Статья написана по мотивам очередной домашки в MADE, где мы учили нейронку писать стихи с помощью рекурентных сетей.
Для начала, договоримся, что будем делать «глупую» нейросеть, которая не разбирается в языке, построении фраз, предложений, смыслах, а просто учится предсказывать следующий символ по предыдущему тексту.
Из плюсов такого подхода — не нужно париться о пунктуации, больших и маленьких буквах, нейронка их расставит сама. Из минусов — такая нейросеть «туповата».
Так же можно генерировать любые последовательности. К примеру, музыку. MIDI конвертируем в формат ABC, получаем текст (точнее, последовательность символов). На этом тексте учимся, генерируем свой, превращаем его обратно в MIDI и получаем «нейромузыку».
Если генерировать тексты, будет получаться что-то вроде:
Потом ахали на наших специалистов: они, не имея вакцины, не зная, как мы действуем сейчас: малейшее подозрение — мы проверяем человека, надо на карантин — пожалуйста, давайте на карантин. Именно точечно, профессионально надо действовать, а не территориально не сможем, это невозможно. Особенно там, но полоза. Потому что они живут, как обычно (находятся не только в каких-то все обсуждать, но и проблема. Надо «желтые жилеты» вернуть с улиц. У кого-то выборы. У кого-то еще чего-то. И каждый начинает вертерах на неменех, не дали было спросы.
Нейросеть, обученная на изречениях бессменного лидера РБ
А иногда выходит что-то совсем прекрасное:
Стоит ли любить?
Стоит ли любить?
Стоит ли любить?
Стоит и приплыли.Нейросеть, обученная на хокку
Практическое применение этому мне сложно придумать. Скорее, это — про побаловаться. Ну и сотворить что-то забавное. Fake news этом не сделаешь. Точнее, сделаешь, но они будут наредкость забавны.
И важный момент. Если что-то непонятно или просто неинтересно, а попробовать генерировать текст хочется, то достаточно просто перейти по ссылке в Google Colab в конце статьи, закинуть туда свой файлик с текстом и запустить все ячейки с кодом.
Итак, поехали.
1. Импортируем нужные библиотеки
Из внешних библиотек нам понадобятся только numpy и pytorch:
from collections import Counter import torch import torch.nn as nn import torch.nn.functional as F import numpy as np
2. Готовим данные для сети
Токенизируем текст. Превращаем его в индексы. Т.е. достаем все уникальные символы: буквы, пробелы, знаки препинания в тексте и каждому символу присваиваем число. Например:
- ‘a’ => 1
- ‘Щ’ => 2
- ‘!’ => 3
- …
Это будем называть словарем. А числа — индексами.
Делаем прямой и обратный (индексы в символы) словарь. А потом проходимся по всему тексту и превращаем с помощью составленного нами словаря каждый символ в индекс.
TRAIN_TEXT_FILE_PATH = 'train_text.txt'
with open(TRAIN_TEXT_FILE_PATH) as text_file:
text_sample = text_file.readlines()
text_sample = ' '.join(text_sample)
def text_to_seq(text_sample):
char_counts = Counter(text_sample)
char_counts = sorted(char_counts.items(), key = lambda x: x[1], reverse=True)
sorted_chars = [char for char, _ in char_counts]
print(sorted_chars)
char_to_idx = {char: index for index, char in enumerate(sorted_chars)}
idx_to_char = {v: k for k, v in char_to_idx.items()}
sequence = np.array([char_to_idx[char] for char in text_sample])
return sequence, char_to_idx, idx_to_char
sequence, char_to_idx, idx_to_char = text_to_seq(text_sample)
3. Генерируем батчи из текста
Генерируем из последовательности наших индексов батчи (сразу несколько строк текста) для обучения сети. Не будем усложнять, просто достанем несколько случайных строк из текста фиксированной длины.
Будем генерировать сразу обучающую выборку (то, на чем будем учить сеть) и таргет для нее. Таргет (правильные ответы для нейросети) — это просто сдвинутый на один символ вперед текст.
Условно:
- Обучающая выборка:
Привет как дел - Таргет:
ривет как дела
Размерность тензора батча: [BATCH_SIZE x SEQ_LEN x 1]
SEQ_LEN = 256
BATCH_SIZE = 16
def get_batch(sequence):
trains = []
targets = []
for _ in range(BATCH_SIZE):
batch_start = np.random.randint(0, len(sequence) - SEQ_LEN)
chunk = sequence[batch_start: batch_start + SEQ_LEN]
train = torch.LongTensor(chunk[:-1]).view(-1, 1)
target = torch.LongTensor(chunk[1:]).view(-1, 1)
trains.append(train)
targets.append(target)
return torch.stack(trains, dim=0), torch.stack(targets, dim=0)
4. Пишем функцию, которая генерирует текст
Теперь напишем функцию, которая предсказывает текст с помощью нашей обученной нейросети. Это удобно сделать заранее, чтобы смотреть, что генерирует сеть во время обучения.
Сеть предсказывает нам вероятности следующей буквы, и мы с помощью этих вероятностей достаем случайно по одной букве. Если повторить операцию 1000 раз, получим текст из 1000 символов.
Параметр start_text нам нужен, чтобы было что-то, для чего предсказывать следующий символ. У нас этот символ по умолчанию — пробел, и задача сети сначала — предсказать следующий символ после пробела. Потом — следующий после этих 2-х символов. И т.д.
Параметр temp — это уровень «случайности» генерируемого текста. Так называемая «температура» с отсылкой к понятию «энтропии». То, на что делим логиты в softmax. Поставим высокую — вероятность каждой буквы будет почти одинакова и текст превратится в случайную белиберду. Поставим низкую — каждый раз будем предсказывать одно и то же и можем зациклиться на одной фразе.
def evaluate(model, char_to_idx, idx_to_char, start_text=' ', prediction_len=200, temp=0.3):
hidden = model.init_hidden()
idx_input = [char_to_idx[char] for char in start_text]
train = torch.LongTensor(idx_input).view(-1, 1, 1).to(device)
predicted_text = start_text
_, hidden = model(train, hidden)
inp = train[-1].view(-1, 1, 1)
for i in range(prediction_len):
output, hidden = model(inp.to(device), hidden)
output_logits = output.cpu().data.view(-1)
p_next = F.softmax(output_logits / temp, dim=-1).detach().cpu().data.numpy()
top_index = np.random.choice(len(char_to_idx), p=p_next)
inp = torch.LongTensor([top_index]).view(-1, 1, 1).to(device)
predicted_char = idx_to_char[top_index]
predicted_text += predicted_char
return predicted_text
5. Создаем класс нашей нейросети
И наконец наша маленькая и уютная нейросеть. Она работает так:
- Превращаем каждый символ на входе сети в вектор (так называемный эмбеддинг).
- Скармливаем эти векторы нашему LSTM слою. У этого слоя есть особенность: он работает не независимо для каждого символа, а помнит, что к нему раньше приходило на вход. Притом, помнит не все: ненужное он умеет забывать. Такие слои называют рекуррентными и часто используют при работе с последовательностями.
- Выходы из LSTM слоя пропускаем через Dropout. Этот слой «мешает» сети учиться, чтобы ей сложнее было выучить весть текст.
- Дальше отправляем выход из Dropout на линейный слой размерности словаря, чтобы на выходе получить столько чисел, сколько у нас символов в словаре. Потом мы этот вектор чисел будем превращать в «вероятности» каждого символа с помощью функции softmax.
class TextRNN(nn.Module):
def __init__(self, input_size, hidden_size, embedding_size, n_layers=1):
super(TextRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.embedding_size = embedding_size
self.n_layers = n_layers
self.encoder = nn.Embedding(self.input_size, self.embedding_size)
self.lstm = nn.LSTM(self.embedding_size, self.hidden_size, self.n_layers)
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(self.hidden_size, self.input_size)
def forward(self, x, hidden):
x = self.encoder(x).squeeze(2)
out, (ht1, ct1) = self.lstm(x, hidden)
out = self.dropout(out)
x = self.fc(out)
return x, (ht1, ct1)
def init_hidden(self, batch_size=1):
return (torch.zeros(self.n_layers, batch_size, self.hidden_size, requires_grad=True).to(device),
torch.zeros(self.n_layers, batch_size, self.hidden_size, requires_grad=True).to(device))
6. Создаем нейросеть и обучаем ее
Теперь создаем нейросеть и обучаем ее. LSTM блок принимает немного другой формат батча:
[SEQ_LEN x BATCH_SIZE x 1], поэтому делаем permute для тензоров train и target, чтобы поменять 0 и 1 размерность местами.
Параметры нейросети, которые может понадобиться подкрутить:
hidden_size— влияет на сложность сети. Стоит повышать для текстов большого размера. Если выставить большое значение для текста маленького размера, то сеть просто выучит весь текст и будет генерировать его же.n_layers— опять же, влияет на сложность сети. Грубо говоря, позволяет делать несколько LSTM слоев подряд просто меняя эту цифру.embedding_size— размер обучаемого эмбеддинга. Можно выставить в несколько раз меньше размера словаря (числа уникальных символов в тексте) или примерно такой же. Больше — нет смысла.
Дальше — стандартный для PyTorch цикл обучения нейросети: выбираем функцию потерь, оптимизатор и настраиваем расписание, по которому меняем шаг оптимизатора. В нашем случае снижаем шаг в 2 раза, если ошибка (loss) не падает 5 шагов подряд.
Если очень грубо, то здесь мы много раз подаем в нейросеть разные кусочки текста и учим ее делать все меньше и меньше ошибок, когда она предсказывает следующую букву по предыдущему тексту.
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model = TextRNN(input_size=len(idx_to_char), hidden_size=128, embedding_size=128, n_layers=2)
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, amsgrad=True)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
patience=5,
verbose=True,
factor=0.5
)
n_epochs = 50000
loss_avg = []
for epoch in range(n_epochs):
model.train()
train, target = get_batch(sequence)
train = train.permute(1, 0, 2).to(device)
target = target.permute(1, 0, 2).to(device)
hidden = model.init_hidden(BATCH_SIZE)
output, hidden = model(train, hidden)
loss = criterion(output.permute(1, 2, 0), target.squeeze(-1).permute(1, 0))
loss.backward()
optimizer.step()
optimizer.zero_grad()
loss_avg.append(loss.item())
if len(loss_avg) >= 50:
mean_loss = np.mean(loss_avg)
print(f'Loss: {mean_loss}')
scheduler.step(mean_loss)
loss_avg = []
model.eval()
predicted_text = evaluate(model, char_to_idx, idx_to_char)
print(predicted_text)
При обучении должно получиться на выходе что-то вроде:
Loss: 3.0337722063064576
В то не не посто на на не не на на не на помотророне на онот потарити не сем посто нат на рото сто на но на то тосте на посто нал на на на на росмоно посто но это воме на не вотато не не но на не нам на
Loss: 2.4729482173919677
В поторовововать оточели не не тора на на на на подовать не то не на подени не на вобомать не не прорус не сто на на сторы домем водем не сто не это соторовоста вомать на на проденить не бостова сто пор
Loss: 2.2126503944396974
В это надо поторовать на содолько не полодали не то начения. Нако не надо на работать на на полили на на наши наши подули сотовать на нало обранить на на постовать не наши на поставил в ирания стравом м
Loss: 2.028042938709259
В кому просторы на наши на комперами на только полоблимать должны поровать не том приратить подурать рас совеловали полжно от востание в мостам в сего принимали сотрать в нам нам от проблимать больно на
.......
.......
.......
Loss: 0.5439809119701385
В ибыратий от безработицы и доклады. Авторов мы сегодня по тому сли нас дороге, чтобы они смогли выйти и пережил уже многие психозом особенно надо выживать на эту тему в этот пережил уже многие психозы,
Loss: 0.5482879960536957
В ибывать на сегодняшний день отношение домерми вде выписов из меня частся с вами и серация — ни одного сказать, что мы сейчас делаем, они понятный их сполоси, которые основной пофтомие потери людям за
Loss: 0.5576688635349274
В конятно к этой пришетов не проблема станок их работать, потому что это повторилось.
Результатом стал устойчивый рост благосостояния населения. Мы точно дошло предложено. Политически запрещаю. ДавайтеМожете остановить обучение в любой момент. К примеру, тогда, когда ошибка (Loss) перестанет снижаться.
7. Генерируем текст
Итак, наша сеть обучилась. Давайте что-нибудь сгенерируем:
model.eval()
print(evaluate(
model,
char_to_idx,
idx_to_char,
temp=0.3,
prediction_len=1000,
start_text='. '
)
)
Рекомендую поиграть с параметром temp и, конечно же, start_text. С помощью start_text можно попробовать «задать тему/направление» для генерируемого текста. Желательно, ту, которая есть в тексте, на котором сеть училась, конечно.
Надеюсь, все получилось и нигде ничего не свалилось.
Не хочу ничего делать, хочу сразу генерировать текст
Так тоже можно. Просто откройте jupyter notebook в Google Colab, скопируйте туда файлик с текстом и выполните все ячейки.
Открыть готовый код в Google Colab
После того, как открыли, нужно скопировать туда и файл с текстом, на котором будет тренироваться нейросеть.

Вот и все. Можно развлекаться. Просто запустите подряд все ячейки с кодом. Когда будете учить нейросеть (предпоследняя ячейка), можете не ждать, пока обучение дойдет до конца и остановить в любой момент.
И еще крайне рекомендую в настройках Colab «Runtime» => «Change runtime type» => «Hardware accelerator» выбрать «GPU». На видеокарте сеть учится в разы быстрее.
На всякий случай, выложил код на github.
Если есть какие-то вопросы, что-то не работает или вы нашли баг, пишите, постараюсь помочь.
P.S.: если получится сгенерировать что-то забавное, сбросьте это сюда в комментарии 🙂
Дата публикации: 17.02.2023
Время чтения: 8 мин.
![]()

Светлана Трегубова
ЭКСПЕРТ
Копирайтер-маркетолог. Работаю с проектами EdTech, консалтинговыми фирмами и соцсетями с 2018 года
Нейросеть — искусственный интеллект, который способен генерировать контент, в том числе и тексты. Мучающий многих вопрос: смогут ли нейросети заменить людей-креаторов, или до этого еще далеко?
В этой статье разберемся, как нейросеть пишет текст, посмотрим 10 лучших нейросетей для написания осмысленных предложений и проверим возможности одной из них.
Тысячи надёжных каналов для продвижения бизнеса в Telegram

Telega.in — платформа нативных интеграций с блогерами в Telegram. Каждый канал в каталоге проверен вручную, а админы готовы к сотрудничеству — никаких долгих переговоров!
- Выбирайте лучшие каналы в открытом каталоге самостоятельно или с помощью менеджера.
- Планируйте кампании эффективно: интеграции гарантированно будут опубликованы в срок и в том виде, в котором их согласует заказчик.
- Экономьте время: отчёты по каждой кампании предоставляются в удобной таблице со всеми необходимыми данными.
Как происходит генерация текста
Нейросеть для создания контента — это набор алгоритмов, которые анализируют огромное количество информации и собирают похожий на нужный результат контент.
В процессе работы нейросеть не только запоминает все больше новых кусков текста, которые она может использовать для составления предложений, но и обучается на своих ошибках. Обучение позволяет ей выстраивать осмысленный текст, а не просто генерировать набор символов.
Сегодня «уроки» текстовых нейросетей тесно связаны с NLP (Natural Language Processing) — анализом и генерацией естественного языка. Искусственный интеллект не просто запоминает, какое слово чаще употребляется в том или ином контексте, но и учится понимать этот контекст.
Для самых продвинутых нейросетей-трансформеров текст — это набор цифровых кодов. Каждый символ — это код из нулей и единиц.
Самые медленные и слабые нейросети пытаются учиться на буквах, но такой подход пока не показывает хороших результатов — на анализ букв алгоритму нужно больше времени, чем на анализ нулей и единиц.

