Статья будет полезна специалистам, которые хотели бы автоматизировать свою работу. Для работы со скриптами потребуются минимальные знания программирования и установленные библиотеки. Для каждого примера в конце есть ссылка на полный код, который нужно открывать в Jupyter Notebook. Больше скриптов в Telegram-канале seo_python.
С каждым годом процесс оптимизации требует всё больше технических навыков. Среди текущих требований к специалисту часто указывают, что необходимо знание какого-либо языка программирования, например, Python.
Python — простой и лаконичный язык, позволяющий автоматизировать значительную часть рутинных задач и анализировать данные, что особенно актуально при работе с крупными проектами.
Одно из преимуществ языка — наличие большого количества написанных библиотек. Так как многие сервисы отдают свои данные по API, у специалистов есть возможность без глубоких знаний программирования писать скрипты для решения рабочих задач.
В западных блогах часто можно встретить подборки специалистов, которые делятся своими наработками. В рунете такой информации пока мало, поэтому в этой статье я бы хотел рассказать о полезных библиотеках и поделиться своим набором скриптов, которые постоянно использую в работе.
1. Генерация RSS-фида для турбо-страниц «Яндекса»
Этот способ подходит для случаев, когда необходимо быстро запустить и протестировать турбо-страницы. Рекомендую использовать скрипт для генерации RSS-канала для статейных сайтов, контент которых изменяется редко. Этот метод подходит для быстрого запуска страниц с целью проверить теорию и посмотреть результаты внедрения технологии «Яндекса».
Что потребуется:
- Netpeak Spider.
- Базовые знания применения XPath.
- Установленные Python-библиотеки.
Плюсы подхода:
- Быстрое внедрение. Не требуется помощь программиста.
- Не нужно подключение к базе, где хранится контент. Весь контент и его разметку берём прямо со страниц (одновременно минус).
- Используем стандартные SEO-инструменты.
Минусы:
- Необновляемый XML-файл. После изменения контента требуется пересобрать контент и формировать новый XML.
- Новые страницы также не будут попадать в файл. Для них будет необходимо заново парсить контент и формировать XML.
- Создаём нагрузку на свой сайт при сборе контента.
Ниже описана последовательность работ.
Подготавливаем данные
С помощью Screaming frog seo spider или Netpeak Spider парсим контент страниц, для которых будем подключать турбо-страницы.
На этом этапе подготавливаем данные для обязательных элементов, необходимых при формировании XML-файла.
Обязательные поля:
- Link — URL страницы.
- H1 — заголовок страницы.
- Turbo:content — содержимое страницы.
Используя XPath, парсим контент страниц со всей HTML-разметкой. Копируем через панель разработчика или пишем свой запрос (например, //div[@class=’entry-content entry—item’]).
Экспортируем полученные данные в CSV. В результате в CSV-файле должно быть три столбца:
- Link.
- H1.
- Turbo:content.
Скрипт генерации файла
Подключаем нужные библиотеки.
import csv
import pandas as pd
import os
import math
Считываем файл с подготовленными данными.
data = pd.read_csv(‘internal_all — internal_all.csv’) #дописать «, header=1», если проблема при считывании заголовка
data = data[[‘Address’, ‘H1-1’, ‘текст 1’]]
## Если в таблицу попали лишние страницы, их можно легко отфильтровать. Ниже примеры.
# data = data[data[‘Status Code’]==200] # Фильтруем страницы с 200 ответом
# data = data[~data[‘Address’].str.contains(‘page’)] # Фильтруем страницы не содержащие «»
# data = data.drop(index=0)
Выводим информацию о количестве строк в файле и итоговом количестве RSS-файлов, которые будут сгенерированы.
rows_in_rss = 1000 # количество строк в одном rss-канале
total_rows = len(data) — 1
total_xml_file = math.ceil((total_rows-1)/rows_in_rss)
print(‘Всего в файле строк:’, total_rows)
print(‘Будет сгенерировано xml-файлов:’, total_xml_file)
Формируем структуру RSS-канала. Создаём функцию create_xml, отвечающую за создание начала файла.
def create_xml(item_count_next):
rss_file = open(‘rss{:.0f}.xml’.format(item_count_next/rows_in_rss), ‘w’, encoding=»utf-8″)
rss_file.write(
«»»<?xml version=»1.0″ encoding=»UTF-8″?>
<rss xmlns:yandex=»http://news.yandex.ru»
xmlns:media=»http://search.yahoo.com/mrss/»
xmlns:turbo=»http://turbo.yandex.ru»
version=»2.0″>
<channel>»»»)
rss_file.close()
Функция close_xml будет закрывать файл.
def close_xml(item_count_next):
rss_file = open(‘rss{:.0f}.xml’.format(item_count_next/rows_in_rss), ‘a’, encoding=»utf-8″)
rss_file.write(
‘ </channel>’ + ‘n’+
‘</rss>’
)
rss_file.close()
В функцию data_for_rss передаём номер первой и последней строки. Для этого промежутка будем формировать RSS.
Построчно считываем строки в датафрейме и формируем <item>, записывая получившиеся данные в XML-файл. Каждая строка в датафрейме — новая страница.
def data_for_rss(item_count_prev, item_count_next):
data_rss = data[item_count_prev:item_count_next]
if len(data_rss) != 0:
with open(‘rss{:.0f}.xml’.format(item_count_next/rows_in_rss), ‘a’, encoding=»utf-8″) as rss_file:
for index, row in data_rss.iterrows():
url = str(row[0])
h1 = str(row[1])
text = str(row[2])
rss_file.write(«»»<item turbo=»true»>
<link>»»»+ url + «»»</link>
<turbo:content>
<![CDATA[
<header> <h1>»»»+ h1 +»»»</h1>
</header>»»»
+ text+
«»»<div data-block=»share» data-network=»vkontakte,odnoklassniki,facebook,twitter»></div>
]]>
</turbo:content>
</item>»»»)
Делаем проверку размера получившихся фидов. Размер XML-файла не должен превышать 15 МБ. Если размер получился больше, изменяем количество строк в одном файле, изменяя значение переменной rows_in_rss.
def size_file(item_count_next):
size_final_file_MB = os.path.getsize(‘rss{:.0f}.xml’.format(item_count_next/rows_in_rss))/1024/1024
if size_final_file_MB < 15:
print(‘Файл создан’)
else:
print(‘Нужно уменьшить шаг’)
Финальный шаг — генерация фидов.
item_count_prev = 0
item_count_next = 1000 # должен быть равен rows_in_rss
count_rss = 0
print(total_xml_file)
while count_rss < total_xml_file:
create_xml(item_count_next)
data_list = data_for_rss(item_count_prev,item_count_next)
close_xml(item_count_next)
size_file(item_count_next)
item_count_prev += rows_in_rss
item_count_next += rows_in_rss
count_rss += 1
Остаётся добавить RSS в личном кабинете «Яндекс.Вебмастера» и настроить меню, лого, счётчики систем аналитики.
Ссылка на скрипт (открывать в Jupyter Notebook).
2. Техническое задание для копирайтеров
ТЗ для копирайтеров — довольно рутинная работа, которая занимает много времени у специалиста. Ниже рассмотрим три варианта автоматизации этого процесса, используя различные сервисы:
- Семантического ядра нет, статья не написана.
- Семантическое ядро есть, статья не написана.
- Статья написана, требуется рерайт.
Что потребуется:
- Подписка на сервис с доступом к API.
- Подписка на сервис с пополненным балансом.
- Установленные Python-библиотеки.
- Кластеризованное семантическое ядро (я использую KeyAssort) для случая, когда ядро есть, а статья не написана.
Ниже рассмотрим все варианты, для каждого я распишу плюсы и минусы этих подходов. Стоит помнить, что результаты, которые выдают сервисы, стоит перепроверять. Так как везде есть свои технические нюансы.
Вариант 1. Семантического ядра нет, статья не написана
Рассмотрим случай, когда нужно написать статью, но у вас нет готового семантического ядра. Для этого подхода нам понадобится только основной маркерный запрос статьи.
Плюсы подхода:
- Не тратим время на сбор ядра (подходит для статей с широкой семантикой и хорошей видимостью URL конкурентов в топе).
- В работу берём максимальное количество ключей, по которым конкуренты имеют видимость.
Минусы:
- Нужна подписка на сервисы.
- Данные, которые выдают сервисы, не всегда точны. Например, Megaindex не определяет длину текста меньше определённого количества знаков (около 200 символов). Поэтому показатели выборочно стоит перепроверить.
- Не можем повлиять на кластеризацию.
Подключаем необходимые библиотеки.
import requests
import json
import pymorphy2
import re
import urllib.request as urlrequest
from urllib.parse import urlencode
from collections import Counter
Нам понадобятся:
- Token — токен API MegaIndex.
- Ser_id — регион, по которому будут сниматься данные. Полный список можно получить, используя метод get_ser.
- Keywords_list — список ключевых слов, для которых будем получать данные.
token = «xxxxxxxxxxxxxxxxxxx»
ser_id = 174 #ID поисковой системы яндекс_спб
keywords_list = [‘основной маркерный запрос статьи №1’, ‘основной маркерный запрос статьи №2’, ‘основной маркерный запрос статьи №3’]
morph = pymorphy2.MorphAnalyzer() # создаем экземпляр pymorphy2, понадобится нам дальше для морфологического анализа
Для получения ключевых слов по нужным нам маркерным запросам будем использовать метод url_keywords API Serpstat. Этот метод возвращает ключевые фразы в топе поисковой системы по заданному URL. Получать будем видимость конкурентов по URL, которые находятся в топе выбранной поисковой системы.
Для работы берём пример кода из документации и оборачиваем его в функцию serpstat_keywords. Подставляем свои значения для token и региона se, по которому будем получать данные. Получить полный список регионов можно здесь.
def serpstat_keywords(url):
host = ‘http://api.serpstat.com/v3’
method = ‘url_keywords’
params = {
‘query’: ‘{}’.format(url), # string for get info
‘se’: ‘y_213’, # string search engine, y_2 — спб, y_213 — мск
‘token’: ‘xxxxxxxxxxxxxxxxxxx’, # string personal token
}
api_url = «{host}/{method}?{params}».format(
host=host,
method=method,
params=urlencode(params)
)
try:
json_data = urlrequest.urlopen(api_url).read()
except Exception as e0:
print(«API request error: {error}».format(error=e0))
pass
data = json.loads(json_data)
return data
Используя регулярное выражение, разбиваем исходную фразу на слова. Каждое слово лемматизируем, проверяем на часть речи и добавляем в результирующий список. Возвращаем готовый список.
def morph_word_lemma(key):
meaningfullPoSes=[‘NPRO’, ‘PREP’, ‘CONJ’, ‘PRCL’, ‘INTJ’] # фильтруем граммемы https://pymorphy2.readthedocs.io/en/latest/user/grammemes.html
reswords=[]
for word in re.findall(«([А-ЯЁа-яё0-9]+(-[А-ЯЁа-яё0-9]+)*)», key): # фразу бьем на слова
word = word[0]
word_normal_form = morph.parse(word)[0].normal_form
form = morph.parse(word)[0].tag
if form.POS in meaningfullPoSes:
continue
else:
reswords.append(word_normal_form)
return reswords
Не забываем, что pymorphy2 работает только с русским языком. Если в словосочетаниях будут фразы на другом языке, он их пропустит.
Составляем словарь вида «Лемма: [количество упоминаний леммы]».
def counter_dict_list(list_values):
list_values_all=[]
for item in list_values:
list_values_word_lemma = morph_word_lemma(item)
for item in list_values_word_lemma:
list_values_all.append(item)
dict_values_word_lemma = dict(Counter(list_values_all))
sorted_dict_values_word_lemma = list(dict_values_word_lemma.items())
sorted_dict_values_word_lemma.sort(key=lambda i: i[1], reverse=True)
sorted_dict_values_word_lemma = dict(sorted_dict_values_word_lemma)
return (sorted_dict_values_word_lemma)
Создаём финальный файл и записываем строку заголовка.
# чистим файл и записываем строку заголовка
f = open(‘api.txt’, ‘w’)
f.write(«key»+’t’ + «base_urls»+ ‘t’ + ‘symbols_median’ + ‘t’ + ‘n’)
f.close()
Получаем данные по API и парсим полученный текст.
def megaindex_text_score(key):
keyword_list = []
uniq_keyword_list = []
try:
url = ‘http://api.megaindex.com/visrep/text_score?key={}&words={}&ser_id={}’.format(token, key, ser_id)
r = requests.get(url)
json_string = r.text
parsed_string = json.loads(json_string)[‘data’]
list_base_urls = parsed_string[‘serps’][0][‘base_urls’]
symbols_median = parsed_string[‘old_api’][‘fragments’][‘long’][‘symbols_median’]
except Exception as ex_megaindex:
print(«API megaindex request error: {error}».format(error=ex_megaindex))
list_base_urls = []
symbols_median = ‘Данные не получены’
for url in list_base_urls:
url = url.replace(‘http:’, ‘https:’)
data = serpstat_keywords(url)
try:
for keyword in data[‘result’][‘hits’]:
keyword_list.append(keyword[‘keyword’])
except:
pass
for item in set(keyword_list):
uniq_keyword_list.append(item)
count_lemma = counter_dict_list(uniq_keyword_list)
return (list_base_urls, symbols_median, count_lemma)
Проходимся по списку маркерных запросов и генерируем задание.
print (‘Всего будет сгенерировано ТЗ: ‘, len(keywords_list))
for keywords in keywords_list:
print(keywords)
try:
list_base_urls, symbols_median, count_lemma = megaindex_text_score(keywords)
except Exception as ex:
pass
print(f’Errow: {ex}’)
with open(‘api.txt’, ‘a’) as f:
f.write(‘{}t{}t{}tnn’.format(keywords, list_base_urls, symbols_median))
f.write(‘Лемма’ +’t’ + ‘Количество повторений’ + ‘n’)
for key, value in count_lemma.items():
f.write(‘{}t{}n’.format(key, value))
f.write(‘n’+’n’+’n’)
print (‘end’)
Получившийся результат переносим в «Google Таблицы». Пример ТЗ.
