Время на прочтение
3 мин
Количество просмотров 104K
В этой статье я постараюсь понятно рассказать о парсинге данных и его нюансах.

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
- Поиск данных
- Извлечение информации
- Сохранение данных
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
И сделаем наш первый get-запрос.
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2"
r = requests.get(URL_TEMPLATE)
print(r.status_code)
Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
print(r.text)
Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
<h2 class="add-bottom-sm"><a href="/ru/jobs/3682040/" title="Комірник, вакансия от 5 ноября 2019">Комірник</a></h2>У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
soup = bs(r.text, "html.parser")
vacancies_names = soup.find_all('h2', class_='add-bottom-sm')
for name in vacancies_names:
print(name.a['title'])
Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
<p class="overflow">Some information about vacancy.</p>Получаем такой код.
vacancies_info = soup.find_all('p', class_='overflow')
for name in vacancies_names:
print('https://www.work.ua'+name.a['href'])
for info in vacancies_info:
print(info.text)
И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
URL_TEMPLATE = "https://www.work.ua/ru/jobs-odesa/?page=2"
FILE_NAME = "test.csv"
def parse(url = URL_TEMPLATE):
result_list = {'href': [], 'title': [], 'about': []}
r = requests.get(url)
soup = bs(r.text, "html.parser")
vacancies_names = soup.find_all('h2', class_='add-bottom-sm')
vacancies_info = soup.find_all('p', class_='overflow')
for name in vacancies_names:
result_list['href'].append('https://www.work.ua'+name.a['href'])
result_list['title'].append(name.a['title'])
for info in vacancies_info:
result_list['about'].append(info.text)
return result_list
df = pd.DataFrame(data=parse())
df.to_csv(FILE_NAME)
После запуска появится файл test.csv — с результатами поиска.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
#статьи
- 13 май 2022
-

0
Не надо тыкать мне в лицо своим питоном: простой парсинг сайтов на Node.js для тех, кто ничего об этом не знает.
Иллюстрация: Node.js / Colowgee для Skillbox Media

Парсинг, также известный как веб-скрейпинг, — это автоматизированный сбор данных по Сети. И у него тысячи возможных способов применения в профессиях, связанных с постоянной работой с информацией. На примере парсинга статей с двух сайтов с помощью JavaScript и фреймворка Node.js я покажу, как он может помочь современному журналисту, пиарщику и маркетологу — тем, кто, казалось бы, далёк от программирования.
Предположим, у нас есть сайт-источник и мы хотим прочитать все статьи на нём, чтобы разобраться в определённой теме или сделать подборку новостей. Страниц на сайте много, и листать ленту очень долго. Что делать? Было бы удобно сначала получить список публикаций, а потом отфильтровать нужные.
Вкратце процедуру сбора данных с сайта можно описать следующим образом:
- Определяем сайт-источник и желаемые данные.
- Выясняем способ пагинации (перехода по страницам) и структуру кода сайта.
- Любым из множества возможных способов делаем последовательные сетевые запросы по каждой странице. Если у сайта есть API — используем API, если нет — другие инструменты.
- Переводим полученные данные в удобный формат.
- Записываем итоговые данные в файл.
Успех зависит от правильного анализа сайта. Нам нужно будет выяснить:
- Как происходит переход на следующую страницу. Это нужно, чтобы парсер делал всё автоматически, — в противном случае сбор завершится на первой же странице. Обычно это происходит при нажатии кнопки типа «Далее» или «Следующая страница» — а парсер имитирует нажатие.
- Правильное и точное место, где в HTML-разметке сайта содержатся нужные материалы. Для этого придётся определить местонахождение (вложенность) блоков, а также их селекторы.
Запросы нужно делать «вежливо», то есть с некоторой задержкой, чтобы не навредить сайту-источнику (например, не очень хорошо запускать цикл из сотни мгновенных запросов сразу ко всем страницам архива).
И категорически запрещено нарушать авторские права. Перед разработкой парсера стоит ознакомиться с пользовательским соглашением, которое может прямо запрещать автоматический сбор данных.
Для примера парсинга я взял два сайта, пагинация которых устроена по-разному: в первом случае это клик по кнопке «Следующая страница», а во втором — бесконечная подгрузка.
Наш парсер будет работать на языке JavaScript и в среде выполнения Node.js с использованием дополнительных модулей axios и jsdom:
- С помощью языка JavaScript мы будем объявлять переменные и константы, а также запускать функции и циклы.
- Фреймворк Node.js позволит выполнять всё это не в браузере, а через командную строку Windows.
- Встроенный в Node.js модуль fs (сокращение от file system) позволит работать с файловой системой компьютера, чтобы создавать файлы с результатом.
- Дополнительно скачиваемый модуль axios позволит в удобном виде делать HTTP-запросы по ссылкам.
- Дополнительно скачиваемый модуль jsdom позволит разбирать получаемый результат в виде DOM‑дерева, как если бы это делалось в браузере.
Перейдём к установке. Для этого нужно скачать и установить любым из способов Node.js с официального сайта. После этого с JavaScript-кодом можно будет работать из командной строки, в том числе запускать JS-файлы и отдельные команды.
Вместе с Node.js устанавливается так называемый менеджер пакетов npm, он позволит установить модули axios и jsdom. Открываем командную строку и вводим по очереди команды npm install axios и npm install jsdom — после каждой нужно дождаться завершения установки пакета. Можно установить модули в папку по умолчанию или в папку со своим проектом, это на ваше усмотрение.
Обратите внимание, что в качестве дополнительных модулей мы выбрали одни из наиболее популярных решений — об этом говорит статистика их скачиваний за неделю в каталоге npm. Логика такая: если их так часто используют, значит, они проверены и работают более или менее надёжно.
В классическом случае каждая страница с материалами сайта — отдельная, переход инициируется пользователем по клику. Для парсинга нужно по очереди перебрать все страницы, делая остановки на каждой и записывая необходимые данные, а затем переходить к следующей, пока доступные страницы не закончатся.
Посмотрим, как такой вид перехода реализован на сайте профессионального журнала «Журналист», и попробуем его спарсить. Этот сайт был выбран в качестве объекта для парсинга по следующим причинам:
- Во-первых, мы с редактором Skillbox Media «Код» согласились, что это классный журнал
- Во-вторых, структура пагинации журнала позволяет использовать его для демонстрации технологии.
- В-третьих, редакция «Журналиста» любезно согласилась нам помочь.

На сайте содержатся материалы примерно за шесть лет: больше 160 страниц, на каждой примерно пара десятков статей — итого почти 3000 материалов. Что получим на выходе: HTML-файл со списком названий статей и ссылками.
Выясняем способ перехода между страницами. Здесь переход по страницам происходит по нажатию кнопки «Читать ещё» под статьями, которая отправляет на сервер запрос вида «https://jrnlst.ru/node?page=2" и таким образом подгружает на ту же страницу дополнительные материалы, относящиеся к следующей странице.
Но мы воспользуемся вторым способом, который есть на сайте: ссылками вида «https://jrnlst.ru/?page=[номер страницы]», которые загружают именно отдельные страницы со статьями. Нумерация идёт с нулевой страницы (главной), хотя это прямо и не указывается.
Находим последнюю страницу, на которой нужно завершить сбор. Экспериментально я установил, что на момент написания статьи последней была страница под номером 162: на ней под статьями вместо кнопки перехода находится лаконичная надпись «Пока что это всё».
Нашёл я её просто: переходил по ссылкам с произвольными номерами страниц, начав с «page=200» (выбрал как предположение) и постепенно сокращая цифры, — здесь всё зависит от сайта, времени его существования и предположительной частоты обновления. Получается, у нас 163 страницы, так как мы должны учесть и нулевую (главную).
Показываем парсеру, где в HTML-коде находится нужная информация. С помощью встроенных в браузер инструментов веб-разработки изучаем структуру кода и выясняем — нужные нам заголовки в HTML‑иерархии находятся вот по какому пути: элемент с классом «block-views-articles-latest-on-front-block» → первый элемент с классом «view-content» → все элементы с классом «flex-teaser-square» (по очереди) → в каждом из них первый элемент с классом «views-field views-field-title» → в каждом из них первый элемент с тегом ‘a’ (то есть гиперссылка с названием статьи).
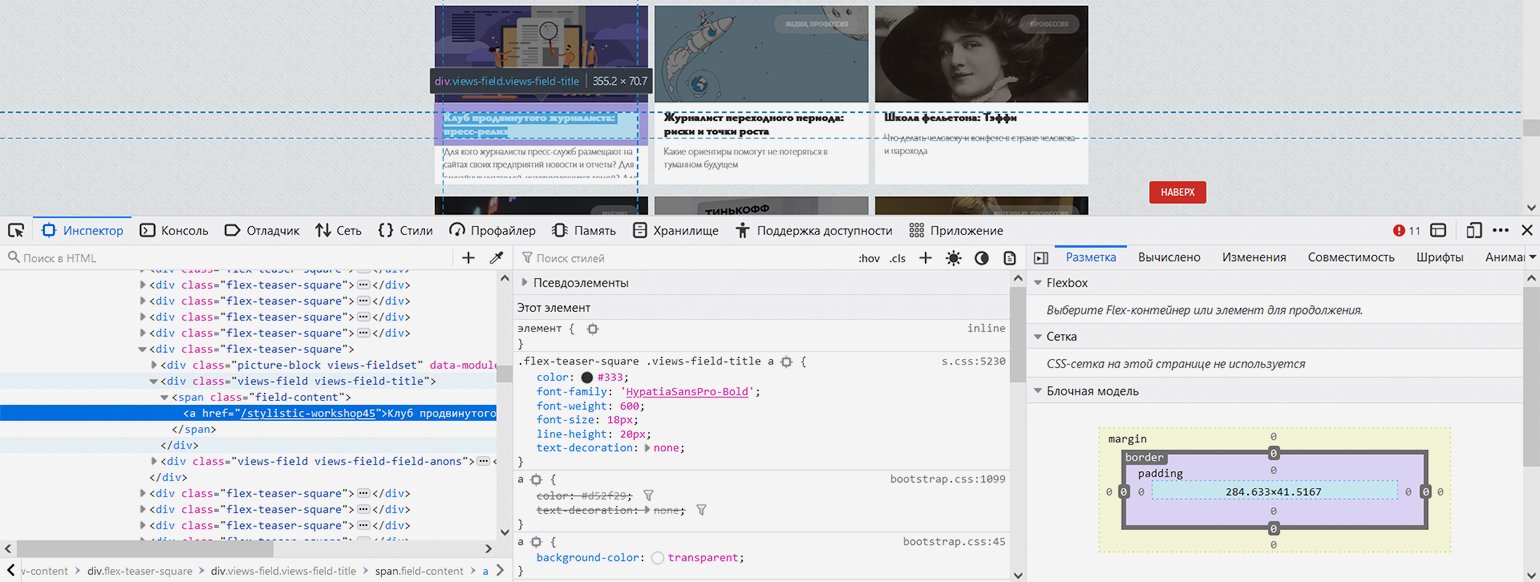
Скриншот: Евгений Колесников для Skillbox Media
Теперь, когда у нас есть все необходимые данные для парсера, давайте автоматизируем процесс сборки материалов.
Наш парсер будет состоять из двух файлов — JS-файл с собственно кодом и bat-файл для запуска по клику:
- Создадим файл с именем «JJ Articles Parser.js» (JJ — удобное сокращение от «журнал „Журналист“» — никакой магии). В этом файле будет практически весь наш исполняемый код.
- Создадим файл start.bat и пропишем в нём следующие команды:
cd "D:ваш_путьJJ Articles Parser" node JJ_articles_parser.js pause
Здесь всё просто:
- Первая строка — командой cd переходим в нужные диск и папку.
- Вторая строка запускает интерпретатор Node.js и тут же передаёт ему в обработку наш JS-файл.
- Команда pause делает так, чтобы командная строка не выключалась после выполнения кода.
Теперь займёмся кодом самого парсера:
/* Парсер статей журнала «Журналист» (https://jrnlst.ru) */ // Записывает заголовки и ссылки на статьи в HTML-файл // Написан на Node.js с использованием модулей axios и jsdom const axios = require('axios'); // Подключение модуля axios для скачивания страницы const fs = require('fs'); // Подключение встроенного в Node.js модуля fs для работы с файловой системой const jsdom = require("jsdom"); // Подключение модуля jsdom для работы с DOM-деревом (1) const { JSDOM } = jsdom; // Подключение модуля jsdom для работы с DOM-деревом (2) const pagesNumber = 162; // Количество страниц со статьями на сайте журнала на текущий день. На каждой странице до 18 статей const baseLink = 'https://jrnlst.ru/?page='; // Типовая ссылка на страницу со статьями (без номера в конце) var page = 0; // Номер первой страницы для старта перехода по страницам с помощью пагинатора var parsingTimeout = 0; // Стартовое значение задержки следующего запроса (увеличивается с каждым запросом, чтобы не отправлять их слишком часто) function paginator() { function getArticles() { var link = baseLink + page; // Конструктор ссылки на страницу со статьями для запроса по ней console.log('Запрос статей по ссылке: ' + link); // Уведомление о получившейся ссылке // Запрос к странице сайта axios.get(link) .then(response => { var currentPage = response.data; // Запись полученного результата const dom = new JSDOM(currentPage); // Инициализация библиотеки jsdom для разбора полученных HTML-данных, как в браузере // Определение количества ссылок на странице, потому что оно у них не всегда фиксированное. Это значение понадобится в цикле ниже var linksLength = dom.window.document.getElementById('block-views-articles-latest-on-front-block').getElementsByClassName('view-content')[0].getElementsByClassName('flex-teaser-square').length; // Перебор и запись всех статей на выбранной странице for (i = 0; i < linksLength; i++) { // Получение относительных ссылок на статьи (так в оригинале) var relLink = dom.window.document.getElementById('block-views-articles-latest-on-front-block').getElementsByClassName('view-content')[0].getElementsByClassName('flex-teaser-square')[i].getElementsByClassName('views-field views-field-title')[0].getElementsByTagName('a')[0].outerHTML; // Превращение ссылок в абсолютные var article = relLink.replace('/', 'https://jrnlst.ru/') + '<br>' + 'n'; // Уведомление о найденных статьях console.log('На странице ' + 'найдена статья: ' + article); // Запись результата в файл fs.appendFileSync('ПУТЬ/articles.html', article, (err) => { if (err) throw err; }); }; if (page > pagesNumber) { console.log('Парсинг завершён.')}; // Уведомление об окончании работы парсера }); page++; // Увеличение номера страницы для сбора данных, чтобы следующий запрос был на более старую страницу }; for (var i = page; i <= pagesNumber; i++) { var getTimer = setTimeout(getArticles, parsingTimeout); // Запуск сбора статей на конкретной странице с задержкой parsingTimeout += 10000; // Определение времени, через которое начнётся повторный запрос (к следующей по счёту странице) }; return; // Завершение работы функции }; paginator(); // Запуск перехода по страницам и сбора статей
Посмотреть код на Pastebin
На всё ровно 50 строк с учётом детальных комментариев для читающего и уведомлений в консоль о ходе выполнения программы.
Концептуально этот парсер работает так:
- Подключаем нужные модули.
- Определяем константы: количество страниц сайта, основную часть ссылки (кроме номера страницы, который как раз меняется).
- Определяем стартовые значения основных переменных: начало прохода с нулевой страницы и нулевую задержку запросов, которая будет постоянно увеличиваться.
- Определяем основную функцию парсера под названием paginator(), в которой находится почти весь код.
- Последней строкой запускаем эту функцию.
Отдельно скажем об устройстве функции paginator().
Внутри неё есть ещё одна функция — getArticles(), которая конструирует ссылку на последующую страницу из постоянной «базовой части» и номера, делает GET-запрос с помощью команды модулю axios, разбирает результат как DOM-дерево с помощью модуля jsdom, вынимает все ссылки на странице, превращает их из относительных в абсолютные, записывает результат в файл и увеличивает переменную с номером страницы для использования в следующем запросе.
Цикл for, который запускает внутреннюю функцию getArticles() — по расписанию и со всё увеличивающейся задержкой. Установлена задержка в 10 секунд, потому что это не будет сильно нагружать сайт, а общее время выполнения не окажется слишком долгим — плюс разработчики сайта сами рекомендовали такое время в директиве crawl-delay в файле robots.txt (хотя так делают разработчики далеко не всех сайтов, потому что эта директива считается устаревшей). Каждый последующий запуск функции инициирует запрос к более старой странице, поскольку каждый предыдущий запуск увеличивает переменную с номером страницы на 1.
Функция getArticles() запускается, пока переменная с номером следующей страницы не превысит константу с общим количеством страниц. Тогда выполнение всего кода завершается с уведомлением в консоль. В противном случае парсер пытался бы стучаться в двери сайта бесконечно, в чём нет никакого смысла.
Скриншот: Евгений Колесников для Skillbox Media
Когда код написан и настроен, остаётся только запустить его кликом по батнику (start.bat) и наблюдать в реальном времени за выполнением. Примерно через полчаса мы получим HTML-файл со списком всех 2920 статей ссылками, как и планировалось.
Напомним, второй способ — это загрузка дополнительных статей на ту же страницу. Обычно в таких случаях простых способов перейти на какую-то дату или в конец просто нет. Страницы со статьями, конечно же, существуют, но только для сервера, обрабатывающего запрос на подгрузку, а не для пользователя.
Для демонстрации этого способа пагинации по предложению редактора Тимура спарсим рубрику «Код» Skillbox Media (без новостей, только статьи). Как тут, спрашивается, применить описанные выше принципы сбора, если видимой нумерации страниц нет? Пойдём по тем же шагам, что и в прошлом примере.
В этом случае наши действия будут иными: нужно открыть в браузере инструменты веб-разработки на вкладке «Сеть», чтобы пошпионить за выполняемыми сайтом запросами, а после этого нажать на странице рубрики на кнопку «Показать ещё», подгружающую дополнительные материалы.

Скриншот: Евгений Колесников для Skillbox Media
В списке запросов можно увидеть POST-запрос к сайту skillbox.ru на выполнение PHP-файла с говорящим названием getArticlesIndex.php, ответ возвращается в часто используемом формате разметки данных JSON. URL запроса: https://skillbox.ru/local/ajax/getArticlesIndex.php — при этом на вкладке «Запрос» можно увидеть, что он передаётся с такими параметрами:
{
"params[SECTION_ID]": "10",
"params[CODE_EXCLUDE]": "news",
"params[FIRST_IS_FULL]": "Y",
"params[COUNT]": "7",
"params[PAGE_NUM]": "2",
"params[FIELDS][]": "PROPERTY_FAKE_COUNTER",
"params[CACHE_TYPE]": "A",
"params[COMPONENT_TEMPLATE]": "articles"
}
Параметр «PAGE_NUM», равный в данном случае 2, соответствует как раз номеру страницы, «SECTION_ID», равный 10, соответствует рубрике «Код», которую мы собрались парсить, а «COUNT», равный 7, — количеству выводимых на странице материалов.
Обратите внимание, что загрузка дополнительных статей в данном случае оформлена как POST-запрос, а не GET- (обычно GET-запрос используется для получения данных с сервера, а POST-запрос — для отправки). Почему это так — отдельный вопрос, выходящий за рамки статьи. При разработке парсера мы должны подстроиться под логику разработчиков сайта, однако ради любопытства попробуем провести небольшой эксперимент.
Если мы скопируем указанную выше ссылку и перейдём по ней без указания параметров, то сайт выдаст ошибку («status: error») — он просто не будет знать, какую информацию мы у него просим. Здесь браузер передаст именно GET-запрос, а не POST-, однако сайт всё равно нам отвечает (сообщение об ошибке — тоже сообщение).
