java.lang.Object#hashCode
Введение
Что такое hash? Это некоторое число, генерируемое на основе объекта и описывающее его состояние. Это число вычисляется на основе hash-функции.
Метод int hashCode() является реализация hash-функции для Java-объекта. Возвращаемое число в Java считается hash-кодом объекта.
Объявление метода выглядит так:
/** * Answers an integer hash code for the receiver. Any two * objects which answer <code>true</code> when passed to * <code>.equals</code> must answer the same value for this * method. * * @return the receiver's hash. * * @see #equals */ public int hashCode() { return J9VMInternals.fastIdentityHashCode(this); }
Возможно, вас напугала стрчока J9VMInternals.fastIdentityHashCode(this), но пока для простоты считайте,
что эта реализация зависит отJVM.
В hash — таблицах или ассоциативных маассивах (их еще называют словари, мапы) важность hashCode-а нельзя недооценивать.
Представим, что у нас есть массив пар ключ-значение.
Для поиска по ключу в таком массиве вам надо обойти весь массив, заглянуть в каждую ячейку и сравнить ключ.
Долго? Долго!
А теперь вспомним, что хэш — это по сути метаинформация о состоянии объекта, некоторое число.
И мы можем просто взять хэш, по нему понять в какой ячейке хранится искомая пара и просто взять ее оттуда, без перебора всего массива!
Быстро? Гораздо быстрее, чем просто итерация по всему массиву!
Да, могут быть коллизии — ситуации, когда разным объектам будет сгенерирован одинаковый хэш,
но решить коллизию можно через equals и это все еще быстрее, чем проходить весь массив.
По сути, главное преимущество в быстродействии ассоциативных массивов основано на работе с hashCode.
Именно за счет хэша мы можем вставлять и получать данные за O(1), то есть за время пропорциональное вычислению хэш-функции.
Если планируется использовать объекты в качестве ключа в ассоциативном массиве, то переопределять hashCode надо обязательно.
Переопределение
Требования
Еще раз посмотрим на метод:
/** * Answers an integer hash code for the receiver. Any two * objects which answer <code>true</code> when passed to * <code>.equals</code> must answer the same value for this * method. * * @return the receiver's hash. * * @see #equals */ public int hashCode() { // ...... }
Контракт hashCode предъявляет следующие требования к реализации:
- Если вызвать метод
hashCodeна одном и том же объекте, состояние которого не меняли, то будет возвращено одно и то же значение. - Если два объекта равны, то вызов
hashCodeдля каждого обязан давать один и тот же результат.
Равенство объектов проверяется через вызов метода equals.
- Если два объекта имеют один и тот же
hash-код, то это не гарантирует равенства объектов.
Проще говоря, разный hash-код у двух объектов — это гарантия того, что объекты не равны, в то время как одинаковый hash-код не гарантирует равенства.
Cитуация, когда разные объекты имеют одинаковые hash-код, называется collision или коллизией.
Логично, что коллизии возможны, так как размер
intограничен, да и реализации хэш-функции могут быть далеко не идеальны.
Реализация метода hashCode по-умолчанию возвращает разные значения hash-кодов для разных объектов:
public class Test { public static void main(String[] args) { System.out.println(new Person(4).hashCode()); System.out.println(new Person(4).hashCode()); } } class Person { private int age; public Person(int age) { this.age = age; } }
Что это за значения? По-умолчанию hashCode() возвращает значение, которое называется идентификационный хэш (identity hash code).
В документации сказано:
This is typically implemented by converting the internal address of the object into an integer, but this implementation technique is not required by the Java™ programming language.
Поэтому реализация зависит от JVM.
Более подробно об этом можно прочесть в разделе полезные ссылки.
Пока можете не акцентировать внимание на том, как реализована hash-функция по-умолчанию и запомнить, что для разных объетов будут всегда возвращены разные значения hash-кодов, не взирая на состояние объекта.
Исходя из описания контракта метода можно понять, что hashCode, наряду с equals, играет важную роль в сравнении объектов.
По сути он показывает изменилось ли состояние объекта, которое мы используем в equals для сравнения.
Именно поэтому, если вы переопределяете equals, то вы обязаны переопределить hashCode.
Самый очевидный и самый плохой пример как можно переопределить hashCode — это всегда возвращать константу:
@Override public int hashCode() { return 14; }
Для равных объектов такой метод вернет одно и то же число, что удовлетворяет спецификации.
Но, делать так категорически не рекомендуется.
Во-первых, если состояние объекта с такой реализацией hashCode, будет изменено, то это никак не отразится на hashCode.
Что уже наталкивает на мысль, что такая реализация не совсем верна.
Во-вторых, такая реализация гарантирует возникновение коллизий всегда.
А значит, использовать такой подход — это лишить себя всех преимуществ, которые дает нам использование ассоциативных массивов.
Теперь, когда мы решили, что возвращать всегда одно и то же значение — это плохое решение, давайте поговорим о том, что нужно включать в рассчет hashCode.
Перво-наперво, необходимо исключить избыточные поля, которые не участвуют в equals.
Далее необходимо выбрать базу: число, которое будет основной вычисления hash-кода.
По историческим причинам обычно за базу берут число 31.
Кто-то говорит, что это взято из-за близости к числу 32, т.е степени двойки 2^5 - 1.
Кто-то утверждает, что был проведен эксперимент и наиболее лучшей базой получились числа 31 и 33, а 31 понравилось больше.
В целом, вы можете выбрать за базу что хотите, но обычно выбирают 31.
Многие IDE (например, IDEA) генерят hashCode именно с такой базой.
Правила вычисления hashCode:
-
Присваиваем переменной result ненулевое значение — базу.
-
Далее для каждого значимого поля в объекте вычисляем
hashCode, по следующим правилам:-
Если поле
boolean—(f ? 1 : 0) -
Если поле
byte,char,shortилиint—(int) f -
Если поле
long—(int)(f ^ (f >>> 32)) -
Если поле
float, тоFloat.floatToIntBits(f); -
Если поле
double, тоDouble.doubleToLongBits(f), а затем как сlong. -
Если поле это ссылка на другой объект, то рекурсивно вызовите
hashCode() -
Если поле
null, то возвращаем0. -
Если поле это массив, то обрабатываем так, как будто каждый элемент массива — это поле объекта.