Нужно понимать, что «количество упоминаний леммы» в ТЗ — это сколько раз лемма встречалась в ключевых словах.
Вариант 2. Статья написана, требуется рерайт
Подход применим для случаев, когда статья уже написана, но не получает трафика.
Плюсы подхода:
- В автоматическом режиме получаем средний объём текста в топ-10, объём анализируемого текста и разницу этих величин.
- В работу берём максимальное количество ключей, по которым конкуренты имеют видимость.
Минусы (те же, что и у варианта номер один):
- Нужна подписка на сервисы.
- Данные, которые выдают сервисы, не всегда точны. Например, Megaindex не определяет длину текста меньше определённого количества знаков (около 200 символов). Поэтому показатели выборочно стоит перепроверить.
- Не можем повлиять на кластеризацию.
Набор библиотек аналогичен варианту номер один, отличается набор входных параметров. Вместо списка основных маркерных запросов передаём словарь следующего вида:
{‘основной маркерный запрос статьи №1′:’url, соответствующий основному маркерному запросу’}
token = «xxxxxxxxxxxxxxxxxxx»
ser_id = 174 #ID поисковой системы яндекс_спб — 174
keywords_url_dict = {‘основной маркерный запрос статьи №1′:’url_основного маркерного запроса статьи №1’, ‘основной маркерный запрос статьи №2′:’url_основного маркерного запроса статьи №2’}
morph = pymorphy2.MorphAnalyzer() # создаем экземпляр pymorphy2, понадобится нам дальше для морфологического анализа
Следующие функции копируем из первого варианта:
- serpstat_keywords;
- morph_word_lemma;
- counter_dict_list.
Чистим файл и записываем строку заголовка.
f = open(‘api.txt’, ‘w’)
f.write(«key»+’t’+»compare_urls» + ‘t’ + «base_urls»+ ‘t’ + «relevance» + ‘t’ + ‘symbols median’ + ‘t’ +’symbols text’+ ‘t’ + ‘symbols diff’+ ‘t’+ ‘words median’ + ‘t’ + ‘words value text’ + ‘t’ + ‘words diff’ + ‘n’)
f.close()
Получаем данные по API и парсим полученный текст. Получать будем следующие данные для ТЗ:
- list_base_urls — список URL в топ-10 по маркерному запросу;
- relevance — релевантность анализируемой страницы страницам в топе;
- symbols_median — медиана длины текста (знаков без пробелов) по топу;
- symbols_text — количество символов в анализируемом тексте;
- symbols_diff — разница symbols_median и symbols_text;
- words_median — медиана слова в URL по топу;
- words_value_text — медиана слов в анализируемом тексте;
- words_diff — разница слов;
- count_lemma— посчитанные леммы.
def megaindex_text_score(key, key_url):
keyword_list = []
uniq_keyword_list = []
try:
url = ‘http://api.megaindex.com/visrep/text_score?key={}&words={}&ser_id={}&compare_urls={}’.format(token, key, ser_id, key_url)
r = requests.get(url)
json_string = r.text
parsed_string = json.loads(json_string)[‘data’]
list_base_urls = parsed_string[‘serps’][0][‘base_urls’]
relevance = parsed_string[‘serps’][0][‘compare_urls’][0][‘relevance’]*100
symbols_median = parsed_string[‘old_api’][‘fragments’][‘long’][‘symbols_median’]
symbols_text = parsed_string[‘old_api’][‘compare_docs’][key_url][‘fragments’][‘long’][‘symbols’]
symbols_diff = symbols_median — symbols_text
words_median = parsed_string[‘serps’][0][‘compare_urls’][0][‘diffs’][‘word_count’][‘long’][‘median’]
words_value_text = parsed_string[‘serps’][0][‘compare_urls’][0][‘diffs’][‘word_count’][‘long’][‘value’]
words_diff = parsed_string[‘serps’][0][‘compare_urls’][0][‘diffs’][‘word_count’][‘long’][‘diff’]
except Exception as ex_megaindex:
print(«API megaindex request error: {error}».format(error=ex_megaindex))
list_base_urls = []
symbols_median = ‘Данные не получены’
for url in list_base_urls:
url = url.replace(‘http:’, ‘https:’)
data = serpstat_keywords(url)
try:
for keyword in data[‘result’][‘hits’]:
keyword_list.append(keyword[‘keyword’])
except:
pass
for item in set(keyword_list):
uniq_keyword_list.append(item)
count_lemma = counter_dict_list(uniq_keyword_list)
return (list_base_urls, relevance, symbols_median, symbols_text, symbols_diff, words_median, words_value_text, words_diff, count_lemma)
Проходимся по списку маркерных запросов и генерируем задание.
print (‘Всего будет сгенерировано ТЗ: ‘, len(keywords_url_dict))
for keywords in keywords_url_dict.keys():
print(keywords, keywords_url_dict[keywords])
try:
list_base_urls, relevance, symbols_median, symbols_text, symbols_diff, words_median, words_value_text, words_diff, count_lemma = megaindex_text_score(keywords, keywords_url_dict[keywords])
except Exception as ex:
pass
print(f’Errow: {ex}’)
with open(‘api.txt’, ‘a’) as f:
f.write(‘{}t{}t{}t{}t{}t{}t{}t{}t{}t{}tnn’.format(keywords, keywords_url_dict[keywords], list_base_urls, relevance, symbols_median, symbols_text, symbols_diff, words_median, words_value_text, words_diff))
f.write(‘Лемма’ +’t’ + ‘Количество повторений’ + ‘n’)
for key, value in count_lemma.items():
f.write(‘{}t{}n’.format(key, value))
f.write(‘n’+’n’+’n’)
print (‘end’)
Вариант 3. Семантическое ядро есть, статья не написана
Рассмотрим ситуацию, когда у специалиста есть собранное и кластеризованное семантическое ядро.
Плюсы подхода:
- Работаем уже с тщательно проработанным и кластеризованным семантическим ядром.
Минусы (почти те же, что и у первого варианта):
- Нужна подписка на сервисы.
- Данные, которые выдают сервисы, не всегда точны. Например, Megaindex не определяет длину текста меньше определённого количества знаков (около 200 символов). Поэтому показатели выборочно стоит перепроверить.
Подключаем необходимые библиотеки, указываем токен для работы с Megaindex и ser_id нужного региона.
import pymorphy2
import requests
import json
import re
morph = pymorphy2.MorphAnalyzer()
token = «xxxxxxxxxxxxxxxxxxxxx»
ser_id = 174 #174 #ID поисковой системы яндекс_спб
Для работы скрипта нам понадобится txt-файл (‘data_tz.txt’) с кластеризованным ядром.
Формат файла: Ключ → Группа; разделитель табуляция.
item_dict = {}
flag = True
with open(‘data_tz.txt’) as file:
for line in file:
if flag:
flag = False # пропускаем строку заголовка
else:
line = line.strip().split(‘ ‘)
word = line[0]
group = line[1]
if group not in item_dict:
item_dict[group] = []
item_dict[group].append(word)
else:
item_dict[group].append(word)
Работаем со словарём, полученным на предыдущем шаге. Для каждой группы обходим все ключевые фразы, разбиваем их на слова, нормализуем и добавляем в словарь.
group_word_count_dict = {}
for key, value in item_dict.items():
group_word_count_dict.setdefault(key, {})
for item in value:
for word in re.findall(«([А-ЯЁа-яё0-9]+(-[А-ЯЁа-яё0-9]+)*)», item):
word = word[0]
word = morph.parse(word)[0].normal_form
form = morph.parse(word)[0].tag
#не добавляем в словарь местоимение-существительное, предлог, союз, частица, междометие
if (‘NPRO’ in form or ‘PREP’ in form or ‘CONJ’ in form or ‘PRCL’ in form or ‘INTJ’ in form):
continue
else:
group_word_count_dict[key].setdefault(word, 0)
if word in group_word_count_dict[key]:
group_word_count_dict[key][word] += 1
#Сортировка получивщегося словаря
for key, value in group_word_count_dict.items():
sorted_group_word_count_dict = list(value.items())
sorted_group_word_count_dict.sort(key=lambda i: i[1], reverse=True)
sorted_group_word_count_dict = dict(sorted_group_word_count_dict)
group_word_count_dict[key] = sorted_group_word_count_dict
print(group_word_count_dict)
print(‘end’)
Получаем данные по API и парсим полученный текст.
def megaindex_text_score(key):
try:
url = ‘http://api.megaindex.com/visrep/text_score?key={}&words={}&ser_id={}’.format(token, key, ser_id)
r = requests.get(url)
json_string = r.text
parsed_string = json.loads(json_string)[‘data’]
list_base_urls = parsed_string[‘serps’][0][‘base_urls’]
symbols_median = parsed_string[‘old_api’][‘fragments’][‘long’][‘symbols_median’]
except Exception as ex_megaindex:
print(«API megaindex request error: {error}».format(error=ex_megaindex))
list_base_urls = [‘Данные не получены’]
symbols_median = 0
return(list_base_urls, symbols_median)
Подготавливаем финальный файл.
# чистим файл
f = open(‘group_word_lemma.txt’, ‘w’)
f.write(‘Группа’ +’t’ + ‘Конкуренты’ +’t’ + ‘Символов ЗБП’+ ‘n’)
f.close()
with open(‘group_word_lemma.txt’ , ‘a’) as f:
for key_dict, value_dict in group_word_count_dict.items():
base_urls, symbols_median = megaindex_text_score(key_dict)
if symbols_median < 8000: # Ограничение по количеству символов
print(key_dict, base_urls, symbols_median)
f.write(‘{}t{}t{}nn’.format(key_dict, base_urls, symbols_median))
f.write(‘Лемма’ +’t’ + ‘Количество повторений’ + ‘n’)
for key, value in value_dict.items():
print(key, value)
f.write(‘{}t{}n’.format(key, value))
f.write(‘n’+’n’+’n’)
print(‘end’)
Проходимся по списку групп и генерируем задание.
with open(‘group_word_lemma.txt’ , ‘a’) as f:
for key_dict, value_dict in group_word_count_dict.items():
base_urls, symbols_median = megaindex_text_score(key_dict)
if symbols_median < 8000: # Ограничение по количеству символов
print(key_dict, base_urls, symbols_median)
f.write(‘{}t{}t{}nn’.format(key_dict, base_urls, symbols_median))
f.write(‘Лемма’ +’t’ + ‘Количество повторений’ + ‘n’)
for key, value in value_dict.items():
print(key, value)
f.write(‘{}t{}n’.format(key, value))
f.write(‘n’+’n’+’n’)
print(‘end’)
Так как основной маркерный запрос в этом случае — название категории, нужно следить за полнотой и правильностью её написания.
Аналогично первому варианту, получившийся результат переносим в «Google Таблицы». Получившееся ТЗ в таком же формате.
Предложенные скрипты можно дорабатывать, добавляя в них и другие важные на ваш взгляд требования к тексту.
Имея список URL конкурентов, можно парсить:
- Title страниц.
- Заголовки H1 — H6.
- Количество нумерованных, маркированных списков, изображений на странице и так далее.
Аналогичным способом делать морфологический анализ тегов, заголовков и выдавать рекомендации по количеству элементов и упоминаний лемм в этих тегах.
3. Анализ логов
При техническом аудите сайтов полезно анализировать логи сайта. Возможные варианты анализа:
- Использовать возможности, которые предоставляет хостер. Чаще всего это решение в виде надстройки, например, AWStats. Минусы: не гибко, чаще всего предоставляется определённый набор графиков, которые никак не изменить.
- Использовать платные решения. Например, Screaming Frog SEO Log File Analyser — бесплатная версия работает с файлами до 1000 строк. Минусы: цена, не всегда логи вашего сервера будут соответствовать тому виду, который требуется для работы в программе.
- Использовать ELK-стек (elastic + logstash + kibana). Минусы: требуются знания по настройке хранилища и передаче в него данных.
- Решение на Python с использованием библиотек.
Подробнее что про то, что такое логи, их структуру и содержание можно почитать в статье. Перейдём к скрипту.
Что потребуется:
- Лог-файлы сайта.
- Установленные Python-библиотеки.
Плюсы подхода:
- Бесплатное решение.
- Можно быстро проанализировать лог-файл в любом формате.
- Легко обрабатывает большие файлы на несколько миллионов записей.
Минусы:
- Хранение данных на своём устройстве (если работаете не на выделенном сервере).
- Чтобы проанализировать данные за новый период, необходимо заново считать данные, разобрать и записать их в анализируемый CSV-файл.
- В приведённом скрипте только базовые универсальные примеры анализа.
Для работы будем использовать библиотеку apache-log-parser, подробная документация по ссылке на GitHub.
import apache_log_parser
import csv
Для начала обработаем наш лог-файл и запишем данные в CSV. Если файлов несколько, склеить их можно следующей командой:
!cat access.log.1 access.log.2 access.log.3 > all_log.log
Создаем файл log.csv и записываем в него строку заголовка с названием столбцов. Столбцы определяются в соответствии с вашим лог-файлом.
csv_file = open(‘log.csv’, ‘w’)
data = [[‘remote_host’, ‘server_name2’, ‘query_string’, ‘time_received_isoformat’, ‘request_method’, ‘request_url’, ‘request_http_ver’, ‘request_url_scheme’, ‘request_url_query’, ‘status’, ‘response_bytes_clf’, ‘request_header_user_agent’, ‘request_header_user_agent__browser__family’, ‘request_header_user_agent__browser__version_string’, ‘request_header_user_agent__os__family’, ‘request_header_user_agent__os__version_string’, ‘request_header_user_agent__is_mobile’]]
with csv_file:
writer = csv.writer(csv_file)
writer.writerows(data)
csv_file.close()
Читаем построчно access.log, парсим строку и записываем разобранные данные в CSV. Используем функцию make_parser, которая принимает строку из файла журнала в указанном нами формате и возвращает проанализированные значения в виде словаря.
Формат строки из журнала указывается в make_parserс помощью поддерживаемых значений, указанных в документации, — supported values.
Пример строки
54.36.148.252 example.ru — [13/Oct/2019:12:00:01 +0300] «GET /lenta/example/example/p1 HTTP/1.1» 301 5 «-» «Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)» 0.137 0.137 .
