Время на прочтение
3 мин
Количество просмотров 30K
Здравствуйте. Меня зовут Сережа. Я хочу рассказать о том, как я писал простейшего вэб паука.

Поскольку это некоммерческий проект, созданный исключительно на моём энтузиазме, при работе я руководствовался следующим:
1. Минимум необходимых функций (сканирование web, сохранение необходимого в БД, простенький UI для доступа)
2. 0 финансовых затрат:
— В качестве сервера использую нетбук, который покупал в свое время для учебы acer aspare ONE KAV60, весьма бюджетный даже на момент покупки (2008 год), сейчас его процессора atom в 1600 МГц не хватает даже для нормальной работы в MS OFFICE
— Интернет — проводной домашний. Благо IP уже пол года не менялся, не пришлось заказывать статический
3. Минимум временых затрат. Проект делался после работы и дачи.
В качестве ПО использованы:
- ОС XUBUNTU
- Сервер ngINX
- nodeJS
- СУБД mySQL
- Для UI: jQuery, bootstrap3
В рунете есть популярный развлекательный ресурс (назовем его Пикабу — ссылку не даю, дабы не сочли рекламой). Представляет из себя развлекательные посты, размещаемые пользователями и комментарии. Модераторы ресурса жестко (по-моему мнению иногда даже через чур) следят за содержанием комментариев. В результате их работы часто вместо комментария можно увидеть следующее:

Наш робот будет через определённые промежутки времени сканировать ресурс в поиске новых комментариев, которые будет вносить в БД, дабы всегда можно было посмотреть, что не понравилось модератору.
Нам потребуются следующие модули:
var jsdom = require("jsdom");
var mysql = require('mysql');
var CronJob = require('cron').CronJob;
В основе нашего робота будет 2 функции:
// * * * Ищем ссылки на страницы
function get_links(){
jsdom.env('http://pikabu.ru',function(err, window){
if (err)
return false;
var page = window.document.getElementsByClassName('to-comments')
for (var i=0; i<page.length; i+=2)
get_comments(page[i].getAttribute('href'));
})
}Этой функцией мы запрашиваем главную страницу ресурса и ищем элементы с классом «.to-comments». В них хранятся ссылки на страницы с комментариями. Поскольку эти элементы идут впаре, нам нужен только каждый второй.
В данной функции нам очень помогает модуль jsdom. Он преобразует html код в DOM дерево, в котором мы легко можем найти нужный элемент.
Как мы видим, эта функция вызывает get_comments()
function get_comments(link){
jsdom.env(link,function(err, window){
if (err)
return false;
var comment = window.document.getElementsByClassName('comment')
for (var i=0; i<comment.length; i++){
var id = comment[i].getAttribute('data-id');
var author = comment[i].getElementsByClassName('post_author')[0].textContent;
// Если коммент удален
var block = comment[i].getElementsByClassName('comment_text')[0].getElementsByTagName('span');
if (block.length > 0 && block[0].textContent.substr(0,11)=='Комментарий'){
console.log(block[0].baseURI+'#comment_'+id);
continue}
var com = comment[i].getElementsByClassName('comment_text')[0].outerHTML.replace(/"/g, '"').replace(/n|t/g, '').replace('previews_gif_comm', 'big_size_comm_an');
var query = 'INSERT IGNORE comments (id, user, comment) VALUES ('+id+', "'+author+'", "'+com+'")';
DBconnection.query(query, function(err, rows, fields) {
if (err) throw err;
});
}
console.log(new Date()+' DATA ADDED...');
});
}Здесь мы также пробегаемся по дереву, ищем элементы с классом «comment», выделяем из них нужные элементы: id комментария, автора, отсеиваем удаленные комменты, убираем спецсимволы, немного переделываем код (убираем превьюшки) и заносим всё это в БД. В таблице comments поле id уникально, поэтому mySQL сама следит, чтобы не было дублированных комментариев.
Нам осталось завести таймер, пробуждающий робота каждые 5 минут. В node.JS это можно реализовать при помощи модуля croneJob — аналог планировщика crone в linux.
var job = new CronJob('*/5 * * * *', function(){
get_links();
});
job.start(); На этом пока всё. Наш паук научился лазить по ресурсу и сохранять комментарии. Если хотите могу написать статью, про вэб интерфейс к этому роботу или про плагин хрома для этого робота.
#статьи
- 28 окт 2022
-

0
Рассказываем и показываем, как запросто вытянуть данные из сайта и «разговорить» его без утюга, паяльника и мордобоя.
Иллюстрация: Катя Павловская для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Для парсинга используют разные языки программирования: Python, JavaScript или даже Go. На самом деле инструмент не так важен, но некоторые языки делают парсинг удобнее за счёт наличия специальных библиотек — например, Beautiful Soup в Python.
В этой статье разберёмся в основах парсинга — вспомним про структуру HTML-запроса и спарсим сведения о погоде с сервиса «Яндекса». А ещё поделимся записью мастер-класса, на котором наш эксперт в веб-разработке покажет, как с нуля написать веб-парсер.
Парсинг (от англ. parsing — разбор, анализ), или веб-скрейпинг, — это автоматизированный сбор информации с интернет-сайтов. Например, можно собрать статьи с заголовками с любого сайта, что полезно для журналистов или социологов. Программы, которые собирают и обрабатывают информацию из Сети, называют парсерами (от англ. parser — анализатор).
Сам парсинг используется для решения разных задач: с его помощью телеграм-боты могут получать информацию, которую затем показывают пользователям, маркетологи — подтягивать данные из социальных сетей, а бизнесмены — узнавать подробности о конкурентах.
Существуют различные подходы к парсингу: можно забирать информацию через API, который предусмотрели создатели сервиса, или получать её напрямую из HTML-кода. В любом из этих случаев важно помнить, как вообще мы взаимодействуем с серверами в интернете и как работают HTTP-запросы. Начнём с этого!
HTTP (HyperText Transfer Protocol, протокол передачи гипертекста) — протокол для передачи произвольных данных между клиентом и сервером. Он называется так, потому что изначально использовался для обмена гипертекстовыми документами в формате HTML.
Для того чтобы понять, как работает HTTP, надо помнить, что это клиент-серверная структура передачи данных․ Клиент, например ваш браузер, формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передаётся обратно клиенту. В нашем примере клиент — это браузер.
Запрос состоит из трёх частей:
- Строка запроса (request line): указывается метод передачи, версия HTTP и сам URL, к которому обращается сервер.
- Заголовок (message header): само сообщение, передаваемое серверу, его параметры и дополнительная информация).
- Тело сообщения (entity body): данные, передаваемые в запросе. Это необязательная часть.
Посмотрим на простой HTTP-запрос, которым мы воспользуемся для получения прогноза погоды:
_GET /https://yandex.com.am/weather/ HTTP/1.1_
В этом запросе можно выделить три части:
- _GET — метод запроса. Метод GET позволяет получить данные с ресурса, не изменяя их.
- /https://yandex.com.am/weather/ — URL сайта, к которому мы обращаемся.
- HTTP/1.1_ — указание на версию HTTP.
Ответ на запрос также имеет три части: _HTTP/1.1 200 OK_. В начале указывается версия HTTP, цифровой код ответа и текстовое пояснение. Существующих ответов несколько десятков. Учить их не обязательно — можно воспользоваться документацией с пояснениями.
Сам HTTP-запрос может быть написан в разных форматах. Рассмотрим два самых популярных: XML и JSON.
JSON (англ. JavaScript Object Notation) — простой формат для обмена данными, созданный на основе JavaScript. При этом используется человекочитаемый текст, что делает его лёгким для понимания и написания:
({
<font color="#069">"firstName"</font> : <font color="#069">"Антон"</font>,
<font color="#069">"lastName"</font> : <font color="#069">"Яценко"</font>
});
Для того чтобы получить информацию в формате JSON, необходимо подготовить правильный HTTP-запрос:
var requestURL = 'test.json'; var request = new XMLHttpRequest(); request.open('GET', requestURL); request.responseType = 'json'; request.send();
В его структуре можно выделить пять логических частей:
- var requestURL — переменная с указанием на URL-адреса с необходимой информацией;
- var request = new XMLHttpRequest () — создание нового экземпляра объекта запроса из конструктора XMLHttpRequest с помощью ключевого слова new;
- request.open (‘GET’, requestURL) — открытие нового запроса с использованием метода GET. Обязательно указываем нашу переменную с URL-адресом;
- request.responseType = ‘json’ — явно обозначаем получаемый формат данных как JSON;
- request.send () — отправляем запрос на получение информации.
XML — язык разметки, который определяет набор правил для кодирования документов, записанных в текстовом формате. От JSON отличается большей сложностью — проще всего увидеть это на примере:
<font color="#069"><person></font> <font color="#069"><firstname></font>Антон<font color="#069"></firstname></font> <font color="#069"><lastname></font>Яценко<font color="#069"></lastname></font> <font color="#069"></person></font>
Чтобы получить информацию, хранящуюся на сервере как XML или HTML, потребуется воспользоваться той же библиотекой, как и в случае с JSON, но в качестве responseType следует указать Document.
var requestURL = 'test.txt'; var request = new XMLHttpRequest(); request.open('GET', requestURL); request.responseType = 'document'; request.send();
Какой из форматов лучше выбрать? Кажется, что JSON легче для восприятия. Но выбор между определённым форматом HTTP-запроса зависит и от решаемой задачи. Подробно обсудим это в будущих материалах.
А сегодня разберёмся с основами веб-скрейпинга — используем стандартные библиотеки Python и научимся работать с различными полезными инструментами.
Самый простой способ разобраться в парсинге — что-то спарсить. Создадим программу, которая будет показывать информацию о погоде в вашем городе.
Для этого пройдём через три последовательных шага:
- Подключим библиотеки, которые помогут нам спарсить информацию с помощью Python (как установить Python на Windows, macOS и Linux — смотрите в нашей статье).
- Зайдём на сайт, с которого мы планируем парсить информацию, и изучим его исходный код. Важно будет найти те элементы, которые содержат нужную информацию.
- Напишем код и спарсим данные.
Подключаем библиотеки
Подключаем библиотеки
В разных языках программирования есть свои библиотеки для парсинга информации с сайтов. Например, в JavaScript используется библиотека Puppeteer, а на Python популярна библиотека Beautiful Soup. Принципы их работы похожи. Но сначала нужно разобраться с запуском Python на компьютере.
Просто так написать код в текстовом документе не получится. Можно воспользоваться одним из способов:
- Использовать терминал на macOS или Linux, или воспользоваться командной строкой в Windows. Для этого предварительно потребуется установить Python в систему. Мы подробно писали об этом в отдельном материале.
- Воспользоваться одним из онлайн-редакторов, позволяющих работать с кодом на Python без его установки: Google Colab, python.org, onlineGDB или другим.
После установки на свой компьютер Python или запуска онлайн-редактора кода можно переходить к импорту библиотек.
