Дизассемблер своими руками
Время на прочтение
4 мин
Количество просмотров 47K
Знание структуры машинных команд уже много лет не является обязательным, для того, чтобы человек мог назвать себя программистом. Естественно так было не всегда. До появления первых ассемблеров программирование осуществлялось непосредственно в машинном коде. Каторжная работа, сопряженная с большим количеством ошибок. Современные ассемблеры позволяют (в разумной степени) абстрагироваться от железа, метода кодирования команд. Что уж говорить о компиляторах высокоуровневых языков. Они поражают сложностью своей реализации и той простотой, с которой программисту позволяется преобразовывать исходный код в последовательность машинных команд (причем преобразовывать, в достаточной степени, оптимально). От программиста требуется лишь знание любимого языка/ IDE. Знание того, во что преобразует компилятор исходный листинг вовсе не обязательно.
Тем же, кому интересно взглянуть на краткое описание структуры кодирования машинных команд, пример реализации и исходный код дизассемблера для x86 архитектуры, добро пожаловать.
Создание дизассемблера для x86 архитектуры является, хотя задачей и не особо сложной, но все, же довольно специфичной. От программиста требуются определенного рода знания – знания того, как микропроцессор распознает последовательность “байтиков” в машинном коде. Далеко не в каждом вузе можно получить такие знания в объеме достаточном для написания полнофункционального современного дизассемблера – приходится искать самому (как правило, на английском языке). Данный пост не претендует на полноту освещение проблемы создания дизассемблера, в нем лишь кратко рассказывается то, как был написан дизассемблер для x86 архитектуры, 32-разрядного режима исполнения команд. Так же хотелось бы отметить вероятность возможных неточностей при переводе некоторых понятий из официальной спецификации.
Структура команд для intel x86
Структура команды следующая:
• Опциональные префиксы (каждый префикс имеет размер 1 байт)
• Обязательный опкод команды (1 или 2 байта)
• Mod_R/M – байтик, определяющий структуру операндов команды — опциональный.
• Опциональные байты, занимаемые операндами команды (иногда разделено как один байт поля SIB[Scale, Index, Base], смещения и непосредственного значения).
Префиксы
Существуют следующие префиксы:
Первые шесть изменяют сегментный регистр, используемый командой при обращении к ячейке памяти.
• 0x26 – префикс замены сегмента ES
• 0x2E – префикс замены сегмента CS
• 0x36 – префикс замены сегмента SS
• 0x3E – префикс замены сегмента DS
• 0x64 – префикс замены сегмента FS
• 0x65 – префикс замены сегмента GS
• 0x0F – префикс дополнительных команд (иногда его не считают за настоящий префикс – в этом случае считается, что опкод команды состоит из двух байт, первый из которых 0x0F)
• 0x66 – префикс переопределения размера операнда (к примеру, вместо регистра eax будет использоваться ax)
• 0x67 – префикс переопределения размера адреса (см ниже)
• 0x9B – префикс ожидания (WAIT)
• 0xF0 – префикс блокировки (LOCK с его помощью реализуется синхронизация многопоточных приложений)
• 0xF2 – префикс повторенья команды REPNZ – работа с последовательностями байт (строками)
• 0xF3 – префикс повторенья команды REP – работа с последовательностями байт (строками)
Каждый из этих префиксов меняет семантику и (или) структуру машинной инструкции (например, ее длину или выбор мнемоники).
Опкоды команд.
Опкод команды иногда один, иногда вмести с префиксом (ами) однозначно определяет мнемонику (название) команды. Команд много. И при усложнении современных микропроцессоров их количество не уменьшается – новые команды появляются, а устаревшие не исчезают (обратная совместимость). Список опкодов и команд ассоциированных с ними, как правило, можно скачать на официальных сайтах производителей микропроцессоров.
Байт Mod_R/M состоит из следующих полей:
• Mod – первые два бита (значение от 0 до 3)
• R/M – следующие три бита (значение от 0 до 7)
• Value of ModR/M – следующие три бита (значение от 0 до 7)
Реализация:
Для написания дизассемблера мы будем использовать следующую страничку: http://ref.x86asm.net/geek32.html.
Мы видим несколько таблиц. В сущности, только эти таблицы и описание их полей нам и понадобятся, для написания дизассемблера. Конечно, дополнительно требуется способность к логическому рассуждению и свободное время.
В первой таблице представлен список машинных команд, не содержащих префикс 0x0F. Во второй список команд содержащих этот префикс (большинство этих команд появились в микропроцессорах семейства “Pentium with MMX” или более поздних).
Следующие три таблицы позволяют преобразовать байт Mod_R/M в последовательность операндов команды для 32-битного режима кодировки команд. Причем каждая последующая из этих трех таблиц уточняет разбор Mod_R/M байта частных случаев предыдущей таблицы.
Последняя таблица позволяет преобразовать байт Mod_R/M в последовательность операндов команды для 16-битного режима кодировки команд. По умолчанию считается, что команда кодируется в 32-битном режиме. Для смены режима кодировки используется префикс переопределения размера адреса (0x67).
Первое, что необходимо сделать, это перенести первые две таблицы в удобные для работы структуры данных. На том же сайте можно скачать xml-версии данных таблиц, и уже их преобразовать в красивые сишные структуры. Я же поступил иначе – загрузил html таблицы в Excel, и уже там, написав несложный скриптик на VBA, получил исходный сишный код, который, уже после ручных исправлений представлял собой требуемые структуры данных.
Сам алгоритм дизассемблирования достаточно прост:
• Собирается список префиксов, используемых в текущей машинной инструкции
• Ищется в одной из двух таблиц соответствующее поле в зависимости от опкода, префиксов и поколения (модели) целевого (искомого) микропроцессора.
• Найденная нами запись характеризуется списком полей такими как поколение (модель) микропроцессора, с которого появилась поддержка данной команды или, например, список флагов, которые данная команда может изменить. Нас же, в основном, интересуют лишь мнемоника (название) команды и список операндов. Проанализировав все операнды найденной и поля байта Mod_R/M, мы сможем узнать текстовое представление и длину команды.
Количество операндов может колебаться от нуля до трех. Исходные таблицы содержат более сотни типов операндов. Некоторые операнды дублируются – у них различные названия, но последовательность действий обработки Mod_R/M байта (и возможно последующих байтов) у них одинакова.
Для просмотра примера обработки различных операндов и примера дизассемблирования простейшей функции “Hello world” можно скачать исходный код дизассемблера для компилятора C++ Builder 6.
PS:
Не факт, что кому-то из прочитавших этот пост, когда-либо понадобится информация, почерпнутая из него (дизассемблеры пишут единицы), но, в любом случае этот дизассемблер тестировался и даже входит в состав достаточно большего коммерческого протектора, исходники открыты и распространяются свободно )
Автор: Сергей Чубченко. Дата публикации: 29.08.2005
Дизассемблер своими руками
Как часто Вы слышали про дизассемблеры? Думаю не стоит объяснять что это такое и для чего это нужно. Вы наверняка не раз отлаживали свой проект в Olly Debugger’е или искали ошибку в ассемблерном коде штатными средствами. Во всех подобных продуктах есть дизассемблер, который довольно быстро разбирает скомпилированный машинный код из EXE файла на ассемблерный код который можно изучать и изменять. В этой статье я опишу как можно самостоятельно написать простенький дизассемблер под свои нужды.
Введение
Для начала думаю нелишне напомнить, для чего все же может пригодиться самодельный дизассемблер. Особенно это актуально, если Ваша работа связана с анализом вирусов в антивирусной лаборатории. В этом случае вы постоянно сталкиваетесь с EXE упаковщиками. Такими программами, которые способны сжимать бинарный код в 2 или более раза, при этом оставив его работоспособным. Из бесплатных представителей таких программ Вы наверняка знаете тот же UPX. А задумывались ли Вы как пишут распаковщики для таких продуктов? Вряд ли. А зря! Ядро распаковщиков, особенно статических (которые распаковывают программу без запуска) основано именно на дизассемблере, который в совокупности с анализатором кода позволяет понять код распаковываемой программы и распаковать ее используя нужный алгоритм упаковщика. Если Вы когда-нибудь решите написать такой распаковщик, то без самодельного дизассемблера не обойтись.
Дизассемблирование
Вы наверняка задаетесь вопросом: «А как это вообще работает и почему бы не написать дизассемблер с нуля?». Как бы это не было тривиально — ответ на него можно получить только осознав, насколько именно Вам сложно написать дизассемблер используя только Intel’овские мануалы на архитектуру процессора. Я лишь кратко рассмотрю принципы кодирования ассемблерных команд, чтобы принцип дизассемблирования был более прозрачным. А дальше решать Вам!
Каждый байт секции кода программы участвует в формировании той или иной машинной инструкции. Чтобы правильно определить начало следующей команды нужно правильно (как бы это сделал процессор) дизассемблировать предыдущую. Для этого необходимо четко представлять себе формат команд ассемблера. Команды процессора Intel кодируются следующим образом:

При этом единственный обязательный параметр это «код операции», остальные используются в зависимости от сложности и навороченности той или иной команды. Например «преффикс» используется довольно редко, зато префиксы могут поистине творить чудеса над командами, к примеру префикс 66h меняет размерности регистров и адресов при этом в 16 битной программе этот префикс позволяет юзать 32 битные регистры, а в 32 битной — 16 битные. Поля modR/M позволяют определить формат данных, с которыми оперирует программа, будь то регистры, адреса и прочее. Поле SIB расширяет возможности адресации 32 битного режима. Процессор узнает о присутствии этого поля по битам 100b в поле R/M. Далее идут непосредственно смешения и операнды, описанные в структуре modR/M+SIB.
Расшифровкой именно этих команд и занимается дизассемблер. Чтобы его написать самому с нуля потребуется море сил и времени. Хотя есть два пути. Наиболее простой из них — составить таблицу опкодов и используя нее дизассемблировать команды (именно этот принцип используется в большинстве дизассемблеров длин и в дельфевом декомпилере DeDe). Второй путь — самый сложный. Он подразумевает полное отсутствие таблиц и использование для дизассемблирования только тех данных что описывают мануалы от авторов процессора.
Какой путь выберете Вы — решать только Вам. Я предлагаю на начальном этапе использовать уже готовые решения. Об одном из таких решений читайте ниже.
Выбираем компонент
Как ни странно, если очень сильно постараться, можно найти целых два бесплатных дизассемблера, которые можно внедрить в свою программу на Delphi. Первый можно взять из свободно распространяющегося исходника декомпилятора Delphi — DeDe. При желании этот исходник Вы можете взять на wasm.ru и самостоятельно его изучить. Мы же рассмотрим второй дизассемблер, поставляющийся в виде компонента для Delphi и бесплатный для некоммерческого использования. Называется данный компонент madDisAsm и входит в состав большой библиотеки компонентов называющейся madCollection. Взять эту коллекцию можно отсюда: http://madshi.bei.t-online.de/madCollection.exe. Ссылка актуальна на момент выхода статьи. Теперь когда Вы скачал все что нужно, давайте разберемся, что мы имеем. А имеем мы 8 мощных компонентов, среди которых даже есть madBasic (бешеный барсик :)). Как Вы понимаете, из данного мощного пакета нам потребуется только madDisAsm. Его и рассмотрим.
madDisAsm
Данный компонент практически недокументирован. Документированы только прототипы функций и структур. Примеров же использования нет ни одного, отсюда следует что разбираться придется самим. Чтобы использовать данный компонент в нашем проекте подключим его в разделе Uses модуля так:
uses madDisAsm;
Теперь давайте рассмотрим главные функции данного компонента, которых две. Первая позволяет дизассемблировать код по команде. При этом все надстройки над кодом Вы можете реализовывать самостоятельно в ходе декомпилирования. Прототип функции имеет вид:
function ParseCode (code: pointer; var disAsm: string) : TCodeInfo; overload;
code — pointer на бинарный код программы, который мы хотим дизассемблировать;
disAsm — переменная в которую будет занесена первая дизассемблированная строчка.
TCodeInfo — структура дизассемблированной строчки. одним из элементов этой структуры является ссылка на следующую строчку, которую мы можем использовать для цикличного вызова функции. Вот полный прототип данной структуры:
TCodeInfo = record
IsValid : boolean; // определяет валидность pointer’а на код
Opcode : word; // Опкод, один ($00xx) или два ($0fxx) байта
ModRm : byte; // ModRm байт (о нем я уже писал), если присутствует, иначе 0
Call : boolean; // эта инструкция call?
Jmp : boolean; // эта инструкция jmp?
RelTarget : boolean; // адрес относительный (или абсолютный) ?
Target : pointer; // абсолютный адрес
PTarget : pointer; // pointer на информацию в коде
PPTarget : TPPointer; // pointer на pointer с информацией
TargetSize : integer; // размер информации в байтах (1/2/4)
Enlargeable : boolean; // может ли размер опкода быть расширенным?
This : pointer; // адрес начала инструкции
Next : pointer; // адрес следующей инструкции
end;
Также для нас будет интересная еще одна функция. Ее особенностью является то, что она способна дизассемблировать всю функцию целиком, автоматически находя конец функции по команде retn. Вот ее прототип:
function ParseFunction (func: pointer; var disAsm: string) : TFunctionInfo; overload;
Тут все аналогично предыдущей функции, только в данном случае код будет дизассемблироваться не покомандно а целиком, при этом компонент попытается сам определить ссылки на API и прочие данные, что есть огромный плюс. Структура, возвращаемая данной функцией покруче:
TFunctionInfo = record
IsValid : boolean;
EntryPoint : pointer;
CodeBegin : pointer;
CodeLen : integer;
LastErrorAddr : pointer;
LastErrorNo : cardinal;
LastErrorStr : string;
CodeAreas : array of record
AreaBegin : pointer;
AreaEnd : pointer;
CaseBlock : boolean;
OnExceptBlock : boolean;
CalledFrom : pointer;
Registers : array [0..7] of pointer;
end;
FarCalls : array of record
Call : boolean; // это CALL или JMP?
CodeAddr1 : pointer; // начало инструкции call
CodeAddr2 : pointer; // начало следующей инструкции
Target : pointer;
RelTarget : boolean;
PTarget : pointer;
PPTarget : TPPointer;
end;
UnknownTargets : array of record
Call : boolean;
CodeAddr1 : pointer;
CodeAddr2 : pointer;
end;
Interceptable : boolean;
Copy : record
IsValid : boolean;
BufferLen : integer;
LastErrorAddr : pointer;
LastErrorNo : cardinal;
LastErrorStr : string;
end;
end;
Есть и еще одна третья функция, которая вообще недокументированна:
function ParseFunctionEx (func: pointer; var disAsm: string, exceptAddr: Pointer; maxLines: Integer; autoDelimiters: Boolean);
Насколько я понял эта функция не возвращает структуры, зато дизассемблирует весь код нужной нам функции и кладет его в переменную disAsm. exceptAddr насколько я понял — это адрес конца дизассемблируемой функции (указывать необязательно), maxLines — число дизассемблируемых строк (если 0, то все), autoDelimiters — точно не могу сказать, но ориентировочно это — завершать ли функцию первым ret’ом или нет.
Кодим
Теперь, когда мы разобрались с работой компонента давайте писать дизассемблер! Открываем Delphi и создадим новый проект, затем поместим на форму пару Edit’ов, Memo и два CommandButton’а. В результате этих несложных манипуляций мы получим что-то похожее на интерфейс программы.
