В этой статье мы сделаем парсер сайтов Node.js, или просто на JavaScript, думаю вам будет интересно.
Но стоит предупредить, что по сути это будет перевод другой статьи, ссылка на оригинал в ссылке внизу.
Ещё мы уже делали парсеры страниц но на других языках программирования, вот они:
- Простой парсер страниц на PHP;
- Парсер страниц на Python;
Подготовка проекта:
У вас должен быть установлен Node.JS, если не знаете как это сделать, то почитайте эти статьи:
- Как установить Node.js на любую версию Windows;
- Как установить Node.JS на Linux или на Ubuntu 19.04;
Теперь нужно подготовить проект, для этого создайте папку где будет храниться его, вписываем эту команду:
То есть таким образом мы инициализировали проект, теперь скачаем все нужные библиотеки, через команду npm.
|
npm install —save request request-promise cheerio |
На этом подготовка закончена
Пишем парсер на javascript:
Сначала мы будем начинать с более простого примера, и постепенно всё сложнее и солжне.
Берем HTML страницу:
Давайте для примера получим страницу со американскими президентами из Википедии, откроем для этого текстовой редактор и напишем функцию для получения HTML-кода.
|
const rp = require(‘request-promise’); const url = ‘https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States’; rp(url) .then(function(html){ //Получилось! console.log(html); }) .catch(function(err){ //ошибка }); |
В терминале у нас должно появиться весь HTML документ.
Использование Chrome DevTools:
Круто, мы получили необработанный HTML с веб-страницы! Но теперь нам нужно разобраться в этом гигантском куске текста. Для этого нам нужно использовать Chrome DevTools, чтобы мы могли легко искать что нам нужно в HTML.
Использовать Chrome DevTools просто: просто откройте Google Chrome и щелкните правой кнопкой мыши на элемент, который вы хотите посмотреть (я щелкаю правой кнопкой мыши на Джорджа Вашингтона) :

Теперь просто нажмите кнопку «Посмотреть код», и Chrome откроет панель инструментов DevTools, позволяющую легко проверить исходный HTML-код страницы.

Парсим HTML с помощью Cheerio.js:
Замечательно, Chrome DevTools теперь показывает нам точный шаблон, который мы должны искать в коде (тег big с гиперссылкой внутри него).
Давайте воспользуемся Cheerio.js для синтаксического анализа полученного ранее HTML, чтобы вернуть список ссылок на отдельные страницы Википедии президентов США.
|
const rp = require(‘request-promise’); const $ = require(‘cheerio’); const url = ‘https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States’; rp(url) .then(function(html){ // Получили HTML console.log($(‘big > a’, html).length); console.log($(‘big > a’, html)); }) .catch(function(err){ // Ошибка }); |
Вот что должно вывестись в терминале:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
45 { ‘0’: { type: ‘tag’, name: ‘a’, attribs: { href: ‘/wiki/George_Washington’, title: ‘George Washington’ }, children: [ [Object] ], next: null, prev: null, parent: { type: ‘tag’, name: ‘big’, attribs: {}, children: [Array], next: null, prev: null, parent: [Object] } }, ‘1’: { type: ‘tag’ ... |
То есть суть библиотеки Cheerio.js в том, что вы можете брать элемент по селектору из строчного элемента и вы получаете объект со всеми его параметрами, что бы подробнее узнать о библиотеки, перейдите по ссылке ссылке.
Мы проверяем, что возвращено ровно 45 элементов (количество президентов США), а это означает, что на странице нет никаких дополнительных скрытых тегов big.
Теперь мы можем пройти и получить список ссылок на страницу Википедии на всех 45 президентов, взяв их из раздела «атрибуты» каждого элемента.
|
const rp = require(‘request-promise’); const $ = require(‘cheerio’); const url = ‘https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States’; rp(url) .then(function(html){ // Получили Страницу const wikiUrls = []; for (let i = 0; i < 45; i++) { wikiUrls.push($(‘big > a’, html)[i].attribs.href); } console.log(wikiUrls); }) .catch(function(err){ // Ошибка }); |
Вот что должно вывестись в терминал:
|
[ ‘/wiki/George_Washington’, ‘/wiki/John_Adams’, ‘/wiki/Thomas_Jefferson’, ‘/wiki/James_Madison’, ‘/wiki/James_Monroe’, ‘/wiki/John_Quincy_Adams’, ‘/wiki/Andrew_Jackson’, ... ] |
Мы получили ссылки на 45 президентов США, таким же образом вы можете формировать новые теги и выводить их на сайт, или отправлять по RestAPI.
В целом это ещё не вся переведённая статья, но мне кажется этого хватит чтобы сделать хороший парсер на Node.JS, если надо всё перевести, то пишите комментарии.
Вывод:
В этой статье вы прочитали как сделать парсер сайтов Node.js, думаю вам было интересно и полезно.
Ссылка на оригинал.
Подписываетесь на соц-сети:
Оценка:
Загрузка…
Также рекомендую:

Web scraping is mostly connection and data programming so using a web language for scraping seems like a natural fit, so can we scrape using javascript?
In this tutorial, we’ll learn web scraping with NodeJS and Javascript. We’ll cover an in-depth look at HTTP connections, HTML parsing, popular web scraping libraries and common challenges and web scraping idioms.
Finally, we’ll finish everything off with an example web scraping project — https://www.etsy.com/ product scraper that illustrates two major challenges encountered when web scraping in NodeJS: cookie tracking and CSRF tokens.
Overview and Setup
NodeJS in web scraping is mostly known because of Puppeteer browser automation toolkit. Using web browser automation for web scraping has a lot of benefits, though it’s a complex and resource-heavy approach to javascript web scraping.
With a little reverse engineering and a few clever nodeJS libraries we can achieve similar results without the entire overhead of a web browser!
Web Scraping With a Headless Browser: Puppeteer
For more on using browser automation with Puppeteer we have an entire introduction article that covers basic usage, best practices, tips and tricks and an example project!

In this article, we’ll focus on a few tools in particular. For connection, we’ll be using axios HTTP client and for parsing we’ll focus on cheerio HTML tree parser, let’s install them using these command line instructions:
$ mkdir scrapfly-etsy-scraper
$ cd scrapfly-etsy-scraper
$ npm install cheerio axios
Making Requests
Connection is a vital part of every web scraper and NodeJS has a big ecosystem of HTTP clients, though in this tutorial we’ll be using the most popular one — axios.
HTTP in a Nutshell
To collect data from a public resource, we need to establish a connection with it first. Most of the web is served over HTTP. This protocol can be summarized as: client (our scraper) sends a request for a specific document and the server replies with the requested document or an error — a very straight-forward exchange:
illustration of a standard http exchange
As you can see in this illustration: we send a request object which consists of method (aka type), location and headers. In turn, we receive a response object which consists of status code, headers and document content itself.
In our axios example this looks something like this:
import axios from 'axios';
// send request
response = await axios.get('https://httpbin.org/get');
// print response
console.log(response.data);
Though for node js web scraping we need to know few key details about requests and responses: method types, headers, cookies… Let’s take a quick overview.
Request Methods
HTTP requests are conveniently divided into a few types that perform a distinct function. Most commonly in web scraping we use:
GETrequests a document — most commonly used method in scraping.POSTsends a document to receive one. For example, this is used in form submissions like login, search etc.HEADchecks the state of a resources. This is mostly used to check whether a web page has updated it’s contents as these type of requests are super fast.
Other methods aren’t as commonly encountered but it’s good to be aware of them nevertheless:
PATCHrequests are intended to update a document.PUTrequests are intended to either create a new document or update it.DELETErequests are intended to delete a document.
Request Location — The URL
URL (Universal Resource Location) is the most important part of our request — it tells where our nodejs scraper should look for the resources. Though URLs can be quite complicated, let’s take a look at how they are structured:
Example of a URL structure
Here, we can visualize each part of a URL:
- protocol — is either
httporhttps. - host — is the address/domain of the server.
- location — is the location of the resource we are requesting.
- parameters — allows customizing of a resource. For example
language=enwould give us the English version of the resource.
If you’re ever unsure of a URL’s structure, you can always fire up Node’s interactive shell (node in the terminal) and let it figure it out for you:
$ node
> new URL("http://www.domain.com/path/to/resource?arg1=true&arg2=false")
URL {
href: 'http://www.domain.com/path/to/resource?arg1=true&arg2=false',
origin: 'http://www.domain.com',
protocol: 'http:',
username: '',
password: '',
host: 'www.domain.com',
hostname: 'www.domain.com',
port: '',
pathname: '/path/to/resource',
search: '?arg1=true&arg2=false',
searchParams: URLSearchParams { 'arg1' => 'true', 'arg2' => 'false' },
hash: ''
}
Request headers indicate meta information about our request. While it might appear like request headers are just minor metadata details in web scraping, they are extremely important.
Headers contain essential details about the request, like who’s requesting the data? What type of data they are expecting? Getting these wrong might result in a scraping error.
Let’s take a look at some of the most important headers and what they mean:
User-Agent is an identity header that tells the server who’s requesting the document.
# example user agent for Chrome browser on Windows operating system:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36
Whenever you visit a web page in your web browser identifies itself with a User-Agent string that looks something like «Browser Name, Operating System, Some version numbers».
User-agent helps the server to determine whether to serve or deny the client. When scraping we want to blend in to prevent being blocked so it’s best to set user agent to look like that one of a browser.
Cookie is used to store persistent data. This is a vital feature for websites to keep track of user state: user logins, configuration preferences etc.
Accept headers (also Accept-Encoding, Accept-Language etc.) contain information about what sort of content we’re expecting. Generally when web-scraping we want to mimic this of one of the popular web browsers, like Chrome browser use:
text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
X- prefixed headers are special custom headers. These are important to keep an eye on when web scraping, as they might configure important functionality of the scraped website/webapp.
These are a few of the most important observations, for more see the extensive full documentation page: MDN HTTP Headers
Response Status Code
Once we send our request we’ll eventually receive a response and the first thing we’ll notice is the status code. Status codes indicate whether the request succeded, failed or needs something more (like authentication/login).
Let’s take a quick look at the status codes that are most relevant to web scraping:
- 200 range codes generally mean success!
- 300 range codes tend to mean redirection. In other words, if we request page at
/product1.htmlit might be moved to a new location like/products/1.html. - 400 range codes mean the request is malformed or denied. Our node web scraper could be missing some headers, cookies or authentication details.
- 500 range codes typically mean server issues. The website might be unavailable right now or is purposefully disabling access to our web scraper.
The next thing we notice about our response is the metadata — also known as headers.
When it comes to web scraping, response headers provide some important information for connection functionality and efficiency.
For example, Set-Cookie header requests our client to save some cookies for future requests, which might be vital for website functionality. Other headers such as Etag, Last-Modified are intended to help the client with caching to optimize resource usage.
Finally, just like with request headers, headers prefixed with an X- are custom web functionality headers that we might need to integrate to our scraper.
We took a brief overlook of core HTTP components, and now it’s time we give it a go and see how HTTP works in practical Node!
Making GET Requests
Now that we’re familiar with the HTTP protocol and how it’s used in javascript scraping let’s send some requests!
Let’s start with a basic GET request:
import axios from 'axios';
const response = await axios.get('https://httpbin.org/get');
console.log(response.data);
Here we’re using http://httpbin.org HTTP testing service to retrieve a simple HTML page. When run, this script should print basic details about our made request:
{
args: {},
headers: {
Accept: 'application/json, text/plain, */*',
Host: 'httpbin.org',
'User-Agent': 'axios/0.25.0',
},
origin: '180.111.222.223',
url: 'https://httpbin.org/get'
}
Making POST requests
POST type requests are used to interact with the website through its interactive features like login, search functionality or result filtering.
For these requests our scraper needs to send something to receive the response. That something is usually a JSON document:
import axios from 'axios';
const response = await axios.post('https://httpbin.org/post', {'query': 'cats', 'page': 1});
console.log(response.data);
Another document type we can POST is form data type. For this we need to do a bit more work and use form-data package:
import axios from 'axios';
import FormData from 'form-data';
function makeForm(data){
var bodyFormData = new FormData();
for (let key in data){
bodyFormData.append(key, data[key]);
}
return bodyFormData;
}
const resposne = await axios.post('https://httpbin.org/post', makeForm({'query': 'cats', 'page': 1}));
console.log(response.data);
Axios is smart enough to fill in the required header details (like content-type and content-length) based on the data argument. So, if we’re sending an object it’ll set Content-Type header to application/json and form data to application/x-www-form-urlencoded — pretty convenient!
As we’ve covered before our requests must provide some metadata which helps the server to determine what content to return or whether to cooperate with us at all.
Often, this metadata can be used to identify web scrapers and block them, so when scraping we should avoid standing out and mimic a modern web browser.
To start all browsers set User-Agent and Accept headers. To set them in our axios scraper we should create a Client and copy the values from a Chrome web browser:
import axios from 'axios';
const response = await axios.get(
'https://httpbin.org/get',
{headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}}
);
console.log(response.data);
This will ensure that every request client is making will include these default headers.
How Headers Are Used to Block Web Scrapers and How to Fix It
For a complete guide on headers in web scraper blocking see our full introduction article.

Tip: Set Default Settings
When scraping we typically want to apply the same configuration to multiple requests like setting those User-Agent headers for every request our scraper is making to avoid being blocked.
Axios comes with a great shortcut that allows to configure default values for all connections:
import axios from 'axios';
const session = axios.create({
headers: {'User-Agent': 'tutorial program'},
timeout: 5000,
proxy: {
host: 'proxy-url',
port: 80,
auth: {username: 'my-user', password: 'my-password'}
}
}
)
const response1 = await session.get('http://httpbin.org/get');
console.log(response1.data);
const response2 = await session.get('http://httpbin.org/get');
console.log(response2.data);
Here we created an instance of axios that will apply custom headers, timeout and proxy settings to every request!
Tip: Automatic Cookie Tracking
Sometimes when web-scraping we care about persistent connection state. For websites where we need to login or configure preferences like currency or language — cookies are used to do all of that!