BeautifulSoup — библиотека, которая позволяет работать с HTML- и XML-кодом. Подключить её очень просто:
from bs import BeautifulSoup
Дополнительно потребуется библиотека requests, которая помогает сделать запрос на нужный нам адрес сайта. Импортируется она в одну строку:
import requests
Всё. Все библиотеки готовы к работе — они помогут получить исходный код сайта и найти в нём нужную информацию.
Важно! Библиотека Beautiful Soup чаще всего предустановлена в используемой среде разработке или в Jupyter Notebook, но иногда её нет. Если при попытке её импорта вы получаете ошибку, то выполните команду для её установки, а потом повторите запросы на импорт:
pip3 install bs4
В качестве источника прогнозы погоды будем использовать сайт «Яндекс.Погода». Перейдём на него и в строке поиска найдём свой город. В нашем случае это будет Москва.
Посмотрите внимательно на адресную строку — она ещё пригодится нам в дальнейшем: https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526.
Обычно в адресной строке там нет названия города, а есть географические координаты точки, для которой показана текущая погода (у нас это центр Москвы).
Теперь посмотрим на исходный код страницы и найдём место, где хранится текущая температура. Нас интересует обведённый на скриншоте сайта блок:
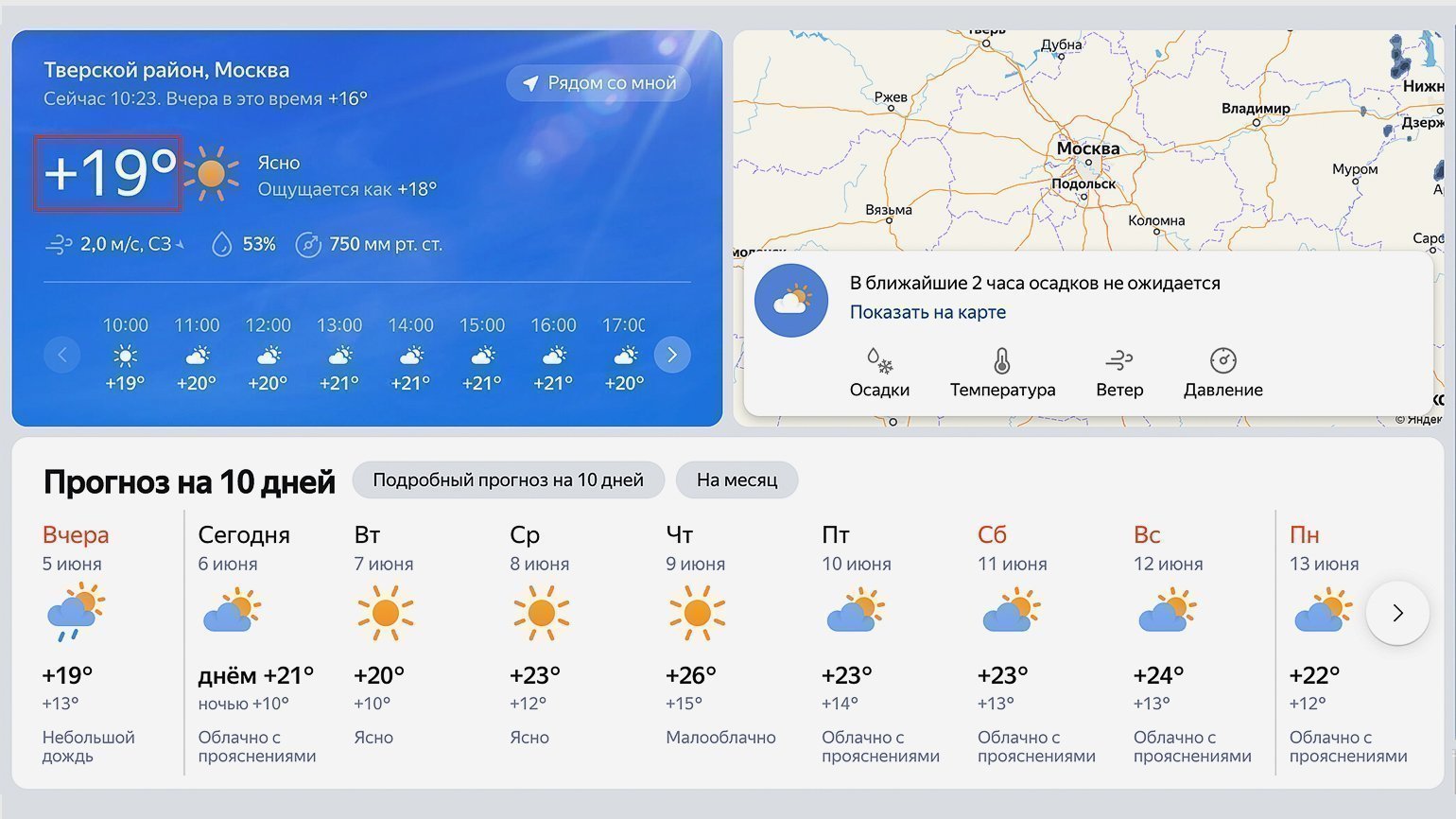
Для просмотра HTML-кода откроем «Инспектор кода». Для этого можно использовать комбинации горячих клавиш: в Google Chrome на macOS — ⌥ + ⌘ + I, на Windows — Сtrl + Shift + I или F12. Инспектор кода выглядит как дополнительное окно в браузере с несколькими вкладками:
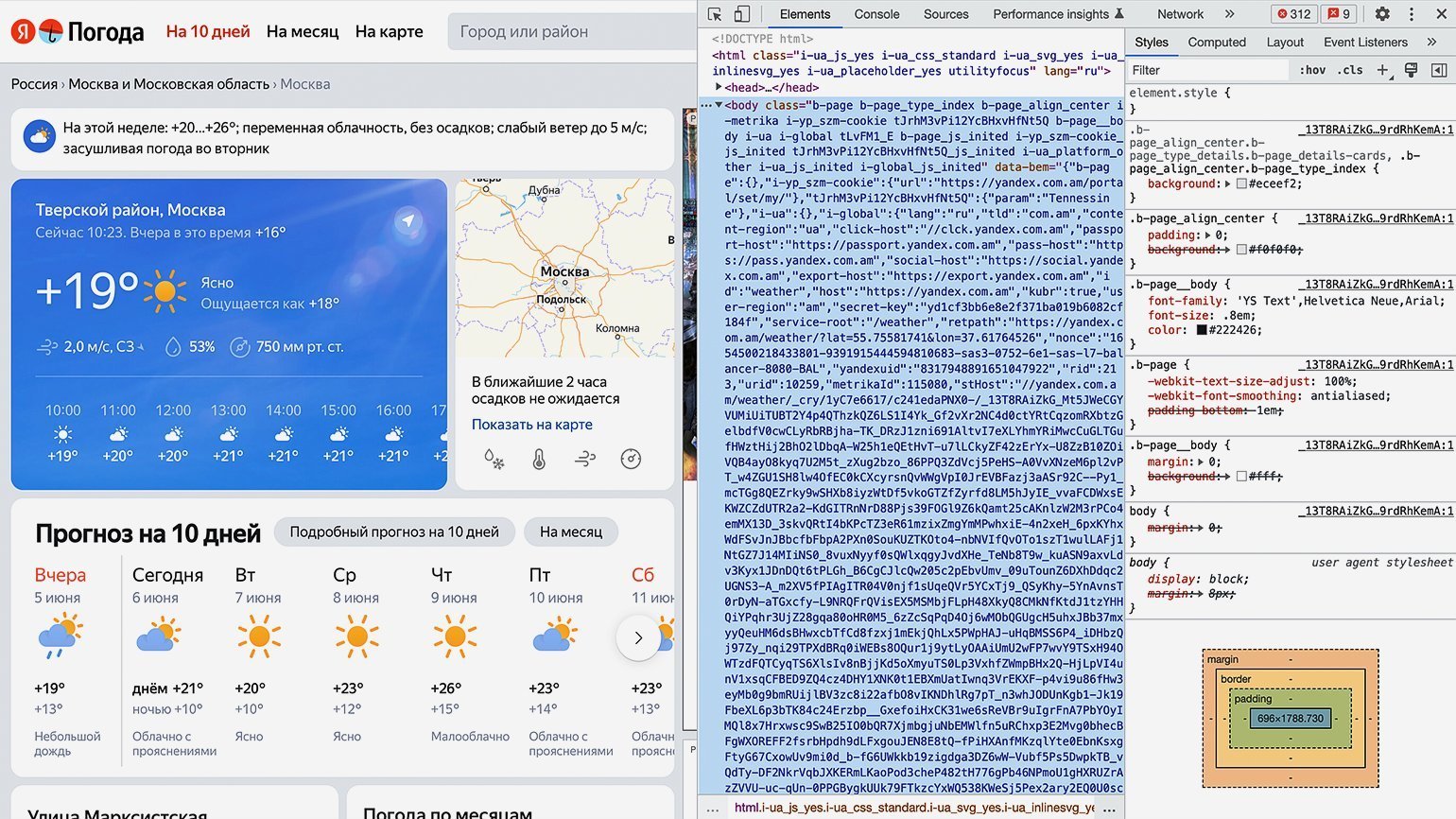
Переключаться между вкладками не надо, так как вся необходимая информация уже есть на первой.
Теперь найдём блок в коде, где хранится значение температуры. Для этого следует последовательно разворачивать блоки кода, располагающиеся внутри тега <body>. Сделать это можно, нажимая на символ ▶.
Как понять, что мы на правильном пути? Инспектор кода при наведении на блок кода подсвечивает на сайте ту область, за которую он отвечает. Переходим последовательно вглубь HTML-кода и находим нужный нам элемент.
В нашем случае пришлось проделать большой путь: элемент с классом «b‑page__container» → первый элемент с классом «content xKNTdZXiT5r0Tp0FJZNQIGlNu xIpbRdHA» → элемент с классом «xKNTdZXiT5r0vvENJ» → элемент с классом «fact card card_size_big» → элемент с классом «fact__temp-wrap xFNjfcG6O4pAfvHM» → элемент с классом «link fact__basic fact__basic_size_wide day-anchor xIpbRdHA» → элемент с классом «temp fact__temp fact__temp_size_s». Именно последнее название класса нам потребуется на следующем шаге.
