Post Views: 13 171
В этой главе мы познакомимся с нейронными сетями и узнаем для чего они были спроектированы. Эта глава служит фундаментом для последующих глав, в то время как эта показывает базовые понятия нейронных сетей. В этой главе мы покроем следующие темы:
- Искусственные нейроны
- Весы(weights) и смещения(biases)
- Активационные функции(activation functions)
- Слои нейронов(layers)
- Реализация нейронной сети на Java
Раскрывая нейронные сети
Во-первых, термин «нейронные сети» может создать снимок мозга в вашем сознании, в частности для тех, кто ранее познакомился с ним. В действительности это правда, мы считаем мозг — большая и естественная нейронная сеть. Однако что мы можем сказать об искусственных нейронных сетях (ANN — artificial neural network)? Хорошо, он начинается с антонима естественный и первая мысль, которая приходит в нашу голову — это картинка искусственного мозга или робота учитывает термин «искусственный«. В этом случае, мы так же имеем дело с созданием структуры, похожей и вдохновленной человеческим мозгом; поэтому это названо искусственным интеллектом. Поэтому читатель, который не имел прошлого опыта с ANN, сейчас может думать, что книга учит, как строить интеллектуальные системы, включая искусственный мозг, способный эмулировать человеческое сознание, используя Java программы, не так ли? Конечно мы не будем покрывать создание искусственного мышления машин как в трилогии Матрицы; однако эта книга растолкует несколько неимоверных способностей и что могут эти структуры. Мы предоставим читателю Java исходники с определением и созданием основных нейросетевых структур, воспользоваться всеми преимуществами языка программирования Java.
Почему искусственные нейронные сети?
Мы не можем начать говорить про нейросети без понимания их происхождения, включая также термин. Мы используем термины нейронные сети (NN) и ANN взаимозаменяемо в этой книге, хотя NN более общий, покрывая также
естественные нейронные сети. Таким образом, что же такое на самом деле ANN? Давайте изучим немного историю этого термина.
В 1940-ых нейрофизиолог Warren McCulloch и математик Walter Pits спроектировали первую математическую реализацию искусственного нейрона, комбинируя нейронаучный фундамент с математическими операциями. В то время многие исследования осуществлялись на понимании человеческого мозга и как и если бы мог смоделирован, но в пределах области неврологии. Идея McCulloch и Pits была реально уникальна, потому что добавлен математический компонент. Далее, считая, что мозг состоит из миллиардов нейронов, каждый из них взаимосвязан с другими миллионами, в результате чего в некоторых триллионах соединениях, мы говорим о гигантской структуре сети. Однако, каждый нейрон очень простой, действуя как простой процессор, способный суммировать и распространять сигналы.
На базе этого факта, McCulloch и Pits спроектировали простую модель для одного нейрона, первоначально симулируя человеческое зрение. Доступные калькуляторы или компьютеры в то время были очень редкими, но способные иметь дело с математическими операциями достаточно хорошо; с другой стороны, даже современные задачи, такие как компьютерное зрение и распознавание звуков не очень легко программируются без специальных фреймворков, основанных на математических операциях и функциях. Тем не менее, человеческий мозг может выполнять эти последние задачи эффективнее чем первые, и этот факт реально побуждает ученых исследователей.
Таким образом, ANN должна быть структурой для выполнения таких задач, как распознавание образов, обучение из данных и прогнозирование трендов, как эксперт может делать на основании знаний, в отличие от обычного алгоритмического подхода, что требует установки шагов для достижения определенной цели. ANN напротив имеет возможность изучать, как решить задачу самостоятельно, вследствие хорошо взаимосвязанной структуре сети.
| Задачи, быстро решаемые человеком | Задачи, быстро решаемые компьютером |
| Классификация изображений
Распознавание голоса идентификация лиц Прогнозирование событий на основе предыдущего опыта |
Комплексные вычисления
Исправление грамматических ошибок Обработка сигналов Управление операционной системой |
Как устроены нейронные сети
Можно сказать, что ANN — это естественная структура, таким образом она имеет схожести с человеческим мозгом. Как показано на следующей картинке, естественный нейрон состоит из ядра, дендритов и аксона. Аксон продолжается в несколько ветвей, формируя синапсы с другими дендритами нейронов.
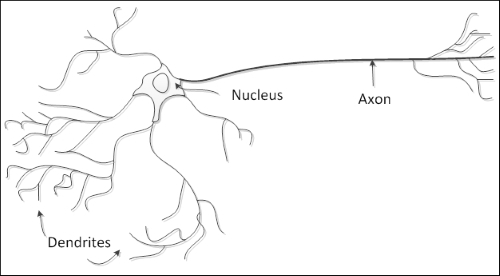
Таким образом, искусственный нейрон имеет похожую структуру. Он состоит из ядра(единицы обработки), несколько дендритов(аналогично входам), и одного аксона(аналогично выходу), как показано на следующей картинке:
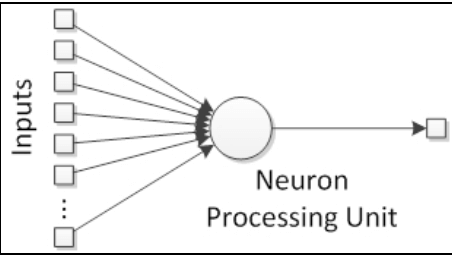
Соединения между нейронами формируют так называемую нейронную сеть, аналогично синапсам в естественной структуре.
Самый базовый элемент — искусственный нейрон
Доказано, что естественные нейроны — обработчики сигналов поскольку они получают микросигналы в дендритах, что вызывает сигнал в аксонах в зависимости от их силы или величины. Мы можем поэтому подумать, что нейрон как имеющий сборщик сигналов во входах(inputs) и активационную единицу в выходе(output), что вызывает сигнал, который будет передаваться другим нейронам. Таким образом, мы можем определить искусственную нейронную структуру, как показано на следующем рисунке:
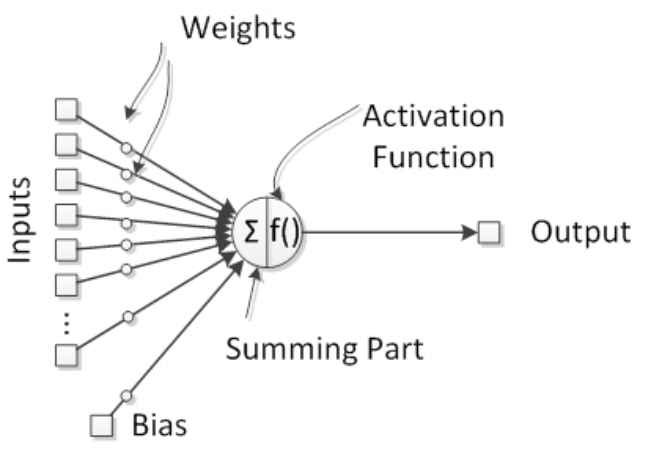
В естественных нейронах есть пороговый потенциал, когда он достигается, включается аксон и сигнал передается другим нейронам. Поведение включения эмулируется активационной функцией, которая доказана быть полезной в представлении нелинейных поведений в нейронах.