Unfortunately, by default axios doesn’t support cookie tracking, however it can be enabled via axios-cookiejar-support extension package:
import axios from 'axios';
import { CookieJar } from 'tough-cookie';
import { wrapper } from 'axios-cookiejar-support';
const jar = new CookieJar();
const session = wrapper(axios.create({ jar }));
async function setLocale(){
// set cookies:
let respSetCookies = await session.get('http://httpbin.org/cookies/set/locale/usa');
// retrieve existing cookies:
let respGetCookies = await session.get('http://httpbin.org/cookies');
console.log(respGetCookies.data);
}
setLocale();
In the example above, we’re configuring axios instance with a cookie jar object which allows us to have persistent cookies in our web scraping session. If we run this script we should see:
{ cookies: { locale: 'usa' } }
Now that we’re familiar HTTP connection and how can we use it in axios HTTP client package let’s take a look at the other half of the web scraping process: parsing HTML data!
Parsing HTML
HTML (HyperText Markup Language) is a text data structure that powers the web. The great thing about it is that it’s intended to be machine-readable text content, which is great news for web-scraping as we can easily parse the relevant data with javascript code!
HTML is a tree-type structure that lends easily to parsing. For example, let’s take this simple HTML content:
<head>
<title>
</title>
</head>
<body>
<h1>Introduction</h1>
<div>
<p>some description text: </p>
<a class="link" href="http://example.com">example link</a>
</div>
</body>
This is a basic HTML document that a simple website might serve. You can already see the tree-like structure just by indentation of the text, but we can even go further and illustrate it:
example of a HTML node tree. Note that branches are ordered (left-to-right)
This tree structure is brilliant for web scraping as we can easily navigate the whole document and extract specific parts that we want.
For example, to find the title of the website, we can see that it’s under <body> and under <h1> element. In other words — if we wanted to extract 1000 titles for 1000 different pages, we would write a rule to find body->h1->text rule, but how do we execute this rule?
When it comes to HTML parsing, there are two standard ways to write these rules: CSS selectors and XPATH selectors. Let’s see how can we use them in NodeJS and Cheerio next.
CSS Selectors with Cheerio
Cheerio is the most popular HTML parsing package in NodeJS which allows us to use CSS selectors to select specific nodes of an HTML tree.
Parsing HTML with CSS Selectors
For more on CSS selectors see our complete introduction tutorial which covers basic usage, tips and tricks and common web scraping idioms

To use Cheerio we have to create a tree parser object from an HTML string and then we can use a combination of CSS selectors and element functions to extract specific data:
import cheerio from 'cheerio';
const tree = cheerio.load(`
<head>
<title>My Website</title>
</head>
<body>
<div class="content">
<h1>First blog post</h1>
<p>Just started this blog!</p>
<a href="http://scrapfly.io/blog">Checkout My Blog</a>
</div>
</body>
`);
console.log({
// we can extract text of the node:
title: tree('.content h1').text(),
// or a specific attribute value:
url: tree('.content a').attr('href')
});
In the example above, we’re loading Cheerio with our example HTML document and highlighting two ways of selecting relevant data. To select the text of an HTML element we’re using text() method and to select a specific attribute we’re using the attr() method.
XPath Selectors with Xmldom
While CSS selectors are short, robust and easy to read sometimes when dealing with complex web pages we might need something more powerful. For that nodeJS also supports XPATH selectors via libraries like xpath and @xmldom/xmldom:
import xpath from 'xpath';
import { DOMParser } from '@xmldom/xmldom'
const tree = new DOMParser().parseFromString(`
<head>
<title>My Website</title>
</head>
<body>
<div class="content">
<h1>First blog post</h1>
<p>Just started this blog!</p>
<a href="http://scrapfly.io/blog">Checkout My Blog</a>
</div>
</body>
`);
console.log({
// we can extract text of the node, which returns `Text` object:
title: xpath.select('//div[@class="content"]/h1/text()', tree)[0].data,
// or a specific attribute value, which return `Attr` object:
url: xpath.select('//div[@class="content"]/a/@href', tree)[0].value,
});
Here, we’re replicating our Cheerio example in xmldom + xpath setup selecting title text and the URL’s href attribute.
Parsing HTML with Xpath
For more on XPATH selectors see our complete introduction tutorial which covers basic usage, tips and tricks and common web scraping idioms

We looked into two methods of parsing HTML content with NodeJS: using CSS selectors with Cheerio and using Xpath selectors with xmldom + xpath. Generally, it’s best to stick with Cheerio as it complies with HTML standard better and CSS selectors are easier to work with.
Let’s put everything we’ve learned by exploring an example project next!
Example Project: etsy.com
We’ve learned about HTTP connections using axios and HTML parsing using cheerio and now it’s time to put everything together and solidify our knowledge.
In this section, we’ll write an example scraper for https://www.etsy.com/ which is a user-driven e-commerce website (like Ebay but for crafts). We chose this example to cover two most popular challenges when web scraping with javascript: session cookies and csrf headers.
We’ll write a scraper that scrapes the newest products appearing in the vintage product category:
- We’ll go to https://www.etsy.com/ and change our currency/region to USD/US.
- Then we’ll go to product directory and find most recent product urls.
- For each of those urls we’ll scrape product name, price and other details.
Let’s start off by establishing connection with etsy.com and setting our preferred currency/region:
import cheerio from 'cheerio'
import axios from 'axios';
import { wrapper } from 'axios-cookiejar-support';
import { CookieJar } from 'tough-cookie';
const jar = new CookieJar();
const session = wrapper(
axios.create({
jar: jar,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
})
);
async function setLocale(currency, region){
let _prewalk = await session.get('https://www.etsy.com/');
let tree = cheerio.load(_prewalk.data);
let csrf = tree('meta[name=csrf_nonce]').attr('content');
try{
let resp = await session.post(
'https://www.etsy.com/api/v3/ajax/member/locale-preferences',
{currency:currency, language:"en-US", region: region},
{headers: {'x-csrf-token': csrf}},
);
}catch (error){
console.log(error);
}
}
await setLocale('USD', 'US');
Here, we are creating an axios instance with cookie tracking support. Then we are connecting to Etsy’s homepage and looking for csrf token which allows us to interact with Etsy’s backend API. Finally, we’re sending preference request to this API which returns some tracking cookies that our cookiejar saves automatically for us.
CSRF token is a special security token used in modern web. It essentially tells the webserver that are continuing our communication and not just randomly popping in somewhere in the middle. In etsy example we started communication by requesting homepage, there we found a token which lets us continue our session. For more on CSRF tokens we recommend this stackoverflow thread
From here, every request we make using our axios instance will include these preference cookies — meaning all of our scrape data will be in USD currency.
With site preferences sorted we can continue with our next step — collect newest product urls in the /vintage/ category:
async function findProducts(category){
let resp = await session.get(
`https://www.etsy.com/c/${category}?explicit=1&category_landing_page=1&order=date_desc`
);
let tree = cheerio.load(resp.data);
return tree('a.listing-link').map(
(i, node) => tree(node).attr('href')
).toArray();
}
console.log(await findProducts('vintage'));
Here, we defined our function which given a category name will return urls from first page. Notice, we’ve added order=date_desc to sort results in descending order by date to pick up only the latest products.
We’re left with implementing product scraping itself:
async function scrapeProduct(url){
let resp = await session.get(url);
let tree = cheerio.load(resp.data);
return {
url: url,
title: tree('h1').text().trim(),
description: tree('p[data-product-details-description-text-content]').text().trim(),
price: tree('div[data-buy-box-region=price] p[class*=title]').text().trim(),
store_url: tree('a[aria-label*="more products from store"]').attr('href').split('?')[0],
images: tree('div[data-component=listing-page-image-carousel] img').map(
(i, node) => tree(node).attr('data-src')
).toArray()
};
}
Similarly to earlier all we’re doing in this function is retrieving HTML of the product page and extract product details from the HTML content.
Finally, it’s time to put everything together as a runner function:
async function scrapeVintage(){
await setLocale('USD', 'US');
let productUrls = await findProducts('vintage');
return Promise.all(productUrls.map(
(url) => scrapeProduct(url)
))
}
console.log(await scrapeVintage());
Here we’re combining all of our defined functions into one scraping task which should produce results like:
[
{
url: 'https://www.etsy.com/listing/688372741/96x125-turkish-oushak-area-rug-vintage?click_key=467d607c570b0d7760a78a00c820a1da4d1e4d0d%3A688372741&click_sum=5f5c2ff9&ga_order=date_desc&ga_search_type=vintage&ga_view_type=gallery&ga_search_query=&ref=sc_gallery-1-1&frs=1&cns=1&sts=1',
title: '9.6x12.5 Turkish Oushak Area Rug, Vintage Wool Rug, Faded Orange Handmade Home Décor, Distressed Blush Beige, Floral Bordered Oriental Rugs',
description: '★ This special rug <...>',
price: '$2,950.00',
store_url: 'https://www.etsy.com/shop/SuffeArt',
images: [
'https://i.etsystatic.com/18572096/r/il/7480a4/3657436348/il_794xN.3657436348_oxay.jpg',
'https://i.etsystatic.com/18572096/r/il/afa2b7/3705052531/il_794xN.3705052531_9xsa.jpg',
'https://i.etsystatic.com/18572096/r/il/dbde4f/3657436290/il_794xN.3657436290_a64r.jpg',
'https://i.etsystatic.com/18572096/r/il/b2002d/3705052595/il_794xN.3705052595_4c7m.jpg',
'https://i.etsystatic.com/18572096/r/il/6ad90d/3705052613/il_794xN.3705052613_kzey.jpg',
'https://i.etsystatic.com/18572096/r/il/ccec83/3705052663/il_794xN.3705052663_1472.jpg',
'https://i.etsystatic.com/18572096/r/il/8be8c9/3657436390/il_794xN.3657436390_5su0.jpg',
'https://i.etsystatic.com/18572096/r/il/c4f65e/3705052709/il_794xN.3705052709_4u9r.jpg',
'https://i.etsystatic.com/18572096/r/il/806141/3705052585/il_794xN.3705052585_fn8p.jpg'
]
},
...
]
Using this example javascript web scraper, we’ve learned about two important sraping concepts: cookies and headers. We configured currency preferences, learned how to deal with csrf tokens and finally, how to scrape and parse product information!
There are many more challenges in web-scraping, so before we wrap this tutorial up let’s take a look at some of them.
Avoiding Blocking with ScrapFly
Unfortunately identifying nodeJS based web scrapers is really easy which can lead to web scraper blocking.
How to Scrape Without Getting Blocked? In-Depth Tutorial
For more on how scrapers are being identified and blocked see our full introduction article.

To avoid being blocked we can use ScrapFly API which acts as a middleware between client and the server — optimizing all of the requests.
ScrapFly service does the heavy lifting for you
To use ScrapFly all we have to do is to tell axios to send requests through ScrapFly url. We can use this handy wrapper function:
import axios from 'axios';
const ScrapflyOptions = {'key': 'YOUR SCRAPFLY KEY'}
async function getScrapfly(url, options = {}) {
return (await axios.get(
'https://api.scrapfly.io/scrape',
{ params: { ...ScrapflyOptions, ...options, 'url': url } }
)).data;
}
console.log(getScrapfly("http://etsy.com"));
Now, we can we can make requests directly through ScrapFly and take advantage it’s many features like javascript rendering which uses a real web browser to fully render a web page:
scrape = await getScrapfly("http://etsy.com/", {render_js: true});
print(scrape.result.content)
Or anti-scraping protection bypass which allows scraping of pages protected by anti-scraping protection services:
scrape = await getScrapfly("http://etsy.com/", {asp: true});
print(scrape.result.content)
We can also configure what proxy type and geographical location ScrapFly requests use:
scrape = await getScrapfly("http://etsy.com/", {country: "US", proxy_pool: "public_residential_pool"});
print(scrape.result.content)
For full feature set see our full documentation.
FAQ
To wrap up this tutorial let’s take a look at frequently asked questions about web scraping in JS:
What’s the difference between nodejs and puppeteer in web scraping?
Puppeteer is a popular browser automation library for Nodejs. It is frequently used for web scraping. However, we don’t always need a web browser to web scrape. In this article, we’ve learned how can we use Nodejs with a simple HTTP client to scrape web pages. Browsers are very complicated and expensive to run and upkeep so HTTP client web scrapers are much faster and cheaper.
How to scrape concurrently in NodeJS?
Since NodeJS javascript code is naturally asynchronous we can perform concurrent requests to scrape multiple pages by wrapping a list of scrape promises in Promise.all or Promise.allSettled functions. These async await functions take a list of promise objects and executes them in parallel which can speed up web scraping process hundreds of times:
urls = [...]
async function scrape(url){
...
};
let scrape_promises = urls.map((url) => scrape(url));
await Promise.all(scrape_promises);
How to use proxy in NodeJS?
When scraping at scale we might need to use proxies to prevent blocking. Most NodeJS http client libraries implement proxy support through simple arguments. For example in axios library we can set proxy using sessions:
const session = axios.create({
proxy: {
host: 'http://111.22.33.44', //proxy ip address with protocol
port: 80, // proxy port
auth: {username: 'proxy-auth-username', password: 'proxy-auth-password'} // proxy auth if needed
}
}
)
What is the best nodejs web scraping library?
Web Scraping with Cheerio and Nodejs is the most popular way to scrape without using browser automation (Puppeteer) and Axios is the most popular way to make HTTP requests. Though less popular alternatives like xmldom shouldn’t be overlooked as they can help with scraping more complex web pages.
How to click buttons, input text do other browser actions in NodeJS?
Since NodeJS engine is not fully browser compliant we cannot automatically click buttons or submit forms. For this something like Puppeteer needs to be used to automate a real web browser. For more see Web Scraping With a Headless Browser: Puppeteer
Summary
In this extensive introduction article we’ve introduced ourselves with NodeJS web scraping ecosystem. We looked into using axios as our HTTP client to collect multiple pages and using cheerio/@xmldom/xmldom to parse information from this data using CSS/XPATH selectors.
Finally, we wrapped everything up with an example nodejs web scraper project which scrapes vintage product information from https://www.etsy.com/ and looked into ScrapFly’s middleware solution which takes care of difficult web scraping challenges such as scaling and blocking!
JavaScript, Программирование, Компиляторы
Рекомендация: подборка платных и бесплатных курсов PR-менеджеров — https://katalog-kursov.ru/
Здравствуйте! Представляю вам любительский перевод руководства реализации своего языка программирования на JavaScript — PL Tutorial.
