Вы в жизни не раз сталкивался с разными протоколами — одни использовал, другие, возможно, реверсил. Одни были легко читаемы, в других без hex-редактора не разобраться. В сегодняшней статье я покажу, как создать свой собственный сетевой протокол передачи данных, который будет работать поверх TCP/IP. Мы разработаем свою структуру данных и реализуем сервер на C#.
Итак, протокол передачи данных — это соглашение между приложениями о том, как должны выглядеть передаваемые данные. Например, сервер и клиент могут использовать WebSocket в связке с JSON. Вот так приложение на Android могло бы запросить погоду с сервера:
|
{ «request»: «getWeather», «city»: «cityname» } |
И сервер мог бы ответить:
|
{ «success»: true, «weatherHumanReadable»: «Warm», «degrees»: 18 } |
Пропарсив ответ по известной модели, приложение предоставит информацию пользователю. Выполнить парсинг такого пакета можно, только располагая информацией о его строении. Если ее нет, протокол придется реверсить.
Содержание
- Создание базовой структуры протокола
- Написание клиента и сервера
- Запись и считывание данных из пакетов
- Установка значения
- Проверка на работоспособность
- Ввод типов пакетов
- Создание структуры пакетов для их сериализации и десериализации
- Создание сериализатора
- Создание десериализатора
- Первое рукопожатие
- Имплементация простой защиты протокола
- Заключение
Создание базовой структуры протокола
Этот протокол будет базовым для простоты. Но мы будем вести его разработку с расчетом на то, что впоследствии его расширим и усложним.
Первое, что необходимо ввести, — это наш собственный заголовок, чтобы приложения могли отличать пакеты нашего сетевого протокола. У нас это будет набор байтов
0xAF,
0xAA,
0xAF. Именно они и будут стоять в начале каждого сообщения.
Почти каждый бинарный протокол имеет свое «магическое число» (также «заголовок» и «сигнатура») — набор байтов в начале пакета. Оно используется для идентификации пакетов своего протокола. Остальные пакеты будут игнорироваться.
Каждый пакет будет иметь тип и подтип и будет размером в байт. Так мы сможем создать 65 025 (255 * 255) разных типов пакетов. Пакет будет содержать в себе поля, каждое со своим уникальным номером, тоже размером в один байт. Это предоставит возможность иметь 255 полей в одном пакете. Чтобы удостовериться в том, что пакет дошел до приложения полностью (и для удобства парсинга), добавим байты, которые будут сигнализировать о конце пакета.
Завершенная структура пакета:
|
XPROTOCOL PACKET STRUCTURE (offset: 0) HEADER (3 bytes) [ 0xAF, 0xAA, 0xAF ] (offset: 3) PACKET ID (offset: 3) PACKET TYPE (1 byte) (offset: 4) PACKET SUBTYPE (1 byte) (offset: 5) FIELDS (FIELD[]) (offset: END) PACKET ENDING (2 bytes) [ 0xFF, 0x00 ] FIELD STRUCTURE (offset: 0) FIELD ID (1 byte) (offset: 1) FIELD SIZE (1 byte) (offset: 2) FIELD CONTENTS |
Назовем наш протокол передачи данных, как вы могли заметить, XProtocol. На третьем сдвиге начинается информация о типе пакета. На пятом начинается массив из полей. Завершающим звеном будут байты
0xFF и
0x00, закрывающие пакет.
Написание клиента и сервера
Для начала нужно ввести основные свойства, которые будет иметь пакет:
- тип пакета;
- подтип;
- набор полей.
|
public class XPacket { public byte PacketType { get; private set; } public byte PacketSubtype { get; private set; } public List<XPacketField> Fields { get; set; } = new List<XPacketField>(); } |
Добавим класс для описания поля пакета, в котором будут его данные, ID и размер.
|
public class XPacketField { public byte FieldID { get; set; } public byte FieldSize { get; set; } public byte[] Contents { get; set; } } |
Сделаем обычный конструктор приватным и создадим статический метод для получения нового экземпляра объекта.
|
private XPacket() {} public static XPacket Create(byte type, byte subtype) { return new XPacket { PacketType = type, PacketSubtype = subtype }; } |
Теперь можно задать тип пакета и поля, которые будут внутри него. Создадим функцию для этого. Записывать будем в поток
MemoryStream. Первым делом запишем байты заголовка, типа и подтипа пакета, а потом отсортируем поля по возрастанию
FieldID.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public byte[] ToPacket() { var packet = new MemoryStream(); packet.Write( new byte[] {0xAF, 0xAA, 0xAF, PacketType, PacketSubtype}, 0, 5); var fields = Fields.OrderBy(field => field.FieldID); foreach (var field in fields) { packet.Write(new[] {field.FieldID, field.FieldSize}, 0, 2); packet.Write(field.Contents, 0, field.Contents.Length); } packet.Write(new byte[] {0xFF, 0x00}, 0, 2); return packet.ToArray(); } |
Теперь запишем все поля. Сначала пойдет ID поля, его размер и данные. И только потом конец пакета —
0xFF,
0x00.
Теперь пора научиться парсить пакеты.
Минимальный размер пакета — 7 байт.
HEADER (3) +
TYPE (1) +
SUBTYPE (1) +
PACKET ENDING (2)
Проверяем размер входного пакета, его заголовок и два последних байта. После валидации пакета получим его тип и подтип.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public static XPacket Parse(byte[] packet) { if (packet.Length < 7) { return null; } if (packet[0] != 0xAF || packet[1] != 0xAA || packet[2] != 0xAF) { return null; } var mIndex = packet.Length — 1; if (packet[mIndex — 1] != 0xFF || packet[mIndex] != 0x00) { return null; } var type = packet[3]; var subtype = packet[4]; var xpacket = Create(type, subtype); /* <—> */ |
Пора перейти к парсингу полей. Так как наш пакет заканчивается двумя байтами, мы можем узнать, когда закончились данные для парсинга. Получим ID поля и его размер, добавим к списку. Если пакет будет поврежден и будет существовать поле с
ID, равным нулю, и
SIZE, равным нулю, то необходимости его парсить нет.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
/* <—> */ var fields = packet.Skip(5).ToArray(); while (true) { if (fields.Length == 2) { return xpacket; } var id = fields[0]; var size = fields[1]; var contents = size != 0 ? fields.Skip(2).Take(size).ToArray() : null; xpacket.Fields.Add(new XPacketField { FieldID = id, FieldSize = size, Contents = contents }); fields = fields.Skip(2 + size).ToArray(); } } |
У кода выше есть проблема: если подменить размер одного из полей, парсинг завершится с необработанным исключением или пропарсит пакет неверно. Необходимо обеспечить безопасность пакетов. Но об этом поговорим чуть позже.
Запись и считывание данных из пакетов
Из-за строения класса
XPacket нужно хранить бинарные данные для полей. Чтобы установить значение поля, нам необходимо конвертировать имеющиеся данные в массив байтов. Язык C# не предоставляет идеальных способов сделать это, поэтому внутри пакетов будут передаваться только базовые типы:
int,
double,
float и так далее. Так как они имеют фиксированный размер, можно считать его напрямую из памяти.
РЕКОМЕНДУЕМ:
Программирование в консоли
Чтобы получить чистые байты объекта из памяти, иногда используется метод небезопасного кода и указателей, но есть и способы проще: благодаря классу
Marshal в C# можно взаимодействовать с
unmanaged-областями нашего приложения. Чтобы перевести любой объект фиксированной длины в байты, мы будем пользоваться такой функцией:
|
public byte[] FixedObjectToByteArray(object value) { var rawsize = Marshal.SizeOf(value); var rawdata = new byte[rawsize]; var handle = GCHandle.Alloc(rawdata, GCHandleType.Pinned); Marshal.StructureToPtr(value, handle.AddrOfPinnedObject(), false); handle.Free(); return rawdata; } |
Здесь мы делаем следующее:
- получаем размер нашего объекта;
- создаем массив, в который будет записана вся информация;
- получаем дескриптор на наш массив и записываем в него объект.
Теперь сделаем то же самое, только наоборот.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
private T ByteArrayToFixedObject<T>(byte[] bytes) where T: struct { T structure; var handle = GCHandle.Alloc(bytes, GCHandleType.Pinned); try { structure = (T) Marshal.PtrToStructure(handle.AddrOfPinnedObject(), typeof(T)); } finally { handle.Free(); } return structure; } |
Только что вы научились превращать объекты в массив байтов и обратно. Сейчас можно добавить функции для установки и получения значений полей. Давайте сделаем функцию для простого поиска поля по его ID.
|
public XPacketField GetField(byte id) { foreach (var field in Fields) { if (field.FieldID == id) { return field; } } return null; } |
Добавим функцию для проверки существования поля.
|
public bool HasField(byte id) { return GetField(id) != null; } |
Получаем значение из поля.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
public T GetValue<T>(byte id) where T : struct { var field = GetField(id); if (field == null) { throw new Exception($«Field with ID {id} wasn’t found.»); } var neededSize = Marshal.SizeOf(typeof(T)); if (field.FieldSize != neededSize) { throw new Exception($«Can’t convert field to type {typeof(T).FullName}.n» + $«We have {field.FieldSize} bytes but we need exactly {neededSize}.»); } return ByteArrayToFixedObject<T>(field.Contents); } |
Добавив несколько проверок и используя уже известную нам функцию, превратим набор байтов из поля в нужный нам объект типа
T.
Установка значения
Мы можем принять только объекты
Value—Type. Они имеют фиксированный размер, поэтому мы можем их записать.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
public void SetValue(byte id, object structure) { if (!structure.GetType().IsValueType) { throw new Exception(«Only value types are available.»); } var field = GetField(id); if (field == null) { field = new XPacketField { FieldID = id }; Fields.Add(field); } var bytes = FixedObjectToByteArray(structure); if (bytes.Length > byte.MaxValue) { throw new Exception(«Object is too big. Max length is 255 bytes.»); } field.FieldSize = (byte) bytes.Length; field.Contents = bytes; } |
Проверка на работоспособность
Проверим создание пакета, его перевод в бинарный вид и парсинг назад.
|
var packet = XPacket.Create(1, 0); packet.SetValue(0, 123); packet.SetValue(1, 123D); packet.SetValue(2, 123F); packet.SetValue(3, false); var packetBytes = packet.ToPacket(); var parsedPacket = XPacket.Parse(packetBytes); Console.WriteLine($«int: {parsedPacket.GetValue<int>(0)}n» + $«double: {parsedPacket.GetValue<double>(1)}n» + $«float: {parsedPacket.GetValue<float>(2)}n» + $«bool: {parsedPacket.GetValue<bool>(3)}»); |
Судя по всему, все работает прекрасно. В консоли должен появиться результат.
|
int: 123 double: 123 float: 123 bool: False |
Ввод типов пакетов
Запомнить ID всех пакетов, которые будут созданы, сложно. Отлаживать пакет с типом
N и подтипом
Ns не легче, если не держать все ID в голове. В этом разделе мы дадим нашим пакетам имена и привяжем эти имена к ID пакета. Для начала создадим перечисление, которое будет содержать имена пакетов.
|
public enum XPacketType { Unknown, Handshake } |
Unknown будет использоваться для типа, который нам неизвестен.
Handshake — для пакета рукопожатия.
Теперь, когда нам известны типы пакетов, пора привязать их к ID. Необходимо создать менеджер, который будет этим заниматься.
|
public static class XPacketTypeManager { private static readonly Dictionary<XPacketType, Tuple<byte, byte>> TypeDictionary = new Dictionary<XPacketType, Tuple<byte, byte>>(); /* < … > */ } |
Статический класс хорошо подойдет для этой функции. Его конструктор вызывается лишь один раз, что позволит нам зарегистрировать все известные типы пакетов. Невозможность вызвать статический конструктор извне поможет не проходить повторную регистрацию типов.
РЕКОМЕНДУЕМ:
Обработка сложных форм на Python с помощью WTForms
Dictionary<TKey, TValue> хорошо подходит для этой задачи. Поместим тип (
XPacketType) как ключ,
Tuple<T1, T2> будет хранить в себе значение типа и подтипа пакета:
T1 — тип,
T2 — подтип.
Создаем функцию для регистрации типов пакета.
|
public static void RegisterType(XPacketType type, byte btype, byte bsubtype) { if (TypeDictionary.ContainsKey(type)) { throw new Exception($«Packet type {type:G} is already registered.»); } TypeDictionary.Add(type, Tuple.Create(btype, bsubtype)); } |
Имплементируем получение информации по типу:
|
public static Tuple<byte, byte> GetType(XPacketType type) { if (!TypeDictionary.ContainsKey(type)) { throw new Exception($«Packet type {type:G} is not registered.»); } return TypeDictionary[type]; } |
И конечно, получение типа пакета. Структура может выглядеть несколько хаотичной, но она будет работать.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
public static XPacketType GetTypeFromPacket(XPacket packet) { var type = packet.PacketType; var subtype = packet.PacketSubtype; foreach (var tuple in TypeDictionary) { var value = tuple.Value; if (value.Item1 == type && value.Item2 == subtype) { return tuple.Key; } } return XPacketType.Unknown; } |
Создание структуры пакетов для их сериализации и десериализации
Чтобы не парсить все ручками, обратимся к сериализации и десериализации классов. Для этого надо создать класс и расставить атрибуты. Все остальное код сделает самостоятельно; потребуется только атрибут с информацией о том, с какого поля писать и читать.
|
[AttributeUsage(AttributeTargets.Field)] public class XFieldAttribute : Attribute { public byte FieldID { get; } public XFieldAttribute(byte fieldId) { FieldID = fieldId; } } |
Используя
AttributeUsage, мы установили, что наш атрибут можно будет установить только на поля классов.
FieldID будет использоваться для хранения ID поля внутри пакета.
Создание сериализатора
Для сериализации и десериализации в C# используется
Reflection. Этот набор классов позволит узнать всю нужную информацию и установить значение полей во время рантайма.
Для начала необходимо собрать информацию о полях, которые будут участвовать в процессе сериализации. Для этого можно использовать простое выражение LINQ.
|
private static List<Tuple<FieldInfo, byte>> GetFields(Type t) { return t.GetFields(BindingFlags.Instance | BindingFlags.NonPublic | BindingFlags.Public) .Where(field => field.GetCustomAttribute<XFieldAttribute>() != null) .Select(field => Tuple.Create(field, field.GetCustomAttribute<XFieldAttribute>().FieldID)) .ToList(); } |
Так как необходимые поля помечены атрибутом
XFieldAttribute, найти их внутри класса не составит труда. Сначала получим все нестатичные, приватные и публичные поля при помощи
GetFields(). Выбираем все поля, у которых есть наш атрибут. Собираем новый
IEnumerable, который содержит
Tuple<FieldInfo, byte>, где
byte — ID нашего поля в пакете.
Здесь мы вызываем
GetCustomAttribute<>() два раза. Это не обязательно, но таким образом код будет выглядеть аккуратнее.
Итак, теперь вы умеете получать все
FieldInfo для типа, который будете сериализовать. Пришло время создать сам сериализатор: у него будут обычный и строгий режимы работы. Во время обычного режима будет игнорироваться тот факт, что разные поля используют один и тот же ID поля внутри пакета.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public static XPacket Serialize(byte type, byte subtype, object obj, bool strict = false) { var fields = GetFields(obj.GetType()); if (strict) { var usedUp = new List<byte>(); foreach (var field in fields) { if (usedUp.Contains(field.Item2)) { throw new Exception(«One field used two times.»); } usedUp.Add(field.Item2); } } var packet = XPacket.Create(type, subtype); foreach (var field in fields) { packet.SetValue(field.Item2, field.Item1.GetValue(obj)); } return packet; } |
Внутри
foreach происходит самое интересное:
fields содержит все нужные поля в виде
Tuple<FieldInfo, byte>.
Item1 — искомое поле,
Item2 — ID этого поля внутри пакета. Перебираем их все, следом устанавливаем значения полей при помощи
SetPacket(byte, object). Теперь пакет сериализован.
Создание десериализатора
Создавать десериализатор в разы проще. Нужно использовать функцию
GetFields(), которую мы имплементировали в прошлом разделе.
|
public static T Deserialize<T>(XPacket packet, bool strict = false) { var fields = GetFields(typeof(T)); var instance = Activator.CreateInstance<T>(); if (fields.Count == 0) { return instance; } /* <—> */ |
После того как мы подготовили все к десериализации, можем приступить к делу. Выполняем проверки для режима
strict, бросая исключение, когда это нужно.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
/* <—> */ foreach (var tuple in fields) { var field = tuple.Item1; var packetFieldId = tuple.Item2; if (!packet.HasField(packetFieldId)) { if (strict) { throw new Exception($«Couldn’t get field[{packetFieldId}] for {field.Name}»); } continue; } /* Очень важный костыль, который многое упрощает * Метод GetValue<T>(byte) принимает тип как type-параметр * Наш же тип внутри field.FieldType * Используя Reflection, вызываем метод с нужным type-параметром */ var value = typeof(XPacket) .GetMethod(«GetValue»)? .MakeGenericMethod(field.FieldType) .Invoke(packet, new object[] {packetFieldId}); if (value == null) { if (strict) { throw new Exception($«Couldn’t get value for field[{packetFieldId}] for {field.Name}»); } continue; } field.SetValue(instance, value); } return instance; } |
Создание десериализатора завершено. Теперь можно проверить работоспособность кода. Для начала создадим простой класс.
|
class TestPacket { [XField(0)] public int TestNumber; [XField(1)] public double TestDouble; [XField(2)] public bool TestBoolean; } |
Напишем простой тест.
|
var t = new TestPacket {TestNumber = 12345, TestDouble = 123.45D, TestBoolean = true}; var packet = XPacketConverter.Serialize(0, 0, t); var tDes = XPacketConverter.Deserialize<TestPacket>(packet); if (tDes.TestBoolean) { Console.WriteLine($«Number = {tDes.TestNumber}n» + $«Double = {tDes.TestDouble}»); } |
После запуска программы должны отобразиться две строки:
|
Number = 12345 Double = 123,45 |
А теперь перейдем к тому, для чего все это создавалось.
Первое рукопожатие
Рукопожатие используется в протоколах для того, чтобы удостовериться, что клиент и сервер используют одинаковый протокол, и проверить соединение. В данном случае рукопожатие будет использовано, чтобы проверить, работает ли протокол.
Примеры работы с сокетами вы найдете в официальной документации в главе Socket Code Examples.
Мы создали простой пакет для обмена рукопожатиями.
|
public class XPacketHandshake { [XField(1)] public int MagicHandshakeNumber; } |
Рукопожатие будет инициировать клиент. Он отправляет пакет рукопожатия с рандомным числом, а сервер в свою очередь должен ответить числом, на 15 меньше полученного.
Отправляем пакет на сервер.
|
var rand = new Random(); HandshakeMagic = rand.Next(); client.QueuePacketSend( XPacketConverter.Serialize( XPacketType.Handshake, new XPacketHandshake { MagicHandshakeNumber = HandshakeMagic }).ToPacket()); |
При получении пакета от сервера обрабатываем
handshake отдельной функцией.
|
private static void ProcessIncomingPacket(XPacket packet) { var type = XPacketTypeManager.GetTypeFromPacket(packet); switch (type) { case XPacketType.Handshake: ProcessHandshake(packet); break; case XPacketType.Unknown: break; default: throw new ArgumentOutOfRangeException(); } } |
Десериализуем, проверяем ответ от сервера.
|
private static void ProcessHandshake(XPacket packet) { var handshake = XPacketConverter.Deserialize<XPacketHandshake>(packet); if (HandshakeMagic — handshake.MagicHandshakeNumber == 15) { Console.WriteLine(«Handshake successful!»); } } |
На стороне сервера есть свой идентичный
ProcessIncomingPacket. Разберем процесс обработки пакета на стороне сервера. Десериализуем пакет рукопожатия от клиента, отнимаем пятнадцать, сериализуем и отправляем обратно.
|
private void ProcessHandshake(XPacket packet) { Console.WriteLine(«Recieved handshake packet.»); var handshake = XPacketConverter.Deserialize<XPacketHandshake>(packet); handshake.MagicHandshakeNumber -= 15; Console.WriteLine(«Answering..»); QueuePacketSend( XPacketConverter.Serialize(XPacketType.Handshake, handshake) .ToPacket()); } |
Собираем и проверяем.

