Исходные данные – это фундамент для успешной работы в области анализа и обработки данных. Существует множество источников данных, и веб-сайты являются одним из них. Часто они могут быть вторичным источником информации, например: сайты агрегации данных (Worldometers), новостные сайты (CNBC), социальные сети (Twitter), платформы электронной коммерции (Shopee) и так далее. Эти веб-сайты предоставляют информацию, необходимую для проектов по анализу и обработке данных.
Но как нужно собирать данные? Мы не можем копировать и вставлять их вручную, не так ли? В такой ситуации решением проблемы будет парсинг сайтов на Python. Этот язык программирования имеет мощную библиотеку BeautifulSoup, а также инструмент для автоматизации Selenium. Они оба часто используются специалистами для сбора данных разных форматов. В этом разделе мы сначала познакомимся с BeautifulSoup.
ШАГ 1. УСТАНОВКА БИБЛИОТЕК
Прежде всего, нам нужно установить нужные библиотеки, а именно:
- BeautifulSoup4
- Requests
- pandas
- lxml
Для установки библиотеки вы можете использовать pip install [имя библиотеки] или conda install [имя библиотеки], если у вас Anaconda Prompt.
«Requests» — это наша следующая библиотека для установки. Ее задача — запрос разрешения у сервера, если мы хотим получить данные с его веб-сайта. Затем нужно установить pandas для создания фрейма данных и lxml, чтобы изменить HTML на формат, удобный для Python.
ШАГ 2. ИМПОРТИРОВАНИЕ БИБЛИОТЕК
После установки библиотек давайте откроем вашу любимую среду разработки. Мы предлагаем использовать Spyder 4.2.5. Позже на некоторых этапах работы мы столкнемся с большими объемами выводимых данных и тогда Spyder будет удобнее в использовании чем Jupyter Notebook.
Итак, Spyder открыт и мы можем импортировать необходимую библиотеку:
# Import library
from bs4 import BeautifulSoup
import requests
ШАГ 3. ВЫБОР СТРАНИЦЫ
В этом проекте мы будем использовать webscraper.io. Поскольку данный веб-сайт создан на HTML, код легче и понятнее даже новичкам. Мы выбрали эту страницу для парсинга данных:
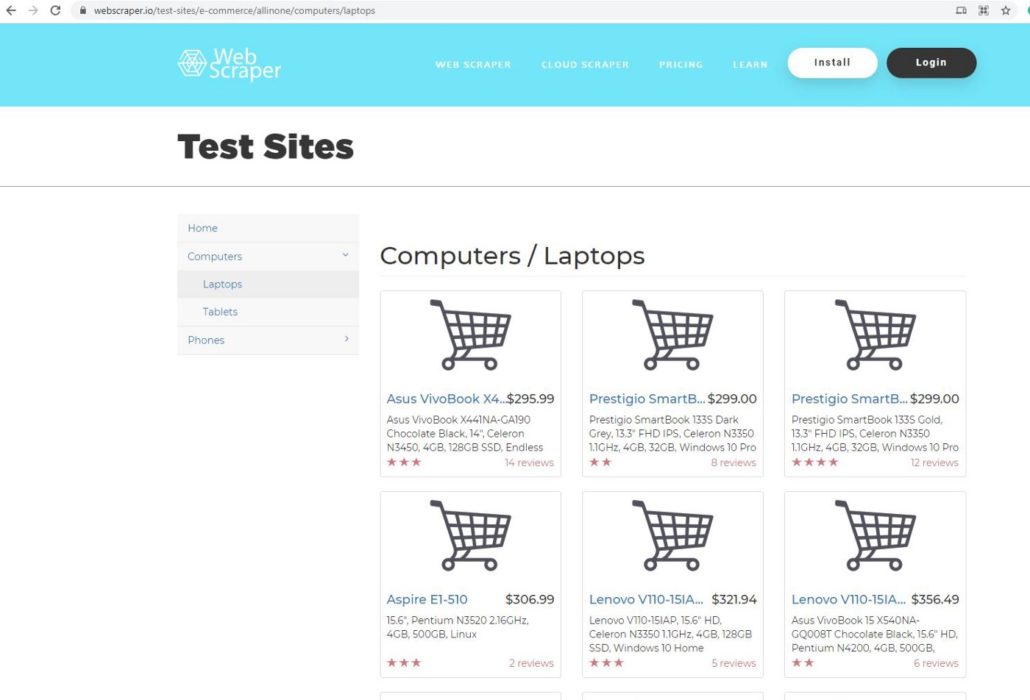
Она является прототипом веб-сайта онлайн магазина. Мы будем парсить данные о компьютерах и ноутбуках, такие как название продукта, цена, описание и отзывы.
ШАГ 4. ЗАПРОС НА РАЗРЕШЕНИЕ
После выбора страницы мы копируем ее URL-адрес и используем request, чтобы запросить разрешение у сервера на получение данных с их сайта.
# Define URL
url = ‘https://webscraper.io/test-sites/e-commerce/allinone/computers/laptops'#
Ask hosting server to fetch url
requests.get(url)
Результат <Response [200]> означает, что сервер позволяет нам собирать данные с их веб-сайта. Для проверки мы можем использовать функцию request.get.
pages = requests.get(url)
pages.text
Когда вы выполните этот код, то на выходе получите беспорядочный текст, который не подходит для Python. Нам нужно использовать парсер, чтобы сделать его более читабельным.
# parser-lxml = Change html to Python friendly format
soup = BeautifulSoup(pages.text, ‘lxml’)
soup

ШАГ 5. ПРОСМОТР КОДА ЭЛЕМЕНТА
Для парсинга сайтов на Python мы рекомендуем использовать Google Chrome, он очень удобен и прост в использовании. Давайте узнаем, как с помощью Chrome просмотреть код веб-страницы. Сначала нужно щелкнуть правой кнопкой мыши страницу, которую вы хотите проверить, далее нажать Просмотреть код и вы увидите это:
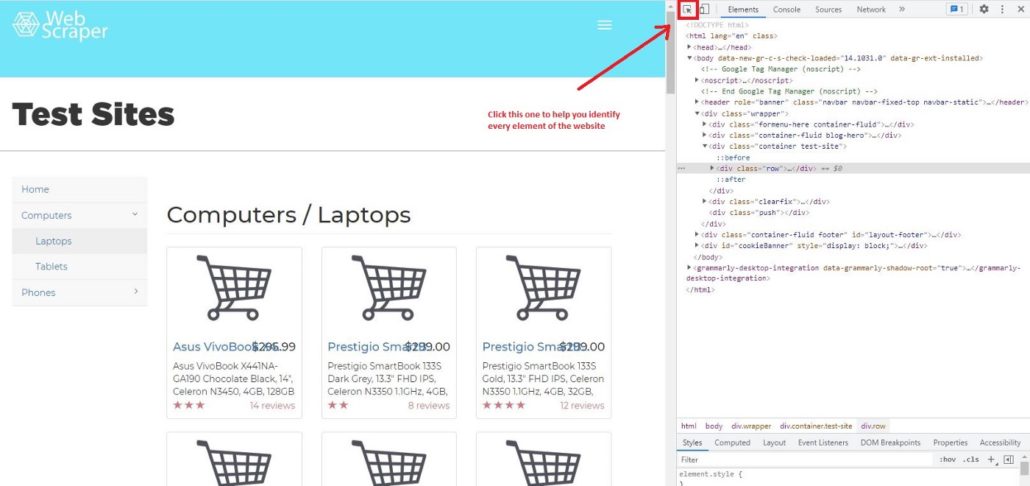
Затем щелкните Выбрать элемент на странице для проверки и вы заметите, что при перемещении курсора к каждому элементу страницы, меню элементов показывает его код.
