Всем привет!
Продолжаем цикл статей по разработке браузерного движка.
В данной статье я расскажу как создать самый быстрый HTML-парсер c DOM. Мы рассмотрим HTML спецификацию и чем она плоха относительно производительности и потребления ресурсов при разборе HTML.
С данной темой я докладывался на прошедшем HighLoad++. Конференцию не каждый может посетить, плюс в статье больше деталей.
Я предполагаю, что читатель обладает базовыми знаниями об HTML: теги, ноды, элементы, пространство имён.
Спецификация HTML
Прежде чем начать хоть как-то затрагивать реализацию HTML-парсера необходимо понять какой HTML спецификации верить.
Существует две HTML спецификации:
- WHATWG
- Apple, Mozilla, Google, Microsoft
- W3C
- Большой список компаний
Естественно, выбор пал на лидеров отрасли — WHATWG. Живой стандарт, большие компании у каждой из которых есть свой браузер/браузерный движок.
UPDATE: К сожалению, приведенные ссылки на спецификации не открываются из России. Видимо, «эхо войны» с телеграмм.
Процесс парсинга HTML
Процесс построения HTML дерева можно разделить на четыре части:
- Декодер
- Предварительная обработка
- Токенизатор
- Построение дерева
Рассмотрим каждую стадию по отдельности.
Декодер
Токенизатор принимает на вход юникод символы (code points). Соответственно, нам необходимо конвертировать текущий байтовый поток в юникод символы. Для этого необходимо воспользоваться спецификацией Encoding.
Если мы имеем HTML с неизвестной кодировкой (нет HTTP заголовка) то нам необходимо её определить до начала декодирования. Для этого мы воспользуемся алгоритмом encoding sniffing algorithm.
Если очень кратко то суть алгоритма сводится к тому, что мы ждем 500мс или первые 1024 байта из байтового потока и запускаем алгоритм prescan a byte stream to determine its encoding который пробует найти тег <meta> с атрибутами http-equiv, content или charset и пытается понять какую кодировку указал разработчик HTML.
В спецификации Encoding оговаривается минимальный набор поддерживаемых кодировок браузерным движком (всего 21): UTF-8, ISO-8859-2, ISO-8859-7, ISO-8859-8, windows-874, windows-1250, windows-1251, windows-1252, windows-1254, windows-1255, windows-1256, windows-1257, windows-1258, gb18030, Big5, ISO-2022-JP, Shift_JIS, EUC-KR, UTF-16BE, UTF-16LE и x-user-defined.
Предварительная обработка
После того как мы декодировали байты в юникод символы нам необходимо провести «зачистку». А именно, заменить все символы возврата каретки (r) за которыми следует символ перевода строки (n) на символ возврата каретки (r). Затем, заменить все символы возврата каретки на символ перевода строки (n).
Так описано в спецификации. То есть, rn => r, r => n.
Но, на самом деле так никто не делает. Делают проще:
Если попался символ возврата каретки (r) то смотрим есть ли символ перевода строки (n). Если есть то меняем оба символа на символ перевода строки (n), если нет то меняем только первый символ (r) на перевод строки (n).
На этом предварительная обработка данных завершена. Да, всего-то надо избавиться от символов возврата каретки, чтобы они не попадали в токенизатор. Токенизатор не ожидает и не знает, что делать с символом возврата каретки.
Ошибки парсинга
Чтобы в дальнейшем не возникало вопросов стоит сразу рассказать, что такое ошибка парсинга (parse error).
На самом деле ничего страшного. Звучит грозно, но по факту это лишь предупреждение о том, что мы ожидали одно, а имеем другое.
Ошибка парсинга не остановит процесс обработки данных или построение дерева. Это сообщение которое сигнализирует, что у нас не валидный HTML.
Ошибку парсига можно получить за суррогатные пары, , неверное расположение тега, неверный <!DOCTYPE> и ещё всякие.
К слову, некоторые ошибки парсинга ведут к последствиям. К примеру, если указать «плохой» <!DOCTYPE> то HTML дерево будет помечен как QUIRKS и изменится логика работы некоторых DOM функций.
Токенизатор
Как уже было сказано ранее, токенизатор принимает на вход юникод символы. Это конечный автомат (state machine) который имеет 80 состояний. В каждом состоянии условия для юникод символов. В зависимости от пришедшего символа токенизатор может:
- Поменять своё состояние
- Сформировать токен и поменять состояние
- Ничего не делать, ждать следующий символ
Токенизатор создает токены шести видов: DOCTYPE, Start Tag, End Tag, Comment, Character, End-Of-File. Которые поступают в стадию построения дерева.
Примечательно, что токенизатор знает не о всех своих состояниях, а где о 40% (взял с потолка, для примера). «Зачем же остальные?» — спросите вы. Об остальных 60% знает стадия построения дерева.
Это сделано для того, чтобы правильно парсить такие теги как <textarea>, <style>, <script>, <title> и так далее. То есть, обычно те теги в которых мы не ожидаем других тегов, а только закрытие себя.
К примеру, тег <title> не может содержать в себе других тегов. Любые теги в <title> будут восприниматься как текст пока он не встретит закрывающий тег для себя </title>.
Зачем так сделано? Ведь можно было просто указать токенизатору, что если встретим тег <title> то идем по «нужному нам пути». И это было бы верно если не namespaces! Да, пространство имён влияет на поведение стадии построения дерева, которая в свою очередь меняет поведение токенизатора.
Для примера, рассмотрим поведение тега <title> в HTML и SVG пространстве имен:
HTML
<title><span>Текст</span></title>Результат построения дерева:
<title>
"<span>Текст</span>"SVG
<svg><title><span>Текст</span></title></svg>Результат построения дерева:
<svg>
<title>
<span>
"Текст"Мы видим, что в первом случаи (HTML namespace) тег <span> является текстом, не был создан элемент span. Во втором случае (SVG namespace) на основе тега <span> был создан элемент. То есть, в зависимости от пространства имени теги ведут себя по-разному.
Но, это ещё не всё. Тортиком на этом «празднике жизни» служит тот факт, что сам токенизатор должен знать в каком пространстве имен находится стадия построения дерева. И нужно это исключительно для того, чтобы правильно обработать CDATA.
Рассмотрим два примера с CDATA, два пространства имён:
HTML
<div><![CDATA[ Текст ]]></div>Результат построения дерева:
<div>
<!--[CDATA[ Текст ]]-->SVG
<div><svg><![CDATA[ Текст ]]></svg></div>Результат построения дерева:
<div>
<svg>
" Текст "В первом случаи (HTML namespace) токенизатор воспринял CDATA за комментарий. Во втором случае токенизатор разобрал структуру CDATA и получил данные из неё. В общем, правило такое: если встречаем CDATA не в HTML пространстве имён то парсим его, иначе считаем за комментарий.
Вот такая получается жёсткая связь между токенизатором и построением дерева. Токенизатор должен знать в каком пространстве имен сейчас находится стадия построения дерева, а стадия построения дерева может менять состояния токенизатора.
Токены
Ниже будут рассмотрены все шесть видов токенов создаваемых токенизатором. Тут стоит отметить, что все токены имеют подготовленные данные, то есть уже обработанные и «готовые к употреблению». Это значит, что все именнованные символьные ссылки (named character references), вроде ©, будут преобразованы в юникод символы.
DOCTYPE Token
Токен DOCTYPE имеет свою структуру не похожую на остальные теги. Токен содержит в себе:
- Имя
- Public-идентификатор
- System-идентификатор
В современном HTML единственный правильный/валидный DOCTYPE должен иметь следующий вид:
<!DOCTYPE html>Все остальные <!DOCTYPE> будут считаться ошибкой парсинга.
Start Tag Token
Открывающий тег может содержать в себе:
- Имя тега
- Атрибуты
- Флаги
К примеру,
<div key="value" />Открывающий тег может содержать флаг self-closing. Данный флаг никак не влияет на закрытие тега, но может вызвать ошибку парсинга для не void элементов.
End Tag Token
Закрывающий тег. Обладает всеми свойствами токена открывающего тега, но имеет перед именем тега косую /.
</div key="value" />Закрывающий тег может содержать флаг self-closing который вызовет ошибку парсинга. Так же, ошибку парсинга вызовут атрибуты у закрывающего тега. Они будут правильно распарсены, но выброшены на стадии построения дерева.
Токен комментария содержит в себе весь текст комментария. То есть, он полностью копируется из потока в токен.
Пример,
<!-- Комментарий -->Character Token
Пожалуй самый интересный токен. Токен юникод символа. Может содержать в себе один (только один) символ.
На каждый символ в HTML будет создаваться токен и отправляться в стадию построения дерева. Это очень накладно.
Давайте рассмотрим как это работает.
Возьмём HTML данные:
<span>Слава императору! ®</span>Как вы думаете сколько будет создано токенов для приведенного примера? Ответ: 22.
Рассмотрим список создаваемых токенов:
Start tag token: <span>
Character token: С
Character token: л
Character token: а
Character token: в
Character token: а
Character token:
Character token: и
Character token: м
Character token: п
Character token: е
Character token: р
Character token: а
Character token: т
Character token: о
Character token: р
Character token: у
Character token: !
Character token:
Character token:
End tag token: </span>
End-of-file tokenНе утешительно, правда? Но, конечно, многие создатели парсеров HTML по факту имеет только один токен в процессе обработки. Пуская его по кругу и затирая каждый раз новыми данными.
Забежим вперед и ответим на вопрос: зачем так сделано? Почему не брать этот текст единым куском? Ответ кроется в стадии построения дерева.
Токенизатор бесполезен без стадии построения HTML дерева. Именно на стадии построения дерева происходит склейка текста с разными условиями.
Условия, примерно, такие:
- Если пришел символьный токен с
U+0000(NULL) то вызываем ошибку парсинга и игнорируем токен. - Если пришёл один из
U+0009(CHARACTER TABULATION),U+000A(LINE FEED (LF)),U+000C(FORM FEED (FF)) илиU+0020(SPACE) character токен тогда вызвать алгоритм восстановить активные элементы форматирования и вставить токен в дерево.
Символьный токен добавляется в дерево по алгоритму:
- Если текущая позиция вставки это не текстовая нода, тогда создать текстовую ноду, вставить её в дерево и добавить к ней данные из токена.
- Иначе добавить данные из токена к существующей текстовой ноде.
Это поведение создает много проблем. Необходимость на каждый символ создавать токен и отправлять на анализ в стадию построения дерева. Мы не знаем размер текстовой ноды и нам приходится либо заранее выделить много памяти, либо делать реалоки. Всё это крайне накладно по памяти, либо по времени.
End-Of-File Token
Простой и понятный токен. Данные закончились — сообщим об этом стадии построения дерева.
Построение дерева
Построение дерева — это конечный автомат имеющий 23 состояния с множеством условий для токенов (тегов, текста). Стадия построения дерева самая большая, занимает значимую часть спецификации, а так же способна вызывать летаргический сон и раздражение.
Всё устроено очень просто. На вход принимаются токены и в зависимости от токена переключается состояние построения дерева. На выходе мы имеем настоящий DOM.
Проблемы?
Давольно очевидными выглядят следующие проблемы:
Посимвольное копирование
На вход каждое состояние токенизатора принимает по одному символу которые он копирует/конвертирует в случаи необходимости: имена тегов, атрибуты, комментарии, символы.
Это очень расточительно как по памяти так и по времени. Мы вынуждены заранее выделить неизвестное количество памяти под каждый атрибут, имя тега, комментарий и так далее. А это, соответственно, ведет к реалокам, а реалоки ведут к потерянному времени.
А если представить, что HTML содержит 1000 тегов, а в каждом теге хотя бы по одному атрибуту, то мы получим адски медленную работу парсера.
Символьный токен
Второй проблемой является символьный токен. Получается, что мы создаем токен на каждый символ и отдаём его в построение дерева. Построение дерева не знает сколько у нас будет этих токенов и не может сразу выделить память под нужное количество символов. Соответственно, тут все те же реалоки + постоянные проверки на присутствие текстовой ноды в текущем состоянии дерева.
Монолитность системы
Большой проблемой является зависимость всего от всего. То есть, токенизатор зависит от состояния построения дерева, а построение дерева может управлять токенизатором. И всему виной пространство имен (namespaces).
Как будем решать проблемы?
Далее я опишу реализацию HTML парсера в своём проекте Lexbor, а так же решения всех озвученных проблем.
Предварительная обработка
Убираем предварительную обработку данных. Обучим токенизатор понимать возврат каретки (r) как пробельный символ. Таким образом он будет прокинут в стадию построения дерева где мы с ним и разберёмся.
Токены
Легким движением руки мы унифицируем все токены. У нас будет один токен на всё. Вообще, во всём процессе парсинга будет только один токен.
Наш унифицированный токен будет содержать следующие поля:
- Tag ID
- Begin
- End
- Attributes
- Flags
Tag ID
Мы не будем работать с текстовым представлением имени тега. Переводим всё в цифры. Цифры легко сравнивать, с ними легче работать.
Создаём статическую хеш-таблицу из всех известных тегов. Создаём перечисление (enum) из всех известных тегов. То есть, нам нужно жестко назначить каждому тегу идентификатор. Соответственно, в хеш-таблице ключом будет имя тега, а значением записать из перечисления.
Для примера:
typedef enum {
LXB_TAG__UNDEF = 0x0000,
LXB_TAG__END_OF_FILE = 0x0001,
LXB_TAG__TEXT = 0x0002,
LXB_TAG__DOCUMENT = 0x0003,
LXB_TAG__EM_COMMENT = 0x0004,
LXB_TAG__EM_DOCTYPE = 0x0005,
LXB_TAG_A = 0x0006,
LXB_TAG_ABBR = 0x0007,
LXB_TAG_ACRONYM = 0x0008,
LXB_TAG_ADDRESS = 0x0009,
LXB_TAG_ALTGLYPH = 0x000a,
/* ... */
}Из примера видно, что мы создали теги для END-OF-FILE токена, для текста, документа. Всё это ради дальнейшего удобства. Приоткрывая занавес скажу, что в ноде (DOM Node Interface) у нас будет присутствовать Tag ID. Сделано это для того, чтобы не делать два сравнения: на тип ноды и на элемент. То есть, если нам нужен DIV элемент то мы делаем одну проверку в ноде:
if (node->tag_id == LXB_TAG_DIV) {
/* Best code */
}Но, можно конечно сделать и так:
if (node->type == LXB_DOM_NODE_TYPE_ELEMENT && node->tag_id == LXB_TAG_DIV) {
/* Oh, code */
}Два нижних подчёркивания в LXB_TAG__ нужны для того, чтобы отделить общие теги от системных. Иначе говоря, пользователь может создать тег с именем text или end-of-file и если мы потом будем искать по имени тега то никаких ошибок не возникнет. Все системные теги начинаются с символа #.