От переводчика
Мы создадим свой язык программирования — ?зык (в оригинале — ?anguage). В процессе создания мы будем использовать достаточно много интересных техник, таких как рекурсивный спуск, стиль передачи управления, базовые техники оптимизации. Будет создано две версии интерпретатора — обычный и CPS-интерпретатор, транс-компилятор в JavaScript.
Автор оригинала — Mihai Bazon, автор известной библиотеки UglifyJS (инструмент для минимизации и форматирования JS-кода).
Вступление
Если вы когда-нибудь писали свой компилятор или интерпретатор, то здесь не будет ничего нового для вас. Но если вы используете регулярные выражения, чтобы «распарсить» что-либо, что выглядит как язык программирования, то прочитайте секцию про парсинг. Давайте писать код, в котором меньше багов!
Статья разделена на части в порядке “от простого к сложному”. Я не рекомендую вам пропускать части статьи, кроме случая, когда вы хорошо понимаете тему. Вы всегда можете вернуться назад, если вы не понимаете что-то.
Что мы собираемся выучить:
- Что такое парсер, и как его написать.
- Как написать интерпретатор.
- Передача продолжения, и почему это важно.
- Написание (транс-)компилятора.
- Стиль передачи продолжения.
- Несколько базовых техник оптимизации кода.
- Примеры, что в нашем ?зыке нового по сравнению с JavaScript.
Вместе с этим я покажу, почему Lisp — великий язык программирования. Тем не менее, язык, над которым мы работаем не является Lisp. У него богаче синтаксис (классическая инфиксная нотация, которую все знают), примерно такой, как Scheme (кроме макросов). Хорошо, или нет, но макросы это главная фича Lisp — то, чего другие языки (кроме диалектов Lisp) не могут сделать так хорошо, как он. (Да, я знаю про SweetJS… близко, но не то.)
Но сначала давайте представим наш язык программирования.
?зык
Перед тем, как что-то делать, у нас должна быть четкая картина того, что мы хотим сделать. Неплохо было бы написать описание грамматики языка, но я собираюсь сделать проще — написать пример простой программы, так что вот примеры ?зыка:
# это комментарий
println("Hello World!");
println(2 + 3 * 4);
# функции создаются с помощью ключевых слов `lambda` или `?`
fib = lambda (n) if n < 2 then n else fib(n - 1) + fib(n - 2);
println(fib(15));
print-range = ?(a, b) # `?` это одно и то же, что и `lambda`
if a <= b then { # `then` здесь опционален, как вы можете увидеть ниже
print(a);
if a + 1 <= b {
print(", ");
print-range(a + 1, b);
} else println(""); # новая строка
};
print-range(1, 5);Примечание о названии переменных
Обратите внимание, что идентификаторы могут содержать символ минуса (print-range). Это дело вкуса. Я всегда ставлю пробелы вокруг операторов. Мне не очень нравится верблюжийРегистр и тире лучше, чем невидимый пробел («_»). Как круто, что можно делать так, как ты хочешь, когда ты делаешь что-то сам.
Вывод:
Hello World!
14
610
1, 2, 3, 4, 5?зык выглядит похожим на JavaScript, но в целом это не так. Во-первых, здесь нет инструкций (statements), только выражения. Выражение должно возвращать значение и может быть использовано в любом месте другого выражения. Точки с запятой нужны, чтобы разделить выражения в «последовательности» выражений. Фигурные скобки { и } создают такую последовательность, которая сама является выражением, а её значение — последнее значение из последовательности. Следующая программа правильная:
a = {
fib(10); # не имеет побочных эффектов, но вызывается в любом случае
fib(15) # последняя точка с запятой не является обязательной
};
print(a); # выводит 610Функции создаются с помощью ключевых слов lambda или ?. После этого в скобках идет (возможно пустой) список названий аргументов, разделенных запятой. Тело функции — одно выражение, но может быть заключено в последовательность {...}. Также стоит заметить, что нет ключевого слова return. Функция возвращает значение последнего выражения.
Также, нет var. Для того, чтобы добавить переменную вы можете использовать то, что JavaScript-программисты называют IIFE. Используйте lambda, объявите переменные как аргументы. У переменных область видимости — функция, а функции — замыкания, как в JavaScript [прим. перевод.: до ES6.].
Даже if является выражением. В JavaScript для этого используется тернарный оператор:
a = foo() ? bar() : baz(); // JavaScript
a = if foo() then bar() else baz(); # ?зыкКлючевое слово then не обязательное, если ветка является последовательностью ({...}), как вы могли видеть выше. В другом случае оно необходимо. else используется в случае, если присутствует альтернативная ветка. И снова, then и else принимают выражение, как тело, но вы можете объединить несколько выражений в одно, используя {...}. Если else отсутствует, и условие равно false, то и результат всего if является false. Стоит заметить, что false это ключевое слово, представляющее значение, которое является единственным ложным значением в ?зыке:
if foo() then print("OK");выведет OK тогда, и только тогда, когда результат foo() не является false. Также, есть ключевое слово true, но абсолютно все, что не является false (в рамках JavaScript, оператор ===) будет считаться как true в ветвлениях (включая число 0 и пустую строку "").
Заметьте, что нет нужды в скобках вокруг выражения в if. Если вы добавите их, это не будет ошибкой, потому, что ( начинает выражение, но они просто лишние.
Вся программа может быть распарсена даже, если её окружить круглыми скобками, поэтому вы должны добавлять ; после каждого выражения. Последнее выражения является исключением.
Отлично, это наш маленький ?зык. Он не является идеальным. Синтаксис выглядит красивым, но в нём есть недостатки. Есть много отсутствующих возможностей, таких, как объекты и массивы. Мы на них не обращаем внимание, так как они не являются основными для нашего просто языка программирования.
Дальше, мы напишем парсер для нашего языка.
Превращение кода в AST
Создание парсера это сложная задача. По сути, он должен брать кусок кода и превращать его в AST (абстрактное синтаксическое дерево). AST — структурированное представление программы в памяти, абстрактное — потому, что оно не содержит полной информации о коде, только семантику. Описание AST находится в отдельной части.
Например, у нас есть следующий код:
sum = lambda(a, b) {
a + b;
};
print(sum(1, 2));Наш парсер будет генерировать дерево, как JavaScript объект:
{
type: "prog",
prog: [
// первая строка:
{
type: "assign",
operator: "=",
left: { type: "var", value: "sum" },
right: {
type: "lambda",
vars: [ "a", "b" ],
body: {
// тело должно было быть "prog", но потому, что
// оно содержит только одно выражение, парсер
// превратил его в само выражение.
type: "binary",
operator: "+",
left: { type: "var", value: "a" },
right: { type: "var", value: "b" }
}
}
},
// вторая строка:
{
type: "call",
func: { type: "var", value: "print" },
args: [{
type: "call",
func: { type: "var", value: "sum" },
args: [ { type: "num", value: 1 },
{ type: "num", value: 2 } ]
}]
}
]
}Основная сложность в создании парсера состоит в сложности правильно организовать код. Парсер должен работать на более высоком уровне, чем чтение символов из строки. Несколько рекомендаций, чтобы уменьшить сложность кода:
- Писать много небольших функций. В каждой функции делать одну вещь и делать её хорошо.
- Не пробовать использовать регулярных выражений для парсинга. Они просто не работают. Они могут быть полезными в лексическом анализаторе, но, для простоты, мы их использовать не будем.
- Не пробовать угадывать. Когда не уверены, как распарсить что-то, бросать исключение, содержащее местоположение ошибки (строка и колонка).
Чтобы оставлять код проще, мы его разделим на три части, которые в свою очередь разделены на много маленьких функций:
- Поток символов
- Поток токенов (лексем)
- Парсер
Поток символов
Это самая простая часть. Мы создадим объект «потока», который будет представлять операции последовательного чтения символов из строки. Он содержит четыре функции:
peek()— возвращает следующий символ, не извлекая его из потока.next()— возвращает следующий символ, извлекая его из потока.eof()— возвращаетtrue, если больше нет символов в потоке.croak(msg)— бросает исключение, содержащее сообщение (msg) и текущее положение в потоке.
Последняя функция нужна для того, чтобы можно было просто бросать исключение, содержащее местоположение ошибки.
Вот весь код этого объекта (назовем его InputStream). Он достаточно мал, так что у вас не должно быть проблем с ним:
function InputStream(input) {
var pos = 0, line = 1, col = 0;
return {
next : next,
peek : peek,
eof : eof,
croak : croak,
};
function next() {
var ch = input.charAt(pos++);
if (ch == "n") line++, col = 0; else col++;
return ch;
}
function peek() {
return input.charAt(pos);
}
function eof() {
return peek() == "";
}
function croak(msg) {
throw new Error(msg + " (" + line + ":" + col + ")");
}
}Обратите внимание, что это не обычный объект (который создается через new). Чтобы получить этот объект, нужно: var stream = InputStream(string).
Дальше мы напишем следующий уровень абстракции: Поток токенов (лексем).
Поток токенов (лексем)
Токенизатор (лексер) использует поток символов и возвращает объект с таким же интерфейсом, но возвращаемые значения функций peek()/next() будут токенами. Токен — тип с двумя свойствами: type, value. Вот несколько примеров токенов:
{ type: "punc", value: "(" } // спец. символы: скобки, комма, точка с запятой и т. д.
{ type: "num", value: 5 } // числа
{ type: "str", value: "Hello World!" } // строки
{ type: "kw", value: "lambda" } // ключевые слова
{ type: "var", value: "a" } // идентификаторы
{ type: "op", value: "!=" } // операторыПробельные символы (пробел, табуляция, переносы строк) и комментарии просто пропускаются.
Чтобы написать токенизатор, нам нужно внимательнее посмотрать на наш язык. Идея в том, чтобы заметить, что в зависимости от текущего символа (input.peek()) мы можем решить, какой токен нужно читать:
- Во первых, пропускать пробельные символы.
- Если
input.eof(), то возвращатьnull. - Если это символ
#, то пропускать все символы до конца строки (и возвратить следующий токен). - Если это кавычка, то считываем строку.
- Если это цифра, то считываем число.
- Если это буква, то считываем слово, и возвращаем либо идентификатор, либо ключевое слово.
- Если это один из специальных символов, то возвращаем соответствующий токен.
- Если это один из символов операторов, то возвращаем соответствующий токен.
- Если ничего из выше сказанного не подходит, то бросаем исключение, используя
input.croak().
У нас будет функция read_next, основная функция токенизатора:
function read_next() {
read_while(is_whitespace);
if (input.eof()) return null;
var ch = input.peek();
if (ch == "#") {
skip_comment();
return read_next();
}
if (ch == '"') return read_string();
if (is_digit(ch)) return read_number();
if (is_id_start(ch)) return read_ident();
if (is_punc(ch)) return {
type : "punc",
value : input.next()
};
if (is_op_char(ch)) return {
type : "op",
value : read_while(is_op_char)
};
input.croak("Can't handle character: " + ch);
}Здесь можно заметить много дополнительных функций, которые возвращают разные типы токенов, такие, как read_string(), read_number() и т. д… Они вынесены в отдельные функции, так что код выглядит проще и красивее.
Также, интересно то, что мы не забираем все символы сразу: каждый раз, когда парсер будет просить следующий токен, мы будем читать один токен. Если случиться какая-то ошибка, мы даже не прочитаем все символы.
read_ident() прочитает все символы подряд, которые могут быть частью идентификатора (is_id()). Идентификатор должен начинаться с буквы, ?, или _, и могут содержать эти же символы, числа, или любые из: ?!-<>=. Из этого следует, что foo-bar не будет прочитан, как три токена, а как один (var-токен). Это нужно для того, чтобы можно было определять функции с такими названиями, как is-pair? или string>= (извините, это Лиспер во мне).
Также, read_ident() будет проверять, есть ли идентификатор в списке известных ключевых слов, и если он там есть, будет возвращен kw-токен, вместо var-токена.
Я думаю, код говорит сам за себя, так что вот готовый токенизатор для нашего языка:
Весь код
function TokenStream(input) {
var current = null;
var keywords = " if then else lambda ? true false ";
return {
next : next,
peek : peek,
eof : eof,
croak : input.croak
};
function is_keyword(x) {
return keywords.indexOf(" " + x + " ") >= 0;
}
function is_digit(ch) {
return /[0-9]/i.test(ch);
}
function is_id_start(ch) {
return /[a-z?_]/i.test(ch);
}
function is_id(ch) {
return is_id_start(ch) || "?!-<>=0123456789".indexOf(ch) >= 0;
}
function is_op_char(ch) {
return "+-*/%=&|<>!".indexOf(ch) >= 0;
}
function is_punc(ch) {
return ",;(){}[]".indexOf(ch) >= 0;
}
function is_whitespace(ch) {
return " tn".indexOf(ch) >= 0;
}
function read_while(predicate) {
var str = "";
while (!input.eof() && predicate(input.peek()))
str += input.next();
return str;
}
function read_number() {
var has_dot = false;
var number = read_while(function(ch){
if (ch == ".") {
if (has_dot) return false;
has_dot = true;
return true;
}
return is_digit(ch);
});
return { type: "num", value: parseFloat(number) };
}
function read_ident() {
var id = read_while(is_id);
return {
type : is_keyword(id) ? "kw" : "var",
value : id
};
}
function read_escaped(end) {
var escaped = false, str = "";
input.next();
while (!input.eof()) {
var ch = input.next();
if (escaped) {
str += ch;
escaped = false;
} else if (ch == "\") {
escaped = true;
} else if (ch == end) {
break;
} else {
str += ch;
}
}
return str;
}
function read_string() {
return { type: "str", value: read_escaped('"') };
}
function skip_comment() {
read_while(function(ch){ return ch != "n" });
input.next();
}
function read_next() {
read_while(is_whitespace);
if (input.eof()) return null;
var ch = input.peek();
if (ch == "#") {
skip_comment();
return read_next();
}
if (ch == '"') return read_string();
if (is_digit(ch)) return read_number();
if (is_id_start(ch)) return read_ident();
if (is_punc(ch)) return {
type : "punc",
value : input.next()
};
if (is_op_char(ch)) return {
type : "op",
value : read_while(is_op_char)
};
input.croak("Can't handle character: " + ch);
}
function peek() {
return current || (current = read_next());
}
function next() {
var tok = current;
current = null;
return tok || read_next();
}
function eof() {
return peek() == null;
}
}- Функция
next()не всегда вызываетread_next(), потому, что может быть токен, который был считан раньше (с помощью функцииpeek()). Для этого у нас есть переменнаяcurrent, которая содержит текущий токен. - Поддерживаются только десятичные числа в обычной нотации (не поддерживаются 1E5, 0x и т. д.). Но если бы мы хотели добавить их поддержку, мы бы изменили только
read_number(). - В отличие от JavaScript, единственные символы, которые не могут быть не экранированными в строке — кавычка и обратный слэш. Строки могут содержать переводы строк, символы табуляции и что-либо. Мы не интерпретируем стандартные комбинации, как
n,tи т. д… Это очень просто переделать (read_string()).
