В данном туториале мы научимся собирать данные и сообщения участников чатов и каналов Telegram, а также сохранять эту информацию в виде JSON-файлов, которые далее легко анализировать или экспортировать в базы данных.
Для указанных задач будет использоваться Python не ниже версии 3.5, а также высокоуровневая библиотека для работы с Telegram API – Telethon. Установить библиотеку можно с помощью менеджера пакетов pip:
pip3 install telethon
Для подключения к Telegram API необходимы api_id и api_hash. Эти параметры выдаются при регистрации приложения в инструментах разработчика (при отсутствии доступа используйте VPN). Для авторизации указываем номер телефона, к которому привязан аккаунт Telegram.
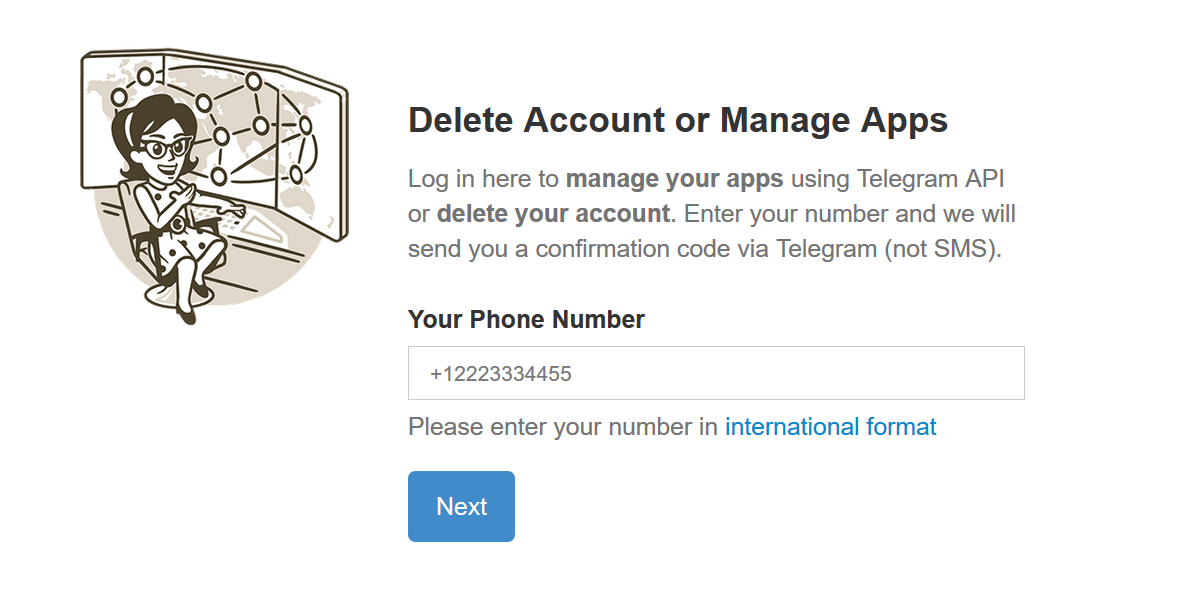
Вводим пришедший в Telegram численно-буквенный код и попадаем на страницу регистрации нового приложения. Заполняем форму, достаточно первых двух граф:
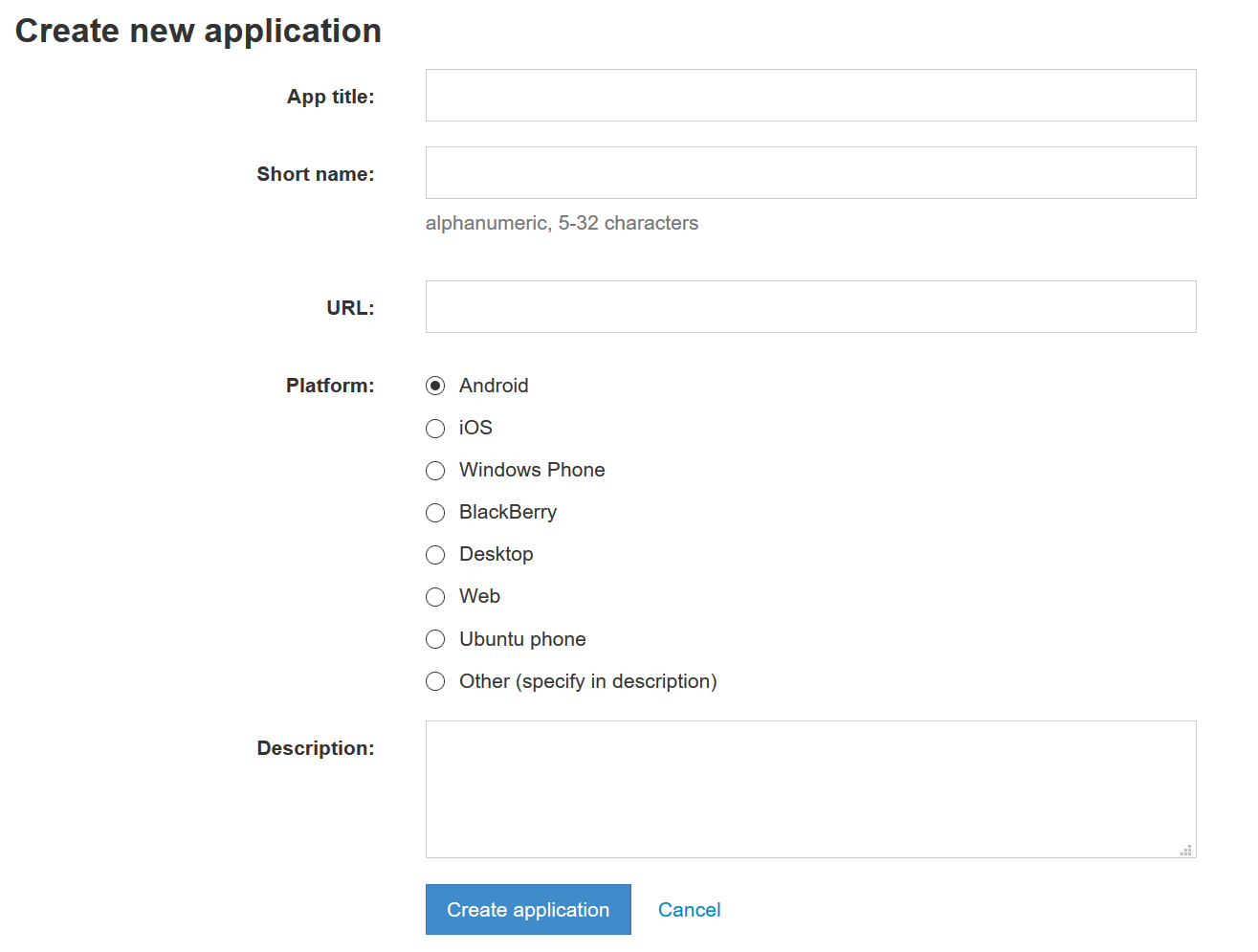
В результате попадаем на страницу конфигурации приложения. Находим оба параметра, а также доступные MTProto-сервера и открытые (публичные) ключи.
Избегая проблем с безопасностью, сохраняем учетные данные в отдельном файле config.ini следующей структуры:
[Telegram]
api_id = Telegram-API-ID
api_hash = Telegram-API-Hash
username = Your-Telegram-Username
Поле username далее будет использоваться лишь для автоматического сохранения сессии под именем username.session. Одному клиенту соответствует одна сессия, учтите это в случае запуска нескольких клиентов.
Создаем клиент Telegram
Начнем с импорта библиотек.
import configparser
import json
from telethon.sync import TelegramClient
from telethon import connection
# для корректного переноса времени сообщений в json
from datetime import date, datetime
# классы для работы с каналами
from telethon.tl.functions.channels import GetParticipantsRequest
from telethon.tl.types import ChannelParticipantsSearch
# класс для работы с сообщениями
from telethon.tl.functions.messages import GetHistoryRequest
Встроенные модули configparser и json применяем соответственно для чтения параметров и вывода данных. Из библиотеки Telethon импортируем класс клиента Telegram и класс исключений. Внутренний модуль connection необходим при использовании прокси-сервера. Остальные элементы модуля telethon.tl используются для запросов необходимых нам списков (участников канала/чата и их сообщений).
Теперь считаем учетные данные из config.ini:
# Считываем учетные данные
config = configparser.ConfigParser()
config.read("config.ini")
# Присваиваем значения внутренним переменным
api_id = config['Telegram']['api_id']
api_hash = config['Telegram']['api_hash']
username = config['Telegram']['username']
Создадим объект клиента Telegram API:
client = TelegramClient(username, api_id, api_hash)
При необходимости прописываем прокси. При использовании протокола MTProxy прокси задается в виде кортежа (сервер, порт, ключ).
proxy = (proxy_server, proxy_port, proxy_key)
client = TelegramClient(username, api_id, api_hash,
connection=connection.ConnectionTcpMTProxyRandomizedIntermediate,
proxy=proxy)
Запускаем клиент:
client.start()
При первом запуске платформа запросит номер телефона, и вслед – код подтверждения. Так же, как если бы вы входили в учетную запись в приложении или браузере.
Для сбора, обработки и сохранения информации мы создадим две функции:
dump_all_participants(сhannel)заберет данные о пользователях администрируемого нами сообществаchannel;dump_all_messages(сhannel)соберет все сообщения. Для этой функции достаточно, чтобы у вас был доступ к сообществу (необязательно быть администратором).
Обе функции будут вызываться в теле функции main, в которой пользователь передаст ссылку на интересующий источник:
url = input("Введите ссылку на канал или чат: ")
channel = await client.get_entity(url)
Касательно написания вызова функций стоит оговориться, что Telethon является асинхронной библиотекой. Поэтому в коде используются операторы async и await. В связи с этим функция main полностью будет выглядеть так:
async def main():
url = input("Введите ссылку на канал или чат: ")
channel = await client.get_entity(url)
await dump_all_participants(channel)
await dump_all_messages(channel)
Заметим, что из-за асинхронности Telethon может некорректно работать в средах, использующих те же подходы (Anaconda, Spyder, Jupyter).
Рекомендуемым способом управления клиентом является менеджер контекстов with. Его мы запустим в конце скрипта после описания вложенных в main функций.
with client:
client.loop.run_until_complete(main())
Собираем данные об участниках
Telegram не выводит все запрашиваемые данные за один раз, а выдает их в пакетном режиме, по 100 записей за каждый запрос.
async def dump_all_participants(channel):
"""Записывает json-файл с информацией о всех участниках канала/чата"""
offset_user = 0 # номер участника, с которого начинается считывание
limit_user = 100 # максимальное число записей, передаваемых за один раз
all_participants = [] # список всех участников канала
filter_user = ChannelParticipantsSearch('')
while True:
participants = await client(GetParticipantsRequest(channel,
filter_user, offset_user, limit_user, hash=0))
if not participants.users:
break
all_participants.extend(participants.users)
offset_user += len(participants.users)
Устанавливаем ограничение в 100, начинаем со смещения 0, создаем список всех участников канала all_participants. Внутри бесконечного цикла передаем запрос GetParticipantsRequest.
Проверяем, есть ли у объекта participants свойство users. Если нет, выходим из цикла. В обратном случае добавляем новых членов в список all_participants, а длину полученного списка добавляем к смещению offset_user. Следующий запрос забирает пользователей, начиная с этого смещения. Цикл продолжается до тех пор, пока не соберет всех фолловеров канала.
Самый простой способ сохранить собранные данные в структурированном виде – воспользоваться форматом JSON. Базы данных, такие как MySQL, MongoDB и т. д., стоит рассматривать лишь для очень популярных каналов и большого количества сохраняемой информации. Либо если вы планируете такое расширение в будущем.
В JSON-файле можно хранить и всю информацию о каждом пользователе, но обычно достаточно лишь нескольких параметров. Покажем на примере, как ограничиться набором определенных данных:
all_users_details = [] # список словарей с интересующими параметрами участников канала
for participant in all_participants:
all_users_details.append({"id": participant.id,
"first_name": participant.first_name,
"last_name": participant.last_name,
"user": participant.username,
"phone": participant.phone,
"is_bot": participant.bot})
with open('channel_users.json', 'w', encoding='utf8') as outfile:
json.dump(all_users_details, outfile, ensure_ascii=False)
Итак, для каждого пользователя создается свой словарь данных и добавляется в общий список all_user_details, который записывается в JSON-файл.
Собираем сообщения
Ситуация со сбором сообщений идентична сбору сведений о пользователях. Отличия сводятся к трем пунктам:
- Вместо клиентского запроса
GetParticipantsRequestнеобходимо отправитьGetHistoryRequestсо своим набором параметров. Так же, как и в случае со списком участников запрос ограничен сотней записей за один раз. - Для списка сообщений важна их последовательность. Чтобы получать последние сообщения, нужно правильно задать смещение в
GetHistoryRequest(с конца). - Чтобы корректно сохранить данные о времени публикации сообщений в JSON-файле, нужно преобразовать формат времени.
Итоговый код:
import configparser
import json
from telethon.sync import TelegramClient
from telethon import connection
# для корректного переноса времени сообщений в json
from datetime import date, datetime
# классы для работы с каналами
from telethon.tl.functions.channels import GetParticipantsRequest
from telethon.tl.types import ChannelParticipantsSearch
# класс для работы с сообщениями
from telethon.tl.functions.messages import GetHistoryRequest
# Считываем учетные данные
config = configparser.ConfigParser()
config.read("config.ini")
# Присваиваем значения внутренним переменным
api_id = config['Telegram']['api_id']
api_hash = config['Telegram']['api_hash']
username = config['Telegram']['username']
proxy = (proxy_server, proxy_port, proxy_key)
client = TelegramClient(username, api_id, api_hash,
connection=connection.ConnectionTcpMTProxyRandomizedIntermediate,
proxy=proxy)
client.start()
async def dump_all_participants(channel):
"""Записывает json-файл с информацией о всех участниках канала/чата"""
offset_user = 0 # номер участника, с которого начинается считывание
limit_user = 100 # максимальное число записей, передаваемых за один раз
all_participants = [] # список всех участников канала
filter_user = ChannelParticipantsSearch('')
while True:
participants = await client(GetParticipantsRequest(channel,
filter_user, offset_user, limit_user, hash=0))
if not participants.users:
break
all_participants.extend(participants.users)
offset_user += len(participants.users)
all_users_details = [] # список словарей с интересующими параметрами участников канала
for participant in all_participants:
all_users_details.append({"id": participant.id,
"first_name": participant.first_name,
"last_name": participant.last_name,
"user": participant.username,
"phone": participant.phone,
"is_bot": participant.bot})
with open('channel_users.json', 'w', encoding='utf8') as outfile:
json.dump(all_users_details, outfile, ensure_ascii=False)
async def dump_all_messages(channel):
"""Записывает json-файл с информацией о всех сообщениях канала/чата"""
offset_msg = 0 # номер записи, с которой начинается считывание
limit_msg = 100 # максимальное число записей, передаваемых за один раз
all_messages = [] # список всех сообщений
total_messages = 0
total_count_limit = 0 # поменяйте это значение, если вам нужны не все сообщения
class DateTimeEncoder(json.JSONEncoder):
'''Класс для сериализации записи дат в JSON'''
def default(self, o):
if isinstance(o, datetime):
return o.isoformat()
if isinstance(o, bytes):
return list(o)
return json.JSONEncoder.default(self, o)
while True:
history = await client(GetHistoryRequest(
peer=channel,
offset_id=offset_msg,
offset_date=None, add_offset=0,
limit=limit_msg, max_id=0, min_id=0,
hash=0))
if not history.messages:
break
messages = history.messages
for message in messages:
all_messages.append(message.to_dict())
offset_msg = messages[len(messages) - 1].id
total_messages = len(all_messages)
if total_count_limit != 0 and total_messages >= total_count_limit:
break
with open('channel_messages.json', 'w', encoding='utf8') as outfile:
json.dump(all_messages, outfile, ensure_ascii=False, cls=DateTimeEncoder)
async def main():
url = input("Введите ссылку на канал или чат: ")
channel = await client.get_entity(url)
await dump_all_participants(channel)
await dump_all_messages(channel)
with client:
client.loop.run_until_complete(main())
Если для анализа сообщений потребуются не все записи, задайте их число в переменной total_count_limit. Если нужна только сборка сообщений канала, достаточно закомментировать вызов await dump_all_participants(channel).
Таким образом, с помощью Python и Telethon мы написали скрипт, собирающий и сохраняющий данные и реплики участников сообществ Telegram.
Есть ли у вас опыт работы с Telegram API?
#статьи
- 17 окт 2022
-

