Из песочницы, Компиляторы, Python
Рекомендация: подборка платных и бесплатных курсов Python — https://katalog-kursov.ru/

Пишем свой «Язык программирования» на Python3
1. Лексер
В этой статье мы сделаем, так сказать python2, создание переменных, вывод их в консоль
Если вам зайдёт, то сделаю 2 часть поста 

Для начала, определимся с названием языка — к примеру «xnn»
Теперь создадим файл xnn.py и запишем туда основной код:
import sys #Импортируем библиотеку sys
import os #Импортируем библиотеку os
dir = os.path.abspath(os.curdir) #Узнаём откуда запущен компилятор
p = str(dir) + '\' + str(sys.argv[1]) #sys.argv[1] - определяем 1 аргумент
print(p) # Выводим ддиректорию + файл
modules = ['if', 'else', 'while', 'for', '=', '==', '{', '}', '[', ']', '(', ')', '//'] #Создаём все зарезервированные слова
var = [] #Создаём список для лексера
vars_ = {} #Создаём список для переменных
with open(p, 'r', encoding="UTF-8") as f: #Отрываем файл из аргумента
for ex in f.read().split(): #Распределяем все слова
var.append(ex) #Записываем все слова в список var
print(var) # $ Выводим список $
Что мы делаем:
- Импортируем библиотеки os и sys
- С помощью os определяем откуда запущен компилятор, (в будущем раскажу зачем)
- Создаём путь к файлу + берём сам файл из аргумента — получаем его через sys.argv
- Дальше выводим сам путь, с файлом (в будущем это надо будет удалить)
- Создаём все зарезервированные слова — пока, нам это не надо, но в будещем понядобиться дял вывода ошибок
- Создаём списки для лексера и переменных
- Создаём сам лексер, для этого открываем файл, в режиме чтения, обязательно в
encoding=«UTF-8»
если этого не сделать, то вместо русских букв, будут иероглифы!
- С помощью for ex in read().split() распределяем весь текст на слова и помещаем каждое слово отдельно в ex
- Дальше записываем каждое слово в список var
- И выведим сам список — в будущем нужно будет удалить вывод :/
Создание файла .xnn
Теперь создадим сам файл который будем парсить, а также изменим способ открытия

Откроем его и запишем туда:
pr = Привет
rprint pr
2. Создание Компилятора
Теперь создадим компилятор!
Для этого дополним наш файл кодом, чтобы получилось вот так:
import sys #Импортируем библиотеку sys
import os #Импортируем библиотеку os
dir = os.path.abspath(os.curdir) #Узнаём откуда запущен компилятор
p = str(dir) + '\' + str(sys.argv[1]) #sys.argv[1] - определяем 1 аргумент
print(p) # Выводим ддиректорию + файл
modules = ['if', 'else', 'while', 'for', '=', '==', '{', '}', '[', ']', '(', ')', '//'] #Создаём все зарезервированные слова
var = [] #Создаём список для лексера
vars_ = {} #Создаём список для переменных
try:
with open(p, 'r', encoding="UTF-8") as f: #Отрываем файл из аргумента
for ex in f.read().split(): #Распределяем все слова
var.append(ex) #Записываем все слова в список var
print(var) # $ Выводим список $
a = -1 #Устанавливаем значение на каком сейчас var
for i in var: #Перебираем все значения
a = a + 1 #Добавляем что это значение просмотренно
if i == '=': #Если находим совпадение с "="
vars_[var[a-1]] = var[a+1] #в список vars_ добавляем занчение до и после "="
if i == 'rprint':
let = var[a+1]
for key, value in vars_.items():
if key == let:
print(value)
except FileNotFoundError:
print('Error! Файл не найден!')
Что мы делаем?
Мы перебираем все значения в var и при нахождении того или инного зарезервировонного слова, делаем определённые действия
Присваивание переменных
При совпадении i с «=» добавляем в список
vars_
значение, до «=» как key, а после «=», как value — таким образом образуя переменную
Вывод переменных
При совпадении i с «rprint» ищем в списке
vars_
совпадение для этой переменной, которое получаем через нашего друга, списка
var
После нахождение выводим значение переменной
Работа в действии
Для того чтобы скомпилировать файл, вводим данные команды в cmd:
cd path/to/files
python xnn.py prog.xnn
На выход получаем:
C:UsersHoopengoDesktopxnnprog.xnn
['pr', '=', 'Привет', 'rprint', 'pr']
Привет
3. Компиляция в .exe
Создадим копию папки с файлами и отредактируем файл xnn.py
import sys #Импортируем библиотеку sys
import os #Импортируем библиотеку os
dir = os.path.abspath(os.curdir) #Узнаём откуда запущен компилятор
p = str(dir) + '\' + str(sys.argv[1]) #sys.argv[1] - определяем 1 аргумент
modules = ['if', 'else', 'while', 'for', '=', '==', '{', '}', '[', ']', '(', ')', '//'] #Создаём все зарезервированные слова
var = [] #Создаём список для лексера
vars_ = {} #Создаём список для переменных
try:
with open(p, 'r', encoding="UTF-8") as f: #Отрываем файл из аргумента
for ex in f.read().split(): #Распределяем все слова
var.append(ex) #Записываем все слова в список var
a = -1 #Устанавливаем значение на каком сейчас var
for i in var: #Перебираем все значения
a = a + 1 #Добавляем что это значение просмотренно
if i == '=': #Если находим совпадение с "="
vars_[var[a-1]] = var[a+1] #в список vars_ добавляем занчение до и после "="
if i == 'rprint':
let = var[a+1]
for key, value in vars_.items():
if key == let:
print(value)
except FileNotFoundError:
print('Error! Файл не найден!')
Установим auto-py-to-exe
Полная информация по установке есть по этой ссылке
Введём в консоль:
auto-py-to-exe
pip install auto-py-to-exe
auto-py-to-exe
Запустится браузер. Выбираем там путь к файлу и One File
Мои Предустоновка

4. Создание установщика
В копированной папке создадим файл bat.py:
import os
with open('path\xnn.exe', 'r', encoding='UTF-8') as f:
lean = f.read()
directory_folder = r"C:\Windows\System32\xnn.exe"
folder_path = os.path.dirname(directory_folder) # Путь к папке с файлом
if not os.path.exists(folder_path): #Если пути не существует создаем его
os.makedirs(folder_path)
with open(directory_folder, 'w', encoding='UTF-8') as file: # Открываем фаил и пишем
file.write(lean)
После этого компилируем его в .exe и бросаем в туже директорию, должно получится так:

5. Установка
Теперь установим
Для этого отроем файл bat.exe, после чего произведотся установка
Перезапустим консоль и введём:
cd path/to/file
xnn prog.xnn
И получим:
Привет
Если пишет что «xnn не является внутренней командой», то самостоятельно добавьте файл xnn.exe в папку «C:WindowsSystem32».
Может ли студент второго курса написать JIT-компилятор Питона, конкурирующий по производительности с промышленным решением? С учётом того, что он это сделает за две недели за зачёт по программированию.
Как оказалось, может, но с нюансами.
Предисловие
Обучаясь в РТУ МИРЭА, на специальности «Программная инженерия» я попал на семестровый курс программирования на Питоне. Питон я знал до этого, поэтому не хотелось много с ним возиться. Благо творчество студентов поощряется, иногда даже «автоматами». Собственно, стимулируемый этим «автоматом» и тягой к написанию системных модулей я написал JIT-компилятор, который назвал MetaStruct.
С кодом проекта можно ознакомиться в репозитории.
Предыдущий мой опыт в написании низкоуровневых программ оказался нежизнеспособным и весьма поучительным. Но об этом сегодня речь не пойдёт.
Стандартная реализация Python — CPython — достаточно медленная. В сравнении с C++ называют замедление в 20-30 раз. Но целое сообщество программистов на Питоне готовы заплатить эту цену ради удобства синтаксиса, быстроты написания, изящности и выразительности кода.
На этой почве появляются разнообразные способы оптимизации выполнения программ на Питоне. Такие диалекты как Cython и RPython пытаются решить проблему «разгона» Питона за счёт статической типизации и компиляции модулей.
В области JIT-компиляции промышленным решением является проект Numba, спонсируемый такими технологическими гигантами как Intel, AMD и NVIDIA. Именно с этим пакетом мне предложили и посоревноваться, написав миниатюрный JIT-компилятор программ на Питоне.
В этой статье я хочу рассказать, с какими трудностями я, как программист достаточно прикладной, столкнулся при написании такой довольно низкоуровневой вещи, как миниатюрный JIT-компилятор.
Принцип работы