-
-
После каждого обработанного поля объединяем его
hashCodeс текущим значением:result = 31 * result + c; // c - это hashCode обработанного поля.
-
Возвращаем результат.
Пример приведем с помощью многострадального класса Person:
public class Person { private int age; private int number; private double salary; private String name; private CarKey carKey; public Person(int age, int number, String name, double salary, CarKey carKey) { this.age = age; this.number = number; this.name = name; this.salary = salary; this.carKey = carKey; } @Override public int hashCode() { int result = 31; result = result * 17 + age; result = result * 17 + number; long lnum = Double.doubleToLongBits(number); result = result * 17 + (int)(lnum ^ (lnum >>> 32)); result = result * 17 + name.hashCode(); result = result * 17 + carKey.hashCode(); return result; } // override equals // ... }
Также, с версии Java 8+ в классе java.util.Objects есть вспомогательные методы для генерации hashCode:
@Override public int hashCode() { return Objects.hash(age, number, salary, name, carKey); }
Использование hashCode в equals
Так как hashCode допускает возникновение коллизий, то использовать его в equals нет смысла.
Методы идут в паре, но использование одного в другом не желательно и бесмыссленно.
hashCode призван облегчить поиск объектов в каких-то структурах, например, ассоциативных массивах.
equals — это уже непосредственно про сравнение объектов.
Классы-обертки над примитивами
Помните, что типы-обертки, которые по размеру меньше или равны int, возвращают в качестве hashCode свое значение.
Продемонстрируем:
public class Test { public static void main(String[] args) { Integer a = 5000; System.out.println(a.hashCode()); // 5000 } }
Так как Long превосходит int, то, разумеется, возвращать свое значение в качестве hashCode он не может.
Вместо этого используется более сложный алгоритм, который работает с значением long (как в примере Person-а).
Массивы
Помните, что хэш-код массива не зависит от хранимых в нем элементов, а присваивается при создании массива!
int[] arr = {1, 2, 3, 4, 5}; System.out.println(arr.hashCode()); // меняем элемент в массиве arr[0] = 100; // hashCode массива не изменяется System.out.println(arr.hashCode());
Результат:
Решением является использовать статический метод для рассчета hashCode у массивов: Arrays.hashCode(...):
int[] arr = {1, 2, 3, 4, 5}; System.out.println(Arrays.hashCode(arr)); arr[0] = 100; System.out.println(Arrays.hashCode(arr));
Результат:
Заключение
Хэш — это некоторое число, генерируемое на основе объекта и описывающее его состояние.
Метод hashCode, наряду с equals, играет важную роль в сравнении объектов.
По сути он показывает изменилось ли состояние объекта, которое мы используем в equals для сравнения.
Если планируется использовать объекты в качестве ключа в ассоциативном маассиве, то переопределять hashCode обязательно.
Если в классе переопределяется equals, то обязательно надо переопределять hashCode и наоборот.
Эти методы всегда должны определяться парой!
Плохая реализация hash-функции даст вам большое количество коллизий, что сведет на нет все преимущества использования ассоциативных массивов.
Помните, что большинство IDE сейчас легко сгенерируют вам
hashCode, чтобы вы не писали его вручную.Также, существуют сторонние проекты, которые берут кодогенерацию на себя, например, проект lombok.
Существуют и сторонние библиотеки, помогающие в вычисленииhashCode, например apache commons.
Полезные ссылки
- Владимир Долженко — Внутрь VM сквозь замочную скважину hashCode
- Как работает hashCode() по умолчанию?
- Разбираемся с hashCode() и equals()
- What role does hashCode play when comparing two objects
- Java equals() and hashCode() Contracts
Время на прочтение
4 мин
Количество просмотров 46K
Часто на собеседованиях приходится спрашивать про функцию hashCode().
Я не буду здесь перечислять все свойства этой функции и ее связь с другой, не менее важной функцией equals(). Данная информация есть во всех учебниках по Java и я не вижу смысла ее здесь повторять. Мне бы хотелось остановиться лишь на одном свойстве: hashCode должен быть равномерно распределен на области значений функции. Я задумался: “А чем гарантировано равномерное распределение?”
Забегая вперед, скажу, что я пришел к довольно интересным выводам. Мне бы хотелось, чтобы меня поправили, если я где-то ошибся в рассуждениях.
Спросим у Гуру
Вначале я решил обратиться к Java документации на Object.hashCode(). Как каждый может убедиться, там нет информации, которая нас интересует. После этого я пошел к Гуру. Брюс Эккель написал 5 страниц, кивнул на Блоха (точнее списал у него), привел пример со строками, а в конце посоветовал использовать “полезные библиотеки”. Джошуа Блох поступил лучше: он предложил алгоритм вычисления, высказался о пользе простых чисел и… тоже привел пример. Я не могу не удержаться от цитирования:
The multiplier 37 was chosen because it is an odd prime. … The advantages of using a prime number are less clear, but it is traditional to use primes for this purpose.
Никто из авторов не удосужился провести анализ приведенного алгоритма и доказать его корректность.
Алгоритм (в вольном пересказе)
1) Взять число, отличное от нуля, к примеру 17. Для удобства, назовем его p. Присвоить переменной result это начальное значение (result = p).
2) Для каждого поля вычислить hashCode c по некоторым правилам. Эти правила, нас сейчас не очень интересуют, они не влияют на результат. Для простоты будем работать с целыми числами (int) и будем принимать hashCode равным самому значению числа…
3) Скомбинировать result и полученный hashCode с: result = result * q + c, где q = 37, потому что, как мы помним, оно нечетное и простое.
4) Вернуть result.
Анализ алгоритма
Сначала сделаем несколько допущений:
1) Как уже сказано выше, будем работать с целыми числами.
