Поисковые технологии или в чем загвоздка написать свой поисковик
Время на прочтение
3 мин
Количество просмотров 56K
Когда-то давно взбрела мне в голову идея: написать свой собственный поисковик. Было это очень давно, тогда я еще учился в ВУЗе, мало чего знал про технологии разработки больших проектов, зато отлично владел парой десятков языков программирования и протоколов, да и сайтов своих к тому времени было понаделано много.
Ну есть у меня тяга к монструозным проектам, да…
В то время про то, как они работают было известно мало. Статьи на английском и очень скудные. Некоторые мои знакомые, которые были тогда в курсе моих поисков, на основе нарытых и мной и ими документов и идей, в том числе тех, которые родились в процессе наших споров, сейчас делают неплохие курсы, придумывают новые технологии поиска, в общем, эта тема дала развитие довольно интересным работам. Эти работы привели в том числе к новым разработкам разных крупных компаний, в том числе Google, но я лично прямого отношения к этому не имею.
На данный момент у меня есть собственный, обучающийся поисковик от и до, со многими нюансами – подсчетом PR, сбором статистик-тематик, обучающейся функцией ранжирования, ноу хау в виде отрезания несущественного контента страницы типа меню и рекламы. Скорость индексации примерно полмиллиона страниц в сутки. Все это крутится на двух моих домашних серверах, и в данный момент я занимаюсь масштабированием системы на примерно 5 свободных серверов, к которым у меня есть доступ.
Здесь я в первый раз, публично, опишу то, что было сделано лично мной. Думаю, многим будет интересно как же работают Яндекс, Google и почти все мне известные поисковики изнутри.
Есть много задач при построении таких систем, которые почти нереально решить в общем случае, однако с помощью некоторых ухищрений, придумок и хорошего понимания как работает железячная часть Вашего компьютера можно серьезно упростить. Как пример – пересчет PR, который в случае нескольких десятков миллионов страниц уже невозможно поместить в самой большой оперативной памяти, особенно если Вы, как и я, жадны до информации, и хотите кроме 1 цифры хранить еще много полезностей. Другая задача – хранение и обновление индекса, как минимум двумерной базы данных, в которой конкретному слову сопоставляется список документов, на которых оно встречается.
Просто вдумайтесь, Google хранит, по одной из оценок, более 500 миллиардов страниц в индексе. Если бы каждое слово встречалось на 1 странице только 1 раз, и на хранение этого надо было 1 байт – что невозможно, т.к. надо хранить хотя бы id страницы – уже от 4 байт, так вот тогда объем индекса бы был 500гб. В реальности одно слово встречается на странице в среднем до 10 раз, объем информации на вхождение редко когда меньше 30-50 байт, весь индекс увеличивается в тысячи раз… Ну и как прикажите это хранить? А обновлять?
Ну вот, как это все устроено и работает, я буду рассказывать планомерно, так же как и про то как считать PR быстро и инкрементально, про то как хранить миллионы и миллиарды текстов страниц, их адреса и быстро искать по адресам, как организованы разные части моей базы данных, как инкрементально обновлять индекс на много сотен гигов, ну и наверное расскажу как сделать обучающийся алгоритм ранжирования.
На сегодня объем только индекса, по которому происходит поиск — 57Gb, увеличивается каждый день примерно на 1Gb. Объем сжатых текстов – 25Gb, ну и я храню кучу другой полезной инфы, объем которой очень трудно посчитать из-за ее обилия.
Вот полный список статей которые относятся к моему проекту и описаны здесь:
0. Поисковые технологии или в чем загвоздка написать свой поисковик
1. С чего начинается поисковик, или несколько мыслей про crawler
2. Общие слова про устройство поиска в Web
3. Dataflow работы поисковой машины
4. Про удаление малозначимых частей страниц при индексации сайта
5. Методы оптимизации производительности приложения при работе с РБД
6. Немного про проектирование баз данных для поисковой машины
7. AVL деревья и широта их применения
8. Работа с URL и их хранение
9. Построение индекса для поисковой машины
Каждый пользователь в интернете может назвать несколько популярных поисковых систем. Но при этом некоторые из них не оставляют идею создать собственную такую систему, поэтому вопрос: «Как создать свой поисковик?» остается на слуху.
Свой поисковик может быть двух типов:
большая поисковая система, которая будет работать по всему интернету и составлять конкуренцию Google, Яндекс, Bing и др.;
небольшой поисковик, организованный на своем сайте с различными свойства поиска.
