1. Вступление
Сталкиваясь с необходимостью контролировать работу других программистов, начинаешь понимать, что, помимо вещей, которым люди учатся достаточно легко и быстро, находятся проблемы, для устранения которых требуется существенное время.
Сравнительно быстро можно обучить человека пользоваться необходимым инструментарием и документацией, правильной коммуникации с заказчиком и внутри команды, правильному целеполаганию и расстановке приоритетов (ну, конечно, в той мере, в которой сам всем этим владеешь).
Но когда дело доходит собственно до кода, все становится гораздо менее однозначно. Да, можно указать на слабые места, можно даже объяснить, что с ними не так. И в следующий раз получить ревью с абсолютно новым набором проблем.
Профессии программиста, как и большинству других профессий, приходится учиться каждый день в течение нескольких лет, а, по большому счету, и всю жизнь. Вначале ты осваиваешь набор базовых знаний в объеме N семестровых курсов, потом долго топчешься по различным граблям, перенимаешь опыт старших товарищей, изучаешь хорошие и плохие примеры (плохие почему-то чаще).
Говоря о базовых знаниях, надо отметить, что умение писать красивый профессиональный код — это то, что по тем или иным причинам, в эти базовые знания категорически не входит. Вместо этого, в соответствующих заведениях, а также в книжках, нам рассказывают про алгоритмы, языки, принципы ООП, паттерны дизайна…
Да, все это необходимо знать. Но при этом, понимание того, как должен выглядеть достойный код, обычно появляется уже при наличии практического (чаще в той или иной степени негативного) опыта за плечами. И при условии, что жизнь “потыкала” тебя не только в сочные образцы плохого кода, но и в примеры всерьез достойные подражания.
В этом-то и заключается вся сложность: твое представление о “достойном” и “красивом” коде полностью основано на личном многолетнем опыте. Попробуй теперь передать это представление в сжатые сроки человеку с совсем другим опытом или даже вовсе без него.
Но если для нас действительно важно качество кода, который пишут люди, работающие вместе с нами, то попробовать все же стоит!
2. Зачем нам нужен красивый код?
Обычно, когда мы работаем над конкретным программным продуктом, эстетические качества кода заботят нас далеко не в первую очередь.
Нам гораздо важнее наша производительность, качество реализации функционала, стабильность его работы, возможность модификации и расширения и т.д.
Но являются ли эстетические качества кода фактором, положительно влияющим на вышеперечисленные показатели?
Мой ответ: да, и при этом, одним из самых важных!
Это так, потому что красивый код, вне зависимости от субъективной трактовки понятия о красоте, обладает следующими (в той или иной степени сводимыми друг к другу) важнейшими качествами:
- Читаемость. Т.е. возможность, глядя на код, быстро понять реализованный алгоритм, и оценить, как будет вести себя программа в том или ином частном случае.
- Управляемость. Т.е. возможность в минимальные сроки внести в код требуемые поправки, избежав при этом различных неприятных предсказуемых и непредсказуемых последствий.
Почему эти качества действительно являются важнейшими, и как они способствуют повышению показателей, указанных в начале параграфа, уверен, очевидно любому, кто занимается программированием.
А теперь, чтобы от общих слов перейти к конкретике, давайте сделаем обратный ход и скажем, что именно читаемый и управляемый код обычно воспринимается нами как красивый и профессионально написанный. Соответственно, на обсуждении того, как добиться этих качеств, мы далее и сосредоточимся.
3. Три базовых принципа.
Переходя к изложению собственного опыта, отмечу, что, работая над читаемостью и управляемостью своего и чужого кода, я постепенно пришел к следующему пониманию.
Вне зависимости от конкретного языка программирования и решаемых задач, для того, чтобы фрагмент кода в достаточной степени обладал этими двумя качествами необходимо, чтобы он был:
- максимально линейным;
- коротким;
- самодокументированным.
Можно бесконечно перечислять различные хинты и техники, с помощью которых можно сделать код красивее. Но я утверждаю, что наилучших, или, во всяком случае, достаточно хороших результатов можно достигнуть, ориентируясь именно на эти три принципа.
Поэтому дальше я постараюсь подробно пояснить их суть, а также описать набор основных техник, с помощью которых можно привести свой код в соответствие с этими принципами.
4. Линеаризация кода.
Мне кажется, что из трех базовых принципов, именно линейность является самым неочевидным, и именно ей чаще всего пренебрегают.
Наверное, потому что за годы учебы (и, возможно, научной деятельности) мы привыкли обсуждать от природы нелинейные алгоритмы с оценками типа O(n3), O(nlogn) и т.д.
Это все, конечно, хорошо и важно, но, говоря о реализации бизнес-логики в реальных проектах, обычно приходится иметь дело с алгоритмами совсем другого свойства, больше напоминающими иллюстрации к детским книжкам по программированию. Что-то типа такого (взято из гугла):
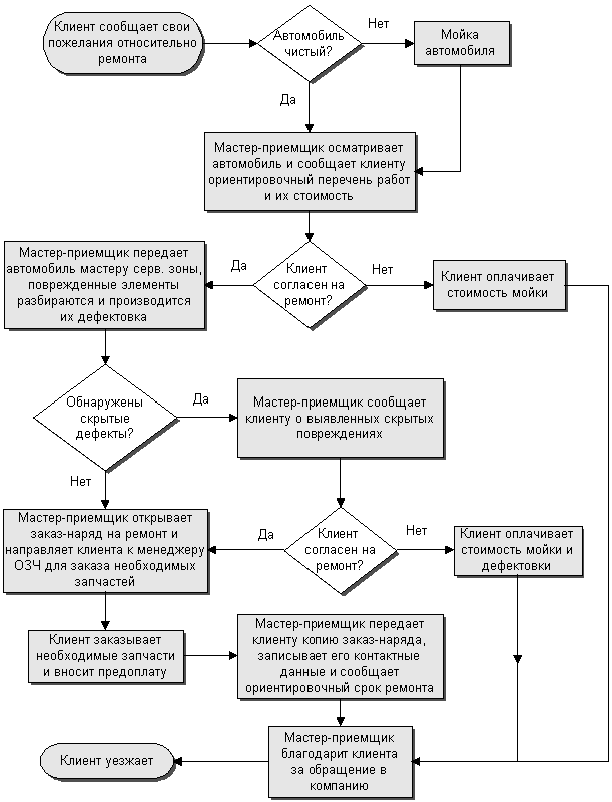
Таким образом, с линейностью я связываю не столько асимптотическую сложность алгоритма, сколько максимальное количество вложенных друг в друга блоков кода, либо же уровень вложенности максимально длинного подучастка кода.
Например, идеально линейный фрагмент:
do_a();
do_b();
do_c();
И совсем не линейный:
do_a();
if (check) {
something();
} else {
anything();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
}
Именно “куски” второго типа мы и будем пытаться переписать при помощи определенных техник.
Примечание: поскольку здесь и далее нам потребуется примеры кода для иллюстрации тех или иных идей, сразу условимся, что они будут написаны на абстрактном обобщенном C-like языке, кроме тех случаев, когда потребуются особенности конкретного существующего языка. Для таких случаев будет явно указано, на каком языке написан пример (конкретно будут встречаться примеры на Java и Javascript).
4.1. Техника 1. Выделяем основную ветку алгоритма.
В подавляющем большинстве случаев в качестве основной ветки имеет смысл взять максимально длинный успешный линейный сценарий алгоритма.
Попробуем сделать это на основе “алгоритма авторемонта” на диаграмме выше:
- Клиент сообщает пожелания.
- Мастер осматривает и говорит стоимость.
- Поиск дефектов.
- Составляем заказ на запчасти.
- Берем предоплату, обозначаем срок.
- Клиент уезжает.
Именно эта основная ветка у нас в идеале должна быть на нулевом уровне вложенности.
listen_client();
if (!is_clean()) {
...
}
check_cost();
if (!client_agree()) {
...
}
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
bye();
Давайте для сравнения рассмотрим вариант, где на нулевом уровне находится альтернативная ветка, вместо основной:
listen_client();
if (!is_clean()) {
...
}
check_cost();
if (client_agree()) {
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
} else {
...
}
bye();
Как видно, уровень вложенности значительной части кода вырос, и смотреть на код в целом уже стало менее приятно.
4.2. Техника 2. Используем break, continue, return или throw, чтобы избавиться от блока else.
Плохо:
...
if (!client_agree()) {
...
} else {
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
bye();
}
Лучше:
...
if (!client_agree()) {
...
return;
}
find_defects();
if (defects_found()) {
...
}
create_request();
take_money();
bye();
Разумеется, неверным был бы вывод, что вообще никогда не нужно использовать оператор else. Во-первых, не всегда контекст позволяет поставить break, continue, return или throw (хотя часто как раз таки позволяет). Во-вторых, выигрыш от этого может быть не столь очевиден, как в примере выше, и простой else будет выглядеть гораздо проще и понятней, чем что-либо еще.
Ну и в-третьих, существуют определенные издержки при использовании множественных return в процедурах и функциях, из-за которых многие вообще расценивают данный подход как антипаттерн (мое личное мнение: обычно преимущества все-таки покрывают эти издержки).
Поэтому эта (и любая другая) техника должна восприниматься как подсказка, а не как безусловная инструкция к действию.
4.3. Техника 3. Выносим сложные подсценарии в отдельные процедуры.
Т.к. в случае “алгоритма ремонта” мы довольно удачно выбрали основную ветку, то альтернативные ветки у нас все остались весьма короткими.
Поэтому продемонстрируем технику на основе “плохого” примера из начала главы:
Плохо:
do_a()
if (check) {
something();
} else {
anything();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
}
Лучше:
procedure do_on_whatever() {
for (a in b) {
if (good(a)) {
something();
}
}
}
do_a();
if (check) {
something();
} else {
anything();
if (whatever()) {
do_on_whatever();
}
}
Обратите внимание, что правильно выбрав имя выделенной процедуре, мы, кроме того, сразу же повышаем самодокументированность кода. Теперь для данного фрагмента в общих чертах должно быть понятно, что он делает и зачем нужен.
Однако следует иметь в виду, что та же самодокументированность сильно пострадает, если у вынесенной части кода нет общей законченной задачи, которую этот код выполняет. Затруднения в выборе правильного имени для процедуры могут быть индикатором именно такого случая (см. п. 6.1).
4.4. Техника 4. Выносим все, что возможно, во внешний блок, оставляем во внутреннем только то, что необходимо.
Плохо:
if (check) {
do_a();
something();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
} else {
do_a();
anything();
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
}
Лучше:
do_a();
if (check) {
something();
} else {
anything();
}
if (whatever()) {
for (a in b) {
if (good(a)) {
something();
}
}
}
4.5. Техника 5 (частный случай предыдущей). Помещаем в try…catch только то, что необходимо.
Надо отметить, что блоки try…catch вообще являются болью, когда речь идет о читаемости кода, т.к. часто, накладываясь друг на друга, они сильно повышают общий уровень вложенности даже для простых алгоритмов.
Бороться с этим лучше всего, минимизируя размер участка внутри блока. Т.е. все строки, не предполагающие появление исключения, должны быть вынесены за пределы блока. Хотя в некоторых случаях с точки зрения читаемости более выигрышным может оказаться и строго противоположный подход: вместо того, чтобы писать множество мелких блоков try..catch, лучше объединить их в один большой.
Кроме того, если ситуация позволяет не обрабатывать исключение здесь и сейчас, а выкинуть вниз по стеку, обычно лучше именно так и поступить. Но надо иметь в виду, что вариативность тут возможна только в том случае, если вы сами можете задавать или менять контракт редактируемой вами процедуры.
4.6. Техника 6. Объединяем вложенные if-ы.
Тут все очевидно. Вместо:
if (a) {
if (b) {
do_something();
}
}
пишем:
if (a && b) {
do_something();
}
4.7. Техника 7. Используем тернарный оператор (a? b: c) вместо if.
Вместо:
if (a) {
var1 = b;
} else {
var1 = c;
}
пишем:
var1 = a ? b : c;
Иногда имеет смысл даже написать вложенные тернарные операторы, хотя это предполагает от читателя знания приоритета, с которым вычисляются подвыражения тернарного оператора.
Вместо:
if (a) {
var1 = b;
} else if (aa) {
var1 = c;
} else {
var1 = d;
}
пишем:
var1 = a ? b :
aa ? c : d;
Но злоупотреблять этим, пожалуй, не стоит.
Заметим, что инициализация переменной var1 теперь осуществляется одной единственной операцией, что опять же сильно способствует самодокументированности (см п. 6.8).
4.8. Суммируя вышесказанное, попробуем написать полную реализацию алгоритма ремонта максимально линейно.
listen_client();
if (!is_clean()) {
wash();
}
check_cost();
if (!client_agree()) {
pay_for_wash();
bye();
return;
}
find_defects();
if (defects_found()) {
say_about_defects();
if (!client_agree()) {
pay_for_wash_and_dyagnosis();
bye();
return;
}
}
create_request();
take_money();
bye();
На этом можно было бы и остановиться, но не совсем здорово выглядит то, что нам приходится 3 раза вызывать bye() и, соответственно, помнить, что при добавлении новой ветки, его придется каждый раз писать перед return (собственно, издержки множественных return).
Можно было бы решить проблему через try…finally, но это не совсем правильно, т.к. в данном случае не идет речи об обработке исключений. Да и делу линеаризации такой подход бы сильно помешал.
Давайте сделаем так (на самом деле, я тут применил п. 5.1 еще до того, как его написал):
procedure negotiate_with_client() {
check_cost();
if (!client_agree()) {
pay_for_wash();
return;
}
find_defects();
if (defects_found()) {
say_about_defects();
if (!client_agree()) {
pay_for_wash_and_dyagnosis();
return;
}
}
create_request();
take_money();
}
listen_client();
if (!is_clean()) {
wash();
}
negotiate_with_client();
bye();
Если вы думаете, что мы сейчас записали что-то тривиальное, то, в принципе, так и есть. Однако уверяю, что во многих живых проектах вы увидели бы совсем другую реализацию этого алгоритма…
5. Минимизация кода.
