О чем данный учебник
Данный учебник представляет собой что-то типа «штампа моей памяти» по языку SQL (DDL, DML), т.е. это информация, которая накопилась по ходу профессиональной деятельности и постоянно хранится в моей голове. Это для меня достаточный минимум, который применяется при работе с базами данных наиболее часто. Если встает необходимость применять более полные конструкции SQL, то я обычно обращаюсь за помощью в библиотеку MSDN расположенную в интернет. На мой взгляд, удержать все в голове очень сложно, да и нет особой необходимости в этом. Но знать основные конструкции очень полезно, т.к. они применимы практически в таком же виде во многих реляционных базах данных, таких как Oracle, MySQL, Firebird. Отличия в основном состоят в типах данных, которые могут отличаться в деталях. Основных конструкций языка SQL не так много, и при постоянной практике они быстро запоминаются. Например, для создания объектов (таблиц, ограничений, индексов и т.п.) достаточно иметь под рукой текстовый редактор среды (IDE) для работы с базой данных, и нет надобности изучать визуальный инструментарий заточенный для работы с конкретным типом баз данных (MS SQL, Oracle, MySQL, Firebird, …). Это удобно и тем, что весь текст находится перед глазами, и не нужно бегать по многочисленным вкладкам для того чтобы создать, например, индекс или ограничение. При постоянной работе с базой данных, создать, изменить, а особенно пересоздать объект при помощи скриптов получается в разы быстрее, чем если это делать в визуальном режиме. Так же в скриптовом режиме (соответственно, при должной аккуратности), проще задавать и контролировать правила наименования объектов (мое субъективное мнение). К тому же скрипты удобно использовать в случае, когда изменения, делаемые в одной базе данных (например, тестовой), необходимо перенести в таком же виде в другую базу (продуктивную).
Язык SQL подразделяется на несколько частей, здесь я рассмотрю 2 наиболее важные его части:
- DDL – Data Definition Language (язык описания данных)
- DML – Data Manipulation Language (язык манипулирования данными), который содержит следующие конструкции:
- SELECT – выборка данных
- INSERT – вставка новых данных
- UPDATE – обновление данных
- DELETE – удаление данных
- MERGE – слияние данных
Т.к. я являюсь практиком, как таковой теории в данном учебнике будет мало, и все конструкции будут объясняться на практических примерах. К тому же я считаю, что язык программирования, а особенно SQL, можно освоить только на практике, самостоятельно пощупав его и поняв, что происходит, когда вы выполняете ту или иную конструкцию.
Данный учебник создан по принципу Step by Step, т.е. необходимо читать его последовательно и желательно сразу же выполняя примеры. Но если по ходу у вас возникает потребность узнать о какой-то команде более детально, то используйте конкретный поиск в интернет, например, в библиотеке MSDN.
При написании данного учебника использовалась база данных MS SQL Server версии 2014, для выполнения скриптов я использовал MS SQL Server Management Studio (SSMS).
Кратко о MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) — утилита для Microsoft SQL Server для конфигурирования, управления и администрирования компонентов базы данных. Данная утилита содержит редактор скриптов (который в основном и будет нами использоваться) и графическую программу, которая работает с объектами и настройками сервера. Главным инструментом SQL Server Management Studio является Object Explorer, который позволяет пользователю просматривать, извлекать объекты сервера, а также управлять ими. Данный текст частично позаимствован с википедии.
Для создания нового редактора скрипта используйте кнопку «New Query/Новый запрос»:
Для смены текущей базы данных можно использовать выпадающий список:

Для выполнения определенной команды (или группы команд) выделите ее и нажмите кнопку «Execute/Выполнить» или же клавишу «F5». Если в редакторе в текущий момент находится только одна команда, или же вам необходимо выполнить все команды, то ничего выделять не нужно.
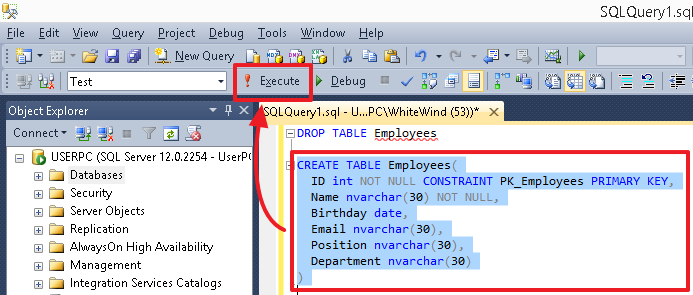
После выполнения скриптов, в особенности создающих объекты (таблицы, столбцы, индексы), чтобы увидеть изменения, используйте обновление из контекстного меню, выделив соответствующую группу (например, Таблицы), саму таблицу или группу Столбцы в ней.
Собственно, это все, что нам необходимо будет знать для выполнения приведенных здесь примеров. Остальное по утилите SSMS несложно изучить самостоятельно.
Немного теории
Реляционная база данных (РБД, или далее в контексте просто БД) представляет из себя совокупность таблиц, связанных между собой. Если говорить грубо, то БД – файл в котором данные хранятся в структурированном виде.
СУБД – Система Управления этими Базами Данных, т.е. это комплекс инструментов для работы с конкретным типом БД (MS SQL, Oracle, MySQL, Firebird, …).
Примечание
Т.к. в жизни, в разговорной речи, мы по большей части говорим: «БД Oracle», или даже просто «Oracle», на самом деле подразумевая «СУБД Oracle», то в контексте данного учебника иногда будет употребляться термин БД. Из контекста, я думаю, будет понятно, о чем именно идет речь.
Таблица представляет из себя совокупность столбцов. Столбцы, так же могут называть полями или колонками, все эти слова будут использоваться как синонимы, выражающие одно и тоже.
Таблица – это главный объект РБД, все данные РБД хранятся построчно в столбцах таблицы. Строки, записи – тоже синонимы.
Для каждой таблицы, как и ее столбцов задаются наименования, по которым впоследствии к ним идет обращение.
Наименование объекта (имя таблицы, имя столбца, имя индекса и т.п.) в MS SQL может иметь максимальную длину 128 символов.
Для справки – в БД ORACLE наименования объектов могут иметь максимальную длину 30 символов. Поэтому для конкретной БД нужно вырабатывать свои правила для наименования объектов, чтобы уложиться в лимит по количеству символов.
SQL — язык позволяющий осуществлять запросы в БД посредством СУБД. В конкретной СУБД, язык SQL может иметь специфичную реализацию (свой диалект).
DDL и DML — подмножество языка SQL:
- Язык DDL служит для создания и модификации структуры БД, т.е. для создания/изменения/удаления таблиц и связей.
- Язык DML позволяет осуществлять манипуляции с данными таблиц, т.е. с ее строками. Он позволяет делать выборку данных из таблиц, добавлять новые данные в таблицы, а так же обновлять и удалять существующие данные.
В языке SQL можно использовать 2 вида комментариев (однострочный и многострочный):
-- однострочный комментарий
и
/*
многострочный
комментарий
*/
Собственно, все для теории этого будет достаточно.
DDL – Data Definition Language (язык описания данных)
Для примера рассмотрим таблицу с данными о сотрудниках, в привычном для человека не являющимся программистом виде:
| Табельный номер | ФИО | Дата рождения | Должность | Отдел | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | i.ivanov@test.tt | Директор | Администрация |
| 1001 | Петров П.П. | 03.12.1983 | p.petrov@test.tt | Программист | ИТ |
| 1002 | Сидоров С.С. | 07.06.1976 | s.sidorov@test.tt | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | 17.04.1982 | a.andreev@test.tt | Старший программист | ИТ |
В данном случае столбцы таблицы имеют следующие наименования: Табельный номер, ФИО, Дата рождения, E-mail, Должность, Отдел.
Каждый из этих столбцов можно охарактеризовать по типу содержащемся в нем данных:
- Табельный номер – целое число
- ФИО – строка
- Дата рождения – дата
- E-mail – строка
- Должность – строка
- Отдел – строка
Тип столбца – характеристика, которая говорит о том какого рода данные может хранить данный столбец.
Для начала будет достаточно запомнить только следующие основные типы данных используемые в MS SQL:
| Значение | Обозначение в MS SQL | Описание |
|---|---|---|
| Строка переменной длины | varchar(N) и nvarchar(N) |
При помощи числа N, мы можем указать максимально возможную длину строки для соответствующего столбца. Например, если мы хотим сказать, что значение столбца «ФИО» может содержать максимум 30 символов, то необходимо задать ей тип nvarchar(30). Отличие varchar от nvarchar заключается в том, что varchar позволяет хранить строки в формате ASCII, где один символ занимает 1 байт, а nvarchar хранит строки в формате Unicode, где каждый символ занимает 2 байта. Тип varchar стоит использовать только в том случае, если вы на 100% уверены, что в данном поле не потребуется хранить Unicode символы. Например, varchar можно использовать для хранения адресов электронной почты, т.к. они обычно содержат только ASCII символы. |
| Строка фиксированной длины | char(N) и nchar(N) |
От строки переменной длины данный тип отличается тем, что если длина строка меньше N символов, то она всегда дополняется справа до длины N пробелами и сохраняется в БД в таком виде, т.е. в базе данных она занимает ровно N символов (где один символ занимает 1 байт для char и 2 байта для типа nchar). На моей практике данный тип очень редко находит применение, а если и используется, то он используется в основном в формате char(1), т.е. когда поле определяется одним символом. |
| Целое число | int | Данный тип позволяет нам использовать в столбце только целые числа, как положительные, так и отрицательные. Для справки (сейчас это не так актуально для нас) – диапазон чисел который позволяет тип int от -2 147 483 648 до 2 147 483 647. Обычно это основной тип, который используется для задания идентификаторов. |
| Вещественное или действительное число | float | Если говорить простым языком, то это числа, в которых может присутствовать десятичная точка (запятая). |
| Дата | date | Если в столбце необходимо хранить только Дату, которая состоит из трех составляющих: Числа, Месяца и Года. Например, 15.02.2014 (15 февраля 2014 года). Данный тип можно использовать для столбца «Дата приема», «Дата рождения» и т.п., т.е. в тех случаях, когда нам важно зафиксировать только дату, или, когда составляющая времени нам не важна и ее можно отбросить или если она не известна. |
| Время | time | Данный тип можно использовать, если в столбце необходимо хранить только данные о времени, т.е. Часы, Минуты, Секунды и Миллисекунды. Например, 17:38:31.3231603 Например, ежедневное «Время отправления рейса». |
| Дата и время | datetime | Данный тип позволяет одновременно сохранить и Дату, и Время. Например, 15.02.2014 17:38:31.323 Для примера это может быть дата и время какого-нибудь события. |
| Флаг | bit | Данный тип удобно применять для хранения значений вида «Да»/«Нет», где «Да» будет сохраняться как 1, а «Нет» будет сохраняться как 0. |
Так же значение поля, в том случае если это не запрещено, может быть не указано, для этой цели используется ключевое слово NULL.
Для выполнения примеров создадим тестовую базу под названием Test.
Простую базу данных (без указания дополнительных параметров) можно создать, выполнив следующую команду:
CREATE DATABASE Test
Удалить базу данных можно командой (стоит быть очень осторожным с данной командой):
DROP DATABASE Test
Для того, чтобы переключиться на нашу базу данных, можно выполнить команду:
USE Test
Или же выберите базу данных Test в выпадающем списке в области меню SSMS. При работе мною чаще используется именно этот способ переключения между базами.
Теперь в нашей БД мы можем создать таблицу используя описания в том виде как они есть, используя пробелы и символы кириллицы:
CREATE TABLE [Сотрудники](
[Табельный номер] int,
[ФИО] nvarchar(30),
[Дата рождения] date,
[E-mail] nvarchar(30),
[Должность] nvarchar(30),
[Отдел] nvarchar(30)
)
В данном случае нам придется заключать имена в квадратные скобки […].
Но в базе данных для большего удобства все наименования объектов лучше задавать на латинице и не использовать в именах пробелы. В MS SQL обычно в данном случае каждое слово начинается с прописной буквы, например, для поля «Табельный номер», мы могли бы задать имя PersonnelNumber. Так же в имени можно использовать цифры, например, PhoneNumber1.
На заметку
В некоторых СУБД более предпочтительным может быть следующий формат наименований «PHONE_NUMBER», например, такой формат часто используется в БД ORACLE. Естественно при задании имя поля желательно чтобы оно не совпадало с ключевыми словами используемые в СУБД.
По этой причине можете забыть о синтаксисе с квадратными скобками и удалить таблицу [Сотрудники]:
DROP TABLE [Сотрудники]
Например, таблицу с сотрудниками можно назвать «Employees», а ее полям можно задать следующие наименования:
- ID – Табельный номер (Идентификатор сотрудника)
- Name – ФИО
- Birthday – Дата рождения
- Email – E-mail
- Position – Должность
- Department – Отдел
Очень часто для наименования поля идентификатора используется слово ID.
Теперь создадим нашу таблицу:
CREATE TABLE Employees(
ID int,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Для того, чтобы задать обязательные для заполнения столбцы, можно использовать опцию NOT NULL.