На схеме выше показано, какие этапы проходит функция на Питоне, становясь скомпилированным модулем на С++:
-
Функция, которую мы хотим оптимизировать, помечается аннотацией
@jit, примерно так:
@jit
def sum(x: int, y: int) -> int:
res: int = x + y
return res-
Аннотация, получая объект функции, с помощью
inspect.getsource(func_object)получает текст функции в виде строки. -
С помощью функции
ast.parse(func_py_text)текст функции превращается в абстрактное синтаксическое дерево (AST) языка Питон -
Моя программа проходится по дереву через метод
visit(), наследуясь отast.NodeVisitor, и получает на выходе текст программы на C++, который записывается в файл. Для примера выше, он будет примерно таким:
extern "C" int sum(int x, int y) {
int res = (x + y);
return res;
}-
Через
subprocess.run()происходит вызов компилятора g++, который выдаёт динамически подключаемую библиотеку (в зависимости от платформы файлом.dllили.so)
g++ -O2 -c source.cpp -o object.o
g++ -shared object.o -o lib.dll-
При помощи вызова
ctypes.LibraryLoader(CDLL).LoadLibrary(dll_filename)Динамическая библиотека подключается к среде выполнения и даёт доступ к скомпилированному варианту исходной функции. -
Конечный пользователь, добавивший над функцией аннотацию
@jit, пользуется совершенно другим вариантом своего кода, ничего не подозревая.
Процесс достаточно трудоёмкий для функции сложения из примера, но при частых вызовах и большом количестве вычислений внутри функции время компиляции окупается.
Если бы это был не Питон, а какой-нибудь предметно-ориентированный язык, то пришлось бы писать парсер и обход получившегося абстрактного дерева, и решение не было бы уже таким коротким. Но в моём случае, инфраструктура Питона и его гибкость сыграли мне на руку.
Впечатляющие результаты
Наверное, стоит от технической части переходить к части визуализации и маркетинга.
Созданный алгоритм JIT-компиляции был протестирован на нескольких простых алгоритмических задачах:
-
Сумма двух чисел
-
Хеш-функция для целых чисел
-
Вычисление экспоненты через ряд Тейлора
-
Числа Фибоначчи
С расчётами и графиками можно подробнее ознакомиться в
Jupyter-блокноте
Для оценки времени выполнения использованы функции timeit() и repeat() модуля timeit. Для отрисовки графиков — модуль matplotlib
В примерах будут сравниваться три реализации функций:
-
Просто функция питона
-
Оптимизированных аннотацией
@jit -
Оптимизированных аннотацией
@numba.jit
Сумма двух чисел

def py_sum(x: int, y: int) -> int:
res: int = x + y
return resНа задаче сложения двух целых чисел никакой оптимизации не видно, даже наоборот. Накладные расходы на вызов функции из dll-файла и обработка результата занимает много времени по сравнению с самими расчётами. Numba обставила моего «питомца» в 3 раза на этом примере.
Хеш-функция для целых чисел

Обычно, для чисел из небольшого диапазона в качестве хеша используют их самих. Однако на просторах Интернета я нашёл такую хеш-функцию:
def py_hash(x: int) -> int:
x = ((x >> 16) ^ x) * 0x45d9f3b
x = ((x >> 16) ^ x) * 0x45d9f3b
x = (x >> 16) ^ x
return xАвтором сообщения утверждается, что значение параметра 0x45d9f3b позволяет достичь наибольшей «случайности» бит внутри числа. По крайней мере, для хеш-функций такого вида.
Numba оказалась хорошо оптимизированной под битовые операции. Не совсем понятно, откуда она взялась. Оставим этот вопрос открытым, но мне кажется, спонсорство главных производителей процессоров и видеокарт не прошло даром. Мой же вариант оказался слегка быстрее простого Питона, и то не всегда.
Вычисление экспоненты через ряд Тейлора

Питон явно показал себя неважно, поэтому посмотрим на двух оптимизаторов отдельно.

Странное большое время для маленького x, выяснилось, обосновано тем, что Numba делает какие-то отложенные шаги компиляции при первом запуске. На общей её производительности это почти никак не сказывается.
def py_exp(x: float) -> float:
res: float = 0
threshold: float = 1e-30
delta: float = 1
elements: int = 0
while delta > threshold:
elements = elements + 1
delta = delta * x / elements
while elements >= 0:
res += delta
delta = delta * elements / x
elements -= 1
return resКому интересен матан, экспонента считается по формуле соответствующего ряда Тейлора:

Алгоритм прекращается, когда разница между дельтами двух итераций становится меньше порога, либо превращается в машинный ноль. Суммирование происходит от меньших членов к большим для уменьшения потерь точности.
Наконец-то моё творение начало соперничать с Numba. На больших объёмах вычислений однозначного лидера нет.
Числа Фибоначчи

def fib(n: int) -> int:
if n < 2:
return 1
return fib(n - 1) + fib(n - 2)Несмотря на то, что аннотация позволяет компилировать функции по одной, в ней всё ещё можно использовать рекурсию.
На рекурсии Питон вообще перестал за себя отвечать. Что там с оптимизаторами?

