемент — запрос, который реализует интерфейс
java.sql.Statement. Кроме этого интерфейса используются тажке java.sql.PreparedStatement и java.sql.CallableStatement, но о них мы поговорим несколько позже.
Что здесь важно отметить — создание запроса делается через обращение к методу объекта java.sql.Connection — createStatement. И опять обращаю ваше внмание, что каждый производитель СУБД пишет свою реализацию всех интерфейсов.
Т.к. реализация java.sql.Connection будет под определенный тип СУБД, то и реализация java.sql.Statement тоже будет под определенный тип СУБД. В качестве домашного задания — попробуйте через рефлексию узнать настоящие имена этих класов.
Вторая строка с помощью объекта-запроса java.sql.Statement делает запрос в таблицу st_student и получает еще один важный элемент — объект java.sql.ResultSet.
После получения данных в виде объекта ResultSet, мы можем через его методы “пробежать” по всему набору данных (это очень похоже на итераторы в коллекциях) и выбрать поля из этого набора.
|
while (rs.next()) { String str = rs.getString(«contact_id») + «:» + rs.getString(2); System.out.println(«Contact:» + str); } |
Как видите, все достаточно несложно. Упрощенно ResultSet можно рассматривать, как указатель на строку в таблице. Метод rs.next() делает попытку передвинуться на следущую запись. В случае успеха он возвращает true и передвигает указатель на следущую строку. Если строки закончились (или их не было вообще), возвращается false.
Когда мы передвинулись на следущую строку, то с помощью набора методов можно получить значения колонок в строке — мы использовали метод getString() в двух вариантах — один находит колонку по имени, второй — по индексу. Учтите, что номера колонок начинаются с 1, а не с 0, как это делается в массивах и коллекциях. Кроме метода getString() для получения строк, ResultSet имеет методы для получения чисел (цеых и вещественных), дат и много чего еще.
И наконец обратите внимание, что я вызываю у всех объектов метод close(). Особенно важным (я бы даже сказал критичным) является закрытие Connection. Закрытие Statement тоже является достаточно хорошим решением, но не настолько критичным, В этом случае вы просто быстрее освобождаете память от ресурсов, которые создавались при запросе. Учтите, что Statement закрывается автоматически при уничтожении объекта. Что же касается ResultSet, то он автоматически закрывается в момент закрытия Statement.
Этот момент весьма важен, но пока я не буду останавливаться на тонкостях — просто примите это как важную необходимость.
Также советую обратить внимание на способ построения обработки исключений. Сначала я создаю коннект во внешнем блоке try … catch и потом уже во внутреннем блоке try … catch выполняю запрос и получаю из результата данные. В этом же блоке в разделе finally происходит закрытие соединения.
Такое построение дает уверенность, что вне зависимости от результата выполнения запроса и получения данных, соединение будет обязательно закрыто.
Т.к. при работе приложения исключения при выполнении запроса не должны быть частыми, то “незакрытие” Statement не должно повлечь каких-либо осложнений. Хотя кто-то может со мной не согласиться и решительно скажет, что надо закрывать все — вполне допускаю такой вариант.
Исходный код проекта на NetBeans вы можете закачать здесь — SimpleDb
Я поместил в архив JDBC-драйвер для PostgreSQL и ссылка на него из проекта относительная, так что по идее все должно работать сразу. Если не будет, то это значит — вам придется приложить некоторое количество усилий. Может это и хорошо — лучше станете понимать материал.
Итак, мы с вами сделали первый шаг на пути изучения JDBC — в качестве самостоятельной работы попробуйте создать свою базу данных, таблицу, заполнить ее данными и сделать запрос из приложения на Java.
И теперь нас ждет следующая статья: Возможности JDBC — второй этап
Появилась необходимость сделать приложение на java с подключением БД.
Сама программа будет находится на локальном компьютере слабой конфигурации и без сети. Поэтому выбрана была база SQLite.
Порывшись в сети на простые понятные примеры, ничего найти подходящего не удалось. Пришлось собирать все с разных статей и разных форумов. Надеюсь, данная информация будет полезной.
Для создания самой БД была использована утилита SQLiteadmin, найденная в просторах интернета.
Создание БД сводится к паре действий.
Создаем саму базу и указываем куда ее сохранить.

Появившиеся слева папки показывают о успешном создании БД.

Далее переходим к созданию проекта, заполняем необходимые данные, нажимаем NEXT и сразу подгружаем скачанную здесь библиотеку (библиотека для подключения БД к проекту).

После создания проекта, создаю 2 класса.
Первый класс для запуска:
import java.sql.SQLException;
public class db {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
conn.Conn();
conn.CreateDB();
conn.WriteDB();
conn.ReadDB();
conn.CloseDB();
}
}
Во втором классе сделана основная реализация:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class conn {
public static Connection conn;
public static Statement statmt;
public static ResultSet resSet;
// --------ПОДКЛЮЧЕНИЕ К БАЗЕ ДАННЫХ--------
public static void Conn() throws ClassNotFoundException, SQLException
{
conn = null;
Class.forName("org.sqlite.JDBC");
conn = DriverManager.getConnection("jdbc:sqlite:TEST1.s3db");
System.out.println("База Подключена!");
}
// --------Создание таблицы--------
public static void CreateDB() throws ClassNotFoundException, SQLException
{
statmt = conn.createStatement();
statmt.execute("CREATE TABLE if not exists 'users' ('id' INTEGER PRIMARY KEY AUTOINCREMENT, 'name' text, 'phone' INT);");
System.out.println("Таблица создана или уже существует.");
}
// --------Заполнение таблицы--------
public static void WriteDB() throws SQLException
{
statmt.execute("INSERT INTO 'users' ('name', 'phone') VALUES ('Petya', 125453); ");
statmt.execute("INSERT INTO 'users' ('name', 'phone') VALUES ('Vasya', 321789); ");
statmt.execute("INSERT INTO 'users' ('name', 'phone') VALUES ('Masha', 456123); ");
System.out.println("Таблица заполнена");
}
// -------- Вывод таблицы--------
public static void ReadDB() throws ClassNotFoundException, SQLException
{
resSet = statmt.executeQuery("SELECT * FROM users");
while(resSet.next())
{
int id = resSet.getInt("id");
String name = resSet.getString("name");
String phone = resSet.getString("phone");
System.out.println( "ID = " + id );
System.out.println( "name = " + name );
System.out.println( "phone = " + phone );
System.out.println();
}
System.out.println("Таблица выведена");
}
// --------Закрытие--------
public static void CloseDB() throws ClassNotFoundException, SQLException
{
conn.close();
statmt.close();
resSet.close();
System.out.println("Соединения закрыты");
}
}
После запуска получаем данный результат:

Коментарии по коду и вопрос, что за команда, можно поискать в интернете. Данная статья имеет вид знакомства создания БД SQLite в проекте Java.
Так же соблюдение всех пробелов и запятых значительно упростит создание проекта, проще копировать и изменять данные.
В этой статье мы научимся подключаться к базе данных MySQL из Java-кода и выполнять простые запросы для получения и обновления данных. Для того, чтобы получить доступ к базе данных, мы будем использовать JDBC (Java Database Connectivity) API, который входит в стандартную библиотеку Java. JDBC позволяет подключиться к любой базе данных: Postgres, MySQL, SQL Server, Oracle и т. д. — при наличии соответствующей реализации драйвера, необходимого для подключения. Для базы данных MySQL мы будем использовать драйвер Type 4 JDBC из пакета mysql-connector-java-5.1.23-bin.jar. Он написан на чистой Java, а значит, нам не понадобятся какие-либо нативные библиотеки или ODBC-мост. Все, что нам надо будет сделать — это положить JAR-файл в директорию, содержащуюся в CLASSPATH. JAR-файл содержит класс com.mysql.jdbc.Driver, необходимый для подключения к MySQL. Если его не окажется в CLASSPATH, во время выполнения программы выбросится исключение java.lang.ClassNotFoundException, поэтому убедитесь, что вы правильно настроили пути.
Кстати, если вы ищете хорошую книгу по использованию JDBC, обратите внимание на Practical Database Programming with Java (Ying Bai). Это относительно новая книга, и в ней рассматриваются две самые популярные базы данных: Oracle и SQL Server 2008. В книге используется IDE NetBeans для примеров и описываются все инструменты, необходимые для работы с базами данных в Java. Это отличная книга для начинающих и опытных программистов.
Подключаем базу данных MySQL с помощью JDBC
Для того, чтобы подключить базу данных MySQL, нам потребуется четыре вещи:
- Строка подключения JDBC (например:
jdbc:mysql://localhost:3306/test). - Имя пользователя (root).
- Пароль (root).
- База данных с некоторым количеством таблиц для примера (например, база данных книг).
Строка подключения для MySQL начинается с jdbc:mysql. Это название протокола соединения, за которым следуют хост и порт подключения, на которых запущена база данных. В нашем случае это localhost с портом по умолчанию 3306 (если вы его не поменяли при установке). Следующая часть — test — имя базы данных, которая уже существует в MySQL. Мы можем создать таблицу Books:
CREATE TABLE `books` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`author` varchar(50) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1и наполнить её хорошими книгами:
INSERT INTO test.books (id, `name`, author)
VALUES (1, 'Effective Java', 'Joshua Bloch');
INSERT INTO test.books (id, `name`, author)
VALUES (2, 'Java Concurrency in Practice', 'Brian Goetz');Программа на Java, которая использует базу данных
Теперь давайте напишем программу на Java, которая будет подключаться к нашей базе данных, запущенной на localhost. Важно помнить о том, что необходимо закрывать соединение, запросы и результат выполнения после завершения работы с ними. Также важно закрывать их в finally-блоке, со своей try/catch оберткой, поскольку сам метод close() может кинуть исключение, что приведет к утечке ресурсов. За подробной информацией вы можете обратиться к этой статье. Кроме того, вы можете использовать обертку try-with-resource, которая появилась в Java 7. Более того, это стандартный способ работы с ресурсами в Java 1.7.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/**
* Simple Java program to connect to MySQL database running on localhost and
* running SELECT and INSERT query to retrieve and add data.