Для уже существующей таблицы поля можно переопределить при помощи следующих команд:
-- обновление поля ID
ALTER TABLE Employees ALTER COLUMN ID int NOT NULL
-- обновление поля Name
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
На заметку
Общая концепция языка SQL для большинства СУБД остается одинаковой (по крайней мере, об этом я могу судить по тем СУБД, с которыми мне довелось поработать). Отличие DDL в разных СУБД в основном заключаются в типах данных (здесь могут отличаться не только их наименования, но и детали их реализации), так же может немного отличаться и сама специфика реализации языка SQL (т.е. суть команд одна и та же, но могут быть небольшие различия в диалекте, увы, но одного стандарта нет). Владея основами SQL вы легко сможете перейти с одной СУБД на другую, т.к. вам в данном случае нужно будет только разобраться в деталях реализации команд в новой СУБД, т.е. в большинстве случаев достаточно будет просто провести аналогию.Чтобы не быть голословным, приведу несколько примеров тех же команд для СУБД ORACLE:
-- создание таблицы CREATE TABLE Employees( ID int, -- в ORACLE тип int - это эквивалент(обертка) для number(38) Name nvarchar2(30), -- nvarchar2 в ORACLE эквивалентен nvarchar в MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- обновление полей ID и Name (здесь вместо ALTER COLUMN используется MODIFY(…)) ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- добавление PK (в данном случае конструкция выглядит как и в MS SQL, она будет показана ниже) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);Для ORACLE есть отличия в плане реализации типа varchar2, его кодировка зависит настроек БД и текст может сохраняться, например, в кодировке UTF-8. Помимо этого длину поля в ORACLE можно задать как в байтах, так и в символах, для этого используются дополнительные опции BYTE и CHAR, которые указываются после длины поля, например:
NAME varchar2(30 BYTE) -- вместимость поля будет равна 30 байтам NAME varchar2(30 CHAR) -- вместимость поля будет равна 30 символовКакая опция будет использоваться по умолчанию BYTE или CHAR, в случае простого указания в ORACLE типа varchar2(30), зависит от настроек БД, так же она иногда может задаваться в настройках IDE. В общем порой можно легко запутаться, поэтому в случае ORACLE, если используется тип varchar2 (а это здесь порой оправдано, например, при использовании кодировки UTF-8) я предпочитаю явно прописывать CHAR (т.к. обычно длину строки удобнее считать именно в символах).
Но в данном случае если в таблице уже есть какие-нибудь данные, то для успешного выполнения команд необходимо, чтобы во всех строках таблицы поля ID и Name были обязательно заполнены. Продемонстрируем это на примере, вставим в таблицу данные в поля ID, Position и Department, это можно сделать следующим скриптом:
INSERT Employees(ID,Position,Department) VALUES
(1000,N'Директор',N'Администрация'),
(1001,N'Программист',N'ИТ'),
(1002,N'Бухгалтер',N'Бухгалтерия'),
(1003,N'Старший программист',N'ИТ')
В данном случае, команда INSERT также выдаст ошибку, т.к. при вставке мы не указали значения обязательного поля Name.
В случае, если бы у нас в первоначальной таблице уже имелись эти данные, то команда «ALTER TABLE Employees ALTER COLUMN ID int NOT NULL» выполнилась бы успешно, а команда «ALTER TABLE Employees ALTER COLUMN Name int NOT NULL» выдала сообщение об ошибке, что в поле Name имеются NULL (не указанные) значения.
Добавим значения для полю Name и снова зальем данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
Так же опцию NOT NULL можно использовать непосредственно при создании новой таблицы, т.е. в контексте команды CREATE TABLE.
Сначала удалим таблицу при помощи команды:
DROP TABLE Employees
Теперь создадим таблицу с обязательными для заполнения столбцами ID и Name:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Можно также после имени столбца написать NULL, что будет означать, что в нем будут допустимы NULL-значения (не указанные), но этого делать не обязательно, так как данная характеристика подразумевается по умолчанию.
Если требуется наоборот сделать существующий столбец необязательным для заполнения, то используем следующий синтаксис команды:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Или просто:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Так же данной командой мы можем изменить тип поля на другой совместимый тип, или же изменить его длину. Для примера давайте расширим поле Name до 50 символов:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Первичный ключ
При создании таблицы желательно, чтобы она имела уникальный столбец или же совокупность столбцов, которая уникальна для каждой ее строки – по данному уникальному значению можно однозначно идентифицировать запись. Такое значение называется первичным ключом таблицы. Для нашей таблицы Employees таким уникальным значением может быть столбец ID (который содержит «Табельный номер сотрудника» — пускай в нашем случае данное значение уникально для каждого сотрудника и не может повторяться).
Создать первичный ключ к уже существующей таблице можно при помощи команды:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
Где «PK_Employees» это имя ограничения, отвечающего за первичный ключ. Обычно для наименования первичного ключа используется префикс «PK_» после которого идет имя таблицы.
Если первичный ключ состоит из нескольких полей, то эти поля необходимо перечислить в скобках через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1,поле2,…)
Стоит отметить, что в MS SQL все поля, которые входят в первичный ключ, должны иметь характеристику NOT NULL.
Так же первичный ключ можно определить непосредственно при создании таблицы, т.е. в контексте команды CREATE TABLE. Удалим таблицу:
DROP TABLE Employees
А затем создадим ее, используя следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
CONSTRAINT PK_Employees PRIMARY KEY(ID) -- описываем PK после всех полей, как ограничение
)
После создания зальем в таблицу данные:
INSERT Employees(ID,Position,Department,Name) VALUES
(1000,N'Директор',N'Администрация',N'Иванов И.И.'),
(1001,N'Программист',N'ИТ',N'Петров П.П.'),
(1002,N'Бухгалтер',N'Бухгалтерия',N'Сидоров С.С.'),
(1003,N'Старший программист',N'ИТ',N'Андреев А.А.')
Если первичный ключ в таблице состоит только из значений одного столбца, то можно использовать следующий синтаксис:
CREATE TABLE Employees(
ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, -- указываем как характеристику поля
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
На самом деле имя ограничения можно и не задавать, в этом случае ему будет присвоено системное имя (наподобие «PK__Employee__3214EC278DA42077»):
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30),
PRIMARY KEY(ID)
)
Или:
CREATE TABLE Employees(
ID int NOT NULL PRIMARY KEY,
Name nvarchar(30) NOT NULL,
Birthday date,
Email nvarchar(30),
Position nvarchar(30),
Department nvarchar(30)
)
Но я бы рекомендовал для постоянных таблиц всегда явно задавать имя ограничения, т.к. по явно заданному и понятному имени с ним впоследствии будет легче проводить манипуляции, например, можно произвести его удаление:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Но такой краткий синтаксис, без указания имен ограничений, удобно применять при создании временных таблиц БД (имя временной таблицы начинается с # или ##), которые после использования будут удалены.
Подытожим
На данный момент мы рассмотрели следующие команды:
- CREATE TABLE имя_таблицы (перечисление полей и их типов, ограничений) – служит для создания новой таблицы в текущей БД;
- DROP TABLE имя_таблицы – служит для удаления таблицы из текущей БД;
- ALTER TABLE имя_таблицы ALTER COLUMN имя_столбца … – служит для обновления типа столбца или для изменения его настроек (например для задания характеристики NULL или NOT NULL);
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения PRIMARY KEY(поле1, поле2,…) – добавление первичного ключа к уже существующей таблице;
- ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения – удаление ограничения из таблицы.
Немного про временные таблицы
Вырезка из MSDN. В MS SQL Server существует два вида временных таблиц: локальные (#) и глобальные (##). Локальные временные таблицы видны только их создателям до завершения сеанса соединения с экземпляром SQL Server, как только они впервые созданы. Локальные временные таблицы автоматически удаляются после отключения пользователя от экземпляра SQL Server. Глобальные временные таблицы видны всем пользователям в течение любых сеансов соединения после создания этих таблиц и удаляются, когда все пользователи, ссылающиеся на эти таблицы, отключаются от экземпляра SQL Server.
Временные таблицы создаются в системной базе tempdb, т.е. создавая их мы не засоряем основную базу, в остальном же временные таблицы полностью идентичны обычным таблицам, их так же можно удалить при помощи команды DROP TABLE. Чаще используются локальные (#) временные таблицы.
Для создания временной таблицы можно использовать команду CREATE TABLE:
CREATE TABLE #Temp(
ID int,
Name nvarchar(30)
)
Так как временная таблица в MS SQL аналогична обычной таблице, ее соответственно так же можно удалить самому командой DROP TABLE:
DROP TABLE #Temp
Так же временную таблицу (как собственно и обычную таблицу) можно создать и сразу заполнить данными возвращаемые запросом используя синтаксис SELECT … INTO:
SELECT ID,Name
INTO #Temp
FROM Employees
На заметку
В разных СУБД реализация временных таблиц может отличаться. Например, в СУБД ORACLE и Firebird структура временных таблиц должна быть определена заранее командой CREATE GLOBAL TEMPORARY TABLE с указанием специфики хранения в ней данных, дальше уже пользователь видит ее среди основных таблиц и работает с ней как с обычной таблицей.
Нормализация БД – дробление на подтаблицы (справочники) и определение связей
Наша текущая таблица Employees имеет недостаток в том, что в полях Position и Department пользователь может ввести любой текст, что в первую очередь чревато ошибками, так как он у одного сотрудника может указать в качестве отдела просто «ИТ», а у второго сотрудника, например, ввести «ИТ-отдел», у третьего «IT». В итоге будет непонятно, что имел ввиду пользователь, т.е. являются ли данные сотрудники работниками одного отдела, или же пользователь описался и это 3 разных отдела? А тем более, в этом случае, мы не сможем правильно сгруппировать данные для какого-то отчета, где, может требоваться показать количество сотрудников в разрезе каждого отдела.
Второй недостаток заключается в объеме хранения данной информации и ее дублированием, т.е. для каждого сотрудника указывается полное наименование отдела, что требует в БД места для хранения каждого символа из названия отдела.
Третий недостаток – сложность обновления данных полей, в случае если изменится название какой-то должности, например, если потребуется переименовать должность «Программист», на «Младший программист». В данном случае нам придется вносить изменения в каждую строчку таблицы, у которой Должность равняется «Программист».
Чтобы избежать данных недостатков и применяется, так называемая, нормализация базы данных – дробление ее на подтаблицы, таблицы справочники. Не обязательно лезть в дебри теории и изучать что из себя представляют нормальные формы, достаточно понимать суть нормализации.
Давайте создадим 2 таблицы справочники «Должности» и «Отделы», первую назовем Positions, а вторую соответственно Departments:
CREATE TABLE Positions(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
CREATE TABLE Departments(
ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY,
Name nvarchar(30) NOT NULL
)
Заметим, что здесь мы использовали новую опцию IDENTITY, которая говорит о том, что данные в столбце ID будут нумероваться автоматически, начиная с 1, с шагом 1, т.е. при добавлении новых записей им последовательно будут присваиваться значения 1, 2, 3, и т.д. Такие поля обычно называют автоинкрементными. В таблице может быть определено только одно поле со свойством IDENTITY и обычно, но необязательно, такое поле является первичным ключом для данной таблицы.
На заметку
В разных СУБД реализация полей со счетчиком может делаться по своему. В MySQL, например, такое поле определяется при помощи опции AUTO_INCREMENT. В ORACLE и Firebird раньше данную функциональность можно было съэмулировать при помощи использования последовательностей (SEQUENCE). Но насколько я знаю в ORACLE сейчас добавили опцию GENERATED AS IDENTITY.
Давайте заполним эти таблицы автоматически, на основании текущих данных записанных в полях Position и Department таблицы Employees:
-- заполняем поле Name таблицы Positions, уникальными значениями из поля Position таблицы Employees
INSERT Positions(Name)
SELECT DISTINCT Position
FROM Employees
WHERE Position IS NOT NULL -- отбрасываем записи у которых позиция не указана
То же самое проделаем для таблицы Departments:
INSERT Departments(Name)
SELECT DISTINCT Department
FROM Employees
WHERE Department IS NOT NULL
Если теперь мы откроем таблицы Positions и Departments, то увидим пронумерованный набор значений по полю ID:
SELECT * FROM Positions
| ID | Name |
|---|---|
| 1 | Бухгалтер |
| 2 | Директор |
| 3 | Программист |
| 4 | Старший программист |
SELECT * FROM Departments
| ID | Name |
|---|---|
| 1 | Администрация |
| 2 | Бухгалтерия |
| 3 | ИТ |
Данные таблицы теперь и будут играть роль справочников для задания должностей и отделов. Теперь мы будем ссылаться на идентификаторы должностей и отделов. В первую очередь создадим новые поля в таблице Employees для хранения данных идентификаторов:
-- добавляем поле для ID должности
ALTER TABLE Employees ADD PositionID int
-- добавляем поле для ID отдела
ALTER TABLE Employees ADD DepartmentID int
Тип ссылочных полей должен быть каким же, как и в справочниках, в данном случае это int.
Так же добавить в таблицу сразу несколько полей можно одной командой, перечислив поля через запятую:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Теперь пропишем ссылки (ссылочные ограничения — FOREIGN KEY) для этих полей, для того чтобы пользователь не имел возможности записать в данные поля, значения, отсутствующие среди значений ID находящихся в справочниках.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID
FOREIGN KEY(PositionID) REFERENCES Positions(ID)
И то же самое сделаем для второго поля:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID
FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Теперь пользователь в данные поля сможет занести только значения ID из соответствующего справочника. Соответственно, чтобы использовать новый отдел или должность, он первым делом должен будет добавить новую запись в соответствующий справочник. Т.к. должности и отделы теперь хранятся в справочниках в одном единственном экземпляре, то чтобы изменить название, достаточно изменить его только в справочнике.
Имя ссылочного ограничения, обычно является составным, оно состоит из префикса «FK_», затем идет имя таблицы и после знака подчеркивания идет имя поля, которое ссылается на идентификатор таблицы-справочника.
Идентификатор (ID) обычно является внутренним значением, которое используется только для связей и какое значение там хранится, в большинстве случаев абсолютно безразлично, поэтому не нужно пытаться избавиться от дырок в последовательности чисел, которые возникают по ходу работы с таблицей, например, после удаления записей из справочника.
Так же в некоторых случаях ссылку можно организовать по нескольким полям:
ALTER TABLE таблица ADD CONSTRAINT имя_ограничения
FOREIGN KEY(поле1,поле2,…) REFERENCES таблица_справочник(поле1,поле2,…)
В данном случае в таблице «таблица_справочник» первичный ключ представлен комбинацией из нескольких полей (поле1, поле2,…).