Внезапно, реализованная в проекте компиляция начала работать в 4 раза быстрее, чем Numba. Получается, что с задачами разветвлённой рекурсии мой JIT-компилятор неплохо справляется.
Это одно из самых интересных мест всего исследования, которое можно было бы продолжить.
Мысли сходятся
На самом деле, такой подход к оптимизации не нов в мире программирования. Чем-то похожим занимался Владимир Макаров, оптимизируя Ruby до уровня языка передачи регистров RTL в своём проекте MJIT.
Существуют даже оптимизации сделанные поверх решения Макарова, о которых можно почитать здесь.
В частности, в исследованиях отмечается, что выбор компилятора, будь то GCC или LLVM, существенно не сказывается на производительности. В моём решении использован g++ из-за большей портируемости скомпилированного кода.
Для ускорения вычислений в проекте Ruby используются также предкомплированные заголовки. Однако, для студенческой работы такой уровень оптимизации не требуется.
Непредвиденные трудности
Конечно же, всё заработало не с первого раза. Вероятно, даже не с десятого. Поэтому хотелось бы привести здесь небольшую «работу над ошибками»
Типы данных
Питон медленный во многом из-за динамической типизации, так как довольно много времени уходит на определение типа переменной перед её использованием. Также, идеология «всё есть объект» раздувает примитивные типы данных до размера остальных объектов и классов. Чтобы ускорить вычисления, нужно использовать именно примитивы, а не объекты.
Проблема в том, что из кода на Питоне не всегда очевидно, какого типа будет переменная. Продвинутые оптимизаторы умеют определять тип переменной «на лету» из контекста. Я решил не усложнять жизнь , а усложнить код, и использовать аннотации типов.
Про использование аннотаций типов есть хорошие статьи в официальной документации или на Хабре.
Пусть нужно скомпилировать ту самую функцию сложения:
def sum(x, y):
res = x + y
return resКакой-нибудь компилируемый язык, C++ например, за такую программу спасибо не скажет. Добавим аннотации:
def sum(x: int, y: int) -> int:
res: int = x + y
return resВ этом примере явного объявления типов требуют три вещи:
-
Аргументов функции
-
Возвращаемое из функции значение
-
Локальные переменные
В базовой реализации будет только три типа данных:
|
Тип данных Python |
Тип данных C++ |
|---|---|
|
bool |
bool |
|
int |
int |
|
float |
double |
Использование более сложных типов данных выходит за задачу миниатюрности компилятора. Но стоит отметить, что строки, коллекции и объекты Питона могут быть поддержаны с использованием Python C API
Кодирование имён функций
С++ видоизменяет названия функций согласно их сигнатуре и аргументам. Например, функцию int f(int x) компилятор может преобразовать в _Z1fi. Подробнее о соглашении именования функции при компиляции можно узнать, например, здесь
После переименования к функциям уже нельзя обратиться по первоначальному названию. Конечно, можно было бы написать свой алгоритм, который делает те же преобразования, что и компилятор. Но на самом деле, существует более простое решение, к которому мне пришлось в итоге прийти.
При добавлении к объявлению функции префикса extend "C" имена не будут кодироваться:
extern "C" int sum(int x, int y) {
int res = (x + y);
return res;
}Так происходит, потому что мы явно указываем, что имена функций должны кодироваться по соглашению языка C, то есть, никак.
Запуск DLL
Как программисту, плохо знакомому с чем-то ниже C++, мне было трудно понять, как подключить собранную dll-библиотеку к Питону. Изначально была идея использовать rundll32.exe для запуска. Почитав Википедию и ещё одно обсуждение, я немного разочаровался в прикладной применимости и портируемости этого решения.
Потом я нашёл статью с говорящим названием: What’s the guidance on when to use rundll32? Easy: Don’t use it
Только после этого я был направлен на путь истинный, а точнее, на использование модуля ctypes. В этот момент мои скомпилированные функции впервые начали возвращать мне значения прямо в Питоне.
Вызов функции из DLL
Всё шло гладко, пока я оперировал целыми числами. При попытке считать дробные… возвращались целые очень странного формата.
# просто питон
print(exp(0.1))
# >>> 1.1051709180756475
# моё чудо
print(jit_exp(0.1))
# >>> -1285947181Как оказалось, по умолчанию, все функции, импортируемые из dll работают с аргументами как с int и возвращают тоже int. Тут до меня дошло, что возвращать просто строку программы на C++ из транслятора недостаточно. Из функций необходимо ещё получить сигнатуру, чтобы потом применить нужные типы из модуля ctypes. Метод посещения объявления функции начал выглядеть вот так:
def visit_FunctionDef(self, node: FunctionDef) -> Tuple[str, dict]:
ret_type = self.visit(node.returns)
name = node.name
args, args_signature = [], []
for arg in node.args.args:
arg, arg_type = self.visit(arg)
args.append(f"{arg_type} {arg}")
args_signature.append(ctype_convert(arg_type))
args = ", ".join(args)
res = f"extern "C" {ret_type} {name}({args}) {{n"
res += self.dump_body(node.body) + "}"
signature = {
"argtypes": args_signature,
"restype": ctype_convert(ret_type)
}
return res, signatureПоявился метод встраивания этих типов в сигнатуру dll:
def jit(func: Callable) -> Callable:
exec_module, signatures = compile_dll(func)
name = func.__name__
jit_func = exec_module[name]
jit_func.argtypes = signatures[name]["argtypes"]
jit_func.restype = signatures[name]["restype"]
return jit_funcДля того чтобы функции вызывались так же хорошо, как с целыми числами, достаточно было поменять у функций внутри загруженного dll атрибуты argtypes и restype. Сами типы для подстановки были взяты из модуля ctypes:
def ctype_convert(type_str: str):
match type_str:
case "int":
return ctypes.c_int
case "double":
return ctypes.c_double
case "bool":
return ctypes.c_bool
case _:
raise Exception(f"unsupported type str {type_str}")После всех этих накручиваний костылей махинаций ответ экспоненты начал совпадать с Питоном.
Подробнее про использование функций, загруженных из DLL, можно почитать в этой статье
Немного магии
Хороший код не пишется сразу. Например, в моём проекте основные блоки пришлось переписать два раза. В крупных проектах борьба с тех. долгом вообще может уходить в бесконечность, но я пока что, к сожалению или к счастью, с этим не сталкивался.
Я хотел показать на примере функции синтаксического разбора бинарной операции ast.BinOp как можно по-разному писать код, который будет в разной степени сложно поддерживать.
Словарь с типами
Это самая первая реализация:
def dump_bin_op(module: ast.BinOp) -> str:
res = ""
left = dump_expr(module.left)
right = dump_expr(module.right)
op = module.op
bin_op_signs = {
ast.Add: "+",
ast.Sub: "-",
ast.Div: "/",
ast.Mult: "*",
# и ещё 6-8 бинарных операций
}
op_sign = bin_op_signs[type(op)]
return f"({left} {op_sign} {right})"По сравнению с блоком if-elif-elif-elif-...-else такой код кажется проще. Но тут происходит явное обращение к типу через type(), что не очень хорошо.
Match/case
Тут мне посоветовали начать уже использовать плюшки версии Питона 3.10 на полную катушку, а именно, применить сравнение по шаблону и оператор match/case
def dump_bin_op(module: ast.BinOp) -> str:
match module:
case ast.BinOp(op=ast.Add()):
op_sign = "+"
case ast.BinOp(op=ast.Sub()):
op_sign = "-"
case ast.BinOp(op=ast.Div()):
op_sign = "/"
case ast.BinOp(op=ast.Mult()):
op_sign = "*"
# и ещё 6-8 бинарных операций
case _:
raise Exception(f"unsupported bin op type {op_type}")
left = dump_expr(module.left)
right = dump_expr(module.right)
return f"({left} {op_sign} {right})"Код стал чуточку короче и выразительнее. Шаблоны после слова case можно всячески усложнять, выбирая всё более специфичные случаи. Какой-нибудь switch/case в другом языке программирования такого себе не может позволить. Подробнее про возможности оператора match/case можно узнать тут
Вот ещё маленький пример, решающий проблему занижения регистра для констант True и False:
def visit_Constant(self, node: Constant) -> str:
match node:
case Constant(value=True):
return "true"
case Constant(value=False):
return "false"
case _:
return str(node.value)Выглядит покрасивее, чем if node.value == True:. Но тут уже на вкус и цвет.
ast.NodeVisitor
Вот я и пришёл к тому, что давно написали за меня, но я об этом никогда не слышал, поэтому ещё не применил.
Как ни странно, модуль, описывающий абстрактное дерево в виде структуры, предоставляет также и методы для его обхода. Этот метод называется ast.NodeVisitor.visit()
Как следует из названия, NodeVisitor реализует шаблон проектирования Посетитель, позволяющий создавать новую внешнюю функциональность с минимальным изменением уже написанного кода.
Для написания своего посетителя необходимо объявить класс-наследник класса ast.NodeVisitor:
class DumpVisitor(ast.NodeVisitor):
...
def visit_BinOp(self, node: ast.BinOp) -> str:
return f"({self.visit(node.left)} {self.visit(node.op)} {self.visit(node.right)})"
def visit_Add(self, node: ast.Add) -> str:
return "+"
def visit_Sub(self, node: ast.Sub) -> str:
return "-"
def visit_Div(self, node: ast.Div) -> str:
return "/"
def visit_Mult(self, node: ast.Mult) -> str:
return "*"
# ещё 6-8 методов обхода бинарных операций
... # и не только
Код остальных методов посетителя можно изучить в репозитории.
Код стал более модульным, названия и сигнатуры методов уже придуманы за нас, выбор нужного метода происходит без нашего участия. Вот на этом варианте я и решил остановиться.
Во время написания кода на Питоне у меня возникает чувство ощущения красоты, краткости и мощи собственного кода. В этом есть какая-то магия.
Подсчёт строк
Дабы не потерять доверие читателя, я провёл подсчёт строк кода транслятора:
|
Код |
Объём |
|---|---|
|
Аннотация и процесс компиляции |
36 |
|
Транслятор на NodeVisitor |
221 |
|
Итого |
257 |
Остальные файлы, как оказалось, к процессу исполнения напрямую не причастны. Я даже не стал исключать того большого числа пустых строк, которого требует PEP8. Получается, что даже немного наврал читателю насчёт числа строк. Пусть он меня простит.
Думаю, такой небольшой проект можно было бы легко поддерживать, если бы в этом была бы необходимость.
Итог
Хочу сказать спасибо @true-grue за наставничество при написании этого проекта и этой статьи. Как оказывается, писать статьи труднее, чем писать код в ящик.
Проекту в плане функционала есть куда расти. Поддержка строк, коллекций, объектов, классов. Правда с учётом полученного зачёта, предлагаю энтузиастам, взяв моё решение за основу, добиться большей производительности и функциональности.
Предел у этого совершенства всё равно есть. На поддержке библиотек такие решения оптимизации обычно отказываются работать либо поддерживают самые популярные и базовые, такие как Numpy или PIL.
И всё же, если очень захотеть, можно заставить Питон работать быстрее, уничтожая один из извечных аргументов программистов на C++ и Java против использования Python.
compiler-in-python
In this project we will try to build a compiler using Python and some powerful libraries as it was explain by Marcelo Andrade in his post Writing your own programming language and compiler with Python.
Compilers
A compiler can be any program that translates one text into another. Since a computer can only read 1s and 0s, and humans write better Code than they do binary, compilers were made to turn that human-readable text into computer-readable machine code.
Compilers take source code and produce binary. They have several steps of processing to do before their programs are runnable:
- Reads the individual characters of the source code you give it.
- Sorts the characters into words, numbers, symbols, and operators. (These are called Tokens)
- Takes the sorted characters and determines the operations they are trying to perform by matching them against patterns, and making a tree of the operations.
- Iterates over evry operation in the tree made in the last step, and finally, generates the equivalent binary.
Our compiler can be divided intro three components:
- Lexer
- Parser
- Code Generator
For the Lexer and Parser we’ll be using RPLY, really similar to PLY: a Python library with lexical and parsing tools, but with a better API. And for the Code Generator, we’ll use LLVMlite, a Python library for binding LLVM components. Using LLVM, it is possible to optimize your compilation without learning compiling optimization, and LLVMLite it´s a really good library to work with compilers.
Lexical Analysis
The first step is to split the input up character by character. This step is called Lexical Analysis or Tokenization. The major idea is that we group characters together to form our words, identifiers, symbols, and more.
We use minimal structures to define or tokens, for example:
Our Lexer would divide this string into this list of Tokens
TOKEN('PRINT','print')
TOKEN('OPEN_PAREN','(')
TOKEN('NUMBER','4')
TOKEN('SUM','+')
TOKEN('NUMBER','4')
TOKEN('SUB','-')
TOKEN('NUMBER','2')
TOKEN('SEMI_COLON',';')
Parser
Parsing, syntax analysis, or syntactic analysis is the process of analysing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. That´s why our second component in our compiler is the Parser. It will take the list of tokens as input and create a AST as output.
Inside an ast.py file in which we put all clases that are going to be called on the Parser and create the AST. For example:
class Number(), class BinaryOp(), class Sum(), class Sub(), class Print().
Next we need to create the parser, in which we’ll use ParserGenerator from RPLY inside a file name parser.py. And finally, we’ll update our file main.py to combine Parser with Lexer.
We’ll see the output being the result of print(4 + 4 — 2), which is equal to printing 6.
With these two components, we have a functional compiler that interprets our own language with Python. However, it still doesn’t create a machine language code and is not well optimized. To do this, we’ll need the most complex part of the compiler, code generation with LLVM.

