Время на прочтение
3 мин
Количество просмотров 104K
В этой статье я постараюсь понятно рассказать о парсинге данных и его нюансах.

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
- Поиск данных
- Извлечение информации
- Сохранение данных
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
И сделаем наш первый get-запрос.
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2"
r = requests.get(URL_TEMPLATE)
print(r.status_code)
Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
print(r.text)
Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
<h2 class="add-bottom-sm"><a href="/ru/jobs/3682040/" title="Комірник, вакансия от 5 ноября 2019">Комірник</a></h2>У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
soup = bs(r.text, "html.parser")
vacancies_names = soup.find_all('h2', class_='add-bottom-sm')
for name in vacancies_names:
print(name.a['title'])
Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
<p class="overflow">Some information about vacancy.</p>Получаем такой код.
vacancies_info = soup.find_all('p', class_='overflow')
for name in vacancies_names:
print('https://www.work.ua'+name.a['href'])
for info in vacancies_info:
print(info.text)
И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2"
FILE_NAME = "test.csv"
def parse(url = URL_TEMPLATE):
result_list = {'href': [], 'title': [], 'about': []}
r = requests.get(url)
soup = bs(r.text, "html.parser")
vacancies_names = soup.find_all('h2', class_='add-bottom-sm')
vacancies_info = soup.find_all('p', class_='overflow')
for name in vacancies_names:
result_list['href'].append('https://www.work.ua'+name.a['href'])
result_list['title'].append(name.a['title'])
for info in vacancies_info:
result_list['about'].append(info.text)
return result_list
df = pd.DataFrame(data=parse())
df.to_csv(FILE_NAME)
После запуска появится файл test.csv — с результатами поиска.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
#статьи
- 28 окт 2022
-

0
Рассказываем и показываем, как запросто вытянуть данные из сайта и «разговорить» его без утюга, паяльника и мордобоя.
Иллюстрация: Катя Павловская для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Для парсинга используют разные языки программирования: Python, JavaScript или даже Go. На самом деле инструмент не так важен, но некоторые языки делают парсинг удобнее за счёт наличия специальных библиотек — например, Beautiful Soup в Python.
В этой статье разберёмся в основах парсинга — вспомним про структуру HTML-запроса и спарсим сведения о погоде с сервиса «Яндекса». А ещё поделимся записью мастер-класса, на котором наш эксперт в веб-разработке покажет, как с нуля написать веб-парсер.
Парсинг (от англ. parsing — разбор, анализ), или веб-скрейпинг, — это автоматизированный сбор информации с интернет-сайтов. Например, можно собрать статьи с заголовками с любого сайта, что полезно для журналистов или социологов. Программы, которые собирают и обрабатывают информацию из Сети, называют парсерами (от англ. parser — анализатор).
Сам парсинг используется для решения разных задач: с его помощью телеграм-боты могут получать информацию, которую затем показывают пользователям, маркетологи — подтягивать данные из социальных сетей, а бизнесмены — узнавать подробности о конкурентах.
Существуют различные подходы к парсингу: можно забирать информацию через API, который предусмотрели создатели сервиса, или получать её напрямую из HTML-кода. В любом из этих случаев важно помнить, как вообще мы взаимодействуем с серверами в интернете и как работают HTTP-запросы. Начнём с этого!
HTTP (HyperText Transfer Protocol, протокол передачи гипертекста) — протокол для передачи произвольных данных между клиентом и сервером. Он называется так, потому что изначально использовался для обмена гипертекстовыми документами в формате HTML.
Для того чтобы понять, как работает HTTP, надо помнить, что это клиент-серверная структура передачи данных․ Клиент, например ваш браузер, формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передаётся обратно клиенту. В нашем примере клиент — это браузер.
Запрос состоит из трёх частей:
- Строка запроса (request line): указывается метод передачи, версия HTTP и сам URL, к которому обращается сервер.
- Заголовок (message header): само сообщение, передаваемое серверу, его параметры и дополнительная информация).
- Тело сообщения (entity body): данные, передаваемые в запросе. Это необязательная часть.
Посмотрим на простой HTTP-запрос, которым мы воспользуемся для получения прогноза погоды:
_GET /https://yandex.com.am/weather/ HTTP/1.1_
В этом запросе можно выделить три части:
- _GET — метод запроса. Метод GET позволяет получить данные с ресурса, не изменяя их.
- /https://yandex.com.am/weather/ — URL сайта, к которому мы обращаемся.
- HTTP/1.1_ — указание на версию HTTP.
Ответ на запрос также имеет три части: _HTTP/1.1 200 OK_. В начале указывается версия HTTP, цифровой код ответа и текстовое пояснение. Существующих ответов несколько десятков. Учить их не обязательно — можно воспользоваться документацией с пояснениями.
Сам HTTP-запрос может быть написан в разных форматах. Рассмотрим два самых популярных: XML и JSON.
JSON (англ. JavaScript Object Notation) — простой формат для обмена данными, созданный на основе JavaScript. При этом используется человекочитаемый текст, что делает его лёгким для понимания и написания:
({
<font color="#069">"firstName"</font> : <font color="#069">"Антон"</font>,
<font color="#069">"lastName"</font> : <font color="#069">"Яценко"</font>
});
Для того чтобы получить информацию в формате JSON, необходимо подготовить правильный HTTP-запрос:
var requestURL = 'test.json'; var request = new XMLHttpRequest(); request.open('GET', requestURL); request.responseType = 'json'; request.send();
В его структуре можно выделить пять логических частей:
- var requestURL — переменная с указанием на URL-адреса с необходимой информацией;
- var request = new XMLHttpRequest () — создание нового экземпляра объекта запроса из конструктора XMLHttpRequest с помощью ключевого слова new;
- request.open (‘GET’, requestURL) — открытие нового запроса с использованием метода GET. Обязательно указываем нашу переменную с URL-адресом;
- request.responseType = ‘json’ — явно обозначаем получаемый формат данных как JSON;
- request.send () — отправляем запрос на получение информации.
XML — язык разметки, который определяет набор правил для кодирования документов, записанных в текстовом формате. От JSON отличается большей сложностью — проще всего увидеть это на примере:
<font color="#069"><person></font> <font color="#069"><firstname></font>Антон<font color="#069"></firstname></font> <font color="#069"><lastname></font>Яценко<font color="#069"></lastname></font> <font color="#069"></person></font>
Чтобы получить информацию, хранящуюся на сервере как XML или HTML, потребуется воспользоваться той же библиотекой, как и в случае с JSON, но в качестве responseType следует указать Document.
var requestURL = 'test.txt'; var request = new XMLHttpRequest(); request.open('GET', requestURL); request.responseType = 'document'; request.send();
Какой из форматов лучше выбрать? Кажется, что JSON легче для восприятия. Но выбор между определённым форматом HTTP-запроса зависит и от решаемой задачи. Подробно обсудим это в будущих материалах.
А сегодня разберёмся с основами веб-скрейпинга — используем стандартные библиотеки Python и научимся работать с различными полезными инструментами.
Самый простой способ разобраться в парсинге — что-то спарсить. Создадим программу, которая будет показывать информацию о погоде в вашем городе.
Для этого пройдём через три последовательных шага:
- Подключим библиотеки, которые помогут нам спарсить информацию с помощью Python (как установить Python на Windows, macOS и Linux — смотрите в нашей статье).
- Зайдём на сайт, с которого мы планируем парсить информацию, и изучим его исходный код. Важно будет найти те элементы, которые содержат нужную информацию.
- Напишем код и спарсим данные.
Подключаем библиотеки
Подключаем библиотеки
В разных языках программирования есть свои библиотеки для парсинга информации с сайтов. Например, в JavaScript используется библиотека Puppeteer, а на Python популярна библиотека Beautiful Soup. Принципы их работы похожи. Но сначала нужно разобраться с запуском Python на компьютере.
Просто так написать код в текстовом документе не получится. Можно воспользоваться одним из способов:
- Использовать терминал на macOS или Linux, или воспользоваться командной строкой в Windows. Для этого предварительно потребуется установить Python в систему. Мы подробно писали об этом в отдельном материале.
- Воспользоваться одним из онлайн-редакторов, позволяющих работать с кодом на Python без его установки: Google Colab, python.org, onlineGDB или другим.
После установки на свой компьютер Python или запуска онлайн-редактора кода можно переходить к импорту библиотек.
BeautifulSoup — библиотека, которая позволяет работать с HTML- и XML-кодом. Подключить её очень просто:
from bs import BeautifulSoup
Дополнительно потребуется библиотека requests, которая помогает сделать запрос на нужный нам адрес сайта. Импортируется она в одну строку:
import requests
Всё. Все библиотеки готовы к работе — они помогут получить исходный код сайта и найти в нём нужную информацию.
Важно! Библиотека Beautiful Soup чаще всего предустановлена в используемой среде разработке или в Jupyter Notebook, но иногда её нет. Если при попытке её импорта вы получаете ошибку, то выполните команду для её установки, а потом повторите запросы на импорт:
pip3 install bs4
В качестве источника прогнозы погоды будем использовать сайт «Яндекс.Погода». Перейдём на него и в строке поиска найдём свой город. В нашем случае это будет Москва.
Посмотрите внимательно на адресную строку — она ещё пригодится нам в дальнейшем: https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526.
Обычно в адресной строке там нет названия города, а есть географические координаты точки, для которой показана текущая погода (у нас это центр Москвы).
Теперь посмотрим на исходный код страницы и найдём место, где хранится текущая температура. Нас интересует обведённый на скриншоте сайта блок:
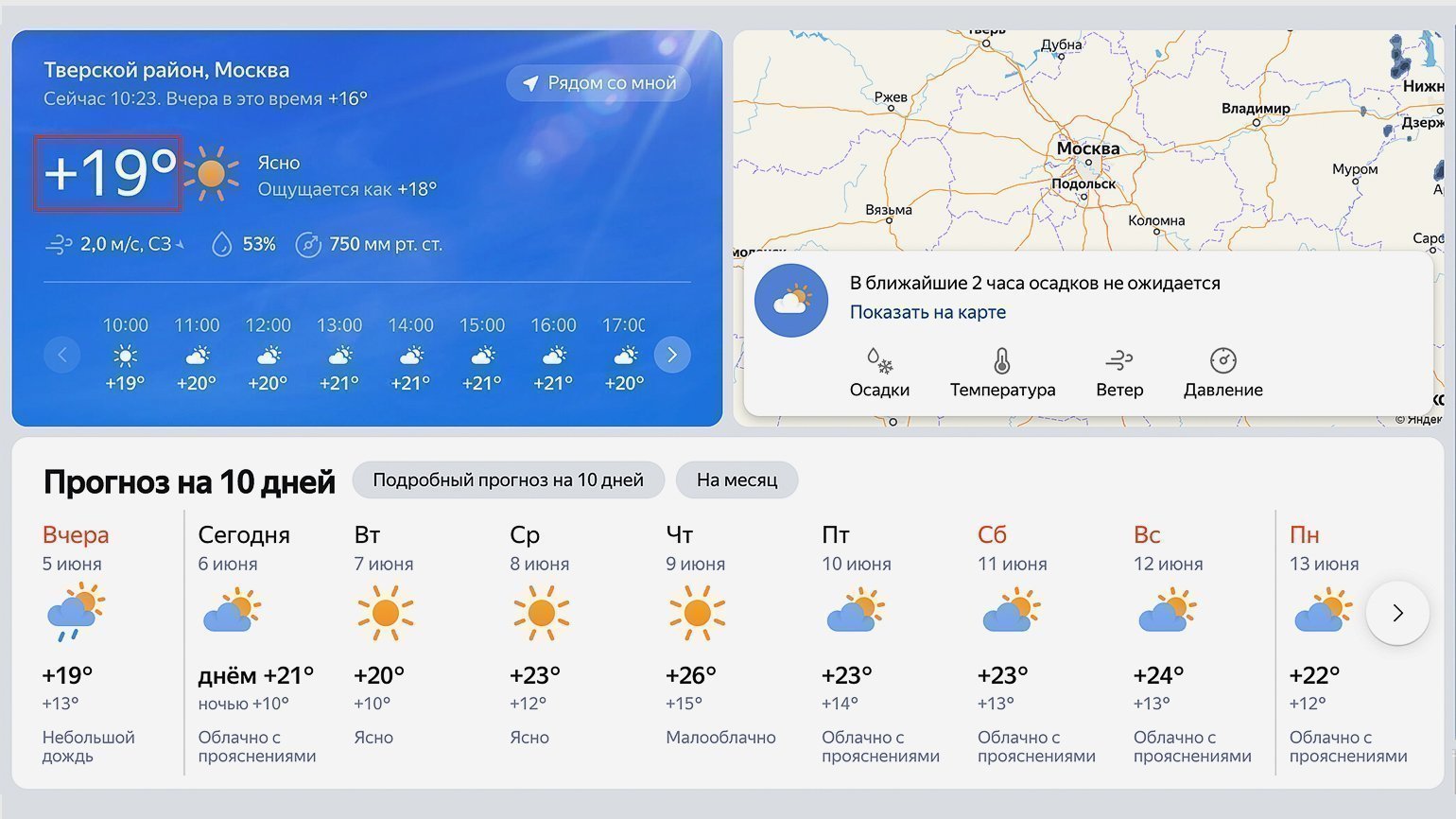
Для просмотра HTML-кода откроем «Инспектор кода». Для этого можно использовать комбинации горячих клавиш: в Google Chrome на macOS — ⌥ + ⌘ + I, на Windows — Сtrl + Shift + I или F12. Инспектор кода выглядит как дополнительное окно в браузере с несколькими вкладками:
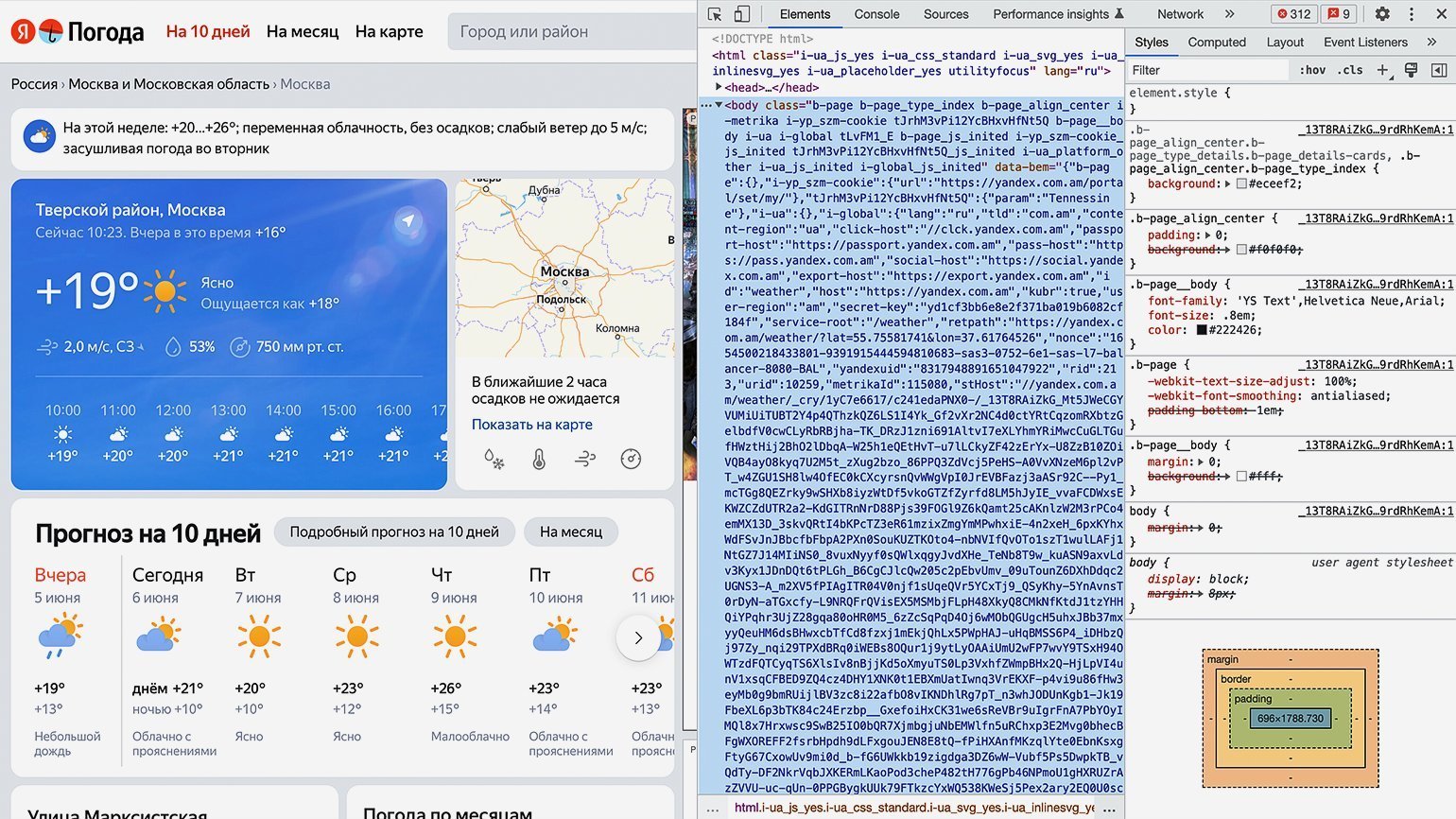
Переключаться между вкладками не надо, так как вся необходимая информация уже есть на первой.
Теперь найдём блок в коде, где хранится значение температуры. Для этого следует последовательно разворачивать блоки кода, располагающиеся внутри тега <body>. Сделать это можно, нажимая на символ ▶.
Как понять, что мы на правильном пути? Инспектор кода при наведении на блок кода подсвечивает на сайте ту область, за которую он отвечает. Переходим последовательно вглубь HTML-кода и находим нужный нам элемент.
В нашем случае пришлось проделать большой путь: элемент с классом «b‑page__container» → первый элемент с классом «content xKNTdZXiT5r0Tp0FJZNQIGlNu xIpbRdHA» → элемент с классом «xKNTdZXiT5r0vvENJ» → элемент с классом «fact card card_size_big» → элемент с классом «fact__temp-wrap xFNjfcG6O4pAfvHM» → элемент с классом «link fact__basic fact__basic_size_wide day-anchor xIpbRdHA» → элемент с классом «temp fact__temp fact__temp_size_s». Именно последнее название класса нам потребуется на следующем шаге.
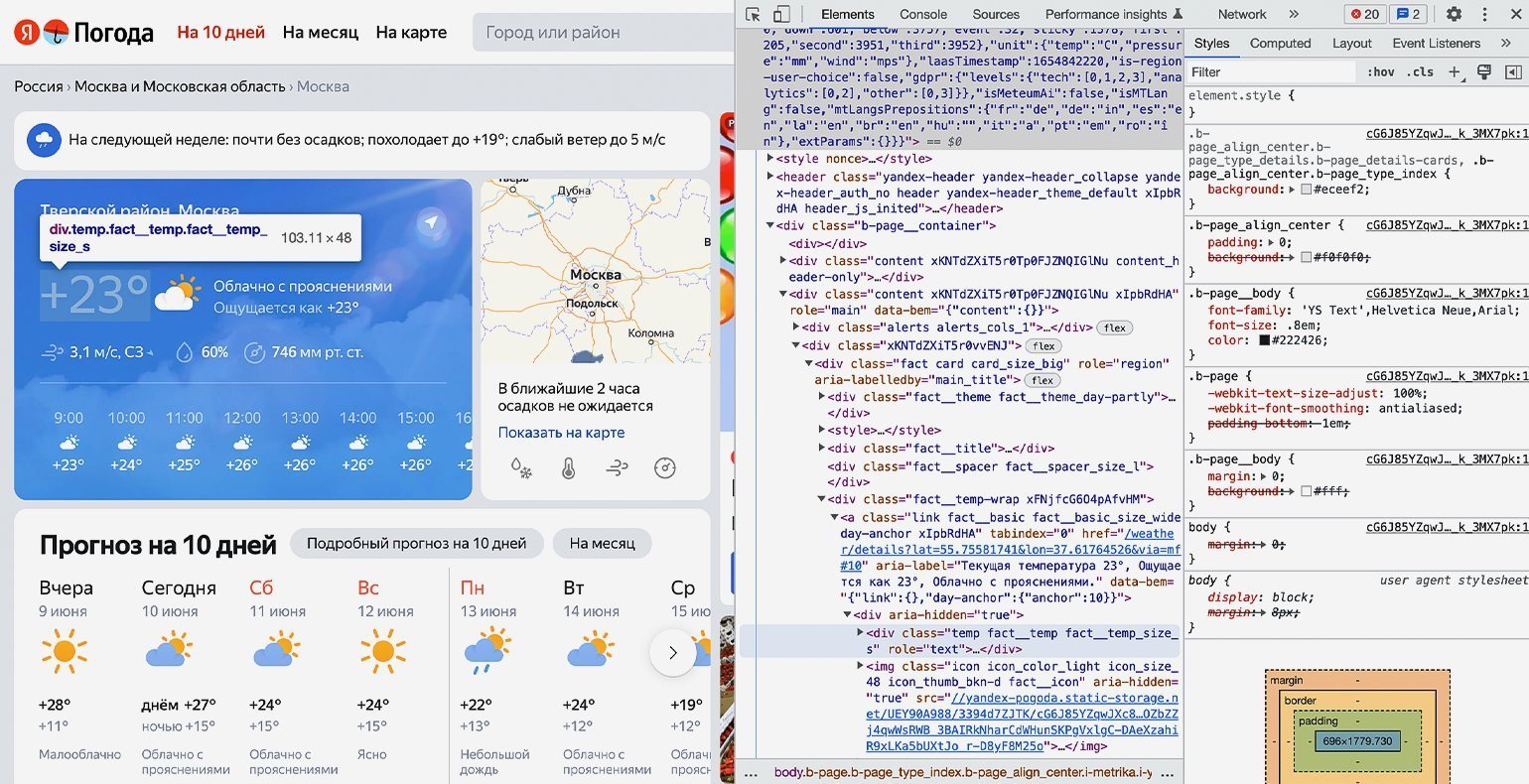
Продолжаем писать команды в терминал, командную строку, IDE или онлайн-редактор кода Python. На этом шаге нам остаётся использовать подключённые библиотеки и достать значения температуры из элемента <span=»temp fact__temp fact__temp_size_s»>. Но для начала надо проверить работу библиотек.
Сохраняем в переменную URL-адрес страницы, с которой мы планируем парсить информацию:
url = 'https://yandex.com.am/weather/?lat=55.75581741&lon=37.61764526'
Создадим к ней запрос и посмотрим, что вернёт сервер:
response = requests.get(url) print(response)
В нашем случае получаем ответ:
<Response [200]>
Отлично. Ответ «200» значит, что библиотека requests работает правильно и сервер отдаёт нам информацию со страницы.
Теперь получим исходный код, используя библиотеку Beautiful Soup и сразу выведем результат на экран:
bs = BeautifulSoup(response.text,"lxml") print(bs)
После выполнения на экране виден код всей страницы полностью:

Но весь код нам не нужен — мы должны выводить только тот блок кода, где хранится значение температуры. Напомним, что это <span=»temp fact__temp fact__temp_size_s»>. Найдём его значение с помощью функции find() библиотеки Beautiful Soup.
Функция find() принимает два аргумента:
- указание на тип элемента HTML-кода, в котором происходит поиск;
- наименование этого элемента.
В нашем случае код будет следующим:
temp = bs.find('span', 'temp__value temp__value_with-unit')
И сразу выведем результат на экран с помощью print:
print(temp)
Получаем:
<span class="temp__value temp__value_with-unit">+17</span>
Получилось! Но кроме нужной нам информации есть ещё HTML-тег с классом — а он тут лишний. Избавимся от него и оставим только значения температуры с помощью свойства text:
print(temp.text)
Результат:
+17
Всё получилось. Мы смогли узнать текущую температуру в городе с сайта «Яндекс.Погода», используя библиотеку Beautiful Soup для Python. Её можно использовать для своих задач — например, передавая в виджет на своём сайте, — или создать бота для погоды.
Если вы совсем новичок в веб-скрапинге, но хотите написать свой парсер (например, для автоматической генерации отчётов в Excel), рекомендуем посмотреть вебинар от Михаила Овчинникова — ведущего инженера-программиста из Badoo. Он на понятном примере объясняет основы языка Python и принципы веб-скрапинга. Уже в начале видеоурока вы запустите простой парсер и научитесь читать данные в формате HTML и JSON.
Бесплатная библиотека Selenium позволяет эмулировать работу веб-браузера — то есть «маскировать» веб-запросы скрипта под действия человека в Google Chrome или Safari. Почему это важно? Сайты умеют распознавать ботов и блокируют IP-адреса, с которых отправляются автоматические запросы.
Избежать «бана» можно двумя способами: изучить HTTP, принципы работы Python с вебом и написать свой эмулятор с нуля или воспользоваться готовым инструментом. Во втором случае Selenium — одно из лучших и самых удобных решений.
О том, как работать с библиотекой, рассказал Михаил Овчинников:
Парсинг помогает получить нужную информацию с любого сайта. Для него можно использовать разные языки программирования, но некоторые из них содержат стандартные библиотеки для веб-скрейпинга, например Beautiful Soup на Python.
А ещё мы рекомендуем внимательно изучить официальную документацию по библиотекам, которые мы использовали для парсинга. Например, можно углубиться в возможности и нюансы использования библиотеки Beautiful Soup на Python.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать
Парсинг в Python – это метод извлечения большого количества данных с нескольких веб-сайтов. Термин «парсинг» относится к получению информации из другого источника (веб-страницы) и сохранению ее в локальном файле.
Например: предположим, что вы работаете над проектом под названием «Веб-сайт сравнения телефонов», где вам требуются цены на мобильные телефоны, рейтинги и названия моделей для сравнения различных мобильных телефонов. Если вы собираете эти данные вручную, проверяя различные сайты, это займет много времени. В этом случае важную роль играет парсинг веб-страниц, когда, написав несколько строк кода, вы можете получить желаемые результаты.

