Время на прочтение
4 мин
Количество просмотров 6.1K
Привет, Хабр. В рамках курса «Machine Learning. Advanced» подготовили для вас перевод интересного материала.
Также всех желающих приглашаем посмотреть открытый урок на тему
«Multi-armed bandits для оптимизации AB тестирования».

Извлекаем разговоры из аудиозаписи с легкостью, используя Python.
В этой статье вы узнаете, как использовать IBM Speech to Text API для распознавания речи из файла аудиозаписи. Мы будем использовать бесплатную версию API, которая имеет некоторые ограничения, такие как, например, длина звукового файла. Подробнее об API я расскажу в этой статье чуть позже. Позвольте мне начать с предоставления вам некоторой справочной информации о применении распознавания речи в нашей повседневной жизни.
Предпосылки
Если вы читаете эту статью, я уверен, что вы знакомы с термином «искусственный интеллект» и осознаете его важность. Никого не повергнет в шок, если я скажу, что одно из лучших применений искусственного интеллекта в повседневной жизни — это распознавание речи.
Распознавание речи из аудио позволяет нам как минимум экономить время — мы говорим, вместо того, чтобы что-либо набирать. Это делает использование наших технологических устройств более увлекательным и простым. Эта технология также помогает нам взаимодействовать с этими устройствами без написания какого-либо кода. Представьте, что люди должны знать программирование, чтобы отдавать команды Алексе или Сири. Это было бы очень тупо.

Мне не терпится показать вам распознаватель речи в действии. Давай приступим к работе. Вот шаги, которым мы будем следовать в этом проекте.
Содержание:
-
Облачные сервисы распознавания речи
-
Шаг 1 — Библиотека
-
Шаг 2 — Импорт аудиоклипа
-
Шаг 3 — Определение распознавателя
-
Шаг 4 — Распознаватель речи в действии
-
Заключительный шаг — Экспорт результата
Облачные сервисы распознавания речи
Многие гигантские технологические компании имеют собственные распознавательные модели. Я поделюсь некоторыми из них здесь, чтобы вы увидели общую картину. Эти API-интерфейсы работают через облако и могут быть доступны из любой точки мира, если есть подключение к интернету. Кроме того, большинство из них являются платными, но их можно протестировать бесплатно. Например, Microsoft предлагает годовой бесплатный доступ для облачной учетной записи Azure.
Вот некоторые из наиболее популярных облачных сервисов преобразования речи в текст:
-
Google Cloud
-
IBM Watson
-
Microsoft Azure
-
Amazon Transcribe
Шаг 1 — Библиотека
Для этого проекта нам понадобится всего одна библиотека. И это SpeechRecognition. SpeechRecognition распространяется бесплатно с открытым исходным кодом. Она поддерживает несколько механизмов распознавания речи и API. Такие как; Microsoft Azure Speech, Google Cloud Speech, API IBM Watson Speech to Text и другие. В этом проекте мы будем тестировать IBM Watson Speech to Text API. Не стесняйтесь изучить исходный код и документацию пакета SpeechRecognition здесь.
Начнем с установки пакета. Мы собираемся использовать pip, менеджер библиотек Python.
pip install SpeechRecognitionПосле завершения процесса установки мы можем открыть наш редактор кода. Вы также можете использовать Jupyter Notebook.
import speech_recognition as s_rШаг 2 — Импорт
Я записал голосовую заметку с помощью компьютера. Он был в формате m4a, но распознаватель не работает с форматом m4a. Вот почему мне пришлось преобразовать его в wav формат.
audio_file = s_r.AudioFile('my_clip.wav')
Шаг 3 — Определение распознавателя
На этом этапе все, что мы сделаем, это определим распознаватель речи. Ранее мы импортировали библиотеку. А теперь мы создадим новую переменную и присвоим ей атрибут распознавания.
rcgnzr = s_r.Recognizer()Шаг 4 — Распознаватель речи в действии
Пришло время действия! Мы запустим IBM speech to text на нашем аудиофайле. Перед запуском распознавателя я запущу функции, называемые “adjust_for_ambient_noise” и “record”, которые подавят шум и улучшат звук. Таким образом, наш распознаватель сможет выдавать более точные результаты.
with audio_file as source:
rcgnzr.adjust_for_ambient_noise(source)
clean_audio = rcgnzr.record(source)Отлично, теперь у нас есть достаточно чистая аудиозапись. А теперь давайте запустим распознаватель речи IBM. (Мне потребовалось несколько часов, чтобы понять, как IBM Speech-to-Text API интегрируется с библиотекой Python SpeechRecogniton). Вот лучший способ вызвать распознаватель через API:
recognized_speech_ibm = r.recognize_ibm(clean_audio, username="apkikey", password= "your API Key")Примечание: API IBM не работает без API-ключа. Нам нужно будет получить его на странице IBM Watson. Мне пришлось создать учетную запись для тестирования этой Speech-to-Text модели. Что мне понравилось в модели IBM, так это, что я могу обрабатывать 500 минут записей в месяц, используя триальную учетную запись, что более чем достаточно для учебных целей.
Последний шаг — экспорт результата
Мы почти закончили. Пора проверить результат. Наш распознаватель обнаружил речь в аудиофайле на предыдущем шаге. Мы продолжим и проверим, как это сработало. Если результат нас устроит, мы экспортируем его в текстовый документ.
Чтобы проверить распознанную речь, выведем переменную с распознанным текстом:
print(recognized_speech_ibm)
Выглядит хорошо. Мой аудиофайл был распознан как надо. Я читал абзац из этой статьи. Если вы не удовлетворены результатом, есть много способов предварительной обработки аудиофайла для получения лучших результатов. Вот хорошая статья, в которой представлена более подробная информация о распознавании речи и о том, как повысить качество распознавания.
Теперь я экспортирую распознанную речь в текстовый документ. Мы увидим сообщение «ready!» в нашем терминале по завершении экспорта.
with open('recognized_speech.txt',mode ='w') as file:
file.write("Recognized Speech:")
file.write("n")
file.write(recognized)
print("ready!")Поздравляю! Если вы читаете этот абзац, вы создали распознаватель речи. Надеемся, что вам понравилось это практическое руководство и вы узнали что-то новое сегодня. Лучший способ практиковать свои навыки программирования — заниматься интересными проектами. Я написал множеством других практических проектов, подобных этому. Не стесняйтесь обращаться ко мне, если у вас возникнут вопросы при реализации программы.
Подключайтесь. Посетите мой блог и YouTube, чтобы получить заряд вдохновения. Спасибо.
Узнать подробнее о курсе «Machine Learning. Advanced».
Посмотреть открытый урок на тему «Multi-armed bandits для оптимизации AB тестирования».

В маркетинге нужно постоянно работать с текстом: описывать концепции и тезисы, составлять брифы, придумывать вовлекающие и продающие формулировки. Это часто приходится делать прямо на ходу, когда под рукой нет ноутбука. В таких случаях свежую идею удобно наговорить голосом.
Расскажу про инструменты, которые делают работу с устным текстом проще. Программы для преобразования речи в текст позволяют надиктовать короткую заметку или объёмную статью. А функция транскрибации аудио и видеофайлов помогает в расшифровке длинных интервью и переговоров.
| Что нужно сделать | Какой инструмент подойдёт |
| Надиктовать текст в браузере | Google Документы, Speech to Text BOT, Speechpad, Dictation |
| Надиктовать текст на смартфон | Google Keep, Dictation для iOS, Speechnotes для Android |
| Транскрибировать аудио и видео | Speechlogger, Vocalmatic, RealSpeaker, Google Документы, Speechpad, Dictation |
| Расшифровать аудио- и видеозапись вручную | Zapisano |
Для онлайн-конвертации голоса в текст
Онлайн-конвертеры помогают записывать текст голосом. Принцип таких сервисов примерно одинаков: вы чётко проговариваете слова, а система преобразует их в текст и записывает. Полученный результат, скорее всего, придётся отредактировать: проставить знаки препинания, проверить правильность написания сложных слов. Чтобы сократить объём редактуры, используйте высокочувствительный микрофон, медленно и разборчиво произносите слова.
Google Документы
Сервис Google Документы позволяет переводить устную речь в записанный текст. Это встроенная функция с поддержкой разных языков.