Теперь у нас есть мощные инструменты, чтобы легко написать парсер, но сначала я б рекомендовал посмотреть описание AST.
Описание AST
Как указано выше, парсер буде строить структуру, которая показывает семантику программы. AST состоит из узлов (nodes). Каждый узел — обычный JavaScript объект, у которого есть свойство type, которое определяет тип узла, а также дополнительная информация, которая зависит от типа.
| Тип | Структура |
|---|---|
| num | { type: "num", value: NUMBER } |
| str | { type: "str", value: STRING } |
| bool | { type: "bool", value: true or false } |
| var | { type: "var", value: NAME } |
| lambda | { type: "lambda", vars: [ NAME... ], body: AST } |
| call | { type: "call", func: AST, args: [ AST... ] } |
| if | { type: "if", cond: AST, then: AST, else: AST } |
| assign | { type: "assign", operator: "=", left: AST, right: AST } |
| binary | { type: "binary", operator: OPERATOR, left: AST, right: AST } |
| prog | { type: "prog", prog: [ AST... ] } |
| let | { type: "let", vars: [ VARS... ], body: AST } |
Примеры
Числа (num):
123.5{ type: "num", value: 123.5 }Строки (str):
"Hello World"{ type: "str", value: "Hello World!" }true и false (bool):
true
false{ type: "bool", value: true }
{ type: "bool", value: false }Идентификаторы (var):
foo{ type: "var", value: "foo" }Функции (lambda):
lambda (x) 10 # или
? (x) 10{
type: "lambda",
vars: [ "x" ],
body: { type: "num", value: 10 }
}Позже мы добавим необязательный параметр name, чтобы поддерживать функции с именем, но первая версия парсера не будет поддерживать их.
Вызовы функций (call):
foo(a, 1){
"type": "call",
"func": { "type": "var", "value": "foo" },
"args": [
{ "type": "var", "value": "a" },
{ "type": "num", "value": 1 }
]
}Ветвления (if):
if foo then bar else baz{
"type": "if",
"cond": { "type": "var", "value": "foo" },
"then": { "type": "var", "value": "bar" },
"else": { "type": "var", "value": "baz" }
}без else:
if foo then bar{
"type": "if",
"cond": { "type": "var", "value": "foo" },
"then": { "type": "var", "value": "bar" }
}Присваивание (assign):
a = 10{
"type": "assign",
"operator": "=",
"left": { "type": "var", "value": "a" },
"right": { "type": "num", "value": 10 }
}Бинарные операторы (binary):
x + y * z{
"type": "binary",
"operator": "+",
"left": { "type": "var", "value": "x" },
"right": {
"type": "binary",
"operator": "*",
"left": { "type": "var", "value": "y" },
"right": { "type": "var", "value": "z" }
}
}Последовтельности (prog):
{
a = 5;
b = a * 2;
a + b;
}{
"type": "prog",
"prog": [
{
"type": "assign",
"operator": "=",
"left": { "type": "var", "value": "a" },
"right": { "type": "num", "value": 5 }
},
{
"type": "assign",
"operator": "=",
"left": { "type": "var", "value": "b" },
"right": {
"type": "binary",
"operator": "*",
"left": { "type": "var", "value": "a" },
"right": { "type": "num", "value": 2 }
}
},
{
"type": "binary",
"operator": "+",
"left": { "type": "var", "value": "a" },
"right": { "type": "var", "value": "b" }
}
]
}Переменные, заключенные в блоки (let):
let (a = 10, b = a * 10) {
a + b;
}{
"type": "let",
"vars": [
{
"name": "a",
"def": { "type": "num", "value": 10 }
},
{
"name": "b",
"def": {
"type": "binary",
"operator": "*",
"left": { "type": "var", "value": "a" },
"right": { "type": "num", "value": 10 }
}
}
],
"body": {
"type": "binary",
"operator": "+",
"left": { "type": "var", "value": "a" },
"right": { "type": "var", "value": "b" }
}
}Первая версия парсера не будет поддерживать этот тип узла, мы добавим его позже.
Парсер
Парсер будет строить дерево, которое описано выше.
Благодаря работе, которую мы проделали в токенизаторе, парсер работает с потоком токенов, вместо потока символов. Здесь все ещё есть много дополнительных функций, чтобы упростить структуру. Мы поговорим про основные из них. Давайте начнем с высокоуровневых, парсер функции:
function parse_lambda() {
return {
type: "lambda",
vars: delimited("(", ")", ",", parse_varname),
body: parse_expression()
};
}Эта функция будет вызвана, когда ключевое слово lambda уже было взято из потока токенов, так что нам осталось только взять названия аргументов. Но так, как они находятся в скобках и разделены запятыми, мы сделаем это с помощью функции delimited, которая принимает следующие аргументы: start, stop, separator, функция parser, которая парсит каждый элемент отдельно. В данном случае, мы используем функцию parse_varname, которая бросает ошибку, если заметит что-то, что выглядит не как переменная. Тело функции — выражение, так что мы его получаем с помощью parse_expression.
Функция delimited более низкоуровневая:
function delimited(start, stop, separator, parser) {
var a = [], first = true;
skip_punc(start);
while (!input.eof()) {
if (is_punc(stop)) break;
if (first) first = false; else skip_punc(separator);
if (is_punc(stop)) break; // последний разделитель может быть пропущен
a.push(parser());
}
skip_punc(stop);
return a;
}Как вы можете заметить, она использует ещё больше функций: is_punc и skip_punc. Первая возвращает true, если текущий токен является заданным знаком пунктуации (не извлекая его), тогда как skip_punc проверит, является ли текущий токен заданным знаком и извлекает его (или бросает исключение в противном случае).
Функция, которая парсит целую программу, похоже, самая простая:
function parse_toplevel() {
var prog = [];
while (!input.eof()) {
prog.push(parse_expression());
if (!input.eof()) skip_punc(";");
}
return { type: "prog", prog: prog };
}Так как у нас только выражения, мы просто вызываем parse_expression() и читаем выражения, пока не прочитаем все. Используя skip_punc(";"), мы делаем ; обязательной после каждого выражения.
Ещё один простой пример — parse_if():
function parse_if() {
skip_kw("if");
var cond = parse_expression();
if (!is_punc("{")) skip_kw("then");
var then = parse_expression();
var ret = { type: "if", cond: cond, then: then };
if (is_kw("else")) {
input.next();
ret.else = parse_expression();
}
return ret;
}Она пропускает ключевое слово if (бросает исключение, если текущий токен — не ключевое слово if), читает условие используя parse_expression(). Если дальше не идет символ {, то требуется ключевое слово then (синтаксис выглядит не очень без этого). Ветки — просто выражения, поэтому мы просто снова используем parse_expression() для них. Ветка else не обязательная, поэтому мы сначала проверяем присутствие ключевого слово, перед тем, как парсить её.
Имея много маленьких функций, мы можем сделать код простым. Мы написали парсер почти так, как было б если использовали для этого высокоуровненый язык специально для разбора синтаксиса. Все эти функции «взаимо-рекурсивные», то-есть у нас есть parse_atom(), который в зависимости от текущего токена, вызывает другие функции. Одна из них — parse_if() (вызывается, когда текущий токен — if) и она в свою очередь вызывает parse_expression(). Но parse_expression() вызывает parse_atom(). Здесь нет бесконечной рекурсии потому, что одна из функций всегда извлекает хотя-бы один токен.
Этот вид метод парсинга называется Методом рекурсивного спуска, и по сути, самый простой в написании.
Более низкий уровень: parse_atom() и parse_expression()
Функция parse_atom() вызывает другую функцию, в зависимости от текущего токена:
function parse_atom() {
return maybe_call(function(){
if (is_punc("(")) {
input.next();
var exp = parse_expression();
skip_punc(")");
return exp;
}
if (is_punc("{")) return parse_prog();
if (is_kw("if")) return parse_if();
if (is_kw("true") || is_kw("false")) return parse_bool();
if (is_kw("lambda") || is_kw("?")) {
input.next();
return parse_lambda();
}
var tok = input.next();
if (tok.type == "var" || tok.type == "num" || tok.type == "str")
return tok;
unexpected();
});
}Когда она видит открывающую скобку, тогда должно идти скобочное выражение, поэтому, пропуская скобку, функция вызывает parse_expression() и ожидает после этого пропустить закрывающую скобку. Если она видит какое-то ключевое слово, то она вызывает соответствующую функцию. Если она видит константу или идентификатор, то возвращает её как есть. И если ничего не подходит, то вызывает unexpected(), который бросает исключение.
Когда она видит {, то вызывает parse_prog, чтобы разобрать последовательность выражений. Также, parse_prog делает простую оптимизацию: если между { и } нет выражений, то она возвращает false, если только одно выражение, то возвращает только его. В противном случае возвращается узел prog с массивом выражений.
// мы собираемся использовать узел FALSE в нескольких местах,
// поэтому я делаю его глобальным.
var FALSE = { type: "bool", value: false };
function parse_prog() {
var prog = delimited("{", "}", ";", parse_expression);
if (prog.length == 0) return FALSE;
if (prog.length == 1) return prog[0];
return { type: "prog", prog: prog };
}А вот и функция parse_expression(). В отличие от parse_atom(), она будет парсить как можно больше выражений, используя maybe_binary():
function parse_expression() {
return maybe_call(function(){
return maybe_binary(parse_atom(), 0);
});
}Функции maybe_*
Эти функции проверяют, что идет после выражения и решают, обернуть выражение в свой узел, или вернуть его как есть.
Функция maybe_call() очень простая: она получает функция, которая парсит текущее выражение, и, если после выражения встречается (, то оно оборачивается в узер call. Заметьте, как delimited() подходит для парсинга списка аргументов:
function maybe_call(expr) {
expr = expr();
return is_punc("(") ? parse_call(expr) : expr;
}
function parse_call(func) {
return {
type: "call",
func: func,
args: delimited("(", ")", ",", parse_expression)
};
}Приоритет операторов
Функция maybe_binary(left, my_prec) используется, чтобы объединять такие выражения, как 1 + 2 * 3. Суть в том, что, чтобы разобрать их правильно, нужно правильно определить приоритет операторов:
var PRECEDENCE = {
"=": 1,
"||": 2,
"&&": 3,
"<": 7, ">": 7, "<=": 7, ">=": 7, "==": 7, "!=": 7,
"+": 10, "-": 10,
"*": 20, "/": 20, "%": 20,
};Этот код значит, что * «сильнее», чем +, поэтому, выражение 1 + 2 * 3 будет прочитано как (1 + (2 * 3)) вместо ((1 + 2) * 3).
Суть в том, что прочитать только одно выражение (read_atom) и передать его в maybe_binary() (левое выражение), и приоритет текущего оператора (my_prec). Функция maybe_binary будет смотреть, что следует дальше. Если она не видит оператор, или у него приоритет ниже, тогда левое выражение просто возвращается.
Если это оператор, у которого приоритет выше, чем у текущего, тогда он оборачивается в новый узел с типом binary, левым выражением, и для правого выражения повторяется то же, но с новым приоритетом оператора (*):
function maybe_binary(left, my_prec) {
var tok = is_op();
if (tok) {
var his_prec = PRECEDENCE[tok.value];
if (his_prec > my_prec) {
input.next();
var right = maybe_binary(parse_atom(), his_prec) // (*);
var binary = {
type : tok.value == "=" ? "assign" : "binary",
operator : tok.value,
left : left,
right : right
};
return maybe_binary(binary, my_prec);
}
}
return left;
}Обратите внимание, перед тем, как мы возвращаем новый узел, мы также вызываем maybe_binary, передавая старый приоритет (my_prec), для того, чтобы обернуть выражение в ещё одно, если дальше идут ещё операторы. Если что-то непонятно, прочитайте код снова (возможно, попробуйте выполнить код в голове для некоторых выражений), пока он не станет понятным.
Также, следуя из того, что my_prec сразу равен 0, любой оператор будет пробовать создавать узел с типом binary (или assign для оператора =).
В парсере есть ещё несколько функций, которые я покажу ниже.