* @author Javin Paul
*/
public class JavaToMySQL {
// JDBC URL, username and password of MySQL server
private static final String url = "jdbc:mysql://localhost:3306/test";
private static final String user = "root";
private static final String password = "root";
// JDBC variables for opening and managing connection
private static Connection con;
private static Statement stmt;
private static ResultSet rs;
public static void main(String args[]) {
String query = "select count(*) from books";
try {
// opening database connection to MySQL server
con = DriverManager.getConnection(url, user, password);
// getting Statement object to execute query
stmt = con.createStatement();
// executing SELECT query
rs = stmt.executeQuery(query);
while (rs.next()) {
int count = rs.getInt(1);
System.out.println("Total number of books in the table : " + count);
}
} catch (SQLException sqlEx) {
sqlEx.printStackTrace();
} finally {
//close connection ,stmt and resultset here
try { con.close(); } catch(SQLException se) { /*can't do anything */ }
try { stmt.close(); } catch(SQLException se) { /*can't do anything */ }
try { rs.close(); } catch(SQLException se) { /*can't do anything */ }
}
}
}При первом запуске у вас, возможно, будет ошибка No suitable driver found for jdbc:mysql, если драйвера MySQL нет в CLASSPATH:
java.sql.SQLException: No suitable driver found for jdbc:mysql://localhost:3306/test/book
at java.sql.DriverManager.getConnection(DriverManager.java:689)
at java.sql.DriverManager.getConnection(DriverManager.java:247)
at JavaToMySQL.main(JavaToMySQL.java:29)
Exception in thread "main" java.lang.NullPointerException
at JavaToMySQL.main(JavaToMySQL.java:46)
Java Result: 1Добавим нужный JAR-файл в путь и снова запустим программу. Другая частая ошибка — указать таблицу в строке соединения: jdbc:mysql://localhost:3306/test/book. В этом случае вылетит следущее исключение:
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Unknown database 'test/book'
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance
(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance
(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:408)
at com.mysql.jdbc.Util.handleNewInstance(Util.java:411)
at com.mysql.jdbc.Util.getInstance(Util.java:386)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1053)Успешный запуск программы выведет на экран следующее:
Total number of books in the table: 2Результат верный, поскольку у нас в таблице только две книги: «Effective Java» и «Java Concurrency in Practice».
Кстати, если у вас был драйвер при компиляции, но отсутствует при запуске, вы получите исключение java.lang.ClassNotFoundException: com.mysql.jdbc.Driver. О том, как исправить эту ошибку, вы можете прочитать здесь.
Получаем данные с помощью SELECT-запроса в JDBC
Для получения данных из БД вы можете выполнить SELECT-запрос. В первом примере мы уже его использовали, но получили только количество строк. Теперь мы вернем сами строки. Большая часть программы останется без изменений, за исключением SQL-запроса и кода, возвращающего данные из объекта ResultSet:
String query = "select id, name, author from books";
rs = stmt.executeQuery(query);
while (rs.next()) {
int id = rs.getInt(1);
String name = rs.getString(2);
String author = rs.getString(3);
System.out.printf("id: %d, name: %s, author: %s %n", id, name, author);
}Этот код выведет на экран следующее:
id: 1, name: Effective Java, author: Joshua Bloch
id: 2, name: Java Concurrency in Practice, author: Brian GoetzТут есть пара моментов, на которые следует обратить внимание. Метод rs.getInt(1) используется для получения столбца с целочисленным типом, в нашем случае это столбец «id». Индексы в JDBC начинаются с единицы, поэтому rs.getInt(1) вернет значение первого столбца как целое число. В случае, если вы укажете неверный индекс (многие разработчики вызывают rs.getInt(0) для получения первого столбца), выбросится исключение InvalidColumnIndexException. Доступ к столбцам по индексу чреват ошибками, поэтому лучше использовать имя столбца, например, rs.getInt("id"). Подробнее об этом вы можете прочитать в этой статье. Метод getString() используется для получения строковых значений из базы (например, VARCHAR). Цикл будет выполняться, пока rs.next() не вернет false. Это значит, что строки закончились. В нашем случае в таблице две строки, поэтому цикл выполнится два раза, выводя информацию о книгах из таблицы на экран.
Добавляем данные с помощью INSERT-запроса в JDBC
Добавление данных мало отличается от их получения: мы просто используем INSERT-запрос вместо SELECT-запроса и метод executeUpdate() вместо executeQuery(). Этот метод используется для запросов INSERT, UPDATE и DELETE, а также для SQL DDL выражений, таких как CREATE, ALTER или DROP. Эти команды не возвращают результата, поэтому мы убираем все упоминания ResultSet‘а в коде и изменяем запрос соответственно:
String query = "INSERT INTO test.books (id, name, author) n" +
" VALUES (3, 'Head First Java', 'Kathy Sieara');";
// executing SELECT query
stmt.executeUpdate(query);После запуска программы вы можете проверить таблицу в СУБД. На этот раз вы увидите три записи в таблице:
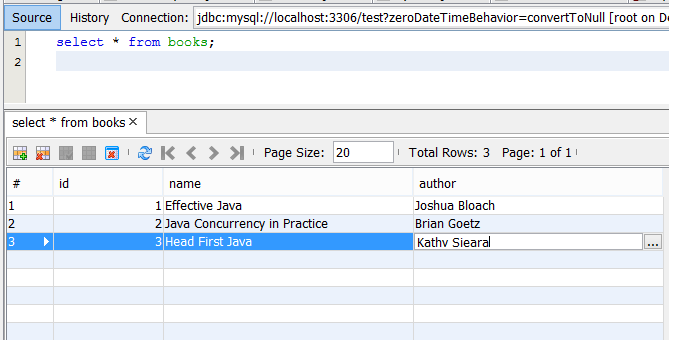
Теперь вы умеете подключаться к MySQL из Java-приложения и выполнять SELECT, INSERT, DELETE и UPDATE-запросы так же, как и в MySQL GUI. Для подключения мы используем объект Connection, для чтения результатов запроса — ResultSet. Убедитесь перед подключением, что сервер MySQL запущен и mysql-connector-java-5.1.17-bin.jar находится в CLASSPATH, чтобы избежать ClassNotFoundException.
Когда разберетесь с подключением и простыми запросами, имеет смысл изучить, как использовать подготавливаемые запросы (Prepared Statement) в Java для избежания SQL-инъекции. В боевом коде всегда следует использовать подготавливаемые запросы и связывание переменных.
Если вам понравилось это руководство и не терпится узнать больше о подключении и работе с базой данных из Java-программ, обратите внимание на следующие статьи:
- Как подключиться к БД Oracle из Java-приложения;
- Отличия межу Connected RowSet и Disconnected RowSet в Java;
- Как использовать пул соединений в Spring;
- 5 способов улучшить производительность БД в приложениях на Java;
- Отличия между java.util.Date и java.sql.Date в Java;
- Как выполнить INSERT или UPDATE, используя пакетные запросы JDBC;
- Десять вопросов по JDBC на собеседованиях.
Полезные ссылки
- Если у вас нет базы данных MySQL, вы можете ее скачать здесь;
- Есди у вас нет драйвера MySQL для JDBC, вы можете скачать его отсюда;
- Рекомендованную книгу «Practical Database Programming with Java» можно купить на Amazon.
Перевод статьи «How to Connect to MySQL database in Java with Example»
В процессе работы Java может взаимодействовать с таблицами, файлами, базами данных. Последним и будет уделено внимание в статье далее. При помощи JDBC удается справиться с различными вопросами при написании сложного софта.
Особенности Джавы в программировании
Джава – язык программирования, который появился в 1995 году. С тех пор он перетерпел множество доработок и нововведений. Совершенствуется по сей день. Образовал отдельное семейство J-языков. Все они начали привлекать современных программистов.
Хотя Джава является относительно старым способом общения с аппаратным и программным обеспечением, это – идеальный вариант для разработчиков. Применяется при создании:
- веб-софта (основное направление);
- игр и развлекательного контента;
- сложных приложений.
Предусматривает следующие особенности:
- относительно простой синтаксис;
- отсутствие необходимости долгого изучения – даже новичок быстро разберется с Java;
- собственный движок;
- функциональность;
- кроссплатформенность – перенести софт с одной ОС на другую не составит никакого труда.
С Java работают разного рода движки и библиотеки. Основной принцип языка звучит как «меньше кода – больше действий». И JDBC существенно упрощают написание сложных кодификаций в том или ином случае. Главное знать, как работать с этим элементом.
Основные понятия – что пригодится программисту
Чтобы получить на выходе при коддинге качественный контент, его нужно уметь записывать. Для этого разработчику требуется использовать весь функционал языка в правильном, грамотном направлении. И подключать JDBC в том числе.
Перед началом изучения БД и их подключения к Джаве, каждый программер должен запомнить несколько терминов. С соответствующими понятиями он будет сталкиваться повсеместно. И не только в Java, но и при задействовании иных языков.