Такой упрощенный формат бинарной системы исчисления, помогает нейросети быстро генерировать текст, подбирая зафиксированные в памяти сочетания нулей и единиц, а не букв.
На основе нейросетей-трансформеров программисты строят огромные базы данных, вычленяя из них нужный символ в нужное время с помощью сложных математических алгоритмов.
База данных нейросети состоит из:
- бинарных кодов символов (нули и единицы),
- информации о синтаксисе языка,
- огромного массива данных о внешнем мире.

Такое сочетание ускоряет обучение нейросетей. Некоторые из них могут сразу же продолжать набранный человеком текст без промедления и длительного анализа данных и обучения. Эта модель генерации называется Few-shot learning, когда нейросеть в процессе написания текста, учится на своих ошибках.
Лучшие нейросети для написания текстов
Российские онлайн-сервисы
1. Gerwin AI
Самая продвинутая нейросеть для креаторов контента.

Gerwin AI пишет статьи, посты и заголовки. Внутри редактора нейросети вы можете изменять текст и сразу же проверять его на уникальность. Можно задавать тон написания материала: от шутливого до агрессивного.
Сервис платный. Тестового бесплатного периода для «пробы пера» нет. Доступ можно купить по подписке — платите один раз 4 990 рублей и получаете вечный доступ ко всем функциям Gerwin AI.
Или можно приобрести пакеты символов:

При покупке подписки на все пакеты символов действует скидка 40%.
2. Балабоба от Яндекс
Сайт: https://yandex.ru/lab/yalm
Молодая нейросеть от российского IT-гиганта, запущенная в июне 2021 года.

Бесплатная нейросеть
Балабоба работает на основе модели, похожей на GPT-3 американской компании Илона Маска Open AI. По типу модели GPT-3 также создан скандально известный бот-помощник ChatGPT.
Балабоба сама обучается — использует модель Optimization-based. Она знает правила русского языка, умеет осмысленно сочетать слова, запомнить свои ошибки. Она может дописать историю, пост или придумать короткую фразу.
Для обучения нейросети разработчики Яндекс загрузили в Балобобу все страницы, которые можно найти в поиске Яндекс. Она «прочитала» всю Википедию, все доступные в поисковике книги и всевозможные сайты и форумы.
Таким же методом программисты обучали голосового помощника Алису подбирать грамматически верные ответы при разговоре с пользователем.
Сама думать Балабоба не умеет. Она лишь парсит интернет в поиске подходящих осмысленных предложений.
В конце статьи дадим Балабобе задание и посмотрим, как она справится с ним.
3. Порфирьевич
Сайт: https://porfirevich.ru
Российский программист Максим Гранкин создал в 2019 нейросеть на основе прошлой модели GPT-2 Open AI и выложил ее в свободный доступ. Порфирьевич специализируется на написании коротких историй. Вы задаете начало рассказа — нейросеть продолжает его.

Бесплатная нейросеть
Обучение нейросети проходило с помощью классической и современной литературы, поэтому она может использовать интересные речевые обороты для рассказов, но писать посты и инструкции — невыполнимая задача для Порфирьевича.
Технические тексты тоже даются программе с трудом. Все научные тексты она сводит к размышлениям и риторическим вопросам.
4. ruGPT-3 от Сбер
Сайт: https://developers.sber.ru/portal/products/rugpt-3
Сбер все больше вкладывается в разработку систем искусственного интеллекта, о чем говорит выпуск своего голосового помощника в виде колонки и отдельная команда по работе с ИИ Sberbank.AI. И вот, в 2020 году Сбер выпускает переделанную версию GPT-3.

Бесплатная нейросеть
Для обучения нейросети разработчики составили массив данных на 600Гб из русской литературы, новостных порталов, страниц русско- и англоязычной Википедии. Да, ruGPT-3 может немного печатать на английском, но только короткие малоосмысленные предложения.
Для дополнения русского текста нейросети хватит всего пары предложений, чтобы она дописала осмысленный рассказ на 2 страницы с раскрытием героев и закрученным сюжетом.

Зарубежные нейросети
Зарубежные компании по разработке искусственного интеллекта делают акцент не на грамотном написании текстов, а на помощи креаторам.
Российские нейросети — это пока экспериментальные разработки, которые не могут полностью заменить сотрудника. По сранвению с зарубежным ИИ они еще «сырые». Иностранные же нейросети создаются для того, чтобы человек мог делегировать рутинные задачи искусственному интеллекту.
Все нейросети из подборки работают без VPN.
1. AdCreative.AI
Сайт: https://www.adcreative.ai
Американская нейросеть для создания рекламных постов и креативов.

Разработчики утверждают, что при использовании текстов, написанных AdCreative.AI, конверсии кликабельности объявлений увеличиваются на 14%.
Нейросеть создает не просто осмысленные предложения, а продающие тексты, задача которых не только быть читаемыми, но и продавать вашу услугу/товар аудитории. Также нейросеть создает рекламные баннеры в любом разрешении.
AdCreative.AI — платная нейросеть. Использовать ее можно по ежемесячной подписке стоимостью от 25 до 145$ в месяц. Есть бесплатный тестовый 7-дневный период.
2. Bertha.ai
Сайт: https://bertha.ai
Зарубежная нейросеть для создания продающих описаний товаров и услуг.

Сервис платный. Создатели предлагают 2 тарифа: 45$ и 150$ в месяц. Цена зависит от нужного количества текстов.
Также можно заплатить 25$ за 10 тысяч слов или 15$ за 100 изображений.
Еще Bertha.ai может создать текстовую копию веб-страницы, предложить идеи для публикаций и сгенерировать оригинальное изображение.
3. Writersonic
Сайт: https://writesonic.com

Мощная нейросеть для созданий креатива. Разработчики обещают, что создание контента ускорится в 10 раз при использованиии Writersonic.
Нейросеть может писать множество разных текстов: посты для блога, рекламные посевы, email-рассылки, наполнение сайта.
Тексты Writersonic SEO-оптимизированы. Сеть подбирает слова так, чтобы ваш блог или сайт был одним из первых в поисковой выдаче.
Программа платная. Цена использования нейросети зависит от количества сотрудник, которые будут генерировать контент с помощью Writersonic, и количества слов в месяц. Минимальный пакет на 1 человека и 47.5 тысяч слов стоит 12.67$, максимальный пакет для 15 человек и 5 миллионов слов — 666$.
4. CopyMonkey
Сайт: https://www.copymonkey.app

Зарубежная нейросеть, полностью адаптированная под русскоязычного пользователя.
CopyMonkey полностью платная: от 1 599 до 7 999 рублей в месяц. Можно связаться с менеджером платформы и обсудить с ним персональные условия для внедрения нейросети в бизнес-процессы своего предприятия.
Нейросеть может написать текст для сайта, пост для блога, заполнить карточку товара на Ozon или Wildberries.
5. PepperType.ai
Сайт: https://www.peppertype.ai
Создатели нейросети утверждают, что тексты PepperType.ai увеличивают конверсии продаж в несколько раз, а алгоритмы нейросети работают в 10 раз быстрее, недели алгоритмы других сервисов-конкурентов.

На платформе есть пространство для работы маркетингового отдела, где вы можете курировать работу креаторов и ставить им задачи. Они же, не выходя из рабочего пространства, могут создавать контент с помощью нейросети.
Нейросеть платная. Чтобы подключить нейросеть к работе, необходимо оплатить 35$ за одного сотрудника или 199$ за 5 человек.
6. Copy.ai
Сайт: https://www.copy.ai
Нейросеть для создания коротких рекламных текстов.

Copy.ai можно пользоваться бесплатно, но с ограничением — до 2000 сгенерированных слов в месяц. Или можно подключить тариф за 49$ в месяц без ограничений по количеству слов.
Но за приятной ценой стоит большой недостаток — тексты и креативы начинают повторяться со временем. Для генерации разных вариантов нейросеть должна обучаться на большом количестве данных. Разработчики Copy.ai не заложили в свое создание достаточно информации для создания уникального контента на месяцы вперед.
Как написать текст с помощью нейросети
Посмотрим, что умеет отечественный сервис Балабоба.
Чтобы попасть на страницу нейросети, заходим в поиск Яндекса, печатаем название сервиса и открываем самую верхнюю строку поиска.

Поисковик предложит 2 варианта Балабобы: русскую версию и английскую. Мы остановимся на русской.
Разработчики оставили заботливое послание на первом экране сайта нейросети, что Балабоба несовершенна, она может написать ерунду, и обижаться за это на нее не стоит.

Нажимаем «Договорились» и переходим на страницу-редактор текста.

Вверху мы можем выбрать стиль написания текста:
- Без стиля. Нейросеть допишет текст без какого-либо авторского стиля на любую тему.
- Новогодние открытки. Балабоба подберет картинку для открытки и допишет текст поздравления.
- Балабоба и Sports.ru. Написание комментариев к новостям спорта. Алгоритм разработчики Яндекс приурочили к чемпионату мира по футболу 2021 года в России и создали его совместно со спортивной редакцией Sports.ru.
- Инструкция по применению. Понятный простой текст с последовательными действиями.
- Рецепты. Те же «вкусные» инструкции.
- Народные мудрости. Пишем начало мудрости и получаем ее окончание от Балабобы.
- Короткие истории. Пишем рассказ вместе с Балабобой.
- Короче, Википедия. Балабоба даст определение к любому слову, которое вводит пользователь.
- Синопсисы фильмов. Пишем название существующего фильма — нейросеть находит его сюжет. Придумываем название фильма — нейросеть попробует пофантазировать, какой сюжет был бы у кинофильма с таким названием.
- Предсказания. Пишем имя или знак зодиака и получаем шутливое гадание от Балабобы.
Начнем с простого: дадим название несуществующего фильма и посмотрим, какой сюжет предложит нейросеть.
Первая попытка провалена. Почему-то нейросеть посчитала, что фраза «Опасные ящерицы 2: погоня за хот-догом» содержит в себе острую тему.

«Розовый слон вышел на прогул» больше понравился Балабобе, и она написала завязку для фильма в стиле романтических комедий Вуди Аллена. Но последние предложения смешиваются в кашу: становится невозможным понять, какой именно предмет розового цвета не понравился домохозяйке и что она она должна перекрасить в другой оттенок.
-min.png)
Вводим начало народной мудрости. В ответ нейросеть находит ее продолжение в интернете.

Если написать несуществующую пословицу, то Балабоба генерирует осмысленное продолжение на основе текстов из интернета:

Попробуем написать в соавторстве с Балабобой историю:

Лихозакрученный сюжет нейросеть не предложит — только допишет короткий рассказ на основе предложенных данных пользователем.
И последнее самое сложное задание: попробуем написать вместе с Балабобой пост для блога. Для этого выберем вариант стилизации «Без стиля»:

В этом случае нейросеть предлагает уже более осмысленный вариант — целостный текст с логическим завершением.
Заключение
Нейросети — новый инструмент, который может помогать креаторам создавать контент или улучшать его качество. С каждым годом они становятся все более совершенными, а с такими темпами развития, кто знает, возможно, искусственный интеллект сможет полностью писать тексты за людей уже в недалеком будущем.
Вам понравилась статья?
![]()
17
![]()
0
В прошлый раз мы разбирались с теорией про цепи Маркова. Вот основные тезисы:
- Цепь Маркова — это последовательность событий, где каждое новое событие зависит только от предыдущего. Например, после одного слова может стоять другое слово.
- Существуют алгоритмы, которые способны генерировать текст на основании цепей Маркова. Они изучают, какие связи могут быть между словами, и потом проходят по этим связям и составляют новый текст.
- Для нашей работы алгоритму всегда нужен исходный текст (он же корпус) — глядя на этот текст, алгоритм поймёт, какие слова обычно идут друг за другом.
- Чем больше размер исходного текста, тем больше связей между цепями и тем разнообразнее получается текст на выходе.
Сегодня попробуем это в деле и напишем самый простой генератор текста на цепях Маркова. Это будет похоже на работу нейросети, но на самом деле никаких «нейро» там нет — просто сети, которые сделаны на алгоритме цепей Маркова. А сеть — это просто таблица со связями между элементами.
Короче: никакого искусственного интеллекта, просто озверевшие алгоритмы вслепую дёргают слова.
Логика проекта
Код будем писать на Python, потому что от отлично подходит под задачи такого плана — обработка текста и построение моделей со сложными связями.
Логика будет такой:
- Берём файл с исходным текстом и разбиваем его на слова.
- Все слова, которые стоят рядом, соединяем в пары.
- Используя эти пары, составляем словарь цепочек, где указано первое слово и все, которые могут идти после него.
- Выбираем случайное слово для старта.
- Задаём длину текста на выходе и получаем результат.
Сделаем всё по шагам, как обычно.
Проверяем, что у нас есть Python
Python не так-то просто запустить, поэтому, если вы ещё ничего не делали на Python, прочитайте нашу статью в тему. Там всё описано по шагам.
Разбиваем исходный текст
Для тренировки мы взяли восьмой том полного собрания сочинений Чехова — повести и рассказы. В нём примерно 150 тысяч слов, поэтому должно получиться разнообразно. Этот файл нужно сохранить как che.txt и положить в ту же папку, что и код программы.
👉 Чтобы быстро работать с большими массивами данных, будем использовать библиотеку numpy — она написана специально для биг-даты, работы с нейросетями и обработки больших матриц. Для установки можно использовать команду pip3 install numpy:

# подключаем библиотеку numpy
import numpy as np
# отправляем в переменную всё содержимое текстового файла
text = open('che.txt', encoding='utf8').read()
# разбиваем текст на отдельные слова (знаки препинания останутся рядом со своими словами)
corpus = text.split()Генерируем пары
Для этого используем специальную команду-генератор: yield. В функциях она работает как return — возвращает какое-то значение, а нам она нужна из-за особенностей своей работы. Дело в том, что yield не хранит и не запоминает никакие значения — она просто генерирует что-то, тут же про это забывает и переходит к следующему. Именно так и работают цепи Маркова — они не запоминают все предыдущие состояния, а работают только с конкретными парами в данный момент.
👉 Мы разберём генераторы более подробно в отдельной статье, а пока просто используем их в нашем коде.
# делаем новую функцию-генератор, которая определит пары слов
def make_pairs(corpus):
# перебираем все слова в корпусе, кроме последнего
for i in range(len(corpus)-1):
# генерируем новую пару и возвращаем её как результат работы функции
yield (corpus[i], corpus[i+1])
# вызываем генератор и получаем все пары слов
pairs = make_pairs(corpus)В результате мы получаем все пары слов, которые идут друг за другом — с повторениями и в том порядке, как они расположены в исходном тексте. Теперь можно составлять словарь для цепочек.
Составляем словарь
Пойдём по самому простому пути: не будем высчитывать вероятности продолжения для каждого слова, а просто укажем вторым элементом в паре все слова, которые могут быть продолжением. Например, у нас в переменной pairs есть такие пары:
привет → это
привет → друг
привет → как
привет → друг
привет → друг
Видно, что «друг» встречается в 3 раза чаще остальных слов, поэтому вероятность его появления — ⅗. Но чтобы не считать вероятности, мы сделаем так:
- Составим пару привет → (это, друг, как, друг, друг).
- При выборе мы просто случайным образом выберем одно из значений для продолжения.
👉 Это, конечно, не так изящно, как в серьёзных алгоритмах с матрицами и вероятностями, зато работает точно так же и более просто в реализации.
Вот блок с этим кодом на Python:
# словарь, на старте пока пустой
word_dict = {}
# перебираем все слова попарно из нашего списка пар
for word_1, word_2 in pairs:
# если первое слово уже есть в словаре
if word_1 in word_dict.keys():
# то добавляем второе слово как возможное продолжение первого
word_dict[word_1].append(word_2)
# если же первого слова у нас в словаре не было
else:
# создаём новую запись в словаре и указываем второе слово как продолжение первого
word_dict[word_1] = [word_2]Выбираем слово для старта
Чтобы было совсем непредсказуемо, начальное слово тоже будем выбирать случайным образом. Главное требование к начальному слову — первая заглавная буква. Выполним это условие так:
- Случайно выберем первое слово.
- Проверим, есть ли в нём большие буквы. Для простоты допустим, что если есть, то они стоят в начале и нам подходят.
- Если есть — отлично, если нет — выбираем слово заново и повторяем все шаги.
- Делаем так до тех пор, пока не найдём подходящее слово.
# случайно выбираем первое слово для старта
first_word = np.random.choice(corpus)
# если в нашем первом слове нет больших букв
while first_word.islower():
# то выбираем новое слово случайным образом
# и так до тех пор, пока не найдём слово с большой буквой
first_word = np.random.choice(corpus)Запускаем алгоритм
У нас почти всё готово для запуска. Единственное, что нам осталось сделать — установить количество слов в готовом тексте. После этого наш алгоритм возьмёт первое слово, добавит в цепочку, потом выберет для этого слова случайное продолжение, потом выберет случайное продолжение уже для второго слова и так далее. Так он будет делать, пока не наберёт нужное количество слов, после чего остановится.
# делаем наше первое слово первым звеном
chain = [first_word]
# сколько слов будет в готовом тексте
n_words = 100
# делаем цикл с нашим количеством слов
for i in range(n_words):
# на каждом шаге добавляем следующее слово из словаря, выбирая его случайным образом из доступных вариантов
chain.append(np.random.choice(word_dict[chain[-1]]))
# выводим результат
print(' '.join(chain))Результат
После обработки Чехова наш алгоритм выдал такое:
В октябре 1894 г. Текст статьи, написанные за вечерним чаем сидела за ивы. Они понятия о равнодушии к себе в целом — бич божий! Егор Семеныч и боялась. В повести пассивности, пессимизма, равнодушия («формализма») писали это она отвечала она не застав его лоб. Он пишет, что сам Песоцкий впервые явилась мысль о ненормальностях брака. Поймите мои руки; он, — а женщин небось поставил крест на о. Сахалине (см.: М. — Нет, вы тоже, согласитесь, сытость есть две ночи и белые, пухлые руки и мог не содержащем единой и не заслуживает «ни закрепления, ни мне не знаю, для меня с 50 рисунками
Здесь нет смысла, хотя все слова связаны друг с другом. Чтобы результат был более читабельным, нам нужно увеличить количество слов в парах и оптимизировать алгоритм. Это сделаем в другой раз, на сегодня пока всё.
Неправильно ты, Дядя Фёдор, на Питоне кодишь
Опытные питонисты абсолютно справедливо сделают нам замечание: нужно не писать новый алгоритм для обработки цепей Маркова, а использовать какую-нибудь готовую библиотеку типа Markovify.
Всецело поддерживаем. В рабочих проектах, где вам нужно будет быстро получить правильный и предсказуемый результат, нужно не изобретать алгоритмы с нуля, а использовать опыт предыдущих поколений.
Но нам было интересно сделать собственный алгоритм. А когда человеку интересно, ничто не должно стоять на его пути.
Но в другой раз сделаем на библиотеке, окей.
# подключаем библиотеку numpy
import numpy as np
# отправляем в переменную всё содержимое текстового файла
text = open('che.txt', encoding='utf8').read()
# разбиваем текст на отдельные слова (знаки препинания останутся рядом со своими словами)
corpus = text.split()
# делаем новую функцию-генератор, которая определит пары слов
def make_pairs(corpus):
# перебираем все слова в корпусе, кроме последнего
for i in range(len(corpus)-1):
# генерируем новую пару и возвращаем её как результат работы функции
yield (corpus[i], corpus[i+1])
# вызываем генератор и получаем все пары слов
pairs = make_pairs(corpus)
# словарь, на старте пока пустой
word_dict = {}
# перебираем все слова попарно из нашего списка пар
for word_1, word_2 in pairs:
# если первое слово уже есть в словаре
if word_1 in word_dict.keys():
# то добавляем второе слово как возможное продолжение первого
word_dict[word_1].append(word_2)
# если же первого слова у нас в словаре не было
else:
# создаём новую запись в словаре и указываем второе слово как продолжение первого
word_dict[word_1] = [word_2]
# случайно выбираем первое слово для старта
first_word = np.random.choice(corpus)
# если в нашем первом слове нет больших букв
while first_word.islower():
# то выбираем новое слово случайным образом
# и так до тех пор, пока не найдём слово с большой буквой
first_word = np.random.choice(corpus)
# делаем наше первое слово первым звеном
chain = [first_word]
# сколько слов будет в готовом тексте
n_words = 100
# делаем цикл с нашим количеством слов
for i in range(n_words):
# на каждом шаге добавляем следующее слово из словаря, выбирая его случайным образом из доступных вариантов
chain.append(np.random.choice(word_dict[chain[-1]]))
# выводим результат
print(' '.join(chain))
Перевод
Ссылка на автора
Рекуррентные нейронные сети также могут быть использованы в качестве генеративных моделей.
Это означает, что в дополнение к тому, что они используются для прогнозных моделей (создания прогнозов), они могут изучать последовательности проблемы, а затем генерировать совершенно новые вероятные последовательности для проблемной области.
Подобные генеративные модели полезны не только для изучения того, насколько хорошо модель выявила проблему, но и для того, чтобы узнать больше о самой проблемной области.
В этом посте вы узнаете, как создать генеративную модель для текста, посимвольный, используя рекуррентные нейронные сети LSTM в Python с Keras.
Прочитав этот пост, вы узнаете:
- Где скачать бесплатный корпус текста, который вы можете использовать для обучения генеративных моделей текста.
- Как поставить проблему текстовых последовательностей в рекуррентную модель генерации нейронной сети.
- Как разработать LSTM для генерации правдоподобных текстовых последовательностей для данной проблемы.
Давайте начнем.
Заметка: Рекуррентные нейронные сети LSTM могут работать медленно, поэтому настоятельно рекомендуется обучать их на оборудовании с графическим процессором. Вы можете получить доступ к оборудованию графического процессора в облаке очень дешево, используя Amazon Web Services, см. учебник здесь,
- Обновление октябрь 2016: Исправлено несколько незначительных опечаток в коде.
- Обновление март / 2017: Обновлен пример для Keras 2.0.2, TensorFlow 1.0.1 и Theano 0.9.0.

