
Почему мне пришла в голову идея разработать собственный компилятор? Однажды мне на глаза попалась книга, где описывались примеры проектирования в AutoCAD на встроенном в него языке AutoLISP. Я захотел c ними разобраться, но прежде меня заинтересовал сам ЛИСП. “Неплохо бы поближе познакомиться с ним”, – подумал я и начал подыскивать литературу и среду разработки. С литературой все оказалось просто – по ЛИСПу ее море в Интернете. Достаточно зайти на портал [1]. Дело оставалось за малым – найти хорошую среду программирования, и вот тут-то начались трудности. Компиляторов под ЛИСП тоже немало, но все они оказались мне малопонятны. Ни один пример из Вики, по разным причинам, не отработал нормально в скачанных мною компиляторах. Собственно, серьезно я с ними не разбирался, но, увы, во многих не нашел как скомпилировать EXE-файл. Самое интересное, что компиляторы эти были собраны разными людьми практически в домашних условиях…
Виталий Белик
by Stilet
И мне пришла в голову мысль: а почему бы не попробовать самому написать свой компилятор или, основываясь на каком-либо диалекте какого-либо языка, свой собственный язык программирования? К тому же на форумах я часто видел темы, где слезно жаловались на тиранов-преподавателей, поставивших задачу написания курсовой – компилятора или эвалюатора (программы, вычисляющей введенное в виде строки выражение). Мне стало еще интереснее: а что если простому студенту, не искушенному книгами Вирта или Страуструпа, написать такую программу? Появился мотив.
In the Beginning
Итак, начнем. Прежде всего, нужно поставить задачу хотя бы на первом этапе. Задача будет банальная: доказать самому себе, что написание компилятора не такой уж сложный и страшный процесс. И что мы, хитрые и смекалистые, способны родить в муках собственного творчества шедевр, который, возможно, полюбится массам. Да и вообще: приятно писать программы на собственном языке, не так ли?
Что ж, цель поставлена. Теперь самое время определиться со следующими пунктами:
- Под какую платформу будет компилировать код программа?
- На каком языке будет код, переводимый в машинный язык?
- На чем будем писать сам компилятор?
Первый пункт достаточно важен, ибо широкое разнообразие операционных систем (даже три монстра – Windows, Linux и MacOS) уже путают все карты. Их исполняемые файлы по-разному устроены, так что нам, простым смертным, придется выбрать из этой “кагалы” одну операционную систему и, соответственно, ее формат исполняемых файлов. Я предлагаю начать с Windows, просто потому, что мне нравится эта операционная система более других. Это не значит, что я терпеть не могу Linux, просто я его не очень хорошо знаю, а такие начинания лучше делать по максимуму, зная систему, для которой проектируешь.
Два остальных пункта уже не так важны. В конце концов, можно придумать свой собственный диалект языка. Я предлагаю взять один из старейших языков программирования – LISP. Из всех языков, что я знаю, он мне кажется более простым по синтаксису, более атомарным, ибо в нем каждая операция берется в скобочки; таким образом, к нему проще написать анализатор. С выбором, на чем писать, еще проще: писать нужно на том языке, который лучше всего знаешь. Мне ближе паскалевидные языки, я хорошо знаю Delphi, поэтому в своей разработке я избираю именно его, хотя никто не мешает сделать то же самое на Си. Оба языка прекрасно подходят для написания такого рода программ. Я не беру в расчет Ассемблер потому, что его диалект приближен к машинному языку, а не к человеческому.
To Shopping
Выяснив платформу, для которой будем писать компилятор (я имею в виду Win32), подберем все необходимое для комфортной работы. Давайте составим список, что же нам пригодится в наших изысканиях.
Для начала нам просто крайне необходимо выяснить, как же все-таки компиляторы генерируют исполняемые EXE-файлы под Windows. Для этого стоит почитать немного об устройстве этих “экзэшек”, как их часто называют, покопаться в их “кишках”. В этом могут помочь современные отладчики и дизассемблеры, способные показать, из чего состоит “экзэшка”. Я знаю два, на мой взгляд, лучших инструмента: OllyDebugger (он же “Оля”) и The Interactive Disassembler (в простонародье зовущийся IDA).
Оба инструмента можно достать на их официальных сайтах http://www.ollydbg.de/ и http://www.hex-rays.com/idapro. Они помогут нам заглянуть в святая святых – храм, почитаемый загрузчиком исполнимых файлов, – и посмотреть, каков интерьер этого храма, дабы загрузчик наших экзэшек чувствовал себя в нем так же комфортно, как “ковбой в подгузниках Хаггис”.
Также нам понадобится какая-нибудь экзэшка в качестве жертвы, которую мы будем препарировать этими скальпелями-дизассемблерами. Здесь все сложнее. Дело в том, что благородные компиляторы имеют дурную привычку пихать в экзэшник, помимо необходимого для работы кода, всякую всячину, зачастую ненужную. Это, конечно, не мусор, но без него вполне можно обойтись, а вот для нашего исследования внутренностей экзэшек он может стать серьезной помехой. Мы ведь не Ричарды Столлманы и искусством реверсинга в совершенстве не владеем. Поэтому нам лучше было бы найти такую программу, которая содержала бы в себе как можно меньше откомпилированного кода, дабы не отвлекаться на него. В этом нам может помочь компилятор Ассемблера для Windows. Я знаю два неплохих компилятора: Macro Assembler (он же MASM) и Flat Assembler (он же FASM). Я лично предпочитаю второй – у него меньше мороки при компилировании программы, есть собственный редактор, в отличие от MASM компиляция проходит нажатием одной-единственной кнопки. Для MASM разработаны среды проектирования, например MASM Builder. Это достаточно неплохой визуальный инструмент, где на форму можно кидать компоненты по типу Delphi или Visual Studio, но, увы, не лишенный багов. Поэтому воспользуемся FASM. Скачать его можно везде, это свободно распространяемый инструмент. Ну и, конечно, не забудем о среде, на которой и будет написан наш компилятор. Я уже сказал, что это будет Delphi. Если хотите конкретнее – Delphi 6.
The Theory and Researching
Прежде чем приступить к написанию компилятора, неплохо бы узнать, что это за формат “экзэшка” такой. Согласно [2], Windows использует некий PE-формат. Это расширение ранее применявшегося в MS-DOS, так называемого MZ формата [3]. Сам чистый MZ-формат простой и незатейливый – это 32 байта (в минимальном виде, если верить FASM; Турбо Паскаль может побольше запросить), где содержится описание для DOS-загрузчика. В Windows его решили оставить, видимо, для совместимости со старыми программами. Вообще, если честно, размер DOS-заголовка может варьироваться в зависимости от того, что после этих 28 байт напихает компилятор. Это может быть самая разнообразная информация, например для операционок, которые не смогли бы использовать скомпилированный DOS или Windows-экзэшник, представленная в качестве машинного кода, который прерываниями BIOS выводит на экран надпись типа “Эта программа не может быть запущена…”. Кстати, сегодняшние компиляторы поступают так же.
Давайте посмотрим на это чудо техники, воспользовавшись простенькой программой, написанной на чистом Ассемблере FASM (см. Рис. 1):

Рис. 1. Исходник для препарирования
Сохраним файл под неким именем, например Dumpy. Нажмем F9 или выберем в меню пункт RUN. В той же папке будет создан EXE-файл. Это и будет наша жертва, которую мы будем препарировать. Теперь ничто не мешает нам посмотреть: “из чего же, из чего же сделаны наши девчонки?”.
Запустим OllyDebuger. Откроем в “Оле” наш экзэшник. Поскольку фактически кода в нем нет, нас будет интересовать его устройство, его структура. В меню View есть пункт Memory, после выбора которого “Оля” любезно покажет структуру загруженного файла (см. Рис. 2):
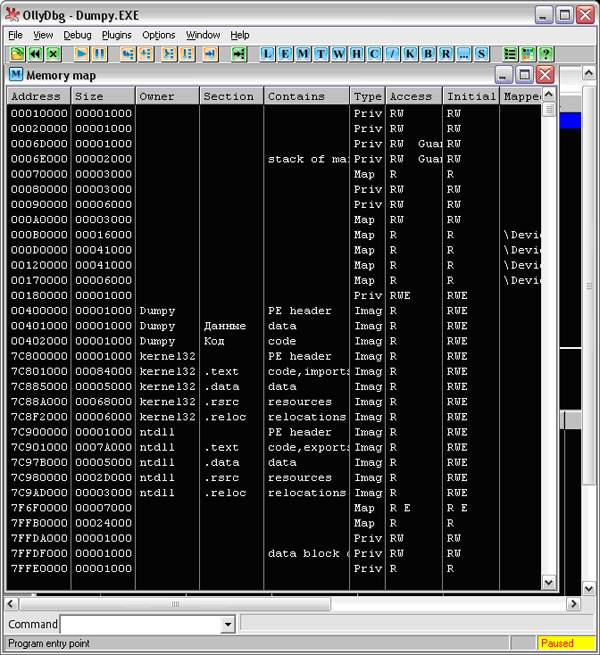
Рис. 2. Карта памяти Dumpy
Это не только сам файл, но и все, что было загружено и применено вместе с ним, библиотеки, ресурсы программы и библиотек, стек и прочее, разбитое на блоки, называемые секциями. Из всего этого нас будут интересовать три секции, владелец которых Dumpy, – это непосредственно содержимое загруженного файла.
Собственно, эти секции были описаны нами в исходнике, я не зря назвал их по-русски (ведь операционной системе все равно, как названы секции, главное – их имена должны укладываться точь-в-точь в 8 байт. Это придется учесть обязательно).
Заглянем в первую секцию PE Header. Сразу же можем увидеть (см. Рис. 3), что умная “Оля” подсказывает нам, какие поля* у этой структуры:
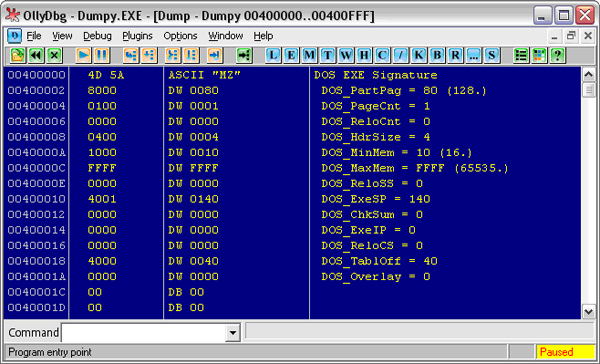
Рис. 3. MZ-заголовок
* Комментарий автора.
Сразу хочу оговориться, не все из этих полей нам важны. Тем паче что сам Windows использует из них от силы 2-3 поля. Прежде всего, это DOS EXE Signature – здесь (читайте в Википедии по ссылке выше) помещаются две буквы MZ – инициалы создателя MS-DOS, и поле DOS_PartPag. В нем указывается размер MZ-заголовка в байтах, после которых помещается уже PE-заголовок.
Последнее поле, которое для нас важно, находится по смещению 3Ch от начала файла (см. Рис. 4):
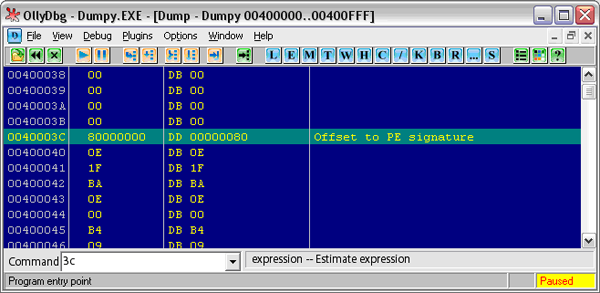
Рис. 4. Смещение на PE-заголовок
Это поле – точка начала РЕ-заголовка. В Windows, в отличие от MS-DOS, MZ-заголовок заканчивается именно на отметке 40**, что соответствует 64 байтам. При написании компилятора будем соблюдать это правило неукоснительно.
* Комментарий автора.
Обратите внимание! Далее, с 40-го смещения, “Оля” показывает какую-то белиберду. Эта белиберда есть атавизм DOS и представляет из себя оговоренную выше информацию, с сообщением о том, что данная программа может быть запущена только под DOS-Windows. Этакий перехватчик ошибок. Как показывает практика, этот мусор можно без сожаления выкинуть. Наш компилятор не будет генерировать его, сразу переходя к PE-заголовку.
Что ж, перейдем непосредственно к PE-заголовку (см. Рис. 5). Как показывает “Оля”, нам нужно перейти на 80-й байт. Да, чуть не забыл. Все числа адресации указываются в 16-тиричной системе счисления. Для этого после чисел ставится латинская буква “H”. “Оля” не показывает ее, принимая эту систему по умолчанию для адресации. Это нужно учесть, чтобы не запутаться в исследованиях. Фактически 80h – это 128-й байт.
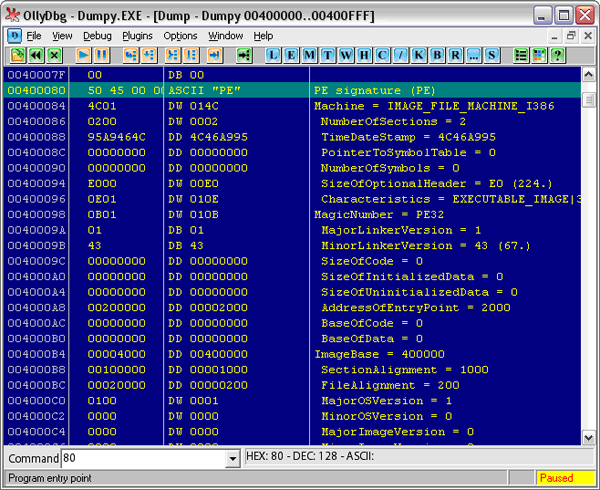
Рис. 5. Начало РЕ-заголовка
Вот она, святая обитель характеристик экзэшника. Именно этой информацией пользуется загрузчик Windows, чтобы расположить файл в памяти и выделить ему необходимую память для нужд. Вообще, считается, что этот формат хорошо описан в литературе. Достаточно выйти через Википедию по ссылкам в ее статьях [4] или банально забить в поисковик фразу вроде “ФОРМАТ ИСПОЛНЯЕМЫХ ФАЙЛОВ PortableExecutables (PE)”, как сразу же можно найти кучу описаний. Поэтому я поясню только основные его поля, которые нам понадобятся непосредственно для написания компилятора…
Прежде всего, это PE Signature – 4-хбайтовое поле. В разной литературе оно воспринимается по-разному. Иногда к нему приплюсовывают еще поле Machine, оговариваясь, чтобы выравнять до 8 байт. Мы же, как любители исследовать, доверимся “Оле” с “Идой” и будем разбирать поля непосредственно по их подсказкам. Это поле содержит две латинские буквы верхнего регистра “PE”, как бы намекая нам, что это Portable Executable-формат.
