Введение
Создать программу искусственного интеллекта, которая воспринимает человеческую речь и отвечает на вопросы, не так сложно, как кажется. Такое чудо можно сотворить за один день с помощью нескольких пакетов Python и API.
Вот ответы бота на некоторые вопросы.
Я: КАКОВА ЧИСЛЕННОСТЬ НАСЕЛЕНИЯ БРАЗИЛИИ?
БОТ: ПО ОЦЕНКАМ, НАСЕЛЕНИЕ БРАЗИЛИИ СОСТАВЛЯЕТ БОЛЕЕ 209 МИЛЛИОНОВ ЧЕЛОВЕК.
Я: КАКОЕ НА ВКУС МОРОЖЕНОЕ?
БОТ: БОЛЬШИНСТВО ВИДОВ МОРОЖЕНОГО НА ВКУС СЛАДКИЕ И СЛИВОЧНЫЕ.
Я: КАК ПОЛЬЗОВАТЬСЯ ПАЛОЧКАМИ ДЛЯ ЕДЫ?
БОТ: ЧТОБЫ ИСПОЛЬЗОВАТЬ ПАЛОЧКИ ДЛЯ ЕДЫ, НУЖНО ДЕРЖАТЬ ПО ОДНОЙ В КАЖДОЙ РУКЕ. ПОМЕСТИТЕ ПАЛОЧКУ ДЛЯ ЕДЫ В ДОМИНИРУЮЩУЮ РУКУ МЕЖДУ БОЛЬШИМ И УКАЗАТЕЛЬНЫМ ПАЛЬЦАМИ И УДЕРЖИВАЙТЕ ЕЕ СРЕДНИМ ПАЛЬЦЕМ. ПОМЕСТИТЕ ПАЛОЧКУ ДЛЯ ЕДЫ В НЕДОМИНИРУЮЩУЮ РУКУ МЕЖДУ БОЛЬШИМ И УКАЗАТЕЛЬНЫМ ПАЛЬЦАМИ И УДЕРЖИВАЙТЕ ЕЕ БЕЗЫМЯННЫМ ПАЛЬЦЕМ И МИЗИНЦЕМ. ЧТОБЫ ВЗЯТЬ ЕДУ, ИСПОЛЬЗУЙТЕ ПАЛОЧКУ ДЛЯ ЕДЫ В ДОМИНИРУЮЩЕЙ РУКЕ, ЧТОБЫ УДЕРЖИВАТЬ ЕДУ, А ЗАТЕМ ИСПОЛЬЗУЙТЕ ЭТУ ПАЛОЧКУ ДЛЯ ЕДЫ.
Конечно, это не самые содержательные ответы. А концовка ответа про палочки для еды и вовсе довольно странная. Однако тот факт, что подобное приложение может интерпретировать речь и отвечать на вопросы, какими бы ограниченными ни казались ответы, довольно поразителен. К тому же мы можем посмотреть, как устроен виртуальный ассистент и поэкспериментировать с ним.
Что делает эта программа
- Файл запускается через командную строку, когда пользователь готов задать вопрос.
- PyAudio позволяет микрофону компьютера улавливать речевые данные.
- Аудиоданные хранятся в переменной под названием
stream, затем кодируются и преобразуются в JSON-данные. - JSON-данные поступают в API AssemblyAI для преобразования в текст, после чего текстовые данные отправляются обратно.
- Текстовые данные поступают в API OpenAI, а затем направляются в движок
text-davinci-002для обработки. - Ответ на вопрос извлекается и отображается на консоли под заданным вопросом.
API и высокоуровневый дизайн
В этом руководстве используются два базовых API:
- AssemblyAI для преобразования аудио в текст.
- OpenAI для интерпретации вопроса и получения ответа.
Дизайн (высокий уровень)
Этот проект содержит два файла: main и openai_helper.
Скрипт main используется в основном для API-соединения “голос-текст”. Он включает в себя настройку сервера WebSockets, заполнение всех параметров, необходимых для PyAudio, и создание асинхронных функций, необходимых для одновременной отправки и получения речевых данных между приложением и сервером AssemblyAI.
openai_helper — файл с коротким именем, используемый исключительно для подключения к OpenAI-движку text-davinci-002. Это соединение обеспечивает получение ответов на вопросы.
Разбор кода
main.py
Сначала импортируем все библиотеки, которые будут использованы приложением. Для некоторых из них может потребоваться Pip-установка (в зависимости от того, использовали ли вы их). Обратите внимание на комментарии к коду ниже:
#PyAudio предоставляет привязку к Python для PortAudio v19, кроссплатформенной библиотеки ввода-вывода аудио. Позволяет микрофону компьютера взаимодействовать с Python
import pyaudio
#Библиотека Python для создания сервера Websocket - двустороннего интерактивного сеанса связи между браузером пользователя и сервером
import websockets
#asyncio - это библиотека для написания параллельного кода с использованием синтаксиса async/await
import asyncio
#Этот модуль предоставляет функции для кодирования двоичных данных в печатаемые символы ASCII и декодирования таких кодировок обратно в двоичные данные
import base64
#В Python есть встроенный пакет json, который можно использовать для работы с данными JSON
import json
#"Подтягивание" функции из другого файла
from openai_helper import ask_computerТеперь устанавливаем параметры PyAudio. Эти параметры являются настройками по умолчанию, найденными в интернете. Вы можете поэкспериментировать с ними по мере необходимости, но мне параметры по умолчанию подошли отлично. Устанавливаем переменную stream в качестве начального контейнера для аудиоданных, а затем выводим параметры устройства ввода по умолчанию в виде словаря. Ключи словаря отражают поля данных в структуре PortAudio. Вот код:
#Настройка параметров микрофона
#Сколько байт данных приходится на каждый обработанный фрагмент звука
FRAMES_PER_BUFFER = 3200
#Битовый целочисленный формат аудиовхода/выхода порта по умолчанию
FORMAT = pyaudio.paInt16
#Моноформатный канал (то есть нам нужен только входной аудиосигнал, поступающий с одного направления)
CHANNELS = 1
#Желаемая частота в Гц входящего аудиосигнала
RATE = 16000
p = pyaudio.PyAudio()
#Начинает запись, создает переменную stream, присваивает параметры
stream = p.open(
format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=FRAMES_PER_BUFFER
)
print(p.get_default_input_device_info())Далее создаем несколько асинхронных функций для отправки и получения данных, необходимых для преобразования голосовых вопросов в текст. Эти функции выполняются параллельно, что позволяет преобразовывать речевые данные в формат base64, конвертировать их в JSON, отправлять на сервер через API, а затем получать обратно в читаемом формате. Сервер WebSockets также является важной частью приведенного ниже скрипта, поскольку именно он делает прямой поток бесшовным.
#Необходимая нам конечная точка AssemblyAI
URL = "wss://api.assemblyai.com/v2/realtime/ws?sample_rate=16000"
auth_key = "enter key here"#Создание асинхронной функции, чтобы она могла продолжать работать и отправлять поток речевых данных в API до тех пор, пока это необходимо
async def send_receive():
print(f'Connecting websocket to url ${URL}')
async with websockets.connect(
URL,
extra_headers=(("Authorization", auth_key),),
ping_interval=5,
ping_timeout=20
) as _ws:
await asyncio.sleep(0.1)
print("Receiving SessionBegins ...")
session_begins = await _ws.recv()
print(session_begins)
print("Sending messages ...")
async def send():
while True:
try:
data = stream.read(FRAMES_PER_BUFFER, exception_on_overflow=False)
data = base64.b64encode(data).decode("utf-8")
json_data = json.dumps({"audio_data":str(data)})
await _ws.send(json_data)
except websockets.exceptions.ConnectionClosedError as e:
print(e)
assert e.code == 4008
break
except Exception as e:
assert False, "Not a websocket 4008 error"
await asyncio.sleep(0.01)
return True
async def receive():
while True:
try:
result_str = await _ws.recv()
result = json.loads(result_str)
prompt = result['text'] if prompt and result['message_type'] == 'FinalTranscript':
print("Me:", prompt)
answer = ask_computer(prompt)
print("Bot", answer)
except websockets.exceptions.ConnectionClosedError as e:
print(e)
assert e.code == 4008
break
except Exception as e:
assert False, "Not a websocket 4008 error"
send_result, receive_result = await asyncio.gather(send(), receive())
asyncio.run(send_receive())
Теперь у нас есть простое API-соединение с OpenAI. Если вы посмотрите на строку 44 приведенного выше кода (main3.py), то увидите, что мы извлекаем функцию ask_computer из этого другого файла и используем ее результаты в качестве ответов на вопросы.
Заключение
Это отличный проект для всех, кто не прочь взять на вооружение ту самую технологию, благодаря которой функционируют Siri и Alexa. Его реализация не требует большого опыта в программировании, потому что для обработки данных используется API.
Весь код хранится в этом репозитории.
Источник
Просмотры: 1 644
Отличный гайд про нейросеть от теории к практике. Вы узнаете из каких элементов состоит ИНС, как она работает и как ее создать самому.
Если вы в поисках пособия по искусственным нейронным сетям (ИНС), то, возможно, у вас уже имеются некоторые предположения относительно того, что это такое. Но знали ли вы, что нейронные сети — основа новой и интересной области глубинного обучения? Глубинное обучение — область машинного обучения, в наше время помогло сделать большой прорыв во многих областях, начиная с игры в Го и Покер с живыми игроками, и заканчивая беспилотными автомобилями. Но, прежде всего, глубинное обучение требует знаний о работе нейронных сетей.

В этой статье будут представлены некоторые понятия, а также немного кода и математики, с помощью которых вы сможете построить и понять простые нейронные сети. Для ознакомления с материалом нужно иметь базовые знания о матрицах и дифференциалах. Код будет написан на языке программирования Python с использованием библиотеки numpy. Вы построите ИНС, используя Python, которая с высокой точностью классифицировать числа на картинках.
1 Что такое искусственная нейросеть?
Искусственные нейросеть (ИНС) — это программная реализация нейронных структур нашего мозга. Мы не будем обсуждать сложную биологию нашей головы, достаточно знать, что мозг содержит нейроны, которые являются своего рода органическими переключателями. Они могут изменять тип передаваемых сигналов в зависимости от электрических или химических сигналов, которые в них передаются. Нейросеть в человеческом мозге — огромная взаимосвязанная система нейронов, где сигнал, передаваемый одним нейроном, может передаваться в тысячи других нейронов. Обучение происходит через повторную активацию некоторых нейронных соединений. Из-за этого увеличивается вероятность вывода нужного результата при соответствующей входной информации (сигналах). Такой вид обучения использует обратную связь — при правильном результате нейронные связи, которые выводят его, становятся более плотными.
Искусственные нейронные сети имитируют поведение мозга в простом виде. Они могут быть обучены контролируемым и неконтролируемым путями. В контролируемой ИНС, сеть обучается путем передачи соответствующей входной информации и примеров исходной информации. Например, спам-фильтр в электронном почтовом ящике: входной информацией может быть список слов, которые обычно содержатся в спам-сообщениях, а исходной информацией — классификация для уведомления (спам, не спам). Такой вид обучения добавляет веса связям ИНС, но это будет рассмотрено позже.
Неконтролируемое обучение в ИНС пытается «заставить» ИНС «понять» структуру передаваемой входной информации «самостоятельно». Мы не будем рассматривать это в данном посте.
2 Структура ИНС
2.1 Искусственный нейрон
Биологический нейрон имитируется в ИНС через активационную функцию. В задачах классификации (например определение спам-сообщений) активационная функция должна иметь характеристику «включателя». Иными словами, если вход больше, чем некоторое значение, то выход должен изменять состояние, например с 0 на 1 или -1 на 1 Это имитирует «включение» биологического нейрона. В качестве активационной функции обычно используют сигмоидальную функцию:
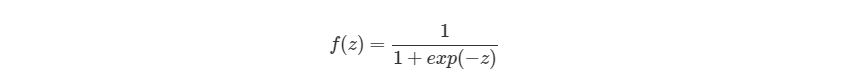
Которая выглядит следующим образом:
import matplotlib.pylab as plt
import numpy as np
x = np.arange(-8, 8, 0.1)
f = 1 / (1 + np.exp(-x))
plt.plot(x, f)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.show()
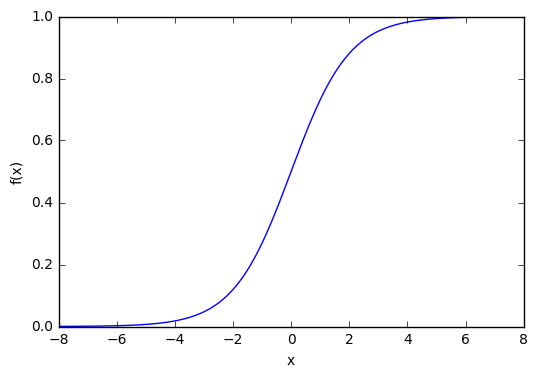
Из графика можно увидеть, что функция «активационная» — она растет с 0 до 1 с каждым увеличением значения х. Сигмоидальная функция является гладкой и непрерывной. Это означает, что функция имеет производную, что в свою очередь является очень важным фактором для обучения алгоритма.
2.2 Узлы
Как было упомянуто ранее, биологические нейроны иерархически соединены в сети, где выход одних нейронов является входом для других нейронов. Мы можем представить такие сети в виде соединенных слоев с узлами. Каждый узел принимает взвешенный вход, активирует активационную функцию для суммы входов и генерирует выход.
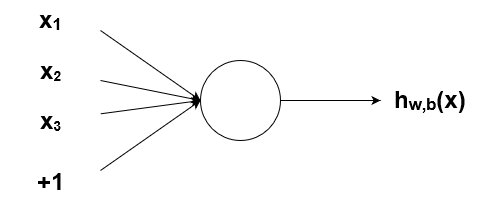
Круг на картинке изображает узел. Узел является «местоположением» активационной функции, он принимает взвешенные входы, складывает их, а затем вводит их в активационную функцию. Вывод активационной функции представлен через h. Примечание: в некоторых источниках узел также называют перцептроном.
Что такое «вес»? По весу берутся числа (не бинарные), которые затем умножаются на входе и суммируются в узле. Иными словами, взвешенный вход в узел имеет вид:
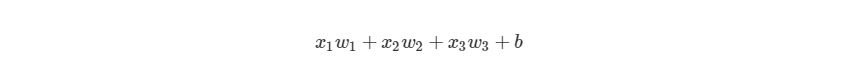
где wi— числовые значения веса ( b мы будем обсудим позже). Весы нам нужны, они являются значениями, которые будут меняться в течение процесса обучения. b является весом элемента смещения на 1, включение веса b делает узел гибким. Проще это понять на примере.
2.3 Смещение
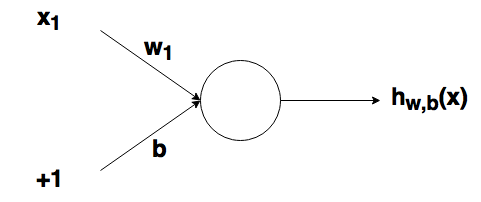
Рассмотрим простой узел, в котором есть по одному входу и выходу:

