Web crawling is a powerful technique to collect data from the web by finding all the URLs for one or multiple domains. Python has several popular web crawling libraries and frameworks.
In this article, we will first introduce different crawling strategies and use cases. Then we will build a simple web crawler from scratch in Python using two libraries: Requests and Beautiful Soup. Next, we will see why it’s better to use a web crawling framework like Scrapy. Finally, we will build an example crawler with Scrapy to collect film metadata from IMDb and see how Scrapy scales to websites with several million pages.
What is a web crawler?
Web crawling and web scraping are two different but related concepts. Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code.
A web crawler starts with a list of URLs to visit, called the seed. For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue. All the HTML or some specific information is extracted to be processed by a different pipeline.
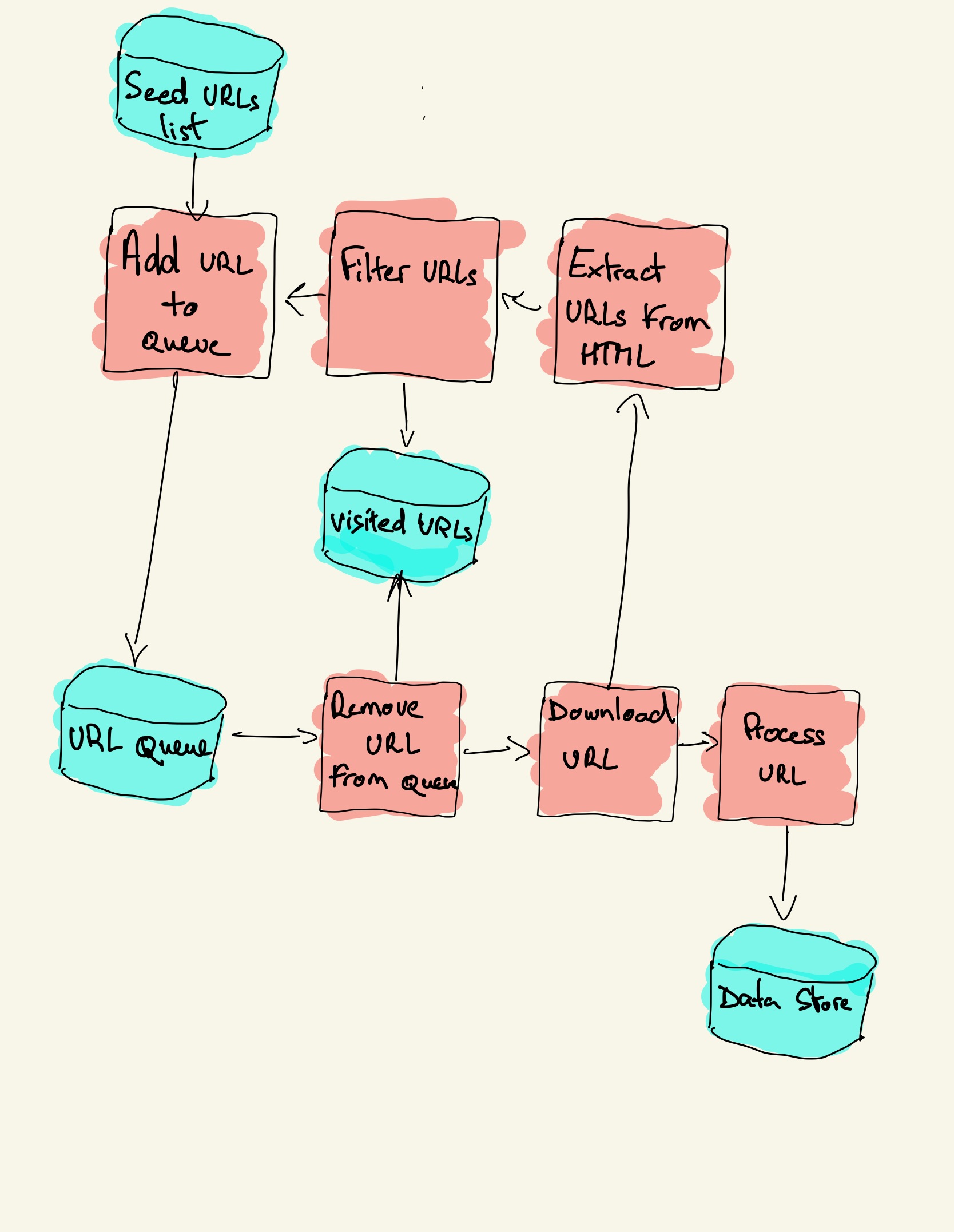
Web crawling strategies
In practice, web crawlers only visit a subset of pages depending on the crawler budget, which can be a maximum number of pages per domain, depth or execution time.
Many websites provide a robots.txt file to indicate which paths of the website can be crawled, and which ones are off-limits. There’s also sitemap.xml, which is a bit more explicit than robots.txt and specifically instructs bots which paths should be crawled and provide additional metadata for each URL.
Popular web crawler use cases include:
- Search engines (e.g. Googlebot, Bingbot, Yandex Bot…) collect all the HTML for a significant part of the Web. This data is indexed to make it searchable.
- SEO analytics tools on top of collecting the HTML also collect metadata like the response time, response status to detect broken pages and the links between different domains to collect backlinks.
- Price monitoring tools crawl e-commerce websites to find product pages and extract metadata, notably the price. Product pages are then periodically revisited.
- Common Crawl maintains an open repository of web crawl data. For example, the archive from May 2022 contains 3.45 billion web pages.
Next, we will compare three different strategies for building a web crawler in Python. First, using only standard libraries, then third party libraries for making HTTP requests and parsing HTML, and, finally, a web crawling framework.
Building a simple web crawler in Python from scratch
To build a simple web crawler in Python we need at least one library to download the HTML from a URL and another one to extract links. Python provides the standard libraries urllib for performing HTTP requests and html.parser for parsing HTML. An example Python crawler built only with standard libraries can be found on Github.
There are also other popular libraries, such as Requests and Beautiful Soup, which may provide an improved developer experience when composing HTTP requests and handling HTML documents. If you wan to learn more, you can check this guide about the best Python HTTP client.
You can install the two libraries locally.
A basic crawler can be built following the previous architecture diagram.
import logging
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
logging.basicConfig(
format='%(asctime)s %(levelname)s:%(message)s',
level=logging.INFO)
class Crawler:
def __init__(self, urls=[]):
self.visited_urls = []
self.urls_to_visit = urls
def download_url(self, url):
return requests.get(url).text
def get_linked_urls(self, url, html):
soup = BeautifulSoup(html, 'html.parser')
for link in soup.find_all('a'):
path = link.get('href')
if path and path.startswith('/'):
path = urljoin(url, path)
yield path
def add_url_to_visit(self, url):
if url not in self.visited_urls and url not in self.urls_to_visit:
self.urls_to_visit.append(url)
def crawl(self, url):
html = self.download_url(url)
for url in self.get_linked_urls(url, html):
self.add_url_to_visit(url)
def run(self):
while self.urls_to_visit:
url = self.urls_to_visit.pop(0)
logging.info(f'Crawling: {url}')
try:
self.crawl(url)
except Exception:
logging.exception(f'Failed to crawl: {url}')
finally:
self.visited_urls.append(url)
if __name__ == '__main__':
Crawler(urls=['https://www.imdb.com/']).run()
Our bot here defines a Crawler class with a couple of helper methods (download_url using the Requests library, get_linked_urls using the Beautiful Soup library, and add_url_to_visit to filter URLs) and then continues by instantiating the class with our IMDb start URL and calling its run() method.
The run will run as long as there are pending URLs in urls_to_visit, will pass each URL to crawl(), extract any links, and add them to urls_to_visit — rinse and repeat.
To run our crawler, simply enter this command on your command line.
The crawler logs one line for each visited URL.
INFO:Crawling: https://www.imdb.com/
INFO:Crawling: https://www.imdb.com/?ref_=nv_home
INFO:Crawling: https://www.imdb.com/calendar/?ref_=nv_mv_cal
INFO:Crawling: https://www.imdb.com/list/ls016522954/?ref_=nv_tvv_dvd
INFO:Crawling: https://www.imdb.com/chart/top/?ref_=nv_mv_250
INFO:Crawling: https://www.imdb.com/chart/moviemeter/?ref_=nv_mv_mpm
INFO:Crawling: https://www.imdb.com/feature/genre/?ref_=nv_ch_gr
The code is very simple but there are many performance and usability issues to solve before successfully crawling a complete website.
- The crawler is slow and supports no parallelism. As can be seen from the timestamps, it takes about one second to crawl each URL. Each time the crawler makes a request it waits for the response and doesn’t do much else.
- The download URL logic has no retry mechanism, the URL queue is not a real queue and not very efficient with a high number of URLs.
- The link extraction logic doesn’t support standardizing URLs by removing URL query string parameters, doesn’t handle relative anchor/fragment URLs (i.e.
href="#myanchor"), and doesn’t support filtering URLs by domain or filtering out requests to static files. - The crawler doesn’t identify itself and ignores the robots.txt file.
Next, we will see how Scrapy provides all these functionalities and makes it easy to extend for your custom crawls.
Web crawling with Scrapy
Scrapy is the most popular web scraping and crawling Python framework with close to 50k stars on Github. One of the advantages of Scrapy is that requests are scheduled and handled asynchronously. This means that Scrapy can send another request before the previous one has completed or do some other work in between. Scrapy can handle many concurrent requests but can also be configured to respect the websites with custom settings, as we’ll see later.
Scrapy has a multi-component architecture. Normally, you will implement at least two different classes: Spider and Pipeline. Web scraping can be thought of as an ETL where you extract data from the web and load it to your own storage. Spiders extract the data and pipelines load it into the storage. Transformation can happen both in spiders and pipelines, but I recommend that you set a custom Scrapy pipeline to transform each item independently of each other. This way, failing to process an item has no effect on other items.
On top of all that, you can add spider and downloader middlewares in between components as it can be seen in the diagram below.
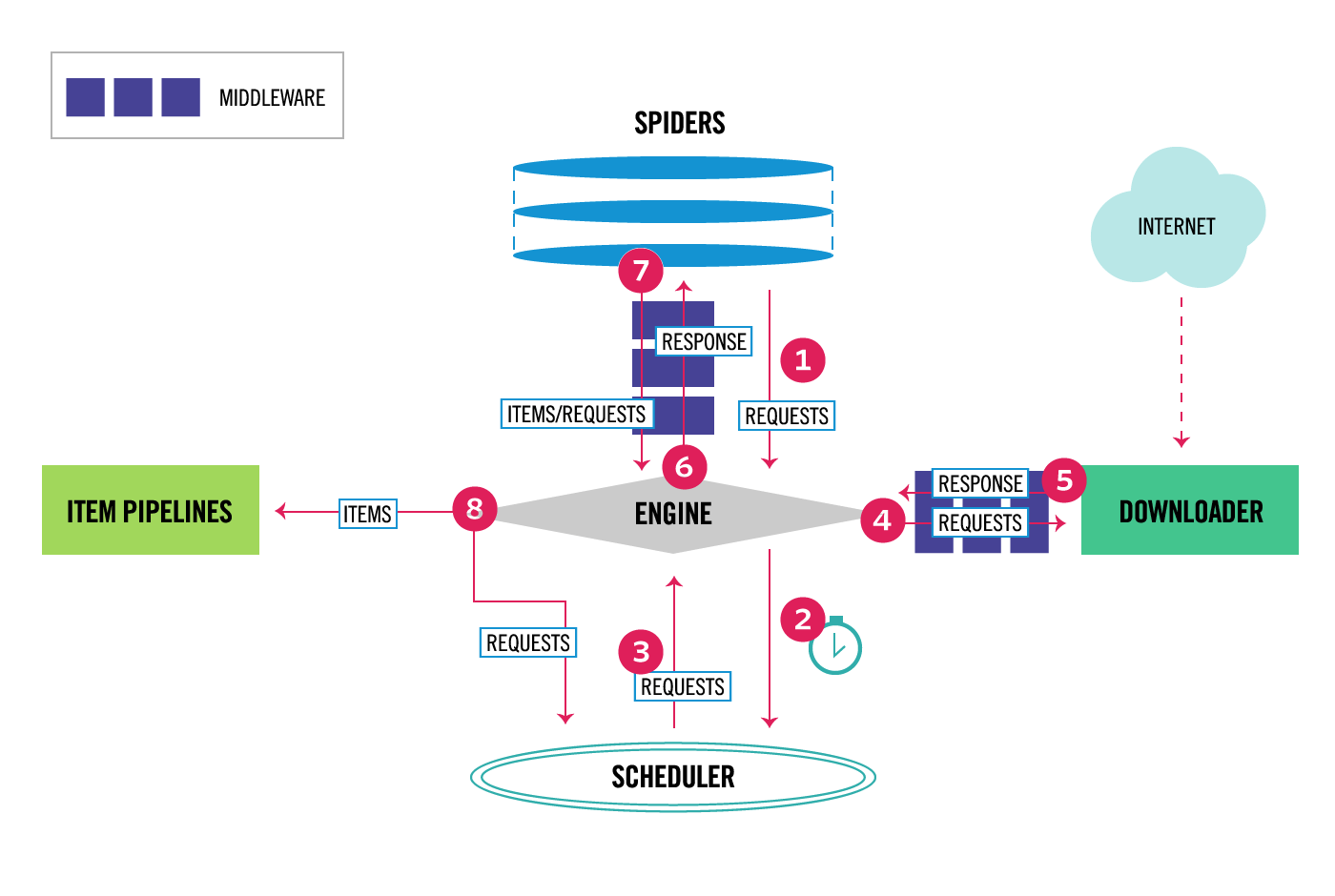
Scrapy Architecture Overview [source]
If you used Scrapy before, you know that a web scraper is defined as a class that inherits from the base Spider class and implements a parse method to handle each response. If you are new to Scrapy, you can read this article for easy scraping with Scrapy.
from scrapy.spiders import Spider
class ImdbSpider(Spider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
def parse(self, response):
pass
Scrapy also provides several generic spider classes: CrawlSpider, XMLFeedSpider, CSVFeedSpider and SitemapSpider. The CrawlSpider class inherits from the base Spider class and provides an extra rules attribute to define how to crawl a website. Each rule uses a LinkExtractor to specify which links are extracted from each page. Next, we will see how to use each one of them by building a crawler for IMDb, the Internet Movie Database.
Building an example Scrapy crawler for IMDb
Before trying to crawl IMDb, I checked IMDb robots.txt file to see which URL paths are allowed. The robots file only disallows 26 paths for all user-agents. Scrapy reads the robots.txt file beforehand and respects it when the ROBOTSTXT_OBEY setting is set to true. This is the case for all projects generated with the Scrapy command startproject.
scrapy startproject scrapy_crawler
This command creates a new project with the default Scrapy project folder structure.
scrapy_crawler/
├── scrapy.cfg
└── scrapy_crawler
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
├── __init__.py
Then you can create a spider in scrapy_crawler/spiders/imdb.py with a rule to extract all links.
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (Rule(LinkExtractor()),)
Now, simply launch the crawler with the scrapy command
scrapy crawl imdb --logfile imdb.log
You will get lots of logs, including one log for each request. Exploring the logs I noticed that even if we set allowed_domains to only crawl web pages under https://www.imdb.com, there were requests to external domains, such as amazon.com.
[scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.amazon.com/b/?&node=5160028011&ref_=ft_iba> from <GET [https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba](https://www.imdb.com/whitelist-offsite?url=https%3A%2F%2Fwww.amazon.com%2Fb%2F%3F%26node%3D5160028011%26ref_%3Dft_iba&page-action=ft-iba&ref=ft_iba)>
IMDb redirects paths under /whitelist-offsite and /whitelist to external domains. There is an open Scrapy Github issue that shows that external URLs don’t get filtered out when OffsiteMiddleware is applied before RedirectMiddleware. To fix this issue, we can configure the link extractor to skip URLs starting with two regular expressions.
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (
Rule(LinkExtractor(
deny=[
re.escape('https://www.imdb.com/offsite'),
re.escape('https://www.imdb.com/whitelist-offsite'),
],
)),
)
Rule and LinkExtractor classes support several arguments to filter URLs. For example, you can ignore specific file extensions and reduce the number of duplicate URLs by sorting or collapsing query strings.
If you don’t find a specific argument for your use case, you can use the parameter process_value of LinkExtractor or process_links of Rule. For example, we got the same page twice, once as plain URL, another time with additional query string parameters.
- https://www.imdb.com/name/nm1156914/
- https://www.imdb.com/name/nm1156914/?mode=desktop&ref_=m_ft_dsk
To limit the number of crawled URLs, we can remove all query strings from URLs with the url_query_cleaner function from the w3lib library and use it in process_links.
from w3lib.url import url_query_cleaner
def process_links(links):
for link in links:
link.url = url_query_cleaner(link.url)
yield link
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (
Rule(LinkExtractor(
deny=[
re.escape('https://www.imdb.com/offsite'),
re.escape('https://www.imdb.com/whitelist-offsite'),
],
), process_links=process_links),
)
Now that we have limited the number of requests to process, we can add a parse_item method to extract data from each page and pass it to a pipeline to store it. For example, we can either take response.text process it in a different pipeline or select the HTML metadata.