2) Будем считать, что hashCode принимает значения от 0 до 232. То есть мы не будем работать с отрицательными значениями.
3) Будем считать, что переполнения при умножении и сложении не происходит. Будем использовать только небольшие исходные значения.
4) Будем считать, что данные, на основании которых строится hashCode распределены, равномерно.
Чтобы быть более конкретным, я стану рассматривать точки с целочисленными координатами (x, y) на плоскости в двухмерном пространстве, при условии, что x>= 0, y>=0.
Запишем hash функцию для точки P1 (x1, y1):
(p*q + x1)*q + y1 = h
h — значение hash функции.
Теперь я хочу рассмотреть какую-нибудь другую точку P2(x2, y2) у которой будет такая же hash функция. То есть это как раз случай коллизии:
(p*q + x2)*q + y2 = h
Вычтем из первого выражение второе:
q(x1-x2) + y1 — y2 = 0 (Обратите внимание, что множитель, содержащий p пропал после вычитания)
Вынесем q в правую часть:
(x1 — x2) / (y2-y1) = q (понятно, что знаменатель должен быть отличен от нуля)
Если подобрать такие значения x1, x2, y1, y2, что выполнится полученное равенство, то эти координаты будут соответствовать значениям аргумента hash функции, при которой возникнет коллизия.
Можно предложить такой вариант:
x1 = 38
x2 = 1
y2= 2
y1 = 1
То есть точки P(38, 1) и P(1, 2) имеют одинаковый hashCode… Я думал, что имея 4 миллиарда возможных значений для hash кода, можно было бы избежать коллизий хотя бы в квадрате 100×100!
Теперь рассмотрим случай n переменных, независимо изменяющихся от 0 до некоторого M. Хотелось бы найти максимальное значение M, такое, что хорошо написанная функция hashCode не имела бы коллизий на промежутке от 0 до M по всем n переменным. После недолгих раздумий, получаем значение для M:
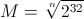
Для случая точек на плоскости M принимает значение 65536.
Похоже, что формула, приведенная Блохом, будет давать приемлемое распределение hash кодов для случая 8 и более переменных.
Рассмотрим теперь точки в трехмерном пространстве. Напишем небольшую программу, которая в тройном цикле перебирает точки от 0 до 100 (всего миллион точек) и считает количество коллизий. Код этой программы элементарный, поэтому не буду его здесь приводить. Интересен результат: я получил 901692 коллизий! То есть чуть более, чем 90%. Получается, что Блох, под видом hash функции, предложил функцию для получения коллизий?
Хороший hashCode для случая двух переменных
Теперь попробуем построить хороший алгоритм для случая двух переменных (x1, y1). Чтобы равномерно раскидать значения x1 и y1 на числовой плоскости, воспользуемся умножением: умножим x1 на некоторое число p, а y1 — на q. Пока не будем накладывать на p и q никаких условий. Для получения значения hash функции, сложим эти произведения:
p*x1+q*y1=h
Воспользуемся приёмом, описанным выше: найдем x2, y2, такие, что значение hash функции выдаст коллизию.
p*x2+q*y2=h
Вычтем из первого равенства второе:
p*(x1-x2) + q(y1-y2) = 0
или
(x1-x2)/(y2-y1)=q/p (при условии, что знаменатель не равен нулю)
Если q взять равным 37, а p — 1, то получим формулу от Блоха.
Из последней формулы и из того факта, что мы работаем с целыми числами, следует:
1) Разность (x1-x2) пропорциональна q, разность (y2-y1) пропорциональна p.
2) Чем больше p и q, тем больше может быть расстояние между точками.
3) p и q должны быть взаимно простыми.
4) Имея верхнее ограничение на h=232, получаем, что каждое из произведений p*x1, q*y1 должны быть меньше, чем 232/2. Отсюда следует, что p и q должны быть меньше 32768. К примеру 32765 и 32767 Тут следует напомнить о нашем допущении: мы работаем только с положительными числами. Когда произойдет переполнение при сложении, мы окажемся в отрицательной части числовой оси. Предлагаю читателям поразмыслить над этим самостоятельно
Выводы
Как писал Дональд Кнут в главе про генератор псевдослучайных последовательностей, если алгоритм выглядит сложно и запутанно, это еще не означает, что он работает правильно (недословное изложение).
Те кто используют реализацию hash функции от Джошуа Блоха, но имеют большое количество хешируемых переменных, могут спать спокойно. Так же могут не волноваться те, у кого различного рода Hash-коллекции не являются узким местом в производительности.
Если же вы бьетесь за производительность своего кода, учитываете все возможные мелочи, то вам, пожалуй, следует взглянуть на свои реализации hashCode() свежим взглядом. Учитывая, что хешируемые значения, могут быть не равномерно распределены для вашей конкретной бизнес области, вы сможете написать hash функцию с лучшим распределением hash кодов, чем любой сгенерированный вариант. Переписав hashCode(), вам, возможно, следует взглянуть на equals(): может быть вы сможете меньшим числом проверок вернуть значение false.
Спасибо тем, кто дочитал до конца.
Литература:
Bruce Eckel “Thinking in Java Third Edition”
Joshua Bloch “Effective Java: Programming Language Guide”
1. Обзор
Хеширование является фундаментальной концепцией информатики.
В Java эффективные алгоритмы хеширования стоят за некоторыми из самых популярных коллекций, которые у нас есть — например,
HashMap
(для более глубокого изучения
HashMap
, не стесняйтесь проверять ссылку:/java-hashmap[эта статья]) и
https://docs.oracle.com/javase/7/docs/api/java/util/HashSet
.html[HashSet].
В этой статье мы сосредоточимся на том, как
hashCode ()
работает, как он играет на коллекциях и как правильно его реализовать.
2. Использование
hashCode ()
в структурах данных
Простейшие операции с коллекциями могут быть неэффективными в определенных ситуациях.