Пример разбора
with open(‘all_log.log’) as file:
for line in file:
line = line.strip()
line_parser = apache_log_parser.make_parser(«%h %V %q %t «%r» %>s %b «%{Referer}i» «%{User-Agent}i»»)
log_line_data = line_parser(f'{line}’)
#Пишем в файл нужные данные
data = [[log_line_data[‘remote_host’], log_line_data[‘server_name2’], log_line_data[‘query_string’], log_line_data[‘time_received_isoformat’], log_line_data[‘request_method’], log_line_data[‘request_url’], log_line_data[‘request_http_ver’], log_line_data[‘request_url_scheme’], log_line_data[‘request_url_query’], log_line_data[‘status’], log_line_data[‘response_bytes_clf’], log_line_data[‘request_header_user_agent’], log_line_data[‘request_header_user_agent__browser__family’], log_line_data[‘request_header_user_agent__browser__version_string’], log_line_data[‘request_header_user_agent__os__family’], log_line_data[‘request_header_user_agent__os__version_string’], log_line_data[‘request_header_user_agent__is_mobile’]]]
csv_file = open(‘log.csv’, ‘a’)
with csv_file:
writer = csv.writer(csv_file)
writer.writerows(data)
Далее анализируем полученный CSV-файл. Анализ можно провести в Excel или любом другом удобном инструменте. Для примера рассмотрим несколько вариантом получения данных на Python.
Подключаем библиотеку для анализа данных и считываем файл.
import pandas as pd
data = pd.read_csv(‘log.csv’)
Посмотрим распределение страниц по статус коду страниц.
status_code_count = data[‘status’].value_counts()
print(status_code_count)
Посчитаем количество страниц со статусом 410 для каждого user-agent.
data[data[‘status’]==410][‘request_header_user_agent__browser__family’].value_counts()
В результате работы скрипта мы получили готовый CSV-файл с разобранными по столбцам записями из лог-файла. Далее можно анализировать данные в соответствии с вашими целями.
Осенью прошлого года был запущен сайт www.iso.ru, разработанный компанией ADT. «Движок» сайта, представляющий собой набор CGI скриптов, был написан на Perl. По прошествии полугода эксплуатации возникла необходимость расширить функциональность сайта. Поэтому встал вопрос о выборе языка для написания скриптов.
Perl хорошо подходит для обработки текстов и широко используется для web-программирования, однако программы, написанные на Perl, трудночитаемы и неудобны для сопровождение из-за специфического синтаксиса Perl’a. Если стоит задача быстро написать небольшой скрипт усилиями одного человека и у вас специфический склад мышления, то, возможно, Perl — это то, что вам нужно. Если же требуется разработать достаточно сложную систему и затем организовать ее поддержку коллективом специалистов, то для этих целей, на мой взгляд, более подходит Python.
Python сочетает в себе понятный синтаксис и мощь, имеет развитые средства обработки текста и создания web-приложений. Python доступен для различных операционных систем, таких как UNIX (Linux), MacOS, MS-Windows 3.1, Windows NT, OS/2 и даже MS-DOS. Скрипты, написаные на Python являются хорошо переносимыми между платформами. Если бы возникла задача перенести сайт www.iso.ru с платформы Linux на Windows NT, потребовались бы минимальные изменения кода (по существу, пришлось бы только исправить пути к файлам шаблонов).
- Формирование HTML из шаблонов
- Работа с сервером баз данных MySQL
- Отправка форм
- Проверка корректности форм
- Административный интерфейс
Таким образом, решено было использовать Python для написания скриптов для сайта www.iso.ru. «Движок» сайта состоял из следующих логических частей (скриптов):
- Главная страница — вывод главной страницы сайта, списка новостей и событий.
- Новости — вывод текста новости, списка архивных новостей сайта, клуба, технологий.
- События — вывод текста события.
- Регистрация — осуществление процедуры регистрации посетителя: запись в базу данных информации о посетителе, контроль уникальности учетных записей.
- Работа с посетителями — проверка входного имени и пароля, организация скачивания файлов с сайта, подписка на новости, доступ к страницам технической поддержки.
- Формоотправитель — скрипт, занимающийся отправкой заполненых посетителем форм на e-mail поддержки сайта.
- Журнал — работа с базой данных журнала статей по IT-технологиям.
- Гостевая книга — запись и просмотр комментариев к статьям журнала.
- Конференции
- Административный интерфейс — редактирование таблиц базы данных сайта, загрузка новых статей, новостей, событий, выгрузка данных из базы в формат CSV, управление конференциями.
В первую очередь было решено расширить функциональность журнала -добавить систему оценки статей и сервис выбора самой интересной в данном номере. Таким образом, в список потребовалось добавить еще один скрипт. Все остальные скрипты также нужно было в большей или меньшей степени усовершенствовать.
Все скрипты написаны достаточно стандартным образом: создается экземпляр класса FieldStorage, который читает содержимое формы, затем, в зависимости от наличия и содержания определенных ключей организуется ветвление, обработка данных и вывод результата. В этой статье мне хотелось бы только поделиться опытом преодоления некоторых трудностей, возникших при разработке скриптов для www.iso.ru.
Как известно, вывод любой CGI программы состоит из двух частей: заголовка и данных, которые разделяются пустой строкой. Сначала программа должна сообщить клиенту, какой тип данных он будет получать. Это достигается печатью набора HTTP заголовков в стандартный вывод. Например, строка
print 'Content-Type: text/htmln'
сообщает браузеру, что он будет получать стандартный HTML.
Затем, после разделительной строки, идут произвольные данные (обычно, код HTML). Конечно, можно просто вывести HTML текст оператором print, вставленным в тело программы, но это подходит лишь для небольших фрагментов HTML кода. Когда же необходимо вывести несколько десятков строчек, исходный текст программы становиться очень большим и нечитаемым, к тому же иногда необходимо использовать одни и те же фрагменты кода с незначительными изменениями. В этом случае удобно использовать шаблоны.
Шаблон представляет собой текстовый файл, содержащий HTML код с переменными, которые впоследствии будут заменяться необходимыми значениями. Имена переменных желательно сделать такими, чтобы исключить их случайное повторение внутри HTML кода (например, не нужно использовать переменную с именем table, так как потом в результате пострадают все определения таблиц). Для переменных в своих шаблонах я использую следующее соглашение: имя переменной начинается и заканчивается символом $ (например, $var_name$). Это исключает возмоожность совпадения с тегами HTML и словами в тексте документа.
Вот пример шаблона гостевой книги, хранящийся в файле guestbook.tmpl:
<table width=100% align=center>
<tr>
<td width=100%>
<table width=100% align=center>
<tr>
<td><b>$date$</b> $time$ $author$</td>
</tr>
</table>
<table width =100%>
<tr>
<td>
<div align="justify"><p>$message$<br><br>
<table>
<tr>
<td bgcolor="#074473">
<img src="/img/gif.gif" width=200 height=1>
</td>
</tr>
</table>
</td>
</tr>
</table>
<img src="/img/gif.gif" width="1" height="5" alt="" border="0">
</td>
<td><img src="/img/gif.gif" width="30" height="1" alt="" border="0"></td>
</tr>
</table>
Для удобства работы можно написать функцию, читающую шаблон и заменяющую все переменные в нем на нужные значения. Она получает в качестве аргументов имя шаблона и словарь, представляющий собой набор пар <имя переменной> : <значение>. Возвращает функция сконструированный текст. Функция может выгладеть примерно так:
def replace_tmpl( tmpl, var_list ):
lines = open( tmpl ).readlines()
src = "%s"*len(lines) % tuple(lines)
for key, var in var_list.items():
src = string.replace( src, key, var )
return src
А вот скрипт, выводящий запись в гостевой книге:
print 'Content-Type: text/htmlnn'
guestbook = '/usr/local/apache/cgi-bin/templates//guestbook.tmpl'
body = replace_tmpl(guestbook, {'$date$' : '2001-06-07',
'$author$' : 'Артемов Олег', '$message$' : 'Очень полезная статья'}) print body
Все динамические странички на сайте www.iso.ru формируются таким способом.
Практически любой сайт, содержащий элементы взаимодействия с пользователем использует какие-либо базы данных. Сайт www.iso.ru не является исключением. В базе данных хранятся новости, события, статьи журнала, информация по зарегистрированным пользователям и многое другое. Мы используем сервер баз данных MySQL.
На данный момент MySQL является наиболее популярной платформой для создания web-приложений, так как это простой и в тоже время довольно мощный и надежный SQL сервер. MySQL как и Python поддерживает широчайший спектр платформ, включая Linux и Windows NT. Для работы с MySQL в Python используется библиотека MySQLdb, существующая как для Linux, так и для Win32.
Работа с базой данных проходит достаточно стандартно. Сначала создается объект, устанавливающий соединение с БД (Connection Object):
mydb=MySQLdb.Connect(db='iso',host='localhost', user='root',unix_socket='/tmp/mysql.sock')
Затем создается объект-курсор:
После этого можно выполнять любые SQL запросы к базе данных:
cursor.execute('SELECT * FROM guestbook ORDER by date DESC')
Далее получаем результат запроса:
resultset = cursor.fetchall()
Метод fetchall возвращает кортеж записей, состоящих из кортежей полей, которые можно перебрать в цикле. Приведенная ниже программа выбирает из базы гостевой книги все сообщения автора «Иванов», подставляет их в шаблон и передает браузеру.
print 'Content-Type: text/htmlnn'
guestbook = '/usr/local/apache/cgi-bin/templates//guestbook.tmpl'
mydb=MySQLdb.Connect(db='iso',host='localhost',
user='root',unix_socket='/tmp/mysql.sock')
cursor.execute('SELECT date, author, massage FROM guestbook WHERE author="Иванов"')
resultset = cursor.fetchall()
body = ''
for row in resultset:
body = body+replace_tmpl(guestbook, {'$date$' : row[0].strftime("%d-%m-%Y"), '$author$' : str(row[1]),
'$message$' : str(row[2]))
print body
Часто возникает задача передачи данных от пользователя на сайт (пожелания по работе сайта, материалы, которые пользователю хотелось бы разместить на сайте и т.д). В простейшем случае — это текстовое сообщение, набираемое в форме и посылаемое затем на электронный адрес поддержки сайта. В этом случае форма может выглядеть следующим образом:
<form action="/cgi-bin/forms.cgi" METHOD="GET"> Организация: <input type="Text" size="20" name="org"> Ваше имя: <input type="Text" size="20" name="name"> Ваш e-mail: <input type="Text" size="20" name="email"> Тема: <input type="Text" size="20" name="tema"> Сообщение: <textarea cols="20" rows="6" name="message"></textarea> <input type="reset" value="Очистить">$nbsp; $nbsp; $nbsp; $nbsp; <input type="submit" value="Отправить"> </form>
Для отправки сообщений по протоколу SMTP нужно использовать библиотеку smtplib. Определяя экземпляр класса SMTP, устанавливаем соединение с SMTP сервером:
import smtplib
mail=smtplib.SMTP("smtpserver.ru")
Формируем тело сообщения из полученных данных в соответствии с RFC822:
form = cgi.FieldStorage()
keys = {}
for k in form.keys():
keys[k] = form[k].value
msg = """Subject: Новостьn #тема сообщения
From: Intersoft Web Server <admin@iso.ru>n #отправитель
MIME-Version: 1.0n #версия MIME
Content-Type: text/htmlnn #тип сообщения
<br>Имя: %s #тело сообщения
<br>E-mail: %s
<br>Тема: %s
<br>Сообщение: %s""" %
(keys['name'], keys['email'], keys['tema'], keys['message'])
Затем вызываем метод sendmail для отсылки сообщения:
mail.sendmail( 'admin@iso.ru', 'market@iso.ru', msg )
Здесь admin@iso.ru — адрес отправителя, market@iso.ru — адрес получателя. Можно реализовать и более сложную функциональность с пересылкой вложенных файлов. Для начала в форму нужно добавить поле ввода file:
<input name="attach" type="file" size="12">
Для создания почтового сообщения с вложениями удобно пользоваться классом MimeWriter, определенным в модуле MimeWriter. Чтобы избежать загромождения тела программы, можно написать функцию, получающую на входе текст сообщения (text), содержание поля file формы (file), имя файла (name), тему письма (subj), адрес получателя (address) и отправляющую по этому адресу письмо с вложением. Отправителем в данном случае всегда является admin@iso.ru.
Функция представляет файл в кодировке base64 и конструирует многокомпонентный документ MIME, который отправляет по адресу address.
import mimetools, MimeWriter, StringIO, smtplib, cgi, os
#задаем каталог для временных файлов
temp_dir = '/tmp/'
def send_attach(text, file, name, subj, address):
#полное имя временного файла
tmp_file = temp_dir + name + '.txt'
#имя загружаемого файла
src_file = temp_dir + name
#принимаем загружаемый файл
infile = open(src_file, 'wb')
#и записываем его в каталог для временных файлов
infile.write(file)
infile.close()
#создаем экземпляр класса MimeWriter
outfile = open(tmp_file, 'wb')
mw = MimeWriter.MimeWriter(outfile)
#создаем объект для записи многокомпонентного сообщения
mw.startmultipartbody("mixed")
#записываем заголовки
mw.flushheaders()
#создаем часть сообщения типа text/html и записываем туда text
subpart = mw.nextpart()
pout = subpart.startbody("text/html", [])
pout.write(text)
#создаем следующую часть сообщения
subpart = mw.nextpart()
#добавляем заголовок
subpart.addheader('Content-transfer-encoding', 'base64')
#определяем тип как application/octet-stream
pout = subpart.startbody("application/octet-stream", [("name", name)])
#открываем загружаемый файл и кодируем его в base64,
#результат записываем в pout
infile = open(src_file, "rb")
mimetools.encode(infile,pout,'base64')
infile.close()
#завершаем многокомпонентное сообщение
mw.lastpart()
outfile.close()
#далее посылаем стандартное сообщение с помощью класса SMTP,
#тело сообщения читаем из сформированного ранее файла.
f = open(tmp_file, 'rb')
msg = f.read()
f.close()
mail=smtplib.SMTP("smtpserver.ru")
out = StringIO.StringIO()
out.write( "Subject: %sn" % subj )
out.write( "From: %sn" % 'Intersoft Web Server ' )
out.write( "MIME-Version: 1.0n" )
out.write( msg )
mail.sendmail( 'market@iso.ru', address, out.getvalue() )
out.close()
#удаляем временные файлы
os.unlink(src_file)
os.unlink(tmp_file)
А вот пример использования этой функции:
send_attach(msg, form['attach'].value, form['attach'].filename.split('')[-1], 'Attachment', 'market@iso.ru')
Большинство CGI-скриптов работают с данными, полученными из форм. Для успешного использования этих данных необходимо проверить их корректность. В простейшем случае, это — просто проверка существования заполненного поля:
form = cgi.FieldStorage()
if form.has_key('keyname'):
#действия с данными
В более сложных случаях, таких как проверка корректности введенного e-mail адреса требуется использование модуля re для сопоставления полученных данных с регулярными выражениями. Например, регулярное выражение [-_w0-9]+@[-_w0-9]+.w+ определяет e-mail адрес следующим образом: [-_w0-9] обозначает любую букву, цифру или знак «-» и «_», + — одно или более повторений предыдущего выражения, @ — «собака», . — точка, w+ — не менее одной буквы. Таким образом все адреса вида name@domain1.domain2 попадают под это определение.
