Распознавание речи для чайников
Время на прочтение
9 мин
Количество просмотров 163K

В этой статье я хочу рассмотреть основы такой интереснейшей области разработки ПО как Распознавание Речи. Экспертом в данной теме я, естественно, не являюсь, поэтому мой рассказ будет изобиловать неточностями, ошибками и разочарованиями. Тем не менее, главной целью моего «труда», как можно понять из названия, является не профессиональный разбор проблемы, а описание базовых понятий, проблем и их решений. В общем, прошу всех заинтересовавшихся пожаловать под кат!
Пролог
Начнём с того, что наша речь — это последовательность звуков. Звук в свою очередь — это суперпозиция (наложение) звуковых колебаний (волн) различных частот. Волна же, как нам известно из физики, характеризуются двумя атрибутами — амплитудой и частотой.
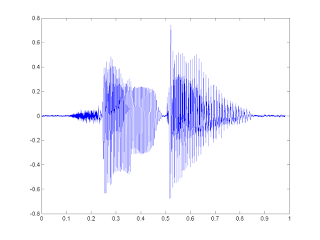
Для того, что бы сохранить звуковой сигнал на цифровом носителе, его необходимо разбить на множество промежутков и взять некоторое «усредненное» значение на каждом из них.
Таким вот образом механические колебания превращаются в набор чисел, пригодный для обработки на современных ЭВМ.
Отсюда следует, что задача распознавания речи сводится к «сопоставлению» множества численных значений (цифрового сигнала) и слов из некоторого словаря (русского языка, например).
Давайте разберемся, как, собственно, это самое «сопоставление» может быть реализовано.
Входные данные
Допустим у нас есть некоторый файл/поток с аудиоданными. Прежде всего нам нужно понять, как он устроен и как его прочесть. Давайте рассмотрим самый простой вариант — WAV файл.


Формат подразумевает наличие в файле двух блоков. Первый блок — это заголовка с информацией об аудиопотоке: битрейте, частоте, количестве каналов, длине файла и т.д. Второй блок состоит из «сырых» данных — того самого цифрового сигнала, набора значений амплитуд.
Логика чтения данных в этом случае довольно проста. Считываем заголовок, проверяем некоторые ограничения (отсутствие сжатия, например), сохраняем данные в специально выделенный массив.
Пример.
Распознавание
Чисто теоретически, теперь мы можем сравнить (поэлементно) имеющийся у нас образец с каким-нибудь другим, текст которого нам уже известен. То есть попробовать «распознать» речь… Но лучше этого не делать 
Наш подход должен быть устойчив (ну хотя бы чуть-чуть) к изменению тембра голоса (человека, произносящего слово), громкости и скорости произношения. Поэлементным сравнением двух аудиосигналов этого, естественно, добиться нельзя.
Поэтому мы пойдем несколько иным путём.
Фреймы
Первым делом разобьём наши данные по небольшим временным промежуткам — фреймам. Причём фреймы должны идти не строго друг за другом, а “внахлёст”. Т.е. конец одного фрейма должен пересекаться с началом другого.
Фреймы являются более подходящей единицей анализа данных, чем конкретные значения сигнала, так как анализировать волны намного удобней на некотором промежутке, чем в конкретных точках. Расположение же фреймов “внахлёст” позволяет сгладить результаты анализа фреймов, превращая идею фреймов в некоторое “окно”, движущееся вдоль исходной функции (значений сигнала).
Опытным путём установлено, что оптимальная длина фрейма должна соответствовать промежутку в 10мс, «нахлёст» — 50%. С учётом того, что средняя длина слова (по крайней мере в моих экспериментах) составляет 500мс — такой шаг даст нам примерно 500 / (10 * 0.5) = 100 фреймов на слово.
Разбиение слов
Первой задачей, которую приходится решать при распознавании речи, является разбиение этой самой речи на отдельные слова. Для простоты предположим, что в нашем случае речь содержит в себе некоторые паузы (промежутки тишины), которые можно считать “разделителями” слов.
В таком случае нам нужно найти некоторое значение, порог — значения выше которого являются словом, ниже — тишиной. Вариантов тут может быть несколько:
- задать константой (сработает, если исходный сигнал всегда генерируется при одних и тех же условиях, одним и тем же способом);
- кластеризовать значения сигнала, явно выделив множество значений соответствующих тишине (сработает только если тишина занимает значительную часть исходного сигнала);
- проанализировать энтропию;
Как вы уже догадались, речь сейчас пойдёт о последнем пункте Начнём с того, что энтропия — это мера беспорядка, “мера неопределённости какого-либо опыта” (с). В нашем случае энтропия означает то, как сильно “колеблется” наш сигнал в рамках заданного фрейма.
Для того, что бы подсчитать энтропию конкретного фрейма выполним следующие действия:
- предположим, что наш сигнал пронормирован и все его значения лежат в диапазоне [-1;1];
- построим гистограмму (плотность распределения) значений сигнала фрейма:
рассчитаем энтропию, как 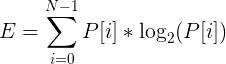 ;
;
Пример.
И так, мы получили значение энтропии. Но это всего лишь ещё одна характеристика фрейма, и для того, что бы отделить звук от тишины, нам по прежнему нужно её с чем-то сравнивать. В некоторых статьях рекомендуют брать порог энтропии равным среднему между её максимальным и минимальным значениями (среди всех фреймов). Однако, в моём случае такой подход не дал сколь либо хороших результатов.
К счастью, энтропия (в отличие от того же среднего квадрата значений) — величина относительно самостоятельная. Что позволило мне подобрать значение её порога в виде константы (0.1).
Тем не менее проблемы на этом не заканчиваются  Энтропия может проседать по середине слова (на гласных), а может внезапно вскакивать из-за небольшого шума. Для того, что бы бороться с первой проблемой, приходится вводить понятие “минимально расстояния между словами” и “склеивать” близ лежачие наборы фреймов, разделённые из-за проседания. Вторая проблема решается использованием “минимальной длины слова” и отсечением всех кандидатов, не прошедших отбор (и не использованных в первом пункте).
Энтропия может проседать по середине слова (на гласных), а может внезапно вскакивать из-за небольшого шума. Для того, что бы бороться с первой проблемой, приходится вводить понятие “минимально расстояния между словами” и “склеивать” близ лежачие наборы фреймов, разделённые из-за проседания. Вторая проблема решается использованием “минимальной длины слова” и отсечением всех кандидатов, не прошедших отбор (и не использованных в первом пункте).
Если же речь в принципе не является “членораздельной”, можно попробовать разбить исходный набор фреймов на определённым образом подготовленные подпоследовательности, каждая из которых будет подвергнута процедуре распознавания. Но это уже совсем другая история
MFCC
И так, мы у нас есть набор фреймов, соответствующих определённому слову. Мы можем пойти по пути наименьшего сопротивления и в качестве численной характеристики фрейма использовать средний квадрат всех его значений (Root Mean Square). Однако, такая метрика несёт в себе крайне мало пригодной для дальнейшего анализа информации.
Вот тут в игру и вступают Мел-частотные кепстральные коэффициенты (Mel-frequency cepstral coefficients). Согласно Википедии (которая, как известно, не врёт) MFCC — это своеобразное представление энергии спектра сигнала. Плюсы его использования заключаются в следующем:
- Используется спектр сигнала (то есть разложение по базису ортогональных [ко]синусоидальных функций), что позволяет учитывать волновую “природу” сигнала при дальнейшем анализе;
- Спектр проецируется на специальную mel-шкалу, позволяя выделить наиболее значимые для восприятия человеком частоты;
- Количество вычисляемых коэффициентов может быть ограничено любым значением (например, 12), что позволяет “сжать” фрейм и, как следствие, количество обрабатываемой информации;
Давайте рассмотрим процесс вычисления MFCC коэффициентов для некоторого фрейма.
Представим наш фрейм в виде вектора 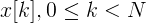 , где N — размер фрейма.
, где N — размер фрейма.
Разложение в ряд Фурье
Первым делом рассчитываем спектр сигнала с помощью дискретного преобразования Фурье (желательно его “быстрой” FFT реализацией).
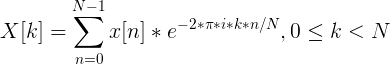
Так же к полученным значениям рекомендуется применить оконную функцию Хэмминга, что бы “сгладить” значения на границах фреймов.

То есть результатом будет вектор следующего вида:
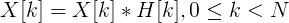
Важно понимать, что после этого преобразования по оси Х мы имеем частоту (hz) сигнала, а по оси Y — магнитуду (как способ уйти от комплексных значений):
Расчёт mel-фильтров
Начнём с того, что такое mel. Опять же согласно Википедии, mel — это “психофизическая единица высоты звука”, основанная на субъективном восприятии среднестатистическими людьми. Зависит в первую очередь от частоты звука (а так же от громкости и тембра). Другими словами, эта величина, показывающая, на сколько звук определённой частоты “значим” для нас.
Преобразовать частоту в мел можно по следующей формуле (запомним её как «формула-1»):

Обратное преобразование выглядит так (запомним её как «формула-2»):
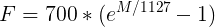
График зависимости mel / частота:

Но вернёмся к нашей задаче. Допустим у нас есть фрейм размером 256 элементов. Мы знаем (из данных об аудиоформате), что частота звука в данной фрейме 16000hz. Предположим, что человеческая речь лежит в диапазоне от [300; 8000]hz. Количество искомых мел-коэффициентов положим M = 10 (рекомендуемое значение).