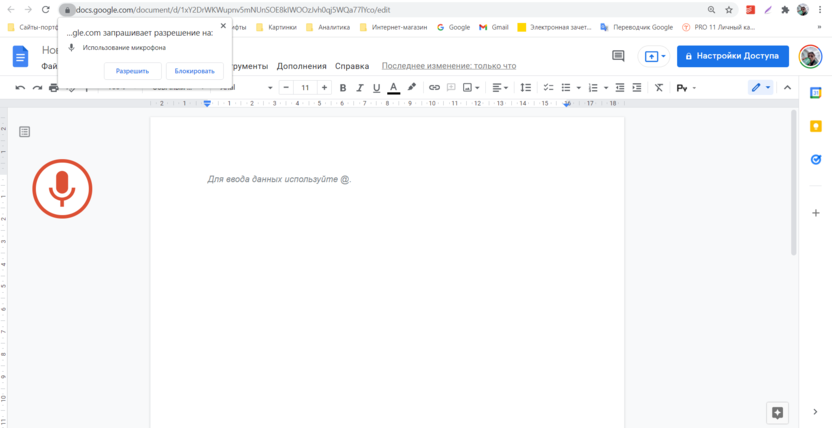
Для активации голосового ввода перейдите в раздел «Инструменты» и кликните на «Голосовой ввод».
Для использования голосового ввода в Google Документах не требуется установка плагинов
Затем нажмите на кнопку и говорите. Постарайтесь произносить слова медленно и чётко. Система умеет распознавать знаки препинания — просто говорите в нужных местах «Точка», «Запятая» и так далее. Также на русском языке можно использовать команды «Новая строка» и «Новый абзац». На английском языке перечень голосовых команд более обширный, полный список можно посмотреть в Справке.
Так выглядит результат голосового ввода от в Google Документах
Сервис неплохо конвертирует голос в текст при условии чёткого и правильного произношения. Но корректура всё равно может понадобиться — поправить регистр, проверить расстановку знаков препинаний и написание сложных слов.
Также в Google Документах можно транскрибировать аудио- и видеофайлы. Для этого включите воспроизведение файла на другом устройстве рядом с основным микрофоном. Способ работает, если речь в записи чёткая, разборчивая и не слишком быстрая. Для лучшего распознавания можно использовать замедленное воспроизведение.
Speech to Text BOT
Онлайн-сервис работает через браузер Chrome на десктопе и некоторых мобильных устройствах. Интерфейс интуитивно понятен: есть окно ввода текста, кнопка с микрофоном для запуска записи и список поддерживаемых команд.
Speech to Text BOT различает знаки препинания и заглавные буквы
Сервис поддерживает десятки разных языков. В настройках доступно форматирование текста: разные типа и размеры шрифта, написание предложений с заглавной буквы. Записанный текст можно редактировать, скачивать, отправлять в печать, копировать. Сервис неплохо переводит речь в текст при надиктовке, но не транскрибирует аудио- и видеофайлы, даже при их хорошем качестве.
Speechpad
Speechpad — удобный онлайн-блокнот для речевого ввода. Здесь можно надиктовывать текст на одном из пятнадцати доступных языков. Доступно параллельное форматирование текста: замена регистра, добавление знаков пунктуации и тегов. Запись речи включается и выключается по необходимости.
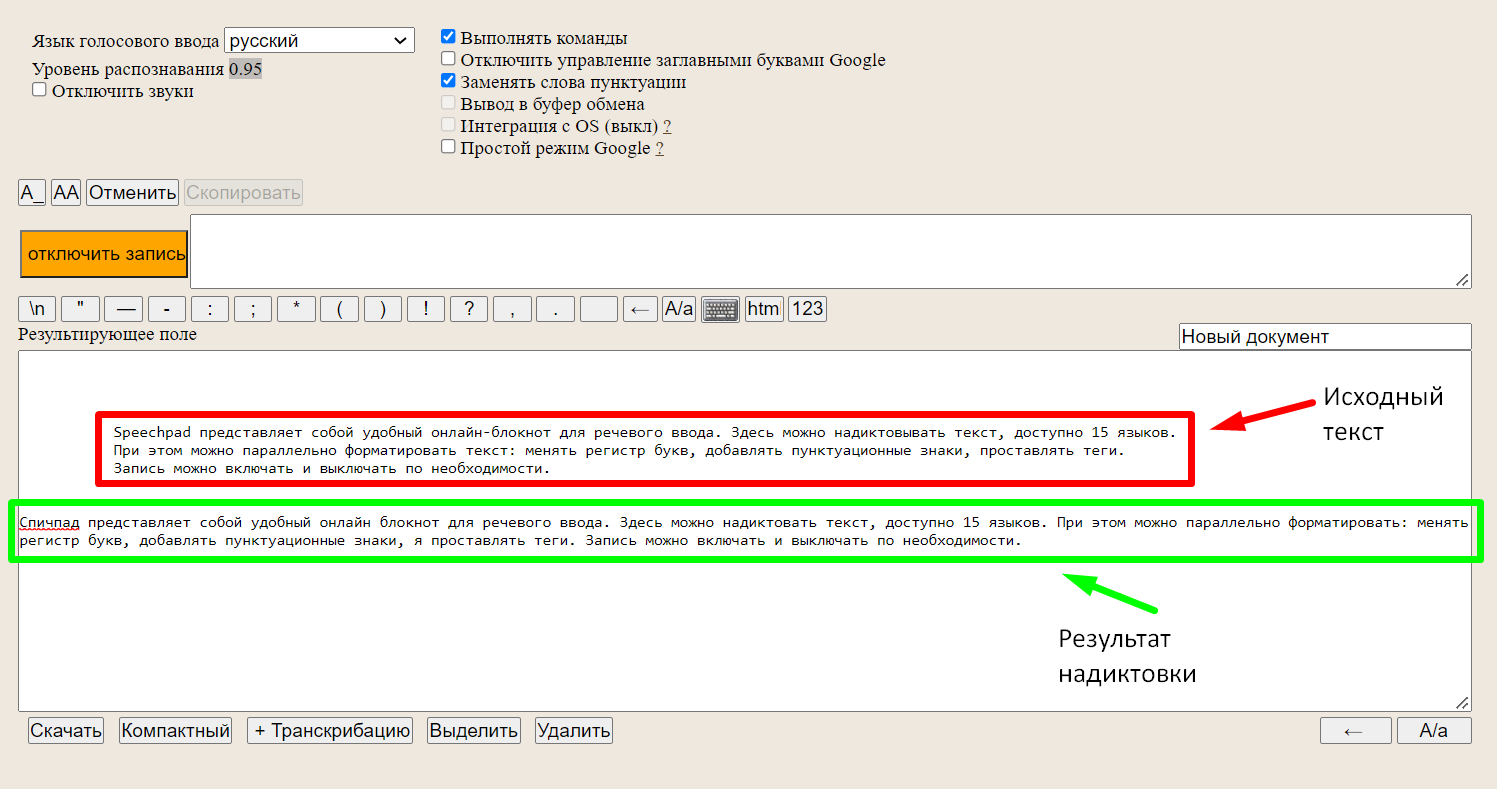
После диктовки в Speechpad получился почти точный текст
Speechpad поддерживает преобразование в текст аудио- и видеозаписей. Для этого кликните на кнопку «+Транскрибацию» под полем ввода. После обновления страницы загрузите нужный файл, укажите ссылку или ID видео с YouTube. При необходимости настройте параметры: качество и скорость воспроизведения, указание временных меток, защиту от шумов. После этого можно включать запись. Результат преобразования в текстовом формате появится в окошке блокнота на этой же странице.