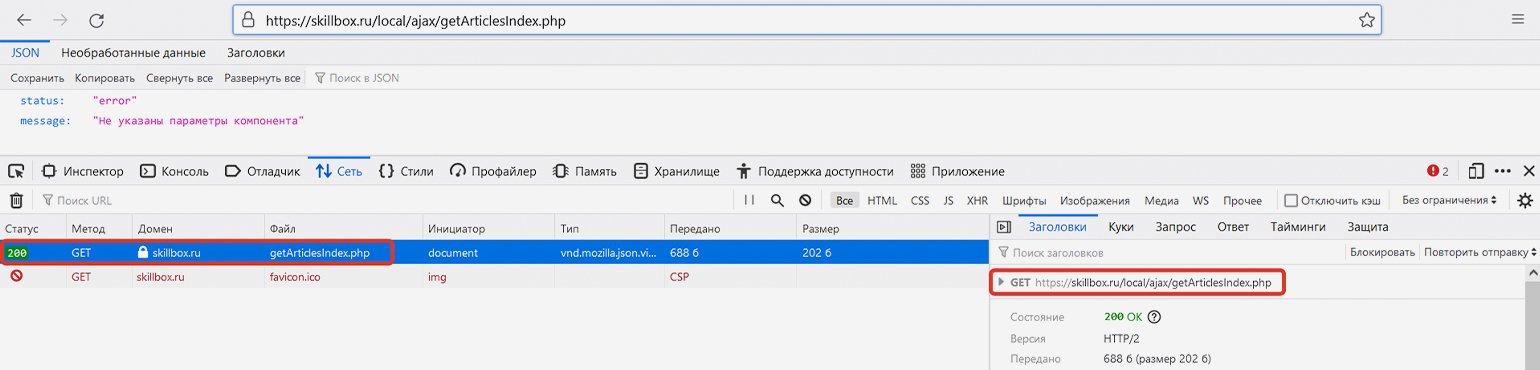
Скриншот: Евгений Колесников для Skillbox Media
Если попробовать сделать прямой запрос по той же ссылке и с указанием правильных параметров, то опять же в результате GET-запроса получим JSON-ответ с HTML-кодом дополнительных статей и статусом «ok».
Например, соединим базовую ссылку и указанные выше параметры в единую строку — https://skillbox.ru/local/ajax/getArticlesIndex.php?params[SECTION_ID]=10& params[CODE_EXCLUDE]=news& params[FIRST_IS_FULL]=Y& params[COUNT]=7& params[PAGE_NUM]=2& params[FIELDS][]=PROPERTY_FAKE_COUNTER& params[CACHE_TYPE]=A& params[COMPONENT_TEMPLATE]=articles — и сделаем GET-запрос, перейдя по конечной ссылке. В ответ сайт отдаст данные в JSON-формате — это будет разметка списка статей на второй странице, в чём легко убедиться, найдя в этой мешанине через поиск доступные на сайте названия статей.
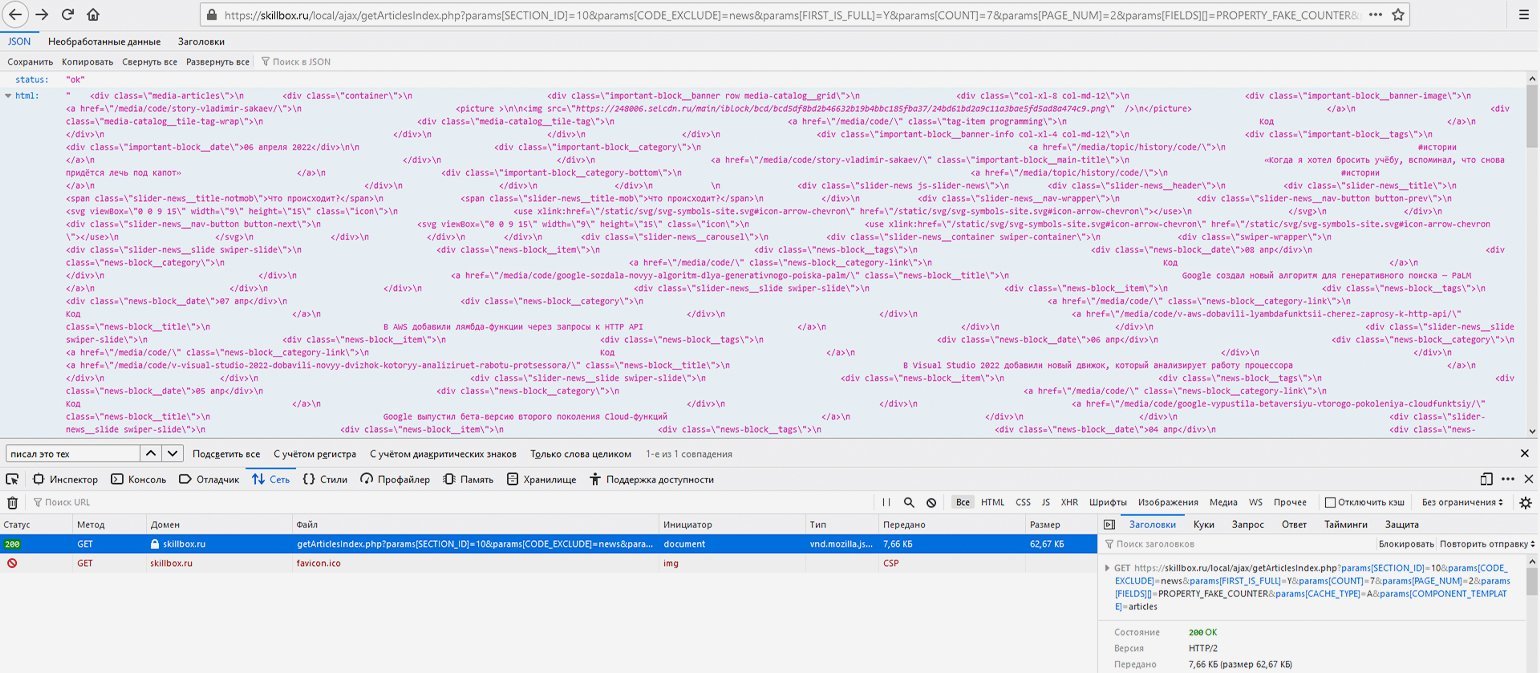
Скриншот: Евгений Колесников для Skillbox Media
Теперь, когда мы примерно поняли структуру пагинации, нужно определиться, где же парсеру надо остановиться — где заканчиваются статьи.
Загуглив фразу «Skillbox запустил медиа», находим материал «Подборка статей Skillbox в честь запуска медиа» от 8 июля 2018 года в блоге Skillbox на Medium. Это уже что-то — теперь можно догадаться, что статьи на сайте появились примерно в первой половине 2018 года.
Как и в предыдущем примере, начинаем искать номер последней страницы перебором параметра «[PAGE_NUM]». Если введённого номера страницы нет, сайт отдаёт первую страницу — в таком случае номер нужно уменьшить.
На момент написания статьи последняя страница была под номером 101, на каждой — по семь материалов: исходя из этого было сделано предположение, что всего в рубрике «Код» должно быть примерно 707 статей (в реальности их оказалось 705, потому что на последней странице было только пять публикаций). В данном случае автор мог сверить подсчёты с редактором раздела, который подтвердил их правильность, — однако так везёт далеко не всегда. Судя по выданному сайтом результату, первая статья раздела — «Какой язык программирования учить новичку. Выбираем JavaScript» от 3 мая 2018 года.
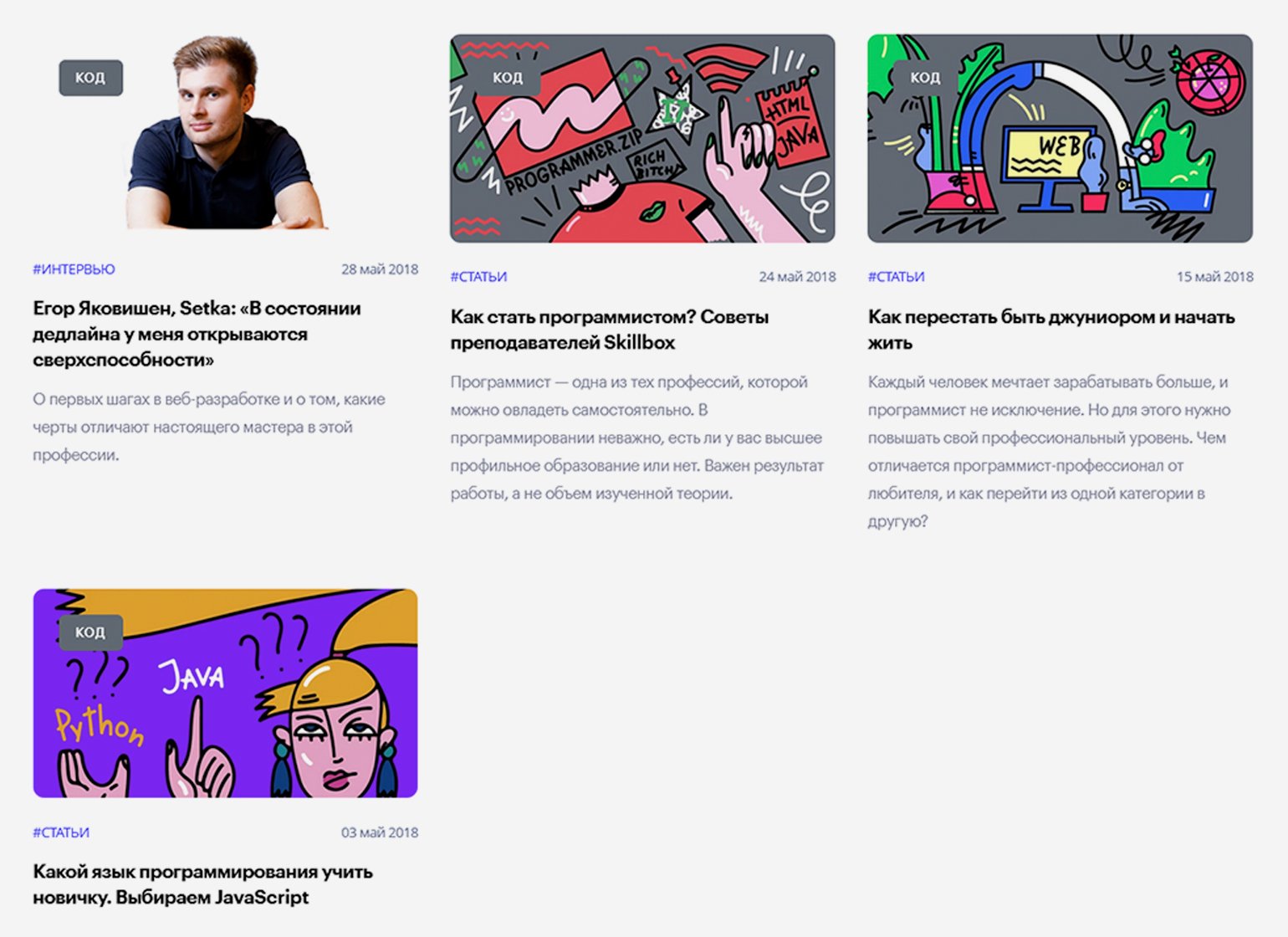
Скриншот: Евгений Колесников для Skillbox Media
Вернёмся к первой странице рубрики и попробуем с помощью инструментов веб-разработчика найти местонахождение ссылок на статьи, чтобы указать его парсеру.
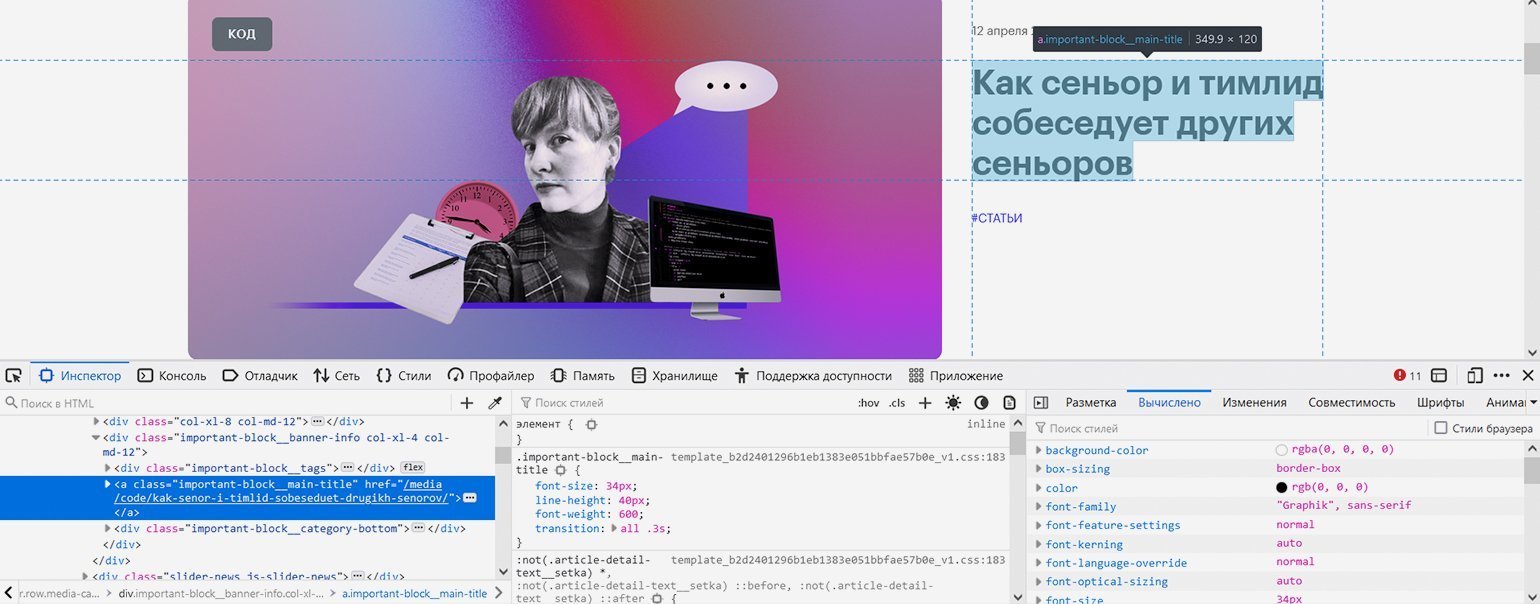
Скриншот: Евгений Колесников для Skillbox Media
Со статьёй в закрепе проблем нет — она такая одна, это элемент с классом «important-block__main-title».
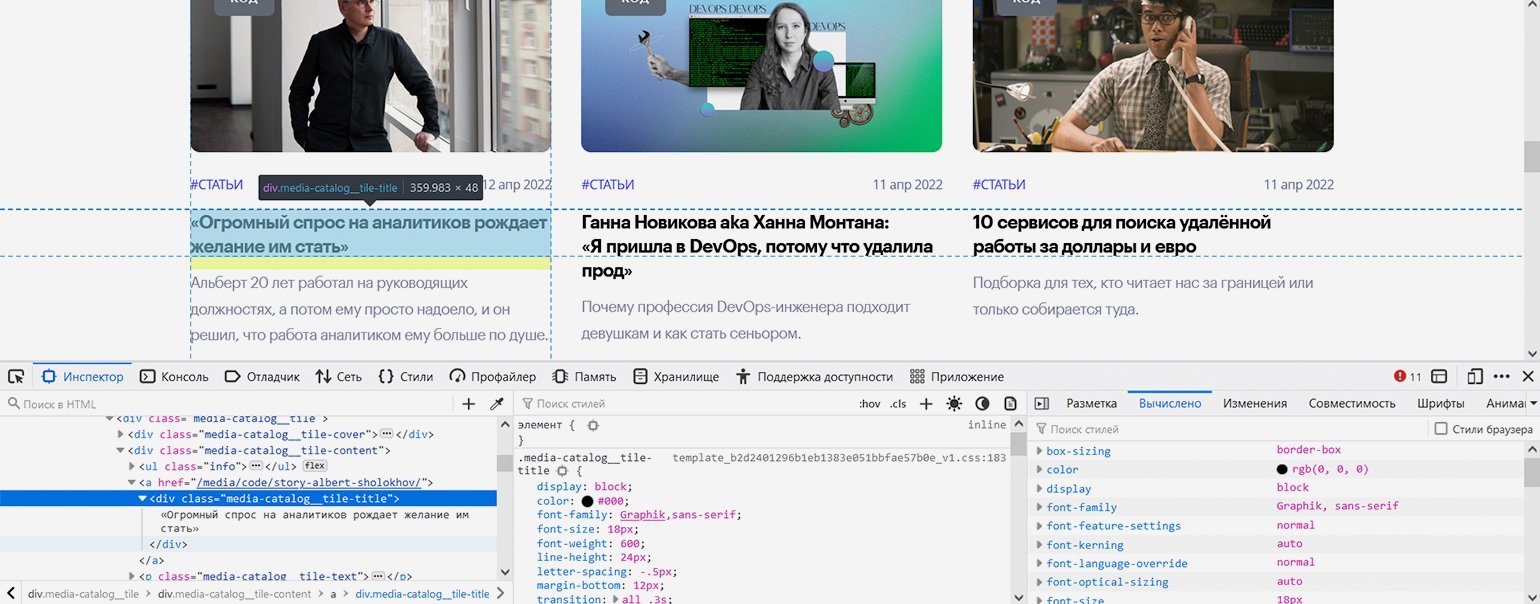
Скриншот: Евгений Колесников для Skillbox Media
С остальными посложнее: блочный элемент <div> с классом «media-catalog__tile-title» вложен в ссылку — элемент <a>, что довольно необычно. <div> содержит только текст заголовка, а у ссылки <a> не указан класс — но всё это мы решим с помощью правильной навигации.
Создаём два файла — skbx_code_articles_parser.js с кодом и start.bat для его запуска. Батник копируем почти без изменений — отличаться будут только путь и имя запускаемого скрипта. В JS-файл вставляем следующий код:
/* Парсер статей рубрики «Код» портала Skillbox Media (https://skillbox.ru/media/code/) */ // Записывает заголовки и ссылки на статьи в HTML-файл // Написан на Node.js с использованием модулей axios и jsdom const axios = require('axios'); // Подключаем к Node.js модуль axios для скачивания страницы const fs = require('fs'); // Подключение встроенного в Node.js модуля fs для работы с файловой системой const jsdom = require("jsdom"); // Подключение модуля jsdom для работы с DOM-деревом (1) const { JSDOM } = jsdom; // Подключение модуля jsdom для работы с DOM-деревом (2) const pagesNumber = 101; // Количество страниц со статьями на сайте журнала на текущий день. На каждой странице по семь статей var page = 1; // Номер первой страницы для старта перехода по страницам с помощью пагинатора var parsingTimeout = 0; // Стартовое значение задержки следующего запроса (увеличивается с каждым запросом, чтобы не отправлять их слишком часто) // Определяем стартовые параметры запроса (меняться будет только номер страницы) var params = new URLSearchParams(); params.append('params[SECTION_ID]', '10'); params.append('params[CODE_EXCLUDE]', 'news'); params.append('params[FIRST_IS_FULL]', 'Y'); params.append('params[COUNT]', '7'); params.append('params[PAGE_NUM]', '1'); params.append('params[FIELDS][]', 'PROPERTY_FAKE_COUNTER'); params.append('params[CACHE_TYPE]', 'A'); params.append('params[COMPONENT_TEMPLATE]', 'articles'); function paginator() { function getArticles() { console.log('Запрос статей со страницы ' + params.get('params[PAGE_NUM]')); // Уведомление о номере текущей страницы // Запрос к странице сайта axios.post('https://skillbox.ru/local/ajax/getArticlesIndex.php?', params) .then(response => { var currentPage = response.data; // Запись полученного результата var jsonToHtml = currentPage.html; // Получаем из JSON-ответа только HTML-код const dom = new JSDOM(jsonToHtml); // Инициализация библиотеки jsdom для разбора полученных HTML-данных, как в браузере // Парсинг закреплённой статьи var pinnedHeaderSpaces = dom.window.document.getElementsByClassName('important-block__main-title')[0].innerHTML; // Получение заголовка закреплённой статьи с лишними пробелами var pinnedHeader = pinnedHeaderSpaces.trim(); // Заголовок закреплённой статьи с удалёнными лишними пробелами var pinnedLink = dom.window.document.getElementsByClassName('important-block__main-title')[0].getAttribute('href'); // Получение относительной ссылки на закреплённую статью var pinnedArticle = '<a href="https://skillbox.ru' + pinnedLink + '">' + pinnedHeader + '</a><br>'+ 'n'; // Итоговая ссылка с заголовком закреплённой статьи console.log('На странице найдена закреплённая статья: ' + pinnedArticle); // Запись закреплённой статьи в файл fs.appendFileSync('ПУТЬ/articles.html', pinnedArticle, (err) => { if (err) throw err; }); // Парсинг остальных шести статей на странице var articlesNumber = dom.window.document.getElementsByClassName('media-catalog__tile-title').length; // Определение количества ссылок на странице, потому что на последней странице их меньше. Эта цифра понадобится в цикле ниже for (var art = 0; art < articlesNumber; art++) { var articleHeaderSpaces = dom.window.document.getElementsByClassName('media-catalog__tile-title')[art].innerHTML; // Получение заголовка статьи с лишними пробелами var articleHeader = articleHeaderSpaces.trim(); // Заголовок статьи с удалёнными лишними пробелами var articleLink = dom.window.document.getElementsByClassName('media-catalog__tile')[art].getElementsByClassName('media-catalog__tile-title')[0].parentElement.getAttribute('href'); // Получение относительной ссылки на статью var article = '<a href="https://skillbox.ru' + articleLink + '">' + articleHeader + '</a><br>'+ 'n'; // Итоговая ссылка с заголовком статьи console.log('На странице найдена статья: ' + article); // Запись статьи в файл fs.appendFileSync('ПУТЬ/articles.html', article, (err) => { if (err) throw err; }); }; if (page > pagesNumber) { console.log('Парсинг завершён.'); // Уведомление об окончании работы парсера }; }); page++; // Увеличение номера страницы для сбора данных, чтобы следующий запрос был на более старую страницу params.set('params[PAGE_NUM]', page); return; }; for (var i = page; i <= pagesNumber; i++) { var getTimer = setTimeout(getArticles, parsingTimeout); // Запуск сбора статей на конкретной странице с задержкой parsingTimeout += 10000; // Определение времени, через которое начнётся повторный запрос (к следующей по счёту странице) }; return; }; paginator(); // Запуск перехода по страницам и сбора статей
Посмотреть код на Pastebin
Наш код изменился, но всё ещё похож на прошлый. Обратите внимание на ряд нюансов:
- Делаем не GET-, а POST-запрос, поэтому вместо метода axios.get() будем использовать axios.post() (строка 29).