Но всё же, нода может хранить текстовое представление имени тега. Для 98.99999% нод этот параметр будет равен NULL. В некоторых пространствах имён нам необходимо прописать префикс или имя тега с фиксированным регистром. К примеру, baseProfile в SVG namespace.
Логика работы простая. Если мы имеем тег с чётко оговоренным регистром то:
- Добавляем его в общую базу тегов в нижнем регистре. Получаем идентификатор тега.
- К ноде добавляем идентификатор тега и оригинальное имя тега в текстовом представлении.
Пользовательские теги (custom elements)
Разработчик может создавать любые теги в HTML. Так-как мы имеем в статической хеш-таблице только те теги о которых знаем, а пользователь может создать любые то нам нужна динамическая хеш-таблица.
Выглядит всё очень просто. Когда к нам прийдет тег мы посмотрим есть ли он в статической хеш-таблицы. Если тега нет то посмотрим в динамической, если и там нет то увеличиваем счётчик идентификаторов на один и добавляем тег в динамическую таблицу.
Всё описанное происходит на стадии токенизатора. Внутри токенизатора и после все сравнения идут по Tag ID (за редким исключением).
Begin and End
Теперь в токенизаторе у нас не будет обработки данных. Мы ничего не будет копировать и конвертировать. Мы просто берём указатели на начало и конец данных.
Вся обработка данных, таких как символьные ссылки, будет происходить на стадии построения дерева.
Таким образом мы будем знать размер данных для последующего выделения памяти.
Attributes
Тут всё так же просто. Мы ничего не копируем, а просто сохраняем указатели на начало/конец имени и значения атрибутов. Все преобразования происходят в момент построения дерева.
Flags
Так как мы унифицировали токены нам надо как-то сообщить построению дерева о типе токена. Для этого используется битмап поле Flags.
Поле может содержать в себе следующие значения:
enum {
LXB_HTML_TOKEN_TYPE_OPEN = 0x0000,
LXB_HTML_TOKEN_TYPE_CLOSE = 0x0001,
LXB_HTML_TOKEN_TYPE_CLOSE_SELF = 0x0002,
LXB_HTML_TOKEN_TYPE_TEXT = 0x0004,
LXB_HTML_TOKEN_TYPE_DATA = 0x0008,
LXB_HTML_TOKEN_TYPE_RCDATA = 0x0010,
LXB_HTML_TOKEN_TYPE_CDATA = 0x0020,
LXB_HTML_TOKEN_TYPE_NULL = 0x0040,
LXB_HTML_TOKEN_TYPE_FORCE_QUIRKS = 0x0080,
LXB_HTML_TOKEN_TYPE_DONE = 0x0100
};Помимо типа токена, открывающий или закрывающий, есть значения для конвертера данных. Только токенизатор знает как правильно конвертировать данные. Соответственно, токенизатор помечает в токене как данные должны быть обработаны.
Character Token
Из ранее описанного можно сделать вывод, что символьный токен у нас исчез. Да, теперь у нас есть новый тип токена: LXB_HTML_TOKEN_TYPE_TEXT. Теперь мы создаём токен на весь текст между тегами помечая, как его в дальнейшем надо обработать.
Из-за этого нам прийдется изменить условия в построении дерева. Нам нужно обучить его работать не с символьными токенами, а с текстовыми: конвертировать, удалять ненужные символы, пропускать пробелы и так далее.
Но, здесь ничего сложного нет. В стадии построения дерева изменения будут минимальны. А вот токенизатор теперь у нас не соответствует спецификации от слова совсем. Но, он нам и не нужен, это нормально. Наша задача получить HTML/DOM дерево полностью соответствующее спецификации.
Стадии токенизатора
Чтобы обеспечить высокую скорость обработки данных в токенизаторе мы в каждую стадию добавим свой итератор. По спецификации у нас каждая стадия принимает по одному символу и в зависимости от пришедшего символа принимает решения. Но, правда в том, что это очень затратно.
К примеру, чтобы перейти от стадии ATTRIBUTE_NAME к стадии ATTRIBUTE_VALUE нам нужно найти пробельный символ в имени атрибута, что будет свидетельствовать об его окончании. По спецификации мы должны скармливать по символу в стадию ATTRIBUTE_NAME пока не встретиться пробельный символ, и эта стадия не переключится на другую. Это очень затратно, обычно это реализуют через вызов функции на каждый символ или колбека вроде «tkz->next_code_point()».
Мы же добавляем в стадию ATTRIBUTE_NAME цикл и передадим входящий буфер целиком. В цикле ищем нужные нам символы для переключения и продолжаем работу на следующей стадии. Тут мы получим много выигрыша, даже оптимизации компилятора.
Но! Самое страшное, что мы тем самым сломали поддержку чанков (chunks) из коробки. Благодаря посимвольной обработки в каждой стадии токенизатора у нас была поддержка чанков, а теперь мы это сломали.
Как исправить? Как реализовать поддержку чанков?! Всё просто, вводим понятия входящих буферов (Incoming Buffer).
Incoming Buffer
Часто HTML парсят кусками (chunks). Например, если данные мы получаем по сети. Чтобы не простаивать в ожидании оставшихся данных мы можем отправить на обработку/парсинг уже полученные данные. Естественно, данные могут быть «порваны» в любом месте. К примеру, имеем два буфера:
Первый
<div clasВторой
s="oh-no-oh-no">Так как мы ничего не копируем на стадии токенизации, а только берем указатели на начало и конец данных то у нас появляется проблема. Указатели на разные пользовательские буфера. А учитывая тот факт, что разработчики часто используют один и тот же буфер для данных то мы имеем дело с указателем на начало несуществующих данных.
Чтобы решить озвученные проблемы нам необходимо понимать когда данные из пользовательского буфера больше не нужны.
Решение очень простое:
- Если мы парсим кусками то каждый входящий кусок мы копируем во входящий буфер (Incoming Buffer).
- После парсинга текущего куска (ранее скопированного) мы смотрим, а не остался ли какой нибудь незавершенный токен? То есть, присутствуют ли указатели на текущий пользовательский буфер в последнем токене. Если указатели отсутствуют то освобождаем входящий буфер, если нет то оставляем его до тех пор пока он нужен. В 99% случаев входящий буфер уничтожится при поступлении следующего куска.
Флагом «копировать входящий буфер» можно управлять. Для цельных данных копирование не происходит.
Конечно, данную логику можно оптимизировать и усложнить. Можно не копировать предварительно весь буфер, а после обработки скопировать только нужные (оставшийся хвост) данные и поменять указатель в токене на наш новый буфер. Получится всё лучше и быстрее. Но, данная оптимизация, на текущий момент, является преждевременной. Текущая реализация работает быстро и не затратно по памяти.
Проблема: данные в токене
С проблемой парсинга кусков мы разобрались, можно выдохнуть. Но, при нашем подходе хранения указателей возникает другая проблема: в определенный момент возникает необходимость посмотреть на данные в токене. Мы этого сделать не можем. Если мы будем заглядывать в данные токена то нам придётся склеивать их (если они из разных кусков), а это дико затратно по времени. В спецификации есть пару моментов когда надо посмотреть чего мы там накопили в токене.
Решается данная проблема просто: добавлением дополнительных стадий обработки в токенизатор. То есть, мы заранее знаем когда будут проверки и можем пойти по разному пути обработки данных в токенизаторе.
Стадия построения дерева
Тут изменения минимальны.
У нас больше нет символьных токенов, но зато появились текстовые. Соответственно, нам необходимо обучить стадию построения дерева понимать новый токен.
Вот как это выглядит:
По спецификации
tree_build_in_body_character(token) {
if (token.code_point == '') {
/* Parse error, ignore token */
}
else if (token.code_point == whitespaces) {
/* Insert element */'
}
/* ... */
}В Lexbor HTML
tree_build_in_body_character(token) {
lexbor_str_t str = {0};
lxb_html_parser_char_t pc = {0};
pc.drop_null = true;
tree->status = lxb_html_token_parse_data(token, &pc, &str,
tree->document->mem->text);
if (token->type & LXB_HTML_TOKEN_TYPE_NULL) {
/* Parse error */
}
/* Insert element if not empty */
}Из примера видно, что мы убрали все условия на проверку символов и создали общую функцию для обработки текста. В функцию передается аргумент с параметрами о том как преобразовывать данные:
pc.replace_null /* Заменить все '' на заменяющий символ (REPLACEMENT CHARACTER (U+FFFD)) */
pc.drop_null /* Удалить все '' */
pc.is_attribute /* Если данные являются значением атрибута то парсить их надо "с умом" */
pc.state /* Стадия обработки. Можно указать с парсингом символьных ссылок или без. */В каждой стадии построения дерева есть свои условия для символьных токенов. Где-то надо выкидывать , а где-то заменять их на REPLACEMENT CHARACTER. Где-то надо конвертировать символьные ссылки, а где-то нет. И все эти параметры могу как угодно комбинироваться.
Конечно же, на словах всё звучит просто. По факту необходимо быть предельно внимательным. К примеру, все пробельные символы до начала тега <head> должны быть выброшены. Возникает проблема, если к нам прийдет текстовый токен у которого в начале пробелы, а дальше текст: » а тут текст «. Мы должны отрезать пробелы в начале текста и посмотреть не осталось ли там чего, если данные ещё остались то под видом нового токена продолжить обработку.
Смешной тег <sarcasm>
В HTML спецификации (в разделе построения дерева) говорится о теге sarcasm. Я видел не раз как разработчики парсеров слепо включали обработку этого тега.
An end tag whose tag name is "sarcasm"
Take a deep breath, then act as described in the "any other end tag" entry below.Писатели спецификации шутят.
Итог
После всех перестановок и манипуляций мы имеем самый быстрый и полноценный HTML парсер с поддержкой DOM/HTML Interfaces который строит HTML/DOM дерево полностью соответствующее HTML спецификации.
Если суммировать всё то, что мы изменили:
- Убирали предварительную обработку (перенесли в токенизатор)
- Токенизатор
- Добавили Incoming Buffer
- Унифицировали токены
- Вместо имён Tag ID
- Символьный токен: не один, а N+ символов
- Свой итератор в каждом состоянии
- Обработка токена в построении дерева
- Один токен на всё
- Построение дерева
- Модифицируем условия для символьных токенов
На i7 2012 года, на одном ядре, мы имеем среднюю скорость парсинга 235MB в секунду (Amazon-страницы).
Конечно же, я знаю как увеличить этот показатель в 1.5/2 раза, то есть запас ещё есть. Но, мне необходимо двигаться дальше. Собственно, а дальше парсинг CSS и создание собственного грамара (Grammar, то есть, генерация эффективного кода для парсинга по Grammar). В отличии от парсинга HTML, парсинг CSS намного сложнее, там есть где «развернуться».
Исходники
Описанный подход парсинга и построения HTML дерева реализован в Lexbor HTML.
P.S.
Следующая статья будет о парсинге CSS и Grammar. Как обычно, статья будет на готовый код. Ждать где-то 6-8 месяцев.
Для тех, у кого есть время
Не стесняйтесь помогать проекту. К примеру, если вы любите в свободное время писать документацию.
Не стесняйтесь поддерживать проект рублём (на другие валюты я тоже не обижусь). Об этом в личку.
Спасибо за внимание!
![]()
Загрузить PDF
![]()
Загрузить PDF
Хотя существует много интернет-браузеров, таких как Internet Explorer, Firefox и Google Chrome, которые можно загрузить и установить на компьютер бесплатно, самостоятельное создание веб-браузеров дает вам больший контроль над тем, как вы хотите работать в Интернете. С пользовательским веб-браузером вы можете не только решить, каким должен быть внешний вид, но также можете добавлять пользовательские кнопки и функции. Visual Basic является одной из самых распространенных программ, используемых для создания веб-браузера.
Шаги
-

1
Установите Visual Basic на ваш компьютер: либо загрузите программное обеспечение с сайта Visual Basic Developer Center, либо используя установочный диск.
-
2
Запустите Visual Basic и начните новый проект, перейдя в меню File и нажав на кнопку «New Project.»
-
3
Просмотрите «Text» и выберите «Web Browser» на странице формы, которая появится.
-
4
Перейдите в «View» в верхней строке меню, просмотрите «Other Windows» и нажмите на «Toolbox.» На экране появится панель инструментов Visual Basic.
-
5
Дважды щелкните на инструменте WebBrowser на панели инструментов.
-
6
Нажмите на иконку со стрелкой вправо в верхнем правом углу формы и нажмите «Undock in Parent Container.» Это изменит вид формы от полного экрана до меньшего окна в интерфейсе Visual Basic.
-
7
Измените форму веб-браузера до нужного размера с помощью кликабельных контуров вокруг нее.
-
8
Установите URL (Uniform Resource Locator) свойство для адреса веб-сайта, который вы хотите посетить. Откроется тестовый веб-сайт, и вы сможете увидеть, как веб-сайт будет выглядеть, когда открывается через ваш интернет-браузер.
-
9
Создайте новую кнопку и назначьте ей следующие свойства.
- Текст на кнопке должен содержать «Go.»
- Назовите кнопку «GoBtn.»
-
10
Активизируйте кнопку, дважды щелкнув по ней. На экране выскочит Private Sub. Введите следующий код между Private и End Subs ( можно заменить «URL» любым веб-адресом):
- WebBrowser1.Navigate(URL)
-
11
Протестируйте кнопку, щелкнув по ней. Это перекинет вас от тестового сайта на сайт назначения, назначенный для кнопки.
-
12
Выберите инструмент TextBox на панели инструментов.
-
13
Перетащите инструмент TextBox и поместите его на пользовательскую форму веб-браузера, которую вы создаете.
-
14
Назовите текстовое поле, к примеру — «addressTxt.»
-
15
Вернитесь к кнопке, созданную ранее, и замените URL на «addressTxt.Text.» Это означает, что вы хотите использовать кнопку для перехода к любому URL, введенному в адресную строку.
-
16
Протестируйте адресную строку, используя ее для посещения различных веб-сайтов.
-
17
Сохраните веб-браузер, который вы только что создали в качестве программы через Visual Basic, выбрав команду для сохранения через меню File.
Реклама

















Советы
- Создание веб-браузеров не всегда необходимо для извлечения выгоды от пользовательских настроек. Многие заранее разработанные Интернет-браузеры, такие как Firefox и Google Chrome, позволяют настроить внешний вид и функции браузера с помощью различных фонов, дополнений и приложений. Тем не менее, их возможности по настройке по-прежнему ограничены.
- Если вы хотите создать веб-браузер без использования Visual Basic, то можете рассмотреть такие программы, как QR WebBrowser Maker и Flock Social Web Browser Maker. Эти программы имеют предустановленные параметры, которые можно выбрать для предоставления вашему веб-браузеру пользовательских настроек.