To select the HTML metadata in the header tag we can specify our own XPath expressions but I find it better to use a library, extruct, that extracts all metadata from an HTML page. You can install it with pip install extruct.
import re
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from w3lib.url import url_query_cleaner
import extruct
def process_links(links):
for link in links:
link.url = url_query_cleaner(link.url)
yield link
class ImdbCrawler(CrawlSpider):
name = 'imdb'
allowed_domains = ['www.imdb.com']
start_urls = ['https://www.imdb.com/']
rules = (
Rule(
LinkExtractor(
deny=[
re.escape('https://www.imdb.com/offsite'),
re.escape('https://www.imdb.com/whitelist-offsite'),
],
),
process_links=process_links,
callback='parse_item',
follow=True
),
)
def parse_item(self, response):
return {
'url': response.url,
'metadata': extruct.extract(
response.text,
response.url,
syntaxes=['opengraph', 'json-ld']
),
}
I set the follow attribute to True so that Scrapy still follows all links from each response, even if we provided a custom parse method. I also configured extruct to extract only Open Graph metadata and JSON-LD, a popular method for encoding linked data using JSON in the Web, used by IMDb. You can run the crawler and store items in JSON lines format to a file.
scrapy crawl imdb --logfile imdb.log -o imdb.jl -t jsonlines
The output file imdb.jl contains one line for each crawled item. For example, the extracted Open Graph metadata, for a movie taken from the <meta> tags in the HTML, looks like this.
{
"url": "http://www.imdb.com/title/tt2442560/",
"metadata": {"opengraph": [{
"namespace": {"og": "http://ogp.me/ns#"},
"properties": [
["og:url", "http://www.imdb.com/title/tt2442560/"],
["og:image", "https://m.media-amazon.com/images/M/MV5BMTkzNjEzMDEzMF5BMl5BanBnXkFtZTgwMDI0MjE4MjE@._V1_UY1200_CR90,0,630,1200_AL_.jpg"],
["og:type", "video.tv_show"],
["og:title", "Peaky Blinders (TV Series 2013u2013 ) - IMDb"],
["og:site_name", "IMDb"],
["og:description", "Created by Steven Knight. With Cillian Murphy, Paul Anderson, Helen McCrory, Sophie Rundle. A gangster family epic set in 1900s England, centering on a gang who sew razor blades in the peaks of their caps, and their fierce boss Tommy Shelby."]
]
}]}
}
The JSON-LD for a single item is too long to be included in the article, here is a sample of what Scrapy extracts from the <script type="application/ld+json"> tag.
"json-ld": [
{
"@context": "http://schema.org",
"@type": "TVSeries",
"url": "/title/tt2442560/",
"name": "Peaky Blinders",
"image": "https://m.media-amazon.com/images/M/MV5BMTkzNjEzMDEzMF5BMl5BanBnXkFtZTgwMDI0MjE4MjE@._V1_.jpg",
"genre": ["Crime","Drama"],
"contentRating": "TV-MA",
"actor": [
{
"@type": "Person",
"url": "/name/nm0614165/",
"name": "Cillian Murphy"
},
...
]
...
}
]
Exploring the logs, I noticed another common issue with crawlers. By sequentially clicking on filters, the crawler generates URLs with the same content, only that the filters were applied in a different order.
- https://www.imdb.com/name/nm2900465/videogallery/content_type-trailer/related_titles-tt0479468
- https://www.imdb.com/name/nm2900465/videogallery/related_titles-tt0479468/content_type-trailer
Long filter and search URLs is a difficult problem that can be partially solved by limiting the length of URLs with a Scrapy setting, URLLENGTH_LIMIT.
I used IMDb as an example to show the basics of building a web crawler in Python. I didn’t let the crawler run for long as I didn’t have a specific use case for the data. In case you need specific data from IMDb, you can check the IMDb Datasets project that provides a daily export of IMDb data or Cinemagoer, a Python package specifically for fetching and handling IMDb data.
Web crawling at scale
If you attempt to crawl a big website like IMDb, with over 130 million pages (at least according to Google), it’s important to crawl responsibly by adjusting your crawler and tweaking its settings accordingly.
- USER_AGENT — Allows you to specify the user agent and provide possible contact details
- DOWNLOAD_DELAY — Specifies for how many seconds your crawler should wait between requests
- CONCURRENT_REQUESTS_PER_DOMAIN — Indicates how many simultaneous requests maximum your crawler should send to one site
- AUTOTHROTTLE_ENABLED — Enables automated and dynamic request throttling
Notice that Scrapy crawls are optimized for a single domain by default. If you are crawling multiple domains check these settings to optimize for broad crawls, including changing the default crawl order from depth-first to breath-first. To limit your crawl budget, you can limit the number of requests with the CLOSESPIDER_PAGECOUNT setting of the close spider extension.
With the default settings, Scrapy crawls about 600 pages per minute for a website like IMDb. Crawling 130 million pages would take about half a year at that speed with a single robot. If you need to crawl multiple websites it can be better to launch separate crawlers for each big website or group of websites. If you are interested in distributed web crawls, you can read how a developer crawled 250M pages with Python in less than two days using 20 Amazon EC2 machine instances.
In some cases, you may run into websites that require you to execute JavaScript code to render all the HTML. Fail to do so, and you may not collect all links on the website. Because nowadays it’s very common for websites to render content dynamically in the browser I wrote a Scrapy middleware for rendering JavaScript pages using ScrapingBee’s API.
Conclusion
We compared the code of a Python crawler using third-party libraries for downloading URLs and parsing HTML with a crawler built using a popular web crawling framework. Scrapy is a very performant web crawling framework and it’s easy to extend with your custom code. But you need to know all the places where you can hook your own code and the settings for each component.
Configuring Scrapy properly becomes even more important when crawling websites with millions of pages. If you want to learn more about web crawling I suggest that you pick a popular website and try to crawl it. You will definitely run into new issues, which makes the topic fascinating!
💡 While this article does cover quite a bit of the more advanced topics (e.g. request throttling) there are still quite a few details to take into account to successfully crawl sites.
For example, some sites only serve geo-restricted content, perform browser fingerprinting, or require the client to solve CAPTCHAs. There’s another article which addresses these issues and goes into detail on how you can scrape the web without getting blocked, please feel free to check it out.
Finding the right CSS selector can be, admittedly, a lot of fun, but if your project is on a schedule, you may not want to have to deal with user agents, distributed IP addresses, rate limiting, and headless browser instances. And that’s exactly what ScrapingBee was made for and where it can help you to have a hassle-free SaaS web-scraping experience — please check out our no-code data extraction platform.
Sources
- Scrapy CrawlSpider documentation
- Configuring Scrapy for broad crawls
- How to crawl a quarter billion webpages in 40 hours
- How to execute JavaScript with Scrapy?
Why would anyone want to collect more data when there is so much already? Even though the magnitude of information is alarmingly large, you often find yourself looking for data that is unique to your needs.
For example, what would you do if you wanted to collect info on the history of your favorite basketball team or your favorite ice cream flavor?
Enterprise data collection is essential in the day-to-day life of a data scientist because the ability to collect actionable data on trends of the modern-day means possible business opportunities.
In this tutorial, you’ll learn about web crawling via a simple online store.
HTML anatomy refresher
Let’s review basic HTML anatomy. Nearly all websites on the Internet are built using the combination of HTML and CSS code (including JavaScript, but we won’t talk about it here).
Below is a sample HTML code with some critical parts annotated.
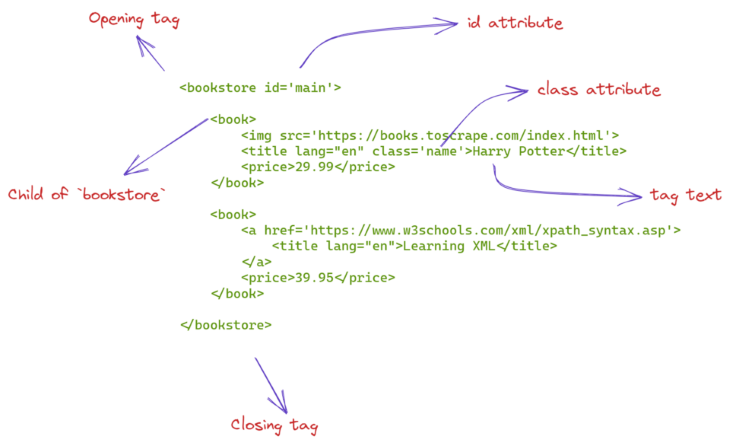
The HTML code on the web will be a bit more complicated than this, however. It will be nearly impossible to just look at the code and figure out what it’s doing. For this reason, we will learn about more sophisticated tools to make sense of massive HTML pages, starting with XPath syntax.
XPath with lxml
The whole idea behind web scraping is to use automation to extract information from the massive sea of HTML tags and their attributes. One of the tools, among many, to use in this process is using XPath.
XPath stands for XML path language. XPath syntax contains intuitive rules to locate HTML tags and extract information from their attributes and texts. For this section, we will practice using XPath on the HTML code you saw in the above picture:
sample_html = """
<bookstore id='main'>
<book>
<img src='https://books.toscrape.com/index.html'>
<title lang="en" class='name'>Harry Potter</title>
<price>29.99</price>
</book>
<book>
<a href='https://www.w3schools.com/xml/xpath_syntax.asp'>
<title lang="en">Learning XML</title>
</a>
<price>39.95</price>
</book>
</bookstore>
"""
To start using XPath to query this HTML code, we will need a small library:
pip install lxml
LXML allows you to read HTML code as a string and query it using XPath. First, we will convert the above string to an HTML element using the fromstring function:
from lxml import html source = html.fromstring(sample_html) >>> source <Element bookstore at 0x1e612a769a0> >>> type(source) lxml.html.HtmlElement
Now, let’s write our first XPath code. We will select the bookstore tag first:
>>> source.xpath("//bookstore")
[<Element bookstore at 0x1e612a769a0>]
Simple! Just write a double forward slash followed by a tag name to select the tag from anywhere of the HTML tree. We can do the same for the book tag:
>>> source.xpath("//book")
[<Element book at 0x1e612afcb80>, <Element book at 0x1e612afcbd0>]
As you can see, we get a list of two book tags. Now, let’s see how to choose an immediate child of a tag. For example, let’s select the title tag that comes right inside the book tag:
>>> source.xpath("//book/title")
[<Element title at 0x1e6129dfa90>]
We only have a single element, which is the first title tag. We didn’t choose the second tag because it is not an immediate child of the second book tag. But we can replace the single forward slash with a double one to choose both title tags:
>>> source.xpath("//book//title")
[<Element title at 0x1e6129dfa90>, <Element title at 0x1e612b0edb0>]
Now, let’s see how to choose the text inside a tag:
>>> source.xpath("//book/title[1]/text()")
['Harry Potter']
Here, we are selecting the text inside the first title tag. As you can see, we can also specify which of the title tags we want using brackets notation. To choose the text inside that tag, just follow it with a forward slash and a text() function.
Finally, we look at how to locate tags based on their attributes like id, class, href, or any other attribute inside <>. Below, we will choose the title tag with the name class:
>>> source.xpath("//title[@class='name']")
[<Element title at 0x1e6129dfa90>]
As expected, we get a single element. Here are a few examples of choosing other tags using attributes:
>>> source.xpath("//*[@id='main']") # choose any element with id 'main'
[<Element bookstore at 0x1e612a769a0>]
>>> source.xpath("//title[@lang='en']") # choose a title tag with 'lang' attribute of 'en'.
[<Element title at 0x1e6129dfa90>, <Element title at 0x1e612b0edb0>]
I suggest you look at this page to learn more about XPath.
Creating a class to store the data
For this tutorial, we will be scraping this online store’s computers section:
We will be extracting every item’s name, manufacturer, and price. To make things easier, we will create a class with these attributes:
class StoreItem:
"""
A general class to store item data concisely.
"""
def __init__(self, name, price, manufacturer):
self.name = name
self.price = price
self.manufacturer = manufacturer
Let’s initialize the first item manually:
item1 = StoreItem("Lenovo IdeaPad", 749, "Walmart")
Getting the page source
Now, let’s get down to the serious business. To scrape the website, we will need its HTML source. Achieving this requires using another library:
pip install requests
Requests allow you to send HTTPS requests to websites and, of course, get back the result with their HTML code. It is as easy as calling its get method and passing the webpage address:
import requests HOME_PAGE = "https://slickdeals.net/computer-deals/?page=1" >>> requests.get(HOME_PAGE) <Response [200]>
If the response comes with a 200 status code, the request was successful. To get the HTML code, we use the content attribute:
r = requests.get(HOME_PAGE) source = html.fromstring(r.content) >>> source <Element html at 0x1e612ba63b0>
Above, we are converting the result to an LXML compatible object. As we probably repeat this process a few times, we will convert it into a function:
def get_source(page_url): """ A function to download the page source of the given URL. """ r = requests.get(page_url) source = html.fromstring(r.content) return source source = get_source(HOME_PAGE) >>> source <Element html at 0x1e612d11770>
But, here is a problem — any website contains tens of thousands of HTML code, which makes visual exploration of the code impossible. For this reason, we will turn to our browser to figure out which tags and attributes contain the information we want.
After loading the page, right-click anywhere on the page and choose Inspect to open developer tools:
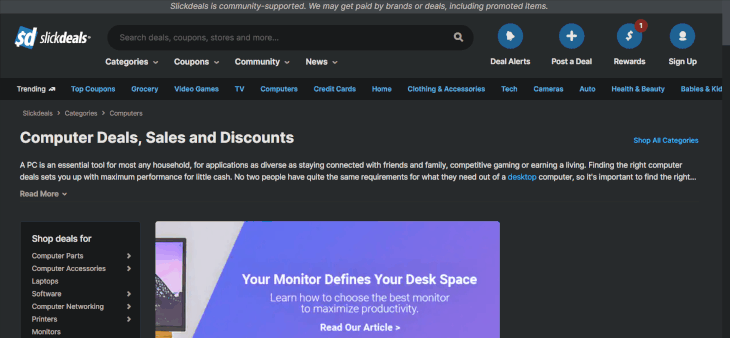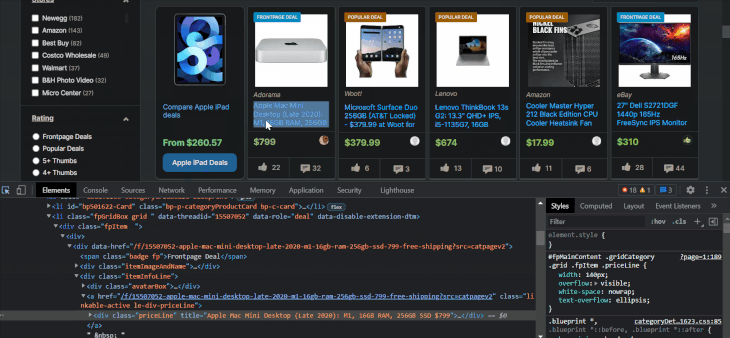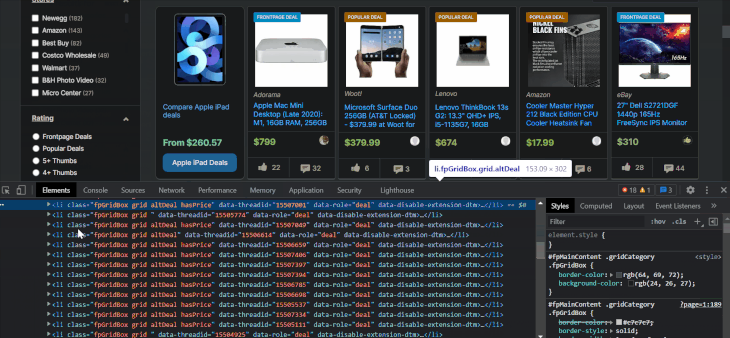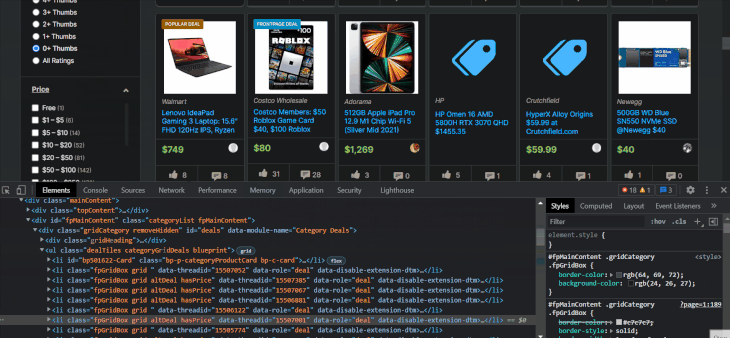
Using the selector arrow, you can hover over and click on parts of the page to find out the element below the cursor and figure out their associated attributes and info. It will also change the bottom window to move to the location of the selected element.
As we can see, all stored items are within li elements, with a class attribute containing the words fpGridBox grid. Let’s choose them using XPath:
source = get_source(HOME_PAGE)
li_list = source.xpath("//li[contains(@class, 'fpGridBox grid')]")
>>> len(li_list)
28
Because the class names are changing, we are using part of the class name that is common in all li elements. As a result, we have selected 28 li elements, which you can double-check by counting them on the web page itself.
