Кратчайшее введение в создание компилятора
Давайте сделаем компилятор арифметических выражений. Такой, который переведет исходный текст в обратной польской форме записи (ее еще называют RPN или ПОЛИЗ) в промежуточный код стековой машины. Но у нас не будет интерпретатора стекового кода, как вы, возможно, могли подумать. Далее мы сразу переведем результат в представление на языке Си. То есть у нас получится компилятор RPN в Си.
Кстати говоря, писать компилятор мы будем на Python. Но пусть это не останавливает тех, кто предпочитает какой-то иной язык программирования. Вот вам полезное упражнение: переведите приведенный код на ваш любимый язык. Или воспользуйтесь уже готовым переводом:
Реализация на F# (автор gsomix):
первая версия,
SSA-версия
Начнем с синтаксического анализа
def scan(source): tokens = source.split() return [(('Push', int(x)) if x[0].isdigit() else ('Op', x)) for x in tokens]
Что мы здесь сделали? Функция scan получает от пользователя строку в обратной польской форме записи («2 2 +»).
А на выходе мы получаем промежуточное представление. Вот такое, например:
[('Push', 2), ('Push', 2), ('Op', '+')]
Итак, мы уже получили компилятор. Но уж очень он несерьезный. Вспомним, что изначально речь шла о коде на Си.
Займемся трансляцией в Си
def trans(ir): code = [] for (tag, val) in ir: if tag == 'Push': code.append('st[sp] = %d;' % val) code.append('sp += 1;') elif tag == 'Op': code.append('st[sp - 2] = st[sp - 2] %s st[sp - 1];' % val) code.append('sp -= 1;') return 'n'.join(code)
Что здесь происходит? Давайте посмотрим на вывод данной функции (на том же примере с «2 2 +»).
st[sp] = 2; sp += 1; st[sp] = 2; sp += 1; st[sp - 2] = st[sp - 2] + st[sp - 1]; sp -= 1;
Да, это уже похоже на код на Си. Массив st играет роль стека, а sp — его указатель. Обычно с этими вещами работают виртуальные стековые машины.
Вот только самой машины — интерпретатора у нас-то и нет. Есть компилятор. Что нам осталось? Надо добавить необходимое обрамление для программы на Си.
Наш первый компилятор в готовом виде
ST_SIZE = 100 C_CODE = r"""#include <stdio.h> int main(int argc, char** argv) { int st[%d], sp = 0; %s printf("%%dn", st[sp - 1]); return 0; }""" def scan(source): tokens = source.split() return [(('Push', int(x)) if x[0].isdigit() else ('Op', x)) for x in tokens] def trans(ir): code = [] for (tag, val) in ir: if tag == 'Push': code.append('st[sp] = %d;' % val) code.append('sp += 1;') elif tag == 'Op': code.append('st[sp - 2] = st[sp - 2] %s st[sp - 1];' % val) code.append('sp -= 1;') return 'n'.join(code) def rpn_to_c(source): return C_CODE % (ST_SIZE, trans(scan(source))) print rpn_to_c('2 2 +')
Остается скомпилировать вывод данной программы компилятором Си.
Вы все еще готовы продолжать? Тогда давайте обсудим, что у нас получилось. Есть один сомнительный момент — наш компилятор транслирует константные выражения, а ведь их можно вычислить просто на этапе компиляции. Нет смысла переводить их в код. Но давайте пока считать, что какие-то аргументы могут попасть в стек извне. Например, из аргументов командной строки. Остановимся на том, что практический смысл нашей разработке можно придать и позднее. Сейчас же важно получить общее представление о построении простейших компиляторов, верно?
Компилятор с использованием формы SSA
Вам нравится заголовок? SSA — это звучит очень солидно для любого компиляторщика. А мы уже сейчас будем использовать эту самую SSA. Что это такое? Давайте двигаться по порядку.
Мы генерируем в данный момент код на Си, безо всяких виртуальных машин. Но зачем нам тогда рудимент в виде операций со стеком? Давайте заменим эти операции работой с обычными переменными из Си. Причем, мы не будем экономить переменные — для каждого выражения заведем новое имя. Пусть компилятор Си сам со всем этим разбирается. Получается, что у нас каждой переменной значение присваивается лишь однажды. А это, кстати говоря, и есть форма SSA.
Вот наш новый компилятор.
C_CODE = r"""#include <stdio.h> int main(int argc, char** argv) { %s printf("%%dn", %s); return 0; }""" def scan(source): tokens = source.split() return [(('Push', int(x)) if x[0].isdigit() else ('Op', x)) for x in tokens] def trans(ir): (stack, code) = ([], []) name_cnt = 0 for (tag, val) in ir: if tag == 'Push': code.append('int t%d = %d;' % (name_cnt, val)) stack.append('t%d' % name_cnt) name_cnt += 1 elif tag == 'Op': (a, b) = (stack.pop(), stack.pop()) code.append('int t%d = %s %s %s;' % (name_cnt, b, val, a)) stack.append('t%d' % name_cnt) name_cnt += 1 return ('n'.join(code), stack.pop()) def rpn_to_c(source): return C_CODE % trans(scan(source)) print rpn_to_c('2 2 +')
Обратите внимание — стека в коде на Си уже нет, а работа с ним имитируется в процессе трансляции. На стеке, который используется в процессе компиляции, содержатся не значения, а имена переменных.
Вот окончательный результат:
#include <stdio.h> int main(int argc, char** argv) { int t0 = 2; int t1 = 2; int t2 = t0 + t1; printf("%dn", t2); return 0; }
Похоже, пришла пора расширять возможности нашего входного языка, как вы считаете? И двигаться, на мой взгляд, здесь можно в направлении стековых языков, таких как Forth, Postscript, Joy или Factor. Конечно же, можно и пойти путем усложнения входного синтаксиса. Но все эти вопросы давайте оставим для следующих заметок. Успехов в построении компиляторов!
Intro
A typical compiler does the following steps:
- Parsing: the source text is converted to an abstract syntax tree (AST).
- Resolution of references to other modules (C postpones this step till linking).
- Semantic validation: weeding out syntactically correct statements that make no sense, e.g. unreachable code or duplicate declarations.
- Equivalent transformations and high-level optimization: the AST is transformed to represent a more efficient computation with the same semantics. This includes e.g. early calculation of common subexpressions and constant expressions, eliminating excessive local assignments (see also SSA), etc.
- Code generation: the AST is transformed into linear low-level code, with jumps, register allocation and the like. Some function calls can be inlined at this stage, some loops unrolled, etc.
- Peephole optimization: the low-level code is scanned for simple local inefficiencies which are eliminated.
Most modern compilers (for instance, gcc and clang) repeat the last two steps once more. They use an intermediate low-level but platform-independent language for initial code generation. Then that language is converted into platform-specific code (x86, ARM, etc) doing roughly the same thing in a platform-optimized way. This includes e.g. the use of vector instructions when possible, instruction reordering to increase branch prediction efficiency, and so on.
After that, object code is ready for linking. Most native-code compilers know how to call a linker to produce an executable, but it’s not a compilation step per se. In languages like Java and C# linking may be totally dynamic, done by the VM at load time.
Remember the basics
- Make it work
- Make it beautiful
- Make it efficient
This classic sequence applies to all software development, but bears repetition.
Concentrate on the first step of the sequence. Create the simplest thing that could possibly work.
Read the books!
Read the Dragon Book by Aho and Ullman. This is classic and is still quite applicable today.
Modern Compiler Design is also praised.
If this stuff is too hard for you right now, read some intros on parsing first; usually parsing libraries include intros and examples.
Make sure you’re comfortable working with graphs, especially trees. These things is the stuff programs are made of on the logical level.
Define your language well
Use whatever notation you want, but make sure you have a complete and consistent description of your language. This includes both syntax and semantics.
It’s high time to write snippets of code in your new language as test cases for the future compiler.
Use your favorite language
It’s totally OK to write a compiler in Python or Ruby or whatever language is easy for you. Use simple algorithms you understand well. The first version does not have to be fast, or efficient, or feature-complete. It only needs to be correct enough and easy to modify.
It’s also OK to write different stages of a compiler in different languages, if needed.
Prepare to write a lot of tests
Your entire language should be covered by test cases; effectively it will be defined by them. Get well-acquainted with your preferred testing framework. Write tests from day one. Concentrate on ‘positive’ tests that accept correct code, as opposed to detection of incorrect code.
Run all the tests regularly. Fix broken tests before proceeding. It would be a shame to end up with an ill-defined language that cannot accept valid code.
Create a good parser
Parser generators are many. Pick whatever you want. You may also write your own parser from scratch, but it only worth it if syntax of your language is dead simple.
The parser should detect and report syntax errors. Write a lot of test cases, both positive and negative; reuse the code you wrote while defining the language.
Output of your parser is an abstract syntax tree.
If your language has modules, the output of the parser may be the simplest representation of ‘object code’ you generate. There are plenty of simple ways to dump a tree to a file and to quickly load it back.
Create a semantic validator
Most probably your language allows for syntactically correct constructions that may make no sense in certain contexts. An example is a duplicate declaration of the same variable or passing a parameter of a wrong type. The validator will detect such errors looking at the tree.
The validator will also resolve references to other modules written in your language, load these other modules and use in the validation process. For instance, this step will make sure that the number of parameters passed to a function from another module is correct.
Again, write and run a lot of test cases. Trivial cases are as indispensable at troubleshooting as smart and complex.
Generate code
Use the simplest techniques you know. Often it’s OK to directly translate a language construct (like an if statement) to a lightly-parametrized code template, not unlike an HTML template.
Again, ignore efficiency and concentrate on correctness.
Target a platform-independent low-level VM
I suppose that you ignore low-level stuff unless you’re keenly interested in hardware-specific details. These details are gory and complex.
Your options:
- LLVM: allows for efficient machine code generation, usually for x86 and ARM.
- CLR: targets .NET, multiplatform; has a good JIT.
- JVM: targets Java world, quite multiplatform, has a good JIT.
Ignore optimization
Optimization is hard. Almost always optimization is premature.
Generate inefficient but correct code. Implement the whole language before you try to optimize the resulting code.
Of course, trivial optimizations are OK to introduce. But avoid any cunning, hairy stuff before your compiler is stable.
So what?
If all this stuff is not too intimidating for you, please proceed! For a simple language, each of the steps may be simpler than you might think.
Seeing a ‘Hello world’ from a program that your compiler created might be worth the effort.
Intro
A typical compiler does the following steps:
- Parsing: the source text is converted to an abstract syntax tree (AST).
- Resolution of references to other modules (C postpones this step till linking).
- Semantic validation: weeding out syntactically correct statements that make no sense, e.g. unreachable code or duplicate declarations.
- Equivalent transformations and high-level optimization: the AST is transformed to represent a more efficient computation with the same semantics. This includes e.g. early calculation of common subexpressions and constant expressions, eliminating excessive local assignments (see also SSA), etc.
- Code generation: the AST is transformed into linear low-level code, with jumps, register allocation and the like. Some function calls can be inlined at this stage, some loops unrolled, etc.
- Peephole optimization: the low-level code is scanned for simple local inefficiencies which are eliminated.
Most modern compilers (for instance, gcc and clang) repeat the last two steps once more. They use an intermediate low-level but platform-independent language for initial code generation. Then that language is converted into platform-specific code (x86, ARM, etc) doing roughly the same thing in a platform-optimized way. This includes e.g. the use of vector instructions when possible, instruction reordering to increase branch prediction efficiency, and so on.
After that, object code is ready for linking. Most native-code compilers know how to call a linker to produce an executable, but it’s not a compilation step per se. In languages like Java and C# linking may be totally dynamic, done by the VM at load time.
Remember the basics
- Make it work
- Make it beautiful
- Make it efficient
This classic sequence applies to all software development, but bears repetition.
Concentrate on the first step of the sequence. Create the simplest thing that could possibly work.
Read the books!
Read the Dragon Book by Aho and Ullman. This is classic and is still quite applicable today.
Modern Compiler Design is also praised.
If this stuff is too hard for you right now, read some intros on parsing first; usually parsing libraries include intros and examples.
Make sure you’re comfortable working with graphs, especially trees. These things is the stuff programs are made of on the logical level.
Define your language well
Use whatever notation you want, but make sure you have a complete and consistent description of your language. This includes both syntax and semantics.
It’s high time to write snippets of code in your new language as test cases for the future compiler.
Use your favorite language
It’s totally OK to write a compiler in Python or Ruby or whatever language is easy for you. Use simple algorithms you understand well. The first version does not have to be fast, or efficient, or feature-complete. It only needs to be correct enough and easy to modify.
It’s also OK to write different stages of a compiler in different languages, if needed.
Prepare to write a lot of tests
Your entire language should be covered by test cases; effectively it will be defined by them. Get well-acquainted with your preferred testing framework. Write tests from day one. Concentrate on ‘positive’ tests that accept correct code, as opposed to detection of incorrect code.
Run all the tests regularly. Fix broken tests before proceeding. It would be a shame to end up with an ill-defined language that cannot accept valid code.
Create a good parser
Parser generators are many. Pick whatever you want. You may also write your own parser from scratch, but it only worth it if syntax of your language is dead simple.
The parser should detect and report syntax errors. Write a lot of test cases, both positive and negative; reuse the code you wrote while defining the language.
Output of your parser is an abstract syntax tree.
If your language has modules, the output of the parser may be the simplest representation of ‘object code’ you generate. There are plenty of simple ways to dump a tree to a file and to quickly load it back.
Create a semantic validator
Most probably your language allows for syntactically correct constructions that may make no sense in certain contexts. An example is a duplicate declaration of the same variable or passing a parameter of a wrong type. The validator will detect such errors looking at the tree.
The validator will also resolve references to other modules written in your language, load these other modules and use in the validation process. For instance, this step will make sure that the number of parameters passed to a function from another module is correct.
Again, write and run a lot of test cases. Trivial cases are as indispensable at troubleshooting as smart and complex.
Generate code
Use the simplest techniques you know. Often it’s OK to directly translate a language construct (like an if statement) to a lightly-parametrized code template, not unlike an HTML template.
Again, ignore efficiency and concentrate on correctness.
Target a platform-independent low-level VM
I suppose that you ignore low-level stuff unless you’re keenly interested in hardware-specific details. These details are gory and complex.
Your options:
- LLVM: allows for efficient machine code generation, usually for x86 and ARM.
- CLR: targets .NET, multiplatform; has a good JIT.
- JVM: targets Java world, quite multiplatform, has a good JIT.
Ignore optimization
Optimization is hard. Almost always optimization is premature.
Generate inefficient but correct code. Implement the whole language before you try to optimize the resulting code.
Of course, trivial optimizations are OK to introduce. But avoid any cunning, hairy stuff before your compiler is stable.
So what?
If all this stuff is not too intimidating for you, please proceed! For a simple language, each of the steps may be simpler than you might think.
Seeing a ‘Hello world’ from a program that your compiler created might be worth the effort.
Как я написал компилятор C за 40 дней +64
C, Компиляторы
Рекомендация: подборка платных и бесплатных курсов C# — https://katalog-kursov.ru/
Предлагаю вам перевод дневника Руи Уэяма (Rui Ueyama), программиста из Google, который он вел во время работы над реализацией компилятора языка C около трех с половиной лет назад (но опубликовал только в минувшем декабре).
Этот дневник не несет какой-то практической пользы и не является туториалом, но мне было очень интересно его прочитать, надеюсь и вам эта история тоже понравится 
Я написал C компилятор за 40 дней, который назвал 8cc. Это дневник написанный мной в то время. Код и его историю можно посмотреть на GitHub.
День 8
Я пишу компилятор. Он начал работать после написания примерно 1000 строк кода. Вот несколько примеров, которые уже работают:
int a = 1;
a + 2; // => 3
int a = 61;
int *b = &a;
*b; // => 61
Массивы корректно преобразовываются в указатели, так что код ниже тоже работает. Также поддерживается вызов функций.
char *c = "ab" + 1;
printf("%c", *c); // => b
Реализовать это было не сложно, т.к. я делаю это уже второй раз. Я научился лучше управляться с массивами и указателями.
День 15
Я далеко продвинулся в реализации компилятора и он работает на удивление хорошо. Нетривиальные программы, например эта — решающая задачу о восьми ферзях, компилируются и запускаются.
Конечно ему не хватает многих функций. Эти примеры программ подобраны так, чтобы не использовать их.
Реализация довольно проста; нет даже распределения регистров (register allocation).
Он компилирует исходные программы в код стековой машины, которая использует системный стек в качестве стека. Каждая операция требует обращения к памяти. Но пока меня это устраивает.
В начале компилятор умещался примерно в 20 строк и единственное на что он был способен это прочитать целое значение со стандартного входа и запустить программу которая тут же завершается возвращая это целое.
