Далее будет представлено максимально простое объяснение того, как работают нейронные сети, а также показаны способы их реализации в Python. Приятная новость для новичков – нейронные сети не такие уж и сложные. Термин нейронные сети зачастую используют в разговоре, ссылаясь на какой-то чрезвычайно запутанный концепт. На деле же все намного проще.
Данная статья предназначена для людей, которые ранее не работали с нейронными сетями вообще или же имеют довольно поверхностное понимание того, что это такое. Принцип работы нейронных сетей будет показан на примере их реализации через Python.
Содержание статьи
- Создание нейронных блоков
- Простой пример работы с нейронами в Python
- Создание нейрона с нуля в Python
- Пример сбор нейронов в нейросеть
- Пример прямого распространения FeedForward
- Создание нейронной сети прямое распространение FeedForward
- Пример тренировки нейронной сети — минимизация потерь, Часть 1
- Пример подсчета потерь в тренировки нейронной сети
- Python код среднеквадратической ошибки (MSE)
- Тренировка нейронной сети — многовариантные исчисления, Часть 2
- Пример подсчета частных производных
- Тренировка нейронной сети: Стохастический градиентный спуск
- Создание нейронной сети с нуля на Python
Создание нейронных блоков
Для начала необходимо определиться с тем, что из себя представляют базовые компоненты нейронной сети – нейроны. Нейрон принимает вводные данные, выполняет с ними определенные математические операции, а затем выводит результат. Нейрон с двумя входными данными выглядит следующим образом:
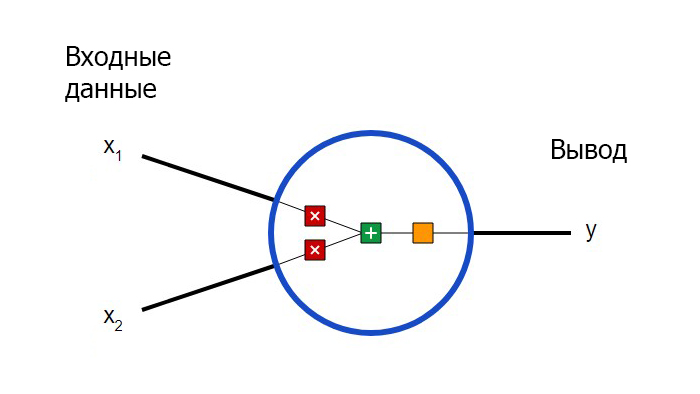
Здесь происходят три вещи. Во-первых, каждый вход умножается на вес (на схеме обозначен красным):
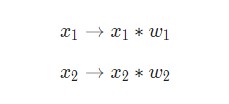
Затем все взвешенные входы складываются вместе со смещением b (на схеме обозначен зеленым):
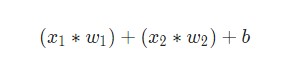
Наконец, сумма передается через функцию активации (на схеме обозначена желтым):
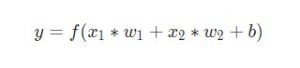
Функция активации используется для подключения несвязанных входных данных с выводом, у которого простая и предсказуемая форма. Как правило, в качестве используемой функцией активации берется функция сигмоида:
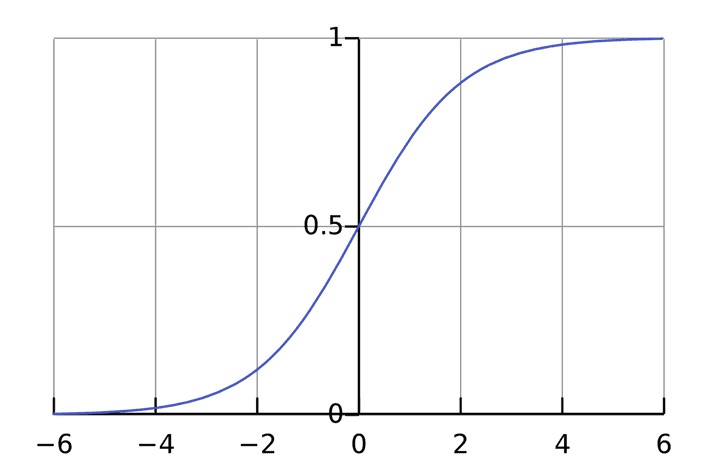
Функция сигмоида выводит только числа в диапазоне (0, 1). Вы можете воспринимать это как компрессию от (−∞, +∞) до (0, 1). Крупные отрицательные числа становятся ~0, а крупные положительные числа становятся ~1.
Предположим, у нас есть нейрон с двумя входами, который использует функцию активации сигмоида и имеет следующие параметры:
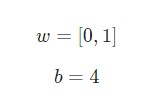
w = [0,1] — это просто один из способов написания w1 = 0, w2 = 1 в векторной форме. Присвоим нейрону вход со значением x = [2, 3]. Для более компактного представления будет использовано скалярное произведение.
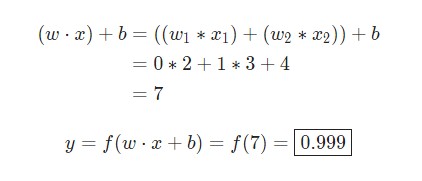
С учетом, что вход был x = [2, 3], вывод будет равен 0.999. Вот и все. Такой процесс передачи входных данных для получения вывода называется прямым распространением, или feedforward.
Создание нейрона с нуля в Python
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Приступим к имплементации нейрона. Для этого потребуется использовать NumPy. Это мощная вычислительная библиотека Python, которая задействует математические операции:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import numpy as np def sigmoid(x): # Наша функция активации: f(x) = 1 / (1 + e^(-x)) return 1 / (1 + np.exp(—x)) class Neuron: def __init__(self, weights, bias): self.weights = weights self.bias = bias def feedforward(self, inputs): # Вводные данные о весе, добавление смещения # и последующее использование функции активации total = np.dot(self.weights, inputs) + self.bias return sigmoid(total) weights = np.array([0, 1]) # w1 = 0, w2 = 1 bias = 4 # b = 4 n = Neuron(weights, bias) x = np.array([2, 3]) # x1 = 2, x2 = 3 print(n.feedforward(x)) # 0.9990889488055994 |
Узнаете числа? Это тот же пример, который рассматривался ранее. Ответ полученный на этот раз также равен 0.999.
Пример сбор нейронов в нейросеть
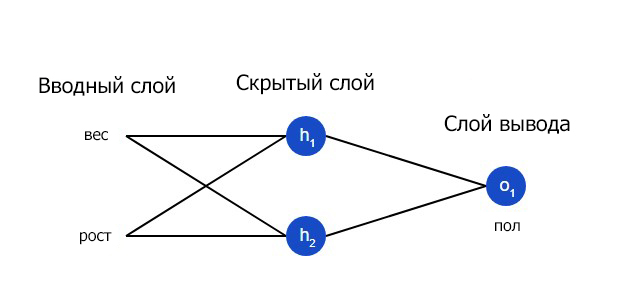
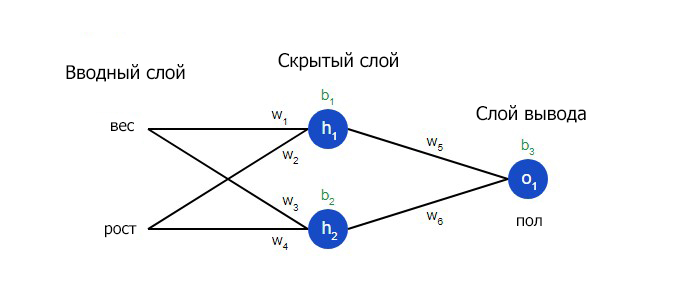
Нейронная сеть по сути представляет собой группу связанных между собой нейронов. Простая нейронная сеть выглядит следующим образом:
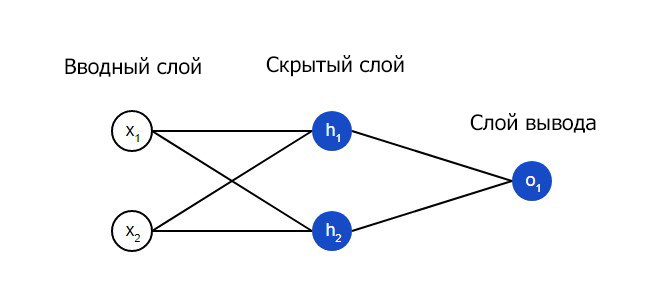
На вводном слое сети два входа – x1 и x2. На скрытом слое два нейтрона — h1 и h2. На слое вывода находится один нейрон – о1. Обратите внимание на то, что входные данные для о1 являются результатами вывода h1 и h2. Таким образом и строится нейросеть.
Скрытым слоем называется любой слой между вводным слоем и слоем вывода, что являются первым и последним слоями соответственно. Скрытых слоев может быть несколько.
Пример прямого распространения FeedForward
Давайте используем продемонстрированную выше сеть и представим, что все нейроны имеют одинаковый вес w = [0, 1], одинаковое смещение b = 0 и ту же самую функцию активации сигмоида. Пусть h1, h2 и o1 сами отметят результаты вывода представленных ими нейронов.
Что случится, если в качестве ввода будет использовано значение х = [2, 3]?
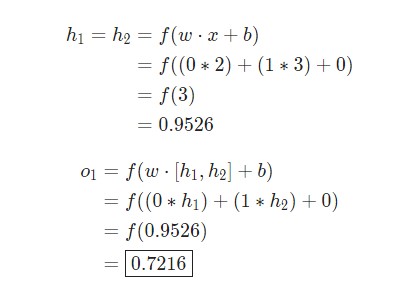
Результат вывода нейронной сети для входного значения х = [2, 3] составляет 0.7216. Все очень просто.
Нейронная сеть может иметь любое количество слоев с любым количеством нейронов в этих слоях.
Суть остается той же: нужно направить входные данные через нейроны в сеть для получения в итоге выходных данных. Для простоты далее в данной статье будет создан код сети, упомянутая выше.
Создание нейронной сети прямое распространение FeedForward
Далее будет показано, как реализовать прямое распространение feedforward в отношении нейронной сети. В качестве опорной точки будет использована следующая схема нейронной сети:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import numpy as np # … Здесь код из предыдущего раздела class OurNeuralNetwork: «»» Нейронная сеть, у которой: — 2 входа — 1 скрытый слой с двумя нейронами (h1, h2) — слой вывода с одним нейроном (o1) У каждого нейрона одинаковые вес и смещение: — w = [0, 1] — b = 0 «»» def __init__(self): weights = np.array([0, 1]) bias = 0 # Класс Neuron из предыдущего раздела self.h1 = Neuron(weights, bias) self.h2 = Neuron(weights, bias) self.o1 = Neuron(weights, bias) def feedforward(self, x): out_h1 = self.h1.feedforward(x) out_h2 = self.h2.feedforward(x) # Вводы для о1 являются выводами h1 и h2 out_o1 = self.o1.feedforward(np.array([out_h1, out_h2])) return out_o1 network = OurNeuralNetwork() x = np.array([2, 3]) print(network.feedforward(x)) # 0.7216325609518421 |
Мы вновь получили 0.7216. Похоже, все работает.
Пример тренировки нейронной сети — минимизация потерь, Часть 1
Предположим, у нас есть следующие параметры:
| Имя/Name | Вес/Weight (фунты) | Рост/Height (дюймы) | Пол/Gender |
| Alice | 133 | 65 | F |
| Bob | 160 | 72 | M |
| Charlie | 152 | 70 | M |
| Diana | 120 | 60 | F |
Давайте натренируем нейронную сеть таким образом, чтобы она предсказывала пол заданного человека в зависимости от его веса и роста.
Мужчины Male будут представлены как 0, а женщины Female как 1. Для простоты представления данные также будут несколько смещены.
| Имя/Name | Вес/Weight (минус 135) | Рост/Height (минус 66) | Пол/Gender |
| Alice | -2 | -1 | 1 |
| Bob | 25 | 6 | 0 |
| Charlie | 17 | 4 | 0 |
| Diana | -15 | -6 | 1 |
Для оптимизации здесь произведены произвольные смещения
135и66. Однако, обычно для смещения выбираются средние показатели.
Потери
Перед тренировкой нейронной сети потребуется выбрать способ оценки того, насколько хорошо сеть справляется с задачами. Это необходимо для ее последующих попыток выполнять поставленную задачу лучше. Таков принцип потери.
В данном случае будет использоваться среднеквадратическая ошибка (MSE) потери:
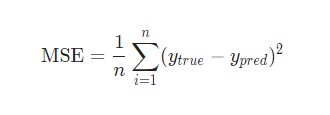
Давайте разберемся:
n– число рассматриваемых объектов, которое в данном случае равно 4. ЭтоAlice,Bob,CharlieиDiana;y– переменные, которые будут предсказаны. В данном случае это пол человека;ytrue– истинное значение переменной, то есть так называемый правильный ответ. Например, дляAliceзначениеytrueбудет1, то естьFemale;ypred– предполагаемое значение переменной. Это результат вывода сети.
(ytrue - ypred)2 называют квадратичной ошибкой (MSE). Здесь функция потери просто берет среднее значение по всем квадратичным ошибкам. Отсюда и название ошибки. Чем лучше предсказания, тем ниже потери.
Лучшие предсказания = Меньшие потери.
Тренировка нейронной сети = стремление к минимизации ее потерь.
Пример подсчета потерь в тренировки нейронной сети
Скажем, наша сеть всегда выдает 0. Другими словами, она уверена, что все люди — Мужчины. Какой будет потеря?
| Имя/Name | ytrue | ypred | (ytrue — ypred)2 |
| Alice | 1 | 0 | 1 |
| Bob | 0 | 0 | 0 |
| Charlie | 0 | 0 | 0 |
| Diana | 1 | 0 | 1 |
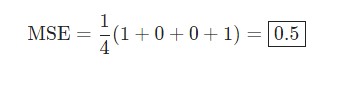
Python код среднеквадратической ошибки (MSE)
Ниже представлен код для подсчета потерь:
|
import numpy as np def mse_loss(y_true, y_pred): # y_true и y_pred являются массивами numpy с одинаковой длиной return ((y_true — y_pred) ** 2).mean() y_true = np.array([1, 0, 0, 1]) y_pred = np.array([0, 0, 0, 0]) print(mse_loss(y_true, y_pred)) # 0.5 |
При возникновении сложностей с пониманием работы кода стоит ознакомиться с quickstart в NumPy для операций с массивами.
Тренировка нейронной сети — многовариантные исчисления, Часть 2
Текущая цель понятна – это минимизация потерь нейронной сети. Теперь стало ясно, что повлиять на предсказания сети можно при помощи изменения ее веса и смещения. Однако, как минимизировать потери?
В этом разделе будут затронуты многовариантные исчисления. Если вы не знакомы с данной темой, фрагменты с математическими вычислениями можно пропускать.
Для простоты давайте представим, что в наборе данных рассматривается только Alice:
| Имя/Name | Вес/Weight (минус 135) | Рост/Height (минус 66) | Пол/Gender |
| Alice | -2 | -1 | 1 |
Затем потеря среднеквадратической ошибки будет просто квадратической ошибкой для Alice:
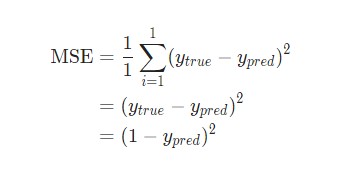
Еще один способ понимания потери – представление ее как функции веса и смещения. Давайте обозначим каждый вес и смещение в рассматриваемой сети:
Затем можно прописать потерю как многовариантную функцию:

