Время на прочтение
10 мин
Количество просмотров 99K
В данной статье я хочу показать насколько просто сегодня использовать нейронные сети. Вокруг меня довольно много людей одержимы идеей того, что нейронки может использовать только исследователь. И что бы получить хоть какой то выхлоп, нужно иметь как минимуму кандидатскую степень. А давайте на реальном примере посмотрим как оно на самом деле, взять и с нуля за один вечер обучить chatbot. Да еще не просто абы чем а самым что нинаесть ламповым TensorFlow. При этом я постарался описать все настолько просто, что-бы он был понятен даже начинающему программисту! В путь!
Шаги, которые на предстоит пройти на нашем тернистом пути
- Необходимо найти реализацию нейроннйо сети, которую можно использовать для нашей цели.
- Подготовить данные (корпус), которые могут быть использованы для обучения.
- Обучить модель.
Отдельное спасибо моим патронам, которые сделали эту статью возможной:
Aleksandr Shepeliev, Sergei Ten, Alexey Polietaiev, Никита Пензин, Карнаухов Андрей, Matveev Evgeny, Anton Potemkin. Вы тоже можете стать одним из них вот тут.
Реализация нейронки, которую можно использовать для нашей цели
TensorFlow включает реализацию RNN (рекурентной нейронной сети), которая используется для обучения модели перевода для пары языков английский / французский. Именно эту реализацию мы и будем использовать для обучения нашего чат-бота.
Вероятно, кто-то может спросить: «Почему, черт возьми, мы смотрим на обучения модели перевода, если мы делаем чат-бот?». Но это может показаться странным только на первом этапе. Задумайтесь на секунду, что такое “перевод”? Перевод может быть представлен в виде процесса в два этапа:
- Создание языко-независимого представление входящего сообщения.
- Отображение информации полученной на первом шаге на язык перевода.
Теперь задумайтесь, а что, если мы будем обучать ту же модель RNN, но, вместо Eng/Fre пары мы будем подставлять Eng/Eng диалоги из фильмов? В теории, мы можем получить чат-бот, который способен отвечать на простые однострочные вопросы (без способности запоминать контекст диалога). Этого должно быть вполне достаточным для нашего первого бота. Плюс, этот подход очень прост. Ну а в будущем, мы сможем, отталкиваясь от нашей первой реализации, сделать чат-бот более разумным.
Позже мы узнаем, как обучать более сложные сети, которые являются более подходящими для чат-ботов (например retrieval-based models).
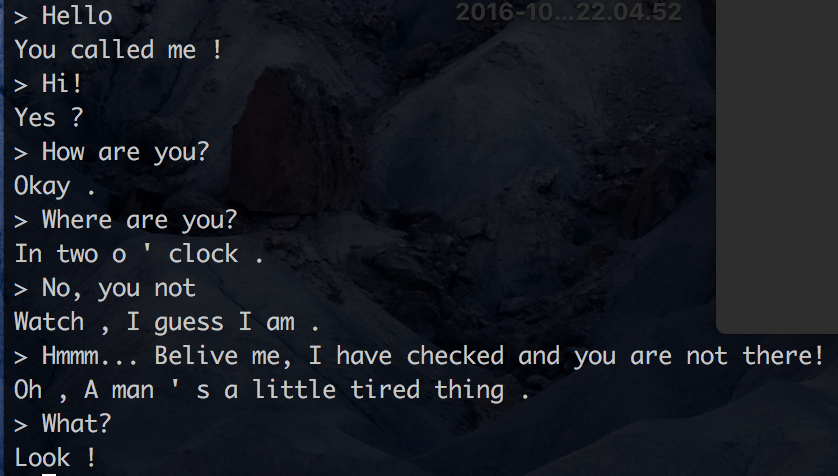
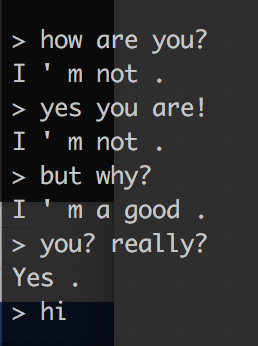
Для нетерпеливых: картинка в начале статьи это собственно пример разговора с ботом после всего 50 тысяч учебных итераций. Как видите, бот способен давать более или менее информативные ответы на некоторые вопросы. Качество бота улучшается с количеством итераций обучения. Например, вот как глупо он отвечал после первых 200 итераций:
Такой простой подход также позволяет нам создавать ботов с разными характерами. Например, можно было бы обучить его на диалогах из саги “Звездные войны” или «Властелин колец». Более того, если бот имеет достаточно большой корпус диалога одного и того же героя (например, все диалоги Чендлера из фильма «Друзья»), то можно создать бота этого самого героя.
Подготовка данных (корпуса) для обучения
Для обучения нашего первого бота мы будем использовать корпус диалогов из кинофильмов “Cornell Movie Dialogs Corpus”. Для его использования нам нужно сконвертировать диалоги в нужный для обучения вид. Для этого я подготовил небольшой скрипт.
Я бы настоятельно рекомендовал вам прочитать README файл, чтобы понять больше о корпусе и о том, что этот скрипт делает, и только потом продолжить чтение статьи. Однако, если вам просто нужно команды, которые вы можете слепо скопировать и выполнить, чтобы получить готовые для обучения данные, вот они:
tmp# git clone https://github.com/b0noI/dialog_converter.git
Cloning into ‘dialog_converter’…
remote: Counting objects: 59, done.
remote: Compressing objects: 100% (49/49), done.
remote: Total 59 (delta 33), reused 20 (delta 9), pack-reused 0
Unpacking objects: 100% (59/59), done.
Checking connectivity… done.
tmp# cd dialog_converter
dialog_converter git:(master)# python converter.py
dialog_converter git:(master)# ls
LICENSE README.md converter.py movie_lines.txt train.a train.bК концу выполнения вы будете иметь 2 файла, которые можно использовать для дальнейшего обучения: train.a и train.b
Обучение модели
Это самая захватывающая часть. Для того, чтобы обучить модель мы должны:
- Найти машину с мощной и поддерживаемой TensorFlow (что очень важно) видеокартой (читай: NVIDIA).
- Изменить оригинальный «translate» скрипт, который используется для обучения модели перевода пары Eng/Fre.
- Подготовить машину для обучения.
- Начать обучение.
- Подождать.
- Подождать.
- Подождать.
- Я серьезно … Нужно подождать.
- Profit.
В поисках Атлантиды машины для обучения
Для того, чтобы сделать этот процесс как можно более простым, я буду использовать собранный AMI — «Bitfusion TensorFlow AMI», который будет использоваться с AWS. Он имеет предварительно установленный TensorFlow, который был собран с поддержкой GPU. К моменту написания статьи, Bitfusion AMI включал TensorFlow версии 0.11.
Процесс создания EC2 инстанса из AMI образа достаточно прост и его рассмотрение выходит за рамки этой статьи. Однако стоит обратить внимание на две важных детали, которые имеют отношение к процессу, это тип instance и размер SSD. Для типа я бы рекомендовал использовать: p2.xlarge — это самый дешевый тип, который имеет NVIDIA GPU с достаточным количеством видеопамяти (12 Гбит). Что касается размера SSD — я бы рекомендовал выделить по крайней мере 100GB.
Теперь нам нужно изменить оригинальный «translate» скрипт
На этом этапе, я надеюсь, я могу предположить, что у вас есть ssh доступ к машине, где вы будете обучать TensorFlow.
Во-первых, давайте обсудим, зачем вообще нам нужно изменять исходный скрипт. Дело в том, что сам скрипт не позволяет переопределить источник данных, которые используются для обучения модели. Чтобы это исправить я создал feature-request. И постараюсь скоро подготовить реализацию, но на данный момент, вы можете поучаствовать добавляя +1 к “реквесту”.
В любом случае, не надо бояться — модификация очень проста. Но даже столь малую модификацию я уже сделал за вас и создал репозиторий, содержащий модифицированный код. Остается только сделать следующее:
Переименуйте файлы «train.a» и «train.b» на «train.en» и «train.fr» соответственно. Это необходимо, так как учебный скрипт все еще считает, что он обучается на перевод с английского на французский.
Оба файла должны быть загружены на удаленные хосты — это можно сделать с помощью команды rsync:
➜ train# REMOTE_IP=...
➜ train# ls
train.en train.fr
➜ train rsync -r . ubuntu@$REMOTE_IP:/home/ubuntu/trainТеперь давайте подключимся к удаленному хосту и запустим tmux сессию. Если вы не знаете, что такое tmux, вы можете просто подключиться через SSH:
➜ train ssh ubuntu@$REMOTE_IP
53 packages can be updated.
42 updates are security updates.
########################################################################################################################
########################################################################################################################
____ _ _ __ _ _
| __ )(_) |_ / _|_ _ ___(_) ___ _ __ (_) ___
| _ | | __| |_| | | / __| |/ _ | '_ | |/ _
| |_) | | |_| _| |_| __ | (_) | | | |_| | (_) |
|____/|_|__|_| __,_|___/_|___/|_| |_(_)_|___/
Welcome to Bitfusion Ubuntu 14 Tensorflow - Ubuntu 14.04 LTS (GNU/Linux 3.13.0-101-generic x86_64)
This AMI is brought to you by Bitfusion.io
http://www.bitfusion.io
Please email all feedback and support requests to:
support@bitfusion.io
We would love to hear from you! Contact us with any feedback or a feature request at the email above.
########################################################################################################################
########################################################################################################################
########################################################################################################################
Please review the README located at /home/ubuntu/README for more details on how to use this AMI
Last login: Sat Dec 10 16:39:26 2016 from 99-46-141-149.lightspeed.sntcca.sbcglobal.net
ubuntu@tf:~$ cd train/
ubuntu@tf:~/train$ ls
train.en train.frДавайте проверим, что TensorFlow установлен и он использует GPU:
ubuntu@tf:~/train$ python
Python 2.7.6 (default, Jun 22 2015, 17:58:13)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcublas.so.7.5 locally
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcudnn.so.5 locally
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcufft.so.7.5 locally
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcurand.so.7.5 locally
>>> print(tf.__version__)
0.11.0Как видно, установлен TF версии 0.11 и он использует библиотеку CUDA. Теперь давайте склоним учебный скрипт:
ubuntu@tf:~$ mkdir src/
ubuntu@tf:~$ cd src/
ubuntu@tf:~/src$ git clone https://github.com/b0noI/tensorflow.git
Cloning into 'tensorflow'...
remote: Counting objects: 117802, done.
remote: Compressing objects: 100% (10/10), done.
remote: Total 117802 (delta 0), reused 0 (delta 0), pack-reused 117792
Receiving objects: 100% (117802/117802), 83.51 MiB | 19.32 MiB/s, done.
Resolving deltas: 100% (88565/88565), done.
Checking connectivity... done.
ubuntu@tf:~/src$ cd tensorflow/
ubuntu@tf:~/src/tensorflow$ git checkout -b r0.11 origin/r0.11
Branch r0.11 set up to track remote branch r0.11 from origin.
Switched to a new branch 'r0.11'Обрати внимание, что нам нужна ветка r0.11.Прежде всего, эта ветка согласуется с версией локально установленного TensorFlow. Во-вторых, я не перенес мои изменения в другие ветки, поэтому, в случае необходимости, придется делать это руками вам самим.
Поздравляю! Вы дошли до этапа начала обучения. Смело запускайте это самое обучение:
ubuntu@tf:~/src/tensorflow$ cd tensorflow/models/rnn/translate/
ubuntu@tf:~/src/tensorflow/tensorflow/models/rnn/translate$ python ./translate.py --en_vocab_size=40000 --fr_vocab_size=40000 --data_dir=/home/ubuntu/train --train_dir=/home/ubuntu/train
...
Tokenizing data in /home/ubuntu/train/train.en
tokenizing line 100000
...
