Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Время на прочтение
10 мин
Количество просмотров 103K
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
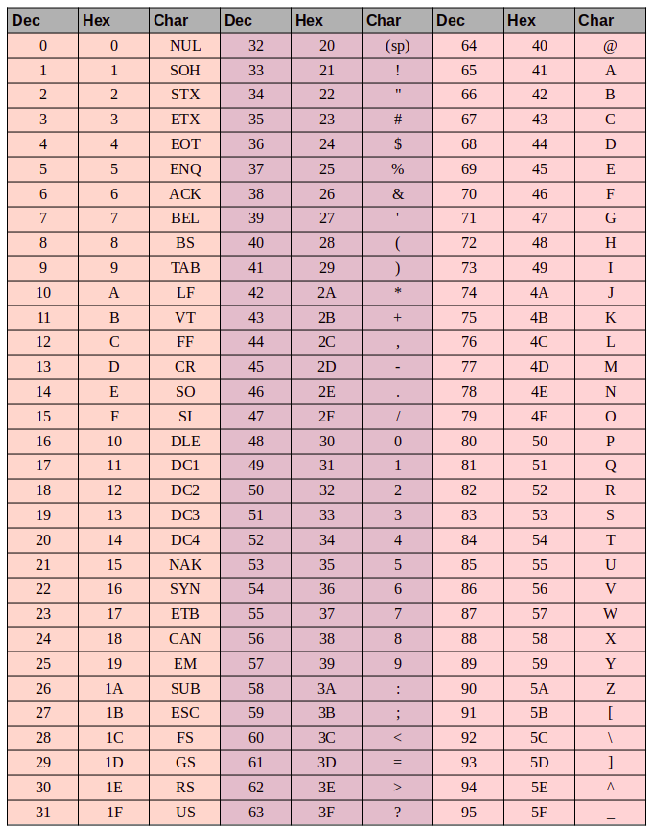
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Кодирование строк
Кодирование строк


![]()
Чтобы компьютер смог отобразить передаваемые ему символы, они должны быть представлены в конкретной кодировке. Навряд ли найдется человек, который никогда не сталкивался с кракозябрами: открываешь интернет-страницу, а там – набор непонятных знаков; хочешь прочесть книгу в текстовом редакторе, а вместо слов получаешь сплошные знаки вопроса. Причина заключается в неверной процедуре декодирования текста (если сильно упростить, то программа пытается представить американцу, например, букву «Щ», осуществляя поиск в английском алфавите).
Возникают вопросы: что происходит, кто виноват? Ответ не будет коротким.
1. Компьютер – человек
Так сложилось, что компьютерная техника оперирует единицами и нулями. На вашей же клавиатуре представлено не менее 100 клавиш. Все, что вы вводите при печати, в итоге преобразуется в те самые бинарные величины.
В этом суть кодировки. ПК запоминает любые буквы, числа и знаки в виде определенного значения из единиц и нулей. Для примера: английская буква «Y» в двоичном коде выглядит как «0b1011001», а в шестнадцатеричном как «0x59».
Для осмысленного диалога пользователя и компьютера требуется двусторонний переводчик:
– «человеческие» строки необходимо перекодировать в байты;
– «компьютерную» речь требуется преобразовать в воспринимаемые пользователем осмысленные структуры.
В языке Python за это отвечают функции encode / decode. Важно кодировать и декодировать сообщение в одинаковой кодировке, чтобы не столкнуться с проблемой бессмысленных наборов символов.
Так как первые вычислительные машины были малоемкими, для представления в их памяти всего набора требуемых знаков хватало 7 бит (или 128 символов). Сюда входил весь английский алфавит в верхнем и нижнем регистрах, цифры, знаки, вспомогательные символы.

