Нейросетевой синтез речи своими руками
Время на прочтение
12 мин
Количество просмотров 74K
Синтез речи на сегодняшний день применяется в самых разных областях. Это и голосовые ассистенты, и IVR-системы, и умные дома, и еще много чего. Сама по себе задача, на мой вкус, очень наглядная и понятная: написанный текст должен произноситься так, как это бы сделал человек.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Синтез речи
Чтобы построить систему синтеза речи, нужна целая команда специалистов из разных областей. По каждой из них существует целая масса алгоритмов и подходов. Написаны докторские диссертации и толстые книжки с описанием фундаментальных подходов. Давайте для начала поверхностно разберемся с каждой их них.
Лингвистика
- Нормализация текста. Для начала нам нужно развернуть все сокращения, числа и даты в текст. 50е годы XX века должно превратиться в пятидесятые годы двадцатого века, а г. Санкт-Петербург, Большой пр. П.С. в город Санкт-Петербург, Большой проспект Петроградской Стороны. Это должно происходить так естественно, как если бы человека попросили прочитать написанное.
- Подготовка словаря ударений. Расстановка ударений может производиться по правилам языка. В английском ударение часто ставится на первый слог, а в испанском — на предпоследний. При этом из этих правил существует целая масса исключений, не поддающихся какому-то общему правилу. Их обязательно нужно учитывать. Для русского языка в общем смысле правил расстановки ударения вообще не существует, так что без словаря с расставленными ударениями совсем никуда не деться.
- Снятие омографии. Омографы — это слова, которые совпадают в написании, но различаются в произношении. Носитель языка легко расставит ударения: дверной замок и замок на горе. А вот ключ от замка — задача посложнее. Полностью снять омографию без учета контекста невозможно.
Просодика
- Выделение синтагм и расстановка пауз. Синтагма представляет относительно законченный по смыслу отрезок речи. Когда человек говорит, он обычно вставляет паузы между фразами. Нам нужно научиться разделять текст на такие синтагмы.
- Определение типа интонации. Выражение завершенности, вопроса и восклицания — самые простые интонации. А вот выразить иронию, сомнение или воодушевление задача куда сложнее.
Фонетика
- Получение транскрипции. Так как в конечном итоге мы работаем с произнесением, а не с написанием, то очевидно вместо букв (графем), логично использовать звуки (фонемы). Преобразование графемной записи в фонемную — отдельная задача, состоящая из множества правил и исключений.
- Вычисление параметров интонации. В этот момент нужно решить как будет меняться высота основного тона и скорость произнесения в зависимости от расставленных пауз, подобранной последовательности фонем и типа выражаемой интонации. Помимо основного тона и скорости есть и другие параметры, с которыми можно долго экспериментировать.
Акустика
- Подбор звуковых элементов. Системы синтеза оперируют так называемыми аллофонами — реализациями фонемы, зависящими от окружения. Записи из обучающих данных нарезаются на кусочки по фонемной разметке, которые образуют аллофонную базу. Каждый аллофон характеризуется набором параметров, таких как контекст (фонемы соседи), высота основного тона, длительность и прочие. Сам процесс синтеза представляет собой подбор правильной последовательности аллофонов, наиболее подходящих в текущих условиях.
- Модификация и звуковые эффекты. Для получившихся записей иногда нужна постобработка, какие-то специальные фильтры, делающие синтезируемую речь чуть ближе к человеческой или исправляющие какие-то дефекты.
Если вдруг вам показалось, что все это можно упростить, прикинуть в голове или быстро подобрать какие-то эвристики для отдельных модулей, то просто представьте, что вам нужно сделать синтез на хинди. Если вы не владеете языком, то вам даже не удастся оценить качество вашего синтеза, не привлекая кого-то, кто владел бы языком на нужном уровне. Мой родной язык русский, и я слышу, когда синтез ошибается в ударениях или говорит не с той интонацией. Но в тоже время, весь синтезированный английский для меня звучит примерно одинаково, не говоря уже о более экзотических языках.
Реализации
Мы попытаемся найти End-2-End (E2E) реализацию синтеза, которая бы взяла на себя все сложности, связанные с тонкостями языка. Другими словами, мы хотим построить систему, основанную на нейронных сетях, которая бы на вход принимала текст, а на выходе давала бы синтезированную речь. Можно ли обучить такую сеть, которая позволила бы заменить целую команду специалистов из узких областей на команду (возможно даже из одного человека), специализирующуюся на машинном обучении?
На запрос end2end tts Google выдает целую массу результатов. Во главе — реализация Tacotron от самого Google. Самым простым мне показалось идти от конкретных людей на Github, которые занимаются исследованиям в этой области и выкладывают свои реализации различных архитектур.
Я бы выделил троих:
- Kyubyong Park
- Keith Ito
- Ryuichi Yamamoto
Загляните к ним в репозитории, там целый кладезь информации. Архитектур и подходов к задаче E2E-синтеза довольно много. Среди основных:
- Tacotron (версии 1, 2).
- DeepVoice (версии 1, 2, 3).
- Char2Wav.
- DCTTS.
- WaveNet.
Нам нужно выбрать одну. Я выбрал Deep Convolutional Text-To-Speech (DCTTS) от Kyubyong Park в качестве основы для будущих экспериментов. Оригинальную статью можно посмотреть по ссылке. Давайте поподробнее рассмотрим реализацию.
Автор выложил результаты работы синтеза по трем различным базам и на разных стадиях обучения. На мой вкус, как не носителя языка, они звучат весьма прилично. Последняя из баз на английском языке (Kate Winslet’s Audiobook) содержит всего 5 часов речи, что для меня тоже является большим преимуществом, так как моя база содержит примерно сопоставимое количество данных.
Через некоторое время после того, как я обучил свою систему, в репозитории появилась информация о том, что автор успешно обучил модель для корейского языка. Это тоже довольно важно, так как языки могут сильно разниться и робастность по отношению к языку — это приятное дополнение. Можно ожидать, что в процессе обучения не потребуется особого подхода к каждому набору обучающих данных: языку, голосу или еще каким-то характеристикам.
Еще один важный момент для такого рода систем — это время обучения. Tacotron на том железе, которое у меня есть, по моим оценкам учился бы порядка 2 недель. Для прототипирования на начальном уровне мне показалось это слишком ресурсоемким. Педали, конечно, крутить не пришлось бы, но на создание какого-то базового прототипа потребовалось бы очень много календарного времени. DCTTS в финальном варианте учится за пару дней.
У каждого исследователя есть набор инструментов, которыми он пользуется в своей работе. Каждый подбирает их себе по вкусу. Я очень люблю PyTorch. К сожалению, на нем реализации DCTTS я не нашел, и пришлось использовать TensorFlow. Возможно в какой-то момент выложу свою реализацию на PyTorch.
Данные для обучения
Хорошая база для реализации синтеза — это основной залог успеха. К подготовке нового голоса подходят очень основательно. Профессиональный диктор произносит заранее подготовленные фразы в течение многих часов. Для каждого произнесения нужно выдержать все паузы, говорить без рывков и замедлений, воспроизвести правильный контур основного тона и все это в купе с правильной интонацией. Кроме всего прочего, не все голоса одинаково приятно звучат.
У меня на руках была база порядка 8 часов, записанная профессиональным диктором. Сейчас мы с коллегами обсуждаем возможность выложить этот голос в свободный доступ для некоммерческого использования. Если все получится, то дистрибутив с голосом помимо самих записей будет включать в себя точные текстовки для каждой из них.
Начнем
Мы хотим создать сеть, которая на вход принимала бы текст, а на выходе давала бы синтезированный звук. Обилие реализаций показывает, что это возможно, но есть конечно и ряд оговорок.
Основные параметры системы обычно называют гиперпараметрами и выносят в отдельный файл, который называется соответствующим образом: hparams.py или hyperparams.py, как в нашем случае. В гиперпараметры выносится все, что можно покрутить, не трогая основной код. Начиная от директорий для логов, заканчивая размерами скрытых слоев. После этого гиперпараметры в коде используются примерно вот так:
from hyperparams import Hyperparams as hp
batch_size = hp.B # размер батча берем из гиперпараметровДалее по тексту все переменные имеющие префикс hp. берутся именно из файла гиперпараметров. Подразумевается, что эти параметры не меняются в процессе обучения, поэтому будьте осторожны перезапуская что-то с новыми параметрами.
Текст
Для обработки текста обычно используются так называемый embedding-слой, который ставится самым первым. Суть его простая — это просто табличка, которая каждому символу из алфавита ставит в соответствие некий вектор признаков. В процессе обучения мы подбираем оптимальные значения для этих векторов, а когда синтезируем по готовой модели, просто берем значения из этой самой таблички. Такой подход применяется в уже довольно широко известных Word2Vec, где строится векторное представление для слов.
Для примера возьмем простой алфавит:
['a', 'b', 'c']В процессе обучения мы выяснили, что оптимальные значения каждого их символов вот такие:
{
'a': [0, 1],
'b': [2, 3],
'c': [4, 5]
}Тогда для строчки aabbcc после прохождения embedding-слоя мы получим следующую матрицу:
[[0, 1], [0, 1], [2, 3], [2, 3], [4, 5], [4, 5]]Эта матрица дальше подается на другие слои, которые уже не оперируют понятием символ.
В этот момент мы видим первое ограничение, которое у нас появляется: набор символов, который мы можем отправлять на синтез, ограничен. Для каждого символа должно быть какое-то ненулевое количество примеров в обучающих данных, лучше с разным контекстом. Это значит, что нам нужно быть осторожными в выборе алфавита.
В своих экспериментах я остановился на варианте:
# Алфавит задается в файле с гиперпараметрами
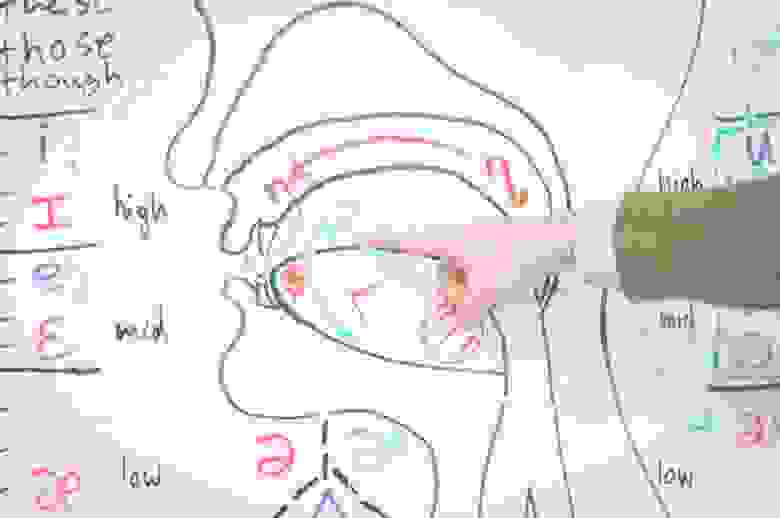
vocab = "E абвгдеёжзийклмнопрстуфхцчшщъыьэюя-" Это алфавит русского языка, дефис, пробел и обозначение конца строки. Тут есть несколько важных моментов и допущений:
- Я не добавлял в алфавит знаки препинания. С одной стороны, мы действительно их не произносим. С другой, по знакам препинания мы делим фразу на части (синтагмы), разделяя их паузами. Как система произнесет казнить нельзя помиловать?
- В алфавите нет цифр. Мы ожидаем, что они будут развернуты в числительные перед подачей на синтез, то есть нормализованы. Вообще все E2E-архитектуры, которые я видел, требуют именно нормализованный текст.
- В алфавите нет латинских символов. Английский система уметь произносить не будет. Можно попробовать транслитерацию и получить сильный русский акцент — пресловутый лет ми спик фром май харт.
- В алфавите есть буква ё. В данных, на который я обучал систему, она стояла там, где нужно, и я решил этот расклад не менять. Однако, в тот момент, когда я оценивал получившиеся результаты, выяснилось, что теперь перед подачей на синтез эту букву тоже нужно ставить правильно, иначе система произносит именно е, а не ё.
В будущих версиях можно уделить каждому из пунктов более пристальное внимание, а пока оставим в таком немного упрощенном виде.
Звук
Почти все системы оперируют не самим сигналом, а разного рода спектрами полученными на окнах с определенным шагом. Я не буду вдаваться в подробности, по этой теме довольно много разного рода литературы. Сосредоточимся на реализации и использованию. В реализации DCTTS используются два вида спектров: амплитудный спектр и мел-спектр.
Считаются они следующим образом (код из этого листинга и всех последующих взят из реализации DCTTS, но видоизменен для наглядности):
# Получаем сигнал фиксированной частоты дискретизации
y, sr = librosa.load(wavename, sr=hp.sr)
# Обрезаем тишину по краям
y, _ = librosa.effects.trim(y)
# Pre-emphasis фильтр
y = np.append(y[0], y[1:] - hp.preemphasis * y[:-1])
# Оконное преобразование Фурье
linear = librosa.stft(y=y,
n_fft=hp.n_fft,
hop_length=hp.hop_length,
win_length=hp.win_length)
# Амплитудный спектр
mag = np.abs(linear)
# Мел-спектр
mel_basis = librosa.filters.mel(hp.sr, hp.n_fft, hp.n_mels)
mel = np.dot(mel_basis, mag)
# Переводим в децибелы
mel = 20 * np.log10(np.maximum(1e-5, mel))
mag = 20 * np.log10(np.maximum(1e-5, mag))
# Нормализуем
mel = np.clip((mel - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1)
mag = np.clip((mag - hp.ref_db + hp.max_db) / hp.max_db, 1e-8, 1)
# Транспонируем и приводим к нужным типам
mel = mel.T.astype(np.float32)
mag = mag.T.astype(np.float32)
# Добиваем нулями до правильных размерностей
t = mel.shape[0]
num_paddings = hp.r - (t % hp.r) if t % hp.r != 0 else 0
mel = np.pad(mel, [[0, num_paddings], [0, 0]], mode="constant")
mag = np.pad(mag, [[0, num_paddings], [0, 0]], mode="constant")
# Понижаем частоту дискретизации для мел-спектра
mel = mel[::hp.r, :]
Для вычислений почти во всех проектах E2E-синтеза используется библиотека LibROSA (https://librosa.github.io/librosa/). Она содержит много полезного, рекомендую заглянуть в документацию и посмотреть, что в ней есть.
Теперь давайте посмотрим как амплитудный спектр (magnitude spectrum) выглядит на одном из файлов из базы, которую я использовал:
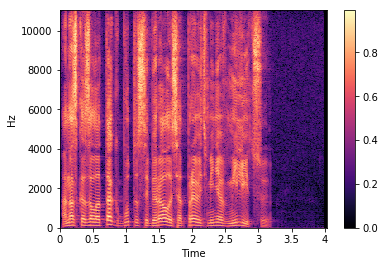
Такой вариант представления оконных спекторов называется спектрограммой. На оси абсцисс располагается время в секундах, на оси ординат — частота в герцах. Цветом выделяется амплитуда спектра. Чем точка ярче, тем значение амплитуды больше.
Мел-спектр — это амплитудный спектр, но взятый на мел-шкале с определенным шагом и окном. Количество шагов мы задаем заранее, в большинстве реализаций для синтеза используется значение 80 (задается параметром hp.n_mels). Переход к мел-спектру позволяет сильно сократить количество данных, но этом сохранить важные для речевого сигнала характеристики. Мел-спектрограмма для того же файла выглядит следующим образом:
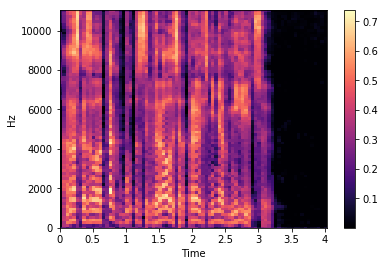
Обратите внимание на прореживание мел-спектров во времени на последней строке листинга. Мы берем только каждый 4 вектор (hp.r == 4), соответственно уменьшая тем самым частоту дискретизации. Синтез речи сводится к предсказанию мел-спектров по последовательности символов. Идея простая: чем меньше сети приходится предсказывать, тем лучше она будет справляться.
Хорошо, мы можем получить спектрограмму по звуку, но послушать мы ее не можем. Соответственно нам нужно уметь восстанавливать сигнал обратно. Для этих целей в системах часто используется алгоритм Гриффина-Лима и его более современные интерпретации (к примеру, RTISILA, ссылка). Алгоритм позволяет восстановить сигнал по его амплитудным спектрам. Реализация, которую использовал я:
def griffin_lim(spectrogram, n_iter=hp.n_iter):
x_best = copy.deepcopy(spectrogram)
for i in range(n_iter):
x_t = librosa.istft(x_best,
hp.hop_length,
win_length=hp.win_length,
window="hann")
est = librosa.stft(x_t,
hp.n_fft,
hp.hop_length,
win_length=hp.win_length)
phase = est / np.maximum(1e-8, np.abs(est))
x_best = spectrogram * phase
x_t = librosa.istft(x_best,
hp.hop_length,
win_length=hp.win_length,
window="hann")
y = np.real(x_t)
return yА сигнал по амплитудной спектрограмме можно восстановить вот так (шаги, обратные получению спектра):
# Транспонируем
mag = mag.T
# Денормализуем
mag = (np.clip(mag, 0, 1) * hp.max_db) - hp.max_db + hp.ref_db
# Возвращаемся от децибел к аплитудам
mag = np.power(10.0, mag * 0.05)
# Восстанавливаем сигнал
wav = griffin_lim(mag**hp.power)
# De-pre-emphasis фильтр
wav = signal.lfilter([1], [1, -hp.preemphasis], wav)Давайте попробуем получить амплитудный спектр, восстановить его обратно, а затем послушать.
Оригинал:
Восстановленный сигнал:
На мой вкус, результат стал хуже. Авторы Tacotron (первая версия также использует этот алгоритм) отмечали, что использовали алгоритм Гриффина-Лима как временное решение для демонстрации возможностей архитектуры. WaveNet и ему подобные архитектуры позволяют синтезировать речь лучшего качества. Но они более тяжеловесные и требуют определенных усилий для обучения.
Обучение
DCTTS, который мы выбрали, состоит из двух практически независимых нейронных сетей: Text2Mel и Spectrogram Super-resolution Network (SSRN).
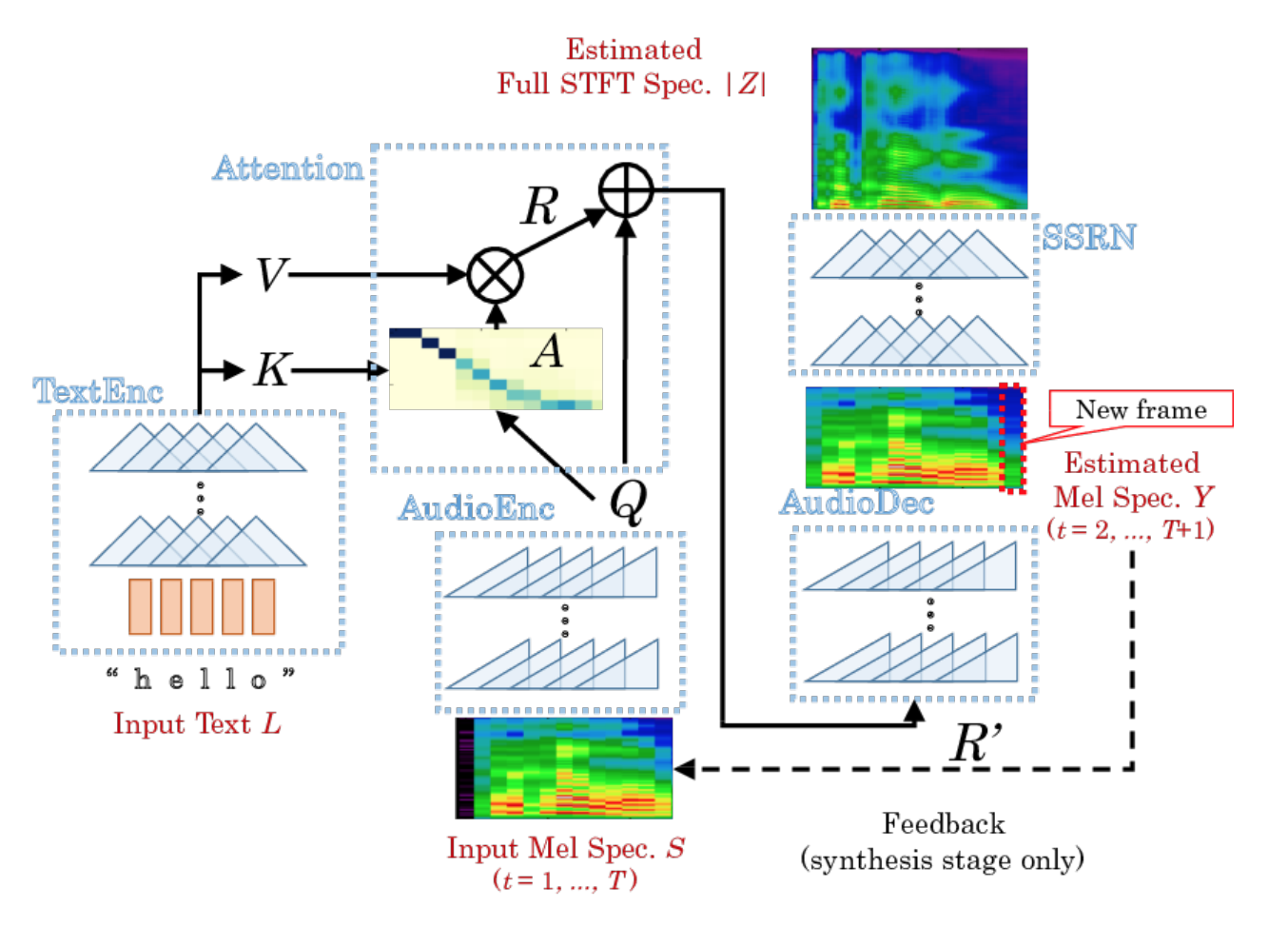
Text2Mel предсказывает мел-спектр по тексту, используя механизм внимания (Attention), который увязывает два энкодера (TextEnc, AudioEnc) и один декодер (AudioDec). Обратите внимание, что Text2Mel восстанавливает именно разреженный мел-спектр.
SSRN восстанавливает из мел-спектра полноценный амплитудный спектр, учитывая пропуски кадров и восстанавливая частоту дискретизации.
Последовательность вычислений довольно подробно описана в оригинальной статье. К тому же есть исходный код реализации, так что всегда можно отладиться и вникнуть в тонкости. Обратите внимание, что автор реализации отошел в некоторых местах от статьи. Я бы выделил два момента:
- Появились дополнительные слои для нормализации (normalization layers), без которых, по словам автора, ничего не работало.
- В реализации используется механизм исключения (dropout) для лучшей регуляризации. В статье этого нет.
Я взял голос, включающий в себя 8 часов записей (несколько тысяч файлов). Оставил только записи, которые:
- В текстовках содержат только буквы, пробелы и дефисы.
- Длина текстовок не превышает hp.max_N.
- Длина мел-спектров после разреживания не превышает hp.max_T.
У меня получилось чуть больше 5 часов. Посчитал для всех записей нужные спекты и поочередно запустил обучение Text2Mel и SSRN. Все это делается довольно безхитростно:
$ python prepro.py
$ python train.py 1
$ python train.py 2Обратите внимание, что в оригинальном репозитории prepro.py именуется как prepo.py. Мой внутренний перфекционист не смог этого терпеть, так что я его переименовал.
DCTTS содержит только сверточные слои, и в отличие от RNN реализаций, вроде Tacotron, учится значительно быстрее.
На моей машине с Intel Core i5-4670, 16 Gb RAM и GeForce 1080 на борту 50 тыс. шагов для Text2Mel учится за 15 часов, а 75 тыс. шагов для SSRN — за 5 часов. Время требуемое на тысячу шагов в процессе обучения у меня почти не менялось, так что можно легко прикинуть, сколько потребуется времени на обучение с большим количеством шагов.
Размер батча можно регулировать параметром hp.B. Периодически процесс обучения у меня валился с out-of-memory, так что я просто делил на 2 размер батча и перезапускал обучение с нуля. Полагаю, что проблема кроется где-то в недрах TensorFlow (я использовал не самый свежий) и тонкостях реализации батчинга. Я с этим разбираться не стал, так как на значении 8 все падать перестало.
Результат
После того, как модели обучились, можно наконец запустить и синтез. Для этого заполняем файлик с фразами и запускаем:
$ python synthesize.pyЯ немного поправил реализацию, чтобы генерировать фразы из нужного файла.
Результаты в виде WAV-файлов будут сохранены в директорию samples. Вот примеры синтеза системой, которая получилась у меня:
Выводы и ремарки
Результат превзошел мои личные ожидания по качеству. Система расставляет ударения, речь получается разборчивой, а голос узнаваем. В целом получилось неплохо для первой версии, особенно с учетом того, что для обучения использовалось всего 5 часов обучающих данных.
Остаются вопросы по управляемости таким синтезом. Пока невозможно даже исправить ударение в слове, если оно неверное. Мы жестко завязаны на максимальную длину фразы и размер мел-спектрограммы. Нет возможности управлять интонацией и скоростью воспроизведения.
Я не выкладывал мои изменения в коде оригинальной реализации. Они коснулись только загрузки обучающих данных и фраз для синтеза уже по готовой системе, а также значений гиперпараметров: алфавит (hp.vocab) и размер батча (hp.B). В остальном реализация осталась оригинальная.
В рамках рассказа я совсем не коснулся темы продакшн реализации таких систем, до этого полностью E2E-системам синтеза речи пока очень далеко. Я использовал GPU c CUDA, но даже в этом случае все работает медленнее реального времени. На CPU все работает просто неприлично медленно.
Все эти вопросы будут решаться в ближайшие годы крупными компаниями и научными сообществами. Уверен, что это будет очень интересно.
Озвучиваем системное время и любой текст в Windows и Linux. Используем pytts3, espeak, RHVoice, gTTS, Speech dispatcher.
https://gbcdn.mrgcdn.ru/uploads/post/1991/og_image/84f8204b6001e08386ade835e344324a.png

Синтез речи может пригодиться вам в работе над мобильным помощником, умным домом на Raspberry Pi, искусственным интеллектом, игрой, системой уведомлений и звуковым интерфейсом. Голосовые сообщения донесут информацию до пользователя, которому некогда читать текст. Кроме того, если программа умеет озвучивать свой интерфейс, она доступна незрячим и слабовидящим. Есть системы управления компьютером без опоры на зрение. Одна из самых популярных — NVDA (NonVisual Desktop Access) — написана на Python с добавлением C++.
Давайте посмотрим, как использовать text-to-speech (TTS) в Python и подключать синтезаторы голоса к вашей программе. Эту статью я хотела назвать «Говорящая консоль», потому что мы будем писать консольное приложение для Windows, Linux, а потенциально — и MacOS. Потом решила выбрать более общее название, ведь от наличия GUI суть не меняется. На всякий случай поясню: консоль в данном случае — терминал Linux или знакомая пользователям Windows командная строка.
Цель выберем очень скромную: создадим приложение, которое будет каждую минуту озвучивать текущее системное время.
Готовим поляну
Прежде чем писать и тестировать код, убедимся, что операционная система готова к синтезу речи, в том числе на русском языке.
Чтобы компьютер заговорил, нужны:
- голосовой движок (синтезатор речи) с поддержкой нужных нам языков,
- голоса дикторов для этого движка.
В Windows есть штатный речевой интерфейс Microsoft Speech API (SAPI). Голоса к нему выпускают, помимо Microsoft, сторонние производители: Nuance Communications, Loquendo, Acapela Group, IVONA Software.
Есть и свободные кроссплатформенные голосовые движки:
- RHVoice от Ольги Яковлевой — имеет четыре голоса для русского языка (один мужской и три женских), а также поддерживает татарский, украинский, грузинский, киргизский, эсперанто и английский. Работает в Windows, GNU/Linux и Android.
- eSpeak и его ответвление — eSpeak NG — c поддержкой более 100 языков и диалектов, включая даже латынь. NG означает New Generation — «новое поколение». Эта версия разрабатывается сообществом с тех пор, как автор оригинальной eSpeak перестал выходить на связь. Система озвучит ваш текст в Windows, Android, Linux, Mac, BSD. При этом старый eSpeak стабилен в ОС Windows 7 и XP, а eSpeak NG совместим с Windows 8 и 10.