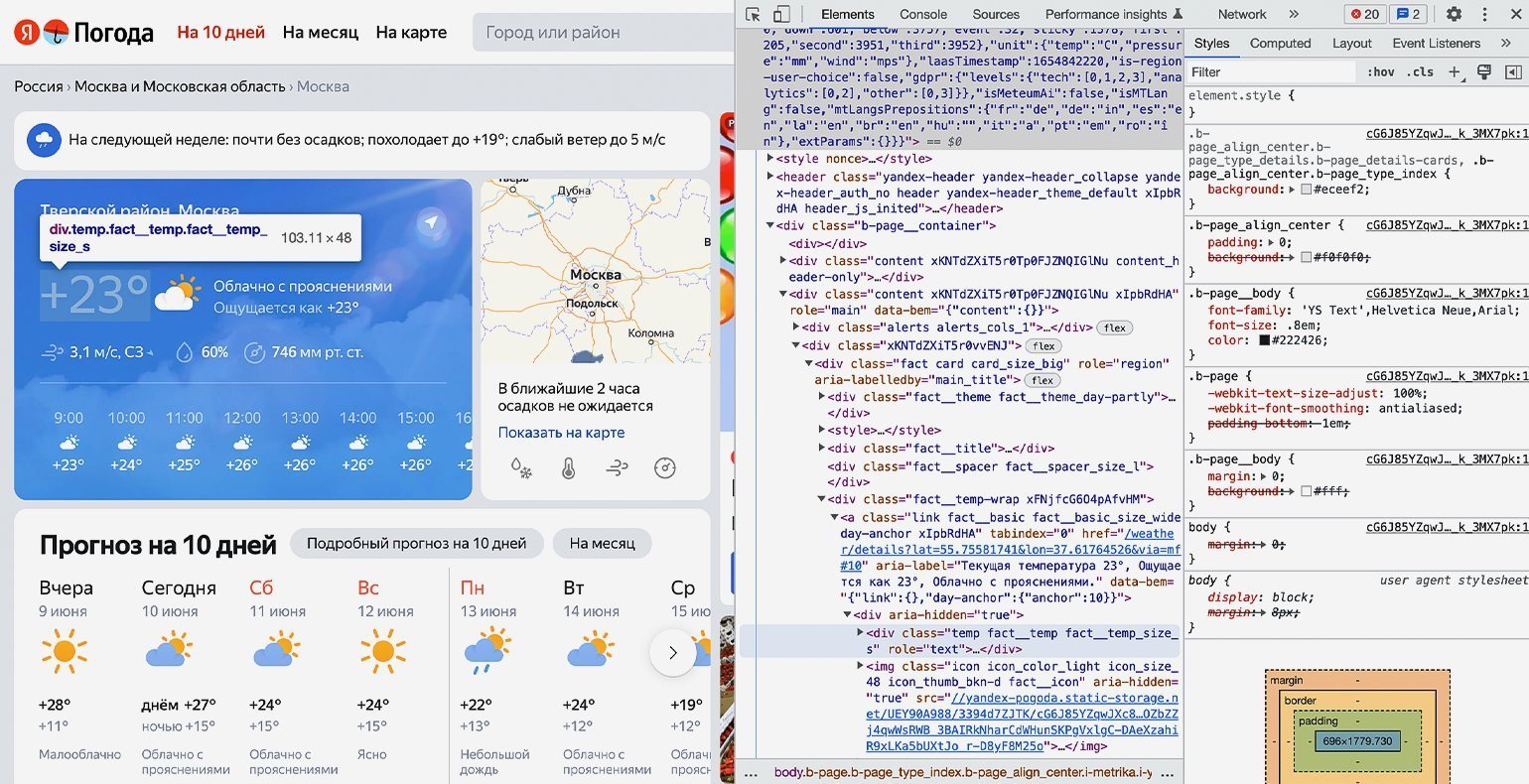
Продолжаем писать команды в терминал, командную строку, IDE или онлайн-редактор кода Python. На этом шаге нам остаётся использовать подключённые библиотеки и достать значения температуры из элемента <span=»temp fact__temp fact__temp_size_s»>. Но для начала надо проверить работу библиотек.
Сохраняем в переменную URL-адрес страницы, с которой мы планируем парсить информацию:
url = 'https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526'
Создадим к ней запрос и посмотрим, что вернёт сервер:
response = requests.get(url) print(response)
В нашем случае получаем ответ:
<Response [200]>
Отлично. Ответ «200» значит, что библиотека requests работает правильно и сервер отдаёт нам информацию со страницы.
Теперь получим исходный код, используя библиотеку Beautiful Soup и сразу выведем результат на экран:
bs = BeautifulSoup(response.text,"lxml") print(bs)
После выполнения на экране виден код всей страницы полностью:

Но весь код нам не нужен — мы должны выводить только тот блок кода, где хранится значение температуры. Напомним, что это <span=»temp fact__temp fact__temp_size_s»>. Найдём его значение с помощью функции find() библиотеки Beautiful Soup.
Функция find() принимает два аргумента:
- указание на тип элемента HTML-кода, в котором происходит поиск;
- наименование этого элемента.
В нашем случае код будет следующим:
temp = bs.find('span', 'temp__value temp__value_with-unit')
И сразу выведем результат на экран с помощью print:
print(temp)
Получаем:
<span class="temp__value temp__value_with-unit">+17</span>
Получилось! Но кроме нужной нам информации есть ещё HTML-тег с классом — а он тут лишний. Избавимся от него и оставим только значения температуры с помощью свойства text:
print(temp.text)
Результат:
+17
Всё получилось. Мы смогли узнать текущую температуру в городе с сайта «Яндекс.Погода», используя библиотеку Beautiful Soup для Python. Её можно использовать для своих задач — например, передавая в виджет на своём сайте, — или создать бота для погоды.
Если вы совсем новичок в веб-скрапинге, но хотите написать свой парсер (например, для автоматической генерации отчётов в Excel), рекомендуем посмотреть вебинар от Михаила Овчинникова — ведущего инженера-программиста из Badoo. Он на понятном примере объясняет основы языка Python и принципы веб-скрапинга. Уже в начале видеоурока вы запустите простой парсер и научитесь читать данные в формате HTML и JSON.
Бесплатная библиотека Selenium позволяет эмулировать работу веб-браузера — то есть «маскировать» веб-запросы скрипта под действия человека в Google Chrome или Safari. Почему это важно? Сайты умеют распознавать ботов и блокируют IP-адреса, с которых отправляются автоматические запросы.
Избежать «бана» можно двумя способами: изучить HTTP, принципы работы Python с вебом и написать свой эмулятор с нуля или воспользоваться готовым инструментом. Во втором случае Selenium — одно из лучших и самых удобных решений.
О том, как работать с библиотекой, рассказал Михаил Овчинников:
Парсинг помогает получить нужную информацию с любого сайта. Для него можно использовать разные языки программирования, но некоторые из них содержат стандартные библиотеки для веб-скрейпинга, например Beautiful Soup на Python.
А ещё мы рекомендуем внимательно изучить официальную документацию по библиотекам, которые мы использовали для парсинга. Например, можно углубиться в возможности и нюансы использования библиотеки Beautiful Soup на Python.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать
Парсеры новостных сайтов достаточно востребованы, например, если у вас новостой агрегатор, или, к примеру, вам нужно собирать местные новости из различных ресурсов для показа на своем сайте с географическим таргетированием, то вам необходим парсер. Также данные новостных агенств и СМИ часто используются для проведения исследований, машинного обучения и анализа. Распарсить новостую ленту на большинстве ресурсов, как правило, несложно, именно поэтому мы возьмем один из простых сайтов, а именно РИА Новости и научим вас писать парсеры самостоятельно.
Мы будем использовать Google Chrome как наш основной инструмент для работы с сайтом, и для начала мы советуем вам поставить расширение для Google Chrome: Quick Javascript Switcher — оно позволит вам быстро выключать и включать Javascript для сайтов. Это используется для того, чтобы быстро определить как именно данные выводятся на страницу: на стороне сервера или с помошью Javascript (это могут быть данные, внедренные в JS на странице, скрытый блок на странице, который включается JS или же данные забираются дополнительным XHR запросом).
Давайте откроем страницу с лентой https://ria.ru/lenta/ в нашем браузере и отключим JS для сайта с помощью расширения которое мы поставили ранее:
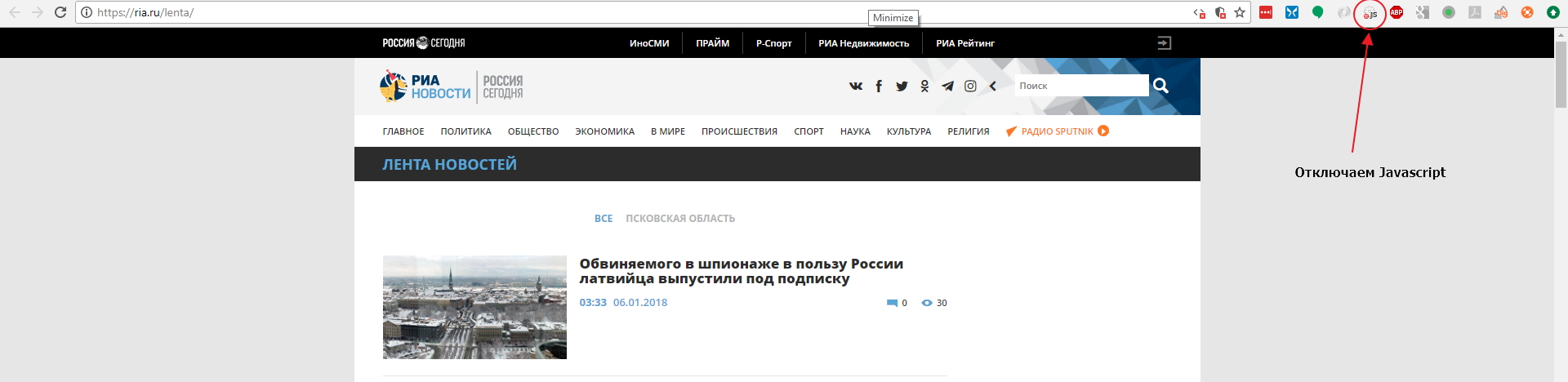
Мы увидим что данные ленты отображаются в браузере. Это означает, что новостная лента формируется на стороне сервера и мы сможем забрать данные просто загрузив страницу в парсер. Однако на странице показано только 20 последних заголовков и что же нам делать если нужно забирать 200 последних? Нам придется изучить механизм работы пагинатора. На разных сайтах пагинаторы работают по разному, поэтому не существует универсального решения и для каждого сайта вам придется разбираться в механизме его работы.
Откроем Chrome Dev Tools — инструменты для разработчика, которые встроены в Google Chrome. Для этого кликнем правой кнопкой мыши в любом месте страницы и выберем опцию «Показать код»:
После этого у вас откроется интерфейс разработчика:
В основном мы будем взаимодействовать с вкладками Elements и Network. Elements — поможет нам работать с DOM структурой, находить элементы страницы, проверять CSS селекторы, искать CSS селекторы и содержимое, и так далее. Во вкладке Network мы можем изучать запросы, которые делает браузер к серверу. Это потребуется нам для нахождения XHR или JS запросов, или же если нам нужно изучить структуру какого-либо запроса (заголовки, куки и тд) для точной имитации его в парсере. Если вы незнакомы с инструментами для разработчика, мы рекомендуем вам посмотреть следующее обзорное видео: Chrome DevTools. Обзор основных возможностей веб-инспектора.