Собственно, теперь обновим поля PositionID и DepartmentID значениями ID из справочников. Воспользуемся для этой цели DML командой UPDATE:
UPDATE e
SET
PositionID=(SELECT ID FROM Positions WHERE Name=e.Position),
DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department)
FROM Employees e
Посмотрим, что получилось, выполнив запрос:
SELECT * FROM Employees
| ID | Name | Birthday | Position | Department | PositionID | DepartmentID | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | Директор | Администрация | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | Программист | ИТ | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | Бухгалтер | Бухгалтерия | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | Старший программист | ИТ | 4 | 3 |
Всё, поля PositionID и DepartmentID заполнены соответствующие должностям и отделам идентификаторами надобности в полях Position и Department в таблице Employees теперь нет, можно удалить эти поля:
ALTER TABLE Employees DROP COLUMN Position,Department
Теперь таблица у нас приобрела следующий вид:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | NULL | NULL | 2 | 1 |
| 1001 | Петров П.П. | NULL | NULL | 3 | 3 |
| 1002 | Сидоров С.С. | NULL | NULL | 1 | 2 |
| 1003 | Андреев А.А. | NULL | NULL | 4 | 3 |
Т.е. мы в итоге избавились от хранения избыточной информации. Теперь, по номерам должности и отдела можем однозначно определить их названия, используя значения в таблицах-справочниках:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON d.ID=e.DepartmentID
LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
|---|---|---|---|
| 1000 | Иванов И.И. | Директор | Администрация |
| 1001 | Петров П.П. | Программист | ИТ |
| 1002 | Сидоров С.С. | Бухгалтер | Бухгалтерия |
| 1003 | Андреев А.А. | Старший программист | ИТ |
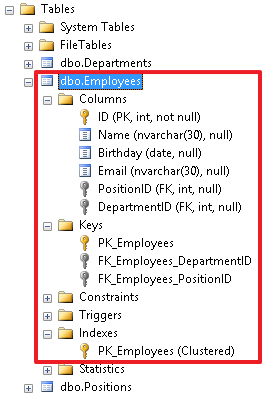
В инспекторе объектов мы можем увидеть все объекты, созданные для в данной таблицы. Отсюда же можно производить разные манипуляции с данными объектами – например, переименовывать или удалять объекты.
Так же стоит отметить, что таблица может ссылаться сама на себя, т.е. можно создать рекурсивную ссылку. Для примера добавим в нашу таблицу с сотрудниками еще одно поле ManagerID, которое будет указывать на сотрудника, которому подчиняется данный сотрудник. Создадим поле:
ALTER TABLE Employees ADD ManagerID int
В данном поле допустимо значение NULL, поле будет пустым, если, например, над сотрудником нет вышестоящих.
Теперь создадим FOREIGN KEY на таблицу Employees:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID
FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
Давайте, теперь создадим диаграмму и посмотрим, как выглядят на ней связи между нашими таблицами:
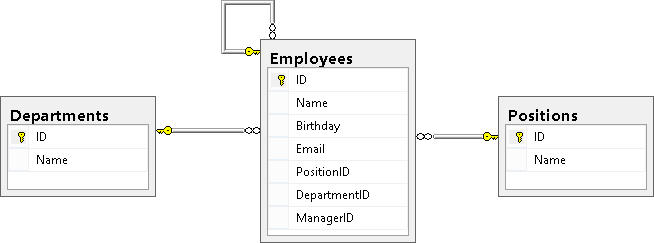
В результате мы должны увидеть следующую картину (таблица Employees связана с таблицами Positions и Depertments, а так же ссылается сама на себя):
Напоследок стоит сказать, что ссылочные ключи могут включать дополнительные опции ON DELETE CASCADE и ON UPDATE CASCADE, которые говорят о том, как вести себя при удалении или обновлении записи, на которую есть ссылки в таблице-справочнике. Если эти опции не указаны, то мы не можем изменить ID в таблице справочнике у той записи, на которую есть ссылки из другой таблицы, так же мы не сможем удалить такую запись из справочника, пока не удалим все строки, ссылающиеся на эту запись или, же обновим в этих строках ссылки на другое значение.
Для примера пересоздадим таблицу с указанием опции ON DELETE CASCADE для FK_Employees_DepartmentID:
DROP TABLE Employees
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
ON DELETE CASCADE,
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
)
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
Удалим отдел с идентификатором 3 из таблицы Departments:
DELETE Departments WHERE ID=3
Посмотрим на данные таблицы Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Сидоров С.С. | 1976-06-07 | NULL | 1 | 2 | 1000 |
Как видим, данные по отделу 3 из таблицы Employees так же удалились.
Опция ON UPDATE CASCADE ведет себя аналогично, но действует она при обновлении значения ID в справочнике. Например, если мы поменяем ID должности в справочнике должностей, то в этом случае будет производиться обновление DepartmentID в таблице Employees на новое значение ID которое мы задали в справочнике. Но в данном случае это продемонстрировать просто не получится, т.к. у колонки ID в таблице Departments стоит опция IDENTITY, которая не позволит нам выполнить следующий запрос (сменить идентификатор отдела 3 на 30):
UPDATE Departments
SET
ID=30
WHERE ID=3
Главное понять суть этих 2-х опций ON DELETE CASCADE и ON UPDATE CASCADE. Я применяю эти опции очень в редких случаях и рекомендую хорошо подумать, прежде чем указывать их в ссылочном ограничении, т.к. при нечаянном удалении записи из таблицы справочника это может привести к большим проблемам и создать цепную реакцию.
Восстановим отдел 3:
-- даем разрешение на добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name) VALUES(3,N'ИТ')
-- запрещаем добавление/изменение IDENTITY значения
SET IDENTITY_INSERT Departments OFF
Полностью очистим таблицу Employees при помощи команды TRUNCATE TABLE:
TRUNCATE TABLE Employees
И снова перезальем в нее данные используя предыдущую команду INSERT:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219',2,1,NULL),
(1001,N'Петров П.П.','19831203',3,3,1003),
(1002,N'Сидоров С.С.','19760607',1,2,1000),
(1003,N'Андреев А.А.','19820417',4,3,1000)
Подытожим
На данным момент к нашим знаниям добавилось еще несколько команд DDL:
- Добавление свойства IDENTITY к полю – позволяет сделать это поле автоматически заполняемым (полем-счетчиком) для таблицы;
- ALTER TABLE имя_таблицы ADD перечень_полей_с_характеристиками – позволяет добавить новые поля в таблицу;
- ALTER TABLE имя_таблицы DROP COLUMN перечень_полей – позволяет удалить поля из таблицы;
- ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения FOREIGN KEY(поля) REFERENCES таблица_справочник(поля) – позволяет определить связь между таблицей и таблицей справочником.
Прочие ограничения – UNIQUE, DEFAULT, CHECK
При помощи ограничения UNIQUE можно сказать что значения для каждой строки в данном поле или в наборе полей должно быть уникальным. В случае таблицы Employees, такое ограничение мы можем наложить на поле Email. Только предварительно заполним Email значениями, если они еще не определены:
UPDATE Employees SET Email='i.ivanov@test.tt' WHERE ID=1000
UPDATE Employees SET Email='p.petrov@test.tt' WHERE ID=1001
UPDATE Employees SET Email='s.sidorov@test.tt' WHERE ID=1002
UPDATE Employees SET Email='a.andreev@test.tt' WHERE ID=1003
А теперь можно наложить на это поле ограничение-уникальности:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Теперь пользователь не сможет внести один и тот же E-Mail у нескольких сотрудников.
Ограничение уникальности обычно именуется следующим образом – сначала идет префикс «UQ_», далее название таблицы и после знака подчеркивания идет имя поля, на которое накладывается данное ограничение.
Соответственно если уникальной в разрезе строк таблицы должна быть комбинация полей, то перечисляем их через запятую:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения UNIQUE(поле1,поле2,…)
При помощи добавления к полю ограничения DEFAULT мы можем задать значение по умолчанию, которое будет подставляться в случае, если при вставке новой записи данное поле не будет перечислено в списке полей команды INSERT. Данное ограничение можно задать непосредственно при создании таблицы.
Давайте добавим в таблицу Employees новое поле «Дата приема» и назовем его HireDate и скажем что значение по умолчанию у данного поля будет текущая дата:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
Или если столбец HireDate уже существует, то можно использовать следующий синтаксис:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
Здесь я не указал имя ограничения, т.к. в случае DEFAULT у меня сложилось мнение, что это не столь критично. Но если делать по-хорошему, то, думаю, не нужно лениться и стоит задать нормальное имя. Делается это следующим образом:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
Та как данного столбца раньше не было, то при его добавлении в каждую запись в поле HireDate будет вставлено текущее значение даты.
При добавлении новой записи, текущая дата так же будет вставлена автоматом, конечно если мы ее явно не зададим, т.е. не укажем в списке столбцов. Покажем это на примере, не указав поле HireDate в перечне добавляемых значений:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Сергеев С.С.','s.sergeev@test.tt')
Посмотрим, что получилось:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Сергеев С.С. | NULL | s.sergeev@test.tt | NULL | NULL | NULL | 2015-04-08 |
Проверочное ограничение CHECK используется в том случае, когда необходимо осуществить проверку вставляемых в поле значений. Например, наложим данное ограничение на поле табельный номер, которое у нас является идентификатором сотрудника (ID). При помощи данного ограничения скажем, что табельные номера должны иметь значение от 1000 до 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
Ограничение обычно именуется так же, сначала идет префикс «CK_», затем имя таблицы и имя поля, на которое наложено это ограничение.
Попробуем вставить недопустимую запись для проверки, что ограничение работает (мы должны получить соответствующую ошибку):
INSERT Employees(ID,Email) VALUES(2000,'test@test.tt')
А теперь изменим вставляемое значение на 1500 и убедимся, что запись вставится:
INSERT Employees(ID,Email) VALUES(1500,'test@test.tt')
Можно так же создать ограничения UNIQUE и CHECK без указания имени:
ALTER TABLE Employees ADD UNIQUE(Email)
ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Но это не очень хорошая практика и лучше задавать имя ограничения в явном виде, т.к. чтобы разобраться потом, что будет сложнее, нужно будет открывать объект и смотреть, за что он отвечает.
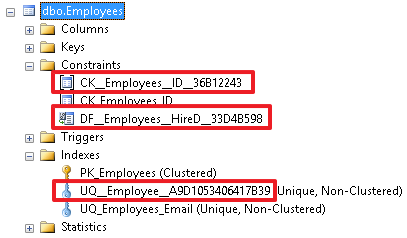
При хорошем наименовании много информации об ограничении можно узнать непосредственно по его имени.
И, соответственно, все эти ограничения можно создать сразу же при создании таблицы, если ее еще нет. Удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями одной командой CREATE TABLE:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL DEFAULT SYSDATETIME(), -- для DEFAULT я сделаю исключение
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT UQ_Employees_Email UNIQUE (Email),
CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999)
)
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3)
Немного про индексы, создаваемые при создании ограничений PRIMARY KEY и UNIQUE
Как можно увидеть на скриншоте выше, при создании ограничений PRIMARY KEY и UNIQUE автоматически создались индексы с такими же названиями (PK_Employees и UQ_Employees_Email). По умолчанию индекс для первичного ключа создается как CLUSTERED, а для всех остальных индексов как NONCLUSTERED. Стоит сказать, что понятие кластерного индекса есть не во всех СУБД. Таблица может иметь только один кластерный (CLUSTERED) индекс. CLUSTERED – означает, что записи таблицы будут сортироваться по этому индексу, так же можно сказать, что этот индекс имеет непосредственный доступ ко всем данным таблицы. Это так сказать главный индекс таблицы. Если сказать еще грубее, то это индекс, прикрученный к таблице. Кластерный индекс – это очень мощное средство, которое может помочь при оптимизации запросов, пока просто запомним это. Если мы хотим сказать, чтобы кластерный индекс использовался не в первичном ключе, а для другого индекса, то при создании первичного ключа мы должны указать опцию NONCLUSTERED:
ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения
PRIMARY KEY NONCLUSTERED(поле1,поле2,…)
Для примера сделаем индекс ограничения PK_Employees некластерным, а индекс ограничения UQ_Employees_Email кластерным. Первым делом удалим данные ограничения:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
А теперь создадим их с опциями CLUSTERED и NONCLUSTERED:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID)
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Теперь, выполнив выборку из таблицы Employees, мы увидим, что записи отсортировались по кластерному индексу UQ_Employees_Email:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
|---|---|---|---|---|---|---|
| 1003 | Андреев А.А. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 2015-04-08 |
| 1000 | Иванов И.И. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | 2015-04-08 |
| 1001 | Петров П.П. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 |
| 1002 | Сидоров С.С. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 2015-04-08 |
До этого, когда кластерным индексом был индекс PK_Employees, записи по умолчанию сортировались по полю ID.
Но в данном случае это всего лишь пример, который показывает суть кластерного индекса, т.к. скорее всего к таблице Employees будут делаться запросы по полю ID и в каких-то случаях, возможно, она сама будет выступать в роли справочника.
Для справочников обычно целесообразно, чтобы кластерный индекс был построен по первичному ключу, т.к. в запросах мы часто ссылаемся на идентификатор справочника для получения, например, наименования (Должности, Отдела). Здесь вспомним, о чем я писал выше, что кластерный индекс имеет прямой доступ к строкам таблицы, а отсюда следует, что мы можем получить значение любого столбца без дополнительных накладных расходов.
Кластерный индекс выгодно применять к полям, по которым выборка идет наиболее часто.