Как создать свой поисковик и создать конкуренцию известным «поисковым гигантам»
Создать свой поисковик наподобие Гугла и Яндекса, на самом деле, не так сложно. Любой более-менее уверенный в себе разработчик сможет это сделать. Любой поисковик состоит из 3-х основных элементов:
Пользовательский интерфейс.
Базы данных с сайтами для их индекса.
Поисковый робот, который будет обходить сайты и обновлять/добавлять информацию о них в базу данных.
Техническая реализация поисковой системы не так сложна, как кажется. Плюс в сети есть уже много готовых скриптов как платных, так и бесплатных, с помощью которых вы сможете реализовать свою идею. Создать свой поисковик можно самостоятельно или в небольшой команде. В принципе, если найти соратников в команду, которые готовы поработать на голом энтузиазме, создать свой поисковик можно практически бесплатно.
Но проблема в другом. Сможете ли вы создать действительно конкурирующий программный продукт? Ведь для того, чтобы конкурировать с известными поисковиками, вам нужно будет:
нанять высококвалифицированных специалистов и организовать им рабочее пространство;
оборудовать собственный дата-центр или арендовать мощности у надежной компании;
быть готовым в течение нескольких лет терпеть убытки.
И при этом никто не даст гарантий, что ваш поисковик станет популярным и вы сможете его монетизировать. Потому что пока вы будете развивать свой продукт, Гугл с Яндексом также будут развиваться. А чтобы их «переплюнуть», вам нужно будет внедрить в свой продукт какую-нибудь «фишку» или ноу-хау, чтобы переманить к себе пользователей — это что касается функционала. А с технической стороны ваш поиск должен быть точнее, быстрее и эффективнее, чем у ваших конкурентов, чтобы пользователи это «почувствовали» и перешли на вашу сторону.
Почему люди в основном пользуются Гуглом или Яндексом (или другими)? Потому что им там комфортно и им там нравится. Поэтому, чтобы пользователи перешли именно к вашему поисковику, вы должны стать лучше.
Вот и получается, что создать свой поисковик нетрудно, но вот развивать его и сделать конкурентоспособным — на это потребуется немало усилий и финансовых вложений. Но с другой стороны, Гугл тоже когда-то был в позиции «новичка», а в кого он превратился спустя годы упорного труда — мы все прекрасно видим.
Другое дело с локальными поисковиками, которые вы можете организовать на собственном сайте.
Как создать небольшой локальный поисковик на своем сайте
Небольшой локальный поисковик — это более «приземленная» идея поисковой системы. И в некоторых ситуациях подобный поисковик будет работать эффективнее, чем глобальный Гугл с Яндексом. Например, когда вам нужно ограничить объем поиска. Допустим, у вас есть некий веб—ресурс, который ведет взаимоотношения с 500 поставщиками и 400 различными партнерами, плюс в качестве дополнительной информации вы используете еще 900 разных источников. Вы можете организовать собственную поисковую систему на 1000+ источников, чтобы вашим клиентам было проще искать нужную информацию, касающуюся ваших услуг или товаров. Если они будут это делать через глобальную поисковую систему, то в выдаче у них будет очень много «мусора», который, по сути, им никогда не пригодится. А ваша ПС даст именно те результаты, которые нужны вашим клиентам.
В качестве дополнения собственная тематическая ПС — это:
удобство поиска для ваших клиентов;
дополнительный способ монетизации вашего проекта;
много плюсов к вашему престижу, брендингу и узнаваемости.
Что самое интересное — подобные локальные системы организовать довольно просто. В сети есть масса готовых решений по этому поводу. Самое узнаваемое решение — это создать свой поисковик, используя поисковый потенциал Google. Для этого пройдите по ссылке.
Заключение
Теперь вы знаете, как можно создать свой поисковик. Если это будет глобальная поисковая система, то к этому нужно подготовиться финансово и морально. Если локальный поисковик на собственном сайте, то самый простой способ — это использовать готовое решение. При этом если вы с программированием на «ты», то для вас не составит труда создать свой собственный поисковик с нуля.
Предыстория
Все началось с того, что мне стало трудно находить нужную информацию, файлы. Чем больше файлов и папок у меня образовывалось, тем больше времени уходило на поиски нужного. Я понял, что каждый раз искать в бесконечных списках файлов и папок, особенно с условием вложенности это не вариант для больших объемов данных.