Extracting the data
Now, let’s start extracting the item details from the li elements. Let’s first look at how to find the item’s name using the selector arrow:
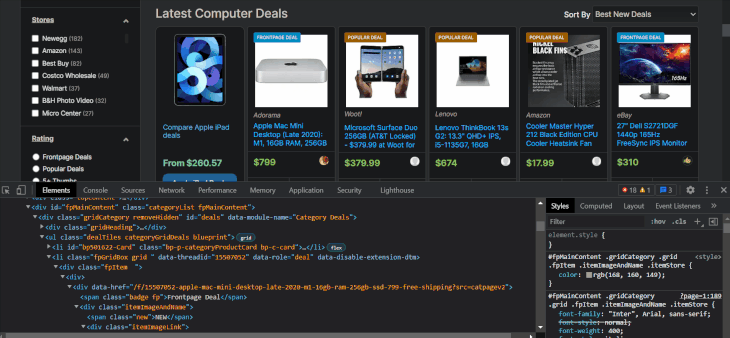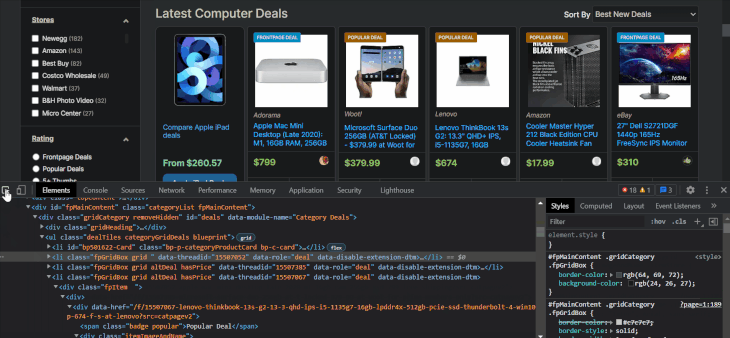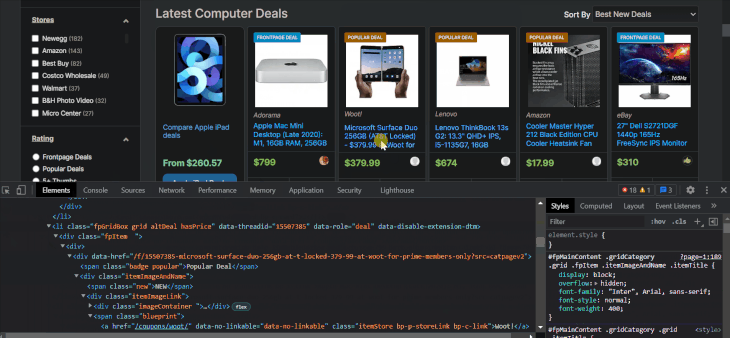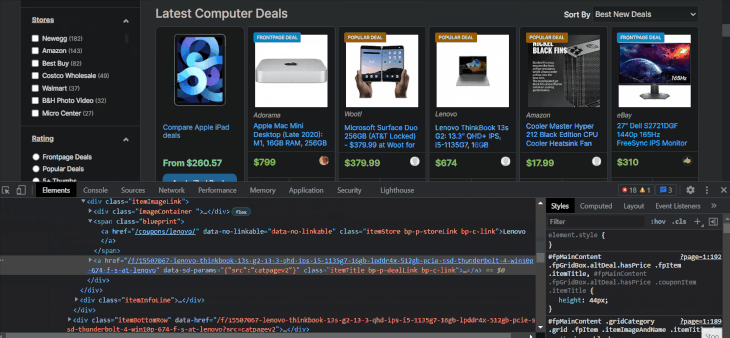
The item names are located inside tags with class names that contain the itemTitle keyword. Let’s select them with XPath to make sure:
item_names = [
li.xpath(".//a[@class='itemTitle bp-p-dealLink bp-c-link']") for li in li_list
]
>>> len(item_names)
28
As expected, we got 28 item names. This time, we are using chained XPath on li elements, which requires starting the syntax with a dot. Below, I will write the XPath for other item details using the browser tools:
li_xpath = "//li[contains(@class, 'fpGridBox grid')]" # Choose the `li` items names_xpath = ".//a[@class='itemTitle bp-p-dealLink bp-c-link']/text()" manufacturer_xpath = ".//*[contains(@class, 'itemStore bp-p-storeLink')]/text()" price_xpath = ".//*[contains(@class, 'itemPrice')]/text()"
We have everything we need to scrape all the items on the page. Let’s do it in a loop:
li_list = source.xpath(li_xpath) items = list() for li in li_list: name = li.xpath(names_xpath) manufacturer = li.xpath(manufacturer_xpath) price = li.xpath(price_xpath) # Store inside a class item = StoreItem(name, price, manufacturer) items.append(item) >>> len(items) 28
Handling the pagination
We now have all items on this page. However, if you scroll down, you’ll see the Next button, indicating that there are more items to scrape. We don’t want to visit all pages manually one by one because there can be hundreds.
But if you pay attention to the URL when we click on the Next button every time:

The page number changes at the end. Now, I’ve checked that there are 22 pages of items on the website. So, we will create a simple loop to iterate through the pagination and repeat the scraping process:
from tqdm.notebook import tqdm # pip install tqdm
# Create a list to store all
items = list()
for num in tqdm(range(1, 23)):
url = f"https://slickdeals.net/computer-deals/?page={num}"
source = get_source(url) # Get HTML code
li_list = source.xpath(li_xpath)
for li in li_list:
name = clean_text(li.xpath(names_xpath))
manufacturer = clean_text(li.xpath(manufacturer_xpath))
price = clean_text(li.xpath(price_xpath))
# Store inside a class
item = StoreItem(name, price, manufacturer)
items.append(item)
I am also using the tqdm library, which displays a progress bar when wrapped around an iterable:
Let’s check how many items we have:
>>> len(items) 588
588 computers! Now, let’s store the items we have into a CSV file.
Storing the data
To store the data, we will use the Pandas library to create a DataFrame and save it to a CSV:
import pandas as pd
df = pd.DataFrame(
{
"name": [item.name for item in items],
"price": [item.price for item in items],
"manufacturer": [item.manufacturer for item in items],
}
)
df.head()
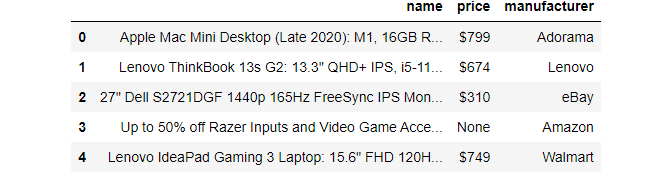
There you go! Let’s finally save it to a file:
df.to_csv("data/scaped.csv", index=False)
Conclusion
This tutorial was a straightforward example of how to use a web crawler in Python. While mastering the tools you learned today will be more than enough for most of your scraping needs, you may need a few additional tools for particularly nasty websites.
Specifically, I suggest you learn about BeautifulSoup if you don’t feel like learning XPath syntax, as BeautifulSoup offers an OOP approach to querying the HTML code.
For websites that require logging in or changes dynamically using JavaScript, you should learn one of the best libraries in Python , Selenium. Finally, for enterprise web scraping, there is Scrapy, which covers pretty much every aspect there is to web scraping. Thanks for reading!
Cut through the noise of traditional error reporting with LogRocket

LogRocket is a digital experience analytics solution that shields you from the hundreds of false-positive errors alerts to just a few truly important items. LogRocket tells you the most impactful bugs and UX issues actually impacting users in your applications.
Then, use session replay with deep technical telemetry to see exactly what the user saw and what caused the problem, as if you were looking over their shoulder.
LogRocket automatically aggregates client side errors, JS exceptions, frontend performance metrics, and user interactions. Then LogRocket uses machine learning to tell you which problems are affecting the most users and provides the context you need to fix it.
Focus on the bugs that matter — try LogRocket today.
Разработка сканера Python от входа до реального боя (версия микрокурса)
Глава 1 Введение
Основная цель краулера — получить содержимое веб-страницы и проанализировать его. Пока эта цель может быть достигнута, никаких проблем нет.
Что касается доступа к веб-страницам, эта книга в основном представляет два сторонних модуля Python: один — это запросы, а другой — фреймворк сканера Scrapy.
Что касается синтаксического анализа веб-контента, эта книга в основном представляет три способа: регулярные выражения, XPath и BeautifulSoup. Два метода получения веб-страниц и три метода анализа веб-страниц могут быть свободно сопоставлены и использоваться по желанию.
Глава 2 Основы Python
Очки знаний
- Создайте среду разработки Python.
- Базовые знания и типы данных Python.
- Условные операторы и операторы цикла в Python.
- Определение и использование функций Python.
- Код объектно-ориентированного программирования на основе Python.
Глава 3 Регулярные выражения и файловые операции
Очки знаний
- Основные символы регулярных выражений.
- Как использовать регулярные выражения в Python.
- Навыки извлечения регулярных выражений.
- Python читает и записывает текстовые файлы и файлы CSV.
Глава 4 Разработка простого веб-краулера
Очки знаний
- Установка и использование запросов.
- Разработка многопоточных краулеров.
- Общие алгоритмы для поисковых роботов.
Разработка многопоточного краулера
Освоив запросы и регулярные выражения, вы можете начать сканирование некоторых простых URL-адресов.
Однако в настоящее время поисковый робот имеет только один процесс и один поток, поэтому он называется однопоточным поисковым роботом. Однопоточные сканеры посещают только одну страницу за раз и не могут полностью использовать пропускную способность сети компьютера. Страница занимает не более нескольких сотен КБ, поэтому, когда сканер просматривает страницу, дополнительная скорость сети и время между отправкой запроса и получением исходного кода теряются.
Если сканер может получить доступ к 10 страницам одновременно, это эквивалентно увеличению скорости сканирования в 10 раз. Для достижения этой цели необходимо использовать технологию многопоточности.
Один поток на микроуровне похож на выполнение нескольких задач одновременно на макроуровне. Этот механизм мало влияет на операции с интенсивным вводом-выводом (ввод-вывод), но для операций с интенсивным использованием ЦП, поскольку может использоваться только одно ядро ЦП, он будет иметь очень Большое влияние. Поэтому, когда дело доходит до программ с интенсивными вычислениями, вам необходимо использовать несколько процессов.Множественные процессы Python не зависят от GIL.
Потому что краулерОперации с интенсивным вводом-выводом, Особенно при запросе исходного кода веб-страницы, если вы используете для разработки один поток, это будет тратить много времени на ожидание возврата веб-страницы, поэтому применение технологии многопоточности к сканеру может значительно повысить эффективность поискового робота.
Библиотека многопроцессорной обработки (многопроцессорность)
Сама по себе multiprocessing — это многопроцессорная библиотека Python, используемая для обработки операций, связанных с многопроцессорностью. Однако, поскольку ресурсы памяти и стека не могут быть напрямую разделены между процессами, а стоимость запуска нового процесса намного выше, чем стоимость потоков, использование нескольких потоков для обхода имеет больше преимуществ, чем использование нескольких процессов. Под многопроцессорностью есть фиктивный модуль, который позволяет потокам Python использовать различные методы многопроцессорности.
Под dummy есть класс Pool, который используется для реализации пула потоков. В этом пуле потоков есть метод map (), который позволяет всем потокам в пуле потоков выполнять функцию «одновременно».
from multiprocessing.dummy import Pool as ThreadPool
# Используйте карту для реализации многопоточных сканеров
pool = ThreadPool(4)
pool.map(crawler_func, data_list)
pool.close()
pool.join()
Общие алгоритмы поиска
- DFS
- BFS
В процессе разработки краулера следует выбирать в первую очередь глубину или ширину? Это требует выбора на основе просматриваемых данных.
резюме
В этой главе объясняется установка и использование запросов, а также то, как использовать многопроцессорную многопроцессорную библиотеку Python для реализации многопоточных поисковых роботов.
Глава 5 Высокопроизводительный анализ содержимого HTML
Очки знаний
- HTML-инфраструктура.
- Используйте XPath для извлечения полезной информации из исходного кода HTML.
- Используйте Beautiful Soup4 для извлечения полезной информации из исходного кода HTML.
Beautiful Soup4
Beautiful Soup4 (BS4) — это сторонняя библиотека для Python, используемая для извлечения данных из HTML и XML.
pip install beautifulsoup4
резюме
Извлечение необходимой информации с веб-страниц — самая важная, но основная операция при разработке поискового робота. Только освоив и свободно используя регулярные выражения, XPath и Beautiful Soup4 для извлечения информации с веб-страниц, обучение поискового робота можно считать входом.
XPath — это язык запросов, разработанный на языке C, поэтому он очень быстрый. Но XPath требует некоторой практики, прежде чем его можно будет гибко использовать.
Beautiful Soup4 — это инструмент для извлечения данных с веб-страниц. Начать работу с ним несложно, и он обладает мощными функциями, но поскольку он разработан на основе Python,Медленнее, чем XPath. Читатели могут выбрать тот, который им нравится, в качестве основного метода извлечения данных. В этой книге используется XPath, поэтому остальное содержимое будет объяснено в XPath.
Глава 6 Python и база данных
база данных
В этой главе рассказывается о двух базах данных MongoDB и Redis. Среди них MongoDB используется для хранения больших объемов данных, а Redis используется как кеш и очередь для хранения временных данных.
Очки знаний
- Установка MongoDB и Redis.
- MongoDB добавляет, удаляет, изменяет и проверяет операции.
- Список Redis и операции сбора.
Установите MongoDB под Mac OS
brew update
brew install mongodb
# Start MongoDB
mongod --config /usr/local/etc/mongod.conf
Инструмент графического управления-RoboMongo
RoboMongo — это кроссплатформенный инструмент управления MongoDB, вы можете запрашивать или изменять MongoDB в графическом интерфейсе.
Данные хранятся в MongoDB в соответствии с иерархической связью «База данных» — «Коллекции» — «Документ». Если вы используете структуру данных Python для проведения аналогии, документ эквивалентен словарю, коллекция эквивалентна списку, содержащему множество словарей, а библиотека эквивалентна большому словарю. Каждая пара ключ-значение в большом словаре соответствует коллекции. Ключ — это имя коллекции, а значение — это коллекция.
Установка PyMongo
Модуль PyMongo представляет собой пакет интерфейса для операций Python с MongoDB, который может реализовывать такие операции, как добавление, удаление, изменение и сортировка MongoDB.
pip install pymongo
Использование PyMongo
(1) Инициализируйте базу данных с помощью PyMongo
Чтобы использовать PyMongo для работы с MongoDB, вам сначала необходимо инициализировать соединение с базой данных. Если MongoDB работает на локальном компьютере, а порт не изменен или добавлены имя пользователя и пароль, тогда нет необходимости принимать параметры при инициализации экземпляра MongoClient и записывать их напрямую как:
from pymongo import MongoClient
client = MongoClient()
Если MongoDB работает на других серверах, вам необходимо использовать «URI (унифицированный идентификатор ресурса, унифицированный идентификатор ресурса)», чтобы указать адрес подключения. Формат MongoDB URI:
mongodb://имя пользователя:Пароль @ IP-адрес сервера или доменное имя:Порт
Есть два способа инициализировать базы данных и коллекции в PyMongo.
# Способ 1:
from pymongo import MongoClient
client = MongoClient()
database= client.Chapter6
collection = database.spider
# Обратите внимание, что при использовании метода 1 «Chapter6» и «spider» в коде не являются именами переменных, они являются непосредственно именем библиотеки и именем коллекции.
# Способ 2:
from pymongo import MongoClient
client = MongoClient()
database = client['Chapter6']
collection = database['spider']
# При использовании метода 2 укажите имя библиотеки и имя коллекции в квадратных скобках. В этом случае, помимо записи обычных строк непосредственно в квадратных скобках, вы также можете записать переменную.
По умолчанию MongoDB разрешает только локальный доступ к базе данных. Это связано с тем, что MongoDB не имеет пароля доступа по умолчанию. По соображениям безопасности доступ к внешней сети запрещен.
Если вам нужно получить доступ к базе данных из внешней сети, вам необходимо изменить файл конфигурации mongod.conf, используемый при установке MongoDB.
(2) Вставить данные
Операция вставки MongoDB очень проста. Используемый метод — это insert (параметр), а вставленный параметр — это словарь Python.Вставьте фрагмент данныхКод выглядит следующим образом.
from pymongo import MongoClient
client = MongoClient()
database = client['Chapter6']
collection = database['spider']
data = {'id': 123, 'name': 'kingname', 'age': 20, 'salary': 999999}
collection.insert(data)
# MongoDB автоматически добавит столбец "_id". Данные в этом столбце называются ObjectId. ObjectId рассчитывается по определенному алгоритму в момент вставки данных в MongoDB. Следовательно, столбец _id представляет время вставки данных, оно не повторяется и всегда увеличивается. С помощью определенного алгоритма ObjectId можно обратить на время.