Иногда в таблицах создают ключ по суррогатному полю, вот в этом случае бывает полезно сохранить опцию CLUSTERED индекс для более подходящего индекса и указать опцию NONCLUSTERED при создании суррогатного первичного ключа.
Подытожим
На данном этапе мы познакомились со всеми видами ограничений, в их самом простом виде, которые создаются командой вида «ALTER TABLE имя_таблицы ADD CONSTRAINT имя_ограничения …»:
- PRIMARY KEY – первичный ключ;
- FOREIGN KEY – настройка связей и контроль ссылочной целостности данных;
- UNIQUE – позволяет создать уникальность;
- CHECK – позволяет осуществлять корректность введенных данных;
- DEFAULT – позволяет задать значение по умолчанию;
- Так же стоит отметить, что все ограничения можно удалить, используя команду «ALTER TABLE имя_таблицы DROP CONSTRAINT имя_ограничения».
Так же мы частично затронули тему индексов и разобрали понятие кластерный (CLUSTERED) и некластерный (NONCLUSTERED) индекс.
Создание самостоятельных индексов
Под самостоятельностью здесь имеются в виду индексы, которые создаются не для ограничения PRIMARY KEY или UNIQUE.
Индексы по полю или полям можно создавать следующей командой:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Так же здесь можно указать опции CLUSTERED, NONCLUSTERED, UNIQUE, а так же можно указать направление сортировки каждого отдельного поля ASC (по умолчанию) или DESC:
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
При создании некластерного индекса опцию NONCLUSTERED можно отпустить, т.к. она подразумевается по умолчанию, здесь она показана просто, чтобы указать позицию опции CLUSTERED или NONCLUSTERED в команде.
Удалить индекс можно следующей командой:
DROP INDEX IDX_Employees_Name ON Employees
Простые индексы так же, как и ограничения, можно создать в контексте команды CREATE TABLE.
Для примера снова удалим таблицу:
DROP TABLE Employees
И пересоздадим ее со всеми созданными ограничениями и индексами одной командой CREATE TABLE:
CREATE TABLE Employees(
ID int NOT NULL,
Name nvarchar(30),
Birthday date,
Email nvarchar(30),
PositionID int,
DepartmentID int,
HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(),
ManagerID int,
CONSTRAINT PK_Employees PRIMARY KEY (ID),
CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID),
CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID),
CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID),
CONSTRAINT UQ_Employees_Email UNIQUE(Email),
CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999),
INDEX IDX_Employees_Name(Name)
)
Напоследок вставим в таблицу наших сотрудников:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES
(1000,N'Иванов И.И.','19550219','i.ivanov@test.tt',2,1,NULL),
(1001,N'Петров П.П.','19831203','p.petrov@test.tt',3,3,1003),
(1002,N'Сидоров С.С.','19760607','s.sidorov@test.tt',1,2,1000),
(1003,N'Андреев А.А.','19820417','a.andreev@test.tt',4,3,1000)
Дополнительно стоит отметить, что в некластерный индекс можно включать значения при помощи указания их в INCLUDE. Т.е. в данном случае INCLUDE-индекс чем-то будет напоминать кластерный индекс, только теперь не индекс прикручен к таблице, а необходимые значения прикручены к индексу. Соответственно, такие индексы могут очень повысить производительность запросов на выборку (SELECT), если все перечисленные поля имеются в индексе, то возможно обращений к таблице вообще не понадобится. Но это естественно повышает размер индекса, т.к. значения перечисленных полей дублируются в индексе.
Вырезка из MSDN. Общий синтаксис команды для создания индексов
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Подытожим
Индексы могут повысить скорость выборки данных (SELECT), но индексы уменьшают скорость модификации данных таблицы, т.к. после каждой модификации системе будет необходимо перестроить все индексы для конкретной таблицы.
Желательно в каждом случае найти оптимальное решение, золотую середину, чтобы и производительность выборки, так и модификации данных была на должном уровне. Стратегия по созданию индексов и их количества может зависеть от многих факторов, например, насколько часто изменяются данные в таблице.
Заключение по DDL
Как можно увидеть, язык DDL не так сложен, как может показаться на первый взгляд. Здесь я смог показать практически все его основные конструкции, оперируя всего тремя таблицами.
Главное — понять суть, а остальное дело практики.
Удачи вам в освоении этого замечательного языка под названием SQL.
Часть вторая — habrahabr.ru/post/255523
Предлагаем вашему вниманию статью с кричащим названием «SQL за 20 минут». Конечно, весь SQL за 20 минут вы не освоите, но хороший старт получите.
Каждый уважающий себя веб-разработчик должен знать SQL. Хоть он и существует аж с 70-х годов прошлого века, он до сих пор очень широко используется, и без него будет сложно создать нечто серьёзное. Большинство full-stack фреймворков умеют работать с SQL. В их числе: ActiveRecord, Doctrine, Hibernate и многие другие. Несмотря на это, иногда приходится «замарать руки» и пуститься в настоящий SQL.
Именно поэтому мы подготовили короткое вступление, в котором мы пройдёмся по фундаментальным вещам в SQL. Мы настоятельно рекомендуем вам попробовать все приведённые ниже примеры самостоятельно, ведь, как известно, теория — ничто без практики.
Что ж, приступим!
Создаём таблицу
Для того, чтобы создать таблицу в SQL, используется выражение CREATE TABLE. Он принимает в качестве параметров все колонки, которые мы хотим внести, а также их типы данных.
Давайте создадим табличку с названием «Months», в которой будет три колонки:
- id — иными словами, порядковый номер месяца (целочисленный тип или int)
- name — название месяца (строка или varchar(10) (10 символов — максимальная длина строки))
- days — число дней в конкретном месяце (целочисленный тип или int)
Код будет выглядеть вот так:
CREATE TABLE months (id int, name varchar(10), days int);
Также, когда создаются таблицы, принято добавлять так называемый primary key. Это колонка, значения в которой уникальны. Чаще всего primary key колонкой является id, но в нашем случае это может быть и name, так как имена всех месяцев уникальны. Для более подробной информации предлагаем перейти по этой ссылке.
Ввод данных
Теперь давайте добавим пару месяцев в нашу табличку. Сделать это можно с помощью команды INSERT. Есть два разных способа использовать INSERT:
Первый способ не подразумевает указания названий колонок, а лишь принимает значения в том порядке, в котором они указаны в таблице.
INSERT INTO months VALUES (1,'January',31);
Первый способ короче второго, однако если в будущем мы захотим добавить дополнительные колонки, все предыдущие запросы работать не будут. Для решения данной проблемы следует использовать второй способ. Его суть в том, что перед вводом данных мы указываем названия колонок.
INSERT INTO months (id,name,days) VALUES (2,'February',29);
В случае, если мы не укажем одну из колонок, на её место будет записано NULL или заданное значение по умолчанию, но это уже совсем другая история.
Select
Данный запрос используется в случае, если нам нужно показать данные в таблице. Наверное, самым простым примером использования SELECT будет следующий запрос:
SELECT * FROM characters
Результатом данного запроса будет таблица со всеми данными в таблице characters. Знак звёздочки (*) означает то, что мы хотим показать все столбцы из таблицы без исключений. Так как в базе данных обычно больше одной таблицы, нам необходимо указывать название таблицы, данные из которой мы хотим посмотреть. Сделать это мы можем, используя ключевое слово FROM.
Когда вам нужны лишь некоторые столбцы из таблицы, то вы можете указать их имена через запятую вместо звёздочки.
SELECT name, weapon FROM characters
Также иногда нам нужно отсортировать выводимые данные. Для этого мы используем ORDER BY «название столбца». ORDER BY имеет два модификатора: ASC (по возрастанию) (по умолчанию) и DESC (по убыванию).
SELECT name, weapon FROM characters ORDER BY name DESC
Where
Теперь мы знаем, как показать только конкретные столбцы, но что если мы хотим включить в вывод лишь некоторые конкретные строки? Для этого мы используем WHERE. Данное ключевое слово позволяет нам фильтровать данные по определённому условию.
В следующем запросе мы выведем только тех персонажей, которые в качестве оружия используют пистолет.
SELECT * FROM characters WHERE weapon = 'pistol';
И/или
Условия в WHERE могут быть написаны с использованием логических операторов (AND/OR) и математические операторы сравнения (=, <, >, <=, >=, <>).
К примеру, у нас есть табличка, в которой записаны данные о 4 самых продаваемых музыкальных альбомах всех времён. Давайте выведем только те, жанром которых является рок, а продажи были меньше, чем 50 миллионов копий.
SELECT * FROM albums WHERE genre = 'rock' AND sales_in_millions <= 50 ORDER BY released
In/Between/Like
Условия в WHERE могут быть записаны с использованием ещё нескольких команд, которыми являются:
- IN — сравнивает значение в столбце с несколькими возможными значениями и возвращает true, если значение совпадает хотя бы с одним значением
- BETWEEN — проверяет, находится ли значение в каком-то промежутке
- LIKE — ищет по шаблону
К примеру, мы можем сделать запрос для вывода данных об альбомах в жанре pop или soul:
SELECT * FROM albums WHERE genre IN ('pop','soul');
Если мы хотим вывести все альбомы, которые были выпущены в промежутке между 1975 и 1985 годом, мы можем использовать следующую запись:
SELECT * FROM albums WHERE released BETWEEN 1975 AND 1985;
Также, если мы хотим вывести все альбомы, в названии которых есть буква ‘R’, мы можем использовать следующую запись:
SELECT * FROM albums WHERE album LIKE '%R%';
Знак % означает любую последовательность символов (0 символов тоже считается за последовательность).
Если мы хотим вывести все альбомы, первая буква в названии которых — ‘R’, то запись слегка изменится:
SELECT * FROM albums WHERE album LIKE 'R%';
В SQL также есть инверсия. Для примера, попробуйте самостоятельно написать NOT перед любым логическим выражением в условии (NOT BETWEEN и так далее).
Функции
В SQL полно встроенных функций для выполнения разных операций. Мы же покажем вам только наиболее часто используемые:
- COUNT() — возвращает число строк
- SUM() — возвращает сумму всех полей с числовыми значениями в них
- AVG() — возвращает среднее значение среди строк
- MIN()/MAX() — возвращает минимальное/максимальное значение среди строк
Чтобы вывести год выпуска самого старого альбома, в таблице можно использовать следующий запрос:
SELECT MIN(released) FROM albums;
Обратите внимание, что если вы напишете запрос, в котором вам, к примеру, нужно будет вывести имя и среднее значение чего-либо, то вы получите ошибку на выводе.
Допустим, вы пишете такой запрос:
SELECT name, avg(age) FROM students;
Чтобы избежать ошибки, вам следует добавить следующую строку:
GROUP BY name
Причиной тому является, что запись avg(age) является совокупной (aggregated), и вам необходимо группировать значения по имени.
Вложенные Select
В предыдущих шагах мы изучили, как делать простые вычисления с данными. Если мы хотим использовать результат данных вычислений, то часто нам необходимо использовать так называемые вложенные запросы. Допустим, нам необходимо вывести артиста, альбом и год выпуска самого старого альбома в таблице.
Вывести эти столбцы можно, используя следующий запрос:
SELECT artist, album, released FROM albums;
Также мы знаем, как получить самый ранний год из имеющихся:
SELECT MIN(released) FROM album;
Объединить эти запросы можно в WHERE:
SELECT artist,album,released FROM albums WHERE released = ( SELECT MIN(released) FROM albums );
Присоединение таблиц
В сложных базах данных чаще всего у нас есть несколько связанных таблиц. К примеру, у нас есть две таблицы: про видеоигры и про разработчиков.
В таблице video_games есть столбец developer_id, в данном случае он является так называемым foreign_key. Чтобы было проще понять, developer_id — это связывающее звено между двумя таблицами.
Если мы хотим вывести всю информацию об игре, включая информацию о её разработчике, нам необходимо подключить вторую таблицу. Чтобы это сделать, можно использовать INNER JOIN:
SELECT video_games.name, video_games.genre, game_developers.name, game_developers.country FROM video_games INNER JOIN game_developers ON video_games.developer_id = game_developers.id;
Это, наверное, самый простой пример использования JOIN. Есть ещё несколько вариантов его использования. Для более подробной информации предлагаем перейти по этой ссылке.
Псевдонимы
Если вы взгляните на предыдущий пример, то вы заметите, что есть два столбца, названных одинаково: «name». Часто это может запутать. Решением данной проблемы являются псевдонимы. Они, к слову, помогают сделать название столбца красивее или понятнее в случае необходимости.
Чтобы присвоить столбцу псевдоним, можно использовать ключевое слово AS:
SELECT games.name, games.genre, devs.name AS developer, devs.country FROM video_games AS games INNER JOIN game_developers AS devs ON games.developer_id = devs.id;
Update
Зачастую нам нужно изменить данные в таблице. В SQL это делается с помощью UPDATE.
Использование UPDATE включает в себя:
- выбор таблицы, в которой находится поле, которое мы хотим изменить
- запись нового значения
- использование WHERE, чтобы обозначить конкретное место в таблице
Предположим, у нас есть таблица с самыми высокооценёнными сериалами всех времён. Однако у нас есть проблема: «Игра Престолов» обозначена как комедия и нам определённо нужно это изменить:
UPDATE tv_series SET genre = 'drama' WHERE name = 'Game of Thrones';
Удаление записей из таблицы
Удаление записи из таблицы через SQL — очень простая операция. Всё, что нужно — это обозначить, что именно мы хотим удалить.
DELETE FROM tv_series WHERE id = 4;
Примечание: убедитесь, что используете WHERE, когда удаляете запись из таблицы. Иначе вы удалите все записи из таблицы, сами того не желая.