Для облегчения сопровождения сайта был разработан административный интерфейс — набор скриптов для контроля за контентом. Он состоит из следующих частей:
- Главный административный скрипт; скрипт позволяет:
- добавить новость, событие, статью в журнал, создать новую тему для журнала и новый журнал со статьей;
- редактировать (и удалять) новости, события, статьи журнала, темы журнала, атрибуты пользователей, комментарии к статьям.
- Скрипт управления конференциями; скрипт обеспечивает просмотр и удаление сообщений, добавление новых конференций.
- Скрипт выгрузки данных; скрипт отвечает за экспорт данных из таблиц в формат CSV.
Все скрипты достаточно жестко привязаны к структуре сайта, поэтому нет смысла подробно разбирать их. Хочу затронуть только один момент: удобно сделать отдельную таблицу для размещения информации о полях таблиц, используемых скриптами сайта. Это позволит писать универсальные функции администрирования для разных таблиц. Например, функция, реализующая вывод списка записей на нашем сайте построена следующим образом: на входе она получает имя таблицы, по нему читается информация о таблице из служебной таблицы (названия полей, выводить ли поле в списке и т.д.) и на основании полученной информации выводится список записей. Так как список, состоящий из всех полей, очень громоздкий (статья в журнале может занимать несколько страниц), в списке выводятся только те поля, для которых в служебной таблице стоит флаг вывода в списке. Благодаря этому добавление новых таблиц в базу требует лишь записи информации о них в служебную таблицу.
В этой статье мы разберемся, как создать HTML скрапер на Python, который получает неофициальный доступ к коду сайта и позволяет извлечь необходимые данные.
Отличие от вызовов API
Альтернативный метод получения данных сайта — вызовы API. Взаимодействие с API — это официально предоставляемый владельцем сайта способ получения данных прямо из БД или обычных файлов. Обычно для этого требуется разрешение владельца сайта и специальный токен. Однако апи доступен не всегда, поэтому скрапинг так привлекателен, однако его законность вызывает вопросы.
Юридические соображения
Скрапинг может нарушать копирайт или правила использования сайта, особенно когда он используется для получения прибыли, конкурентного преимущества или причинения ущерба (например из-за слишком частых запросов). Однако скрапинг публично доступен и используется для личного использования, академических целей или безвредного некоммерческого использования.
Если данные являются платными, требуют регистрации, имеют явную защиту от скрапинга, содержат конфиденциальные данные или личные данные пользователей, то нужно избегать любого из видов скрапинга.
Установка Beautiful Soup в Python
Beautiful Soup — это Python библиотека для скрапинга данных сайтов через HTML код.
Установите последнюю версию библиотеки.
$ pip install beautifulsoup4Чтобы делать запросы, установите requests (библиотеку для отправки HTTP запросов):
$ pip install requestsИмпортируйте библиотеки в файле Python или Jupiter notebook:
from bs4 import BeautifulSoup
import requestsИ несколько стандартных библиотек, которые потребуются для скрапинга на Python:
import re
from re import sub
from decimal import Decimal
import io
from datetime import datetime
import pandas as pdВведение
Представьте, что мы хотим произвести скрапинг платформы, содержащей общедоступные объявления о недвижимости. Мы хотим получить цену недвижимости, ее адрес, расстояние, название станции и ближайший до нее тип транспорта для того, чтобы узнать, как цены на недвижимость распределяются в зависимости от доступности общественного транспорта в конкретном городе.
Предположим, что запрос приведет к странице результатов, которая выглядит следующим образом:

Как только мы узнаем, в каких элементах сайта хранятся необходимые данные, нам нужно придумать логику скрапинга, которая позволит нам получить всю нужную информацию из каждого объявления.
Нам предстоит ответить на следующие вопросы:
- Как получить одну точку данных для одного свойства (например данные из тега price в первом объявлении)?
- Как получить все точки данных для одного свойства со всей страницы (например все теги price с одной страницы)?
- Как получить все точки данных для одного свойства всех страниц с результатами (например все теги price со всех страниц с результатами)?
- Как устранить несоответствие, когда данные могут быть разных типов (например, есть некоторые объявления, в которых в поле цены указана цена по запросу. В конечном итоге у нас будет столбец, состоящий из числовых и строковых значений, что в нашем случае не позволяет провести анализ)?
- Как лучше извлечь сложную информацию (Например, предположим, что каждое объявление содержит информацию об общественном транспорте, например “0,5 мили до станции метро XY”)?
Логика получения одной точки данных
Все примеры кода для скрапинга на Python можно найти в Jupiter Notebook файле на GitHub автора.
Запрос кода сайта
Во-первых, мы используем поисковый запрос, который мы сделали в браузере в скрипте Python:
# поиск в определённой зоне
url = 'https://www.website.com/london/page_size=25&q=london&pn=1'
# делаем запрос и получаем html
html_text = requests.get(url).text
# используем парсер lxml
soup = BeautifulSoup(html_text, 'lxml')Переменная soup содержит полный HTML-код страницы с результатами поиска.
Поиск тегов-свойств
Для этого нам потребуется браузер. Некоторые популярные браузеры предлагают удобный способ получения информации о конкретном элементе напрямую. В Google Chrome вы можете выбрать любой элемент сайта и, нажав правой кнопкой, выбрать пункт «Исследовать элемент» . Справа откроется код сайта с выделенным элементом.
HTML классы и атрибут id
HTML-классы и id в основном используются для ссылки на класс в таблице стилей CSS, чтобы данные могли отображаться согласованным образом.
В приведенном выше примере, класс, используемый для получения информации о ценах из одного объявления, также применяется для получения цен из других объявлений (что соответствует основной цели класса).
Обратите внимание, что HTML-класс также может ссылаться на ценники за пределами раздела объявлений (например, специальные предложения, которые не связаны с поисковым запросом, но все равно отображаются на странице результатов). Однако для целей этой статьи мы фокусируемся только на ценах в объявлениях о недвижимости.
Вот почему мы сначала ориентируемся на объявление и ищем HTML-класс только в исходном коде для конкретного объявления:
# используем парсер lxml
soup = BeautifulSoup(html_text, 'lxml')
# находим одно объявление
ad = soup.find('div', class_ = 'css-ad-wrapper-123456')
# находим цену
price = ad.find('p', class_ = 'css-aaabbbccc').textИспользование .text в конце метода find() позволяет нам возвращать только обычный текст, как показано в браузере. Без .text он вернет весь исходный код строки HTML, на которую ссылается класс:

Важное примечание: нам всегда нужно указывать элемент, в данном случае это p.
Логика получения всех точек данных с одной страницы
Чтобы получить ценники для всех объявлений, мы применяем метод find.all() вместо find():
ads = ad.find_all('p', class_ = 'css-ad-wrapper-123456')Переменная ads теперь содержит HTML-код для каждого объявления на первой странице результатов в виде списка списков. Этот формат хранения очень полезен, так как он позволяет получить доступ к исходному коду для конкретных объявлений по индексу.
Чтобы получить все ценники, мы используем словарь для сбора данных:
map = {}
id = 0
# получаем все элементы
ads = ad.find_all('p', class_ = 'css-ad-wrapper-123456')
for i in range(len(ads)):
ad = ads[i]
id += 1
map[id] = {}
# находим цену
price = ad.find('p', class_ = 'css-aaabbbccc').text
# находим адрес
address = ad.find('p', class_ = 'css-address-123456').text
map[id]["address"] = address
map[id]["price"] = priceВажное примечание: использование идентификатора позволяет находить объявления в словаре:
 Получение точек данных со всех страниц
Получение точек данных со всех страниц
 Получение точек данных со всех страниц
Получение точек данных со всех страницОбычно результаты поиска либо разбиваются на страницы, либо бесконечно прокручиваются вниз.
Вариант 1. Веб-сайт с пагинацией
URL-адреса, полученные в результате поискового запроса, обычно содержат информацию о текущем номере страницы.

Как видно на рисунке выше, окончание URL-адреса относится к номеру страницы результатов.
Важное примечание: номер страницы в URL-адресе обычно становится видимым со второй страницы. Использование базового URL-адреса с дополнительным фрагментом &pn=1 для вызова первой страницы по-прежнему будет работать (в большинстве случаев).
Применение одного цикла for-loop поверх другого позволяет нам перебирать страницы результатов:
url = 'https://www.website.com/london/page_size=25&q=london&pn='
map = {}
id = 0
# максимальное количество страниц
max_pages = 15
for p in range(max_pages):
cur_url = url + str(p + 1)
print("Скрапинг страницы №: %d" % (p + 1))
html_text = requests.get(cur_url).text
soup = BeautifulSoup(html_text, 'lxml')
ads = soup.find_all('div', class_ = 'css-ad-wrapper-123456')
for i in range(len(ads)):
ad = ads[i]
id += 1
map[id] = {}
price = ad.find('p', class_ = 'css-aaabbbccc').text
address = ad.find('p', class_ = 'css-address-123456').text
map[id]["address"] = address
map[id]["price"] = priceОпределение последней страницы результатов
Вы можете задаться вопросом, как определить последнюю страницу результатов? В большинстве случаев после достижения последней страницы, любой запрос с большим числом, чем фактическое число последней страницы, приведет нас обратно на первую страницу. Следовательно, использование очень большого числа для ожидания завершения сценария не работает. Через некоторое время он начнет собирать повторяющиеся значения.
Чтобы решить эту проблему, мы будем проверять, есть ли на странице кнопка с такой ссылкой:
url = 'https://www.website.com/london/page_size=25&q=london&pn='
map = {}
id = 0
# используем очень большое число
max_pages = 9999
for p in range(max_pages):
cur_url = url + str(p + 1)
print("Скрапинг страницы №: %d" % (p + 1))
html_text = requests.get(cur_url).text
soup = BeautifulSoup(html_text, 'lxml')
ads = soup.find_all('div', class_ = 'css-ad-wrapper-123456')
# ищем ссылку в кнопке
page_nav = soup.find_all('a', class_ = 'css-button-123456')
if(len(page_nav) == 0):
print("Максимальный номер страницы: %d" % (p))
break
(...)Вариант 2. Сайт с бесконечным скроллом
В таком случае HTML скрапер не сработает. Альтернативные методы мы обсудим в конце статьи.
Устранение несогласованности данных
Если нам нужно избавиться от ненужных данных в самом начале скрапинга на Python, мы можем использовать обходной метод:
Функция для определения аномалий
def is_skipped(price):
'''
Определение цен, которые не являются ценами
(например "Цена по запросу")
'''
for i in range(len(price)):
if(price[i] != '£' and price[i] != ','
and (not price[i].isdigit())):
return True
return FalseИ применить его при сборе данных:
(...)
for i in range(len(ads)):
ad = ads[i]
id += 1
map[id] = {}
price = ad.find('p', class_ = 'css-aaabbbccc').text
# пропускаем объявление без корректной цены
if(is_skipped(price)): continue
map[id]["price"] = priceФорматирование данных на лету
Мы могли заметить, что цена хранится в строке вместе с запятыми с символом валюты. Мы можем исправить это ещё на этапе скрапинга:
def to_num(price):
value = Decimal(sub(r'[^d.]', '', price))
return float(value)Используем эту функцию:
(...)
for i in range(len(ads)):
ad = ads[i]
id += 1
map[id] = {}
price = ad.find('p', class_ = 'css-aaabbbccc').text
if(is_dropped(price)): continue
map[id]["price"] = to_num(price)
(...)Получение вложенных данных
Информация об общественном транспорте имеет вложенную структуру. Нам потребуются данные о расстоянии, названии станции и типе транспорта.
Отбор информации по правилам
Каждый кусочек данных представлен в виде: число миль, название станции. Используем слово «миль» в качестве разделителя.
map[id]["distance"] = []
map[id]["station"] = []
transport = ad.find_all('div', class_ = 'css-transport-123')
for i in range(len(transport)):
s = transport[i].text
x = s.split(' miles ')
map[id]["distance"].append(float(x[0]))
map[id]["station"].append(x[1])Первоначально переменная transport хранит два списка в списке, поскольку есть две строки информации об общественном транспорте (например, “0,3 мили Слоун-сквер”, “0,5 мили Южный Кенсингтон”). Мы перебираем эти списки, используя len транспорта в качестве значений индекса, и разделяем каждую строку на две переменные: расстояние и станцию.
Поиск дополнительных HTML атрибутов для визуальной информации
В коде страницы мы можем найти атрибут testid, который указывает на тип общественного транспорта. Он не отображается в браузере, но отвечает за изображение, которое отображается на странице. Для получения этих данных нам нужно использовать класс css-StyledIcon:
map[id]["distance"] = []
map[id]["station"] = []
map[id]["transport_type"] = []
transport = ad.find_all('div', class_ = 'css-transport-123')
type = ad.find_all('span', class_ = 'css-StyledIcon')
for i in range(len(transport)):
s = transport[i].text
x = s.split(' miles ')
map[id]["distance"].append(float(x[0]))
map[id]["station"].append(x[1])
map[id]["transport_type"].append(type[i]['testid'])Преобразование в датафрейм и экспорт в CSV
Когда скрапинг выполнен, все извлеченные данные доступны в словаре словарей.
