Оглавление
- Введение
- Краткое содержание
- План первой части
- Начало
- Создаем виртуальное окружение
- Добавляем зависимости
- Инициализируем Flask проект
- Добавляем первую конечную точку REST API
- Создаем конфигурационный файл нашего API
- Связываем Connexion c приложением
- Получаем данные от конечной точки people
- Изучаем документацию API
- Создаем полноценный API
- Работа с компонентами
- Создание нового персонажа
- Обработка персонажа
- Изучаем документацию API
- Заключение
Введение
Большинство современных веб-приложений работают на основе REST API. Это позволяет разработчикам отделить код фронтенда от внутренней логики, а пользователям — динамически взаимодействовать с интерфейсом.
В этой серии статей, состоящей из трех частей, мы создадим REST API на базе веб-фреймворка Flask.
Мы сделаем базовый проект Flask, добавим к нему конечные точки и подключим к базе данных SQLite. Далее мы протестируем наш проект при помощи документации API от Swagger UI , которую создадим по ходу дела.
Из первой части данной серии статей вы узнаете, как:
- создавать проект Flask при помощи REST API
- обрабатывать HTTP-запросы при помощи Connexion
- определять конечные точки API при помощи спецификации OpenAPI
- взаимодействовать с API для управления данными
- создавать пользовательскую документацию по API при помощи Swagger UI.
Затем мы перейдем ко второй части. В ней мы рассмотрим использование базы данных для постоянного хранения информации (вместо использования для этого оперативной памяти).
Эта серия статей представляет собой практическое руководство по созданию REST API при помощи фреймворка Flask и взаимодействию с ним при помощи CRUD-операций. Вы можете скачать код первой части данного проекта по данной ссылке.
Краткое содержание
В этой серии статей мы построим REST API, с помощью которого сможем оставлять записки-напоминания для вымышленных персонажей. Это те сущности, которые могут посещать нас в течение года. В этой части мы создадим следующих персонажей: Зубную фею, Пасхального кролика и кнехта Рупрехта.
Понятно, что мы хотим быть с ними в хороших отношениях. Поэтому, чтобы увеличить шансы на хорошие подарки, мы будем отправлять им всем записки.
Взаимодействовать со своим приложением мы сможем при помощи документации API. По ходу дела мы создадим базовый фронтенд, отражающий содержимое нашей базы данных.
В этой статье мы создадим базовый проект Flask и подключим к нему свои первые конечные точки API. В итоге мы сможем увидеть список персонажей во фронтенде и управлять всеми ими в бэкенде.
Используя Swagger UI, мы создадим удобную документацию для нашего API. Это даст нам возможность проверять работу API на каждом этапе данной статьи и отслеживать все наши конечные точки.
План первой части
Помимо создания основы для нашего проекта Flask мы собираемся создать REST API, который будет обеспечивать доступ к группе персонажей и отдельным лицам в этой группе. Вот дизайн API для такой группы людей:
| Действие | HTTP-запрос | URL-путь | Описание |
|---|---|---|---|
| Чтение | GET | /api/people | Считываем группу персонажей |
| Создание | POST | /api/people | Создаем нового персонажа |
| Чтение | GET | /api/people/<lname> | Считываем конкретного персонажа |
| Обновление | PUT | /api/people/<lname> | Обновляем существующего персонажа |
| Удаление | DELETE | /api/people/<lname> | Удаляем персонажа |
REST API, который мы будем создавать, должен обслуживать простую структуру данных персонажей, где ключами будут выступать их «фамилии» а любые обновления будут помечаться новой отметкой времени.
Набор данных, с которым мы будем работать, выглядит следующим образом:
PEOPLE = {
"Fairy": {
"fname": "Tooth",
"lname": "Fairy",
"timestamp": "2022-10-08 09:15:10",
},
"Ruprecht": {
"fname": "Knecht",
"lname": "Ruprecht",
"timestamp": "2022-10-08 09:15:13",
},
"Bunny": {
"fname": "Easter",
"lname": "Bunny",
"timestamp": "2022-10-08 09:15:27",
}
}
Одной из целей API является отделение данных от приложения, которое их использует. Таким образом скрываются детали реализации этих данных. Позже мы сохраним данные в базе, но для начала нам подойдет и структура данных в оперативной памяти.
Начало
В этом разделе мы подготовим среду разработки для нашего Flask-проекта. Начнем с создания виртуальной среды и установки всех необходимых зависимостей.
Создаем виртуальное окружение
В этом разделе мы создадим структуру проекта. Корневую папку нашего проекта можно назвать как угодно. Например, назовем ее rp_flask_api/. Итак, создадим папку и перейдем в нее:
$ mkdir rp_flask_api $ cd rp_flask_api
Мы создали корневую папку проекта rp_flask_api/. Файлы и папки, которые мы создадим в ходе этой серии статей, будут расположены либо в этой папке, либо в ее подпапках.
После перехода в папку проекта рекомендуется создать и активировать виртуальную среду. Это позволит устанавливать любые зависимости не для всей системы, а только в виртуальной среде нашего проекта.
Настроить виртуальную среду можно следующим образом:
# Для Windows PS> python -m venv venv PS> .venvScriptsactivate (venv) PS> # Для Linux или macOS $ python -m venv venv $ source venv/bin/activate (venv) $
С помощью этих команд мы создаем и активируем виртуальную среду с именем venv, используя встроенный в Python модуль venv.
Запись (venv) перед приглашением командной строки показывает, что мы успешно создали и активировали виртуальную среду.
Добавляем зависимости
После создания и активации виртуальной среды настало время установить Flask при помощи менеджера pip:
(venv) $ python -m pip install Flask==2.2.2
Микрофреймворк Flask — это основная зависимость, которая требуется нашему проекту. Поверх Flask установим Connexion для обработки HTTP-запросов:
(venv) $ python -m pip install "connexion[swagger-ui]==2.14.1"
Чтобы использовать автоматически создаваемую документацию по API, мы устанавливаем Connexion с добавленной поддержкой Swagger UI. Со всеми этими пакетами мы познакомимся чуть позже.
Инициализируем Flask-проект
Основным файлом Flask-проекта будет app.py. Создаем файл его в директории rp_flask_api/ и добавляем в него следующий код:
# app.py
from flask import Flask, render_template
app = Flask(__name__)
@app.route("/")
def home():
return render_template("home.html")
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8000, debug=True)
Мы импортируем Flask, предоставляя приложению доступ к функциям данного модуля. После этого создаем экземпляр приложения Flask с именем app.
Далее, при помощи декоратора @app.route("/"), мы подключаем маршрут URL «/» к функции home(). Эта функция вызывает функцию Flask render_template(), чтобы получить файл home.html из каталога шаблонов и вернуть его в браузер.
Если вкратце, этот код создает и запускает базовый веб-сервер и заставляет его возвращать шаблон home.html, который будет отображаться в браузере при переходе по URL-адресу «/».
Примечание: Сервер разработки Flask по умолчанию использует порт 5000. В более новых версиях macOS этот порт уже используется macOS AirPlay. Выше мы изменили порт своего приложения Flask на порт 8000. При желании можно вместо этого изменить настройки AirPlay на своем Mac.
Сервер Flask ожидает, что файл home.html находится в каталоге шаблонов с именем templates/. Создадим каталог templates/ и добавим в него файл home.html со следующим содержанием:
<!-- templates/home.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>RP Flask REST API</title>
</head>
<body>
<h1>
Hello, World!
</h1>
</body>
</html>
Flask поставляется с движком шаблонов Jinja, который позволяет существенно совершенствовать шаблоны. Но наш шаблон home.html представляет собой простой HTML-файл без каких-либо функций Jinja. На данный момент это нормально, потому что первая цель home.html — убедиться, что наш проект Flask работает так, как задумано.
Когда созданная нами виртуальная среда Python активна, мы можем запустить свое приложение при помощи следующей команды (при этом нужно находиться в каталоге, содержащем файл app.py):
(venv) $ python app.py
Когда вы запускаете app.py, веб-сервер запускается через порт 8000. Если вы откроете браузер и перейдете по адресу http://localhost:8000, вы должны увидеть фразу Hello, World!:
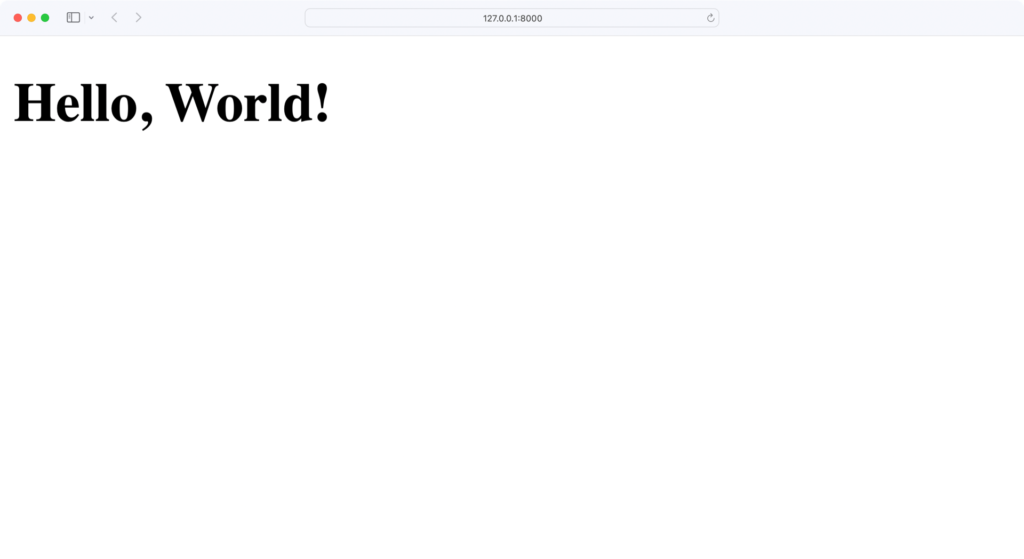
Поздравляем, наш веб-сервер запущен! Позже мы расширим файл home.html для работы с нашим REST API.
На данный момент структура нашего проекта Flask имеет следующий вид:
rp_flask_api/ │ ├── templates/ │ └── home.html │ └── app.py
Это отличная структура для запуска любого проекта Flask.
В следующих разделах мы расширим данный проект и добавим в него первые конечные точки REST API.
Теперь, имея работающий веб-сервер, мы можем добавить первую конечную точку REST API. Для этого мы применим Connexion, который установили в предыдущем разделе.
Модуль Connexion позволяет программе на Python использовать со Swagger спецификацию OpenAPI .
Спецификация OpenAPI представляет собой формат описания API для REST API и предоставляет множество функций, в том числе:
- проверку входных и выходных данных вашего API
- настройку URL-адресов конечных точек API и ожидаемых параметров.
При использовании OpenAPI вместе со Swagger можно создать пользовательский интерфейс для работы с API. Для этого необходимо создать конфигурационный файл, к которому наше Flask-приложение будет иметь доступ.