- Используем интерфейс URLSearchParams для передачи и чтения найденных выше параметров сетевого запроса в особом формате (строки 14–23, 27 и 62–63).
- Немного затрагиваем получение данных из JSON-формата, но только в одной строчке (строки 32–33).
- На каждой странице сначала отдельно парсим закреплённую статью, а потом шесть обычных, следуя логике вёрстки сайта.
Скриншот: Евгений Колесников для Skillbox Media
Как и в прошлом примере, запускаем парсер кликом на файл start.bat и примерно 17 минут ждём результата — HTML-файла со списком из 705 статей.
И ваш парсер тоже. Вы можете читать этот материал через день или через год после выхода. На момент подготовки статьи сайт Skillbox Media выводил по семь статей на странице: одну в закрепе и шесть снизу. Впоследствии разработчики неожиданно удвоили выдачу — теперь уже выводится по 14 статей в следующем порядке: одна в закрепе, шесть снизу, снова одна в закрепе и ещё шесть снизу.
Мы решили оставить этот факт как часть урока о парсерах: сайт, который вы собираете, может в любой момент поменять дизайн и структуру материалов, поэтому не следует ожидать, что ваш сборщик будет работать вечно даже на одном и том же ресурсе.
В ходе теста выяснилось, что с выдачей 14 материалов вместо семи указанный выше код также справляется, поскольку параметры с номером страницы и количеством статей на ней взаимосвязаны и ответ сервера адаптируется под ваш запрос (даже если он построен по старому принципу).
Однако, если, как и раньше, подстраиваться под логику разработчиков, будет разумно поменять навигацию: указать в константе в два раза меньшее число страниц и поменять порядок перебора расположенных на них элементов — имея в два раза больше статей на каждой, для сохранения правильного порядка мы должны задать проход по алгоритму «первый закреп, обычные статьи с первой по шестую, второй закреп, обычные статьи с седьмой по 12-ю». Вы можете сделать это самостоятельно в качестве упражнения.
Мы рассмотрели два рабочих способа автоматического сбора материалов на сайтах СМИ. Есть и другие варианты: парсить список материалов в Excel-таблицу, в файл закладок для импорта в браузер, сделать красивый дизайн, автоматически отправлять результат в Telegram-чат через бота, сортировать, проводить контент-анализ (рубрики, ключевые слова, частота публикации), вставлять галочки для отметки прочитанного и так далее — насколько хватит фантазии.
Вероятно, приведённый выше код не идеален, ведь он написан не профессиональным программистом, а журналистом, применяющим программирование в работе. Это важный момент: он показывает, что сейчас программирование нужно всем и доступно всем, если выйти за пределы привычных методов работы и изучить что-то новое.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать
Меня зовут Максим Кульгин и моя компания xmldatafeed занимается парсингом сайтов в России порядка четырех лет. Ежедневно мы парсим более 500 крупнейших интернет-магазинов в России и на выходе мы отдаем данные в формате Excel/CSV и делаем готовую аналитику для маркетплейсов.
Но если вы планируете сами заняться парсингом и ищите инструменты для его реализации, то ниже мы подобрали лучшие решения, в том числе ориентированные на пользователей, которые не занимаются программированием.
Хотя вы можете разработать собственный инструмент для парсинга интересующих вас веб-сайтов, знающие люди говорят, что, ввязавшись в такое мероприятие, вы не только потратите свое время, но и другие необходимые ресурсы, если только у вас нет для этого весомых причин. Вместо того чтобы идти таким путем, вам нужно исследовать рынок уже существующих программных решений, чтобы найти подходящее вам и воспользоваться им. Когда дело касается инструментов для парсинга веб-сайтов, вам нужно знать, что на рынке много таких инструментов.
Однако не все из них похожи друг на друга. Некоторые лучше зарекомендовали себя, другие популярнее остальных. При этом у каждого из инструментов своя сложность и продолжительность изучения. Схожее разнообразие наблюдается и в специализации инструментов, а также в поддержке платформ и языков программирования. Тем не менее мы всё еще можем прийти к согласию относительно лучших на рынке инструментов для парсинга веб-сайтов и каждый из них будет рассмотрен ниже. Список состоит из инструментов, предназначенных как для тех, у кого есть навыки программирования, так и для тех, у кого таких навыков нет.
Парсинг веб-сайтов изначально был задачей программистов, поскольку нужно написать программные коды, перед тем как веб-сайт можно будет парсить, поэтому на рынке представлено много инструментов, созданных специально для программистов. Инструменты для парсинга веб-сайтов, предназначенные для программистов, реализованы в виде библиотек и фреймворков, которые разработчик будет использовать в своем коде для реализации необходимого поведения своего парсера.
Библиотеки Python для парсинга веб-сайтов
Python — самый популярный язык программирования для разработки парсеров благодаря простому синтаксису, быстрому обучению и множеству доступных библиотек, которые облегчают работу разработчиков. Ниже рассматриваются некоторые из библиотек и фреймворков для парсинга, доступных разработчикам на Python.
Scrapy
Scrapy — фреймворк для реализации обхода (сканирования) и парсинга веб-сайтов, написанный на Python для разработчиков, работающих с этим языком программирования. Scrapy считается полноценным фреймворком, поэтому в нем по умолчанию присутствует всё необходимое для парсинга веб-сайтов, включая модуль для отправки HTTP-запросов и извлечения данных из загруженной HTML-страницы.
Им можно пользоваться бесплатно, и у него открытый исходный код. Кроме того, при парсинге есть возможность сохранения данных. Однако Scrapy не выполняет JavaScript-код — необходимо обратиться за помощью к другой библиотеке. Вы можете воспользоваться Splash или Selenium — популярным инструментом для автоматизации браузера.
PySpider
PySpider — еще один инструмент для парсинга веб-сайтов, который вы можете использовать для разработки сценариев (скриптов) на Python. В отличие от Scrapy данный инструмент может выполнять JavaScript-код, поэтому не требуется использовать Selenium. Однако PySpider по сравнению со Scrapy выглядит менее завершенным программным решением, поскольку Scrapy развивается с 2008 года, а также обладает более качественной документацией и более крупным сообществом пользователей. Но эти факты не делают PySpider каким-то ущербным. Напротив, PySpider включает в себя несколько уникальных возможностей, например веб-интерфейс с редактором сценариев.
Requests — HTTP-библиотека, облегчающая отправку HTTP-запросов. Она создана на основе библиотеки urllib. Это надежный инструмент, который позволяет вам создавать более надежные парсеры. Он удобен в использовании и сокращает объем кода.
Очень важно, что он позволяет управлять файлами cookie и сессиями, а также, помимо всего прочего, аутентификацией и автоматической организацией пула соединений. Библиотека requests бесплатна, и разработчики на Python могут использовать ее для скачивания веб-страниц, перед тем как применять парсер для выборки необходимых им данных.
BeautifulSoup
BeautifulSoup упрощает процесс извлечения данных из веб-страниц. Эта библиотека использует анализатор кода HTML и XML, предоставляя вам характерные для Python способы осуществления доступа к данным. BeautifulSoup стал одним из наиболее важных инструментов для парсинга веб-сайтов на рынке благодаря легкости парсинга, которую он обеспечивает.
Фактически в большинстве обучающих материалов на тему парсинга веб-сайтов используется BeautifulSoup с целью показать новичкам как писать парсеры. При использовании этой библиотеки одновременно с библиотекой Requests для отправки HTTP-запросов разрабатывать парсеры становится гораздо проще, чем при использовании Scrapy или PySpider.
Selenium
Scrapy, Requests и BeautifulSoup не помогут вам, если целевой веб-сайт использует подход AJAX, то есть если он зависит от асинхронных запросов, предназначенных для загрузки определенных фрагментов веб-страницы при помощи JavaScript. Если вы обращаетесь к такой веб-странице, вам нужно использовать Selenium — инструмент автоматизации браузера. Его можно применять для автоматизации браузеров с поддержкой headless-режима, например Chrome и Firefox. Более ранние версие могут автоматизировать PhantomJS.
Парсеры на основе Node.js (JavaScript)
Node.js тоже становится популярной платформой для создания парсеров благодаря популярности JavaScript. У Node.js есть множество инструментов для парсинга веб-сайтов, но не настолько много по сравнению с Python. Два самых популярных инструмента для среды выполнения Node.js рассмотрены ниже.
Cheerio
Cheerio для Node.js — это как BeautifulSoup для Python. Это библиотека анализа данных, которая предоставляет API для сканирования содержимого веб-страницы и управления им. У нее нет возможности выполнения JavaScript-кода, поэтому для этой цели вам нужен браузер в headless-режиме. Единственная задача Cheerio — предоставить вам доступ к jQuery, который используется в качестве API для извлечения данных из веб-страницы. Cheerio — гибкая, быстрая и довольно удобная библиотека.
Puppeteer
Puppeteer — один из лучших инструментов для парсинга веб-сайтов, который могут использовать разработчики на JavaScript. Это инструмент автоматизации браузера, предоставляющий высокоуровневый API для управления браузером Chrome. Puppeteer был разработан компанией Google и предназначен для использования только с браузером Chrome и другими браузерами на основе Chromium. В отличие от кроссплатформенного Selenium, Puppeteer можно использовать только в среде Node.js.
Прикладные интерфейсы (API) для парсинга веб-сайтов
Программисты, не обладающие опытом использования прокси-серверов для парсинга веб-сайтов с серьезной защитой от парсинга или не желающие беспокоиться об управлении прокси-серверами и о решении капч, могут воспользоваться API для парсинга, который позволяет извлекать данные из веб-сайтов или скачивать веб-страницы целиком, чтобы затем вытаскивать из них нужные данные. Ниже рассматриваются лучшие прикладные интерфейсы для парсинга веб-сайтов.
AutoExtract API
- Размер пула прокси-серверов: не разглашается.
- Поддержка геотаргетинга: присутствует ограниченная поддержка.
- Стоимость: $60 за 100 000 запросов.
- Бесплатное пробное использование: 10 000 запросов за 14 дней.
- Особые функции: извлечение необходимых данных из веб-сайтов.
AutoExtract API — один из лучших API для парсинга веб-сайтов, который вы можете найти на рынке. Он был разработан компанией Scrapinghub, создателем Crawlera — API для работы с прокси-серверами. Scrapinghub выполняет львиную долю работы по сопровождению Scrapy — популярного фреймворка для создания парсеров, ориентированного на Python-программистов.
AutoExtract API — основанный на API инструмент извлечения данных, который позволит вам собирать данные с веб-сайтов без необходимости предварительного изучения их внутренней структуры, то есть вам не потребуется код, написанный специально для какого-либо веб-сайта. AutoExtract API поддерживает извлечение данных из новостных веб-сайтов и блогов, товаров на сайтах электронной коммерции, вакансий, данных о транспортных средствах и прочих данных.
ScrapingBee
- Размер пула прокси-серверов: не разглашается.
- Поддержка геотаргетинга: присутствует.
- Стоимость: начинается с $29 за 250 000 единиц доступа («кредитов») к API.
- Бесплатное пробное использование: 1 000 обращений к API.
- Особые функции: управление браузером в headless-режиме для исполнения JavaScript-кода.
ScrapingBee — API для парсинга веб-сайтов, позволяющий скачивать веб-страницы. Благодаря ScrapingBee вы сможете думать не о блоках, а о самом извлечении данных из загруженной веб-страницы, которую ScrapingBee возвращает вам в качестве ответа.
ScrapingBee удобен в использовании и для этого требуется всего лишь делать запросы к API. ScrapingBee задействует большой пул IP-адресов, используемых для отправки ваших запросов, что защищает вас от блокировки на тех веб-сайтах, данные из которых вы собираете. Кроме того, ScrapingBee помогает вам управлять браузером Chrome в headless-режиме, что непросто, особенно при масштабировании кластера серверов (Selenium Grid), на которых функционируют браузеры Chrome в headless-режиме.
Scraper API
- Размер пула прокси-серверов: более 40 миллионов.
- Поддержка геотаргетинга: зависит от выбранного тарифного плана.
- Стоимость: начинается с $29 за 250 000 обращений к API.
- Бесплатное пробное использование: 1 000 обращений к API.
- Особые функции: решение капч и работа с браузерами в headless-режиме.
Обрабатывая каждый месяц более пяти миллиардов запросов к API, Scraper API — сила, с которой нужно считаться на рынке прикладных интерфейсов для парсинга веб-сайтов. Это довольно функциональная система, которая позволяет вам управлять множеством задач, включая ротацию IP-адресов с использованием их собственного пула прокси-серверов, включающего в себя более 40 миллионов IP-адресов.
Помимо ротации IP-адресов Scraper API также управляет браузерами в headless-режиме и избавит вас от необходимости работы непосредственно с капчами. Это быстрый и надежный API для парсинга веб-сайтов. Среди его пользователей, которые перечислены на сайте разработчиков, можно найти множество компаний из списка Fortune 500. При этом цены находятся на приемлемом уровне.
Zenscrape
- Размер пула прокси-серверов: более 30 миллионов.
- Поддержка геотаргетинга: присутствует ограниченная поддержка.
- Стоимость: начинается с $8,99 за 50 000 запросов.
- Бесплатное пробное использование: 1 000 запросов.
- Особые функции: управление браузерами Chrome в headless-режиме.
Zenscrape позволит вам без проблем извлекать данные из веб-сайтов по доступной цене — у них, как и у аналогов, даже есть тарифный план с бесплатным пробным использованием, чтобы вы могли протестировать их сервис, перед тем как тратить деньги.
Zenscrape скачает вам веб-страницу в том виде, в котором она отображается обычным пользователям, а также может работать с основанным на геотаргетинге контентом в зависимости от выбранного вами тарифного плана. Очень важно, что Zenscrape отлично справляется с выполнением кода на JavaScript, поскольку все запросы осуществляются с помощью Chrome в headless-режиме. Zenscrape даже поддерживает популярные JavaScript-фреймворки.
ScrapingAnt
- Размер пула прокси-серверов: не разглашается.
- Поддержка геотаргетинга: присутствует.
- Стоимость: начинается с $9 за 5 000 запросов.
- Бесплатное пробное использование: присутствует.
- Особые функции: решение капч и выполнение кода на JavaScript.
Парсинг веб-сайтов с безжалостными системами противодействия спаму — сложная задача, поскольку вам приходится иметь дело со множеством препятствий. ScrapingAnt может помочь вам преодолеть все препятствия и легко получить все необходимые данные.
ScrapingAnt позволяет выполнять JavaScript-код, используя Chrome в headless-режиме, работает с прокси-серверами и помогает вам избегать капч. ScrapingAnt также управляет пользовательскими файлами cookie и первичной обработкой выходных данных. Цены можно назвать лояльными, поскольку вы можете начать пользоваться этим API для парсинга веб-сайтов всего за $9.
Лучшие инструменты парсинга веб-сайтов для людей без навыков программирования
Раньше для парсинга веб-сайтов вам нужно было писать программный код. Теперь это уже не так, ведь появились инструменты парсинга, предназначенные специально для людей, не обладающих навыками программирования. Благодаря этим инструментам не нужно писать программные коды для парсинга необходимых данных из Всемирной паутины. Эти инструменты могут быть реализованы в виде устанавливаемого на компьютер программного обеспечения (ПО), облачного решения или расширения для браузера.
ПО для парсинга веб-сайтов
На рынке есть много ПО, которое можно использовать для парсинга всевозможных данных из Всемирной паутины без необходимости уметь программировать. Ниже представлена пятерка лучших на данный момент представителей такого ПО.
Octoparse
- Стоимость: начинается с $75 в месяц.
- Бесплатное пробное использование: 14 дней с ограничениями.
- Формат вывода данных: CSV, Excel, JSON, MySQL и SQLServer.
- Поддержка операционных систем: Windows.
Octoparse делает парсинг веб-сайтов простым для любого пользователя. Благодаря Octoparse вы можете быстро превратить весь веб-сайт в структурированную электронную таблицу всего за несколько кликов. Octoparse не требует наличия навыков программирования, так как всё, что от вас требуется для получения нужных данных, — всего лишь перемещать курсор мыши и щелкать ею. Octoparse может собирать данные с любых веб-сайтов, включая веб-сайты, на которых используется AJAX и применяются серьезные меры противодействия парсингу. Это ПО использует ротацию IP-адресов, чтобы «заметать следы» вашего IP-адреса. Помимо ПО для компьютеров, разработчики предлагают облачное решение и даже 14-дневный период бесплатного использования.
Helium Scraper
- Стоимость: разовая оплата — от $99 с доступом к основным обновлениям в течение трех месяцев.
- Бесплатное пробное использование: 10 дней без ограничений по функционалу.
- Формат вывода данных: CSV и Excel.
- Поддержка операционных систем: Windows.
Helium Scraper — другое ПО, которое можно использовать для парсинга веб-сайтов при отсутствии навыков программирования. Вы можете собирать сложные данные, определяя свои собственные действия, выполняемые при парсинге. Кроме того, если вы разработчик, то можете запускать на выполнение свои файлы с JavaScript-кодом. Благодаря несложной организации работы, Helium Scraper не только удобен в использовании, но и позволяет быстро выполнять нужные операции благодаря простому и логичному интерфейсу. Кроме того, Helium Scraper — ПО для парсинга, предоставляющее множество функций, включая планирование парсинга, ротацию прокси-серверов, управление текстом, вызовы API и прочее.
ParseHub
- Стоимость: версия для настольных компьютеров бесплатна.
- Формат вывода данных: JSON и Excel.
- Поддержка операционных систем: Windows, Mac и Linux.
ParseHub предлагается в двух версиях: приложение для настольных компьютеров, которое можно использовать бесплатно, и платное облачное решение для парсинга, включающее в себя дополнительные возможности и не требующее установки. ParseHub в виде приложения для настольных компьютеров облегчает парсинг любого интересующего вас веб-сайта, даже если у вас нет навыков программирования. Всё потому, что данное ПО предоставляет интерфейс point-and-click, то есть в котором доступ к функциям осуществляется через наведение курсора мыши на соответствующие графические элементы и щелчки кнопкой мыши. Этот интерфейс предназначен для того, чтобы подготовить ParseHub к извлечению необходимых вам данных. ParseHub прекрасно работает с современными веб-сайтами и позволяет вам скачивать извлеченные данные в популярных файловых форматах.
ScrapeStorm
- Стоимость: начинается с $49,99 в месяц.
- Бесплатное пробное использование: есть бесплатный тарифный план — Starter, но в нем присутствуют ограничения.
- Форматы вывода данных: TXT, CSV, Excel, JSON, MySQL, Google Таблицы и так далее.
- Поддержка операционных систем: Windows, Mac и Linux.
ScrapeStorm отличается от других приложений для настольных компьютеров, представленных выше, поскольку здесь интерфейс point-and-click используется только тогда, когда ScrapeStorm не может обнаружить требуемые данные. ScrapeStorm применяет искусственный интеллект для обнаружения определенных фрагментов данных на веб-страницах. ScrapeStorm быстр, надежен и удобен в использовании. Что касается поддержки операционных систем, то ScrapeStorm работает на Windows, Mac и Linux. Данное ПО поддерживает множественный экспорт данных и позволяет осуществлять парсинг в масштабе предприятия. Интересен тот факт, что ScrapeStorm создан бывшими разработчиками поисковых роботов Google.