Все работает!
Имплементация простой защиты протокола
Наш протокол будет иметь два типа пакетов — обычный и защищенный. У обычного наш стандартный заголовок, а у защищенного вот такой:
[0x95, 0xAA, 0xFF].
Чтобы отличать зашифрованные пакеты от обычных, потребуется добавить свойство внутрь класса
XPacket.
|
public bool Protected { get; set; } |
После этого модифицируем функцию
XPacket.Parse(byte[]), чтобы она принимала и расшифровывала новые пакеты. Вначале модифицируем функцию проверки заголовка:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
var encrypted = false; if (packet[0] != 0xAF || packet[1] != 0xAA || packet[2] != 0xAF) { if (packet[0] == 0x95 || packet[1] == 0xAA || packet[2] == 0xFF) { encrypted = true; } else { return null; } } |
Как будет выглядеть наш зашифрованный пакет? По сути, это будет пакет в пакете (вроде пакета с пакетами, который вы прячете на кухне, только здесь защищенный пакет содержит в себе зашифрованный обычный пакет).
Теперь необходимо расшифровать и распарсить зашифрованный пакет. Позволяем пометить пакет как продукт расшифровки другого пакета.
|
public static XPacket Parse(byte[] packet, bool markAsEncrypted = false) |
Добавляем функциональность в цикл парсинга полей.
|
if (fields.Length == 2) { return encrypted ? DecryptPacket(xpacket) : xpacket; } |
Так как мы принимаем только структуры как типы данных, мы не сможем записать
byte[] внутрь поля. Поэтому немного модифицируем код, добавив новую функцию, которая будет принимать массив данных.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
public void SetValueRaw(byte id, byte[] rawData) { var field = GetField(id); if (field == null) { field = new XPacketField { FieldID = id }; Fields.Add(field); } if (rawData.Length > byte.MaxValue) { throw new Exception(«Object is too big. Max length is 255 bytes.»); } field.FieldSize = (byte) rawData.Length; field.Contents = rawData; } |
Сделаем такую же, но уже для получения данных из поля.
|
public byte[] GetValueRaw(byte id) { var field = GetField(id); if (field == null) { throw new Exception($«Field with ID {id} wasn’t found.»); } return field.Contents; } |
Теперь все готово для создания функции расшифровки пакета. Шифрование будет использовать класс
RijndaelManaged со строкой в качестве пароля для шифрования. Строка с паролем будет константна. Это шифрование поможет защититься от атаки типа MITM.
Создадим класс, который будет шифровать и расшифровывать данные.
Так как процесс шифрования выглядит идентично, возьмем готовое решение для шифрования строки с Stack Overflow и адаптируем его для себя.
Модифицируем методы, чтобы они принимали и возвращали массивы байтов.
|
public static byte[] Encrypt(byte[] data, string passPhrase) public static byte[] Decrypt(byte[] data, string passPhrase) |
И простой хендлер, который будет хранить секретный ключ.
|
public class XProtocolEncryptor { private static string Key { get; } = «2e985f930853919313c96d001cb5701f»; public static byte[] Encrypt(byte[] data) { return RijndaelHandler.Encrypt(data, Key); } public static byte[] Decrypt(byte[] data) { return RijndaelHandler.Decrypt(data, Key); } } |
Затем создаем функцию для расшифровки. Данные обязательно должны быть в поле с ID = 0. Как иначе нам его искать?
|
private static XPacket DecryptPacket(XPacket packet) { if (!packet.HasField(0)) { return null; } var rawData = packet.GetValueRaw(0); var decrypted = XProtocolEncryptor.Decrypt(rawData); return Parse(decrypted, true); } |
Получаем данные, расшифровываем и парсим заново. То же самое проделываем с обратной процедурой.
РЕКОМЕНДУЕМ:
Как сделать свою структуру данных в Python
Вводим свойство, чтобы пометить надобность в заголовке зашифрованного пакета.
|
private bool ChangeHeaders { get; set; } |
Создаем простой пакет и помечаем, что в нем зашифрованные данные.
|
public static XPacket EncryptPacket(XPacket packet) { if (packet == null) { return null; } var rawBytes = packet.ToPacket(); var encrypted = XProtocolEncryptor.Encrypt(rawBytes); var p = Create(0, 0); p.SetValueRaw(0, encrypted); p.ChangeHeaders = true; return p; } |
И добавляем две функции для более удобного обращения.
|
public XPacket Encrypt() { return EncryptPacket(this); } public XPacket Decrypt() { return DecryptPacket(this); } |
Модифицируем
ToPacket(), чтобы тот слушался значения
ChangeHeaders.
|
packet.Write(ChangeHeaders ? new byte[] {0x95, 0xAA, 0xFF, PacketType, PacketSubtype} : new byte[] {0xAF, 0xAA, 0xAF, PacketType, PacketSubtype}, 0, 5); |
Проверяем:
|
var packet = XPacket.Create(0, 0); packet.SetValue(0, 12345); var encr = packet.Encrypt().ToPacket(); var decr = XPacket.Parse(encr); Console.WriteLine(decr.GetValue<int>(0)); |
В консоли получаем число
12345.
Заключение
Только что мы создали свой собственный протокол. Это был долгий путь от базовой структуры на бумаге до его полной имплементации в коде. Надеюсь, вам было интересно!
Исходный код проекта можно найти в GitHub.

 (8 оценок, среднее: 4,25 из 5)
(8 оценок, среднее: 4,25 из 5)
![]() Загрузка…
Загрузка…
Первые прямые трансляции с места событий появились в России почти 70 лет назад и вели их из передвижной телевизионной станции (ПТС), которая внешне походила на «троллейбус» и позволяла вести эфиры не из студии. А всего лишь три года назад Periscope позволил вместо «троллейбуса» использовать мобильный телефон.
Но это приложение имело ряд проблем, связанных, например, с задержками в эфирах, с невозможностью смотреть трансляции в высоком качестве и т.д.
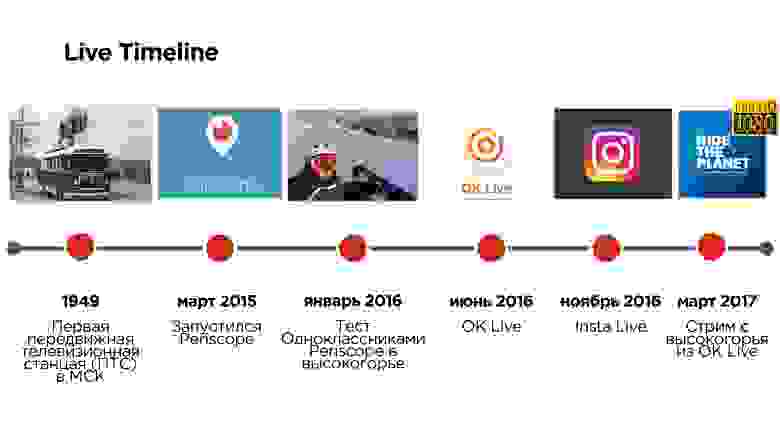
Еще через полгода, летом 2016, Одноклассники запустили свое мобильное приложение OK Live для стриминга, в котором постарались решить эти проблемы.
Александр Тоболь отвечает за техническую часть видео в Одноклассниках и на Highload++ 2017 рассказал про то, как писать свой UDP протокол, и зачем это может потребоваться.
Из расшифровки его доклада вы узнаете все про другие протоколы стриминга видео, какие есть нюансы, и про то, какие уловки иногда требуются.
Говорят, что надо всегда начинать с архитектуры и ТЗ — якобы без этого нельзя! Так и сделаем.
Архитектура и ТЗ
На слайде ниже схема архитектуры любого стримингового сервиса: видео подается на вход, преобразуется и передается на выход. К этой архитектуре мы добавили еще немножко требований: видео должно подаваться с десктопов и мобильных телефонов, а на выход — попадать на те же десктопы, мобильные телефоны, smartTV, Chromcast, AppleTV и другие устройства — все, на чем можно играть видео.
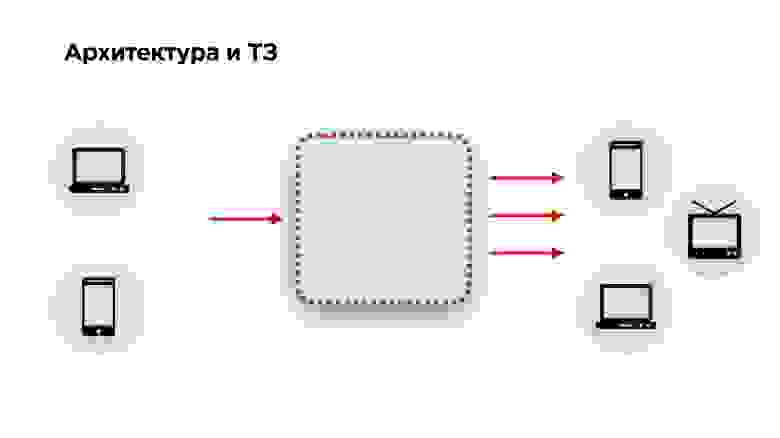
Дальше переходим к техническому заданию. Если у вас есть заказчик, у вас есть ТЗ. Если вы — социальная сеть, ТЗ у вас нет. Как его составить?
Можно конечно опросить пользователей и узнать все, что они хотят. Но это будет целая куча желаний, которые никак не коррелируют с тем, что людям действительно надо.
Мы решили пойти методом от противного и посмотрели, что пользователи НЕ хотят видеть от сервиса трансляции.
- Первое, что не хочет пользователь — это видеть задержку на старте трансляции.
- Пользователь не хочет видеть некачественную картинку стрима.
- Если в трансляции есть интерактив, когда пользователь общается со своей аудиторией (встречные прямые эфиры, звонки и т.д.), то он не хочет видеть задержку между стримером и зрителем.
Так выглядит обычный стриминговый сервис. Посмотрим, что можно сделать, чтобы вместо обычного сделать — крутой стриминговый сервис.

Начать можно было бы с просмотра всех протоколов стриминга, выбрать наиболее интересные и сравнить их. Но мы сделали по-другому.
Что у конкурентов?
Мы начали с изучения сервисов конкурентов. Открываем Periscope — что у них?
Как всегда, главное — архитектура.
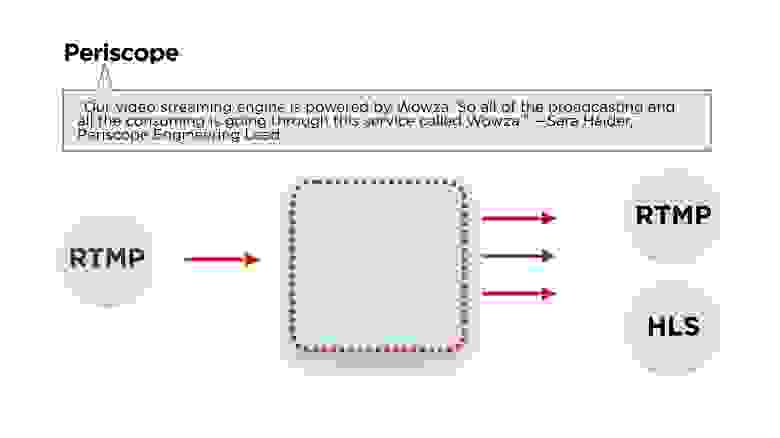
Сара Хайдер, ведущий инженер Periscope, пишет, что для бэкенда они используют Wowza. Если еще немножко почитать статьи, то мы увидим, что стрим они делают с использованием протокола RTMP, а раздают его либо в RTMP, либо в HLS. Посмотрим, что это за протоколы и как они работают.
Протестируем Periscope на три наших главных требования.

Скорость старта у них приемлемая (меньше секунды на хороших сетях), постоянноекачество порядка 600 px (не HD) и при этом задержки могут составлять до 12 секунд.
Кстати, как померить задержку в трансляции?
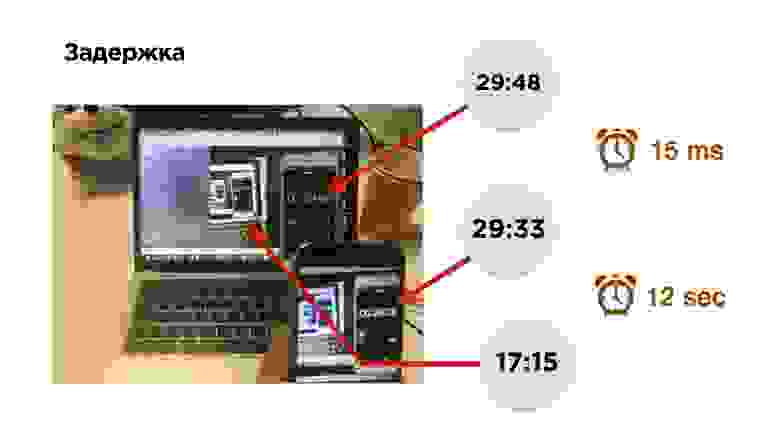
Это фотография измерения задержки. Есть мобильный телефон с таймером. Мы включаем трансляцию и видим изображение этого телефона на экране. За 0,15 миллисекунд изображение попало на сенсор камеры и вывелось из видеопамяти на экран телефона. После этого мы включаем браузер и смотрим трансляцию.
Ой! Она немножко отстала — примерно на 12 секунд.
Чтобы найти причины задержки, попрофилируем стриминг видео.
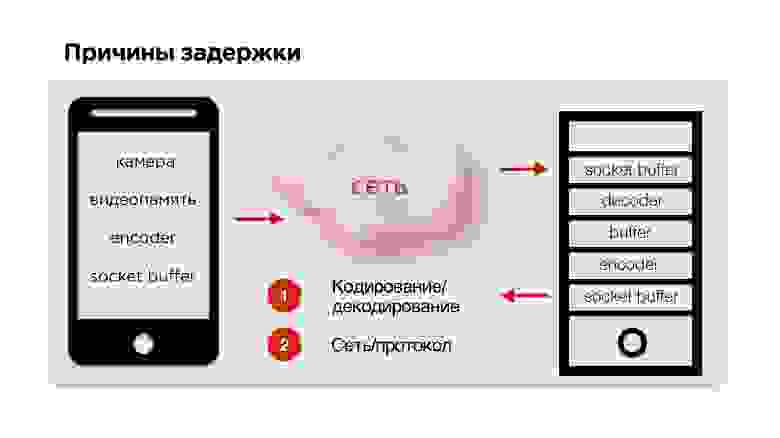
Итак, есть мобильный телефон, видео идет с камеры и попадает в видеобуфер. Тут задержки минимальны (≈0,15 мс). Потом кодировщик кодирует сигнал, упаковывает в пакет и отправляет в socket-буфер. Это все летит в сеть. Дальше на принимающем устройстве происходит все то же самое.
В принципе, есть две основные трудные точки, которые нужно рассмотреть:
- кодирование/декодирование видео;
- сетевые протоколы.
Кодирование/декодирование видео
Немного расскажу про кодирование. Вы все равно с ним столкнетесь, если будете делать Low Latency Live Streaming.
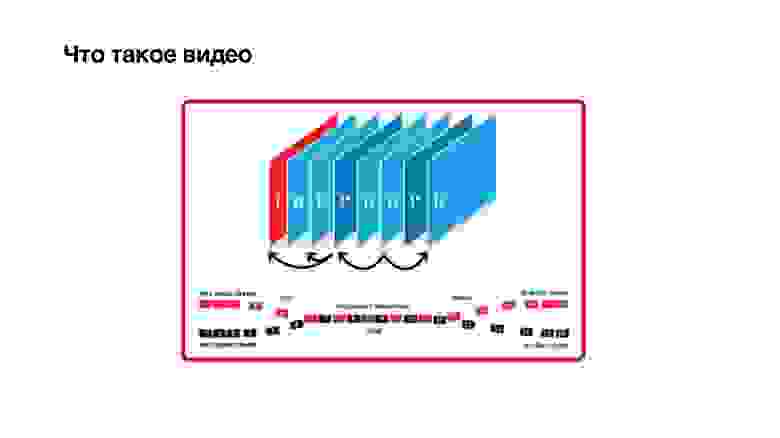
Что такое видео? Это набор кадров, но не совсем простых. Кадры бывают трех типов: I, P и B-frame:
- I-frame — это просто jpg. По сути, это опорный кадр, он ни от кого не зависит и содержит четкую картинку.
- P-frame зависит исключительно от предыдущих кадров.
- Хитрые B-frame могут зависеть от будущего. Это означает, что чтобы посчитать b-frame, нужно, чтобы с камеры пришли еще и будущие кадры. Только тогда с некоторой задержкой можно декодировать b-frame.
Отсюда видно, что B-кадры вредны. Попробуем их убрать.
- Если вы стримите с мобильного устройства, можно попробовать включить профайл baseline. Он отключит B-frame.
- Можно попробовать настроить кодек и уменьшить задержку на будущие кадры, чтобы кадры приходили быстрее.
- Еще одна важная штука в тюнинге кодека — это включение CBR (константного битрейта).
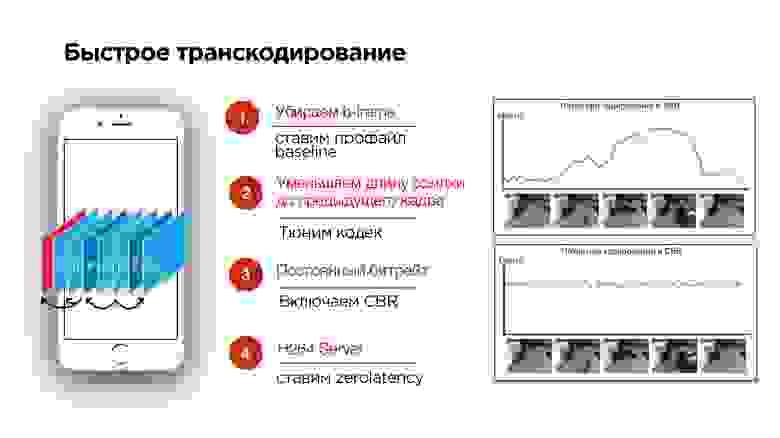
Как работают кодеки, проиллюстрировано на слайде выше. В рассматриваемом примере на видео статическая картинка, ее кодирование экономит место на диске, т.к. там почти ничего не меняется, и битрейт видео низкий. Происходят изменения — растет энтропия, растет битрейт видео — для хранения на диске это здорово.
Но в тот момент, когда начались активные изменения, и вырос битрейт, скорее всего все данные в сеть не пролезут. Это как раз то, что происходит, когда вы делаете видеозвонок и начинаете поворачиваться, а у вашего абонента подтормаживает картинка. Это связано с тем, что сеть не успевает адаптироваться под изменение битрейта.
Надо включать CBR. Не все кодеки на Android будут его корректно поддерживать, но они будут к этому стремиться. То есть нужно понимать, что с CBR идеальной картины мира, как на нижней картинке, вы не получите, но включить его все-таки стоит.
4. А на бэкенде необходимо добавить к H264 кодеку zerolatency — это позволит как раз не делать зависимости в кадрах на будущее.
Протоколы передачи видео
Рассмотрим, какие протоколы стриминга предлагает индустрия. Я их условно разбил на два типа:
- потоковые протоколы;
- cегментные протоколы.

Потоковые протоколы — это протоколы из мира p2p звонков: RTMP, webRTC, RTSP/RTP. Они отличаются тем, что пользователи договариваются о том, какой у них канал, подбирают битрейт кодека соответственно каналу. А еще у них есть дополнительные команды такого рода, как «дай мне опорный кадр». Если вы потеряли кадр, в этих протоколах вы можете заново его запросить.
Отличие сегментных протоколов в том, что никто ни с кем никак не договаривается. Они режут видео на сегменты, хранят каждый сегмент в различных качествах, и клиент сам может выбирать, какой сегмент смотреть. Каждый сегмент начинается с опорного кадра.
Рассмотрим протоколы более детально. Начнем с потоковых протоколов и разберемся, с какими проблемами мы можем столкнуться, если будем использовать потоковые протоколы для broadcast-стриминга.
Потоковые протоколы
Periscope использует RTMP. Этот протокол появился в 2009 году, и Adobe сначала не полностью его специфицировал. Потом у него были определенного рода трудности с тем, что Adobe хотел продавать исключительно свой сервер. То есть RTMP развивался довольно трудно. Его основная проблема в том, что он использует TCP, но почему-то именно его выбрал Periscope.

Если почитать детально, то оказывается, что Periscope использует RTMP для трансляции с малым количеством зрителей. Как раз такие трансляции, если у вас недостаточный канал, скорее всего, вы не сможете посмотреть.
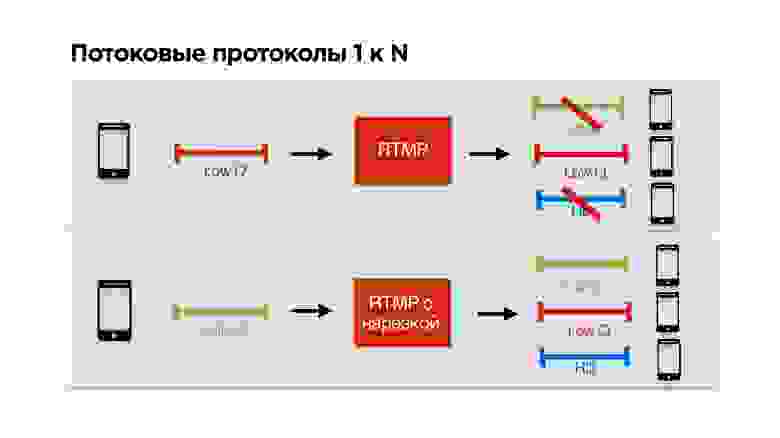
Рассмотрим на конкретном примере. Есть пользователь с узким каналом связи, который смотрит вашу трансляцию. Вы с ним договариваетесь по RTMP о низком битрейте и начинаете персонально для него стримить.
К вам приходит еще пользователь с классным интернетом, у вас тоже классный интернет, но вы уже с кем-то договорились о низком качестве, и получается так, что этот третий с классным интернетом смотрит стрим в плохом качестве, несмотря на то, что мог бы смотреть в хорошем.
Эту проблему мы решили устранить. Мы сделали, чтобы можно было RTMP подрезать для каждого клиента персонально, то есть стримящие договариваются с сервером, стримят на максимально возможном качестве, а каждый клиент получает то качество, которое позволяет ему сеть.
Здорово!
Но все равно RTMP у нас поверх TCP, и никто нас от блокировки начала очереди не застраховал.
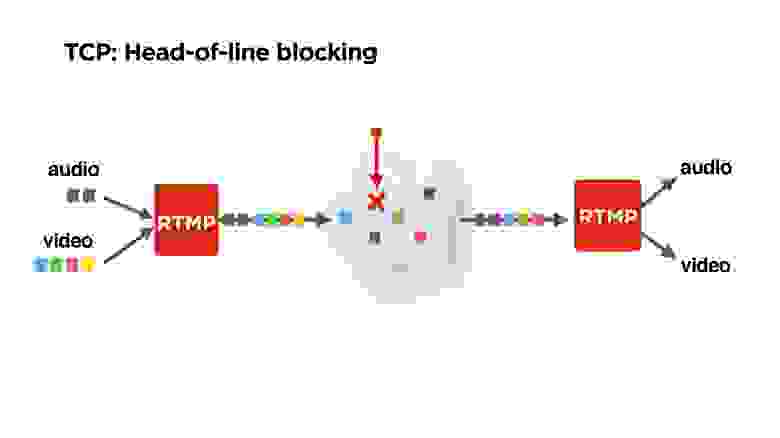
На рисунке это проиллюстрировано: к нам поступают аудио и видео фреймы, RTMP их пакует, возможно их как-то перемешивает, и они улетают в сеть.
Но допустим, мы теряем один пакет. Возможно, что тот самый желтый потерянный пакет — это вообще P-frame от какого-то предыдущего — его можно было бы дропнуть. Возможно, как минимум, можно было бы играть аудио. Но TCP нам не отдаст остальные пакеты, так как он гарантирует доставку и последовательность пакетов. С этим надо как-то бороться.
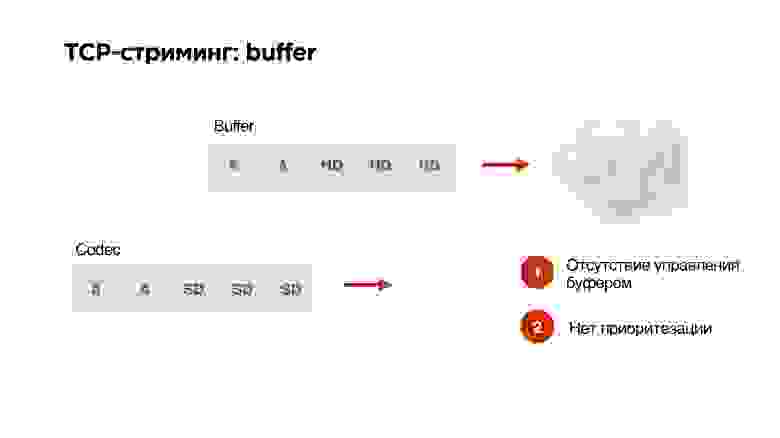
Существует еще одна проблема использования протокола TCP в стриминге.
Допустим, у нас есть буфер и высокая пропускная способность сети. Мы генерируем туда из нашего кодека пакеты в высоком разрешении. Потом — оп! — сеть стала работать хуже. На кодеке мы уже указали, что битрейт нужно понизить, но готовые пакеты уже в очереди и никаким образом изъять их оттуда нельзя. TCP отчаянно пытается пропихнуть HD-пакеты через наш 3G.
У нас нет никакого управления буфером, нет приоритезации, поэтому TCP крайне не подходит для стриминга.