Реклама
Об этой статье
Эту страницу просматривали 26 941 раз.
Была ли эта статья полезной?
PYTHON SCRIPTS
Создайте свой собственный браузер Chrome с Python PyQt5
Как создать простой веб-браузер на Python?

В этом пошаговом руководстве по программированию на Python я покажу вам, как создать простой браузер с использованием платформы PyQt5. Браузер позволит нам открыть URL-адрес в окне, похожем на Chrome.
Python — это объектно-ориентированный язык программирования. Библиотека Qt, написанная на C ++, используется для разработки собственных графических приложений для настольных ПК и создает кроссплатформенный код, поэтому это хороший инструмент для разработки многоплатформенных приложений. Мы можем легко создать наш собственный веб-браузер на Python с помощью библиотеки PyQT5, и версия Python 3 хорошо подойдет для этого руководства, хотя Python 2.7 все еще используется во многих организациях, а также в моей среде.
Демо
PyQt5
Qt — это набор кроссплатформенных библиотек C ++, реализующих высокоуровневые API для доступа ко многим аспектам современных настольных и мобильных систем. К ним относятся службы определения местоположения и позиционирования, мультимедиа, NFC и Bluetooth, веб-браузер на основе Chromium, а также традиционная разработка пользовательского интерфейса.
PyQt5 — это полный набор привязок Python для Qt v5. Он реализован в виде более чем 35 модулей расширения и позволяет использовать Python в качестве языка разработки приложений, альтернативного C ++, на всех поддерживаемых платформах, включая iOS и Android.
PyQt5 также может быть встроен в приложения на основе C ++, чтобы пользователи этих приложений могли настраивать или улучшать функциональность этих приложений. «источник»
Установка пакета
Https://carbon.now.sh/?bg=rgba%252874%252C144%252C226%252C1%2529&t=seti&wt=none&l=auto&ds=false&dsyoff=20px&dsblur=68px&wc=true&wa=true&hl=ru&fl=ru&fl=ru&fl=ru&hl=ru&hl=ru&hl=ru&hl=ru&fl=1 Fira + Code & fs = 18px & lh = 132% 2525 & si = false & es = 2x & wm = false & code = pip% 252520install% 252520PyQt5% 25250Apip% 252520install% 252520PyQtWebEngine
Я создал файл `requirements.txt` для установки необходимых пакетов с помощью pip.
PyQt5==5.15.4 PyQt5-Qt5==5.15.2 PyQt5-sip==12.9.0 PyQt5-stubs==5.15.2.0 PyQtWebEngine==5.15.4 PyQtWebEngine-Qt5==5.15.2
Установите требования из файла requirements.txt
pip install -r requirements.txt
Создать веб-браузер
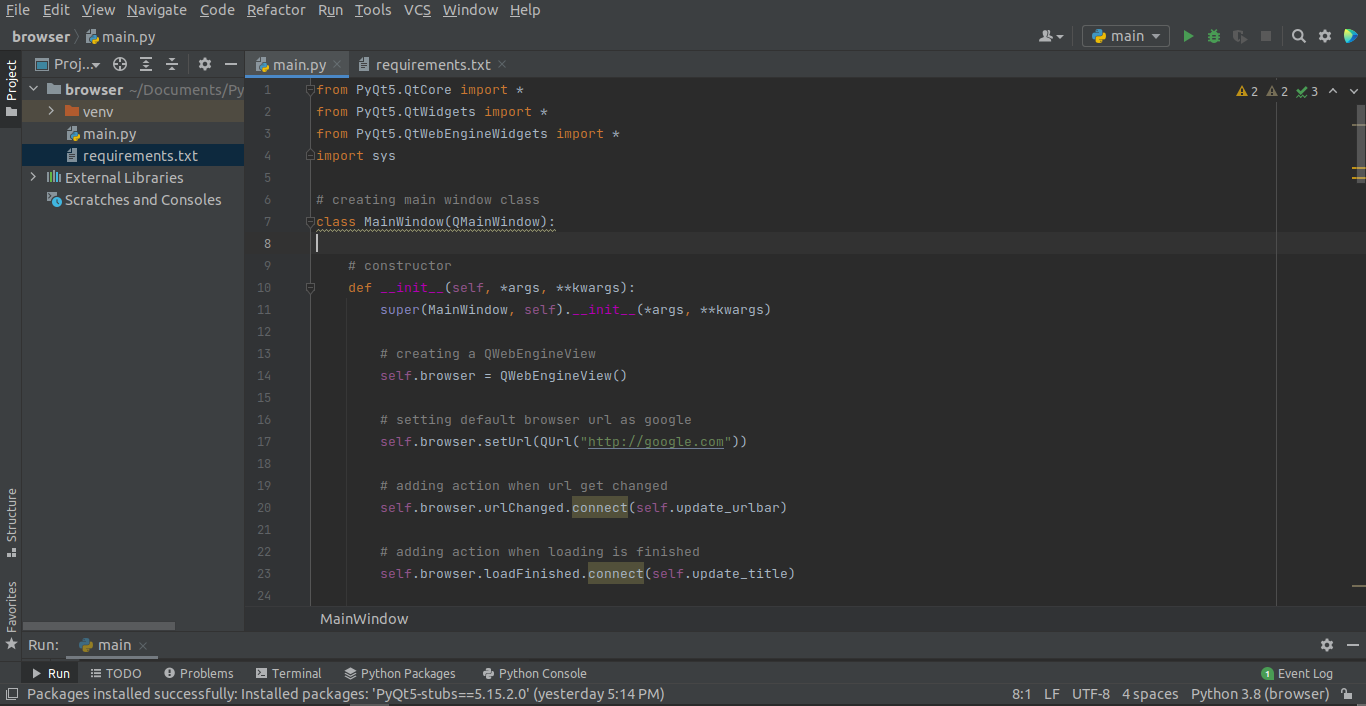
Чтобы создать веб-браузер, выполните следующие действия.
Импортировать пакеты
from PyQt5.QtCore import * from PyQt5.QtWidgets import * from PyQt5.QtWebEngineWidgets import * import sys
Создать главные окна
class MainWindow(QMainWindow):
# constructor
def __init__(self, *args, **kwargs):
super(MainWindow, self).__init__(*args, **kwargs)
# creating a QWebEngineView
self.browser = QWebEngineView()
# setting default browser url as google
self.browser.setUrl(QUrl("http://google.com"))
# adding action when url get changed
self.browser.urlChanged.connect(self.update_urlbar)
# adding action when loading is finished
self.browser.loadFinished.connect(self.update_title)
# set this browser as central widget or main window
self.setCentralWidget(self.browser)
# creating a status bar object
self.status = QStatusBar()
# adding status bar to the main window
self.setStatusBar(self.status)
Создать приложение PyQt
# creating a pyQt5 application
app = QApplication(sys.argv)
# setting name to the application
app.setApplicationName("Chrome Web Browser")
# creating a main window object
window = MainWindow()
Запустить приложение
# loop app.exec_()
Я предоставил правильные комментарии внутри части кодирования, она автоматически все объяснит.
Вот файл main.py
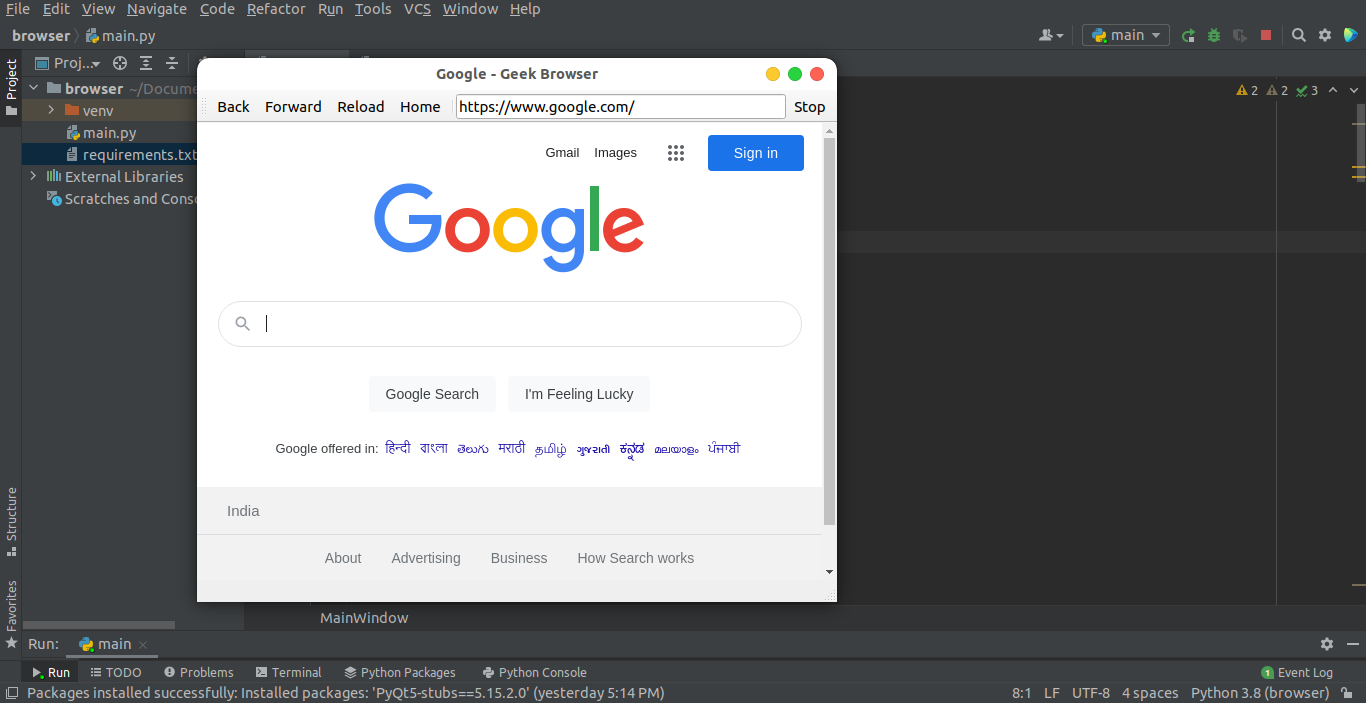
Запустите приложение
Чтобы запустить приложение, откройте терминал внутри корневого каталога вашего проекта и запустите —
python3 main.py
Это запустит веб-браузер.
Заключение
Я рассмотрел все основные вещи, необходимые для создания веб-браузера с использованием библиотеки Python и PyQt5. Я надеюсь, что это поможет вам создавать потрясающие проекты. Вы можете добавить в него новые функции и прислать мне ответ. Пожалуйста, хлопайте в ладоши и подписывайтесь на меня, чтобы прочитать больше подобных статей. Эта статья была навеяна этим.
Спасибо за чтение!
Больше контента на plainenglish.io
from PyQt5.QtCore import *
from PyQt5.QtWidgets import *
from PyQt5.QtGui import *
from PyQt5.QtWebEngineWidgets import *
from PyQt5.QtPrintSupport import *
import os
import sys
class MainWindow(QMainWindow):
def __init__(self, *args, **kwargs):
super(MainWindow, self).__init__(*args, **kwargs)
self.browser = QWebEngineView()
self.browser.urlChanged.connect(self.update_urlbar)
self.browser.loadFinished.connect(self.update_title)
self.setCentralWidget(self.browser)
self.status = QStatusBar()
self.setStatusBar(self.status)
navtb = QToolBar("Navigation")
self.addToolBar(navtb)
back_btn = QAction("Back", self)
back_btn.setStatusTip("Back to previous page")
back_btn.triggered.connect(self.browser.back)
navtb.addAction(back_btn)
next_btn = QAction("Forward", self)
next_btn.setStatusTip("Forward to next page")
next_btn.triggered.connect(self.browser.forward)
navtb.addAction(next_btn)
reload_btn = QAction("Reload", self)
reload_btn.setStatusTip("Reload page")
reload_btn.triggered.connect(self.browser.reload)
navtb.addAction(reload_btn)
home_btn = QAction("Home", self)
home_btn.setStatusTip("Go home")
home_btn.triggered.connect(self.navigate_home)
navtb.addAction(home_btn)
navtb.addSeparator()
self.urlbar = QLineEdit()
self.urlbar.returnPressed.connect(self.navigate_to_url)
navtb.addWidget(self.urlbar)
stop_btn = QAction("Stop", self)
stop_btn.setStatusTip("Stop loading current page")
stop_btn.triggered.connect(self.browser.stop)
navtb.addAction(stop_btn)
self.show()
def update_title(self):
title = self.browser.page().title()
self.setWindowTitle("% s - Geek Browser" % title)
def navigate_home(self):
def navigate_to_url(self):
q = QUrl(self.urlbar.text())
if q.scheme() == "":
q.setScheme("http")
self.browser.setUrl(q)
def update_urlbar(self, q):
self.urlbar.setText(q.toString())
self.urlbar.setCursorPosition(0)
app = QApplication(sys.argv)
app.setApplicationName("Geek Browser")
window = MainWindow()
app.exec_()
from PyQt5.QtCore import *
from PyQt5.QtWidgets import *
from PyQt5.QtGui import *
from PyQt5.QtWebEngineWidgets import *
from PyQt5.QtPrintSupport import *
import os
import sys
class MainWindow(QMainWindow):
def __init__(self, *args, **kwargs):
super(MainWindow, self).__init__(*args, **kwargs)
self.browser = QWebEngineView()
self.browser.urlChanged.connect(self.update_urlbar)
self.browser.loadFinished.connect(self.update_title)
self.setCentralWidget(self.browser)
self.status = QStatusBar()
self.setStatusBar(self.status)
navtb = QToolBar("Navigation")
self.addToolBar(navtb)
back_btn = QAction("Back", self)
back_btn.setStatusTip("Back to previous page")
back_btn.triggered.connect(self.browser.back)
navtb.addAction(back_btn)
next_btn = QAction("Forward", self)
next_btn.setStatusTip("Forward to next page")
next_btn.triggered.connect(self.browser.forward)
navtb.addAction(next_btn)
reload_btn = QAction("Reload", self)
reload_btn.setStatusTip("Reload page")
reload_btn.triggered.connect(self.browser.reload)
navtb.addAction(reload_btn)
home_btn = QAction("Home", self)
home_btn.setStatusTip("Go home")
home_btn.triggered.connect(self.navigate_home)
navtb.addAction(home_btn)
navtb.addSeparator()
self.urlbar = QLineEdit()
self.urlbar.returnPressed.connect(self.navigate_to_url)
navtb.addWidget(self.urlbar)
stop_btn = QAction("Stop", self)
stop_btn.setStatusTip("Stop loading current page")
stop_btn.triggered.connect(self.browser.stop)
navtb.addAction(stop_btn)
self.show()
def update_title(self):
title = self.browser.page().title()
self.setWindowTitle("% s - Geek Browser" % title)
def navigate_home(self):
def navigate_to_url(self):
q = QUrl(self.urlbar.text())
if q.scheme() == "":
q.setScheme("http")
self.browser.setUrl(q)
def update_urlbar(self, q):
self.urlbar.setText(q.toString())
self.urlbar.setCursorPosition(0)
app = QApplication(sys.argv)
app.setApplicationName("Geek Browser")
window = MainWindow()
app.exec_()
Чтобы создать сегодня свой сайт, совсем необязательно знать языки программирования, большинство веб-ресурсов не пишется, а собирается в различных программах-конструкторах, получивших в последнее время широкое распространение. Конструкторы эти становятся настолько совершенными, что создавать в них можно даже собственные десктопные приложения. Пример работы в одном из таких конструкторов мы сегодня рассмотрим, создав в нём с нуля свой браузер.