Например, это вызывает линейный поиск, который крайне неэффективен для списков огромных размеров:
List<String> words = Arrays.asList("Welcome", "to", "Baeldung");
if (words.contains("Baeldung")) {
System.out.println("Baeldung is in the list");
}
Java предоставляет ряд структур данных, специально предназначенных для решения этой проблемы — например, несколько реализаций интерфейса
Map
представляют собой таблицы
hash.
При использовании хеш-таблицы
эти коллекции вычисляют значение хеш-функции для данного ключа, используя метод
hashCode ()
, и используют это значение для внутреннего хранения данных, чтобы операции доступа были намного более эффективными.
3. Понимание того, как
hashCode ()
работает
Проще говоря,
hashCode ()
возвращает целочисленное значение, сгенерированное алгоритмом хеширования.
Объекты, которые равны (согласно их
equals ()
), должны возвращать тот же хэш-код.
Не требуется, чтобы разные объекты возвращали разные хеш-коды.
Генеральный контракт
hashCode ()
гласит:
-
Всякий раз, когда он вызывается на один и тот же объект более одного раза в течение
При выполнении Java-приложения
hashCode ()
должен последовательно возвращать одно и то же значение при условии, что никакая информация, используемая в сравнениях сравнения объекта, не изменяется. Это значение не должно оставаться согласованным при выполнении одного приложения другим исполнением того же приложения
-
Если два объекта равны по методу
equals (Object)
,
затем вызов метода
hashCode ()
для каждого из двух объектов должен давать одно и то же значение
-
Не обязательно, если два объекта неравны в соответствии с
equals(java.lang.Object)
, затем вызывая метод
hashCode
для каждого из двух объектов должен давать разные целочисленные результаты. Однако разработчики должны знать, что получение разных целочисленных результатов для неравных объектов повышает производительность хеш-таблиц.
«Насколько это практически возможно, метод
hashCode ()
, определенный классом
Object
, действительно возвращает разные целые числа для разных объектов. (Это обычно реализуется путем преобразования внутреннего адреса объекта в целое число, но этот метод реализации не требуется языком программирования JavaTM.) »
__
4. Наивная
hashCode ()
Реализация
На самом деле довольно просто иметь наивную реализацию
hashCode ()
, которая полностью соответствует вышеуказанному контракту.
Чтобы продемонстрировать это, мы собираемся определить пример класса
User
, который переопределяет реализацию метода по умолчанию:
public class User {
private long id;
private String name;
private String email;
//standard getters/setters/constructors
@Override
public int hashCode() {
return 1;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null) return false;
if (this.getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id
&& (name.equals(user.name)
&& email.equals(user.email));
}
//getters and setters here
}
Класс
User
предоставляет пользовательские реализации для
equals ()
и
hashCode ()
, которые полностью соответствуют соответствующим контрактам. Более того, нет ничего незаконного в том, что
hashCode ()
возвращает любое фиксированное значение.
Однако эта реализация снижает функциональность хэш-таблиц до нуля, поскольку каждый объект будет храниться в одном и том же контейнере. **
В этом контексте поиск в хеш-таблице выполняется линейно и не дает нам никакого реального преимущества — подробнее об этом в разделе 7.
5. Улучшение реализации
hashCode ()
Давайте немного улучшим текущую реализацию
hashCode ()
, включив все поля класса
User
, чтобы он мог давать разные результаты для неравных объектов:
@Override
public int hashCode() {
return (int) id ** name.hashCode() ** email.hashCode();
}
Этот основной алгоритм хеширования определенно намного лучше предыдущего, поскольку он вычисляет хеш-код объекта, просто умножая хеш-коды полей
name
и
email
и
id
.
В общих чертах, мы можем сказать, что это разумная реализация
hashCode ()
, если мы поддерживаем соответствие реализации
equals ()
.
6. Стандартный
hashCode ()
Реализации
Чем лучше алгоритм хэширования, который мы используем для вычисления хеш-кодов, тем выше будет производительность хеш-таблиц.
Давайте посмотрим на «стандартную» реализацию, которая использует два простых числа, чтобы добавить еще больше уникальности к вычисляемым хеш-кодам:
@Override
public int hashCode() {
int hash = 7;
hash = 31 ** hash + (int) id;
hash = 31 ** hash + (name == null ? 0 : name.hashCode());
hash = 31 ** hash + (email == null ? 0 : email.hashCode());
return hash;
}
Хотя важно понимать роли, которые играют методы
hashCode ()
и
equals ()
, нам не нужно каждый раз реализовывать их с нуля, поскольку большинство IDE могут генерировать пользовательские реализации
hashCode ()
и
equals ()
начиная с Java 7 мы получили служебный метод
Objects.hash ()
для удобного хеширования:
Objects.hash(name, email)@Override
public int hashCode() {
int result = (int) (id ^ (id >>> 32));
result = 31 ** result + name.hashCode();
result = 31 ** result + email.hashCode();
return result;
}@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime ** result + ((email == null) ? 0 : email.hashCode());
result = prime ** result + (int) (id ^ (id >>> 32));
result = prime ** result + ((name == null) ? 0 : name.hashCode());
return result;
}
В дополнение к вышеуказанным реализациям
hashCode ()
на основе IDE также возможно автоматически генерировать эффективную реализацию, например, используя
Lombok
. В этом случае зависимость
lombok-maven
должна быть добавлена в
pom.xml
:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok-maven</artifactId>
<version>1.16.18.0</version>
<type>pom</type>
</dependency>
Теперь достаточно аннотировать класс
User
с помощью
@ EqualsAndHashCode
:
@EqualsAndHashCode
public class User {
//fields and methods here
}<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
И
hashCode ()
может быть реализовано так:
public class User {
public int hashCode() {
return new HashCodeBuilder(17, 37).
append(id).
append(name).
append(email).
toHashCode();
}
}
В общем, универсального рецепта, которого можно придерживаться при реализации
hashCode ()
, не существует. Мы настоятельно рекомендуем прочитать
Joshua Bloch’s Effective Java
, где представлен список
подробные рекомендации
для реализации эффективных алгоритмов хеширования.