Запомнить рекомендуется следующую информацию:
- API – своеобразный набор правил, принципов, процедур и протоколов для создания контента (помогают «общаться» со службами из вне);
- алгоритмы – правила и инструкции, необходимые для решения тех или иных вопросов;
- символ – минимальная единица информации, равная одной буквенной записи;
- объект – несколько связанных между собой переменных, констант, а также иных структур данных, способных быть выбранными и проходить совместную обработку;
- класс – набор свойств объектов с общими «чертами» (шаблон, описывающий поведение тех или иных элементов в коде);
- массив – список/группа схожих типов значений информации, подлежащая объединению в единое целое;
- переменная – место хранилища информации;
- оператор – элемент программного кода, способный манипулировать операндами;
- операнд – объекты, которыми можно управлять через всевозможные операторы;
- метод – функция или процедура, которая принадлежит к тому или иному объекту (действия, присущие внутри заданного класса или элемента кодификации).
Теперь можно более углубленно рассматривать JDBC и базы данных в Джаве. Перечисленные термины – это база, о которой должен знать каждый потенциальный разработчик. И не важно, какой именно «способ общения» с ПО и «железом» выбран.
БД – определение
После того, как с теорией коддинга покончено, стоит более глубоко рассмотреть базы данных и принципы работы с ними в Java. Пример подключения соответствующего элемента к кодификации будет представлен ниже. Он поспособствует закреплению рассмотренной информации.
База данных – место, где хранится та или иная информация. Она должна относиться к структурированному типу, в противном случае целесообразно говорить о BigData. Использовать имеющиеся электронные сведения предлагается посредством специальных языковых запросов.
Бд отвечают не только за хранение, но и за обработку, корректировку, вывод данных. Так принято называть файл или их группу стандартной структуры. Наглядный и элементарный пример – таблицы Excel.
Система управления
Для использования и управления рассматриваемым объектом в информационных технологиях используются специальные системы. Называются СУБД. Представлены программным обеспечением, отвечающим за взаимодействие внешних приложений с информацией, а также дополнительными службами. К последним относят:
- восстановление;
- копирование резервного характера;
- журналирование;
- иные служебные операции.
Отличительной чертой является то, что взаимодействие обеспечивается специальными запросами. Оные задействованы в базах данных.
Разновидности СУБД
Пользователь может выбрать одну из нескольких СУБД для дальнейшей работы. Каждый вид оных имеет собственные сильные и слабые стороны.
Сегодня Java предлагает следующую классификацию систем управления БД по методу организации хранения информации:
- Иерархические. Структура представляет собой своеобразное дерево. Пример – файловые системы, начинающиеся с корневой папки дисков.
- Сетевые. Это – откорректированные иерархические. Каждый узел может обладать несколькими «родителями».
- Объектно-ориентированные. Здесь все материалы электронного типа организованы как классы или объекты с атрибутами и принципами взаимодействия по законам ООП.
- Реляционные. Представлены таблицами. Они могут иметь связь между собой. Информация здесь имеет структурированный характер.
В Java JDBC лучше всего останавливаться на последнем варианте. Реляционные «хранилища электронных материалов» на практике распространены больше остальных. На их основе составление приложений с JDBC не доставит существенных хлопот.
Языки запросов
Для того, чтобы похвастаться хорошими результатами работы с БД в программировании, важно не только знать основы работы с ними, но и наиболее популярные «хранилища информации». Каждый вариант имеет собственные нюансы и особенности, отражающиеся при коддинге.
Сегодня при написании программ чаще всего используются такие базы, как:
- MySQL – СУБД Oracle. Является бесплатной. Работает как на Linux, так в Windows. Имеет высокую производительность, если использовать при узком круге поставленных задач. Выступает в качестве функционально простого варианта. MySQL применяется на практике в узком спектре задач. Встречается преимущественно в мелких и средних разработках.
- Oracle – первый настоящий вариант СУБД. Написан на Ассемблере. Изначально имел поддержку исключительно базовых свойств SQL. Имеет отличную сетевую производительность, а также автоматическую оптимизацию. Обладает поддержкой подключаемых «сторонних» БД и живую миграцию. Хорошо производит сжатие электронных материалов. Используется в различных операционных системах.
- SQL – вариант, увидевший свет в 90-х. Разработчиком выступила компания Microsoft. С самого момента возникновения соответствующий вариант служит для работы с БД в Windows и продуктах Майкрософт. Имеет облачные технологии, резервное копирование, гибридные решения облачного типа. Отлично подходит для бизнес-аналитики.
Для того, чтобы задействовать соответствующие варианты в программном коде Java, требуется освоить так называемый JDBC. С ним будут работать все программеры, желающие заниматься внедрением информационных хранилищ в собственные приложения.
JDBC – это…
JDBC расшифровывается как Java DataBase Connectivity. Говоря дословно – соединения с «хранилищами электронных структурированных материалов» в Джаве. Это – платформенно-независимый стандарт. Используется для того, чтобы обеспечивать взаимодействие Java-контента со всевозможными СУБД.
Имеет реализацию в виде пакета java.sql. Он включен в состав Java SE. В первом ряду при работе с соответствующим элементом выступает SQL. Но и MySQL тоже весьма хорошо функционирует вместе с JDBC.
Принцип подключения – к БД и драйверам
JDBC в своей основе имеет концепцию драйверов. Driver позволяет получать соединение (getconnection) с БД. Для реализации поставленной задачи задействуют специальные URL-адреса.
Драйверы заключаются динамически (тогда, когда используемая утилита функционирует). Алгоритм «активации» будет следующим:
- Происходит загрузка софта.
- Драйвер инициализируется и загружается.
- Осуществляется самостоятельная регистрация drivers.
- Вызов производится «автоматом». Это происходит тогда, когда используемое приложение требует URL с протоколом, за который отвечают драйверы.
JDBC использует экземпляры классов java.sql. После того, как это было сделано, происходит передача тех или иных команд для корректировки информации. JDBC посредством драйверов взаимодействует с СУБД и выводит тот или иной результат.
Принцип работы с БД
JDBC работает с «электронными хранилищами информации» через специальные запросы. О них необходимо знать каждому потенциальному разработчику до того, как будет рассмотрен образец применения БД на практике в приложении.

После установления connections происходит import java information. Система получает запрос и создает специальный объект для его последующей передачи. Завершающий этап работы JDBC – это закрытие всех имеющихся соединений.
Драйверы и URL для баз информации
Ниже представлена таблица, которая поможет новичкам лучше ориентироваться в JDBC. Это – шаблоны, используемые при написании программных кодификаций.

Теперь можно try working с БД через JDBC. Это – наиболее простой и распространенный поход.
Активная работа через JDBC
Взаимодействие с хранилищами электронных структурированных материалов может осуществляться в Java при помощи main interfaces. Возможны три варианта развития событий. Select one осуществляется с учетом того, что каждый подход реализуется всеми драйверами и имеет ряд нюансов.
Выбор предоставляется из следующих интерфейсов:
- Statement. Задействован для доступа к БД при решении общих вопросов. Активно применяется на практике со static SQL. А именно – выражениями во время функционирования утилиты. Не принимает параметры.
- PreparedStatement. Интерфейс, напоминающий предыдущий. Способен принимать различные параметры.
- CallableStatement. Помогает заполучить доступ к разнообразным процедурам «хранилищ структурированных данных». Как и предыдущий вариант, принимает параметры в процессе функционирования контента.
Далее каждый вариант будет рассмотрен более подробно. Для каждого имеется свой example применения.
Интерфейс Statement
Для того, чтобы создать объект, используют команду типа:
Statement statement = connection.createstatement();
Экземпляр можно будет задействовать для обработки SQL-запросов. Интерфейс для реализации задачи имеет три метода, который реализуются конкретикой в JDBC:
- Boolean execute (String SQL) – выполняет statement, если заранее не ясно, является ли строка запросом или же это своеобразное обновление. Возвращаемое значение True будет, когда за счет команды был создан результирующий набор.
- Int (public void) executeUpdate (строка SQL). Отвечает за обновления. Возвращает количество обновленных строк. Задействованы операторы Delete, Update и Insert.
- ResultSet executeQuery – выполняет запросы (select). Отвечает за возврат обработки результирующего набора.
Для того, чтобы работать с БД в Java, необходимо уметь хоть немного программировать на соответствующем языке.
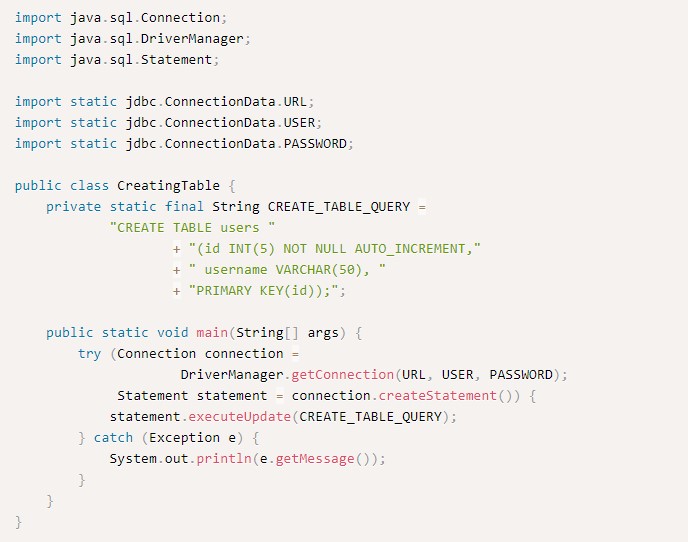
Выше представлен код примера создания таблицы. На него могут опираться как новички, так и продвинутые разработчики.
Интерфейс ResultSet
Это – результирующий набор хранилища. Обеспечивает построчный доступ к результатам запросов. Поддерживает указатель при выполнении оных на текущую обрабатываемую строчку. Утилита будет последовательно перемещаться по результатам до окончания обработки или закрытия.