Давайте теперь взглянем на мобильные сети. Возможно для жителей столиц это будет удивительно, но наша средняя мобильная сеть выглядит примерно так:
- 1,1 Мбит/с трафика;
- 0,1% packet loss;
- 300 мс средний RTT.
А если посмотреть некоторые регионы и конкретных операторов, то у них среднедневной процент потери пакетов более 3%, а RTT от 600 мс — это нормально.
TCP — это, с одной стороны, классный протокол — очень трудно научить машину ездить сразу же и по хайвэю, и по бездорожью. Но научить ее потом еще и летать по беспроводным сетям оказалось очень сложно.
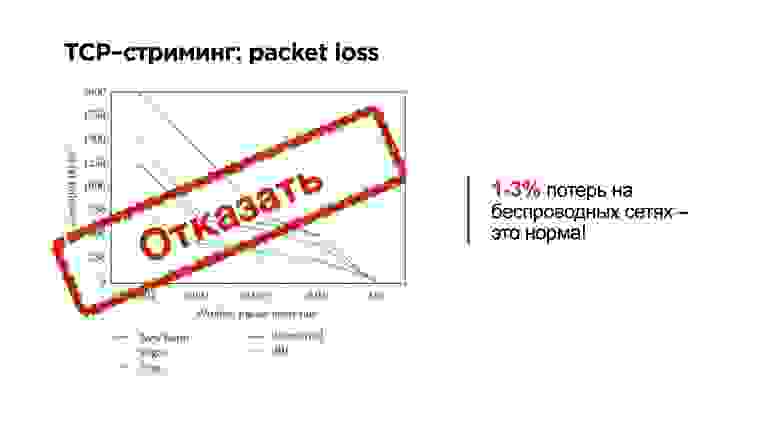
Потеря даже 0,001% пакетов приводит к снижению пропускной способности на 30%. То есть наш пользователь не доутилизирует канал на 30% из-за неэффективности работы TCP протокола в сетях со случайной потерей пакетов.
В определенных регионах packet loss доходит до 1%, тогда у пользователя остается порядка 10% процентов пропускной способности.
Поэтому на TCP делать не будем.
Посмотрим, что есть еще в мире стриминга из UDP.
Протокол WebRTC очень хорошо зарекомендовал себя для p2p звонков. На очень популярных сайтах пишут, что использовать для звонков его очень здорово, а вот для доставки видео и музыки — не хорошо.
Его основная проблема в том, что он пренебрегает потерями. При всех непонятных ситуациях он просто дропает.
Есть еще некоторая проблема в его привязанности к звонкам, дело в том, что он шифрует все. Поэтому, если вы ведете броадкаст на трансляцию, и нет необходимости шифровать весь аудио/видео поток, запуская WebRTC, вы все равно напрягаете свой процессор. Возможно, вам это не нужно.

RTP-стриминг — это базовый протокол передачи данных по UDP. Ниже на слайде справа приведен набор расширений и RFC, которые пришлось реализовать в WebRTC для того, чтобы адаптировать этот протокол для звонков. В принципе, можно попробовать сделать что-то подобное — набрать набор расширений к RTP и получить UDP стриминг. Но это очень сложно.
Вторая проблема в том, что если кто-то из ваших клиентов не поддерживает какой-либо extension, то протокол не заработает.

Сегментные протоколы
Хорошим примером сегментного протокола видео является MPEG-Dash. Он состоит из manifest-файла, который вы выкладываете у себя на портале. Он содержит ссылки на файлы в разных качествах, в начале файла есть некоторый индекс, который говорит, в каком месте файла начинается какой сегмент.
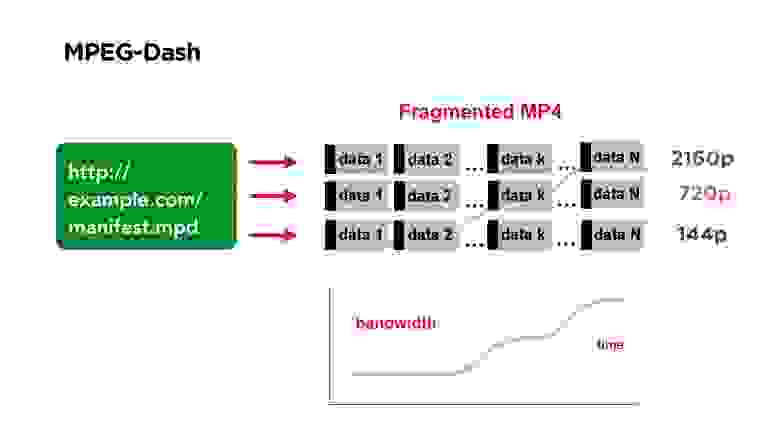
Все видео разбито на сегменты, например, по 3 секунды, каждый сегмент начинается с опорного кадра. Если вы смотрите такое видео и у вас меняется битрейт, то вы просто на стороне клиента начинаете брать сегмент того качества, которое вам нужно.
Еще одним примером сегментного стриминга является HLS.
MPEG-Dash — решение от Google, оно хорошо работает в Android, а Apple-решение более старое, у него есть ряд определенных недостатков.
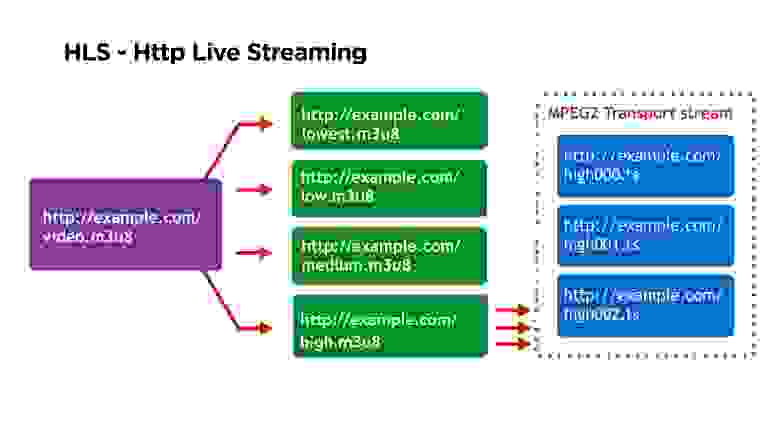
Первый из них — это то, что основной манифест содержит ссылки на вторичные манифесты, вторичные манифесты по каждому конкретному качеству содержат ссылки на каждый отдельный сегмент, а каждый отдельный сегмент представлен отдельным файлом.
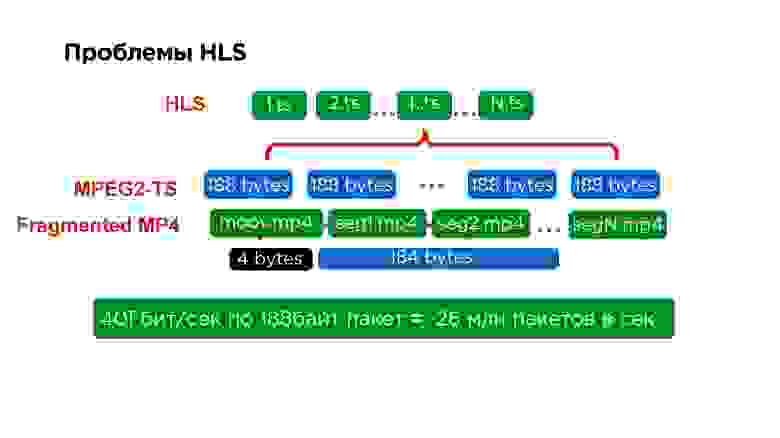
Если взглянуть еще более детально, то внутри каждого сегмента находится MPEG2-TS. Этот протокол делали еще для спутника, размер его пакета 188 байт. Упаковывать видео в такой размер очень неудобно, особенно потому, что вы все время его снабжаете небольшим хедером.
На самом деле это трудно не только серверам, которые для того, чтобы обработать 40 Гб трафика должны собрать 26 млн пакетов, но это еще трудно и на клиенте. Поэтому, когда мы переписали iOS плеер на MPEG-Dash, мы даже увидели некоторый прирост производительности.
Но Apple не стоит на месте. В 2016 году они наконец-то анонсировали, что у них есть возможность запихнуть фрагмент от MPEG4 в HLS. Тогда они обещали это добавить только для разработчиков, но вроде бы сейчас должна появиться поддержка на macOS и iOS.
То есть, казалось бы, фрагментный стриминг удобный — приходите, берете нужный фрагмент, с опорного кадра стартуете — работает.
Минус: понятно, что опорный кадр, с которого вы стартовали — это не тот кадр, который сейчас у того, кто стримит. Поэтому всегда появляется задержка.
Вообще есть возможность допилить HLS до задержек порядка 5 секунд, кто-то говорит, что ему удалось получить 4, но в принципе решение использовать фрагментный стриминг для трансляции не очень хорошее.

Сложность vs задержка
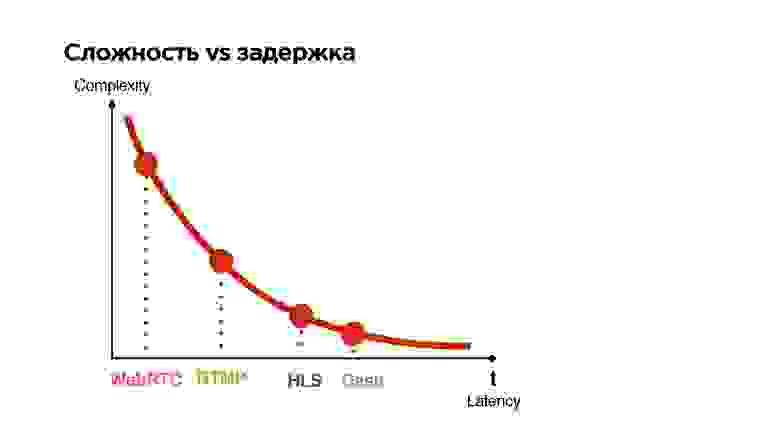
Посмотрим на все имеющиеся протоколы и рассортируем их по двум параметрам:
- latency, который они дают между трансляцией и смотрящим;
- complexity (сложность).
Чем меньшую задержку гарантирует протокол, тем он более сложный.
Что мы хотим?
Мы хотим сделать UDP-протокол для стриминга от 1 к N с задержкой, сравнимой с p2p связью, с возможностью опционального шифрования пакетов в зависимости от того, приватная или публичная трансляция.
Какие есть еще варианты? Можно подождать, например, когда Google выпустит свой QUIC.
Расскажу немного, что это такое. Google позиционирует Google QUIC, как замену TCP — некий TCP 2.0. Его разрабатывают с 2013 года, сейчас спецификации у него нет, зато он полностью доступен в Google Chrome, и мне кажется, что они иногда включают его некоторым пользователям для того, чтобы посмотреть, как он работает. В принципе, можно зайти в настройки, включить себе QUIC, зайти на любой Google сайт и получить этот ресурс по UDP.
Мы решили не ждать, пока они все специфицируют, и запилить свое решение.
Требования к протоколу:
- Многопоточность, то есть мы имеем несколько потоков — управляющий, видео, аудио.
- Опциональная гарантия доставки — управляющий поток имеет 100% гарантию, видео нам нужно меньше всего — мы там можем дропать фрейм, аудио нам все-таки бы хотелось.
- Приоритезация потоков — чтобы аудио уходило вперед, а управляющий вообще летел.
- Опциональное шифрование: или все данные, или только заголовки и критичные данные.

Это стандартный треугольник: если хорошая сеть, то высокое качество и низкие задержки. Как только появляется нестабильная сеть, начинают пропадать пакеты, мы балансируем между качеством и задержкой. У нас есть выбор: либо подождать, пока сеть наладится и отправить все, что накопилось, либо дропнуть и как-то с этим жить.
Если сортировать протоколы по такому принципу, то видно, что чем меньше время ожидания, тем хуже качество — довольно простой вывод.
Мы хотим свой протокол вклинить в зону, где задержки близки к WebRTC, но при этом иметь возможность его немножко отодвинуть, потому что все-таки у нас не звонки, а трансляции. Пользователь хочет в конечном итоге получать качественный стрим.
Разработка
Давайте уже начнем писать UDP протокол, но сначала посмотрим на статистику.
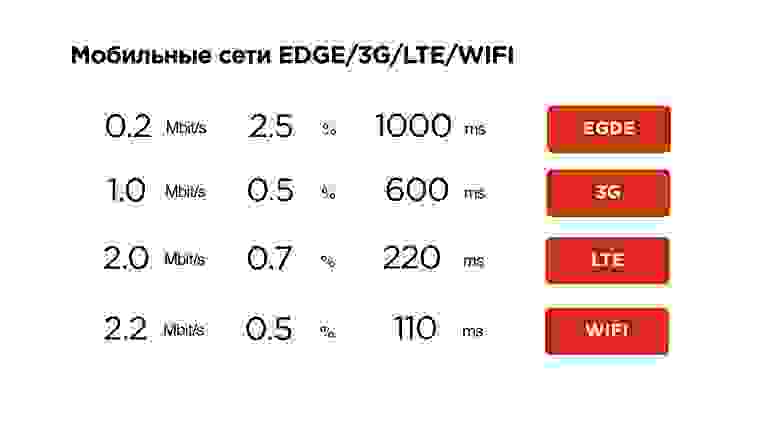
Это наша статистика по мобильным сетям. Тут видно, что средний интернет чуть больше мегабита, packet loss около 1% — это нормально, и RTT в районе 600 мс — на 3G это просто средние величины.
Будем на это ориентироваться при написании протокола — поехали!
UDP-протокол
Открываем socket UDP, забираем данные, упаковываем, отправляем. Берем вторую пачку от кодека, еще отправляем. Вроде бы все здорово!
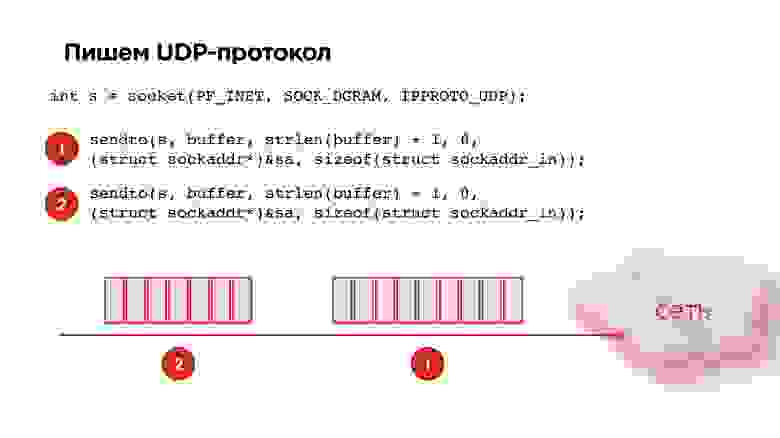
Но мы получим такую картину: если мы начинаем беспорядочно слать UDP пакеты в socket, то по статистике к 21-му пакету вероятность того, что он дойдет, будет всего лишь 85%. То есть packet loss уже будет 15%, что никуда не годится. Это нужно исправлять.

Исправляется это стандартно. На рисунке проиллюстрирована жизнь без Pacer и жизнь с Pacer.
Pacer — это такая штука, которая раздвигает пакеты во времени и контролирует их потерю; смотрит, какой сейчас packet loss, в зависимости от этого адаптируется под скорость канала.
Как мы помним, для мобильных сетей 1-3% packet loss — это норма. Соответственно, надо с этим как-то работать. Что делать, если мы теряем пакеты?
Retransmit
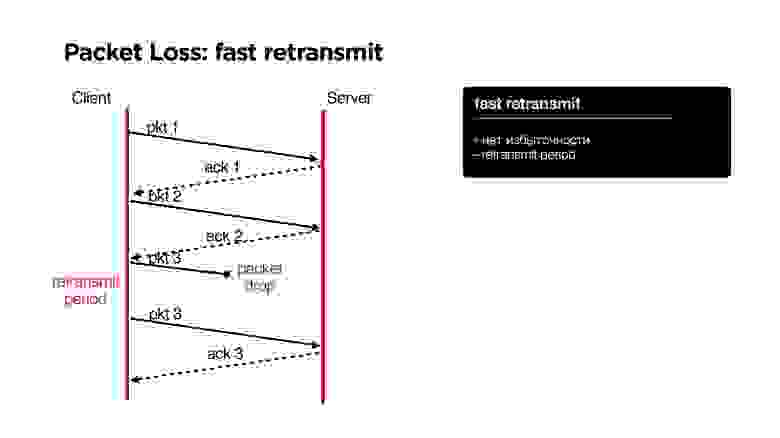
В TCP, как известно, есть алгоритм fast retransmit: мы отправляем один пакет, второй, если пакет потеряли, то через некоторое время (retransmit period) отправляем этот же пакет.
Какие здесь плюсы? Никаких проблем, никакой избыточности, но есть минус — некоторый retransmit period.

Кажется, что очень просто: через какое-то время нужно повторить пакет, если вы не получили на него подтверждение. Логично, что это может быть время равное времени пинга. Но ping — это величина не стабильная, и поэтому точно через средний RTT time определить, что потерян пакет, мы не можем.
Для того, чтобы это оценить можно, например, использовать такую величину, как jitter: мы считаем разницу между всеми нашими ping-пакетами. Например, в примере выше, средняя величина равна 46 мс. На нашем портале средний jitter — 50.
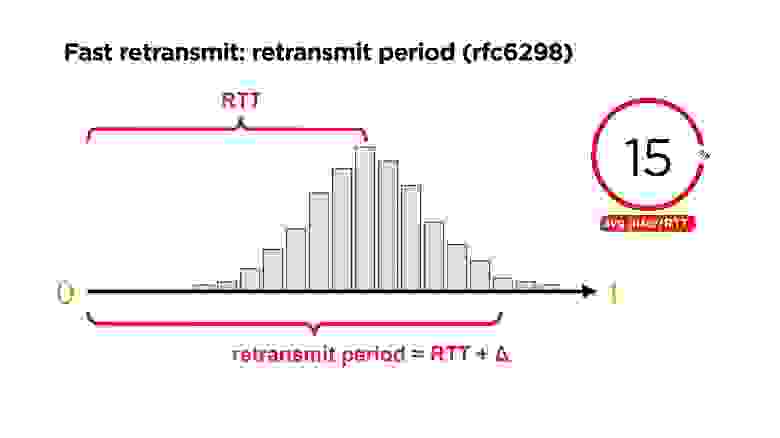
Посмотрим на распределение вероятности приходов пакетов ко времени. Есть некоторый RTT и некоторая величина, после которой мы можем действительно понять, что acknowledge не пришел и повторить отправку пакета. В принципе, есть RFC6298, который в TCP говорит, как это можно хитро посчитать.
Мы это делаем через jitter. На портале у нас jitter по ping примерно 15%. Понятно, что retransmit period должен быть, как минимум, на 20% больше, чем RTT.

Еще один кейс с retransmit. С прошлого раза у нас был acknowledge на второй пакет. Мы отправляем третий пакет, который теряется, другие пакеты пока ходят. После этого наступает retransmit period, и мы отправляем третий пакет еще раз. Он еще раз дропнулся, и мы еще раз отправляем его.
Если у нас случается двойная потеря пакета, то на retransmit появляется новая проблема. Если у нас, например, packet loss 5%, и мы отправляем 400 пакетов, то на 400 пакетов у нас 1 раз точно будет ситуация двойного packet-drop, то есть, когда мы через retransmit period отправили пакет, и он еще раз не дошел.
Эту ситуацию можно исправить, добавив некоторую избыточность. Можно начать отправлять пакет, например, если мы получили acknowledge от другого пакета. Считаем, что опережение — это редкая ситуация, можем начать отправку третьего пакет в момент, обозначенный speculative retransmit на слайде выше.
Можно еще пошаманить со спекулятивным retransmit, и все будет неплохо работать.
Но тут мы заговорили про избыточность. А что, если добавить Forward Error Correction? Давайте просто все наши пакеты снабдим, например, XOR. Если мы точно знаем, что в мобильных сетях все так печально, то давайте просто добавим еще один пакетик.
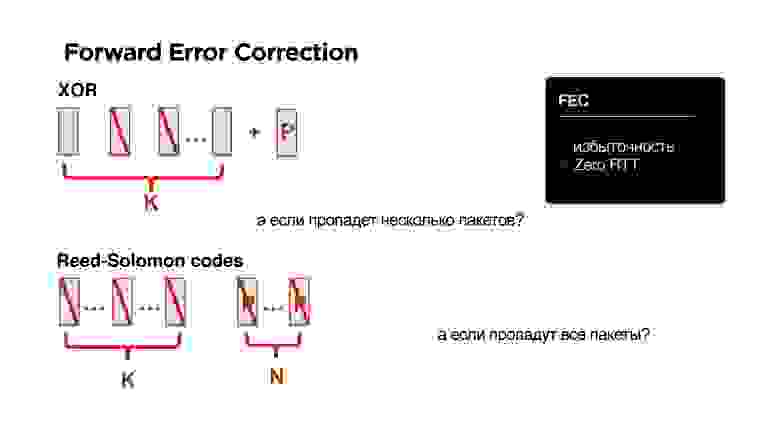
Здорово! Нам не нужны никакие round trip, но у нас уже появилась избыточность.
А что, если пропадет не один пакет, а сразу два? Давайте вместо XOR возьмем другое решение — например, есть код Reed-Solomon, Fountain codes и т.д. Идея такая: если есть K пакетов, можно добавить к ним N пакетов так, что любые N можно было потерять.
Вроде бы классно!
Хорошо, если у нас такая плохая сеть, что пропали просто все пакеты, то к нашему Forward Error Correction очень удобно добавляется negative acknowledgement.
NACK
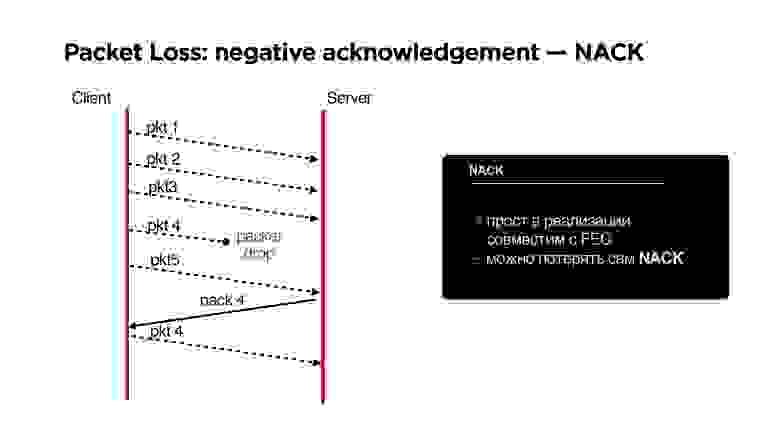
Если мы потеряли столько пакетов, что наш parity protection (назовем его так) нас уже не спасает, запрашиваем этот пакет дополнительно.
Плюсы NACK:
- Простой в реализации, правда можно потерять и сам negative acknowledgement, но это мелкая проблема.
- Хорошо совместим с FEC.
Итого, есть два интересных решения:
- С одной стороны, FEC + NACK;
- С другой стороны, Fast retransmit.
Посмотрим, как распределены потери пакетов.
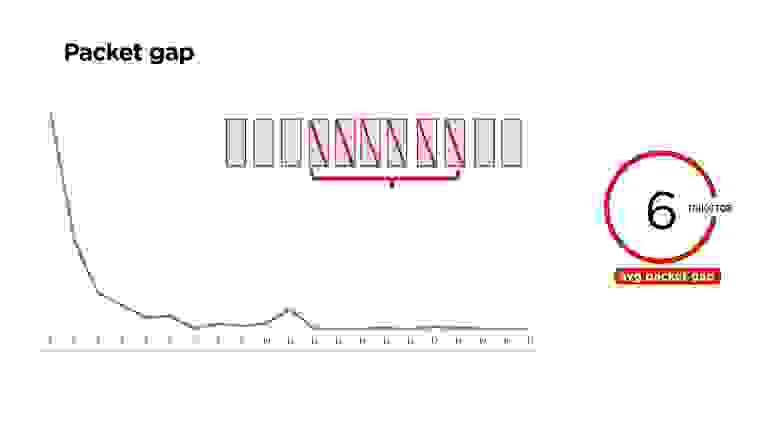
Оказывается, что пакеты теряются не равномерно по одной штучке, а пачками (выше график распределений). Причем есть интересные пики, например, на 11 пакетах, есть еще пики на 60-80 пакетах. Они повторяются, и мы изучаем, откуда они берутся.
В среднем на нашем портале теряется по 6 пакетов.