Для того, что бы разложить полученный выше спектр по mel-шкале, нам потребуется создать “гребёнку” фильтров. По сути, каждый mel-фильтр это треугольная оконная функция, которая позволяет просуммировать количество энергии на определённом диапазоне частот и тем самым получить mel-коэффициент. Зная количество мел-коэффициентов и анализируемый диапазон частот мы можем построить набор таких вот фильтров:
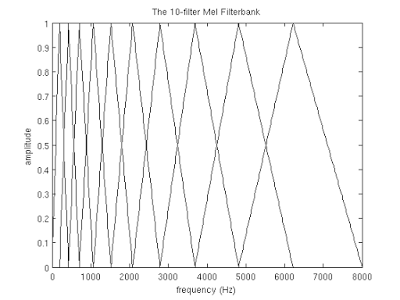
Обратите внимание, что чем больше порядковый номер мел-коэффициента, тем шире основание фильтра. Это связано с тем, что разбиение интересующего нас диапазона частот на обрабатываемые фильтрами диапазоны происходит на шкале мелов.
Но мы опять отвлеклись. И так для нашего случая диапазон интересующих нас частот равен [300, 8000]. Согласно формуле-1 в на мел-шкале этот диапазон превращается в [401.25; 2834.99].
Далее, для того, что бы построить 10 треугольных фильтров нам потребуется 12 опорных точек:
m[i] = [401.25, 622.50, 843.75, 1065.00, 1286.25, 1507.50, 1728.74, 1949.99, 2171.24, 2392.49, 2613.74, 2834.99]
Обратите внимание, что на мел-шкале точки расположены равномерно. Переведём шкалу обратно в герцы с помощью формулы-2:
h[i] = [300, 517.33, 781.90, 1103.97, 1496.04, 1973.32, 2554.33, 3261.62, 4122.63, 5170.76, 6446.70, 8000]
Как видите теперь шкала стала постепенно растягиваться, выравнивая тем самым динамику роста “значимости” на низких и высоких частотах.
Теперь нам нужно наложить полученную шкалу на спектр нашего фрейма. Как мы помним, по оси Х у нас находится частота. Длина спектра 256 — элементов, при этом в него умещается 16000hz. Решив нехитрую пропорцию можно получить следующую формулу:
f(i) = floor( (frameSize+1) * h(i) / sampleRate)
что в нашем случае эквивалентно
f(i) = 4, 8, 12, 17, 23, 31, 40, 52, 66, 82, 103, 128
Вот и всё! Зная опорные точки на оси Х нашего спектра, легко построить необходимые нам фильтры по следующей формуле:

Применение фильтров, логарифмирование энергии спектра
Применение фильтра заключается в попарном перемножении его значений со значениями спектра. Результатом этой операции является mel-коэффициент. Поскольку фильтров у нас M, коэффициентов будет столько же.
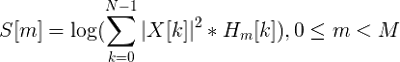
Однако, нам нужно применить mel-фильтры не к значениям спектра, а к его энергии. После чего прологарифмировать полученные результаты. Считается, что таким образом понижается чувствительность коэффициентов к шумам.
Косинусное преобразование
Дискретное косинусное преобразование (DCT) используется для того, что бы получить те самые “кепстральные” коэффициенты. Смысл его в том, что бы “сжать” полученные результаты, повысив значимость первых коэффициентов и уменьшив значимость последних.
В данном случае используется DCTII без каких-либо домножений на 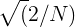 (scale factor).
(scale factor).
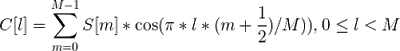
Теперь для каждого фрейма мы имеем набор из M mfcc-коэффициентов, которые могут быть использованы для дальнейшего анализа.
Примеры код для вышележащих методов можно найти тут.
Алгоритм распознавания
Вот тут, дорогой читатель, тебя и ждёт главное разочарование. В интернетах мне довелось увидеть множество высокоинтеллектуальных (и не очень) споров о том, какой же способ распознавания лучше. Кто-то ратует за Скрытые Марковские Модели, кто-то — за нейронные сети, чьи-то мысли в принципе невозможно понять
В любом случае немало предпочтений отдаётся именно СММ, и именно их реализацию я собираюсь добавить в свой код… в будущем
На данный момент, предлагаю остановится на гораздо менее эффективном, но в разы более простом способе.
И так, вспомним, что наша задача заключается в распознавании слова из некоторого словаря. Для простоты, будем распознавать называния первых десять цифр: “один“, “два“, “три“, “четыре“, “пять“, “шесть“, “семь“, “восемь“, “девять“, “десять“.
Теперь возьмем в руки айфон/андроид и пройдёмся по L коллегам с просьбой продиктовать эти слова под запись. Далее поставим в соответствие (в какой-нибудь локальной БД или простом файле) каждому слову L наборов mfcc-коэффициентов соответствующих записей.
Это соответствие мы назовём “Модель”, а сам процесс — Machine Learning! На самом деле простое добавление новых образцов в базу имеет крайне слабую связь с машинным обучением… Но уж больно термин модный
Теперь наша задача сводится к подбору наиболее “близкой” модели для некоторого набора mfcc-коэффициентов (распознаваемого слова). На первый взгляд задачу можно решить довольно просто:
- для каждой модели находим среднее (евклидово) расстояние между идентифицируемым mfcc-вектором и векторами модели;
- выбираем в качестве верной ту модель, среднее расстояние до которой будет наименьшим;
Однако, одно и тоже слово может произносится как Андреем Малаховым, так и каким-нибудь его эстонским коллегой. Другими словами размер mfcc-вектора для одного и того же слова может быть разный.
К счастью, задача сравнения последовательностей разной длины уже решена в виде Dynamic Time Warping алгоритма. Этот алгоритм динамическо программирования прекрасно расписан как в буржуйской Wiki, так и на православном Хабре.
Единственное изменение, которое в него стоит внести — это способ нахождения дистанции. Мы должны помнить, что mfcc-вектор модели — на самом деле последовательность mfcc-“подвекторов” размерности M, полученных из фреймов. Так вот, DTW алгоритм должен находить дистанцию между последовательностями эти самых “подвекторов” размерности M. То есть в качестве значений матрицы расстояний должны использовать расстояния (евклидовы) между mfcc-“подвекторами” фреймов.
Пример.
Эксперименты
У меня не было возможности проверить работу данного подхода на большой “обучающей” выборке. Результаты же тестов на выборке из 3х экземпляров для каждого слова в несинтетических условиях показали мягко говоря нелучший результат — 65% верных распознаваний.
Тем не менее моей задачей было создание максимального простого приложения для распознавания речи. Так сказать “proof of concept”
Реализация
Внимательный читатель заметил, что статья содержит множество ссылок на GitHub-проект. Тут стоит отметить, что это мой первый проект на С++ со времён университета. Так же это моя первая попытка рассчитать что-то сложнее среднего арифметического со времён того же университета… Другими словами it comes with absolutely no warranty (с)

“In this 10-year time frame, I believe that we’ll not only be using the keyboard and the mouse to interact but during that time we will have perfected speech recognition and speech output well enough that those will become a standard part of the interface.” — Bill Gates, 1 October 1997
Technology has come a long way, and with each new advancement, the human race becomes more attached to it and longs for these new cool features across all devices.
With the advent of Siri, Alexa, and Google Assistant, users of technology have yearned for speech recognition in their everyday use of the internet. In this post, I’ll be covering how to integrate native speech recognition and speech synthesis in the browser using the JavaScript WebSpeech API.
According to the Mozilla web docs:
The Web Speech API enables you to incorporate voice data into web apps. The Web Speech API has two parts: SpeechSynthesis (Text-to-Speech), and SpeechRecognition (Asynchronous Speech Recognition.)
Requirements we will need to build our application
For this simple speech recognition app, we’ll be working with just three files which will all reside in the same directory:
index.htmlcontaining the HTML for the app.style.csscontaining the CSS styles.index.jscontaining the JavaScript code.
Also, we need to have a few things in place. They are as follows:
- Basic knowledge of JavaScript.
- A web server for running the app. The Web Server for Chrome will be sufficient for this purpose.
Setting up our speech recognition app
Let’s get started by setting up the HTML and CSS for the app. Below is the HTML markup:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Speech Recognition</title>
<link rel="stylesheet" href="style.css">
<link href="https://fonts.googleapis.com/css?family=Shadows+Into+Light" rel="stylesheet">
<!-- load font awesome here for icon used on the page -->
</head>
<body>
<div class="container"> <!--page container -->
<div class="text-box" contenteditable="true"></div> <!--text box which will contain spoken text -->
<i class="fa fa-microphone"></i> <!-- microphone icon to be clicked before speaking -->
</div>
<audio class="sound" src="chime.mp3"></audio> <!-- sound to be played when we click icon => http://soundbible.com/1598-Electronic-Chime.html -->
<script src="index.js"></script> <!-- link to index.js script -->
</body>
</html>Here is its accompanying CSS style:
body {
background: #1e2440;
color: #f2efe2;
font-size: 16px;
font-family: 'Kaushan Script', cursive;
font-family: 'Shadows Into Light', cursive;
}
.container {
position: relative;
border: 1px solid #f2efe2;
width: 40vw;
max-width: 60vw;
margin: 0 auto;
border-radius: 0.1rem;
background: #f2efe2;
padding: 0.2rem 1rem;
color: #1e2440;
overflow: scroll;
margin-top: 10vh;
}
.text-box {
max-height: 70vh;
overflow: scroll;
}
.text-box:focus {
outline: none;
}
.text-box p {
border-bottom: 1px dotted black;
margin: 0px !important;
}
.fa {
color: white;
background: #1e2440;
border-radius: 50%;
cursor: pointer;
margin-top: 1rem;
float: right;
width: 2rem;
height: 2rem;
display: flex !important;
align-items: center;
justify-content: center;
}
@media (max-width: 768px) {
.container {
width: 85vw;
max-width: 85vw;
}
.text-box {
max-height: 55vh;
}
}Copying the code above should result in something similar to this:

Powering up our speech recognition app with the WebSpeech API
As of the time of writing, the WebSpeech API is only available in Firefox and Chrome. Its speech synthesis interface lives on the browser’s window object as speechSynthesis while its speech recognition interface lives on the browser’s window object as SpeechRecognition in Firefox and as webkitSpeechRecognition in Chrome.