0
Собираем данные о подписчиках телеграм-каналов и чатов с помощью библиотеки Telethon.
Иллюстрация: Катя Павловская для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Для анализа телеграм-каналов и чатов используют парсеры данных. Это специальные программы, которые позволяют получить информацию о подписчиках, публикациях и обсуждениях с помощью механизмов самого мессенджера (API). Существует немало коммерческих парсеров, однако создать их можно и самостоятельно — используя специальные библиотеки для языков программирования.
В этой статье мы научимся работать с библиотекой Telethon для Python, которая автоматизирует работу по сбору данных из мессенджера: напишем на ней простой парсер для получения информации о подписчиках телеграм-групп или каналов. Это первая часть урока — во второй части будем парсить уже сообщения пользователей.
Написать парсер для Telegram можно на любом языке программирования, позволяющем работать с API: Python, JavaScript, Go и так далее. Каждый из них имеет свою универсальную библиотеку для работы с любыми API, а некоторые — даже специализированные библиотеки для Telegram.
Мы остановимся на Python — одном из самых популярных языков программирования. В экосистеме Python есть удобная асинхронная библиотека для работы с API Telegram — Telethon. Её используют для парсинга информации из мессенджера, управления сообществами и создания ботов. У Telethon два больших преимущества: подробная документация и большая популярность в комьюнити. Работает библиотека тоже отлично 
В мессенджере две сущности: каналы и чаты. Они различаются тем, что в каналах пишут только администратор или модераторы, а в чатах может писать любой пользователь. Нам это интересно потому, что возможности парсинга для них различаются.
Канал. Если к каналу не подключены комментарии, то список пользователей можно спарсить только при выполнении следующих условий:
- это ваш канал;
- в нём более 200 подписчиков.
Если одно из условий не выполняется, получить информацию о пользователях будет невозможно. Если же к каналу подключён чат, то работа с ним не отличается от парсинга чатов.
Чат. Ограничений на парсинг нет. Главное — чтобы вы были участником этого чата. Если вас в нём нет и он закрыт, спарсить ничего не получится.
Перейдём к написанию кода: получим данные для доступа к API Telegram и напишем парсер списка участников.
Регистрируемся в разделе инструментов разработчика Telegram
Для работы с API Telegram нам необходимо получить api_id и api_hash. Сделать это можно в разделе инструментов разработчика Telegram. Это обязательное действие не только при создании нашего бота, но и при создании любого бота или парсера, который задействует API мессенджера.
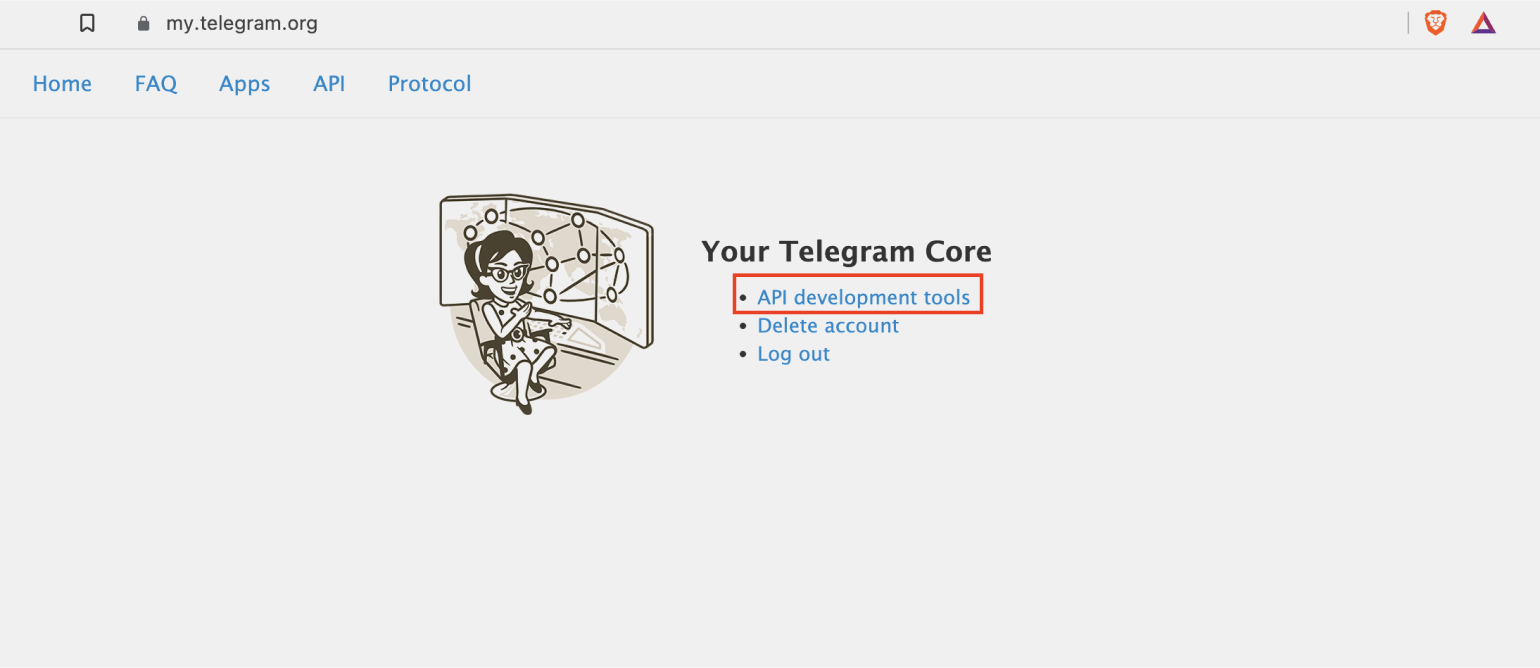
Переходим по ссылке и авторизуемся, используя номер телефона, привязанный к вашему профилю в мессенджере. После авторизации необходимо выбрать пункт API development tools:
В открывшейся форме заполняем пустые поля. Всё заполнять необязательно, главное — указать полное и краткое имя приложения:
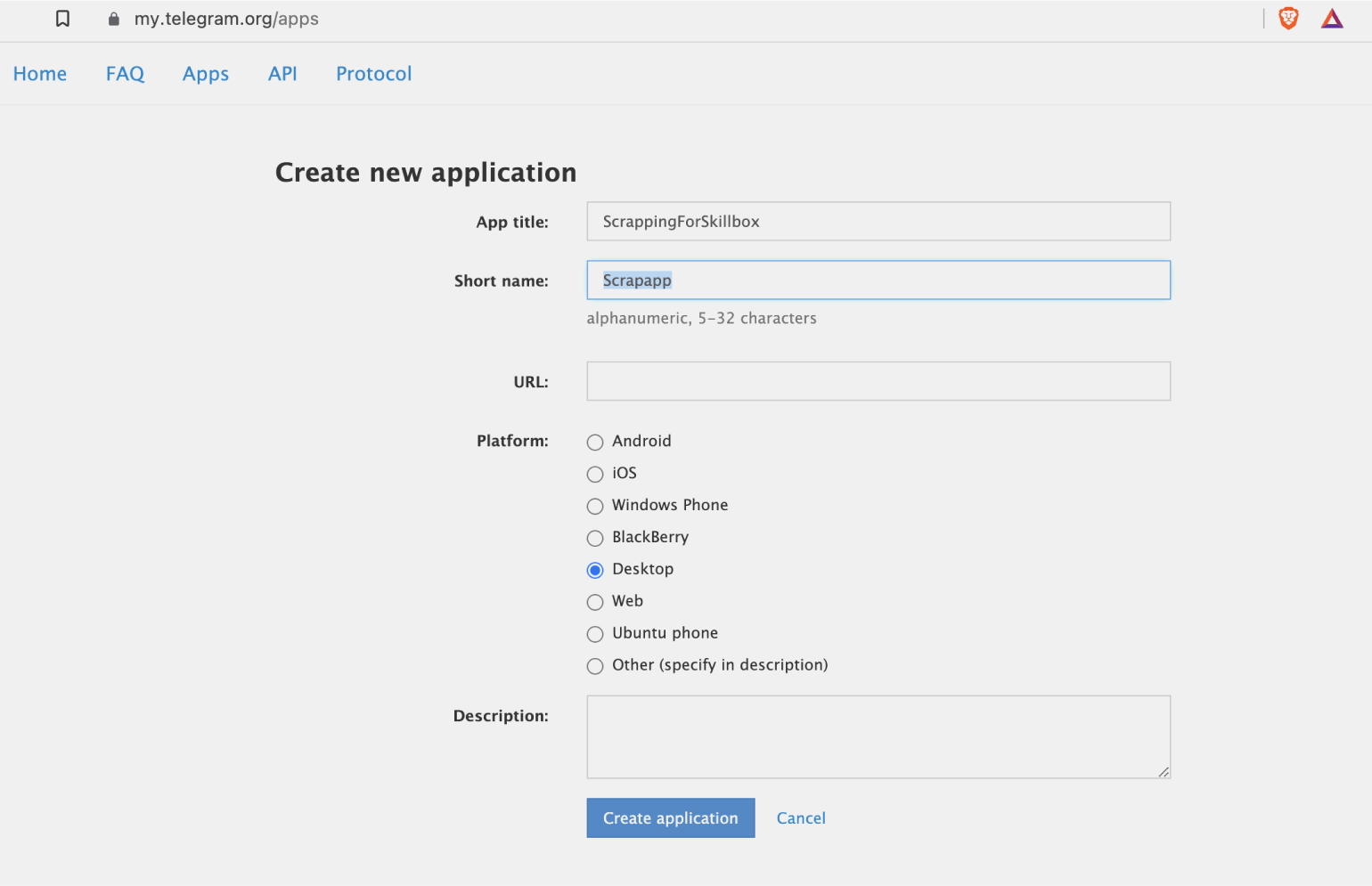
После нажатия Create application откроется страница, на которой нас интересует два параметра:
- api-id — 18377495;
- api-hash — a0c785ad0fd3e92e7c131f0a70987987.
Важно!
Не отправляйте свои api-id и api-hash третьим лицам. Их могут использовать для работы с мессенджером от вашего имени.
Для написания кода парсера мы будем использовать Visual Studio Code. Это стандартная IDE, которую можно заменить на любую другую — например, на PyCharm или онлайн-редактор типа Google Colab.
Если вы никогда не работали на своём компьютере с Python, его будет необходимо установить. Сделать это проще всего по нашей инструкции.
Теперь откроем вкладку «Терминал» в нашей IDE и установим библиотеку для парсинга данных:
python3 -m pip install telethon
Импортируем её и дополнительные библиотеки:
from telethon.sync import TelegramClient import csv from telethon.tl.functions.messages import GetDialogsRequest from telethon.tl.types import InputPeerEmpty
Разберём все импорты построчно:
- from telethon.sync import TelegramClient — класс, позволяющий нам подключаться к клиенту мессенджера и работать с ним;
- from telethon.tl.functions.messages import GetDialogsRequest — функция, позволяющая работать с сообщениями в чате;
- from telethon.tl.types import InputPeerEmpty — конструктор для работы с InputPeer, который передаётся в качестве аргумента в GetDialogsRequest;
- import csv — библиотека для работы с файлами в формате CSV.
После импорта библиотек запустим клиент Telegram API. Для этого добавим код с нашими api-id, api-hash и номером телефона:
api_id = 18377495 api_hash = 'a0c785ad0fd3e92e7c131f0a70987987' phone = 'ваш номер телефона, привязанный к профилю' client = TelegramClient(phone, api_id, api_hash)
Теперь остаётся запустить клиент:
client.start()
Сохраним и запустим код парсера. В терминале нам предложат ввести номер телефона, который мы использовали для получения api-id и api-hash, а после этого в мессенджер придёт пятизначный код, который также потребуется вести. Важно, что номер мы вводим без символа +. Если данные верны, появится сообщение о том, что авторизация прошла успешно:

После входа в систему в папке с кодом появится файл .session. Это файл базы данных, который делает сессию постоянной, то есть как бы не даёт нам разлогиниться. База данных благодаря библиотеке Telethon создаётся автоматически (формат — SQLite) — в ней хранится информация о текущей сессии парсинга: хеш, IP-адрес, с которого она производится, время сессии и другие технические данные подключения.
Будем собирать информацию из чатов, на которые подписан пользователь. Это удобно, так как позволяет обращаться к ним, не указывая конкретный адрес, а выбирая из списка.
Начнём с создания пустых списков, которые пригодятся для хранения списка чатов, и инициализируем две переменные (они используются для фильтрации чатов):
chats = [] last_date = None size_chats = 200 groups=[]
Теперь создадим два списка: chats и groups. Первый будем использовать, чтобы получать список чатов. А во второй будем складывать список чатов после проверки. Кроме того, ограничим максимальное количество получаемых групп с помощью переменной size_chats (присвоим ей значение 200) и создадим переменную last_date со значением None, которой воспользуемся позже.
Напишем запрос для получения списка групп:
result = client(GetDialogsRequest(
offset_date=last_date,
offset_id=0,
offset_peer=InputPeerEmpty(),
limit=size_chats,
hash = 0
))
chats.extend(result.chats)
offset_date и offset_peer мы передаём с пустыми значениями. Обычно они используются для фильтрации полученных данных, но здесь мы хотим получить весь список. Лимит по количеству элементов в ответе задаём 200, передавая в параметр limit переменную size_chats.
Так как мы планируем, что парсер будет работать только с каналами, а не с личными чатами (то есть перепиской) пользователя, необходимо добавить ещё одну проверку:
for chat in chats: try: if chat.megagroup== True: groups.append(chat) except: continue
Проверка работает очень просто: если у группы будет стандартный параметр megagroup, то мы добавляем её в наш список. Если параметра нет, мы пропускаем группу.
Настроим выведение списка всех полученных групп, чтобы пользователь мог самостоятельно выбрать нужную. Создадим простой цикл, который выведет названия групп с их номерами:
print('Выберите номер группы из перечня:') i=0 for g in groups: print(str(i) + '- ' + g.title) i+=1
Теперь дадим пользователю возможность выбрать нужную группу из списка для последующего парсинга:
g_index = input("Введите нужную цифру: ")
target_group=groups[int(g_index)]
Теперь всё готово к парсингу.
Перейдём к парсингу. Напишем код и разберёмся в его логике:
print('Узнаём пользователей...') all_participants = [] all_participants = client.get_participants(target_group) print('Сохраняем данные в файл...') with open("members.csv","w",encoding='UTF-8') as f: writer = csv.writer(f,delimiter=",",lineterminator="n") writer.writerow(['username','name','group']) for user in all_participants: if user.username: username= user.username else: username= "" if user.first_name: first_name= user.first_name else: first_name= "" if user.last_name: last_name= user.last_name else: last_name= "" name= (first_name + ' ' + last_name).strip() writer.writerow([username,name,target_group.title]) print('Парсинг участников группы успешно выполнен.')
В первой части кода мы создаём переменную all_participants, в которой сохраняем данные пользователей, полученные в результате парсинга. Сам парсинг происходит в одну строку — мы используем стандартный метод Telethon client.get_participants(), где в скобках передаём целевую группу или канал, откуда хотим парсить данные.
После этого переходим к сохранению данных в файл формата CSV. Для этого мы используем стандартный модуль csv, позволяющий работать с этим типом файлов. Подробнее о модуле можно узнать из его документации.
Для начала откроем файл в режиме записи (если файла с таким названием в директории нет, он автоматически создаётся), явно указав кодировку UTF-8. Это важно, так как пользователи в мессенджере часто устанавливают себе имена не в кодировке ASCII. Затем создадим объект CSV writer и запишем первую строку (заголовок) в CSV-файл. Теперь остаётся пройтись по каждому элементу списка all_participants и записать все элементы в CSV-файл.
Парсим для каждого участника его юзернейм, имя и название группы. Так как имя может состоять из имени и фамилии, то для присвоения значения конечной переменной name воспользуемся конкатенацией строк, объединив имя и фамилию в одну строку.
Важно!
Не каждый пользователь имеет юзернейм, видимый для нас. Если у пользователя нет юзернейма, API вернёт None. Чтобы избежать записи None, явно укажем в условиях добавление вместо этого пустой строки. Аналогичную опцию сделаем для имени и фамилии.
Теперь запустим и проверим работоспособность нашего парсера. Для этого открываем терминал и переходим в папку, где сохранён наш код:

Запустим файл main.py. Для этого напишем в терминале:
python3 main.py
В ответ на это мы получим запрос на выбор группы для парсинга:
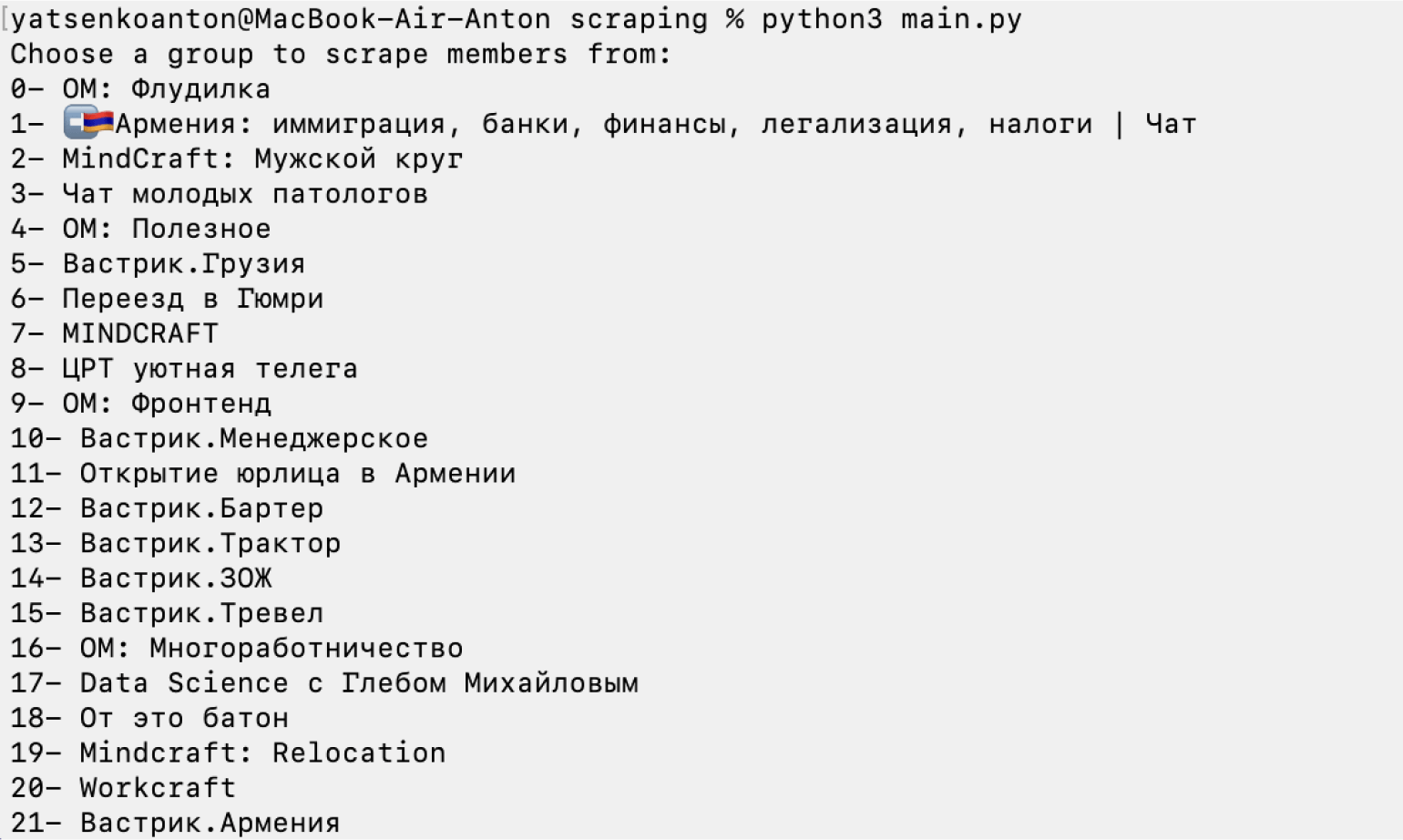
Выберем любую группу, введя в терминал нужную цифру. В нашем случае это будет группа «Вастрик.ЗОЖ».

Теперь мы видим текстовые сообщения, которые «зашивали» в код. И главное, понимаем, что парсинг прошёл удачно.
Откроем нашу папку. В ней появился файл members.csv:

Откроем его и посмотрим на содержимое:

Скриншот: Telethon / Skillbox Media
Всё получилось! В файле мы видим всех пользователей группы с указанием их юзернейма и имени, включающего также фамилию с дополнительными символами.
В следующей части мы научимся парсить сообщения из чатов. Изучим новые методы и объекты библиотеки Telethon и поработаем с форматом JSON, который особенно удобен для хранения текстовой информации.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать

Научитесь: Профессия Python-разработчик
Узнать больше
Время на прочтение
7 мин
Количество просмотров 29K