Представим, что нам нужно немного отредактировать w1. В таком случае, как изменится потеря L после внесения поправок в w1?
На этот вопрос может ответить частная производная ![]() . Как же ее вычислить?
. Как же ее вычислить?
Здесь математические вычисления будут намного сложнее. С первой попытки вникнуть будет непросто, но отчаиваться не стоит. Возьмите блокнот и ручку – лучше делать заметки, они помогут в будущем.
Для начала, давайте перепишем частную производную в контексте ![]() :
:
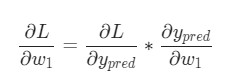 Данные вычисления возможны благодаря дифференцированию сложной функции.
Данные вычисления возможны благодаря дифференцированию сложной функции.
Подсчитать ![]() можно благодаря вычисленной выше
можно благодаря вычисленной выше L = (1 - ypred)2:
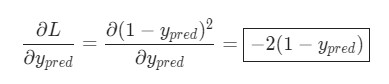
Теперь, давайте определим, что делать с ![]() . Как и ранее, позволим
. Как и ранее, позволим h1, h2, o1 стать результатами вывода нейронов, которые они представляют. Дальнейшие вычисления:
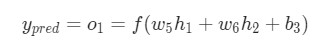 Как было указано ранее, здесь
Как было указано ранее, здесь f является функцией активации сигмоида.
Так как w1 влияет только на h1, а не на h2, можно записать:
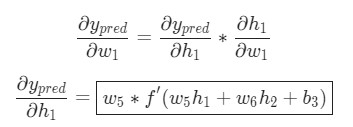 Использование дифференцирования сложной функции.
Использование дифференцирования сложной функции.
Те же самые действия проводятся для ![]() :
:
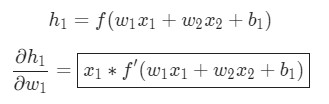 Еще одно использование дифференцирования сложной функции.
Еще одно использование дифференцирования сложной функции.
В данном случае х1 — вес, а х2 — рост. Здесь f′(x) как производная функции сигмоида встречается во второй раз. Попробуем вывести ее:
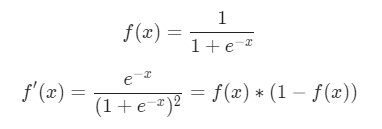
Функция f'(x) в таком виде будет использована несколько позже.
Вот и все. Теперь ![]() разбита на несколько частей, которые будут оптимальны для подсчета:
разбита на несколько частей, которые будут оптимальны для подсчета:
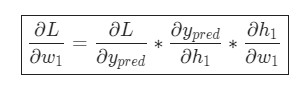
Эта система подсчета частных производных при работе в обратном порядке известна, как метод обратного распространения ошибки, или backprop.
У нас накопилось довольно много формул, в которых легко запутаться. Для лучшего понимания принципа их работы рассмотрим следующий пример.
Пример подсчета частных производных
В данном примере также будет задействована только Alice:
| Имя/Name | Вес/Weight (минус 135) | Рост/Height (минус 66) | Пол/Gender |
| Alice | -2 | -1 | 1 |
Здесь вес будет представлен как 1, а смещение как 0. Если выполним прямое распространение (feedforward) через сеть, получим:
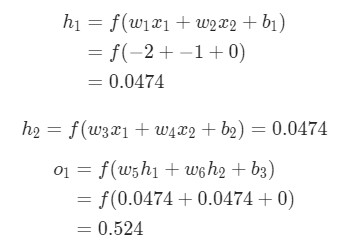
Выдачи нейронной сети ypred = 0.524. Это дает нам слабое представление о том, рассматривается мужчина Male (0), или женщина Female (1). Давайте подсчитаем ![]() :
:

Напоминание: мы вывели
f '(x) = f (x) * (1 - f (x))ранее для нашей функции активации сигмоида.
У нас получилось! Результат говорит о том, что если мы собираемся увеличить w1, L немного увеличивается в результате.
Тренировка нейронной сети: Стохастический градиентный спуск
У нас есть все необходимые инструменты для тренировки нейронной сети. Мы используем алгоритм оптимизации под названием стохастический градиентный спуск (SGD), который говорит нам, как именно поменять вес и смещения для минимизации потерь. По сути, это отражается в следующем уравнении:
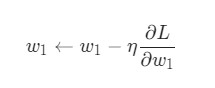
η является константой под названием оценка обучения, что контролирует скорость обучения. Все что мы делаем, так это вычитаем ![]() из
из w1:
Если мы применим это на каждый вес и смещение в сети, потеря будет постепенно снижаться, а показатели сети сильно улучшатся.
Наш процесс тренировки будет выглядеть следующим образом:
- Выбираем один пункт из нашего набора данных. Это то, что делает его стохастическим градиентным спуском. Мы обрабатываем только один пункт за раз;
- Подсчитываем все частные производные потери по весу или смещению. Это может быть
 ,
,  и так далее;
и так далее; - Используем уравнение обновления для обновления каждого веса и смещения;
- Возвращаемся к первому пункту.
Давайте посмотрим, как это работает на практике.
Создание нейронной сети с нуля на Python
Наконец, мы реализуем готовую нейронную сеть:
| Имя/Name | Вес/Weight (минус 135) | Рост/Height (минус 66) | Пол/Gender |
| Alice | -2 | -1 | 1 |
| Bob | 25 | 6 | 0 |
| Charlie | 17 | 4 | 0 |
| Diana | -15 | -6 | 1 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 |
import numpy as np def sigmoid(x): # Функция активации sigmoid:: f(x) = 1 / (1 + e^(-x)) return 1 / (1 + np.exp(—x)) def deriv_sigmoid(x): # Производная от sigmoid: f'(x) = f(x) * (1 — f(x)) fx = sigmoid(x) return fx * (1 — fx) def mse_loss(y_true, y_pred): # y_true и y_pred являются массивами numpy с одинаковой длиной return ((y_true — y_pred) ** 2).mean() class OurNeuralNetwork: «»» Нейронная сеть, у которой: — 2 входа — скрытый слой с двумя нейронами (h1, h2) — слой вывода с одним нейроном (o1) *** ВАЖНО ***: Код ниже написан как простой, образовательный. НЕ оптимальный. Настоящий код нейронной сети выглядит не так. НЕ ИСПОЛЬЗУЙТЕ этот код. Вместо этого, прочитайте/запустите его, чтобы понять, как работает эта сеть. «»» def __init__(self): # Вес self.w1 = np.random.normal() self.w2 = np.random.normal() self.w3 = np.random.normal() self.w4 = np.random.normal() self.w5 = np.random.normal() self.w6 = np.random.normal() # Смещения self.b1 = np.random.normal() self.b2 = np.random.normal() self.b3 = np.random.normal() def feedforward(self, x): # x является массивом numpy с двумя элементами h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1) h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2) o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3) return o1 def train(self, data, all_y_trues): «»» — data is a (n x 2) numpy array, n = # of samples in the dataset. — all_y_trues is a numpy array with n elements. Elements in all_y_trues correspond to those in data. «»» learn_rate = 0.1 epochs = 1000 # количество циклов во всём наборе данных for epoch in range(epochs): for x, y_true in zip(data, all_y_trues): # — Выполняем обратную связь (нам понадобятся эти значения в дальнейшем) sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1 h1 = sigmoid(sum_h1) sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2 h2 = sigmoid(sum_h2) sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3 o1 = sigmoid(sum_o1) y_pred = o1 # — Подсчет частных производных # — Наименование: d_L_d_w1 представляет «частично L / частично w1» d_L_d_ypred = —2 * (y_true — y_pred) # Нейрон o1 d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1) d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1) d_ypred_d_b3 = deriv_sigmoid(sum_o1) d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1) d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1) # Нейрон h1 d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1) d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1) d_h1_d_b1 = deriv_sigmoid(sum_h1) # Нейрон h2 d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2) d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2) d_h2_d_b2 = deriv_sigmoid(sum_h2) # — Обновляем вес и смещения # Нейрон h1 self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1 self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2 self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1 # Нейрон h2 self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3 self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4 self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2 # Нейрон o1 self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5 self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6 self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3 # — Подсчитываем общую потерю в конце каждой фазы if epoch % 10 == 0: y_preds = np.apply_along_axis(self.feedforward, 1, data) loss = mse_loss(all_y_trues, y_preds) print(«Epoch %d loss: %.3f» % (epoch, loss)) # Определение набора данных data = np.array([ [—2, —1], # Alice [25, 6], # Bob [17, 4], # Charlie [—15, —6], # Diana ]) all_y_trues = np.array([ 1, # Alice 0, # Bob 0, # Charlie 1, # Diana ]) # Тренируем нашу нейронную сеть! network = OurNeuralNetwork() network.train(data, all_y_trues) |
Вы можете поэкспериментировать с этим кодом самостоятельно. Он также доступен на Github.
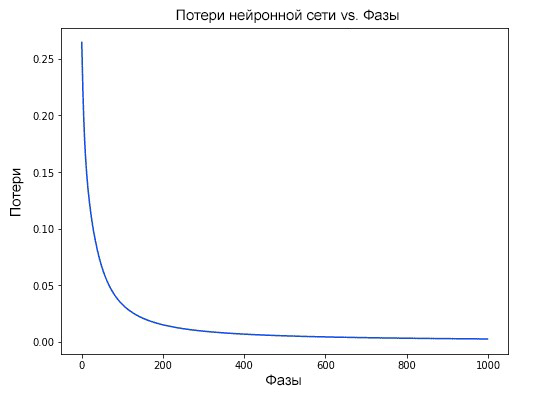
Наши потери постоянно уменьшаются по мере того, как учится нейронная сеть:
Теперь мы можем использовать нейронную сеть для предсказания полов:
|
# Делаем предсказания emily = np.array([—7, —3]) # 128 фунтов, 63 дюйма frank = np.array([20, 2]) # 155 фунтов, 68 дюймов print(«Emily: %.3f» % network.feedforward(emily)) # 0.951 — F print(«Frank: %.3f» % network.feedforward(frank)) # 0.039 — M |
Что теперь?
У вас все получилось. Вспомним, как мы это делали:
- Узнали, что такое нейроны, как создать блоки нейронных сетей;
- Использовали функцию активации сигмоида в отношении нейронов;
- Увидели, что по сути нейронные сети — это просто набор нейронов, связанных между собой;
- Создали набор данных с параметрами вес и рост в качестве входных данных (или функций), а также использовали пол в качестве вывода (или маркера);
- Узнали о функциях потерь и среднеквадратичной ошибке (MSE);
- Узнали, что тренировка нейронной сети — это минимизация ее потерь;
- Использовали обратное распространение для вычисления частных производных;
- Использовали стохастический градиентный спуск (SGD) для тренировки нейронной сети.
Подробнее о построении нейронной сети прямого распросранения Feedforward можно ознакомиться в одной из предыдущих публикаций.
Спасибо за внимание!