Думаю, было бы лишним пояснять, что уменьшая количество кода, используемого для реализации заданного функционала, мы делаем код гораздо более читаемым и надежным.
В этом смысле, идеальное инженерное решение — это, когда ничего не сделано, но все работает, как требуется. Разумеется, в реальном мире крайне редко доступны идеальные решения, и поэтому у нас, программистов, пока еще есть работа. Но стремиться стоит именно к такому идеалу.
5.1. Техника 1. Устраняем дублирование кода.
О копипасте и вреде, от него исходящем, сказано уже так много, что добавить что-то новое было бы сложно. Тем не менее, программисты, поколение за поколением, интенсивно используют этот метод для реализации программного функционала.
Разумеется, самым очевидным методом борьбы с проблемой является вынесение переиспользуемого кода в отдельные процедуры и классы.
При этом всегда возникает проблема выделения общего из частного. Зачастую даже не всегда понятно, чего больше у похожих кусков кода: сходства или различий. Выбор тут делается исключительно по ситуации. Тем не менее, наличие одинаковых участков размером в пол-экрана сразу говорит о том, что данный код можно и нужно записать существенно короче.
Стоит также упомянуть весьма полезную технику устранения дублирования, описанную в п. 4.3.
Распространить ее можно дальше одних лишь операторов if. Например, вместо:
procedure proc1() {
init();
do1();
}
procedure proc2() {
init();
do2();
}
proc1();
proc2();
запишем:
init();
do1();
do2();
Или обратный вариант. Вместо:
a = new Object();
init(a);
do(a);
b = new Object();
init(b);
do(b);
запишем:
procedure proc(a) {
init(a);
do(a);
}
proc(new Object());
proc(new Object());
5.2. Техника 2. Избегаем лишних условий и проверок.
Лишние проверки — зло, которое можно встретить практически в любой программе. Сложно описать, насколько самые тривиальные процедуры и алгоритмы могут быть засорены откровенно ненужными, дублирующимися и бессмысленными проверками.
Особенно это касается, конечно же, проверок на null. Как правило, вызвано подобное извечным страхом программистов перед вездесущими NPE и желанием лишний раз от них перестраховаться.
Далеко не редким видом ненужной проверки является следующий пример:
obj = new Object();
...
if (obj != null) {
obj.call();
}
Не смотря на свою очевидную абсурдность, встречаются такие проверки с впечатляющей регулярностью. (Cразу же оговорюсь, что пример не касается тех редких языков и сред, где оператор new() может вернуть null. В большинстве случаев (в т.ч. в Java) подобное в принципе невозможно).
Сюда же можно включить десятки других видов проверок на заведомо выполненное (или заведомо не выполненное) условие.
Вот, например, такой случай:
obj = factory.getObject();
obj.call1();
// если бы obj был null, мы бы уже умерли )
if (obj != null) {
obj.call2();
}
Встречается в разы чаще, чем предыдущий тип проверок.
Третий пример чуть менее очевиден, чем первые два, но распространен просто повсеместно:
procedure proc1(obj) {
if (!is_valid(obj)) return;
obj.call1();
}
procedure proc2(obj) {
if (!is_valid(obj)) return;
obj.call2();
}
obj = factory.getObject();
if (is_valid(obj) {
proc1(obj);
proc2(obj);
}
Как видно, автор данного отрезка панически боится нарваться на невалидный объект, поэтому проверяет его перед каждым чихом. Не смотря на то, что иногда такая стратегия может быть оправдана (особенно, если proc1() и proc2() экспортируются в качестве API), во многих случаях это просто засорение кода.
Варианты тут могут быть разными:
- Для каждой процедуры обозначить входной контракт, требующий от вызывающего соблюдения определенных условий валидности. После этого удалить страхующие проверки и целиком перенести ответственность за валидность входных данных на вызывающий код. Для Java, например, хорошей практикой может быть пометка “опасных” методов и полей аннотацией @Nullable. Таким образом, мы неявно обозначим, что остальные поля и методы могут принимать/возвращать значение null.
- Вообще не создавать невалидных объектов! Этот подход предполагает выполнение всех процедур валидации на этапе создания объекта, чтобы сам факт успешного создания уже гарантировал валидность. Разумеется, для этого как минимум требуется, чтобы мы контролировали класс фабрики или иные механизмы создания объектов. Либо, чтобы имеющаяся реализация давала нам такую гарантию.
Может быть, на первый взгляд, эти варианты кажутся чем-то невозможным или даже страшным, тем не менее, в реальности с их помощью можно существенно повысить читаемость и надежность кода.
Еще одним полезным подходом является применение паттерна NullObject, предполагающего использование объекта с ничего не делающими, но и не вызывающими ошибок, методами вместо “опасного” null. Частным случаем такого подхода можно считать отказ от использования null для переменных-коллекций в пользу пустых коллекций.
Сюда же относятся специальные null-safe библиотеки, среди которых хотелось бы выделить набор библиотек apache-commons для Java. Он позволяет сэкономить огромное количество места и времени, избавив от необходимости писать бесконечные рутинные проверки на null.
5.3. Техника 3. Избегаем написания “велосипедов”. Используем по максимуму готовые решения.
Велосипеды — это почти как копипаст: все знают, что это плохо, и все регулярно их пишут. Можно лишь посоветовать хотя бы пытаться бороться с этим злом.
Большую часть времени перед нами встают задачи или подзадачи, которые уже множество раз были решены, будь то сортировка или поиск по массиву, работа с форматами 2D графики или long-polling сервера на Javascript. Общее правило заключается в том, что стандартные задачи имеют стандартное решение, и это решение дает нам возможность получить нужный результат, написав минимум своего кода.
Порой есть соблазн, вместо того, чтобы что-то искать, пробовать и подгонять, быстренько набросать на коленке свой велосипед. Иногда это может быть оправдано, но если речь идет о поддерживаемом в долгосрочной перспективе коде, минутная “экономия” может обернуться часами отладки и исправления ошибок на пропущенных корнер-кейсах.
С другой стороны, лишь слегка затрагивая достаточно обширную тему, хотелось бы сказать, что иногда “велосипедная” реализация может или даже должна быть предпочтена использованию готового решения. Обычно это верно в случае, когда доверие к качеству готового решения не выше, чем к собственному коду, либо в случае, когда издержки от внедрения новой внешней зависимости оказываются технически неприемлемы.
Тем не менее, возвращаясь к вопросу о краткости кода, безусловно, использование стандартных (например, apache-commons и guava для Java) и нестандартных библиотек является одним из наиболее действенных способов уменьшить размеры собственного кода.
5.4. Техника 4. Оставляем в коде только то, что действительно используется.
“Висящие” функции, которые никем нигде не вызываются; участки кода, которые никогда не выполняются; целые классы, которые нигде не используются, но их забыли удалить — уверен, каждый мог наблюдать такие вещи в своем проекте, и может быть, даже воспринимал их, как должное.
На деле же, любой код, в том числе неиспользуемый, требует плату за свое содержание в виде потраченного внимания и времени.
Поскольку неиспользуемый код реально не выполняется и не тестируется, в нем могут содержатся некорректные вызовы тех или иных процедур, ненужные или неправильные проверки, обращения к процедурам и внешним библиотекам, которые больше ни для чего не нужны, и множество других сбивающих с толку или просто вредных вещей.
Таким образом, удаляя ненужные и неиспользуемые участки, мы не только уменьшаем размеры кода, но и, что не менее важно, способствуем его самодокументированности.
5.5. Техника 5. Используем свои знания о языке и полагаемся на наличие этих знаний у читателя.
Одним из эффективных способов сделать свой код проще, короче и понятней является умелое использование особенностей конкретного языка: различных умолчаний, приоритетов операций, кратких форм записи и т.д.
В качестве иллюстрации приведу наиболее, с моей точки зрения, яркий пример для языка Javascript.
Очень часто при разборе строковых выражений можно увидеть такие нагромождения:
if (obj != null && obj != undefined && obj.s != null && obj.s != undefined && obj.s != '') {
// do something
}
Выглядит пугающе, в том числе и с точки зрения “а не забыл ли автор еще какую-нибудь проверку”. На самом деле, зная особенность языка Javascript, в большинстве подобных случаев всю проверку можно свести до тривиальной:
if (obj && obj.s) {
// do something
}
Дело в том, что благодаря неявному приведению к boolean, проверка if (obj) {} отсеет:
- false
- null
- undefined
- 0
- пустую строку
В общем, она отсеет большинство тривиальных значений, которые мы можем себе представить. К сожалению, повторюсь, программисты используют эту особенность достаточно редко, из-за чего их “перестраховочные” проверки выглядят весьма громоздко.
Аналогично, сравните следующие формы записи:
if (!a) {
a = defaultValue;
}
и
a = a || defaultValue;
Второй вариант выглядит проще, благодаря использованию специфичной семантики логических операций в скриптовых языках.
6. Самодокументированный код.
Термин “самодокументированность” наиболее часто употребляется при описании свойств таких форматов, как XML или JSON. В этом контексте подразумевается наличие в файле не только набора данных, но и сведений об их структуре, о названиях сущностей и полей, задаваемых этими данными.
Читая XML файл мы, даже ничего не зная о контексте, почти всегда можем составить представление о том, что описывает данный файл, что за данные в нем представлены и даже, возможно, как они будут использованы.
Распространяя эту идею на программный код, под термином “самодокументированность” хотелось бы объединить множество свойств кода, позволяющих быстро, без детального разбора и глубокого вникания в контекст понять, что делает данный код.
Хотелось бы противопоставить такой подход “внешней” документированности, которая может выражаться в наличии комментариев или отдельной документации. Не отрицая необходимости в определенных случаях того и другого, отмечу, что, когда речь идет о читаемости кода, методы самодокументирования оказываются значительно более эффективными.
6.1. Техника 1. Тщательно выбираем названия функций, переменных и классов. Не стоит обманывать людей, которые будут читать наш код.
Самое главное правило, которое следует взять за основу при написании самодокументированного кода — никогда не обманывайте своего читателя.
Если поле называется name, там должно храниться именно название объекта, а не дата его создания, порядковый номер в массиве или имя файла, в который он сериализуется. Если метод называется compare(), он должен именно сравнивать объекты, а не складывать их в хэш таблицу, обращение к которой можно будет найти где-нибудь на 1000 строк ниже по коду. Если класс называется NetworkDevice, то в его публичных методах должны быть операции, применимые к устройству, а не реализация быстрой сортировки в общем виде.
Сложно выразить словами, насколько часто, несмотря на очевидность этого правила, программисты его нарушают. Думаю, не стоит пояснять, каким образом это сказывается на читаемости их кода.
Чтобы избежать таких проблем, необходимо максимально тщательно продумывать название каждой переменной, каждого метода и класса. При этом надо стараться не только корректно, но и, по возможности, максимально полно охарактеризовать назначение каждой конструкции.
Если этого сделать не получается, причиной обычно являются мелкие или грубые ошибки дизайна, поэтому воспринять такое надо минимум как тревожный “звоночек”.
Очевидно, так же стоит минимизировать использование переменных с названиями i, j, k, s. Переменные с такими названиями могут быть только локальными и иметь только самую общепринятую семантику. В случае i, j, это могут счетчики циклов или индексы в массиве. Хотя, по возможности, и от таких счетчиков стоит избавляться в пользу циклов foreach и функциональных выражений.
Переменные же с названиями ii, i1, ijk42, asdsa и т.д, не стоит использовать никогда. Ну разве что, если вы работаете с математическими алгоритмами… Нет, лучше все-таки никогда.
6.2. Техника 2. Стараемся называть одинаковые вещи одинаково, а разные — по-разному.
Одна из самых обескураживающих трудностей, возникающих при чтении кода — это употребляемые в нем синонимы и омонимы. Иногда в ситуации, когда две разных сущности названы одинаково, приходится тратить по несколько часов, чтобы разделить все случаи их использования и понять, какая именно из сущностей подразумевается в каждом конкретном случае. Без такого разделения нормальный анализ, а следовательно и осмысленная модификация кода, невозможны в принципе. А встречаются подобные ситуации намного чаще, чем можно было бы предположить.
Примерно то же самое можно сказать и об “обратной” проблеме — когда для одной и той же сущности/операции/алгоритма используется несколько разных имен. Время на анализ такого кода может возрасти по сравнению с ожидаемым в разы.
Вывод простой: в своих программах к возникновению синонимов и омонимов надо относиться крайне внимательно и всеми силами стараться подобного избегать.
6.3. Техника 3. “Бритва Оккама”. Не создаем сущностей, без которых можно обойтись.
Как уже говорилось в п. 5.4., любой участок кода, любой объект, функция или переменная, которые вы создаете, в дальнейшем, в процессе поддержки, потребует себе платы в виде вашего (или чужого) времени и внимания.
Из этого следует самый прямой вывод: чем меньше сущностей вы введете, тем проще и лучше в итоге окажется ваш код.
Типичный пример “лишней” переменной:
...
int sum = counSum();
int increasedSum = sum + 1;
operate(increasedSum);
...
Очевидно, переменная increasedSum является лишней сущностью, т.к. описание объекта, который она хранит (sum + 1) характеризует данный объект гораздо лучше и точнее, чем название переменной. Таким образом код стоит переписать следующим образом (“заинлайнить” переменную):
...
int sum = counSum();
operate(sum + 1);
...
Если далее по коду сумма нигде не используется, можно пойти и дальше:
...
operate(countSum() + 1);
...
Инлайн ненужных переменных — это один из способов сделать ваш код короче, проще и понятней.
Однако применять его стоит лишь в случае, если этот прием способствует самодокументированности, а не противоречит ей. Например:
double descr = b * b - 4 * a *c;
double x1 = -b + sqrt(descr) / (2 * a);
В этом случае инлайн переменной descr вряд ли пойдет на пользу читаемости, т.к. данная переменная используется для представления определенной сущности из предметной области, а, следовательно, наличие переменной способствует самодокументированности кода, и сама переменная под “бритву Оккама” не попадает.
Обобщая принцип, продемонстрированный на данном примере, можно заключить следующее: желательно в своей программе создавать переменные/функции/объекты, только если они имеют прототипы в предметной области. При этом, в соответствии с п. 6.1, надо стараться, чтобы название этих объектов максимально ясно выражало это соответствие. Если же такого соответствия нет, вполне возможно, что использование переменной/функции/объекта лишь перегружает ваш код, и их удаление пойдет программе только на пользу.