Тема создания ботов для Telegram становится все более популярной, привлекая программистов попробовать свои силы на этом поприще. У каждого периодически возникают идеи и задачи, которые можно решить, написав тематического бота. Для меня, как программиста на JS, пример такой актуальной задачи — мониторинг рынка вакансий по соответствующей тематике.
Однако одним из наиболее популярных языков и технологий в сфере создания ботов является Python, предлагающий программисту огромное количество хороших библиотек для обработки и парсинга различных источников информации в виде текста. Мне же захотелось сделать это именно на JavaScript — одном из моих любимых языков.
Задача
Основная задача: создать детализированную ленту вакансий с тегированием и приятной визуальной разметкой. Ее можно разбить на отдельные подзадачи:
- взаимодействие с Telegram API;
- парсинг RSS-лент сайтов с вакансиями;
- парсинг отдельно взятой вакансии;
- тематическое тегирование;
- визуальное оформление информации;
- предотвращение дублирования.
Сначала я думал использовать универсального готового бота, например, @TheFeedReaderBot. Но после его детального изучения выяснилось, что тегирование полностью отсутствует, а возможности по настройке отображения контента сильно ограничены. К счастью, современный Javascript предоставляет множество библиотек, которые помогут решить эти проблемы. Но обо всем по порядку.
Каркас бота
Конечно, можно было бы напрямую взаимодействовать с REST API Telegram, но с точки зрения трудозатрат проще взять готовые решения. Поэтому я выбрал npm-пакет slimbot, на который ссылаются официальные туториалы по созданию ботов. И хотя мы будем только отправлять сообщения, этот пакет существенно упростит жизнь, позволив создать внутренний API бота как сущности:
const Slimbot = require('slimbot');
const config = require('./config.json');
const bot = new Slimbot(config.TELEGRAM_API_KEY);
bot.startPolling();
function logMessageToAdmin(message, type='Error') {
bot.sendMessage(config.ADMIN_USER, `<b>${type}</b>n<code>${message}</code>`, {
parse_mode: 'HTML'
});
}
function postVacancy(message) {
bot.sendMessage(config.TARGET_CHANNEL, message, {
parse_mode: 'HTML',
disable_web_page_preview: true,
disable_notification: true
});
}
module.exports = {
postVacancy,
logMessageToAdmin
};
В качестве планировщика будем использовать обычный setInterval, а для парсинга RSS – feed-read, а источником вакансий будут сайты «Мой круг» и hh.ru.
const feed = require("feed-read");
const config = require('./config.json');
const HhAdapter = require('./adapters/hh');
const MoikrugAdapter = require('./adapters/moikrug');
const bot = require('./bot');
const { FeedItemModel } = require('./lib/models');
function processFeed(articles, adapter) {
articles.forEach(article => {
if (adapter.isValid((article))) {
const key = adapter.getKey(article);
new FeedItemModel({
key,
data: article
}).save().then(
model => adapter.parseItem(article).then(bot.postVacancy),
() => {}
);
}
});
}
setInterval(() => {
feed(config.HH_FEED, function (err, articles) {
if (err) {
bot.logMessageToAdmin(err);
return;
}
processFeed(articles, HhAdapter);
});
feed(config.MOIKRUG_FEED, function (err, articles) {
if (err) {
bot.logMessageToAdmin(err);
return;
}
processFeed(articles, MoikrugAdapter);
});
}, config.REQUEST_PERIOD_TIME);
Парсинг отдельно взятой вакансии
Из-за различной структуры страниц с вакансиями для каждого сайта-источника реализация парсинга своя. Поэтому в ход пошли адаптеры, предоставляющие унифицированный интерфейс. Для работы с DOM на сервере подошла библиотека jsdom, с которой можно выполнять стандартные операции: нахождение элемента по CSS-селектору, получение содержимого элемента, которые мы активно используем.
MoikrugAdapter
const request = require('superagent');
const jsdom = require('jsdom');
const { JSDOM } = jsdom;
const { getTags } = require('../lib/tagger');
const { getJobType } = require('../lib/jobType');
const { render } = require('../lib/render');
function parseItem(item) {
return new Promise((resolve, reject) => {
request
.get(item.link)
.end(function(err, res) {
if(err) {
console.log(err);
reject(err);
return;
}
const dom = new JSDOM(res.text);
const element = dom.window.document.querySelector(".vacancy_description");
const salaryElem = dom.window.document.querySelector(".footer_meta .salary");
const salary = salaryElem ? salaryElem.textContent : 'Не указана.';
const locationElem = dom.window.document.querySelector(".footer_meta .location");
const location = locationElem && locationElem.textContent;
const title = dom.window.document.querySelector(".company_name").textContent;
const titleFooter = dom.window.document.querySelector(".footer_meta").textContent;
const pureContent = element.textContent;
resolve(render({
tags: getTags(pureContent),
salary: `ЗП: ${salary}`,
location,
title,
link: item.link,
description: element.innerHTML,
jobType: getJobType(titleFooter),
important: Array.from(element.querySelectorAll('strong')).map(e => e.textContent)
}))
});
});
}
function getKey(item) {
return item.link;
}
function isValid() {
return true
}
module.exports = {
getKey,
isValid,
parseItem
};
HhAdapter
const request = require('superagent');
const jsdom = require('jsdom');
const { JSDOM } = jsdom;
const { getTags } = require('../lib/tagger');
const { getJobType } = require('../lib/jobType');
const { render } = require('../lib/render');
function parseItem(item) {
const splited = item.content.split(/n<p>|</p><p>|</p>n/).filter(i => i);
const [
title,
date,
region,
salary
] = splited;
return new Promise((resolve, reject) => {
request
.get(item.link)
.end(function(err, res) {
if(err) {
console.log(err);
reject(err);
return;
}
const dom = new JSDOM(res.text);
const element = dom.window.document.querySelector('.b-vacancy-desc-wrapper');
const title = dom.window.document.querySelector('.companyname').textContent;
const pureContent = element.textContent;
const tags = getTags(pureContent);
resolve(render({
title,
location: region.split(': ')[1] || region,
salary: `ЗП: ${salary.split(': ')[1] || salary}`,
tags,
description: element.innerHTML,
link: item.link,
jobType: getJobType(pureContent),
important: Array.from(element.querySelectorAll('strong')).map(e => e.textContent)
}))
});
});
}
function getKey(item) {
return item.link;
}
function isValid() {
return true
}
module.exports = {
getKey,
isValid,
parseItem
};
Форматирование
После парсинга нужно представить информацию в удобном виде, но с API Telegram не так много возможностей для этого: в сообщениях можно проставлять только теги и символы юникода (смайлики и стикеры не в счет). На входе получается пара смысловых полей в описании и само описание в «сыром» HTML. После недолгого поиска находим решение — библиотеку html-to-text. После детального изучения API и его реализации невольно удивляешься, почему функции форматирования вызываются не из динамического конфига, а через замыкание, что нивелирует многие плюсы, предоставленные конфигурационными параметрами. И чтобы красиво выводить bullets вместо li в списках, приходится немного схитрить:
const htmlToText = require('html-to-text');
const whiteSpaceRegex = /^s*$/;
function render({
title, location, salary, tags, description, link, important = [], jobType=''
}) {
let formattedDescription = htmlToText
.fromString(description, {
wordwrap: null,
noLinkBrackets: true,
hideLinkHrefIfSameAsText: true,
format: {
unorderedList: function formatUnorderedList(elem, fn, options) {
let result = '';
const nonWhiteSpaceChildren = (elem.children || []).filter(
c => c.type !== 'text' || !whiteSpaceRegex.test(c.data)
);
nonWhiteSpaceChildren.forEach(function(elem) {
result += ' <b>●</b> ' + fn(elem.children, options) + 'n';
});
return 'n' + result + 'n';
}
}
})
.replace(/ns*n/g, 'n');
important.filter(text => text.includes(':')).forEach(text => {
formattedDescription = formattedDescription.replace(
new RegExp(text, 'g'),
`<b>${text}</b>`
)
});
const formattedTags = tags.map(t => '#' + t).join(' ');
const locationFormatted = location ? `#${location.replace(/ |-/g, '_')} `: '';
return `<b>${title}</b>n${locationFormatted}#${jobType}n<b>${salary}</b>n${formattedTags}n${formattedDescription}n${link}`;
}
module.exports = {
render
};
Тегирование
Допустим, у нас есть красивые описания вакансий, но не хватает тегирования. Чтобы решить этот вопрос, я токенизировал естественный русский язык с помощью библиотеки az. Так у меня получилась фильтрация слов в потоке токенов и замена тегами при наличии соответствующих слов в словаре тегов.
const Az = require('az');
const namesMap = require('../resources/tagNames.json');
function onlyUnique(value, index, self) {
return self.indexOf(value) === index;
}
function getTags(pureContent) {
const tokens = Az.Tokens(pureContent).done();
const tags = tokens.filter(t => t.type.toString() === 'WORD')
.map(t => t.toString().toLowerCase().replace('-', '_'))
.map(name => namesMap[name])
.filter(t => t)
.filter(onlyUnique);
return tags;
}
module.exports = {
getTags
};
Формат словаря
{
"js": "JS",
"javascript": "JS",
"sql": "SQL",
"ангуляр": "Angular",
"angular": "Angular",
"angularjs": "Angular",
"react": "React",
"reactjs": "React",
"реакт": "React",
"node": "NodeJS",
"nodejs": "NodeJS",
"linux": "Linux",
"ubuntu": "Ubuntu",
"unix": "UNIX",
"windows": "Windows"
....
}
Деплой и все остальное
Чтобы публиковать каждую вакансию только один раз, я использовал базу данных MongoDB, сведя все к уникальности ссылок самих вакансий. Для мониторинга процессов и их логов на сервере выбрал менеджер процессов pm2, где деплой осуществляется обычным bash скриптом. К слову сказать, в качестве сервера используется самый простой Droplet от Digital Ocean.
Скрипт деплоя
#!/usr/bin/env bash
# rs - алиас для конфигурацци доступа к серверу
rsync ./ rs:/var/www/js_jobs_bot --delete -r --exclude=node_modules
ssh rs "
. ~/.nvm/nvm.sh
cd /var/www/js_jobs_bot/
mv prod-config.json config.json
npm i && pm2 restart processes.json
"
Выводы
Делать простеньких ботов оказалось не сложно, нужно лишь желание, знание какого-нибудь языка программирования (желательно Python или JS) и пара дней свободного времени. Результаты работы моего бота (как и тематическую ленту вакансий) вы можете найти в соответствующем канале — @jsjobs.
P.S. Полную версию исходников можно найти в моем репозитории
Просмотров статьи: 883
Регистрация аккаунта разработчика и настройка клиента
Всем привет! Парсинг сайтов — дело веселое, можно использовать эти данные для своего ресурса или же делать это на заказ. А что если скачать, к примеру, все сообщения из телеграм-чата или список его участников, а затем использовать эти данные для аналитики или еще лучше, для формирования своей базы данных пользователей, которым интересна та или иная тема.
В этой серии статей мы с Вами рассмотрим как написать свой отдельный клиент Telegram, который будет собирать данные из интересных нам чатов, а также посмотрим, как сохранять эти сведения в свою базу данных.
Для создания отдельного клиента хорошо подойдет асинхронная библиотека «Telethon» (Вот репозиторий библиотеки). Сама библиотека может использоваться как для создания телеграм-ботов, так и для создания отдельных приложений работающих с API Telegram. Главным преимуществом является понятная документация в которой можно найти ответы на все вопросы (необходимо знание английского языка).
Создание нашего проекта начнем с регистрации аккаунта разработчика здесь

Вводим пришедший в Telegram численно-буквенный код и попадаем на страницу регистрации нового приложения. Заполняем форму, достаточно первых двух граф:

Если все введено верно вы увидите следующие сведения.

