Исходные данные – это фундамент для успешной работы в области анализа и обработки данных. Существует множество источников данных, и веб-сайты являются одним из них. Часто они могут быть вторичным источником информации, например: сайты агрегации данных (Worldometers), новостные сайты (CNBC), социальные сети (Twitter), платформы электронной коммерции (Shopee) и так далее. Эти веб-сайты предоставляют информацию, необходимую для проектов по анализу и обработке данных.
Но как нужно собирать данные? Мы не можем копировать и вставлять их вручную, не так ли? В такой ситуации решением проблемы будет парсинг сайтов на Python. Этот язык программирования имеет мощную библиотеку BeautifulSoup, а также инструмент для автоматизации Selenium. Они оба часто используются специалистами для сбора данных разных форматов. В этом разделе мы сначала познакомимся с BeautifulSoup.
ШАГ 1. УСТАНОВКА БИБЛИОТЕК
Прежде всего, нам нужно установить нужные библиотеки, а именно:
- BeautifulSoup4
- Requests
- pandas
- lxml
Для установки библиотеки вы можете использовать pip install [имя библиотеки] или conda install [имя библиотеки], если у вас Anaconda Prompt.
«Requests» — это наша следующая библиотека для установки. Ее задача — запрос разрешения у сервера, если мы хотим получить данные с его веб-сайта. Затем нужно установить pandas для создания фрейма данных и lxml, чтобы изменить HTML на формат, удобный для Python.
ШАГ 2. ИМПОРТИРОВАНИЕ БИБЛИОТЕК
После установки библиотек давайте откроем вашу любимую среду разработки. Мы предлагаем использовать Spyder 4.2.5. Позже на некоторых этапах работы мы столкнемся с большими объемами выводимых данных и тогда Spyder будет удобнее в использовании чем Jupyter Notebook.
Итак, Spyder открыт и мы можем импортировать необходимую библиотеку:
# Import library
from bs4 import BeautifulSoup
import requests
ШАГ 3. ВЫБОР СТРАНИЦЫ
В этом проекте мы будем использовать webscraper.io. Поскольку данный веб-сайт создан на HTML, код легче и понятнее даже новичкам. Мы выбрали эту страницу для парсинга данных:
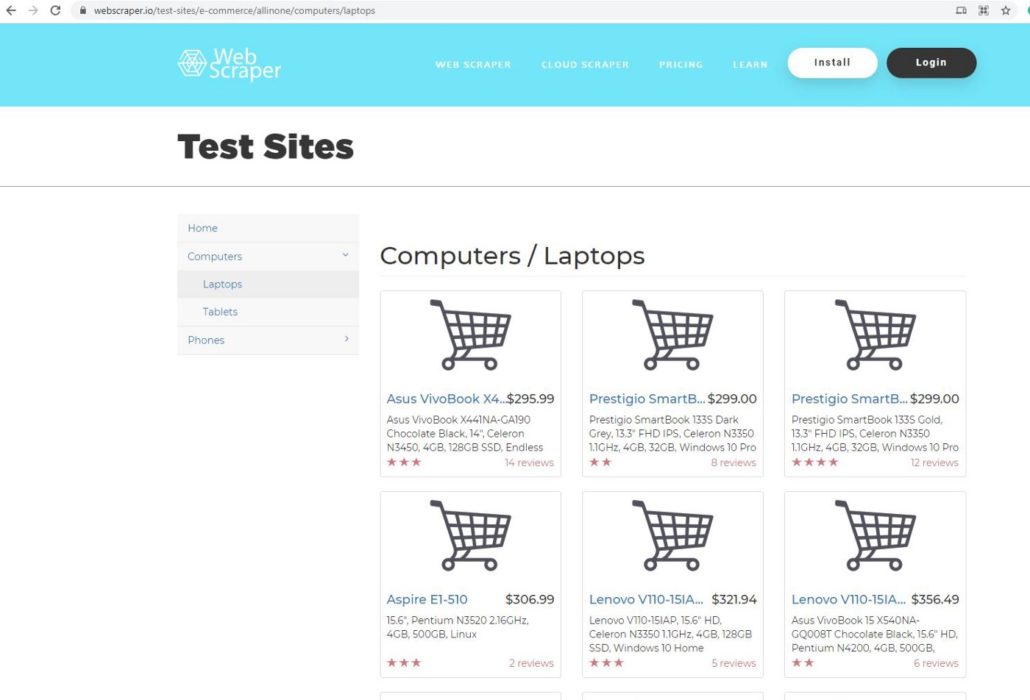
Она является прототипом веб-сайта онлайн магазина. Мы будем парсить данные о компьютерах и ноутбуках, такие как название продукта, цена, описание и отзывы.
ШАГ 4. ЗАПРОС НА РАЗРЕШЕНИЕ
После выбора страницы мы копируем ее URL-адрес и используем request, чтобы запросить разрешение у сервера на получение данных с их сайта.
# Define URL
url = ‘https://webscraper.io/test-sites/e-commerce/allinone/computers/laptops'#
Ask hosting server to fetch url
requests.get(url)
Результат <Response [200]> означает, что сервер позволяет нам собирать данные с их веб-сайта. Для проверки мы можем использовать функцию request.get.
pages = requests.get(url)
pages.text
Когда вы выполните этот код, то на выходе получите беспорядочный текст, который не подходит для Python. Нам нужно использовать парсер, чтобы сделать его более читабельным.
# parser-lxml = Change html to Python friendly format
soup = BeautifulSoup(pages.text, ‘lxml’)
soup

ШАГ 5. ПРОСМОТР КОДА ЭЛЕМЕНТА
Для парсинга сайтов на Python мы рекомендуем использовать Google Chrome, он очень удобен и прост в использовании. Давайте узнаем, как с помощью Chrome просмотреть код веб-страницы. Сначала нужно щелкнуть правой кнопкой мыши страницу, которую вы хотите проверить, далее нажать Просмотреть код и вы увидите это:
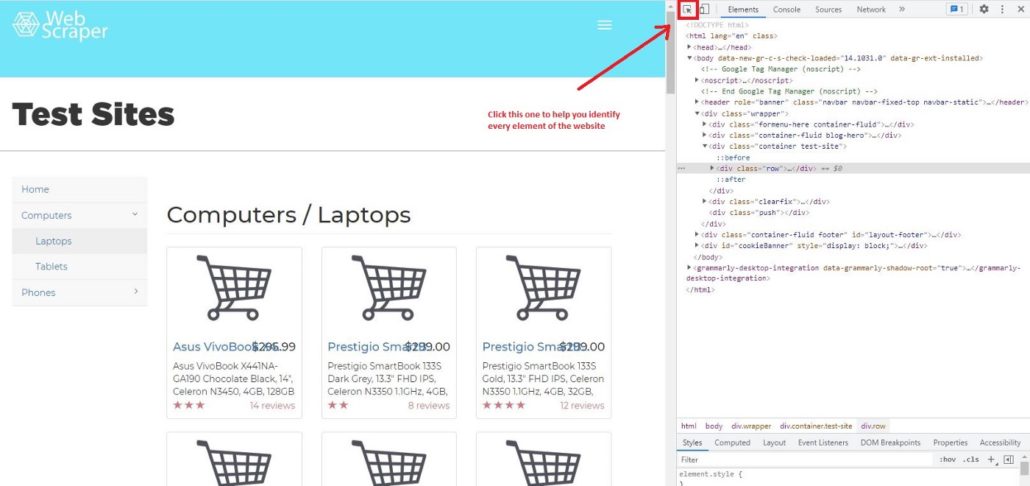
Затем щелкните Выбрать элемент на странице для проверки и вы заметите, что при перемещении курсора к каждому элементу страницы, меню элементов показывает его код.
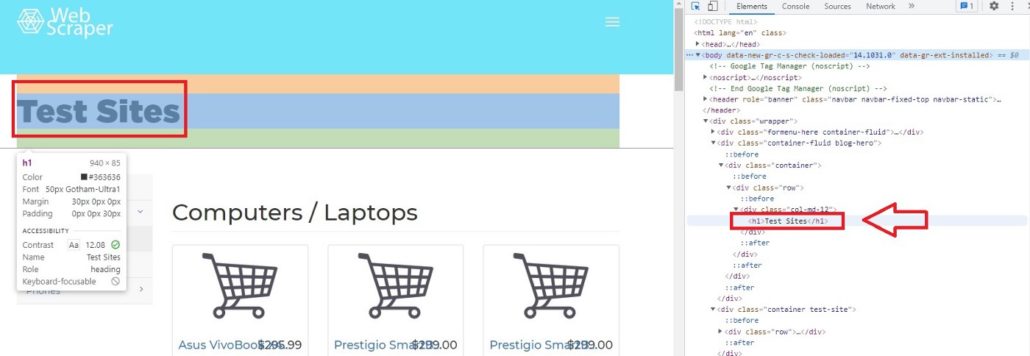
Например, если мы переместим курсор на Test Sites, элемент покажет, что Test Sites находится в теге h1. В Python, если вы хотите просмотреть код элементов сайта, можно вызывать теги. Характерной чертой тегов является то, что они всегда имеют < в качестве префикса и часто имеют фиолетовый цвет.
Как выбрать решение для парсинга сайтов: классификация и большой обзор программ, сервисов и фреймворков
ШАГ 6. ДОСТУП К ТЕГАМ
Если мы, к примеру, хотим получить доступ к элементу h1 с помощью Python, мы можем просто ввести:
# Access h1 tag
soup.h1
Результат будет:
soup.h1
Out[11]: <h1>Test Sites</h1>
Вы можете получить доступ не только к однострочным тегам, но и к тегам класса, например:
# Access header tagsoup.header#Access div tag soup.div
Не забудьте перед этим определить soup, поскольку важно преобразовать HTML в удобный для Python формат.
Вы можете получить доступ к определенному из вложенных тегов. Вложенные теги означают теги внутри тегов. Например, тег <p> находится внутри другого тега <header>. Но когда вы получаете доступ к определенному тегу из <header>, Python всегда покажет результаты из первого индекса. Позже мы узнаем, как получить доступ к нескольким тегам из вложенных.
# Access string from nested tags
soup.header.p
Результат:
soup.header.p
Out[10]: <p>Web Scraper</p>
Вы также можете получить доступ к строке вложенных тегов. Нужно просто добавить в код string.
# Access string from nested tags
soup.header.p
soup.header.p.string
Результат:
soup.header.p
soup.header.p.string
Out[12]: ‘Web Scraper’
Следующий этап парсинга сайтов на Python — это получение доступа к атрибутам тегов. Для этого мы можем использовать функциональную возможность BeautifulSoup attrs. Как результат применения attrs мы получим словарь.
# Access ‘a’ tag in <header>
a_start = soup.header.a
a_start#
Access only the attributes using attrs
a_start.attrs
Результат:
Out[16]:{‘data-toggle’: ‘collapse-side’,
‘data-target’: ‘.side-collapse’,
‘data-target-2’: ‘.side-collapse-container’}
Мы можем получить доступ к определенному атрибуту. Учтите, что Python рассматривает атрибут как словарь, поэтому data-toggle, data-target и data-target-2 являются ключом. Вот пример получение доступа к ‘data-target:
a_start[‘data-target’]
Результат:
a_start[‘data-target’]
Out[17]: ‘.side-collapse’
Мы также можем добавить новый атрибут. Имейте в виду, что изменения влияют только на веб-сайт локально, а не на веб-сайт в мировом масштабе.
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Результат:
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Out[18]:
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</a>
Парсинг таблицы с сайта на Python: Пошаговое руководство
ШАГ 7. ДОСТУП К КОНКРЕТНЫМ АТРИБУТАМ ТЕГОВ
Мы узнали, что в теге может быть больше чем один вложенный тег. Например, если мы запустим soup.header.div, <div> будет иметь много вложенных тегов. Учтите, что мы вызываем только <div> внутри <header >, поэтому другой тег внутри <header> не будет показан.
Результат:
soup.header.div
Out[26]:
<div class=”container”><div class=”navbar-header”>
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</div>
Как мы видим, в одном теге находится много атрибутов и вопрос заключается в том, как получить доступ только к тому атрибуту, который нам нужен. В BeautifulSoup есть функция ‘find’ и ‘find_all’. Чтобы было понятнее, мы покажем вам, как использовать обе функции и чем они отличаются друг от друга. В качестве примера найдем цену каждого товара. Чтобы увидеть код элемента цены, просто наведите курсор на индикатор цены.
После перемещения курсора мы можем определить, что цена находится в теге h4, значение класса pull-right price.
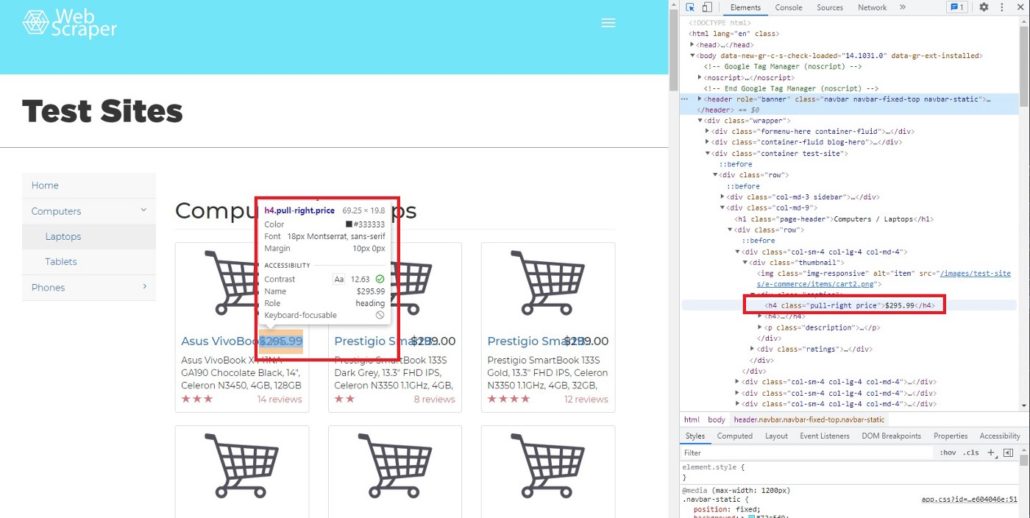
Далее мы хотим найти строку элемента h4, используя функцию find:
# Searching specific attributes of tags
soup.find(‘h4’, class_= ‘pull-right price’)
Результат:
Out[28]: <h4 class=”pull-right price”>$295.99</h4>
Как видно, $295,99 — это атрибут (строка) h4. Но что будет, если мы используем find_all.
# Using find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)
Результат:
Out[29]:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>,
<h4 class=”pull-right price”>$356.49</h4>,
....
</h4>]
Вы заметили разницу между find и find_all?
Да, все верно, find нужно использовать для поиска определенных атрибутов, потому что он возвращает только один результат. Для парсинга больших объемов данных (например, цена, название продукта, описание и т. д.), используйте find_all.
Кроме того, можем получить часть результата функции find_all. В данном случае мы хотим видеть только индексы с 3-го до 5-го.
# Slicing the results of find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)[2:5]
Результат:
Out[32]:[<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>]
[!] Не забывайте, что в Python индекс первого элемента в списке — 0, а последний не учитывается.
ШАГ 8. ИСПОЛЬЗОВАНИЕ ФИЛЬТРА
При необходимости мы можем найти несколько тегов:
# Using filter to find multiple tagssoup.find_all(['h4', 'a', 'p'])soup.find_all(['header', 'div'])
soup.find_all(id = True) # class and id are special attribute so it can be written like this
soup.find_all(class_= True)
Поскольку class и id являются специальными атрибутами, поэтому можно писать class_ и id вместо ‘class’ или ‘id’.
Использование фильтра поможет нам получить необходимые данные с веб-сайта. В нашем случае это название, цена, отзывы и описания. Итак, сначала определим переменные.
# Filter by name name = soup.find_all(‘a’, class_=’title’) # Filter by priceprice = soup.find_all(‘h4’, class_ = ‘pull-right price’)# Filter by reviews reviews = soup.find_all(‘p’, class_ = ‘pull-right’)# Filter by description description = soup.find_all(‘p’, class_ =’description’)
Фильтр по названию:
[<a class=”title” href=”/test-sites/e-commerce/allinone/product/545" title=”Asus VivoBook X441NA-GA190">Asus VivoBook X4…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/546" title=”Prestigio SmartBook 133S Dark Grey”>Prestigio SmartB…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/547" title=”Prestigio SmartBook 133S Gold”>Prestigio SmartB…</a>,
...
</a>]
Фильтр по цене:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$306.99</h4>,
...
</h4>]
Фильтр по отзывам:
[<p class=”pull-right”>14 reviews</p>,<p class=”pull-right”>8 reviews</p>,
<p class=”pull-right”>12 reviews</p>,<p class=”pull-right”>2 reviews</p>,
...
</p>]
Фильтр по описанию:
[<p class=”description”>Asus VivoBook X441NA-GA190 Chocolate Black, 14", Celeron N3450, 4GB, 128GB SSD, Endless OS, ENG kbd</p>,
<p class=”description”>Prestigio SmartBook 133S Dark Grey, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
<p class=”description”>Prestigio SmartBook 133S Gold, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
...
</p>]
ШАГ 9. ОЧИСТКА ДАННЫХ
Очевидно, результаты все еще в формате HTML, поэтому нам нужно очистить их и получить только строку элемента. Используем для этого функцию text.
Text может служить для сортировки строк HTML кода, однако нужно определить новую переменную, например:
# Try to call priceprice1 = soup.find(‘h4’, class_ = ‘pull-right price’)
price1.text
Результат:
Out[55]: ‘$295.99’
На выходе получается только строка из кода, но этого недостаточно. На следующем этапе мы узнаем, как парсить все строки и сделать из них список.
ШАГ 10. ИСПОЛЬЗОВАНИЕ ЦИКЛА FOR ДЛЯ СОЗДАНИЯ СПИСКА СТРОК
Чтобы сделать список из всех строк, необходимо создать цикл for.
# Create for loop to make string from find_all list
product_name_list = []
for i in name:
name = i.text
product_name_list.append(name)price_list = []
for i in price:
price = i.text
price_list.append(price)
review_list = []
for i in reviews:
rev = i.text
review_list.append(rev)
description_list = []
for i in description:
desc = i.text
description_list.append(desc)ШАГ 11. СОЗДАНИЕ ФРЕЙМА ДАННЫХ
После того, как мы создали цикл for и все строки были добавлены в списки, остается заключительный этап парсинга сайтов на Python — построить фрейм данных. Для этой цели нам нужно импортировать библиотеку pandas.
# Create dataframe# Import library import pandas as pdtabel = pd.DataFrame({‘Product Name’:product_name_list, ‘Price’: price_list, ‘Reviews’:review_list, ‘Description’:description_list})
Теперь эти данные можно использовать для работы в проектах по анализу и обработке данных, в машинном обучении, для получения другой ценной информации.