6.4. Техника 4. Всегда стараемся предпочитать явное неявному, а прямое — косвенному.
Общий принцип прост: любые явно выписанные алгоритмы или условия уже являются самодокументированными, т. к. их назначение и принцип действия уже описаны ими же самими. Наоборот, любые косвенные условия и операции с сайд-эффектами сильно затрудняют понимание сути происходящего.
Можно привести грубый пример, подразумевая, что жизнь подкидывает подобные примеры совсем не редко.
Косвенное условие:
if (i == abs(i)) {
}
Прямое условие:
if (i >= 0) {
}
Оценить разницу в читаемости, думаю, несложно.
6.5. Техника 5. Все, что можно спрятать в private (protected), должно быть туда спрятано. Инкапсуляция — наше все.
Говорить о пользе и необходимости следования принципу инкапсуляции при написании программ в данной статье я считаю излишним.
Хотелось бы только подчеркнуть роль инкапсуляции, как механизма самодокументирования кода. В первую очередь, инкапсуляция позволяет четко выделить внешний интерфейс класса и обозначить его “точки входа”, т. е. методы, в которых может быть начато выполнение кода, содержащегося в классе. Это позволяет человеку, изучающему ваш код, сохранить огромное количество времени, сфокусировавшись на функциональном назначении класса и абстрагировавшись от деталей реализации.
6.6. Техника 6. (Обобщение предыдущего) Все объекты объявляем в максимально узкой области видимости.
Принцип максимального ограничения области видимости каждого объекта можно распространить шире, чем привычная нам инкапсуляция из ООП.
Простой пример:
Object someobj = createSomeObj();
if (some_check()) {
// Don't need someobj here
} else {
someobj.call();
}
Очевидно, такое объявление переменной someobj затрудняет понимание ее назначения, т. к. читающий ваш код будет искать обращения к ней в значительно более широкой области, чем она используется и реально нужна.
Нетрудно понять, как сделать этот код чуть-чуть лучше:
if (some_check()) {
// Don't need someobj here
} else {
Object someobj = createSomeObj();
someobj.call();
}
Ну или, если переменная нужна для единственного вызова, можно воспользоваться еще и п. 6.3:
if (some_check()) {
// Don't need someobj here
} else {
createSomeObj().call();
}
Отдельно хотелось бы оговорить случай, когда данная техника может не работать или работать во вред. Это переменные, инициализируемые вне циклов. Например:
Object someobj = createSomeObj();
for (int i = 0; i < 10; i++) {
someobj.call();
}
Если создание объекта через createSomeObj() — дорогая операция, внесение ее в цикл может неприятно сказаться на производительности программы, даже если читаемость от этого и улучшится.
Такие случаи не отменяют общего принципа, а просто служат иллюстрацией того, что каждая техника имеет свою область применения и должна быть использована вдумчиво.
6.7. Техника 7. Четко разделяем статический и динамический контекст. Методы, не зависящие от состояния объекта, должны быть статическими.
Смешение или вообще отсутствие разделения между статическим и динамическим контекстом — не самое страшное, но весьма распространенное зло.
Приводит оно к появлению ненужных зависимостей от состояния объекта в потенциально статических методах, либо вообще к неправильному управлению состоянием объекта. Как следствие — к затруднению анализа кода.
Поэтому необходимо стараться обращать внимание и на данный аспект, явно выделяя методы, не зависящие от состояния объекта.
6.8. Техника 8. Стараемся не разделять объявление и инициализацию объекта.
Данный прием позволяет совместить декларацию имени объекта с немедленным описанием того, что объект из себя представляет. Именно это и является ярким примером следования принципу самодокументированности.
Если данной техникой пренебречь, читателю придется для каждого объекта искать по коду, где он был объявлен, нет ли у него где-нибудь инициализации другим значением и т.д. Все это затрудняет анализ кода и увеличивает время, необходимое для того, чтобы в коде разобраться.
Именно поэтому, например, функциональные операции из apache CollectionUtils и guava Collections2 часто предпочтительней встроенных в Java foreach циклов — они позволяют совместить объявление и инициализацию коллекции.
Сравним:
// getting “somestrings” collection somehow
...
Collection<String> lowercaseStrings = new ArrayList<String>();
/* collection is uninitialized here, need to investigate the initializion */
for (String s : somestrings) {
lowercaseStrings.add(StringUtils.lowerCase(s));
}
c:
// getting “somestrings” collection somehow
...
Collection<String> lowercaseStrings = Collections2.transform(somestrings, new Function<String, String>() {
@Override
public String apply(String s) {
return StringUtils.lowerCase(s);
}
}));
Если мы используем Java 8, можно записать чуть короче:
...
Collection<String> lowercaseStrings = somestrings.stream()
.map( StringUtils::lowerCase ).collect(Collectors.toList());
Ну и стоит упомянуть случай, когда разделять объявление и инициализацию переменных так или иначе приходится. Это случай использования переменной в блоках finally и catch (например, для освобождения какого-нибудь ресурса). Тут уже ничего не остается, кроме как объявить переменную перед try, а инициализировать внутри блока try.
6.9. Техника 9. Используем декларативный подход и средства функционального программирования для обозначения, а не сокрытия сути происходящего.
Данный принцип может быть проиллюстрирован примером из предыдущего пункта, в котором мы использовали эмуляцию функционального подхода в Java с целью сделать наш код понятнее.
Для большей наглядности рассмотрим еще и пример на Javascript (взято отсюда: http://habrahabr.ru/post/154105).
Сравним:
var str = "mentioned by";
for(var i =0; l= tweeps.length; i < l; ++i){
str += tweeps[i].name;
if(i< tweeps.length-1) {str += ", "}
}
c:
var str = "mentioned by " + tweeps.map(function(t){
return t.name;
}).join(", ");
Ну а примеры использования функционального подхода, убивающие читаемость… Давайте на этот раз сэкономим свои нервы и обойдемся без них.
6.10. Техника 10. Пишем комментарии только, если без них вообще не понятно, что происходит.
Как уже говорилось выше, принцип самодокументирования кода противопоставляется документированию с помощью комментариев. Хотелось бы коротко пояснить, чем же так плохи комментарии:
- В хорошо написанном коде они не нужны.
- Если поддержка кода часто становится трудоемкой задачей, поддержкой комментариев обычно просто никто не занимается и через некоторое время комментарии устаревают и начинают обманывать людей (“comments lie”).
- Они засоряют собой пространство, тем самым ухудшая внешний вид кода и затрудняя читаемость.
- В подавляющем большинстве случаев они пишутся лично Капитаном Очевидностью.
Ну а нужны комментарии в случаях, когда написать код хорошо по тем или иным причинам не представляется возможным. Т.е. писать их надо для пояснения участков кода, без них трудночитаемых. К сожалению, в реальной жизни такое встречается регулярно, хотя расценивать это следует лишь как неизбежный компромисс.
Также как разновидность подобного компромисса следует расценивать необходимость спецификации контракта метода/класса/процедуры при помощи комментариев, если его не получается явно выразить другими языковыми средствами (см п. 5.2).
7. Философское заключение.
Закончив изложение основных техник и приемов, с помощью которых можно сделать код чуть красивее, следует еще раз явно сформулировать: ни одна из техник не является безусловным руководством к действию. Любая техника — лишь возможное средство достижения той или иной цели.
В нашем случае целью является получение максимально читаемого и управляемого кода. Который одновременно будет приятен с эстетической точки зрения.
Изучая примеры, приведенные в текущей статье, можно легко заметить, что, как сами исходные принципы (линейность, минимальность, самодокументированность), так и конкретные техники не являются независимыми друг от друга. Применяя одну технику мы можем также косвенно следовать и совсем другой. Улучшая один из целевых показателей, мы можем способствовать улучшению других.
Однако, у данного явления есть и обратная сторона: нередки ситуации, когда принципы вступают в прямое противоречие друг с другом, а также со множеством других возможных правил и догм программирования (например с принципами ООП). Воспринимать это надо совершенно спокойно.
Встречаются и такие случаи, когда однозначно хорошего решения той или иной проблемы вообще не существует, или это решение по ряду причин нереализуемо (например, заказчик не хочет принимать потенциально опасные изменения в коде, даже если они способствуют общему улучшению качества).
В программировании, как и в большинстве других областей человеческой деятельности, не может существовать универсальных инструкций к исполнению. Каждая ситуация требует отдельного рассмотрения и анализа, а решение должно приниматься исходя из понимания особенностей ситуации.
В целом, этот факт нисколько не отменяет полезности как вывода и понимания общих принципов, так и владения конкретными способами их воплощения в жизнь. Именно поэтому я надеюсь, что все изложенное в статье может оказаться действительно полезно для многих программистов.
Ну и еще пара слов о том, с чего мы начинали — о красоте нашего кода. Даже зная о “продвинутых” техниках написания красивого кода, не стоит пренебрегать самыми простыми вещами, такими, как элементарное автоформатирование и следование установленному в проекте стилю кодирования. Зачастую одно лишь форматирование способно сотворить с уродливым куском кода настоящие чудеса. Как и разумное группирование участков кода с помощью пустых строк и переносов.
Не стоит забывать и о таком средстве, как статические анализаторы кода, которые позволяют выявить множество проблем (в том числе, описанных в данной статье) автоматически, благо сейчас они встроены в большинство популярных IDE.
И самое последнее. Всегда стоит помнить о субъективности эстетического восприятия вещей. Поэтому уделяя внимание этому вопросу, следует с пониманием относиться к чужим вкусам и привычкам.
Приятного вам программирования!
Программисты в первую очередь работают с языком. Поэтому написание программ похоже на любой другой вид письменной работы. Сначала вы излагаете свои мысли как есть, а затем «причесываете» до тех пор, пока текст не будет легко читаться. Качество кода – результат проявления небезразличного отношения к делу и показатель профессионализма.
Почему важна читаемость кода
Чтение кода происходит чаще, чем написание. Есть большая разница между обучением программированию и реальной работой в компании. Вначале мы и пишем, и читаем собственные программы. Но чем дальше мы продвигаемся, тем чаще нам приходится не писать, а читать код. Чем легче код читается, тем проще с ним работать другим людям.
Пишите код так, как будто сопровождать его будет склонный к насилию психопат, который знает, где вы живете
Чем проще читать код, тем проще его сопровождать. Понятный, читаемый код легче тестировать, в нем легче отлавливать ошибки – они не скрываются в его запутанной структуре. Плохо оформленный код неприятно изучать, читать, тестировать, сложно дополнять. Рано или поздно плохой код становится проще переписать.
Эстетическое восприятие кода влияет на удобство работы. Казалось бы, гораздо важнее производительность, возможность модификации, расширения… Но все эти показатели улучшаются, если код соответствует нашему чувству прекрасного. Глядя на качественно написанный код, можно быстро понять алгоритм и то, как работает программа для разных входных данных. Чистый код читается, как хорошо написанная проза: слова превращаются в зрительные образы.
Стиль кода определяет его будущее. Стиль и дисциплина продолжают жить в коде, даже если в нем не осталось ни одной исходной строки.
С чего начать: документация по стилю оформления кода
Все дороги программиста ведут к документации. В каждом языке существует свой стандарт оформления кода. Для Python используется документ PEP-8, для PHP – стандартные рекомендации PSR-1 и PSR-2, для Java – Java Coding Conventions, для JavaScript – Airbnb JavaScript Style Guide или Google JavaScript Style Guide. Документ для вашего языка вы найдете по поисковому запросу <Название языка> Code Style.
Когда вы работаете в группе разработчиков, нужно использовать принятые в команде правила. Стиль должен быть единым, как будто код был написан одним здравомысленным человеком.
В популярных IDE заложена возможность автоматической настройки стиля кода под стандарты – общие или предложенные командой. Разберитесь, как настроить среду под необходимое оформление. Потраченное время сэкономит многие часы рутинной работы.
Применение стандартов – лучший подход для новичка. Читающий не будет отвлекаться на оформление и сразу погрузится в тонкости выбранных подходов, а не расстановок переносов. Изложенные ниже правила понадобятся для того, чтобы понять, как действовать в тех случаях, когда стандарт не дает никаких рекомендаций.
Роберт Мартин «Чистый код. Создание, анализ и рефакторинг»
Как Библиотека программиста, мы не могли обойтись без упоминания замечательной книги Роберта Мартина о чистом коде и анализе программ. В книге приводятся примеры для языка Java, но большинство идей справедливы для любых языков.
Книга в сообществе Книги для программистов
Книга на Ozon
Всё что изложено ниже, в значительной мере представляет сжатый конспект этой книги с дополнениями из нашего опыта в проектировании программ. Итак, приступим к практикам.
Главное правило чистого кода: выразительные имена
Содержательность. К выбору названий любых объектов нужно подходить со всей ответственностью. Выразительные имена позволяют писать код, не требующий комментариев.
Полезно не только исходно выбирать ясные имена, но и заменять названия на более удачные, если они нашлись позже. Современные среды программирования позволяют легко заменить название переменной во всём коде, так что это не должно быть проблемой.
Сравните. До:
public List < int[] > getThem() {
List < int[] > list1 = new ArrayList < int[] > ();
for (int[] x: theList)
if (x[0] == 4)
list1.add(x);
return list1;
}
После:
public List < int[] > getFlaggedCells() {
List < int[] > flaggedCells = new ArrayList < int[] > ();
for (int[] cell: gameBoard)
if (cell[STATUS_VALUE] == FLAGGED)
flaggedCells.add(cell);
return flaggedCells;
}
В первом примере непонятно, что вообще происходит, хотя в этом коде нет ни сложных выражений, ни каких-либо странностей. В результате правок сам код никак не изменился. Если знать, что это часть игры «Сапер», то теперь из кода понятно: здесь обрабатывается список ячеек игрового поля. Этот код можно улучшать и далее, но уже в результате простого переименования переменных стало понятно, что происходит.
Избегайте любых двусмысленностей и ложных ассоциаций. Если в объекте перечисляется список, но сам объект не является списком, нельзя в составе его названия употреблять слово list – это запутывает читающего.