Web Scrapping извлекает данные с веб-сайтов в неструктурированном формате. Это помогает собрать эти неструктурированные данные и преобразовать их в структурированную форму.
Законен ли веб-скрапинг?
Здесь возникает вопрос, является ли веб-скрапинг законным или нет. Ответ в том, что некоторые сайты разрешают это при легальном использовании. Веб-парсинг – это просто инструмент, который вы можете использовать правильно или неправильно.
Непубличные данные доступны не всем; если вы попытаетесь извлечь такие данные, это будет нарушением закона.
Есть несколько инструментов для парсинга данных с веб-сайтов, например:
- Scrapping-bot
- Scrapper API
- Octoparse
- Import.io
- Webhose.io
- Dexi.io
- Outwit
- Diffbot
- Content Grabber
- Mozenda
- Web Scrapper Chrome Extension
Почему и зачем использовать веб-парсинг?

Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
- Динамический мониторинг цен
Широко используется для сбора данных с нескольких интернет-магазинов, сравнения цен на товары и принятия выгодных ценовых решений. Мониторинг цен с использованием данных, переданных через Интернет, дает компаниям возможность узнать о состоянии рынка и способствует динамическому ценообразованию. Это гарантирует компаниям, что они всегда превосходят других.
- Исследования рынка
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
- Сбор электронной почты
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
- Новости и мониторинг контента
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
- Тренды в социальных сетях
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
- Исследования и разработки
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
Зачем использовать именно Python?
Есть и другие популярные языки программирования, но почему мы предпочитаем Python другим языкам программирования для парсинга веб-страниц? Ниже мы описываем список функций Python, которые делают его наиболее полезным языком программирования для сбора данных с веб-страниц.
- Динамичность
В Python нам не нужно определять типы данных для переменных; мы можем напрямую использовать переменную там, где это требуется. Это экономит время и ускоряет выполнение задачи. Python определяет свои классы для определения типа данных переменной.
- Обширная коллекция библиотек
Python поставляется с обширным набором библиотек, таких как NumPy, Matplotlib, Pandas, Scipy и т. д., которые обеспечивают гибкость для работы с различными целями. Он подходит почти для каждой развивающейся области, а также для извлечения данных и выполнения манипуляций.
- Меньше кода
Целью парсинга веб-страниц является экономия времени. Но что, если вы потратите больше времени на написание кода? Вот почему мы используем Python, поскольку он может выполнять задачу в нескольких строках кода.
- Сообщество с открытым исходным кодом
Python имеет открытый исходный код, что означает, что он доступен всем бесплатно. У него одно из крупнейших сообществ в мире, где вы можете обратиться за помощью, если застряли где-нибудь в коде Python.
Основы веб-парсинга
Веб-скраппинг состоит из двух частей: веб-сканера и веб-скребка. Проще говоря, веб-сканер – это лошадь, а скребок – колесница. Сканер ведет парсера и извлекает запрошенные данные. Давайте разберемся с этими двумя компонентами веб-парсинга:
- Сканер
 Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
 Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Как работает Web Scrapping?
Давайте разберем по шагам, как работает парсинг веб-страниц.
Шаг 1. Найдите URL, который вам нужен.
Во-первых, вы должны понимать требования к данным в соответствии с вашим проектом. Веб-страница или веб-сайт содержит большой объем информации. Вот почему отбрасывайте только актуальную информацию. Проще говоря, разработчик должен быть знаком с требованиями к данным.
Шаг – 2: Проверка страницы
Данные извлекаются в необработанном формате HTML, который необходимо тщательно анализировать и отсеивать мешающие необработанные данные. В некоторых случаях данные могут быть простыми, такими как имя и адрес, или такими же сложными, как многомерные данные о погоде и данные фондового рынка.
Шаг – 3: Напишите код
Напишите код для извлечения информации, предоставления соответствующей информации и запуска кода.
Шаг – 4: Сохраните данные в файле
Сохраните эту информацию в необходимом формате файла csv, xml, JSON.
Начало работы с Web Scrapping
Давайте разберемся с необходимой библиотекой для Python. Библиотека, используемая для разметки веб-страниц.
- Selenium-Selenium – это библиотека автоматического тестирования с открытым исходным кодом. Она используется для проверки активности браузера. Чтобы установить эту библиотеку, введите в терминале следующую команду.
pip install selenium
Примечание. Рекомендуется использовать IDE PyCharm.

- Pandas – библиотека для обработки и анализа данных. Используется для извлечения данных и сохранения их в желаемом формате.
- BeautifulSoup
BeautifulSoup – это библиотека Python, которая используется для извлечения данных из файлов HTML и XML. Она в основном предназначена для парсинга веб-страниц. Работает с анализатором, обеспечивая естественный способ навигации, поиска и изменения дерева синтаксического анализа. Последняя версия BeautifulSoup – 4.8.1.
Давайте подробно разберемся с библиотекой BeautifulSoup.
Установка BeautifulSoup
Вы можете установить BeautifulSoup, введя следующую команду:
pip install bs4
Установка парсера
BeautifulSoup поддерживает парсер HTML и несколько сторонних парсеров Python. Вы можете установить любой из них в зависимости от ваших предпочтений. Список парсеров BeautifulSoup:
| Парсер | Типичное использование |
|---|---|
| Python’s html.parser | BeautifulSoup (разметка, “html.parser”) |
| lxml’s HTML parser | BeautifulSoup (разметка, «lxml») |
| lxml’s XML parser | BeautifulSoup (разметка, «lxml-xml») |
| Html5lib | BeautifulSoup (разметка, “html5lib”) |
Мы рекомендуем вам установить парсер html5lib, потому что он больше подходит для более новой версии Python, либо вы можете установить парсер lxml.
Введите в терминале следующую команду:
pip install html5lib

BeautifulSoup используется для преобразования сложного HTML-документа в сложное дерево объектов Python. Но есть несколько основных типов объектов, которые чаще всего используются:
- Ярлык
Объект Tag соответствует исходному документу XML или HTML.
soup = bs4.BeautifulSoup("Extremely bold)
tag = soup.b
type(tag)
Выход:
<class "bs4.element.Tag">
Тег содержит множество атрибутов и методов, но наиболее важными особенностями тега являются имя и атрибут.
-
- Имя
У каждого тега есть имя, доступное как .name:
tag.name
- Атрибуты
Тег может иметь любое количество атрибутов. Тег имеет атрибут “id”, значение которого – “boldest”. Мы можем получить доступ к атрибутам тега, рассматривая тег как словарь.
tag[id]
Мы можем добавлять, удалять и изменять атрибуты тега. Это можно сделать, используя тег как словарь.
# add the element tag['id'] = 'verybold' tag['another-attribute'] = 1 tag # delete the tag del tag['id']
- Многозначные атрибуты
В HTML5 есть некоторые атрибуты, которые могут иметь несколько значений. Класс (состоит более чем из одного css) – это наиболее распространенный многозначный атрибут. Другие атрибуты: rel, rev, accept-charset, headers и accesskey.
class_is_multi= { '*' : 'class'}
xml_soup = BeautifulSoup('', 'xml', multi_valued_attributes=class_is_multi)
xml_soup.p['class']
# [u'body', u'strikeout']
- Навигационная строка
Строка в BeautifulSoup ссылается на текст внутри тега. BeautifulSoup использует класс NavigableString для хранения этих фрагментов текста.
tag.string # u'Extremely bold' type(tag.string) #
Неизменяемая строка означает, что ее нельзя редактировать. Но ее можно заменить другой строкой с помощью replace_with().
tag.string.replace_with("No longer bold")
tag
В некоторых случаях, если вы хотите использовать NavigableString вне BeautifulSoup, unicode() помогает ему превратиться в обычную строку Python Unicode.
- BeautifulSoup объект
Объект BeautifulSoup представляет весь проанализированный документ в целом. Во многих случаях мы можем использовать его как объект Tag. Это означает, что он поддерживает большинство методов, описанных для навигации по дереву и поиска в дереве.
doc=BeautifulSoup("INSERT FOOTER HEREHere's the footer","xml")
doc.find(text="INSERT FOOTER HERE").replace_with(footer)
print(doc)
Выход:
?xml version="1.0" encoding="utf-8"?> #
Пример парсера
Давайте разберем пример, чтобы понять, что такое парсер на практике, извлекая данные с веб-страницы и проверяя всю страницу.
Для начала откройте свою любимую страницу в Википедии и проверьте всю страницу, перед извлечением данных с веб-страницы вы должны убедиться в своих требованиях. Рассмотрим следующий код:
#importing the BeautifulSoup Library
importbs4
import requests
#Creating the requests
res = requests.get("https://en.wikipedia.org/wiki/Machine_learning")
print("The object type:",type(res))
# Convert the request object to the Beautiful Soup Object
soup = bs4.BeautifulSoup(res.text,'html5lib')
print("The object type:",type(soup)
Выход:
The object type <class 'requests.models.Response'> Convert the object into: <class 'bs4.BeautifulSoup'>
В следующих строках кода мы извлекаем все заголовки веб-страницы по имени класса. Здесь знания внешнего интерфейса играют важную роль при проверке веб-страницы.
soup.select('.mw-headline')
for i in soup.select('.mw-headline'):
print(i.text,end = ',')
Выход:
Overview,Machine learning tasks,History and relationships to other fields,Relation to data mining,Relation to optimization,Relation to statistics, Theory,Approaches,Types of learning algorithms,Supervised learning,Unsupervised learning,Reinforcement learning,Self-learning,Feature learning,Sparse dictionary learning,Anomaly detection,Association rules,Models,Artificial neural networks,Decision trees,Support vector machines,Regression analysis,Bayesian networks,Genetic algorithms,Training models,Federated learning,Applications,Limitations,Bias,Model assessments,Ethics,Software,Free and open-source software,Proprietary software with free and open-source editions,Proprietary software,Journals,Conferences,See also,References,Further reading,External links,
В приведенном выше коде мы импортировали bs4 и запросили библиотеку. В третьей строке мы создали объект res для отправки запроса на веб-страницу. Как видите, мы извлекли весь заголовок с веб-страницы.