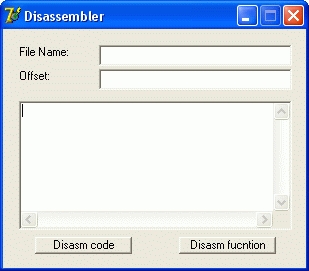
Теперь самое время поподробнее рассказать для чего будут использоваться два текстовых поля. В первое мы будем вводить имя открываемого для дизассемблирования файла, а во второе — адрес начала дизассемблируемого кода. Так как дизассемблер понимает только pointer’ы на код — напишем функцию которая будет открывать EXE, считывать с указанного смещения код в переменную и возвращать на нее pointer. Собственно функция будет иметь вид:
function TfrmMain.GetCode(strFileName: string; strOffset: string): pointer;
var
hFile: integer;
read_bytes: cardinal;
EP_code: array[1..64000] of byte;
begin
//открываем файл
hFile:=CreateFileA(pchar(strFileName), GENERIC_READ, FILE_SHARE_READ + FILE_SHARE_WRITE, NIL, OPEN_EXISTING, FILE_ATTRIBUTE_NORMAL, 0);
//если файл открыт успешно
if hFile<>-1 then begin
//устанавливаем файловый указатель на начало дизассемблируемого кода
SetFilePointer(hFile,StrToInt(strOffset),NIL,FILE_BEGIN);
//считываем 64000 байт кода
ReadFile(hFile,EP_Code,64000,read_bytes,NIL);
//закрываем файл
CloseHandle(hFile);
//возвращаем pointer на считанный код
result:=@EP_Code;
end else begin
//если не смогли открыть файл — выходим
exit;
end;
end;
В данной функции я использовал исключительно Win32 API. Это позволяет добиться максимальной скорости кода и простоты переносимости на другие языки программирования. Теперь напишем функцию, которая будет покомандно дизассемблировать код, pointer на который будет в нее передаваться:
function TfrmMain.Disasm(strAsm: pointer): string;
var
strDisAsm, strdasm: string;
retval: TCodeInfo;
begin
//получим в strDisAsm первую строчку кода, а в retval — структуру, в которой имеется pointer на следующую ассемблерную команду
retval:=madDisAsm.ParseCode(strAsm,strDisAsm);
//в переменной strdasm мы будем хранить весь дизассемблированный листинг
strdasm:=strDisAsm;
//перебераем циклом команды до тех пор пока не встретим ret
while strpos(pchar(strDisAsm),’ret’)= nil do begin
//дизассемблируем очередную команду
retval:=madDisAsm.ParseCode(retval.Next,strDisAsm);
//добавляем ее в конец дизассемблированного листинга
strdasm:=strdasm + #13#10 + strDisAsm;
end;
//возвращаем дизассемблированный код
result:=strdasm;
end;
Код перестанет дизассемблироваться, когда программа наткнется на первый ret. Если программа не найдет ret, то она продолжит декомпилировать память до тех пор пока не вызовет ошибку доступа. Не забудьте сделать проверку этого. Теперь, когда основные функции готовы — нам осталось написать только обработчики для кнопок на форме. Код кнопки Dasasm будет выглядеть так:
procedure TfrmMain.cmdDisasmClick(Sender: TObject);
begin
txtDisasm.Text:=Disasm(GetCode(txtFileName.Text, txtOffset.Text));
end;
Код кнопка Dasasm function будет выглядеть так:
procedure TfrmMain.cmdDisAsmFunctionClick(Sender: TObject);
var
strDisAsm: string;
begin
madDisasm.ParseFunctionEx(GetCode(txtFileName.Text, txtOffset.Text),strDisAsm,nil,0,true);
txtDisasm.Text:=strDisAsm;
end;
Теперь, когда дизассемблер готов, напишем тестовый проект для его проверки.
Пишем тестовый проект
Раз мы написали дизассемблер, то самое логичное писать тестовый проект на ассемблере. Самым удобным на мой взгляд редактором и компилятором ассемблера является Fasm, который плюс к своему удобству и простоте очень часто обновляется и версия к версии становится все стабильнее и лучше. Взять его можно на wasm.ru. Уже скачали? Тогда запускаем и вводим следующий код:
include ’win32ax.inc’
.data
;создаем переменные с данными
Serial db ’Some program’,0
_MsgCaption db ’Disasm this’,0
.code
start:
;вывод сообщения на экран, что может быть проще
invoke MessageBox,0,Serial,_MsgCaption,MB_OK
;выход из программы
invoke ExitProcess,0
;установим конец процедуры, чтобы наш дизассемблер не завис
retn
.end start
Компилируем. Получаем EXE файл размером 2 килобайта. Да, дельфям до ассемблера далеко.
Тестируем
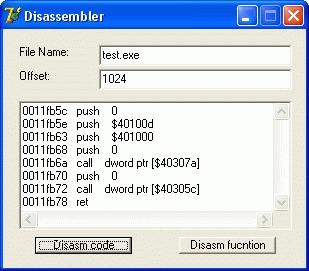
Запускайте скорее только что написанный дизассемблер. Вводите в одно текстовое поле путь к тестовому проекту, а во второе адрес точки входа: 1024 (400h). Для простеньких ассемблерных программ адрес точки входа часто равен смещению секции кода, которое часто равно именно 400h. В любом случае эти данные всегда можно взять открыва программу в любом бесплатном PE Editor’е. Жмем теперь любую из кнопок декомпилера и видими в Memo код, напоминающий только что написанный нами, но в более строгом виде:
0011fb5c push 0
0011fb5e push $40100d
0011fb63 push $401000
0011fb68 push 0
0011fb6a call dword ptr [$40307a]
0011fb70 push 0
0011fb72 call dword ptr [$40305c]
0011fb78 ret
Как видите, все прекрасно работает!
Заключение
Ну вот в общем и все что хотелось рассказать. Надеюсь, Вы без труда найдете применение написанному нами дизассемблеру.
Одним из приоритетных направлений в разработке любого продукта является его отладка. Ведь мало написать удовлетворяющий требованиям исправно работающий код, так нужно ещё и протестить его в «токсических условиях», на предмет выявления всевозможных ошибок. Для этих целей, инженеры Microsoft включили в состав ОС полноценный механизм дебага в виде двух библиотек пользовательского режима: это Dbgeng.dll – основной движок отладки (Debug Engine), и Dbghelp.dll – вспомогательный процессор отладочных символов PDB (Program Database).
На моей Win-7, библиотека символов имеет размер 0.8 Мб и выдаёт на экспорт аж 205 стандартных API-функций, а вот вторая Dbgeng.dll в три раза тяжелее своего (со)брата с размером ~2.5 Мб, зато экспортирует с выхлопной трубы всего 3 функции. От сюда следует, что эта либа от нас явно что-то скрывает, поскольку жалкие три процедуры никак не могут весить более двух мегабайт. В данной статье мы попытаемся заглянуть внутрь отладочного движка Engine, и в качестве примера вытащим из него полноценный дизассемблер инструкций процессоров х86.
Оглавление:
1. Знакомство с системным механизмом отладки;
2. Component-Object-Model в ассемблере;
3. Структура СОМ-библиотеки Dbgeng.dll;
4. Практика – пишем дизассемблер;
5. Заключение.
—————————————————————
1. Знакомство с механизмом отладки
Первые библиотеки отладки, так-же известные как файлы «Symbolic Debugger Engine», были созданы компанией Microsoft в 2001-году для операционной системы Windows-XP. Большая часть либы Dbghelp.dll содержит в себе функции с префиксом(Sym), что говорит об их принадлежности к символьному процессору. Они позволяют по указанному адресу вычислять имена функций, определять типы данных, а также номер строки и название файла, в котором эта строка находится. Поддерживаются и обратные операции, например поиск адреса функции по её имени. Это достаточно творческая единица, если знать как ею пользоваться (
Ссылка скрыта от гостей
на сайте мелкософт).
В состав этой библиотеки входят и привычные нам функции, без каких-либо префиксов. Например потянув за всего одну EnumerateLoadedModules() можно получить список всех модулей DLL (вместе с виртуальной базой и размером), которые загружены в интересующее нас приложение. Поскольку вся черновая работа происходит в фоне, то в большинстве случаях это удобно. На входе, функция требует лишь дескриптор процесса (в примере ниже я передаю -1, т.е. текущий процесс), и адрес callback-процедуры, куда она в цикле будет сбрасывать информацию о модулях. Функция связана со-своей «обратной процедурой» невидимой нитью, так-что программный цикл выстраивать не нужно – обход на автомате прекращается, как только коллбэк возвращает родителю ошибку:
C-подобный:
format pe console
entry start
include 'win32ax.inc'
;//----------
.code
start: cinvoke printf,<10,' Base Size Name',
10,' ----------|-----------|-----------------',0>
invoke EnumerateLoadedModules,-1,Modules,0
cinvoke getch
cinvoke exit,0
;//----------
proc Modules mName,mBase,mSize,mUser ;//<-------- Callback-процедура
cinvoke printf,<10,' 0x%08X 0x%08X %s',0>,[mBase],[mSize],[mName]
ret
endp
;//----- ИМПОРТ ----------
section '.idata' import data readable
library msvcrt,'msvcrt.dll',dbghelp,'dbghelp.dll'
import msvcrt, printf,'printf',getch,'_getch',exit,'exit'
import dbghelp, EnumerateLoadedModules,'EnumerateLoadedModules'
Всё идёт прекрасно до тех пор, пока мы не сталкиваемся с вызовом функций из основного движка-отладки Dbgeng.dll – здесь и начинается самое интересное. Эта библиотека построена по модели СОМ (Component-Object-Model), а значит и вызывать из неё функции нужно соответствующим образом. Но проблема в том, что в отличии от крестов С++ и прочих высокоуровневых языков, ни один из ассемблеров не поддерживает на данный момент технологию COM/ActiveX, и врядли уже будет поддерживать в будущем. Ассемблер – это язык низкого уровня, а прослойка СОМ находится в иерархии намного выше.
Как уже упоминалось, библиотека Dbgeng.dll выдаёт на экспорт всего 3-функции (см.в тотале по ctrl+q) – это DebugCreate(), DebugConnect() и DebugConnectWide(). Но под капотом у неё припрятаны ещё порядка 300 внутренних, неэкспортируемых обычным способом функций. Чтобы подобраться к ним, для начала нужно разобраться, что вообще такое COM-интерфейс и как его реализуют современные компиляторы – вот об этом и поговорим..
2. Component-Object-Model в ассемблере
COM – многокомпонентная, клиент-серверная модель объектов Microsoft, которая является продолжением OLE и фундаментальной основой многих других технологий, в том числе ActiveX и DCOM (Distributed COM, работа с сетью). Ключевым аспектом COM является то, что эта технология обеспечивает связь между клиентом (нашим приложением) и сервером (операционной системой) посредством «интерфейсов». Именно интерфейс предоставляет клиенту способ узнать у сервера, какие конкретно возможности он поддерживает на текущий момент.
В терминологии языка С++ интерфейс – это абстрактный базовый класс, все методы которого являются виртуальными. То-есть вызов этих методов осуществляется через специальную таблицу-указателей, известную как vTable. Например, вызов метода QueryInterface из интерфейса IUnknown будет выглядеть так: IUnknown::QueryInterface(). На сайте rsdn имеется
Ссылка скрыта от гостей
, выделенный специально под описание всех нюансов СОМ-технологии.
Если-же посмотреть на СОМ глазами ассемблера, то интерфейс представляет собой ничто-иное, как обычную структуру в памяти. Чтобы придерживаться общих правил, мы будем называть её так-же, т.е. «vTable». В свою очередь методы – это лишь иное название уже привычных нам API-функций, а указатели на эти функции хранятся внутри интерфейса. Таким образом, интерфейс можно рассматривать как массив указателей на СОМ-функции. Влиться в эту тему поможет ветка на
Ссылка скрыта от гостей
, где представлены материалы по СОМ с реальными примерами на ассемблере – «допризывникам» настоятельно рекомендуется к прочтению.
В операционной системе Win имеется огромное количество СОМ-интерфейсов и это не удивительно, ведь Microsoft строит системы используя объектно-ориентированный подход программирования, а частью ООП является как-раз-таки OLE/ActiveX/СОМ. Чтобы из этого общего пула у нас была возможность выбрать и использовать в своих программах конкретный интерфейс, система назначает ему уникальный идентификатор GUID. Собрав в единую базу, Win хранит все эти идентификаторы в своём кусте реестра под названием «HKEY_CLASSES_ROOTInterface». Если выбрать любой GUID в левом окне, то в правом получим отождествлённое с этим идентификатором, название интерфейса:

СОМ-сервер операционной системы имеет базовый интерфейс под названием «IUnknown». Он глобален и все остальные наследуются именно от него. GUID этого интерфейса имеет значение {00000000-0000-0000-C000-000000000046}. В своей тушке интерфейс хранит указатели на три метода (функции) и на ассемблере будет выглядеть так:
C-подобный:
struct IUnknown
QueryInterface dd 0 ;// метод позволяет найти адрес интерфейса в памяти, по его GUID.
AddRef dd 0 ;// метод счётчика-ссылок на интерфейс
Release dd 0 ;// метод уменьшает счётчик (при достижении нуля интерфейс освобождается)
endsКак видим, при помощи IUnknown и его метода QueryInterface() можно найти адрес любого СОМ-интерфейса в системе, но только при условии, что мы знаем GUID искомого (нужно будет передать его в качестве аргумента этому методу). Важно запомнить, что базовый интерфейс IUnknown входит в состав буквально всех СОМ-интерфейсов, занимая первые три указателя в нём. СОМ-сервер инкапсулирует его во-все интерфейсы, чтобы вести над ними учёт.
Например, когда мы получаем от сервера ссылку (указатель) на какой-нибудь интерфейс, его метод AddRef() на автомате увеличивает внутренний счётчик-обращений к данному интерфейсу. Если-же интерфейс нам больше не нужен, мы должны вызвать его метод Release(), который соответственно уменьшит этот счётчик на 1. Сервер периодически парсит счётчики активных интерфейсов и если обнаруживает в нём нуль, то из-за ненадобности сразу выгружает его из памяти. Так реализуется «время жизни» СОМ-интерфейсов, и это стандартная схема учёта системных структур, в памяти Win.
3. Структура СОМ-библиотеки Dbgeng.dll
Будем считать, что прошлись по макушкам СОМ-технологии, и теперь рассмотрим её реализацию внутри главного героя этой статьи – библиотеки Dbgeng.dll. В каком-то смысле, эта библиотека сама является полноценным СОМ-сервером, поскольку GUID’ы её интерфейсов не прописаны в системном реестре Win, хотя библиотека и является детищем самой Microsoft. Из этических соображений, все разработчики СОМ-интерфейсов обязаны сопровождать свой продукт полной документацией, чтобы армия прикладных программистов могла использовать незнакомые интерфейсы в своих программах. Связано это с тем, что не зная GUID мы просто не сможем найти ни один интерфейс в системе, и соответственно лишимся возможности вызывать из него методы.
Движок-отладки Dbgeng.dll отлично документирован в репозитории мягких – общие сведения о нём можно почерпнуть
Ссылка скрыта от гостей
. Что касается описания непосредственно имеющихся в наличии методов и GUID всех интерфейсов, то они находятся в заголовочном файле Dbgeng.h, электронная версия которого
Ссылка скрыта от гостей
. Судя по этому хидеру, в данную библиотеку включён не один, а целая дюжина связанных с отладкой различных интерфейсов, и в каждом из них имеются свои функции (методы). Исторически, 16-байтные GUID интерфейсов принято обозначать как IID, что подразумевает «Interface-Identifier».