Привет!
Я хочу рассказать об удивительном событии, о котором я узнал пару месяцев назад. Оказывается, одна популярная python-утилита уже более года распространяется в виде бинарных файлов, которые компилируются прямо из python. И речь не про банальную упаковку каким-нибудь PyInstaller-ом, а про честную Ahead-of-time компиляцию целого python-пакета. Если вы удивлены так же как и я, добро пожаловать под кат.
Объясню, почему я считаю это событие по-настоящему удивительным. Существует два вида компиляции: Ahead-of-time (AOT), когда весь код компилируется до запуска программы и Just in time compiler (JIT), когда непосредственно компиляция программы под требуемую архитектуру процессора осуществляется во время ее выполнения. Во втором случае первоначальный запуск программы осуществляется виртуальной машиной или интерпретатором.
Если сгруппировать популярные языки программирования по типу компиляции, то получим следующий список:
-
Ahead-of-time compiler: C, C++, Rust, Kotlin, Nim, D, Go, Dart;
-
Just in time compiler: Lua, С#, Groovy, Dart.
В python из коробки нет JIT компилятора, но отдельные библиотеки, предоставляющие такую возможность, существуют давно
Смотря на эту таблицу, можно заметить определенную закономерность: статически типизированные языки находятся в обеих строках. Некоторые даже могут распространяться с двумя версиями компиляторов: Kotlin может исполняться как с JIT JavaVM, так и с AOT Kotlin/Native. То же самое можно сказать про Dart (версии 2). A вот динамически типизированные языки компилируются только JIT-ом, что впрочем вполне логично.
При запуске виртуальная машина сначала накапливает информацию о типах переменных, затем после накопления статистики, запускается компиляция наиболее нагруженных частей программы. Виртуальная машина отслеживает типы аргументов и переключает выполнение программы между уже скомпилированными и не скомпилированными участками кода в зависимости от текущих значений переменных.
При использовании JIT компиляции типы не очень то и нужны, ведь информация о типах собирается во время работы программы. Поэтому все популярные динамически типизированные языки программирования распространяются именно с JIT компилятором. Но как быть с AOT компиляцией кода, в котором нет типов? Меня очень заинтересовал этот вопрос, и я полез разбираться.
Итак, вернемся к утилите, о которой говорилось в начале статьи. Речь про mypy — наиболее популярный синтаксический анализатор python-кода.

С апреля 2019 года эта утилита распространяется в скомпилированном виде, о чем рассказывается в блоге проекта. А для компиляции используется еще одна утилита от тех же авторов — mypyc. Погуглив немного, я нашел достаточно большую статью “Путь к проверке типов 4 миллионов строк Python-кода” про становление и развитие mypy (на Хабре доступен перевод: часть 1, часть 2, часть 3). Там немного рассказывается о целях создания mypyc: столкнувшись с недостаточной производительностью mypy при разборе крупных python-проектов в Dropbox, разработчики добавили кеширование результатов проверки кода, а затем возможность запуска утилиты как сервиса. Но исчерпав очевидные возможности оптимизации, столкнулись с выбором: переписать все на go или на cython. В результате проект пошел по третьему пути — написание своего AOT python-компилятора.
Дело в том, что для правильной работы mypy и так необходимо построить то же синтаксическое дерево, что и интерпретатору во время исполнения кода. То есть mypy уже “понимает” python, но использует эту информацию только для статистического анализа, а вот mypyc может преобразовывать эту информацию в полноценный бинарный код.
Думаю тут многие решили, что разобрались в вопросе того, как скомпилировать динамически типизированный python-код. Python c версии 3.4 поддерживает аннотацию типов, а mypy как раз и используется для проверки корректности аннотаций. Получается, python как бы уже и не динамически типизированный язык, что позволяет применить AOT компиляцию. Но загвоздка в том, что mypyc может компилировать и неаннотированный код!
Функция bubble_sort
Для примера рассмотрим функцию сортировки “пузырьком”. Файл lib.py:
def bubble_sort(data):
n = len(data)
for i in range(n - 1):
for j in range(n - i - 1):
if data[j] > data[j + 1]:
buff = data[j]
data[j] = data[j + 1]
data[j + 1] = buff
return dataУ типов нет аннотаций, но это не мешает mypyc ее скомпилировать. Чтобы запустить компиляцию, нужно установить mypyc. Он не распространяется отдельным пакетом, но если у вас установлен mypy, то и mypyc уже присутствует в системе! Запускаем mypyc, следующей командой:
> mypyc lib.pyПосле запуска в проекте будут созданы следующие директории:
-
.mypy_cache— mypy кэш, mypyc неявно запускает mypy для разбора программы и получения AST; -
build— артефакты сборки; -
lib.cpython-38-x86_64-linux-gnu.so— собственно сборка под целевую платформу. Данный файл представляет из себя готовый CPython Extension.
CPython Extension — встроенный в CPython механизм взаимодействия с кодом, написанным на С/C++. По сути это динамическая библиотека, которую CPython умеет загружать при импорте нашего модуля lib. Через данный механизм осуществляется взаимодействие с модулями, написанными на python.
Компиляция состоит из двух фаз:
-
Компиляция python кода в код С;
-
Компиляция С в бинарный .so файл, для этого mypyc сам запускает gcc (gcc и python-dev также должен быть установлены).
Файл lib.cpython-38-x86_64-linux-gnu.so имеет преимущество перед lib.py при импорте на соответствующей платформе, и исполняться теперь будет именно он.
Ну и давайте сравним производительность модуля до и после компиляции. Для этого создадим файл main.py с кодом запуска сортировки:
import lib
data = lib.bubble_sort(list(range(5000, 0, -1)))
assert data == list(range(1, 5001))Получим примерно следующие результаты:
|
До |
После |
|
real 5.68 user 5.60 sys 0.01 |
real 2.78 user 2.73 sys 0.01 |
Ожидаемо скомпилированный код оказался быстрее (~ в 2 раза), что неплохо, так как для такого результата нам потребовалось запустить лишь одну команду. Хотя от скомпилированного кода привычно ожидаешь большего.