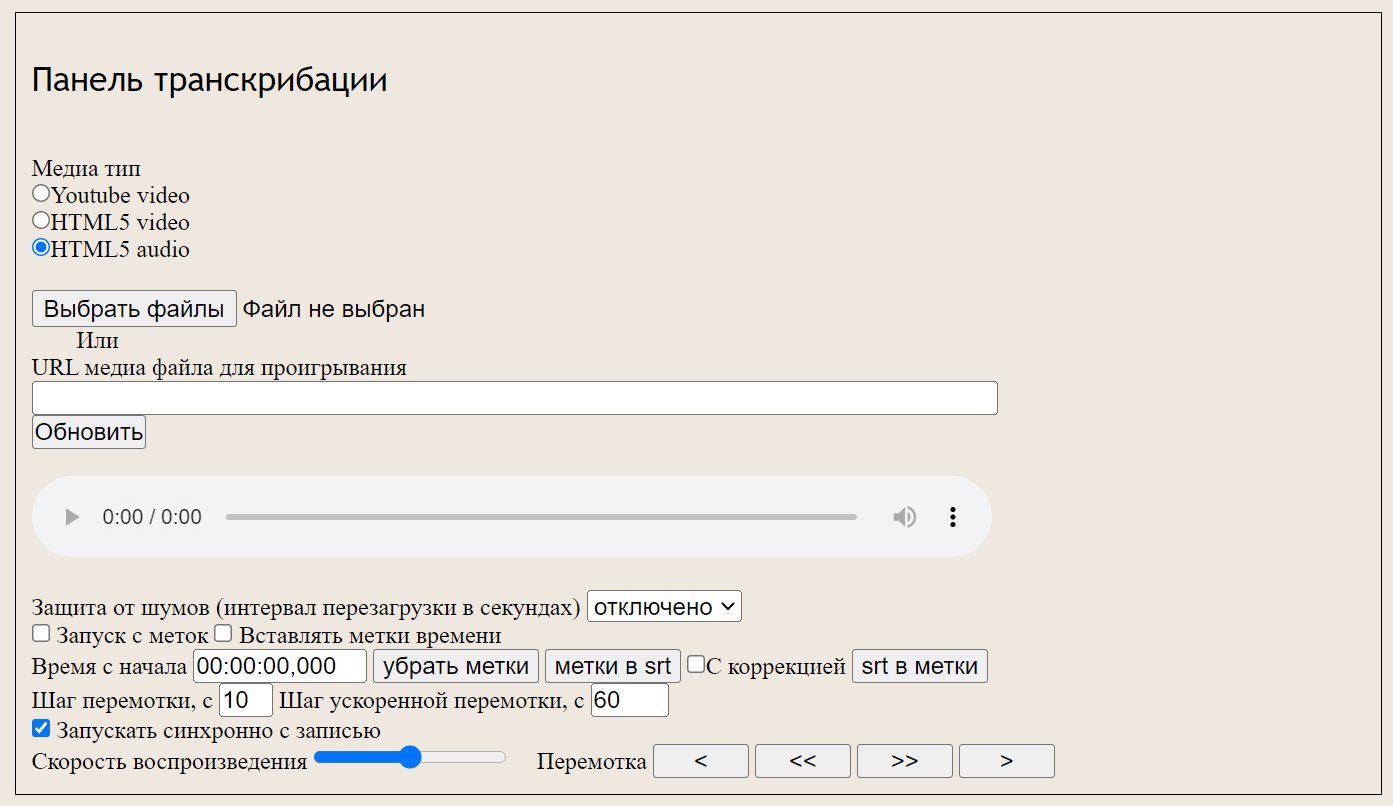
При конвертации записи в текст можно настраивать скорость воспроизведения, чтобы результат был более точным
Можно установить расширение, чтобы использовать голосовой ввод в любом текстовом поле браузера. Также есть модуль интеграции с Windows, Mac или Linux.
Dictation
Индийский сервис Dictation поддерживает более 100 языков, включая русский. Принцип работы схож с Google Документами, но скорость распознавания выше. При надиктовке используйте команды «Новая строка» и «Новый абзац». Указание знаков препинания учитывается не всегда, но их можно проставить вручную при редактуре полученного текста.
При надиктовке в Dictation могут не распознаваться или неверно преобразовываться отдельные слова
Результат можно отформатировать и отредактировать, скопировать, сохранить, опубликовать, твитнуть, отправить по email или распечатать. Качество распознавания в Dictation позволяет транскрибировать аудио- и видеофайлы. Для этого нужно включить их воспроизведение рядом с микрофоном. Готовый текст потребует редактуры.
Для преобразования речи в текст на мобильных устройствах
Если нужно записать какую-то мысль или идею вдалеке от рабочего стола, используйте мобильные сервисы. С их помощью можно надиктовать текст, сохранить его или отправить в другое приложение.
Google Keep
Google Keep позволяет надиктовывать заметки голосом. Сервис преобразует речь в текст, который при необходимости можно отредактировать. Созданные заметки синхронизируются на разных устройствах одного аккаунта. Их можно открыть на телефоне или компьютере, через приложение или веб-версию, в Google Документах или в Gmail.
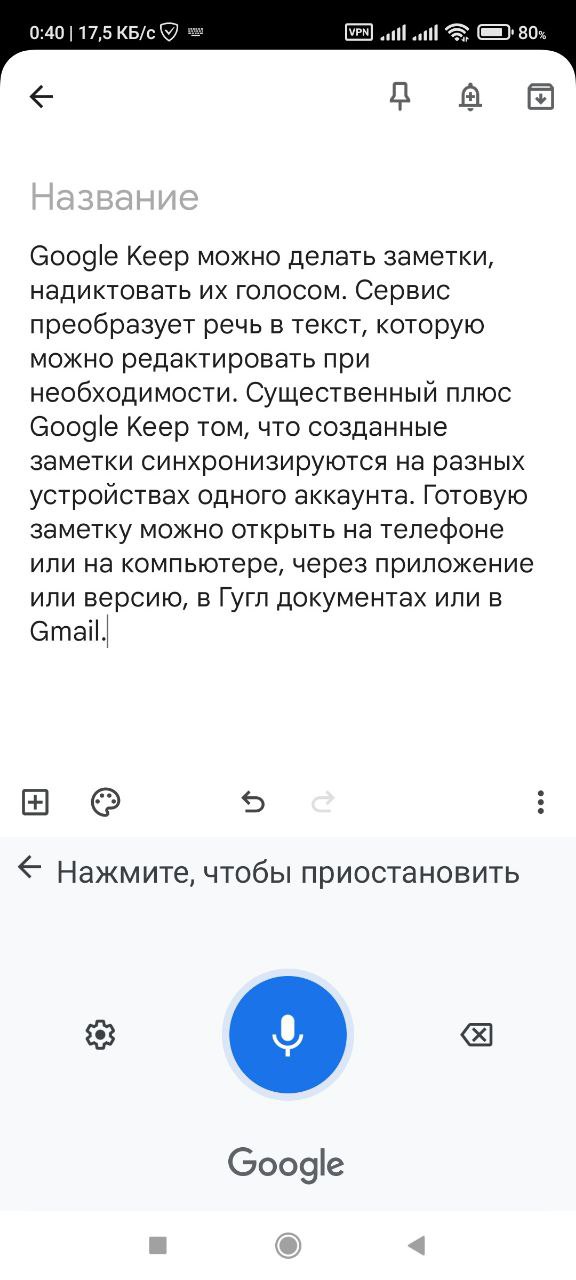
При записи текста голосом в Google Keep можно делать паузы
Заметки из Google Keep можно копировать в Google Документы и отправлять через email или в соцсети.
Dictation для iOS
Плюс этого приложения для iOS — в отсутствии ограничений по времени диктовки. Dictation поддерживает 40 языков, а надиктованный текст можно быстро перевести на другой язык.

В Dictation можно быстро писать заметки для соцсетей
Также приложение позволяет транскрибировать аудиофайлы. Все записи синхронизируются на разных устройствах при включенном iCloud. Надиктованными текстами можно делиться: отправлять в мессенджеры или по email.
Speechnotes для Android
Приложение Speechnotes работает на основе распознавания речи Google. Для начала записи достаточно кликнуть по кнопке микрофона и начать говорить. Некоторые знаки пунктуации можно озвучивать голосом, для других доступна встроенная клавиатура, которой можно пользоваться прямо в процессе надиктовки.
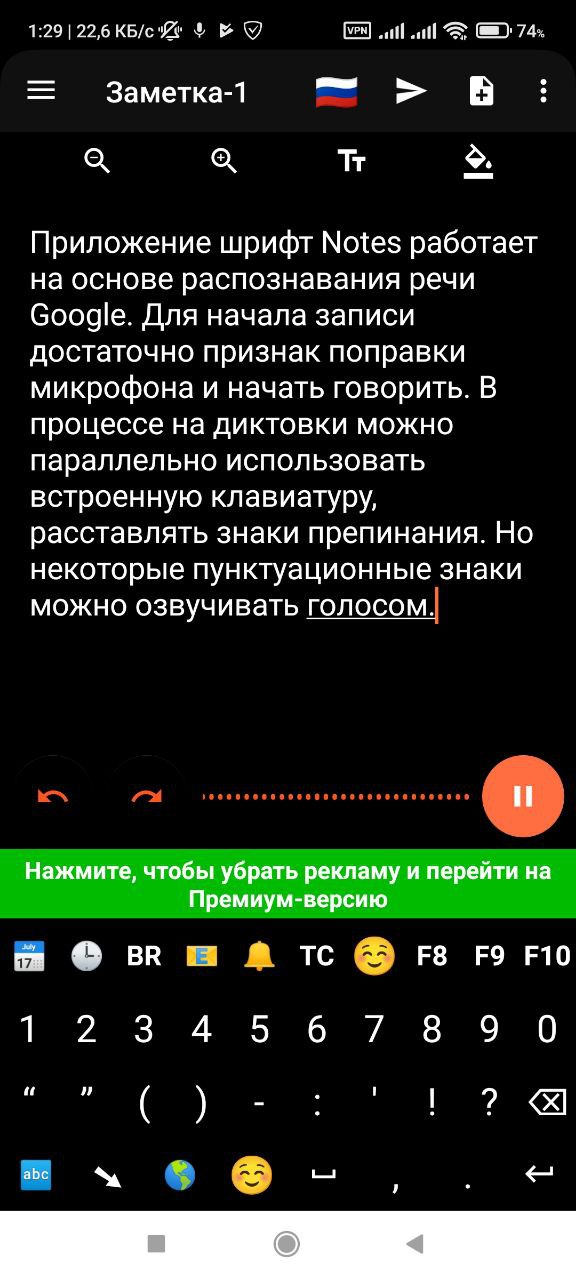
Результат надиктовки в Speechnotes требует совсем незначительной редактуры
Готовый текст можно отредактировать, сохранить, переслать, распечатать. В премиум-версии (от 1,5$) доступно создание клавиш для вставки самых используемых фраз.