Создаем конфигурационный файл нашего API
Конфиг Swagger — это файл YAML или JSON, содержащий наши определения OpenAPI. Этот файл содержит всю информацию, необходимую для настройки сервера.
Создадим файл с именем swagger.yml и начнем добавлять в него метаданные:
# swagger.yml openapi: 3.0.0 info: title: "RP Flask REST API" description: "An API about people and notes" version: "1.0.0"
При определении API мы должны установить версию определения OpenAPI. Для этого используется ключевое слово openapi. Строка версии важна, так как некоторые части структуры OpenAPI могут со временем измениться.
Кроме того, точно так же, как каждая новая версия Python включает новые функции, в спецификации OpenAPI могут быть добавлены или исключены ключевые слова.
Ключевое слово info начинает область действия информационного блока API:
- title: заголовок, включенный в систему пользовательского интерфейса, сгенерированную Connexion
- description: описание того, что API дает возможность сделать
- version: значение версии API
Затем добавьте серверы и URL-адреса, которые определяют корневой путь вашего API:
# swagger.yml # ... servers: - url: "/api"
Указав «/api» в качестве значения URL-адреса, мы сможем получить доступ ко всем путям API относительно http://localhost:8000/api.
Конечные точки API мы определим в блоке путей paths:
# swagger.yml
# ...
paths:
/people:
get:
operationId: "people.read_all"
tags:
- "People"
summary: "Read the list of people"
responses:
"200":
description: "Successfully read people list"
Блок paths определяет конфигурацию URL-адреса для каждой конечной точки API:
/people: относительный URL-адрес вашей конечной точки APIget: HTTP-метод, которому будет отвечать конечная точка по этому URL-адресу
Вместе с определением url в servers это создает URL-адрес конечной точки GET /api/people — http://localhost:8000/api/people.
Блок get определяет конфигурацию URL-адреса отдельной конечной точки /api/people:
- operationId: функция Python, которая отвечает на запрос
- tags: теги, связанные с данной конечной точкой; они позволяют группировать операции в пользовательском интерфейсе
- summary: отображаемый текст пользовательского интерфейса для данной конечной точки
- responses: коды состояния, которые посылает данная конечная точка
OperationId должен содержать строку. Connexion будет использовать форму people.read_all, чтобы найти функцию Python с именем read_all() в модуле people нашего проекта. Позже в данной статье мы создадим соответствующий код.
Блок responses определяет конфигурацию возможных кодов состояния. Здесь мы определяем успешный ответ для кода состояния 200, содержащий некоторый текст описания description.
Ниже файл swagger.yml приведен полностью:
# swagger.yml
openapi: 3.0.0
info:
title: "RP Flask REST API"
description: "An API about people and notes"
version: "1.0.0"
servers:
- url: "/api"
paths:
/people:
get:
operationId: "people.read_all"
tags:
- "People"
summary: "Read the list of people"
responses:
"200":
description: "Successfully read people list"
Мы организовали этот файл в иерархическом порядке. Каждый уровень отступа представляет собой уровень владения или область действия.
Например, paths отмечает начало блока, где определены все URL-адреса конечных точек API. Значение /people представляет собой начало блока, где будут определены все конечные точки по URL-адресу /api/people. Область get в разделе /people содержит определения, связанные с HTTP-запросом GET к конечной точке по URL-адресу /api/people. Этот шаблон действует для всего конфига.
Файл swagger.yml похож на план нашего API. С помощью спецификаций, включенных в этот файл, мы определяем, какие данные может ожидать наш веб-сервер и как сервер должен отвечать на запросы. Но пока наш проект Flask ничего не знает о файле swagger.yml. Для соединения OpenAPI с Flask-приложением мы будем использовать Connexion.
Связываем Connexion c приложением
Чтобы добавить URL-адрес конечной точки REST API в наше Flask-приложение при помощи Connexion, нужно выполнить два шага:
- Добавить конфигурационный файл API в наш проект.
- Связать Flask-приложение с этим файлом.
В предыдущем разделе мы уже добавили файл под именем swagger.yml. Чтобы подключить его к нашему Flask-приложнию, нужно прописать его в файле app.py:
# app.py
from flask import render_template # Remove: import Flask
import connexion
app = connexion.App(__name__, specification_dir="./")
app.add_api("swagger.yml")
@app.route("/")
def home():
return render_template("home.html")
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8000, debug=True)
Выражение import connexion добавляет модуль в программу. Следующий шаг — это создание экземпляра класса Connexion вместо Flask. Flask-приложение по прежнему будет создано, но теперь у него появятся дополнительные функции.
Одним из параметров данного приложения является specification_dir (6 строка). Он сообщает классу Connexion, в какой директории искать конфигурационный файл. В данном случае он находится в той же папке, что и файл app.py.
В следующей строке мы читаем файл swagger.yml и настраиваем систему для обеспечения функциональности класса Connexion.
Получаем данные от конечной точки people
В файле swagger.yml мы настроили Connexion со значением operationId "people.read_all". Поэтому, когда API получает HTTP-запрос для GET /api/people, наше приложение Flask вызывает функцию read_all() в модуле people.
Чтобы это заработало, надо создать файл people.py с функцией read_all():
# people.py
from datetime import datetime
def get_timestamp():
return datetime.now().strftime(("%Y-%m-%d %H:%M:%S"))
PEOPLE = {
"Fairy": {
"fname": "Tooth",
"lname": "Fairy",
"timestamp": get_timestamp(),
},
"Ruprecht": {
"fname": "Knecht",
"lname": "Ruprecht",
"timestamp": get_timestamp(),
},
"Bunny": {
"fname": "Easter",
"lname": "Bunny",
"timestamp": get_timestamp(),
}
}
def read_all():
return list(PEOPLE.values())
В строке 5 мы создаем вспомогательную функцию с именем get_timestamp(), которая генерирует строковое представление текущей метки времени.
Затем мы определяем структуру данных словаря PEOPLE (в строке 8), с которой и будем работать в этой статье.
Словарь PEOPLE заменяет нам базу данных. Поскольку PEOPLE является переменной модуля, ее состояние сохраняется между вызовами REST API. Однако любые данные, которые мы изменим, будут потеряны при перезапуске веб-приложения. Это, разумеется не идеально, но пока сойдет и так.
Затем мы создаем функцию read_all() (строка 26). Наш сервер запустит эту функцию, когда получит HTTP-запрос на GET /api/people. Возвращаемое значение функции read_all() — это список словарей с информацией о персонаже.
Запустив код нашего сервера и перейдя в браузере по адресу http://localhost:8000/api/people, мы увидим список персонажей на экране:
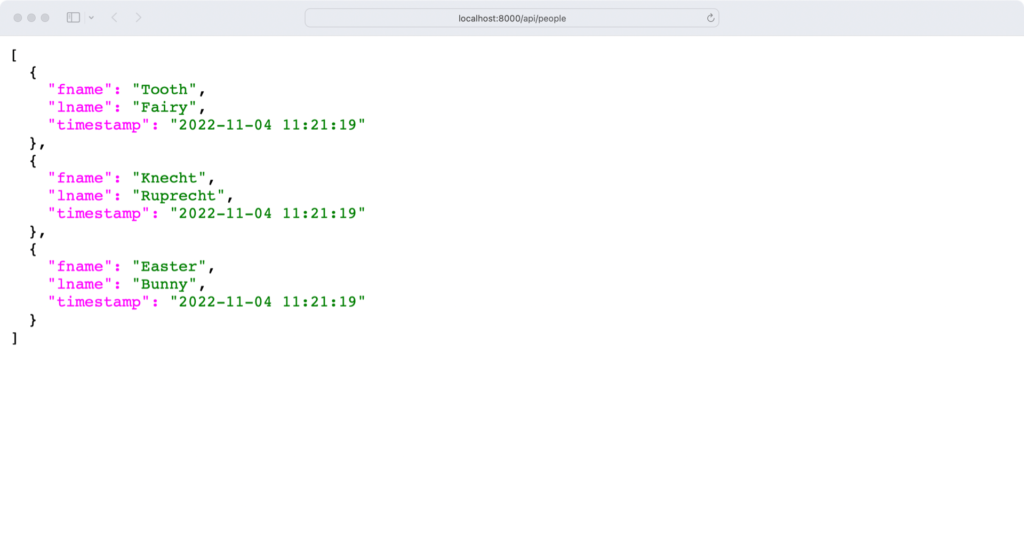
Поздравляем, вы только что создали свою первую конечную точку API! Прежде чем продолжить создание REST API с несколькими конечными точками, давайте потратим еще немного времени и изучим API немного подробнее.
Изучаем документацию API
На данный момент у нас есть REST API, работающий только с одной конечной точкой. Наше приложение Flask знает, что обслуживать, на основе нашей спецификации API в файле swagger.yml. Кроме того, класс Connexion использует swagger.yml для создания для нас документации по API.
Перейдём по адресу localhost:8000/api/ui, чтобы увидеть документацию по API в действии:
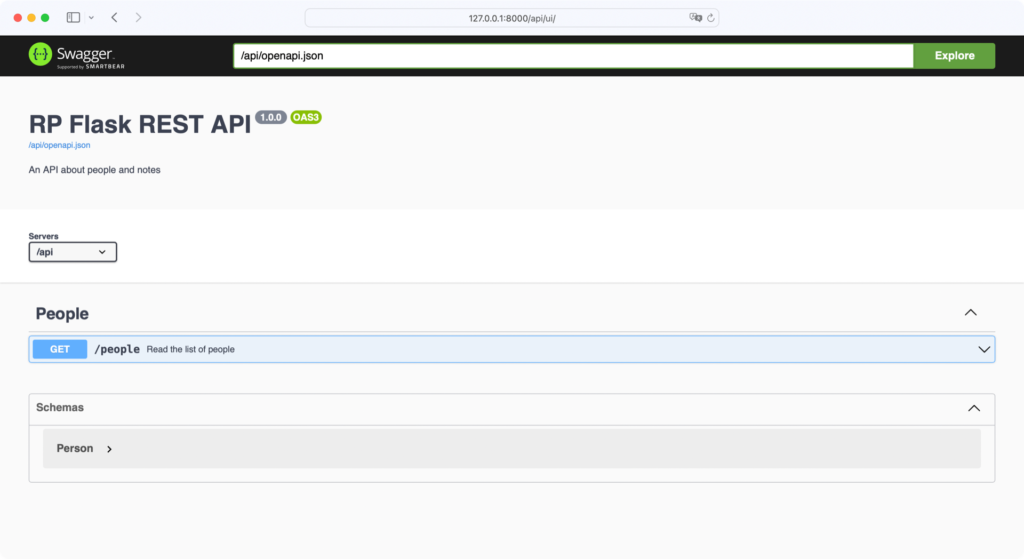
Это первоначальный интерфейс Swagger. Он показывает список URL конечных точек, поддерживаемых нашей конечной точкой http://localhost:8000/api. Класс Connexion создает его автоматически при анализе файла swagger.yml.