We are going to set the recognition interface to SpeechRecognition regardless of the browser we’re on:
window.SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition;Next we’ll instantiate the speech recognition interface:
const recognition = new SpeechRecognition();
const icon = document.querySelector('i.fa.fa-microphone')
let paragraph = document.createElement('p');
let container = document.querySelector('.text-box');
container.appendChild(paragraph);
const sound = document.querySelector('.sound');In the code above, apart from instantiating speech recognition, we also selected the icon, text-box, and sound elements on the page. We also created a paragraph element which will hold the words we say, and we appended it to the text-box.
Whenever the microphone icon on the page is clicked, we want to play our sound and start the speech recognition service. To achieve this, we add a click event listener to the icon:
icon.addEventListener('click', () => {
sound.play();
dictate();
});
const dictate = () => {
recognition.start();
}In the event listener, after playing the sound, we went ahead and created and called a dictate function. The dictate function starts the speech recognition service by calling the start method on the speech recognition instance.
To return a result for whatever a user says, we need to add a result event to our speech recognition instance. The dictate function will then look like this:
const dictate = () => {
recognition.start();
recognition.onresult = (event) => {
const speechToText = event.results[0][0].transcript;
paragraph.textContent = speechToText;
}
}The resulting event returns a SpeechRecognitionEvent which contains a results object. This in turn contains the transcript property holding the recognized speech in text. We save the recognized text in a variable called speechToText and put it in the paragraph element on the page.
If we run the app at this point, click the icon and say something, it should pop up on the page.
Wrapping it up with text to speech
To add text to speech to our app, we’ll make use of the speechSynthesis interface of the WebSpeech API. We’ll start by instantiating it:
const synth = window.speechSynthesis;Next, we will create a function speak which we will call whenever we want the app to say something:
const speak = (action) => {
utterThis = new SpeechSynthesisUtterance(action());
synth.speak(utterThis);
};The speak function takes in a function called the action as a parameter. The function returns a string which is passed to SpeechSynthesisUtterance. SpeechSynthesisUtterance is the WebSpeech API interface that holds the content the speech recognition service should read. The speechSynthesis speak method is then called on its instance and passed the content to read.
To test this out, we need to know when the user is done speaking and says a keyword. Luckily there is a method to check that:
const dictate = () => {
...
if (event.results[0].isFinal) {
if (speechToText.includes('what is the time')) {
speak(getTime);
};
if (speechToText.includes('what is today's date
')) {
speak(getDate);
};
if (speechToText.includes('what is the weather in')) {
getTheWeather(speechToText);
};
}
...
}
const getTime = () => {
const time = new Date(Date.now());
return `the time is ${time.toLocaleString('en-US', { hour: 'numeric', minute: 'numeric', hour12: true })}`
};
const getDate = () => {
const time = new Date(Date.now())
return `today is ${time.toLocaleDateString()}`;
};
const getTheWeather = (speech) => {
fetch(`http://api.openweathermap.org/data/2.5/weather?q=${speech.split(' ')[5]}&appid=58b6f7c78582bffab3936dac99c31b25&units=metric`)
.then(function(response){
return response.json();
})
.then(function(weather){
if (weather.cod === '404') {
utterThis = new SpeechSynthesisUtterance(`I cannot find the weather for ${speech.split(' ')[5]}`);
synth.speak(utterThis);
return;
}
utterThis = new SpeechSynthesisUtterance(`the weather condition in ${weather.name} is mostly full of ${weather.weather[0].description} at a temperature of ${weather.main.temp} degrees Celcius`);
synth.speak(utterThis);
});
};In the code above, we called the isFinal method on our event result which returns true or false depending on if the user is done speaking.
If the user is done speaking, we check if the transcript of what was said contains keywords such as what is the time , and so on. If it does, we call our speak function and pass it one of the three functions getTime, getDate or getTheWeather which all return a string for the browser to read.
Our index.js file should now look like this:
window.SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition;
const synth = window.speechSynthesis;
const recognition = new SpeechRecognition();
const icon = document.querySelector('i.fa.fa-microphone')
let paragraph = document.createElement('p');
let container = document.querySelector('.text-box');
container.appendChild(paragraph);
const sound = document.querySelector('.sound');
icon.addEventListener('click', () => {
sound.play();
dictate();
});
const dictate = () => {
recognition.start();
recognition.onresult = (event) => {
const speechToText = event.results[0][0].transcript;
paragraph.textContent = speechToText;
if (event.results[0].isFinal) {
if (speechToText.includes('what is the time')) {
speak(getTime);
};
if (speechToText.includes('what is today's date')) {
speak(getDate);
};
if (speechToText.includes('what is the weather in')) {
getTheWeather(speechToText);
};
}
}
}
const speak = (action) => {
utterThis = new SpeechSynthesisUtterance(action());
synth.speak(utterThis);
};
const getTime = () => {
const time = new Date(Date.now());
return `the time is ${time.toLocaleString('en-US', { hour: 'numeric', minute: 'numeric', hour12: true })}`
};
const getDate = () => {
const time = new Date(Date.now())
return `today is ${time.toLocaleDateString()}`;
};
const getTheWeather = (speech) => {
fetch(`http://api.openweathermap.org/data/2.5/weather?q=${speech.split(' ')[5]}&appid=58b6f7c78582bffab3936dac99c31b25&units=metric`)
.then(function(response){
return response.json();
})
.then(function(weather){
if (weather.cod === '404') {
utterThis = new SpeechSynthesisUtterance(`I cannot find the weather for ${speech.split(' ')[5]}`);
synth.speak(utterThis);
return;
}
utterThis = new SpeechSynthesisUtterance(`the weather condition in ${weather.name} is mostly full of ${weather.weather[0].description} at a temperature of ${weather.main.temp} degrees Celcius`);
synth.speak(utterThis);
});
};Let’s click the icon and try one of the following phrases:
- What is the time?
- What is today’s date?
- What is the weather in Lagos?
We should get a reply from the app.
Conclusion
In this article, we’ve been able to build a simple speech recognition app. There are a few more cool things we could do, like select a different voice to read to the users, but I’ll leave that for you to do.
If you have questions or feedback, please leave them as a comment below. I can’t wait to see what you build with this. You can hit me up on Twitter @developia_.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
“In this 10-year time frame, I believe that we’ll not only be using the keyboard and the mouse to interact but during that time we will have perfected speech recognition and speech output well enough that those will become a standard part of the interface.” — Bill Gates, 1 October 1997
Technology has come a long way, and with each new advancement, the human race becomes more attached to it and longs for these new cool features across all devices.
With the advent of Siri, Alexa, and Google Assistant, users of technology have yearned for speech recognition in their everyday use of the internet. In this post, I’ll be covering how to integrate native speech recognition and speech synthesis in the browser using the JavaScript WebSpeech API.
According to the Mozilla web docs:
The Web Speech API enables you to incorporate voice data into web apps. The Web Speech API has two parts: SpeechSynthesis (Text-to-Speech), and SpeechRecognition (Asynchronous Speech Recognition.)
Requirements we will need to build our application
For this simple speech recognition app, we’ll be working with just three files which will all reside in the same directory:
index.htmlcontaining the HTML for the app.style.csscontaining the CSS styles.index.jscontaining the JavaScript code.
Also, we need to have a few things in place. They are as follows:
- Basic knowledge of JavaScript.
- A web server for running the app. The Web Server for Chrome will be sufficient for this purpose.
Setting up our speech recognition app
Let’s get started by setting up the HTML and CSS for the app. Below is the HTML markup:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Speech Recognition</title>
<link rel="stylesheet" href="style.css">
<link href="https://fonts.googleapis.com/css?family=Shadows+Into+Light" rel="stylesheet">
<!-- load font awesome here for icon used on the page -->
</head>
<body>
<div class="container"> <!--page container -->
<div class="text-box" contenteditable="true"></div> <!--text box which will contain spoken text -->
<i class="fa fa-microphone"></i> <!-- microphone icon to be clicked before speaking -->
</div>
<audio class="sound" src="chime.mp3"></audio> <!-- sound to be played when we click icon => http://soundbible.com/1598-Electronic-Chime.html -->
<script src="index.js"></script> <!-- link to index.js script -->
</body>
</html>Here is its accompanying CSS style:
body {
background: #1e2440;
color: #f2efe2;
font-size: 16px;
font-family: 'Kaushan Script', cursive;
font-family: 'Shadows Into Light', cursive;
}
.container {
position: relative;
border: 1px solid #f2efe2;
width: 40vw;
max-width: 60vw;
margin: 0 auto;
border-radius: 0.1rem;
background: #f2efe2;
padding: 0.2rem 1rem;
color: #1e2440;
overflow: scroll;
margin-top: 10vh;
}
.text-box {
max-height: 70vh;
overflow: scroll;
}
.text-box:focus {
outline: none;
}
.text-box p {
border-bottom: 1px dotted black;
margin: 0px !important;
}
.fa {
color: white;
background: #1e2440;
border-radius: 50%;
cursor: pointer;
margin-top: 1rem;
float: right;
width: 2rem;
height: 2rem;
display: flex !important;
align-items: center;
justify-content: center;
}
@media (max-width: 768px) {
.container {
width: 85vw;
max-width: 85vw;
}
.text-box {
max-height: 55vh;
}
}Copying the code above should result in something similar to this:
Powering up our speech recognition app with the WebSpeech API
As of the time of writing, the WebSpeech API is only available in Firefox and Chrome. Its speech synthesis interface lives on the browser’s window object as speechSynthesis while its speech recognition interface lives on the browser’s window object as SpeechRecognition in Firefox and as webkitSpeechRecognition in Chrome.