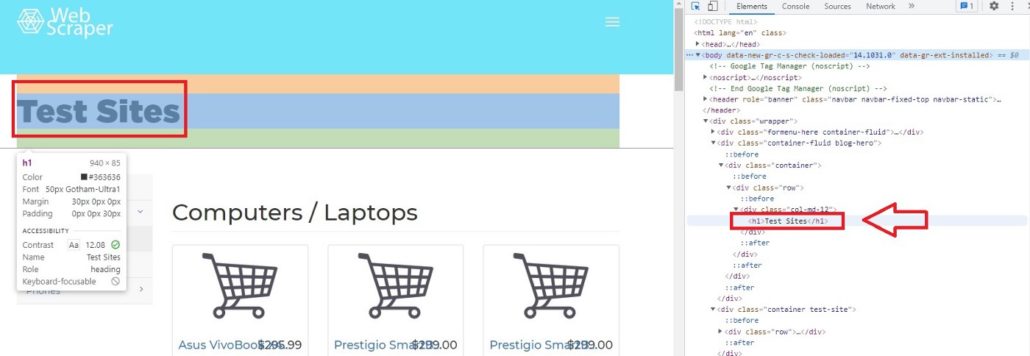
Например, если мы переместим курсор на Test Sites, элемент покажет, что Test Sites находится в теге h1. В Python, если вы хотите просмотреть код элементов сайта, можно вызывать теги. Характерной чертой тегов является то, что они всегда имеют < в качестве префикса и часто имеют фиолетовый цвет.
Как выбрать решение для парсинга сайтов: классификация и большой обзор программ, сервисов и фреймворков
ШАГ 6. ДОСТУП К ТЕГАМ
Если мы, к примеру, хотим получить доступ к элементу h1 с помощью Python, мы можем просто ввести:
# Access h1 tag
soup.h1
Результат будет:
soup.h1
Out[11]: <h1>Test Sites</h1>
Вы можете получить доступ не только к однострочным тегам, но и к тегам класса, например:
# Access header tagsoup.header#Access div tag soup.div
Не забудьте перед этим определить soup, поскольку важно преобразовать HTML в удобный для Python формат.
Вы можете получить доступ к определенному из вложенных тегов. Вложенные теги означают теги внутри тегов. Например, тег <p> находится внутри другого тега <header>. Но когда вы получаете доступ к определенному тегу из <header>, Python всегда покажет результаты из первого индекса. Позже мы узнаем, как получить доступ к нескольким тегам из вложенных.
# Access string from nested tags
soup.header.p
Результат:
soup.header.p
Out[10]: <p>Web Scraper</p>
Вы также можете получить доступ к строке вложенных тегов. Нужно просто добавить в код string.
# Access string from nested tags
soup.header.p
soup.header.p.string
Результат:
soup.header.p
soup.header.p.string
Out[12]: ‘Web Scraper’
Следующий этап парсинга сайтов на Python — это получение доступа к атрибутам тегов. Для этого мы можем использовать функциональную возможность BeautifulSoup attrs. Как результат применения attrs мы получим словарь.
# Access ‘a’ tag in <header>
a_start = soup.header.a
a_start#
Access only the attributes using attrs
a_start.attrs
Результат:
Out[16]:{‘data-toggle’: ‘collapse-side’,
‘data-target’: ‘.side-collapse’,
‘data-target-2’: ‘.side-collapse-container’}
Мы можем получить доступ к определенному атрибуту. Учтите, что Python рассматривает атрибут как словарь, поэтому data-toggle, data-target и data-target-2 являются ключом. Вот пример получение доступа к ‘data-target:
a_start[‘data-target’]
Результат:
a_start[‘data-target’]
Out[17]: ‘.side-collapse’
Мы также можем добавить новый атрибут. Имейте в виду, что изменения влияют только на веб-сайт локально, а не на веб-сайт в мировом масштабе.
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Результат:
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Out[18]:
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</a>
Парсинг таблицы с сайта на Python: Пошаговое руководство
ШАГ 7. ДОСТУП К КОНКРЕТНЫМ АТРИБУТАМ ТЕГОВ
Мы узнали, что в теге может быть больше чем один вложенный тег. Например, если мы запустим soup.header.div, <div> будет иметь много вложенных тегов. Учтите, что мы вызываем только <div> внутри <header >, поэтому другой тег внутри <header> не будет показан.
Результат:
soup.header.div
Out[26]:
<div class=”container”><div class=”navbar-header”>
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</div>
Как мы видим, в одном теге находится много атрибутов и вопрос заключается в том, как получить доступ только к тому атрибуту, который нам нужен. В BeautifulSoup есть функция ‘find’ и ‘find_all’. Чтобы было понятнее, мы покажем вам, как использовать обе функции и чем они отличаются друг от друга. В качестве примера найдем цену каждого товара. Чтобы увидеть код элемента цены, просто наведите курсор на индикатор цены.
После перемещения курсора мы можем определить, что цена находится в теге h4, значение класса pull-right price.
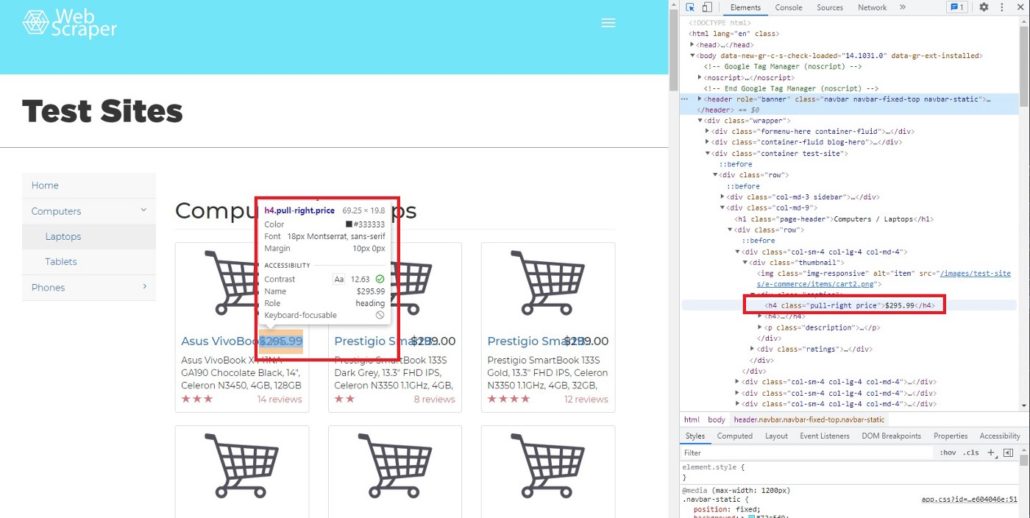
Далее мы хотим найти строку элемента h4, используя функцию find:
# Searching specific attributes of tags
soup.find(‘h4’, class_= ‘pull-right price’)
Результат:
Out[28]: <h4 class=”pull-right price”>$295.99</h4>
Как видно, $295,99 — это атрибут (строка) h4. Но что будет, если мы используем find_all.
# Using find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)
Результат:
Out[29]:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>,
<h4 class=”pull-right price”>$356.49</h4>,
....
</h4>]
Вы заметили разницу между find и find_all?
Да, все верно, find нужно использовать для поиска определенных атрибутов, потому что он возвращает только один результат. Для парсинга больших объемов данных (например, цена, название продукта, описание и т. д.), используйте find_all.
Кроме того, можем получить часть результата функции find_all. В данном случае мы хотим видеть только индексы с 3-го до 5-го.
# Slicing the results of find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)[2:5]
Результат:
Out[32]:[<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>]
[!] Не забывайте, что в Python индекс первого элемента в списке — 0, а последний не учитывается.
ШАГ 8. ИСПОЛЬЗОВАНИЕ ФИЛЬТРА
При необходимости мы можем найти несколько тегов:
# Using filter to find multiple tagssoup.find_all(['h4', 'a', 'p'])soup.find_all(['header', 'div'])
soup.find_all(id = True) # class and id are special attribute so it can be written like this
soup.find_all(class_= True)
Поскольку class и id являются специальными атрибутами, поэтому можно писать class_ и id вместо ‘class’ или ‘id’.