C-подобный:
;// Названия и GUID'ы интерфейсов Dbgeng.dll
;//****************************************************
IID_IUnknown dd 0x00000000, 0x00000000, 0x000000c0, 0x46000000
IID_IDebugAdvanced dd 0xf2df5f53, 0x47bd071f, 0x3457e69d, 0x89d6fec3
IID_IDebugBreakpoint dd 0x5bd9d474, 0x423a5975, 0xa8648bb8, 0x650e11e7
IID_IDebugClient dd 0x27fe5639, 0x4f478407, 0x11ee6483, 0xc88ab08f
IID_IDebugControl dd 0x5182e668, 0x416e105e, 0xef2492ad, 0xba240480
IID_IDebugDataSpaces dd 0x88f7dfab, 0x4c3a3ea7, 0xe8c4fbae, 0xaa736110
IID_IDebugEventCallbacks dd 0x337be28b, 0x4d725036, 0x5fc4bfb6, 0xaa2e9fbb
IID_IDebugInputCallbacks dd 0x9f50e42c, 0x499ef136, 0x0373979a, 0x2ded946c
IID_IDebugOutputCallbacks dd 0x4bf58045, 0x4c40d654, 0x3068afb0, 0xdc56f390
IID_IDebugRegisters dd 0xce289126, 0x45a79e84, 0xbb677e93, 0x93146918
IID_IDebugSymbolGroup dd 0xf2528316, 0x44310f1a, 0xd011edae, 0xabe2e196
IID_IDebugSymbols dd 0x8c31e98c, 0x48a5983a, 0xe56f1690, 0x50a967d6
IID_IDebugSystemObjects dd 0x6b86fe2c, 0x4f0c2c4f, 0x4317a29d, 0x27c3ac11
Одной из примечательных особенностей СОМ-интерфейсов является их масштабируемость. Так, если мы захотим изменить уже существующий интерфейс, то достаточно написать недостающие методы, и добавить указатели на них в конец прежнего интерфейса. К примеру, каждый из представленных выше 13-ти фейсов имеет дополнительные экземпляры, к именам которых добавляется порядковый номер по типу: IDebugClient (основной интерфейс), и дальше IDebugClient2 (3,4,5,6,7). Каждый последующий экземпляр включает в себя какие-то свежие методы и ему назначается новый GUID, в результате чего интерфейс шагает в ногу со-временем.
Если учитывать все интерфейсы вместе с расширенными, то в библиотеке Dbgeng.dll операционной системы Win7 зарегистрировано всего 35 СОМ-интерфейсов, а общее число методов в них приближается к отметке 300. Забегая вперёд скажу, что не все они реализованы на должном уровне, в чём мы убедимся позже. Здесь нужно отметить, что движок-отладки включённый в состав ОС отличается от движка ядерного отладчика «WinDbg» – у системного версия [6.1.7601], а у того, что использует отладчик [6.12.2]. Системный файл плохо зарекомендовал себя тем, что в нём вырезана поддержка удалённой отладки, что является козырем отладочного ядра WinDbg. Поэтому и размеры библиотек у них разные, о чём свидетельствует скрин ниже:

Посмотрим на рисунок ниже, где представлена обобщённая структура библиотеки Dbgeng.dll.
Чтобы воспользоваться услугами сервера-отладки, мы должны сначала активировать его функцией CoInitialize() из библиотеки подсистемы исполнения OLE32.dll. Теперь нужно создать «клиента отладки» функцией DebugCreate() из либы Dbgeng.dll, передав ей в виде аргумента GUID интерфейса «IDebugClient::». Это основной интерфейс клиента, где собраны часто используемые им (т.е. нашим приложением) методы.
Если зайти отладчиком OllyDbg в функцию DebugCreate() по [F7], то можно обнаружить, что она проделывает массу полезной работы – например копирует из тушки движка в пространство пользователя различные структуры, находит через GetProcAddress() и подключает вспомогательные функции отладки из библиотеки Ntdll.dll типа: DbgEvent(), DbgBreakPoint() и многое другое. Именно эта функция создаёт полный контекст отладки в памяти ОЗУ, и нам остаётся лишь вызывать методы из требуемых СОМ-интерфейсов:

В качестве демонстрационного примера для вводной части, предлагаю код ниже, который в цикле будет запрашивать у базового интерфейса «IUnknown::» все имеющиеся в наличии интерфейсы отладочного движка. Как уже упоминалось, всего в библиотеке Dbgeng.dll их зарегистрировано 35-штук (вместе с расширенными), а GUID’ы этих интерфейсов я вынес во-внешний инклуд (см.скрепку в конце статьи). По сути здесь нет ничего особенного, однако следующий нюанс требует некоторого пояснения..
Значит передаём функции DebugCreate() GUID интерфейса «IDebugClient::», на что функция возвращает нам адрес этого интерфейса в памяти. Если вернуться к рис.выше, то можно обнаружить, что первые три метода в любом интерфейсе, есть копия базового интерфейса «IUnknown::», а первый метод – как-раз нужный нам QueryInterface(). Он ожидает на входе два аргумента – это GUID искомого интерфейса, и указатель на переменную, куда метод сохранит его адрес.
Особое внимание нужно обратить на способ вызова СОМ-методов в ассемблере. Дело в том, что помимо обозначенных прототипом аргументов, мы всегда должны добавлять ещё один лишний аргумент – в спецификации его назвали «This» и представляет он собой адрес интерфейса. Другими словами, перед вызовом любого метода из какого-либо интерфейса, мы должны явно указать серверу, из какого именно осуществляем вызов. Этот аргумент(This) всегда является первым аргументом метода – вот пример:
C-подобный:
format pe console
include 'win32ax.inc'
entry start
;//----------
.data
InterfaceName:
dd i01,i02,i03,i04,i05,i06,i07,i08,i09,i10 ;// таблица указателей на имена интерфейсов
dd i11,i12,i13,i14,i15,i16,i17,i18,i19,i20
dd i21,i22,i23,i24,i25,i26,i27,i28,i29,i30
dd i31,i32,i33,i34,i35
i01 db 10,' IUnknown..............: ',0
i02 db 10,10,' IDebugAdvanced........: ',0
i03 db 10,' IDebugAdvanced2.......: ',0
i04 db 10,' IDebugAdvanced3.......: ',0
i05 db 10,10,' IDebugBreakpoint......: ',0
i06 db 10,' IDebugBreakpoint2.....: ',0
i07 db 10,' IDebugBreakpoint3.....: ',0
i08 db 10,10,' IDebugClient..........: ',0
i09 db 10,' IDebugClient2.........: ',0
i10 db 10,' IDebugClient3.........: ',0
i11 db 10,' IDebugClient4.........: ',0
i12 db 10,' IDebugClient5.........: ',0
i13 db 10,' IDebugClient6.........: ',0
i14 db 10,' IDebugClient7.........: ',0
i15 db 10,10,' IDebugControl.........: ',0
i16 db 10,' IDebugControl2........: ',0
i17 db 10,' IDebugControl3........: ',0
i18 db 10,' IDebugControl4........: ',0
i19 db 10,' IDebugControl5........: ',0
i20 db 10,' IDebugControl6........: ',0
i21 db 10,' IDebugControl7........: ',0
i22 db 10,10,' IDebugDataSpaces......: ',0
i23 db 10,' IDebugDataSpaces2.....: ',0
i24 db 10,' IDebugDataSpaces3.....: ',0
i25 db 10,10,' IDebugEventCallbacks..: ',0
i26 db 10,' IDebugInputCallbacks..: ',0
i27 db 10,' IDebugOutputCallbacks.: ',0
i28 db 10,' IDebugOutputCallbacks2: ',0
i29 db 10,10,' IDebugRegisters.......: ',0
i30 db 10,' IDebugSymbolGroup.....: ',0
i31 db 10,' IDebugSymbols.........: ',0
i32 db 10,' IDebugSymbols2........: ',0
i33 db 10,10,' IDebugSystemObjects...: ',0
i34 db 10,' IDebugSystemObjects2..: ',0
i35 db 10,' IDebugSystemObjects3..: ',0
Client dd 0 ;// переменная под адрес интерфейса "IDebugClient"
iOffset dd 0 ;// переменная под адрес остальных интерфейсов (обновляется в цикле)
buff db 0
;//----------
.code
start: invoke SetConsoleTitle,<'*** Debug Engine QueryInterface v0.1 ***',0>
invoke CoInitialize,0 ;// активируем СОМ-сервер
;// Создаём клиента отладки (в переменную Client получим указатель на интерфейс)
invoke DebugCreate,IID_IDebugClient,Client
xchg ebx,eax
cinvoke printf,<10,' Client Interface......: %08X',0>,[Client]
cmp ebx,S_OK
jnz @error ;// если ошибка..
;// Перебрать имеющиеся в движке интерфейсы
mov ecx,35 ;// всего зарегистрировано (длина цикла для LOOP)
mov esi,GuidTable ;// адрес таблицы-гуидов в инклуде "Dbgeng.inc"
mov ebx,InterfaceName ;// адрес таблицы с именами интерфейсов
@@: push ecx esi ebx ebx ;// запомнить для организации цикла!
mov eax,[Client] ;// адрес интерфейса "IDebugClient"
mov edx,[eax] ;// берём из него сразу-же первый указатель на метод QueryInterface()
push iOffset ;// куда сохранять указатель на интерфейс
push esi ;// GUID очередного интерфейса
push [Client] ;// аргумент "This" (от куда вызываем метод)
call dword[edx] ;// QueryInterface()!
pop ebx ;//
mov edx,[ebx] ;// указатель на имя из таблицы
cinvoke printf,<'%s%08X',0>,edx,[iOffset] ;// вывести на консоль имя и адрес интерфейса
pop ebx esi ecx ;// восстановить данные цикла
add esi,16 ;// следующий GUID в таблице
add ebx,4 ;// следующий указатель на имя
loop @b ;// промотать цикл ECX-раз..
@exit: invoke CoUninitialize ;// освобождаем СОМ-сервер
cinvoke getch ;//
cinvoke exit,0 ;// GAME OVER!
;//===== ОБРАБОТКА ОШИБКИ ======================
@error: cinvoke printf,<10,' Operation ERROR!!!',0>
jmp @exit
;//----- ИМПОРТ ----------
section '.idata' import data readable
library msvcrt,'msvcrt.dll',dbgeng,'dbgeng.dll',
ole32, 'ole32.dll', kernel32,'kernel32.dll'
import msvcrt, printf,'printf',getch,'_getch',exit,'exit'
import dbgeng, DebugCreate, 'DebugCreate'
import ole32, CoInitialize,'CoInitialize',CoUninitialize,'CoUninitialize'
include 'apikernel32.inc'
include 'equatesdbgeng.inc' ;//<-------- подключаем свой инклуд!!!
Посмотрим на результат работы программы..
Интерфейсы, у которых адресом является нуль, не реализованы в движке-отладки Dbgeng.dll и вызывать из них методы нельзя (получим исключение Access-Violation с кодом 0xC0000005, т.к. будет попытка чтения адреса нуль). Ну с интерфейсами Client::[6,7] и Control::[5,6,7] всё понятно – как видим, это обновы предыдущих и добавлены они только начиная с Win-8. Однако мне так и не удалось найти ответа, почему отсутствуют интерфейсы Breakpoint:: и Callbacks::. Ради эксперимента я даже пробовал подключать не системную библиотеку Dbgeng.dll, а переименовав подсовывал программе либу ядерного отладчика WinDbg, и всё-равно получал аналогичную картину. После нескольких попыток было решено оставить этот вопрос открытым, до лучших времён.
Из остальных интерфейсов можно смело вызывать их методы. Например, лист методов интерфейса IDebugClient::[2,3,4] выглядит так.. а остальные – перечислены в созданном мной инклуде Dbgeng.inc (см.скрепку). Обратите внимание, как добавляются расширенные интерфейсы к предыдущим. Каждый из них включает в себя полный список всех/своих предков, и только в конце добавляются новые.
C-подобный:
;// Методы интерфейсов (в комментах указаны аргументы)
;//***********************************************************
struct IUnknown
QueryInterface dd 0 ;// InterfaceId, pInterface
AddRef dd 0 ;//
Release dd 0 ;//
ends
struct IDebugClient
Header IUnknown ;//<----------- всякий интерфейс начинается с IUnknown
AttachKrnl dd 0 ;// Flags, ConnectOptions
GetKrnlConnectionOptions dd 0 ;// Buffer, BufferSize, OptionsSize
SetKrnlConnectionOptions dd 0 ;// Options
StartProcessServer dd 0 ;// Flags, Options, Reserved
ConnectProcessServer dd 0 ;// RemoteOptions, Server64
DisconnectProcessServer dd 0 ;// Server64
GetRunProcessSysIds dd 0 ;// Server64, Ids, Count, ActualCount
GetRunProcessSysIdExName dd 0 ;// Server, ExeName, Flags, Id
GetRunProcessDescription dd 0 ;// 9 argumets
AttachProcess dd 0 ;// Server64, PId, AttachFlags
CreateProcess dd 0 ;// Server64, CommandLine, CreateFlags
CreateProcessAndAttach dd 0 ;// Server, CommandLine, CreateFlags, PId, AttachFlags
GetProcessOptions dd 0 ;// Options
AddProcessOptions dd 0 ;// Options
RemoveProcessOptions dd 0 ;// Options
SetProcessOptions dd 0 ;// Options
OpenDumpFile dd 0 ;// DumpFile
WriteDumpFile dd 0 ;// DumpFile, Qualifier
ConnectSession dd 0 ;// Flags, HistoryLimit
StartServer dd 0 ;// Options
OutputServers dd 0 ;// OutputControl, Machine, Flags
TerminateProcesses dd 0 ;//
DetachProcesses dd 0 ;//
EndSession dd 0 ;// Flags
GetExitCode dd 0 ;// Code
DispatchCallbacks dd 0 ;// Timeout
ExitDispatch dd 0 ;// Client
CreateClient dd 0 ;// Client
GetInputCallbacks dd 0 ;// Callbacks
SetInputCallbacks dd 0 ;// Callbacks
GetOutputCallbacks dd 0 ;// Callbacks
SetOutputCallbacks dd 0 ;// Callbacks
GetOutputMask dd 0 ;// Mask
SetOutputMask dd 0 ;// Mask
GetOtherOutputMask dd 0 ;// Client, Mask
SetOtherOutputMask dd 0 ;// Client, Mask
GetOutputWidth dd 0 ;// Columns
SetOutputWidth dd 0 ;// Columns
GetOutputLinePrefix dd 0 ;// Buffer, BufferSize, PrefixSize
SetOutputLinePrefix dd 0 ;// Prefix
GetIdentity dd 0 ;// Buffer, BufferSize, IdentitySize
OutputIdentity dd 0 ;// OutputControl, Flags, Format
GetEventCallbacks dd 0 ;// Callbacks
SetEventCallbacks dd 0 ;// Callbacks
FlushCallbacks dd 0 ;//
ends
struct IDebugClient2
Previous IDebugClient ;//<------ IDebugClient2 включает в себя весь предыдущий интерфейс!