Здесь можно заметить, что все эти реализации используют число 31 в некоторой форме — это потому, что 31 обладает хорошим свойством — его умножение может быть заменено битовым сдвигом, который быстрее стандартного умножения:
7. Обработка хеш-коллизий
Внутреннее поведение хеш-таблиц поднимает соответствующий аспект этих структур данных: даже при эффективном алгоритме хеширования два или более объектов могут иметь одинаковый хеш-код, даже если они неравны. Таким образом, их хеш-коды будут указывать на один и тот же сегмент, даже если они будут иметь разные ключи хеш-таблицы.
Эта ситуация широко известна как коллизия хешей, и для ее обработки существуют
various методологии
, каждая из которых имеет свои плюсы и минусы.
HashMap
в Java использует
https://en.wikipedia.org/wiki/Hash
table#Separate
chaining
with
linked__lists[the отдельный метод сцепления]для обработки коллизий:
-
«Когда два или более объектов указывают на один и тот же сегмент, они просто сохраняются в связанном списке. В таком случае хеш-таблица представляет собой массив связанных списков, и каждый объект с таким же хешем добавляется в связанный список по индексу корзины в массиве. **
-
В худшем случае к нескольким сегментам будет привязан связанный список, а поиск объекта в списке будет выполняться линейно ** ».
Методологии коллизий хэшей в двух словах показывают, почему так важно эффективно реализовать
hashCode ()
Java 8 принесла интересную
enhancement для реализации
HashMap
— если размер сегмента превышает определенный порог, связанный список заменяется древовидной картой. Это позволяет достичь
_O (
logn
)
поиска вместо пессимистического
O (n) _
.
8. Создание простого приложения
Чтобы проверить функциональность стандартной реализации
hashCode ()
, давайте создадим простое Java-приложение, которое добавляет некоторые объекты
User
в
HashMap
и использует ссылку:/slf4j-with-log4j2-logback[SLF4J]для регистрации сообщений на консоли каждый время вызывается метод.
Вот точка входа примера приложения:
public class Application {
public static void main(String[]args) {
Map<User, User> users = new HashMap<>();
User user1 = new User(1L, "John", "[email protected]");
User user2 = new User(2L, "Jennifer", "[email protected]");
User user3 = new User(3L, "Mary", "[email protected]");
users.put(user1, user1);
users.put(user2, user2);
users.put(user3, user3);
if (users.containsKey(user1)) {
System.out.print("User found in the collection");
}
}
}
И это реализация
hashCode ()
:
public class User {
//...
public int hashCode() {
int hash = 7;
hash = 31 ** hash + (int) id;
hash = 31 ** hash + (name == null ? 0 : name.hashCode());
hash = 31 ** hash + (email == null ? 0 : email.hashCode());
logger.info("hashCode() called - Computed hash: " + hash);
return hash;
}
}
Единственная деталь, на которую стоит обратить внимание, это то, что каждый раз, когда объект сохраняется в хеш-карте и проверяется с помощью метода
containsKey ()
, вызывается
hashCode ()
и вычисленный хеш-код выводится на консоль:
----[main]INFO com.baeldung.entities.User - hashCode() called - Computed hash: 1255477819[main]INFO com.baeldung.entities.User - hashCode() called - Computed hash: -282948472[main]INFO com.baeldung.entities.User - hashCode() called - Computed hash: -1540702691[main]INFO com.baeldung.entities.User - hashCode() called - Computed hash: 1255477819
User found in the collection
----
9. Заключение
Очевидно, что для создания эффективных реализаций
hashCode ()
часто требуется сочетание нескольких математических понятий (то есть простых и произвольных чисел), логических и базовых математических операций.
Несмотря на это, вполне возможно эффективно реализовать
hashCode ()
, не прибегая к этим методам вообще, при условии, что мы обеспечиваем, чтобы алгоритм хеширования создавал разные хеш-коды для неравных объектов и был совместим с реализацией
equals ()
.
Как всегда, все примеры кода, показанные в этой статье, доступны на GitHub
over
.
Методы equals и hashCode в Java в чём-то очень схожи, и даже вместе генерируются средствами IDE, таких как IntelliJ IDEA. Что в них общего, каковы отличия, и что будет, если использовать только один из методов?
- Метод equals()
- Контракт equals()
- Использование equals
- Метод hashcode()
- Контракт hashCode()
- Использование hashCode
- Почему equals и hashCode в Java переопределяются вместе
Как вы наверняка знаете, сравнение посредством == в Java сравнивает ссылки, но объекты таким образом не сравнить. Следующий пример подобного сравнения двух строк вернёт false:
public static void main(String[] args) {
//false
System.out.println(new String("Tproger") == new String("Tproger"));
}Пусть значения и одинаковы, но переменные String указывают на разные объекты.
Тут-то в игру и вступает метод equals(), предусмотренный в Java для сравнения именно объектов. Данный метод проверяет два объекта одного происхождения на логическую равность.
То есть, сравнивая два объекта, программисту необходимо понять, эквивалентны ли их поля. При этом необязательно все поля должны быть идентичными, поскольку метод equals() подразумевает именно логическое равенство.
Контракт equals() в Java
Используя equals, мы должны придерживаться основных правил, определённых в спецификации Java:
- Рефлексивность —
x.equals(x)возвращаетtrue. - Симметричность —
x.equals(y) <=> y.equals(x). - Транзитивность —
x.equals(y) <=> y.equals(z) <=> x.equals(z). - Согласованность — повторный вызов
x.equals(y)должен возвращать значение предыдущего вызова, если сравниваемые поля не изменялись. - Сравнение null —
x.equals(null)возвращаетfalse.
Использование equals
Предположим, у нас есть класс Programmer, в котором предусмотрены поля с должность и зарплатой:
public class Programmer {
private final String position;
private final int salary;
protected Programmer(String position, int salary) {
this.position = position;
this.salary = salary;
}
}В переопределённом методе equals() обе переменные участвуют в проверке. Также вы всегда можете убрать ту переменную, которую не хотите проверять на равенство.