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
С помощью статьи PhD Оксфордского университета и автора книг о глубоком обучении Эндрю Траска показываем, как написать простую нейронную сеть на Python. Она умещается всего в девять строчек кода и выглядит вот так:
from numpy import exp, array, random, dot
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
random.seed(1)
synaptic_weights = 2 * random.random((3, 1)) — 1
for iteration in xrange(10000):
output = 1 / (1 + exp(-(dot(training_set_inputs, synaptic_weights))))
synaptic_weights += dot(training_set_inputs.T, (training_set_outputs — output) * output * (1 — output))
print 1 / (1 + exp(-(dot(array([1, 0, 0]), synaptic_weights))))
Чуть ниже объясним как получается этот код и какой дополнительный код нужен к нему, чтобы нейросеть работала. Но сначала небольшое отступление о нейросетях и их устройстве.
Человеческий мозг состоит из ста миллиардов клеток, которые называются нейронами. Они соединены между собой синапсами. Если через синапсы к нейрону придет достаточное количество нервных импульсов, этот нейрон сработает и передаст нервный импульс дальше. Этот процесс лежит в основе нашего мышления.

Мы можем смоделировать это явление, создав нейронную сеть с помощью компьютера. Нам не нужно воссоздавать все сложные биологические процессы, которые происходят в человеческом мозге на молекулярном уровне, нам достаточно знать, что происходит на более высоких уровнях.
Для этого мы используем математический инструмент — матрицы, которые представляют собой таблицы чисел. Чтобы сделать все как можно проще, мы смоделируем только один нейрон, к которому поступает входная информация из трех источников и есть только один выход (рис. 1). Наша задача — научить нейронную сеть решать задачу, которая изображена на рисунке ниже. Первые четыре примера будут нашим тренировочным набором. Получилось ли у вас увидеть закономерность? Что должно быть на месте вопросительного знака — 0 или 1?

Вы могли заметить, что вывод всегда равен значению левого столбца. Так что ответом будет 1.
Но как научить наш нейрон правильно отвечать на заданный вопрос? Для этого мы зададим каждому входящему сигналу вес, который может быть положительным или отрицательным числом. Если на входе будет сигнал с большим положительным весом или отрицательным весом, то это сильно повлияет на решение нейрона, которое он подаст на выход. Прежде чем мы начнем обучение модели, зададим для каждого примера случайное число в качестве веса. После этого мы можем приняться за тренировочный процесс, который будет выглядеть следующим образом:
- В качестве входных данных мы возьмем примеры из тренировочного набора. Потом мы воспользуемся специальной формулой для расчета выхода нейрона, которая будет учитывать случайные веса, которые мы задали для каждого примера.
- Далее посчитаем размер ошибки, который вычисляется как разница между числом, которое нейрон подал на выход и желаемым числом из примера.
- В зависимости от того, в какую сторону нейрон ошибся, мы немного отрегулируем вес этого примера.
- Повторим этот процесс 10 000 раз.

В какой-то момент веса достигнут оптимальных значений для тренировочного набора. Если после этого нейрону будет дана новая задача, которая следует такой же закономерности, он должен дать верный ответ.
Итак, что же из себя представляет формула, которая рассчитывает значение выхода нейрона? Для начала мы возьмем взвешенную сумму входных сигналов:
![]()
После этого мы нормализуем это выражение, чтобы результат был между 0 и 1. Для этого, в этом примере, я использую математическую функцию, которая называется сигмоидой:
![]()
Если мы нарисуем график этой функции, то он будет выглядеть как кривая в форме буквы S (рис. 4).

Подставив первое уравнения во второе, мы получим итоговую формулу выхода нейрона.
![]()
Вы можете заметить, что для простоты мы не задаем никаких ограничений на входящие данные, предполагая, что входящий сигнал всегда достаточен для того, чтобы наш нейрон подал сигнал на выход.
Во время тренировочного цикла (он изображен на рисунке 3) мы постоянно корректируем веса. Но на сколько? Для того, чтобы вычислить это, мы воспользуемся следующей формулой:
![]()
Давайте поймем почему формула имеет такой вид. Сначала нам нужно учесть то, что мы хотим скорректировать вес пропорционально размеру ошибки. Далее ошибка умножается на значение, поданное на вход нейрона, что, в нашем случае, 0 или 1. Если на вход был подан 0, то вес не корректируется. И в конце выражение умножается на градиент сигмоиды. Разберемся в последнем шаге по порядку:
- Мы использовали сигмоиду для того, чтобы посчитать выход нейрона.
- Если на выходе мы получаем большое положительное или отрицательное число, то это значит, что нейрон был весьма уверен в том или ином решении.
- На рисунке 4 мы можем увидеть, что при больших значениях переменной градиент принимает маленькие значения.
- Если нейрон уверен в том, что заданный вес верен, то мы не хотим сильно корректировать его. Умножение на градиент сигмоиды позволяет добиться такого эффекта.
Градиент сигмоиды может быть найден по следующей формуле:
![]()
Таким образом, подставляя второе уравнение в первое, конечная формула для корректировки весов будет выглядеть следующим образом:
![]()
Существуют и другие формулы, которые позволяют нейрону обучаться быстрее, но преимущество этой формулы в том, что она достаточно проста для понимания.
Хотя мы не будем использовать специальные библиотеки для нейронных сетей, мы импортируем следующие 4 метода из математической библиотеки numpy:
- exp — функция экспоненты
- array — метод создания матриц
- dot — метод перемножения матриц
- random — метод, подающий на выход случайное число
Теперь мы можем, например, представить наш тренировочный набор с использованием array():
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])=
training_set_outputs = array([[0, 1, 1, 0]]).T
Функция .T транспонирует матрицу из горизонтальной в вертикальную. В результате компьютер хранит эти числа таким образом:

Теперь мы готовы к более изящной версии кода. После нее добавим несколько финальных замечаний.
Обратите внимание, что на каждой итерации мы обрабатываем весь тренировочный набор одновременно. Таким образом наши переменные все являются матрицами.
Итак, вот полноценно работающий пример нейронной сети, написанный на Python:
from numpy import exp, array, random, dot
class NeuralNetwork():
def __init__(self):
Задаем порождающий элемент для генератора случайных чисел, чтобы он генерировал одинаковые числа при каждом запуске программы
random.seed(1)
Мы моделируем единственный нейрон с тремя входящими связями и одним выходом. Мы задаем случайные веса в матрице размера 3 x 1, где значения весов варьируются от -1 до 1, а среднее значение равно 0.
self.synaptic_weights = 2 * random.random((3, 1)) — 1
Функция сигмоиды, график которой имеет форму буквы S.
Мы используем эту функцию, чтобы нормализовать взвешенную сумму входных сигналов.
def __sigmoid(self, x):
return 1 / (1 + exp(-x))
Производная от функции сигмоиды. Это градиент ее кривой. Его значение указывает насколько нейронная сеть уверена в правильности существующего веса.
def __sigmoid_derivative(self, x):
return x * (1 — x)
Мы тренируем нейронную сеть методом проб и ошибок, каждый раз корректируя вес синапсов.
def train(self, training_set_inputs, training_set_outputs, number_of_training_iterations):
for iteration in xrange(number_of_training_iterations):
Тренировочный набор передается нейронной сети (одному нейрону в нашем случае).
output = self.think(training_set_inputs)
Вычисляем ошибку (разницу между желаемым выходом и выходом, предсказанным нейроном).
error = training_set_outputs — output
Умножаем ошибку на входной сигнал и на градиент сигмоиды. В результате этого, те веса, в которых нейрон не уверен, будут откорректированы сильнее. Входные сигналы, которые равны нулю, не приводят к изменению веса.
adjustment = dot(training_set_inputs.T, error * self.__sigmoid_derivative(output))
Корректируем веса.
self.synaptic_weights += adjustment
Заставляем наш нейрон подумать.
def think(self, inputs):
Пропускаем входящие данные через нейрон.
return self.__sigmoid(dot(inputs, self.synaptic_weights))
if __name__ == «__main__»:
Инициализируем нейронную сеть, состоящую из одного нейрона.
neural_network = NeuralNetwork()
print «Random starting synaptic weights:
» print neural_network.synaptic_weights
Тренировочный набор для обучения. У нас это 4 примера, состоящих из 3 входящих значений и 1 выходящего значения.
training_set_inputs = array([[0, 0, 1], [1, 1, 1], [1, 0, 1], [0, 1, 1]])
training_set_outputs = array([[0, 1, 1, 0]]).T
Обучаем нейронную сеть на тренировочном наборе, повторяя процесс 10000 раз, каждый раз корректируя веса.
neural_network.train(training_set_inputs, training_set_outputs, 10000)
print «New synaptic weights after training:
» print neural_network.synaptic_weights
Тестируем нейрон на новом примере.
print «Considering new situation [1, 0, 0] -> ?:
» print neural_network.think(array([1, 0, 0]))
Этот код также можно найти на GitHub. Обратите внимание, что если вы используете Python 3, то вам будет нужно заменить команду “xrange” на “range”.
Попробуйте теперь запустить нейронную сеть, используя в терминале эту команду:
python main.py
Результат должен быть таким:
Random starting synaptic weights:
[[-0.16595599]
[ 0.44064899]
[-0.99977125]]
New synaptic weights after training:
[[ 9.67299303]
[-0.2078435 ]
[-4.62963669]]
Considering new situation
[1, 0, 0] -> ?: [ 0.99993704]
Ура, мы построили простую нейронную сеть с помощью Python!
Сначала нейронная сеть задала себе случайные веса, затем обучилась на тренировочном наборе. После этого она предсказала в качестве ответа 0.99993704 для нового примера [1, 0, 0]. Верный ответ был 1, так что это очень близко к правде!
Традиционные компьютерные программы обычно не способны обучаться. И это то, что делает нейронные сети таким поразительным инструментом: они способны учиться, адаптироваться и реагировать на новые обстоятельства. Точно так же, как и человеческий мозг.
Конечно, мы создали модель всего лишь одного нейрона для решения очень простой задачи. Но что если мы соединим миллионы нейронов? Сможем ли мы таким образом однажды воссоздать реальное сознание?
2. Регрессия
Следующий тип задач — это регрессия.
Суть этой задачи — получить на выходе из нейронной сети не класс, а конкретное число, например:
— Определение возраста по фото
— Прогнозирование курса акций
— Оценка стоимости недвижимости
Например, у нас есть данные об объекте недвижимости, такие как: метраж, количество комнат, тип ремонта, развитость инфраструктуры в окрестностях этого объекта, удаленность от метро и т.д.
И нашей задачей является предсказать цену на этот объект, исходя из имеющихся данных. Задачи такого плана — это задачи регрессии, т.к. на выходе мы ожидаем получить стоимость — конкретное число.
3. Прогнозирование временных рядов
Прогнозирование временных рядов — это задача, во многом схожая с регрессией.
Суть её заключается в том, что у нас есть динамический временной ряд значений, и нам нужно понять, какие значения будут идти в нем дальше.
Например, это задачи по предсказанию:
— Курсов акций, нефти, золота, биткойна
— Изменению процессов в котлах (давление, концентрация тех или иных веществ и т.д.)
— Количества трафика на сайте
— Объемов потребления электроэнергии и т.д.
Даже автопилот Tesla отчасти тоже можно отнести к задаче этого типа, ведь видеоряд следует рассматривать как временной ряд из картинок.
Возвращаясь же к примеру с оценкой процессов, происходящих в котлах, задача, по сути, является двойной.
С одной стороны, мы предсказываем временной ряд давления и концентрации тех или иных веществ, а с другой — распознаем по этому временному ряду паттерны, чтобы оценить, критичная ситуация, или нет. И здесь уже идет распознавание образов.
Именно поэтому мы сразу отметили тот факт, что не всегда есть четкая граница между разными типами задач.
4. Кластеризация
Кластеризация — это обучение, когда нет учителя.
В этой ситуации у нас есть много данных и неизвестно, какие из них к какому классу относятся, при этом есть предположение, что там есть некоторое количество классов.
Например, это:
— Выявление классов читателей при email-рассылках
— Выявление классов изображений
Типичная маркетинговая задача — эффективно вести email-рассылку. Допустим, у нас есть миллион email-адресов, и мы ведем некую рассылку.
Разумеется, люди ведут себя совершенно по-разному: кто-то открывает почти все письма, кто-то не открывает почти ничего.
Кто-то постоянно кликает по ссылкам в письмах, а кто-то просто их читает и кликает крайне редко.
Кто-то открывает письма по вечерам в выходные, а кто-то — утром в будние, и так далее.
Задача кластеризации в этом случае — это анализ всего объема данных и выделение нескольких классов подписчиков, обладающих сходными поведенческими паттернами (в рамках, каждого класса, разумеется).
Другая задача этого типа — это, например, выявление классов для изображений. Один из проектов в нашей Лаборатории — это работа с фентези-картинками.
Если передать эти изображения нейронной сети, то, после их анализа, она, к примеру «скажет» нам, что обнаружила 17 различных классов.
Допустим, один класс — это изображение с замками. Другой — это картинки с изображением человека по центру. Третий класс — это когда на картинке дракон, четвертый — это много персонажей на фоне природного ландшафта, происходит какая-нибудь битва, и т.д.
Это примеры типичных задач кластеризации.
5. Генерация
Генеративные сети (GAN) — это самый новый, недавно появившийся тип сетей, который стремительно развивается.
Если говорить кратко, то их задача – машинное творчество. Под машинным творчеством подразумевается генерация любого контента:
— Текстов (стихи, тексты песен, рассказы)
— Изображений (в том числе фотореалистичных)
— Аудио (генерация голоса, музыкальных произведений) и т.д.
Кроме того, в этот список можно добавить и задачи трансформации контента:
— раскрашивание черно-белых фильмов в цветные
— изменение сезона в видеоролике (например, трансформация окружающей среды из зимы в лето) и др.
В случае с «переделкой» сезона изменения затрагивают все важные аспекты. Например, есть видео с регистратора, в котором машина зимой едет по улицам города, вокруг лежит снег, деревья стоят голые, люди в шапках и т.д.
Параллельно с этим роликом идет другой, переделанный в лето. Там уже вместо снега зеленые газоны, деревья с листвой, люди легко одеты и т.д.
Безусловно, есть и некоторые другие типы задач, которые решают нейронные сети, но все основные мы с вами рассмотрели.
1. Самообучение
Косвенно мы уже касались этой момента выше, поэтом сейчас раскроем его чуть больше.
Суть самообучения заключается в том, что мы задаем общий алгоритм, как она будет обучаться, а дальше она сама «понимает», как некое явление или процесс устроены изнутри.
Суть самообучения заключается в том, что нейронной сети для успешной работы нужно дать правильные, подготовленные данные и прописать алгоритм, по которому она будет обучаться.
В качестве иллюстрации для этой особенности можно привести генетический алгоритм, суть которого мы рассмотрим на примере программы с летающими по экрану монитора смайликами.
Одновременно перемещалось 50 смайликов, и они могли замедляться / ускоряться и менять направление своего движения.
В алгоритме мы заложили, что если они вылетают за край экрана или попадают под клик мыши, то «умирают».
После «смерти» тут же создавался новый смайлик, причем на основании того, кто «прожил» дольше всего.
Это была вероятностная функция, которая отдавала приоритет «рождения» новых смайликов тем, кто прожил дольше всех и минимизировала вероятность появления «потомства» у тех, кто быстро улетел за пределы экрана или попался под клик мыши.
Сразу после запуска программы все смайлики начинают летать хаотично и быстро «умирают», улетая за края экрана.
Проходит буквально 1 минута, и они научаются не «умирать», улетая за правый край экрана, но улетают вниз. Еще через минуту они перестают улетать вниз. Через 5 минут они уже вообще не умирают.
Смайлики разбились на несколько групп: кто-то летал вдоль периметра экрана, кто-то топтался в центре, кто-то нарезал восьмерки, и т.д. При этом мышкой мы их еще не кликали.
Теперь мы начали кликать по ним мышкой и, естественно, они тут же умирали, потом что еще не обучались избегать курсора.
Через 5 минут было невозможно поймать ни одного из них. Как только к ним приближался курсор, смайлики делали какой-нибудь кульбит и уходили от клика — поймать их было невозможно.
Самое важное и восхитительное во всем это то, что мы не закладывали в них алгоритм, как не улетать за края экрана и уворачиваться от мышки. И если первый момент реализовать несложно, то со вторым все на порядок сложнее.
Можно было бы потратить примерно неделю времени и создать нечто подобное, но прелесть в том, что мы добились такого же или даже лучшего результата, потратив на программирование пару часов и еще несколько минут на то, чтобы произошло обучение.
Вдобавок к этому, поменяв пару строчек кода, мы могли бы довнести в их алгоритм обучения любую другую функцию. Например, если это происходит на фоне рабочего стола — не залезать на иконки, которые на нем есть.
Или мы хотим, чтобы они не сталкивались друг с другом. Или мы хотим поделить их на 2 группы, раскрашенных в разные цвета и хотим, чтобы они не сталкивались со смайликами другого цвета. И так далее.
И они обучились бы этому за те же самые 5-10 минут по тем же принципам генетических алгоритмов.
Надеюсь, что этот пример показал вам потрясающую силу всего, что связано с искусственным интеллектом и нейронными сетями.
При всем при этом важно иметь компетенцию писать такие генетические алгоритмы и уметь подавать такой сети правильные входные данные.
Так, в рассмотренном выше примере сначала никак не удавалось добиться сколь-нибудь значимого прогресса в обучении смайликов по той причине, что в качестве входных данных им подавалось расстояние до краев экрана и расстояние до курсора мыши.
В результате этого нейронной сети не хватало мощности обучиться на таком типе данных, и прогресса практически не было.
После этого в качестве входных параметров стали передаваться другие значения — единица, деленная на расстояние до края экрана и единица, деленная на расстояние до курсора.
Результат — прекрасное обучение, о котором мы только что говорили. Почему? Потому что когда они подлетали к краю экрана, этот параметр начинал зашкаливать, его изменение происходило очень быстро, и в этой комбинации нейронная сеть смогла выявить важную закономерность и обучиться.
На этом с самообучением всё, двигаемся дальше.
2. Требуется обучающая выборка
Нейронным сетям для обучения требуется обучающая выборка. Это главный минус, т.к. обычно нужно собрать много данных.
К примеру, если мы пишем распознавание лиц в классическом машинном обучении, то нам не нужна база из фотографий – достаточно нескольких фото, по которым человек сам составит алгоритм определения лица, или даже сделает это по памяти, вообще без фото.
В случае с нейронными сетями ситуация иная – нужна большая база того, на чем мы хотим обучить нейронную сеть. При этом важно не только собрать базу, но и определенным образом её предобработать.
Поэтому очень часто сбор базы производится в том числе фрилансерами или крупными бизнесами (классический пример — сбор данных компанией Google для того, чтобы показывать нам капчи).
На своем курсе мы делаем на это упор — в том числе в Лабораториях и во время подготовки дипломных работ. Важно научиться собирать эти данные руками, получив ценный опыт, поняв, как это делается правильно, и на что нужно обратить внимание.
Если вы освоите это сами, то в будущем сможете писать в том числе и правильные ТЗ для подрядчиков, получая качественные, нужные вам результаты.
3. Не требуется понимания явления человеком
Третий пункт — это огромный плюс нейронных сетей.
Можно не быть экспертом в какой-либо предметной области, но, будучи экспертом в нейронных сетях решить практически любую задачу.
Да, экспертность, безусловно влияет в плюс, т.к. мы можем лучше предобработать данные и, возможно, быстрее решить задачу, но в целом это не является критическим фактором.
Если в классическом машинном обучении не являясь экспертом в предметной области (например, атомная энергетика, машиностроение, геологические процессы и т.п.) мы вообще не сможем решить задачу, то здесь это вполне реально.
4. Значительно точнее в большинстве задач
Следующее значимое преимущество нейронных сетей — их высокая точность.
Например, аварийность автопилотов Tesla на пробег в 1 млн. км. примерно в 10 раз ниже, чем аварийность обычного водителя.
Точность предсказания медицинских диагнозов по МРТ также выше, чем у специалистов-врачей.
Нейронные сети обыгрывают людей практически в любые игры: шахматы, покер, го, компьютерные игры и т.д.
Одним словом, их точность значительно выше практически во всех задачах, что и привело к их все более и более активному использованию в самых разных сферах жизни человека, начиная с маркетинга и финансов, и заканчивая медициной, промышленностью и искусством.
5. Непонятно, как работают внутри
Однако, при всех этих возможностях у нейронных сетей есть следующий минус — непонятно, как они работают «внутри».
Мы не можем туда влезть и понять, как там все устроено, как она «мыслит». Это все скрыто в весах, в цифрах.
Более или менее «увидеть» то, что происходит внутри возможно, разве что, в сверточных сетях при работе с изображениями, но даже это не позволяет нам получить полной картины.
Типичный пример того, что нейронная сеть в чем-то похожа на черный ящик — это ситуации, когда, например идет судебный процесс, в ходе которого какие-нибудь компании обращаются в Яндекс и спрашивают, почему именно этот сайт, а не какой-то другой выводится именно на этот позиции в выдаче.
И Яндекс не может ответить на подобные вопросы, т.к. это решение принимается нейронной сетью, а не чётко прописанным алгоритмом, который можно полностью объяснить.
Ответить на такой вопрос — задача столь же нетривиальная, как, например, предсказать точную траекторию, по которой именно с этого стола скатится именно этот металлический шарик, положенный именно в это конкретное место.
Да, законы гравитации нам известны, однако предсказать в точности, как именно будет происходить его движение, практически невозможно.
То же самое с нейронной сетью. Принципы её работы ясны, однако понять, как она сработает в каждом конкретном случае не представляется возможным.
Строение биологического нейрона
Для того, чтобы понять, как устроен искусственный нейрон, начнем с того, что вспомним, как функционирует обычная нервная клетка.
Именно её строение и функционирование Уоррен Мак-Каллок (американский нейропсихолог, нейрофизиолог, теоретик искусственных нейронных сетей и один из основателей кибернетики) и Уолтер Питтс (американский нейролингвист, логик и математик) взяли как основу для модели искусственного нейрона еще в середине прошлого века.
Итак, как выглядит нейрон?
У нейрона есть тело, которое накапливает и некоторым образом преобразует сигнал, приходящий к нему через дендриты – короткие отростки, функция которых заключается в приеме сигналов от других нервных клеток.
Накопив сигнал, нейрон передает его по цепочке дальше, другим нейронам, но уже по длинному отростку – аксону, который, в свою очередь, связан с дендритами других нейронов, и так далее.
Конечно, это крайне примитивная модель, т.к. каждый нейрон в нашем мозге может быть связан с тысячами других нейронов.
Следующий момент, на который нам нужно обратить внимание — это то, каким образом сигнал передается от аксона к дендритам следующего нейрона.
Дендриты с аксонами связаны не напрямую, а через так называемые синапсы, и когда сигнал доходит до конца аксона, в синапсе происходит выброс нейромедиатора, определяющего, как именно сигнал будет передан дальше.
Нейромедиаторы — биологически активные химические вещества, посредством которых осуществляется передача электрохимического импульса от нервной клетки через синаптическое пространство между нейронами, а также, например, от нейронов к мышечной ткани или железистым клеткам.
Иными словами, нейромедиатор является неким мостиком между аксоном и множеством дендритов принимающей сигнал клетки.
Если нейромедиатора выбросится много, то сигнал передастся полностью или даже будет усилен. Если же его выбросится мало, то сигнал будет ослаблен, либо вовсе погашен и не передастся другим нейронам.
Таким образом, процесс формирования устойчивых нейронных дорожек (уникальных цепочек связей между нейронами), являющихся биологической основой процесса обучения, зависит от того, сколько будет выброшено нейромедиатора.
Все наше обучение с самого детства построено именно на этом и образование совсем новых связей происходит достаточно редко.
В основном, все наше обучение и освоение новых навыков связано с настройкой того, сколько выбрасывается нейромедиатора в местах контакта аксонов и дендритов.
Например, у нас в нервной системе может быть установлена связь между понятиями «яблоко» и «груша». Т.е. как только мы видим яблоко, слышим слово «яблоко» или просто думаем о нем, в нашем мозгу по механизму ассоциации возникает образ груши, т.к. между этими понятиями у нас установлена связь — сформирована нейронная дорожка.
При этом между понятиями «яблоко» и подушка такой связи, скорее всего нет, поэтому образ яблока не вызывает у нас ассоциаций с подушкой — соответствующая нейронная связь очень слаба или отсутствует.
Интересный момент, о котором также стоит упомянуть, заключается в том, что у насекомых аксон и дендрит связаны напрямую, без выделения нейромедиатора, поэтому у них не происходит обучения в том виде, как оно происходит у животных и человека.
В течение жизни они не обучаются. Они рождаются уже умея всё, что они будут уметь в течение жизни.
Например, каждая конкретная муха не способна научиться облетать стекла — она всегда будет в них биться, что мы с вами постоянно и наблюдаем.
Все нейронные связи у них уже существуют, а сила передачи каждого сигнала уже отрегулирована определенным образом для всех имеющихся связей.
С одной стороны, такая негибкость в плане обучения имеет свои минусы.
С другой стороны, у насекомых, как правило, очень высокая скорость реакции именно за счет другой организации нервных связей, за счет отсутствия веществ-медиаторов, которые, будучи своеобразными посредниками, естественным образом замедляют процесс передачи сигналов.
При всем при этом обучение у насекомых все же может происходить, но только эволюционно — от поколения к поколению.
Допустим, если способность облетать стекла станет важных фактором, способствующим выживанию вида как такового, то за некоторое количество поколений все мухи в мире научатся их облетать.
Пока этого не могло произойти, т.к. сами стекла существую относительно недавно, а для эволюционного обучения могут потребоваться десятки тысяч лет.
Если же это не играет важной роли для сохранения вида, то данная модель поведения так и не будет ими приобретена.
Обычно при работе математическими нейронами используются следующие обозначения:
X – входные данные
W – веса
H – тело нейрона
Y – выход нейронной сети
Входные данные — это сигналы, поступающие к нейрону.
Веса – это эквиваленты синаптической связи и выброса нейромедиатора, представленные в виде чисел, в том числе отрицательных.
Вес представлен действительным числом, на которое будет умножено значение входящего в нейрон сигнала.
Иными словами, вес показывает, насколько сильно между собой связаны те или иные нейроны — это коэффициент связи между ними.
В теле нейрона накапливается взвешенная сумма от перемножения значений входящих сигналов и весов.
Если говорить кратко, то процесс обучения нейронной сети — это процесс изменения весов, т.е. коэффициентов связи между имеющимися в ней нейронами.
В процессе обучения веса меняются, и, если вес положительный, то идет усиление сигнала в нейроне, к которому он приходит.
Если вес нулевой, то влияние одного нейрона на другой отсутствует. Если же вес отрицательный, то идет погашение сигнала в принимающего нейроне.
И, наконец, выход нейронной сети — это то, что мы получаем в результате обработки нейроном поданного на него сигнала. Это некая функция от накопившейся в теле нейрона взвешенной суммы.
Эти функции бывают разные, например, если мы имеем дело с функцией Хевисайда, то если в теле нейрона накопилась сумма больше определенного порога, то на выходе будет единица. Если же меньше порога — ноль.
На выходе из нейрона возможны разные значения, однако чаще всего их стараются приводить к диапазону от -1 до 1 или, что бывает еще чаще — от 0 до 1.
Еще один пример — это функция ReLU (на иллюстрации не представлена), которая работает иначе: если значение взвешенной суммы в теле нейрона отрицательно, то идет преобразование в 0, а если положительно, то в X.
Так, если значение на нейроне было -100 то после обработки функцией ReLU оно станет равным 0. Если же это значение равно, например, 15,7, то на выходе будут те же 15,7.
Также для обработки сигнала с тела нейрона применяются сигмоидальные функции (логистическая и гиперболический тангенс) и некоторые другие. Обычно они используются для «сглаживания» значений некоторой величины.
К счастью, для написания кода необязательно понимать различные формулы и графики этих функций, т.к. они уже заложены в библиотеках, используемых для работы с нейронными сетями.
Простейший пример классификации 2 объектов
Теперь, когда мы разобрались с общим принципом работы, давайте посмотрим на простейший пример, иллюстрирующий процесс классификации 2 объектов с помощью нейронной сети.
Представим, что нам нужно отличить входной вектор (1,0) от вектора (0,1). Допустим, черное от белого, или белое от черного.
При этом, в нашем распоряжении есть простейшая сеть из 2 нейронов.
Допустим, что мы зададим верхней связи вес «+1», а нижней – «-1». Теперь, если мы подадим на вход вектор (1,0), то на выходе мы получим 1.
Если же мы подадим на вход вектор (0,1), то на выходе получим уже -1.
Для упрощения примера будем считать, что у нас здесь используется тождественная активационная функция, при которой f(x) равно самому x, т.е. функция никак не преобразует аргумент.
Таким образом, наша нейронная сеть может классифицировать 2 разных объекта. Это совсем-совсем примитивный пример.
Обратите внимание на то, что в данном примере мы сами назначаем веса «+1» и «-1», что не совсем неправильно. В действительности они подбираются автоматически в процессе обучения сети.
Обучение нейронной сети – это подбор весов.
Любая нейронная сеть состоит из 2 составляющих:
- Архитектура
- Веса
Архитектура — это её структура и то, как она устроена изнутри (об этом мы поговорим чуть позже).
И когда мы подаем на вход нейронной сети данные, нам нужно её обучить, т.е. подобрать веса между нейронами так, чтобы она действительно выполняла то, что мы от неё ожидаем, допустим, умела отличать фото кошек от фото собак.
На самом деле, обучением нейронной сети можно назвать также и подбор архитектуры в процессе исследования.
Так, например, если мы работаем с генетическими алгоритмами, то в процессе обучения нейронная сеть может менять не только веса, но еще и свою структуру.
Но это скорее исключение, чем правило, поэтому в общем случае под обучением нейронной сети мы будем понимать именно процесс подбора весов.
1. С учителем
Обучение с учителем — это одна из самых частых задач. В этом случае у нас есть выборка, и мы знаем по ней правильные ответы.
Мы точно заранее знаем, что на этих 10 тыс. фото — собаки, а на этих 10 тыс. фото — кошки.
Или мы точно знаем курс каких-нибудь акций на протяжении длительного времени.
Допустим, 5 дней до этого дня были такие цены, а на следующий день цена стала такой-то. Затем смещаемся на день вперед, и мы снова знаем: 5 дней цены были такие, а на следующий день цена стала такой-то, и так далее.
Или мы знаем характеристики домов и их реальные цены, если мы говорим про прогнозирование цен на недвижимость.
Все это — примеры обучения с учителем.
2. Без учителя
Второй тип обучения — это обучение без учителя (кластеризация).
В этом случае мы подаем на вход сети некие данные и предполагаем, что в них можно выделить несколько классов.
Пример: у нас есть большая база email-адресов людей, с которыми мы взаимодействуем.
Они открывают наши письма, читают их, переходят или не переходят по ссылкам. Они делают это в то или иное время суток и т.д.
Обладая этой информацией (например, благодаря статистике почтового рассыльщика), мы можем передать нейронной сети эти данные с «просьбой» выделить несколько классов читателей, которые по тем или иным критериям будут схожи между собой.
Используя эти данные, мы смогли бы выстраивать более эффективную маркетинговую стратегию взаимодействия с каждой из таких групп людей.
Обучение без учителя используется в тех случаях, когда требуется обнаружить внутренние взаимосвязи, зависимости и закономерности, существующие между объектами, но заранее мы не знаем, в чем именно заключаются эти закономерности.
3. С подкреплением
Третий тип обучения — это обучение с подкреплением. Оно немного похоже на обучение с учителем, когда есть готовая база верных ответов. Отличие заключается в том, что в этом случае у нейронной сети нет всей базы сразу, а дополнительные данные приходят в процессе обучения и дают сети обратную связь о том, достигнута цель или нет.
Простой пример: бот проходит некий лабиринт и на 59 шаге получает информацию о том, что он «упал в яму» или после 100 шагов, выделенных на выход из лабиринта, он узнает, что «не дошел до выхода».
Таким образом нейронная сеть понимает, что последовательность её действий не привела к нужному результату и обучается, корректируя свои действия.
Т.е. заранее сеть не знает, что верно, а что – нет, но получает обратную связь, когда происходит некое событие. По этому принципу строятся практически все игры, а также различные агенты и боты.
Кстати, пример с умирающими смайликами, который мы рассматривали выше — это также обучение с подкреплением.
Кроме того, это автопилоты, подбор стиля под пожелания конкретного человека, исходя из его предыдущих выборов и т.д.
Например, нейронная сеть генерирует 20 картинок и человек выбирает из них 3, которые ему больше всего нравятся. Затем нейронная сеть создает еще 20 картинок и человек снова выбирает то, что ему нравится больше всего и т.д.
Таким образом, сеть выявляет предпочтения человека по стилю изображения, цветовой гамме и другим характеристикам, и может создавать изображения под вкусы каждого конкретного человека.
Одной из ключевых задач при создании нейронных сетей является выбор её архитектуры. Он производится разработчиком, исходя из стоящей перед ним задачи и, в общем случае, нейронная сеть обучается только за счет изменения весов.
Исключение – генетические алгоритмы, когда популяция нейронных сетей в процессе обучения самостоятельно пересобирает саму себя и свою архитектуру в том числе.
Однако в подавляющем большинстве случаев в процессе обучения архитектура нейронной сети самопроизвольно не меняется.
Все изменения в нее вносит сам разработчик через добавление или удаление слоев, увеличение или уменьшение количества нейронов на каждом слое и т.д.
Давайте посмотрим на основные архитектуры и начнем с классического примера — полносвязной нейронной сети прямого распространения.
Полносвязная нейронная сеть прямого распространения — это сеть, в которой каждый нейрон связан со всеми остальными нейронами, находящимися в соседних слоях, и в которой все связи направлены строго от входных нейронов к выходным.
Слева на рисунке мы видим входной слой, на который приходит сигнал. Правее находятся два скрытых слоя, и самый правый слой из двух нейронов – выходной слой.
Эта сеть может решить задачу классификации, если нам нужно выделить два любых класса – допустим, кошек и собак.
Например, верхний из этих двух нейронов отвечает за класс «собаки» и может иметь значения 0 или 1. Нижний – за класс «кошки», и имеет возможность принимать те же самые значения – 0 или 1.
Другой вариант — она может, к примеру, прогнозировать 2 параметра — давление и температуру в котле на основании 3 неких входных данных.
Чтобы лучше понять, как это работает, давайте посмотрим, как такая полносвязная сеть может использоваться, допустим, для прогнозирования погоды.
В этом примере мы подаем на вход температурные данные по трем последним дням, а на выходе хотим получить предсказания на два следующих дня.
Между входным и выходным слоями у нас есть 2 скрытых слоя, в которых нейронная сеть будет обобщать данные.
Например, в первом скрытом слое один нейрон будет отвечать за такое простое понятие, как «температура растет».
Другой нейрон будет отвечать за понятие «температура падает».
Третий – за понятие «температура неизменна».
Четвертый – «температура очень высокая».
Пятый – «температура высокая».
Шестой – «температура нормальная».
Седьмой – «температура низкая».
Восьмой – «совсем низкая».
Девятый – «температура скакнула вниз и вернулась».
И так далее.
Мы, разумеется, называет все это словами, понятными нам, в то время как сеть сама в процессе обучения сделает так, что каждый из нейронов будет за что-то отвечать, чтобы эффективно обобщать данные.
И каждый из нейронов первого скрытого слоя (в т.ч. обведенный на картинке) будет отвечать за выделение определенного признака в поступивших данных.
Например, если он отвечает за понятие «температура растет», то нейрон с температурой +17 со входного слоя будет входить в него с положительным весом.
Нейрон с температурой +15 – с нулевым весом, а нейрон с температурой +12 – с отрицательным весом.
Если этот так, т.е. температура реально росла и подавались такие данные, обведенный на рисунке нейрон будет активироваться. Если же температура падала, он останется неактивированным.
Нейроны второго скрытого слоя (например, обведенный на картинке ниже), будут отвечать за более высокоуровневые признаки, например, за то, что это осень. Или за то, что это любое другое время года.
На активацию данного нейрона будет положительно влиять падение температуры, свойственное осени.
Если наблюдается постепенный рост температуры, то, скорее всего, это статистически будет влиять в минус, т.е. не будет активировать данный нейрон.
Понятно, что бывают ситуации, когда осенью температура растет, но, скорее всего, статистически рост температуры в течение 3 дней будет отрицательно влиять на этот нейрон.
То, что температура слишком высокая, точно будет отрицательно влиять на нейрон, отвечающий за осень, т.к. не бывает очень высоких температур в это время года, и так далее.
И, наконец, нейроны 2 скрытого слоя соединяются с двумя выходными нейронами, которые выдают предсказание по температуре.
При этом обратите внимание, что сами мы не задаем, за что будет отвечать каждый из нейронов (это было бы примером классического машинного обучения). Нейронная сеть сама сделает нейроны «ответственными» за те или иные понятия.
Более того, в рамках нейронной сети привычные нам понятия, такие как «весна», «осень», «температура падает» и т.д. не существуют. Мы просто обозначили их так для своего удобства, чтобы нам было понятнее, что примерно происходит внутри во время обучения.
В действительности же нейронная сеть сама в процессе обучения выделит именно те свойства, которые нужны для решения данной конкретной задачи.
Важно понимать, что нейронная сеть именно с такой архитектурой не будет правильно прогнозировать температуру – это упрощенный пример, показывающий, как внутри сети может происходить выделение различных признаков (так называемый процесс feature extraction).
Процесс выделения признаков хорошо иллюстрирует работа свёрточных нейронных сетей.
Допустим, на вход сети мы подаем фото кошек и собак, и сеть начинает их анализировать.
На первых слоях сеть определяет наиболее общие признаки: линия, круг, темное пятно, угол, близкий к прямому, яркое пятно на фоне темного и т.д.
На следующем слое сеть сможет извлечь уже иные признаки: ухо, лапа, голова, нос, хвост и т.д.
Еще дальше, на следующем слое будет идет анализ уже такого плана:
— здесь хвост загнут вверх, это коррелирует с лайкой, значит собака;
— а тут короткие лапы, а у кошек нет коротких лап, поэтому, скорее всего, собака, такса;
— а вот здесь треугольное ухо с белым кончиком, похоже на такую-то породу кошки, и т.д.
Примерно таким образом происходит процесс feature extraction.
Безусловно, чем больше нейронов в сети, тем более детальные, специфические свойства она может выделить.
Если же нейронов немного, она сможет работать только «крупными мазками», т.к. у нее не хватит мощности проанализировать все возможные комбинации признаков.
Таким образом, общий принцип выделения свойств — это все большее обобщение при переходе с одного слоя на другой, от низкого уровня ко все более высокому.
Итак, давайте снова вспомним, что из себя представляет нейронная сеть.
Во-первых, это архитектура.
Она задается разработчиком, т.е. мы сами определяем, сколько у сети слоев, как они связаны, сколько нейронов на каждом слое, есть ли у этой сети память (об этом чуть позже), какие у нее активационные функции и т.д.
Архитектуру сети можно представить, например, как обычный JSON, YAML или XML-файл (текстовые файлы, в которых можно полностью отразить её структуру).
Во-вторых, это обученные веса.
Веса нейронной сети хранятся в совокупности матриц в виде действительных чисел, количество которых (чисел) равно общему количеству связей между нейронами в самой сети.
Количество самих матриц зависит от количества слоев и того, как нейроны разных слоев связаны друг с другом.
Веса задаются в начале обучения (обычно случайным образом) и подбираются в процессе обучения.
Таким образом, сеть можно легко сохранить через сохранение её архитектуры и весов, а в дальнейшем снова использовать её, обратившись к файлам с архитектурой и весами.
Обучение полносвязной сети методом обратного распространения ошибки (градиентного спуска)
Как же обучается полносвязная нейронная сеть прямого распространения? Давайте рассмотрим этот вопрос на примере метода обратного распространения ошибки, являющегося модификацией метода классического градиентного спуска.
Это метод обновления весов нейронной сети, при котором распространение сигналов ошибки происходит от выходов сети к её входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы.
Сразу отметим, что это не самый продвинутый алгоритм, и при работе с библиотекой Keras мы будем использовать более эффективные решения.
Также важно понимать, что в других типах сетей обучение происходит по другим алгоритмам, однако сейчас нам важно понять общий принцип.
Вернемся к примеру про прогнозирование температуры и допустим, что в качестве выходного сигнала у нас есть 2 вещественных числа т.е. значения температуры в градусах по 2 дням.
Таким образом, мы знаем правильные ответы, т.е. какая температура была на самом деле, и знаем те ответы, которые дала нам нейронная сеть.
В качестве способа измерения величины ошибки при обучении сети мы будем использовать так называемую функцию среднеквадратичной ошибки.
Например, в первый день сеть предсказала нам 10 градусов, а реально было 12. Про второй день она сказала, что будет 11 градусов, и реально также было 11.
Среднеквадратичная ошибка в этом случае составит сумму квадратов разностей предсказанной и реальной температур: ((10-12)² + (11-11)²)/2 = 2.
В процессе обучения нейронной сети алгоритмы (в т.ч. Back Propagation – алгоритм обратного распространения ошибки) ориентированы на то, чтобы менять веса так, чтобы уменьшать эту среднеквадратичную ошибку.
Если она будет равна нулю, это значит, что нейронная сеть гарантированно точно распознает, например, все образы в обучающей выборке.
Понятно, что на практике в ноль она никогда не сходится, но близко к нулю — вполне возможно, и точность в этом случае будет очень высокая.
Метод градиентного спуска
Представим теперь, что у нас есть некоторая поверхность ошибки. Допустим, у нас есть нейронная сеть, в которой 2 веса, и мы можем эти веса менять.
Понятно, что разным значениям этих весов будет соответствовать разная ошибка нейронной сети.
Таким образом, взяв эти значения, мы можем создать двухмерную поверхность, на которой видны соотношения значений весов W₁ и W₂ и значений ошибок X₀-X₄ (см. иллюстрацию).
Теперь представим, что у нас в нейронной сети не два, а тысяча весов, и разные комбинации этих тысяч весов соответствуют разным ошибкам при одной и той же обучающей выборке. В этом случае у нас получается уже тысячемерная поверхность.
Мы можем менять тысячу действительных чисел и каждый раз получать новое значение ошибки.
И эту тысячемерную поверхность можно сравнить с поверхностью измятого одеяла со своими локальными максимумами и минимумами (соответственно максимальными и минимальными значениями функции на заданном множестве). Это и будет называться поверхностью ошибки.
Так вот, обучение нейронной сети – это продвижение по этой тысячемерной поверхности разных весов и получение разных ошибок. И где-то на этой поверхности есть глобальный минимум – такая комбинация этой тысячи весов, при которой ошибка минимальна.
Локальных же минимумов может быть много, и в них значение ошибки достаточно низкое.
Поэтому обучение нейронной сети можно представить как это осмысленное перемещение по этой тысячемерной поверхности с целью добиться минимальной ошибки в некоторой точке.
При этом глобальный минимум, как правило, никто не ищет – он один, а пространство для поиска огромное. Именно поэтому нашей целью обычно являются как раз локальные минимумы. При всем при этом стоит отметить, что заранее мы не можем знать, какой именно минимум мы нашли – один из локальных, либо глобальный.
Но как именно происходит перемещение по поверхности ошибки? Давайте разберемся.
Важный момент заключается в том, что мы можем посчитать производную ошибки по весам. Иными словами, мы можем математически просчитать, как изменится ошибка, если мы чуть-чуть изменим в какую-то сторону веса.
Таким образом, мы можем вычислить, куда нам нужно сместить веса, чтобы ошибка у нас гарантированно уменьшилась при следующем шаге обучения.
Именно таким образом мы пошагово ищем необходимое направление спуска по поверхности ошибки.
Если мы шагнем слишком широко, то можем перескочить локальный минимум и подняться выше по поверхности ошибки, что для нас нежелательно.
Если же шаг будет небольшим, то мы шагнем вниз, ближе к локальному минимуму, затем снова пересчитаем направление движения и снова сделаем небольшой шаг.
Да, продвинутые алгоритмы могут, например, «перелезть через горку» и найти более глубокий локальный минимум и т.д., но в целом алгоритм обучения построен именно так.
Мы работаем с многомерной поверхностью ошибки в рамках наших весов и ищем, куда нам двигаться, чтобы прийти в локальный минимум, по возможности, максимально глубокий.
Такая архитектура позволяет поэтапно выделять разные признаки на разных слоях. Первые слои при этом выделяют самые простые признаки, например:
— справа – белое, слева – черное
— по центру – яркое, по краям – тусклое
— линия под 45 градусов
— и т.д.
На иллюстрации ниже изображена одномерная свёрточная сеть, в которой не все нейроны связаны со всеми, а каждый нейрон последующего слоя «смотрит» на два нейрона предыдущего слоя (за исключением входного слоя слева).
При этом вы можете обратить внимание, что в правой части свёрточная сеть переходит в полносвязную, т.е. идет объединение двух архитектур. Для чего это нужно вы узнаете буквально несколькими предложениями ниже.
Выделение признаков происходит постепенно, слой за слоем, например: линия – овал – лапа, что отражено на трех иллюстрациях ниже.
В генеративной сети у нас две нейронных сети: одна генерирует образы, а вторая пытается отличить эти образы от некоторых эталонных.
Например, одна сеть-детектор смотрит на фентези-картинки, а другая пытается создавать новые картинки и говорит: «А попробуй отличить фентези-картинки от моих».
Сначала она генерирует картинки, которые сеть-детектор легко отличает, потому что они не очень похожи на фентези-картинки.
Но потом та сеть, которая создает картинки, обучается все больше, и сеть-детектор уже едва может отличить фентези-картинки, которые мы подали ей на вход сами от тех, что сгенерировала вторая сеть.
И сейчас, когда мы рассмотрели основные архитектуры, давайте вспомним типы задач, которые решаются нейронными сетями и сопоставим их с архитектурами, которые для подходят для их решения.
1. Распознавание образов производится средствами полносвязных, свёрточных, рекуррентных сетей.
2. Языковые задачи чаще всего решаются с помощью рекуррентных сетей с памятью, и иногда — с помощью одномерных свёрточных.
3. Обработка аудио и голоса — это полносвязные, одномерные свёрточные, иногда рекуррентные сети.
4. Задачи регрессии и прогнозирования временных рядов решаются с помощью полносвязных и рекуррентных сетей.
5. Наконец, машинное творчество — это генеративные свёрточные и генеративные полносвязные сети.
Таким образом, мы видим, что стандартные архитектуры пересекаются и используются в задачах разного типа.
Мы будем проходить все эти архитектуры: сначала полносвязные, потом свёрточные, рекуррентные и генеративные. После чего уже будем изучать сложные комбинации архитектур.
На этом шаге мы берем какую-нибудь архитектуру исходя из имеющейся задачи и получаем первичные результаты на обучающей и тестовой выборках.
Допустим, у нас задача распознавания кошек и собак. Значит берем сверточную сеть.
Попробуем простую сеть на 5 слоев по 20 нейронов в каждой, а в конце — 2 слоя полносвязной, и обучим.
В результате мы получаем какие-то базовые результаты, некую первичную точность. И уже после этого начинаем думать, как можно её повысить, например:
— создаем различные варианты архитектур (допустим, несколько десятков вариантов) и собираем статистику по ошибке и точности для каждого из вариантов
— пробуем разные активационные функции
— повышаем качество данных (избавление от зашумленных данных)
— и так далее…
В итоге, путем экспериментов и проверки своих предположений мы доводим качество работы сети до желаемого уровня.
И, наконец, наша production-часть обращается к сервису и производит распознавание.
После вывода в production, разумеется, можно продолжить исследования и постепенно улучшать работу сети и подменять её по мере доработки — либо архитектуру, либо веса, либо и то, и другое.
Скажем, вы обучили сеть на относительно небольшом объеме данных, а через некоторое время вам пришло данных в 10 раз больше. Безусловно, стоит переобучить сеть на большем объеме данных и, вполне возможно, повысить качество её работы.
Для этого мы постоянно сравниваем результаты работы нашей сети по точности распознавания на тестовой выборке.
При этом важно постоянно помнить о том, что в области нейронных сетей даже близко нет детерминированных ответов — это всегда исследование и изобретение.
Итак, мы дошли с вами до нашего главного инструмента в создании нейронных сетей — библиотек.
Что такое библиотека? Это набор функций, которые позволяют нам собрать и обучить нейронную сеть без необходимости глубоко понимать математическую базу, лежащую в основе этих процессов.
Совсем недавно библиотек еще не было, но сейчас уже есть достаточно хороший выбор, существенно облегчающий жизнь разработчика и экономящий его время.
Мы не будем останавливаться на каждой библиотеке отдельно — это, скорее, мини-обзор существующих решений, чтобы вы могли в целом в них ориентироваться.
Так, на настоящее время наиболее известными являются следующие библиотеки:
- TensorFlow (Google)
- CNTK (Microsoft)
- Theano (Монреальский институт алгоритмов обучения (MILA))
- Pytorch (Facebook)
- и так далее
- Сама видеокарта (GPU)
- CUDA (программно-аппаратная архитектура параллельных вычислений, которая позволяет существенно увеличить вычислительную производительность благодаря использованию графических процессоров фирмы Nvidia)
- cuDNN (библиотека, содержащая оптимизированные для GPU реализации сверточных и рекуррентных сетей, различных функций активации, алгоритма обратного распространения ошибки и т.п., что позволяет обучать нейронные сети на GPU в несколько раз быстрее, чем просто CUDA)
- TensorFlow, CNTK, Theano (надстройки над cuDNN)
Keras же, в свою очередь, использует в качестве бэкенда TensorFlow и некоторые другие библиотеками, позволяя нам пользоваться уже готовым кодом, написанными именно для создания нейронных сетей.
Еще один важный момент, который нужно отметить — это вопрос о том, как со всем этим работает Python. Многие говорят, что он работает медленно.
Да, это так, но Keras генерирует не код Python, Keras генерирует код С++, и именно он уже используется непосредственно для работы нейронной сети, поэтому все работает быстро.
Наш учебный процесс будет построен именно вокруг Google Colaboratory (демонстрации кода, домашние задания и т.д.), и в целом это очень удобно, однако, если вы хотите, то можете работать и в своей, привычной вам среде.
Запускать Google Colaboratory рекомендуется под Google Chrome, и при первой попытке открыть ноутбук (так называется любой документ в Google Colaboratory) вам будет предложено установить в браузер приложение Colaboratory, чтобы в будущем оно автоматически «подхватывало» файлы такого типа.
Теперь, после установки Colaboratory мы можем перейти уже непосредственно к практической части.
В первой строке мы импортируем предустановленный датасет MNIST с изображениями рукописных цифр, которые мы будем распознавать.
Затем мы подключаем библиотеки Sequential и Dense т.к. работаем с полносвязной сетью прямого распространения.
Наконец, мы импортируем дополнительные библиотеки, позволяющие нам работать с данными (NumPy, Matplotlib и др.).
Сразу обратите внимание на модульную структуру ноутбука, благодаря которой вы можете в любом порядке чередовать блоки кода и текстовые поля.
Для того, чтобы добавить новую ячейку кода, текстовое поле или поменять порядок их следования воспользуйтесь, кнопками CODE, TEXT и CELL прямо под основным меню.
Ну и, наконец, для запуска фрагмента кода нам нужно просто нажать на значок play слева вверху от кода. Он появляется при выделении блока с кодом, либо при наведении мышки на пустые квадратные скобки, если блок не выделен.
Следующим шагом с помощью функции load_data мы подгружаем данные, необходимые для обучения сети, где x_train_org и y_train_org – данные обучающей выборки, а x_test_org и y_test_org – данные тестовой выборки.
Их названий выборок понятно, что обучающую выборку мы используем для того, чтобы обучить сеть, в то время как тестовая используется для того, чтобы проверить, насколько качественно произошло это обучение.
Смысл тестовой выборки в том, чтобы проверить, насколько точно отработает наша сеть с данными, с которыми она не сталкивалась ранее. Именно это является самой важной метрикой оценки сети.
В x_train_org находятся сами изображения цифр, на которых обучается сеть, а y_train_org – правильные ответы, какая именно цифра изображена на том или ином изображении.
Сразу важно отметить, что формат представления правильных ответов на выходе из сети — one hot encoding. Это одномерный массив (вектор), хранящий 10 цифр – 0 или 1. При этом положение единицы в этом векторе и говорит нам о верном ответе.
Например, если цифра на картинке изображен 0, то вектор будет выглядеть как в первой строке на картинке ниже.
Если на изображении цифра 2, то единица в векторе будет стоять в 3 позиции (как в строке 2).
Если же на изображении цифра 9, то единица в векторе будет стоять в последней, десятой позиции.
Это объясняется тем, что нумерация в массивах по умолчанию начинается с нуля.
Изначально на вход сети в обучающей выборке подается 60 тыс. изображений размером 28 на 28 пикселей. В тестовой выборке таких изображений 10 тыс. штук.
Наша задача — привести их к одномерному массиву (вектору), размерность которого будет не 28 на 28, а 1 на 784, что мы и делаем в коде выше.
Следующий наш шаг – это так называемая нормализация данных, их «выравнивание» с целью привести их значения к диапазону от 0 до 1.
Дело в том, что до нормализации изображение каждой рукописной цифры (все они представлены в градациях серого) представлено числами от 0 до 255, где 0 представляет собой чёрный цвет, а 255 — белый).
Однако для эффективной работы сети нам необходимо привести их к другому диапазону, что мы и делаем, разделив каждое значение на 255.
В данном случае количество нейронов (800) уже подобрано эмпирически. При таком количестве нейронная сеть обучается лучше всего (безусловно, на старте своих исследований мы можем пробовать самые разные варианты, постепенно приходя к оптимальному).
В качестве выходного слоя у нас будет полносвязный слой из 10 нейронов – по количеству рукописных цифр, которые мы распознаём.
И наконец, функция softmax будет преобразовывать вектор из 10 значений в другой вектор, в котором каждая координата представлена вещественным числом в интервале [0,1] и сумма этих координат равна 1.
Эта функция применяется в машинном обучении для задач классификации, когда количество классов больше двух, при этом полученные координаты трактуются как вероятности того, что объект принадлежит к определенному классу.
После этого мы компилируем сеть и выходим на экран ее архитектуру.
Сначала мы записываем сеть в файл, затем можем проверить, что он сохранился, после чего сохраняем файл на компьютер с помощью метода download.
Ну что ж, теперь настало время проверить, как наша сеть распознает рукописные цифры, которые она еще не видела. Для этого нам понадобится тестовая выборка, которая, наряду с обучающей, также входит в датасет MNIST.
Для начала выберем произвольную цифру из набора тестовых данных и выведем её на экран:
Теперь, когда мы получили некие первичные результаты, мы можем продолжить процесс исследования, меняя различные параметры нашей нейронной сети.
Например, мы можем поменять количество нейронов во входном слое и уменьшить их количество с 800, например, до 10.
Для того, чтобы запустить сеть обучаться повторно после внесенных изменений с нуля, нам необходимо заново пересобрать модель, запустить код с измененными параметрами сети и снова её скомпилировать (в противном случае сеть будет дообучаться, что требуется далеко не всегда).
Для этого мы просто заново нажимаем на play последовательно во всех трех блоках кода (см. ниже).
В результате этих действий вы увидите, что исходные данные изменились, и сеть теперь имеет 2 слоя по 10 нейронов, вместо 800 и 10, которые были ранее.
Как мы видим, даже при одном нейроне в скрытом слое сеть достигла точности почти в 38%. Понятно, что с таким результатом она едва ли найдет практическое применение, однако мы делаем это просто для понимания того, как могут разниться результаты при изменении архитектуры.
Итак, завершая разбор кода, следует сделать важную оговорку: то, что мы смотрим точность на обучающей выборке – это просто пример для понимания того, как это работает.
В действительности, качество работы сети нужно замерять исключительно на тестовой выборке с данными, с которыми нейронная сеть еще не сталкивалась ранее.
И теперь, когда мы немного поэкспериментировали, давайте подведем небольшой итог и посмотрим, как подойти к проведению экспериментов с нейронными сетями системно, чтобы получать действительно статистически значимые результаты.
Итак, мы берем одну модель сети, и в цикле формируем из имеющихся данных 100 разных обучающих и тестовых выборок в пропорции 80% — обучающая выборка, и 20% — тестовая.
Далее на всех этих данных мы проводим 100 обучений нейронной сети со случайной точки (каждый раз сеть стартует со случайными весами) и получаем некую ошибку на тестовой выборке — среднюю за эти 100 обучений на данной конкретной архитектуре (но с разными комбинациями обучающей и тестовой выборок).
Потом берется другая архитектура и делается то же самое. Таким образом мы можем проверить, например несколько десятков вариантов архитектур по 100 обучений на каждой, в результате чего получим статистически значимые результаты своих экспериментов и сможем выбрать самую точную сеть.
Ну что ж, на этом мы завершаем данный обзор и надеемся, что он помог вам лучше понять как работают нейронные сети, и как можно быстро написать свою первую нейронную сеть на Python.
Что такое машинное обучение и почему это важно?
Машинное обучение — это область искусственного интеллекта, использующая статистические методы, чтобы предоставить компьютерным системам способность «учиться». То есть постепенно улучшать производительность в конкретной задаче, с помощью данных без явного программирования. Хороший пример — то, насколько эффективно (или не очень) Gmail распознает спам или насколько совершеннее стали системы распознавания голоса с приходом Siri, Alex и Google Home.
С помощью машинного обучения решаются следующие задачи:
- Распознавание мошенничества — отслеживание необычных шаблонов в транзакциях кредитных карт или банковских счетов
- Предсказание — предсказание будущей цены акций, курса обмена валюты или криптовалюты
- Распознавание изображений — определение объектов и лиц на картинках
Машинное обучение — огромная область, и сегодня речь пойдет лишь об одной из ее составляющих.
Обучение с учителем
Обучение с учителем — один из видов машинного обучения. Его идея заключается в том, что систему сначала учат понимать прошлые данные, предлагая много примеров конкретной проблемы и желаемый вывод. Затем, когда система «натренирована», ей можно давать новые входные данные для предсказания выводов.
Например, как создать спам-детектор? Один из способов — интуиция. Можно вручную определять правила: например «содержит слово деньги» или «включает фразу Western Union». И пусть иногда такие системы работают, в большинстве случаев все-таки сложно создать или определить шаблоны, опираясь исключительно на интуицию.
С помощью обучения с учителем можно тренировать системы изучать лежащие в основе правила и шаблоны за счет предоставления примеров с большим количеством спама. Когда такой детектор натренирован, ему можно дать новое письмо, чтобы он попытался предсказать, является ли оно спамом.
Обучение с учителем можно использовать для предсказания вывода. Есть два типа проблем, которые решаются с его помощью: регрессия и классификация.
- В регрессионных проблемах мы пытаемся предсказать непрерывный вывод. Например, предсказание цены дома на основе данных о его размере
- В классификационных — предсказываем дискретное число качественных меток. Например, попытка предсказать, является ли письмо спамом на основе количества слов в нем.