Детальное рассмотрение по сетям показывает, что чем хуже сеть, тем больше это количество. В таблице указано время, которое сеть была недоступна. Например, Wi-Fi недоступен 22 мс и теряет 5 пакетов, 3G может за 34 мс потерять 8 пакетов.

Вопрос: если мы знаем, что у нас 90% packet loss на портале укладывается в 10 пакетов, и при этом средний gap равен 25 мс, что будет работать лучше — FEC + NACK или Fast retransmit?
Тут, наверное, надо рассказать, что Google, когда делал свой протокол QUIC в 2013 году, ставил Forward Error Correction во главу, думая, что он решит все проблемы. Но в 2015 они его отключили.
Мы протестировали оба варианта и у нас не получилось завести FEC + NACK, но мы еще пытаемся и не отчаиваемся.
Рассмотрим, как он работает.

Это цифры, близкие к средней сети, проcто чтобы было удобно считать:
- 1 Мб/с сеть;
- 1% packet loss;
- 300 мс RTT;
- 1 000 байт — размер пересылаемых пакетов;
- 1 000 пакетов в секунду уходит.
Мы хотим справляться с потерей сразу до 10 пакетов. Соответственно при packet loss в 1% нам нужно к 1 000 пакетов добавлять 10. Логично — почему нельзя к 100 пакетам добавлять 1 — потому что, если мы потеряли интервал хотя бы в 2 пакета, мы не восстановимся.
Мы начинаем делать такие добавки, и вроде бы все здорово. И тут на 500-м пакете, теряем ту самую пачку из 10 штук.
У нас есть варианты:
- Дождаться оставшиеся 500 пакетов и восстановить данные через Forward Error Correction. Но на это у нас потратится примерно полсекунды, а пользователь эти данные ждет.
- Можно воспользоваться NACK, причем это дешевле, чем дожидаться кодов коррекции.
- А еще можно просто взять Fast Retransmit, не добавлять никаких кодов коррекции и получить тот же самый результат.
Поэтому Forward Error Correction действительно работает, но работает на очень узком диапазоне — когда gap небольшой и можно раз в 200-300 пакетов вставлять это избыточное кодирование.
Fast Retransmit
Это работает так: после того, как мы потеряли пачку в 10 пакетов, отправив пока другие пакеты, понимаем, что у нас retransmit period прошел, и отправляем эти пакеты заново.
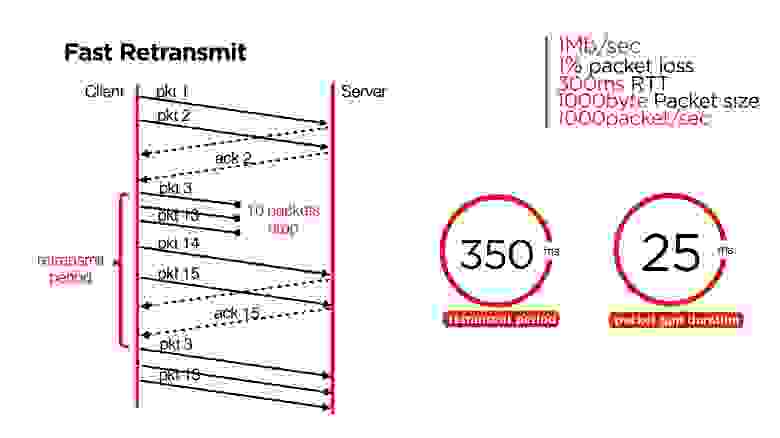
Самое интересное в том, что retransmit period на такой сети будет 350 мс, а средняя длительность этого packet gap — 25-30 мс, пусть даже 100. Это означает, что к моменту, когда retransmit начнет обрабатывать пакеты, в большинстве случаев сеть уже восстановится и они уйдут.
У нас получилось, что эта штука работает лучше и быстрее.
Дополнительные опции
Когда вы пишете свой протокол поверх UDP и у вас есть возможность отправки пакетов, вы получаете дополнительные плюшки.

Есть буфер отправки, в нем лежит опорный кадр, к нему p/b-кадры. Они равномерно уходят в сеть. Тут они перестали уходить в сеть, а в очередь прилетели еще пакеты.
Вы понимаете, что на самом деле все пакеты, которые лежат в очереди, уже больше не интересны клиенту, потому что прошло, например, больше 0,5с и надо на клиенте просто склеить разрыв и жить дальше.
Вы можете, имея информацию о том, что у вас хранится в этих пакетах, почистить не только опорный кадр, но и все p/b, от него зависящие, и оставить исключительно нужные и целостные данные, которые потом могут потребоваться клиенту.
MTU
Так как мы сами пишем протокол, то придется столкнуться с IP fragmentation. Думаю, многие про это знают, но на всякий случай вкратце расскажу.

У нас есть сервер, он отправляет какие-то пакеты в сеть, они приходят к маршрутизатору и на его уровне MTU (maximum transmission unit) становится ниже, чем размер пакета, который пришел. Он дробит пакет на большой и маленький (здесь 1100 и 400 байт) и отправляет.
В принципе, проблемы нет, это все соберется на клиенте и будет работать. Но если мы теряем 1 пакет, мы дропаем все пакеты, плюс получаем дополнительные издержки на header’ы пакетов. Поэтому, если вы пишете свой протокол, идеально работать в размере MTU.
Как его посчитать?
На самом деле Google не заморачивается, ставит порядка 1200 байт в своем QUIC и не занимается его подбором, потому что IP фрагментация потом все пакетики соберет.
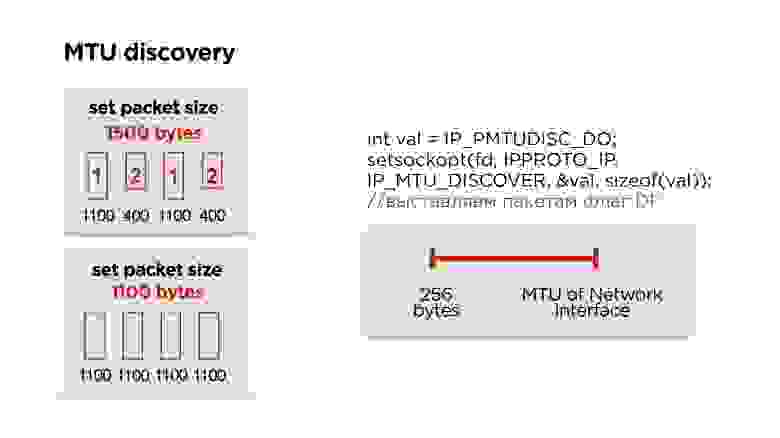
Мы делаем точно также — сначала ставим какой-то дефолтный размер и начинаем слать пакеты — пусть он их фрагментирует.
Параллельно запускаем отдельный поток и создаем socket с флагом запрета фрагментации для всех пакетов. Если маршрутизатор встречает такой пакет и не может эти данные фрагментировать, то он дропнет пакет и возможно по ICMP вам отправит, что есть проблемы, но скорее всего, ICMP будет закрыт и этого не будет. Поэтому мы просто, например, три раза пытаемся отправить пакет определенного размера с каким-то интервалом. Если он не дошел, мы считаем, что MTU превышен и дальше его уменьшаем.
Таким образом, имея MTU интернет интерфейса, который есть на устройстве, и какое-то минимальное MTU, просто одномерным поиском подбираем правильный MTU. После этого корректируем размер пакета в протоколе.
На самом деле, он иногда меняется. Мы были удивлены, но в процессе переключения Wi-Fi и пр. MTU меняется. Этот параллельный процесс лучше не останавливать и время от времени подправлять MTU.
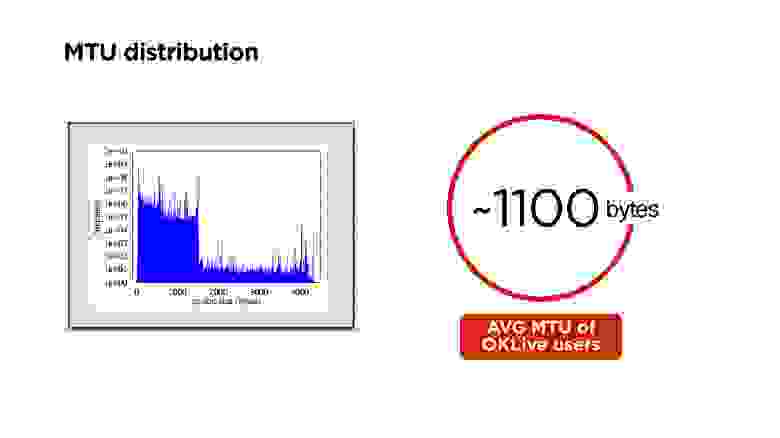
Выше распределение MTU в мире. У нас на портале получилось около 1100 байт.
Шифрование
Мы говорили, что мы хотим опционально управлять шифрованием. Делаем самый простой вариант — Diffie-Hellman на эллиптических кривых. Делаем его опционально — шифруем только управляющие пакеты и заголовки, чтобы man-in-the-middle не мог получить ключ трансляции, перехватить и так далее.

Если трансляция приватная, то можем добавить еще и шифрование всех данных.
Пакеты шифруем AES-256 независимо, чтобы packet drop никак не влиял на дальнейшее шифрование пакетов.
Приоритезация
Помните, мы хотели от протокола еще приоритезацию.

У нас есть метаданные, аудио и видеофреймы, мы их успешно отправляем в сеть. Потом наша сеть сгорает в аду и долго-долго не работает — мы понимаем, что нам нужно дропать пакеты.
Мы приоритетно дропаем видеопакеты, потом пытаемся дропать аудио и никогда не трогаем управляющие пакеты, потому что по ним могут ходить такие данные, как изменение разрешения и другие важные вопросы.
Дополнительная плюшка по поводу UDP
Если вы будете писать свой UDP протокол, например, с двухсторонней связью, то нужно понимать, что есть NAT Unbinding и шанс, что вы не сможете обратно с сервера найти клиента.
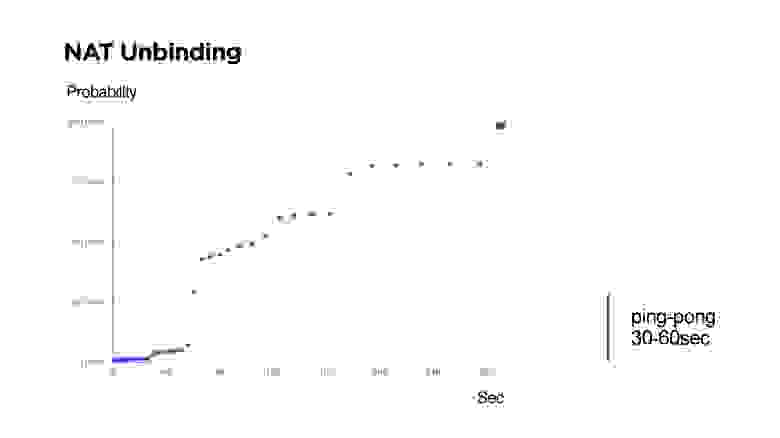
На слайде как раз времена, когда не удалось достучаться до клиента с сервера по UDP.
Многие скептики говорят, что маршрутизаторы устроены так, что NAT Unbinding вытесняет в первую очередь именно UDP маршруты. Но выше видно, что если Keep-Alive или ping будет меньше 30 секунд, то с вероятностью 99% будет возможно достичь клиента.
Доступность UDP на мобильных устройствах в мире
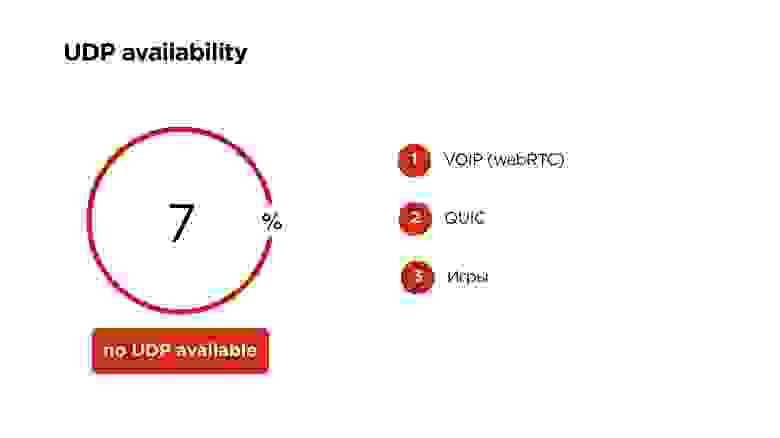
Google говорит, что 6%, но у нас получилось, что 7% мобильных пользователей не могут пользоваться UDP. В этом случае мы оставляем наш прекрасный протокол с приоритезацией, шифрованием и всем, только на TCP.
На UDP сейчас работает VOIP по WebRTC, Google QUIC, и многие игры работают по UDP. Поэтому верить, что UDP на мобильных устройствах закроют, я бы не стал.
В итоге мы:
- Снизили задержку между стримером и смотрящим до 1 с.
- Избавились от накопительного эффекта в буферах, то есть трансляция не отстает.
- Снизилось количество stall’ов у зрителей.
- Смогли поддержать на мобильных устройствах FullHD стриминг.
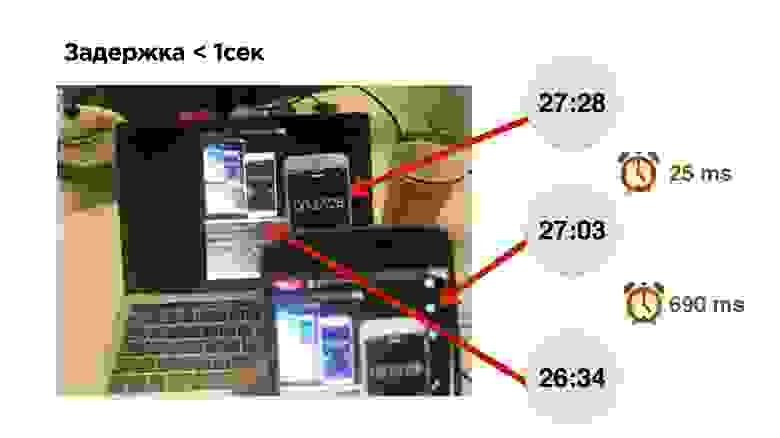
- Задержка в нашем мобильном приложении OK Live 25 мс — на 10 мс дольше, чем работает сканер камеры, но это не так страшно.
- Трансляция на Web показывает задержку всего 690 мс — космос!
Что еще умеет стриминг на Одноклассниках
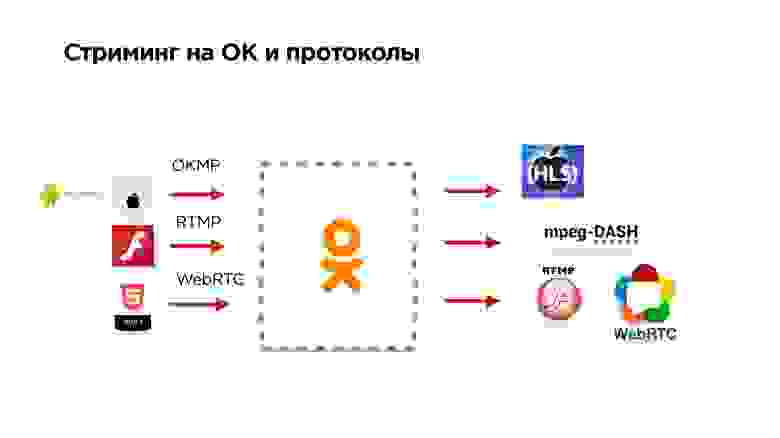
- Принимает наш протокол OKMP с мобильных устройств;
- может принимать RTMP и WebRTC;
- выдает на выходе HLS, MPEG-Dash и т.д.
Если вы были внимательны, то заметили, что я сказал, что мы можем взять у пользователя, например, WebRTC и сконвертировать его в RTMP.
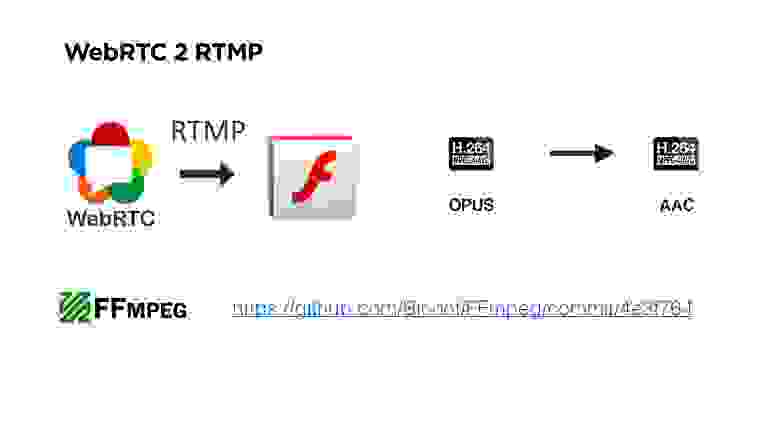
Тут есть нюанс. На самом деле WebRTC — протокол, ориентированный на дроп пакетов, и у него используется аудио кодек OPUS. В RTMP использовать OPUS нельзя.
На серверах бэкенда мы везде используем RTMP. Поэтому нам пришлось сделать еще некоторый фикс в FF MPEG, который позволяет запихнуть OPUS в RTMP, его сконвертировать в AAC и отдать пользователям уже в HLS или еще в чем-то.
Как это выглядит у нас внутри?
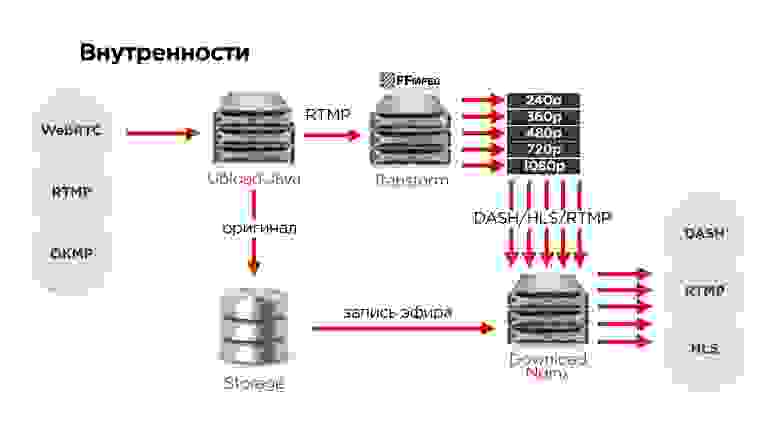
- Пользователи по одному из протоколов загружают оригинал видео на наши upload-сервера.
- Там мы разворачиваем протокол.
- По RTMP отправляем на один из серверов трансформации видео.
- Оригинал всегда сохраняем в распределенное хранилище, чтобы ничего не пропало.
- После этого все видео поступают на сервер раздачи.
По железу у нас получилось следующее:

Расскажу еще немного про отказоустойчивость:
- Upload-сервера распределены по разным дата-центрам, стоят за разными IP.
- Пользователи приходят, по DNS получают IP.
- Upload-сервер отправляет видео на серверы нарезки, те нарезают и отдают серверам раздачи.
- Под более популярные трансляции мы начинаем добавлять большее количество серверов раздачи.
- Все, что пришло от пользователя, сохраняем в хранилище, чтобы потом создать архив трансляций и ничего не потерять.
- Хранилище отказоустойчивое, распределенное по трем дата-центрам.
Чтобы определить, какой сервер сейчас отвечает за трансляцию, мы используем ZooKeeper. Для каждой трансляции храним ноду и делаем эфемерные ноды под каждый сервер. По сути, это такая штука, которая позволяет для стрима создать очередь серверов, которые будут обрабатывать. Всегда текущий лидер в этой очереди занимается обработкой стрима.
Тестировать отказоустойчивость будем по-быстрому. Начнем сразу же с пропадания всего дата-центра.
Что при этом произойдет?
- Пользователь на DNS возьмет следующий IP другого upload-сервера.
- К этому времени ZooKeeper поймет, что сервер в том дата-центре умер, и выберет для другой сервер нарезки.
- Download-серверы узнают, кто теперь отвечает за трансформацию этого стрима и будут это раздавать.
В принципе, все это произойдет с минимальными задержками.
Использование протокола в продукте
Мы сделали мобильное приложение для стриминга OK Live. Оно полностью интегрировано с порталом. Пользователи там могут общаться, вести прямые эфиры, есть карта эфиров, список популярных эфиров — в общем, все, что можно хотеть.
Также мы добавили возможность вести эфиры в FullHD. К Android-устройству можно подключать action-камеру на Android.