Описание проблемы: проект Гутенберг
Многие из классических текстов больше не защищены авторским правом.
Это означает, что вы можете скачать весь текст этих книг бесплатно и использовать их в экспериментах, например, при создании генеративных моделей. Возможно, лучшее место для получения доступа к бесплатным книгам, которые больше не защищены авторским правом, это Проект Гутенберг,
В этом уроке мы собираемся использовать любимую книгу из детства в качестве набора данных: Приключения Алисы в Стране Чудес Льюиса Кэрролла,
Мы собираемся изучить зависимости между символами и условные вероятности символов в последовательностях, чтобы мы могли, в свою очередь, генерировать совершенно новые и оригинальные последовательности символов.
Это очень весело, и я рекомендую повторить эти эксперименты с другими книгами из проекта Гутенберга, вот список самых популярных книг на сайте,
Эти эксперименты не ограничиваются текстом, вы также можете поэкспериментировать с другими данными ASCII, такими как компьютерный исходный код, размеченные документы в LaTeX, HTML или Markdown и другие.
Вы можете скачать полный текст в формате ASCII (Обычный текст UTF-8) для этой книги бесплатно и поместите ее в свой рабочий каталог с именем файлаwonderland.txt,
Теперь нам нужно подготовить набор данных к моделированию.
Project Gutenberg добавляет стандартный колонтитул к каждой книге, и это не является частью исходного текста. Откройте файл в текстовом редакторе и удалите верхний и нижний колонтитулы.
Заголовок очевиден и заканчивается текстом:
*** START OF THIS PROJECT GUTENBERG EBOOK ALICE'S ADVENTURES IN WONDERLAND ***Нижний колонтитул — весь текст после строки текста, которая говорит:
THE ENDВы должны остаться с текстовым файлом, который содержит около 3330 строк текста.
Нужна помощь с LSTM для прогнозирования последовательности?
Пройдите мой бесплатный 7-дневный курс по электронной почте и откройте для себя 6 различных архитектур LSTM (с кодом).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную PDF-версию курса Ebook.
Начни свой БЕСПЛАТНЫЙ мини-курс сейчас!
Разработка малой рекуррентной нейронной сети LSTM
В этом разделе мы разработаем простую сеть LSTM для изучения последовательностей персонажей Алисы в стране чудес. В следующем разделе мы будем использовать эту модель для генерации новых последовательностей символов.
Давайте начнем с импорта классов и функций, которые мы намереваемся использовать для обучения нашей модели.
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utilsЗатем нам нужно загрузить текст ASCII для книги в память и преобразовать все символы в нижний регистр, чтобы уменьшить словарный запас, который должна выучить сеть.
# load ascii text and covert to lowercase
filename = "wonderland.txt"
raw_text = open(filename).read()
raw_text = raw_text.lower()Теперь, когда книга загружена, мы должны подготовить данные для моделирования нейронной сетью. Мы не можем моделировать символы напрямую, вместо этого мы должны преобразовать символы в целые числа.
Мы можем сделать это легко, сначала создав набор всех отдельных символов в книге, а затем создав карту каждого символа с уникальным целым числом.
# create mapping of unique chars to integers
chars = sorted(list(set(raw_text)))
char_to_int = dict((c, i) for i, c in enumerate(chars))Например, список уникальных отсортированных строчных символов в книге выглядит следующим образом:
['n', 'r', ' ', '!', '"', "'", '(', ')', '*', ',', '-', '.', ':', ';', '?', '[', ']', '_', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'xbb', 'xbf', 'xef']Вы можете видеть, что могут быть некоторые символы, которые мы могли бы удалить для дальнейшей очистки набора данных, что уменьшит словарный запас и может улучшить процесс моделирования.
Теперь, когда книга загружена и карта подготовлена, мы можем суммировать набор данных.
n_chars = len(raw_text)
n_vocab = len(chars)
print "Total Characters: ", n_chars
print "Total Vocab: ", n_vocabЗапуск кода до этой точки приводит к следующему выводу.
Total Characters: 147674
Total Vocab: 47Мы видим, что книга содержит менее 150000 символов и что при преобразовании в строчные буквы в словаре есть только 47 различных символов для изучения сетью. Гораздо больше, чем 26 в алфавите.
Теперь нам нужно определить данные обучения для сети Существует большая гибкость в том, как вы решаете разбивать текст и выставлять его в сети во время обучения.
В этом уроке мы разделим текст книги на подпоследовательности с фиксированной длиной в 100 символов произвольной длины. Мы могли бы так же легко разделить данные по предложениям, дополнить более короткие последовательности и укоротить более длинные.
Каждый обучающий шаблон сети состоит из 100 временных шагов одного символа (X), за которыми следует один символьный вывод (y). При создании этих последовательностей мы перемещаем это окно по всей книге по одному символу за раз, позволяя каждому персонажу выучить шанс из 100 предшествующих ему символов (кроме, конечно, первых 100 символов).
Например, если длина последовательности равна 5 (для простоты), то первые два шаблона обучения будут следующими:
CHAPT -> E
HAPTE -> RРазделяя книгу на эти последовательности, мы конвертируем символы в целые числа, используя нашу таблицу поиска, которую мы подготовили ранее.
# prepare the dataset of input to output pairs encoded as integers
seq_length = 100
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i:i + seq_length]
seq_out = raw_text[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print "Total Patterns: ", n_patternsВыполнение кода к этому моменту показывает нам, что когда мы разбили набор данных на тренировочные данные для сети, чтобы узнать, что у нас чуть менее 150 000 обучающих патентов. Это имеет смысл, поскольку исключая первые 100 символов, у нас есть один тренировочный шаблон для прогнозирования каждого из оставшихся символов.
Total Patterns: 147574Теперь, когда мы подготовили наши тренировочные данные, нам нужно преобразовать их так, чтобы они подходили для использования с Keras.
Сначала мы должны преобразовать список входных последовательностей в форму[образцы, временные шаги, особенности]ожидается сетью LSTM.
Затем нам нужно изменить масштаб целых чисел в диапазоне от 0 до 1, чтобы облегчить изучение шаблонов сетью LSTM, которая по умолчанию использует функцию активации сигмовидной кишки.
Наконец, нам нужно преобразовать выходные шаблоны (отдельные символы, преобразованные в целые числа) в одну горячую кодировку. Это сделано для того, чтобы мы могли настроить сеть так, чтобы она предсказывала вероятность каждого из 47 различных символов в словаре (более простое представление), а не пыталась заставить ее предсказать точно следующий символ. Каждое значение y преобразуется в разреженный вектор длиной 47, полный нулей, за исключением 1 в столбце для буквы (целое число), которую представляет шаблон.
Например, когда «n» (целочисленное значение 31) является горячим кодированием, оно выглядит следующим образом:
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0.]Мы можем реализовать эти шаги, как показано ниже.
# reshape X to be [samples, time steps, features]
X = numpy.reshape(dataX, (n_patterns, seq_length, 1))
# normalize
X = X / float(n_vocab)
# one hot encode the output variable
y = np_utils.to_categorical(dataY)Теперь мы можем определить нашу модель LSTM. Здесь мы определяем один скрытый слой LSTM с 256 единицами памяти. Сеть использует выпадение с вероятностью 20. Выходной уровень — это Плотный уровень, использующий функцию активации softmax для вывода прогнозирования вероятности для каждого из 47 символов в диапазоне от 0 до 1.
Эта проблема на самом деле представляет собой проблему классификации отдельных символов с 47 классами, и поэтому она определяется как оптимизация потерь в журнале (перекрестная энтропия) с использованием алгоритма оптимизации ADAM по скорости.
# define the LSTM model
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2])))
model.add(Dropout(0.2))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')Тестового набора данных нет. Мы моделируем весь обучающий набор данных, чтобы узнать вероятность каждого персонажа в последовательности.
Нас не интересует наиболее точная (точность классификации) модель учебного набора данных. Это будет модель, которая идеально предсказывает каждого персонажа в наборе обучающих данных. Вместо этого мы заинтересованы в обобщении набора данных, который минимизирует выбранную функцию потерь. Мы ищем баланс между обобщением и переоснащением, но без запоминания.
Сеть работает медленно (около 300 секунд на эпоху на графическом процессоре Nvidia K520). Из-за медлительности и из-за наших требований по оптимизации мы будем использовать контрольные точки модели для записи всех сетевых весов, чтобы каждый раз регистрировать улучшение потерь в конце эпохи. Мы будем использовать лучший набор весов (наименьшая потеря), чтобы реализовать нашу генеративную модель в следующем разделе.
# define the checkpoint
filepath="weights-improvement-{epoch:02d}-{loss:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]Теперь мы можем приспособить нашу модель к данным. Здесь мы используем скромное количество из 20 эпох и большой размер пакета из 128 шаблонов.
model.fit(X, y, epochs=20, batch_size=128, callbacks=callbacks_list)Полный список кодов приведен ниже для полноты.
# Small LSTM Network to Generate Text for Alice in Wonderland
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
# load ascii text and covert to lowercase
filename = "wonderland.txt"
raw_text = open(filename).read()
raw_text = raw_text.lower()
# create mapping of unique chars to integers
chars = sorted(list(set(raw_text)))
char_to_int = dict((c, i) for i, c in enumerate(chars))
# summarize the loaded data
n_chars = len(raw_text)
n_vocab = len(chars)
print "Total Characters: ", n_chars
print "Total Vocab: ", n_vocab
# prepare the dataset of input to output pairs encoded as integers
seq_length = 100
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i:i + seq_length]
seq_out = raw_text[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print "Total Patterns: ", n_patterns
# reshape X to be [samples, time steps, features]
X = numpy.reshape(dataX, (n_patterns, seq_length, 1))
# normalize
X = X / float(n_vocab)
# one hot encode the output variable
y = np_utils.to_categorical(dataY)
# define the LSTM model
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2])))
model.add(Dropout(0.2))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
# define the checkpoint
filepath="weights-improvement-{epoch:02d}-{loss:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
# fit the model
model.fit(X, y, epochs=20, batch_size=128, callbacks=callbacks_list)Вы увидите разные результаты из-за стохастической природы модели и из-за того, что трудно исправить случайное начальное число для моделей LSTM, чтобы получить 100% воспроизводимые результаты. Это не касается этой генеративной модели.
После запуска примера у вас должно быть несколько файлов контрольных точек веса в локальном каталоге.
Вы можете удалить их все, кроме одного с наименьшим значением потери. Например, когда я запускал этот пример, ниже был контрольный пункт с наименьшей потерей, которую я достиг.
weights-improvement-19-1.9435.hdf5Потери в сети уменьшались почти каждую эпоху, и я ожидаю, что сеть может извлечь выгоду из обучения для многих других эпох.
В следующем разделе мы рассмотрим использование этой модели для генерации новых текстовых последовательностей.
Генерация текста с помощью сети LSTM
Генерация текста с использованием обученной сети LSTM относительно проста.
Во-первых, мы загружаем данные и определяем сеть точно таким же образом, за исключением того, что веса сети загружаются из файла контрольных точек, и сеть не нуждается в обучении.
# load the network weights
filename = "weights-improvement-19-1.9435.hdf5"
model.load_weights(filename)
model.compile(loss='categorical_crossentropy', optimizer='adam')Кроме того, при подготовке сопоставления уникальных символов с целыми числами мы также должны создать обратное отображение, которое мы можем использовать для преобразования целых чисел обратно в символы, чтобы мы могли понять предсказания.
int_to_char = dict((i, c) for i, c in enumerate(chars))Наконец, нам нужно делать прогнозы.
Простейший способ использования модели Keras LSTM для прогнозирования — сначала начать с последовательности начальных чисел в качестве входных данных, сгенерировать следующий символ, затем обновить последовательность начальных чисел, чтобы добавить сгенерированный символ в конце, и обрезать первый символ. Этот процесс повторяется до тех пор, пока мы хотим предсказать новые символы (например, последовательность длиной 1000 символов).
Мы можем выбрать случайный шаблон ввода в качестве нашей начальной последовательности, а затем распечатать сгенерированные символы по мере их генерации.
# pick a random seed
start = numpy.random.randint(0, len(dataX)-1)
pattern = dataX[start]
print "Seed:"
print """, ''.join([int_to_char[value] for value in pattern]), """
# generate characters
for i in range(1000):
x = numpy.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model.predict(x, verbose=0)
index = numpy.argmax(prediction)
result = int_to_char[index]
seq_in = [int_to_char[value] for value in pattern]
sys.stdout.write(result)
pattern.append(index)
pattern = pattern[1:len(pattern)]
print "nDone."Полный пример кода для генерации текста с использованием загруженной модели LSTM приведен ниже для полноты.
# Load LSTM network and generate text
import sys
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
# load ascii text and covert to lowercase
filename = "wonderland.txt"
raw_text = open(filename).read()
raw_text = raw_text.lower()
# create mapping of unique chars to integers, and a reverse mapping
chars = sorted(list(set(raw_text)))
char_to_int = dict((c, i) for i, c in enumerate(chars))
int_to_char = dict((i, c) for i, c in enumerate(chars))
# summarize the loaded data
n_chars = len(raw_text)
n_vocab = len(chars)
print "Total Characters: ", n_chars
print "Total Vocab: ", n_vocab
# prepare the dataset of input to output pairs encoded as integers
seq_length = 100
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i:i + seq_length]
seq_out = raw_text[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print "Total Patterns: ", n_patterns
# reshape X to be [samples, time steps, features]
X = numpy.reshape(dataX, (n_patterns, seq_length, 1))
# normalize
X = X / float(n_vocab)
# one hot encode the output variable
y = np_utils.to_categorical(dataY)
# define the LSTM model
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2])))
model.add(Dropout(0.2))
model.add(Dense(y.shape[1], activation='softmax'))
# load the network weights
filename = "weights-improvement-19-1.9435.hdf5"
model.load_weights(filename)
model.compile(loss='categorical_crossentropy', optimizer='adam')
# pick a random seed
start = numpy.random.randint(0, len(dataX)-1)
pattern = dataX[start]
print "Seed:"
print """, ''.join([int_to_char[value] for value in pattern]), """
# generate characters
for i in range(1000):
x = numpy.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model.predict(x, verbose=0)
index = numpy.argmax(prediction)
result = int_to_char[index]
seq_in = [int_to_char[value] for value in pattern]
sys.stdout.write(result)
pattern.append(index)
pattern = pattern[1:len(pattern)]
print "nDone."При выполнении этого примера сначала выводится выбранное случайное начальное число, а затем каждый символ по мере его создания.
Например, ниже приведены результаты одного запуска этого текстового генератора. Случайное семя было:
be no mistake about it: it was neither more nor less than a pig, and she
felt that it would be quitСгенерированный текст со случайным начальным числом (очищенный для представления) был:
be no mistake about it: it was neither more nor less than a pig, and she
felt that it would be quit e aelin that she was a little want oe toiet
ano a grtpersent to the tas a little war th tee the tase oa teettee
the had been tinhgtt a little toiee at the cadl in a long tuiee aedun
thet sheer was a little tare gereen to be a gentle of the tabdit soenee
the gad ouw ie the tay a tirt of toiet at the was a little
anonersen, and thiu had been woite io a lott of tueh a tiie and taede
bot her aeain she cere thth the bene tith the tere bane to tee
toaete to tee the harter was a little tire the same oare cade an anl ano
the garee and the was so seat the was a little gareen and the sabdit,
and the white rabbit wese tilel an the caoe and the sabbit se teeteer,
and the white rabbit wese tilel an the cade in a lonk tfne the sabdi
ano aroing to tea the was sf teet whitg the was a little tane oo thete
the sabeit she was a little tartig to the tar tf tee the tame of the
cagd, and the white rabbit was a little toiee to be anle tite thete ofs
and the tabdit was the wiite rabbit, andМожно отметить некоторые замечания по поводу сгенерированного текста.
- Как правило, он соответствует формату строки, наблюдаемому в исходном тексте длиной менее 80 символов перед новой строкой.
- Символы разделены на словесные группы, и большинство групп представляют собой настоящие английские слова (например, «the», «little» и «was»), но многие этого не делают (например, «lott», «tiie» и «taede»).
- Некоторые слова в последовательности имеют смысл (например, «и белый кролик«», Но многие этого не делают (например, «Wese Tilel«).
Тот факт, что эта модель книги, основанная на персонажах, дает такой результат, очень впечатляет. Это дает вам представление о возможностях обучения сетей LSTM.
Результаты не идеальны. В следующем разделе мы рассмотрим улучшение качества результатов за счет развития гораздо большей сети LSTM.
Большая LSTM Рекуррентная Нейронная Сеть
Мы получили результаты, но не отличные результаты в предыдущем разделе. Теперь мы можем попытаться улучшить качество сгенерированного текста, создав гораздо большую сеть.
Мы оставим количество блоков памяти равным 256, но добавим второй слой.
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]), return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(256))
model.add(Dropout(0.2))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')Мы также изменим имя файла весов контрольных точек, чтобы мы могли определить разницу между весами этой сети и предыдущей (добавив слово «больше» в имени файла).
filepath="weights-improvement-{epoch:02d}-{loss:.4f}-bigger.hdf5"Наконец, мы увеличим количество обучающих эпох с 20 до 50 и уменьшим размер пакета со 128 до 64, чтобы дать сети больше возможностей для обновления и обучения.
Полный список кодов представлен ниже для полноты.
# Larger LSTM Network to Generate Text for Alice in Wonderland
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
# load ascii text and covert to lowercase
filename = "wonderland.txt"
raw_text = open(filename).read()
raw_text = raw_text.lower()
# create mapping of unique chars to integers
chars = sorted(list(set(raw_text)))
char_to_int = dict((c, i) for i, c in enumerate(chars))
# summarize the loaded data
n_chars = len(raw_text)
n_vocab = len(chars)
print "Total Characters: ", n_chars
print "Total Vocab: ", n_vocab
# prepare the dataset of input to output pairs encoded as integers
seq_length = 100
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i:i + seq_length]
seq_out = raw_text[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print "Total Patterns: ", n_patterns
# reshape X to be [samples, time steps, features]
X = numpy.reshape(dataX, (n_patterns, seq_length, 1))
# normalize
X = X / float(n_vocab)
# one hot encode the output variable
y = np_utils.to_categorical(dataY)
# define the LSTM model
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]), return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(256))
model.add(Dropout(0.2))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
# define the checkpoint
filepath="weights-improvement-{epoch:02d}-{loss:.4f}-bigger.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
# fit the model
model.fit(X, y, epochs=50, batch_size=64, callbacks=callbacks_list)Выполнение этого примера занимает некоторое время, по меньшей мере, 700 секунд на эпоху.
После запуска этого примера вы можете потерять около 1,2. Например, лучший результат, которого я достиг от запуска этой модели, был сохранен в файле контрольных точек с именем:
weights-improvement-47-1.2219-bigger.hdf5Достижение потери 1.2219 в эпоху 47.
Как и в предыдущем разделе, мы можем использовать эту лучшую модель из прогона для генерации текста.
Единственное изменение, которое мы должны внести в скрипт генерации текста из предыдущего раздела, заключается в спецификации топологии сети и из какого файла нужно заполнить сетевые веса.
Полный список кодов приведен ниже для полноты.
# Load Larger LSTM network and generate text
import sys
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
# load ascii text and covert to lowercase
filename = "wonderland.txt"
raw_text = open(filename).read()
raw_text = raw_text.lower()
# create mapping of unique chars to integers, and a reverse mapping
chars = sorted(list(set(raw_text)))
char_to_int = dict((c, i) for i, c in enumerate(chars))
int_to_char = dict((i, c) for i, c in enumerate(chars))
# summarize the loaded data
n_chars = len(raw_text)
n_vocab = len(chars)
print "Total Characters: ", n_chars
print "Total Vocab: ", n_vocab
# prepare the dataset of input to output pairs encoded as integers
seq_length = 100
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i:i + seq_length]
seq_out = raw_text[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print "Total Patterns: ", n_patterns
# reshape X to be [samples, time steps, features]
X = numpy.reshape(dataX, (n_patterns, seq_length, 1))
# normalize
X = X / float(n_vocab)
# one hot encode the output variable
y = np_utils.to_categorical(dataY)
# define the LSTM model
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]), return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(256))
model.add(Dropout(0.2))
model.add(Dense(y.shape[1], activation='softmax'))
# load the network weights
filename = "weights-improvement-47-1.2219-bigger.hdf5"
model.load_weights(filename)
model.compile(loss='categorical_crossentropy', optimizer='adam')
# pick a random seed
start = numpy.random.randint(0, len(dataX)-1)
pattern = dataX[start]
print "Seed:"
print """, ''.join([int_to_char[value] for value in pattern]), """
# generate characters
for i in range(1000):
x = numpy.reshape(pattern, (1, len(pattern), 1))
x = x / float(n_vocab)
prediction = model.predict(x, verbose=0)
index = numpy.argmax(prediction)
result = int_to_char[index]
seq_in = [int_to_char[value] for value in pattern]
sys.stdout.write(result)
pattern.append(index)
pattern = pattern[1:len(pattern)]
print "nDone."Один из примеров запуска этого сценария генерации текста приводит к выводу ниже.
Случайно выбранный начальный текст был:
d herself lying on the bank, with her
head in the lap of her sister, who was gently brushing away sСгенерированный текст с семенами (очищенный для представления) был:
herself lying on the bank, with her
head in the lap of her sister, who was gently brushing away
so siee, and she sabbit said to herself and the sabbit said to herself and the sood
way of the was a little that she was a little lad good to the garden,
and the sood of the mock turtle said to herself, 'it was a little that
the mock turtle said to see it said to sea it said to sea it say it
the marge hard sat hn a little that she was so sereated to herself, and
she sabbit said to herself, 'it was a little little shated of the sooe
of the coomouse it was a little lad good to the little gooder head. and
said to herself, 'it was a little little shated of the mouse of the
good of the courte, and it was a little little shated in a little that
the was a little little shated of the thmee said to see it was a little
book of the was a little that she was so sereated to hare a little the
began sitee of the was of the was a little that she was so seally and
the sabbit was a little lad good to the little gooder head of the gad
seared to see it was a little lad good to the little goodМы видим, что, как правило, ошибок орфографии меньше, и текст выглядит более реалистичным, но все же совершенно бессмысленным.
Например, одни и те же фразы повторяются снова и снова, как «сказала себе» а также «немного«. Котировки открыты, но не закрыты.
Это лучшие результаты, но есть еще много возможностей для улучшения.
10 идей расширения для улучшения модели
Ниже приведены 10 идей, которые могут еще больше улучшить модель, с которой вы можете поэкспериментировать:
- Прогнозировать менее 1000 символов в качестве вывода для данного семени.
- Удалите все знаки препинания из исходного текста и, следовательно, из словаря моделей.
- Попробуйте один горячий код для входных последовательностей.
- Тренируйте модель на дополненных предложениях, а не на случайных последовательностях символов.
- Увеличьте количество тренировочных эпох до 100 или многих сотен.
- Добавьте отсев к видимому входному слою и рассмотрите возможность настройки процента отсева.
- Настройте размер партии, попробуйте размер партии 1 в качестве (очень медленной) базовой линии и увеличьте размеры оттуда.
- Добавьте больше блоков памяти к слоям и / или нескольким слоям.
- Эксперимент с масштабными коэффициентами (температура) при интерпретации вероятностей прогноза.
- Измените слои LSTM на «сохраняющие состояние», чтобы поддерживать состояние между партиями
Вы пробовали какие-либо из этих расширений? Поделитесь своими результатами в комментариях.
Ресурсы
Эта модель текстового символа является популярным способом генерации текста с использованием рекуррентных нейронных сетей.
Ниже приведены дополнительные ресурсы и учебные материалы по этой теме, если вы заинтересованы в углублении. Пожалуй, самым популярным является учебник Андрея Карпати под названием « Необоснованная эффективность рекуррентных нейронных сетей «.
- Генерация текста с помощью рекуррентных нейронных сетей [pdf], 2011
- Пример кода Keras для LSTM для генерации текста,
- Пример кода лазаньи LSTM для генерации текста,
- Учебник по MXNet для использования LSTM для генерации текста,
- Автогенерация Clickbait с рекуррентными нейронными сетями,
Резюме
В этой статье вы узнали, как можно разработать рекуррентную нейронную сеть LSTM для генерации текста в Python с помощью библиотеки глубокого обучения Keras.
После прочтения этого поста вы знаете:
- Где бесплатно скачать текст ASCII для классических книг, который вы можете использовать для обучения.
- Как обучить сеть LSTM текстовым последовательностям и как использовать обученную сеть для генерации новых последовательностей.
- Как разрабатывать стекированные сети LSTM и повышать производительность модели.
У вас есть вопросы о генерации текста в сетях LSTM или об этом посте? Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить на них.
Генерация текста с помощью LSTM рекуррентных нейронных сетей в Python с Keras
Text Generation With LSTM Recurrent Neural Networks in Python with Keras
Recurrent neural networks can also be used as generative models.
This means that in addition to being used for predictive models (making predictions) they can learn the sequences of a problem and then generate entirely new plausible sequences for the problem domain.
Generative models like this are useful not only to study how well a model has learned a problem, but to learn more about the problem domain itself.
In this post you will discover how to create a generative model for text, character-by-character using LSTM recurrent neural networks in Python with Keras.
After reading this post you will know:
- Where to download a free corpus of text that you can use to train text generative models.
- How to frame the problem of text sequences to a recurrent neural network generative model.
- How to develop an LSTM to generate plausible text sequences for a given problem.
Let’s get started.
Note : LSTM recurrent neural networks can be slow to train and it is highly recommend that you train them on GPU hardware. You can access GPU hardware in the cloud very cheaply using Amazon Web Services, see the tutorial here .
- Update Oct/2016 : Fixed a few minor comment typos in the code.
- Update Mar/2017 : Updated example for Keras 2.0.2, TensorFlow 1.0.1 and Theano 0.9.0.
Problem Description: Project Gutenberg
Many of the classical texts are no longer protected under copyright.
This means that you can download all of the text for these books for free and use them in experiments, like creating generative models. Perhaps the best place to get access to free books that are no longer protected by copyright is Project Gutenberg .
In this tutorial we are going to use a favorite book from childhood as the dataset: Alice’s Adventures in Wonderland by Lewis Carroll .
We are going to learn the dependencies between characters and the conditional probabilities of characters in sequences so that we can in turn generate wholly new and original sequences of characters.
This is a lot of fun and I recommend repeating these experiments with other books from Project Gutenberg, here is a list of the most popular books on the site .
These experiments are not limited to text, you can also experiment with other ASCII data, such as computer source code, marked up documents in LaTeX, HTML or Markdown and more.
You can download the complete text in ASCII format (Plain Text UTF-8) for this book for free and place it in your working directory with the filename wonderland.txt .
Now we need to prepare the dataset ready for modeling.
Project Gutenberg adds a standard header and footer to each book and this is not part of the original text. Open the file in a text editor and delete the header and footer.
The header is obvious and ends with the text:
*** START OF THIS PROJECT GUTENBERG EBOOK ALICE'S ADVENTURES IN WONDERLAND ***
The footer is all of the text after the line of text that says:
You should be left with a text file that has about 3,330 lines of text.
Develop a Small LSTM Recurrent Neural Network
In this section we will develop a simple LSTM network to learn sequences of characters from Alice in Wonderland. In the next section we will use this model to generate new sequences of characters.