Что касается поиска по названию файла, то количество символов, указанных в названии ограниченно и слова при поиске должны быть в строго определенной последовательности. Тем более, если система индексирует другие, не нужные для поиска файла (системные файлы, файлы проектов), то поиск выдает много «мусора».
Поиск по содержанию файла даёт не самый релевантный результат. Может выдать бесполезные результаты с содержанием содержащие ключевые слова, но не относящиеся к тому, что действительно необходимо найти.
Более того по содержанию можно искать только текстовые файлы.
Структура содержания информации
Структура папок представляется собой в виде дерева. Мне это не нравится, потому что каждая папка может содержать только определенные файлы, если не учитывать копирование и ссылки.
Так же это можно представить с примером из реальной жизни, для того, чтобы найти зелёное свежее яблоко сорт «девственный». Необходимо найти отдел с фруктами, затем отдел с яблоками, затем ищем зеленные, затем сорт, ну там ещё их на свежие, не свежие фасуют в этом воображаемом примере и наконец найти нужное apple.
Усложняется ещё все и тем, что я не помню есть ли там вообще яблоки, и если есть, то хранятся ли они в отделе фрукты там продаются.
А почему бы об этом просто не попросить прихвостня(они уже у всех есть, правда?) -«Принеси мне зелёное свежее яблоко».
Как сразу становится удобно!
В общем, всем этим я хочу сказать, что поиск нужной информации в папках хорош, если папок немного и если помнить какие папки существуют, а не перебирать все подряд.
А вот если мы не знаем существуют ли яблоки вообще, то спрашиваем прихвостня:
— «Яблоки есть?»
— «Есть, господин! Сотни, игрушечные, красные, гнилые..».
— «Мне нужно свежее яблоко».
— «Понял! Есть красное свежее яблоко «Сирота», красное свежее яблоко «курага»,..».
— «А что насчёт зелёного свежего яблока».
— «Есть! Зелёное свежее яблоко «Пух-тибидух» и Зелёное свежее яблоко «Девственный»».
— «В таком случае, принеси мне, пожалуй, Зелёное свежее яблоко «Девственный»».
— «Да, сэр».
Вот последняя фраза как раз таки и стала названием приложения. Как ответ на команду пользователя — «Yes Sir».
Возвращаясь к яблокам. Заметили, что в первом случае нужно искать яблоки не пойми где, а во втором мы задаём уточняющие условия к запросу! ?
Приведу пример более реалистичный. Есть папка с музыкой и подпапки для разделения на жанры. Но что если в какой-то момент мне захочется послушать французскую музыку не зависимо от жанра. Вот тут то и вся проблемность древовидной структуры папок вылазит. Можно конечно, как советовали на форумах, создавать отдельные папки под язык произведения и кидать ссылки, но опяяяттть папкии..
А вот, что произойдет, если каждому файлу установить теги с жанром, языком, ну и конечно что это музыка, песня.
В этом случае возможно группировать, сортировать музыку гораздо гибче. Например скомбинировав 3 тега: французская, русская, рок можно получить то, чего стандартными средствами Windows не возможно, ну или я чего-то не знаю.
Попытки найти готовое решение.
Первой идеей было воспользоваться «тегированием» файлов, папок. Таким образом можно искать информацию комбинируя теги, не зависимо от порядка слов. И лучшими приложениями для этого, могу выделить XYplorer и Tagging for windows. Первая из себя представляет отдельный файловый менеджер с опцией тегирования. Второе приложение — дополнение к стандартному файловому менеджеру. Однако они позволяют искать файлы только на ПК и конечно нельзя написать как в Гугл поисковике запрос близкий к пользователю, а алгоритм уже бы сам выбрал из запроса теги и отсортировал информацию по приоритету. В последствии удалил обе, они подвисали и крашились частенько (возможно дело в моих надстройках Windows, не хочу делать антипиар этих отличных программ).
Визуальный поиск
В попытках найти оптимальный способ поиска доходило до странного. Я больше визуал и поэтому загружал изображения более менее подходящее по теме информации в социальную сеть ВКонтакте, а саму информацию сохранял в комментариях под изображениями. Это дало некоторый прирост в скорости поиска и пользоваться можно с любого устройства. Но как вы, наверное, понимаете долго это продолжаться не могло. В конечном итоге я стал задумываться а к какой информации относится это изображение : «Рельсы означает адреса знакомых или желаемые места для путешествия..». Ну а уж то, что под одним изображением образуется портянка из информации без возможности вложенности — это фиаско, бро.