Надеюсь, это руководство будет вам полезно, особенно для тех, кто изучает парсинг сайтов на Python. До новых встреч в следующем проекте.
Если у вас возникнут сложности с парсингом сайтов на Python или с парсингом приложений, обращайтесь в компанию iDatica — напишите письмо или заполните заявку указав все детали задачи по парсингу.
Парсинг в Python – это метод извлечения большого количества данных с нескольких веб-сайтов. Термин «парсинг» относится к получению информации из другого источника (веб-страницы) и сохранению ее в локальном файле.
Например: предположим, что вы работаете над проектом под названием «Веб-сайт сравнения телефонов», где вам требуются цены на мобильные телефоны, рейтинги и названия моделей для сравнения различных мобильных телефонов. Если вы собираете эти данные вручную, проверяя различные сайты, это займет много времени. В этом случае важную роль играет парсинг веб-страниц, когда, написав несколько строк кода, вы можете получить желаемые результаты.

Web Scrapping извлекает данные с веб-сайтов в неструктурированном формате. Это помогает собрать эти неструктурированные данные и преобразовать их в структурированную форму.
Законен ли веб-скрапинг?
Здесь возникает вопрос, является ли веб-скрапинг законным или нет. Ответ в том, что некоторые сайты разрешают это при легальном использовании. Веб-парсинг – это просто инструмент, который вы можете использовать правильно или неправильно.
Непубличные данные доступны не всем; если вы попытаетесь извлечь такие данные, это будет нарушением закона.
Есть несколько инструментов для парсинга данных с веб-сайтов, например:
- Scrapping-bot
- Scrapper API
- Octoparse
- Import.io
- Webhose.io
- Dexi.io
- Outwit
- Diffbot
- Content Grabber
- Mozenda
- Web Scrapper Chrome Extension
Почему и зачем использовать веб-парсинг?

Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
- Динамический мониторинг цен
Широко используется для сбора данных с нескольких интернет-магазинов, сравнения цен на товары и принятия выгодных ценовых решений. Мониторинг цен с использованием данных, переданных через Интернет, дает компаниям возможность узнать о состоянии рынка и способствует динамическому ценообразованию. Это гарантирует компаниям, что они всегда превосходят других.
- Исследования рынка
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
- Сбор электронной почты
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
- Новости и мониторинг контента
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
- Тренды в социальных сетях
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
- Исследования и разработки
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
Зачем использовать именно Python?
Есть и другие популярные языки программирования, но почему мы предпочитаем Python другим языкам программирования для парсинга веб-страниц? Ниже мы описываем список функций Python, которые делают его наиболее полезным языком программирования для сбора данных с веб-страниц.
- Динамичность
В Python нам не нужно определять типы данных для переменных; мы можем напрямую использовать переменную там, где это требуется. Это экономит время и ускоряет выполнение задачи. Python определяет свои классы для определения типа данных переменной.
- Обширная коллекция библиотек
Python поставляется с обширным набором библиотек, таких как NumPy, Matplotlib, Pandas, Scipy и т. д., которые обеспечивают гибкость для работы с различными целями. Он подходит почти для каждой развивающейся области, а также для извлечения данных и выполнения манипуляций.
- Меньше кода
Целью парсинга веб-страниц является экономия времени. Но что, если вы потратите больше времени на написание кода? Вот почему мы используем Python, поскольку он может выполнять задачу в нескольких строках кода.
- Сообщество с открытым исходным кодом
Python имеет открытый исходный код, что означает, что он доступен всем бесплатно. У него одно из крупнейших сообществ в мире, где вы можете обратиться за помощью, если застряли где-нибудь в коде Python.
Основы веб-парсинга
Веб-скраппинг состоит из двух частей: веб-сканера и веб-скребка. Проще говоря, веб-сканер – это лошадь, а скребок – колесница. Сканер ведет парсера и извлекает запрошенные данные. Давайте разберемся с этими двумя компонентами веб-парсинга:
- Сканер
 Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
 Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Как работает Web Scrapping?
Давайте разберем по шагам, как работает парсинг веб-страниц.
Шаг 1. Найдите URL, который вам нужен.
Во-первых, вы должны понимать требования к данным в соответствии с вашим проектом. Веб-страница или веб-сайт содержит большой объем информации. Вот почему отбрасывайте только актуальную информацию. Проще говоря, разработчик должен быть знаком с требованиями к данным.
Шаг – 2: Проверка страницы
Данные извлекаются в необработанном формате HTML, который необходимо тщательно анализировать и отсеивать мешающие необработанные данные. В некоторых случаях данные могут быть простыми, такими как имя и адрес, или такими же сложными, как многомерные данные о погоде и данные фондового рынка.
Шаг – 3: Напишите код
Напишите код для извлечения информации, предоставления соответствующей информации и запуска кода.
Шаг – 4: Сохраните данные в файле
Сохраните эту информацию в необходимом формате файла csv, xml, JSON.
Начало работы с Web Scrapping
Давайте разберемся с необходимой библиотекой для Python. Библиотека, используемая для разметки веб-страниц.
- Selenium-Selenium – это библиотека автоматического тестирования с открытым исходным кодом. Она используется для проверки активности браузера. Чтобы установить эту библиотеку, введите в терминале следующую команду.
pip install selenium
Примечание. Рекомендуется использовать IDE PyCharm.