Теперь он содержит около 2000 строк. Если посмотреть git, то кажется он развивался таким образом:
- добавлены «+» и «-«
- разделены фазы синтаксического анализа и генерации кода
- добавлены «*» и «/»
- добавлены переменные (неявно подразумевающие тип int)
- добавлен вызов функций
- добавлены строки
- разделены генератор меток (tokenizer) и анализ синтаксиса
- поддержка объявления базовых типов
- добавлены указатели и массивы
- поддержка выражений инициализации массивов
- добавлен «if»
- поддерживается объявление функций
- добавлены «for» и «return»
- поддерживается присвоение указателей
- добавлено «==»
- добавлены индексация массивов и арифметика указателей
- добавлены «++», «—» и «!»
День 17
Я успешно реализовал структуры. Структура — это такой объект, который может занимать больше одного машинного слова. Их сложнее реализовать, чем примитивные типы, но это было легче чем я ожидал.
Кажется, это работает как надо; я могу определить структуру, содержащую структуру. Я могу определить указатель на структуру и разыменовать его. Структуры, содержащие массивы и массивы структур также работают. Хотя я уже знал, что код теоретически должен работать, я все равно обрадовался, когда он действительно заработал, даже в таком сложном случае.
Однако, я не чувствую, что я полностью понимаю, почему этот код работает правильно. Он ощущается немного магическим из-за его рекурсивной природы.
Я не могу передавать структуры в функции. В соглашении о вызовах для x86 структура копируется на стек и указатель на нее передается функции. Но в x86-64 вы должны разделить структуру на несколько частей данных и передать их через регистры. Это сложно, так что это я пока отложу. Передача структур по значению нужна реже, чем передача указателей на них.
День 18
Реализовать объединения было легче, т.к. это просто вариант структуры, в котором все поля имеют одинаковое смещение. Также реализован оператор «->». Проще простого.
Организовать поддержку чисел с плавающей точкой было тяжело. Похоже неявное преобразование типов между int и float работает, но числа с плавающей точкой не могут быть переданы в функции. В моем компиляторе все параметры функций сначала помещаются на стек, а затем записываются в регистры в порядке определенном в соглашении о вызовах x86-64. Но в этом процессе видимо есть баг. Он возвращает ошибку доступа к памяти (SIGSEGV). Его сложно отлаживать, рассматривая ассемблерный вывод, потому что мой компилятор не оптимизирует ассемблер для чтения. Я думал, что смогу закончить с этим за день, но я ошибался.
День 19
Я потратил время впустую, потому что забыл что в соответствии с соглашением о вызовах x86-64 кадр стека должен быть выровнен на 16 байт. Я обнаружил, что printf() падает с SEGV, если передать ей несколько чисел с плавающей точкой. Я попытался найти условия при которых это можно воспроизвести. Оказалось что имеет значение положение стекового кадра, что заставило меня вспомнить про требования ABI x86-64.
Я совсем не позаботился об этом, так что кадр стека был выровнен только по 8 байт, но print() не жаловалась пока принимала только целые числа. Эта проблема может быть легко исправлена корректировкой стекового кадра до вызова инструкции CALL. Но таких проблем не избежать если, тщательно не читать спецификацию перед написанием кода.
День 20
Я поменял отступы в коде компилятора с 2 на 4. Я больше привык к использованию 2-ух пробельных отступов, потому что такие используются на моей работе в Google. Но по некоторым причинам мне кажется отступы в 4 пробела больше подходят для «красивой программы с открытым исходным кодом».
Есть еще одно, более значимое, изменение. Я переписал тесты из shell скриптов на C. До этого изменения каждая тестовая функция компилируемая моим компилятором, связываллась с main() которая компилировалась GCC и затем запускалась shell скриптом. Это было медленно, т.к. порождало много процессов для каждого теста. У меня не было выбора когда я начинал проект, т.к. у моего компилятора не было многих функций. Например, он не мог сравнить результат с ожидаемым значением из-за отсутствия операторов сравнения. Теперь он достаточно мощный, чтобы компилировать код тестов. Так что я переписал их, чтобы сделать их быстрее.
Еще я реализовал большие типы, такие как long и double. Написание кода было веселым потому что я очень быстро преуспел в реализации этих функций.
День 21
Я почти закончил реализацию препроцессора C за один день. На самом деле это порт из моей предыдущей попытки написать компилятор.
Реализация препроцессора C не простая задача.
Это часть стандарта C, так это определено в спецификации. Но спецификация говорит слишком мало, чтобы это могло быть полезным для самостоятельной реализации. Спецификация включает несколько макросов с их развернутая формой, но она очень мало говорит о самом алгоритме. Я думаю она даже не объясняет детали его ожидаемого поведения. В общем, он недоспецифицирован.
Насколько я знаю, PDF в этом блоге единственный и лучший ресурс о том как реализовать препроцессор языка C. Алгоритм описанный в документе (алгоритм Дейва Проссера) пытается развернуть столько токенов сколько возможно, избегая бесконечного разворачивания макроса. Каждый токен имеет свою историю разворачивания, так что токены не разворачиваются одним и тем же макросом более одного раза.
Препроцессор C сам по себе является независимым языком. У него много особенностей, и только матерые программисты C хорошо его понимают.
День 22
Пытался заставить компилятор читать системные заголовки, так что теперь он понимает #include. Пока я пытался, я получал много ошибок. Это выявило, что моему препроцессру до сих пор не хватает многих функций, например операторы которые можно использовать только в #if. Существует и много багов кроме этого. Я исправлял их, как только находил.
Системные заголовочные файлы большие и запутанные. Они требуют много функций от компилятора, таких как enum и typedef. Я реализовал их одну за другой, но иногда я срезал углы. Я пытаюсь прочитать stdio.h. Понятия не имею как много времени это может занять.
Компилятор сейчас состоит из 4000 строк. Небольшой компилятор LCC содержит 12000 строк. Используя его как гайд, я думаю, мой компилятор скоро сможет работать как настоящий компилятор C.
Я удивлен, что написал 500 строк кода сегодня. Я могу работать в потоке на протяжении 12 часов, но это может быть неэффективно, т.к. я устаю не замечая этого. В любом случае я должен признать, что я человек с большим количеством свободного времени.
День 24
Я не помню что я исправил, но теперь stdio.h может подключаться. Это очень круто, потому что типы функций определенных в заголовочном файле теперь корректно обрабатываются.
Схема, которую я использую для реализации своего компилятора, подразумевает создание компилятора для небольшого подмножества языка и затем развитие его в настоящий язык C. До недавнего момента, я не сильно пытался реализовывать функции, которые не до конца понимаю. Я мог писать столько кода сколько хочу и оставлять остальное. Это было весело.
Внешние штуки, такие как система заголовков, стали причиной многих проблем. Теперь я должен реализовать все функции которые ожидаются от «настоящего» компилятора C. Я сделал много грязных хаков, чтобы прочитать stdio.h. Например, я реализовал хак для игнорирования всех вхождений токена «const». Это расстраивает меня.
Вы можете спросить, почему бы не сделать это правильным способом с самого начала. Я бы сказал, что это не весело. Слишком. Например синтаксис объявления типов в C слишком запутанный без какой либо вменяемой причины и реализовывать его совсем не интересно.
Не смотря на это есть некоторые вещи которых я не могу избежать. Вероятно, мне следует изменить мой взгляд, чтобы реализовать все функции, от начала и до конца. Я могу найти это интересным по мере приближения к цели. Иногда, мне приходится писать больше кода, чем я хочу для того, чтобы достичь цели.
День 25
Я застрял на два дня с реализацией синтаксиса определений и объявлений без какого-либо успеха. Почему я не могу закончить это? Я сделал указатели и структуры за один день работы. Я чувствую что недооценил это. Может быть мне нужен план?
День 26
В сложной ситуации как эта, я, вероятно, должен вспомнить тот факт что компилятор был всего в одном файле, чтобы увидеть как я продвинулся за месяц. Он просто считывал целое через scanf() и печатал его через printf(). Действительно, я очень серьезно продвинулся за один месяц. Да, я думаю могу сделать это.
День 28
Закончил писать парсер для объявлений и определений. Думаю причина по которой я терпел неудачи была в том, что я пытался написать слишком много деталей с самого начала, так что я написал псевдокод чтобы убедиться что правильно все понимаю и затем конвертировал его в реальный код.
Я пишу на C уже почти 15 лет, но только сегодня я почувствовал, что, наконец, понимаю синтаксис типов в С. Не удивительно, что я не мог писать работающий код. Это потому, что я просто не понимал его правильно.
Код, который я только что написал слишком сложен и хрупок, что даже я с трудом его понимаю. Я не верю, что Деннис Ритчи, создатель языка C, понимал последствия того, что он делал. Я подозреваю, что он придумав синтаксис, написал код, который оказался сложнее, чем он ожидал, и, в итоге, был стандартизирован комитетом ANSI. Трудно реализовать стандартизированный язык, потому что вы должны сделать все правильно. Скорее легче написать свой собственный игрушечный язык.
День 29
Реализовал еще много операторов и почистил код.
Сегодня моему компилятору впервые удалось скомпилировать один из своих файлов. Когда я связал его с другими файлами, скомпилированными с помощью GCC, он оказался рабочим. И получившийся компилятор тоже кажется работает. Похоже цель становится ближе.
День 30
Я реализовал switch-case, continue, break и goto сегодня. Когда я писал тест кейсы для goto, код тестов быстро превратился спагетти код, который я не мог прочитать. Это меня рассмешило. Я убедился, почему goto считается вредным.
День 31
Реализовал функции для varargs, а именно va_start, va_arg и va_end. Они используются не часто, но я нуждался в них для компиляции функций, например printf.
Спецификация vararg для C не очень хорошо продумана. Если вы передаете все аргументы функции через стек, va_start может быть реализован довольно легко, но на современных процессорах и в современных соглашениях о вызовах аргументы передаются через регистры, чтобы уменьшить накладные расходы на вызов функций. Поэтому спецификация не соответствует реальности.
Грубо говоря, ABI для x86-64, стандартизированное AMD, требует чтобы функции с переменным числом аргументов копировали все регистры в стек, чтобы подготовиться к последующему вызову va_start. Я понимаю, что у них не было другого выбора, но это все равно выглядит неуклюже.
Мне стало интересно как другие компиляторы обрабатывают функции с переменным числом аргументов. Я посмотрел на заголовки TCC и, похоже, они не совместимы с ABI x86-64. Если структура данных для varargs отличается, то функции передающие va_list (такие как vprintf) становятся несовместимыми. Или я ошибаюсь? [И я действительно ошибаюсь — они совместимы.] Я также посмотрел на Clang, но он выглядит запутанным. Я не стал читать его. Если я буду читать слишком много кода других компиляторов, это может испортить веселье от собственной реализации.
День 32
После исправления незначительных проблем и добавления управляющих последовательностей для строковых литералов (до сих пор не было » и подобных вещей), получилось скомпилировать еще один файл. Я чувствую уверенный прогресс.
Я пытался реализовать поддержку функций, имеющих более шести параметров, но не смог закончить это за один день. В x86-64 первые 6 целочисленных параметров передаются через регистры, а оставшиеся через стек. Сейчас поддерживается передача только через регистры. Передачу через стек не сложно реализовать, но она требует слишком много времени для отладки. Я думаю в моем компиляторе нет функций, имеющих более шести параметров, так что я пока отложу их реализацию.
День 33
Еще три файла скомпилированы сегодня. Итого 6 из 11. Но если считать строки кода, то это около 10% от общего числа. Оставшиеся файлы намного больше, так как содержат код ядра компилятора.
Еще хуже то, что в файлах ядра я использую относительно новые особенности C, такие как составные литералы и назначенные инициализаторы. Они сильно усложняют самокомпиляцию. Я не должен был использовать их, но переписывать код на простом старом C будет не продуктивно, поэтому я хочу поддерживать их в своем компиляторе. Хотя на это потребуется время.
День 34
Несколько замечаний о средствах отладки. Так как компилятор — это сложный кусок кода, который состоит из многих этапов, необходим способ как-то исследовать его для отладки. Мой компилятор не исключение; я реализовал несколько функций, которые посчитал полезными.
Во-первых, лексический анализатор запоминает свою позицию чтения и когда он прерывается по непредвиденным причинам, он возвращает эту позицию. Это позволяет легко найти баг, когда компилятор не принимает корректные входные данные.
Есть опция командной строки для печати внутреннего абстрактного синтаксического дерева. Если есть ошибка в синтаксическом анализаторе, я хочу посмотреть на синтаксическое дерево.
Генератор кода позволяет широко использовать рекурсию, потому что он генерирует фрагменты ассемблерного кода, когда обходит абстрактное синтаксическое дерево. Так я смог реализовать печать мини трассировки стека для каждой строки ассемблерного вывода. Я если я замечаю что-то неправильное, я могу проследить за генератором кода, посмотрев на его вывод.
Большинство внутренних структур данных имеют функции для преобразования в строку. Это полезно при использовании printf для отладки.
Я всегда пишу юнит-тесты, когда пишу новую функцию. Даже реализовав ее, я стараюсь сохранять код компилирующимся, чтобы запускать тесты. Тесты пишутся так, чтобы выполняться за короткий промежуток времени, так что вы можете запускать их так часто, как вам хочется.
День 36
Реализовал составные литералы и переписал инициализатор структур и массивов. Мне не нравилась предыдущая реализация. Теперь инициализатор стал лучше. Я должен был написать красивый код с самого начала, но поскольку я понял это, только написав рабочий код, переписывание было неизбежным.
Думаю, единственная особенность, которой не хватает для самокомпиляции, это присваивание структур. Надеюсь все будет работать как задумано без особой отладки, когда она будет реализована.
День 37
Файл, содержащий токенайзер скомпилирован, но получившийся компилятор второго поколения по некоторым причинам не генерирует корректный ассемблерный код. Хотя код, генерируемый компилятором первого поколения проходит все тесты. Такой вот коварный баг.
Думаю, что у меня нет другого выбора, кроме использования printf для отладки, потому что второе поколение компилируется через мой компилятор, который не поддерживает отладочную информацию. Я добавил printf в подозрительных местах. Отладочные сообщения printf отображались при компиляции второго поколения, что меня несколько удивило. Я хотел чтобы отладочные сообщения выводились только когда я использую второе поколение, так что я не ожидал что вывод будет работать, когда второе поколение только создается.
Мне это напоминает фильм «Начало». Мы должны идти глубже, чтобы воспроизвести этот баг. Это забавная часть отладки самокомпилирующегося компилятора.
День 38
Я исправил проблему, возникавшую во втором поколении, если лексический анализатор был самоскомпилирован. Она вызывала баг при котором -1 > 0 иногда возвращало true (я забыл про знаковое расширение). Есть еще один баг в размещении структур (struct layout). Осталось только три файла.
День 39
Генератор кода теперь тоже может скомпилировать себя. Осталось два файла. Работа почти закончена, хотя мне, возможно, не стоит быть чересчур оптимистичным. Могут оставаться еще неожиданные подводные камни.
Я исправил много проблем, вызванных плохим качеством кода, который я писал на ранней стадии этого проекта. Это утомило меня.
Я верил, что имел все возможности для самокомпиляции, но это не правда. Нет даже префиксных операторов инкремента/декремента. Для некоторых особенностей C99 я переписал часть компилятора, чтобы сделать его более удобным для компиляции. Так как я не ожидал добраться до возможности самокомпиляции так быстро, я использовал столько новых особенностей C, сколько хотел.
День 40
Ура! Мой компилятор теперь может полностью себя скомпилировать!
Это заняло около 40 дней. Это очень короткий промежуток времени, для написания самокомпилируемого компилятора C. Вы так не думаете? Я считаю, что мой подход — вначале сделать небольшой компилятор для очень ограниченного подмножества C, и затем преобразовать его в настоящий компилятор C очень хорошо сработал. В любом случае сегодня я очень счастлив.
Смотря на свой код, даже зная что я сам написал его, я ощущаю его немного волшебным, потому что он может принять сам себя на входе и преобразовать в ассемблер.
Осталось много багов и нереализованных особенностей. Я, наверное, закончу с ними, а потом начну работу по улучшению выходного кода.
Исходный код находится здесь. Я не знаю, стоит ли это читать, но может быть интересно посмотреть его как образец кода на языке C, который может обработать простой компилятор в 5000 строк.
День 41
Вернулся к систематической разработке, так как была достигнута большая веха. Я изменил код, пытаясь читать его, как если бы я был третьим лицом, и, в итоге, удовлетворился качеством кода. Это напоминает подрезку дерева бонсай.
Я добавил тест для повторного запуска самокомпиляции, чтобы убедиться, что результаты оказываются одинаковыми для второго и третьего поколения файлов. Если я правильно помню, у GCC есть подобный тест.