Ввод для активационной функции в этом узле просто x1w1. На что влияет изменение в w1 в этой простой сети?
w1 = 0.5
w2 = 1.0
w3 = 2.0
l1 = 'w = 0.5'
l2 = 'w = 1.0'
l3 = 'w = 2.0'
for w, l in [(w1, l1), (w2, l2), (w3, l3)]:
f = 1 / (1 + np.exp(-x * w))
plt.plot(x, f, label = l)
plt.xlabel('x')
plt.ylabel('h_w(x)')
plt.legend(loc = 2)
plt.show()
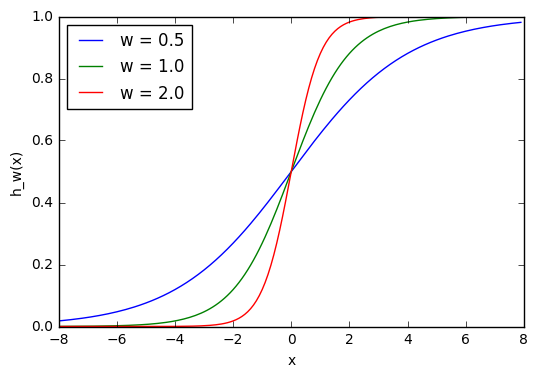
Здесь мы можем видеть, что при изменении веса изменяется также уровень наклона графика активационной функции. Это полезно, если мы моделируем различные плотности взаимосвязей между входами и выходами. Но что делать, если мы хотим, чтобы выход изменялся только при х более 1? Для этого нам нужно смещение. Рассмотрим такую сеть со смещением на входе:
w = 5.0
b1 = -8.0
b2 = 0.0
b3 = 8.0
l1 = 'b = -8.0'
l2 = 'b = 0.0'
l3 = 'b = 8.0'
for b, l in [(b1, l1), (b2, l2), (b3, l3)]:
f = 1 / (1 + np.exp(-(x * w + b)))
plt.plot(x, f, label = l)
plt.xlabel('x')
plt.ylabel('h_wb(x)')
plt.legend(loc = 2)
plt.show()
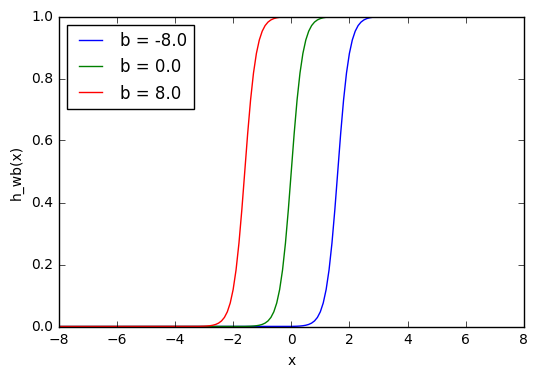
Из графика можно увидеть, что меняя «вес» смещения b, мы можем изменять время запуска узла. Смещение очень важно в случаях, когда нужно имитировать условные отношения.
2.4 Составленная структура
Выше было объяснено, как работает соответствующий узел / нейрон / перцептрон. Но, как вы знаете, в полной нейронной сети находится много таких взаимосвязанных между собой узлов. Структуры таких сетей могут принимать мириады различных форм, но самая распространенная состоит из входного слоя, скрытого слоя и выходного слоя. Пример такой структуры приведены ниже:
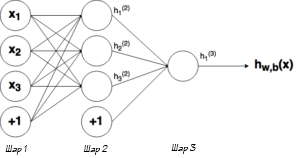
Ну рисунке выше можно увидеть три слоя сети — Слой 1 является входным слоем, где сеть принимает внешние входные данные. Слой 2 называют скрытым слоем, этот слой не является частью ни входа, ни выхода. Примечание: нейронные сети могут иметь несколько скрытых слоев, в данном примере для примера был показан лишь один. И наконец, Слой 3 является исходным слоем. Вы можете заметить, что между Шаром 1 (Ш1) и Шаром 2 (Ш2) существует много связей. Каждый узел в Ш1 имеет связь со всеми узлами в Ш2, при этом от каждого узла в Ш2 идет по одной связи к единому выходному узлу в Ш3. Каждая из этих связей должна иметь соответствующий вес.
2.5 Обозначение
Вся математика, приведенная выше, требует очень точной нотации. Нотация, которая используется здесь, используется и в руководстве по глубинному обучению от Стэнфордского Университета. В следующих уравнениях вес соответствующего связи будет обозначаться как w ij(l), где i — номер узла в слое l+1, а j- номер узла в слое l. Например, вес связи между узлом 1 в слое 1 и узлом 2 в слое 2 будет обозначаться как w 21(l). Непонятно, почему индексы 2-1 означают связь 1-2? Такая нотация более понятна, если добавить смещения.
Из графика выше видно, что смещение 1 связано со всеми узлами в соседнем слое. Смещение в Ш1 имеет связь со всеми узлами в Ш2. Так как смещение не является настоящим узлом с активационной функцией, оно не имеет и входов (его входное значение всегда равно константе). Вес связи между смещением и узлом будем обозначать через bi(l), где i- номер узла в слое l+1, так же, как в w ij(l). К примеру с w 21(l) вес между смещением в Ш1 и вторым узлом в Ш2 будет иметь обозначение b2(1).
Помните, что эти значения -w ij(l)и bi(l) — будут меняться в течение процесса обучения ИНС.
Обозначение связи с исходным узлом будет выглядеть следующим образом: hjl, где j- номер узла в слое l. Тогда в предыдущем примере, связью с исходным узлом является h1(2).
Теперь давайте рассмотрим, как рассчитывать выход сети, когда нам известны вес и вход. Процесс нахождения выхода в нейронной сети называется процессом прямого распространения.
3 Процесс прямого распространения
Чтобы продемонстрировать, как находить выход, имея уже известный вход, в нейронных сетях, начнем с предыдущего примера с тремя слоями. Ниже такая система представлена в виде системы уравнений:
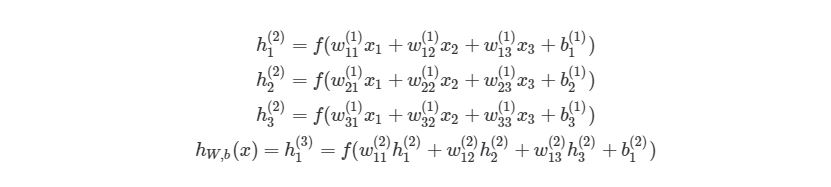
, где f(∙) — активационная функция узла, в нашем случае сигмоидальная функция. В первой строке h1(2)— выход первого узла во втором слое, его входами соответственно являются w11(1)x1(1), w12(1)x2(1),w13(1)x3(1) и b1(1). Эти входы было сложены, а затем переданы в активационную функцию для расчета выхода первого узла. С двумя следующими узлами аналогично.
Последняя строка рассчитывает выход единого узла в последнем третьем слое, он является конечной исходной точкой в нейронной сети. В нем вместо взвешенных входных переменных (x1,x2,x3)берутся взвешенные выходы узлов с другой слоя (h1(2),h2(2),h3(2))и смещения. Такая система уравнений также хорошо показывает иерархическую структуру нейронной сети.
3.1 Пример прямого распространения
Приведем простой пример первого вывода нейронной сети языке Python . Обратите внимание, веса w11(1),w12(1),… между Ш1 и Ш2 идеально могут быть представлены в матрице:
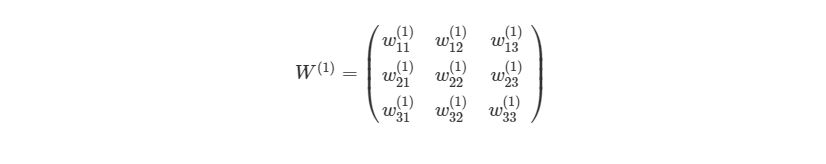
Представим эту матрицу через массивы библиотеки numpy.
import numpy as np
w1 = np.array([
[0.2, 0.2, 0.2],
[0.4, 0.4, 0.4],
[0.6, 0.6, 0.6]
])
Мы просто присвоили некоторые рандомные числовые значения весу каждой связи с Ш1. Аналогично можно сделать и с Ш2:
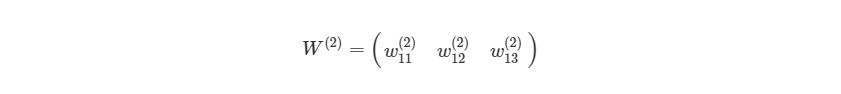
w2 = np.zeros((1, 3))
w2[0, : ] = np.array([0.5, 0.5, 0.5])
Мы можем присвоить некоторые значения весу смещения в Ш1 и Ш2:
b1 = np.array([0.8, 0.8, 0.8])
b2 = np.array([0.2])
Наконец, перед написанием основной программы для расчета выхода нейронной сети, напишем отдельную функцию для активационной функции:
def f(x):
return 1 / (1 + np.exp(-x))
3.2 Первая попытка реализовать процесс прямого распространения
Приведем простой способ расчета выхода нейронной сети, используя вложенные циклы в Python. Позже мы быстро рассмотрим более эффективные способы.
def simple_looped_nn_calc(n_layers, x, w, b):
for l in range(n_layers - 1): #Формируется входной массив - перемножения весов в каждом слое# Если первый слой, то входной массив равен вектору х# Если слой не первый, вход для текущего слоя равен# выходу предыдущего
if l == 0:
node_in = x
else :
node_in = h #формирует выходной массив для узлов в слое l + 1
h = np.zeros((w[l].shape[0], ))#проходит по строкам массива весов
for i in range(w[l].shape[0]): #считает сумму внутри активационной функции
f_sum = 0 #проходит по столбцам массива весов
for j in range(w[l].shape[1]):
f_sum += w[l][i][j] * node_in[j] #добавляет смещение
f_sum += b[l][i]
#использует активационную функцию для расчета
#i - того выхода, в данном случае h1, h2, h3
h[i] = f(f_sum)
return h
Данная функция принимает в качестве входа номер слоя в нейронной сети, х — входной массив / вектор:
w = [w1, w2]
b = [b1, b2] #Рандомный входной вектор x
x = [1.5, 2.0, 3.0]
Функция сначала проверяет, чем является входной массив для соответствующего слоя с узлами / весами. Если рассматривается первый слой, то входом для второго слоя является входной массив xx, Умноженный на соответствующие веса. Если слой не первый, то входом для последующего будет выход предыдущего.
Вызов функции:
simple_looped_nn_calc(3, x, w, b)
возвращает результат 0.8354. Можно проверить правильность, вставив те же значения в систему уравнений:

3.3 Более эффективная реализация
Использование циклов — не самый эффективный способ расчета прямого распространения на языке Python , потому что циклы в этом языке программирования работают довольно медленно. Мы кратко рассмотрим лучшие решения. Также можно будет сравнить работу алгоритмов, используя функцию в IPython:
%timeit simple_looped_nn_calc(3, x, w, b)
В данном случае процесс прямого распространения с циклами занимает около 40 микросекунд. Это довольно быстро, но не для больших нейронных сетей с > 100 узлами на каждом слое, особенно при их обучении. Если мы запустим этот алгоритм на нейронной сети с четырьмя слоями, то получим результат 70 микросекунд. Эта разница является достаточно значительной.
3.4 Векторизация в нейронных сетях
Можно более компактно написать предыдущие уравнения, тем самым найти результат эффективнее. Сначала добавим еще одну переменную zi(l), которая является суммой входа в узел i слоя l, Включая смещение. Тогда для первого узла в Ш2, z будет равна:
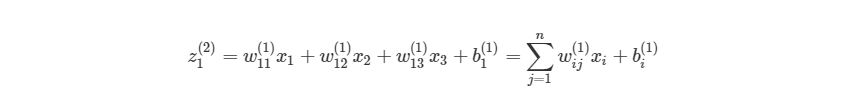
, где n- количество узлов в Ш1. Используя это обозначение, систему уравнений можно сократить:
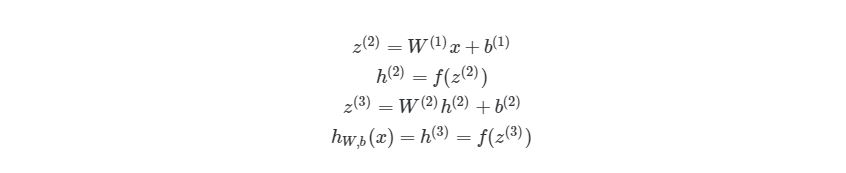
Обратите внимание на W, что означает матричную форму представления весов. Помните, что теперь все элементы в уравнении сверху являются матрицами / векторами. Но на этом упрощение не заканчивается. Данные уравнения можно свести к еще более краткому виду:
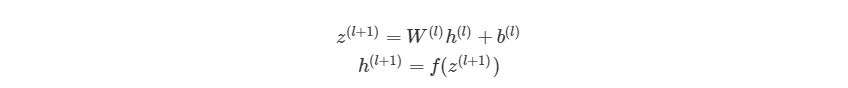
Так выглядит общая форма процесса прямого распространения, выход слоя l становится входом в слой l+1. Мы знаем, что h(1) является входным слоем x, а h(nl)(где nl- номер слоя в сети) является исходным слоем. Мы также не стали использовать индексы i и j-за того, что можно просто перемножить матрицы — это даст нам тот же результат. Поэтому данный процесс и называется «векторизацией». Этот метод имеет ряд плюсов. Во-первых, код его реализации выглядит менее запутанным. Во-вторых, используются свойства по линейной алгебре вместо циклов, что делает работу программы быстрее. С numpy можно легко сделать такие подсчеты. В следующей части быстро повторим операции над матрицами, для тех, кто их немного подзабыл.
3.5 Умножение матриц
Распишем z(l+1)=W(l)h(l)+b(l) на выражение из матрицы и векторов входного слоя ( h(l)=x):