Теперь у нас есть механизм, который позволяет вести прямые трансляции. Например, мы проводили прямую линию с Президентом через OK Live и транслировали ее на всю страну. Пользователи смотрели и через встречный стрим могли попадать в эфир и задавать свои вопросы.
То есть, по сути, два встречных стрима на минимальной задержке обеспечивают некий формат публичной конференцсвязи.
На самом деле мы уложились где-то в 2 секунды — секунда туда и секунда обратно. Помните тот «троллейбус», про который я рассказывал в начале статьи — он сейчас выглядит как 2 огромных грузовика. Для ТВ эфира снять с камеры и просто все смикшировать с задержкой в порядка 1-2 с совершенно нормально.
В действительности нам удалось у себя воспроизвести что-то сравнимое с текущими современными ПТС.
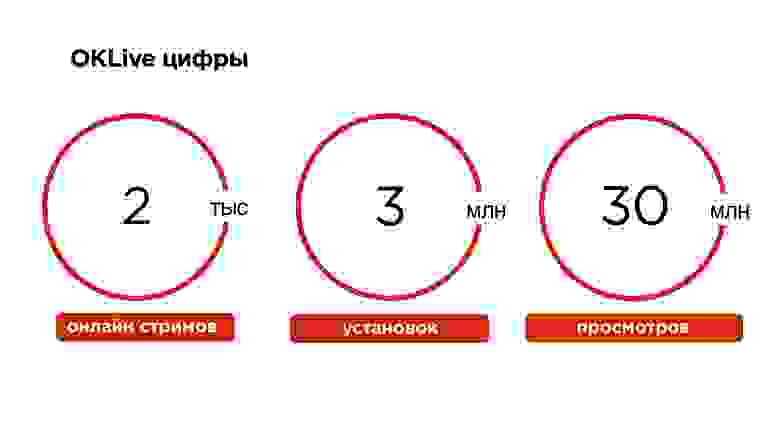
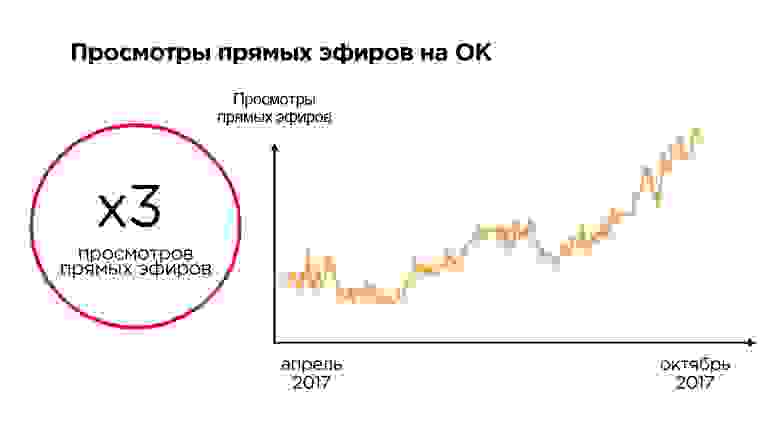
Прямые эфиры — это текущий тренд. За последние полтора года на портале ОК они выросли в три раза (не без помощи приложения OK Live).
Все трансляции по умолчанию записываются. У нас порядка 50 тысяч стримов в сутки, это генерирует порядка 17 терабайт трафика в сутки, а вообще все видео на портале генерирует около петабайта данных в месяц.

Что получили мы:
- Смогли гарантировать длительность задержки между стримером и зрителями.
- Сделали первое мобильное FullHD приложение для стриминга на динамично меняющемся мобильном интернет-канале.
- Получили возможность терять дата-центры и при этом не прерывать трансляции
Что узнали вы:
- Что такое видео и как его стримить.
- Что можно писать свой UDP протокол, если вы точно знаете, что у вас очень специфичная задача и конкретные пользователи.
- Про архитектуру любого стримингового сервиса — видео входит на вход, преобразуется, и выходит на выход.
На Highload++ Siberia Александр Тоболь обещает рассказать про сервис звонков на ОК, будет интересно узнать, что из рассмотренного в этой статье удалось применить, а что пришлось реализовывать совершенно заново.
В этой же секции на узкоспециальные темы планируются доклады:
- Евгения Россинского (ivi) о системе сбора подробной статистики работы узлов CDN.
- Антона Русакова (Badoo) об интеграции платежных систем без использования собственного биллинга.
Самодельный протокол передачи данных
Дата: 1 Февраля 2014. Автор: Алексей
Всем привет!
Пример работы ПК и слева.
Пример работы мастера и два слева.
Программа виртуальный Мастер для отладки протокола MHBUS.
Сегодня я решил поделится своим мнением на тему самодельных протоколов передачи
данных по любой линии передач. Возник у меня вопрос о мониторинге температуры
комнат и улицы в загородном доме с дальнейшей передачей на сервер по GSM. Вот
тут и встал вопрос как сделать сбор температур. Особо не задумываясь было принято
решение в использовании датчиков температуры DS18S20. Простота, быстрота и точность
вполне устраивает. Работает датчик по шине 1-Wire что устраивало опять же
простотой и длинна аж до 300 метров. Но при дальнейшем развитии проекта
потребовалось задавать пределы температур с дальнейшей обработкой по превышению.
С учетом того что датчиков много и обрабатывать данные по каждому слишком
расточительно (мне так показалась), то решили сделать модульный датчик и обвязать
по шине RS-485. Теперь каждый датчик состоял из DS18S20, MAX485, а управляла всем
этим ATmega8. Ну с железом разобрались, теперь протокол. Сначала я полез на форумы
поспрашать что по чем. Все в один голос MODBUS. Скачал и распечатал полный мануал
на этот протокао, изучил и понял что в моем случае это из пушки по воробьям.
Дай думаю спрошу, может кто что свое наваял по проще. Ага, ща… Я не нашел ни
одного решения. То ли никто не пробовал, то ли жалко поделиться. Короче решил я
придумать свой велосипед и поделится с Вами. Если возникнут какие-то вопросы,
пожелания, критика принимаю все. Это мое первое написание протокола.
Ну… Поехали.
Для хохмы я его назвал MH-BUS. MH — это по тому что Мой Домашний 
Первым делом я решил избавится от плавающей длинны пакета, то есть длинна данных
имеет фиксированную длину. Это связано с тем, что в CodeVisionAVR размер переменной
типа float равна 4 байта. А с учетом того что передаем таким типом переменных
в основном температуру, то длинна передаваемых данных всегда равна 4 байта.
В те же 4 байта можно смело запихнуть long int и передавать число аж 4294967296.
С данными разобрались, а теперь нужно как-то объяснить контроллеру что с ними
делать. Для этого используется один байт с кодом команды. По этому коду ведомое
устройство всегда знает что ему надо делать. Если ведомое устройство занимается
только одним делом, например меряет какой-то параметр, то по команде оно может
передать измеренное значение. А что делать если устройство модульное и имеет
много параметров? Для этой цели существует один байт регистра(ну прям как в
MODBUS). Данный байт передает номер регистра в котором ведомое устройство хранит
значения какого-то параметра. Ах да, как же ведомое устройство узнает что команда
передана именно ему? А вот за это отвечает еще один байт и в него нужно записать
адрес. И наконец весь этот огород обрамляют два байта, стартовый и стоповый.
Теперь давайте взглянем на картинку пакета.

Теперь все по порядку.
1) Старт байт: Всегда принимает значение 0xAA.
2) Адрес: Адрес ведомого устройства.
3) Команда: Команда ведомому устройству.
4) Регистр: Адрес регистра где ведомое устройство хранит параметр.
5) Данные: 3-й байт данных.
6) Данные: 2-й байт данных.
7) Данные: 1-й байт данных.
8) Данные: 0-й байт данных.
9) Контрольная: 1-й байт контрольной суммы.
10) Сумма: 0-й байт контрольной суммы.
11) Стоп байт: Всегда принимает значение 0x55.
Стартовый байт выбран 0xAA не случайно. Если его посмотреть в бинаре то получем
b10101010. Это для защиты от помех. Создать такую наводку достаточно сложно, а
исказить легко. Стоповый байт 0x55 это побитное отрицание стартового b01010101.
Таким образом контроллер всегда знает где начало пакета, а где конец. Адресный
байт может принимать значение в диапазоне от 0x01 до 0x33. Это дает возможность
подключить к шине 50 ведомых устройств. Нулевой адрес выбран свободным и является
широковещательным. То есть его принимают все ведомые устройства не зависимо от
своего адреса. Это нужно например для подачи команды перезагрузки ведомых
устройств или если устройства впервые появились на линии и имеют адреса 0xFF
(это обязательный адрес свежеподключенного устройства для избегания коллизий
адресного пространства). Если подключить сразу несколько устройств с адресами 0xFF
то как они узнают кому пришла команда на смену адреса? Вот здесь и нужна
широковещательная передача. По нулевому адресу передаем команду на изменение адреса
ведомого устройства, а в байтах данных передаем его идентификационный номер.
Помните сколько вариантов можно переслать. Я принял такое решение для того
чтобы не залезать в настройки ведомых устройств. Просто подключили к мастеру и
указали ИН. Все, дальше мастер сам разберется какой адрес дать.
После адреса идет байт команд. Диапазон команд может быть от 0x21 до 0xFF.
О командах мы поговорим чуть позже.
Далее идет байт регистра. Диапазон регистров от 0x01 до 0xFF.
Нулевой застолбил на всякий случай.
Далее четыре байта это данные. Записываются они шиворот на выворот, то есть слева
на право но с последнего байта к первому. Связано это с конвертацией float в
массив из четырех char.
Далее идут два байта контрольной суммы. Они также идут задом на перед. Как считать
контрольную сумму. Не мудрствуя лукаво я решил убить трех зайцев одним выстрелом.
Первый заяц это защита данных, второй простота подсчета и третий минимальная
нагрузка на процессор. И так, расчет ведется следующим образом: берем значения
байта адреса, байта команды, байта регистра, четыре байта данных и просто
алгебраически складываем их. Почему два байта? Если сложить семь данных байт со
значениями 0xFF то получим число 0x06F9. Как видно оно вполне влезает в два байта.
Теперь давайте разбирать команды.
0x21 - Изменить адрес ведомого устройства с текущего на новый. Новый адрес
передается в байте регистра. (при широковещательной передаче ведомое
устройство выполняет команду при совпадении ИН передаваемого со своим)
0x22 - Вернуть значение температуры.(только если датчик измеряет один параметр)
0x23 - Вернуть значение давления.(только если датчик измеряет один параметр)
0x24 - Резерв (для каких-нибудь еще датчиков)
0x25 - Резерв (для каких-нибудь еще датчиков)
0x26 - Резерв (для каких-нибудь еще датчиков)
0x27 - Резерв (для каких-нибудь еще датчиков)
0x28 - Резерв (для каких-нибудь еще датчиков)
0x29 - Резерв (для каких-нибудь еще датчиков)
0x2A - Вернуть параметр находящийся по адресу регистра
0x2B - Вернуть дискрет находящийся по адресу регистра
0x2C - Вернуть байт данных
0x2D - Вернуть 2 байта данных
0x2E - Вернуть 3 байта данных
0x2F - Вернуть 4 байта данных
0x30 - Вернуть 8 дискретов подряд начиная с адреса регистра
0x31 - Вернуть 16 дискретов подряд начиная с адреса регистра
0x32 - Вернуть 24 дискретов подряд начиная с адреса регистра
0x33 - Вернуть 32 дискретов подряд начиная с адреса регистра
0x34 - Записать параметр находящийся по адресу регистра (например предел)
0x35 - Записать дискрет находящийся по адресу регистра
0x36 - Записать байт данных
0x37 - Записать 2 байта данных
0x38 - Записать 3 байта данных
0x39 - Записать 4 байта данных
0x3A - Записать 8 дискретов подряд начиная с адреса регистра
0x3B - Записать 16 дискретов подряд начиная с адреса регистра
0x3C - Записать 24 дискретов подряд начиная с адреса регистра
0x3D - Записать 32 дискретов подряд начиная с адреса регистра
Для начала я считаю что этих команд достаточно. Самое важное то что ведомое
устройство обязано вернуть ответ на любой запрос, даже если ответ не требуется.
При команде не требующей ответа, ведомое устройство возвращает обязательно
свой адрес, номер команды и номер регистра если использовался, а в байты данных
записывает любую ахинею для более точного формирования контрольной суммы. Это
требуется для предотвращения зависания мастера на случай падения ведомого. Если
после запроса ведомое устройство не отвечает некоторое время, то считается
мертвым и выкидывается из опроса. Так же можно сформировать об этом какую-нибудь
ошибку. Но это уже на Ваш вкус.
Теперь самое интересное. Ошибки. Ведь не всегда все хорошо, ведомое получило
запрос на возврат температуру, а сам измеряет давление. Или датчик помер и
получить параметр не возможно. Что делать? Нужно об это сказать мастеру. Вот
для этих целей придумал номера ошибок. Номера ошибок при ответе ведомого модуля
записываются в байт регистра.
0x01 - Несоответствие стопового байта со значением 0x55 0x02 - Несовпадение контрольной суммы 0x03 - Неприемлемая команда 0x04 - Отсутствие в модуле запрашиваемого регистра 0x05 - Неисправность измерительного датчика в модуле 0x06 - Невозможность произвести запись параметра 0x07 - Экзотическая ошибка. Описание ошибки записывается в байты данных. 0x08 - Несоответствие стартового байта со значением 0xAA 0x09 - Модуль не отвечает (по таймауту) 0x0A - Несовпадения адреса 0x0B - Адрес вне диапазона 0x0C - Адрес не записался 0x0D - Несовпадение ID устройства с передаваемым от Мастера 0x0E - Битый пакет 0x0F - Резерв
Ну с теорией покончили, давайте посмотрим на это безобразие в живую. Я тестил на
все том же датчике температуры. Для начала давайте рассмотрим пакет запроса.
Слева направо.

Первый байт 170 в HEX 0xAA. Знакома? Правильно старт байт.
Второй байт 1 это адрес.
Третий байт, плохо видно, это двойная кавычка. В HEX выглядит как 0x22. Команда.
Четвертый байт 0. Мы же хотим температуру узнать и все.
Байты данные раны нулю, так как мы ничего не передаем. Можно записать туда все
что угодно для усиления защиты
Девятый байт это решетка в HEX 0x23.
Десятый байт ноль.
Одиннадцатый байт буква U в HEX 0x55. Правильно, стоп байт.
Давайте ради интереса проверим контрольную сумму. Если вспомнить про задом
наперед то контрольная сумма равна 0x0023. Теперь складываем адрес, команду,
регистр и данные. 0x01+0x22+0x00+0x00+0x00+0x00+0x00 = 0x23. Ух ты! Совпала.
Теперь давайте рассмотрим ответный пакет.

Первый байт 170. С ним все ясно.
Второй адрес 1.
Третий команда 0x22. Это хорошо, пакет дошел без ошибок.
Четвертый ноль.
Данные. Шиворот навыворот склеиваем байты. А+208+0+0 и переводим в HEX. Это будет
0x41D00000.
Контрольная сумма равна 0x0134 (мой логический регистратор выводит значения в виде
ASCII кодов, а если нет такого кода, то выводит в десятичном виде. Поэтому 4 на
картинке это 0x34 она без одинарных ковычек.
Считаем 0x01+0x22+0x00+0x00+0x00+0xD0+0x41 = 0x134. Ура! Совпало.
И самое интересное, че он нам прислал.
Для этого давайте переведем из HEX во float. Это можно сделать здесь он-лайн Впишем наш
0x41D00000 и жмем Convert to float.
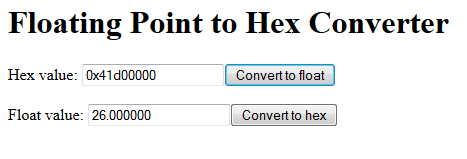
Уау! 26.0 градусов по Цельсию. А че кажет ЖК-дисплей?

А это весь зоопарк в сборе.

Пример работы ПК и слева.
Пример работы мастера и два слева.
Программа виртуальный Мастер для отладки протокола MHBUS.
Ну как-то так. Предложения, отзывы, критика принимаются в любом количестве.
Евгений 09.07.14
Интересная информация, хотелось бы
посмотреть на исходники этого протокола.
Сам с аврками еще мало общался, но есть
такая задачка, в которой нужно
передавать тактовый импульс и данные по
одному проводу с помощью RC-цепочки.
Вообще интересна реализация
«самопальных» протоколов и т.д
Не могли бы Вы поделиться таковой? (в
том числе и Вашим протоколом, если
можно)
Адрес моей почты — rulo90@mail.ru
Спасибо!
Алексей 09.07.14
У меня хард умер и старые проекты с ним.
Если найду этот проект, то спину.
Юрий 01.07.15 00:36
Сделай статтю, или покажи на примере как соединить два микроконтроллера AVR на расстоянии до 400 м, по шине rs485.
Буду очень признателен.
Алексей 01.07.15 08:07
Да. Надо написать. Блин я и забыл про 485. Сделаем.
Юрий 07.07.15 12:43
Заинтересовал Ваш протокол передачи данних, покажите как на примере реализовать его. Спасибо.
Алексей 07.07.15 17:59
Хорошо. Я попробую написать библиотеку для протокола к ведомому и ведущему устройствам.
Антон 24.10.15 13:38
Отличная статья. Когда мы сможем увидеть исходники или библиотеку передачи? Заранее благодарер
Алексей 24.10.15 19:46
В разработке. А если честно, то лень. Начал, половину сделал и забросил. Надо раскачаться.
CrazyPit 21.02.16 23:22
советую использовать модбас.. хотябы функции чтения записи.
этого достаточно. пишется просто да и исходников полон интернет.
берете 2 функции и все..
за таймингами можно не следить(вот и у вас уже свой доморощенный протокол)
Алексей 22.02.16 10:38
Так этот уже готов. А модбас груженый.
e_gorka 12.08.16 06:46
А если в данных или в контрольной сумме окажется 0xAA или 0x55?
Алексей 12.08.16 08:37
И что? В пакете старт и стоп байты находятся в определннных местах и никак не пересекаются с контрольной суммой.
Юрий 18.08.16 11:15
Алексей добрый день!
Как с Вами можно связаться!
У меня к Вам множество вопросов, может работа Вам подойдет?
Мой телефон для связи: 89255071195 www.steamwash.ru
Мы занимаемся распределенным датчиком температуры, и у нас стал вопрос передачи температурных данных по протоколу Modbus/
Юрий 18.08.16 11:16
Ой не тот адрес записал:WWW.OPTICALPATH.RU
Алексей 18.08.16 11:57
А при чем здесь MODBUS и я? Я MODBUS не использую в своих проектах из-за его загруженности. Это промышленный протокол и для его реализации под МК уже написано куча библиотек. Не понимаю суть вопроса. А вопросы можно писать в обратную связь.
Ну а чего тут особо сильно думать то? Транспортный протокол известен/задан UPD — соответственно теперь надо озаботиться следующим уровнем стека протоколов (согласно великой могучей науке) — фактически прикладным уровнем.
На одной стороне сервер принимаем/посылает массив байтов, а на другой стороне клиент аналогично принимает/посылает массив байтов.
Обычно массив байтов полагается структурировать в виде структуры/класса, например:
public class MyProtocolData
{
private String header; //некий заголовок показывающий чего шлем или что шлем?
private String senderId; //идентификатор отправителя (если надо)
private String addressId; //идентификатор получателя (если надо)
private int chunkId; //очередность куска данных
private int dataLength; //длина данных
private byte[] data; //данные
}
В общем все ограничено только вашей фантазией.
Update
Посылка байтов также лишена романтики и выглядит примерно так (грубо):
byte[] sendData;
DatagramSocket mySocket = new DatagramSocket(port, address);
DatagramPacket sendPacket =new DatagramPacket(sendData, sendData.length, address, port);
mySocket.send(sendPacket);
Основы сетевого программирования
44 мин на чтение
(52.704 символов)
Основные понятия сетевого программирования
Чем сетевые приложения отличаются от обычных?