В статье я ориентируюсь только на перечисленные свободные синтезаторы, чтобы мы могли писать кроссплатформенный код и не были привязаны к проприетарному софту.
По качеству голоса RHVoice неплох и к нему быстро привыкаешь, а вот eSpeak очень специфичен и с акцентом. Зато eSpeak запускается на любом утюге и подходит как вариант на крайний случай, когда ничто другое не работает или не установлено у пользователя.
Установка речевых движков, голосов и модулей в Windows
С установкой синтезаторов в Windows проблем возникнуть не должно. Единственный нюанс — для русского голоса eSpeak и eSpeak NG нужно скачать расширенный словарь произношения. Распакуйте архив в подкаталог espeak-data или espeak-ng-data в директории программы. Теперь замените старый словарь новым: переименуйте ru_dict-48 в ru_dict, предварительно удалив имеющийся файл с тем же именем (ru_dict).
Теперь установите модули pywin32, python-espeak и py-espeak-ng, которые потребуются нам для доступа к возможностям TTS:
pip install pywin32 python-espeak pyttsx3 py-espeak-ng
Если у вас на компьютере соседствуют Python 2 и 3, здесь и далее пишите «pip3», а при запуске скриптов — «python3».
Установка eSpeak(NG) в Linux
Подружить «пингвина» с eSpeak, в том числе NG, можно за минуту:
sudo apt-get install espeak-ng python-espeak
pip3 install py-espeak-ng pyttsx3
Дальше загружаем и распаковываем словарь ru_dict с официального сайта:
wget http://espeak.sourceforge.net/data/ru_dict-48.zip
unzip ru_dict-48.zip
Теперь ищем адрес каталога espeak-data (или espeak-ng-data) где-то в /usr/lib/ и перемещаем словарь туда. В моем случае команда на перемещение выглядела так:
sudo mv ru_dict-48 /usr/lib/i386-linux-gnu/espeak-data/ru_dict
Обратите внимание: вместо «i386» у вас в системе может быть «x86_64…» или еще что-то. Если не уверены, воспользуйтесь поиском:
find /usr/lib/ -name «espeak-data»
Готово!
RHVoice в Linux
Инструкцию по установке RHVoice в Linux вы найдете, например, в начале этой статьи. Ничего сложного, но времени занимает больше, потому что придется загрузить несколько сотен мегабайт.
Смысл в том, что мы клонируем git-репозиторий и собираем необходимые компоненты через scons.
Для экспериментов в Windows и Linux я использую одни и те же русские голоса: стандартный ‘ru’ в eSpeak и Aleksandr в RHVoice.

Как проверить работоспособность синтезатора
Прежде чем обращаться к движку, убедитесь, что он установлен и работает правильно.
Проверить работу eSpeak в Windows проще всего через GUI — достаточно запустить TTSApp.exe в папке с программой. Дальше открываем список голосов, выбираем eSpeak-RU, вводим текст в поле редактирования и жмем на кнопку Speak.
Обратиться к espeak можно и из терминала. Базовые консольные команды для eSpeak и NG совпадают — надо только добавлять или убирать «-ng» после «espeak»:
espeak -v ru -f D:my.txt
espeak-ng -v en «The Cranes are Flying»
echo «Да, это от души. Замечательно. Достойно восхищения» |RHVoice-test -p Aleksandr
Как нетрудно догадаться, первая команда с ключом -f читает русский текст из файла. Чтобы в Windows команда espeak подхватывалась вне зависимости от того, в какой вы директории, добавьте путь к консольной версии eSpeak (по умолчанию — C:Program FileseSpeakcommand_line) в переменную окружения Path. Вот как это сделать.
Библиотека pyttsx3
PyTTSx3 — удобная кроссплатформенная библиотека для реализации TTS в приложениях на Python 3. Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Это очень удобно: пишете код один раз и он работает везде. Кстати, eSpeak NG поддерживается наравне с исходной версией.
А теперь примеры!
Просмотр голосов
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
Первый вопрос всегда в том, какие голоса установлены на стороне пользователя. Поэтому создадим скрипт, который покажет все доступные голоса, их имена и ID. Назовем файл, например, list_voices.py:
import pyttsx3
tts = pyttsx3.init() # Инициализировать голосовой движок.
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Это нам и нужно:
voices = tts.getProperty(‘voices’)
# Перебрать голоса и вывести параметры каждого
for voice in voices:
print(‘=======’)
print(‘Имя: %s’ % voice.name)
print(‘ID: %s’ % voice.id)
print(‘Язык(и): %s’ % voice.languages)
print(‘Пол: %s’ % voice.gender)
print(‘Возраст: %s’ % voice.age)
Теперь открываем терминал или командную строку, переходим в директорию, куда сохранили скрипт, и запускаем list_voices.py.
Результат будет примерно таким:
В Linux картина будет похожей, но с другими идентификаторами.
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID. Однако этого хватит, чтобы решить следующую нашу задачу: написать код, который выберет русский голос и что-то им произнесет.
Например, у голоса RHVoice Aleksandr есть преимущество — его имя уникально, потому что записано транслитом и в таком виде не встречается у других известных производителей голосов. Но через pyttsx3 этот голос будет работать только в Windows. Для воспроизведения в Linux ему нужен Speech Dispatcher (подробнее чуть позже), с которым библиотека взаимодействовать не умеет. Как общаться с «диспетчером» еще обсудим, а пока разберемся с доступными голосами.
Как выбрать голос по имени
В Windows голос удобно выбирать как по ID, так и по имени. В Linux проще работать с именем или языком голоса. Создадим новый файл set_voice_and_say.py:
import pyttsx3
tts = pyttsx3.init()
voices = tts.getProperty(‘voices’)
# Задать голос по умолчанию
tts.setProperty(‘voice’, ‘ru’)
# Попробовать установить предпочтительный голос
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.setProperty(‘voice’, voice.id)
tts.say(‘Командный голос вырабатываю, товарищ генерал-полковник!’)
tts.runAndWait()
В Windows вы услышите голос Aleksandr, а в Linux — стандартный русский eSpeak. Если бы мы вовсе не указали голос, после запуска нас ждала бы тишина, так как по умолчанию синтезатор говорит по-английски.
Обратите внимание: tts.say() не выводит реплики мгновенно, а собирает их в очередь, которую затем нужно запустить на воспроизведение командой tts.runAndWait().
Выбор голоса по ID
Часто бывает, что в системе установлены голоса с одинаковыми именами, поэтому надежнее искать необходимый голос по ID.
Заменим часть написанного выше кода:
for voice in voices:
ru = voice.id.find(‘RHVoiceAnna’) # Найти Анну от RHVoice
if ru > -1: # Eсли нашли, выбираем этот голос
tts.setProperty(‘voice’, voice.id)
Теперь в Windows мы точно не перепутаем голоса Anna от Microsoft и RHVoice. Благодаря поиску в подстроке нам даже не пришлось вводить полный ID голоса.
Но когда мы пишем под конкретную машину, для экономии ресурсов можно прописать голос константой. Выше мы запускали скрипт list_voices.py — он показал параметры каждого голоса в ОС. Тогда-то вы и могли обратить внимание, что в Windows идентификатором служит адрес записи в системном реестре:
import pyttsx3
tts = pyttsx3.init()
EN_VOICE_ID = «HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensMS-Anna-1033-20DSK»
RU_VOICE_ID = «HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokenEnumsRHVoiceAnna»
# Использовать английский голос
tts.setProperty(‘voice’, EN_VOICE_ID)
tts.say(«Can you hear me say it’s a lovely day?»)
# Теперь — русский
tts.setProperty(‘voice’, RU_VOICE_ID)
tts.say(«А напоследок я скажу»)
tts.runAndWait()
Как озвучить системное время в Windows и Linux

Это крошечное приложение каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Создадим новый файл с именем time_tts.py. Всего, что мы разобрали выше, должно хватить, чтобы вы без проблем прочли и поняли следующий код:
# «Говорящие часы» — программа озвучивает системное время
from datetime import datetime, date, time
import pyttsx3, time
tts = pyttsx3.init()
tts.setProperty(‘voice’, ‘ru’) # Наш голос по умолчанию
tts.setProperty(‘rate’, 150) # Скорость в % (может быть > 100)
tts.setProperty(‘volume’, 0.8) # Громкость (значение от 0 до 1)
def set_voice(): # Найти и выбрать нужный голос по имени
voices = tts.getProperty(‘voices’)
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.setProperty(‘voice’, voice.id)
else:
pass
def say_time(msg): # Функция, которая будет называть время в заданном формате
set_voice() # Настроить голос
tts.say(msg)
tts.runAndWait() # Воспроизвести очередь реплик и дождаться окончания речи
while True:
time_checker = datetime.now() # Получаем текущее время с помощью datetime
if time_checker.second == 0:
say_time(‘{h} {m}’.format(h=time_checker.hour, m=time_checker.minute))
time.sleep(55)
else:
pass
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+Break или Ctrl+C (в Windows и Linux соответственно).
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь оперативную память, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры. А пока посмотрим на другие инструменты.
Обертка для eSpeak NG
Модуль называется py-espeak-ng. Это альтернатива pyttsx3 для случаев, когда вам нужен или доступен только один синтезатор — eSpeak NG. Не дай бог, конечно. Впрочем, для быстрых экспериментов с голосом очень даже подходит. Принцип использования покажется вам знакомым:
from espeakng import ESpeakNG
engine = ESpeakNG()
engine.speed = 150
engine.say(«I’d like to be under the sea. In an octopus’s garden, in the shade!», sync=True)
engine.speed = 95
engine.pitch = 32
engine.voice = ‘russian’
engine.say(‘А теперь Горбатый!’, sync=True)
Обратите внимание на параметр синхронизации реплик sync=True. Без него синтезатор начнет читать все фразы одновременно — вперемешку. В отличие от pyttsx3, обертка espeakng не использует команду runAndWait(), и пропуск параметра sync сбивает очередь чтения.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open(«test.txt», «r»)
data = text_file.read()
tts.say(data, sync=True)
text_file.close()
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
Управляем речью через Speech Dispatcher в Linux
До сих пор по результатам работы нашего кода в Linux выводился один суровый eSpeak. Пришло время позаботиться о друзьях Tux’а и порадовать их сравнительно реалистичными голосами RHVoice. Для этого нам понадобится Speech Dispatcher — аналог MS SAPI. Он позволяет управлять всеми установленными в системе голосовыми движками и вызывать любой из них по необходимости.
Скорее всего Speech Dispatcher есть у вас в системе по умолчанию. Чтобы обращаться к нему из кода Python, надо установить модуль speechd:
sudo apt install python3-speechd
Пробуем выбрать синтезатор RHVoice с помощью «диспетчера» и прочесть текст:
import speechd
tts_d = speechd.SSIPClient(‘test’)
tts_d.set_output_module(‘rhvoice’)
tts_d.set_language(‘ru’)
tts_d.set_rate(50)
tts_d.set_punctuation(speechd.PunctuationMode.SOME)
tts_d.speak(‘И нежный вкус родимой речи так чисто губы холодит’)
tts_d.close()
Ура! Наконец-то наше Linux-приложение говорит голосом, похожим на человеческий. Обратите внимание на метод .set_output_module() — он позволяет выбрать любой установленный движок, будь то espeak, rhvoice или festival. После этого синтезатор прочтет текст голосом, предписанным для данного движка по умолчанию. Если задан только язык — голосом по умолчанию для данного языка.
Получается, чтобы сделать кроссплатформенное приложение с поддержкой синтезатора RHVoice, нужно совместить pyttsx3 и speechd: проверить, в какой системе работает наш код, и выбрать SAPI или Speech Dispatcher. А в любой непонятной ситуации — откатиться на неказистый, но вездеходный eSpeak.
Однако для этого программа должна знать, где работает. Определить текущую ОС и ее разрядность очень легко! Лично я предпочитаю использовать для этого стандартный модуль platform, который не нужно устанавливать:
import platform
system = platform.system() # Вернет тип системы.
bit = platform.architecture() # Вернет кортеж, где разрядность — нулевой элемент
print(system)
print(bit[0])
Пример результата:
Windows
64bit
Кстати, не обязательно решать все за пользователя. На базе pyttsx3 вы при желании создадите меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
Модуль Google TTS — голоса из интернета

Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS(‘Иван Федорович Крузенштерн. Человек и пароход!’, lang=’ru’)
tts.save(‘tts_output.mp3’)
После запуска этого кода в директории, где лежит скрипт, появится запись. Чтобы воспроизвести файл «не отходя от кассы», придется использовать еще какой-то модуль или фреймворк. Годится pygame или pyglet.
Вот листинг приложения, которое построчно читает txt-файлы с помощью связки gtts и PyGame. Я заметила, что для нормальной работы этого скрипта текст из text.txt должен быть в кодировке Windows-1251 (ANSI).
Выводим текст через NVDA

Мы научились озвучивать приложение с помощью установленных в системе синтезаторов. Но что если большинству пользователей эта фишка не нужна, и мы хотим добавить речь исключительно как опцию для слабовидящих? В таком случае не обязательно писать код озвучивания: достаточно передать текст интерфейса другому приложению — экранному диктору.
Одна из самых популярных программ экранного доступа в Windows — бесплатная и открытая NVDA. Для связи с ней к нашему приложению нужно привязать библиотеку nvdaControllerClient (есть варианты для 32- и 64-разрядных систем). Узнавать разрядность системы вы уже умеете.
Еще для работы с экранным диктором нам понадобятся модули ctypes и time. Создадим файл nvda.py, где напишем модуль связи с NVDA:
import time, ctypes, platform
# Загружаем библиотеку клиента NVDA
bit = platform.architecture()
if bit[0] == ’32bit’:
clientLib = ctypes.windll.LoadLibrary(‘nvdaControllerClient32.dll’)
elif bit[0] == ’64bit’:
clientLib = ctypes.windll.LoadLibrary(‘nvdaControllerClient64.dll’)
else:
errorMessage=str(ctypes.WinError(res))
ctypes.windll.user32.MessageBoxW(0,u»Ошибка! Не удалось определить разрядность системы!»,0)
# Проверяем, запущен ли NVDA
res = clientLib.nvdaController_testIfRunning()
if res != 0:
errorMessage=str(ctypes.WinError(res))
ctypes.windll.user32.MessageBoxW(0,u»Ошибка: %s»%errorMessage,u»нет доступа к NVDA»,0)
def say(msg):
clientLib.nvdaController_speakText(msg)
time.sleep(1.0)
def close_speech():
clientLib.nvdaController_cancelSpeech()
Теперь эту заготовку можно применить в коде основной программы:
import nvda
nvda.say(‘Начать игру’)
# … другие реплики или сон
nvda.close_speech()
Если NVDA неактивна, после запуска кода мы увидим окошко с сообщением об ошибке, а если работает — услышим от нее заданный текст.
Плюс подхода в том, что незрячий пользователь будет слышать тот голос, который сам выбрал и настроил в NVDA.
Заключение
Ваша программа уже глаголет устами хотя бы одного из установленных синтезаторов? Поздравляю! Как видите, это не слишком сложно и «в выигрыше даже начинающий». Еще больше радуют перспективы использования TTS в ваших проектах. Все, что можно вывести как текст, можно и озвучить.
Представьте утилиту, которая при внезапной проблеме с экраном телефона или монитора сориентирует пользователя по речевым подсказкам, поможет спокойно сохранить данные и штатно завершить работу. Или как насчет прослушивания входящей почты, когда вы не за монитором? Напишите, когда, на ваш взгляд, TTS полезна, а когда только раздражает. Говорящая программа с какими функциями пригодилась бы вам?
История о том, как разработать технологию для синтеза речи с бюджетом 3 миллиона рублей (с примерами и этапами).
Всем привет. Мы уже писали здесь статью об использовании голосового бота в колл-центре транспортной компании и сейчас мы пошли дальше. Мы решили создать собственный синтез речи, способный конкурировать с такими гигантами как Google, Yandex, Amazon и относительно новыми игроками на этом рынке как Тинькофф, АБК и Vera Voice.
Пару слов о нас
Мы команда из 35 человек децентрализованно работающих по разным городам и странам. В 2016 году мы начали работать под брендом Twin. Тогда мы начинали с простых голосовых ботов. Сейчас это уже более сложные модели со сложными сценариями, машинным обучением и гибкой маршрутизацией в телефонии. Не буду подробно останавливаться на этом, гораздо подробнее и интереснее это описано на нашем сайте.
Сейчас я немного опишу вводную информацию по синтезу речи в 2020 году: что есть на рынке, как это используется, для чего, сколько стоит и какие проблемы возникают. Кому эта информация не интересна, примеры синтеза начинаются после заголовка “Первые результаты”. Приятного прочтения!
Почему синтез, а не записанный голос?
Сейчас синтез речи используется в основном в различных умных колонках, голосовых помощниках и в меньшей степени для уведомлений и общения с клиентом. Мы подробнее остановимся именно на синтезе для телефонии.
Почему в звонках используется синтез речи? При общении с голосовым ботом или при уведомлении от голосового бота часто озвучиваются различные переменные, масштаб вариаций которых может достигать несколько миллионов значений. Например, уведомление о доставке груза, где используются ФИО, даты, город, улица, числа. Одних только имён может быть около 60 тысяч и озвучить всё диктором будет трудоемкой задачей и помимо этого добавит зависимости от одного диктора. Таким образом, для гибкости и оперативности при разработке голосовых ботов синтез подходит наилучшим образом нежели предзаписанная речь.
Плюсы и минусы синтеза речи и записи диктора
Синтез
Плюсы: позволяет синтезировать речь на основе любого текста в реальном времени.
Минусы: при большом объёме синтезированной речи очень сложно придать ей необходимую и естественную эмоциональную окраску.
Запись
Плюсы: мы можем придать любой эмоциональный окрас, скорость и тембр речи, объяснив диктору, что мы в итоге хотим услышать.
Минусы: очень сложно и трудозатрано предзаписать большой объём переменной информации и учесть все возможные доработки сценариев бота.
При совмещении плюсов и минусов предзаписи и индивидуального синтеза речи мы получим идеальное сочетание.
Вот пример стороннего синтеза при звонке
Кто предоставляет данную технологию сейчас
К 2020 году на рынке сформировались несколько глобальных игроков и несколько локальных со своими плюсами и минусами.
Глобальные: Google, Amazon
Локальные: Yandex, Tinkoff, АБК, Vera Voice
В конце 2019 года мы задумались о реализации собственного синтеза. Да, в краткосрочной перспективе это получается невыгодно, но в перспективе от 2-х лет эта история очень интересна для нас. Дополнительным толчком также стали запросы от клиентов с потребностью синтеза речи определенного диктора. То есть у клиентов возникла потребность создать гибридный вариант голоса при звонках, когда часть диалога происходит с использованием предзаписанных реплик, а переменные синтезируются на основе голоса их диктора.
Сколько стоит разработка собственного синтеза речи?
Итак, на первый взгляд эта идея кажется обязательной для компании, работающей в сфере голосовых ботов, но цена реализации неизвестна. В процессе исследования мы поняли, что реализовать синтез мы можем, но его качество в большей степени зависит от собранных данных исходного голоса и его доработок, потому что основные и ключевые технологии создания синтеза открыты и доступны.
Для сравнения, в 2019 Tinkoff только на свой суперкомпьютер «Колмогоров» потратили около 1 млн. долларов без расходов на разработку программного обеспечения. О стоимости разработки ПО можно только гадать, информацию в открытых источниках мне не удалось найти.
Что мы хотели получить в результате?
Нам нужен был качественный синтез со стоимостью разработки не более 3 млн. рублей и возможностью активно масштабировать эту модель в течении 1 года, а дальше пополнять уже новый бюджет за счет новых клиентов. Ключевыми критериями были:
- Стоимость разработки и сопровождения ПО
-
Приемлемое качество для использования в телефонии
-
Возможность создавать синтез на основе 1 часа речи диктора
Решение
Практически любой синтез речи на базе нейронных сетей состоит из 3 основных модулей:
- Нормализация текста.
- Синтез спектрограммы из текста.
- Синтез аудиоданных из спектрограммы (вокодер).
Для своей реализации синтеза речи мы решили дорабатывать Tacotron 2 и WaveGlow под свои нужды.
Вот что из этого вышло
Первые результаты.
Во время первых попыток обучения Tacotron 2 мы разбирались с архитектурой нейронной сети: как с ней работать, как её обучать и использовать. Первые результаты нас не устроили, но потом удалось добиться устойчивого синтеза с минимальными проблемами. За исключением того, что спектрограмма переводилась в аудиоданные с помощью алгоритма Гриффин-Лима, который даёт крайне сильный «металлический отблеск» в полученной синтезированной речи.
Для наглядности я прикреплю к каждому из этапов примеры синтеза и оригинальной записи диктора.
Синтез
Оригинал
Второй этап
Звучание синтеза было явно на уровне крайне сырого прототипа и вряд ли бы устроило какого-либо клиента. На начальном этапе мы сомневались в привлекательности будущего результата, поэтому решили пойти дальше и разбираться с более качественными подходами для перевода спектрограммы в аудиоданные. Теперь синтез речи стал полностью нейросетевым и звучит намного приятнее, естественнее. Так же были вручную проверены и очищены данные для обучения, что немного упростило и ускорило процесс обучения.
Синтез
Оригинал
Третий этап
Добавили небольшие изменения в архитектуре нейронной сети, пересмотрели подходы к обучению моделей, подготовили аудиозаписи для обучения, добавили перевод слов в набор фонем. Благодаря этому получилось обучить модель всего на 3-х часах аудиозаписей, вместо 10-20 часов ранее.
Синтез
Оригинал
Четвертый этап
Русский язык
На этом этапе мы провели более масштабную работу. Добавили ещё несколько изменений в архитектуре нейронной сети, оптимизировали процесс подготовки аудиозаписей и обучения, добавили расстановку ударений и обработку ударных и безударных фонем. Существенно доработали процесс обучения моделей, благодаря которым получилось обучить модель всего на 1-м часе аудиозаписей без особой потери в качестве и стабильности синтеза.
Английский язык
Параллельно мы записали 1 час с англоговорящим диктором и перенесли полученный результата с русского языка на английский. Архитектура нейронной сети и процессы обучения такие же, как на русском языке, но пока что без перевода слов в набор фонем и поддержки ударений. Модель для английского языка обучена так же на 1-ом часе аудиозаписей.
Синтез на английском языке
А теперь текущий вариант синтеза речи на русском языке
Синтез 1
Оригинал 1
Оригинал 2
Оригинал 3
Оригинал 4
Оригинал 5
Заключение
Раньше для озвучивания переменных нам нужно было выбирать максимально похожий синтезированный голос у сторонних сервисов, но это сильно выбивалось из контекста диалога. Теперь для создания синтеза одного диктора требуется не более 1-го часа записи.
Можем ли мы синтезировать голос актеров и публичных личностей для использования в киноиндустрии? Скорее можем, но технология предполагает более масштабное и технологичное применение в голосовых ботах, где объем синтеза гораздо больше.
На текущий момент мы продолжаем двигаться в сторону улучшения качества синтеза, так как есть ещё ряд идей как сделать голос ещё реалистичнее. Запустили несколько пилотных проектов с текущими российскими клиентами и получили несколько запросов от зарубежных компаний.
Спасибо, что дочитали до конца. В комментариях будем рады ответить на вопросы или выслушать предложения и идей.
Синтезатор речи «для роботов» с нуля +17
Программирование, Алгоритмы
Рекомендация: подборка платных и бесплатных курсов таргетированной рекламе — https://katalog-kursov.ru/