День 42
Есть часть информации, которую можно передать следующему поколению только через исполняемые файлы в двоичном формате, несмотря на то что она не записывается в исходный код компилятора.
Например, мой компилятор интерпретирует «n» (последовательность обратного слеша и символа «n») в строковый литерал «n» (в данном случае символ новой строки). Если вы подумаете об этом, вы можете счесть это немного странным, потому что он не располагает информацией о реальном ASCII коде для «n». Информация о коде символа не присутствует в исходном коде, но передается из компилятора, компилирующего компилятор. Символы новой строки моего компилятора могут быть прослежены до GCC.
Компиляторы могут передать гораздо больше информации, чем код символа.
Эта удивительная история была представлена Кеном Томпсоном в его лекции при получении премии Тьюринга. Информация, которую Кен добавил в раннюю версию Unix компилятора давала возможность программе для входа пользователей принимать некоторые особенные пароли, так что Кен мог войти в любую учетную запись Unix. Он также сделал так чтобы компилятор распознавал собственную компиляцию и передавал хак программы для входа дочернему компилятору, так что этот бэкдор (которого не было в исходном коде) передавался из поколения в поколение. Вы не могли удалить его, даже если бы тщательно осмотрели каждую строчку исходного кода компилятора и перекомпилировали его, поскольку компилятор, который обрабатывает исходный код был заражен. Это удивительная история, не правда ли?
День 43
Переписал реализацию парсера для операторов на метод рекурсивного спуска вместо использования первенства операторов (operator-precedence parser). Я думаю, что причина для того, чтобы выбрать парсер использующий приоритет операторов это простота и скорость, но грамматика используемая в для операторов в C слишком запутанная для обработки таким способом (например, индексы массивов или различные виды унарных операторов). Код теперь легче читать, чем раньше, потому что большие функции разбиваются на множество мелких. Также теперь должно быть легче добавить проверку ошибок в парсер.
Техники написания парсеров — это один из моих самых полезных навыков как программиста. Он помогал мне бесчисленное количество раз.
Однако, когда я читал спецификацию языка Си, чтобы написать парсер для грамматики использующий рекурсивный спуск, я обнаружил, что некоторые производные являются леворекурсивными. Мне пришлось некоторое время подумать и открыть учебник еще раз, чтобы вспомнить, как переписать грамматику, чтобы сделать ее праворекурсивной. Устранение левой рекурсии является базовой темой в синтаксическом анализе, которая описывается в любом вводном учебнике. Но я не мог вспомнить такие элементарные вещи, так как не использовал технику на протяжении длительного периода времени.
День 44
Входные данные сейчас преобразуются таким образом: строка символов > последовательность токенов > последовательность токенов после подстановки макросов > абстрактное синтаксическое дерево > x86-64 ассемблер. Последний переход, возможно делает слишком много и слишком запутан. Он выполняет различные виды операций, такие как неявные преобразования типов и разворачивание имен меток, пока производит ассемблерный код. Теоретически, я, вероятно, должен определить промежуточный язык между АСД и ассемблером.
Я снова читал Dragon Book по этой теме, не чувствуя, что я полностью ее понял. Книга слишком абстрактна, так что я не могу немедленно применить ее моем случае.
Мой компилятор в два раза медленнее чем GCC когда компилирует сам себя. Это не так плохо, как я думал. Мой компилятор генерирует жутко бесхитростный ассемблер, но такой код не медленнее на порядок.
День 45
Мне было интересно, как gcov будет работать на моем коде. Он нашел множество ветвей кода, которые не прошли юнит тесты. Я нашел несколько багов, добавив тесты для этих ветвей кода. Инструменты покрытия кода действительно полезны.
День 46
Я чувствую, что у меня кончились идеи о том, что делать с компилятором. Для меня было не сложно добраться до текущего состояния разработки, потому что мне не пришлось изучать новые штуки, но вещи за пределами этой точки кажется трудновыполнимым.
Я вынес неявное преобразование типов из генератора кода. Они сейчас явно представлены в АСД. Это позволяет легко понять, что происходит под капотом. Я также сделал бессистемные улучшения в различных местах. Я думал, что работа была почти завершена, но в действительности существовало множество нереализованных особенностей и ошибок.
Я стал лучше понимать оптимизацию компилятора, после того как прочитал еще несколько страниц из Dragon Book. Я мог бы начать писать код, если разберусь в этом еще чуть-чуть лучше.
День 52
Я искал таинственный баг в течение трех дней: если вы округлите вверх или вниз указатель стека для выравнивания к 16-байтовой границе, компилятор второго поколения выводит сообщение об ошибке для корректных входных данных. Такого рода ошибки отлаживать труднее, чем обычные фатальные ошибки.
Моим первым предположением было: неправильное выравнивание указателя стека. Но это не так, потому что указатель стека был уже правильно выровнен по 16-байтовой границе. Я не мог найти баги в ассемблерном выводе. Я решил разделить пополам.
Я пытался компилировать каждый файл через мой компилятор, а остальное через GCC чтобы определить функцию, с которой я могу воспроизвести проблему. Но казалось, что функция не содержит ошибок. Это не функция, которая выводит сообщение об ошибке — они даже не в одном файле. Теория заключается в том, что одна функция создает неверные данные которые вызывают ошибки в других функциях.
После продолжительной бессистемной отладки, я наконец нашел причину: компилятор не инициализирует поля структуры нулями. Спецификация C требует, чтобы при инициализации структуры, поля, не инициализирующиеся значениями, компилятор должен автоматически заполнять нулями. Я знал спецификацию когда писал код (поэтому мой код зависит от этого поведения), но я забыл его реализовать. В результате некоторые поля структур инициализировались мусором вместо нулей. Мусорные данные меняются в зависимости от текущей позиции стека, поэтому изменение указателя стека случайным образом изменяло поведение программы.
В итоге, после трехдневной отладки была исправлена всего одна строка. Хотелось бы иметь какие-то средства чтобы упростить подобную отладку.
День 53
Исправлена еще одна загадочная ошибка. Если компилировать некоторые файлы с помощью GCC, а остальные — моим компилятором, то полученный компилятор сообщает о синтаксических ошибках при корректных входных данных. Такие проблемы должны быть связаны с совместимостью ABI. Моим первым предположением было, что проблема может быть связана с разметкой структур или тем как аргументы передаются в функции, но ассемблерный выход для них кажется правильными.
Я снова сузил поиск до конкретного файла, разделяемого пополам. Я переносил функции по очереди из одного файла в другой, чтобы найти функцию, которая была причиной проблемы. Эта функция была не маленькой, поэтому я разделял ее и переносил код в другой файл. Наконец я получил несколько строк кода. Я скомпилировал их, с помощью GCC и моего компилятора и сравнил.
Единственная разница заключалась в этом: мой компилятор проверяет все биты в регистре, чтобы определить содержит ли он булево значение true, тогда как GCC проверяет только младшие 8 бит. Таким образом, например, если значение в регистре 512 (= 29 или 0x100), то мой компилятор воспринимает его как true, тогда как GCC считает по-другому. GCC на самом деле возвращает некоторое очень большое число с нулями в наименее значимых 8 битах, что воспринимается как false.
Из-за этой несовместимости, цикл, который использует для проверки условия выхода функцию, скомпилированную с помощью GCC (при этом сам цикл компилируется моим компилятором) прекращается сразу же на первой итерации. В результате, макросы препроцессора не определяются. И какие-то из токенов оставались неопределенными и поэтому парсер сообщал о синтаксических ошибках при некоторых входных данных. Причина была далеко от того места, где сообщалось об ошибке, но я, наконец, отловил ее.
Спецификация x86-64 ABI имеет небольшую заметку о том, что только младшие 8 бит являются значимыми для логических возвращаемых значений. Я читал это, но в первый раз не понял что это значит, так что я даже не помнил, что такое указание существовало. Но теперь для меня это предельно ясно. У меня смешанные чувства — я узнал новые вещи, но я мог бы их узнать, не тратя на это столько времени.
День 55
Реализованы битовые поля.
Вы можете упаковать несколько переменных в небольшой области с использованием битовых полей, но компилятор все равно должен создавать пространство между ними в зависимости от их типов. Мое быстрое исследование вывода GCC выявило такие правила (конечно, без гарантии, что они правильны):
- Выравнивание первого битового поля подчиняется выравниванию типа. Например, для «int x:5», x выравнивается по 4-байтовой границе (предполагается, что int — это 32 бита).
- Любая переменная не должна пересекать свои естественные границы. Например, для «int x:10», x не должен пересекать 4-байтовую границу. Если оставшееся число битов слишком мало, чтобы удовлетворить этому условию, они остаются неиспользованными и следующее битовое поле начинается в следующих границах.
Обращение к битовому полю требует больше одной машинной инструкции, потому что CPU не имеет инструкций для доступа к отдельным битам в памяти. Вы должны прочитать в регистр память, содержащую битовое поле, а затем использовать & маску для чтения битового поля. Когда вы записываете его в память, вы должны сначала прочитать память, содержащую битовое поле, применить побитовую маску &, побитовое «или», чтобы получить новое значение, и затем записать значение обратно в память.
День 56
Реализованы вычисляемые goto (computed goto). Обычный goto может ссылаться только на одну метку, но вычисляемый goto может принимать указатель и передавать управление на этот адрес. Этого нет в стандарте C и существует как расширение для GCC. Если вы когда-либо писали виртуальную машину с очень большим switch-case, вы, скорее всего, знаете об этой возможности. Эта функция часто используется, чтобы заменить большой переключатель switch-case на таблицу преобразований и вычисляемый goto.
Вычисляемый goto компилируется в единую инструкцию непрямого перехода. Наверное, это легче понять в терминах ассемблера. Мой компилятор генерирует ассемблер, так что это было очень легко реализовать.
День 57
Реализовал C11 _Generic, потому что я хотел использовать его в своем компиляторе. Но после реализации, я заметил, что GCC 4.6.1 не поддерживает _Generic. Я не могу использовать эту функцию так как если я использую ее, то GCC не сможет компилировать мой компилятор.
Я также реализовал функцию typeof(), которая также является расширением GCC. Обе эти функции не используются в данный момент, но это нормально, так как для их реализации потребовалось очень мало кода.
День 58
Добавил диграфы из C99. Диграф — это необычная функция для специфичных окружений, в которых невозможно использовать некоторые символы. Например, «<:» определяется как псевдоним для «[«. Диграфы могут быть преобразованы в обычные символы при токенизации, так что это бесполезно, но и безвредно.
В С89 есть триграфы, которые очевидно вредны. Триграфы — трехбуквенные последовательности символов, которые преобразуются в один символов везде, где они появляются в исходном коде. Например, printf(«huh??!») выведет не «huh??!», а «huh|» потому что «??!» это триграф для «|». Это сильно сбивает с толку. У меня нет планов, поддерживать триграфы.
День 62
Я пытаюсь скомпилировать TCC. Но пока я далек от успеха из-за нереализованных функций и ошибок.
TCC — это маленький компилятор C, размер которого составляет от 20К до 30к строк кода. Если вы удалите поддержку архитектур кроме x86-64, количество строк, вероятно, будет около 10К-20К. Удивительно видеть, что такой маленький компилятор поддерживает такое множество функций. Фабрис Беллар, создатель ТСС, — гений.
Я несколько раз попытался прочитать исходный код TCC, но все еще не понимаю всю картину. Компиляторы это сложные программы, поэтому вы обычно хотите разбить их на небольшие управляемые части, но исходный код ТСС ощущается, как монолитный компилятор. Я не могу писать такой великолепный код. Я не знаю, хочу ли я подражать, но то что в мире есть кто-то, кто может писать такой код, действительно производит на меня впечатление.
День 73
Безуспешно продолжал работать над компиляцией TCC. Конечно это тяжело, потому что если она пройдет, это значит мой компилятор имеет те же функции что и TCC. Компиляция других компиляторов полезна для отладки, но по своей природе она придираеся к каждой детали спецификации языка.
Общие замечания
Сразу скачиваем полный комплект разработчика парсеров.
В инфраструктуре PascalABC.NET несложно создавать компиляторы простых языков программирования. Программы, получаемые на таких языках, компилируются в .NET-код и работают, как и любой .NET-код, практически так же производительно, как и машинный.
Для создания компилятора важно понимать следующее. Компилятор имеет несколько внутренних представлений.
- Вначале текст программы разбирается им в так называемое синтаксическое дерево. Синтаксическое дерево содержит представленный в виде дерева текст программы — семантика на этом уровне не учитывается, проверяется только соответствие синтаксическим конструкциям. Например, на уровне синтаксического дерева не распознаётся ошибка описания двух переменных с одним именем — с точки зрения синтаксиса ошибки нет.
- Затем синтаксическое дерево переводится в семантическое дерево. Семантическое дерево учитывает все правила, которые сформулированы в описании языка: в частности, то, что в одном пространстве имен нельзя описать две переменные с одним именем. Кроме этого, в семантическом дереве хранится существенно больше информации, чем в синтаксическом: каждая переменная имеет тип, относится к определенному пространству имен, для подпрограмм проверяется соответствие количества и типов формальных и фактических параметров и т.д.
- Заметим, что семантическое дерево, если получено, то содержит правильную программу. Семантическое дерево откомпилированного модуля можно сохранить на диск для ускорения компиляции. В PascalABC.NET так и происходит: если модуль успешно откомпилирован, то он сохраняется в .pcu-файл — это не что иное как записанное на диск семантическое дерево модуля. Если при компиляции основной программы к ней подключен данный модуль, то он повторно не компилируется — его дерево разворачивается из .pcu-файла в память, что гораздо быстрее.
- Наконец, по семантическому дереву генерируется .NET-код.
Заметим, что такое разделение на синтаксическое и семантическое деревья позволяет упростить процесс создания новых языков. В частности, если язык достаточно простой и похож на Паскаль, то он может быть переведен в синтаксическое дерево, после чего достаточно использовать стандартный преобразователь в семантическое дерево и генератор кода. Для более сложных языков с семантикой, отличной от Паскаля, для некоторых узлов синтаксического дерева необходимо писать свой преобразователь в узлы семантического дерева. в ещё более сложных ситуациях имеющихся узлов семантического дерева может оказаться недостаточно, поэтому придется создавать новые и писать для них генерацию .NET-кода.
Далее мы будем рассматривать только такие языки, в которых текст программы достаточно перевести в синтаксическое дерево, что означает, что семантика конструкций — такая же, как и в Паскале. Например, это означает, что целый тип неявно преобразуется в вещественный, но не наоборот.
Следует отметить, что в большинстве ситуаций за счёт проведения дополнительных проверок перевода в узлы синтаксического дерева вполне достаточно. Далее это станет понятнее на конкретных примерах.
Рассмотрим создание простого языка, который мы назовём Oberon00. Это — подмножество языка Oberon с двумя типами — INTEGER и BOOLEAN — и возможностью вызывать процедуры из внешних модулей.
Что нужно для создания компилятора
Для создания компилятора, интегрированного в среду PascalABC.NET, нам потребуется создать несколько файлов. В случае языка Oberon00 потребуется создать:
- Oberon00Parser.dll — библиотеку, содержащую парсер языка (ее следует скопировать в папку установки PascalABC.NET)
- Oberon00.xhsd — файл подсветки синтаксиса (скопировать в папку PascalABC.NETHighlighting)
Кроме этого, обычно требуется системный модуль, содержащий стандартные подпрограммы. Его можно создать на языке Паскаль. Пусть для Оберона00 этот модуль называется Oberon00System.pas. Требуется откомпилировать его в .pcu и затем
- Скопировать Oberon00System.pas в папку PascalABC.NETLibSource
- Скопировать Oberon00System.pcu в папку PascalABC.NETLib
Перезапустив среду PascalABC.NET, мы получим новый компилятор.
Для того чтобы сразу увидеть конечный результат, можно скопировать полный комплект разработчика парсеров.
Что входит в комплект разработчика парсеров
- Папка DLL, содержащая dll из комплекта PascalABC.NET, необходимые для создания парсера.
- Папка GPLex_GPPG, содержащая генератор компиляторов GPLex+GPPG и документацию к нему.
- Папка Install, содержащая файлы, которые необходимо скопировать в папку PascalABC.NET для того чтобы в оболочке PascalABc.NET появился компилятор нового языка.
- Файл generate_all.bat для компиляции файлов .lex и .y в файлы .cs, компиляции проекта и получения библиотеки Oberon00Parser.dll и копирования этого файла в папку Install.
Далее разберем последовательно, как создать парсер.