Зачастую метод equals в Java определяется вместе с hashCode, но здесь мы рассмотрим первый метод отдельно:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Programmer that = (Programmer) o;
if (salary != that.salary) return false;
return Objects.equals(position, that.position);
}Определим объекты programmer1 и programmer2 типа Programmer с одинаковыми значениями. При их сравнении с помощью == вернётся false, так как это разные объекты. Если же мы используем для сравнения метод equals(), вернётся true:
public class Main extends Programmer {
protected Main(String position, int salary) {
super(position, salary);
}
public static void main(String[] args) {
Programmer programmer1 = new Programmer("Junior", 300);
Programmer programmer2 = new Programmer("Junior", 300);
//false
System.out.println(programmer1 == programmer2);
//true
System.out.println(programmer1.equals(programmer2));
}
}А вот такой результат мы получим, если хотя бы одна переменная (обозначенное поле объекта) из метода equals() не совпадёт:
public class Main extends Programmer {
protected Main(String position, int salary) {
super(position, salary);
}
public static void main(String[] args) {
Programmer programmer1 = new Programmer("Junior", 300);
Programmer programmer2 = new Programmer("Middle", 300);
//false
System.out.println(programmer1 == programmer2);
//false
System.out.println(programmer1.equals(programmer2));
}
}Метод hashcode() в Java
Наконец, мы дошли до сравнения методов equals и hashCode в языке Java.
Фундаментальное отличие в том, что hashCode() — это метод для получения уникального целочисленного номера объекта, своего рода его идентификатор. Благодаря хешу (номеру) можно, например, быстро определить местонахождение объекта в коллекции.
Это число используется в основном в хеш-таблицах, таких как HashMap. При этом хеш-функция получения числа на основе объекта должна быть реализована таким образом, чтобы обеспечить равномерное распределение элементов по хэш-таблице. А также минимизировать возможность появления коллизий, когда по разным ключам функция вернёт одинаковое значение.
В случае Java, метод hashCode() возвращает для любого объекта 32-битное число типа int. Сравнить два числа между собой гораздо быстрее, чем сравнить два объекта методом equals(), особенно если в нём используется много полей.
Контракт hashCode() в Java
- Повторный вызов
hashCodeдля одного и того же объекта должен возвращать одинаковые хеш-значения, если поля объекта, участвующие в вычислении значения, не менялись. - Если
equals()для двух объектов возвращаетtrue,hashCode()также должен возвращать для них одно и то же число. - При этом неравные между собой объекты могут иметь одинаковый
hashCode.
Использование hashCode
Вернёмся к нашему классу Programmer. По-хорошему, вместе с equals() должен быть использован и метод hashCode():
public class Programmer {
private final String position;
private final int salary;
protected Programmer(String position, int salary) {
this.position = position;
this.salary = salary;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Programmer that = (Programmer) o;
if (salary != that.salary) return false;
return Objects.equals(position, that.position);
}
@Override
public int hashCode() {
int result = position != null ? position.hashCode() : 0;
result = 31 * result + salary;
return result;
}
}Почему equals и hashCode в Java переопределяются вместе
Сперва производится сравнение по хешу, чтобы понять, совпадают ли объекты, а только после подключается equals, чтобы определить, совпадают ли значения полей объекта.
Рассмотрим два сценария.
1. equals есть, hashCode нет
С точки зрения метода equals два объекта будут логически равны, но по hashCode они не будут иметь ничего общего. Таким образом, помещая некий объект в хэш-таблицу, мы рискуем не получить его обратно по ключу:
Map<Point, String> m = new HashMap<>();
m.put(new Point(1, 1), "Point A");
//pointName == null
String pointName = m.get(new Point(1, 1));2. hashCode есть, equals нет
Метод equals по умолчанию сравнивает указатели на объекты, определяя, ссылаются ли они на один и тот же объект. Следовательно, пример из предыдущего пункта по идее должен выполняться. Но мы по-прежнему не сможем найти наш объект в хэш-таблице.
Для успешного поиска объекта в хэш-таблице помимо сравнения хэш-значений ключа используется также определение логического равенства ключа с искомым объектом.
Читайте также об условных операторах в Java.
Афоризм
Сейчас я расшатаю Вам здоровье.
Наталья Резник
Поддержка проекта
Если Вам сайт понравился и помог, то будем признательны за Ваш «посильный» вклад в его поддержку и развитие
• Yandex.Деньги
410013796724260
• Webmoney
R335386147728
Z369087728698
В классе Object, который является родительским классом для объектов java, определен метод hashCode(),
позволяющий получить уникальный целый номер для данного объекта. Когда объект сохраняют в коллекции типа
HashSet, то данный номер позволяет быстро определить его местонахождение в коллекции и
извлечь. Функция hashCode() объекта Object возвращает целое число int, размер которого равен 4-м
байтам и значение которого располагается в диапазоне от -2 147 483 648 до 2 147 483 647.
Рассмотрим простой пример HashCodeTest.java, который в консоли будет печатать значение hashCode.
public class HashCodeTest
{
public static void main(String[] args)
{
int hCode = (new Object()).hashCode();
System.out.println("hashCode = " + hCode);
}
}
Значение hashCode программы можно увидеть в консоли.
По умолчанию, функция hashCode() для объекта возвращает номер ячейки памяти, где объект сохраняется. Поэтому,
если изменение в код приложения не вносятся, то функция должна выдавать одно и то же значение. При незначительном
изменении кода значение hashCode также изменится.
Функция сравнения объектов equals()
В родительском классе Object наряду с функцией hashCode() имеется еще и логическая функция
equals(Object)/ Функция equals(Object) используется для проверки равенства двух объектов. Реализация
данной функции по умолчанию просто проверяет по ссылкам два объекта на предмет их эквивалентности.