Естественно, браузер будет обладать минимальным набором функций, но ведь мы и не претендуем на звание профессиональных разработчиков. В качестве конструктора мы будем использовать Visual Studio Community 2019 — бесплатную интегрированную среду разработки для написания и запуска кода на разных платформах. Название может показаться пугающим, в действительности ничего такого архисложного нет, код писать почти не придется, вместо него мы будем собирать его готовые блоки, представленные графическими элементами.
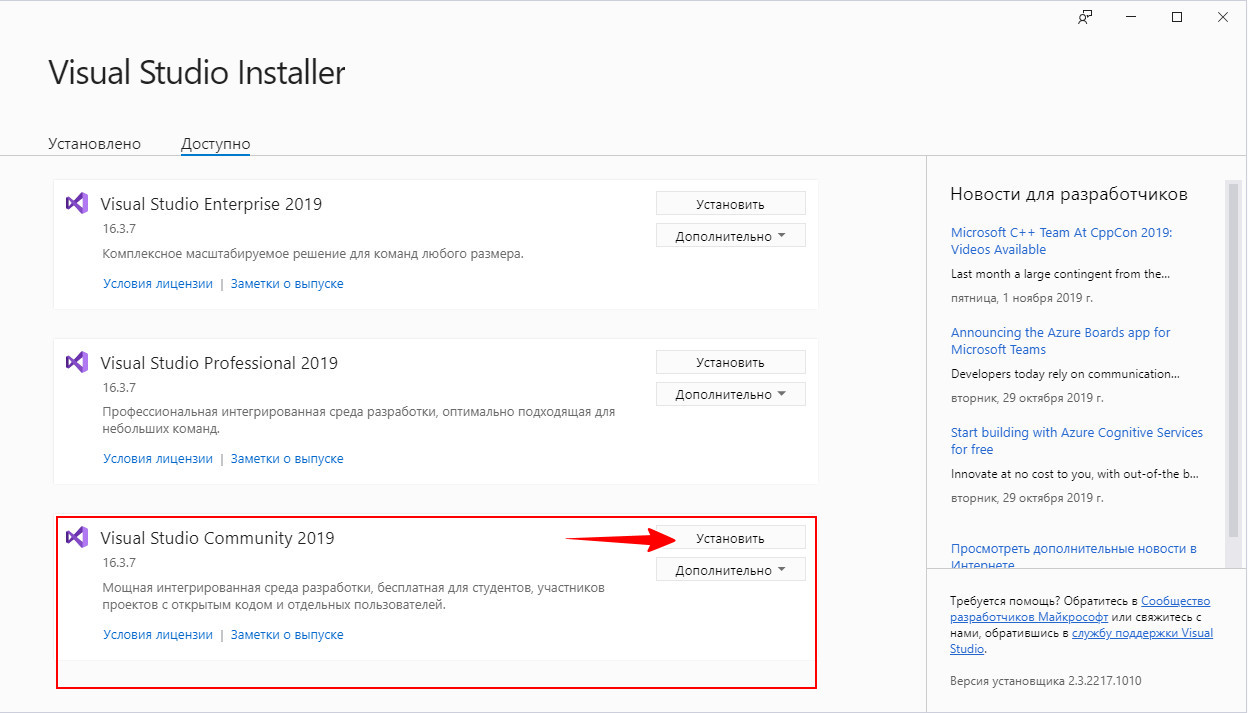
Итак, идем на сайт visualstudio.microsoft.com/ru, скачиваем файл автономного установщика и запускаем.
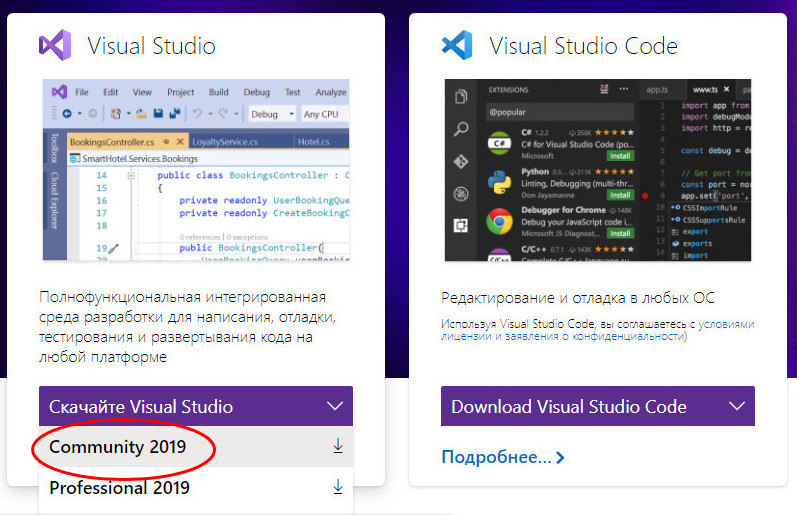
Выбираем установку Visual Studio Community 2019.
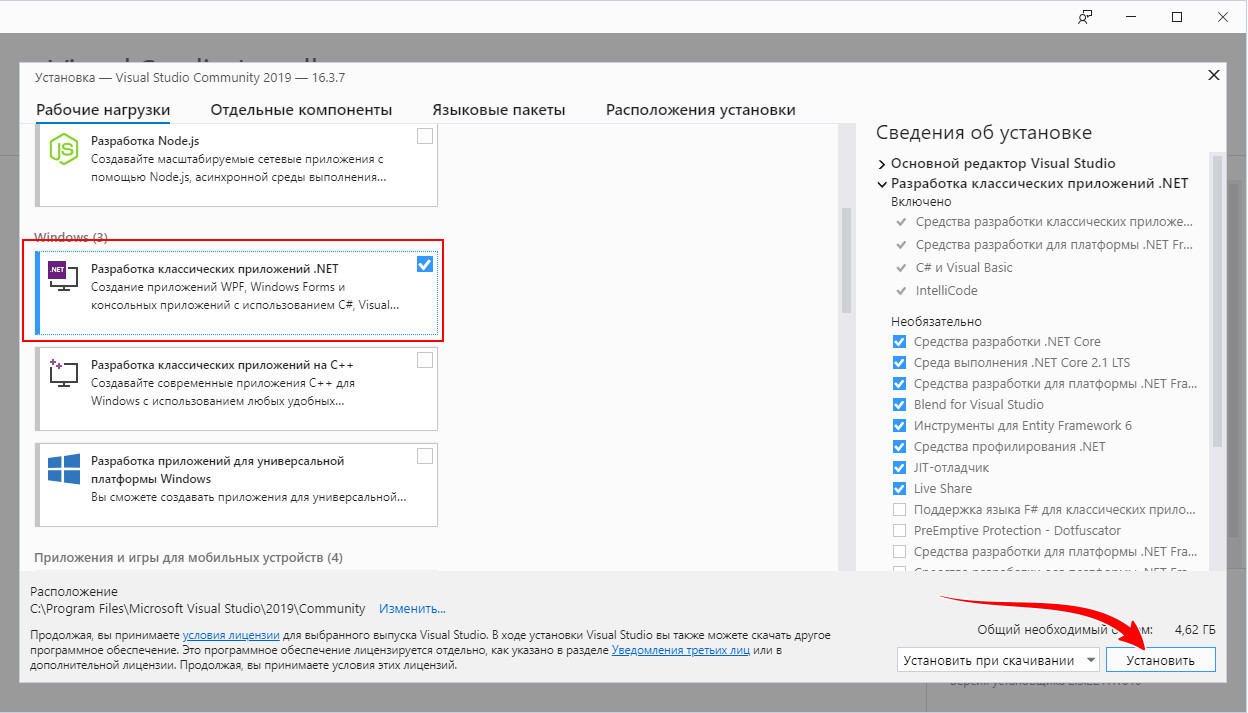
В меню «Рабочие нагрузки» выбираем блок «Windows», а в нём — опцию «Разработка классических приложений .NET». Жмем «Установить».
Процедура займет определенное время, поскольку потребуется скачать более гигабайта данных.
По завершении установки и запуска платформы.
Выбираем в меню «Создание проекта».
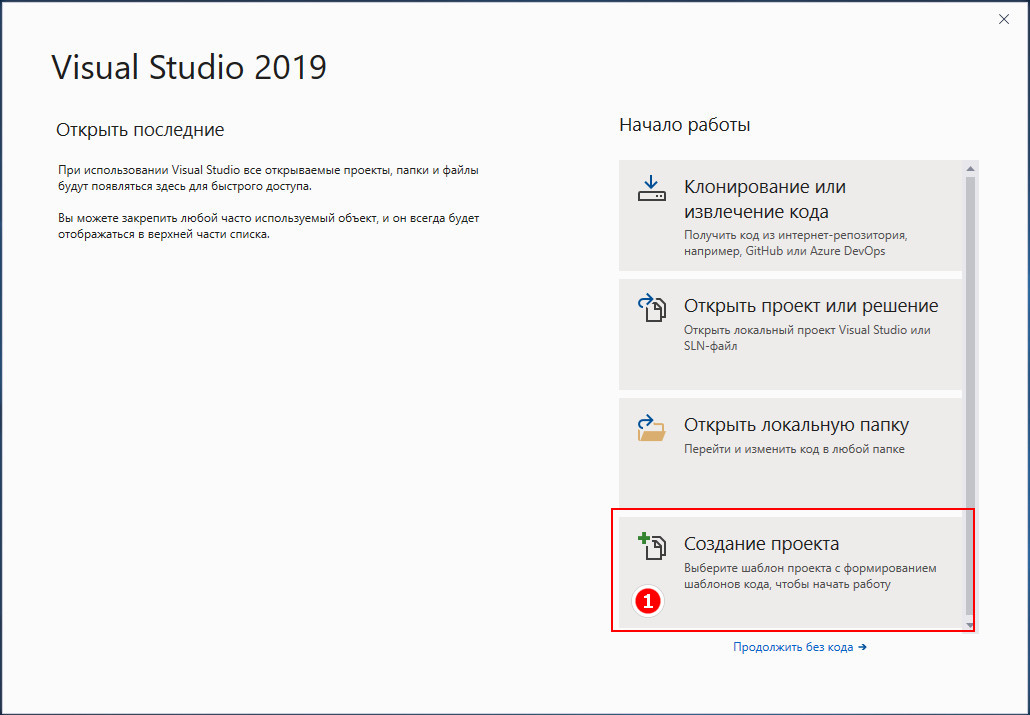
Прокручиваем список шаблонов и находим в нём Приложение Windows Forms в (.NET Framework).
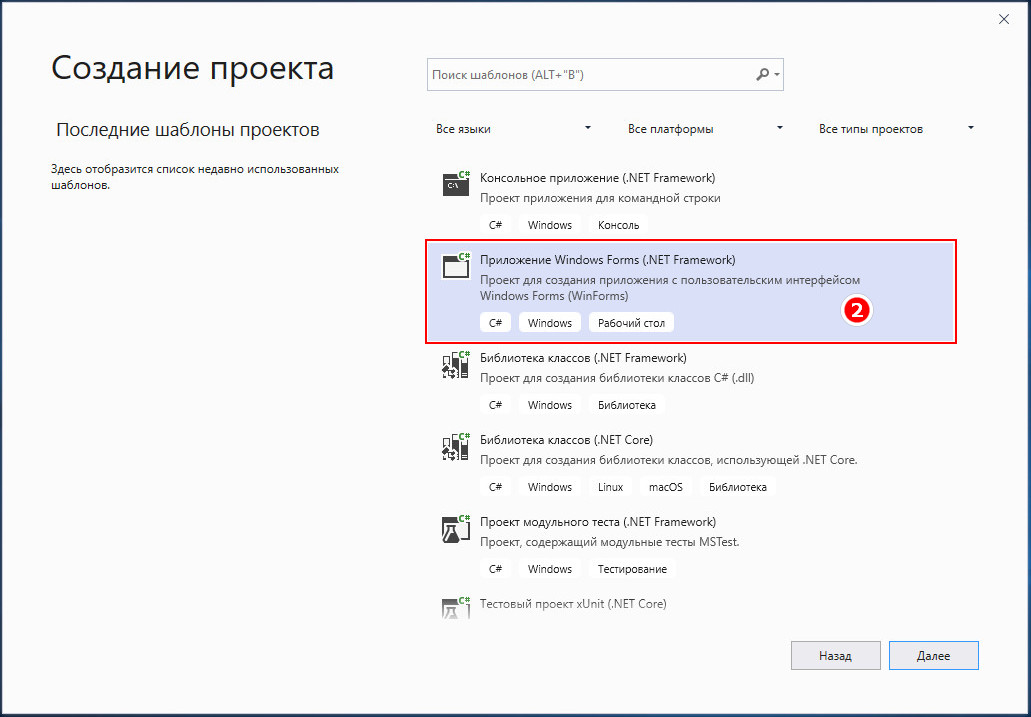
Жмем «Далее», даем будущему браузеру имя и нажимаем «Создать».