Сейчас нам нужно добраться до конца страницы и найти там пагинатор. Мы видим что здесь он организован как одна кнопка «ЗАГРУЗИТЬ ЕЩЕ», которая подгружает следующие 20 записей используя XHR (Ajax) запрос, то есть если вы кликните на кнопку, ничего не произойдет, поскольку мы выключили Javascript для этого сайта.
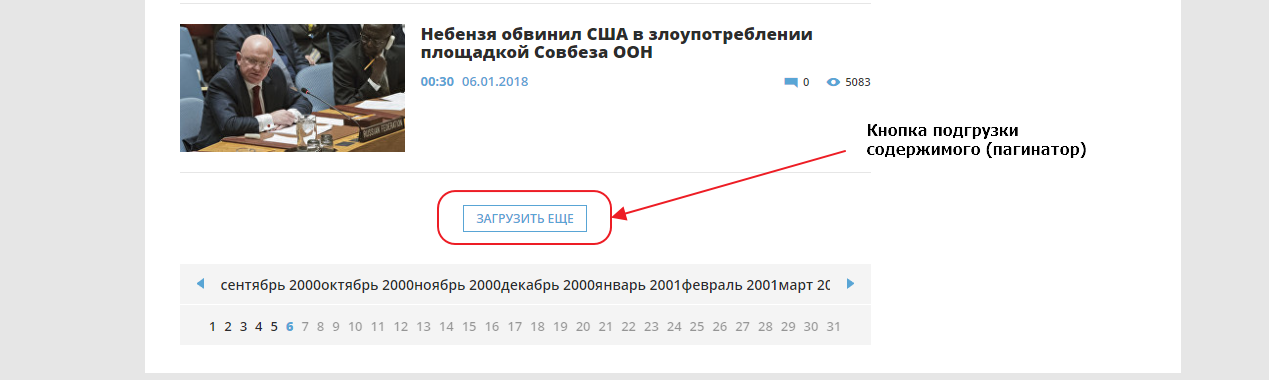
Первым делом найдем эту кнопку в элементах. Для того, чтобы это сделать быстро, можно воспользоваться специальным инструментом для выбора элемента на странице:
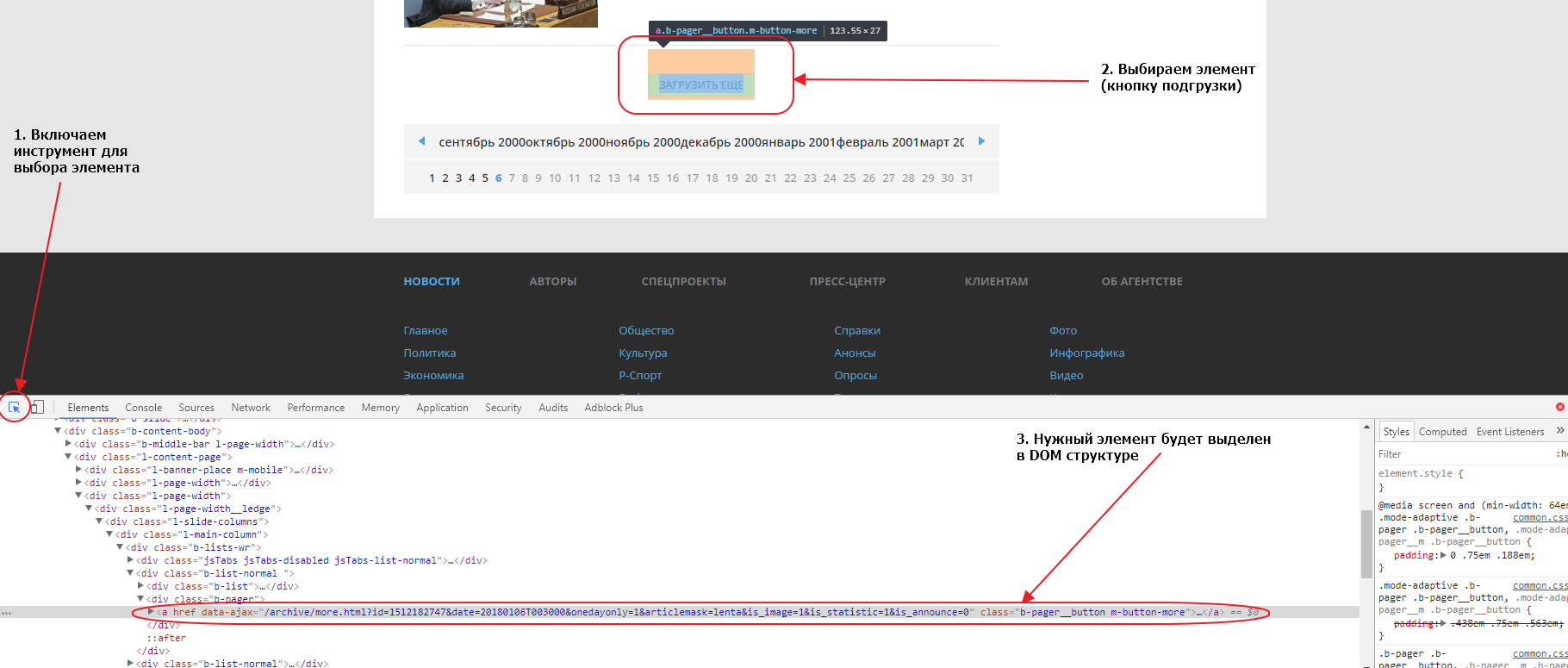
Если мы внимательно посмотрим на элемент, мы увидим что атрибут href у него пустой. Именно поэтому ничего не происходит при нажатии на линк, если отключен Javascript. Однако, мы видим что URL, используемый для подгрузки, указан в атрибуте data-ajax, именно этот URL и используется JS для подгрузки следующих 20 записей при нажатии на кнопку. Так как URL нам известен, нам совершенно не нужно анализировать запросы во вкладке Network. Соответсвенно, чтобы забрать следующие 20 записей, нам нужно забрать парсером этот URL:
https://ria.ru/archive/more.html?id=1512199556&date=20180106T154008&onedayonly=1&articlemask=lenta&is_image=1&is_statistic=1&is_announce=0.
Если загрузить в новой вкладке браузера этот URL мы получим следующие 20 записей и увидим что там тоже есть кнопка для загрузки следующих записей. Теперь нам нужно найти селектор (CSS селектор) для этого элемента. Сделаем это во второй вкладке, в которой у нас загружены вторые 20 записей. Также открываем в этой вкладке инструменты разработчика и выбираем элемент-ссылку «Загрузить еще», так, чтобы элемент выделился в DOM структуре. Теперь нужно кликнуть правой кнопкой мыши на элементе, затем выбрать опцию Copy и следом опцию Copy selector:
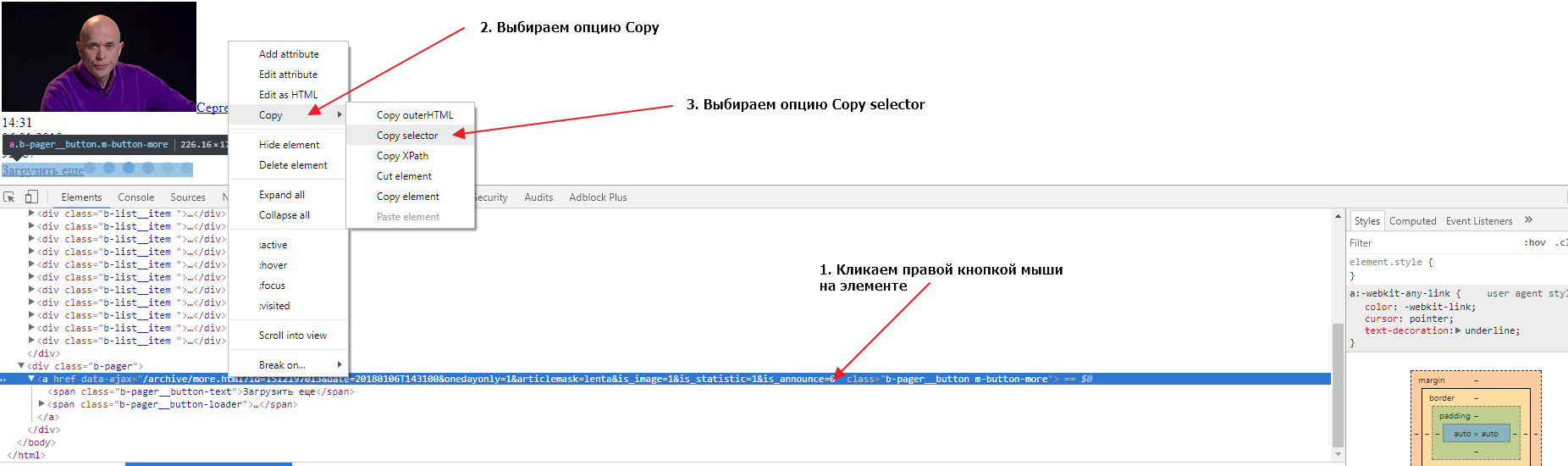
Давайте проверим, выбирает ли наш селектор ровно один элемент во второй и первой вкладке браузера. Для этого нужно в инструментах разработчика сделать активной вкладку Elements, нажать сочетание клавиш CTRL + F и в открывшуюся форму вставить наш селектор:

Мы видим, что селектор выбирает только один элемент, что очень хорошо. Если бы селектор выбирал несколько элементов, нам бы пришлось проверить все выбранные элементы и, либо подкорректировать селектор, так чтобы он выбирал только один элемент, либо в парсере брать срез найденных по селектору элементов, поскольку нам нужен только один элемент.
Тоже самое нужно сделать для другой вкладки, там где у нас открыта начальная страница. Сделать это нужно, чтобы удостовериться, что селекторы одинаковые на основной странице и на странице подгрузки. Иметь одну логику работы всегда лучше чем несколько, поэтому принцип унификации очень важен, в том числе и для подбора CSS селекторов. Если мы попробуем поискать наш селектор, мы обнаружим, что ничего не найдено. Дело в том, что элемент div.b-pager > a не находится в руте ноды body. Если мы уберем из пути body > и оставим только div.b-pager > a, то наш элемент будет найден в обеих вкладках и только один раз.
Мы определили, что для организации подгрузки данных в парсере, после загрузки страницы, мы должны найти элемент div.b-pager > a, забрать содержимое атрибута data-ajax и пройти по этому URL. Поскольку на страницах с подгрузкой структура элементов такая же, мы можем использовать единый логический блок. А для организации переходов по страницам мы можем использовать пул линков. Изначально мы поместим в пул только первый URL https://ria.ru/lenta/ и затем на каждой итерации мы будем добавлять в пул новый URL, который мы будем извлекать с загруженной страницы. Так мы организуем пагинацию в нашем парсере.