Вот методы, с которыми работает ResultSet:

Также есть public void close() throws SQLExceptions, который позволяет закрывать ResultSet вручную. А вот код-пример:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
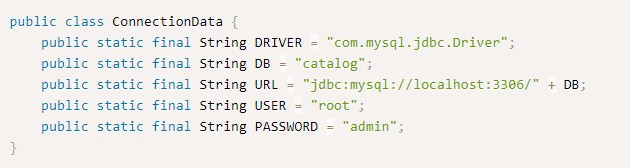
import static jdbc.ConnectionData.URL;
import static jdbc.ConnectionData.USER;
import static jdbc.ConnectionData.PASSWORD;
public class RetrieveDataPreparedStatement {
private static final String SELECT_QUERY =
"SELECT * FROM users WHERE id>? AND username LIKE ?";
public static void main(String[] args) {
try (Connection connection =
DriverManager.getConnection(URL, USER, PASSWORD);
PreparedStatement preparedStatement =
connection.prepareStatement(SELECT_QUERY)) {
preparedStatement.setInt(1, 2);
preparedStatement.setString(2, "P%");
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
System.out.printf("%d%23s%n", resultSet.getInt("id"), resultSet.getString("username"));
}
} catch (SQLException e) {
System.out.println(e.getMessage());
}
}
}Интерфейс PreparedStatement
Основное отличие – это наличие параметров. Выражение с соответствующими элементами имеет знаки вопроса в контенте:
![]()
Перед выполнением посланного запроса значение каждого «?» устанавливается методами setXxx(). Вот пример применения интерфейса:

JDBC пример в программировании на Java удалось рассмотреть. И далеко не один. Это лишь шаблоны, на которые можно опираться пользователю.
Чтобы такие выражения как insert into, sql, import void и другие, встречающиеся в программировании, не вызывали вопросов, стоит посетить компьютерные курсы. Есть дистанционные варианты, помогающие разобрать в программировании на разных языках «с нуля». Программы рассчитаны на срок до года. Пользователи могут выбрать узкую направленность (специализацию), а также уровень своего мастерства. Полезные обучающие программы по БД в Java есть как для новичков, так и для продвинутых разработчиков.


SQLite JDBC Tutorial
The goal of this tutorial is to learn how to write a program in Java to work with SQLite database.
This tutorial covers the basics of JDBC and SQLite-JDBC.
An example code is also provided to practice on JDBC.
Here is the outline of this tutorial:
- JDBC: At a Glance
- SQLite-JDBC
- Example
JDBC: At a Glance
The Java Database Connectivity, or JDBC in short, is a standard for dealing with a relational database in Java.
JDBC APIs enable developers to interact with a database regradless of the vendor.
These functionalities entail [1]:
- Creating and managing data source connections
- Integrating SQL with Java programs, i.e. sending SQL queries to data source
- Processing retrieved results from data source
Now, let’s see how to use JDBC APIs in programs. In the following, the key classes in JDBC are introduced:
DriverManager:
Applications can establish a connection to a data source via this class.
DriverManagerrequires a Driver class typically implemented by third parties.
These drivers can be determined using Java dynamic loading mechanismClass.forName("a.b.Class").
We also need to specify a data source URL. The Driver class and the URL are provided by database vendors.
Depending on the database, you may need to pass other information such as credentials and configuration properties.
Connection con = DriverManager.getConnection( "jdbc:myDriver:myDatabase", username, password);
The following Table lists required JDBC information for some well-known open-source databases.
| Database | JDBC Driver | JDBC URL |
|---|---|---|
| MySQL | com.mysql.jdbc.Driver |
jdbc:mysql://HOST:PORT/DATABASE_NAME |
| PostgreSQL | org.postgresql.Driver |
jdbc:postgresql://HOST/DATABASE_NAME |
| SQLite | org.sqlite.JDBC |
jdbc:sqlite:DATABASE_FILE |
Connectionclass contains information about the underlying connection to the data source.
For sending SQL statements to the database, we need to create aStatementobject.
Statement stmt = con.createStatement();
Statementclass is used to execute SQL statements.
ResultSet rs = stmt.executeQuery("SELECT column1 FROM Table1"); stmt.executeUpdate("INSERT INTO Table1 VALUES (value1,value2)");
ResultSetclass represents results returned by the data source.
ResultSetoperates like an iterator, i.e. it points to the current row of data and its pointer should be moved forward to read the data.
while (rs.next()) { System.out.println(rs.getString("column1")); }
All JDBC APIs are provided in java.sql and javax.sql packages.
SQLite-JDBC
SQLite-JDBC [2] is the JDBC Driver we’re using for SQLite in this tutorial.
SQLite supports in-memory data management. In order to SQLite without any files, JDBC URL should be defined as jdbc:sqlite::memory:.
Also, for storing data in a file, JDBC URL must be jdbc:sqlite:/path/myfile.db (UNIX-style) or jdbc:sqlite:C:/path/myfile.db (Windows-style).
Here is an example code to acquire an in-memory SQLite connection:
Class.forName("org.sqlite.JDBC"); try (Connection con = DriverManager.getConnection("jdbc:sqlite::memory:")) { Statement stmt = con.createStatement(); } catch (SQLException e) { System.err.println(e.getMessage()); }
SQLite-JDBC library provides SQLiteConfig object to configure connections.
SQLiteConfig offers a wide of range configurations, most of which requires detailed knowledge on SQLite.
Here, we leverage it to enforce foreign key constraints (which is not enabled by default):
SQLiteConfig config = new SQLiteConfig(); config.enforceForeignKeys(true); Connection con = DriverManager.getConnection("jdbc:sqlite::memory:", config.toProperties());
Example
Let’s put what we discussed into practice. Consider the following schema:
- course (course_id, title, seats_available)
- student (student_id, name)
- take (student_id, course_id, enroll_date)
The goal here is to write a program that is able to perform two tasks:
First, the program must support enrolling a student to a course.
In order to do that, it prompts user for student id and course id.
Then, after performing preliminary validations, the program must insert a row to take table
and update seats_available in course table.
The second task is defined to work with ResultSet class.
In this task, the program retrieves information of students, but not all in once.
The program must load information page by page, called pagination, because the number of students may be so large
that it does’nt fit into memory. The details of pagination in SQLite is provided in [3].
The code can be found in SQLiteJDBCExample.java.
Running the Example
Before running the code, you need to compile the code. The code is located in src
and depends on SQLite-JDBC library, located in lib.
You can compile the code using the following command:
mkdir target
javac -cp "lib/sqlite-jdbc-3.20.0.jar" -d target src/SQLiteJDBCExample.java
The class file is generated in target folder.
The following command can be used to run the code:
java -cp "lib/sqlite-jdbc-3.20.0.jar:target" SQLiteJDBCExample <arg>
The argument can be either paginate or enroll.
References
[1] https://docs.oracle.com/javase/tutorial/jdbc/overview/index.html
[2] https://github.com/xerial/sqlite-jdbc
[3] https://www.sqlite.org/cvstrac/wiki?p=ScrollingCursor
Программирование, Java, API, Блог компании OTUS. Онлайн-образование
Рекомендация: подборка платных и бесплатных курсов Java — https://katalog-kursov.ru/
Будущих студентов курса «Java Developer. Professional» и всех интересующихся приглашаем принять участие в открытом уроке на тему «Введение в Spring Data Jdbc».А сейчас делимся традиционным переводом полезного материала.

В этой статье дается обзор популярных библиотек и API для работы с базами данных в Java, в том числе JDBC, Hibernate, JPA, jOOQ, Spring Data и других.
Java и базы данных: введение
Каждый раз при необходимости взаимодействия с базами данных появляются три вопроса:
-
Какой подход использовать при разработке: java-first или database-first? Писать сначала Java-классы или SQL-запросы? Будет ли использоваться уже существующая база данных?
-
Каким способом выполнять SQL-запросы: как простые для CRUD-операций (select from, insert into, update where), так и более сложные для отчетов?
-
Как проще реализовать объектно-реляционное отображение (object-relational mapping, ORM)? И что вообще значит отображение между объектами Java и таблицами/строками базы данных?
Для иллюстрации концепции объектно-реляционного отображения рассмотрим следующий класс:
public class User {
private Integer id;
private String firstName;
private String lastName;
// Constructor/Getters/Setters....
}В дополнение к этому классу в базе данных есть таблица USERS, которая может выглядеть следующим образом:
|
id |
first_name |
last_name |
|
1 |
hansi |
huber |
|
2 |
max |
mutzke |
|
3 |
donald |
trump |
Как вы будете отображать Java-класс на эту таблицу?
Для этого есть несколько вариантов:
-
JDBC — самый низкий уровень.
-
Удобные и легковесные SQL-фреймворки, такие как jOOQ или Spring JDBC.
-
Полноценные ORM, такие как Hibernate или другие реализации JPA.
В этом руководстве мы рассмотрим различные варианты, но для начала очень важно понять основы JDBC. Зачем? Потому что все библиотеки и фреймворки, будь то Spring или Hibernate, под капотом используют JDBC.
JDBC: низкоуровневый доступ к базе данных
Что такое JDBC?
Самый низкоуровневый способ доступа к базам данных в Java — это использование JDBC API (Java Database Connectivity). Все фреймворки, рассматриваемые ниже, используют JDBC под капотом. И, конечно, вы можете выполнять SQL-запросы, используя JDBC напрямую.
Преимущество JDBC в том, что вам не нужны сторонние зависимости, так как JDBC входит в состав любого JDK / JRE. Вам нужен только соответствующий JDBC-драйвер вашей базы данных.
Если вы хотите узнать больше о том, как начать работу с JDBC, где найти драйверы, как настроить пулы соединений и выполнять SQL-запросы, я рекомендую сначала прочитать мою статью What is JDBC? («Что такое JDBC?») и после нее вернуться к этой статье.