Нажав на конечную точку /people в интерфейсе, вы увидите больше информации о вашем API.
Будет выведена структура ожидаемого ответа, тип содержимого этого ответа и введенный нами текст описания конечной точки в файле swagger.yml. При любом изменении файла конфигурации меняется и пользовательский интерфейс Swagger.
Мы даже можем проверить конечную точку, нажав кнопку «Try it out». Эта функция может быть чрезвычайно полезна, когда наш API быстро растет. Документация API, сгенерированная Swagger UI, дает вам возможность исследовать API и экспериментировать с ним без необходимости писать для этого какой-либо код.
Использование OpenAPI со Swagger UI обеспечивает удобный и понятный способ создания URL-адресов конечных точек API. Пока что мы создали только одну конечную точку для обслуживания всех персонажей сразу. В следующем разделе мы добавим дополнительные конечные точки для создания, обновления и удаления персонажей в нашем словаре.
Создание полноценного API
Пока у нашего REST API есть только одна конечная точка. Пора создать API, обеспечивающий полный CRUD-доступ к нашей структуре персонажей. Как вы помните, определение нашего API выглядит следующим образом:
| Действие | HTTP-запрос | URL-путь | Описание |
|---|---|---|---|
| Чтение | GET | /api/people | Считываем группу персонажей |
| Создание | POST | /api/people | Создаем нового персонажа |
| Чтение | GET | /api/people/<lname> | Считываем конкретного персонажа |
| Обновление | PUT | /api/people/<lname> | Обновляем существующего персонажа |
| Удаление | DELETE | /api/people/<lname> | Удаляем персонажа |
Чтобы реализовать это, нам надо расширить файлы swagger.yml и people.py соответствующим образом.
Работа с компонентами
Прежде чем определять новые пути API в файле swagger.yml, нам нужно добавить новый блок для компонентов.
Компоненты — это строительные блоки в нашей спецификации OpenAPI, на которые мы можем ссылаться из других частей спецификации.
Добавьте блок components вместе с блоком schemas для одного персонажа:
# swagger.yml
openapi: 3.0.0
info:
title: "RP Flask REST API"
description: "An API about people and notes"
version: "1.0.0"
servers:
- url: "/api"
components:
schemas:
Person:
type: "object"
required:
- lname
properties:
fname:
type: "string"
lname:
type: "string"
# ...
Мы создаем эти блоки во избежание дублирования кода. На данный момент в блоке schemas мы сохраняем только модель Person:
- type: тип данных
- required: требуемые свойства
Дефис (-) перед -lname указывает, что required может содержать список свойств. Любое свойство, которое мы определяем как обязательное, также должно существовать в properties, включая следующие:
- fname: имя персонажа
- lname: его «фамилия»
Ключ type определяет значение, связанное с его родительским ключом. Для Person все свойства являются строками. Позже в этом руководстве мы представим эту схему в виде словаря Python.
Создание нового персонажа
Расширим конечные точки API, добавив новый блок для запроса POST в блоке /people:
# swagger.yml
# ...
paths:
/people:
get:
# ...
post:
operationId: "people.create"
tags:
- People
summary: "Create a person"
requestBody:
description: "Person to create"
required: True
content:
application/json:
schema:
x-body-name: "person"
$ref: "#/components/schemas/Person"
responses:
"201":
description: "Successfully created person"
Структура запроса post похожа на существующую схему запроса get. Первое отличие состоит в том, что на сервер мы также отправляем requestBody. В конце концов, нам нужно сообщить Flask информацию, необходимую для создания нового персонажа. Второе отличие — это operationId, для которого мы устанавливаем значение people.create.
Внутри content мы определяем application/json как формат обмена данными нашего API.
В своих запросах к API и ответах API мы можем использовать различные типы данных. В настоящее время в качестве формата обмена данными обычно используют JSON. Это хорошая новость для нас как Python-разработчиков, поскольку объекты JSON очень похожи на словари Python. Например:
{
"fname": "Tooth",
"lname": "Fairy"
}
Этот объект JSON напоминает компонент Person, который мы определили ранее в файле swagger.yml и на который мы ссылаемся с помощью $ref в блоке schema.
Мы также используем код состояния HTTP 201, который является успешным ответом, указывающим на создание нового ресурса.
Примечание: Если вы хотите узнать больше о кодах состояния HTTP, то можете ознакомиться с документацией Mozilla на эту тему.
При помощи выражения people.create мы говорим серверу искать функцию create() в модуле people. Откроем файл people.py и добавим туда функцию create():
# people.py
from datetime import datetime
from flask import abort
# ...
def create(person):
lname = person.get("lname")
fname = person.get("fname", "")
if lname and lname not in PEOPLE:
PEOPLE[lname] = {
"lname": lname,
"fname": fname,
"timestamp": get_timestamp(),
}
return PEOPLE[lname], 201
else:
abort(
406,
f"Person with last name {lname} already exists",
)
В строке 4 мы импортируем функцию Abort() из модуля Flask. Использование этой функции помогает нам отправить сообщение об ошибке в строке 20. Мы вызываем сообщение об ошибке, когда тело запроса не содержит фамилии или когда персонаж с такой фамилией уже существует.
Примечание: Фамилия персонажа должна быть уникальной, потому что мы используем lname в качестве ключа словаря PEOPLE. Это означает, что в вашем проекте пока не может быть двух персонажей с одинаковой фамилией.
Если данные в теле запроса валидны, мы обновляем словарь PEOPLE в строке 13 и возвращаем новый объект и HTTP-код 201 в строке 18.
Обработка персонажа
На данный момент мы можем создать нового персонажа и получить их полный список. В этом разделе мы обновим файлы swagger.yml и people.py, чтобы они работали с новым путем, который будет обрабатывать одного существующего пользователя.
Откроем файл swagger.yml и добавим следующий код:
# swagger.yml
# ...
components:
schemas:
# ...
parameters:
lname:
name: "lname"
description: "Last name of the person to get"
in: path
required: True
schema:
type: "string"
paths:
/people:
# ...
/people/{lname}:
get:
operationId: "people.read_one"
tags:
- People
summary: "Read one person"
parameters:
- $ref: "#/components/parameters/lname"
responses:
"200":
description: "Successfully read person"
Как и в случае с нашим путем /people, мы начинаем с операции get для пути /people/{lname}. Подстрока {lname} является заполнителем для фамилии, которую мы должны передать в качестве параметра URL. Так, например, URL-путь api/people/Ruprecht содержит имя Рупрехта (Ruprecht) в качестве lname.
Примечание: URL-параметры чувствительны к регистру. Это означает, что мы должны ввести фамилию, например Ruprecht, с заглавной буквой R.
Параметр lname мы будем использовать и в других операциях. Поэтому имеет смысл создать для него отдельный компонент и ссылаться на него там, где это необходимо.
operationId указывает на функцию read_one() в файле people.py, поэтому снова перейдём к этому файлу и создадим отсутствующую функцию:
# people.py
# ...
def read_one(lname):
if lname in PEOPLE:
return PEOPLE.get[lname]
else:
abort(
404, f"Person with last name {lname} not found"
)
Когда наше приложение Flask находит данную фамилию в словаре PEOPLE, оно возвращает данные для этого конкретного персонажа. В противном случае сервер вернет код ответа HTTP 404 (ошибка).
Чтобы иметь возможность обновлять существующего персонажа, изменим файл swagger.yml:
# swagger.yml
# ...
paths:
/people:
# ...
/people/{lname}:
get:
# ...
put:
tags:
- People
operationId: "people.update"
summary: "Update a person"
parameters:
- $ref: "#/components/parameters/lname"
responses:
"200":
description: "Successfully updated person"
requestBody:
content:
application/json:
schema:
x-body-name: "person"
$ref: "#/components/schemas/Person"
При таком определении операции put наш сервер ожидает функцию update() в файле people.py:
# people.py
# ...
def update(lname, person):
if lname in PEOPLE:
PEOPLE[lname]["fname"] = person.get("fname", PEOPLE[lname]["fname"])
PEOPLE[lname]["timestamp"] = get_timestamp()
return PEOPLE[lname]
else:
abort(
404,
f"Person with last name {lname} not found"
)
Функция update() принимает аргументы lname и person. Если персонаж с данной фамилией уже существует, то мы просто обновляем соответствующие значения в словаре PEOPLE.
Чтобы удалить персонажа из нашего набора данных, нужно использовать операцию delete:
# swagger.yml
# ...
paths:
/people:
# ...
/people/{lname}:
get:
# ...
put:
# ...
delete:
tags:
- People
operationId: "people.delete"
summary: "Delete a person"
parameters:
- $ref: "#/components/parameters/lname"
responses:
"204":
description: "Successfully deleted person"
Добавим соответствующую функцию delete() в файл person.py:
# people.py
from flask import abort, make_response
# ...
def delete(lname):
if lname in PEOPLE:
del PEOPLE[lname]
return make_response(
f"{lname} successfully deleted", 200
)
else:
abort(
404,
f"Person with last name {lname} not found"
)
Если персонаж, которого мы хотим удалить, есть в нашем наборе данных, то мы удаляем этот элемент из словаря PEOPLE.
Итак, мы закончили работу над фалами people.py и swagger.yml.
Когда созданы все конечные точки для управления пользователями, пришло время опробовать наш API. Поскольку мы использовали Connexion для подключения нашего проекта Flask к Swagger, документация по API будет готова после перезапуска сервера.
Изучаем документацию API
После обновления файлов swagger.yml и people.py система Swagger UI также обновится.
Этот UI (пользовательский интерфейс) позволяет просматривать всю документацию, которую мы включили в файл swagger.yml, и взаимодействовать со всеми конечными точками по заданным URL-адресам для осуществления CRUD-операций.
К сожалению, любые внесенные вами изменения не сохранятся после перезапуска приложения Flask. Вот почему в следующей части этого руководства мы подключим к своему проекту базу данных.
Заключение
В первой части нашей серии статей мы создали REST API с помощью веб-фреймворка Flask на Python. При помощи модуля Connexion и дополнительной настройки мы создали полезную документацию и интерактивную систему. Это делает создание REST API очень приятным занятием.
Мы разобрали, как:
- создать базовый проект Flask с
REST API. - обрабатывать HTTP-запросы при помощи модуля Connexion.
- задать конечные точки API, используя спецификацию OpenAPI
- взаимодействовать с API для управления данными
- создать документацию по API при помощи Swagger UI.
Во второй части этой серии мы разберем, как использовать базу данных для сохранения наших данных вместо того, чтобы полагаться на хранилище в оперативной памяти, как мы это делали сейчас.
Перевод статьи Филиппа Аксани «Python REST APIs With Flask, Connexion, and SQLAlchemy – Part 1».

Программист, писатель и предприниматель из США. Он в основном работает в веб-разработке.