Теперь нам нужно определить как нам забирать новости со страниц, для этого нам нужно найти главный элемент блока в который обернута каждая новость. Сделать это мы можем точно так же, как мы делали это для кнопки подгрузки данных:
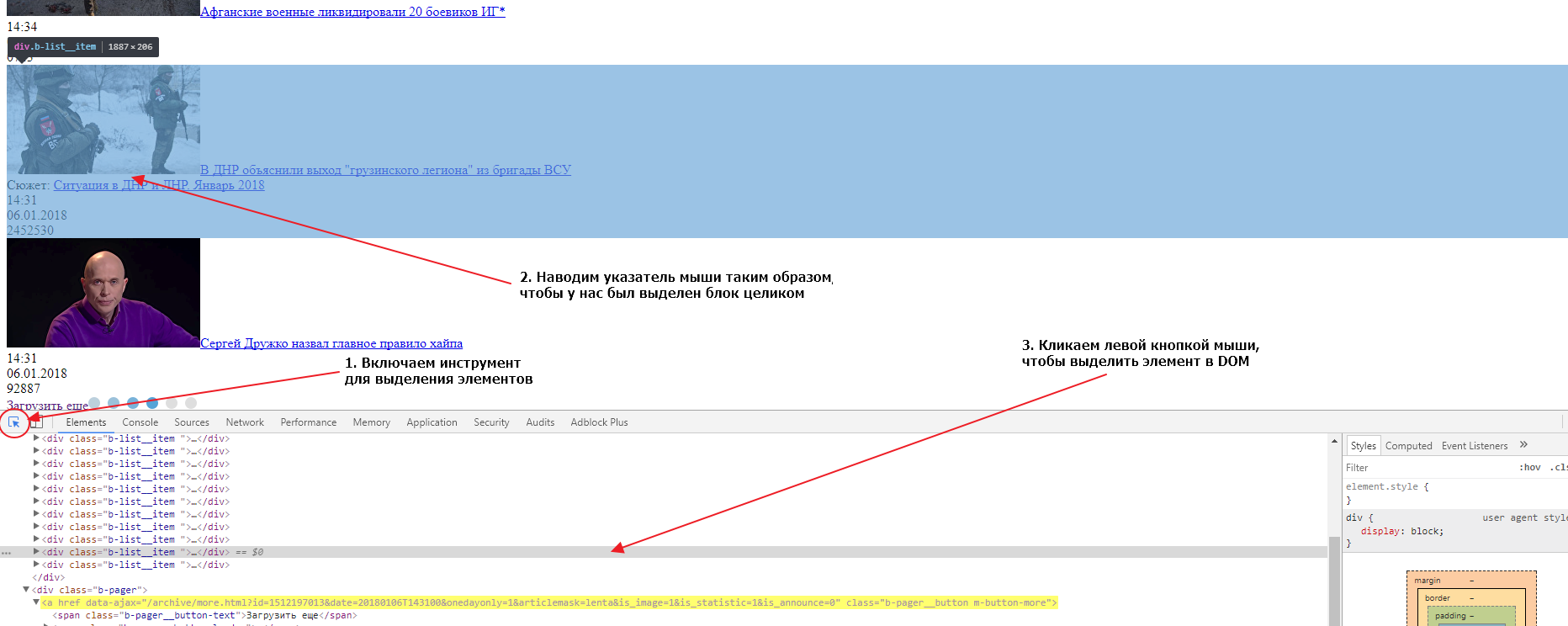
Если вы внимательно посмотрите на DOM структуру, вы увидите, что каждая новость обернута в элемент div с классом b-list__item. Таких элементов на странице ровно 20. Это и есть элемент, который нам нужен и CSS селектор для него будет div.b-list__item. Давайте сейчас проверим, насколько верно мы определили селектор для обеих вкладок (страницы с подгрузкой и основной страницы). Делаем мы это так же как мы проверяли валидность селектора для кнопки подгрузки. На обеих страницах селектор найдет по 20 элементов, значит наш селектор верен и мы можем его использовать.
Наш парсер на каждой странице должен находить этот селектор, и затем для каждого найденного элемента создавать новый объект данных, проходить в дочерние элементы, извлекать данные и записывать их в поля этого объекта данных, записывать объект данных в базу данных.
Давайте откроем один из элементов. Посмотрим какие у него есть дочерние элементы и какие данные нам нужны:

URL до страницы с новостью — находится просто в теге a, у этого тега нет класса или других атрибутов, кроме href. Поэтому единственный селектор, который мы можем использовать — a. Обратите внимание, что селекторы мы строим относительно родительского блока, поскольку мы в нем находимся, а не относительно всей страницы. Однако при таком селекторе если в блоке новости друг окажется еще один тег a в наших данных будет записан только последний, а нам нужен первый, поэтому мы можем брать срез элементов (элемент с номером 0) или же мы можем проверять в нашем a наличие дочернего элемента span с классом b-list__item-title. В последнем случае наш селектор будет выглядеть как a:haschild(span.b-list__item-title).
Изображение — нам нужно забрать URL до зображения, который находится в атрибуте src тега img. У этого тега есть атрибут itemprop=»associatedMedia», который выглядит достаточно надежным признаком для выборки нужного тега img. Поэтому мы можем использовать его в CSS селекторе: img[itemprop=»associatedMedia»].
Заголовок — здесь нет никаких подводных камней, наш заголовок находится в элементе span с классом b-list__item-title, поэтому CSS селектор будет таким: span.b-list__item-title.
Время и Дата — так же просто как и заголовок, получаем селекторы div.b-list__item-time и div.b-list__item-date соответственно.
Количество комментариев и Количество просмотров — находятся в элементах span с классом b-statistic__number, то так как в текущем блоке по такому селектору будут найдены оба элемента, то мы можем либо использовать срезы для выбора определенного элемента, либо использовать родительский элемент как часть селектора. В первом случае родительский элемент — это тег span с классом m-comments, и наш селектор получается таким span.m-comments > span.b-statistic__number. Во втором случае, родительский тег span с классом m-views формирует CSS селектор: span.m-views > span.b-statistic__number.
Вот мы и определили все селекторы для выбора полей которые нам надо собрать. Также давайте ограничим количество забираемых новостей, сделаем так чтобы парсер забирал 200 первых новостей (или 10 страниц). Мы можем организовать это с помощью счетчика, будем считать количество загруженных страниц и если счетчик примет значение более 9, просто не будем добавлять новый линк в пул. Займемся теперь написанием конфигурации парсера:
---
config:
debug: 2
agent: Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14
do:
# Устанавливаем счетчик страниц равным 1
- counter_set:
name: pages
value: 1
# Добавляем начальный URL в пул
- link_add:
url:
- https://ria.ru/lenta/
# Начинаем итерацию по пулу с последовательной загрузкой страниц из пула
- walk:
to: links
do:
# Делаем паузу 2 секунды для уменьшения нагрузки на сервер источника
- sleep: 2
# Находим кнопку подгрузки
- find:
path: div.b-pager > a
do:
# Считываем в регистр значение счетчика pages
- counter_get: pages
# проверяем если значение регистра больше 9
- if:
type: int
gt: 9
else:
# если значение меньше 9 - парсим значение аттрибута data-ajax текущего элемента в регистр
- parse:
attr: data-ajax
# делаем нормализацию значения в регистре, убираем лишние пробелы, унифицируем пробельные символы в ASCII пробелы
- space_dedupe
# удаляем все ведущие и завершающие пробелы значения в регистре, если они есть
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и добавляем линк в пул
- normalize:
routine: url
- link_add
# Находим все блоки с новостями и начинаем итерировать по найденным элементам
- find:
path: div.b-list__item
do:
# создаем новый объект данных с именем item
- object_new: item
# находим элемент с URL к странице с новостью
- find:
path: a:haschild(span.b-list__item-title)
do:
# парсим значение атрибута href в регистр
- parse:
attr: href
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле url объекта item
- normalize:
routine: url
- object_field_set:
object: item
field: url
# находим элемент с заголовком новости
- find:
path: span.b-list__item-title
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле headline объекта item
- object_field_set:
object: item
field: headline
# находим элемент с изображением
- find:
path: img[itemprop="associatedMedia"]
do:
# парсим значение атрибута src текущего элемента в регистр
- parse:
attr: src
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
- normalize:
routine: url
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле image объекта item
- object_field_set:
object: item
field: image
# находим элемент с временем
- find:
path: div.b-list__item-time
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле time объекта item
- object_field_set:
object: item
field: time
# находим элемент с датой
- find:
path: div.b-list__item-date
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле date объекта item
- object_field_set:
object: item
field: date
# находим элемент с количеством комментариев
- find:
path: span.m-comments > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле comments объекта item
- object_field_set:
object: item
field: comments
# находим элемент с количеством просмотров
- find:
path: span.m-views > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле views объекта item
- object_field_set:
object: item
field: views
# сохраняем объект данных item в базу данных
- object_save:
name: item
# увеличиваем значение счетчика pages на 1
- counter_increment:
name: pages
by: 1Вам осталось создать новый диггер на платформе Diggernaut, перенести в него этот сценарий и запустить. Надеемся что этот материал был полезен и помог вам в изучении нашего мета-языка.
Удачного парсинга!
Пишем простой парсер файлов (для начинающих) -6
.NET, C#
Рекомендация: подборка платных и бесплатных курсов таргетированной рекламе — https://katalog-kursov.ru/
В этой статье я хотел бы рассказать как написать простой парсер на примере сайтов aimp.ru и geekbrains.ru. Статья предназначена строго для тех, кто уже имеет базовые знания о языке программирования C# и уже написал свой первый «Hello world».
Мне всегда нравился аудиоплеер Aimp (нет, это не реклама), но встроенных скинов у него слишком мало, а заходить на сайт, смотреть скины, скачивать и пробовать как они будут смотреться на деле не было никакого желания. Поэтому я решил написать парсер скинов с данного сайта. Немного посмотрев сайт, я заметил, что скины там хранятся последовательно с присвоенным id. Т.к. до недавнего времени я знал только 1С и немного командную строку, то недолго думая я решил написать его в командной строке. Но при тестировании обнаружил, что если скачивать большое количество файлов, то во-первых часть может просто не скачаться, а во-вторых может произойти переполнение оперативной памяти. В итоге я тогда бросил эту затею.
Не так давно начав изучать C# я решил вернуться к этой идее, дабы попрактиковаться немного. Что из этого получилось читайте под катом.
Для разработки нам понадобится только среда разработки, я использовал Visual Studio, вы можете использовать любую другую на ваш вкус.
Я не буду углубляться в базовые понятия C#, для этого написано множество различных книг и отснято бесчисленное количество роликов.
Для начала запустим Visual Studio и создадим консольное приложение (т.к.