Поначалу этого вполне хватало. Кодировка получила имя ASCII (читается как «аски» или «эски»). В Пайтоне вы и сегодня можете посмотреть на символы ASCII. Для этого имеется встроенный модуль string.
import string
print(string.ascii_letters)
print(string.digits)
print(string.punctuation)
Результат выполнения кода
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789
!"#$%&'()*+,-./:;<=>?@[]^_`{|}~С другими свойствами модуля можете ознакомиться самостоятельно.
Время шло, компьютеризация общества ширилась, 128 символов стало не хватать. Оставшийся последний 8-ой бит также выделили для кодирования (а это еще 128 знаков). В итоге появилось большое количество кодировок (кириллическая, немецкая и т.п.). Такая ситуация привела к проблемам. Уже в то время англичанин, получающий электронное письмо из России, мог увидеть не русские буквы, а набор непонятных закорючек.
Потребовалось указание кодировок в заголовках документов.
3. Юникод-стандарт
Как вы считаете, сколько нужно символов, чтобы хватило всем и навсегда? 10_000? Конечно, нет. Уже сегодня более 100_000 знаков имеет свое числовое представление. И это не предел. Люди постоянно придумывают новые «буквы».
Откройте свой телефон и создайте пустое сообщение. Зайдите в раздел «смайликов». Да их тут больше сотни! И это не картинки в большинстве своем. Они являются символами определенной кодировки. Если вы застали времена, когда SMS-технологии только начинали развиваться, то этих самых «смайлов» было не более десятка. Лет через 10 их количество станет «неприличным».
Упомянутая выше кодировка ASCII в своем расширенном варианте породила большое количество новых. Основная беда: имея 128 вариантов обозначить символ, мы никак не сумеем внедрить туда буквы других языков. В частности, какой-нибудь символ под номером 201 в кириллице даст совсем не русскую букву, если отослать его в Румынию. Следовательно, говоря кому-то «посмотри на 201-ый символ» мы не даем никакой гарантии, что собеседник увидит то же.
Для решения задачи был разработан стандарт Unicode. Отметим, что это не определенная кодировка, а именно набор правил. Суть юникода – связь символа и определенного числа без возможного повторения. Если мы кого-то попросим показать символ, скрытый под номером «1000», то в любой точке планеты он будет одним и тем же графическим элементом.

Всего в Unicode стандарте на сегодня имеется место под более чем 1,1 млн знаков:
- UTF-8 – кодировка символов юникод в двоичном виде. Использует от 1 до 4 байт. Так как наиболее часто используемые символы занимают 1 байт (в частности, аски-символы), то UTF-8 оптимальна для английского текста, но не для азиатского.
- UTF-16 используется для кодирования 2-мя или 4-мя байтами. Считается удобным способом для пользователей азиатских стран с иероглифическим письмом.
- UTF-32 представляет все символы при помощи 4 байт. Используется редко, так как потребляет много памяти. Тем не менее, быстро работает при наличии мощностей.
4. Кодирование и декодирование строк
Пользователям Python 3 версии повезло. Все символы и документы заранее приводятся к кодировке UTF-8. И если где-то в коде вы напишете строку «Ёжик в тумане» или «אֱלִיעֶזֶר וְהַגֶזֶר», то будьте уверены, они не превратятся в абракадабру и не приведут к ошибкам.
Тем не менее, строковые методы decode / encode не потеряли свою актуальность. По умолчанию все преобразования осуществляются в кодировке UTF-8, но никто не мешает задать нужную вам.
Пример – Интерактивный режим
>>> 'Ёжик'.encode()
b'xd0x81xd0xb6xd0xb8xd0xba'
>>> 'Ёжик в тумане'.encode().decode()
'Ёжик в тумане'
>>> 'Ёжик в тумане'.encode().decode('utf-16')
'臐뛐룐뫐퀠₲苑菑볐냐뷐뗐'Поясним полученные результаты и принцип работы этих методов.