Для тех, кто не знает или забыл, как перемножаются матрицы. Когда матрица весов умножается на вектор, каждый элемент в строке матрицы весов умножается на каждый элемент в столбце вектора, после этого все произведения суммируются и создается новый вектор (3х1). После перемножения матрицы на вектор, добавляются элементы из вектора смещения и получается конечный результат.
Каждая строка полученного вектора соответствует аргументу активационной функции в оригинальной НЕ матричной системе уравнений выше. Это означает, что в Python мы можем реализовать все, не используя медленные циклы. К счастью, библиотека numpy дает возможность сделать это достаточно быстро, благодаря функциям-операторам над матрицами. Рассмотрим код простой и быстрой версии функции simple_looped_nn_calc:
def matrix_feed_forward_calc(n_layers, x, w, b):
for l in range(n_layers - 1):
if l == 0:
node_in = x
else :
node_in = h
z = w[l].dot(node_in) + b[l]
h = f(z)
return h
Обратите внимание на строку 7, в которой происходит перемножение матрицы и вектора. Если вместо функции умножения a.dot (b) вы используете символ *, то получится нечто похожее на поэлементное умножение вместо настоящего произведения матриц.
Если сравнить время работы этой функции с предыдущей на простой сети с четырьмя слоями, то мы получим результат лишь на 24 микросекунды меньше. Но если увеличить количество узлов в каждом слое до 100-100-50-10, то мы получим гораздо большую разницу. Функция с циклами в этом случае дает результат 41 миллисекунду, когда у функции с векторизацией это занимает лишь 84 микросекунды. Также существуют еще более эффективные реализации операций над матрицами, которые используют пакеты глубинного обучения, такие как TensorFlow и Theano.
На этом все о процессе прямого распространения в нейронных сетях. В следующих разделах мы поговорим о способах обучения нейронных сетей, используя градиентный спуск и обратное распространение.
4 Градиентный спуск и оптимизация
Расчеты значений весов, которые соединяют слои в сети, это как раз то, что мы называем обучением системы. В контролируемом обучении идея заключается в том, чтобы уменьшить погрешность между входом и нужным выходом. Если у нас есть нейросеть с одним выходным слоем и некоторой вход xx и мы хотим, чтобы на выходе было число 2, но сеть выдает 5, то нахождение погрешности выглядит как abs(2-5)=3. Говоря языком математики, мы нашли норму ошибки L1(Это будет рассмотрено позже).
Смысл контролируемого обучения в том, что предоставляется много пар вход-выход уже известных данных и нужно менять значения весов, основываясь на этих примерах, чтобы значение ошибки стало минимальным. Эти пары входа-выхода обозначаются как (x(1),y(1)),…,(x(m),y(m)), где m является количеством экземпляров для обучения. Каждое значение входа или выхода может представлять собой вектор значений, например x(1) не обязательно только одно значение, оно может содержать N-размерный набор значений. Предположим, что мы обучаем нейронную сеть выявлению спам-сообщений — в таком случае x(1) может представлять собой количество соответствующих слов, которые встречаются в сообщении:
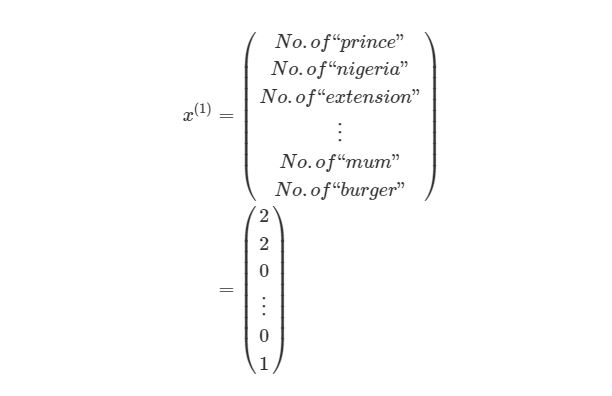
y(1) в этом случае может представлять собой единое скалярное значение, например, 1 или 0, обозначающий, было сообщение спамом или нет. В других приложениях это также может быть вектор с K измерениями. Например, мы имеем вход xx, Который является вектором черно-белых пикселей, считанных с фотографии. При этом y может быть вектором с 26 элементами со значениями 1 или 0, обозначающие, какая буква была изображена на фото, например (1,0,…,0)для буквы а, (0,1,…,0) для буквы б и т. д.
В обучении сети, используя (x,y), целью является улучшение нахождения правильного y при известном x. Это делается через изменение значений весов, чтобы минимизировать погрешность. Как тогда менять их значение? Для этого нам и понадобится градиентный спуск. Рассмотрим следующий график:
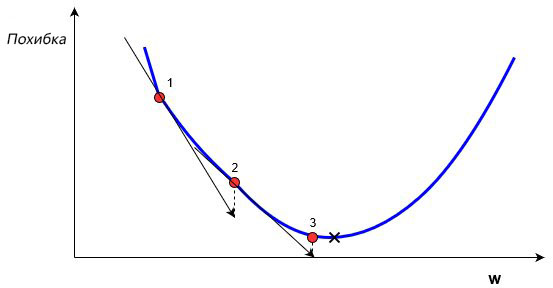
На этом графике изображено погрешность, зависящую от скалярного значения веса, w. Минимально возможная погрешность обозначена черным крестиком, но мы не знаем какое именно значение w дает нам это минимальное значение. Подсчет начинается с рандомного значения переменной w, которая дает погрешность, обозначенную красной точкой под номером «1» на кривой. Нам нужно изменить w таким образом, чтобы достичь минимальной погрешности, черного крестика. Одним из самых распространенных способов является градиентный спуск.
Сначала находится градиент погрешности на «1» по отношению к w. Градиент является уровнем наклона кривой в соответствующей точке. Он изображен на графике в виде черных стрелок. Градиент также дает некоторую информацию о направлении — если он положителен при увеличении w, то в этом направлении погрешность будет увеличиваться, если отрицательный — уменьшаться (см. График). Как вы уже поняли, мы пытаемся сделать, чтобы погрешность с каждым шагом уменьшалась. Величина градиента показывает, как быстро кривая погрешности или функция меняется в соответствующей точке. Чем больше значение, тем быстрее меняется погрешность в соответствующей точке в зависимости от w.
Метод градиентного спуска использует градиент, чтобы принимать решение о следующей смены в w для того, чтобы достичь минимального значения кривой. Он итеративным методом, каждый раз обновляет значение w через:
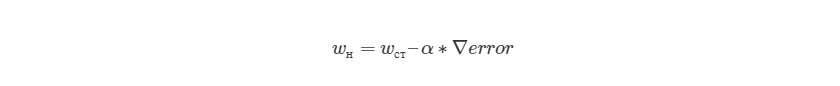
, где wн означает новое значение w, wст— текущее или «старое» значение w, ∇error является градиентом погрешности на wст и α является шагом. Шаг α также будет означать, как быстро ответ приближается к минимальной погрешности. При каждой итерации в таком алгоритме градиент должен уменьшаться. Из графика выше можно заметить, что с каждым шагом градиент «стихает». Как только ответ достигнет минимального значения, мы уходим из итеративного процесса. Выход можно реализовать способом условия «если погрешность меньше некоторого числа». Это число называют точностью.
4.1 Простой пример на коде
Рассмотрим пример простой имплементации градиентного спуска для нахождения минимума функции f(x)=x4-3x3+2 на языке Python . Градиент этой функции можно найти аналитически через производную f»(x)=4x3-9x2. Это означает, что для любого xx мы можем найти градиент по этой простой формуле. Мы можем найти минимум через производную — x=2.25.
x_old = 0 # Нет разницы, какое значение, главное abs(x_new - x_old) > точность
x_new = 6 # Алгоритм начинается с x = 6
gamma = 0.01 # Размер шага
precision = 0.00001 # Точность
def df(x):
y = 4 * x * * 3 - 9 * x * * 2
return y
while abs(x_new - x_old) > precision:
x_old = x_new
x_new += -gamma * df(x_old)
print("Локальный минимум находится на %f" % x_new)
Вывод этой функции: «Локальный минимум находится на 2.249965», что удовлетворяет правильному ответу с некоторой точностью. Этот код реализует алгоритм изменения веса, о котором рассказывалось выше, и может находить минимум функции с соответствующей точностью. Это был очень простой пример градиентного спуска, нахождение градиента при обучении нейронной сети выглядит несколько иначе, хотя и главная идея остается той же — мы находим градиент нейронной сети и меняем веса на каждом шагу, чтобы приблизиться к минимальной погрешности, которую мы пытаемся найти. Но в случае ИНС нам нужно будет реализовать градиентный спуск с многомерным вектором весов.
Мы будем находить градиент нейронной сети, используя достаточно популярный метод обратного распространения ошибки, о котором будет написано позже. Но сначала нам нужно рассмотреть функцию погрешности более детально.
4.2 Функция оценки
Существует более общий способ изобразить выражения, которые дают нам возможность уменьшить погрешность. Такое общее представление называется функция оценки. Например, функция оценки для пары вход-выход (xz, yz) в нейронной сети будет выглядеть следующим образом:
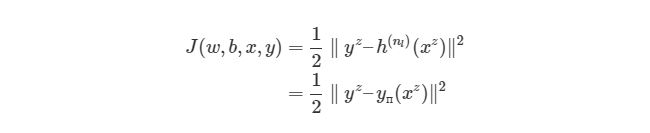
Выражение является функцией оценки учебного экземпляра zth, где h(nl)является выходом последнего слоя, то есть выход нейронной сети. h(nl) можно представить как yпyп, Что означает полученный результат, когда нам известен вход xz. Две вертикальные линии означают норму L2 погрешности или сумму квадратов ошибок. Сумма квадратов погрешностей является довольно распространенным способом представления погрешностей в системе машинного обучения. Вместо того, чтобы брать абсолютную погрешность abs(ypred(xz)-yz), мы берем квадрат погрешности. Мы не будем обсуждать причину этого в данной статье. 1/2 в начале просто константой, которая нормализует ответ после того, как мы продифференцируем функцию оценки во время обратного распространения.
Обратите внимание, что приведенная ранее функция оценки работает только с одной парой (x,y). Мы хотим минимизировать функцию оценки со всеми mm парами вход-выход:
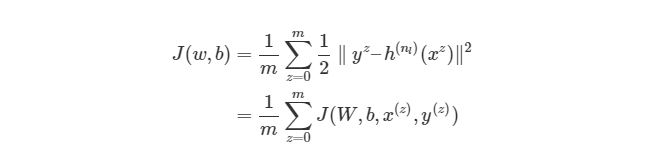
Тогда как же мы будем использовать функцию J для обучения наших сетей? Конечно, используя градиентный спуск и обратное распространение ошибок. Сначала рассмотрим градиентный спуск в нейронных сетях более детально.
4.3 Градиентный спуск в нейронных сетях
Градиентный спуск для каждого веса w(ij)(l) и смещение bi(l) в нейронной сети выглядит следующим образом:
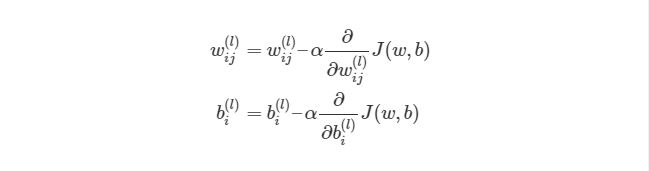
Выражение выше фактически аналогично представлению градиентного спуска:
wnew=wold-α*∇error. Нет лишь некоторых обозначений, но достаточно понимать, что слева расположены новые значения, а справа — старые. Опять же задействован итерационный метод для расчета весов на каждой итерации, но на этот раз основываясь на функции оценки J(w,b).
Значения ∂/∂wij(l)и ∂/∂bi(l) являются частными производными функции оценки, основываясь на значениях веса. Что это значит? Вспомните простой пример градиентного спуска ранее, каждый шаг зависит от наклона погрешности / оценки по отношению к весу. Производная также имеет значение наклона / градиента. Конечно, производная обозначается как d/dx. x в нашем случае является вектором, а это значит, что наша производная тоже будет вектором, который является градиент каждого измерения x.
4.4 Пример двумерного градиентного спуска
Рассмотрим пример стандартного двумерного градиентного спуска. Ниже представлены диаграмму работы двух итеративных двумерных градиентных спусков:
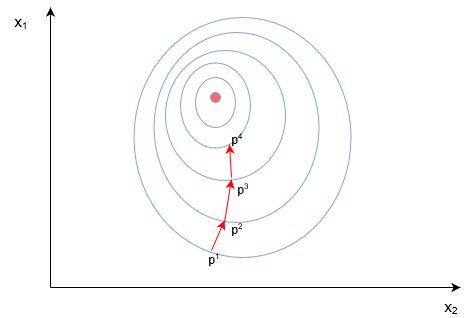
Синим обозначены контуры функции оценки, они обозначают области, в которых значение погрешности примерно одинаковы. Каждый шаг (p1→p2→p3) В градиентном спуске используют градиент или производную, которые обозначаются стрелкой / вектором. Этот вектор проходит через два пространства [x1, x2][x1,x2]и показывает направление, в котором находится минимум. Например, производная, исчисленная в p1 может быть d/dx=[2.1,0.7], Где производная является вектором с двумя значениями. Частичная производная ∂/∂x1 в этом случае равна скаляру →[2.1]- иными словами, это значение градиента только в одном измерении поискового пространства (x1).
В нейронных сетях не существует простой полной функции оценки, с которой можно легко посчитать градиент, похожей на функцию, которую мы ранее рассматривали f(x)=x4-3x3+2). Мы можем сравнить выход нейронной сети с нашим ожидаемым значением y(z), После чего функция оценки будет меняться из-за изменения в значениях веса, но как мы это сделаем со всеми скрытыми слоями в сети?
Поэтому нам нужен метод обратного распространения. Этот метод дает нам возможность «делить» функцию оценки или ошибку со всеми весами в сети. Другими словами, мы можем выяснить, как каждый вес влияет на погрешность.
4.5 Углубляемся в обратное распространение
Если математика вам не очень хорошо дается, то вы можете пропустить этот раздел. В следующем разделе вы узнаете, как реализовать обратное распространение языке программирования. Но если вы не против немного больше поговорить о математике, то продолжайте читать, вы получите более глубокие знания по обучению нейронных сетей.
Сначала, давайте вспомним базовые уравнения для нейронной сети с тремя слоями из предыдущих разделов:
Выход этой нейронной сети находится по формуле:
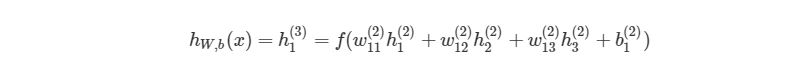
Мы можем упростить это уравнение к h1(3)=f(z1(2)), добавив новое значение z1(2), которое означает:
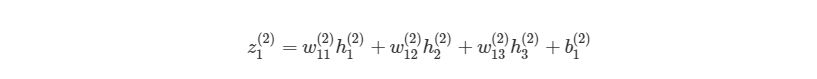
Предположим, что мы хотим узнать, как влияет изменение в весе w12(2) на функцию оценки. Это означает, что нам нужно вычислить ∂J/∂w12(2). Чтобы сделать это, нужно использовать правило дифференцирования сложной функции:
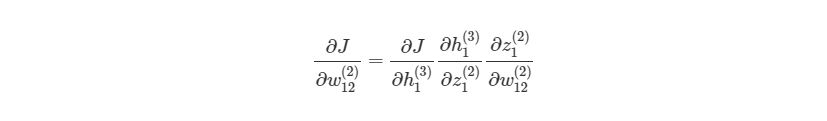
Если присмотреться, то правая часть полностью сокращается (по принципу 2552=22=1). ∂J∂w12(2) были разбиты на три множителя, два из которых можно прекрасно заменить. Начнем с ∂z1(2)/∂w12(2):
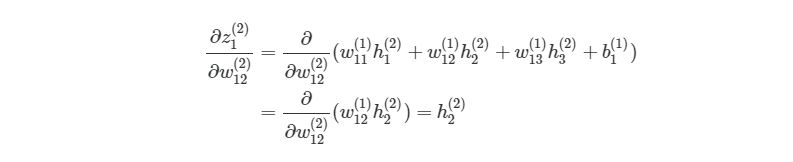
Частичная производная z1(2) по w12(2) зависит только от одного произведения в скобках, w12(1)h2(2), Так как все элементы в скобках, кроме w12(2), не изменяются. Производная от константы всегда равна 1, а ∂/∂w12(2))сокращается до просто h2(2), Что является обычным выходом второго узла из слоя 2.
Следующая частичная производная сложной функции ∂h1(3)/∂z1(2) является частичной производной активационной функции выходного узла h1(3). Так что нам нужно брать производные активационной функции, следует условие ее включения в нейронные сети — функция должна быть дифференцированной. Для сигмоидальной активационной функции производная будет выглядеть так:
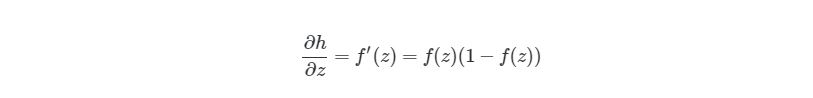
, где f(z)является самой активационной функцией. Теперь нам нужно разобраться, что делать с ∂J∂h1(3). Вспомните, что J(w,b,x,y) есть функция квадрата погрешности, выглядит так:
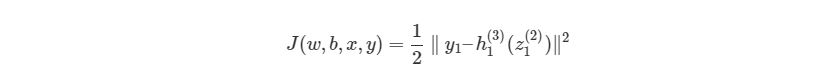
здесь y1 является ожидаемым выходом для выходного узла. Опять используем правило дифференцирования сложной функции:
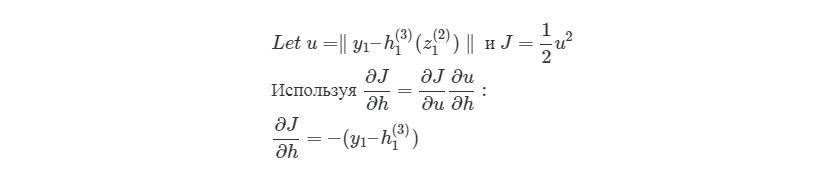
Мы выяснили, как находить ∂J/∂w12(2)по крайней мере для весов связей с исходным слоем. Перед тем, как перейти к одному из скрытых слоев, введем некоторые новые значения δ, чтобы немного сократить наши выражения:
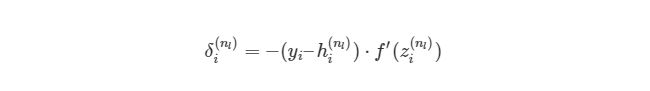
, где i является номером узла в выходном слое. В нашем примере есть только один узел, поэтому i=1. Напишем полный вид производной функции оценки:
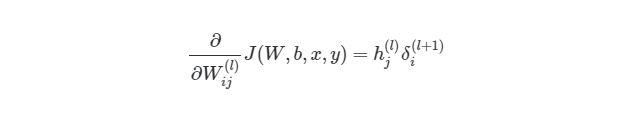
, где выходной слой, в нашем случае, l=2, а i соответствует номеру узла.
4.6 Распространение в скрытых слоях
Что делать с весами в скрытых слоях (в нашем случае в слое 2)? Для весов, которые соединены с выходным слоем, производная ∂J/∂h=-(yi-hi(nl))имела смысл, т.к. функция оценки может быть сразу найдена через сравнение выходного слоя с существующими данными. Но выходы скрытых узлов не имеют подобных уже существующих данных для проверки, они связаны с функцией оценки только через другие слои узлов. Как мы можем найти изменения в функции оценки из-за изменений весов, которые находятся глубоко в нейронной сети? Как уже было сказано, мы используем метод обратного распространения.
Мы уже сделали тяжелую работу по правилу дифференцирования сложных функций, теперь рассмотрим все более графически. Значение, которое будет обратно распространяться, — δi(nl), т.к. оно в ближайшей связи с функцией оценки. А что с узлом j во втором слое (скрытом слое)? Как он влияет на δi(nl) в нашей сети? Он меняет другие значения из-за веса wij(2)(см. диаграмму ниже, где j=1 i=1).
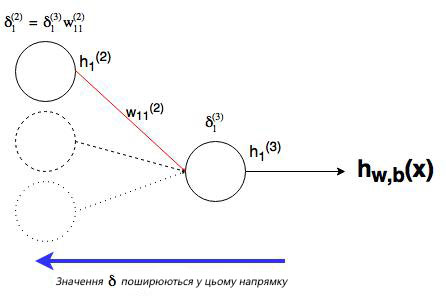
Как можно понять из рисунка, выходной слой соединяется со скрытым узлом из-за веса. В случае, когда в исходном слое есть только один узел, общее выражение скрытого слоя будет выглядеть так:
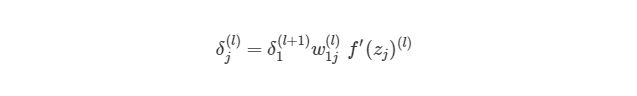
, где j номер узла в слое l. Но что будет, если в исходном слое находится много выходных узлов? В этом случае δj(l) находится по взвешенной сумме всех связанных между собой погрешностей, как показано на диаграмме ниже:
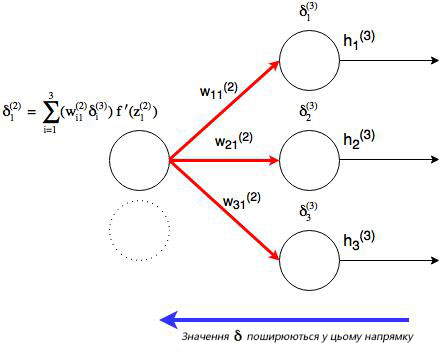
На рисунке показано, что каждое значение δ из исходного слоя суммируется для нахождения δ1(2), Но каждый выход δ должен быть взвешенным соответствующими значению wi1(2). Другими словами, узел 1 в слое 2 способствует изменениям погрешностей в трех выходных узлах, при этом полученная погрешность (или значение функции оценки) в каждом из этих узлов должна быть «передана назад» значению δ этого узла. Сформируем общее выражение значение δ для узлов в скрытом слое:
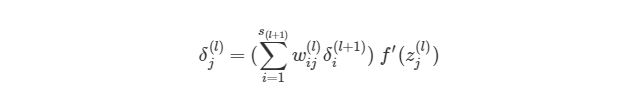 , где j является номером узла в слое l, i- номер узла в слое l+1(что аналогично обозначениям, которое мы использовали ранее). s(l+1)— это количество узлов в слое l+1.
, где j является номером узла в слое l, i- номер узла в слое l+1(что аналогично обозначениям, которое мы использовали ранее). s(l+1)— это количество узлов в слое l+1.
Теперь мы знаем, как находить:
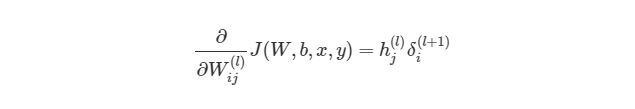 Но что делать с весами смещения? Принцип работы с ними аналогичный обычным весам, используя правила дифференцирования сложных функций:
Но что делать с весами смещения? Принцип работы с ними аналогичный обычным весам, используя правила дифференцирования сложных функций:
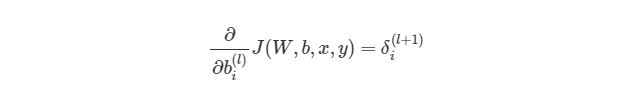
Отлично, теперь мы знаем, как реализовать градиентный спуск в нейронных сетях:
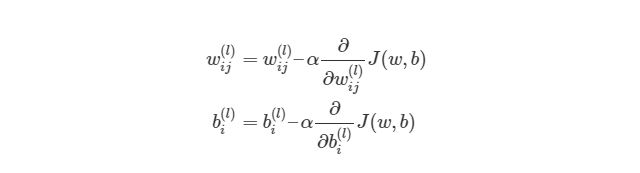