API, Application Programming Interface (программный интерфейс приложения), — очень широкое понятие в бэкенд-разработке. Тот API, который мы рассмотрим сегодня, представляет собой сайт без фронтенд-составляющей. Вместо рендеринга HTML-страниц, бэкенд возвращает данные в JSON формате для использования их в нативных или веб-приложениях. Самое пристальное внимание при написании API (как и при написании вебсайтов) нужно обратить на то, как он будет использоваться. Сегодня мы поговорим о том, как использовать Django для создания API для простого приложения со списком дел.
Нам понадобится несколько инструментов. Для выполнения всех шагов я бы рекомендовал вам, вместе с данной статьей, клонировать вот этот учебный проект из GitHub-репозитория. Также вы должны установить Python 3, Django 2.2, и djangorestframework 3.9 (из репозитория запустите pip install -r requirements.txt для установки библиотек). Если не все будет понятно с установкой Django, можно воспользоваться официальной документацией. Также вам нужно будет скачать бесплатную версию Postman. Postman – отличный инструмент для разработки и тестирования API, но в этой статье мы воспользуемся лишь его самыми базовыми функциями.
Для начала откройте папку taskmanager, содержащую manage.py, и выполните python manage.py migrate в командной строке, чтобы применить миграции баз данных к дефолтной sqlite базе данных Django. Создайте суперпользователя с помощью python manage.py createsuperuserи не забудьте записать имя пользователя и пароль. Они понадобятся нам позже. Затем выполните python manage.py runserver для взаимодействия с API.
Вы можете работать с API двумя способами: просматривая фронтенд Django REST фреймворка или выполняя http-запросы. Откройте браузер и перейдите к 127.0.0.1:8000 или к localhost через порт 8000, где Django-проекты запускаются по умолчанию. Вы увидите веб-страницу со списком доступных конечных точек API. Это важнейший принцип в RESTful подходе к API-разработке: сам API должен показывать пользователям, что доступно и как это использовать.
Сначала давайте посмотрим на функцию api_index в views.py. Она содержит список конечных точек, которые вы посещаете.
@define_usage(returns={'url_usage': 'Dict'})
@api_view(['GET'])
@permission_classes((AllowAny,))
def api_index(request):
details = {}
for item in list(globals().items()):
if item[0][0:4] == 'api_':
if hasattr(item[1], 'usage'):
details[reverse(item[1].__name__)] = item[1].usage
return Response(details)
API функции для каждого представления (view в Django) обернуты тремя декораторами. Мы еще вернемся к @define_usage. @api_view нужен для Django REST фреймворка и отвечает за две вещи: шаблон для веб-страницы, которая в результате получится, и HTTP-метод, поддерживаемый конечной точкой. Чтобы разрешить доступ к этому url без проверки подлинности,@permission_classes, также из Django REST фреймворка, задан как AllowAny. Главная функция API обращается к глобальной области видимости приложения чтобы «собрать» все определенные нами функции. Так как мы добавили к каждой функции представления префикс api_, мы можем легко их отфильтровать и вернуть словарь, содержащий информацию об их вызовах. Детали вызовов предоставляются пользовательским декоратором, написанным в decorators.py.
def define_usage(params=None, returns=None):
def decorator(function):
cls = function.view_class
header = None
# Нужна ли аутентификация для вызова этого представления?
if IsAuthenticated in cls.permission_classes:
header = {'Authorization': 'Token String'}
# Создаем лист доступных методов, исключая 'OPTIONS'
methods = [method.upper() for method in cls.http_method_names if method != 'options']
# Создаем словарь для ответа
usage = {'Request Types': methods, 'Headers': header, 'Body': params, 'Returns': returns}
# Защита от побочных эффектов
@wraps(function)
def _wrapper(*args, **kwargs):
return function(*args, **kwargs)
_wrapper.usage = usage
return _wrapper
return decorator
Декоратор — часть синтаксиса, которая позволяет легко определять функции высокого порядка, чтобы добавить функциям представления атрибуты (как классам). Представления на основе функций с декораторами — отличный компромисс между простыми функциями и представлениями на основе классов в Django. Этот декоратор предоставляет четыре информационных элемента: типы запросов, заголовки, параметры и возвращаемое значение каждой функции. Декоратор генерирует заголовок и информацию о методе на основе информации, полученной от других декораторов, прикрепленных к функции, и принимает в качестве входных данных параметры и возвращаемые значения на момент вызова данного декоратора.
Помимо вывода результатов index-запроса, мы также будем использовать наш API для взаимодействия с данными пользователя, так что нам понадобится какой-то способ аутентификации. Если бы это был не просто учебный проект, а что-то посерьезнее, можно было бы реализовать регистрацию пользователей (к тому же, это отличная практика, если вы хотите проверить, насколько вы разобрались с понятиями из этой статьи). Но вместо этого мы просто войдем под учетной записью суперпользователя, которую создали заранее.
@define_usage(params={'username': 'String', 'password': 'String'},
returns={'authenticated': 'Bool', 'token': 'Token String'})
@api_view(['POST'])
@permission_classes((AllowAny,))
def api_signin(request):
try:
username = request.data['username']
password = request.data['password']
except:
return Response({'error': 'Please provide correct username and password'},
status=HTTP_400_BAD_REQUEST)
user = authenticate(username=username, password=password)
if user is not None:
token, _ = Token.objects.get_or_create(user=user)
return Response({'authenticated': True, 'token': "Token " + token.key})
else:
return Response({'authenticated': False, 'token': None})
Важно отметить, что для того, чтобы идентификация на основе токенов заработала, нужно настроить несколько параметров. Гид по настройке можно найти в файле settings.py учебного проекта.
Чтобы верифицировать пользователя, метод api_signin запрашивает имя пользователя и пароль и использует встроенный в Django метод authenticate. Если предоставленные учетные данные верны, он возвращает токен, позволяющий клиенту получить доступ к защищенным конечным точкам API. Помните о том, что данный токен предоставляет те же права доступа, что и пароль, и поэтому должен надежно храниться в клиентском приложении. Теперь мы наконец можем поработать с Postman. Откройте приложение и используйте его для отправки post-запроса к /signin/, как показано на скриншоте.

Теперь, когда у вас есть токен для вашего пользователя, можно разобраться и с остальными составляющими API. Так что давайте немного отвлечемся и посмотрим на Django-модель, лежащую в основе API.
class Task(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE) #Каждая задача принадлежит только одному пользователю
description = models.CharField(max_length=150) #У каждой задачи есть описание
due = models.DateField() #У каждой задачи есть дата выполнения, тип datetime.date
Модель Task представляет собой довольно простой подход к менеджменту задач нашего приложения. Каждый элемент имеет описание, например, «Написать API с помощью Django» и дату выполнения. Задачи также связаны внешним ключом с объектом Django User, что означает, что каждая задача принадлежит только одному конкретному пользователю, но каждый пользователь может иметь неограниченное количество задач или не иметь вовсе. Каждый объект Django также имеет идентификатор, уникальное целое число, которое можно использовать для ссылки на индивидуальные задачи.
Приложения типа этого часто называют CRUD-приложениями, от «Create, Read, Update, Destroy» (Создание, Чтение, Модификация, Удаление), четырех операций, поддерживаемых нашим приложением на объектах Task.
Для начала создадим пустой список задач, связанных с конкретным пользователем. Используйте Postman для создания GET-запроса к /all/, как на скриншоте ниже. Не забудьте добавить токен к заголовкам этого и всех последующих запросов.

@define_usage(returns={'tasks': 'Dict'})
@api_view(['GET'])
@authentication_classes((SessionAuthentication, BasicAuthentication, TokenAuthentication))
@permission_classes((IsAuthenticated,))
def api_all_tasks(request):
tasks = taskSerializer(request.user.task_set.all(), many=True)
return Response({'tasks': tasks.data})
Функция api_all_tasks довольно проста. Стоит обратить внимание лишь на смену требований к проверке подлинности и классов разрешения на аутентификацию токеном. У нас есть новый декоратор @authentication_classes, позволяющий выполнять как дефолтные методы аутентификации Django REST framework, так иTokenAuthentication. Это позволяет нам ссылаться на все экземпляры User как на request.user, как если бы пользователи залогинились через стандартную Django-сессию. Декоратор @define_usage показывает нам, что api_all_tasks не принимает параметров (в отличие от GET-запроса) и возвращает лишь одну вещь — список задач. Поскольку данная функция возвращает данные в формате JSON (JavaScript Object Notation), мы используем сериализатор, чтобы сообщить Django, как парсить данные для отправки.
class taskSerializer(serializers.ModelSerializer):
class Meta:
model = Task
fields = ('id', 'description', 'due')
Эта простая модель определяет данные для класса Task: идентификатор, описание и дату выполнения. Сериализаторы могут добавлять и исключать поля и данные из модели. Например, вот этот сериализатор не возвращает идентификатор пользователя, т.к. он бесполезен для конечного клиента.
@define_usage(params={'description': 'String', 'due_in': 'Int'},
returns={'done': 'Bool'})
@api_view(['PUT'])
@authentication_classes((SessionAuthentication, BasicAuthentication, TokenAuthentication))
@permission_classes((IsAuthenticated,))
def api_new_task(request):
task = Task(user=request.user,
description=request.data['description'],
due=date.today() + timedelta(days=int(request.data['due_in'])))
task.save()
return Response({'done': True})
Теперь нам нужно создать задачу. Для этого используем api_new_task. Обычно для создания объекта в базе данных используется PUT-запрос. Обратите внимание, что этот метод, как и два других, не требует предварительной сериализации данных. Вместо этого мы передаем параметры в конструктор объекта класса Task, их же мы затем сохраним в базу данных. Мы отправляем количество дней для выполнения задачи, так как это гораздо проще, чем пытаться отправить объект Python-класса Date. Затем в API мы сохраняем какую-нибудь дату в далеком будущем. Чтобы увидеть созданный объект, нужно создать запрос к /new/ для создания задачи и повторить запрос к /all/.
@define_usage(params={'task_id': 'Int', 'description': 'String', 'due_in': 'Int'},
returns={'done': 'Bool'})
@api_view(['POST'])
@authentication_classes((SessionAuthentication, BasicAuthentication, TokenAuthentication))
@permission_classes((IsAuthenticated,))
def api_update_task(request):
task = request.user.task_set.get(id=int(request.data['task_id']))
try:
task.description = request.data['description']
except: #Обновление описания необязательно
pass
try:
task.due = date.today() + timedelta(days=int(request.data['due_in']))
except: #Обновление даты выполнения необязательно
pass
task.save()
return Response({'done': True})
Для редактирования только что созданной задачи нужно создать POST-запрос к api_update_task через /update/. Мы включаем task_id для ссылки на правильную задачу из пользовательского task_set. Код здесь будет немного сложнее, т.к. мы хотим иметь возможность обновлять описания и/ или дату выполнения задачи.