Для автоматической транскрибации аудио и видео
Ручная расшифровка аудио- и видеофайлов, как правило, занимает много времени. Надо прослушать небольшую часть записи, сделать паузу, записать, снова включить запись — и так много раз. Если доверить расшифровку специализированным сервисам, получение результата займёт столько же времени, сколько длится запись, или даже меньше.
Speechlogger
Speechlogger преобразовывает голос в текст. Также его можно использовать как блокнот. В сервисе есть функция расшифровки аудио- и видеофайлов в форматах .aac, .m4a, .avi, .mp3, .mp4, .mpeg, .ogg, .raw, .flac, .wav.
Speechlogger работает с применением технологий искусственного интеллекта. При транскрибации автоматически проставляется пунктуация и временные метки. Для начала работы нужна авторизация через Google аккаунт.
В Speechlogger можно включить или отключить временные метки
Стоимость расшифровки — $0,1/минута. Минимальная сумма для пополнения баланса — $4,5. Время обработки соответствует длительности записи. Уведомление о готовности приходит на email. Точность расшифровки варьируется от 100 до 84% и зависит от качества записи.
Vocalmatic
В этом сервисе можно конвертировать в текст аудио- и видеофайлы. Vocalmatic поддерживает 100+ языков, в том числе и русский. Готовый текст можно подправить в онлайн-редакторе и сохранить в Word или Блокнот.
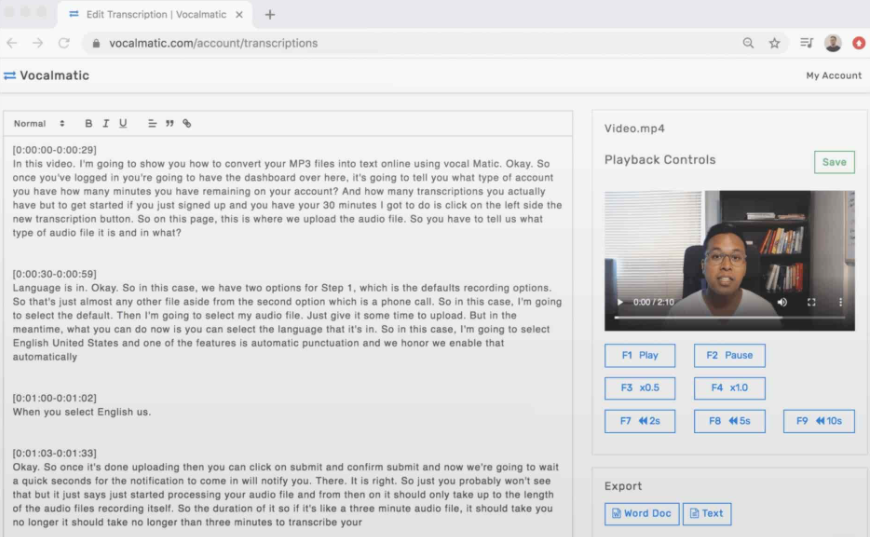
В редакторе Vocalmatic можно сразу отредактировать текст
Для новой учётной записи доступно 30 минут бесплатной расшифровки. Этого хватает, чтобы проверить качество готового текста. Час транскрипции стоит $15, но чем больше часов покупаешь единовременно, тем ниже цена.
RealSpeaker
Сервис позволяет транскрибировать аудио- и видеофайлы длительностью до 180 минут. Для запуска расшифровки нужно выбрать язык записи, загрузить файл и запустить процесс. Транскрибация платная — 8 руб./минута. Есть возможность потестировать сервис, поскольку 1,5 минуты расшифровки доступны бесплатно.
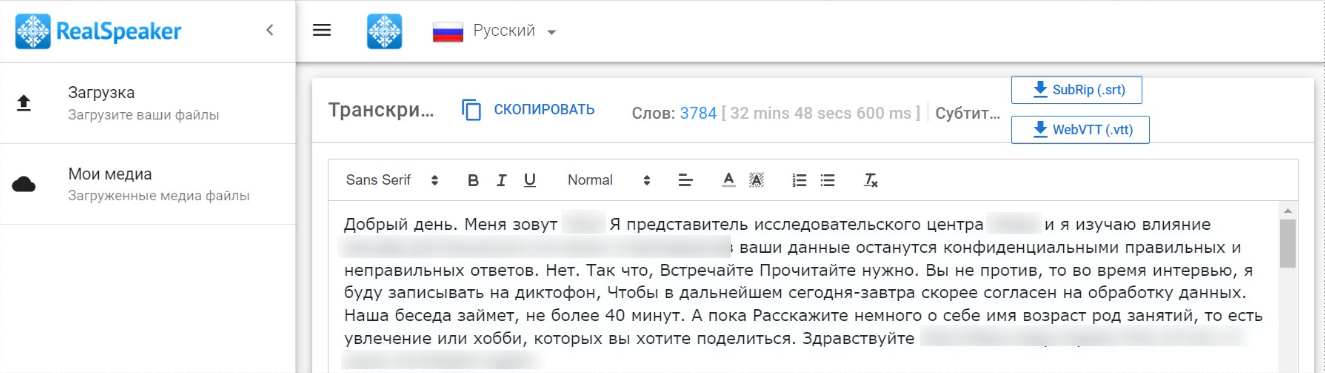
При транскрибации в RealSpeaker автоматически проставляются знаки препинания
Готовый текст можно подкорректировать в онлайн-редакторе, а затем скопировать или скачать в формате SRT или WebVTT. Стоит учитывать, что все результаты попадают в общее хранилище. Если в процессе загрузки файла оставить галочку «Сделать файл неудаляемым в течение 24 часов», то результат расшифровки нельзя удалить в течение суток. Если галочку убрать, то результат расшифровки можно удалить сразу после его копирования.
Для ручной расшифровки аудио- и видеозаписей
Результат автоматической расшифровки почти всегда требует доработки — проставить знаки препинания, подправить термины, заменить неверное написание отдельных слов. Если времени на доработку материала нет и нужна идеальная расшифровка, лучше доверить преобразование записей живым людям. Можно поискать частного специалиста или воспользоваться услугами специализированного сервиса.
Zapisano
Zapisano — сервис профессиональной ручной расшифровки аудио и видео: транскрибацией занимаются не машины, а люди. Это обеспечивает качественный результат, отсутствие «мусора» и верную пунктуацию. Помимо русского сервис поддерживает и некоторые иностранные языки.

При расшифровке файлов в Zapisano тексты сразу редактируют
Стоимость расшифровки зависит от сложности документа и временного периода. Так в категории «Стандарт» обработка файла стоит от 19 до 50 рублей за минуту, а длительность расшифровки варьируется от пяти до одного дня. Чем сложнее материал и выше срочность, тем дороже услуга. Можно самостоятельно просчитать стоимость при помощи тарифного калькулятора.
Ни один сервис с автоматическим преобразованием речи в текст не заменяет качественной ручной транскрибации. В большинстве случаев результат придётся редактировать. Но инструменты для перевода голоса в текст могут пригодиться при создании быстрых заметок, надиктовке объёмных материалов или черновой расшифровке записей.
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы и интервью с экспертами диджитала.
Продолжаем серию статей по практическому применению Python. Попробуем решить задачу транскрибации записи речи из аудио в текст. Это не rocket science  Такие задачи уже решаются продуктами на рынке и довольно неплохо (Сбер, Yandex). Моя цель – не конкурировать, а показать, что такие серьезные задачи можно начать решать с минимальным порогом входа: достаточно базовых знаний в программировании на Python.
Такие задачи уже решаются продуктами на рынке и довольно неплохо (Сбер, Yandex). Моя цель – не конкурировать, а показать, что такие серьезные задачи можно начать решать с минимальным порогом входа: достаточно базовых знаний в программировании на Python.
Направление естественного анализа речи – целая область в NLP (Natural Language Processing). Дело в том, что компьютер очень быстро считает, но вот с пониманием смысла у него проблемы. Программа может быстро подсчитать количество слов в произведении «Война и мир», но с анализом смысла будут проблемы. А вот NLP пытается докопаться до смыслов.