Давайте сначала рассмотрим только одно объявление, чтобы лучше продемонстрировать заключительные шаги трансформации.
 Преобразуем словарь в список списков, чтобы избавиться от вложенности
Преобразуем словарь в список списков, чтобы избавиться от вложенности
result = []
cur_row = 0
for idx in range(len(map[1]["distance"])):
result.append([])
result[cur_row].append(str(map[1]["uuid"]))
result[cur_row].append(str(map[1]["price"]))
result[cur_row].append(str(map[1]["address"]))
result[cur_row].append(str(map[1]["distance"][idx]))
result[cur_row].append(str(map[1]["station"][idx]))
result[cur_row].append(str(map[1]["transport_type"][idx]))
cur_row += 1
Создаём датафрейм
df = pd.DataFrame(result, columns = ["ad_id", "price", "address",
"distance", "station", "transport_type"])
Мы можем экспортировать датафрейм в CSV:
filename = 'test.csv'
df.to_csv(filename)Преобразование всех объявлений в датафрейм:
result = []
cur_row = 0
for id in map.keys():
cur_price = map[id]["price"]
cur_address = map[id]["address"]
for idx in range(len(map[id]["distance"])):
result.append([])
result[cur_row].append(int(cur_id))
result[cur_row].append(float(cur_price))
result[cur_row].append(str(cur_address))
result[cur_row].append(float(map[id]["distance"][idx]))
result[cur_row].append(str(map[id]["station"][idx]))
result[cur_row].append(str(map[id]["transport_type"][idx]))
cur_row += 1
# преобразование в датафрейм
df = pd.DataFrame(result, columns = ["ad_id", "price","address", "distance", "station", "transport_type"])
# экспорт в csv
filename = 'test.csv'
df.to_csv(filename)Мы это сделали! Теперь наш скрапер готов к тестированию.
Ограничения HTML скрапинга и его альтернативы
Этот пример показывает, насколько простым может быть скрапинг HTML на Python в стандартном случае. Для этого не нужно исследовать документацию. Это требует, скорее, творческого мышления, чем опыта веб-разработки.
Однако HTML скраперы имеют недостатки:
- Можно получить доступ только к информации в HTML-коде, которая загружается непосредственно при вызове URL-адреса. Веб-сайты, которые требуют JavaScript и Ajax для загрузки контента, не будут работать.
- HTML-классы или идентификаторы могут изменяться в связи с обновлениями веб-сайта.
- Может быть легко обнаружен, если запросы кажутся аномальными для веб-сайта (например, очень большое количество запросов в течение короткого промежутка времени).
Альтернативы:
- Shell скрипты — загружают всю страницу, с помощью регулярных выражений могут обрабатывать html.
- Screen scraper — изображают реального пользователя, используют браузер (Selenium, PhantomJS).
- ПО для скрапинга — рассчитаны на стандартные случаи, не требуют написания кода (webscraper.io).
- Веб сервисы скраперы — не требуют написания кода, хорошо справляются со скрапингом, платные (zyte.com).
Здесь вы найдёте список инструментов и библиотек для скрапинга.
Источник Turn Website Data Into Data Sets: A Beginner’s Guide to Python Web Scraping
Проще всего создать динамические страницы на Python при помощи CGI-скриптов. CGI-скрипты — это исполняемые файлы, которые выполняются веб-сервером, когда в URL запрашивается соответствующий скрипт.
Сегодня я расскажу про то, как написать Hello world, как CGI-скрипт.
Настройка локального сервера
В Python уже есть встроенный CGI сервер, поэтому его настройка элементарна.
Для запуска из консоли (для любителей linux-систем). Запускать нужно из той папки, где мы хотим работать:
python3 -m http.server --cgi
Для сидящих на Windows чуть проще будет запуск Python файла (заметьте, что он должен находиться в той же папке, в которой мы планируем работать!):
from http.server import HTTPServer, CGIHTTPRequestHandler server_address = ("", 8000) httpd = HTTPServer(server_address, CGIHTTPRequestHandler) httpd.serve_forever()
Теперь откройте браузер и в адресной строке наберите localhost:8000
Если у вас примерно такая же картина, значит, у вас все заработало!
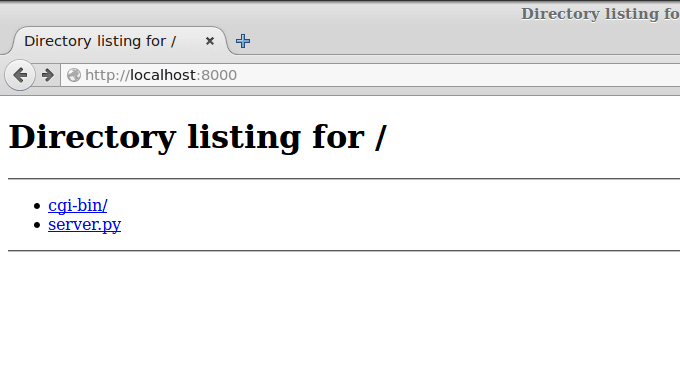
Теперь в той папке, где мы запустили сервер, создаём папку cgi-bin (у меня она уже создана).
В этой папке создаём скрипт hello.py со следующим содержимым:
#!/usr/bin/env python3 print("Content-type: text/html") print() print("<h1>Hello world!</h1>")
Первая строка говорит о том, что это Python скрипт (CGI-скрипты можно не только на Python писать).
Вторая строка печатает заголовок. Он обозначает, что это будет html файл (бывает ещё css, javascript, pdf и куча других, и браузер различает их по заголовкам).
Третья строка (просто символ новой строки) отделяет заголовки от тела ответа.
Четвёртая печатает Hello world.
Теперь переходим на localhost:8000/cgi-bin/hello.py
И радуемся!
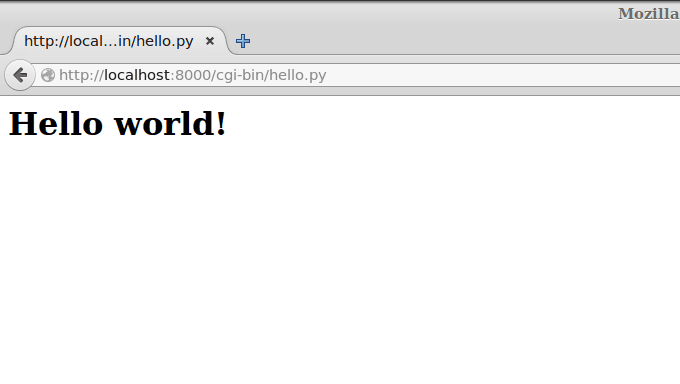
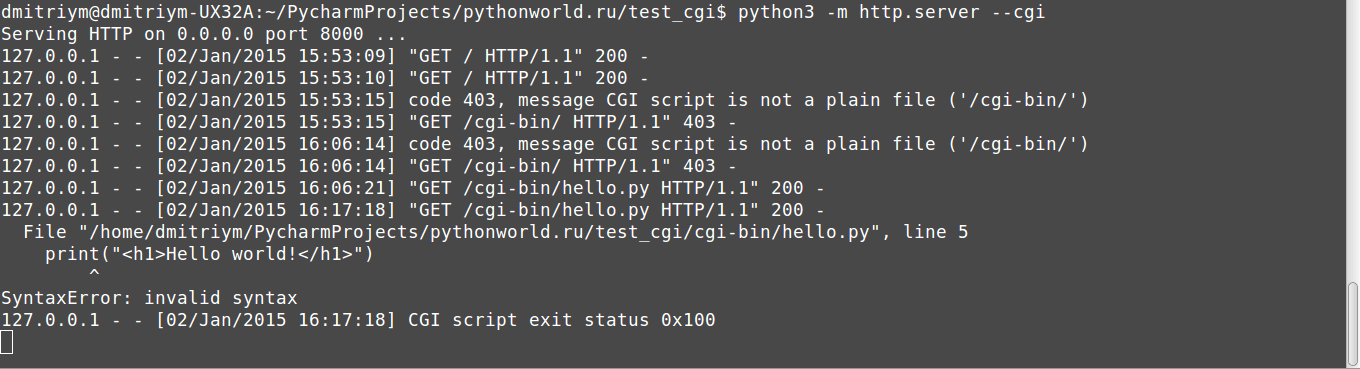
Если у вас не работает, проверьте, установлены ли права на выполнение.
Также в консоли запущенного сервера появляются сообщения об ошибках. Например, убрал скобочку и обновил страницу:
В следующей части мы рассмотрим обработку данных форм и cookies.
Для вставки кода на Python в комментарий заключайте его в теги <pre><code class=»python3″>Ваш код</code></pre>
Научитесь парсить веб-страницы с помощью Python, чтобы быстро собирать данные с нескольких сайтов с экономией времени и усилий.
6 min read


Узнайте, как создать парсер на Python для сканирования всего сайта и извлечения данных с помощью веб-скрапинга.
Веб-скрапинг — это извлечение веб-данных. Парсер же — это инструмент, который выполняет веб-скрапинг и обычно представлен в виде скрипта. Python — один из самых простых и надежных языков сценариев. Кроме того, он поставляется с широким спектром библиотек для веб-скрапинга. Это делает Python идеальным языком программирования для парсинга веб-страниц. Ведь веб-скрапинг с Python занимает всего несколько строк кода.
В этом руководстве вы узнаете, как создать простой парсер Python. Он будет просматривать весь сайт, извлекая данные с каждой страницы. Затем сохранит их в CSV-файл. Это руководство поможет вам понять, какие библиотеки Python лучшие для парсинга данных, как их использовать. Следуйте нашему пошаговому плану и научитесь создавать скрипт Python для веб-скрапинга.
Содержание:
- Требования
- Лучшие библиотеки веб-скрапинга Python
- Создание парсера на Python
- Вывод
- Часто задаваемые вопросы
Требования
Чтобы создать парсер Python, вам необходимы:
- Python 3.4+
- pip (менеджер пакетов)
Если на вашем компьютере не установлен Python, скачайте его по первой ссылке выше. Если у вас ОС Windows, обязательно установите флажок «Добавить python.exe в PATH» при установке Python, как показано ниже:
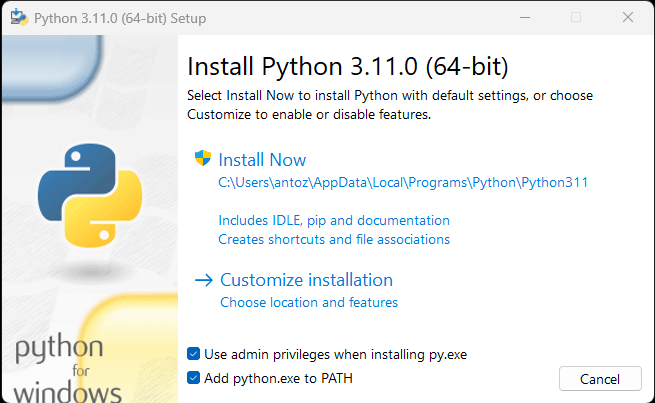
Так Windows автоматически распознает команды Python и pip в терминале. Отметим, что pip — это менеджер пакетов для Python. Он включен по умолчанию в Python 3.4 или более поздней версии. То есть вам не нужно устанавливать его вручную.
Теперь все готово для создания вашего первого парсера Python. Но сначала вам нужна библиотека веб-скрапинга Python!
Лучшие библиотеки веб-скрапинга Python
Вы можете создать сценарий парсинга страниц с нуля с помощью Python vanilla, но это не идеальное решение. Python имеет широкий выбор доступных библиотек. Для веб-скрапинга есть несколько на выбор. Давайте рассмотрим самые важные из них!
Requests
Библиотека Requests позволяет выполнять HTTP-запросы в Python. Она упрощает отправку HTTP-запросов, особенно по сравнению со стандартными HTTP-библиотеками Python. Requests играют ключевую роль в проекте веб-скрапинга Python, поскольку для соскабливания данных на веб-странице сначала нужно получить их с помощью HTTP-запроса GET. Кроме того, может потребоваться выполнение других HTTP-запросов к серверу целевого сайта.
Вы можете установить requests с помощью следующей команды pip:
pip install requestsBeautiful Soup
Библиотека Beautiful Soup Python упрощает сбор информации с веб-страниц. Она работает с любым парсером HTML или XML и предоставляет все необходимое для итерации, поиска и изменения дерева синтаксического анализа. Обратите внимание, что Beautiful Soup можно использовать с html.parser – парсером, который входит в стандартную библиотеку Python и позволяет анализировать текстовые файлы HTML. Вы можете использовать Beautiful Soup для обхода DOM и извлечения из него необходимых данных.
Вы можете установить Beautiful Soup с помощью pip следующим образом:
pip install beautifulsoup4Selenium
Selenium — это усовершенствованная система автоматизированного тестирования с открытым исходным кодом, которая позволяет выполнять операции на веб-странице в браузере. Другими словами, вы можете использовать Selenium, чтобы заставить браузер выполнять определенные задачи. А также использовать в качестве библиотеки веб-скрапинга благодаря возможностям безголового браузера. Это веб-браузер, который работает без GUI (графического пользовательского интерфейса).
Таким образом, веб-страницы, посещаемые в Selenium, будут отображаться в реальном браузере, способном запускать JavaScript. В результате Selenium позволит парсить сайты, зависящие от JavaScript. Учитывайте, что вы не можете добиться этого с помощью requests или любого другого HTTP-клиента, потому что вам нужен браузер для запуска JavaScript, тогда как requests просто позволяют выполнять HTTP-запросы.