Сетевыми приложениями мы будем называть любые приложения, которые обмениваются данными, используя компьютерную сеть. Это довольно широкое определение, и, конечно, мы не сможем рассмотреть все многообразие обширного мира сетевых технологий, который, вдобавок развивается очень быстро и новые технологии, приемы и методики появляются чуть ли не каждый день. Поэтому в данном пособии мы сконцентрируемся на освоении базовых схем обмена информацией по сети, которые лежат в основе всех более продвинутых вещей. Используя полученные знания вы сами сможете строить все более и более сложные схемы взаимодействия разных приложений и разных компонентов одного приложения по сети.
Сетевые приложения могут обмениваться информацией с другими, сторонними приложениями либо строить взаимодействие по сети между компонентами одного и того же приложения, написанного одним автором или одной командой.
Возможность обмениваться данными по сети открывает перед разработчиком широкий круг возможностей.
Вы можете обращаться к сторонним сервисам, имеющим открытое API. Сегодня существует множество сервисов, постоянно действующих в сети и предоставляющих способ обмена данными в автоматизированном формате через специальную схему взаимодействия, то есть публичный интерфейс, или API. Например, ваша программа может обратиться к погодному сервису и получить данные о погоде в определенном месте или городе.
Также вы можете сами разработать такой публичный сервис. Если ваше приложение может выдавать информацию по запросу неограниченному кругу лиц, вы можете опубликовать в Интернете приложение, которое будет обрабатывать входящие соединения и отвечать на запросы. Нужно только спроектировать API вашего сервиса, реализовать и задокументировать его.
Можно строить распределенные приложения. Сейчас довольно распространены приложения, основой функционирования которых является взаимодействие множества компонентов, запущенных на совершенно независимых компьютерах сети. Так работают, например, пиринговые сети, системы распределенных вычислений или ботнеты.
Добавьте к любой вашей программе возможность самостоятельно обновляться по сети. Почти все программы имеют подсистему автоматической и регулярной проверки сервера разработчика программы на предмет выхода новой версии. При наличии такой можно предложить пользователю скачать ее, либо обновиться самостоятельно.
Можно использовать централизованную схему клиент-сервер. В таком случае ваша программа может быть разделена на две логические части — клиентскую, которая запускается на компьютере пользователя и предоставляет ему интерфейс, и серверную, которая работает на сервере, принадлежащем разработчику, и может заниматься, например, доступом к базе данных. Логика работы программы тоже может быть разделена на две части.
Можно организовывать централизованное хранилище данных. Это удобно, если, например, вам нужно собирать данные от пользователей вашей программы в одном месте, либо предоставить пользователям возможность обмениваться сообщениями.
Если вы организуете взаимодействие с клиентами посредством нескольких каналов, можно позаботиться об омниканальности — возможности сохранять информацию о всех взаимодействиях с пользователем по любым каналам, создавая ощущение бесшовности. Такую схему активно используют, например, банки. Вы можете зайти в мобильное приложение, совершить там какую-то операцию, а затем зайти в личный кабинет на веб-сайте банка и продолжить работу с того же места.
Выводы:
- Сетевые приложения — это программы, которые обмениваются данными через сеть.
- В подавляющем большинстве случаев обмен идет на основе протоколов TCP/IP.
- В настоящее время все более или менее развитые приложения являются сетевыми в той или иной мере.
- Приложения обмениваются данными с другими либо между своими компонентами.
- Можно обращаться к сторонним сервисам
- Создание публичного сервиса — это тоже задача сетевого программирования.
- Многопользовательские приложения очень распространены в определенных предметных областях.
- Автоматические обновления — это возможность, которая есть почти во всех программных продуктах.
- Одна из частных задач сетевого программирования — удаленное хранение данных
- Для экономики и бизнеса важна омниканальность взаимодействия с клиентами и пользователями.
В чем сложности создания сетевых приложений?
Разработка сетевых приложений — отдельная дисциплина информатики, требующая от программиста некоторых дополнительных знаний и умений. Естественно, для создания приложений, использующих возможности компьютерной сети необходимо знать основы функционирования таких сетей, понимать главные сетевые протоколы, понятие маршрутизации и адресации. В подавляющем большинстве случаев на практике используются протоколы семейства TCP/IP. Это сейчас универсальный механизм передачи данных. Но сами сетевые приложения могут интенсивно использовать разные конкретные протоколы, находящиеся на разных уровнях модели OSI.
Например, в этой теме мы в основном будем говорить об использовании TCP и UDP сокетов, то есть будем работать на транспортном уровне модели OSI. Но можно работать и на других уровнях с использованием других протоколов. Так веб приложения наиболее активно полагаются на протокол HTTP и его защищенную модификацию — HTTPS. Поэтому так важно знать все многообразие существующих схем и протоколов обмена данными. Ведь при проектировании приложения нужно выбрать тот протокол, уровень, который наилучшим образом подходит для решений стоящей перед разработчиками прикладной задачи.
Кроме того, при проектировании и реализации сетевых приложений на вас, как на разработчике лежит задача продумывания конкретного обмена данными. Используемый протокол регламентирует порядок передачи данных, но конкретную схему, последовательность обмена создает разработчик конкретного приложения. Вам надо определиться, какие данные будут передаваться по сети, в каком формате, в каком порядке. Будете ли вы использовать, например, JSON или XML, может, стоит придумать свой формат данных? После соединения, какой модуль начинает передачу, сколько итераций передачи будет проходить за одно соединение, как обозначить конец передачи, нужно ли регламентировать объем передаваемой информации, нужно ли использовать шифрование данных — это все примеры вопросов, которые необходимо будет решить в ходе разработки. Фактически, каждое сетевое приложение — это по сути еще один, очень конкретный протокол передачи, которые для себя придумывают разработчики специально для этого приложения.
Еще одна область, непосредственно связанная с сетевым обменом — это параллельное программирование. Сетевые приложения обычно очень активно используют многопоточности или другие средства обеспечения многозадачности. Какие-то операции должны выполняться в фоне, пока выполняются другие. Такое приложение становится гораздо более сложным по своей структуре. И необходимо отдельно заботиться о том, чтобы оно работало корректно при всех возможных условиях. Это происходит за счет обеспечения потокобезопасности, использования правильных архитектурных и дизайнерских шаблонов, специальных алгоритмов и структур данных.
Отдельный вопрос, непосредственно связанный с сетевым программированием — обеспечение безопасности и конфиденциальности обмена данными. Любое приложение, принимающее данные по сети должно быть рассчитано на то, что его может вызвать и передать данные любое приложение или пользователь. В том числе, с неизвестными или деструктивными целями. Поэтому в сетевых приложениях необходимо применять проверки входных данных, валидацию всей принимаемой информации, возможно — механизмы аутентификации пользователей. Если же ваше приложение отправляет данные — здесь тоже возможны риски того, что они попадут не по назначению. Так можно применять те же механизмы аутентификации, шифрования трафика. Особенно аккуратным надо быть, если ваше приложение собирает, хранит или передает персональные данные пользователей. В этом случае могут применяться определенные юридические нормы и обязательства, которые разработчики обязаны соблюдать.
Надо помнить, что сетевые приложения используют не только протоколы и соглашения передачи данных, но и конкретную физическую сетевую инфраструктуру. И у нее есть определенные параметры, которые необходимо учитывать — полоса пропускания, надежность, доступность. Как будет работать приложение, если в какой-то момент перестанет быть доступна сеть? Какая скорость передачи данных нужна для бесперебойной работы серверной части приложения? На сколько одновременных подключений рассчитан каждый программный модуль? За этим всем нужно следить не только на этапе проектирования, принятия решений, но и в процессе работы приложения — организовывать постоянный мониторинг, продумывать вопросы управления нагрузкой, дублирования, репликации данных и так далее.
Выводы:
- Нужно знать основы организации компьютерной сети.
- Для некоторых приложений необходимо знать особенности конкретных сетевых протоколов, например, HTTP.
- Необходимо также отдельно заботиться о согласованности обмена информацией между компонентами приложения.
- Написание многопоточных приложений требует специальных усилий по обеспечению потокобезопасности.
- Также не нужно забывать о вопросах безопасности, конфиденциальности, валидации получаемых данных.
- Также существуют вопросы управления нагрузкой ваших сервисов и сетевой инфраструктуры.
- Необходимо также помнить о доступности сети и ограниченности полосы пропускания.
Какие основные подходы к их построению?
При создании сетевых приложений первый вопрос, который должен решить для себя разработчик — создание высокоуровневой архитектуры приложений. Из каких частей (модулей) оно будет состоять, как именно они будут обмениваться данными и с кем. Будет ли обмен происходить только между модулями самого приложения или будут предусмотрены обращения к внешним сервисам?
Не затрагивая пока вопросов использования сторонних сервисов и программ, рассмотрим два самых популярных архитектурных паттерна для сетевых приложений. В принципе, любое сетевое приложение может быть либо клиент-серверным, либо распределенным.

Самая популярная архитектура сетевых приложений — клиент серверная. Она подразумевает, что приложение состоит из серверной части и клиентской. Сервером мы будем называть именно часть программной системы, модуль, который постоянно (резидентно) выполняется и ждет запросов от клиентов. Когда запрос поступает, сервер его обрабатывает, понимает, что клиент хочет получить и выдает ему ответ.
При этом может быть одновременно запущенно несколько экземпляров клиентского модуля программы. Но как правило, они все идентичны (во всяком случае, они должны использовать идентичный протокол обмена данными), поэтому нет смысла их рассматривать отдельно, мы будем говорить об одном клиентском модуле.
Клиент в такой схеме — это модуль программы, который непосредственно взаимодействует с пользователем программы и в зависимости от его действий может инициировать соединение с сервером, чтобы произвести определенные операции.
Сервер непосредственно с клиентом не взаимодействует. Его задача — выполнять запросы клиентов. Он в такой схеме является центральным элементом. Распределение функционала между клиентом и сервером — другими словами, какие операции вашей программы должны относиться к клиентской части, а какие к серверной — тоже предмет проектирования. Определенно одно — все, что касается пользовательского интерфеса — это прерогатива клиентской части. В зависимости от задачи вы можете делать клиент более “тонким”, то есть оставить только интерфейс и больше ничего (тогда при любых действиях пользователя клиент будет запрашивать сервер и просить его выполнять операции), либо более “толстым” — то есть выносить на клиент часть непосредственного фукнционала приложения.
Достоинством клиент-серверной архитектуры является ее простота и понятность. Приложение явно делиться на четко обозначенные модули, между ними налаживается довольно типичная схема обмена данными. Но у нее есть и недостатки. Если по каким-то причинам сервер становится недоступен, то полноценно пользоваться приложением нельзя. То есть сервер — это потенциальная точка отказа.
Тем не менее, на основе клиент-серверного принципа работают большинство сетевых приложений, почи все сетевые службы, на работу с ним ориентированы большинство библиотек и фреймворков. Так что инструменты разработки обычно помогают реализовывать именно такую архитектуру приложений.

Альтернативой клиент-серверным приложениям выступают распределенные. В них программа не делится на клиент и сервер, а состоит из множества однотипных модулей, которые совмещают в себе функции и клиента и сервера. Такие модули, будучи запущенными одновременно, могут подсоединяться друг к другу и выполнять обмен данными в произвольном порядке.
Типичным примером распределенных приложений являются пиринговые сети. В них каждый экземпляр приложения может подключаться к любому другому и налаживать многосторонний обмен информацией. Такие приложения образуют сеть подключений, подобно тому, как организован сам Интернет. Такое приложение не зависит от работы центрального сервера и может продолжать функционировать даже если большая часть этой сети будет отсутствовать или будет недоступной.
Несмотря на все достоинства, проектировать, реализовывать и поддерживать распределенные приложения может быть значительно сложнее, чем клиент-серверные. Это происходит потому, что клиент-сервер, более четко определенный протокол, ему нужно лишь следовать и все будет работать так, как предполагается. А в распределенных приложениях все приходится проектировать и продумывать с нуля.
Выводы:
- Есть две главные архитектуры построения сетевых приложений — клиент-серверная и распределенная.
- Сервер — это компьютер, программа или процесс, обеспечивающий доступ к информационным ресурсам.
- Клиент обычно инициирует соединение и делает запрос к ресурсу.
- Клиент-серверная архитектура является централизованной со всеми присущими недостатками и преимуществами.
- Распределенная архитектура может обойти некоторые ограничения централизованной.
- Распределенные приложения сложнее проектировать и управлять ими.
Основы взаимодействия через сокеты
Что такое TCP-сокеты?

Со́кет (англ. socket — разъём) — название программного интерфейса для обеспечения обмена данными между процессами. Процессы при таком обмене могут исполняться как на одной ЭВМ, так и на различных ЭВМ, связанных между собой сетью.
Сокеты — это самый базовый механизм сетевого взаимодействия программ, абстрагированный от конкретной реализации сети. Сокеты работают на транспортном уровне модели OSI — там же, где и протокол TCP и UDP.
Каждый сетевой интерфейс IP-сети имеет уникальный в этой сети адрес (IP-адрес). Упрощенно можно считать, что каждый компьютер в сети Интернет имеет собственный IP-адрес. При этом в рамках одного сетевого интерфейса может быть несколько (до 65536) сетевых портов. Для установления сетевого соединения приложение клиента должно выбрать свободный порт и установить соединение с серверным приложением, которое слушает (listen) порт с определенным номером на удаленном сетевом интерфейсе. Пара IP-адрес и порт характеризуют сокет (гнездо) — начальную (конечную) точку сетевой коммуникации.
Сокеты могут применяться для связи процессов как на удаленной машине, так и на локальной. В первом случае, естественно, необходимо, чтобы удаленная машина была доступна по сети. Это можно проверить при помощи команды пинг. Во втором случае сокеты могут выступать как механизм межпроцессного взаимодействия. Или вы можете использовать одну машину для всех процессов-компонентов вашей программной системы, например, для отладки в процессе разработки.
Для создания соединения TCP/IP необходимо два сокета: один на локальной машине, а другой — на удаленной. Таким образом, каждое сетевое соединение имеет IP-адрес и порт на локальной машине, а также IP-адрес и порт на удаленной машине. Как правило, порт локальной машины (исходящий порт) не так важен и его номер не особенно используется в практике. Но порт серверного сокета — это важная информация
Сокеты могут быть клиентские и серверные. Серверный сокет — это функция в программе, которая сидит на определенном порту и “слушает” входящие соединения. Процедура создания серверного сокета аналогична вводу текста из консоли: программа блокируется до тех пор, пока пользователь не ввел что-то. Когда это случилось, программа разблокируется и может продолжать выполнение и обработку полученных данных. Также и серверный сокет: ждет, когда к нему подключится клиент и тогда продолжает выполнение программы и может считывать данные из сокета (которые послал клиент) и отправлять данные в сокет. Клиентский же сокет, наоборот, сразу пытается подключиться к определенном узлу сети (это может быть локальная машина, или, чаще, удаленный компьютер) и на определенный сетевой порт. Если на этой машине на этом порту “сидит” серверный сокет, то подключение происходит успешно. Если же данный сокет никем не прослушивается, то процедура подключения возвращает ошибку.
В языке программирования Python существует стандартный модуль socket, который реализует все необходимые функции для организации обмена сообщениями через сокеты. Для его использования его достаточно импортировать (так как это модуль стандартной библиотеки, устанавливать его не нужно, он идет в поставке с дистрибутивом Python):
Для начала построения сетевого взаимодействия необходимо создать сокет:
Здесь ничего особенного нет и данная часть является общей и для клиентских и для серверных сокетов. Дальше мы будем писать код отдельно для сервера и для клиента.
Существует несколько видов сокетов, которые немного различаются по сфере применения и деталях реализации. Самыми распространенными являются Интернет-сокеты. Они используются для пересылки информации между процессами. Есть еще сокеты UNIX, они не используют Интернет-протоколы для обмена сообщениями, и используются для организации межпроцессного взаимодействия.
Также среди Интернер сокетов существуют потоковые и датаграммные сокеты.
Датаграммные сокеты называют “сокеты без соединения”, они используют протокол UDP вместо TCP. Потоковые сокеты обеспечивают гарантированную доставку, очередность сообщений, они более надежны. Протокол HTTP использует именно потоковые сокеты для соединения клиента с сервером. UDP обычно используется для передачи потокового медиа, когда скорость критичнее риска потери единичных пакетов.
Выводы:
- Сокеты — это базовый механизм сетевого взаимодействия программ.
- Для работы сокетов не нужно специальное программное обеспечение, они работают на уровне операционных систем.
- Сокет состоит из адреса хоста и номера сетевого порта.
- Для соединения необходимо создать два сокета — в двух модуля программы, которые нужно соединить.
- Стандартный модуль Python socket позволяет создавать сокеты и работать с ними.
- Еще отдельный вид сокетов применяется для организации межпроцессного взаимодействия в *nix системах.
- Сокеты могут использовать протокол TCP либо UDP.
Каковы правила использования номеров портов?
Для эффективного использования сетевых сокетов необходимо вспомнить концепцию сетевых портов, так как сокеты их активно используют.

IP-адрес или любой другой способ адресации хоста позволяет нам идентифицировать узел сети. Номер порта позволяет указать конкретное приложение на этом хосте, которому предназначен пакет. Номер порта нужен, так как на любом компьютере может быть одновременно запущено множество приложений, осуществляющих обмен данными по сети. Если использовать аналогию с почтовыми адресами, то IP-адрес — это номер дома, а порт — это номер квартиры в этом доме.
Номер порта — это всего лишь 16-битное число, которое указывается в пакете, передающемся по сети. Не нужно путать сетевой порт с физическими разъемами, это чисто программная концепция.
Так как на номер порта отведено 16 бит, существует всего 65536 возможных портов. Причем, номера портов отдельно считаются по протоколам TCP и UDP. Таким образом, на компьютере одновременно может существовать более 130 тысяч процессов, обменивающихся данными. На практике, свободных портов всегда в избытке и хватает даже для работы множества высоконагруженных серверов.
Но не все номера портов созданы равными. Первые 1024 являются “системными” и используются в основном стандартными приложениями. Существует общепринятое соглашение, какие сетевые службы используют системные порты. Например, служба веб-сервера по умолчанию использует 80 порт для соединений по протоколу HTTP и 443 — для протокола HTTPS. Служба SSH использует порт номер 22. И так далее. Любая стандартная сетевая служба имеет некоторый порт по умолчанию. Кстати, хорошим показателем практикующего администратора является запоминание часто используемых номеров стандартных портов. Специально это учить не нужно, только если вы не хотите блеснуть знаниями на собеседовании.
Для использования системных портов обычно требуются повышенные привилегии. Это сделано для того, чтобы обычные пользователи не “забивали” стандартные порты и не мешали работе системных сетевых служб. Мы вообще не рекомендуем использовать системные порты. Остальные могут использоваться совершенно произвольно и их более чем достаточно для повседневных нужд.
Кстати, хоть сетевые службы используют определенные стандартные порты, они вполне могут быть переназначены на свободные. Служба не “привязана” к номеру порта, это легко регулируется настройками. Например, строго рекомендуется при настройке службы SSH менять стандартный 22 порт на случайный для повышения безопасности.
Порты назначаются процессу при попытке открыть серверный сокет. В этот момент происходит связывание сокета с номером порта, который выбрал программист. Помните, что если вы пытаетесь использовать занятый порт, то это спровоцирует программную ошибку. Поэтому в реальных приложениях стоит сначала проверять, свободен ли порт или нет, либо (что гораздо проще) обрабатывать исключение при попытке связаться с занятым портом.
Сетевые администраторы могут в целях безопасности блокировать соединения на некоторые порты. Так же поступают и программы-файерволлы. Это требуется для повышения безопасности сервера. Вообще, по умолчанию, все порты “закрыты”, то есть подключения к ним блокируется файерволлом. При необходимости системный администратор может “открыть” обмен данными по определенному номеру порта в настройках файерволла. Это следует учитывать при попытках подключения к удаленным машинам.
Выводы:
- Порт — это всего лишь число в IP-пакете.
- Номер порта нужен, чтобы обратиться к определенному процессу на конкретном хосте.
- Всего существует 65536 TCP-портов и 65536 UDP-портов.
- Первые 1024 порта являются системными — их можно использовать только администраторам.
- Распространенные сетевые службы имеют стандартные номера портов, их лучше не занимать.
- Порт назначается при открытии серверного сокета. Можно занять только свободный порт.
- Системные администраторы, программы-файерволлы могут заблокировать, “закрыть” обмен данными по номерам портов.
Почему стоит начать именно с изучения сокетов?

Сокеты, которые мы рассматриваем как базовый инструмент сетевого взаимодействия, относятся к транспортному уровню модели OSI. Мы можем рассматривать механизмы передачи данных на любом уровне. Но начинаем изучение сетевых приложений именно с транспортного уровня и на это есть свои причины.
Более высокоуровневые механизмы требуют установленного и настроенного специального программного обеспечения. Чтобы написать веб-приложение, нам нужен веб-клиент и веб-сервер, настроенные и готовые к работе. Такая же ситуация с любой другой службой Интернета. Конечно, на практике большинство популярных сетевых приложений используют более высокоуровневые протоколы, например, тот же HTTP.
Использование сокетов позволяет строить приложения, обменивающиеся данными по сети, но при этом не требующие специального программного обеспечения. Даже если вы планируете использовать в профессиональной деятельности прикладные протоколы, все они в основе своей работы используют механизм сокетов, так что его понимание будет полезно всем.
С другой стороны, более низкоуровневые протоколы не абстрагируются от конкретной реализации сети. Например, на физическом уровне мы должны будем иметь дело с протоколами передачи данных по витой паре, беспроводному каналу, решать проблемы помех, интерференции сигналов и прочие технические вопросы. Это не позволит нам сконцентрироваться на сутевых вопросах создания сетевых алгоритмов.
Поэтому транспортные сокеты — это компромиссный вариант между прикладными и физическими протоколами.
Выводы:
- Сокеты не требуют специального программного обеспечения.
- Сокеты не зависят от конкретной физической реализации сети.
- Сокеты хороши для понимания основ сетевого взаимодействия.
Как организуется обмен данными через TCP-сокеты?

Для соединения двух программ необходимо создать два сокета — один серверный и один клиентский. Они обычно создаются в разных процессах. Причем эти процессы могут быть запущены как на одной машине, так и на разных, на механизм взаимодействия это не влияет.
Работа с сокетами происходит через механизм системных вызовов. Все эти вызовы аналогичны вызовам, осуществляющим операции с файлами. Список этих вызовов определен в стандарте POSIX и не зависит от используемой операционной системы или языка программирования. В большинстве языков программирования присутствуют стандартные библиотеки, которые реализуют интерфейс к этим системным вызовам. Поэтому работа с сокетами достаточно просто и бесшовно организуется на любом языке программирования и на любой операционной системе.
Давайте рассмотрим общую схему взаимодействия через сокеты и последовательность действий, которые нужно совершить, чтобы организовать соединение. Первым всегда создается серверный сокет. Он назначается на определенный порт и начинает его ожидать (прослушивать) входящие соединения. Создание сокета, связывание сокета с портом и начало прослушивания — это и есть системные вызовы.
Причем при выполнении системных вызовов могут случиться нестандартные ситуации, то есть исключения. Обычно это происходит при связывании с портом. Если вы попытаетесь занять системный порт, не обладая парами администратора, или попытаетесь занять порт, уже занятый другим процессом, возникнет программная ошибка времени выполнения. Такие ситуации надо обрабатывать в программе.
Прослушивание порта — это блокирующая операция. Это значит, что программа при начале прослушивания останавливается и ждет входящих подключений. Как только поступит подключение, программа возобновится и продолжит выполнение со следующей инструкции.
В другом процессе создается клиентский сокет. Клиент может подключиться к серверному сокету по адресу и номеру порта. Если этот порт является открытым (то есть его прослушивает какой-то процесс), то произойдет соединение и на сервере выполнится метод accept. Важно следить за тем, чтобы клиент подключился именно к нужному порту. На практике из-за этого происходит много ошибок.
Соединение с серверным сокетом — это тоже системный вызов. При этом вызове тоже часто случаются ошибки. Естественно, если не удастся установить сетевое соединение с удаленным хостом по адресу, это будет ошибка. Такое случается, если вы неправильно указали IP-адрес, либо удаленная машина недоступна по сети. Еще ошибка может возникнуть, если порт, к которому мы хотим подключиться свободен, то есть не прослушивается никаким процессом. Также не стоит забывать, что порт на удаленной машине может быть закрыт настройками файерволла.
После этого устанавливается двунаправленное соединение, которое можно использовать для чтения и записи данных. Интерфейс взаимодействия с сокетом очень похож на файловые операции, только при записи информации, она не сохраняется на диск, а посылается в сокет, откуда может быть прочитана другой стороной. Чтение информации из сокета — это также блокирующая операция.
Следует помнить, что сокеты предоставляют потоковый интерфес передачи данных. Это значит, что через сокет не получится посылать сообщения “пакетами”. По сути, сокет предоставляет два непрерывных потока — один от сервера к клиенту, другой — от клиента к серверу. Мы не можем прочитать отдельное сообщение из этого потока. При чтении мы указываем количество бит, которые хотим прочитать. И процесс будет ждать, пока другой не отправит в сокет необходимое количество (ну либо не закроет сокет). Более понятны особенности работы в потоковом режиме станут на практике.
После обмена данными, сокеты рекомендуется закрывать. Закрытие сокета — это тоже специальный системный вызов. Закрывать нужно как клиентский, так и серверный сокет. Если вы забудете закрыть сокет, то операционная система все еще будет считать соответствующий порт занятым. После завершения процесса, который открыл сокет, все открытые дескрипторы (файлы, устройства, сокеты) автоматически закрываются операционной системой. Но при этом может пройти определенной время, в течении которого сокет будет считаться занятым. Это доставляет довольно много проблем, например, при отладке программ, когда приходится часто подключаться и переподключаться к одному и тому же порту. Так что серверные сокеты надо закрывать обязательно.
Еще одно замечание. Так как сокет — это пара адрес-порт, и сокета для соединения нужно два, получается что и порта тоже нужно два? Формально, да, у нас есть клиент — его адрес и номер порта, и сервер — его адрес и номер порта. Первые называются исходящими (так как запрос на соединение происходит от них), а вторые — входящие (запрос приходит на них, на сервер). Для того, чтобы соединение прошло успешно, клиент должен знать сокет сервера. А вот сервер не должен знать сокет клиента. При установке соединения, адрес и порт клиента отправляются серверу для информации. И если адрес клиента иногда используется для его идентификации (я тебя по IP вычислю), то исходящий порт обычно не нужен. Но откуда вообще берется этот номер? Он генерируется операционной системой случайно из незанятых несистемных портов. При желании его можно посмотреть, но пользы от этого номера немного.
Выводы:
- Серверный сокет назначается на определенный свободный порт и ждет входящих соединений.
- Клиентский сокет сразу соединяется с северным. Тот должен уже существовать.
- Сокет — это двунаправленное соединение. В него можно читать и писать, как в файл.
- Сокет — это битовый потоковый протокол, строки нужно определенным образом кодировать в битовый массив пред отправкой.
- После использования сокет нужно закрыть, иначе порт будет считаться занятым.
- Существует входящий и исходящий номер порта. Но исходящий номер назначается случайно и редко используется.
Простейшие клиент и сервер
Что мы хотим сделать?