WebHarvy
- Стоимость: разовая оплата — от $139 за однопользовательскую лицензию.
- Бесплатное пробное использование: 14 дней с ограничениями.
- Формат вывода данных: CSV, Excel, XML, JSON и MySQL.
- Поддержка операционных систем: Windows.
WebHarvy — очередное ПО для парсинга веб-сайтов и извлечения данных с веб-страниц, которое вы можете установить на свой компьютер. Это ПО позволяет вам осуществлять парсинг посредством ввода одной единственной строки кода и выбирать место сохранения собранных данных: в файле или в системе управления базами данных. Оно представляет собой наглядный инструмент, который можно применять для парсинга любых данных из веб-страниц, например адресов электронной почты, ссылок, изображений и даже целых HTML-файлов. WebHarvy включает в себя средство для обнаружения структурированных данных и сканирует сразу несколько веб-страниц.
Парсеры веб-сайтов, реализованные в виде расширений браузера
Среда браузера становится популярным «местом обитания» парсеров, и есть много инструментов парсинга веб-сайтов, которые вы можете установить для своего браузера в качестве расширений и дополнительных модулей, чтобы облегчить себе задачу сбора данных с веб-сайтов. Некоторые из них рассмотрены ниже.
Расширение «Web Scraper»
- Стоимость: бесплатно.
- Бесплатное пробное использование: версия для Chrome предоставляется абсолютно бесплатно.
- Формат вывода данных: CSV.
Webscraper.io — расширение для браузеров Chrome и Firefox, представляющее собой один из лучших инструментов для парсинга веб-сайтов, который вы можете использовать, чтобы с легкостью извлекать данные с веб-страниц. Более 250 000 тысяч пользователей установили его и сочли чрезвычайно полезным. Подобные расширения для браузеров не требуют от вас навыков программирования, поскольку в них используется графический интерфейс (point-and-click). Интересно, что расширение «Web Scraper» можно применять для парсинга даже самых продвинутых и современных веб-сайтов, на которых есть много возможностей, реализованных с помощью JavaScript.
Расширение «Data Miner»
- Стоимость: начинается с $19,99 в месяц.
- Бесплатное пробное использование: 500 веб-страниц в месяц.
- Формат вывода данных: CSV и Excel.
Расширение «Data Miner» доступно только для браузеров Google Chrome и Microsoft Edge. Оно позволяет собирать данные с веб-страниц и сохранять их в CSV или электронную таблицу Excel. В отличие от расширения от Webscraper.io, которое предлагается бесплатно, расширение «Data Miner» будет бесплатным только в случае, если вы будете парсить не более 500 веб-страниц за один месяц. В противном случае вам нужно будет оформить подписку на платный тарифный план. Благодаря этому расширению вы можете парсить любую веб-страницу, не задумываясь о блоках, а конфиденциальность ваших данных будет под защитой.
Scraper
- Стоимость: полностью бесплатное расширение.
- Бесплатное пробное использование: присутствует.
- Формат вывода данных: CSV, Excel и TXT.
Scraper — расширение для Chrome, которое, по всей видимости, разработано и поддерживается одним разработчиком — у Scraper даже нет своего веб-сайта, как у вышеупомянутых инструментов. Scraper не такой продвинутый по сравнению с рассмотренными выше расширениями, но он полностью бесплатный. Основная проблема со Scraper состоит в том, что пользователям необходимо знать XPath, поскольку в Scraper применяется именно этот язык запросов. В связи с этим Scraper нельзя назвать благосклонным к начинающим пользователям.
SimpleScraper
- Стоимость: бесплатно.
- Бесплатное пробное использование: версия для Chrome предоставляется абсолютно бесплатно.
- Формат вывода данных: JSON.
SimpleScraper — другой парсер в виде расширения для браузера Chrome. Установив это расширение в свой Chrome, парсинг веб-сайтов станет удобным и бесплатным, поскольку вы сможете превратить любой веб-сайт в API. Расширение позволит очень быстро извлекать с веб-страниц структурированные данные. При этом оно работает на всех веб-сайтах, включая те из них, на которых используется много кода на языке JavaScript. Если вам нужен более гибкий вариант данного инструмента, то можете обратить внимание на облачное решение от тех же разработчиков, но оно платное.
Agenty Scraping Agent
- Стоимость: бесплатно.
- Бесплатное пробное использование: 14-дневный бесплатный пробный период с сотней «кредитов», которые можно потратить на парсинг веб-страниц.
- Формат вывода данных: электронные таблицы Google, CSV и Excel.
- Услуга ротации IP-адресов.
С помощью Agenty Scraping Agent вы можете начать собирать данные с веб-страниц, не думая о блоках. Это платный инструмент, но разработчики предлагают и бесплатную пробную версию. Agenty Scraping Agent разработан для современной Всемирной паутины и поэтому может без проблем собирать данные с веб-сайтов, активно использующих JavaScript. Интересно, что инструмент при этом довольно хорошо работает на старых веб-сайтах.
Прокси-серверы для парсинга веб-сайтов
Прокси-серверы действительно необходимы, если только вы не используете API для парсинга, который обычно считается затратным решением. Когда речь идет о прокси-серверах для парсинга веб-сайтов, пользователям советуют обратиться к поставщикам прокси-серверов с резидентными сменными IP-адресами, которые уберегут их от сложностей управления прокси-серверами. Ниже представлены три лучших доступных на рынке сервиса для ротации IP-адресов.
Luminati
- Размер пула прокси-серверов: более 72 миллионов.
- Расположение прокси-серверов: все страны мира.
- Возможность параллельной работы: без ограничений.
- Допустимая пропускная способность: от 40 ГБ.
- Стоимость: начинается с $500 в месяц за 40 ГБ.
Luminati, пожалуй, — лучший поставщик прокси-серверов на рынке. Он обладает крупнейшей в мире сетью прокси-серверов с более 72 миллионов резидентных IP-адресов в своем пуле прокси-серверов. Он остается одним из самых безопасных, надежных и быстрых решений. Интересно, что Luminati совместим с большинством популярных веб-сайтов, существующих сегодня во Всемирной паутине. У Luminati есть лучшая система управления сессиями, поскольку она позволяет вам определять сроки хранения сессий. Также Luminati обладает прокси-серверами со скоростной ротацией IP-адресов, которые меняют IP-адрес после каждого запроса. Однако у Luminati высокая стоимость.
Smartproxy
- Размер пула прокси-серверов: более 10 миллионов.
- Расположение прокси-серверов: 195 географических пунктов по всему миру.
- Возможность параллельной работы: без ограничений.
- Допустимая пропускная способность: от 5 ГБ.
- Стоимость: начинается с $75 в месяц за 5 ГБ.
Smartproxy обладает пулом резидентных прокси-серверов, в который входят более 10 миллионов IP-адресов. Прокси-серверы Smartproxy довольно неплохо показывают себя при парсинге веб-сайтов благодаря системе управления сессиями. У Smartproxy есть прокси-серверы, которые могут хранить сессию и один и тот же IP-адрес в течение десяти минут, что идеально для парсинга веб-сайтов, основанных на авторизации пользователей. Для обычных веб-сайтов вы можете использовать прокси-серверы со скоростной ротацией, которые меняют IP-адрес после каждого запроса. Прокси-серверы Smartproxy располагаются приблизительно в 195 странах и в восьми крупных городах по всему миру.
Crawlera
- Размер пула IP-адресов: точное количество не разглашается, но, вероятно, десятки тысяч.
- Расположение прокси-серверов: не отличается большим количеством пунктов размещения.
- Допустимая пропускная способность: без ограничений.
- Стоимость: начинается с $99 за 200 000 запросов.
Crawlera позволяет вам фокусироваться на самих данных, помогая присматривать за прокси-серверами. Crawlera выглядит ущербно по сравнению с Luminati, если говорить о количестве имеющихся в системе IP-адресов.
Но в отличие от Luminati, при использовании которого вы можете наткнуться на капчи, Crawlera применяет некоторые приемы, гарантирующие получение запрашиваемых вами веб-страниц. Однако у Crawlera нет прокси-серверов, размещенных во всех странах и разных городах по всему миру, как у Luminati. Их цены зависят от количества запросов, а не от потребляемого трафика.
Сервисы для парсинга веб-сайтов
Бывает, что вам даже не хотелось бы заниматься парсингом нужных данных, а хочется просто получить их. Если прямо сейчас вы находитесь в таком положении, то сервисы для парсинга веб-сайтов — это беспроигрышный вариант.
Scrapinghub
ScrapingHub заслужили авторитет в сфере парсинга веб-сайтов благодаря наличию как бесплатных, так и платных инструментов, предназначенных для разработчиков парсеров. Помимо этих инструментов, у ScrapingHub также есть сервис предоставления данных, в котором нужно всего лишь описать необходимые вам данные, и вам отправят стоимость их извлечения. Более 2 000 компаний воспользовались данным сервисом для обеспечения своей работы.
ScrapeHero
ScrapeHero — еще один сервис парсинга веб-сайтов, к которому можно обратиться, чтобы собрать нужные вам данные в том случае, если вы не хотите испытать на себе все сложности самостоятельного парсинга данных. ScrapeHero — гораздо более молодая компания по сравнению со Scrapinghub, но довольно востребованная среди предпринимателей. С помощью ScrapeHero вы можете получить данные о рынке недвижимости, данные из прессы, данные из социальных медиа и прочие данные. Чтобы узнать расценки сервиса, вам нужно связаться с разработчиками.
Octoparse Data Scraping Service
Octoparse известны тем, что предоставляют не только приложение для настольных компьютеров для парсинга веб-сайтов, но и облачное решение. Кроме того, у них есть сервис для парсинга, в рамках которого они с гордостью предлагают предпринимателям услуги парсинга данных. С помощью этого сервиса вы можете получать данные из социальных медиа, данные из веб-сайтов электронной коммерции, данные о розничной торговле, вакансии и другие данные, которые можно найти во Всемирной паутине.
PromptCloud
Если вы не хотите усложнять себе жизнь парсерами, прокси-серверами, серверами, инструментами для решения капч и прикладными интерфейсами для парсинга веб-сайтов, то PromptCloud — ваш выбор. Для использовании PromptCloud вам нужно всего лишь отправить свои требования к данным и ожидать их довольно оперативной доставки в нужном вам формате. Благодаря PromptCloud вы получаете очищенные данные с веб-страниц без каких-либо технических трудностей. Это полностью управляемый пользователем сервис с прекрасной службой поддержки.
FindDataLab
FindDataLab — поставщик услуг по парсингу веб-сайтов, который позволяет вам извлекать данные из Всемирной паутины, а также отслеживать цены и управлять репутацией. С помощью данного сервиса любой веб-сайт можно превратить в данные нужного формата. От вас требуется только охарактеризовать необходимые вам данные, после чего с вами свяжутся и сообщат стоимость их извлечения.
Заключение
Глядя на этот список инструментов для парсинга веб-сайтов, в котором сначала приводятся инструменты для разработчиков, а затем инструменты для людей без навыков программирования, вы согласитесь, что парсинг веб-сайтов стал проще.
И благодаря множеству доступных инструментов, у вас настолько широкий выбор, что если какие-то инструменты вам не подойдут, то другие будут в самый раз. У вас больше нет причин отказываться от анализа данных, потому что парсеры помогут вам вытаскивать их из веб-страниц.
| Парсинг — это процесс извлечения информации из сайтов. Научиться этому можно достаточно быстро, 30-40 минут достаточно чтобы понять принципы и потом использовать этот навык для повседневной работы. Соответственно, многие хотят научиться создавать парсеры самостоятельно. Например, для тех, кто самостоятельно делаем автоматизацию в интернет-магазинах, часто нужно делать парсинг интернет-магазинов: выгрузить картинки или описания товаров (с характеристиками) с сайта поставщика. |
Перейти в парсер
Регистрация |
Чему вы научитесь, используя эту инструкцию?
1) самостоятельно делать простые парсеры.
2) массово выгружать информацию из категорий товаров.
3) выгружать данные в файлы YML,Excel,CSV,JSON.
Видео-инструкция по созданию парсера
Создадите настройку для нового парсера
На следующем шаге введите ссылку на карточку товара и на категорию
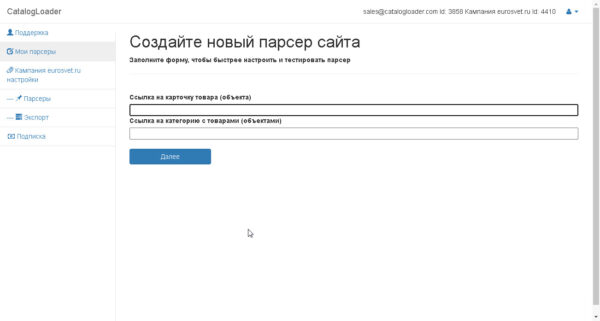
Для примера ввели ссылки для сайта eurosvet.ru
Карточка товара
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki/podvesnoy-svetilnik-so-steklyannym-plafonom-50208-1-yantarnyy-a052491
Ссылка на категорию
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
и нажмите на кнопку «Далее»
и вы попадете на страницу где будет настраиваться парсер для вашего конкретного сайта.
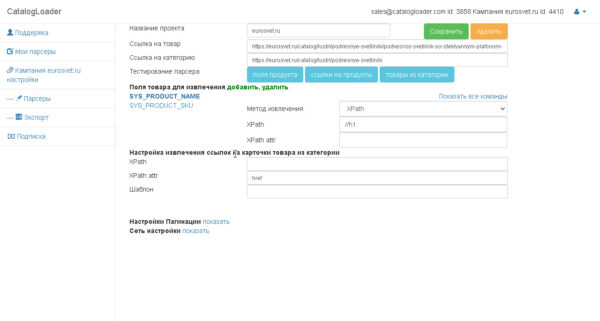
Настройка парсера
Можно выделить следующие этапы в настройке парсера сайта:
1. Настройка извлечения полей для конкретного продукта.
2. Настройка извлечения ссылок на карточки товаров из категории.
3. Настройка пагинаций (на английском pagination).
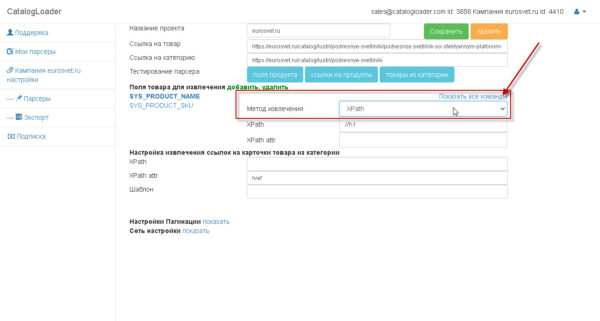
1. Настройка извлечения полей для конкретного продукта.
Важно! как только вы настроили поле, то тестируйте его извлечение через кнопку «Поля продукта».
И вы увидите как отработает парсер для вашего продукта.
Блок, который отвечает за извлечение полей — отмечен на картинке:
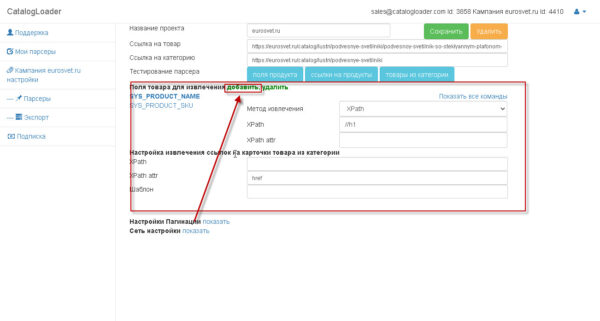
чтобы добавить новые поле -нажимайте на кнопку «добавить», если надо удалить,то ,сперва, надо выделить соответствующее поле, а потом кликнуть на соответствующую кнопку.
На следующей картинке показан диалог добавления новых полей.
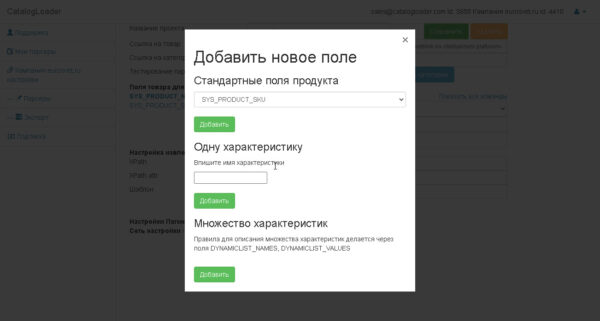
Есть 3 вида полей.
1) простые(базовые). — SYS_PRODUCT_SKU, SYS_PRODUCT_NAME, SYS_PRODUCT_MANUFACTURER и т.д.
это соответствунно Артикул, имя и производитель товара.
SYS_PRODUCT_IMAGES_ALL — это поле куда должно быть записаны все картинки продукта.
2) характеристики.-определяются характеристики товара, например, название вы можете задать самостоятельно.
3) динамические характеристики. Это тоже задает извлечение характеристик из таблицы значений.
для этого нужно будет задать DYNAMICLIST_NAMES, DYNAMICLIST_VALUES поля таким образом чтобы количество извлекаемых названий и значений было одинаково.
Как извлекать значения
Для любого поля можно указать как оно будет извлекаться.
Есть два варианта:
1)Xpath
2)RegEx (Regular Expresstion)- регулярное выражение.
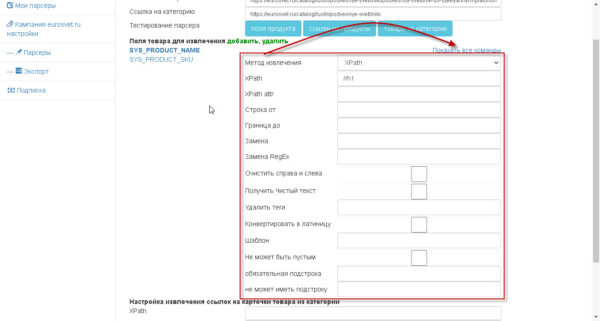
дополнительно к командам можно добавить дополнительную обработку.
2. Настройка извлечения ссылок на карточки товаров из категории.
Важно! как только вы настроили «извлечение ссылок на карточки продуктов из категории», то тестируйте его извлечение через кнопку «ссылки на продукты». И вы увидите как отработает парсер для вашей категории. Ссылки соберутся без пагинаций.
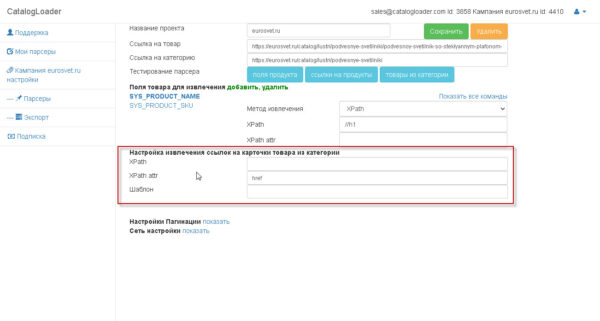
поле «Шаблон» в этой области нужно для того чтобы задать абсолютный путь для ссылки,если это необходимо. Обычно оставляется пустым.
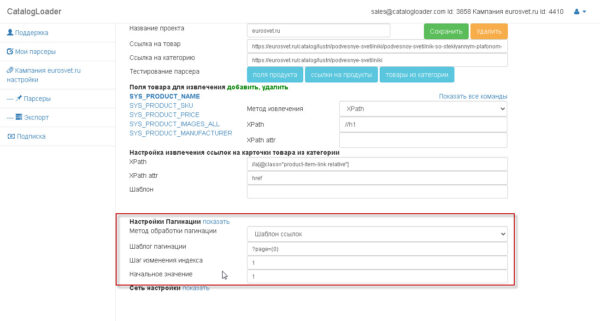
3. Настройка пагинаций (на английском pagination).
Если вы уже дошли до этого шага, то это значит что вы уже сделали 90% работы. После завершения настроек по пагинации чтобы протестировать парсер надо будет нажать на кнопку «товары из категории».