We are going to set the recognition interface to SpeechRecognition regardless of the browser we’re on:
window.SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition;Next we’ll instantiate the speech recognition interface:
const recognition = new SpeechRecognition();
const icon = document.querySelector('i.fa.fa-microphone')
let paragraph = document.createElement('p');
let container = document.querySelector('.text-box');
container.appendChild(paragraph);
const sound = document.querySelector('.sound');In the code above, apart from instantiating speech recognition, we also selected the icon, text-box, and sound elements on the page. We also created a paragraph element which will hold the words we say, and we appended it to the text-box.
Whenever the microphone icon on the page is clicked, we want to play our sound and start the speech recognition service. To achieve this, we add a click event listener to the icon:
icon.addEventListener('click', () => {
sound.play();
dictate();
});
const dictate = () => {
recognition.start();
}In the event listener, after playing the sound, we went ahead and created and called a dictate function. The dictate function starts the speech recognition service by calling the start method on the speech recognition instance.
To return a result for whatever a user says, we need to add a result event to our speech recognition instance. The dictate function will then look like this:
const dictate = () => {
recognition.start();
recognition.onresult = (event) => {
const speechToText = event.results[0][0].transcript;
paragraph.textContent = speechToText;
}
}The resulting event returns a SpeechRecognitionEvent which contains a results object. This in turn contains the transcript property holding the recognized speech in text. We save the recognized text in a variable called speechToText and put it in the paragraph element on the page.
If we run the app at this point, click the icon and say something, it should pop up on the page.
Wrapping it up with text to speech
To add text to speech to our app, we’ll make use of the speechSynthesis interface of the WebSpeech API. We’ll start by instantiating it:
const synth = window.speechSynthesis;Next, we will create a function speak which we will call whenever we want the app to say something:
const speak = (action) => {
utterThis = new SpeechSynthesisUtterance(action());
synth.speak(utterThis);
};The speak function takes in a function called the action as a parameter. The function returns a string which is passed to SpeechSynthesisUtterance. SpeechSynthesisUtterance is the WebSpeech API interface that holds the content the speech recognition service should read. The speechSynthesis speak method is then called on its instance and passed the content to read.
To test this out, we need to know when the user is done speaking and says a keyword. Luckily there is a method to check that:
const dictate = () => {
...
if (event.results[0].isFinal) {
if (speechToText.includes('what is the time')) {
speak(getTime);
};
if (speechToText.includes('what is today's date
')) {
speak(getDate);
};
if (speechToText.includes('what is the weather in')) {
getTheWeather(speechToText);
};
}
...
}
const getTime = () => {
const time = new Date(Date.now());
return `the time is ${time.toLocaleString('en-US', { hour: 'numeric', minute: 'numeric', hour12: true })}`
};
const getDate = () => {
const time = new Date(Date.now())
return `today is ${time.toLocaleDateString()}`;
};
const getTheWeather = (speech) => {
fetch(`http://api.openweathermap.org/data/2.5/weather?q=${speech.split(' ')[5]}&appid=58b6f7c78582bffab3936dac99c31b25&units=metric`)
.then(function(response){
return response.json();
})
.then(function(weather){
if (weather.cod === '404') {
utterThis = new SpeechSynthesisUtterance(`I cannot find the weather for ${speech.split(' ')[5]}`);
synth.speak(utterThis);
return;
}
utterThis = new SpeechSynthesisUtterance(`the weather condition in ${weather.name} is mostly full of ${weather.weather[0].description} at a temperature of ${weather.main.temp} degrees Celcius`);
synth.speak(utterThis);
});
};In the code above, we called the isFinal method on our event result which returns true or false depending on if the user is done speaking.
If the user is done speaking, we check if the transcript of what was said contains keywords such as what is the time , and so on. If it does, we call our speak function and pass it one of the three functions getTime, getDate or getTheWeather which all return a string for the browser to read.
Our index.js file should now look like this:
window.SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition;
const synth = window.speechSynthesis;
const recognition = new SpeechRecognition();
const icon = document.querySelector('i.fa.fa-microphone')
let paragraph = document.createElement('p');
let container = document.querySelector('.text-box');
container.appendChild(paragraph);
const sound = document.querySelector('.sound');
icon.addEventListener('click', () => {
sound.play();
dictate();
});
const dictate = () => {
recognition.start();
recognition.onresult = (event) => {
const speechToText = event.results[0][0].transcript;
paragraph.textContent = speechToText;
if (event.results[0].isFinal) {
if (speechToText.includes('what is the time')) {
speak(getTime);
};
if (speechToText.includes('what is today's date')) {
speak(getDate);
};
if (speechToText.includes('what is the weather in')) {
getTheWeather(speechToText);
};
}
}
}
const speak = (action) => {
utterThis = new SpeechSynthesisUtterance(action());
synth.speak(utterThis);
};
const getTime = () => {
const time = new Date(Date.now());
return `the time is ${time.toLocaleString('en-US', { hour: 'numeric', minute: 'numeric', hour12: true })}`
};
const getDate = () => {
const time = new Date(Date.now())
return `today is ${time.toLocaleDateString()}`;
};
const getTheWeather = (speech) => {
fetch(`http://api.openweathermap.org/data/2.5/weather?q=${speech.split(' ')[5]}&appid=58b6f7c78582bffab3936dac99c31b25&units=metric`)
.then(function(response){
return response.json();
})
.then(function(weather){
if (weather.cod === '404') {
utterThis = new SpeechSynthesisUtterance(`I cannot find the weather for ${speech.split(' ')[5]}`);
synth.speak(utterThis);
return;
}
utterThis = new SpeechSynthesisUtterance(`the weather condition in ${weather.name} is mostly full of ${weather.weather[0].description} at a temperature of ${weather.main.temp} degrees Celcius`);
synth.speak(utterThis);
});
};Let’s click the icon and try one of the following phrases:
- What is the time?
- What is today’s date?
- What is the weather in Lagos?
We should get a reply from the app.
Conclusion
In this article, we’ve been able to build a simple speech recognition app. There are a few more cool things we could do, like select a different voice to read to the users, but I’ll leave that for you to do.
If you have questions or feedback, please leave them as a comment below. I can’t wait to see what you build with this. You can hit me up on Twitter @developia_.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
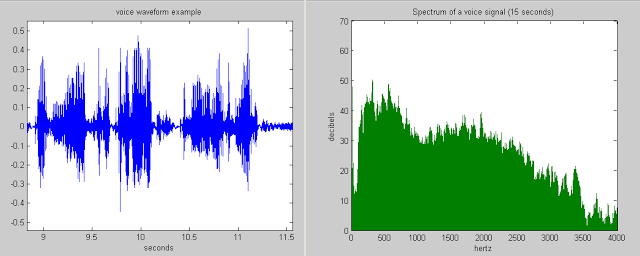
В основе систем распознавания речи стоит скрытая марковская модель, суть модели заключается в том, что при рассмотрении сигнала в промежутке небольшой длительности (от пяти до 10 миллисекунд), возможна его аппроксимация как при стационарном процессе.
Если простыми словами, скрытую марковскую модель можно объяснить на примере.
Допустим, есть два человека, которые каждый вечер созваниваются и обсуждают свои действия в течение дня. Выбор одного из друзей: ходил за покупками; гулял в парке; занимался домашними делами. При выборе активности, он полагался лишь на погоду. Второй же знал о погоде, которая была на тот момент в месте первого и, основываясь на выборе первого, мог догадаться, какая погода была в какой-то момент.
То есть, допустим, мы делим сигнал на фрагменты скажем в 10 миллисекунд и выделяем кепстральные коэффициенты, которые, по сути, являются графиком зависимости мощности от частоты сигнала отображающегося на векторе действительных чисел. Результатом скрытой марковской модели является последовательность этих векторов.
В последствии мы сопоставляем фонемы и эти векторы, а так как звук фонемы изменяется от источника к источнику, то процесс сопоставления требует обучения.
Для python существует несколько пакетов которые используются в данной сфере речи, такие как apiai, assemblyai и другие, но Speech Recognition выделяется среди них довольно высокой простотой использования.
Библиотека Speech Recognition — это, инструмент для передачи речевых API от компаний (google, microsoft, sound hound, ibm, а также pocketsphinx), который в отличие от остальных имеет возможность работы офлайн.
Для демонстрации работы в данной статье я буду использовать дефолтный Google Speech API.
Также для работы с инструментами потребуется библиотека pyAudio.
Установим библиотеку для распознавания речи:
pip install SpeechRecognition
Для работы с инструментами звукозаписи
pip install pyAudio
Бываю некие сложности с установкой pyaudio через pip, поэтому альтернативный вариант — установка pipwin или conda
Для анализа звуковых данных
pip install librosa
Для работы с wave файлами
pip install wave
и импортируем в код
import speech_recognition as speech_r
import pyaudio
import wave
Для начала нужно выставить параметры записи звука:
CHUNK = 1024 # определяет форму ауди сигнала
FRT = pyaudio.paInt16 # шестнадцатибитный формат задает значение амплитуды
CHAN = 1 # канал записи звука
RT = 44100 # частота
REC_SEC = 5 #длина записи
OUTPUT = «output.wav»
Далее нужно создать объект для обращения к устройству звукозаписи:
p = pyaudio.PyAudio()
и открыть поток для записи звука:
stream = p.open(format=FRT,channels=CHAN,rate=RT,input=True,frames_per_buffer=CHUNK) # открываем поток для записи
print(«rec»)
frames = [] # формируем выборку данных фреймов
for i in range(0, int(RT / CHUNK * REC_SEC)):
data = stream.read(CHUNK)
frames.append(data)
print(«done»)
и закрываем поток
stream.stop_stream() # останавливаем и закрываем поток
stream.close()
p.terminate()
Дальше нам нужно записать оцифрованную звуковую дорожку в файл.