Давайте приступим к практическому знакомству с обменом информацией между процессами через сокеты. Для этого мы создадим простейшую пару клиент-сервер. Это будут две программы на Python, которые связываются друг с другом, передают друг другу какую-то информацию и закрываются.
Мы начнем с самой простой схемы передачи данных, а затем будем ее усложнять и на этих примерах будет очень легко понять, как работают сокеты, как они устроены и для чего могут быть применены.
Мы будем организовывать один набор сокетов. Так что один из них должен быть клиентским, а другой — серверным. Поэтому один процесс мы будем называть сервером, а другой — клиентом. Однако, такое разделение условно и одна и та же программа может выступать и клиентом для одного взаимодействия и сервером — для другого. Можно сказать, что клиент и сервер — это просто роли в сетевом взаимодействии. Инициирует соединение всегда клиент, это и определяет его роль в сетевом взаимодействии. То есть, то процесс, который первый начинает “стучаться” — тот и клиент.
При разработке сетевых приложений вам придется много раз запускать оба этих процесса. Вполне естественно, что часто они будут завершаться ошибками. Помните, что для соединения всегда первым должен быть запущен сервер, а затем клиент.
Как создать простой эхо-сервер?
Для начала нам нужно определиться, какой порт будет использовать наш сервер. Мы можем использовать любой несистемный номер порта. Лучше заранее убедиться, что он в данный момент не используется в вашей системе. Например, если вы используете сервер баз данных MS SQL он обычно занимает порт 5432. Мы в учебных примерах будет использовать номер 9090 — это запоминающееся, но ничем не особенное число. Вы можете использовать другой.
Для начала импортируем модуль socket:
Теперь можно создать сокет одноименным конструктором из этого модуля:
Теперь переменная sock хранит ссылку на объект сокета. И через эту переменную с сокетом можно производить все необходимые операции.
После этого свяжем сокет с номером порта при помощи метода bind:
Этот метод принимает один аргумент — кортеж из двух элементов. Поэтому обратите внимание на двойные круглые скобки. Первый элемент кортежа — это сетевой интерфейс. Он задает имя сетевого адаптера, соединения к которому нас интересуют. Вы же знаете, что на компьютере может быть несколько адаптеров, и он может быть подключен одновременно к нескольким сетям. Вот с помощью этого параметра можно выбрать соединения из какой конкретно сети мы будем принимать. Если оставить эту строку пустой, то сервер будет доступен для всех сетевых интерфейсов. Так как мы не будем заниматься программированием межсетевых экранов, мы будем использовать именно это значение.
Второй элемент кортежа, который передается в метод bind — это, собственно, номер порта. Для примера выберем порт 9090.
Теперь у нас все готово, чтобы принимать соединения. С помощью метода listen мы запустим для данного сокета режим прослушивания. Метод принимает один аргумент — максимальное количество подключений в очереди. Установим его в единицу. Чуть позже мы узнаем, на что влияем длина очереди подключений сервера.
Теперь, мы можем принять входящее подключение с помощью метода accept, который возвращает кортеж с двумя элементами: новый сокет (объект подключения) и адрес клиента. Именно этот новый сокет и будет использоваться для приема и посылке клиенту данных.
1
conn, addr = sock.accept()
Обратите внимание, что это блокирующая операция. То есть в этот момент выполнение программы приостановится и она будет ждать входящие соединения.
Объект conn мы будем использовать для общения с этим подключившимся клиентом. Переменная addr — это всего лишь кортеж их двух элементов — адреса хоста клиента и его исходящего порта. При желании можно эту информацию вывести на экран.
Так мы установили с клиентом связь и можем с ним общаться. Чтобы получить данные нужно воспользоваться методом recv, который в качестве аргумента принимает количество байт для чтения. Мы будем читать из сокета 1024 байт (или 1 кб):
1
2
data = conn.recv(1024)
conn.send(data.upper())
Обратите внимание, что прием и отправка сообщений происходит через объект conn, а не sock. Объект conn — это подключение к конкретному клиенту. Это особенность работы именно TCP-сокетов, при использовании протокола UDP все немного по-другому.
Тут есть один неудобный момент. При чтении нам нужно указать объем данных, которые мы хотим прочитать. Это обязательный параметр. Помните мы говорили, что сокеты — это потоковый механизм? Именно поэтому нельзя прочитать сообщение от клиента “целиком”. Ведь клиент может присылать в сокет информацию порциями, в произвольный момент времени, произвольной длины. В сокете, а точнее во входящем потоке, все эти сообщения “склеются” и будут представлены единым байтовым массивом.
Поэтому сервер обычно не знает, какое именно количество информации ему нужно прочитать. Но это решается довольно просто. Можно организовать бесконечный цикл, в котором читать данные какой-то определенной длины и каждый раз проверять, получили мы что-то или нет:
1
2
3
4
5
while True:
data = conn.recv(1024)
if not data:
break
conn.send(data)
Это работает потому, что после того, как клиент отослал всю информацию, он закрывает соединение. В таком случае на сервере метод recv возвращает пустое значение. Это сигнал завершения передачи.
Метод recv(), как мы говорили, тоже является блокирующей операцией. Он разблокируется (то есть продолжает выполняться) в двух случаях: когда клиент прислал необходимый объем данных, либо когда клиент закрыл соединение.
Еще, если вы обратили внимание, после получения данных мы их отправляем обратно клиенту методом send(). Это метод посылает данные через сокет. Это уже не блокирующая операция, ведь данные посылаются тут же и не нужно ничего ждать.
Конечно, на практике такой сервер был бы бесполезным. Реальные сервера посылают клиенту какие-то другие данные, ответы на его запросы, например. Но наш простой сервер служит только для отладки и обучения. Такой сервер по понятным причинам называется “эхо-сервер”.
После получения порции данных и отсылки их обратно клиенту можно и закрыть соединение:
На этом написание сервера закончено. Он принимает соединение, принимает от клиента данные, возвращает их клиенту и закрывает соединение. Вот что у нас получилось в итоге
1
2
3
4
5
6
7
8
9
10
11
12
13
#!/usr/bin/env python
import socket
sock = socket.socket()
sock.bind(('', 9090))
sock.listen(1)
conn, addr = sock.accept()
print 'connected:', addr
while True:
data = conn.recv(1024)
if not data:
break
conn.send(data)
conn.close()
Как создать простейший клиент?
Клиентское приложение еще короче и проще. Клиент использует точно такой же объект socket.
1
2
import socket
sock = socket.socket()
Вместо привязывания и прослушивания порта мы сразу осуществляем соединение методом connect. Для этого указывается IP-адрес хоста, на котором запущен сервер и номер порта, который он прослушивает.
1
sock.connect(('localhost', 9090))
В качестве адреса можно использовать IP-адрес, доменное имя, либо специальное имя localhost. В нашем случае, так как мы пока подключаемся к другому процессу на той же машине, будем использовать его (либо адрес 127.0.0.1, что абсолютно эквивалентно).
При неуспешном соединении метод listen выбросит исключение. Существует несколько причин — хост может быть недоступен по сети, либо порт может не прослушиваться никаким процессом.
Послание данных в сокет осуществляется методом send. Но тут есть один подводный камень. Дело в том, что сокеты — это еще и байтовый протокол. Поэтому в него не получится просто так отправить, например, строку. Ее придется преобразовать в массив байт. Для этого в Python существует специальный строковый метод — encode(). Его параметром является кодировка, которую нужно использовать для кодирования текста. Если кодировку не указывать, то будет использоваться Unicode. Рекомендуем это так и оставить. Вот что получится в итоге:
1
2
msg = 'hello, world!'
sock.send(msg.encode())
Дальше мы читаем 1024 байт данных и закрываем сокет. Для большей надежности чтение данных можно организовать так же как на сервере — в цикле.
1
2
data = sock.recv(1024)
sock.close()
Если мы обмениваемся текстовой информацией, то надо помнить, что данные полученные из сокета — это тоже байтовый массив. Чтобы преобразовать его в строку (например, для вывода на экран), нам нужно воспользоваться методом decode(), который выполняет операцию, обратную encode(). Понятно, что кодировки при этом должны совпадать. Вообще, нет ни одной причины использовать не Unicode.
Здесь важно помнить вот что. Этот клиент хорошо подходит к тому серверу, который мы создавали в предыдущем пункте. Ведь после установки соединения сервер ожидает приема информации (методом recv). А клиент после соединения сразу начинает отдавать информацию (методом send). Если бы же обе стороны начали ждать приема, они бы намертво заблокировали друг друга. О порядке передачи информации нужно определиться заранее. Но в общем случае, обычно именно клиент первым передает запрос, сервер его читает, передает ответ, который читает клиент.
Вот что у нас получилось в итоге:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#!/usr/bin/env python
import socket
sock = socket.socket()
sock.connect(('localhost', 9090))
msg = 'hello, world!'
sock.send(msg.encode())
data = sock.recv(1024)
sock.close()
print(data.decode())
Какие ограничения данного подхода?
Созданные нами клиент и сервер вполне функциональны, но у них есть ряд серьезных ограничений, которые могут затруднить более сложную работу. Например, можно заметить, что сервер выполняет только одну операцию, то есть принимает запрос, выдает ответ и на этом соединение заканчивается. Это, в принципе, не так страшно, ведь всегда можно открыть повторное соединение.
Но наш сервер может обслужить только одного клиента. Ведь после закрытия сокета программа заканчивается и сервер завершается. На практике сервера обычно работают постоянно, в бесконечном цикле, и ждут запросов от клиента. После завершения работы с одним клиентом они продолжают ожидать входящих соединений. Но это исправить можно очень просто (в следующем пункте).
Еще можно заметить, что в работе и клиента и сервера часто встречаются блокирующие операции. Само по себе это неплохо, и даже необходимо. Но представим себе, что клиент по каким-то причинам аварийно завершил свою работу. Или упала сеть. Если в это время сервер ждал сообщения от клиента (то есть заблокировался методом recv), то он останется ждать неопределенно долго. То есть упавший клиент может нарушить работу сервера. Это не очень надежно. Но это тоже легко исправить с помощью установки таймаутов.
Более сложная проблема состоит в том, что сервер способен одновременно работать только с одним клиентом. Вот это исправить уже сложнее, так как потребует многопоточного программирования. Но есть еще один вариант — использовать UDP-сокеты.
Так что давайте познакомимся с некоторыми приемами, которые позволяют обойти или исправить эти недостатки.
Как сделать сервер многоразовым?
Одно из самых заметных отличий нашего простейшего сервера от “настоящего” — его одноразовость. То есть он рассчитан только на одно подключение, после чего просто завершается. исправить эту ситуацию можно очень просто, обернув все действия после связывания сокета с портом и до закрытия сокета в вечный цикл:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#!/usr/bin/env python
import socket
sock = socket.socket()
sock.bind(('', 9090))
sock.listen(1)
while True:
conn, addr = sock.accept()
print 'connected:', addr
while True:
data = conn.recv(1024)
if not data:
break
conn.send(data)
conn.close()
Теперь наш сервер после завершения соединения с одним клиентом переходит на следующую итерацию цикла и начинает снова слушать входящие соединение. И к нему может подключиться как тот же самый клиент, так и новый.
Заодно можно в коде сервера сделать небольшой рефакторинг, чтобы он был более универсальным и удобным для внесения изменений. Рефакторинг — это изменение кода без изменение функциональности. Чем понятнее, проще и системнее организация кода, тем проще его развивать, поддерживать и вносить изменения. Инструкции, отвечающие за разные вещи в хорошем коде должны быть отделены от других. Это помогает в нем ориентироваться.
Например, само собой напрашивается создание констант для параментов сокета — интерфейса и номера порта:
1
2
3
4
5
HOST = ""
PORT = 33333
TYPE = socket.AF_INET
PROTOCOL = socket.SOCK_STREAM
Кроме адреса мы еще выделили тип и протокол сокета. Это параметры конструктора socket(), которые мы раньше не использовали. Первый параметр задает тип создаваемого сокета — Интернет-сокет или UNIX-сокет. Мы будем использовать только первый тип, но сейчас мы зададим его явно. Второй параметр — это тип используемого протокола. Потоковые сокеты используют протокол TCP, а датаграммные — UDP. Скоро мы будем создавать и UDP-соединение, так что не лишним будет прописать это тоже в явном виде.
После этих изменений код создания и связывания сокета будет выглядеть следующим образом:
1
2
srv = socket.socket(TYPE, PROTOCOL)
srv.bind((HOST, PORT))
Еще одним этапом рефакторинга можно выделить функцию, обрабатывающую запрос от клиента. Сейчас у нас на сервере обработки запроса не происходит, но в будущем любой сервер каким-то образом что-то делает с запросом клиента и выдает получившийся результат. Логично сделать специальную функцию, чтобы работа с запросом была отделена в коде от механики организации соединения:
1
2
3
4
5
6
7
8
9
10
def do_something(x):
# ...
return x
# ...
srv = socket.socket(TYPE, PROTOCOL)
srv.bind((HOST, PORT))
# ...
Еще хорошей идеей, хотя бы на этапе разработки будет добавить отладочные сообщения в тем моменты, когда на сервере выполняются определенные действия. Это поможет нам визуально понимать, как выполняется код сервера, следить за ним по сообщениям в консоли и очень полезно для обучения.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
srv.listen(1)
print("Слушаю порт 33333")
sock, addr = srv.accept()
print("Подключен клиент", addr)
while 1:
pal = sock.recv(1024)
if not pal:
break
print("Получено от %s:%s:" % addr, pal)
lap = do_something(pal)
sock.send(lap)
print("Отправлено %s:%s:" % addr, lap)
sock.close()
print("Соединение закрыто")
Кроме того, такие отладочные сообщения служат заменой комментариям в коде. Сейчас комментарии особенно и не нужны, потому что их названия переменных, отладочных сообщений, имен функций понятно, что происходит в программе. Такой код называется самодокументируемым.
Конечно, код можно улучшать до бесконечности, но мы на этом остановимся. Вот что у нас получилось в итоге — многоразовый эхо-сервер:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import socket, string
HOST = ""
PORT = 33333
TYPE = socket.AF_INET
PROTOCOL = socket.SOCK_STREAM
def do_something(x):
return x
srv = socket.socket(TYPE, PROTOCOL)
srv.bind((HOST, PORT))
while 1:
srv.listen(1)
print("Слушаю порт 33333")
sock, addr = srv.accept()
print("Подключен клиент", addr)
while 1:
pal = sock.recv(1024)
if not pal:
break
print("Получено от %s:%s:" % addr, pal)
lap = do_something(pal)
sock.send(lap)
print("Отправлено %s:%s:" % addr, lap)
sock.close()
print("Соединение закрыто")
Как задать таймаут прослушивания?
Как мы говорили раньше, блокирующие операции в коде программы должны быть объектом пристального внимания программиста. Блокировки программы могут существенно замедлять ее выполнение (об этом мы поговорим потом, когда будем изучать многозадачное программирование), могут быть источником ошибок.
Модуль socket позволяет выполнять блокирующие операции в нескольких режимах. Режим по умолчанию — блокирующий. В нем при выполнении операции программа будет ждать неопределенно долго наступления внешнего события — установки соединения или отправки другой стороной данных.
Можно использовать другой режим — режим таймаута — путем вызова метода settimeout(t) перед выполнением потенциально блокирующей операции. Тогда программа тоже заблокируется, но будет ждать только определенное время — t секунд. Если по прошествии этого времени нужное событие не произойдет, то метод выбросит исключение.
Таймаут можно “вешать” как на подключение, как и на чтение данных их сокета:
1
2
3
4
5
6
7
8
9
10
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(("",0))
sock.listen(1)
# accept can throw socket.timeout
sock.settimeout(5.0)
conn, addr = sock.accept()
# recv can throw socket.timeout
conn.settimeout(5.0)
conn.recv(1024)
В таком случае, лучше обрабатывать возможное исключение, чтобы оно не привело к аварийному завершения программы:
1
2
3
4
5
6
# recv can throw socket.timeout
conn.settimeout(5.0)
try:
conn.recv(1024)
except socket.timeout:
print("Клиент не отправил данные")
Как обмениваться объектами по сокетам?
В работе сетевых приложений часто возникает задача передать через сокет не просто байтовый массив или строку, а объект или файл произвольного содержания. Во многих языках программирования существует специальный механизм, который позволяет преобразовать произвольный объект в строку таким образом, чтобы потом весь объект можно было бы восстановить их этой строки.
Такой процесс называется сериализация объектов. Она применяется, например, при сохранении данных программы в файл. Но с тем же успехом ее можно использовать и для передачи объектов через сокеты.
В Python существует стандартный модуль pickle, который нужен для сериализации объектов. Из этого модуля нам понадобится две операции. Метод dumps(obj) преобразует объект в строковое представление, сериализует его. Метод loads(str) восстанавливает объект из строки — десериализует его.
Давайте рассмотрим пример, когда в сокет отправляется сериализованный словарь:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import socket
import pickle
s = socket.socket()
s.bind(("", 9090))
s.listen(1)
while True:
clientsocket, address = s.accept()
d = {1:"hi", 2: "there"}
msg = pickle.dumps(d).encode()
clientsocket.send(msg)
Имейте в виду, что на месте словаря может быть любой сложный объект. А это значит, что мы можем передавать через сокеты в сериализованном виде практически любою информацию.
На другой стороне прочитать и восстановить объект из сокета можно, например, так:
1
2
3
msg = conn.recv(1024)
d = pickle.loads(msg.decode())
В чем особенности UDP-сокетов?
До сих пор мы рассматривали только сокеты, использующие в своей работе протокол TCP. Этот протокол еще называют протоколом с установкой соединения. Но в сокетах можно использовать и протокол UDP. И такие сокеты (их еще называют датаграммными) имеют с воей реализации несколько отличий. Давайте их рассмотрим.
Создание UDP сокета очень похоже, только надо явно указывать агрументы конструктора socket() ведь по умолчанию создаются TCP сокеты:
1
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
Обратите внимание на второй параметр — именно он задает протокол передачи данных. Раньше мы использовали значение socket.SOCK_STREAM — это TCP-сокет. Для UDP-сокетов нужно значение socket.SOCK_DGRAM.
Связывание серверного сокета с портом происходит точно так же:
Дальше пойдут различия. UDP-сокеты не требуют установки соединения. Они способны принимать данные сразу. Но для этого используется другой системный вызов (и соответствующий ему метод Python) — recvfrom. Этот метод блокирует программу и когда присоединится любой клиент, возвращает сразу и данные и сокет клиента:
1
data, addr = s.recvfrom(1024)
Этот метод также работает в потоковом режиме. То есть нам нужно указывать количество байт, которые мы хотим считать. Но при следующем вызове метода recvfrom() могут придти данные уже от другого клиента. Надо понимать, что UDP-сокеты являются “неразборчивыми”, то есть в него может писать несколько клиентов одновременно, “вперемешку”. Для этого каждый раз и возвращается исходящий сокет, чтобы мы могли понять, от какого клиента пришли эти данные.
Что касается клиентского сокета, то здесь все еще проще:
1
2
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.sendto(msg, (host, port))
То есть сразу после создания сокет готов к передаче данных. Но каждый раз нам нужно указывать, куда мы эти данные посылаем.
UDP-сокеты даже проще по своей организации, чем TCP. Меньше шагов нужно сделать, чтобы обмениваться информацией. Но UDP является протоколом без гарантированной доставки. Они ориентирован на скорость и простоту передачи данных, в то время как TCP — на надежность связи.
В конце приведем пример кода сервера и клиента, обменивающихся данными через UDP-сокеты. Код сервера совсем короткий. Но это такой же эхо-сервер, только работающий на другом протоколе:
1
2
3
4
5
6
7
8
import socket
port = 5000
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.bind(("", port))
while 1:
data, addr = s.recvfrom(1024)
print(data)
s.sendto(data, addr)
Код клиента приведем в более подробном виде. Механику работы сокетов мы уже рассмотрели, попробуйте проанализировать в этом коде обработку исключений и вывод отладочных сообщений:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import socket
import sys
try:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
except socket.error:
print('Failed to create socket')
sys.exit()
host = 'localhost';
port = 8888;
while(1) :
msg = raw_input('Enter message to send: ')
try :
s.sendto(msg, (host, port))
reply, addr = s.recvfrom(1024)
print('Server reply : ' + reply)
except socket.error, msg:
print('Error Code : ' + str(msg[0]) + ' Message ' + msg[1])
sys.exit()
Сообщения
Все остальные сообщения в протоколе принимают форму <length prefix><message ID><payload>. Длина префикса состоит из четырех байт big-endian значения. Идентификатор сообщения — это один десятичный символ. Полезная нагрузка (payload) непосредственно зависит от сообщения.
keep-alive: <len=0000>
keep-alive сообщения — это сообщения с нулевыми байтами, length prefix установлен в ноль. Не существует идентификатора сообщения и никакой полезной нагрузки сообщение не несёт. Пир может закрыть соединение, если он не получают никаких сообщений (keep-alive или любого другого сообщения) в течение определенного периода времени, поэтому keep-alive сообщение нацелено на поддержание связи. Это время, обычно равно двум минутам.
choke: <len=0001><id=0>
Choke-сообщение — это сообщение фиксированной длины без полезной нагрузки.
unchoke: <len=0001><id=1>
Unchoke-сообщение — это сообщение фиксированной длины без полезной нагрузки.
interested: <len=0001><id=2>
Interested-сообщение — это сообщение фиксированной длины без полезной нагрузки.
not interested: <len=0001><id=3>
Non interested-сообщение — это сообщение фиксированной длины без полезной нагрузки.
have: <len=0005><id=4><piece index>
Have-сообщение фиксированной длины. Полезная нагрузка — это с указвнием нулей (zero-based) индекс куска, который только что был успешно скачан и проверен с помощью хэша.
Конструкторское замечание: Это строгое определение, в реальности some games may be played. В частности, поскольку крайне маловероятно, чтобы пиры загружали куски, которые они уже имеют, пир может не рекламировать (advertise) наличие кусков пирам, которые эти куски имеют. Подавление HAVE-сообщений («HAVE supression») как минимум приведет к 50% сокращению числа сообщений, а это сокращение примерно на 25-35% накладных расходов протокола (protocol overhead). В то же время, возможно целесообразно отправить HAVE-сообщение пирам, которые уже имеют этот кусок, поскольку он будет полезен в определении его редкости.
Вредоносные пиры также могут выбирать оглашение (advertise) имеющихся кусков, которые пир точно никогда не загрузит. Due to this attempting to model peers using this information is a bad idea
bitfield: <len=0001+X><id=5><bitfield>
Bitfield сообщение может быть направлено сразу же после того, последовательность «рукопожатий» будет завершена, и до любых других сообщений. Оно является необязательным, и клиентам, не имеющих куски, нет нужды отсылать его.
Bitfield сообщение переменной длины, где X — это длина bitfield’a. Полезная нагрузка сообщения — bitfield представление кусков, которые были успешно загружены. Старший разряд в первом байте соответствует куску с индексом 0. Биты, которые пустые указывают пропавший кусок, а установленные биты обозначают валидные и доступные куски. Запасные биты в конце устанавливаются в ноль.
Bitfield неверной длины считается ошибочным. Клиенты должны разорвать соединение, если они получают bitfields неверного размера, или если bitfield имеет произвольный набор запасных битов.
request: <len=0013><id=6><index><begin><length>
Сообщение-запрос фиксированной длины, используется для запросы блока. Полезная нагрузка сообщения содержит следующую информацию:
index: целое число, определяющее с указанием нулей (zero-based) индекс куска
begin: целое с указанием нулей смещение байтов внутри куска
length: целое число, определяющее запрашиваемую длину.
This section is under dispute! Please use the discussion page to resolve this!
View 1. Согласно официальной спецификациям, «Все текущие реализаций используют 2^15 (32KB) куски, и закрывают соединения, которые запрашивают количество данных более 2^17 (128Kb).» Уже в версии 3 или 2004, это поведение было изменено на использование 2^14 (16Кб) блоков. Начиная с версии 4.0 или mid-2005, соединение в Mainline при запросах больше, чем 2^14 (16Кб), и некоторые клиенты последовали этому примеру. Помните, что block-запросы меньше, чем куски (>= 2^18 байт), поэтому будут необходимы многочисленные запросы, чтобы скачать весь кусок.
Собственно, спецификация позволяет 2^15 (32Кб) запросы. Реальность такова, что все клиенты начиная с сегодняшнего момента будут использовать 2 ^ 14 (16Кб) запросы. Из-за клиентов, которые привязаны к такому размеру запросов, рекомендуется реализовывать программы, делающие запросы именно такого размера. Меньшие размеры запросов приводят к повышению накладных расходов в связи с увеличением количества требуемых запросов, проектировщики советуют не делать размер запросов меньше, чем 2 ^ 14 (16Кб).
Выбор предельного размера запрашиваемого блока не очень ясен. Mainline версии 4 осуществляет 16Кб-ые запросы, большинство клиентов будут использовать этот размер. В то же время размер 2^14 (16Кб) представляется полу-официальным (наполовину официальным, потому что официальная документация протокола не обновлялась) , поэтому, по сути, неправильным (не соответствующим спецификации). В то же время, разрешение бо’льших запросов расширяет набор возможных пиров, и при исключении очень низкой пропускной способности соединения (<256кб/сек), несколько блоков будет загружено в один choke-timeperiod, таким образом простое предписание старого предела размера блока вызывает минимальное ухудшение работы. Из-за этого фактора, рекомендуется только старое 2^17 (128 КБ) максимальное ограничение размера.
View 2. Текущая версия имеет по крайней мере следующие ошибки: Mainline начали использовать 2^14 (16384) байт запросы, когда он был единственным из существующих клиентов, только «официальная спецификация» все ещё говорила об устаревшем 32768-байтовом значении, которое не было в действительности ни размером значения по умолчанию, ни позволенным максимумом. В версии 4 поведение запросов не изменилось, но максимально допустимый размер запроса стал равным значению размера по умолчанию. В последней версии Mainline максимум изменился до 32768 (заметьте, что это первое появление 32768 либо для значения по умолчанию, либо для максимального размера запроса с момента появления первой версии). Утверждение: «большинство старых клиентов используют 32KB запросы» — является ложным. Обсуждение запросов не принимает последствия латентности во внимание.
piece: <len=0009+X><id=7><index><begin><block>
Piece-сообщение переменной длины, где X — длина блока. Полезная нагрузка сообщения содержит следующую информацию:
index: целое определяющее с указанием нулей индекс куска
begin: целое, определяющее с указанием нулей байтовое смещение внутри куска
block: блок данных, который есть подмножество куска с определённым индексом
cancel: <len=0013><id <= 8><index><begin><length>
Cancel-сообщение фиксированной длины, используется для отмены блокировки запросов. Полезная нагрузка сообщения идентична той, которая была в «сообщении-запросе» («request» message). Сообщение обычно используется во время стратегии «Конца игры» (End game, см. ниже раздел Алгоритмы).
port: <len=0003><id=9><listen-port>
Port-сообщение отсылается посредством новых версий Mainline, которая реализует DHT Tracker. Порт для прослушивания является портом который DHT узел прослушивает. Этот пир должен быть вставлен в локальную таблицу маршрутизации (если DHT Tracker поддерживается).
Все знают протокол TCP / IP, но не многие его понимают, лучше написать небольшой взгляд.
Я знаю, что чтение скучно, не умеет читать, и это подрывает уверенность каждого. Дело не в том, что наши головы не так хороши, как у других. Это потому, что наш метод неправильный.
Все технологии разрабатываются из приложений, поэтому идите снизу вверх и сначала выполните задачу.
Требуются предварительные знания
-
Знание драйвера Linux: Первоначальное понимание сетевого протокола не обязательно требовало понимания драйвера Linux, но, поскольку в этом примере в качестве основы используется виртуальная сетевая карта Linux, для понимания исходного кода требуется простое понимание. В настоящее время нет коротких и ясных хороших рекомендаций к статье, которые можно добавить позже.
-
Принцип построения драйвера TUN / TAP виртуальной сетевой карты
http://www.ibm.com/developerworks/cn/linux/l-tuntap/
Приведенный выше URL-адрес представляет собой статью, которая, на мой взгляд, более понятна и понятна, и я рекомендую ее. -
Формат заголовка Ethernet (уровень L2), формат заголовка ARP, функции протокола ARP и процесс внедрения. Я думаю, что следующая статья на английском сайте лучше объяснена.
-
- Сначала разберитесь в заголовках так называемого стека протоколов 7 уровней. Я не планирую говорить обо всех семи уровнях здесь, но три уровня, включая заголовок Ethernet (уровень L1), заголовок IP (уровень L2) и заголовок TCP / UDP (уровень L3). Слишком много разговоров, но не легко понять. Структура всего стека протоколов суммируется из конкретных приложений.
- Затем посмотрите на фактически перехваченный пакет.
- Наконец, посмотрите, как генерируется весь пакет, включая данные и три заголовка. Какие протоколы генерируются и порядок генерации. После создания пакета он отправляется в драйвер Ethernet.