Прежде чем анализировать речь, ее необходимо перевести в текст, а уже его подвергать анализу. Напрямую анализировать аудио – такого я не встречал (поправьте, если есть реализации, очень интересно посмотреть). В этой статье мы как раз займемся расшифровкой аудио в текст.
Для работы нам понадобится Python 3.8+, библиотека для распознавания речи – Vosk. Немного про библиотеку Vosk:
- Поддерживает 20+ языков и диалектов.
- Работает без доступа к сети даже на мобильных устройствах – Raspberry Pi, Android, iOS.
- Устанавливается с помощью простой команды pip3 install vosk без дополнительных шагов.
- Сделана для потоковой обработки звука, что позволяет реализовать мгновенную реакцию на команды.
- Поддерживает несколько популярных языков программирования – Java, C#, Javascript, Python.
- Позволяет быстро настраивать словарь распознавания для улучшения точности распознавания.
- Позволяет идентифицировать говорящего.
- Библиотека активно контрибьютится и поддерживается.
Перевод аудио в текст
Чтобы реализовать транскрибацию из аудио в текст, нам необходимо решить следующие задачи:
- Вытащить части речи из аудио.
- Расставить пробелы на паузах между частями речи.
- Добавить пунктуацию в текст.
Все действия буду делать на машине с Ubuntu 20 (Python 3.8) со следующей конфигурацией:
- CPU 2vCPU.
- RAM 12GB.
- HDD 20GB.
Причина использования такого количества RAM в том, что мы делаем распознавание на универсальной модели, то есть модели размером 50 Мб, которая требует в разы меньше оперативной памяти в работе, чем полноценная модель. Правда, качество распознавания в этом случае уменьшится.
Создаем директорию speech:
mkdir speech
cd speech
Далее необходимо поставить зависимости для Python:
apt install python3-pip
pip3 install ffmpeg
pip3 install pydub
pip3 install vosk
pip3 install torch
pip3 install transformers
Также скачиваем и распаковываем модель для распознавания русской речи, выполнив команды:
curl -o ./model.zip https://alphacephei.com/vosk/models/vosk-model-ru-0.22.zip
unzip model.zip
mv vosk-model-ru-0.22/ model
rm -rf model.zip
В результате этих действий мы скопировали к себе модель, разархивировали ее и переименовали директорию. Также удалили скачанный архив. Всё-таки он весит 1.5 Гб. Для расстановки пунктуации делаем похожие действия: скачиваем еще одну модель весом 1.5 Гб.
curl -o recasepunc.zip https://alphacephei.com/vosk/models/vosk-recasepunc-ru-0.22.zip
unzip recasepunc.zip
mv vosk-recasepunc-ru-0.22/ recasepunc
rm -rf recasepunc.zip
Код файла app.py, который выполняет перевод аудио в текст.
from vosk import Model, KaldiRecognizer, SetLogLevel
from pydub import AudioSegment
import subprocess
import json
import os
SetLogLevel(0)
# Проверяем наличие модели
if not os.path.exists("model"):
print ("Please download the model from https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit (1)
# Устанавливаем Frame Rate
FRAME_RATE = 16000
CHANNELS=1
model = Model("model")
rec = KaldiRecognizer(model, FRAME_RATE)
rec.SetWords(True)
# Используя библиотеку pydub делаем предобработку аудио
mp3 = AudioSegment.from_mp3('Song.mp3')
mp3 = mp3.set_channels(CHANNELS)
mp3 = mp3.set_frame_rate(FRAME_RATE)
# Преобразуем вывод в json
rec.AcceptWaveform(mp3.raw_data)
result = rec.Result()
text = json.loads(result)["text"]
# Добавляем пунктуацию
cased = subprocess.check_output('python3 recasepunc/recasepunc.py predict recasepunc/checkpoint', shell=True, text=True, input=text)
# Записываем результат в файл "data.txt"
with open('data.txt', 'w') as f:
json.dump(cased, f, ensure_ascii=False, indent=4)
Последний штрих – разместить файл Song.mp3 в нашей директории с исполняемым файлом app.py. Затем запускаем app.py. В результате наша программа обработает файл .mp3 и на основе натренированных моделей из библиотеки Vosk сделает транскрибацию аудио в текст с сохранением результата в файл data.txt.
***
Наша реализация решает поставленные задачи в начале статьи. Но это скорее MVP, чем продуманное решение для продакшена. Если мы начнем углубляться, то перед нами встанут задачи обработки больших аудио (от часа и более), организации многопоточности, балансировки и горизонтального масштабирования и много чего интересного. Библиотека VOSK позволяет со всем этим справиться. Но это уже другая история
Материалы по теме
- 📊 NLP и визуализация текста на примере твитов о президентских выборах в США
- 🤖 Практическое руководство по NLP: изучаем классификацию текстов с помощью библиотеки fastText
- Обзор четырёх популярных NLP-моделей 🙊 💬
- NLP – это весело! Обработка естественного языка на Python
Speech-to-Text (Russian)
![]()
Проект для распознавания речи на русском языке на основе pykaldi.
Установка
Самостоятельная (Linux)
- Установить kaldi:
https://kaldi-asr.org/doc/tutorial_setup.html
- Установить необходимые Python-библиотеки:
$ pip install -r requirements.txt
- Установить pykaldi:
- С помощью conda (с поддержкой GPU):
$ conda install -c pykaldi pykaldi
- С помощью conda (без поддержки GPU):
$ conda install -c pykaldi pykaldi-cpu
- Собрать из исходников (раздел From Source):
https://github.com/pykaldi/pykaldi
- Добавить в PATH пути к компонентам kaldi:
$ PATH /kaldi/src/featbin:/kaldi/src/ivectorbin:/kaldi/src/online2bin:/kaldi/src/rnnlmbin:/kaldi/src/fstbin:$PATH
- Склонировать репозиторий проекта:
$ git clone https://github.com/SergeyShk/Speech-to-Text-Russian.git
- Отредактировать файл model/conf/ivector_extractor.conf, указав в нем корректные директории
Docker
- Собрать docker-образ:
$ docker build -t speech_recognition:latest .
Или
$ docker pull ghcr.io/sergeyshk/stt-ru:0.2.0
- Создать docker-том для работы с внешними данными:
$ docker volume create -d local -o type=none -o o=bind -o device=[DIR] asr_volume
- Запустить docker-контейнер:
$ docker run -it --rm -p 9000:9000 -p 5000:5000 -v asr_volume:/archive speech_recognition
Структура проекта
Файлы проекта расположены в директории /speech_recognition:
- start_recognition.py — скрипт запуска процедуры распознавания;
- /tools — набор инструментов для распознавания:
- data_preparator.py — скрипт подготовки данных для распознавания;
- recognizer.py — скрипт распознавания речи;
- segmenter.py — скрипт сегментации речи;
- transcriptins_parser.py — скрипт парсинга результатов распознавания;
- /model — набор файлов для модели распознавания;
- /web — веб-приложение с демо-стендом распознавания речи;
- /examples — набор ноутбуков с примерами работы инструментов.
Модель
В качестве акустической и языковой модели используется русскоязычная модель от alphacep:
http://alphacephei.com/kaldi/kaldi-ru-0.6.tar.gz
При необходимости использования собственной модели, необходимо заменить соответствующие файлы в директории /model.
Внимание! Размер файла HCLG.fst составляет более 500МБ, поэтому для корректного клонирования репозитория необходимо установить на свой компьютер GitHub LFS. Также можно скачать данный файл вручную с соответствующей страницы проекта.