Удаление таблиц
Если мы хотим удалить все данные из таблицы, но при этом оставить саму таблицу, нам следует использовать команду TRUNCATE:
TRUNCATE TABLE table_name;
В случае, если мы хотим удалить саму таблицу, то нам следует использовать команду DROP:
DROP TABLE table_name;
Заключение
На этой ноте мы завершаем данный SQL-туториал. Само собой, это не всё, и для полного освоения нужно ещё много изучить, однако данное вступление даст вам толчок для дальнейшего изучения.
Более подробные уроки по SQL вы можете найти, перейдя по следующим ссылкам:
- Codeacademy курс SQL
- SQL Fiddle: онлайн-инструмент для тестирования SQL запросов
Другие статьи по теме
5 сайтов для оттачивания навыков написания SQL-запросов
Видеокурс по работе с MySQL
Больше полезной информации вы найдете на нашем телеграм-канале «Библиотека программиста».
Приветствую Вас на сайте Info-Comp.ru! Сегодня я продолжаю рассказ о языке SQL, и в этом материале я немного расскажу о том, как создаются и выполняются SQL запросы к базе данных, а точнее какие инструменты (программы) для этого используются.

Содержание
- Как создать SQL запрос? Где писать SQL код?
- Инструменты для создания SQL запросов
- Microsoft SQL Server
- Oracle Database
- MySQL
- PostgreSQL
- Выводы
В одной из прошлых статей я рассказал Вам, что такое SQL и какие СУБД бывают, но у начинающих, кто только начинает работать с базами данных, могут возникнуть определённые вопросы, например, как работать с этими базами данных, как подключиться к базе и как выполнить SQL запрос?
Обычный случай, когда человек только что установил себе какую-нибудь СУБД (например, для изучения SQL) и не знает, что делать дальше, где писать SQL код? какую программу запустить?
Или другой, еще более распространённый вариант, когда уже есть установленный SQL сервер, а начинающему программисту (IT-ку), которому сказали, что он будет еще сопровождать SQL сервер, нужно подключиться к этому серверу и выполнить какой-нибудь SQL запрос или инструкцию, а он, так как никогда не работал с серверами баз данных, конечно же, не знает, как это сделать. И все это на самом деле логично, ведь наличие установленного сервера баз данных не говорит о том, что на сервере также есть средства управления этим сервером и средства разработки SQL инструкций, так как это отдельные программы, которые устанавливаются на клиентском компьютере (но можно установить и на самом сервере).
Поэтому сегодня, специально для начинающих SQL программистов, я расскажу о том, какие инструменты нужны для того, чтобы создавать и выполнять SQL запросы к базе данных, иными словами, где писать SQL запросы. При этом я расскажу про инструменты для всех популярных СУБД: Microsoft SQL Server, Oracle Database, MySQL и PostgreSQL. Так как для каждой СУБД используются отдельные инструменты, но есть, конечно же, и универсальные инструменты, которые умеют работать одновременно практически со всеми из вышеперечисленных баз данных.
Если у Вас возникает вопрос, как послать SQL запрос к базе данных из приложения при его разработке (например, Вы начинающий программист Java, C# или других языков), то это делается непосредственно из самой IDE (среды программирования), используя специальные драйверы для подключения к БД. Устанавливать перечисленные в данной статье инструменты необязательно, они нужны для прямой работы с базой данных: разработка и отладка SQL инструкций, выполнение административных задач и так далее.
Инструменты для создания SQL запросов
Сейчас я перечислю и коротко расскажу про инструменты, которые можно использовать для написания SQL запросов и их выполнения на различных SQL серверах, при этом функционал этих инструментов не ограничивается редактором SQL запросов, на самом деле большинство современных программ для работы с базами данных являются многофункциональными, их могут использовать как разработчики, так и администраторы баз данных.
В этом материале я перечислю только некоторые инструменты, так как на самом деле их очень много. Кстати, если Вы знаете или уже пользуетесь каким-нибудь инструментом, но его в перечисленном ниже списке не обнаружили, то пишите об этом в комментариях, я думаю, всем читателям будет интересно узнать, какие еще существуют средства создания SQL запросов.
Также обязательно отмечу, что, так как здесь перечислены качественные и многофункциональные инструменты, большинство из них, конечно же, платные, но у них есть бесплатные версии или пробный период. Если Вы будете заниматься SQL разработкой на более-менее нормальном уровне, то возможно стоит и отдать деньги за понравившееся Вам решение.
Однако с другой стороны, для начинающих в целях обучения или для небольших проектов покупать отдельный, пусть и очень функциональный и удобный инструмент, я думаю, не стоит, так как достаточно будет использовать стандартные средства, которые обычно разработчики конкретной СУБД предоставляют бесплатно. Основные стандартные средства я буду отмечать, чтобы Вы понимали, от чего Вам нужно отталкиваться, если Вы начинающий.
Microsoft SQL Server
Начну я, конечно же, с Microsoft SQL Server, так как я уже достаточно долго работаю с данной СУБД. Microsoft SQL Server – это система управления базами данных от компании Microsoft. Она очень популярна в корпоративном секторе, особенно в крупных компаниях.
Инструментов для работы с Microsoft SQL Server много, однако самый распространённый и популярный вариант – это, конечно же, SQL Server Management Studio.
SQL Server Management Studio
SQL Server Management Studio (SSMS) — это бесплатная графическая среда для управления инфраструктурой SQL Server, разработанная компанией Microsoft. С помощью Management Studio Вы можете разрабатывать и выполнять инструкции T-SQL, а также администрировать Microsoft SQL Server.
Среда SQL Server Management Studio – это основной, стандартный инструмент для работы с Microsoft SQL Server.
Если стандартного функционала SSMS Вам недостаточно, то для этой среды разработано очень много различных плагинов и надстроек, которые расширяют функционал Management Studio.
Более подробно про SQL Server Management Studio, включая то, как установить данную среду, я рассказывал в статье – Обзор и установка SQL Server Management Studio.
Дополнительные материалы:
- Страница продукта – https://docs.microsoft.com/ru-RU/sql/ssms/download-sql-server-management-studio-ssms;
- SQL код – книга для изучения языка SQL.
SQL Server Data Tools
SQL Server Data Tools – это еще один инструмент для работы с Microsoft SQL Server, разработанный компанией Microsoft. Данный инструмент входит в состав Visual Studio, и устанавливается он как отдельная рабочая нагрузка. Предназначен SQL Server Data Tools в первую очередь для разработчиков приложений.
Если Вы разрабатываете программы с помощью Visual Studio, при этом у Вас возникла необходимость работы с Microsoft SQL Server, то SQL Server Data Tools будет для Вас очень удобным и привычным инструментом.
Страница продукта – https://docs.microsoft.com/ru-ru/sql/ssdt/download-sql-server-data-tools-ssdt
dbForge Studio for SQL Server
dbForge Studio for SQL Server – это мощная среда для разработки и администрирования баз данных в Microsoft SQL Server. Разработчиком данной среды является компания Devart, у которой, кстати, есть много инструментов для работы с Microsoft SQL Server, про один инструмент я уже рассказывал в статье – Как сравнить и синхронизировать две базы данных в Microsoft SQL Server? Кроме того, у Devart есть и инструменты для работы с другими СУБД, про некоторые я сегодня еще расскажу.
Страница продукта – https://www.devart.com/ru/dbforge/sql/studio/
Red Gate SQL Prompt
Red Gate SQL Prompt – еще один мощнейший инструмент для работы с Microsoft SQL Server. С помощью него также можно разрабатывать SQL инструкции и администрировать SQL сервер. Данную среду разрабатывает компания Redgate Software, которая специализируется на работе с данными, у нее есть инструменты и для работы с другими СУБД, но основным направлением является Microsoft SQL Server.
Страница продукта – https://www.red-gate.com/products/sql-development/sql-prompt/
Navicat for SQL Server
Navicat for SQL Server – это графический инструмент для разработки и администрирования баз данных в Microsoft SQL Server. С помощью него можно создавать, редактировать и удалять любые объекты базы данных, разрабатывать и выполнять SQL запросы и инструкции, а также просматривать данные в таблицах, включая двоичные и шестнадцатеричные данные.
Страница продукта – https://www.navicat.com/en/products/navicat-for-sqlserver
EMS SQL Management Studio for SQL Server
EMS SQL Management Studio for SQL Server – это комплексное решение для разработки и администрирования баз данных в Microsoft SQL Server. Разработкой занимается компания EMS, которая специализируется на разработке инструментов администрирования баз данных и приложений для управления данными. У нее много инструментов для работы с разными СУБД.
Страница продукта – https://www.sqlmanager.net/products/studio/mssql/
DataGrip
DataGrip – это универсальный инструмент для работы с базами данных, он умеет работать с Microsoft SQL Server, PostgreSQL, MySQL, Oracle, Sybase, DB2 и другими. Разработчиком DataGrip выступает JetBrains.
Страница продукта – https://www.jetbrains.com/datagrip/
SQL Enlight
SQL Enlight – еще одно приложение для разработки T-SQL кода. Разработкой занимается компания Ubitsoft.
Страница продукта – https://ubitsoft.com/
SQLCMD
SQLCMD – это стандартный консольный инструмент для работы с Microsoft SQL Server от компании Microsoft. Его использовать как основное средство разработки и администрирования SQL Server не получится, он в основном предназначен для каких-то служебных задач, выполнения скриптов и так далее. Его я сюда включил, так как начинающим программистам и администраторам SQL сервера об этом инструменте знать нужно.
Oracle Database
Oracle Database – это система управления базами данных от компании Oracle. Это также очень популярная СУБД, и также среди крупных компаний.
Инструментов для работы с Oracle Database также много, вот некоторые из них.
Oracle SQL Developer
Oracle SQL Developer – это стандартный, бесплатный и основной инструмент для разработчика баз данных Oracle.
Разработкой занимается компания Oracle. С помощью Oracle SQL Developer можно разрабатывать инструкции на PL/SQL и выполнять SQL запросы.
Страница продукта – https://www.oracle.com/database/technologies/appdev/sql-developer.html
SQL Navigator for Oracle
SQL Navigator for Oracle – это удобный и не менее популярный инструмент для работы с Oracle Database.

Страница продукта – https://www.quest.com/products/sql-navigator/
Navicat for Oracle
Navicat for Oracle – это инструмент для разработки и администрирования баз данных Oracle Database. Этот инструмент имеет широкий набор функций для облегчения управления данными, таких как инструмент моделирования данных, синхронизация данных, импорт и экспорт данных.
Страница продукта – https://www.navicat.com/en/products/navicat-for-oracle
EMS SQL Management Studio for Oracle
EMS SQL Management Studio for Oracle – это комплексное решение для разработки и администрирования баз данных Oracle Database. Разработкой занимается компания EMS, продукты которой я уже упоминал сегодня.
Страница продукта – https://www.sqlmanager.net/ru/products/studio/oracle
dbForge Studio for Oracle
dbForge Studio for Oracle – еще один продукт компании Devart, который предназначен для разработки и обслуживания баз данных Oracle Database, он также имеет очень мощный функционал.
Страница продукта – https://www.devart.com/ru/dbforge/oracle/
MySQL
MySQL – это система управления базами данных также от компании Oracle, но только она распространяется бесплатно. MySQL получила широкое применение в интернете как средство хранения данных сайтов.
Для работы с MySQL существует очень много инструментов, вот самые популярные и функциональные.
MySQLWorkbench
MySQL Workbench – это основной и стандартный инструмент для работы с MySQL.
Он позволяет осуществлять разработку на SQL и администрировать MySQL сервер.
Страница продукта – https://www.mysql.com/products/workbench/
PHPMyAdmin
PHPMyAdmin – это бесплатный веб-инструмент для работы с MySQL. Очень широкую популярность он приобрел в интернете, так как именно PHPMyAdmin используют для разработки баз данных на многих web-сайтах, а также на большинстве хостинг-провайдерах для управления базой MySQL используется именно PHPMyAdmin.
Дополнительные материалы:
- Страница продукта – https://www.phpmyadmin.net/
- Пример установки PHPMyAdmin на Linux Mint
Navicat for MySQL
Navicat for MySQL – это инструмент для администрирования и разработки баз данных MySQL и MariaDB. Navicat for MySQL позволяет подключаться и работать с базами данных в MySQL и MariaDB одновременно.
Страница продукта – https://www.navicat.com/en/products/navicat-for-mysql
dbForge Studio for MySQL
dbForge Studio for MySQL – это мощное решение для разработки и управления базами данных MySQL и MariaDB. Данный инструмент позволяет создавать и выполнять SQL запросы, разрабатывать и отлаживать процедуры и функции, а также управлять объектами баз данных MySQL с помощью удобного графического пользовательского интерфейса.
Страница продукта – https://www.devart.com/ru/dbforge/mysql/
EMS SQL Management Studio for MySQL
EMS SQL Management Studio for MySQL – это еще одно комплексное и мощное решение от компании EMS, на этот раз для разработки и администрирования баз данных MySQL. Данный инструмент содержит все необходимые компоненты для работы с MySQL: редактор SQL запросов, средство импорта, экспорта и сравнения данных и много других, предназначенных не только для разработчиков, но и для администраторов и аналитиков данных.
Страница продукта – https://www.sqlmanager.net/ru/products/studio/mysql
SQL Maestro for MySQL
SQL Maestro for MySQL – это еще один инструмент разработки и администрирования баз данных MySQL и MariaDB.
Страница продукта – https://www.sqlmaestro.com/products/mysql/maestro/
PostgreSQL
PostgreSQL – эта бесплатная система управления базами данных, и она очень популярна и функциональна.
Для работы с PostgreSQL можно использовать следующие инструменты.
pgAdmin
pgAdmin – это основное, стандартное средство для разработки баз данных PostgreSQL, которое распространяется бесплатно.
pgAdmin достаточно удобный инструмент для разработчика, с помощью него можно разрабатывать SQL инструкции, выполнять SQL запросы, создавать объекты базы данных и многое другое.