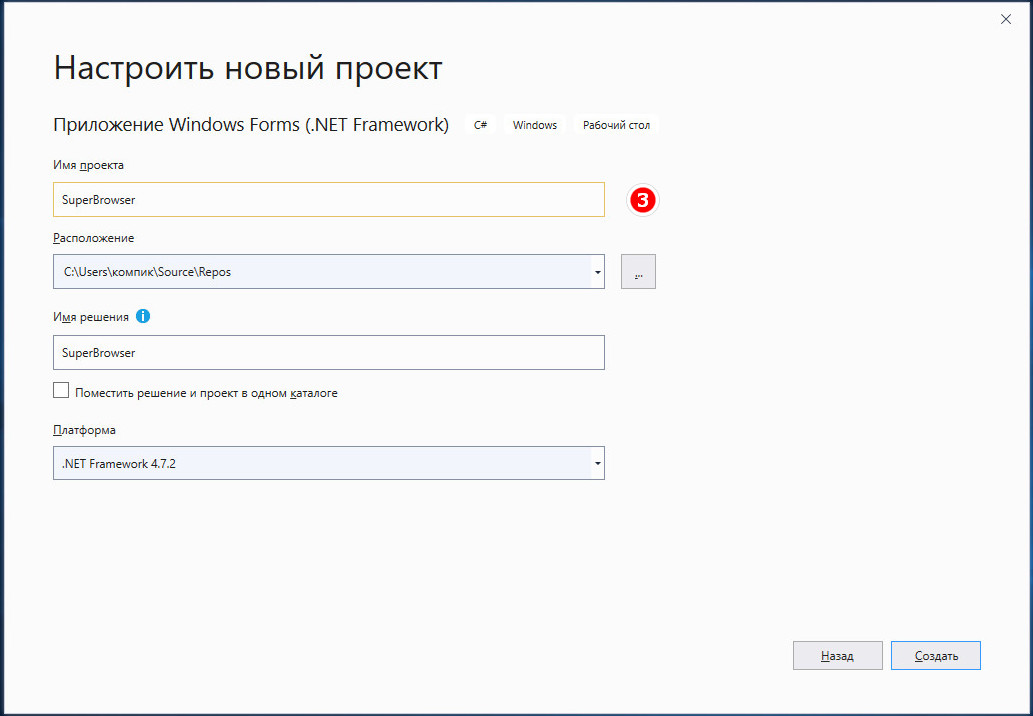
Через несколько секунд перед нами предстает пустая форма, в ней будем размещать элементы управления веб-обозревателем. Вызываем нажатием на узкую полоску слева панель инструментов, раскрываем пункт «Все формы Windows Form» и выбираем двойным кликом «WebBrowser».
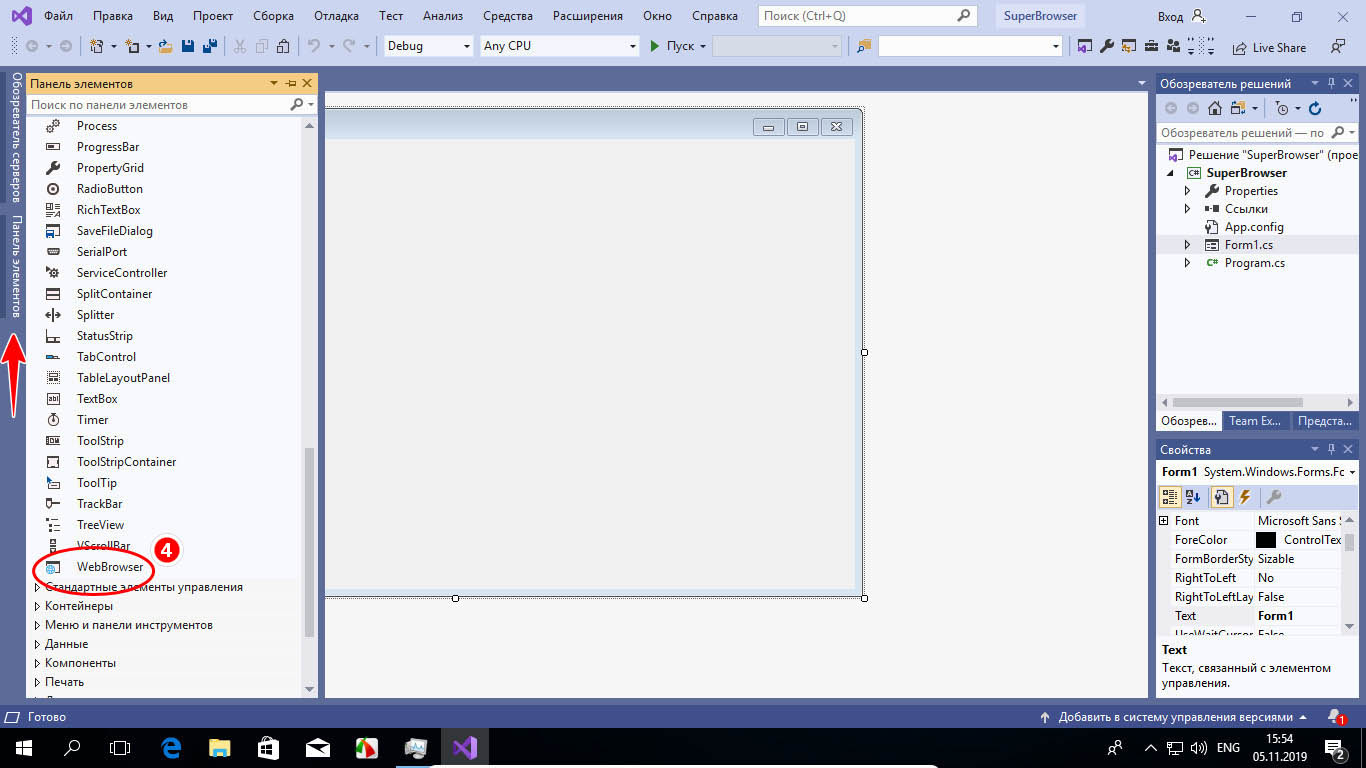
Справа располагаются другие две панели, верхняя содержит список файлов проекта, нижняя — свойства пока еще пустого окна. Здесь можно изменять параметры выбранного элемента — устанавливать размеры окна, его прозрачность, фон, включать и отключать полосы прокрутки и так далее. Если это будет не окно, а другой элемент, скажем, кнопка, то и параметры будут другие.
Рабочее окно уже есть, теперь следует позаботиться об элементах управления. Создадим область для панели инструментов обозревателя. Кликаем по маленькой иконке-треугольнику около кнопки закрытия окна и жмем «Открепить в родительском контейнере».
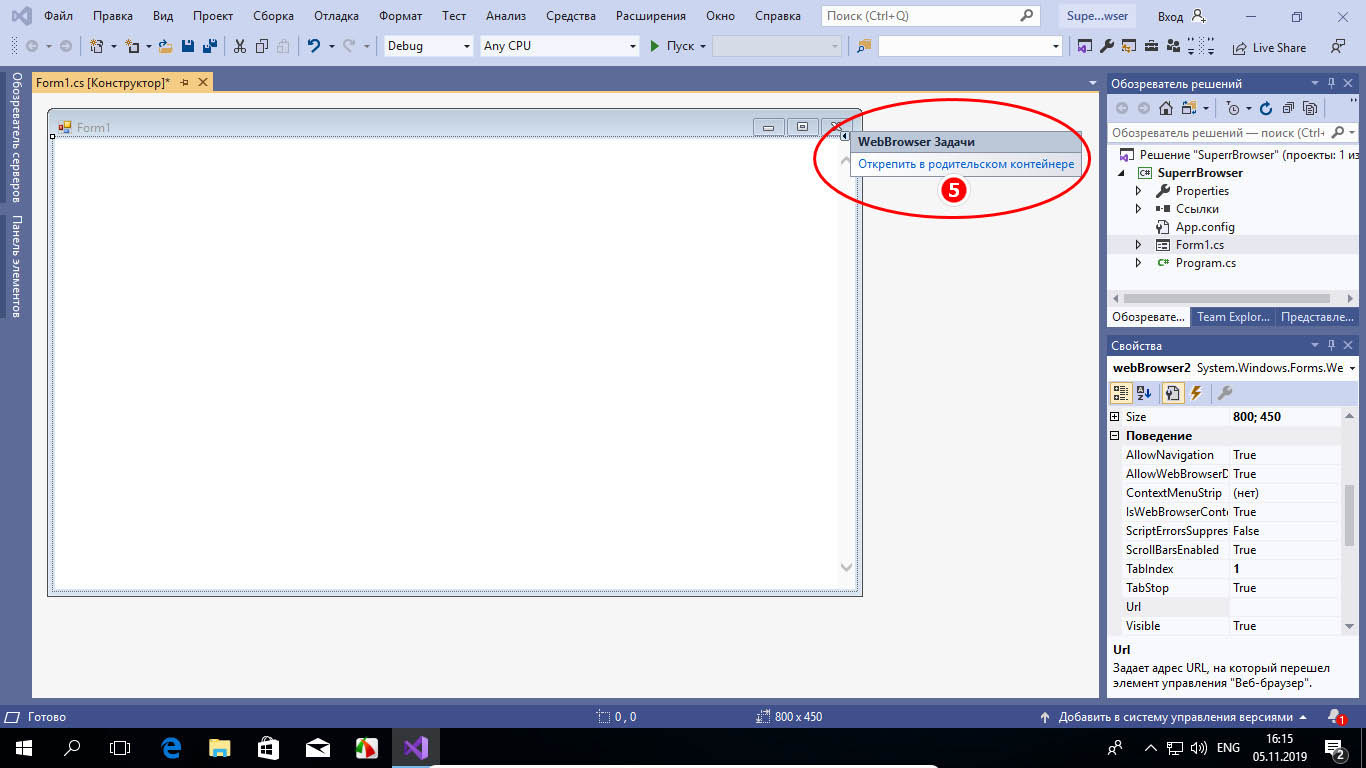
А затем растягиваем появившуюся пунктирную линию в окне будущего браузера, формируя таким образом панель управления.
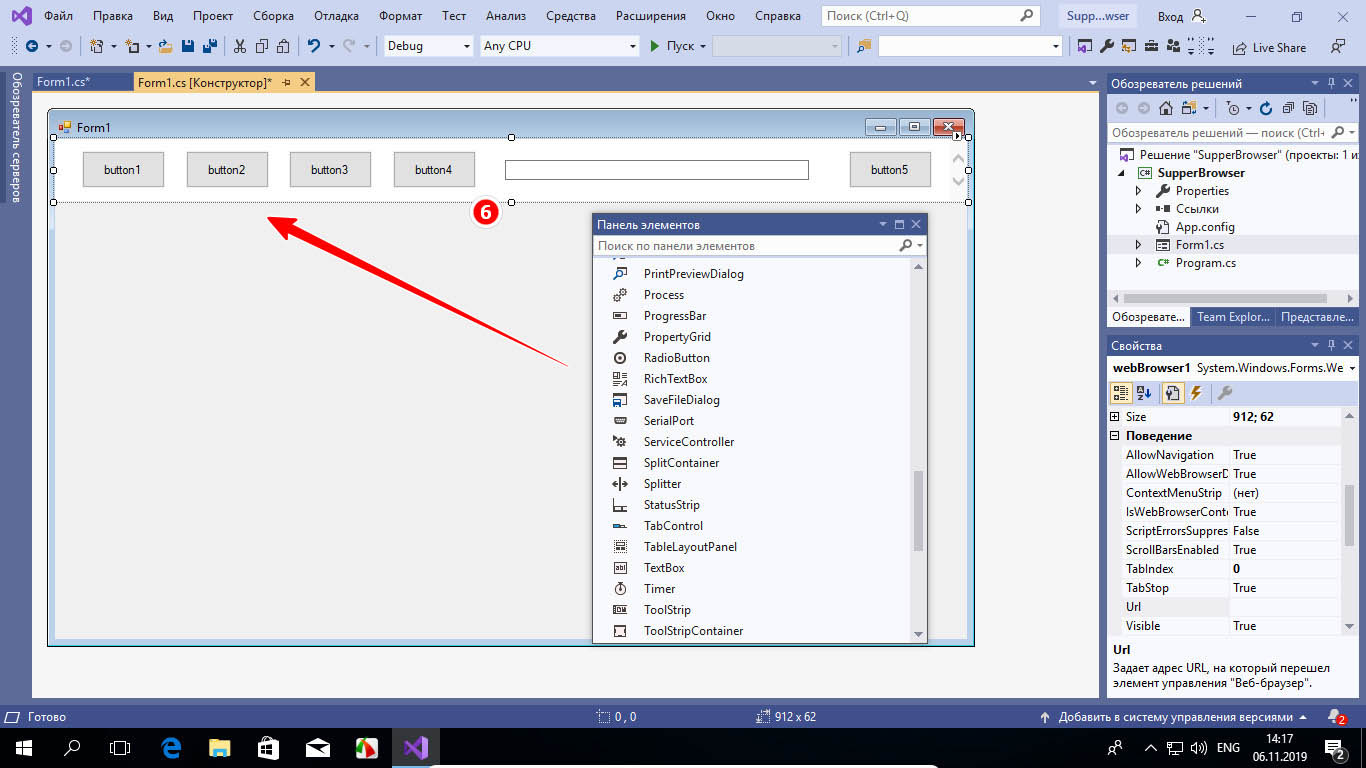
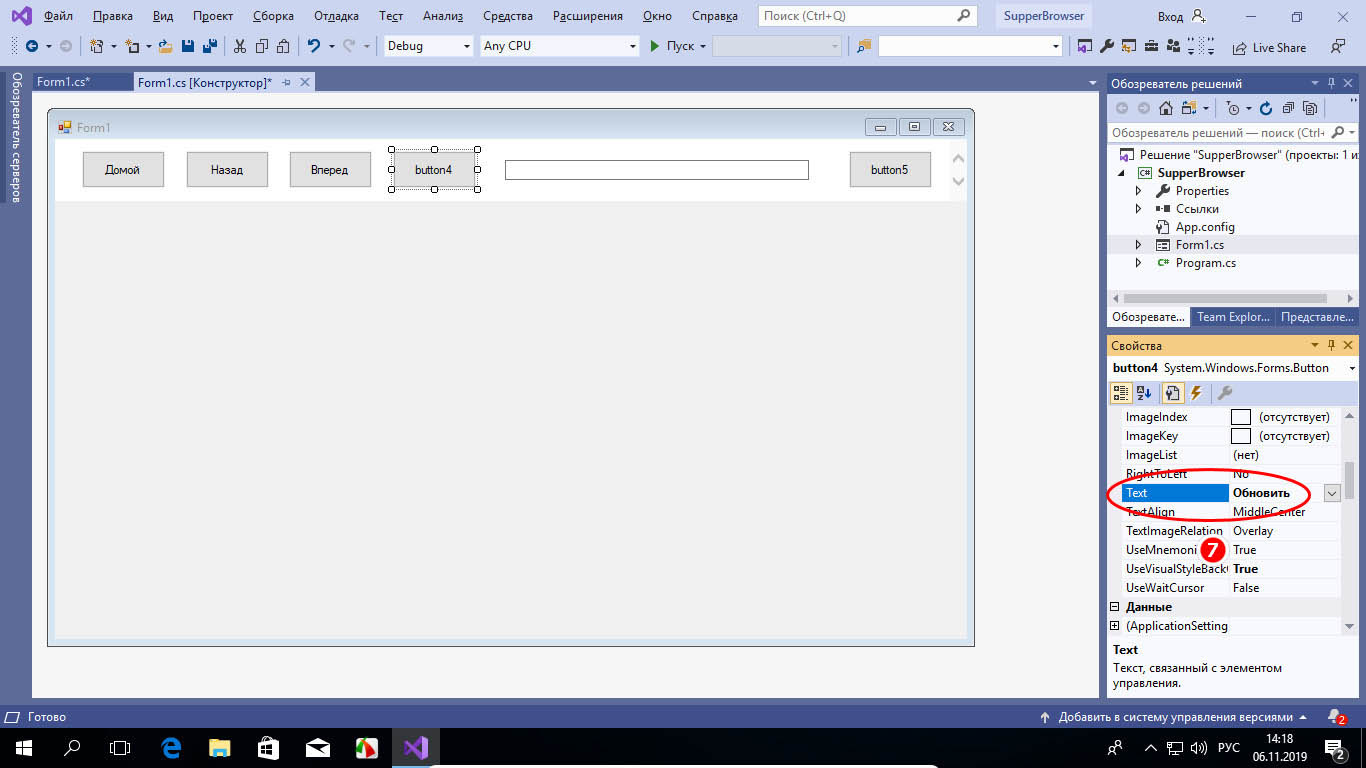
Теперь создадим кнопки «Вперед», «Назад» и «Домой», «Обновить», для чего возвращаемся на панель инструментов и перетаскиваем на форму элемент «Button» столько раз, сколько нужно создать кнопок.