Давным-давно посетила меня идея создать синтезатор речи с «голосом робота», как, например, в песне Die Roboter группы Kraftwerk. Поиски информации по «голосу робота» привели к историческому факту, что подобное звучание синтетической речи характерно для вокодеров, которые используются для сжатия речи (2400 — 9600 бит/c). Голос человека, синтезированный вокодером, отдает металлическим звучанием и становится похожим на тот самый «голос робота». Музыкантам понравился данный эффект искажения речи, и они стали активно его использовать в своем творчестве.
Поиски информации по реализации вокодера вывели меня на книгу «Теория и применение цифровой обработки сигналов», где расписано почти все, что необходимо для создания собственного синтезатора речи на основе вокодера.
Небольшое замечание касательно выбора способа реализации синтеза речи
Конечно, можно было бы и не париться с созданием вокодера, а просто сделать базу заранее записанных звуков всех фонем и проигрывать их в соответствии с текстом. Данный способ мне не был интересен, поэтому я решил сделать синтезатор речи именно с синтезом всех звуков, как согласных, так и гласных. Вокодер для этих целей был выбран потому, что его проще обучить, чем формантный синтезатор речи, хотя звучание в обоих случаях было бы именно то, которое мне нужно. К тому же, синтезирование звуков, возможно, позволит реализовать синтезатор речи на базе микроконтроллера stm32 без внешней памяти! Вопрос тут скорее в том, хватит ли скорости работы МК.
Под спойлером представлен результат обработки речи вокодером
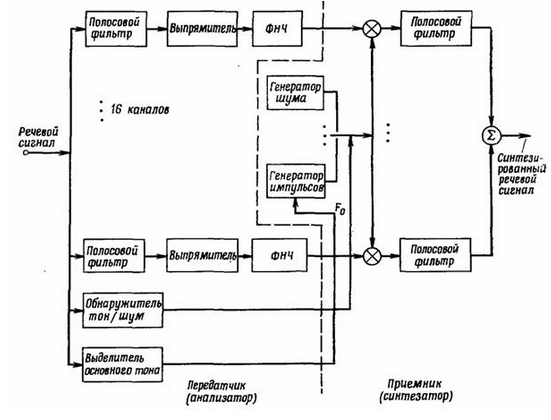
Краткая теория работы вокодера
Самая основная часть вокодера — это гребенка полосовых фильтров. Именно она формирует спектр синтетической речи или, наоборот, определяет уровни спектра естественной человеческой речи в приемной части устройства. Как передающая, так и принимающая часть вокодера содержит гребенку полосовых фильтров.
Принимающая человеческую речь часть вокодера также определяет, помимо спектра звука, является ли звук шумовым, или у него есть тон. Для тона определяется его период. Сигналы с выходов полосовых фильтров детектируются, пропускаются через ФНЧ и используются в дальнейшем в качестве коэффициентов для модуляции сигналов на полосовых фильтрах синтезирующей части вокодера.
Синтезирующая часть вокодера содержит генератор шума и тона (читай: генератор случайной числовой последовательности на основе сдвигового регистра и генератора меандра), а также переключатель между этими двумя генераторами. Сигнал от одного из двух генераторов подается на вход гребенки полосовых фильтров. Для каждого фильтра на входе сигнал от генератора тона или шума модулируется соответствующим коэффициентом. И наконец, с выхода всех фильтров суммируем сигнал и получаем синтезированную речь.
Если кто не понял мое описание работы вокодера, вот блок-схема:
Не все так просто
Чтобы вокодер
хоть как-то
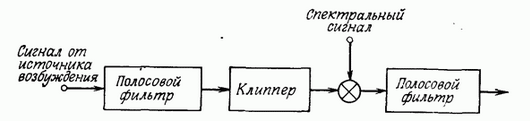
понятно звучал, нужно выполнить пару требований к его полосовым фильтрам. Нет времени объяснять, просто поверье, что нужно использовать БИХ фильтры Бесселя (пруфы на 749 странице). Также, нужно распределить спектр речи неравномерно по фильтрам, особенно если у нас их немного (в моей реализации вокодера их всего 16 штук). Есть еще одна прелюбопытнейшая вещь, с которой вы можете ознакомиться все в той же книжке. А именно, представим, что сначала мы пропускаем сигнал от генератора тона или шума через гребенку фильтров, затем с выхода каждого фильтра ограничиваем сигнал двумя уровнями -1 и +1 и затем модулируем сигналы и снова пропускаем каждый сигнал через такой же фильтр, как ранее. По идее, такая схема не должна давать ощутимой разницы в синтезируемой речи. Тем не менее, такой прием выравнивания спектра существенно улучшает синтетическую речь вокодера. Почему так, лучше прочесть в книжке. Ну а тем, кому лень читать, скажу кратко: это из-за флуктуаций речи человека. На картинке снизу представлена блок-схема «улучшения» вокодера.
Что же касательно того, как распределить частоты между фильтрами… Основные частоты человеческой речи находятся в диапазоне примерно до 4-5 кГц (очень примерно). Я взял предел в 4 кГц и, используя психофизическую единицу измерения высоты звука «мел», распределил равномерно, правда не по герцам, а по мелам.
Что дает такой способ синтеза речи?
Если коэффициенты модуляции полосовых фильтров «смещать» по номеру фильтра, можно получить из женского голоса мужской. И это несмотря на то, что диапазоны фильтров (в моей реализации вокодера) в частотной области распределены не равномерно.
Также можно менять интонацию речи, можно вообще все менять. Единственный минус остается
отстойное
низкое качество речи.
Прослушать то, как меняется женская речь в мужскую, можно тут:
женский голос без изменений (монотонный)
мужской голос из женского (монотонный)
А если мужской голос сделать еще более мужским?
очень мужской голос (монотонный)
Немного кода
Весь код я пока выкладывать не буду (так как еще не дописал синтезатор речи — будет вторая статья). Ниже представлен код для определения высоты основного тона (также можно определить, тон или шум). Для этого измеряется энтропия сигнала, энтропия сигнала после ФНЧ на 600 Гц (в частотной области тона), а также число правильных совпадений в определителе периода тона.
Код определения высоты основного тона.
#include <math.h>
#include <stdio.h>
/*
speesy_Entropy_f - возвращает энтропию сигнала (функция не моя)
speesy_GetBasicTone - получить высоту основного тона
speesy_GetAllCoincidence - число совпадений в функции определения высоты основного тона
speesy_GetBasicToneEntropy - энтропия сигнала в области высоты основного тона
speesy_SetFreqMeander - установить частоту меандра
speesy_Meander - возвращает сигнал меандра
*/
#define SPEESY_SAMPLE_FREQ8 8000
#define SPEESY_SAMPLE_FREQ16 16000
#define SPEESY_SAMPLE_FREQ SPEESY_SAMPLE_FREQ16
#define SPEESY_MEANDER_MAX 100
#define FOR_FLOAT_EPSILON 1.19209e-007
static float speesy_all_coincidence = 0; //число правильных совпадений в определителе периода основного тона
static float speesy_fliter600_Entropy = 1.0;
static float speesy_meander_period = 0.01;//для генератора меандра
float speesy_Entropy_f(const float* source, unsigned long int start, unsigned long int finish, unsigned char binsCount, float minRaw, float maxRaw) {
float entropy = 0;
float binSize = fabs(maxRaw - minRaw) / (float)binsCount;
//FOR_FLOAT_EPSILON == numeric_limits<float>::epsilon()
if (fabs(binSize) < FOR_FLOAT_EPSILON) {
return 0;
}
//float* p = new float[binsCount];
float p[256];
for (unsigned char i = 0; i < binsCount; i++) {
p[i] = 0.0;
}
// Calculate probabilities
unsigned char index;
float value;
for (unsigned long int i = start; i <= finish; i++) {
value = source[i]; //for 8-bit data
index = floor((value - minRaw) / binSize);
if (index >= binsCount) {
index = binsCount - 1;
}
p[index] += 1.0;
}
unsigned char Normalize_size = finish - start + 1;
for (unsigned char i = 0; i < binsCount; i++) {
p[i] /= Normalize_size;
}
for (unsigned char i = 0; i < binsCount; i++) {
if (p[i] > FOR_FLOAT_EPSILON) {
entropy += p[i] * log2(p[i]);
}
}
entropy = -entropy;
return entropy;
}
float speesy_GetBasicTone(float source) {
static float matrix[6][6] ={0,0,0,0,0,0,
0,0,0,0,0,0,
0,0,0,0,0,0,
0,0,0,0,0,0,
0,0,0,0,0,0,
0,0,0,0,0,0};
const float max_detector_p = 0.0255;
const float min_detector_p = 0.0016;
static float detector_p[6] = {min_detector_p};
static float detector_old_p[6] = {min_detector_p};
static float detector_t[6] = {0};
static float detector_tay[6] = {0.016};
static float detector_t_end = 0;
//static float detector_beta[6] = {0};
static float detector_value[6] = {0};
float f_data = 0;
//char detector_p_t0_f = 0;
static float sig_old = 0;
static char sig_p = 0;
static char sig_m = 0;
static unsigned short tim160 = 0;
float detector_m1;
float detector_m2;
float detector_m3;
float detector_m4;
float detector_m5;
float detector_m6;
int detector_data = 0;
static float detector_old_m1;
static float detector_old_m4 = 0;
static char speesy_tone_i = 0;
static char speesy_tone_x = 0;
static char speesy_tone_y = 0;
static char speesy_tone_inter = 0;
//char n_coincidence[4] ={0};
char n_coincidence_matrix[6][4] ={0};
static float out_t;
#if SPEESY_SAMPLE_FREQ == SPEESY_SAMPLE_FREQ8
static float source_data[16] = {0};
const int max_source_data = 16;
const float p_conts = 0.000125;
#endif // SPEESY_SAMPLE_FREQ
#if SPEESY_SAMPLE_FREQ == SPEESY_SAMPLE_FREQ16
static float source_data[32] = {0};
const int max_source_data = 32;
const float p_conts = 0.0000625;
#endif // SPEESY_SAMPLE_FREQ
/*************Filter 600 Hz**********************/
#if SPEESY_SAMPLE_FREQ == SPEESY_SAMPLE_FREQ8
const float filter600_ACoef1[5] = {
0.00161978575856732190,
0.00647914303426928760,
0.00971871455140393280,
0.00647914303426928760,
0.00161978575856732190
};
const float filter600_BCoef1[4] = {
-2.63228606617055720000,
2.68865140959361830000,
-1.25580694576241330000,
0.22536111137571077000
};
#endif // SPEESY_SAMPLE_FREQ
#if SPEESY_SAMPLE_FREQ == SPEESY_SAMPLE_FREQ16
const float filter600_ACoef1[5] = {
0.00013538805748957640,
0.00054155222995830559,
0.00081232834493745844,
0.00054155222995830559,
0.00013538805748957640
};
const float filter600_BCoef1[4] = {
-3.29078386336302660000,
4.09122986596582550000,
-2.27618508727807440000,
0.47792443748067198000
};
#endif // SPEESY_SAMPLE_FREQ
static float filter600_y[5] = {0}; //output samples
static float filter600_x[5] = {0}; //input samples
static float out_filter600[240] = {0};
short out_i = 0;
filter600_x[4] = filter600_x[3];
filter600_y[4] = filter600_y[3];
filter600_x[3] = filter600_x[2];
filter600_y[3] = filter600_y[2];
filter600_x[2] = filter600_x[1];
filter600_y[2] = filter600_y[1];
filter600_x[1] = filter600_x[0];
filter600_y[1] = filter600_y[0];
filter600_x[0] = source;
filter600_y[0] = filter600_ACoef1[0] * filter600_x[0];
filter600_y[0] += filter600_ACoef1[1] * filter600_x[1] - filter600_BCoef1[0] * filter600_y[1];
filter600_y[0] += filter600_ACoef1[2] * filter600_x[2] - filter600_BCoef1[1] * filter600_y[2];
filter600_y[0] += filter600_ACoef1[3] * filter600_x[3] - filter600_BCoef1[2] * filter600_y[3];
filter600_y[0] += filter600_ACoef1[4] * filter600_x[4] - filter600_BCoef1[3] * filter600_y[4];
/***************End Filter 600 Hz*********************/
for (out_i = 239;out_i>0; out_i--) {
out_filter600[out_i] = out_filter600[out_i - 1];
}
out_filter600[0] = filter600_y[0];
if (tim160 < 160) {tim160 = tim160 + 1;}
else {
tim160 = 0;
speesy_fliter600_Entropy = speesy_Entropy_f(out_filter600,0,159,255,-32768,32768);
speesy_fliter600_Entropy = speesy_Entropy_f(out_filter600,160,239,255,-32768,32768);
}
detector_m1 = 0;
detector_m2 = 0;
detector_m3 = 0;
detector_m4 = 0;
detector_m5 = 0;
detector_m6 = 0;
//printf("nSpeesy max_source_data = %dn",max_source_data);
if (filter600_y[0] >= 0) {
if (filter600_y[0] > sig_old) {sig_p = 1;}
else {
if (sig_p == 1) {
sig_p = 0;
detector_m1 = filter600_y[0];
if (detector_m1 > detector_old_m1) {
detector_m3 = detector_m1 - detector_old_m1;
} else detector_m3 = 0;
detector_m2 = detector_m1 + detector_old_m4;
detector_old_m1 = detector_m1;
}
}
sig_old = filter600_y[0];
} else {
if ((-filter600_y[0]) > sig_old) {sig_m = 1;}
else {
if (sig_m == 1) {
sig_m = 0;
detector_m4 = -filter600_y[0];
if (detector_m4 > detector_old_m4) {
detector_m6 = detector_m4 - detector_old_m4;
} else detector_m6 = 0;
detector_m5 = detector_m4 + detector_old_m1;
detector_old_m4 = detector_m4;
}
}
sig_old = -filter600_y[0];
}
/*****************************************************/
//ИОН6
if (detector_t[5] > detector_tay[5]) { //если время больше tay
f_data = detector_value[5]*(exp(-(detector_t[5] - detector_tay[5])/(detector_p[5]/0.695))); //экспоненциальный разряд
if (detector_m6 > f_data) { //больше уровня
detector_value[5] = detector_m6; //обновляем уровень
detector_p[5] = (detector_t[5] + detector_p[5])/2; //среднее значение периода
if (detector_p[5] > max_detector_p) detector_p[5] = max_detector_p;
if (detector_p[5] < min_detector_p) detector_p[5] = min_detector_p;
detector_tay[5] = 0.4*detector_p[5]; //новое тау
detector_t[5] = 0;
//detector_p_t0_f = 1;
matrix[5][2] = matrix[5][1];
matrix[5][1] = matrix[5][0];
matrix[5][0] = detector_p[5];
} else {
detector_t[5] = detector_t[5] + p_conts; //инкремент времени
}
} else {
detector_t[5] = detector_t[5] + p_conts;
}
//ИОН5
if (detector_t[4] > detector_tay[4]) { //если время больше tay
f_data = detector_value[4]*(exp(-(detector_t[4] - detector_tay[4])/(detector_p[4]/0.695))); //экспоненциальный разряд
if (detector_m5 > f_data) { //больше уровня
detector_value[4] = detector_m5; //обновляем уровень
detector_p[4] = (detector_t[4] + detector_p[4])/2; //среднее значение периода
if (detector_p[4] > max_detector_p) detector_p[4] = max_detector_p;
if (detector_p[4] < min_detector_p) detector_p[4] = min_detector_p;
detector_tay[4] = 0.4*detector_p[4]; //новое тау
detector_t[4] = 0;
//detector_p_t0_f = 1;
matrix[4][2] = matrix[4][1];
matrix[4][1] = matrix[4][0];
matrix[4][0] = detector_p[4];
} else {
detector_t[4] = detector_t[4] + p_conts; //инкремент времени
}
} else {
detector_t[4] = detector_t[4] + p_conts;
}
//ИОН4
if (detector_t[3] > detector_tay[3]) { //если время больше tay
f_data = detector_value[3]*(exp(-(detector_t[3] - detector_tay[3])/(detector_p[3]/0.695))); //экспоненциальный разряд
if (detector_m4 > f_data) { //больше уровня
detector_value[3] = detector_m4; //обновляем уровень
detector_p[3] = (detector_t[3] + detector_p[3])/2; //среднее значение периода
if (detector_p[3] > max_detector_p) detector_p[3] = max_detector_p;
if (detector_p[3] < min_detector_p) detector_p[3] = min_detector_p;
detector_tay[3] = 0.4*detector_p[3]; //новое тау
detector_t[3] = 0;
//detector_p_t0_f = 1;
matrix[3][2] = matrix[3][1];
matrix[3][1] = matrix[3][0];
matrix[3][0] = detector_p[3];
} else {
detector_t[3] = detector_t[3] + p_conts; //инкремент времени
}
} else {
detector_t[3] = detector_t[3] + p_conts;
}
//ИОН3
if (detector_t[2] > detector_tay[2]) { //если время больше tay
f_data = detector_value[2]*(exp(-(detector_t[2] - detector_tay[2])/(detector_p[2]/0.695))); //экспоненциальный разряд
if (detector_m3 > f_data) { //больше уровня
detector_value[2] = detector_m3; //обновляем уровень
detector_p[2] = (detector_t[2] + detector_p[2])/2; //среднее значение периода
if (detector_p[2] > max_detector_p) detector_p[2] = max_detector_p;
if (detector_p[2] < min_detector_p) detector_p[2] = min_detector_p;
detector_tay[2] = 0.4*detector_p[2]; //новое тау
detector_t[2] = 0;
//detector_p_t0_f = 1;
matrix[2][2] = matrix[2][1];
matrix[2][1] = matrix[2][0];
matrix[2][0] = detector_p[2];
} else {
detector_t[2] = detector_t[2] + p_conts; //инкремент времени
}
} else {
detector_t[2] = detector_t[2] + p_conts;
}
//ИОН2
if (detector_t[1] > detector_tay[1]) { //если время больше tay
f_data = detector_value[1]*(exp(-(detector_t[1] - detector_tay[1])/(detector_p[1]/0.695))); //экспоненциальный разряд
if (detector_m2 > f_data) { //больше уровня
detector_value[1] = detector_m2; //обновляем уровень
detector_p[1] = (detector_t[1] + detector_p[1])/2; //среднее значение периода
if (detector_p[1] > max_detector_p) detector_p[1] = max_detector_p;
if (detector_p[1] < min_detector_p) detector_p[1] = min_detector_p;
detector_tay[1] = 0.4*detector_p[1]; //новое тау
detector_t[1] = 0;
//detector_p_t0_f = 1;
matrix[1][2] = matrix[1][1];
matrix[1][1] = matrix[1][0];
matrix[1][0] = detector_p[1];
} else {
detector_t[1] = detector_t[1] + p_conts; //инкремент времени
}
} else {
detector_t[1] = detector_t[1] + p_conts;
}
//ИОН1
if (detector_t[0] > detector_tay[0]) { //если время больше tay
f_data = detector_value[0]*(exp(-(detector_t[0] - detector_tay[0])/(detector_p[0]/0.695))); //экспоненциальный разряд
if (detector_m1 > f_data) { //больше уровня
detector_value[0] = detector_m1; //обновляем уровень
detector_p[0] = (detector_t[0] + detector_p[0])/2; //среднее значение периода
if (detector_p[0] > max_detector_p) detector_p[0] = max_detector_p;
if (detector_p[0] < min_detector_p) detector_p[0] = min_detector_p;
detector_tay[0] = 0.4*detector_p[0]; //новое тау
detector_t[0] = 0;
//detector_p_t0_f = 1;
matrix[0][2] = matrix[0][1];
matrix[0][1] = matrix[0][0];
matrix[0][0] = detector_p[0];
} else {
detector_t[0] = detector_t[0] + p_conts; //инкремент времени
}
} else {
detector_t[0] = detector_t[0] + p_conts;
}
/************************************************************************/
if (detector_t_end == 0) {
for (speesy_tone_x = 0;speesy_tone_x<6;speesy_tone_x++) {
matrix[speesy_tone_x][3] = matrix[speesy_tone_x][0] + matrix[speesy_tone_x][1];
matrix[speesy_tone_x][4] = matrix[speesy_tone_x][1] + matrix[speesy_tone_x][2];
matrix[speesy_tone_x][5] = matrix[speesy_tone_x][1] + matrix[speesy_tone_x][2] + matrix[speesy_tone_x][0];
}
for (speesy_tone_inter = 0; speesy_tone_inter<4;speesy_tone_inter++) {
n_coincidence_matrix[0][speesy_tone_inter] = 0;
n_coincidence_matrix[1][speesy_tone_inter] = 0;
n_coincidence_matrix[2][speesy_tone_inter] = 0;
n_coincidence_matrix[3][speesy_tone_inter] = 0;
n_coincidence_matrix[4][speesy_tone_inter] = 0;
n_coincidence_matrix[5][speesy_tone_inter] = 0;
for (speesy_tone_x = 0;speesy_tone_x<6;speesy_tone_x++) {
for (speesy_tone_y = 0;speesy_tone_y<6;speesy_tone_y++) {
//printf("nValue_matrix %f",matrix[speesy_tone_x][speesy_tone_y]);
//printf("nmatrix %f",(float)matrix[speesy_tone_x][speesy_tone_y]);
for (speesy_tone_i = 0;speesy_tone_i<6;speesy_tone_i++) {
//printf("nmatrix %f",(float)matrix[speesy_tone_x][speesy_tone_y]);
//printf("nspeesy_tone_i %d",speesy_tone_i);
//printf("nsr matrix %f",(float)matrix[speesy_tone_i][0]);
if (((speesy_tone_y != 0)&(speesy_tone_x!=speesy_tone_i))|(speesy_tone_y > 0))
if ((matrix[speesy_tone_i][0] >= 0.0016)&(matrix[speesy_tone_i][0] <= 0.0031)) {
f_data = 0.0001*((float)speesy_tone_inter + 1.0);
if ((((float)matrix[speesy_tone_i][0] + (float)f_data) >= (float)matrix[speesy_tone_x][speesy_tone_y])&
(((float)matrix[speesy_tone_i][0] - (float)f_data) <= (float)matrix[speesy_tone_x][speesy_tone_y])) {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] = n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] + 1;
//printf("ncoincidence 0.0016 - 0.0031");
}
} else
if ((matrix[speesy_tone_i][0] > 0.0031)&(matrix[speesy_tone_i][0] <= 0.0063)) {
f_data = 0.0002*((float)speesy_tone_inter + 1.0);
if ((((float)matrix[speesy_tone_i][0] + (float)f_data) >= (float)matrix[speesy_tone_x][speesy_tone_y])&
(((float)matrix[speesy_tone_i][0] - (float)f_data) <= (float)matrix[speesy_tone_x][speesy_tone_y])) {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] = n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] + 1;
//printf("ncoincidence 0.0031 - 0.0063");
}
} else
if ((matrix[speesy_tone_i][0] > 0.0063)&(matrix[speesy_tone_i][0] <= 0.0127)) {
f_data = 0.0004*((float)speesy_tone_inter + 1.0);
if ((((float)matrix[speesy_tone_i][0] + (float)f_data) >= (float)matrix[speesy_tone_x][speesy_tone_y])&
(((float)matrix[speesy_tone_i][0] - (float)f_data) <= (float)matrix[speesy_tone_x][speesy_tone_y])) {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] = n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] + 1;
//printf("ncoincidence 0.0063 - 0.0127");
}
} else
if ((matrix[speesy_tone_i][0] > 0.0127)&(matrix[speesy_tone_i][0] <= 0.0255)) {
f_data = 0.0008*((float)speesy_tone_inter + 1.0);
if (((matrix[speesy_tone_i][0] + f_data) >= matrix[speesy_tone_x][speesy_tone_y])&
((matrix[speesy_tone_i][0] - f_data) <= matrix[speesy_tone_x][speesy_tone_y])) {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] = n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] + 1;
//printf("ncoincidence 0.0127 - 0.0255");
}
} else {
//printf("nNO coincidence");
}
//printf("ncoincidence %d",n_coincidence_matrix[speesy_tone_i][speesy_tone_inter]);
} //end for
} //end for
for (speesy_tone_inter = 0; speesy_tone_inter<4;speesy_tone_inter++) {
for (speesy_tone_i = 0;speesy_tone_i<6;speesy_tone_i++) {
//printf("nDo mat_ton %d",(int)n_coincidence_matrix[speesy_tone_i][speesy_tone_inter]);
}
}
if (speesy_tone_inter == 0) {
for (speesy_tone_i = 0;speesy_tone_i<6;speesy_tone_i++) {
if (n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] >= 1) {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] -= 1;
} else {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] = 0;
}
}
} else
if (speesy_tone_inter == 1) {
for (speesy_tone_i = 0;speesy_tone_i<6;speesy_tone_i++) {
if (n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] >= 2) {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] -= 2;
} else {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] = 0;
}
}
} else
if (speesy_tone_inter == 2) {
for (speesy_tone_i = 0;speesy_tone_i<6;speesy_tone_i++) {
if (n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] >= 5) {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] -= 5;
} else {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] = 0;
}
}
} else
if (speesy_tone_inter == 3) {
for (speesy_tone_i = 0;speesy_tone_i<6;speesy_tone_i++) {
if (n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] >= 7) {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] -= 7;
} else {
n_coincidence_matrix[speesy_tone_i][speesy_tone_inter] = 0;
}
}
}
} //end for
} //end for () for inter
out_t = 0;
speesy_tone_x = 0;
for (speesy_tone_inter = 0; speesy_tone_inter<4;speesy_tone_inter++) {
for (speesy_tone_i = 0;speesy_tone_i<6;speesy_tone_i++) {
//printf("n mat_ton %d",(int)n_coincidence_matrix[speesy_tone_i][speesy_tone_inter]);
if (speesy_tone_x < n_coincidence_matrix[speesy_tone_i][speesy_tone_inter]) {
speesy_tone_x = n_coincidence_matrix[speesy_tone_i][speesy_tone_inter];
out_t = matrix[speesy_tone_i][0];
}
}
}
speesy_all_coincidence = speesy_tone_x;
} // end if
detector_t_end = detector_t_end + p_conts;
if (detector_t_end > 0.01) detector_t_end = 0;
return out_t;
}
float speesy_GetAllCoincidence(void) {
return speesy_all_coincidence;
}
float speesy_GetBasicToneEntropy(void) {
return speesy_fliter600_Entropy;
}
void speesy_SetFreqMeander(float freq) {
if (freq > 0) {
speesy_meander_period = (1.0/freq)/2;
}
}
signed char speesy_Meander(void) {
static float tim = 0;
static signed char out = SPEESY_MEANDER_MAX;
if (tim < speesy_meander_period) {
tim = tim + 0.0000625;
} else {
tim = 0;
out = -out;
}
return out;
}
А так же код гребенки полосовых фильтров.
#define SPEESY_NCOEF 4
#define SPEESY_MAXCAN 16
#define SPEESY_SAMPLE_FREQ8 8000
#define SPEESY_SAMPLE_FREQ16 16000
#define SPEESY_SAMPLE_FREQ SPEESY_SAMPLE_FREQ16
#if SPEESY_SAMPLE_FREQ == SPEESY_SAMPLE_FREQ16
//const float speesy_gain_correction_factor[16] = {1};
//for 0-88 Hz
const float ACoef1[SPEESY_NCOEF+1] = {
0.00000010368236408362,
0.00000041472945633450,
0.00000062209418450175,
0.00000041472945633450,
0.00000010368236408362
};
const float BCoef1[SPEESY_NCOEF] = {
-3.89262720221970990000,
5.68304206565440850000,
-3.68807460061232460000,
0.89766108913372833000
};
//for 88-188 Hz ---
const float ACoef2[SPEESY_NCOEF+1] = {
0.00046664702180067459,
0.00000000000000000000,
-0.00093329404360134919,
0.00000000000000000000,
0.00046664702180067459
};
const float BCoef2[SPEESY_NCOEF] = {
-3.92772838537582160000,
5.78986681239677910000,
-3.79636811635581890000,
0.93423598091247251000
};
//for 188-300 Hz
const float ACoef3[SPEESY_NCOEF+1] = {
0.00068858979234044106,
0.00000000000000000000,
-0.00137717958468088210,
0.00000000000000000000,
0.00068858979234044106
};
const float BCoef3[SPEESY_NCOEF] = {
-3.90771680345434060000,
5.74278248379999570000,
-3.76163133600848760000,
0.92663841158343707000
};
//for 300-426 Hz
const float ACoef4[SPEESY_NCOEF+1] = {
0.00088886359477686550,
0.00000000000000000000,
-0.00177772718955373100,
0.00000000000000000000,
0.00088886359477686550
};
const float BCoef4[SPEESY_NCOEF] = {
-3.87697578244056950000,
5.67379106513293690000,
-3.71429576416733910000,
0.91785164973031175000
};
//for 426-569 Hz
const float ACoef5[SPEESY_NCOEF+1] = {
0.00089752885269638212,
0.00000000000000000000,
-0.00179505770539276420,
0.00000000000000000000,
0.00089752885269638212
};
const float BCoef5[SPEESY_NCOEF] = {
-3.83152224876138180000,
5.57511629406004070000,
-3.64956251837243120000,
0.90729235654450602000
};
//for 569-729 Hz
const float ACoef6[SPEESY_NCOEF+1] = {
0.00117165116363920890,
0.00000000000000000000,
-0.00234330232727841770,
0.00000000000000000000,
0.00117165116363920890
};
const float BCoef6[SPEESY_NCOEF] = {
-3.76921491262598970000,
5.44568593950509160000,
-3.56948525439078870000,
0.89685259841470821000
};
//for 729-910 Hz
const float ACoef7[SPEESY_NCOEF+1] = {
0.00148423763165421900,
0.00000000000000000000,
-0.00296847526330843790,
0.00000000000000000000,
0.00148423763165421900
};
const float BCoef7[SPEESY_NCOEF] = {
-3.68252961240084180000,
5.27062615397503010000,
-3.46252708324253880000,
0.88411914122102575000
};
//for 910-1113 Hz
const float ACoef8[SPEESY_NCOEF+1] = {
0.00200280660037213200,