Желаемый функционал
Я подумал, что было бы отлично разработать приложение, которое бы подходило по таким критериям:
1. Можно использовать с любого устройства без возможности подключения к интернету.
2. Поиск личной информации настолько быстро, насколько это возможно.
3. Поиск должен быть простым как Google Search.
4. Возможность сохранить всю текстовую информацию в текстовый файл.
Выбор технологий
1. По первому пункту из желаний было решено разработать веб приложение, так как с любого устройства, на котором есть браузер, можно получить к нему доступ. Данные хранятся в localstorage браузера, но при открытии сайта сразу выгружаются в переменную для обеспечения лучшей скорости.
Для синхронизации данных с другим устройством, браузером я взял базу данных mysql от 000webhost бесплатно, но потом перестал использовать из-за ограничений на обьем.
Сейчас единственный способ для обновления пользовательских данных — импорт и экспорт файла. Однако я делаю это очень редко, тк в основном пользуюсь только со смартфона.
Что касается оффлайн режима — я использовал serviceworking. Необходимо только один раз зайти на сайт, чтобы все ресурсы сайта подгрузились и дальше использовать полностью оффлайн из браузера.
2. Быстрый поиск.
Раз поиск должен осуществляться подобно Гугл поисковику, то нужно чтобы каждое слово из запроса проверялось на существующий из уже созданного блока информации. Таким блоком у меня выступает объект с ключами: уникальное название блока, действие(показать информацию, открыть ссылку..), содержимое, теги.
Итак по ключу «теги» у нас будет храниться массив из символов(слов) для конкретного блока информации.
Сразу возьмём пример блока:
Название: как создать сайт,
Действие: показать информацию,
Содержимое: берём html, добавляем js и украшаем css,
Теги: создание сайта, веб программирование, верстка.
Массив из тегов формируется из текстов полученных с полей ввода для тегов и названия. Каждое слово это тег, разделять можно запятой и пробелом. Была идея конечно сделать как на Ютубе, теги как словосочетания, но я я решил остановиться на более широкой выдаче по ключевым словам.
Из примера блока выше массив тегов будет таким: [«как», «создать», «сайт», «создание», «сайта», «веб» «программирование», «верстка»]
Теперь самое важное — определиться как будет происходить поиск. Первое что пришло в голову это брать каждое слово из поискового запроса и сравнивать с каждым словом из тега каждого блока. В голову как пришло, так и ушло, это отвратительная идея. Следующей идеей было создание объекта, в котором каждый тег это отдельный ключ а значение это массив из индексов блоков.
3. Итак, при вводе запроса проверяется существует ли слово в хранилище тегов, если да, то блок добавляется в массив на отображение.
Теперь нужно отсортировать по приоритету. Чем выше результат в выдаче, тем более он подходит запросу. Это я реализовал с помощью количества ключевых слов в запросе, чем больше слов из запроса содержится в массиве тегов блока, тем более блок прионитетнее.
4. И насчёт сохранение в файл совсем кратко. Можно сохранять и импортировать файл в виде json.
Так же мой опыт с использованием ВКонтакте как поисковик по изображениям дал мне идею для возможности добавлять изображение к каждому блоку при желании.
Итоги
В результате я сделал то, чем пользуюсь уже больше года. Как веб, так и ПК версия оказались очень полезными. Использую для работы и личной жизни. Скорость поиска, которую я в итоге получил меня многократно выручала, когда нужно было найти что-то очень быстро.
Ответвление в другие проекты
Веб приложение мне настолько понравилось, что я захотел написать программу для исполнения программ по команде от запроса пользователя на ПК. Вдохновлённый голосовыми помощниками, я создал программу, которая ищет и исполняет файлы, ссылки на которые сохранены в программе, у которой поиск соответственно так же подобен веб поисковику. Особенность в том, что можно перетащить файл/файлы напрямую в программу и алгоритм автоматически установит теги исходя из названия файла и папок, в которых он содержится. Но это тема другого поста, если этот окажется интересным..
Послесловие
Буду рад любым комментариям. Узнать ваше мнение по поводу идеи. Полная ли это ерунда. Или, в чем я почти не сомневаюсь, есть уже приложения с подобной реализацией.
Спасибо!!
Все началось с того, что мне стало трудно находить нужную информацию, файлы. Чем больше файлов и папок у меня образовывалось, тем больше времени уходило на поиски нужного. Я понял, что каждый раз искать в бесконечных списках файлов и папок, особенно с условием вложенности это не вариант для больших объемов данных.