Остерегайтесь малозаметных различий – имена объектов должны существенно отличаться друг от друга. По этой причине плохи длинные имена с повторяющимся элементами – чтобы сличить их друг с другом, тратятся лишние силы и время. Избегайте использования в именах переменных строчной буквы L и прописных I, O – они часто путаются с единицей и нулем.
Путаница также возникает, если несколько синонимичных слов и выражений используются для обозначениях разных сущностей, например, controller, manager и driver.
Имя должно легко произноситься. Используйте для названий слова. Если названия состоят из сокращений, каждый начинает произносить их по-своему, что затрудняет взаимопонимание. А при чтении кода каждый раз «спотыкаешься» о такое название.
Имя должно быть удобным для поиска. Слишком короткие имена трудно искать в большом объеме текста. Однобуквенные имена можно использовать только для локальных переменных в коротких методах и для счетчиков циклов (i, j, k). Обычно называя объект одной буквой, вы всего лишь создаете временный заменитель. Но не бывает ничего более постоянного, чем что-то «временное». Проверяйте грамотность написания выбранных слов.
Правильно выбирайте часть речи. Классы и объекты желательно называть существительными и их комбинациями: Account, WikiPage, HTMLParser. Имена функций и методов лучше представлять глаголами или глагольными словосочетаниями: delete_page, writeField(name). Для методов чтения/записи и предикатов используйте стандартные префиксы get, set, is.
Заменяйте «магические» числа именованными константами. Одно из самых древних правил разработки. Магическими называют числа, о которых сходу нельзя сказать, что они означают. Например: 100, 1.1, 42, 1000000. Выделяйте такие числа в соответствующие константы с конкретным названиями. Например, вместо числа 86400 в теле кода приятнее встретить константу SECONDS_PER_DAY.
Не стоит следовать этому правилу, как и любому другому, безоговорочно. В формулах некоторые константы лучше воспринимаются в числовой записи.
Одно слово для каждой концепции. Для одной и той же идеи, реализующей одну механику, используйте одно слово. Например, для добавления элементов одинаковым образом – метод add. Однако, если механика и семантика изменились, потребуется и другое слово (например, insert, append), описывающее новую концепцию.
Ваш код будут читать программисты. Не стесняйтесь использовать термины из области информатики, общепринятые названия алгоритмов и паттернов. Такие имена сообщают информацию быстрее, чем сам код.
Помещайте имена в соответствующий контекст. Например, имена street, house_number, city понятнее смотрятся внутри класса Address.
Избегайте остроумия и каламбуров в названиях. Шутки имеют свойство быть понятными лишь ограниченное время и для конкретной аудитории, знакомой с первоисточником. Отдавайте предпочтение ясности перед развлекательностью. Шутки можно приберечь для презентации, которая происходит «здесь и сейчас». Хороший код способен выйти далеко за границы вашей культуры.
Среды разработки продолжают развиваться. Уже нет никакой необходимости кодировать типы в именах, создавать префиксы для членов классов. Всю нужную информацию можно получить из цветового выделения или контекстно-зависимых подсказок сред разработки. Добавление префиксов убивает удобство поиска по автодополнению – выпадает слишком много имен, начинающихся с одинаковых символов.
Функции
Компактность. Уже в 80-е годы считалось, что функция должна занимать не более одного экрана. Экраны VT100 состояли из 24 строк и 80 столбцов. В наши дни на экране можно разместить гораздо больше инфорфмации, но лучше ограничиться тем же объемом. Самоограничение позволяет видеть точку объявления каждой используемой переменной и держать в уме всю «историю», которую рассказывает функция.
Вполне вероятно, что тот, кто будет сопровождать ваш код, не будет иметь возможности работать на большом мониторе. Например, ему необходимо одновременно разместить на одном рабочем столе экрана ноутбука несколько окон. Среды разработки позволяют установить ограничение, «верхнюю планку» (то есть правую 😉 ).
Блоки if, else, while должны иметь минимальный размер, чтобы информацию о них можно было держать в уме. Старайтесь избегать отрицательных условий – на их восприятие обычно уходит чуть больше времени, чем на положительные. То есть запись if (buffer.shouldCompact()) предпочтительнее записи if (!buffer.shouldNotCompact().
Правило одной операции. Плохой код пытается сделать слишком много всего, намерения программиста расплываются для читателя. Поэтому стоит ввести важное правило:
Функция должна выполнять только одну операцию, выполнять ее хорошо, и ничего другого она делать не должна.
Каждая функция должна делать то, что вы от нее ожидали из названия. Если функция действует не так, как она названа, читатель кода перестает доверять автору программы, ему приходится самостоятельно разбираться во всех подробностях реализации.
Я люблю, чтобы мой код был элегантным и эффективным. Логика должны быть достаточно прямолинейной, чтобы ошибкам было трудно спрятаться; зависимости — минимальными, чтобы упростить сопровождение; обработка ошибок — полной в соответствии с выработанной стратегией; а производительность — близкой к оптимальной, чтобы не искушать людей загрязнять код беспринципными оптимизациями. Чистый код хорошо решает одну задачу.
Исключения вместо кодов ошибок. Используйте исключения (try-catch, try-except) вместо возвращения кодов ошибок. Возвращение кодов приводит к слишком глубокой вложенности.
К тому же при использовании исключений код обработки ошибок изолируются от ветви нормального выполнения. Сами блоки лучше выделять в отдельные функции. Вместе с исключением нужно передавать контекст ошибки – сообщение, содержащее сведения об операции и типе сбоя.
Соблюдайте уровни абстракции. Одна функция – один уровень абстракции. Смешение уровней абстракции создает путаницу, функция обрастает слишком большим количеством второстепенных подробностей. Старайтесь соблюдать ясную иерархию.
Код читается сверху вниз. По мере чтения уровни абстракции должны меняться равномерно. Каждая функция должна быть окружена функциями единого уровня абстракции.
Ограничивайте число аргументов. Чем больше аргументов у функции, тем сложнее с ней работать. Необходимость функций с количеством аргументов большим двух должна быть подкреплена очень вескими доводами. Каждый новый аргумент критически усложняет процедуру тестирования. Если функция должна получать более двух аргументов, скорее всего, эти аргументы образуют концепцию, заслуживающую собственного имени.
Комментарии
Это непопулярное мнение, но в большинстве случаев комментарии – зло. Код должен быть самодокументированным. Комментарий – всегда признак неудачи: мы не смогли написать код так, что он понятен без комментариев. Проверьте, можно ли выразить свое намерение в самом коде.
В чём проблема? Программисты умеют сопровождать код, но не комментарии. В растущем коде комментарии быстро устаревают, частично или полностью переставая соответствовать ситуации. Только код правдиво сообщает своим содержанием, что он в действительности делает. Лучше потратить время на исправление запутанного кода, чем добавлять к плохому коду комментарии.
Однако есть несколько видов комментариев, которые выглядят достаточно оправданными.
TODO-комментарии. Бывает так: нужно было успеть к дедлайну, пришлось писать код быстро, поэтому в нем остались дыры. То есть всё работает, но реализация ущербная. Укажите все недоработки и создайте под них задачи. Каждый комментарий указывает на недоработку или потенциальную уязвимость.
Юридические комментарии. Корпоративные стандарты могут принуждать вставлять комментарии по юридическим соображениям. Ограничьтесь в таком комментарии описанием лицензии и ссылкой на внешний документ.
Предупреждения о последствиях. Иногда бывает полезно предупредить других программистов о нежелательных последствиях:
// Не запускайте, если только не располагаете
// излишками свободного времени.
Комментарий также может подчеркивать важность обстоятельства, которое на первый взгляд кажется несущественным.
По-настоящему плохие комментарии
Бывают такие типы комментариев, которые лучше никогда не делать.
Закомментированный программный код. «Когда-нибудь в будущем раскомментирую этот код, приведу всё в порядок. Или вдруг эта идея кому-то поможет». Любой закомментированный код только ухудшает ситуацию. Все изменения хранятся в контроле версий – удаляйте такой код на корню. Это просто мусор: «потом» равносильно «никогда». Если что-то действительно нужно сделать, создайте краткий TODO-комментарий и задачу.
Мертвые функции – идентичные по смыслу предыдущему пункту функции и методы, которые не вызываются в программе. Пользуйтесь системой контроля версий и без зазрений совести удаляйте любой код, который не используется во время выполнения программы.
Избыточные комментарии. Задайте себе вопрос: стал ли код понятнее после прочтения комментария? Часто комментарии просто загромождают код и скрывают его смысл, излагая очевидные вещи. Иногда в комментарии включаются описания не относящихся к делу подробностей. Но профессионал бережет не только свое, но и чужое время, и не отвлекает читающего без повода.
Журнальные комментарии и ссылки на авторов. Некоторые программисты добавляют комментарий в начало файла при редактировании. Или указывают, кто и когда внес исправления. Когда-то это было оправдано, но теперь у нас есть системы контроля версий – это гораздо лучший способ обозначить границы зоны ответственности каждого.
Позиционные маркеры. Иногда любят отмечать определенные группы и позиции в исходных файлах:
// Классы //////////////////////////////////
Качественно организованный код способен внятно рассказать историю без балластных заголовков.
Уровень файлов программ
Минималистичность. Чем меньше кода, тем лучше. Имя файла должно быть простым, но содержательным. Маленькие файлы обычно более понятны, чем большие. Но размер файла, конечно, не должен быть самоцелью.
Код должен быть максимально линейным. Чем больше вложенность кода, тем сложнее его читать. Следите за тем, как двигаются ваши глаза. В хорошем коде вы двигаетесь строка за строкой, лишь изредка возвращаясь к предыдущим строчкам. Вложенность более трех уровней указывает на то, что с кодом нужно поработать: переписать условия проверок и циклов (использовать return и функциональное программирование), разбить код на меньшие методы.
Отдельные «мысли» следует отделять друг от друга пустыми строками. Каждая пустая строка – зрительная подсказка: описание одной концепции закончилось, далее следует новая. При просмотре кода взгляд концентрируется на первых строчках – в них больше всего информации, как в началах абзацев этого текста.
Тесно связанные концепции, должны располагаться вблизи друг друга. Не заставляйте читателя прыгать между файлами или постоянно скроллить файл. По той же причине переменные нужно объявлять как можно ближе к месту использования. Однако переменные экземпляров лучше объявлять в одном месте, обычно в начале класса, так как в хорошо спроектированном классе переменные используются большинством методов класса.
Пробелы для группировки взаимосвязанных элементов. Пробелы улучшают читаемость кода, если они стоят вокруг операторов присваивания, после запятых при перечислении переменных. В формулах пробелы используются для подчеркивания приоритета: не ставятся между множителями, но отбивают знаки сложения и вычитания.
Отступы. Размер отступов должен соответствовать позиции кода в иерархии. Это общая практика, которая позволяет быстро пропускать области видимости, не относящиеся к текущей ситуации. Не поддавайтесь искушению нарушить правила расстановки отступов для коротких команд.
Некоторые замечания по поводу архитектуры и тестов
В системе должны выполняться все тесты. Тесты – главный способ, с помощью которого можно понять, что система контролируема. А только контролируемую систему можно проверить.
Три закона тестирования по методологии TDD. Тестовый код не менее важен, чем код продукта. Соблюдение следующих трех правил позволяет организовать работу так, чтобы тесты охватывали все аспекты кода продукта:
- Не пишете код продукта, пока не напишете отказной модульный тест.
- Не пишите модульный тест в объеме большем, чем необходимо для отказа.
- Не пишите код продукта в объеме большем, чем необходимо для прохождения текущего отказного теста.
F.I.R.S.T. Качественные тесты должны обладать пятью характеристиками, первые буквы которых образуют указанный акроним:
- Fast. Тесты должны выполняться быстро.
- Independent. Тесты не должны зависеть друг от друга и выполняться в любом порядке.
- Repeatable. Тесты должны давать воспроизводимые в любой среде результаты.
- Self-validating. Результат выполнения теста – логический признак: тест пройден или нет. Иначе результаты приобретают субъективный характер.
- Timely. Тест должен создаваться своевременно. Тесты нужно писать непосредственно перед написанием кода.
Повышение уровня абстракции и устранение дубликатов. Все программы состоят из очень похожих элементов, а все задачи программирования сводятся к работе с ограниченным набором действий. Многие из этих действий могут быть описаны в одних и тех же терминах, например, извлечение элемента из коллекции. В подобных ситуациях правильно инкапсулировать реализацию в более абстрактном классе. Повышение уровня абстракции позволяет избежать дублирования и многократно применения одного и того же кода, лучше понять, что действительно происходит в программе, уйдя от частностей.
Если что-то в программе делается снова и снова, значит, какая-то важная концепция не нашла своего отражения в коде. Нужно попытаться понять, что это такое, и выразить идею в виде кода. Избегайте дубликатов, это всегда лишняя работа, лишний риск, лишняя сложность.
Несколько языков в одном исходном файле. Современные среды программирования позволяют объединять в одном файле код, написанный на разных языках. Результат получается запутанным, неаккуратным и ненадежным. Чтобы четко разграничить ответственность, в файле должен преобладать один язык. Сведите к минимуму количество и объем кода на дополнительных языках.
Не нужно бездумно следовать догмам. Не переусердствуйте с сокращением кода функций и классов. Всегда руководствуйтесь здравым смыслом.
Заключение
Чистый код выглядит так, как если его автор над ним тщательно потрудился. Вы не можете найти очевидных возможностей для его улучшения. Попытавшись его улучшить, вы вновь вернетесь к тому же коду.
Чтобы писать чистый код, который бы никого не удивлял, необходимо раз за разом сознательно применять описанные приемы. При чтении чистого кода вы улыбаетесь, как при виде искусно сделанной музыкальной шкатулки. Код можно назвать красивым, если у вас создается впечатление, что язык был создан специально для этой задачи.
Расскажите нам о правилах, которые вы применяете для написания своего программного кода. Какие open source программы, на ваш взгляд, имеют лучшее качество кода?
Есть мириады способов написать плохой код. К счастью, чтобы подняться до уровня качественного кода, достаточно следовать 15 правилам. Их соблюдение не сделает из вас мастера, но позволит убедительно имитировать его.