Весь код
var FALSE = { type: "bool", value: false };
function parse(input) {
var PRECEDENCE = {
"=": 1,
"||": 2,
"&&": 3,
"<": 7, ">": 7, "<=": 7, ">=": 7, "==": 7, "!=": 7,
"+": 10, "-": 10,
"*": 20, "/": 20, "%": 20,
};
return parse_toplevel();
function is_punc(ch) {
var tok = input.peek();
return tok && tok.type == "punc" && (!ch || tok.value == ch) && tok;
}
function is_kw(kw) {
var tok = input.peek();
return tok && tok.type == "kw" && (!kw || tok.value == kw) && tok;
}
function is_op(op) {
var tok = input.peek();
return tok && tok.type == "op" && (!op || tok.value == op) && tok;
}
function skip_punc(ch) {
if (is_punc(ch)) input.next();
else input.croak("Expecting punctuation: "" + ch + """);
}
function skip_kw(kw) {
if (is_kw(kw)) input.next();
else input.croak("Expecting keyword: "" + kw + """);
}
function skip_op(op) {
if (is_op(op)) input.next();
else input.croak("Expecting operator: "" + op + """);
}
function unexpected() {
input.croak("Unexpected token: " + JSON.stringify(input.peek()));
}
function maybe_binary(left, my_prec) {
var tok = is_op();
if (tok) {
var his_prec = PRECEDENCE[tok.value];
if (his_prec > my_prec) {
input.next();
return maybe_binary({
type : tok.value == "=" ? "assign" : "binary",
operator : tok.value,
left : left,
right : maybe_binary(parse_atom(), his_prec)
}, my_prec);
}
}
return left;
}
function delimited(start, stop, separator, parser) {
var a = [], first = true;
skip_punc(start);
while (!input.eof()) {
if (is_punc(stop)) break;
if (first) first = false; else skip_punc(separator);
if (is_punc(stop)) break;
a.push(parser());
}
skip_punc(stop);
return a;
}
function parse_call(func) {
return {
type: "call",
func: func,
args: delimited("(", ")", ",", parse_expression),
};
}
function parse_varname() {
var name = input.next();
if (name.type != "var") input.croak("Expecting variable name");
return name.value;
}
function parse_if() {
skip_kw("if");
var cond = parse_expression();
if (!is_punc("{")) skip_kw("then");
var then = parse_expression();
var ret = {
type: "if",
cond: cond,
then: then,
};
if (is_kw("else")) {
input.next();
ret.else = parse_expression();
}
return ret;
}
function parse_lambda() {
return {
type: "lambda",
vars: delimited("(", ")", ",", parse_varname),
body: parse_expression()
};
}
function parse_bool() {
return {
type : "bool",
value : input.next().value == "true"
};
}
function maybe_call(expr) {
expr = expr();
return is_punc("(") ? parse_call(expr) : expr;
}
function parse_atom() {
return maybe_call(function(){
if (is_punc("(")) {
input.next();
var exp = parse_expression();
skip_punc(")");
return exp;
}
if (is_punc("{")) return parse_prog();
if (is_kw("if")) return parse_if();
if (is_kw("true") || is_kw("false")) return parse_bool();
if (is_kw("lambda") || is_kw("?")) {
input.next();
return parse_lambda();
}
var tok = input.next();
if (tok.type == "var" || tok.type == "num" || tok.type == "str")
return tok;
unexpected();
});
}
function parse_toplevel() {
var prog = [];
while (!input.eof()) {
prog.push(parse_expression());
if (!input.eof()) skip_punc(";");
}
return { type: "prog", prog: prog };
}
function parse_prog() {
var prog = delimited("{", "}", ";", parse_expression);
if (prog.length == 0) return FALSE;
if (prog.length == 1) return prog[0];
return { type: "prog", prog: prog };
}
function parse_expression() {
return maybe_call(function(){
return maybe_binary(parse_atom(), 0);
});
}
}Благодарности
Очень благодарен Marijn Haverbeke, автору библиотеки parse-js (Common Lisp), благодаря которой я понял, как писать парсеры. Парсер, описанный выше предназначен для намного более простого языка, чем JS, но идеи взяты именно из него.
Следующая часть: Как реализовать язык программирования на JavaScript. Часть 2: Интерпретатор
Статья обновлена 19 января 2020 в связи с изменениями структуры JS необходимой для извлечения query_hash в парсере по тэгам. Механика автоподгрузки на страницах сайтов осуществляется с помощью Javascript. Поэтому, для того, чтобы определить на какой URL нам нужно обращаться и какие параметры использовать, нам нужно либо досконально изучить JS код который работает на странице, либо, и что предпочтительней, изучить запросы, которые делает браузер при прокрутке страницы вниз. Изучить запросы мы можем с помощью Инструментов для разработчика, которые встроены во все современные браузеры. В нашей статье мы будем использовать Google Chrome, но вы можете использовать любой другой браузер, приняв во внимание, что инструменты разработчика могут выглядеть по разному в разных браузерах.
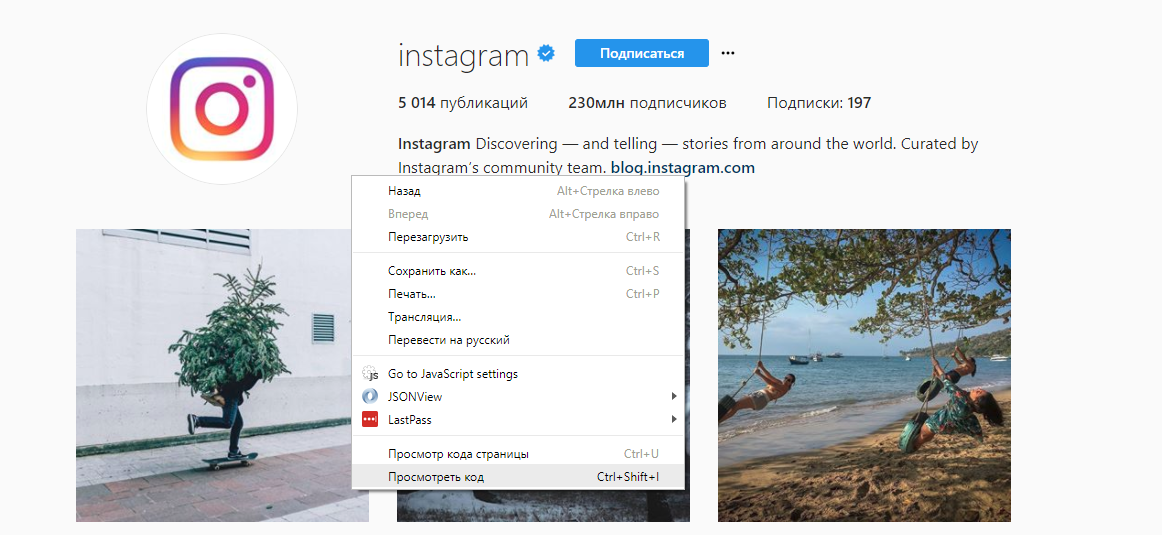
Изучать нашу задачу мы будем на примере Instagram, а именно, используя официальный канал Instagram. Откроем эту страницу в браузере, и запустим Chrome Dev Tools — инструменты для разработчика, которые встроены в Google Chrome. Для этого кликнем правой кнопкой мыши в любом месте страницы и выберем опцию «Просмотреть код» или нажмите «Ctrl+Shift+I»:
У нас откроется окно инструментов, где мы перейдем во вкладку Network и в фильтрах выберем показ только XHR запросов. Мы это делаем для того, чтобы отфильтровать ненужные нам запросы. После этого перезагрузим страницу в браузере с помощью кнопки Reload в интерфейсе браузера или клавиши «F5» на клавиатуре.
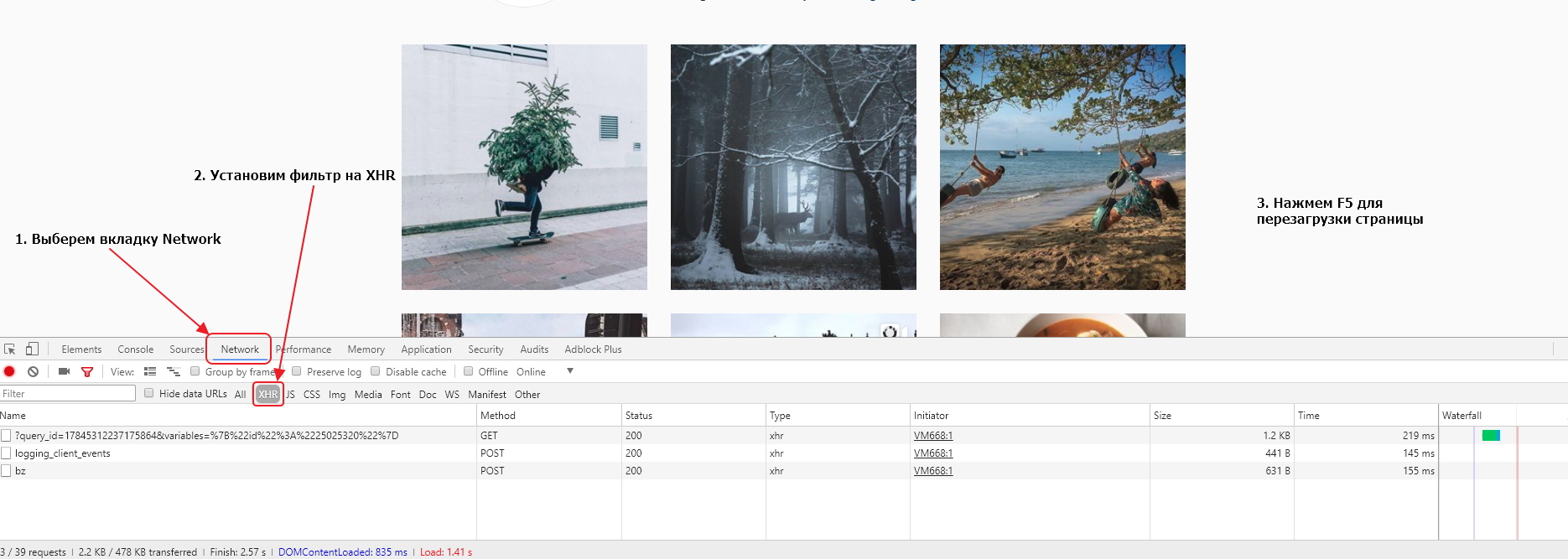
Давайте теперь прокрутим страницу вниз несколько раз с помощью колесика мышки, что вызовет подгрузку контента. Каждый раз, когда при прокручивании мы будем достигать нижней части страницы, JS будет делать XHR запрос на сервер, получать данные и добавлять их на страницу. В результате, у нас в списке окажется несколько запросов, которые выглядят почти одинаково. Скорее всего они нам и нужны.

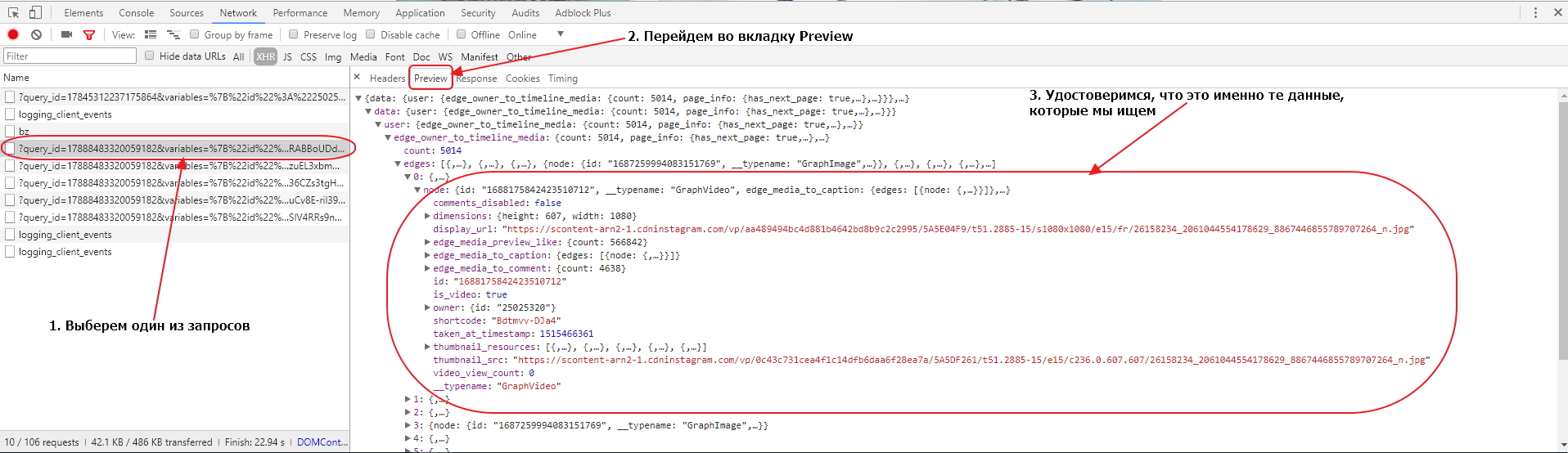
Чтобы удостовериться в этом, мы должны выбрать один из запросов и в открывшемся окне перейти во вкладку Preview. Там мы сможем увидеть отформатированное содержимое, которое сервер прислал в браузер по этому запросу. Доберемся до одного из конечных элементов и удостоверимся, что там находятся данные об изображениях, которые есть у нас на странице.
Убедившись, что это нужные нам запросы, рассмотрим один из них более внимательно. Для этого перейдем во вкладку Headers. Там мы можем найти информацию о том, на какой именно URL производится запрос, какой тип запроса (POST или GET) используется, а также какие параметры передаются с запросом.

Параметры запроса лучше изучать в секции Query String Parameters, прокрутив рабочее окно в панели инструментов вниз до конца:

Результатом нашего анализа станут следующие факты:
URL запроса: https://www.instagram.com/graphql/query/
Тип запроса: GET
Передаваемые параметры: query_hash и variables
Очевидно, что в query_hash передается статичный id, который генерируется, скорее всего, когда вы заходите на страницу. В variables же передаются некие параметры в JSON формате, влияющие на выборку данных.