Что касается поиска по названию файла, то количество символов, указанных в названии ограниченно и слова при поиске должны быть в строго определенной последовательности. Тем более, если система индексирует другие, не нужные для поиска файла (системные файлы, файлы проектов), то поиск выдает много «мусора».
Поиск по содержанию файла даёт не самый релевантный результат. Может выдать бесполезные результаты с содержанием содержащие ключевые слова, но не относящиеся к тому, что действительно необходимо найти.
Более того, по содержанию можно искать только текстовые файлы.
Ссылка на проект — тут.
Структура содержания информации
Структура папок представляется собой в виде дерева. Мне это не нравится, потому что каждая папка может содержать только определенные файлы, если не учитывать копирование и ссылки.
Так же это можно представить с примером из реальной жизни, для того, чтобы найти зелёное свежее яблоко сорт «Девственный». Необходимо найти отдел с фруктами, затем отдел с яблоками, затем ищем зеленные, затем сорт, ну там ещё их на свежие, не свежие фасуют в этом воображаемом примере и наконец найти нужное apple.
Усложняется ещё все и тем, что я не помню есть ли там вообще яблоки, и если есть, то хранятся ли они в отделе фрукты.
А почему бы об этом просто не попросить прихвостня (они уже у всех есть, правда?): «Принеси мне зелёное свежее яблоко».
Как сразу становится удобно!
В общем, всем этим я хочу сказать, что поиск нужной информации в папках хорош, если папок немного и если помнить какие папки существуют, а не перебирать все подряд.
А вот если мы не знаем существуют ли яблоки вообще, то спрашиваем прихвостня:
— Яблоки есть?
— Есть, господин! Сотни, игрушечные, красные, гнилые….
— Мне нужно свежее яблоко.
— Понял! Есть красное свежее яблоко «Сирота», красное свежее яблоко «Курага», …
— А что насчёт зелёного свежего яблока.
— Есть! Зелёное свежее яблоко «Пух-тибидух» и Зелёное свежее яблоко «Девственный».
— В таком случае, принеси мне, пожалуй, Зелёное свежее яблоко «Девственный».
— Да, сэр.
Вот последняя фраза как раз таки и стала названием приложения. Как ответ на команду пользователя — «Yes Sir».
Возвращаясь к яблокам. Заметили, что в первом случае нужно искать яблоки не пойми где, а во втором мы задаём уточняющие условия к запросу?
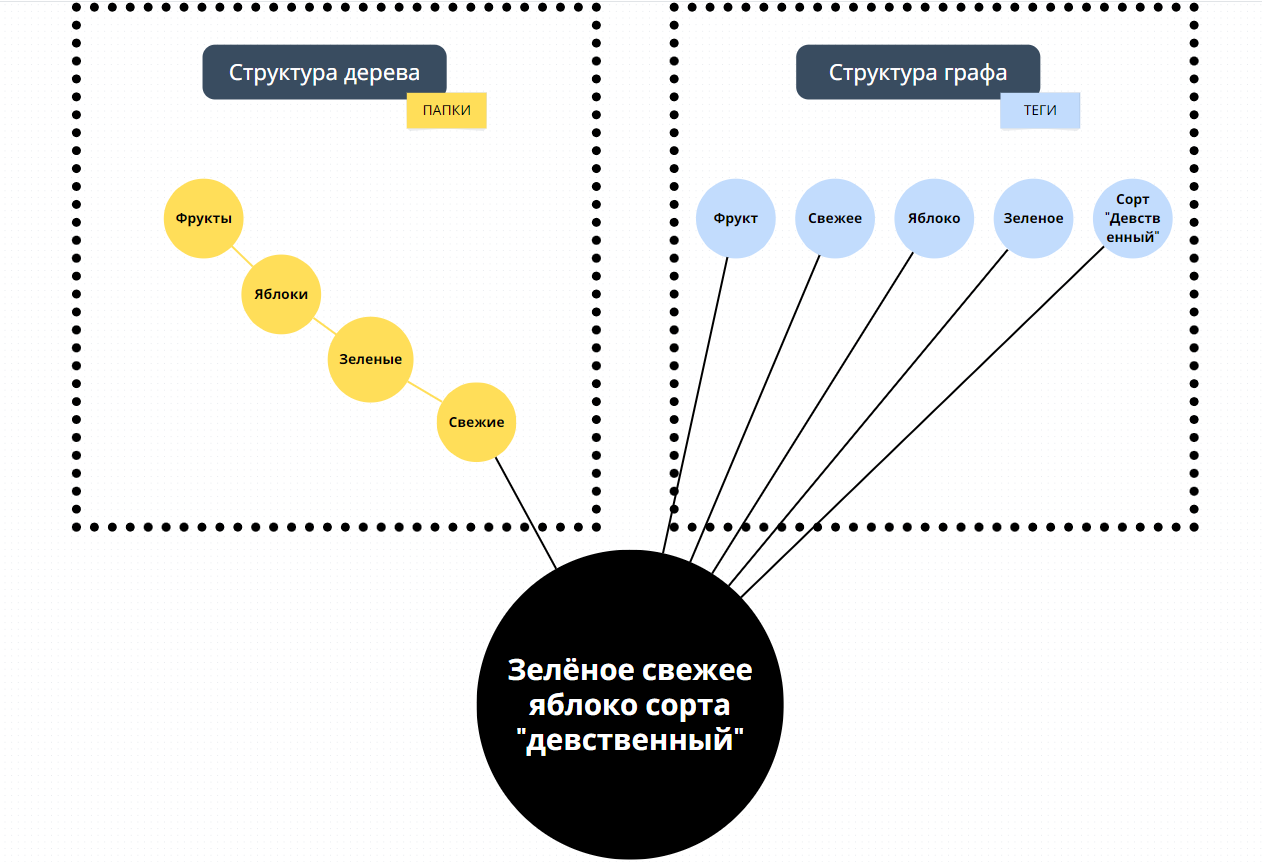
Для нахождения нужного результата, используя древовидную структуру (папки), приходится обходить все узлы. А в случае графа (теги) можно получить результат, в лучшем случае, за проход по единственному узлу.