WriteDumpFile2 dd 0 ;// DumpFile,Qualifier,FormatFlags,Comment
AddDumpInformationFile dd 0 ;// InfoFile,Type
EndProcessServer dd 0 ;// Server
WaitForProcessServerEnd dd 0 ;// Timeout
IsKrnlDebuggerEnabled dd 0 ;//
TerminateCurrentProcess dd 0 ;//
DetachCurrentProcess dd 0 ;//
AbandonCurrentProcess dd 0 ;//
ends
struct IDebugClient3
Previous IDebugClient2
GetRunProcessSysIdExNameWide dd 0 ;// Server,PCWSTR ExeName,Flags,PId
GetRunProcessDescriptionWide dd 0 ;// 9 arguments (see Dbgeng.h)
CreateProcessWide dd 0 ;// Server,CommandLine,CreateFlags
CreateProcessAndAttachWide dd 0 ;// Server,CmdLine,CreateFlags,ProcessId,AttachFlags
ends
struct IDebugClient4
Previous IDebugClient3
OpenDumpFileWide dd 0 ;// FileName,FileHandle
WriteDumpFileWide dd 0 ;// FileName,FileHandle,Qualifier,FormatFlags,Comment
AddDumpInfoFileWide dd 0 ;// FileName,FileHandle,Type
GetNumberDumpFiles dd 0 ;// PNumber
GetDumpFile dd 0 ;// Index,Buffer,BufferSize,PNameSize,Handle,PType
GetDumpFileWide dd 0 ;// Index,Buffer,BufferSize,PNameSize,Handle,PType
ends
4. Практика – пишем дизассемблер
Теперь, на финишной прямой, собрав воедино всё/вышеизложенное напишем дизассемблер, одноимённый метод которого лежит в интерфейсе IDebugControl::. Чтобы на поверхность всплыла исключительно полезная составляющая кода, я ограничился дизаcсемблированием лишь текущей программы. В идеале, нужно было дать возможность юзеру выбирать исполняемый файл, но в этом случае «пайлоад» утонул-бы в массе дополнительных функций. Здесь главное понять суть, а окружение – это уже второстепенная задача и дело вкуса. Значит алго будет такой:
1. При помощи метода QueryInterface() найти адреса интерфейсов IDebugClient:: и IDebugControl::;
2. Внутри интерфейса IDebugClient:: найти указатель на метод AttachProcess(), чтобы прицепить отладчик к текущему (или любому другому) процессу;
3. Внутри интерфейса IDebugControl:: найти указатели на методы WaitForEvent() и Disassemble() – первый ожидает события отладки, а второй генерит событие Disasm;
4. Вызвать все эти методы, обязательно в указанном выше порядке;
5. Последний метод Disassemble() сбросит в буфер дизассемблированную строку – вывести её на консоль!
6. Прокрутить цикл[5] столько раз, сколько хотим «переварить» инструкций.
7. Выход из программы.
Ну и собственно вот реализация этого алгоритма на ассемблере FASM.
Все строки кода прокомментированы, а если что-то непонятно, то всегда можно задать вопрос в комментариях статьи:
C-подобный:
format pe console
include 'win32ax.inc'
entry start
;//----------
.data
title db '*** Disassembler v0.1 ***',0
clientFace db 10,' Client Interface............: %08X',0
ctrlFace db 10,' Control Interface...........: %08X',0
Client dd 0 ;// адреса СОМ-интерфейсов
Control dd 0 ;// ...^^^
Attach dd 0 ;// указатели на методы из интерфейсов
WaitEvent dd 0 ;// ...^^^
Disasm dd 0 ;// ...^^^
pNextOffs dd 0,0
DisasmSize dd 0
buff db 0
;//----------
.code
start: invoke SetConsoleTitle,title
invoke CoInitialize,0
;// Запрашиваем интерфейс клиента
invoke DebugCreate,IID_IDebugClient,Client
xchg ebx,eax
cinvoke printf,clientFace,[Client]
cmp ebx,S_OK
jnz @error
;// Проверить наличие интерфейса 'IDebugControl'
mov eax,[Client] ;// таблица клиента
mov edx,[eax] ;// адрес метода 'QueryInterface' в ней
push Control ;// сюда получим указатель
push IID_IDebugControl ;// GUID запрашиваемого интерфейса
push [Client] ;// This = в каком интерфейсе искать
call dword[edx] ;// QueryInterface!!!
;// Проверить на ошибку
xchg ebx,eax
cinvoke printf,ctrlFace,[Control]
cmp ebx,S_OK
jnz @error
;// Получаем адреса нужных нам методов из интерфейсов ==================
;// IDebugClient::AttachProcess
mov esi,[Client]
mov esi,[esi]
mov eax,[esi+IDebugClient.AttachProcess]
mov [Attach],eax
cinvoke printf,<10,' Client AttachProcess method: %08X',0>,eax
;// IDebugControl::WaitForEvent
mov esi,[Control]
mov esi,[esi]
mov eax,[esi+IDebugControl.WaitForEvent]
mov [WaitEvent],eax
cinvoke printf,<10,' Control WaitForEvent method: %08X',0>,eax
;// IDebugControl::Disassemble
mov esi,[Control]
mov esi,[esi]
mov eax,[esi+IDebugControl.Disassemble]
mov [Disasm],eax
cinvoke printf,<10,' Control Disassemble method: %08X',0>,eax
;//***********************************************************
@process:
;// Подцепить отладчик к текущему процессу ()
invoke GetCurrentProcessId
mov ebx,DEBUG_ATTACH_NONINVASIVE + DEBUG_ATTACH_NONINVASIVE_NO_SUSPEND
push ebx ;// флаги
push eax ;// Pid процесса
push 0 0 ;// Ulong64 Server
push [Client] ;// This
call dword[Attach]
cinvoke printf,<10,' Attach ReturnCode: %08x',0>,eax
;// Ожидать событие отладки..
push -1 ;// INFINITY (ждать бесконечно)
push 0 ;// DEBUG_WAIT_DEFAULT
push [Control] ;// This
call dword[WaitEvent]
cinvoke printf,<10,' DbgWait ReturnCode: %08x',10,10,0>,eax
;//===== Вызвать дизассемблер!!! ============================
mov ebx,start ;// адрес первой инструкции
mov ecx,25 ;// всего дизассемблировать инструкций
@@: push ecx ebx ;// запомнить для цикла..
push pNextOffs ;// получим адрес сл.инструкции
push DisasmSize ;// получим размер данных в буфере
push 256 ;// размер буфера
push buff ;// адрес приёмного буфа
push DEBUG_DISASM_EFFECTIVE_ADDRESS ;// флаг дизасма
push 0 ;// см.ниже vvv
push ebx ;// qword-адрес в памяти для дизасма
push [Control] ;// This
call dword[Disasm]
cinvoke printf,<' %s',0>,buff ;// распечатать дизасм-листинг!
pop ebx ecx ;// восстановить данные цикла
mov ebx,[pNextOffs] ;// адрес сл.инструкции из переменной
loop @b ;// промотать ECX-раз..
@exit: cinvoke getch ;// GAME OVER!
invoke CoUninitialize ;// освободить СОМ-сервер
cinvoke exit,0 ;//
;//===== ПРОЦЕДУРЫ ===============================
@error: cinvoke printf,<10,' Operation ERROR!!!',0>
jmp @exit
;//----- ИМПОРТ ----------
section '.idata' import data readable
library msvcrt,'msvcrt.dll',dbgeng,'dbgeng.dll',
ole32, 'ole32.dll', kernel32,'kernel32.dll'
import msvcrt, printf,'printf',getch,'_getch',exit,'exit'
import dbgeng, DebugCreate,'DebugCreate'
import ole32, CoInitialize,'CoInitialize',CoUninitialize,'CoUninitialize'
include 'apikernel32.inc'
include 'equatesdbgeng.inc'
;//----- РЕСУРСЫ ---------
section '.rsrc' resource data readable
directory RT_VERSION,ver
resource ver, 1, LANG_NEUTRAL, vInfo
versioninfo vInfo,
VOS__WINDOWS32, VFT_APP, VFT2_UNKNOWN,
LANG_ENGLISH + SUBLANG_DEFAULT, 1252,
'CompanyName' , 'https://codeby.net',
'LegalCopyright' , 'Copyright 2020-2021 (c)Marylin',
'ProductName' , 'Windows 7',
'ProductVersion' , '6.1.7601.3821',
'FileDescription' , 'DbgEngine Disassembler',
'FileVersion' , '0.0.1',
'OriginalFilename', 'DbgDisasm.exe'
Здесь я добавил некоторую вспомогательную информацию в шапке, чтобы продемонстрировать расположение интерфейсов и их методов. Так, первые две строчки указывают на наше пользовательское пространство памяти, куда функция DebugCreate() любезно сбросила указатели на интерфейсы. А вот сами методы находятся уже внутри библиотеки Dbgeng.dll, о чём свидетельствует их адреса с базой 0x5D0D0000. Если вызов метода возвращает в EAX=0, значит он прошёл успешно (константа S_OK), иначе в EAX получим следующие коды ошибок:
C-подобный:
;// Перечень ошибок - WinError.h.
;//---------------------------------------------
S_OK = 0 ;// операция выполнена успешно!
S_FALSE = 1 ;// без ошибок, но получена только часть результата (см.буфер)
E_NOINTERFACE = 80004002h ;// интерфейс не найден
E_POINTER = 80004003h ;// неверный указатель
E_ABORT = 80004004h ;// операция отвергнута
E_FAIL = 80004005h ;// операция не может быть выполнена
E_ACCESSDENIED = 80070005h ;// доступ запрещён (отладчик находится в безопасном режиме)
E_HANDLE = 80070006h ;// проблема с дескриптором
E_OUTOFMEMORY = 8007000Eh ;// ошибка выделения памяти
E_INVALIDARG = 80070057h ;// неверный аргумент метода
E_UNEXPECTED = 8000FFFFh ;// отладчик в неправильном состоянии (см.WaitForEvent)
5. Заключение.
Программирование СОМ-интерфейсов открывает перед нами огромные возможности, поскольку в своих/больших штанинах они прячут достаточно интересные методы, подобраться к которым можно только через указатель на интерфейс, аля GUID. По модели СОМ построена добрая половина системных библиотек – объектная модель позволяет нам работать с такими механизмами как WMI (инструментарий Windows), технологией DirectX, с библиотекой Shell32.dll и многое другое. Как упоминалось выше, любой СОМ-интерфейс обязан быть документированным, поэтому проблем не возникает – главное уловить логическую нить, а дальше уже дело техники.
По уже отработанной схеме, в скрепку ложу два исполняемых файла, а так-же инклуд с описанием GUID’ов всех интерфейсов движка Dbgeng.dll, с полным описанием входящих в их состав методов. Всем удачи, пока!
I’m interested in writing an x86 dissembler as an educational project.
The only real resource I have found is Spiral Space’s, «How to write a disassembler». While this gives a nice high level description of the various components of a disassembler, I’m interested in some more detailed resources. I’ve also taken a quick look at NASM’s source code but this is somewhat of a heavyweight to learn from.
I realize one of the major challenges of this project is the rather large x86 instruction set I’m going to have to handle. I’m also interested in basic structure, basic disassembler links, etc.
Can anyone point me to any detailed resources on writing a x86 disassembler?
![]()
Jay Bosamiya
2,9512 gold badges13 silver badges33 bronze badges
asked May 29, 2009 at 3:50
![]()
1
Take a look at section 17.2 of the 80386 Programmer’s Reference Manual. A disassembler is really just a glorified finite-state machine. The steps in disassembly are:
- Check if the current byte is an instruction prefix byte (
F3,F2, orF0); if so, then you’ve got aREP/REPE/REPNE/LOCKprefix. Advance to the next byte. - Check to see if the current byte is an address size byte (
67). If so, decode addresses in the rest of the instruction in 16-bit mode if currently in 32-bit mode, or decode addresses in 32-bit mode if currently in 16-bit mode - Check to see if the current byte is an operand size byte (
66). If so, decode immediate operands in 16-bit mode if currently in 32-bit mode, or decode immediate operands in 32-bit mode if currently in 16-bit mode - Check to see if the current byte is a segment override byte (
2E,36,3E,26,64, or65). If so, use the corresponding segment register for decoding addresses instead of the default segment register. - The next byte is the opcode. If the opcode is
0F, then it is an extended opcode, and read the next byte as the extended opcode. - Depending on the particular opcode, read in and decode a Mod R/M byte, a Scale Index Base (SIB) byte, a displacement (0, 1, 2, or 4 bytes), and/or an immediate value (0, 1, 2, or 4 bytes). The sizes of these fields depend on the opcode , address size override, and operand size overrides previously decoded.
The opcode tells you the operation being performed. The arguments of the opcode can be decoded form the values of the Mod R/M, SIB, displacement, and immediate value. There are a lot of possibilities and a lot of special cases, due to the complex nature of x86. See the links above for a more thorough explanation.
answered May 29, 2009 at 4:57
![]()
Adam RosenfieldAdam Rosenfield
385k96 gold badges510 silver badges586 bronze badges
2
I would recommend checking out some open source disassemblers, preferably distorm and especially «disOps (Instructions Sets DataBase)» (ctrl+find it on the page).
The documentation itself is full of juicy information about opcodes and instructions.
Quote from https://code.google.com/p/distorm/wiki/x86_x64_Machine_Code
80×86 Instruction:
A 80×86 instruction is divided to a
number of elements:
- Instruction prefixes, affects the behaviour of the instruction’s
operation.- Mandatory prefix used as an opcode byte for SSE instructions.
- Opcode bytes, could be one or more bytes (up to 3 whole bytes).
- ModR/M byte is optional and sometimes could contain a part of the
opcode itself.- SIB byte is optional and represents complex memory indirection
forms.- Displacement is optional and it is a value of a varying size of
bytes(byte, word, long) and used as an
offset.- Immediate is optional and it is used as a general number value built
from a varying size of bytes(byte,
word, long).The format looks as follows:
/------------------------------------------------------------------------------------------------------------------------------------------- |*Prefixes | *Mandatory Prefix | *REX Prefix | Opcode Bytes | *ModR/M | *SIB | *Displacement (1,2 or 4 bytes) | *Immediate (1,2 or 4 bytes) | -------------------------------------------------------------------------------------------------------------------------------------------/ * means the element is optional.
The data structures and decoding phases are explained in https://code.google.com/p/distorm/wiki/diStorm_Internals
Quote:
Decoding Phases
- [Prefixes]
- [Fetch Opcode]
- [Filter Opcode]
- [Extract Operand(s)]
- [Text Formatting]
- [Hex Dump]
- [Decoded Instruction]
Each step is explained also.
The original links are kept for historical reasons:
http://code.google.com/p/distorm/wiki/x86_x64_Machine_Code and http://code.google.com/p/distorm/wiki/diStorm_Internals
![]()
viv
1032 silver badges3 bronze badges
answered May 29, 2009 at 4:41
![]()
hannsonhannson
4,4578 gold badges37 silver badges46 bronze badges
3
Start with some small program that has been assembled, and which gives you both the generated code and the instructions. Get yourself a reference with the instruction architecture, and work through some of the generated code with the architecture reference, by hand. You’ll find that the instructions have a very stereotypical structure of inst op op op with varying number of operands. All you need to do is translate the hex or octal representation of the code to match the instructions; a little playing around will reveal it.
That process, automated, is the core of a disassembler. Ideally, you’re probably going to want to construct a n array of instruction structures internally (or externally, if the program is really large). You can then translate that array into the instructions in assembler format.
![]()
answered May 29, 2009 at 4:00
![]()
Charlie MartinCharlie Martin
109k24 gold badges194 silver badges260 bronze badges
You need a table of opcodes to load from.