Давая жизнь нейронам — активационная функция
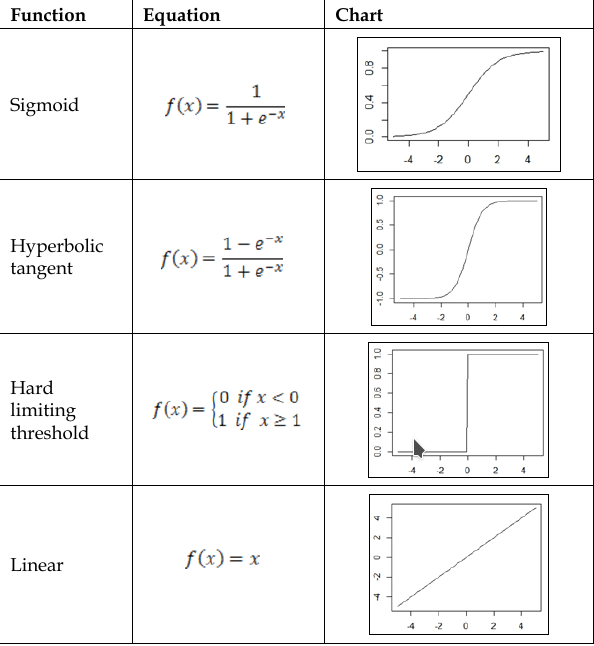
Вывод нейрона получен благодаря активационной функции. Этот компонент добавляет нелинейность обработке нейронных сетей, которым это необходимо,потому что естественный нейрон имеет нелинейные поведения. Активационная функция обычно связана между двумя значениями на выходе, поэтому является нелинейной функцией, но в некоторых случаях она может быть линейной.
Четыре самых используемых активационных фунций:
- Сигмоида(Sygmoid)
- Гиперболический тангенс(Hyberbolic tangent)
- Жесткая пороговая функция(Hard limiting threshold)
- Линейная(linear)
Уравнения и графики ассоциирующиеся с этими функциями, показаны
в следующей таблице:
Фундаментальные величины — весы(weights)
В нейронных сетях, синапсы представляют собой соединения между нейронами и имеют возможность усиливать или смягчать нейронные сигналы, например, перемножать сигналы, таким образом улучшать их. Итак, путем модификации нейронных сетей, нейронные весы(weights) могут повлиять на нейронный вывод(output), следовательно нейронная активация может быть зависима от ввода и от весов. При условии, что inputs идут от других нейронов или от внешнего мира, весы(weights) считаются установленными нейронными соединениями между нейронами. Таким образом, с тех пор как весы являются внутренними для нейронных сетей, мы можем считать их как знания нейронных сетей, предоставленные изменения весов будут изменять возможности нейронных сетей и поэтому — действия.
Важный параметр — смещение
Искуственный нейрон может иметь независимый элемент, который добавляет специальный сигнал для активации функции.
Части образующие целое — слои
Естественные нейроны организованы в слои, каждый из которых предоставляет специальный уровень обработки; например, входные слои получают прямой раздражитель из внешнего мира, и выходные слои активируют действия, которые повлияют на внешний мир. Между этими слоями есть несколько скрытых слоев, в смысле, что они не взаимодействуют напрямую с внешним миром. В искусственных нейронных сетях все нейроны в слое делят те же входы и активационную функцию, как показано на изображении:
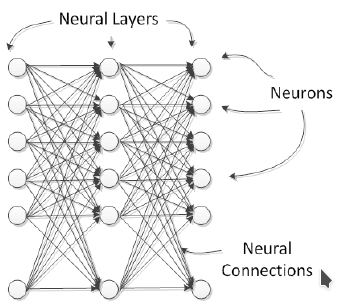
Нейронные сети могут быть составлены из нескольких соединенных слоев, которые называются многослойными сетями. Обычные нейронные сети могут быть разделены на 3 класса:
1. Input layer;
2. Hidden layer;
3. Output layer;
На практике, дополнительный нейронный слой добавляет другой уровень
абстракции внешней стимуляции, тем самым повышая способность
нейронных сетей представлять больше комплексных данных.
Каждая нейросеть имеет как минимум входной/выходной слой независимо от количества слоев. В случае с многослойной сетью, слои между входом и выходом названы скрытыми.
Изучение архитектуры нейронных сетей
В принципе, нейронные сети могут иметь разные разметки, зависимые от того как нейроны или нейронные слои соединены друг с другом. Каждая архитектура нейронных сетей спроектирована для определенного результата. Нейронные сети могут быть применены для некоторогоколичества проблем и зависимые от природы проблемы, нейронную сеть следует спроектировать в целях этой проблемы более продуктивно. Обычно, существует 2 модальности архитектуры нейронных сетей:
1. Нейронные соединения:
1.1 Однослойные(monolayer) сети;
1.2 Многослойные(multilayer) сети;
2. Поток сигналов:
2.1 Сети прямой связи(Feedforward networks);
2.2 Сети обратной связи(Feedback networks);
Однослойные сети
Нейронная сеть получает на вход сигналы и кормит их в нейроны, которые в очереди продуцируют выходные сигналы. Нейроны могут быть соединены с другими с или без использования рекуррентности. Примеры таких архитектур: однослойный персептрон, Adaline(адаптивный линейный нейрон), самоорганизованная карта, нейронная сеть Элмана(Elman) и Хопфилда.
Многослойные сети
В этой категории нейроны делятся во много слоев, каждый слой соответствует параллельному расположению нейронов, которые делят одни и те же входные данные, как показано на рисунке:
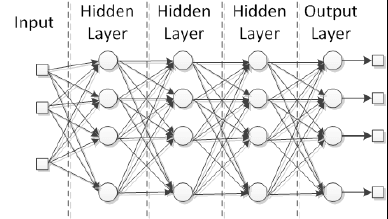
Радиальные базисные функции и многослойные персептроны – хорошие примеры этой архитектуры. Такие сети реально полезны для апроксимации реальных данных в функцию, специально спроектированной для представлении этих данных. Более того, благодаря тому, что они имеют много слоев обработки, эти сети адаптивны для изучения из нелинейных данных, возможности отделить их или легче определять знания, которые воспроизводят или распознают эти данные.
Сети прямой связи(feedforward networks)
Поток сигналов в нейронных сетях может быть только в одном направлении или рекуррентности. В первом случае мы называем архитектуру нейронных сетей – feedforward, начиная с входных сигналов кормили во входной слой; затем, после обработки, они отправляются в следующий слой, как показано на ричунке про многослойную секцию. Многослойные персептроны и радиальные базисные функции – хорошие примеры feedforward сети.