Запуск
Распознавание речи
- Подготовить директорию для размещения WAV-файлов;
- Для запуска процедуры распознавания речи выполнить команду:
$ ./start_recognition.py /archive/wav /archive/output -dw -l
- Для запуска режима мониторинга директории выполнить команду:
$ ./start_recognition.py /archive/wav /archive/output -l -t 60 -d 1
Описание параметров запуска доступно по команде:
$ ./start_recognition.py -h
usage: start_recognition.py [-h] [-rm REC_MODEL] [-rg REC_GRAPH] [-rw REC_WORDS] [-rc REC_CONF] [-ri REC_ICONF] [-sm SEGM_MODEL] [-sc SEGM_CONF] [-sp SEGM_POST] [-p PROCESSES] [-l] [-dw] [-t TIME] [-d DELTA] WAV OUT Запуск процедуры распознавания речи positional arguments: WAV Путь к .WAV файлам аудио OUT Путь к директории с результатами распознавания optional arguments: -h, --help show this help message and exit -rm REC_MODEL, --rec_model REC_MODEL Путь к .MDL файлу модели распознавания -rg REC_GRAPH, --rec_graph REC_GRAPH Путь к .FST файлу общего графа распознавания -rw REC_WORDS, --rec_words REC_WORDS Путь к .TXT файлу текстового корпуса -rc REC_CONF, --rec_conf REC_CONF Путь к .CONF конфигурационному файлу распознавания -ri REC_ICONF, --rec_iconf REC_ICONF Путь к .CONF конфигурационному файлу векторного экстрактора -sm SEGM_MODEL, --segm_model SEGM_MODEL Путь к .RAW файлу модели сегментации -sc SEGM_CONF, --segm_conf SEGM_CONF Путь к .CONF конфигурационному файлу сегментации -sp SEGM_POST, --segm_post SEGM_POST Путь к .VEC файлу апостериорных вероятностей сегментации -p PROCESSES, --processes PROCESSES Количество процессов для обработки файлов -l, --log Логировать результат распознавания -dw, --delete_wav Удалять .WAV файлы после распознавания -t TIME, --time TIME Пауза перед очередным сканированием директории в секундах -d DELTA, --delta DELTA Дельта, выдерживаемая до чтения файла в минутах
Демонстрационный стенд
- Запустить веб-сервер:
$ cd web
$ ./app.py
- Перейти по адресу:
http://0.0.0.0:5000
Сервис ноутбуков
- Запустить сервис:
$ jupyter notebook --no-browser --ip=0.0.0.0 --port=9000 --allow-root
- Перейти по адресу:
http://0.0.0.0:9000
В первом случае обе программы пропустили огромные куски текста — Realspeaker из нераспознанных 51 слов попытался восстановить только 3 («я», «пацан», «по»), остальные просто пропустил. Vocalmatic — из того же количества нераспознанных слов попытался восстановить 4 («общается», «до», «работы», «потом»). Так как в задаче распознавания речи применяются рекуррентные нейронные сети, которые могут угадывать пропущенные элементы по контексту (как это делает человек), такое огромное количество просто пропущенного текста говорит о том, что все эти слова были восприняты как шум — печать принтера, мелодия на телефоне, топот, разговор по скайпу за соседним столом.
«Нормальная навигация» у Realspeaker превратилась в «нормального пацана» (хотя слово «навигация» он отлично знает и распознал его в конце текста). А «получается он нормальная навигация» у Vocalmatic превратилось в «нормально общается». Видимо, в том корпусе текстов, на базе которых обучаются данные нейронные сети, гораздо чаще встречаются сочетания слов «нормальный пацан» и «нормально общается» (может, они обучаются на архивах ФСИН?).
Удивительно, что программы не распознают предлоги: выдают «принципе», а не «в принципе», «соответствии», а не «в соответствии».
Получается, что качество распознавания текстов в обеих программах колеблется от 20% до 97%. Для высокого качества необходимо создать идеальные условия. Но, увы, брать комментарии в отдельной комнате не получится, потому что комментарий сопровождается показом на компьютере тех фичей, о которых идет речь. Просить программистов говорить громко и внятно бесполезно. Всех вокруг замолчать, не дышать и не шевелиться — тоже. Так что под наши реальные задачи программы все-таки пока не подходят, несмотря на все достижения в обучении рекуррентных нейронных сетей. Но если вы транскрибируете идеально записанные тексты, обе программы станут вам отличными помощниками.
·
7 min read
· Updated
aug 2022
· Machine Learning
· Application Programming Interfaces
Disclosure: This post may contain affiliate links, meaning when you click the links and make a purchase, we receive a commission.
Speech recognition is the ability of computer software to identify words and phrases in spoken language and convert them to human-readable text. In this tutorial, you will learn how you can convert speech to text in Python using the SpeechRecognition library.
As a result, we do not need to build any machine learning model from scratch, this library provides us with convenient wrappers for various well-known public speech recognition APIs (such as Google Cloud Speech API, IBM Speech To Text, etc.).
Note that if you do not want to use APIs, and directly perform inference on machine learning models instead, then definitely check this tutorial, in which I’ll show you how you can use the current state-of-the-art machine learning model to perform speech recognition in Python.
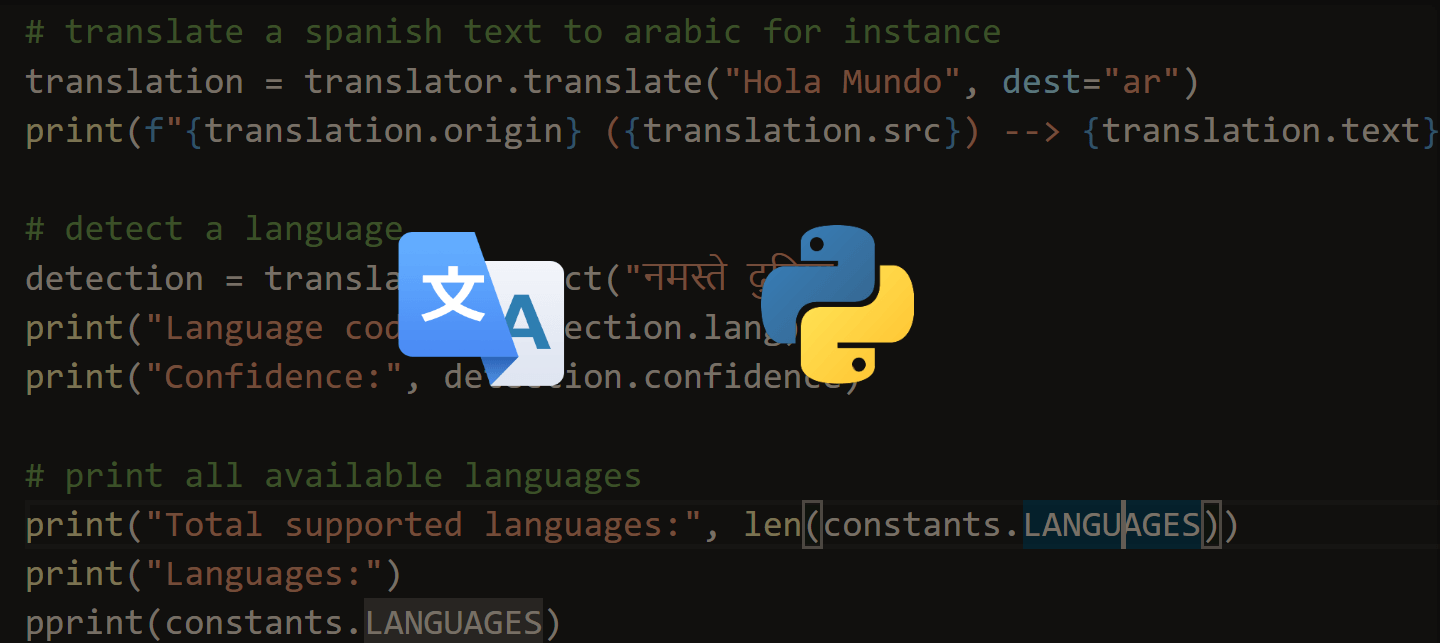
Learn also: How to Translate Text in Python.
Alright, let’s get started, installing the library using pip:
pip3 install SpeechRecognition pydubOkay, open up a new Python file and import it:
import speech_recognition as srThe nice thing about this library is it supports several recognition engines:
- CMU Sphinx (offline)
- Google Speech Recognition
- Google Cloud Speech API
- Wit.ai
- Microsoft Bing Voice Recognition
- Houndify API
- IBM Speech To Text
- Snowboy Hotword Detection (offline)
We gonna use Google Speech Recognition here, as it’s straightforward and doesn’t require any API key.
Reading from a File
Make sure you have an audio file in the current directory that contains English speech (if you want to follow along with me, get the audio file here):
filename = "16-122828-0002.wav"This file was grabbed from the LibriSpeech dataset, but you can use any audio WAV file you want, just change the name of the file, let’s initialize our speech recognizer:
# initialize the recognizer
r = sr.Recognizer()The below code is responsible for loading the audio file, and converting the speech into text using Google Speech Recognition:
# open the file
with sr.AudioFile(filename) as source:
# listen for the data (load audio to memory)
audio_data = r.record(source)
# recognize (convert from speech to text)
text = r.recognize_google(audio_data)
print(text)This will take a few seconds to finish, as it uploads the file to Google and grabs the output, here is my result:
I believe you're just talking nonsenseThe above code works well for small or medium size audio files. In the next section, we gonna write code for large files.