Желающие также могут создать текстовое поле для ввода текстовых данных (TextBox) и кнопки перехода, но мы ограничимся четырьмя элементами. Разместив их на форме должным образом, кликаем по каждому из них и настраиваем их параметры — даем им соответствующие наименования, меняем, если нужно, цвет и так далее. Теперь настала пора самого главного — назначения управляющим элементам действий. Для этого дважды кликаем по каждой из кнопок и прописываем в месте, где установился курсор следующий код:
• Для кнопки «Обновить» — webBrowser1.Refresh();
• Для кнопки «Домой» — webBrowser1.Navigate(«www.google.com»);
• Для кнопки «Вперед» — webBrowser1.GoForward();
• Для кнопки «Назад» — webBrowser1.GoBack();
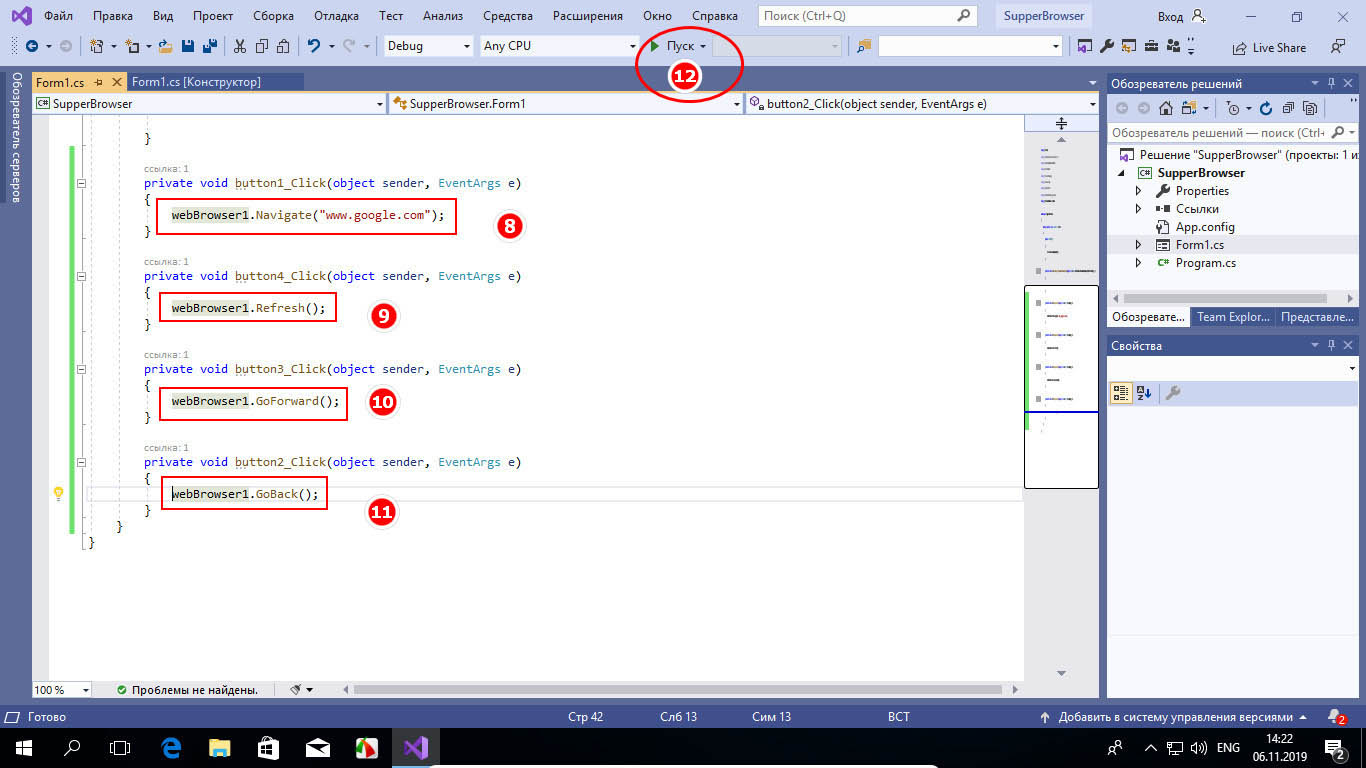
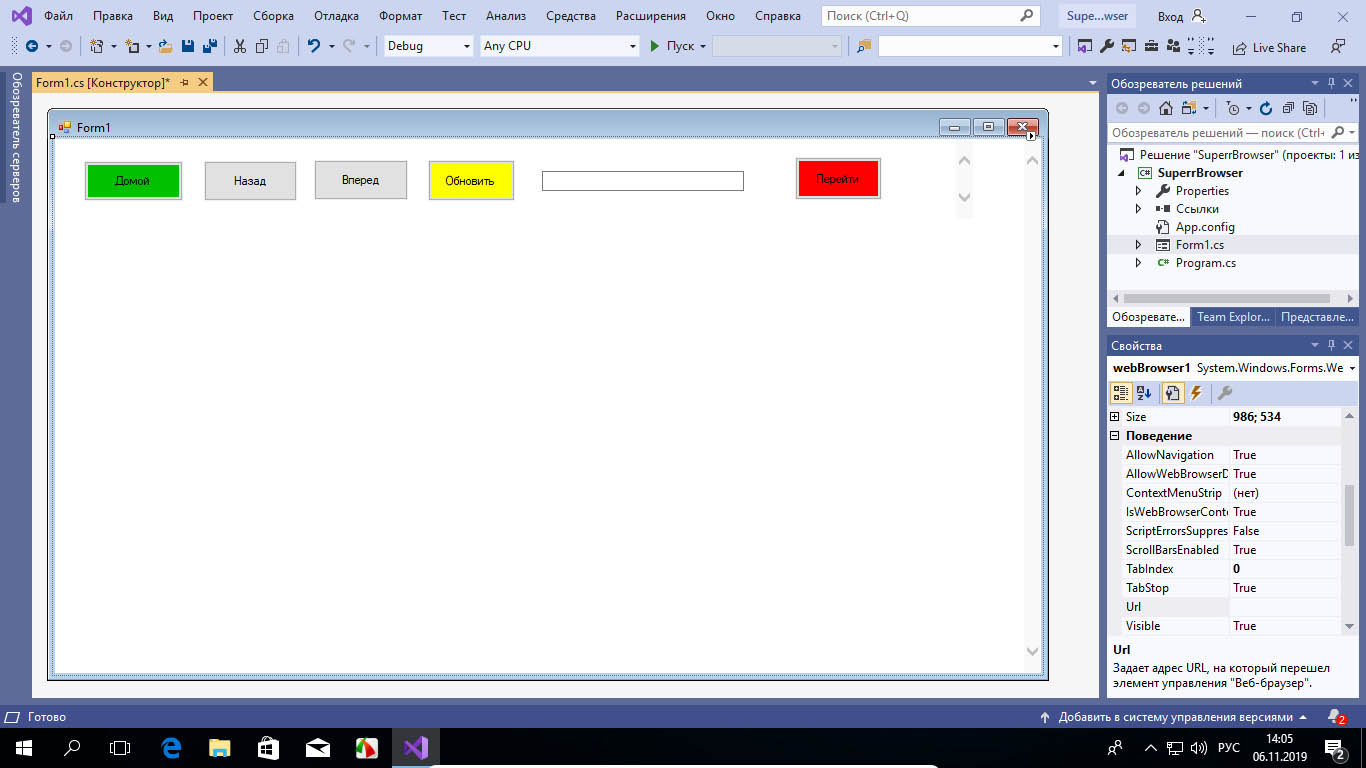
Сохраняем результат через меню «Файл» -> «Сохранить всё» и запускаем компиляцию приложения нажатием кнопки «Пуск» на панели управления средой разработки (исполняемый файл находится в папке проекта).
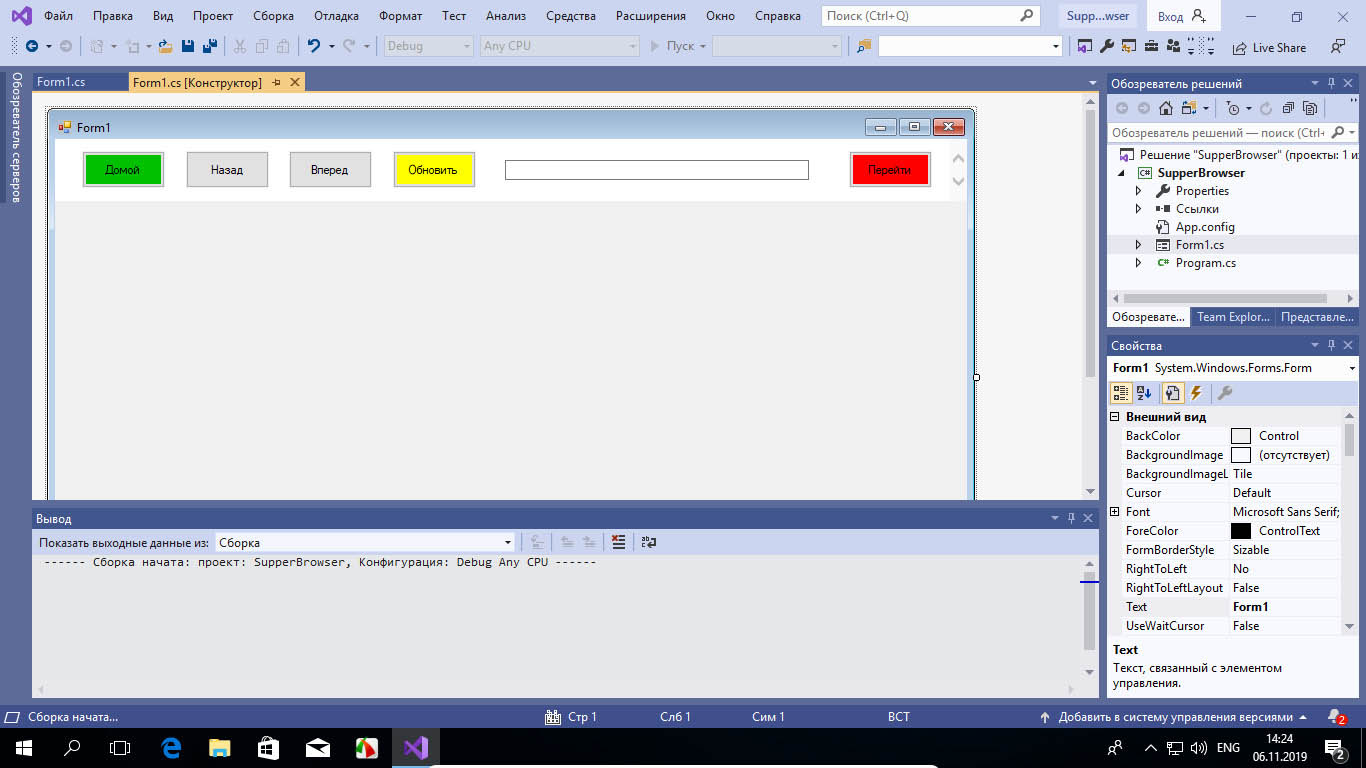
Через несколько секунд собственноручно сконструированный браузер запустится.
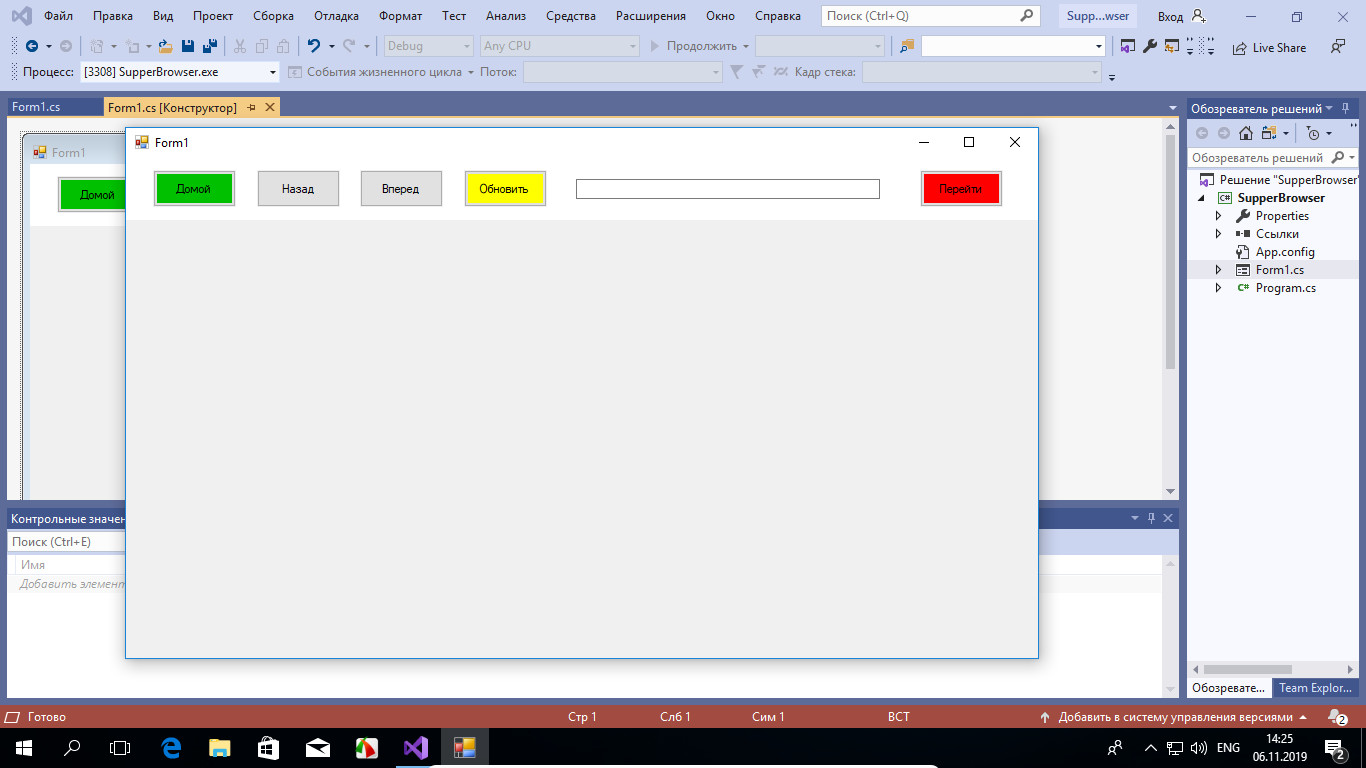
Если элементы на форме окажутся не там, где предполагалось, исправляем, перемещая их в визуальном редакторе.