Задача encode() – представить строку в виде объекта типа bytes (предваряется литералом b). Если знак относится к ASCII, то его байтовое представление будет выглядеть как оригинальный символ. В случае когда он выходит за пределы ASCII, то заменяется байтовым представлением (x — эскейп-последовательность для обозначения 16-ричных чисел в языке Python).
Пример — интерактивный режим
>>> 'Python'.encode()
b'Python'
>>> 'Пайтон'.encode()
B'xd0x9fxd0xb0xd0xb9xd1x82xd0xbexd0xbd'Метод decode() преобразует последовательность байтов в привычную нам строку. Если задать другую кодировку, то можем получить либо неожиданный результат (как в последнем примере, где русские слова превратились в набор корейских иероглифов), либо ошибку UnicodeDecodeError, если в требуемой кодировке нет такого сочетания байтов или они выходят за ее границы.
Читайте также
5. Инструментарий для работы с кодировками
В Python встроено большое разнообразие функций и методов для работы с кодированием-декодированием строк. Часть из них менее актуальна, но на практике могут встречаться.
Перечислим те, которые вам могут понадобиться, а затем опробуем их на практике:
6. Практические примеры
Для усвоения материала попрактикуемся в применении изученного.
А. Функция ascii
Примеры – Интерактивный режим
>>> ascii(12)
'12'
>>> ascii('cat')
"'cat'"
>>> ascii('шапка')
"'\u0448\u0430\u043f\u043a\u0430'"Экранирование русского слова связано с тем, что ни один из символов не включен в стандартный набор знаков ascii (т.е. не имеет 1-байтового представления).
Б. Применение функции str для получения строк
Примеры – Интерактивный режим
>>> str(123)
'123'
>>> str(b'xd0x9fxd0xb0xd0xb9xd1x82xd0xbexd0xbd', 'utf8')
'Пайтон'В. Функция bytes
Превращает в объект bytes не только строки или числа, но и последовательности чисел (каждое из которых соответствует определенному символу).
Примеры – Интерактивный режим
>>> bytes('well done', 'ascii')
b'well done'
>>> bytes('Юта', 'utf16')
b'xffxfe.x04Bx040x04'
>>> bytes((80, 77, 99, 101))
b'PMce'Г. Модуль unicodedata
Позволяет узнать имя любого юникод-символа, а также отобразить его по имени. С другими свойствами можете ознакомиться самостоятельно.
Примеры – Интерактивный режим
>>> import unicodedata
>>> unicodedata.name('Я')
'CYRILLIC CAPITAL LETTER YA'
>>> unicodedata.lookup('GIRL')
'????'
>>> unicodedata.lookup('Trigram for Heaven')
'☰'Задачи по темам
Решаем задачи и отвечаем на вопросы по теме «Целые числа»: работаем с типом данных int
Решаем задачи и отвечаем на вопросы по теме «Числа с плавающей точкой»: работаем с типом данных float
Решаем задачи и отвечаем на вопросы по теме «Логический тип данных»: работаем с типом данных bool
Строки как тип данных в Python. Основные методы и свойства строк. Примеры работы со строками, задачи с решениями.
Д. Отображение любого Юникод-символа
Функция chr() может принимать числа любой стандартной системы счисления (десятичной, двоичной, восьмеричной или шестнадцатеричной).
Функция ord() возвращает десятичное число, соответствующее символу юникод. Если требуется, мы это число можем преобразовать к любому иному основанию.
Примеры – Интерактивный режим
>>> chr(0o144)
'd'
>>> chr(0b1100100)
'd'
>>> chr(0x64)
'd'
>>> chr(100)
'd'
>>> ord('d')
100Также попробуем немного экзотики. Если какой-то из символов не отображается, у вас нет шрифта в системе, который поддерживает эти знаки.
Примеры – Интерактивный режим
>>> chr(0x131B0) # Египетский иероглиф
????
>>> chr(0x1F5A4) # Черное сердечко
'????'