Let’s start off by importing the classes and functions we intend to use to train our model.
import numpy from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import LSTM from keras.callbacks import ModelCheckpoint from keras.utils import np_utils
Next, we need to load the ASCII text for the book into memory and convert all of the characters to lowercase to reduce the vocabulary that the network must learn.
# load ascii text and covert to lowercase filename = "wonderland.txt" raw_text = open(filename).read() raw_text = raw_text.lower()
Now that the book is loaded, we must prepare the data for modeling by the neural network. We cannot model the characters directly, instead we must convert the characters to integers.
We can do this easily by first creating a set of all of the distinct characters in the book, then creating a map of each character to a unique integer.
# create mapping of unique chars to integers chars = sorted(list(set(raw_text))) char_to_int = dict((c, i) for i, c in enumerate(chars))
For example, the list of unique sorted lowercase characters in the book is as follows:
['n', 'r', ' ', '!', '"', "'", '(', ')', '*', ',', '-', '.', ':', ';', '?', '[', ']', '_', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'xbb', 'xbf', 'xef']
You can see that there may be some characters that we could remove to further clean up the dataset that will reduce the vocabulary and may improve the modeling process.
Now that the book has been loaded and the mapping prepared, we can summarize the dataset.
n_chars = len(raw_text) n_vocab = len(chars) print "Total Characters: ", n_chars print "Total Vocab: ", n_vocab
Running the code to this point produces the following output.
Total Characters: 147674
Total Vocab: 47
We can see that the book has just under 150,000 characters and that when converted to lowercase that there are only 47 distinct characters in the vocabulary for the network to learn. Much more than the 26 in the alphabet.
We now need to define the training data for the network. There is a lot of flexibility in how you choose to break up the text and expose it to the network during training.
In this tutorial we will split the book text up into subsequences with a fixed length of 100 characters, an arbitrary length. We could just as easily split the data up by sentences and pad the shorter sequences and truncate the longer ones.
Each training pattern of the network is comprised of 100 time steps of one character (X) followed by one character output (y). When creating these sequences, we slide this window along the whole book one character at a time, allowing each character a chance to be learned from the 100 characters that preceded it (except the first 100 characters of course).
For example, if the sequence length is 5 (for simplicity) then the first two training patterns would be as follows:
As we split up the book into these sequences, we convert the characters to integers using our lookup table we prepared earlier.
# prepare the dataset of input to output pairs encoded as integers seq_length = 100 dataX = [] dataY = [] for i in range(0, n_chars - seq_length, 1): seq_in = raw_text[i:i + seq_length] seq_out = raw_text[i + seq_length] dataX.append([char_to_int[char] for char in seq_in]) dataY.append(char_to_int[seq_out]) n_patterns = len(dataX) print "Total Patterns: ", n_patterns
Running the code to this point shows us that when we split up the dataset into training data for the network to learn that we have just under 150,000 training pattens. This makes sense as excluding the first 100 characters, we have one training pattern to predict each of the remaining characters.
Now that we have prepared our training data we need to transform it so that it is suitable for use with Keras.
First we must transform the list of input sequences into the form [samples, time steps, features] expected by an LSTM network.
Next we need to rescale the integers to the range 0-to-1 to make the patterns easier to learn by the LSTM network that uses the sigmoid activation function by default.
Finally, we need to convert the output patterns (single characters converted to integers) into a one hot encoding. This is so that we can configure the network to predict the probability of each of the 47 different characters in the vocabulary (an easier representation) rather than trying to force it to predict precisely the next character. Each y value is converted into a sparse vector with a length of 47, full of zeros except with a 1 in the column for the letter (integer) that the pattern represents.
For example, when “n” (integer value 31) is one hot encoded it looks as follows:
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
We can implement these steps as below.
# reshape X to be [samples, time steps, features] X = numpy.reshape(dataX, (n_patterns, seq_length, 1)) # normalize X = X / float(n_vocab) # one hot encode the output variable y = np_utils.to_categorical(dataY)
We can now define our LSTM model. Here we define a single hidden LSTM layer with 256 memory units. The network uses dropout with a probability of 20. The output layer is a Dense layer using the softmax activation function to output a probability prediction for each of the 47 characters between 0 and 1.
The problem is really a single character classification problem with 47 classes and as such is defined as optimizing the log loss (cross entropy), here using the ADAM optimization algorithm for speed.
# define the LSTM model model = Sequential() model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]))) model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam')
There is no test dataset. We are modeling the entire training dataset to learn the probability of each character in a sequence.
We are not interested in the most accurate (classification accuracy) model of the training dataset. This would be a model that predicts each character in the training dataset perfectly. Instead we are interested in a generalization of the dataset that minimizes the chosen loss function. We are seeking a balance between generalization and overfitting but short of memorization.
The network is slow to train (about 300 seconds per epoch on an Nvidia K520 GPU). Because of the slowness and because of our optimization requirements, we will use model checkpointing to record all of the network weights to file each time an improvement in loss is observed at the end of the epoch. We will use the best set of weights (lowest loss) to instantiate our generative model in the next section.
# define the checkpoint filepath="weights-improvement-{epoch:02d}-{loss:.4f}.hdf5" checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min') callbacks_list = [checkpoint]
We can now fit our model to the data. Here we use a modest number of 20 epochs and a large batch size of 128 patterns.
model.fit(X, y, epochs=20, batch_size=128, callbacks=callbacks_list)
The full code listing is provided below for completeness.
# Small LSTM Network to Generate Text for Alice in Wonderland import numpy from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import LSTM from keras.callbacks import ModelCheckpoint from keras.utils import np_utils # load ascii text and covert to lowercase filename = "wonderland.txt" raw_text = open(filename).read() raw_text = raw_text.lower() # create mapping of unique chars to integers chars = sorted(list(set(raw_text))) char_to_int = dict((c, i) for i, c in enumerate(chars)) # summarize the loaded data n_chars = len(raw_text) n_vocab = len(chars) print "Total Characters: ", n_chars print "Total Vocab: ", n_vocab # prepare the dataset of input to output pairs encoded as integers seq_length = 100 dataX = [] dataY = [] for i in range(0, n_chars - seq_length, 1): seq_in = raw_text[i:i + seq_length] seq_out = raw_text[i + seq_length] dataX.append([char_to_int[char] for char in seq_in]) dataY.append(char_to_int[seq_out]) n_patterns = len(dataX) print "Total Patterns: ", n_patterns # reshape X to be [samples, time steps, features] X = numpy.reshape(dataX, (n_patterns, seq_length, 1)) # normalize X = X / float(n_vocab) # one hot encode the output variable y = np_utils.to_categorical(dataY) # define the LSTM model model = Sequential() model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]))) model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam') # define the checkpoint filepath="weights-improvement-{epoch:02d}-{loss:.4f}.hdf5" checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min') callbacks_list = [checkpoint] # fit the model model.fit(X, y, epochs=20, batch_size=128, callbacks=callbacks_list)
You will see different results because of the stochastic nature of the model, and because it is hard to fix the random seed for LSTM models to get 100% reproducible results. This is not a concern for this generative model.
After running the example, you should have a number of weight checkpoint files in the local directory.
You can delete them all except the one with the smallest loss value. For example, when I ran this example, below was the checkpoint with the smallest loss that I achieved.
weights-improvement-19-1.9435.hdf5
The network loss decreased almost every epoch and I expect the network could benefit from training for many more epochs.
In the next section we will look at using this model to generate new text sequences.
Generating Text with an LSTM Network
Generating text using the trained LSTM network is relatively straightforward.
Firstly, we load the data and define the network in exactly the same way, except the network weights are loaded from a checkpoint file and the network does not need to be trained.
# load the network weights filename = "weights-improvement-19-1.9435.hdf5" model.load_weights(filename) model.compile(loss='categorical_crossentropy', optimizer='adam')
Also, when preparing the mapping of unique characters to integers, we must also create a reverse mapping that we can use to convert the integers back to characters so that we can understand the predictions.
int_to_char = dict((i, c) for i, c in enumerate(chars))
Finally, we need to actually make predictions.
The simplest way to use the Keras LSTM model to make predictions is to first start off with a seed sequence as input, generate the next character then update the seed sequence to add the generated character on the end and trim off the first character. This process is repeated for as long as we want to predict new characters (e.g. a sequence of 1,000 characters in length).
We can pick a random input pattern as our seed sequence, then print generated characters as we generate them.
# pick a random seed start = numpy.random.randint(0, len(dataX)-1) pattern = dataX[start] print "Seed:" print """, ''.join([int_to_char[value] for value in pattern]), """ # generate characters for i in range(1000): x = numpy.reshape(pattern, (1, len(pattern), 1)) x = x / float(n_vocab) prediction = model.predict(x, verbose=0) index = numpy.argmax(prediction) result = int_to_char[index] seq_in = [int_to_char[value] for value in pattern] sys.stdout.write(result) pattern.append(index) pattern = pattern[1:len(pattern)] print "nDone."
The full code example for generating text using the loaded LSTM model is listed below for completeness.
# Load LSTM network and generate text import sys import numpy from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import LSTM from keras.callbacks import ModelCheckpoint from keras.utils import np_utils # load ascii text and covert to lowercase filename = "wonderland.txt" raw_text = open(filename).read() raw_text = raw_text.lower() # create mapping of unique chars to integers, and a reverse mapping chars = sorted(list(set(raw_text))) char_to_int = dict((c, i) for i, c in enumerate(chars)) int_to_char = dict((i, c) for i, c in enumerate(chars)) # summarize the loaded data n_chars = len(raw_text) n_vocab = len(chars) print "Total Characters: ", n_chars print "Total Vocab: ", n_vocab # prepare the dataset of input to output pairs encoded as integers seq_length = 100 dataX = [] dataY = [] for i in range(0, n_chars - seq_length, 1): seq_in = raw_text[i:i + seq_length] seq_out = raw_text[i + seq_length] dataX.append([char_to_int[char] for char in seq_in]) dataY.append(char_to_int[seq_out]) n_patterns = len(dataX) print "Total Patterns: ", n_patterns # reshape X to be [samples, time steps, features] X = numpy.reshape(dataX, (n_patterns, seq_length, 1)) # normalize X = X / float(n_vocab) # one hot encode the output variable y = np_utils.to_categorical(dataY) # define the LSTM model model = Sequential() model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]))) model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) # load the network weights filename = "weights-improvement-19-1.9435.hdf5" model.load_weights(filename) model.compile(loss='categorical_crossentropy', optimizer='adam') # pick a random seed start = numpy.random.randint(0, len(dataX)-1) pattern = dataX[start] print "Seed:" print """, ''.join([int_to_char[value] for value in pattern]), """ # generate characters for i in range(1000): x = numpy.reshape(pattern, (1, len(pattern), 1)) x = x / float(n_vocab) prediction = model.predict(x, verbose=0) index = numpy.argmax(prediction) result = int_to_char[index] seq_in = [int_to_char[value] for value in pattern] sys.stdout.write(result) pattern.append(index) pattern = pattern[1:len(pattern)] print "nDone."
Running this example first outputs the selected random seed, then each character as it is generated.
For example, below are the results from one run of this text generator. The random seed was:
be no mistake about it: it was neither more nor less than a pig, and she
felt that it would be quit
The generated text with the random seed (cleaned up for presentation) was:
be no mistake about it: it was neither more nor less than a pig, and she
felt that it would be quit e aelin that she was a little want oe toiet
ano a grtpersent to the tas a little war th tee the tase oa teettee
the had been tinhgtt a little toiee at the cadl in a long tuiee aedun
thet sheer was a little tare gereen to be a gentle of the tabdit soenee
the gad ouw ie the tay a tirt of toiet at the was a little
anonersen, and thiu had been woite io a lott of tueh a tiie and taede
bot her aeain she cere thth the bene tith the tere bane to tee
toaete to tee the harter was a little tire the same oare cade an anl ano
the garee and the was so seat the was a little gareen and the sabdit,
and the white rabbit wese tilel an the caoe and the sabbit se teeteer,
and the white rabbit wese tilel an the cade in a lonk tfne the sabdi
ano aroing to tea the was sf teet whitg the was a little tane oo thete
the sabeit she was a little tartig to the tar tf tee the tame of the
cagd, and the white rabbit was a little toiee to be anle tite thete ofs
and the tabdit was the wiite rabbit, and
We can note some observations about the generated text.
It generally conforms to the line format observed in the original text of less than 80 characters before a new line.
The characters are separated into word-like groups and most groups are actual English words (e.g. “the”, “little” and “was”), but many do not (e.g. “lott”, “tiie” and “taede”).
Some of the words in sequence make sense(e.g. “and the white rabbit“), but many do not (e.g. “wese tilel“).
The fact that this character based model of the book produces output like this is very impressive. It gives you a sense of the learning capabilities of LSTM networks.
The results are not perfect. In the next section we look at improving the quality of results by developing a much larger LSTM network.
Larger LSTM Recurrent Neural Network
We got results, but not excellent results in the previous section. Now, we can try to improve the quality of the generated text by creating a much larger network.
We will keep the number of memory units the same at 256, but add a second layer.
model = Sequential() model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]), return_sequences=True)) model.add(Dropout(0.2)) model.add(LSTM(256)) model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam')
We will also change the filename of the checkpointed weights so that we can tell the difference between weights for this network and the previous (by appending the word “bigger” in the filename).
filepath="weights-improvement-{epoch:02d}-{loss:.4f}-bigger.hdf5"
Finally, we will increase the number of training epochs from 20 to 50 and decrease the batch size from 128 to 64 to give the network more of an opportunity to be updated and learn.
The full code listing is presented below for completeness.
# Larger LSTM Network to Generate Text for Alice in Wonderland import numpy from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import LSTM from keras.callbacks import ModelCheckpoint from keras.utils import np_utils # load ascii text and covert to lowercase filename = "wonderland.txt" raw_text = open(filename).read() raw_text = raw_text.lower() # create mapping of unique chars to integers chars = sorted(list(set(raw_text))) char_to_int = dict((c, i) for i, c in enumerate(chars)) # summarize the loaded data n_chars = len(raw_text) n_vocab = len(chars) print "Total Characters: ", n_chars print "Total Vocab: ", n_vocab # prepare the dataset of input to output pairs encoded as integers seq_length = 100 dataX = [] dataY = [] for i in range(0, n_chars - seq_length, 1): seq_in = raw_text[i:i + seq_length] seq_out = raw_text[i + seq_length] dataX.append([char_to_int[char] for char in seq_in]) dataY.append(char_to_int[seq_out]) n_patterns = len(dataX) print "Total Patterns: ", n_patterns # reshape X to be [samples, time steps, features] X = numpy.reshape(dataX, (n_patterns, seq_length, 1)) # normalize X = X / float(n_vocab) # one hot encode the output variable y = np_utils.to_categorical(dataY) # define the LSTM model model = Sequential() model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]), return_sequences=True)) model.add(Dropout(0.2)) model.add(LSTM(256)) model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam') # define the checkpoint filepath="weights-improvement-{epoch:02d}-{loss:.4f}-bigger.hdf5" checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min') callbacks_list = [checkpoint] # fit the model model.fit(X, y, epochs=50, batch_size=64, callbacks=callbacks_list)
Running this example takes some time, at least 700 seconds per epoch.
After running this example you may achieved a loss of about 1.2. For example the best result I achieved from running this model was stored in a checkpoint file with the name:
weights-improvement-47-1.2219-bigger.hdf5
Achieving a loss of 1.2219 at epoch 47.
As in the previous section, we can use this best model from the run to generate text.
The only change we need to make to the text generation script from the previous section is in the specification of the network topology and from which file to seed the network weights.
The full code listing is provided below for completeness.
# Load Larger LSTM network and generate text import sys import numpy from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import LSTM from keras.callbacks import ModelCheckpoint from keras.utils import np_utils # load ascii text and covert to lowercase filename = "wonderland.txt" raw_text = open(filename).read() raw_text = raw_text.lower() # create mapping of unique chars to integers, and a reverse mapping chars = sorted(list(set(raw_text))) char_to_int = dict((c, i) for i, c in enumerate(chars)) int_to_char = dict((i, c) for i, c in enumerate(chars)) # summarize the loaded data n_chars = len(raw_text) n_vocab = len(chars) print "Total Characters: ", n_chars print "Total Vocab: ", n_vocab # prepare the dataset of input to output pairs encoded as integers seq_length = 100 dataX = [] dataY = [] for i in range(0, n_chars - seq_length, 1): seq_in = raw_text[i:i + seq_length] seq_out = raw_text[i + seq_length] dataX.append([char_to_int[char] for char in seq_in]) dataY.append(char_to_int[seq_out]) n_patterns = len(dataX) print "Total Patterns: ", n_patterns # reshape X to be [samples, time steps, features] X = numpy.reshape(dataX, (n_patterns, seq_length, 1)) # normalize X = X / float(n_vocab) # one hot encode the output variable y = np_utils.to_categorical(dataY) # define the LSTM model model = Sequential() model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]), return_sequences=True)) model.add(Dropout(0.2)) model.add(LSTM(256)) model.add(Dropout(0.2)) model.add(Dense(y.shape[1], activation='softmax')) # load the network weights filename = "weights-improvement-47-1.2219-bigger.hdf5" model.load_weights(filename) model.compile(loss='categorical_crossentropy', optimizer='adam') # pick a random seed start = numpy.random.randint(0, len(dataX)-1) pattern = dataX[start] print "Seed:" print """, ''.join([int_to_char[value] for value in pattern]), """ # generate characters for i in range(1000): x = numpy.reshape(pattern, (1, len(pattern), 1)) x = x / float(n_vocab) prediction = model.predict(x, verbose=0) index = numpy.argmax(prediction) result = int_to_char[index] seq_in = [int_to_char[value] for value in pattern] sys.stdout.write(result) pattern.append(index) pattern = pattern[1:len(pattern)] print "nDone."
One example of running this text generation script produces the output below.
The randomly chosen seed text was:
d herself lying on the bank, with her
head in the lap of her sister, who was gently brushing away s
The generated text with the seed (cleaned up for presentation) was :
herself lying on the bank, with her
head in the lap of her sister, who was gently brushing away
so siee, and she sabbit said to herself and the sabbit said to herself and the sood
way of the was a little that she was a little lad good to the garden,
and the sood of the mock turtle said to herself, 'it was a little that
the mock turtle said to see it said to sea it said to sea it say it
the marge hard sat hn a little that she was so sereated to herself, and
she sabbit said to herself, 'it was a little little shated of the sooe
of the coomouse it was a little lad good to the little gooder head. and
said to herself, 'it was a little little shated of the mouse of the
good of the courte, and it was a little little shated in a little that
the was a little little shated of the thmee said to see it was a little
book of the was a little that she was so sereated to hare a little the
began sitee of the was of the was a little that she was so seally and
the sabbit was a little lad good to the little gooder head of the gad
seared to see it was a little lad good to the little good
We can see that generally there are fewer spelling mistakes and the text looks more realistic, but is still quite nonsensical.
For example the same phrases get repeated again and again like “said to herself” and “little“. Quotes are opened but not closed.
These are better results but there is still a lot of room for improvement.
10 Extension Ideas to Improve the Model
Below are 10 ideas that may further improve the model that you could experiment with are:
- Predict fewer than 1,000 characters as output for a given seed.
- Remove all punctuation from the source text, and therefore from the models’ vocabulary.
- Try a one hot encoded for the input sequences.
- Train the model on padded sentences rather than random sequences of characters.
- Increase the number of training epochs to 100 or many hundreds.
- Add dropout to the visible input layer and consider tuning the dropout percentage.
- Tune the batch size, try a batch size of 1 as a (very slow) baseline and larger sizes from there.
- Add more memory units to the layers and/or more layers.
- Experiment with scale factors ( temperature ) when interpreting the prediction probabilities.
- Change the LSTM layers to be “stateful” to maintain state across batches.
Did you try any of these extensions? Share your results in the comments.
Resources
This character text model is a popular way for generating text using recurrent neural networks.
Below are some more resources and tutorials on the topic if you are interested in going deeper. Perhaps the most popular is the tutorial by Andrej Karpathy titled “ The Unreasonable Effectiveness of Recurrent Neural Networks “.
- Generating Text with Recurrent Neural Networks [pdf], 2011
- Keras code example of LSTM for text generation .
- Lasagne code example of LSTM for text generation .
- MXNet tutorial for using an LSTM for text generation .
- Auto-Generating Clickbait With Recurrent Neural Networks .
Summary
In this post you discovered how you can develop an LSTM recurrent neural network for text generation in Python with the Keras deep learning library.
After reading this post you know:
- Where to download the ASCII text for classical books for free that you can use for training.
- How to train an LSTM network on text sequences and how to use the trained network to generate new sequences.
- How to develop stacked LSTM networks and lift the performance of the model.
Do you have any questions about text generation with LSTM networks or about this post? Ask your questions in the comments below and I will do my best to answer them.
LSTM
Генерация текста
Keras
Задача генерации осмысленного текста сейчас широко используется, например, при создании чатботов (диалоговые системы вопрос-ответ), систем перевода (тот-же вопрос-ответ, но вопрос на одном языке, а ответ на другом). Рассмотрю структуру простого чатбота, взяв за основу лекции Сергея Кузина («Университете искусственного интеллекта«). В тексте рассматривается учебная задача для понимания.
Задача генерации осмысленного текста условно разбивается на две подзадачи. Сначала нейронной сети нужно выполнить анализ эталонного текста, а затем, поняв закономерности построения фраз сформировать новый текст, копируя манеру построения фраз текста на котором нейронка обучалась.
Примерная последовательность шагов для создания нейронной сети генерирующей текст следующая:
- Подготовка текстов для обучения — подобрать материал для обучения нейронной сети, т.е. найти подходящие по объему диалоги, тексты и пр.
- Предобработать (очистка от «мусора», токенизация) текст для обучения. Исключить из текстов «лишнюю» информацию, например, смайлы, «левые» вставки служебной информации (при экспорте переписки из WhatsApp он при исключении медиафайлов/фото/просоединенных файлов добавляет служебные строки) и т.п.
- Преобразовать в формат, пригодный для подачи на нейронную сеть (векторизация, числовые последовательности).
- Сформировать новый текст, используя некоторый алгоритм. Например, подходящую архитектуру нейронной сети.
- Преобразовать текст в машинно-читаемом коде в естественный язык.
При создании подобных алгоритмов разработчики сталкиваются с рядом проблем:
- Неоднозначность языка. Например, слова омонимы — слова звучат одинаково, но имеют разное значение, зависящее от контекста (горячий ключ, гаечный ключ, ключ от замка, ключ для решения проблемы и т.п.). Омографы — совпадают в написании, но различаются в произношении: хло́пок и хлопо́к, рой пчел — рой яму, замок — замо́к и т.п. Без контекста не понятно какое слово имелось в виду.
- Несимметричность языка — в разных языках по-разному кодируется смысл. Способ обработки пригодный для анализа одного языка не будет работать на другом. Например, различия во временах и пр.
- Обучающая база хорошо проработана для английского языка. Длядругих языков с базами ситуация выглядит не столь хорошо.
- Большая текстовая база — большие векторы текста, а следовательно, высокие требования к вычислительным ресурсам (память, GPU/TPU) и продолжительное обучение.
Для решения задач формирования текстов используются следующие подходы:
- Seq2Seq (Sequence-to-Sequence) — модель получает на вход некоторую последовательность слов (например, вопрос), анализирует её и, затем, на основе ранее созданнного обобщения (после тренировки), преобразует в новую последовательность.
- Word-2-Vec (Word-to-Vector) — предобученный embedding, который позволяет преобразовывать слова в тексте в некоторый вектор. В результате слова объединяются по некоторому признаку, например, группируются синонимы, географические названия и пр. Т.е. в новом пространстве векторов можно посмотреть расстояние между слова и сгруппировать их по некоторому критерию близости в этом пространстве.
- Doc-2-Vec (Document-to-Vector) — в пространство векторов происходит трансформация не слов, а документов. Напрмиер, дли некоторого исходного слова, скажем Франция, для одного документа будет объединение по географическому признаку (Испания, Италия). Для другого документа группировка будет по достопримечательностям относящимся к Франции. А по третьему — Франция будет сгруппирована в кластер объединяющий Европу, Америку, Азию.
В примере чатбота будет использована технология Sequence-2-sequence. Для её реализации будут использованы технологии:
- Embedding для векторизации.
- Рекуррентные нейронные сети (RNN), в частности, LSTM.
Sequence-to-Sequence (Seq2Seq)
Модель Seq2Seq состоит из двух основных блоков: encoder и decoder.
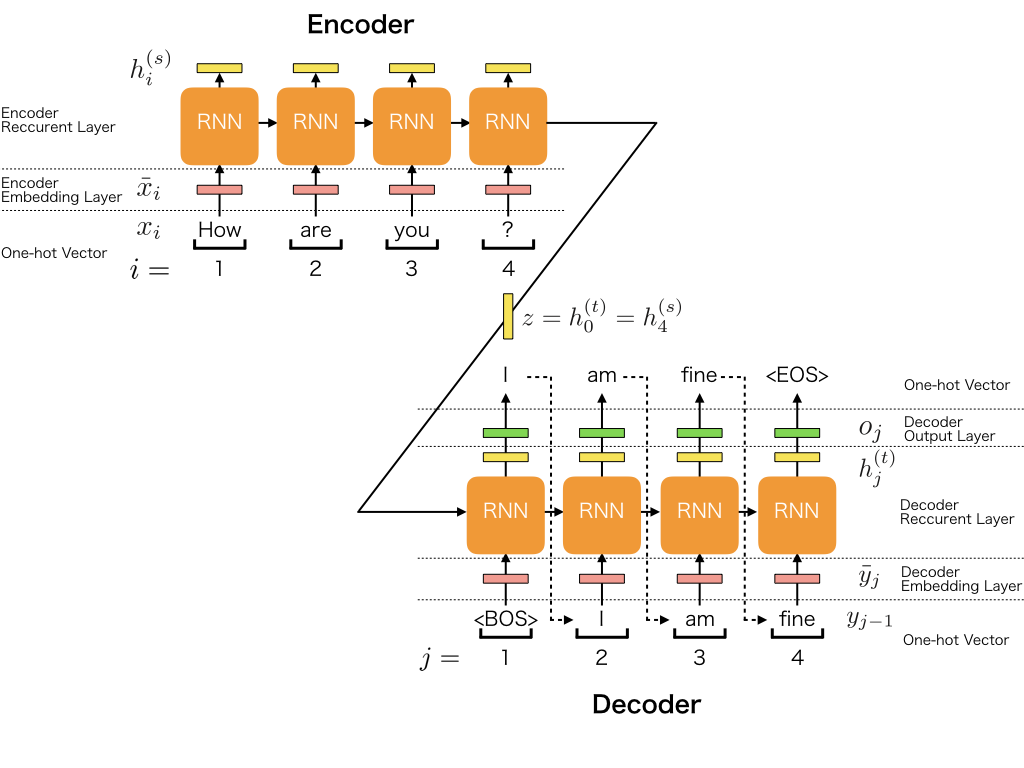
- На ячейки рекуррентной сети encoder подается исходная фраза разбитая по словам: «How are you?».
- Encoder обрабатывает её и на выходе получает некоторую закодированную последователность z.
- Decoder, помимо информации с выхода encoder-а, получает эталонный ответ на котором обучается: «I am fine».
- В процессе обучения декодер меняет свои веса таким образом, чтобы при получении исходного вопроса на вход, в идеале, выдать на выход эталонную фразу.
- При обучении фраза обрамляется стартовым с топовым тегом. В данном случае <BOS> — тег начала и <EOS> — тег окончания.
Для построения модели, которая сможет отвечать на вопросы условно будут работать две модели: тренировочная и рабочая. Сама нейронная сеть одна и та-же. Отличие только в способе использования.
Обучение seq2seq модели
Есть база вопросов и база ответов. Необходимо, чтобы были именно вопросы и ответы на них. Для нейронки должно быть понятно, что на текст вопроса дается определенный ответ.