Однако, для такой реализации, нам нужно будет снова применить циклы. Как мы уже знаем из предыдущих разделов, циклы в языке программирования Python работают довольно медленно. Нам нужно будет понять, как можно векторизовать такие подсчеты.
4.7 Векторизация обратного распространения
Для того, чтобы понять, как векторизовать процесс градиентного спуска в нейронных сетях, рассмотрим сначала упрощенную векторизованную версию градиента функции оценки (внимание: это пока неправильная версия!):
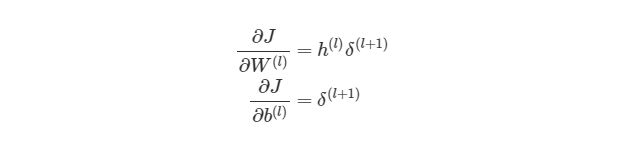
Что представляет собой h(l)? Все просто, вектор (sl×1), где sl является количеством узлов в слое l. Как тогда выглядит произведение h(l)δ(l+1)? Мы знаем, что α×∂J/∂W(l) должно быть того же размера, что и матрица весов W(l), Мы также знаем, что результат h(l)δ(l+1) должен быть того же размера, что и матрица весов для слоя l. Иными словами, произведение должно быть размера (sl + 1× sl).
Мы знаем, что δ(l+1) имеет размер (sl+1×1), а h (l)— размер (sl×1). По правилу умножения матриц, если матрицу (n×m)умножить на матрицу (o×p), То мы получим матрицу размера (n×p). Если мы просто перемножим h(l) на δ(l+1), то количество столбцов в первом векторе (один столбец) не будет равно количеству строк во втором векторе (3 строки). Поэтому, для того, чтобы можно было умножить эти матрицы и получить результат размера (sl+1× sl), Нужно сделать трансформирование. Оно меняет в матрице столбцы на строки и наоборот (например матрицу вида (sl×1)на (1×sl)). Трансформирование обозначается как буква T над матрицей. Мы можем сделать следующее:
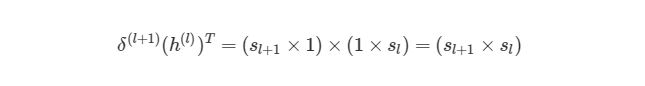
Используя операцию трансформирования, мы можем достичь результата, который нам нужен.
Еще одно трансформирование нужно сделать с суммой погрешностей в обратном распространении:
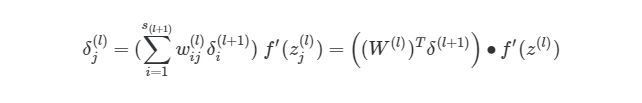
символ (∙) в предыдущем выражении означает поэлементное умножение (произведение Адамара), не является умножением матриц. Обратите внимание, что произведение матриц (((W(l))Tδ(l+1))требует еще одного сложения весов и значений δ.
4.8 Реализация этапа градиентного спуска
Как тогда интегрировать векторизацию в этапы градиентного спуска нашего алгоритма? Во-первых, вспомним полный вид нашей функции оценки, который нам нужно сократить:
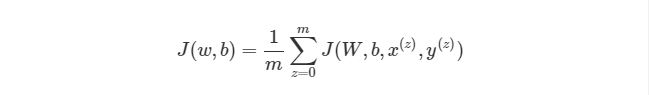
Из формулы видно, что полная функция оценки состоит из суммы поэтапных расчетов функции оценки. Также следует вспомнить, как находится градиентный спуск (поэлементная и векторизованная версии):
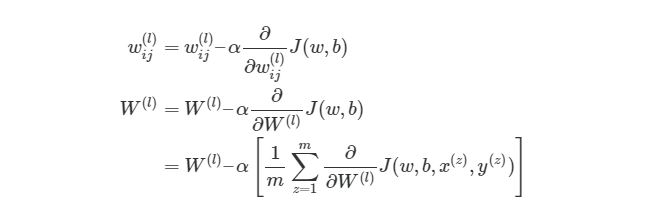
Это означает, что по прохождению через экземпляры обучения нам нужно иметь отдельную переменную, которая равна сумме частных производных функции оценки каждого экземпляра. Такая переменная соберет в себе все значения для «глобального» подсчета. Назовем такую «суммированную» переменную ΔW(l). Соответствующая переменная для смещения будет обозначаться как Δb(l). Следовательно, при каждой итерации в процессе обучения сети нам нужно будет сделать следующие шаги:
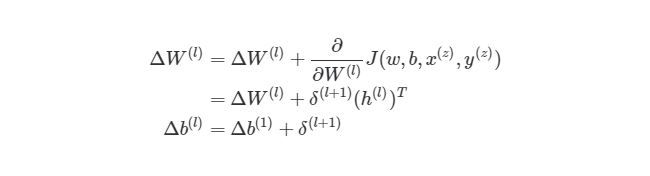
Выполняя эти операции на каждой итерации, мы подсчитываем упомянутую ранее сумму Σmz= 1∂/∂W(l)J( w , b , x(z), y(z))(и аналогичная формула для b). После того, как будут проитерированы все экземпляры и получены все значения δ, мы обновляем значения параметров веса:
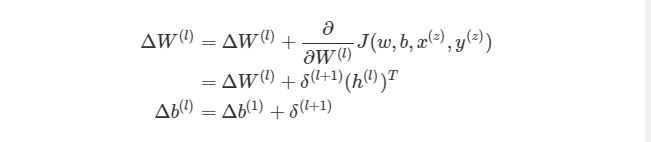
4.9 Конечный алгоритм градиентного спуска
И, наконец, мы пришли к определению метода обратного распространения через градиентный спуск для обучения наших нейронных сетей. Финальный алгоритм обратного распространения выглядит следующим образом:
Рандомная инициализация веса для каждого слоя W(l). Когда итерация < границы итерации:
01. Зададим ΔW и Δb начальное значение ноль.
02. Для экземпляров от 1 до m: а. Запустите процесс прямого распространения через все nl слоев. Храните вывод активационной функции в h(l)б. Найдите значение δ( nl) выходного слоя. Обновите ΔW(l)и Δb( l ) для каждого слоя.
03. Запустите процесс градиентного спуска, используя:
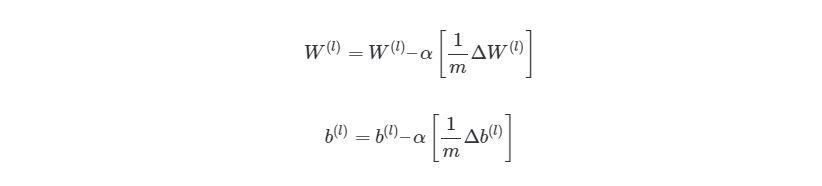
Из этого алгоритма следует, что мы будем повторять градиентный спуск, пока функция оценки не достигнет минимума. На этом этапе нейросеть считается обученной и готовой к использованию.
Далее мы попробуем реализовать этот алгоритм на языке программирования для обучения нейронной сети распознаванию чисел, написанных от руки.
5 Имплементация нейросети языке Python
В предыдущем разделе мы рассмотрели теорию по обучению нейронной сети через градиентный спуск и метод обратного распространения. В этом разделе мы используем полученные знания на практике — напишем код, который прогнозирует, основываясь на данных MNIST. База данных MNIST — это набор примеров в нейронных сетях и глубинном обучении. Она включает в себя изображения цифр, написанных от руки, с соответствующими ярлыками, которые объясняют, что это за число. Каждое изображение размером 8х8 пикселей. В этом примере мы используем сети данных MNIST для библиотеки машинного обучения scikit learn в языке программирования Python . Пример такого изображения можно увидеть под кодом:
from sklearn.datasets
import load_digits
digits = load_digits()
print(digits.data.shape)
import matplotlib.pyplot as plt
plt.gray()
plt.matshow(digits.images[1])
plt.show()
Код, который мы собираемся написать в нашей нейронной сети, будет анализировать цифры, которые изображают пиксели на изображении. Для начала, нам нужно отсортировать входные данные. Для этого мы сделаем две следующие вещи:
01. Масштабировать данные.
02. Разделить данные на тесты и учебные тесты.
5.1 Масштабирование данных
Почему нам нужно масштабировать данные? Во-первых, рассмотрим представление пикселей одного из сетов данных:
digits.data[0, : ]
Out[2]:
array([0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13.,
15., 10., 15., 5., 0., 0., 3., 15., 2., 0., 11.,
8., 0., 0., 4., 12., 0., 0., 8., 8., 0., 0.,
5., 8., 0., 0., 9., 8., 0., 0., 4., 11., 0.,
1., 12., 7., 0., 0., 2., 14., 5., 10., 12., 0.,
0., 0., 0., 6., 13., 10., 0., 0., 0.
])
Заметили ли вы, что входные данные меняются в интервале от 0 до 15? Достаточно распространенной практикой является масштабирование входных данных так, чтобы они были только в интервале от [0, 1], или [1, 1]. Это делается для более легкого сравнения различных типов данных в нейронной сети. Масштабирование данных можно легко сделать через библиотеку машинного обучения scikit learn:
from sklearn.preprocessing import StandardScaler
X_scale = StandardScaler()
X = X_scale.fit_transform(digits.data)
X[0,:]
Out[3]:
array([ 0. , -0.33501649, -0.04308102, 0.27407152, -0.66447751,
-0.84412939, -0.40972392, -0.12502292, -0.05907756, -0.62400926,
0.4829745 , 0.75962245, -0.05842586, 1.12772113, 0.87958306,
-0.13043338, -0.04462507, 0.11144272, 0.89588044, -0.86066632,
-1.14964846, 0.51547187, 1.90596347, -0.11422184, -0.03337973,
0.48648928, 0.46988512, -1.49990136, -1.61406277, 0.07639777,
1.54181413, -0.04723238, 0. , 0.76465553, 0.05263019,
-1.44763006, -1.73666443, 0.04361588, 1.43955804, 0. ,
-0.06134367, 0.8105536 , 0.63011714, -1.12245711, -1.06623158,
0.66096475, 0.81845076, -0.08874162, -0.03543326, 0.74211893,
1.15065212, -0.86867056, 0.11012973, 0.53761116, -0.75743581,
-0.20978513, -0.02359646, -0.29908135, 0.08671869, 0.20829258,
-0.36677122, -1.14664746, -0.5056698 , -0.19600752])
Стандартный инструмент масштабирования в scikit learn нормализует данные через вычитание и деление. Вы можете видеть, что теперь все данные находятся в интервале от -2 до 2. По же на счет выходных данных yy, то обычно нет необходимости их масштабировать.
5.2 Создание тестов и учебных наборов данных
В машинном обучении появляется такой феномен, который называется «переобучением». Это происходит, когда модели, во время учебы, становятся слишком запутанными — они достаточно хорошо обучены, но когда им передаются новые данные, которые они никогда на «видели», то результат, который они выдают, становится плохим. Иными словами, модели генерируются не очень хорошо. Чтобы убедиться, что мы не создаем слишком сложные модели, обычно набор данных разбивают на учебные наборы и тестовые наборы. Учебный набором данных, на которых модель будет учиться, а тестовый набор — это данные, на которых модель будет тестироваться после завершения обучения. Количество учебных данных должно быть всегда больше тестовых данных. Обычно они занимают 60-80% от набора данных.
Опять же, scikit learn легко разбивает данные на учебные и тестовые наборы:
from sklearn.model_selection import train_test_split
y = digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4)
В этом случае мы выделили 40% данных на тестовые наборы и 60% соответственно на обучение. Функция train_test_split в scikit learn добавляет данные рандомно в различные базы данных — то есть, функция не берет первые 60% строк для учебного набора, а то, что осталось, использует как тестовый.
5.3 Настройка выходного слоя
Для того, чтобы получать результат — числа от 0 до 9, нам нужен выходной слой. Более-менее точная нейросеть, как правило, имеет выходной слой с 10 узлами, каждый из которых выдает число от 0 до 9. Мы хотим научить сеть так, чтобы, например, при цифре 5 на изображении, узел с цифрой 5 в исходном слое имел наибольшее значение. В идеале, мы бы хотели иметь следующий вывод: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]. Но на самом деле мы можем получить что-то похожее на это: [0.01, 0.1, 0.2, 0.05, 0.3, 0.8, 0.4, 0.03, 0.25, 0.02]. В таком случае мы можем взять крупнейших индекс в исходном массиве и считать это нашим полученным числом.
В данных MNIST нужны результаты от изображений записаны как отдельное число. Нам нужно конвертировать это единственное число в вектор, чтобы его можно было сравнивать с исходным слоем с 10 узлами. Иными словами, если результат в MNIST обозначается как «1», то нам нужно его конвертировать в вектор: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]. Такую конвертацию осуществляет следующий код:
import numpy as np
def convert_y_to_vect(y):
y_vect = np.zeros((len(y), 10))
for i in range(len(y)):
y_vect[i, y[i]] = 1
return y_vect
y_v_train = convert_y_to_vect(y_train)
y_v_test = convert_y_to_vect(y_test)
y_train[0], y_v_train[0]
Out[8]:
(1, array([ 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.]))
Этот код конвертирует «1» в вектор [0, 1, 0, 0, 0, 0, 0, 0, 0, 0].
5.4 Создаем нейросеть
Следующим шагом является создание структуры нейронной сети. Для входного слоя, мы знаем, что нам нужно 64 узла, чтобы покрыть 64 пикселей изображения. Как было сказано ранее, нам нужен выходной слой с 10 узлами. Нам также потребуется скрытый слой в нашей сети. Обычно, количество узлов в скрытых слоях не менее и не больше количества узлов во входном и выходном слоях. Объявим простой список на языке Python , который определяет структуру нашей сети:
nn_structure = [64, 30, 10]
Мы снова используем сигмоидальную активационную функцию, так что сначала нужно объявить эту функцию и ее производную:
def f(x):
return 1 / (1 + np.exp(-x))
def f_deriv(x):
return f(x) * (1 - f(x))
Сейчас мы не имеем никакого представления, как выглядит наша нейросеть. Как мы будем ее учить? Вспомним наш алгоритм из предыдущих разделов:
Рандомно инициализируем веса для каждого слоя W(l) Когда итерация <границы итерации:
01. Зададим ΔW и Δb начальное значение ноль.
02. Для экземпляров от 1 до m: а. Запустите процесс прямого распространения через все nl слоев. Храните вывод активационной функции в h(l)б. Найдите значение δ( nl) выходного слоя. Обновите ΔW(l)и Δb( l ) для каждого слоя.
03. Запустите процесс градиентного спуска, используя:
Значит первым этапом является инициализация весов для каждого слоя. Для этого мы используем словари в языке программирования Python (обозначается через {}). Рандомные значения предоставляются весам для того, чтобы убедиться, что нейросеть будет работать правильно во время обучения. Для рандомизации мы используем random_sample из библиотеки numpy. Код выглядит следующим образом:
import numpy.random as r
def setup_and_init_weights(nn_structure):
W = {}
b = {}
for l in range(1, len(nn_structure)):
W[l] = r.random_sample((nn_structure[l], nn_structure[l-1]))
b[l] = r.random_sample((nn_structure[l],))
return W, b
Следующим шагом является присвоение двум переменным ΔW и Δb нулевых начальных значений (они должны иметь такой же размер, что и матрицы весов и смещений)
def init_tri_values(nn_structure):
tri_W = {}
tri_b = {}
for l in range(1, len(nn_structure)):
tri_W[l] = np.zeros((nn_structure[l], nn_structure[l-1]))
tri_b[l] = np.zeros((nn_structure[l],))
return tri_W, tri_b
Далее запустим процесс прямого распространения через нейронную сеть:
def feed_forward(x, W, b):
h = {1: x}
z = {}
for l in range(1, len(W) + 1):
#Если первый слой, то весами является x, в противном случае
#Это выход из последнего слоя
if l == 1:
node_in = x
else:
node_in = h[l]
z[l+1] = W[l].dot(node_in) + b[l] # z^(l+1) = W^(l)*h^(l) + b^(l)
h[l+1] = f(z[l+1]) # h^(l) = f(z^(l))
return h, z
И наконец, найдем выходной слой δ (nl) и значение δ (l) в скрытых слоях для запуска обратного распространения:
def calculate_out_layer_delta(y, h_out, z_out):
# delta^(nl) = -(y_i - h_i^(nl)) * f'(z_i^(nl))
return -(y-h_out) * f_deriv(z_out)
def calculate_hidden_delta(delta_plus_1, w_l, z_l):
# delta^(l) = (transpose(W^(l)) * delta^(l+1)) * f'(z^(l))
return np.dot(np.transpose(w_l), delta_plus_1) * f_deriv(z_l)
Теперь мы можем соединить все этапы в одну функцию:
def train_nn(nn_structure, X, y, iter_num=3000, alpha=0.25):
W, b = setup_and_init_weights(nn_structure)
cnt = 0
m = len(y)
avg_cost_func = []
print('Начало градиентного спуска для {} итераций'.format(iter_num))
while cnt 1:
delta[l] = calculate_hidden_delta(delta[l+1], W[l], z[l])
# triW^(l) = triW^(l) + delta^(l+1) * transpose(h^(l))
tri_W[l] += np.dot(delta[l+1][:,np.newaxis], np.transpose(h[l][:,np.newaxis]))
# trib^(l) = trib^(l) + delta^(l+1)
tri_b[l] += delta[l+1]
# запускает градиентный спуск для весов в каждом слое
for l in range(len(nn_structure) - 1, 0, -1):
W[l] += -alpha * (1.0/m * tri_W[l])
b[l] += -alpha * (1.0/m * tri_b[l])
# завершает расчеты общей оценки
avg_cost = 1.0/m * avg_cost
avg_cost_func.append(avg_cost)
cnt += 1
return W, b, avg_cost_func
Функция сверху должна быть немного объяснена. Во-первых, мы не задаем лимит работы градиентного спуска, основываясь на изменениях или точности функции оценки. Вместо этого, мы просто запускаем её с фиксированным числом итераций (3000 в нашем случае), а затем наблюдаем, как меняется общая функция оценки с прогрессом в обучении. В каждой итерации градиентного спуска, мы перебираем каждый учебный экземпляр (range (len (y)) и запускаем процесс прямого распространения, а после него и обратное распространение. Этап обратного распространения является итерацией через слои, начиная с выходного слоя к началу — range (len (nn_structure), 0, 1). Мы находим среднюю оценку на исходном слое (l == len (nn_structure)). Мы также обновляем значение ΔW и Δb с пометкой tri_W и tri_b, для каждого слоя, кроме исходного (исходный слой не имеет никакого связи, который связывает его со следующим слоем).
И наконец, после того, как мы прошлись по всем учебным экземплярам, накапливая значение tri_W и tri_b, мы запускаем градиентный спуск и меняем значения весов и смещений:
После окончания процесса, мы возвращаем полученные вес и смещение со средней оценкой для каждой итерации. Теперь время вызвать функцию. Ее работа может занять несколько минут, в зависимости от компьютера.
W, b, avg_cost_func = train_nn(nn_structure, X_train, y_v_train)
Мы можем увидеть, как функция средней оценки уменьшилась после итерационной работы градиентного спуска:
plt.plot(avg_cost_func)
plt.ylabel('Средняя J')
plt.xlabel('Количество итераций')
plt.show()
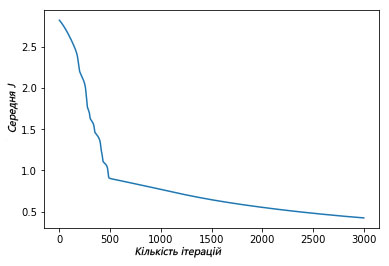
Выше изображен график, где показано, как за 3000 итераций нашего градиентного спуска функция средней оценки снизилась и маловероятно, что подобная итерация изменит результат.
5.5 Оценка точности модели
Теперь, после того, как мы научили нашу нейросеть MNIST, мы хотим увидеть, как хорошо она работает на тестах. Дан входной тест (64 пикселя), нам нужно получить вывод нейронной сети — это делается через запуск процесса прямого распространения через сеть, используя наши полученные значения веса и смещения. Как было сказано ранее, мы выбираем результат выходного слоя через выбор узла с максимальным выводом. Для этого можно использовать функцию numpy.argmax, она возвращает индекс элемента массива с наибольшим значением:
def predict_y(W, b, X, n_layers):
m = X.shape[0]
y = np.zeros((m,))
for i in range(m):
h, z = feed_forward(X[i, :], W, b)
y[i] = np.argmax(h[n_layers])
return y
Теперь, наконец, мы можем оценить точность результата (процент раз, когда сеть выдала правильный результат), используя функцию accuracy_score из библиотеки scikit learn:
from sklearn.metrics import accuracy_score
y_pred = predict_y(W, b, X_test, 3)
accuracy_score(y_test, y_pred)*100
Мы получили результат 86% точности. Звучит довольно неплохо? На самом деле, нет, это довольно низкая точностью. В наше время точность алгоритмов глубинного обучения достигает 99.7%, мы немного отстали.
Предлагаем также посмотреть:
- Лучший видеокурс по нейронным сетям на русском
- Подборка материалов по нейронным сетям
- Введение в глубинное обучение