Невозможно говорить о машинном обучении с учителем, не затронув модели обучения с учителем. Это как говорить о программировании, не касаясь языков программирования или структур данных. Модели обучения — это те самые структуры, что поддаются тренировке. Их вес (или структура) меняется по мере того, как они формируют понимание того, что нужно предсказывать. Есть несколько видов моделей обучения, например:
- Случайный лес (random forest)
- Наивный байесовский классификатор (naive Bayes)
- Логистическая регрессия (logistic regression)
- Метод k-ближайших соседей (k nearest neighbors)
В этом материале в качестве модели будет использоваться нейронная сеть.
Понимание работы нейронных сетей
Нейронные сети получили такое название, потому что их внутренняя структура должна имитировать человеческий мозг. Последний состоит из нейронов и синапсов, которые их соединяют. В момент стимуляции нейроны «активируют» другие с помощью электричества.
Каждый нейрон «активируется» в первую очередь за счет вычисления взвешенной суммы вводных данных и последующего результата с помощью результирующей функции. Когда нейрон активируется, он в свою очередь активирует остальные, которые выполняют похожие вычисления, вызывая цепную реакцию между всеми нейронами всех слоев.
Стоит отметить, что пусть нейронные сети и вдохновлены биологическими, сравнивать их все-таки нельзя.