Следующее за ним поле указывает, для какого семейства процессоров пригоден данный код. Всего их, как показывает литература, 7 видов:
0000h __unknown
014Ch __80386
014Dh __80486
014Eh __80586
0162h __MIPS Mark I (R2000, R3000)
0163h __MIPS Mark II (R6000)
0166h __MIPS Mark III (R4000)
Думаю, нам стоит выбрать из всего этого второй вид – 80386. Кстати, наблюдательные личности могли заметить, что в компиляторах Ассемблера есть директива, указывающая, какое семейство процессора использовать, как, например, в MASM (см. Рис. 6):
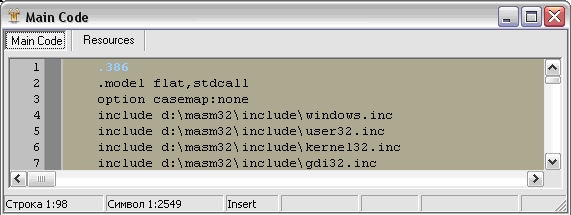
Рис. 6. Указание семейства процессоров в МАСМ
386 как раз и говорит о том, что в этом поле будет стоять значение 014Ch***.
* Комментарий автора.
Обратите внимание на одну небольшую, но очень важную особенность: байты в файле непосредственно идут как бы в перевернутом виде. Вместо 14С в файл нужно писать байты в обратном порядке, начиная с младшего, т. е. получится 4С01 (0 здесь дополняет до байта. Это для человеческого глаза сделано, иначе все 16-тиричные редакторы показывали бы нестройные 4С1. (Согласитесь, трудно было понять, какие две цифры из этого числа к какому байту относятся.) Эту особенность обязательно придется учесть. Для простоты нелишним было бы написать пару функций, которые число превращают в такую вот перевернутую последовательность байт (что мы в дальнейшем и сделаем).
Следующее важное для нас поле – NumberOfSections. Это количество секций без учета PE-секции. Имеются в виду только те секции, которые принадлежат файлу (в карте памяти их владелец – Dumpy). В нашем случае это “Данные” и “код”.
Следующее поле хоть и не столь важно, но я его опишу. Это TimeDateStamp – поле, где хранится дата и время компиляции. Вообще, я его проигнорирую, не суть важно сейчас, когда был скомпилирован файл. Впрочем, если кому захочется помещать туда время, то флаг в руки.
Сразу хочу предупредить, что меня как исследователя не интересовали поля с нулевыми значениями. На данном этапе они действительно неважны, поэтому в компиляторе их и нужно будет занулить.
Следующее важное поле – SizeOfOptionalHeader. Оно содержит число, указывающее, сколько байт осталось до начала описания секций. В принципе, нас будет устраивать число 0Eh (224 байта).
Далее идет поле “характеристики экзэшника”. Мы и его будем считать константным:
Characteristics (EXECUTABLE_IMAGE|32BIT_MACHINE|LINE_NUMS_STRIPPED|LOCAL_SYMS_STRIPPED)
И равно оно 010Eh. На этом поле заканчивается так называемый “файловый заголовок” и начинается “Опциональный”.
Следующее поле – MagicNumber. Это тоже константа. Так называемое магическое число. Если честно, я не очень понял, для чего оно служит, в разных источниках это поле преподносится по-разному, но все хором ссылаются на знаменитый дизассемблер HIEW, в котором якобы впервые появилось описание этого поля именно в таком виде. Примем на веру.
Следующие два поля, хоть и не нулевые, но нам малоинтересны. Это: MajorLinkerVersion и MinorLinkerVersion. Это два байта версии компилятора. Угадайте, что я туда поставил?
Следующее важное поле – AddressOfEntryPoint. Важность этого поля в том, что оно указывает на адрес, с которого начинается первая команда, – с нее процессор начнет выполнение. Дело в том, что на этапе компиляции значение этого поля не сразу известно. Ее формула достаточно проста. Сначала указывается адрес первой секции плюс ее размер. К ней плюсуются размеры остальных секций до секции, считаемой секцией кода. Например, в нашей жертве это выглядит так (см. Рис. 7):
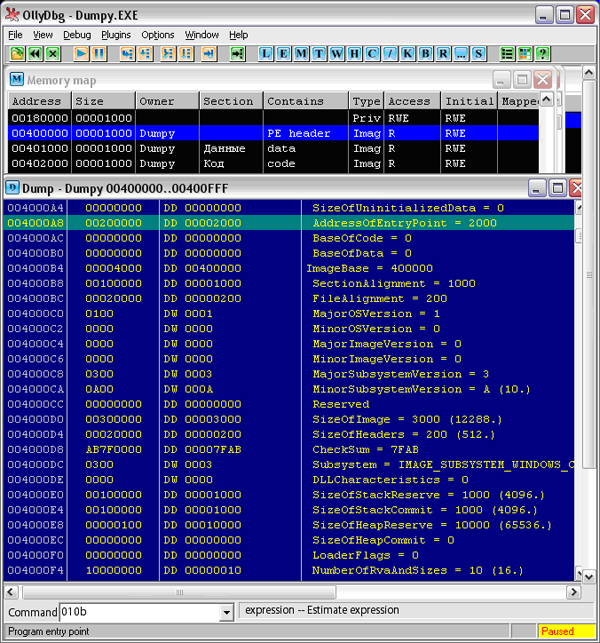
Рис. 7. Расчет точки входа
Здесь секция кода вторая по счету, значит, Адрес точки входа равен размеру секции “Данные” плюс ее начало и равен 2000. К этому еще пририсовывается базовый адрес, в который загрузчик “сажает” файл, но он в вычислении для нашего компилятора не участвует. Поэтому в жертве точка входа имеет значение 2000.
Следующее поле – ImageBase. Это поле я приму как константу, хотя и не оговаривается ее однозначное значение. Это значение указывает адрес, с которого загрузчик поместит файл в память. Оно должно нацело делиться на 64000. В общем, необязательно указывать именно 400000h, можно и другой адрес. Уже не помню, где я слышал, что загрузчик может на свое усмотрение поменять это число, если вдруг в тот участок памяти нельзя будет загружать, но не будем это проверять, а примем на веру как константу =400000h.
Следующая важная константа – SectionAlignment. Это значение говорит о размере секций после загрузки. Принцип прост: каждая секция (имеется в виду ее реализация) дополняется загрузчиком пустыми байтами до числа, указанного в этом поле. Это так называемое выравнивание секций. Тут уж хороший компилятор должен думать самостоятельно, какой размер секций ему взять, чтобы все переменные (или сам код), которые в коде используются, поместились без проблем. Согласно спецификации, это число должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). В принципе, пока что для простенького компилятора можно принять это значение как константу. Нас вполне устроит среднее значение 1000h (4096 байт – не правда ли, расточительный мусор? На этом весь Windows построен – живет на широкую ногу, память экономить не умеет).
Далее следует поле FileAlignment. Это тоже хитрое поле. Оно содержит значение, сколько байт нужно дописать в конец каждой секции в сам файл, т. е. выравнивание секции, но уже в файле. Это значение тоже должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). Неплохо бы рассчитывать функцией это поле в зависимости от размеров, данных в секции.
Следующие поля – MajorSubsystemVersion и MinorSubsystemVersion – примем на веру как константы. 3h и Аh соответственно. Это версия операционной системы, под которую рассчитывается данная компиляция****.
* Комментарий автора.
Я не проверял на других ОС: у меня WinXP. В принципе можно не полениться и попробовать пооткрывать “Олей” разные программы, рассчитанные на другие версии Windows.
Далее из значимых следует SizeOfImage. Это размер всего заголовка, включая размер описания всех секций. Фактически это сумма PE-заголовка плюс его выравнивание, плюс сумма всех секций, учитывая их выравнивание. Ее тоже придется рассчитывать.
Следующее поле – SizeOfHeaders (pазмеp файла минус суммарный pазмеp описания всех секций в файле). В нашем случае это 1536-512 * 2=200h (512 байт). Однако РЕ тоже выравнен! Это поле тоже нужно будет рассчитывать.
Далее следует не менее коварное поле – CheckSum. Это CRC сумма файла. Ужас… Мы еще файл не создали, а нам уже нужно ее посчитать (опять-таки вспоминается Микрософт злым громким словом). Впрочем, и тут можно вывернуться. В Win API предусмотрена функция расчета CRC для области данных в памяти, проще говоря, массива байт – CheckSumMappedFile. Можно ей скормить наш эмбрион файла. Причем веселье в том, что эта операция должна быть самой последней до непосредственной записи в файл. Однако, как показывает практика, Windows глубоко наплевать на это поле, так что мы вполне можем не морочить себе голову этим расчетом (согласитесь, держать в файле поле, которое никому не нужно, да еще и напрягать нас лишним расчетом – это глупо, но, увы, в этом изюминка политики Микрософта. Складывается впечатление, что программисты, писавшие Windows, никак не согласовывали между собой стратегию. Спонтанно писали. Импровизировали).
Следующее поле – Subsystem. Может иметь следующие значения*****:
- IMAGE_SUBSYSTEM_WINDOWS_CUI=3. Это говорит о том, что наш откомпилированный экзэшник является консольной программой.
- IMAGE_SUBSYSTEM_WINDOWS_GUI=4. Это говорит о том, что экзэшник может создавать окна и оперировать сообщениями.
* Комментарий автора.
Для справки, кто хорошо знает Delphi: директивы компилятора {$APPTYPE GUI} и {$APPTYPE CONSOLE} именно эти параметры и выставляет.
Вот, собственно, и все важные для нас параметры. Остальные можно оставить константно, как показывает “Оля”:
DLLCharacteristics = 0
SizeOfStackReserve = 1000h (4096)
SizeOfStackCommit = 1000h (4096)
SizeOfHeapReserve = 10000h (65536)
NumberOfRvaAndSizes = 10h (16)
И остаток забить нулями (посмотрите в “Оле” до начала секций, какие там еще параметры). О них можно почитать подробнее по ссылкам, которые я привел.
После идет описание секций. Каждое описание занимает 32 байта. Давайте взглянем на них (Рис. 8):
Рис. 8. Описание секций
В начале секции идет ее имя (8 байт), после этого поле – VirtualSize, описывает (я процитирую из уроков Iczeliona) “RVA-секции. PE-загpузчик использует значение в этом поле, когда мэппиpует секцию в память. То есть, если значение в этом поле pавняется 1000h и файл загpужен в 400000h, секция будет загpужена в 401000h”.
Однако “Оля” почему-то показывает для обеих секций одно и то же значение 9. Что это? Я не понял, почему так. Пока оставим это как данное. Вдруг в будущем разберемся.
Далее следует VirtualAddres, который указывает, с какого адреса плюс ImageBase будет начинаться в памяти секция – это важное поле, именно оно станет для нашего компилятора базой для расчета адреса к переменной. Собственно, адрес этот напрямую зависит от размера секции. Следующий параметр PointerToRawData – это смещение на начало секции в скомпилированном файле. Как я понял, этот параметр компиляторы любят подводить под FileAlignment. И последнее – поле Characteristics. Сюда прописывается доступ к секции. В нашем случае для секции кода оно будет равным 60000020=CODE|EXECUTE|READ, а для секции данных C0000040=INITIALIZED_DATA |READ|WRITE.
Вот и все. Закончилось описание заголовка. Далее он выравнивается нулями до 4095 байт (с этим числом связан один прикол). В файле мы его будем дополнять до FileAlignment (в нашем случае до 200h).
Hello world. Hey! Is There Anybody Out There?
Вот мы и прошлись по кишкам нашей жертвы – экзэшника. Напоследок попробуем на скорую руку закрутить простейший компилятор для DOS-системы без PE-заголовка. Для этого подойдут инструменты, которые так почему-то любят преподавать до сих пор.
Я говорю о классическом Паскале. Итак, предположим, злобный преподаватель поставил задачу: написать компилятор программы вывода на экран некой строки, которую мы опишем для компилятора, введя ее ручками (см. листинг 1):
var header,commands,s:string;
e,i:integer;
f:file;
begin
{Это MZ-заголовок}
header:=#$4D#$5A#$3E#$00#$01#$00#$
00#$00#$02#$00#$00#$01#$FF#$FF#$02#$00#$00;
header:=header+#$10#$00#$00#
$00#$00#$00#$00#$1C#$00#$00#$00#$00#$00#$00#$00;
writeln(
‘give me welcome ![]() ’);readln(s);
’);readln(s);
{Поскольку у нас все в одном сегменте, и код и данные, лежащие непосредственно в конце кода, нужно, чтобы регистр, содержащий базу данных, указывал на код. Предположим, мы будем считать, что и сам код представляет из себя данные. Для этого поместим в стек адрес сегмента кода}
{*******************************************************************************************}
Commands:=#$0E; { push cs}
{и внесем из стека этот адрес в регистр сегмента данных}
Commands:=Commands+#$1F; { pop ds}
Commands:=Commands+#$B4#$09; { mov ah, 9 – Вызовем функцию вывода строки на экран}
{Передадим в регистр DX-адрес на строку. Поскольку пока что строка у нас не определена, передадим туда нули, а позже подкорректируем это место}
Commands:=Commands+#$BA#$
00#$00; { mov dx, }
{Запомним место, которое нужно будет скорректировать. Этим приемом я буду пользоваться, чтобы расставить адреса в коде, который обращается к переменным}
e:=length(commands)-1;
{Выведем на экран строку}
Commands:=Commands+#$CD#$21;
{ int 21h ; DOS – PRINT STRING}
{подождем, пока пользователь не нажмет любую клавишу}
Commands:=Commands+#$B4#$01; { mov ah, 1}
Commands:=Commands+#$CD#$21; { int 21h ; DOS – KEYBOARD INPUT}
{После чего корректно завершим программу средствами DOS}
Commands:=Commands+#$B4#$4C; { mov ah, 4Ch}
Commands:=Commands+#$CD#$21; {int 21h ; DOS – 2+ – QUIT WITH EXIT CODE (EXIT)}
Commands:=Commands+#$C3; {retn}
{*******************************************************************************************}
{Теперь будем править адреса, обращающиеся к переменной. Поскольку само значение переменной у нас после всего кода (и переменная) одно, мы получим длину уже имеющегося кода – это и будет смещение на начало переменной}
i:=length(commands);
{В запомненное место, куда нужно править, запишем в обратном порядке это смещение}
commands[e]:=chr(lo
(i));
commands[e+1]:=chr(hi(i));
{Учтем, что в DOS есть маленький атавизм – строки там должны завершаться символом $. По крайней мере, для этой функции.}
commands:=commands+s+‘$’;
{не забудем дописать в начало заголовок}
commands:=header+commands;
{Теперь скорректируем поле DOS_PartPag. Для DOS-программ оно указывает на общий размер файла. Честно говоря, я не знаю, зачем это было нужно авторам, может быть, когда они изобретали это, еще не было возможности получать размер файла из FAT. Опять-таки запишем в обратном порядке}
i:=length(commands);
commands[3]:=chr(lo(i))
;
commands[4]:=chr(hi(i));
{Ну, и кульминация этого апофигея – запись скомпилированного массива байт в файл. Все заметили, что я воспользовался типом String, – он в паскалевских языках был изначально развит наиудобнейшим образом}
Assign(f,‘File.exe’);rewrite(f);
BlockWrite(f,commands[1],length(commands), e);
Close(f);
end.