Сразу оговорюсь, данных будет немного больше, но нам важны параметры App api_id и App api_hash.
Поздравляю! Вы зарегистрировали ваше приложение в API Telegram. Закрывать страничку пока не стоит. Мы будем брать оттуда значения App api_id, App api_hash, Short_name для нашего приложения.
Переходим в PyCharm
Хорошим тоном будет не хранить в коде наш хэш и app_id, поэтому давайте сделаем красиво =) Используем библиотеку configparser для создания файла настроек. Создайте в корне проекта файл с расширением .ini (пример config.ini) и давайте поместим туда наши данные из аккаунта разработчика который мы зарегистрировали.

И да, я знаю про venv и переменные окружения. Вы можете использовать удобный вам метод.
Далее нас ждет самое интересное. Давайте установим в наш проект саму библиотеку Telethon командой «pip install telethon» и импортируем в проект класс TelegramClient из нашей установленной библиотеки.
import configparser
from telethon import TelegramClientДалее давайте настроим передачу наших данных в подключение из файла настроек
config = configparser.ConfigParser()
config.read("config.ini")
# Присваиваем значения внутренним переменным
api_id: str = config['Telegram']['api_id']
api_hash = config['Telegram']['api_hash']
username = config['Telegram']['username']
client = TelegramClient(username, api_id, api_hash)
client.start()Обратите внимание что в файле «config.ini» первой строкой мы указали [Telegram]. С помощью этих тэгов мы просто не будем путаться в переменных настроек и разделять их в одном файле.
Создадим нашу главную функцию и запросим у сервера телеграм сведения о нас.
async def main():
about_me = await client.get_entity('me')
print(about_me)Наша библиотека Telethon асинхронная а значит функции и методы мы будем использовать с добавлением ключевых слов async и await (кстати можно и без них но не рекомендую)
Для того, что бы наш клиент не закрывался после запуска мы добавим в конце нашего файла такую запись
with client:
client.loop.run_until_complete(main())……почти =)
Первый запуск
При первом запуске в консоли PyCharm вас попросит ввести ваш номер телефона или токен бота

Это нужно, что бы создать файл сессии он будет хранится в корне проекта с расширением .session ( удалять их не стоит о них поговорим позднее)
Вводите ваш номер телефона в международном формате без «+»

Вам снова пришел код в аккаунт телеграмм только теперь из 5 цифр. Введите их.
Поздравляю вы запустили ваш клиент Телеграм.
Так что же вернула нам наша функция main
about_me = await client.get_entity('me')
наша переменная about_me теперь содержит объект User с специфическим типом данных библиотеки telethon.
Внутри объекта вы можете увидеть данные о вашем аккаунте.

Для того, что бы посмотреть отдельные сведения давайте сделаем вот такой код
async def main():
about_me = await client.get_entity('me')
print('Имя:', about_me.first_name)
print('Ник:', about_me.username)
print('Id', about_me.id)
print('Телефон', about_me.phone)И вуаля….
Имя: Lesharack
Ник: Davengerist
Id 1060217*****
Телефон 375297******
Ну в вашем случае звездочек не будет.
Только что сервер Телеграм рассказал вам о вас чуть больше чем вы видите в своем аккаунте. В следующей статье мы немного обнаглеем и соберем с серверов Телеграм сведения об участниках какого-нибудь чата.
Утечка данных из Telegram — проблема Telegram.
прим. автора
Все сведения которые мы будем получать являются общедоступными. И эти же сведения мы можем увидеть и через официальное приложение. Но я все-таки призываю Вас не использовать полученные знания в плохих целях. Вся изложенная информация подается с целью образования и популяризации языка программирования, его библиотек и возможностей.
Полный код парсера Телеграм
import configparser
from telethon import TelegramClient
config = configparser.ConfigParser()
config.read("config.ini")
# Присваиваем значения внутренним переменным
api_id: str = config['Telegram']['api_id']
api_hash = config['Telegram']['api_hash']
username = config['Telegram']['username']
client = TelegramClient(username, api_id, api_hash)
client.start()
async def main():
about_me = await client.get_entity('me')
print('Имя:', about_me.first_name)
print('Ник:', about_me.username)
print('Id', about_me.id)
print('Телефон', about_me.phone)
with client:
client.loop.run_until_complete(main())
Если это было вам полезно — вы можете сказать нам спасибо!
👾 TELEGRAM PARSER BOT
Бот для парсинга информации в телеграме. Ниже описана инструкция по настройке.
Установка зависимостей >> Скачивание файлов программы >> Получение API ключей >> Первичная настройка >> Запуск
⚙ ТРЕБОВАНИЯ:
- Версия Python 3.6+
📦 БИБЛИОТЕКИ:
В следующей команде описана установка двух библиотек. Достаточно будет одной (
pyrogram) , но разработчик рекомендует установить иtgcrypto. С ним бот работает на порядок быстрее.
pip install pyrogram tgcrypto
💾 КАЧАЕМ БОТА:
В консоли переходим в директорию где будет находиться бот и выполняеем следующую команду:
git clone https://github.com/ettercaper/TelegramParserBot.git
🔐 ПОЛУЧАЕМ API KEYS:
Далее нужно получить api_id и api_hash для аккаунта в телеге с которого будем парсить контент.
- Переходим по ссылке my.telegram.org/apps.
- Логинимся в системе, и заполняем все необходимые поля.
- Полученные по итогу api_id и api_hash надо вписать в файл
config.iniв соответствующие строки.
🚀 ЗАПУСК ПРОГРАММЫ:
В папке с ботом:
При первом запуске консоль запросит авторизацию.
Сначала надо будет ввести номер телефона в международном формате, потом код который придёт в самом мессенджере. Если установлен пароль на вход, то и его тоже запросит. После этого будет создан файл в корневой директории:
account.session— это файл сессии, через него программа будет авторизовываться в последующие запуски.На этом настройка закончена, жмём
CTRL+Cдля выхода из программы. И можно запускать бот снова.
🔥 КОМАНДЫ / ПАРСЕРЫ:
| Команды: | Описание: |
|---|---|
/parse_users arg |
Парсинг пользователей чата и их публичных данных. 💬 Детальнее |

Содержание
- 1 Парсинг телеграм каналов и чатов
- 1.1 Парсинг телеграм каналов
- 1.2 Парсинг телеграм чатов
- 2 Заключение
Мы уже рассказывали про Телеграм-боты для пробива. Сегодня продолжим говорить про телегу и рассмотрим еще одну популярную тему — парсинг телеграм каналов и чатов.
Еще по теме: Угон Телеграм и как от этого защититься
Последнее время, на всяких компьютерных форумах и сайтах часто поднимают вопрос парсинга чатов и каналов Телеграм. Некоторые пытаются впарить свои сервисы, которые как правило еще то разводилово. Другие, делая умный, вид пытаются чему-то научить. Непорядок подумал я посмотрев на это дело и решил самостоятельно разобраться.
Парсинг телеграм каналов и чатов
В данной статье я постараюсь понятным языком (даже для далеких от программирования пользователей) рассказать, как парсить Телеграм, что можно сделать, а что нельзя и насколько это трудоемко. Заранее предупреждаю. Я не буду выкладывать готовые исходники, но покажу примеры для наглядности.
Всем известно, что в телеге существуют чаты и каналы, где иногда кучкуются большое количество пользователей. Стоит иметь список юзеров, например для рассылки или приглашений.
Как правило под словом «парсинг» в контексте Telegram подразумевается получение списка пользователей чата или канала. Но иногда, еще и получение списка сообщений.
Парсинг телеграм каналов
Канал — это площадка в Телеграм, где подписчикам разрешается только читать сообщения создателя канала. Писать коментарии юзеры не могут, за исключением тех случаев, когда к каналу Telegram привязан чат для комментариев. Тогда у пользователей появляется возможность комментировать сообщения канала.
Вы можете получить список подписчиков канала без привязанного к нему чата с комментариями, только если это ваш канал и у него менее 200 пользотелей. Если какое-то из этих условий не выполняется, парсинг Телеграм реализовать не получится и никто не сможет его провести, что бы вам там ни обещали. Может быть, в ближайщем будущем появятся новые способы, но на даннй момент рабочих способов не существует.
Если к каналу привязан чат с комментариями, тогда спарсить пользователей телеги вы сможете точно так же, как в случае с каким-ниобудь чатом.
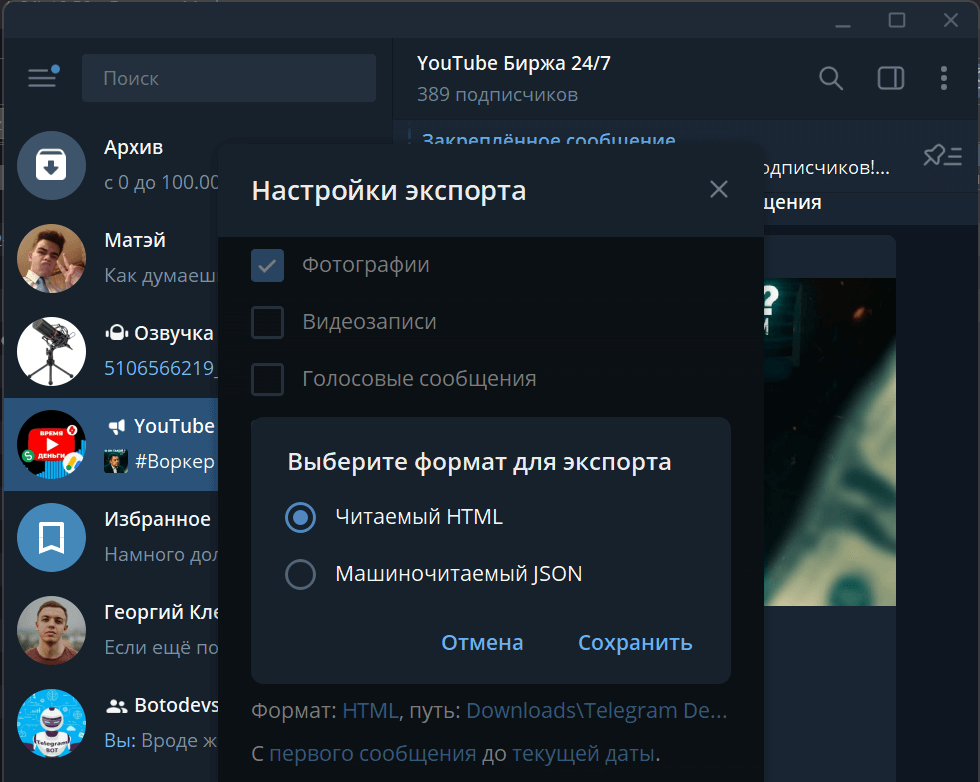
Список сообщений на канале можно получить двумя способами: программно, через API Telegram и ручками, экспортом списка сообщений с помощью клиента.
Для этого в меню чата выбираем пункт «Экспорт».