Лексический анализатор GPLex и синтаксический анализатор GPPG
Итак, наша задача — разобрать текст программы и по нему получить синтаксическое дерево программы. Такой построитель синтаксического дерева программы будем называть парсером или синтаксическим анализатором. Для работы синтаксического анализатора необходим также сканер или лексический анализатор, который разбивает программу на лексемы — неделимые слова. Например, в языке Паскаль лексемами являются ключевые слова, идентификаторы, числовые и строковые константы, знаки операций (:= <> и т.д.).
Синтаксические анализаторы обычно создаются с помощью специальных программ, называемых генераторами компиляторов. Одним из наиболее известных генераторов компиляторов является Yacc (Yet Another Compiler of Compilers) — и в паре с ним работает генератор лексических анализаторов Lex.
Наиболее полной реализацией Yacc-Lex для .NET, генерирующей код парсера на C#, является GPLex+GPPG, разработанный Queensland University of Technology, Австралия. Вот странички продуктов: GPLex и GPPG. Однако рекомендуется скачать исполнимые файлы отсюда — они содержат небольшие модификации, связанные с корректной русификацией.
Создание лексического анализатора
Класс Scanner
Создаваемый в результате компиляции .lex-файла класс Scanner содержит несколько важных методов и свойств. Рассмотрим их подробнее.
- Функция int yylex() возвращает уникальный номер лексемы. Все лексемы хранятся в перечислимом типе Tokens. По-существу, возвращается номер константы в перечислимом типе Tokens — например, для лексемы ID возвращается (int)Tokens.ID
- Помимо уникального номера некоторые лексемы должны возвращать дополнительные значения. Таким значением для идентификатора является его строковое представление, для INTNUM — целое число и т.д. Дополнительное значение для некоторых лексем возвращается в свойстве yylval, которое имеет тип ValueType и содержит ряд полей различных типов — для каждой лексемы может быть предусмотрено своё поле. Например, для лексемы ID предусмотрено поле string sVal, а для лексемы INTNUM — поле iVal.
Объяснение того, как это поле сопоставляется с типом лексемы, отложим до знакомства с содержимым файла .y
- Свойство yytext возвращает строковое представление текущей лексемы
- Свойство yylloc содержит положение лексемы в тексте, задаваемое типом LexLocation из пространства имен QUT.Gppg. Он хранит координаты начала и конца лексемы
Файл .lex
Лексический анализатор обычно создается в файле с расширением .lex. Он имеет вид:
Определения %% Правила %% Пользовательский код
Рассмотрим файл лексического анализатора Oberon00.lex:
%namespace GPPGParserScanner %using PascalABCCompiler.Oberon00Parser; Alpha [a-zA-Z_] Digit [0-9] AlphaDigit {Alpha}|{Digit} INTNUM {Digit}+ ID {Alpha}{AlphaDigit}* %% ":=" { return (int)Tokens.ASSIGN; } ";" { return (int)Tokens.SEMICOLUMN; } "-" { return (int)Tokens.MINUS; } "+" { return (int)Tokens.PLUS; } "*" { return (int)Tokens.MULT; } "/" { return (int)Tokens.DIVIDE; } "<" { return (int)Tokens.LT; } ">" { return (int)Tokens.GT; } "<=" { return (int)Tokens.LE; } ">=" { return (int)Tokens.GE; } "=" { return (int)Tokens.EQ; } "#" { return (int)Tokens.NE; } "(" { return (int)Tokens.LPAREN; } ")" { return (int)Tokens.RPAREN; } "," { return (int)Tokens.COLUMN; } "~" { return (int)Tokens.NOT; } "&" { return (int)Tokens.AND; } "." { return (int)Tokens.COMMA; } ":" { return (int)Tokens.COLON; } "!" { return (int)Tokens.EXCLAMATION; } x01 { return (int)Tokens.INVISIBLE; } {ID} { int res = Keywords.KeywordOrIDToken(yytext); if (res == (int)Tokens.ID) yylval.sVal = yytext; return res; } {INTNUM} { yylval.iVal = int.Parse(yytext); return (int)Tokens.INTNUM; } %{ yylloc = new QUT.Gppg.LexLocation(tokLin, tokCol, tokELin, tokECol); %} %% public override void yyerror(string format, params object[] args) { string errorMsg = PT.CreateErrorString(args); PT.AddError(errorMsg,yylloc); }
После обработки генератором лексических анализаторов GPLex мы получим одноименный cs-файл Oberon00.cs, содержащий класс Scanner лексического анализатора.
Разберем содержимое .lex-файла подробнее.
Секция определений
Вначале рассмотрим первую часть, содержащую определения лексем:
%namespace GPPGParserScanner %using PascalABCCompiler.Oberon00Parser; Alpha [a-zA-Z_] Digit [0-9] AlphaDigit {Alpha}|{Digit} INTNUM {Digit}+ ID {Alpha}{AlphaDigit}*
Строка %namespace GPPGParserScanner означает, что класс сканера будет помещен в пространство имен GPPGParserScanner
Строка %using PascalABCCompiler.Oberon00Parser; приводит к генерации соответствующей строки в cs-файле. Пространство имен PascalABCCompiler.Oberon00Parser полностью находится во вспомогательном файле Oberon00ParserTools.cs, который содержит различные глобальные описания и подпрограммы (подробнее содержимое этого файла будет объяснено позже).
Далее идёт описание некоторых лексем в виде регулярных выражений. Например, целое число INTNUM представляет собой последовательность одной или более цифр {Digit}+, а идентификатор ID — последовательность букв или цифр, начинающуюся с буквы: {Alpha}{AlphaDigit}*
Секция правил
Вторая секция (между первым и вторым %%) является основной и содержит действия, которые необходимо выполнить, когда распознана та или иная лексема.
":=" { return (int)Tokens.ASSIGN; } ";" { return (int)Tokens.SEMICOLUMN; } "-" { return (int)Tokens.MINUS; } "+" { return (int)Tokens.PLUS; } "*" { return (int)Tokens.MULT; } "/" { return (int)Tokens.DIVIDE; } "<" { return (int)Tokens.LT; } ">" { return (int)Tokens.GT; } "<=" { return (int)Tokens.LE; } ">=" { return (int)Tokens.GE; } "=" { return (int)Tokens.EQ; } "#" { return (int)Tokens.NE; } "(" { return (int)Tokens.LPAREN; } ")" { return (int)Tokens.RPAREN; } "," { return (int)Tokens.COLUMN; } "~" { return (int)Tokens.NOT; } "&" { return (int)Tokens.AND; } "." { return (int)Tokens.COMMA; } ":" { return (int)Tokens.COLON; } "!" { return (int)Tokens.EXCLAMATION; } x01 { return (int)Tokens.INVISIBLE; } {ID} { int res = Keywords.KeywordOrIDToken(yytext); if (res == (int)Tokens.ID) yylval.sVal = yytext; return res; } {INTNUM} { yylval.iVal = int.Parse(yytext); return (int)Tokens.INTNUM; }
Здесь приведены действия в случае если встречена та или иная лексема. Большинство действий просто возвращает порядковый номер лексемы в перечислимом типе Tokens.
Последняя лексема — INVISIBLE — символ с кодом 1 — необязательна и является вспомогательной для компилятора выражений языка (необходим для поддержки IntelliSense).
В случае лексемы INTNUM в поле yylval.iVal дополнительно возвращается целое число, соответствующее лексеме: int.Parse(yytext). Обратим внимание, что здесь нет никакой защиты от неправильного преобразования (например, в случае очень длинного целого). Причина — чтобы пока не усложнять изложение обработкой ошибок.
В случае лексемы ID вначале проверяется, не является ли она ключевым словом, и если является, то возвращается целое, соответствующее лексеме ключевого слова (например, для BEGIN возвращается (int)Tokens.BEGIN), а если не является, то возвращается (int)Tokens.ID и параллельно в поле yylval.sVal возвращается строковое представление идентификатора. Именно на этом уровне мы можем задать, чувствителен ли наш язык к регистру (например, преобразованием всех идентификаторов к UpperCase).
Секция правил завершается следующим кодом:
%{ yylloc = new QUT.Gppg.LexLocation(tokLin, tokCol, tokELin, tokECol); %}
Этот код позволяет для каждой лексемы получать её местоположение в тексте. Вникать в этот код не надо — он просто необходим.
Секция пользовательского кода
Наконец, в секции пользовательского кода содержится единственный переопределенный в классе Scanner метод
public override void yyerror(string format, params object[] args) { string errorMsg = PT.CreateErrorString(args); PT.AddError(errorMsg,yylloc); }
Он вызывается всякий раз когда происходит синтаксическая ошибка. Здесь мы пользуемся услугами статического класса PT, который находится в файле Oberon00ParserTools.cs. PT.CreateErrorString(args) формирует строку ошибки, а PT.AddError(errorMsg,yylloc); добавляет ошибку в список ошибок компиляции PascalABC.NET. Здесь интересно то, что в случае автоматического вызова yyerror в args попадают токены, которые ожидались после данного.
Генерация кода лексического анализатора
Для генерации кода лексического анализатора следует выполнить команду:
gplex.exe /unicode oberon00.lex
Здесь gplex.exe — генератор лексических анализаторов, хранящийся в папке GPLex_GPPG, параметр /unicode указывает на то, что созданный лексический анализатор будет распознавать файлы в кодировке unicode (заметим, что он будет распознавать и однобайтные кодировки).
Создание синтаксического анализатора
Общая информация
Синтаксический анализатор — ядро нашего компилятора. Он строится по .y — файлу, в котором записываются правила грамматики языка и действия, которые выполняются по этим правилам. Каждое из действий создает соответствующий узел в синтаксическом дереве. Все узлы синтаксического дерева представляют собой иерархию классов с общим предком syntax_tree_node и описаны во внешней библиотеке SyntaxTree.dll.
Для понимания дальнейшего следует иметь некоторое начальное представление о грамматиках языков программирования, о том, как они порождают языки и об автоматах, которые проверяют, принадлежит ли данная цепочка символов языку, порождаемому грамматикой. Более конкретно, следует представлять, что такое контекстно-свободная грамматика, что Yacc-Lex системы работают с так называемыми LL(k) грамматиками, являющимися достаточно широким подмножеством контекстно-свободных грамматик.
В процессе построения грамматик придется сталкиваться с недостижимыми и циклическими продукциями грамматик, неоднозначными грамматиками. Необходимо уметь исправлять подобные ситуации хотя бы методом проб и ошибок. Особенно необходимо понимать, что Shift-Reduce — конфликты грамматик допустимы и разрешаются в пользу более длинной правой части продукции, а Reduce-Reduce — конфликты недопустимы и свидетельствуют об ошибках проектирования грамматики.
Соответствующую информацию можно прочитать в книге Ахо «Компиляторы: принципы, технологии, инструменты».
Некоторые классы синтаксического дерева
Как уже было сказано, синтаксическое дерево состоит из объектов классов — наследников syntax_tree_node. Перечислим некоторые важные классы — наследники syntax_tree_node, которые будут нами использованы для реализации парсера Оберона00:
ident - идентификатор ident_list - список идентификаторов uses_list - список модулей и пространств имен в секции uses unit_or_namespace - модуль или пространство имен block - блок program_module - программа int32_const - целая константа bool_const - логическая константа expression - выражение (базовый класс для всех выражений) expression_list - список выражений un_expr - унарное ввыражение bin_expr - бинарное выражение assign - оператор присваивания if_node - условный оператор while_node - оператор цикла while empty_statement - пустой оператор method_call - вызов метода или внешней подпрограммы statement_list - последовательность операторов named_type_reference - имя типа declarations - описания var_def_statement - описания переменных с одним типом variable_definitions - секция объявлений переменных simple_const_definition - определение именованной константы consts_definitions_list - секция определений именованных констант
Каждый класс имеет свои поля, все необходимые поля заполняются обычно в конструкторе класса. В базовом классе syntax_tree_node имеется поле source_context типа SourceContext, определяющее местоположение конструкции, соответствующей синтаксическому узлу, в тексте программы. Именно поэтому каждый конструктор синтаксического дерева содержит последним параметром объект класса SourceContext.
Просмотреть все узлы синтаксического дерева, их свойства и методы можно с помощью утилиты
Просмотрщик классов синтаксического дерева
Правила грамматики
Правила грамматики содержат терминальные символы (терминалы), которые распознаются лексическим анализатором, и нетерминальные символы (нетерминалы). Каждое правило грамматики выражает нетерминал через другие терминалы и нетерминалы. Например, для оператора присваивания имеется следующее правило:
AssignOperator : ID ASSIGN expr ;
Здесь нетерминал AssignOperator выражается через терминалы ID и ASSIGN и нетерминал expr, который будет определен в другом правиле.
Нетерминал, с которого начинается разбор, называется стартовым символом грамматики. Этот нетерминал описывает всю программу. В нашей грамматике это module, а соответствующее стартовое правило имеет вид:
module : MODULE ident SEMICOLUMN Declarations BEGIN StatementSequence END ident COMMA
В конечном итоге все нетерминалы выражаются через терминалы, образующие основную программу. Соответствующий процесс получения программы из стартового символа называется выводом, а правила грамматики — правилами вывода.
В каждом правиле может быть несколько альтернатив, разделяемых символом |:
IfStatement : IF expr THEN StatementSequence END | IF expr THEN StatementSequence ELSE StatementSequence END ;
Правила могут быть рекурсивными. Например, правило для фактических параметров имеет вид:
factparams : expr | factparams COLUMN expr ;
Обратим внимание, что данное правило является леворекурсивным, поскольку рекурсивное вхождение нетерминала factparams в правую часть правила находится с левой стороны. Для рассматриваемых нами генераторов компиляторов леворекурсивные правила являются предпочтительнее праворекурсивных.
Формат .y-файла
.y-файл имеет такой же формат, как и .lex:
Определения %% Правила %% Пользовательский код
Раздел определений .y-файла
Общий вид
Рассмотрим раздел определений файла Oberon00.y
%{ public syntax_tree_node root; // Корневой узел синтаксического дерева public GPPGParser(AbstractScanner<ValueType, LexLocation> scanner) : base(scanner) { } %} %output=oberon00yacc.cs %parsertype GPPGParser %union { public bool bVal; public string sVal; public int iVal; public named_type_reference ntr; public ident_list il; public var_def_statement vds; public variable_definitions vdss; public expression ex; public expression_list el; public ident id; public statement st; public statement_list sl; public declarations decl; public Operators op; public simple_const_definition scd; public consts_definitions_list cdl; } %using PascalABCCompiler.SyntaxTree %using PascalABCCompiler.Errors %using PascalABCCompiler.Oberon00Parser %namespace GPPGParserScanner %start module %token <sVal> ID %token <iVal> INTNUM %token <bVal> TRUE FALSE %token <op> PLUS MINUS MULT DIVIDE AND OR LT GT LE GE EQ NE %token NOT %token ASSIGN SEMICOLUMN LPAREN RPAREN COLUMN COMMA COLON EXCLAMATION %token TRUE FALSE ODD BOOLEAN INTEGER %token IF THEN ELSE BEGIN END WHILE DO MODULE CONST VAR %token INVISIBLE %type <id> ident %type <ntr> type %type <ex> expr ConstExpr %type <st> Assignment IfStatement WhileStatement WriteStatement Statement %type <st> EmptyStatement ProcCallStatement %type <sl> StatementSequence %type <decl> Declarations %type <el> factparams %type <il> IDList %type <vds> VarDecl %type <vdss> VarDeclarations VarDeclarationsSect %type <scd> ConstDecl %type <cdl> ConstDeclarations ConstDeclarationsSect %left LT GT LE GE EQ NE %left PLUS MINUS OR %left MULT DIVIDE AND %left NOT %left UMINUS
Начальные строки
Он состоит из нескольких неравнозначных частей. Первая часть заключена в символы %{ %} и содержит код на C#, который будет вставлен в создаваемый класс Parser:
public syntax_tree_node root; // Корневой узел синтаксического дерева public GPPGParser(AbstractScanner<ValueType, LexLocation> scanner) : base(scanner) { }
Здесь root — корневой узел синтаксического дерева программы, он явно описан как поле класса GPPGParser.
Описываемый во второй строке конструктор носит технический характер — его просто необходимо в этом месте написать. Думаю, что эта строчка связана с неудачным проектированием генератора парсеров GPPG — разработчик забыл в генерируемый класс включить этот нужный конструктор.
Строка
означает, что компиляция .y-файла с помощью gppg.exe будет осуществляться в файл oberon00yacc.cs
Строка
говорит о том, что класс парсера будет иметь имя GPPGParser
Строки
%using PascalABCCompiler.SyntaxTree %using PascalABCCompiler.Errors %using PascalABCCompiler.Oberon00Parser
означают подключение в коде парсера соответствующих пространств имен (точки с запятой в конце строк не нужны в отличие от лексического анализатора — видимо, это ошибка проектирования gppg),
а строка
%namespace GPPGParserScanner
означает, что класс парсера будет помещен в пространство имен GPPGParserScanner.