Не удивляет, что программа получилась небольшой? Почему-то преподаватели, дающие такое задание, уверены, что студент завалится. Думаю, такие преподаватели сами не смогли бы написать компилятор. А студенты смогут, ибо, как видим, самая большая сложность – это найти нужные машинные коды для решения задачи. А уж скомпилировать их в код, подкорректировать заголовок и расставить адреса переменных – задача второстепенной сложности. В изучении ассемблерных команд поможет любая книга по Ассемблеру. Например, книга Абеля “Ассемблер для IBM PC”. Еще неплохая книга есть у Питера Нортона, где он приводит список функций DOS и BIOS.
Впрочем, можно и банальнее. Наберите в поисковике фразу “команды ассемблера описание”. Первая же ссылка выведет нас на что-нибудь вроде [5] или [6], где описаны команды Ассемблера. Например, если преподаватель задал задачку написать компилятор сложения двух чисел, то наши действия будут следующими:
- Выясняем, какая команда складывает числа. Для этого заглянем в книгу того же Абеля, где дается такой пример:
сложение содержимого
ADD AX,25 ;Прибавить 25
ADD AX,25H ;Прибавить 37 - Значит, нам нужна команда ADD. Теперь определимся: нам же нужно сложить две переменные, а это ячейки памяти; эта команда не умеет складывать сразу из переменной в переменную, для нее нужно сначала слагаемое поместить в регистр (AX для этого лучше подходит), а уж потом суммировать в него. Для помещения из памяти в регистр (согласно тому же Абелю) нужна команда
mov [адрес], ax
- Таким образом, инструкции будут выглядеть так:
mov [Адрес первой переменной], ax
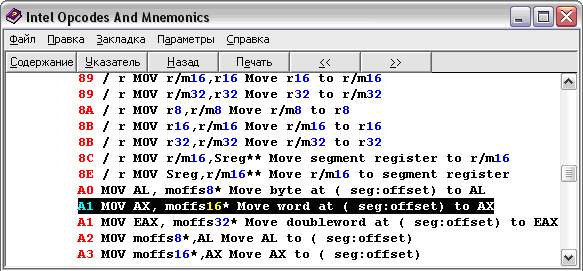
add [Адрес второй переменной], ax - Теперь нужно определиться с кодами этих команд. В комплекте с MASM идет хелп, где описаны команды и их опкоды (машинные коды, операционные коды). Вот, например, как выглядит опкод команды MOV из переменной:
Рис. 9. Опкоды MOV
Видим (см. Рис. 9), что его опкод A1 (тут тоже любят 16-тиричность). Таким образом, выяснив все коды, можно написать компилятор что-то вроде этого (см. листинг 2):
Commands:= Commands+#$A1#$00#$00; { mov [Из памяти] в AX}
aPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной a}
Commands:= Commands+#$03#$06#$00#$00;{ $03 – Это опкод команды ADD $06 – Это номер регистра AX}
bPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной b}
Commands:= Commands+#$A3#$00#$00; { mov из AX в переменку b}
b2Pos:= Length(Commands)-1;
{Запомним позицию для корректировки для переменной b}А далее, в конце, скорректируем эти позиции (см. листинг 3):
commands:= commands+#$01#$00; {Это переменка a, ее значение}
i:= length(commands);
commands[aPos]:= chr(lo(i)); {Не забудем, что адреса в перевернутом виде}
commands[
aPos+1]:= chr(hi(i)); {Поэтому сначала запишем младший байт}
commands:= commands+#$02#$00; {Это переменка b, ее значение}
i:= length(commands);
commands[bPos]:= chr
(lo(i)); {Поскольку переменка b фигурирует в коде}
commands[bPos+1]:= chr(hi(i)); {дважды придется корректировать ее}
commands[b2Pos]:= chr
span style=”color: #66cc66;”>(lo(i));
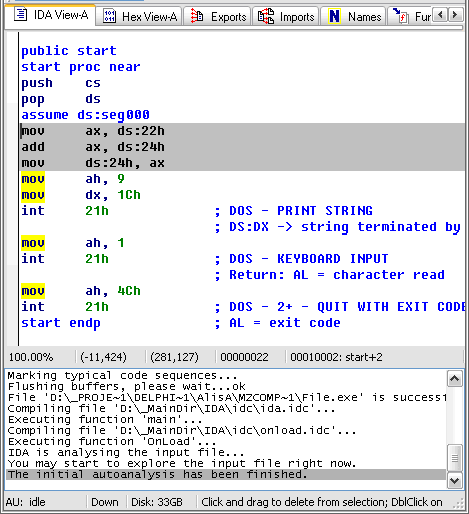
commands[b2Pos+1]:= chr(hi(i));Запустим компилятор, он скомпилирует экзэшник, который посмотрим в “Иде” (см. Рис. 10):
Рис. 10. Реверсинг нашего кода
Все верно, в регистр пошло значение одной переменной, сложилось со второй и во вторую же записалось. Это эквивалентно паскалевскому b:=b+a;
* Комментарий автора.
Обратите внимание: значения переменных мы заранее проинициализировали. При желании можно сделать, чтобы компилятор спросил их инициальное значение, и подставить в нужное место:
commands:=commands+#$01#$00; {Вот сюда вместо этих циферок}.
Post Scriptum
Ну как, студенты, воспряли духом? Теперь понятен смысл, куда двигаться в случае столкновения с такими задачами? Это вряд ли потянет на курсовую, но вполне подойдет для простенькой контрольной. А вот следующая задача – написать транслятор – уже действительно тянет даже на хороший диплом, так что пока переварим все то, что выше, а в следующий раз попробуем приготовить основное ядро компилятора, дабы потом уже делать упор на сам код программы.
Сам себе компилятор (или руководство по мазохизму для дзенствующих)
Сам себе компилятор (или руководство по мазохизму для дзенствующих) — Архив WASM.RU
Предисловие
FatMoon, ты извращенец! Знаешь об этом?
SerrgioДа, об этом я знаю. Подозревать начал еще в раннем детстве, когда
- пробовал на вкус акварельные «медовые» краски;
- пытался залить чернила в стержень авторучки;
- приносил домой гусениц, кормил их листьями и вылуплял бабочек.
Когда я сел за компьютер, подозрения перешли в твердую уверенность.
Да, похоже, что я извращенец. Хотя все относительно — видал я таких извращенцев,
по сравнению с которыми я просто … пуританин! А писать на ассемблере под
WINDOWS не извращение? Молчите? И в этом молчании я слышу глас рассудка.
ї А. Сапковский.
О чем эта статья? О программировании на ассемблере без компилятора, об отладчике
DEBUG из стандартного пакета DOS/WINDOWS, о машинном коде и прочим смежным
темам.
Alex FatMoonКак обычно пишутся программы на ассемблере? В редакторе — не суть важно, каком
— набирается исходный текст, содержащий директивы ассемблера, мнемокоды инструкций,
определения данных и метки. Затем вызывается компилятор — не суть важно, какой
— который транслирует исходный файл в объектный. Затем линкер собирает исполняемый
файл из одного или нескольких объектных модулей. Знакомая картина, не правда
ли? Однако необходимо ли все это для создания работоспособной программы? Нет,
конечно же. Для создания .com — файлов вполне достаточно отладчика DEBUG. Вот
об этом и будет речь.Почти любой отладчик имеет функцию транслирования мнемокодов в машинный код
с возможностью записи на диск набранного блока. Поэтому в принципе эти же приемы
могут быть использованы и с другими утилитами. Почему все-таки я описываю DEBUG?
Он есть практически на любой машине, где установлена любая из версий MS-DOS
или WINDOWS. Он прост в использовании, не требователен к ресурсам, знает почти
все машинные коды и даже поддерживает инструкции сопроцессора. Он — первый друг
взломщика сейвов к играм и просто хакера. И вообще — одно из лучших творений
МикроСофт. Лежит он, родимый, в директории C:DOS или C:WINDOWSCOMMAND
— даже если ваши папки называются по-другому и расположены на других дисках,
найти его нетрудно. Переходим к непосредственному использованию.Программирование без компилятора
Русские сначала придумывают себе препятствия, а потом их
преодолевают.
(известный факт)
Входите узкими вратами, ибо широки врата и просторен путь, ведущий в геену
огненную.
(Евангелие от Матфея)Да, если у вас есть компилятор, использовать что-то еще нет нужды. Но представим
себе, что компилятора нет. Или мы только начали изучать ассемблер и в принципе
знаем мнемокоды по богатому опыту программирования на БК, Спектруме или Микроше,
но о директивах имеем только общее представление. И напряженно думаем, с какими
ключами запускать этот tasm? И почему tasm выдает ошибки при компиляции,
хотя все написано правильно (кто бы мог подумать, что ss: mov ax, [si]
на самом деле должно быть записано как mov ax, ss:[si]?). Тогда это для
вас. А также если есть желание понять, как же работает компилятор и зачем он
все-таки нужен. Подумав (от «DOOM») и перекрестясь (наведя перекрестье
на последнего из монстров, нажав «fire primary» и выйдя из
игры), приступим!Пример программы.
Главная команда отладчика, которую будем использовать, «А»ssembly.
Итак, входим в отладчик, набираемa 100и видим адрес ххх:0100. От нас ждут ввода инструкций. Собственно, можно набирать
программу. Пример:a 100 mov ah,09 mov dx,0100 int 21 ret db "Hello, world!$"и готово. Однако это еще не конец. Надо скорректировать dx — 0100 туда засылается
просто для того, чтобы обозначить команду. Ведь когда мы пишем:mov dx,xxxмы еще не знаем адреса, с которого начнется строка «Hello, world!$»,
не так ли? Этот адрес мы узнаем только после того, как введем «ret».
Итак, запоминаем в cx длину нашей программы — она равна адресу инструкции после
строки, где мы нажали «Enter», чтобы выйти из режима компиляции, за
вычетом 0100 — адрес, с которого начинается программа типа «COM».
У меня для вышеприведенной программы получилось 016h. Значит, набираем:rcx 16А теперь корректируем адрес — строка начинается с 0108. Набираем:
a 102 mov dx,108Осталось сохранить программу на диске:
n hello.com wВуаля! Теперь в директории, где мы находились перед вызовом отладчика, есть
файл hello.com длиной в 22 байта, исправно печатающий при запуске строку
«Hello, world!» и возвращающий управление ОС. Просто, не так ли? И
никаких компиляторов. На самом деле в роли такового выступили мы сами — назначили
строке фиктивный адрес (0100), затем заменили его на точный (0108). Вся помощь
отладчика заключалась в переводе мнемокодов в машинные. Не можем же мы помнить
все машинные коды!Это кажется элементарным, не спорю. Попробуем сделать что-нибудь более сложное,
и затем попытаемся оптимизировать это. То есть, обычная процедура для любой
программы — сначала «рыхлый» код, от которого добиваются работоспособности,
затем оптимизация. Лично я придерживаюсь именно такой тактики, и нахожу ее достаточно
удобной. Для примера выведем бегущую строку на обычный текстовый экран 80*25
— разрешение, к которому все привыкли (надеюсь) в Norton Commander. Не
претендуя на оригинальность, скажу, что нам потребуется две строки в качестве
данных/переменных. Одна из строк будет оригиналом, а вторая — служить для хранения
подстроки. Алгоритм весьма прост:
- Цикл: вырезать подстроку выбранной длины;
- переместить курсор на выбранное место на экране;
- вывести подстроку;
- сделать задержку;
- сдвинуться в строке на символ;
- если не конец строки, то продолжать цикл.
Но перед тем, как набивать в отладчике код, я несколько облегчу вам работу.
Перенаправление ввода-вывода в ДОС.
Каждый раз набивать программу в отладчике было бы очень долго и может навсегда
отвратить от программирования. К счастью, в ДОС (и, в частности,(«в частности»
убрать) в коммандной строке Windows (согласен, переставить слово надо)) можно
использовать перенаправление стандартного ввода-вывода. Как это делается? Пишем
текстовый файл, например, содержащий предыдущую программу «Hello, world!»,
в виде:----8<--- a 100 mov ah,09 mov dx,108 int 21 ret db "Hello, world!$"rcx 16 n hello.com w q--->8---Не забудьте пустую строку после DB (она выводит отладчик из режима ассемблирования),
и не забываем поставить в конце команду выхода! Сохраняем его под именем, например,
hello.dbg и пишем в командной строке:debug < hello.dbgВ результате отладчик берет команды не с клавиатуры, а из файла. Вводит программу
на языке ассемблера начиная с адреса 0100, и сохраняет на диск под именем hello.com.
И выходит в ДОС. А что, почти обычная программа — только вместоORG 0100hимеем
a 100и еще команды в конце.
Точно также, чтобы получить красивый листинг при дизассемблировании, не обязательно
делать PrintScreen после команды «u». Поскольку это
наша программа и мы знаем, где находится код, а где данные, создаем файл d_hello.dbg,
содержащий следующие строки:u 100,107 d 108,115 qИ набираем в командной строке
debug hello.com < d_hello.dbg > hello.dizЗдесь мы перенаправляем как ввод (из файла d_hello.dbg), так и вывод
(в файл hello.diz).В результате получаем еще и файл hello.diz, содержащий дизассемблированную
программу.Таким образом, имеем debug в роли компилятора, и некий файл, содержащий
команды отладчика и мнемокоды, в качестве программы. Для «компиляции»
вызываем отладчик, используя ввод из файла, а для дизассемблирования — используем
ввод из файла и вывод в файл вместо ввода с клавиатуры и вывода на экран. Да,
не зацикливайтесь на расширениях — они в данном случае произвольны. Все эти
файлы в принципе могут быть с расширением «.txt» или вообще
без расширений — кому как удобнее.[прим.: Но это ещё не всё! В отличие от «простого» компилятора
DEBUG может также сразу и выполнять (почти «интерпретировать»)
нашу «программу» (по аналогии с бейсиком), поэтому сохранять результат
трансляции в отдельный файл нет необходимости — достаточно вместо команд RCX
и N поставить G=100, не забыв завершить нашу программу инструкцией
INT 3, если мы желаем увидеть содержимое регистров, с которым наша
программа завершается. Итак, делаем следующий файл:a xor ax,ax mov es,ax ; сегмент 0 es: mov ax,[46c] ; адрес таймера в области данных BIOS es: mov dx,[46e] int 3 ; DX:AX содержат значение системного таймераg=100 qсохраняем это под именем ticks, даём команду DEBUG<TICKS>RESULT,
и наблюдаем в файле RESULT в регистрах DX и AX значение
системного таймера. Впрочем, конкретно для данного случая наша программа может
быть «короче»:d 0:46c l 4 qИспользование внешнего файла и комментариев в нём также облегчает «настройку»
адресов. Например, в исходном файле на месте меток можно вставить соответствующий
комментарий, а в инструкциях перехода вместо имён меток будет фиктивное значение.
Разумеется, в исходном файле не должно быть команды G, ведь программа ещё
не завершена. Например:a mov ax,100 mov cx,100 ;top: dec ax loop 100 ; top int 3;g=100 qПосле первого «прохода» (выполнения DEBUG с перенаправлением
ввода-вывода) следует проанализировать вывод на наличие сообщений об ошибках.