Для этого нам и пригодится библиотека wave:
w = wave.open(OUTPUT, ‘wb’)
w.setnchannels(CHAN)
w.setsampwidth(p.get_sample_size(FRT))
w.setframerate(RT)
w.writeframes(b».join(frames))
w.close()
В итоге мы получаем готовую звуковую дорожку записанную с микрофона устройства и готовую к распознаванию для этого нам потребуется библиотека Speech Recognition:
sample = speech_r.WavFile(‘C:\Users\User\Desktop\1\pythonProject\output.wav’)
Непосредственно для распознавания текста нам потребуется класс Recognizer он имеет множество функций, а также определяет каким API мы будем пользоваться:
r = speech_r.Recognizer()
Открываем записанный файл.
Для расшифровки сигнала мы будем использовать метод recognize_google().
Для использования данного метода необходим объект AudioData и для дальнейшей работы требуется преобразовать сигнал в объект модуля Speech_recognition для этого существует метод record():
with sample as audio:
content = r.record(audio)
но, перед тем как передать сигнал на расшифровку, нужно очистить его от шумов. У библиотеки speech_recognition есть для этого метод adjust_for_ambient_noise()
with sample as audio:
content = r.record(audio)
r.adjust_for_ambient_noise(audio)
Так как выбранный нами Api поддерживает русский язык мы можем им воспользоваться:
print(r.recognize_google(audio, language=»ru-RU»))
Распознаватель возвращает: «Привет»
Таким образом у нас получается небольшой распознаватель речи буквально в пару строк кода. В момент, когда речь прекращается он автоматически переводит ее в текст.
Далее можно приступить к получению аналитических данных с помощью библиотеки librosa. Для начала загружаем наш файл:
A_Data = ‘C:\Users\User\Desktop\1\pythonProject\output.wav’
y , sf = librosa.load(A_Data)
в данном случае мы получаем значения временного ряда звука в качестве массива с частотой дискретизации.
Далее мы можем вернуть график массива нашей звуковой дорожки. Для работы с графиком импортируем pyplot из библиотеки matplotlib и используем librosa.display.waveplot() для построения графика массива:
import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize=(14, 5))
librosa.display.waveplot(y, sr=sf)
В самом начале я упоминал про кепстральные коэффициенты, они обычно используются для определения тембральных аспектов музыкального инструмента или голоса и мы можем построить их тепловую карту и хроматограмму.
fcc = librosa.feature.mfcc(y=y, sr=sf, hop_length=8192, n_mfcc=12)
import seaborn as sns
from matplotlib import pyplot as plt
fcc_delta = librosa.feature.delta(fcc)
sns.heatmap(fcc_delta)
plt.show()
chromo = librosa.feature.chroma_cqt(y=y, sr=sf)
sns.heatmap(chromo)
plt.show()
Надеюсь, что данный материал будет полезен при решении задач по распознаванию речи.
Вы когда-нибудь задумывались о том, как Google Assistant или Amazon Alexa распознает все, что вы говорите? Помимо огромного успеха на рынке систем распознавания, большая часть сотовых устройств имеет функцию распознавания речи через некоторые встроенные приложения или сторонние приложения.
Не обязательно, но большинство таких систем распознавания речи построено и развернуто с помощью пакетов и библиотек python. В определенной степени Python доказал, что это важный аспект обозримого будущего. Причина довольно очевидна. Чтобы включить распознавание речи в Python, вам потребуется определенный уровень интерактивности и доступности, соответствующий технологиям.
Концепция доступности заслуживает рассмотрения, потому что распознавание позволяет пожилым людям, людям с ограниченными физическими возможностями или слабовидящим людям взаимодействовать с машинами и быстро решать свои проблемы с помощью современных услуг и продуктов, не выбирая случайные приложения с графическим интерфейсом пользователя.
В этой статье мы научимся создавать систему распознавания речи и голоса на Python. Чтобы облегчить процесс понимания того, как она устроена, эта статья призвана научить вас, как построить систему с меньшими усилиями и с большим энтузиазмом. Но прежде чем перейти к проекту, давайте поговорим о некоторых не менее важных аспектах, которые нужно знать разработчику.
Как работает распознавания речи?
Прежде чем переходить к деталям и сложностям проекта, вы должны составить и понять краткий обзор работы распознавания речи. Хотя для начала работы нет никаких предварительных условий, все же хорошо владеть основами языка программирования Python.
Распознавание речи возникло в результате исследований, проведенных Bell Labs еще в 1950 году, с ограничениями только для одного говорящего и с ограниченной базой словарного запаса. Современные приложения для распознавания речи прошли долгий путь с момента появления древних аналогов.
Говоря о составляющих, первая из них – это речь. Она должна быть преобразована из звука в сигнал, который может проходить через микрофон и может быть преобразована в цифровые данные. Это делается с помощью аналого-цифрового преобразователя. После того, как данные оцифрованы, несколько моделей могут легко преобразовать звук в текст.

Современные распознаватели речи основаны на менее известной концепции Hidden Markov Model (HMM). Подход основан на предположениях, сформулированных для речевого сигнала, когда он сохраняется в течение короткого периода (скажем, пять миллисекунд), и его можно назвать стационарным процессом, то есть процессом, основанным на статистике, которая не меняется с течением времени.
В типичном HMM разделение речи по умолчанию на сигнал составляет около десяти миллисекунд, разделенных на различные фрагменты. Спектр мощности каждого фрагмента помогает сигналам построить функцию и сгенерировать частоту, которая позже отображается на вектор действительных чисел, называемый кепстральным коэффициентом.
Размеры отображаемого вектора довольно малы, всего 10, по сравнению с некоторыми точными системами, которые могут иметь размеры, достигающие 32 или более. Сгенерированный окончательный результат HMM принимает форму векторных последовательностей.
Группа векторов играет важную роль в декодировании речи в текст с помощью фонем, которые являются основными единицами речи. Вычисление фонем зависит от обучения, так как говорящие различаются, и даже у одного и того же говорящего иногда бывает разное произношение. Поэтому, чтобы справиться с этой проблемой, рассматривается специальный алгоритм, определяющий наиболее относительные слова, образующие последовательность фонем.
Весь процесс, который вы только что изучили, довольно дорог с точки зрения вычислений. Нейронные сети используются для преобразования функций и размеров в современных системах распознавания речи, снижая потребность в HMM.
Кроме того, детекторы голосовой активности (VAD) также используются для уменьшения некоторой части аудиосигнала, которая может содержать речь. В основном он используется для распознавания неважных частей речи и предотвращения их принятия во внимание.
Пакеты распознавания речи
В цепочке PyPI существует несколько пакетов для распознавания речи. Вот некоторые из них:
- Assembly
- Apia
- SpeechRecognition
- Wit
- Watson-developer-cloud
Вышеуказанные пакеты, такие как apiai и wit, предлагают функцию обработки естественного языка. Эта встроенная функция помогает определить намерения говорящего и выходит за рамки обычного распознавания речи. Другие пакеты в основном ориентированы на преобразование речи в текст.
Из вышеперечисленных пакетов выделяется только один пакет – SpeechRecognition.
Для распознавания речи требуется некоторый ввод в виде звука, и пакет SpeechRecognition легко извлекает этот тип ввода. Для доступа к микрофонам и последующей обработки звука с нуля не требуются сложные скрипты. Еще одним преимуществом этого пакета является то, что он сэкономит ваше время и может выполнить инструкции за несколько минут.
Библиотека SpeechRecognition ведет себя как обложка или оболочка для различных API, созданных исключительно для речи. Он невероятно гибкий и маневренный. Одним из таких API является API Google Web Speech, который поддерживает жестко заданное распознавание речи по умолчанию.
Библиотека SpeechRecognition очень проста в использовании, а пакет легко импортировать как проект python. Также важно отметить, что этот пакет может не включать в себя все API, доступные сегодня. Таким образом, вам нужно точно определить, какой пакет вам нужен для создания распознавателя речи.
Возможно, вы теоретически поняли сильные и слабые стороны некоторых распознавателей речи и получили представление о том, как работает распознаватель речи, давайте продолжим установку пакета SpeechRecognition в локальную среду, используя процедуры установки, приведенные ниже.
Установка SpeechRecognition
Пакет SpeechRecognition совместим с различными версиями языка Python, такими как 2.6, 2.7 и 3.3+. Также могут потребоваться другие установки, если ваша версия python устарела. Предполагая, что у вас есть версия Python 3.3+ в вашей локальной системе, вы можете выполнить метод установки с терминала с помощью pip.
$ pip install SpeechRecognition
После установки вы должны проверить, правильно ли интерпретируется установка, используя следующий код, приведенный ниже.
>>> import speech_recognition as sr >>> sr._version_'3.8.1'
SpeechRecognition может работать исключительно хорошо, если вы работаете с аудиофайлами в пакете. Однако могут потребоваться и некоторые зависимости. Поэтому, чтобы упростить этот процесс, полезен пакет PyAudio для захвата входных сигналов с микрофона.
Класс распознавателя
Магия SpeechRecognition проявляется только в присутствии класса Recognizer. Основная цель Recognizer – распознавать речь вместе с вариантами чтения различных речей, а затем управлять функциями и проверять речь, исходящую от источника звука.
Чтобы создать распознаватель, вам нужно создать его экземпляр. Итак, введите приведенный ниже код в интерпретатор Python.
>>> r=sr.Recognizer()
Существуют различные методы создания экземпляров Recognizer, которые могут распознавать речь из источника звука с поддержкой API. Некоторые из них перечислены ниже.
recognize_bing(): Microsoft Bing Speech recognize_google(): Google Web Speech API recognize_google_cloud(): Google Cloud Speech - requires installation of the google-cloud-speech package recognize_houndify(): Houndify by SoundHound recognize_ibm(): IBM Speech to Text recognize_sphinx(): CMU Sphinx - requires installing PocketSphinx recognize_wit(): Wit.ai
Из этих пакетов, пакет распознавания_sphinx() предназначен для работы в автономном режиме при использовании с CMU Sphinx Engine. Остальным пакетам для работы требуется подключение к Интернету.