Дополнительные материалы:
- Страница продукта – https://www.pgadmin.org/
- Пример установки pgAdmin 4 на Windows 7
EMS SQL Management Studio for PostgreSQL
EMS SQL Management Studio for PostgreSQL – это комплексное решение для разработки и администрирования баз данных PostgreSQL. Данный инструмент так же, как все остальные продукты компании EMS, имеет очень широкий функционал от простого редактора SQL запросов до инструмента сравнения данных.
Страница продукта – https://www.sqlmanager.net/ru/products/studio/postgresql
Navicat for PostgreSQL
Navicat for PostgreSQL – это простой графический инструмент для разработки баз данных PostgreSQL. Он позволяет писать и выполнять SQL запросы любой сложности.
Страница продукта – https://www.navicat.com/en/products/navicat-for-postgresql
dbForge Studio for PostgreSQL
dbForge Studio for PostgreSQL – это еще один мощный инструмент от компании Devart, на этот раз для работы с PostgreSQL. Он позволяет разрабатывать и выполнять запросы, редактировать код в удобном интерфейсе, формировать отчеты, модифицировать данные, а также осуществлять импорт и экспорт данных.
Страница продукта – https://www.devart.com/dbforge/postgresql/studio/
psql
psql – это стандартная консольная утилита для работы с PostgreSQL. Используется в основном для автоматизации различных служебных задач, хотя вести SQL разработку в ней также можно.
DataGrip
Также осуществлять разработку баз данных PostgreSQL можно и с помощью уже упомянутого в этой статье универсального инструмента DataGrip от компании JetBrains.
Выводы
Как видите, существует очень много инструментов для работы с базами данных, при этом многие компании специализируется на выпуске программ для баз данных, и у них есть версии для каждой популярной СУБД. Такие инструменты очень функциональны, и они, конечно же, платные. Но, как я уже отмечал, функционала стандартных средств, которые предоставляются бесплатно, для создания и выполнения SQL запросов будет вполне достаточно.
На сегодня это все, удачи Вам, пока!
👉 Система управления базами данных (СУБД) — это отдельная программа, которая работает как сервер, независимо от PHP.
Создавать свои базы данных, таблицы и наполнять их данными можно прямо из этой же программы, но для выполнения этих операций прежде придётся познакомиться с ещё одним языком программирования — SQL.
SQL или Structured Query Language (язык структурированных запросов) — язык программирования, предназначенный для управления данными в СУБД. Все современные СУБД поддерживают SQL.
На языке SQL выражаются все действия, которые можно провести с данными: от записи и чтения данных, до администрирования самого сервера СУБД. Для повседневной работы совсем не обязательно знать весь этот язык; достаточно ознакомиться лишь с основными понятиями синтаксиса и ключевыми словами.
Кроме того, SQL очень простой язык по своей структуре, поэтому его освоение не составит большого труда.
Язык SQL — это в первую очередь язык запросов, а кроме того он очень похож на естественный язык. Каждый раз, когда требуется прочитать или записать любую информацию в БД, требуется составить корректный запрос. Такой запрос должен быть выражен в терминах SQL.
Например, чтобы вывести на экран все записи из таблицы города, составим такой запрос:
ПРОЧИТАТЬ всё ИЗ ТАБЛИЦЫ 'города'Если перевести этот запрос на язык SQL, то корректным результатом будет:
SELECT * FROM 'cities'Теперь напишем запрос на добавление в таблицу города нового города:
ВСТАВЬ В ТАБЛИЦУ 'города' ЗНАЧЕНИЯ 'имя города' = 'Санкт-Петербург'Перевод на SQL:
INSERT INTO 'cities' SET 'name' = 'Санкт-Петербург'Эта команда создаст в таблице города новую запись, где полю имя города будет присвоено значение Санкт-Петербург.
С помощью SQL можно не только добавлять и читать данные, но и:
- удалять и обновлять записи в таблицах;
- создавать и редактировать сами таблицы;
- производить операции над данными: считать сумму, получать самое большое или малое значение, и так далее;
- настраивать работу сервера СУБД.
MySQL
Существует множество различных реляционных СУБД. Самая известная СУБД — это Microsoft Access, входящая в состав офисного пакета приложений Microsoft Office. Нет никаких препятствий для использования в качестве СУБД MS Access, но для задач веб-программирования гораздо лучше подходит альтернативная программа — MySQL.
В отличие от MS Access, MySQL абсолютно бесплатна, может работать на серверах с Linux, обладает гораздо большей производительностью и безопасностью, что делает её идеальным кандидатом на роль базы данных в веб-разработке.
Подавляющее большинство сайтов и приложений на PHP используют в качестве СУБД именно MySQL.
Установка
Последняя версия MySQL доступна для загрузки по ссылке: https://dev. mysql. com/downloads/mysql/. На этой странице следует выбрать MySQL Installer for Windows и нажать на кнопку Download для загрузки.
В процессе установки запомните директорию, куда вы устанавливаете MySQL (скрывается под ссылкой Advanced options). На шаге Accounts and Roles установщик попросит придумать пароль для доступа к БД (MySQL Root Password) — обязательно запомните или запишите этот пароль — он вам ещё понадобится.
Если для своей работы вы используете программную среду OpenServer, то этот раздел можно смело пропустить, так как в состав OpenServer уже входит свежая версия MySQL.
Выполнение запросов
По умолчанию, если вы не устанавливали дополнительные программы, у MySQL нет графического интерфейса пользователя. Это значит, что единственный способ работы с ней — это использование командной строки.
- Откройте командную строку (Выполнить —
cmd.exe). - Перейдите в каталог с установленной MySQL:
cd /d <каталог установки>/bin. - Выполните:
mysql -uroot -p. - Введите пароль, заданный при установке.
Если вы всё выполнили верно, то в командной строке запустится клиент для работы с MySQL (вы поймете это по строке приглашения «mysql>»). С этого момента можно вводить любые SQL запросы, но каждый запрос обязательно должен заканчиваться точкой с запятой ;.
Оператор SQL create database: создание новой базы данных>
Приступим к практике — начнём создавать базу данных для ведения погодного дневника.
Начать следует с создания новой базы данных для нашего сайта. Новая БД в MySQL создаётся простой командой:
CREATE DATABASE <имя базы данных>После этого MySQL создаст для нас новую БД, в которой будет происходить вся дальнейшая работа. Это важно: после создания БД её невозможно будет переименовать, а только удалить и создать заново. По этой причине крайне внимательно подойдите к выбору имени для базы данных.
create table
Зачем нужен: создание таблиц
Создав новую БД, сообщим MySQL, что теперь мы собираемся работать именно с ней. Выбор активной БД выполняется командой:
USE <имя базы>;Пришло время создать первые таблицы! Для ведения дневника по всем правилам, понадобится создать три таблицы: города (cities), пользователи (users) и записи о погоде weather_log. В подразделе «Запись» этой главы описано, как должна выглядеть структура таблицы weather_log. Переведём это описание на язык SQL:
CREATE TABLE weather_log (
id INT AUTO_INCREMENT PRIMARY KEY,
city_id INT,
day DATE,
temperature INT,
cloud TINYINT DEFAULT 0
);Чтобы ввести многострочную команду в командной строке используйте символ в конце каждой строки, кроме последней.
Теперь создадим таблицу городов:
CREATE TABLE cities (
id INT AUTO_INCREMENT PRIMARY KEY,
name CHAR(128)
)MySQL может показать созданную таблицу, если попросить об этом командой:
SHOW COLUMNS FROM weather_logВ ответе будут перечислены все поля таблицы, их тип и другие характеристики.
Что такое первичный ключ
В примере с созданием новой таблицы при перечислении необходимых полей первым полем идёт id INT AUTO_INCREMENT PRIMARY KEY. Это поле называется первичным ключом. Обязательно создавать первичный ключ в каждой таблице.
👉 Первичный ключ — это особенное поле, в котором сохраняется уникальный идентификатор записи.
Первичный ключ нужен, чтобы у программиста и базы данных всегда была возможность однозначно обратиться к одной конкретной записи для её чтения, обновления или удаления. Если назначить поле первичным ключом, то БД будет следить за тем, чтобы значение в этом поле больше не повторялось в таблице.
А если ещё и добавить аттрибут AUTO_INCREMENT, то MySQL при добавлении новых записей будет заполнять это поле сама. AUTO_INCREMENT будет играть роль счётчика — каждая новая запись в таблице получит значение на единицу больше максимального существующего значения.
insert into
Зачем нужен: добавление записи в таблицу
Начнём с добавления новых данных в таблицу. Для добавления записи используется следующий синтаксис:
insert into <название таблицы> set <имя столбца1> = <значение2>, <имя столбца2> = <значение2>...В начале добавим город в таблицу городов:
insert into cities set name = 'Санкт-Петербург'При добавлении записи необязательно указывать значения для всех полей. Многие из полей имеют значения по умолчанию, которые сами заполняются при сохранении.
Теперь создадим запись о погоде за сегодня.
При определении таблицы weatherlog мы решили ссылаться на город, путём записи в поле cityid идентификатора города из таблицы cities. Так как мы только что добавили новый город, ничего не мешает использовать его идентификатор в записи о погоде.
Идентификатором города будет первичный ключ, который также был определён в качестве первого поля таблицы. Нумерация этого поля начинается с единицы, значит первая добавленная запись имеет идентификатор 1. Зная это, запрос на добавление записи о погоде в Санкт-Петербурге за третье сентября 2017 года выглядит так:
INSERT INTO weather_log SET city_id = 1, day = '2017-09-03', temperature = 5, cloud = 1;select. Чтение информации из БД
Для вывода информации из БД используются запросы типа SELECT.
В запросе нужно указать имя таблицы, необходимые поля, а также дополнительные параметры (будут рассмотрены в следующем уроке).
SELECT <перечисление полей> FROM <имя таблицы>Например, чтобы получить список всех доступных городов:
SELECT id, name FROM citiesВсе погодные записи:
SELECT id, day, city_id, temperature, cloud FROM weather_logВместо перечисления всех столбцов можно использовать знак звездочки — *.
Оператор update: обновление информации в БД
При добавлении записи очень легко совершить ошибку: сделать опечатку, не указать значение для одного из полей, и так далее. Естественно, язык SQL предлагает возможности для редактирования уже созданных записей.
Предположим, что при добавлении погодной записи пользователь ошибся и ввёл неверную дату. Чтобы исправить эту ошибку, нужно использовать оператор обновления — UPDATE. Запрос с этим оператором позволяет обновить значение одного или нескольких полей в существующей записи. Выглядит он так:
UPDATE <имя таблицы> SET <имя столбца1> = <значение2>, <имя столбца2> = <значение2>... WHERE <имя столбца> = <значение>Но чтобы правильно составить запрос, необходимо определить условие для поиска записи, которую предлагается обновить. В противном случае, если не указать это условие, то будут обновлены абсолютно все записи в таблице.
В качестве такого условия лучше всего использовать первичный идентификатор записи. Поэтому, прежде чем выполнять запрос обновления, нужно выполнить запрос на чтение информации из таблицы, чтобы узнать, под каким идентификатором сохранилась ошибочная запись. Допустим, этот идентификатор — единица, а правильная дата — седьмое декабря 2022 года.
Запрос на обновление:
UPDATE weather_log SET day = '2022-12-07' WHERE id = 1Оператор join: объединение записей из двух таблиц
В нашей таблице для хранения погодного дневника город сохраняется как идентификатор, поэтому при обычном чтении данных из этой таблицы вместо названия города стоит непонятное число. Чтобы подставить на место числа действительное значение, а конкретнее — название города, в SQL существуют операторы объединения — JOIN. Поддержка операторов объединения и позволяет базе данных называться реляционной.
Поменяем запрос на показ погодных записей, чтобы он объединял две таблицы, а в поле города показывалось его название, а не идентификатор:
SELECT day, cities.name, temperature, cloud FROM weather_log JOIN cities ON weather_log.city_id = cities.idВажно усвоить три самых главных момента:
- При чтении из объединённых таблиц, в перечислении полей после SELECT нужно явно указывать в поле имени также имя таблицы, с которой производится объединение.
- Всегда есть основная таблица (тб1), из которой читается большинство полей, и присоединяемая (тб2), имя которой определяется после оператора JOIN.
- Помимо указания имени второй таблицы, обязательно следует указать условие, по которому будет происходить объединение. В этом примере таким условием будет соответствие идентификатора города из тб1 (
weather_log.city_id) первичному ключу города из тб2 (cities.id).
Добро пожаловать на первый урок по реляционным базам данных и языку SQL.
Реляционные базы данных представляют собой набор таблиц с информацией.
Вроде такой:
| id | name | count | price |
|---|---|---|---|
| 1 | Телевизор | 3 | 43200.00 |
| 2 | Микроволновая печь | 4 | 3200.00 |
| 3 | Холодильник | 3 | 12000.00 |
| 4 | Роутер | 1 | 1340.00 |
| 5 | Компьютер | 0 | 26150.00 |
Или такой:
| id | first_name | last_name | birthday | age |
|---|---|---|---|---|
| 1 | Дмитрий | Иванов | 1996-12-11 | 20 |
| 2 | Олег | Лебедев | 2000-02-07 | 17 |
| 3 | Тимур | Шевченко | 1998-04-27 | 19 |
| 4 | Светлана | Иванова | 1993-08-06 | 23 |
| 5 | Олег | Ковалев | 2002-02-08 | 15 |
| 6 | Алексей | Иванов | 1993-08-05 | 23 |
| 7 | Алена | Процук | 1997-02-28 | 18 |
Каждая таблица состоит из столбцов и строк.
Посмотрим внимательней на таблицу products, которая хранит данные о товарах в интернет-магазине. Таблица содержит 4 столбца: id, name, count и price. Каждый из столбцов отвечает за какой-то определенный тип информации: id — это уникальный номер товара, name — его имя, count — количество, price — цена.