Поместите несколько словарей в список и используйте список в качестве параметра метода insert () для достиженияМассовая вставка данных, код показан ниже.
from pymongo import MongoClient
client = MongoClient()
database = client['Chapter6']
collection = database['spider']
more_data = [
{'id': 2, 'name': «Чжан Сань», 'age': 10, 'salary': 0},
{'id': 3, 'name': "Ли Си", 'age': 30, 'salary': -100},
{'id': 4, 'name': 'Ван Пять', 'age': 40, 'salary': 1000},
{'id': 5, 'name': 'Иностранец', 'age': 50, 'salary': "неизвестно"},
]
collection.insert(more_data)
(3) Обычный поиск
Соответствующий метод функции поиска MongoDB:
find(Условия запроса, Поле возврата)
find_one(Условие запроса, поле возврата)
Общие методы запроса следующие3Вид письма.
content = collection.find()
content = collection.find({'age': 29})
content = collection.find({'age': 29}, {'_id': 0, 'name': 1, 'salary': 1})
(4) Логический запрос
PyMongo также поддерживает логические запросы, такие как больше, меньше, больше или равно, меньше или равно, равно и не равно.
collection.find({'age': {'$gt': 29}}) # Запросить все записи возрастом> 29
collection.find({'age': {'$gte': 29, '$lte': 40}}) #Query 29 ≤ age ≤ 40 записей
collection.find({'salary': {'$ne: 29}}) # Запрашивать все записи, где зарплата не равна 29
(5) Отсортируйте результаты запроса
# MongoDB поддерживает сортировку результатов запроса. Метод сортировки - sort (). Его формат:
handler.find().sort("Название столбца", 1или-1)
# Запрос обычно используется вместе с find (). Например:
collection.find({'age': {'$gte': 29, '$lte': 40}}).sort('age', -1)
collection.find({'age': {'$gte': 29, '$lte': 40}}).sort('age', 1)
(6) Обновить записи
Обновление может использовать методы update_one () и update_many (). Их формат:
collection.update_one(параметр1, параметр2)
collection.update_many(параметр1, параметр2)
(7) Удалить записи
Для удаления можно использовать методы delete_one () и delete_many (). Их формат:
collection.delete_one(параметр)
collection.delete_many(параметр)
(8) Исключение дублирования результатов запроса
Чтобы удалить дубликаты, используйте метод unique (), формат:
collection.distinct("Название столбца")
Разработайте переключатель
Рассмотрим вопрос: как спроектировать переключатель, чтобы понять, что программа может быть приостановлена в любое время из любого места в мире, где есть сеть, без завершения процесса программы, и программа может быть возобновлена в любое время.
Самый простой способ — использовать базу данных. Создайте на сервере базу данных, к которой могут получить доступ программа и контроллер. База данных называется «Switch_DB». Создайте набор «Switch» в базе данных. В этом наборе есть только одна запись, которая называется «Status». Она имеет только два значения: «On» и «Off».
Установите Redis под Mac OS
brew update
brew install redis
# Запустить Redis
redis-server /usr/local/etc/redis.conf
Использование интерактивной среды Redis
redis-cli
Общие операции
keys * Вы можете увидеть, сколько «ключей» есть в настоящее время.
Списки и коллекции Redis в основном используются в процессе разработки краулера.
(1) Список
Список Redis — это двусторонняя очередь с возможностью чтения и записи.
lpush key value1 value2 value 3…
Если вы хотите проверить длину списка, вы можете использовать ключевое слово «llen». Первая буква «l» этого ключевого слова соответствует первой букве английского «list» (список).
Если вы не удаляете данные в списке и хотите их прочитать, вам нужно использовать ключевое слово «lrange», где «l» соответствует первой букве английского «list». Формат «lrange»:
lrange key start end
# Среди них start - это начальная позиция, а end - конечная позиция. Например:
lrange chapter_6 0 3
# Важно отметить, что в Python срезы представляют собой интервалы, закрываемые слева и открывающиеся справа.Например, test [0: 3] означает чтение 0-го, 1-го и 2-го значений списка. Однако параметр lrange - это замкнутый интервал, включающий начало и конец, поэтому на рисунке 6-35 будут 4 значения с индексами 0, 1, 2 и 3.
(2) Коллекция
Коллекции Redis аналогичны коллекциям Python. Здесь нет порядка и значения не повторяются. Чтобы добавить данные в коллекцию, используется ключевое слово «sadd». «S» здесь соответствует английскому слову «set» (набор). Используемый формат:
sadd key value1 value2 value3
Установите Redis-py
pip install redis
Предложения по оптимизации для MongoDB
Читайте меньше пишите меньше обновляйте
- Рекомендуется вставить в MongoDBСначала поместите данные в список, а затем вставьте их один раз после того, как они накопятся до определенной суммы。
- Для чтения данных, если позволяет память, следуетЧитать данные в память сразу, Попробуйте сократить операцию чтения до MongoDB.
- В некоторых случаях операции обновления должны выполняться по очереди. Рекомендуется изменить действие обновления на вставку. Таким образом можно добиться эффекта пакетного обновления. В частности, это пакетная вставка данных в новую коллекцию MongoDB, затем удаление исходной коллекции и, наконец, изменение новой коллекции на исходное имя коллекции.
Можно использовать Redis без MongoDB
Чтобы повысить эффективность, необходимо внедрить Redis. Поскольку Redis — это база данных на основе памяти, даже если она часто читается / записывается, влияние на производительность намного меньше, чем частое чтение / запись MongoDB. Создайте коллекцию «crawled_url» в Redis. Перед сканированием URL-адреса сканер сначала добавит этот URL-адрес в эту коллекцию. Если он возвращает 1, это означает, что этот URL-адрес ранее не сканировался, и сканеру необходимо сканировать страницу с подробностями. Если он возвращает 0, это означает, что этот URL уже сканировался ранее и нет необходимости сканировать его снова. Фрагмент кода примера выглядит следующим образом:
for url in url_list: #url_list - это список URL-адресов страницы сведений о каждом сообщении, полученный на странице списка панели сообщений.
if client.sadd('crawled_url', url) == 1:
crawl(url)
Упражнение
Целевой сайт:http://dongyeguiwu.zuopinj.com/5525/。
Целевое содержание: текстовое содержание первой главы тринадцатой главы романа «Белая ночь».
Требования к задаче: напишите два сканера, сканер 1 получает URL-адреса первой главы 13-й главы романа «Белая ночь» с http://dongyeguiwu.zuopinj.com/ 5525 / и добавляет URL-адрес в Redis как url_queue В списке. Сканер 2 считывает URL-адрес из списка с именем url_queue в Redis, вводит URL-адрес для сканирования определенного содержимого каждой главы, а затем сохраняет содержимое в MongoDB.
# 1 Используйте XPath, чтобы получить URL-адрес каждой главы, а затем добавьте их в Redis. Основной код выглядит следующим образом:
url_list = selector.xpath('//div[@class="book_list"]/ul/li/a/@href')
for url in url_list:
client.lpush('url_queue', url)
# 2 Для сканеров, которые просматривают текст, если список url_queue в Redis не является пустым, они должны прочитать URL из него и сканировать данные. Следовательно, код такой:
content_list = []
while client.llen('url_queue') > 0:
url = client.lpop('url_queue').decode()
source = requests.get(url).content
selector = html.fromstring(source)
chapter_name = selector.xpath('//div[@class="h1title"]/h1/text()')[0]
content = selector.xpath('//div[@id="htmlContent"]/p/text()')
content_list.append({'title': chapter_name, 'content': 'n'.join(content)})
handler.insert(content_list)
Пусконаладочные работы и эксплуатация
После запуска поискового робота 1 в Redis должен появиться список с именем url_queue, выполните следующий код:
llen url_queue
После запуска краулера 2 url_queue в Redis исчезнет, а содержимое каждой главы романа будет сохранено в MongoDB.
резюме
В этой главе в основном объясняется использование MongoDB и Redis. Среди них MongoDB в основном используется для хранения различных потребностей поисковых роботов.Постоянно сохраненные данные, А Redis используется для хранения различныхПромежуточные данные。
За счет сокращения частого чтения / записи MongoDB и использования Redis для компенсации некоторых недостатков MongoDB эффективность работы краулера может быть значительно улучшена.
Руки
Если сканер 1 добавляет 10 000 URL в url_queue, то сканер 2 работает на 3 компьютерах одновременно, обратите внимание, какой эффект может быть достигнут.
Глава 7 Асинхронная загрузка и заголовки запроса
Очки знаний
- Получить асинхронно загруженные данные.
- Подделанные заголовки HTTP-запросов.
- Смоделируйте браузер для получения данных веб-сайта.
Сканирование страницы входа в версию AJAX
Решено сканирование страницы входа в версию AJAX, отправив запрос через POST
резюме
В этой главе в основном представлены различные методы использования поисковых роботов для получения асинхронно загружаемых веб-страниц. Для обычной асинхронной загрузки вы можете использовать запросы для отправки запросов AJAX напрямую для получения загруженного содержимого.
Отправленный запрос может содержать некоторые специальные значения, которые поступают из исходного кода веб-страницы или другого запроса AJAX.
При отправке запроса необходимо обращать внимание на то, чтобы заголовок запроса, отправляемый запросами, соответствовал заголовку запроса браузера, чтобы лучше обмануть сервер веб-сайта для получения данных.
Для более сложной асинхронной загрузки вы можете использовать Selenium и ChromeDriver для загрузки веб-страницы непосредственно на этом этапе, а затем вы можете напрямую получить необходимый контент с загруженной веб-страницы.
Глава 8 Имитация входа и кода подтверждения
Очки знаний
- Используйте Selenium для управления браузером для автоматического входа на сайт.
- Используйте файлы cookie для входа на сайт.
- Смоделируйте форму для входа на сайт.
- Сканер распознает простой проверочный код.
Есть много способов реализовать имитацию входа в систему
- Используйте Selenium для управления входом в браузер
- Вход с помощью файлов cookie простой и грубый
- Вход в систему с использованием фиктивной формы отправки более сложен, но его можно автоматизировать.
Войти с помощью файлов cookie
Файл cookie — это небольшой фрагмент данных, который хранится в браузере, когда пользователь использует браузер для посещения веб-сайта. Файлы cookie во множественном числе Файлы cookie используются для представления различных файлов cookie. Некоторые из них используются для записи информации о статусе пользователя; некоторые используются для записи поведения пользователя при работе; а некоторые из них выполняют наиболее важную функцию современных сетей: записывают информацию об авторизации — находится ли пользователь в системе и в какую учетную запись входит пользователь.
Чтобы пользователи не могли входить в систему каждый раз, когда они посещают веб-сайт, браузер помещает часть зашифрованной информации в файлы cookie после того, как пользователь успешно входит в систему в первый раз. В следующий раз, когда пользователь зайдет на сайт, веб-сайт сначала проверит, есть ли эта зашифрованная информация в файлах cookie. Если это законно, пропустите операцию входа и сразу войдите на страницу входа.
Использование файлов cookie для входа на веб-страницу может не только обойти этап входа в систему, но и обойти проверочный код веб-сайта.
Модуль сеанса с использованием запросов.
Так называемый сеанс относится к сеансу. Веб-сайт сохраняет каждый идентификатор сеанса (идентификатор сеанса) в файлах cookie браузера для идентификации пользователя. Модуль запросов Session может автоматически сохранять некоторую информацию, возвращаемую сайтом. Фактически, метод requests.get (), использованный в предыдущих главах, по-прежнему создает сеанс на нижнем уровне, а затем использует сеанс для доступа к нему.
Для HTTPS-сайтов при отправке запросов нужно указать параметр verify = False, иначе сканер сообщит об ошибке.
С этим параметром сканер по-прежнему будет сообщать предупреждение, потому что сертификат HTTPS отсутствует.
Для HTTPS-сайтов при отправке запросов нужно указать параметр verify = False, иначе сканер сообщит об ошибке.
Логин с макетной формы
- Отправка запроса через POST решает проблему сканирования AJAX-версии страницы входа.
- Но на самом деле все больше веб-сайтов используют методы отправки форм для входа в систему.
Используйте модуль запросов Session для имитации этого входа
Проверочный код-код невооруженным глазом
1. С браузером
Мы говорили о файлах cookie при моделировании входа в систему. Файлы cookie могут использоваться для обхода входа в систему и прямого посещения веб-сайта, на котором необходимо выполнить вход. Таким образом, для веб-сайтов, которым необходимо ввести код подтверждения для входа, вы можете вручную войти на веб-сайт в браузере, получить файлы cookie через Chrome, а затем использовать файлы cookie для посещения веб-сайта. Таким образом, вы можете вручную ввести проверочный код один раз, а затем перестать входить в систему на долгое время.
2. Без браузера
Для кода подтверждения, который нужен только для идентификации изображения, вы можете использовать этот метод: сначала загрузите код подтверждения на местном уровне, затем определите его невооруженным глазом и вручную введите его сканеру.
Код подтверждения-автоматическое кодирование
1. Распознавание изображений Python
Сила Python в том, что он имеет множество сторонних библиотек. Для распознавания кода проверки в Python также есть готовые библиотеки. Открытый источникБиблиотека OCR pytesseract с механизмом распознавания изображений tesseract, Может использоваться для преобразования текста на картинке в текст. Этот метод редко используется в краулерах. Поскольку большинство проверочных кодов теперь имеют мешающие текстуры, редко возможно использовать автономный метод распознавания изображений для их идентификации. Таким образом, если вы используете этот метод, возможны только две ситуации: проверочный код веб-сайта чрезвычайно прост и понятен, а для обучения tesseract используется большое количество проверочных кодов.
(1) Установите тессеракт
brew install tesseract
(2) Установите библиотеку Python
Чтобы использовать tesseract для распознавания изображений, вам необходимо установить две сторонние библиотеки:
pip install Pillow
pip install pytesseract
# Среди них Pillow - это сторонняя библиотека, предназначенная для обработки изображений в Python, а pytesseract - сторонняя библиотека, предназначенная для работы с tesseract.
(3) Использование тессеракта
① Импортируйте pytesseract и Pillow.
② Откройте картинку.
③ Идентификация.
import pytesseract
from PIL import Image
image = Image.open('Verification code.png')
code = pytesseract.image_to_string(image)
print(code)
2. Веб-сайт кодирования
(1) Введение веб-сайта кодирования
Веб-сайт, идентифицированный кодом онлайн-проверки, называемый веб-сайтом кодирования. Некоторые из этих веб-сайтов используют технологию глубокого обучения для определения проверочных кодов, а на некоторых работает много людей.Код подтверждения идентификации человеческой плоти。
Веб-сайт предоставляет интерфейс для реализации услуги идентификации кода подтверждения. Теоретически использование веб-сайта кодирования может идентифицировать любой проверочный код, который проверяется вводом.
(2) Используйте онлайн-кодирование
Поищите в Baidu или Google поисковый запрос «Код подтверждения онлайн-идентификации», и вы найдете множество веб-сайтов, которые предоставляют онлайн-код. Однако, поскольку, как правило, использование такого рода веб-сайтов требует оплаты, необходимо обратить внимание на безопасность собственности.
Облачное кодирование
Упражнение: Автоматический вход в сеть оболочки Guo
Целевой сайт:https://www.guokr.com。
Целевое содержание: исходный код интерфейса настройки профиля.
Используйте технологию имитации логина и распознавания кода подтверждения для автоматического входа на GuoKel.com. В интерфейсе входа на Gok.com есть проверочный код. Используйте ручное или онлайн-кодирование, чтобы определить проверочный код и позволить роботу войти в систему. После входа в систему исходный код интерфейса «Настройки личной информации» может отображаться правильно.
Затронутые точки знаний:
- Код подтверждения идентификации сканера.
- Вход в систему моделирования краулера.
резюме
В этой главе в основном рассказывается о моделировании входа в систему и распознавании кода подтверждения. Проще всего использовать Selenium для имитации входа в систему. Но недостаток этого метода в том, что он работает медленно.
Вход в систему с помощью файлов cookie может быть однократным вручную и долгосрочным автоматическим.
Суть моделируемой формы входа в систему состоит в том, чтобы инициировать запрос POST для входа в систему, а модуль Session необходим для сохранения информации для входа.
Распознавание проверочного кода в основном предназначено для автоматизации проверочного кода, который необходимо ввести. Включая ручной ввод и онлайн-кодирование. Для кодов подтверждения щелчком и перетаскиванием рекомендуется использовать файлы cookie для входа в систему.
Глава 9 Захват пакетов и рептилия-посредник
Очки знаний
- Используйте Charles для захвата пакетов данных апплетов App и WeChat.
- Используйте mitmproxy для разработки поисковых роботов-посредников.
Сбор данных
Так называемый захват пакетов, говоря простым языком, — это процесс перехвата, просмотра, изменения или пересылки пакетов данных в процессе сетевой передачи данных.
Если пакеты данных, отправленные и полученные в сети, понимаются как экспресс-посылки, то проверьте содержимое в процессе экспресс-доставки, это захват пакетов.
Charles
Чтобы упростить процесс поиска данных, необходимо попытаться выполнить прямой поиск всех запрашиваемых возвращаемых данных веб-страницы в глобальном масштабе.
Для достижения этой цели вам нужно использовать Charles. Charles — это кроссплатформенный инструмент для захвата HTTP-пакетов. Используйте его для перехвата пакетов запросов HTTP или HTTPS, таких как Chrome.
Получение пакетов HTTPS
Запросы при получении пакетов HTTPS с помощью Charles будут часто терпеть неудачу. Это происходит потому, что сертификат SSL не установлен.
Первым шагом является установка сертификата: Чтобы установить сертификат SSL, выберите в строке меню команду «Справка» — «SSL-проксирование» — «Установить сертификат Charles Root».
Второй шаг — настройка прокси-сервера SSL: после установки сертификата выберите в строке меню команду «Прокси-сервер» — «Параметры прокси-сервера SSL», чтобы открыть диалоговое окно настроек прокси-сервера SSL.
Настройка и использование системы iOS
Для устройств Apple сначала убедитесь, что компьютер и устройство Apple подключены к одному и тому же Wi-Fi. Выберите команду «Справка» — «Локальный IP-адрес» в строке меню Charles, и появится диалоговое окно, отображающее IP-адрес интрасети текущего компьютера.
Далее настраиваем телефон. Войдите в настройки системы, выберите «Беспроводная локальная сеть», а затем щелкните значок с буквой i в кружке справа от подключенной точки доступа Wi-Fi.
Первый шаг — настроить HTTP-прокси на телефоне.
Второй шаг — использовать браузер Safari, поставляемый с системой iOS, чтобы посетить https://chls.pro/ssl. Установите сертификат.