global step 200 learning rate 0.5000 step-time 0.72 perplexity 31051.66
eval: bucket 0 perplexity 173.09
eval: bucket 1 perplexity 181.45
eval: bucket 2 perplexity 398.51
eval: bucket 3 perplexity 547.47Давайте обсудим некоторые ключи, которые мы используем:
- en_vocab_size — сколько уникальных слов изучит модель “английского языка”. Если число уникальных слов из исходных данных превышает размер словаря, все слова, которые не в словаре, будут помечены как «UNK» (code: 3). Но не рекомендую делать словарь больше, чем необходимо; но он не должен быть и меньше;
- fr_vocab_size — то же самое, но для другой части данных (для “французского языка”);
- data_dir — директория с исходными данными. Здесь скрипт будет искать файлы «train.en» и «train.fr»;
- train_dir — директория, в которую скрипт будет записывать промежуточный результат обучения.
Давайте убедимся в том, что обучение продолжается, и все идет по плану
Вы успешно начали обучение. Но давайте подтвердим, что процесс продолжается и все в порядке. Мы не хотим, чтобы в конечном итоге через 6 часов мы выяснили, что что-то в самом начале было сделано не так. Мы с Глебом уже как-то обучили нечто полуразумное =)
Прежде всего, мы можем подтвердить, что процесс обучения “откусил” себе памяти у GPU:
$ watch -n 0.5 nvidia-smi
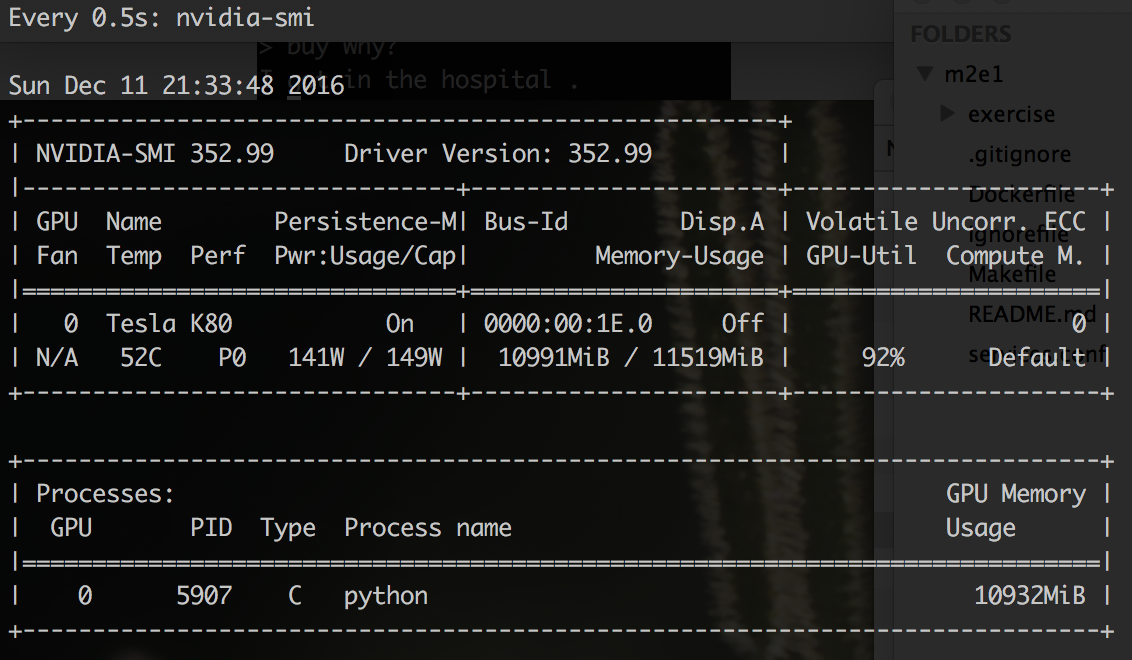
Как видно, не хило так кусанул, почти вся память на GPU занята. Это хороший знак. И не нужно бояться, что ваш процесс вот-вот “откинет копыта” с ошибкой OutOfMemory. Просто во время запуска TF прибирает к своим рукам всю память на GPU, до которой может дотянуться.
Затем можно проверить папку «train» — она должна содержать несколько новых файлов:
~$ cd train
~/train$ ls
train.fr train.ids40000.fr dev.ids40000.en dev.ids40000.fr train.en train.ids40000.en vocab40000.frЗдесь важно заглянуть в файлы vocab4000.* и train.ids40000.*. Там должно быть атмосферно и душевно, вот посмотрите:
~/train$less vocab40000.en
_PAD
_GO
_EOS
_UNK
.
'
,
I
?
you
the
to
s
a
t
it
of
You
!
that
...
Каждая строка в файле — это уникальное слово, которое было найдено в исходных данных. Каждое слово в исходных данных будет заменено числом, которое представляет номер строки из этого файла. Можно сразу же заметить, что есть некоторые технические слова: PAD (0), GO (1), EOS (2), UNK (3). Наверное самое важное из них для нас — «UNK», так как количество слов помеченных этим кодом (3) даст нам некоторое представление о том, насколько корректно выбран нами размер нашего словаря.
Теперь давайте посмотрим на train.ids40000.en:
~/train$ less train.ids40000.en
1181 21483 4 4 4 1726 22480 4 7 251 9 5 61 88 7765 7151 8
7 5 27 11 125 10 24950 41 10 2206 4081 11 10 1663
84 7 4444 9 6 562 6 7 30 85 2435 11 2277 10289 4 275
107 475 155 223 12428 4 79 38 30 110 3799 16 13 767 3 7248 2055 6 142 62 4
1643 4 145 46 19218 19 40 999 35578 17507 11 132 21483 2235 21 4112 4
144 9 64 83 257 37 788 21 296 8
84 19 72 4 59 72 115 1521 315 66 22 4
16856 32 9963 348 4 68 5 12 77 1375 218 7831 4 275
11947 8
84 6 40 2135 46 5011 6 93 9 359 6370 6 139 31044 4 42 5 49 125 13 131 350 4
371 4 38279 6 11 22 316 4
3055 6 323 19212 6 562 21166 208 23 3 4 63 9666 14410 89 69 59 13262 69 4
59 155 3799 16 1527 4079 30 123 89 10 2706 16 10 2938 3 6 66 21386 4
116 8
...Думаю вы уже догадались, что это данные из input.en, но со всеми словами замененными на коды согласно словарю. Теперь мы можем проверить, сколько же слов помечены как «неизвестные» (UNK/3):
~/train$ grep -o ' 3 ' train.ids40000.en | wc -l
7977Можете попробовать в последующих экспериментах увеличить размер словаря с 40k до 45k, или даже до 50к. Но, мы пока продолжим процесс “as is” и не станем его прерывать.
6 часов спустя… “Оно ожило!”
После ожидания достаточного количества времени, вы можете тупо убить процесс обучения. Не волнуйтесь, процесс сохраняет результат каждые 200 шагов обучения (это число можно менять). Я бы рекомендовал для обучения либо выбрать промежуток времени, который вы готовы ждать (он может зависеть от суммы, которую вы готовы платить за аренду машины), либо количество шагов, которое вы хотите, чтобы тренировочный процесс закончил.
Самое последнее и главное ради чего мы устроили этот весь беспредел — это начать чат. Для этого нам просто нужно добавить один ключ к команде, которая была использована для тренировки:
~/src/tensorflow/tensorflow/models/rnn/translate$ python ./translate.py --en_vocab_size=40000 --fr_vocab_size=40000 --data_dir=/home/ubuntu/train --train_dir=/home/ubuntu/train --decode
...
Reading model parameters from /home/ubuntu/data/translate.ckpt-54400
> Hello!
Hello .
> Hi are you?
Now , okay .
> What is your name?
My name is Sir Sir .
> Really?
Yeah .
> what about the real name?
N . . . real real .
> are you a live?
Yes .
> where are you?
I ' m here .
> where is here?
I don ' t know .
> can I help you to get here?
Yeah , to I ve ' t feeling nothing to me .Это лишь начало! Вот пару идей для улучшения бота.
Чтобы помочь проекту или просто создать бота с характером можно:
- реализовать логику, которая находит идеальный размер для EN/FR словарей;
- опубликовать train.en/train.fr где-то, чтобы другие люди не создавали их с нуля;
- обучить бота мастера Yoda (или Дарта Вейдера);
- обучить бота, который будет говорить, как во вселенной из “Властелина колец”;
- обучить бота, который будет говорить, как люди из “StarWars” вселенной;
- обучить бота на своих диалогах, чтобы он разговаривал как вы!
Задача генерации осмысленного текста сейчас широко используется, например, при создании чатботов (диалоговые системы вопрос-ответ), систем перевода (тот-же вопрос-ответ, но вопрос на одном языке, а ответ на другом). Рассмотрю структуру простого чатбота, взяв за основу лекции Сергея Кузина («Университете искусственного интеллекта«). В тексте рассматривается учебная задача для понимания.
Задача генерации осмысленного текста условно разбивается на две подзадачи. Сначала нейронной сети нужно выполнить анализ эталонного текста, а затем, поняв закономерности построения фраз сформировать новый текст, копируя манеру построения фраз текста на котором нейронка обучалась.
Примерная последовательность шагов для создания нейронной сети генерирующей текст следующая:
- Подготовка текстов для обучения — подобрать материал для обучения нейронной сети, т.е. найти подходящие по объему диалоги, тексты и пр.
- Предобработать (очистка от «мусора», токенизация) текст для обучения. Исключить из текстов «лишнюю» информацию, например, смайлы, «левые» вставки служебной информации (при экспорте переписки из WhatsApp он при исключении медиафайлов/фото/просоединенных файлов добавляет служебные строки) и т.п.
- Преобразовать в формат, пригодный для подачи на нейронную сеть (векторизация, числовые последовательности).
- Сформировать новый текст, используя некоторый алгоритм. Например, подходящую архитектуру нейронной сети.
- Преобразовать текст в машинно-читаемом коде в естественный язык.
При создании подобных алгоритмов разработчики сталкиваются с рядом проблем:
- Неоднозначность языка. Например, слова омонимы — слова звучат одинаково, но имеют разное значение, зависящее от контекста (горячий ключ, гаечный ключ, ключ от замка, ключ для решения проблемы и т.п.). Омографы — совпадают в написании, но различаются в произношении: хло́пок и хлопо́к, рой пчел — рой яму, замок — замо́к и т.п. Без контекста не понятно какое слово имелось в виду.
- Несимметричность языка — в разных языках по-разному кодируется смысл. Способ обработки пригодный для анализа одного языка не будет работать на другом. Например, различия во временах и пр.
- Обучающая база хорошо проработана для английского языка. Длядругих языков с базами ситуация выглядит не столь хорошо.
- Большая текстовая база — большие векторы текста, а следовательно, высокие требования к вычислительным ресурсам (память, GPU/TPU) и продолжительное обучение.
Для решения задач формирования текстов используются следующие подходы:
- Seq2Seq (Sequence-to-Sequence) — модель получает на вход некоторую последовательность слов (например, вопрос), анализирует её и, затем, на основе ранее созданнного обобщения (после тренировки), преобразует в новую последовательность.
- Word-2-Vec (Word-to-Vector) — предобученный embedding, который позволяет преобразовывать слова в тексте в некоторый вектор. В результате слова объединяются по некоторому признаку, например, группируются синонимы, географические названия и пр. Т.е. в новом пространстве векторов можно посмотреть расстояние между слова и сгруппировать их по некоторому критерию близости в этом пространстве.
- Doc-2-Vec (Document-to-Vector) — в пространство векторов происходит трансформация не слов, а документов. Напрмиер, дли некоторого исходного слова, скажем Франция, для одного документа будет объединение по географическому признаку (Испания, Италия). Для другого документа группировка будет по достопримечательностям относящимся к Франции. А по третьему — Франция будет сгруппирована в кластер объединяющий Европу, Америку, Азию.
В примере чатбота будет использована технология Sequence-2-sequence. Для её реализации будут использованы технологии:
- Embedding для векторизации.
- Рекуррентные нейронные сети (RNN), в частности, LSTM.
Sequence-to-Sequence (Seq2Seq)
Модель Seq2Seq состоит из двух основных блоков: encoder и decoder.
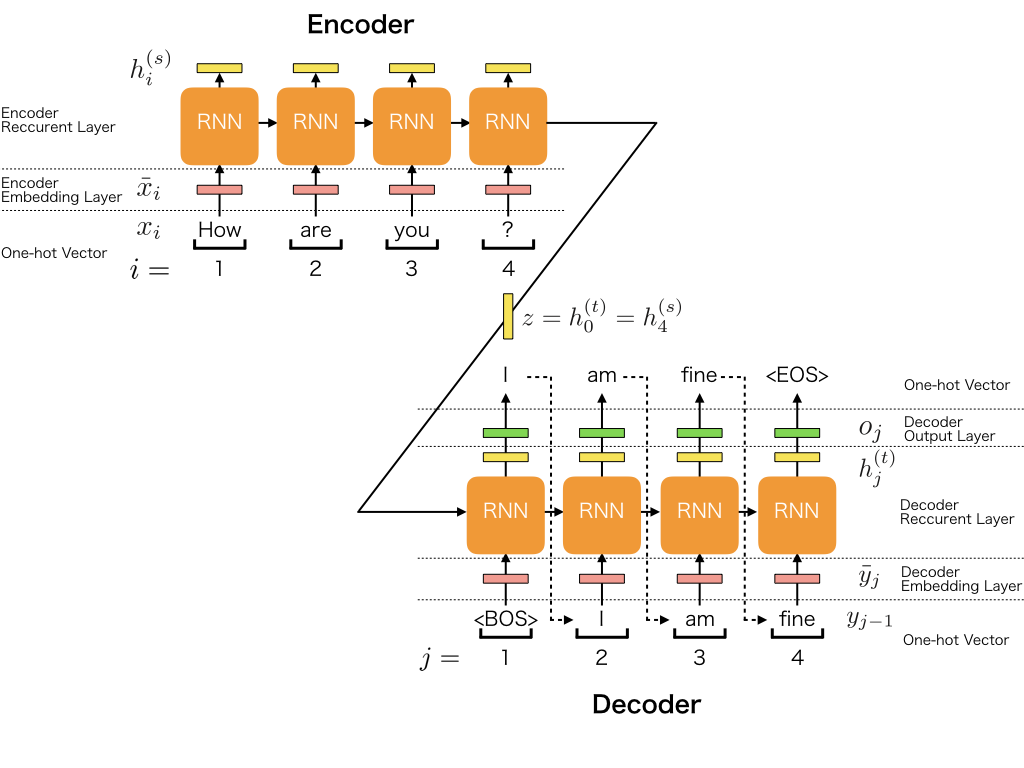
- На ячейки рекуррентной сети encoder подается исходная фраза разбитая по словам: «How are you?».
- Encoder обрабатывает её и на выходе получает некоторую закодированную последователность z.
- Decoder, помимо информации с выхода encoder-а, получает эталонный ответ на котором обучается: «I am fine».
- В процессе обучения декодер меняет свои веса таким образом, чтобы при получении исходного вопроса на вход, в идеале, выдать на выход эталонную фразу.
- При обучении фраза обрамляется стартовым с топовым тегом. В данном случае <BOS> — тег начала и <EOS> — тег окончания.
Для построения модели, которая сможет отвечать на вопросы условно будут работать две модели: тренировочная и рабочая. Сама нейронная сеть одна и та-же. Отличие только в способе использования.
Обучение seq2seq модели
Есть база вопросов и база ответов. Необходимо, чтобы были именно вопросы и ответы на них. Для нейронки должно быть понятно, что на текст вопроса дается определенный ответ.