Пример JDBC
Например, у вас есть база данных с таблицей Users, приведенной выше, вы хотите написать запрос, выбирающий всех пользователей из этой таблицы, и получить результат в виде List<User> — списка объектов Java.
Небольшой спойлер: JDBC совсем не поможет вам в конвертации из SQL в Java-объекты (и в обратную сторону). Давайте посмотрим код:
package com.marcobehler;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
public class JdbcQueries {
public static void main(String[] args) throws SQLException {
try (Connection conn = DriverManager
.getConnection("jdbc:mysql://localhost/test?serverTimezone=UTC",
"myUsername", "myPassword")) {
PreparedStatement selectStatement = conn.prepareStatement("select * from users");
ResultSet rs = selectStatement.executeQuery();
List<User> users = new ArrayList<>();
while (rs.next()) { // will traverse through all rows
Integer id = rs.getInt("id");
String firstName = rs.getString("first_name");
String lastName = rs.getString("last_name");
User user = new User(id, firstName, lastName);
users.add(user);
}
}
}
}Сначала обратим внимание на этот фрагмент:
try (Connection conn = DriverManager
.getConnection("jdbc:mysql://localhost/test?serverTimezone=UTC",
"myUsername", "myPassword")) {Здесь мы открываем соединение с базой данных MySQL. Не забудьте обернуть вызов DriverManager.getConnection в блок try-with-resources, чтобы после выхода из этого блока, соединение было автоматически закрыто.
PreparedStatement selectStatement = conn.prepareStatement("select * from users");
ResultSet rs = selectStatement.executeQuery();SQL-запрос выполняется через создание и выполнение PreparedStatement. (PreparedStatement позволяет использовать плейсхолдеры параметров в виде ? в запросах, но пока мы это опустим.)
List<User> users = new ArrayList<>();
while (rs.next()) { // will traverse through all rows
Integer id = rs.getInt("id");
String firstName = rs.getString("first_name");
String lastName = rs.getString("last_name");
User user = new User(id, firstName, lastName);
users.add(user);
}Для формирования результирующего списка необходимо вручную пройтись по ResultSet (то есть по всем строкам, которые вернул SQL-запрос), а затем также вручную создать необходимые объекты Java, вызывая соответствующие геттеры для каждой строки ResultSet с правильными именами столбцов и типами (getString(), getInt()).
В этом примере (для упрощения и удобства) мы упустили два момента:
-
Плейсхолдеры в SQL-запросах (например:
select * from USERS where name = ? and registration_date = ?). Для защиты от SQL-инъекций.
-
Обработку транзакций, которая включает в себя начало и коммит транзакции, а также ее откат в случае ошибки.
Однако приведенный выше пример довольно хорошо демонстрирует, почему JDBC считается низкоуровневым: для перехода от SQL к Java и обратно требуется много ручной работы.
Итог по JDBC
При использовании JDBC вы в основном работаете с «голым железом». У вас под рукой вся мощь и скорость SQL и JDBC, но вам нужно вручную конвертировать результаты SQL-запросов в объекты Java. Вам также нужно следить за соединениями с базой данных и вручную открывать и закрывать их.
Здесь на сцену выходят удобные и легкие фреймворки, о которых мы расскажем в следующем разделе.
ORM-фреймворки: Hibernate, JPA и другие
Java-разработчикам, как правило, более комфортно писать код на Java, чем на SQL. Поэтому многие новые проекты пишутся с использованием подхода java-first, который означает, что сначала вы создаете Java-классы, а потом соответствующие таблицы базы данных.
Это, естественно, приводит к вопросу объектно-реляционного отображения: как смапить только что написанный Java-класс с таблицей базы данных (которая еще не создана)? И можно ли на основе Java-классов сгенерировать схему базы данных (по крайней мере, первоначальную).
Именно здесь вступают в игру полноценные ORM, такие как Hibernate и другие реализации JPA.
Что такое Hibernate?
Hibernate — это зрелый ORM-фреймворк (Object-Relational Mapping, объектно-реляционное отображение), который впервые был выпущен в 2001 году (!). Текущая стабильная версия 5.4.X, версия 6.x находится в разработке.
Несмотря на то что про Hibernate написано бесчисленное количество книг, я предприму попытку резюмировать его сильные стороны:
-
Позволяет (относительно) легко преобразовывать таблицы базы данных в java-классы без какого-либо сложного кода, кроме конфигурирования маппинга.
-
Позволяет не писать SQL-код для таких простых CRUD-операций, как создание, удаление или изменение пользователя.
-
Предлагает несколько вариантов (HQL, Criteria API) для выполнения запросов поверх SQL. Можно сказать, что это «объектно-ориентированная» версия SQL.
Наконец, давайте посмотрим на примеры кода. Представьте, что у вас есть следующая таблица в базе данных, которая, по сути, является той же таблицей, которую мы использовали выше в примере с JDBC.
create table users (
id integer not null,
first_name varchar(255),
last_name varchar(255),
primary key (id)
)И соответствующий класс Java.
public class User {
private Integer id;
private String firstName;
private String lastName;
//Getters and setters are omitted for brevity
}Также я предполагаю, что вы скачали hibernate-core.jar и добавили в свой проект. Как теперь сказать Hibernate, что ваш класс User.java должен быть отображен в таблицу Users? Для этого используются аннотации Hibernate.
Аннотации Hibernate для настройки отображения
Без дополнительной конфигурации Hibernate не знает, какой из классов с какой таблицей базы данных связан. Должен ли класс User.java отображаться в таблицу Invoices (счета) или в таблицу Users (пользователи)?
Изначально для настройки маппинга использовались xml-файлы. Мы не будем рассматривать использование xml-файлов, так как в последние годы этот подход был заменен использованием аннотаций.
Возможно, вы уже сталкивались с некоторыми из таких аннотаций как @Entity, @Column или @Table. Давайте посмотрим, как наш класс User.java, приведенный выше, будет выглядеть с этими аннотациями.
import javax.persistence.Entity;
import javax.persistence.Table;
import javax.persistence.GeneratedValue;
import javax.persistence.Column;
import javax.persistence.Id;
@Entity
@Table(name="users")
public static class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name="first_name")
private String firstName;
@Column(name="last_name")
private String lastName;
//Getters and setters are omitted for brevity
}В рамках данной статьи я не буду подробно разбирать каждую из аннотаций, приведу только краткое описание:
-
@Entity — маркер для Hibernate, что надо связать этот класс с таблицей базы данных.
-
@Table — указывает Hibernate, в какую таблицу базы данных нужно отобразить класс.
-
@Column — указывает Hibernate, в какой столбец базы данных нужно отобразить поле.
-
@Id и @GeneratedValue — указывает Hibernate, что это первичный ключ таблицы и что он генерируется автоматически базой данных.
Конечно, аннотаций гораздо больше, но вы уже примерно поняли подход с аннотациями. С Hibernate вы пишете свои классы, а затем аннотируете их соответствующими аннотациями.
Как начать работать с Hibernate (5.x)
После аннотирования классов вам нужно настроить сам Hibernate. Точкой входа, практически для всего в Hibernate, является класс SessionFactory, который вам нужно сконфигурировать.
SessionFactory обрабатывает ваши аннотации и позволяет создать Session. Объект Session, по сути, является соединением с базой данных (а точнее, оберткой для старого доброго JDBC-соединения) с дополнительным функционалом поверх. Session используется для выполнения SQL / HQL / Criteria — запросов.
Но сначала немного кода для первоначальной настройки Hibernate.
В последних версиях Hibernate (> 5.x) этот код выглядит немного некрасиво, и такие фреймворки как Spring заботятся об этой инициализации за вас. Но если вы хотите начать работу с голым Hibernate, то эту настройку вам необходимо выполнить вручную.
public static void main(String[] args) {
// Hibernate specific configuration class
StandardServiceRegistryBuilder standardRegistry
= new StandardServiceRegistryBuilder()
.configure()
.build();
// Here we tell Hibernate that we annotated our User class
MetadataSources sources = new MetadataSources( standardRegistry );
sources.addAnnotatedClass( User.class );
Metadata metadata = metadataSources.buildMetadata();
// This is what we want, a SessionFactory!
SessionFactory sessionFactory = metadata.buildSessionFactory();
}Полный пример можете посмотреть здесь.
Простой пример Hibernate
Теперь, когда вы настроили маппинг и создали SessionFactory, осталось только получить Session (считайте, что соединение с базой данных) из SessionFactory, а затем, например, сохранить пользователя в базу данных.
В терминах Hibernate / JPA это называется «persistence» (персистентность, постоянство), потому что вы сохраняете объекты Java в таблицы базы данных. Однако, в конце концов, это удобный способ сказать: сохрани этот объект в базе данных, т.е. сгенерируй SQL для INSERT (вставки).
Да, вам больше не нужно писать SQL самому: Hibernate сделает это за вас.
Session session = sessionFactory.openSession();
User user = new User();
user.setFirstName("Hans");
user.setLastName("Dampf");
// this line will generate and execute the "insert into users" sql for you!
session.save( user );По сравнению с голым JDBC больше не нужно возиться с PreparedStatement и параметрами, Hibernate позаботится о том, чтобы создать правильный SQL (если ваши аннотации маппинга поставлены правильно!).
Давайте посмотрим, как будут выглядеть простые SQL-выражения (select, update и delete).