Приведу пример более реалистичный. Есть папка с музыкой и подпапки для разделения на жанры. Но что если в какой-то момент мне захочется послушать французскую музыку не зависимо от жанра. Вот тут то и вся проблемность древовидной структуры папок вылазит. Можно конечно, как советовали на форумах, создавать отдельные папки под язык произведения и кидать ссылки, но опять папки…
А вот, что произойдет, если каждому файлу установить теги с жанром, языком, ну и конечно что это музыка, песня.
В этом случае возможно группировать, сортировать музыку гораздо гибче. Например, скомбинировав 3 тега: французская, русская, рок можно получить то, чего стандартными средствами Windows не возможно, ну или я чего-то не знаю.
Попытки найти готовое решение
Первой идеей было воспользоваться «тегированием» файлов, папок. Таким образом можно искать информацию комбинируя теги, не зависимо от порядка слов. И лучшими приложениями для этого, могу выделить XYplorer и Tagging for windows. Первая из себя представляет отдельный файловый менеджер с опцией тегирования. Второе приложение — дополнение к стандартному файловому менеджеру. Однако они позволяют искать файлы только на ПК и конечно нельзя написать как в Гугл поисковике запрос близкий к пользователю, а алгоритм уже бы сам выбрал из запроса теги и отсортировал информацию по приоритету. В последствии удалил обе, они подвисали и крашились частенько (возможно дело в моих надстройках Windows, не хочу делать анти пиар этих отличных программ).
Визуальный поиск
В попытках найти оптимальный способ поиска доходило до странного. Я больше визуал и поэтому загружал изображения более менее подходящее по теме информации в социальную сеть ВКонтакте, а саму информацию сохранял в комментариях под изображениями. Это дало некоторый прирост в скорости поиска и пользоваться можно с любого устройства. Но как вы, наверное, понимаете долго это продолжаться не могло. В конечном итоге я стал задумываться а к какой информации относится это изображение, на котором рельсы — означает адреса знакомых или желаемые места для путешествия… Ну а уж то, что под одним изображением образуется портянка из информации без возможности вложенности — это фиаско, бро.
Желаемый функционал
Я подумал, что было бы отлично разработать приложение, которое бы подходило по таким критериям:
- Можно использовать с любого устройства без возможности подключения к интернету.
- Поиск личной информации настолько быстро, насколько это возможно.
- Поиск должен быть простым как Google Search.
- Возможность сохранить всю текстовую информацию в текстовый файл.
Выбор технологий
1. По первому пункту из желаний было решено разработать веб приложение, так как с любого устройства, на котором есть браузер, можно получить к нему доступ. Данные хранятся в localstorage браузера, но при открытии сайта сразу выгружаются в переменную для обеспечения лучшей скорости.