Использование фильтра поможет нам получить необходимые данные с веб-сайта. В нашем случае это название, цена, отзывы и описания. Итак, сначала определим переменные.
# Filter by name name = soup.find_all(‘a’, class_=’title’) # Filter by priceprice = soup.find_all(‘h4’, class_ = ‘pull-right price’)# Filter by reviews reviews = soup.find_all(‘p’, class_ = ‘pull-right’)# Filter by description description = soup.find_all(‘p’, class_ =’description’)
Фильтр по названию:
[<a class=”title” href=”/test-sites/e-commerce/allinone/product/545" title=”Asus VivoBook X441NA-GA190">Asus VivoBook X4…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/546" title=”Prestigio SmartBook 133S Dark Grey”>Prestigio SmartB…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/547" title=”Prestigio SmartBook 133S Gold”>Prestigio SmartB…</a>,
...
</a>]
Фильтр по цене:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$306.99</h4>,
...
</h4>]
Фильтр по отзывам:
[<p class=”pull-right”>14 reviews</p>,<p class=”pull-right”>8 reviews</p>,
<p class=”pull-right”>12 reviews</p>,<p class=”pull-right”>2 reviews</p>,
...
</p>]
Фильтр по описанию:
[<p class=”description”>Asus VivoBook X441NA-GA190 Chocolate Black, 14", Celeron N3450, 4GB, 128GB SSD, Endless OS, ENG kbd</p>,
<p class=”description”>Prestigio SmartBook 133S Dark Grey, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
<p class=”description”>Prestigio SmartBook 133S Gold, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
...
</p>]
ШАГ 9. ОЧИСТКА ДАННЫХ
Очевидно, результаты все еще в формате HTML, поэтому нам нужно очистить их и получить только строку элемента. Используем для этого функцию text.
Text может служить для сортировки строк HTML кода, однако нужно определить новую переменную, например:
# Try to call priceprice1 = soup.find(‘h4’, class_ = ‘pull-right price’)
price1.text
Результат:
Out[55]: ‘$295.99’
На выходе получается только строка из кода, но этого недостаточно. На следующем этапе мы узнаем, как парсить все строки и сделать из них список.
ШАГ 10. ИСПОЛЬЗОВАНИЕ ЦИКЛА FOR ДЛЯ СОЗДАНИЯ СПИСКА СТРОК
Чтобы сделать список из всех строк, необходимо создать цикл for.
# Create for loop to make string from find_all list
product_name_list = []
for i in name:
name = i.text
product_name_list.append(name)price_list = []
for i in price:
price = i.text
price_list.append(price)
review_list = []
for i in reviews:
rev = i.text
review_list.append(rev)
description_list = []
for i in description:
desc = i.text
description_list.append(desc)ШАГ 11. СОЗДАНИЕ ФРЕЙМА ДАННЫХ
После того, как мы создали цикл for и все строки были добавлены в списки, остается заключительный этап парсинга сайтов на Python — построить фрейм данных. Для этой цели нам нужно импортировать библиотеку pandas.
# Create dataframe# Import library import pandas as pdtabel = pd.DataFrame({‘Product Name’:product_name_list, ‘Price’: price_list, ‘Reviews’:review_list, ‘Description’:description_list})
Теперь эти данные можно использовать для работы в проектах по анализу и обработке данных, в машинном обучении, для получения другой ценной информации.

Надеюсь, это руководство будет вам полезно, особенно для тех, кто изучает парсинг сайтов на Python. До новых встреч в следующем проекте.
Если у вас возникнут сложности с парсингом сайтов на Python или с парсингом приложений, обращайтесь в компанию iDatica — напишите письмо или заполните заявку указав все детали задачи по парсингу.
Парсинг в Python – это метод извлечения большого количества данных с нескольких веб-сайтов. Термин «парсинг» относится к получению информации из другого источника (веб-страницы) и сохранению ее в локальном файле.
Например: предположим, что вы работаете над проектом под названием «Веб-сайт сравнения телефонов», где вам требуются цены на мобильные телефоны, рейтинги и названия моделей для сравнения различных мобильных телефонов. Если вы собираете эти данные вручную, проверяя различные сайты, это займет много времени. В этом случае важную роль играет парсинг веб-страниц, когда, написав несколько строк кода, вы можете получить желаемые результаты.

Web Scrapping извлекает данные с веб-сайтов в неструктурированном формате. Это помогает собрать эти неструктурированные данные и преобразовать их в структурированную форму.
Законен ли веб-скрапинг?
Здесь возникает вопрос, является ли веб-скрапинг законным или нет. Ответ в том, что некоторые сайты разрешают это при легальном использовании. Веб-парсинг – это просто инструмент, который вы можете использовать правильно или неправильно.
Непубличные данные доступны не всем; если вы попытаетесь извлечь такие данные, это будет нарушением закона.
Есть несколько инструментов для парсинга данных с веб-сайтов, например:
- Scrapping-bot
- Scrapper API
- Octoparse
- Import.io
- Webhose.io
- Dexi.io
- Outwit
- Diffbot
- Content Grabber
- Mozenda
- Web Scrapper Chrome Extension
Почему и зачем использовать веб-парсинг?

Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
- Динамический мониторинг цен
Широко используется для сбора данных с нескольких интернет-магазинов, сравнения цен на товары и принятия выгодных ценовых решений. Мониторинг цен с использованием данных, переданных через Интернет, дает компаниям возможность узнать о состоянии рынка и способствует динамическому ценообразованию. Это гарантирует компаниям, что они всегда превосходят других.
- Исследования рынка
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
- Сбор электронной почты
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
- Новости и мониторинг контента
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
- Тренды в социальных сетях
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
- Исследования и разработки
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
Зачем использовать именно Python?
Есть и другие популярные языки программирования, но почему мы предпочитаем Python другим языкам программирования для парсинга веб-страниц? Ниже мы описываем список функций Python, которые делают его наиболее полезным языком программирования для сбора данных с веб-страниц.
- Динамичность
В Python нам не нужно определять типы данных для переменных; мы можем напрямую использовать переменную там, где это требуется. Это экономит время и ускоряет выполнение задачи. Python определяет свои классы для определения типа данных переменной.
- Обширная коллекция библиотек
Python поставляется с обширным набором библиотек, таких как NumPy, Matplotlib, Pandas, Scipy и т. д., которые обеспечивают гибкость для работы с различными целями. Он подходит почти для каждой развивающейся области, а также для извлечения данных и выполнения манипуляций.
- Меньше кода
Целью парсинга веб-страниц является экономия времени. Но что, если вы потратите больше времени на написание кода? Вот почему мы используем Python, поскольку он может выполнять задачу в нескольких строках кода.
- Сообщество с открытым исходным кодом
Python имеет открытый исходный код, что означает, что он доступен всем бесплатно. У него одно из крупнейших сообществ в мире, где вы можете обратиться за помощью, если застряли где-нибудь в коде Python.
Основы веб-парсинга
Веб-скраппинг состоит из двух частей: веб-сканера и веб-скребка. Проще говоря, веб-сканер – это лошадь, а скребок – колесница. Сканер ведет парсера и извлекает запрошенные данные. Давайте разберемся с этими двумя компонентами веб-парсинга:
- Сканер
 Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
 Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Как работает Web Scrapping?
Давайте разберем по шагам, как работает парсинг веб-страниц.
Шаг 1. Найдите URL, который вам нужен.
Во-первых, вы должны понимать требования к данным в соответствии с вашим проектом. Веб-страница или веб-сайт содержит большой объем информации. Вот почему отбрасывайте только актуальную информацию. Проще говоря, разработчик должен быть знаком с требованиями к данным.