Давайте проведем небольшой эксперимент, возьмем URL с параметрами, который использовался для загрузки данных:
https://www.instagram.com/graphql/query/?query_hash=df16f80848b2de5a3ca9495d781f98df&variables=%7B%22id%22%3A%2225025320%22%2C%22first%22%3A12%2C%22after%22%3A%22AQDsbvCEthjsp_O_8UO9vPTHKy6Qea2H_RRxe7v46B2XKXhSYVTv8FLSDk0BxmXqLw_T1R9aB8DB51Kp2hp80mP51bKdG9Ahy4eKWT9h3QplzA%22%7D
Если бы до последнего апдейта API мы бы взяли и вставили его в адресную строку браузера и нажали Enter, то мы бы увидели как загрузится страница в JSON формате:
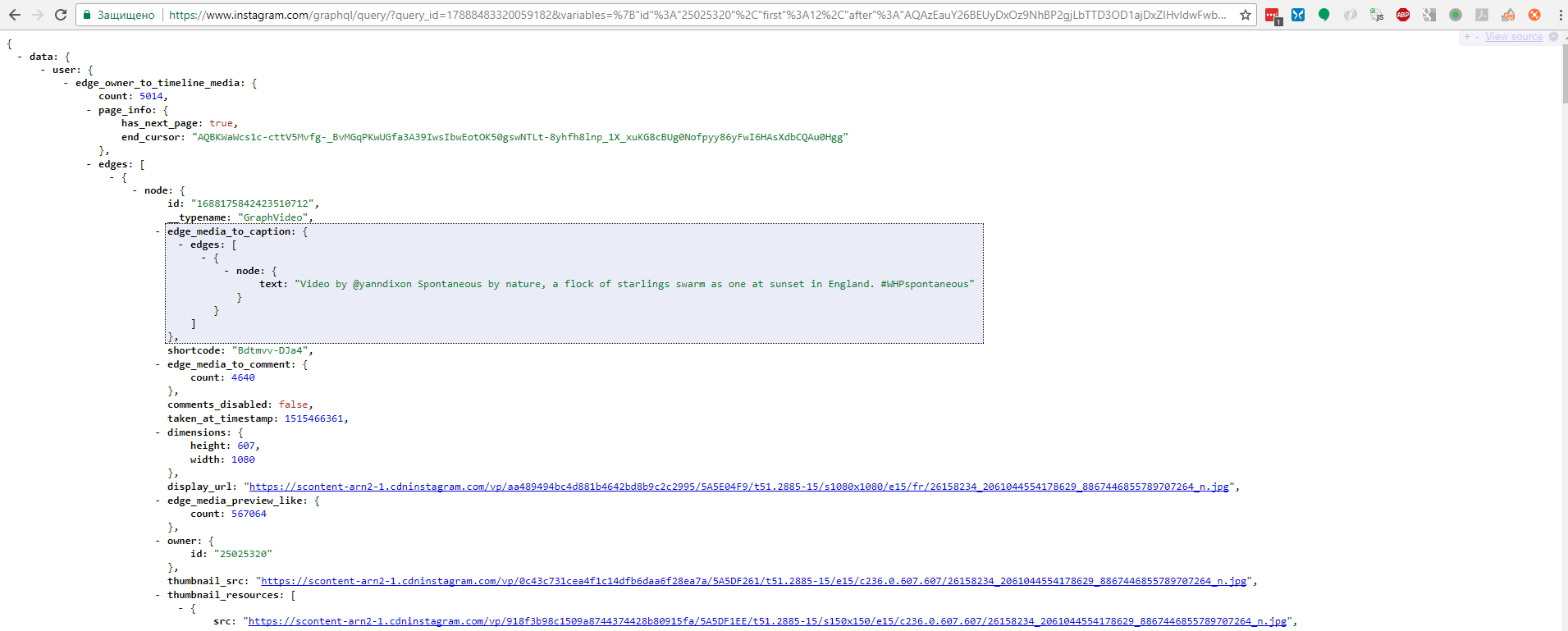
Однако, теперь просто так API Инстаграма не отдает данные, для этого необходимо рассчитать подпись для запроса и передать ее в заголовке запроса. Этот вопрос более подробно рассматривается ниже. Без корректного заголовка все что мы получим сейчас — это ошибку 403.
Теперь нам нужно понять, откуда берется query_hash. Если мы перейдем во вкладку Elements и попытаемся найти (CTRL+F) наш query_hash f2405b236d85e8296cf30347c9f08c2a, то мы узнаем что на самой странице его нет, а значит он подгружается или генерируется где-то в коде Javascript. Поэтому, перейдем опять во вкладку Network и поставим фильтр на JS. Таким образом мы увидим только запросы на JS файлы. Последовательно перебирая запрос за запросом, будем искать наш id в загруженных файлах: просто выбираем запрос, затем открываем в открывшейся панели вкладку Response чтобы увидеть содержимое JS и делаем поиск нашего id (CTRL+F). После нескольких неудачных попыток, мы обнаружим, что наш id находится в следующем JS файле:
https://www.instagram.com/static/bundles/ProfilePageContainer.js/031ac4860b53.js
а фрагмент кода, который обрамляет id, выглядит так:
s.pagination},queryId:"f2405b236d85e8296cf30347c9f08c2a"
Соответственно, для получения query_hash нам надо найти на первой странице URL на ProfilePageContainer.js файл, извлечь этот URL, забрать JS файл по этому URL, распарсить место с нужным нам id и записать его в переменную для дальнейшего использования.
Теперь давайте посмотрим, что за переменные передаются в variables:
{"id":"25025320","first":12,"after":"AQAzEauY26BEUyDxOz9NhBP2gjLbTTD3OD1ajDxZIHvldwFwboiBnIcglaL6Kb_yDssRABBoUDdIls5V8unGC86hC2qk_IeLFUcH2QPTrY3f4A"}
Если мы проанализируем все XHR запросы с догружаемыми данными, что мы обнаружим, что меняется только параметр after. Поэтому id скорее всего есть id канала, который мы парсим, first — количество записей, которые сервер должен отдать по запросу, а after — очевидно id последней показанной записи.
Нам нужно найти место, из которого мы можем извлечь id канала, для этого первым делом мы поищем текст 25025320 в исходном коде начальной страницы. Перейдем во вкладку Elements и сделаем поиск (CTRL+F) нашего id. Мы обнаружим, что он есть в JSON структуре на самой странице, именно оттуда мы и можем его извлечь:
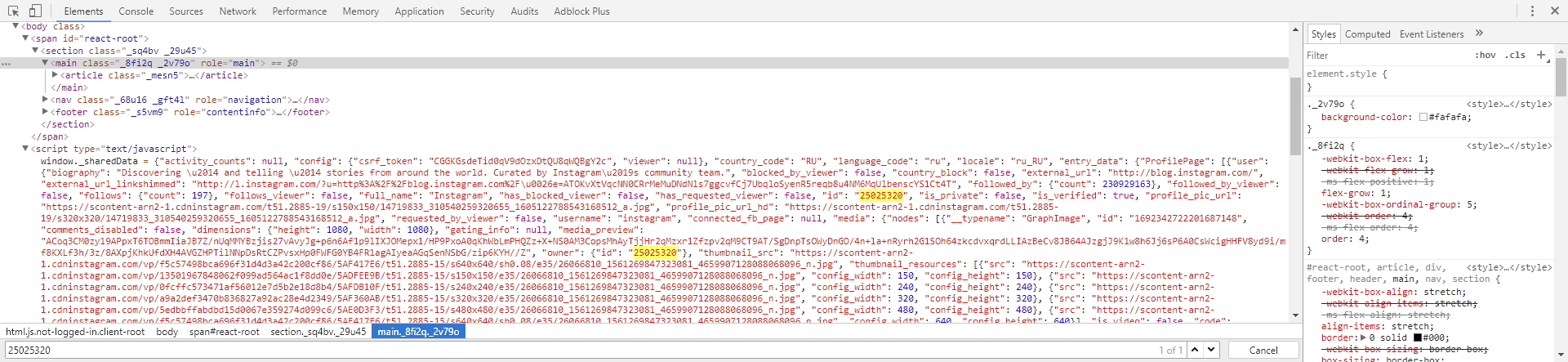
Вроде все понятно, но где нам брать этот самый after для каждой последующей подгрузки? Все очень просто. Если мы загрузим в браузере следующий URL:
https://www.instagram.com/graphql/query/?query_hash=df16f80848b2de5a3ca9495d781f98df&variables=%7B%22id%22%3A%2225025320%22%2C%22first%22%3A12%2C%22after%22%3A%22AQAzEauY26BEUyDxOz9NhBP2gjLbTTD3OD1ajDxZIHvldwFwboiBnIcglaL6Kb_yDssRABBoUDdIls5V8unGC86hC2qk_IeLFUcH2QPTrY3f4A%22%7D
мы увидим, что там есть следующая структура:
data: {
user: {
edge_owner_to_timeline_media: {
count: 5014,
page_info: {
has_next_page: true,
end_cursor: "AQCCoEpYvQtj0-NgbaQUg9g4ffOJf8drV2RieFJw1RA3E9lDoc8euxXjeuwlUEtXB6CRS9Zs2ZGJcNKseKF9f6b0cN0VC3ck8rnTfOw5q8nlJw"
}
}
}
}
То есть, в нашей логике мы сможем использовать значение поля has_next_page чтобы знать переходить ли на следующую страницу или нет и end_cursor как значение параметра after.
Сейчас мы напишем заготовку нашего парсера, загрузим первую страницу и попытаемся загрузить JS файл с query_id. Создайте диггер в вашем аккаунте Diggernaut и добавьте в него следующую конфигурацию:
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:Установите диггер в режим Отладка. Теперь нам нужно запустить наш парсер и после того как он отработает посмотреть лог. В конце лога мы увидим как диггернаут работает с JS файлами. Он преобразовывает их в следующую структуру:
<html>
<head></head>
<body>
<body_safe>
<script>
... JS код будет здесь
</script>
</body_safe>
</body>
</html>
А значит селектор для забора всего JS будет script. Давайте допишем функцию парсинга query_id из JS:
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: profilePosts.byUserId.get[^,]+,queryId:&s*quot;([^&]+)&s*quot;
# Сохраняем полученное значение в переменной
- variable_set: queryidСохраним наш парсер и снова запустим. Подождем когда он закончит работу и посмотрим в лог. В логе мы увидим следующую строчку:
Set variable queryid to register value: 42323d64886122307be10013ad2dcc44
Это значит, что query_hash был успешно извлечен и записан в переменную с именем queryid.
Теперь мы извлечем id канала. Как вы помните, он есть в JSON объекте на самой странице. Поэтому нам нужно взять содержимое определенного элемента script, вытащить оттуда JSON, конвертировать его в XML и забрать нужное нам значение, используя CSS селектор.
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: profilePosts.byUserId.get[^,]+,queryId:&s*quot;([^&]+)&s*quot;
# Сохраняем полученное значение в переменной
- variable_set: queryid
# находим элемент script, который содержит текст window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# извлекаем JSON
- filter:
args: window._sharedDatas+=s+(.+)s*;s*$
# конвертим JSON в XML
- normalize:
routine: json2xml
# превращаем XML строку в DOM блок
- to_block
- find:
path: body_safe
do:
# Находим элемент в котором хранится id канала
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: chidЕсли вы внимательно посмотрите в лог, то увидите, что JSON структура трансформируется в DOM следующим образом:
<body_safe>
<activity_counts></activity_counts>
<config>
<csrf_token>qNVodzmebd0ZnAEOYxFCPpMV1XWGEaDz</csrf_token>
<viewer></viewer>
</config>
<country_code>US</country_code>
<display_properties_server_guess>
<orientation></orientation>
<pixel_ratio>1.5</pixel_ratio>
<viewport_height>480</viewport_height>
<viewport_width>360</viewport_width>
</display_properties_server_guess>
<entry_data>
<profilepage>
<logging_page_id>profilePage_25025320</logging_page_id>
<graphql>
<user>
<biography>Discovering — and telling — stories from around the world. Curated by Instagram’s community
team.</biography>
<blocked_by_viewer>false</blocked_by_viewer>
<connected_fb_page></connected_fb_page>
<country_block>false</country_block>
<external_url>http://blog.instagram.com/</external_url>
<external_url_linkshimmed>http://l.instagram.com/?u=http%3A%2F%2Fblog.instagram.com%2F&e=ATM_VrrL-_PjBU0WJ0OT_xPSlo-70w2PtE177ZsbPuLY9tmVs8JmIXfYgban04z423i2IL8M</external_url_linkshimmed>
<followed_by>
<count>230937095</count>
</followed_by>
<followed_by_viewer>false</followed_by_viewer>
<follows>
<count>197</count>
</follows>
<follows_viewer>false</follows_viewer>
<full_name>Instagram</full_name>
<has_blocked_viewer>false</has_blocked_viewer>
<has_requested_viewer>false</has_requested_viewer>
<id>25025320</id>
<is_private>false</is_private>
<is_verified>true</is_verified>
<edge_owner_to_timeline_media>
<count>5014</count>
<edges>
<node>
<safe___typename>GraphVideo</safe___typename>
<comments_disabled>false</comments_disabled>
<dimensions>
<height>607</height>
<width>1080</width>
</dimensions>
<display_url>https://scontent-iad3-1.cdninstagram.com/vp/9cdd0906e30590eed4ad793888595629/5A5F5679/t51.2885-15/s1080x1080/e15/fr/26158234_2061044554178629_8867446855789707264_n.jpg</display_url>
<edge_media_preview_like>
<count>573448</count>
</edge_media_preview_like>
<edge_media_to_caption>
<edges>
<node>
<text>Video by @yanndixon Spontaneous by nature,
a flock of starlings swarm as one
at sunset in England. #WHPspontaneous</text>
</node>
</edges>
</edge_media_to_caption>
<edge_media_to_comment>
<count>4709</count>
</edge_media_to_comment>
<id>1688175842423510712</id>
<is_video>true</is_video>
<owner>
<id>25025320</id>
</owner>
<shortcode>Bdtmvv-DJa4</shortcode>
<taken_at_timestamp>1515466361</taken_at_timestamp>
<thumbnail_resources>
<config_height>150</config_height>
<config_width>150</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_resources>
<config_height>240</config_height>
<config_width>240</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_resources>
<config_height>320</config_height>
<config_width>320</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_resources>
<config_height>480</config_height>
<config_width>480</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_resources>
<config_height>640</config_height>
<config_width>640</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_src>https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</thumbnail_src>
<video_view_count>2516274</video_view_count>
</node>
</edges>
...
<page_info>
<end_cursor>AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ</end_cursor>
<has_next_page>true</has_next_page>
</page_info>
</edge_owner_to_timeline_media>
</user>
</graphql>
</profilepage>
</entry_data>
<rollout_hash>45ca3dc3d5fd</rollout_hash>
<show_app_install>true</show_app_install>
<zero_data></zero_data>
</body_safe>
Это поможет нам построить CSS селекторы для забора первых 12 записей и маркера последней записи, который нужен нам для забора следующих 12 записей. Напишем логику для извлечения данных, а также начем формировать пул (pool) линков со ссылками на фиды (feeds) с подгружаемыми данными. Далее начнем итерацию по пулу линков и посмотрим как преобразует Diggernaut полученный JSON, так, чтобы мы смогли построить корректные CSS селекторы для логики парсера.