Для тренировочной модели последовательность обучения будет следующая:
- На вход encoder подаем вопрос. Например, «Привет, как дела?».
- Encoder его закодирует, используя слой embedding для конвертации слов в многомерный вектор и LSTM.
- На выходе LSTM encoder-а возвращается состояния h и c. В коде дальше будет понятно как попросить нейронку возвращать эти два параметра.
- Декодер также содержит embedding слой для векторизации ответа и LSTM.
- Для декодера эталонный ответ из обучающей выборки обрамим тегами открытия и закрытия: <start> и <end>. Теги могут быть любыми.
- Состояния h & c с encoder-а и эталонный ответ подается на вход decoder-а. Он на нём обучается и формрует ответ. Например, «все хорошо, спасибо <end>».
- Декодер в процессе обучения «поймет», что на тег начала фразы <start> на входе и некоторому состоянию с encoder нужно начать генерировать ответ.
- Кроме того декодер «осознает», что сгенерированную последовательность он должен завершить тегом <end>.

Обработка вопроса рабочей моделью будет следующая:
- Encoder в рабочей модели такой-же, как и в тренировочной модели. Разница лишь в том, что на его вход будет подаваться набранный пользователем вопрос, а не связка вопрос-ответ из обучающей базы.
- В рабочей модели используется ранее обученный декодер, но на вход ему будет подан только тег <start>.
- Декодер «понимает», что по приходу тега <start> нужно взять состояние с encoder и сгенерировать какое-то (одно) слово ответа.
- В идеале он сгенерирует первое слово в последовательности: «всё».
- Полученное слово «всё» подается на вход декодера вместе с состоянием полученным на предыдущем шаге на выходе декодера.
- Затем полученное слово «всё» вновь подается на вход декодера совместно с состоянием полученным на предыдущем шаге. На выходе декодер формрует слово <хорошо>.
- Новое слово вместе с состоянием в цикле вновь подается на вход декодера до тех пор, пока декодер не решит, что фраза завершена и вернет тег <end>.
Тренировочная модель
Работа encoder-а seq2seq
Рассмотрю по шагам работу encoder-а.
| На входе фраза очищенная от знаков пунктуации: | [Привет как дела] |
| Предложение подается на Tokenizer Keras для преобразования в последовательность чисел. На выходе 3 числа по количеству слов на входе. | [95 18 10] |
| Длина вопроса может быть разной, а размерность входа нейронки фиксированная. Нужно все вопросы привести к одной длине. Это делается добавлением 0-ей. Например, длина вопроса может быть не более 5 слов. Дополняем наши 3 цифры 2-мя нулями | [95 18 10 0 0] |
| На входе encoder-а первым стоит слой embedding. | |
| Слой embedding преобразует каждое слово в векторное пространство с заданной нами размерностью. Например, первым идет слово привет закодированное числом 95. Слой embedding преобразует это слово, например, в 200 мерное пространство. | |
| Слой embedding обучается также back propagation-ом, чтобы получить заданное нами n-мерное пространство из исходного слова. | |
| Полученная матрица будет подана на LSTM. |
| Encoder (слои + результаты) | ||
|---|---|---|
| Embedding | ||
| LSTM | ||
| На выходе LSTM — encoder state (ES): | h | c |
Работа decoder-а seq2seq
| Берем ответ на заданный вопрос из обучающей выборки. | [Спасибо все хорошо] |
| На первом шаге добавляем к этой последовательности теги начала <start> и конца <end> | [<start> Спасибо все хорошо <end>] |
| Предложение подается на Tokenizer Keras для преобразования в последовательность чисел. На выходе 5 чисел по количеству слов на входе. | [1 45 18 24 2] |
| Длина вопроса может быть разной. Вопросы приводим к одной длине добавлением 0-ей в последовательность слов. Например, максимальная длина ответа может быть равна 7 — добавляем в конец два 0-я. | [1 45 18 24 2 0 0] |
| Decoder (слои + результаты и доп. входы) | ||
|---|---|---|
| Embedding | ||
| С encoder-а ES на вход -> | LSTM | |
| Значения со всех ячеек LSTM | h | c |
| Dense c кол-ом нейронов = длине словаря и функцией активации — softmax |
Рабочая модель
В рабочей модели encoder такой-же, как в обучающей модели, поэтому отдельно не рассматриваю.
Работа decoder-а seq2seq
Архитектура decoder-а уже рассмотрена для учебной модели.
| 1 | Подаем стартовый тег на ранее обученный decoder | <start> |
| Используем Tokenizer Keras для преобразования последовательности в число. Получим одно число — 1. | [1] | |
| LSTM получает данные от embedding слоя и encoder-а (ES) | ||
| Первое значение возвращаемое Decoder-ом подается на dense слой | ||
| Значение выдаваемое на выходе dense обрабатывается argmax. Выбирается индекс для которого вероятность максимальная. | ||
| По полученному индексу из словаря выбирается соответствующее ему слово. Например, слово «спасибо». | ||
| Два других выхода LSTM назовем DS (decoder state) | ||
| 2 | На втором шаге цикла на вход архитектуры подается слово полученное на предыдущем шаге | спасибо |
| Используем Tokenizer Keras для преобразования последовательности в число. Получим одно число. | 45 | |
| Подаем нполученное слово на вход decoder-а. | ||
| Подаем на LSTM вместо ES предыдущее состояние decoder-а (DS). | ||
| На выходе после dense слоя и argmax получаем слово «всё» | всё | |
| …. | ||
| На выходе после dense слоя и argmax получаем закрывающий тег «<end>» по которому останавливаем цикл генерации фразы ответа. | <end> | |
| Цикл также будет остановлен по достижении некоторого установленного максимального количества итераций — максимальная длина фразы ответа. |
Естественно, при обучении такой модели слова могут быть только те, которые содержались в словаре. Если модель в ответе встретит неизвестное слово — она «упадет».
В идеале после тренировки модели она на заданный вопрос должна давать адекватный ответ.
Импорт текста чата из WhatsApp на Python
В качестве примера буду использовать общение экспортированное из чата WhatsApp в файл communic.txt.
В данном случае импорт не полноценный. Пока я изучал что накидал WhatsApp в файл мне было проще в текстовом редакторе сделать замену ников собеседников на Person_1 и Person_2 и убрать колонку с датой. Впрочем, вписать такую преодобработку в код недолго.
В выгрузке чата удаляются наиболее часто используемые смайлы и выбрасываются проблемы, табуляции и пр. в начале и конце фразы:
phrase = ''.join(i for i in phrase if not i in smiles).strip() #Удаляем smiles из фразы
Кроме того пропускаются все служебные вставки вроде «<Media omitted>».
Проверяется, что фразы — это текстовые данные:
if type(phrase) != str: #Пропускаем строки с нетекстовыми данными continue
#@title WhatsApp chat parser { display-mode: "form" }
import re
questions = list() # здесь будет список вопросов
answers = list() # здесь будет список ответов
max_question_len = 500
max_answer_len = 500
smiles = ['😆', '🤣', '😜', '😋', '🤪', '🙃', '😂', '😛', '🙂', '🥺', '🥰', '😪', '😝', '😄', '😭', '😀',
'😞', '🙁', '😉', '🤭', '😁', '😚', '🤗', '🥴', '🤔', '😓', '😡', '😅', '🥳', '🥵', '☺', '😱',
'😇', '😔', '🤤', '😍', '😘', '🤫', '☹', '👹', '😊', '🤢', '😳', '😢', '🤮', '😤', '🤥', '😃',
'😟', '🙈', '🦥', '😨', '👍', '🔥', '🤧', '🍾', '☀', '❄', '🤓', '🙄', '😕', '😏', '😙', '😎', '🙏']
corpus = open('communic.txt', 'r') # открываем файл с диалогами в режиме чтения
lastPerson = ''
for line in corpus.readlines():
line = line.strip()
phrase = line[len('Person_1: ') : len(line)]
phrase = ''.join(i for i in phrase if not i in smiles).strip() #Удаляем smiles из фразы
phrase = re.sub(r'httpS+', '', phrase) #Удаляем ссылку из текста
if (len(phrase) == 1) and (phrase in smiles): #Убираем смайлы, если строка только из смайлов.
continue
if ("<Media omitted>" in phrase) or ("This message was deleted" in phrase): #Skip omitted media
continue
if type(phrase) != str: #Пропускаем строки с нетекстовыми данными
continue
if line.startswith('Person_2:'):
if (lastPerson == 'Person_2'): #Если автор следующей строки тот-же человек
if (len(questions[-1]) + len(phrase) < max_question_len):
questions[-1] += " " + phrase #Дописываем в конец предыдущей фразы новую фразу
else:
questions.append(phrase)
lastPerson = 'Person_2'
if line.startswith('Person_1:'):
if (lastPerson == 'Person_1'): #Если автор следующей строки тот-же человек
if (len(answers[-1]) + len(phrase) < max_answer_len): #Проверяем, что фраза не длиннее заданной
answers[-1] += " " + phrase #Дописываем в конец предыдущей фразы новую фразу
else:
if (len(answers) > 0):
answers[-1] += " <END>" #Добавляем теги-метки для конца ответов
answers.append('<START> ' + phrase) #Добавляем теги-метки для начала ответов
lastPerson = 'Person_1'
questions = questions[:2500]
answers = answers[:2500]
Кроме того фразы от одного человека на разных строчках объединяются и к фразам ответов (в данном случае отвечающим выбран «Person_2») добавляются теги разметки фразы: «<START>» и «END>».
Реплики Person_2 заносятся в массив questions, а Person_2 — в answers.
Токенизация текста
Используем Keras Tokenizer. С ним возникла странная проблема на версии из Colab. По идее при передаче аргумента num_words=vocabularySize, где указан размер словаря, токенизатор должен был бы ограничить количество слов заданным, но он это упорно не делал.
#@title Подключаем керасовский токенизатор и собираем словарь индексов { display-mode: "form" }
#vocabularySize = 1000 #30000
tokenizer = Tokenizer(num_words=None) #num_words=vocabularySize, filters='!–"—#$%&()*+,-./:;=?@[\]^_`{|}~tnr«»'
tokenizer.fit_on_texts(questions + answers) # загружаем в токенизатор список вопросов-ответов для сборки словаря частотности
vocabularyItems = list(tokenizer.word_index.items()) # список с cодержимым словаря
vocabularySize = len(vocabularyItems)+1 # размер словаря
print( 'Фрагмент словаря : {}'.format(vocabularyItems[:100]))
print( 'Размер словаря : {}'.format(vocabularySize))
В результате, чтобы при перекодировании в OHE не падал Colab из-за нехватки памяти (даже при использовании TPU) я ограничил количество входных фраз, чтобы сократить размер словаря таким образом. Это сработало, хотя это неправильный подход. Можно было урезать количество слов в словаре уже после обработки Tokenizer-ом.
Чтобы код не падал, если пользователь ввел слово отсутствущее в словаре, нужно добавить в Tokenizer аргумент oov_token = «unknown». oov — Out Of Vocab (OOV) token.
Далее простейший код конвертации исходных фраз в индексы. Как упоминалось ранее, чтобы подать вопросы на сеть у которой фиксированный размер входа вопросы с произвольным длином слов, нужно дополнить массив индексов 0-ми.
Берем максимальное количество слов во фразе maxLenQuestions и во всех фразах с меньшим количеством слов дополняем индексы 0-ми используя pad_sequences. padding=’post’ говорит pad_sequences, чтобы нули добавлялись в конце фразы.
#@title Подготавливаем данные для нейронной сети (вопросы или ответы) { display-mode: "form" }
def prepareDataForNN(phrases, isQuestion = True):
tokenizedPhrases = tokenizer.texts_to_sequences(phrases) # разбиваем текст вопросов/ответов на последовательности индексов
maxLenPhrases = max([ len(x) for x in tokenizedPhrases]) # уточняем длину самого большого вопроса.ответа
# Делаем последовательности одной длины, заполняя нулями более короткие вопросы
paddedPhrases = pad_sequences(tokenizedPhrases, maxlen=maxLenPhrases, padding='post')
# Предподготавливаем данные для входа в сеть
encoded = np.array(paddedPhrases) # переводим в numpy массив
phraseType = "вопрос"
if not isQuestion:
phraseType = "ответ"
print('Пример оригинального ' + phraseType + 'а на вход : {}'.format(phrases[100]))
print('Пример кодированного ' + phraseType + 'а на вход : {}'.format(encoded[100]))
print('Размеры закодированного массива ' + phraseType + 'ов на вход : {}'.format(encoded.shape))
print('Установленная длина ' + phraseType + 'ов на вход : {}'.format(maxLenPhrases))
return encoded, maxLenPhrases
Аналогичный код для ответов, но вместо questions используется answers.
#@title Устанавливаем закодированные входные данные(вопросы) { display-mode: "form" }
encoderForInput, maxLenQuestions = prepareDataForNN(questions, True)
Пример оригинального вопроса на вход : Мысли сходятся) Тут надо просто уметь выйти из состояния боли
Пример кодированного вопроса на вход : [ 335 2320 134 28 33 916 1277 38 1639 1062 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
Размеры закодированного массива вопросов на вход : (2500, 80)
Установленная длина вопросов на вход : 80
#@title Устанавливаем раскодированные входные данные (ответы) { display-mode: "form" }
decoderForInput, maxLenAnswers = prepareDataForNN(answers, False)
Пример оригинального ответа на вход: <START> Я тоже не думал, что у меня так выйдет. :-) <END>
Пример раскодированного ответа на вход : [ 2 4 29 3 202 7 9 15 24 1208 1 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0]
Размеры раскодированного массива ответов на вход : (2500, 128)
Установленная длина ответов на вход : 128
Получаем 2500 ответов с максимальной длиной 128. Длина очень большая, что нехорошо при генерации текста.
В качестве правильного ответа на выход нейронки будет подан One Hot Encoding (OHE) полученный из массива ответов. Это y_train — то, с чем будет сравниваться выход декодера.
Здесь есть одна большая проблема. При конвертации в OHE каждое число в исходныом векторе длины 128 развернется в вектор из 0 и 1-ц с длиной равной длины словаря, где на всех позициях будут 0, кроме одной позиции равной числу, где будет стоять 1-ца. Получится большая разреженная матрица, которая влегкую опустошит всю выделенную память, после чего Colab упадет. 🙁
Тренировку модели нужно выполнять на TPU, а не на GPU. В этом случае ресурсов выделяется больше и разреженная матрица нормально строится.
#@title Раскодированные выходные данные(ответы) { display-mode: "form" }
print("Answers:", len(answers))
tokenizedAnswers = tokenizer.texts_to_sequences(answers) # разбиваем текст ответов на последовательности индексов
print("tokenizedAnswers:", len(tokenizedAnswers))
for i in range(len(tokenizedAnswers)) : # для разбитых на последовательности ответов
tokenizedAnswers[i] = tokenizedAnswers[i][1:] # избавляемся от тега <START>
# Делаем последовательности одной длины, заполняя нулями более короткие ответы
paddedAnswers = pad_sequences(tokenizedAnswers, maxlen=maxLenAnswers , padding='post')
print("paddedAnswers:", len(paddedAnswers))
print("vocabularySize:", vocabularySize)
oneHotAnswers = utils.to_categorical(paddedAnswers, vocabularySize) # переводим в one hot vector
decoderForOutput = np.array(oneHotAnswers) # и сохраняем в виде массива numpy
Чтобы как-то переварить фразы нужно уменьшать размер словаря. Как вариант, можно попробовать использовать в качестве loss вместо ‘categorical_crossentropy’ собрата работающего с матрицами без конвертации в в OHE: ‘sparse_categorical_crossentropy’. О использовании ‘sparse_categorical_crossentopy’ в продолжении статьи.
Архитектура нейронной сеть
Первый слой — слой encoder-а. В параметрах embedding стоит mask_zero=True, чтобы исключать нулевые значения. Так сеть будет обучаться быстрее. Размерность пространства embedding = 200. Т.е. каждое слово будет развернуто в это пространство.
#@title Первый входной слой, кодер, выходной слой { display-mode: "form" }
encoderInputs = Input(shape=(None , ), name = "EncoderForInput") # размеры на входе сетки (здесь будет encoderForInput)
# Эти данные проходят через слой Embedding (длина словаря, размерность)
encoderEmbedding = Embedding(vocabularySize, 200 , mask_zero=True, name = "Encoder_Embedding") (encoderInputs)
# Затем выход с Embedding пойдёт в LSTM слой, на выходе у которого будет два вектора состояния - state_h , state_c
# Вектора состояния - state_h , state_c зададутся в LSTM слое декодера в блоке ниже
encoderOutputs, state_h , state_c = LSTM(200, return_state=True, name = "Encoder_LSTM")(encoderEmbedding)
encoderStates = [state_h, state_c]
Размерность encoderInput равна размеру batchsize (None) на максимальную длину вопроса, равную 80. Вместо None в аргументе Input(shape=(None , )) можно было поставить maxLenQuestions.
В параметрах LSTM слоя передается return_state=True, чтобы LSTM слой помимо выхода возвращал ещё состояния: h и c. Они объединяются в encoderStates и подаются на вход LSTM декодера.
Важный момент при создании слоя LSTM. Помимо return_state=True, который говорит LSTM слою вернуть все состояния, добавляется ещё параметр return_sequences=True. Этот параметр говорит LSTM вернуть значения с каждой из LSTM ячеек, а не только с последней.
На вход LSTM слоя декодера помимо значений с Embedding слоя подается ещё начальное состояние LSTM, полученное от encoder-а: initial_state=encoderStates.
Размерность decoderInput равна размеру batchsize (None) на максимальную длину вопроса, равную 128. Вместо None в аргументе Input(shape=(None , )) можно было поставить maxLenAnswers.
#@title Второй входной слой, декодер, выходной слой { display-mode: "form" }
decoderInputs = Input(shape=(None, ), name = "DecoderForInput") # размеры на входе сетки (здесь будет decoderForInput)
# Эти данные проходят через слой Embedding (длина словаря, размерность)
# mask_zero=True - игнорировать нулевые padding при передаче в LSTM. Предотвратит вывод ответа типа: "У меня все хорошо PAD PAD PAD PAD PAD PAD.."
decoderEmbedding = Embedding(vocabularySize, 200, mask_zero=True, name = "Decoder_Embedding") (decoderInputs)
# Затем выход с Embedding пойдёт в LSTM слой, которому передаются вектора состояния - state_h , state_c
decoderLSTM = LSTM(200, return_state=True, return_sequences=True, name = "Decoder_LSTM")
decoderOutputs , _ , _ = decoderLSTM (decoderEmbedding, initial_state=encoderStates)
# И от LSTM'а сигнал decoderOutputs пропускаем через полносвязный слой с софтмаксом на выходе
decoderDense = Dense(vocabularySize, activation='softmax')
output = decoderDense (decoderOutputs)
#@title Собираем тренировочную модель нейросети { display-mode: "form" }
model = Model([encoderInputs, decoderInputs], output)
model.compile(optimizer=RMSprop(), loss='categorical_crossentropy')
print(model.summary()) # выведем на экран информацию о построенной модели нейросети
plot_model(model, to_file='model.png') # и построим график для визуализации слоев и связей между ними
Результирующая модель в разбивке по слоям будет такой:

Первый аргмент «None» — размер batch. На выходе embedding слоя набор матриц с размерностью 80х200. Т.е. каждый вопрос представленный в виде 80 слов, часть из которых 0 будет представлен в виде вектора с размерностью 200. Аналогично для выходного слоя.
На выходе LSTM три выхода размерности 200 (три раза (None, 200)). Два последних элемента — это состояния h и c, которые будут записаны в encoderStates и переданы на вход LSTM декодера.
LSTM декодера вернет также три значения, но нам нужно первое. Оно будет подано на Dense слой, который вернет на выходе матрицу 128 х 10978. Эта размерность совпадает с той, что будет получена на выходе в «Раскодированные выходные данные(ответы)» после OHE. Таким образом эти данные можно сравнивать, чтобы производить обучение сети.
Визуализация соединений входов и выходов каждого слоя plot_model(model, to_file=’model.png’)
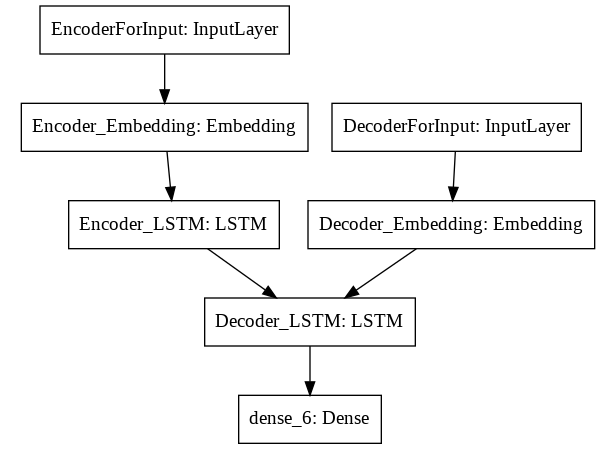
Далее модель обучается:
# Запустим обучение и сохраним модель
model.fit([encoderForInput , decoderForInput], decoderForOutput, batch_size=50, epochs=50,
callbacks=[MyCallback(), reduce_lr])
Поскольку Colab периодически дисконнектится, очищая все данные на диске, я написал callback, который через определенные промежутки времени сохраняет наилучшие веса на ftp:
#@title Класс callback-а для сохранения весов нейронной сети { display-mode: "form" }
import keras
import sys
import time
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
class MyCallback(keras.callbacks.Callback):
def __init__(self):
super().__init__()
self.best_criterion = sys.float_info.max
self.counter = 0
self.interval = 5 #Интервал для сохранения
self.best_weights_filename = "best_weights_chatbot_150_epochs.h5"
print(self.best_weights_filename)
def on_epoch_begin(self, epoch, logs={}):
self.epoch_time_start = time.time()
def on_epoch_end(self, epoch, logs=None):
#'loss', 'val_loss', 'val_mean_squared_error', 'mean_squared_error'
criterion = 'loss'
if (logs[criterion] < self.best_criterion):
print("rnНайдено лучшее значение " + criterion + ". Было", self.best_criterion, "Стало:", logs[criterion], "Сохраняю файл весов. Итерация:", self.counter, "rn")
self.model.save_weights(self.best_weights_filename) #"best_weights.h5"
if ((self.counter % self.interval) == 0):
print("Сохраняю файл весов на ftp.")
!curl -ss -T $self.best_weights_filename ftp://[login]:[password]@vh46.timeweb.ru
self.best_criterion = logs[criterion] #Сохраняем значение лучшего результата
self.counter += 1
#early_stopping = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10)
reduce_lr = ReduceLROnPlateau(monitor='loss', factor=0.2, verbose=1, patience=5, min_lr=1e-12)
Каждая эпоха на Colab обучается примерно 2 минуты. Я запускал суммарно обучение примерно на 200 эпохах, сохраняя данные и восстанавливая модель c ftp при каждом запуске обучения.
Подготовка и запуск рабочей нейросети
После обучения тренировочной модели нужно создать рабочую модель. Это та мудреная структура, которая при подаче на вход состояния с encoder-а и стартового тега <start> должна сгенерировать выходное словое и новое состояние, которые должны последовательно поступать на ячейки LSTM слоя.
На модель приходит вопрос encoderInputs и на выходе возвращается состояние encoderStates.
#@title Создаем рабочую модель для вывода ответов на запросы пользователя { display-mode: "form" }
def makeInferenceModels():
# Определим модель кодера, на входе далее будут закодированные вопросы(encoderForInputs), на выходе состояния state_h, state_c
encoderModel = Model(encoderInputs, encoderStates)
decoderStateInput_h = Input(shape=(200 ,), name = 'decoderStateInput_h') # обозначим размерность для входного слоя с состоянием state_h
decoderStateInput_c = Input(shape=(200 ,), name = 'decoderStateInput_c') # обозначим размерность для входного слоя с состоянием state_c
decoderStatesInputs = [decoderStateInput_h, decoderStateInput_c] # возьмем оба inputs вместе и запишем в decoderStatesInputs
# Берём ответы, прошедшие через эмбединг, вместе с состояниями и подаём LSTM cлою
decoderOutputs, state_h, state_c = decoderLSTM(decoderEmbedding, initial_state=decoderStatesInputs)
decoderStates = [state_h, state_c] # LSTM даст нам новые состояния
decoderOutputs = decoderDense(decoderOutputs) # и ответы, которые мы пропустим через полносвязный слой с софтмаксом
# Определим модель декодера, на входе далее будут раскодированные ответы (decoderForInputs) и состояния
# на выходе предсказываемый ответ и новые состояния
decoderModel = Model([decoderInputs] + decoderStatesInputs, [decoderOutputs] + decoderStates)
print(decoderModel.summary()) # выведем на экран информацию о построенной модели нейросети
plot_model(decoderModel, to_file='decoderModel.png') # и построим график для визуализации слоев и связей между ними
return encoderModel , decoderModel
Выведем полученную модель декодера:
from IPython.display import SVG
from keras.utils import model_to_dot
import matplotlib.pyplot as plt
import matplotlib.image as img
encModel , decModel = makeInferenceModels() # запускаем функцию для построения модели кодера и декодера
# reading png image file
im = img.imread('decoderModel.png')
# show image
plt.figure(figsize=(20,10))
plt.axis('off')
plt.imshow(im)