Шаг – 2: Проверка страницы
Данные извлекаются в необработанном формате HTML, который необходимо тщательно анализировать и отсеивать мешающие необработанные данные. В некоторых случаях данные могут быть простыми, такими как имя и адрес, или такими же сложными, как многомерные данные о погоде и данные фондового рынка.
Шаг – 3: Напишите код
Напишите код для извлечения информации, предоставления соответствующей информации и запуска кода.
Шаг – 4: Сохраните данные в файле
Сохраните эту информацию в необходимом формате файла csv, xml, JSON.
Начало работы с Web Scrapping
Давайте разберемся с необходимой библиотекой для Python. Библиотека, используемая для разметки веб-страниц.
- Selenium-Selenium – это библиотека автоматического тестирования с открытым исходным кодом. Она используется для проверки активности браузера. Чтобы установить эту библиотеку, введите в терминале следующую команду.
pip install selenium
Примечание. Рекомендуется использовать IDE PyCharm.

- Pandas – библиотека для обработки и анализа данных. Используется для извлечения данных и сохранения их в желаемом формате.
- BeautifulSoup
BeautifulSoup – это библиотека Python, которая используется для извлечения данных из файлов HTML и XML. Она в основном предназначена для парсинга веб-страниц. Работает с анализатором, обеспечивая естественный способ навигации, поиска и изменения дерева синтаксического анализа. Последняя версия BeautifulSoup – 4.8.1.
Давайте подробно разберемся с библиотекой BeautifulSoup.
Установка BeautifulSoup
Вы можете установить BeautifulSoup, введя следующую команду:
pip install bs4
Установка парсера
BeautifulSoup поддерживает парсер HTML и несколько сторонних парсеров Python. Вы можете установить любой из них в зависимости от ваших предпочтений. Список парсеров BeautifulSoup:
| Парсер | Типичное использование |
|---|---|
| Python’s html.parser | BeautifulSoup (разметка, “html.parser”) |
| lxml’s HTML parser | BeautifulSoup (разметка, «lxml») |
| lxml’s XML parser | BeautifulSoup (разметка, «lxml-xml») |
| Html5lib | BeautifulSoup (разметка, “html5lib”) |
Мы рекомендуем вам установить парсер html5lib, потому что он больше подходит для более новой версии Python, либо вы можете установить парсер lxml.
Введите в терминале следующую команду:
pip install html5lib

BeautifulSoup используется для преобразования сложного HTML-документа в сложное дерево объектов Python. Но есть несколько основных типов объектов, которые чаще всего используются:
- Ярлык
Объект Tag соответствует исходному документу XML или HTML.
soup = bs4.BeautifulSoup("Extremely bold)
tag = soup.b
type(tag)
Выход:
<class "bs4.element.Tag">
Тег содержит множество атрибутов и методов, но наиболее важными особенностями тега являются имя и атрибут.
-
- Имя
У каждого тега есть имя, доступное как .name:
tag.name
- Атрибуты
Тег может иметь любое количество атрибутов. Тег имеет атрибут “id”, значение которого – “boldest”. Мы можем получить доступ к атрибутам тега, рассматривая тег как словарь.
tag[id]
Мы можем добавлять, удалять и изменять атрибуты тега. Это можно сделать, используя тег как словарь.
# add the element tag['id'] = 'verybold' tag['another-attribute'] = 1 tag # delete the tag del tag['id']
- Многозначные атрибуты
В HTML5 есть некоторые атрибуты, которые могут иметь несколько значений. Класс (состоит более чем из одного css) – это наиболее распространенный многозначный атрибут. Другие атрибуты: rel, rev, accept-charset, headers и accesskey.
class_is_multi= { '*' : 'class'}
xml_soup = BeautifulSoup('', 'xml', multi_valued_attributes=class_is_multi)
xml_soup.p['class']
# [u'body', u'strikeout']
- Навигационная строка
Строка в BeautifulSoup ссылается на текст внутри тега. BeautifulSoup использует класс NavigableString для хранения этих фрагментов текста.
tag.string # u'Extremely bold' type(tag.string) #
Неизменяемая строка означает, что ее нельзя редактировать. Но ее можно заменить другой строкой с помощью replace_with().
tag.string.replace_with("No longer bold")
tag
В некоторых случаях, если вы хотите использовать NavigableString вне BeautifulSoup, unicode() помогает ему превратиться в обычную строку Python Unicode.
- BeautifulSoup объект
Объект BeautifulSoup представляет весь проанализированный документ в целом. Во многих случаях мы можем использовать его как объект Tag. Это означает, что он поддерживает большинство методов, описанных для навигации по дереву и поиска в дереве.
doc=BeautifulSoup("INSERT FOOTER HEREHere's the footer","xml")
doc.find(text="INSERT FOOTER HERE").replace_with(footer)
print(doc)
Выход:
?xml version="1.0" encoding="utf-8"?> #
Пример парсера
Давайте разберем пример, чтобы понять, что такое парсер на практике, извлекая данные с веб-страницы и проверяя всю страницу.
Для начала откройте свою любимую страницу в Википедии и проверьте всю страницу, перед извлечением данных с веб-страницы вы должны убедиться в своих требованиях. Рассмотрим следующий код:
#importing the BeautifulSoup Library
importbs4
import requests
#Creating the requests
res = requests.get("https://en.wikipedia.org/wiki/Machine_learning")
print("The object type:",type(res))
# Convert the request object to the Beautiful Soup Object
soup = bs4.BeautifulSoup(res.text,'html5lib')
print("The object type:",type(soup)
Выход:
The object type <class 'requests.models.Response'> Convert the object into: <class 'bs4.BeautifulSoup'>
В следующих строках кода мы извлекаем все заголовки веб-страницы по имени класса. Здесь знания внешнего интерфейса играют важную роль при проверке веб-страницы.
soup.select('.mw-headline')
for i in soup.select('.mw-headline'):
print(i.text,end = ',')
Выход:
Overview,Machine learning tasks,History and relationships to other fields,Relation to data mining,Relation to optimization,Relation to statistics, Theory,Approaches,Types of learning algorithms,Supervised learning,Unsupervised learning,Reinforcement learning,Self-learning,Feature learning,Sparse dictionary learning,Anomaly detection,Association rules,Models,Artificial neural networks,Decision trees,Support vector machines,Regression analysis,Bayesian networks,Genetic algorithms,Training models,Federated learning,Applications,Limitations,Bias,Model assessments,Ethics,Software,Free and open-source software,Proprietary software with free and open-source editions,Proprietary software,Journals,Conferences,See also,References,Further reading,External links,
В приведенном выше коде мы импортировали bs4 и запросили библиотеку. В третьей строке мы создали объект res для отправки запроса на веб-страницу. Как видите, мы извлекли весь заголовок с веб-страницы.

Веб-страница Wikipedia Learning
Давайте разберемся с другим примером: мы сделаем GET-запрос к URL-адресу и создадим объект дерева синтаксического анализа (soup) с использованием BeautifulSoup и встроенного в Python парсера “html5lib”.
Здесь мы удалим веб-страницу по указанной ссылке (https://www.javatpoint.com/). Рассмотрим следующий код:
following code: # importing the libraries from bs4 import BeautifulSoup import requests url="https://www.javatpoint.com/" # Make a GET request to fetch the raw HTML content html_content = requests.get(url).text # Parse the html content soup = BeautifulSoup(html_content, "html5lib") print(soup.prettify()) # print the parsed data of html
Приведенный выше код отобразит весь html-код домашней страницы javatpoint.