@define_usage(params={'task_id': 'Int'},
returns={'done': 'Bool'})
@api_view(['DELETE'])
@authentication_classes((SessionAuthentication, BasicAuthentication, TokenAuthentication))
@permission_classes((IsAuthenticated,))
def api_delete_task(request):
task = request.user.task_set.get(id=int(request.data['task_id']))
task.delete()
return Response({'done': True})
Используйте DELETE-запрос кapi_delete_task через /delete/ для удаления задачи. Этот метод работает аналогично функции api_update_task, за исключением того, что вместо изменения задачи он удаляет ее.
Сегодня мы с вами разобрались, как реализовать index-запрос, аутентификацию на основе токенов и четыре основных HTTP-метода для Django API. Вы можете использовать эти знания для поддержки любых веб- и нативных мобильных приложений или для разработки публичного API для обмена данными. Не стесняйтесь клонировать учебный проект, содержащий весь код, представленный в этой статье, и попробуйте реализовать такие расширения как пагинация, ограничение числа запросов и создание пользователя.
В этой статье мы рассмотрим новый фреймворк Arrested, который используется для создания REST API при помощи Python. Мы используем Docker, SQLAlchemy и прочие инструменты для создания API на тему Звездных Войн всего за пять минут!
Это первый пост в серии в будущей серии статей, нацеленных на помощь людям в построении REST API Python. Мы собрали коллекцию инструментов, которые помогут вам быстро начать и не слишком напрягаться на протяжении работы. В данном материале мы представим вам фреймворк Arrested, который используется для создания API при помощи Flask. Данный фреймворк нацелен сделать создание REST API безболезненным процессом. Подходит для быстрого использования в проектах, при этом легко расширяется для особых требований.
В данной статье мы рассмотрим
- Использование Cookie Cutter шаблона для установки приложения Flask вместе с базой данных SQLAlchemy ORM для взаимодействия с базой данных, Kim Mappers для сериализации и сортировки, хранилище Docker для среды разработки и пример пользовательского API;
- Создание ресурсов на тему Звездных Войн, для получения списков персонажей, создания новых персонажей, поиск персонажей по ID и наконец, обновление и удаление персонажа.
Список ресурсов инструментов, которые мы будем использовать
- Docker – используется во всех наших примерах;
- Git – для клонирования некоторых хранилищ;
- Cookie Cutter – инструмент для создания проектных шаблонов;
- Flask – наш фреймворк Arrested работает на Flask, микро-фреймворке для Python, который в свою очередь базируется на Werkzeug;
- Kim – фреймворк Python для сортировки и сериализации;
- Arrested – фреймворк для быстрого создания API при помощи Flask
Создаем приложение ?
Мы используем Cookie Cutter для быстрого создания базовой структуры приложения и избегания всех скучных этапов перед созданием ресурса, который будет выдавать персонажей из нашей базы данных «Звездных Войн«. Если вы не хотите использовать Cookie Cutter, вы можете скачать готовую структуру здесь.
|
$ cookiecutter gh:mikeywaites/arrested—cookiecutter project_name [Arrested Users API]: star wars project_slug [star—wars]: package_name [star_wars]: |
Теперь у нас есть базовый скелет приложения, давайте создадим контейнер Docker и создадим базу данных:
|
$ cd star_wars $ docker—compose build $ docker—compose run —rm api flask db upgrade |
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Теперь запускаем контейнер API и создаем запрос к конечной точке, чтобы убедиться в том, что все работает корректно.
|
$ docker—compose up api $ curl —u admin:secret localhost:8080/v1/users | python —m json.tool { «payload»: [] } |
Ву а ля. Мы создали рабочий REST API за 5 минут.
Конечно, мы получили рабочий REST API, но вся тяжелая работа уже была сделана за вас, но вы все еще понятия не имеет, как использовать Arrested для создания API в Python. В следующем разделе мы рассмотрим, как создавать базовый API для нашей базы данных персонажей Звездных Войн.
Создаем ресурс персонажей
Теперь, когда у нас есть установленное приложение, мы можем начать создание Python API наших персонажей. Мы добавим конечные точки, которые позволяют клиенту получать список персонажей, создавать новых, выполнять поиск персонажей, обновлять и удалять персонажей. Перед созданием нового API нам нужно создать модель Character и CharacterMapper.
|
$ touch star_wars/models/character.py $ touch star_wars/apis/v1/characters.py $ touch star_wars/apis/v1/mappers/character.py |
Начнем с очень простого объекта Character, который нужно назвать.
|
from .base import db, BaseMixin __all__ = [‘Character’] class Character(BaseMixin, db.Model): __tablename__ = ‘character’ name = db.Column(db.Unicode(255), nullable=False) |
Далее нам нужно импортировать модель в models/__init__.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import datetime from flask_sqlalchemy import SQLAlchemy from sqlalchemy.ext.declarative import declared_attr db = SQLAlchemy() class BaseMixin(object): @declared_attr def id(cls): return db.Column(db.Integer, primary_key=True) @declared_attr def created_at(cls): return db.Column(db.DateTime, default=datetime.datetime.utcnow) @declared_attr def updated_at(cls): return db.Column(db.DateTime, default=datetime.datetime.utcnow) from .user import * from .character import * |
Создаем миграцию для новой модели
|
$ docker—compose run —rm api flask db revision «character model» INFO [alembic.runtime.migration] Context impl SQLiteImpl. INFO [alembic.runtime.migration] Will assume non—transactional DDL. INFO [alembic.autogenerate.compare] Detected added table ‘character’ Generating /opt/code/star_wars/migrations/d7d80c02d806_character_model.py ... done # Выполняем файлы миграции для создание таблиц в базе данных $ docker—compose run —rm api flask db upgrade |
Редактируем файл «star_wars/apis/v1/mappers/character.py» который мы ранее создали для объекта CharacterMapper. Он отвечает за сериализацию и сортировку наших данных в API.
|
from kim import field from .base import BaseMapper from star_wars.models import Character class CharacterMapper(BaseMapper): __type__ = Character name = field.String() |
Теперь импортируем мэппер в модуль mapper/__init__.py
|
from .user import UserMapper from .character import CharacterMapper |
Великолепно! Теперь у нас есть модель базы данных и способ её сериализации, давайте создадим конечную точку, которая позволяет нашим клиентам API получить список персонажей. Добавьте следующий код в созданный нами файл «api/v1/characters.py«.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from arrested import Resource from arrested.contrib.kim_arrested import KimEndpoint from arrested.contrib.sql_alchemy import DBListMixin from star_wars.models import db, Character from .mappers import CharacterMapper characters_resource = Resource(‘characters’, __name__, url_prefix=‘/characters’) class CharactersIndexEndpoint(KimEndpoint, DBListMixin): name = ‘list’ many = True mapper_class = CharacterMapper model = Character def get_query(self): stmt = db.session.query(Character) return stmt characters_resource.add_endpoint(CharactersIndexEndpoint) |
Теперь нам нужно зарегистрировать наш Resource при помощи объекта Arrested API. Откройте модуль «api/v1/__init__.py» и импортируйте characters_resource. Укажите «defer=True«, чтобы Arrested отложил регистрацию маршрутов с Flask, пока объект API не инициализируется.
|
from arrested import ArrestedAPI from .users import users_resource from .characters import characters_resource from .middleware import basic_auth api_v1 = ArrestedAPI(url_prefix=‘/v1’, before_all_hooks=[basic_auth]) api_v1.register_resource(users_resource, defer=True) api_v1.register_resource(characters_resource, defer=True) |
Давайте проведем тестовый запуск нашего API. Убедитесь в том, что контейнер Docker запущен и затем используйте команду curl, которая выполнит GET запрос к ресурсу персонажей.
|
$ docker—compose up api $ curl —u admin:secret localhost:8080/v1/characters | python —m json.tool { «payload»: [] } |
Чудесно! Мы получили ответ, но не получили ни одного объекта персонажа из нашей базы данных, но это пока что. Теперь нам нужно получить способность создавать новых персонажей при помощи DBCreateMixin
Наш модуль characters.py теперь выглядит следующим образом:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from arrested import Resource from arrested.contrib.kim_arrested import KimEndpoint from arrested.contrib.sql_alchemy import DBListMixin, DBCreateMixin from star_wars.models import db, Character from .mappers import CharacterMapper characters_resource = Resource(‘characters’, __name__, url_prefix=‘/characters’) class CharactersIndexEndpoint(KimEndpoint, DBListMixin, DBCreateMixin): name = ‘list’ many = True mapper_class = CharacterMapper model = Character def get_query(self): stmt = db.session.query(Character) return stmt characters_resource.add_endpoint(CharactersIndexEndpoint) |
Все, что нам нужно для поддержки создания нашего объекта Character – это добавить DBCreateMixin в CharactersIndexEndpoint. Интеграция Arrested с SQLAlchemy и Kim позволяет обработать входящие данные, конвертируя вводные данные JSON Python в объект Character, с последующим сохранением в базе данных. Давайте пойдем дальше и создадим Персонажа.
|
curl —u admin:secret —H «Content-Type: application/json» —d ‘{«name»:»Darth Vader»}’ —X POST localhost:8080/v1/characters | python —m json.tool { «payload»: { «created_at»: «2017-11-22T08:18:26.044931», «id»: 1, «name»: «Darth Vader», «updated_at»: «2017-11-22T08:18:26.044958» } } |
Дарт Вейдер удачно создан! Теперь, если мы выполним запрос GET, как мы делали это ранее в нашем API, то наш Дарт Вейдер должен вернуться.
|
curl —u admin:secret localhost:8080/v1/characters | python —m json.tool { «payload»: [ { «created_at»: «2017-11-22T08:18:26.044931», «id»: 1, «name»: «Darth Vader», «updated_at»: «2017-11-22T08:18:26.044958» } ] } |
Теперь нам нужно установить конечную точку, которая позволяет клиентам получить персонажа, используя ID ресурса.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
from arrested import Resource from arrested.contrib.kim_arrested import KimEndpoint from arrested.contrib.sql_alchemy import DBListMixin, DBCreateMixin, DBObjectMixin from star_wars.models import db, Character from .mappers import CharacterMapper characters_resource = Resource(‘characters’, __name__, url_prefix=‘/characters’) class CharactersIndexEndpoint(KimEndpoint, DBListMixin, DBCreateMixin): name = ‘list’ many = True mapper_class = CharacterMapper model = Character def get_query(self): stmt = db.session.query(Character) return stmt class CharacterObjectEndpoint(KimEndpoint, DBObjectMixin): name = ‘object’ url = ‘/<string:obj_id>’ mapper_class = CharacterMapper model = Character def get_query(self): stmt = db.session.query(Character) return stmt characters_resource.add_endpoint(CharactersIndexEndpoint) characters_resource.add_endpoint(CharacterObjectEndpoint) |
Мы добавили новую конечную точку – CharacterObjectEndpoint и зарегистрировали её в ресурсе персонажей. DBObjectMixin позволяет нам получать ресурс по ID, обновлять тот или иной ресурс, а также удалить ресурс. Давайте попробуем!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Получаем персонажа с ID 1 curl —u admin:secret localhost:8080/v1/characters/1 | python —m json.tool { «payload»: { «created_at»: «2017-11-22T08:18:26.044931», «id»: 1, «name»: «Darth Vader», «updated_at»: «2017-11-22T08:18:26.044958» } } # После этого мы можем обновить имя персонажа curl —u admin:secret —H «Content-Type: application/json» —d ‘{«id»: 1, «name»:»Anakin Skywalker»}’ —X PUT localhost:8080/v1/characters/1 | python —m json.tool { «payload»: { «created_at»: «2017-11-22T08:18:26.044931», «id»: 1, «name»: «Anakin Skywalker», «updated_at»: «2017-11-22T08:18:26.044958» } } # И наконец, мы можем удалить персонажа curl —u admin:secret —X DELETE localhost:8080/v1/characters/1 |
Что-ж, вот и все. Это было введение в создание REST API в Python при помощи Arrested. Следите за дальнейшими обновлениями, у нас готовится много чего полезного!