Чтобы ответить на вопрос “как компилируется динамически типизированный код”, придется заглянуть в представление этой функции на С. Но разобрать ее будет достаточно сложно, поэтому давайте попробуем разобраться с примером попроще.
Функция sum(a, b)
Скомпилируем функцию суммы от двух переменных:
def sum(a, b):
return a + bПеред запуском компиляции я ожидал увидеть примерно следующий код на С:
int sum(int a, int b) {
return a + b;
}Однако результат оказался cущественно иным (код немного упрощен):
PyObject *CPyDef_sum(PyObject *cpy_r_a, PyObject *cpy_r_b){
return PyNumber_Add(cpy_r_a, cpy_r_b);
}Рассмотрим, что тут происходит. Во-первых, так как мы не знаем типы входных переменных, функция в качестве аргументов принимает указатели на объекты класса PyObject, по сути это внутренние CPython структуры. Далее компилятор должен сложить эти объекты, но как, если настоящие типы аргументов неизвестны во время компиляции: это могут быть целые числа, числа с плавающей точкой, списки и вообще не факт, что аргументы можно складывать, тогда нужно вернуть ошибку. И что же делает в этом случае mypyc?
Как оказалось, все очень просто: он просит CPython самостоятельно сложить эти аргументы. Функция PyNumber_Add — это внутренняя функция СPython, которая доступна из расширения, ведь СPython отлично умеет складывать свои объекты.
Взаимодействие CPython c Extension можно изобразить следующим диалогом:
— А посчитай-ка мне функцию sum для A, B;
— Хорошо, но скажи сначала, сколько будет A + B;
— Будет С;
— Хорошо, тогда держи ответ — С.
Вот такой нехитрый прием используется при компиляции динамического кода: компилируем все, что можем, а все остальное отдаем интерпретатору.
Конечно, данный пример выглядит гротескно, но даже несмотря на такую неэффективность, mypyc позволяет добиться существенного прироста производительности, как в примере с сортировкой.
Функция sum(a: int, b: int)
Итак, у нас получилось скомпилировать python, и мы разобрались с тем, как это работает, а также увидели определенную неэффективность полученного результата. Теперь попробуем разобраться в том, как можно это улучшить. Очевидно, что основная проблема заключается во множественном взаимодействии CPython — Extension. Но как это побороть?
Для повышения эффективности, нужно, чтобы расширение, получив управление, могло как можно дольше оставлять его у себя без обращения к CPython. Если бы у mypyc была информация о типах переменных, то он бы мог самостоятельно произвести сложение без возврата управления. Но вывести типы самостоятельно mypyc не может, он даже не контролирует код, из которого осуществляется вызов функции sum. Соответственно, ему нужно помочь, проставив аннотации вручную. Давайте посмотрим, как поменяется результирующая С-функция, если добавить аннотацию типов:
def sum(a: int, b: int):
return a + bСкомпилированный результат на C (немного очищенный):
PyObject *CPyDef_sum(CPyTagged cpy_r_a, CPyTagged cpy_r_b) {
CPyTagged cpy_r_r0;
PyObject *cpy_r_r1;
cpy_r_r0 = CPyTagged_Add(cpy_r_a, cpy_r_b);
cpy_r_r1 = CPyTagged_StealAsObject(cpy_r_r0);
return cpy_r_r1;
}Главное, что можно заметить: функция существенно поменялась, а значит, компилятор реагирует на появление аннотации. Давайте разбираться, что изменилось.
Теперь CPyDef_sum получает на вход не указатели на PyObject, а структуры CPyTagged. Это все еще не int, но уже и не часть CPython, а часть библиотек mypyc, которую он добавляет в скомпилированный код расширения. Для ее инициализации в рантайме сначала проверяется тип, так что теперь функция sum работает только с int и обойти аннотацию не получится.
Далее происходит вызов CPyTaggetAdd вместо PyNumber_Add. Это уже внутренняя функция mypyc. Если заглянуть в код CPyTaggetAdd, то можно понять, что там происходит проверка диапазонов значений a и b, и если они укладываются в int, то происходит простое суммирование, а также проверка на переполнение:
if (likely(CPyTagged_CheckShort(left) && CPyTagged_CheckShort(right))) {
CPyTagged sum = left + right;
if (likely(!CPyTagged_IsAddOverflow(sum, left, right))) {
return sum;
}
}Таким образом, наш диалог CPython — Extension превращается из абсурдного в нормальный:
— А посчитай-ка мне функцию sum для A, B;
— Хорошо, тогда держи ответ С.
Функция bubble_sort(data: List[int])
Настало время вернуться к функции сортировки, чтобы провести замеры скорости. Изменим начальную функцию, добавив аннотацию для data:
def bubble_sort(data: List[int]):
…Скомпилируем результат и замерим время сортировки:
|
Без компиляции |
С компиляцией, без аннотации типов |
С компиляцией и аннотацией типов |
|
real 5.68 user 5.60 sys 0.01 |
real 2.78 user 2.73 sys 0.01 |
real 1.32 user 1.30 sys 0.01 |
Итак, мы получили еще двукратное ускорение относительно скомпилированного, не аннотированного кода, и четырехкратное относительно оригинального!