Рассмотрим пример сравнения двух однотипных объектов Test следующего вида :
class Test
{
int f1 = -1;
int f2 = -1;
public Test (final int f1, final int f2)
{
this.f1 = f1;
this.f2 = f2;
}
public int getF1()
{
return this.f1;
}
public int getF2()
{
return this.f2;
}
}
Создадим 2 объекта типа Test с одинаковыми значениями и сравним объекты с использованием функции equals().
public class EqualsExample
{
public static void main(String[] args)
{
Test obj1 = new Test(11, 12);
Test obj2 = new Test(11, 12);
System.out.println("Объекты :ntobj1 = " + obj1 +
"ntobj2 = " + obj2);
System.out.println("hashCode объектов :" +
"ntobj1.hashCode = " + obj1.hashCode() +
"ntobj2.hashCode = " + obj2.hashCode());
System.out.println("Сравнение объектов :" +
"ntobj1.equals(obj2) = " + obj1.equals(obj2));
}
}
Результат выполнения программы будет выведен в консоль :
Объекты :
obj1 = example.Test@780324ff
obj2 = example.Test@16721ee7
hashCode объектов :
obj1.hashCode = 2013471999
obj2.hashCode = 376577767
Сравнение объектов :
obj1.equals(obj2) = false
Не трудно было догадаться, что результат сравнения двух объектов вернет «false». На самом деле, это не совсем верно,
поскольку объекты идентичны и в real time application метод должен вернуть true. Чтобы достигнуть этого корректного
поведения, необходимо переопределить метод equals() объекта Test.
@Override
public boolean equals(Object obj)
{
if (this == obj)
return true;
else if (obj == null)
return false;
else if (getClass() != obj.getClass())
return false;
Test other = (Test) obj;
if (f1 != other.getF1())
return false;
else if (f2 != other.getF2())
return false;
return true;
}
Вот теперь функция сравнения equals() возвращает значение «true». Достаточно ли этого? Попробуем добавить
объекты в коллекцию HashSet и посмотрим, сколько объектов будет в коллекции? Для этого в в метод main
примера EqualsExample добавим следующие строки :
Set<Test> objects = new HashSet<Test>();
objects.add(obj1);
objects.add(obj2);
System.out.println("Коллекция :nt" + objects);
Однако в коллекции у нас два объекта.
Коллекция : [example.Test@780324ff, example.Test@16721ee7]
Поскольку Set содержит только уникальные объекты, то внутри HashSet должен быть только один экземпляр. Чтобы
этого достичь, объекты должны возвращать одинаковый hashCode. То есть нам необходимо переопределить также
функцию hashCode() вместе с equals().
@Override
public int hashCode()
{
final int prime = 31;
int result = 1;
result = prime * result + f1;
result = prime * result + f2;
return result;
}
Вот теперь все будет корректно выполняться — для двух объектов с одинаковыми параметрами функция
equals() вернет значение «true», и в коллекцию попадет только один объект. В консоль будет
выведен следующий текст работы программы :
Объекты : obj1 = example.Test@696 obj2 = example.Test@696 hashCode объектов : obj1.hashCode = 1686 obj2.hashCode = 1686 Сравнение объектов : obj1.equals(obj2) = true Коллекция : [example.Test@696]
Таким образом, переопределяя методы hashCode() и equals() мы можем корректно управлять
нашими объектами, не допуская их дублирования.
Использование библиотеки commons-lang.jar для переопределения hashCode() и equals()
Процесс формирования методов hashCode() и equals() в IDE Eclipse автоматизирован. Для создания данных
методов необходимо правой клавишей мыши вызвать контекстное меню класса (кликнуть на классе) и выбрать пункт меню
Source (Class >> Source), в результате которого будет открыто следующее окно со списком меню для класса.
 и equals()")
Выбираем пункт меню «Generate hachCode() and equals()» и в класс будут добавлены соответствующие методы.
@Override
public int hashCode()
{
final int prime = 31;
int result = 1;
result = prime * result + f1;
result = prime * result + f2;
return result;
}
@Override
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Test other = (Test) obj;
if (f1 != other.f1)
return false;
if (f2 != other.f2)
return false;
return true;
}
Библиотека Apache Commons включает два вспомогательных класса HashCodeBuilder и
EqualsBuilder для вызова методов hashCode() и equals(). Чтобы включить их в класс
необходимо внести следующие изменения.
import org.apache.commons.lang.builder.EqualsBuilder;
import org.apache.commons.lang.builder.HashCodeBuilder;
...
@Override
public int hashCode()
{
final int prime = 31;
return new HashCodeBuilder(getF1()%2 == 0 ?
getF1() + 1 :
getF1(), prime).toHashCode();
}
@Override
public boolean equals(Object obj)
{
if (this == obj)
return true;
else if (obj == null)
return false;
else if (getClass() != obj.getClass())
return false;
Test other = (Test) obj;
return new EqualsBuilder().append(getF1(),other.getF1()).isEquals();
}
Примечание : желательно в методах hashCode() и equals() не использовать ссылки на поля, заменяйте их
геттерами. Это связано с тем, что в некоторых технологиях java поля загружаются при помощи отложенной загрузки
(lazy load) и не доступны, пока не вызваны их геттеры.
Скачать пример
Исходный код рассмотренного примера в виде проекта Eclipse можно
скачать здесь (263 Kб).
At SitePoint we’re always looking to expand the range of topics we cover. Lately, we’ve set our sights on exploring the world of Java. If you’re a strong Java developer who wants to contribute to our coverage, get in touch with a few ideas for articles you’d like to write.
So you’ve decided that identity isn’t enough for you and wrote a nice equals implementation?
Great! But now you have to implement hashCode as well.
Let’s see why and how to do it correctly.
Equality and Hash Code
While equality makes sense from a general perspective, hash codes are much more technical. If we were being a little hard on them, we could say that they are just an implementation detail to improve performance.
Most data structures use equals to check whether they contain an element. For example:
List<String> list = Arrays.asList("a", "b", "c");
boolean contains = list.contains("b");
The variable contains is true because, while instances of "b" are not identical (again, ignoring String interning), they are equal.
Comparing every element with the instance given to contains is wasteful, though, and a whole class of data structures uses a more performant approach. Instead of comparing the requested instance with each element they contain, they use a shortcut that reduces the number of potentially equal instances and then only compare those.