The fundamental lookup datastructure is a trie, however a table will do well enough if you don’t care much about speed.
To get the base opcode type, beginswith match on the table.
There are a few stock ways of decoding register arguments; however, there are enough special cases to require implementing most of them individually.
Since this is educational, have a look at ndisasm.
answered May 29, 2009 at 4:02
![]()
JoshuaJoshua
39.8k8 gold badges72 silver badges128 bronze badges
Checkout objdump sources — it’s a great tool, it contains many opcode tables and it’s sources can provide a nice base for making your own disassembler.
answered Aug 7, 2011 at 23:27
![]()
Всем привет. Тут такое дело: ещё одна моя реверсерская мечта сбылась — я написал процессорный модуль для IDA Pro с нуля, за два дня! Если вы когда-то тоже хотели написать свой модуль, но боялись начать — думаю, моя статья сможет помочь.
В качестве кода, который требуется дизасемблировать, будет выступать код виртуальной машины из очень крутого хоррора, который выходил сначала на SNES, потом на PS1, PC и Wonderswan — «Clock Tower — The First Fear«. В игре имеется 9 концовок (sic!), атмосфера гнетущая, а в качестве главного злодея выступает «Scissorman» (человек с руками-ножницами). Заинтересовал? Тогда добро пожаловать…
 для IDA Pro - 1")
О самой виртуальной машине
Собственно, сам код, выполняющий опкоды виртуальной машины, не будет являться предметом данной статьи, но, вот краткая информация о нём:
-
115 опкодов на все случаи жизни
-
для анализа VM я анализировал исполняемые файлы для PS1 и PC, на SNES виртуальной машины нет
-
уже написан дизассемблер-декомпилятор для Ghidra (ссылки в конце статьи)
 для IDA Pro - 2")
Подготовка
Итак, приступим к написанию кода. Я писал в Visual Studio на C/C++, но вы можете писать и на Python.
Структура проекта
Согласно устоявшимся принципам разработки процессорных модулей для IDA Pro (которые можно найти в IDA SDK), нам понадобится создать следующие пока ещё пустые файлы:
Инклуды:
-
cpu_name.hpp(где cpu_name — краткое имя вашего процессорного модуля, в моём случае это adc) -
ins.hpp(будет содержать enum со списком всех опкодов)
Файлы с кодом:
-
ana.cpp(здесь будет находиться код анализатора (хорошо, что не как у radare2 — anal) -
emu.cpp(сюда мы будем писать код эмулятора) -
ins.cpp(имена опкодов и их feature-флаги — здесь) -
out.cpp(код, который отвечает за сам вывод мнемоник/операндов и прочей атрибутики, типа запятых, скобок и т.д.) -
reg.cpp(можно предположить, что это про регистры, но нет — это про регистрацию модуля, его флаги и прочую конфигурацию. Именно здесь начинается модуль)
 для IDA Pro - 3")
Об анализаторе, эмуляторе и выводе
Чтобы проще было изучать готовые процессорные модули и, соответственно, писать свои, стоит сначала понять, что же такое анализатор (ana), эмулятор (emu) и вывод (out). Начнём с ana.
Анализатор (ana)
Задачи анализатора: чтение входных данных, формирование опкодов и операндов для них. Обычно, это выглядит так: читаем байт/ворд/дворд, находим соответствие одному из наших опкодов, затем читаем данные до тех пор, пока не заполним данные для каждого операнда (индекс регистра/адрес в памяти/смещение для прыжка и т.п.). Пока читаем, формируется итоговая длина инструкции.
Эмулятор (emu)
После того, как анализатор закончил свою работу, в дело вступает эмулятор. Его задача: формирование ссылок и пост-анализ кода. Ссылки могут быть:
-
на следующую инструкцию, если это не return, jump и другие подобные инструкции
-
на адреса в памяти: чтение/запись/обычное смещение
-
на стек и локальные переменные
Под пост-анализом подразумевается, именование каких-то известных встроенных функций, портов, адресов в памяти. Ещё можно добавлять в очередь для анализа адреса из операндов, где также необходимо дизассемблировать/создать функцию.
Вывод (out)
И, наконец, финальный этап для процессорного модуля — код для вывода накопленной информации об инструкциях (out). Данная часть вызывается Идой только тогда, когда инструкция попадает в область видимости листинга. И именно здесь кроется причина, почему процессорный модуль для Гидры умеет в декомпиляцию из коробки, а модуль из Иды — нет. Выводилка последней — это, фактически, простая printf того, что вы ей укажете, с возможностями вставлять отступы, делать вывод цветным и т.д. Никакого тебе IR (Intermediate Representation). Поэтому, если хочешь декомпилятор для экзотической платформы, у тебя два варианта:
-
Использовать Ghidra
-
Не использовать Ghidra. Вместо этого изощряться через Вывод. Годится лишь для простых виртуальных машин
В случае простой виртуальной машины. каковой является VM из Clock Tower, можно извратиться и выводить сразу псевдо-сишный код (ничего страшного в этом нет). Я так и сделал.
Пишем процессорный модуль
Хватит разглагольствовать, давайте уже писать код. Открываем Visual Studio, создаём пустой проект DLL, прописываем пути к инклудам и библиотекам IDA SDK. Указываем следующие процессорные директивы (все три являются обязательными):
__NT__
__IDP__
__X64__Если необходима поддержка вашего процессорного модуля Идой с 64-битным адресным пространством, также добавляем флаг:
__EA64__Теперь открываем reg.cpp и вставляем следующий шаблон:
#include "adc.hpp" // your main VM include
processor_t LPH = {
IDP_INTERFACE_VERSION,
0x8000 + 666, // proc ID
PR_USE32 | PR_DEFSEG32 | PRN_HEX | PR_WORD_INS | PR_BINMEM | PR_NO_SEGMOVE | PR_CNDINSNS, // flags
0, // flags2
8, 8, // bits in a byte (code/data)
shnames, // short processor names
lnames, // long processor names
asms, // assembler definitions
notify, // callback to create our proc module instance
regnames, // register names
qnumber(regnames), // registers count
rVcs, rVds, // number of first/last segment register
0, // segment register size
rVcs, rVds, // virtual code/data segment register
NULL, // typical code start sequences
retcodes, // return opcodes bytes
0, ADCVM_last, // indices of first/last opcodes (in enum)
Instructions, // array of instructions
};В файл adc.hpp необходимо прописать некоторые важные инклуды:
#pragma once
#include "../idaidp.hpp" // this file is located in IDA_SDK/module/ dir
#include "ins.hpp"Ключевых моментов здесь 3:
-
proc ID— идентификатор вашего процессорного модуля. Все пользовательские модули должны иметь номер >= 0x8000 -
Флаги— их много, и позволяют они достаточно тонко настроить работу процессорного модуля. Список флагов и их описания здесь -
rVcs/rVds— в моей виртуальной машине регистры не используются, но Иде всё равно требуется указать хотя бы виртуальные регистры. Ими мы займёмся позднее
Первым идёт shnames:
static const char* const shnames[] = { "ADCVM", NULL };Здесь мы перечисляем все процессоры, которые поддерживает наш модуль (конечно, их может быть несколько. В конце списка обязательно должен быть NULL.
Далее создаём lnames:
static const char* const lnames[] = { "Clock Tower: Clock Tower ADC VM", NULL };То же самое, только можно указать более длинное имя. Обратите внимание на саму строку — всё, что в ней расположено до двоеточия, является именем семейства процессоров. Итого, вся эта информация в Иде будет отображаться следующим образом:
 для IDA Pro - 4")
Следующий кусок кода, на котором многие останавливаются (в том числе и я когда-то) — это описание ассемблера. Что он из себя представляет в понимании Иды? Фактически, по большей части, это — солянка из никем не используемых и никому не нужных элементов синтаксиса ассемблера, которые выводятся в листинг самой Идой (далеко не все) без нашего участия. В основном, это касается нераспознанных данных, массивов и других директив (типа: org, end, equ, public, xref).
Нужны они, или нет, а заполнять придётся. Лучшим вариантом будет взять готовый из какого-нибудь SDK-шного модуля и чуть-чуть изменить. У меня получилось следующее:
static const asm_t adcasm = {
AS_COLON | ASH_HEXF3,
0,
"Clock Tower Virtual Machine Bytecode",
0,
NULL, // header lines
"org", // org
"end", // end
";", // comment string
'"', // string delimiter
''', // char delimiter
""'", // special symbols in char and string constants
"dc", // ascii string directive
"dcb", // byte directive
"dc", // word directive
NULL, // double words
NULL, // qwords
NULL, // oword (16 bytes)
NULL, // float (4 bytes)
NULL, // double (8 bytes)
NULL, // tbyte (10/12 bytes)
NULL, // packed decimal real
"bs#s(c,) #d, #v", // arrays (#h,#d,#v,#s(...)
"ds %s", // uninited arrays
"equ", // equ
NULL, // 'seg' prefix (example: push seg seg001)
"*", // current IP (instruction pointer)
NULL, // func_header
NULL, // func_footer
"global", // "public" name keyword
NULL, // "weak" name keyword
"xref", // "extrn" name keyword
// .extern directive requires an explicit object size
NULL, // "comm" (communal variable)
NULL, // get_type_name
NULL, // "align" keyword
'(', ')', // lbrace, rbrace
"%", // mod
"&", // and
"|", // or
"^", // xor
"!", // not
"<<", // shl
">>", // shr
"sizeof", // sizeof
AS2_BYTE1CHAR,// One symbol per processor byte
};Из всего, что здесь написано, нам нужны только флаги (они отвечают за то, как будут отображаться числа, строки, смещения), и имя для нашего ассемблера. Подробнее про структуру asm_t можно почитать здесь, ну а мы двигаем дальше.
Как уже было сказано, notify-колбэк отвечает за создание объекта класса процессорного модуля в момент, когда это нужно Иде. Смысла менять его код нет, поэтому берём как есть:
static int data_id;
ssize_t idaapi notify(void* user_data, int notification_code, va_list va) {
if (notification_code == processor_t::ev_get_procmod) {
data_id = 0;
return size_t(SET_MODULE_DATA(adcvm_t));
}
return 0;
}Заменяем только adcvm_t на имя класса вашего будущего модуля. Также, обращаем внимание на макрос SET_MODULE_DATA. Он отвечает за вызов функции set_module_data и создание экземпляра нашего процессора. Требует объявленного выше int data_id;. Тушкой модуля займёмся чуточку позже, а пока перейдём к регистрам.
В случае виртуальной машины из Clock Tower, вместо регистров используются адреса в рабочей (work) памяти. Но Ида, к сожалению, не может избавиться от своего сегментного прошлого и хочет в любом случае указанных cs и ds регистров, даже если они нигде не используются. Поэтому, regnames будет выглядеть следующим образом:
static const char* const regnames[] = {
"cs", "ds"
};Здесь вместо NULL в конце списка, Ида принимает количество регистров, которое можно указать через макрос: qnumber(regnames). Далее необходимо создать enum с самими регистрами (которых нет):
static enum adcvm_regs {
rVcs, rVds
};Именно на элементы этого enum-а мы и сослались в структуре. С регистрами покончено, и можно переходить к помощи Иде в распознавании типовых участков кода. Прологов в моём случае не имеется, поэтому указываем NULL, а вот коды возврата есть, поэтому пишем:
static const uchar retcode[] = { 0x00, 0xFF };
static const bytes_t retcodes[] = {
{ sizeof(retcode), retcode },
{ 0, NULL }
};В разбираемой мной VM, все опкоды имеют минимальную длину два байта, а код инструкции return имеет значение { 0x00, 0xFF }. Итак, мы плавно перешли к самим инструкциям.
Инструкции
Как уже было сказано, опкодов в случае Clock Tower VM ровно 115. Их имена были заботливо оставлены разработчиками прямо в исполняемых файлах (для отладочного вывода, который был в итоге выпилен). В общем, берём эти имена, и добавляем к ним префикс в виде имени процессорного модуля: ADCVM, получаем enum, который необходимо расположить в ins.hpp. В итоге имеем вот такую портянку:
Мой ins.hpp
#pragma once
extern const instruc_t Instructions[]; // to reference it from reg.cpp
enum nameNum {
ADCVM_null = 0,
ADCVM_ret,
ADCVM_div,
ADCVM_mul,
ADCVM_sub,
ADCVM_add,
ADCVM_dec,
ADCVM_inc,
ADCVM_mov,
ADCVM_equ,
ADCVM_neq,
ADCVM_gre,
ADCVM_lwr,
ADCVM_geq,
ADCVM_leq,
ADCVM_cmp_end,
ADCVM_allend,
ADCVM_jmp,
ADCVM_call,
ADCVM_evdef,
ADCVM_end,
ADCVM_if,
ADCVM_while,
ADCVM_nop,
ADCVM_endif,
ADCVM_endwhile,
ADCVM_else,
ADCVM_msginit,
ADCVM_msgattr,
ADCVM_msgout,
ADCVM_setmark,
ADCVM_msgwait,
ADCVM_evstart,
ADCVM_bgload,
ADCVM_palload,
ADCVM_bgmreq,
ADCVM_sprclr,
ADCVM_absobjanim,
ADCVM_objanim,
ADCVM_allsprclr,
ADCVM_msgclr,
ADCVM_screenclr,
ADCVM_screenon,
ADCVM_screenoff,
ADCVM_screenin,
ADCVM_screenout,
ADCVM_bgdisp,
ADCVM_bganim,
ADCVM_bgscroll,
ADCVM_palset,
ADCVM_bgwait,
ADCVM_wait,
ADCVM_bwait,
ADCVM_boxfill,
ADCVM_bgclr,
ADCVM_setbkcol,
ADCVM_msgcol,
ADCVM_msgspd,
ADCVM_mapinit,
ADCVM_mapload,
ADCVM_mapdisp,
ADCVM_sprent,
ADCVM_setproc,
ADCVM_sceinit,
ADCVM_userctl,
ADCVM_mapattr,
ADCVM_mappos,
ADCVM_sprpos,
ADCVM_spranim,
ADCVM_sprdir,
ADCVM_gameinit,
ADCVM_continit,
ADCVM_sceend,
ADCVM_mapscroll,
ADCVM_sprlmt,
ADCVM_sprwalkx,
ADCVM_allsprdisp,
ADCVM_mapwrt,
ADCVM_sprwait,
ADCVM_sereq,
ADCVM_sndstop,
ADCVM_sestop,
ADCVM_bgmstop,
ADCVM_doornoset,
ADCVM_rand,
ADCVM_btwait,
ADCVM_fawait,
ADCVM_sclblock,
ADCVM_evstop,
ADCVM_sereqpv,
ADCVM_sereqspr,
ADCVM_scereset,
ADCVM_bgsprent,
ADCVM_bgsprpos,
ADCVM_bgsprset,
ADCVM_slantset,
ADCVM_slantclr,
ADCVM_dummy,
ADCVM_spcfunc,
ADCVM_sepan,
ADCVM_sevol,
ADCVM_bgdisptrn,
ADCVM_debug,
ADCVM_trace,
ADCVM_tmwait,
ADCVM_bgspranim,
ADCVM_abssprent,
ADCVM_nextcom,
ADCVM_workclr,
ADCVM_bgbufclr,
ADCVM_absbgsprent,
ADCVM_aviplay,
ADCVM_avistop,
ADCVM_sprmark,
ADCVM_bgmattr,
ADCVM_last, // required item
};
ins.cpp
Теперь нам предстоит наверное самая муторная работёнка, а именно — формирование списка имён опкодов и указание feature-флагов для них (что это — расскажу позднее). Открываем ins.cpp, вставляем в него следующий шаблон, и начинаем заполнять:
#include "adc.hpp" // your main VM include
const instruc_t Instructions[] = {
{ "", 0 }, // dummy empty instruction
};
CASSERT(qnumber(Instructions) == ADCVM_last);Каждый элемент списка инструкций представляет из себя структуру instruc_t с полями: имя инструкции, feature-флаги инструкции.