Сети обратной связи(Feedback networks)
Когда нейронная сеть имеет некоторый вид внутреннего рецидива, это значит, что сигналы вернулись обратно в нейрон или слой, который уже получил и обработал сигнал, сеть – это тип feedback-а. Посмотрите на картинку:
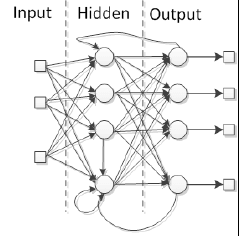
Специальная причина добавить рекуррентность в сеть – это выработка динамического поведения, в частности когда сеть адресует проблемы, включая временные ряды или распознавание образов, которые требуют внутреннюю память для подкрепления обучающего процесса. Тем не менее, такие сети особенно трудны в тренировке, в конечном счете не в состоянии учиться. Многие feedback сети – однослойные, такие как сети Элмана(Elman) и Хопфилда(Hopfield), но возможно и построить рекуррентную многослойную сеть, такие как эхо и рекуррентные многослойные персептронные сети.
От незнания к знаниям — процесс обучения
Нейронные сети обучаются благодаря регулировке соединений между нейронами, а именно весов. Как уже упоминалось в структуре нейронных секций, весы представляют собой знания нейронных сетей. Разные весы призывают сеть вырабатывать разные результаты для тех же входных данных. Таким образом, нейронная сеть может улучшить эти результаты, адаптируя эти весы следуя обучающемуся правилу. Основная схема обучения показана на следующем рисунке:
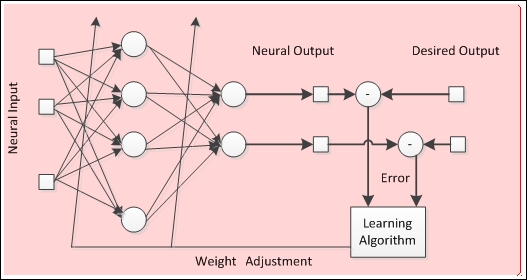
Процесс, показанный на предыдущей схеме, называется контролируемое обучение(supervised learning), потому что это желаемый вывод, но нейронные сети могут обучаться только входных данных, без желаемого результата(контролируемое обучение). Во второй главе, «Как обучаются нейронные сети», мы собираемся глубже погрузиться в процесс обучения нейронных сетей.
Давайте начнем реализацию! Нейронные сети на практике
В этой книге мы покроем все процессы реализации нейронных сетей на Java. Java — это объектно-ориентированный язык программирования, созданный в 1990-ые маленькой группой инженеров из Sun Microsystems, позже приобретенной компанией Oracle в 2010-ых. Сегодня, Java представлена во многих устройствах, которые участвуют в нашей повседневной жизни. В объектно-ориентированном языке, таком как Java, мы имеем дело склассами и объектами. Класс — план чего-то в реальной жизни, а объект — образец такого плана, например, car(класс, ссылающийся на все машины) и my car(объект, ссылающийся на конкретную машину — мою). Java классы обычно состоят из атрибутов и методов(или функций), которые включают принципы объектно-ориентированного программирования(ООП). Мы собираемся кратко рассмотреть эти принципы без углубления в них, поскольку цель этой книги — просто спроектировать и создать нейронные сети с практической точки зрения. В этом процессе четыре принципа уместны и нуждаются в рассмотрении:
- Абстракция: Перевод проблем и правил реальной жизни в сферу программирования, рассматривая только их уместные особенности и отпуская детали, которые часто мешают разработке.
- Инкапсуляция: Аналогично инкапсуляции продукта, при которой некоторые соответствующие функции раскрыты открыто (публичные(public) методы), в то время как другие хранится скрытым в пределах своего домена (частного(private) или защищенного(protected)), избегая неправильное использование или избыток информации.
- Наследование: В реальной мире, много классов этих объектов представляют собой атрибуты и методы в иерархической манере; например, велосипед может быть супер-классом для машин и грузовиков.Таким образом, в ООП эта концепция позволяет из одного класса перенимать все свойства в другой класс, тем самым избегая переписывания кода.
- Полиморфизм: Во многом схожа с наследованием, но с изменениями в методах со схожими сигнатурами, представляющие разные поведения в разных классах.
Используя концепции нейронных сетей, представленные в этой главе и коцепции ООП, мы сейчас собираемся проектировать самый первый класс, реализующий нейронную сеть. Как можно увидеть, нейронная сеть состоит из слоев, нейронов, весов, активационных функций и смещений, и трех типов слоев: входные, скрытые и выходные. Каждый слой может иметь один или несколько нейронов. Каждый нейрон соединен друг с другом входом/выходом или другими нейронами, и эти соединения называются весами.
Важно выделить, что нейронная сеть может иметь много скрытых слоев или вообще их не иметь, количество нейронов в слое может различаться. Тем не менее, входные и выходные слои имеют одинаковое кол-во нейронов, как количество нейронных входов/выходов соответственно. Так начнем же реализацию. Сначала, мы собираемся определить 6 классов, Детально показанные тут:
|
Имя класса: Neuron |
|
|
Атрибуты |
|
| private ArrayList<Double> listOfWeightIn | Переменная ArrayList дробных чисел представляет список входных весов |
| private ArrayList<Double> listOfWeightOut | Переменная ArrayList дробных чисел представляет список выходных весов |
|
Методы |
|
| public double initNeuron() | Инициализирует функции listOfWeightIn, listOfWeightOut с псевдослучайными числами |
| Параметры: нет | |
| Возвращает: Псевдослучайное число | |
| public ArrayList<Double> getListOfWeightIn() | Геттер ListOfWeightIn |
| Параметры: нет | |
| Возвращает: список дробных чисел, сохраненной в переменной ListOfWeightIn | |
| public void setListOfWeightIn(ArrayList<Double> listOfWeightIn) | Сеттер ListOfWeightIn |
| Параметры: список дробных чисел, сохранненных в объекте класса | |
| Возвращает: ничего | |
| public ArrayList<Double> getListOfWeightOut() | Геттер ListOfWeightOut |
| Параметры: нет | |
| Возвращает: список дробных чисел, сохраненной в переменной ListOfWeightOut | |
| public void setListOfWeightOut(ArrayList<Double> listOfWeightOut) | Сеттер ListOfWeightOut |
| Параметры: список дробных чисел, сохранненных в объекте класса | |
| Возвращает: ничего | |