Рисунок 1: структура заголовка IP
Исключая поле IP Option, заголовок IP содержит всего 20 байтов. Значение каждого поля показано на рисунке выше.
Давайте снова посмотрим на реальный перехваченный пакет UDP:
Рисунок 2: фактический перехваченный пакет UDP
- Ethernet-заголовок
Существует поле «тип» (0800 в вышеприведенном примере, которое представляет пакет данных, передаваемый с уровня протокола IP), и значение каждого типа равно следующему:
0x0600 XNS
0x0800 IP
0x0806 ARP
0x6003 DECnet
- Заголовок IP
Внутри красного поля находится 20-байтовый IP-заголовок, значение каждого поля должно быть внимательно рассмотрено. -
Заголовок UDP
Заголовок IP
Следующие 8 байтов заголовка UDP. Он добавляется протоколом UDP верхнего уровня.Прежде всего, данные (полезная нагрузка), конечно, генерируются прикладным уровнем (например, прикладным программным обеспечением принтера EPSON). (На рисунке выше показан пакет связи между моим программным обеспечением принтера EPSON и принтером). Прикладное программное обеспечение принтера EPSON генерирует пакет данных и сбрасывает его на уровень UDP (L3). Этот протокол UDP добавляет заголовок UDP (синий прямоугольник на рисунке выше) перед данными. Затем протокол UDP был передан вниз и передан на уровень IP (уровень L2) .Этому протоколу IP предшествовал заголовок IP. Затем он передается вниз, передается на уровень карты Ethernet (уровень L1), добавляет заголовок Ethernet впереди, а затем передает весь пакет данных в драйвер Ethernet. Этот пакет включает три заголовка и данные для отправки ( Полезная нагрузка), и, наконец, драйвер Ethernet отправляет весь пакет через сетевой кабель.
После прочтения конкретного примера давайте рассмотрим весь стек протоколов.
Протокол ARP (Address Resolution Protocol) является специальным сетевым стандартным протоколом. Это необязательно. Работает на уровне L2.
Протокол разрешения адресов отвечает за преобразование адресов протоколов более высокого уровня (IP-адресов) в адреса физических сетей.
http://network-panda.blogspot.jp/2015/06/brief-introduction-to-protocols-1-arp.html
http://www.tcpipguide.com/free/t_ARPMessageFormat.htm
Когда хост принимает пакет ARP (будь то широковещательный запрос или двухточечный ответ), драйвер принимающего устройства отправляет этот пакет в модуль протокола ARP. :
Хорошо, пока, я думаю, что основы подготовки уже готовы. Давайте поэкспериментируем сейчас.
Давайте напишем стек протоколов TCP / IP, 1: Ethernet, ARP
Написание стека протоколов TCP / IP самостоятельно может показаться сложной задачей. На самом деле, TCP накопил спецификации за время жизни более тридцати лет.
Однако основные спецификации кажутся компактными. Важными компонентами являются: разбор заголовка TCP, конечный автомат, управление перегрузкой и расчет времени ожидания повторной передачи.
Наиболее часто используемые протоколы Уровня 2 и Уровня 3 находятся на уровнях Ethernet и IP, соответственно. По сравнению со сложностью TCP это кажется намного проще.
В этой серии блогов мы будем реализовывать минимальный стек протоколов TCP / IP в Linux.
Они предназначены только для обучения. Чтобы глубже изучить, пожалуйста, узнайте больше о сетевом и системном программировании.
содержание
Оборудование TUN / TAP
Формат кадра Ethernet
Анализ кадра Ethernet
Протокол геокодирования
Алгоритм геокодирования
Заключение
source
Оборудование TUN / TAP
Для перехвата базовых сетевых данных из ядра мы будем использовать устройство TUN / TAP.
[Connie Note]
Драйвер tun / tap реализует функцию виртуальной сетевой карты, tun указывает, что виртуальное устройство является устройством двухточечного соединения, а tap указывает, что виртуальное является устройством Ethernet. Эти два устройства реализуют различную инкапсуляцию для сетевых пакетов. ,
Используя драйвер tun / tap, вы можете передать сетевой пакет, обработанный стеком протокола TCP / IP, любому процессу, использующему драйвер tun / tap. Процесс обрабатывается и затем отправляется физическому ссылка.
Короче говоря, устройства TUN / TAP обычно используются сетевыми приложениями пространства пользователя для манипулирования данными L3 или L2 соответственно.
Популярный примерtunneling, Один из пакетов упакован в полезную нагрузку другого пакета.
Преимущество устройств TUN / TAP заключается в том, что их легко встроить в программы пользовательского пространства, и они используются во многих программах, таких как OpenVPN.
Поскольку мы хотим создать свой собственный стек сетевых протоколов из уровня L2, нам нужно устройство TAP. Мы создаем это так:
/ *
* Взято из файла ядра / network / tuntap.txt
*/
int tun_alloc(char *dev)
{
struct ifreq ifr;
int fd, err;
if( (fd = open("/dev/net/tap", O_RDWR)) < 0 ) {
print_error("Cannot open TUN/TAP dev");
exit(1);
}
CLEAR(ifr);
/* Flags: IFF_TUN - TUN device (no Ethernet headers)
* IFF_TAP - TAP device
*
* IFF_NO_PI - Do not provide packet information
*/
ifr.ifr_flags = IFF_TAP | IFF_NO_PI;
if( *dev ) {
strncpy(ifr.ifr_name, dev, IFNAMSIZ);
}
if( (err = ioctl(fd, TUNSETIFF, (void *) &ifr)) < 0 ){
print_error("ERR: Could not ioctl tun: %sn", strerror(errno));
close(fd);
return err;
}
strcpy(dev, ifr.ifr_name);
return fd;
}Затем возвращенный дескриптор файла fd может использоваться для чтения и записи данных в буфер Ethernet виртуального устройства.
Флаг IFF_NO_PI имеет решающее значение, в противном случае мы добавим ненужную информацию о пакете в кадр Ethernet. Вы можете посмотреть на драйверы устройств ядраИсходный кодИ убедитесь сами.
Формат кадра Ethernet
Многие различные сетевые технологии Ethernet соединяют компьютеры с магистралью локальных сетей (LAN). Как и все физические технологии, стандарт Ethernet существенно изменился по сравнению с первым решением, опубликованным в 1980 году компаниями Digital Equipment, Intel и Xerox.
Первая версия Ethernet была очень медленной в современных стандартах, около 10 Мбит / с, используя полудуплексную связь, что означает, что вы можете отправлять или получать данные, но не одновременно. Вот почему протокол управления доступом к среде (MAC) должен быть включен в поток данных организации. Даже сегодня, если интерфейс Ethernet работает в полудуплексном режиме, обнаружение конфликта множественного доступа (CSMA / CD) все еще необходимо из-за MAC.
Стандарт Ethernet 100BASE-T с использованием витой пары делает возможным полнодуплексную связь, а также обеспечивает более высокую пропускную способность для связи. Кроме того, возросла популярность коммутаторов Ethernet, что делает CSMA / CD устаревшим.
Рабочая группа IEEE 802.33 поддерживает различные стандарты Ethernet.
Далее мы рассмотрим заголовок кадра Ethernet. Это может быть объявлено как структура C:
#include <linux/if_ether.h>
struct eth_hdr
{
unsigned char dmac[6];
unsigned char smac[6];
uint16_t ethertype; // Тип Ethernet
unsigned char payload []; // полезная нагрузка
} __attribute__((packed));DMAC и Smac — довольно понятные проекты. Они содержат адреса взаимодействующих сторон (пункт назначения и источник) соответственно.
Ethertype элемента перегрузки является 2-октетным элементом. Его значение зависит от его значения. Это может быть длина полезной нагрузки или тип полезной нагрузки. В частности, если значение этого поля больше или равно 1536, это поле указывает тип полезной нагрузки (такой как IPv4, ARP). Если значение меньше этого значения, в поле указывается длина полезной нагрузки.
После поля ethertype в кадре Ethernet может быть несколько разных меток. Эти теги могут использоваться для описания типа кадра виртуальной локальной сети (VLAN), качества обслуживания (QoS). На этот раз метки кадров Ethernet были исключены из нашего кода, поэтому соответствующие поля не были указаны в нашей инструкции протокола.
Поле полезной нагрузки содержит указатель на полезную нагрузку кадра Ethernet. В нашем примере это будет пакет ARP или IPv4. Если длина полезной нагрузки меньше требуемого минимума в 48 байтов (без меток), число байтов добавляется в конец полезной нагрузки для удовлетворения спроса.
Нам также необходимо включить заголовочный файл Linux if_ether.h, который обеспечивает отображение между типами etherty и шестнадцатеричными значениями.
Наконец, формат кадра Ethernet также включает в себя поле проверки кадра, которое использует проверку циклическим избыточным кодом (CRC) для проверки целостности кадра. В нашем примере мы пропустим эту обработку.
Разбор кадров Ethernet
Упакованное свойство объявления структуры — это деталь, которая указывает компилятору не оптимизировать 4-байтовую выровненную структуру памяти структуры данных. Этот атрибут используется из-за способа, которым мы «анализируем» буфер протокола, который является надлежащим буфером данных структуры протокола:
struct eth_hdr hdr = (struct eth_hdr ) buf;
Портативный, немного трудоемкий метод, который вручную сериализует данные протокола. Таким образом, компилятор может свободно добавлять байты заполнения, чтобы лучше соответствовать требованиям выравнивания данных разных процессоров.
Общая схема анализа и обработки кадрового буфера Ethernet проста:
if (tun_read(buf, BUFLEN) < 0) {
print_error("ERR: Read from tun_fd: %sn", strerror(errno));
}
struct eth_hdr *hdr = init_eth_hdr(buf);
handle_frame(&netdev, hdr);Функция handle_frame включает следующее действие кадра Ethernet на основе значения поля ethertype кадра Ethernet.
Протокол разрешения адресов
Протокол разрешения адресов (ARP) используется для динамического сопоставления 48-битного адреса Ethernet (MAC-адреса) с адресом протокола (таким как адрес IPv4). Ключевым моментом здесь является то, что ARP должен соответствовать многим различным протоколам L3, не только IPv4, но и таким протоколам, как CHAOS. Они объявлены как 16-битные адреса протокола.
Обычно вы знаете IP-адреса некоторых служб в вашей локальной сети, но для установления фактической связи вам также необходимо знать аппаратный адрес (MAC). Поэтому ARP используется для широковещательной передачи запросов в сеть и требует, чтобы владелец IP-адреса сообщал свой аппаратный адрес.
Формат пакета ARP относительно прост:
struct arp_hdr
{
uint16_t hwtype;
uint16_t protype;
unsigned char hwsize;
unsigned char prosize;
uint16_t opcode;
unsigned char data[];
} __attribute__((packed));Заголовок ARP (arp_hdr) содержит 2-октетное поле hwtype, которое зависит от типа канального уровня. В нашем случае это значение всегда 0x0001.
Прототип 2-октетного поля указывает тип протокола. В нашем примере это IPv4 и соответствующее значение 0x0800.
Поля hwsize и prosize имеют размер в 1 октет, который представляет размер оборудования и поля протокола, соответственно. В нашем примере это 6-байтовые MAC-адреса и 4-байтовые IP-адреса.
2-октетное поле кода операции указывает тип пакета ARP. Это может быть запрос ARP (1), ответ ARP (2), запрос RARP (3) или (4) ответ RARP.
Поле данных содержит фактическую полезную нагрузку сообщения ARP, и в нашем случае это будет содержать конкретную информацию для IPv4:
struct arp_ipv4
{
unsigned char smac[6];
uint32_t sip;
unsigned char dmac[6];
uint32_t dip;
} __atПоля smac и dmac содержат 6-байтовые MAC-адреса отправителя и получателя соответственно. sip и dip содержат IP-адреса отправителя и получателя соответственно.
Алгоритм разрешения адресов
В оригинальной спецификации описан этот простой алгоритм разрешения адресов
?Do I have the hardware type in ar$hrd?
Yes: (almost definitely)
[optionally check the hardware length ar$hln]?Do I speak the protocol in ar$pro?
Yes:
[optionally check the protocol length ar$pln]
Merge_flag := false
If the pair <protocol type, sender protocol address> is
already in my translation table, update the sender
hardware address field of the entry with the new
information in the packet and set Merge_flag to true.
?Am I the target protocol address?
Yes:
If Merge_flag is false, add the triplet <protocol type,
sender protocol address, sender hardware address> to
the translation table.
?Is the opcode ares_op$REQUEST? (NOW look at the opcode!!)
Yes:
Swap hardware and protocol fields, putting the local
hardware and protocol addresses in the sender fields.
Set the ar$op field to ares_op$REPLY
Send the packet to the (new) target hardware address on
the same hardware on which the request was received.
Таким образом, таблица трансляции используется для хранения результатов протокола ARP, чтобы хосты могли видеть, есть ли у них записи в их кеше. Это предотвращает нежелательные запросы ARP от спама в сети.
Алгоритм находится вarp.cВ действительности.
Наконец, окончательный тест реализации ARP — проверить, правильно ли он отвечает на запрос ARP.
[[email protected] lvl-ip]$ arping -I tap0 10.0.0.4
ARPING 10.0.0.4 from 192.168.1.32 tap0
Unicast reply from 10.0.0.4 [00:0C:29:6D:50:25] 3.170ms
Unicast reply from 10.0.0.4 [00:0C:29:6D:50:25] 13.309ms[[email protected] lvl-ip]$ arp
Address HWtype HWaddress Flags Mask Iface
10.0.0.4 ether 00:0c:29:6d:50:25 C tap0
Сетевой стек ядра распознает ответ ARP от нашего пользовательского стека сетевых протоколов и заполняет записи виртуального сетевого устройства в его кэше ARP. Успех!
вывод
Обработка фреймов Ethernet и минимальная реализация ARP относительно просты и могут быть выполнены в несколько строк кода. Ободрение довольно велико, потому что вы можете иметь свое собственное устройство Ethernet в ARP-кэше хоста Linux!
Исходный код проекта можно найти по адресуGitHubНашел это.
В следующих статьях мы продолжим реализацию ICMP-эхо и ответа (ping) и анализа IPv4-пакетов.
Если вам понравилась эта статья, вы можете поделиться ею со своими подписчиками и подписаться на меня в Twitter!