Веб-страница Wikipedia Learning
Давайте разберемся с другим примером: мы сделаем GET-запрос к URL-адресу и создадим объект дерева синтаксического анализа (soup) с использованием BeautifulSoup и встроенного в Python парсера “html5lib”.
Здесь мы удалим веб-страницу по указанной ссылке (https://www.javatpoint.com/). Рассмотрим следующий код:
following code: # importing the libraries from bs4 import BeautifulSoup import requests url="https://www.javatpoint.com/" # Make a GET request to fetch the raw HTML content html_content = requests.get(url).text # Parse the html content soup = BeautifulSoup(html_content, "html5lib") print(soup.prettify()) # print the parsed data of html
Приведенный выше код отобразит весь html-код домашней страницы javatpoint.
Используя объект BeautifulSoup, то есть soup, мы можем собрать необходимую таблицу данных. Напечатаем интересующую нас информацию с помощью объекта soup:
- Напечатаем заголовок веб-страницы.
print(soup.title)
Выход даст следующий результат:
<title>Tutorials List - Javatpoint</title>
- В приведенных выше выходных данных тег HTML включен в заголовок. Если вам нужен текст без тега, вы можете использовать следующий код:
print(soup.title.text)
Выход: это даст следующий результат:
Tutorials List - Javatpoint
- Мы можем получить всю ссылку на странице вместе с ее атрибутами, такими как href, title и ее внутренний текст. Рассмотрим следующий код:
for link in soup.find_all("a"):
print("Inner Text is: {}".format(link.text))
print("Title is: {}".format(link.get("title")))
print("href is: {}".format(link.get("href")))
Вывод: он напечатает все ссылки вместе со своими атрибутами. Здесь мы отображаем некоторые из них:
href is: https://www.facebook.com/javatpoint Inner Text is: The title is: None href is: https://twitter.com/pagejavatpoint Inner Text is: The title is: None href is: https://www.youtube.com/channel/UCUnYvQVCrJoFWZhKK3O2xLg Inner Text is: The title is: None href is: https://javatpoint.blogspot.com Inner Text is: Learn Java Title is: None href is: https://www.javatpoint.com/java-tutorial Inner Text is: Learn Data Structures Title is: None href is: https://www.javatpoint.com/data-structure-tutorial Inner Text is: Learn C Programming Title is: None href is: https://www.javatpoint.com/c-programming-language-tutorial Inner Text is: Learn C++ Tutorial
Программа: извлечение данных с веб-сайта Flipkart
В этом примере мы удалим цены, рейтинги и название модели мобильных телефонов из Flipkart, одного из популярных веб-сайтов электронной коммерции. Ниже приведены предварительные условия для выполнения этой задачи:
- Python 2.x или Python 3.x с установленными библиотеками Selenium, BeautifulSoup, Pandas.
- Google – браузер Chrome.
- Веб-парсеры, такие как html.parser, xlml и т. д.
Шаг – 1: найдите нужный URL.
Первым шагом является поиск URL-адреса, который вы хотите удалить. Здесь мы извлекаем детали мобильного телефона из Flipkart. URL-адрес этой страницы: https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off.
Шаг 2: проверка страницы.
Необходимо внимательно изучить страницу, поскольку данные обычно содержатся в тегах. Итак, нам нужно провести осмотр, чтобы выбрать нужный тег. Чтобы проверить страницу, щелкните элемент правой кнопкой мыши и выберите «Проверить».
Шаг – 3: найдите данные для извлечения.
Извлеките цену, имя и рейтинг, которые содержатся в теге «div» соответственно.
Шаг – 4: напишите код.
from bs4 import BeautifulSoupas soup
from urllib.request import urlopen as uReq
# Request from the webpage
myurl = "https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off"
uClient = uReq(myurl)
page_html = uClient.read()
uClient.close()
page_soup = soup(page_html, features="html.parser")
# print(soup.prettify(containers[0]))
# This variable held all html of webpage
containers = page_soup.find_all("div",{"class": "_3O0U0u"})
# container = containers[0]
# # print(soup.prettify(container))
#
# price = container.find_all("div",{"class": "col col-5-12 _2o7WAb"})
# print(price[0].text)
#
# ratings = container.find_all("div",{"class": "niH0FQ"})
# print(ratings[0].text)
#
# #
# # print(len(containers))
# print(container.div.img["alt"])
# Creating CSV File that will store all data
filename = "product1.csv"
f = open(filename,"w")
headers = "Product_Name,Pricing,Ratingsn"
f.write(headers)
for container in containers:
product_name = container.div.img["alt"]
price_container = container.find_all("div", {"class": "col col-5-12 _2o7WAb"})
price = price_container[0].text.strip()
rating_container = container.find_all("div",{"class":"niH0FQ"})
ratings = rating_container[0].text
# print("product_name:"+product_name)
# print("price:"+price)
# print("ratings:"+ str(ratings))
edit_price = ''.join(price.split(','))
sym_rupee = edit_price.split("?")
add_rs_price = "Rs"+sym_rupee[1]
split_price = add_rs_price.split("E")
final_price = split_price[0]
split_rating = str(ratings).split(" ")
final_rating = split_rating[0]
print(product_name.replace(",", "|")+","+final_price+","+final_rating+"n")
f.write(product_name.replace(",", "|")+","+final_price+","+final_rating+"n")
f.close()
Выход:

Мы удалили детали iPhone и сохранили их в файле CSV, как вы можете видеть на выходе. В приведенном выше коде мы добавили комментарий к нескольким строкам кода для тестирования. Вы можете удалить эти комментарии и посмотреть результат.


Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Рассмотрим еще один практический кейс парсинга сайтов с помощью библиотеки BeautifulSoup: что делать, если на сайте нет готовой выгрузки с данными и нет API для удобной работы, а страниц для ручного копирования очень много?
Недавно мне понадобилось получить данные с одного сайта. Готовой выгрузки с информацией на сайте нет. Данные я вижу, вот они передо мной, но не могу их выгрузить и обработать. Возник вопрос: как их получить? Немного «погуглив», я понял, что придется засучить рукава и самостоятельно парсить страницу (HTML). Какой тогда инструмент выбрать? На каком языке писать, чтобы с ним не возникло проблем? Языков программирования для данной задачи большой набор, выбор пал на Python за его большое разнообразие готовых библиотек.
Примером для разбора основ возьмем сайт с отзывами banki_ru и получим отзывы по какому-нибудь банку.
Задачу можно разбить на три этапа:
- Загружаем страницу в память компьютера или в текстовый файл.
- Разбираем содержимое (HTML), получаем необходимые данные (сущности).
- Сохраняем в необходимый формат, например, Excel.
Инструменты
Для начала нам необходимо отправлять HTTP-запросы на выбранный сайт. У Python для отправки запросов библиотек большое количество, но самые распространённые urllib/urllib2 и Requests. На мой взгляд, Requests — удобнее, примеры буду показывать на ней.
А теперь сам процесс. Были мысли пойти по тяжелому пути и анализировать страницу на предмет объектов, содержащих нужную информацию, проводить ручной поиск и разбирать каждый объект по частям для получения необходимого результата. Но немного походив по просторам интернета, я получил ответ: BeautifulSoup – одна из наиболее популярных библиотек для парсинга. Библиотеки найдены, приступаем к самому интересному: к получению данных.
Загрузка и обработка данных
Попробуем отправить запрос HTTP на сайт, чтобы получить первую страницу с отзывами по какому-нибудь банку и сохранить в файл, для того, чтобы убедиться, получаем ли мы нужную нам информацию.
import requests
from bs4 import BeautifulSoup
bank_id = 1771062 #ID банка на сайте banki.ru
url = ‘https://www.banki.ru/services/questions-answers/?id=%d&p=1’ % (bank_id) # url страницы
r = requests.get(url)
with open(‘test.html’, ‘w’) as output_file:
output_file.write(r.text)
После исполнения данного скрипта получится файл text.html.
Открываем данный файл и видим, что необходимые данные получили без проблем.
Теперь очередь для разбора страницы на нужные фрагменты. Обрабатывать будем последние 10 страниц плюс добавим модуль Pandas для сохранения результата в Excel.
Подгружаем необходимые библиотеки и задаем первоначальные настройки.
import requests
from bs4 import BeautifulSoup
import pandas as pd
bank_id = 1771062 #ID банка на сайте banki.ru
page=1
max_page=10
url = ‘https://www.banki.ru/services/questions-answers/?id=%d&p=%d’ % (bank_id, page) # url страницы
На данном этапе необходимо понять, где находятся необходимые фрагменты. Изучаем разметку страницы с отзывами и определяем, какие объекты будем вытаскивать из страницы.
Подробно покопавшись во внутренностях страницы, мы увидим, что необходимые данные «вопросы-ответы» находятся в блоках <table class:qaBlock >, соответственно, сколько этих блоков на странице, столько и вопросов.
result = pd.DataFrame()
r = requests.get(url) #отправляем HTTP запрос и получаем результат
soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга
tables=soup.find_all(‘table’, {‘class’: ‘qaBlock’}) #Получаем все таблицы с вопросами
for item in tables:
res=parse_table(item)
Приступая к получению самих данных, я кратко расскажу о двух функциях, которые будут использованы:
- Find(‘table’) – проводит поиск по странице и возвращает первый найденный объект типа ‘table’. Вы можете искать и ссылки find(‘table’) и рисунки find(‘img’). В общем, все элементы, которые изображены на странице;
- find_all(‘table’) – проводит поиск по странице и возвращает все найденные объекты в виде списка
У каждой из этих функций есть методы. Я расскажу от тех, которые использовал:
- find(‘table’).text – этот метод вернет текст, находящийся в объекте;
- find(‘a’).get(‘href’) – этот метод вернет значение ссылки
Теперь, уже обладая этими знаниями и навыками программирования на Python, написал функцию, которая разбирает таблицу с отзывом на нужные данные. Каждые стадии кода дополнил комментариями.
def parse_table(table):#Функция разбора таблицы с вопросом
res = pd.DataFrame()
id_question=0
link_question=»
date_question=»
question=»
who_asked=»
who_asked_id=»
who_asked_link=»
who_asked_city=»
answer=»
question_tr=table.find(‘tr’,{‘class’: ‘question’})
#Получаем сам вопрос
question=question_tr.find_all(‘td’)[1].find(‘div’).text.replace(‘<br />’,’n’).strip()
widget_info=question_tr.find_all(‘div’, {‘class’:’widget__info’})
#Получаем ссылку на сам вопрос
link_question=’https://www.banki.ru’+widget_info[0].find(‘a’).get(‘href’).strip()
#Получаем уникальным номер вопроса
id_question=link_question.split(‘=’)[1]
#Получаем того кто задал вопрос
who_asked=widget_info[1].find(‘a’).text.strip()
#Получаем ссылку на профиль
who_asked_link=’https://www.banki.ru’+widget_info[1].find(‘a’).get(‘href’).strip()
#Получаем уникальный номер профиля
who_asked_id=widget_info[1].find(‘a’).get(‘href’).strip().split(‘=’)[1]
#Получаем из какого города вопрос
who_asked_city=widget_info[1].text.split(‘(‘)[1].split(‘)’)[0].strip()
#Получаем дату вопроса
date_question=widget_info[1].text.split(‘(‘)[1].split(‘)’)[1].strip()
#Получаем ответ если он есть сохраняем
answer_tr=table.find(‘tr’,{‘class’: ‘answer’})
if(answer_tr!=None):
answer=answer_tr.find_all(‘td’)[1].find(‘div’).text.replace(‘<br />’,’n’).strip()
#Пишем в таблицу и возвращаем
res=res.append(pd.DataFrame([[id_question,link_question,question,date_question,who_asked,who_asked_id,who_asked_link,who_asked_city,answer]], columns = [‘id_question’,’link_question’,’question’,’date_question’,’who_asked’,’who_asked_id’,’who_asked_city’,’who_asked_link’,’answer’]), ignore_index=True)
#print(res)
return(res)
Функция возвращает DataFrame, который можно накапливать и экспортировать в EXCEL.
result = pd.DataFrame()
r = requests.get(url) #отправляем HTTP запрос и получаем результат
soup = BeautifulSoup(r.text) #Отправляем полученную страницу в библиотеку для парсинга
tables=soup.find_all(‘table’, {‘class’: ‘qaBlock’}) #Получаем все таблицы с вопросами
for item in tables:
res=parse_table(item)
result=result.append(res, ignore_index=True)
result.to_excel(‘result.xlsx’)
Резюме
В результате мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup, а также получили пригодные для дальнейшего анализа данные об отзывах с сайта banki.ru. А вот и сама результирующая таблица.
Приобретенные навыки можно использовать для получения данных с других сайтов и получать обобщенную и структурированную информацию с бескрайних просторов Интернета.
Я надеюсь, моя статья была полезна. Спасибо за внимание.
Исходные данные – это фундамент для успешной работы в области анализа и обработки данных. Существует множество источников данных, и веб-сайты являются одним из них. Часто они могут быть вторичным источником информации, например: сайты агрегации данных (Worldometers), новостные сайты (CNBC), социальные сети (Twitter), платформы электронной коммерции (Shopee) и так далее. Эти веб-сайты предоставляют информацию, необходимую для проектов по анализу и обработке данных.
Но как нужно собирать данные? Мы не можем копировать и вставлять их вручную, не так ли? В такой ситуации решением проблемы будет парсинг сайтов на Python. Этот язык программирования имеет мощную библиотеку BeautifulSoup, а также инструмент для автоматизации Selenium. Они оба часто используются специалистами для сбора данных разных форматов. В этом разделе мы сначала познакомимся с BeautifulSoup.
ШАГ 1. УСТАНОВКА БИБЛИОТЕК
Прежде всего, нам нужно установить нужные библиотеки, а именно:
- BeautifulSoup4
- Requests
- pandas
- lxml
Для установки библиотеки вы можете использовать pip install [имя библиотеки] или conda install [имя библиотеки], если у вас Anaconda Prompt.
«Requests» — это наша следующая библиотека для установки. Ее задача — запрос разрешения у сервера, если мы хотим получить данные с его веб-сайта. Затем нужно установить pandas для создания фрейма данных и lxml, чтобы изменить HTML на формат, удобный для Python.
ШАГ 2. ИМПОРТИРОВАНИЕ БИБЛИОТЕК
После установки библиотек давайте откроем вашу любимую среду разработки. Мы предлагаем использовать Spyder 4.2.5. Позже на некоторых этапах работы мы столкнемся с большими объемами выводимых данных и тогда Spyder будет удобнее в использовании чем Jupyter Notebook.
Итак, Spyder открыт и мы можем импортировать необходимую библиотеку:
# Import library
from bs4 import BeautifulSoup
import requests
ШАГ 3. ВЫБОР СТРАНИЦЫ
В этом проекте мы будем использовать webscraper.io. Поскольку данный веб-сайт создан на HTML, код легче и понятнее даже новичкам. Мы выбрали эту страницу для парсинга данных:
Она является прототипом веб-сайта онлайн магазина. Мы будем парсить данные о компьютерах и ноутбуках, такие как название продукта, цена, описание и отзывы.
ШАГ 4. ЗАПРОС НА РАЗРЕШЕНИЕ
После выбора страницы мы копируем ее URL-адрес и используем request, чтобы запросить разрешение у сервера на получение данных с их сайта.
# Define URL
url = ‘https://webscraper.io/test-sites/e-commerce/allinone/computers/laptops'#
Ask hosting server to fetch url
requests.get(url)
Результат <Response [200]> означает, что сервер позволяет нам собирать данные с их веб-сайта. Для проверки мы можем использовать функцию request.get.
pages = requests.get(url)
pages.text
Когда вы выполните этот код, то на выходе получите беспорядочный текст, который не подходит для Python. Нам нужно использовать парсер, чтобы сделать его более читабельным.
# parser-lxml = Change html to Python friendly format
soup = BeautifulSoup(pages.text, ‘lxml’)
soup