Feature-флаги представляют из себя краткое описание того, что представляет из себя конкретная инструкция на совсем примитивном уровне, типа:
-
CF_STOP— инструкция не передаёт управление на следующую -
CF_USE1—CF_USE8— используются операнды 1-8 -
CF_CHG1—CF_CHG8— изменяются операнды 1-8 -
CF_CALL— вызов функции -
CF_JUMP— прыжок на другую инструкцию
Самое интересное, что эти флаги не нужны Иде (а зачем, спрашивается, мы их указываем?). Они будут использоваться только вами (далее увидите как именно), тем не менее данную формальность всё равно необходимо соблюсти. Поэтому, вот вам парочка «типичных» инструкций и их флагов:
{ "return", CF_STOP },{ "jmp", CF_USE1 | CF_JUMP | CF_STOP },{ "call", CF_USE1 | CF_JUMP | CF_CALL },{ "mul", CF_USE1 | CF_USE2 | CF_CHG1 },Думаю, флаги в этих примерах говорят сами за себя. В случае, если операндов нет, вместо флагов указываем 0.
Класс procmod_t
Покончив с рутиной в виде описания инструкций, настало время заняться ядром нашего процессорного модуля. Поэтому, открываем adc.hpp и вставляем в него после инклудов следующий шаблон:
struct adcvm_t : public procmod_t {
virtual ssize_t idaapi on_event(ssize_t msgid, va_list va) override;
int idaapi ana(insn_t* _insn);
int idaapi emu(const insn_t& insn) const;
void handle_operand(const insn_t& insn, const op_t& op, bool isload) const;
};Именно эти функции будут выполнять всё необходимое для того, чтобы превратить набор байтиков входного файла в красивый дизассемблерный (а можно и псевдо-сишный) листинг. Открываем reg.cpp, и дополняем его следующим шаблоном кода:
ssize_t idaapi adcvm_t::on_event(ssize_t msgid, va_list va) {
int retcode = 1;
switch (msgid) {
case processor_t::ev_init: {
inf_set_be(false); // our vm uses little endian
inf_set_gen_lzero(true); // we want to align every hex-value with zeroes
} break;
case processor_t::ev_term: {
clr_module_data(data_id);
} break;
case processor_t::ev_newfile: {
auto* fname = va_arg(va, char*); // here we can load additional data from a current dir
} break;
case processor_t::ev_is_cond_insn: {
const auto* insn = va_arg(va, const insn_t*);
return is_cond_insn(insn->itype);
} break;
case processor_t::ev_is_ret_insn: {
const auto* insn = va_arg(va, const insn_t*);
return (insn->itype == ADCVM_ret) ? 1 : -1;
} break;
case processor_t::ev_is_call_insn: {
const auto* insn = va_arg(va, const insn_t*);
return (insn->itype == ADCVM_call) ? 1 : -1;
} break;
case processor_t::ev_ana_insn: {
auto* out = va_arg(va, insn_t*);
return ana(out);
} break;
case processor_t::ev_emu_insn: {
const auto* insn = va_arg(va, const insn_t*);
return emu(*insn);
} break;
case processor_t::ev_out_insn: {
auto* ctx = va_arg(va, outctx_t*);
out_insn(*ctx);
} break;
case processor_t::ev_out_operand: {
auto* ctx = va_arg(va, outctx_t*);
const auto* op = va_arg(va, const op_t*);
return out_opnd(*ctx, *op) ? 1 : -1;
} break;
default:
return 0;
}
return retcode;
}Имена ивентов, которые перехватывает наш колбэк достаточно говорящие, поэтому я разберу лишь некоторые из них:
-
ev_init— инициализация процессорного модуля. Здесь мы задаём основные свойства, которые нельзя задать флагами. Например, порядок байт (endianness) -
ev_term— если пришло данное событие, необходимо выполнитьclr_module_dataдля корректной работы в случае, если запущено несколько экземпляров Иды с нашим модулем
Не все указанные в этом колбэке методы у нас пока созданы, поэтому их созданием как раз и займёмся. И первым у нас идёт анализатор (ana).
ana() и ana.cpp
Открываем файл ana.cpp, и вставляем в него ещё один шаблон:
#include "adc.hpp"
int idaapi adcvm_t::ana(insn_t* _insn) {
if (_insn == NULL) {
return 0;
}
insn_t& insn = *_insn;
uint16 code = insn.get_next_word();
switch (code) {
case 0: {
} break;
default: {
return 0;
} break;
}
return insn.size;
}Началось… Именно здесь мы будем заполнять структуры insn_t (сама инструкция) и op_t (каждый из операндов). Давайте разбираться.
Для начала мы должны прочитать необходимый токен, который сможет сказать нам, что за опкод у нас на очереди. В моём случае каждая инструкция имеет переменную длину, но сам опкод без операндов имеет длину 2 байта, т.е. word. Его и читаем. Чтение будет происходить согласно указанному ранее порядку байт. К тому же, чтение с использованием конструкции insn.get_next_xxxx() увеличит значение длины формируемой инструкции на соответствующее значение.
Например, инструкция возврата из функции в моём случае имеет значение 0xFF00. Добавим её в наш оператор switch(code), и заполним заодно одно из полей структуры инструкции (insn_t):
switch (code) {
// ...
case 0xFF00: {
insn.itype = ADCVM_ret;
} break;
// ...
}Поле itype — содержит номер инструкции (который обычно привязан к enum-у со всеми имеющимися опкодами). Именно это поле можно будет использовать, чтобы выполнять разные действия для разных инструкций.
Теперь давайте разберём опкод div, который имеет два операнда: dest (делимое) и src (делитель) и сохраняет результат в dest. Так будет выглядеть формирование каждого из операндов (для удобства, были созданы отдельные функции, которые можно использовать в дальнейшем):
static void op_var(insn_t& insn, op_t& x) {
x.offb = (char)insn.size;
uint16 ref = insn.get_next_word();
x.addr = x.value = get_var_addr(ref); // convert short value to a mem address
x.dtype = dt_word;
x.type = o_mem;
}
static void op_var_or_val(insn_t& insn, op_t& x) {
x.offb = (char)insn.size;
uint16 ref = x.value = insn.get_next_word();
bool isvar = is_var(ref); // mem variable or just a word value
if (isvar) {
x.addr = x.value = get_var_addr(ref);
}
x.dtype = dt_word;
x.type = isvar ? o_mem : o_imm;
}
// ...
switch (code) {
// ...
case 0xFF0A: {
insn.itype = ADCVM_div;
op_var(insn, insn.Op1);
op_var_or_val(insn, insn.Op2);
} break;
// ...
}Пройдёмся по основным полям операндов, которые здесь заполняются:
-
offb— смещение на операнд относительно начала инструкции. Если операнды кодируются битами, или значение не известно, можно использовать значение0. Данное число будет использоваться эмулятором (т.е. нами), и встроенным hex-редактором при отображении операнда -
addr— целевой адрес, если данный операнд содержит ссылку -
value— значение, если данный операнд содержит число. Сюда же можно поместить дополнительное смещение, если, например, требуется дельта для значения вaddr -
dtype— тип данных по целевому адресу вaddr, либо значения вvalue. Все основные типы описаны здесь -
type— тип собственно операнда. Это может быть: ссылка на данные (o_mem), число (o_imm), ссылка на код (o_near). Другие типы описаны здесь
Ещё можно использовать поле reg, если у вас используются регистры. Если их нет, данное поле можно использовать под свои нужды. Ещё под эти самые нужды можно занимать поля: specval, specflag1—specflag4.
Отдельная история — когда вам нужно больше чем 8 операндов. У меня было именно так (9). Решил данную проблему как раз использованием полей reg и specval. Ещё у меня прямо в некоторые инструкции могут быть закодированы: строки (не ссылки, а сами символы), массивы. Сохранить их все в указанные поля не выйдет, поэтому заполняем хотя бы основные, а в остальные закидываем всю возможную информацию, которую сможем использовать потом в эмуляторе и выводе: количество элементов массива. длину строки и т.д.
На этом работа анализатора завершена и мы переходим к формированию ссылок на код и данные.
emu() и emu.cpp
Ещё один шаблон, который предстоит заполнить (кидать в одноимённый файл):
#include "adc.hpp"
void adcvm_t::handle_operand(const insn_t& insn, const op_t& op, bool isload) const {
switch (op.type) {
case o_imm: { // val
set_immd(insn.ea);
op_num(insn.ea, op.n);
} break;
case o_mem: { // var
insn.create_op_data(op.addr, op);
insn.add_dref(op.addr, op.offb, isload ? dr_R : dr_W);
} break;
case o_near: { // code
switch (insn.itype) {
case ADCVM_call: {
insn.add_cref(op.addr, op.offb, fl_CN);
} break;
case ADCVM_jmp: {
insn.add_cref(op.addr, op.offb, fl_JN);
} break;
default: {
insn.add_dref(op.addr, op.offb, dr_O);
} break;
}
} break;
}
}
int adcvm_t::emu(const insn_t& insn) const {
uint32 feature = insn.get_canon_feature(ph);
bool flow = ((feature & CF_STOP) == 0);
if (feature & CF_USE1) handle_operand(insn, insn.Op1, 1);
if (feature & CF_USE2) handle_operand(insn, insn.Op2, 1);
if (feature & CF_USE3) handle_operand(insn, insn.Op3, 1);
if (feature & CF_USE4) handle_operand(insn, insn.Op4, 1);
if (feature & CF_USE5) handle_operand(insn, insn.Op5, 1);
if (feature & CF_USE6) handle_operand(insn, insn.Op6, 1);
if (feature & CF_USE7) handle_operand(insn, insn.Op7, 1);
if (feature & CF_USE8) handle_operand(insn, insn.Op8, 1);
if (feature & CF_CHG1) handle_operand(insn, insn.Op1, 0);
if (feature & CF_CHG2) handle_operand(insn, insn.Op2, 0);
if (feature & CF_CHG3) handle_operand(insn, insn.Op3, 0);
if (feature & CF_CHG4) handle_operand(insn, insn.Op4, 0);
if (feature & CF_CHG5) handle_operand(insn, insn.Op5, 0);
if (feature & CF_CHG6) handle_operand(insn, insn.Op6, 0);
if (feature & CF_CHG7) handle_operand(insn, insn.Op7, 0);
if (feature & CF_CHG8) handle_operand(insn, insn.Op8, 0);
if (flow) {
add_cref(insn.ea, insn.ea + insn.size, fl_F);
}
return 1;
}Имеем несколько совершенно непонятных вызовов API-функций из IDA SDK, которые стоит пояснить.
-
set_immd— указание Иде, что в данной инструкции содержится число. Зачем это ей нужно, не знаю -
op_num— указание Иде на то, что в данном операнде имеется число, что повлияет на его вывод. Возможно, вызов данной функции также активирует возможности по изменению представления числа через горячие клавиши -
create_op_data— классная функция, которая автоматически устанавливает для целевого адреса тип данных из операнда. Например, если опкод mov копирует word в переменную в памяти, то тип данных для неё будет установлен какword -
insn.add_dref— добавление ссылки на данные для конкретной инструкции и операнда. Также можно пометить, это ссылка на чтение (dr_R) или на запись (dr_W), либо простая ссылка (dr_O) -
insn.add_cref— добавление ссылки на код. Это применяется для прыжков (jump) — fl_JN, вызовов (call) —fl_CN, либо обычного потока исполнения (codeflow) —fl_F
Как вы могли заметить, именно здесь и используются указанные нами в ins.cpp флаги (больше нигде). Также, инструкции с условными переходами требуют добавления для них второй ссылки (на случай ложности условия, первая — на случай истинности).
out_insn() и out.cpp
Осталось дело за малым — вывести инструкции с операндами на экран. Для этого возьмём ещё один шаблон:
Шаблон out.cpp
#include "adc.hpp"
class out_adcvm_t : public outctx_t {
out_adcvm_t(void) = delete; // not used
public:
bool out_operand(const op_t& x);
void out_insn(void);
};
CASSERT(sizeof(out_adcvm_t) == sizeof(outctx_t));
DECLARE_OUT_FUNCS_WITHOUT_OUTMNEM(out_adcvm_t);
bool out_adcvm_t::out_operand(const op_t& x) {
switch (x.type) {
case o_void: {
return false;
} break;
case o_imm: {
out_value(x, OOFS_IFSIGN | OOFW_IMM);
} break;
case o_near:
case o_mem: {
if (!out_name_expr(x, x.addr)) {
out_tagon(COLOR_ERROR);
out_btoa(x.addr, 16);
out_tagoff(COLOR_ERROR);
remember_problem(PR_NONAME, insn.ea);
}
} break;
}
return true;
}
void out_adcvm_t::out_insn(void) {
out_mnemonic();
int n = 0;
while (n < UA_MAXOP) {
if (!insn.ops[n].shown()) {
n++;
continue;
}
if (insn.ops[n].type == o_void) {
break;
}
out_one_operand(n);
if (n + 1 < UA_MAXOP && insn.ops[n + 1].type != o_void) {
out_symbol(',');
out_char(' ');
}
n++;
}
flush_outbuf();
}Не всё понятно в данном шаблоне сразу. Например, что это за класс out_adcvm_t, который наследуется от outctx_t, а за ним обращение к какому-то странному макросу DECLARE_OUT_FUNCS_WITHOUT_OUTMNEM. К тому же, здесь объявлен ещё один метод out_insn(void), без аргументов. Последнее может сбить с толку, т.к. в файле reg.cpp мы видели следующее обращение к методу out_insn:
switch (msgid) {
case processor_t::ev_out_insn: {
auto* ctx = va_arg(va, outctx_t*);
out_insn(*ctx);
} break;
}Видим, что здесь у данного метода есть входной аргумент. В общем, если вкратце, то вся магия как раз в макросе DECLARE_OUT_FUNCS_WITHOUT_OUTMNEM, который создаёт для нас вспомагательные методы out_insn и out_opnd для более удобного вывода данных в листинг, открывая при этом для использования дополнительные функции из класса outctx_t. Более подробно изучить данную логику можно в файле idaidp.hpp вашего IDA SDK.
Финал
Что, уже? Да, действительно, мы только что закончили писать процессорный модуль для IDA Pro для виртуальной машины из игры Clock Tower — The First Fear. На деле, это оказалось не так и сложно.
Конечно, есть нюансы, куда без них (например, мне пришлось повозиться в выводом строк в кодировке SHIFT-JIS), с операндами, которых больше 8, с массивами. Но, всё это уже позади: модуль успешно дизассемблирует весь загруженный бинарь, справляется как VM из версии для PS1, так и для PC.
Да, в моём случае архитектура оказалась относительно простой виртуальной машиной и, в вашем случае, это может быть что-то посложнее, для чего захочется иметь декомпилятор. Тогда, вариант (пока) здесь только один — Ghidra (о том, как я создавал процессорный модуль для неё я расскажу в следующий раз). Я же могу себе позволить выводить около-сишный листинг прямо в окно дизассемблера Иды.