Потом следует проверить значения закомментированных меток и скопировать эти
значения в соответствующие места (в данном случае значение метки top нужно
вставить после инструкции loop). Теперь можно расскоментарить команду G и
программа готова.Вывод «бегущей строки» — создание программы с помощью отладчика.
Итак, набираем сразу в виде файла, чтобы потом «скомпилировать» его
отладчиком.---------Start of file------------ a 100 mov cx,555 push cx mov si,200 sub cx,555 sub si,cx mov di,400 mov cx,14 rep movsb mov byte ptr [di],24 mov bh,0 mov dx,0c1f mov ah,02 int 10 mov dx,400 mov ah,09 int 21 mov ah, 86 inc cx inc cx xor dx,dx int 15 mov ah,01 int 16 pop cx jnz 0140 loop 0103 jmp 0100 ret db " ******** This is a long long string." db " It can be up to 64K long! You never see such long string" db " before! Enjoy it. Here may be some of your text and " db "advertizing. Just type what you want together" db " with WISPA chocolate! This program is debug handwork." db " All rights reserved. Decompilation and dizassembly " db " prohibited! The length of this string now 477 bytes" db " but length of code that print them is only 59 bytes." db " Sorry for my english, I write as I can. Alex FatMoon. $"rcx 400 n r_string.com w q ------------End of file----------Не забудьте поставить пробел перед долларом — он нужен, что бы конец строки
затирал символы, остающиеся от предыдущего вывода. Сделаю некоторые пояснения:
- 555 — обозначил длину строки. На самом деле тут должно быть число, равное
«адрес конца строки» — «адрес начала строки».- 0200 — обозначим адрес начала строки. Мы его пока не знаем, но потом в листинге
легко найдем.- 0400 — адрес начала подстроки. Подстрока начнется сразу после конца строки.
Этот адрес мы тоже пока не знаем.- 0140 — адрес инструкции «ret». Он идет непосредственно перед строкой.
И его тоже пока не знаем.Сохраняем на диске 1К, поскольку точной длины программы опять же не знаем.
Для тех, кто ввел очень длинную строку — можете сохранять не 0400h, а
ff00h. Наверняка где-то в начале этого блока все-таки уместилась наша«гигантская»
программа.Теперь загружаем в отладчик почти готовый r_string.com, и дизассемблируем,
отмечая исправления, которые надо внести: строка начинается с 013ch,
длина всей программы 0219h, длина строки = 0319h-013ch=01ddh,
адрес «ret» — 013bh. Вносим изменения — можно прямо в отладчике,
можно в текстовом файле. Все должно работать. Оптимизация, очистка экрана в
начале и прочее — на ваше усмотрение.[прим.: как упоминалось выше, для этого ничего дизассемблировать
не нужно, достаточно выполнить один проход «компиляции» с перенаправлением
вывода, после чего значения всех меток станут известны]Послесловие
Блаженны больные, ибо исцелятся.
(почти из Библии)
И тебя вылечат… И меня вылечат!
(«Иван Васильевич меняет профессию»)Вот собственно для этого и нужен компилятор — назначить адреса меткам и переменным
и правильно вставить их в машинный код. Чем больше переменных и переходов, тем
сложнее написать программу в отладчике. И слава богу, что это делать не обязательно,
поскольку есть компиляторы. Если же читатель достаточно безумен, чтобы попробовать
самостоятельно написать довольно объемистый проект, флаг в руки. Моего терпения
хватило однажды на двух-килобайтную видеодемку, и я думаю, что писать программы
под ДОС, используя только debug, вполне реально. Хотя и неудобно. А вот для
написания небольших скриптов и тестовых фрагментов использование DEBUG в качестве
компилятора — самое оно. И, кстати, при этом автоматом решается проблема лицензионности
компилятора. J
При этом надо помнить несколько вещей:
- смена сегментного регистра делается в две команды, поскольку это префикс,
как и REP, LOCK и другие. То есть
mov si, es:[di]
записывается в видеes:
mov si, [di]- переходы типа short возможны лишь в пределах 128 байт выше или ниже.
Из-за этого могут быть проблемы при вводе программ вышеописанным способом.- отладчик не выдаст ошибки, если какая-то инструкция неправильна. То есть,
выдаст, но мы ее можем не увидеть, если используем перенаправленный ввод.- некоторые машинные коды 186-го, 286-го, 386-го и выше процов к сожалению
остаются для debug’а неизвестными, а именно:pusha
popa
push <immediate>
bound
arpl
- все команды, появившиеся в 486 и позднее
- все команды, использующие 32-битную адресацию и операнды
- insb / insw
- и некоторые другие.
Проблему можно решить, занося непосредственно код через
db <opcode>Да, если вы хотите писать в отладчике, все эти машинные коды придется запомнить.
После этого в голове возникает каша из цифр и букв, и человек неадекватно реагирует
на окружающих. Вот и я… пойду-ка лечиться! Поскольку подобные упражнения легко
могут подорвать психическое здоровье, всем рекомендую лекарство — бутылочки
3 пива минимум.ї Alex Antipoff aka FatMoon, 2002.
© FatMoon / HI-TECH
 ]
]
archive
New Member
- Регистрация:
- 27 фев 2017
- Публикаций:
- 532

В одной из статей было рассказано, как создать свой собственный виртуальный Forth-процессор, пригодный для исполнения некоторых команд, упрощающих процесс создания компиляторов/интерпретаторов стековых языков программирования. В этой же статье была продемонстрирована простейшая программа в форме шестнадцатеричных кодов, которые легко понимаются эмулятором того самого виртуального процессора, но написание более сложных программ (даже простейших нетривиальных процедур) является крайне сложным процессом.
В этот раз попробуем упростить написание программ для J1, используя предложение из той самой статьи о написании собственного ассемблера…
Создание ассемблера крайне трудоемкое дело, но только не в нашем случае: у нас слишком простой процессор — именно под такой мотивацией мы и будем создавать ассемблер, который будет транслировать некоторое подобие ассемблерных команд (они называются ассемблерным мнемониками или просто мнемониками) в их шестнадцатеричное представление, которое мы будем записывать в некоторый удобный файловый формат для последующего запуска.
Для начала создадим удобный синтаксис нашего ассемблера с учетом того, что этот синтаксис должен легко читаться, а также легко интерпретироваться транслятором. Обеспечивая минимальное множество поддерживаемых команд, которое при необходимости может быть расширено, синтаксис ассемблера будет выглядеть так:
<мнемоника_1>
<мнемоника_2>
...
tag <имя_метки_1>
<мнемоника_1>
<мнемоника_2>
...
<имя процедуры>:
<мнемоника_1>
<мнемоника_2>
...
В таком ассемблере поддерживаются базовые мнемоники, которые обеспечивают исполнение минимальных инструкций процессора J1, условные/безусловные переходы на некоторую именованную метку, создание и вызов именновых процедур и размещение литералов в стек. Данные особенности транслятора освобождают от необходимости вручную расчитывать адреса переходов и размещения процедур, поскольку именование меток/процедур обеспечивает сокрытие адресов от программиста ценой невозможности ручного указания передачи управления по адресу (хотя это не особо и проблема: при необходимости можно добавить и интерпретацию числовых адресов вместо меток).
В ассемблере будут поддерживаться следующие инструкции:
nop нет операции add сложение xor исключающее или and побитовое и or побитовое или invert побитовое инвертирование eq равенство lt меньше ult беззнаковое меньше swap обмен значений стека dup дублирование вершины стека drop удалить вершину стека over поместить на вершину предпоследнее число из стека nip удаление предпоследнего числа из стека pushr поместить вершину стека данных в стек вызовов popr поместить вершину стека вызовов в стек данных load загрузить в стек значение из ячейки памяти store сохранить в ячейку памяти значение из стека dsp глубина стека данных lsh сдвиг влево rsh сдвиг вправо decr декремент up увеличить указатель стека данных на 1 down уменьшить указатель стека данных на 1 copy копирование halt останов процессора
Теперь приступим к реализации ассемблера и для начала определим необходимые «заимствования» из стандартной библиотеки и ряд псевдонимов для описания предметной области ассемблера:
import std.algorithm; import std.conv; import std.range; import std.stdio; import std.string; alias Instruction = ushort; alias Command = Instruction[]; alias TranslationTable = Command[string]; enum TranslationTable MNEMONICS = [ "nop" : [0x6000], "add" : [0x6202], "xor" : [0x6502], "and" : [0x6302], "or": [0x6402], "invert" : [0x6600], "eq" : [0x6702], "lt" : [0x6802], "ult" : [0x6f02], "swap" : [0x6180], "dup" : [0x6081], "drop" : [0x6102], "over" : [0x6181], "nip" : [0x6002], "pushr" : [0x6146], "popr" : [0x6b89], "load" : [0x6c00], "store" : [0x6022, 0x6102], "dsp" : [0x6e81], "lsh" : [0x6d02], "rsh" : [0x6902], "decr" : [0x6a00], "up" : [0x6001], "down" : [0x6002], "copy" : [0x6100], "halt": [0xffff] ]; alias Name = string; alias Address = ushort; alias JumpTable = Address[Name];
Псевдонимы обьеспечивают удобство для обозначения таких понятий как инструкция (т.е элементарная шестнадцатеричная команда J1), команда (т.е ряд последовательных шестнадцатеричных инструкций), а также трансляционную таблицу (таблица, которая определяет в какую последовательность инструкций транслируется каждая из поддерживаемых мнемоник). Также, мы определяем три псевдонима, которые будут описывать таблицу переходов по меткам/процедурам.
Алгоритм транслятора очень прост: загружаем исходный текст программы на ассемблере в транслятор, выполняем обработку исходного текста, заменяя мнемоники ассемблера на шестнадцатеричные команды и обрабатывая инструкции условного/безусловного перехода (заменяем эти команды заранее вычисленными шестнадцатеричными значениями), выполнив все подстановки и вычисления, сохраняем результат в файл в удобном формате.
Для выполнения намеченного алгоритма на первом этапе нужно выполнить своеобразное препроцессирование файла, вычислив адреса именнованных меток и адреса именованных процедур, поскольку необходимые «теги» (так условно назовем имена процедур/меток) могут встречаться как в начале файла с исходным кодом, так и в его конце, а это может усложнить процесс трансляции файла. Препроцессирование в этом случае будет означать генерирование таблицы переходов, которая представляет собой ассоциативный массив, в котором роль ключей будут выполнять «теги», а в роли значений — адреса «тегов». Генерирование таблицы переходов выглядит так: поскольку каждая команда ассемблера расположена с новой строки (это по сути дела обязательный элемент синтаксиса ассемблера), то сначала выполняется разбиение листинга на строки и инициализация счетчика адресов нулем. Далее, идет просмотр списка строк с постепенным увеличением на 1 счетчика адресов в том случае, если встреченная строка содержит или мнемонику или элементарную инструкцию (у нас 4 таких инструкции: push/jmp/jz/call), в противном же случае — увеличение счетчика адресов не произойдет, но может произойти добавление «тега» в таблицу переходов на основании его типа (т.е добавление адресов именованной метки отличается о добавления именованной процедуры). В остальных случаях препроцессирование игнорирует увеличение счетчика адресов, считая, что строка в таких случаях не несет никакой смысловой нагрузки. Также важный момент: приращение счетчика адреса в случае наличия мнемоники в трансляционной таблице осуществляется не на единицу, а на длину (т.е на количество элементарных шестнадцатеричных команд) мнемоники в инструкциях.
Код всей процедуры выглядит так:
// подготовка таблицы переходов
auto createJumpTable(string assemblerListing, ref JumpTable table)
{
string[] preparedListing = assemblerListing.strip.splitLines;
Address address = 0;
foreach (assemblerMnemonic; preparedListing)
{
string mnemonic = assemblerMnemonic.strip.split[0].strip;
// обработка управляющих инструкций
if ((mnemonic == "push" ) || (mnemonic == "jmp" ) || (mnemonic == "jz" ) || (mnemonic == "call" ))
{
address++;
}
// обработка процедур
if (mnemonic.endsWith(":"))
{
string procedureName = mnemonic[0..$-1];
table[procedureName] = address;
}
// обработка меток
if (mnemonic == "tag")
{
string tagName = assemblerMnemonic.strip.split[1].strip;
table[tagName] = address;
}
// обработка обычных инструкций
if (mnemonic in MNEMONICS)
{
address += MNEMONICS[mnemonic].length;
}
}
}
Следующий шаг ассемблера после получения таблицы переходов — это выполнение генерации последовательности шестнадцатеричных команд на основе таблицы переходов. Разбор ассемблерного листинга осуществляется следующим образом: производится разбиение исходного листинга на массив строк, далее из каждой строки извлекается мнемоника и/или базовая команда и ее аргумент, после чего происходит поиск мнемоники в трансляционной таблице и выборка из нее нужного кода и помещение его в массив шестнадцатеричных команд (т.е в итоговый результат ассемблерования). В случае, если окажется что мнемоника представляет собой одну из элементарных инструкций, то произойдет разбор инструкции и превращение ее в одну шестнадцатеричную команду, а дальнейшие операции совпадают с описанным ранее случаем.
Выглядит трансляция в шестнадцатеричные коды вот так:
// транслировать в шестнадцатеричные коды
auto toAssemblerCodes(string assemblerListing, JumpTable table)
{
Command command;
string mnemonic, argument;
string[] preparedListing = assemblerListing.strip.splitLines;
foreach (assemblerMnemonic; preparedListing)
{
mnemonic = assemblerMnemonic.strip.split[0].strip;
if (assemblerMnemonic.strip.split.length > 1)
{
argument = assemblerMnemonic.strip.split[1].strip;
}
else
{
argument = "";
}
switch (mnemonic)
{
case "push":
command ~= 0x8000 | to!Instruction(argument);
break;
case "jmp":
command ~= 0x0000 | table[argument];
break;
case "jz":
command ~= 0x2000 | table[argument];
break;
case "call":
command ~= 0x4000 | table[argument];
break;
case "ret":
auto lastCommand = command[$-1];
command[$-1] = 0x1000 | lastCommand;
break;
default:
break;
}
if (mnemonic in MNEMONICS)
{
command ~= MNEMONICS[mnemonic];
}
}
return command;
}
Теперь самое интересное: нас интересует итоговый набор шестнадцатеричных кодов после ассемблирования необходимо преобразовать в файл удобного формата.
Помните, в статье про J1 я упоминал про то, что существуют и аппаратные его реализации в виде прпоектов для FPGA/ASIC ?
Файл удобного формата был бы очень кстати, если бы предполагалась загрузка кодов процессора прямо в плату FPGA, и тут стоит вспомнить то, что J1 работает с памятью некоторого размера и не имеет портов ввода/вывода. Это обстоятельство позволяет предположить, что тут удобнее всего был файл, который представляет собой нечто вроде слепка памяти, который можно напрямую загрузить в плату. Именно такие раздумья меня привели к поиску максимально простого формата файла, который легко бы разбирался и при этом его можно было бы напрямую загрузить в плату (хотя я таким и не занимался)…
К счастью, формат нашелся и называется он Memory Initialization File (или сокращенно MIF). Используется данный формат для инициализации модулей памяти, которые работают внутри FPGA плат фирмы Altera (кстати, уже давно эта контора является подразделением компании Intel) и он очень простой — это текстовой файл (не бинарный) с простым человекочитаемым заголовком и его очень просто разбирать.