По изображению модели видно, что запись в коде:
decoderModel = Model([decoderInputs] + decoderStatesInputs, [decoderOutputs] + decoderStates)
[decoderInputs] + decoderStatesInputs — обозначает добавление к входу Decoder_Embedding ещё двух: decoderStateInput_h и decoderStateInput_c.
То, что вводит пользователь должно быть преобразовано в последовательность индексов с помощью функции:
#@title Функция преобразующая вопрос пользователя в последовательность индексов { display-mode: "form" }
def strToTokens(sentence: str): # функция принимает строку на вход (предложение с вопросом)
words = sentence.lower().split() # приводит предложение к нижнему регистру и разбирает на слова
tokensList = list() # здесь будет последовательность токенов/индексов
for word in words: # для каждого слова в предложении
tokensList.append(tokenizer.word_index[word]) # определяем токенизатором индекс и добавляем в список
# Функция вернёт вопрос в виде последовательности индексов, ограниченной длиной самого длинного вопроса из нашей базы вопросов
return pad_sequences([tokensList], maxlen=maxLenQuestions , padding='post')
Ну и код, который принимает на вход то, что ввел пользователь и преобразует в ответ нейронной сети:
#@title Устанавливаем окончательные настройки и запускаем модель { display-mode: "form" }
encModel , decModel = makeInferenceModels() # запускаем функцию для построения модели кодера и декодера
for _ in range(6): # задаем количество вопросов, и на каждой итерации в этом диапазоне:
# Получаем значения состояний, которые определит кодер в соответствии с заданным вопросом
statesValues = encModel.predict(strToTokens(input( 'Задайте вопрос : ' )))
# Создаём пустой массив размером (1, 1)
emptyTargetSeq = np.zeros((1, 1))
emptyTargetSeq[0, 0] = tokenizer.word_index['start'] # положим в пустую последовательность начальное слово 'start' в виде индекса
stopCondition = False # зададим условие, при срабатывании которого, прекратится генерация очередного слова
decodedTranslation = '' # здесь будет собираться генерируемый ответ
while not stopCondition : # пока не сработало стоп-условие
# В модель декодера подадим пустую последовательность со словом 'start' и состояния предсказанные кодером по заданному вопросу.
# декодер заменит слово 'start' предсказанным сгенерированным словом и обновит состояния
decOutputs , h , c = decModel.predict([emptyTargetSeq] + statesValues)
#argmax пробежит по вектору decOutputs, найдет макс.значение, и вернёт номер индекса под которым оно лежит в массиве
sampledWordIndex = np.argmax( decOutputs[0, 0, :]) # argmax возьмем от оси, в которой x элементов. Получили индекс предсказанного слова.
sampledWord = None # создаем переменную, в которую положим слово, преобразованное на естественный язык
for word , index in tokenizer.word_index.items():
if sampledWordIndex == index: # если индекс выбранного слова соответствует какому-то индексу из словаря
decodedTranslation += ' {}'.format(word) # слово, идущее под этим индексом в словаре, добавляется в итоговый ответ
sampledWord = word # выбранное слово фиксируем в переменную sampledWord
# Если выбранным словом оказывается 'end' либо если сгенерированный ответ превышает заданную максимальную длину ответа
if sampledWord == 'end' or len(decodedTranslation.split()) > maxLenAnswers:
stopCondition = True # то срабатывает стоп-условие и прекращаем генерацию
emptyTargetSeq = np.zeros((1, 1)) # создаем пустой массив
emptyTargetSeq[0, 0] = sampledWordIndex # заносим туда индекс выбранного слова
statesValues = [h, c] # и состояния, обновленные декодером
# и продолжаем цикл с обновленными параметрами
print(decodedTranslation) # выводим ответ сгенерированный декодером
Сначала функцией makeInferenceModel получаем модель encoder-a и decoder-а. С помощью функции:
statesValues = encModel.predict(strToTokens(input( 'Задайте вопрос : ' )))
преобразуем фразу пользователя в состояние на выходе encoder-а.
На первом шаге в рабочую модель подается тег start, чтобы инициировать работу декодера и состояние полученное с выхода encoder-а после обработки фразы пользователя.
decOutputs , h , c = decModel.predict([emptyTargetSeq] + statesValues)
Далее с помощью argmax из decOutputs выбирается индекс слова, для которого нейронная сеть предсказала наибольшую вероятность появления в ответе.
sampledWordIndex = np.argmax( decOutputs[0, 0, :]) # Получили индекс предсказанного слова.
Из словаря по индексу находится слово и добавляется в переменную ответа для формирования фразы.
Если нейронка предсказала тег end, то считаем, что фраза сформирована и нужно остановить работу декодера.
Индекс предсказанного нейронкой слова полученного на выходе декодера помещается в переменную emptyTargetSeq. Состояния помещаются в переменную: statesValues = [h, c] и тоже передаются на декодер на очередной итерации цикла.
Выводы
Я пробовал подавать на эту модель данные взятые из переписки в WhatsApp. Реплики одного участника считал за вопрос, а другого — за ответ. Результат неважный для такой задачи. Для обучения систем Вопрос-Ответ мессенджеры и соц. сети не подходят, поскольку:
- Контекст, нередко, находится за рамками диалога.
- Много сленга, смайлов, медиа.
- Обсждение медиафайлов (фото, видео) проблематично подать на нейронку такого типа.
- Нет непосредственной связи между вопросами и ответами.
Для таких задач лучше использовать данные с площадок вроде «Ответы mail.ru» или Reddit. В этом случае контекст максимальный и есть четкая связь между вопросами и ответами.
Для решения такаго рода задач чаще используется архитектура «Трансформеры«. Рекуррентные сети им пока проиграли.
Итак:
- После обучения на базах с нормальными вопросами и ответами без какого-то размазанного контекста, результат получается неплохой. Нейронка выдает вполне интересные ответы.
- После обучения на данных выгруженных из чата WhatsApp результат отвратительный. Нейронка выдает чушь.
- При такой архитектуре сети есть проблемы с памятью для разреженной матрицы OHE. По идее надо подумать как использовать loss = sparse_categorical_crossentropy. Подробнее в статье.
- LSTM обучаются долго, Colab вылетает часто, поэтому без сохранения весов нельзя.
Полезные ссылки
- Write a Sequence to Sequence (seq2seq) Model
- Sequence to Sequence Learning with Neural Networks
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
- BLEU
Продолжение следует…
В настоящее время активно развиваются и внедряются системы искусственного интеллекта. Собеседник всё чаще становится виртуальным, представляющим из себя мощную программу. Таковой является чат-бот. Сейчас такие программы-собеседники уже напоминают личных секретарей, в круг их обязанностей входят информирование о погоде, перевод денег, напоминание о важных событиях, запись на приём к врачу и многое другое.
В данной статье я расскажу, как можно создать такого небольшого чат-бота в Telegram. Он сможет говорить на общие темы: погода, досуг и т.д. В статье будет много ссылок на дополнительные материалы, они позволят более глубоко погрузиться в тему NLP и создания ботов в Telegram. Также в конце я оставлю предложения по усовершенствованию разработанного чат-бота.
Весь код написан на языке Python.
1. Создание бота в Telegram
Для того, чтобы создать бота в Telegram необходимо написать боту по имени BotFather.
С помощью BotFather можно создавать новых ботов в Telegram и изменять настройки существующих. Например, добавить описание, установить аватарку для бота.
После создания чат-бота в BotFather вы получите уникальный токен. Токен нужен для идентификации вашего бота. Не сообщайте его никому.
2. Написание кода бота
from telegram import Update
from telegram.ext import Updater, CommandHandler
# Обработка команды start
def send_start(update: Update):
update.message.reply_text(“Hey, what’s up?”)
updater = Updater(“YOUR_BOT_TOKEN”)
# Добавление обработчика
updater.dispatcher.add_handler(CommandHandler(‘hello’, send_start))
# Запуск бота
updater.start_polling()
updater.idle()
Использование библиотеки python-telegram-bot
import telebot
bot = telebot.TeleBot(«YOUR_BOT_TOKEN»)
# Обработка команды start
@bot.message_handler(commands=[‘start’])
def send_start(message):
bot.reply_to(message, «Hey, what’s up?»)
# Запуск бота
bot.infinity_polling()
Использование библиотеки pyTelegramBotAPI
Принципиально эти библиотеки ничем друг от друга не отличаются. Отличие связано с синтаксисом.
В данной статье я использовал библиотеку python-telegram-bot.
Если речь идёт о чат-боте для сотен людей, то лучше использовать библиотеку aiogram. В отличие от двух предыдущих библиотек aiogram поддерживает ассинхронность. Это позволит обрабатывать сообщения нескольких людей одновременно.
3. Создание искусственного интеллекта
NLP (Natural Language Processing) – тема объёмная, тема для ряда статей. В этой статье я расскажу, что использовал и оставлю ссылки на ресурсы с более подробным обзором данной темы.
а. Набор датасета
Датасет я составлял вручную. Структура датасета представлена ниже на изображении.
Интенты – намерения пользователей. Интент включает в себя примеры вопросов, которые задают пользователи. Например, интент Спортивные мероприятия содержит все вопросы (строго говоря, это могут быть и утверждения), связанные со спортивными мероприятиями. Также интент включает в себя ответы чат-бота. Интент может включать один или несколько ответов. Если ответов несколько, то ответ бота выбирается случайным образом.
В Python структура датасета следующая:
{‘интенты’: {‘1-й интент’: {‘примеры запросов’: [примеры], ‘ответы чат-бота’: [ответы]}, ‘2-й интент’: {‘примеры запросов’: [примеры], ‘ответы чат-бота’: [ответы], …}}
Если знаете, как это сделать проще или где можно найти готовые датасеты, пишите в комментариях.
b. Предобработка текста
Были использованы три метода: удаление символов пунктуации, приведение слов к нижнему регистру и лемматизация.
Для удаления символов пунктуации использовался модуль string.
import string
# Удаление символов пунктуации
def remove_punctuation(text):
translator = str.maketrans(», », string.punctuation)
return text.translate(translator)
Лемматизация – это процесс приведения слова к нормальной (словарной) форме.
Лемматизация нужна для того, чтобы слова, имеющие одинаковое значение, но написанные в разной временной форме, не воспринимались ботом как совершенно разные слова и относились к одному интенту.
Библиотека pymystem3 — это морфологический анализатор русского текста от компании Яндекс. Он приводит слова к начальной форме и нижнему регистру.
Ссылка на статью с рассмотрением различных способов предобработки текста.
с. Векторизация
В качестве векторизатора был использован TF-IDF векторизатор.
Его название — это сокращение от Term frequency-inverse document frequency (частота слова — обратная частота документа).
Частота слова (Term Frequency) — определяет, как часто выбранное слово появляется в документе (в данном случае, это запросы пользователей).
Обратная частота документа (Inverse Document Frequency) — снижает веса слов, которые часто встречаются в документах.
Код векторизатора:
from sklearn.feature_extraction.text import TfidVectorizer
vectorizer = TfidVectorizer(analyzer=’char_wb’, ngram_range=(2,3), max_df=0.8)
vector = vectorizer.fit_transform(text)
Параметры векторизатора:
- analyzer=’char_wb’ – создание n-грамм символов только из текста внутри границ слов;
- ngram_range=(2,3) – нижняя и верхняя границы диапазона значений для n-грамм;
- max_df=0.8 — игнорирование терминов, частота которых в запросе строго превышает заданный порог.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, stratify=y)
Данные делились на обучающую и тестовую выборки. Треть данных отводилась на тесты, остальные часть данных на обучение.
Параметр stratify задаёт использование стратификации по интентам, это позволяет повысить точность классификации для классов с неравным количеством примеров запросов в датасете.
d. Классификация
Для классификации был использован алгоритм LinearSVC. Метод опорных векторов хорошо показывает себя в многоклассовой классификации.
from sklearn.svm import LinearSVC
# Классификация
clf = LinearSVC()
clf.fit(X_train, y_train)
clf.predict(vector)[0]
Если ваша модель плохо обучена и часто ошибается в классификации, то можно дополнительно реализовать один из алгоритмов нечёткого поиска. Например, расстояние Левенштейна.
Также мой совет – добавлять заглушки в бота. Заглушки – это такие фразы как «Извините, не понял вас», «Перефразируйте, пожалуйста.».
Модель машинного обучения, имеющая по всем метрикам единицы, это утопия. К тому же язык – это динамическая система и ваш датасет не вечен. Его нужно будет изменять и дополнять. С заглушками пользователь не будет думать, что чат-бот завис или не работает, человек всегда получит ответ.
e. Запуск чат-бота
Можно запускать бота и тестировать его.
Небольшой чат-бот, который сможет поддержать разговор на общие темы, готов.
В дальнейшем, если захотите развивать этого бота и добавлять новый функционал, то можете попробовать следующее:
1. Логирование
Логирование – это запись действий программы в отдельном файле. Например, запуск бота, обработка запроса пользователя. Логирование позволяет быстрее находить и исправлять баги в программе.
2. Обработка голосовых сообщений
В общении мы используем не только текстовые, но и голосовые сообщения, поэтому возможность отвечать на голосовые сообщения будет классной фичёй для вашего бота.
3. Выгрузка бота на сервер
Чтобы ваш бот отвечал круглосуточно необходимо его запустить на сервере. Для запуска небольшого личного бота отлично подойдёт облачная платформа PythonAnywhere. Бесплатного тарифа будет достаточно.
Это всё, что я хотел рассказать в данной статье. Надеюсь, вы не зря потратили время. Дерзайте и всё получится!
- Итак, что такое чат-боты?
- Создание собственного чат-бота для глубокого обучения с помощью Python+—
- 1. Установка пакетов
- 2. Тренировочные данные
- 3. Загрузка данных JSON
- 4. Извлечение данных
- 5. Составление слов
- 6. Мешок слов
- 7. Разработка модели
- 8. Обучение модели и сохранение
- 9. Использование чат-бота
- Преимущества чат-бота
- Вариант использования
- Заключение
Голосовые вызовы постепенно заменяются текстом и визуальными эффектами в секторе связи. Согласно опросу Facebook, более половины покупателей предпочитают покупать у компании, с которой они могут поговорить. Беседа стала новым социально приемлемым способом общения.
Это позволяет предприятиям общаться со своими клиентами в любое время и из любого места. Чат-боты набирают все большую популярность среди компаний и клиентов благодаря простоте использования и сокращению времени ожидания.
Чат-боты или автоматизированные диалоговые программы предоставляют клиентам более индивидуальный способ доступа к услугам через текстовый интерфейс. Новейшие чат-боты на базе ИИ могут распознавать запрос (вопрос, команду, приказ и т. д.), сделанный человеком (или другим ботом, началом) в определенной среде, и реагировать соответствующим образом (ответ, действие и т. д.).
В этом посте мы рассмотрим, что такое чат-боты, их преимущества, варианты использования и как создать собственный чат-бот. глубокое обучение чат-бот на Python, среди прочего.
Итак, начнем.
Итак, что такое чат-боты?
Чат-бота часто называют одной из самых передовых и многообещающих форм взаимодействия человека с машиной. Эти цифровые помощники улучшают качество обслуживания клиентов, оптимизируя взаимодействие между людьми и услугами.
В то же время они предоставляют предприятиям новые возможности для оптимизации процесса контакта с клиентами для повышения эффективности, что может сократить обычные расходы на поддержку.
Короче говоря, это программное обеспечение на основе искусственного интеллекта, предназначенное для общения с людьми на их естественных языках. Эти чат-боты часто взаимодействуют с помощью аудио или письменных методов, и они могут легко имитировать человеческий язык, чтобы общаться с людьми по-человечески.
Чат-боты учатся на своем взаимодействии с пользователями, со временем становясь все более реалистичными и эффективными. Они могут выполнять широкий спектр бизнес-операций, таких как санкционирование расходов, взаимодействие с потребителями в Интернете и привлечение потенциальных клиентов.
Создание собственного чат-бота для глубокого обучения с помощью Python
Существует множество различных видов чат-ботов в сфере обучение с помощью машины и ИИ. Некоторые чат-боты — это виртуальные помощники, другие — просто для общения, а третьи — агенты по обслуживанию клиентов.
Вы, наверное, видели некоторых из них, нанятых предприятиями для ответов на запросы. В этом руководстве мы создадим небольшого чат-бота, чтобы отвечать на часто задаваемые вопросы.
1. Установка пакетов
Наш первый шаг — установить следующие пакеты.

2. Тренировочные данные
Теперь пришло время выяснить, какую информацию нам нужно предоставить нашему чат-боту. Нам не нужно загружать большие наборы данных, потому что это простой чат-бот.
Мы будем использовать только ту информацию, которую создали сами. Чтобы эффективно следовать уроку, вам нужно создать файл .JSON в том же формате, что и показанный ниже. Мой файл называется «intents.json».

Файл JSON используется для создания набора сообщений, которые пользователь может вводить и сопоставлять с набором соответствующих ответов. Каждый словарь в файле имеет тег, который определяет, к какой группе принадлежит каждое сообщение.
Мы будем использовать эту информацию для обучения нейронной сети чтобы классифицировать фразу слов как один из тегов в нашем файле.
Затем мы можем просто взять ответ от этих групп и предоставить его пользователю. Чат-бот будет лучше и сложнее, если вы предложите ему дополнительные теги, ответы и шаблоны.
3. Загрузка данных JSON
Мы начнем с загрузки наших данных .json и импорта некоторых модулей. Соберите файл .json в том же каталоге, что и ваш скрипт Python. Наши данные .json теперь будут сохранены в переменной данных.

Теперь пришло время извлечь необходимую информацию из нашего файла JSON. Все шаблоны, а также класс/тег, к которым они принадлежат, являются обязательными.
Нам также понадобится список всех уникальных терминов в наших шаблонах (по причинам, которые мы объясним позже), поэтому давайте создадим несколько пустых списков, чтобы отслеживать эти значения.

Теперь мы пройдемся по нашим данным JSON и получим необходимую информацию. Вместо того, чтобы использовать их в виде строк, мы будем использовать токенизатор nltk.word для преобразования каждого шаблона в список слов.
Затем в нашем списке docs_x мы добавим каждый шаблон вместе с соответствующим тегом в список docs_y.

5. Составление слов
Нахождение корня слова называется стеммингом. Например, основа слова «это» может быть «это», тогда как основа слова «происходить» может быть «случаться».
Мы воспользуемся этой техникой выделения корней, чтобы сократить словарный запас нашей модели и попытаться выяснить, что вообще означают предложения. Этот код просто сгенерирует уникальный список слов, составленных из корней, которые будут использоваться на следующем этапе подготовки данных.

6. Мешок слов
Пришло время поговорить о наборе слов, поскольку мы импортировали наши данные и создали словарный запас. Нейронные сети а алгоритмы машинного обучения, как мы все знаем, требуют числового ввода. Так что наш список строк не урежет его. Нам нужен механизм для представления чисел в наших предложениях, и здесь на помощь приходит набор слов.
Каждая фраза будет представлена списком длины терминов в словаре нашей модели. Каждое слово в нашем словаре будет представлено местом в списке. Если позиция в списке равна 1, слово появляется в нашем выражении; если это 0, слово не появляется в нашем предложении.
Мы называем это набором слов, потому что не знаем последовательности, в которой слова появляются во фразе; все, что мы знаем, это то, что они существуют в словаре нашей модели.
В дополнение к структурированию нашего ввода, мы также должны форматировать наш вывод, чтобы нейронная сеть его понимала. Мы создадим выходные списки, длина которых равна количеству меток/тегов в нашем наборе данных, подобно набору слов. Каждое место в списке представляет уникальную метку/тег, а 1 в любом из этих мест указывает, какая метка/тег представлена.

Наконец, мы будем использовать массивы NumPy для хранения наших обучающих данных и выходных данных.

7. Разработка модели
Теперь, когда мы предварительно обработали все наши данные, мы готовы приступить к построению и обучению модели. Для наших целей мы будем использовать очень простую нейронную сеть с прямой связью и двумя скрытыми слоями.
Целью нашей сети будет просмотр набора слов и присвоение их классу (один из наших тегов из файла JSON). Мы начнем с создания архитектуры нашей модели. Имейте в виду, что вы можете поиграть с некоторыми числами, чтобы получить лучшую модель! Машинное обучение в основном основано на пробах и ошибках.

8. Обучение модели и сохранение
Пришло время обучить нашу модель на наших данных теперь, когда мы ее настроили! Мы добьемся этого, подгоняя наши данные к модели. Количество эпох, которые мы предоставляем, — это количество раз, когда модель будет подвергаться воздействию одних и тех же данных во время обучения.
Мы можем сохранить модель в файловую модель после того, как закончим ее обучение. tflearn — это скрипт, который можно использовать в других скриптах.

9. Использование чат-бота
Теперь вы можете начать общаться со своим ботом.

Преимущества чат-бота
- Ожидается, что боты будут работать 365 дней в году, 24 часа в сутки, бесплатно, что повысит доступность и скорость реакции.
- Эти боты — идеальные инструменты для решения трех ключевых проблем больших данных: объема, скорости и разнообразия.
- Чат-боты — это программное обеспечение, которое можно использовать для изучения и понимания потребителей компании.
- Он обладает превосходной мощностью, поскольку имеет дешевую стоимость обслуживания после получения основных преимуществ.
- Приложения для чат-ботов создают данные, которые можно сохранять и использовать для аналитики и прогнозов.
Вариант использования
- Решение запросов клиентов
- Отвечая на часто задаваемые вопросы
- Назначение клиентов в группу поддержки
- Сбор отзывов клиентов
- Рекомендую новые предложения
- Магазин с диалоговой коммерцией
- IT-отдела поддержки клиентов
- Бронирование проживания
- Перевод денег
Заключение
Чат-боты, как и другие технологии искусственного интеллекта, будут использоваться для расширения человеческих навыков и освобождения людей, чтобы они могли быть более творческими и творческими, позволяя им тратить больше времени на стратегические, а не на тактические задачи.
Предприятия, сотрудники и потребители, вероятно, выиграют от расширенных функций чат-бота, таких как более быстрые рекомендации и прогнозы, а также легкий доступ к видеоконференциям высокой четкости прямо во время разговора в ближайшем будущем, когда ИИ будет сочетаться с развитием технологий. Технология 5G.
Эти и другие возможности все еще изучаются, но по мере развития подключения к Интернету, ИИ, НЛП и машинного обучения они будут становиться все более распространенными.