есть два варианта как настраивать пагинацию
1. через шаблон
2. через «следующую ссылку»
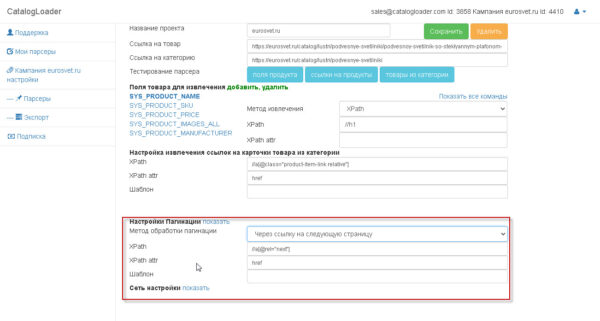
Что такое «следующая ссылка» вам поможет понять следующее изображение:
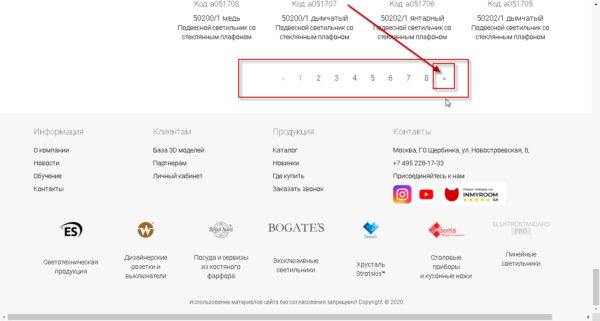
т.е. та ссылка, которая определяет переход из текущей страницы каталога на следующую.
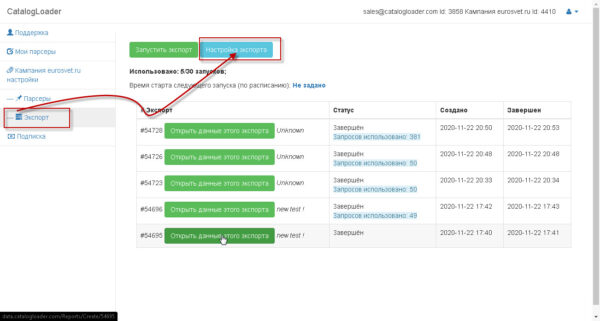
Как запускать парсер
Есть два способа:
1) из настроек парсера, путем нажатия на кнопку «товары из категории»
2) из вкладки «Экспорт», путем нажатия на кнопку «запустить экспорт»
два этих способа предложат вам следующий экран, на котором надо будет задать откуда брать «входные» ссылки
для старта парсера
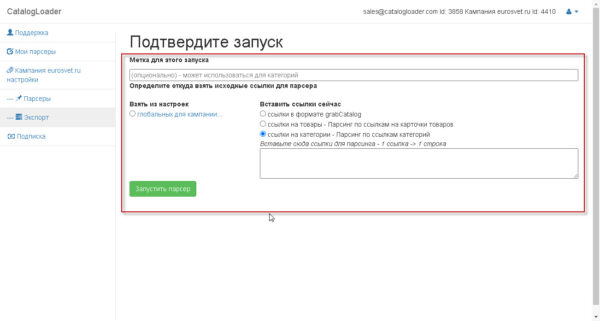
в самом простом варианте использования, вы на каждый запуск определяет ссылка или на карточки товаров или на категории,выбирая соответствующий режим работы.
Если надо задать статический список или карточек товаров или категорий, то для этого надо задать grabCatalog файл через глобальные настройки кампании один раз, а потом уже использовать каждый следующий раз вручную или через запуск по-расписанию парсера.
Что такое grabCatalog формат
Это текстовый файл, который определяет
1)иерархию категорий, которая будет извлекаться
2)названия и ссылки (опционально) на категории, которые будет извлекаться
3)ссылки на карточки товаров (опционально).
важно знать о формате
# — (знак Решетка) — определяет уровень иерархии
[path] — отделяет имя категории от ссылки на категорию
пример : 1 категория будет парсится
#Подвесные светильники[path]https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
пример : 2 категории будет парсится
#Подвесные светильники[path]https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
#Потолочные светильники[path]https://eurosvet.ru/catalog/lustri/potolochnie-svetilniki
пример : 2 категории будет парсится, но они заданы как подкатегории 1 категории верхнего уровня.
#Cветильники
##Подвесные светильники[path]https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
##Потолочные светильники[path]https://eurosvet.ru/catalog/lustri/potolochnie-svetilniki
пример : заданы 2 ссылки на продукт (задаются после названия категории).
#Cветильники
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki/podvesnoy-svetilnik-so-steklyannym-plafonom-50208-1-yantarnyy-a052491
https://eurosvet.ru/catalog/lustri/potolochnie-svetilniki/potolochnaya-lyustra-571-a052390
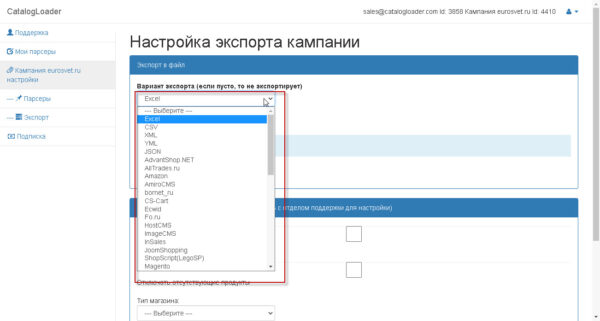
Как настроить выгрузку данных в определенный тип файла
Краткий Урок-введение в Xpath для парсинга сайтов с примерами.
Для выбора тегов и наборов тегов в HTML документе XPath использует выражения путей. Тег Извлекается следуя по заданному пути или по, так называемым, шагам.
Пример HTML файла
Для примера будет использоваться следующий HTML файл

Выбор тегов (как извлечь конкретные теги через XPath)
Чтобы извлечь теги в HTML документе, XPath использует выражения. Тег Извлекается по заданному пути. Наиболее полезные выражения пути:
| Xpath Выражение | Результат |
|---|---|
| имя_тега | Извлекает все узлы с именем «имя_тега» |
| / | Извлекает от корневого тега |
| // | Извлекает узлы от текущего тега, соответствующего выбору, независимо от их местонахождения |
| . | Извлекает текущий узел |
| .. | Извлекает родителя текущего тега |
| @ | Извлекает атрибуты |
Некоторые выборки по HTML документу из примера:
| Xpath Выражение | Результат |
|---|---|
| messages | Извлекает все узлы с именем «messages» |
| /messages | Извлекает корневой элемент сообщений Важно знать!: Если путь начинается с косой черты ( / ), то он всегда представляет абсолютный путь к элементу! |
| messages/note | Извлекает все элементы note, являющиеся потомками элемента messages |
| //note | Извлекает все элементы note независимо от того, где в документе они находятся |
| messages//note | Извлекает все элементы note, являющиеся потомками элемента messages независимо от того, где они находятся от элемента messages |
| //@date | Извлекает все атрибуты с именем date |
Предикаты
Предикаты позволяют найти конкретный Тег или Тег с конкретным значением.
Предикаты всегда заключаются в квадратные скобки [].
В следующей таблице приводятся некоторые выражения XPath с предикатами, позволяющие сделать выборки по HTML документу из примера
| Xpath Выражение | Результат |
|---|---|
| /messages/note[1] | Извлекает первый элемент note, который является прямым потомком элемента messages. Важно знать!: В IE 5,6,7,8,9 первым узлом будет [0], однако согласно W3C это должен быть [1]. Чтобы решить эту проблему в IE, нужно установить опцию SelectionLanguage в значение XPath. В JavaScript: HTML.setProperty(«SelectionLanguage»,»XPath»); |
| /messages/note[last()] | Извлекает последний элемент note, который является прямым потомком элемента messages. |
| /messages/note[last()-1] | Извлекает предпоследний элемент note, который является прямым потомком элемента messages. |
| /messages/note[position()<3] | Извлекает первые два элемента note, которые являются прямыми потомками элемента messages. |
| //heading[@date] | Извлекает все элементы heading, у которых есть атрибут date |
| //heading[@date=»11/12/2020″] | Извлекает все элементы heading, у которых есть атрибут date со значением «11/12/2020» |
Выбор неизвестных заранее тегов
Чтобы найти неизвестные заранее узлы HTML документа, XPath позволяет использовать специальные символы.
| Спецсимвол | Описание |
|---|---|
| * | Соответствует любому тегу элемента |
| @* | Соответствует любому тегу атрибута |
| node() | Соответствует любому тегу любого типа |
Спецсимволы, пример выражения XPath со спецсимволами:
| Xpath Выражение XPath | Результат |
|---|---|
| /messages/* | Извлекает все элементы, которые являются прямыми потомками элемента messages |
| //* | Извлекает все элементы в документе |
| //heading[@*] | Извлекает все элементы heading, у которых есть по крайней мере один атрибут любого типа |
Если надо выбрать нескольких путей
Использование оператора | в выражении XPath позволяет делать выбор по нескольким путям.
В следующей таблице приводятся некоторые выражения XPath, позволяющие сделать выборки по демонстрационному HTML документу:
| Xpath Выражение XPath | Результат |
|---|---|
| //note/heading | //note/body | Извлекает все элементы heading И body из всех элементов note |
| //heading | //body | Извлекает все элементы heading И body во всем документе |
Парсеры новостных сайтов достаточно востребованы, например, если у вас новостой агрегатор, или, к примеру, вам нужно собирать местные новости из различных ресурсов для показа на своем сайте с географическим таргетированием, то вам необходим парсер. Также данные новостных агенств и СМИ часто используются для проведения исследований, машинного обучения и анализа. Распарсить новостую ленту на большинстве ресурсов, как правило, несложно, именно поэтому мы возьмем один из простых сайтов, а именно РИА Новости и научим вас писать парсеры самостоятельно.
Мы будем использовать Google Chrome как наш основной инструмент для работы с сайтом, и для начала мы советуем вам поставить расширение для Google Chrome: Quick Javascript Switcher — оно позволит вам быстро выключать и включать Javascript для сайтов. Это используется для того, чтобы быстро определить как именно данные выводятся на страницу: на стороне сервера или с помошью Javascript (это могут быть данные, внедренные в JS на странице, скрытый блок на странице, который включается JS или же данные забираются дополнительным XHR запросом).
Давайте откроем страницу с лентой https://ria.ru/lenta/ в нашем браузере и отключим JS для сайта с помощью расширения которое мы поставили ранее:
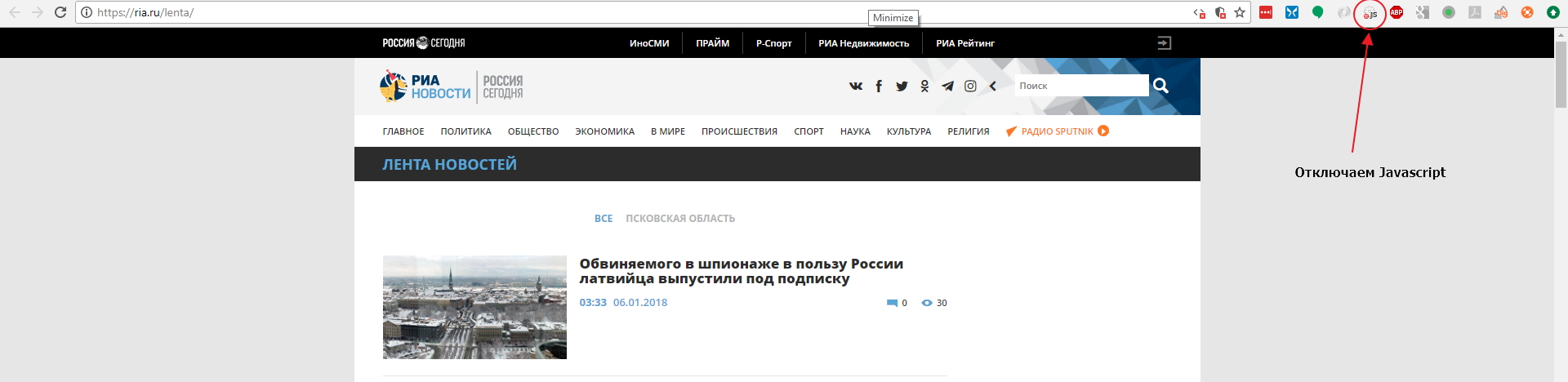
Мы увидим что данные ленты отображаются в браузере. Это означает, что новостная лента формируется на стороне сервера и мы сможем забрать данные просто загрузив страницу в парсер. Однако на странице показано только 20 последних заголовков и что же нам делать если нужно забирать 200 последних? Нам придется изучить механизм работы пагинатора. На разных сайтах пагинаторы работают по разному, поэтому не существует универсального решения и для каждого сайта вам придется разбираться в механизме его работы.
Откроем Chrome Dev Tools — инструменты для разработчика, которые встроены в Google Chrome. Для этого кликнем правой кнопкой мыши в любом месте страницы и выберем опцию «Показать код»:
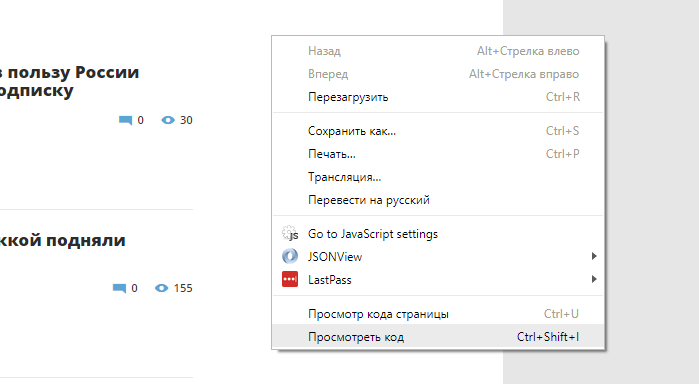
После этого у вас откроется интерфейс разработчика:
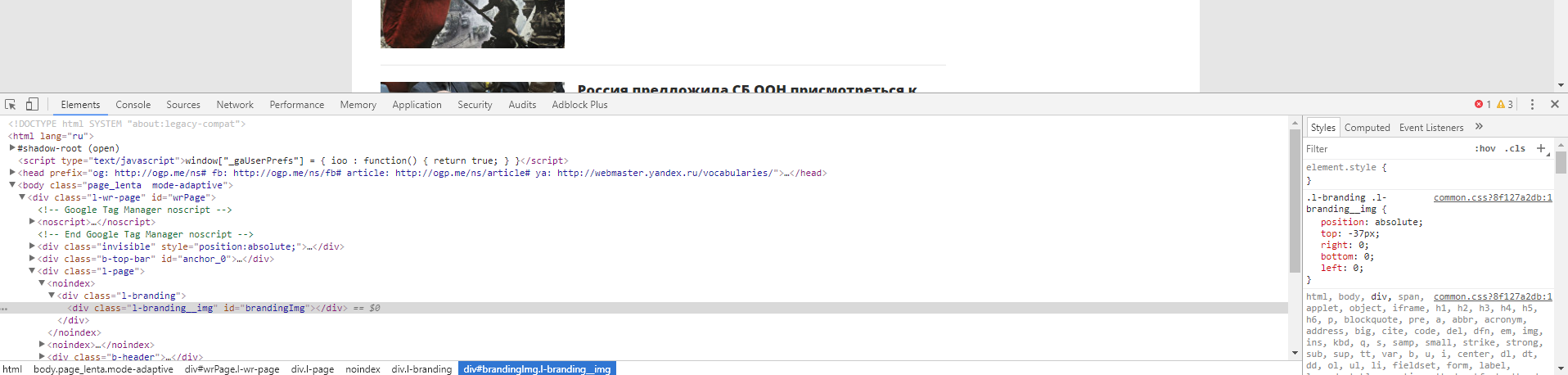
В основном мы будем взаимодействовать с вкладками Elements и Network. Elements — поможет нам работать с DOM структурой, находить элементы страницы, проверять CSS селекторы, искать CSS селекторы и содержимое, и так далее. Во вкладке Network мы можем изучать запросы, которые делает браузер к серверу. Это потребуется нам для нахождения XHR или JS запросов, или же если нам нужно изучить структуру какого-либо запроса (заголовки, куки и тд) для точной имитации его в парсере. Если вы незнакомы с инструментами для разработчика, мы рекомендуем вам посмотреть следующее обзорное видео: Chrome DevTools. Обзор основных возможностей веб-инспектора.
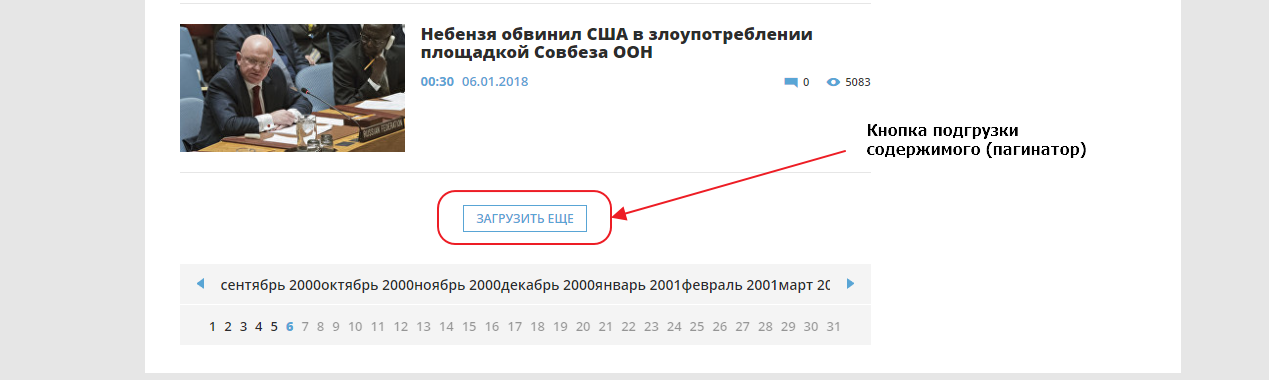
Сейчас нам нужно добраться до конца страницы и найти там пагинатор. Мы видим что здесь он организован как одна кнопка «ЗАГРУЗИТЬ ЕЩЕ», которая подгружает следующие 20 записей используя XHR (Ajax) запрос, то есть если вы кликните на кнопку, ничего не произойдет, поскольку мы выключили Javascript для этого сайта.