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
TL;DR: Throughout this article, we will use Flask and Python to develop a RESTful API. We will create an endpoint that returns static data (dictionaries). Afterward, we will create a class with two specializations and a few endpoints to insert and retrieve instances of these classes. Finally, we will look at how to run the API on a Docker container. The final code developed throughout this article is available in this GitHub repository. I hope you enjoy it!
«Flask allows Python developers to create lightweight RESTful APIs.»
Tweet This

Summary
This article is divided into the following sections:
- Why Python?
- Why Flask?
- Bootstrapping a Flask Application
- Creating a RESTful Endpoint with Flask
- Mapping Models with Python Classes
- Serializing and Deserializing Objects with Marshmallow
- Dockerizing Flask Applications
- Securing Python APIs with Auth0
- Next Steps
Why Python?
Nowadays, choosing Python to develop applications is becoming a very popular choice. As StackOverflow recently analyzed, Python is one of the fastest-growing programming languages, having surpassed even Java in the number of questions asked on the platform. On GitHub, the language also shows signs of mass adoption, occupying the second position among the top programming languages in 2021.
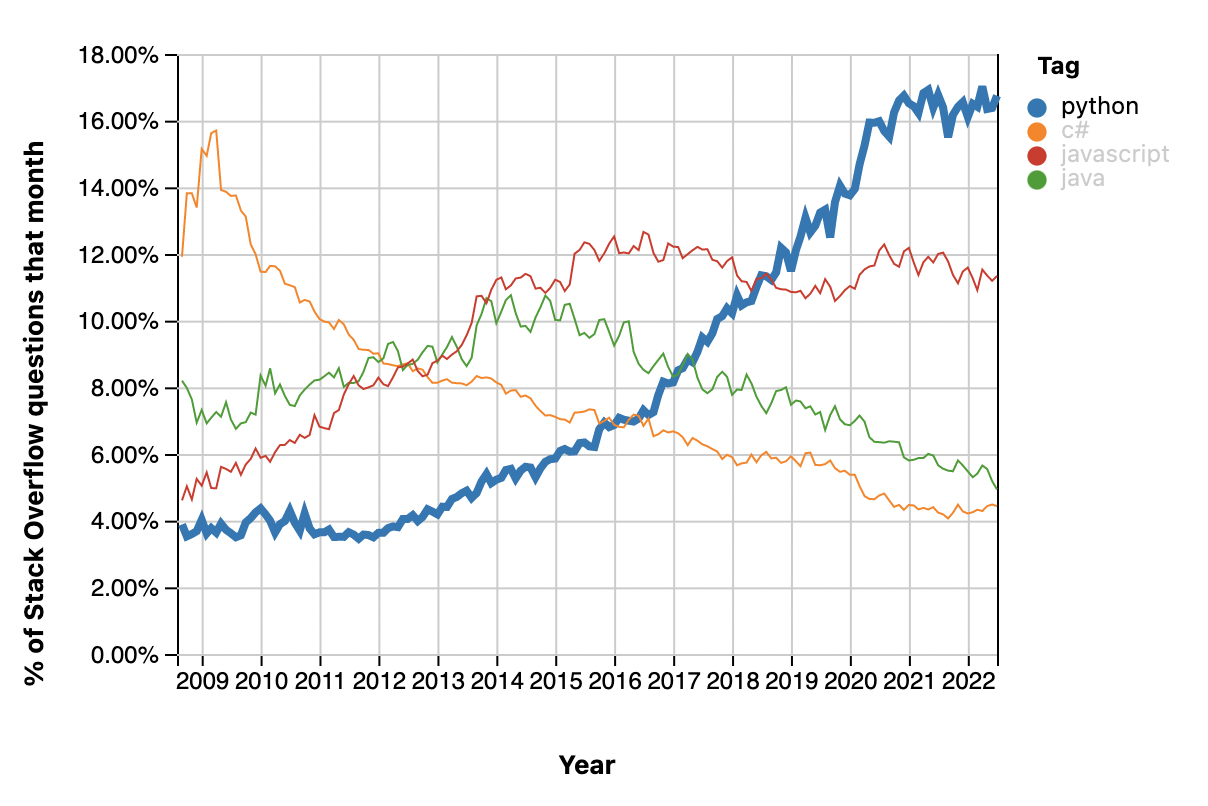
The huge community forming around Python is improving every aspect of the language. More and more open source libraries are being released to address many different subjects, like Artificial Intelligence, Machine Learning, and web development. Besides the tremendous support provided by the overall community, the Python Software Foundation also provides excellent documentation, where new adopters can learn its essence fast.
Why Flask?
When it comes to web development on Python, there are three predominant frameworks: Django, Flask, and a relatively new player FastAPI. Django is older, more mature, and a little bit more popular. On GitHub, this framework has around 66k stars, 2.2k contributors, ~ 350 releases, and more than 25k forks.
FastAPI is growing at high speed, with 48k stars on Github, 370 contributors, and more than 3.9k forks. This elegant framework built for high-performance and fast-to-code APIs is not one to miss.
Flask, although less popular, is not far behind. On GitHub, Flask has almost 60k stars, ~650 contributors, ~23 releases, and nearly 15k forks.
Even though Django is older and has a slightly more extensive community, Flask has its strengths. From the ground up, Flask was built with scalability and simplicity. Flask applications are known for being lightweight, mainly compared to their Django counterparts. Flask developers call it a microframework, where micro (as explained here) means that the goal is to keep the core simple but extensible. Flask won’t make many decisions for us, such as what database to use or what template engine to choose. Lastly, Flask has extensive documentation that addresses everything developers need to start.
FastAPI follows a similar «micro» approach to Flask, though it provides more tools like automatic Swagger UI and is an excellent choice for APIs. However, as it is a newer framework, many more resources and libraries are compatible with frameworks like Django and Flask but not with FastAPI.
Being lightweight, easy to adopt, well-documented, and popular, Flask is a good option for developing RESTful APIs.
Bootstrapping a Flask Application
First and foremost, we will need to install some dependencies on our development machine. We will need to install Python 3, Pip (Python Package Index), and Flask.
Installing Python 3
If we are using some recent version of a popular Linux distribution (like Ubuntu) or macOS, we might already have Python 3 installed on our computer. If we are running Windows, we will probably need to install Python 3, as this operating system does not ship with any version.
After installing Python 3 on our machine, we can check that we have everything set up as expected by running the following command:
python --version
# Python 3.8.9Note that the command above might produce a different output when we have a different Python version. What is important is that you are running at least Python 3.7 or newer. If we get «Python 2» instead, we can try issuing python3 --version. If this command produces the correct output, we must replace all commands throughout the article to use python3 instead of just python.
Installing Pip
Pip is the recommended tool for installing Python packages. While the official installation page states that pip comes installed if we’re using Python 2 >= 2.7.9 or Python 3 >= 3.4, installing Python through apt on Ubuntu doesn’t install pip. Therefore, let’s check if we need to install pip separately or already have it.
# we might need to change pip by pip3
pip --version
# pip 9.0.1 ... (python 3.X)If the command above produces an output similar to pip 9.0.1 ... (python 3.X), then we are good to go. If we get pip 9.0.1 ... (python 2.X), we can try replacing pip with pip3. If we cannot find Pip for Python 3 on our machine, we can follow the instructions here to install Pip.
Installing Flask
We already know what Flask is and its capabilities. Therefore, let’s focus on installing it on our machine and testing to see if we can get a basic Flask application running. The first step is to use pip to install Flask:
# we might need to replace pip with pip3
pip install FlaskAfter installing the package, we will create a file called hello.py and add five lines of code to it. As we will use this file to check if Flask was correctly installed, we don’t need to nest it in a new directory.
# hello.py
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
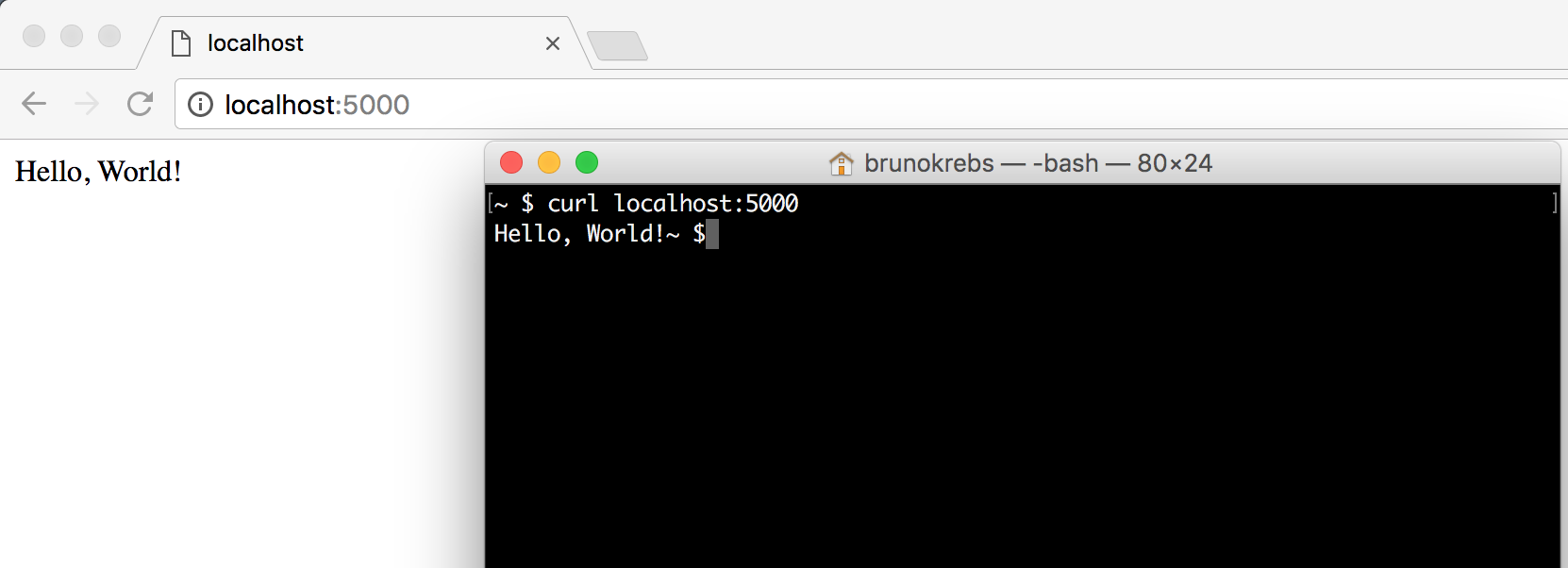
return "Hello, World!"These 5 lines of code are everything we need to handle HTTP requests and return a «Hello, World!» message. To run it, we execute the following command:
flask --app hello run
* Serving Flask app 'hello'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://127.0.0.1:5000
Press CTRL+C to quitOn Ubuntu, we might need to edit the
$PATHvariable to be able to run flask directly. To do that, let’stouch ~/.bash_aliasesand thenecho "export PATH=$PATH:~/.local/bin" >> ~/.bash_aliases.