Правило 1. Следуйте стандартам оформления кода.
У каждого языка программирования есть свой стандарт оформления кода, который говорит, как надо делать отступы, где ставить пробелы и скобки, как называть объекты, как комментировать код и т.д.
Например, в этом куске кода в соответствии со стандартом есть 12 ошибок:
for(i=0 ;i
Изучайте стандарт внимательно, учите основы наизусть, следуйте правилам как заповедям, и ваши программы станут лучше, чем большинство, написанные выпускниками вузов.
Многие организации подстраивают стандарты под свои специфические нужды. Например, Google разработал стандарты для более чем 12 языков программирования. Они хорошо продуманы, так что изучите их, если вам нужна помощь в программировании под Google. Стандарты даже включают в себя настройки редактора, которые помогут вам соблюдать стиль, и специальные инструменты, верифицирующие ваш код на соответствию этому стилю. Используйте их.
Правило 2. Давайте наглядные имена.
Ограниченные медленными, неуклюжими телетайпами, программисты в древности использовали контракты для имён переменных и процедур, чтобы сэкономить время, стуки по клавишам, чернила и бумагу. Эта культура присутствует в некоторых сообществах ради сохранения обратной совместимости. Возьмите, например, ломающую язык функцию C wcscspn (wide character string complement span). Но такой подход неприменим в современном коде.
Используйте длинные наглядные имена наподобие complementSpanLength, чтобы помочь себе и коллегам понять свой код в будущем. Исключения составляют несколько важных переменных, используемых в теле метода, наподобие итераторов циклов, параметров, временных значений или результатов исполнения.
Гораздо важнее, чтобы вы долго и хорошо думали перед тем, как что-то назвать. Является ли имя точным? Имели ли вы в виду highestPrice или bestPrice? Достаточно ли специфично имя, дабы избежать его использования в других контекстах для схожих по смыслу объектов? Не лучше ли назвать метод getBestPrice заместо getBest? Подходит ли оно лучше других схожих имён? Если у вас есть метод ReadEventLog, вам не стоит называть другой NetErrorLogRead. Если вы называете функцию, описывает ли её название возвращаемое значение?
В заключение, несколько простых правил именования. Имена классов и типов должны быть существительными. Название метода должно содержать глагол. Если метод определяет, является ли какая-то информация об объекте истинной или ложной, его имя должно начинаться с «is». Методы, которые возвращают свойства объектов, должны начинаться с «get», а устанавливающие значения свойств — «set».
Правило 3. Комментируйте и документируйте.
Начинайте каждый метод и процедуру с описания в комментарии того, что данный метод или процедура делает, параметров, возвращаемого значения и возможных ошибок и исключений. Опишите в комментариях роль каждого файла и класса, содержимое каждого поля класса и основные шаги сложного кода. Пишите комментарии по мере разработки кода. Если вы полагаете, что напишете их потом, то обманываете самого себя.
Вдобавок, убедитесь, что для вашего приложения или библиотеки есть руководство, объясняющее, что ваш код делает, определяющий его зависимости и предоставляющий инструкции для сборки, тестирования, установки и использования. Документ должен быть коротким и удобным; просто README-файла часто достаточно.
Правило 4. Не повторяйтесь.
Никогда не копируйте и не вставляйте код. Вместо этого выделите общую часть в метод или класс (или макрос, если нужно), и используйте его с соответствующими параметрами. Избегайте использования похожих данных и кусков кода. Также используйте следующие техники:
- Создание справочников API из комментариев, используя Javadoc и Doxygen.
- Автоматическая генерация Unit-тестов на основе аннотаций или соглашений об именовании.
- Генерация PDF и HTML из одного размеченного источника.
- Получение структуры классов из базы данных (или наоборот).
Правило 5. Проверяйте на ошибки и реагируйте на них.
Методы могут возвращать признаки ошибки или генерировать исключения. Обрабатывайте их. Не полагайтесь на то, что диск никогда не заполнится, ваш конфигурационный файл всегда будет на месте, ваше приложение будет запущено со всеми нужными правами, запросы на выделение памяти всегда будут успешно исполнены, или что соединение никогда не оборвётся. Да, хорошую обработку ошибок тяжело написать, и она делает код длиннее и труднее для чтения. Но игнорирование ошибок просто заметает проблему под ковёр, где ничего не подозревающий пользователь однажды её обнаружит.
Правило 6. Разделяйте код на короткие, обособленные части.
Каждый метод, функция или блок кода должн умещаться в обычном экранном окне (25-50 строк). Если получилось длиннее, разделите на более короткие куски. Даже внутри метода разделяйте длинный код на блоки, суть которых вы можете описать в комментарии в начале каждого блока.
Более того, каждый класс, модуль, файл или процесс должен выполнять определённый род задач. Если часть кода выполняет совершенно разнородные задачи, то разделите его соответственно.
Правило 7. Используйте API фреймворков и сторонние библиотеки.
Изучите, какие функции доступны с помощью API вашего фреймворка. а также что могут делать развитые сторонние библиотеки. Если библиотеки поддерживаются вашим системным менеджером пакетов, то они скорее всего окажутся хорошим выбором. Используйте код, удерживающий от желания изобретать колесо (при том бесполезной квадратной формы).
Правило 8. Не переусердствуйте с проектированием.
Проектируйте только то, что актуально сейчас. Ваш код можно делать довольно обобщённым, чтобы он поддерживал дальнейшее развитие, но только в том случае, если он не становится от этого слишком сложным. Не создавайте параметризованные классы, фабрики, глубокие иерархии и скрытые интерфейсы для решения проблем, которых даже не существует — вы не можете угадать, что случится завтра. С другой стороны, когда структура кода не подходит под задачу, не стесняйтесь рефакторить его.
Правило 9. Будьте последовательны.
Делайте одинаковые вещи одинаковым образом. Если вы разрабатываете метод, функциональность которого похожа на функциональность уже существующего, то используйте похожее имя, похожий порядок параметров и схожую структура тела. То же самое относится и к классам. Создавайте похожие поля и методы, делайте им похожие интерфейсы, и сопоставляйте новые имена уже существующим в похожих классах.
Ваш код должен соответствовать соглашениям вашего фреймворка. Например, хорошей практикой является делать диапазоны полуоткрытыми: закрытыми (включающими) слева (в начале диапазона) и открытыми (исключающими) справа (в конце). Если для конкретного случая нет соглашений, то сделайте выбор и фанатично придерживайтесь его.
Правило 10. Избегайте проблем с безопасностью.
Современный код редко работает изолированно. У него есть неизбежный риск стать мишенью атак. Они необязательно должны приходить из интернета; атака может происходить через входные данные вашего приложения. В зависимости от вашего языка программирования и предметной области, вам возможно стоит побеспокоиться о переполнении буфера, кросс-сайтовых сценариях, SQL-инъекциях и прочих подобных проблемах. Изучите эти проблемы, и избегайте их в коде. Это не сложно.
Правило 11. Используйте эффективные структуры данных и алгоритмы.
Простой код часто легче сопровождать, чем такой же, но изменённый ради эффективности. К счастью, вы можете совмещать сопровождаемость и эффективность, используя структуры данных и алгоритмы, которые даёт ваш фреймворк. Используйте map, set, vector и алгоритмы, которые работают с ними. Благодаря этому ваш код станет чище, быстрее, более масштабируемым и более экономным с памятью. Например, если вы сохраните тысячу значений в отсортированном множестве, то операция пересечения найдёт общие элементы с другим множеством за такое же число операций, а не за миллион сравнений.
Правило 12. Используйте Unit-тесты.
Сложность современного ПО делает его установку дороже, а тестирование труднее. Продуктивным подходом будет сопровождение каждого куска кода тестами, которые проверяют корректность его работы. Этот подход упрощает отладку, т.к. он позволяет обнаружить ошибки раньше. Unit-тестирование необходимо, когда вы программируете на языках с динамической типизацией, как Python и JavaScript, потому что они отлавливают любые ошибки только на этапе исполнения, в то время как языки со статической типизацией наподобие Java, C# и C++ могут поймать часть из них во время компиляции. Unit-тестирование также позволяет рефакторить код уверенно. Вы можете использовать XUnit для упрощения написания тестов и автоматизации их запуска.
Правило 13. Сохраняйте код портируемым.
Если у вас нет особой причины, не используйте функциональность, доступную только на определённой платформе. Не полагайтесь на то, что определённые типы данных (как integer, указатели и временные метки) будут иметь конкретную длину (например, 32 бита), потому что этот параметр отличается на разных платформах. Храните сообщения программы отдельно от кода и на зашивайте параметры, соответствующие определённой культуре (например, разделители дробной и целой части или формат даты). Соглашения нужны для того, чтобы код мог запускаться в разных странах, так что сделайте локализацию настолько безболезненной, насколько это возможно.
Правило 14. Делайте свой код собираемым.
Простая команда должна собирать ваш код в форму, готовую к распространению. Команда должна позволять вам быстро выполнять сборку и запускать необходимые тесты. Для достижения этой цели используйте средства автоматической сборки наподобие Make, Apache Maven, или Ant. В идеале, вы должны установить интеграционную систему, которая будет проверять, собирать и тестировать ваш код при любом изменении.
Правило 15. Размещайте всё в системе контроля версий.
Все ваши элементы — код, документация, исходники инструментов, сборочные скрипты, тестовые данные — должны быть в системе контроля версий. Git и GitHub делают эту задачу дешёвой и беспроблемной. Но вам также доступны и многие другие мощные инструменты и сервисы. Вы должны быть способны собрать и протестировать вашу программу на сконфигурированной системе, просто скачав её с репозитория.
Заключение.
Сделав эти 15 правил частью вашей ежедневной практики, вы в конце концов создадите код, который легче читать, который хорошо протестирован, с большей вероятностью запустится корректно и который будет гораздо проще изменить, когда придёт время. Вы также убережёте себя и ваших пользователей от большого числа головных болей.
Перевод статьи «15 Rules for Writing Quality Code»
#статьи
- 7 сен 2021
-

0
Они взорвали мой мозг, и я мгновенно стал программировать лучше.
zaidi razak / Shutterstock

Фулстек-разработчик. Любимый стек: Java + Angular, но в хорошей компании готова писать хоть на языке Ада.

об авторе
Разработчик ПО. Увлечён искусственным интеллектом и компьютерным зрением.
Вы слышали про объектную гимнастику (Object Calisthenics)? Если нет, то вам точно стоит её освоить! Тем более что это всего-то девять правил.
Я рассказывал о них многим разработчикам, и все они реагировали схоже. Сначала думали, что это шутка: «Как вообще можно хоть какой-то код написать по этим правилам?» Но, поприменяв их, обычно соглашались, что код и правда становится чище — причём почти мгновенно.
Понятие «объектная гимнастика» ввёл Джефф Бэй (Jeff Bay) в своей книге «The ThoughtWorks Anthology» (на русском не издавалась. — Пер.). Так он назвал группу упражнений на объектно-ориентированное программирование.

Применяя объектную гимнастику, можно сделать код:
- читабельнее;
- удобнее:
• для отладки,
• тестирования,
• повторного использования
• и сопровождения.
Считайте это упражнением. Вам нужно научиться выполнять эти правила при кодинге. А вот в повседневном программировании какими-то из них всегда можно пожертвовать — если следовать им слишком сложно или результат того не стоит.
Итак, выберите себе кодерскую задачку, начните её решать и постарайтесь строго следовать этим принципам. Даже если некоторые из них поначалу кажутся глупыми, просто продолжайте.
То есть одно значение отступа на весь метод. Так его легче будет читать.
Вам придётся извлечь и вынести в отдельные методы некоторые фрагменты кода — например, условия и циклы. Этим новым методам нужно будет дать говорящие имена и вызвать их из исходного метода.

Изображение: Джордж Студенко
- выполняется принцип единственной ответственности (SRP);
- имена становятся понятнее,
- методы — короче,
- и их удобнее использовать повторно.
Вложенные условия усложняют код, делают его нелинейным.
Мы решили слегка отойти от оригинальной статьи и добавили пояснения к каждому способу. — Пер.
- Использовать значения по умолчанию.
Например, ваша программа работает с объектами-фруктами: яблоками и грушами. По конвейеру движутся коробки с фруктами. Некоторые коробки подписаны, некоторые — нет. Если коробка не подписана, то вы считаете, что в ней лежат яблоки, — ну, так договорились.
В этом случае вы можете написать что-то вроде:
если коробка подписана, считать, что внутри те фрукты, которые указаны на коробке
иначе считать, что там яблоки
А ещё вы можете по умолчанию считать, что в коробке яблоки, и менять это значение, только если встретите надпись «груши».
- Практиковать ранний возврат из метода.
Этот способ подойдёт для тривиального случая.
Вместо:
если условие1 выполняй действие1
иначе выполняй действие2
можно написать:
если условие1 выполняй действие1 и вернись
а ниже внутри того же метода расположить обработку второго условия — ведь исполнение дойдёт до него, только если не сработает условие1.
- Выносить ветвления кода в отдельные методы.
В этом случае методы будут просто вызываться друг за другом, а проверки условий окажутся у них внутри. Если условие не выполнится, программа вернётся на уровень выше и вызовет следующий метод со следующей проверкой.
- Применить полиморфизм.
Полиморфизм — один из столпов ООП. Благодаря ему один и тот же метод может по-разному реализовываться в иерархии классов.
Здесь автор говорит о том, что конструкцию с несколькими условиями иногда бывает уместно заменить вызовом одного метода.
Так получится сделать, если создать систему классов-наследников, в которых по-разному определить этот один метод.
- Задействовать шаблон проектирования «Состояние».
Шаблон проектирования «Состояние» полезен, когда в зависимости от состояния системы одно и то же действие (переход к следующему этапу) должно обрабатываться по-разному.
Например, кофейный автомат сначала ждёт выбора напитка, потом оплаты, а только после этого готовит кофе.
Метод перехода на следующий шаг можно написать с кучей проверок типа «если сейчас я на шаге N, то делай то-то», а можно создать классы для каждого состояния и прописать действия по переходу на следующий шаг в них.