Для синхронизации данных с другим устройством, браузером я взял базу данных mysql от 000webhost бесплатно, но потом перестал использовать из-за ограничений на объем. Сейчас единственный способ для обновления пользовательских данных — импорт и экспорт файла. Однако я делаю это очень редко, т.к. в основном пользуюсь только со смартфона. Что касается офлайн режима — я использовал serviceworking. Необходимо только один раз зайти на сайт, чтобы все ресурсы сайта загрузились и дальше использовать полностью офлайн из браузера.
2. Быстрый поиск.
Раз поиск должен осуществляться подобно Гугл поисковику, то нужно чтобы каждое слово из запроса проверять на существующий из уже созданного блока информации. Таким блоком у меня выступает объект с ключами: уникальное название блока, действие(показать информацию, открыть ссылку…), содержимое, теги.
Итак, по ключу «теги» у нас будет храниться массив из символов(слов) для конкретного блока информации.
Сразу возьмём пример блока.
Название: как создать сайт.
Действие: показать информацию.
Содержимое: берём html, добавляем js и украшаем css.
Теги: создание сайта, веб программирование, верстка.
Массив из тегов формируется из текстов полученных с полей ввода для тегов и названия. Каждое слово это тег, разделять можно запятой и пробелом. Была идея конечно сделать как на Ютубе, теги как словосочетания, но я решил остановиться на более широкой выдаче по ключевым словам. Из примера блока выше массив тегов будет таким: [«как», «создать», «сайт», «создание», «сайта», «веб», «программирование», «верстка»].
Теперь самое важное — определиться как будет происходить поиск. Первое, что пришло в голову это брать каждое слово из поискового запроса и сравнивать с каждым словом из тега каждого блока. В голову как пришло, так и ушло, это отвратительная идея. Следующей идеей было создание объекта, в котором каждый тег это отдельный ключ, а значение это массив из индексов блоков.
3. Итак, при вводе запроса проверяется есть ли слово в хранилище тегов, если да, то блок добавляется в массив на отображение.Теперь нужно отсортировать по приоритету. Чем выше результат в выдаче, тем более он подходит запросу. Это я реализовал с помощью количества ключевых слов в запросе, чем больше слов из запроса содержится в массиве тегов блока, тем более блок приоритетнее.
4. И насчёт сохранение в файл совсем кратко. Можно сохранять и импортировать файл в виде json.Так же мой опыт с использованием ВКонтакте как поисковик по изображениям дал мне идею для возможности добавлять изображение к каждому блоку при желании.
Итоги
В результате я сделал то, чем пользуюсь уже больше года. Как веб, так и ПК версия оказались очень полезными. Использую для работы и личной жизни. Скорость поиска, которую я в итоге получил меня многократно выручала, когда нужно было найти что-то очень быстро.
Ответвление в другие проекты
Веб приложение мне настолько понравилось, что я захотел написать программу для исполнения программ по команде от запроса пользователя на ПК. Вдохновлённый голосовыми помощниками, я создал программу, которая ищет и исполняет файлы. А поиск соответственно так же подобен веб поисковику. Особенность в том, что можно перетащить файл/файлы напрямую в программу и алгоритм автоматически установит теги исходя из названия файла и папок, в которых он содержится. Но это тема другого поста, если этот окажется интересным.
Послесловие
Буду рад любым комментариям. Узнать ваше мнение по поводу идеи. Полная ли это ерунда. Или, в чем я почти не сомневаюсь, есть уже приложения с подобной реализацией. Спасибо!
Как сделать свой поисковик
Самыми популярными сайтами в сети интернет являются поисковые системы. С их помощью всегда можно найти нужную вам информацию. Давайте попробуем создать свой собственный поисковик по той схеме, по которой работали самые первые поисковики. В последствии вы сможете доработать свой поисковик и превратить его в полноценный и современный. Это зависит от ваших умений и готовности. Итак, ниже приведена инструкция по созданию мета-поисковика.

Инструкция
Разделите свой поисковик на три части. Первая часть – это интерфейс будущего веб-поисковика, который пишется на языке PHP. Вторая часть – это индекс (база данных My SQL), в которой хранится вся информация о страницах. Третья часть – это поисковой робот, который будет индексировать веб-страницы и заносить их данные в индекс, его делают на языке Delphi.
Начнём создавать интерфейс. Создайте файл index.php. Для этого разделите страницу на две части, используя таблицы. Первая часть – поисковая форма, вторая – результаты поиска. В верхней части создайте форму, которая будет посылать информацию файлу index.php методом get. На ней будут расположены три элемента – текстовое поле и ещё две кнопки. Одна кнопка нужна для отправки запроса, вторая – для очистки поля (эта кнопка не обязательна).