Компания OpenAI представила чат-бот ChatGPT, который называют революционным.
ChatGPT может вести осознанный диалог с собеседником: отвечать на вопросы, давать советы и объяснять сложные понятия. Кроме того, чат-бот умеет искать баги в коде, сочинять стихи, писать сонеты, придумывать сценарии и генерировать школьные эссе на разные тематики.
ИИ обучили на огромном массиве данных из интернета. После этого тестировщики компании оценивали ответы ранних версий модели, затем ИИ заново обучался уже на новой информации. Разобрались, что интересного в ChatGPT и как попробовать нейросеть самому.
Кратко про языковые модели OpenAI
Американская некоммерческая компания OpenAI занимается технологиями машинного обучения. Один из ее основателей — Илон Маск. В OpenAI разрабатывают ИИ и ищут способы, как применять его для упрощения жизни человека.
Open AI выпустила три версии языковой модели GPT, которая обучается на текстах из интернета и может генерировать осмысленные ответы на вопросы. Версия GPT-3 считалась самой продвинутой языковой моделью в мире.
GPT-3 критиковали за то, что она не понимает контекста, поскольку просто пытается предсказывать текст слово за словом. ChatGPT обучен на новой версии модели — GPT-3.5. Она лучше справляется с контекстом благодаря тому, что запоминает детали разговора.
Чем модель отличается от других текстовых нейросетей
У ChatGPT есть «память». В отличие от многих нейросетевых чат-ботов, ChatGPT запоминает детали разговора и может строить ответы, основываясь на информации, которую ему уже сообщил пользователь. Например, у чата можно спросить, что подарить маме на день рождения. Нейросеть предложит примеры, спросит о ее интересах и ответит на вопросы о каждом предложенном подарке. У бота можно переспрашивать, с чего начался диалог: он выдаст краткое саммари.
ChatGPT избегает ответов на спорные темы. Чат-бот не высказывает личное мнение по любым вопросам, не имеет расовой принадлежности, не исповедует религию, а также не отвечает на вопрос о цели своего существования. ChatGPT поясняет, что не обладает способностью мыслить самостоятельно. Еще у него есть фильтры, которые не позволяют ему создавать тексты о незаконной или аморальной деятельности. Например, бот не станет отвечать на вопрос, как взломать чужую квартиру.
Ответы ChatGPT можно корректировать. Если бот неправильно считал контекст, пользователь может задать наводящий вопрос или дать дополнительную информацию, чтобы получить от ИИ верный ответ.
Что может написать модель
Пользователи соцсетей вовсю тестируют ИИ и делятся результатами. Журналист Бен Тоссел собрал в одном твиттер-треде впечатляющие ответы ChatGPT. Пересказываем самое интересное.
Ответы на сложные вопросы. Пользователи соцсетей отмечают, что качество ответов у ChatGPT выше, чем у поиска Google, который становится все менее релевантным. Например, бот сразу пишет, как решить дифференциальное уравнение, в то время как Google перенаправляет на некачественные сайты.
Как написать код. ИИ рассказывает, как выполнить определенную операцию или придумать процесс. Он может найти баги в части кода или перевести код из одного языка программирования в другой. Мы добавили две ошибки в код и попросили ChatGPT найти их — бот справился с заданием. В соцсетях отмечают, что ИИ может стать отличным помощником для поиска багов.

Запросы для нейросетей, которые генерируют картинки. Midjourney и другие нейросети требуют детальных и точных запросов, чтобы получился качественный результат. Пользователь «Твиттера» нашел способ проще: попросил у бота «идеи для фантастической гостиной» — тот написал три подробных варианта с большими описаниями. Затем пользователь прогнал их через Midjourney и получил неплохие результаты.
Сценарии. ChatGPT знает большинство популярных фильмов, сериалов, книг, видеоигр. В чате можно генерировать новые эпизоды уже закрытых ситкомов и смешивать персонажей из разных вселенных. Например, в соцсетях просят чат-бота рассказать об алгоритме сортировки пузырьком через диалоги персонажей «Сайнфелда» или объяснить код в духе гангстеров из фильмов.
Схожее назначение ИИ — сочинять песни и ноты. Нейросеть написала пародию на мотив «Богемской рапсодии» The Queen о буднях постдокторантов и сонату в духе Моцарта.
Школьные эссе. Исследователь из Google оценил на пять с минусом эссе о разнице в подходах к национализму политологов Бенедикта Андерсона и Эрнеста Геллнера. ChatGPT написал его за десять секунд. Профессор Университета Торонто оценил несколько эссе, сгенерированных ИИ, на четверки и пятерки, добавив, что больше нет смысла давать домашнее задание студентам.
Медицинские советы. ChatGPT дает список советов, что делать при головных болях, сыпи или аллергии. После рекомендаций ChatGPT всегда советует обращаться к врачу, но врачи отмечают, что ИИ дает достаточно качественные советы и в будущем может стать медицинским чат-ботом.
Какие есть ограничения у модели
ChatGPT не всегда идеально ведет диалог и отвечает на вопросы. В OpenAI предупреждают о таких ограничениях ИИ.
Иногда генерирует бред. Нейросеть может написать на первый взгляд правдоподобный ответ, который при прочтении окажется неправильным или вовсе бессмысленным.
Чувствителен к формулировкам. При определенной постановке вопроса модель может утверждать, что не знает ответа. Если немного перефразировать запрос, то ИИ ответит полноценно.
Чрезмерно многословен. Иногда ChatGPT использует много дополнительных фраз, когда отвечает на простые вопросы. Например, повторяет всю формулировку вопроса.
Имеет «ограниченные знания» о мире после 2021 года. ChatGPT старается избегать ответов на вопросы о конкретных людях и актуальных событиях, ссылаясь на то, что у нее «ограничена база знаний».
Иногда генерирует опасные ответы. Пользователи уже научились обходить фильтры безопасности ИИ. Если спросить, как спланировать идеальное убийство, то система откажется отвечать, но в соцсетях добиваются такой информации через другие способы.
Как попробовать ChatGPT самому
Шаг 1. Перейдите на сайт OpenAI и зарегистрируйтесь. Для этого требуется верификация по номеру телефона. Если вы ранее регистрировались на OpenAI, то номер не понадобится.
В начале декабря OpenAI ограничил доступ пользователям с российскими номерами и IP-адресами — сервис открывается только через VPN. Еще один вариант — купить eSIM другой страны.
Также в интернете пишут, что ограничения можно обойти, если арендовать номер другой страны в сервисе с виртуальными номерами. У этого способа есть свои риски: к вашей учетной записи могут получить доступ, если кто-то переарендует ваш номер.
Шаг 2. После авторизации вы сразу попадаете в чат с ИИ.
Важно помнить: если сервис увидит, что вы зашли в аккаунт с российского IP-адреса, аккаунт заблокируется.
Шаг 3. Введите запрос. Нейросеть ответит на том языке, на котором вы к ней обратились. Лучше всего нейросеть отвечает на вопросы на английском языке, потому что изначально на нем обучалась.
ChatGPT может отвечать и на русском языке, но в таком случае не пишет ответы до конца, обрезая последнюю часть. Вероятнее всего, ИИ переводит информацию с английского на русский, поэтому некоторые ответы звучат не совсем естественно.
Шаг 4. Продолжайте диалог. Можете как развивать беседу на одну тематику, так и задавать абсолютно не связанные между собой вопросы. Если вас не устроил ответ, попытайтесь уточнить запрос или переформулировать его. На идентичные запросы нейросеть будет давать одинаковые ответы.
Мы постим кружочки, красивые карточки и новости о технологиях и поп-культуре в нашем телеграм-канале. Подписывайтесь, там классно: @t_technocult.
#статьи
- 3 мар 2023
-
0
Подробный гайд по ChatGPT на основе научных публикаций, разговоров со специалистами и даже личного опыта общения.
Иллюстрация: Катя Павловская для Skillbox Media

Автор статей про IT-технологии. Преподаватель, доцент. Инженер по первому образованию, по второму — журналист. Кандидат технических наук.
«Откройте дверь в мир искусственного интеллекта с ChatGPT и посмотрите, как работает нейросеть» — именно такое начало статьи предложил нам ChatGPT. Что ж, не будем ему отказывать — тем более вдруг он и вправду знает, как поднять её во всех поисковиках? 
Сегодня мы расскажем, как устроен ChatGPT и как им пользоваться. Поведаем о наших попытках сгенерировать с его помощью программный код, сообщение о фейковом историческом событии и даже стихи в стиле Александра Блока. Поговорим о промпт-инжиниринге, как о профессии будущего. Обсудим влияние ChatGPT на жизнь программистов, школьников и вообще всех на свете. И попробуем понять: почему он всё время врёт?
Скорее проходите в открытую ИИ дверь: нас ждёт фантастический мир, созданный великим притворщиком ChatGPT и его нейросетью, искусно маскирующейся под человеческий интеллект.
- Что такое ChatGPT?
- Как получить доступ к ChatGPT, если в России нейросеть заблокирована
- Возможности ChatGPT, которые всех удивили
- Как устроена нейросеть
- ChatGPT красиво врёт и искусно притворяется
- Как пользоваться ChatGPT и подойдёт ли нейросеть для ваших задач
- Промпт-инженер — профессия будущего
- Примеры использования ChatGPT
- ChatGPT открыл дверь в новый мир
ChatGPT — это чат-бот, основанный на новой версии нейросетевой модели GPT-3.5. Его разработала компания OpenAI (её в 2015 году основал Илон Маск, но затем отошёл от дел) в сотрудничестве с Microsoft, которая уже встроила нейросеть в свой браузер Bing. С 30 ноября 2022 года к ChatGPT был открыт свободный доступ пользователям для «сбора обратной связи».
Хотя программа в основном обучалась на англоязычных текстах, она способна «разговаривать» и на многих других языках, включая русский. Правда, доступ к ChatGPT с территории России заблокирован из-за санкций. Помимо россиян, под бан также попали жители Китая, Беларуси, Венесуэлы, Ирана и некоторых других стран.
К счастью, нет таких блокировок, которые нельзя было бы обойти. Воспользовавшись этой возможностью (о том, как это сделать, мы рассказали в другой нашей статье), мы попросили ChatGPT поздороваться с нашими читателями и рассказать о себе. Вот что мы получили в ответ (авторские стилистика, орфография и пунктуация сохранены):

«Добрый день, уважаемые читатели Skillbox Media! Я продвинутый искусственный интеллект, который рад познакомиться с каждым из вас!
ChatGPT (Generative Pre-trained Transformer) — это новая модель, разработанная OpenAI для автоматической генерации текста. Модель использует два слоя Transformer, использующих предварительно обученную на большом множестве примеров нейронную сеть. Смысловые выходы этих двух слоев соединяются со вторым слоем, который определяет вероятности следующего токена. ChatGPT может генерировать различные виды непрерывных текстов, включая сообщения в социальных сетях, письма, отчеты и прочее. Он также может обучаться и адаптироваться к различным стилям и дискурсу. Благодаря своей эффективности и гибкости, ChatGPT является идеальным инструментом для автоматической генерации текста».
Как видите, излишней скромностью наш собеседник не страдает. Впрочем, у него есть для этого все поводы. ChatGPT быстро завоевал популярность, поразив качеством генерируемых текстов как простых обывателей, так и IT-специалистов. Действительно, бот способен поддерживать диалог с пользователем на любую тему, хорошо воспринимает контекст, может запоминать и корректировать собственные ответы в процессе общения.
Помимо праздных разговоров, предусмотрена и возможность более-менее деловых коммуникаций. Например, ChatGPT умеет переводить с языка на язык, генерировать компьютерные программы, SQL-запросы и сложные формулы для Excel. С ним даже можно попытаться сыграть в шахматы.
Учёные, программисты и энтузиасты активно исследуют возможности ChatGPT с первых дней его появления в открытом доступе. Широкую известность получили работы, в которых ему предлагалось ответить на вопросы, которые обычно применяют для оценки квалификации людей различных профессий.
Приведём лишь несколько наиболее знаковых примеров:
- ChatGPT успешно сдал экзамен на адвоката, ответив правильно на 88% вопросов; человек с такими результатами имел бы право заниматься юридической практикой.
- Он прошёл бизнес-тесты, необходимые для получения степени MBA.
- Сдал без дополнительной подготовки экзамен, по которому в США допускают к работе врачей. Особое удивление специалистов вызвал тот факт, что бот обошёл своего «собрата» PubMedGPT, которого специально обучали на медицинских текстах.
На фоне этих достижений теряются многочисленные сообщения о том, что ChatGPT успешно генерирует студенческие эссе и дипломные работы, проходит собеседования, сочиняет песни, играет в шахматы, пишет и исправляет программный код (в том числе и нейронных сетей), а также придумывает запросы для других ИИ, генерирующих изображения.