Пара слов о mypyc
Если вы уже бросились компилировать ваши пакеты, то стоит задержаться на пару минут, чтобы дочитать этот абзац до конца. Главным недостатком mypyc пока остается стабильность: он все еще в альфе, точнее, сейчас это вообще не самостоятельный проект, а часть mypy. Собственно он и создавался специально под задачу увеличения производительности mypy и для этой цели он уже более года как стабилен. Но как общее решение по компиляции любого python-кода, он еще сыроват, о чем авторы предупреждают на странице проекта.
Также существуют принципиальные ограничения, накладываемые на компилируемый код или на код, взаимодействующий со скомпилированным:
-
Принудительная проверка типов в рантайме;
-
В компилируемом коде запрещается monkey patching;
-
Mypy хранит классы в С структурах для увеличения скорости доступа к атрибутам, но это приводит к проблемам совместимости.
Эти ограничения носят принципиальный характер и являются следствием архитектуры компилятора. Но из них проистекают другие ограничения, например, невозможность использования модуля стандартной библиотеки abc. Помимо этого, есть большая порция недоработок и багов. Чаще всего они приводят к тому, что код gcc отказывается компилировать полученный С код, при этом, чтобы понять настоящую причину ошибки, приходится прокручивать в голове непростую процедуру реверс инжиниринга. Пока резутльт таков, что при компиляции одного из моих проектов, без проблем компилировалось примерно 20 % модулей, зато каких либо проблем при работе с уже скомпилированными модулями я не заметил.
Тем не менее, большая часть улучшений в их Roadmap закрыта, и проект готовится к публичному релизу.
Nuitka
Уже в процессе работы над статьей, я узнал про еще один проект с аналогичными целями. Механизм работы Nuitka сильно напоминает описанный выше. Разница заключается в том, что Nuitka компилирует Python модуль в С++ код, который также собирается в СPython Extension. Дополнительно существует возможность собрать весь проект в один исполняемый файл, тогда уже сам CPython подключается к проекту как динамическая библиотека libpython.
Nuitka пока не учитывает аннотацию типов, поэтому результирующий код и скорость работы не зависят от наличия аннотаций. Полученная же скорость в моем тесте соответствует результату mypy на не аннотированном коде.
Завершение
Недавно один мой коллега высказал мнение, что mypy сильно усложняет ему жизнь: из текста ошибок невозможно понять, “чего он от меня хочет”, а анализатор из PyCharm немного лучше. Теперь я понимаю, что он недооценивает mypy. Так как он намного большее, чем просто синтаксический анализатор. По сути он реализует подмножество языка, потенциал которого в плане оптимизации сильно превосходит обычный python. Поэтому встранивание mypy в пайплайн проекта — инвестиция не только в поиск ошибок, но и будущий перфоманс приложения. Мне очень понравилось, что взаимодействие с CPython осуществляется через механизм расширений интерпретатора, ведь это позволяет сделать выборочную компиляцию наиболее нагруженных модулей, оставив большую часть кода без изменений. Такой путь представляется мне наиболее безопасным (учитывая, что mypyc до сих пор в альфе). Конечно, использовать ли mypyc на продакшене, решать вам, но если вы уже уперлись в потолок по производительности и подумываете о том, чтобы переписать какие-то части на низкоуровневые языки, то стоит попробовать запустить mypyc, тем более, что сделать это просто, если вы уже используете mypy.
P.S.
Надеюсь, вам было интересно узнать о новом способе повышения производительности python, а также глубже разобраться в механизме компиляции динамически типизированного кода. Если тема окажется интересной, то в следующей статье планирую больше рассказать про mypyc, его ограничения и частые ошибки, а также, как их можно обойти.
UPD
В комментариях подсказали, об еще одном python компиляторе — Cython, оказывается теперь он умеет компилировать python код напрямую (минуя ручную фазу преобразования кода в cython-код). Судя по замерам cython пока не учитыват аннотацию типов, но время выполнения (real 1.82) оказалось посередине между результатом mypyc на аннотированном и не аннотированном кода. Но возможно ее добавят в будущем.
Автор: Eвгений Зуев
Источник
In this article, we are going to learn how to create your own programming language using SLY(Sly Lex Yacc) and Python. Before we dig deeper into this topic, it is to be noted that this is not a beginner’s tutorial and you need to have some knowledge of the prerequisites given below.
Prerequisites
- Rough knowledge about compiler design.
- Basic understanding of lexical analysis, parsing and other compiler design aspects.
- Understanding of regular expressions.
- Familiarity with Python programming language.
Getting Started
Install SLY for Python. SLY is a lexing and parsing tool which makes our process much easier.
pip install sly
Building a Lexer
The first phase of a compiler is to convert all the character streams(the high level program that is written) to token streams. This is done by a process called lexical analysis. However, this process is simplified by using SLY
First let’s import all the necessary modules.
Python3
Now let’s build a class BasicLexer which extends the Lexer class from SLY. Let’s make a compiler that makes simple arithmetic operations. Thus we will need some basic tokens such as NAME, NUMBER, STRING. In any programming language, there will be space between two characters. Thus we create an ignore literal. Then we also create the basic literals like ‘=’, ‘+’ etc., NAME tokens are basically names of variables, which can be defined by the regular expression [a-zA-Z_][a-zA-Z0-9_]*. STRING tokens are string values and are bounded by quotation marks(” “). This can be defined by the regular expression ”.*?”.
Whenever we find digit/s, we should allocate it to the token NUMBER and the number must be stored as an integer. We are doing a basic programmable script, so let’s just make it with integers, however, feel free to extend the same for decimals, long etc., We can also make comments. Whenever we find “//”, we ignore whatever that comes next in that line. We do the same thing with new line character. Thus, we have build a basic lexer that converts the character stream to token stream.
Python3
class BasicLexer(Lexer):
tokens = { NAME, NUMBER, STRING }
ignore = 't '
literals = { '=', '+', '-', '/',
'*', '(', ')', ',', ';'}
NAME = r'[a-zA-Z_][a-zA-Z0-9_]*'
STRING = r'".*?"'
@_(r'd+')
def NUMBER(self, t):
t.value = int(t.value)
return t
@_(r'//.*')
def COMMENT(self, t):
pass
@_(r'n+')
def newline(self, t):
self.lineno = t.value.count('n')
Building a Parser
First let’s import all the necessary modules.
Python3
Now let’s build a class BasicParser which extends the Lexer class. The token stream from the BasicLexer is passed to a variable tokens. The precedence is defined, which is the same for most programming languages. Most of the parsing written in the program below is very simple. When there is nothing, the statement passes nothing. Essentially you can press enter on your keyboard(without typing in anything) and go to the next line. Next, your language should comprehend assignments using the “=”. This is handled in line 18 of the program below. The same thing can be done when assigned to a string.
Python3
class BasicParser(Parser):
tokens = BasicLexer.tokens
precedence = (
('left', '+', '-'),
('left', '*', '/'),
('right', 'UMINUS'),
)
def __init__(self):
self.env = { }
@_('')
def statement(self, p):
pass