мне лень делать формы
нам не нужен интерфейс). Среда разработки нам сама подготовит шаблон проекта. У нас получится что-то вроде этого:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ConsoleApplication2
{
class Program
{
static void Main(string[] args)
{
}
}
}
Удаляем директивы которыми мы пользоваться сейчас не будем:
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
И добавляем те директивы, которыми будем пользоваться:
using System.Diagnostics; // Нужна, чтобы запускать внешние процессы
using System.Net; // Нужна, чтобы работать с Web
using System.Threading; // Нужна, чтобы скоротать время
После чего в методе Main объявляем переменную:
WebClient wc = new WebClient(); // Она нужна непосредственно для работы с Web
Парсим Aimp скины
Далее мы пишем саму функцию:
static string DownloadSkinsForAimp(WebClient wc)
{
Console.WriteLine("Downloading began");
try
{
for (int i = 0; i <= 5; i++)
{
string id = "79" + i;
string name = GetNameOfSkin(wc, id);
// Путь, откуда мы будем скачивать
string path = "aimp.ru/index.php?do=download&sub=catalog&id=" + id;
try
{
// Запускаем нужный нам браузер и передаем ему в качестве аргумента путь скачивания
Process.Start("chrome.exe", path);
Console.WriteLine("Download " + name + " is succesfull!");
// Ждем 5 секунд, чтобы вкладки успевали закрываться, иначе может быть переполнение памяти
Thread.Sleep(5000);
}
catch
{
Console.WriteLine("Download" + name + "failed");
}
}
}
catch
{
return "nSomething went is wrong";
}
return "nDownloading complete";
}
Все скины скачиваются в директорию, заданную в настройках браузера.
Конструкции try/catch нам нужны для того, чтобы программа не «вываливалась» из-за ошибок. Хотя можно было обойтись и без них.
Вы могли заметить функцию GetNameOfSkin. Она нужна для того, чтобы получить название скина, который мы скачиваем. Можно обойтись и без неё, она нужна только для красоты, но раз мы только учимся, то напишем и её:
static string GetNameOfSkin(WebClient wc, string id)
{
// Получаем строку с html разметкой
string html = wc.DownloadString("http://www.aimp.ru/index.php?do=catalog&rec_id=" + id);
// Находим в ней первое упоминание нужного нам id и удаляем ненужную левую часть
// Название скина начинается через 5 символов после этого id
string rightPartOfHtml = html.Substring(html.IndexOf(id) + 5);
// Находим конец названия и удаляем оставшуюся правую часть
string name = rightPartOfHtml.Substring(0, rightPartOfHtml.IndexOf("<")).Replace(" ", "_");
// В итоге нам возвращается только само название скина
return name;
}
Далее в методе Main нужно вызвать скачивание на выполнение:
Console.WriteLine(DownloadSkinsForAimp(wc)); // На консоль нужно выводить потому, что
// метод возвращает нам строку с результатом выполнения
Парсим сертификаты Geekbrains
Сертификаты на сайте хранятся в открытом виде, и открыв их через сайт, как скины aimp мы сможем их скачать только вручную нажав кнопку скачать. Но это не дело, мы же программисты.
Тут нам на помощь приходит класс WebClient, а именно его метод DownloadFile. Ему мы просто передаем путь для скачивания и путь для сохранения и он все делает за нас. Звучит легко, попробуем сделать:
static string DownloadCertificates(WebClient wc)
{
// Нужна для того, чтобы определить имя текущего пользователя
string currentUser = Environment.UserName;
Console.WriteLine("Downloading began");
try
{
for (int i = 0; i <= 5; i++)
{
try
{
// Все сертификаты на данном сайте хранятся в формате '.pdf'
wc.DownloadFile("https://geekbrains.ru//certificates//7075" + i + ".pdf", "c:\users\" + currentUser + "\downloads\7075" + i + ".pdf");
Console.WriteLine("Download certificate №7075" + i + " is succesfull");
}
catch
{
Console.WriteLine("Download certificate №7075" + i + " is failed");
}
}
}
catch
{
return "nSomething went is wrong";
}
return "nDownloading certificates are complite!";
}
И после чего точно также вызываем эту функцию из метода Main.
Вообще обе эти функции ещё есть куда дорабатывать, но я думаю для ознакомления и самых базовых функций парсинга они вполне подойдут. Кому лень все это собирать в один проект — вот ссылка на GitHub.
Спасибо за внимание и надеюсь, кому-нибудь это поможет.
P.S.: Сертификаты с geekbrains можно скачать и
изменить имя и фамилию владельца на свою
полюбоваться на них.
P.P.S.: Все скины, скачанные с сайта Aimp, хранятся в формате ‘.zip’ и при желании функцию можно доработать, чтобы она сама их разархивировала. Также можно добавить, чтобы они сразу переносились в папку со скинами Aimp.
P.P.P.S.: Статья является исключительно познавательной и не несет рекламный характер.
Постоянно в Интернете, ничего не успеваете? Парсинг сайта спешит на помощь! Разбираемся, как автоматизировать получение нужной информации.

Чтобы быть в курсе, кто получит кубок мира в 2019 году, или как будет выглядеть будущее страны в ближайшие 5 лет, приходится постоянно зависать в Интернете. Но если вы не хотите тратить много времени на Интернет и жаждете оставаться в курсе всех событий, то эта статья для вас. Итак, не теряя времени, начнём!
Доступ к новейшей информации получаем двумя способами. Первый – с помощью API, который предоставляют медиа-сайты, а второй – с помощью парсинга сайтов (Web Scraping).
Использование API предельно просто, и, вероятно, лучший способ получения обновлённой информации – вызвать соответствующий программный интерфейс. Но, к сожалению, не все сайты предоставляют общедоступные API. Таким образом, остаётся другой путь – парсинг сайтов.
Парсинг сайта
Это метод извлечения информации с веб-сайтов. Эта методика преимущественно фокусируется на преобразовании неструктурированных данных – в формате HTML – в Интернете в структурированные данные: базы данных или электронные таблицы. Парсинг сайта включает в себя доступ к Интернету напрямую через HTTP или через веб-браузер. В этой статье будем использовать Python, чтобы создать бот для получения контента.
Последовательность действий
- Получить URL страницы, с которой хотим извлечь данные.
- Скопировать или загрузить HTML-содержимое страницы.
- Распарсить HTML-содержимое и получить необходимые данные.
Эта последовательность помогает пройти по URL-адресу нужной страницы, получить HTML-содержимое и проанализировать необходимые данные. Но иногда требуется сперва войти на сайт, а затем перейти по конкретному адресу, чтобы получить данные. В этом случае добавляется ещё один шаг для входа на сайт.
Пакеты
Для анализа HTML-содержимого и получения необходимых данных используется библиотека Beautiful Soup. Это удивительный пакет Python для парсинга документов формата HTML и XML.
Для входа на веб-сайт, перехода к нужному URL-адресу в рамках одного сеанса и загрузки HTML-содержимого будем использовать библиотеку Selenium. Selenium Python помогает при нажатии на кнопки, вводе контента и других манипуляциях.
Погружение в код
Сначала импортируем библиотеки, которые будем использовать:
# импорт библиотек from selenium import webdriver from bs4 import BeautifulSoup
Затем укажем драйверу браузера путь к Selenium, чтобы запустить наш веб-браузер (Google Chrome). И если не хотим, чтобы наш бот отображал графический интерфейс браузера, добавим опцию headless в Selenium.
Браузеры без графического интерфейса (headless) предоставляют автоматизированное управление веб-страницей в среде, аналогичной популярным веб-браузерам, но выполняются через интерфейс командной строки или с использованием сетевых коммуникаций.
# путь к драйверу chrome
chromedriver = '/usr/local/bin/chromedriver'
options = webdriver.ChromeOptions()
options.add_argument('headless') # для открытия headless-браузера
browser = webdriver.Chrome(executable_path=chromedriver, chrome_options=options)
После настройки среды путём определения браузера и установки библиотек приступаем к HTML. Перейдём на страницу входа и найдём идентификатор, класс или имя полей для ввода адреса электронной почты, пароля и кнопки отправки, чтобы ввести данные в структуру страницы.
# Переход на страницу входа
browser.get('http://playsports365.com/default.aspx')
# Поиск тегов по имени
email = browser.find_element_by_name('ctl00$MainContent$ctlLogin$_UserName')
password = browser.find_element_by_name('ctl00$MainContent$ctlLogin$_Password')
login = browser.find_element_by_name('ctl00$MainContent$ctlLogin$BtnSubmit')
Затем отправим учётные данные в эти HTML-теги, нажав кнопку «Отправить», чтобы ввести информацию в структуру страницы.
# добавление учётных данных для входа
email.send_keys('********')
password.send_keys('*******')
# нажатие на кнопку отправки
login.click()
После успешного входа в систему перейдём на нужную страницу и получим HTML-содержимое страницы.
# После успешного входа в систему переходим на страницу «OpenBets»
browser.get('http://playsports365.com/wager/OpenBets.aspx')
# Получение HTML-содержимого
requiredHtml = browser.page_source
Когда получили HTML-содержимое, единственное, что остаётся, – парсинг. Распарсим содержимое с помощью библиотек Beautiful Soup и html5lib.
html5lib – это пакет Python, который реализует алгоритм парсинга HTML5, на который сильно влияют современные браузеры. Как только получили нормализованную структуру содержимого, становится доступным поиск данных в любом дочернем элементе тега html. Искомые данные присутствуют в теге table, поэтому ищем этот тег.
soup = BeautifulSoup(requiredHtml, 'html5lib')
table = soup.findChildren('table')
my_table = table[0]
Один раз находим родительский тег, а затем рекурсивно проходим по дочерним элементам и печатаем значения.
# получение тегов и печать значений
rows = my_table.findChildren(['th', 'tr'])
for row in rows:
cells = row.findChildren('td')
for cell in cells:
value = cell.text
print (value)
Чтобы выполнить указанную программу, установите библиотеки Selenium, Beautiful Soup и html5lib с помощью pip. После установки библиотек команда #python <program name> выведет значения в консоль.
Так парсятся данные с любого сайта.
Если же парсим веб-сайт, который часто обновляет контент, например, результаты спортивных соревнований или текущие результаты выборов, целесообразно создать задание cron для запуска этой программы через конкретные интервалы времени.
Используете парсинг сайта?
Для вывода результатов необязательно ограничиваться консолью, правда?
Как вы предпочитаете отображать данные подобных программ: выводить на панель уведомлений, отправлять на почту или иначе? Делитесь полезными находками

Надеемся, вам понравилась статья.
Оригинал
В этой статье мы познакомимся с парсингом сайтов (web scraping), который можно использовать, например, для пополнения базы email-адресов, создания сводки новостных лент, сравнения цен на один продукт среди нескольких коммерческих ресурсов или извлечения данных из поисковых машин.
Мы рассмотрим парсинг через API сайтов — такой подход достаточно прост и не требует парсинга всей страницы. Он может не работать, если владельцами ресурса установлены специальные настройки, но в большинстве случаев является неплохим решением.
Как это работает?
Примерно так: парсер посылает странице get-запрос, получает данные в виде HTML / XML и извлекает их в желаемом формате. Для загрузки файлов через консоль подходит утилита WGET, но можно выбрать и любой другой подходящий инструмент на просторах Сети.