Строка
означает, что стартовым в нашей грамматике является нетерминал module (обычно эту строку можно не писать — считается, что стартовым является нетерминал в левой части первого правила).
Описание используемых терминалов
Все используемые терминалы должны быть описаны в секции определений следующим образом:
%token ASSIGN SEMICOLUMN LPAREN RPAREN COLUMN COMMA COLON EXCLAMATION
Именно по этим определениям формируется перечислимый тип Tokens, который встречался в .lex-файле.
Кроме этого, некоторым терминалам и нетерминалам можно задавать тип.
Типы терминалов и нетерминалов
Большинство нетерминалов и некоторые терминалы должны иметь тип. Например, терминал ID имеет тип string, а терминал INTNUM — тип int.
Для задания этих типов используют структуру-объединение вида
%union { public bool bVal; public string sVal; public int iVal; public ident id; public ident_list il; public statement st; public statement_list sl; ... }
Если с терминалом или нетерминалом необходимо связать значение некоторого типа, то поле этого типа описывается в структуре union. Например, чтобы связать с терминалом ID значение строкового типа, необходимо описать в структуре union поле
После этого необходимо описать типизированный терминал следующим образом:
Аналогично чтобы связать с нетерминалом Assignment тип statement, необходимо описать в структуре union поле
и после этого связать поле st с нетерминалом Assignment следующим образом:
Полный код описаний для типов терминалов и нетерминалов, а также полей структуры union имеет вид:
%union { public bool bVal; public string sVal; public int iVal; public named_type_reference ntr; public ident_list il; public var_def_statement vds; public variable_definitions vdss; public expression ex; public expression_list el; public ident id; public statement st; public statement_list sl; public declarations decl; public Operators op; public simple_const_definition scd; public consts_definitions_list cdl; } %token <sVal> ID %token <iVal> INTNUM %token <bVal> TRUE FALSE %token <op> PLUS MINUS MULT DIVIDE AND OR LT GT LE GE EQ NE %token NOT %token ASSIGN SEMICOLUMN LPAREN RPAREN COLUMN COMMA COLON EXCLAMATION %token TRUE FALSE ODD BOOLEAN INTEGER %token IF THEN ELSE BEGIN END WHILE DO MODULE CONST VAR %token INVISIBLE %type <id> ident %type <ntr> type %type <ex> expr ConstExpr %type <st> Assignment IfStatement WhileStatement WriteStatement Statement %type <st> EmptyStatement ProcCallStatement %type <sl> StatementSequence %type <decl> Declarations %type <el> factparams %type <il> IDList %type <vds> VarDecl %type <vdss> VarDeclarations VarDeclarationsSect %type <scd> ConstDecl %type <cdl> ConstDeclarations ConstDeclarationsSect
Приоритеты операций языка
Чтобы не задавать приоритеты операций в грамматике, в Yacc-системах используется секция задания приоритетов операций. Она имеет вид:
%left LT GT LE GE EQ NE %left PLUS MINUS OR %left MULT DIVIDE AND %left NOT %left UMINUS
Операции задаются в порядке от самого низкого приоритета до самого высокого.
После такого задания приоритетов операций в грамматике выражений можно писать:
expr : expr PLUS expr | expr MULT expr | expr AND expr | expr OR expr | expr EQ expr ...
и это не вызовет неоднозначности грамматики.
Секция правил грамматики
Попробуем проследить, как распознаются правила грамматики.
Правило Assignment
Рассмотрим вначале правило для оператора присваивания:
Assignment : ident ASSIGN expr { $$ = new assign($1, $3, Operators.Assignment,@$); } ;
Здесь формируется узел синтаксического дерева для оператора присваивания. assign — это класс — наследник syntax_tree_node, который хранит всю синтаксическую информацию об операторе присваивания: идентификатор в левой части, выражение в правой части, тип оператора присваивания (в данном случае обычное присваивание, есть ещё += *= и т.д.), а также позиция конструкции присваивания в тексте программы. В данной записи $$ обозначает нетерминал в левой части, $1 — первый символ (нетерминал или терминал) в правой части правила, $2 — второй символ в правой части правила и т.д. Таким образом, $$ соответствует символу
Assignment, $1 — символу ident, а $3 — символу expr. Очень важно, что если типы соответствующих символов были прописаны в секции описаний, то выражения $$, $1, $2 и т.д. имеют ровно эти типы. Узнаем в разделе описаний типы Assignment, ident и expr:
%type <st> Assignment %type <id> ident %type <ex> expr
Теперь заглянём в структуру union:
%union { public expression ex; public ident id; public statement st; }
Таким образом, можно сделать вывод, что $$ имеет тип statement, $1 — тип ident, а $3 — тип expression.
Если окажется, что для какого-то нетерминала или терминала не определен тип, то считается, что соответствующий символ $… имеет тип Object.
Наконец, обратим внимание на символ @$. Он соответствует положению в тексте символа Assignment из левой части правила. Тип символа @$ — LexLocation (это стандартный тип библиотеки GPPG), неявно преобразующийся в тип SourceContext (это тип библиотеки PascalABC.NET; можно для простоты считать, что @$ имеет тип SourceContext). Аналогично @1 — это SourceContext для первого символа в правой части, @2 — для второго и т.д.
Как правило, в большинстве узлов @$ будет передаваться в качестве последнего параметра конструктора.
Правило StatementSequence
Правило для StatementSequence имеет вид:
StatementSequence : Statement { $$ = new statement_list($1,@$); } | StatementSequence SEMICOLUMN Statement { $1.Add($3,@$); $$ = $1; } ;
Здесь формируется список операторов, которые в программе разделены точкой с запятой. Обратим внимание, что за счёт леворекурсивности этого правила первым заканчивается разбор первого оператора Statement — в этот момент мы и создаём statement_list вызовом конструктора. В рекурсивной части считается, что statement_list уже создан, и мы добавляем в него следующий Statement с помощью метода Add класса statement_list.
Во втором правиле есть и ещё одна тонкость, рассмотрим её подробнее — она часто встречается. Рассмотрим ещё раз второе правило внимательнее:
StatementSequence : StatementSequence SEMICOLUMN Statement { $1.Add($3,@$); $$ = $1; }
Здесь надо понимать, что на момент разбора этого правила StatementSequence в левой части ещё не определен, а StatementSequence в правой части, напротив, определен на предыдущих шагах. Поэтому мы вначале к переменной $1, связанной со StatementSequence в правой части и имеющей тип statement_list, добавляем Statement, хранящийся в $3, после чего инициализируем StatementSequence в левой части, присваивая ему StatementSequence из правой части: $$ = $1. За счёт ссылочной модели объектов в C# здесь можно было бы поступить и иначе:
{ $$ = $1; $$.Add($3,@$); }
или даже так:
{ $$ = $1; $1.Add($3,@$); }
— всё равно после присваивания $$ = $1 переменные $$ и $1 указывают на один объект.
Правила Statement
Проследим далее за правилами Statement:
Statement: Assignment | IfStatement | WhileStatement | WriteStatement | ProcCallStatement | EmptyStatement ;
Здесь нет действий в {}, поэтому по умолчанию всегда подразумевается действие $$ := $1, что нам и надо.
Рассмотрим ещё несколько правил, в которых есть ранее не встречавшиеся моменты.
Правило ident
Чтобы не преобразовывать всякий раз строковый ID в узел синтаксического дерева ident, введено правило:
ident : ID { $$ = new ident($1,@$); } ;
Правило для унарного минуса
Правило для унарного минуса имеет вид:
expr : MINUS expr %prec UMINUS { $$ = new un_expr($2,Operators.Minus,@$); }
Ключевое слово %prec меняет в рамках одного правила приоритет операции MINUS и делает его таким же, как и у UMINUS. Заметим, что терминал UMINUS — фиктивный — он не может возникнуть при лексическом разборе, и задаётся только в секции приоритетов операций — последним и, значит, самым приоритетным.
Правило для всей программы
Вся программа на Oberon00 представляет собой модуль:
module : MODULE ident SEMICOLUMN mainblock ident COMMA
По этому правилу производятся следующие действия:
{ if ($2.name != $5.name) PT.AddError("Имя "+$5.name+" должно совпадать с именем модуля "+$2.name,@5); // Подключение стандартного модуля Oberon00System, написанного на PascalABC.NET var ul = new uses_list("Oberon00System"); // Формирование модуля основной программы (используется фабричный метод вместо конструктора) root = program_module.create($2, ul, $4, @$); }
Поясним их подробнее. Во-первых, проверяется, совпадает ли имя модуля в начале и в конце программы и если нет. то генерируется семантическая ошибка с помощью PT.AddError (эта ошибка будет добавлена в окно ошибок компиляции). Заметим, что на этапе построения синтаксического дерева можно распознать и диагностировать некоторые синтаксические ошибки.
Затем в начало списка подключаемых модулей добавляется так называемый системный модуль Oberon00System — он написан на Паскале и должен быть откомпилирован в .pcu.
После этого формируется синтаксический узел для всей программы (класс program_module) и присваивается переменной root.
Создание системного модуля
Напишем для компилятора Oberon00 простой системный модуль на паскале Obеron00System.pas:
unit Oberon00System; interface procedure Print(o: object); procedure Println(o: object); procedure Println; implementation uses System; procedure Print(o: object); begin Console.Write(o); end; /// Вывести значение procedure Println(o: object); begin Console.WriteLine(o); end; procedure Println; begin Console.WriteLine; end; end.
Именно он подключается автоматически к любой программе на Обероне в действиях для правила module:
... var ul = new uses_list("Oberon00System");
В принципе, этот модуль можно было написать на самом Обероне, но в Обероне нет возможности прямого доступа к .NET-библиотекам.
Замечательная особенность среды PascalABC.NET — возможность совмещать разные языки программирования в одном проекте на уровне исходных кодов.
Обработка ошибок
Создание парсера-плагина для среды PascalABC.NET
Инсталляция плагина

Почему мне пришла в голову идея разработать собственный компилятор? Однажды мне на глаза попалась книга, где описывались примеры проектирования в AutoCAD на встроенном в него языке AutoLISP. Я захотел c ними разобраться, но прежде меня заинтересовал сам ЛИСП. “Неплохо бы поближе познакомиться с ним”, – подумал я и начал подыскивать литературу и среду разработки. С литературой все оказалось просто – по ЛИСПу ее море в Интернете. Достаточно зайти на портал [1]. Дело оставалось за малым – найти хорошую среду программирования, и вот тут-то начались трудности. Компиляторов под ЛИСП тоже немало, но все они оказались мне малопонятны. Ни один пример из Вики, по разным причинам, не отработал нормально в скачанных мною компиляторах. Собственно, серьезно я с ними не разбирался, но, увы, во многих не нашел как скомпилировать EXE-файл. Самое интересное, что компиляторы эти были собраны разными людьми практически в домашних условиях…
Виталий Белик
by Stilet
И мне пришла в голову мысль: а почему бы не попробовать самому написать свой компилятор или, основываясь на каком-либо диалекте какого-либо языка, свой собственный язык программирования? К тому же на форумах я часто видел темы, где слезно жаловались на тиранов-преподавателей, поставивших задачу написания курсовой – компилятора или эвалюатора (программы, вычисляющей введенное в виде строки выражение). Мне стало еще интереснее: а что если простому студенту, не искушенному книгами Вирта или Страуструпа, написать такую программу? Появился мотив.
In the Beginning
Итак, начнем. Прежде всего, нужно поставить задачу хотя бы на первом этапе. Задача будет банальная: доказать самому себе, что написание компилятора не такой уж сложный и страшный процесс. И что мы, хитрые и смекалистые, способны родить в муках собственного творчества шедевр, который, возможно, полюбится массам. Да и вообще: приятно писать программы на собственном языке, не так ли?
Что ж, цель поставлена. Теперь самое время определиться со следующими пунктами:
- Под какую платформу будет компилировать код программа?
- На каком языке будет код, переводимый в машинный язык?
- На чем будем писать сам компилятор?
Первый пункт достаточно важен, ибо широкое разнообразие операционных систем (даже три монстра – Windows, Linux и MacOS) уже путают все карты. Их исполняемые файлы по-разному устроены, так что нам, простым смертным, придется выбрать из этой “кагалы” одну операционную систему и, соответственно, ее формат исполняемых файлов. Я предлагаю начать с Windows, просто потому, что мне нравится эта операционная система более других. Это не значит, что я терпеть не могу Linux, просто я его не очень хорошо знаю, а такие начинания лучше делать по максимуму, зная систему, для которой проектируешь.
Два остальных пункта уже не так важны. В конце концов, можно придумать свой собственный диалект языка. Я предлагаю взять один из старейших языков программирования – LISP. Из всех языков, что я знаю, он мне кажется более простым по синтаксису, более атомарным, ибо в нем каждая операция берется в скобочки; таким образом, к нему проще написать анализатор. С выбором, на чем писать, еще проще: писать нужно на том языке, который лучше всего знаешь. Мне ближе паскалевидные языки, я хорошо знаю Delphi, поэтому в своей разработке я избираю именно его, хотя никто не мешает сделать то же самое на Си. Оба языка прекрасно подходят для написания такого рода программ. Я не беру в расчет Ассемблер потому, что его диалект приближен к машинному языку, а не к человеческому.
To Shopping
Выяснив платформу, для которой будем писать компилятор (я имею в виду Win32), подберем все необходимое для комфортной работы. Давайте составим список, что же нам пригодится в наших изысканиях.
Для начала нам просто крайне необходимо выяснить, как же все-таки компиляторы генерируют исполняемые EXE-файлы под Windows. Для этого стоит почитать немного об устройстве этих “экзэшек”, как их часто называют, покопаться в их “кишках”. В этом могут помочь современные отладчики и дизассемблеры, способные показать, из чего состоит “экзэшка”. Я знаю два, на мой взгляд, лучших инструмента: OllyDebugger (он же “Оля”) и The Interactive Disassembler (в простонародье зовущийся IDA).
Оба инструмента можно достать на их официальных сайтах http://www.ollydbg.de/ и http://www.hex-rays.com/idapro. Они помогут нам заглянуть в святая святых – храм, почитаемый загрузчиком исполнимых файлов, – и посмотреть, каков интерьер этого храма, дабы загрузчик наших экзэшек чувствовал себя в нем так же комфортно, как “ковбой в подгузниках Хаггис”.
Также нам понадобится какая-нибудь экзэшка в качестве жертвы, которую мы будем препарировать этими скальпелями-дизассемблерами. Здесь все сложнее. Дело в том, что благородные компиляторы имеют дурную привычку пихать в экзэшник, помимо необходимого для работы кода, всякую всячину, зачастую ненужную. Это, конечно, не мусор, но без него вполне можно обойтись, а вот для нашего исследования внутренностей экзэшек он может стать серьезной помехой. Мы ведь не Ричарды Столлманы и искусством реверсинга в совершенстве не владеем. Поэтому нам лучше было бы найти такую программу, которая содержала бы в себе как можно меньше откомпилированного кода, дабы не отвлекаться на него. В этом нам может помочь компилятор Ассемблера для Windows. Я знаю два неплохих компилятора: Macro Assembler (он же MASM) и Flat Assembler (он же FASM). Я лично предпочитаю второй – у него меньше мороки при компилировании программы, есть собственный редактор, в отличие от MASM компиляция проходит нажатием одной-единственной кнопки. Для MASM разработаны среды проектирования, например MASM Builder. Это достаточно неплохой визуальный инструмент, где на форму можно кидать компоненты по типу Delphi или Visual Studio, но, увы, не лишенный багов. Поэтому воспользуемся FASM. Скачать его можно везде, это свободно распространяемый инструмент. Ну и, конечно, не забудем о среде, на которой и будет написан наш компилятор. Я уже сказал, что это будет Delphi. Если хотите конкретнее – Delphi 6.
The Theory and Researching
Прежде чем приступить к написанию компилятора, неплохо бы узнать, что это за формат “экзэшка” такой. Согласно [2], Windows использует некий PE-формат. Это расширение ранее применявшегося в MS-DOS, так называемого MZ формата [3]. Сам чистый MZ-формат простой и незатейливый – это 32 байта (в минимальном виде, если верить FASM; Турбо Паскаль может побольше запросить), где содержится описание для DOS-загрузчика. В Windows его решили оставить, видимо, для совместимости со старыми программами. Вообще, если честно, размер DOS-заголовка может варьироваться в зависимости от того, что после этих 28 байт напихает компилятор. Это может быть самая разнообразная информация, например для операционок, которые не смогли бы использовать скомпилированный DOS или Windows-экзэшник, представленная в качестве машинного кода, который прерываниями BIOS выводит на экран надпись типа “Эта программа не может быть запущена…”. Кстати, сегодняшние компиляторы поступают так же.