Примечание: важно быть осторожным с ключом по умолчанию, предоставленным в SpeechRecognition. Он в основном используется для тестирования и в целях безопасности, и он может быть отозван Google. Таким образом, SpeechRecognition имеет интерфейс API, который может переводить эти ключи по умолчанию для осторожного использования.
Метод each_recognize _ *() может вызвать исключение с именем speech_recognition.RequestError exception. Это могло произойти из-за того, что API может быть недоступен из-за поврежденной установки. Для остальных методов, показанных выше, RequestError может быть сгенерирован, если достигнуты лимиты в рамках их квоты, или если имеются проблемы с сервером или подключением к Интернету. Может возникнуть проблема, которая выглядит примерно так.
Traceback(most recent call last): File "", line 1, in TypeError: recognize_google() missing 1 required positional argument: 'audio_data'
Работа с аудиофайлами
Перед тем как приступить к работе с пакетом SpeechRecognition в Python, вам сначала необходимо загрузить аудиофайл. SpeechRecognition упрощает работу с аудиофайлами, сохраняя их в том же каталоге интерпретатора Python, который вы используете в данный момент. Это делается с помощью класса AudioFile. Этот класс необходимо инициализировать и указать путь к аудиофайлу, чтобы диспетчер контекста предоставлял удобный интерфейс для чтения файлов и их содержимого.
Поддерживаемые типы файлов
Типы форматов файлов, которые поддерживает SpeechRecognition, указаны ниже:
- WAV: формат должен быть в PCM / LPCM
- AIFF
- AIFF-C
- FLAC: формат должен быть собственным FLAC
Если у вас Windows, Linux или macOS на базе x-86, работать с файлами FLAC проще. Помимо этих операционных систем, вам может потребоваться установить кодировщик FLAC, который даст доступ к инструменту командной строки.
Сбор данных с помощью record()
Функция record() используется для захвата данных из файла с помощью интерпретатора python в вашем файле. Например, имя файла – «harvard.wav», код интерпретатора Python для кодирования этого метода будет следующим.
>>> hardvard = sr.AudioFile('harvard.wav')
>>> with harvard as source:
Audio = r.record(source)
Этот код откроет диспетчер контекста для чтения содержимого файла и сохранит данные в экземпляре AudioFile, известном как источник. Затем метод record() запишет реальные данные из файла. Чтобы убедиться, что данные записаны, вы можете проверить это с помощью следующего кода.
>>> type(audio)
В качестве альтернативы вы также можете вызвать распознавание_google(), чтобы звук распознавался. Это может зависеть от скорости вашего интернета, от того, как записывается звук и сколько секунд отображаются результаты.
>>> r.recognize_google(audio)
Этот код будет транскрибировать все данные, присутствующие в файле, и записывать распознанный звук в текстовом формате.
Захват длительности и смещения сегмента
Если вы хотите записать в файл только определенный фрагмент речи, метод record() может сделать это, распознав ключевое слово duration, за которым следует аргумент, который останавливает речь через несколько секунд. Например, вам может потребоваться захватить первые 5 секунд речи из файла «harvard.wav»; вы можете сделать это, используя следующий метод, указанный ниже.
>>> with harvard as source:
Audio = r.record(source, duration=5)
>> >r.recognize_google(audio)
При использовании внутри блока, метод record() всегда намеревается продвигаться вперед в файловом потоке. Обычно это означает, что запись повторяется в течение четырех секунд и возвращает первый четырехсекундный звук, если вы записываете в течение первых четырех секунд. Это явление можно проиллюстрировать с помощью фрагмента кода, приведенного ниже.
>>> with harvard as source: ... audio1 = r.record(source, duration=4) ... audio2 = r.record(source, duration=4) ... >>> r.recognize_google(audio1) 'the stale smell of old beer lingers' >>> r.recognize_google(audio2) 'it takes heat to bring out the odor a cold dip.'
Вы можете заметить, что audio2 содержит часть третьей фазы звука. Также есть случаи, когда вы указываете продолжительность, и запись останавливается на полпути, что обычно ухудшает прозрачность звука.
Кроме того, при указании метода record() вы даже можете установить конкретную начальную точку, используя аргумент через ключевое слово offset. Начальная точка представляет собой количество секунд от файла до начала записи. Таким образом, чтобы захватить вторую фразу из аудиофайла, вы можете выбрать 5 или 3 секунды в зависимости от ваших потребностей, используя метод ниже.
>>> with harvard as source: ... audio = r.record(source, offset=4, duration=3) ... >>> r.recognize_google(audio)
Важность ключевого слова длительности и смещения падает на сегментацию файла, содержащего звук. Если вы уже знаете звуковые кадры, вы можете столкнуться с неточной транскрипцией. Чтобы визуализировать этот эффект, используйте следующий код, попробовав интерпретатор Python.
>>> with harvard as source: ... audio = r.record(source, offset=4.7, duration=2.8) ... >>> r.recognize_google(audio)
В приведенном выше фрагменте кода указано, что запись начинается через 4,7 секунды, и начальная фраза будет пропущена. Точно так же, когда запись закончится, захваченная фраза не будет соответствовать фазе начала.
Еще одна причина пропуска фраз, которая приводит к неточной транскрипции, – это шум. Чистый звук может хорошо работать, но в реальном мире нет такого места без шума.
Влияние шума на распознавание речи
Нет места без шума. Все методы распознавания речи были разработаны для устранения и уменьшения нежелательного шума, присутствующего в речи, который снижает мощность захвата аудиокадров. Шум может снизить точность приложений.
Чтобы понять, как шум влияет на распознавание речи, вам необходимо загрузить файл с именем «jackhammer.wav» и убедиться, что он сохранен в рабочем каталоге интерпретатора. Предполагая, что в этом файле громко произносится фраза «JavaTpoint – лучший сайт обучения java», вам необходимо записать ее в фоновом режиме. Для этого рассмотрим метод ниже.
>>> jackhammer = sr.AudioFile('jackhammer.wav')
>>> with jackhammer as source:
... audio = r.record(source)
...
>>> r.recognize_google(audio)
Чтобы справиться с шумом, можно попробовать еще один метод после вышеуказанного шага – использовать метод adjust_for_ambient_noise() класса Recognizer.
>>> with jackhammer as source: ... r.adjust_for_ambient_noise(source) ... audio = r.record(source) ... >>> r.recognize_google(audio)
В приведенном выше фрагменте кода отсутствует начальный вывод, а вывод печатается без первого слова. Следовательно, когда метод record() захватывает звук, первая часть аудиофайла потребляется, а последующие данные захватываются. Метод adjust_for_ambient_noise() считывает первую секунду аудиофайла, а Recognizer калибрует уровень шума аудио.
Если вы хотите настроить временные рамки с помощью adjust_for_ambient_noise(), вы можете использовать ключевое слово duration во фрагменте кода, присвоив ему числовое значение в секундах. Если вы не присваиваете никакого значения, по умолчанию принимается одно значение, но рекомендуется уменьшить его до 0,5. Следующий фрагмент кода демонстрирует ту же технику.
>>> with jackhammer as source: ... r.adjust_for_ambient_noise(source, duration=0.5) ... audio = r.record(source) ... >>> r.recognize_google(audio)
Приведенный выше фрагмент кода вернет весь аудиофайл, который вы ранее пропустили в начале. Хотя в некоторых случаях очень сложно обработать или устранить эффект шума, потому что сигнал может быть слишком шумным, чтобы с ним можно было справиться.
Поэтому вам, возможно, придется прибегнуть к другим методам предварительной обработки звука для решения такой проблемы. Для этого вы можете использовать программное обеспечение для редактирования аудио или пакет Python, например SciPy. Пакет может предварительно обработать аудиофайл и отфильтровать шум.
Кроме того, при работе с зашумленными файлами полезно использовать фактический ответ API, поскольку большинство API возвращают строки JSON с множеством транскрипций.
Точно так же метод распознавания_google() обязан доставить аналогичные зашифрованные файлы, если только он не принудительно доставляет полный ответ. Этот метод может быть практически реализован с использованием определенных аргументов и ключевых слов, таких как show_all, который возвращается для метода accept_google().
>>> r.recognize_google(audio, show_all=True)
{'alternative': [
{'transcript': 'javatpoint best is the programming site'},
{'transcript': 'the javatpoint site is best programming'},
{'transcript': 'javatpoint programming is the best site'},
{'transcript': 'the programming is javatpoint best site'},
{'transcript': 'best is the programming site javatpoint'},
], 'final': True}
В приведенном выше фрагменте кода метод accept_google() возвращает словарь с альтернативным ключом, который указывает на различные транскрипции, показанные выше. Хотя структура ответа может иметь разные формы из-за различий от API к API, она в основном используется для отладки.
К настоящему моменту вы ознакомились с основами распознавания речи и его пакетами на Python. Следующий этап обучения включает в себя расшифровку аудиофайлов, делая проект более интерактивным, принимая входные данные с микрофона.
Тренировка с микрофонным входом
Вы можете получить доступ к своему микрофону с помощью пакета SpeechRecognizer, установив пакет с именем PyAudio. Для этого сохраните текущие изменения и закройте интерпретатор. Затем установите PyAudio с помощью того же процесса, что и для SpeechRecognizer.
$ pip install pyaudio
После установки, чтобы проверить, совместима ли она с используемой версией распознавателя речи, введите следующую команду.
$ python -m speech_recognizer
После этого шага вам необходимо убедиться, что ваш микрофон по умолчанию включен и не приглушен. Если вы не столкнулись с какими-либо проблемами при установке и тестировании, вы должны увидеть что-то подобное на терминале.
A moment of silence, please? Set minimum energy threshold to 600.4452854381937 Say something!
Попробуйте поиграть, опробовав микрофон и проверив, как пакет SpeechRecognizer расшифровывает вашу речь.