@_('var_assign')
def statement(self, p):
return p.var_assign
@_('NAME "=" expr')
def var_assign(self, p):
return ('var_assign', p.NAME, p.expr)
@_('NAME "=" STRING')
def var_assign(self, p):
return ('var_assign', p.NAME, p.STRING)
@_('expr')
def statement(self, p):
return (p.expr)
@_('expr "+" expr')
def expr(self, p):
return ('add', p.expr0, p.expr1)
@_('expr "-" expr')
def expr(self, p):
return ('sub', p.expr0, p.expr1)
@_('expr "*" expr')
def expr(self, p):
return ('mul', p.expr0, p.expr1)
@_('expr "/" expr')
def expr(self, p):
return ('div', p.expr0, p.expr1)
@_('"-" expr %prec UMINUS')
def expr(self, p):
return p.expr
@_('NAME')
def expr(self, p):
return ('var', p.NAME)
@_('NUMBER')
def expr(self, p):
return ('num', p.NUMBER)
The parser should also parse in arithmetic operations, this can be done by expressions. Let’s say you want something like shown below. Here all of them are made into token stream line-by-line and parsed line-by-line. Therefore, according to the program above, a = 10 resembles line 22. Same for b =20. a + b resembles line 34, which returns a parse tree (‘add’, (‘var’, ‘a’), (‘var’, ‘b’)).
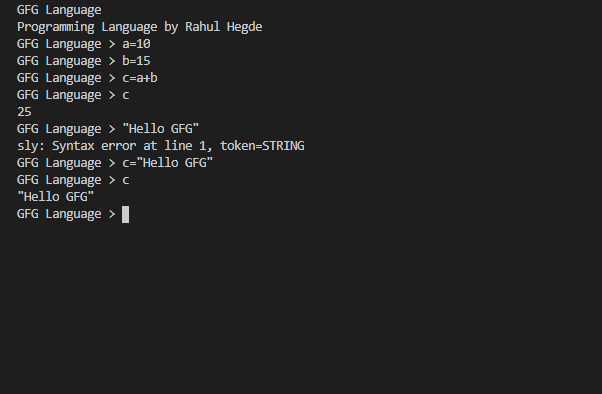
GFG Language > a = 10 GFG Language > b = 20 GFG Language > a + b 30
Now we have converted the token streams to a parse tree. Next step is to interpret it.
Execution
Interpreting is a simple procedure. The basic idea is to take the tree and walk through it to and evaluate arithmetic operations hierarchically. This process is recursively called over and over again till the entire tree is evaluated and the answer is retrieved. Let’s say, for example, 5 + 7 + 4. This character stream is first tokenized to token stream in a lexer. The token stream is then parsed to form a parse tree. The parse tree essentially returns (‘add’, (‘add’, (‘num’, 5), (‘num’, 7)), (‘num’, 4)). (see image below)
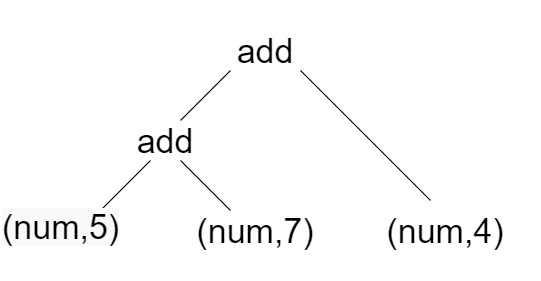
The interpreter is going to add 5 and 7 first and then recursively call walkTree and add 4 to the result of addition of 5 and 7. Thus, we are going to get 16. The below code does the same process.
Python3
class BasicExecute:
def __init__(self, tree, env):
self.env = env
result = self.walkTree(tree)
if result is not None and isinstance(result, int):
print(result)
if isinstance(result, str) and result[0] == '"':
print(result)
def walkTree(self, node):
if isinstance(node, int):
return node
if isinstance(node, str):
return node
if node is None:
return None
if node[0] == 'program':
if node[1] == None:
self.walkTree(node[2])
else:
self.walkTree(node[1])
self.walkTree(node[2])
if node[0] == 'num':
return node[1]
if node[0] == 'str':
return node[1]
if node[0] == 'add':
return self.walkTree(node[1]) + self.walkTree(node[2])
elif node[0] == 'sub':
return self.walkTree(node[1]) - self.walkTree(node[2])
elif node[0] == 'mul':
return self.walkTree(node[1]) * self.walkTree(node[2])
elif node[0] == 'div':
return self.walkTree(node[1]) / self.walkTree(node[2])
if node[0] == 'var_assign':
self.env[node[1]] = self.walkTree(node[2])
return node[1]
if node[0] == 'var':
try:
return self.env[node[1]]
except LookupError:
print("Undefined variable '"+node[1]+"' found!")
return 0
Displaying the Output
To display the output from the interpreter, we should write some codes. The code should first call the lexer, then the parser and then the interpreter and finally retrieves the output. The output in then displayed on to the shell.
Python3
if __name__ == '__main__':
lexer = BasicLexer()
parser = BasicParser()
print('GFG Language')
env = {}
while True:
try:
text = input('GFG Language > ')
except EOFError:
break
if text:
tree = parser.parse(lexer.tokenize(text))
BasicExecute(tree, env)
It is necessary to know that we haven’t handled any errors. So SLY is going to show it’s error messages whenever you do something that is not specified by the rules you have written.
Execute the program you have written using,
python you_program_name.py
Footnotes
The interpreter that we built is very basic. This, of course, can be extended to do a lot more. Loops and conditionals can be added. Modular or object oriented design features can be implemented. Module integration, method definitions, parameters to methods are some of the features that can be extended on to the same.
In this article, we are going to learn how to create your own programming language using SLY(Sly Lex Yacc) and Python. Before we dig deeper into this topic, it is to be noted that this is not a beginner’s tutorial and you need to have some knowledge of the prerequisites given below.
Prerequisites
- Rough knowledge about compiler design.
- Basic understanding of lexical analysis, parsing and other compiler design aspects.
- Understanding of regular expressions.
- Familiarity with Python programming language.
Getting Started
Install SLY for Python. SLY is a lexing and parsing tool which makes our process much easier.
pip install sly
Building a Lexer
The first phase of a compiler is to convert all the character streams(the high level program that is written) to token streams. This is done by a process called lexical analysis. However, this process is simplified by using SLY
First let’s import all the necessary modules.
Python3
Now let’s build a class BasicLexer which extends the Lexer class from SLY. Let’s make a compiler that makes simple arithmetic operations. Thus we will need some basic tokens such as NAME, NUMBER, STRING. In any programming language, there will be space between two characters. Thus we create an ignore literal. Then we also create the basic literals like ‘=’, ‘+’ etc., NAME tokens are basically names of variables, which can be defined by the regular expression [a-zA-Z_][a-zA-Z0-9_]*. STRING tokens are string values and are bounded by quotation marks(” “). This can be defined by the regular expression ”.*?”.
Whenever we find digit/s, we should allocate it to the token NUMBER and the number must be stored as an integer. We are doing a basic programmable script, so let’s just make it with integers, however, feel free to extend the same for decimals, long etc., We can also make comments. Whenever we find “//”, we ignore whatever that comes next in that line. We do the same thing with new line character. Thus, we have build a basic lexer that converts the character stream to token stream.
Python3
class BasicLexer(Lexer):
tokens = { NAME, NUMBER, STRING }
ignore = 't '
literals = { '=', '+', '-', '/',
'*', '(', ')', ',', ';'}
NAME = r'[a-zA-Z_][a-zA-Z0-9_]*'
STRING = r'".*?"'
@_(r'd+')
def NUMBER(self, t):
t.value = int(t.value)
return t
@_(r'//.*')
def COMMENT(self, t):
pass
@_(r'n+')
def newline(self, t):
self.lineno = t.value.count('n')
Building a Parser
First let’s import all the necessary modules.
Python3
Now let’s build a class BasicParser which extends the Lexer class. The token stream from the BasicLexer is passed to a variable tokens. The precedence is defined, which is the same for most programming languages. Most of the parsing written in the program below is very simple. When there is nothing, the statement passes nothing. Essentially you can press enter on your keyboard(without typing in anything) and go to the next line. Next, your language should comprehend assignments using the “=”. This is handled in line 18 of the program below. The same thing can be done when assigned to a string.
Python3
class BasicParser(Parser):
tokens = BasicLexer.tokens
precedence = (
('left', '+', '-'),
('left', '*', '/'),
('right', 'UMINUS'),
)
def __init__(self):