- Применить шаблон проектирования «Стратегия».
Шаблон проектирования «Стратегия» определяет семейство схожих алгоритмов и помещает каждый из них в отдельный класс.
В вызывающем классе хранится ссылка на стратегию, которую сейчас нужно использовать. Так что вместо множества проверок типа «если…, то…» вызывается один метод класса-стратегии.
- код не дублируется,
- становится проще
- и читается легче.
Оборачивая примитивные типы в классы, мы инкапсулируем (скрываем) тип. Если позже в ходе рефакторинга мы захотим изменить примитивные типы, это можно будет сделать в одном месте.
А ещё такой код легче воспринимать, ведь по сигнатуре объекта-обёртки сразу ясно, что передавать методу в качестве параметров.
Примечание переводчика
В оригинальной книге правило звучит так: «оборачивайте примитивы и строки».
Например, если метод принимает параметр типа int, это мало о чём говорит. Другое дело, если тип параметра будет, скажем, Hour. Мы оборачиваем целое число (часов) в класс. В тот же класс можно добавить проверку допустимых значений, и тогда никто не сможет передать в метод 36 или другое неподходящее число.
- Соблюдается инкапсуляция.
- Появляются подсказки для типов.
- Можно изолировать схожее поведение в отдельных методах и использовать их повторно.
Это следствие закона Деметры: «Общайся только с друзьями» (речь об общении между классами с помощью вызова методов друг друга. — Пер.).
Точку вы используете для вызова методов в Java или С#. Вызовы типа object.getProperty().getSubProperty().doSomething() — это очень плохая практика! Классы не должны знать так много деталей реализации других классов.
- Соблюдается инкапсуляция.
- Выполняется принцип открытости/закрытости.
Вы когда-нибудь встречали странное сокращённое название метода или переменной. Такое, что назначение их без контекста можно понять пятью разными способами?
Если вам приходится сокращать название метода, возможно, этот метод делает больше, чем должен. То есть нарушен принцип единственной ответственности. Поразмыслите над этим.
Поразмыслили? А теперь не сокращайте наименования!
- Соблюдается SRP.
- Вы избегаете путаницы.
- Нет дублирования кода.
Делайте их небольшими:
- 15–20 строк на метод,
- 50 строк на класс,
- 10 классов на пакет.
В конце концов, если ваш класс специализируется на чём-то одном, он не должен быть большим, верно?
- Соблюдается SRP.
- Модули уменьшаются.
- Код становится хорошо согласованным (coherent).
Один класс должен иметь дело с одним состоянием, максимум с двумя. Так что, если в классе более двух переменных экземпляра, возможно, он нарушает принцип единственной ответственности.
Примечание переводчика
Переменная экземпляра (instance variable, атрибут) — переменная, которая хранит свойство объекта — экземпляра класса. Этим она отличается от статической переменной (относится к классу, а не к его экземпляру) и от локальной переменной, которая объявляется в членах класса — например, в методах.
Кажется, это требование очень сложно выполнить. Уверен, вы видели классы с десятками параметров в конструкторе, так ведь?
Отлично! Почему бы не сгруппировать их в один объект? Или ещё раз хорошенько подумать о том, точно ли у этого класса идеальная архитектура и не делает ли он слишком много лишнего.
- В модулях поддерживается сильная связность (high cohesion).
- Соблюдается инкапсуляция.
- Становится меньше зависимостей между различными сущностями программы.
Это похоже на правило №3, только применительно к коллекциям.
Внутри вашего класса может быть по-прежнему простая коллекция. Но, обернув её в класс, вы в будущем сможете легко провести рефакторинг: например, изменить тип коллекции.
Примечание переводчика
В книге The ThoughtWorks Anthology автор акцентирует внимание на том, что в таком классе — обёртке над коллекцией вообще не должно быть других членов, кроме этой коллекции. Зато туда можно добавить методы фильтрации или добавления/удаления элементов.
- Появляются более функциональные классы-обёртки над тривиальными коллекциями.
- Остаётся только одно место, которое отвечает за поведение коллекции, — удобно, если нужно что-то исправить.
- Соблюдается инкапсуляция.
Не принимайте решений вне класса, позвольте ему самому заниматься своим делом. Иными словами, следуйте принципу «Рассказывай, а не спрашивай».
- Соблюдается принцип открытости/закрытости.
Теперь вы знаете всё! Следовать этим принципам сперва будет сложно. Появится искушение всё бросить. Но воспринимайте это как вызов себе — соберитесь и упражняйтесь (никаких оправданий!).
А вот строго выполнять все эти правила в ежедневной разработке вовсе не обязательно. Помните про компромиссные варианты и выбирайте то, что лучше.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать
Набор практик хорошего кода, не зависящих от языка программирования, опубликовал сайт proglib.io. Примените их, и ваш код будет не только работать, но и читаться.

Программисты в первую очередь работают с языком. Поэтому написание программ похоже на любой другой вид письменной работы. Сначала вы излагаете свои мысли как есть, а затем «причесываете» до тех пор, пока текст не будет легко читаться. Качество кода – результат проявления небезразличного отношения к делу и показатель профессионализма.
Почему важна читаемость кода
Чтение кода происходит чаще, чем написание. Есть большая разница между обучением программированию и реальной работой в компании. Вначале мы и пишем, и читаем собственные программы. Но чем дальше мы продвигаемся, тем чаще нам приходится не писать, а читать код. Чем легче код читается, тем проще с ним работать другим людям.
«Пишите код так, как будто сопровождать его будет склонный к насилию психопат, который знает, где вы живете», — Джон Вуд в доске обсуждений по C++, 1991 г.
Чем проще читать код, тем проще его сопровождать. Понятный, читаемый код легче тестировать, в нем легче отлавливать ошибки – они не скрываются в его запутанной структуре. Плохо оформленный код неприятно изучать, читать, тестировать, сложно дополнять. Рано или поздно плохой код становится проще переписать.
Эстетическое восприятие кода влияет на удобство работы. Казалось бы, гораздо важнее производительность, возможность модификации, расширения… Но все эти показатели улучшаются, если код соответствует нашему чувству прекрасного. Глядя на качественно написанный код, можно быстро понять алгоритм и то, как работает программа для разных входных данных. Чистый код читается как хорошо написанная проза: слова превращатся в зрительные образы.
Стиль кода определяет его будущее. Стиль и дисциплина продолжают жить в коде, даже если в нем не осталось ни одной исходной строки.
С чего начать: документация по стилю оформления кода
Все дороги программиста ведут к документации. В каждом языке существует свой стандарт оформления кода. Для Python используется документ PEP-8, для PHP – стандартные рекомендации PSR-1 и PSR-2, для Java – Java Coding Conventions, для JavaScript – Airbnb JavaScript Style Guide или Google JavaScript Style Guide. Документ для вашего языка вы найдете по поисковому запросу <Название языка> Code Style.
Когда вы работаете в группе разработчиков, нужно использовать принятые в команде правила. Стиль должен быть единым, как будто код был написан одним здравомысленным человеком.
В популярных IDE заложена возможность автоматической настройки стиля кода под стандарты – общие или предложенные командой. Разберитесь, как настроить среду под необходимое оформление. Потраченное время сэкономит многие часы рутинной работы.
Применение стандартов – лучший подход для новичка. Читающий не будет отвлекаться на оформление и сразу погрузится в тонкости выбранных подходов, а не расстановок переносов. Изложенные ниже правила понадобятся для того, чтобы понять, как действовать в тех случаях, когда стандарт не дает никаких рекомендаций.

Роберт Мартин «Чистый код. Создание, анализ и рефакторинг»
Конечно, мы не могли обойтись без упоминания замечательной книги Роберта Мартина о чистом коде и анализе программ. В ней приводятся примеры для языка Java, но большинство идей справедливы для любых языков.
Всё что изложено ниже, в значительной мере представляет сжатый конспект этой книги с дополнениями из нашего опыта в проектировании программ. Итак, приступим к практикам.
Главное правило чистого кода: выразительные имена
Содержательность. К выбору названий любых объектов нужно подходить со всей ответственностью. Выразительные имена позволяют писать код, не требующий комментариев.
Полезно не только исходно выбирать ясные имена, но и заменять названия на более удачные, если они нашлись позже. Современные среды программирования позволяют легко заменить название переменной во всём коде, так что это не должно быть проблемой.
Сравните. До:
public List < int[] > getThem() {
List < int[] > list1 = new ArrayList < int[] > ();
for (int[] x: theList)
if (x[0] == 4)
list1.add(x);
return list1;
}
После:
public List < int[] > getFlaggedCells() {
List < int[] > flaggedCells = new ArrayList < int[] > ();
for (int[] cell: gameBoard)
if (cell[STATUS_VALUE] == FLAGGED)
flaggedCells.add(cell);
return flaggedCells;
}
В первом примере непонятно, что вообще происходит, хотя в этом коде нет ни сложных выражений, ни каких-либо странностей. В результате правок сам код никак не изменился. Если знать, что это часть игры «Сапер», то теперь из кода понятно: здесь обрабатывается список ячеек игрового поля. Этот код можно улучшать и далее, но уже в результате простого переименования стало понятно, что происходит.
Избегайте любых двусмысленностей и ложных ассоциаций. Если в объекте перечисляется список, но сам объект не является списком, нельзя в составе его названия употреблять слово list – это запутывает читающего.
Остерегайтесь малозаметных различий – имена объектов должны существенно отличаться друг от друга. По этой причине плохи длинные имена с повторяющимся элементами – чтобы сличить их друг с другом, тратятся лишние силы и время. Избегайте использования в именах переменных строчной буквы L и прописных I, O – они часто путаются с единицей и нулем.
Путаница также возникает, если несколько синонимичных слов и выражений используются для обозначениях разных сущностей, например, controller, manager и driver.
Имя должно легко произноситься. Используйте для названий слова. Если названия состоят из сокращений, каждый начинает произносить их по-своему, что затрудняет взаимопонимание. А при чтении кода каждый раз «спотыкаешься» о такое название.
Имя должно быть удобным для поиска. Слишком короткие имена трудно искать в большом объеме текста. Однобуквенные имена можно использовать только для локальных переменных в коротких методах и счетчиков циклов (i, j, k). Обычно называя объект одной буквой, вы всего лишь создаете временный заменитель. Но не бывает ничего более постоянного, чем что-то «временное». Проверяйте грамотность написания выбранных слов.
Правильно выбирайте часть речи. Классы и объекты желательно называть существительными и их комбинациями: Account, WikiPage, HTMLParser. Имена функций и методов лучше представлять глаголами или глагольными словосочетаниями: delete_page, writeField(name). Для методов чтения/записи и предикатов используйте стандартные префиксы get, set, is.
Заменяйте «магические» числа именованными константами. Одно из самых древних правил разработки. Магическими называют числа, о которых сходу нельзя сказать, что они означают. Например: 100, 1.1, 42, 1000000. Выделяйте такие числа в соответствующие константы с конкретным названиями. Например, вместо числа 86400 в теле кода приятнее встретить константу SECONDS_PER_DAY.
Не стоит следовать этому правилу, как и любому другому, безоговорочно. В формулах некоторые константы лучше воспринимаются в числовой записи.
Одно слово для каждой концепции. Для одной и той же идеи, реализующей одну механику, используйте одно слово. Например, для добавления элементов одинаковым образом – метод add. Однако, если механика и семантика изменились, потребуется и другое слово (например, insert, append), описывающее новую концепцию.
Ваш код будут читать программисты. Не стесняйтесь использовать термины из области информатики, общепринятые названия алгоритмов и паттернов. Такие имена сообщают информацию быстрее, чем сам код.
Помещайте имена в соответствующий контекст. Например, имена street, house_number, city понятнее смотрятся внутри класса Address.
Избегайте остроумия и каламбуров в названиях. Шутки имеют свойство быть понятными лишь ограниченное время и для конкретной аудитории, знакомой с первоисточником. Отдавайте предпочтение ясности перед развлекательностью. Шутки можно приберечь для презентации, которая происходит «здесь и сейчас». Хороший код способен выйти далеко за границы вашей культуры.
Рабочие среды продолжают развиваться. Уже нет никакой необходимости кодировать типы в именах, создавать префиксы для членов классов. Всю нужную информацию можно получить из цветового выделения или контекстно-зависимых подсказок сред разработки. Добавление префиксов убивает удобство поиска по автовыполнению – выпадает слишком много имен, начинающихся с одинаковых символов.

Функции
Компактность. Уже в 80-е годы считалось, что функция должна занимать не более одного экрана. Экраны VT100 тогда состояли из 24 строк и 80 столбцов. В наши дни на экране можно разместить гораздо больше инорфмации, но лучше ограничиться тем же объемом. Самоограничение позволяет видеть точку объявления каждой используемой переменной и держать в уме всю «историю», которую рассказывает функция.
Вполне вероятно, что тот, кто будет сопровождать ваш код, не будет иметь возможности работать на большом мониторе. Например, ему необходимо одновременно разместить на одном рабочем столе экрана ноутбука несколько окон. Среды разработки позволяют установить ограничение, «верхнюю планку» (то есть правую 😉 ).
Блоки if, else, while должны иметь минимальный размер, чтобы информацию о них можно было держать в уме. Старайтесь избегать отрицательных условий – на их восприятие обычно уходит чуть больше времени, чем на положительные. То есть запись if (buffer.shouldCompact()) предпочтительнее записи if (!buffer.shouldNotCompact().
Правило одной операции. Плохой код пытается сделать слишком много всего, намерения программиста расплываются для читателя. Поэтому стоит ввести важное правило:
Функция должна выполнять только одну операцию, выполнять ее хорошо, и ничего другого она делать не должна.
Каждая функция должна делать то, что вы от нее ожидали из названия. Если функция действует не так, как она названа, читатель кода перестает доверять автору программы, ему приходится самостоятельно разбираться во всех подробностях реализации.