- Pandas – библиотека для обработки и анализа данных. Используется для извлечения данных и сохранения их в желаемом формате.
- BeautifulSoup
BeautifulSoup – это библиотека Python, которая используется для извлечения данных из файлов HTML и XML. Она в основном предназначена для парсинга веб-страниц. Работает с анализатором, обеспечивая естественный способ навигации, поиска и изменения дерева синтаксического анализа. Последняя версия BeautifulSoup – 4.8.1.
Давайте подробно разберемся с библиотекой BeautifulSoup.
Установка BeautifulSoup
Вы можете установить BeautifulSoup, введя следующую команду:
pip install bs4
Установка парсера
BeautifulSoup поддерживает парсер HTML и несколько сторонних парсеров Python. Вы можете установить любой из них в зависимости от ваших предпочтений. Список парсеров BeautifulSoup:
| Парсер | Типичное использование |
|---|---|
| Python’s html.parser | BeautifulSoup (разметка, “html.parser”) |
| lxml’s HTML parser | BeautifulSoup (разметка, «lxml») |
| lxml’s XML parser | BeautifulSoup (разметка, «lxml-xml») |
| Html5lib | BeautifulSoup (разметка, “html5lib”) |
Мы рекомендуем вам установить парсер html5lib, потому что он больше подходит для более новой версии Python, либо вы можете установить парсер lxml.
Введите в терминале следующую команду:
pip install html5lib

BeautifulSoup используется для преобразования сложного HTML-документа в сложное дерево объектов Python. Но есть несколько основных типов объектов, которые чаще всего используются:
- Ярлык
Объект Tag соответствует исходному документу XML или HTML.
soup = bs4.BeautifulSoup("Extremely bold)
tag = soup.b
type(tag)
Выход:
<class "bs4.element.Tag">
Тег содержит множество атрибутов и методов, но наиболее важными особенностями тега являются имя и атрибут.
-
- Имя
У каждого тега есть имя, доступное как .name:
tag.name
- Атрибуты
Тег может иметь любое количество атрибутов. Тег имеет атрибут “id”, значение которого – “boldest”. Мы можем получить доступ к атрибутам тега, рассматривая тег как словарь.
tag[id]
Мы можем добавлять, удалять и изменять атрибуты тега. Это можно сделать, используя тег как словарь.
# add the element tag['id'] = 'verybold' tag['another-attribute'] = 1 tag # delete the tag del tag['id']
- Многозначные атрибуты
В HTML5 есть некоторые атрибуты, которые могут иметь несколько значений. Класс (состоит более чем из одного css) – это наиболее распространенный многозначный атрибут. Другие атрибуты: rel, rev, accept-charset, headers и accesskey.
class_is_multi= { '*' : 'class'}
xml_soup = BeautifulSoup('', 'xml', multi_valued_attributes=class_is_multi)
xml_soup.p['class']
# [u'body', u'strikeout']
- Навигационная строка
Строка в BeautifulSoup ссылается на текст внутри тега. BeautifulSoup использует класс NavigableString для хранения этих фрагментов текста.
tag.string # u'Extremely bold' type(tag.string) #
Неизменяемая строка означает, что ее нельзя редактировать. Но ее можно заменить другой строкой с помощью replace_with().
tag.string.replace_with("No longer bold")
tag
В некоторых случаях, если вы хотите использовать NavigableString вне BeautifulSoup, unicode() помогает ему превратиться в обычную строку Python Unicode.
- BeautifulSoup объект
Объект BeautifulSoup представляет весь проанализированный документ в целом. Во многих случаях мы можем использовать его как объект Tag. Это означает, что он поддерживает большинство методов, описанных для навигации по дереву и поиска в дереве.
doc=BeautifulSoup("INSERT FOOTER HEREHere's the footer","xml")
doc.find(text="INSERT FOOTER HERE").replace_with(footer)
print(doc)
Выход:
?xml version="1.0" encoding="utf-8"?> #
Пример парсера
Давайте разберем пример, чтобы понять, что такое парсер на практике, извлекая данные с веб-страницы и проверяя всю страницу.
Для начала откройте свою любимую страницу в Википедии и проверьте всю страницу, перед извлечением данных с веб-страницы вы должны убедиться в своих требованиях. Рассмотрим следующий код:
#importing the BeautifulSoup Library
importbs4
import requests
#Creating the requests
res = requests.get("https://en.wikipedia.org/wiki/Machine_learning")
print("The object type:",type(res))
# Convert the request object to the Beautiful Soup Object
soup = bs4.BeautifulSoup(res.text,'html5lib')
print("The object type:",type(soup)
Выход:
The object type <class 'requests.models.Response'> Convert the object into: <class 'bs4.BeautifulSoup'>
В следующих строках кода мы извлекаем все заголовки веб-страницы по имени класса. Здесь знания внешнего интерфейса играют важную роль при проверке веб-страницы.
soup.select('.mw-headline')
for i in soup.select('.mw-headline'):
print(i.text,end = ',')
Выход:
Overview,Machine learning tasks,History and relationships to other fields,Relation to data mining,Relation to optimization,Relation to statistics, Theory,Approaches,Types of learning algorithms,Supervised learning,Unsupervised learning,Reinforcement learning,Self-learning,Feature learning,Sparse dictionary learning,Anomaly detection,Association rules,Models,Artificial neural networks,Decision trees,Support vector machines,Regression analysis,Bayesian networks,Genetic algorithms,Training models,Federated learning,Applications,Limitations,Bias,Model assessments,Ethics,Software,Free and open-source software,Proprietary software with free and open-source editions,Proprietary software,Journals,Conferences,See also,References,Further reading,External links,
В приведенном выше коде мы импортировали bs4 и запросили библиотеку. В третьей строке мы создали объект res для отправки запроса на веб-страницу. Как видите, мы извлекли весь заголовок с веб-страницы.

Веб-страница Wikipedia Learning
Давайте разберемся с другим примером: мы сделаем GET-запрос к URL-адресу и создадим объект дерева синтаксического анализа (soup) с использованием BeautifulSoup и встроенного в Python парсера “html5lib”.
Здесь мы удалим веб-страницу по указанной ссылке (https://www.javatpoint.com/). Рассмотрим следующий код:
following code: # importing the libraries from bs4 import BeautifulSoup import requests url="https://www.javatpoint.com/" # Make a GET request to fetch the raw HTML content html_content = requests.get(url).text # Parse the html content soup = BeautifulSoup(html_content, "html5lib") print(soup.prettify()) # print the parsed data of html
Приведенный выше код отобразит весь html-код домашней страницы javatpoint.
Используя объект BeautifulSoup, то есть soup, мы можем собрать необходимую таблицу данных. Напечатаем интересующую нас информацию с помощью объекта soup:
- Напечатаем заголовок веб-страницы.
print(soup.title)
Выход даст следующий результат:
<title>Tutorials List - Javatpoint</title>
- В приведенных выше выходных данных тег HTML включен в заголовок. Если вам нужен текст без тега, вы можете использовать следующий код:
print(soup.title.text)
Выход: это даст следующий результат:
Tutorials List - Javatpoint
- Мы можем получить всю ссылку на странице вместе с ее атрибутами, такими как href, title и ее внутренний текст. Рассмотрим следующий код:
for link in soup.find_all("a"):
print("Inner Text is: {}".format(link.text))
print("Title is: {}".format(link.get("title")))
print("href is: {}".format(link.get("href")))
Вывод: он напечатает все ссылки вместе со своими атрибутами. Здесь мы отображаем некоторые из них:
href is: https://www.facebook.com/javatpoint Inner Text is: The title is: None href is: https://twitter.com/pagejavatpoint Inner Text is: The title is: None href is: https://www.youtube.com/channel/UCUnYvQVCrJoFWZhKK3O2xLg Inner Text is: The title is: None href is: https://javatpoint.blogspot.com Inner Text is: Learn Java Title is: None href is: https://www.javatpoint.com/java-tutorial Inner Text is: Learn Data Structures Title is: None href is: https://www.javatpoint.com/data-structure-tutorial Inner Text is: Learn C Programming Title is: None href is: https://www.javatpoint.com/c-programming-language-tutorial Inner Text is: Learn C++ Tutorial
Программа: извлечение данных с веб-сайта Flipkart
В этом примере мы удалим цены, рейтинги и название модели мобильных телефонов из Flipkart, одного из популярных веб-сайтов электронной коммерции. Ниже приведены предварительные условия для выполнения этой задачи:
- Python 2.x или Python 3.x с установленными библиотеками Selenium, BeautifulSoup, Pandas.
- Google – браузер Chrome.
- Веб-парсеры, такие как html.parser, xlml и т. д.
Шаг – 1: найдите нужный URL.
Первым шагом является поиск URL-адреса, который вы хотите удалить. Здесь мы извлекаем детали мобильного телефона из Flipkart. URL-адрес этой страницы: https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off.
Шаг 2: проверка страницы.
Необходимо внимательно изучить страницу, поскольку данные обычно содержатся в тегах. Итак, нам нужно провести осмотр, чтобы выбрать нужный тег. Чтобы проверить страницу, щелкните элемент правой кнопкой мыши и выберите «Проверить».
Шаг – 3: найдите данные для извлечения.
Извлеките цену, имя и рейтинг, которые содержатся в теге «div» соответственно.
Шаг – 4: напишите код.
from bs4 import BeautifulSoupas soup
from urllib.request import urlopen as uReq
# Request from the webpage
myurl = "https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"
uClient = uReq(myurl)
page_html = uClient.read()
uClient.close()
page_soup = soup(page_html, features="html.parser")
# print(soup.prettify(containers[0]))
# This variable held all html of webpage
containers = page_soup.find_all("div",{"class": "_3O0U0u"})
# container = containers[0]
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price[0].text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings[0].text)
#
# #
# # print(len(containers))
# print(container.div.img["alt"])
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratingsn"
f.write(headers)
for container in containers:
product_name = container.div.img["alt"]
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container[0].text.strip()
rating_container = container.find_all("div",{"class":"niH0FQ"})
ratings = rating_container[0].text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee[1]
split_price = add_rs_price.split("E")
final_price = split_price[0]
split_rating = str(ratings).split(" ")
final_rating = split_rating[0]
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"n")
f.close()
Выход:

Мы удалили детали iPhone и сохранили их в файле CSV, как вы можете видеть на выходе. В приведенном выше коде мы добавили комментарий к нескольким строкам кода для тестирования. Вы можете удалить эти комментарии и посмотреть результат.


Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Сслыка на статью
Содержание:
- Ваш первый веб-скрапер
- Извлекаем файлы из HTML методами String объекта
- HTML парсер на Python
- Использование объекта BeautifulSoup. Методы:
- Взаимодействие с HTML формами
- Взаимодействие с сайтом в реальном времени
- Заключение
Веб-скарпинг — это автоматизированный процесс сбора данных с сайта.
Интернет – является центром всей информации на Земле, к сожалению, многая информация не является правдивой. Множество дисциплин, таких как : data science, business intelligence стараются искать истинную информацию и получать из неё пользу для бизнеса.
В данном гайде мы научимся:
— Парсить веб-сайт используя string методы и обычные выражения
— Парсить используя HTML parser
— Взаимодействовать с формами и другими компонентами сайта
Сбор информации с веб-сайта
Повторим ещё раз, веб-скрапинг — это автоматизированный сбор данных с сайтов. Но некоторые сайты запрещают парсить их данные при помощи того инструмента, который мы разработаем с вами в нынешнем гайде. Сайты могут запрещать парсить свои данные по след. Причинам:
- Количество запросов. Сайт может просто не справиться и затормозить.
- Важная информация.
Ваш первый Web scraper
Первый пакет, который мы используем, называется urlib. Он поможет нам работать с url. Данный модуль содержит urlopen() его нужно импортировать.
from urllib.request import urlopen
Далее присваиваем переменной url адрес в формате String.
url = "http://olympus.realpython.org/profiles/aphrodite"
Для того чтобы открыть данный сайт в python:
page = urlopen(url)
urlopen() возвращает нам объект типа HTTPResponse
>>> page <http.client.HTTPResponse object at 0x105fef820>
Для того чтобы прочитать объект HTTPResponse нужно воспользоваться методом .read() далее декодировать файл при помощи .decode():
>>> html_bytes = page.read()
>>> html = html_bytes.decode("utf-8")
Теперь вы можете вывести данные переменной, чтобы увидеть контент сайта.
print(html) <html> <head> <title>Profile: Aphrodite</title> </head> <body bgcolor="yellow"> <center> <br><br> <img src="/static/aphrodite.gif" /> <h2>Name: Aphrodite</h2> <br><br> Favorite animal: Dove <br><br> Favorite color: Red <br><br> Hometown: Mount Olympus </center> </body> </html>
И когда у вас есть HTML как текст, вы можете извлечь информацию из него разными способами.
Извлекаем файлы из HTML методами String объекта
Одним из методов извлечения информации HTML файла могут быть string методы. Например, .find() для поиска через текст .
.fing() возвращает индекс первого входа нужного нам символа/тега. Покажем на примере «<title>» методом .find().
>>> title_index = html.find("<title>")
>>> title_index
14
Для того чтобы найти начало заголовка нам нужно к индексу добавить длину тега «<title>».
>>> start_index = title_index + len("<title>")
>>> start_index
21
Также можем найти место где заканчивается «<title>»:
>>> end_index = html.find("</title>")
>>> end_index
39
Наконец, мы можем извлечь всё что находится в «<title>», зная первый и последний индекс:
>>> title = html[start_index:end_index] >>> title 'Profile: Aphrodite'
На самом деле, HTML файл может быть намного менее предсказуемым, чем на Aphrodite странице. Поэтому далее мы вам покажем другой способ, который может решить эту задачу.
Регулярные выражения
Регулярные выражения — это паттерны, которые используются для поиска внутри текста типа string. Для этого нам нужна библиотека re.
Мы импортируем модуль re.
>>> import re
Регулярные выражения используют специальные метасимволы для определения разных паттернов. Например символ «*» разрешает вводить любые символы после себя.
Покажем на примере .findall() мы будем искать все совпадения с требуемым для нас выражением (первый элемент — то что мы ищем, второй — в каком тексте).
>>> re.findall("ab*c", "ac")
['ac']
Используя параметр re.IGNORECASE позволяет методу не учитывать регистр.
>>> re.findall("ab*c", "ABC")
[]
>>> re.findall("ab*c", "ABC", re.IGNORECASE)
['ABC']
Метод .replace() — заменяет все символы в тексте на требуемые нам символы.
Метод .sub() — «<.*>» для замены всего что находится между < и >.
Давайте взглянем ближе на регулярные выражения:
- <title*?> — отмечает открытие тега «title»
- *? — отмечает весь текст после открытие тега «<title>»
- </title*?> — отмечает элемент, который закрывает тег.
HTML парсер на Python
Ладно, хватит играться и развлекаться пора использовать серьёзные вещи для парсинг. К нашему счастью, в библиотеках Python есть множество инструментов, которые созданы для разных задач. Для парсинга нам подойдет Beautiful soup.
Скачиваем Beautiful soup
Воспользуемся терминалом:
$ python3 -m pip install beautifulsoup4
Теперь, вернёмся в едитор.
Создание объекта типа BeautifulSoup
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = "http://olympus.realpython.org/profiles/dionysus"
page = urlopen(url)
html = page.read().decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
Наша программа совершит 3 действия:
- Откроет URL
- Прочитает элементы и переведёт их в String
- Присвоит это объекту типа BeautifulSoup
При создании переменной «soup» мы передаём два аргумента, первый это сайт, который мы парсим, второй — какой парсер использовать.
Использование объекта BeautifulSoup. Методы:
.get_text()
>>> print(soup.get_text()) Profile: Dionysus Name: Dionysus Hometown: Mount Olympus Favorite animal: Leopard Favorite Color: Wine
Как можно заметить, есть много пустых строк, это результат появления символов новой строки в тексте HTML. Их можно убрать используя метод .replace() .
.find()
Если вам нужно что то найти, используйте .find()
>>> soup.find_all("img")
[<img src="/static/dionysus.jpg"/>, <img src="/static/grapes.png"/>]
Данная команда возвращает все теги <img>.
Tag
Каждый объект становится тегом, поэтому можно использовать методы.
.name
>>> image1.name 'img'
Даст нам имя переменной
[«src»]
Этот метод даст нам путь к файлу, например:
>>> image1["src"] '/static/dionysus.jpg' >>> image2["src"] '/static/grapes.png'
.title
Можем увидеть что находится в заголовке
>>> soup.title <title>Profile: Dionysus</title>
.string
Этот метод убирает теги, покажем на примере title:
>>> soup.title.string 'Profile: Dionysus'
Взаимодействие с HTML формами
Библиотека urllib идеально подходит для сбора информации с сайта, но иногда нам приходится взаимодействовать с сайтом, заполнять формы, нажать на кнопку. В этом нам поможет модуль MechanicalSoup.
Устанавливаем модуль
$ python3 -m pip install MechanicalSoup
Создаём объект типа Browser
>>> import mechanicalsoup >>> browser = mechanicalsoup.Browser()
Можем запросить url
>>> url = "http://olympus.realpython.org/login" >>> page = browser.get(url)
Если мы проверим «page» , то нам вернётся 200 — это значит что с сайтом всё в порядке. Если вернётся 404 или 500, то есть ошибка со стороны сайта/сервера.
.soup
Показывает нам структуру HTML
>>> page.soup <html> <head> <title>Log In</title> </head> <body bgcolor="yellow"> <center> <br/><br/> <h2>Please log in to access Mount Olympus:</h2> <br/><br/> <form action="/login" method="post" name="login"> Username: <input name="user" type="text"/><br/> Password: <input name="pwd" type="password"/><br/><br/> <input type="submit" value="Submit"/> </form> </center> </body> </html>
Взаимодействие с сайтом в реальном времени
Иногда, нужно получать информацию с сайта в реальном времени. К примеру, нажимать кнопку «Обновить», что не было самым приятным, но теперь всё изменилось.
Теперь мы можем использовать .get() объекта Browser.
Во-первых, нужно определить какой элемент требует обновления, скорее всего нужно просто найти id.
<h2 id="result">4</h2>
Давайте на примере разберёмся.
import mechanicalsoup
browser = mechanicalsoup.Browser()
page = browser.get("http://olympus.realpython.org/dice")
tag = page.soup.select("#result")[0]
result = tag.text
print(f"The result of your dice roll is: {result}")
В этом примере, метод .select() ищет элемент с id=result(#result) .
Прежде всего, советуем установить промежуток, чтобы сайт успевал перезагружаться. Используйте time.sleep(5) — 5 секунд.
Полный вариант:
import time
import mechanicalsoup
browser = mechanicalsoup.Browser()
for i in range(4):
page = browser.get("http://olympus.realpython.org/dice")
tag = page.soup.select("#result")[0]
result = tag.text
print(f"The result of your dice roll is: {result}")
time.sleep(10)
Когда вы запустите программу, вы сразу увидите первый результат, который будет выведен на консоль. Далее будет перерыв в 10 секунд и всё повторится.
После 4 циклов программа остановится.
Используя такую технику, вы сможете собирать данные сайта в реальном времени, но будьте осторожны, слишком частые запросы буду подозрительны для сайта. Иначе ваш ip будет заблокирован и не будет возможности зайти на него.
Так же возможно сломать сервер, на котором хостится сайт, поэтому советуем читать «Правила пользования» (Terms of use)
Заключение
Python уникальный инструмент для множества задач. В данном уроке мы научились собирать информацию с сайта и переводить его в текст.
Только не забывайте, не все хотят делиться информацией в интернете. Всегда читайте Правила пользования, уважайте других контент-мейкеров.
Рассмотрим еще один практический кейс парсинга сайтов с помощью библиотеки BeautifulSoup: что делать, если на сайте нет готовой выгрузки с данными и нет API для удобной работы, а страниц для ручного копирования очень много?
Недавно мне понадобилось получить данные с одного сайта. Готовой выгрузки с информацией на сайте нет. Данные я вижу, вот они передо мной, но не могу их выгрузить и обработать. Возник вопрос: как их получить? Немного «погуглив», я понял, что придется засучить рукава и самостоятельно парсить страницу (HTML). Какой тогда инструмент выбрать? На каком языке писать, чтобы с ним не возникло проблем? Языков программирования для данной задачи большой набор, выбор пал на Python за его большое разнообразие готовых библиотек.
Примером для разбора основ возьмем сайт с отзывами banki_ru и получим отзывы по какому-нибудь банку.
Задачу можно разбить на три этапа:
- Загружаем страницу в память компьютера или в текстовый файл.
- Разбираем содержимое (HTML), получаем необходимые данные (сущности).
- Сохраняем в необходимый формат, например, Excel.
Инструменты
Для начала нам необходимо отправлять HTTP-запросы на выбранный сайт. У Python для отправки запросов библиотек большое количество, но самые распространённые urllib/urllib2 и Requests. На мой взгляд, Requests — удобнее, примеры буду показывать на ней.
А теперь сам процесс. Были мысли пойти по тяжелому пути и анализировать страницу на предмет объектов, содержащих нужную информацию, проводить ручной поиск и разбирать каждый объект по частям для получения необходимого результата. Но немного походив по просторам интернета, я получил ответ: BeautifulSoup – одна из наиболее популярных библиотек для парсинга. Библиотеки найдены, приступаем к самому интересному: к получению данных.
Загрузка и обработка данных
Попробуем отправить запрос HTTP на сайт, чтобы получить первую страницу с отзывами по какому-нибудь банку и сохранить в файл, для того, чтобы убедиться, получаем ли мы нужную нам информацию.
import requests
from bs4 import BeautifulSoup
bank_id = 1771062 #ID банка на сайте banki.ru
url = ‘https://www.banki.ru/services/questions-answers/?id=%d&p=1’ % (bank_id) # url страницы
r = requests.get(url)
with open(‘test.html’, ‘w’) as output_file:
output_file.write(r.text)
После исполнения данного скрипта получится файл text.html.
Открываем данный файл и видим, что необходимые данные получили без проблем.
Теперь очередь для разбора страницы на нужные фрагменты. Обрабатывать будем последние 10 страниц плюс добавим модуль Pandas для сохранения результата в Excel.
Подгружаем необходимые библиотеки и задаем первоначальные настройки.
import requests
from bs4 import BeautifulSoup
import pandas as pd
bank_id = 1771062 #ID банка на сайте banki.ru
page=1
max_page=10
url = ‘https://www.banki.ru/services/questions-answers/?id=%d&p=%d’ % (bank_id, page) # url страницы
На данном этапе необходимо понять, где находятся необходимые фрагменты. Изучаем разметку страницы с отзывами и определяем, какие объекты будем вытаскивать из страницы.
Подробно покопавшись во внутренностях страницы, мы увидим, что необходимые данные «вопросы-ответы» находятся в блоках <table class:qaBlock >, соответственно, сколько этих блоков на странице, столько и вопросов.
result = pd.DataFrame()
r = requests.get(url) #отправляем HTTP запрос и получаем результат
soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга
tables=soup.find_all(‘table’, {‘class’: ‘qaBlock’}) #Получаем все таблицы с вопросами
for item in tables:
res=parse_table(item)
Приступая к получению самих данных, я кратко расскажу о двух функциях, которые будут использованы:
- Find(‘table’) – проводит поиск по странице и возвращает первый найденный объект типа ‘table’. Вы можете искать и ссылки find(‘table’) и рисунки find(‘img’). В общем, все элементы, которые изображены на странице;
- find_all(‘table’) – проводит поиск по странице и возвращает все найденные объекты в виде списка
У каждой из этих функций есть методы. Я расскажу от тех, которые использовал:
- find(‘table’).text – этот метод вернет текст, находящийся в объекте;
- find(‘a’).get(‘href’) – этот метод вернет значение ссылки
Теперь, уже обладая этими знаниями и навыками программирования на Python, написал функцию, которая разбирает таблицу с отзывом на нужные данные. Каждые стадии кода дополнил комментариями.
def parse_table(table):#Функция разбора таблицы с вопросом
res = pd.DataFrame()
id_question=0
link_question=»
date_question=»
question=»
who_asked=»
who_asked_id=»
who_asked_link=»
who_asked_city=»
answer=»
question_tr=table.find(‘tr’,{‘class’: ‘question’})
#Получаем сам вопрос
question=question_tr.find_all(‘td’)[1].find(‘div’).text.replace(‘<br />’,’n’).strip()
widget_info=question_tr.find_all(‘div’, {‘class’:’widget__info’})
#Получаем ссылку на сам вопрос
link_question=’https://www.banki.ru’+widget_info[0].find(‘a’).get(‘href’).strip()
#Получаем уникальным номер вопроса
id_question=link_question.split(‘=’)[1]
#Получаем того кто задал вопрос
who_asked=widget_info[1].find(‘a’).text.strip()
#Получаем ссылку на профиль
who_asked_link=’https://www.banki.ru’+widget_info[1].find(‘a’).get(‘href’).strip()
#Получаем уникальный номер профиля
who_asked_id=widget_info[1].find(‘a’).get(‘href’).strip().split(‘=’)[1]
#Получаем из какого города вопрос
who_asked_city=widget_info[1].text.split(‘(‘)[1].split(‘)’)[0].strip()
#Получаем дату вопроса
date_question=widget_info[1].text.split(‘(‘)[1].split(‘)’)[1].strip()
#Получаем ответ если он есть сохраняем
answer_tr=table.find(‘tr’,{‘class’: ‘answer’})
if(answer_tr!=None):
answer=answer_tr.find_all(‘td’)[1].find(‘div’).text.replace(‘<br />’,’n’).strip()
#Пишем в таблицу и возвращаем
res=res.append(pd.DataFrame([[id_question,link_question,question,date_question,who_asked,who_asked_id,who_asked_link,who_asked_city,answer]], columns = [‘id_question’,’link_question’,’question’,’date_question’,’who_asked’,’who_asked_id’,’who_asked_city’,’who_asked_link’,’answer’]), ignore_index=True)
#print(res)
return(res)
Функция возвращает DataFrame, который можно накапливать и экспортировать в EXCEL.
result = pd.DataFrame()
r = requests.get(url) #отправляем HTTP запрос и получаем результат
soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга
tables=soup.find_all(‘table’, {‘class’: ‘qaBlock’}) #Получаем все таблицы с вопросами
for item in tables:
res=parse_table(item)
result=result.append(res, ignore_index=True)
result.to_excel(‘result.xlsx’)
Резюме
В результате мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup, а также получили пригодные для дальнейшего анализа данные об отзывах с сайта banki.ru. А вот и сама результирующая таблица.
Приобретенные навыки можно использовать для получения данных с других сайтов и получать обобщенную и структурированную информацию с бескрайних просторов Интернета.
Я надеюсь, моя статья была полезна. Спасибо за внимание.
Веб-парсинг на Python – это гораздо больше, чем просто извлечение контента с помощью селекторов CSS. Благодаря приемам и идеям из этой статьи вы сможете более надежно, быстро и эффективно собирать данные.
Начинаем
Сперва установите все необходимые библиотеки, запустив pip install.
pip install requests beautifulsoup4 pandas
Получить HTML-код из URL-адреса мы можем при помощи библиотеки requests. Затем контент передается в BeautifulSoup, после чего можно начать получать данные и делать запросы с помощью селекторов. В детали вдаваться мы не будем, лишь скажем, что селекторы CSS используются для получения отдельных элементов и содержимого страницы. Синтаксис при этом бывает разный, но это мы рассмотрим позже.
import requests
from bs4 import BeautifulSoup
response = requests.get("https://zenrows.com")
soup = BeautifulSoup(response.content, 'html.parser')
print(soup.title.string)
Чтобы не запрашивать HTML каждый раз, мы можем сохранить его в HTML-файле и уже оттуда загружать BeautifulSoup. Чисто для демонстрации давайте сделаем это вручную. Самый простой способ – это просмотреть исходный код страницы, скопировать и вставить его в файл. Важно посетить страницу без входа в систему, как это сделал бы поисковый робот.
Получение HTML-кода может показаться простой задачей, но это далеко не так. Вообще эта тема тянет на отдельную полноценную статью, так что здесь мы затронем ее лишь вскользь. Мы советуем использовать статический подход из примера ниже, поскольку многие сайты после нескольких запросов начнут перенаправлять вас на страницу входа. Некоторые покажут капчу, и в худшем случае ваш IP будет забанен.
with open("test.html") as fp:
soup = BeautifulSoup(fp, "html.parser")
print(soup.title.string) # Web Data Automation Made Easy - ZenRows
После статической загрузки из файла мы сможем делать сколько угодно попыток запросов, не имея проблем проблем с сетью и не опасаясь блокировки.
Изучите сайт перед тем, как начать писать код
Прежде чем начать писать программу, нужно понять содержание и структуру страницы. Это можно сделать довольно просто при помощи браузера. Мы будем использовать DevTools Chrome, но в других браузерах есть аналогичные инструменты.
Например, мы можем открыть любую страницу продукта на Amazon. Беглый просмотр покажет нам название продукта, цену, доступность и многие другие поля. Перед копированием всех этих селекторов мы рекомендуем потратить пару минут на поиск скрытых входных данных, метаданных и сетевых запросов.
Пользуясь Chrome DevTools или аналогичными инструментами, проявляйте осторожность. Контент, который вы увидите, возможно, был изменен в результате работы JavaScript и сетевых запросов. Да, это утомительно, но иногда нужно исследовать исходный HTML, чтобы избежать запуска JavaScript.
Дисклеймер: мы не будем включать URL-запрос в фрагменты кода для каждого примера. Все они похожи на первый. И помните: сохраняйте HTML-файл локально, если собираетесь протестировать его несколько раз.
Скрытые инпуты
Скрытые инпуты позволяют разработчикам включать поля ввода, которые конечные пользователи не могут видеть или изменять. Многие формы используют их для включения внутренних идентификаторов или токенов безопасности.
В продуктах Amazon мы видим, что их довольно много. Некоторые из них будут доступны в других местах или форматах, но иногда они уникальны. В любом случае имена скрытых инпутов обычно более стабильны, чем имена классов.