Вот примерно так выглядит этот файл:
-- Quartus II generated Memory Initialization File (.mif) WIDTH=<ширина значений, помещаемых в память>; DEPTH=<количество значений>; ADDRESS_RADIX=HEX; DATA_RADIX=HEX; CONTENT BEGIN <первый адрес> : <значение>; ... <последний адрес> : <значение>; END;
В нашем случае, WIDTH=16 (так как у нас 16-битные значения), DEPTH=16384 (так как у нас память включает в себя именно столько значений), ADRESS_RADIX и DATA_RADIX указывают на то в каком формате будут указаны адреса и значения, в нашем случае это шестнадцатеричные коды из 4х цифр.
Реализация записи полученных шестнадцатеричных команд в альтеровский файл инициализации памяти может быть описана следующим образом:
// превратить в файл инициализации Альтеры
auto toMIF(Command command, string filename, ushort depth = 16_384)
{
enum string HEADER =
`-- Quartus II generated Memory Initialization File (.mif)
WIDTH=16;
DEPTH=%d;
ADDRESS_RADIX=HEX;
DATA_RADIX=HEX;
CONTENT BEGIN
`;
while (command.length < depth)
{
command ~= cast(ushort) 0xFFFF;
}
File file;
file.open(filename, "w");
file.writef(HEADER, depth);
for (ushort i = 0; i < command.length; i++)
{
string index = format("%0.4x", i).toUpper;
string data = format("%0.4x", command[i]).toUpper;
file.writefln("t%s : %s;", index, data);
}
file.write("END;");
}
Объединить процедуры в единый механизм транслятора, который будет обрабатывать произвольный файл с листингом и записывать в любой иной файл можно следующим образом (не претендуя на полноту реализации, конечно):
import std.algorithm;
import std.conv;
import std.range;
import std.stdio;
import std.string;
alias Instruction = ushort;
alias Command = Instruction[];
alias TranslationTable = Command[string];
enum TranslationTable MNEMONICS = [
"nop" : [0x6000],
"add" : [0x6202],
"xor" : [0x6502],
"and" : [0x6302],
"or": [0x6402],
"invert" : [0x6600],
"eq" : [0x6702],
"lt" : [0x6802],
"ult" : [0x6f02],
"swap" : [0x6180],
"dup" : [0x6081],
"drop" : [0x6102],
"over" : [0x6181],
"nip" : [0x6002],
"pushr" : [0x6146],
"popr" : [0x6b89],
"load" : [0x6c00],
"store" : [0x6022, 0x6102],
"dsp" : [0x6e81],
"lsh" : [0x6d02],
"rsh" : [0x6902],
"decr" : [0x6a00],
"up" : [0x6001],
"down" : [0x6002],
"copy" : [0x6100],
"halt": [0xffff]
];
alias Name = string;
alias Address = ushort;
alias JumpTable = Address[Name];
// подготовка таблицы переходов
auto createJumpTable(string assemblerListing, ref JumpTable table)
{
string[] preparedListing = assemblerListing.strip.splitLines;
Address address = 0;
foreach (assemblerMnemonic; preparedListing)
{
string mnemonic = assemblerMnemonic.strip.split[0].strip;
// обработка управляющих инструкций
if ((mnemonic == "push" ) || (mnemonic == "jmp" ) || (mnemonic == "jz" ) || (mnemonic == "call" ))
{
address++;
}
// обработка процедур
if (mnemonic.endsWith(":"))
{
string procedureName = mnemonic[0..$-1];
table[procedureName] = address;
}
// обработка меток
if (mnemonic == "tag")
{
string tagName = assemblerMnemonic.strip.split[1].strip;
table[tagName] = address;
}
// обработка обычных инструкций
if (mnemonic in MNEMONICS)
{
address += MNEMONICS[mnemonic].length;
}
}
}
// транслировать в шестнадцатеричные коды
auto toAssemblerCodes(string assemblerListing, JumpTable table)
{
Command command;
string mnemonic, argument;
string[] preparedListing = assemblerListing.strip.splitLines;
foreach (assemblerMnemonic; preparedListing)
{
mnemonic = assemblerMnemonic.strip.split[0].strip;
if (assemblerMnemonic.strip.split.length > 1)
{
argument = assemblerMnemonic.strip.split[1].strip;
}
else
{
argument = "";
}
switch (mnemonic)
{
case "push":
command ~= 0x8000 | to!Instruction(argument);
break;
case "jmp":
command ~= 0x0000 | table[argument];
break;
case "jz":
command ~= 0x2000 | table[argument];
break;
case "call":
command ~= 0x4000 | table[argument];
break;
case "ret":
auto lastCommand = command[$-1];
command[$-1] = 0x1000 | lastCommand;
break;
default:
break;
}
if (mnemonic in MNEMONICS)
{
command ~= MNEMONICS[mnemonic];
}
}
return command;
}
// превратить в файл инициализации Альтеры
auto toMIF(Command command, string filename, ushort depth = 16_384)
{
enum string HEADER =
`-- Quartus II generated Memory Initialization File (.mif)
WIDTH=16;
DEPTH=%d;
ADDRESS_RADIX=HEX;
DATA_RADIX=HEX;
CONTENT BEGIN
`;
while (command.length < depth)
{
command ~= cast(ushort) 0xFFFF;
}
File file;
file.open(filename, "w");
file.writef(HEADER, depth);
for (ushort i = 0; i < command.length; i++)
{
string index = format("%0.4x", i).toUpper;
string data = format("%0.4x", command[i]).toUpper;
file.writefln("t%s : %s;", index, data);
}
file.write("END;");
}
void main(string[] args)
{
import std.file;
auto assemblerListing = cast(string) std.file.read(args[1]);
JumpTable jumps;
createJumpTable(assemblerListing, jumps);
assemblerListing.toAssemblerCodes(jumps).toMIF(args[2]);
}
Теперь для испытаний напишем простой цикл для J1 c помощью которого выполним умножение двух чисел:
push 5 push 5000 store jmp cycle multiply: add ret tag cycle push 1024 call multiply push 5000 load decr dup jz end push 5000 store jmp cycle tag end halt
Что происходит в ассемблерном листинге ?
Для начала размещаем число 5 в ячейке памяти по адресу 5000 (число 5 — это второй множитель) и осуществляем переход на метку cycle, где начинается весь основной цикл. После перехода размещаем первый множитель — число 1024 в стеке, после чего вызываем процедуру умножения (она просто осуществляет сложение двух чисел в стеке, но будет вызывана несколько раз, что и приведет к получению результата умножения), затем размещаем адрес первого множителя в стеке (это число 5000), затем используем адрес для загрузки значения из памяти в стек, выполняем уменьшение на единицу загруженного значения, выполняем дублирование уменьшенного значения, команда jz выполняет сравнение значения на стеке с 0, и если сравнение было успешным, то выполняется переход на метку end (т.е выполянется переход на условие окончания программы). Если переход не удался, то выполняется следующая за jz инструкция, т.о после этого мы помещаем в стек число 5000 (адрес ячейки памяти со вторым множителем) и выполняем переход на метку cycle. Переход на метку cycle фактически дает бесконечный цикл, единственным условием выхода из которого служит наличие нуля на вершине стека — данное условие проверяется инструкцией jz, а конечным сам цикл делает уменьшение на единицу значения ячейки памяти с последующим размещением этого значения в стеке и дублированием его. Дублирование в нашем случае нужно для того, что значение могло быть использовано для последующего выполнения перехода на условие окончание, которым является служебная команда halt.
Прежде чем проводить испытания данного кода, нам потребуется исходный код эмулятора J1, которы можно взять из статьи про виртуальный процессор. Также необходимо внести правку в один из методов класса J1_CPU, а именно в метод executeProgram:
void executeProgram()
{
// 0xffff = HALT
while (RAM[programCounter] != 0xffff)
{
writefln("{pc : %d, instruction : %0.4x}", programCounter, RAM[programCounter]);
// RAM.toMIF("dump.mif");
execute(RAM[programCounter]);
print;
}
}
правка небольшая и обеспечивает несколько иную интерпретацию команды halt, которая теперь имеет шестнадцатеричный код 0xffff (также можно раскоментировать закоментированную строку, чтобы в конце работы программы иметь дамп памяти процессора в удобном виде, правда для этого необходимо скопировать процедуру toMIF из исходных кодов ассемблера). После этого добавляем процедуру загрузки MIF-файла и модифицируем процедуру main для того, чтобы запускать программу, заключенную в MIF-файле:
auto fromMIF(string filename)
{
ushort[16_384] commands;
auto content = cast(string) std.file.read(filename);
auto begin = content.indexOf("CONTENT BEGIN") + "CONTENT BEGIN".length;
auto end = content.indexOf("END;");
content = content[begin..end].strip;
foreach (index, line; content.splitLines)
{
auto separatorIndex = line.indexOf(":") + 1;
auto dataLine = line[separatorIndex..$-1].strip.toLower;
commands[index] = parse!ushort(dataLine, 16);
}
return commands;
}
void main(string[] args)
{
J1_CPU j1 = new J1_CPU;
uint16[16_384] ram = fromMIF(args[1]);
j1.setMemory(ram);
j1.executeProgram;
}
Теперь можно запускать J1 с описанной выше ассемблерной программой, которая дает вот такой результат:
{pc : 0, instruction : 8005}
[rs] : [0, 5, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 1, instruction : 9388}
[rs] : [0, 5, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 2, instruction : 6022}
[rs] : [0, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 3, instruction : 6102}
[rs] : [0, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 4, instruction : 0006}
[rs] : [0, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [0, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [0, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [1024, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [1024, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [1024, 5, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [1024, 4, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [1024, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [1024, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 13, instruction : 9388}
[rs] : [1024, 4, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 14, instruction : 6022}
[rs] : [1024, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 15, instruction : 6102}
[rs] : [1024, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 16, instruction : 0006}
[rs] : [1024, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [1024, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [1024, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [2048, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [2048, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [2048, 4, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [2048, 3, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [2048, 3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [2048, 3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 13, instruction : 9388}
[rs] : [2048, 3, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 14, instruction : 6022}
[rs] : [2048, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 15, instruction : 6102}
[rs] : [2048, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 16, instruction : 0006}
[rs] : [2048, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [2048, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [2048, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [3072, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [3072, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [3072, 3, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [3072, 2, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [3072, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [3072, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 13, instruction : 9388}
[rs] : [3072, 2, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 14, instruction : 6022}
[rs] : [3072, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 15, instruction : 6102}
[rs] : [3072, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 16, instruction : 0006}
[rs] : [3072, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [3072, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [3072, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [4096, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [4096, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [4096, 2, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [4096, 1, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [4096, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [4096, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 13, instruction : 9388}
[rs] : [4096, 1, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 14, instruction : 6022}
[rs] : [4096, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 15, instruction : 6102}
[rs] : [4096, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 16, instruction : 0006}
[rs] : [4096, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [4096, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [4096, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [5120, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [5120, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [5120, 1, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [5120, 0, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [5120, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [5120, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Итак, в этой статье был описан простейший вариант ассемблера для виртуального процессора, который транслирует программу в файл инициализации памяти. Данный ассемблер дает код, который может быть пригоден для записи в память, которую можно сформировать внутри FPGA платы фирмы Altera. Конечно, не стоит рассчитывать на то, что описанный транслятор совершенен и что он пригоден для реальных боевых задач. Многое можно улучшить как в коде ассемблерного транслятора, так и в функционале (например можно добавить макродирективы и расширить набор команд), также многим может показаться, что мы напрямую привязаны к платам Altera, но весь приведенный код является экспериментальным и может быть именно вы, наш, читатель сможете внести свой вклад в его улучшение.