«Я люблю, чтобы мой код был элегантным и эффективным. Логика должны быть достаточно прямолинейной, чтобы ошибкам было трудно спрятаться; зависимости — минимальными, чтобы упростить сопровождение; обработка ошибок — полной в соответствии с выработанной стратегией; а производительность — близкой к оптимальной, чтобы не искушать людей загрязнять код беспринципными оптимизациями. Чистый код хорошо решает одну задачу», — Бьёрн Страуструп, создатель языка С++
Исключения вместо кодов ошибок. Используйте исключения (try-catch, try-except) вместо возвращения кодов ошибок. Возвращение кодов приводит к слишком глубокой вложенности.
К тому же при использовании исключений код обработки ошибок изолируются от ветви нормального выполнения. Сами блоки лучше выделять в отдельные функции. Вместе с исключением нужно передавать контекст ошибки – сообщение, содержащее сведения об операции и типе сбоя.
Соблюдайте уровни абстракции. Одна функция – один уровень абстракции. Смешение уровней абстракции создает путаницу, функция обрастает слишком большим количеством второстепенных подробностей. Старайтесь соблюдать ясную иерархию.
Код читается сверху вниз. По мере чтения уровни абстракции должны меняться равномерно. Каждая функция должна быть окружена функциями единого уровня абстракции.
Ограничивайте число аргументов. Чем больше аргументов у функции, тем сложнее с ней работать. Необходимость функций с количеством аргументов большим двух должна быть подкреплена очень вескими доводами. Каждый новый аргумент критически усложняет процедуру тестирования. Если функция должна получать более двух аргументов, скорее всего, эти аргументы образуют концепцию, заслуживающую собственного имени.
Комментарии
Это непопулярное мнение, но в большинстве случаев комментарии – зло. Код должен быть самодокументированным. Комментарий – всегда признак неудачи: мы не смогли написать код так, что он понятен без комментариев. Проверьте, можно ли выразить свое намерение в самом коде.
В чём проблема? Программисты умеют сопровождать код, но не комментарии. В растущем коде комментарии быстро устаревают, частично или полностью переставая соответствовать ситуации. Только код правдиво сообщает своим содержанием, что он в действительности делает. Лучше потратить время на исправление запутанного кода, чем добавлять к плохому коду комментарии.
Однако есть несколько видов комментариев, которые выглядят достаточно оправданными.
TODO-комментарии. Бывает так: нужно было успеть к дедлайну, пришлось писать код быстро, поэтому в нем остались дыры. То есть всё работает, но реализация ущербная. Укажите все недоработки и создайте под них задачи. Каждый комментарий указывает на недоработку или потенциальную уязвимость.
Юридические комментарии. Корпоративные стандарты могут принуждать вставлять комментарии по юридическим соображениям. Ограничьтесь в таком комментарии описанием лицензии и ссылкой на внешний документ.
Предупреждения о последствиях. Иногда бывает полезно предупредить других программистов о нежелательных последствиях:
// Не запускайте, если только не располагаете // излишками свободного времени.
Комментарий также может подчеркивать важность обстоятельства, которое на первый взгляд кажется несущественным.

По-настоящему плохие комментарии
Бывают такие типы комментариев, которые лучше никогда не делать.
Закомментированный программный код. «Когда-нибудь в будущем расскомментирую этот код, приведу всё в порядок. Или вдруг эта идея кому-то поможет». Любой закомментированный код только ухудшает ситуацию. Все изменения хранятся в контроле версий – удаляйте такой код на корню. Это просто мусор: «потом» равносильно «никогда». Если что-то действительно нужно сделать, создайте краткий TODO-комментарий и задачу.
Мертвые функции – идентичные по смыслу предыдущему пункту функции и методы, которые не вызываются в программе. Пользуйтесь системой контроля версий и без зазрений совести удаляйте любой код, который не используется во время выполнения программы.
Избыточные комментарии. Задайте себе вопрос: стал ли код понятнее после прочтения комментария? Часто комментарии просто загромождают код и скрывают его смысл, излагая очевидные вещи. Иногда в комментарии включаются описания не относящихся к делу подробностей. Но профессионал бережет не только свое, но и чужое время, и не отвлекает читающего без повода.
Журнальные комментарии и ссылки на авторов. Некоторые программисты добавляют комментарий в начало файла при редактировании. Или указывают, кто и когда внес исправления. Когда-то это было оправдано, но теперь у нас есть системы контроля версий – это гораздо лучший способ обозначить границы зоны ответственности каждого.
Позиционные маркеры. Иногда любят отмечать определенные группы и позиции в исходных файлах:
// Классы //////////////////////////////////
Качественно организованный код способен внятно рассказать историю без балластных заголовков.
Уровень файлов программ
Минималистичность. Чем меньше кода, тем лучше. Имя файла должно быть простым, но содержательным. Маленькие файлы обычно более понятны, чем большие. Но размер файла, конечно, не должен быть самоцелью.
Код должен быть максимально линейным. Чем больше вложенность кода, тем сложнее его читать. Следите за тем, как двигаются ваши глаза. В хорошем коде вы двигаетесь строка за строкой, лишь изредка возвращаясь к предыдущим строчкам. Вложенность более трех уровней указывает на то, что с кодом нужно поработать: переписать условия проверок и циклов (использовать return и функциональное программирование), разбить код на меньшие методы.
Отдельные «мысли» следует отделять друг от друга пустыми строками. Каждая пустая строка – зрительная подсказка: описание одной концепции закончилось, далее следует новая. При просмотре кода взгляд концентрируется на первых строчках – в них больше всего информации, как в началах абзацев этого текста.
Тесно связанные концепции, должны располагаться вблизи друг друга. Не заставляйте читателя прыгать между файлами или постоянно скроллить файл. По той же причине переменные нужно объявлять как можно ближе к месту использования. Однако переменные экземпляров лучше объявлять в одном месте, обычно в начале класса (то есть в одном месте), так как в хорошо спроектированном классе переменные используются большинством методов класса.
Пробелы для группировки взаимосвязанных элементов. Пробелы улучшают читаемость кода, если они стоят вокруг операторов присваивания, после запятых при перечислении переменных. В формулах пробелы используются для подчеркивания приоритета: не ставятся между множителями, но отбивают знаки сложения и вычитания.
Отступы. Размер отступов должен соответствовать позиции кода в иерархии. Это общая практика, которая позволяет быстро пропускать области видимости, не относящиеся к текущей ситуации. Не поддавайтесь искушению нарушить правила расстановки отступов для коротких команд.

Некоторые замечания по поводу архитектуры и тестов
В системе должны выполняться все тесты. Тесты – главный способ, с помощью которого можно понять, что система контролируема. А только контролируемую систему можно проверить.
Три закона тестирования по методологии TDD. Тестовый код не менее важен, чем код продукта. Соблюдение следующих трех правил позволяет организовать работу так, чтобы тесты охватывали все аспекты кода продукта:
- Не пишете код продукта, пока не напишете отказной модульный тест.
- Не пишите модульный тест в объеме большем, чем необходимо для отказа.
- Не пишите код продукта в объеме большем, чем необходимо для прохождения текущего отказного теста.
F.I.R.S.T. Качественные тесты должны обладать пятью характеристиками, первые буквы которых образуют указанный акроним:
- Fast. Тесты должны выполняться быстро.
- Independent. Тесты не должны зависеть друг от друга и выполняться в любом порядке.
- Repeatable. Тесты должны давать воспроизводимые в любой среде результаты.
- Self-validating. Результат выполнения теста – логический признак: тест пройден или нет. Иначе результаты приобретают субъективный характер.
- Timely. Тест должен создаваться своевременно. Тесты нужно писать непосредственно перед написанием кода.
Повышение уровня абстракции и устранение дубликатов. Все программы состоят из очень похожих элементов, а все задачи программирования сводятся к работе с ограниченным набором действий. Многие из этих действий могут быть описаны в одних и тех же терминах, например, извлечение элемента из коллекции. В подобных ситуациях правильно инкапсулировать реализацию в более абстрактном классе. Повышение уровня абстракции позволяет избежать дублирования и многократно применения одного и того же кода, лучше понять, что действительно происходит в программе, уйдя от частностей.
Если что-то в программе делается снова и снова, значит, какая-то важная концепция не нашла своего отражения в коде. Нужно попытаться понять, что это такое, и выразить идею в виде кода. Избегайте дубликатов, это всегда лишняя работа, лишний риск, лишняя сложность.
Несколько языков в одном исходном файле. Современные среды программирования позволяют объединять в одном файле код, написанный на разных языках. Результат получается запутанным, неаккуратным и ненадежным. Чтобы четко разграничить ответственность, в файле должен преобладать один язык. Сведите к минимуму количество и объем кода на дополнительных языках.
Не нужно бездумно следовать догмам. Не переусердствуйте с сокращением кода функций и классов. Всегда руководствуйтесь здравым смыслом.
Заключение
Чистый код выглядит так, как если его автор над ним тщательно потрудился. Вы не можете найти очевидных возможностей для его улучшения. Попытавшись его улучшить, вы вновь вернетесь к тому же коду.
Чтобы писать чистый код, который бы никого не удивлял, необходимо раз за разом сознательно применять описанные приемы. При чтении чистого кода вы улыбаетесь, как при виде искусно сделанной музыкальной шкатулки. Код можно назвать красивым, если у вас создается впечатление, что язык был создан специально для этой задачи.

Автор курса по С++ в Яндекс.Практикуме Маша Гутовская рассказала, что такое красивый код, и объяснила, почему начинающим разработчикам важно сразу учиться писать код красиво. В конце текста вас ждет чеклист с советами и полезными материалами.
Зачем писать красивый код
Красивый код — это работающий, понятный и читаемый код, который написан по определённым стандартам. Такой код экономит время самого разработчика и его коллег, потому что он структурирован и понятно оформлен, его легко читать и использовать, а написанные на нём программы легче поддерживать, «дебажить» и тестировать.
Если красивый код станет привычкой, принципом работы, с которым вы входите в профессию, то вам будет гораздо проще в дальнейшем. Попав в компанию, которая работает по общепринятым стандартам, вам не придётся переучиваться и менять собственные подходы к разработке.
Это также может сослужить добрую службу на собеседовании. С большей вероятностью рекрутеры отдадут предпочтение тому разработчику, который умеет писать красивый код.
Три уровня красоты кода
Я занимаюсь проектами для интернета вещей, умного дома и медицинского оборудования. Обсуждать красоту кода я буду на примере С++, так как работаю на нём. Но думаю, что мой подход актуален для любого языка. Я бы выделила три уровня красоты кода.
Визуальный уровень
Вы работаете не в вакууме, у вас есть коллеги, начальники, подчинённые. Даже если код вы пишете один, его кто-то использует. Чтобы избежать вкусовщины и разночтений, в IT-компаниях создают так называемые coding conventions — стандарты оформления кода. Это фиксированный набор правил, который определяет, как должен выглядеть код в компании. Многие разработчики создают собственные руководства. Некоторые из них выложены в открытых источниках, к примеру, руководство по стилю Google лежит на GitHub. Если вы разделяете эти положения, используйте их для написания своего кода, а опытный наставник поможет вам исправить шероховатости.
Уровень восприятия
Код должен быть красиво организован. Важны названия переменных, размеры классов, функций и методов, а также частота использования условных выражений. Обилие if, else и switch case создаёт нагромождение условий и частных случаев. И это не только визуальная проблема: такой код сложнее понимать, дорабатывать и поддерживать.
Структурный уровень
Код должен быть продуман с точки зрения архитектуры. Бывает, что он написан по всем правилам, но если вы попытаетесь внести изменения, поправить класс или фичу, то всё рассыплется. Просто потому, что архитектура кода плохо продумана.Представьте, что новому разработчику в команде нужно найти баг в программе. Для этого он должен суметь быстро и без посторонней помощи понять, как устроен ваш код: все элементы должны стоять на привычных местах и не должно быть неявных зависимостей.Чтобы избежать плохой архитектуры, рекомендую освоить принципы SOLID и писать код в соответствии с этими принципами. SOLID (single responsibility, open-closed, Liskov substitution, interface segregation, dependency inversion) — это пять принципов объектно-ориентированного программирования. Это набор правил, которым нужно следовать при создании структуры классов. Я советую подробнее узнать об этих принципах и других важных аспектах красоты кода, прочитав книгу Роберта Мартина «Чистый код».
Code smells и рефакторинг
Отчасти из-за отсутствия чёткой регламентации в отрасли возник термин code smells. Так говорят, когда код вроде работает и даже соответствует всем правилам компании, но что-то в нём не так. В таком случае полезно провести рефакторинг — переработку кода, которая не затрагивает его работу, но облегчает понимание. Подробнее об этом понятии можно почитать в книге Мартина Фаулера «Рефакторинг. Улучшение существующего кода».
Допустим, вы написали код. Прошло полгода, вы успели поучаствовать в разных проектах и написать не одну сотню строк. Стоит ли возвращаться к нему и делать рефакторинг? Обязательно. Во-первых, это повысит качество самого кода, а вы научитесь замечать детали, которые надо исправлять и которых стоит избегать в будущем. Во-вторых, вероятно, вам будет нужно время от времени рефакторить и чужой код — сможете набить руку на своём же старом. В блоке полезных ссылок в конце статьи вы найдете ссылку на отличный ресурс о том, как делать правильный рефакторинг.
Разберём код, в котором можно найти много проблем:
Этот код вполне соответствует правилам оформления. Но что мешает понять его легко и быстро?
Запутанные наименования, которые только усложняют понимание
— Название функции не соответствует тому, что она делает.
— Переменная типа int названа словом «condition», что выглядит сомнительно с точки зрения логики. Обычно условием можно называть какое-то выражение, проверку чего-то. Тип int — это число. Сказать, что число четыре является условием чего-то, странно.
— В названии функции заявлено, что она должна считать элементы. Вряд ли пользователь ожидает, что с элементами вектора что-то произойдет, тем более, что контейнер передаётся как константная ссылка. Но внутри функции константность убирается, и элементы контейнера меняются! Поэтому вызов такой функции может быть небезопасен.
— Непонятно, что скрывается за числом 10. Важно это обозначить, чтобы после возможных изменений в программе не появился баг. Ведь если никто не вспомнит о значении, никто не проверит код на ошибки.
Визуальный мусор
— Мёртвый код (закомментированный вызов ProcceedElementsCheck). Довольно сложно, на мой взгляд, понять, какой логики придерживался автор на этом участке. Причина — закомментированный код.