Метаданные
Хотя некоторый контент отображается через пользовательский интерфейс, его может быть проще извлечь с помощью метаданных. Например, можно получить количество просмотров в числовом формате и дату публикации в формате ГГГГ-ММ-ДД для видео на YouTube. Да, эти данные можно увидеть на сайте, но их можно получить и с помощью всего пары строк кода. Несколько минут на написание кода точно окупятся.
interactionCount = soup.find('meta', itemprop="interactionCount")
print(interactionCount['content']) # 8566042
datePublished = soup.find('meta', itemprop="datePublished")
print(datePublished['content']) # 2014-01-09
XHR-запросы
Некоторые сайты загружают пустой шаблон и вставляют в него все данные через XHR-запросы. В таких случаях проверки исходного HTML будет недостаточно. Нам нужно исследовать сеть, в частности XHR-запросы.
Возьмем, к примеру, Auction. Заполните форму с любым городом и выполните поиск. Вы будете перенаправлены на страницу результатов, которая, пока выполняются запросы для введенного вами города, представляет собой страницу-каркас.
Это вынуждает нас использовать headless-браузер, который может выполнять JavaScript и перехватывать сетевые запросы. Иногда вы можете вызвать конечную точку XHR напрямую, но обычно для этого требуются файлы cookie или другие методы аутентификации. Или вас могут немедленно забанить, поскольку это не обычный путь пользователя. Будьте осторожны.
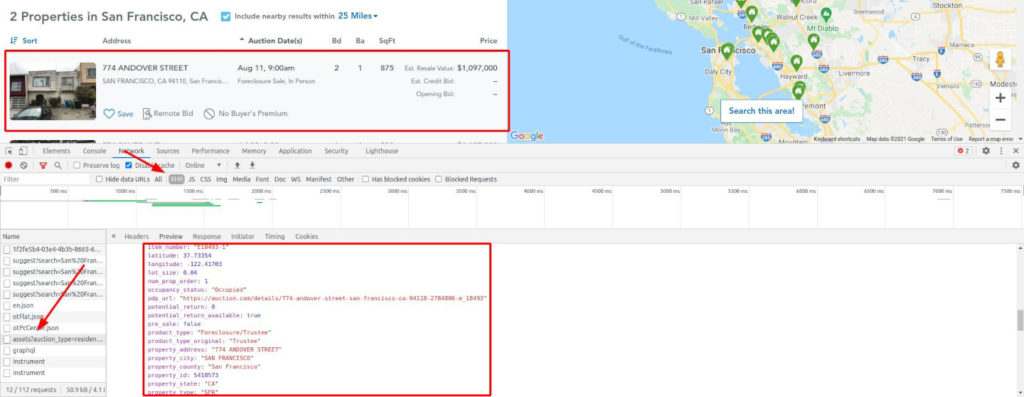
Мы наткнулись на золотую жилу! Взгляните еще раз на изображение.
Все возможные данные, уже очищенные и отформатированные, готовы к извлечению. А также геолокация, внутренние идентификаторы, цена в числовом виде без форматирования, год постройки и т. д.
Рецепты и хитрости для извлечения надежного контента
Уймите свой пыл ненадолго. Получить все с помощью селекторов CSS – это вариант, но есть еще множество других опций. Давайте рассмотрим больше инструментов и идей. Тогда вы сможете самостоятельно принимать решения, зная обо всех альтернативах.
Получение внутренних ссылок
Теперь мы начнем использовать BeautifulSoup для получения значимого контента. Эта библиотека позволяет нам получать контент по идентификаторам, классам, псевдоселекторам и т.д. Мы рассмотрим лишь небольшую часть ее возможностей.
В этом примере со страницы будут извлечены все внутренние ссылки. Упростим себе задачу и будем считать внутренними только ссылки, начинающиеся с косой черты. В более полном варианте следует проверить домен и поддомены.
internalLinks = [
a.get('href') for a in soup.find_all('a')
if a.get('href') and a.get('href').startswith('/')]
print(internalLinks)
Получив все эти ссылки, мы можем убрать дубликаты и поставить их в очередь для последующего парсинга. Поступая таким образом, мы могли бы создать поискового робота для всего сайта, а не только для одной страницы. Однако это уже совсем другая тема, ведь количество страниц для сканирования может увеличиваться, как снежный ком.
[python_ad_block]
Будьте осторожны, выполняя это автоматически. Вы можете получить сотни ссылок за несколько секунд, что приведет к слишком большому количеству запросов к одному и тому же сайту. При неосторожном обращении можно нарваться на капчу или бан.
Извлечение ссылок на социальные сети и электронную почту
Другой распространенной задачей парсинга является извлечение ссылок на соцсети и email-адресов. Точного определения для «ссылок на соцсети» нет, поэтому мы будем получать их, основываясь на домене. Что касается email-адресов, то здесь есть два варианта: ссылки «mailto» и проверка всего текста.
Для примера мы будем использовать тестовый сайт.
Для начала получим все ссылки, как в предыдущем примере. Затем переберем их, проверяя, есть ли среди них домены соцсетей или «mailto». Если да, добавим такие URL-адреса в список и выведем конечный список на экран.
links = [a.get('href') for a in soup.find_all('a')]
to_extract = ["facebook.com", "twitter.com", "mailto:"]
social_links = []
for link in links:
for social in to_extract:
if link and social in link:
social_links.append(link)
print(social_links)
# ['mailto:****@webscraper.io',
# 'https://www.facebook.com/webscraperio/',
# 'https://twitter.com/webscraperio']
Эту задачу можно решить и с помощью регулярных выражений. Конечно, если вы не дружите с regexp, это немного сложнее. Основная идея в том, что мы ищем совпадение текста с заданным паттерном.
В нашем случае паттерн — некоторое количество символов (в основном, букв и цифр), за которым идет знак @, а затем опять символы (домен), точка и еще от двух до четырех символов (домен верхнего уровня. Этому паттерну будет соответствовать, например, test@example.com.
Обратите внимание, что этот паттерн несовершенен: он не учитывает составные домены верхнего уровня, такие как co.uk.
Наше регулярное выражение можно запустить для всего контента (HTML) или только для текста. Мы используем HTML, хотя при этом полученные email-адреса будут дублироваться (они есть и в тексте, и в href).
emails = re.findall(
r"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Za-z]{2,4}",
str(soup))
print(emails) # ['****@webscraper.io', '****@webscraper.io']
Автоматический парсинг таблиц
HTML-таблицы все еще широко применяются на сайтах. Мы можем воспользоваться этим, поскольку они обычно структурированы и хорошо отформатированы.
Используя в качестве примера список самых продаваемых альбомов из Википедии, мы извлечем все значения в датафрейм pandas. Это простой пример, но со всеми данными нужно обращаться так, как если бы они были получены из набора данных.
Мы начинаем с поиска таблицы и перебора всех строк tr. Для каждой из них мы ищем ячейки td или th. Дальше удаляем заметки и сворачиваемое содержимое из таблиц (необязательный шаг). Затем добавляем вырезанный текст ячейки в строку и строку — в окончательный вывод.
table = soup.find("table", class_="sortable")
output = []
for row in table.findAll("tr"):
new_row = []
for cell in row.findAll(["td", "th"]):
for sup in cell.findAll('sup'):
sup.extract()
for collapsible in cell.findAll(
class_="mw-collapsible-content"):
collapsible.extract()
new_row.append(cell.get_text().strip())
output.append(new_row)
print(output)
# [
# ['Artist', 'Album', 'Released', ...],
# ['Michael Jackson', 'Thriller', '1982', ...]
# ]
Другой способ – использовать pandas и напрямую импортировать HTML, как показано ниже. При таком подходе все будет сделано за нас: первая строка будет соответствовать заголовкам, а остальные будут вставлены как контент с правильным типом. read_html() возвращает массив, поэтому мы берем первый элемент, а затем удаляем столбец, у которого нет содержимого.
Попав в датафрейм, мы можем выполнить любую операцию. Например — упорядочить по продажам, поскольку pandas преобразовала некоторые столбцы в числа. Или вывести сумму продаж. Здесь это не очень полезно, но идея понятна.
import pandas as pd
table_df = pd.read_html(str(table))[0]
table_df = table_df.drop('Ref(s)', 1)
print(table_df.columns) # ['Artist', 'Album', 'Released' ...
print(table_df.dtypes) # ... Released int64 ...
print(table_df['Claimed sales*'].sum()) # 422
print(table_df.loc[3])
# Artist Pink Floyd
# Album The Dark Side of the Moon
# Released 1973
# Genre Progressive rock
# Total certified copies... 24.4
# Claimed sales* 45
Извлечение информации не из HTML, а из метаданных
Как было замечено ранее, есть способы получить важные данные, не полагаясь на визуальный контент. Давайте рассмотрим пример с «Ведьмаком» от Netflix. Мы попробуем получить список актеров. Легко, правда?
actors = soup.find(class_="item-starring").find(
class_="title-data-info-item-list")
print(actors.text.split(','))
# ['Henry Cavill', 'Anya Chalotra', 'Freya Allan']
Что, если бы мы сказали вам, что актеров и актрис четырнадцать? Вы попытаетесь получить все имена? Не прокручивайте дальше, если хотите попробовать самостоятельно.
Помните: актеров больше, чем кажется на первый взгляд. Вы знаете троих – поищите их в исходном HTML. Честно говоря, внизу есть еще одно место, где показан весь состав, но постарайтесь его избегать.
Netflix включает фрагмент Schema.org со списком актеров и актрис и многими другими данными. Как и в примере с YouTube, иногда удобнее использовать этот подход. Например, даты обычно отображаются в «машинном» формате, который более удобен при парсинге.
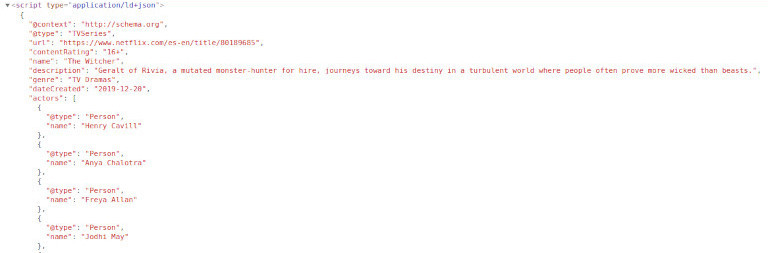
import json
ldJson = soup.find("script", type="application/ld+json")
parsedJson = json.loads(ldJson.contents[0])
print([actor['name'] for actor in parsedJson['actors']])
# [... 'Jodhi May', 'MyAnna Buring', 'Joey Batey' ...]
Разберем следующий пример, используя Instagram-профиль Билли Айлиш. После посещения нескольких страниц вы будете перенаправлены на страницу входа. Будьте осторожны при парсинге Instagram и используйте для тестирования локальный HTML-код.
Обычным подходом будет поиск класса, в нашем случае — Y8-fY. Мы не рекомендуем использовать эти классы, поскольку они, вероятно, изменятся. Судя по виду, они созданы автоматически. Многие современные веб-сайты используют подобный CSS, который генерируется при каждом изменении. Для нас это означает, что мы не можем полагаться на эти классы.
План Б: header ul > li, верно? Это сработает. Но для этого нам нужен рендеринг JavaScript, поскольку он отсутствует при первой загрузке. А как было сказано ранее, этого следует избегать.
Взгляните на исходный HTML. Заголовок и описание включают подписчиков, подписки и количество постов. Это может быть проблемой, поскольку они имеют строковый формат, но мы можем с этим справиться. Если мы хотим только эти данные, нам не понадобится headless-браузер. Отлично!
metaDescription = soup.find("meta", {'name': 'description'})
print(metaDescription['content'])
# 87.9m Followers, 0 Following, 493 Posts ...
Скрытая информация о продукте в онлайн-магазине
Комбинируя некоторые из уже рассмотренных методов, мы хотим извлечь невидимую информацию о продукте. Наш первый пример — это eCommerce-магазин Shopify – Spigen.
Мы сможем извлечь требуемые данные наверняка: не из имени продукта и не из «хлебных крошек», поскольку мы не можем быть уверены в их надежности.