// Hibernate generates: "select from users where id = 1"
User user = session.get( User.class, 1 );
// Hibernate generates: "update users set...where id=1"
session.update(user);
// Hibernate generates: "delete from useres where id=1"
session.delete(user);Как использовать Hibernate Query Language (HQL)
До сих пор мы рассматривали только простые примеры персистентности, такие как сохранение или удаление объекта User. Но бывают случаи, когда вам нужно больше контроля и более сложные SQL-запросы. Для этого Hibernate предлагает свой язык запросов, так называемый HQL (Hibernate Query Language).
HQL похож на SQL, но ориентирован на Java-объекты и фактически не зависит от используемой СУБД. Теоретически это означает, что один и тот же HQL-запрос будет работать со всеми базами данных (MySQL, Oracle, Postgres и т. д.), но с тем недостатком, что вы потеряете доступ к специфическим возможностям СУБД.
Что же означает, что «HQL ориентирован на Java-объекты»? Давайте посмотрим на пример:
List<User> users = session.createQuery("select from User u where u.firstName = 'hans'", User.class).list();
session.createQuery("update User u set u.lastName = :newName where u.lastName = :oldName")
.executeUpdate();Оба запроса очень похожи на свои SQL-эквиваленты, но обратите внимание, что вы обращаетесь не к таблицам и столбцам базы данных (first_name), а к свойствам (u.firstName) вашего класса User.java! Затем Hibernate конвертирует этот HQL в соответствующий SQL для конкретной базы данных. В случае с SELECT он автоматически преобразует полученные данные в объекты User.
Для получения подробной информации обо всех возможностях HQL обратитесь к разделу HQL в документации Hibernate.
Как использовать Criteria API
В HQL-запросах вы, по сути, все еще пишете и конкатенируете обычные строки (хотя есть поддержка в IDE, таком как IntelliJ). Но самое интересное — это динамический HQL / SQL (формирование разных WHERE в зависимости от пользовательского ввода).
Для этого Hibernate предлагает другой способ написания запросов — Criteria API. Есть две версии Criteria API (1 и 2), которые существуют одновременно. Версия 1 устарела и когда-нибудь будет удалена в Hibernate 6.x, но она гораздо проще, чем версия 2.
Criteria API (v2) имеет более крутую кривую обучения и требует некоторой дополнительной настройки проекта. Вам необходимо настроить плагин обработки аннотаций для генерации «статической метамодели» ваших аннотированных классов. А затем писать запросы с использованием сгенерированных классов.
Давайте посмотрим на то, как переписать наш пример с HQL на Criteria API.
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<User> criteria = builder.createQuery( User.class );
Root<User> root = criteria.from( User.class );
criteria.select( root );
criteria.where( builder.equal( root.get( User_.firstName ), "hans" ) );
List<User> users = entityManager.createQuery( criteria ).getResultList();Как видите, вы жертвуете удобочитаемостью и простотой ради типобезопасности и гибкости. Например, легко добавлять if-else для построения динамических выражений where на лету.
Но обратите внимание, что для нашего простого примера с «select * from users where firstName =?» теперь получилось целых шесть строк кода.
Недостатки Hibernate
С использованием Hibernate можно реализовать не только простые маппинги, которые были рассмотрены выше. В реальной жизни все бывает намного сложнее. Также Hibernate предлагает массу других удобных функций: каскадные операции, ленивая загрузка (lazy load), кеширование и многое другое. Это действительно сложный фреймворк, который нельзя изучить просто взяв какой-то кусок кода из туториала в свой проект.
Это несколько неожиданно приводит к двум основным проблемам:
-
Довольно много разработчиков рано или поздно начинают говорить, что «Hibernate творит какую-то магию, которую никто не понимает» или что-то вроде этого. Но это только по причине того, что им не хватает базовых знаний о том, как работает Hibernate.
-
Некоторые разработчики считают, что при использовании Hibernate больше не нужно разбираться в SQL. Хотя реальность такова, что чем сложнее проект, тем больше знаний и навыков работы с SQL требуется для анализа сгенерированного Hibernate’ом SQL-кода и его оптимизации.
Для решения этих двух проблем у вас есть только один выход: необходимо хорошо изучить Hibernate и SQL.
Какие есть хорошие туториалы и книги по Hibernate?
Отличная книга «Java Persistence with Hibernate«. В ней 608 страниц, что уже говорит о сложности Hibernate. Но после ее прочтения вы значительно улучшите свои знания в области Hibernate.
Если вам нужна дополнительная информация, обязательно посетите сайты Влада Михалчи (Vlad Mihalcea) и Торбена Янссена (Thorben Janssen). Они оба являются признанными экспертами по Hibernate и регулярно публикуют потрясающий контент.
Если вы любите смотреть видеокурсы, то можете посмотреть скринкасты по Hibernate на этом сайте. Они уже не самые новые, но дадут вам быстрый старт во вселенную Hibernate.
Что такое Java Persistence API (JPA)?
До сих пор мы говорили только о простом Hibernate, но как насчет JPA? Как он связан с Hibernate?
JPA — это всего лишь спецификация, а не реализация или библиотека. JPA определяет стандарт того, какой функционал должен присутствовать в библиотеке, чтобы она была совместимой с JPA. Есть несколько реализация JPA, например, Hibernate, EclipseLink или TopLink.
Проще говоря, если ваша библиотека поддерживает, например, сохранение объектов в базе данных, предоставляет возможности маппинга и выполняет запросы (например, Criteria API и т. п.) и др., то вы можете назвать ее JPA-совместимой.
Таким образом, вместо написания кода, специфичного для Hibernate или EclipseLink, вы пишете JPA-специфичный код. А затем просто добавляете в JPA-проект библиотеки (Hibernate) с файлом конфигурации, и получаете доступ к базе данных. На практике это означает, что JPA — еще одна абстракция поверх Hibernate.
Текущие версии JPA
-
JPA 1.0 — утверждена в 2006 г.
-
JPA 2.0 — утверждена в 2009 г.
-
JPA 2.1 — утверждена в 2013 г.
-
JPA 2.2 — утверждена в 2017 г.
Есть множество блогов, которые кратко описывают изменения по версиям, но Vlad Mihalcea и Thorben Janssen делают это лучше всех.
В чем же тогда разница между Hibernate и JPA?
Теоретически JPA позволяет вам не обращать внимания на то, какой persistance-провайдер (Hibernate, EclipseLink и т.д.) вы используете в своем проекте.
Поскольку на практике на сегодняшний день самой популярной реализацией JPA является Hibernate, функционал в JPA часто является подмножеством функционала Hibernate. Например, JPQL — это HQL с меньшим количеством функций. И хотя допустимый запрос JPQL всегда будет допустимым запросом HQL, в обратную сторону это не так.
Таким образом, поскольку сам процесс выпуска спецификации JPA требует времени, а результат — это общий знаменатель функционала существующих библиотек, то предлагаемые им функции являются лишь подмножеством функционала, предлагаемого, например, Hibernate. Иначе Hibernate, EclipseLink и TopLink были бы совершенно идентичными.
Что использовать: JPA или Hibernate?
В реальных проектах у вас, по сути, есть два варианта:
-
Вы либо используете по максимуму JPA без использования Hibernate-специфичных вещей, отсутствующих в JPA.
-
Либо везде используете только Hibernate (я предпочитаю этот вариант).
Простой пример работы с JPA
В JPA точкой входа для всего, связанного с персистентностью, является EntityManagerFactory, а также EntityManager.
Давайте посмотрим на пример выше, в котором мы сохраняли пользователей с помощью JDBC и Hibernate API. Только на этот раз мы сохраним их с помощью JPA API.
EntityManagerFactory factory = Persistence.createEntityManagerFactory( "org.hibernate.tutorial.jpa" );
EntityManager entityManager = factory.createEntityManager();
entityManager.getTransaction().begin();
entityManager.persist( new User( "John Wayne") );
entityManager.persist( new User( "John Snow" ) );
entityManager.getTransaction().commit();
entityManager.close();За исключением разных названий (persist и save, EntityManager и Session), код выглядит точно так же, как в примере с голым Hibernate.
А если вы посмотрите исходный код Hibernate, то увидите там следующее:
package org.hibernate;
public interface Session extends SharedSessionContract, EntityManager, HibernateEntityManager, AutoCloseable {
// methods
}
// and
public interface SessionFactory extends EntityManagerFactory, HibernateEntityManagerFactory, Referenceable, Serializable, java.io.Closeable {
// methods
}Подводя итог:
-
Hibernate SessionFactory — это JPA EntityManagerFactory
-
Hibernate Session — это JPA EntityManager
Все просто.
Как использовать JPQL
Как уже упоминалось ранее, в JPA есть свой язык запросов — JPQL. По сути, он представляет собой урезанный HQL (Hibernate), при этом запросы JPQL всегда являются действительными запросами HQL, но не наоборот.
Следовательно, обе версии одного и того же запроса будут выглядеть буквально одинаково:
// HQL
int updatedEntities = session.createQuery(
"update Person " +
"set name = :newName " +
"where name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();
// JPQL
int updatedEntities = entityManager.createQuery(
"update Person p " +
"set p.name = :newName " +
"where p.name = :oldName" )
.setParameter( "oldName", oldName )
.setParameter( "newName", newName )
.executeUpdate();Как использовать Criteria API в JPA
По сравнению с HQL и JPQL, Criteria API в JPA существенно отличается от Criteria API в Hibernate. Мы уже рассмотрели Criteria API для Hibernate выше в соответствующем разделе.
Какие еще есть реализации JPA?
Реализаций JPA больше, чем только Hibernate. В первую очередь на ум приходят EclipseLink (см. Hibernate vs Eclipselink) и (более старый) TopLink.
По сравнению с Hibernate они не очень распространены, хотя вы их можете встретить в корпоративных системах. Есть также и другие проекты, такие как BatooJPA. В большинстве случаев эти библиотеки уже заброшены и больше не поддерживаются, потому что поддерживать полностью совместимую с JPA библиотеку довольно сложно.