Мы будем использовать написанный для Node.js программный пакет osmosis, включающий селектор css3/xpath и небольшой http-обработчик. Есть и другие фреймворки вроде Webdriver и CasperJS, но в данном случае они нам не понадобятся.
Настраиваем проект
- Устанавливаем Node.js, поставляемый с менеджером пакетов npm.
- Создаём новую папку, например,
webscrap. - Переходим в неё:
cd webscrap. - Запускаем из консоли
npm initдля создания файлаpackage.json. - Запускаем
npm i osmosis --save, чтобы установить пакет для парсинга. Дополнительных зависимостей, кроме как от обработчика и селектора, у него не будет. - Открываем
package.jsonи создаём новый стартовый скрипт для последующего запуска командыnpm start.
Итоговый package.json будет выглядеть примерно так:
{
"name": "webscrap",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"start": "node index"
},
"dependencies": {
"osmosis": "^1.1.2"
}
}Создаём файл index.js, в нём будем делать всю работу.
Парсим информативный заголовок в Google
Это самый базовый пример, с помощью которого мы познакомимся с пакетом и запустим первый Node-скрипт. Помещаем код ниже в файл index.js и запускаем из консоли команду npm start. Она выведет заголовок веб-страницы:
const osmosis = require('osmosis');
osmosis
.get('www.google.com')
.set({'Title': 'title'}) // альтернатива: `.find('title').set('Title')`
.data(console.log) // выведет {'Title': 'Google'}Разберём, что делают методы. Первый метод get получает веб-страницу в сжатом формате. Следующий метод set выберет элемент заголовка, представленный в виде css3-селектора. Наконец, метод data с console.log обеспечивают вывод. Метод set также принимает строки в качестве аргумента.
Получаем релевантные результаты в Google
Допустим, мы хотим получить результаты по ключевому слову analytics. Делаем следующее:
osmosis
.get('https://www.google.co.in/search?q=analytics')
.find('#botstuff')
.set({'related': ['.card-section .brs_col p a']})
.data(function(data) {
console.log(data);
})Вот и всё. Этот код извлечёт все соответствующие ключевые слова с первой страницы результатов поиска, поместит их в массив и запишет в лог в консоли. Логика, стоящая за этим, такова: мы сначала анализируем веб-страницу через инструменты разработчика, проверяем блок, в котором находится слово (в данном случае это div #botstuff), и сохраняем его в массив через селектор .card-section .brs_col p a, который найдёт все соответствующие ключевые слова на странице.
Увеличиваем количество страниц при релевантном поиске
Для этого нужно добавить цепочку вызовов (chaining method), вычислив атрибут href у тега anchor (<a>). Мы ограничимся пятью страницами, чтобы Google не посчитал нас за бот. Если необходимо выставить время между парсингом соседних страниц, добавляем метод .delay(ms) после каждого .paginate().
osmosis
.get('https://www.google.co.in/search?q=analytics')
.paginate('#navcnt table tr > td a[href]', 5)
.find('#botstuff')
.set({'related': ['.card-section .brs_col p a']})
.data(console.log)
.log(console.log) // включить логи
.error(console.error) // на случай нахождения ошибкиПарсим адреса электронной почты с сайта Shopify
В данном случае мы будем собирать email-адреса и названия всех приложений, последовательно перемещаясь с помощью метода .follow, и потом помечать необходимые селекторы в консоли разработчика:
osmosis
.get('http://apps.shopify.com/categories/sales')
.find('.resourcescontent ul.app-card-grid')
.follow('li a[href]')
.find('.resourcescontent')
.set({
'appname': '.app-header__details h1',
'email': '#AppInfo table tbody tr:nth-child(2) td > a'
})
.log(console.log) // включить логи
.data(console.log)Код выше можно скомбинировать с методом .paginate, чтобы собрать полностью весь контент (но при этом нас могут и заблокировать).
Теперь нужно сохранить данные в файле, сделать это можно так (пример модификации кода выше, сохранение в формате json):
const fs = require('fs');
let savedData = [];
osmosis
.get(..).find(..).follow(..).find(..)
.set(..)
.log(console.log)
.data(function(data) {
console.log(data);
savedData.push(data);
})
.done(function() {
fs.writeFile('data.json', JSON.stringify( savedData, null, 4), function(err) {
if(err) console.error(err);
else console.log('Data Saved to data.json file');
})
});Вот мы и закончили с основами, продолжайте экспериментировать. Но, пожалуйста, не используйте полученные знания во вред другим пользователям Сети.
Перевод статьи «Web Scraping in Node.js with Multiple Examples»
| Парсинг — это процесс извлечения информации из сайтов. Научиться этому можно достаточно быстро, 30-40 минут достаточно чтобы понять принципы и потом использовать этот навык для повседневной работы. Соответственно, многие хотят научиться создавать парсеры самостоятельно. Например, для тех, кто самостоятельно делаем автоматизацию в интернет-магазинах, часто нужно делать парсинг интернет-магазинов: выгрузить картинки или описания товаров (с характеристиками) с сайта поставщика. |
Перейти в парсер
Регистрация |
Чему вы научитесь, используя эту инструкцию?
1) самостоятельно делать простые парсеры.
2) массово выгружать информацию из категорий товаров.
3) выгружать данные в файлы YML,Excel,CSV,JSON.
Видео-инструкция по созданию парсера
Создадите настройку для нового парсера
На следующем шаге введите ссылку на карточку товара и на категорию
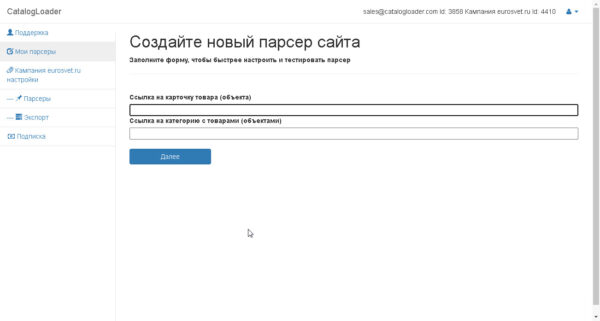
Для примера ввели ссылки для сайта eurosvet.ru
Карточка товара
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki/podvesnoy-svetilnik-so-steklyannym-plafonom-50208-1-yantarnyy-a052491
Ссылка на категорию
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
и нажмите на кнопку «Далее»
и вы попадете на страницу где будет настраиваться парсер для вашего конкретного сайта.
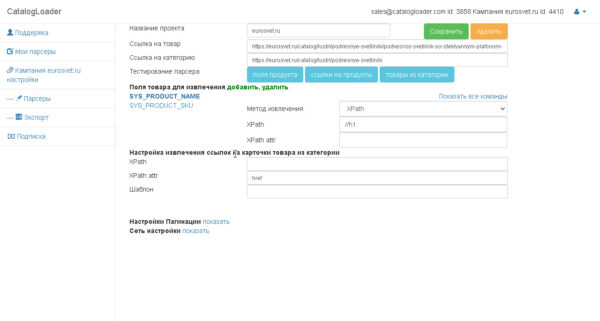
Настройка парсера
Можно выделить следующие этапы в настройке парсера сайта:
1. Настройка извлечения полей для конкретного продукта.
2. Настройка извлечения ссылок на карточки товаров из категории.
3. Настройка пагинаций (на английском pagination).
1. Настройка извлечения полей для конкретного продукта.
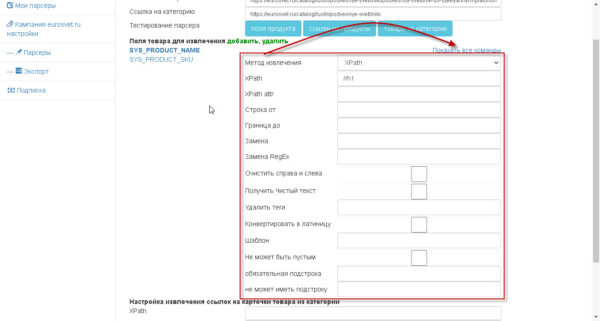
Важно! как только вы настроили поле, то тестируйте его извлечение через кнопку «Поля продукта».
И вы увидите как отработает парсер для вашего продукта.
Блок, который отвечает за извлечение полей — отмечен на картинке:
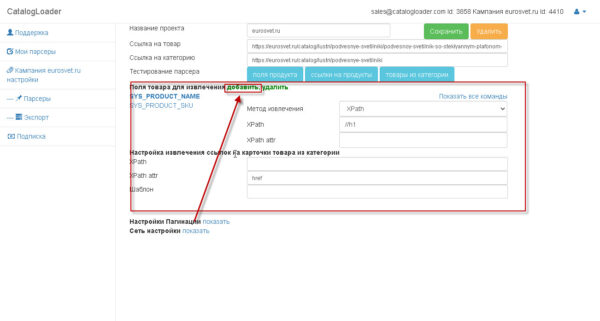
чтобы добавить новые поле -нажимайте на кнопку «добавить», если надо удалить,то ,сперва, надо выделить соответствующее поле, а потом кликнуть на соответствующую кнопку.
На следующей картинке показан диалог добавления новых полей.
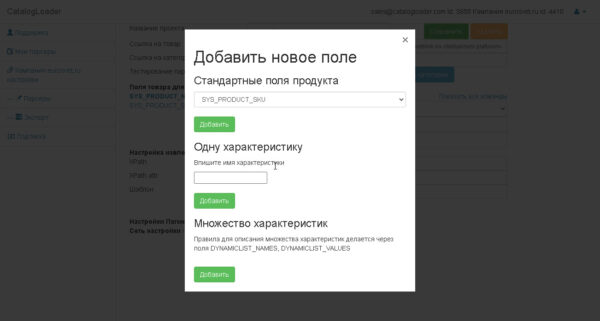
Есть 3 вида полей.
1) простые(базовые). — SYS_PRODUCT_SKU, SYS_PRODUCT_NAME, SYS_PRODUCT_MANUFACTURER и т.д.
это соответствунно Артикул, имя и производитель товара.
SYS_PRODUCT_IMAGES_ALL — это поле куда должно быть записаны все картинки продукта.
2) характеристики.-определяются характеристики товара, например, название вы можете задать самостоятельно.
3) динамические характеристики. Это тоже задает извлечение характеристик из таблицы значений.
для этого нужно будет задать DYNAMICLIST_NAMES, DYNAMICLIST_VALUES поля таким образом чтобы количество извлекаемых названий и значений было одинаково.
Как извлекать значения
Для любого поля можно указать как оно будет извлекаться.
Есть два варианта:
1)Xpath
2)RegEx (Regular Expresstion)- регулярное выражение.
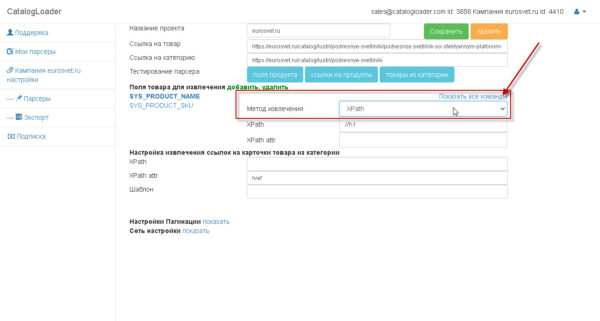
дополнительно к командам можно добавить дополнительную обработку.