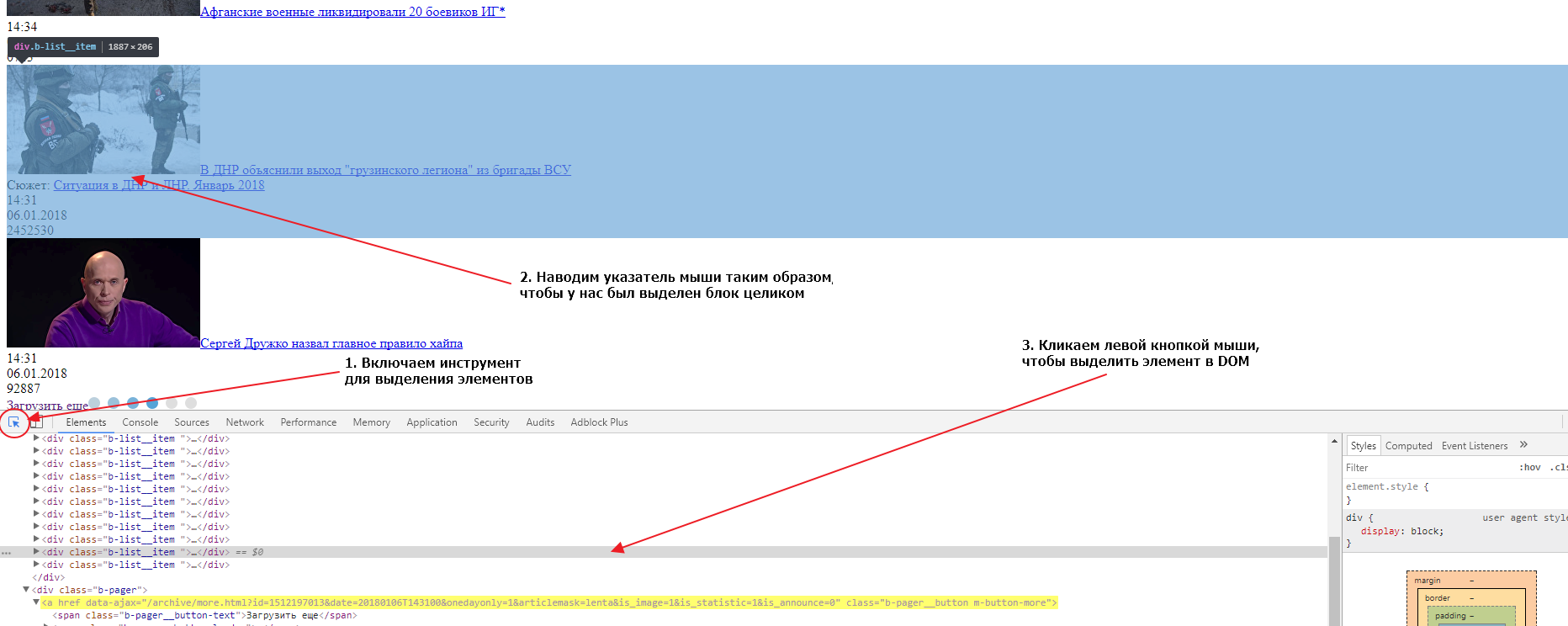
Первым делом найдем эту кнопку в элементах. Для того, чтобы это сделать быстро, можно воспользоваться специальным инструментом для выбора элемента на странице:
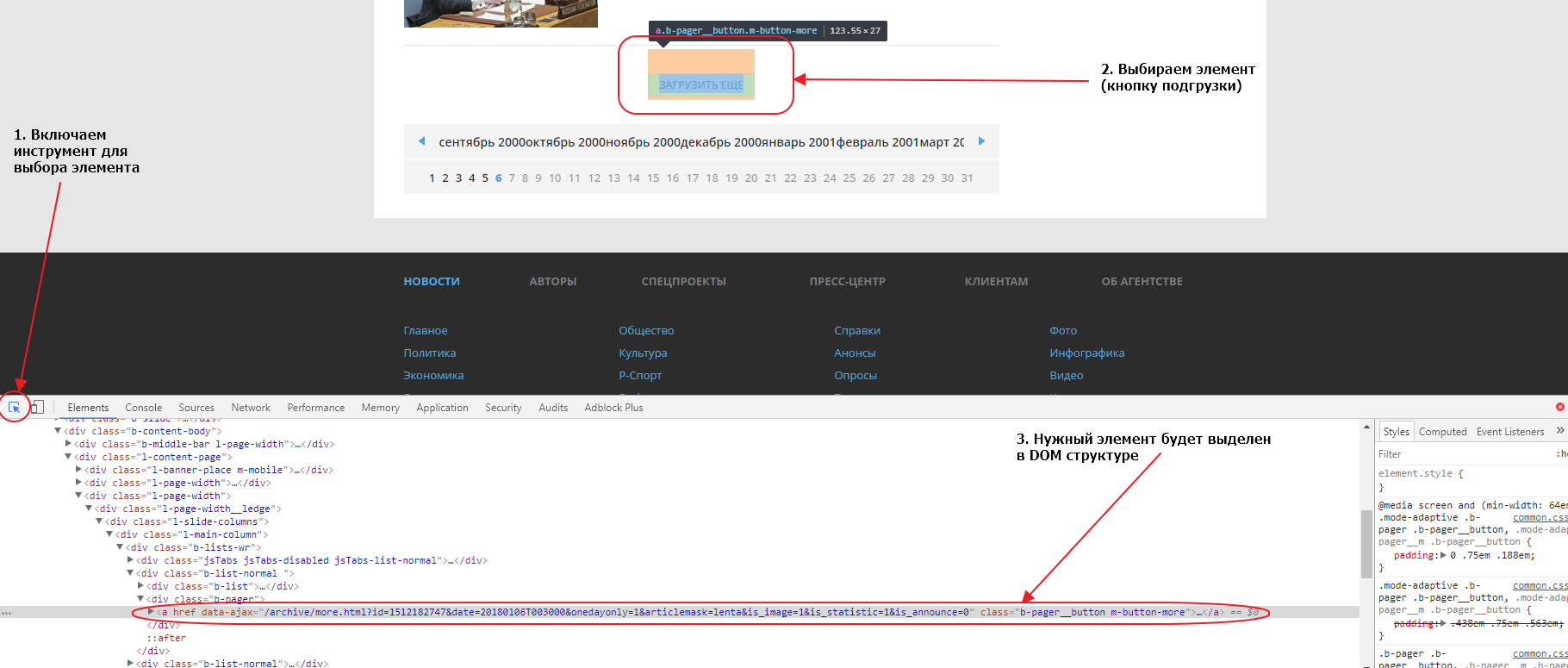
Если мы внимательно посмотрим на элемент, мы увидим что атрибут href у него пустой. Именно поэтому ничего не происходит при нажатии на линк, если отключен Javascript. Однако, мы видим что URL, используемый для подгрузки, указан в атрибуте data-ajax, именно этот URL и используется JS для подгрузки следующих 20 записей при нажатии на кнопку. Так как URL нам известен, нам совершенно не нужно анализировать запросы во вкладке Network. Соответсвенно, чтобы забрать следующие 20 записей, нам нужно забрать парсером этот URL:
https://ria.ru/archive/more.html?id=1512199556&date=20180106T154008&onedayonly=1&articlemask=lenta&is_image=1&is_statistic=1&is_announce=0.
Если загрузить в новой вкладке браузера этот URL мы получим следующие 20 записей и увидим что там тоже есть кнопка для загрузки следующих записей. Теперь нам нужно найти селектор (CSS селектор) для этого элемента. Сделаем это во второй вкладке, в которой у нас загружены вторые 20 записей. Также открываем в этой вкладке инструменты разработчика и выбираем элемент-ссылку «Загрузить еще», так, чтобы элемент выделился в DOM структуре. Теперь нужно кликнуть правой кнопкой мыши на элементе, затем выбрать опцию Copy и следом опцию Copy selector:
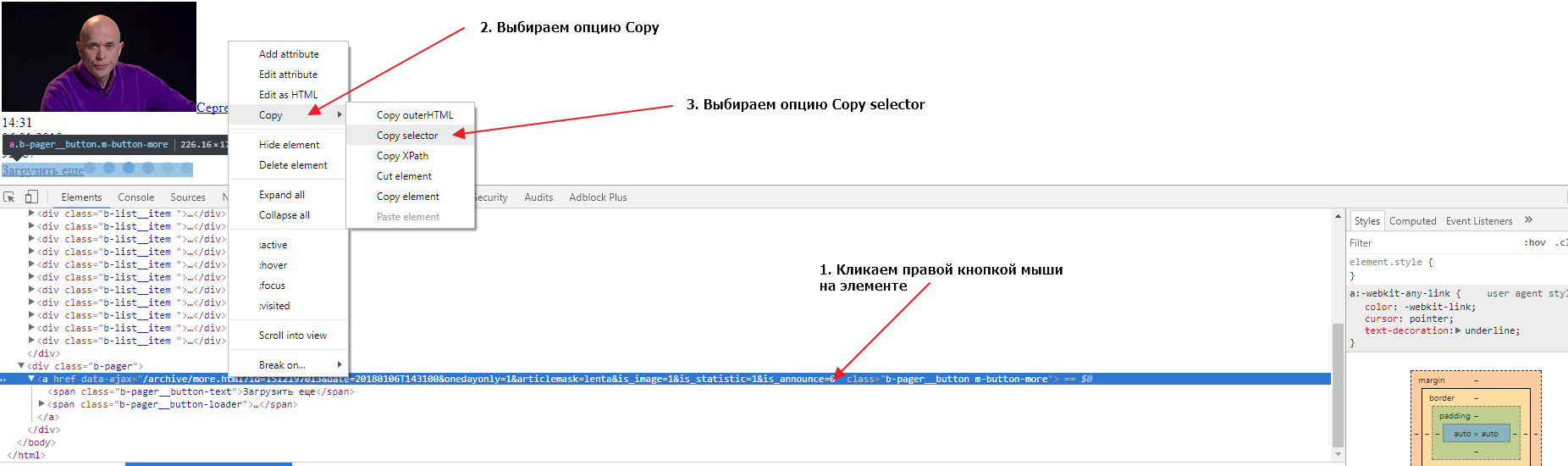
Давайте проверим, выбирает ли наш селектор ровно один элемент во второй и первой вкладке браузера. Для этого нужно в инструментах разработчика сделать активной вкладку Elements, нажать сочетание клавиш CTRL + F и в открывшуюся форму вставить наш селектор:

Мы видим, что селектор выбирает только один элемент, что очень хорошо. Если бы селектор выбирал несколько элементов, нам бы пришлось проверить все выбранные элементы и, либо подкорректировать селектор, так чтобы он выбирал только один элемент, либо в парсере брать срез найденных по селектору элементов, поскольку нам нужен только один элемент.
Тоже самое нужно сделать для другой вкладки, там где у нас открыта начальная страница. Сделать это нужно, чтобы удостовериться, что селекторы одинаковые на основной странице и на странице подгрузки. Иметь одну логику работы всегда лучше чем несколько, поэтому принцип унификации очень важен, в том числе и для подбора CSS селекторов. Если мы попробуем поискать наш селектор, мы обнаружим, что ничего не найдено. Дело в том, что элемент div.b-pager > a не находится в руте ноды body. Если мы уберем из пути body > и оставим только div.b-pager > a, то наш элемент будет найден в обеих вкладках и только один раз.
Мы определили, что для организации подгрузки данных в парсере, после загрузки страницы, мы должны найти элемент div.b-pager > a, забрать содержимое атрибута data-ajax и пройти по этому URL. Поскольку на страницах с подгрузкой структура элементов такая же, мы можем использовать единый логический блок. А для организации переходов по страницам мы можем использовать пул линков. Изначально мы поместим в пул только первый URL https://ria.ru/lenta/ и затем на каждой итерации мы будем добавлять в пул новый URL, который мы будем извлекать с загруженной страницы. Так мы организуем пагинацию в нашем парсере.
Теперь нам нужно определить как нам забирать новости со страниц, для этого нам нужно найти главный элемент блока в который обернута каждая новость. Сделать это мы можем точно так же, как мы делали это для кнопки подгрузки данных:
Если вы внимательно посмотрите на DOM структуру, вы увидите, что каждая новость обернута в элемент div с классом b-list__item. Таких элементов на странице ровно 20. Это и есть элемент, который нам нужен и CSS селектор для него будет div.b-list__item. Давайте сейчас проверим, насколько верно мы определили селектор для обеих вкладок (страницы с подгрузкой и основной страницы). Делаем мы это так же как мы проверяли валидность селектора для кнопки подгрузки. На обеих страницах селектор найдет по 20 элементов, значит наш селектор верен и мы можем его использовать.
Наш парсер на каждой странице должен находить этот селектор, и затем для каждого найденного элемента создавать новый объект данных, проходить в дочерние элементы, извлекать данные и записывать их в поля этого объекта данных, записывать объект данных в базу данных.
Давайте откроем один из элементов. Посмотрим какие у него есть дочерние элементы и какие данные нам нужны:

URL до страницы с новостью — находится просто в теге a, у этого тега нет класса или других атрибутов, кроме href. Поэтому единственный селектор, который мы можем использовать — a. Обратите внимание, что селекторы мы строим относительно родительского блока, поскольку мы в нем находимся, а не относительно всей страницы. Однако при таком селекторе если в блоке новости друг окажется еще один тег a в наших данных будет записан только последний, а нам нужен первый, поэтому мы можем брать срез элементов (элемент с номером 0) или же мы можем проверять в нашем a наличие дочернего элемента span с классом b-list__item-title. В последнем случае наш селектор будет выглядеть как a:haschild(span.b-list__item-title).
Изображение — нам нужно забрать URL до зображения, который находится в атрибуте src тега img. У этого тега есть атрибут itemprop=»associatedMedia», который выглядит достаточно надежным признаком для выборки нужного тега img. Поэтому мы можем использовать его в CSS селекторе: img[itemprop=»associatedMedia»].
Заголовок — здесь нет никаких подводных камней, наш заголовок находится в элементе span с классом b-list__item-title, поэтому CSS селектор будет таким: span.b-list__item-title.
Время и Дата — так же просто как и заголовок, получаем селекторы div.b-list__item-time и div.b-list__item-date соответственно.
Количество комментариев и Количество просмотров — находятся в элементах span с классом b-statistic__number, то так как в текущем блоке по такому селектору будут найдены оба элемента, то мы можем либо использовать срезы для выбора определенного элемента, либо использовать родительский элемент как часть селектора. В первом случае родительский элемент — это тег span с классом m-comments, и наш селектор получается таким span.m-comments > span.b-statistic__number. Во втором случае, родительский тег span с классом m-views формирует CSS селектор: span.m-views > span.b-statistic__number.
Вот мы и определили все селекторы для выбора полей которые нам надо собрать. Также давайте ограничим количество забираемых новостей, сделаем так чтобы парсер забирал 200 первых новостей (или 10 страниц). Мы можем организовать это с помощью счетчика, будем считать количество загруженных страниц и если счетчик примет значение более 9, просто не будем добавлять новый линк в пул. Займемся теперь написанием конфигурации парсера:
---
config:
debug: 2
agent: Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14
do:
# Устанавливаем счетчик страниц равным 1
- counter_set:
name: pages
value: 1
# Добавляем начальный URL в пул
- link_add:
url:
- https://ria.ru/lenta/
# Начинаем итерацию по пулу с последовательной загрузкой страниц из пула
- walk:
to: links
do:
# Делаем паузу 2 секунды для уменьшения нагрузки на сервер источника
- sleep: 2
# Находим кнопку подгрузки
- find:
path: div.b-pager > a
do:
# Считываем в регистр значение счетчика pages
- counter_get: pages
# проверяем если значение регистра больше 9
- if:
type: int
gt: 9
else:
# если значение меньше 9 - парсим значение аттрибута data-ajax текущего элемента в регистр
- parse:
attr: data-ajax
# делаем нормализацию значения в регистре, убираем лишние пробелы, унифицируем пробельные символы в ASCII пробелы
- space_dedupe
# удаляем все ведущие и завершающие пробелы значения в регистре, если они есть
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и добавляем линк в пул
- normalize:
routine: url
- link_add
# Находим все блоки с новостями и начинаем итерировать по найденным элементам
- find:
path: div.b-list__item
do:
# создаем новый объект данных с именем item
- object_new: item
# находим элемент с URL к странице с новостью
- find:
path: a:haschild(span.b-list__item-title)
do:
# парсим значение атрибута href в регистр
- parse:
attr: href
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле url объекта item
- normalize:
routine: url
- object_field_set:
object: item
field: url
# находим элемент с заголовком новости
- find:
path: span.b-list__item-title
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле headline объекта item
- object_field_set:
object: item
field: headline
# находим элемент с изображением
- find:
path: img[itemprop="associatedMedia"]
do:
# парсим значение атрибута src текущего элемента в регистр
- parse:
attr: src
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# проверяем, если значение в регистре содержит любой буквенный, цифровой символ, или символ подчеркивания
- if:
match: w+
do:
- normalize:
routine: url
# если такой символ найден, делаем нормализацию значения в регистре, используя режим url и сохраняем значение в поле image объекта item
- object_field_set:
object: item
field: image
# находим элемент с временем
- find:
path: div.b-list__item-time
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле time объекта item
- object_field_set:
object: item
field: time
# находим элемент с датой
- find:
path: div.b-list__item-date
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле date объекта item
- object_field_set:
object: item
field: date
# находим элемент с количеством комментариев
- find:
path: span.m-comments > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле comments объекта item
- object_field_set:
object: item
field: comments
# находим элемент с количеством просмотров
- find:
path: span.m-views > span.b-statistic__number
do:
# парсим текстовое содержимое текущего элемента в регистр
- parse
# проводим стандартную нормализацию данных
- space_dedupe
- trim
# сохраняем значение регистра в поле views объекта item
- object_field_set:
object: item
field: views
# сохраняем объект данных item в базу данных
- object_save:
name: item
# увеличиваем значение счетчика pages на 1
- counter_increment:
name: pages
by: 1Вам осталось создать новый диггер на платформе Diggernaut, перенести в него этот сценарий и запустить. Надеемся что этот материал был полезен и помог вам в изучении нашего мета-языка.
Удачного парсинга!
В этой статье мы познакомимся с парсингом сайтов (web scraping), который можно использовать, например, для пополнения базы email-адресов, создания сводки новостных лент, сравнения цен на один продукт среди нескольких коммерческих ресурсов или извлечения данных из поисковых машин.
Мы рассмотрим парсинг через API сайтов — такой подход достаточно прост и не требует парсинга всей страницы. Он может не работать, если владельцами ресурса установлены специальные настройки, но в большинстве случаев является неплохим решением.
Как это работает?
Примерно так: парсер посылает странице get-запрос, получает данные в виде HTML / XML и извлекает их в желаемом формате. Для загрузки файлов через консоль подходит утилита WGET, но можно выбрать и любой другой подходящий инструмент на просторах Сети.
Мы будем использовать написанный для Node.js программный пакет osmosis, включающий селектор css3/xpath и небольшой http-обработчик. Есть и другие фреймворки вроде Webdriver и CasperJS, но в данном случае они нам не понадобятся.
Настраиваем проект
- Устанавливаем Node.js, поставляемый с менеджером пакетов npm.
- Создаём новую папку, например,
webscrap. - Переходим в неё:
cd webscrap. - Запускаем из консоли
npm initдля создания файлаpackage.json. - Запускаем
npm i osmosis --save, чтобы установить пакет для парсинга. Дополнительных зависимостей, кроме как от обработчика и селектора, у него не будет. - Открываем
package.jsonи создаём новый стартовый скрипт для последующего запуска командыnpm start.
Итоговый package.json будет выглядеть примерно так:
{
"name": "webscrap",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"start": "node index"
},
"dependencies": {
"osmosis": "^1.1.2"
}
}Создаём файл index.js, в нём будем делать всю работу.
Парсим информативный заголовок в Google
Это самый базовый пример, с помощью которого мы познакомимся с пакетом и запустим первый Node-скрипт. Помещаем код ниже в файл index.js и запускаем из консоли команду npm start. Она выведет заголовок веб-страницы:
const osmosis = require('osmosis');
osmosis
.get('www.google.com')
.set({'Title': 'title'}) // альтернатива: `.find('title').set('Title')`
.data(console.log) // выведет {'Title': 'Google'}Разберём, что делают методы. Первый метод get получает веб-страницу в сжатом формате. Следующий метод set выберет элемент заголовка, представленный в виде css3-селектора. Наконец, метод data с console.log обеспечивают вывод. Метод set также принимает строки в качестве аргумента.
Получаем релевантные результаты в Google
Допустим, мы хотим получить результаты по ключевому слову analytics. Делаем следующее:
osmosis
.get('https://www.google.co.in/search?q=analytics')
.find('#botstuff')
.set({'related': ['.card-section .brs_col p a']})
.data(function(data) {
console.log(data);
})Вот и всё. Этот код извлечёт все соответствующие ключевые слова с первой страницы результатов поиска, поместит их в массив и запишет в лог в консоли. Логика, стоящая за этим, такова: мы сначала анализируем веб-страницу через инструменты разработчика, проверяем блок, в котором находится слово (в данном случае это div #botstuff), и сохраняем его в массив через селектор .card-section .brs_col p a, который найдёт все соответствующие ключевые слова на странице.
Увеличиваем количество страниц при релевантном поиске
Для этого нужно добавить цепочку вызовов (chaining method), вычислив атрибут href у тега anchor (<a>). Мы ограничимся пятью страницами, чтобы Google не посчитал нас за бот. Если необходимо выставить время между парсингом соседних страниц, добавляем метод .delay(ms) после каждого .paginate().
osmosis
.get('https://www.google.co.in/search?q=analytics')
.paginate('#navcnt table tr > td a[href]', 5)
.find('#botstuff')
.set({'related': ['.card-section .brs_col p a']})
.data(console.log)
.log(console.log) // включить логи
.error(console.error) // на случай нахождения ошибкиПарсим адреса электронной почты с сайта Shopify
В данном случае мы будем собирать email-адреса и названия всех приложений, последовательно перемещаясь с помощью метода .follow, и потом помечать необходимые селекторы в консоли разработчика:
osmosis
.get('http://apps.shopify.com/categories/sales')
.find('.resourcescontent ul.app-card-grid')
.follow('li a[href]')
.find('.resourcescontent')
.set({
'appname': '.app-header__details h1',
'email': '#AppInfo table tbody tr:nth-child(2) td > a'
})
.log(console.log) // включить логи
.data(console.log)Код выше можно скомбинировать с методом .paginate, чтобы собрать полностью весь контент (но при этом нас могут и заблокировать).
Теперь нужно сохранить данные в файле, сделать это можно так (пример модификации кода выше, сохранение в формате json):
const fs = require('fs');
let savedData = [];
osmosis
.get(..).find(..).follow(..).find(..)
.set(..)
.log(console.log)
.data(function(data) {
console.log(data);
savedData.push(data);
})
.done(function() {
fs.writeFile('data.json', JSON.stringify( savedData, null, 4), function(err) {
if(err) console.error(err);
else console.log('Data Saved to data.json file');
})
});Вот мы и закончили с основами, продолжайте экспериментировать. Но, пожалуйста, не используйте полученные знания во вред другим пользователям Сети.
Перевод статьи «Web Scraping in Node.js with Multiple Examples»
Сегодняшний проект послужит основой многих наших дальнейших программ. Мы научимся собирать с сайтов любые данные, которые нам нужны.