Класс микрофона
Класс микрофона используется для создания экземпляра системы для распознавания аудиофайла из источника. Чтобы использовать этот класс, вам необходимо импортировать его, открыв другой сеанс интерпретатора и создав класс распознавателя, как показано ниже.
>>> import speech_recognizer as sr >>> r.=sr.Recognizer()
Вам необходимо использовать микрофон по умолчанию в системе вместо использования аудиофайла из источника. Вы можете сделать это, используя показанный ниже метод.
>>> mic = sr.Microphone()
Если вы не можете распознать микрофон по умолчанию вашей системы, вам может потребоваться указать один из индексов устройства. Вы можете получить список всех доступных имен микрофонов с помощью метода list_microphone_names() в классе микрофона.
>>> sr.Microphone.list_microphone_names() ['HDA Intel PCH: ALC272 Analog(hw:0,0)', 'HDA Intel PCH: HDMI 0(hw:0,3)', 'sysdefault', 'front', 'surround40', 'surround51', 'surround71', 'hdmi', 'pulse', 'dmix', 'default']
Индекс устройства, определенный в приведенном выше коде, известен как индекс, содержащий список доступных имен микрофонов в системе. Например, в приведенном выше выводе микрофон с названием «передний» расположен в списке под индексом 3. Это можно сделать с помощью метода, приведенного ниже.
>>> mic = sr.Microphone(device_index=3)
Код является всего лишь примером, поэтому его не рекомендуется запускать в интерпретаторе. Для большинства проектов следует использовать системный микрофон по умолчанию.
Ввод микрофона с помощью listen()
Другой метод, который вы здесь изучите, – это метод listen(), используемый для захвата ввода с микрофона. Поскольку вы уже создали экземпляр микрофона, самое время сделать ввод.
Как и большинство классов AudioFile, микрофон также рассматривается как диспетчер контекста. Он захватывает ввод через класс Recognizer, имеющий внутри блок, принимая его в качестве первого аргумента, а затем записывает ввод из источника до момента, когда микрофон обнаруживает тишину. Чтобы обрисовать это, давайте посмотрим, как это применяется с использованием данного кода.
>>> with mic as source: ... audio = r.listen(source) ...
После того, как приведенный выше код будет выполнен с блоком, вы должны попробовать что-то сказать в микрофон и подождать некоторое время. Через некоторое время интерпретатор может предложить отобразить. Как только вы увидите “>>>” в качестве возвращенного приглашения, это означает, что распознаватель сможет распознать все, что вы говорите.
Если Recognizer не возвращает подсказку, возможно, слышен некоторый внешний шум. Вы можете остановить это, нажав Ctrl + C, чтобы запросить ответ.
Чтобы настроить шум, преобладающий в вашей речи, вам может потребоваться использовать тот же метод adjust_for_ambient_noise() класса Recognizer. Поскольку вход микрофона непредсказуем по сравнению с аудиофайлом, всегда рекомендуется делать это во время прослушивания входного сигнала микрофона. Чтобы получить точный и бесшумный вывод, вы можете попробовать его с помощью метода listen(), как показано.
>>> with mic as source: ... r.adjust_for_ambient_noise(source) ... audio = r.listen(source) ...
При запуске кода подождите несколько секунд, чтобы метод adjust_for_ambient Noise() выполнил свои задачи. После того, как код скомпилирован и запущен, попробуйте сказать что-нибудь в микрофон и подождите, пока переводчик распознает речь. Если он распознает и возвращает приглашение, значит, он работает нормально.
Вы также можете использовать ключевое слово duration и попытаться использовать его снова для получения определенного кадра речи, которую хотите распознать. Между тем, документация SpeechRecognizer рекомендует использовать ключевое слово duration, если оно имеет продолжительность 0,5 или меньше.
Вы также можете обнаружить, что ключевое слово duration не используется в некоторых случаях, и, следовательно, оно имеет значение по умолчанию для получения лучших результатов. Кроме того, возможно, что минимальное значение зависит от входа микрофона. Следовательно, продолжительность одной секунды предпочтительно считается лучшей для такого рода задач.
Нераспознаваемая речь
С помощью thebcodebase вы создали в интерпретаторе ощутимый код, используя микрофон, чтобы добавить неразборчивые шумы. Совершенно очевидно, что вы можете получить подобное сообщение об ошибке.
Traceback(most recent call last):
File "", line 1, in
File
"/home/david/real_python/speech_recognition_primer/venv/lib/pyth
on3.5/site-packages/speech_recognition/__init__.py", line 858, in recognize_google
if not isinstance(actual_result, dict) or
len(actual_result.get("alternative", [])) == 0: raise
UnknownValueError()
speech_recognition.UnknownValueError
Эта ошибка возникает из-за нераспознанного характера речи, захваченной через микрофон в качестве входной, и, следовательно, кодовая база API недостаточно развита, чтобы транскрибировать эти короткие посторонние шумы или звуки голоса.
Также может быть случай, когда переводчик может подсказывать, распознавая текущий ввод и отображая что-то, даже не близкое к тому, что было захвачено через микрофон. Следовательно, такие действия, как хлопки в ладоши, щелчки или другие полосы, могут вызвать исключение или неправильный вывод, соответственно.
Резюме
В этом длинном руководстве по распознаванию речи в Python вы с нуля узнали, как работает расписание. Вы прошли путь от концептуальных знаний до практического опыта по созданию простого распознавателя речи на Python в реальном времени, который может слышать вашу речь и отображать ее в текстовом формате на консоли.
Вы также узнали о некоторых критических методах решения проблемы, которая обычно возникает при использовании пакета SpeechRecognizer, и выяснили, как исправить эти проблемы.
Python, являющийся широко используемым языком программирования и сценариев, охватывает большинство приложений распознавания речи с помощью его внешних библиотек и фреймворков, которые демонстрируют его способность справляться с критическими проблемами с помощью всего нескольких строк простого и читаемого кода.


Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.

Распознавание речи, как следует из названия, относится к автоматическому распознаванию человеческой речи. Распознавание речи является одной из важнейших задач в области взаимодействия человека с компьютером. Если вы когда-либо общались с Alexa или когда-либо приказывали Сири выполнить задание, вы уже испытали силу распознавания речи.
Распознавание речи имеет различные приложения — от автоматической транскрипции речевых данных (например, голосовой почты) до взаимодействия с роботами посредством речи.
В этом руководстве вы увидите, как мы можем разработать очень простое приложение для распознавания речи, способное распознавать речь как из аудиофайлов, так и в режиме реального времени с микрофона. Итак, начнем без дальнейших церемоний.
В Python было разработано несколько библиотек распознавания речи. Однако мы будем использовать библиотеку SpeechRecognition, которая является самой простой из всех библиотек.
Установка библиотеки SpeechRecognition
Выполните следующую команду для установки библиотеки:
pip install SpeechRecognitionРаспознавание речи из аудио файлов
В этом разделе вы увидите, как мы можем переводить речь из аудиофайла в текст. Аудиофайл, который мы будем использовать в качестве входных данных, можно скачать по этой ссылке. Загрузите файл в вашу локальную файловую систему.
Первым шагом, как всегда, является импорт необходимых библиотек. В этом случае нам нужно импортировать только что загруженную библиотеку speech_recognition.
import speech_recognition as speech_recog
Для преобразования речи в текст нам нужен единственный класс — это класс Recognizer из модуля speech_recognition. В зависимости от базового API, используемого для преобразования речи в текст, класс Recognizer имеет следующие методы:
recognize_bing(): Использует Microsoft Bing Speech APIrecognize_google(): Использует Google Speech APIrecognize_google_cloud(): Использует Google Cloud Speech APIrecognize_houndify(): Использует Houndify API от SoundHoundrecognize_ibm(): Использует IBM Speech to Text APIrecognize_sphinx(): Использует PocketSphinx API
Среди всех вышеперечисленных способов метод recognize_sphinx() можно использовать в автономном режиме для перевода речи в текст.
Чтобы распознать речь из аудиофайла, мы должны создать объект класса AudioFile модуля speech_recognition. Путь аудиофайла, который вы хотите перевести в текст, передается в конструктор класса AudioFile. Выполните следующий скрипт:
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
В приведенном выше коде обновите путь к аудиофайлу, который вы хотите расшифровать.
Мы будем использовать метод recognize_google() для расшифровки наших аудио файлов. Тем не менее, метод recognize_google() требует объект AudioData модуля speech_recognition в качестве параметра. Чтобы преобразовать наш аудиофайл в объект AudioData, мы можем использовать метод record() класса Recognizer. Нам нужно передать объект AudioFile методу record(), как показано ниже:
with sample_audio as audio_file:
audio_content = recog.record(audio_file)
Теперь, если вы проверите тип переменной audio_content, вы увидите, что она имеет тип speech_recognition.AudioData.
Результат:
speech_recognition.AudioData
Теперь мы можем просто передать объект audio_content методу recognize_google() объекта класса Recognizer(), и аудиофайл будет преобразован в текст. Выполните следующий скрипт:
recog.recognize_google(audio_content)
Результат:
'Bristol O2 left shoulder take the winding path to reach the lake no closely the size of the gas tank degrees office 30 face before you go out the race was badly strained and hung them the stray cat gave birth to kittens the young girl gave no clear response the meal was called before the bells ring what weather is in living'
Приведенный выше результат показывает текст аудиофайла. Вы можете видеть, что файл не был на 100% правильно транскрибирован, но точность довольно разумная.
Установка длительности и значений смещения
Вместо того, чтобы транскрибировать полную речь, вы также можете транскрибировать определенный сегмент аудиофайла. Например, если вы хотите транскрибировать только первые 10 секунд аудиофайла, вам нужно передать 10 в качестве значения параметра duration метода record(). Посмотрите на следующий скрипт:
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
with sample_audio as audio_file:
audio_content = recog.record(audio_file, duration=10)
recog.recognize_google(audio_content)
Результат:
'Bristol O2 left shoulder take the winding path to reach the lake no closely the size of the gas'
Таким же образом вы можете пропустить некоторую часть аудиофайла с самого начала, используя параметр offset. Например, если вы не хотите транскрибировать первые 4 секунды звука, передайте 4 в качестве значения для атрибута offset. Например, следующий скрипт пропускает первые 4 секунды аудиофайла, а затем транскрибирует аудиофайл в течение 10 секунд.