Введение
Недавно появились устройства, способные думать на таком же уровне, что и человек. Сегодня же ты можешь спокойно написать дипломную работу не листая тонны контента и имея под рукой всего-лишь один сайт. Наверное, ты уже понял, о чем идет речь. Нейросети буквально заполняют наш мир. Но я думаю тебе всегда было интересно, как на самом деле работает такой алгоритм, и какие методы обучения лежат в основе искусственного интеллекта. В этой статье я приоткрою завесу и расскажу тебе, как создать свою нейросеть без каких-либо особых усилий.
План работы
Давай я коротко опишу план нашей работы. Первым делом следует разобраться с тем, как вообще работает нейросеть и что она из себя представляет. После этого мы воспользуемся утилитами для ее написания и попробуем реализовать все это дело. Для визуализации всей работы я решил воспользоваться движком Unity, поэтому тебе следует его установить. По мимо этого мы создадим тестовую комнату и зададим цель для нашей нейронной сети. Думаю, нескольких строчек для описания всей работы будет достаточно, поэтому перейдем в раздел установки необходимых компонентов.
Среда для разработки
Как говорилось ранее, тебе потребуются базовые знания языка программирования C#, а также наличие под рукой движка Unity. Я использую Unity версии 2021 года, но для работы может сгодиться и более новая среда. Также тебе нужно установить Python 3.10 и выше. К нему мы подключим модули глубокого обучения и библиотеки для математических вычислений. Весь список необходимых модулей я предоставил ниже:
- mlagents
- numpy (не выше 1.19.4)
- torch (не ниже 1.7.1)
- CUDA Toolkit
Добавлю немного слов к требованиям по железу. Я тестировал все на процессоре Intel Core i7 4700MQ в сочетании с древней видеокартой NVIDIA GeForce GTX 765M. В основном подойдет любой другой процессор. Видеокарту придется использовать от зеленых и я сейчас не про внеземную цивилизацию, а компанию NVIDIA. Вся проблема заключается именно в утилите CUDA, которая позволяет использовать видеочипы в полную мощь и от них будет зависеть скорость обучения твоей нейросети. Также более современные версии модуля Numpy не подойдут в работе и будут вызывать критические ошибки, а все дело в том, что разработчики изменили метод, который позволяет программе присваивать определенные типы переменных. Поэтому если ты увидишь в логах слова float и ему подобные, будь уверен в том, что вся проблема кроется в версии numpy. В остальном проблем возникнуть не должно. Также для установки основного компонента PyTorch нужно использовать эту команду:
Код:
pip3 install torch -f https://download.pytorch.org/whl/torch_stable.htmlУстановка займет достаточно много времени, так как файл с пакетами и необходимыми функциями весит 2.4 ГБ. Во время процедуры не выключай систему и не позволяй ей уходить в режим сна.
Как работают нейросети
Перед любой работой нужно иметь базовые знания, чем мы сейчас и займемся. Я постараюсь максимально понятно и подробно рассказать про работу нейронной сети, затрагивая как можно меньше математических кривых и других непонятных терминов. Первым делом давай определимся с тем, что такое нейронная сеть:
Нейросеть — это понятие напрямую связано с биологией и понимается как последовательность нейронов, которые соединяются между собой синапсами. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти.
Если сравнивать с человеком, то нейронная сеть на основе определенных событий делает вывод и записывает его во временную память. Всю ее работу можно буквально представить в виде весов, на которых лежат благоприятные и неблагоприятные условия. К примеру если нейросеть упадет в пропасть, то шанс смерти от этого события возрастет. Повторив процедуру пару раз она сделает вывод о том, что благоприятных исходов такого события нету и его лучше не повторять в дальнейшем. Теперь давай разберемся с составляющими частями слова нейросеть. Ведь оно напрямую связано с таким термином, как нейрон.
Нейрон — вычислительная единица, которая способна получать и обрабатывать информацию, а также передавать ее. В основном нейроны бывают трех типов: входные, скрытые и выходные. Если в нейросети имеется огромное количество нейронов, то используется термин слоя, для более точной классификации.
На языке машин нейроны способы работать только с тремя числами в диапазоне от -1 до 1. Если работа происходит с более большими числами, то они записываются в виде дроби, а точнее единица делится на это число. Для передачи информации между нейронами используется такое понятие как синапс. Он содержит всего лишь один параметр — вес. От него зависит значимость информации и скорость ее дальнейшей обработки. Чем больше вес, тем быстрее информация перейдет от одного нейрона в другой. На этапе инициализации нейронной сети весь вес распределяется в абсолютно случайном порядке.
Чтобы на выходе получать нужный диапазон принято использовать функции активации, которые нормализируют входную информацию и на выходе получают требуемые значения. Всего существует три основных типа функций: линейная, сигмоид и гиперболический тангенс. Их я затрагивать не стану, более подробную информацию ты сможешь найти на просторах интернета.
Итак, после небольшого экскурса в мир нейросетей стоит приступить к ее реализации, чем мы сейчас и займемся.
Создаем нейронную сеть в Unity
На первом этапе открываем сам Unity и создаем 3D проект. Я выбрал этот движок, чтобы визуально показать тебе как работает и обучается нейросеть в режиме реального времени. После создания добавим несколько объектов в наш проект. Это будут стены, кубик, пространство и небольшой мячик. Основная идея в том, чтобы научить нейросеть добираться до определенного объекта. В проекте все выглядит таким образом:

Также не забываем накинуть на Goal и Cube физику, а точнее Rigidbody. В случае с главным объектом все физические свойства стоит применять к родительскому объекту (Agent). Таким образом мы создадим необходимые условия для того, чтобы фигуры могли взаимодействовать. После этого стоит добавить к стене и нашему шарику скрипты. В них мы ничего записывать не будем, а всего лишь инициализируем для дальнейшей работы. Чтобы это сделать, тебе нужно перейти в инспектор и добавить компонент с названием C# Script. Отлично, теперь перейдем к созданию сенсоров, которые отвечают за перемещение в пространстве и накинем пульт управления для нашего кубика. Все это делается таким же образом, что я описал чуть выше. Теперь перейдем к написанию скриптов. Перед этим стоит перейти на вкладку Window -> Packet Manager и после на просторах Unity скачать пакет ML-Agents.
Первым делом убираем все лишние и оставляем публичный класс с идентификатором Agent:
C#:
public class Cube_AI : Agent
{
}Сюда мы поместим все необходимые компоненты для управления. Перед этим у тебя должны быть импортированы следующие библиотеки:
C#:
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;После этого нашей нейросети потребуется объект, до которого она должна дойти. Для этого используем такую команду:
C#:
public override void OnEpisodeBegin()
{
transform.position = Vector3.zero;
}Переходим к главному этапу, а именно сенсорам, которые отвечают за координацию в пространстве. Я не буду добавлять зрение и ограничусь объектами вокруг нашей нейросети. Проще говоря, сама нейронка будет слепая, но ее главным ориентиром будет служить пространство вокруг, как раз для этого и потребуются наши сенсоры. Задаем основной объект и цель, до которой следует добраться:
C#:
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(transform.position);
sensor.AddObservation(targetTransform.position);
}Отлично, ориентация в пространстве у нас есть, но стоит подумать о передвижении, для этого зададим координаты по которым можно перемещаться и скорость передвижения. Делается это в несколько строчек кода:
C#:
public override void OnActionReceived(ActionBuffers actions)
{
float moveX = actions.ContinuousActions[0];
float moveZ = actions.ContinuousActions[1];
float moveSpeed = 1f;
transform.position += new Vector3(moveX, 0, moveZ) * Time.deltaTime * moveSpeed;
}Теперь наш объект умеет двигаться, но пока что у него нет интеллекта и цели, ради которой он будет это делать. Поэтому займемся этим, попутно добавляя векторы перемещения для более точной координации:
C#:
public override void Heuristic(in ActionBuffers actionsOut)
{
ActionSegment<float> continuousActions = actionsOut.ContinuousActions;
continuousActions[0] = Input.GetAxisRaw("Horizontal");
continuousActions[1] = Input.GetAxisRaw("Vertical");
}
private void OnTriggerEnter(Collider other)
{
if (other.TryGetComponent<Goal>(out Goal goal))
{
SetReward(+1f);
EndEpisode();
}
if (other.TryGetComponent<Wall>(out Wall wall))
{
SetReward(-1f);
EndEpisode();
}
}Чтобы не заморачиваться давай я коротко объясню, что здесь происходит. В первом цикле мы задаем векторы передвижения вместе с их индексом. После этого создаем условные циклы, которые будут поощрять нашу нейросеть за выполнение цели или наоборот «ругать» за попытку побега. Таким образом мы делаем баланс для наших весов, которые позволят нейронке в дальнейшем понимать, что можно делать, а что лучше не стоит. Также добавляем функцию завершения эпизода и настройку управления можно спокойно закрывать.
Теперь к родительской точке Agent подключаем наш скрипт и добавляем также Decision Requester, его ты можешь найти по пути Add Component -> ML Agents. По мимо этого у тебя должен появиться параметр Target Transform. В него мы помещаем наш шар, который будет главной целью нейросети. Все настройки оставляем по умолчанию и приступаем к подключению мозга кубика.
Для этого тебе потребуется перейти в папку с проектом и в пути к нему прописать команду cmd, чтобы открыть папку через консоль. Начало обучения происходит непосредственно через само окно терминала. Мы всего лишь даем нейросети цель и объект, которым она может управлять. Нейронка является самым простым прототипом и имеет функцию глубокого обучения (к сожалению, оно еще и долгое). Чтобы произошла магия и кубик начал подавать признаки жизни тебе следует ввести в консоли следующую команду:
Спустя несколько секунд должен появиться логотип Unity и фраза о том, что открылся порт для прослушивания и подключения. Если у тебя появилась ошибка, то следует переустановить все пакеты или проверить инспектор и правильность настроенных параметров. Теперь остается нажать кнопку Пуск в самом окне проекта и ждать результата. В случае успеха ты увидишь метаданные объекта и Behavior Name. Остается только ждать и наблюдать за обучением. При последующих запусках рекомендуется добавить флаг —force, чтобы обнулить всю работу и перезапустить нейросеть. Перед этим убедись, что Python находится в самом проекте. Если его нет, то стоит прописать такие команды:
Код:
py -m venv venv
venvScriptsactivateРезультат работы может быть непредсказуемый и совершенно неожиданный, начиная от обычного выполнения задачи методом проб и ошибок и заканчивая простым бездействием. Также есть несколько вариантов базовых нейросетей, с которыми можно ознакомиться в самом пакете. Для их эксплуатации тебе придется добавить зрение объекту и несколько других сенсоров для ориентации. В остальном песочница и искусственный интеллект в твоем распоряжении. Небольшой аквариум с примитивным, но саморазвивающимся мозгом. Теперь стоит подвести итоги.
Подводим итоги
Написание нейронных сетей это очень трудоемкий и затратный процесс, но наблюдать за их обучением очень интересно и завораживающе. В этой статье я максимально коротко и понятно рассказал тебе как визуализировать работу нейронной сети и разместить ее прямо у себя на устройстве. Ты можешь натренировать ее под свои нужды или использовать в дальнейшем для развлечения, но с точки зрения безопасности такие «искусственные мозги» могут нанести огромный ущерб в неумелых руках или просто тех, кто хочет развлечься.
C#:
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
public class Cube_AI : Agent
{
[SerializeField] private Transform targetTransform;
public override void OnEpisodeBegin()
{
transform.position = Vector3.zero;
}
public override void CollectObservations(VectorSensor sensor)
{
sensor.AddObservation(transform.position);
sensor.AddObservation(targetTransform.position);
}
public override void OnActionReceived(ActionBuffers actions)
{
float moveX = actions.ContinuousActions[0];
float moveZ = actions.ContinuousActions[1];
float moveSpeed = 1f;
transform.position += new Vector3(moveX, 0, moveZ) * Time.deltaTime * moveSpeed;
}
public override void Heuristic(in ActionBuffers actionsOut)
{
ActionSegment<float> continuousActions = actionsOut.ContinuousActions;
continuousActions[0] = Input.GetAxisRaw("Horizontal");
continuousActions[1] = Input.GetAxisRaw("Vertical");
}
private void OnTriggerEnter(Collider other)
{
if (other.TryGetComponent<Goal>(out Goal goal))
{
SetReward(+1f);
EndEpisode();
}
if (other.TryGetComponent<Wall>(out Wall wall))
{
SetReward(-1f);
EndEpisode();
}
}
}
Развитие науки идет с использованием стандартных методов. Сбор исходных данных, построение моделей, тестирование моделей опытами, открытая публикация для проверки сообществом. Все достаточно просто. Ядро науки составляют модели. Примеры моделей, которые известны всем со школьной парты: U=I*R; F=m*a. Даже на основе приведенных двух моделей вы можете нагенерировать миллионы школьных задачек. Если же модель устаревает и становится неактуальной, она уходит в архивы истории.
Попробуем промоделировать развитие искусственного интеллекта, основанного на нейросетях. Математическая модель одного нейрона постоянно совершенствуется и уточняется: y=f(sum(wi*xi)+b). Архитектуры нейросетей динамично развиваются. Замечательно, но как показала история весь этот процесс длительный и идет уже не одно десятилетие.
Зададимся вопросом каков дальнейший более-менее оптимальный путь развития искусственного интеллекта? Допустим удастся кое-как сделать первичную нейросеть обладающую разумом. Что если поставить ей задачу постоянного самосовершенствования. Задать ей вопрос что еще требуется для ее дальнейшего развития. Затем помочь ей запустить эти процессы саморазвития, самомодификации и самосозидания. Теоретически вычислительная мощность нейросети неограниченна, возможно она попросит ее сделать например размером с дом, город или планету. Интересно о чем она будет думать? Будет ли способен такой Сверхразум ответить на вопросы, которые так волнуют человечество: освоение космоса, улучшение генетики, развитие социальных систем.
Биологические нейросети очевидно работают, но поставлены в жесткие эволюционные рамки. Достаточно простая идея — создать первичную искусственную разумную нейросеть, которая подскажет как ее совершенствовать. Это быстрее и лучше чем самим ломать головы из каких деталей лепить муравьёв-терминаторов в стиле Boston Dynamics. Риски конечно есть, но подход делай что должен и будь что будет адекватно описывает текущую ситуацию.
Так, вроде бы понятно все написано. Сингулярность …
Сегодня у нас нестандартный проект: будем устанавливать и запускать настоящую нейросеть у себя на компьютере.
👉 Мы пока не будем подробно разбирать тонкости работы алгоритмов и писать нейронку с нуля. Вместо этого мы используем уже готовые скрипты и алгоритмы и попробуем повторить это в домашних условиях. Вам достаточно использовать команды в той же последовательности, и вы получите тот же результат.
И ещё: нейросети — это на самом деле скучно, медленно и не очень эффектно в настройке. Мы привыкли сразу видеть классный и красивый результат, а то, что было до этого, нам обычно не показывают. Эта статья работает наоборот: долго показывает весь процесс, а финальный результат получается за пару секунд.
В этом суть нейросетей: долгая и кропотливая работа ради эффектной концовки.
Что сделаем
Мы настроим и обучим нейросеть, которая будет распознавать картинки и говорить, какой цветок мы ей показываем — розу, тюльпан или что-то другое. Мы используем цветы, потому что скачали уже готовый, собранный и размеченный набор фотографий, на котором нейронка может научиться. Если вы хотите, чтобы она научилась распознавать на фото вас или ваших друзей, нужно будет собрать другой датасет и переобучить нейронку.
Как собрать и настроить такой датасет — расскажем в другой раз.
Что понадобится
Python версии 3.8 и выше, обязательно под архитектуру x64. Если взять 32-разрядную версию, то нужная в проекте библиотека tensorflow работать не будет. Мы использовали версию 3.9.7.
Остальное установим в процессе. Главное — рабочий Python (по ссылке — как его установить).
👉 Все команды, которые есть в проекте, мы будем запускать в командной строке. Чтобы не было ошибок и затыков, лучше всего запустить её от имени администратора (в Windows) или с правами суперпользователя root (в Mac OS и Linux).
Создаём виртуальное окружение
Чтобы не раскидывать файлы, скрипты и картинки по всему компьютеру, создадим в питоне виртуальное окружение — специальный проект, который хранит все данные внутри своей папки. Он не мешает остальным проектам и не влияет на работу других программ.
Чтобы подключить себе виртуальное окружение, запускаем команду:
pip install --upgrade virtualenv