Давайте посмотрим на это чудо техники, воспользовавшись простенькой программой, написанной на чистом Ассемблере FASM (см. Рис. 1):

Рис. 1. Исходник для препарирования
Сохраним файл под неким именем, например Dumpy. Нажмем F9 или выберем в меню пункт RUN. В той же папке будет создан EXE-файл. Это и будет наша жертва, которую мы будем препарировать. Теперь ничто не мешает нам посмотреть: “из чего же, из чего же сделаны наши девчонки?”.
Запустим OllyDebuger. Откроем в “Оле” наш экзэшник. Поскольку фактически кода в нем нет, нас будет интересовать его устройство, его структура. В меню View есть пункт Memory, после выбора которого “Оля” любезно покажет структуру загруженного файла (см. Рис. 2):
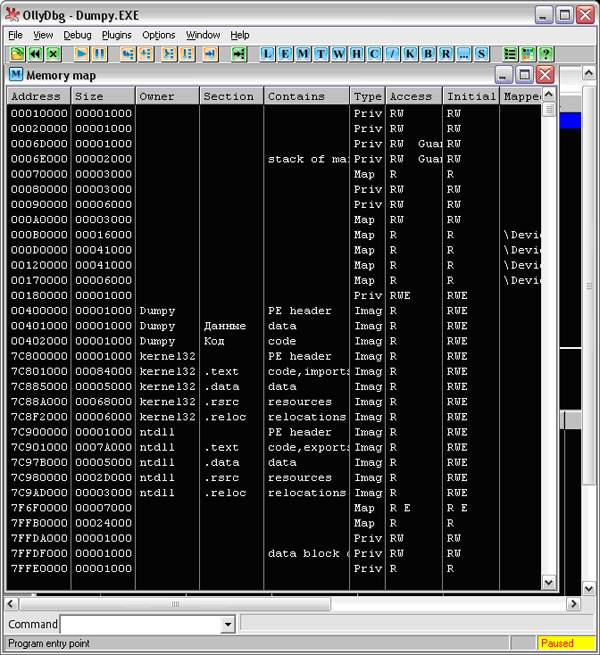
Рис. 2. Карта памяти Dumpy
Это не только сам файл, но и все, что было загружено и применено вместе с ним, библиотеки, ресурсы программы и библиотек, стек и прочее, разбитое на блоки, называемые секциями. Из всего этого нас будут интересовать три секции, владелец которых Dumpy, – это непосредственно содержимое загруженного файла.
Собственно, эти секции были описаны нами в исходнике, я не зря назвал их по-русски (ведь операционной системе все равно, как названы секции, главное – их имена должны укладываться точь-в-точь в 8 байт. Это придется учесть обязательно).
Заглянем в первую секцию PE Header. Сразу же можем увидеть (см. Рис. 3), что умная “Оля” подсказывает нам, какие поля* у этой структуры:
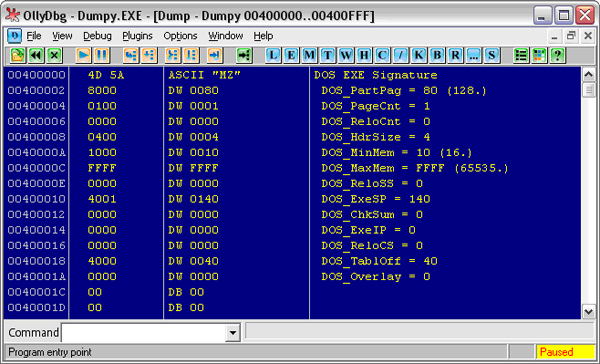
Рис. 3. MZ-заголовок
* Комментарий автора.
Сразу хочу оговориться, не все из этих полей нам важны. Тем паче что сам Windows использует из них от силы 2-3 поля. Прежде всего, это DOS EXE Signature – здесь (читайте в Википедии по ссылке выше) помещаются две буквы MZ – инициалы создателя MS-DOS, и поле DOS_PartPag. В нем указывается размер MZ-заголовка в байтах, после которых помещается уже PE-заголовок.
Последнее поле, которое для нас важно, находится по смещению 3Ch от начала файла (см. Рис. 4):
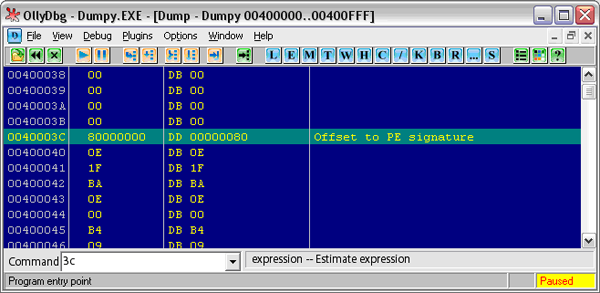
Рис. 4. Смещение на PE-заголовок
Это поле – точка начала РЕ-заголовка. В Windows, в отличие от MS-DOS, MZ-заголовок заканчивается именно на отметке 40**, что соответствует 64 байтам. При написании компилятора будем соблюдать это правило неукоснительно.
* Комментарий автора.
Обратите внимание! Далее, с 40-го смещения, “Оля” показывает какую-то белиберду. Эта белиберда есть атавизм DOS и представляет из себя оговоренную выше информацию, с сообщением о том, что данная программа может быть запущена только под DOS-Windows. Этакий перехватчик ошибок. Как показывает практика, этот мусор можно без сожаления выкинуть. Наш компилятор не будет генерировать его, сразу переходя к PE-заголовку.
Что ж, перейдем непосредственно к PE-заголовку (см. Рис. 5). Как показывает “Оля”, нам нужно перейти на 80-й байт. Да, чуть не забыл. Все числа адресации указываются в 16-тиричной системе счисления. Для этого после чисел ставится латинская буква “H”. “Оля” не показывает ее, принимая эту систему по умолчанию для адресации. Это нужно учесть, чтобы не запутаться в исследованиях. Фактически 80h – это 128-й байт.
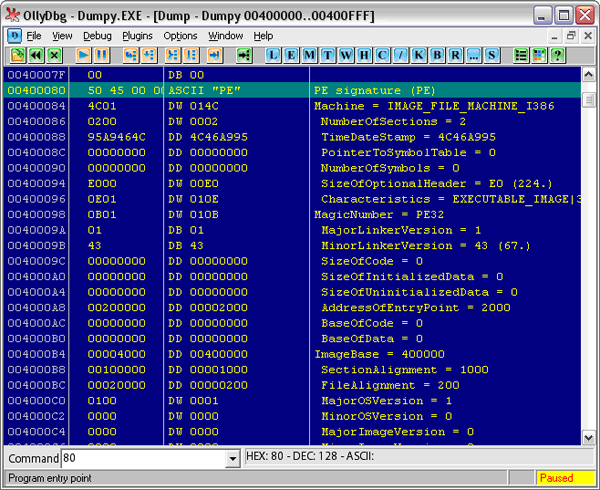
Рис. 5. Начало РЕ-заголовка
Вот она, святая обитель характеристик экзэшника. Именно этой информацией пользуется загрузчик Windows, чтобы расположить файл в памяти и выделить ему необходимую память для нужд. Вообще, считается, что этот формат хорошо описан в литературе. Достаточно выйти через Википедию по ссылкам в ее статьях [4] или банально забить в поисковик фразу вроде “ФОРМАТ ИСПОЛНЯЕМЫХ ФАЙЛОВ PortableExecutables (PE)”, как сразу же можно найти кучу описаний. Поэтому я поясню только основные его поля, которые нам понадобятся непосредственно для написания компилятора…
Прежде всего, это PE Signature – 4-хбайтовое поле. В разной литературе оно воспринимается по-разному. Иногда к нему приплюсовывают еще поле Machine, оговариваясь, чтобы выравнять до 8 байт. Мы же, как любители исследовать, доверимся “Оле” с “Идой” и будем разбирать поля непосредственно по их подсказкам. Это поле содержит две латинские буквы верхнего регистра “PE”, как бы намекая нам, что это Portable Executable-формат.
Следующее за ним поле указывает, для какого семейства процессоров пригоден данный код. Всего их, как показывает литература, 7 видов:
0000h __unknown
014Ch __80386
014Dh __80486
014Eh __80586
0162h __MIPS Mark I (R2000, R3000)
0163h __MIPS Mark II (R6000)
0166h __MIPS Mark III (R4000)
Думаю, нам стоит выбрать из всего этого второй вид – 80386. Кстати, наблюдательные личности могли заметить, что в компиляторах Ассемблера есть директива, указывающая, какое семейство процессора использовать, как, например, в MASM (см. Рис. 6):
Рис. 6. Указание семейства процессоров в МАСМ
386 как раз и говорит о том, что в этом поле будет стоять значение 014Ch***.
* Комментарий автора.
Обратите внимание на одну небольшую, но очень важную особенность: байты в файле непосредственно идут как бы в перевернутом виде. Вместо 14С в файл нужно писать байты в обратном порядке, начиная с младшего, т. е. получится 4С01 (0 здесь дополняет до байта. Это для человеческого глаза сделано, иначе все 16-тиричные редакторы показывали бы нестройные 4С1. (Согласитесь, трудно было понять, какие две цифры из этого числа к какому байту относятся.) Эту особенность обязательно придется учесть. Для простоты нелишним было бы написать пару функций, которые число превращают в такую вот перевернутую последовательность байт (что мы в дальнейшем и сделаем).
Следующее важное для нас поле – NumberOfSections. Это количество секций без учета PE-секции. Имеются в виду только те секции, которые принадлежат файлу (в карте памяти их владелец – Dumpy). В нашем случае это “Данные” и “код”.
Следующее поле хоть и не столь важно, но я его опишу. Это TimeDateStamp – поле, где хранится дата и время компиляции. Вообще, я его проигнорирую, не суть важно сейчас, когда был скомпилирован файл. Впрочем, если кому захочется помещать туда время, то флаг в руки.
Сразу хочу предупредить, что меня как исследователя не интересовали поля с нулевыми значениями. На данном этапе они действительно неважны, поэтому в компиляторе их и нужно будет занулить.
Следующее важное поле – SizeOfOptionalHeader. Оно содержит число, указывающее, сколько байт осталось до начала описания секций. В принципе, нас будет устраивать число 0Eh (224 байта).
Далее идет поле “характеристики экзэшника”. Мы и его будем считать константным:
Characteristics (EXECUTABLE_IMAGE|32BIT_MACHINE|LINE_NUMS_STRIPPED|LOCAL_SYMS_STRIPPED)
И равно оно 010Eh. На этом поле заканчивается так называемый “файловый заголовок” и начинается “Опциональный”.
Следующее поле – MagicNumber. Это тоже константа. Так называемое магическое число. Если честно, я не очень понял, для чего оно служит, в разных источниках это поле преподносится по-разному, но все хором ссылаются на знаменитый дизассемблер HIEW, в котором якобы впервые появилось описание этого поля именно в таком виде. Примем на веру.
Следующие два поля, хоть и не нулевые, но нам малоинтересны. Это: MajorLinkerVersion и MinorLinkerVersion. Это два байта версии компилятора. Угадайте, что я туда поставил?
Следующее важное поле – AddressOfEntryPoint. Важность этого поля в том, что оно указывает на адрес, с которого начинается первая команда, – с нее процессор начнет выполнение. Дело в том, что на этапе компиляции значение этого поля не сразу известно. Ее формула достаточно проста. Сначала указывается адрес первой секции плюс ее размер. К ней плюсуются размеры остальных секций до секции, считаемой секцией кода. Например, в нашей жертве это выглядит так (см. Рис. 7):
Рис. 7. Расчет точки входа
Здесь секция кода вторая по счету, значит, Адрес точки входа равен размеру секции “Данные” плюс ее начало и равен 2000. К этому еще пририсовывается базовый адрес, в который загрузчик “сажает” файл, но он в вычислении для нашего компилятора не участвует. Поэтому в жертве точка входа имеет значение 2000.
Следующее поле – ImageBase. Это поле я приму как константу, хотя и не оговаривается ее однозначное значение. Это значение указывает адрес, с которого загрузчик поместит файл в память. Оно должно нацело делиться на 64000. В общем, необязательно указывать именно 400000h, можно и другой адрес. Уже не помню, где я слышал, что загрузчик может на свое усмотрение поменять это число, если вдруг в тот участок памяти нельзя будет загружать, но не будем это проверять, а примем на веру как константу =400000h.
Следующая важная константа – SectionAlignment. Это значение говорит о размере секций после загрузки. Принцип прост: каждая секция (имеется в виду ее реализация) дополняется загрузчиком пустыми байтами до числа, указанного в этом поле. Это так называемое выравнивание секций. Тут уж хороший компилятор должен думать самостоятельно, какой размер секций ему взять, чтобы все переменные (или сам код), которые в коде используются, поместились без проблем. Согласно спецификации, это число должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). В принципе, пока что для простенького компилятора можно принять это значение как константу. Нас вполне устроит среднее значение 1000h (4096 байт – не правда ли, расточительный мусор? На этом весь Windows построен – живет на широкую ногу, память экономить не умеет).
Далее следует поле FileAlignment. Это тоже хитрое поле. Оно содержит значение, сколько байт нужно дописать в конец каждой секции в сам файл, т. е. выравнивание секции, но уже в файле. Это значение тоже должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). Неплохо бы рассчитывать функцией это поле в зависимости от размеров, данных в секции.
Следующие поля – MajorSubsystemVersion и MinorSubsystemVersion – примем на веру как константы. 3h и Аh соответственно. Это версия операционной системы, под которую рассчитывается данная компиляция****.
* Комментарий автора.
Я не проверял на других ОС: у меня WinXP. В принципе можно не полениться и попробовать пооткрывать “Олей” разные программы, рассчитанные на другие версии Windows.
Далее из значимых следует SizeOfImage. Это размер всего заголовка, включая размер описания всех секций. Фактически это сумма PE-заголовка плюс его выравнивание, плюс сумма всех секций, учитывая их выравнивание. Ее тоже придется рассчитывать.
Следующее поле – SizeOfHeaders (pазмеp файла минус суммарный pазмеp описания всех секций в файле). В нашем случае это 1536-512 * 2=200h (512 байт). Однако РЕ тоже выравнен! Это поле тоже нужно будет рассчитывать.
Далее следует не менее коварное поле – CheckSum. Это CRC сумма файла. Ужас… Мы еще файл не создали, а нам уже нужно ее посчитать (опять-таки вспоминается Микрософт злым громким словом). Впрочем, и тут можно вывернуться. В Win API предусмотрена функция расчета CRC для области данных в памяти, проще говоря, массива байт – CheckSumMappedFile. Можно ей скормить наш эмбрион файла. Причем веселье в том, что эта операция должна быть самой последней до непосредственной записи в файл. Однако, как показывает практика, Windows глубоко наплевать на это поле, так что мы вполне можем не морочить себе голову этим расчетом (согласитесь, держать в файле поле, которое никому не нужно, да еще и напрягать нас лишним расчетом – это глупо, но, увы, в этом изюминка политики Микрософта. Складывается впечатление, что программисты, писавшие Windows, никак не согласовывали между собой стратегию. Спонтанно писали. Импровизировали).
Следующее поле – Subsystem. Может иметь следующие значения*****:
- IMAGE_SUBSYSTEM_WINDOWS_CUI=3. Это говорит о том, что наш откомпилированный экзэшник является консольной программой.
- IMAGE_SUBSYSTEM_WINDOWS_GUI=4. Это говорит о том, что экзэшник может создавать окна и оперировать сообщениями.
* Комментарий автора.
Для справки, кто хорошо знает Delphi: директивы компилятора {$APPTYPE GUI} и {$APPTYPE CONSOLE} именно эти параметры и выставляет.
Вот, собственно, и все важные для нас параметры. Остальные можно оставить константно, как показывает “Оля”:
DLLCharacteristics = 0
SizeOfStackReserve = 1000h (4096)
SizeOfStackCommit = 1000h (4096)
SizeOfHeapReserve = 10000h (65536)
NumberOfRvaAndSizes = 10h (16)
И остаток забить нулями (посмотрите в “Оле” до начала секций, какие там еще параметры). О них можно почитать подробнее по ссылкам, которые я привел.
После идет описание секций. Каждое описание занимает 32 байта. Давайте взглянем на них (Рис. 8):
Рис. 8. Описание секций
В начале секции идет ее имя (8 байт), после этого поле – VirtualSize, описывает (я процитирую из уроков Iczeliona) “RVA-секции. PE-загpузчик использует значение в этом поле, когда мэппиpует секцию в память. То есть, если значение в этом поле pавняется 1000h и файл загpужен в 400000h, секция будет загpужена в 401000h”.