Напоследок прикладываю полный код процессора J1 с модификациями:
import std.conv : to;
// 16-разрядное беззнаковое целое
alias int16 = short;
// 16-разрядное беззнаковое целое
alias uint16 = ushort;
class J1_CPU
{
private
{
enum RAM_SIZE = 16_384;
// стек данных
uint16[33] dataStack;
// стек вызовов
uint16[32] returnStack;
// память
uint16[RAM_SIZE] RAM;
// указатель на вершину стека данных
int16 dataPointer;
// указатель на вершину стека вызовов
int16 returnPointer;
// счетчик инструкций
uint16 programCounter;
// маски для различения типов инструкций j1
enum J1_INSTRUCTION : uint16
{
JMP = 0x0000,
JZ = 0x2000,
CALL = 0x4000,
ALU = 0x6000,
LIT = 0x8000
};
// маски для различения аргументов инструкций j1
enum J1_DATA : uint16
{
LITERAL = 0x7fff,
TARGET = 0x1fff
};
// исполнение команд АЛУ
auto executeALU(uint16 instruction)
{
uint16 q;
uint16 t;
uint16 n;
uint16 r;
// вершина стека
if (dataPointer > 0)
{
t = dataStack[dataPointer];
}
// элемент под вершиной стека
if (dataPointer > 0)
{
n = dataStack[dataPointer - 1];
}
// предыдущий адрес возврата
if (returnPointer > 0)
{
r = returnStack[returnPointer - 1];
}
// увеличить счетчик инструкций
programCounter++;
// извлечение кода операции АЛУ
uint16 operationCode = (instruction & 0x0f00) >> 8;
// опознание операций
switch (operationCode)
{
case 0:
q = t;
break;
case 1:
q = n;
break;
case 2:
q = to!uint16(t + n);
break;
case 3:
q = t & n;
break;
case 4:
q = t | n;
break;
case 5:
q = t ^ n;
break;
case 6:
q = to!uint16(~to!int(t));
break;
case 7:
q = (t == n) ? 1u : 0u;
break;
case 8:
q = (to!int16(n) < to!int16(t)) ? 1u : 0u; break; case 9: q = n >> t;
break;
case 10:
q = to!uint16(t - 1u);
break;
case 11:
q = returnStack[returnPointer];
break;
case 12:
q = RAM[t];
break;
case 13:
q = to!uint16(n << t);
break;
case 14:
q = to!uint16(dataPointer + 1u);
break;
case 15:
q = (n < t) ? 1u : 0u; break; default: break; } // код действия с указателем на стек данных // (+1 - увеличить указатель, 0 - не трогать, -1 уменьшить (= 2 в двоичном коде)) uint16 ds = instruction & 0x0003; // код действия с указателем на стек возвратов // (+1 - увеличить указатель, 0 - не трогать, -1 уменьшить (= 2 в двоичном коде)) uint16 rs = (instruction & 0x000c) >> 2;
switch (ds)
{
case 1:
dataPointer++;
break;
case 2:
dataPointer--;
break;
default:
break;
}
switch (rs)
{
case 1:
returnPointer++;
break;
case 2:
returnPointer--;
break;
default:
break;
}
// флаг NTI
if ((instruction & 0x0020) != 0)
{
RAM[t] = n;
}
// флаг TR
if ((instruction & 0x0040) != 0)
{
returnStack[returnPointer] = t;
}
// флаг TR
if ((instruction & 0x0080) != 0)
{
dataStack[dataPointer-1] = t;
}
// флаг RPC
if ((instruction & 0x1000) != 0)
{
programCounter = returnStack[returnPointer];
}
if (dataPointer >= 0)
{
dataStack[dataPointer] = q;
}
}
}
public
{
auto execute(uint16 instruction)
{
// опознать тип инструкции
uint16 instructionType = instruction & 0xe000;
// операнд над которым осуществляется инструкция
uint16 operand = instruction & J1_DATA.TARGET;
// распознать конкретную инструкцию процессора
switch (instructionType)
{
// безусловный переход
case J1_INSTRUCTION.JMP:
programCounter = operand;
break;
// переход на адрес, если на вершине стека 0
case J1_INSTRUCTION.JZ:
if (dataStack[dataPointer] == 0)
{
programCounter = operand;
}
else
{
programCounter++;
}
dataPointer--;
break;
// передать управление на адрес
case J1_INSTRUCTION.CALL:
returnPointer++;
returnStack[returnPointer] = to!uint16(programCounter + 1);
programCounter = operand;
break;
// выполнить инструкцию АЛУ
case J1_INSTRUCTION.ALU:
executeALU(operand);
break;
// положить на стек литерал
case J1_INSTRUCTION.LIT:
operand = instruction & J1_DATA.LITERAL;
dataPointer++;
dataStack[dataPointer] = operand;
programCounter++;
break;
default:
break;
}
}
this()
{
this.RAM = new uint16[RAM_SIZE];
this.dataPointer = 0;
this.returnPointer = 0;
this.programCounter = 0;
}
void print()
{
writeln("[rs] : ", dataStack);
writeln("[rs] : ", returnStack);
}
void executeProgram()
{
// 0xffff = HALT
while (RAM[programCounter] != 0xffff)
{
writefln("{pc : %d, instruction : %0.4x}", programCounter, RAM[programCounter]);
// RAM.toMIF("dump.mif");
execute(RAM[programCounter]);
print;
}
}
void setMemory(uint16[RAM_SIZE] ram)
{
this.RAM = ram;
}
auto getMemory()
{
return RAM;
}
}
}
import std.algorithm;
import std.conv;
import std.file;
import std.range;
import std.string;
import std.stdio;
// превратить в файл инициализации Альтеры
auto toMIF(uint16[16_384] command, string filename, ushort depth = 16_384)
{
enum string HEADER =
`-- Quartus II generated Memory Initialization File (.mif)
WIDTH=16;
DEPTH=%d;
ADDRESS_RADIX=HEX;
DATA_RADIX=HEX;
CONTENT BEGIN
`;
File file;
file.open(filename, "w");
file.writef(HEADER, depth);
for (ushort i = 0; i < command.length; i++)
{
string index = format("%0.4x", i).toUpper;
string data = format("%0.4x", command[i]).toUpper;
file.writefln("t%s : %s;", index, data);
}
file.write("END;");
}
auto fromMIF(string filename)
{
ushort[16_384] commands;
auto content = cast(string) std.file.read(filename);
auto begin = content.indexOf("CONTENT BEGIN") + "CONTENT BEGIN".length;
auto end = content.indexOf("END;");
content = content[begin..end].strip;
foreach (index, line; content.splitLines)
{
auto separatorIndex = line.indexOf(":") + 1;
auto dataLine = line[separatorIndex..$-1].strip.toLower;
commands[index] = parse!ushort(dataLine, 16);
}
return commands;
}
void main(string[] args)
{
J1_CPU j1 = new J1_CPU;
uint16[16_384] ram = fromMIF(args[1]);
j1.setMemory(ram);
j1.executeProgram;
}
Автор: xrnd | Рубрика: Учебный курс | 30-01-2010 | Распечатать запись
 Распечатать запись
Распечатать записьУчиться программировать начнем с процессора Intel 8086. Будем писать программы под DOS 🙂 Программирование под Windows и Linux сложнее, а нам надо с чего-то начинать. Поэтому начнем с простого и понятного 16-битного процессора 8086.
Практическая ценность от программирования под DOS в наше время не очень большая, если вы, конечно, не собираетесь тесно работать с этой операционной системой. Но она позволит нам быстро освоить основы ассемблера, а потом мы уже перейдем к программированию под 32-битные системы.
Все программы учебного курса вы сможете запустить под Windows. Конечно, реально они будут работать в эмуляторе DOS, в режиме виртуального процессора 8086. Но для учебных целей это вполне подойдёт.
Для программирования на ассемблере нам прежде всего необходим компилятор. Наиболее известные компиляторы это TASM, MASM и FASM. В моем учебном курсе я буду использовать FASM. Это довольно новый, удобный, быстро развивающийся компилятор ассемблера, написанный на себе самом 🙂 Его преимущества — это поддержка сложных макросов и мультиплатформенность. Есть версии под DOS, Windows и Linux, что меня особенно радует )
С его помощью можно сгенерировать файл любого формата, не обязательно исполняемый файл, так что FASM — это превосходный инструмент для экспериментов и исследований.
Последнюю версию FASM’a можно скачать с официального сайта http://flatassembler.net.
На момент написания этой статьи последняя версия 1.68. Можно скачать с моего сайта (версия под Windows). Все программы учебного курса я буду компилить этой версией. Хотя наверно и другими получится ))) Для установки содержимое архива надо распаковать в какую-нибудь папку. Например, у меня это будет папка C:FASM.
Для отладки написанных программ будем использовать старый добрый Turbo Debugger из пакета TASM. Скачать можно с моего сайта. Архив также надо распаковать в какую-нибудь папку. У меня это будет
C:TD.
Также от вас потребуется голова, прямые руки и желание ковыряться в ассемблерных командах! 🙂 Любые вопросы по теме можно писать в комментариях к статьям. Я постараюсь на все ответить. Можете писать мне на почту xrnd fasmworld.ru
fasmworld.ru
Желаю удачи, в следующей статье начнем писать нашу первую программу.
Следующая часть »
Пишем загрузчик на Ассемблере и С. Часть 1 +4
Блог компании RUVDS.com
Рекомендация: подборка платных и бесплатных курсов Python — https://katalog-kursov.ru/
Введение
Эта статья представляет собой ознакомительный материал о написании загрузчика на С и Ассемблере, но здесь я не буду вдаваться в сравнение производительности итогового кода, созданного на этих языках. В этой работе я просто вкратце изложу процесс загрузки флоппи-образа через написание собственного кода с последующим его внедрением в загрузочный сектор устройства. Все содержание статьи будет разделено на несколько частей, так как за раз достаточно сложно изложить всю нужную информацию и о компьютерах, и об устройствах загрузки, и о написании самого кода. Здесь я поясню наиболее общие аспекты компьютерной науки и суть процесса загрузки, а также обобщил значение и важность каждого этапа, чтобы упростить их понимание и запоминание. Если же вам потребуется более подробное объяснение, то можете дополнительно почитать другие статьи, которых в интернете нынче предостаточно.
О чем пойдет речь?
В этой статье мы рассмотрим написание кода программы и его копирование в загрузочный сектор образа флоппи-диска, после чего с помощью x86-эмулятора bochs для Linux научимся проверять работоспособность дискеты с загрузчиком.
О чем речь не пойдет
В этой статье я не объясняю, почему загрузчик нельзя написать на других подобных Ассемблеру языках, а также не говорю о недостатках его написания на одном языке в отношении другого. Поскольку наша цель – познакомиться с написанием загрузочного кода, я не хочу нагружать вас более продвинутыми темами типа скорости, уменьшения кода и т.д.
Структура статьи
В начале мы начнем со знакомства с основами, после чего перейдем к написанию самого кода. В общем структура будет такова:
• Знакомство с Bootable Devices (загрузочными устройствами).
• Введение в среду разработки.
• Знакомство с микропроцессором.
• Написание кода на Ассемблере.
• Написание кода на компиляторе.
• Разработка мини-программы для отображения прямоугольников.
К сведению:
• Эта статья окажется наиболее полезной, если у вас уже есть хоть какой-то опыт программирования. Несмотря на ее ознакомительный характер, написание загрузочных программ на Ассемблере и C может оказаться непростой задачей. Поэтому новичкам в программировании я рекомендую сначала ознакомиться с несколькими более базовыми вводными материалами и уже потом возвращаться к этому.
• На протяжении статьи я буду постепенно представлять в форме вопросов и ответов различную компьютерную терминологию. Вообще, я написал это руководство так, как будто обращаю его самому себе. А роль таких дискуссионных вставок в виде вопрос-ответ – помочь мне лучше понять важность и назначение рассматриваемого материала в повседневной жизни. Вот пример: Что вы подразумеваете под компьютерами? или Зачем они мне нужны, ведь я намного умнее их?
Что ж, будем начинать
Знакомство с загрузочными устройствами
Что происходит при включении стандартного компьютера?
Обычно при нажатии кнопки включения питания от нее подается сигнал блоку питания о необходимости подачи необходимого напряжения на внутреннее и внешнее оборудование компьютера, такое как процессор, монитор, клавиатура и пр. Процессор инициализирует ПЗУ-чип BIOS (базовую систему ввода/вывода) для загрузки содержащейся в нем исполняемой программы, также именуемой BIOS.
После запуска BIOS выполняет следующие задачи:
• Тестирование оборудования при подаче питания (Power On self Test).
• Проверка частоты и доступности шин.
• Проверка системных часов и аппаратной информации в CMOS RAM.
• Проверка настроек системы, предустановок оборудования и т.д.
• Тестирование подключенного оборудования, начиная с RAM, дисководов, оптических приводов, HDD и т.д.
• В зависимости от определенной в разделе загрузочных устройств информации выполняет поиск загрузочного диска и переходит к его инициализации.
К сведению: все x86-CPU в процессе загрузки запускаются в рабочем режиме, называемом Real Mode.
Что такое загрузочное устройство?
Загрузочным называется устройство, содержащее загрузочный сектор или блок загрузки. BIOS считывает это устройство, начиная с загрузки этого загрузочного сектора в RAM для выполнения, после чего переходит далее.
Что такое сектор?
Сектор – это особый раздел загрузочного диска, размер которого обычно составляет 512 байт. Чуть позже я подробнее поясню о том, как измеряется память компьютера и приведу сопутствующую терминологию.
Что такое загрузочный сектор?
Загрузочный сектор или блок загрузки – это область загрузочного устройства, в которой содержится загружаемый в RAM машинный код, за что отвечает встроенная в ПК прошивка на стадии инициализации. На флоппи-диске размер сектора составляет 512 байт. Чуть позже о байтах будет сказано дополнительно.
Как работает загрузочное устройство?
При его инициализации BIOS ищет и загружает первый сектор (загрузочный) в RAM и начинает его выполнение. Расположенный в загрузочном секторе код является первой программой, которую можно отредактировать для определения дальнейшего функционирования компьютера после его запуска. Здесь я имею в виду, что вы можете написать собственный код и скопировать его в загрузочный сектор, чтобы система работала так, как вам нужно. Сам же этот код и будет называться тем самым начальным загрузчиком.
Что такое начальный загрузчик?
В компьютерной области загрузчиком называется программа, выполняемая при каждой инициализации загрузочного устройства при запуске и перезагрузке ПК. Технически это выполняемый машинный код, соответствующий архитектуре типа используемого в системе CPU или микропроцессора.
Какие есть виды микропроцессоров?
Я приведу основные:
• 16 битные
• 32 битные
• 64 битные
Чем больше значение бит, тем к большему объему памяти имеют доступ программы, получая большую производительность с точки зрения временного хранилища и пр. На сегодня есть два основных производителя микропроцессоров – Intel и AMD. На протяжении статьи я буду обращаться только к процессорам семейства Intel (x86).
В чем отличие процессоров Intel и AMD?
Каждый производитель использует свой уникальный способ проектирования микропроцессоров с аппаратной точки зрения и в плане используемых для взаимодействий наборов инструкций.
Знакомство со средой разработки
Что такое реальный режим?
Я уже упоминал, что все процессоры x86 при загрузке с устройства запускаются в реальном режиме. Это очень важно иметь в виду при написании загрузочного кода для любого устройства. Реальный режим поддерживает только 16-битные инструкции. Поэтому создаваемый вами код для загрузки в загрузочную запись или сектор должен компилироваться в 16-битный формат. В реальном режиме инструкции могут работать только с 16 битами одновременно. Например, у 16-битного CPU будет конкретная инструкция, способная складывать в одном цикле два 16-битных числа. Если же для процесса будет необходимо сложить два 32-битных числа, то потребуется больше циклов, выполняющих сложение 16 битных чисел.
Что такое набор инструкций?
Это гетерогенная коллекция сущностей, ориентированных на конкретную архитектуру микропроцессора, с помощью которых пользователь может взаимодействовать с ним. Здесь я подразумеваю коллекцию сущностей, состоящую из внутренних типов данных, инструкций, регистров, режимов адресации, архитектуры памяти, обработки прерываний и исключений, а также внешнего I/O. Обычно для семейства микропроцессоров создаются общие наборы инструкций. Процессор Intel-8086 относится к семейству 8086, 80286, 80386, 80486, Pentium, Pentium I, II, III, которое также известно как семейство x86. В этой статье я будут использовать набор инструкций, относящийся именно к этому типу процессоров.
Как написать код для загрузочного сектора устройства?
Для реализации этой задачи необходимо иметь представление о:
• Операционной системе (GNU Linux).
• Ассемблере (GNU Assembler).
• Наборе инструкций (семейство x86).
• Написании инструкций x86 на GNU Assembler для x86 микропроцессоров.
• Компиляторе (как вариант язык C).
• Линкер (GNU linker ld)
• Эмулятор x86, наподобие bochs, для тестирования.
Что такое операционная система?
Объясню очень просто. Это большой набор различных программ, написанных сотнями и даже тысячами профессионалов, которые помогают пользователям в решении их повседневных задач. К таким задам можно отнести подключение к интернету, общение в соцсетях, создание и редактирование файлов, работу с данными, игры и многое другое. Все это реализуется с помощью операционной системы. Помимо этого, ОС также регулирует функционирование аппаратных средств, обеспечивая для вас оптимальным режим работы.
Отдельно отмечу, что все современные ОС работают в защищенном режиме.
Какие виды ОС бывают?
• Windows
• Linux
• MAC
• …
Что значит защищенный режим?
В отличие от реального режима, защищенный поддерживает 32-битные инструкции. Но вам об этом задумываться не стоит, так как нас не особо волнует процесс функционирования ОС.
Что такое Ассемблер?
Ассемблер преобразует передаваемые пользователем инструкции в машинный код.
Разве компилятор делает не то же самое?
На более высоком уровне да, но, фактически, внутри компилятора этим занимается именно ассемблер.
А почему компилятор не может генерировать машинный код напрямую?
Основная задача компилятора состоит в преобразовании инструкций пользователя в их промежуточный набор, называемый инструкциями ассемблера, после чего ассемблер преобразует их в соответствующий машинный код.
Зачем нужна ОС для написания кода загрузочного сектора?
Прямо сейчас я не хочу вдаваться в подробности и ограничусь пояснением в рамках материала текущей статьи. Как я говорил, для написания инструкций, которые поймет микропроцессор, нам нужен компилятор. Он, в свою очередь, разрабатывается в качестве утилиты ОС и используется через нее, соответственно.