Selenium предоставляет все необходимое для создания парсера без потребности в других библиотеках. Вы можете установить его с помощью следующей команды pip:
pip install seleniumСоздание парсера на Python
Теперь давайте узнаем, как создать парсер на Python. Цель этого руководства — научиться извлекать все данные о цитатах на сайте Quotes to Scrape. Вы научитесь извлекать текст, автора и список тегов для каждой цитаты.
Но сначала давайте взглянем на целевой сайт. Вот как выглядит веб-страница Quotes to Scrape:
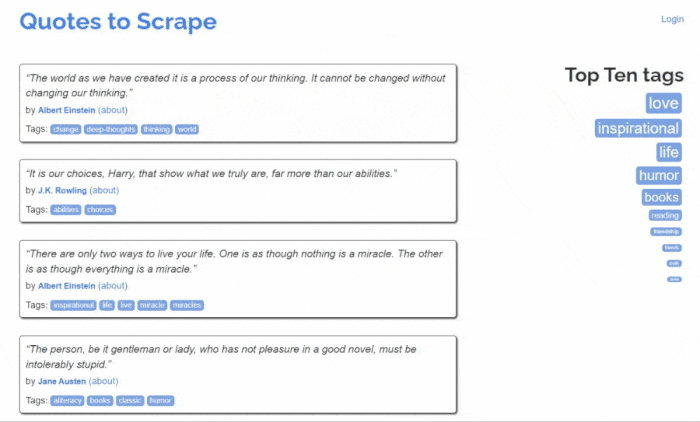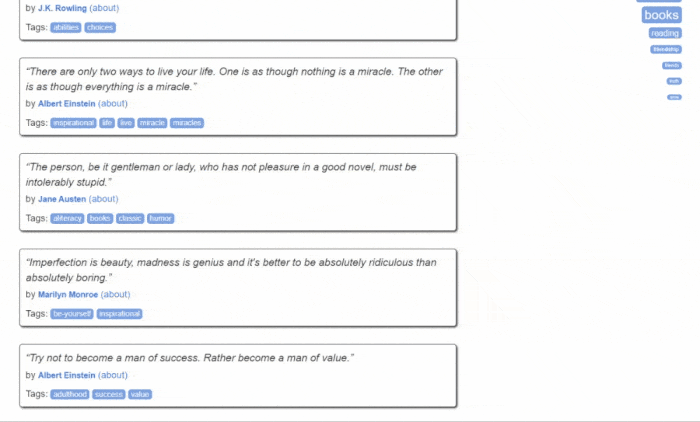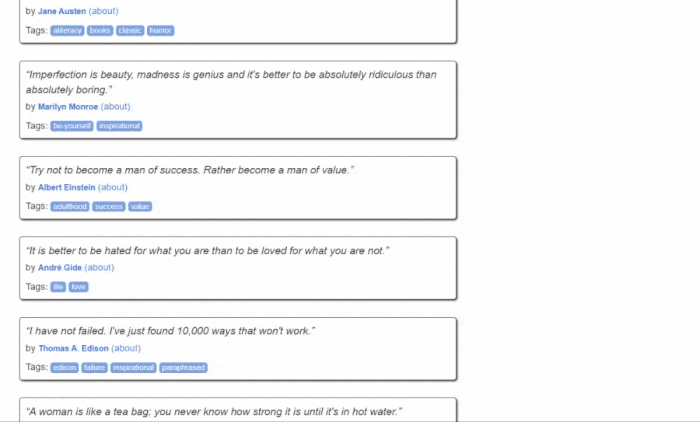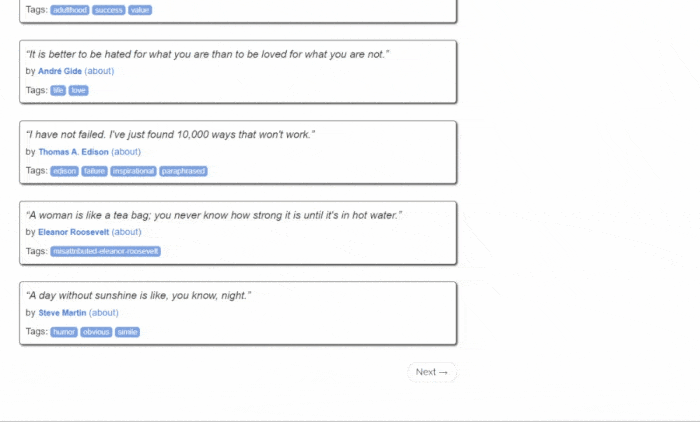
Как видите, Quotes to Scrape — это не что иное, как песочница для парсинга веб-страниц. Сайт содержит разбитый на страницы список цитат. Парсер Python, который вы собираетесь создать, извлечет все цитаты на каждой странице, и предоставит их в виде данных CSV.
Теперь пришло время понять, какие библиотеки Python для парсинга лучше всего подходят для достижения этой цели. Как вы можете увидеть на картинке ниже на вкладке Network окна Chrome DevTools целевой сайт не выполняет запросов Fetch/XHR.
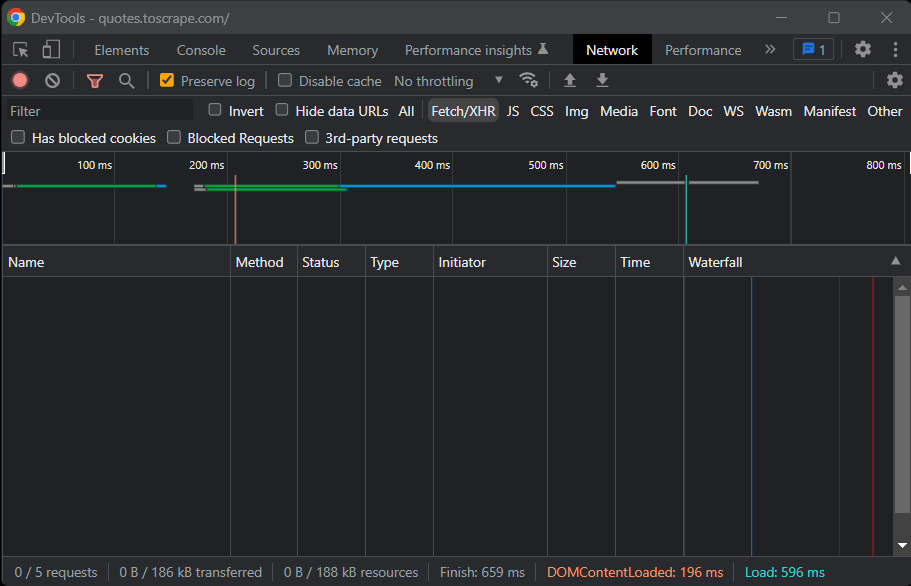
Другими словами, Quotes to Scrape не использует JavaScript для извлечения данных на веб-страницах. Это обычная ситуация для большинства сайтов, отображаемых на сервере. Поскольку целевой сайт не использует JavaScript для отображения страницы или извлечения данных, вам не нужен Selenium для парсинга. Вы можете использовать его, но это не обязательно.
Как вы уже узнали, Selenium открывает страницы в браузере. Поскольку это занимает время и ресурсы, Selenium вызывает расходы на производительность. Вы можете избежать этого, используя Beautiful Soup вместе с Requests. Теперь давайте узнаем, как создать простой скрипт парсинга веб-страниц на Python для извлечения данных с сайта с помощью Beautiful Soup.
Приступим
Прежде чем написать первые строки кода, вам необходимо настроить проект парсинга на Python. Технически необходим только один файл .py. Однако использование расширенной IDE (интегрированной среды разработки) упростит процесс написания кода. Здесь вы узнаете, как настроить проект Python в PyCharm 2022.2.3, но подойдет и любая другая IDE.
Откройте PyCharm и выберите «Файл > Новый проект…». Во всплывающем окне «Новый проект» выберите «Pure Python» и создайте свой проект.
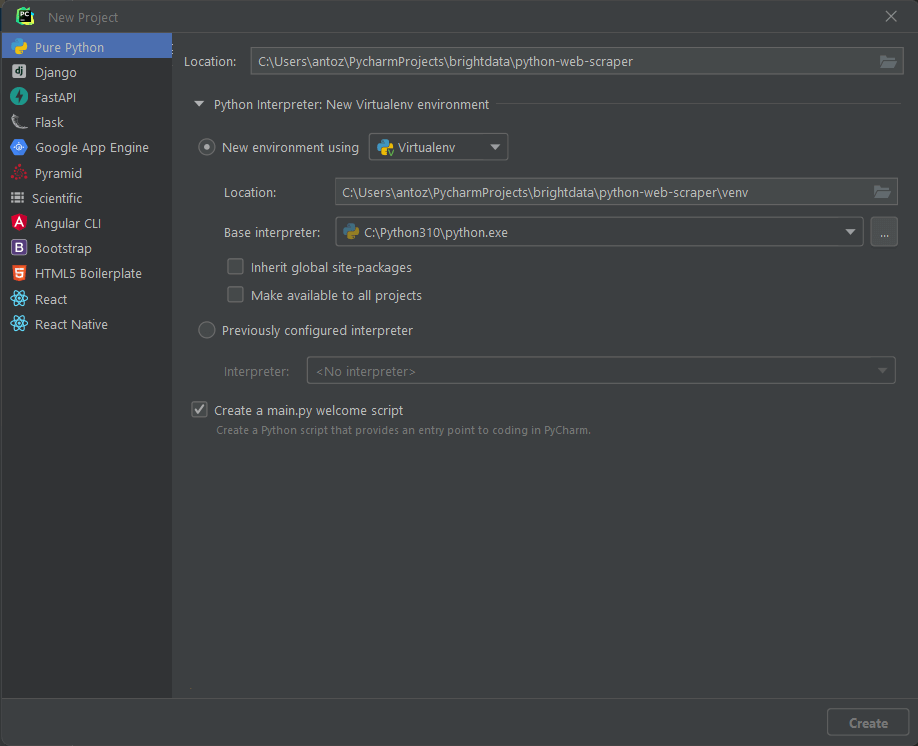
Например, вы можете назвать свой проект python-web-scraper. Нажмите «Создать», и теперь у вас будет доступ к вашему пустому проекту Python. По умолчанию PyCharm инициализирует файл main.py. Вы можете переименовать его в scraper.py. Вот как теперь будет выглядеть ваш проект:
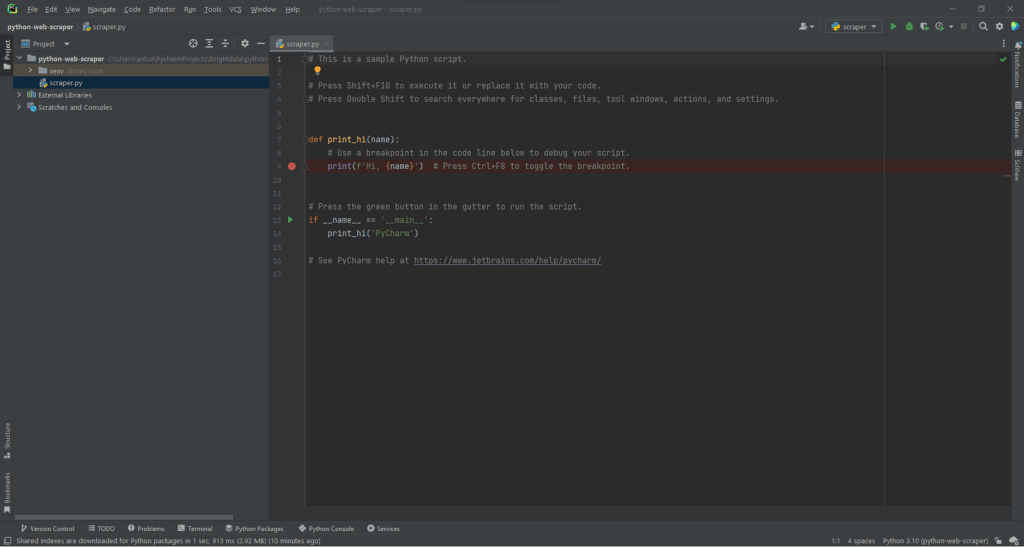
Как видите, PyCharm автоматически инициализирует для вас файл Python. Не обращайте внимания на его содержимое и удаляйте каждую строку кода, чтобы начать с нуля.
Теперь пришло время установить зависимости проекта. Вы можете установить Requests и Beautiful Soup, запустив в терминале следующую команду:
pip install requests beautifulsoup4Эта команда установит обе библиотеки одновременно. Дождитесь завершения установки. Теперь вы готовы использовать Beautiful Soup и Requests для создания поискового робота и парсера на Python. Обязательно импортируйте две библиотеки, добавив следующие строки в начало файла скрипта scraper.py:
import requests
from bs4 import BeautifulSoupPyCharm подсветит эти две строки серым цветом, потому что библиотеки не используются в коде. Если он подчеркнет их красным цветом, значит, что-то пошло не так в процессе установки. В этом случае попробуйте установить их снова.
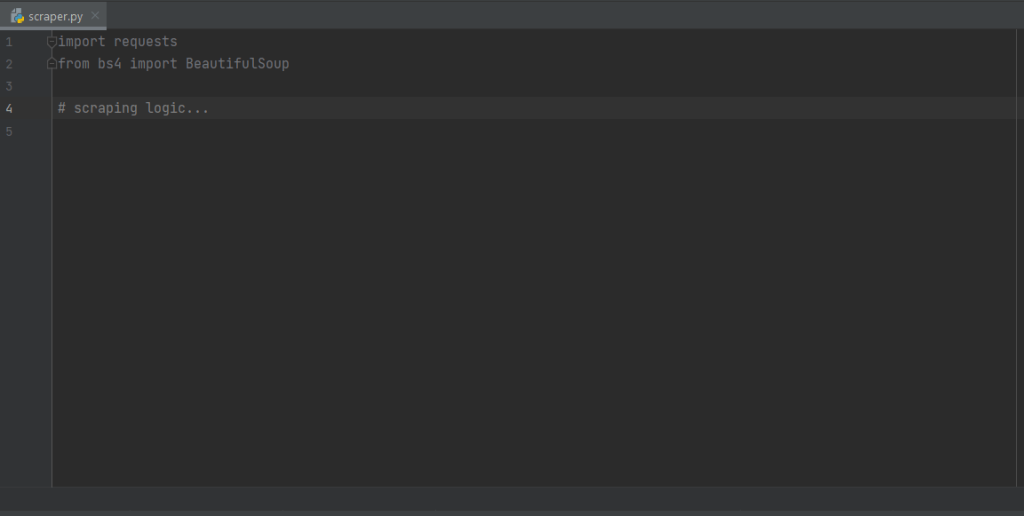
Вот как теперь должен выглядеть ваш файл scraper.py. Теперь вы можете приступить к определению логики парсинга веб-страниц.