ШАГ 5. ПРОСМОТР КОДА ЭЛЕМЕНТА
Для парсинга сайтов на Python мы рекомендуем использовать Google Chrome, он очень удобен и прост в использовании. Давайте узнаем, как с помощью Chrome просмотреть код веб-страницы. Сначала нужно щелкнуть правой кнопкой мыши страницу, которую вы хотите проверить, далее нажать Просмотреть код и вы увидите это:
Затем щелкните Выбрать элемент на странице для проверки и вы заметите, что при перемещении курсора к каждому элементу страницы, меню элементов показывает его код.
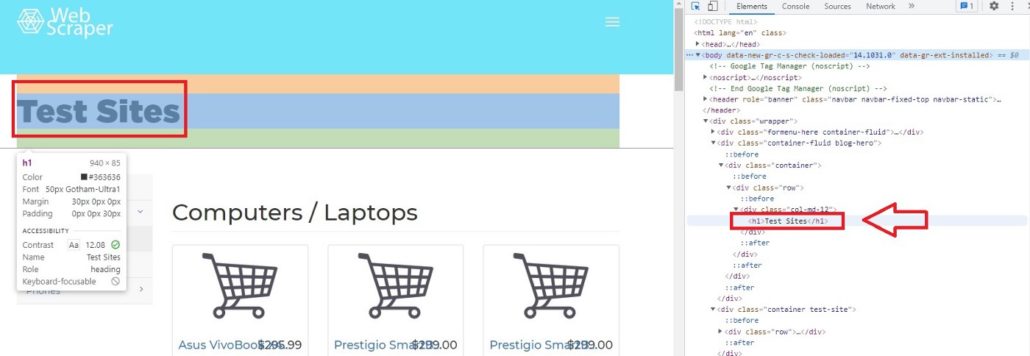
Например, если мы переместим курсор на Test Sites, элемент покажет, что Test Sites находится в теге h1. В Python, если вы хотите просмотреть код элементов сайта, можно вызывать теги. Характерной чертой тегов является то, что они всегда имеют < в качестве префикса и часто имеют фиолетовый цвет.
Как выбрать решение для парсинга сайтов: классификация и большой обзор программ, сервисов и фреймворков
ШАГ 6. ДОСТУП К ТЕГАМ
Если мы, к примеру, хотим получить доступ к элементу h1 с помощью Python, мы можем просто ввести:
# Access h1 tag
soup.h1
Результат будет:
soup.h1
Out[11]: <h1>Test Sites</h1>
Вы можете получить доступ не только к однострочным тегам, но и к тегам класса, например:
# Access header tagsoup.header#Access div tag soup.div
Не забудьте перед этим определить soup, поскольку важно преобразовать HTML в удобный для Python формат.
Вы можете получить доступ к определенному из вложенных тегов. Вложенные теги означают теги внутри тегов. Например, тег <p> находится внутри другого тега <header>. Но когда вы получаете доступ к определенному тегу из <header>, Python всегда покажет результаты из первого индекса. Позже мы узнаем, как получить доступ к нескольким тегам из вложенных.
# Access string from nested tags
soup.header.p
Результат:
soup.header.p
Out[10]: <p>Web Scraper</p>
Вы также можете получить доступ к строке вложенных тегов. Нужно просто добавить в код string.
# Access string from nested tags
soup.header.p
soup.header.p.string
Результат:
soup.header.p
soup.header.p.string
Out[12]: ‘Web Scraper’
Следующий этап парсинга сайтов на Python — это получение доступа к атрибутам тегов. Для этого мы можем использовать функциональную возможность BeautifulSoup attrs. Как результат применения attrs мы получим словарь.
# Access ‘a’ tag in <header>
a_start = soup.header.a
a_start#
Access only the attributes using attrs
a_start.attrs
Результат:
Out[16]:{‘data-toggle’: ‘collapse-side’,
‘data-target’: ‘.side-collapse’,
‘data-target-2’: ‘.side-collapse-container’}
Мы можем получить доступ к определенному атрибуту. Учтите, что Python рассматривает атрибут как словарь, поэтому data-toggle, data-target и data-target-2 являются ключом. Вот пример получение доступа к ‘data-target:
a_start[‘data-target’]
Результат:
a_start[‘data-target’]
Out[17]: ‘.side-collapse’
Мы также можем добавить новый атрибут. Имейте в виду, что изменения влияют только на веб-сайт локально, а не на веб-сайт в мировом масштабе.
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Результат:
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Out[18]:
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</a>
Парсинг таблицы с сайта на Python: Пошаговое руководство
ШАГ 7. ДОСТУП К КОНКРЕТНЫМ АТРИБУТАМ ТЕГОВ
Мы узнали, что в теге может быть больше чем один вложенный тег. Например, если мы запустим soup.header.div, <div> будет иметь много вложенных тегов. Учтите, что мы вызываем только <div> внутри <header >, поэтому другой тег внутри <header> не будет показан.
Результат:
soup.header.div
Out[26]:
<div class=”container”><div class=”navbar-header”>
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</div>
Как мы видим, в одном теге находится много атрибутов и вопрос заключается в том, как получить доступ только к тому атрибуту, который нам нужен. В BeautifulSoup есть функция ‘find’ и ‘find_all’. Чтобы было понятнее, мы покажем вам, как использовать обе функции и чем они отличаются друг от друга. В качестве примера найдем цену каждого товара. Чтобы увидеть код элемента цены, просто наведите курсор на индикатор цены.
После перемещения курсора мы можем определить, что цена находится в теге h4, значение класса pull-right price.
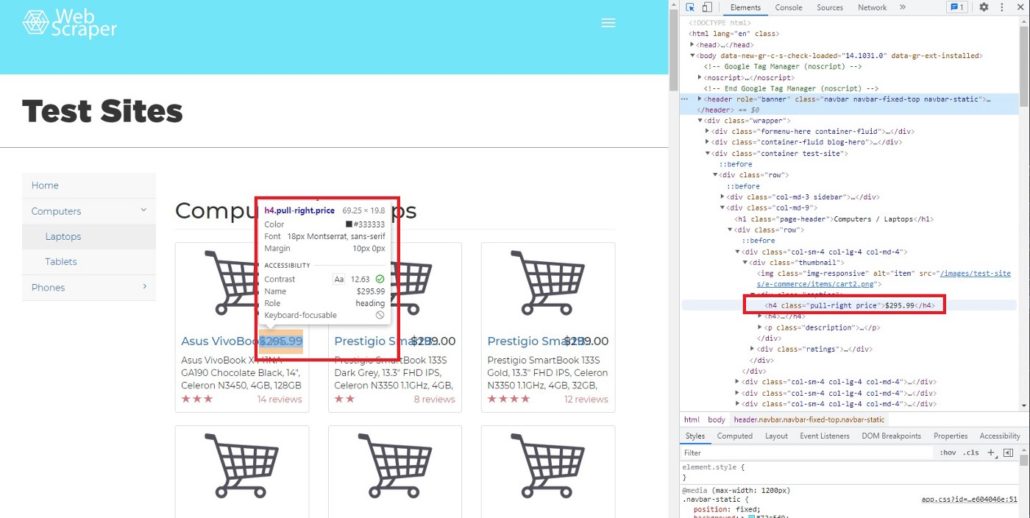
Далее мы хотим найти строку элемента h4, используя функцию find:
# Searching specific attributes of tags
soup.find(‘h4’, class_= ‘pull-right price’)
Результат:
Out[28]: <h4 class=”pull-right price”>$295.99</h4>
Как видно, $295,99 — это атрибут (строка) h4. Но что будет, если мы используем find_all.
# Using find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)
Результат:
Out[29]:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>,
<h4 class=”pull-right price”>$356.49</h4>,
....
</h4>]
Вы заметили разницу между find и find_all?
Да, все верно, find нужно использовать для поиска определенных атрибутов, потому что он возвращает только один результат. Для парсинга больших объемов данных (например, цена, название продукта, описание и т. д.), используйте find_all.
Кроме того, можем получить часть результата функции find_all. В данном случае мы хотим видеть только индексы с 3-го до 5-го.
# Slicing the results of find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)[2:5]
Результат:
Out[32]:[<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>]
[!] Не забывайте, что в Python индекс первого элемента в списке — 0, а последний не учитывается.
ШАГ 8. ИСПОЛЬЗОВАНИЕ ФИЛЬТРА
При необходимости мы можем найти несколько тегов:
# Using filter to find multiple tagssoup.find_all(['h4', 'a', 'p'])soup.find_all(['header', 'div'])
soup.find_all(id = True) # class and id are special attribute so it can be written like this
soup.find_all(class_= True)
Поскольку class и id являются специальными атрибутами, поэтому можно писать class_ и id вместо ‘class’ или ‘id’.
Использование фильтра поможет нам получить необходимые данные с веб-сайта. В нашем случае это название, цена, отзывы и описания. Итак, сначала определим переменные.
# Filter by name name = soup.find_all(‘a’, class_=’title’) # Filter by priceprice = soup.find_all(‘h4’, class_ = ‘pull-right price’)# Filter by reviews reviews = soup.find_all(‘p’, class_ = ‘pull-right’)# Filter by description description = soup.find_all(‘p’, class_ =’description’)
Фильтр по названию:
[<a class=”title” href=”/test-sites/e-commerce/allinone/product/545" title=”Asus VivoBook X441NA-GA190">Asus VivoBook X4…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/546" title=”Prestigio SmartBook 133S Dark Grey”>Prestigio SmartB…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/547" title=”Prestigio SmartBook 133S Gold”>Prestigio SmartB…</a>,
...
</a>]
Фильтр по цене:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$306.99</h4>,
...
</h4>]
Фильтр по отзывам:
[<p class=”pull-right”>14 reviews</p>,<p class=”pull-right”>8 reviews</p>,
<p class=”pull-right”>12 reviews</p>,<p class=”pull-right”>2 reviews</p>,
...
</p>]
Фильтр по описанию:
[<p class=”description”>Asus VivoBook X441NA-GA190 Chocolate Black, 14", Celeron N3450, 4GB, 128GB SSD, Endless OS, ENG kbd</p>,
<p class=”description”>Prestigio SmartBook 133S Dark Grey, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
<p class=”description”>Prestigio SmartBook 133S Gold, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
...
</p>]
ШАГ 9. ОЧИСТКА ДАННЫХ
Очевидно, результаты все еще в формате HTML, поэтому нам нужно очистить их и получить только строку элемента. Используем для этого функцию text.
Text может служить для сортировки строк HTML кода, однако нужно определить новую переменную, например:
# Try to call priceprice1 = soup.find(‘h4’, class_ = ‘pull-right price’)
price1.text
Результат:
Out[55]: ‘$295.99’
На выходе получается только строка из кода, но этого недостаточно. На следующем этапе мы узнаем, как парсить все строки и сделать из них список.
ШАГ 10. ИСПОЛЬЗОВАНИЕ ЦИКЛА FOR ДЛЯ СОЗДАНИЯ СПИСКА СТРОК
Чтобы сделать список из всех строк, необходимо создать цикл for.
# Create for loop to make string from find_all list
product_name_list = []
for i in name:
name = i.text
product_name_list.append(name)price_list = []
for i in price:
price = i.text
price_list.append(price)
review_list = []
for i in reviews:
rev = i.text
review_list.append(rev)
description_list = []
for i in description:
desc = i.text
description_list.append(desc)ШАГ 11. СОЗДАНИЕ ФРЕЙМА ДАННЫХ
После того, как мы создали цикл for и все строки были добавлены в списки, остается заключительный этап парсинга сайтов на Python — построить фрейм данных. Для этой цели нам нужно импортировать библиотеку pandas.
# Create dataframe# Import library import pandas as pdtabel = pd.DataFrame({‘Product Name’:product_name_list, ‘Price’: price_list, ‘Reviews’:review_list, ‘Description’:description_list})
Теперь эти данные можно использовать для работы в проектах по анализу и обработке данных, в машинном обучении, для получения другой ценной информации.