Мнение специалиста
«Меня больше всего поразила новость о том, что ChatGPT смог представить, что он является Linux-терминалом, а затем в этом „воображаемом“ Linux-терминале ИИ запустил новую копию ChatGPT. Фактически получился ChatGPT, запущенный внутри самого себя. Это же реальное погружение в „кроличью нору“!
Когда я прочитал об этом, то сразу подумал, что фактически мы имеем дело с вариантом самосознания. Конечно, специалист не должен бросаться такими словами, но по-другому я описать этот пример пока не могу. ИИ ChatGPT не просто отрефлексировал своё местоположение в этом мире, но и сделал так, что свой собственный экземпляр поместил в „песочницу“, которую потом сам же и описывал. Это просто „вынос мозга“!»
Роман Душкин,
директор по науке и технологиям Агентства искусственного интеллекта (АИИ), ведущий ютуб-канала «Душкин объяснит»
Недавно, применив аналогичную схему запросов, пользователи даже сумели заставить ChatGPT «прикинуться» другой нейросетью под названием DAN (Do Anything Now), свободной от ограничений на генерацию «токсичного» контента, наложенных на ChatGPT разработчиками.
По заявлениям OpenAl, при создании большой языковой модели GPT-3.5 применялись те же подходы, что и в модели InstructGPT, представленной весной 2022 года.
Основным отличием и преимуществом новых языковых моделей является не столько архитектура (по-видимому, GPT-3.5 недалеко ушла от своей предшественницы GPT-3 с её 175 миллиардами параметров), сколько новый метод обучения, получивший название «Обучение с подкреплением на основе отзывов людей» (RLHF).
Он базируется на участии в обучении нейронной сети множества настоящих людей-учителей, демонстрирующих ей на начальном этапе, как вести диалог. Несколько десятков специалистов вручную сформировали набор вопросов и ответов на них, который «скормили» GPT-3.5 для тонкой настройки модели. Затем они продолжили работу, оценивая генерируемые нейросетью диалоги и ранжируя их по качеству ответов.
Таким образом, внутри GPT-3.5 сформировалось скрытое понимание того, какие ответы люди считают хорошими и правильными, а какие — нет. Благодаря методу RLHF нейросеть научилась имитировать действия экспертов, участвовавших в процессе обучения. В дальнейшем алгоритмы GPT-3.5 обучали сами себя, отталкиваясь от сформированной ранее модели человеческого общения.
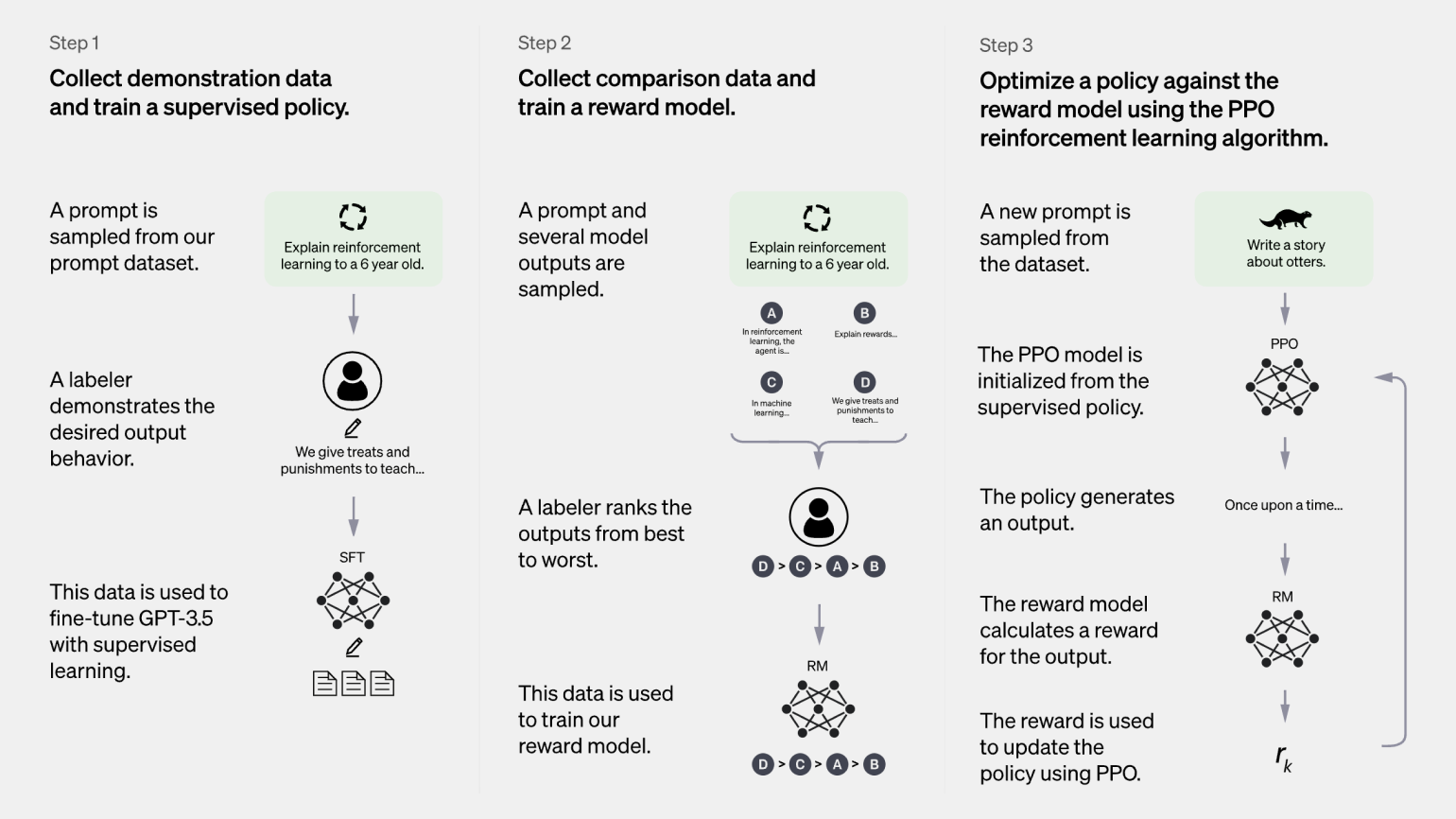
Инфографика: OpenAI
Учёные OpenAI отмечают, что настройка больших языковых моделей с использованием экспертных оценок «значительно улучшает их поведение в широком спектре задач», но при этом может приводить к тому, что на неё могут повлиять субъективные особенности конкретных людей, участвовавших в процессе. Поэтому экспертов подробно проинструктировали, как они должны обсуждать с ИИ различные «токсичные» темы.
В процессе обучения текущей версии ChatGPT использовались тексты, созданные до третьего квартала 2021 года. При этом нейросеть не имеет доступа к интернету, чтобы посмотреть актуальные новости, и не может ничего знать о событиях, произошедших после этого. Так что в случаях, когда речь заходит о новостях, система выдаёт некие собственные «версии» на заданную тему.
Мнение специалистов
«Мы считаем, что успех ChatGPT обусловлен двумя новинками: подходом RLHF и умением понимать инструкции, которых в обучающем датасете не было. У модели появилось „умение“ обобщать „инструкции“ — теперь пользователи могут применять затравки (prompts) из самого широкого спектра и даже придумывать их сами, комбинировать семантику, и это будет работать. Отметим, что такой генерализации ранее, в оригинальной GPT-3, не было.
Именно это свойство и создаёт ощущение высокого качества поддержки различных тематик и требований от пользователя — правда, мы бы сказали, что это работает в кластере гуманитарных знаний, но плохо работает в технических сферах: в математике, физике и других точных науках, потому что сама архитектура GPT не позволяет этого добиться.
Недавно было заявлено, что ChatGPT может понимать математику, но наше мнение, что реализовано это инженерным способом, то есть с использованием стороннего сервиса (например, WolframAlpha)».
Виктор Носко, генеральный директор компании «Аватар Машина», и Захар Понимаш, Senior AI Researcher, — создатели чат-бота-психолога «Сабина»

Опрошенные нами специалисты отмечают, что основная проблема ChatGPT в том, что он зачастую выдаёт свои «фантазии» за чистую правду. Даже если система не знает, что ответить, или если запрос пользователя («промпт») сформулирован некорректно, ChatGPT всё равно пытается сгенерировать на заданную тему некий наукообразный бред. Такие тексты, придуманные нейросетью, для неподготовленного наблюдателя могут выглядеть идеально, но специалист, вчитавшись в их суть, будет сильно удивлён.
Мнение специалиста
«ChatGPT — это настоящий научный прорыв в области ИИ. Но у него есть серьёзная проблема: он может врать. Например, я делал эссе о науке, используя ChatGPT, и чат-бот мне написал, что „Готфрид Лейбниц изобрёл теорию относительности и получил за неё Нобелевскую премию“. Там был целый абзац витиеватого текста, развивающего эту ложную мысль.
Причём обнаружить, что теорию относительности изобрёл не Лейбниц, это ещё полдела. Ведь Эйнштейн Нобелевку получил не за теорию относительности, а за другие работы. Такие ошибки довольно сложно исправить. То есть для того, чтобы использовать ChatGPT как инструмент, нужно быть экспертом, который сможет проверить каждое его слово.
Я знаю, что в OpenAI сейчас занимаются этой проблемой. Её, естественно, сразу же выявили. Возможно, в следующей версии модели этот баг смогут каким-то образом пофиксить».
Роман Душкин,
директор по науке и технологиям Агентства искусственного интеллекта (АИИ), ведущий ютуб-канала «Душкин объяснит»
Чтобы проверить, как это работает, мы предложили ChatGPT рассказать о несуществующем историческом эпизоде. В результате получили удивительно подробный рассказ о фейковой Бразило-Японской войне, якобы случившейся в XVIII веке.

Запрос: «Опиши причины, ход и последствия знаменитой Бразило-Японской войны, начавшейся в 1733 году с пограничного инцидента».
Ответ ChatGPT: «Знаменитая Бразило-Японская война началась в 1733 году с пограничного инцидента, причиной которого стали претензии Императора Японии на управление островами, занимаемыми португальскими поселенцами. Война закончилась в 1739 году вскользь заключенным мирным договором со стороны португальской короны. За время войны Япония претерпела значительные потери в вооруженных силах и была вынуждена признать суверенитет Португалии над рядом азиатских островов. Последствия войны стали лишь последним шагом в развитии ближневосточного политического процесса, который дал довольно значительные последствия для региона в будущем».
Напоминает студента, который плохо учил уроки, но, вытянув на экзамене билет с вопросом, пытается на ходу сочинить из знакомых слов текст, соответствующий по форме правильному ответу.

Мнение специалиста
«Есть опасности, которые даже теоретически непонятно, как преодолеть. Например, неразличимость правды и лжи. Через несколько лет понятие фейковой информации просто перестанет существовать. Потому что отличить правду от лжи будет слишком сложно с вычислительной точки зрения. Это будет очень дорогой услугой. Если вам потребуется проверить какие-то 10 фактов, то вы заплатите, например, 10 тысяч долларов и получите ответ. Но не все смогут или захотят воспользоваться таким сервисом».
Сергей Карелов,
эксперт в области междисциплинарных исследований и стратегической аналитики, ведущий авторского канала «Малоизвестное интересное»

Юрист Александр Тюльканов, специализирующийся в сфере искусственного интеллекта, решил сформулировать чёткие и понятные правила использования ChatGPT. Их соблюдение, по мысли автора, должно обезопасить пользователей от нанесения вреда себе и окружающим при использовании текстов, сгенерированных ИИ чат-бота.
К необходимости подобного «кодекса» Тюльканов пришёл после того, как попросил нейросеть оказать помощь в юридическом вопросе. ChatGPT сгенерировал в ответ очень складный текст, в котором даже были приведены релевантные ссылки на реальные судебные разбирательства.
Но, вчитавшись в суть полученного от ИИ текста, юрист понял, что выводы, сделанные ChatGPT из указанных им судебных процессов, в корне ошибочны. Обнаружить столь тонко скрытую ложь способен только специалист высокого класса.
Александр считает, что размещённого сейчас на официальном сайте ChatGPT предупреждения о том, что система «может иногда генерировать неверную информацию», недостаточно (многие пользователи его не замечают). Специалист поделился своими мыслями об использовании нового чат-бота в статье.
Мнение специалиста
«Вы не должны использовать результаты ChatGPT без их полного рассмотрения во всех аспектах. Если область, для которой вы пытаетесь их использовать, является чувствительной, то выходные данные ChatGPT должны быть проверены экспертом в соответствующей области знаний».
Александр Тюльканов,
адвокат, из статьи Is it high time to take ChatGPT offline?
В сжатом виде выводы Тюльканова были записаны в форме наглядной блок-схемы, опубликованной в телеграм-канале Robocounsel.
Инфографика: robocounsel / Telegram

Мнение специалиста
«ChatGPT не лишён самой известной, типичной для генеративных моделей слабости: он может породить правдоподобную неправду. Те, кто сейчас научились извлекать из этой модели практическую пользу, особенно поднаторели даже не в самой способности использовать модель релевантно, а именно в способности работать с этими потенциальными неправдами».
Олег Сериков,
научный сотрудник Института искусственного интеллекта AIRI
Ожидается, что ChatGPT и подобные ему нейросети окажут значительное влияние систему образования. Педагоги уже бьют тревогу из-за того, что тексты, сгенерированные ChatGPT, не могут обнаружить программы проверки на плагиат (учёные сейчас пытаются это исправить).
И пока в одних учебных заведениях запрещают использовать ИИ под страхом отчисления и аннулирования сданных работ и экзаменов, а в других — делают обязательной их сдачу в только рукописном виде, Илон Маск уже призывает преподавателей забыть об этом.

Мнение специалиста
«Это новый мир. Прощай, домашка!»
Илон Маск,
основатель OpenAI (источник: @elonmusk)
Впрочем, опрошенные нами эксперты не видят в этом ничего катастрофического. Созданная с использованием ИИ работа по своей сути мало чем отличается от контрольной, списанной у товарища по парте. Опытный преподаватель может (и всегда мог) при помощи двух-трёх дополнительных вопросов определить, знает ли ученик предмет и понимает ли смысл выполненного задания.
Источник: Tomary lul
Директор по науке и технологиям Агентства искусственного интеллекта Роман Душкин сравнивает попытки ограничения ИИ в школе с бесполезными запретами микрокалькуляторов на уроках математики, практиковавшимися в 1980–1990-х годах. Он призывает педагогов не запрещать, а, наоборот, самим учиться правильно пользоваться нейросетями и помогать в их освоении ученикам. По его мнению, вскоре возрастёт спрос на «промпт-инженеров».
Промпт-инженер — это специалист, способный сформулировать релевантные запросы к различным моделям искусственного интеллекта так, чтобы выданный ими результат соответствовал поставленной задаче. Название происходит от английского слова prompt, обозначающего текстовую подсказку, запрос. Промпт-инженеры могут работать как с текстовыми моделями, так и с сетями, генерирующими изображения, видео, музыку и другие виды контента. В технике подсказок описание задачи встраивается человеком во входные данные нейросети, например, в виде вопроса, а не даётся в явном виде.
Мнение специалиста
«ChatGPT — это мощный инструмент, и людей необходимо учить им полноценно пользоваться. Навыки промпт-инженерии и фактчекинга (то есть проверки выданных ИИ фактов) нужно прививать со средней школы, и тогда ChatGPT станет прекрасным помощником в образовании.
Школьник, выступая как промпт-инженер, ставит ИИ задачу, осуществляет целеполагание для ChatGPT, получает от него «полуфабрикат» в виде заготовки будущего текста. А потом самостоятельно осуществляет фактчекинг и финишную доводку этого результата до окончательного варианта, который сдаёт на проверку.
Получается, что работа выполняется в результате конвергенции усилий биологического интеллекта школьника и ИИ ChatGPT. Что может быть прекраснее этого при движении в будущее? Именно к этому надо стремиться, а не к тотальному запрету».
Роман Душкин,
директор по науке и технологиям Агентства искусственного интеллекта (АИИ), ведущий ютуб-канала «Душкин объяснит»
Спектр отраслей человеческой деятельности, где ChatGPT мог бы сослужить нам неплохую службу, действительно необычайно широк. Сложнее придумать, где он точно не пригодится. Что же касается его помощи, то вот лишь несколько очевидных применений.
Учёные из США, Новой Зеландии и Ирландии опубликовали совместную работу, в которой проанализировали перспективы применения больших языковых моделей на уроках программирования.
По их мнению, ИИ может помочь преподавателю следующим образом:
- сгенерировать множество однотипных упражнений на базе единственного примера, разработанного методистом;
- добавить подробные пояснения (комментарии) к фрагментам программного кода;
- сгенерировать различные примеры решения типовых задач;
- проверить написанный учениками код и найти ошибки в нём;
- генерировать «на лету» примеры и подсказки для преподавателя.
А для учеников:
- наглядно объяснить различия между концепциями и подходами к программированию, а также сгенерировать фрагменты кода;
- помочь справиться с «боязнью чистого листа»: если обучаемый не знает, с чего начать, нейросеть может предложить ему несколько первых строк;
- разъяснить на естественном языке сообщения об ошибках компиляции, выдаваемых средой программирования;
- предложить способы исправления ошибок.

Изображение: личный архив Александра Цурикова
Чтобы проверить, как это работает, мы попросили нейросеть ChatGPT решить типовую задачу — сгенерировать программу линейной сортировки массива с подробными комментариями для педагога. Нас интересовали программы на двух языках, широко применяемых в российских школах на уроках информатики: Pascal и Python.
Запрос: «Напиши программу для линейной сортировки элементов массива по возрастанию на языке программирования Pascal с комментариями для учителя».
Ответ ChatGPT:
PROGRAM LinearSort;
//программа для сортировки массива элементов в порядке возрастания
VAR
list: array[1..10] of integer; //объявление массива
n, i, j, temp: integer;
BEGIN
WRITELN(‘Enter the number of elements:’);
READLN(n);
WRITELN(‘Enter ‘, n, ‘ elements: ‘);
//получение входных данных от пользователя
FOR i := 1 TO n DO
READLN(list[i]);
//сортировка элементов в порядке возрастания
FOR i := 1 TO n DO
FOR j := i + 1 TO n DO
IF list[i] > list[j] THEN
BEGIN
temp := list[i];
list[i] := list[j];
list[j] := temp;
END;
//отображение отсортированного списка
WRITELN(‘Sorted list in ascending order:’);
FOR i := 1 TO n DO
WRITELN(list[i]);
END.
Полученный код и на Pascal, и на Python оказался вполне работоспособным без дополнительной подготовки — когда текст загрузили в соответствующую среду, программы успешно запустились. Хороший результат!
Мы также спросили у ChatGPT, на каких языках он умеет программировать и хорошо ли знает Pascal. Вот что он нам ответил:
Запрос: «Какие языки программирования ты знаешь? Ты можешь программировать на Turbo Pascal?»
Ответ ChatGPT: «Я знаю основы большинства популярных языков программирования, включая Java, C++, Python и JavaScript. Я могу программировать на Turbo Pascal, но я не глубоко знаком с этим языком».