Reading Large Audio Files
If you want to perform speech recognition of a long audio file, then the below function handles that quite well:
# importing libraries
import speech_recognition as sr
import os
from pydub import AudioSegment
from pydub.silence import split_on_silence
# create a speech recognition object
r = sr.Recognizer()
# a function that splits the audio file into chunks
# and applies speech recognition
def get_large_audio_transcription(path):
"""
Splitting the large audio file into chunks
and apply speech recognition on each of these chunks
"""
# open the audio file using pydub
sound = AudioSegment.from_wav(path)
# split audio sound where silence is 700 miliseconds or more and get chunks
chunks = split_on_silence(sound,
# experiment with this value for your target audio file
min_silence_len = 500,
# adjust this per requirement
silence_thresh = sound.dBFS-14,
# keep the silence for 1 second, adjustable as well
keep_silence=500,
)
folder_name = "audio-chunks"
# create a directory to store the audio chunks
if not os.path.isdir(folder_name):
os.mkdir(folder_name)
whole_text = ""
# process each chunk
for i, audio_chunk in enumerate(chunks, start=1):
# export audio chunk and save it in
# the `folder_name` directory.
chunk_filename = os.path.join(folder_name, f"chunk{i}.wav")
audio_chunk.export(chunk_filename, format="wav")
# recognize the chunk
with sr.AudioFile(chunk_filename) as source:
audio_listened = r.record(source)
# try converting it to text
try:
text = r.recognize_google(audio_listened)
except sr.UnknownValueError as e:
print("Error:", str(e))
else:
text = f"{text.capitalize()}. "
print(chunk_filename, ":", text)
whole_text += text
# return the text for all chunks detected
return whole_textNote: You need to install Pydub using pip for the above code to work.
The above function uses split_on_silence() function from pydub.silence module to split audio data into chunks on silence. The min_silence_len parameter is the minimum length of silence to be used for a split.
silence_thresh is the threshold in which anything quieter than this will be considered silence, I have set it to the average dBFS minus 14, keep_silence argument is the amount of silence to leave at the beginning and the end of each chunk detected in milliseconds.
These parameters won’t be perfect for all sound files, try to experiment with these parameters with your large audio needs.
After that, we iterate over all chunks and convert each speech audio into text, and then adding them up altogether, here is an example run:
path = "7601-291468-0006.wav"
print("nFull text:", get_large_audio_transcription(path))Note: You can get 7601-291468-0006.wav file here.
Output:
audio-chunkschunk1.wav : His abode which you had fixed in a bowery or country seat.
audio-chunkschunk2.wav : At a short distance from the city.
audio-chunkschunk3.wav : Just at what is now called dutch street.
audio-chunkschunk4.wav : Sooner bounded with proofs of his ingenuity.
audio-chunkschunk5.wav : Patent smokejacks.
audio-chunkschunk6.wav : It required a horse to work some.
audio-chunkschunk7.wav : Dutch oven roasted meat without fire.
audio-chunkschunk8.wav : Carts that went before the horses.
audio-chunkschunk9.wav : Weather cox that turned against the wind and other wrongheaded contrivances.
audio-chunkschunk10.wav : So just understand can found it all beholders.
Full text: His abode which you had fixed in a bowery or country seat. At a short distance from the city. Just at what is now called dutch street. Sooner bounded with proofs of his ingenuity. Patent smokejacks. It required a horse to work some. Dutch oven roasted meat without fire. Carts that went before the horses. Weather cox that turned against the wind and other wrongheaded contrivances. So just understand can found it all beholders.So, this function automatically creates a folder for us and puts the chunks of the original audio file we specified, and then it runs speech recognition on all of them.
Reading from the Microphone
This requires PyAudio to be installed in your machine, here is the installation process depending on your operating system:
Windows
You can just pip install it:
pip3 install pyaudioLinux
You need to first install the dependencies:
sudo apt-get install python-pyaudio python3-pyaudio
pip3 install pyaudioMacOS
You need to first install portaudio, then you can just pip install it:
brew install portaudio
pip3 install pyaudioNow let’s use our microphone to convert our speech:
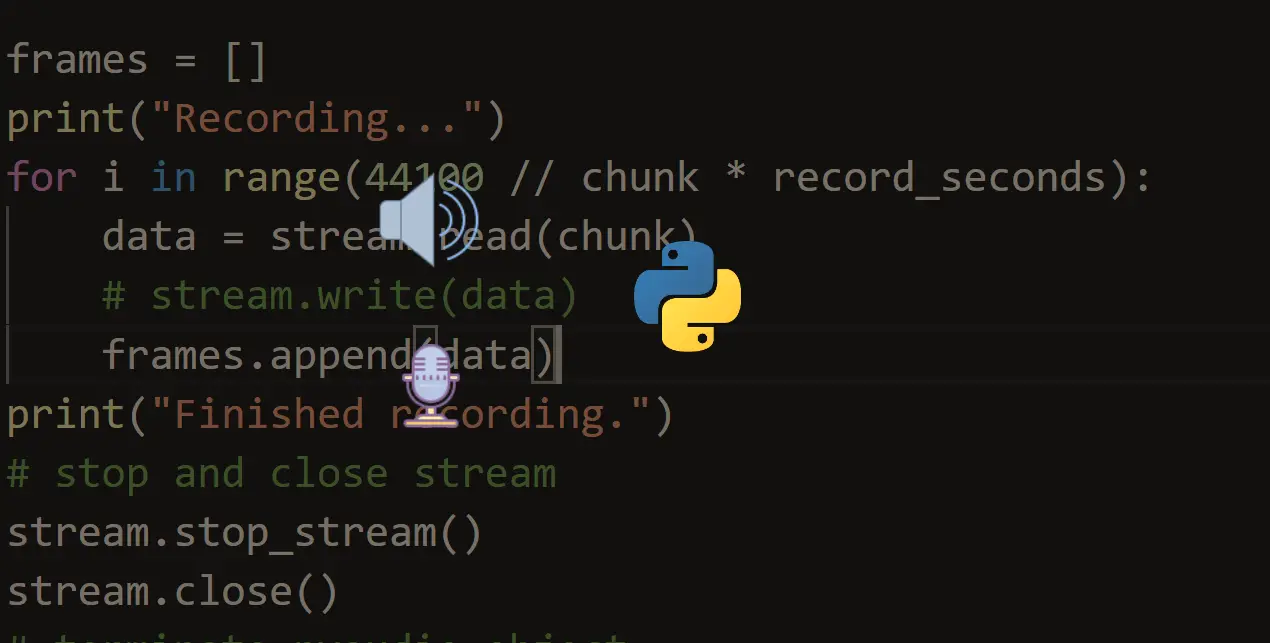
with sr.Microphone() as source:
# read the audio data from the default microphone
audio_data = r.record(source, duration=5)
print("Recognizing...")
# convert speech to text
text = r.recognize_google(audio_data)
print(text)This will hear from your microphone for 5 seconds and then try to convert that speech into text!
It is pretty similar to the previous code, but we are using the Microphone() object here to read the audio from the default microphone, and then we used the duration parameter in the record() function to stop reading after 5 seconds and then uploads the audio data to Google to get the output text.
You can also use the offset parameter in the record() function to start recording after offset seconds.
Also, you can recognize different languages by passing language parameter to the recognize_google() function. For instance, if you want to recognize Spanish speech, you would use:
text = r.recognize_google(audio_data, language="es-ES")Check out supported languages in this StackOverflow answer.
Conclusion
As you can see, it is pretty easy and simple to use this library for converting speech to text. This library is widely used out there in the wild. Check the official documentation.
If you want to convert text to speech in Python as well, check this tutorial.
Finally, if you’re a beginner and want to learn Python, I suggest you take the Python For Everybody Coursera course, in which you’ll learn a lot about Python. You can also check our resources and courses page to see the Python resources I recommend on various topics!
Read Also: How to Recognize Optical Characters in Images in Python.
Happy Coding ♥
View Full Code
![]() View on Skillshare
View on Skillshare
Read Also
Comment panel
Транскрибация (расшифровка) – это метод перевода информации из аудио или видео в текстовый формат. Такой подход актуален для слабослышащих, при расшифровке интервью и создании субтитров (для тех, кому нужно посмотреть видеоролик или прослушать аудио без звука). Цель транскрибации – перевести речь в текстовый формат, который будет понятен любому человеку.
Для расшифровки аудио в текст сегодня используется профессиональный софт. О лучших программах для расшифровки аудио мы и поговорим в данной статье.
Google Docs
Google Docs – онлайн-сервис для работы с текстом и данными. Внутри платформы можно включить микрофон, который поможет перевести речь в письменный формат. Для его активации следует воспользоваться комбинацией клавиш Ctrl+Shift+S, затем выбрать язык и нажать на значок микрофона.
Увы, но сервис очень плохо справляется с тихой и шумной диктофонной записью, но отлично с диктовкой в микрофон. Главный недостаток – работает только в активном окне Google Docs, то есть наговорить что-то с другой вкладки или включить запись на компьютере не получится.
Плюсы:
- бесплатный продукт;
- автоматическое сохранение текста;
- возможность сразу же отредактировать материал.