После этого выбираем формат для экспорта и жмем «Сохранить».
Парсинг телеграм чатов
С чатами гораздо интереснее. Вручную вытащить список юзеров через стандартный клиент не получится, разве что сидеть с блокнотом и ручкой и выписывать всю интересующую информацию. Способ не очень, так что придется посмотреть в сторону родного API Телеграм или, если хотите упростить себе жизнь, на какую‑нибудь библиотеку, например Telethon.
В Telethon есть функция GetParticipantsRequest, которая получает на вход некую сущность (entity), а на выходе выдает список пользователей.
Итак, попробуем скормить ей какой‑нибудь чат.
|
async def test1(client): chat_id = ‘https://t.me/kakoy-to-chat’ chat_entity = await client.get_entity(chat_id) participants = await client(GetParticipantsRequest( chat_entity, ChannelParticipantsSearch(»), offset=0, limit=200, hash=0)) for user in participants.users: print(user) return |
И посмотрим, что можно получить с помощью данной функции:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
User(id=306742xxx, is_self=False, contact=False, mutual_contact=False, deleted=False, bot=False, bot_chat_history=False, bot_nochats=False, verified=False, restricted=False, min=False, bot_inline_geo=False, support=False, scam=False, apply_min_photo=True, fake=False, access_hash=669983103xxxxx, first_name=‘??u200d>?’, last_name=None, username=‘prosto_user_name’, phone=None, photo=UserProfilePhoto(photo_id=13174487829112xxxx, dc_id=2, has_video=False, stripped_thumb=b‘x01x08x08x04xe0xaaxe0x8fx9bx8cQEx14x90xcf’), status=UserStatusRecently(), bot_info_version=None, restriction_reason=[], bot_inline_placeholder=None, lang_code=None) |
Чаще всего требуются поля
id,
username,
first_name и
last_name,
phone. Кроме того, здесь еще и куча признаков:
bot,
verified,
scam,
fake,
photo,
status и т.д.
Как видите, информация самая разная. Некоторые специалисты по парсингу Telegram при этом умудряются заявлять, что им удалось получить только ID, а юзернеймы с телефонами — за отдельные деньги. Ловко, ничего не скажешь!
Телефоны, конечно, в этом списке будут отображаться только в том случае, если пользователь в настройках не отключил показ телефона всем.
Кстати, иногда предлагают определять еще и пол пользователя. Таких данных Telegram не предоставляет и не имеет. Мне известно только два способа получать эту информацию:
- анализировать юзернеймы и имена, прогонять их по заранее созданной базе и делать, если возможно, какие‑то выводы. Если имя пользователя, например, Карина, Юля или Алёна, можно считать его женщиной;
- скачивать все сообщения из чата для каждого пользователя, вытаскивать оттуда глаголы и смотреть, насколько часто они заканчиваются на букву «а». Логично предположить, что у женщин таких случаев будет гораздо больше, чем у мужчин.
Очевидно, что оба способа не дают никаких гарантий и позволяют определять пол лишь с некоторой вероятностью и к тому же требуют дополнительных усилий.
Внимательно присмотревшись к результату работы GetParticipantsRequest, мы увидим, что независимо от числа участников чата и от параметра
limit нам выдают максимум 200 пользователей. Когда в группе меньше 200 участников, этого достаточно, но если их больше, то придется еще поднапрячься.
Мои эксперименты с параметром
offset показали, что он нужен, чтобы указывать смещение в списке пользователей. По умолчанию это смещение равно нулю, но если организовать цикл, на каждой итерации которого увеличивать
offset, то будет скачиваться по 200 юзеров и можно парсить до бесконечности (ну или пока не закончатся все юзеры). Например, так:
|
offset = 0 while True: participants = await client(GetParticipantsRequest( channel, ChannelParticipantsSearch(»), offset, limit, hash=0)) if not participants.users: break #… # Тут делаем что-то с юзерами из списка participants.users #… offset += len(participants.users) |
Однако довольно быстро выясняется, что функция GetParticipantsRequest возвращает максимум 10 тысяч пользователей. Как увеличить этот лимит, выяснить пока не удалось. Есть мнение, что это невозможно.
Параметр
filter позволяет задать критерии, которым должны соответствовать возвращаемые результаты.
Есть следующие варианты:
- ChannelParticipantsAdmins;
- ChannelParticipantsBanned;
- ChannelParticipantsBots;
- ChannelParticipantsContacts;
- ChannelParticipantsKicked;
- ChannelParticipantsMentions;
- ChannelParticipantsRecent;
- ChannelParticipantsSearch.
Тут уже можно экспериментировать: попробовать получить список всех админов, например, или всех, кто онлайн. Парсить пользователей в онлайне — вообще хорошая идея. Если делать это регулярно, то можно отсеять неактивных участников, которые добавились в группку и забыли о ней.
Нас больше всего должен заинтересовать параметр ChannelParticipantsSearch, позволяющий искать пользователей по юзернейму или его части. Давайте попробуем замутить цикл:
|
chat_id = ‘https://t.me/stepnru’ chat_entity = await client.get_entity(chat_id) keys = [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’, ‘G’, ‘H’, ‘I’, ‘J’, ‘K’, ‘L’, ‘M’, ‘N’, ‘O’, ‘P’, ‘Q’, ‘R’, ‘S’, ‘T’, ‘U’, ‘V’, ‘W’, ‘X’, ‘Y’, ‘Z’] for key in keys: offset = 0 participants = await client(GetParticipantsRequest( chat_entity, ChannelParticipantsSearch(key), offset, limit=200, hash=0)) print(key + «: « + str(participants.count)) |
Поясняю: мы взяли весь алфавит и перебрали буквы, пытаясь найти пользователей, в
user_name которых она есть.
Смотрим, что получилось:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
A: 28068 B: 11188 C: 5721 D: 15950 E: 7522 F: 5280 G: 8812 H: 4002 I: 9233 J: 3642 K: 15177 L: 8264 M: 20343 N: 10546 O: 5903 P: 9001 Q: 1009 R: 9882 S: 22445 T: 9881 U: 2376 V: 12249 W: 2581 X: 1749 Y: 4324 Z: 4283 |
Как видно, иногда список результатов содержит меньше 10 тысяч, и тогда мы можем вытащить его полностью, иногда — больше, и тогда мы опять получим только первые 10 тысяч. Однако тест на группе со 190 тысячами юзеров позволил узнать данные о 140 тысячах, а это уже немало!
Наверняка существуют и другие способы поиграть с фильтрами и вытащить еще больше людей из чата. Пусть это будет вам домашним заданием.
Обратите внимание: этот способ работает намного дольше, и парсинг группы с несколькими десятками юзеров может занимать до нескольких десятков минут.
Сохранять результаты я рекомендую не в текстовый файл, а в какую‑нибудь базу данных, например SQLite:
|
def add_users_in_base(bd_name, users): sqlite_connection = sqlite3.connect(bd_name) cursor = sqlite_connection.cursor() for user in users: sqlite_insert_query = «INSERT INTO users (id, deleted, bot, bot_chat_history ….. phone) VALUES (?,?,?,?,?,?,?,?) « data_tuple = ( user.id, user.deleted, user.bot, user.bot_chat_history, .... user.phone) try: cursor.execute(sqlite_insert_query, data_tuple) except sqlite3.Error as er: pass sqlite_connection.commit() cursor.close() sqlite_connection.close() |
Так сразу отсеиваются дубликаты, и потом будет намного удобнее работать с полученными данными: искать, сортировать, конвертировать.
Заключение
Итак, я вам показал, как извлечь из чата информацию о 10 тысячах его участников, а с применением фильтров — гораздо больше. Немного поэкспериментировав, вы сможете написать скрипты, которые соберут нужную вам информацию в удобном виде.
Если вдруг знаете еще какие‑то интересные методы по этой теме, не забудьте поделиться с нами в комментах!
РЕКОМЕНДУЕМ:
- Сколько стоит пробить человека
- Лучшие сайты для пробива людей
Парсинг в телеграме поможет работникам сферы маркетинга разных направленностей: SMMщикам, арбитражникам и владельцам онлайн-бизнеса. В статье поговорим о способах парсинга чатов и каналов в telegram и как ими пользоваться.