- Эта диаграмма иллюстрирует процесс активации, через который проходит каждый нейрон. Рассмотрим схему слева направо.
- Все вводные данные (числовые значения) из входящих нейронов считываются. Они определяются как x1…xn.
- Каждый ввод умножается на взвешенную сумму, ассоциированную с этим соединением. Ассоциированные веса обозначены как W1j…Wnj.
- Все взвешенные вводы суммируются и передаются активирующей функции. Она читает этот ввод и трансформирует его в числовое значение k-ближайших соседей.
- В итоге числовое значение, которое возвращает эта функция, будет вводом для другого нейрона в другом слое.
Слои нейронной сети
Нейроны внутри нейронной сети организованы в слои. Слои — это способ создать структуру, где каждый содержит 1 или большее количество нейронов. В нейронной сети обычно 3 или больше слоев. Также всегда определяются 2 специальных слоя, которые выполняют роль ввода и вывода.
- Слой ввода является точкой входа в нейронную сеть. В рамках программировании его можно воспринимать как аргумент функции.
- Вывод — это результат работы нейронной сети. В терминах программирования это возвращаемое функцией значение.
Слои между ними описываются как «скрытые слои». Именно там происходят все вычисления. Все слои в нейронной сети кодируются как признаковые описания.
Выбор количества скрытых слоев и нейронов
Нет золотого правила, которым стоит руководствоваться при выборе количества слоев и их размера (или числа нейронов). Как правило, стоит попробовать как минимум 1 такой слой и дальше настраивать размер, проверяя, что работает лучше всего.