Надеюсь, это руководство будет вам полезно, особенно для тех, кто изучает парсинг сайтов на Python. До новых встреч в следующем проекте.
Если у вас возникнут сложности с парсингом сайтов на Python или с парсингом приложений, обращайтесь в компанию iDatica — напишите письмо или заполните заявку указав все детали задачи по парсингу.
Продолжаем наш небольшой курс по парсингу на Python. В предыдущем уроке, мы с вами ознакомились с тем как устроен парсер на python, и спарсили заголовок сайта wordpress.org. В этом уроке мы продолжим парсить тот же сайт, но теперь перейдем к более сложным операциям. Сегодня мы с вами разберемся с тем, как парсить, и сохранять данные в csv файл.
Содержание:
- Постановка задачи для парсинга
- Анализ html разметки страницы
- Создание парсера на Python
- Запись данных в csv
- Домашнее задание
- Заключение
Постановка задачи для парсинга
И так открываем сайт wordpress.org, и переходим в раздел «Плагины». В этом разделе мы видим четыре блока, в которых отображаются различные плагины.




Наша задача на этом уроке заключается в том, что бы получить:
- Название каждого плагина
- Ссылку на плагин
- Количество отзывов
- Сохранить полученные данные в csv файл
Для начала работы, нам необходимо подготовить свое рабочее окружение,для этого:
- Открываем свой Pycharm (Или редактор, который вы используете)
- Создаем новый проект
- Импортируем библиотеки, как и в предыдущем уроке
- Дополнительно импортируем библиотеку csv (import csv)
Отлично, с постановкой задачи мы почти разобрались, ниже у нас код, который является каркасом парсера. Быстро пробежимся по коду, и закрепим наши знания, полученные в прошлом уроке.
import requests
from bs4 import BeautifulSoup
LINK = 'https://wordpress.org'
def get_html(link):
response = requests.get(link)
return response.text
def get_data(html):
soup = BeautifulSoup(html, 'lxml')
def main():
pass
if __name__=="__main__":
main()
- Функция get_html() — принимает адрес сайта, и возвращает свойство text объекта response
- Функция get_data() — принимает html код. Создаем экземпляр класса BS. Как и в первом уроке, мы передали два параметра (html, и lxml)
- Функция main() — пока пустая функция, если не знакомы с оператором pass, советую почитать про данный оператор
- Точка входа
Анализ html разметки страницы
Следующим шагом, нам необходимо провести анализ html разметки страницы. Переходим на сайт wordpress.org, и открываем инспектор кода в браузере (наводим мышью на нужную область, и кликаем правой кнопкой мыши, в появившемся меню, выбираем «Исследовать элемент«)
Как мы видим, у нас 4 блока с плагинами, и каждый блок заключен в тег section. Продолжим исследование html разметки страницы. Нам необходимо найти теги, внутри которых находятся необходимы нам данные.
- Ссылка на плагин
- Текст ссылки на плагин
- Количество отзывов
Отлично! Мы с вами проанализировали html код страницы, и выяснили в каких тегах хранятся наши данные. Ниже я описал структуру html страницы.

У нас есть структура html разметки, мы наглядно видим до каких тегов нам необходимо добраться, что бы получить нужные нам данные. Следующим шагом, мы напишем парсер, который будет собирать необходимые нам данные.
Ниже представлен листинг кода, который возвращает нам все найденные теги section.
import requests
from bs4 import BeautifulSoup
LINK = 'https://wordpress.org/plugins/'
def get_html(link):
response = requests.get(link)
return response.text
def get_data(html):
soup = BeautifulSoup(html, 'lxml')
articles = soup.find_all('article')
return articles
def main():
link = LINK
print(get_data(get_html(link)))
if __name__=="__main__":
main()
Как видите в данном коде, появилось небольшое дополнение.
- В функции get_data() мы создали переменную articles
- Обратились к soup с помощью find_all, что бы найти все теги article, которые есть на странице
- Для того, что бы убедиться в том, что мы идем в правильном направлении, мы можем воспользоваться методом len()
- return len(article), в случае если все правильно, то функция вернет нам 16, так как у нас всего 16 плагинов на странице
- Если у вас возникает ошибка, опишите проблему в комментариях
Отлично, по сути наш парсер почти готов. Теперь, наша задача состоит в том, что бы в цикле получить нужные нам данные.
import requests
from bs4 import BeautifulSoup
def get_html(url):
r = requests.get(url)
return r.text
def refinde(str):
s = str.split(' ')[0]
return s.replace(',','')
def get_data(html):
soup = BeautifulSoup(html, 'lxml')
articles = soup.find_all('article')
for article in articles:
h3 = article.find('h3', class_='entry-title').text
link = article.find('h3', class_='entry-title').find('a').get('href')
rating = article.find('div', class_="plugin-rating").find('span', class_="rating-count").find('a').text
print (h3,link,refinde(rating))
def main():
url ='https://wordpress.org/plugins'
print(get_data(get_html(url)))
if __name__ == '__main__':
main()
Как видите, с каждым разом к нашему коду добавляется новый функционал. Как вы понимаете основная операция происходит у нас в функции get_data(), и так же у нас появилась новая функция refinde().
- В функции get_data(), мы нашли все теги article, с помощью метода find_all. Данный метод возвращает нам все найденные элементы в виде списка.
- Запускаем цикл for, и перебираем полученный список.
- Сначала ищем теги h3, и забираем текст заключенный между ними. Это и есть заголовок нашего плагина
- Затем ищем ссылку на заголовок
- Далее ищем количество отзывов
Теперь немного поговорим про нашу новую функцию refinde(). Как видите данная функция применяется непосредственно к переменной rating. Все дело в том, что при парсинге «количества отзывов», у нас по мимо самого количества, парсится еще и остальная ненужная информация в виде текста и запятых между цифрами. Проще говоря, результат который мы получаем без функции, следующий:
- 1,985 total ratings (без функции refinde)
- 1985 с функцией refinde()
Сама функция работает достаточно просто.
- Функция принимает один аргумент в виде строки
- Для строки используем метод split(), который по пробелу разбивает строку, и возвращает нам ее в виде списка, из этого списка, мы забираем первый элемент.
- Первым элементом является число (количество скачиваний), но она содержит запятую, а так как мы хотим сохранить наши данные в csv, то лучше нам от нее избавиться
- Используем метод replace(), и заменяем запятую на пустой символ
И так друзья, подведем итоги этой главы. У нас с вами получилось спарсить все нужные данные, если вы все сделали правильно, то у вас должен получится следующий результат.
В случае если у вас возникают трудности в понимании материала, или у вас другие проблемы, пишите в комментариях, буду рад вам помочь.
Запись в csv
Вот мы и подошли в плотную к завершении этого большого урока. Мы получили все данные, которые нас интересовали, но нам теперь их надо как то сохранить. И так, для таких моментов Python предоставляет нам встроенный модуль csv, которым мы и воспользуемся.
import requests
from bs4 import BeautifulSoup
import csv
def get_html(url):
r = requests.get(url)
return r.text
def refinde(str):
s = str.split(' ')[0]
return s.replace(',','')
def write_csv(data):
with open('listplugins3.csv', 'a') as f:
recorder = csv.writer(f)
recorder.writerow((data['h3'],
data['link'],
data['rating']))
def get_data(html):
soup = BeautifulSoup(html, 'lxml')
articles = soup.find_all('article')
for article in articles:
h3 = article.find('h3', class_='entry-title').text
link = article.find('h3', class_='entry-title').find('a').get('href')
rating = article.find('div', class_="plugin-rating").find('span', class_="rating-count").find('a').text
rating = refinde(rating)
data ={'h3':h3,
'link':link,
'rating':rating}
write_csv(data)
def main():
url ='https://wordpress.org/plugins'
print(get_data(get_html(url)))
if __name__ == '__main__':
main()
Как видите наш код код изменился, у нас появилась новая функция записи в csv. Поехали разбираться.
- Внутри функции get_data() мы создали словарь, куда внесли все полученные ранее нами значения
- Создали функцию write_csv()
- Функция работает довольно просто, создаем/открываем файл для записи
- Будьте внимательны с флагами, которые вы указываете. К примеру ‘w‘, всегда будет перезаписывать существующий файл, а флаг ‘a‘, это как append в списках, добавлять новые данные в конец файла
- Далее используем writerow() и передаем туда кортеж с нашими данными
- И в самом конце, в функции get_data() мы вызываем нашу новую функцию write_csv() и передаем туда наш словарь
После запуска нашего скрипта, у нас появится файл listplugins3.csv. Открыть данный файл можно как в Excel, так и в другом стороннем редакторе. Конечный результат сбора данных, вы можете увидеть ниже.

Домашнее задание
Друзья, в целом вы уже должны понимать, как работает парсер. Конечно, существует огромное количество разновидностей сайтов, и к каждому сайту должен быть свой подход. Но, на данном этапе, вы уже можете парсить, поэтому, в качестве домашнего задания, рекомендую вам спарсить данные со страницы с темами wordpress.org/themes.

Получите и сохраните, ссылку на тему оформления, и его название. Трудностей у вас возникнуть не должно, если все же они будут, добро пожаловать в комментарии.
Заключение
В этом уроке, я постарался насколько это возможно подробно объяснить как все устроено. В следующих уроках, такие подробности будут опущены. Сегодня нам удалось спарсить название/ссылку/рейтинг 16 плагинов. Конечно, это можно было бы сделать и в ручную, и не пришлось бы копаться в коде, и изучать что то. Но представьте себе, что у вас не 16 плагинов, а 10 000.Для таких случаев и создаются парсеры. Достаточно понять, как устроена структура страницы, и вы одним махом сможете собрать все данные подходящие под ваш шаблон.
На следующих уроках, мы будем рассматривать и другие виды сайтов, и в целом как правильно писать парсеры, что бы они не падали во время работы, будем использовать try…except конструкции, и прочие. Запомните, чем больше парсеров вы напишите, тем быстрее у вас появится опыт, и понимание того, как все устроено изнутри.
Урок 3. Парсинг таблиц на Python
Научитесь парсить веб-страницы с помощью Python, чтобы быстро собирать данные с нескольких сайтов с экономией времени и усилий.
6 min read