Какую ОС можно использовать?
Так как я писал загрузочные программы под Ubuntu, то и вам для ознакомления с данным руководством порекомендую именно эту ОС.
Какой следует использовать компилятор?
Я писал загрузчики при помощи GNU GCC и демонстрировать компиляцию кода я буду на нем же. Как протестировать рукописный код для загрузочного сектора? Я представлю вам эмулятор x86, который существенно помогает дорабатывать код, не требуя постоянной перезагрузки компьютера при редактировании загрузочного сектора устройства.
Знакомство с микропроцессором
Прежде чем изучать программирование микропроцессора, нам необходимо разобрать использование регистров.
Что такое регистры?
Регистры подобны утилитам микропроцессора, служащим для временного хранения данных и управления ими согласно нашим потребностям. Предположим, пользователь хочет сложить 2 и 3, для чего он просит компьютер сохранить число 3 в одном регистре, а 2 в другом, после чего сложить содержимое этих регистров. В итоге CPU помещает результат в еще один регистр, который и представляет нужным пользователю вывод. Всего существует четыре типа регистров:
• регистры общего назначения;
• сегментные регистры;
• индексные регистры;
• регистры стека.
Я дам краткое пояснение по каждому типу.
Регистры общего назначения: используются для хранения временных данных, необходимых программе в процессе выполнения. Каждый такой регистр имеет 16 бит в ширину и 2 байта в длину.
• AX – регистр сумматора;
• BX – регистр базового адреса;
• CX – регистр-счетчик;
• DX – регистр данных.
Сегментные регистры: служат для представления микропроцессору адреса памяти. Здесь нам нужно знать два термина:
• Сегмент: как правило, это начало блока памяти.
• Смещение: It is the index of memory block onto it.
Пример: у нас есть байт, представляющий значение “X” и расположенный в блоке памяти со стартовым адресом 0x7c00 в 10-й позиции от начала этого блока. В данной ситуации мы выразим сегмент как 0x7c00, а смещение как 10.
Абсолютным адресом тогда будет 0x7c00 + 10.
Они делятся на четыре категории:
• CS – сегмент кода;
• SS – сегмент стека;
• DS – сегмент данных;
• ES – расширенный сегмент.
При этом нужно учитывать ограничения этих регистров, а именно невозможность прямого присваивания адреса. Вместо этого нам приходится копировать адрес сначала в регистры общего назначения, после чего снова копировать его уже в сегментные. Например, для решения задачи обнаружения байта “X” мы делаем следующее:
movw $0x07c0, %ax
movw %ax , %ds
movw (0x0A) , %ax Происходит же здесь вот что:
• set 0x07c0 * 16 in AX
• set DS = AX = 0x7c00
• set 0x7c00 + 0x0a to ax
Я дам описание разных режимов адресации, понимание которых нам потребуется при написании программ.
Регистры стека:
• BP – базовый указатель;
• SP – указатель стека.
Индексные регистры:
• SI – регистр индекса источника.
• DI – регистр индекса получателя.
• AX: используется CPU для арифметических операций.
• BX: может содержать адрес процедуры или переменной (это также могут SI, DI и BP) и использоваться для выполнения арифметических операций и перемещения данных.
• CX: выступает в роли счетчика цикла при повторении инструкций.
• DX: It holds the high 16 bits of the product in multiply (also handles divide operations).
• CS: хранит базовый адрес всех выполняемых инструкций программы.
• SS: хранит базовый адрес стека.
• DS: хранит предустановленный адрес переменных.
• ES: хранит дополнительный базовый адрес переменных памяти.
• BP: содержит предполагаемое смещение из регистра SS. Часто используется подпрограммами для обнаружения переменных, переданных в стек вызывающей программой. an assumed offset from the SS register.
• SP: содержит смещение вершины стека.
• SI: используется в инструкциях перемещения строк. При этом на исходную строку указывает регистр SI.
• DI: выступает в роли места назначения для инструкций перемещения строк.
Что такое бит?
В вычислительных средах бит является наименьшей единицей данных, представляя их в двоичном формате, где 1 = да, а 0 = нет.
Дополнительно о регистрах:
Ниже описано дальнейшее подразделение регистров:
• AX: первые 8 бит AX обозначаются как AL, а последние 8 бит как AH.
• BX: первые 8 бит BX обозначаются как BL, а последние 8 как как BH.
• CX: первые 8 бит CX обозначаются как CL, а последние 8 бит как CH.
• DX: первые 8 бит DX обозначаются как DL, а последние 8 бит как DH.
Как обращаться к функциям BIOS?
BIOS предоставляет ряд функций, позволяющих распределять приоритеты ЦПУ. Доступ к этим возможностям BIOS можно получить с помощью прерываний.
Что такое прерывания?
Для приостановки стандартного потока программы и обработки событий, требующих быстрой реакции, используются прерывания. Например, при перемещении мыши, соответствующее аппаратное обеспечение прерывает текущую программу для обработки этого перемещения. В результате прерывания управление передается специальной программе-обработчику. Каждому типу прерывание присваивается целое число. В начальной области физической памяти располагается таблица векторов прерываний, в которой находятся сегментированные адреса их обработчиков. Номер прерывания, по сути, является индексом из этой таблицы.
Какую службу прерываний будем использовать мы?
Bios interrupt 0x10.
Написание кода в Ассемблере
Какие типы данных доступны в GNU Assembler?
Типы данных используются для определения их характеристик и могут быть следующими:
• байт
• слово
• целочисленными (int)
• ascii
• asciz
байт: состоит из восьми бит. Байт считается наименьшей единицей хранения информации в процессе программирования.
слово: единица данных, состоящая из 16 бит.
Что такое int?
Int – это целочисленный тип данных, состоящий из 32 бит, которые могут быть представлены четырьмя байтами или двумя словами.
Что такое ascii?
Тип данных, представляющий группу байтов без нулевого символа.
Что такое asciiz?
Тип данных, выражающий группу байтов, завершающуюся символом нуль.
Как генерировать код для реального режима в Ассемблере?
В процессе запуска ЦПУ в реальном режиме (16 бит) мы можем задействовать только встроенные функции BIOS. Я имею в виду, что мы можем с помощью этих функций написать собственный код загрузчика, поместить его в загрузочный сектор и выполнить загрузку. Давайте рассмотрим написание на Ассемблере небольшого фрагмента кода, который генерирует код 16-битный код ЦПУ через GNU Assembler.
Let us see how to write a small piece of code in assembler that generates 16-bit CPU code through GNU Assembler.
Example: test.S .code16 #генерирует 16-битный код
.text #расположение исполняемого кода
.globl _start;
_start: #точка входа
. = _start + 510 #перемещение из позиции 0 в 510-й байт
.byte 0x55 #присоединение сигнатуры загрузки
.byte 0xaa #присоединение сигнатуры загрузкиПояснения к приведенному коду:
• .code16: это директива, отдаваемая ассемблеру для генерации не 32-битно, а 16-битного кода. Зачем это нужно? Ассемблер вы будете использовать через операционную систему, а код загрузчика будете писать с помощью компилятора. Но я также говорил, что ОС работает в защищенном 32-битном режиме. Поэтому, по умолчанию ассемблер в такой ОС будет производить 32-битный код, что не соответствует нашей задаче. Данная же директива исправляет этот нюанс, и мы получаем 16-битный код.
• .text: этот раздел содержит фактические машинные инструкции, составляющие вашу программу.
• .globl _start: .global делает символ видимым для компоновщика. Если вы определите символ в своей подпрограмме, его значение станет доступным для других связанных с ней подпрограмм. В противном случае символ получает свои атрибуты от символа с таким же именем, находящегося в другом файле, связанном с той же программой.
• _start: точка входа в основной код, а также предустановленная точка входа для компоновщика. = _start + 510: обход от начальной позиции до 510-го байта.
• .byte 0x55: первый байт, определяемый как часть сигнатуры загрузки (511-й байт).
• .byte 0xaa: последний байт, определяемый как часть сигнатуры загрузки (512-й байт).
Как скомпилировать программу ассемблера?
Сохраните код в файле test.S и введите в командной строке:
• as test.S -o test.o
• ld –Ttext 0x7c00 —oformat=binary test.o –o test.bin
Что означают эти команды?
• as test.S –o test.o: преобразует заданный код в промежуточную объектную программу, которая затем преобразуется уже в машинный код.
• —oformat=binary сообщает компоновщику, что выходной двоичный файл должен быть простым двоичным образом, т.е. не иметь кода запуска, связывания адресов и пр.
• –Ttext 0x7c00 сообщает компоновщику, что адрес “text” (сегмент кода) нужно загрузить в 0x7c00, чтобы он вычислил верный абсолютный адрес.
Что такое сигнатура загрузки?
Давайте вспомним о загрузочном секторе, используемом BIOS для запуска системы. Но как BIOS узнает о наличии такого сектора на устройстве? Тут нужно пояснить, что состоит он из 512 байт, в которых для 510-го байта ожидается символ 0x55, а для 511-го символ 0xaa. Исходя из этого, BIOS проверяет соответствие двух последний байт загрузочного сектора этим значениям и либо продолжает загрузку, либо сообщает о ее невозможности. При помощи шестнадцатеричного редактора можно просматривать содержимое двоичного файла в более читабельном виде, и ниже я привел снимок этого файла в качестве примера.
Как скопировать исполняемый код на загрузочное устройство и протестировать его?
Чтобы создать образ для дискеты размером 1.4 Мб введите в командную строку следующее:
• dd if=/dev/zero of=floppy.img bs=512 count=2880
Чтобы скопировать этот код в загрузочный сектор файла образа, введите:
• dd if=test.bin of=floppy.img
Для тестирования программы введите:
• bochs
Если bochs не установлен, тогда можно ввести следующие команды:
• sudo apt-get install bochs-x
Файл-образец bochsrc.txtmegs: 32
#romimage: file=/usr/local/bochs/1.4.1/BIOS-bochs-latest, address=0xf0000
#vgaromimage: /usr/local/bochs/1.4.1/VGABIOS-elpin-2.40
floppya: 1_44=floppy.img, status=inserted
boot: a
log: bochsout.txt
mouse: enabled=0 В результате должно отобразиться стандартное окно эмуляции bochs:
Что мы видим
Если теперь заглянуть в файл test.bin через hex-редактор, то вы увидите, что сигнатура загрузки находится после 510-го байта:
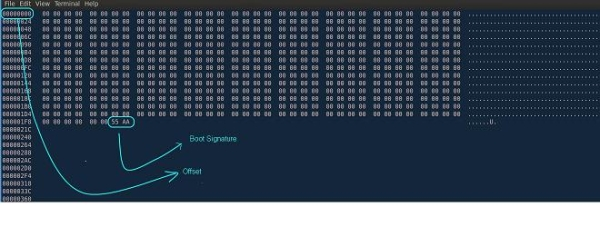
Пока ничего не произошло, так как в коде мы еще ничего не прописали, и вы просто увидите сообщение “Booting from Floppy”. Давайте рассмотрим еще несколько примеров написания кода на ассемблере.
Образец: test2.S .code16 #генерирует 16-битный код
.text #расположение исполняемого кода
.globl _start;
_start: #точка входа
movb $'X' , %al #выводимый символ
movb $0x0e, %ah #выводимый служебный код bios
int $0x10 #прерывание цпу
. = _start + 510 #перемещение из позиции 0 в 510-й байт
.byte 0x55 #присоединение сигнатуры загрузки
.byte 0xaa #присоединение сигнатуры загрузкиПосле ввода этого кода сохраните его в test2.S и выполните компиляцию согласно прежним инструкциям, изменив лишь имя исходного файла. После компиляции, копирования кода в загрузочный сектор и выполнения команды bochs вы должны увидеть экран аналогичный приведенному ниже, где теперь отображается указанная нами в коде буква X.
Мои поздравления!
Что мы видим
При просмотре в hex-редакторе вы увидите, что символ X находится во второй позиции от начального адреса.

Теперь давайте сделаем что-нибудь другое, например выведем на экран текст.
Образец: test3.S.code16 #генерирует 16-битный код
.text #расположение исполняемого кода
.globl _start;
_start: #точка входа
#выводит 'H'
movb $'H' , %al
movb $0x0e, %ah
int $0x10
#выводит 'e'
movb $'e' , %al
movb $0x0e, %ah
int $0x10
#выводит 'l'
movb $'l' , %al
movb $0x0e, %ah
int $0x10
#выводит 'l'
movb $'l' , %al
movb $0x0e, %ah
int $0x10
#выводит 'o'
movb $'o' , %al
movb $0x0e, %ah
int $0x10
#выводит ','
movb $',' , %al
movb $0x0e, %ah
int $0x10
#выводит «пробел»
movb $' ' , %al
movb $0x0e, %ah
int $0x10
#выводит 'W'
movb $'W' , %al
movb $0x0e, %ah
int $0x10
#выводит'o'
movb $'o' , %al
movb $0x0e, %ah
int $0x10
#выводит 'r'
movb $'r' , %al
movb $0x0e, %ah
int $0x10
#выводит 'l'
movb $'l' , %al
movb $0x0e, %ah
int $0x10
#выводит 'd'
movb $'d' , %al
movb $0x0e, %ah
int $0x10
. = _start + 510 #перемещение из позиции 0 к 510-му байту
.byte 0x55 #присоединение сигнатуры загрузки
.byte 0xaa #присоединение сигнатуры загрузкиСохраните файл как test3.S. После компиляции и всех сопутствующих действий вы увидите следующий экран:
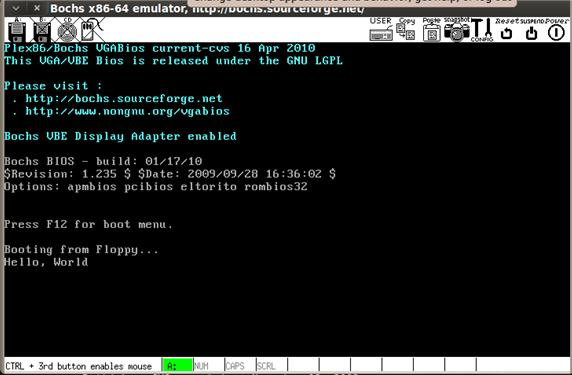
Что мы видим
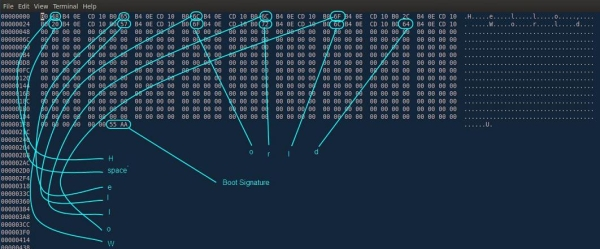
Хорошо. Теперь сделаем что-нибудь еще, например, напишем программу, выводящую на экран фразу “Hello, World”.
Мы также определим функции и макросы, с помощью которых будем выводить эту строку.