Однако “Оля” почему-то показывает для обеих секций одно и то же значение 9. Что это? Я не понял, почему так. Пока оставим это как данное. Вдруг в будущем разберемся.
Далее следует VirtualAddres, который указывает, с какого адреса плюс ImageBase будет начинаться в памяти секция – это важное поле, именно оно станет для нашего компилятора базой для расчета адреса к переменной. Собственно, адрес этот напрямую зависит от размера секции. Следующий параметр PointerToRawData – это смещение на начало секции в скомпилированном файле. Как я понял, этот параметр компиляторы любят подводить под FileAlignment. И последнее – поле Characteristics. Сюда прописывается доступ к секции. В нашем случае для секции кода оно будет равным 60000020=CODE|EXECUTE|READ, а для секции данных C0000040=INITIALIZED_DATA |READ|WRITE.
Вот и все. Закончилось описание заголовка. Далее он выравнивается нулями до 4095 байт (с этим числом связан один прикол). В файле мы его будем дополнять до FileAlignment (в нашем случае до 200h).
Hello world. Hey! Is There Anybody Out There?
Вот мы и прошлись по кишкам нашей жертвы – экзэшника. Напоследок попробуем на скорую руку закрутить простейший компилятор для DOS-системы без PE-заголовка. Для этого подойдут инструменты, которые так почему-то любят преподавать до сих пор.
Я говорю о классическом Паскале. Итак, предположим, злобный преподаватель поставил задачу: написать компилятор программы вывода на экран некой строки, которую мы опишем для компилятора, введя ее ручками (см. листинг 1):
var header,commands,s:string;
e,i:integer;
f:file;
begin
{Это MZ-заголовок}
header:=#$4D#$5A#$3E#$00#$01#$00#$
00#$00#$02#$00#$00#$01#$FF#$FF#$02#$00#$00;
header:=header+#$10#$00#$00#
$00#$00#$00#$00#$1C#$00#$00#$00#$00#$00#$00#$00;
writeln(
‘give me welcome ![]() ’);readln(s);
’);readln(s);
{Поскольку у нас все в одном сегменте, и код и данные, лежащие непосредственно в конце кода, нужно, чтобы регистр, содержащий базу данных, указывал на код. Предположим, мы будем считать, что и сам код представляет из себя данные. Для этого поместим в стек адрес сегмента кода}
{*******************************************************************************************}
Commands:=#$0E; { push cs}
{и внесем из стека этот адрес в регистр сегмента данных}
Commands:=Commands+#$1F; { pop ds}
Commands:=Commands+#$B4#$09; { mov ah, 9 – Вызовем функцию вывода строки на экран}
{Передадим в регистр DX-адрес на строку. Поскольку пока что строка у нас не определена, передадим туда нули, а позже подкорректируем это место}
Commands:=Commands+#$BA#$
00#$00; { mov dx, }
{Запомним место, которое нужно будет скорректировать. Этим приемом я буду пользоваться, чтобы расставить адреса в коде, который обращается к переменным}
e:=length(commands)-1;
{Выведем на экран строку}
Commands:=Commands+#$CD#$21;
{ int 21h ; DOS – PRINT STRING}
{подождем, пока пользователь не нажмет любую клавишу}
Commands:=Commands+#$B4#$01; { mov ah, 1}
Commands:=Commands+#$CD#$21; { int 21h ; DOS – KEYBOARD INPUT}
{После чего корректно завершим программу средствами DOS}
Commands:=Commands+#$B4#$4C; { mov ah, 4Ch}
Commands:=Commands+#$CD#$21; {int 21h ; DOS – 2+ – QUIT WITH EXIT CODE (EXIT)}
Commands:=Commands+#$C3; {retn}
{*******************************************************************************************}
{Теперь будем править адреса, обращающиеся к переменной. Поскольку само значение переменной у нас после всего кода (и переменная) одно, мы получим длину уже имеющегося кода – это и будет смещение на начало переменной}
i:=length(commands);
{В запомненное место, куда нужно править, запишем в обратном порядке это смещение}
commands[e]:=chr(lo
(i));
commands[e+1]:=chr(hi(i));
{Учтем, что в DOS есть маленький атавизм – строки там должны завершаться символом $. По крайней мере, для этой функции.}
commands:=commands+s+‘$’;
{не забудем дописать в начало заголовок}
commands:=header+commands;
{Теперь скорректируем поле DOS_PartPag. Для DOS-программ оно указывает на общий размер файла. Честно говоря, я не знаю, зачем это было нужно авторам, может быть, когда они изобретали это, еще не было возможности получать размер файла из FAT. Опять-таки запишем в обратном порядке}
i:=length(commands);
commands[3]:=chr(lo(i))
;
commands[4]:=chr(hi(i));
{Ну, и кульминация этого апофигея – запись скомпилированного массива байт в файл. Все заметили, что я воспользовался типом String, – он в паскалевских языках был изначально развит наиудобнейшим образом}
Assign(f,‘File.exe’);rewrite(f);
BlockWrite(f,commands[1],length(commands), e);
Close(f);
end.
Не удивляет, что программа получилась небольшой? Почему-то преподаватели, дающие такое задание, уверены, что студент завалится. Думаю, такие преподаватели сами не смогли бы написать компилятор. А студенты смогут, ибо, как видим, самая большая сложность – это найти нужные машинные коды для решения задачи. А уж скомпилировать их в код, подкорректировать заголовок и расставить адреса переменных – задача второстепенной сложности. В изучении ассемблерных команд поможет любая книга по Ассемблеру. Например, книга Абеля “Ассемблер для IBM PC”. Еще неплохая книга есть у Питера Нортона, где он приводит список функций DOS и BIOS.
Впрочем, можно и банальнее. Наберите в поисковике фразу “команды ассемблера описание”. Первая же ссылка выведет нас на что-нибудь вроде [5] или [6], где описаны команды Ассемблера. Например, если преподаватель задал задачку написать компилятор сложения двух чисел, то наши действия будут следующими:
- Выясняем, какая команда складывает числа. Для этого заглянем в книгу того же Абеля, где дается такой пример:
сложение содержимого
ADD AX,25 ;Прибавить 25
ADD AX,25H ;Прибавить 37 - Значит, нам нужна команда ADD. Теперь определимся: нам же нужно сложить две переменные, а это ячейки памяти; эта команда не умеет складывать сразу из переменной в переменную, для нее нужно сначала слагаемое поместить в регистр (AX для этого лучше подходит), а уж потом суммировать в него. Для помещения из памяти в регистр (согласно тому же Абелю) нужна команда
mov [адрес], ax
- Таким образом, инструкции будут выглядеть так:
mov [Адрес первой переменной], ax
add [Адрес второй переменной], ax - Теперь нужно определиться с кодами этих команд. В комплекте с MASM идет хелп, где описаны команды и их опкоды (машинные коды, операционные коды). Вот, например, как выглядит опкод команды MOV из переменной:
Рис. 9. Опкоды MOV
Видим (см. Рис. 9), что его опкод A1 (тут тоже любят 16-тиричность). Таким образом, выяснив все коды, можно написать компилятор что-то вроде этого (см. листинг 2):
Commands:= Commands+#$A1#$00#$00; { mov [Из памяти] в AX}
aPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной a}
Commands:= Commands+#$03#$06#$00#$00;{ $03 – Это опкод команды ADD $06 – Это номер регистра AX}
bPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной b}
Commands:= Commands+#$A3#$00#$00; { mov из AX в переменку b}
b2Pos:= Length(Commands)-1;
{Запомним позицию для корректировки для переменной b}А далее, в конце, скорректируем эти позиции (см. листинг 3):
commands:= commands+#$01#$00; {Это переменка a, ее значение}
i:= length(commands);
commands[aPos]:= chr(lo(i)); {Не забудем, что адреса в перевернутом виде}
commands[
aPos+1]:= chr(hi(i)); {Поэтому сначала запишем младший байт}
commands:= commands+#$02#$00; {Это переменка b, ее значение}
i:= length(commands);
commands[bPos]:= chr
(lo(i)); {Поскольку переменка b фигурирует в коде}
commands[bPos+1]:= chr(hi(i)); {дважды придется корректировать ее}
commands[b2Pos]:= chr
span style=”color: #66cc66;”>(lo(i));
commands[b2Pos+1]:= chr(hi(i));Запустим компилятор, он скомпилирует экзэшник, который посмотрим в “Иде” (см. Рис. 10):
Рис. 10. Реверсинг нашего кода
Все верно, в регистр пошло значение одной переменной, сложилось со второй и во вторую же записалось. Это эквивалентно паскалевскому b:=b+a;
* Комментарий автора.
Обратите внимание: значения переменных мы заранее проинициализировали. При желании можно сделать, чтобы компилятор спросил их инициальное значение, и подставить в нужное место:
commands:=commands+#$01#$00; {Вот сюда вместо этих циферок}.
Post Scriptum
Ну как, студенты, воспряли духом? Теперь понятен смысл, куда двигаться в случае столкновения с такими задачами? Это вряд ли потянет на курсовую, но вполне подойдет для простенькой контрольной. А вот следующая задача – написать транслятор – уже действительно тянет даже на хороший диплом, так что пока переварим все то, что выше, а в следующий раз попробуем приготовить основное ядро компилятора, дабы потом уже делать упор на сам код программы.

Привет, друзья!
Представляю вашему вниманию перевод этой замечательной статьи.
Сегодня мы вместе с вами разработаем простейший компилятор кода на JavaScript. Без учета комментариев наша программа будет состоять примерно из 250 строк кода.
Мы будем компилировать lisp-подобные вызовы функций в C-подобные. Например, если у нас имеется 2 функции, add и subtract, то выглядеть они будут так:
Разумеется, это далеко не полный синтаксис LIST или C, но нам вполне этого хватит для демонстрации многих основных частей современного компилятора.
Если вам это интересно, прошу под кат.
Введение
Процесс компиляции кода условно можно разделить на 3 стадии:
- Разбор или парсинг (parsing) — сырой или необработанный (raw) код преобразуется в абстрактное представление (abstract representation).
- Преобразование или трансформация (transformation) — всевозможные операции (манипуляции) с абстрактным представлением кода, которые зависят от задач, решаемых компилятором.
- Генерация кода (code generation) — преобразование ранее трансформированного представления в новый код.
Парсинг
Парсинг, как правило, состоит из 2 этапов: лексического анализа (lexical analysis) и синтаксического анализа (syntactic analysis).
- Лексический анализ заключается в разделении необработанного кода на части, которые называются токенами (tokens). Эта задача выполняется так называемым токенизатором (tokenizer) или лексером (lexer). Токены — это массив небольших объектов, описывающих изолированные (относительно автономные) части синтаксиса. Токены могут быть числами, подписями (labels) (дополнительной, служебной информацией), пунктуацией, операторами, чем угодно.
- Синтаксический анализ заключается в преобразовании токенов в представление, описывающее каждую часть синтаксиса и ее отношения с другими частями (следующей, предыдущей, обоими и т.д.). Такое представление известно под названием промежуточного (intermediate) представления кода или абстрактного синтаксического дерева (abstract syntax tree, AST). AST — это объект с несколькими уровнями вложенности, содержащий представление кода, с которым, с одной стороны, удобно работать, с другой стороны, он содержит большое количество необходимой служебной информации.
Для такого синтаксиса:
(add 2 (subtract 4 2))Токены могут выглядеть так:
// paren - это parenthesis - скобка
[
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
]А AST так:
{
type: 'Program',
body: [
{
type: 'CallExpression',
name: 'add',
params: [
{
type: 'NumberLiteral',
value: '2',
},
{
type: 'CallExpression',
name: 'subtract',
params: [
{
type: 'NumberLiteral',
value: '4',
},
{
type: 'NumberLiteral',
value: '2',
}
]
}
]
}
]
}Трансформация
Следующий тип или стадия компиляции — это трансформация кода. На этой стадии мы берем AST из последнего шага и модифицируем его. Мы можем манипулировать AST на том же языке (программирования) или перевести его на другой язык.
Посмотрим, как мы можем трансформировать наше AST.
Вы могли заметить, что в нашем AST есть элементы, которые выглядят очень похоже. Речь идет об объектах со свойством type. Такие объекты называются узлами (nodes) AST. Эти узлы содержат определенные свойства, описывающие одну изолированную часть дерева.
У нас может быть узел NumberLiteral:
{
type: 'NumberLiteral',
value: '2',
}Или узел CallExpression:
{
type: 'CallExpression',
name: 'add',
params: [/* вложенные узлы */]
}В процессе трансформации AST мы можем манипулировать узлами, добавляя/удаляя/заменяя свойства, добавляя новые узлы, удаляя существующие узлы либо создавая новые сущности на его основе.
Поскольку наша цель — перевод функции на другой язык, мы сосредоточимся на создании нового AST, предназначенного для целевого (target) языка.
Обход
Для переноса каждого узла в новое AST, нам необходим какой-то способ для обхода (traverse) старого AST. Процесс обхода заключается в «посещении» каждого узла при движении в глубину (depth-first) (см. поиск в глубину, поиск в ширину).
Для приведенного выше AST порядок будет следующим:
Program— начинаем с верхнего уровня AST.CallExpression (add)— перемещаемся к первому элементу тела (body)Program.NumberLiteral (2)— перемещаемся к первому элементу параметров (params)CallExpression.CallExpression (subtract)— перемещаемся ко второму элементу параметровCallExpression.NumberLiteral (4)— перемещаемся к первому элементу параметров второгоCallExpression.NumberLiteral (2)— перемещаемся ко второму элементу параметров второгоCallExpression.
Если мы будем манипулировать этим AST напрямую вместо создания отдельного AST, нам придется прибегать к помощи всевозможных абстракций. Однако в данном случае нам достаточно посетить каждый узел.
Посетитель
Основная идея состоит в том, что мы создаем объект «посетителя» (visitor), который содержит методы, названия которых совпадают с разными типами узлов:
const visitor = {
NumberLiteral() {},
CallExpression() {}
}При обходе AST мы вызываем эти методы на посетителе при «входе» (enter) в узел совпадающего типа.
Кроме самого узла имеет смысл передавать посетителю ссылку на предка этого узла:
const visitor = {
NumberLiteral(node, parent) {},
CallExpression(node, parent) {}
}Также существует возможность вызывать вещи на «выходе» (exit) из узла. Представим приведенное выше дерево в виде списка:
- Program
- CallExpression
- NumberLiteral
- CallExpression
- NumberLiteral
- NumberLiteralСпускаясь вниз по дереву, рано или поздно мы упираемся в тупик (branch with dead end — ветку с мертвым концом). После этого мы «выходим» из этой ветки. Таким образом, спускаясь вниз, мы «входим» в каждый узел, а поднимаясь, «выходим» из него.
-> Program (вход)
-> CallExpression (вход)
-> Number Literal (вход)
<- Number Literal (выход)
-> Call Expression (вход)
-> Number Literal (вход)
<- Number Literal (выход)
-> Number Literal (вход)
<- Number Literal (выход)
<- CallExpression (выход)
<- CallExpression (выход)
<- Program (выход)Финальный посетитель может выглядеть так:
const visitor = {
NumberLiteral: {
enter(node, parent) {},
exit(node, parent) {}
},
CallExpression: {
enter(node, parent) {},
exit(node, parent) {}
}
}Генерация кода
Завершающей стадией компиляции является генерация кода. Иногда компиляторы делают вещи, пересекающиеся с трансформацией (совершают дополнительные операции), но по большей части генерация кода означает преобразование AST обратно в код.
Генераторы кода работают по-разному, некоторые используют существующие токены, другие создают отдельное представление кода, чтобы иметь возможность «печатать» (print) узлы линейно. Большинство генераторов применяет первый подход.
Наш генератор кода будет заранее знать, как «печатать» все типы узлов AST. Он будет рекурсивно вызывать себя для печати вложенных узлов до тех пор, пока все узлы не превратятся в одну длинную строку кода.
Вот и все! Мы на самом высоком уровне рассмотрели все основные части, из которых состоит компилятор.
Приступаем к его реализации.
Токенизатор
Начнем с первого этапа — парсинга: лексического анализа, выполняемого с помощью токенизатора.