Совсем недавно Instagram сделал изменения в публичном API, теперь для авторизация делается не по CSRF токену, а по специальной сигнатуре, которая рассчитывается используя новый параметр rhx_gis, передаваемый в sharedData странице канала и передаваемые в запросе переменные. Алгоритм можно узнать при разборе JS. Этот алгоритм мы используем и будем автоматически подписывать запросы. Для этого нам нужно извлечь rhx_gis параметр.
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: profilePosts.byUserId.get[^,]+,queryId:&s*quot;([^&]+)&s*quot;
# Сохраняем полученное значение в переменной
- variable_set: queryid
# находим элемент script, который содержит текст window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# извлекаем JSON
- filter:
args: window._sharedDatas+=s+(.+)s*;s*$
# конвертим JSON в XML
- normalize:
routine: json2xml
# превращаем XML строку в DOM блок
- to_block
- find:
path: body_safe
do:
# Находим элемент в котором хранится id канала
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: chid
# Находим элемент в котором хранится rhx_gis
- find:
path: rhx_gis
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: rhxgis
# Находим элементы записей и итерируем по ним
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("<%register%>")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL на первую подгрузку
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=<%queryid%>&variables=%7B%22id%22%3A%22<%chid%>%22%2C%22first%22%3A12%2C%22after%22%3A%22<%cursor_encoded%>%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: '<%rhxgis%>:{"id":"<%chid%>","first":12,"after":"<%cursor%>"}'
- normalize:
routine: md5
- variable_set: signature
# Устанавливаем счетчик подгрузок в 0
- counter_set:
name: pages
value: 0
# Итерируем по пулу и загружаем текущий линк и используем подпись в заголовках запроса
- walk:
to: links
headers:
x-instagram-gis: <%signature%>
x-requested-with: XMLHttpRequest
do:После запуска в логе мы можем увидеть вот такую структуру, с которой нам нужно работать:
<html>
<head></head>
<body>
<body_safe>
<activity_counts></activity_counts>
<config>
<csrf_token>qNVodzmebd0ZnAEOYxFCPpMV1XWGEaDz</csrf_token>
<viewer></viewer>
</config>
<country_code>US</country_code>
<display_properties_server_guess>
<orientation></orientation>
<pixel_ratio>1.5</pixel_ratio>
<viewport_height>480</viewport_height>
<viewport_width>360</viewport_width>
</display_properties_server_guess>
<entry_data>
<profilepage>
<logging_page_id>profilePage_25025320</logging_page_id>
<graphql>
<user>
<biography>Discovering — and telling — stories from around the world. Curated by Instagram’s community
team.</biography>
<blocked_by_viewer>false</blocked_by_viewer>
<connected_fb_page></connected_fb_page>
<country_block>false</country_block>
<external_url>http://blog.instagram.com/</external_url>
<external_url_linkshimmed>http://l.instagram.com/?u=http%3A%2F%2Fblog.instagram.com%2F&e=ATM_VrrL-_PjBU0WJ0OT_xPSlo-70w2PtE177ZsbPuLY9tmVs8JmIXfYgban04z423i2IL8M</external_url_linkshimmed>
<followed_by>
<count>230937095</count>
</followed_by>
<followed_by_viewer>false</followed_by_viewer>
<follows>
<count>197</count>
</follows>
<follows_viewer>false</follows_viewer>
<full_name>Instagram</full_name>
<has_blocked_viewer>false</has_blocked_viewer>
<has_requested_viewer>false</has_requested_viewer>
<id>25025320</id>
<is_private>false</is_private>
<is_verified>true</is_verified>
<edge_owner_to_timeline_media>
<count>5014</count>
<edges>
<node>
<safe___typename>GraphVideo</safe___typename>
<comments_disabled>false</comments_disabled>
<dimensions>
<height>607</height>
<width>1080</width>
</dimensions>
<display_url>https://scontent-iad3-1.cdninstagram.com/vp/9cdd0906e30590eed4ad793888595629/5A5F5679/t51.2885-15/s1080x1080/e15/fr/26158234_2061044554178629_8867446855789707264_n.jpg</display_url>
<edge_media_preview_like>
<count>573448</count>
</edge_media_preview_like>
<edge_media_to_caption>
<edges>
<node>
<text>Video by @yanndixon Spontaneous by nature,
a flock of starlings swarm as one
at sunset in England. #WHPspontaneous</text>
</node>
</edges>
</edge_media_to_caption>
<edge_media_to_comment>
<count>4709</count>
</edge_media_to_comment>
<id>1688175842423510712</id>
<is_video>true</is_video>
<owner>
<id>25025320</id>
</owner>
<shortcode>Bdtmvv-DJa4</shortcode>
<taken_at_timestamp>1515466361</taken_at_timestamp>
<thumbnail_resources>
<config_height>150</config_height>
<config_width>150</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/1ec5640a0a97e98127a1a04f1be62b6b/5A5F436E/t51.2885-15/s150x150/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_resources>
<config_height>240</config_height>
<config_width>240</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/8c972cdacf536ea7bc6764279f3801b3/5A5EF038/t51.2885-15/s240x240/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_resources>
<config_height>320</config_height>
<config_width>320</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/a74e8d0f933bffe75b28af3092f12769/5A5EFC3E/t51.2885-15/s320x320/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_resources>
<config_height>480</config_height>
<config_width>480</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/59790fbcf0a358521f5eb81ec48de4a6/5A5F4F4D/t51.2885-15/s480x480/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_resources>
<config_height>640</config_height>
<config_width>640</config_width>
<src>https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</src>
</thumbnail_resources>
<thumbnail_src>https://scontent-iad3-1.cdninstagram.com/vp/556243558c189f5dfff4081ecfdf06cc/5A5F43E1/t51.2885-15/e15/c236.0.607.607/26158234_2061044554178629_8867446855789707264_n.jpg</thumbnail_src>
<video_view_count>2516274</video_view_count>
</node>
</edges>
...
<page_info>
<end_cursor>AQAchf_lNcgUmnCZ0JTwqV_p3J0f-N21HeHzR2xplwxalNZDXg9tNmrBCzkegX1lN53ROI_HVoUZBPtdxZLuDyvUsYdNoLRb2-z6HMtJoTXRYQ</end_cursor>
<has_next_page>true</has_next_page>
</page_info>
</edge_owner_to_timeline_media>
</user>
</graphql>
</profilepage>
</entry_data>
<rollout_hash>45ca3dc3d5fd</rollout_hash>
<show_app_install>true</show_app_install>
<zero_data></zero_data>
</body_safe>
</body>
</html>
Мы намеренно укоротили исходный код, убрав повторяющиеся элементы. Теперь мы можем описать логику парсинга всех нужных нам полей, а также добавить ограничитель на количество подгрузок, скажем, 10. Также мы добавим паузу, для менее агрессивного парсинга. В результате мы получим финальную версию нашего парсера Instagram.
---
config:
agent: Firefox
debug: 2
do:
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/instagram/
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка ProfilePageContainer.js
- if:
match: ProfilePageContainer.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: profilePosts.byUserId.get[^,]+,queryId:&s*quot;([^&]+)&s*quot;
# Сохраняем полученное значение в переменной
- variable_set: queryid
# находим элемент script, который содержит текст window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# извлекаем JSON
- filter:
args: window._sharedDatas+=s+(.+)s*;s*$
# конвертим JSON в XML
- normalize:
routine: json2xml
# превращаем XML строку в DOM блок
- to_block
- find:
path: body_safe
do:
# Находим элемент в котором хранится id канала
- find:
path: entry_data > profilepage > graphql > user > id
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: chid
# Находим элемент в котором хранится rhx_gis
- find:
path: rhx_gis
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: rhxgis
# Находим элементы записей и итерируем по ним
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: entry_data > profilepage > graphql > user > edge_owner_to_timeline_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("<%register%>")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL на первую подгрузку
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=<%queryid%>&variables=%7B%22id%22%3A%22<%chid%>%22%2C%22first%22%3A12%2C%22after%22%3A%22<%cursor_encoded%>%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: '<%rhxgis%>:{"id":"<%chid%>","first":12,"after":"<%cursor%>"}'
- normalize:
routine: md5
- variable_set: signature
# Устанавливаем счетчик подгрузок в 0
- counter_set:
name: pages
value: 0
# Итерируем по пулу и загружаем текущий линк и используем подпись в заголовках запроса
- walk:
to: links
headers:
x-instagram-gis: <%signature%>
x-requested-with: XMLHttpRequest
do:
- sleep: 3
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: edge_owner_to_timeline_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то проверяем счетчик подгрузок, больше ли он 10
- counter_get: pages
- if:
type: int
gt: 10
else:
# Если нет, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("<%register%>")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL следующей подгрузки
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=<%queryid%>&variables=%7B%22id%22%3A%22<%chid%>%22%2C%22first%22%3A12%2C%22after%22%3A%22<%cursor_encoded%>%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: '<%rhxgis%>:{"id":"<%chid%>","first":12,"after":"<%cursor%>"}'
- normalize:
routine: md5
- variable_set: signature
# Находим элементы записей и итерируем по ним
- find:
path: edge_owner_to_timeline_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Увеличим счетчик подгрузок на 1
- counter_increment:
name: pages
by: 1Теперь мы пожем перевести наш диггер в Активный режим и запустить его. Как результат в вашем наборе данных будут подобные записи.
[{
"item": {
"caption": "Photo by @williamknOut with the old, in with the new. ? #TheWeekOnInstagram",
"comments": "5073",
"likes": "571325",
"url": "https://scontent-sjc3-1.cdninstagram.com/vp/d064d34902bbaba17456da7043307001/5ADF67CC/t51.2885-15/e35/26066810_1561269847323081_4659907128088068096_n.jpg",
"video": "false"
}
}
,{
"item": {
"caption": "Photo by @thatbloomn“I waited. I waited a lot,” says Roland Kraemer (@thatbloom), who knelt patiently in the snow to capture this moment. “I was inspired by the fact that you don’t necessarily have to travel far to take good photos. This was taken almost in my backyard.” #TheWeekOnInstagram",
"comments": "10468",
"likes": "1235401",
"url": "https://scontent-sjc3-1.cdninstagram.com/vp/4782daed87f1da6d3f22f6d02e2730fa/5AF16142/t51.2885-15/e35/26152364_141930706473591_386722995680313344_n.jpg",
"video": "false"
}
}
,{
"item": {
"caption": "Photo by @tiagoovarjaonLate afternoon light, good friends and the ocean. ? #TheWeekOnInstagram",
"comments": "4280",
"likes": "708045",
"url": "https://scontent-sjc3-1.cdninstagram.com/vp/8f95ddb0d51ff26a11fa19df3d22d51a/5AEDD312/t51.2885-15/e35/26225106_1942276889134646_4232956111503753216_n.jpg",
"video": "false"
}
}]
Надеемся что данная статья поможет вам в изучении мета-языка и теперь вы сможете решать задачи по парсингу страниц с подгрузкой без затруднений. В качестве домашнего задания, попробуйте разобраться с тем как работает версия парсера для поиска по хэштегам. Ниже приведим код парсера:
---
config:
agent: Firefox
debug: 2
do:
# Инициальзируем переменную в которую записываем hashtag
- variable_set:
field: tag
value: beard
# Загружаем начальную страницу
- walk:
to: https://www.instagram.com/explore/tags/<%tag%>
do:
# Ищем элементы script которые подгружают JS
- find:
path: script[type="text/javascript"]
do:
# Парсим значение атрибута src
- parse:
attr: src
# Проверяем, нужный ли это Javascript, нам нужен тот, у которого в URL есть строка Consumer.js
- if:
match: Consumer.js
do:
# Переходим по URL скрипта
- walk:
to: value
do:
# Ищем элемент, содержащий искомый JS
- find:
path: script
do:
# Парсим контент элемента, используя фильтр с регулярным выражением
- parse:
filter: T.pagination},queryId:&s*quot;([^&]+)&s*quot;
# Сохраняем полученное значение в переменной
- variable_set: queryid
# находим элемент script, который содержит текст window._sharedData
- find:
path: script:contains("window._sharedData")
do:
- parse
- space_dedupe
- trim
# извлекаем JSON
- filter:
args: window._sharedDatas+=s+(.+)s*;s*$
# конвертим JSON в XML
- normalize:
routine: json2xml
# превращаем XML строку в DOM блок
- to_block
- find:
path: body_safe
do:
# Находим элемент в котором хранится rhx_gis
- find:
path: rhx_gis
do:
# Парсим содержимое элемента
- parse
# Сохраняем полученное значение в переменной
- variable_set: rhxgis
# Находим элементы записей и итерируем по ним
- find:
path: entry_data > tagpage > graphql > hashtag > edge_hashtag_to_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: entry_data > tagpage > graphql > hashtag > edge_hashtag_to_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("<%register%>")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL на первую подгрузку
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=<%queryid%>&variables=%7B%22tag_name%22%3A%22<%tag%>%22%2C%22first%22%3A12%2C%22after%22%3A%22<%cursor_encoded%>%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: '<%rhxgis%>:{"tag_name":"<%tag%>","first":12,"after":"<%cursor%>"}'
- normalize:
routine: md5
- variable_set: signature
# Устанавливаем счетчик подгрузок в 0
- counter_set:
name: pages
value: 0
# Итерируем по пулу и загружаем текущий линк и используем подпись в заголовках запроса
- walk:
to: links
headers:
x-instagram-gis: <%signature%>
x-requested-with: XMLHttpRequest
do:
- sleep: 3
# Находим элемент, в котором хранятся данные для подгрузки
- find:
path: edge_hashtag_to_media > page_info
do:
# Находим элемент, в котором хранятся данные о наличии следующей страницы
- find:
path: has_next_page
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: hnp
# Читаем содержимое переменной в регистр
- variable_get: hnp
# Проверяем равно ли значение 'true'
- if:
match: 'true'
do:
# Если да, то проверяем счетчик подгрузок, больше ли он 10
- counter_get: pages
- if:
type: int
gt: 10
else:
# Если нет, то находим элемент с курсором
- find:
path: end_cursor
do:
# Парсим содержимое элемента
- parse
# Сохраняем значение в переменную
- variable_set: cursor
# URL-энкодим параметр
- eval:
routine: js
body: '(function () {return encodeURIComponent("<%register%>")})();'
# Сохраняем значение в переменную
- variable_set: cursor_encoded
# Формируем пул линков и добавляем в него URL следующей подгрузки
- link_add:
url: https://www.instagram.com/graphql/query/?query_hash=<%queryid%>&variables=%7B%22tag_name%22%3A%22<%tag%>%22%2C%22first%22%3A12%2C%22after%22%3A%22<%cursor_encoded%>%22%7D
# Формируем подпись и записываем ее в переменную signature
- register_set: '<%rhxgis%>:{"tag_name":"<%tag%>","first":12,"after":"<%cursor%>"}'
- normalize:
routine: md5
- variable_set: signature
# Находим элементы записей и итерируем по ним
- find:
path: edge_hashtag_to_media > edges > node
do:
# Создаем новый объект с именем item
- object_new: item
# Находим элемент с URL изображения
- find:
path: display_url
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: url
# Находим элемент с описанием записи
- find:
path: edge_media_to_caption > edges > node > text
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: caption
# Находим элемент с флагом видео это или нет
- find:
path: is_video
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: video
# Находим элемент с количеством комментариев
- find:
path: edge_media_to_comment > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: comments
# Находим элемент с количеством лайков
- find:
path: edge_media_preview_like > count
do:
# Парсим содержимое элемента
- parse
# Записываем значение в поле объекта item
- object_field_set:
object: item
field: likes
# записываем объект в базу
- object_save:
name: item
# Увеличим счетчик подгрузок на 1
- counter_increment:
name: pages
by: 1Большой интерес пользователей к статье Учимся парсить сайты с библиотекой PHP Simple HTML DOM Parser показал, что тема парсеров очень актуальна. В продолжении темы, хочу рассказать, как можно парсить сайты используя JavaScript и всю мощь библиотеки jQuery, взамен Simple HTML DOM Parser.