This shortcut is the hash code, which can be seen as an object’s equality boiled down to an integer value. Instances with the same hash code are not necessarily equal but equal instances have the same hash code. (Or should have, we will discuss this shortly.) Such data structures are often named after this technique, recognizable by the Hash in their name, with HashMap the most notable representative.
This is how they generally work:
- When an element is added, its hash code is used to compute the index in an internal array (called a bucket).
- If other, non-equal elements have the same hash code, they end up in the same bucket and must be bundled together, e.g. by adding them to a list.
- When an instance is given to
contains, its hash code is used to compute the bucket. Only elements therein are compared to the instance.
This way, very few, ideally no equals comparisons are required to implement contains.
As equals, hashCode is defined on Object.
Thoughts on Hashing
If hashCode is used as a shortcut to determine equality, then there is really only one thing we should care about: Equal objects should have the same hash code.
This is also why, if we override equals, we must create a matching hashCode implementation! Otherwise things that are equal according to our implementation would likely not have the same hash code because they use Object‘s implementation.
The hashCode Contract
Quoting the source:
The general contract of
hashCodeis:
- Whenever it is invoked on the same object more than once during an execution of a Java application, the
hashCodemethod must consistently return the same integer, provided no information used in equals comparisons on the object is modified. This integer need not remain consistent from one execution of an application to another execution of the same application.- If two objects are equal according to the
equals(Object)method, then calling thehashCodemethod on each of the two objects must produce the same integer result.- It is not required that if two objects are unequal according to the
equals(Object)method, then calling thehashCodemethod on each of the two objects must produce distinct integer results. However, the programmer should be aware that producing distinct integer results for unequal objects may improve the performance of hash tables.
The first bullet mirrors the consistency property of equals and the second is the requirement we came up with above. The third states an important detail that we discuss will in a moment.

Implementing hashCode
A very easy implementation of Person.hashCode is the following:
@Override
public int hashCode() {
return Objects.hash(firstName, lastName);
}
The person’s hash code is computed by computing the hash codes for the relevant fields and combining them. Both is left to Objects‘ utility function hash.
Selecting Fields
But which fields are relevant? The requirements help answer this: If equal objects must have the same hash code, then hash code computation should not include any field that is not used for equality checks. (Otherwise two objects that only differ in those fields would be equal but have different hash codes.)
So the set of fields used for hashing should be a subset of the fields used for equality. By default both will use the same fields but there are a couple of details to consider.
Consistency
For one, there is the consistency requirement. It should be interpreted rather strictly. While it allows the hash code to change if some fields change (which is often unavoidable with mutable classes), hashing data structures are not prepared for this scenario.
As we have seen above the hash code is used to determine an element’s bucket. But if the hash-relevant fields change, the hash is not recomputed and the internal array is not updated.
This means that a later query with an equal object or even with the very same instance fails! The data structure computes the current hash code, different from the one used to store the instance, and goes looking in the wrong bucket.
Conclusion: Better not use mutable fields for hash code computation!
Performance
Hash codes might end up being computed about as often as equals is called. This can very well happen in performance critical parts of the code so it makes sense to think about performance. And unlike equals there is a little more wiggle room to optimize it.
Unless sophisticated algorithms are used or many, many fields are involved, the arithmetic cost of combining their hash codes is as negligible as it is unavoidable. But it should be considered whether all fields need to be included in the computation! Particularly collections should be viewed with suspicion. Lists and sets, for example, will compute the hash for each of their elements. Whether calling them is necessary should be considered on a case-by-case basis.
If performance is critical, using Objects.hash might not be the best choice either because it requires the creation of an array for its varargs.
But the general rule about optimization holds: Don’t do it prematurely! Use a common hash code algorithm, maybe forego including the collections, and only optimize after profiling showed potential for improvement.
Collisions
Going all-in on performance, what about this implementation?
@Override
public int hashCode() {
return 0;
}
It’s fast, that’s for sure. And equal objects will have the same hash code so we’re good on that, too. As a bonus, no mutable fields are involved!
But remember what we said about buckets? This way all instances will end up in the same! This will typically result in a linked list holding all the elements, which is terrible for performance. Each contains, for example, triggers a linear scan of the list.
So what we want is as few items in the same bucket as possible! An algorithm that returns wildly varying hash codes, even for very similar objects, is a good start.
How to get there partly depends on the selected fields. The more details we include in the computation, the more likely it is for the hash codes to differ. Note how this is completely opposite to our thoughts about performance. So, interestingly enough, using too many or too few fields can result in bad performance.
The other part to preventing collisions is the algorithm that is used to actually compute the hash.
Computing The Hash
The easiest way to compute a field’s hash code is to just call `hashCode` on it. Combining them could be done manually. A common algorithm is to start with some arbitrary number and to repeatedly multiply it with another (often a small prime) before adding a field’s hash:
int prime = 31;
int result = 1;
result = prime * result + ((firstName == null) ? 0 : firstName.hashCode());
result = prime * result + ((lastName == null) ? 0 : lastName.hashCode());
return result;
This might result in overflows, which is not particularly problematic because they cause no exceptions in Java.
Note that even great hashing algorithms might result in uncharacteristically frequent collisions if the input data has specific patterns. As a simple example assume we would compute the hash of points by adding their x and y-coordinates. May not sound too bad until we realize that we often deal with points on the line f(x) = -x, which means x + y == 0 for all of them. Collisions, galore!
But again: Use a common algorithm and don’t worry until profiling shows that something isn’t right.
Summary
We have seen that computing hash codes is something like compressing equality to an integer value: Equal objects must have the same hash code and for performance reasons it is best if as few non-equal objects as possible share the same hash.
This means that hashCode must always be overridden if equals is.
When implementing hashCode:
- Use a the same fields that are used in
equals(or a subset thereof). - Better not include mutable fields.
- Consider not calling
hashCodeon collections. - Use a common algorithm unless patterns in input data counteract them.
Remember that hashCode is about performance, so don’t waste too much energy unless profiling indicates necessity.