Вы, безусловно, хотите, чтобы у используемого вами фреймворка было активное сообщество для поддержки и дальнейшего развития. У Hibernate, вероятно, самое большое сообщество по состоянию на 2020 год.
QueryDSL
Почему такую библиотеку, как QueryDSL, мы рассматриваем в разделе про JPA? До сих пор мы писали запросы HQL / JPQL вручную (т.е. через конкатенацию строк), либо с помощью довольно сложного Criteria API (2.0).
QueryDSL пытается предоставить вам лучшее из обоих миров: более простое построение запросов по сравнению с Criteria API, больше типобезопасность и меньше использования обычных строк.
Следует отметить, что QueryDSL какое-то время не поддерживался, но начиная с 2020 года, снова набрал обороты. Он также поддерживает не только JPQ, но и NoSQL базы данных, такие как MongoDB или Lucene.
Давайте посмотрим на пример кода QueryDSL, который выполняет SQL "select * from users where first_name =: name"
QUser user = QUser.user;
JPAQuery<?> query = new JPAQuery<Void>(entityManager);
List<User> users = query.select(user)
.from(user)
.where(user.firstName.eq("Hans"))
.fetch();Откуда взялся класс QUser? QueryDSL создал его автоматически во время компиляции из класса User, аннотированного аннотациями JPA / Hibernate, с помощью соответствующего плагина компилятора, обрабатывающего аннотации.
Вы можете использовать эти сгенерированные классы для выполнения типобезопасных запросов к базе данных. Разве они не читаются намного лучше по сравнению с JPA Criteria 2.0?
ORM-фреймворки в Java: резюме
ORM-фреймворки — это зрелое и сложное программное обеспечение. Главная опасность при их использовании — думать, что при использовании какой-либо из реализаций JPA вам больше не нужно знать SQL.
Да, это правда, что ORM позволяет вам быстро стартануть с маппингом классов на таблицы баз данных. Но при отсутствии базовых знаний о том, как это все работает, позже в проекте вы столкнетесь с серьезными проблемами производительности и поддержки.
Убедитесь, что вы хорошо понимаете, как работает Hibernate, SQL и ваша база данных.
SQL-библиотеки: легковесный подход
Все библиотеки, рассматриваемые далее, имеют более легковесный подход, ориентированный на базы данных (database-first), по сравнению с подходом ORM, ориентированным на Java (java-first).
Они хорошо работают, если у вас есть существующая (легаси) база данных или вы начинаете новый проект с нуля и создаете базу данных перед написанием Java-классов.
jOOQ
jOOQ — популярная библиотека от Лукаса Эдера (Lukas Eder). Лукас также ведет очень интересный блог обо всем, что касается SQL, баз данных и Java.
По сути, работа с jOOQ сводится к следующему:
-
Для подключения к базе данных и создания классов Java, которые представляют ваши таблицы и столбцы базы данных, используется генератор кода jOOQ.
-
Для написания SQL-запросов вместо простых строк с использованием голого JDBC используются эти сгенерированные классы.
-
jOOQ превращает эти классы и запросы в SQL, выполняет его и возвращает результат.
Итак, представьте, что вы настроили генератор кода jOOQ и работаете с таблицей Users, которую мы использовали ранее. jOOQ сгенерирует класс USERS для таблицы, который позволит выполнить следующий типобезопасный запрос к базе данных:
// "select u.first_name, u.last_name, s.id from USERS u inner join SUBSCRIPTIONS s
// on u.id = s.user_id where u.first_name = :name"
Result<Record3<String, String, String>> result =
create.select(USERS.FIRST_NAME, USERS.LAST_NAME, SUBSCRIPTIONS.ID)
.from(USERS)
.join(SUBSCRIPTIONS)
.on(USERS.SUBSCRIPTION_ID.eq(SUBSCRIPTIONS.ID))
.where(USERS.FIRST_NAME.eq("Hans"))
.fetch();jOOQ не только помогает создавать и выполнять SQL-запросы в соответствии со схемой базы данных, но также помогает с CRUD-операциями, маппингом между POJO и записями базы данных.
Он также помогает получить доступ ко всему функционалу вашей базы данных (оконные функции, pivot, flashback-запросы, OLAP, хранимые процедуры и прочее, специфическое для вашей БД).
Более подробное введение вы можете посмотреть в этом небольшом руководстве по jOOQ.
MyBatis
MyBatis — еще один популярный и активно поддерживаемый проект для решений database-first. MyBatis — это форк IBATIS 3.0, который сейчас находится в Apache Attic.
Для работы с MyBatis используется SQLSessionFactory (не путайте с SessionFactory из Hibernate). После создания SQLSessionFactory вы можете выполнять SQL-запросы к базе данных. Сами SQL-запросы находятся либо в файлах XML, либо в аннотациях интерфейсов.
Давайте посмотрим на пример с аннотациями:
package org.mybatis.example;
public interface UserMapper {
@Select("SELECT * FROM users WHERE id = #{id}")
User selectUser(int id);
}Соответствующая XML-конфигурация:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.mybatis.example.UserMapper">
<select id="selectUser" resultType="User">
select * from users where id = #{id}
</select>
</mapper>
Далее можно использовать этот интерфейс следующим образом:
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectUser(1);MyBatis также имеет встроенные функции маппинга, то есть он может преобразовывать данные из таблицы в объект User. Но работает это только для простых случаев, когда, например, имена столбцов совпадают. В противном случае вам придется конфигурировать маппинг самостоятельно в XML-файле конфигурации.
Также MyBatis уделяет довольно много внимания возможностям по работе с динамическим SQL, которые, по сути, являются основанными на XML способами создания сложных динамических SQL-запросов (что-то вроде if-else-when прямо внутри SQL-запроса).
Jdbi
Jdbi — это небольшая библиотека поверх JDBC, которая упрощает доступ к базе данных. Это один из наиболее низкоуровневых SQL-фреймворков. Ее API представлено двумя вариантами.
Во-первых, Fluent API:
Jdbi jdbi = Jdbi.create("jdbc:h2:mem:test"); // (H2 in-memory database)
List<User> users = jdbi.withHandle(handle -> {
handle.execute("CREATE TABLE user (id INTEGER PRIMARY KEY, name VARCHAR)");
// Named parameters from bean properties
handle.createUpdate("INSERT INTO user(id, name) VALUES (:id, :name)")
.bindBean(new User(3, "David"))
.execute();
// Easy mapping to any type
return handle.createQuery("SELECT * FROM user ORDER BY name")
.mapToBean(User.class)
.list();
});Во-вторых, декларативный API:
// Define your own declarative interface
public interface UserDao {
@SqlUpdate("CREATE TABLE user (id INTEGER PRIMARY KEY, name VARCHAR)")
void createTable();
@SqlUpdate("INSERT INTO user(id, name) VALUES (:id, :name)")
void insertBean(@BindBean User user);
@SqlQuery("SELECT * FROM user ORDER BY name")
@RegisterBeanMapper(User.class)
List<User> listUsers();
}
public class MyApp {
public static void main(String[] args) {
Jdbi jdbi = Jdbi.create("jdbc:h2:mem:test");
jdbi.installPlugin(new SqlObjectPlugin());
List<User> userNames = jdbi.withExtension(UserDao.class, dao -> {
dao.createTable();
dao.insertBean(new User(3, "David"));
return dao.listUsers();
});
}
}
fluent-jdbc
fluent-jdbc — библиотека, аналогичная Jdbi. Удобная обертка над чистым JDBC. Больше примеров вы можете посмотреть на ее домашней странице.
FluentJdbc fluentJdbc = new FluentJdbcBuilder()
.connectionProvider(dataSource)
.build();
Query query = fluentJdbc.query();
query
.update("UPDATE CUSTOMER SET NAME = ?, ADDRESS = ?")
.params("John Doe", "Dallas")
.run();
List<Customer> customers = query.select("SELECT * FROM CUSTOMER WHERE NAME = ?")
.params("John Doe")
.listResult(customerMapper);SimpleFlatMapper
SimpleFlatMapper немного слабоват с точки зрения документации, но это отличная небольшая библиотека, которая помогает вам мапить ResultSet из JDBC и Record из jOOQ на POJO. На самом деле, поскольку это «всего лишь» маппер, он интегрируется с большинством фреймворков баз данных, упомянутых в этом руководстве начиная с JDBC, jOOQ, queryDSL, JDBI и заканчивая Spring JDBC.
Давайте рассмотрим пример использования с JDBC:
// will map the resultset to User POJOs
JdbcMapper<DbObject> userMapper =
JdbcMapperFactory
.newInstance()
.newMapper(User.class)
try (PreparedStatement ps = con.prepareStatement("select * from USERS")) {
ResultSet rs = ps.executeQuery());
userMapper.forEach(rs, System.out::println); //prints out all user pojos
}Spring JDBC и Spring Data
Вселенная Spring на самом деле представляет собой огромную экосистему, поэтому вам не следует начинать сразу со Spring Data, а лучше сначала разобраться с более низкоуровневыми вещами в Spring.
Spring JDBC Template
JDBCTemplate — один из старейших вспомогательных классов в Spring (точнее, в зависимости spring-jdbc). Он существует с 2001 года, и его не следует путать с Spring Data JDBC.
Он представляет собой обертку над JDBC-соединениями и предлагает удобную обработку ResultSet, соединений, ошибок, а также обеспечивает интеграцию с @Transactional-фреймворком в Spring.
Он представлен двумя вариантами: JdbcTemplate и NamedParameterJdbcTemplate. Давайте посмотрим на несколько примеров кода, чтобы понять, как их использовать.