У нас есть рабочий проект на цепях Маркова. Цепи Маркова — это несложный алгоритм, который анализирует сочетаемость слов в заданном тексте и выдаёт новый текст на основе старого. Похоже на работу нейронок, но на самом деле это просто перебор слов и бессмысленное их сочетание.
Для работы наших первых проектов на цепях Маркова мы скачали книгу с рассказами Чехова. Программа анализирует сочетаемость чеховских слов и выдаёт текст в чеховском духе (хотя и бессмысленный).
Но что, если мы хотим сделать текст не в духе Чехова, а в духе журнала «Код»? Или в духе какого-нибудь издания-иноагента? Или сделать генератор статей в духе какого-нибудь блогера?
Решение — написать программу, которая посмотрит на сайте наши статьи и вытащит оттуда весь значимый текст. Единственное, что для этого понадобится, — список ссылок на статьи, но мы их уже собрали, когда делали проект с гаданием на статьях Кода.
Программа будет работать на Python на локальной машине. Алгоритм:
👉 Главное в таких проектах — знать структуру содержимого страницы и понимать, где именно и в каких тегах находятся нужные для вас данные.
Чтобы было проще, на старте сделаем программу, которая собирает названия страниц. Как освоимся — сделаем что посложнее.
Прежде чем заниматься парсингом (сбором) со страницы чего угодно, нужно выяснить, где это лежит и в какой кодировке. Мы знаем, что все статьи Кода созданы по одному и тому же шаблону, поэтому нам достаточно посмотреть, как устроена одна, чтобы понять их все.
Смотрим исходный код любой нашей статьи. Нас интересуют два момента — кодировка страницы и тег <title>. Нам нужно убедиться, что в этом теге прописано название.
Эта строчка означает, что страница работает с кодировкой UTF-8. Запомним это.
Теперь пролистываем исходный код ниже и находим тег <title> — именно он отвечает за заголовок страницы. Убеждаемся, что он есть и с ним всё в порядке:
В проекте нам понадобятся две библиотеки: urllib и BeautifulSoup.
Первая отвечает за доступ к страницам по их адресу, причём оттуда нам будет нужна только одна команда urlopen().read — она отправляется по указанному адресу и получает весь исходный код страницы.
Вторая библиотека входит в состав большой библиотеки bs4 — в ней уже собраны все команды для парсинга исходного HTML-кода и разбора тегов. Чтобы установить bs4, запускаем терминал и пишем:
Теперь объявим список страниц, которые нужно посетить и забрать оттуда заголовки. Мы уже составили такой список для проекта с гаданием на статьях Кода, поэтому просто возьмём его оттуда и адаптируем под Python:
url = [
«https://thecode.media/is-not-defined-jquery/»,
«https://thecode.media/arduino-projects-2/»,
«https://thecode.media/10-raspberry/»,
«https://thecode.media/easy-css/»,
«https://thecode.media/to-be-front/»,
«https://thecode.media/cryptex/»,
«https://thecode.media/ali-coders/»,
«https://thecode.media/po-glandy/»,
«https://thecode.media/megaexcel/»,
«https://thecode.media/chat-bot-generators/»,
«https://thecode.media/wifi/»,
«https://thecode.media/andri-oxa/»,
«https://thecode.media/free-hosting/»,
«https://thecode.media/hotwheels/»,
«https://thecode.media/do-not-disturb/»,
«https://thecode.media/dyno-ai/»,
«https://thecode.media/snake-ai/»,
«https://thecode.media/leet/»,
«https://thecode.media/ninja/»,
«https://thecode.media/supergirl/»,
«https://thecode.media/vpn/ «,
«https://thecode.media/what-is-wordpress/»,
«https://thecode.media/hardware/»,
«https://thecode.media/division/»,
«https://thecode.media/nuggets/»,
«https://thecode.media/binary-notation/»,
«https://thecode.media/bootstrap/»,
«https://thecode.media/chat-bot/»,
«https://thecode.media/myadblock3000/»,
«https://thecode.media/trello/»,
«https://thecode.media/python-time/»,
«https://thecode.media/editor/»,
«https://thecode.media/timer/»,
«https://thecode.media/intro-bootstrap/»,
«https://thecode.media/php-form/»,
«https://thecode.media/hr-quiz/»,
«https://thecode.media/c-sharp/»,
«https://thecode.media/showtime/»,
«https://thecode.media/uchtel-rasskazhi/»,
«https://thecode.media/sshhhh/»,
«https://thecode.media/marry-me-python/»,
«https://thecode.media/haters-gonna-code/»,
«https://thecode.media/speed-css/»,
«https://thecode.media/fired/»,
«https://thecode.media/zabuhal/»,
«https://thecode.media/est-tri-shkatulki/»,
«https://thecode.media/milk-that/»,
«https://thecode.media/binary-mouse/»,
«https://thecode.media/bowling/»,
«https://thecode.media/dealership/»,
«https://thecode.media/best-seller/»,
«https://thecode.media/hr/»,
«https://thecode.media/no-comments/»,
«https://thecode.media/drakoni-yajca/»,
«https://thecode.media/who-is-who/»,
«https://thecode.media/get-a-room/»,
«https://thecode.media/alps/»,
«https://thecode.media/handshake/»,
«https://thecode.media/choose-life/»,
«https://thecode.media/high-voltage/»,
«https://thecode.media/spy/»,
«https://thecode.media/squirrelrrel/»,
«https://thecode.media/so-agile/»,
«https://thecode.media/wedding/»,
«https://thecode.media/supper/»,
«https://thecode.media/le-tarakan/»,
«https://thecode.media/batareyki-besyat/»,
«https://thecode.media/dr_jekyll/»,
«https://thecode.media/everybody_lies/»,
«https://thecode.media/electrician/»,
«https://thecode.media/einstein/»,
«https://thecode.media/bugz/»,
«https://thecode.media/needforspeed/»,
«https://thecode.media/be-smart/»,
«https://thecode.media/bot-online/»,
«https://thecode.media/microb/»,
«https://thecode.media/jquery/»,
«https://thecode.media/split-screen/»,
«https://thecode.media/calculus/»,
«https://thecode.media/big-data-sales/»,
«https://thecode.media/ambient/»,
«https://thecode.media/fatality/»,
«https://thecode.media/biggest-loser/»,
«https://thecode.media/wifi/»,
«https://thecode.media/nosock/»,
«https://thecode.media/variables/»,
«https://thecode.media/start_python/»,
«https://thecode.media/i-gonna-code/»,
«https://thecode.media/sigi-est/»,
«https://thecode.media/nes-game/»,
«https://thecode.media/live-view/»,
«https://thecode.media/remote/»,
«https://thecode.media/arduino-code/»,
«https://thecode.media/horses/»,
«https://thecode.media/runinstein/»,
«https://thecode.media/wp-template/»,
«https://thecode.media/tilda/»,
«https://thecode.media/todo/»,
«https://thecode.media/telebot/»,
«https://thecode.media/summator-2/»,
«https://thecode.media/get-rich-coding/»,
«https://thecode.media/content-manager/»,
«https://thecode.media/vzrosly-stal/»,
«https://thecode.media/py-install/»,
«https://thecode.media/quantum/»,
«https://thecode.media/dns/»,
«https://thecode.media/practicum/»,
«https://thecode.media/react/»,
«https://thecode.media/1september/»,
«https://thecode.media/summator/»,
«https://thecode.media/vds/»,
«https://thecode.media/made-in-china/»,
«https://thecode.media/bar/»,
«https://thecode.media/zodiac/»,
«https://thecode.media/crc32/»,
«https://thecode.media/css-links/»,
«https://thecode.media/oop_battle/»,
«https://thecode.media/be-combo/»,
«https://thecode.media/unity/»,
«https://thecode.media/data-science/»,
«https://thecode.media/junior/»,
«https://thecode.media/qc/»,
«https://thecode.media/be-middle/»,
«https://thecode.media/senior/»,
«https://thecode.media/teamlead/»,
«https://thecode.media/frontend/»,
«https://thecode.media/lift/»,
«https://thecode.media/be-fuzzy/»,
«https://thecode.media/best-2020/»,
«https://thecode.media/git/»,
«https://thecode.media/stt-cloud/»,
«https://thecode.media/matrix-pills/»,
«https://thecode.media/na-stile/»,
«https://thecode.media/no-coffee/»,
«https://thecode.media/framelibs/»,
«https://thecode.media/children/»,
«https://thecode.media/balls-possibly/»,
«https://thecode.media/le-meduza/»,
«https://thecode.media/electricity/»,
«https://thecode.media/tailored-swift/»,
«https://thecode.media/objective/»,
«https://thecode.media/host/»,
«https://thecode.media/go-public/»,
«https://thecode.media/how-internet-works-1/»,
«https://thecode.media/domain/»,
«https://thecode.media/this-is-object/»,
«https://thecode.media/ole-ole-ole/»,
«https://thecode.media/thousand/»,
«https://thecode.media/average/»,
«https://thecode.media/stt-python/»,
«https://thecode.media/ping-pong/»,
«https://thecode.media/pygames/»,
«https://thecode.media/odobreno/»,
«https://thecode.media/qwerty123/»,
«https://thecode.media/neurocorrector/»,
«https://thecode.media/neuro-cam/»,
«https://thecode.media/10-jquery/»,
«https://thecode.media/repeat/»,
«https://thecode.media/assembler/»,
«https://thecode.media/sublime-one-love/»,
«https://thecode.media/zloy/»,
«https://thecode.media/mariya-ivanovna/»,
«https://thecode.media/ruby/»,
«https://thecode.media/electron-password/»,
«https://thecode.media/plane/»,
«https://thecode.media/glitch/»,
«https://thecode.media/security/»,
«https://thecode.media/stupid-2019/»,
«https://thecode.media/jquery-search/»,
«https://thecode.media/pimp-my-pass/»,
«https://thecode.media/text-ultimate/»,
«https://thecode.media/hurry/»,
«https://thecode.media/siri/»,
«https://thecode.media/zero-cool/»,
«https://thecode.media/small-talk/»,
«https://thecode.media/die-hard/»,
«https://thecode.media/le-piton/»,
«https://thecode.media/hr-code/»,
«https://thecode.media/nano-code/»,
«https://thecode.media/the_question/»,
«https://thecode.media/godlike/»,
«https://thecode.media/be-logic/»,
«https://thecode.media/snake-js/»,
«https://thecode.media/be-mobile/»,
«https://thecode.media/baboolya/»,
«https://thecode.media/timelag/»,
«https://thecode.media/doors/»,
«https://thecode.media/phone-code/»,
«https://thecode.media/snake-arduino/»,
«https://thecode.media/css-intro/»,
«https://thecode.media/le-timer/»,
«https://thecode.media/oop_battle/»,
«https://thecode.media/good-morning/»,
«https://thecode.media/study-bot/»,
«https://thecode.media/python-bot/»,
«https://thecode.media/robot-quiz/»,
«https://thecode.media/hacking-quiz/»,
«https://thecode.media/lulz-quiz/»,
«https://thecode.media/hard-quiz/»,
«https://thecode.media/torrent/»,
«https://thecode.media/travel/»,
«https://thecode.media/le-snob/»,
«https://thecode.media/no-spagetti/»,
«https://thecode.media/house/»,
«https://thecode.media/cryptorush/»,
«https://thecode.media/coronarelax/»,
«https://thecode.media/pure/»,
«https://thecode.media/c-cpp/»,
«https://thecode.media/machine-loving/»,
«https://thecode.media/orwell/»,
«https://thecode.media/darknet/»,
«https://thecode.media/ai/»,
«https://thecode.media/oop-class/»,
«https://thecode.media/cookie/»,
«https://thecode.media/malware/»,
«https://thecode.media/ftp/»,
«https://thecode.media/html/»,
«https://thecode.media/java/»,
«https://thecode.media/php-haters/»,
«https://thecode.media/tor/»,
«https://thecode.media/crack-safe/»,
«https://thecode.media/epidemic/»,
«https://thecode.media/hash-brown/»,
«https://thecode.media/java-js/»,
«https://thecode.media/js-types/»,
«https://thecode.media/losers/»,
«https://thecode.media/ssl/»,
«https://thecode.media/uncaughtsyntaxerror-unexpected-identifier/»,
«https://thecode.media/uncaughtsyntaxerror-unexpected-token/»,
«https://thecode.media/uncaughttyperrror-cannot-read-property/»,
«https://thecode.media/mobile-dev/»,
«https://thecode.media/verevka/»,
«https://thecode.media/speed/»,
«https://thecode.media/buckwheat/»,
«https://thecode.media/distance/»,
«https://thecode.media/node-js/»,
«https://thecode.media/pascal/»,
«https://thecode.media/ill-be-clean/»,
«https://thecode.media/to-be-back/»,
«https://thecode.media/replaceable/»,
«https://thecode.media/code-review/»,
«https://thecode.media/gasoline/»,
«https://thecode.media/to-be-test/»,
«https://thecode.media/scala/»,
«https://thecode.media/row-power/»,
«https://thecode.media/percent/»,
«https://thecode.media/с/»,
«https://thecode.media/things/»,
«https://thecode.media/prof-newsletter/»,
«https://thecode.media/backend/»,
«https://thecode.media/immortal-pong/»,
«https://thecode.media/blind/»,
«https://thecode.media/go-faster/»,
«https://thecode.media/cpp/»,
«https://thecode.media/uncaught-syntaxerror-unexpected-end-of-input/»,
«https://thecode.media/stress-quiz/»,
«https://thecode.media/secret-pong/»,
«https://thecode.media/override/»,
«https://thecode.media/whg/»,
«https://thecode.media/profit/»,
«https://thecode.media/memas/»,
«https://thecode.media/digital-sound/»,
«https://thecode.media/api/»,
«https://thecode.media/be-math-2/»,
«https://thecode.media/backup/»,
«https://thecode.media/backup-master/»,
«https://thecode.media/glvrd/»,
«https://thecode.media/id/»,
«https://thecode.media/uncaught-syntaxerror-missing-after-argument-list/»,
«https://thecode.media/ex-startup/»,
«https://thecode.media/doom-everywhere/»,
«https://thecode.media/template-one/»,
«https://thecode.media/david-roganov/»,
«https://thecode.media/spacex/»,
«https://thecode.media/webstorm/»,
«https://thecode.media/json/»,
«https://thecode.media/treger/»,
«https://thecode.media/ya-blitz/»,
«https://thecode.media/radius/»,
«https://thecode.media/xhr/»,
«https://thecode.media/treger2/»,
«https://thecode.media/raidemption/»,
«https://thecode.media/chief-technical-officer/»,
«https://thecode.media/summary/»,
«https://thecode.media/ex-wallpaper/»,
«https://thecode.media/soap/»,
«https://thecode.media/decompose/»,
«https://thecode.media/desc/»,
«https://thecode.media/sprint/»,
«https://thecode.media/bye-or-die/»,
«https://thecode.media/who-win/»,
«https://thecode.media/vladimir-olokhtonov/»,
«https://thecode.media/lossless/»,
«https://thecode.media/parse/»,
«https://thecode.media/typeerror-is-not-an-abject/»,
«https://thecode.media/backup-me/»,
«https://thecode.media/stress-test/»,
«https://thecode.media/syntaxerror-missing-formal-parameter/»,
«https://thecode.media/start-fast/»,
«https://thecode.media/halkechev/»,
«https://thecode.media/halkechev2/»,
«https://thecode.media/le-design/»,
«https://thecode.media/syntaxerror-missing-after-property-id/»,
«https://thecode.media/attrb-mthd/»,
«https://thecode.media/headphones/»,
«https://thecode.media/active-noise-cancelling/»,
«https://thecode.media/remote-work-quiz/»,
«https://thecode.media/garbage/»,
«https://thecode.media/ubuntu-linux/»,
«https://thecode.media/trie/»,
«https://thecode.media/func/»,
«https://thecode.media/laravel/»,
«https://thecode.media/save-json/»,
«https://thecode.media/syntaxerror-missing-after-formal-parameters/»,
«https://thecode.media/recursion/»,
«https://thecode.media/haskell/»,
«https://thecode.media/gen/»,
«https://thecode.media/db/»,
«https://thecode.media/boosting/»,
«https://thecode.media/pavel-sviridov/»,
«https://thecode.media/mnogo/»,
«https://thecode.media/sokr/»,
«https://thecode.media/dbsm/»,
«https://thecode.media/pik-balmera/»,
«https://thecode.media/kanban/»,
«https://thecode.media/check-list/»,
«https://thecode.media/text-quiz/»,
«https://thecode.media/mysql/»,
«https://thecode.media/mysql/»,
«https://thecode.media/rust/»,
«https://thecode.media/manage-this/»,
«https://thecode.media/altshuller/»,
«https://thecode.media/interview/»,
«https://thecode.media/fotorama/»,
«https://thecode.media/tetris/»,
«https://thecode.media/ai-tetris/»,
«https://thecode.media/scrum/»,
«https://thecode.media/speed-two/»,
«https://thecode.media/quick-share/»,
«https://thecode.media/stack/»,
«https://thecode.media/mobile-first/»,
«https://thecode.media/nosql/»,
«https://thecode.media/narazves/»,
«https://thecode.media/oop-class-2/»,
«https://thecode.media/design-first/»,
«https://thecode.media/arcanoid/»,
«https://thecode.media/donut/»,
«https://thecode.media/casino/»,
«https://thecode.media/heap/»,
«https://thecode.media/rust/»,
«https://thecode.media/float/»,
«https://thecode.media/markdown/»,
«https://thecode.media/books/»,
«https://thecode.media/daniil-popov/»,
«https://thecode.media/android-developer/»,
«https://thecode.media/symbols/»,
«https://thecode.media/oauth/»,
«https://thecode.media/kotlin/»,
«https://thecode.media/todo/»,
«https://thecode.media/plotly/»,
«https://thecode.media/no-digit-code/»,
«https://thecode.media/asymmetric/»,
«https://thecode.media/qi/»,
«https://thecode.media/vernam/»,
«https://thecode.media/vernam-js/»,
«https://thecode.media/shtykov/»,
«https://thecode.media/memory/»,
«https://thecode.media/ark/»,
«https://thecode.media/7-oshibok-na-sobesedovanii/»,
«https://thecode.media/dh/»,
«https://thecode.media/typescript/»,
«https://thecode.media/stark/»,
«https://thecode.media/crypto/»,
«https://thecode.media/zapusk-2/»,
«https://thecode.media/fingerprint/»,
«https://thecode.media/puzzle/»,
«https://thecode.media/python-time-2/»,
«https://thecode.media/no-chance/»,
«https://thecode.media/lossy/»,
«https://thecode.media/1wire/»,
«https://thecode.media/pasha-flipper/»,
«https://thecode.media/perl/»,
«https://thecode.media/alexey-vasilev/»,
«https://thecode.media/viasat/»,
«https://thecode.media/podcast/»,
«https://thecode.media/copy-ya-ru/»,
«https://thecode.media/mircrosd/»,
«https://thecode.media/bash/»,
«https://thecode.media/rotation/»,
«https://thecode.media/css-grid/»,
«https://thecode.media/train/»,
«https://thecode.media/grid-2/»,
«https://thecode.media/za-proezd/»,
«https://thecode.media/grid-3/»,
«https://thecode.media/david/»,
«https://thecode.media/alien-vs-predator/»,
«https://thecode.media/grid-portfolio/»,
«https://thecode.media/podcast-lavka/»,
«https://thecode.media/it-start-2/»,
«https://thecode.media/anastasiya-nikulina/»,
«https://thecode.media/linter/»,
«https://thecode.media/bomberman/»,
«https://thecode.media/5-linters/»,
«https://thecode.media/lineynaya-algebra-vektory/»,
«https://thecode.media/no-nda/»,
«https://thecode.media/code-swap/»,
«https://thecode.media/how-to-start/»,
«https://thecode.media/referenceerror-invalid-left-hand-side-in-assignment/»,
«https://thecode.media/vectors-operations/»,
«https://thecode.media/oop-abstract/»,
«https://thecode.media/leonov/»,
«https://thecode.media/lucky-strike/»,
«https://thecode.media/browser/»,
«https://thecode.media/2020/»,
«https://thecode.media/3d-stars/»,
«https://thecode.media/anna-leonova/»,
«https://thecode.media/cold-fusion/»,
«https://thecode.media/normalize/»,
«https://thecode.media/hotkey/»,
«https://thecode.media/oven/»,
«https://thecode.media/vim/»,
«https://thecode.media/draw/»,
«https://thecode.media/visual-studio-code/»,
«https://thecode.media/tetris-2/»,
«https://thecode.media/start-now/»,
«https://thecode.media/lapsha-1/»,
«https://thecode.media/cubism/»,
«https://thecode.media/lapsha-2/»,
«https://thecode.media/zerocode/»,
«https://thecode.media/cat/»,
«https://thecode.media/static/»,
«https://thecode.media/komm/»,
«https://thecode.media/path-js/»,
«https://thecode.media/cloudly/»,
«https://thecode.media/haters-gonna-code-2/»,
«https://thecode.media/csp/»,
«https://thecode.media/mitin-says-no/»,
«https://thecode.media/hire-js/»,
«https://thecode.media/tableau/»,