After executing these commands, we can reach our application by opening a browser and navigating to http://127.0.0.1:5000/ or by issuing curl http://127.0.0.1:5000/.
Virtual environments (virtualenv)
Although PyPA—the Python Packaging Authority group—recommends pip as the tool for installing Python packages, we will need to use another package to manage our project’s dependencies. It’s true that pip supports package management through the requirements.txt file, but the tool lacks some features required on serious projects running on different production and development machines. Among its issues, the ones that cause the most problems are:
pipinstalls packages globally, making it hard to manage multiple versions of the same package on the same machine.requirements.txtneed all dependencies and sub-dependencies listed explicitly, a manual process that is tedious and error-prone.
To solve these issues, we are going to use Pipenv. Pipenv is a dependency manager that isolates projects in private environments, allowing packages to be installed per project. If you’re familiar with NPM or Ruby’s bundler, it’s similar in spirit to those tools.
pip install pipenvNow, to start creating a serious Flask application, let’s create a new directory that will hold our source code. In this article, we will create Cashman, a small RESTful API that allows users to manage incomes and expenses. Therefore, we will create a directory called cashman-flask-project. After that, we will use pipenv to start our project and manage our dependencies.
# create our project directory and move to it
mkdir cashman-flask-project && cd cashman-flask-project
# use pipenv to create a Python 3 (--three) virtualenv for our project
pipenv --three
# install flask a dependency on our project
pipenv install flaskThe second command creates our virtual environment, where all our dependencies get installed, and the third will add Flask as our first dependency. If we check our project’s directory, we will see two new files:
Pipfilecontains details about our project, such as the Python version and the packages needed.Pipenv.lockcontains precisely what version of each package our project depends on and its transitive dependencies.
Python modules
Like other mainstream programming languages, Python also has the concept of modules to enable developers to organize source code according to subjects/functionalities. Similar to Java packages and C# namespaces, modules in Python are files organized in directories that other Python scripts can import. To create a module on a Python application, we need to create a folder and add an empty file called __init__.py.
Let’s create our first module on our application, the main module, with all our RESTful endpoints. Inside the application’s directory, let’s create another one with the same name, cashman. The root cashman-flask-project directory created before will hold metadata about our project, like what dependencies it has, while this new one will be our module with our Python scripts.
# create source code's root
mkdir cashman && cd cashman
# create an empty __init__.py file
touch __init__.pyInside the main module, let’s create a script called index.py. In this script, we will define the first endpoint of our application.
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
return "Hello, World!"As in the previous example, our application returns a «Hello, world!» message. We will start improving it in a second, but first, let’s create an executable file called bootstrap.sh in the root directory of our application.
# move to the root directory
cd ..
# create the file
touch bootstrap.sh
# make it executable
chmod +x bootstrap.shThe goal of this file is to facilitate the start-up of our application. Its source code will be the following:
#!/bin/sh
export FLASK_APP=./cashman/index.py
pipenv run flask --debug run -h 0.0.0.0The first command defines the main script to be executed by Flask. The second command runs our Flask application in the context of the virtual environment listening to all interfaces on the computer (-h 0.0.0.0).
Note: we are setting flask to run in debug mode to enhance our development experience and activate the hot reload feature, so we don’t have to restart the server each time we change the code. If you run Flask in production, we recommend updating these settings for production.
To check that this script is working correctly, we run ./bootstrap.sh to get similar results as when executing the «Hello, world!» application.
* Serving Flask app './cashman/index.py'
* Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5000
* Running on http://192.168.1.207:5000
Press CTRL+C to quitCreating a RESTful Endpoint with Flask
Now that our application is structured, we can start coding some relevant endpoints. As mentioned before, the goal of our application is to help users to manage incomes and expenses. We will begin by defining two endpoints to handle incomes. Let’s replace the contents of the ./cashman/index.py file with the following:
from flask import Flask, jsonify, request
app = Flask(__name__)
incomes = [
{ 'description': 'salary', 'amount': 5000 }
]
@app.route('/incomes')
def get_incomes():
return jsonify(incomes)
@app.route('/incomes', methods=['POST'])
def add_income():
incomes.append(request.get_json())
return '', 204Since improving our application, we have removed the endpoint that returned «Hello, world!» to users. In its place, we defined an endpoint to handle HTTP GET requests to return incomes and another endpoint to handle HTTP POST requests to add new ones. These endpoints are annotated with @app.route to define routes listening to requests on the /incomes endpoint. Flask provides great documentation on what exactly this does.
To facilitate the process, we currently manipulate incomes as dictionaries. However, we will soon create classes to represent incomes and expenses.
To interact with both endpoints that we have created, we can start our application and issue some HTTP requests:
# start the cashman application
./bootstrap.sh &
# get incomes
curl http://localhost:5000/incomes
# add new income
curl -X POST -H "Content-Type: application/json" -d '{
"description": "lottery",
"amount": 1000.0
}' http://localhost:5000/incomes
# check if lottery was added
curl localhost:5000/incomes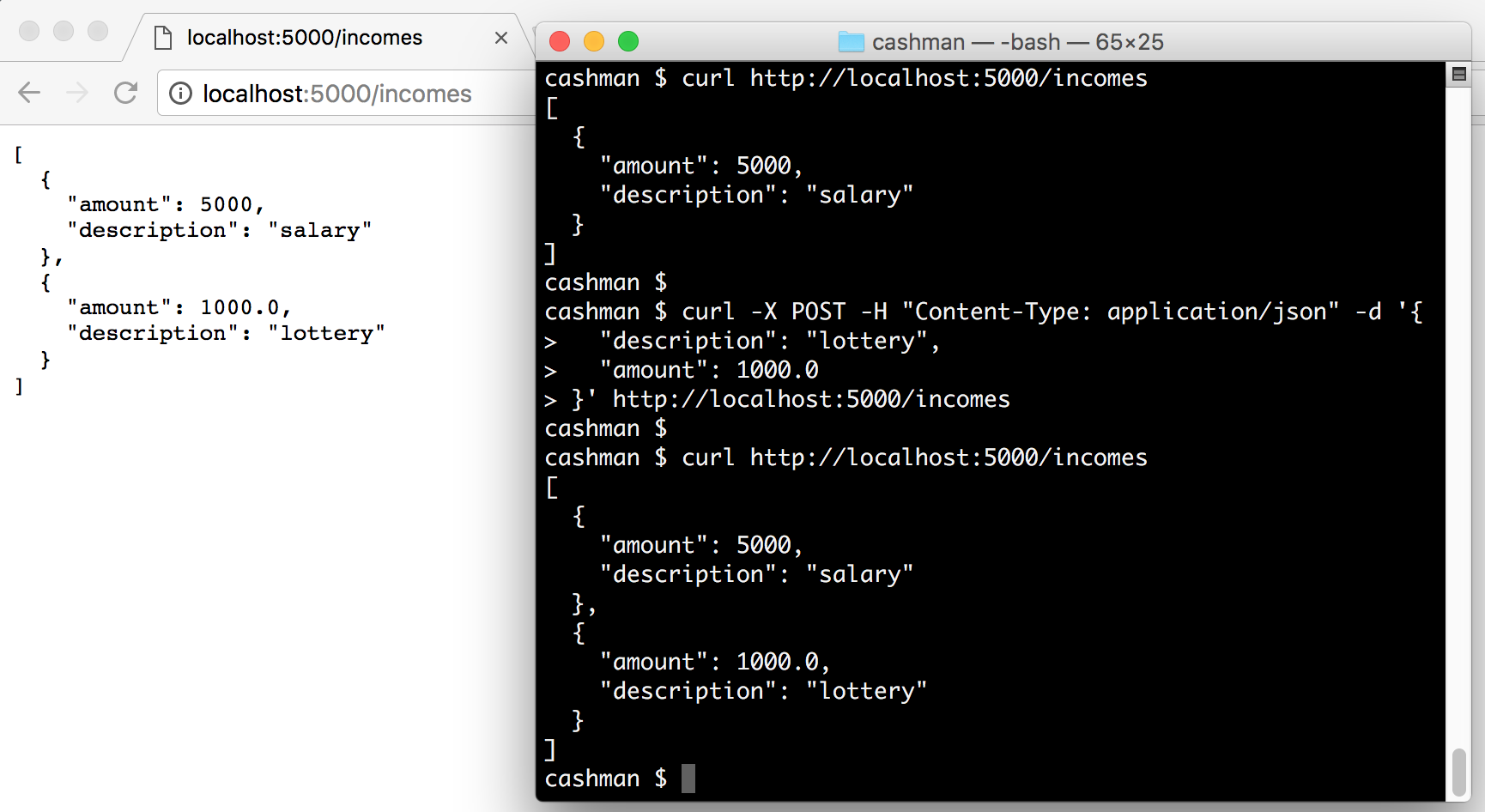
Mapping Models with Python Classes
Using dictionaries in a simple use case like the one above is enough. However, for more complex applications that deal with different entities and have multiple business rules and validations, we might need to encapsulate our data into Python classes.
We will refactor our application to learn the process of mapping entities (like incomes) as classes. The first thing that we will do is create a submodule to hold all our entities. Let’s create a model directory inside the cashman module and add an empty file called __init__.py on it.
# create model directory inside the cashman module
mkdir -p cashman/model
# initialize it as a module
touch cashman/model/__init__.pyMapping a Python superclass
We will create three classes in this new module/directory: Transaction, Income, and Expense. The first class will be the base for the two others, and we will call it Transaction. Let’s create a file called transaction.py in the model directory with the following code:
import datetime as dt
from marshmallow import Schema, fields
class Transaction(object):
def __init__(self, description, amount, type):
self.description = description
self.amount = amount
self.created_at = dt.datetime.now()
self.type = type
def __repr__(self):
return '<Transaction(name={self.description!r})>'.format(self=self)
class TransactionSchema(Schema):
description = fields.Str()
amount = fields.Number()
created_at = fields.Date()
type = fields.Str()Besides the Transaction class, we also defined a TransactionSchema. We will use the latter to deserialize and serialize instances of Transaction from and to JSON objects. This class inherits from another superclass called Schema that belongs on a package not yet installed.