Образец: test4.S#генерирует 16-битный код
.code16
#указывает на расположение исполняемого кода
.text
.globl _start;
#точка входа загрузочного кода
_start:
jmp _boot #переход к загрузочному коду
welcome: .asciz "Hello, Worldnr" #здесь мы определяем строку
.macro mWriteString str #макрос, вызывающий функцию для вывода строки
leaw str, %si
call .writeStringIn
.endm
#функция для вывода строки
.writeStringIn:
lodsb
orb %al, %al
jz .writeStringOut
movb $0x0e, %ah
int $0x10
jmp .writeStringIn
.writeStringOut:
ret
_boot:
mWriteString welcome
#перемещение от начала к 510-му байту и присоединение сигнатуры загрузки
. = _start + 510
.byte 0x55
.byte 0xaa Сохраните файл как test4.S. После компиляции и всего за ней следующего теперь вы увидите следующий экран:
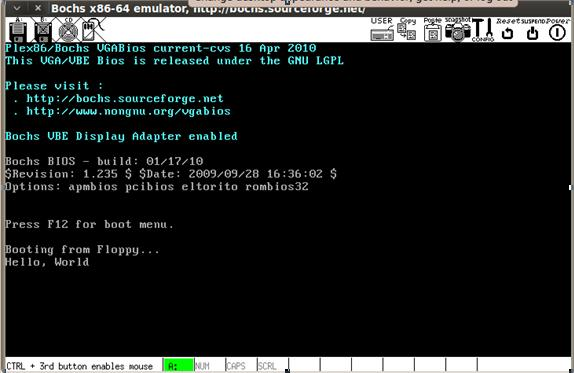
Отлично! Если вы поняли все проделанные мной действия и успешно создали аналогичную программу, то я вас еще раз поздравляю!
Что мы видим
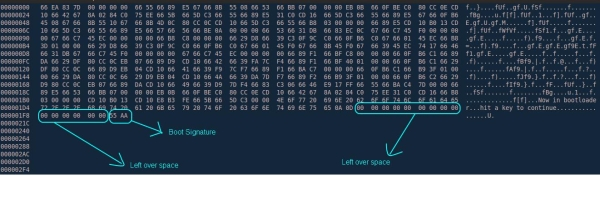
Что такое функция?
Функция – это блок кода, имеющий имя и переиспользуемое свойство.
Что такое макрос?
Макрос – это фрагмент кода с присвоенным именем, на место использования которого подставляется содержимое этого макроса.
В чем синтаксическое отличие функции и макроса?
Для вызова функции используется следующий синтаксис:
• push • call А для макроса такой:
• macroname Но так как синтаксис вызова и применения макроса проще, чем у функции, я предпочел использовать в основном коде именно его, а не функцию.
Написание кода в компиляторе С
Что такое C?
С – это язык программирования общего назначения, разработанный сотрудником Bell Labs Деннисом Ритчи в 1969-1973 годах.
Почему мы используем именно этот язык? Причина в том, что написанные на нем программы, как правило, не велики и отличаются высокой скоростью. Помимо этого, он включает низкоуровневые возможности, которые обычно доступны только в ассемблере или машинном языке. При этом С также является структурированным.
Что нужно для написания кода на С?
Мы будем использовать компилятор GNU C под названием GCC.
Как писать программы в компиляторе GCC на C?
Давайте разберем это на примере.
Образец: test.c__asm__(".code16n");
__asm__("jmpl $0x0000, $mainn");
void main() {
} File: test.ldENTRY(main);
SECTIONS
{
. = 0x7C00;
.text : AT(0x7C00)
{
*(.text);
}
.sig : AT(0x7DFE)
{
SHORT(0xaa55);
}
} Для компиляции программы введите в командной строке:
• gcc -c -g -Os -march=i686 -ffreestanding -Wall -Werror test.c -o test.o
• ld -static -Ttest.ld -nostdlib —nmagic -o test.elf test.o
• objcopy -O binary test.elf test.bin
Что значат эти команды?
Первая преобразует код C в промежуточную объектную программу, которая в последствии преобразуется в машинный код.
• gcc -c -g -Os -march=i686 -ffreestanding -Wall -Werror test.c -o test.o:
Что значат эти команды?Что означают флаги?
• -c: используется для компиляции исходного кода без линковки.
• -g: генерирует отладочную информацию для отладчика GDB.
• -Os: оптимизация размера кода.
• -march: генерирует код для конкретной архитектуры ЦПУ (в нашем случае i686)
• -ffreestanding: в среде отдельных программ может отсутствовать стандартная библиотека, и инструкции запуска программы не обязательно располагаются в “main”.
• -Wall: активирует все предупреждающие сообщения компилятора. Рекомендуется всегда использовать эту опцию.
• -Werror: активирует трактовку предупреждений как ошибок.
• test.c: имя входного исходного файла.
• -o: генерация объектного кода.
• test.o: имя выходного файла объектного кода.
С помощью всей этой комбинации флагов мы генерируем объектный код, помогающий нам в обнаружении ошибок и предупреждений, а также создаем более эффективный код для данного типа ЦПУ. Если не указать march=i686, будет сгенерирован код для используемой вами машины, поэтому всегда нужно указывать, для какого именно типа ЦПУ он создается.
• ld -static -Ttest.ld -nostdlib —nmagic test.elf -o test.o:
Эта команда вызывает компоновщик из командной строки, и ниже я поясню, как именно мы его используем.
Что значат эти флаги?
• -static: не проводить линковку с общими библиотеками.
• -Ttest.ld: разрешает компоновщику следовать командам из его скрипта.
• -nostdlib: разрешает компоновщику генерировать код, не линкуя функции запуска стандартной библиотеки C.
• —nmagic: разрешает компоновщику генерировать код без кода _start_SECTION и _stop_SECTION.
• test.elf: имя входного файла (соответствующий платформе формат хранения исполняемых файлов. Windows: PE, Linux: ELF)
• -o: генерация объектного кода.
• test.o: имя выходного файла объектного кода.
Что такое компоновщик?
Он выполняет последний этап компиляции. ld (компоновщик) получает один или более объектных файлов либо библиотек и совмещает их в один, как правило исполняемый, файл. В ходе этого процесса он обрабатывает ссылки на внешние символы, присваивает конечные адреса процедурам/функциям и переменным, а также корректирует код и данные для отражения актуальных адресов.
Не забывайте, что мы не используем в коде стандартные библиотеки и сложные функции.
• objcopy -O binary test.elf test.bin
Эта команда служит для генерации независимого от платформы кода. Обратите внимание, что в Linux исполняемые файлы хранятся не так, как в Windows. В каждой системе свой способ хранения, но мы создаем всего-навсего небольшой загрузочный код, который на данный момент не зависит от ОС.
Зачем в программе C использовать инструкции ассемблера?
В реальном режиме к функциям BIOS можно легко обратиться через прерывания при помощи инструкций ассемблера, в связи с чем мы их и используем в коде.
Как скопировать код на загрузочное устройство и проверить его?
Чтобы создать образ для дискеты размером 1.4 Мб, введите в командную строку:
• dd if=/dev/zero of=floppy.img bs=512 count=2880
Чтобы скопировать код в загрузочный сектор файла образа, введите:
• dd if=test.bin of=floppy.img
Для проверки программы введите:
• bochs
Должно отобразиться стандартное окно эмуляции:
Что мы видим: как и в первом нашем примере, пока что здесь отображается только сообщение “Booting from Floppy”.
Для вложения инструкция ассемблера в программу C мы используем ключевое слово __asm__.
• Дополнительно мы задействуем __volatile__, указывая компилятору, что код нужно оставить как есть без изменений.
Такой способ вложения называется встраивание ассемблерного кода.
Теперь рассмотрим еще несколько примеров написания кода с помощью компилятора.
Пишем программу для вывода на экран ‘X’
Образец: test2.c
__asm__(".code16n");
__asm__("jmpl $0x0000, $mainn");
void main() {
__asm__ __volatile__ ("movb $'X' , %aln");
__asm__ __volatile__ ("movb $0x0e, %ahn");
__asm__ __volatile__ ("int $0x10n");
}Написав этот код, сохраните файл как test2.c и скомпилируйте его согласно приведенным выше инструкциям, изменив имя исходного файла. После компиляции, копирования кода в загрузочный сектор и выполнения команды bochs вы, как и ранее, увидите следующий экран, где отображается буква X:
Теперь напишем программу для вывода фразы “Hello, World”
Мы также определим функции и макросы, с помощью которых и выведем данную строку.
Образец: test3.c
/* генерирует 16-битный код */
__asm__(".code16n");
/* переходит к точке входа загрузочного кода */
__asm__("jmpl $0x0000, $mainn");
void main() {
/* выводит 'H' */
__asm__ __volatile__("movb $'H' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'e' */
__asm__ __volatile__("movb $'e' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'l' */
__asm__ __volatile__("movb $'l' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'l' */
__asm__ __volatile__("movb $'l' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'o' */
__asm__ __volatile__("movb $'o' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит ',' */
__asm__ __volatile__("movb $',' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит ' ' */
__asm__ __volatile__("movb $' ' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'W' */
__asm__ __volatile__("movb $'W' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'o' */
__asm__ __volatile__("movb $'o' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'r' */
__asm__ __volatile__("movb $'r' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'l' */
__asm__ __volatile__("movb $'l' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'd' */
__asm__ __volatile__("movb $'d' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
}
Сохраните весь этот код в файле test3.c и следуйте уже знакомым вам инструкциям, изменив имя исходного файла и скопировав скомпилированный код в загрузочный сектор дискеты. Теперь должна отобразиться надпись Hello, World:
Напишем программу C для вывода строки “Hello, World”
При этом мы определим функцию, выводящую эту строку на экран.
Образец: test4.c
/*генерирует 16-битный код*/
__asm__(".code16n");
/*переход к точке входа в загрузочный код*/
__asm__("jmpl $0x0000, $mainn");
/* пользовательская функция для вывода серии знаков, завершаемых нулевым символом*/
void printString(const char* pStr) {
while(*pStr) {
__asm__ __volatile__ (
"int $0x10" : : "a"(0x0e00 | *pStr), "b"(0x0007)
);
++pStr;
}
}
void main() {
/* вызов функции printString со строкой в качестве аргумента*/
printString("Hello, World");
} Сохраните этот код в файле test3.c и снова проследуйте всем инструкциям компиляции. В результате после выполнения bochs на экране отобразится следующее:
Все это время мы учились путем преобразования программ ассемблера в программы C. К настоящему моменту вы должны уже хорошо уяснить процесс их написания на обоих этих языках, а также уметь выполнять компиляцию и проверку.
Далее мы перейдем к написанию циклов и их использованию в функциях, а также познакомимся с другими службами BIOS.
Мини-проект для отображения прямоугольников
Образец: test5.c
/* генерирация 16-битного кода */
__asm__(".code16n");
/* переход к главной функции или программному коду */
__asm__("jmpl $0x0000, $mainn");
#define MAX_COLS 320 /* количество столбцов экрана */
#define MAX_ROWS 200 /* количество строк экрана */
/* функция для вывода строки*/
/* input ah = 0x0e*/
/* input al = <выводимый символ>*/
/* прерывание: 0x10*/
/* мы используем прерывание 0x10 с кодом функции 0x0e для вывода байта из al*/
/* эта функция получает в качестве аргумента строку и выводит символ за символом, пока не достигнет нуля*/
void printString(const char* pStr) {
while(*pStr) {
__asm__ __volatile__ (
"int $0x10" : : "a"(0x0e00 | *pStr), "b"(0x0007)
);
++pStr;
}
}
/* функция, получающая сигнал о нажатии клавиши на клавиатуре */
/* input ah = 0x00*/
/* input al = 0x00*/
/* прерывание: 0x10*/
/* эта функция регистрирует нажатие пользователем клавиши для продолжения выполнения */
void getch() {
__asm__ __volatile__ (
"xorw %ax, %axn"
"int $0x16n"
);
}
/* функция вывода на экран окрашенного пикселя в заданном столбце и строке */
/* входной ah = 0x0c*/
/* входной al = нужный цвет*/
/* входной cx = столбец*/
/* входной dx = строка*/
/* прерывание: 0x10*/
void drawPixel(unsigned char color, int col, int row) {
__asm__ __volatile__ (
"int $0x10" : : "a"(0x0c00 | color), "c"(col), "d"(row)
);
}
/* функции очистки экрана и установки видео режима в формате 320x200 пикселей*/
/* функция для очистки экрана */
/* входной ah = 0x00 */
/* входной al = 0x03 */
/* прерывание = 0x10 */
/* функция для установки видео режима */
/* входной ah = 0x00 */
/* входной al = 0x13 */
/* прерывание = 0x10 */
void initEnvironment() {
/* очистка экрана */
__asm__ __volatile__ (
"int $0x10" : : "a"(0x03)
);
__asm__ __volatile__ (
"int $0x10" : : "a"(0x0013)
);
}
/* функция вывода прямоугольников в порядке уменьшения их размера */
/* я выбрал следующую последовательность отрисовки: */
/* из левого верхнего угла в левый нижний, затем в правый нижний, оттуда в верхний правый и в завершении в верхний левый край */
void initGraphics() {
int i = 0, j = 0;
int m = 0;
int cnt1 = 0, cnt2 =0;
unsigned char color = 10;
for(;;) {
if(m < (MAX_ROWS - m)) {
++cnt1;
}
if(m < (MAX_COLS - m - 3)) {
++cnt2;
}
if(cnt1 != cnt2) {
cnt1 = 0;
cnt2 = 0;
m = 0;
if(++color > 255) color= 0;
}
/* верхний левый -> левый нижний */
j = 0;
for(i = m; i < MAX_ROWS - m; ++i) {
drawPixel(color, j+m, i);
}
/* левый нижний -> правый нижний */
for(j = m; j < MAX_COLS - m; ++j) {
drawPixel(color, j, i);
}
/* правый нижний -> правый верхний */
for(i = MAX_ROWS - m - 1 ; i >= m; --i) {
drawPixel(color, MAX_COLS - m - 1, i);
}
/* правый верхний -> левый верхний */
for(j = MAX_COLS - m - 1; j >= m; --j) {
drawPixel(color, j, m);
}
m += 6;
if(++color > 255) color = 0;
}
}
/* эта функция является загрузочным кодом и вызывает следующие функции: */
/* вывод на экран сообщения, предлагающего пользователю нажать любую клавишу для продолжения. После нажатия клавиши происходит отрисовка прямоугольников в порядке убывания их размера */
void main() {
printString("Now in bootloader...hit a key to continuenr");
getch();
initEnvironment();
initGraphics();
}Сохраните все это в файле test5.c и следуйте все тем же инструкциям компиляции с последующим копированием кода в загрузочный сектор дискеты.
Теперь в качестве результата должен отобразиться следующий экран:
Нажмите любую клавишу.
Что мы видим:
Если внимательно рассмотреть содержимое исполняемого файла, то можно заметить, что у нас практически кончилось свободное пространство. Поскольку размер загрузочного сектор ограничен 512Кб, мы смогли вместить только несколько функций, таких как инициализация среды и вывод цветных прямоугольников. Вот снимок содержимого файла:
На этом первая часть серии статей заканчивается. В следующей части я расскажу о режимах адресации, используемых для обращения к данным и чтения дискет. Помимо этого, мы рассмотрим, почему загрузчики обычно пишутся на ассемблере, а не на C, а также ограничения последнего в контексте генерации кода.