 для IDA Pro - 5")
 для IDA Pro - 6")
Спасибо за внимание.
Ссылки
-
Основной репозиторий
-
Документация по IDA SDK
P.S.
Прошу прощения за большие куски кода не под спойлером — Хабр при попытке вставить блок кода в спойлер (на новом редакторе) просто виснет.
Пример дизассемблера .COM-файлов для DOS. Написан на Turbo Assembler 4.1. Разрабатывается группой студентов исключительно в учебных целях.
Авторы управляющей части:
Кравцов Дмитрий, idkravitz@gmail.com
Харитонов Роман, refaim.vl@gmail.com
Авторы модулей разбора инструкций:
Гренкин Глеб — логические инструкции (and, or, xor, test, not)
Елизаров Сергей — инструкции сложения (add, adc)
Кравцов Дмитрий — пустая инструкция (nop), арифметические сдвиги (sal, sar)
Пинчук Олег — инструкции деления (div, idiv)
Харитонов Роман — условные переходы (jxx)
Тестирование и code review:
Бураго Игорь
Лукащук Максим
Строкач Александр
Полезные ссылки:
Assembler IBM PC: http://mini-soft.ru/book/assem/index.php
TASM 3.0 Manual: http://www.citforum.ru/programming/tasm3r/index.shtml
TASM Reference Book: http://www.codenet.ru/progr/asm/tasm/index.php
DOS Function codes: http://spike.scu.edu.au/~barry/interrupts.html
MS-DOS 5.0 Programmer's Reference: http://www.ousob.com/ng/dos5/index.php
FAQ для студентов 236 и 238 групп ИМКН ДВГУ:
Q: Какие программы нужны для работы?
A: 1. Turbo Assembler for DOS (версии не ниже 4.1): http://cloud.github.com/downloads/refaim/disasm/TASM_4.1.ZIP
2. MinGW Make: http://github.com/downloads/refaim/disasm/mingw-make-win32.zip
Q: Что нужно сделать, чтобы начать писать дизассемблер?
A: 0. Скачать последнюю версию исходного кода: http://github.com/refaim/disasm/zipball/master
1. В файле make.bat указать путь к TASM на вашем компьютере.
Пример файла make.bat:
------------------------------------------------------------------
@echo off
SET TASM_PATH=C:/TASM/BIN
mingw32-make %*
------------------------------------------------------------------
Путь должен быть набран с использованием прямых ('/'), а не обратных ('') слешэй. Без завершающего слэша и без кавычек.
2. Переименовать файл example.asm в p_<название_вашей_команды>.asm. Например: p_jmp.asm, p_mov.asm, p_xor.asm. Префикс "p_" нужен для того, чтобы ваш файл был автоматически подключен при сборке проекта утилитой make. Будьте осторожны: TASM для DOS умеет понимать только имена файлов стандарта 8.3 (не более 8 символов на имя, не более 3 символов на расширение).
3. В полученном файле переименовать процедуру parse в parse_<название_вашей_команды>. Например: parse_jmp, parse_add.
4. Дописать полученное имя процедуры в файл funcs.inc, отделив его запятой от уже имеющихся там имён.
Пример файла funcs.inc:
------------------------------------------------------------------
FUNCS equ parse_jxx, parse_nop, parse_add
------------------------------------------------------------------
Q: Как скомпилировать дизассемблер?
A: С помощью файла "make.bat". Как им пользоваться:
"make [CFG=<debug|release>] [all|clean|debug|test]"
all -- собрать дизассемблер, clean -- удалить все полученные в результате сборки файлы, debug -- собрать дизассемблер и открыть его в Turbo Debugger'е, test -- собрать тестовый пример test.asm.
Все параметры опциональны. Запуск "make" без параметров аналогичен "make clean all CFG=debug".
"CFG=debug" отличается от "CFG=release", как легко догадаться, наличием отладочной информации.
Q: Как это всё работает?
A: Основная процедура main из файла main.asm читает байты из входного файла и в цикле вызывает пользовательские процедуры, которые осуществляют разбор. Имена процедур она берет из файла funcs.inc.
Q: А что за файл такой -- "main.asm"? Что с ним делать?
A: Ничего. Он уже работает и трогать его не нужно, а то всё сломается.
Q: А "common.asm"?
A: Его тоже трогать не надо. Но пользоваться определенными в нем процедурами можно.
Q: Куда же тогда писать мой код?
A: В файл "p_<название_вашей_команды>.asm". Внутри него -- куда угодно. Главное, чтобы была экспортируемая (директивой public) процедура, имя которой записано в файле "funcs.inc".
Q: А что мне разбирать? Откуда брать байты? Куда класть результат?
A: После передачи управления вашей процедуре в регистре si находится адрес буфера со входными данными (байтами из файла), а в регистре di адрес выходного буфера, куда нужно писать выходную строку. Выходная строка должна заканчиваться символом перехода на новую строку (LF, ASCII 10) и не должна содержать символа "$" (ASCII 36). Перед возвратом из процедуры вам нужно прибавить к регистрам si и di количество прочитанных и записанных байт соответственно. Если не удалось распознать команду, трогать эти регистры и писать что-либо в выходной буфер не нужно.
Q: Как быть с регистрами?
A: Состояние регистров до вызова вашей процедуры должно совпадать с их состоянием после возврата (исключая регистры si и di, о которых написано выше). Сохранение регистров обеспечивается директивой uses в начале процедуры: "uses ax, bx, dx" (сохранять нужно только используемые регистры). Кто будет портить регистры, зачёта не получит, гарантирую.
Q: А что за директива "locals" в начале файла?
A: Она позволяет создавать в процедурах локальные метки. Префикс, обозначающий локальность -- "@@" (например, "@@exit").
Q: Я всё прочитал, но ничего не понял. Что делать?
A: Посмотреть примеры: "p_nop.asm" и "p_jxx.asm".
Q: Я написал свой дизассемблер, что теперь?
A: Если вы уверены в его работоспособности, ЖЕЛАТЕЛЬНО отправить его авторам (см. выше — Авторы). Вам нужно отправить только модуль p_{имя_команды}.asm. После того как мы убедимся, что ваша программа работает корректно, мы включим её в официальную версию.
А.Б.КРУПНИК
В данной статье мне хочется рассказать о дизассемблировании большой
программы (графического редактора). Не будучи знатоком ассемблера, не
зная до сих пор, как использовать большинство возможностей своего дизассемблера(DisDoc 2.3), я все же решился написать эту статью, так как прекрасно помню, в какой кромешной тьме начинал заниматься дизассемблированием.
Тогда, год назад, я попробовал дизассемблировать простенькую программу и был страшно удивлен тем, что дизассемблер делает это неправильно, и
при повторном ассеблировании программа не работала так, как надо. Тогда же
мне удалось поговорить со знающим человеком и, хотя я чувствовал себя наивным дурачком, мне удалось выяснить главное: ПОЛНОЕ,АВТОМАТИЧЕСКОЕ ДИЗАССЕМБЛИРОВАНИЕ НЕВОЗМОЖНО, над тем текстом, который выдает дизассемблер, нужно довольно долго работать, прежде чем ассемблирование этого текста даст работоспособную программу.
В дальнейшем я постараюсь рассказать о тех приемах, которые превращают
«плохой» текст в «хороший» , т.е. в текст, который не только дает корректно
работающую программу при ассемблировании, но и позволяет себя изменить, чтобы усовершенствовать исходную программу.
ПОЧЕМУ DisDoc?
SOURSER — это название знают все, кто хотя бы краем уха слышал о дизассеблировании. Считается, что это дизассеблер замечательный, мощный, не имеющий конкурентов. Я думаю, что слухи об огромных преимуществах SOURSERа силь но преувеличены. У меня сложилось такое впечатление, что при дизассемблирова нии небольших программ (до 7 кб.) SOURSER предпочтительнее. Когда программа велика (в моем случае — 58 кб ), SOURSER работает очень медленно и, на мой взгляд, не дает никаких преимуществ.
Выбор дизассемблера DisDoc 2.3 был для меня во многом случаен. Начиная работу, я получил тексты на ассемблере как с помощью SOURSERa (версия 3.07), так и с помощью дизассемблера DisDoc 2.3. Затем оба текста после устранения очевидных ошибок были ассемблированы. И вот, то, что было выдано SOURSERом, повисло сразу, а то, что выдал DisDoc 2.3, прежде чем повиснуть, вывело на экран несколько линий. Это и определило выбор. В процессе работы я не раз имел возможность оценить основное преимущество дизассемблера DisDoc — интуитивно понятный, неизощренный, удобный и компактный листинг.
Чтобы понять дальнейшее, необходимо познакомиться с отрывком из листинга, который выдает DisDoc 2.3
mov cx,WORD PTR ds:d02453 ;02430 b02430: add cx,bx ;02434 mov bx,99e7h ;02436 mov dx,WORD PTR ds:d02449 ;02439 mov al,BYTE PTR ds:d02446 ;0243d call s383 ;<09060> ;02440 push cs ;02443 pop ds ;02444 ret ;02445 ;----------------------------------------------------- d02446 db 00 ;02446 . d02447 db 00,00 ;02447 .. d02449 db 00,00 ;02449 ..
В поле комментариев указано смещение, которое имела данная инструкция в исходной программе. Например, если вы в исходной программе, подвергаемой дизассемблированию, посмотрите отладчиком смещение 02434, то там окажется инструкция add cx,bx — на это можно положиться! Очень хороши названия меток и элементов данных. По ним сразу можно понять, какое смещение они имели в исходной программе. Например, метка b02430 имела смещение 02430, элемент данных d02446 имел смещение 02446 и т.д. То же самое относится и к подпрограммам. После вызова подпрограммы в треугольных скобках указано смещение, которое имела эта подпрограмма в исходной программе. Например, подпрограмма s383 начиналась в исходной программе со смещения 09060. Такая организация листинга позволяет сохранить однозначное соответствие с исходной программой, что дает возможность проверить отладчиком сомнительные куски кода и данных, сравнить текст, выданный дизассемблером с тем, что есть на самом деле. Это поистине драгоценная возможность. Нужно сказать, что DisDoc имеет большие недостатки, о которых речь еще пойдет, и, следовательно, применение того или иного дизассемблера — дело вкуса.
В любом случае обязательно встретятся
Фундаментальные проблемы
1. Проблема OFFSETa
Предположим, что в тексте, который выдал дизаccемблер есть такой фрагмент:
mov ax,bx ;1 shl ax,1 ;004bc ;2 mov si,8429h ;3 add si,ax ;4 push WORD PTR [si] ;5
Что засылается в регистр si в третьей строчке — число 8429h или смещение некой метки? На этот вопрос позволяет ответить пятая строчка, из которой видно, что регистр si используется для косвенной адресации. Значит, исправленный фрагмент должен выглядеть следующим образом:
mov ax,bx ;1 shl ax,1 ;004bc ;2 mov si,OFFSET d08429 ;3 add si,ax ;4 push WORD PTR [si] ;5 ................................ d08429 db 0ff,0ff,0f6 ;8429 db 0ff,0d8,0ff,0a6,0ff,60 ;0842c .....`
Возможно, здесь у многих возникнет сомнение — нужно ли заменять число на соответствующий OFFSET — ведь, казалось бы, в заново ассемблированной программе данные будут иметь то же смещение? К сожалению, это не так. Во первых, мы,как правило, не знаем, какой ассемблер применялся при транслировании оригинального текста, а коды, полученные с помощью разных ассемблеров будут иметь разную длину, что приведет к изменению смещений. Например, команда AND CX,0007h транслируется MASMом 5.1 и TASMом 1.01 как 83E107 и занимает 3 байтa. Но эта же команда может быть транслирована как 81E10700 и занимать 4 байта. Во-вторых, даже если смещение сохранится, программа не поддастся модификации, так как при вставке какого-либо фрагмента кода изменятся смещения и все «развалится». Итак, OFFSETы позволяют склеить программу, делают ее пригодной для модификации. Разобранный пример достаточно примитивен. Попробуем рассмотреть более сложные ситуации и первым делом исследуем фрагмент текста, выданный дизассемблером:
mov bx,9006h ;08f66 b08f75: mov WORD PTR ds:d087d0,bx ;08f75 ................................. call WORD PTR cs:d087d0 ;08fc3 ...................................... ;----------------------------------------------------- push dx ;09006 call s419 ;<099a3> ;09007 mov al,BYTE PTR [si] ;0900a mov BYTE PTR [si],0ffh ;0900c pop dx ;0900f ret ;09010 ;-----------------------------------------------------
Здесь возникает тот-же вопрос — что такое 9006h в первой строчке фрагмента — смещение или просто число? Ответить на этот вопрос помогает информация, помещенная дизассемблером в поле комментариев. Мы уже говорили о том что числа, помещенные в этом поле, представляют собой смещения, которые имела инструкция в исходной программе, подвергаемой дизассемблированию. Нетрудно догадаться, что в приведенном фрагменте осуществляется косвенный вызов подпрограммы, и, следовательно, 9006h — это смещение, а не число. Фрагмент должен быть исправлен так:
mov bx,OFFSET d09006 ;08f66 ...................................... ;----------------------------------------------------- d09006: push dx ;09006 ...................................... ret ;09010
Рассмотрим еще один пример косвенного вызова подпрограммы, в котором OFFSET попадает в область данных.
s390 proc near .......................................................... mov ax,WORD PTR [bx+8792h] ;092c7 mov WORD PTR ds:d087d2,ax ;092cb ........................................................... call WORD PTR cs:d087d2 ;093c8 ret ;093d4 ;----------------------------------------------------- ror ah,1 ;093d5 ;LO]-->[HI..LO]-->[HI jb b093da ;093d7 ;Jump if < (no sign) ret ;093d9 b093da: inc si ;093da ret ;093db ............................................................
Чтобы выяснить, что представляет собой 8792h, нужно посмотреть в область со смещениями, близкими к этому числу. Приведем соответствующий фрагмент, выданный дизассемблером:
d08790 db 00,00,0d5,93 ;08790 ...... .............................................................