Конечно, это будет очень простой браузер без закладок, поддержки тем и расширений, да и корректность отображения сайтов в нём в не гарантируется, зато вы можете быть уверены в его «чистоте».
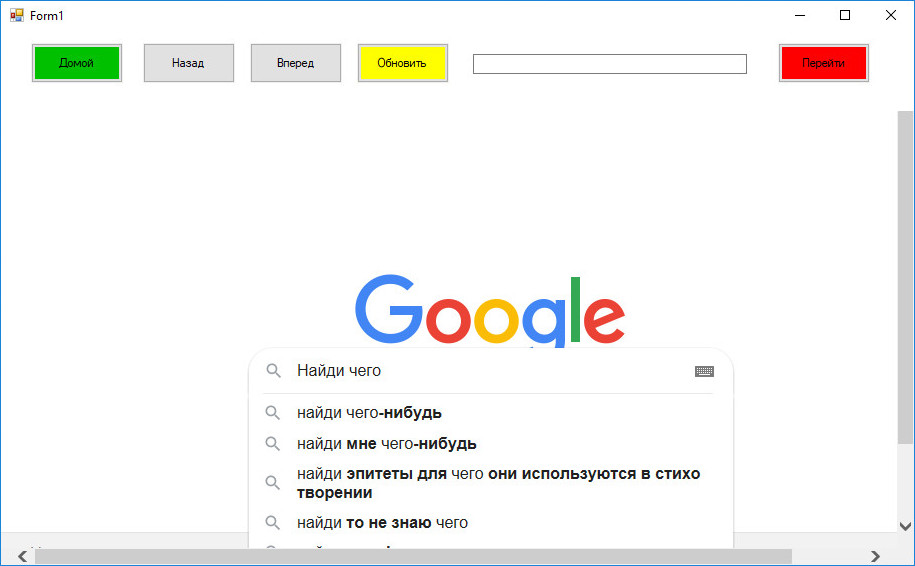
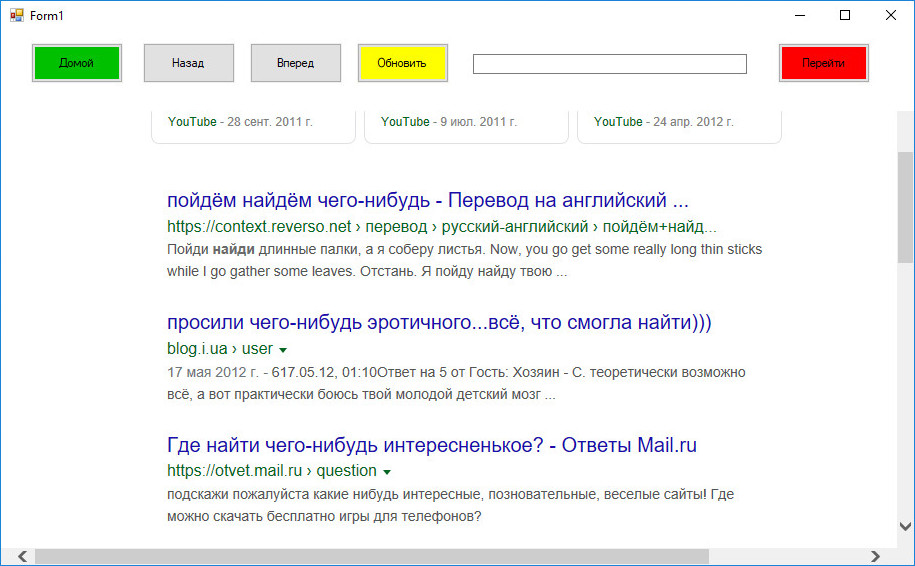
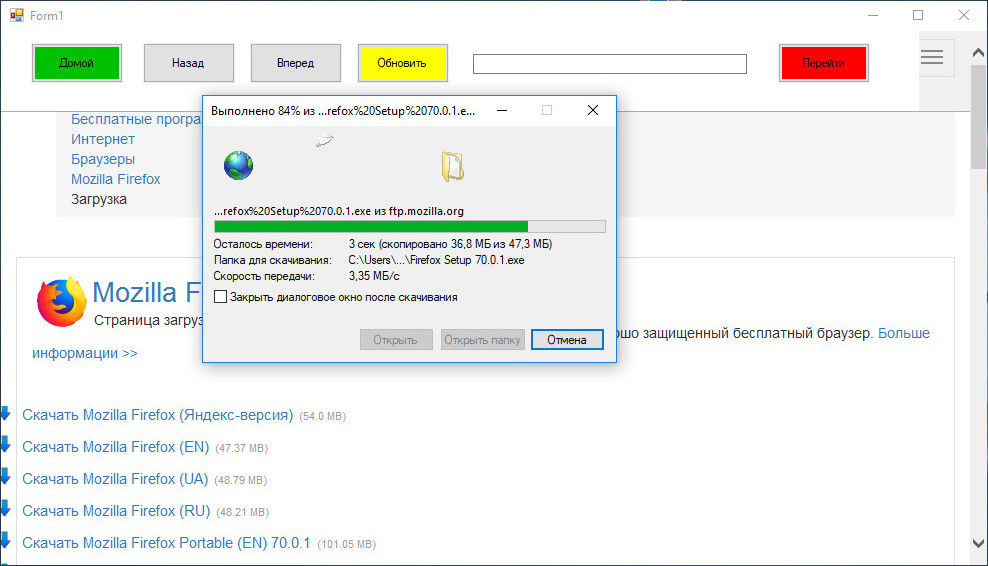
Размер созданного браузера у нас составил всего 9,5 килобайт, но этого вполне хватило, чтобы вместить в него базовый функционал, обеспечивающий не только веб-серфинг, но и скачивание файлов, а также просмотр мультимедийного контента в потоковом режиме.
![]() Загрузка…
Загрузка…
Разработка под Windows, HTML, JavaScript, Блог компании Microsoft, Microsoft Edge
Рекомендация: подборка платных и бесплатных курсов JavaScript — https://katalog-kursov.ru/
За последние несколько месяцев мы внесли множество улучшений в движок рендеринга Microsoft Edge (EdgeHTML), делая особый акцент на совместимости с современными браузерами и соответствии новым и грядущим стандартам. Помимо того, что EdgeHTML лежит в основе браузера Microsoft Edge, он также доступен для приложений на Universal Windows Platform (UWP) через элемент управления WebView. Сегодня мы хотим рассказать, как можно использовать WebView для создания своего браузера в Windows 10.
Используя стандартные веб-технологии, включая JavaScript, HTML и CSS, мы создали простое UWP-приложение, которое содержит внутри WebView и реализует базовую функциональность: навигацию и работу с избранным. Подобные приемы могут быть использованы в любом UWP-приложении для прозрачной интеграции веб-контента.
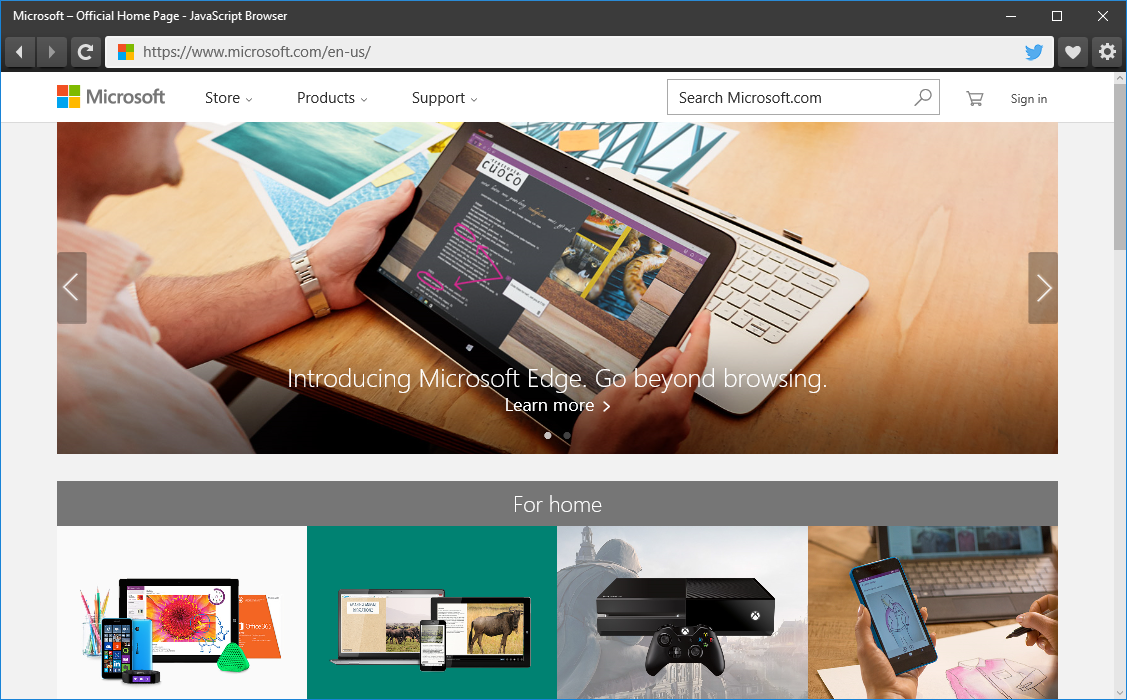
В основе нашего примера лежит мощный элемент управления WebView. Помимо комплексного набора API, данный элемент также позволяет преодолеть некоторые ограничения, присущие iframe, например, отслеживание фреймов (когда некоторый сайт меняет свое поведение в случае выполнения внутри iframe) и сложность определения загрузки документа. В дополнение x-ms-webview, — так WebView задается в HTML, — дает доступ к функциональности, не доступной в iframe, в частности, улучшенный доступ к локальному контенту и возможности делать снимки содержимого. Когда вы используете элемент управления WebView, вы получаете тот же самый движок, что и в Microsoft Edge.
Создаем браузер
Как было написано выше, браузер базируется на элементе управления WebView для HTML, а для создания и оживления пользовательского интерфейса в основном используется JavaScript. Проект создан в Visual Studio 2015 и представляет собой универсальное Windows-приложение на JavaScript.
Помимо JavaScript, мы также использовали немного HTML и CSS, а также некоторое количество строк кода на C++ для поддержки комбинаций клавиш, но это не требуется в простом случае.
Также мы пользуемся новыми возможностями нового ECMAScript 2015 (ES2015), поддерживаемыми в Chakra, JavaScript-движке, работающем в Microsoft Edge и элементе управления WebView. ES2015 позволил нам сократить количество генерируемого и шаблонного кода, тем самым существенно упростив реализацию идеи. Мы использовали следующие возможности ES2015 при создании приложения: Array.from(), Array.prototype.find(), arrow functions, method properties, const, for-of, let, Map, Object.assign(), Promises, property shorthands, Proxies, spread operator, String.prototype.includes(), String.prototype.startsWith(), Symbols, template strings и Unicode code point escapes.
Интерфейс пользователя
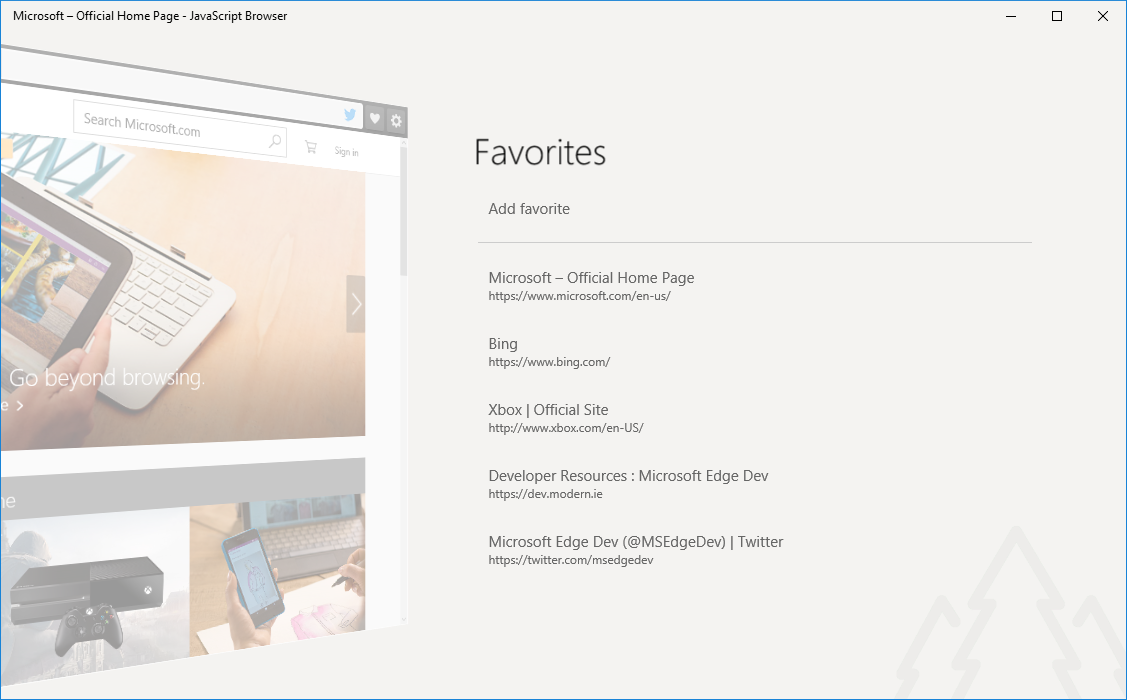
Пользовательский интерфейс включает следующие десять компонентов:
- Заголовок
- Кнопка назад
- Кнопка вперед
- Кнопка обновления
- Favicon
- Адресная строка
- Кнопка «пошарить в Твиттере»
- Кнопка и меню избранного
- Кнопка и меню настроек
- Элемент управления WebView
Дополнительная функциональность
Мы также реализовали несколько дополнительных возможностей, чтобы сделать работу с браузером еще более приятной:
- Сочетания клавиш: нажатие F11 переводит в полноэкранный режим, ESC выходит из полноэкранного режима, Ctrl+L выделяет адресную строку;
- CSS transitions для анимации меню
- Управление кэшем
- Управление избранным
- Анализ вводимых адресов – например, “bing.com” переводит на http(s)://bing.com, а “seahawks” ищет в Bing
- Автоматическое изменение выделения адресной строки при фокусе
- Отзывчивый дизайн
Использование WebView
<div class="navbar">
<!-- ... -->
</div>
<x-ms-webview id="WebView"></x-ms-webview>
Введенный для JavaScript-приложений в Windows 8.1 элемент управления WebView, иногда также упоминаемый по имени тега x-ms-webview, позволяет хостить веб-контент внутри вашего Windows-приложения. Он доступен как для HTML, так и для XAML.Для начала работы достаточно разместить соответствующий элемент в коде страницы.