Подключение к целевому URL для сканирования
Первое, что нужно сделать в парсере, — это подключиться к целевому сайту. Сначала получите полный URL-адрес страницы из браузера. Обязательно скопируйте также раздел протокола http:// или https:// HTTP. Вот как выглядит полный URL-адрес целевого сайта:
https://quotes.toscrape.comТеперь можете использовать запросы для загрузки страницы со следующей строкой кода:
page = requests.get('https://quotes.toscrape.com')Эта строка просто присваивает результат метода request.get() переменной page. За сценой request.get() выполняет запрос GET, используя URL-адрес, переданный в качестве параметра. Затем он возвращает объект Response, содержащий ответ сервера на HTTP-запрос.
Если HTTP-запрос выполнен успешно, код page.status_ будет содержать 200. HTTP 200 OK – код ответа состояния, который указывает на то, что HTTP-запрос был выполнен успешно. Код состояния HTTP 4xx или 5xx будет означать ошибку. Это может произойти по нескольким причинам. Учитывайте, что многие сайты блокируют запросы без допустимого заголовка User-Agent. Это строка, которая характеризует приложение и версию операционной системы, откуда пришел запрос. Узнайте больше о User-Agent для веб-скрапинга.
Вы можете установить заголовок User-Agent в запросах следующим образом:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get('https://quotes.toscrape.com', headers=headers)теперь запросы будут выполнять HTTP-запрос, если заголовки будут переданы в качестве параметра.
На что следует обратить внимание, так это на свойство page.text. Оно будет содержать HTML-документ, возвращенный сервером в строковом формате. Передайте свойство text в Beautiful Soup, чтобы извлечь данные из веб-страницы. Давайте узнаем, как это сделать.
Извлечение данных с помощью парсера Python
Чтобы извлечь данные с веб-страницы, сначала нужно определить элементы HTML, которые содержат нужные вам данные. В частности, необходимо найти селекторы CSS для извлечения этих элементов из DOM. Подойдут инструменты разработки от вашего браузера. В Chrome щелкните правой кнопкой мыши на интересующем вас элементе HTML и выберите Inspect (Проверить).
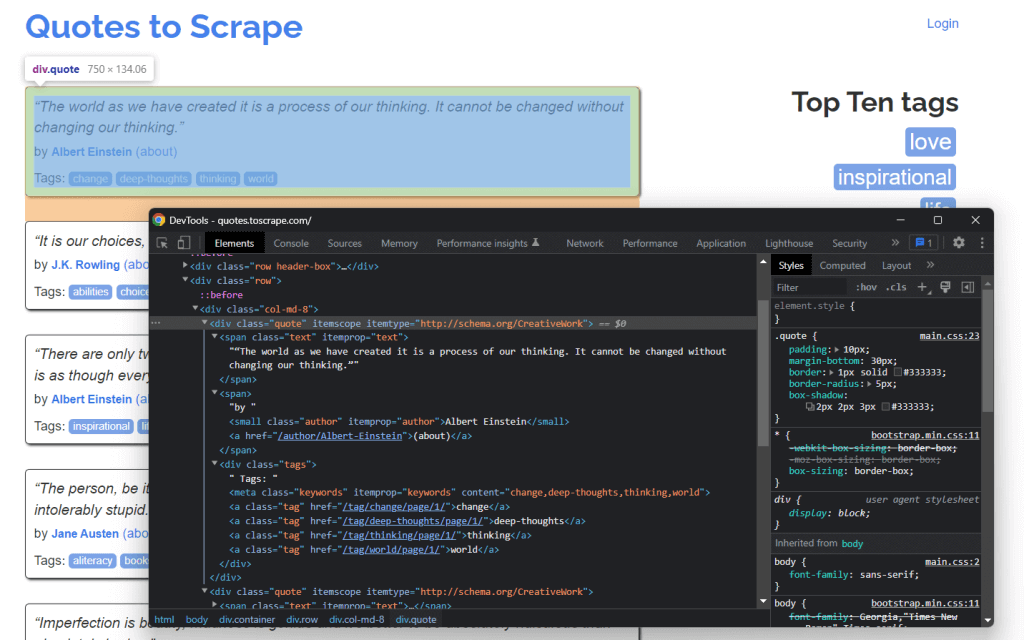
Как видите, HTML-элемент цитаты <div> идентифицируется классом цитаты (quote). Он содержит:
- Текст цитаты в HTML-элементе <span>
- Автор цитаты в HTML-элементе <small>
- Список тегов в элементе <div>, каждый из которых содержится в HTML-элементе <a>.
В частности, вы можете извлечь эти данные, используя следующие селекторы CSS в .quote:
.text.author.tags .tag
Давайте теперь узнаем, как добиться этого с помощью Beautiful Soup в Python. Во-первых, давайте передадим HTML-документ page.text конструктору BeautifulSoup():
soup = BeautifulSoup(page.text, 'html.parser')Второй параметр указывает синтаксический анализатор, который Beautiful Soup будет использовать для анализа HTML-документа. Переменная soup теперь содержит объект BeautifulSoup. Это дерево синтаксического анализа, в результате разбора HTML-документа в page.text, с помощью встроенного в Python html.parser.
Теперь инициализируйте переменную, которая будет содержать список всех отсканированных данных.
quotes = []Пришло время использовать soup для извлечения элементов из DOM:
quote_elements = soup.find_all('div', class_='quote')Метод find_all() вернет список всех HTML-элементов <div>, идентифицированных классом цитаты (quote). Другими словами, эта строка кода эквивалентна применению CSS-селектора .quote для получения списка HTML-элементов цитаты на странице. Затем можно выполнить итерации по списку цитат для получения данных о цитатах, как показано ниже:
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)Благодаря методу find() из Beautiful Soup вы можете извлечь один интересующий элемент HTML. Поскольку тегов, связанных с цитатой, больше одного, их следует хранить в списке.
Затем вы можете преобразовать эти данные в словарь и добавить их в список следующим образом:
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)Хранение извлеченных данных в таком формате словаря облегчит доступ к вашим данным для их понимания.
Вы только что узнали, как извлечь все данные о цитатах с одной страницы. Но имейте в виду, что целевой сайт состоит из нескольких страниц. Давайте научимся сканировать весь сайт.
Реализация логики сканирования
Внизу главной страницы вы можете найти HTML-элемент «Далее →» <a>, который перенаправляет на следующую страницу целевого сайта. Этот элемент HTML содержится на всех страницах, кроме последней. Такой сценарий распространен на любом сайте с разбивкой на страницы.
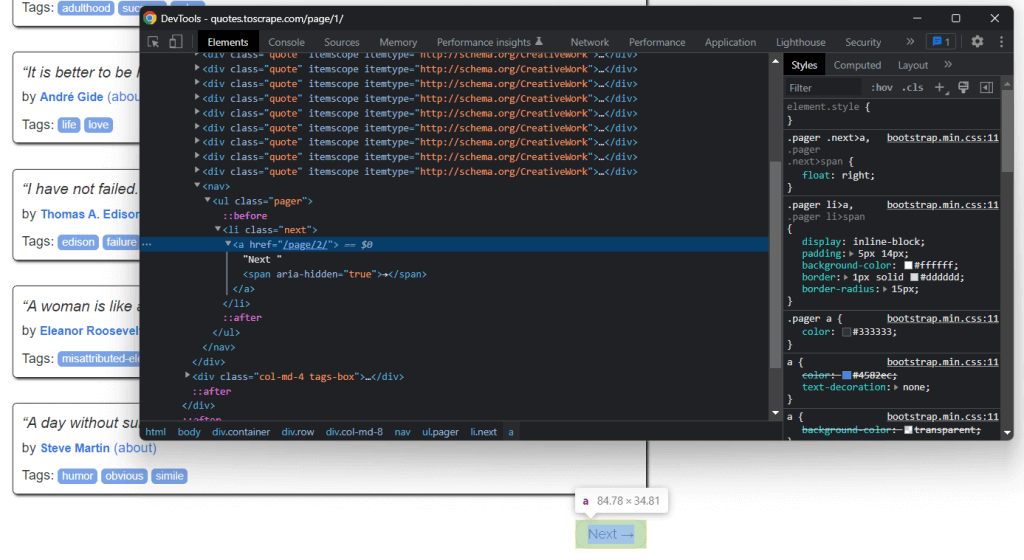
Перейдя по ссылке в HTML-элементе «Далее →» <a>, вы можете легко перемещаться по всему сайту. Итак, начнем с главной и посмотрим, как пройти каждую страницу, из которой состоит целевой сайт. Вам нужно найти HTML-элемент .next <li> и извлечь относительную ссылку на следующую страницу.
Вы можете реализовать логику сканирования так:
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# retrieving the page and initializing soup...
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')Этот цикл выполняет итерации по каждой странице до тех пор, пока не останется следующая страница. В частности, он извлекает относительный URL следующей страницы и использует его для создания URL следующей страницы для сканирования. Затем загружается следующая страница, он сканирует ее и повторяет логику.
Вы только что узнали, как реализовать логику сканирования для парсинга всего сайта. Пришло время посмотреть, как преобразовать извлеченные данные в более удобный формат.
Преобразование данных в формат CSV
Рассмотрим, как преобразовать список словарей, содержащих отсканированные данные цитаты, в файл CSV. Сделать это можно с помощью следующих строк:
import csv
# scraping logic...
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()Этот фрагмент кода записывает данные цитаты, содержащиеся в списке словарей, в файл quotes.csv. Обратите внимание, что csv является частью стандартной библиотеки Python. Таким образом, вы можете импортировать и использовать его без дополнительной зависимости. Вам просто нужно создать файл с помощью open(). Затем вы можете заполнить его функцией writerow() из объекта Writer библиотеки csv. Это позволит записать каждый словарь цитат как строку в CSV-формате в CSV-файл.
Вы перешли от необработанных данных сайта к структурированным данным в файле CSV. Процесс извлечения завершен, и теперь вы можете посмотреть на весь парсер Python.
Собираем все вместе
Вот как выглядит полный скрипт парсинга веб-страниц на Python:
import requests
from bs4 import BeautifulSoup
import csv
def scrape_page(soup, quotes):
# retrieving all the quote <div> HTML element on the page
quote_elements = soup.find_all('div', class_='quote')
# iterating over the list of quote elements
# to extract the data of interest and store it
# in quotes
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)
# appending a dictionary containing the quote data
# in a new format in the quote list
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# defining the User-Agent header to use in the GET request below
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# retrieving the target web page
page = requests.get(base_url, headers=headers)
# parsing the target web page with Beautiful Soup
soup = BeautifulSoup(page.text, 'html.parser')
# initializing the variable that will contain
# the list of all quote data
quotes = []
# scraping the home page
scrape_page(soup, quotes)
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping the new page
scrape_page(soup, quotes)
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()Как видите, вы можете создать парсер веб-страниц менее чем из 100 строк кода. Этот скрипт Python позволяет сканировать весь сайт, автоматически извлекать его данные и преобразовывать в файл CSV.
Поздравляем! Теперь вы знаете, как создать парсер Python с помощью библиотек Requests и Beautiful Soup!
Запуск скрипта веб-скрапинга Python
Если вы являетесь пользователем PyCharm, запустите скрипт, нажав кнопку ниже:

Или запустите следующую команду Python в терминале внутри каталога проекта:
python scraper.pyПодождите, пока процесс завершится, и теперь у вас будет доступ к файлу quotes.csv. Откройте его. Он должен содержать следующие данные:
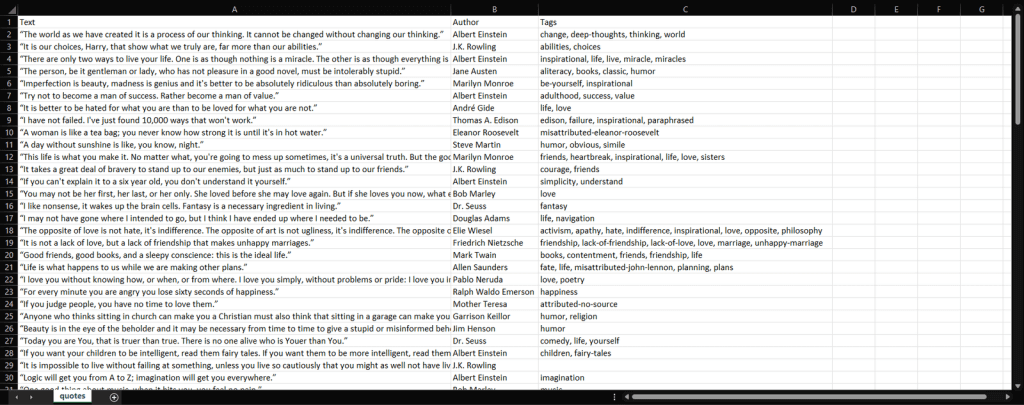
Вуаля! Теперь у вас есть все 100 цитат с целевого сайта в одном CSV-файле!
Вывод
Из этого руководства вы узнали, что такое парсинг веб-страниц, что вам нужно для начала работы с Python и какие библиотеки Python являются лучшими для парсинга. Также вы увидели, как использовать Beautiful Soup и Requests для создания парсера на реальном примере и убедились, что, парсинг на Python занимает всего несколько строк кода.
Тем не менее парсинг веб-страниц сопряжен с рядом проблем. В частности, все большую популярность приобретают анти-боты и анти-скрапинговые технологии. Поэтому вам нужен продвинутый автоматизированный инструмент для веб-скрапинга от Bright Data.
Чтобы избежать блокировки, мы также рекомендуем выбрать прокси-сервер в зависимости от вашего сценария использования из различных прокси-сервисов, которые предоставляет Bright Data.