«https://thecode.media/impossible/»,
«https://thecode.media/csp-on/»,
«https://thecode.media/maze/»,
«https://thecode.media/mix/»,
«https://thecode.media/le-beton/»,
«https://thecode.media/3d-print/»,
«https://thecode.media/5-and-a-half/»,
«https://thecode.media/lineynaya-zavisimost-vektorov/»,
«https://thecode.media/fast-m1/»,
«https://thecode.media/ninja-run/»,
«https://thecode.media/matrix-101/»,
«https://thecode.media/arm-x86/»,
«https://thecode.media/piano-js/»,
«https://thecode.media/10-swift/»,
«https://thecode.media/travel-plane/»,
«https://thecode.media/extention/»,
«https://thecode.media/obratnaya-matritsa/»,
«https://thecode.media/svg/»,
«https://thecode.media/freelance/»,
«https://thecode.media/brat-2/»,
«https://thecode.media/angular/»,
«https://thecode.media/rgb/»,
«https://thecode.media/10-go/»,
«https://thecode.media/coffee/»,
]
Теперь перебираем все элементы этого массива в цикле, используя всю мощь библиотек. Обратите внимание на строчку, где мы получаем исходный код страницы — мы сразу конвертируем его в нужную кодировку, которую выяснили на предыдущем этапе:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
url = [
"https://thecode.media/is-not-defined-jquery/",
"https://thecode.media/arduino-projects-2/",
"https://thecode.media/10-raspberry/",
"https://thecode.media/easy-css/",
"https://thecode.media/to-be-front/",
"https://thecode.media/cryptex/",
"https://thecode.media/ali-coders/",
"https://thecode.media/po-glandy/",
"https://thecode.media/megaexcel/",
"https://thecode.media/chat-bot-generators/",
"https://thecode.media/wifi/",
"https://thecode.media/andri-oxa/",
"https://thecode.media/free-hosting/",
"https://thecode.media/hotwheels/",
"https://thecode.media/do-not-disturb/",
"https://thecode.media/dyno-ai/",
"https://thecode.media/snake-ai/",
"https://thecode.media/leet/",
"https://thecode.media/ninja/",
"https://thecode.media/supergirl/",
"https://thecode.media/vpn/ ",
"https://thecode.media/what-is-wordpress/",
"https://thecode.media/hardware/",
"https://thecode.media/division/",
"https://thecode.media/nuggets/",
"https://thecode.media/binary-notation/",
"https://thecode.media/bootstrap/",
"https://thecode.media/chat-bot/",
"https://thecode.media/myadblock3000/",
"https://thecode.media/trello/",
"https://thecode.media/python-time/",
"https://thecode.media/editor/",
"https://thecode.media/timer/",
"https://thecode.media/intro-bootstrap/",
"https://thecode.media/php-form/",
"https://thecode.media/hr-quiz/",
"https://thecode.media/c-sharp/",
"https://thecode.media/showtime/",
"https://thecode.media/uchtel-rasskazhi/",
"https://thecode.media/sshhhh/",
"https://thecode.media/marry-me-python/",
"https://thecode.media/haters-gonna-code/",
"https://thecode.media/speed-css/",
"https://thecode.media/fired/",
"https://thecode.media/zabuhal/",
"https://thecode.media/est-tri-shkatulki/",
"https://thecode.media/milk-that/",
"https://thecode.media/binary-mouse/",
"https://thecode.media/bowling/",
"https://thecode.media/dealership/",
"https://thecode.media/best-seller/",
"https://thecode.media/hr/",
"https://thecode.media/no-comments/",
"https://thecode.media/drakoni-yajca/",
"https://thecode.media/who-is-who/",
"https://thecode.media/get-a-room/",
"https://thecode.media/alps/",
"https://thecode.media/handshake/",
"https://thecode.media/choose-life/",
"https://thecode.media/high-voltage/",
"https://thecode.media/spy/",
"https://thecode.media/squirrelrrel/",
"https://thecode.media/so-agile/",
"https://thecode.media/wedding/",
"https://thecode.media/supper/",
"https://thecode.media/le-tarakan/",
"https://thecode.media/batareyki-besyat/",
"https://thecode.media/dr_jekyll/",
"https://thecode.media/everybody_lies/",
"https://thecode.media/electrician/",
"https://thecode.media/einstein/",
"https://thecode.media/bugz/",
"https://thecode.media/needforspeed/",
"https://thecode.media/be-smart/",
"https://thecode.media/bot-online/",
"https://thecode.media/microb/",
"https://thecode.media/jquery/",
"https://thecode.media/split-screen/",
"https://thecode.media/calculus/",
"https://thecode.media/big-data-sales/",
"https://thecode.media/ambient/",
"https://thecode.media/fatality/",
"https://thecode.media/biggest-loser/",
"https://thecode.media/wifi/",
"https://thecode.media/nosock/",
"https://thecode.media/variables/",
"https://thecode.media/start_python/",
"https://thecode.media/i-gonna-code/",
"https://thecode.media/sigi-est/",
"https://thecode.media/nes-game/",
"https://thecode.media/live-view/",
"https://thecode.media/remote/",
"https://thecode.media/arduino-code/",
"https://thecode.media/horses/",
"https://thecode.media/runinstein/",
"https://thecode.media/wp-template/",
"https://thecode.media/tilda/",
"https://thecode.media/todo/",
"https://thecode.media/telebot/",
"https://thecode.media/summator-2/",
"https://thecode.media/get-rich-coding/",
"https://thecode.media/content-manager/",
"https://thecode.media/vzrosly-stal/",
"https://thecode.media/py-install/",
"https://thecode.media/quantum/",
"https://thecode.media/dns/",
"https://thecode.media/practicum/",
"https://thecode.media/react/",
"https://thecode.media/1september/",
"https://thecode.media/summator/",
"https://thecode.media/vds/",
"https://thecode.media/made-in-china/",
"https://thecode.media/bar/",
"https://thecode.media/zodiac/",
"https://thecode.media/crc32/",
"https://thecode.media/css-links/",
"https://thecode.media/oop_battle/",
"https://thecode.media/be-combo/",
"https://thecode.media/unity/",
"https://thecode.media/data-science/",
"https://thecode.media/junior/",
"https://thecode.media/qc/",
"https://thecode.media/be-middle/",
"https://thecode.media/senior/",
"https://thecode.media/teamlead/",
"https://thecode.media/frontend/",
"https://thecode.media/lift/",
"https://thecode.media/be-fuzzy/",
"https://thecode.media/best-2020/",
"https://thecode.media/git/",
"https://thecode.media/stt-cloud/",
"https://thecode.media/matrix-pills/",
"https://thecode.media/na-stile/",
"https://thecode.media/no-coffee/",
"https://thecode.media/framelibs/",
"https://thecode.media/children/",
"https://thecode.media/balls-possibly/",
"https://thecode.media/le-meduza/",
"https://thecode.media/electricity/",
"https://thecode.media/tailored-swift/",
"https://thecode.media/objective/",
"https://thecode.media/host/",
"https://thecode.media/go-public/",
"https://thecode.media/how-internet-works-1/",
"https://thecode.media/domain/",
"https://thecode.media/this-is-object/",
"https://thecode.media/ole-ole-ole/",
"https://thecode.media/thousand/",
"https://thecode.media/average/",
"https://thecode.media/stt-python/",
"https://thecode.media/ping-pong/",
"https://thecode.media/pygames/",
"https://thecode.media/odobreno/",
"https://thecode.media/qwerty123/",
"https://thecode.media/neurocorrector/",
"https://thecode.media/neuro-cam/",
"https://thecode.media/10-jquery/",
"https://thecode.media/repeat/",
"https://thecode.media/assembler/",
"https://thecode.media/sublime-one-love/",
"https://thecode.media/zloy/",
"https://thecode.media/mariya-ivanovna/",
"https://thecode.media/ruby/",
"https://thecode.media/electron-password/",
"https://thecode.media/plane/",
"https://thecode.media/glitch/",
"https://thecode.media/security/",
"https://thecode.media/stupid-2019/",
"https://thecode.media/jquery-search/",
"https://thecode.media/pimp-my-pass/",
"https://thecode.media/text-ultimate/",
"https://thecode.media/hurry/",
"https://thecode.media/siri/",
"https://thecode.media/zero-cool/",
"https://thecode.media/small-talk/",
"https://thecode.media/die-hard/",
"https://thecode.media/le-piton/",
"https://thecode.media/hr-code/",
"https://thecode.media/nano-code/",
"https://thecode.media/the_question/",
"https://thecode.media/godlike/",
"https://thecode.media/be-logic/",
"https://thecode.media/snake-js/",
"https://thecode.media/be-mobile/",
"https://thecode.media/baboolya/",
"https://thecode.media/timelag/",
"https://thecode.media/doors/",
"https://thecode.media/phone-code/",
"https://thecode.media/snake-arduino/",
"https://thecode.media/css-intro/",
"https://thecode.media/le-timer/",
"https://thecode.media/oop_battle/",
"https://thecode.media/good-morning/",
"https://thecode.media/study-bot/",
"https://thecode.media/python-bot/",
"https://thecode.media/robot-quiz/",
"https://thecode.media/hacking-quiz/",
"https://thecode.media/lulz-quiz/",
"https://thecode.media/hard-quiz/",
"https://thecode.media/torrent/",
"https://thecode.media/travel/",
"https://thecode.media/le-snob/",
"https://thecode.media/no-spagetti/",
"https://thecode.media/house/",
"https://thecode.media/cryptorush/",
"https://thecode.media/coronarelax/",
"https://thecode.media/pure/",
"https://thecode.media/c-cpp/",
"https://thecode.media/machine-loving/",
"https://thecode.media/orwell/",
"https://thecode.media/darknet/",
"https://thecode.media/ai/",
"https://thecode.media/oop-class/",
"https://thecode.media/cookie/",
"https://thecode.media/malware/",
"https://thecode.media/ftp/",
"https://thecode.media/html/",
"https://thecode.media/java/",
"https://thecode.media/php-haters/",
"https://thecode.media/tor/",
"https://thecode.media/crack-safe/",
"https://thecode.media/epidemic/",
"https://thecode.media/hash-brown/",
"https://thecode.media/java-js/",
"https://thecode.media/js-types/",
"https://thecode.media/losers/",
"https://thecode.media/ssl/",
"https://thecode.media/uncaughtsyntaxerror-unexpected-identifier/",
"https://thecode.media/uncaughtsyntaxerror-unexpected-token/",
"https://thecode.media/uncaughttyperrror-cannot-read-property/",
"https://thecode.media/mobile-dev/",
"https://thecode.media/verevka/",
"https://thecode.media/speed/",
"https://thecode.media/buckwheat/",
"https://thecode.media/distance/",
"https://thecode.media/node-js/",
"https://thecode.media/pascal/",
"https://thecode.media/ill-be-clean/",
"https://thecode.media/to-be-back/",
"https://thecode.media/replaceable/",
"https://thecode.media/code-review/",
"https://thecode.media/gasoline/",
"https://thecode.media/to-be-test/",
"https://thecode.media/scala/",
"https://thecode.media/row-power/",
"https://thecode.media/percent/",
"https://thecode.media/things/",
"https://thecode.media/prof-newsletter/",
"https://thecode.media/backend/",
"https://thecode.media/immortal-pong/",
"https://thecode.media/blind/",
"https://thecode.media/go-faster/",
"https://thecode.media/cpp/",
"https://thecode.media/uncaught-syntaxerror-unexpected-end-of-input/",
"https://thecode.media/stress-quiz/",
"https://thecode.media/secret-pong/",
"https://thecode.media/override/",
"https://thecode.media/whg/",
"https://thecode.media/profit/",
"https://thecode.media/memas/",
"https://thecode.media/digital-sound/",
"https://thecode.media/api/",
"https://thecode.media/be-math-2/",
"https://thecode.media/backup/",
"https://thecode.media/backup-master/",
"https://thecode.media/glvrd/",
"https://thecode.media/id/",
"https://thecode.media/uncaught-syntaxerror-missing-after-argument-list/",
"https://thecode.media/ex-startup/",
"https://thecode.media/doom-everywhere/",
"https://thecode.media/template-one/",
"https://thecode.media/david-roganov/",
"https://thecode.media/spacex/",
"https://thecode.media/webstorm/",
"https://thecode.media/json/",
"https://thecode.media/treger/",
"https://thecode.media/ya-blitz/",
"https://thecode.media/radius/",
"https://thecode.media/xhr/",
"https://thecode.media/treger2/",
"https://thecode.media/raidemption/",
"https://thecode.media/chief-technical-officer/",
"https://thecode.media/summary/",
"https://thecode.media/ex-wallpaper/",
"https://thecode.media/soap/",
"https://thecode.media/decompose/",
"https://thecode.media/desc/",
"https://thecode.media/sprint/",
"https://thecode.media/bye-or-die/",
"https://thecode.media/who-win/",
"https://thecode.media/vladimir-olokhtonov/",
"https://thecode.media/lossless/",
"https://thecode.media/parse/",
"https://thecode.media/typeerror-is-not-an-abject/",
"https://thecode.media/backup-me/",
"https://thecode.media/stress-test/",
"https://thecode.media/syntaxerror-missing-formal-parameter/",
"https://thecode.media/start-fast/",
"https://thecode.media/halkechev/",
"https://thecode.media/halkechev2/",
"https://thecode.media/le-design/",
"https://thecode.media/syntaxerror-missing-after-property-id/",
"https://thecode.media/attrb-mthd/",
"https://thecode.media/headphones/",
"https://thecode.media/active-noise-cancelling/",
"https://thecode.media/remote-work-quiz/",
"https://thecode.media/garbage/",
"https://thecode.media/ubuntu-linux/",
"https://thecode.media/trie/",
"https://thecode.media/func/",
"https://thecode.media/laravel/",
"https://thecode.media/save-json/",
"https://thecode.media/syntaxerror-missing-after-formal-parameters/",
"https://thecode.media/recursion/",
"https://thecode.media/haskell/",
"https://thecode.media/gen/",
"https://thecode.media/db/",
"https://thecode.media/boosting/",
"https://thecode.media/pavel-sviridov/",
"https://thecode.media/mnogo/",
"https://thecode.media/sokr/",
"https://thecode.media/dbsm/",
"https://thecode.media/pik-balmera/",
"https://thecode.media/kanban/",
"https://thecode.media/check-list/",
"https://thecode.media/text-quiz/",
"https://thecode.media/mysql/",
"https://thecode.media/mysql/",
"https://thecode.media/rust/",
"https://thecode.media/manage-this/",
"https://thecode.media/altshuller/",
"https://thecode.media/interview/",
"https://thecode.media/fotorama/",
"https://thecode.media/tetris/",
"https://thecode.media/ai-tetris/",
"https://thecode.media/scrum/",
"https://thecode.media/speed-two/",
"https://thecode.media/quick-share/",
"https://thecode.media/stack/",
"https://thecode.media/mobile-first/",
"https://thecode.media/nosql/",
"https://thecode.media/narazves/",
"https://thecode.media/oop-class-2/",
"https://thecode.media/design-first/",
"https://thecode.media/arcanoid/",
"https://thecode.media/donut/",
"https://thecode.media/casino/",
"https://thecode.media/heap/",
"https://thecode.media/rust/",
"https://thecode.media/float/",
"https://thecode.media/markdown/",
"https://thecode.media/books/",
"https://thecode.media/daniil-popov/",
"https://thecode.media/android-developer/",
"https://thecode.media/symbols/",
"https://thecode.media/oauth/",
"https://thecode.media/kotlin/",
"https://thecode.media/todo/",
"https://thecode.media/plotly/",
"https://thecode.media/no-digit-code/",
"https://thecode.media/asymmetric/",
"https://thecode.media/qi/",
"https://thecode.media/vernam/",
"https://thecode.media/vernam-js/",
"https://thecode.media/shtykov/",
"https://thecode.media/memory/",
"https://thecode.media/ark/",
"https://thecode.media/7-oshibok-na-sobesedovanii/",
"https://thecode.media/dh/",
"https://thecode.media/typescript/",
"https://thecode.media/stark/",
"https://thecode.media/crypto/",
"https://thecode.media/zapusk-2/",
"https://thecode.media/fingerprint/",
"https://thecode.media/puzzle/",
"https://thecode.media/python-time-2/",
"https://thecode.media/no-chance/",
"https://thecode.media/lossy/",
"https://thecode.media/1wire/",
"https://thecode.media/pasha-flipper/",
"https://thecode.media/perl/",
"https://thecode.media/alexey-vasilev/",
"https://thecode.media/viasat/",
"https://thecode.media/podcast/",
"https://thecode.media/copy-ya-ru/",
"https://thecode.media/mircrosd/",
"https://thecode.media/bash/",
"https://thecode.media/rotation/",
"https://thecode.media/css-grid/",
"https://thecode.media/train/",
"https://thecode.media/grid-2/",
"https://thecode.media/za-proezd/",
"https://thecode.media/grid-3/",
"https://thecode.media/david/",
"https://thecode.media/alien-vs-predator/",
"https://thecode.media/grid-portfolio/",
"https://thecode.media/podcast-lavka/",
"https://thecode.media/it-start-2/",
"https://thecode.media/anastasiya-nikulina/",
"https://thecode.media/linter/",
"https://thecode.media/bomberman/",
"https://thecode.media/5-linters/",
"https://thecode.media/lineynaya-algebra-vektory/",
"https://thecode.media/no-nda/",
"https://thecode.media/code-swap/",
"https://thecode.media/how-to-start/",
"https://thecode.media/referenceerror-invalid-left-hand-side-in-assignment/",
"https://thecode.media/vectors-operations/",
"https://thecode.media/oop-abstract/",
"https://thecode.media/leonov/",
"https://thecode.media/lucky-strike/",
"https://thecode.media/browser/",
"https://thecode.media/2020/",
"https://thecode.media/3d-stars/",
"https://thecode.media/anna-leonova/",
"https://thecode.media/cold-fusion/",
"https://thecode.media/normalize/",
"https://thecode.media/hotkey/",
"https://thecode.media/oven/",
"https://thecode.media/vim/",
"https://thecode.media/draw/",
"https://thecode.media/visual-studio-code/",
"https://thecode.media/tetris-2/",
"https://thecode.media/start-now/",
"https://thecode.media/lapsha-1/",
"https://thecode.media/cubism/",
"https://thecode.media/lapsha-2/",
"https://thecode.media/zerocode/",
"https://thecode.media/cat/",
"https://thecode.media/static/",
"https://thecode.media/komm/",
"https://thecode.media/path-js/",
"https://thecode.media/cloudly/",
"https://thecode.media/haters-gonna-code-2/",
"https://thecode.media/csp/",
"https://thecode.media/mitin-says-no/",
"https://thecode.media/hire-js/",
"https://thecode.media/tableau/",
"https://thecode.media/impossible/",
"https://thecode.media/csp-on/",
"https://thecode.media/maze/",
"https://thecode.media/mix/",
"https://thecode.media/le-beton/",
"https://thecode.media/3d-print/",
"https://thecode.media/5-and-a-half/",
"https://thecode.media/lineynaya-zavisimost-vektorov/",
"https://thecode.media/fast-m1/",
"https://thecode.media/ninja-run/",
"https://thecode.media/matrix-101/",
"https://thecode.media/arm-x86/",
"https://thecode.media/piano-js/",
"https://thecode.media/10-swift/",
"https://thecode.media/travel-plane/",
"https://thecode.media/extention/",
"https://thecode.media/obratnaya-matritsa/",
"https://thecode.media/svg/",
"https://thecode.media/freelance/",
"https://thecode.media/brat-2/",
"https://thecode.media/angular/",
"https://thecode.media/rgb/",
"https://thecode.media/10-go/",
"https://thecode.media/coffee/",
]
# открываем текстовый файл, куда будем добавлять заголовки
file = open("zag.txt", "a")
# перебираем все адреса из списка
for x in url:
# получаем исходный код очередной страницы из списка
html_code = str(urlopen(x).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим название страницы с помощью метода find()
s = soup.find('title').text
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file.write(s + '. ')
# закрываем файл
file.close()А дальше логичное продолжение — программа на цепях Маркова, которая будет генерировать заголовки для статей Кода на основе наших старых заголовков.