Нет, мы не будем использовать для обработки js, какой-нибудь серверный интерпретатор, весь парсинг и обработка данных будет происходить на Вашей машине, в Вашем браузере. Браузером будет Google Chrome, а парсер мы реализуем в виде расширения Google Chrome Extension.
Почему Google Chrome, трудно сказать, самым верным ответом наверное будет: «А почему бы и нет?!». Не сомневаюсь, что тоже самое можно будет сделать и для Opera. Однако, эта статья не про написание расширений для браузера( хотя возможно Вы почерпнете для себя и здесь, что-то новое), а про то, как писать client-side парсеры на JavaScript.
Также хочу рассказать про преимущества, которые дает такой подход к написанию парсера.
Во первых: jQuery и JavaScript в целом обладает фантастическим набором методов для работы с DOM документа, Simple HTML DOM Parser тихо курит в сторонке. Навигация по дереву DOM браузер априори обрабатывает очень быстро, это собственно его нативный функционал.
Второе: по планете давным давно шагает WEB 2.0. Для тех кто в танке: веб второй версии подразумевает динамически меняющийся контент сайта. AJAX или просто замена определенного участка страницы через JS сводит на нет работу любого php парсера. Проиллюстрирую на примере:
<html> <body onload="document.body.innerHTML='Страница была создана динамически! Так нужный Вашему парсеру email равен leroy@xdan.ru'"> email:leroy*****.ru </body> </html>
Полагаю Вы догадываетесь, что увидит написанный на php парсер, загрузивший данную страницу, и тупо проверяющий содержание тега body.
Использование браузера в качестве парсер-машины позволяет, обмануть сайт, и выполнить подобные скрипты, получив результирующую страницу.
Итак для начала напишем расширение для Chrome типа Hello World!!!, а затем будем наращивать его функционал. Далее я буду называть наше расширение — приложением, так как расширение увеличивает функционал самого браузера, либо добавляет какие-то фичи к сайту, мы же пишем настоящее приложение, которое работает на базе браузера.
Создайте пустую папку с каким-нибудь внятным названием на латинице. Я назвал парсер xdParser, так обзовем и папку.
В ней создадим два файла main.html и manifest.json, такого содержания:
manifest.json
{
"name": "xdParser v.1.0",
"version": "1.0",
"description": "Parser sites",
"permissions": [
"http://xdan.ru/*"
],
"app": {
"launch": {
"local_path": "main.html"
}
},
"icons": { "48": "Spider-48.png", }
}
Самым интересным параметром для нашего парсера здесь будет permissions, дело в том, что по умолчанию ajax не позволяет cross-domain запросы. Прописав нужный домен в массив permissions, мы сообщаем Google Chrome’у, о том что наш ajax будет использовать кросс-доменные запросы. Если же в массив добавить «<all_urls>», то ajax-запросы будут разрешены для любого домена.
main.html
Привет Мир!!!
Чтобы новое приложение не затерялось в безликой толпе, закиньте в созданную папку набор каких-нибудь иконок, к примеру эти. Иконки должны быть png, иначе они работают не везде. Наверно глюк.
Теперь приложение надо установить, кликаем на панели браузера по иконке с гаечным ключем (Настройки и управление Google Chrome), затем Инструменты -> Расширения, ставим в самом верху галку Режим разработчика
(Настройки и управление Google Chrome), затем Инструменты -> Расширения, ставим в самом верху галку Режим разработчика
Далее кликаем Загрузить распакованное расширение… и указываем путь к вышеназванной папке. Если manifest.json валиден, то приложение установится и мы увидим его среди прочих.
Открываем новую вкладку, в ней переходим на слайд Приложения, и видим там свое.
С Hello World разобрались, теперь напишем наш первый парсер JavaScript на Google Chrome Extensions.
Изменим main.html
<html> <head> <meta http-equiv="content-type" content="text/html; charset=utf-8"/> <title>xdParser v1.1</title> <link href="css/main.css" rel="stylesheet"/> <script type="text/javascript" src="/js/jquery-1.7.2.min.js"></script> <script type="text/javascript" src="/js/main.js"></script> </head> <body> <img id="progress" src="/css/images/progress.gif"/> <input id="starter" type="button" value="Запустить парсер"/> <div id="resultbox"> </div> </body> </html>
Как видно из кода, необходимо создать две подпапки js и css. В js закинуть два файла jquery-1.7.2.min.js и main.js
main.js
(function($){
function ajaxStart(){
$('#progress').show();
}
function ajaxStop(){
$('#progress').hide();
}
function parserGo(){
ajaxStart();
var b = $.ajax('http://xdan.ru');
b.done(function (d) {
analysisSite(d);
ajaxStop();
});
b.fail(function (e, g, f) {
alert('Epic Fail');
ajaxStop();
})
}
function analysisSite(data){
var res = '';
$(data).find('a').each(function(){
res+=$(this).text()+'=>'+$(this).attr('href')+'<br/>';
})
$('#resultbox').html(res);
}
$(function(){
$('#progress').hide();
$('#starter').click(parserGo);
});
})(jQuery);
Тут все просто, на кнопку #starter вешается обработчик события onclick, функция parserGo. В ней мы загружаем главную страницу блога и при удачной загрузке вызываем функцию analysisSite. В которой происходит обработка полученных данных. Запустите парсер. Для примера я вывел все ссылки на главной сайта xdan.ru.
Теперь сделаем что-нибудь посложнее. Возьмем мой пример с парсингом фото из Яндекса при попмощи Simple HTML DOM
Изменим manifest.json
...
"permissions": [
"http://xdan.ru/*",
"http://images.yandex.ru/*"
],
...
не забывайте перезагружать Ваше приложение в расширениях Google Chrome, там же где Вы его устанавливали. Под каждым расширением, в том числе и Вашем есть ссылка Перезагрузить
Иначе изменения внесенные в manifest.json не вступят в силу.
Далее изменим parserGo
...
var url = 'http://images.yandex.ru/yandsearch?text='+encodeURIComponent('Джессика Альба')+'&rpt=image';
...
и analysisSite
$imgs = $(data).find('div.b-image img');
if( $imgs.length ){
requrs($imgs,$imgs.length-1);
}
Как видите я ввел еще одну функцию requrs:
function requrs(data,index){
res+='<img src="'+data[index].src+'"/>';
fs.loadRemoteFile('image'+index+'.jpg',data[index].src,function(){
if( index>0 )requrs(data,index-1);else $('#resultbox').html(res);
});
}
где fs это экземпляр класса fileStorage для работы с файловой системой. Для его инициализации Вам понадобится файл fileStorage.js и в самом начале main.js прописать создание экземпляра этого класса:
(function($){
var fs = new xdFileStorage();
function ajaxStart(){
...
То, как он работает, это тема отдельной статьи, отмечу лишь одни грабли в его использовании: запись следующего файла на диск должна производится только после завершения записи предыдущего. Это очень важно учитывать в асинхронных приложениях, коим и является наш парсер. Поэтому метод loadRemoteFile , одним из своих параметров принимает callback функцию, которая выполняется только по окончании записи файла на диск, и рекурсивно вызывает requrs.
По работе с файлами рекомендую почитать цикл статей по работе с файловой системой в JavaScript Работа с файлами в JavaScript, Часть 1: Основы
В результате файлы с картинками будут аккуратно сложены в папку виртуальной файловой системы Хрома, у меня это папка лежит тут: C:UsersLeroyAppDataLocalGoogleChromeUser DataDefaultFile System, ее название может быть разным и создается самим Хромом. Повторюсь, что это лишь виртуальная файловая система, и картинок с расширением *.jpg Вы здесь не найдете. Все файлы лежат с восьмизначными числовыми именами, начиная от 00000000, без расширения. Но если открыть их какой-нибудь программой для просмотра изображений, они прекрасно откроются. А в браузере на вкладке с нашим приложением мы увидим прекрассную Джессику:
остальные примеры из парсинг фото из Яндекса при попмощи Simple HTML DOM переделайте сами, это не сложно. Мы же рассмотрим более реальный пример парсера.
Есть некая доска объявлений http://www.skelbiu.lt , к примеру нам понадобились все номера телефонов из категории Недвижимость. Для этого нам потребуется спарсить страницу http://www.skelbiu.lt/skelbimai/nekilnojamasis-turtas/ и получить список подкатегорий с их url.
DOM Inspector Google Chrome показывает нам, что все ссылки находятся так:
function parserGo(){
$.ajax('http://www.skelbiu.lt/skelbimai/nekilnojamasis-turtas/').done(function (data) {
var s = '';
$(data).find('#categoriesDiv a').each(function(){
s+=this.innerText+'-'+'http://www.skelbiu.lt'+$(this).attr('href')+'<br/>'
})
$('#resultbox').html(s)
});
}
Отлично, у нас есть названия категорий и их адреса. Теперь необходимо выяснить сколько в каждой категории страниц с объявлениями, и перебрать их все. Для этого найдем на странице ссылку на последнюю страницу в подкатегории. Первая проблема с которой нам придется тут столкнутся, это то, что эта ссылка не имеет уникального идентификатора. Однако мы видим, что следующая за ней ссылка на Следующую страницу имеет id=nextLink, значит найти нужную нам ссылку можно так $last = $(data).find(‘#nextLink’).parent().prev().find(‘a’);
Также выясняется, что страницы работают без ЧПУ и у каждой подкатегории есть числовой идентификатор, он нам понадобится поэтому получим его из href найденной ссылки при помощи регулярного выражения var cat = $last.attr(‘href’).match(/([0-9]+)?&category_id=([0-9]+)&orderBy=[0-9]+/);
function parserGo(){
$.ajax('http://www.skelbiu.lt/skelbimai/nekilnojamasis-turtas/').done(function (data) {
var s = '';
$(data).find('#categoriesDiv a').each(function(){
s+=this.innerText+'-'+'http://www.skelbiu.lt'+$(this).attr('href')+'<br/>'
var name = this.innerText;
var url = 'http://www.skelbiu.lt'+$(this).attr('href');
$.ajax(url).done(function (data) {
$last = $(data).find('#nextLink').parent().prev().find('a'); // находим ссылку на последнюю в подкатегории страницу
var maxpage = parseInt($last.text());// сколько всего страниц
var cat = $last.attr('href').match(/([0-9]+)?&category_id=([0-9]+)&orderBy=[0-9]+/);// выесняем id категории
requrs( cat[2],maxpage,1,url); // запускаем рекурсивную обработку страниц
});
})
$('#resultbox').html(s)
});
}
Итак у нас есть id категории cat[2] и общее количество страниц maxpage. Теперь перебираем их все с 1 до maxpage. Делать это циклом используя асинхронные запросы нецелесообразно, поэтому используем рекурсивную функцию function requrs(catid,fullCount,tik,url), где catid — это id категории, fullCount — общее количество страниц в категории, tik — текущий номер страницы, url — ЧПУ адрес подкатегории.
function requrs(catid,fullCount,tik,url){
if( tik>fullCount )return 0;// конец рекурсии
console.log('Будет спарсена страница '+tik+' категории '+catid);
$.ajax(url+tik+'&category_id='+catid+'&orderBy=1').done(function (data) {
analizeSite(data,function(){
if(tik+1<=fullCount){
requrs(catid,fullCount,tik+1,url); // рекурсивно запускаем функцию
}
},url);
});
}
Осталось распарсить полученные страницы на объявления, загрузить страницу каждого объявления и выдернуть из нее нужный нам телефон. Это сделает функция analizeSite. Каждое объявление можно найти на странице подкатегории таким образом: div.adsInfo a, а на странице с объявлением телефон можно найти регулярным выражением /<!—googleoff: index—>([+0-9]+)<!—googleon: index—>/ посмотрите сами http://www.skelbiu.lt/skelbimai/butas-sviesus-ir-siltas-butas-sviesus-ir-siltas-13926351.html
function analizeSite(data,f,url){
$(data).find('div.adsInfo a').each(function(){
var dt = $.ajax({url:url+$(this).attr('href'),async:false}).responseText;
if(mch = dt.match(/<!--googleoff: index-->([+0-9]+)<!--googleon: index-->/))
console.log(ticker+')Cпарсена страница '+url+$(this).attr('href')+((mch&&mch.length>1)?' найденный номер '+mch[1]:''));
})
if(f)f();// после того как будут спарсены все объявления со страницы, вызываем callback функцию, т.е. запускаем requrs с новым параметром tik
}
Результат мы увидим в консоли JavaScript, увидеть которую можно нажав ctrl+shift+j
Вот и все, как всегда выкладываю все исходники с парсером xdParser v.1.1 Google Chrome Extension