# installing marshmallow as a project dependency
pipenv install marshmallowMarshmallow is a popular Python package for converting complex datatypes, such as objects, to and from built-in Python datatypes. We can use this package to validate, serialize, and deserialize data. We won’t dive into validation in this article, as it will be the subject of another one. Though, as mentioned, we will use marshmallow to serialize and deserialize entities through our endpoints.
Mapping Income and Expense as Python Classes
To keep things more organized and meaningful, we won’t expose the Transaction class on our endpoints. We will create two specializations to handle the requests: Income and Expense. Let’s make a file called income.py inside the model module with the following code:
from marshmallow import post_load
from .transaction import Transaction, TransactionSchema
from .transaction_type import TransactionType
class Income(Transaction):
def __init__(self, description, amount):
super(Income, self).__init__(description, amount, TransactionType.INCOME)
def __repr__(self):
return '<Income(name={self.description!r})>'.format(self=self)
class IncomeSchema(TransactionSchema):
@post_load
def make_income(self, data, **kwargs):
return Income(**data)The only value that this class adds for our application is that it hardcodes the type of transaction. This type is a Python enumerator, which we still have to create, that will help us filter transactions in the future. Let’s create another file, called transaction_type.py, inside model to represent this enumerator:
from enum import Enum
class TransactionType(Enum):
INCOME = "INCOME"
EXPENSE = "EXPENSE"The code of the enumerator is quite simple. It just defines a class called TransactionType that inherits from Enum and that defines two types: INCOME and EXPENSE.
Lastly, let’s create the class that represents expenses. To do that, let’s add a new file called expense.py inside model with the following code:
from marshmallow import post_load
from .transaction import Transaction, TransactionSchema
from .transaction_type import TransactionType
class Expense(Transaction):
def __init__(self, description, amount):
super(Expense, self).__init__(description, -abs(amount), TransactionType.EXPENSE)
def __repr__(self):
return '<Expense(name={self.description!r})>'.format(self=self)
class ExpenseSchema(TransactionSchema):
@post_load
def make_expense(self, data, **kwargs):
return Expense(**data)Similar to Income, this class hardcodes the type of the transaction, but now it passes EXPENSE to the superclass. The difference is that it transforms the given amount to be negative. Therefore, no matter if the user sends a positive or a negative value, we will always store it as negative to facilitate calculations.
Serializing and Deserializing Objects with Marshmallow
With the Transaction superclass and its specializations adequately implemented, we can now enhance our endpoints to deal with these classes. Let’s replace ./cashman/index.py contents to:
from flask import Flask, jsonify, request
from cashman.model.expense import Expense, ExpenseSchema
from cashman.model.income import Income, IncomeSchema
from cashman.model.transaction_type import TransactionType
app = Flask(__name__)
transactions = [
Income('Salary', 5000),
Income('Dividends', 200),
Expense('pizza', 50),
Expense('Rock Concert', 100)
]
@app.route('/incomes')
def get_incomes():
schema = IncomeSchema(many=True)
incomes = schema.dump(
filter(lambda t: t.type == TransactionType.INCOME, transactions)
)
return jsonify(incomes)
@app.route('/incomes', methods=['POST'])
def add_income():
income = IncomeSchema().load(request.get_json())
transactions.append(income)
return "", 204
@app.route('/expenses')
def get_expenses():
schema = ExpenseSchema(many=True)
expenses = schema.dump(
filter(lambda t: t.type == TransactionType.EXPENSE, transactions)
)
return jsonify(expenses)
@app.route('/expenses', methods=['POST'])
def add_expense():
expense = ExpenseSchema().load(request.get_json())
transactions.append(expense)
return "", 204
if __name__ == "__main__":
app.run()The new version that we just implemented starts by redefining the incomes variable into a list of Expenses and Incomes, now called transactions. Besides that, we have also changed the implementation of both methods that deal with incomes. For the endpoint used to retrieve incomes, we defined an instance of IncomeSchema to produce a JSON representation of incomes. We also used filter to extract incomes only from the transactions list. In the end we send the array of JSON incomes back to users.
The endpoint responsible for accepting new incomes was also refactored. The change on this endpoint was the addition of IncomeSchema to load an instance of Income based on the JSON data sent by the user. As the transactions list deals with instances of Transaction and its subclasses, we just added the new Income in that list.
The other two endpoints responsible for dealing with expenses, get_expenses and add_expense, are almost copies of their income counterparts. The differences are:
- instead of dealing with instances of
Income, we deal with instances ofExpenseto accept new expenses, - and instead of filtering by
TransactionType.INCOME, we filter byTransactionType.EXPENSEto send expenses back to the user.
This finishes the implementation of our API. If we run our Flask application now, we will be able to interact with the endpoints, as shown here:
# start the application
./bootstrap.sh
# get expenses
curl http://localhost:5000/expenses
# add a new expense
curl -X POST -H "Content-Type: application/json" -d '{
"amount": 20,
"description": "lottery ticket"
}' http://localhost:5000/expenses
# get incomes
curl http://localhost:5000/incomes
# add a new income
curl -X POST -H "Content-Type: application/json" -d '{
"amount": 300.0,
"description": "loan payment"
}' http://localhost:5000/incomesDockerizing Flask Applications
As we are planning to eventually release our API in the cloud, we are going to create a Dockerfile to describe what is needed to run the application on a Docker container. We need to install Docker on our development machine to test and run dockerized instances of our project. Defining a Docker recipe (Dockerfile) will help us run the API in different environments. That is, in the future, we will also install Docker and run our program on environments like production and staging.
Let’s create the Dockerfile in the root directory of our project with the following code:
# Using lightweight alpine image
FROM python:3.8-alpine
# Installing packages
RUN apk update
RUN pip install --no-cache-dir pipenv
# Defining working directory and adding source code
WORKDIR /usr/src/app
COPY Pipfile Pipfile.lock bootstrap.sh ./
COPY cashman ./cashman
# Install API dependencies
RUN pipenv install --system --deploy
# Start app
EXPOSE 5000
ENTRYPOINT ["/usr/src/app/bootstrap.sh"]The first item in the recipe defines that we will create our Docker container based on the default Python 3 Docker image. After that, we update APK and install pipenv. Having pipenv, we define the working directory we will use in the image and copy the code needed to bootstrap and run the application. In the fourth step, we use pipenv to install all our Python dependencies. Lastly, we define that our image will communicate through port 5000 and that this image, when executed, needs to run the bootstrap.sh script to start Flask.
Note: For our
Dockerfile, we use Python version 3.8, however, depending on your system configuration,pipenvmay have set a different version for Python in the filePipfile. Please make sure that the Python version in bothDockerfileandPipfileare aligned, or the docker container won’t be able to start the server.
To create and run a Docker container based on the Dockerfile that we created, we can execute the following commands:
# build the image
docker build -t cashman .
# run a new docker container named cashman
docker run --name cashman
-d -p 5000:5000
cashman
# fetch incomes from the dockerized instance
curl http://localhost:5000/incomes/The Dockerfile is simple but effective, and using it is similarly easy. With these commands and this Dockerfile, we can run as many instances of our API as we need with no trouble. It’s just a matter of defining another port on the host or even another host.
Securing Python APIs with Auth0
Securing Python APIs with Auth0 is very easy and brings a lot of great features to the table. With Auth0, we only have to write a few lines of code to get:
- A solid identity management solution, including single sign-on
- User management
- Support for social identity providers (like Facebook, GitHub, Twitter, etc.)
- Enterprise identity providers (Active Directory, LDAP, SAML, etc.)
- Our own database of users
For example, to secure Python APIs written with Flask, we can simply create a requires_auth decorator:
# Format error response and append status code
def get_token_auth_header():
"""Obtains the access token from the Authorization Header
"""
auth = request.headers.get("Authorization", None)
if not auth:
raise AuthError({"code": "authorization_header_missing",
"description":
"Authorization header is expected"}, 401)
parts = auth.split()
if parts[0].lower() != "bearer":
raise AuthError({"code": "invalid_header",
"description":
"Authorization header must start with"
" Bearer"}, 401)
elif len(parts) == 1:
raise AuthError({"code": "invalid_header",
"description": "Token not found"}, 401)
elif len(parts) > 2:
raise AuthError({"code": "invalid_header",
"description":
"Authorization header must be"
" Bearer token"}, 401)
token = parts[1]
return token
def requires_auth(f):
"""Determines if the access token is valid
"""
@wraps(f)
def decorated(*args, **kwargs):
token = get_token_auth_header()
jsonurl = urlopen("https://"+AUTH0_DOMAIN+"/.well-known/jwks.json")
jwks = json.loads(jsonurl.read())
unverified_header = jwt.get_unverified_header(token)
rsa_key = {}
for key in jwks["keys"]:
if key["kid"] == unverified_header["kid"]:
rsa_key = {
"kty": key["kty"],
"kid": key["kid"],
"use": key["use"],
"n": key["n"],
"e": key["e"]
}
if rsa_key:
try:
payload = jwt.decode(
token,
rsa_key,
algorithms=ALGORITHMS,
audience=API_AUDIENCE,
issuer="https://"+AUTH0_DOMAIN+"/"
)
except jwt.ExpiredSignatureError:
raise AuthError({"code": "token_expired",
"description": "token is expired"}, 401)
except jwt.JWTClaimsError:
raise AuthError({"code": "invalid_claims",
"description":
"incorrect claims,"
"please check the audience and issuer"}, 401)
except Exception:
raise AuthError({"code": "invalid_header",
"description":
"Unable to parse authentication"
" token."}, 400)
_app_ctx_stack.top.current_user = payload
return f(*args, **kwargs)
raise AuthError({"code": "invalid_header",
"description": "Unable to find appropriate key"}, 400)
return decoratedThen use it in our endpoints:
# Controllers API
# This doesn't need authentication
@app.route("/ping")
@cross_origin(headers=['Content-Type', 'Authorization'])
def ping():
return "All good. You don't need to be authenticated to call this"
# This does need authentication
@app.route("/secured/ping")
@cross_origin(headers=['Content-Type', 'Authorization'])
@requires_auth
def secured_ping():
return "All good. You only get this message if you're authenticated"To learn more about securing Python APIs with Auth0, take a look at this tutorial. Alongside with tutorials for backend technologies (like Python, Java, and PHP), the Auth0 Docs webpage also provides tutorials for Mobile/Native apps and Single-Page applications.
Next Steps
In this article, we learned about the basic components needed to develop a well-structured Flask application. We looked at how to use pipenv to manage the dependencies of our API. After that, we installed and used Flask and Marshmallow to create endpoints capable of receiving and sending JSON responses. In the end, we also looked at how to dockerize the API, which will facilitate the release of the application to the cloud.
Although well structured, our API is not that useful yet. Among the things that we can improve, we are going to cover the following topics in the following article:
- Database persistence with SQLAlchemy
- Add authorization to a Flask API application
- How to handle JWTs in Python
Stay tuned!