| Реализация класса: файл Neuron.java |
| Имя класса: Layer | |
| Заметка: Этот класс абстрактный и не может быть проинициализирован. | |
| Атрибуты | |
| private ArrayList<Neuron> listOfNeurons | Переменная ArrayList объектов класса Neuron |
| private int numberOfNeuronsInLayer | Целочисленное значение для хранения количества нейронов, которая является частью слоя. |
| Методы | |
| public ArrayList<Neuron> getListOfNeurons() | Геттер listOfNeurons |
| Параметры: нет | |
| Возвращает: listOfNeurons | |
| public void setListOfNeurons(ArrayList<Neuron> listOfNeurons) | Сеттер listOfNeurons |
| Параметры: listOfNeurons | |
| Возвращает: ничего | |
| public int getNumberOfNeuronsInLayer() | Геттер numberOfNeuronsInLayer |
| Параметры: нет | |
| Возвращает: numberOfNeuronsInLayer | |
| public void setNumberOfNeuronsInLayer(int numberOfNeuronsInLayer) | Сеттер numberOfNeuronsInLayer |
| Параметры: numberOfNeuronsInLayer | |
| Возвращает: ничего | |
| Реализация класса: файл Layer.java |
| Имя класса: InputLayer | |
| Заметка: Этот класс наследует атрибуты и методы от класса Layer | |
| Атрибуты | |
| Нет | |
| Методы | |
| public void initLayer(InputLayer inputLayer) |
Инициализирует входной слой с дробными псевдорандомными числами |
| Параметры: Объект класса InputLayer | |
| Возвращает: ничего | |
| public void printLayer(InputLayer inputLayer) |
Выводит входные весы слоя |
| Параметры: Объект класса InputLayer | |
| Возвращает: ничего | |
| Реализация класса: файл InputLayer.java |
| Имя класса: HiddenLayer | |
| Заметка: Этот класс наследует атрибуты и методы от класса Layer | |
| Атрибуты | |
| Нет | |
| Методы | |
| public ArrayList<HiddenLayer> initLayer( HiddenLayer hiddenLayer, ArrayList<HiddenLayer> listOfHiddenLayers, InputLayer inputLayer, OutputLayer outputLayer ) |
Инициализирует скрытый слой(и) с дробными псевдослучайными числами |
| Параметры: Объект класса HiddenLayer, список объектов класса HiddenLayer, объект класса InputLayer, объект класса OutputLayer | |
| Возвращает: список скрытых слоев с добавленным слоем | |
| public void printLayer(ArrayList<HiddenLayer> listOfHiddenLayers) |
Выводит входные весы слоя(ев) |
| Параметры: Список объектов класса HiddenLayer | |
| Возвращает: ничего | |
| Реализация класса: файл HiddenLayer.java |
| Имя класса: OutputLayer | |
| Заметка: Этот класс наследует атрибуты и методы от класса Layer | |
| Атрибуты | |
| Нет | |
| Методы | |
| public void initLayer(OutputLayer outputLayer) | Инициализирует выходной слой с дробными псевдорандомными числами |
| Параметры: Объект класса OutputLayer | |
| Возвращает: ничего | |
| public void printLayer(OutputLayer outputLayer) | Выводит входные весы слоя |
| Параметры: Объект класса OutputLayer | |
| Возвращает: ничего | |
| Реализация класса: файл OutputLayer.java |
| Имя класса: NeuralNet | |
| Заметка: Значения в топологии нейросети фиксированы в этом классе(два нейрона во входном слое, два скрытых слоя с тремя нейронами в каждом, и один нейрон в выходном слое). Напоминание: Это первая версия. |
|
| Атрибуты | |
| private InputLayer inputLayer | Объект класса InputLayer |
| private HiddenLayer hiddenLayer | Объект класса HiddenLayer |
| private ArrayList<HiddenLayer> listOfHiddenLayer | Переменная ArrayList объектов класса HiddenLayer. Может иметь больше одного скрытого слоя |
| private OutputLayer outputLayer | Объект класса OutputLayer |
| private int numberOfHiddenLayers | Целочисленное значение для хранения количества слоев, что является частью скрытого слоя |
| Методы | |
| public void initNet() | Инициализирует нейросеть. Слои созданы и каждый список весов нейронов созданы случайно |
| Параметры: нет | |
| Возвращает: ничего | |
| public void printNet() | Печатает нейросеть. Показываются каждое входное и выходное значения каждого слоя. |
| Параметры: нет | |
| Возвращает: ничего | |
| Реализация класса: файл NeuralNet.java |
Огромное преимущество ООП — легко документировать программу в унифицированный язык моделирования(UML). Диаграммы классов UML представляют классы, атрибуты, методы, и отношения между классами очень простым и понятным образом, таким образом, помогая программисту и/или заинтересованным сторонам понять проект в целом. На следующем рисунке представлена самая первая версия диаграммы классов проекта: Сейчас давайте применим эти классы, чтобы получить некоторые результаты.
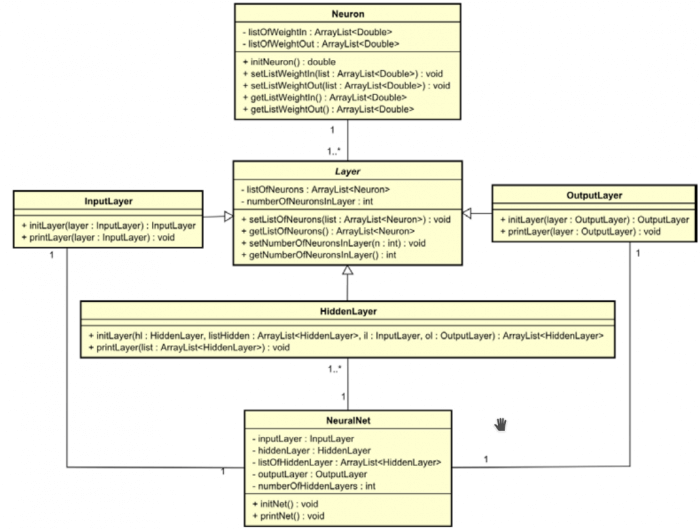
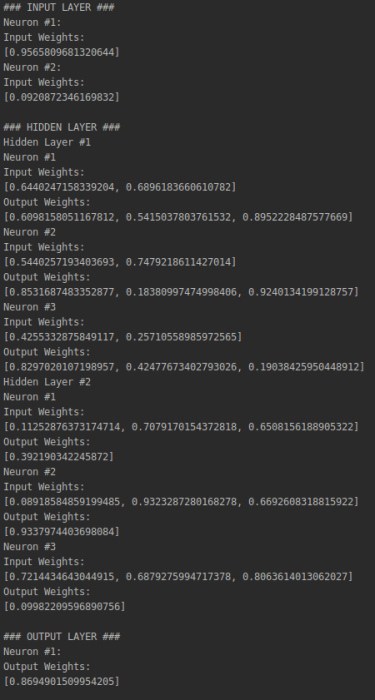
Показанный следующий код имеет тестовый класс, главный метод объектом класса NeuralNet, называнный n. Когда этоn метод вызывается (путем выполнения класса), он вызывает initNet () и printNet () методы из объекта n, генерирующие следующий результат, показанный на рисунке справа после кода. Он представляет собой нейронную сеть с двумя нейронами во входном слое, три в скрытом слое и один в выходном слое:
public class NeuralNetTest {
public static void main(String[] args) {
NeuralNet n = new NeuralNet();
n.initNet();
n.printNet();
}
}
Важно помнить, что каждый раз, когда код запускается, он генерирует новые псевдослучайные значения веса. Итак, когда вы запускаете код, другие значения появятся в консоли:
В сумме
В этой главе мы увидели введение в нейронные сети, что они собой представляют, для чего они используются, и их основные понятия. Мы также видели очень простую реализацию нейронной сети на языке программирования Java, в которой мы применили теоретические концепции нейронной сети на практике, кодируя каждый из элементов нейронной сети. Важно понять основные понятия, прежде чем мы перейти к передовым концепциям. То же самое относится и к коду, реализованному на Java. В следующей главе мы углубимся в процесс обучения нейронной сети и изучим различные типы наклонов на простых примерах.