Используя объект BeautifulSoup, то есть soup, мы можем собрать необходимую таблицу данных. Напечатаем интересующую нас информацию с помощью объекта soup:
- Напечатаем заголовок веб-страницы.
print(soup.title)
Выход даст следующий результат:
<title>Tutorials List - Javatpoint</title>
- В приведенных выше выходных данных тег HTML включен в заголовок. Если вам нужен текст без тега, вы можете использовать следующий код:
print(soup.title.text)
Выход: это даст следующий результат:
Tutorials List - Javatpoint
- Мы можем получить всю ссылку на странице вместе с ее атрибутами, такими как href, title и ее внутренний текст. Рассмотрим следующий код:
for link in soup.find_all("a"):
print("Inner Text is: {}".format(link.text))
print("Title is: {}".format(link.get("title")))
print("href is: {}".format(link.get("href")))
Вывод: он напечатает все ссылки вместе со своими атрибутами. Здесь мы отображаем некоторые из них:
href is: https://www.facebook.com/javatpoint Inner Text is: The title is: None href is: https://twitter.com/pagejavatpoint Inner Text is: The title is: None href is: https://www.youtube.com/channel/UCUnYvQVCrJoFWZhKK3O2xLg Inner Text is: The title is: None href is: https://javatpoint.blogspot.com Inner Text is: Learn Java Title is: None href is: https://www.javatpoint.com/java-tutorial Inner Text is: Learn Data Structures Title is: None href is: https://www.javatpoint.com/data-structure-tutorial Inner Text is: Learn C Programming Title is: None href is: https://www.javatpoint.com/c-programming-language-tutorial Inner Text is: Learn C++ Tutorial
Программа: извлечение данных с веб-сайта Flipkart
В этом примере мы удалим цены, рейтинги и название модели мобильных телефонов из Flipkart, одного из популярных веб-сайтов электронной коммерции. Ниже приведены предварительные условия для выполнения этой задачи:
- Python 2.x или Python 3.x с установленными библиотеками Selenium, BeautifulSoup, Pandas.
- Google – браузер Chrome.
- Веб-парсеры, такие как html.parser, xlml и т. д.
Шаг – 1: найдите нужный URL.
Первым шагом является поиск URL-адреса, который вы хотите удалить. Здесь мы извлекаем детали мобильного телефона из Flipkart. URL-адрес этой страницы: https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off.
Шаг 2: проверка страницы.
Необходимо внимательно изучить страницу, поскольку данные обычно содержатся в тегах. Итак, нам нужно провести осмотр, чтобы выбрать нужный тег. Чтобы проверить страницу, щелкните элемент правой кнопкой мыши и выберите «Проверить».
Шаг – 3: найдите данные для извлечения.
Извлеките цену, имя и рейтинг, которые содержатся в теге «div» соответственно.
Шаг – 4: напишите код.
from bs4 import BeautifulSoupas soup
from urllib.request import urlopen as uReq
# Request from the webpage
myurl = "https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"
uClient = uReq(myurl)
page_html = uClient.read()
uClient.close()
page_soup = soup(page_html, features="html.parser")
# print(soup.prettify(containers[0]))
# This variable held all html of webpage
containers = page_soup.find_all("div",{"class": "_3O0U0u"})
# container = containers[0]
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price[0].text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings[0].text)
#
# #
# # print(len(containers))
# print(container.div.img["alt"])
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratingsn"
f.write(headers)
for container in containers:
product_name = container.div.img["alt"]
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container[0].text.strip()
rating_container = container.find_all("div",{"class":"niH0FQ"})
ratings = rating_container[0].text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee[1]
split_price = add_rs_price.split("E")
final_price = split_price[0]
split_rating = str(ratings).split(" ")
final_rating = split_rating[0]
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"n")
f.close()
Выход:

Мы удалили детали iPhone и сохранили их в файле CSV, как вы можете видеть на выходе. В приведенном выше коде мы добавили комментарий к нескольким строкам кода для тестирования. Вы можете удалить эти комментарии и посмотреть результат.


Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Интернет, пожалуй, самый большой источник информации (и дезинформации) на планете. Самостоятельно обработать множество ресурсов крайне сложно и затратно по времени, но есть способы автоматизации этого процесса. Речь идут о процессе скрейпинга страницы и последующего анализа данных. При помощи этих инструментов можно автоматизировать сбор огромного количества данных. А сообщество Python создало несколько мощных инструментов для этого. Интересно? Тогда погнали!
И да. Хотя многие сайты ничего против парсеров не имеют, но есть и те, кто не одобряет сбор данных с их сайта подобным образом. Стоит это учитывать, особенно если вы планируете какой-то крупный проект на базе собираемых данных.
С сегодня я предлагаю попробовать себя в этой интересной сфере при помощи классного инструмента под названием Beautiful Soup (Красивый суп?). Название начинает иметь смысл если вы хоть раз видели HTML кашу загруженной странички.
В этом примере мы попробуем стянуть данные сначала из специального сайта для обучения парсингу. А в следующий раз я покажу как я собираю некоторые блоки данных с сайта Minecraft Wiki, где структура сайта куда менее дружелюбная.
Этот гайд я написал под вдохновением и впечатлением от подобного на сайте realpython.com, так что многие моменты и примеры совпадают, но содержимое и определённые части были изменены или написаны иначе, т.к. это не перевод. Оригинал: Beautiful Soup: Build a Web Scraper With Python.
Цель: Fake Python Job Site
Этот сайт прост и понятен. Там есть список данных, которые нам и нужно будет вытащить из загруженной странички.

Понятное дело, что обработать так можно любой сайт. Буквально все из тех, которые вы можете открыть в своём браузере. Но для разных сайтов нужен будет свой скрипт, сложность которого будет напрямую зависеть от сложности самого сайта.
Главным инструментом в браузере для вас станет Инспектор страниц. В браузерах на базе хромиума его можно запустить вот так:
Он отображает полный код загруженной странички. Из него же мы будем извлекать интересующие нас данные. Если вы выделите блоки html кода, то при помощи подсветки легко сможете понять, что за что отвечает.
Ладно, на сайт посмотрели. Теперь перейдём в редактор.
Пишем код парсера для Fake Python
Для работы нам нужно будет несколько библиотек: requests и beautifulsoup4. Их устанавливаем через терминал при помощи команд:
|
python —m pip install beautifulsoup4 |
и
|
python —m pip install requests |
После чего пишем следующий код:
|
import requests from bs4 import BeautifulSoup URL = «https://realpython.github.io/fake-jobs/» page = requests.get(URL) soup = BeautifulSoup(page.content, «html.parser») |
Тут мы импортируем новые библиотеки. URL это строка, она содержит ссылку на сайт. При помощи requests.get мы совершаем запрос к веб страничке. Сама функция возвращает ответ от сервера (200, 404 и т.д.), а page.content предоставляет нам полный код загруженной страницы. Тот же код, который мы видели в инспекторе.
Для большего понимания можно вывести принтом оба варианта:
|
print(page) print(page.content) |

Первый дал ответ 200, т.е. ОК. А дальше идёт тот самый будущий суп из html, который нам и нужно будет разобрать.
В следующей строке и вступает в игру BeautifulSoup, куда мы передаём первым аргументом весь код страницы, а вторым указываем, что это анализировать будем именно html.
Хотите увидеть результат? Давайте выведем объект soup.
Да, это всё тот же код, но уже сейчас куда более читаемый. Технически, вы уже получили код страницы при помощи python, но информация в таком виде содержит слишком много лишнего. И сейчас мы научимся его отсекать.
Ищем элементы по ID
Как вы могли заметить, наблюдая за html кодом, есть много блоков с различными параметрами, class, id и т.д. Часто именно id делает элементы разметки уникальными и по этому параметру можно найти интересующие нас части.