Строка отвечает за конкретный товар в таблице. Если мы посмотрим на третью строку, то найдем там «Холодильник» с ценой 12 000 рублей в количестве 3 штук.
Другая таблица — это users, которая хранит данные о пользователях в системе. В таблице 5 столбцов: также уникальный номер пользователя id, имя, фамилия, возраст — age и дата рождения — birthday.
Как я уже говорил, каждый столбец отвечает за какую-то информацию и эта информация относится к определенному типу данных. Столбцы first_name и last_name строковые, age и id содержат числа, а birthday — дату.
Название столбца, его тип и порядок строго задаются на этапе создания таблицы. Об этом мы поговорим в других уроках.
А вот записи таблицы (или строки) заполняются в процессе её использования. Поэтому столбцов у нас жестко 5. А строк может быть сколько угодно. Зарегистрировался пользователь на сайте — добавили строку. Привезли новые товары в магазин — таблица растет.
Добавление, удаление, изменение или получение данных из таблиц, выполняется с помощью языка SQL.
- SQL
- — это язык общения с базами данных.
Давайте попробуем получить информацию из таблицы users. Для этого надо написать и выполнить такой SQL-запрос:
SELECT * FROM usersПолучили всех пользователей из таблицы users:
| id | first_name | last_name | birthday | age |
|---|---|---|---|---|
| 1 | Дмитрий | Иванов | 1996-12-11 | 20 |
| 2 | Олег | Лебедев | 2000-02-07 | 17 |
| 3 | Тимур | Шевченко | 1998-04-27 | 19 |
| 4 | Светлана | Иванова | 1993-08-06 | 23 |
| 5 | Олег | Ковалев | 2002-02-08 | 15 |
| 6 | Алексей | Иванов | 1993-08-05 | 23 |
| 7 | Алена | Процук | 1997-02-28 | 18 |
Рассмотрим SQL запрос подробнее.
Оператор SELECT говорит, что мы будем извлекать данные. После него идет список столцов, которые мы хотим получить. Если указать звездочку (*), как у нас, то получим все столбцы в том порядке, в котором они определены в таблице: id, first_name, last_name и тд. Далее идет конструкция FROM users, которая буквально означает ИЗ users.
То есть вся SQL конструкция читается как ВЫБРАТЬ все столбцы ИЗ таблицы users.
Теперь вместо звездочки напишем: last_name, first_name, birthday, чтобы у нас получился такой SQL-запрос:
SELECT last_name, first_name, birthday FROM usersЕсли его выполнить, то мы снова получим всех пользователей из таблицы users, но на этот раз только фамилию, имя и дату рождения. То есть записи все, а столбцы нет:
| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 2 | Лебедев | Олег | 2000-02-07 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 5 | Ковалев | Олег | 2002-02-08 |
| 6 | Иванов | Алексей | 1993-08-05 |
| 7 | Процук | Алена | 1997-02-28 |
Кроме того, что мы получили не все столбцы, мы дополнительно изменили их порядок на тот, который нам удобен. В оригинальной таблице first_name стоит перед last_name, а у нас наоборот.
Еще обратите внимание, что результатом работы SQL запроса является таблица. То есть мы берем исходную таблицу, которая хранится в базе, и с помощью SQL запроса получаем другую таблицу — с теми данными, которые нам нужны.
И часто требуется получить не все данные, а только те, которые соответствуют какому-то условию. Давайте снова изменим наш SQL-запрос, чтобы он стал таким:
SELECT last_name, first_name, birthday FROM users WHERE age > 18Если его выполнить, то мы получим список пользователей которым уже исполнилось 19 лет:
| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 6 | Иванов | Алексей | 1993-08-05 |
Конструкция WHERE позволяет фильтровать исходные данные в соответствии с нашими условиями. В данном случае мы получаем данные из таблицы users ГДЕ (WHERE) в столбце age значение больше 18.
Так как age — это числовой столбец, то его уместно сравнивать с числами. Если заменить знак больше на равно и снова запустить, то получим всех 18 летних пользователей. А если поставим >= , то получим совершеннолетних пользователей:
SELECT last_name, first_name, birthday FROM users WHERE age >= 18| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 6 | Иванов | Алексей | 1993-08-05 |
| 7 | Процук | Алена | 1997-02-28 |
Как видите SQL запросы довольно просто составлять и читать. Язык создавался для того, чтобы им могли пользоваться люди, которые не умеют программировать.
А теперь самое время потренироваться в SQL, для этого к каждому уроку привязано несколько задач, которые вы можете решать в специальном тренажере прямо на сайте.
Следующий урок
Урок 2. Составные условия
В этом уроке вы узнаете как формировать сложные условия в SQL-запросах с использованием операторов AND и OR.
Посмотреть
Тарифы
-
-
55 видео-уроков
Более 7 часов видео
-
Дополнительные материалы
Схемы, методички, исходные коды
-
Возможность скачать видео
Смотреть уроки можно даже без интернета
-
Доступ к курсу навсегда
Можете освежить знания через год или два
-
271 практическое задание
Практические занятия на тренажере
-
Поддержка преподавателя
Помощь в решении заданий в течение 24 часов
-
Сертификат о прохождении курса
Подтверждение ваших навыков
-
Эталонные решения
Решения преподавателя
-
-
-
55 видео-уроков
Более 7 часов видео
-
Дополнительные материалы
Схемы, методички, исходные коды
-
Возможность скачать видео
Смотреть уроки можно даже без интернета
-
Доступ к курсу навсегда
Условия бесплатного тарифа могут измениться
-
271 практическое задание
Практические занятия на тренажере
-
Поддержка преподавателя
Помощь в решении заданий в течение 24 часов
-
Сертификат о прохождении курса
Подтверждение ваших навыков
-
Эталонные решения
Решения преподавателя
-
Регистрация
Основы SQL
Structured Query Language (SQL) — язык структурированных запросов, с помощью него пишутся специальные запросы (SQL инструкции) к базе данных с целью получения этих данных из базы и для манипулирования этими данными.
С точки зрения реализации язык SQL представляет собой набор операторов, которые делятся на определенные группы и у каждой группы есть свое назначение. В сокращенном виде эти группы называются DDL, DML, DCL и TCL.
DDL – Data Definition Language
Data Definition Language (DDL) – это группа операторов определения данных. Другими словами, с помощью операторов, входящих в эту группы, мы определяем структуру базы данных и работаем с объектами этой базы, т.е. создаем, изменяем и удаляем их.
В эту группу входят следующие операторы:
- CREATE – используется для создания объектов базы данных;
- ALTER – используется для изменения объектов базы данных;
- DROP – используется для удаления объектов базы данных.
DML – Data Manipulation Language
Data Manipulation Language (DML) – это группа операторов для манипуляции данными. С помощью этих операторов мы можем добавлять, изменять, удалять и выгружать данные из базы, т.е. манипулировать ими.
В эту группу входят самые распространённые операторы языка SQL:
- SELECT – осуществляет выборку данных;
- INSERT – добавляет новые данные;
- UPDATE – изменяет существующие данные;
- DELETE – удаляет данные.
DCL – Data Control Language
Data Control Language (DCL) – группа операторов определения доступа к данным. Иными словами, это операторы для управления разрешениями, с помощью них мы можем разрешать или запрещать выполнение определенных операций над объектами базы данных.
TCL – Transaction Control Language
Transaction Control Language (TCL) – группа операторов для управления транзакциями. Транзакция – это команда или блок команд (инструкций), которые успешно завершаются как единое целое, при этом в базе данных все внесенные изменения фиксируются на постоянной основе или отменяются, т.е. все изменения, внесенные любой командой, входящей в транзакцию, будут отменены.
Базовый синтаксис SQL команды SELECT
Одна из основных функций SQL — получение данных из СУБД. Для построения всевозможных запросов к базе данных используется оператор SELECT. Он позволяет выполнять сложные проверки и обработку данных.
Общая структура запроса
SELECT [DISTINCT | ALL] поля_таблиц [FROM список_таблиц] [WHERE условия_на_ограничения_строк] [GROUP BY условия_группировки] [HAVING условия_на_ограничения_строк_после_группировки] [ORDER BY порядок_сортировки [ASC | DESC]] [LIMIT ограничение_количества_записей]
В описанной структуре запроса необязательные параметры указаны в квадратных скобках.
Параметры оператора
- DISTINCT используется для исключения повторяющихся строк из результата
- ALL (по умолчанию) используется для получения всех данных, в том числе и повторений
- FROM перечисляет используемые в запросе таблицы из базы данных
- WHERE — это условный оператор, который используется для ограничения строк по какому-либо условию
- GROUP BY используется для группировки строк
- HAVING применяется после группировки строк для фильтрации по значениям агрегатных функций
- ORDER BY используется для сортировки. У него есть два параметра:
- ASC (по умолчанию) используется для сортировки по возрастанию
- DESC — по убыванию
- LIMIT используется для ограничения количества строк для вывода
SQL-псевдонимы
Псевдонимы используются для представления столбцов или таблиц с именем отличным от оригинального. Это может быть полезно для улучшения читабельности имён и создания более короткого наименования столбца или таблицы.
Например, если в вашей таблице есть столбец good_type_id, вы можете переименовать его просто в id, для того, чтобы сделать его более коротким и удобным в использовании в будущем.
Для создания псевдонимов используется оператор AS:
SELECT good_type_id AS id FROM GoodTypes;
Примеры использования
Вы можете выводить любые строки и числа вместо столбцов:
Для того, чтобы вывести все данные из таблицы Company, вы можете использовать символ «*», который буквально означает «все столбцы»:
Вы можете вывести любой столбец, определённый в таблице, например, town_to из таблицы Trip:
SELECT town_to FROM Trip;
Также вы можете вывести несколько столбцов. Для этого их нужно перечислить через запятую:
SELECT member_name, status FROM FamilyMembers;
Иногда возникают ситуации, в которых нужно получить только уникальные записи. Для этого вы можете использовать DISTINCT. Например, выведем список городов без повторений, в которые летали самолеты:
SELECT DISTINCT town_to FROM Trip;
Эта конструкция используется для формирования словарей, примеры рассмотрим в главе про команду INSERT
Условный оператор WHERE
Ситуация, когда требуется сделать выборку по определенному условию, встречается очень часто. Для этого в операторе SELECT существует параметр WHERE, после которого следует условие для ограничения строк. Если запись удовлетворяет этому условию, то попадает в результат, иначе отбрасывается.
Общая структура запроса с оператором WHERE
SELECT поля_таблиц FROM список_таблиц WHERE условия_на_ограничения_строк [логический_оператор другое_условия_на_ограничения_строк];
В описанной структуре запроса необязательные параметры указаны в квадратных скобках.
В условном операторе применяются операторы сравнения, специальные и логические операторы.
Операторы сравнения
Операторы сравнения служат для сравнения 2 выражений, их результатом может являться ИСТИНА (1), ЛОЖЬ (0) и NULL.
Результат сравнения с NULL является NULL. Исключением является оператор эквивалентности.
| Оператор | Описание |
|---|---|
| = | Оператор равенство |
| <=> | Оператор эквивалентность Аналогичный оператору равенства, с одним лишь исключением: в отличие от него, оператор эквивалентности вернет ИСТИНУ при сравнении NULL <=> NULL |
| <> или != |
Оператор неравенство |
| < | Оператор меньше |
| <= | Оператор меньше или равно |
| > | Оператор больше |
| >= | Оператор больше или равно |
Специальные операторы
-
IS [NOT] NULL— позволяет узнать равно ли проверяемое значение NULL.Для примера выведем всех членов семьи, у которых статус в семье не равен NULL:
SELECT * FROM FamilyMembers WHERE status IS NOT NULL;
-
[NOT] BETWEEN min AND max— позволяет узнать расположено ли проверяемое значение столбца в интервале между min и max.Выведем все данные о покупках с ценой от 100 до 500 рублей из таблицы Payments:
SELECT * FROM Payments WHERE unit_price BETWEEN 100 AND 500;
-
[NOT] IN— позволяет узнать входит ли проверяемое значение столбца в список определённых значений.Выведем имена членов семьи, чей статус равен «father» или «mother»:
SELECT member_name FROM FamilyMembers WHERE status IN ('father', 'mother');
-
[NOT] LIKE шаблон [ESCAPE символ]— позволяет узнать соответствует ли строка определённому шаблону.Например, выведем всех людей с фамилией «Quincey»:
SELECT member_name FROM FamilyMembers WHERE member_name LIKE '% Quincey';
Трафаретные символы
В шаблоне разрешается использовать два трафаретных символа:
- символ подчеркивания (_), который можно применять вместо любого единичного символа в проверяемом значении
- символ процента (%) заменяет последовательность любых символов (число символов в последовательности может быть от 0 и более) в проверяемом значении.
| Шаблон | Описание |
|---|---|
| never% | Сопоставляется любым строкам, начинающимся на «never». |
| %ing | Сопоставляется любым строкам, заканчивающимся на «ing». |
| _ing | Сопоставляется строкам, имеющим длину 4 символа, при этом 3 последних обязательно должны быть «ing». Например, слова «sing» и «wing». |
ESCAPE-символ
ESCAPE-символ используется для экранирования трафаретных символов. В случае если вам нужно найти строки, содержащие проценты (а процент — это зарезервированный символ), вы можете использовать ESCAPE-символ.
Например, вы хотите получить идентификаторы задач, прогресс которых равен 3%:
SELECT job_id FROM Jobs WHERE progress LIKE '3!%' ESCAPE '!';
Если бы мы не экранировали трафаретный символ, то в выборку попало бы всё, что начинается на 3.
Логические операторы
Логические операторы необходимы для связывания нескольких условий ограничения строк.