Третий шаг, настройки доверия сертификату
Настройка и использование Android
Сохраните сертификат Чарльза на рабочий стол компьютера
Сканер апплетов WeChat
Запрос апплета предельно прост, в основном нет проверочной информации, даже если проверочная информация есть, она очень хрупкая.
Гораздо проще использовать Python для запроса фонового интерфейса апплета для получения данных, чем для запроса фонового интерфейса асинхронной загрузки веб-страниц.
Если в процессе разработки краулера на целевом веб-сайте есть апплет WeChat, необходимо сначала выяснить, можно ли получить данные через интерфейс апплета.
Возможности анти-краулера у апплета намного ниже, чем у веб-версии. Использование интерфейса небольшой программы для сканирования данных может значительно повысить эффективность разработки краулера.
Ограничения Чарльза
- Чарльз может перехватывать только пакеты HTTP и HTTPS. Если веб-сайт использует веб-сокет или флэш-сокет, Чарльз ничего не может сделать.
- У некоторых приложений есть собственные сертификаты, а другие сертификаты не могут нормально получить доступ к фоновому интерфейсу. В этом случае собственный сертификат Чарльза нельзя использовать в обычном режиме, и нет возможности получить данные этого приложения.
- Некоторые данные приложения зашифрованы, и после того, как приложение получает данные, оно расшифровывает их внутри.
- В этом случае Чарльз может получать только зашифрованные данные. Если нет способа узнать конкретный метод шифрования данных, нет способа интерпретировать данные, захваченные Чарльзом.
Сканер-посредник
Атака Man-in-the-Middle (MITM) означает, что злоумышленник создает независимые соединения с обоими сторонами связи и обменивается данными, которые они получают, так что оба конца связи думают, что они проходят через частное соединение. Поговорите с другой стороной напрямую, но фактически весь разговор полностью контролируется злоумышленником.
В атаке «человек посередине» злоумышленник может перехватить диалог между двумя взаимодействующими сторонами и вставить новый контент или изменить исходный контент.
Пример: передача заметок в классе
Сканер «человек посередине» — это технология сканирования, использующая принцип атаки «злоумышленник посередине» для захвата данных.
Сбор данных — это простое приложение поискового робота-посредника. Таким образом, использование Charles — это тоже своего рода атака «человек посередине».
Внедрение и установка mitmproxy
Чтобы установить mitmproxy, вам сначала нужно убедиться, что системный Python — Python 3.5 или выше.
brew install mitmproxy
использование mitmproxy
- При запуске mitmproxy появится диалоговое окно с запросом
mitmproxy
- Порт mitmproxy — это порт 8080. Установите прокси-сервер в браузере или на мобильном телефоне. IP-адрес прокси — это IP-адрес компьютера, а порт — порт 8080.
- После настройки прокси-сервера, откройте приложение на телефоне или откройте веб-страницу, вы увидите, что на mitmproxy есть прокрутка данных.
- В настоящее время вы можете получить доступ только к веб-сайтам HTTP. Для доступа к веб-сайтам HTTPS вам также необходимо установить сертификат mitmproxy. После настройки прокси-сервера mitmproxy на мобильном телефоне, посетите http://mitm.it/ через мобильный браузер.
Настройте mitmproxy с помощью Python
Сила mitmproxy в том, что он также поставляется с командой mitmdump. Эта команда может использоваться для запуска сценариев Python, которые соответствуют определенным правилам, и прямого управления HTTP- и HTTPS-запросами и возвращенными пакетами данных в сценарии Python.
Чтобы автоматически отслеживать информацию заголовка запроса и информацию тела, отправляемую веб-сайтом или мобильным телефоном, и получать информацию заголовка и информацию тела, возвращаемую веб-сайтом, необходимо научиться получать запрос и возвращенные пакеты данных в скрипте Python.
Сценарии использования mitmdump
- Файлы cookie часто включаются в заголовки, возвращаемые веб-сайтом.
- Сценарий mitmdump использует функцию print () для распечатки файлов cookie, а затем передает их другому обычному сценарию Python.
- В другом сценарии получите файлы cookie, передаваемые по каналу, и поместите их в Redis.
анализ спроса
Целевое приложение: Keep.
Целевой контент: Keep — популярное фитнес-приложение на данный момент. Цель этого случая — использовать захват пакетов для сканирования горячих тенденций Keep.
Затронутые точки знаний:
- Используйте Charles или mitmproxy для захвата пакетов.
- Разработайте краулер приложений.
резюме
- Захват пакетов — очень полезный метод в процессе разработки поискового робота. Используя Charles, вы можете мгновенно расширить диапазон сканирования с веб-страниц до мобильных приложений и апплетов WeChat.
- Поскольку механизм анти-краулера апплетов WeChat в большинстве случаев очень хрупок, если на целевом веб-сайте есть апплеты WeChat, это может значительно упростить сложность разработки краулера.
- Конечно, веб-сайт может зашифровать данные интерфейса.После того, как приложение получает зашифрованный текст, оно использует встроенный алгоритм для его расшифровки. В такой ситуации нет способа справиться с этим, просто используя захват пакетов, и вам нужно использовать технологию, описанную в следующей главе, чтобы решить эту проблему.
- Использование mitmproxy позволяет реализовать полностью автоматизированную работу сканеров.
- Для веб-сайтов со сложными параметрами использование этого метода захвата пакетов перед отправкой может в определенной степени обойти механизм защиты от сканирования веб-сайта, тем самым обеспечивая сбор данных.
Глава 10 Android-сканер собственных приложений
Очки знаний
Так есть ли способ сканировать данные практически без следа? Ответ положительный. Конечно, некоторые читатели могут подумать, что можно использовать Selenium + ChromeDriver. Таким образом можно управлять только веб-страницами. В этой главе будут представлены сканеры для собственных приложений Android.
- Построение тестовой среды Android.
- Используйте Python для работы с телефонами Android.
- Используйте Python для управления телефонами Android, чтобы реализовать сканеры.
Принцип реализации
В настоящее время Android-приложение имеет две основные формы реализации. Первое — это собственное приложение для Android. Все или большая часть контента этого типа приложений разрабатывается с использованием различных интерфейсов, предоставляемых Android. Например, версия WeChat для Android является собственным приложением для Android. Второй тип — это веб-приложения. Этот вид приложений по сути является браузером, и все содержимое внутри является веб-страницами. Например, приложение 12306 является таким веб-приложением.
Сканер собственных приложений Android (в дальнейшем именуемый сканером приложений) может напрямую считывать текстовую информацию в собственном приложении Android.
UI Automator Viewer
После настройки переменных среды введите «uiautomatorviewer» в окне терминала и нажмите Enter. Если всплывает окно средства просмотра UI Automator, это означает, что среда установлена успешно.
Подключите телефон Android к компьютеру, держите экран телефона включенным и щелкните значок телефона в правой части папки в верхнем левом углу средства просмотра UI Automator. Если вы видите, что в окне появляется экран телефона, это означает, что все прошло хорошо и настройка среды была успешно завершена. . Если во время этого процесса появится какое-либо окно с предупреждением, выберите «Выполнить» или «ОК».
Используйте Python для управления мобильными телефонами
pip install uiautomator
Один момент требует особого объяснения: UI Automator Viewer и Python uiautomator нельзя использовать одновременно.
Как и в случае с Selenium, чтобы управлять элементами в телефоне, вы должны сначала найти объект, которым нужно управлять. Возьмем для примера открытие WeChat, сначала перейдите на страницу с WeChat
from uiautomator import Device
device = Device()
device(text='WeChat').click()
Если к компьютеру подключен только один телефон Android, вам нужно использовать только device = Device () для инициализации подключения устройства. Так что, если к компьютеру подключено много мобильных телефонов? В это время нужно указать серийный номер телефона. Для просмотра серийного номера мобильного телефона необходимо ввести в терминале следующую команду:
adb devices -l
Вы можете увидеть серийный номер телефона на выходе
Селектор
Как узнать, какие селекторы доступны? Выполните следующий код:
from uiautomator import Device
device = Device()
print(device.dump())
В это время терминал выведет информацию о компоновке окна, которая в настоящее время отображается на экране мобильного телефона, в формате XML.
XML здесь эквивалентен HTML на веб-странице, который используется для описания информации макета каждой части окна.
Формат XML очень похож на HTML, формат следующий: <tag attribute 1 = «attribute value 1» attribute 2 = «attribute value 2»> text </ tag>
действующий
- Получить экранный текст;
- Прокрутите экран
- Скользящий экран
- Нажмите на экран
- Ввод текста;
- Определите, существует ли элемент;
- Выключите экран;
- Физические кнопки управления;
- watcher。
Приложение для нескольких устройств (групповое управление)
Основным узким местом использования uiautomator для разработки краулеров является скорость. Поскольку для загрузки элементов на экран требуется время, это время ограничено производительностью телефона и скоростью Интернета. Поэтому для реализации распределенного сканирования лучше использовать несколько телефонов Android. После использования USBHub для расширения USB-порта компьютера проблема с тем, что один компьютер управляет 30 телефонами Android, не возникает. Если можно реализовать хорошее планирование и логику диспетчеризации задач, эффективность сбора данных может быть значительно повышена.
Форма архитектуры системы краулера приложений

Упражнение: BOSS нанимает краулеров напрямую
Миссия: БОСС нанимает приложение напрямую.
BOSS Direct Hiring — это приложение для набора персонала, в котором вы можете увидеть множество вакансий. Список позиций приложения показан на Рисунке 10-44.
Используйте uiautomator для разработки сканера, который будет сканировать с мобильного телефона название каждой должности, зарплаты, кадровой компании, адреса компании, требований к опыту работы и академической квалификации.
резюме
- В этой главе в основном объясняется, как управлять телефоном через Python для получения текстового содержимого в собственном приложении Android. Python использует uiautomator, стороннюю библиотеку, для управления UiAutomator телефонов Android, чтобы имитировать любое рабочее поведение людей на экране телефона и непосредственно читать текст на экране.
- Использовать uiautomator для разработки поисковых роботов очень просто. Но особое внимание нужно уделять работе с различными нештатными ситуациями. В то же время из-за скорости мобильных телефонов следует использовать несколько мобильных телефонов для формирования кластера, чтобы увеличить скорость сканирования.
- Наконец, если вы используете кластер мобильных телефонов для сбора данных, а данные приложения, которые необходимо захватить, поступают из сети, вам необходимо учитывать нагрузку на беспроводной маршрутизатор. Когда к беспроводному маршрутизатору одновременно подключено более определенного количества устройств, некоторые или все устройства могут не иметь доступа к Интернету. Это требует упрощения использования маршрутизаторов промышленного класса.
- Помехи между беспроводными сигналами также являются серьезной проблемой. Использование канала 5G может облегчить его, но, как правило, дешевые телефоны Android не поддерживают каналы Wi-Fi 5G. В настоящее время вы можете как можно больше разделить телефоны, а не собирать их вместе. Использование сетки электромагнитного экранирования для обертывания каждых 10 мобильных телефонов и беспроводного маршрутизатора как группы также может в определенной степени блокировать сигналы Wi-Fi.
Упражнение
Используйте телефон Android для сканирования данных собственного приложения.
Глава 11.
Очки знаний
- Создайте среду Scrapy под Windows, Mac OS и Linux.
- Используйте Scrapy для получения сетевого исходного кода.
- Анализируйте данные через XPath в Scrapy.
- Используйте MongoDB в Scrapy.
- Используйте Redis в Scrapy.
Установите Scrapy под Mac OS
pip install scrapy
Создать проект
$ scrapy startproject offcn
# offcn - название проекта
$ cd offcn
$ scrapy genspider jobbank zw.offcn.com
# jobbank - имя поискового робота
# zw.offcn.com - просканированный URL
# Пробег
$ scrapy crawl jobbank
Итак, как использовать PyCharm для запуска или отладки сканеров Scrapy?
Для этого необходимо создать еще один файл Python. Имя файла может быть любым допустимым именем файла. Здесь с «main.py»В качестве примера.
Содержимое файла main.py выглядит следующим образом:
from scrapy import cmdline
cmdline.execute("scrapy crawl jobbank".split())
Инженерная структура Scrapy
- папка spiders: папка для хранения файлов сканера.
- items.py: Определите данные для захвата.
- pipelines.py: Ответственный за последующую обработку сбора данных.
- settings.py: Различная информация о конфигурации поискового робота.
Но почему там два файла: items.py и pipelines.py? Это связано с тем, что идея Scrapy состоит в том, чтобы отделить сканирование данных от обработки данных.
Файл items.py используется для определения содержимого, которое необходимо сканировать.
Файл pipelines.py используется для предварительной обработки данных, включая, помимо прочего, предварительную очистку данных, хранение данных и т. Д. Данные могут быть сохранены в MongoDB в конвейерах.
Scrapy и MongoDB
В проекте Scrapy может быть несколько поисковых роботов; еще раз взглянув на файл items.py, вы можете обнаружить, что в файле items.py для разных поисковых роботов могут быть определены разные элементы.
Затем настройте pipelines.py. В этом файле вам нужно написать код для сохранения данных в MongoDB. Приведенный здесь код — это самый простой способ инициализировать соединение MongoDB и сохранить данные.
Scrapy и Redis
Scrapy — этоПлатформа распределенного краулераЕсли вы запустите его на автономной машине, как обычный краулер, его преимущества не будут отражены.
Следовательно, чтобы Scrapy развивался в направлении распределенных поисковых роботов, вам необходимо изучить комбинированное использование Scrapy и Redis. Redis используется в качестве краулера в Scrapyочередьсуществовать.
Используйте Redis для кеширования веб-страниц и автоматического удаления дубликатов
pip install scrapy_redis
резюме
В этой главе в основном рассказывается об установке и использовании среды Scrapy для распределенных поисковых роботов Python.
Установка Scrapy в Windows является наиболее сложной, а установка в Mac OS — самой простой.
Поскольку Scrapy использует множество файлов сторонних библиотек, рекомендуется устанавливать Scrapy в виртуальной среде Python, созданной Virtualenv, независимо от того, какая установка системы используется, чтобы не повлиять на среду Python системы.
Используя Scrapy для сканирования веб-страниц, основная часть заключается в создании XPath. Все остальные конфигурации настраиваются один раз и используются на всю жизнь. Поскольку концепция Scrapy заключается в разделении действий по сбору данных и по обработке данных, различные логики обработки данных должны обрабатываться конвейером. Часть сбора данных должна сосредоточиться только на том, как использовать XPath для извлечения данных. После извлечения данных их можно отправить в конвейер для обработки.
Поскольку сканирование данных сканером Scrapy является асинхронной операцией, переход с одной страницы на другую является асинхронным процессом, и требуется функция обратного вызова.
Объем данных, сканируемых Scrapy, очень велик, поэтому для их сохранения следует использовать базу данных. Использование MongoDB упростит работу по сохранению данных.
Чтобы позволить Scrapy использовать MongoDB, вам нужно только настроить процесс хранения данных в конвейере, а затем настроить информацию ITEM_PIPELINES и MongoDB в settings.py.
Использование Redis для кэширования — отправная точка от поискового робота к распределенному поисковому роботу.
После того, как Scrapy установит компонент scrapy_redis, вы сможете использовать Redis.
Чтобы использовать Redis в Scrapy, вам необходимо изменить родительский класс краулера, а также настроить планирование и дедупликацию краулера в settings.py.
В то же время для Python 3 необходимо изменить строку кода scrapy_redis, чтобы поисковый робот мог нормально работать.
Упражнение
Завершите разработку веб-краулера и реализуйте функцию перелистывания страниц, чтобы вы могли сканировать все статьи на страницах с 1 по 5. Используйте сканер для получения URL следующей страницы с текущей страницы и не создавайте его вручную в соответствии с правилами URL.
Подсказка: для функции перелистывания страниц это фактически эквивалентно написанию имени функции функции обратного вызова как собственного: callback = self.parse. Метод синтаксического анализа может вызывать сам себя, но переданный URL-адрес является URL-адресом следующей страницы. Это немного похоже на рекурсию, но рекурсия использует return, а вот yield.
Пожалуйста, подумайте над вопросом.При запросе страницы с подробностями статьи заголовок запроса устанавливается, но когда Scrapy запрашивает страницу со списком статей, где устанавливается заголовок запроса? При запросе страницы со списком сканер получает URL-адрес непосредственно из Redis и автоматически инициирует запрос, не позволяя разработчику установить заголовок запроса. На самом деле это очень большая скрытая опасность, потому что без установки заголовка запроса веб-сайт сразу узнает, что запрос исходит от Scrapy, что очень опасно.
Пожалуйста, обратитесь к документации scrapy_redis, чтобы узнать, как использовать метод make_requests_ from_url (self, url).
Глава 12 Расширенные приложения Scrapy
Очки знаний
- Разработайте промежуточное ПО Scrapy.
- Используйте Scrapyd для развертывания поисковых роботов.
- Установка Nginx и обратный прокси.
- Понять распределенную структуру сканеров.
Middleware
Промежуточное ПО — это основная концепция Scrapy. Использование промежуточного программного обеспечения позволяет настраивать данные до того, как запрос сканера будет инициирован или после того, как запрос вернется, чтобы разработать сканеры, которые адаптируются к различным ситуациям.
Китайское название «промежуточное ПО» — это всего лишь одно слово от «посредника», упомянутого в предыдущей главе. То, что они делают, действительно очень похоже. Как промежуточное программное обеспечение, так и посредники могут захватить данные на полпути, внести некоторые изменения и затем передать данные. Разница в том, что промежуточное ПО — это компонент, который разработчик активно добавляет, в то время как посредник пассивен и обычно представляет собой злонамеренно добавленную ссылку.