0.00000000000000000000,
-0.00400561320074426400,
0.00000000000000000000,
0.00200280660037213200
};
const float BCoef8[SPEESY_NCOEF] = {
-3.56693687706466770000,
5.04696879760847760000,
-3.32877844509510410000,
0.87096927786413736000
};
//for 1113-1343 Hz
const float ACoef9[SPEESY_NCOEF+1] = {
0.00211587349387137120,
0.00000000000000000000,
-0.00423174698774274240,
0.00000000000000000000,
0.00211587349387137120
};
const float BCoef9[SPEESY_NCOEF] = {
-3.41224013209053600000,
4.75975212198515950000,
-3.15521200191456290000,
0.85509175287783645000
};
//for 1343-1601 Hz
const float ACoef10[SPEESY_NCOEF+1] = {
0.00297423038464923910,
0.00000000000000000000,
-0.00594846076929847830,
0.00000000000000000000,
0.00297423038464923910
};
const float BCoef10[SPEESY_NCOEF] = {
-3.21142823810671900000,
4.40933217825630660000,
-2.94127038526055400000,
0.83892403143238325000
};
//for 1601-1892 Hz
const float ACoef11[SPEESY_NCOEF+1] = {
0.00355749937553949790,
0.00000000000000000000,
-0.00711499875107899590,
0.00000000000000000000,
0.00355749937553949790
};
const float BCoef11[SPEESY_NCOEF] = {
-2.95205117909921370000,
3.98864705820180850000,
-2.67338596187190400000,
0.82024999905406459000
};
//for 1892-2219 Hz
const float ACoef12[SPEESY_NCOEF+1] = {
0.00647978043392210490,
0.00000000000000000000,
-0.01295956086784421000,
0.00000000000000000000,
0.00647978043392210490
};
const float BCoef12[SPEESY_NCOEF] = {
-2.62319693441575370000,
3.50739946700623410000,
-2.34648117429591170000,
0.80033689362210914000
};
//for 2219-2588 Hz
const float ACoef13[SPEESY_NCOEF+1] = {
0.00856598928083165260,
0.00000000000000000000,
-0.01713197856166330500,
0.00000000000000000000,
0.00856598928083165260
};
const float BCoef13[SPEESY_NCOEF] = {
-2.21114034361129000000,
2.98277240977037210000,
-1.94961151450908200000,
0.77769319296960093000
};
//for 2588-3004 Hz
const float ACoef14[SPEESY_NCOEF+1] = {
0.02526264992554181800,
0.00000000000000000000,
-0.05052529985108363700,
0.00000000000000000000,
0.02526264992554181800
};
const float BCoef14[SPEESY_NCOEF] = {
-1.70416700060032110000,
2.45684840140417120000,
-1.47852699918255030000,
0.75308204601400430000
};
//for 3004-3472 Hz
const float ACoef15[SPEESY_NCOEF+1] = {
0.03942139343875778600,
0.00000000000000000000,
-0.07884278687751557200,
0.00000000000000000000,
0.03942139343875778600
};
const float BCoef15[SPEESY_NCOEF] = {
-1.09464887950984990000,
1.99774885820253490000,
-0.93284437413716226000,
0.72671843772403244000
};
//for 3472-4000 Hz
const float ACoef16[SPEESY_NCOEF+1] = {
0.11014553344131538000,
0.00000000000000000000,
-0.22029106688263075000,
0.00000000000000000000,
0.11014553344131538000
};
const float BCoef16[SPEESY_NCOEF] = {
-0.38091397871674004000,
1.69738617536193790000,
-0.31794271360590415000,
0.69738617534660274000
};
#endif // SPEESY_SAMPLE_FREQ
static float speesy_y1[SPEESY_NCOEF+1];
static float speesy_x1[SPEESY_NCOEF+1];
static float speesy_y2[SPEESY_NCOEF+1];
static float speesy_x2[SPEESY_NCOEF+1];
static float speesy_y3[SPEESY_NCOEF+1];
static float speesy_x3[SPEESY_NCOEF+1];
static float speesy_y4[SPEESY_NCOEF+1];
static float speesy_x4[SPEESY_NCOEF+1];
static float speesy_y5[SPEESY_NCOEF+1];
static float speesy_x5[SPEESY_NCOEF+1];
static float speesy_y6[SPEESY_NCOEF+1];
static float speesy_x6[SPEESY_NCOEF+1];
static float speesy_y7[SPEESY_NCOEF+1];
static float speesy_x7[SPEESY_NCOEF+1];
static float speesy_y8[SPEESY_NCOEF+1];
static float speesy_x8[SPEESY_NCOEF+1];
static float speesy_y9[SPEESY_NCOEF+1];
static float speesy_x9[SPEESY_NCOEF+1];
static float speesy_y10[SPEESY_NCOEF+1];
static float speesy_x10[SPEESY_NCOEF+1];
static float speesy_y11[SPEESY_NCOEF+1];
static float speesy_x11[SPEESY_NCOEF+1];
static float speesy_y12[SPEESY_NCOEF+1];
static float speesy_x12[SPEESY_NCOEF+1];
static float speesy_y13[SPEESY_NCOEF+1];
static float speesy_x13[SPEESY_NCOEF+1];
static float speesy_y14[SPEESY_NCOEF+1];
static float speesy_x14[SPEESY_NCOEF+1];
static float speesy_y15[SPEESY_NCOEF+1];
static float speesy_x15[SPEESY_NCOEF+1];
static float speesy_y16[SPEESY_NCOEF+1];
static float speesy_x16[SPEESY_NCOEF+1];
static float speesy_cannel[SPEESY_MAXCAN] ={0};
static float speesy_value[SPEESY_MAXCAN] ={0};
static int speesy_i = 0;
const float speesy_gain_correction_factor[16] = {0.95,0.79,0.66,0.66,0.8,0.79,0.8,0.74,0.85,0.79,0.834,0.57,0.54,0.23,0.18,0.082};
void speesy_set_cannel(float * cannel) {
for (speesy_i = 0; speesy_i < SPEESY_MAXCAN; speesy_i++) {
speesy_value[speesy_i] = cannel[speesy_i];
}
}
void speesy_get_value(float * value) {
for (speesy_i = 0; speesy_i < SPEESY_MAXCAN; speesy_i++) {
value[speesy_i] = speesy_cannel[speesy_i] * speesy_gain_correction_factor[speesy_i];
}
}
void speesy_update_filter(float NewSample) {
/*************1***********/
speesy_x1[4] = speesy_x1[3];
speesy_y1[4] = speesy_y1[3];
speesy_x1[3] = speesy_x1[2];
speesy_y1[3] = speesy_y1[2];
speesy_x1[2] = speesy_x1[1];
speesy_y1[2] = speesy_y1[1];
speesy_x1[1] = speesy_x1[0];
speesy_y1[1] = speesy_y1[0];
speesy_x1[0] = speesy_value[0]*NewSample;
speesy_y1[0] = ACoef1[0] * speesy_x1[0];
speesy_y1[0] += ACoef1[1] * speesy_x1[1] - BCoef1[0] * speesy_y1[1];
speesy_y1[0] += ACoef1[2] * speesy_x1[2] - BCoef1[1] * speesy_y1[2];
speesy_y1[0] += ACoef1[3] * speesy_x1[3] - BCoef1[2] * speesy_y1[3];
speesy_y1[0] += ACoef1[4] * speesy_x1[4] - BCoef1[3] * speesy_y1[4];
speesy_cannel[0] = speesy_y1[0];
/*************************/
/*************2***********/
speesy_x2[4] = speesy_x2[3];
speesy_y2[4] = speesy_y2[3];
speesy_x2[3] = speesy_x2[2];
speesy_y2[3] = speesy_y2[2];
speesy_x2[2] = speesy_x2[1];
speesy_y2[2] = speesy_y2[1];
speesy_x2[1] = speesy_x2[0];
speesy_y2[1] = speesy_y2[0];
speesy_x2[0] = speesy_value[1]*NewSample;
speesy_y2[0] = ACoef2[0] * speesy_x2[0];
speesy_y2[0] += ACoef2[1] * speesy_x2[1] - BCoef2[0] * speesy_y2[1];
speesy_y2[0] += ACoef2[2] * speesy_x2[2] - BCoef2[1] * speesy_y2[2];
speesy_y2[0] += ACoef2[3] * speesy_x2[3] - BCoef2[2] * speesy_y2[3];
speesy_y2[0] += ACoef2[4] * speesy_x2[4] - BCoef2[3] * speesy_y2[4];
speesy_cannel[1] = speesy_y2[0];
/*************************/
/*************3***********/
speesy_x3[4] = speesy_x3[3];
speesy_y3[4] = speesy_y3[3];
speesy_x3[3] = speesy_x3[2];
speesy_y3[3] = speesy_y3[2];
speesy_x3[2] = speesy_x3[1];
speesy_y3[2] = speesy_y3[1];
speesy_x3[1] = speesy_x3[0];
speesy_y3[1] = speesy_y3[0];
speesy_x3[0] = speesy_value[2]*NewSample;
speesy_y3[0] = ACoef3[0] * speesy_x3[0];
speesy_y3[0] += ACoef3[1] * speesy_x3[1] - BCoef3[0] * speesy_y3[1];
speesy_y3[0] += ACoef3[2] * speesy_x3[2] - BCoef3[1] * speesy_y3[2];
speesy_y3[0] += ACoef3[3] * speesy_x3[3] - BCoef3[2] * speesy_y3[3];
speesy_y3[0] += ACoef3[4] * speesy_x3[4] - BCoef3[3] * speesy_y3[4];
speesy_cannel[2] = speesy_y3[0];
/*************************/
/*************4***********/
speesy_x4[4] = speesy_x4[3];
speesy_y4[4] = speesy_y4[3];
speesy_x4[3] = speesy_x4[2];
speesy_y4[3] = speesy_y4[2];
speesy_x4[2] = speesy_x4[1];
speesy_y4[2] = speesy_y4[1];
speesy_x4[1] = speesy_x4[0];
speesy_y4[1] = speesy_y4[0];
speesy_x4[0] = speesy_value[3]*NewSample;
speesy_y4[0] = ACoef4[0] * speesy_x4[0];
speesy_y4[0] += ACoef4[1] * speesy_x4[1] - BCoef4[0] * speesy_y4[1];
speesy_y4[0] += ACoef4[2] * speesy_x4[2] - BCoef4[1] * speesy_y4[2];
speesy_y4[0] += ACoef4[3] * speesy_x4[3] - BCoef4[2] * speesy_y4[3];
speesy_y4[0] += ACoef4[4] * speesy_x4[4] - BCoef4[3] * speesy_y4[4];
speesy_cannel[3] = speesy_y4[0];
/*************************/
/*************5***********/
speesy_x5[4] = speesy_x5[3];
speesy_y5[4] = speesy_y5[3];
speesy_x5[3] = speesy_x5[2];
speesy_y5[3] = speesy_y5[2];
speesy_x5[2] = speesy_x5[1];
speesy_y5[2] = speesy_y5[1];
speesy_x5[1] = speesy_x5[0];
speesy_y5[1] = speesy_y5[0];
speesy_x5[0] = speesy_value[4]*NewSample;
speesy_y5[0] = ACoef5[0] * speesy_x5[0];
speesy_y5[0] += ACoef5[1] * speesy_x5[1] - BCoef5[0] * speesy_y5[1];
speesy_y5[0] += ACoef5[2] * speesy_x5[2] - BCoef5[1] * speesy_y5[2];
speesy_y5[0] += ACoef5[3] * speesy_x5[3] - BCoef5[2] * speesy_y5[3];
speesy_y5[0] += ACoef5[4] * speesy_x5[4] - BCoef5[3] * speesy_y5[4];
speesy_cannel[4] = speesy_y5[0];
/*************************/
/*************6***********/
speesy_x6[4] = speesy_x6[3];
speesy_y6[4] = speesy_y6[3];
speesy_x6[3] = speesy_x6[2];
speesy_y6[3] = speesy_y6[2];
speesy_x6[2] = speesy_x6[1];
speesy_y6[2] = speesy_y6[1];
speesy_x6[1] = speesy_x6[0];
speesy_y6[1] = speesy_y6[0];
speesy_x6[0] = speesy_value[5]*NewSample;
speesy_y6[0] = ACoef6[0] * speesy_x6[0];
speesy_y6[0] += ACoef6[1] * speesy_x6[1] - BCoef6[0] * speesy_y6[1];
speesy_y6[0] += ACoef6[2] * speesy_x6[2] - BCoef6[1] * speesy_y6[2];
speesy_y6[0] += ACoef6[3] * speesy_x6[3] - BCoef6[2] * speesy_y6[3];
speesy_y6[0] += ACoef6[4] * speesy_x6[4] - BCoef6[3] * speesy_y6[4];
speesy_cannel[5] = speesy_y6[0];
/*************************/
/*************7***********/
speesy_x7[4] = speesy_x7[3];
speesy_y7[4] = speesy_y7[3];
speesy_x7[3] = speesy_x7[2];
speesy_y7[3] = speesy_y7[2];
speesy_x7[2] = speesy_x7[1];
speesy_y7[2] = speesy_y7[1];
speesy_x7[1] = speesy_x7[0];
speesy_y7[1] = speesy_y7[0];
speesy_x7[0] = speesy_value[6]*NewSample;
speesy_y7[0] = ACoef7[0] * speesy_x7[0];
speesy_y7[0] += ACoef7[1] * speesy_x7[1] - BCoef7[0] * speesy_y7[1];
speesy_y7[0] += ACoef7[2] * speesy_x7[2] - BCoef7[1] * speesy_y7[2];
speesy_y7[0] += ACoef7[3] * speesy_x7[3] - BCoef7[2] * speesy_y7[3];
speesy_y7[0] += ACoef7[4] * speesy_x7[4] - BCoef7[3] * speesy_y7[4];
speesy_cannel[6] = speesy_y7[0];
/*************************/
/*************8***********/
speesy_x8[4] = speesy_x8[3];
speesy_y8[4] = speesy_y8[3];
speesy_x8[3] = speesy_x8[2];
speesy_y8[3] = speesy_y8[2];
speesy_x8[2] = speesy_x8[1];
speesy_y8[2] = speesy_y8[1];
speesy_x8[1] = speesy_x8[0];
speesy_y8[1] = speesy_y8[0];
speesy_x8[0] = speesy_value[7]*NewSample;
speesy_y8[0] = ACoef8[0] * speesy_x8[0];
speesy_y8[0] += ACoef8[1] * speesy_x8[1] - BCoef8[0] * speesy_y8[1];
speesy_y8[0] += ACoef8[2] * speesy_x8[2] - BCoef8[1] * speesy_y8[2];
speesy_y8[0] += ACoef8[3] * speesy_x8[3] - BCoef8[2] * speesy_y8[3];
speesy_y8[0] += ACoef8[4] * speesy_x8[4] - BCoef8[3] * speesy_y8[4];
speesy_cannel[7] = speesy_y8[0];
/*************************/
/*************9***********/
speesy_x9[4] = speesy_x9[3];
speesy_y9[4] = speesy_y9[3];
speesy_x9[3] = speesy_x9[2];
speesy_y9[3] = speesy_y9[2];
speesy_x9[2] = speesy_x9[1];
speesy_y9[2] = speesy_y9[1];
speesy_x9[1] = speesy_x9[0];
speesy_y9[1] = speesy_y9[0];
speesy_x9[0] = speesy_value[8]*NewSample;
speesy_y9[0] = ACoef9[0] * speesy_x9[0];
speesy_y9[0] += ACoef9[1] * speesy_x9[1] - BCoef9[0] * speesy_y9[1];
speesy_y9[0] += ACoef9[2] * speesy_x9[2] - BCoef9[1] * speesy_y9[2];
speesy_y9[0] += ACoef9[3] * speesy_x9[3] - BCoef9[2] * speesy_y9[3];
speesy_y9[0] += ACoef9[4] * speesy_x9[4] - BCoef9[3] * speesy_y9[4];
speesy_cannel[8] = speesy_y9[0];
/*************************/
/*************10***********/
speesy_x10[4] = speesy_x10[3];
speesy_y10[4] = speesy_y10[3];
speesy_x10[3] = speesy_x10[2];
speesy_y10[3] = speesy_y10[2];
speesy_x10[2] = speesy_x10[1];
speesy_y10[2] = speesy_y10[1];
speesy_x10[1] = speesy_x10[0];
speesy_y10[1] = speesy_y10[0];
speesy_x10[0] = speesy_value[9]*NewSample;
speesy_y10[0] = ACoef10[0] * speesy_x10[0];
speesy_y10[0] += ACoef10[1] * speesy_x10[1] - BCoef10[0] * speesy_y10[1];
speesy_y10[0] += ACoef10[2] * speesy_x10[2] - BCoef10[1] * speesy_y10[2];
speesy_y10[0] += ACoef10[3] * speesy_x10[3] - BCoef10[2] * speesy_y10[3];
speesy_y10[0] += ACoef10[4] * speesy_x10[4] - BCoef10[3] * speesy_y10[4];
speesy_cannel[9] = speesy_y10[0];
/*************************/
/*************11***********/
speesy_x11[4] = speesy_x11[3];
speesy_y11[4] = speesy_y11[3];
speesy_x11[3] = speesy_x11[2];
speesy_y11[3] = speesy_y11[2];
speesy_x11[2] = speesy_x11[1];
speesy_y11[2] = speesy_y11[1];
speesy_x11[1] = speesy_x11[0];
speesy_y11[1] = speesy_y11[0];
speesy_x11[0] = speesy_value[10]*NewSample;
speesy_y11[0] = ACoef11[0] * speesy_x11[0];
speesy_y11[0] += ACoef11[1] * speesy_x11[1] - BCoef11[0] * speesy_y11[1];
speesy_y11[0] += ACoef11[2] * speesy_x11[2] - BCoef11[1] * speesy_y11[2];
speesy_y11[0] += ACoef11[3] * speesy_x11[3] - BCoef11[2] * speesy_y11[3];
speesy_y11[0] += ACoef11[4] * speesy_x11[4] - BCoef11[3] * speesy_y11[4];
speesy_cannel[10] = speesy_y11[0];
/*************************/
/*************12***********/
speesy_x12[4] = speesy_x12[3];
speesy_y12[4] = speesy_y12[3];
speesy_x12[3] = speesy_x12[2];
speesy_y12[3] = speesy_y12[2];
speesy_x12[2] = speesy_x12[1];
speesy_y12[2] = speesy_y12[1];
speesy_x12[1] = speesy_x12[0];
speesy_y12[1] = speesy_y12[0];
speesy_x12[0] = speesy_value[11]*NewSample;
speesy_y12[0] = ACoef12[0] * speesy_x12[0];
speesy_y12[0] += ACoef12[1] * speesy_x12[1] - BCoef12[0] * speesy_y12[1];
speesy_y12[0] += ACoef12[2] * speesy_x12[2] - BCoef12[1] * speesy_y12[2];
speesy_y12[0] += ACoef12[3] * speesy_x12[3] - BCoef12[2] * speesy_y12[3];
speesy_y12[0] += ACoef12[4] * speesy_x12[4] - BCoef12[3] * speesy_y12[4];
speesy_cannel[11] = speesy_y12[0];
/*************************/
/*************13***********/
speesy_x13[4] = speesy_x13[3];
speesy_y13[4] = speesy_y13[3];
speesy_x13[3] = speesy_x13[2];
speesy_y13[3] = speesy_y13[2];
speesy_x13[2] = speesy_x13[1];
speesy_y13[2] = speesy_y13[1];
speesy_x13[1] = speesy_x13[0];
speesy_y13[1] = speesy_y13[0];
speesy_x13[0] = speesy_value[12]*NewSample;
speesy_y13[0] = ACoef13[0] * speesy_x13[0];
speesy_y13[0] += ACoef13[1] * speesy_x13[1] - BCoef13[0] * speesy_y13[1];
speesy_y13[0] += ACoef13[2] * speesy_x13[2] - BCoef13[1] * speesy_y13[2];
speesy_y13[0] += ACoef13[3] * speesy_x13[3] - BCoef13[2] * speesy_y13[3];
speesy_y13[0] += ACoef13[4] * speesy_x13[4] - BCoef13[3] * speesy_y13[4];
speesy_cannel[12] = speesy_y13[0];
/*************************/
/*************14***********/
speesy_x14[4] = speesy_x14[3];
speesy_y14[4] = speesy_y14[3];
speesy_x14[3] = speesy_x14[2];
speesy_y14[3] = speesy_y14[2];
speesy_x14[2] = speesy_x14[1];
speesy_y14[2] = speesy_y14[1];
speesy_x14[1] = speesy_x14[0];
speesy_y14[1] = speesy_y14[0];
speesy_x14[0] = speesy_value[13]*NewSample;
speesy_y14[0] = ACoef14[0] * speesy_x14[0];
speesy_y14[0] += ACoef14[1] * speesy_x14[1] - BCoef14[0] * speesy_y14[1];
speesy_y14[0] += ACoef14[2] * speesy_x14[2] - BCoef14[1] * speesy_y14[2];
speesy_y14[0] += ACoef14[3] * speesy_x14[3] - BCoef14[2] * speesy_y14[3];
speesy_y14[0] += ACoef14[4] * speesy_x14[4] - BCoef14[3] * speesy_y14[4];
speesy_cannel[13] = speesy_y14[0];
/*************************/
/*************15***********/
speesy_x15[4] = speesy_x15[3];
speesy_y15[4] = speesy_y15[3];
speesy_x15[3] = speesy_x15[2];
speesy_y15[3] = speesy_y15[2];
speesy_x15[2] = speesy_x15[1];
speesy_y15[2] = speesy_y15[1];
speesy_x15[1] = speesy_x15[0];
speesy_y15[1] = speesy_y15[0];
speesy_x15[0] = speesy_value[14]*NewSample;
speesy_y15[0] = ACoef15[0] * speesy_x15[0];
speesy_y15[0] += ACoef15[1] * speesy_x15[1] - BCoef15[0] * speesy_y15[1];
speesy_y15[0] += ACoef15[2] * speesy_x15[2] - BCoef15[1] * speesy_y15[2];
speesy_y15[0] += ACoef15[3] * speesy_x15[3] - BCoef15[2] * speesy_y15[3];
speesy_y15[0] += ACoef15[4] * speesy_x15[4] - BCoef15[3] * speesy_y15[4];
speesy_cannel[14] = speesy_y15[0];
/*************************/
/*************16***********/
speesy_x16[4] = speesy_x16[3];
speesy_y16[4] = speesy_y16[3];
speesy_x16[3] = speesy_x16[2];
speesy_y16[3] = speesy_y16[2];
speesy_x16[2] = speesy_x16[1];
speesy_y16[2] = speesy_y16[1];
speesy_x16[1] = speesy_x16[0];
speesy_y16[1] = speesy_y16[0];
speesy_x16[0] = speesy_value[15]*NewSample;
speesy_y16[0] = ACoef16[0] * speesy_x16[0];
speesy_y16[0] += ACoef16[1] * speesy_x16[1] - BCoef16[0] * speesy_y16[1];
speesy_y16[0] += ACoef16[2] * speesy_x16[2] - BCoef16[1] * speesy_y16[2];
speesy_y16[0] += ACoef16[3] * speesy_x16[3] - BCoef16[2] * speesy_y16[3];
speesy_y16[0] += ACoef16[4] * speesy_x16[4] - BCoef16[3] * speesy_y16[4];
speesy_cannel[15] = speesy_y16[0];
/*************************/
}
P.S. Называться синтезатор речи будет Speesy (от слов speech и synthesizer).
Привет!
В прошлой части проекта мы запрограммировали систему распознавания речи и проверили, как наш робот исполняет тестовые голосовые команды.
Теперь мы сделаем роботу систему синтеза речи «Text-to-Speech», чтобы он мог откликаться на наши команды, а заодно обучим его навигационным голосовым командам. Поехали!
Содержание
- Звуковые устройства
- Звуковая карта
- Динамики и усилитель звука
- Микрофон
- Подключение к Raspberry Pi
- Проверка звука в Linux
- Изменение индексов аудиоустройств
- Распознавание речи
- История технологии
- Классификация систем распознавания речи
- Архитектура систем распознавания речи
- Выбор системы распознавания речи
- Установка PocketSphinx
- Стек пакетов для работы с аудио в ROS
- Пакет abot_speech_to_text
- Запуск записи звука
- Пример приложения «Speech-to-Text»
- Ключевые фразы
- Голосовые команды
- Акустическая модель
- Фонетический словарь
- Скрипт KWS
- Запуск Keyword Spotting (KWS)
- Построение грамматики
- Ретрансляция аудио
- Скрипт Automatic Speech Recognition (ASR)
- Запуск ASR
- Обработчик команд
- Подключаем светодиоды
- Пакет abot_speech_command
- Библиотека для Troyka HAT
- Нода test_command_executor
- Запуск обработчика команд
- Синтез речи
- Выбор системы синтеза речи
- Пакет abot_text_to_speech
- Запуск вывода звука
- Festival TTS
- Установка и проверка
- Нода для Festival TTS
- Запуск и тест ноды Festival TTS
- Amazon Polly
- Установка и проверка Amazon Polly
- Нода для Amazon Polly TTS
- Запуск и тест ноды Amazon Polly
- RHVoice TTS
- Установка и проверка
- Нода для RHVoice TTS
- Запуск и тест ноды RHVoice
- Правки в KWS
- Голосовое управление роботом
- Придумываем голосовые команды
- Крепление для звуковых устройств
- Обновление URDF-описания и карты
- Узнаём у робота дату и время
- Нода обработчика
- Запуск обработчика
- Узнаём у робота уровень заряда батареи
- Схема подключения
- Нода обработчика
- Запуск обработчика
- Голосовое управление навигацией робота
- Новый метод расстановки виртуальных стен
- Запоминаем точки на карте
- Нода обработчика
- Запуск обработчика
- Заключение
Синтез речи
Отлично, теперь робот может нас слышать и выполнять голосовые команды. Но что если мы хотим, чтобы робот нам отвечал, и сформировалось некое подобие диалога между роботом и человеком?
Для воспроизведения компьютером человеческого голоса необходим синтезатор речи. Подобные системы часто называют просто «Text-to-Speech», или сокращённо TTS.
Системы речевого синтеза работают так же, как «Speech-to-Text», только в обратном порядке.
В «Speech-to-Text» мы как бы разбиваем звук на куски: записываем речь, находим в ней акустические признаки и форманты. Затем по признакам определяем фонемы, из последовательности которых определяем вероятные слова и формируем из них предложения согласно грамматике.
В «Text-to-Speech» же всё наоборот: мы собираем звук по кусочкам — разбиваем предложение на слова, делим их на слоги и фонемы. Затем строим по ним последовательность формант и синтезируем речь из последовательности тонов, шумов и голосовых формант.
Системы TTS, как и «Speech-to-Text», используют разные методы и техники, в том числе скрытые Марковские модели и нейросети. Мы не будем вдаваться в то, как работают системы «Text-to-Speech» и какова их классификация, а лучше сразу рассмотрим применение программного обеспечения.
Выбор системы синтеза речи
Выберем программное обеспечение для синтеза речи на нашем роботе.
Готовых систем синтеза речи столь же много, как и систем распознавания речи. Системы «Text-to-Speech» тоже отличаются производительностью и затачиваются под разные устройства.
При выборе системы «Text-to-Speech» нас в первую очередь интересуют следующие критерии:
- Язык. Раз наш робот распознаёт русский язык, то пусть и говорит на нём.
- Голоса. Было бы здорово, если бы робот мог говорить разными голосами, и у нас была возможность выбора тембра.
- Качество речи. Чем больше синтезированная речь похожа на человеческую, тем лучше.
- Требуемая вычислительная мощность. Программное обеспечение должно быть легковесным, ведь мы собираемся использовать его на Raspberry Pi, а не на мощном стационарном компьютере.
- Цена. Как всегда, мы хотим, чтобы синтез речи был для нас бесплатным или совсем недорогим.
Довольно часто у IT-гигантов системы «Speech-to-Text» и «Text-to-Speech» объединены в единый продукт. Все эти решения поставляются в виде облачных сервисов:
- Yandex.SpeechKit
- Amazon Polly
- Google Text-to-Speech
- IBM Watson Text to Speech
- Microsoft Azure Text to Speech
Принцип работы прост. Отправляете на сервер запрос, содержащий текст, который вы хотите воспроизвести, а в ответ получаете аудиофайл с синтезированной речью. Качество синтезированной облачным сервисом речи, как правило, очень высокое, особенно для английского языка.
Как и в случае со «Speech-to-Text», у всех облачных систем два главных минуса. Первый — необходимость постоянного подключения к интернету. Второй минус — это цена, ведь все облачные системы платные. Стоимость услуг зависит от количества символов в синтезируемом тексте.
Однако если в системе «Speech-to-Text» нам нужен был непрерывный анализ звука, то в «Text-to-Speech» можно существенно сократить объём запросов. Мы можем и вовсе качественно озвучить несколько десятков слов и предложений, сохранить их в виде аудиофайлов и больше не пользоваться сервисом.
В этом проекте мы на примере системы Amazon Polly расскажем, как сделать синтез голоса через интернет.
Мы нашли популярные бесплатные системы синтеза речи, которые работают оффлайн и распространяются как open-source:
- Festival Speech Synthesis System и Festvox
- Flite
- ESpeak
- FreeTTS
- MaryTTS
- Mozilla TTS
- RHVoice
- Mimic
- Silero
Систем и их разновидностей очень много. Одни легковесные, другие — нет. Некоторые системы используют Deep learning, и разобраться с ними без подготовки очень тяжело. Где-то есть поддержка русского языка, а где-то её нет. Помимо этого половину перечисленных систем довольно трудно интегрировать в ROS.
В итоге мы выбрали две оффлайн-системы: Festival и RHVoice. Прежде всего, из-за лёгкости их установки и настройки. К слову, в стеке ROS-пакетов audio_common уже есть поддержка Festival, и нужно только добавить русский язык. Ну а RHVoice можно просто установить пакетом из репозитория.
Итого мы рассмотрим три системы: Amazon Polly, Festival и RHVoice. Протестируем их и для каждой сделаем свою ноду. Все ноды будут взаимозаменяемыми, и вы сможете сами выбрать, какой вариант вам подходит лучше.
Пакет abot_text_to_speech
В стеке abot_sound создадим новый пакет. Назовём его abot_text_to_speech. Этот пакет будет отвечать за синтез речи в ROS и за работу систем «Text-to-Speech» на нашем роботе.
В пакете abot_text_to_speech создадим три папки: sounds для хранения звуковых файлов, launch для файлов запуска и scripts для файлов с исходным кодом на Python.
Оформляем файлы CMakeLists.txt и package.xml. В качестве пакетов зависимостей для abot_speech_to_text устанавливаем пакеты:
roscpprospystd_msgsaudio_common_msgssound_play
Для работы с AWS Polly нам понадобится сторонний Python-пакет boto3. В файл package.xml добавляем следующую строку:
<exec_depend>python3-boto3</exec_depend>
В папке launch-пакета abot_text_to_speech создадим пока что пустой файл запуска abot_text_to_speech.launch, которым мы будем запускать все ноды для синтеза и воспроизведения речи.
Собираем проект:
catkin_make
Запуск вывода звука
Синтезированная роботом речь должна как-то воспроизводиться на наших динамиках. Настроим воспроизведение звука в ROS. Для этого воспользуемся готовой нодой soundplay_node из пакета sound_play.
В файле abot_text_to_speech.launch запустим ноду soundplay_node со следующим параметром:
<launch>
<arg name="device" default="plughw:2" />
<node name="soundplay_node" pkg="sound_play" type="soundplay_node.py" output="screen" >
<param name="device" value="$(arg device)" />
</node>
</launch>
Здесь параметром указываем, через какое звуковое устройство нужно воспроизводить звук. Мы используем динамики, подключённые к USB-звуковой карте, которая имеет в системе индекс 2 — plughw:2.
Воспроизведение звука в ROS-нодах пакета soundplay_node построено не на привычных нам топиках (Topics) и сообщениях (Messages), а на клиент-серверных действиях (Actions). Подробнее читайте в ROS Wiki на страничке библиотеки actionlib.
Протестируем воспроизведение звука в ROS на Raspberry Pi. Запустим ноду soundplay_node свежесозданным launch-файлом:
source devel/setup.bash
roslaunch abot_text_to_speech abot_text_to_speech.launch
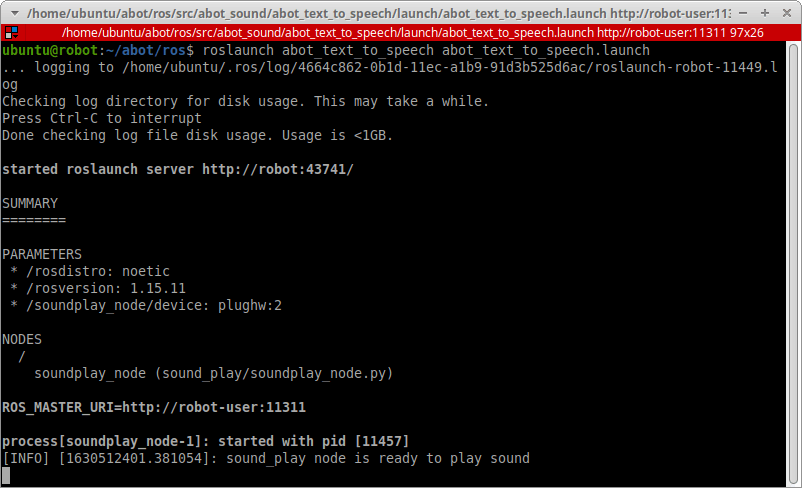
Чтобы было что воспроизводить, запишем любой звук через микрофон. В новом терминале воспользуемся командой arecord. Сохраним запись во временном файле /tmp/test-mic.wav.
arecord -f S16_LE -d 10 -r 16000 -c 1 -D plughw:1 /tmp/test-mic.wav
Отправим этот файл на воспроизведение в запущенную ноду soundplay_node:
source devel/setup.bash
rosrun sound_play play.py /tmp/test-mic.wav