От переводчика
Оригинал книги: Neural Network Programming with Java
Реализация нейронной сети на Java
Пример реализации простой нейронной сети, обучаемой по алгоритму обратного распространенния ошибки.

Layer.java
Базовый интерфейс любого нейронного слоя. Размер слоя — количество нейронов содержащихся в слое и соотвественно размер выходного вектора слоя.
package nnet;
import java.io.Serializable;
/**
* Интерфейс нейронного слоя
*/
public interface Layer extends Serializable {
/**
* Получает размер входного вектора
* @return Размер входного вектора
*/
int getInputSize();
/**
* Получает размер слоя
* @return Размер слоя
*/
int getSize();
/**
* Вычисляет отклик слоя
* @param input Входной вектор
* @return Выходной вектор
*/
float[] computeOutput(float[] input);
}
Network.java
Реализация базовой функциональности нейронной сети, состоящей из нескольких слоев.
package nnet;
import java.io.*;
/**
* Базовая реализация нейронной сети
*/
public class Network implements Serializable {
/**
* Конструирует нейронную сеть с заданными слоями
* @param layers Нейронные слои
*/
public Network(Layer[] layers) {
// проверки
if (layers == null || layers.length == 0) throw new IllegalArgumentException();
// проверим детально
final int size = layers.length;
for (int i = 0; i < size; i++)
if (layers[i] == null || (i > 1 && layers[i].getInputSize() != layers[i - 1].getSize()))
throw new IllegalArgumentException();
// запомним слои
this.layers = layers;
}
/**
* Получает размер входного вектора
* @return Размер входного вектора
*/
public final int getInputSize() {
return layers[0].getInputSize();
}
/**
* Получает размер выходного вектора
* @return Размер выходного вектора
*/
public final int getOutputSize() {
return layers[layers.length - 1].getSize();
}
/**
* Получает размер сети
* @return Размер сети
*/
public final int getSize() {
return layers.length;
}
/**
* Получает нейронный слой по индексу
* @param index Индекс слоя
* @return Нейронный слой
*/
public final Layer getLayer(int index) {
return layers[index];
}
/**
* Вычисляет отклик сети
* @param input Входной вектор
* @return Выходной вектор
*/
public float[] computeOutput(float[] input) {
// проверки
if (input == null || input.length != getInputSize())
throw new IllegalArgumentException();
// вычислим выходной отклик сети
float[] output = input;
final int size = layers.length;
for (int i = 0; i < size; i++)
output = layers[i].computeOutput(output);
// вернем выход
return output;
}
/**
* Сохраняет нейронну сеть в файл
* @param fileName Имя файла
*/
public void saveToFile(String fileName) {
// проверки
if (fileName == null) throw new IllegalArgumentException();
// сохраняем
try {
ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream(fileName));
outputStream.writeObject(this);
outputStream.close();
}
catch (Exception e) {
throw new IllegalArgumentException(e);
}
}
/**
* Загружает нейронную сеть из файла
* @param fileName Имя файла
* @return Нейронную сеть
*/
public static Network loadFromFile(String fileName) {
// проверки
if (fileName == null) throw new IllegalArgumentException();
// загружаем
Object network = null;
try {
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream(fileName));
network = inputStream.readObject();
inputStream.close();
}
catch (Exception e) {
throw new IllegalArgumentException(e);
}
// отдадим сеть
return (Network)network;
}
/**
* Слои
*/
private Layer[] layers;
}
BackpropLayer.java
Интерфейс нейронного слоя обучаемого по алгоритму обратного распространения ошибки. Метод randomize задает начальные случайные значения весов в слое. Метод computeBackwardError вычисляет ошибку в обратном направлении: то есть ту, которая пришла на вход слоя от предыдущего слоя. В качестве параметров computeBackwardError принимает входной вектор, который подавался на вход и вектор ошибки для этого слоя. Метод же adjust подгоняет веса нейроннов в сторону уменьшения ошибки.
package nnet;
/**
* Интерфейс слоя обучаемого по алгоритму обратного распространения ошибки
*/
public interface BackpropLayer extends Layer {
/**
* Придает случайные значения весам нейронов
* @param min Минимальное значение
* @param max Максимальное значение
*/
void randomize(float min,float max);
/**
* Выичисляет следующий вектор ошибки в обратном направлении
* @param input Входной вектор
* @param error Вектор ошибки
* @return Следующий вектор ошибки в обратном направлении
*/
float[] computeBackwardError(float[] input,float[] error);
/**
* Подгоняет веса нейронов в сторону уменьшения ошибки
* @param input Входной вектор
* @param error Вектор ошибки
* @param rate Скорость обучения
* @param momentum Моментум
*/
void adjust(float[] input,float[] error,float rate,float momentum);
}
BackpropNetwork.java
Реализация нейронной сети, обучаемой по алгоритму обратного распространенния ошибки.
package nnet;
/**
* Нейронная сеть обучаемая по алгоритму обратного распространения ошибки
*/
public final class BackpropNetwork extends Network {
/**
* Констрирует нейронную сеть с заданными слоями
* @param layers
*/
public BackpropNetwork(Layer[] layers) {
// передадим родакам
super(layers);
// рандомизируем веса
randomize(0,0.3f);
}
/**
* Придает случайные значения весам нейроннов в сети
* @param min
* @param max
*/
public void randomize(float min,float max) {
// придаем случайные значения весам в сети
final int size = getSize();
for (int i = 0; i < size; i++) {
Layer layer = getLayer(i);
if (layer instanceof BackpropLayer) ((BackpropLayer)layer).randomize(min,max);
}
}
/**
* Обучает сеть паттерну
* @param input Входной вектор
* @param goal Заданный выходной вектор
* @param rate Скорость обучения
* @param momentum Моментум
* @return Текущую ошибку обучения
*/
public float learnPattern(float[] input,float[] goal,float rate,float momentum) {
// проверки
if (input == null || input.length != getInputSize() ||
goal == null || goal.length != getOutputSize()) throw new IllegalArgumentException();
// делаем проход вперед
final int size = getSize();
float[][] outputs = new float[size][];
outputs[0] = getLayer(0).computeOutput(input);
for (int i = 1; i < size; i++)
outputs[i] = getLayer(i).computeOutput(outputs[i - 1]);
// вычислим ошибку выходного слоя
Layer layer = getLayer(size - 1);
final int layerSize = layer.getSize();
float[] error = new float[layerSize];
float totalError = 0;
for (int i = 0; i < layerSize; i++) {
error[i] = goal[i] - outputs[size - 1][i];
totalError += Math.abs(error[i]);
}
// обновим выходной слой
if (layer instanceof BackpropLayer)
((BackpropLayer)layer).adjust(size == 1 ? input : outputs[size - 2],error,rate,momentum);
// идем по скрытым слоям
float[] prevError = error;
Layer prevLayer = layer;
for (int i = size - 2; i >= 0; i--,prevError = error,prevLayer = layer) {
// получим очередной слой
layer = getLayer(i);
// вычислим для него ошибку
if (prevLayer instanceof BackpropLayer)
error = ((BackpropLayer)prevLayer).computeBackwardError(outputs[i],prevError);
else
error = prevError;
// обновим слой
if (layer instanceof BackpropLayer)
((BackpropLayer)layer).adjust(i == 0 ? input : outputs[i - 1],error,rate,momentum);
}
// вернем суммарную ошибку
return totalError;
}
}
SigmoidLayer.java
Реализация сигмоидального слоя. В качестве функции активации может использоваться гиперболический тангенс, либо сигмоидальная функция.