- Оператор NOT — меняет значение специального оператора на противоположный
- Оператор OR — общее значение выражения истинно, если хотя бы одно из них истинно
- Оператор AND — общее значение выражения истинно, если они оба истинны
- Оператор XOR — общее значение выражения истинно, если один и только один аргумент является истинным
Выведем все полёты, которые были совершены на самолёте «Boeing», но, при этом, вылет был не из Лондона:
SELECT * FROM Trip WHERE plane = 'Boeing' AND NOT town_from = 'London';
Выборка сводных данных (из двух и более таблиц)
При формировании сводной выборки данные беруться из нескольких таблиц. В операторе FROM исходные таблицы перечисляются через запятую. Также им могут быть присвоены алиасы. Синтаксис запроса выглядит следующийм образом:
SELECT [ALIAS | TABLE].Название_поля1, [ALIAS | TABLE].Название_поля2,... FROM Table1 [ALIAS], Table2 [ALIAS] ...
При выборке сводных таблиц нужно учитывать, что исходные таблицы перемножаются. Т.е. если на входе у нас были таблицы:
| id | Name |
|---|---|
| 1 | Иванов |
| 2 | Петров |
| id | Name | Phone |
|---|---|---|
| 1 | Иванов | 322223 |
| 2 | Петров | 111111 |
То при простом запросе без условий
SELECT a.*, b.* FROM Table1 a, Table2 b
Получим примерно следующее:
| id | Name | id2 | Name2 | Phone |
|---|---|---|---|---|
| 1 | Иванов | 1 | Иванов | 322223 |
| 1 | Иванов | 2 | Петров | 111111 |
| 2 | Петров | 1 | Иванов | 322223 |
| 2 | Петров | 2 | Петров | 111111 |
Чтобы выбрать уникальные значения, нам нужно использовать оператор WHERE для связи этих таблиц
SELECT a.*, b.Phone FROM Table1 a, Table2 b WHERE a.Name=b.Name
| id | Name | Phone |
|---|---|---|
| 1 | Иванов | 322223 |
| 2 | Петров | 111111 |
Сводные выборки нужны при импорте данных в базу. Сначала вы выделяете из таблиц импорта словари. А потом из таблиц импорта и словарей формируете запрос INSERT ... SELECT для записи данных в основную таблицу.
Вложенные SQL запросы
Вложенный запрос — это запрос на выборку, который используется внутри инструкции SELECT, INSERT, UPDATE или DELETE или внутри другого вложенного запроса. Подзапрос может быть использован везде, где разрешены выражения.
Пример структуры вложенного запроса
SELECT поля_таблиц FROM список_таблиц WHERE конкретное_поле IN ( SELECT поле_таблицы FROM таблица )
Здесь, SELECT поля_таблиц FROM список_таблиц WHERE конкретное_поле IN (...) — внешний запрос, а SELECT поле_таблицы FROM таблица — вложенный (внутренний) запрос.
Каждый вложенный запрос, в свою очередь, может содержать один или несколько вложенных запросов. Количество вложенных запросов в инструкции не ограничено.
Подзапрос может содержать все стандартные инструкции, разрешённые для использования в обычном SQL-запросе: DISTINCT, GROUP BY, LIMIT, ORDER BY, объединения таблиц, запросов и т.д.
Подзапрос может возвращать скаляр (одно значение), одну строку, один столбец или таблицу (одну или несколько строк из одного или нескольких столбцов). Они называются скалярными, столбцовыми, строковыми и табличными подзапросами.
Подзапрос как скалярный операнд
Скалярный подзапрос — запрос, возвращающий единственное скалярное значение (строку, число и т.д.).
Следующий простейший запрос демонстрирует вывод единственного значения (названия компании). В таком виде он не имеет большого смысла, однако ваши запросы могут быть намного сложнее.
SELECT ( SELECT name FROM company LIMIT 1 );
Таким же образом можно использовать скалярные подзапросы для фильтрации строк с помощью WHERE, используя операторы сравнения.
SELECT * FROM FamilyMembers WHERE birthday = ( SELECT MAX(birthday) FROM FamilyMembers );
С помощью данного запроса возможно получить самого младшего члена семьи. Здесь используется подзапрос для получения максимальной даты рождения, которая затем используется для фильтрации строк.
Подзапросы с ANY, IN, ALL
ANY — ключевое слово, которое должно следовать за операцией сравнения (>, <, <>, = и т.д.), возвращающее TRUE, если хотя бы одно из значений столбца подзапроса удовлетворяет обозначенному условию.
SELECT поля_таблицы_1 FROM таблица_1 WHERE поле_таблицы_1 <= ANY (SELECT поле_таблицы_2 FROM таблица_2);
ALL — ключевое слово, которое должно следовать за операцией сравнения, возвращающее TRUE, если все значения столбца подзапроса удовлетворяет обозначенному условию.
SELECT поля_таблицы_1 FROM таблица_1 WHERE поле_таблицы_1 > ALL (SELECT поле_таблицы_2 FROM таблица_2);
IN — ключевое слово, являющееся псевдонимом ключевому слову ANY с оператором сравнения = (эквивалентность), либо <> ALL для NOT IN. Например, следующие запросы равнозначны:
... WHERE поле_таблицы_1 = ANY (SELECT поле_таблицы_2 FROM таблица_2);
... WHERE поле_таблицы_1 IN (SELECT поле_таблицы_2 FROM таблица_2);
Строковые подзапросы
Строковый подзапрос — это подзапрос, возвращающий единственную строку с более чем одной колонкой. Например, следующий запрос получает в подзапросе единственную строку, после чего по порядку попарно сравнивает полученные значения со значениями во внешнем запросе.
SELECT поля_таблицы_1 FROM таблица_1 WHERE (первое_поле_таблицы_1, второе_поле_таблицы_1) = ( SELECT первое_поле_таблицы_2, второе_поле_таблицы_2 FROM таблица_2 WHERE id = 10 );
Данную конструкцию удобно использовать для замены логических операторов. Так, следующие два запроса полностью эквивалентны:
SELECT поля_таблицы_1 FROM таблица_1 WHERE (первое_поле_таблицы_1, второе_поле_таблицы_1) = (1, 1); SELECT поля_таблицы_1 FROM таблица_1 WHERE первое_поле_таблицы_1 = 1 AND второе_поле_таблицы_1 = 1;
Связанные подзапросы
Связанным подзапросом является подзапрос, который содержит ссылку на таблицу, которая была объявлена во внешнем запросе. Здесь вложенный запрос ссылается на внешюю таблицу «таблица_1»:
SELECT поля_таблицы_1 FROM таблица_1 WHERE поле_таблицы_1 IN ( SELECT поле_таблицы_2 FROM таблица_2 WHERE таблица_2.поле_таблицы_2 = таблица_1.поле_таблицы_1 );
Подзапросы как производные таблицы
Производная таблица — выражение, которое генерирует временную таблицу в предложении FROM, которая работает так же, как и обычные таблицы, которые вы указываете через запятую. Так выглядит общий синтаксис запроса с использованием производных таблиц:
SELECT поля_таблицы_1 FROM (подзапрос) [AS] псевдоним_производной_таблицы
Обратите внимание на то, что для производной таблицы обязательно должен указываться её псевдоним, для того, чтобы имелась возможность обратиться к ней в других частях запроса.
Обработка вложенных запросов
Вложенные подзапросы обрабатываются «снизу вверх». То есть сначала обрабатывается вложенный запрос самого нижнего уровня. Далее значения, полученные по результату его выполнения, передаются и используются при реализации подзапроса более высокого уровня и т.д.
Добавление данных, оператор INSERT
Для добавления новых записей в таблицу предназначен оператор INSERT.
Общая структура запроса с оператором INSERT
INSERT INTO имя_таблицы [(поле_таблицы, ...)] VALUES (значение_поля_таблицы, ...) | SELECT поле_таблицы, ... FROM имя_таблицы ...
В описанной структуре запроса необязательные параметры указаны в квадратных скобках. Вертикальной чертой обозначен альтернативный синтаксис.
Значения можно вставлять перечислением с помощью слова values, перечислив их в круглых скобках через запятую или c помощью оператора select. Таким образом, добавить новые записей можно следующими способами:
INSERT INTO Goods (good_id, good_name, type) VALUES (5, 'Table', 2);
INSERT INTO Goods VALUES (5, 'Table', 2);
INSERT INTO Goods SELECT good_id, good_name, type FROM Goods where good_name = 2;
Первичный ключ при добавлении новой записи
Следует помнить, что первичный ключ таблицы является уникальным значением и добавление уже существующего значения приведет к ошибке.
При добавлении новой записи с уникальными индексами выбор такого уникального значения может оказаться непростой задачей. Решением может быть дополнительный запрос, направленный на выявление максимального значения первичного ключа для генерации нового уникального значения.
INSERT INTO Goods SELECT COUNT(*) + 1, 'Table', 2 FROM Goods;
В SQL введен механизм его автоматической генерации. Для этого достаточно снабдить первичный ключ good_id атрибутом AUTO_INCREMENT. Тогда при создании новой записи в качестве значения good_id достаточно передать NULL или 0 — поле автоматически получит значение, равное максимальному значению столбца good_id, плюс единица.
CREATE TABLE Goods ( good_id INT NOT NULL AUTO_INCREMENT ... );
INSERT INTO Goods VALUES (NULL, 'Table', 2);
Пример
Теперь, зная синткасис команд INSERT и SELECT, можем разобраться как создать из исходного набора данных словари и загрузить данные в БД с учетом внешних ключей
Допустим есть список агентов (данные полученные от заказчика в виде CSV-файла), у которых есть поля название, тип и т.д. (далее по тексту я её называю таблица импорта)

В структуре БД поле «тип агента» создано как внешний ключ на таблицу типов


Заполнение словарей
Для добавления «типов агентов» в таблицу AgentType мы будем использовать альтернативный синтаксис INSERT ... SELECT
-
Пишем инструкцию SELECT, которая выбирает уникальные записи из таблицы импорта:
SELECT DISTINCT Тип_агента FROM agents_import
- Ключевое слово DISTINCT относится только к топу полю, перед которым написано. В нашем случае выбирает уникальные названия типов агентов.
- Откуда брать поле Image в предметной области не написано и в исходных данных его нет. Но т.к. в целевой таблице это поле не обязательное, то можно его пропустить
Этот запрос можно выполнить отдельно, чтобы проверить что получится
-
После отладки запроса SELECT перед ним допишем запрос INSERT:
INSERT INTO AgentType (Title) SELECT DISTINCT Тип_агента FROM agents_import
- Поле ID можно пропустить, оно автоинкрементное и создастся само (по крайней мере в MsSQL)
- Количество вставляемых полей (Title) должно быть равным количеству выбираемых полей (Тип_агента)
Если в таблице есть обязательные поля, а нем неоткуда взять для них данные, то мы можем в SELECT вставить фиксированные значения (в примере пустая строка):
```sql INSERT INTO AgentType (Title, Image) SELECT DISTINCT Тип_агента, '' -- ^^ FROM agents_import ```
Заполнение основной таблицы
-
Тоже сначала пишем SELECT запрос, чтобы проверить те ли данные получаются
-
напоминаю, что порядок и количество выбираемых и вставляемых полей должны быть одинаковыми
-
в поле AgentTypeID мы должны вставить ID соответсвующей записи из таблицы AgentType, поэтому выборка у нас из двух таблиц и чтобы не писать перед каждым полем полные названия таблиц мы присваиваем им алиасы
SELECT asi.Наименование_агента, att.ID, asi.Юридический_адрес, asi.ИНН, asi.КПП, asi.Директор, asi.Телефон_агента, asi.Электронная_почта_агента, asi.Логотип_агента, asi.Приоритет FROM agents_import asi, AgentType att WHERE asi.Тип_агента=att.Title
Т.е. мы выбираем перечисленные поля из таблицы agents_import и добавляем к ним ID агента у которого совпадает название.
При выборке из нескольких таблиц исходные данные перемножаются. Т.е. если мы не заполним перед этой выборкой словарь, то
100 * 0 = пустая выборка.Если же мы не укажем условие WHERE, то выберутся, к примеру,
100 * 10 = 1000записей (каждый агент будет в каждой категории). Поэтому важно, чтобы условие WHERE выбирало уникальные значения.Естественно, количество внешних ключей в таблице может быть больше одного, в таком случае в секции FROM перечисляем все используемые словари и в секции WHERE перечисляем условия для всех таблиц объединив их логическим выражением AND
```sql ... WHERE a.Name=b.Name AND a.Title=c.Title AND a.Price=d.Price ... ```где алиасы b, c, d — словарные таблицы, а алиас «а» — таблица импорта
-
-
Написав и проверив работу выборки (она должна возвращать чтолько же записей, сколько в таблице импорта) дописываем команду вставки данных:
INSERT INTO Agent (Title, AgentTypeID, Address, INN, KPP, DirectorName, Phone, Email, Logo, Priority) SELECT asi.Наименование_агента, att.ID, asi.Юридический_адрес, asi.ИНН, asi.КПП, asi.Директор, asi.Телефон_агента, asi.Электронная_почта_агента, asi.Логотип_агента, asi.Приоритет FROM agents_import asi, AgentType att WHERE asi.Тип_агента=att.Title
Практическое задание
В каталоге data этого репозитория находится структура БД (ms.sql) и файлы для импорта: products_k_import.csv, materials_short_k_import.txt, productmaterial_k_import.xlsx.
Необходимо во-первых, восстановить структуру БД из скрипта, во-вторых, импортировать исходные данные в Excel, в-третьих исправить данные (смотрите на структуру таблиц в БД, где-то надо явно указать тип данных, где-то вырезать лишние данные…) и в-четвёртых загрузить исправленные данные в БД (сначала просто импорт во временные таблицы, потом разнести SQL-запросами по нужным таблицам)