// plain JDBC template with ? parameters
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.execute("CREATE TABLE users(" +
"id SERIAL, first_name VARCHAR(255), last_name VARCHAR(255))"); (1)
jdbcTemplate.batchUpdate("INSERT INTO users(first_name, last_name) VALUES (?,?)", Arrays.asList("john", "wayne")); (2)
jdbcTemplate.query(
"SELECT id, first_name, last_name FROM users WHERE first_name = ?", new Object[] { "Josh" },
(rs, rowNum) -> new User(rs.getLong("id"), rs.getString("first_name"), rs.getString("last_name"))
).forEach(user -> log.info(user.toString())); (3)
// named JDBC template with :named parameters
NamedParameterJdbcTemplate namedTemplate = new NamedParameterJdbcTemplate(datasource);
SqlParameterSource namedParameters = new MapSqlParameterSource().addValue("id", 1);
namedParameterJdbcTemplate.queryForObject( (4)
"SELECT * FROM USERS WHERE ID = :id", namedParameters, String.class);-
Сначала мы выполняем SQL для создания таблицы. Обратите внимание, что по сравнению с обычным JDBC здесь не нужно обрабатывать SQLException, так как Spring преобразует их в
RuntimeException. -
Используем знак вопроса (
?) для параметров. -
Используем
RowMapperдля преобразования простого JDBC ResultSet в POJO нашего проекта. -
NamedParameterJdbcTemplateпозволяет ссылаться на параметры в SQL-запросе по имени (например,:id), а не по знаку вопроса (?).
Посмотрев на этот код, вы увидите, что JdbcTemplate на самом деле является всего лишь изящной оберткой вокруг JDBC API.
Как работает управление транзакциями в Spring
Одна из сильных сторон Spring — возможность объявлять транзакции баз данных с помощью аннотации @Transactional.
Эта аннотация не только избавляет вас от необходимости самостоятельно открывать, обрабатывать и закрывать соединения с БД, но также может использоваться совместно с внешними библиотеками, такими как Hibernate, jOOQ или любой другой реализацией JPA, обрабатывая транзакции для них.
Давайте еще раз посмотрим на наш предыдущий пример с JPA, где мы вручную открывали и фиксировали транзакцию через EntityManager (помните, EntityManager — это на самом деле просто Hibernate Session, который представляет собой соединение JDBC на стероидах).
EntityManagerFactory factory = Persistence.createEntityManagerFactory( "org.hibernate.tutorial.jpa" );
EntityManager entityManager = factory.createEntityManager();
entityManager.getTransaction().begin();
entityManager.persist( new Event( "Our very first event!", new Date() ) );
entityManager.persist( new Event( "A follow up event", new Date() ) );
entityManager.getTransaction().commit();
entityManager.close();После интеграции Spring и Hibernate / JPA код становится следующим:
@PersistenceContext
private EntityManager entityManager;
@Transactional
public void doSomeBusinessLogic() {
entityManager.persist( new Event( "Our very first event!", new Date() ) );
entityManager.persist( new Event( "A follow up event", new Date() ) );
}Кажется, код читается гораздо приятнее. Очевидно, что обработка транзакций содержит в себе гораздо больше, но в этой статье мы не будем углубляться в детали.
Если вам интересно разобраться с транзакциями, то вы можете взглянуть на мою электронную книгу Java Database Connections & Transactions («Соединения и транзакции с базами данных в Java»). В ней вы найдете много примеров кода и упражнений, которые помогут вам научиться правильно работать с транзакциями.
Spring Data JPA
Наконец, пришло время взглянуть на Spring Data, миссией которого является «предоставление модели разработки Spring для доступа к данным, сохраняя при этом особенности хранилищ». Ух, что это за заявление о миссии из списка Fortune 500. Что это на самом деле означает?
Spring Data — это общее название множества подпроектов:
-
Два самых популярных, которые мы рассмотрим в этой статье: Spring Data JDBC и Spring Data JPA.
-
И множество других, таких как Spring Data REST, Spring Data Redis или даже Spring Data LDAP. Полный список можете посмотреть на веб-сайте.
Что такое Spring Data JDBC и Spring Data JPA?
Все проекты Spring Data упрощают создание репозиториев/DAO и SQL-запросов. (Есть и другое, но в этой статье остановимся только на этом.)
Небольшое напоминание: есть распространенный паттерн — создание репозитория/DAO для каждого объекта домена.
Если бы у вас был класс User.java, то у вас также был бы репозиторий UserRepository. И у этого UserRepository были бы методы, такие как findByEmail, findById и т. д. Короче говоря, он позволял бы вам выполнять все SQL-операции для таблицы Users.
User user = userRepository.findByEmail("my@email.com")Интересный момент Spring Data заключается в том, что он понимает JPA-аннотации вашего класса User (@Entity, @Column, @Table и т.д.) и автоматически генерирует репозитории! Это означает, что вы получаете все основные CRUD-операции (save, delete, findBy) бесплатно без необходимости писать дополнительный код.
Как написать свои Spring Data JPA-репозитории
Давайте посмотрим на несколько примеров кода. Предполагая, что у вас в classpath есть соответствующие spring-data-{jdbc|jpa}.jar. С добавлением небольшой конфигурации вы могли бы написать следующий код:
import org.springframework.data.jpa.repository.JpaRepository;
import com.marcobehler.domain.User;
public interface MyUserRepository extends JpaRepository<User, Long> {
// JpaRepository contains all of these methods, you do not have to write them yourself!
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
<S extends T> List<S> saveAll(Iterable<S> entities);
// and many more...that you can execute without implementing, because Spring Data JPA will
// automatically generate an implementation for you - at runtime
}Ваш репозиторий просто должен наследоваться от JpaRepository из Spring Data (в случае, если вы используете JPA), и вы получите бесплатно методы find/save (и многие другие), так как они являются частью интерфейса JpaRepository (я добавил их в вышеприведенный пример только для наглядности).
Как писать запросы Spring Data JPA / JDBC
Более того, вы можете писать свои запросы JPA (или запросы SQL), используя соглашения по именованию методов. Это очень похоже, например, на написание запросов в Ruby on Rails.
import org.springframework.data.jpa.repository.JpaRepository;
import com.marcobehler.domain.User;
public interface MyUserRepository extends JpaRepository<User, Long> {
List<User> findByEmailAddressAndLastname(String emailAddress, String lastname);
}Spring при запуске будет читать имя метода и преобразовывать его в соответствующий запрос при каждом выполнении этого метода. Для примера выше генерируется следующий SQL: «select * from Users where email_address = :emailAddress and lastName = :lastName«.
Spring Data JDBC работает по другому (помимо наследования от другого интерфейса CrudRepository). В нем запрос пишется вручную.
import org.springframework.data.repository.CrudRepository;
import org.springframework.data.jdbc.repository.Query;
import com.marcobehler.domain.User;
public interface MyUserRepository extends CrudRepository<User, Long> {
@Query("select * from Users where email = :emailAddress and lastName = :lastName ")
List<User> findByEmailAddressAndLastname(@Param("emailAddress") String emailAddress, @Param("lastName") String lastname);
}То же самое можно сделать и в Spring Data JPA (обратите внимание на другой импорт аннотации @Query и на то, что мы не используем именованные параметры в запросе). Вам по-прежнему не нужно реализовывать этот интерфейс.
import org.springframework.data.jpa.repository.Query;
public interface MyUserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.emailAddress = ?1")
User findByEmailAddress(String emailAddress);
}Spring Data: резюме
Можно сделать несколько выводов:
-
По своей сути Spring Data — это все еще про простой доступ к данным и, следовательно, про репозитории и запросы. Он понимает аннотации javax.persistence и на основе этих аннотаций генерирует для вас DAO.
-
Spring Data JPA — это удобная библиотека поверх JPA / Hibernate. Дело не в том, что это разные библиотеки, а скорее в том, что они работают вместе. Spring Data JPA позволяет вам писать супер-простые JPA-репозитории, при этом предоставляя доступ ко всему функционалу вашего ORM.
-
Spring Data JDBC — это удобная библиотека поверх JDBC. Она позволяет вам писать репозитории на основе JDBC, когда не нужны возможности полноценного ORM (кэширование, ленивая загрузка, …). Это дает больше контроля и меньше магии за кулисами.
И самое главное, Spring Data прекрасно интегрируется с другими Spring-проектами и это очевидный выбор для Spring Boot-проектов.
Опять же, это руководство дает только краткий обзор того, что такое Spring Data, более подробную информацию смотрите в официальной документации.
Что выбрать
К этому моменту вы можете почувствовать себя немного подавленным. Куча разных библиотек и вариантов. Но все это можно подытожить несколькими рекомендациями (как вы, возможно, уже догадались, единственно верного решения не существует):
-
Независимо от того, какую библиотеку для доступа к базам данных вы будете использовать, убедитесь, что вы хорошо разбираетесь в SQL и базах данных (что часто отсутствует у java-разработчиков).
-
Выберите библиотеку с активным сообществом, хорошей документацией и регулярными релизами.
-
Досконально изучите используемые фреймворки для доступа к данным, т.е. потратьте время на чтение этих 608 страниц.
-
Ваш проект отлично будет работать как с обычным Hibernate, так и с Hibernate, завернутым в JPA.
-
Также он будет себя чувствовать отлично с jOOQ или любой из других упомянутых database-first библиотек.
-
Вы также можете комбинировать библиотеки. Например, JPA-реализацию и jOOQ или голый JDBC. Или добавить удобства, используя такие библиотеки как QueryDSL.
Узнать подробнее о курсе «Java Developer. Professional».
Принять участие в открытом уроке на тему
«Введение в Spring Data Jdbc».

ЗАБРАТЬ СКИДКУ