Промежуточное ПО в основном используется для помощи в разработке, а человек посередине в основном используется для кражи, подделки и даже атаки данных.
В Scrapy есть два типа промежуточного программного обеспечения: промежуточное программное обеспечение загрузчика и промежуточное программное обеспечение Spider.
Downloader Middleware
Измените IP-адрес агента, измените файлы cookie, измените User-Agent и автоматически повторите попытку.
Процесс сканирования после добавления промежуточного ПО

Промежуточное ПО агента разработки
Список доступных прокси для промежуточного программного обеспечения прокси не обязательно записывать в settings.py, вы также можете записать их в базу данных или Redis. Жизнеспособная поисковая система, которая автоматически заменяет агентов, должна иметь следующие три функции.
- Существует небольшой сканер ProxySpider, который обращается к основным прокси-сайтам для сканирования и проверки бесплатных прокси, а также сохранения доступных IP-адресов прокси в базе данных.
- В process_request ProxyMiddlerware IP-адрес прокси-сервера случайным образом выбирается из базы данных для использования каждый раз.
- Периодически проверяйте недействительные агенты в базе данных и вовремя удаляйте их.
Активировать промежуточное ПО
После того, как промежуточное ПО написано, вам нужно запустить его в settings.py.
Scrapy поставляется с промежуточным ПО и его порядковым номером

Разработка промежуточного программного обеспечения UA
Случайным образом выберите один элемент из списка UA, настроенного в settings.py, и добавьте его в заголовок запроса.
Разработка промежуточного программного обеспечения для файлов cookie
Для веб-сайтов, которым необходимо войти в систему, файлы cookie могут использоваться для сохранения входа в систему. Поэтому, если вы напишете небольшую программу отдельно и используете Selenium для постоянного входа на веб-сайт с разными учетными записями, вы можете получить много разных файлов cookie. Поскольку файлы cookie по сути представляют собой фрагмент текста, вы можете поместить этот фрагмент текста в Redis. Таким образом, когда сканер Scrapy запрашивает веб-страницу, он может читать файлы cookie из Redis и заменять его поисковым роботом. Таким образом, поисковый робот всегда может оставаться в системе.
Интегрируйте Selenium в промежуточное ПО
Для некоторых проблемных страниц с асинхронной загрузкой ручной поиск его внутреннего API может быть слишком дорогим. В этом случае вы можете использовать Selenium и ChromeDriver или Selenium и PhantomJS для рендеринга веб-страниц.
После интеграции Selenium в промежуточное программное обеспечение асинхронно загруженные страницы можно сканировать как обычные веб-страницы.
Попробуйте еще раз в промежуточном программном обеспечении
Во время работы краулера некоторые запросы могут завершиться ошибкой из-за проблем с сетью или из-за воздействия механизма антискраулера веб-сайта. В некоторых случаях небольшая потеря данных не имеет значения. Например, если из сотен миллионов запросов имеется более десятка неудавшихся запросов, потеря минимальна и нет необходимости повторять попытку. Но есть и другие ситуации, в которых каждый запрос критичен и не может терпеть одного отказа. На данный момент вам нужно использовать промежуточное программное обеспечение, чтобы повторить попытку.
Обработка исключений в промежуточном программном обеспечении
По умолчанию, если запрос не выполняется, Scrapy немедленно повторяет попытку на месте, а затем повторяет попытку снова после сбоя, то есть 3 раза. Если это не удается три раза, запрос отклоняется. В этой логике повтора есть некоторые недостатки. В качестве примера возьмем IP-адрес прокси. Прокси нестабилен, особенно бесплатный прокси. Можно использовать только 3 из 10. И теперь на рынке есть несколько платных провайдеров IP-прокси, после покупки их услуг они будут напрямую предоставлять фиксированный веб-сайт.
Установка этого URL-адреса в качестве прокси для Scrapy может автоматически получать доступ к веб-сайту с другим IP каждую минуту. Если один из IP-адресов выходит из строя, вам нужно подождать одну минуту перед заменой нового IP-адреса. В этом сценарии встроенная логика повторных попыток Scrapy приведет к сбою всех трех попыток.
В этом сценарии, если агент можно заменить немедленно, он будет заменен немедленно; если агент не может быть заменен немедленно, лучшим решением будет отложить повторную попытку. Этого можно добиться с помощью Scrapy_redis.
Запрос сканера поступает из Redis, а URL-адрес после сбоя запроса возвращается в конец Redis.
Если запрос не выполняется после трех повторных попыток, поместите его в конец Redis, чтобы Scrapy потребовалось обработать все предыдущие запросы в списке Redis перед повторной попыткой предыдущего неудачного запроса. Это дает достаточно времени для замены IP.
Сводка функций промежуточного программного обеспечения загрузчика
Функции, которые могут быть реализованы в промежуточном программном обеспечении, могут быть реализованы путем непосредственного написания кода поисковому роботу. Преимущество использования промежуточного программного обеспечения заключается в том, что оно может отделить сканирование данных от других операций. Сосредоточьтесь на написании кода обхода данных в коде поискового робота; сосредоточьтесь на написании прорывных операций защиты от сканирования, входа в систему, повторных попыток и рендеринга AJAX операций в промежуточном программном обеспечении.
Для команды такой способ написания может обеспечить одновременную разработку несколькими людьми и повысить эффективность разработки; для отдельных лиц при написании поисковых роботов нет необходимости учитывать такие операции, как анти-сканер, вход в систему, код проверки и асинхронная загрузка. Кроме того, нет необходимости учитывать, как данные извлекаются при написании промежуточного программного обеспечения. Делайте только одно какое-то время, чтобы мысли стали яснее.
Промежуточное ПО для обходчика
Промежуточное ПО для обходчика очень похоже на промежуточное ПО для загрузчика, за исключением того, что оно обслуживает разные объекты.
Роль промежуточного программного обеспечения загрузчика состоит в том, чтобы запрашивать запросы и возвращать ответы; роль среднего ключа поискового робота — это поисковый робот, в частности файлы, записанные в папке пауков.
Схема потока данных Scrapy

Среди них 4 и 5 представляют собой промежуточное программное обеспечение загрузчика, а 6, 7 — промежуточное программное обеспечение краулера. Промежуточное ПО обходчика будет вызываться в следующих ситуациях.
- Когда он достигает yield scrapy.Request () или yield item, вызывается метод process_spider_output () промежуточного программного обеспечения искателя.
- Когда в коде самого искателя возникает исключение, вызывается метод process_spider_exception () промежуточного программного обеспечения искателя.
- Перед вызовом функции обратного вызова parse_xxx () в сканере вызывается метод process_spider_input () промежуточного программного обеспечения поискового робота.
- Когда он достигает start_requests (), вызывается метод process_start_requests () промежуточного программного обеспечения искателя.
Обработка исключения самого краулера в промежуточном программном обеспечении
Исключение самого краулера может быть обработано в промежуточном программном обеспечении краулера.
Ошибки промежуточного программного обеспечения загрузчика обычно вызваны внешними причинами и не имеют ничего общего с уровнем кода. Текущая ошибка вызвана проблемой самого кода, а сам код написан плохо.
Активируйте промежуточное ПО сканера
В settings.py над элементом конфигурации промежуточного программного обеспечения загрузчика находится элемент конфигурации промежуточного программного обеспечения искателя. Он также аннотирован по умолчанию. Раскомментируйте и добавьте настраиваемое промежуточное ПО искателя.
Несколько встроенных промежуточных программ для краулеров

Ввод / вывод промежуточного программного обеспечения краулера
В промежуточном программном обеспечении краулера есть два менее распространенных метода: process_spider_input (response, spider) и process_spider_output (response, result, spider). Среди них process_spider_input (response, spider) вызывается непосредственно перед вводом функции обратного вызова parse_xxx () после завершения обработки промежуточного программного обеспечения загрузчика.
process_spider_output (ответ, результат, вывод) вызывается, когда поисковый робот запускает yield item или yield scrapy.Request ().
После обработки этого метода, если данные являются элементом, они будут переданы конвейеру; если это запрос, он будет передан планировщику, а затем запустится промежуточное программное обеспечение загрузчика.
Таким образом, в этом методе вы можете внести дополнительные изменения в элемент или запрос. Результатом параметра этого метода является элемент или scrapy.Request (), просканированный поисковым роботом. Так как yield является генератором, генератор можно итерировать, поэтому можно итерировать результат, и вы можете использовать цикл for для его расширения.
Развертывание краулеров
В нормальных условиях сканер будет использовать для работы облачный сервер, что может гарантировать, что поисковый робот будет работать непрерывно 24 часа.
FTP: использование FTP для загрузки кода не только очень неудобно, но также часто вызывает проблему, заключающуюся в том, что последний локальный код перезаписывается кодом сервера.
Git: Преимущество в том, что управление версиями может осуществляться без потери кода. Но есть много этапов работы, вам нужно отправить его локально, войти на сервер и загрузить код с сервера. Если серверов много, входить на каждый сервер и загружать код один раз — пустая трата времени.
Докер: преимущество в том, что все серверы могут иметь одинаковую среду, и развертывание очень удобно. Но вам нужно иметь более глубокое понимание Linux, не дружелюбное по отношению к новичкам и более сложное для начала.
Чтобы преодолеть вышеуказанные проблемы, в этой книге будет использоваться официальный инструмент развертывания, работы и управления поисковыми роботами Scrapy: Scrapyd.
Scrapyd
Scrapyd — это инструмент, официально разработанный Scrapy для развертывания, запуска и управления поисковыми роботами Scrapy. Используя Scrapyd, вы можете развернуть сканер Scrapy одним щелчком мыши и запустить / остановить поисковый робот, посетив URL-адрес. Scrapyd поставляется с простой веб-страницей, вы можете увидеть текущий статус работы краулера или проверить журнал краулера через браузер. Scrapyd предоставляет официальный API, так что все более сложные функции могут быть реализованы посредством вторичной разработки.
Scrapyd может управлять несколькими версиями нескольких поисковых роботов в нескольких проектах Scrapy одновременно. Если вы устанавливаете Scrapyd на нескольких облачных серверах, вы можете написать небольшую программу через Python для развертывания поисковых роботов партиями, запускать сканеры пакетами и останавливать поисковые роботы пакетами.
pip install scrapyd
Инструмент для загрузки сканера Scrapy
Scrapyd необходимо установить на облачном сервере.Если читатель не имеет облачного сервера или хочет протестировать локально, он также может установить его локально.
Затем вам нужно установить scrapyd-client, который представляет собой инструмент для загрузки поисковых роботов Scrapy и стороннюю библиотеку для Python. Вы можете установить его с помощью pip:
pip install scrapyd-client
Этот инструмент необходимо установить только на локальном компьютере, а не на облачном сервере.
Запустить Scrapyd
Далее вам нужно запустить Scrapyd на облачном сервере. По умолчанию Scrapyd недоступен из внешней сети. Чтобы сделать его доступным из внешней сети, необходимо создать файл конфигурации. За исключением bind_address, все остальные можно оставить по умолчанию. Значение bind_address установлено на внешний IP-адрес текущего облачного сервера. После размещения файла конфигурации введите scrapyd в терминале или CMD и нажмите Enter, чтобы запустить Scrapyd.
scrapyd
Теперь откройте браузер и введите «http: // IP-адрес облачного сервера: 6800Адрес формата «» может открыть простую веб-страницу, которая поставляется с Scrapyd
Развернуть сканер
После запуска Scrapyd вы можете приступить к развертыванию поисковых роботов. Откройте любой файл проекта Scrapy, вы увидите, что в корневом каталоге проекта Scrapy автоматически создал файл scrapy.cfg, откройте этот файл. нужно это сейчасУдалите символ комментария в строке 10 и измените IP-адрес на IP-адрес облачного сервера, на котором расположен Scrapyd.。
Наконец, используйте терминал или CMD, чтобы войти в корневой каталог проекта Scrapy, и выполните следующую команду для развертывания искателя:
scrapyd-deploy
Системы Mac OS и Linux, поисковые роботы запуска / остановки
curlЭтот автономный инструмент для запуска сетевых запросов
После загрузки краулера вы можете запустить его. Для систем Mac OS и Linux запускать и останавливать краулеры очень просто. Чтобы запустить краулер, вам необходимо ввести в терминал следующую строку кода.
curl http: // IP-адрес облачного сервера: 6800 / schedule.json -d project=Название проекта краулера -d паук=Имя краулера
Если время работы поискового робота слишком велико и вы хотите завершить его раньше, вы можете использовать следующую команду форматирования для достижения:
curl http: // IP-адрес сервера краулера: 6800 / cancel.json -d project=Название проекта -d работа=JOBID краулера (можно найти на веб-странице)
После запуска это эквивалентно нажатию комбинации клавиш Ctrl + C на сканере.
Система Windows, запуск / остановка краулера
Не существует такого понятия, как терминал Mac OS и Linux, в котором есть curl, встроенный инструмент для инициирования сетевых запросов. Но поскольку это сетевой запрос, вам нужно только использоватьPython и запросыЭто может быть сделано.
- Используйте запросы для отправки запроса на запуск поискового робота
- Используйте запросы, чтобы отправить запрос на закрытие сканера
Выполнять команды для развертывания поисковых роботов на Python
Потому что он выполняется непосредственно при развертывании краулера.scrapyd-deployКоманда, так как использовать Python для автоматизации развертывания сканеров? На самом деле это очень просто. Вы можете выполнять системные команды на Python, используя встроенный модуль os
Пакетное развертывание
использоватьPython и запросыПреимущество состоит не только в том, чтобы помочь Windows реализовать поисковые роботы управления, но также обеспечить пакетное развертывание и поисковые роботы пакетного управления.
Предполагая, что существует сто облачных серверов, если на каждом из них установлен Scrapyd, время, необходимое для развертывания и запуска сканеров в пакетном режиме с использованием Python, не превышает 1 мин.
Вот пример пакетного развертывания и запуска искателя, сначала создайте его в корневом каталоге искателя.файл scrapy_template.cfg。
управление полномочиями
Чтобы компенсировать отсутствие у Scrapyd системы управления разрешениями, ему необходимо использовать другие методы для управления сетевыми запросами. Обратный прокси с управлением полномочиями — решение.
Введение в Nginx
Nginx, произносится как Engine X, представляет собой легкий высокопроизводительный веб-сервер, балансировщик нагрузки и обратный прокси.
Чтобы решить проблему Scrapyd, вам нужно использовать Nginx в качестве обратного прокси.
Прямой прокси и обратный прокси
Так называемый «обратный прокси» отличается от «прямого прокси». Прокси-сервер, использованный в предыдущей главе, является прямым прокси. Прямой прокси помогает запрашивающей стороне (искателю) скрыть личность. Сканер обращается к серверу через прокси, и сервер может видеть только IP прокси, но не искатель;
Обратный прокси помогает серверу скрыть свою личность. Пользователь знает только контент, возвращаемый сервером, но не знает или не должен знать, где был сгенерирован контент.
Используйте Nginx для защиты Scrapyd

После использования обратного прокси Nginx для Scrapyd самому Scrapyd нужно только открыть доступ к интрасети.
Пользователь получает доступ к Nginx, затем Nginx обращается к Scrapyd, затем Scrapyd возвращает результат Nginx, а Nginx возвращает результат пользователю. Таким образом, пока пароль для входа установлен на Nginx, контроль доступа Scrapyd может быть реализован косвенно.
Установка Nginx
sudo apt-get install nginx
После установки вам необходимо рассмотреть следующие два вопроса.
- Есть ли на сервере другие программы, занимающие 80 порт?
- Есть ли на сервере брандмауэр.
/ etc / nginx / sites-available / default, измените все 80 на 81 и сохраните
sudo systemctl restart nginx
Настроить обратный прокси
Сначала откройте /etc/scrapyd/scrapyd.conf, измените элемент bind_address на 127.0.0.1 и измените элемент http_port на 6801. Установите Scrapyd, чтобы разрешить доступ только к интрасети, порт — 6801
Затем настройте Nginx и создайте scrapyd.conf в папке / etc / nginx / sites-available с содержимым:
server {
listen 6800;
location / {
proxy_pass http://127.0.0.1:6801/;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}
Используйте основной метод управления разрешениями авторизации, для авторизованных пользователей измените егоЗапросы на порт 6800 поступают на порт 6801 локально на сервере. Необходимо обратить внимание на запись пути к файлу авторизации в конфигурации: auth_basic_user_file /etc/nginx/conf.d/.htpasswd
Файл записи авторизационной информации будет помещен в файл /etc/nginx/conf.d/.htpasswd позже. После написания этой конфигурации сохраните ее.
Затем выполните следующую команду, чтобы создать мягкое соединение в папке / etc / nginx / sites-enabled:
sudo ln -s /etc/nginx/sites-available/scrapyd.conf /etc/nginx/sites-enabled/
После создания программного подключения необходимо сгенерировать файл конфигурации учетной записи и пароля. Сначала установите пакет apache2-utils:
sudo apt-get install apache2-utils
После установки apache2-utils перейдите в папку /etc/nginx/conf.d и выполните команду для создания файла паролей для пользователя kingname:
sudo htpasswd -c .htpasswd kingname
Приведенная выше команда сгенерирует скрытый файл .htpasswd в папке /etc/nginx/conf.d. С помощью этого файла Nginx может выполнять проверку прав доступа.
Затем перезапустите Nginx:
sudo systemctl restart nginx
После завершения перезагрузки запустите Scrapyd, а затем зайдите в браузер в формате «http: // IP сервера: 6800″‘S URL
Настроить проект Scrapy
В связи с добавлением контроля разрешений для Scrapyd, требуются некоторые незначительные изменения в областях развертывания поисковых роботов и запуска / остановки поисковых роботов, упомянутых в разделе 12.2.1.