2. Настройка извлечения ссылок на карточки товаров из категории.
Важно! как только вы настроили «извлечение ссылок на карточки продуктов из категории», то тестируйте его извлечение через кнопку «ссылки на продукты». И вы увидите как отработает парсер для вашей категории. Ссылки соберутся без пагинаций.
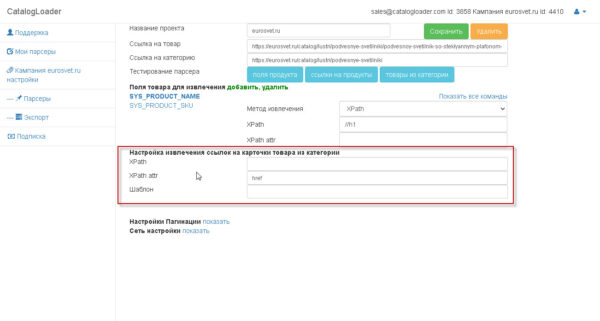
поле «Шаблон» в этой области нужно для того чтобы задать абсолютный путь для ссылки,если это необходимо. Обычно оставляется пустым.
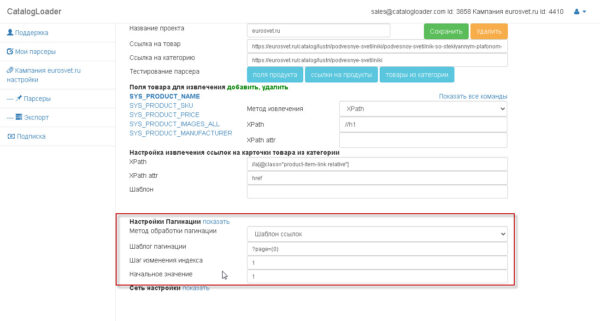
3. Настройка пагинаций (на английском pagination).
Если вы уже дошли до этого шага, то это значит что вы уже сделали 90% работы. После завершения настроек по пагинации чтобы протестировать парсер надо будет нажать на кнопку «товары из категории».
есть два варианта как настраивать пагинацию
1. через шаблон
2. через «следующую ссылку»
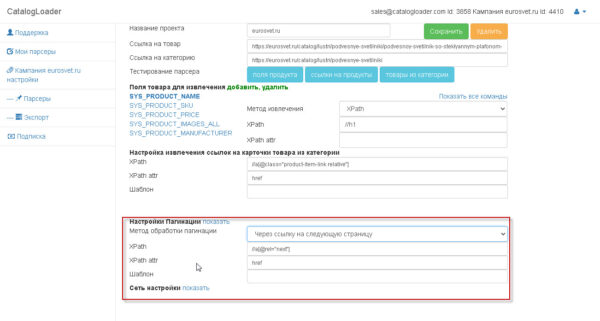
Что такое «следующая ссылка» вам поможет понять следующее изображение:
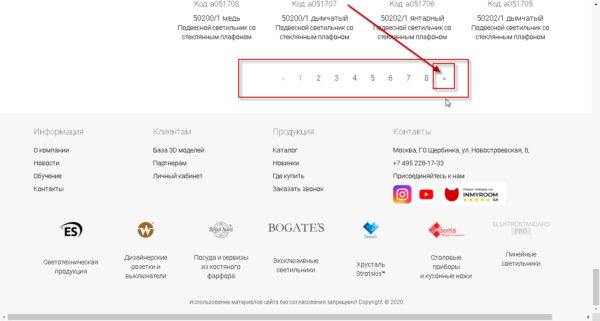
т.е. та ссылка, которая определяет переход из текущей страницы каталога на следующую.
Как запускать парсер
Есть два способа:
1) из настроек парсера, путем нажатия на кнопку «товары из категории»
2) из вкладки «Экспорт», путем нажатия на кнопку «запустить экспорт»
два этих способа предложат вам следующий экран, на котором надо будет задать откуда брать «входные» ссылки
для старта парсера
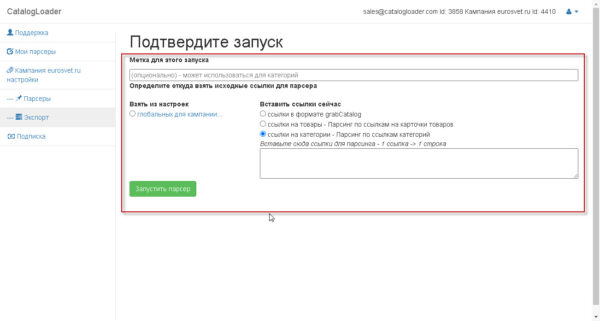
в самом простом варианте использования, вы на каждый запуск определяет ссылка или на карточки товаров или на категории,выбирая соответствующий режим работы.
Если надо задать статический список или карточек товаров или категорий, то для этого надо задать grabCatalog файл через глобальные настройки кампании один раз, а потом уже использовать каждый следующий раз вручную или через запуск по-расписанию парсера.
Что такое grabCatalog формат
Это текстовый файл, который определяет
1)иерархию категорий, которая будет извлекаться
2)названия и ссылки (опционально) на категории, которые будет извлекаться
3)ссылки на карточки товаров (опционально).
важно знать о формате
# — (знак Решетка) — определяет уровень иерархии
[path] — отделяет имя категории от ссылки на категорию
пример : 1 категория будет парсится
#Подвесные светильники[path]https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
пример : 2 категории будет парсится
#Подвесные светильники[path]https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
#Потолочные светильники[path]https://eurosvet.ru/catalog/lustri/potolochnie-svetilniki
пример : 2 категории будет парсится, но они заданы как подкатегории 1 категории верхнего уровня.
#Cветильники
##Подвесные светильники[path]https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
##Потолочные светильники[path]https://eurosvet.ru/catalog/lustri/potolochnie-svetilniki
пример : заданы 2 ссылки на продукт (задаются после названия категории).
#Cветильники
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki/podvesnoy-svetilnik-so-steklyannym-plafonom-50208-1-yantarnyy-a052491
https://eurosvet.ru/catalog/lustri/potolochnie-svetilniki/potolochnaya-lyustra-571-a052390
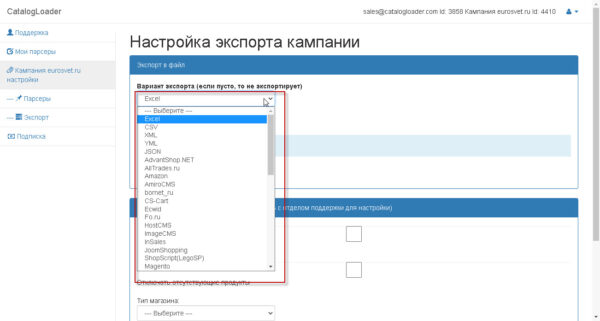
Как настроить выгрузку данных в определенный тип файла
Краткий Урок-введение в Xpath для парсинга сайтов с примерами.
Для выбора тегов и наборов тегов в HTML документе XPath использует выражения путей. Тег Извлекается следуя по заданному пути или по, так называемым, шагам.
Пример HTML файла
Для примера будет использоваться следующий HTML файл

Выбор тегов (как извлечь конкретные теги через XPath)
Чтобы извлечь теги в HTML документе, XPath использует выражения. Тег Извлекается по заданному пути. Наиболее полезные выражения пути:
| Xpath Выражение | Результат |
|---|---|
| имя_тега | Извлекает все узлы с именем «имя_тега» |
| / | Извлекает от корневого тега |
| // | Извлекает узлы от текущего тега, соответствующего выбору, независимо от их местонахождения |
| . | Извлекает текущий узел |
| .. | Извлекает родителя текущего тега |
| @ | Извлекает атрибуты |
Некоторые выборки по HTML документу из примера:
| Xpath Выражение | Результат |
|---|---|
| messages | Извлекает все узлы с именем «messages» |
| /messages | Извлекает корневой элемент сообщений Важно знать!: Если путь начинается с косой черты ( / ), то он всегда представляет абсолютный путь к элементу! |
| messages/note | Извлекает все элементы note, являющиеся потомками элемента messages |
| //note | Извлекает все элементы note независимо от того, где в документе они находятся |
| messages//note | Извлекает все элементы note, являющиеся потомками элемента messages независимо от того, где они находятся от элемента messages |
| //@date | Извлекает все атрибуты с именем date |
Предикаты
Предикаты позволяют найти конкретный Тег или Тег с конкретным значением.
Предикаты всегда заключаются в квадратные скобки [].
В следующей таблице приводятся некоторые выражения XPath с предикатами, позволяющие сделать выборки по HTML документу из примера
| Xpath Выражение | Результат |
|---|---|
| /messages/note[1] | Извлекает первый элемент note, который является прямым потомком элемента messages. Важно знать!: В IE 5,6,7,8,9 первым узлом будет [0], однако согласно W3C это должен быть [1]. Чтобы решить эту проблему в IE, нужно установить опцию SelectionLanguage в значение XPath. В JavaScript: HTML.setProperty(«SelectionLanguage»,»XPath»); |
| /messages/note[last()] | Извлекает последний элемент note, который является прямым потомком элемента messages. |
| /messages/note[last()-1] | Извлекает предпоследний элемент note, который является прямым потомком элемента messages. |
| /messages/note[position()<3] | Извлекает первые два элемента note, которые являются прямыми потомками элемента messages. |
| //heading[@date] | Извлекает все элементы heading, у которых есть атрибут date |
| //heading[@date=»11/12/2020″] | Извлекает все элементы heading, у которых есть атрибут date со значением «11/12/2020» |
Выбор неизвестных заранее тегов
Чтобы найти неизвестные заранее узлы HTML документа, XPath позволяет использовать специальные символы.
| Спецсимвол | Описание |
|---|---|
| * | Соответствует любому тегу элемента |
| @* | Соответствует любому тегу атрибута |
| node() | Соответствует любому тегу любого типа |
Спецсимволы, пример выражения XPath со спецсимволами:
| Xpath Выражение XPath | Результат |
|---|---|
| /messages/* | Извлекает все элементы, которые являются прямыми потомками элемента messages |
| //* | Извлекает все элементы в документе |
| //heading[@*] | Извлекает все элементы heading, у которых есть по крайней мере один атрибут любого типа |
Если надо выбрать нескольких путей
Использование оператора | в выражении XPath позволяет делать выбор по нескольким путям.
В следующей таблице приводятся некоторые выражения XPath, позволяющие сделать выборки по демонстрационному HTML документу:
| Xpath Выражение XPath | Результат |
|---|---|
| //note/heading | //note/body | Извлекает все элементы heading И body из всех элементов note |
| //heading | //body | Извлекает все элементы heading И body во всем документе |