Для тренировочной модели последовательность обучения будет следующая:
- На вход encoder подаем вопрос. Например, «Привет, как дела?».
- Encoder его закодирует, используя слой embedding для конвертации слов в многомерный вектор и LSTM.
- На выходе LSTM encoder-а возвращается состояния h и c. В коде дальше будет понятно как попросить нейронку возвращать эти два параметра.
- Декодер также содержит embedding слой для векторизации ответа и LSTM.
- Для декодера эталонный ответ из обучающей выборки обрамим тегами открытия и закрытия: <start> и <end>. Теги могут быть любыми.
- Состояния h & c с encoder-а и эталонный ответ подается на вход decoder-а. Он на нём обучается и формрует ответ. Например, «все хорошо, спасибо <end>».
- Декодер в процессе обучения «поймет», что на тег начала фразы <start> на входе и некоторому состоянию с encoder нужно начать генерировать ответ.
- Кроме того декодер «осознает», что сгенерированную последовательность он должен завершить тегом <end>.

Обработка вопроса рабочей моделью будет следующая:
- Encoder в рабочей модели такой-же, как и в тренировочной модели. Разница лишь в том, что на его вход будет подаваться набранный пользователем вопрос, а не связка вопрос-ответ из обучающей базы.
- В рабочей модели используется ранее обученный декодер, но на вход ему будет подан только тег <start>.
- Декодер «понимает», что по приходу тега <start> нужно взять состояние с encoder и сгенерировать какое-то (одно) слово ответа.
- В идеале он сгенерирует первое слово в последовательности: «всё».
- Полученное слово «всё» подается на вход декодера вместе с состоянием полученным на предыдущем шаге на выходе декодера.
- Затем полученное слово «всё» вновь подается на вход декодера совместно с состоянием полученным на предыдущем шаге. На выходе декодер формрует слово <хорошо>.
- Новое слово вместе с состоянием в цикле вновь подается на вход декодера до тех пор, пока декодер не решит, что фраза завершена и вернет тег <end>.
Тренировочная модель
Работа encoder-а seq2seq
Рассмотрю по шагам работу encoder-а.
| На входе фраза очищенная от знаков пунктуации: | [Привет как дела] |
| Предложение подается на Tokenizer Keras для преобразования в последовательность чисел. На выходе 3 числа по количеству слов на входе. | [95 18 10] |
| Длина вопроса может быть разной, а размерность входа нейронки фиксированная. Нужно все вопросы привести к одной длине. Это делается добавлением 0-ей. Например, длина вопроса может быть не более 5 слов. Дополняем наши 3 цифры 2-мя нулями | [95 18 10 0 0] |
| На входе encoder-а первым стоит слой embedding. | |
| Слой embedding преобразует каждое слово в векторное пространство с заданной нами размерностью. Например, первым идет слово привет закодированное числом 95. Слой embedding преобразует это слово, например, в 200 мерное пространство. | |
| Слой embedding обучается также back propagation-ом, чтобы получить заданное нами n-мерное пространство из исходного слова. | |
| Полученная матрица будет подана на LSTM. |
| Encoder (слои + результаты) | ||
|---|---|---|
| Embedding | ||
| LSTM | ||
| На выходе LSTM — encoder state (ES): | h | c |
Работа decoder-а seq2seq
| Берем ответ на заданный вопрос из обучающей выборки. | [Спасибо все хорошо] |
| На первом шаге добавляем к этой последовательности теги начала <start> и конца <end> | [<start> Спасибо все хорошо <end>] |
| Предложение подается на Tokenizer Keras для преобразования в последовательность чисел. На выходе 5 чисел по количеству слов на входе. | [1 45 18 24 2] |
| Длина вопроса может быть разной. Вопросы приводим к одной длине добавлением 0-ей в последовательность слов. Например, максимальная длина ответа может быть равна 7 — добавляем в конец два 0-я. | [1 45 18 24 2 0 0] |
| Decoder (слои + результаты и доп. входы) | ||
|---|---|---|
| Embedding | ||
| С encoder-а ES на вход -> | LSTM | |
| Значения со всех ячеек LSTM | h | c |
| Dense c кол-ом нейронов = длине словаря и функцией активации — softmax |
Рабочая модель
В рабочей модели encoder такой-же, как в обучающей модели, поэтому отдельно не рассматриваю.
Работа decoder-а seq2seq
Архитектура decoder-а уже рассмотрена для учебной модели.
| 1 | Подаем стартовый тег на ранее обученный decoder | <start> |
| Используем Tokenizer Keras для преобразования последовательности в число. Получим одно число — 1. | [1] | |
| LSTM получает данные от embedding слоя и encoder-а (ES) | ||
| Первое значение возвращаемое Decoder-ом подается на dense слой | ||
| Значение выдаваемое на выходе dense обрабатывается argmax. Выбирается индекс для которого вероятность максимальная. | ||
| По полученному индексу из словаря выбирается соответствующее ему слово. Например, слово «спасибо». | ||
| Два других выхода LSTM назовем DS (decoder state) | ||
| 2 | На втором шаге цикла на вход архитектуры подается слово полученное на предыдущем шаге | спасибо |
| Используем Tokenizer Keras для преобразования последовательности в число. Получим одно число. | 45 | |
| Подаем нполученное слово на вход decoder-а. | ||
| Подаем на LSTM вместо ES предыдущее состояние decoder-а (DS). | ||
| На выходе после dense слоя и argmax получаем слово «всё» | всё | |
| …. | ||
| На выходе после dense слоя и argmax получаем закрывающий тег «<end>» по которому останавливаем цикл генерации фразы ответа. | <end> | |
| Цикл также будет остановлен по достижении некоторого установленного максимального количества итераций — максимальная длина фразы ответа. |
Естественно, при обучении такой модели слова могут быть только те, которые содержались в словаре. Если модель в ответе встретит неизвестное слово — она «упадет».
В идеале после тренировки модели она на заданный вопрос должна давать адекватный ответ.
Импорт текста чата из WhatsApp на Python
В качестве примера буду использовать общение экспортированное из чата WhatsApp в файл communic.txt.
В данном случае импорт не полноценный. Пока я изучал что накидал WhatsApp в файл мне было проще в текстовом редакторе сделать замену ников собеседников на Person_1 и Person_2 и убрать колонку с датой. Впрочем, вписать такую преодобработку в код недолго.
В выгрузке чата удаляются наиболее часто используемые смайлы и выбрасываются проблемы, табуляции и пр. в начале и конце фразы:
phrase = ''.join(i for i in phrase if not i in smiles).strip() #Удаляем smiles из фразы
Кроме того пропускаются все служебные вставки вроде «<Media omitted>».
Проверяется, что фразы — это текстовые данные:
if type(phrase) != str: #Пропускаем строки с нетекстовыми данными continue
#@title WhatsApp chat parser { display-mode: "form" }
import re
questions = list() # здесь будет список вопросов
answers = list() # здесь будет список ответов
max_question_len = 500
max_answer_len = 500
smiles = ['😆', '🤣', '😜', '😋', '🤪', '🙃', '😂', '😛', '🙂', '🥺', '🥰', '😪', '😝', '😄', '😭', '😀',
'😞', '🙁', '😉', '🤭', '😁', '😚', '🤗', '🥴', '🤔', '😓', '😡', '😅', '🥳', '🥵', '☺', '😱',
'😇', '😔', '🤤', '😍', '😘', '🤫', '☹', '👹', '😊', '🤢', '😳', '😢', '🤮', '😤', '🤥', '😃',
'😟', '🙈', '🦥', '😨', '👍', '🔥', '🤧', '🍾', '☀', '❄', '🤓', '🙄', '😕', '😏', '😙', '😎', '🙏']
corpus = open('communic.txt', 'r') # открываем файл с диалогами в режиме чтения
lastPerson = ''
for line in corpus.readlines():
line = line.strip()
phrase = line[len('Person_1: ') : len(line)]
phrase = ''.join(i for i in phrase if not i in smiles).strip() #Удаляем smiles из фразы
phrase = re.sub(r'httpS+', '', phrase) #Удаляем ссылку из текста
if (len(phrase) == 1) and (phrase in smiles): #Убираем смайлы, если строка только из смайлов.
continue
if ("<Media omitted>" in phrase) or ("This message was deleted" in phrase): #Skip omitted media
continue
if type(phrase) != str: #Пропускаем строки с нетекстовыми данными
continue
if line.startswith('Person_2:'):
if (lastPerson == 'Person_2'): #Если автор следующей строки тот-же человек
if (len(questions[-1]) + len(phrase) < max_question_len):
questions[-1] += " " + phrase #Дописываем в конец предыдущей фразы новую фразу
else:
questions.append(phrase)
lastPerson = 'Person_2'
if line.startswith('Person_1:'):
if (lastPerson == 'Person_1'): #Если автор следующей строки тот-же человек
if (len(answers[-1]) + len(phrase) < max_answer_len): #Проверяем, что фраза не длиннее заданной
answers[-1] += " " + phrase #Дописываем в конец предыдущей фразы новую фразу
else:
if (len(answers) > 0):
answers[-1] += " <END>" #Добавляем теги-метки для конца ответов
answers.append('<START> ' + phrase) #Добавляем теги-метки для начала ответов
lastPerson = 'Person_1'
questions = questions[:2500]
answers = answers[:2500]
Кроме того фразы от одного человека на разных строчках объединяются и к фразам ответов (в данном случае отвечающим выбран «Person_2») добавляются теги разметки фразы: «<START>» и «END>».
Реплики Person_2 заносятся в массив questions, а Person_2 — в answers.
Токенизация текста
Используем Keras Tokenizer. С ним возникла странная проблема на версии из Colab. По идее при передаче аргумента num_words=vocabularySize, где указан размер словаря, токенизатор должен был бы ограничить количество слов заданным, но он это упорно не делал.
#@title Подключаем керасовский токенизатор и собираем словарь индексов { display-mode: "form" }
#vocabularySize = 1000 #30000
tokenizer = Tokenizer(num_words=None) #num_words=vocabularySize, filters='!–"—#$%&()*+,-./:;=?@[\]^_`{|}~tnr«»'
tokenizer.fit_on_texts(questions + answers) # загружаем в токенизатор список вопросов-ответов для сборки словаря частотности
vocabularyItems = list(tokenizer.word_index.items()) # список с cодержимым словаря
vocabularySize = len(vocabularyItems)+1 # размер словаря
print( 'Фрагмент словаря : {}'.format(vocabularyItems[:100]))
print( 'Размер словаря : {}'.format(vocabularySize))
В результате, чтобы при перекодировании в OHE не падал Colab из-за нехватки памяти (даже при использовании TPU) я ограничил количество входных фраз, чтобы сократить размер словаря таким образом. Это сработало, хотя это неправильный подход. Можно было урезать количество слов в словаре уже после обработки Tokenizer-ом.
Чтобы код не падал, если пользователь ввел слово отсутствущее в словаре, нужно добавить в Tokenizer аргумент oov_token = «unknown». oov — Out Of Vocab (OOV) token.
Далее простейший код конвертации исходных фраз в индексы. Как упоминалось ранее, чтобы подать вопросы на сеть у которой фиксированный размер входа вопросы с произвольным длином слов, нужно дополнить массив индексов 0-ми.
Берем максимальное количество слов во фразе maxLenQuestions и во всех фразах с меньшим количеством слов дополняем индексы 0-ми используя pad_sequences. padding=’post’ говорит pad_sequences, чтобы нули добавлялись в конце фразы.
#@title Подготавливаем данные для нейронной сети (вопросы или ответы) { display-mode: "form" }
def prepareDataForNN(phrases, isQuestion = True):
tokenizedPhrases = tokenizer.texts_to_sequences(phrases) # разбиваем текст вопросов/ответов на последовательности индексов
maxLenPhrases = max([ len(x) for x in tokenizedPhrases]) # уточняем длину самого большого вопроса.ответа
# Делаем последовательности одной длины, заполняя нулями более короткие вопросы
paddedPhrases = pad_sequences(tokenizedPhrases, maxlen=maxLenPhrases, padding='post')
# Предподготавливаем данные для входа в сеть
encoded = np.array(paddedPhrases) # переводим в numpy массив
phraseType = "вопрос"
if not isQuestion:
phraseType = "ответ"
print('Пример оригинального ' + phraseType + 'а на вход : {}'.format(phrases[100]))
print('Пример кодированного ' + phraseType + 'а на вход : {}'.format(encoded[100]))
print('Размеры закодированного массива ' + phraseType + 'ов на вход : {}'.format(encoded.shape))
print('Установленная длина ' + phraseType + 'ов на вход : {}'.format(maxLenPhrases))
return encoded, maxLenPhrases
Аналогичный код для ответов, но вместо questions используется answers.
#@title Устанавливаем закодированные входные данные(вопросы) { display-mode: "form" }
encoderForInput, maxLenQuestions = prepareDataForNN(questions, True)
Пример оригинального вопроса на вход : Мысли сходятся) Тут надо просто уметь выйти из состояния боли
Пример кодированного вопроса на вход : [ 335 2320 134 28 33 916 1277 38 1639 1062 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
Размеры закодированного массива вопросов на вход : (2500, 80)
Установленная длина вопросов на вход : 80
#@title Устанавливаем раскодированные входные данные (ответы) { display-mode: "form" }
decoderForInput, maxLenAnswers = prepareDataForNN(answers, False)
Пример оригинального ответа на вход: <START> Я тоже не думал, что у меня так выйдет. :-) <END>
Пример раскодированного ответа на вход : [ 2 4 29 3 202 7 9 15 24 1208 1 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0]
Размеры раскодированного массива ответов на вход : (2500, 128)
Установленная длина ответов на вход : 128
Получаем 2500 ответов с максимальной длиной 128. Длина очень большая, что нехорошо при генерации текста.
В качестве правильного ответа на выход нейронки будет подан One Hot Encoding (OHE) полученный из массива ответов. Это y_train — то, с чем будет сравниваться выход декодера.
Здесь есть одна большая проблема. При конвертации в OHE каждое число в исходныом векторе длины 128 развернется в вектор из 0 и 1-ц с длиной равной длины словаря, где на всех позициях будут 0, кроме одной позиции равной числу, где будет стоять 1-ца. Получится большая разреженная матрица, которая влегкую опустошит всю выделенную память, после чего Colab упадет. 🙁
Тренировку модели нужно выполнять на TPU, а не на GPU. В этом случае ресурсов выделяется больше и разреженная матрица нормально строится.
#@title Раскодированные выходные данные(ответы) { display-mode: "form" }
print("Answers:", len(answers))
tokenizedAnswers = tokenizer.texts_to_sequences(answers) # разбиваем текст ответов на последовательности индексов
print("tokenizedAnswers:", len(tokenizedAnswers))
for i in range(len(tokenizedAnswers)) : # для разбитых на последовательности ответов
tokenizedAnswers[i] = tokenizedAnswers[i][1:] # избавляемся от тега <START>
# Делаем последовательности одной длины, заполняя нулями более короткие ответы
paddedAnswers = pad_sequences(tokenizedAnswers, maxlen=maxLenAnswers , padding='post')
print("paddedAnswers:", len(paddedAnswers))
print("vocabularySize:", vocabularySize)
oneHotAnswers = utils.to_categorical(paddedAnswers, vocabularySize) # переводим в one hot vector
decoderForOutput = np.array(oneHotAnswers) # и сохраняем в виде массива numpy
Чтобы как-то переварить фразы нужно уменьшать размер словаря. Как вариант, можно попробовать использовать в качестве loss вместо ‘categorical_crossentropy’ собрата работающего с матрицами без конвертации в в OHE: ‘sparse_categorical_crossentropy’. О использовании ‘sparse_categorical_crossentopy’ в продолжении статьи.
Архитектура нейронной сеть
Первый слой — слой encoder-а. В параметрах embedding стоит mask_zero=True, чтобы исключать нулевые значения. Так сеть будет обучаться быстрее. Размерность пространства embedding = 200. Т.е. каждое слово будет развернуто в это пространство.
#@title Первый входной слой, кодер, выходной слой { display-mode: "form" }
encoderInputs = Input(shape=(None , ), name = "EncoderForInput") # размеры на входе сетки (здесь будет encoderForInput)
# Эти данные проходят через слой Embedding (длина словаря, размерность)
encoderEmbedding = Embedding(vocabularySize, 200 , mask_zero=True, name = "Encoder_Embedding") (encoderInputs)
# Затем выход с Embedding пойдёт в LSTM слой, на выходе у которого будет два вектора состояния - state_h , state_c
# Вектора состояния - state_h , state_c зададутся в LSTM слое декодера в блоке ниже
encoderOutputs, state_h , state_c = LSTM(200, return_state=True, name = "Encoder_LSTM")(encoderEmbedding)
encoderStates = [state_h, state_c]
Размерность encoderInput равна размеру batchsize (None) на максимальную длину вопроса, равную 80. Вместо None в аргументе Input(shape=(None , )) можно было поставить maxLenQuestions.
В параметрах LSTM слоя передается return_state=True, чтобы LSTM слой помимо выхода возвращал ещё состояния: h и c. Они объединяются в encoderStates и подаются на вход LSTM декодера.
Важный момент при создании слоя LSTM. Помимо return_state=True, который говорит LSTM слою вернуть все состояния, добавляется ещё параметр return_sequences=True. Этот параметр говорит LSTM вернуть значения с каждой из LSTM ячеек, а не только с последней.
На вход LSTM слоя декодера помимо значений с Embedding слоя подается ещё начальное состояние LSTM, полученное от encoder-а: initial_state=encoderStates.
Размерность decoderInput равна размеру batchsize (None) на максимальную длину вопроса, равную 128. Вместо None в аргументе Input(shape=(None , )) можно было поставить maxLenAnswers.
#@title Второй входной слой, декодер, выходной слой { display-mode: "form" }
decoderInputs = Input(shape=(None, ), name = "DecoderForInput") # размеры на входе сетки (здесь будет decoderForInput)
# Эти данные проходят через слой Embedding (длина словаря, размерность)
# mask_zero=True - игнорировать нулевые padding при передаче в LSTM. Предотвратит вывод ответа типа: "У меня все хорошо PAD PAD PAD PAD PAD PAD.."
decoderEmbedding = Embedding(vocabularySize, 200, mask_zero=True, name = "Decoder_Embedding") (decoderInputs)
# Затем выход с Embedding пойдёт в LSTM слой, которому передаются вектора состояния - state_h , state_c
decoderLSTM = LSTM(200, return_state=True, return_sequences=True, name = "Decoder_LSTM")
decoderOutputs , _ , _ = decoderLSTM (decoderEmbedding, initial_state=encoderStates)
# И от LSTM'а сигнал decoderOutputs пропускаем через полносвязный слой с софтмаксом на выходе
decoderDense = Dense(vocabularySize, activation='softmax')
output = decoderDense (decoderOutputs)
#@title Собираем тренировочную модель нейросети { display-mode: "form" }
model = Model([encoderInputs, decoderInputs], output)
model.compile(optimizer=RMSprop(), loss='categorical_crossentropy')
print(model.summary()) # выведем на экран информацию о построенной модели нейросети
plot_model(model, to_file='model.png') # и построим график для визуализации слоев и связей между ними
Результирующая модель в разбивке по слоям будет такой:

Первый аргмент «None» — размер batch. На выходе embedding слоя набор матриц с размерностью 80х200. Т.е. каждый вопрос представленный в виде 80 слов, часть из которых 0 будет представлен в виде вектора с размерностью 200. Аналогично для выходного слоя.
На выходе LSTM три выхода размерности 200 (три раза (None, 200)). Два последних элемента — это состояния h и c, которые будут записаны в encoderStates и переданы на вход LSTM декодера.
LSTM декодера вернет также три значения, но нам нужно первое. Оно будет подано на Dense слой, который вернет на выходе матрицу 128 х 10978. Эта размерность совпадает с той, что будет получена на выходе в «Раскодированные выходные данные(ответы)» после OHE. Таким образом эти данные можно сравнивать, чтобы производить обучение сети.
Визуализация соединений входов и выходов каждого слоя plot_model(model, to_file=’model.png’)
Далее модель обучается:
# Запустим обучение и сохраним модель
model.fit([encoderForInput , decoderForInput], decoderForOutput, batch_size=50, epochs=50,
callbacks=[MyCallback(), reduce_lr])
Поскольку Colab периодически дисконнектится, очищая все данные на диске, я написал callback, который через определенные промежутки времени сохраняет наилучшие веса на ftp:
#@title Класс callback-а для сохранения весов нейронной сети { display-mode: "form" }
import keras
import sys
import time
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
class MyCallback(keras.callbacks.Callback):
def __init__(self):
super().__init__()
self.best_criterion = sys.float_info.max
self.counter = 0
self.interval = 5 #Интервал для сохранения
self.best_weights_filename = "best_weights_chatbot_150_epochs.h5"
print(self.best_weights_filename)
def on_epoch_begin(self, epoch, logs={}):
self.epoch_time_start = time.time()
def on_epoch_end(self, epoch, logs=None):
#'loss', 'val_loss', 'val_mean_squared_error', 'mean_squared_error'
criterion = 'loss'
if (logs[criterion] < self.best_criterion):
print("rnНайдено лучшее значение " + criterion + ". Было", self.best_criterion, "Стало:", logs[criterion], "Сохраняю файл весов. Итерация:", self.counter, "rn")
self.model.save_weights(self.best_weights_filename) #"best_weights.h5"
if ((self.counter % self.interval) == 0):
print("Сохраняю файл весов на ftp.")
!curl -ss -T $self.best_weights_filename ftp://[login]:[password]@vh46.timeweb.ru
self.best_criterion = logs[criterion] #Сохраняем значение лучшего результата
self.counter += 1
#early_stopping = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10)
reduce_lr = ReduceLROnPlateau(monitor='loss', factor=0.2, verbose=1, patience=5, min_lr=1e-12)
Каждая эпоха на Colab обучается примерно 2 минуты. Я запускал суммарно обучение примерно на 200 эпохах, сохраняя данные и восстанавливая модель c ftp при каждом запуске обучения.
Подготовка и запуск рабочей нейросети
После обучения тренировочной модели нужно создать рабочую модель. Это та мудреная структура, которая при подаче на вход состояния с encoder-а и стартового тега <start> должна сгенерировать выходное словое и новое состояние, которые должны последовательно поступать на ячейки LSTM слоя.
На модель приходит вопрос encoderInputs и на выходе возвращается состояние encoderStates.
#@title Создаем рабочую модель для вывода ответов на запросы пользователя { display-mode: "form" }
def makeInferenceModels():
# Определим модель кодера, на входе далее будут закодированные вопросы(encoderForInputs), на выходе состояния state_h, state_c
encoderModel = Model(encoderInputs, encoderStates)
decoderStateInput_h = Input(shape=(200 ,), name = 'decoderStateInput_h') # обозначим размерность для входного слоя с состоянием state_h
decoderStateInput_c = Input(shape=(200 ,), name = 'decoderStateInput_c') # обозначим размерность для входного слоя с состоянием state_c
decoderStatesInputs = [decoderStateInput_h, decoderStateInput_c] # возьмем оба inputs вместе и запишем в decoderStatesInputs
# Берём ответы, прошедшие через эмбединг, вместе с состояниями и подаём LSTM cлою
decoderOutputs, state_h, state_c = decoderLSTM(decoderEmbedding, initial_state=decoderStatesInputs)
decoderStates = [state_h, state_c] # LSTM даст нам новые состояния
decoderOutputs = decoderDense(decoderOutputs) # и ответы, которые мы пропустим через полносвязный слой с софтмаксом
# Определим модель декодера, на входе далее будут раскодированные ответы (decoderForInputs) и состояния
# на выходе предсказываемый ответ и новые состояния
decoderModel = Model([decoderInputs] + decoderStatesInputs, [decoderOutputs] + decoderStates)
print(decoderModel.summary()) # выведем на экран информацию о построенной модели нейросети
plot_model(decoderModel, to_file='decoderModel.png') # и построим график для визуализации слоев и связей между ними
return encoderModel , decoderModel
Выведем полученную модель декодера:
from IPython.display import SVG
from keras.utils import model_to_dot
import matplotlib.pyplot as plt
import matplotlib.image as img
encModel , decModel = makeInferenceModels() # запускаем функцию для построения модели кодера и декодера
# reading png image file
im = img.imread('decoderModel.png')
# show image
plt.figure(figsize=(20,10))
plt.axis('off')
plt.imshow(im)