>>> chr(0x265E) # Черный конь
'♞'
>>> chr(0x111E1) # Сингальское число 1
????
>>> chr(0x4E78) # Китайский иероглиф
'乸'Воспользовавшись базой данных символов юникод, вы сумеете просмотреть все доступные варианты на сегодняшний день с указанием имени, кода, принадлежности.
Как вам материал?


Читайте также
Перевод текста в двоичный код
На чтение 3 мин Опубликовано 02.03.2021
Обновлено 23.10.2022
Всем привет, сегодня поговорим про то, как осуществляется перевод текста в двоичный код. Благодаря этому вы узнаете, как в памяти компьютере записываются различные знаки и символы. Также на этой странице вы сможете осуществить перевод ваших слов в язык юникода.

Содержание статьи
- Конвертер для перевода в Unicode
- Основные определения
- ASCII
- Unicode
- Заключение
Конвертер для перевода в Unicode
Получить текст в Юникод
Введите ваш текст
Конвертация
Основные определения
В начале изучим основы, чтобы в дальнейшем всё было понятно. Здесь не будет ничего сложного, чтобы полностью разобраться в теме, надо знать всего два определения и иметь представление о том, как работать с числами в двоичной системе счисления. Итак, приступим.
Код (в информатике) – это взаимно однозначное отображение символов одного алфавита (цифр) с помощью другого, который удобен для хранения, отображения и передачи данных.
На первый взгляд понятие может показаться непонятным, однако, оно совсем простое. Так, например, буквы русского алфавита мы можем представить с помощью десятичных, двоичных или любых других чисел в различных системах исчисления. Также буквы или слова можно закодировать любыми знаками. Однако тут есть одно условие – должны существовать правила, чтобы переводить значения назад. Исходя из этого положения возникает другое:
Кодирование(в информатике) – это процесс преобразования информации в код.
Для отображения текста разработчиками были придуманы так называемые кодировки – таблицы, где символам одного алфавита сопоставляются определенные числовые или текстовые значения. На данный момент относительно широкую популярность имеют две из них – ASCII и Unicode (Юникод). Ниже предложена информация, для ознакомления.
ASCII
Таблица была разработана в Соединенных Штатах Америки в одна тысяча девятьсот шестьдесят третьем году. Изначально предназначалась для использования в телетайпах. Эти устройства представляли собой печатные машинки, с помощью которых передавались сообщения по электрическому каналу. Физическая модель канала была простейшей – если по нему шел ток, то это трактовали как 1, если тока не было, то 0.
Такой системой пользовались высокопоставленные политические деятели. Например, так передавались слова между руководствами двух сверхдержав – США и СССР. Изначально в этой кодировке использовалось 7 бит информации (можно было переводить 128 символов), однако потом их значение увеличили до 256 (8 бит – 1 байт). Небольшая табличка значений двоичных величин, которые помогут с переводом в АСКИ, представлена ниже.

Unicode
Более современная кодировка. Данный стандарт был предложен в Соединенных штатах в 1991 году. Стоит отметить, что его разработала некоммерческая фирма, которая называлась «Консорциум Юникода». Популярность свою стандарт получил из-за его большого символьного охвата – на данный момент с помощью него можно отобразить почти все знаки и буквы, которые используются на планете. Начиная от символов Римской нотации и заканчивая китайскими иероглифами. Символ в этой кодировке использует 1-4 байта машинной памяти. Числовые значения для перевода различных знаков в двузначный формат можно посмотреть здесь.
Заключение
Вот и все, теперь вы знаете про перевод текста в двоичный код в информатике, а также имеете представление о двух самых популярных кодировках, которые используются на данный момент. При возникновении вопросов можете написать их в комментариях.
Python программист. Увлекаюсь с детства компьютерами и созданием сайтов. Закончил НГТУ (Новосибирский Государственный Технический Университет ) по специальности «Инфокоммуникационные технологии и системы связи».