В данном случае они используют itemprop и включают Product и Offer со schema.org. Вероятно, мы могли бы определить, есть ли товар на складе, просмотрев форму или кнопку «Add to cart». Но в этом нет необходимости, мы можем доверять itemprop = "availability". Что касается бренда, то мы можем использовать тот же сниппет кода, что и для YouTube, но с изменением имени свойства на «brand».
brand = soup.find('meta', itemprop="brand")
print(brand['content']) # Tesla
Другой пример со Shopify: nomz. Мы хотим извлечь количество оценок и среднее значение, доступные в HTML. Однако средняя оценка скрыта от просмотра с помощью CSS.
Здесь есть тег, поставленный исключительно для скринридеров, рядом с которым расположены средняя оценка и счетчик. Последние включают текст, что не является проблемой. Но мы можем добиться большего.
Это несложно, если вы изучите исходный код. Схема продукта будет первым, что вы увидите. Применяя то, чему вы научились на примере с Netflix, получите первый блок «ld + json», проанализируйте JSON, и весь контент будет доступен!
import json
ldJson = soup.find("script", type="application/ld+json")
parsedJson = json.loads(ldJson.contents[0])
print(parsedJson["aggregateRating"]["ratingValue"]) # 4.9
print(parsedJson["aggregateRating"]["reviewCount"]) # 57
print(parsedJson["weight"]) # 0.492kg -> extra, not visible in UI
И последнее. Мы воспользуемся атрибутами данных, которые также распространены в eCommerce. Просматривая страницу с бейсбольными битами онлайн-магазина Marucci Sports, мы видим, что у каждого продукта есть несколько полезных точек данных. Цена в числовом формате, идентификатор, название продукта и категория. У нас есть все данные, которые нам могут понадобиться.
products = []
cards = soup.find_all(class_="card")
for card in cards:
products.append({
'id': card.get('data-entity-id'),
'name': card.get('data-name'),
'category': card.get('data-product-category'),
'price': card.get('data-product-price')
})
print(products)
# [
# {
# "category": "Wood Bats, Wood Bats/Professional Cuts",
# "id": "1945",
# "name": "6 Bat USA Professional Cut Bundle",
# "price": "579.99"
# },
# {
# "category": "Wood Bats, Wood Bats/Pro Model",
# "id": "1804",
# "name": "M-71 Pro Model",
# "price": "159.99"
# },
# ...
# ]
Отлично! Мы получили все данные с этой страницы. Теперь нужно проделать это со второй, а затем с третьей. Действуя постепенно, мы с большей вероятностью не нарвемся на бан.
Не забудьте преобразовать эти данные и сохранить их в CSV-файлах или в базе данных. Вложенные поля непросто экспортировать ни в один из этих форматов.
Итоги
Сегодня мы поговорили о веб-парсинге на Python. Нам бы хотелось, чтобы вы усвоили три урока:
- Селекторы CSS хороши для парсинга, но есть и другие варианты.
- Часть контента может быть скрыта или отсутствовать, но при этом быть доступной через метаданные.
- Старайтесь избегать загрузки JavaScript, чтобы повысить производительность.
Парсинг на Python — это инструмент позволяющий собирать всю открытую информацию с различных сайтов. В этом небольшом курсе, мы с вами пройдем путь от простейшего парсинга заголовка сайта, до парсинга всех данных доступных на сайте. Я постараюсь раскрыть все необходимые моменты. Перед изучением парсинга, крайне желательно иметь базовые знания html, и css, и конечно же Python.
Содержание:
- Введение
- Установка и импорт библиотек в Pycharm
- Анализ html кода страницы
- Парсим полученный html код страницы
- Итоги
- Заключение
В этой части мы поговорим про основы парсинга, и напишем приложение, которое заходит на сайт wordpress.org, и забирает оттуда его заголовок.

Перед началом парсинга, нам необходимо:
- Открыть Pycharm (или ваш редактор)
- Установить все необходимые библиотеки
- BeautifulSoup,requests — в случае если эти библиотеки у вас не установлены, откройте терминал вашего IDE, и средствами pip установите их (pip install название_библиотеки)
- Импортировать библиотеки в свой проект
- Провести анализ страницы, которую мы собираемся парсить
Установка и импорт библиотек в Pycharm
И так, открываем Pycharm, создаем новый проект, и устанавливаем наши библиотеки. Для того, что бы правильно установить библиотеки, переходим на сайт pypi.org, и в строке поиска вводим название нужной нам библиотеки. В данном случае, первая библиотека beautifulsoup. Копируем команду pip, и прописываем в терминале Pycharm, pip install beautifulsoup4.

Аналогично установке BeatifullSoup устанавливаем и библиотеку requests. После того, как мы разобрались с установками библиотек, переходим к коду. В первую очередь, нам необходимо импортировать наши библиотеки, используя ключевое слово import, и создать точку входа.
import requests
from bs4 import BeautifulSoup
if __name__=='__main__':
main()
Отлично, шаблон для парсинга практически готов, теперь нам необходимо создать функцию, которая будет отсылать запрос на нужную нам страницу.
import requests
from bs4 import BeautifulSoup
#функция get_html отсылает запрос на нужный нам сайт
def get_html(link):
response = requests.get(link)
return response.text
if __name__=='__main__':
main()
Как видите, я добавил в наш код функцию get_html(). Данная функция отправляет запрос на нужный нам сайт.
- Мы создали функцию get_html(link) — единственный аргумент, который принимает данная функция, это аргумент link, то есть ссылка, куда нам необходимо отправить запрос.
- Внутри нашей функции, мы создали переменную response, которой присвоили значение requests.get(link). Requests.get отправляет запрос по ссылке, которая принимается в качестве аргумента нашей функцией.
- Мы просим функцию вернуть нам результат запроса в текстовом формате (return response.text)
У нас создана точка входа, но не создана сама функция main(). Следующим шагом, мы создадим функцию main() в которой url, для передачи функции get_html().
import requests
from bs4 import BeautifulSoup
def get_html(link):
response = requests.get(link)
return response.text
#функция main - внутри вызываем функцию get_html
def main():
link='https://wordpress.org'
print(get_html(link))
if __name__=='__main__':
main()
- Мы создали функцию main()
- Объявили переменную link
- Внутри данной функции, вызвали ранее созданную функцию get_html()
- Функции get_html() передали переменную link
- Для наглядности ответа, мы обернули функцию get_html() в функцию print
- Запускаем наш скрипт, и если у вас все правильно, то вы увидите примерно такой же результат, как на анимации ниже.
Если у вас получился такой же результат, то все прекрасно. Вы после запроса сайту wordpress.org, получили в ответ html код страницы. Если у вас возникли проблемы, пишите в комментариях, буду рад вам помочь. Теперь, наша задача состоит в том, что бы распарсить полученный html код.
Анализ html кода страницы
В самом начале, мы договорились, что будем парсить только заголовок. Переходим на сайт wordpress.org, наводим курсор мыши на заголовок «Meet WordPress«, нажимаем правой кнопкой мыши, и выбираем пункт «Исследовать элемент».
Как вы видите, у нас есть определенный уровень вложенности, до тега h1. Нам каким то образом, надо передать весь html код этой страницы, BeatifullSoup, что бы вытащить из всей этой каши, нужный нам заголовок.
Парсим полученный html код страницы
И так, приступаем к заключительной части, первого урока по парсингу данных на Python.
- В этом блоке, мы создадим новую функцию, которая будет принимать html код нашей страницы
- Создадим экземпляр класса Beautifulsoup
- Создадим переменную, и выстроим иерархию тегов, для того, что бы отфильтровать все не нужные нам части, и оставить только заголовок
Я сначала покажу весь исходный листинг кода, а потом разберу, что для чего было сделано.
import requests
from bs4 import BeautifulSoup
def main():
link='https://wordpress.org'
print(get_data(get_html(link)))
def get_html(link):
response = requests.get(link)
return response.text
def get_data(html):
soup = BeautifulSoup(html,'lxml')
h1 = soup.find('div',id="home-welcome").find('header').find('h1').text
return h1
if __name__=='__main__':
main()
- Как видите, у нас появилась новая функция get_data(html), которая в качестве аргумента, принимает html код страницы.
- Внутри данной функции, мы создали переменную, экземпляр класса Beautifulsoup, и в качестве аргумента, передаем ему html код страницы, и название парсера.
- В данном случае, в качестве парсера, я установил парсер lxml, устанавливается так же, как и все остальные библиотеки, в случае, если по каким либо причинам у вас его нет, пропишите в качестве парсера, стандартный парсер python html.parser.
- Далее, я объявил переменную h1, и вот тут начинается самое интересное. Как показано в блоке анализ html кода страницы, нам необходимо разобраться, в иерархии тегов.

На данном скрине, мы видим, что наш заголовок h1 лежит внутри тега header, который лежит внутри блока div. Наша задача, каким то образом достучаться до данного тега. Мы поступаем следующим образом:
def get_data(html): soup = BeautifulSoup(html,'lxml') h1 = soup.find('div',id="home-welcome").find('header').find('h1').text return h1
- Говорим soupнайти блок div с нужным нам id, затем найти тег header, а затем найти тег h1, и вернуть текстовое значение
- И говорим функции get_data() вернуть нам h1.
Окей, вроде у нас все есть, но, если вы заметили, функция main() тоже претерпела небольшие изменения:
def main():
link='https://wordpress.org'
print(get_data(get_html(link)))
Мы обернули функцию get_html() в функцию get_data(). То есть,таким образом мы передали html код страницы функции get_data(), которая собственно и парсит заголовок сайта wordpress.org.
Итоги
Подведем итоги того, что мы сделали, и что у нас получилось. Ниже приведен весь листинг кода, по которому мы с вами сейчас пробежимся, и укомплектуем наши полученные навыки.
import requests
from bs4 import BeautifulSoup
def main():
link='https://wordpress.org'
print(get_data(get_html(link)))
def get_html(link):
response = requests.get(link)
return response.text
def get_data(html):
soup = BeautifulSoup(html,'lxml')
h1 = soup.find('div',id="home-welcome").find('header').find('h1').text
return h1
if __name__=='__main__':
main()
- Импортировали нужные нам библиотеки
- Создали функцию main(), и создали точку входа программы
- Создали функцию get_html() которая отправляет запрос на нужный нам сайт, и в качестве ответа возвращает нам html страницы
- Создали функцию get_data(), которая парсит полученный код html. Переходит по иерархии тегов и блоков, доходит до заголовка, и возвращает нам его.
На самом деле, в этом парсере нет ничего сложного, но на первый взгляд вам может показаться все это мутной кашей, но не спешите забрасывать, через пару уроков, вы сами будете уже писать отличные парсеры. В любом случае, по всем вопросам, смело пишите в комментариях, разберем и проясним вашу проблему.
Заключение
И в заключении хочу добавить следующее. Данный код который мы с вами написали, он может оставаться у вас как шаблон, так как, более сложные парсеры, которые мы будем писать в дальнейшем, основаны на данной структуре кода. Ну, конечно же без итогового результата никак нельзя=).
Урок 2. Парсер на Python
Научитесь парсить веб-страницы с помощью Python, чтобы быстро собирать данные с нескольких сайтов с экономией времени и усилий.
6 min read