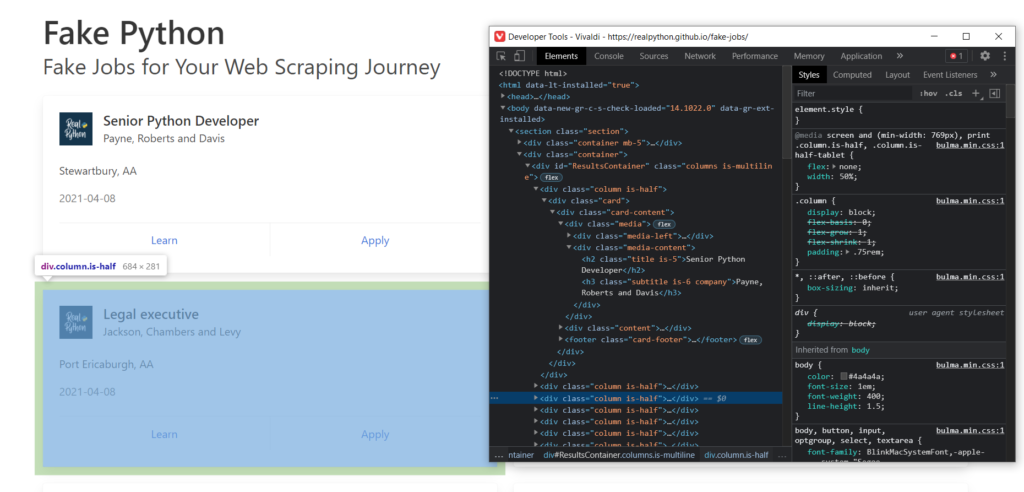
Если брать во внимание разбираемый нами сайт, то вы могли заметить, что все отдельные карточки находятся внутри одного объекта div с id = ResultsContainer:
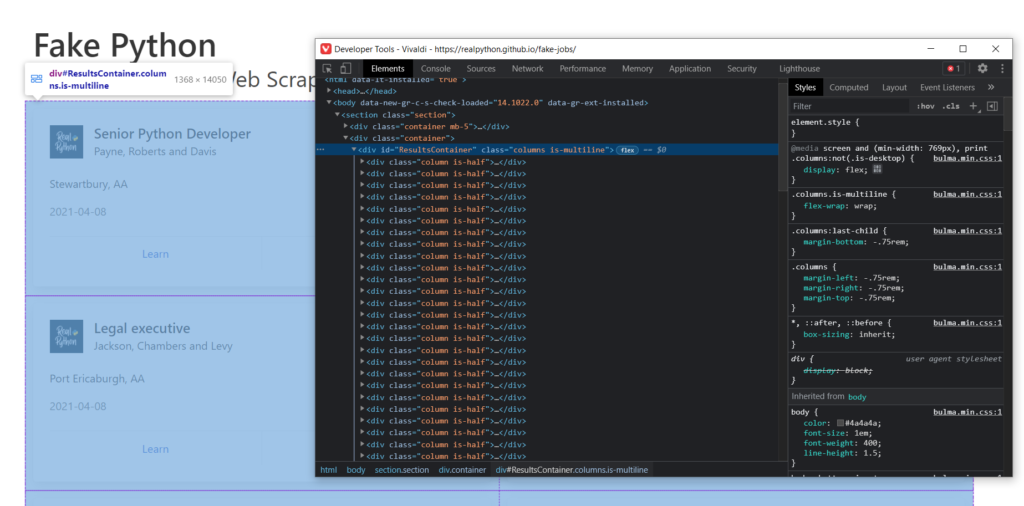
Это нам подходит. Так и пишем, а заодно и выведем результат:
|
results = soup.find(id=«ResultsContainer») print(results) |
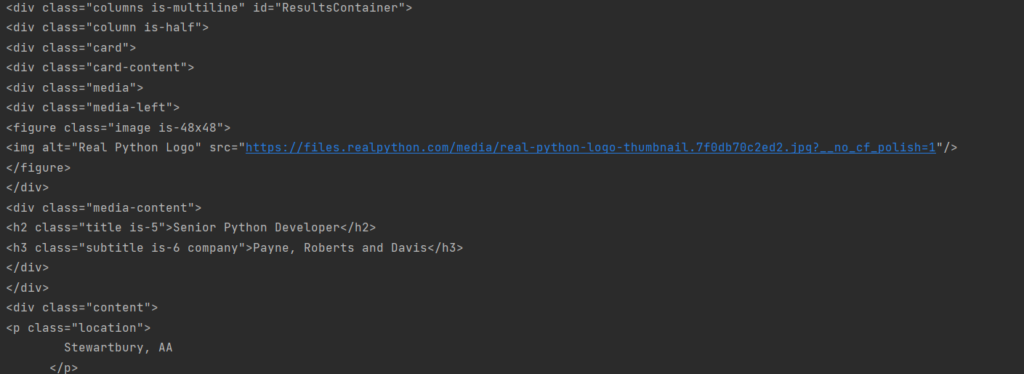
Теперь мы получили только выбранный блок. Да, всё ещё не особо читаемое, да и форматирование не отражает иерархии. С первым мы разберемся далее, а вот второе исправить достаточно просто. Вместо простого принта объекта мы можем использовать функцию prettify.
|
print(results.prettify()) |
А результат станет несколько приятнее для чтения:
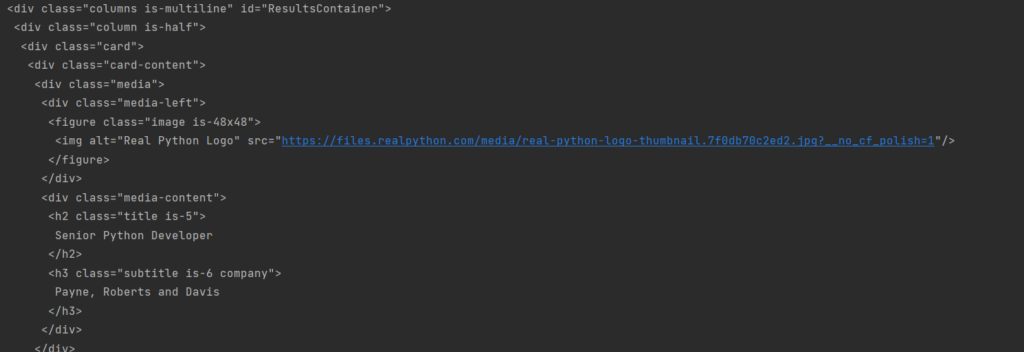
И да, мы получили уже конкретный блок необходимых данных, но это только начало.
Ищем элементы по имени класса
Смотрим дальше. Внутри каждой из полученных карточек есть объект с классом card-content. Мы можем это использовать, чтобы получить массив из всех элементов, которые содержат этот класс.
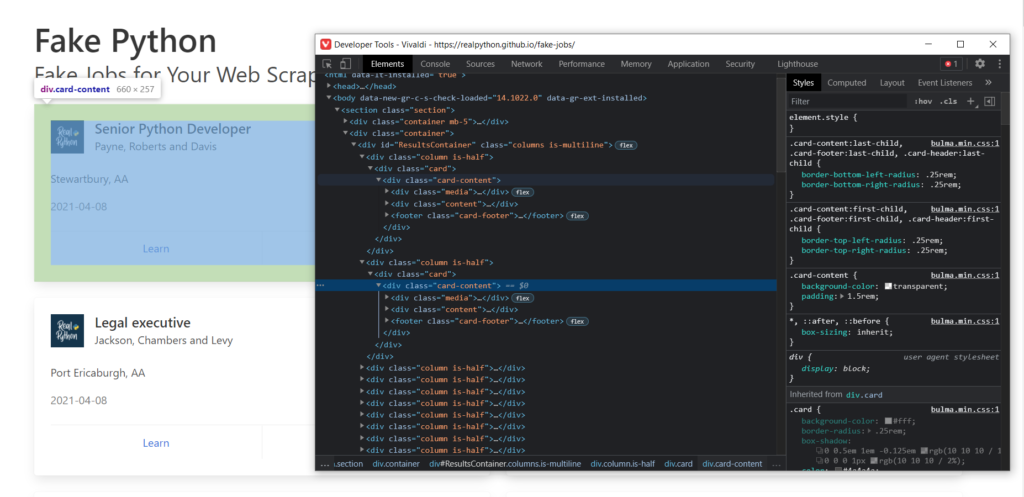
Но так как мы хотим получить только элементы из последнего блока данных, а не всего сайта, то теперь вызываем find_all не от soup, а от results. Достаточно простая система.