Видно, что смещению 08792 соответствует слово 0d5,93. Теперь остается заметить, что со смещения 093d5 в исходной программе начинается фрагмент повисшего кода
ror ah,1 ;093d5 !!!!!! ;LO]-->[HI..LO]-->[HI jb b093da ;093d7 ;Jump if < (no sign) ret ;093d9 b093da: inc si ;093da ret ;093db
Следовательно,весь разобранный пример — это хитроумный косвенный вызов подпрограммы. Исправленный фрагмент должен выглядеть так:
s390 proc near .......................................................... mov ax,WORD PTR [bx+OFFSET d08792] ;092c7 mov WORD PTR ds:d087d2,ax ;092cb ........................................................... call WORD PTR cs:d087d2 ;093c8 ret ;093d4 ;----------------------------------------------------- d093d5: ror ah,1 ;093d5 ;LO]-->[HI..LO]-->[HI jb b093da ;093d7 ;Jump if < (no sign) ret ;093d9 b093da: inc si ;093da ret ;093db ............................................................ d08790 db 00,00 ;08790 ...... d08792 dw OFFSET d093d5 ;08792
Здесь я предвижу большие возражения. Мне скажут, что все это можно интерпретировать иначе, что мои доказательства неубедительны и т.д. С этим я совершенно согласен. Более того, эти доказательства неубедительны и для меня. Гораздо сильнее убеждает то, что программа после ассемблирования работает! Дизассемблирование, как и отладка программ — процесс интуитивный. Опытный человек испытывает особое удовольствие от того, что его немотивированные догадки впоследствии подтверждаются. Как часто мысль, пришедшая в автобусе, во сне, в компании, в самой неподходящей обстановке — оказывается верной! Завершим этот пункт еще одним достаточно хитрым примером. В тексте, который выдал дизассемблер, встретился такой фрагмент:
mov bx,4f71h ;0522b b0522e: pop ax ;0522e cmp ax,bx ;0522f jnz b0522e ;05231 ;Jump not equal(ZF=0) mov BYTE PTR ds:d041f4,00 ;05233 push ax ;05238 ret ;05239 ................................. call s229 ;<04fc4> ;04f71
Возникает все тот же вопрос — что такое 4f71h — число или смещение? Чтобы ответить на этот вопрос, нужно понять, что делает этот участок программы. Давайте попробуем в этом разобраться. Очевидно, из стека выталкивается число, сравнивается с 4f71h и если нет равенства, выталкивается следующее число. Если число равно 4f71h, то оно снова заталкивается в стек и происходит возврат из подпрограммы. Но куда? Ясно, что в то место, смещение которого было в исходной программе равно 4f71h. Как видно из текста, в этом месте стоял вызов подпрограммы s229. Значит, таким странным образом вызывается подпрограмма и 4f71h — это смещение! Исправленный фрагмент должен выглядеть так:
mov bx, OFFSET d04f71 ;0522b b0522e: pop ax ;0522e cmp ax,bx ;0522f jnz b0522e ;05231 ;Jump not equal(ZF=0) mov BYTE PTR ds:d041f4,00 ;05233 push ax ;05238 ret ;05239 ................................. d04f71: call s229 ;<04fc4> ;04f71
2.Как отличить данные от команд?
Любой дизассемблер путает данные и команды. Особенно это относится к .COM программам, где все перемешано. Рассмотрим простой пример:
pop cx ;03e56 ret ;03e57 ;----------------------------------------------------- add BYTE PTR [bx+si],al ;03e58 add BYTE PTR [bx+si],al ;03e5a m03e5c: mov BYTE PTR ds:d05830,01 ;03e5c
В этом фрагменте встретились две вычурных, повисших инструкции:
add BYTE PTR [bx+si],al ;03e58 add BYTE PTR [bx+si],al ;03e5a
Сверху они ограничены инструкцией возврата из подпрограммы ret, а снизу — меткой m03e5c. Ясно, что эти инструкции могут быть только данными. После переделки приведенный фрагмент должен выглядеть так:
pop cx ;03e56 ret ;03e57 ;----------------------------------------------------- d03e58 dw 0 ;03e58 d03e5a db 0 ;03e5a d03e5b db 0 m03e5c: mov BYTE PTR ds:d05830,01 ;03e5c
Тут возникает еще один вопрос: почему в одном случае стоит dw, а в другом — db? Ответ содержится в тексте, который выдал дизассемблер. Там можно найти такие инструкции:
mov si,WORD PTR ds:d03e58 ;03dd0 mov bl,BYTE PTR ds:d03e5a ;03dd4,
Откуда следует, что d03e58 рассматривается как слово, а d03e5a — как байт. Рассмотрим чуть более сложный, но, тем не менее, очень характерный пример.
b03f53: cmp al,05 ;03f53 jnz b03f6b ;03f55 ;Jump not equal(ZF=0) ..................................................... ret ;03f69 ;----------------------------------------------------- add BYTE PTR [si],bh ;03f6a push es ;03f6c jnz b03f79 ;03f6d ;Jump not equal(ZF=0)
В приведенном фрагменте текста метка b03f6b отсутствует. Между тем эта метка должна «разрубить» пополам инструкцию add BYTE PTR [si],bh , которая начинается в оригинальной программе, подвергаемой дизассемблированию, со смещения 03f6a. Выход здесь может быть только один — смещению 03f6a соответствует байт данных, а инструкция начинается со смещения 03f6b. Исправленный фрагмент должен выглядеть так:
b03f53: cmp al,05 ;03f53 jnz b03f6b ;03f55 ;Jump not equal(ZF=0) ...................................................... ret ;03f69 ;----------------------------------------------------- d03f6a db 0 ;03f6a b03f6b: cmp al,06h ;03f6b jnz b03f79 ;03f6d ;Jump not equal(ZF=0)
Путаница между данными и инструкциями возникает довольно часто. SOURSER способен выдавать целые метры бессмысленных инструкций. DisDoc 2.3 в этом отношении ведет себя лучше.
3. Зависимость от транслятора
Программисты на ассемблере склонны пренебрегать правилами хорошего тона, нарушать все мыслимые табу, и это создает дополнительные трудности при дизассемблировании. В качестве примера приведем фрагмент кода, выданного дизассемблером
s25 proc near inc cx ;0086b add di,bp ;0086c adc si,00 ;0086e add dx,si ;00871 push di ;00873 shl di,1 ;00874 ;Multiply by 2's adc dx,00 ;00876 pop di ;00879 ret ;0087a
Этот фрагмент представляется совершенно невинным, и действительно, он дизассемблирован правильно. Вся беда в том, что программист задумал изменять этот фрагмент, то есть резать по живому. Оказывается, в программе есть еще такой кусок
mov di,086bh ;007f8 ...................................... mov BYTE PTR [di],4ah ;00800 mov BYTE PTR [di+07],0f1h ;00803 mov BYTE PTR [di+0ch],0d1h ;00807 ...................................... ret ;00815
Рис.1
Так как di используется для косвенной адресации, нам прежде всего необходимо заменить 086bh на соответствующий OFFSET d0086b и пометить этой меткой начало подпрограммы s25:
s25 proc near d0086b: inc cx ;0086b ..............................................
Далее следует понять, что делают инструкции, приведенные на рис.1 с подпрограммой s25. Пусть эта подпрограмма асслемблирована с помощью TASM 1.01. Выданный ассемблером код будет таким, как показано на рисунке 2.
41 INC CX 41 INC CX 03FD ADD DI,BP 01EF ADD DI,BP 83D600 ADC SI,0000 83D600 ADC SI,0000 03D6 ADD DX,SI 01F2 ADD DX,SI 57 PUSH DI 57 PUSH DI D1E7 SHL DI,1 D1E7 SHL DI,1 83D200 ADC DX,0000 83D2000 ADC DX,0000 5F POP DI 5F POP DI C3 RET C3 RET
Рис.2 Рис.3
Но вся беда в том, что исходная программа была ассемблирована другим ассемблером и имеет вид, показанный на рисунке 3. Как видно из сравнения рисунков 2 и 3, TASM 1.01 и неизвестный ассемблер транслируют инструкции ADD по-разному, и это приводит к катастрофическим последствиям. Действительно, посмотрим, как воздействует участок кода, показанный на Рис.1 (перед этим заменим 086bh на OFFSET d0086b) на подпрограмму s25, транслируемую TASMом (рис.4) и неизвестным ассемблером (рис.5).
4A DEC DX 4A DEC DX 03FD ADD DI,BP 01EF ADD DI,BP 83D600 ADC SI,0000 83D600 ADC SI,0000 03F1 ADD SI,CX ;!!!! 01F1 ADD CX,SI ;!!!! 57 PUSH DI 57 PUSH DI D1E7 SHL DI,1 D1E7 SHL DI,1 83D100 ADC CX,0000 83D100 ADC CX,0000 5F POP DI 5F POP DI C3 RET C3 RET
Рис.4 Рис.5
Сравнение рисунков 4 и 5 показывает, что логика работы программы меняется в зависимости от того, какой ассемблер применялся. Как выкрутиться из этой ситуации, если нужного ассемблера нет под рукой? Самый простой, но не очень красивый путь — поставить «заплатку». Чтобы можно было использовать TASM, подпрогроамма s25 должна выглядеть так:
s25 proc near d0086b: inc cx ;0086b add di,bp ;0086c adc si,00 ;0086e db 01,0f2 ;add dx,si !!!!!! ;00871 push di ;00873 shl di,1 ;00874 ;Multiply by 2's adc dx,00 ;00876 pop di ;00879 ret ;0087a
Особенности и ошибки дизассемблера DisDoc 2.3
К сожалению, DisDoc 2.3 совершает ошибки, иногда регулярные, а иногда редкие, коварные и даже подлые. Самая противная ошибка — случайный пропуск данныхвстречается довольно редко. Начнем с того, что встречается очень часто.
1. EQU — кто тебя выдумал?
В коде, выданном дизассемблером, часто попадаются такие загадочные куски:
;<00465> s12 proc near d0046c equ 00046ch cmp bx,5ah ;00465
Каков смысл присвоения d0046c equ 00046ch ? Чтобы выяснить это, нужно отыскать d0046c в тексте. В нашем случае элемент данных d0046c встречается очень далеко от своего первого появления — в подпрограмме s321
mov ax,0040h ;06257 ;<es = 0040> mov es,ax ;0625a mov al,BYTE PTR es:d0046c ;0625c sti ;06260 ;Turn ON Interrupts b06261: cmp al,BYTE PTR es:d0046c ;06261 jz b06261 ;06266 ;Jump if equal (ZF=1) mov al,BYTE PTR es:d0046c ;06268 dec cx ;0626c jnz b06261 ;0626d ;Jump not equal(ZF=0) pop ax ;0626f out 61h,al ;06270 ;060-067:8024 keybrd contrlr ;<es = 0000> pop es ;06272 ret ;06273 s321 endp
Рис.6
При виде этого текста возникает догадка, что здесь идет зваимодействие с областью данных BIOSa . Действительно, в регистр es засылается число 40, т.е. es будет указывать на адрес 400 — начало этой области. Тогда следующий вопрос — каков смысл адреса 046сh? Легко выяснить, что по этому адресу находится счетчик прерываний от таймера. Если это так, то фрагмент, приведенный на рис.6, обретает смысл — он дает задержку на число прерываний от таймера, заданное в регистре cx. Но если все сказанное верно, то d0046c должно быть равно не 46сh, а просто 6сh! И действительно, если посмотреть подпрограмму s321 отладчиком, то станет ясно, что вместо mov al,BYTE PTR es:d0046c в тексте должно стоять mov al,6ch.
Итак, чтобы исправить эту ошибку, необходимо:
- Удалить из начала подпрограммы s12 присвоение d0046c equ 00046ch
- Переписать приведенный на рис.6 фрагмент s321 следующим образом:
mov ax,0040h ;06257 ;<es = 0040> mov es,ax ;0625a mov al,BYTE PTR es:006ch ;0625c sti ;06260 ;Turn ON Interrupts b06261: cmp al,BYTE PTR es:006ch ;06261 jz b06261 ;06266 ;Jump if equal (ZF=1) mov al,BYTE PTR es:006ch ;06268 dec cx ;0626c jnz b06261 ;0626d ;Jump not equal(ZF=0) pop ax ;0626f out 61h,al ;06270 ;060-067:8024 keybrd contrlr ;<es = 0000> pop es ;06272 ret ;06273 s321 endp
Рассмотрим второй пример. В коде, выданном дизассемблером, встретился такой кусок:
;<0074e> s22 proc near d0076a equ 00076ah d00771 equ 000771h call s24 ;<00791> ;0074e ............... b0076a: push cx ;0076a call s25 ;<0086b> ;0076b call s23 ;<00776> ;0076e pop cx ;00771 dec bx ;00772
Поиск элемента данных d0076a окончился неудачей. А d00771 встретился в таком фрагменте:
..................................... mov BYTE PTR ds:b0076a,51h ;0080b mov BYTE PTR ds:d00771,59h ;00810 ......................................
Здесь явно идет модификация кода подпрограммы s22. Значит, необходимо заменить d00771 на b00771, пометить этой меткой соответствующую инструкцию в s22 и удалить присвоения
d0076a equ 00076ah d00771 equ 000771h
Исправленный фрагмент s22 будет выглядеть так:
;<0074e> s22 proc near call s24 ;<00791> ;0074e ...................................................... b0076a: push cx ;0076a call s25 ;<0086b> ;0076b call s23 ;<00776> ;0076e b00771: pop cx ;00771 dec bx ;00772 .............................................. mov BYTE PTR ds:b0076a,51h ;0080b mov BYTE PTR ds:b00771,59h ;00810 ................................................
Рассмотрим еще один пример. В начале s32 встретились уже знакомые псевдооператоры:
;<00bf7> s32 proc near d00c1c equ 000c1ch d00c1e equ 000c1eh
Если посмотреть в область со смещениями, близкими к с1с, то там окажется кусок повисшего кода, который может быть только данными:
....................................... or al,BYTE PTR [bp+di] ;00c14 add WORD PTR [bx+di],ax ;00c16 add BYTE PTR [bx+si],al ;00c18 add BYTE PTR [bx+si],al ;00c1a mov di,1306h ;00c1c add ax,06c0h ;00c1f ......................................
Рис.7
Теперь нужно поискать идентификаторы d00c1c и d00c1e в тексте, выданном дизассемблером. Очень быстро можно найти фрагменты типа: mov WORD PTR ds:d00c1c,ax, mov WORD PTR ds:d00c1e,ax. Значит, ошибка дизассемблера состоит в том, что он перепутал данные и команды и на этой почве сделал два неправильных присваивания, equ, попавших в начало подпрограммы s32.
Исправления будут заключаться в следующем:
- Убрать из начала подпрограммы s32 два псевдооператора equ.
- Переписать коды на рисунке 7 следующим образом:
d00c14 db 0a,03,01,01,00,00,00,00 ;00c14 d00c1c db 0bf,06 ;00c1c d00c1e db 13,05,0c0,06 ;00c1e
В заключение рассмотрим совсем простенький фрагмент кода:
;<01252> s39 proc near d0125d equ 00125dh d0125f equ 00125fh dec bh ;01252 jz b0124f ;01254 ;Jump if equal (ZF=1) xor ah,ah ;01256 shl al,1 ;01258 ;Multiply by 2's rcl ah,1 ;0125a ;CF<--[HI .. LO]<--CF ret ;0125c ;----------------------------------------------------- add BYTE PTR [bx+si],al ;0125d add BYTE PTR [bx+si],al ;0125f s39 endp
Укажем без комментариев, что подпрогромма s39 должна выглядеть так:
;<01252> s39 proc near dec bh ;01252 jz b0124f ;01254 ;Jump if equal (ZF=1) xor ah,ah ;01256 shl al,1 ;01258 ;Multiply by 2's rcl ah,1 ;0125a ;CF<--[HI .. LO]<--CF ret ;0125c ;----------------------------------------------------- d0125d db 00,00 ;0125d d0125f db 00,00 ;0125f s39 endp
В заключение этого пункта подведем итоги. Значки equ называют всевдооператорами. Если говорить о дизассемблере DisDoc 2.3, то это название удивительно точное. Если в тексте встретится equ — то ошибка рядом. Между тем, иногда DisDoc 2.3 употребляет equ вполне корректно. Так что будьте бдительны и не дайте себя обмануть.
2. Дурные ошибки.
Иногда поведение дизассемблера трудно объяснить. Например, он выдает
add WORD PTR ds:d96be3,07 ;038b6 shr WORD PTR ds:d96be3,cl ;038bb ;Divide by 2's вместо add WORD PTR ds:d06bf3,07 ;038b6 shr WORD PTR ds:d06bf3,cl ;038bb ;Divide by 2's ,
теряет или искажает куски данных. К счастью, это происходит очень редко.