- Что такое парсинг Телеграм
- Плюсы парсинга
- Минусы парсинга
- Сервисы для парсинга
- Telegram Soft
- A-Parser
- OneDash
- Telecobra
- TeleREG
- Боты для парсинг телеграм каналов и чатов
- Где найти телеграм бота для парсинга
- ParserTgChat_bot
- Parsetgbot
- Как написать парсер телеграм-чатов на Python
Что такое парсинг Телеграм
Парсинг — процесс сбора участников чата или контента канала посредством софта для дальнейшего использования полученной информации в маркетинговых целях.
Плюсы парсинга
Готовую базу пользователей можно отсортировать по параметрам для формирования разных ЦА. После чистки в ней не будет дублированных пользователей и ботов, в ваших руках чистая база активных пользователей. Это быстрое и удобное занятие, после обработки все пользователи сохраняются в csv, xlsx или txt файл.
Минусы парсинга
Единственный, но большой минус — инвайтинг и спам рассылки пользователям караются модерацией мессенджера и самими людьми. Когда человек видит рассылку в ЛС, чаще всего сразу кидает отметку «Спам» после нескольких отметок аккаунт уйдёт в бан. Эту проблему можно решит: сделать рассылки более нативными, при инвайтинге пользователи должны увидеть действительно полезный контент. Тогда и жалоб будет меньше. Второй вариант — работать с сетью аккаунтов, и как только один забанят, в ход пойдёт следующий.
Сервисы для парсинга
Не стоит уповать только на бесплатные сервисы. Зачастую они помогают закрыть базовые, несложные задачи. Если нужен комплексный подход, лучше потратить деньги и купить софт, который справится с ними за раз.
Также стоит понимать, что сервисы и боты часто прекращают поддерживаться и перестают работать. Данная подборка парсеров телеграм чатов/каналов актуальна на начало 2023 года.
Telegram Soft

Функциональность сервиса ёмкая. Тот случай, когда один парсер телеграм чатов справится с комплексными задачами. Он может:
- Рассылать сообщения по базе.
- Массовые накрутки на канал.
- Инвайтить в группы и чаты.
- Парсить подписчиков.
- Отвечать на сообщения.
- Проверять номера телефонов на факт регистрации их в Телеграм.
По словам разработчиков, сервис может парсить пользователей из закрытых чатов, что является редкостью. Итоговый список выгружается в txt файл. Пробная версия программы стоит 500 рублей, за это вы получите доступ к программе, инструкции по работе. Программа будет работать 5 часов и вы получите аккаунты в размере 4 шт.
A-Parser
Когда в парсере накапливаются разные функции — его называют комбайном. A-Parser именно такой софт. В нём присутствуют более 90 парсеров, каждый из которых выполняет разные задачи. На сайте разработчиков можно заказать индивидуальный парсер под свои нужды. Тарифы:
- Lite: $179
- Pro: $299
- Enterprise: $479
Стоит уточнить, что полный набор парсеров вы получите только при подписке Pro. В тариф Lite входят только парсеры Google и Яндекс. Каждый из тарифов сильно отличается, перед покупкой внимательно прочитайте возможности каждого.
Софт оплачивается 1 раз, далее вы платите только за обновления программ. Обновления: $49 за 3 месяца, $149 за год или $399 пожизненно.
Подробнее про этот пресет парсера читайте на сайте A-Parser: Обзор парсера публичных групп Telegram Groupscraper.
OneDash
Кроме основных парсеров OneDash обладает:
- Менеджером аккаунтов. Удобное управление вашими учетными записями и массовое редактирование многих параметров (username, bio, аватарка, 2FA и другое).
- Поиск нужных каналов и чатов по ключам. Функция поможет быстро найти каналы с нужной вам целевой аудиторией, поддерживает мультипоточность в работе. Совмещена с Windows и macOS.
Есть возможность оплачивать софт помесячно (1 349 рублей) или купить вечную лицензию единоразово (7 099 рублей).
Telecobra

Программа предоставляет 2 функциональности:
- Регистрация аккаунтов в телеге.
- Инвайтинг в чаты и группы.
Есть и полезные дополнительные функции: создание опросов на канале, накрутка (имитация активности в виде лайков, просмотров постов), создание и управление ботофермами, управление созданными аккаунтами. Судя по функционалу, софт больше подходит арбитражникам. Цены на тарифы: 5 645 , 9 950 и 18 645 рублей. Самый дорогой тариф включает в себя пожизненное использование сервиса.
TeleREG
Основные возможности программы для парсинга TeleREG:
- Регистрация акков через TDATA и sms-сервисы
- Использование прокси
- Бесплатный Zennobox
- Инвайтинг
- Проверка аккаунтов
- Установка аватарки и другие элементы изменения аккаунта
- Рассылка с поддержкой регулярных фраз и автоматическим сокращением ссылок
Есть бесплатный триал период на неограниченный срок. Но в таком случае будут доступны не все функции. Полный доступ стоит 2 000 р/м.
Что такое парсер чатов?
Это функциональность сервисов/ботов, которая позволяет собирать открытые данные о пользователях телеграм через механизм Application Programming Interface (API).
Боты для парсинг телеграм каналов и чатов
Главная проблема ботов — создатели быстро выгорают и перестают поддерживать продукт. Подборка ботов актуальная на январь 2023. ТГ ботами пользуются чаще программ, потому что удобнее делать всё в одном месте. Почти все боты-парсеры пишутся на Python и приклеиваются к телеге с помощью API Telegram.
Где найти телеграм бота для парсинга
- Написать самому. Для этого понадобится знания языка Пайтон и: aiogram, python-telegram-bot, TeleBot, Telethon одна из этих библиотек.
- Сделать с помощью конструктора. Благодаря современным технологиям есть множество конструкторов по созданию телеграм-ботов, в которых не нужны навыки программирования. На нём можно создать бесплатный парсер телеграм под свои нужды.
- Заказать у разработчиков. Достаточно заново посмотреть нашу статью, выше есть несколько сервисов, в которых можно заказать индивидуальный парсер.
- Работать с готовым. В самом телеграме нужно найти бота под нужную задачу и воспользоваться им.
ParserTgChat_bot
Бот может парсить открытые и закрытые каналы и чаты. Для начала работы нужно вписать ID канала/чата и выбрать критерии поиска, на выходе ParserTgChat_bot предоставит список подходящих подписчиков.
Тарифы бота:
- Сутки 90р
- Месяц 390р
- Полгода 890р
- Год 1190р
- Вечная (лаймтайм) 1890р
Parsetgbot
Парсинг бота работает на открытых/закрытых чатах и комментарии в ТГ каналах. В parsetgbot есть несколько режимов работы. Быстрый подходит для чатов с количеством участников не более 10 000. С таким объемом данных бот справляется за пару минут. Результат в формате txt. Тарифы строятся необычным образом, на месячную(безлимитную) подписку и разовую:
Безлимитная подписка:
На день — 579 р
На неделю — 1 750 р
Разовые запросы:
Чат до 10 000 человек — Бесплатно!
Чат более 10 000 человек — 149 р
Все комментаторы в канале — 215 р
Писавшие сообщения в чате — 95 р
Как написать парсер телеграм-чатов на Python
Для функциональности парсинга нам понадобится Python 3 версии. Переходим на сайт https://my.telegram.org и создаем приложение, запоминаем API ID и API HASH.

Устанавливаем зависимости:
- pip3 install —upgrade pyrogram
- pip3 install —upgrade tgcrypto
Создаём 2 файлы и 2 папки: main.py, config.ini и session и chats.
В файл config.ini прописываем следующее:
[pyrogram]
api_id = 1234567
api_hash = bf243ef2d7224ebc6effj42718e5bb68
api_id, api_hash — получены при регистрации приложения в telegram.org.
Данные файла main.py:
import time
import json
from pyrogram import Client
from pyrogram.api.errors import FloodWait
app = Client('session', workdir='./session') # Настройки сессии клиента
chat = '' # Название чата или его ID
string_format = '' # Формат строки для записи
def parser(id):
""" Функция парсинга пользователей """
members = []
offset = 0
limit = 200
while True:
try:
chunk = app.get_chat_members(id, offset)
except FloodWait as e:
time.sleep(e.x)
continue
if not chunk.chat_members:
break
members.extend(chunk.chat_members)
offset += len(chunk.chat_members)
return members
def template(data, template):
""" Функция нормализатора строк """
data = json.loads(str(data))
data['user'].setdefault('first_name', '-')
data['user'].setdefault('last_name', '-')
data['user'].setdefault('username', '-')
data['user'].setdefault('phone_number', '-')
return template.format(id=data['user']['id'],
first_name=data['user']['first_name'],
last_name=data['user']['last_name'],
username=data['user']['username'],
phone_number=data['user']['phone_number'],
status=data['status'])
def wfile(data, template_format, path):
""" Функция записи строк в файл """
with open(path, 'w', encoding='utf8') as file:
file.writelines('Количество пользователей: {0}nn'.format(len(data)))
file.writelines([template(user, template_format) for user in data])
def main():
with app:
data = parser(chat)
wfile(data, string_format, './chats/{0}.txt'.format(chat))
print('Сбор данных закончен!')
if __name__ == '__main__':
main()Заполняем данные:
chat = » # Название чата или его ID
string_format = » # Формат строки для записи
Заполнять только название или ID чата если известно, без https://t.me/
Формат строки — это настройки строки с полученными данными. В скрипт заложены следующие шаблоны.
{id} — ID пользователя
{first_name} — Имя пользователя
{last_name} — Фамилия (Если указана)
{username} — Ник пользователя (Если указан)
{phone_number} — Номер телефона (Если пользователь есть в вашей телефонной книге)
{‘status} — Статус пользователя в чате (Создатель, Администратор или пользователь)
Можно и нужно использовать разделители и перенос строк (n)
К примеру нужно получить все ID и их имена ID: {id} n Имя: {first_name}nn
В папке chats получаем список с таким содержанием. Первая строка количество участников, далее запрошенная вами информация.
Количество пользователей: 156
ID: 1234567
Имя: Иван
ID: 1234567
Имя: Максим
Скрипт работает на чатах до 10000 участников. Запускать обязательно через VPN/прокси.