|
job_elements = results.find_all(«div», class_=«card-content») for job in job_elements: print(«nn») print(job.prettify()) |
Я сразу вывел каждую карточку отдельно, но с отступами:
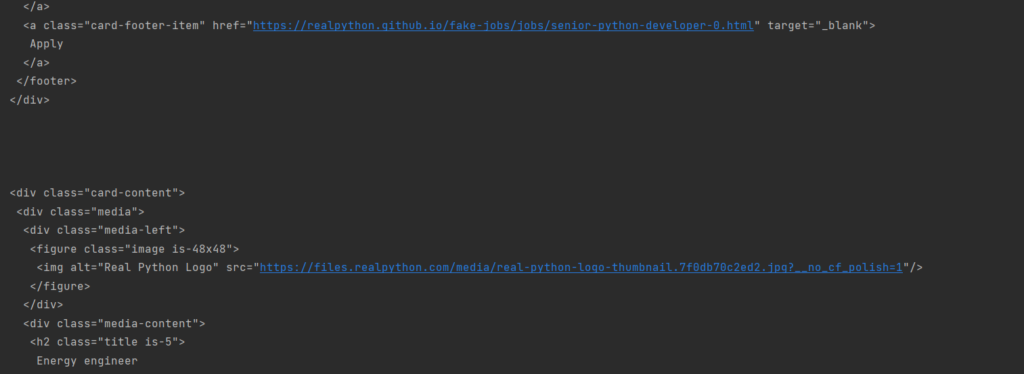
Теперь это не один блок кода, а множество однообразных маленьких. А мы ещё на шаг ближе к цели.
Посмотрим на первый элемент. Тут есть элемент h2 и элемент h3. Они отображают должность и компанию соответственно. При этом у них есть ещё и особые классы: title и company. А ещё есть параграф p с классом location.
Но p, h2 и h3 это не id и не class, так что немного изменим наши параметры для более точной работы функции find.
|
for job in job_elements: title_element = job.find(«h2», class_=«title») company_element = job.find(«h3», class_=«company») location_element = job.find(«p», class_=«location») print(title_element) print(company_element) print(location_element) print() |
Запустите. Теперь выбираем только тогда, когда конкретный компонент имеет указанный класс. Так получим подходящие данные из карточек. Правда, всяк с html кодом. Но чтобы его отбросить просто в print добавляем .text:
|
for job in job_elements: title_element = job.find(«h2», class_=«title») company_element = job.find(«h3», class_=«company») location_element = job.find(«p», class_=«location») print(title_element.text) print(company_element.text) print(location_element.text) print() |
Вывод:
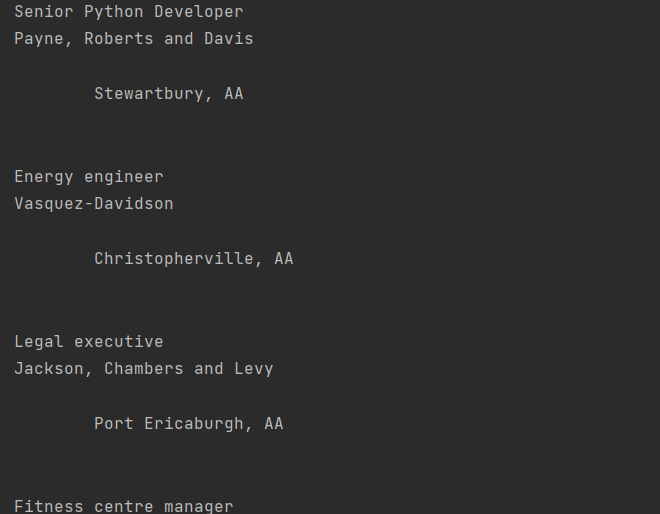
Почти, но местоположение куда-то отпрыгивает из-за наличия кучи лишних отступов. Но так как мы уже выводим не какие-то объекты BS4, а обычные питоновские строки, то мы можем использовать .strip() чтобы удалить все пробелы в начале и конце строки:
|
for job in job_elements: title_element = job.find(«h2», class_=«title») company_element = job.find(«h3», class_=«company») location_element = job.find(«p», class_=«location») print(title_element.text.strip()) print(company_element.text.strip()) print(location_element.text.strip()) print() |
Теперь мы получили большой список должностей, компаний и их местоположений, который в точности совпадает с сайтом, так как и взят именно оттуда. Для наглядности сравним:
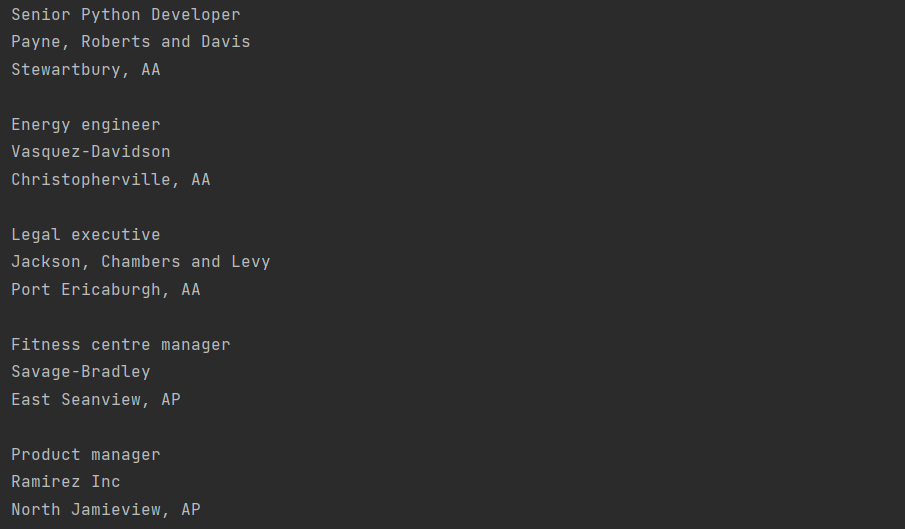
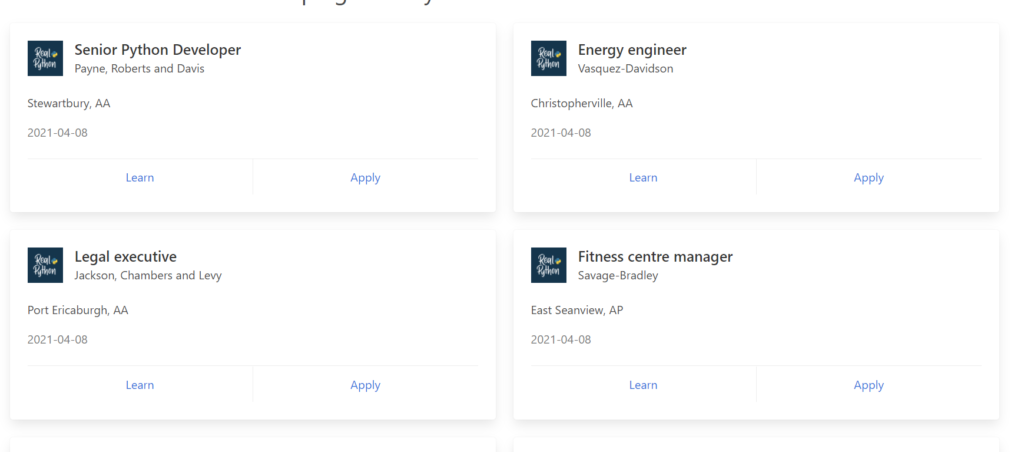
Ищем элементы по содержимому
Да, мы вывели буквально ВСЕ доступные профессии. Но BeautifulSoup позволяет не только найти по параметрам, но и отсеять по-содержимому. Предлагаю закомментировать список всех работ и дописать новый запрос:
|
# job_elements = results.find_all(«div», class_=»card-content») # # for job in job_elements: # title_element = job.find(«h2″, class_=»title») # company_element = job.find(«h3″, class_=»company») # location_element = job.find(«p», class_=»location») # print(title_element.text.strip()) # print(company_element.text.strip()) # print(location_element.text.strip()) # print() python_jobs = results.find_all(«h2», string=«Python») print(python_jobs) |
И запускаем.