Теперь можно устанавливать окружение. Для этого придумаем ему название — мы выбрали tell-me, но вы можете выбрать любое другое:
virtualenv --system-site-packages tell-me

Запускаем окружение:
source tell-me/bin/activate (если у вас мак или линукс)
tell-mescriptsactivate (если у вас виндоус)
Эта команда создаст папку на компьютере (путь к ней можно посмотреть на предыдущем скриншоте на третьей строке, параметр «dest») и запустит в ней виртуальное окружение:

Устанавливаем tensorflow
Tensorflow — открытая библиотека для машинного обучения и работы с нейросетями. Она будет отвечать за то, чтобы наш компьютер мог запустить нейросеть и правильно с ней работать.
Для установки пишем команду:
pip install tensorflow

pip — это программа, которая отвечает в Python за скачивание, установку и обновление библиотек и вспомогательных пакетов. Это как магазин приложений Apple, только для командной строки и для разработчиков.
Чтобы убедиться, что библиотека установилась правильно и работает штатно, проверим её простым тестом.
1. Пишем команду:
python
2. Начало командной строки поменялось на >>> — это значит, питон готов к приёму своих команд. Пишем по очереди такое:
hello = tf.constant('Hello, TensorFlow')
sess = tf.compat.v1.Session()
print(sess.run(hello))
Если в ответ питон нам выдал что-то вроде ‘Hello, TensorFlow’, это значит, что мы всё сделали правильно.

Устанавливаем классификатор
Классификатор в нейросетях — это алгоритм, который смотрит на объекты и пытается понять, к какой категории их отнести. То есть классифицировать.
Задача нашего классификатора — научить нейросеть понимать, чем одни цветы отличаются от других. Если бы мы вместо цветов использовали фото зданий, нейронка бы научилась отличать барокко от роккоко и неоклассицизма.
- Качаем архив с классификатором.
- Распаковываем архив.

3.Копируем содержимое архива в папку tell-me. Если вы выбрали другое название для проекта, замените tell-me на своё название.
Добавляем фото для обучения
Скачиваем уже собранный датасет с цветами, распаковываем его и копируем в папку tell-me → tf_files.

Адаптируем скрипты под актуальную версию tensorflow
👉 На момент написания статьи актуальная версия tensorflow — 2.0. Но скрипты и алгоритмы, которые мы используем, заточены под старую версию, поэтому нужно применить немного магии автозамены:
- Переходим в каталог tell-me/scripts и находим файл retrain.py.
- Открываем его в любом редакторе кода, например Sublime Text 3.
- Нажимаем Ctrl + H или Command + H — включится режим поиска и автозамены текста.
- Первая строка (что заменить) → пишем tf. (с точкой).
- Вторая строка (на что заменить) → пишем tf.compat.v1. (тоже с точкой в конце).
- Нажимаем Replace All (Заменить всё).
- То же самое делаем в файле label-image.py.
- В том же файле label-image.py добавляем после строки 25 «import tensorflow as tf» такую строку:
tf.compat.v1.disable_eager_execution()
Благодаря этому колдунству мы заставим старый скрипт работать с новой библиотекой.
Обучаем нейросеть
- В командной строке командой cd переходим в папку tell-me (или в другую, если у вас проект называется по-другому).
- Запускаем команду:
python scripts/retrain.py
--output_graph=tf_files/retrained_graph.pb
--output_labels=tf_files/retrained_labels.txt
--image_dir=tf_files/flower_photos
Пошёл процесс обучения. В нём 4000 этапов, по времени занимает примерно 20 минут. За это время нейросеть обработает около 250 фото (это очень мало для нейросети) и научится отличать розу от ландышей:

Запускаем нейросеть
Чтобы проверить работу нашей нейросети, скачиваем любой файл с розой из интернета, кладём его в папку tell-me (или как у вас она называется) и пишем такую команду:
python scripts/label_image.py --image image.jpg
Нейросеть думает, а потом выдаёт ответ в виде процентов. В нашем случае она на 98% уверена, что это роза:

А вот как нейросеть реагирует на фото Цукерберга:

50% — что на фото тюльпан, и на 18% — что это одуванчик. А всё потому, что она умеет различать только 5 видов цветов, а не всяких там цукербергов.
Вёрстка:
Кирилл Климентьев
Компании в 21 веке придерживаются подхода, ориентированного на контент, и все дело в качестве и скорости контента. По оценкам, в день публикуется около семи миллионов сообщений в блогах. В условиях такого колоссального объема важно, чтобы компании оставались на переднем крае, когда дело доходит до использования программного обеспечения для написания Искусственного Интеллекта.
Эти инструменты позволяют использовать машинное обучение, чтобы начать печатать, а затем полагаться на ИИ для завершения предложений, проверки грамматики и создания предложений без ошибок.
В этой статье мы оценили и рассмотрел лучшее программное обеспечение для создания искусственного интеллекта, чтобы перенести вашу контент-стратегию в 2020-е годы.
Какое программное обеспечение для создания искусственного интеллекта лучше?
Вот несколько вариантов программного обеспечения для написания ИИ в этом году.
1. Jarvis .

Jarvis-это инструмент для написания ИИ, который поможет вам превратить ваш текст в полностью персонализированное и уникальное произведение искусства. Вы можете написать сообщение в блоге, статью или даже стихотворение вместе с Джарвисом, которое автоматически создаст контент, соответствующий общему стилю вашего письма.
С помощью команды Jarvis вы просто начинаете печатать, и Джарвис закончит ваши предложения за вас. Процесс полностью автоматизирован и работает невероятно хорошо при соблюдении правильной пунктуации, заглавных букв и грамматики.
Затем Джарвис создает произведение искусства в ответ на ваше письмо. Алгоритм преобразует каждое слово в изображение, используя ряд библиотек и алгоритмов, которые используются на протяжении всей программы. Это означает, что Джарвис не просто создает случайные изображения–он создает изображения из реальных слов!
Характеристики
Джарвис использует продвинутый искусственный интеллект для обнаружения ключевых элементов в вашем письме и сопоставляет их с идеальными примерами из более чем миллиона предложений в базе данных Джарвиса. Результаты довольно удивительные, и Джарвис действительно может оживить ваше творчество.
Джарвис оптимизирован для работы с любым типом письма, включая творческое письмо, деловые документы, статьи и даже стихи! Некоторые примеры включают:
- Поиск: Определите ключевые элементы в вашем тексте, такие как имена или места людей, местоимения (например, он/она, я/я), глаголы, прилагательные и существительные.
- Поиск/замена: Вы можете искать определенные слова в тексте по ключевому слову (например, кошка, собака, красный) или синониму (например, животное -> домашнее животное). Эта функция отлично подходит для создания списка часто используемых фраз, таких как “быстрая коричневая лиса”.
- Пунктуация: Добавьте общие знаки препинания, такие как запятые, точки и восклицательные знаки. Эта функция идеально подходит для тех, кто склонен забывать мелкие детали, такие как количество мест, которые нужно использовать после определенного периода.
- Шрифты/стили: С более чем 11 000 бесплатных шрифтов и 2500 категорий для различных стилей письма, вы можете найти идеальный шрифт, соответствующий вашему настроению. Вы также можете изменить цвет текста.
- Цитата/перефразировка: Этот инструмент автоматически идентифицирует цитаты или перефразированные разделы текста из их контекста в вашем контенте. Я использовал эту функцию, чтобы выделить.
Цены
Jarvis поставляется с тремя тарифными планами: Стартовый, Профессиональный и Премиум. Все планы доступны для бесплатной пробной версии.