Ваша запись должна заиграть через динамики.
Festival TTS
Начнём с нашей первой системы «Text-to-Speech» — Festival.
Установка и проверка
В ROS-пакете sound_play уже реализована программная обёртка для работы с Festival, но установить сам софт всё же нужно. Устанавиливаем Festival на Raspberry Pi из репозитория:
sudo apt-get install festival
Устанавливаем русскоязычную модель для Festival:
sudo apt-get install festvox-ru
Проверяем установку и запускаем Festival в терминале:
festival
Мы перейдём в консоль приложения. Выйти из консоли Festival можно сочетанием клавиш «CTRL+D», или набрав в терминале (quit).
В консоли Festival посмотрим все доступные языковые модели и голоса. Вводим:
(voice.list)

kal_diphone — это «захардкоженный» англоязычный голос. А вот mcu_ru_nsh_clunits — это уже мужской русский голос, единственный в TTS Festival. Меняем язык на русский командой:
(voice_msu_ru_nsh_clunits)
Язык сменится только на время работы в консоли Festival! Если вы хотите поменять его навсегда, придётся повозиться с настройками движка. Узнать, как настроить Festival, можно в статье на Wiki Arch Linux.
Произнесём какой-нибудь текст на русском и убедимся, что движок работает. Но какую фразу выбрать для проверки? Пусть нашей тестовой фразой будет самая известная русская панграмма, а за ней вставим какую-нибудь фразу с цифрами, например адрес Амперки:
Cъешь ещё этих мягких французских булок, да выпей чаю! Адрес Амперки: улица Тимура Фрунзе, дом 8 дробь 5, подъезд 1.
В терминале Festival вводим команду с тестовой фразой:
(SayText "Cъешь ещё этих мягких французских булок, да выпей чаю! Адрес Амперки: улица Тимура Фрунзе, дом 8 дробь 5, подъезд 1.")
И слушаем звук с динамиков.
Качество так себе, да и возможный голос всего один. Но, тем не менее, все синтезированные слова нам понятны, движок работает и легко настраивается, так что мы можем его использовать.
Нода для Festival TTS
Напишем ROS-ноду — обёртку для движка Festival. Все ноды для TTS-движков будем писать на Python.
В пакете abot_text_to_speech в папке scripts создадим новый Pyhton-скрипт. Назовём его festvox_tts.py.
#!/usr/bin/env python
# coding: utf-8
import rospy
from std_msgs.msg import String, Bool
from sound_play.libsoundplay import SoundClient
class FestvoxTTS(object):
def __init__(self):
rospy.init_node('festvox_tts')
rospy.on_shutdown(self.shutdown)
self._volume = rospy.get_param('~volume', 1.0)
self._voice = rospy.get_param('~voice', 'voice_msu_ru_nsh_clunits')
self._soundhandle = SoundClient(blocking=True)
rospy.sleep(1)
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
rospy.loginfo("Festival TTS node: Start")
rospy.spin()
def processText(self, text_msg):
rospy.loginfo("Festival TTS node: Got a string: %s", text_msg.data)
self._pub.publish(True)
self._soundhandle.say(text_msg.data, self._voice, self._volume)
self._pub.publish(False)
@staticmethod
def shutdown():
rospy.loginfo("Festival TTS node: Stop")
rospy.sleep(1)
if __name__ == "__main__":
FestvoxTTS()
Как работает эта нода-обёртка?
Мы создали класс FestvoxTTS, экземпляр которого при инициализации cоздаст ROS-ноду festvox_tts.
class FestvoxTTS(object):
def __init__(self):
rospy.init_node('festvox_tts')
rospy.on_shutdown(self.shutdown)
При инициализации ноды создаём клиент SoundClient для воспроизведения звука нодой soundplay_node. Параметр blocking означает, что программа будет блокирована, пока аудиофайл или аудиоданные не проиграются полностью.
self._soundhandle = SoundClient(blocking=True)
С параметрического сервера ROS мы загрузим два параметра voice и volume. Параметром voice будем задавать имя голоса для использования в Festival, а параметром volume — громкость воспроизведения звука нодой soundplay_node.
self._volume = rospy.get_param('~volume', 1.0)
self._voice = rospy.get_param('~voice', 'voice_msu_ru_nsh_clunits')
Нода подписывается на топик /abot/tts/text_to_say, куда мы будем отправлять сообщения типа String с текстовыми строками, которые необходимо синтезировать в речь.
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
Это важно! Мы создали топик /abot/tts/speaking_in_progress с сообщениями типа Bool. Этот топик нужен, чтобы останавливать декодеры «Speech-to-Text». Когда мы скажем роботу голосовую команду, а он начнёт нам отвечать, сам звук его ответа не должен конфликтовать с режимами KWS и ASR. Когда робот говорит, ему не нужно слушать и распознавать свою собственную синтезированную речь.
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
Когда в топик /abot/tts/text_to_say поступает новая строка, мы останавливаем режимы «Speech-to-Text» и отправляем строку в Festival с указанием голоса и громкости. Функция say осуществляет обёртку движка Festival в ROS-ноде soundplay_node.
self._pub.publish(True)
self._soundhandle.say(text_msg.data, self._voice, self._volume)
self._pub.publish(False)
Запуск и тест ноды Festival TTS
В папке launch пакета abot_text_to_speech создадим файл запуска для новой ноды festvox_tts. Назовём его festvox_tts.launch.
<launch>
<arg name="volume" default="1.0" />
<arg name="voice" default="voice_msu_ru_nsh_clunits" />
<node name="festvox_tts" pkg="abot_text_to_speech" type="festvox_tts.py" output="screen" >
<param name="volume" value="$(arg volume)" />
<param name="voice" value="$(arg voice)" />
</node>
</launch>
В launch-файле указываем максимальную громкость звука — 1.0 и имя русского голоса для движка Festival — voice_msu_ru_nsh_clunits.
Включим новый файл запуска ноды festvox_tts в общий файл запуска для наших систем «Text to Speech» — abot_text_to_speech.launch:
<include file="$(find abot_text_to_speech)/launch/festvox_tts.launch" />
Запускаем на Raspberry Pi все TTS-ноды:
source devel/setup.bash
roslaunch abot_text_to_speech abot_text_to_speech.launch
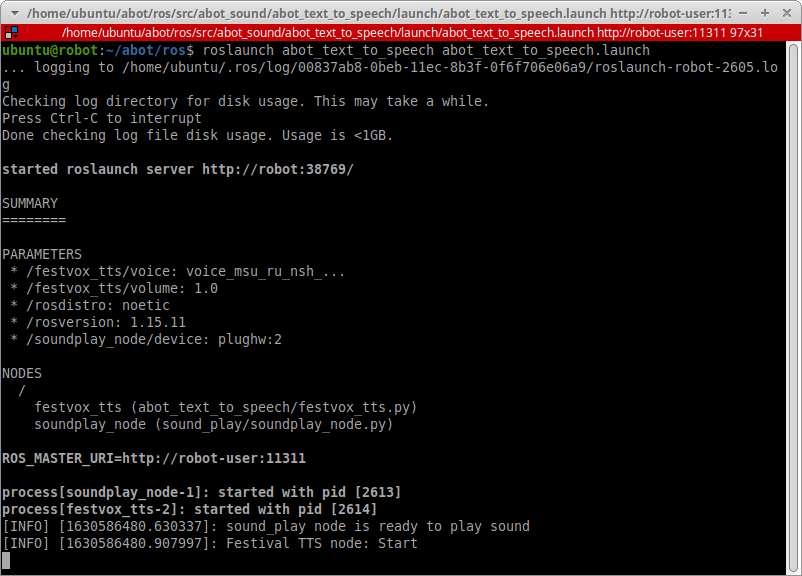
В новом терминале проверяем, появились ли новые топики /abot/tts/text_to_say и /abot/tts/speaking_in_progress.
rostopic list
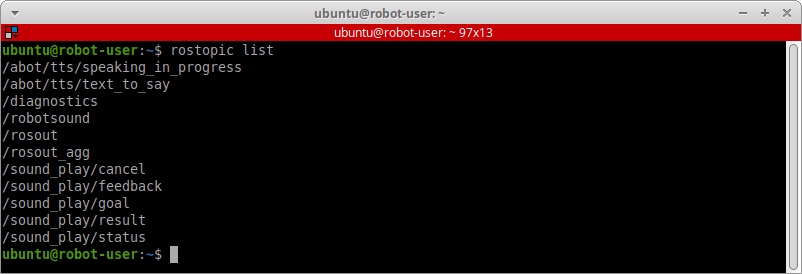
Пробуем отправить в топик /abot/tts/text_to_say какой-ниудь текст, например «Привет Амперка!», и послушаем синтезированный результат через динамики.
rostopic pub -1 /abot/tts/text_to_say std_msgs/String "Привет Амперка!"


Дерево нод и топиков сейчас выглядит так:

Рассмотрим другие системы «Text to Speech».
Amazon Polly
Следующая TTS-система на очереди — Amazon Polly, одна из самых известных в мире. Вы могли слышать синтезированные ей голоса много раз, например в смешных озвучках видео про роботов.
Как мы помним, Amazon Polly — это платный облачный сервис. Он предоставляется Amazon Web Services, или сокращённо AWS.
Это важно! Если вы никогда не пользовались AWS — не пугайтесь, никто сразу не заставит вас покупать какие-то решения или вбивать номер кредитки. Всем новым пользователям AWS бесплатно предоставляются 5 миллионов символов для синтезирования Amazon Polly в течение 12 месяцев. Этого более чем достаточно, чтобы вы протестили свои программы и поняли, нужна вам эта TTS-система или нет.
Установка и проверка Amazon Polly
Сперва вам нужно создать аккаунт Amazon Web Services. На сайте есть подробная инструкция, как начать работу с сервисами AWS.
Затем вам нужно войти в вашу консоль AWS и перейти в настройки вашего аккаунта. В настройках аккаунта нужно найти раздел «Your Security Credentials», в нём перейти в подраздел «Access keys (access key ID and secret access key)» и нажать на кнопку «Create new Access Key». Для вас будет сгенерирован секретный ключ Secret Access Key под определённым идентификатором Access Key ID. Сохраните эти ключи где-нибудь в надёжном месте.
Протестить сервис Amazon Polly очень легко. Просто перейдите на страничку сервиса или воспользуйтесь поиском в консоли AWS. У Amazon Polly TTS есть два типа движков — Standart и Neural. Движок Neural построен на гигантских нейросетях и синтезирует речь, неотличимую от человеческой. Для русского языка в Amazon Polly доступен только стандартный движок и всего два голоса: женский — Tatyana и мужской — Maxim.
Прогоним нашу тестовую фразу женским голосом:
Вот какой получился результат:
Звучит гораздо лучше, чем Festival. На то он и платный сервис.
Также Amazon Polly поддерживает язык разметки синтеза речи, или SSML. Используя специальные теги в вашем тексте, вы можете настроить индивидуальное произношение слов, расставить правильные ударения в словах, добавить эмоциональный окрас в предложениях, например крик или шепот.
Для работы с сервисом AWS на Raspberry Pi установим официальный Python-пакет Boto3 от Amazon:
sudo apt-get install python3-pip
pip install boto3
Нода для Amazon Polly TTS
Напишем ROS-ноду — обёртку для Amazon Polly.
В пакете abot_text_to_speech в папке scripts создадим новый Pyhton-скрипт. Назовём его aws_polly_tts.py.
#!/usr/bin/env python
# coding: utf-8
import rospy
from boto3 import Session
from std_msgs.msg import String, Bool
from sound_play.libsoundplay import SoundClient
class AWSPollyTTS(object):
def __init__(self):
rospy.init_node('aws_polly_tts')
rospy.on_shutdown(self.shutdown)
self._volume = rospy.get_param('~volume', 1.0)
self._aws_speech_sound_file_path = rospy.get_param('~aws_speech_sound_file_path')
self._aws_access_key_id = rospy.get_param('~aws_access_key_id')
self._aws_secret_access_key = rospy.get_param('~aws_secret_access_key')
self._aws_region_name =rospy.get_param('~aws_region_name', 'us-west-2')
self._aws_polly_voice_id =rospy.get_param('~aws_polly_voice_id')
self._session = Session(aws_access_key_id=self._aws_access_key_id, aws_secret_access_key=self._aws_secret_access_key, region_name=self._aws_region_name)
self._polly = self._session.client('polly')
self._soundhandle = SoundClient(blocking=True)
rospy.sleep(1)
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
rospy.loginfo("AWS Polly TTS node: Start")
rospy.spin()
def processText(self, text_msg):
rospy.loginfo("AWS Polly TTS node: Got a string: %s", text_msg.data)
response = self._polly.synthesize_speech(VoiceId=self._aws_polly_voice_id, OutputFormat='ogg_vorbis', Text = text_msg.data)
rospy.loginfo("AWS Polly TTS node: Saving speech to file: %s", self._aws_speech_sound_file_path)
file = open(self._aws_speech_sound_file_path, 'wb')
file.write(response['AudioStream'].read())
file.close()
self._pub.publish(True)
rospy.loginfo('AWS Polly TTS node: Playing "%s".', self._aws_speech_sound_file_path)
self._soundhandle.playWave(self._aws_speech_sound_file_path, self._volume)
self._pub.publish(False)
@staticmethod
def shutdown():
rospy.loginfo("AWS Polly TTS node: Stop")
rospy.sleep(1)
if __name__ == "__main__":
AWSPollyTTS()
Как работает эта нода?
Мы создали класс AWSPollyTTS, экземпляр которого при инициализации cоздаст ROS-ноду aws_polly_tts.
class AWSPollyTTS(object):
def __init__(self):
rospy.init_node('aws_polly_tts')
rospy.on_shutdown(self.shutdown)
С параметрического сервера ROS мы загрузим следующие параметры:
aws_access_key_id— ID секретного ключа AWS.aws_secret_access_key— сам секретный ключ AWS.aws_region_name— регион работы AWS.aws_polly_voice_id— голос, который хотим использовать в Amazon Polly.aws_speech_sound_file_path— абсолютный путь в файловой системе, куда сохранить аудиозапись, полученную от сервера.volume— громкость воспроизведения звука нодойsoundplay_node.
self._volume = rospy.get_param('~volume', 1.0)
self._aws_speech_sound_file_path = rospy.get_param('~aws_speech_sound_file_path')
self._aws_access_key_id = rospy.get_param('~aws_access_key_id')
self._aws_secret_access_key = rospy.get_param('~aws_secret_access_key')
self._aws_region_name =rospy.get_param('~aws_region_name', 'us-west-2')
self._aws_polly_voice_id =rospy.get_param('~aws_polly_voice_id')
Нода подписывается на топик /abot/tts/text_to_say, куда мы отправляем сообщения типа String с текстовыми строками, которые необходимо синтезировать в речь. Также публикуем сообщения Bool в топик /abot/tts/speaking_in_progress для остановки декодеров «Speech-to-Text».
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
При инициализации ноды создаём клиент SoundClient для воспроизведения звука нодой soundplay_node. Параметр blocking означает, что программа будет блокирована, пока аудиофайл или аудиоданные не проиграются полностью.
self._soundhandle = SoundClient(blocking=True)
Запускаем новую сессию с сервисом AWS c указанием секретного ключа, ID ключа и региона. Создаём обьект polly — клиент сервиса Amazon Polly.
self._session = Session(aws_access_key_id=self._aws_access_key_id, aws_secret_access_key=self._aws_secret_access_key, region_name=self._aws_region_name)
self._polly = self._session.client('polly')
Когда в топик /abot/tts/text_to_say поступает новая строка, мы отправляем запрос с этой строкой на сервер Amazon. В запросе указываем ID голоса, который хотим использовать для синтезатора, и формат аудиоданных, который хотим иметь на выходе. Используем только формат OGG, так как нода soundplay_node не умеет воспроизводить сжатые аудиоданные в формате MP3.
response = self._polly.synthesize_speech(VoiceId=self._aws_polly_voice_id, OutputFormat='ogg_vorbis', Text = text_msg.data)
Полученные с сервера аудиоданные сохраняем в файл:
file = open(self._aws_speech_sound_file_path, 'wb')
file.write(response['AudioStream'].read())
file.close()
А затем отправляем этот файл на воспроизведение через клиент ноды soundplay_node, остановив при этом декодеры «Speech-to-Text».
self._pub.publish(True)
self._soundhandle.playWave(self._aws_speech_sound_file_path, self._volume)
self._pub.publish(False)
Запуск и тест ноды Amazon Polly
В папке launch пакета abot_text_to_speech создадим файл запуска для новой ноды aws_polly_tts. Назовём его aws_polly_tts.launch.
<launch>
<arg name="volume" default="1.0" />
<arg name="aws_speech_sound_file_path" default="$(find abot_text_to_speech)/sounds/aws_polly/speech.ogg" />
<arg name="aws_access_key_id" default="PUT YOUR AWS ACCESS KEY ID HERE!" />
<arg name="aws_secret_access_key" default="PUT YOUR AWS SECRET ACCESS KEY HERE!" />
<arg name="aws_region_name" default="us-west-2" />
<arg name="aws_polly_voice_id" default="Tatyana" />
<node name="aws_polly_tts" pkg="abot_text_to_speech" type="aws_polly_tts.py" output="screen" >
<param name="volume" value="$(arg volume)" />
<param name="aws_speech_sound_file_path" value="$(arg aws_speech_sound_file_path)" />
<param name="aws_access_key_id" value="$(arg aws_access_key_id)" />
<param name="aws_secret_access_key" value="$(arg aws_secret_access_key)" />
<param name="aws_region_name" value="$(arg aws_region_name)" />
<param name="aws_polly_voice_id" value="$(arg aws_polly_voice_id)" />
</node>
</launch>
Через launch-файл задаём параметры для параметрического сервера ROS:
volumeи1.0— указываем максимальную громкость воспроизведения звука.aws_access_key_id— здесь указываем ID нашего секретного ключа AWS.aws_secret_access_key— указываем, собственно, сам ключ от сервисов AWS.aws_region_name— для России стандартным регионом являетсяus-west-2.aws_polly_voice_id— голос для движка. Пусть робот говорит женским голосом, для этого задаём IDTatyana.aws_speech_sound_file_path— путь, куда сохранить полученные аудиоданные. Будем сохранять ответы с сервера в OGG-файлspeech.ogg. Сам файл будем хранить в папкеsounds/aws_pollyпакетаabot_text_to_speech.
Включим новый файл запуска ноды aws_polly_tts в общий файл запуска для наших систем «Text to Speech» — abot_text_to_speech.launch, при этом закомментируем предыдущую TTS-систему Festival, чтобы они не конфликтовали.
<!-- <include file="$(find abot_text_to_speech)/launch/festvox_tts.launch" /> -->
<include file="$(find abot_text_to_speech)/launch/aws_polly_tts.launch" />
Запускаем на Raspberry Pi все ноды «Text to Speech»:
source devel/setup.bash
roslaunch abot_text_to_speech abot_text_to_speech.launch
В новом терминале проверяем, появились ли новые топики /abot/tts/text_to_say и /abot/tts/speaking_in_progress.
rostopic list
Затем пробуем отправить в топик /abot/tts/text_to_say тестовый текст «Привет Амперка!» и послушать синтезированный результат уже через динамики.
rostopic pub -1 /abot/tts/text_to_say std_msgs/String "Привет Амперка!"
Дерево нод и топиков в этом случае выглядит так:

Рассмотрим ещё одну TTS-систему.
RHVoice TTS
Мы протестировали уже две системы «Text to Speech». Однако у синтезированной через систему Festival речи довольно низкое качество. Речь, синтезированная через Amazon Polly — качественная, но для нас этот сервис уже полностью платный, так как нашему AWS-аккаунту уже больше нескольких лет. Хочется найти бесплатное решение, работающее оффлайн.
В результате мы остановились на бесплатной TTS-системе RHVoice, которая на наш взгляд, довольно качественно синтезирует речь. Кроме этого данная система создана российскими разработчиками и изначально нацелена именно на русский язык.
Установка и проверка
Устанавливаем RHVoice, используя готовый пакет из их репозитория. Для arm64 есть готовый пакет, так что на Raspberry Pi всё ставится без проблем.
sudo add-apt-repository ppa:linvinus/rhvoice
sudo apt-get update
sudo apt-get install rhvoice
Из коробки над доступны несколько голосов, в том числе четыре русских: Aleksandr, Anna, Elena, Irina.
При установке RHVoice пакетом из репозитория можно проверить установку системы через терминал командой RHVoice-client. Прогоним систему на нашей тестовой фразе. Синтезируем речь, используя женский голос Anna. В команде не забываем указывать индекс звукового устройства для вывода звука — aplay -D plughw:2.
echo "Cъешь ещё этих мягких французских булок да выпей чаю! Адрес Амперки: улица Тимура Фрунзе, дом 8 дробь 5, подъезд 1." | RHVoice-client -s Anna+CLB | aplay -D plughw:2

Послушаем результат:
Чтобы сохранить синтезированную речь в файл, RHVoice рекомендует использовать аудиоредактор Sound eXchange, или просто sox. Устновим его на нашу Raspberry Pi:
sudo apt-get install sox
Теперь мы можем сохранить синтезированную речь в файл. Например, для сохранения синтезированной фразы «Привет Амперка!» во временный файл /tmp/test.wav команда будет выглядить так:
echo "Привет Амперка!" | RHVoice-client -s Anna+CLB | sox -t wav - -r 24000 -c 1 -b 16 -t wav - >/tmp/test.wav
В контейнер WAV будет записан одноканальный 16-битный звук с частотой дискретизации 24 кГц.
Эта TTS-система нам очень понравилась, и мы решили использовать в данном проекте имеено её. Тем не менее, мы также оставили исходные файлы для других систем. Вдруг они вам пригодятся.
Нода для RHVoice TTS
Напишем ROS-ноду — обёртку для RHVoice TTS.
Мы не будем использовать никакие сторонние библиотеки для обёртки системы RHVoice. Просто сделаем так, чтобы ROS-нода на Python внутри себя запускала процесс другой программы, а именно RHVoice-client. В этой ноде будем запускать RHVoice-client точно таким же образом, как мы это делали через терминал.
В пакете abot_text_to_speech в папке scripts создадим новый Pyhton-скрипт. Назовём его rhvoice_tts.py.
#!/usr/bin/env python
# coding: utf-8
import rospy
import subprocess
from std_msgs.msg import String, Bool
from sound_play.libsoundplay import SoundClient
class RHVoiceTTS(object):
def __init__(self):
rospy.init_node('rhvoice_tts')
rospy.on_shutdown(self.shutdown)
self._volume = rospy.get_param('~volume', 1.0)
self._rhvoice_speech_sound_file_path = rospy.get_param('~rhvoice_speech_sound_file_path')
self._rhvoice_voice = rospy.get_param('~rhvoice_voice', 'Anna+CLB')
self._soundhandle = SoundClient(blocking=True)
rospy.sleep(1)
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
rospy.loginfo("RHVoice TTS node: Start")
rospy.spin()
def processText(self, text_msg):
rospy.loginfo("RHVoice TTS node: Got a string: %s", text_msg.data)
rospy.loginfo("RHVoice TTS node: Saving speech to file: %s", self._rhvoice_speech_sound_file_path)
rhvoice_command_line = "echo '" + text_msg.data + "' | RHVoice-client -s " + self._rhvoice_voice + " "
rhvoice_command_line += "| sox -t wav - -r 24000 -c 1 -b 16 -t wav - >" + self._rhvoice_speech_sound_file_path
rospy.loginfo("RHVoice TTS node: Command: %s", rhvoice_command_line)
subprocess.call(rhvoice_command_line, shell=False)
self._pub.publish(True)
rospy.loginfo('RHVoice TTS node: Playing "%s".', self._rhvoice_speech_sound_file_path)
self._soundhandle.playWave(self._rhvoice_speech_sound_file_path, self._volume)
self._pub.publish(False)
rospy.loginfo('RHVoice TTS node: Stop Playing')
@staticmethod
def shutdown():
rospy.loginfo("RHVoice TTS node: Stop")
rospy.sleep(1)
if __name__ == "__main__":
RHVoiceTTS()
Как работает эта нода?
Мы создали класс RHVoiceTTS, экземпляр которого при инициализации cоздаст ROS-ноду rhvoice_tts.
class RHVoiceTTS(object):
def __init__(self):
rospy.init_node('rhvoice_tts')
rospy.on_shutdown(self.shutdown)
С параметрического сервера ROS мы загрузим следующие параметры:
rhvoice_voice— ID голоса, который хотим использовать для синтеза в RHVoice.rhvoice_speech_sound_file_path— абсолютный путь в файловой системе, куда сохранится созданнаяsoxаудиозапись.volume— громкость воспроизведения звука нодойsoundplay_node.
self._volume = rospy.get_param('~volume', 1.0)
self._rhvoice_speech_sound_file_path = rospy.get_param('~rhvoice_speech_sound_file_path')
self._rhvoice_voice = rospy.get_param('~rhvoice_voice', 'Anna+CLB')
Нода подписывается на топик /abot/tts/text_to_say. В этот топик мы отправляем сообщения типа String с текстовыми строками, которые необходимо синтезировать в речь. Также публикуем сообщения Bool в топик /abot/tts/speaking_in_progress для остановки декодеров «Speech-to-Text».
rospy.Subscriber('/abot/tts/text_to_say', String, self.processText)
self._pub = rospy.Publisher('/abot/tts/speaking_in_progress', Bool, queue_size=1)
При инициализации ноды создаём клиент SoundClient для воспроизведения звука нодой soundplay_node. Параметр blocking означает, что программа будет блокирована, пока аудиофайл или аудиоданные не проиграются полностью.
self._soundhandle = SoundClient(blocking=True)
Когда в топик /abot/tts/text_to_say поступает новая строка, мы берем эту строку, путь для сохранения звукового файла, выбранный голос диктора и формируем команду для запуска программы RHVoice-client. Готовая команда выглядит так же, как если бы мы вводили её в терминал. Сформированную команду запускаем в отдельном подпроцессе.
rhvoice_command_line = "echo '" + text_msg.data + "' | RHVoice-client -s " + self._rhvoice_voice + " "
rhvoice_command_line += "| sox -t wav - -r 24000 -c 1 -b 16 -t wav - >" + self._rhvoice_speech_sound_file_path
subprocess.call(rhvoice_command_line, shell=False)
Когда подпросесс с программой RHVoice-client закончит свою работу, у нас будет готовый аудиофайл. Отправляем этот файл на воспроизведение через клиент ноды soundplay_node, остановив при этом декодеры «Speech-to-Text».
self._pub.publish(True)
self._soundhandle.playWave(self._rhvoice_speech_sound_file_path, self._volume)
self._pub.publish(False)
Запуск и тест ноды RHVoice
В папке launch пакета abot_text_to_speech создадим файл запуска для новой ноды rhvoice_tts. Назовём его rhvoice_tts.launch.
<launch>
<arg name="volume" default="1.0" />
<arg name="rhvoice_speech_sound_file_path" default="$(find abot_text_to_speech)/sounds/rhvoice/speech.wav" />
<arg name="rhvoice_voice" default="Anna+Clb" />
<node name="rhvoice_tts" pkg="abot_text_to_speech" type="rhvoice_tts.py" output="screen" >
<param name="volume" value="$(arg volume)" />
<param name="rhvoice_speech_sound_file_path" value="$(arg rhvoice_speech_sound_file_path)" />
<param name="rhvoice_voice" value="$(arg rhvoice_voice)" />
</node>
</launch>
Через launch-файл задаём параметры для параметрического сервера ROS:
volumeи1.0— указываем максимальную громкость воспроизведения звука.rhvoice_speech_sound_file_path— путь, куда сохранить созданныйsoxаудиофайл. Будем сохранять синтезированую речь в WAV-файлspeech.wav. Сам файл будем хранить в папке/sounds/rhvoice/пакетаabot_text_to_speech.rhvoice_voice— выбранный голос для движка RHVoice. Голос задаётся комбинацией из двух голосов. Первый голос — основной, который озвучивает весь текст. Если первым голосом не получается произнести какие-то фонемы или фрагменты речи, то используется второй вспомогательный голос, и все они англоязычные. В нашем пакете их три:alan(муж.),clb(жен.) иslt(жен.). Голоса записываются через символ+. Например, итоговые голоса могут бытьAleksandr+Alan,Anna+Clb,Elena+stl,Irina+stl. Мы используем комбинацию голосовAnna+Clb.
Включим новый файл запуска ноды rhvoice_tts в общий файл запуска для наших систем «Text to Speech» — abot_text_to_speech.launch, при этом закомментируем предыдущие TTS-системы Festival и Amazon Polly, чтобы избежать конфликтов.
<!-- <include file="$(find abot_text_to_speech)/launch/festvox_tts.launch" /> -->
<!-- <include file="$(find abot_text_to_speech)/launch/aws_polly_tts.launch" /> -->
<include file="$(find abot_text_to_speech)/launch/rhvoice_tts.launch" />
Запускаем на Raspberry Pi все наши ноды «Text to Speech»:
source devel/setup.bash
roslaunch abot_text_to_speech abot_text_to_speech.launch
В новом терминале проверяем, появились ли новые топики /abot/tts/text_to_say и /abot/tts/speaking_in_progress.
rostopic list
Затем пробуем отправить в топик /abot/tts/text_to_say тестовый текст «Привет, Амперка!» и послушать синтезированный результат через динамики.
rostopic pub -1 /abot/tts/text_to_say std_msgs/String "Привет Амперка!"
Дерево нод и топиков в этом случае выглядит так:

Правки в KWS
Внесём несколько финальных правок в KWS-скрипт.
Наши ноды «Text to Speech» сейчас используют топик /abot/tts/speaking_in_progress, чтобы сообщать, воспроизводится ли аудио или нет.
Это важный момент. Когда робот воспроизводит синтезированную речь, её не нужно распознавать системой «Speech-to-Text». То есть, пока проигрывается аудио, нам нужно поставить KWS-декодер на паузу.
Для этого в ноде kws_script.py мы подпишемся на топик /abot/tts/speaking_in_progress и создадим простой флажок _tts_is_speaking.
self._tts_is_speaking = bool.data
rospy.Subscriber("/abot/tts/speaking_in_progress", Bool, self.ttsSpeakingCheck)
Каждый раз, когда в топике /abot/tts/speaking_in_progress обновляются данные, мы меняем состояние флага.
def ttsSpeakingCheck(self, bool_msg):
self._tts_is_speaking = bool_msg.data
if self._tts_is_speaking:
rospy.loginfo("KWS control node: Decoder paused while TTS is speaking")
else:
rospy.loginfo("KWS control node: Decoder returned to work")
Обработку аудиобуфера с микрофона выполняем, только если процесс проигрывания аудио с динамиков завершился:
def processAudio(self, audio_buffer):
self._decoder.process_raw(audio_buffer, False, False)
if self._tts_is_speaking is False:
if self._decoder.hyp() is not None:
for seg in self._decoder.seg():
rospy.logwarn("Detected key words: %s ", seg.word)
self._decoder.end_utt()
msg = seg.word
self._kws_data_pub.publish(msg)
self._kws_found = True
self._decoder.start_utt()
if self._kws_found == True:
msg = AudioData()
msg.data = audio_buffer
self._grammar_audio_pub.publish(msg)
Голосовое управление роботом
Отлично, наши системы «Speech-to-Text» и «Text to Speech» работают, и у нас готовы все необходимые ROS-ноды.
Пришло время реализовать голосовое управление в реальном роботе Abot.
Напоминаем, что все исходные файлы нашего робо-проекта можно посмотреть в GitHub-репозитории Abot.
Придумываем голосовые команды
Ключевое слово для режима KWS движка PocketSphinx мы оставили прежнее — «Робот».
Мы начали с простых задач и продолжили более сложными. Для примера мы придумали и реализовали три полезных способа применения голосового управления.
Мы можем узнать у робота время и дату. Очень полезно, если под рукой нет часов и не хочется лезть в телефон.
Запрос роботу для уточнения времени:
- «Робот, который час?»
- «Робот, сколько времени?»
Ответ робота:
- Например, «Время — двадцать три часа пятьдесят восемь минут».
Запрос роботу для уточнения даты:
- «Робот, текущая дата?»
- «Робот, сегодняшнее число?»
Ответ робота:
- Например, «Дата — шестнадцатое февраля, понедельник».
Наш робот ездит на аккумуляторах, и не всегда удобно следить за уровнем их заряда. Мы можем узнать у робота уровень заряда его батареи: просто спросим голосом — и он нам ответит. Используем две команды: одной узнаём, сколько процентов заряда осталось, а второй ещё и узнаём напряжение.
Запрос роботу для уровня заряда батареи:
- «Робот, заряд батареи?»
- «Робот, заряд аккумулятора?»
Ответ робота:
- Например, «Заряд — восемьдесят четыре процента».
Запрос роботу для уровня заряда и напряжения батареи:
- «Робот, заряд батареи, подробно?»
- «Робот, заряд аккумулятора, подробно?»
Ответ робота:
- Например, «Заряд — девяносто девять процентов. Напряжение — 8,4 вольта».
Мы интегрировали голосовое управление в систему навигации робота.
Голосом мы можем задавать роботу навигационные цели на карте. Наш робот обитает в офисе. В качестве навигационной цели мы задали место, где сидит определённый человек, или исходное место робота.
Запросы роботу:
- «Робот, едь к Виктору».
- «Робот, едь к Михаилу».
- «Робот, едь к Антону».
- «Робот, едь домой».
Ответ робота:
- Например: «Еду к Антону». Робот прокладывает путь до точки на карте, где сидит Антон, и начинает движение по маршруту.
Ещё мы можем осуществить голосовое управление простыми движениями робота.
Запросы роботу:
- «Робот, разворот». (Вращение платформы на π рад влево)
- «Робот, поворот влево». (Вращение платформы на π/2 рад влево)
- «Робот, поворот вправо». (Вращение платформы на π/2 рад вправо)
- «Робот, движение вперёд на метр».
- «Робот, движение вперёд на полметра».
- «Робот, движение назад на метр».
- «Робот, движение назад на полметра».
Ответ робота:
- «Выполняю». Робот выполняет указанное перемещение.
Эти движения робота тоже выполняются навигационным стеком ROS.
Сперва мы перенастраиваем систему «Speech-to-Text» на изменённые голосовые команды. Новые настройки мы разместили в папке config пакета abot_speech_to_text. Делаем всё по тому же принципу, как в примере с двумя светодиодами.
Лист ключевых слов abot_kwslist.kwslist содержит единственное слово «Робот» с порогом 1e-5.
робот /1e-5/
Словарь робота abot_dictionary.txt содержит 30 слов. Фонетический словарь abot_dictionary.dic, сгенерированный скриптом text2dict из пакета ru4sphinx, выглядит следующим образом:
аккумулятора a k u m u ll ja t ay r ay
антону a n t oo n u
батареи b ay t a rr je i
виктору vv i k t oo r u
влево v ll je v ay
вперёд f pp i rr jo t
вправо f p r aa v ay
времени v rr je mm i nn i
времени(2) v rr i mm i nn ii
дата d aa t ay
движение d vv i zh ee nn i i
домой d a m oo j
едь j i tt
заряд z a rr ja t
к k y
к(2) k ee
к(3) k
к(4) h
который k a t oo r y j
метр mm je t r
метра mm je t r ay
михаилу mm i h a ii l u
на n aa
назад n a z aa t
поворот p ay v a r oo t
подробно p a d r oo b n ay
пол p oo l
разворот r ay z v a r oo t
робот r oo b ay t
сегодняшнее ss i g oo d nn i sh nn i i
сколько s k oo ll k ay
текущая tt i k uu sch i i
час ch ja s
число ch i s l oo
А так выглядит описание формальной грамматики робота abot_gram.gram:
#JSGF V1.0;
grammar robot_cmd;
public <all_commands> = <state> | <command> ;
<state> = <state_1> | <state_2> | <state_3> ;
<state_1> = сколько времени | который час ;
<state_2> = текущая дата | сегодняшнее число ;
<state_3> = заряд ( батареи | аккумулятора ) [ подробно ] ;
<command> = <command_1> | <command_2> | <command_3> | <command_4> | <command_5> ;
<command_1> = едь ( к виктору | к михаилу | к антону | домой ) ;
<command_2> = разворот ;
<command_3> = поворот влево | поворот вправо ;
<command_4> = движение вперёд на ( метр | пол метра );
<command_5> = движение назад на ( метр | пол метра );
В файле запуска abot_speech_to_text.launch нашей системы «Speech-to-Text» указываем пути до новых файлов настройки:
<arg name="hmm" default="$(find abot_speech_to_text)/model/zero_ru_cont_8k_v3/zero_ru.cd_cont_4000" />
<arg name="dict" default= "$(find abot_speech_to_text)/config/abot_dictionary.dic" />
<arg name="kws" default="$(find abot_speech_to_text)/config/abot_kwslist.kwslist" />
<arg name="gram" default="$(find abot_speech_to_text)/config/abot_gram" />
<arg name="grammar" default="robot_cmd" />
<arg name="rule" default="all_commands" />
Крепление для звуковых устройств
В данный момент микрофон и динамики подключены к Raspberry Pi без какого-либо крепежа — они просто лежат на столе рядом с платой. Но наш робот Abot — мобильный, так что мы не можем оставить висящие провода и болтающийся микрофон. Для звуковых устройств нужно сделать специальное крепление, чтобы они стали неотъемлемой частью робота.
Как и прежде, мы напечатаем крепления для звуковых устройств на 3D-принтере. Главная деталь крепления звука сделана в виде панели или диска, по аналогии c креплением Raspberry Pi и креплением лидара. Деталь напечатали на Prusa i3 MK3S из серого PLA-пластика eSUN.