Использование библиотеки Keras для тренировки простой нейронной сети, которая распознает рукописные цифры
Программистам на Python нет необходимости заново изобретать колесо. Такие библиотеки, как Tensorflow, Torch, Theano и Keras уже определили основные структуры данных для нейронной сети, оставив необходимость лишь декларативно описать структуру нейронной сети.
Keras предоставляет еще и определенную свободу: возможность выбрать количество слоев, число нейронов, тип слоя и функцию активации. На практике элементов довольно много, но в этот раз обойдемся более простыми примерами.
Как уже упоминалось, есть два специальных уровня, которые должны быть определены на основе конкретной проблемы: размер слоя ввода и размер слоя вывода. Все остальные «скрытые слои» используются для изучения сложных нелинейных абстракций задачи.
В этом материале будем использовать Python и библиотеку Keras для предсказания рукописных цифр из базы данных MNIST.
Запуск Jupyter Notebook локально
Если вы еще не работали с Jupyter Notebook, сначало изучите Руководство по Jupyter Notebook для начинающих
Список необходимых библиотек:
- numpy
- matplotlib
- sklearn
- tensorflow
Запуск из интерпретатора Python
Для запуска чистой установки Python (любой версии старше 3.6) установите требуемые модули с помощью pip.
Рекомендую (но не обязательно) запускать код в виртуальной среде.
!pip install matplotlib
!pip install sklearn
!pip install tensorflow
Если эти модули установлены, то теперь можно запускать весь код в проекте.
Импортируем модули и библиотеки:
import numpy as np
import matplotlib.pyplot as plt
import gzip
from typing import List
from sklearn.preprocessing import OneHotEncoder
import tensorflow.keras as keras
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import itertools
%matplotlib inline
База данных MNIST
MNIST — это огромная база данных рукописных цифр, которая используется как бенчмарк и точка знакомства с машинным обучением и системами обработки изображений. Она идеально подходит, чтобы сосредоточиться именно на процессе обучения нейронной сети. MNIST — очень чистая база данных, а это роскошь в мире машинного обучения.
Цель
Натренировать систему, классифицировать каждое соответствующим ярлыком (изображенной цифрой). С помощью набора данных из 60 000 изображений рукописных цифр (представленных в виде изображений 28х28 пикселей, каждый из которых является градацией серого от 0 до 255).
Набор данных
Набор данных состоит из тренировочных и тестовых данных, но для упрощения здесь будет использоваться только тренировочный. Вот так его загрузить:
%%bash
rm -Rf train-images-idx3-ubyte.gz
rm -Rf train-labels-idx1-ubyte.gz
wget -q http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
wget -q http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz

Чтение меток
Есть 10 цифр: (0-9), поэтому каждая метка должна быть цифрой от 0 до 9. Загруженный файл, train-labels-idx1-ubyte.gz, кодирует метки следующим образом:
Файл ярлыка тренировочного набора (train-labels-idx1-ubyte):
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) |
| 0004 | 32 bit integer | 60000 | number of items |
| 0008 | unsigned byte | ?? | label |
| 0009 | unsigned byte | ?? | label |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | label |
Значения меток от 0 до 9.
Первые 8 байт (или первые 2 32-битных целых числа) можно пропустить, потому что они содержат метаданные файлы, необходимые для низкоуровневых языков программирования. Для парсинга файла нужно проделать следующие операции:
- Открыть файл с помощью библиотеки gzip, чтобы его можно было распаковать
- Прочитать весь массив байтов в память
- Пропустить первые 8 байт
- Перебирать каждый байт и приводить его к целому числу
Примечание: если этот файл из непроверенного источника, понадобится куда больше проверок. Но предположим, что этот конкретный является надежным и подходит для целей материала.
with gzip.open('train-labels-idx1-ubyte.gz') as train_labels:
data_from_train_file = train_labels.read()
# Пропускаем первые 8 байт
label_data = data_from_train_file[8:]
assert len(label_data) == 60000
# Конвертируем каждый байт в целое число.
# Это будет число от 0 до 9
labels = [int(label_byte) for label_byte in label_data]
assert min(labels) == 0 and max(labels) == 9
assert len(labels) == 60000
Чтение изображений
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 60000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| 0017 | unsigned byte | ?? | pixel |
| …… | …… | …… | …… |
| xxxx | unsigned byte | ?? | pixel |
Чтение изображений немного отличается от чтения меток. Первые 16 байт содержат уже известные метаданные. Их можно пропустить и переходить сразу к чтению изображений. Каждое из них представлено в виде массива 28*28 из байтов без знака. Все что требуется — читать по одному изображению за раз и сохранять их в массив.
SIZE_OF_ONE_IMAGE = 28 ** 2
images = []
# Перебор тренировочного файла и читение одного изображения за раз
with gzip.open('train-images-idx3-ubyte.gz') as train_images:
train_images.read(4 * 4)
ctr = 0
for _ in range(60000):
image = train_images.read(size=SIZE_OF_ONE_IMAGE)
assert len(image) == SIZE_OF_ONE_IMAGE
# Конвертировать в NumPy
image_np = np.frombuffer(image, dtype='uint8') / 255
images.append(image_np)
images = np.array(images)
images.shape
Вывод: (60000, 784)
В списке 60000 изображений. Каждое из них представлено битовым вектором размером SIZE_OF_ONE_IMAGE. Попробуем построить изображение с помощью библиотеки matplotlib:
def plot_image(pixels: np.array):
plt.imshow(pixels.reshape((28, 28)), cmap='gray')
plt.show()
plot_image(images[25])

Кодирование меток изображения с помощью One-hot encoding
Будем использовать one-hot encoding для превращения целевых меток в вектор.
labels_np = np.array(labels).reshape((-1, 1))
encoder = OneHotEncoder(categories='auto')
labels_np_onehot = encoder.fit_transform(labels_np).toarray()
labels_np_onehot
array([[0., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.]])
Были успешно созданы входные данные и векторный вывод, который будет поступать на входной и выходной слои нейронной сети. Вектор ввода с индексом i будет отвечать вектору вывода с индексом i.
Вводные данные:
labels_np_onehot[999]
Вывод:
array([0., 0., 0., 0., 0., 0., 1., 0., 0., 0.])
Вводные данные:
plot_image(images[999])
Вывод:

В примере выше явно видно, что изображение с индексом 999 представляет цифру 6. Ассоциированный с ним вектор содержит 10 цифр (поскольку имеется 10 меток), а цифра с индексом 6 равно 1. Это значит, что метка правильная.
Разделение датасета на тренировочный и тестовый
Для проверки того, что нейронная сеть была натренирована правильно, берем определенный процент тренировочного набора (60 000 изображений) и используем его в тестовых целях.
Вводные данные:
X_train, X_test, y_train, y_test = train_test_split(images, labels_np_onehot)
print(y_train.shape)
print(y_test.shape)
(45000, 10)
(15000, 10)
Здесь видно, что весь набор из 60 000 изображений бал разбит на два: один с 45 000, а другой с 15 000 изображений.
Тренировка нейронной сети с помощью Keras
model = keras.Sequential()
model.add(keras.layers.Dense(input_shape=(SIZE_OF_ONE_IMAGE,), units=128, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
Вывод:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 128) 100480
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
Для обучения нейронной сети, выполним этот код.
model.fit(X_train, y_train, epochs=20, batch_size=128)
Вывод:
Train on 45000 samples
Epoch 1/20
45000/45000 [==============================] - 2s 54us/sample - loss: 1.3391 - accuracy: 0.6710
Epoch 2/20
45000/45000 [==============================] - 2s 39us/sample - loss: 0.6489 - accuracy: 0.8454
...
Epoch 20/20
45000/45000 [==============================] - 2s 40us/sample - loss: 0.2584 - accuracy: 0.9279
Проверяем точность на тренировочных данных.
model.evaluate(X_test, y_test)
Вывод:
[0.2567395991722743, 0.9264]
Посмотрим результаты
Вот вы и натренировали нейронную сеть для предсказания рукописных цифры с точностью выше 90%. Проверим ее с помощью изображения из тестового набора.
Возьмем случайное изображение — картинку с индексом 1010. Берем предсказанную метку (в данном случае — 4, потому что на пятой позиции стоит цифра 1)
y_test[1010]
Вывод:
array([0., 0., 0., 0., 1., 0., 0., 0., 0., 0.])
Построим изображения соответствующей картинки
plot_image(X_test[1010])

Понимание вывода активационного слоя softmax
Пропустим цифру через нейронную сеть и посмотрим, какой вывод она предскажет.
Вводные данные:
predicted_results = model.predict(X_test[1010].reshape((1, -1)))
Вывод слоя softmax — это распределение вероятностей для каждого вывода. В этом случае их может быть 10 (цифры от 0 до 9). Но ожидается, что каждое изображение будет соответствовать лишь одному.
Поскольку это распределение вероятностей, их сумма приблизительно равна 1 (единице).
predicted_results.sum()
1.0000001
Чтение вывода слоя softmax для конкретной цифры
Как можно видеть дальше, 5-ой индекс действительно близок к 1 (0,99), а это значит, что он с большой долей вероятности является
4… а это так и есть!
predicted_results
array([[1.2202066e-06, 3.4432333e-08, 3.5151488e-06, 1.2011528e-06, 9.9889344e-01, 3.5855610e-05, 1.6140550e-05, 7.6822333e-05, 1.0446112e-04, 8.6736667e-04]], dtype=float32)
Просмотр матрицы ошибок
predicted_outputs = np.argmax(model.predict(X_test), axis=1)
expected_outputs = np.argmax(y_test, axis=1)
predicted_confusion_matrix = confusion_matrix(expected_outputs, predicted_outputs)
predicted_confusion_matrix
array([[1402, 0, 4, 3, 1, 6, 20, 2, 21, 2],
[ 1, 1684, 9, 5, 4, 9, 1, 3, 9, 3],
[ 13, 8, 1280, 9, 19, 5, 12, 15, 17, 8],
[ 6, 8, 37, 1404, 1, 53, 3, 17, 33, 15],
[ 4, 7, 8, 0, 1345, 1, 18, 3, 8, 54],
[ 17, 8, 9, 31, 25, 1157, 25, 3, 24, 12],
[ 9, 6, 10, 0, 10, 12, 1431, 0, 6, 1],
[ 3, 11, 17, 4, 23, 2, 1, 1484, 5, 40],
[ 11, 16, 24, 40, 9, 25, 13, 3, 1348, 25],
[ 5, 5, 6, 16, 31, 6, 0, 43, 7, 1381]],
dtype=int64)
Визуализируем данные
# это код из https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
# Compute confusion matrix
class_names = [str(idx) for idx in range(10)]
cnf_matrix = confusion_matrix(expected_outputs, predicted_outputs)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names,
title='Confusion matrix, without normalization')
plt.show()

Выводы
В течение этого руководства вы должны были разобраться с основными концепциями, которые составляют основу машинного обучения, а также научиться:
- Кодировать и декодировать изображения в наборе данных MNIST
- Кодировать категориальные значения с помощью “one-hot encoding”
- Определять нейронную сеть с двумя скрытыми слоями, а также слой вывода, использующий функцию активации softmax
- Изучать результаты вывода функции активации softmax
- Строить матрицу ошибок классификатора
Библиотеки Sci-Kit Learn и Keras значительно понизили порог входа в машинное обучение — так же, как Python снизил порог знакомства с программированием. Однако потребуются годы (или десятилетия), чтобы достичь экспертного уровня!
Программисты, обладающие навыками машинного обучения, очень востребованы. С помощью упомянутых библиотек и вводных материалов о практических аспектах машинного обучения у всех должна быть возможность познакомиться с этой областью знаний. Даже если теоретических знаний о модели, библиотеке или фреймворке нет.
Затем навыки нужно использовать на практике, разрабатывая более умные продукты, что сделает потребителей более вовлеченными.
Попробуйте сами
Вот что вы можете попробовать сделать сами, чтобы углубиться в мир машинного обучения с Python:
- Поэкспериментируйте с количеством нейронов в скрытом слое. Сможете ли вы увеличить точность?
- Попробуйте добавить больше слоев. Тренируется ли сеть от этого медленнее? Понимаете ли вы, почему?
- Попробуйте RandomForestClassifier (нужна библиотека scikit-learn) вместо нейронной сети. Увеличилась ли точность?