Джарвис-это удивительный инструмент для написания ИИ, который позволяет вам создавать уникальные произведения искусства в ответ на ваши собственные слова! Я использовал эту услугу для всего этого раздела обзора (теперь я чувствую себя вполне удовлетворенным!).
2. Grammarly.

Grammarly начала свою деятельность в 2009 году и позиционирует себя как ведущий инструмент для проверки грамматики и орфографии на рынке. С помощью него вы можете проверять орфографию и грамматику, а также выявлять контекстуальные ошибки, улучшая свои навыки письма.
Grammarly позволяет выполнять проверки на нескольких языках, таких как австралийский, американский и британский английский. Инструмент также содержит положения для проверки на плагиат и содержит предложения о том, как вы можете улучшить качество написанного вами текста.
Один из аспектов Grammarly, который выглядит заманчивым, заключается в том, что он поставляется с простым в использовании плагином для браузера. Как только вы включили это в свой браузер, вы можете выполнять проверки Grammarly при составлении электронных писем и записи в документах Google.
Такая детальная проверка делает процесс записи плавным. С расширением Grammarly вы никогда не будете застигнуты врасплох ошибочными орфографическими, пунктуационными и другими ошибками при написании. Кроме того, интерфейс и подсказки об ошибках очень удобны для пользователя, так что это еще одно преимущество.
Характеристики:
Grammarly использует передовые методы искусственного интеллекта и обработки естественного языка (NLP) для анализа вашего текста. Инструмент помощник по написанию выделяет проблемы со структурой предложений и стилем и даже может помочь вам сделать ваш текст более кратким, ясным и понятным.
Ниже перечислены некоторые функции, которые предлагает Grammarly:
- Проверка орфографии, грамматики и контекстуальных ошибок
- Поддержка нескольких языков
- Проверка на плагиат
- Оценка качества контента
- Простая интеграция с большинством бизнес-приложений
- Надстройка для безопасного браузера
- Полностью основанная на ИИ проверка
- Доступно как на настольных, так и на мобильных устройствах
Цены:

Grammarly разделила свои планы на три уровня: Бесплатный, Премиум и Бизнес. Бесплатные и премиальные планы лучше всего подходят для отдельных маркетологов и профессионалов. Для больших команд лучше, если вы выберете бизнес-план.
3. Wordtune.
Лучше всего подходит для рерайта контента

Wordtune не позиционирует себя как инструмент для проверки грамматики. Вместо этого это один из немногих программных инструментов ИИ, которые пытаются понять контекст и семантику того, что вы пишете. Это детище лабораторий AI21, которое использует несколько языковых моделей для перефразирования предложений.
Используя Wordtune, вы можете работать над тем, чтобы сделать свой контент более привлекательным, привлекательным и удобным для использования. Чтобы помочь вам достичь этого, сервис использует передовые технологии NLP на основе нейронных сетей в сочетании со стандартными инструментами искусственного интеллекта.
Инструмент перефразирует написанный вами контент и переписывает его более плавно и понятно. Он пытается улучшить читабельность текста вместо регулярной проверки грамматики, которая больше фокусируется на синтаксисе, чем на семантике.
Характеристики:
Wordtune помогает вам писать предложения, которые отлично читаются и в то же время сохраняют первоначальный смысл. Он предоставляет вам несколько различных вариантов для каждого предложения, которое вам нужно переписать.
Помимо вышеперечисленного, ниже приведены некоторые другие функции, которые предлагает Wordtune:
- Полностью облачный инструмент
- Функция умной вставки
- Работает со всеми редакторами и почтовыми клиентами
- Перезаписи на основе семантического анализа
- Полный контроль над длиной и стилем предложения
- Предложения в режиме реального времени на основе тезауруса
- Многоязычный поиск слов
- Простая интеграция с сайтами социальных сетей и бизнес-инструментами
Цены:
Как и Grammarly, Wordtune также имеет трехуровневую структуру ценообразования. Бесплатный тарифный план доступен для всех желающих без оплаты или регистрации. Для расширенной функциональности вы можете переключиться на платные планы Премиум-класса, как описано ниже.
1. Бесплатный план за 0 долларов
- Основные предложения
- Основные переписывания
- Надстройка Chrome
2. Премиум-план по цене $9,99 в месяц
- Расширенные переписывания и предложения
- Регуляторы формальности и длины
- Поиск слов
3. Премиальный план для команд
- Все в премиум-классе
- Командный биллинг
- Индивидуальные цены
4. ProWritingAid
Лучше всего подходит для редактирования учебного контента

Если вы имеете дело с учебным контентом, который не допускает грамматических ошибок, то ProWritingAid может значительно облегчить вам задачу. Он предлагает расширенную грамматику и проверку орфографии, а также предложения по стилю. Вы можете выбрать из более чем 1000 стилей письма, которые предварительно встроены в него.
Программное обеспечение помогает авторам улучшать свой контент, предоставляя подробные отчеты, которые могут помочь улучшить их стиль письма. Он также предоставляет вам уникальные предложения по написанию, соответствующие статьи и даже видео и викторины, чтобы сделать процесс редактирования более увлекательным.
ProWritingAid помогает вам искать и отсеивать нежелательные элементы в тексте, такие как избыточный текст, нечеткость и чрезмерно длинные предложения. И, как и большинство алгоритмов редактирования на основе искусственного интеллекта, он учится и помогает вам учиться по мере того, как вы продвигаетесь вперед и используете его больше. Используйте его для исследовательских проектов, профессиональных статей и многого другого.
Характеристики:
Одной из особенностей ProWritingAid, о которой можно упомянуть, является его повсеместное распространение. Приложение предлагает расширение Chrome, надстройку MS Office и даже работает с документами Google и Scrivener. Независимо от того, какой редактор вы используете, ProWritingAid может вам помочь.
Вот список основных функций, которые предлагает этот инструмент:
- Проверка грамматики и плагиата
- Тональный анализ текста
- Подробные показатели вовлеченности
- Форматирование стиля и предложений
- Простая интеграция API
- Полностью облачное решение
- 20 подробных письменных отчетов
- Интеграция с популярными приложениями, такими как Medium и Gmail
Цены:

Расширение Chrome ProWritingAid доступно бесплатно, и вы можете выбрать любой из платных планов в соответствии с вашими потребностями. Планы сегментированы с учетом потребностей пользователей.
Вот краткое описание тарифных планов ProWritingAid:
- Ежемесячный план составляет 20 долларов США в месяц
- Годовой план на уровне 79 долларов США в год
- Пожизненный план в размере 399 долларов США (единовременный платеж)
- Индивидуальный бизнес-план за 6 долларов в месяц
- Бизнес — команды планируют 8 долларов США на пользователя в месяц (минимум два пользователя, счет выставляется ежегодно).
- Корпоративный план по индивидуальным тарифам
Сервис также предоставляет скидки для студентов и оптовые покупки.
5.Sapling.
Лучше всего подходит для сообщений о продажах и поддержке

Sapling-это программное обеспечение-помощник по написанию ИИ, которое работает с платформами обмена сообщениями и CRM. Это помогает отделам продаж и поддержки составлять и отправлять персонализированные ответы клиентам.
Используя этот инструмент, менеджеры также могут получить представление об управлении разговорами и обучении команд для улучшения взаимодействия с клиентами. В настоящее время этот инструмент используется крупными брендами, такими как TaskUs и Lionbridge.
Саженец утверждает, что фиксирует языковые проблемы и ошибки гораздо лучше, чем традиционные средства проверки орфографии, поскольку он использует алгоритм машинного обучения. Он также имеет впечатляющую функцию автозаполнения, которая может помочь ускорить процесс составления ответов.
Характеристики:
С Sapling вам больше не придется зависеть от чат-ботов, которые используют шаткую логику. Инструмент работает для расширения возможностей человеческих агентов, сохраняя и извлекая наиболее распространенные ответы на запросы. Одним щелчком мыши вы можете ответить клиенту и решить его проблемы.
Помимо вышеперечисленного, Sapling также предоставляет доступ к следующим функциям:
- Автозаполнение везде для более быстрого составления
- Библиотека фрагментов, доступная с помощью веб-инструментов
- Хранилище сообщений для вставки предварительно отформатированного текста
- Способность предоставлять ответы «человек в цикле»
- Отчетность, ориентированная на производительность
- Многоканальная поддержка широкого спектра приложений
- Безопасность корпоративного уровня
- Быстрая установка
Цены:

Бесплатный план Sapling содержит основные предложения и может быть использован на бесплатных доменах. Он также предлагает шифрование AES-256 и TLS. Чтобы воспользоваться преимуществами расширенных функций и предложений, вам нужно будет выбрать любой из платных планов.
Вот краткое сравнение структуры ценообразования на Sapling :
- Бесплатный план за 0 долларов в месяц
- Профессиональный план за 25 долларов в месяц
- Корпоративный план по индивидуальным тарифам
6. AI Writer.
Лучше всего подходит для автоматического создания контента

AI Writer подходит для SEO-писателей и контент-ниндзя, у которых нет времени на детальное исследование для написания статей и создания контента для маркетинга. Этот инструмент, по сути, является генератором контента ИИ, который создает для вас статью ИИ на основе информации, которую вы ему предоставляете.
Чтобы использовать программное обеспечение для написания статей, вам необходимо ввести заголовок темы или ключевое слово, и система автоматизации программного обеспечения удалит соответствующую информацию из Интернета и создаст для вас статью. На веб-сайте компании утверждается, что его использование может сэкономить до 33% времени на написание.
Характеристики:
Помимо того, что это программное обеспечение для автоматического написания статей, AI Writer также предоставляет функцию рерайта текста. Здесь вы можете ввести написанную вами статью, и программное обеспечение перефразирует ее. Вы даже можете перефразировать статьи, написанные самим автором ИИ.
Ниже приведены некоторые важные функции, которые предлагает AI Writer:
- Автоматическое написание контента
- Переписывание/изменение формулировки статьи
- API для автоматического ведения блога
- Более быстрое создание контента
- 94,47% Скорость прохождения копировального листа
Цены:

Официальный сайт AI Writer предлагает бесплатную пробную версию с ограниченными возможностями и позволяет создавать автоматические статьи в течение семи дней. Если вы удовлетворены пробной производительностью, вы можете выбрать любой из платных планов.
Вот список платных планов, которые предлагает AI Writer:
- Базовый план на 19 долларов в месяц
- Стандартный план на 49 долларов в месяц
- Индивидуальный план по индивидуальным тарифам
7. Articoolo.
Лучше всего подходит для автоматических статей WordPress

Для блоггеров, работающих на WordPress, Articoolo может быть лучшим решением для быстрого создания контента блога. Это еще одно программное обеспечение для написания статей и генератор контента искусственного интеллекта, который предлагает плагин WordPress, чтобы сделать процесс создания статей плавным и легким.
Используя этот инструмент, вам не придется тратить время на многочасовые исследования и ручной сбор информации. Просто используйте Articoolo, чтобы ускорить процесс и ускорить отслеживание ваших сообщений в блоге.
Характеристики:
Основная услуга, которую предлагает Articoolo, — это создание статей с искусственным интеллектом, но вы также можете использовать ее для переписывания существующих статей. Он даже поставляется с API и плагином WordPress для плавной интеграции с другими приложениями.
Ниже перечислены основные функции Articoolo:
- Быстрое создание и переписывание статей
- Генератор идей и названий тем
- Краткое изложение статьи
- Цитаты и поиск изображений
- Помощник писателя
Цены:

Тарифные планы Articoolo бывают двух типов: планы с оплатой за пользование и Ежемесячные подписки. Они также предлагают групповые и пользовательские подписки для более крупных компаний, которым требуется массовое обслуживание.
Вот список планов ценообразования:
- 19 долларов за 10 статей
- 75 долларов за 50 статей
- 99 долларов за 100 статей
- 29 долларов в месяц за 30 статей
- 49 долларов в месяц за 100 статей
- 99 долларов в месяц за 250 статей
Что такое Искусственный интеллект или Программное обеспечение для написания ИИ?
Программное обеспечение для написания ИИ относится к программным средствам, которые используют методы искусственного интеллекта и машинного обучения для ускорения и поддержки процесса создания письменного контента человеческого качества. Эти инструменты играют важную роль в индустрии контент-маркетинга.
Используя программное обеспечение для написания ИИ, вы можете быстрее создавать статьи в блогах, лучше писать электронные письма и отшлифовывать текст, чтобы привлечь внимание читателей. Инструменты для письма на основе искусственного интеллекта могут помочь вам во всем, от грамматики и синонимов до контекста, стиля и структуры предложений.
В завершении
Одна опечатка может оказать огромное влияние на имидж вашего бренда. В результате любой контент, который вы создаете, должен быть отшлифован, точен и безошибочен. Программное обеспечение для создания ИИ помогает компаниям и стартапам делать именно это и ускорять маркетинговый процесс.
Если вы ищете подходящее программное обеспечение для создания искусственного интеллекта, выберите его из списка ниже:
- Джарвис: Лучшее программное обеспечение для создания искусственного интеллекта
- Grammarly: Лучше всего подходит для безошибочной вычитки
- Wordtune Лучше всего подходит для перефразирования контента
- ProWritingAid Лучше всего подходит для редактирования академического контента
- Саженец Лучше всего подходит для сообщений о продажах и поддержке
- AI-писатель Лучше всего подходит для автоматического создания контента
- Articoolo Лучше всего подходит для автоматических статей WordPress
Независимо от того, хотите ли вы создавать отличный контент или просто выпускать короткие статьи, вышеперечисленные инструменты могут помочь вам в этом. Вы также можете использовать комбинацию нескольких инструментов для повышения качества контента.
Просмотров: 4 909