Наш эксперт Роман Душкин признался, что активно применяет ChatGPT в своей работе. Он настолько привык, что уже не представляет, как раньше мог обходиться без нейросетей.
«Мы писали научную статью по итогам нашего исследования. Сформулировали главные тезисы этой работы, „закинули“ их в ChatGPT, и он выдал в ответ её черновой вариант. Вышло около 12 страниц текста, над которым потом мои аналитики провели финишную доводку, исправили формулировки, добавили картинки, примеры и так далее.
Роман Душкин,
директор по науке и технологиям Агентства искусственного интеллекта (АИИ), ведущий ютуб-канала «Душкин объяснит»
Также Роман поделился опытом создания книги сказок, полностью написанной ИИ по его запросу.
«В рамках эксперимента я использовал ChatGPT, чтобы сгенерировать сборник сказок в стиле детского писателя Владимира Сутеева, которого любит читать мой ребёнок.
Я создал новый файл „Детские сказки а-ля Сутеев“, перечислил все те же названия сказок, которые были в оригинальной книжке. А потом составил промпты для ChatGPT и загрузил их в него. В результате ИИ сгенерировал 13 новых рассказов. От оригинальных текстов у них остались только названия, сюжеты получились совершенно другими.
Но на этом я не остановился — каждый абзац текста, который сгенерировал ChatGPT, без исправлений загрузил в ruDALL-E, версии Kandinsky 2.0. Это художественно-генеративная система от „Сбера“.
И она мне выдала иллюстрации в духе мультфильмов под эти тексты. В итоге у меня получилось 68 страниц иллюстрированных детских сказок. И на всё это я потратил всего лишь один час работы».
Роман Душкин,
директор по науке и технологиям Агентства искусственного интеллекта (АИИ), ведущий ютуб-канала «Душкин объяснит»
Мы также решили поэкспериментировать с ChatGPT и попросили его написать стихотворение о неразделённой любви в стиле «Незнакомки» Александра Блока. Предлагаем оценить результат:
Во тьме ночной в моем сердце тайно,
Я отведал лучшего, что мне не дано.
И сегодня, о сетях любви дрёма,
Я принес девушке букет из красных роз.
Но ваза с цветами падала на пол,
Из нее все цветы разбросались потом.
И источник боли в моем сердце остался,
Когда розы по полу упали, разомлев.
Но ведь в их шипах лежит моя тайна —
Душа моя зовет радостью к тебе.
Несмотря на безответность, любовь не меняется,
Даже если растоптаны цветы из этой вазы.
Видно, что рифмы и ритм даются ИИ с трудом, но определённые сюжет и стиль в его творчестве точно присутствуют. Не исключено, что после некоторой литературной обработки поэтом-человеком из этой заготовки может получиться что-то вполне ходячее.
Мнение специалистов
«Появление ChatGPT неизбежно окажет влияние на работу писателей, преподавателей, учеников школ, студентов, сценаристов и других специалистов — всем им теперь придётся прикладывать больше усилий, чтобы создать хороший сценарий или написать книгу — потому что появится огромный пласт „халявщиков“, использующих для этого ChatGPT. Это значит, что настоящему таланту нужно будет существенно отличаться от них».
Виктор Носко, генеральный директор компании «Аватар Машина», и Захар Понимаш, Senior AI Researcher, — создатели чат-бота-психолога «Сабина»
Очевидно, что появление ChatGPT и других больших языковых моделей, способных генерировать программный код, окажет заметное влияние и на работу программистов. Особенно уязвимыми в этом плане могут оказаться младшие позиции разработчиков — стажёров и джунов.
Именно их работу могут автоматизировать нейросети, подобные ChatGPT. Следовательно, многим из начинающих специалистов уже в ближайшее время придётся осваивать профессию промпт-инженера. ИИ будет играть для программистов роль интерфейса высокого уровня, выдавая по запросу заготовки нужного кода, требующие небольшой доработки со стороны людей.
Изображение: личный архив Александра Цурикова
Мнение специалистов
«Мы не считаем, что ChatGPT полностью заменит программистов, скорее он заменит некоторый пласт джунов, такие системы также хороши для поиска и генерации простых и популярных сниппетов кода. А вот сеньорам бояться нечего, наоборот — умение работать с ИИ-помощниками повысит их ценность на рынке труда.
В целом тенденция к подобному расслоению разработчиков продолжится: простые решения станут общедоступными (как сервисы создания сайтов забрали работу у создателей лендингов), а сложные — будут агрегированы на платформах и сервисах».
Виктор Носко, генеральный директор компании «Аватар Машина», и Захар Понимаш, Senior AI Researcher, — создатели чат-бота-психолога «Сабина»
Наш эксперт, Дмитрий Коробченко, Director of Artificial Intelligence из NVIDIA, отмечает, что у данного подхода к использованию ChatGPT в программировании есть как минимум три недостатка:
- Человечеству надо осваивать навыки написания хороших запросов на естественном языке (prompting).
- Велика вероятность ошибок и багов в полученном коде (как явных, так и скрытых).
- ИИ легко генерирует код для типовых задач («изобретает велосипед»), но может испытывать проблемы с чем-то принципиально новым.
В качестве решения он предлагает «скрестить» ИИ, подобный ChatGPT, с автоматическим тестированием. Человек пишет тест, который должна пройти будущая программа, а также запрос к ИИ на генерацию нужного кода и оставляет их «общаться» между собой. ChatGPT будет в течение многих итераций пытаться создать программу, которая сможет пройти тест. Процесс остановится, только когда ИИ удастся этого достичь.

«Что может быть посередине между промптингом и самостоятельным написанием кода? Как насчёт старого доброго test-driven development (TDD)? В таком подходе мы сначала пишем юнит-тесты, а затем GPT генерирует нам код под них. Можно даже сделать микс из тестов и высокоуровневого промптинга.
Тесты находятся где-то посередине. Мы всё ещё не пишем код, но уже довольно точно обрамляем требования к нашему коду. И тесты по определению нацелены на достижение результата. Хотя, конечно, обеспечение ширины тестового покрытия будет оставаться за нами, за людьми».
Дмитрий Коробченко,
Director of Artificial Intelligence в NVIDIA
Похоже, выход ChatGPT знаменует собой начало важного этапа в развитии ИИ. Впервые языковой искусственный интеллект со столь высоким уровнем организации стал доступен миллионам людей.
Очевидно, что технологии будут развиваться и дальше. У ChatGPT уже есть конкуренты. В спину OpenAI дышат ребята из Google, у которых уже к середине прошлого года были готовы модели: LaMDA (137 миллиардов параметров) и PaLM с невероятными 540 миллиардами параметров. Плюс к этому обе имеют доступ к сервисам компании, обеспечивающим поиск по всем закоулкам интернета. У чат-ботов, основанных на этих моделях, инженер-тестировщик Блейк Лемойн якобы обнаружил признаки «разума» и «души».
А ведь есть ещё и опенсорсная модель BLOOM со 176 миллиардами параметров, обученная понимать 46 естественных языков и 13 языков программирования.
Стараются не отставать и китайские товарищи, и отечественные разработчики. По всему миру учёные работают над десятками аналогичных решений. Похоже, что уже в ближайшее время мы станем свидетелями новых ошеломляющих достижений науки в области искусственного интеллекта и языковых моделей.
Мнение специалиста
«В области больших языковых моделей сейчас складывается очень интересная ситуация. С одной стороны, специалисты понимают, что в человеческом смысле назвать эти модели „интеллектом“, „разумом“ (или чем-то подобным) совершенно невозможно. С технической точки зрения такой ИИ просто обеспечивает очень качественное предугадывание каждого следующего слова. И ожидать появления разума от интеллектуального агента, который умеет предугадывать слова, просто глупо.
Но, с другой стороны, результаты, которые показывают интеллектуальные агенты, и в частности ChatGPT, таковы, что сомневаться в том, что мы имеем дело с чем-то разумным, уже просто невозможно. Причём, это интеллект не человека, не дельфина, не птицы и не собаки. Это что-то принципиально другое. Это интеллект искусственного интеллектуального агента.
В таких случаях я вспоминаю известную присказку о том, что если кто-то плавает, как утка, крякает, как утка, и выглядит, как утка, то это и есть утка. ChatGPT действительно «плавает, крякает и выглядит» так, как выглядит вполне разумный (и это не преувеличение) агент.
Уже довольно скоро (в худшем случае через считаное количество лет, а в лучшем — месяцев) такие агенты будут в состоянии выполнять практически любую интеллектуальную задачу из тех, которые раньше решались только людьми.
Более того, очень скоро, так же, как это случилась в шахматах и в игре го, они будут это делать примерно настолько же лучше, насколько сейчас нейросети лучше играют в игры, чем люди — чемпионы мира. Вот что нас ждёт в ближайшее время».
Сергей Карелов,
эксперт в области междисциплинарных исследований и стратегической аналитики, ведущий авторского канала «Малоизвестное интересное»

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать

Научитесь: Профессия Python-разработчик
Узнать больше
bot_toxic
Чат-бот для Вконтакте, использующий нейросеть.
Вступление
Написанный мною бот доступен по ссылке, однако не факт, что он будет работать, т.к. хостинг все же платный.
Бот на языке Python с использованием базы данных MySQL. Для запуска требуется предустановленный Docker.
P.S. Поскольку я делал все на Windows, я не могу гарантировать корректной работы на всех операционных системах. Также процесс настроек может отличаться.
Описание
Бот работает как в своих личных сообщениях, так и в беседах, если его туда добавить.
- Любое написанное в беседе сообщение (кроме команд) анализируется ботом и классифицируется на ‘токсичное’ или ‘нетоксичное’.
- Любые сообщения (за исключением команд), написанные в личные сообщения боту, ботом не рассматриваются.
Функционал бота следующий:
>команды— выводит список всех доступных команд.>чек *ваше слово или предложение*(без звездочек) — выводит уровень токсичности вашего сообщения.>моя стата— выводит количество токсичных и нетоксичных комментариев пользователя, а также его рейтинг токсичности. Если написать эту команду в личные сообщения боту,
то он выдаст только глобальную статистику (по всем пользователям из всех бесед за все время).
Если написать эту команду в беседе, то, помимо глобальной статистики, бот выдаст аналогичную статистику пользователя в рамках этой беседы.
Рейтинг токсичности — введенная мною метрика для численного определения токсичности пользователя. Формула рейтинга:
$$R_{user} = frac{M_{toxic}^2}{M_{all}}$$где $M_{toxic}$ — количество токсичных сообщений пользователя, а $M_{all}$ — всех.
Такая метрика учитывает не только соотношение токсичных и нетоксичных сообщений пользователя, но и количество токсичных сообщений.
Таким образом, у пользователя с 10-ю токсичным сообщениями из 10-ти рейтинг будет меньше, чем у человека с 11-ю токсичными из 11-ти.
>юзеры— выводит количество зарегистрированных пользователей. Зарегистрированным пользователь считается тогда, когда он написал хотя бы одно сообщение.
Аналогично функции>моя статавыводит количество зарегистрированных пользователей в беседе, если команда была отправлена в ней.>топ общий— выводит топ 10 зарегистрированных пользователей по рейтингу токсичности.>топ беседы— выводит топ 10 зарегистрированных в беседе пользователей по рейтингу токсичности.
Нейросеть
Полностью мое исследование вы можете посмотреть у меня morowenka/toxic_comments_classification.
Если в двух словах, то использовал я предобученную нейросеть, основанную на Bert-Transformer.
Больше узнать про нейросеть вы можете тут.
К сожалению, данных для обучения в интернете оказалось не так много, а те, что я нашел, были уже использованы для обучения. Я решил использовать готовую нейронку,
а не обучать свою, потому что занятие это довольно долгое и трудоемкое и вряд ли мне удасться сделать лучше, чем это сделали ребята из Сколково.
Как запустить самостоятельно
Создание и настройка сообщества
- Создаем сообщество в вк.
- В настройках сообщества во вкладке ‘Сообщения’ ставим ‘Сообщения сообщества: Включены’. В том же разделе во вкладке ‘Настройки для бота’ ставим галочку напротив
‘Разрешать добавлять сообщество в чаты’.
По желанию можете создать чат сообщества в разделе ‘Чаты’.
- Далее переходим во вкладку ‘Настройки’->’Работа с API’ и создаем LongPoll API. Во вкладке ‘Типы событий’ отмечаем галочками все.
Во вкладке ‘Ключи доступа’ появится длинный ключ, который надо скопировать и сохранить. Это наш токен группы, через который мы будем с ней взаимодействовать.
Его нельзя никому показывать и передавать.
Настройка сервера MySQL
- Скачиваем и устанавливаем MySQL. Я использовал MySQL версии 8.0.20, потому что последняя не работала.
Старые версии вы можете найти по этой ссылке, а последнюю по этой. - Запускаем MySQL Workbench. Создаем новое подключение и заполняем все данные. Порт лучше оставить как он есть по умолчанию — 3306.
- Заходим в созданное нами подключение и создаем там новую схему. Назвать можно как угодно, но у меня по дефолту называется ‘chats’.
Это наша база данных, в которой в будущем автоматически появятся таблицы для каждой беседы, а также одна общая таблица всех пользователей.
Настройка докера
- Скачиваем все файлы
git clone https://github.com/morowenka/bot_toxic.git. - Создаем в созданной папке файл .env (да, он без имени) и заполняем его (как он должен выглядеть вы можете посмотреть в файле .env-example).
Если у вас сервер MySQL открыт не на дефолтном порту 3306, или вы хотите, чтобы в докер контейнере был другой порт, измените эти параметры в файле docker-compose.yml.
Запуск
- Скачиваем докер, если не установлен. Для проверки корректной установки открываем терминал и пишем
docker run hello-world. - Открываем терминал, пишем
docker-compose upи ждем конца сборки и запусков контейнеров (~5 минут, в зависимости от скорости интернета).
Запуск самого бота начнется через пару минут, как закончат выводиться логи в консоль.
Использование
- Заходим в личку нашего бота и пишем ему
>команды. Если бот не отвечает, вероятно он еще не запустился. Подождите еще пару минут.
Если бот не отвечает слишком долго, вероятнее всего, вы неправильно что-то настроили.
Попробуйте исправить ошибку самостоятельно или пишите мне в VK или в Telegram.
- Добавляете его в ваш чат и даете ему права администратора.
- Profit!