Проблемы с документированием
— Комментарий над функцией явно устарел и сбивает с толку.
Вероятно, опытный глаз может заметить ещё множество недочётов. Больше примеров плохого кода также можно посмотреть в книге «Чистый код».
Как написать красивый код
1. Следуйте правилам оформления кода (или coding conventions). Даже если вы фрилансите или учитесь, приобретите привычку всегда писать красиво.
2. Используйте специальные инструменты. Для корректировки кода под конкретный стайлгайд существует множество различных плагинов, скриптов и шаблонов для разных сред программирования. IDE (Integrated Development Environment) успешно автоматизирует этот процесс, а вы сможете и время сэкономить, и новый навык освоить.
Вот несколько полезных инструментов для автоматизации.
Plug-in Beautifier для вашей IDE — плагин, который сделает код единообразным, отформатирует, уберёт всё лишнее.
Clang-format — инструмент для автоматического форматирования кода без запуска IDE.
Google C++ Style Guide — руководство по стилю Google, которое можно взять за основу и использовать для создания собственного стайлгайда.
3. Сделайте код понятным. Код должен быть написан так, чтобы без ваших комментариев всё было ясно. Используйте простые названия переменных, классов и методов.
4. Освойте принципы SOLID. Нужно, чтобы ваш код не рассыпался при попытках коллег внести в него изменения.
5. Не забывайте про ревью. Код-ревью — это процесс, во время которого ваш код просматривают и комментируют члены команды. Хороший ревьюер укажет не только на баги в коде, но и на архитектурные недочёты и плохой стиль написания. Кроме этого, он объяснит, как можно было бы сделать работу быстрее и проще. Чтобы писать красивый и правильный код, внимательно относитесь к комментариям ревьюера, и тогда с каждой итерацией недочётов будет всё меньше.
6. Оставляйте время для рефакторинга. После рефакторинга ещё раз протестируйте код. Будет лучше, если ошибки заметите вы, а не ребята из вашей команды или пользователи.
7. Изучайте код новых проектов в open source. Это поможет вам быть в курсе новых практик и подходов. Следите за проектами, которые вам нравятся, смотрите, как и на чём они написаны, задавайте вопросы разработчикам.
8. Читайте книги и ресурсы по теме. Это просто, но работает. Я рекомендую «Чистый код» Роберта Мартина, «Рефакторинг. Улучшение существующего кода» Мартина Фаулера и отличный ресурс о рефакторинге Refactoring.guru.
Software engineering is not just all about learning a language and building some software. As a software engineer or software developer, you are expected to write good software. So the question is what makes good software?. Good software can be judged by reading some piece of code written in the project. If the code is easy to understand and easy to change then definitely it’s a good software and developers love to work on that.  It’s a common thing in development that nobody wants to continue a project with horrible or messy code (It becomes a nightmare for sometimes…). Sometimes developers avoid writing clean code due to deadline pressure. They rush to go faster but what happens actually is they end up with going slower. It creates more bugs which they need to fix later going back on the same piece of code. This process takes much more time than the amount of time spent on writing the code. A study has revealed that the ratio of time spent reading code versus writing is well over 10 to 1.
It’s a common thing in development that nobody wants to continue a project with horrible or messy code (It becomes a nightmare for sometimes…). Sometimes developers avoid writing clean code due to deadline pressure. They rush to go faster but what happens actually is they end up with going slower. It creates more bugs which they need to fix later going back on the same piece of code. This process takes much more time than the amount of time spent on writing the code. A study has revealed that the ratio of time spent reading code versus writing is well over 10 to 1. 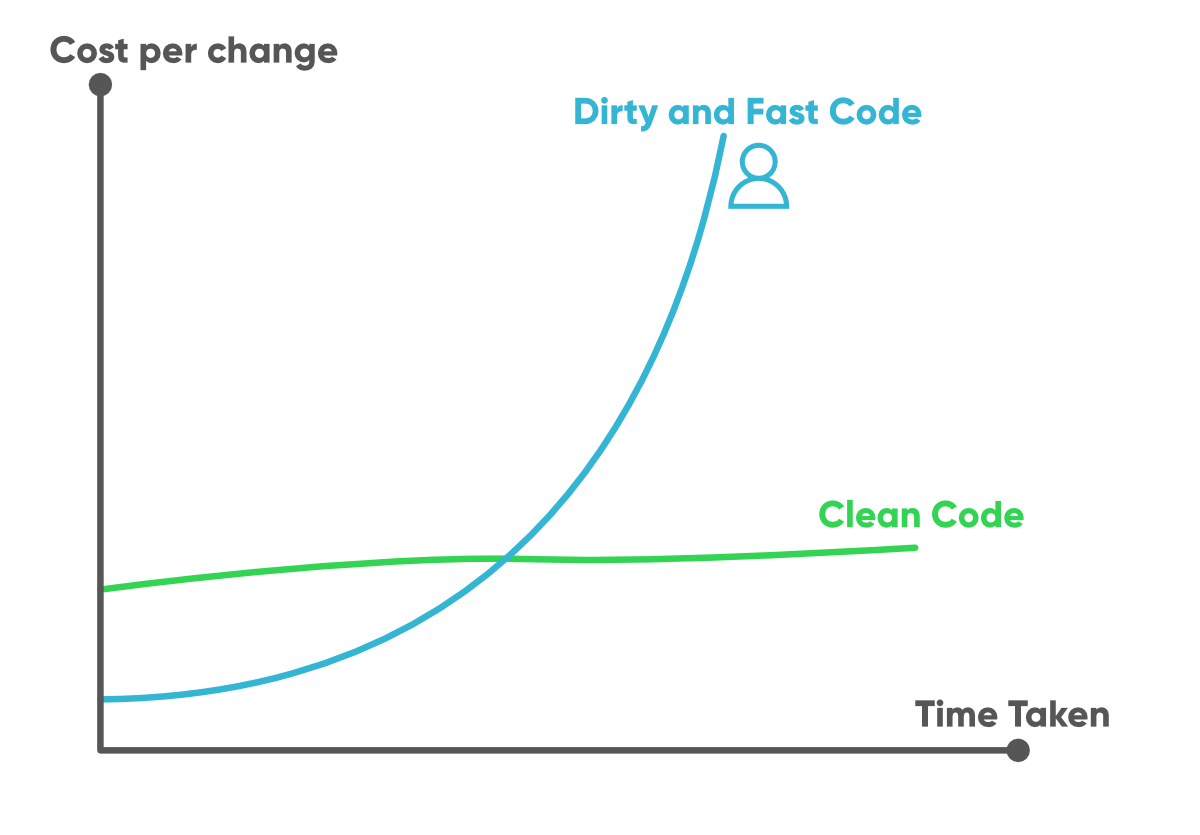 It doesn’t matter if you are a beginner or an experienced programmer, you should always try to become a good programmer (not just a programmer…). Remember that you are responsible for the quality of your code so make your program good enough so that other developers can understand and they don’t mock you every time to understand the messy code you wrote in your project. What Makes a Clean Code: Before we discuss the art of writing clean and better code let’s see some characteristics of it…
It doesn’t matter if you are a beginner or an experienced programmer, you should always try to become a good programmer (not just a programmer…). Remember that you are responsible for the quality of your code so make your program good enough so that other developers can understand and they don’t mock you every time to understand the messy code you wrote in your project. What Makes a Clean Code: Before we discuss the art of writing clean and better code let’s see some characteristics of it…
- Clean code should be readable. If someone is reading your code they should have feeling of reading a poetry or prose.
- Clean code should be elegant. It should be pleasing to read and it should make you smile.
- Clean code should be simple and easy to understand. It should follow single responsibility principle (SRP).
- Clean code should be easy to understand, easy to change and easy to taken care of.
- Clean code should run all the tests.
“Clean code is simple and direct. Clean code reads like a well-written prose. Clean code never obscures the designer’s intent but rather is full of crisp abstractions and straightforward lines of control.” -Grady Booch (Author of Object-Oriented Analysis and Design with Applications)
How to Write Clean and Better Code?
1. Use Meaningful Names
You will be writing a lot of names for variables, functions, classes, arguments, modules, packages, directories and things like that. Make a habit to use meaningful names in your code. Whatever names you mention in your code it should fulfill three purposes…what it does, why it exists and how it is used. For Example:
int b; // number of users.
In the above example, you need to mention a comment along with the name declaration of a variable which is not a characteristic of a good code. The name that you specify in your code should reveal it’s intent. It should specify the purpose of a variable, function or methods. So for the above example, a better variable name would be:- int number_of_users. It may take some time to choose meaningful names but it makes your code much cleaner and easy to read for other developers as well as for yourself. Also, try to limit the names to three or four words.
2. Single Responsibility Principle (SRP)
Classes, Functions or methods are a good way to organize the code in any programming language so when you are writing the code you really need to take care that how to write a function that communicates it’s intent. Most of the beginners do this mistake they write a function that can handle and do almost everything (perform multiple tasks). It makes your code more confusing for developers and creates problems when they need to fix some bugs or find some piece of code. So when you are writing a function you should remember two things to make your function clean and easy to understand…
- They should be small.
- They should do only one thing and they should do it well.
The above two points clearly mention that your function should follow single responsibility principle. Which means it shouldn’t have nested structure or it should not have more than two indent level. Following this technique make your code much more readable and other developers can easily understand or implement another feature if your function fulfills a specific task. Also, make sure that your function should not have more than three arguments. More arguments perform more tasks so try to keep the arguments as less as possible. Passing more than three arguments makes your code confusing, quite large and hard to debug if any problem would be there. If your function has try/catch/finally statement then make a separate function containing just the try-catch-finally statements. Take care of your function name as well. Use a descriptive name for your function which should clearly specify that what it does. Example:
function subtract(x, y) {
return x - y;
}
In the above example the function name clearly shows that it’s purpose is to perform subtraction for two numbers, also it has only two arguments. Read more about writing a good function from the link 7 Common Programming Principles That Every Developer Must Follow and SOLID Principle.
3. Avoid Writing Unnecessary Comments
It’s a common thing that developers use comments to specify the purpose of a line in their code. It’s true that comments are really helpful in explaining the code what it does but it also requires more maintenance of your code. In development code move here and there but if the comment remains at the same place then it can create a big problem. It can create confusion among developers and they get distracted as well due to useless comments. It’s not like that you shouldn’t use comments at all, sometimes it is important, for example…if you are dealing with third party API where you need to explain some behavior there you can use comments to explain your code but don’t write comments where it’s not necessary. Today modern programming languages syntax are English like through and that’s good enough to explain the purpose of a line in your code. To avoid comments in your code use meaningful names for variables, functions or files.
Good code is its own best documentation. As you’re about to add a comment, ask yourself, “How can I improve the code so that this comment isn’t needed?” Improve the code and then document it to make it even clearer. -Steve McConnell
4. Write Readable Code For People
A lot of people especially beginners make mistake while writing a code they write everything in a single line and don’t give proper whitespace, indentation or line breaks in their code. It makes their code messy and difficult to maintain. There’s always a chance that another human will get to your code and they will have to work with it. It wastes other developers’ time when they try to read and understand the messy code. So always pay attention to the formatting of your code. You will also save your time and energy when you will get back to your own code after a couple of days to make some changes. So make sure that your code should have a proper indentation, space and line breaks to make it readable for other people. The coding style and formatting affect the maintainability of your code. A software developer is always remembered for the coding style he/she follow in his/her code.
javascript
class CarouselRightArrow extends Component{render(){return ( <a href="#" className="carousel__arrow carousel__arrow--left" onClick={this.props.onClick}> <span className="fa fa-2x fa-angle-left"/> </a> );}};
class CarouselRightArrow extends Component {
render() {
return (
<a
href="#"
className="carousel__arrow carousel__arrow--left"
onClick={this.props.onClick}
>
<span className="fa fa-2x fa-angle-left" />
</a>
);
}
};
Code formatting is about communication, and communication is the professional developer’s first order of business. -Robert C. Martin (Uncle Bob)
5. Write Unit Tests
Writing Unit test is very important in development. It makes your code clean, flexible and maintainable. Making changes in code and reducing bugs becomes easier. There is a process in software development which is called Test Driven Development (TDD) in which requirements are turned into some specific test cases then the software is improved to pass new tests. According to Robert C. Martin (Uncle Bob), the three laws of TDD demonstrate…
- You are not allowed to write any production code unless it is to make a failing unit test pass.
- You are not allowed to write any more of a unit test than is sufficient to fail, and compilation failures are failures.
- You are not allowed to write any more production code than is sufficient to pass the one failing unit test.

After I jumped on board the unit testing bandwagon, the quality of what I deliver has increased to the point that the amount of respect I get from my colleagues makes me feel awkward. They think I’m blessed or something. I’m not gifted or blessed or even that talented, I just test my code. – Justin Yancey, Senior Systems Development Engineer, Amazon
6. Be Careful With Dependencies
In software development, you really need to be careful about your dependencies. If possible your dependencies should always be a singular direction. It means….let’s say we have a kitchen class which is dependent on a dishwasher class. As long as the dishwasher doesn’t also dependent on the kitchen class this is a one-directional dependency. The kitchen class is just using the dishwasher but the dishwasher doesn’t really care and anyone can use it. It doesn’t have to be a kitchen. This example of one-directional dependency is easier to manage however it’s impossible to always have one-directional dependency but we should try to have as many as possible. When dependency goes in multiple directions, things get much more complicated. In bidirectional dependency both the entities depend on each other, so they have to exist together even though they are separate. It becomes hard to update some systems when their dependencies don’t form a singular direction. So always be careful about managing your dependencies.
7. Make Your Project Well Organized
This is a very common problem in software development that we add and delete so many files or directories in our project and sometimes it becomes complicated and annoying for other developers to understand the project and work on that. We agree that you can not design a perfect organization of folders or files on day one but later on, when your project becomes larger you really need to be careful about the organization of your folder, files, and directories. A well-structured folder and file make everything clear and it becomes easier to understand a complete project, search some specific folder and make changes in it. So make sure that your directory or folder structure should be in an organized manner (Same applies for your code as well). Best Books For Understanding How to Write Clean and Better Code:
- Clean Code
- Code Complete