На данном этапе мы берем строку кода и преобразуем ее в массив токенов:
(add 2 (subtract 4 2)) => [{ type: 'paren', value: '(' }, ...]Определим несколько вспомогательных регулярных выражений:
const WHITESPACE = /s/
const NUMBERS = /[0-9]/
const LETTERS = /[a-z]/ifunction tokenize(input) {
// своего рода курсор (cursor) для отслеживания нашей позиции в коде
let current = 0
// массив токенов
const tokens = []
while (current < input.length) {
// текущий символ
let char = input[current]
// если текущим символом является открывающая или закрывающая скобка
if (char === '(' || char === ')') {
// формируем токен и помещаем его в массив
tokens.push({
type: 'paren',
value: char
})
// инкрементируем курсор (увеличиваем его значение на 1)
current++
// и переходим на следующий цикл итерации
continue
}
// если текущим символом является пробел,
// просто инкрементируем курсор и
// переходим на следующий цикл
if (WHITESPACE.test(char)) {
current++
continue
}
// следующим типом токена является число,
// которое может состоять из любого количества символов
// (add 123 456)
// ^^^ ^^^ числовые токены
// мы хотим "захватывать" (capture) всю последовательность символов в качестве одного токена
if (NUMBERS.test(char)) {
// переменная для последовательности символов, из которых состоит число
let value = ''
// двигаемся по последовательности до достижения символа, который не является числом
// помещаем каждое число в последовательность и увеличиваем значение курсора
while (NUMBERS.test(char)) {
value += char
char = input[++current]
}
// формируем токен и добавляем его в массив
tokens.push({
type: 'number',
value
})
// переходим на следующий цикл
continue
}
// добавляем поддержку для строк, окруженных двойными кавычками (")
// (concat "foo" "bar")
// ^^^ ^^^ строковые токены
if (char === '"') {
let value = ''
// пропускаем открывающую двойную кавычку
char = input[++current]
// двигаемся по последовательности до достижения закрывающей двойной кавычки
while (char !== '"') {
value += char
char = input[++current]
}
// пропускаем закрывающую двойную кавычку
char = input[++current]
tokens.push({
type: 'string',
value
})
continue
}
// последним типом является именованный токен (токен с типом `name`)
// данный тип представляет токен, состоящий из последовательности символов,
// которые не являются числом
// в нашем случае речь идет о названиях функций
// (add 2 4)
// ^^^ именованный токен
if (LETTERS.test(char)) {
let value = ''
while (LETTERS.test(char)) {
value += char
char = input[++current]
}
tokens.push({
type: 'name',
value
})
continue
}
// выбрасываем исключение при наличии в строке кода символа неизвестного типа
throw new TypeError(`Неизвестный символ: ${char}`)
}
// возвращаем массив токенов
return tokens
}Парсер
Парсер берет массив токенов и преобразует его в AST:
[{ type: 'paren', value: '(' }, ...] => { type: 'Program', body: [...] }function parse(tokens) {
// курсор
let current = 0
// в данном случае вместо цикла (`while`) мы используем рекурсию
function walk() {
// извлекаем текущий токен
let token = tokens[current]
// если типом токена является число
if (token.type === 'number') {
// инкрементируем курсор
current++
// возвращаем узел AST типа `NumberLiteral` со значением токена
return {
type: 'NumberLiteral',
value: token.value
}
}
// делаем тоже самое для строки
if (token.type === 'string') {
current++
return {
type: 'StringLiteral',
value: token.value
}
}
// если текущим токеном является открывающая скобка,
// значит, далее будет название (вызов) функции
if (token.type === 'paren' && token.value === '(') {
// пропускаем открывающую скобку
token = tokens[++current]
// создаем базовый узел типа `CallExpression`
// со значением текущего токена в качестве названия,
// поскольку за открывающей скобкой следует именованный токен
const node = {
type: 'CallExpression',
name: token.value,
params: []
}
// пропускаем именованный токен
token = tokens[++current]
/*
* перебираем токены, которые станут параметрами (`params`)
* выражения вызова (`CallExpression`), до достижения закрывающей скобки
*
* здесь в игру вступает рекурсия. Вместо того, чтобы пытаться парсить потенциально бесконечный
* вложенный набор узлов, мы используем рекурсию
*
* рассмотрим наш код на LIST. Мы видим, что
* параметрами `add` является число и вложенное `CallExpression`,
* которое также содержит числа
*
* (add 2 (subtract 4 2))
*
* вы также могли заметить, что в нашем массиве токенов имеется 2 закрывающие скобки
* [
* { type: 'paren', value: '(' },
* { type: 'name', value: 'add' },
* { type: 'number', value: '2' },
* { type: 'paren', value: '(' },
* { type: 'name', value: 'subtract' },
* { type: 'number', value: '4' },
* { type: 'number', value: '2' },
* { type: 'paren', value: ')' }, <<< закрывающая скобка
* { type: 'paren', value: ')' }, <<< закрывающая скобка
* ]
*
* мы используем функцию `walk` для увеличения значения курсора и
* пропуска любых сложенных `CallExpression`
*
* перебираем токены до достижения токена с типом `paren` и значением закрывающей скобки
*/
while (
token.type !== 'paren' ||
(token.type === 'paren' && token.value !== ')')
) {
// вызываем функцию `walk`, которая возвращает узел
// помещаем этот узел в `params`
node.params.push(walk())
token = tokens[current]
}
// пропускаем закрывающую скобку
current++
// и возвращаем узел
return node
}
// если нам встретился токен с неизвестным типом
throw new TypeError(`Неизвестный тип токена: ${type}`)
}
// создаем AST с корневым (root) узлом типа `Program`
const ast = {
type: 'Program',
body: []
}
// вызываем `walk`, которая возвращает узлы AST
// помещаем их в массив `ast.body`
//
// причина, по которой мы делаем это внутри цикла, состоит в том,
// что в нашей программе `CallExpression` могут следовать одно за другим
// вместо того, чтобы быть вложенными
//
// (add 2 2)
// (subtract 4 2)
//
while (current < tokens.length) {
ast.body.push(walk())
}
// возвращаем AST
return ast
}Траверсер
Итак, у нас имеется AST, и мы хотим исследовать каждый узел с помощью посетителя. При посещении узла совпадающего типа должен вызываться соответствующий метод посетителя.
traverse(ast, {
Program: {
enter(node, parent) {
// ...
},
exit(node, parent) {
// ...
}
},
CallExpression: {
enter(node, parent) {
// ...
},
exit(node, parent) {
// ...
}
},
NumberLiteral: {
enter(node, parent) {
// ...
},
exit(node, parent) {
// ...
}
}
})// функция принимает AST и посетителя
function traverse(ast, visitor) {
// данная функция перебирает массив и
// для каждого его элемента вызывает функцию `traverseNode`
function traverseArray(array, parent) {
array.forEach((child) => {
traverseNode(child, parent)
})
}
// данная функция принимает узел и его предка для их передачи методам посетителя
function traverseNode(node, parent) {
// извлекаем методы посетителя по типу узла
const methods = visitor[node.type]
// вызываем метод `enter` при его наличии
if (methods && methods.enter) {
methods.enter(node, parent)
}
// выполняем операцию на основе типа узла
switch (node.type) {
// на верхнем уровне у нас имеется узел типа `Program`
// у этого узла имеется свойство `body` - массив узлов,
// который мы передаем функции `traverseArray`
//
// поскольку `traverseArray`, в свою очередь, вызывает `traverseNode`,
// мы выполняем рекурсивный обход дерева
case 'Program':
traverseArray(node.body, node)
break
// обходим параметры выражения вызова
case 'CallExpression':
traverseArray(node.params, node)
break
// в случае с числом и строкой узлы для посещения отсутствуют,
// поэтому мы их пропускаем
case 'NumberLiteral':
case 'StringLiteral':
break
// если нам встретился узел с неизвестным типом
default:
throw new TypeError(`Неизвестный тип узла: ${node.type}`)
}
// вызываем метод `exit` при его наличии
if (methods && methods.exit) {
methods.exit(node, parent)
}
}
// запускаем обход, вызывая `traverseNode` с AST, но без предка,
// поскольку на верхнем уровне AST не имеет родительских узлов
traverseNode(ast, null)
}Трансформер
Трансформер берет AST, передает его в функцию для обхода вместе с посетителем, что приводит к созданию нового AST.
// оригинальное AST
const originalAst = {
type: 'Program',
body: [{
type: 'CallExpression',
name: 'add',
params: [
{
type: 'NumberLiteral',
value: '2'
},
{
type: 'CallExpression',
name: 'subtract',
params: [
{
type: 'NumberLiteral',
value: '4'
},
{
type: 'NumberLiteral',
value: '2'
}
]
}
]
}]
}
// преобразованное AST
const transformedAst = {
type: 'Program',
body: [{
type: 'ExpressionStatement',
expression: {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: 'add'
},
arguments: [
{
type: 'NumberLiteral',
value: '2'
},
type: 'CallExpression',
callee: {
type: 'Identifier',
name: 'subtract'
},
arguments: [
{
type: 'NumberLiteral',
value: '4'
},
{
type: 'NumberLiteral',
value: '2'
}
]
]
}
}]
}function transform(ast) {
// новое AST
const newAst = {
type: 'Program',
body: []
}
// я собираюсь немного схитрить. Мы будем использовать
// свойство `context` родительского узла - узлы будут помещаться в их родительский контекст
//
// контекст - это ссылка *из* старого AST *на* новый
ast._context = newAst.body
// выполняем обход с AST и посетителем
traverse(ast, {
// первый метод принимает `NumberLiteral`
NumberLiteral: {
// мы посещаем его на входе
enter(node, parent) {
// создаем новый одноименный узел
// и помещаем его в родительский контекст
parent._context.push({
type: 'NumberLiteral',
value: node.value
})
}
},
// делаем тоже самое для `StringLiteral`
StringLiteral: {
enter(node, parent) {
parent._context.push({
type: 'StringLiteral',
value: node.value
})
}
},
// далее следует `CallExpression`
CallExpression: {
enter(node, parent) {
// начинаем с создания нового узла `CallExpression`
// с вложенным `Identifier`
let expression = {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: node.name
},
arguments: []
}
// определяем новый контекст в оригинальном `CallExpression`,
// который содержит ссылку на аргументы `expression`
node._context = expression.arguments
// проверяем, является ли родительский узел `CallExpression`
// если не является
if (parent.type !== 'CallExpression') {
// оборачиваем `CallExpression` в `ExpressionStatement`
// `CallExpression` верхнего уровня в `JS` являются инструкциями
expression = {
type: 'ExpressionStatement',
expression
}
}
// наконец, мы помещаем наше (возможно, обернутое в `ExpressionStatement`) `CallExpression` в родительский контекст
parent._context.push(expression)
}
}
})
// и возвращаем новое AST
return newAst
}Генерация кода
Генератор кода рекурсивно вызывает себя для преобразования каждого узла дерева в одну гигантскую строку кода.
function generateCode(node) {
// выполняем операцию на основе типа узла
switch (node.type) {
// если типом узла является `Program`, мы перебираем узлы в `body`
// и прогоняем их через генератор кода,
// объединяя с помощью символа перевода на новую строку
case 'Program':
return node.body.map(generateCode).join('n')
// для `ExpressionStatement` мы вызываем генератор кода для вложенного `expression`
// и добавляем точку с запятой
case 'ExpressionStatement':
return `${ generateCode(node.expression) };`
// для `CallExpression` мы формируем `callee` (вызываемого)
// добавляем открывающую скобку,
// перебираем узлы из массива `arguments`,
// пропускаем их через генератор, разделяем их запятыми
// и добавляем закрывающую скобку
case 'CallExpression':
return `${ generateCode(node.callee) }(${ node.arguments.map(generateCode).join(', ') })`
// для `Identifier` мы просто возвращаем название узла
case 'Identifier':
return node.name
// возвращаем значение узла
case 'NumberLiteral':
return node.value
// возвращаем значение узла, обернутое в двойные кавычки
case 'StringLiteral':
return `"${ node.value }"`
default:
throw new TypeError(`Неизвестный тип узла: ${node.type}`)
}
}Компилятор
Объединяем все части конвейера (pipeline) для создания нашего компилятора.
1) input => tokenize => tokens
2) tokens => parse => ast
3) ast => transform => newAst
4) newAst => generateCode => outputfunction compile(input) {
const tokens = tokenize(input)
const ast = parse(tokens)
const newAst = transform(ast)
const output = generateCode(newAst)
return output
}Полный код компилятора без комментариев:
const WHITESPACE = /s/
const NUMBERS = /[0-9]/
const LETTERS = /[a-z]/i
function tokenize(input) {
let current = 0
const tokens = []
while (current < input.length) {
let char = input[current]
if (char === '(' || char === ')') {
tokens.push({
type: 'paren',
value: char
})
current++
continue
}
if (WHITESPACE.test(char)) {
current++
continue
}
if (NUMBERS.test(char)) {
let value = ''
while (NUMBERS.test(char)) {
value += char
char = input[++current]
}
tokens.push({
type: 'number',
value
})
continue
}
if (char === '"') {
let value = ''
char = input[++current]
while (char !== '"') {
value += char
char = input[++current]
}
char = input[++current]
tokens.push({
type: 'string',
value
})
continue
}
if (LETTERS.test(char)) {
let value = ''
while (LETTERS.test(char)) {
value += char
char = input[++current]
}
tokens.push({
type: 'name',
value
})
continue
}
throw new TypeError(`Неизвестный символ: ${char}`)
}
return tokens
}
function parse(tokens) {
let current = 0
function walk() {
let token = tokens[current]
if (token.type === 'number') {
current++
return {
type: 'NumberLiteral',
value: token.value
}
}
if (token.type === 'string') {
current++
return {
type: 'StringLiteral',
value: token.value
}
}
if (token.type === 'paren' && token.value === '(') {
token = tokens[++current]
const node = {
type: 'CallExpression',
name: token.value,
params: []
}
token = tokens[++current]
while (
token.type !== 'paren' ||
(token.type === 'paren' && token.value !== ')')
) {
node.params.push(walk())
token = tokens[current]
}
current++
return node
}
throw new TypeError(`Неизвестный тип токена: ${type}`)
}
const ast = {
type: 'Program',
body: []
}
while (current < tokens.length) {
ast.body.push(walk())
}
return ast
}
function traverse(ast, visitor) {
function traverseArray(array, parent) {
array.forEach((child) => {
traverseNode(child, parent)
})
}
function traverseNode(node, parent) {
const methods = visitor[node.type]
if (methods && methods.enter) {
methods.enter(node, parent)
}
switch (node.type) {
case 'Program':
traverseArray(node.body, node)
break
case 'CallExpression':
traverseArray(node.params, node)
break
case 'NumberLiteral':
case 'StringLiteral':
break
default:
throw new TypeError(`Неизвестный тип узла: ${node.type}`)
}
if (methods && methods.exit) {
methods.exit(node, parent)
}
}
traverseNode(ast, null)
}
function transform(ast) {
const newAst = {
type: 'Program',
body: []
}
ast._context = newAst.body
traverse(ast, {
NumberLiteral: {
enter(node, parent) {
parent._context.push({
type: 'NumberLiteral',
value: node.value
})
}
},
StringLiteral: {
enter(node, parent) {
parent._context.push({
type: 'StringLiteral',
value: node.value
})
}
},
CallExpression: {
enter(node, parent) {
let expression = {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: node.name
},
arguments: []
}
node._context = expression.arguments
if (parent.type !== 'CallExpression') {
expression = {
type: 'ExpressionStatement',
expression
}
}
parent._context.push(expression)
}
}
})
return newAst
}
function generateCode(node) {
switch (node.type) {
case 'Program':
return node.body.map(generateCode).join('n')
case 'ExpressionStatement':
return `${generateCode(node.expression)};`
case 'CallExpression':
return `${generateCode(node.callee)}(${node.arguments
.map(generateCode)
.join(', ')})`
case 'Identifier':
return node.name
case 'NumberLiteral':
return node.value
case 'StringLiteral':
return `"${node.value}"`
default:
throw new TypeError(`Неизвестный тип узла: ${node.type}`)
}
}
function compile(input) {
const tokens = tokenize(input)
const ast = parse(tokens)
const newAst = transform(ast)
const output = generateCode(newAst)
return output
}
const lisp1 = '(add 2 2)'
const lisp2 = '(subtract 4 2)'
const lisp3 = '(add 2 (subtract 4 2))'
const c1 = compile(lisp1)
const c2 = compile(lisp2)
const c3 = compile(lisp3)
console.log([c1, c2, c3].join('n'))Посмотрим, как работает наш компилятор (и работает ли?).
Определяем 3 lisp-подобные функции:
const lisp1 = '(add 2 2)'
const lisp2 = '(subtract 4 2)'
const lisp3 = '(add 2 (subtract 4 2))'Преобразуем их в C-подобные функции:
const c1 = compile(lisp1)
const c2 = compile(lisp2)
const c3 = compile(lisp3)Выводим результат в консоль:
console.log([c1, c2, c3].join('n'))
/*
add(2, 2);
subtract(4, 2);
add(2, subtract(4, 2));
*/Поздравляю! Вы только что реализовали свой первый компилятор.
Благодарю за внимание и happy coding!