package nnet;
/**
* Сигмоидальный слой
*/
public final class SigmoidLayer implements BackpropLayer {
/**
* Вес
*/
private final int WEIGHT = 0;
/**
* Дельта
*/
private final int DELTA = 1;
/**
* Констрирует сигмоидальный слой
* @param inputSize Размер входного вектора
* @param size Размер слоя
* @param bipolar Флаг биполярного слоя
*/
public SigmoidLayer(int inputSize,int size,boolean bipolar) {
// проверки
if (inputSize < 1 || size < 1) throw new IllegalArgumentException();
// создаем слой
matrix = new float[size][inputSize + 1][2];
// запомним параметры
this.inputSize = inputSize;
this.bipolar = bipolar;
}
/**
* Конструирует биполярный слой
* @param inputSize Размер входного вектора
* @param size Размер слоя
*/
public SigmoidLayer(int inputSize,int size) {
this(inputSize,size,true);
}
public int getInputSize() {
return inputSize;
}
public int getSize() {
return matrix.length;
}
public float[] computeOutput(float[] input) {
// проверки
if (input == null || input.length != inputSize)
throw new IllegalArgumentException();
// вычислим выход
final int size = matrix.length;
float[] output = new float[size];
for (int i = 0; i < size; i++) {
output[i] = matrix[i][0][WEIGHT];
for (int j = 0; j < inputSize; j++)
output[i] += input[j] * matrix[i][j + 1][WEIGHT];
if (bipolar)
output[i] = (float)Math.tanh(output[i]);
else
output[i] = 1 / (1 + (float)Math.exp(-output[i]));
}
// вернем оклик
return output;
}
public void randomize(float min,float max) {
final int size = matrix.length;
for (int i = 0; i < size; i++) {
for (int j = 0; j < inputSize + 1; j++) {
matrix[i][j][WEIGHT] = min + (max - min) * (float)Math.random();
matrix[i][j][DELTA] = 0;
}
}
}
public float[] computeBackwardError(float[] input,float[] error) {
// проверки
if (input == null || input.length != inputSize ||
error == null || error.length != matrix.length) throw new IllegalArgumentException();
// вычислим входящую ошибку
float[] output = computeOutput(input);
final int size = matrix.length;
float[] backwardError = new float[inputSize];
for (int i = 0; i < inputSize; i++) {
backwardError[i] = 0;
for (int j = 0; j < size; j++)
backwardError[i] += error[j] * matrix[j][i + 1][WEIGHT] *
(bipolar ? 1 - output[j] * output[j] : output[j] * (1 - output[j]));
}
// вернем ошибку
return backwardError;
}
public void adjust(float[] input,float[] error,float rate,float momentum) {
// проверки
if (input == null || input.length != inputSize ||
error == null || error.length != matrix.length) throw new IllegalArgumentException();
// обновляем веса
float[] output = computeOutput(input);
final int size = matrix.length;
for (int i = 0; i < size; i++) {
final float grad = error[i] * (bipolar ? 1 - output[i] * output[i] : output[i] * (1 - output[i]));
// обновляем нулевой вес
matrix[i][0][DELTA] = rate * grad + momentum * matrix[i][0][DELTA];
matrix[i][0][WEIGHT] += matrix[i][0][DELTA];
// обновим остальные веса
for (int j = 0; j < inputSize; j++) {
matrix[i][j + 1][DELTA] = rate * input[j] * grad + momentum * matrix[i][j + 1][DELTA];
matrix[i][j + 1][WEIGHT] += matrix[i][j + 1][DELTA];
}
}
}
/**
* Размер входного вектора
*/
private final int inputSize;
/**
* Флаг биполярного слоя
*/
private final boolean bipolar;
/**
* Матрица слоя
*/
private float[][][] matrix;
}
WTALayer.java
Реализация слоя победитель получает все. Победителем признаеться тот нейрон, у которого выход больше всех нейроннов на величину не менее minLevel. В противном случае все нейронны признаются проигравшими.
package nnet;
/**
* WTA слой
*/
public final class WTALayer implements BackpropLayer {
/**
* Конструирует WTA слой заданного размера и уровнем доверия
* @param size Размер слоя
* @param minLevel Уровень доверия
*/
public WTALayer(int size,float minLevel) {
// проверки
if (size < 1) throw new IllegalArgumentException();
// запомним параметры слоя
this.size = size;
this.minLevel = minLevel;
}
public int getInputSize() {
return size;
}
public int getSize() {
return size;
}
public float[] computeOutput(float[] input) {
// проверки
if (input == null || input.length != size) throw new IllegalArgumentException();
// найдем победителя
int winner = 0;
for (int i = 1; i < size; i++)
if (input[i] > input[winner]) winner = i;
// готовим ответ
float[] output = new float[size];
// проверим на минимальный уровень расхождения
if (minLevel > 0) {
float level = Float.MAX_VALUE;
for (int i = 0; i < size; i++)
if (i != winner && Math.abs(input[i] - input[winner]) < level)
level = Math.abs(input[i] - input[winner]);
if (level < minLevel) return output;
}
// говорим кто победитель
output[winner] = 1;
// вернем отклик
return output;
}
public void randomize(float min,float max) {
}
public float[] computeBackwardError(float[] input,float []error) {
// проверки
if (input == null || input.length != size || error == null ||
error.length != size) throw new IllegalArgumentException();
// расчитываем ошибку
float[] backwardError = new float[size];
float[] output = computeOutput(input);
for (int i = 0; i < size; i++)
backwardError[i] = error[i] + output[i] - input[i];
// вернем входящую ошибку
return backwardError;
}
public void adjust(float[] input,float[] error,float rate,float momentum) {
}
/**
* Получает минимальный уровень между победителем и всеми остальными нейронами
* @return Минимальный уровень между победителем и всеми остальными нейронами
*/
public float getMinLevel() {
return minLevel;
}
/**
* Устанавливает минимальный уровень между победитлем и всеми остальными нейронами
* @param minLevel Новый минимальный уровень
*/
public void setMinLevel(float minLevel) {
this.minLevel = minLevel;
}
/**
* Размер слоя
*/
private final int size;
/**
* Минимальный уровень между победителем и всеми остальными нейронами
*/
private float minLevel;
}
Быстрая нейронная сеть для каждого +19
JAVA, Машинное обучение
Рекомендация: подборка платных и бесплатных курсов Java — https://katalog-kursov.ru/
Данная статья продемонстрирует возможность легко написать свою нейронную сеть на языке Javа. Дабы не изобретать велосипед, возьмем уже хорошо проработанную библиотеку Fast Artificial Neural Network. Использование нейронных сетей в своих Java-проектах — реально. Часто можно услышать упреки в адрес Java касательно скорости выполнения. Хотя разница не так велика — подробно об этом можно узнать в публикации «Производительность C++ vs. Java vs. PHP vs. Python. Тест «в лоб»». Мы будем использовать обертку вокруг библиотеки FANN.