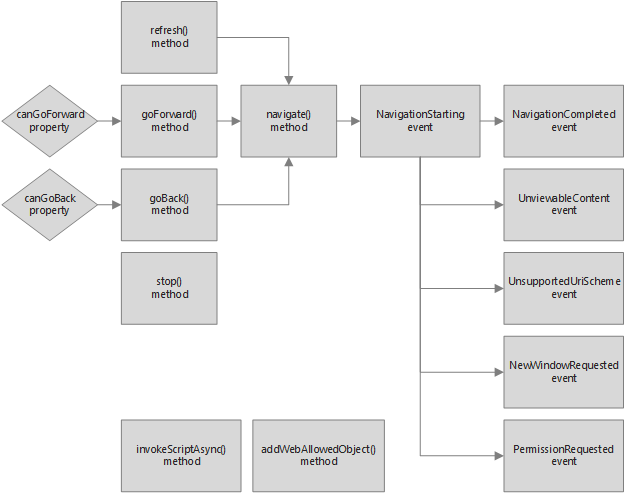
Разработка браузера
Мы будем использовать 15 различных API x-ms-webview. Все кроме двух из них управляют навигацией между страницами с некотором смысле. Давайте посмотрим, как можно использовать данные интерфейсы для создания различных элементов UI.
Управление кнопками назад и вперед
Когда вы нажимаете кнопку назад, браузер возвращает предыдущую страницу из истории браузера, если она доступна. Аналогично, когда вы нажимаете кнопку вперед, браузер возвращает последующую страницу из истории, если она также доступна. Для реализации подобной логики мы используем методы goBack() и goForward(), соответственно. Данные функции автоматически осуществят навигацию на корректную страницу из стека навигации.
После перехода на некоторую страницу, мы также обновляем текущее состояние кнопок, чтобы предотвратить «возможность» навигации, когда мы достигаем одного из концов стека навигации. Другими словами, мы отключаем кнопки навигации вперед или назад, проверяя свойства canGoBack или canGoForward на равенство false.
// Update the navigation state
this.updateNavState = () => {
this.backButton.disabled = !this.webview.canGoBack;
this.forwardButton.disabled = !this.webview.canGoForward;
};
// Listen for the back button to navigate backwards
this.backButton.addEventListener("click", () => this.webview.goBack());
// Listen for the forward button to navigate forwards
this.forwardButton.addEventListener("click", () => this.webview.goForward());
Управление кнопками обновления и остановки
Кнопки обновления и остановки слегка отличаются от остальных компонент панели навигации тем, что они используют одно и то же место в UI. Когда страница загружается, нажатие на кнопку остановит загрузку, спрячет «кольцо прогресса» и отобразит иконку обновления. И наоборот, когда страница загружена, нажатие на кнопку запустит обновление страницы и (в другой части кода) отобразит иконку остановки. Мы используем методы refresh() или stop() в зависимости от текущих условий.
// Listen for the stop/refresh button to stop navigation/refresh the page
this.stopButton.addEventListener("click", () => {
if (this.loading) {
this.webview.stop();
this.showProgressRing(false);
this.showRefresh();
}
else {
this.webview.refresh();
}
});
Управление адресной строкой
В целом, реализация адресной строки может быть очень простой. Когда адрес URL введен в текстовое поле, нажатие Enter вызовет метод navigate(), используя содержимое input-элемента адресной строки в качестве параметра.
Однако современные браузеры пошли сильно дальше и внедряют дополнительную функциональность для удобства пользователей. Это добавляет некоторую сложность в реализации – и тут все зависит от сценариев, которые вы хотите поддержать.
const RE_VALIDATE_URL = /^[-:.&#+()[]$'*;@~!,?%=/w]+$/;
// Attempt a function
function attempt(func) {
try {
return func();
}
catch (e) {
return e;
}
}
// Navigate to the specified absolute URL
function navigate(webview, url, silent) {
let resp = attempt(() => webview.navigate(url));
// ...
}
// Navigate to the specified location
this.navigateTo = loc => {
// ...
// Check if the input value contains illegal characters
let isUrl = RE_VALIDATE_URL.test(loc);
if (isUrl && navigate(this.webview, loc, true)) {
return;
}
// ... Fallback logic (e.g. prepending http(s) to the URL, querying Bing.com, etc.)
};
// Listen for the Enter key in the address bar to navigate to the specified URL
this.urlInput.addEventListener("keypress", e => {
if (e.keyCode === 13) {
this.navigateTo(urlInput.value);
}
});Вот пример сценария, который мы попробовали реализовать. Допустим, в адресную строку введено значение “microsoft.com”. Адрес не является полным. Если такое значение передать в метод navigate(), он завершится неудачей. Наш браузер должен знать, что URL не полный, и уметь определить, какой корректный протокол подставить: http или https. Более того, возможно, что введенное значение и не предполагалось адресом. К примеру, мы могли ввести в адресную строку значение “seahawks”, надеясь, что, как и во многих браузерах, строка также работает как поле поиска. Браузер должен понять, что значение не является адресом, и попробовать «найти» его в поисковой системе.
Отображение favicon
Запрос favicon – нетривиальная задача, так как существует несколько способов, как икона может быть задана. Самый простой способ – это проверить корень веб-сайта на наличие файла «favicon.ico». Однако некоторые сайты могут быть на поддомене и поэтому иметь отличную иконку. К примеру, иконка на “microsoft.com” отличается от иконки на “windows.microsoft.com”. Чтобы исключить двусмысленность, можно использовать другой способ — проверить разметку страницы на наличие link-тека внутри документа с rel-атрибутом, равным “icon” или “shortcut icon”.
Мы используем метод invokeScriptAsync(), чтобы вставить внутрь элемента управления WebView скрипт, который вернет строку в случае успеха. Наш скрипт ищет внутри страницы все элементы с link-теком, проверяет, если rel-атрибут содержит слово “icon”, и в случае совпадения возвращает значение “href”-атрибута назад в приложение.
// Check if a file exists at the specified URL
function fileExists(url) {
return new Promise(resolve =>
Windows.Web.Http.HttpClient()
.getAsync(new URI(url), Windows.Web.Http.HttpCompletionOption.responseHeadersRead)
.done(e => resolve(e.isSuccessStatusCode), () => resolve(false))
);
}
// Show the favicon if available
this.getFavicon = loc => {
let host = new URI(loc).host;
// Exit for cached ico location
// ...
let protocol = loc.split(":")[0];
// Hide favicon when the host cannot be resolved or the protocol is not http(s)
// ...
loc = `${protocol}://${host}/favicon.ico`;
// Check if there is a favicon in the root directory
fileExists(loc).then(exists => {
if (exists) {
console.log(`Favicon found: ${loc}`);
this.favicon.src = loc;
return;
}
// Asynchronously check for a favicon in the web page markup
console.log("Favicon not found in root. Checking the markup...");
let script = "Object(Array.from(document.getElementsByTagName('link')).find(link => link.rel.includes('icon'))).href";
let asyncOp = this.webview.invokeScriptAsync("eval", script);
asyncOp.oncomplete = e => {
loc = e.target.result || "";
if (loc) {
console.log(`Found favicon in markup: ${loc}`);
this.favicon.src = loc;
}
else {
this.hideFavicon();
}
};
asyncOp.onerror = e => {
console.error(`Unable to find favicon in markup: ${e.message}`);
};
asyncOp.start();
});
};
Как упомянуто выше, мы используем в нашем коде возможности из новой спецификации ES2015. Вы могли заметить использование стрелочной нотации во многих примерах выше, а также ряд других возможностей. Вставляемый скрипт – это отличный пример улучшения кода, достигаемого за счет поддержки ES2015.
// Before (ES < 6):
"(function () {var n = document.getElementsByTagName('link'); for (var i = 0; i < n.length; i++) { if (n[i].rel.indexOf('icon') > -1) { return n[i].href; }}})();"
// After (ES6):
"Object(Array.from(document.getElementsByTagName('link')).find(link => link.rel.includes('icon'))).href"Поддержка комбинаций клавиш
В отличие от возможностей, которые мы реализовали выше, поддержка комбинаций клавиш потребует от нас небольшого куска кода на C++ или C#, обернутого в виде Windows Runtime (WinRT) компонента.
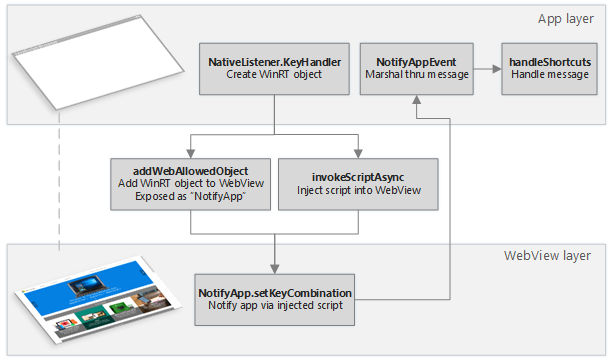
Чтобы определить нажатие горячих клавиш для выполнения тех или иных действий, например, чтобы при нажатии комбинации Ctrl+L выделять адресную строку или по F11 переключаться в полноэкранный режим, нам нужно вставить еще один скрипт в WebView. Для этого мы используем метод invokeScriptAsync(), который мы уже упоминали выше. Однако, нам нужно как-то сообщать назад в слой приложения, когда те или иные клавиши нажаты.
С помощью метода addWebAllowedObject(), мы можем выставить для инжектируемого кода метод, через который можно будет передавать нажимаемые клавиши в слой приложения на JavaScript. Также важно понимать, что в Windows 10, элемент управления WebView выполняется в отдельном потоке. Нам нужно создать диспетчер, который будет передавать события в поток UI, чтобы слой приложения мог их обрабатывать.
KeyHandler::KeyHandler()
{
// Must run on App UI thread
m_dispatcher = Windows::UI::Core::CoreWindow::GetForCurrentThread()->Dispatcher;
}
void KeyHandler::setKeyCombination(int keyPress)
{
m_dispatcher->RunAsync(
CoreDispatcherPriority::Normal,
ref new DispatchedHandler([this, keyPress]
{
NotifyAppEvent(keyPress);
}));
}// Create the C++ Windows Runtime Component
let winRTObject = new NativeListener.KeyHandler();
// Listen for an app notification from the WinRT object
winRTObject.onnotifyappevent = e => this.handleShortcuts(e.target);
// Expose the native WinRT object on the page's global object
this.webview.addWebAllowedObject("NotifyApp", winRTObject);
// ...
// Inject fullscreen mode hot key listener into the WebView with every page load
this.webview.addEventListener("MSWebViewDOMContentLoaded", () => {
let asyncOp = this.webview.invokeScriptAsync("eval", `
addEventListener("keydown", e => {
let k = e.keyCode;
if (k === ${this.KEYS.ESC} || k === ${this.KEYS.F11} || (e.ctrlKey && k === ${this.KEYS.L})) {
NotifyApp.setKeyCombination(k);
}
});
`);
asyncOp.onerror = e => console.error(`Unable to listen for fullscreen hot keys: ${e.message}`);
asyncOp.start();
});Внешний вид браузера
Теперь, когда мы разобрались с ключевыми API WebView, давайте немного улучшим внешний вид нашего браузера.
Брендирование заголовка
Используя API Windows Runtime, мы можем поменять свойство ApplicationView.TitleBar, чтобы настроить цветовую палитру все компонентов заголовка приложения. В нашем браузере при загрузке приложения мы меняем цвета так, чтобы они соответствовали панели навигации. Мы также обновляем цвета при открытии меню, чтобы соответствовать фону меню. Каждый цвет нужно задавать как объект с RGBA свойствами. Для удобства мы создали вспомогательную функцию, генерирующую нужный формат из шестнадцатеричной строковой записи.
//// browser.js
// Use a proxy to workaround a WinRT issue with Object.assign
this.titleBar = new Proxy(Windows.UI.ViewManagement.ApplicationView.getForCurrentView().titleBar, {
"get": (target, key) => target[key],
"set": (target, key, value) => (target[key] = value, true)
});
//// title-bar.js
// Set your default colors
const BRAND = hexStrToRGBA("#3B3B3B");
const GRAY = hexStrToRGBA("#666");
const WHITE = hexStrToRGBA("#FFF");
// Set the default title bar colors
this.setDefaultAppBarColors = () => {
Object.assign(this.titleBar, {
"foregroundColor": BRAND,
"backgroundColor": BRAND,
"buttonForegroundColor": WHITE,
"buttonBackgroundColor": BRAND,
"buttonHoverForegroundColor": WHITE,
"buttonHoverBackgroundColor": GRAY,
"buttonPressedForegroundColor": BRAND,
"buttonPressedBackgroundColor": WHITE,
"inactiveForegroundColor": BRAND,
"inactiveBackgroundColor": BRAND,
"buttonInactiveForegroundColor": GRAY,
"buttonInactiveBackgroundColor": BRAND,
"buttonInactiveHoverForegroundColor": WHITE,
"buttonInactiveHoverBackgroundColor": BRAND,
"buttonPressedForegroundColor": BRAND,
"buttonPressedBackgroundColor": BRAND
});
};Прочие возможности
Индикация прогресса, а также меню настроек и избранного используют CSS transitions для анимации. Из меню настроек временные веб-данные можно очистить, используя метод clearTemporaryWebDataAsync(). А в меню избранного отображаемый список хранится в JSON-файле в корневой папке перемещаемого хранилища данных приложения.
Исходный код
Полный пример кода доступен в нашем репозитарии на GitHub. Вы можете также попробовать демонстрационный браузер, установив соответствующее приложение из Windows Store, или развернув приложение из проекта для Visual Studio.
Создайте свое приложение для Windows 10
С помощью WebView мы смогли создать простой браузер, используя веб-стандарты, буквально за день. Интересно, что вы сможете создать для Windows 10?