self.env = { }
@_('')
def statement(self, p):
pass
@_('var_assign')
def statement(self, p):
return p.var_assign
@_('NAME "=" expr')
def var_assign(self, p):
return ('var_assign', p.NAME, p.expr)
@_('NAME "=" STRING')
def var_assign(self, p):
return ('var_assign', p.NAME, p.STRING)
@_('expr')
def statement(self, p):
return (p.expr)
@_('expr "+" expr')
def expr(self, p):
return ('add', p.expr0, p.expr1)
@_('expr "-" expr')
def expr(self, p):
return ('sub', p.expr0, p.expr1)
@_('expr "*" expr')
def expr(self, p):
return ('mul', p.expr0, p.expr1)
@_('expr "/" expr')
def expr(self, p):
return ('div', p.expr0, p.expr1)
@_('"-" expr %prec UMINUS')
def expr(self, p):
return p.expr
@_('NAME')
def expr(self, p):
return ('var', p.NAME)
@_('NUMBER')
def expr(self, p):
return ('num', p.NUMBER)
The parser should also parse in arithmetic operations, this can be done by expressions. Let’s say you want something like shown below. Here all of them are made into token stream line-by-line and parsed line-by-line. Therefore, according to the program above, a = 10 resembles line 22. Same for b =20. a + b resembles line 34, which returns a parse tree (‘add’, (‘var’, ‘a’), (‘var’, ‘b’)).
GFG Language > a = 10 GFG Language > b = 20 GFG Language > a + b 30
Now we have converted the token streams to a parse tree. Next step is to interpret it.
Execution
Interpreting is a simple procedure. The basic idea is to take the tree and walk through it to and evaluate arithmetic operations hierarchically. This process is recursively called over and over again till the entire tree is evaluated and the answer is retrieved. Let’s say, for example, 5 + 7 + 4. This character stream is first tokenized to token stream in a lexer. The token stream is then parsed to form a parse tree. The parse tree essentially returns (‘add’, (‘add’, (‘num’, 5), (‘num’, 7)), (‘num’, 4)). (see image below)
The interpreter is going to add 5 and 7 first and then recursively call walkTree and add 4 to the result of addition of 5 and 7. Thus, we are going to get 16. The below code does the same process.
Python3
class BasicExecute:
def __init__(self, tree, env):
self.env = env
result = self.walkTree(tree)
if result is not None and isinstance(result, int):
print(result)
if isinstance(result, str) and result[0] == '"':
print(result)
def walkTree(self, node):
if isinstance(node, int):
return node
if isinstance(node, str):
return node
if node is None:
return None
if node[0] == 'program':
if node[1] == None:
self.walkTree(node[2])
else:
self.walkTree(node[1])
self.walkTree(node[2])
if node[0] == 'num':
return node[1]
if node[0] == 'str':
return node[1]
if node[0] == 'add':
return self.walkTree(node[1]) + self.walkTree(node[2])
elif node[0] == 'sub':
return self.walkTree(node[1]) - self.walkTree(node[2])
elif node[0] == 'mul':
return self.walkTree(node[1]) * self.walkTree(node[2])
elif node[0] == 'div':
return self.walkTree(node[1]) / self.walkTree(node[2])
if node[0] == 'var_assign':
self.env[node[1]] = self.walkTree(node[2])
return node[1]
if node[0] == 'var':
try:
return self.env[node[1]]
except LookupError:
print("Undefined variable '"+node[1]+"' found!")
return 0
Displaying the Output
To display the output from the interpreter, we should write some codes. The code should first call the lexer, then the parser and then the interpreter and finally retrieves the output. The output in then displayed on to the shell.
Python3
if __name__ == '__main__':
lexer = BasicLexer()
parser = BasicParser()
print('GFG Language')
env = {}
while True:
try:
text = input('GFG Language > ')
except EOFError:
break
if text:
tree = parser.parse(lexer.tokenize(text))
BasicExecute(tree, env)
It is necessary to know that we haven’t handled any errors. So SLY is going to show it’s error messages whenever you do something that is not specified by the rules you have written.
Execute the program you have written using,
python you_program_name.py
Footnotes
The interpreter that we built is very basic. This, of course, can be extended to do a lot more. Loops and conditionals can be added. Modular or object oriented design features can be implemented. Module integration, method definitions, parameters to methods are some of the features that can be extended on to the same.
Предлагаем вашему вниманию серию статей, опубликованную в блоге Руслана Спивака. В ней автор подробно описывает процесс разработки базового интерпретатора. Серия пополняется, и в этой подборке вы найдете первые части руководства.
Примеры кода приведены на Python, однако подробные пояснения позволят читателю использовать для реализации любой другой удобный язык. В качестве интерпретируемого языка выбран Pascal, однако и здесь вы не будете ограничены — можно обратиться к любому другому языку, с семантикой которого вы хорошо знакомы.
Если вы не знаете, как работает компилятор, то вы не знаете, как работает компьютер. И если вы не уверены на 100%, что знаете, как работает компилятор, то вы не знаете, как он работает. — Стив Йиг
Небольшой ликбез перед прочтением. Компилятор — программа, которая переводит (транслирует) исходный код на языке программирования (высокого уровня) на язык, «более понятный компьютеру» (низкоуровневый). При этом программа сначала полностью транслируется, а затем выполняется. Интерпретатор — такой же транслятор, но выполняющий инструкции «на лету» (пооператорно, построчно), то есть без предварительной компиляции всего кода.
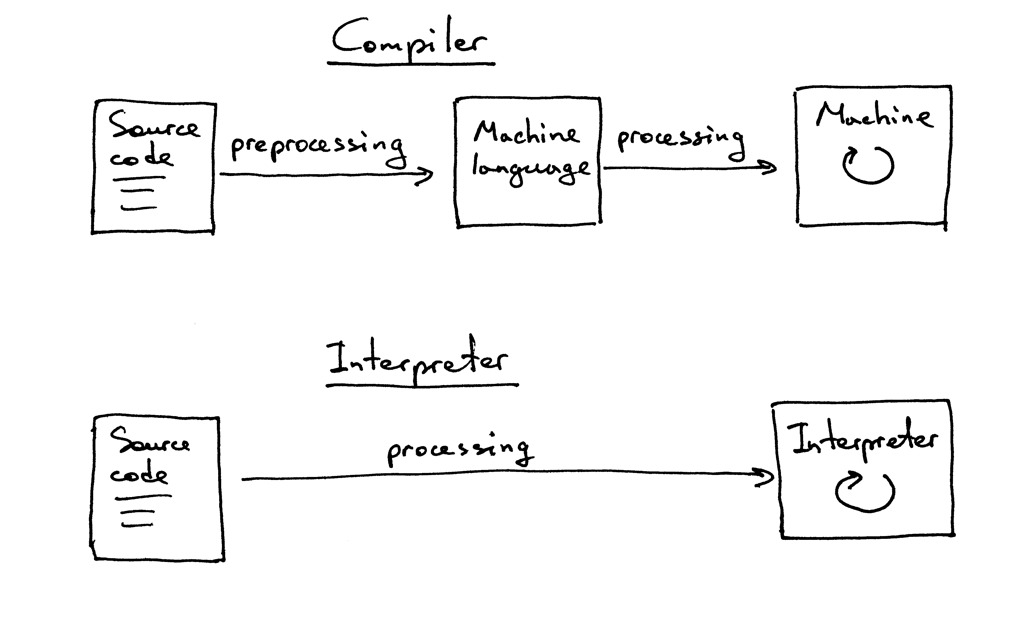
Различие между компилятором и интерпретатором
Почему вам нужно создать свой интерпретатор:
- Написать компилятор — значит задействовать и/или развить сразу несколько различных технических навыков. Причем навыков, которые окажутся полезными в программировании вообще, а не только при написании трансляторов.
- Вы станете чуть ближе к разгадке тайны, как же все-таки работают компьютеры. Компиляторы и интепретаторы — это магия. И нужно чувствовать себя комфортно при работе с этой магией.
- Вы сможете создать собственный язык программирования, восполняющий видимые вам недостатки существующих. А это, во-первых, сейчас модно, а во-вторых, при достаточном везении вы обретете мировую известность.
- Да ну и чем вам еще сейчас можно заняться? (Кстати, мы уже предлагали вам несколько вариантов на зимние каникулы и лето.)
Что приятно, статьи подробно иллюстрируются. Создается впечатление, что автор перед вами ведет настоящую лекцию. Вот, например, одна из синтаксических диаграмм:
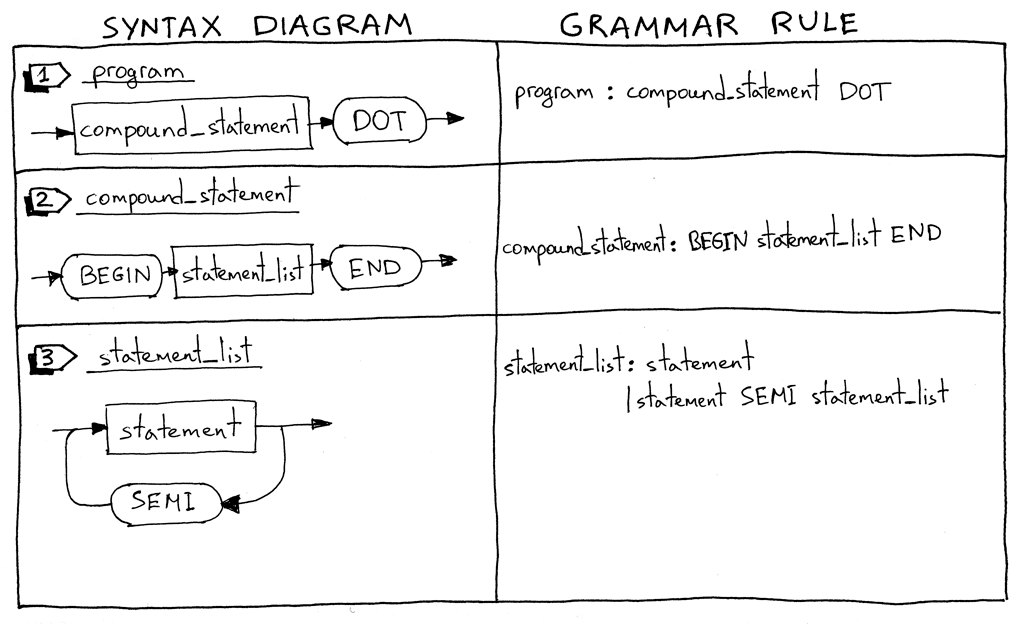
В конце каждой части руководства дается несколько задач для самостоятельной реализации и список полезных книг для более полного изучения вопроса. Итак, теперь приступайте к чтению:
Часть 1. Основные понятия, разбиение на токены и сложение однозначных чисел.
Часть 2. Обработка пробельных символов, многозначные числа.
Часть 3. Синтаксические диаграммы, одиночные умножение и деление.
Часть 4. Множественные умножения и деления, форма Бэкуса-Наура.
Часть 5. Калькулятор с произвольным числом операций, ассоциативность и порядок выполнения операторов.
Часть 6. Заканчиваем калькулятор: произвольный уровень вложенности.
Часть 7. Базовые используемые структуры данных. Также рекомендуем эту серию статей.
Часть 8. Унарные операторы.
Часть 9. Объявление программы, составные операторы, присваивание, таблицы символов и обработка переменных.
Часть 10. Продолжение предыдущей части руководства. Обработка комментариев.
Серия продолжит пополняться, а пока можете обратиться к одному из пособий, которые рекомендует автор в конце каждой части.