Задача
Необходимо написать систему, которая сможет принимать решения за персонажа, который может встретить одного или несколько врагов. Системе может быть известно:
- здоровье персонажа в процентах;
- наличие пистолета;
- количество врагов.
Ответ должен быть в виде одного из действий:
- атаковать;
- бежать;
- прятаться (для внезапной атаки);
- ничего не делать.
Для обучения составим таблицу «уроков»:
| Здоровье | пистолет | Враги | Действие |
|---|---|---|---|
| 50% | 1 | 1 | Атаковать |
| 90% | 1 | 2 | Атаковать |
| 80% | 0 | 1 | Атаковать |
| 30% | 1 | 1 | Прятаться |
| 60% | 1 | 2 | Прятаться |
| 40% | 0 | 1 | Прятаться |
| 90% | 1 | 7 | Бежать |
| 60% | 1 | 4 | Бежать |
| 10% | 0 | 1 | Бежать |
| 60% | 1 | 0 | Ничего |
| 100% | 0 | 0 | Ничего |
Подготовка
Первое, что нужно сделать — собрать и установить libfann.
Затем скачать fannj и jna.
Сделаем файл, который будет содержать набор «уроков»:
11 3 4
0.5 1 1
1 0 0 0
0.9 1 2
1 0 0 0
0.8 0 1
1 0 0 0
0.3 1 1
0 1 0 0
0.6 1 2
0 1 0 0
0.4 0 1
0 1 0 0
0.9 1 7
0 0 1 0
0.5 1 4
0 0 1 0
0.1 0 1
0 0 1 0
0.6 1 0
0 0 0 1
1.0 0 0
0 0 0 1
Теперь обучим нашу ИНС и сохраним ее в файл:
public static void main(String[] args) {
//Для сборки новой ИНС необходимо создасть список слоев
List<Layer> layerList = new ArrayList<Layer>();
layerList.add(Layer.create(3, ActivationFunction.FANN_SIGMOID_SYMMETRIC, 0.01f));
layerList.add(Layer.create(16, ActivationFunction.FANN_SIGMOID_SYMMETRIC, 0.01f));
layerList.add(Layer.create(4, ActivationFunction.FANN_SIGMOID_SYMMETRIC, 0.01f));
Fann fann = new Fann(layerList);
//Создаем тренера и определяем алгоритм обучения
Trainer trainer = new Trainer(fann);
trainer.setTrainingAlgorithm(TrainingAlgorithm.FANN_TRAIN_RPROP);
/* Проведем обучение взяв уроки из файла, с максимальным колличеством
циклов 100000, показывая отчет каждую 100ю итерацию и добиваемся
ошибки меньше 0.0001 */
trainer.train(new File("train.data").getAbsolutePath(), 100000, 100, 0.0001f);
fann.save("ann");
}
Пояснение
Layer
ИНС состоит из слоев нейронов. Первый слой — это нейроны «рецепторы» или нейроны входных данных. Последний слой нейронов выходных данных. Все остальные — это скрытые слои. В нашем случае первый слой имеет 3 нейрона:
уровень здоровья (0.1-1.0);
наличие оружия (1-есть, 0-нету);
количество врагов.
Fann
Объект класса Fann это и есть нейронная сеть, которая создается на основе созданных ранее слоев.
Trainer
Объект класса тренер инкапсулирует алгоритмы обучения нейронной сети переданной при создании тренера. После обучения не забываем сохранить ее в файл.
Проверка результатов
Для проверки нашего обучения воспользуемся следующим кодом:
public static void main(String[] args) {
Fann fann = new Fann("ann");
float[][] tests = {
{1.0f, 0, 1},
{0.9f, 1, 3},
{0.3f, 0, 8},
{1, 1, 8},
{0.1f, 0, 0},
};
for (float[] test:tests){
System.out.println(getAction(fann.run(test)));
}
}
private static String getAction(float[] out){
int i = 0;
for (int j = 1; j < 4; j++) {
if(out[i]<out[j]){
i = j;
}
}
switch (i){
case 0:return "атаковать";
case 1:return "прятаться";
case 2:return "бежать";
case 3:return "ничего не делать";
}
return "";
}
У меня получились такие результаты:
| Здоровье | пистолет | Враги | Действие |
|---|---|---|---|
| 100% | Нет | 1 | Атаковать |
| 90% | Есть | 3 | Прятаться |
| 30% | нет | 8 | Бежать |
| 100% | Есть | 8 | Бежать |
| 10% | Нет | 0 | Ничего не делать |
Буду рад услышать конструктивную критику.
Введение в нейронные сети
Глубокое обучение включает в себя как глубокие нейронные сети, так и глубокое обучение с подкреплением, которые являются подмножеством машинного обучения, которое само по себе является подмножеством искусственного интеллекта. Вообще говоря, глубокие нейронные сети выполняют машинное восприятие, которое извлекает важные функции из необработанных данных и делает своего рода прогноз относительно каждого наблюдения. Примеры включают в себя идентификацию объектов, представленных на изображениях, сопоставление аналоговой речи с письменными транскрипциями, категоризацию текста по настроениям и прогнозирование данных временных рядов.
Хотя нейронные сети были изобретены в прошлом веке, только недавно они вызвали больше волнений. Теперь, когда вычислительная способность использовать в своих интересах идею нейронных сетей существует, они были использованы для установки новых, самых современных результатов в таких областях, как компьютерное зрение, обработка естественного языка и обучение с подкреплением. Одно из известных достижений глубокого обучения было достигнуто учеными из DeepMind, которые создали компьютерную программу под названием AlphaGo, которая побила как бывшего чемпиона мира по Го, так и действующего чемпиона в 2016 и 2017 годах соответственно. Многие эксперты предсказывали, что это достижение не придет еще на десятилетие.