Узнайте, как создать парсер на Python для сканирования всего сайта и извлечения данных с помощью веб-скрапинга.
Веб-скрапинг — это извлечение веб-данных. Парсер же — это инструмент, который выполняет веб-скрапинг и обычно представлен в виде скрипта. Python — один из самых простых и надежных языков сценариев. Кроме того, он поставляется с широким спектром библиотек для веб-скрапинга. Это делает Python идеальным языком программирования для парсинга веб-страниц. Ведь веб-скрапинг с Python занимает всего несколько строк кода.
В этом руководстве вы узнаете, как создать простой парсер Python. Он будет просматривать весь сайт, извлекая данные с каждой страницы. Затем сохранит их в CSV-файл. Это руководство поможет вам понять, какие библиотеки Python лучшие для парсинга данных, как их использовать. Следуйте нашему пошаговому плану и научитесь создавать скрипт Python для веб-скрапинга.
Содержание:
- Требования
- Лучшие библиотеки веб-скрапинга Python
- Создание парсера на Python
- Вывод
- Часто задаваемые вопросы
Требования
Чтобы создать парсер Python, вам необходимы:
- Python 3.4+
- pip (менеджер пакетов)
Если на вашем компьютере не установлен Python, скачайте его по первой ссылке выше. Если у вас ОС Windows, обязательно установите флажок «Добавить python.exe в PATH» при установке Python, как показано ниже:
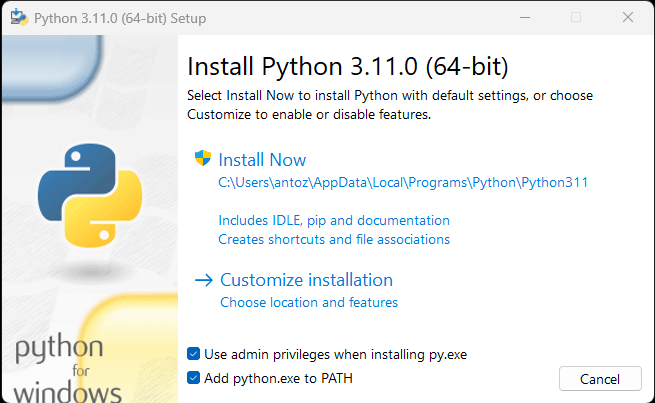
Так Windows автоматически распознает команды Python и pip в терминале. Отметим, что pip — это менеджер пакетов для Python. Он включен по умолчанию в Python 3.4 или более поздней версии. То есть вам не нужно устанавливать его вручную.
Теперь все готово для создания вашего первого парсера Python. Но сначала вам нужна библиотека веб-скрапинга Python!
Лучшие библиотеки веб-скрапинга Python
Вы можете создать сценарий парсинга страниц с нуля с помощью Python vanilla, но это не идеальное решение. Python имеет широкий выбор доступных библиотек. Для веб-скрапинга есть несколько на выбор. Давайте рассмотрим самые важные из них!
Requests
Библиотека Requests позволяет выполнять HTTP-запросы в Python. Она упрощает отправку HTTP-запросов, особенно по сравнению со стандартными HTTP-библиотеками Python. Requests играют ключевую роль в проекте веб-скрапинга Python, поскольку для соскабливания данных на веб-странице сначала нужно получить их с помощью HTTP-запроса GET. Кроме того, может потребоваться выполнение других HTTP-запросов к серверу целевого сайта.
Вы можете установить requests с помощью следующей команды pip:
pip install requestsBeautiful Soup
Библиотека Beautiful Soup Python упрощает сбор информации с веб-страниц. Она работает с любым парсером HTML или XML и предоставляет все необходимое для итерации, поиска и изменения дерева синтаксического анализа. Обратите внимание, что Beautiful Soup можно использовать с html.parser – парсером, который входит в стандартную библиотеку Python и позволяет анализировать текстовые файлы HTML. Вы можете использовать Beautiful Soup для обхода DOM и извлечения из него необходимых данных.
Вы можете установить Beautiful Soup с помощью pip следующим образом:
pip install beautifulsoup4Selenium
Selenium — это усовершенствованная система автоматизированного тестирования с открытым исходным кодом, которая позволяет выполнять операции на веб-странице в браузере. Другими словами, вы можете использовать Selenium, чтобы заставить браузер выполнять определенные задачи. А также использовать в качестве библиотеки веб-скрапинга благодаря возможностям безголового браузера. Это веб-браузер, который работает без GUI (графического пользовательского интерфейса).
Таким образом, веб-страницы, посещаемые в Selenium, будут отображаться в реальном браузере, способном запускать JavaScript. В результате Selenium позволит парсить сайты, зависящие от JavaScript. Учитывайте, что вы не можете добиться этого с помощью requests или любого другого HTTP-клиента, потому что вам нужен браузер для запуска JavaScript, тогда как requests просто позволяют выполнять HTTP-запросы.
Selenium предоставляет все необходимое для создания парсера без потребности в других библиотеках. Вы можете установить его с помощью следующей команды pip:
pip install seleniumСоздание парсера на Python
Теперь давайте узнаем, как создать парсер на Python. Цель этого руководства — научиться извлекать все данные о цитатах на сайте Quotes to Scrape. Вы научитесь извлекать текст, автора и список тегов для каждой цитаты.
Но сначала давайте взглянем на целевой сайт. Вот как выглядит веб-страница Quotes to Scrape:
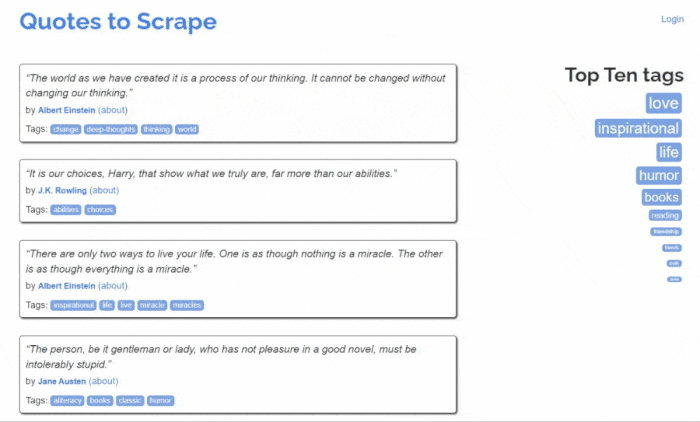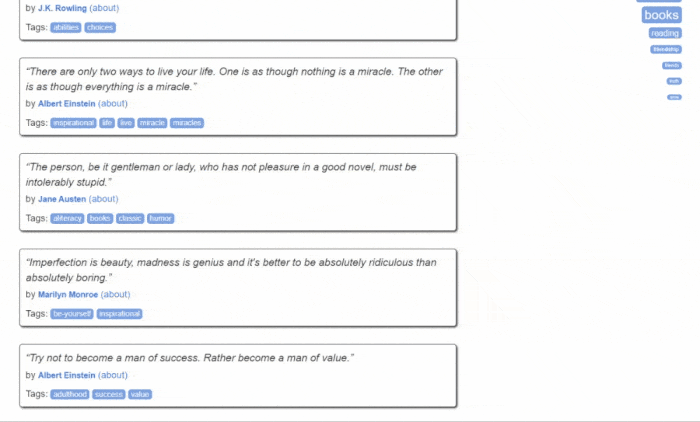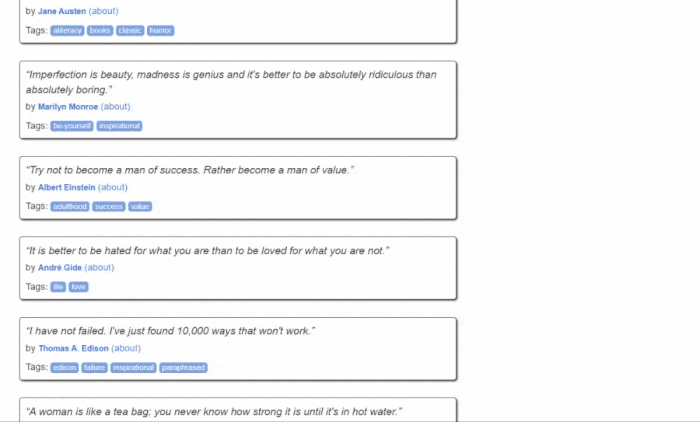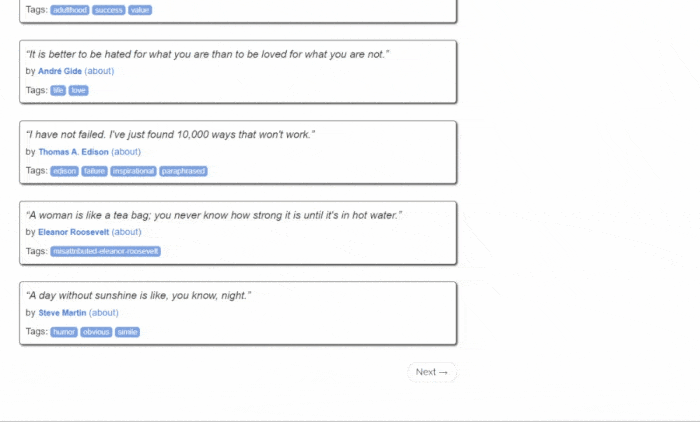
Как видите, Quotes to Scrape — это не что иное, как песочница для парсинга веб-страниц. Сайт содержит разбитый на страницы список цитат. Парсер Python, который вы собираетесь создать, извлечет все цитаты на каждой странице, и предоставит их в виде данных CSV.
Теперь пришло время понять, какие библиотеки Python для парсинга лучше всего подходят для достижения этой цели. Как вы можете увидеть на картинке ниже на вкладке Network окна Chrome DevTools целевой сайт не выполняет запросов Fetch/XHR.
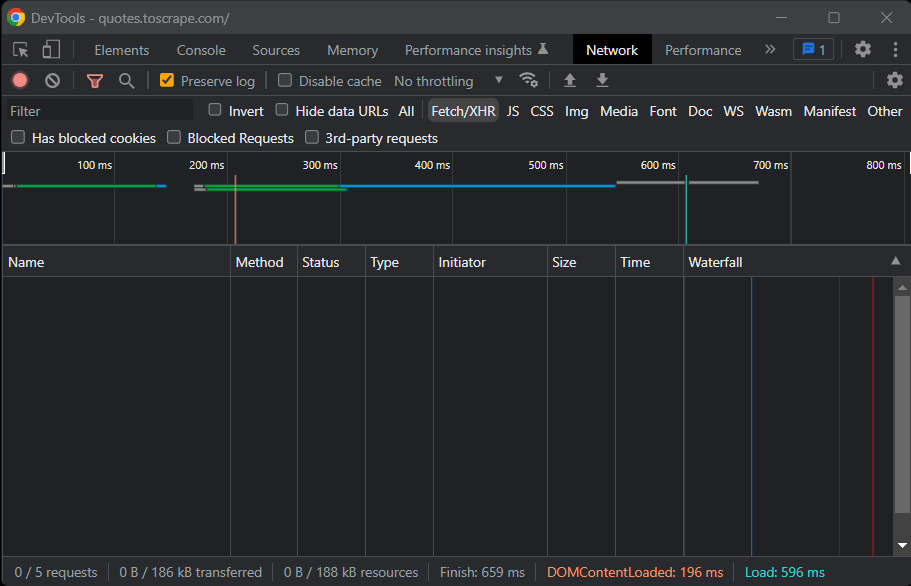
Другими словами, Quotes to Scrape не использует JavaScript для извлечения данных на веб-страницах. Это обычная ситуация для большинства сайтов, отображаемых на сервере. Поскольку целевой сайт не использует JavaScript для отображения страницы или извлечения данных, вам не нужен Selenium для парсинга. Вы можете использовать его, но это не обязательно.
Как вы уже узнали, Selenium открывает страницы в браузере. Поскольку это занимает время и ресурсы, Selenium вызывает расходы на производительность. Вы можете избежать этого, используя Beautiful Soup вместе с Requests. Теперь давайте узнаем, как создать простой скрипт парсинга веб-страниц на Python для извлечения данных с сайта с помощью Beautiful Soup.
Приступим
Прежде чем написать первые строки кода, вам необходимо настроить проект парсинга на Python. Технически необходим только один файл .py. Однако использование расширенной IDE (интегрированной среды разработки) упростит процесс написания кода. Здесь вы узнаете, как настроить проект Python в PyCharm 2022.2.3, но подойдет и любая другая IDE.
Откройте PyCharm и выберите «Файл > Новый проект…». Во всплывающем окне «Новый проект» выберите «Pure Python» и создайте свой проект.
Например, вы можете назвать свой проект python-web-scraper. Нажмите «Создать», и теперь у вас будет доступ к вашему пустому проекту Python. По умолчанию PyCharm инициализирует файл main.py. Вы можете переименовать его в scraper.py. Вот как теперь будет выглядеть ваш проект:
Как видите, PyCharm автоматически инициализирует для вас файл Python. Не обращайте внимания на его содержимое и удаляйте каждую строку кода, чтобы начать с нуля.
Теперь пришло время установить зависимости проекта. Вы можете установить Requests и Beautiful Soup, запустив в терминале следующую команду:
pip install requests beautifulsoup4Эта команда установит обе библиотеки одновременно. Дождитесь завершения установки. Теперь вы готовы использовать Beautiful Soup и Requests для создания поискового робота и парсера на Python. Обязательно импортируйте две библиотеки, добавив следующие строки в начало файла скрипта scraper.py:
import requests
from bs4 import BeautifulSoupPyCharm подсветит эти две строки серым цветом, потому что библиотеки не используются в коде. Если он подчеркнет их красным цветом, значит, что-то пошло не так в процессе установки. В этом случае попробуйте установить их снова.
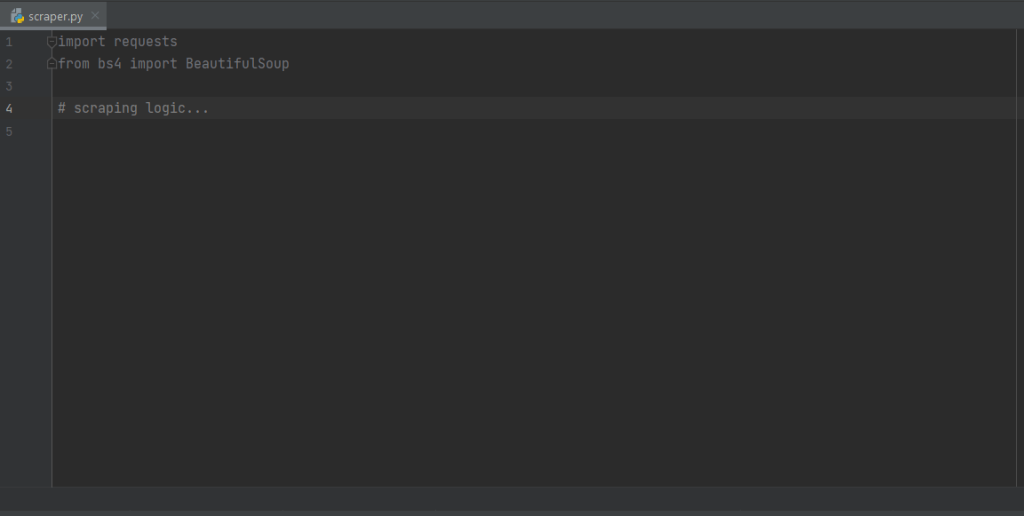
Вот как теперь должен выглядеть ваш файл scraper.py. Теперь вы можете приступить к определению логики парсинга веб-страниц.
Подключение к целевому URL для сканирования
Первое, что нужно сделать в парсере, — это подключиться к целевому сайту. Сначала получите полный URL-адрес страницы из браузера. Обязательно скопируйте также раздел протокола http:// или https:// HTTP. Вот как выглядит полный URL-адрес целевого сайта:
https://quotes.toscrape.comТеперь можете использовать запросы для загрузки страницы со следующей строкой кода:
page = requests.get('https://quotes.toscrape.com')Эта строка просто присваивает результат метода request.get() переменной page. За сценой request.get() выполняет запрос GET, используя URL-адрес, переданный в качестве параметра. Затем он возвращает объект Response, содержащий ответ сервера на HTTP-запрос.
Если HTTP-запрос выполнен успешно, код page.status_ будет содержать 200. HTTP 200 OK – код ответа состояния, который указывает на то, что HTTP-запрос был выполнен успешно. Код состояния HTTP 4xx или 5xx будет означать ошибку. Это может произойти по нескольким причинам. Учитывайте, что многие сайты блокируют запросы без допустимого заголовка User-Agent. Это строка, которая характеризует приложение и версию операционной системы, откуда пришел запрос. Узнайте больше о User-Agent для веб-скрапинга.
Вы можете установить заголовок User-Agent в запросах следующим образом:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get('https://quotes.toscrape.com', headers=headers)теперь запросы будут выполнять HTTP-запрос, если заголовки будут переданы в качестве параметра.
На что следует обратить внимание, так это на свойство page.text. Оно будет содержать HTML-документ, возвращенный сервером в строковом формате. Передайте свойство text в Beautiful Soup, чтобы извлечь данные из веб-страницы. Давайте узнаем, как это сделать.
Извлечение данных с помощью парсера Python
Чтобы извлечь данные с веб-страницы, сначала нужно определить элементы HTML, которые содержат нужные вам данные. В частности, необходимо найти селекторы CSS для извлечения этих элементов из DOM. Подойдут инструменты разработки от вашего браузера. В Chrome щелкните правой кнопкой мыши на интересующем вас элементе HTML и выберите Inspect (Проверить).
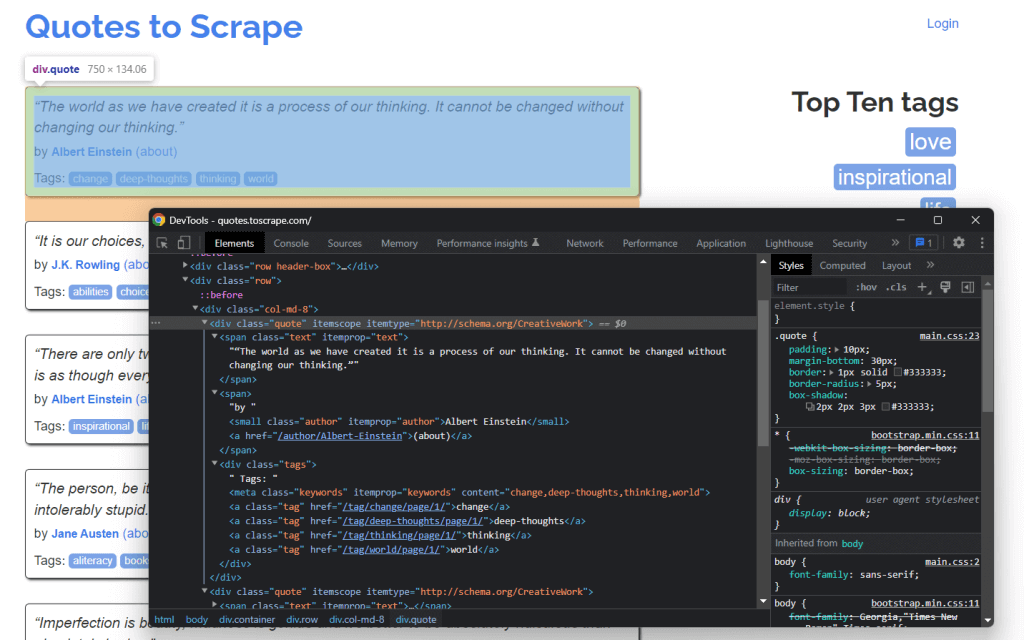
Как видите, HTML-элемент цитаты <div> идентифицируется классом цитаты (quote). Он содержит:
- Текст цитаты в HTML-элементе <span>
- Автор цитаты в HTML-элементе <small>
- Список тегов в элементе <div>, каждый из которых содержится в HTML-элементе <a>.
В частности, вы можете извлечь эти данные, используя следующие селекторы CSS в .quote:
.text.author.tags .tag
Давайте теперь узнаем, как добиться этого с помощью Beautiful Soup в Python. Во-первых, давайте передадим HTML-документ page.text конструктору BeautifulSoup():
soup = BeautifulSoup(page.text, 'html.parser')Второй параметр указывает синтаксический анализатор, который Beautiful Soup будет использовать для анализа HTML-документа. Переменная soup теперь содержит объект BeautifulSoup. Это дерево синтаксического анализа, в результате разбора HTML-документа в page.text, с помощью встроенного в Python html.parser.
Теперь инициализируйте переменную, которая будет содержать список всех отсканированных данных.
quotes = []Пришло время использовать soup для извлечения элементов из DOM:
quote_elements = soup.find_all('div', class_='quote')Метод find_all() вернет список всех HTML-элементов <div>, идентифицированных классом цитаты (quote). Другими словами, эта строка кода эквивалентна применению CSS-селектора .quote для получения списка HTML-элементов цитаты на странице. Затем можно выполнить итерации по списку цитат для получения данных о цитатах, как показано ниже:
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)Благодаря методу find() из Beautiful Soup вы можете извлечь один интересующий элемент HTML. Поскольку тегов, связанных с цитатой, больше одного, их следует хранить в списке.
Затем вы можете преобразовать эти данные в словарь и добавить их в список следующим образом:
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)Хранение извлеченных данных в таком формате словаря облегчит доступ к вашим данным для их понимания.
Вы только что узнали, как извлечь все данные о цитатах с одной страницы. Но имейте в виду, что целевой сайт состоит из нескольких страниц. Давайте научимся сканировать весь сайт.
Реализация логики сканирования
Внизу главной страницы вы можете найти HTML-элемент «Далее →» <a>, который перенаправляет на следующую страницу целевого сайта. Этот элемент HTML содержится на всех страницах, кроме последней. Такой сценарий распространен на любом сайте с разбивкой на страницы.
Перейдя по ссылке в HTML-элементе «Далее →» <a>, вы можете легко перемещаться по всему сайту. Итак, начнем с главной и посмотрим, как пройти каждую страницу, из которой состоит целевой сайт. Вам нужно найти HTML-элемент .next <li> и извлечь относительную ссылку на следующую страницу.
Вы можете реализовать логику сканирования так:
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# retrieving the page and initializing soup...
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping logic...
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')Этот цикл выполняет итерации по каждой странице до тех пор, пока не останется следующая страница. В частности, он извлекает относительный URL следующей страницы и использует его для создания URL следующей страницы для сканирования. Затем загружается следующая страница, он сканирует ее и повторяет логику.
Вы только что узнали, как реализовать логику сканирования для парсинга всего сайта. Пришло время посмотреть, как преобразовать извлеченные данные в более удобный формат.
Преобразование данных в формат CSV
Рассмотрим, как преобразовать список словарей, содержащих отсканированные данные цитаты, в файл CSV. Сделать это можно с помощью следующих строк:
import csv
# scraping logic...
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()Этот фрагмент кода записывает данные цитаты, содержащиеся в списке словарей, в файл quotes.csv. Обратите внимание, что csv является частью стандартной библиотеки Python. Таким образом, вы можете импортировать и использовать его без дополнительной зависимости. Вам просто нужно создать файл с помощью open(). Затем вы можете заполнить его функцией writerow() из объекта Writer библиотеки csv. Это позволит записать каждый словарь цитат как строку в CSV-формате в CSV-файл.
Вы перешли от необработанных данных сайта к структурированным данным в файле CSV. Процесс извлечения завершен, и теперь вы можете посмотреть на весь парсер Python.
Собираем все вместе
Вот как выглядит полный скрипт парсинга веб-страниц на Python:
import requests
from bs4 import BeautifulSoup
import csv
def scrape_page(soup, quotes):
# retrieving all the quote <div> HTML element on the page
quote_elements = soup.find_all('div', class_='quote')
# iterating over the list of quote elements
# to extract the data of interest and store it
# in quotes
for quote_element in quote_elements:
# extracting the text of the quote
text = quote_element.find('span', class_='text').text
# extracting the author of the quote
author = quote_element.find('small', class_='author').text
# extracting the tag <a> HTML elements related to the quote
tag_elements = quote_element.find('div', class_='tags').find_all('a', class_='tag')
# storing the list of tag strings in a list
tags = []
for tag_element in tag_elements:
tags.append(tag_element.text)
# appending a dictionary containing the quote data
# in a new format in the quote list
quotes.append(
{
'text': text,
'author': author,
'tags': ', '.join(tags) # merging the tags into a "A, B, ..., Z" string
}
)
# the url of the home page of the target website
base_url = 'https://quotes.toscrape.com'
# defining the User-Agent header to use in the GET request below
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# retrieving the target web page
page = requests.get(base_url, headers=headers)
# parsing the target web page with Beautiful Soup
soup = BeautifulSoup(page.text, 'html.parser')
# initializing the variable that will contain
# the list of all quote data
quotes = []
# scraping the home page
scrape_page(soup, quotes)
# getting the "Next →" HTML element
next_li_element = soup.find('li', class_='next')
# if there is a next page to scrape
while next_li_element is not None:
next_page_relative_url = next_li_element.find('a', href=True)['href']
# getting the new page
page = requests.get(base_url + next_page_relative_url, headers=headers)
# parsing the new page
soup = BeautifulSoup(page.text, 'html.parser')
# scraping the new page
scrape_page(soup, quotes)
# looking for the "Next →" HTML element in the new page
next_li_element = soup.find('li', class_='next')
# reading the "quotes.csv" file and creating it
# if not present
csv_file = open('quotes.csv', 'w', encoding='utf-8', newline='')
# initializing the writer object to insert data
# in the CSV file
writer = csv.writer(csv_file)
# writing the header of the CSV file
writer.writerow(['Text', 'Author', 'Tags'])
# writing each row of the CSV
for quote in quotes:
writer.writerow(quote.values())
# terminating the operation and releasing the resources
csv_file.close()Как видите, вы можете создать парсер веб-страниц менее чем из 100 строк кода. Этот скрипт Python позволяет сканировать весь сайт, автоматически извлекать его данные и преобразовывать в файл CSV.
Поздравляем! Теперь вы знаете, как создать парсер Python с помощью библиотек Requests и Beautiful Soup!
Запуск скрипта веб-скрапинга Python
Если вы являетесь пользователем PyCharm, запустите скрипт, нажав кнопку ниже:

Или запустите следующую команду Python в терминале внутри каталога проекта:
python scraper.pyПодождите, пока процесс завершится, и теперь у вас будет доступ к файлу quotes.csv. Откройте его. Он должен содержать следующие данные:
Вуаля! Теперь у вас есть все 100 цитат с целевого сайта в одном CSV-файле!
Вывод
Из этого руководства вы узнали, что такое парсинг веб-страниц, что вам нужно для начала работы с Python и какие библиотеки Python являются лучшими для парсинга. Также вы увидели, как использовать Beautiful Soup и Requests для создания парсера на реальном примере и убедились, что, парсинг на Python занимает всего несколько строк кода.
Тем не менее парсинг веб-страниц сопряжен с рядом проблем. В частности, все большую популярность приобретают анти-боты и анти-скрапинговые технологии. Поэтому вам нужен продвинутый автоматизированный инструмент для веб-скрапинга от Bright Data.
Чтобы избежать блокировки, мы также рекомендуем выбрать прокси-сервер в зависимости от вашего сценария использования из различных прокси-сервисов, которые предоставляет Bright Data.
Часто задаваемые вопросы
Веб-скрапинг и сканирование веб-страниц – это часть науки о данных?
Да, веб-скрапинг и сканирование веб-страниц – часть более широкой области науки о данных. Парсинг/сканирование – это основа для всех других продуктов, которые могут быть получены из структурированных и неструктурированных данных. Это включает аналитику, алгоритмические модели/выводы, идеи и «применимые знания».
Как можно извлечь определенные данные с сайта в Python?
Парсинг данных с сайта с помощью Python включает проверку страницы целевого URL, определение данных, которые вы хотите извлечь, написание и запуск кода для извлечения данных и, наконец, их сохранение в желаемом формате.
Как создать парсер с помощью Python?
Первым шагом к созданию парсера данных Python является использование строковых методов для анализа данных сайта, затем анализ данных помощью анализатора HTML и, наконец, взаимодействие с необходимыми формами и компонентами сайта.