Первый — развернуть краулер. Чтобы scrapyd-deploy успешно ввел пароль, вам необходимо изменить файл scrapy.cfg в корневом каталоге краулера, добавив имя пользователя и пароль, где имя пользователя соответствует учетной записи, а пароль соответствует паролю.
После настройки scrapy.cfg команда для развертывания краулера остается неизменной, либо войдите в корневой каталог проекта Scrapy и выполните следующий код:
scrapyd-deploy
Чтобы использовать curl для запуска / остановки краулера, вам нужно всего лишь добавить в команду параметры учетной записи. Параметр учетной записи — «-u имя пользователя: пароль».
Таким образом, команда для запуска краулера:
curl http://45.76.110.210:6800/schedule.json -d project=Название проекта -d паук=Имя краулера -u kingname: гений
Команда для остановки поискового робота:
```shell
curl http://45.76.110.210:6800/cancel.json -d project=Название проекта -d работа=Crawler JOBID-u kingname: гений
Если вы используете Python и запрашиваете запись сценария для управления поисковым роботом, то информацию об учетной записи можно использовать в качестве параметра метода POST. Имя параметра — auth, значение — кортеж, 0-й элемент кортежа — это учетная запись, а первый элемент — пароль:
result = requests.post(start_url, data=start_data, auth=('kingname', 'genius')).text
result = requests.post(end_url, data=end_data, auth=('kingname', 'genius')).text
Введение в распределенную архитектуру
В предыдущей главе мы говорили об архитектуре размещения цели в Redis, а затем предоставления возможности нескольким поисковым роботам читать цель из Redis и затем сканировать.Это фактически распределенная архитектура главный-подчиненный. Используя Scrapy, scrapy_redis и Redis, реализован так называемый распределенный краулер.
Фактически, основная концепция этого распределенного краулера — это центральный узел, также называемый ведущим. На нем запущен Redis, и все URL-адреса веб-сайтов, которые нужно сканировать, находятся в нем. Сканер (подчиненный) на других облачных серверах считывает URL-адрес, который будет сканироваться, из этого общего Redis.
Схема архитектуры распределенного краулера

Пока вы можете получить доступ к главному серверу и прочитать Redis, не имеет значения, какую систему или провайдера используют другие серверы.
Например, используйте Ubuntu в качестве ведущего сканера для назначения задач.
Используйте Raspberry Pi, ПК с Windows 10 и Mac в качестве распределенного ведомого искателя для сканирования веб-сайтов и сохранения результатов в MongoDB, работающем на Mac.
Среди них серверу Ubuntu как мастеру нужно только установить Redis, и его роль заключается только в временной передаче URL-адреса для сканирования, поэтому ему даже не нужно устанавливать Python.
На Mac, Raspberry Pi и ПК с Windows необходимо установить Scrapy и управлять поисковым роботом через Scrapyd. Поскольку поисковый робот всегда будет отслеживать Redis мастера, он находится в режиме ожидания, когда Redis не имеет данных.
Когда цель помещена в Redis, краулер может начать работу. Поскольку Redis — этоОднопоточная база данных, Поэтому несколько поисковых роботов не получат один и тот же URL.
Как выбрать Мастера
Строго говоря, мастеру нужно только иметь возможность запускать Redis и быть доступным для других поисковых роботов. Но лучше, если у вас будет публичный IP. Таким образом, к Мастеру можно получить доступ из любого места в мире, где есть доступ в Интернет. Но если облачного сервера действительно нет, это не означает, что вам нужно тратить деньги на его покупку.Если у вас много компьютеров, вы можете использовать один компьютер в качестве главного, а другие компьютеры в качестве подчиненного.
Мастер может одновременно быть и подчиненным. В примере в главе 11 Scrapy и Redis установлены на одном компьютере. Этот компьютер одновременно является главным и подчиненным.
Мастер должен быть доступен для всех остальных Рабов. Следовательно, если все компьютеры не находятся в одной локальной сети, вам необходимо найти способ получить компьютер или облачный сервер с общедоступным IP-адресом.
В Китае в большинстве случаев IP-адрес, выделяемый операторами связи, является IP-адресом интрасети. В этом случае, даже если IP-адрес известен, нет возможности подключиться извне.
В локальной сети, поскольку локальная сеть имеет один выход, вся локальная сеть имеет один и тот же общедоступный IP-адрес. Для веб-сайта этот IP-адрес используется слишком часто, и, конечно же, он не посещается людьми, что увеличивает вероятность блокировки веб-сайтом. Использование распределенных поисковых роботов не только для увеличения скорости сканирования доступа, но, что более важно, для уменьшения частоты доступа к каждому IP, чтобы веб-сайт ошибочно полагал, что это посещение. Следовательно, если все сканеры используют один выход в одной локальной сети, рекомендуется добавить агента для каждого поискового робота.
В реальной производственной среде идеальная ситуация состоит в том, что общедоступный IP-адрес каждого ведомого устройства отличается, чтобы его можно было быстро сканировать и снизить вероятность блокировки механизмом защиты от обхода.
резюме
Эта глава в основном знакомит с расширенным использованием промежуточного программного обеспечения Scrapy и пакетным развертыванием поисковых роботов.
Использование промежуточного программного обеспечения позволяет поисковому роботу сосредоточиться на извлечении данных, а все вещи, такие как изменение IP-адреса и получение сеансов входа в систему, остаются на усмотрение промежуточного программного обеспечения. Это может сделать код самого краулера более кратким и облегчить совместную разработку.
Используя Scrapyd для развертывания поисковых роботов, можно реализовать поисковые роботы с удаленным переключением и пакетное развертывание поисковых роботов, тем самым реализуя распределенные поисковые роботы.
Глава 13 Правовые и этические вопросы разработки краулеров
резюме
- В процессе разработки краулера и сбора данных чтение соглашения веб-сайта может эффективно выявить и избежать потенциальных юридических рисков.
- Сканер контролирует частоту сканирования веб-сайта и хорошо обрабатывает его, чтобы сканер мог работать дольше.
![]()
Frankie
Posted on Jul 26, 2019
• Updated on Apr 10, 2020
![]()
![]()
![]()
![]()
![]()
Overview
Most Python web crawling/scraping tutorials use some kind of crawling library. This is great if you want to get things done quickly, but if you do not understand how scraping works under the hood then when problems arise it will be difficult to know how to fix them.
In this tutorial I will be going over how to write a web crawler completely from scratch in Python using only the Python Standard Library and the requests module (https://pypi.org/project/requests/2.7.0/). I will also be going over how you can use a proxy API (https://proxyorbit.com) to prevent your crawler from getting blacklisted.
This is mainly for educational purposes, but with a little attention and care this crawler can become as robust and useful as any scraper written using a library. Not only that, but it will most likely be lighter and more portable as well.
I am going to assume that you have a basic understanding of Python and programming in general. Understanding of how HTTP requests work and how Regular Expressions work will be needed to fully understand the code. I won’t be going into deep detail on the implementation of each individual function. Instead, I will give high level overviews of how the code samples work and why certain things work the way they do.
The crawler that we’ll be making in this tutorial will have the goal of «indexing the internet» similar to the way Google’s crawlers work. Obviously we won’t be able to index the internet, but the idea is that this crawler will follow links all over the internet and save those links somewhere as well as some information on the page.
Start Small
The first task is to set the groundwork of our scraper. We’re going to use a class to house all our functions. We’ll also need the re and requests modules so we’ll import them
import requests
import re
class PyCrawler(object):
def __init__(self, starting_url):
self.starting_url = starting_url
self.visited = set()
def start(self):
pass
if __name__ == "__main__":
crawler = PyCrawler()
crawler.start()
Enter fullscreen mode
Exit fullscreen mode
You can see that this is very simple to start. It’s important to build these kinds of things incrementally. Code a little, test a little, etc.
We have two instance variables that will help us in our crawling endeavors later.
starting_url
Is the initial starting URL that our crawler will start out
visited
This will allow us to keep track of the URLs that we have currently visited to prevent visiting the same URL twice. Using a set() keeps visited URL lookup in O(1) time making it very fast.
Crawl Sites
Now we will get started actually writing the crawler. The code below will make a request to the starting_url and extract all links on the page. Then it will iterate over all the new links and gather new links from the new pages. It will continue this recursive process until all links have been scraped that are possible from the starting point. Some websites don’t link outside of themselves so these sites will stop sooner than sites that do link to other sites.
import requests
import re
from urllib.parse import urlparse
class PyCrawler(object):
def __init__(self, starting_url):
self.starting_url = starting_url
self.visited = set()
def get_html(self, url):
try:
html = requests.get(url)
except Exception as e:
print(e)
return ""
return html.content.decode('latin-1')
def get_links(self, url):
html = self.get_html(url)
parsed = urlparse(url)
base = f"{parsed.scheme}://{parsed.netloc}"
links = re.findall('''<as+(?:[^>]*?s+)?href="([^"]*)"''', html)
for i, link in enumerate(links):
if not urlparse(link).netloc:
link_with_base = base + link
links[i] = link_with_base
return set(filter(lambda x: 'mailto' not in x, links))
def extract_info(self, url):
html = self.get_html(url)
return None
def crawl(self, url):
for link in self.get_links(url):
if link in self.visited:
continue
print(link)
self.visited.add(link)
info = self.extract_info(link)
self.crawl(link)
def start(self):
self.crawl(self.starting_url)
if __name__ == "__main__":
crawler = PyCrawler("https://google.com")
crawler.start()
Enter fullscreen mode
Exit fullscreen mode
As we can see a fair bit of new code has been added.
To start, get_html, get_links, crawl, and extract_info methods were added.
get_html()
Is used to get the HTML at the current link
get_links()
Extracts links from the current page
extract_info()
Will be used to extract specific info on the page.
The crawl() function has also been added and it is probably the most important and complicated piece of this code. «crawl» works recursively. It starts at the start_url, extracts links from that page, iterates over those links, and then feeds the links back into itself recursively.
If you think of the web like a series of doors and rooms, then essentially what this code is doing is looking for those doors and walking through them until it gets to a room with no doors. When this happens it works its way back to a room that has unexplored doors and enters that one. It does this forever until all doors accessible from the starting location have been accessed. This kind of process lends itself very nicely to recursive code.
If you run this script now as is it will explore and print all the new URLs it finds starting from google.com
Extract Content
Now we will extract data from the pages. This method (extract_info) is largely based on what you are trying to do with your scraper. For the sake of this tutorial, all we are going to do is extract meta tag information if we can find it on the page.
import requests
import re
from urllib.parse import urlparse
class PyCrawler(object):
def __init__(self, starting_url):
self.starting_url = starting_url
self.visited = set()
def get_html(self, url):
try:
html = requests.get(url)
except Exception as e:
print(e)
return ""
return html.content.decode('latin-1')
def get_links(self, url):
html = self.get_html(url)
parsed = urlparse(url)
base = f"{parsed.scheme}://{parsed.netloc}"
links = re.findall('''<as+(?:[^>]*?s+)?href="([^"]*)"''', html)
for i, link in enumerate(links):
if not urlparse(link).netloc:
link_with_base = base + link
links[i] = link_with_base
return set(filter(lambda x: 'mailto' not in x, links))
def extract_info(self, url):
html = self.get_html(url)
meta = re.findall("<meta .*?name=["'](.*?)['"].*?content=["'](.*?)['"].*?>", html)
return dict(meta)
def crawl(self, url):
for link in self.get_links(url):
if link in self.visited:
continue
self.visited.add(link)
info = self.extract_info(link)
print(f"""Link: {link}
Description: {info.get('description')}
Keywords: {info.get('keywords')}
""")
self.crawl(link)
def start(self):
self.crawl(self.starting_url)
if __name__ == "__main__":
crawler = PyCrawler("https://google.com")
crawler.start()
Enter fullscreen mode
Exit fullscreen mode
Not much has changed here besides the new print formatting and the extract_info method.
The magic here is in the regular expression in the extract_info method. It searches in the HTML for all meta tags that follow the format <meta name=X content=Y> and returns a Python dictionary of the format {X:Y}
This information is then printed to the screen for every URL for every request.
Integrate Rotating Proxy API
One of the main problems with web crawling and web scraping is that sites will ban you either if you make too many requests, don’t use an acceptable user agent, etc. One of the ways to limit this is by using proxies and setting a different user agent for the crawler. Normally the proxy approach requires you to go out and purchase or source manually a list of proxies from somewhere else. A lot of the time these proxies don’t even work or are incredibly slow making web crawling much more difficult.
To avoid this problem we are going to be using what is called a «rotating proxy API». A rotating proxy API is an API that takes care of managing the proxies for us. All we have to do is make a request to their API endpoint and boom, we’ll get a new working proxy for our crawler. Integrating the service into the platform will require no more than a few extra lines of Python.
The service we will be using is Proxy Orbit (https://proxyorbit.com). Full disclosure, I do own and run Proxy Orbit.
The service specializes in creating proxy solutions for web crawling applications. The proxies are checked continually to make sure that only the best working proxies are in the pool.
import requests
import re
from urllib.parse import urlparse
import os
class PyCrawler(object):
def __init__(self, starting_url):
self.starting_url = starting_url
self.visited = set()
self.proxy_orbit_key = os.getenv("PROXY_ORBIT_TOKEN")
self.user_agent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
self.proxy_orbit_url = f"https://api.proxyorbit.com/v1/?token={self.proxy_orbit_key}&ssl=true&rtt=0.3&protocols=http&lastChecked=30"
def get_html(self, url):
try:
proxy_info = requests.get(self.proxy_orbit_url).json()
proxy = proxy_info['curl']
html = requests.get(url, headers={"User-Agent":self.user_agent}, proxies={"http":proxy, "https":proxy}, timeout=5)
except Exception as e:
print(e)
return ""
return html.content.decode('latin-1')
def get_links(self, url):
html = self.get_html(url)
parsed = urlparse(url)
base = f"{parsed.scheme}://{parsed.netloc}"
links = re.findall('''<as+(?:[^>]*?s+)?href="([^"]*)"''', html)
for i, link in enumerate(links):
if not urlparse(link).netloc:
link_with_base = base + link
links[i] = link_with_base
return set(filter(lambda x: 'mailto' not in x, links))
def extract_info(self, url):
html = self.get_html(url)
meta = re.findall("<meta .*?name=["'](.*?)['"].*?content=["'](.*?)['"].*?>", html)
return dict(meta)
def crawl(self, url):
for link in self.get_links(url):
if link in self.visited:
continue
self.visited.add(link)
info = self.extract_info(link)
print(f"""Link: {link}
Description: {info.get('description')}
Keywords: {info.get('keywords')}
""")
self.crawl(link)
def start(self):
self.crawl(self.starting_url)
if __name__ == "__main__":
crawler = PyCrawler("https://google.com")
crawler.start()
Enter fullscreen mode
Exit fullscreen mode
As you can see, not much has really changed here. Three new class variables were created: proxy_orbit_key, user_agent, and proxy_orbit_url
proxy_orbit_key gets the Proxy Orbit API Token from an environment variable named PROXY_ORBIT_TOKEN
user_agent sets the User Agent of the crawler to Firefox to make requests look like they are coming from a browser
proxy_orbit_url is the Proxy Orbit API endpoint that we will be hitting. We will be filtering our results only requesting HTTP proxies supporting SSL that have been checked in the last 30 minutes.
in get_html a new HTTP request is being made to the Proxy Orbit API URL to get the random proxy and insert it into the requests module for grabbing the URL we are trying to crawl from behind a proxy.
If all goes well then that’s it! We should now have a real working web crawler that pulls data from web pages and supports rotating proxies.
UPDATE:
It seems that some people have been having trouble with the final script, specifically get_html method. This is likely due to the lack of a Proxy Orbit API token being set. In the constructor there is a line, self.proxy_orbit_key = os.getenv("PROXY_ORBIT_TOKEN"). This line attempts to get an environmental variable named PROXY_ORBIT_TOKEN which is where your API token should be set. If the token is not set, the line proxy = proxy_info['curl'] will fail because the proxy API will return JSON signifying an unauthenticated request and won’t contain any key curl.
There are two ways to get around this. The first is to signup at Proxy Orbit and get your token and set your PROXY_ORBIT_TOKEN env variable properly. The second way is to replace your get_html function with the following:
def get_html(self, url):
try:
html = requests.get(url, headers={"User-Agent":self.user_agent}, timeout=5)
except Exception as e:
print(e)
return ""
return html.content.decode('latin-1')
Enter fullscreen mode
Exit fullscreen mode
Note that if you replace the get_html function all of your crawler requests will be using your IP address.
The scraping series will not get completed without discussing Scrapy. In this post I am going to write a web crawler that will scrape data from OLX’s Electronics & Appliances’ items. Before I get into the code, how about having a brief intro of Scrapy itself?
What is Scrapy?
From Wikipedia:
Scrapy (/ˈskreɪpi/ skray-pee)[1] is a free and open source web crawling framework, written in Python. Originally designed for web scraping, it can also be used to extract data using APIs or as a general purpose web crawler.[2] It is currently maintained by Scrapinghub Ltd., a web scraping development and services company.
A web crawling framework which has done all the heavy lifting that is needed to write a crawler. What are those things, I will explore further below.
Read on!