Существует много разных видов нейронных сетей, но основная идея их работы проста. Они основаны на человеческом мозге и состоят из одного или нескольких слоев «нейронов», которые являются просто математическими операциями, передающими сигнал от предыдущего слоя. На каждом уровне вычисления применяются к входу нейронов предыдущего уровня, а затем выход передается на следующий уровень. Выходные данные последнего слоя сети будут представлять некоторый прогноз о входных данных, в зависимости от задачи. Задача построения успешной нейронной сети – найти правильные вычисления для применения на каждом уровне.
Нейронные сети могут обрабатывать многомерные числовые и категорические данные и выполнять такие задачи, как регрессия, классификация, кластеризация и извлечение признаков. Нейронная сеть создается путем первоначальной настройки ее архитектуры на основе данных и задачи, а затем путем настройки ее гиперпараметров для оптимизации производительности нейронной сети. После того, как нейронная сеть будет достаточно обучена и настроена, ее можно использовать для обработки новых наборов данных и получения достаточно надежных прогнозов.
Где Eclipse DeepLearning4j подходит
Eclipse Deeplearning4j (DL4J) – это основанный на JVM инструментарий с открытым исходным кодом для построения, обучения и развертывания нейронных сетей. Он был создан для обслуживания сообществ Java и Scala и является удобным, стабильным и хорошо интегрированным с такими технологиями, как Spark, CUDA и cuDNN. Deeplearning4j также интегрируется с инструментами Python, такими как Keras и TensorFlow, для развертывания их моделей в производственной среде на JVM. Он также поставляется с группой библиотек с открытым исходным кодом, которые Skymind объединяет в корпоративный дистрибутив, называемый Skymind Intelligence Layer (SKIL) . Эти библиотеки:
- Deeplearning4j : нейронная сеть DSL (облегчает построение нейронных сетей, интегрированных с конвейерами данных и Spark)
- ND4J : N-мерные массивы для Java, тензорная библиотека: «Затмение января с кодом C и более широкой областью применения». Цель состоит в том, чтобы обеспечить тензорные операции и оптимизированную поддержку для различных аппаратных платформ.
- DataVec : библиотека ETL, которая векторизует и «тензорирует» данные. Извлечение нагрузки преобразования с поддержкой подключения к различным источникам данных и вывода n-мерных массивов через серию преобразований данных
- libnd4j : Pure C ++ библиотека для тензорных операций, которая тесно работает с библиотекой открытого кода JavaCPP (JavaCPP была создана и поддерживается инженером Skymind, но она не является частью этого проекта).
- RL4J : обучение усилению на JVM, интегрированное с Deeplearning4j. Включает глубокое обучение, используемое в AlphaGo и A3C.
- Jumpy : интерфейс Python для библиотеки ND4J, интегрирующийся с Numpy
- Арбитр : Автоматическая настройка нейронных сетей с помощью поиска гиперпараметров. Оптимизация гиперпараметров с использованием поиска по сетке, случайного поиска и байесовских методов.
- ScalNet : Scala API для Deeplearning4j, похожий на Torch или Keras по внешнему виду.
- ND4S : N-мерные массивы для Scala, основанные на ND4J.
Вот несколько причин использовать DeepLearning4j.
Вы являетесь специалистом по данным в этой области или студентом проекта Java, Scala или Python, и вам необходимо интегрироваться со стеком JVM (Hadoop, Spark, Kafka, ElasticSearch, Cassandra); Например, вы хотите масштабировать обучение нейронной сети на Spark через несколько графических процессоров . Вам необходимо исследовать данные, проводить и контролировать эксперименты, которые применяют к данным различные алгоритмы, и проводить обучение на кластерах, чтобы быстро получить точную модель для этих данных.
Вы – инженер данных или разработчик программного обеспечения в корпоративной среде, которому нужны стабильные, многократно используемые конвейеры данных и масштабируемые и точные прогнозы относительно данных. В данном случае используется программная и автоматическая обработка и анализ данных для определения назначенного результата с использованием простых и понятных API.
Пример: построение сети прямой связи
Сеть прямой связи является самой простой формой нейронных сетей, а также одной из первых в мире. Здесь мы опишем пример нейронной сети с прямой связью на основе примера, расположенного здесь, с использованием данных Луны . Данные находятся здесь .
Необработанные данные состоят из файлов CSV с двумя числовыми характеристиками и двумя метками. Обучающие и тестовые наборы находятся в разных файлах CSV с 2000 наблюдениями в обучающем наборе и 1000 наблюдениями в тестовом наборе. Цель задачи – предсказать метку с учетом двух входных функций. Таким образом, мы заинтересованы в классификации.
Сначала мы инициализируем переменные, необходимые для построения нейронной сети с прямой связью. Мы устанавливаем гиперпараметры нейронной сети, такие как скорость обучения и размер пакета, а также переменные, связанные с ее архитектурой, например количество скрытых узлов.
|
01 02 03 04 05 06 07 08 09 10 11 |
|
Поскольку данные находятся в двух файлах CSV, мы инициализируем всего два CSVRecordReaders и два DataSetIterators . RecordReaders проанализирует данные в формате записи, а DataSetIterator направит данные в нейронную сеть в формате, который он может прочитать.
|
1 2 3 4 5 6 7 |
|
Построение сети прямой пересылки
Теперь, когда данные готовы, мы можем настроить конфигурацию нейронной сети, используя MultiLayerConfiguration .
|
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 |
|
Существует один скрытый слой с 20 узлами и выходной слой с двумя узлами, использующий функцию активации softmax и функцию потери отрицательного логарифмического правдоподобия. Мы также устанавливаем, как инициализируются веса нейронной сети и как нейронная сеть будет оптимизировать веса. Чтобы результаты были воспроизводимыми, мы также устанавливаем его начальное значение; то есть мы используем случайно инициализированные веса, но мы сохраняем их случайную инициализацию на тот случай, если нам потребуется начать обучение с той же точки позже, чтобы подтвердить наши результаты.
Обучение и оценка нейронной сети прямой связи
Чтобы фактически создать модель, MultiLayerNetwork инициализируется с использованием ранее установленной конфигурации. Затем мы можем подогнать данные, используя цикл обучения; в качестве альтернативы, если используется MultipleEpochsIterator , тогда функцию подбора нужно вызывать только один раз, чтобы обучить данные с заданным количеством эпох.
|
1 2 3 4 5 6 7 |
|
Как только данные закончат обучение, мы будем использовать набор тестов для оценки нашей модели. Обратите внимание, что testIter создает testIter соответствии с ранее установленным размером пакета 50. Класс Evaluation будет обрабатывать точность вычислений с использованием правильных меток и прогнозов. В конце мы можем распечатать результаты.
|
01 02 03 04 05 06 07 08 09 10 |
|
Этот пример охватывает основы использования MultiLayerNetwork для создания простой нейронной сети с MultiLayerNetwork .

- Чтобы узнать больше, ознакомьтесь с нашей книгой О’Рейли: « Глубокое обучение: подход практикующего»
- И посмотрите руководство по программированию Deeplearning4j