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
with sample_audio as audio_file:
audio_content = recog.record(audio_file, offset=4, duration=10)
recog.recognize_google(audio_content)
Результат:
'take the winding path to reach the lake no closely the size of the gas tank web degrees office dirty face'
Обработка шума
Аудио файл может содержать шум по разным причинам. Шум действительно может повлиять на качество перевода речи в текст. Чтобы уменьшить шум, класс Recognizer содержит метод adjust_for_ambient_noise(), который принимает объект AudioData в качестве параметра. Следующий скрипт показывает, как можно улучшить качество транскрипции, удалив шум из аудиофайла:
sample_audio = speech_recog.AudioFile('E:/Datasets/my_audio.wav')
with sample_audio as audio_file:
recog.adjust_for_ambient_noise(audio_file)
audio_content = recog.record(audio_file)
recog.recognize_google(audio_content)
Результат:
'Bristol O2 left shoulder take the winding path to reach the lake no closely the size of the gas tank web degrees office 30 face before you go out the race was badly strained and hung them the stray cat gave birth to kittens the younger again no clear response the mail was called before the bells ring what weather is in living'
Вывод очень похож на то, что мы получили ранее; это связано с тем, что в аудиофайле уже было очень мало шума.
Распознавание речи с живого микрофона
В этом разделе вы увидите, как вы можете транслировать живое аудио, полученное через микрофон в вашей системе.
Существует несколько способов обработки аудиовхода, полученного через микрофон, и для этого были разработаны различные библиотеки. Одной из таких библиотек является PyAudio. Выполните следующий скрипт для установки библиотеки PyAudio:
Теперь источником транскрибируемого звука является микрофон. Чтобы захватить звук с микрофона, нам нужно сначала создать объект класса Microphone модуля Speach_Recogniton, как показано ниже:
mic = speech_recog.Microphone()
Чтобы увидеть список всех микрофонов в вашей системе, вы можете использовать метод list_microphone_names():
speech_recog.Microphone.list_microphone_names()
Результат:
['Microsoft Sound Mapper - Input',
'Microphone (Realtek High Defini',
'Microsoft Sound Mapper - Output',
'Speakers (Realtek High Definiti',
'Microphone Array (Realtek HD Audio Mic input)',
'Speakers (Realtek HD Audio output)',
'Stereo Mix (Realtek HD Audio Stereo input)']
Это список микрофонов, доступных в моей системе. Имейте в виду, что ваш список, скорее всего, будет выглядеть иначе.
Следующим шагом является захват звука с микрофона. Для этого вам нужно вызвать метод listen() класса Recognizer(). Как и метод record(), метод listen() также возвращает объект speech_recognition.AudioData, который затем может быть передан методу recognize_google().
Следующий скрипт предлагает пользователю что-то сказать в микрофон, а затем печатает все, что сказал пользователь:
with mic as audio_file:
print("Speak Please")
recog.adjust_for_ambient_noise(audio_file)
audio = recog.listen(audio_file)
print("Converting Speech to Text...")
print("You said: " + recog.recognize_google(audio))
Как только вы выполните приведенный выше скрипт, вы увидите следующее сообщение:
В этот момент произнесите все, что хотите, и сделайте паузу. Как только вы сделали паузу, вы увидите транскрипцию всего, что вы сказали. Вот результат, который я получил:
Converting Speech to Text...
You said: hello this is normally from stack abuse abuse this is an article on speech recognition I hope you will like it and this is just a test speech and when I will stop speaking are you in today thank you for Reading
Важно отметить, что если метод recognize_google() не может сопоставить слова, которые вы говорите, с любым из слов в своем хранилище, выдается исключение. Вы можете проверить это, сказав несколько непонятных слов. Вы должны увидеть следующее исключение:
Speak Please
Converting Speech to Text...
---------------------------------------------------------------------------
UnknownValueError Traceback (most recent call last)
in
8 print("Converting Speech to Text...")
9
---> 10 print("You said: " + recog.recognize_google(audio))
11
12
~Anaconda3libsite-packagesspeech_recognition__init__.py in recognize_google(self, audio_data, key, language, show_all)
856 # return results
857 if show_all: return actual_result
--> 858 if not isinstance(actual_result, dict) or len(actual_result.get("alternative", [])) == 0: raise UnknownValueError()
859
860 if "confidence" in actual_result["alternative"]:
UnknownValueError:
Лучшим подходом является использование блока try при вызове метода recognize_google(), как показано ниже:
with mic as audio_file:
print("Speak Please")
recog.adjust_for_ambient_noise(audio_file)
audio = recog.listen(audio_file)
print("Converting Speech to Text...")
try:
print("You said: " + recog.recognize_google(audio))
except Exception as e:
print("Error: " + str(e))
Вывод
Распознавание речи имеет различные полезные приложения в области взаимодействия человека с компьютером и автоматической транскрипции речи. В этой статье кратко объясняется процесс транскрипции речи в Python через библиотеку speech_recognition и объясняется, как переводить речь в текст, когда источником звука является аудиофайл или живой микрофон.

96 434
25 декабря 2018 в 17:03
На Python можно строить как простые программы, так и сложные ИИ системы. В данной статье мы покажем как реализовать распознавание голоса и выполнение различных команд.
Перед стартом работы, вам стоит убедиться в нескольких вещах:
- у вас установлен Python на вашем компьютере;
- у вас установлен текстовый редактор, к примеру PyCharm;
- у вас установлен пакетный менеджер Pip.
Установка библиотек
Для распознавания голоса вам необходимо установить библиотеки:
- SpeechRecognition — команда
pip install SpeechRecognition; - gTTS — команда
pip install gTTS; - PyAudio — команда
pip install PyAudio.
Все библиотеки стоит устанавливать через терминал в ваш проект через программу PyCharm:

После установки всех библиотек начните прописывать код самой программы. Ниже мы приведем весь код программы с комментариями, дабы вам было проще в нём разобраться:
# Подключение всех необходимых библиотек
# Нам нужно: speech_recognition, os, sys, webbrowser
# Для первой бибилотеки прописываем также псевдоним
import speech_recognition as sr
import os
import sys
import webbrowser
# Функция, позволяющая проговаривать слова
# Принимает параметр "Слова" и прогроваривает их
def talk(words):
print(words) # Дополнительно выводим на экран
os.system("say " + words) # Проговариваем слова
# Вызов функции и передача строки
# именно эта строка будет проговорена компьютером
talk("Привет, чем я могу помочь вам?")
"""
Функция command() служит для отслеживания микрофона.
Вызывая функцию мы будет слушать что скажет пользователь,
при этом для прослушивания будет использован микрофон.
Получение данные будут сконвертированы в строку и далее
будет происходить их проверка.
"""
def command():
# Создаем объект на основе библиотеки
# speech_recognition и вызываем метод для определения данных
r = sr.Recognizer()
# Начинаем прослушивать микрофон и записываем данные в source
with sr.Microphone() as source:
# Просто вывод, чтобы мы знали когда говорить
print("Говорите")
# Устанавливаем паузу, чтобы прослушивание
# началось лишь по прошествию 1 секунды
r.pause_threshold = 1
# используем adjust_for_ambient_noise для удаления
# посторонних шумов из аудио дорожки
r.adjust_for_ambient_noise(source, duration=1)
# Полученные данные записываем в переменную audio
# пока мы получили лишь mp3 звук
audio = r.listen(source)
try: # Обрабатываем все при помощи исключений
"""
Распознаем данные из mp3 дорожки.
Указываем что отслеживаемый язык русский.
Благодаря lower() приводим все в нижний регистр.
Теперь мы получили данные в формате строки,
которые спокойно можем проверить в условиях
"""
zadanie = r.recognize_google(audio, language="ru-RU").lower()
# Просто отображаем текст что сказал пользователь
print("Вы сказали: " + zadanie)
# Если не смогли распознать текст, то будет вызвана эта ошибка
except sr.UnknownValueError:
# Здесь просто проговариваем слова "Я вас не поняла"
# и вызываем снова функцию command() для
# получения текста от пользователя
talk("Я вас не поняла")
zadanie = command()
# В конце функции возвращаем текст задания
# или же повторный вызов функции
return zadanie
# Данная функция служит для проверки текста,
# что сказал пользователь (zadanie - текст от пользователя)
def makeSomething(zadanie):
# Попросту проверяем текст на соответствие
# Если в тексте что сказал пользователь есть слова
# "открыть сайт", то выполняем команду
if 'открыть сайт' in zadanie:
# Проговариваем текст
talk("Уже открываю")
# Указываем сайт для открытия
url = 'https://itproger.com'
# Открываем сайт
webbrowser.open(url)
# если было сказано "стоп", то останавливаем прогу
elif 'стоп' in zadanie:
# Проговариваем текст
talk("Да, конечно, без проблем")
# Выходим из программы
sys.exit()
# Аналогично
elif 'имя' in zadanie:
talk("Меня зовут Сири")
# Вызов функции для проверки текста будет
# осуществляться постоянно, поэтому здесь
# прописан бесконечный цикл while
while True:
makeSomething(command())Как видите, программа простая и не требует гигантского количества строчек кода. Сам код можете подстраивать в любую программу, дабы добавить в неё функционал прослушивания речи.
Также предлагаем посмотреть видео, где все описано еще более детально:
Полезные ссылки из видео:
- Скачать редактор PyCharm;
- Скачать пакетный менеджер Pip;
- Скачать Homebrew для установки PyAudio;
- Пример установки библиотеки PyAudio;
- Поддержка различных языков.
Больше интересных новостей