Ничего? Не удивительно. Попробуйте найти там вакансию, которая состоит из одного только слова Python. Find_all ищет точное соответствие для такого запроса, но таких в списке нет. Как вы знаете, даже регистр будет влиять на результат, и это нужно учитывать.
Если мы хотим включить все карточки, где есть определённое слово (python, например), то нужно использовать лямбда функцию. Изменим код выше на этот:
|
python_jobs = results.find_all( «h2», string=lambda text: «python» in text.lower() ) for job_title in python_jobs: print(job_title.text.strip()) |
И теперь мы передали string= не конкретный текст, а функцию, при выполнении условий которой элемент будет добавлен. Запускаем снова. Теперь у нас отобразили целый список подходящих вакансий:
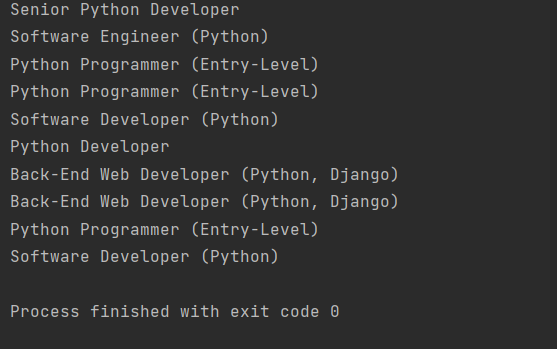
Обращаемся к родителям найденных результатов
Смотрите, только что мы выбрали только заголовки должностей, но компании и остальные данные оказались вне выборки. Но мы знаем, что заголовок h3 с названием компании был в том же блоке, что и заголовок h2 названием должности. Следовательно, если мы перейдём в родителя h2, то сможем выйти и на h3.
|
<div class=«media-content»> <h2 class=«title is-5»>Senior Python Developer</h2> <h3 class=«subtitle is-6 company»>Payne, Roberts and Davis</h3> </div> |
Давайте попробуем это сделать.
Меняем последний цикл, который выводил выбранные вакансии с питоном на такой блок:
|
for job_title in python_jobs: parent = job_title.parent company_element = parent.find(«h3», class_=«company») print(job_title.text.strip()) print(company_element.text.strip()) print() |
В первой же строке я при помощи .parent обращаюсь к родителю заголовка, а это div с классом с media-content, а уже в нём ищу h3 company. И нахожу:
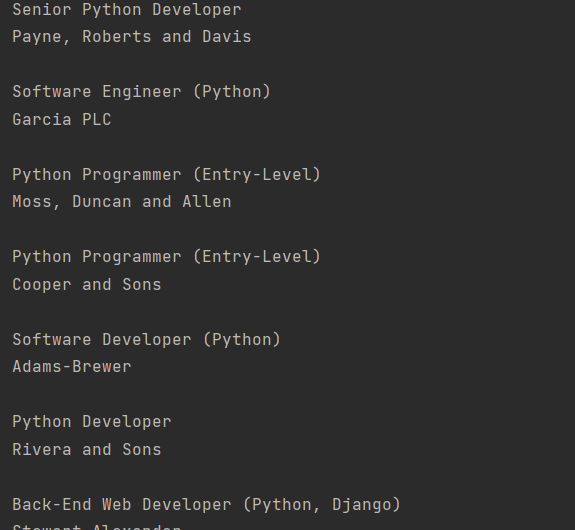
Всё тот же список с Python вакансиями, но теперь ещё и с компаниями. Иногда так даже удобнее.
Мы научились получать текстовое содержимое объектов. Но у каждой карточки есть две кнопки. Попробуем получить их и вывести содержимое. Я поступлю очень лениво и просто из предыдущего примера вернусь к родителю родителя родителя и найду в нём footer карточки, в котором и лежат обе кнопки-ссылки:
|
for job_title in python_jobs: parent = job_title.parent company_element = parent.find(«h3», class_=«company») card_parent = parent.parent.parent.parent card_footer = card_parent.find(«footer», class_=«card-footer») card_links = card_footer.find_all(«a») for link in card_links: print(link.text.strip()) print(job_title.text.strip()) print(company_element.text.strip()) print() |
Вот только понимаете, в чём беда, текст ссылки есть, а ссылки – нет. Сомнительная польза.
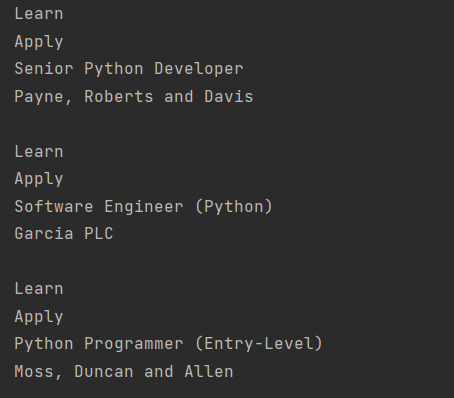
Это связанно с тем, что ссылка href является частью html, это атрибут. И если мы хотим получить текст элемента, то весь html (в т.ч. и атрибуты) будет отброшен. Что мы и увидели. Но извлечь атрибуты из объекта довольно просто. В этом нам помогут квадратные скобки и имя атрибута.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
for job_title in python_jobs: parent = job_title.parent company_element = parent.find(«h3», class_=«company») card_parent = parent.parent.parent.parent card_footer = card_parent.find(«footer», class_=«card-footer») card_links = card_footer.find_all(«a») for link in card_links: link_url = link[«href»] link_text = link.text.strip() print(f«Link for {link_text} is {link_url}») print(job_title.text.strip()) print(company_element.text.strip()) print() |
Результат лучше, чем можно было бы мечтать:
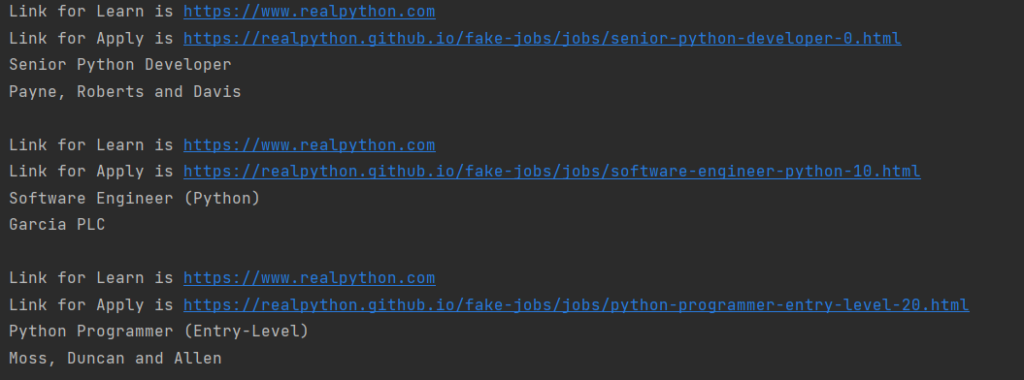
Теперь эти данные готовы для любой обработки, хоть в БД кидай, хоть на сервер пересылай. При этом никто не запрещает вам перейти по новым ссылкам и собрать какие-то данные оттуда. Таким образом можно было бы собрать полные данные о вакансии в одно месте, без необходимости перехода.
На этом пока всё, спасибо за внимание!
Ещё по Python: Графика в Python при помощи модуля Turtle. Часть 1