Creating Project
Scrapy introduces the idea of a project with multiple crawlers or spiders in a single project. This concept is helpful specially if you are writing multiple crawlers of different sections of a site or sub-domains of a site. So, first create the project:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ scrapy startproject olx
New Scrapy project 'olx', using template directory '//anaconda/lib/python2.7/site-packages/scrapy/templates/project', created in:
/Development/PetProjects/ScrapyCrawlers/olx
You can start your first spider with:
cd olx
scrapy genspider example example.com
Creating Crawler
I ran the command scrapy startproject olx which will create a project with name olx and helpful information for next steps. You go to the newly created folder and then execute command for generating first spider with name and the domain of the site to be crawled:
Adnans-MBP:ScrapyCrawlers AdnanAhmad$ cd olx/ Adnans-MBP:olx AdnanAhmad$ scrapy genspider electronics www.olx.com.pk Created spider 'electronics' using template 'basic' in module: olx.spiders.electronics
I generated the code of my first Spider with name electronics, since I am accessing the electronics section of OLX I named it like that, you can name it to anything you want or dedicate your first spider to your spouse or (girl|boy)friend 🙂
The final project structure will be something like given below:
As you can see, there is a separate folder only for Spiders, as mentioned, you can add multiple spiders with in a single project. Let’s open electronics.py spider file. When you open it, you will find something like that:
# -*- coding: utf-8 -*-
import scrapy
class ElectronicsSpider(scrapy.Spider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = ['http://www.olx.com.pk/']
def parse(self, response):
pass
As you can see, ElectronicsSpider is subclass of scrapy.Spider. The name property is actually name of the spider which was given in the spider generation command. This name will help while running the crawler itself. The allowed_domains property tells which domains are accessible for this crawler and strart_urls is the place to mention initial URLs that to be accessed at first place. Beside file structure this is a good feature to draw the boundaries of your crawler.
The parse method, as the name suggests that to parse the content of the page being accessed. Since I am going to write a crawler that goes to multiple pages, I am going to make a few changes.
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class ElectronicsSpider(CrawlSpider):
name = "electronics"
allowed_domains = ["www.olx.com.pk"]
start_urls = [
'https://www.olx.com.pk/computers-accessories/',
'https://www.olx.com.pk/tv-video-audio/',
'https://www.olx.com.pk/games-entertainment/'
]
rules = (
Rule(LinkExtractor(allow=(), restrict_css=('.pageNextPrev',)),
callback="parse_item",
follow=True),)
def parse_item(self, response):
print('Processing..' + response.url)
# print(response.text)
In order to make the crawler navigate to many page, I rather subclassed my Crawler from Crawler instead of scrapy.Spider. This class makes crawling many pages of a site easier. You can do similar with the generated code but you’ll need to take care of recursion to navigate next pages.
The next is to set rules variable, here you mention the rules of navigating the site. The LinkExtractor actually takes parameters to draw navigation boundaries. Here I am using restrict_css parameter to set the class for NEXT page. If you go to this page and inspect element you can find something like this:
pageNextPrev is the class that be used to fetch link of next pages. The call_back parameter tells which method to use to access the page elements. We will work on this method soon.
Do remember, you need to change name of the method from parse() to parse_item() or whatever to avoid overriding the base class otherwise your rule will not work even if you set follow=True.
So far so good, let’s test the crawler I have done so far. Again, go to terminal and write:
Adnans-MBP:olx AdnanAhmad$ scrapy crawl electronics
The 3rd parameter is actually the name of the spider which was set earlier in the name property of ElectronicsSpiders class. On console you find lots of useful information that is helpful to debug your crawler. You can disable the debugger if you don’t want to see debugging information. The command will be similar with --nolog switch.
Adnans-MBP:olx AdnanAhmad$ scrapy crawl --nolog electronics
If you run now it will print something like:
Adnans-MBP:olx AdnanAhmad$ scrapy crawl --nolog electronics Processing..https://www.olx.com.pk/computers-accessories/?page=2 Processing..https://www.olx.com.pk/tv-video-audio/?page=2 Processing..https://www.olx.com.pk/games-entertainment/?page=2 Processing..https://www.olx.com.pk/computers-accessories/ Processing..https://www.olx.com.pk/tv-video-audio/ Processing..https://www.olx.com.pk/games-entertainment/ Processing..https://www.olx.com.pk/computers-accessories/?page=3 Processing..https://www.olx.com.pk/tv-video-audio/?page=3 Processing..https://www.olx.com.pk/games-entertainment/?page=3 Processing..https://www.olx.com.pk/computers-accessories/?page=4 Processing..https://www.olx.com.pk/tv-video-audio/?page=4 Processing..https://www.olx.com.pk/games-entertainment/?page=4 Processing..https://www.olx.com.pk/computers-accessories/?page=5 Processing..https://www.olx.com.pk/tv-video-audio/?page=5 Processing..https://www.olx.com.pk/games-entertainment/?page=5 Processing..https://www.olx.com.pk/computers-accessories/?page=6 Processing..https://www.olx.com.pk/tv-video-audio/?page=6 Processing..https://www.olx.com.pk/games-entertainment/?page=6 Processing..https://www.olx.com.pk/computers-accessories/?page=7 Processing..https://www.olx.com.pk/tv-video-audio/?page=7 Processing..https://www.olx.com.pk/games-entertainment/?page=7
Since I set follow=True, the crawler will check rule for Next Page and will keep navigating unless it hits the page where the rule does not mean, usually the last Page of the listing. Now imagine if I am going to write similar logic with the things mentioned here, first I will have to write code to spawn multiple process, I will also have to write code to navigate not only next page but also restrict my script stay in boundaries by not accessing unwanted URLs, Scrapy takes all this burder off my shoulder and makes me to stay focus on main logic that is, writing the crawler to extract information.
Now I am going to write code that will fetch individual item links from listing pages. I am going to modify code in parse_item method.
item_links = response.css('.large > .detailsLink::attr(href)').extract()
for a in item_links:
yield scrapy.Request(a, callback=self.parse_detail_page)
Here I am fetching links by using .css method of response. As I said, you can use xpath as well, up to you. In this case it is pretty simple:

The anchor link has a class detailsLink, if I only use response.css('.detailsLink') then it’s going to pick duplicate links of a single entry due to repetition of link in img and h3 tags. What I did that I referred the parent class large as well to get unique links. I also used ::attr(href) to extract the href part that is link itself. I am then using extract() method. The reason to use is that .css and .xpath returns SelectorList object, extract() helps to return the actual DOM for further processing. Finally I am yielding links in scrapy.Request with a callback. I have not checked inner code of Scrapy but most probably they are using yield instead of a return because you can yield multiple items and since the crawler needs to take care of multiple links together then yield is the best choice here.
The parse_detail_page method as the name tells is to parse individual information from the detail page. So what actually is happening is:
- You get list of entries in
parse_item - Pass them on in a callback method for further processing.
Since it was only a two level traverse I was able to reach lowest level with help of two methods. If I was going to start crawling from main page of OLX I would have to write 3 methods here; first two to fetch subcategories and their entries and the last one for parsing the actual information. Got my point?
Finally, I am going to parse the actual information which is available on one of the entries like this one.
Parsing information from this page is not different but here’s something that to be done to store parsed information. We need to define model for our data. It means we need to tell Scrapy what information do we want to store for later use. Let’s edit item.py file which was generated earlier by Scrapy.
import scrapy
class OlxItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
OlxItem is the class in which I will set required fields to hold information. I am going to define 3 fields for my model class.
class OlxItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
price = scrapy.Field()
url = scrapy.Field()
I am going to store Title of the post, price and the URL itself. Let’s get back to crawler class and modify parse_detail_page. Now one method is to start writing code, test by running entire crawler and get whether you’re on right track or not but there’s another awesome tool provided by Scrapy.
Scrapy Shell
Scrapy Shell is a command line tool that provides you opportunity to test your parsing code without running thee entire crawler. Unlike the crawler which goes to all the links, Scrapy Shell save the DOM of an individual page for data extraction. In my case I did following:
Adnans-MBP:olx AdnanAhmad$ scrapy shell https://www.olx.com.pk/item/asus-eee-pc-atom-dual-core-4cpus-beautiful-laptops-fresh-stock-IDUVo6B.html#4001329891
Now I can easily test code without hitting same URL again and again. I fetched the title by doing this:
In [8]: response.css('h1::text').extract()[0].strip()
Out[8]: u"Asus Eee PC Atom Dual-Core 4CPU's Beautiful Laptops fresh Stock"
You can find familiar response.css here. Since entire DOM is available, you can play with it.
And I fetch price by doing this:
In [11]: response.css('.pricelabel > strong::text').extract()[0]
Out[11]: u'Rs 10,500'
No need to do anything for fetching url since response.url returns the currently accessed URL.
Now all code is checked, it’s time to incorporate it in parse_detail_page:
title = response.css('h1::text').extract()[0].strip()
price = response.css('.pricelabel > strong::text').extract()[0]
item = OlxItem()
item['title'] = title
item['price'] = price
item['url'] = response.url
yield item
After parsing required information OlxItem instance is being created and properties are being set. So far so good, now it’s time to run crawler and store information, there’s a slight modification in command:
scrapy crawl electronics -o data.csv -t csv
I am passing file name and file format for saving data. Once run, it will generate CSV for you. Easy, isn’t it? Unlike the crawler you are writing on your own you gotta write your own routine for saving data but wait! it does not end here, you can even get data in JSON format, all you have to do is to pass json with -t switch.
One more thing, Scrapy provides you another feature, passing a fixed file name does not make any sense in real world scenarios, how about I could have some facility to generate unique file names? well, for that you need to modify settings.py file and add these two entries:
FEED_URI = 'data/%(name)s/%(time)s.json' FEED_FORMAT = 'json'
Here I am giving pattern of my file, %(name)% is name of crawler itself and time is timestamp. You may learn further about it here. Now when I run scrapy crawl --nolog electronics or scrapy crawl electronics it will generate a json file in data folder, something like this:
[
{"url": "https://www.olx.com.pk/item/acer-ultra-slim-gaming-laptop-with-amd-fx-processor-3gb-dedicated-IDUQ1k9.html", "price": "Rs 42,000", "title": "Acer Ultra Slim Gaming Laptop with AMD FX Processor 3GB Dedicated"},
{"url": "https://www.olx.com.pk/item/saw-machine-IDUYww5.html", "price": "Rs 80,000", "title": "Saw Machine"},
{"url": "https://www.olx.com.pk/item/laptop-hp-probook-6570b-core-i-5-3rd-gen-IDUYejF.html", "price": "Rs 22,000", "title": "Laptop HP Probook 6570b Core i 5 3rd Gen"},
{"url": "https://www.olx.com.pk/item/zong-4g-could-mifi-anlock-all-sim-supported-IDUYedh.html", "price": "Rs 4,000", "title": "Zong 4g could mifi anlock all Sim supported"},
...
]
Conclusion
This was the last(most probably) post in the scraping series. I am planning to come up with some other technology in the coming days. Stay tuned!
Writing scrapers is an interesting journey but you can hit the wall if the site blocks your IP. As an individual, you can’t afford expensive proxies either. Scraper API provides you an affordable and easy to use API that will let you scrape websites without any hassle. You do not need to worry about getting blocked because Scraper API by default uses proxies to access websites. On top of it, you do not need to worry about Selenium either since Scraper API provides the facility of a headless browser too. I also have written a post about how to use it.
Click here to signup with my referral link or enter promo code adnan10, you will get a 10% discount on it. In case you do not get the discount then just let me know via email on my site and I’d sure help you out.
As usual, you can get the code from Github.
Planning to write a book about Web Scraping in Python. Click here to give your feedback
Beautiful Soup (буквально — «прекрасный суп») — это библиотека Python для извлечения данных из HTML и XML. То есть, библиотека для веб-скрапинга.
Давайте разберем задание для технического собеседования.
# Путем веб-краулинга исследуйте веб-страницу и выведите слово, # которое встречается на ней чаще всего, а также # количество вхождений этого слова. # Страница для краулинга: # https://en.wikipedia.org/wiki/Apple_Inc. # Учитывайте только слова из раздела «History».
Итак, дана страница Apple в Википедии. Нам нужно найти слово, которое чаще всего встречается в разделе «History», а также посчитать, сколько раз оно там встречается. Приступим.
1. Первоначальная подготовка
Для начала нам нужно импортировать Beautiful Soup. Установим библиотеку через командную строку:
pip3 install bs4
Если у вас возникли проблемы с установкой, обратитесь к документации.
Далее нужно запросить нашу библиотеку вверху кода. Вот все, что нам понадобится:
from bs4 import BeautifulSoup, Tag import requests from collections import defaultdict
Теперь мы готовы определить нашу функцию.
def find_most_common():
2. Извлечение страницы
Давайте извлечем нашу страницу и распарсим ее при помощи Beautiful Soup. Для этого мы воспользуемся библиотекой requests:
page = requests.get("https://en.wikipedia.org/wiki/Apple_Inc.")
Теперь прогоним полученный документ через Beautiful Soup.
soup = BeautifulSoup(page.text, "html.parser")
Как нам извлечь только раздел «History»? Нужно изучить HTML-код страницы. Там много всякой тарабарщины, но если подчистить, он выглядит так:
<h2>
<span class="mw-headline" id="History">History</span>
</h2>
<div ...>...</div>
<div ...>...</div>
<h3>
<span ...></span>
<span class="mw-headline" id="1976–1984:_Founding_and_incorporation">1976–1984: Founding and incorporation</span>
</h3>
.
.
.
<p>Apple Computer Company was founded on April 1, 1976, by <a href="/wiki/Steve_Jobs" title="Steve Jobs">Steve Jobs</a>...
На сайте Википедии, судя по всему, все содержимое страницы помещено в один блок div. Это значит, что раздел «History» не лежит в собственном div. Это всего лишь заголовок и какое-то содержимое внутри родительского div, в котором содержатся все разделы.
Лучшее, что мы можем сделать, чтобы извлечь только исторический раздел, это просто захватить заголовок и все, что идет после него. Мы захватываем тег <span> с ID «History», а затем идем к его родителю — <h2>. Чтобы захватить все идущее за заголовком, мы можем использовать нотацию Beautiful Soup: next_siblings. Все вместе:
history = soup.find(id="History").parent.next_siblings
3. Подсчет слов
Давайте инициализируем пару переменных. Нам нужна переменная для искомого слова и для количества его вхождений. Еще нам нужен словарь для подсчета всех слов. Что касается словаря, мы используем дефолтный словарь — defaultdict. Он позволяет задать целые числа в качестве типа по умолчанию. Благодаря этому при запросе несуществующего ключа будет создана пара из этого ключа и дефолтного значения — нуля. (Пример использования defaultdict можно посмотреть в статье «Определяем, все ли символы в строке уникальны. Разбор задачи», — прим. ред. Pythonist.ru).
max_count = 0 max_word = "" dd = defaultdict(int)
Теперь мы готовы краулить. Давайте переберем в цикле history, проверяя каждый элемент — elem. Бывает, что Beautiful Soup возвращает вместо элемента то, что называется Navigable String. Мы отфильтруем все, что не является элементом, при помощи метода isinstance() из нашей библиотеки.
for elem in history:
if isinstance(elem, Tag):
Давайте подумаем, что будет происходить дальше. Для каждого элемента в history нам нужно просмотреть текст и посчитать вхождения каждого слова. Но не забудьте, что нам нужно остановиться, когда раздел истории закончится. Следующий раздел находится в том же блоке div, но начинается с тега <h2>. В конце мы можем вывести слово, встречающееся чаще всего, и количество его вхождений. Возвращать будем max_count.
for elem in history:
if isinstance(elem, Tag):
if elem.name == "h2":
print(max_word, "is the most common, appearing", max_count, "times.")
return max_count
А что, если мы еще не дошли до конца раздела? Нам нужно извлечь текст из элемента, вызвав метод get_text() Beautiful Soup, а затем разбить его на слова (по пробелам) при помощи метода split().
words = elem.get_text().split()
Что дальше? Переберем в цикле каждое слово, обновляя его значение в словаре. Поскольку мы используем defaultdict, нам не нужно проверять, есть ли уже такое слово в словаре: мы можем просто добавлять единицу к значению этого слова. Но нужно не забывать обновлять max_word и max_count, если находим слово, встречающееся чаще, чем предыдущее.
for word in words:
dd[word] += 1
if dd[word] > max_count:
max_count = dd[word]
max_word = word
Вот и все! Код должен работать… если только Википедия не сменит макет своего сайта. Давайте-ка добавим итоговую проверку на случай, если это все же произойдет. Все вместе выглядит следующим образом:
from bs4 import BeautifulSoup, Tag
import requests
from collections import defaultdict
def find_most_common():
page = requests.get("https://en.wikipedia.org/wiki/Apple_Inc.")
soup = BeautifulSoup(page.text, "html.parser")
history = soup.find(id="History").parent.next_siblings
max_count = 0
max_word = ""
dd = defaultdict(int)
for elem in history:
if isinstance(elem, Tag):
if elem.name == "h2":
print(max_word, "is the most common, appearing", max_count, "times.")
return max_count
words = elem.get_text().split()
for word in words:
dd[word] += 1
if dd[word] > max_count:
max_count = dd[word]
max_word = word
return "Error"
Проверяем
Эта функция выводит результат на экран, так что мы можем просто запустить ее при помощи find_most_common(). Мы получим следующее:
the is the most common, appearing 328 times.
Это оно! Конечно, эта функция работает только для конкретной страницы (и на момент написания статьи). Основная проблема веб-краулинга в том, что если собственник сайта хоть немного изменит свой контент, функция может сломаться. Также мы не учитывали здесь регистры и пунктуацию: вы можете реализовать это самостоятельно.