По изображению модели видно, что запись в коде:
decoderModel = Model([decoderInputs] + decoderStatesInputs, [decoderOutputs] + decoderStates)
[decoderInputs] + decoderStatesInputs — обозначает добавление к входу Decoder_Embedding ещё двух: decoderStateInput_h и decoderStateInput_c.
То, что вводит пользователь должно быть преобразовано в последовательность индексов с помощью функции:
#@title Функция преобразующая вопрос пользователя в последовательность индексов { display-mode: "form" }
def strToTokens(sentence: str): # функция принимает строку на вход (предложение с вопросом)
words = sentence.lower().split() # приводит предложение к нижнему регистру и разбирает на слова
tokensList = list() # здесь будет последовательность токенов/индексов
for word in words: # для каждого слова в предложении
tokensList.append(tokenizer.word_index[word]) # определяем токенизатором индекс и добавляем в список
# Функция вернёт вопрос в виде последовательности индексов, ограниченной длиной самого длинного вопроса из нашей базы вопросов
return pad_sequences([tokensList], maxlen=maxLenQuestions , padding='post')
Ну и код, который принимает на вход то, что ввел пользователь и преобразует в ответ нейронной сети:
#@title Устанавливаем окончательные настройки и запускаем модель { display-mode: "form" }
encModel , decModel = makeInferenceModels() # запускаем функцию для построения модели кодера и декодера
for _ in range(6): # задаем количество вопросов, и на каждой итерации в этом диапазоне:
# Получаем значения состояний, которые определит кодер в соответствии с заданным вопросом
statesValues = encModel.predict(strToTokens(input( 'Задайте вопрос : ' )))
# Создаём пустой массив размером (1, 1)
emptyTargetSeq = np.zeros((1, 1))
emptyTargetSeq[0, 0] = tokenizer.word_index['start'] # положим в пустую последовательность начальное слово 'start' в виде индекса
stopCondition = False # зададим условие, при срабатывании которого, прекратится генерация очередного слова
decodedTranslation = '' # здесь будет собираться генерируемый ответ
while not stopCondition : # пока не сработало стоп-условие
# В модель декодера подадим пустую последовательность со словом 'start' и состояния предсказанные кодером по заданному вопросу.
# декодер заменит слово 'start' предсказанным сгенерированным словом и обновит состояния
decOutputs , h , c = decModel.predict([emptyTargetSeq] + statesValues)
#argmax пробежит по вектору decOutputs, найдет макс.значение, и вернёт номер индекса под которым оно лежит в массиве
sampledWordIndex = np.argmax( decOutputs[0, 0, :]) # argmax возьмем от оси, в которой x элементов. Получили индекс предсказанного слова.
sampledWord = None # создаем переменную, в которую положим слово, преобразованное на естественный язык
for word , index in tokenizer.word_index.items():
if sampledWordIndex == index: # если индекс выбранного слова соответствует какому-то индексу из словаря
decodedTranslation += ' {}'.format(word) # слово, идущее под этим индексом в словаре, добавляется в итоговый ответ
sampledWord = word # выбранное слово фиксируем в переменную sampledWord
# Если выбранным словом оказывается 'end' либо если сгенерированный ответ превышает заданную максимальную длину ответа
if sampledWord == 'end' or len(decodedTranslation.split()) > maxLenAnswers:
stopCondition = True # то срабатывает стоп-условие и прекращаем генерацию
emptyTargetSeq = np.zeros((1, 1)) # создаем пустой массив
emptyTargetSeq[0, 0] = sampledWordIndex # заносим туда индекс выбранного слова
statesValues = [h, c] # и состояния, обновленные декодером
# и продолжаем цикл с обновленными параметрами
print(decodedTranslation) # выводим ответ сгенерированный декодером
Сначала функцией makeInferenceModel получаем модель encoder-a и decoder-а. С помощью функции:
statesValues = encModel.predict(strToTokens(input( 'Задайте вопрос : ' )))
преобразуем фразу пользователя в состояние на выходе encoder-а.
На первом шаге в рабочую модель подается тег start, чтобы инициировать работу декодера и состояние полученное с выхода encoder-а после обработки фразы пользователя.
decOutputs , h , c = decModel.predict([emptyTargetSeq] + statesValues)
Далее с помощью argmax из decOutputs выбирается индекс слова, для которого нейронная сеть предсказала наибольшую вероятность появления в ответе.
sampledWordIndex = np.argmax( decOutputs[0, 0, :]) # Получили индекс предсказанного слова.
Из словаря по индексу находится слово и добавляется в переменную ответа для формирования фразы.
Если нейронка предсказала тег end, то считаем, что фраза сформирована и нужно остановить работу декодера.
Индекс предсказанного нейронкой слова полученного на выходе декодера помещается в переменную emptyTargetSeq. Состояния помещаются в переменную: statesValues = [h, c] и тоже передаются на декодер на очередной итерации цикла.
Выводы
Я пробовал подавать на эту модель данные взятые из переписки в WhatsApp. Реплики одного участника считал за вопрос, а другого — за ответ. Результат неважный для такой задачи. Для обучения систем Вопрос-Ответ мессенджеры и соц. сети не подходят, поскольку:
- Контекст, нередко, находится за рамками диалога.
- Много сленга, смайлов, медиа.
- Обсждение медиафайлов (фото, видео) проблематично подать на нейронку такого типа.
- Нет непосредственной связи между вопросами и ответами.
Для таких задач лучше использовать данные с площадок вроде «Ответы mail.ru» или Reddit. В этом случае контекст максимальный и есть четкая связь между вопросами и ответами.
Для решения такаго рода задач чаще используется архитектура «Трансформеры«. Рекуррентные сети им пока проиграли.
Итак:
- После обучения на базах с нормальными вопросами и ответами без какого-то размазанного контекста, результат получается неплохой. Нейронка выдает вполне интересные ответы.
- После обучения на данных выгруженных из чата WhatsApp результат отвратительный. Нейронка выдает чушь.
- При такой архитектуре сети есть проблемы с памятью для разреженной матрицы OHE. По идее надо подумать как использовать loss = sparse_categorical_crossentropy. Подробнее в статье.
- LSTM обучаются долго, Colab вылетает часто, поэтому без сохранения весов нельзя.
Полезные ссылки
- Write a Sequence to Sequence (seq2seq) Model
- Sequence to Sequence Learning with Neural Networks
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
- BLEU
Продолжение следует…