Минусы:
- медленная расшифровка;
- распознает не все слова: требуется хорошая диктовка, чтобы получить качественный текст;
- не сможет распознать запись из другой вкладки браузера или плеера.
Операционная система: Web
Ссылка на сервис: Google Docs
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Google Keep
Google Keep – это мобильное приложение для заметок, с помощью которого можно также переводить голосовые записи в текст. Для этого нужно нажать на значок микрофона на панели инструментов. Разговор в аудиоформате будет сохранен вместе с расшифрованным текстом.
Для длительных записей Google Keep, к сожалению, не подойдет, потому что останавливает запись после коротких пауз в диалоге. Но его можно использовать, чтобы расшифровывать уже готовые записи по кускам.
По какой‑то причине распознавание голоса в Keep работает лучше, чем в Гугл-документах: приложение даже угадывает начало новой фразы и помечает его заглавной буквой.
Плюсы:
- легко перевести голосовую запись через микрофон;
- достаточно точно расшифровывает аудио.
Минусы:
- нельзя записывать голосовые аудио с паузами;
- работает только с микрофоном.
Операционная система: Android, iOS, Web
Ссылка на скачивание: Google Keep
Speechpad
Speechpad – бесплатный онлайн-инструмент, с помощью которого можно расшифровать голосовую запись. Работает исключительно со звуком из микрофона, поэтому следует позаботиться о качестве оборудования.
Поддерживается Google Chrome, но есть приложения для iOS и Android. Также возможна интеграция в Windows, Mac и Linux, чтобы обеспечить голосовой ввод в любом текстовом поле. Четкий звук понимает достаточно хорошо, плохой – крайне посредственно.
Плюсы:
- бесплатная программа на русском языке;
- можно отредактировать текст;
- есть инструкции по работе с сервисом;
- воспринимает звуки с соседних вкладок браузера – можно работать с одного устройства.
Минусы:
- транскрибация из файла требует хорошего качества звука, в ином случае расшифровка будет неполной.
Операционная система: Web
Ссылка на сервис: Speechpad
RealSpeaker
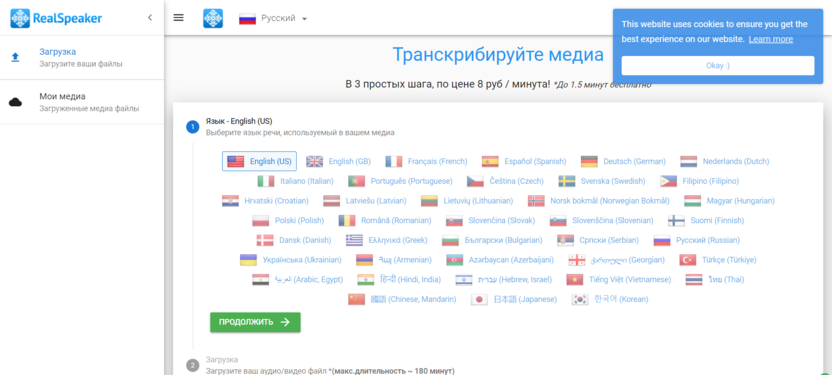
RealSpeaker – платный сервис для перевода аудиофайлов в текстовый контент. Работает исключительно с готовыми файлами, поэтому использовать микрофон, как в предыдущих случаях, не получится.
Перевод аудио в текст бесплатен только в том случае, если запись длится не более 1.5 минут. Далее – 8 руб. за минуту, максимальная продолжительность аудио – 180 мин. Поддерживается более 40 языков, включая русский.
Для работы с сервисом достаточно выбрать язык озвучки, загрузить файл, рассчитать время расшифровки и оплатить услугу.
Плюсы:
- есть возможность работать с файлами;
- простой в использовании сервис.
Минусы:
- платный сервис;
- не позволяет надиктовать текст в микрофон;
- в течение 24 часов файл доступен всем, и его нельзя скрыть.
Операционная система: Web
Ссылка на сервис: RealSpeaker
Dictation
Dictation – бесплатный онлайн-сервис, позволяющий распознавать запись с микрофона. Понимает не только русские слова, но и десятки команд: тире, новую строку и так далее.
Из особенностей – это встроенный редактор, позволяющий форматировать текст, оформлять списки и делать много всего другого. Готовый текст можно отправить на почту, в социальные сети или просто сохранить на компьютере.
Из недостатков – распознает только качественную речь. Если запись была сделана на слабенький микрофон, то получить хороший результат не получится.
Плюсы:
- быстрая отправка результата на почту и в социальные сети;
- есть встроенный редактор;
- отлично и максимально точно справляется с хорошо записанной речью.
Минусы:
- плохо воспринимает некачественную запись.
Операционная система: Web
Ссылка на сервис: Dictation
oTranscribe

Бесплатный веб-сервис для ручной транскрибации текста. Работает как с аудио, так и видео, в том числе с YouTube-роликами. Открывает множество форматов: WAV, MP3, MPEG, WEBM и другие. Можно назначить горячие клавиши для управления воспроизведением. Есть автосохранение, простой текстовый редактор, интерактивные метки, упрощающие навигацию.
Плюсы:
- минималистичный редактор текста;
- автоматически сохраняет документ в формате HTML;
- для удобства пользования можно настроить горячие клавиши.
Минусы:
- нет автоматизации процесса, все нужно делать вручную.
Операционная система: Web
Ссылка на сервис: oTranscribe
Transcribe
Transcribe – это универсальный сервис, в котором можно расшифровать файл или самостоятельно надиктовать текст. Подписка стоит 20 долларов в год. Есть тестовый период на 7 дней, в течение которого можно безлимитно использовать ручную расшифровку и 30 минут пользоваться автоматической транскрибацией.
В редакторе готового текста можно расставить временные метки, а также прослушать интервью на замедленной скорости и исправить неправильно распознанные сервисом места.
Из особенностей можно отметить поддержку множества форматов – 3GP, AAC, AIF, AIFF, AMR, CAF, DSS, FLAC, M4A, MOV, MP3, MP4, OGG, WAV, WEBM, WMA, WMV. Максимальный размер файла – 6 Гб или 420 минут.
Плюсы:
- простой в управлении сервис;
- есть редактор текста в самостоятельной расшифровке;
- поддерживает ссылки с YouTube;
- есть таймкоды;
- файлы можно загрузить как с ПК, так и с облачных сервисов;
- есть подробная инструкция;
- поддерживает большое количество языков и диалектов;
- есть горячие клавиши для быстрой работы.
Минусы:
- платный функционал.
Операционная система: Web
Ссылка на сервис: Transcribe
Dragon Dictation
Dragon Dictation – платная программа для iOS-устройств, способная распознавать продиктованный текст с микрофона. Есть тестовый период на неделю, далее необходимо оформить подписку – $14.99 в месяц или $149 единоразово.
Плюсы:
- позволяет только диктовать текст;
Минусы:
- нельзя расшифровать файлы или ссылки из YouTube;
- платное приложение.
Операционная система: iOS
Ссылка на скачивание: Dragon Dictation
Speechnotes
Speechnotes – онлайн-сервис для браузеров и приложение для Android. В онлайн-версии расшифровка файлов платная – $0.1 за минуту. В приложении же есть бесплатный тестовый период, после его окончания нужно приобрести подписку за 69 рублей в месяц. Также в нем можно сохранять файлы в облако, отправлять их в соцсети и по почте. Онлайн-сервис воспринимает знаки препинания, а приложение распознает еще и смайлики.
Плюсы:
- сохраняет документ в форматах doc и txt, позволяет работать с PDF;
- простой интерфейс;
- есть редактор текста;
- более 50 языков.
Минусы:
- платный сервис.
Операционная система: Web, Android
Ссылка на сервис: Speechnotes, на Android: Speechnotes
Otter
Последний в нашем списке инструмент для расшифровки аудио в текст – это Otter. Работает только с английским языком, но у сервиса есть отличительная особенность: он может запоминать голос диктора – такая возможность позволяет разделять реплики в записях с несколькими собеседниками.
Также можно загрузить аудио или видео с английской речью, в результате чего сервис выведет текст. Некоторые спорные моменты из-за произношения могут расшифровываться неправильно.
Программа будет полезна, если вы работаете с англоязычными источниками.
Плюсы:
- есть функция запоминания голоса;
- бесплатный функционал;
- легко распознает аудио или видео на английском языке.
Минусы:
- работает только с английским языком.
Операционная система: Web, iOS
Ссылка на сервис: Otter
Заключение
Сегодня мы поговорили о лучших сервисах для расшифровки аудио. Каждый из них позволяет буквально в несколько кликов получить желаемый результат, но только в том случае, если исходный файл был в хорошем качестве. Если же запись была записана нечетко, то не все инструменты могут с этим хорошо справиться, особенно те, что доступны бесплатно.