Часто задаваемые вопросы
Веб-скрапинг и сканирование веб-страниц – это часть науки о данных?
Да, веб-скрапинг и сканирование веб-страниц – часть более широкой области науки о данных. Парсинг/сканирование – это основа для всех других продуктов, которые могут быть получены из структурированных и неструктурированных данных. Это включает аналитику, алгоритмические модели/выводы, идеи и «применимые знания».
Как можно извлечь определенные данные с сайта в Python?
Парсинг данных с сайта с помощью Python включает проверку страницы целевого URL, определение данных, которые вы хотите извлечь, написание и запуск кода для извлечения данных и, наконец, их сохранение в желаемом формате.
Как создать парсер с помощью Python?
Первым шагом к созданию парсера данных Python является использование строковых методов для анализа данных сайта, затем анализ данных помощью анализатора HTML и, наконец, взаимодействие с необходимыми формами и компонентами сайта.
 Обновлено: 25.10.2021
Обновлено: 25.10.2021
Опубликовано: 22.10.2021
В данном примере мы будем использовать питон для разработки небольшого скрипта по проверке сайта по его адресу. Вся работа будет выполнена на сервере под управлением Linux. Дополнительно, мы будем выполнять перезапуск веб-сервера nginx, если получим неправильный код ответа.
Подготовка системы
Процесс написания скрипта
Пример готового скрипта
Задание на автоматический запуск
Подготовка к работе
Мы будем работать с python3. Установим его. Наши команды будут отличаться в зависимости от дистрибутива Linux.
а) для дистрибутивов Deb (Debian, Ubuntu, Mint):
apt install python3 python3-pip
б) для дистрибутивов RPM (Rocky Linux, CentOS):
yum install python3 python3-pip
Установка выполнена.
Также нам нужен будет модуль requests, который можно установить с помощью pip:
pip3 install requests
Наш скрипт мы поместим в отдельный каталог /scripts — создадим его:
mkdir /scripts
Создаем сам скрипт:
vi /scripts/check_site.py
#!/usr/bin/env python3
# -*- encoding: utf-8 -*-
* данные строки служебные — первая указывает на путь, по которому должен запускаться интерпретатор, вторая — на кодировку.
Дадим права на запуск скрипта:
chmod +x /scripts/check_site.py
Мы готовы к созданию скрипта.
Процесс
1. Открываем скрипт и добавляем строки:
vi /scripts/check_site.py
…
import requests
response = requests.get(‘https://www.dmosk.ru’)
print(response.status_code)
* в данном примере мы выполним запрос к сайту dmosk.ru, после чего, отобразим код, который вернет сервер.
Попробуем его запустить:
/scripts/check_site.py
Если сайт работает, то мы должны увидеть код 200:
200
2. Снова открываем скрипт, комментируем или удаляем строку print, добавляем некоторые строки:
vi /scripts/check_site.py
…
import subprocess
…
#print(response.status_code)
if response.status_code != 200:
subprocess.run([«systemctl», «restart», «nginx»])
* мы подключаем subprocess для отправки системных команд на сервер, далее мы проверяем, какой код вернул сервер, и если это не 200, то выполняем перезапуск nginx.
В продуктивной среде мы должны принять решение, на какой код какую реакцию повесить на наш скрипт. Так как в некоторых случаях сайт может возвращать другой код (например, 301) и это не обязательно, что он не работает. Также, мы можем применить другие действия — отправка уведомления, перезагрузка сервера и так далее.
3. Подключаем мобильный запросы.
Мы сделали так, что наш скрипт отправлять запрос от браузера на десктопной системе. Но бывает так, что запросы от мобильного устройства обрабатываются по другому. На практике это приводит к тому, что сайт с настольного компьютера открывается, а с мобильного телефона — нет.
И так, открываем наш скрипт:
vi /scripts/check_site.py
Повыше добавим определение переменной с заголовками, а после обычного запроса отправим запрос с мобильного устройства. Также немного модифицируем if:
…
headers_mobile = { ‘User-Agent’ : ‘Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B137 Safari/601.1’}
response = requests.get(‘https://www.dmosk.ru’)
response_mobile = requests.get(‘https://www.dmosk.ru’, headers=headers_mobile)
if response.status_code != 200 or response_mobile.status_code != 200:
…
* и так, мы определили заголовок, который будет говорить, что запрос идет от мобильного клиента; второй запрос мы делаем с учетом данного заголовка; при проверке мы учитываем код ответа для стандартного запроса и запроса с мобильного устройства.
Наш скрипт готов.
Готовый скрипт полностью
В итоге, в нашем примере мы получили такой скрипт:
#!/usr/bin/env python3
# -*- encoding: utf-8 -*-
import requests
import subprocess
headers_mobile = { ‘User-Agent’ : ‘Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B137 Safari/601.1’}
response = requests.get(‘https://www.dmosk.ru’)
response_mobile = requests.get(‘https://www.dmosk.ru’, headers=headers_mobile)
if response.status_code != 200 or response_mobile.status_code != 200:
subprocess.run([«systemctl», «restart», «nginx»])
Автоматическое выполнение
Для выполнения скрипта в автоматическом режиме, добавим задание в cron:
crontab -e
* * * * * /scripts/check_site.py
* в данном примере, выполнение каждую минуту. Подробнее о cron.
Стоит иметь в виду, что, если при проверке сайта сервер будет возвращать неправильный код, наша система будет каждую минуту перезапускать сервер, который может использоваться для других сайтов. Данный пример работы очень грубый — стоит сильно модифицировать скрипт, добавив дополнительные проверки и оповещения, чтобы он не привел к деградации других сайтов и системы.
Здарова, щеглы, сегодня мы своими руками будем писать скрипт на Python. Нам понадобятся: интерпретатор Python 3 под «какая-там-у-вас-ОС», текстовый редактор с подсветкой синтаксиса, например, Sublime Text, Google, упаковка прамирацетама, бутылка минеральной воды и 60 минут свободного времени.
Перед тем как писать скрипт, мы должны определиться, что он вообще будет делать. Делать он будет следующее: получив на вход домен и диапазон IP-адресов, многопоточно проходить список этих адресов, совершать HTTP-запрос к каждому, в попытках понять, на каком же из них размещен искомый домен. Зачем это нужно? Бывают ситуации, когда IP-адрес домена закрыт Cloudflare, или Stormwall, или Incapsula, или еще чем-нибудь, WHOIS история не выдает ничего интересного, в DNS-записях такая же канитель, а, внезапно, один из поддоменов ресолвится в адрес из некоторой подсети, которая не принадлежит сервису защиты. И в этот момент нам становится интересно, вдруг и основной домен размещен в той же самой подсети.
Погнали, сразу выпиваем половину бутылки воды, и пишем следующий код:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 |
import argparse import logging import coloredlogs import ssl import concurrent.futures import urllib.request from netaddr import IPNetwork from collections import deque VERSION = 0.1 def setup_args(): parser = argparse.ArgumentParser( description = ‘Domain Seeker v’ + str(VERSION) + ‘ (c) Kaimi (kaimi.io)’, epilog = », formatter_class = argparse.ArgumentDefaultsHelpFormatter ) parser.add_argument( ‘-d’, ‘—domains’, help = ‘Domain list to discover’, type = str, required = True ) parser.add_argument( ‘-i’, ‘—ips’, help = ‘IP list (ranges) to scan for domains’, type = str, required = True ) parser.add_argument( ‘—https’, help = ‘Check HTTPS in addition to HTTP’, action = ‘store_true’ ) parser.add_argument( ‘—codes’, help = ‘HTTP-codes list that will be considered as good’, type = str, default = ‘200,301,302,401,403’ ) parser.add_argument( ‘—separator’, help = ‘IP/Domain/HTTP-codes list separator’, type = str, default = ‘,’ ) parser.add_argument( ‘—include’, help = ‘Show results containing provided string’, type = str ) parser.add_argument( ‘—exclude’, help = ‘Hide results containing provided string’, type = str ) parser.add_argument( ‘—agent’, help = ‘User-Agent value for HTTP-requests’, type = str, default = ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1’ ) parser.add_argument( ‘—http-port’, help = ‘HTTP port’, type = int, default = 80 ) parser.add_argument( ‘—https-port’, help = ‘HTTPS port’, type = int, default = 443 ) parser.add_argument( ‘—timeout’, help = ‘HTTP-request timeout’, type = int, default = 5 ) parser.add_argument( ‘—threads’, help = ‘Number of threads’, type = int, default = 2 ) args = parser.parse_args() return args if __name__ == ‘__main__’: main() |
Ни одного комментария, какие-то import, непонятные аргументы командной строки и еще эти две последние строчки… Но будьте спокойны, все нормально, это я вам как мастер программирования на Python с 30-минутным стажем говорю. Тем более, как известно, Google не врет, а официальная документация по Python — это вообще неоспоримая истина.
Так что же мы все-таки сделали в вышеописанном фрагменте кода? Мы подключили модули для работы с аргументами коммандной строки, модули для логирования (потокобезопасные между прочим!), модуль для работы с SSL (для одной мелочи, связанной с HTTPS-запросами), модуль для создания пула потоков, и, наконец, модули для совершения HTTP-запросов, работы с IP-адресами и двухсторонней очередью (по поводу различных типов импорта можно почитать здесь).
После этого мы, в соответствии с документацией по модулю argparse, создали вспомогательную функцию, которая будет обрабатывать аргументы, переданные скрипту при запуске из командной строки. Как видите, в скрипте будет предусмотрена работа со списком доменов/IP-диапазонов, а также возможность фильтрации результатов по ключевым словам и по кодам состояния HTTP и еще пара мелочей, как, например, смена User-Agent и опциональная проверка HTTPS-версии искомого ресурса. Последние две строки в основном используются для разделения кода, который будет выполнен при запуске самого скрипта и при импортировании в другой скрипт. В общем тут все сложно, все так пишут. Мы тоже так будем писать. Можно было бы немного модифицировать этот код, например, добавив возврат разных статусов системе в зависимости от того, как отработала функция main, добавить argv в качестве аргумента, и так далее, но мы изучаем Python только 10 минут и ленимся вчитываться в документацию.
Делаем перерыв и выпиваем глоток освежающей минеральной воды.
Поехали дальше.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
def main(): # Обрабатываем аргументы и инициализируем логирование # с блекджеком и цветными записями args = setup_args() coloredlogs.install() # Сообщаем бесполезную информацию, а также запускаем цикл проверки logging.info(«Starting…») try: check_loop(args) except Exception as exception: logging.error(exception) logging.info(«Finished») def check_loop(args): # Создаем пул потоков, еще немного обрабатываем переданные аргументы # и формируем очередь заданий with concurrent.futures.ThreadPoolExecutor(max_workers = args.threads) as pool: domains = args.domains.split(args.separator) ips = args.ips.split(args.separator) codes = args.codes.split(args.separator) tasks = deque([]) for entry in ips: ip_list = IPNetwork(entry) for ip in ip_list: for domain in domains: tasks.append( pool.submit( check_ip, domain, ip, args, codes ) ) # Обрабатываем результаты и выводим найденные пары домен-IP for task in concurrent.futures.as_completed(tasks): try: result = task.result() except Exception as exception: logging.error(exception) else: if result != None: data = str(result[0]) if( ( args.exclude == None and args.include == None ) or ( args.exclude and args.exclude not in data ) or ( args.include and args.include in data ) ): logging.critical(«[+] « + args.separator.join(result[1:])) |
В коде появился минимум комментариев. Это прогресс. Надо войти в кураж (не зря мы заготовили прамирацетам) и дописать одну единственную функцию, которая будет осуществлять, непосредственно, проверку. Ее имя уже упомянуто в коде выше: check_ip.
30 минут спустя
Хорошо-то как. Не зря я говорил, что понадобится час времени. Продолжим.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
def check_ip(domain, ip, args, codes): # Преобразуем IP из числа в строку # Магическая code-flow переменная для совершения двух проверок # И бесполезное логирование ip = str(ip) check_https = False logging.info(«Checking « + args.separator.join([ip, domain])) while True: # Задаем порт и схему для запроса в зависимости от магической переменной schema = ‘https://’ if check_https else ‘http://’; port = str(args.https_port) if check_https else str(args.http_port) request = urllib.request.Request( schema + ip + ‘:’ + port + ‘/’, data = None, headers = { ‘User-Agent’: args.agent, ‘Host’: domain } ) # Совершаем запрос, и если получаем удовлетворительный код состояни HTTP, # то возвращаем содержимое ответа сервера, а также домен и IP try: response = urllib.request.urlopen( request, data = None, timeout = args.timeout, context = ssl._create_unverified_context() ) data = response.read() return [data, ip, domain] except urllib.error.HTTPError as exception: if str(exception.code) in codes: data = exception.fp.read() return [data, ip, domain] except Exception: pass if args.https and not check_https: check_https = True continue return None |
В общем-то весь наш скрипт готов. Приступаем к тестированию.
Неожиданно узнаем, что у блога есть альтернативный IP-адрес. И действительно:
|
curl —i ‘http://188.226.181.47/’ —header ‘Host: kaimi.io’ |
|
HTTP/1.1 301 Moved Permanently Server: nginx/1.4.6 (Ubuntu) Date: Sun, 02 Oct 2016 13:52:43 GMT Content—Type: text/html Content—Length: 193 Connection: keep—alive Location: https://kaimi.io/ <html> <head><title>301 Moved Permanently</title></head> <body bgcolor=«white»> <center><h1>301 Moved Permanently</h1></center> <hr><center>nginx/1.4.6 (Ubuntu)</center> </body> </html> |
Однако:
|
curl —i ‘https://188.226.181.47/’ —header ‘Host: kaimi.io’ |
|
curl: (51) SSL: certificate subject name (*.polygraph.io) does not match target host name ‘188.226.181.47’ |
Какой-то левый хост обрабатывает запросы. Почему? Потому что это прокси, который реагирует на содержимое заголовка Host. В общем скрипт готов, по крайней мере альфа-версия скрипта. Если вам понравилось — подписывайтесь, ставьте лайки, шлите pull-реквесты на github.