Динамики VECO 32KC08-1 и Troyka-усилитель класса D имеют удобные монтажные отверстия. Динамики — под винт M2, Troyka-усилитель — под винт М3. С их креплением проблем нет. А вот на звуковой карте и микрофоне крепёжные отверстия отсутствуют. Для крепления этих компонентов мы напечатали две прижимные пластины под крепёж М2:

Мы закрепили все звуковые устройства на 3D-напечатанной панели:

Подключаем звуковые устройства к Raspberry Pi:

А саму звуковую панель размещаем между панелью крепления RPi и панелью лидара через стойки М3×50:

Обновление URDF-описания и карты
Мы должны задокументировать все новые детали как в 3D-модели робота, так и в URDF-описании. Данное обновление в конструкции робота — отличный пример, что регистрировать изменения стоит обязательно, и вот почему.
Мы установили напечатанную панель со звуковыми устройствами между панелью Raspberry Pi и панелью лидара. Мы поместили её именно в это место для сохранения круговой области действия лидара. Положение лидара стало на 53 мм выше, чем было (высота стойки плюс толщина напечатанной панели). Лидар — это 2D-сенсор, и работает он в плоскости. Теперь плоскость действия лидара стала выше от земли, и мы не можем использовать нашу сохранённую карту в навигации. Ведь та карта была построена на информации с лидара, который стоял ниже. Если мы запустим привычную навигацию по сохранённой карте, робот не сможет локализироваться, ведь теперь он всё видит иначе — выше на 5,3 см. На карте там, где не было преград, могут появиться новые, а там, где они были — могут пропасть.
Обновляем 3D-модель робота в SolidWorks:
Используя плагин solidworks_urdf_exporter, производим экспорт 3D-модели в URDF описание:

Cтроим новую карту методом SLAM, используя геймпад DualShock 4:

Узнаём у робота дату и время
Нода обработчика
В папке src пакета abot_speech_command создаем новую ROS-ноду для обработки наших «временны́х» голосовых команд. Ноду пишем на С++, назовём её vc_get_system_time.
Заголовочный файл vc_get_system_time.h с классом VCGetSystemTime:
#ifndef VC_GET_SYSTEM_TIME_H_
#define VC_GET_SYSTEM_TIME_H_
#include <ros/ros.h>
#include <std_msgs/String.h>
#include <string>
#include <vector>
#include <time.h>
const std::vector<std::string> VOICE_COMMANDS_GET_SYSTEM_TIME = {
"который час",
"сколько времени",
"текущая дата",
"сегодняшнее число"
};
const std::vector<std::string> DAY_STRINGS = {
"первое", "второе", "третье", "четвёртое",
"пятое", "шестое", "седьмое", "восьмое",
"девятое", "десятое", "одиннадцатое", "двенадцатое",
"тринадцатое", "четырнадцатое", "пятнадцатое", "шестнадцатое",
"семнадцатое", "восемнадцатое", "девятнадцатое", "двадцатое",
"двадцать первое", "двадцать второе", "двадцать третье",
"двадацать четвёртое", "двадцать пятое", "двадцать шестое",
"двадцать седьмое", "двадцать восьмое", "двадцать девятое",
"тридцатое", "тридцать первое"
};
const std::vector<std::string> MONTH_STRINGS = {
"января", "февраля", "марта", "апреля",
"мая", "июня", "июля", "августа",
"сентября", "октября", "ноября", "декабря"
};
const std::vector<std::string> DAY_OF_A_WEEK_STRINGS = {
"понедельник", "вторник", "среда", "четверг",
"пятница", "суббота", "воскресенье"
};
class VCGetSystemTime {
public:
VCGetSystemTime();
private:
ros::NodeHandle _node;
ros::Subscriber _stt_sub;
ros::Publisher _tts_pub;
time_t _rawtime;
struct tm* _timeinfo;
void getTimeInfo();
std::string makeTimeString();
std::string makeDateString();
void grammarCallback(const std_msgs::String::ConstPtr& msg);
};
VCGetSystemTime::VCGetSystemTime() {
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetSystemTime::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
}
void VCGetSystemTime::grammarCallback(const std_msgs::String::ConstPtr& msg) {
std::string grammar_string = msg->data.c_str();
if (grammar_string == VOICE_COMMANDS_GET_SYSTEM_TIME[0] || grammar_string == VOICE_COMMANDS_GET_SYSTEM_TIME[1]) {
getTimeInfo();
std_msgs::String tts_string_msg;
tts_string_msg.data = makeTimeString();
_tts_pub.publish(tts_string_msg);
}
if (grammar_string == VOICE_COMMANDS_GET_SYSTEM_TIME[2] || grammar_string == VOICE_COMMANDS_GET_SYSTEM_TIME[3]) {
getTimeInfo();
std_msgs::String tts_string_msg;
tts_string_msg.data = makeDateString();
_tts_pub.publish(tts_string_msg);
}
}
void VCGetSystemTime::getTimeInfo() {
time(&_rawtime);
_timeinfo = localtime(&_rawtime);
}
std::string VCGetSystemTime::makeTimeString() {
int hours = (_timeinfo->tm_hour) % 24;
int minutes = _timeinfo->tm_min;
std::string hours_word_string;
std::string hours_string = std::to_string(hours);
if (hours == 1 || hours == 21)
hours_word_string = " час ";
else if ((hours >= 2 && hours <= 4) || hours == 22 || hours == 23)
hours_word_string = " часа ";
else
hours_word_string = " часов ";
int minutes_second_digit = minutes / 10;
int minutes_fisrt_digit = minutes % 10;
std::string minutes_string;
if (minutes == 1)
minutes_string = "одна";
else if (minutes_fisrt_digit == 1 && minutes_second_digit != 1)
minutes_string = std::to_string(minutes - 1) + " одна";
else if (minutes == 2)
minutes_string = "две";
else if (minutes_fisrt_digit == 2 && minutes_second_digit != 1)
minutes_string = std::to_string(minutes - 2) + " две";
else
minutes_string = std::to_string(minutes);
std::string minutes_word_string;
if (minutes_fisrt_digit == 1)
minutes_word_string = " минута";
else if (minutes_fisrt_digit == 2 || minutes_fisrt_digit == 3 || minutes_fisrt_digit == 4)
minutes_word_string = " минуты";
else
minutes_word_string = " минут";
std::string time_string = "Время " + hours_string + hours_word_string + minutes_string + minutes_word_string;
return time_string;
}
std::string VCGetSystemTime::makeDateString() {
int day = _timeinfo->tm_mday;
int month = _timeinfo->tm_mon;
int week_day = _timeinfo->tm_wday;
std::string day_string = DAY_STRINGS[day - 1];
std::string month_string = MONTH_STRINGS[month];
std::string week_day_string = DAY_OF_A_WEEK_STRINGS[week_day - 1];
std::string date_string = " Дата " + day_string + " " + month_string + " " + week_day_string;
return date_string;
}
#endif // VC_GET_SYSTEM_TIME_H_
И файл vc_get_system_time.cpp самой ноды:
#include <ros/ros.h>
#include "vc_get_system_time.h"
int main(int argc, char **argv) {
ros::init(argc, argv, "vc_get_system_time");
VCGetSystemTime get_system_time;
ROS_INFO("Voice command node 'Get System Time': Start.");
ros::spin();
return 0;
}
Как работает нода?
Подписываемся на топик /abot/stt/grammar_data, куда поступают распознанные в речи голосовые команды. Публикуем текст для движка «Text-to-Speech» в топик /abot/tts/text_to_say.
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetSystemTime::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
Для получения и хранения системного времени используем стандартную библиотеку C++ time.h и метод getTimeInfo нашего класса:
time_t _rawtime;
struct tm* _timeinfo;
void VCGetSystemTime::getTimeInfo() {
time(&_rawtime);
_timeinfo = localtime(&_rawtime);
}
При поступлении в топик /abot/stt/grammar_data новой распознанной голосовой команды осуществляется её поиск среди списка всех «временны́х» команд VOICE_COMMANDS_GET_SYSTEM_TIME в теле функции grammarCallback. Если команда относится к «временны́м», формируется строка-ответ с временем — makeTimeString или датой — makeDateString. Сформированная строка публикуется в топик /abot/tts/text_to_say для синтеза голоса движком «Text-to-Speech».
Мы добавили новые исходные файлы С++, а значит, нужно добавить новое правило сборки в CMakeLists.txt:
add_executable(vc_get_system_time src/vc_get_system_time.cpp)
target_link_libraries(vc_get_system_time ${catkin_LIBRARIES})
Собираем проект:
catkin_make
Запуск обработчика
Для запуска всех нод, которые отвечают за обработку голосовых команд на роботе, создадим новый launch-файл. В папке launch пакета abot_speech_command создаём файл abot_speech_command.launch.
Добавим первую ноду vc_get_system_time с «временны́ми» голосовыми командами:
<launch>
<group ns="/abot" >
<node name="vc_get_system_time" pkg="abot_speech_command" type="vc_get_system_time" output="screen" />
</group>
</launch>
Также создадим ещё один главный launch-файл для запуска вообще всех звуковых нод. Разместим файл в том же пакете abot_speech_command и назовём его abot_sound.launch.
В нём мы запустим все ноды «Text-to-Speech», «Speech-to-Text», а также сам обработчик команд из всех трёх пакетов:
<launch>
<include file="$(find abot_speech_to_text)/launch/abot_speech_to_text.launch" />
<include file="$(find abot_text_to_speech)/launch/abot_text_to_speech.launch" />
<include file="$(find abot_speech_command)/launch/abot_speech_command.launch" />
</launch>
Запускаем все звуковые пакеты:
source devel/setup.bash
roslaunch abot_speech_command abot_sound.launch
Результат работы «временны́х» голосовых команд на видео:
Дерево всех звуковых нод и топиков нашего робота теперь выглядит следующим образом:

Узнаём у робота уровень заряда батареи
Создадим обработчик для наших «батарейных» голосовых команд.
Схема подключения
Чтобы узнать уровнь заряда аккумулятора, нам нужно узнать, какое на нём напряжение, то есть нам нужен аналого-цифровой преобразователь.
На плате Raspberry Pi, которая является основой нашего робота, АЦП и аналоговых пинов нет. Однако мы используем модуль Troyka HAT, а на его расширителе GPIO-портов есть целых восемь аналоговых пинов! Ими и воспользуемся.
Расширитель портов — отдельный микроконтроллер STM32. Напряжение питания логической части микроконтроллера — 3,3 В. Аккумулятор нашего робота состоит из четырёх отдельных Li-Ion аккумуляторов, или «банок». Максимальное напряжение одной банки — 4,2 В, а минимальное — 2,75 В. Две банки соединены последовательно, и две параллельно. То есть мы имеем аккумуляторную 2S-сборку с максимальным напряжением 8,4 В и минимальным напряжением 5,5 В. Мы не можем подключить такое напряжение напрямую к аналоговому пину микроконтроллера — он просто сгорит. Для подключения используем делитель напряжения на двух резисторах.
Никакие печатные платы нам не нужны, просто впаяем резисторы в разрыв трёхпроводного шлейфа «мама-папа».

Используем два резистора: R1 номиналом 1 кОм и R2 номиналом 1,6 кОм. Резисторы — самые обычные и не очень точные, поэтому предварительно уточняем сопротивление мультиметром.

Надёжно изолируем всё термоусадкой:

Отношение на резисторном делителе получилось равным 0,3897. Напряжение на аккумуляторе не может быть больше 8,4 В, а значит, на аналоговый пин не придёт напряжение выше 3,27 В. В итоге мы получили удобный переходничок, через который можно подключить аккумулятор к аналоговому пину и Troyka-контакту на плате Troyka HAT.

Мы подключаем батарею к 7-му пину расширителя GPIO-контактов.
Это важно! При работе с АЦП микроконтроллера на плате Troyka HAT вы можете столкнуться с занижением значения считываемого уровня напряжения. Это связно с использованием защитных стабилитронов на напряжение 3,3 В на гребёнке пинов микроконтроллера. При возникновении подобной проблемы просто удалите с платы нужный стабилитрон и не превышайте входного напряжения 3,3 В. Удалить стабилитрон можно паяльником или феном для SMD-компонентов.

Нода обработчика
В папке src пакета abot_speech_command создаём новую ROS-ноду для обработки наших «батарейных» голосовых команд. Напишем ноду на С++ и назовём её vc_get_battery_state.
Заголовочный файл vc_get_battery_state.h с классом VCGetBatteryState:
#ifndef VC_GET_BATTERY_STATE_H_
#define VC_GET_BATTERY_STATE_H_
#include <ros/ros.h>
#include <std_msgs/String.h>
#include <string>
#include <vector>
#include <GpioExpanderPi.h>
const std::vector<std::string> VOICE_COMMANDS_GET_BATTERY_STATE = {
"заряд батареи",
"заряд аккумулятора",
"заряд батареи подробно",
"заряд аккумулятора подробно"
};
constexpr float V_BATTERY_MAX = 4.2 * 2;
constexpr float V_BATTERY_MIN = 2.75 * 2;
constexpr float V_BATTERY_DIF = V_BATTERY_MAX - V_BATTERY_MIN;
constexpr float V_REF = 3.29;
constexpr float R_DIVIDER = 0.3897307;
constexpr uint8_t GPIO_EXPANDER_DIVIDER_PIN = 7;
class VCGetBatteryState {
public:
VCGetBatteryState(GpioExpanderPi* expander);
private:
ros::NodeHandle _node;
ros::Subscriber _stt_sub;
ros::Publisher _tts_pub;
GpioExpanderPi* _expander;
float _battery_voltage;
int _battery_percentage;
void getVoltage();
std::string makePercentString();
std::string makeVoltageString();
void grammarCallback(const std_msgs::String::ConstPtr& msg);
};
VCGetBatteryState::VCGetBatteryState(GpioExpanderPi* expander) {
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetBatteryState::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
_expander = expander;
}
void VCGetBatteryState::grammarCallback(const std_msgs::String::ConstPtr& msg) {
std::string grammar_string = msg->data.c_str();
if (grammar_string == VOICE_COMMANDS_GET_BATTERY_STATE[0] || grammar_string == VOICE_COMMANDS_GET_BATTERY_STATE[1]) {
getVoltage();
std_msgs::String tts_string_msg;
tts_string_msg.data = makePercentString();
_tts_pub.publish(tts_string_msg);
} else if (grammar_string == VOICE_COMMANDS_GET_BATTERY_STATE[2] || grammar_string == VOICE_COMMANDS_GET_BATTERY_STATE[3]) {
getVoltage();
std_msgs::String tts_string_msg;
tts_string_msg.data = makePercentString() + makeVoltageString();
_tts_pub.publish(tts_string_msg);
}
}
void VCGetBatteryState::getVoltage() {
uint16_t analog_value = _expander->analogRead(GPIO_EXPANDER_DIVIDER_PIN);
float input_voltage = V_REF / 4095.0 * analog_value;
_battery_voltage = input_voltage / R_DIVIDER;
if (_battery_voltage < V_BATTERY_MIN) _battery_voltage = V_BATTERY_MIN;
if (_battery_voltage > V_BATTERY_MAX) _battery_voltage = V_BATTERY_MAX;
_battery_percentage = (_battery_voltage - V_BATTERY_MIN) / V_BATTERY_DIF * 100;
}
std::string VCGetBatteryState::makePercentString() {
int percentage_fisrt_digit = _battery_percentage % 10;
std::string percentage_word_string;
if (percentage_fisrt_digit == 1)
percentage_word_string = " процент";
else if (percentage_fisrt_digit == 2 || percentage_fisrt_digit == 3 || percentage_fisrt_digit == 4)
percentage_word_string = " процента";
else
percentage_word_string = " процентов";
std::string percentage_string = "Заряд " + std::to_string(_battery_percentage) + percentage_word_string;
return percentage_string;
}
std::string VCGetBatteryState::makeVoltageString() {
int int_part = _battery_voltage;
int fractal_part = _battery_voltage * 100 - int_part * 100;
std::string voltage_string = " Напряжение " + std::to_string(int_part) + " точка " + std::to_string(fractal_part) + " вольт";
return voltage_string;
}
#endif // VC_GET_BATTERY_STATE_H_
И файл vc_get_battery_state.cpp самой ноды:
#include <ros/ros.h>
#include <GpioExpanderPi.h>
#include "vc_get_battery_state.h"
int main(int argc, char **argv) {
ros::init(argc, argv, "vc_get_battery_state");
GpioExpanderPi expander;
if (!expander.begin()) {
ROS_ERROR("Voice command node 'Get Battery State': Failed to init I2C communication.");
return -1;
}
VCGetBatteryState get_battery_state(&expander);
ROS_INFO("Voice command node 'Get Battery State': Start.");
ros::spin();
return 0;
}
Как работает нода?
Подписываемся на топик /abot/stt/grammar_data, куда поступают распознанные в речи голосовые команды. Публикуем текст для движка «Text-to-Speech» в топик /abot/tts/text_to_say.
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetSystemTime::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
Для общения с расширителем портов используем библиотеку GpioExpanderPi.h. Создаём новый объект класса GpioExpanderPi, проверяем и запускаем I²C-соединение, передаём ссылку на объект в конструктор нашего класса.
GpioExpanderPi expander;
if (!expander.begin()) {
ROS_ERROR("Voice command node 'Get Battery State': Failed to init I2C communication.");
return -1;
}
VCGetBatteryState get_battery_state(&expander);
При поступлении в топик /abot/stt/grammar_data новой распознанной голосовой команды осуществляется её поиск среди списка всех «батарейных» команд VOICE_COMMANDS_GET_BATTERY_STATE в теле функции grammarCallback. Если команда относится к «батарейным», то мы производим измерение напряжения _battery_voltage на 7 пине расширителя портов функцией getVoltage. В теле этой же функции рассчитываем процент заряда батареи _battery_percentage. Формируем строку-ответ с процентом заряда батареи — makePercentString или напряжением — makeVoltageString. Сформированная строка публикуется в топик /abot/tts/text_to_say для синтеза голоса движком «Text-to-Speech».
Появился новый исходный файл С++ — добавляем новое правило сборки в CMakeLists.txt:
add_executable(vc_get_battery_state src/vc_get_battery_state.cpp)
target_link_libraries(vc_get_battery_state ${catkin_LIBRARIES} -lwiringPi -lGpioExpanderPi)
Собираем проект:
catkin_make
Запуск обработчика
Добавим вторую ноду-обработчик vc_get_battery_state, которая отвечает за «батарейные» голосовые команды, в файл запуска abot_speech_command.launch:
<launch>
<group ns="/abot" >
<node name="vc_get_battery_state" pkg="abot_speech_command" type="vc_get_battery_state" output="screen" />
<node name="vc_get_system_time" pkg="abot_speech_command" type="vc_get_system_time" output="screen" />
</group>
</launch>
Запускаем все звуковые пакеты:
source devel/setup.bash
roslaunch abot_speech_command abot_sound.launch
Результат работы «батарейных» голосовых команд на видео:
Дерево всех звуковых нод и топиков на нашем роботе теперь выглядит так:

Голосовое управление навигацией робота
Мы подошли, пожалуй, к самой интересной части проекта — голосовому управлению в навигации.
Это важно! Данная часть проекта подразумевает, что вы уже разобрались и умеете работать со стеком навигации в ROS. В противном случае вам действительно мало что будет понятно. Настоятельно рекомендуем вам ознакомиться с навигацией в ROS в нашей второй статье проекта.
Новый метод расстановки виртуальных стен
Немного отойдём от звуковых ROS-пакетов и расскажем вам о новом способе расстановки виртуальных стены на карте навигации.
Наш робот развивается, развиваемся и мы. В процессе изучения ROS мы осваиваем новые приёмы. Ранее для установки виртуальных стен мы рисовали их прямо на карте в графическом редакторе GIMP. Этот способ — рабочий, но не самый лучший, так как он сильно влияет на локализацию робота. Ведь, по сути, мы исправляем таким образом «зрение робота».
Для локализации робота лучше вообще не трогать карту созданную методом SLAM.
Мы решили сделать две карты: «истинную» и «ложную».
Истинная карта — та самая, созданная в SLAM без каких-либо правок. Эта карта публикуется с помощью map_server в стандартный для ROS-топик /map. Карта используется в локализации acml и при построении глобальной карты затрат навигации. Файл с картой мы назвали map2_original.
Затем мы взяли истинную карту, нарисовали на ней все нужные виртуальные стены — места, куда роботу не нужно ехать, и сохранили эту карту под новым именем map2_fake. Так у нас получилась как бы «ложная» карта, которую мы также можем опубликовать через map_server, но уже в другой топик с другим пространством имён, например /abot_fake_map/map. Мы не можем использовать «ложную» карту в локализации, так как она слишком сильно изменена. Но мы можем использовать её в качестве дополнительного статического источника преград при построении глобальной карты затрат.
Так выглядит наша «ложная» отредактированная карта:
В пакете abot_navigation в launch-файле abot_navigation.launch загружаем обе карты в разные топики, используя map_server.
<launch>
<!-- Real map -->
<arg name="map_file" default="$(find abot_slam)/maps/map2_original.yaml" />
<node pkg="map_server" name="map_server" type="map_server" args="$(arg map_file)" />
<!-- Fake map -->
<arg name="fake_map_file" default="$(find abot_slam)/maps/map2_fake.yaml" />
<node pkg="map_server" name="map_server" type="map_server" ns="/abot_fake_map" args="$(arg fake_map_file)" />
<node pkg="tf" type="static_transform_publisher" name="fake_map_broadcaster" args="1 0 0 0 0 0 1 /map /abot_fake_map/map 100" />
<include file="$(find abot_navigation)/launch/amcl.launch" />
<include file="$(find abot_navigation)/launch/move_base.launch" />
</launch>
С помощью ноды static_transform_publisher из пакета tf осуществляем связь двух наших фреймов /map и /abot_fake_map/map. По сути, геометрически жёстко связываем обе карты, накладывая одну на другую.
<node pkg="tf" type="static_transform_publisher" name="fake_map_broadcaster" args="1 0 0 0 0 0 1 /map /abot_fake_map/map 100" />
В общих настроках карты затрат costmap_common.yaml добавляем новый слой (layer) — fake_walls. В этом слое параметром указываем путь до топика с ложной картой — /abot_fake_map/map.
robot_radius: 0.1
robot_base_frame: base_footprint
resolution: 0.025
obstacle_range: 6.5
raytrace_range: 7.0
#layer definitions
static:
map_topic: /map
obstacles:
observation_sources: abot_lidar
abot_lidar:
data_type: LaserScan
clearing: true
marking: true
topic: scan
inf_is_valid: true
inflation:
inflation_radius: 2.0
fake_walls:
map_topic: /abot_fake_map/map
В настроках глобальной карты затрат добавляем новый источник данных для построения карты типа costmap_2d::StaticLayer — fake_walls.
global_frame: map
rolling_window: false
track_unknown_space: true
update_frequency: 10.0
publish_frequency: 10.0
transform_tolerance: 0.5
cost_scaling_factor: 10.0
plugins:
- { name: static, type: "costmap_2d::StaticLayer" }
- { name: fake_walls, type: "costmap_2d::StaticLayer" }
- { name: inflation, type: "costmap_2d::InflationLayer" }
Теперь, если запустить процесс навигации робота, мы сможем увидеть, что на глобальной карте затрат появились наши искусственные стены из топика /abot_fake_map/map.
Но при этом робот локализуется только на истинной карте /map — той, что он видел своими «глазами». Такой приём позволяет значительно улучшить качество навигации робота.
Запоминаем точки на карте
Мы решили, что будем использовать голосовые команды, чтобы отправить робота к тому или иному человеку у нас в офисе.
Всего мы подготовили четыре такие голосовые команды:
- «Робот, едь к Виктору».
- «Робот, едь к Михаилу».
- «Робот, едь к Антону».
- «Робот, едь домой».
Выполнение роботом подобной голосовой команды равносильно тому, как если бы мы вручную задали роботу целевую точку маршрута кнопкой 2D Nav Goal на панели инструментов в rviz.
Для всех голосовых команд нужно придумать места на карте, а затем определить координаты этих мест.
Для наших четырёх команд мы придумали следующие приблизительные места на карте:
Запускаем навигацию.
На Raspberry Pi запускаем главный launch-файл робота bringup.launch:
su root
source devel/setup.bash
roslaunch abot_description bringup.launch
На настольном компьютере запускаем ноды навигации:
source devel/setup.bash
roslaunch abot_description display_navigation.launch
Берём в руки геймпад DualShock 4 и рулим роботом к этим точкам на карте. Когда мы добираемся до точки, то узнаем её координаты. В любом новом терминале запускаем ноду tf_echo из пакета tf со следующими аргументами:
rosrun tf tf_echo /map /base_link
Этой командой мы узнаем геометрическую трансформацию фрейма /base_link относительно фрейма /map. Так как сегмент /base_link находится в условном центре нашего робота, мы узнаем, где именно робот находится на карте.
Значение Translation показывает текущую трёхмерную координату (X, Y, Z) робота на карте. Значение Rotation показывает в виде кватериона вращения, или угла ориентации тела робота в точке с этими координатами.
Для всех выбранных четырёх точек мы записываем трёхмерные координаты и кватерионы вращения.
Кватерион вращения — очень полезный инструмент. Изменяя углы ориентации, мы можем задать, куда должен смотреть робот, когда он окажется в целевой точке. Если бы наш робот был гумандоидным, мы могли бы сделать так, чтобы робот приезжал в к человеку и стоял к нему лицом, а не спиной.
Нода обработчика
В папке src пакета abot_speech_command создаём новую ROS-ноду для обработки наших навигационных голосовых команд. Ноду пишем на С++. Назовём её vc_set_navigation_goal.
В официальной документации ROS есть отличная подробная статья о том, как отправлять целевые точки в навигационный стек: Sending Goals to the Navigation Stack.
Заголовочный файл vc_set_navigation_goal.h с классом VCSetNavigationGoal:
#ifndef VC_SET_NAVIGATION_GOAL_H_
#define VC_SET_NAVIGATION_GOAL_H_
#include <ros/ros.h>
#include <std_msgs/String.h>
#include <move_base_msgs/MoveBaseAction.h>
#include <actionlib/client/simple_action_client.h>
#include <string>
#include <vector>
const std::vector<std::string> VOICE_COMMANDS_SET_NAVIGATION_GOAL = {
"едь домой",
"едь к михаилу",
"едь к виктору",
"едь к антону",
"разворот",
"поворот влево",
"поворот вправо",
"движение вперёд на пол метра",
"движение вперёд на метр",
"движение назад на пол метра",
"движение назад на метр",
};
constexpr double POSE_HOME[7] = {0.042, -0.013, 0.018, 0.000, 0.000, 0.031, 1.000};
constexpr double POSE_MIKHAIL[7] = {-1.651, 6.007, 0.018, 0.000, 0.000, 0.675, 0.738};
constexpr double POSE_VICTOR[7] = {-0.978, -4.205, 0.018, 0.000, 0.000, 0.023, 1.000};
constexpr double POSE_ANTON[7] = {12.615, -0.322, 0.018, 0.000, 0.000, 0.728, 0.685};
typedef actionlib::SimpleActionClient<move_base_msgs::MoveBaseAction> MoveBaseClient;
class VCSetNavigationGoal {
public:
VCSetNavigationGoal();
private:
ros::NodeHandle _node;
ros::Subscriber _stt_sub;
ros::Publisher _tts_pub;
MoveBaseClient _ac{"/move_base", true};
void sendGoalMsg(const std::string frame_id, const double parameters[7]);
void grammarCallback(const std_msgs::String::ConstPtr& msg);
};
VCSetNavigationGoal::VCSetNavigationGoal() {
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCSetNavigationGoal::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
while (!_ac.waitForServer(ros::Duration(5.0))) {
ROS_INFO("Voice command node 'Set Navigation Goal': Waiting for the move_base action server to come up");
}
}
void VCSetNavigationGoal::sendGoalMsg(const std::string frame_id, const double parameters[7]) {
move_base_msgs::MoveBaseGoal goal;
goal.target_pose.header.frame_id = frame_id;
goal.target_pose.header.stamp = ros::Time::now();
goal.target_pose.pose.position.x = parameters[0];
goal.target_pose.pose.position.y = parameters[1];
goal.target_pose.pose.position.z = parameters[2];
goal.target_pose.pose.orientation.x = parameters[3];
goal.target_pose.pose.orientation.y = parameters[4];
goal.target_pose.pose.orientation.z = parameters[5];
goal.target_pose.pose.orientation.w = parameters[6];
_ac.sendGoal(goal);
}
void VCSetNavigationGoal::grammarCallback(const std_msgs::String::ConstPtr& text_msg) {
std::string grammar_string = text_msg->data.c_str();
std_msgs::String answer_msg;
if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[0]) {
answer_msg.data = "Еду домой!";
_tts_pub.publish(answer_msg);
sendGoalMsg("map", POSE_HOME);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[1]) {
answer_msg.data = "Еду к Михаилу!";
_tts_pub.publish(answer_msg);
sendGoalMsg("map", POSE_MIKHAIL);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[2]) {
answer_msg.data = "Еду к Виктору!";
_tts_pub.publish(answer_msg);
sendGoalMsg("map", POSE_VICTOR);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[3]) {
answer_msg.data = "Еду к Антону!";
_tts_pub.publish(answer_msg);
sendGoalMsg("map", POSE_ANTON);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[4]) {
answer_msg.data = "Выполняю разворот на месте!";
_tts_pub.publish(answer_msg);
double params[7] = {0, 0, 0, 0, 0, 1, 0};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[5]) {
answer_msg.data = "Выполняю поворот влево!";
_tts_pub.publish(answer_msg);
double params[7] = {0, 0, 0, 0, 0, 0.707, 0.707};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[6]) {
answer_msg.data = "Выполняю поворот вправо!";
_tts_pub.publish(answer_msg);
double params[7] = {0, 0, 0, 0, 0, -0.707, 0.707};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[7]) {
answer_msg.data = "Выполняю!";
_tts_pub.publish(answer_msg);
double params[7] = {0.5, 0, 0, 0, 0, 0, 1};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[8]) {
answer_msg.data = "Выполняю!";
_tts_pub.publish(answer_msg);
double params[7] = {1.0, 0, 0, 0, 0, 0, 1};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[9]) {
answer_msg.data = "Выполняю!";
_tts_pub.publish(answer_msg);
double params[7] = {-0.5, 0, 0, 0, 0, 0, 1};
sendGoalMsg("base_link", params);
}
else if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[10]) {
answer_msg.data = "Выполняю!";
_tts_pub.publish(answer_msg);
double params[7] = {-1.0, 0, 0, 0, 0, 0, 1};
sendGoalMsg("base_link", params);
}
}
#endif // SET_NAVIGATION_GOAL_H_
И файл vc_set_navigation_goal.cpp самой ноды:
#include <ros/ros.h>
#include "vc_set_navigation_goal.h"
int main(int argc, char **argv) {
ros::init(argc, argv, "vc_set_navigation_goal");
VCSetNavigationGoal set_navigation_goal;
ROS_INFO("Voice command node 'Set Navigation Goal': Start.");
ros::spin();
return 0;
}
Как работает нода?
Подписываемся на топик /abot/stt/grammar_data, куда поступают распознанные в речи голосовые команды. Публикуем текст для движка «Text-to-Speech» в топик /abot/tts/text_to_say.
_stt_sub = _node.subscribe("/abot/stt/grammar_data", 1, &VCGetSystemTime::grammarCallback, this);
_tts_pub = _node.advertise<std_msgs::String>("/abot/tts/text_to_say", 1);
Для организации отправки целей (goal) в навигационную ноду нашего робота move_base испольуем Action-клиент. В классе создаём новый объект клиента Action-сервера _ac.
typedef actionlib::SimpleActionClient<move_base_msgs::MoveBaseAction> MoveBaseClient;
MoveBaseClient _ac{"/move_base", true};
Методом sendGoalMsg будем отправлять новые цели на сервер. Каждая новая цель представляет из себя точку (position) с координатами x, y, z и кватерион вращения (orientation) — x, y, z, w. В сумме семь значений типа double. Также нужно указать имя фрейма frame_id, относительно которого указана точка и кватерион.
Это важно! Точка указываются координатой и кватерионом вращения относительно какого-либо фрейма. Так как мы используем клиент навигационного стека движение робота до этой точки осуществляется по фрейму map. Что это значит? Например, мы хотим задать роботу целевую точку находящуюся в метре спереди от робота. Мы указываем соответствующую координату с значением 1 метр по оси X относительно фрейма base_link робота. Траектория движения робота до этой точки не обязательно будет прямой линией длиной в 1 метр! Робот спланирует движение на 1 метр вперед относительно себя но с учетом карты map и соответствующих карт затрат навигационного стека.
void VCSetNavigationGoal::sendGoalMsg(const std::string frame_id, const double parameters[7]) {
move_base_msgs::MoveBaseGoal goal;
goal.target_pose.header.frame_id = frame_id;
goal.target_pose.header.stamp = ros::Time::now();
goal.target_pose.pose.position.x = parameters[0];
goal.target_pose.pose.position.y = parameters[1];
goal.target_pose.pose.position.z = parameters[2];
goal.target_pose.pose.orientation.x = parameters[3];
goal.target_pose.pose.orientation.y = parameters[4];
goal.target_pose.pose.orientation.z = parameters[5];
goal.target_pose.pose.orientation.w = parameters[6];
_ac.sendGoal(goal);
}
Глобально задаём эти семь значений для наших четырёх точек на карте в виде массивов:
constexpr double POSE_HOME[7] = {0.042, -0.013, 0.018, 0.000, 0.000, 0.031, 1.000};
constexpr double POSE_MIKHAIL[7] = {-1.651, 6.007, 0.018, 0.000, 0.000, 0.675, 0.738};
constexpr double POSE_VICTOR[7] = {-0.978, -4.205, 0.018, 0.000, 0.000, 0.023, 1.000};
constexpr double POSE_ANTON[7] = {12.615, -0.322, 0.018, 0.000, 0.000, 0.728, 0.685};
При поступлении в топик /abot/stt/grammar_data новой распознанной голосовой команды осуществляется её поиск среди списка всех навигационных команд VOICE_COMMANDS_SET_NAVIGATION_GOAL в теле функции grammarCallback. Если команда относится к навигационным командам, мы вызываем функцию sendGoalMsg с определённым набором параметров.
Например, для движения робота к точке «Виктор» на карте мы отправляем в Action-сервер новую цель с массивом POSE_VICTOR. Координаты и ориентация указаны относительно карты, поэтому вбиваем имя фрейма map.
sendGoalMsg("map", POSE_VICTOR);
Что насчёт обычных движений робота? Например, для разворота робота на месте нам нужно отправить в функцию sendGoalMsg координату (0, 0, 0) — робот стоит на месте и кватерион (0, 0, 1, 0) — разворот тела робота на 1×π по оси z. При этом всё это нужно сделать не относительно карты (map), а относительно самого робота (base_link).
if (grammar_string == VOICE_COMMANDS_SET_NAVIGATION_GOAL[4]) {
answer_msg.data = "Выполняю разворот на месте!";
_tts_pub.publish(answer_msg);
double params[7] = {0, 0, 0, 0, 0, 1, 0};
sendGoalMsg("base_link", params);
}
Как и в предыдущих обработчиках команд, формируем строку с желаемым ответом робота и публикуем её в топик /abot/tts/text_to_say для синтезатора речи.
Новый исходный файл С++ — новое правило сборки в CMakeLists.txt:
add_executable(vc_set_navigation_goal src/vc_set_navigation_goal.cpp)
target_link_libraries(vc_set_navigation_goal ${catkin_LIBRARIES})
Плюс к этому новая нода использует новые типы сообщений и Action-клиенты, так что нам нужно указать новые пакеты зависимости в файлах CMakeLists.txt и package.xml:
actionlibmove_base_msgs
Собираем проект:
catkin_make
Запуск обработчика
Добавим третью ноду-обработчик vc_set_navigation_goal, которая отвечает за навигационные голосовые команды, в файл запуска abot_speech_command.launch:
<launch>
<group ns="/abot" >
<node name="vc_get_battery_state" pkg="abot_speech_command" type="vc_get_battery_state" output="screen" />
<node name="vc_get_system_time" pkg="abot_speech_command" type="vc_get_system_time" output="screen" />
<node name="vc_set_navigation_goal" pkg="abot_speech_command" type="vc_set_navigation_goal" output="screen" />
</group>
</launch>
На роботе запускаем главный launch-файл bringup.launch под root:
su root
source devel/setup.bash
roslaunch abot_description bringup.launch
На настольном компьютере запускаем навигацию:
source devel/setup.bash
roslaunch abot_description display_navigation.launch
В новом терминале на роботе запускаем все звуковые пакеты не под root:
source devel/setup.bash
roslaunch abot_speech_command abot_sound.launch
Результат работы навигационных голосовых команд на видео:
Сейчас мы запустили все написанные нами за всё время ROS-ноды, поэтому дерево всех нод и топиков теперь выглядит монструозно:
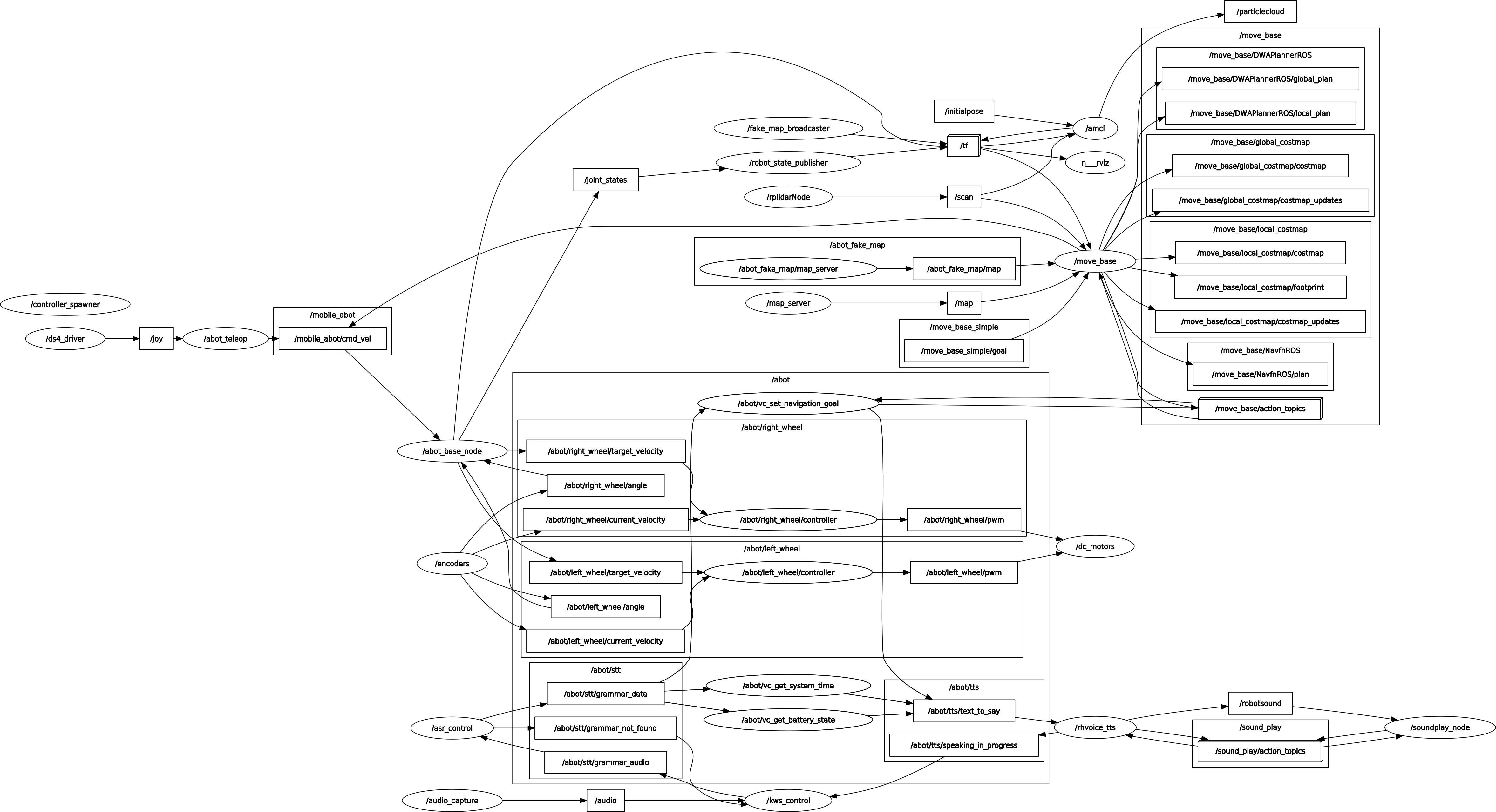
Заключение
Мы завершили очередной апгрейд робота Abot и «прикрутили» к нему голосовое управление со всем необходимым софтом и железом.
Попутно мы разобрались, как работают технологии распознавания и синтеза речи, и какие готовые решения можно взять прямо сейчас, чтобы реализовать управление интуитивными командами на русском языке.
На этом совершенствование робота на ROS не заканчивается — впереди у нас ещё куча идей, следите за новыми выпусками.
До встречи!
Все части проекта
- Часть 1: шасси и бортовая электроника
- Часть 2: дистанционное управление и навигация
- Часть 3: распознавание речи для голосового управления
- 1. Описание
- 1. void MainWindow::start(bool checked)
- 2. void MainWindow::speechStateChange(QTextToSpeech::State state)
- 2. Вспомогательные функции
- 1. void MainWindow::scrollTo()
- 2. bool MainWindow::setActiveBlock(int blockNumber, bool scroll)
- 3. Ударение и Омографы
Библиотека Qt 5.8.0 предоставила программистам возможность использовать системный синтезатор речи. Синтезатор речи — это программа, преобразующая текст в речь. Синтезаторы речи является неотъемлемой частью любой современной операционной системы: Windows (версии 7 и выше), Mac OS, Linux, iOS и Android. Кроссплатформенный интерфейс для управления синтезом речи предоставляет модуль QtTextToSpeech библиотеки Qt.
Для работы с модулем QtTextToSpeech на ОС Windows необходимо:
- установить библиотеку Qt c модулем QtTextToSpeech для компилятора Visual Studio 2015 или старше ( mingw работать не будет );
- установить компилятор Visual Studio 2015 ;
-
установить библиотеку
SAPI 5.1
, если по какой-то причине она отсутствует на вашем компьютере;
-
установить голоса для
синтезатора речи
(если у вас они отсутствуют).
- При сборке проекта необходимо использовать теневую сборку.
Описание
Если при компиляции программы Вы видите сообщение
Error loading text-to-speech plug-in "sapi"то вы сделали что-то неправильно.
Если вы используете Android , то по умолчанию у вас работает online синтезатор. За это вы расплатитесь задержкой при синтезе и потраченным трафиком. Если это вас не устраивает, то устанавливайте offline версию. На Android 5.1 для этого необходимо перейти в «настройки» — «специальные возможности» — «синтез речи» — «синтезатор речи Google » — «установка голосовых данных» — «русский (Россия)» и жмём установить и ожидаем завершения. Кроме того, подготавливаем Qt Creator для создания Android приложений.
Теперь можно приступать к написанию программы. По ссылке вы можете
скачать
проект с исходным кодом программы, описанной ниже. Создаём процесс новый проект qtwidget. В файл проекта подключает необходимый модуль
QT += texttospeechПодключаем библиотеку синтезатора речи
#include <QtTextToSpeech>Создаём указатель на объект класса QTextToSpeech
QTextToSpeech* speech;а затем и сам объект
speech = new QtextToSpeech;Теперь можно генерировать речевые сигналы с помощью функции say(), в качестве аргумента которой нужно передать произносимый текст. В примерах созданных разработчиками Qt Creator приведён простой пример helloSpeech. Рассмотрите его для того, чтобы лучше понять возможности рассматриваемого модуля.
Я перейду к некоторым более сложным вещам. Программа, которую вы можете скачать по ссылке, содержит виджет класса QTextEdit для воспроизводимого текста , управляющие кнопки: старт, стоп, вперёд назад, …, окно для выбора файлов, и окна для настройки синтезатора.
void MainWindow::start(bool checked)
Запускать на воспроизведение можно и большие текстовые фрагменты. Однако это приводит к необязательным задержкам, а в случае online синтезатора на Android и к зависанию программы. Поэтому дробим текст на фрагменты, чем меньше, тем лучше. Для начала я выделяю из текста абзац ( int activeBlock ), а затем разбиваю строку на лист строк ( QStringList readList ) использую точки в качестве разделителя.
void MainWindow::start(bool checked) { if(checked) { if(readList.isEmpty()) { readList = ui->textEdit->document()->findBlockByNumber( activeBlock ).text().split("."); } if(!readList.isEmpty()) { readString = readList.first(); readList.removeFirst(); if(!readString.contains(QRegularExpression("[A-Z]|[a-z]|[0-9]|[А-Я]|[а-я]"))) { readString = ".";//windows не читает точки if(QSysInfo::productType() == "android") readString = " "; } speech->say( readString ); scrollTo(); ui->textEdit->setReadOnly(true); } } else { readList.prepend(readString);// speech->stop(); ui->textEdit->setReadOnly(false); } }void MainWindow::speechStateChange(QTextToSpeech::State state)
На синтезатор передаётся одна строчка. После завершения её воспроизведения speech генерирует сигнал stateChanged. Подключенный к ней слот speechStateChange отвечает за воспроизведение очередной строки.
void MainWindow::speechStateChange( QTextToSpeech::State state) { QString mes; switch(state) { case QTextToSpeech::Ready: if(ui->pushButtonStart->isChecked()) { textBlockSelection(colorClean); if(readList.isEmpty()) { if( setActiveBlock( activeBlock+1 ) ) start(); else stop(); } else { start(); } } mes = "ready"; break; case QTextToSpeech::Speaking: textBlockSelection(Qt::green); mes = "speaking"; break; case QTextToSpeech::Paused: mes = "paused"; break; case QTextToSpeech::BackendError: mes = "error"; break; } }
Вспомогательные функции
Для удобства использования программы в качестве читалки были написаны две вспомогательные функции scrollTo() для прокручивания текста до выбранного абзаца и textBlockSelection( QColor ) для выделения читаемого абзаца цветом фона. Ниже приведён их исходный код.
void MainWindow::scrollTo()
void MainWindow::scrollTo() { if(ui->textEdit->verticalScrollBar()->maximum() == 0) return; QTextDocument *textDoc = ui->textEdit->document(); int value = 0; for(int i = 0; i < activeBlock; i++) { value +=textDoc->findBlockByNumber(i).layout()->lineCount() * textDoc->findBlockByNumber(i).layout()->lineAt(0).height() + textDoc->findBlockByNumber(i).blockFormat().bottomMargin(); } if(value <= ui->textEdit->verticalScrollBar()->maximum()) ui->textEdit->verticalScrollBar()->setValue(value); }bool MainWindow::setActiveBlock(int blockNumber, bool scroll)
bool MainWindow::setActiveBlock(int blockNumber, bool scroll) { readList.clear(); textBlockSelection(colorClean); if(blockNumber < 0) { activeBlock = 0; if(scroll) scrollTo(); return false; } if(blockNumber >= ui->textEdit->document()->blockCount()) { activeBlock = ui->textEdit->document()->blockCount()-1; if(scroll) scrollTo(); return false; } else { activeBlock = blockNumber; if(scroll) scrollTo(); return true; } }Ударение и Омографы
Существенной проблемой для синтезатора речи является ударение. Особенно в тех случаях, когда два слова пишутся одинаково, но имеют разные ударения (омографы). В таком случае, без применения сложных семантических алгоритмов, ударение может быть выставлено только в ручную. И Windows ( в отличии от Android) позволяет это сделать. Для этого нужно поставить знак «`» ( на одной клавиши с буквой ё ). Однако точного механизма работы этого инструмента установить не удалось.

Синтез речи
Познакомимся, как использовать Python для преобразования текста в речь с использованием кроссплатформенной библиотеки pyttsx3. Этот пакет работает в Windows, Mac и Linux. Он использует родные драйверы речи, когда они доступны, и работает в оффлайн режиме.
Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Есть функции, которые здесь не рассматриваются, такие как система событий. Вы можете подключить движок к определенным событиям:
- можно посчитать, сколько слов сказано, и обрезать его,
- можно проверить каждое слово и отрезать его, если есть неуместные слова.
Всегда обращайтесь к официальной документации для получения наиболее точной, полной и актуальной информации https://pyttsx3.readthedocs.io/en/latest/open in new window
Установка пакетов в Windows
Используйте pip для установки пакета. В Windows, вам понадобится дополнительный пакет pypiwin32, который понадобится для доступа к собственному речевому API Windows.
pip install pyttsx3
pip install pypiwin32 # Только для Windows
1
2
Преобразование текста в речь
Для первой программой озвучивания текста используем код:
import pyttsx3
engine = pyttsx3.init() # инициализация движка
# зададим свойства
engine.setProperty('rate', 150) # скорость речи
engine.setProperty('volume', 0.9) # громкость (0-1)
engine.say("I can speak!") # запись фразы в очередь
engine.say("Я могу говорить!") # запись фразы в очередь
# очистка очереди и воспроизведение текста
engine.runAndWait()
# выполнение кода останавливается, пока весь текст не сказан
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
В примере программы даны две фразы на английском и на русском языке. Существует голосовой набор по умолчанию, поэтому вам не нужно выбирать голос. В зависимости от версии windows будет озвучена соответствующая фраза. Например для английской версии windows услышим: «I can speak!»
Доступные синтезаторы по умолчанию
Доступные голоса будут зависеть от версии установленной систем. Вы можете получить список доступных голосов на вашем компьютере. Обратите внимание, что голоса, имеющиеся у вас на компьютере, могут отличаться от чьей-либо машины.
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Получить список доступных голосов можно так:
import pyttsx3
engine = pyttsx3.init() # Инициализировать голосовой движок.
voices = engine.getProperty('voices')
for voice in voices: # голоса и параметры каждого
print('------')
print(f'Имя: {voice.name}')
print(f'ID: {voice.id}')
print(f'Язык(и): {voice.languages}')
print(f'Пол: {voice.gender}')
print(f'Возраст: {voice.age}')
1
2
3
4
5
6
7
8
9
10
11
12
Результат будет примерно таким:
Имя: Microsoft Hazel Desktop - English (Great Britain)
ID: HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-GB_HAZEL_11.0
Язык(и): []
Пол: None
Возраст: None
------
Имя: Microsoft David Desktop - English (United States)
ID: HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_DAVID_11.0
Язык(и): []
Пол: None
Возраст: None
------
Имя: Microsoft Zira Desktop - English (United States)
ID: HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_ZIRA_11.0
Язык(и): []
Пол: None
Возраст: None
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID.
Установка дополнительных голосов в Windows
При желании можно установить дополнительные языковые пакеты согласно инструкции https://support.microsoft.com/en-us/help/14236/language-packs#lptabs=win10open in new window
Для этого выполните указанные ниже действия.
-
Нажмите кнопку Пуск , затем выберите Параметры > Время и язык > Язык.
-
В разделе Предпочитаемые языки выберите Добавить язык.

-
В разделе Выберите язык для установки выберите или введите название языка, который требуется загрузить и установить, а затем нажмите Далее.
-
В разделе Установка языковых компонентов выберите компоненты, которые вы хотите использовать на языке.
-
ВНИМАНИЕ: отключите первый пакет: «Install language pack and set as my Windows display language» — «Установите языковой пакет и установите мой язык отображения Windows»
Иначе переустановиться язык отображения операционной системы.
-
Нажмите Установить.
После установки нового языкового пакета перезагрузка не требуется. Запустив код проверки установленных языков. Новый язык должен отобразиться в списке.
ПРИМЕЧАНИЕ
Не все языковые пакеты поддерживают синтез речи. Для этого опция Speech должны быть в описании установки.
Выбор голоса
Установить голос можно методом setProperty(). Например, используя голосовые идентификаторы, найденные ранее, вы можете настроить голос. В примере показано, как настроить один голос, чтобы сказать что-то, а затем использовать другой голос из другого языка, чтобы сказать что-то другое.
В Windows идентификатором служит адрес записи в системном реестре:
import pyttsx3
engine = pyttsx3.init()
en_voice_id = "HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_EN-US_ZIRA_11.0"
ru_voice_id = "HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_RU-RU_IRINA_11.0"
# Use female English voice
engine.setProperty('voice', en_voice_id)
engine.say('Hello with my new voice.')
# Use female Russian voice
engine.setProperty('voice', ru_voice_id)
engine.say('Привет. Я знаю несколько языков.')
engine.runAndWait()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Как озвучить системное время в Windows
Пример консольного приложения которое будет называть неточное время может быть реализованно следующим кодом:
from datetime import datetime, date, time
import pyttsx3
import time
ru_voice_id = "HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_RU-RU_IRINA_11.0"
engine = pyttsx3.init()
engine.setProperty('voice', ru_voice_id)
def say_time(msg):
engine.say(msg)
engine.runAndWait()
time_checker = datetime.now()
say_time(f'Не точное Мурманское время: {time_checker.hour} часа {time_checker.minute} плюс минус 7 минут')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Привер риложения которое каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+C в Windows.
from datetime import datetime, date, time
import pyttsx3
import time
ru_voice_id = "HKEY_LOCAL_MACHINESOFTWAREMicrosoftSpeechVoicesTokensTTS_MS_RU-RU_IRINA_11.0"
engine = pyttsx3.init()
engine.setProperty('voice', ru_voice_id)
def say_time(msg):
engine.say(msg)
engine.runAndWait()
while True:
time_checker = datetime.now()
if time_checker.second == 0:
say_time(f'Мурманское время: {time_checker.hour} часа {time_checker.minute} минут')
time.sleep(55)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Посмотрите на алгоритм: чтобы уловить смену минуты, следим за значением секунд и ждем, когда оно будет равно нулю. После этого объявляем время и, чтобы поберечь ресурсы производительности, отправляем программу спать на 55 секунд. После этого она снова начнет проверять текущее время и ждать нулевой секунды.
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры.
Упражнения tkinter
- Напишите программу часы, которая показывает текущее время и имеет кнорку, при нажатии на которую можно ушлышать текуще время.
- Внесите измеения с программу что бы при произненсении времени программа корректно склоняла слова: «часы» и «минуты».
- Добавьте с помощью радиокнопки выбор языка озвучки часов.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open("test.txt", "r")
data = text_file.read()
engine.say(data, sync=True)
text_file.close()
1
2
3
4
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
Упражнения tkinter
- Напишите программу текстовым полем и кнопкой которая будет озвучивать написанное.
- Добавьте меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
Модуль Google TTS — голоса из интернета
Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Для работы необходимо установить пакет:
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS('И это тоже интересно!', lang='ru')
tts.save('sound_ru.mp3')
tts = gTTS("It's amazing!", lang='en')
tts.save('sound_en.mp3')
1
2
3
4
5
6
После запуска этого кода в директории, где лежит скрипт, появится запись. Для воспроизведения в питоне придется использовать pygame или pyglet.
Упражнения tkinter
- Напишите программу состояющую из текстового поля, кнопки выбора языка, кнопки «получить аудио». Программа должна преобразовывать текст набранный в текстовом поле в аудио файл, который будет сохраняться в папке с программой.
- Добавьте текстовое поле, куда можно ввести имя для получаемого файла. И сохранять полученный файл с заданным иметем. Реализуйте проверку полей и выводом диалогового окна с сообщением о соотвествующей ошибке.
- Добавьте в программу кнопку выбора каталога для сохранения файла.