Узнайте, как создать парсер на Python для сканирования всего сайта и извлечения данных с помощью веб-скрапинга.
Веб-скрапинг — это извлечение веб-данных. Парсер же — это инструмент, который выполняет веб-скрапинг и обычно представлен в виде скрипта. Python — один из самых простых и надежных языков сценариев. Кроме того, он поставляется с широким спектром библиотек для веб-скрапинга. Это делает Python идеальным языком программирования для парсинга веб-страниц. Ведь веб-скрапинг с Python занимает всего несколько строк кода.
В этом руководстве вы узнаете, как создать простой парсер Python. Он будет просматривать весь сайт, извлекая данные с каждой страницы. Затем сохранит их в CSV-файл. Это руководство поможет вам понять, какие библиотеки Python лучшие для парсинга данных, как их использовать. Следуйте нашему пошаговому плану и научитесь создавать скрипт Python для веб-скрапинга.
Содержание:
- Требования
- Лучшие библиотеки веб-скрапинга Python
- Создание парсера на Python
- Вывод
- Часто задаваемые вопросы
Требования
Чтобы создать парсер Python, вам необходимы:
- Python 3.4+
- pip (менеджер пакетов)
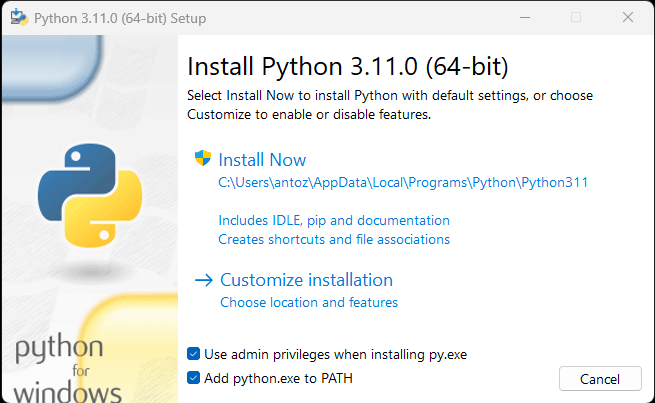
Если на вашем компьютере не установлен Python, скачайте его по первой ссылке выше. Если у вас ОС Windows, обязательно установите флажок «Добавить python.exe в PATH» при установке Python, как показано ниже:
Так Windows автоматически распознает команды Python и pip в терминале. Отметим, что pip — это менеджер пакетов для Python. Он включен по умолчанию в Python 3.4 или более поздней версии. То есть вам не нужно устанавливать его вручную.
Теперь все готово для создания вашего первого парсера Python. Но сначала вам нужна библиотека веб-скрапинга Python!
Лучшие библиотеки веб-скрапинга Python
Вы можете создать сценарий парсинга страниц с нуля с помощью Python vanilla, но это не идеальное решение. Python имеет широкий выбор доступных библиотек. Для веб-скрапинга есть несколько на выбор. Давайте рассмотрим самые важные из них!
Requests
Библиотека Requests позволяет выполнять HTTP-запросы в Python. Она упрощает отправку HTTP-запросов, особенно по сравнению со стандартными HTTP-библиотеками Python. Requests играют ключевую роль в проекте веб-скрапинга Python, поскольку для соскабливания данных на веб-странице сначала нужно получить их с помощью HTTP-запроса GET. Кроме того, может потребоваться выполнение других HTTP-запросов к серверу целевого сайта.
Вы можете установить requests с помощью следующей команды pip:
pip install requestsBeautiful Soup
Библиотека Beautiful Soup Python упрощает сбор информации с веб-страниц. Она работает с любым парсером HTML или XML и предоставляет все необходимое для итерации, поиска и изменения дерева синтаксического анализа. Обратите внимание, что Beautiful Soup можно использовать с html.parser – парсером, который входит в стандартную библиотеку Python и позволяет анализировать текстовые файлы HTML. Вы можете использовать Beautiful Soup для обхода DOM и извлечения из него необходимых данных.
Вы можете установить Beautiful Soup с помощью pip следующим образом:
pip install beautifulsoup4Selenium
Selenium — это усовершенствованная система автоматизированного тестирования с открытым исходным кодом, которая позволяет выполнять операции на веб-странице в браузере. Другими словами, вы можете использовать Selenium, чтобы заставить браузер выполнять определенные задачи. А также использовать в качестве библиотеки веб-скрапинга благодаря возможностям безголового браузера. Это веб-браузер, который работает без GUI (графического пользовательского интерфейса).
Таким образом, веб-страницы, посещаемые в Selenium, будут отображаться в реальном браузере, способном запускать JavaScript. В результате Selenium позволит парсить сайты, зависящие от JavaScript. Учитывайте, что вы не можете добиться этого с помощью requests или любого другого HTTP-клиента, потому что вам нужен браузер для запуска JavaScript, тогда как requests просто позволяют выполнять HTTP-запросы.
Selenium предоставляет все необходимое для создания парсера без потребности в других библиотеках. Вы можете установить его с помощью следующей команды pip:
pip install seleniumСоздание парсера на Python
Теперь давайте узнаем, как создать парсер на Python. Цель этого руководства — научиться извлекать все данные о цитатах на сайте Quotes to Scrape. Вы научитесь извлекать текст, автора и список тегов для каждой цитаты.
Но сначала давайте взглянем на целевой сайт. Вот как выглядит веб-страница Quotes to Scrape:
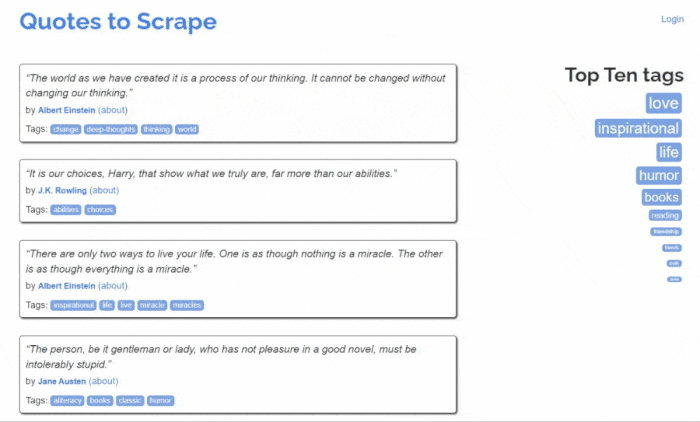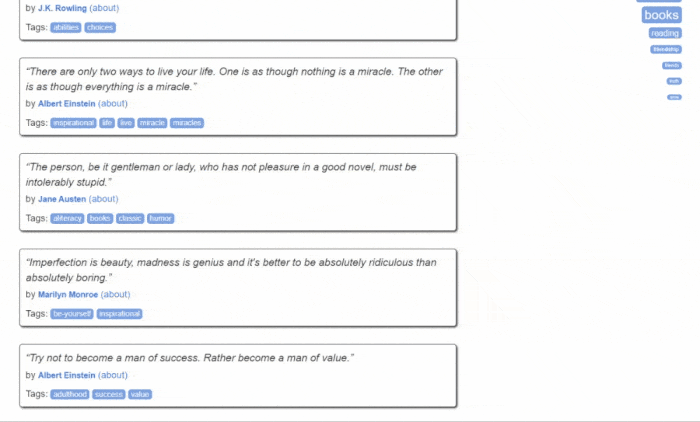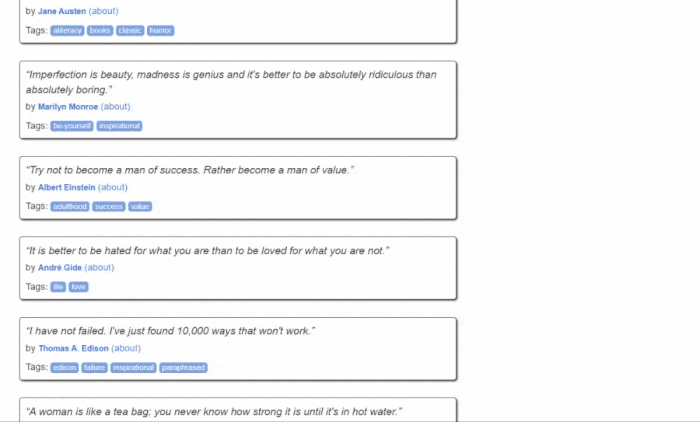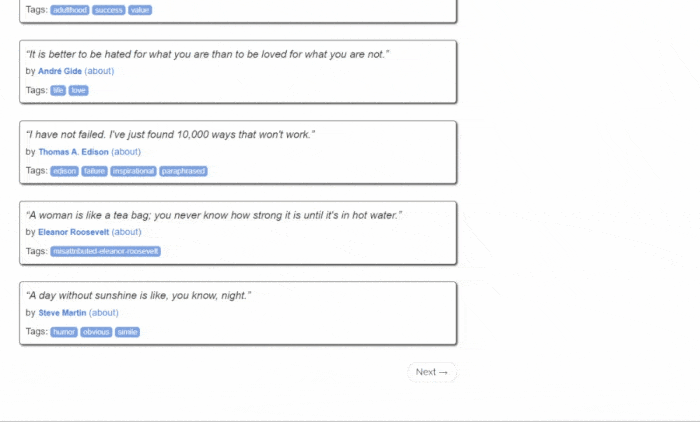
Как видите, Quotes to Scrape — это не что иное, как песочница для парсинга веб-страниц. Сайт содержит разбитый на страницы список цитат. Парсер Python, который вы собираетесь создать, извлечет все цитаты на каждой странице, и предоставит их в виде данных CSV.
Теперь пришло время понять, какие библиотеки Python для парсинга лучше всего подходят для достижения этой цели. Как вы можете увидеть на картинке ниже на вкладке Network окна Chrome DevTools целевой сайт не выполняет запросов Fetch/XHR.
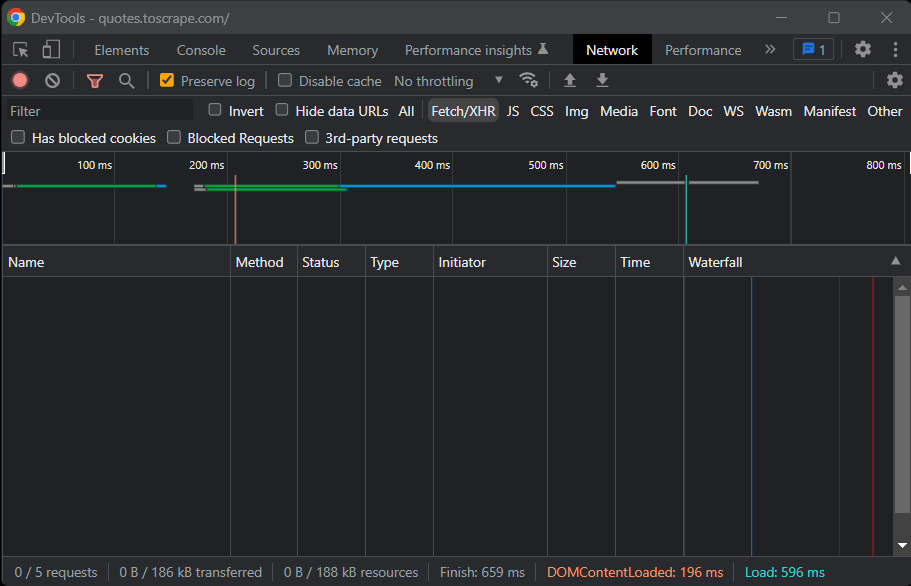
Другими словами, Quotes to Scrape не использует JavaScript для извлечения данных на веб-страницах. Это обычная ситуация для большинства сайтов, отображаемых на сервере. Поскольку целевой сайт не использует JavaScript для отображения страницы или извлечения данных, вам не нужен Selenium для парсинга. Вы можете использовать его, но это не обязательно.
Как вы уже узнали, Selenium открывает страницы в браузере. Поскольку это занимает время и ресурсы, Selenium вызывает расходы на производительность. Вы можете избежать этого, используя Beautiful Soup вместе с Requests. Теперь давайте узнаем, как создать простой скрипт парсинга веб-страниц на Python для извлечения данных с сайта с помощью Beautiful Soup.
Приступим
Прежде чем написать первые строки кода, вам необходимо настроить проект парсинга на Python. Технически необходим только один файл .py. Однако использование расширенной IDE (интегрированной среды разработки) упростит процесс написания кода. Здесь вы узнаете, как настроить проект Python в PyCharm 2022.2.3, но подойдет и любая другая IDE.
Откройте PyCharm и выберите «Файл > Новый проект…». Во всплывающем окне «Новый проект» выберите «Pure Python» и создайте свой проект.
Например, вы можете назвать свой проект python-web-scraper. Нажмите «Создать», и теперь у вас будет доступ к вашему пустому проекту Python. По умолчанию PyCharm инициализирует файл main.py. Вы можете переименовать его в scraper.py. Вот как теперь будет выглядеть ваш проект:
Как видите, PyCharm автоматически инициализирует для вас файл Python. Не обращайте внимания на его содержимое и удаляйте каждую строку кода, чтобы начать с нуля.
Теперь пришло время установить зависимости проекта. Вы можете установить Requests и Beautiful Soup, запустив в терминале следующую команду:
pip install requests beautifulsoup4Эта команда установит обе библиотеки одновременно. Дождитесь завершения установки. Теперь вы готовы использовать Beautiful Soup и Requests для создания поискового робота и парсера на Python. Обязательно импортируйте две библиотеки, добавив следующие строки в начало файла скрипта scraper.py:
import requests
from bs4 import BeautifulSoupPyCharm подсветит эти две строки серым цветом, потому что библиотеки не используются в коде. Если он подчеркнет их красным цветом, значит, что-то пошло не так в процессе установки. В этом случае попробуйте установить их снова.
Вот как теперь должен выглядеть ваш файл scraper.py. Теперь вы можете приступить к определению логики парсинга веб-страниц.
Подключение к целевому URL для сканирования
Первое, что нужно сделать в парсере, — это подключиться к целевому сайту. Сначала получите полный URL-адрес страницы из браузера. Обязательно скопируйте также раздел протокола http:// или https:// HTTP. Вот как выглядит полный URL-адрес целевого сайта:
https://quotes.toscrape.comТеперь можете использовать запросы для загрузки страницы со следующей строкой кода:
page = requests.get('https://quotes.toscrape.com')Эта строка просто присваивает результат метода request.get() переменной page. За сценой request.get() выполняет запрос GET, используя URL-адрес, переданный в качестве параметра. Затем он возвращает объект Response, содержащий ответ сервера на HTTP-запрос.
Если HTTP-запрос выполнен успешно, код page.status_ будет содержать 200. HTTP 200 OK – код ответа состояния, который указывает на то, что HTTP-запрос был выполнен успешно. Код состояния HTTP 4xx или 5xx будет означать ошибку. Это может произойти по нескольким причинам. Учитывайте, что многие сайты блокируют запросы без допустимого заголовка User-Agent. Это строка, которая характеризует приложение и версию операционной системы, откуда пришел запрос. Узнайте больше о User-Agent для веб-скрапинга.
Вы можете установить заголовок User-Agent в запросах следующим образом:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get('https://quotes.toscrape.com', headers=headers)теперь запросы будут выполнять HTTP-запрос, если заголовки будут переданы в качестве параметра.
На что следует обратить внимание, так это на свойство page.text. Оно будет содержать HTML-документ, возвращенный сервером в строковом формате. Передайте свойство text в Beautiful Soup, чтобы извлечь данные из веб-страницы. Давайте узнаем, как это сделать.
Извлечение данных с помощью парсера Python
Чтобы извлечь данные с веб-страницы, сначала нужно определить элементы HTML, которые содержат нужные вам данные. В частности, необходимо найти селекторы CSS для извлечения этих элементов из DOM. Подойдут инструменты разработки от вашего браузера. В Chrome щелкните правой кнопкой мыши на интересующем вас элементе HTML и выберите Inspect (Проверить).
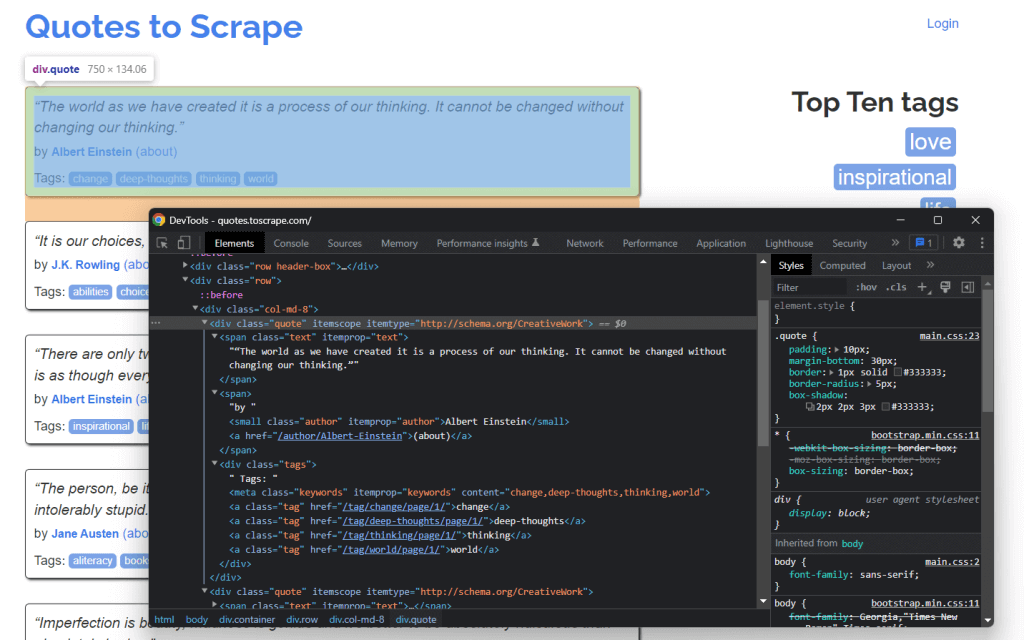
Как видите, HTML-элемент цитаты <div> идентифицируется классом цитаты (quote). Он содержит:
- Текст цитаты в HTML-элементе <span>
- Автор цитаты в HTML-элементе <small>
- Список тегов в элементе <div>, каждый из которых содержится в HTML-элементе <a>.
В частности, вы можете извлечь эти данные, используя следующие селекторы CSS в .quote:
.text.author.tags .tag
Давайте теперь узнаем, как добиться этого с помощью Beautiful Soup в Python. Во-первых, давайте передадим HTML-документ page.text конструктору BeautifulSoup():
soup = BeautifulSoup(page.text, 'html.parser')Второй параметр указывает синтаксический анализатор, который Beautiful Soup будет использовать для анализа HTML-документа. Переменная soup теперь содержит объект BeautifulSoup. Это дерево синтаксического анализа, в результате разбора HTML-документа в page.text, с помощью встроенного в Python html.parser.
Теперь инициализируйте переменную, которая будет содержать список всех отсканированных данных.
quotes = []Пришло время использовать soup для извлечения элементов из DOM:
quote_elements = soup.find_all('div', class_='quote')Метод find_all() вернет список всех HTML-элементов <div>, идентифицированных классом цитаты (quote). Другими словами, эта строка кода эквивалентна применению CSS-селектора .quote для получения списка HTML-элементов цитаты на странице. Затем можно выполнить итерации по списку цитат для получения данных о цитатах, как показано ниже:
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)Благодаря методу find() из Beautiful Soup вы можете извлечь один интересующий элемент HTML. Поскольку тегов, связанных с цитатой, больше одного, их следует хранить в списке.
Затем вы можете преобразовать эти данные в словарь и добавить их в список следующим образом:
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)Хранение извлеченных данных в таком формате словаря облегчит доступ к вашим данным для их понимания.
Вы только что узнали, как извлечь все данные о цитатах с одной страницы. Но имейте в виду, что целевой сайт состоит из нескольких страниц. Давайте научимся сканировать весь сайт.
Реализация логики сканирования
Внизу главной страницы вы можете найти HTML-элемент «Далее →» <a>, который перенаправляет на следующую страницу целевого сайта. Этот элемент HTML содержится на всех страницах, кроме последней. Такой сценарий распространен на любом сайте с разбивкой на страницы.
Перейдя по ссылке в HTML-элементе «Далее →» <a>, вы можете легко перемещаться по всему сайту. Итак, начнем с главной и посмотрим, как пройти каждую страницу, из которой состоит целевой сайт. Вам нужно найти HTML-элемент .next <li> и извлечь относительную ссылку на следующую страницу.
Вы можете реализовать логику сканирования так:
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# retrieving the page and initializing soup...
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')Этот цикл выполняет итерации по каждой странице до тех пор, пока не останется следующая страница. В частности, он извлекает относительный URL следующей страницы и использует его для создания URL следующей страницы для сканирования. Затем загружается следующая страница, он сканирует ее и повторяет логику.
Вы только что узнали, как реализовать логику сканирования для парсинга всего сайта. Пришло время посмотреть, как преобразовать извлеченные данные в более удобный формат.
Преобразование данных в формат CSV
Рассмотрим, как преобразовать список словарей, содержащих отсканированные данные цитаты, в файл CSV. Сделать это можно с помощью следующих строк:
import csv
# scraping logic...
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()Этот фрагмент кода записывает данные цитаты, содержащиеся в списке словарей, в файл quotes.csv. Обратите внимание, что csv является частью стандартной библиотеки Python. Таким образом, вы можете импортировать и использовать его без дополнительной зависимости. Вам просто нужно создать файл с помощью open(). Затем вы можете заполнить его функцией writerow() из объекта Writer библиотеки csv. Это позволит записать каждый словарь цитат как строку в CSV-формате в CSV-файл.
Вы перешли от необработанных данных сайта к структурированным данным в файле CSV. Процесс извлечения завершен, и теперь вы можете посмотреть на весь парсер Python.
Собираем все вместе
Вот как выглядит полный скрипт парсинга веб-страниц на Python:
import requests
from bs4 import BeautifulSoup
import csv
def scrape_page(soup, quotes):
# retrieving all the quote <div> HTML element on the page
quote_elements = soup.find_all('div', class_='quote')
# iterating over the list of quote elements
# to extract the data of interest and store it
# in quotes
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)
# appending a dictionary containing the quote data
# in a new format in the quote list
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# defining the User-Agent header to use in the GET request below
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# retrieving the target web page
page = requests.get(base_url, headers=headers)
# parsing the target web page with Beautiful Soup
soup = BeautifulSoup(page.text, 'html.parser')
# initializing the variable that will contain
# the list of all quote data
quotes = []
# scraping the home page
scrape_page(soup, quotes)
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping the new page
scrape_page(soup, quotes)
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()Как видите, вы можете создать парсер веб-страниц менее чем из 100 строк кода. Этот скрипт Python позволяет сканировать весь сайт, автоматически извлекать его данные и преобразовывать в файл CSV.
Поздравляем! Теперь вы знаете, как создать парсер Python с помощью библиотек Requests и Beautiful Soup!
Запуск скрипта веб-скрапинга Python
Если вы являетесь пользователем PyCharm, запустите скрипт, нажав кнопку ниже:

Или запустите следующую команду Python в терминале внутри каталога проекта:
python scraper.pyПодождите, пока процесс завершится, и теперь у вас будет доступ к файлу quotes.csv. Откройте его. Он должен содержать следующие данные:
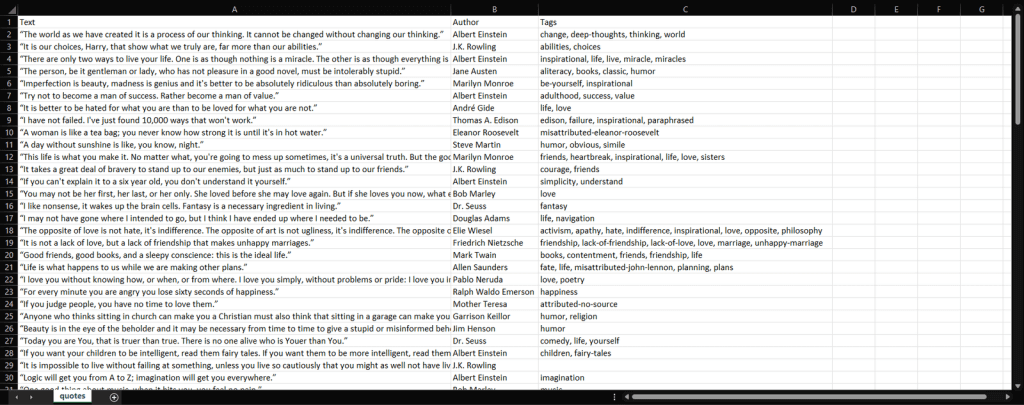
Вуаля! Теперь у вас есть все 100 цитат с целевого сайта в одном CSV-файле!
Вывод
Из этого руководства вы узнали, что такое парсинг веб-страниц, что вам нужно для начала работы с Python и какие библиотеки Python являются лучшими для парсинга. Также вы увидели, как использовать Beautiful Soup и Requests для создания парсера на реальном примере и убедились, что, парсинг на Python занимает всего несколько строк кода.
Тем не менее парсинг веб-страниц сопряжен с рядом проблем. В частности, все большую популярность приобретают анти-боты и анти-скрапинговые технологии. Поэтому вам нужен продвинутый автоматизированный инструмент для веб-скрапинга от Bright Data.
Чтобы избежать блокировки, мы также рекомендуем выбрать прокси-сервер в зависимости от вашего сценария использования из различных прокси-сервисов, которые предоставляет Bright Data.
Часто задаваемые вопросы
Веб-скрапинг и сканирование веб-страниц – это часть науки о данных?
Да, веб-скрапинг и сканирование веб-страниц – часть более широкой области науки о данных. Парсинг/сканирование – это основа для всех других продуктов, которые могут быть получены из структурированных и неструктурированных данных. Это включает аналитику, алгоритмические модели/выводы, идеи и «применимые знания».
Как можно извлечь определенные данные с сайта в Python?
Парсинг данных с сайта с помощью Python включает проверку страницы целевого URL, определение данных, которые вы хотите извлечь, написание и запуск кода для извлечения данных и, наконец, их сохранение в желаемом формате.
Как создать парсер с помощью Python?
Первым шагом к созданию парсера данных Python является использование строковых методов для анализа данных сайта, затем анализ данных помощью анализатора HTML и, наконец, взаимодействие с необходимыми формами и компонентами сайта.