Дайте текстовому полю имя «search», первой кнопке (той, которая отправляет запрос) имя «Искать». Имя самой формы оставьте, как есть – «form1».
Результаты будут выведены в нижней части таблицы при помощи php, поэтому откройте тег <?php и начинайте писать код.
Подключите конфигурационный файл, чтобы подключиться к базе данных.
include «config.php»;
Проверьте, была ли нажата кнопка «Искать».
if (isset($_GET[‘button’])) {код, выполняемый в том случае, если кнопка «Искать» нажата} else {код, выполняемый в том случае, если кнопка «Искать» не нажата}
Если кнопка нажата, то тогда проверьте наличие поискового запроса.
if (isset($_GET[‘search’])){$search=$_GET[‘search’];}
Если поисковой запрос есть, то присвойте переменной $search текст поискового запроса.
Проверьте запрос, чтобы он не был пустым и не был короче трёх символов.
if ($search!=» && strlen($search)>2){ код поиска по базе данных } else {echo «Задан пустой поисковый запрос или строка поиска содержит менее 3 символов.»;}
В том случае, если поисковой запрос будет удовлетворять верхнему условию, запустите сам поисковой скрипт.
Запустите цикл, который выведет результаты поиска через printf.
На этом всё. Если вы обладаете необходимыми знаниями, то вы вполне можете добавить в поисковик нужные вам элементы и составить свой алгоритм его создания.
Видео по теме
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Я не знаю, какой смысл Вы вкладываете в слово «поисковик».
Вам нужно:
1. Получить список документов для индексации.
2. Проиндексировать эти документы.
3. Создать интерфейс, который будет по запросу искать документы.
Технически, все три этапа выполнить не сложно, но работать это будет, мягко говоря, отвратительно.
1. Результатов обычно огромное количество (особенно, если поисковый запрос короткий). Нужно каким-то образом ранжировать документы.
2. Индексированные страницы нужно предварительно обрабатывать (убирать служебную информацию, рекламу, всякие меню и т.п.). Полнотекстовый поиск нужно настраивать… причём, отдельно для каждого языка… желательно, с учётом профессиональных жаргонов… Основная сложность — омонимы, которых очень много. Чтобы получить возможность точной настройки, вероятно, придётся писать свой движок.
3. Поисковый запрос нужно предварительно обрабатывать (например, убрать предлоги… и при этом оставить «с», если это название языка). Нужно настраивать и алгоритм вычисления релевантности.
И для решения данных задач не существует готовых формальных алгоритмов. Требуется ручная настройка. Видишь «косяк» в результатах поиска, что-нибудь «подкручиваешь», чтобы от него избавиться, и надеешься, что твои исправления не добавят новые «косяки» в другом месте.
з.ы. Пример полнотекстового поиска с открытым исходным кодом:
http://sphinxsearch.com/
![]()
Download Article
Short and simple guide to create your own search engine
![]()
Download Article
Building your own search engine using Google CSE (Custom Search Engine). If you are looking to build a simple search engine, the best place to start would be with the Google CSE (Custom Search Engine), which allows you to build a search engine quickly and easily. There are also advanced features for advanced users.
Steps
-

1
Go to the Google CSE (Custom Search Engine) site. Create an account by following the instructions there.
-
2
Follow the instructions to build your own search engine.
Advertisement
-
3
Transfer code. You can use the code on your own webpage if you buy a domain and build a custom search site. Many others have done this.



Advertisement
Add New Question
-
Question
Do I have to pay if I make my own search engine?

No, it’s completely free of charge. Some other services might require you pay, but this method should be free.
-
Question
How do I develop a search engine that has not been done before?
Modify the search engine by clicking «control panel,» and link it to your own paid domain using the code.
-
Question
How can I make money by developing my own search engine? And can I get help from a software engineer?
To make money, you can display ads on your engine (just make sure they’re unobtrusive). Also, I’m sure you won’t need a software engineer if you use CSE.
See more answers
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
-
Yahoo! has discontinued their custom search engine.
-
Google Custom Search Engines let you earn money on clicks. When people click on the advertisements which appear on your search engine’s results page, you share the income with Google.
Thanks for submitting a tip for review!
Advertisement
About This Article
Thanks to all authors for creating a page that has been read 168,859 times.