Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
Сегодня поговорим о bash-скриптах. Это — сценарии командной строки, написанные для оболочки bash. Существуют и другие оболочки, например — zsh, tcsh, ksh, но мы сосредоточимся на bash. Этот материал предназначен для всех желающих, единственное условие — умение работать в командной строке Linux.
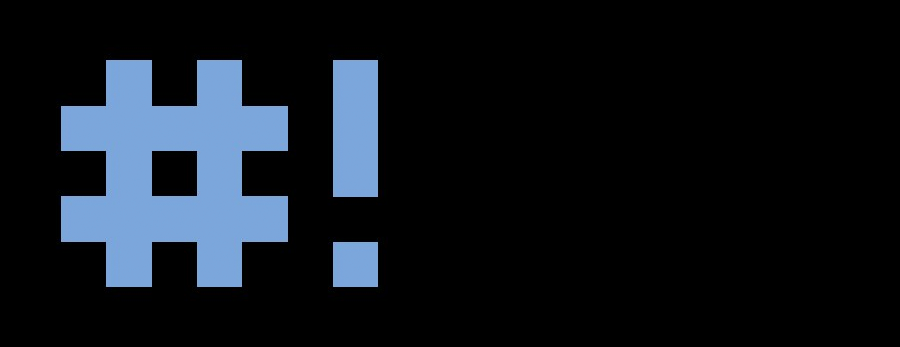
Сценарии командной строки — это наборы тех же самых команд, которые можно вводить с клавиатуры, собранные в файлы и объединённые некоей общей целью. При этом результаты работы команд могут представлять либо самостоятельную ценность, либо служить входными данными для других команд. Сценарии — это мощный способ автоматизации часто выполняемых действий.

Итак, если говорить о командной строке, она позволяет выполнить несколько команд за один раз, введя их через точку с запятой:
pwd ; whoami
На самом деле, если вы опробовали это в своём терминале, ваш первый bash-скрипт, в котором задействованы две команды, уже написан. Работает он так. Сначала команда pwd выводит на экран сведения о текущей рабочей директории, потом команда whoamiпоказывает данные о пользователе, под которым вы вошли в систему.
Используя подобный подход, вы можете совмещать сколько угодно команд в одной строке, ограничение — лишь в максимальном количестве аргументов, которое можно передать программе. Определить это ограничение можно с помощью такой команды:
getconf ARG_MAXКомандная строка — отличный инструмент, но команды в неё приходится вводить каждый раз, когда в них возникает необходимость. Что если записать набор команд в файл и просто вызывать этот файл для их выполнения? Собственно говоря, тот файл, о котором мы говорим, и называется сценарием командной строки.
Как устроены bash-скрипты
Создайте пустой файл с использованием команды touch. В его первой строке нужно указать, какую именно оболочку мы собираемся использовать. Нас интересует bash, поэтому первая строка файла будет такой:
#!/bin/bash
В других строках этого файла символ решётки используется для обозначения комментариев, которые оболочка не обрабатывает. Однако, первая строка — это особый случай, здесь решётка, за которой следует восклицательный знак (эту последовательность называют шебанг) и путь к bash, указывают системе на то, что сценарий создан именно для bash.
Команды оболочки отделяются знаком перевода строки, комментарии выделяют знаком решётки. Вот как это выглядит:
#!/bin/bash
# This is a comment
pwd
whoamiТут, так же, как и в командной строке, можно записывать команды в одной строке, разделяя точкой с запятой. Однако, если писать команды на разных строках, файл легче читать. В любом случае оболочка их обработает.
Установка разрешений для файла сценария
Сохраните файл, дав ему имя myscript, и работа по созданию bash-скрипта почти закончена. Сейчас осталось лишь сделать этот файл исполняемым, иначе, попытавшись его запустить, вы столкнётесь с ошибкой Permission denied.

Попытка запуска файла сценария с неправильно настроенными разрешениями
Сделаем файл исполняемым:
chmod +x ./myscriptТеперь попытаемся его выполнить:
./myscriptПосле настройки разрешений всё работает как надо.
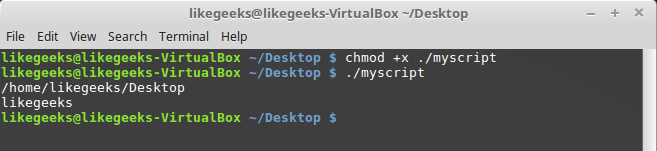
Успешный запуск bash-скрипта
Вывод сообщений
Для вывода текста в консоль Linux применяется команда echo. Воспользуемся знанием этого факта и отредактируем наш скрипт, добавив пояснения к данным, которые выводят уже имеющиеся в нём команды:
#!/bin/bash
# our comment is here
echo "The current directory is:"
pwd
echo "The user logged in is:"
whoamiВот что получится после запуска обновлённого скрипта.
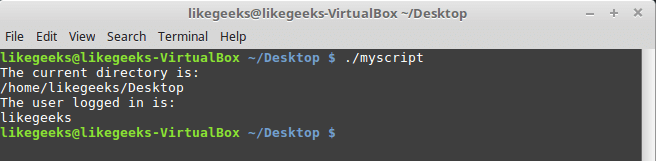
Вывод сообщений из скрипта
Теперь мы можем выводить поясняющие надписи, используя команду echo. Если вы не знаете, как отредактировать файл, пользуясь средствами Linux, или раньше не встречались с командой echo, взгляните на этот материал.
Использование переменных
Переменные позволяют хранить в файле сценария информацию, например — результаты работы команд для использования их другими командами.
Нет ничего плохого в исполнении отдельных команд без хранения результатов их работы, но возможности такого подхода весьма ограничены.
Существуют два типа переменных, которые можно использовать в bash-скриптах:
- Переменные среды
- Пользовательские переменные
Переменные среды
Иногда в командах оболочки нужно работать с некими системными данными. Вот, например, как вывести домашнюю директорию текущего пользователя:
#!/bin/bash
# display user home
echo "Home for the current user is: $HOME"
Обратите внимание на то, что мы можем использовать системную переменную $HOME в двойных кавычках, это не помешает системе её распознать. Вот что получится, если выполнить вышеприведённый сценарий.

Использование переменной среды в сценарии
А что если надо вывести на экран значок доллара? Попробуем так:
echo "I have $1 in my pocket"
Система обнаружит знак доллара в строке, ограниченной кавычками, и решит, что мы сослались на переменную. Скрипт попытается вывести на экран значение неопределённой переменной $1. Это не то, что нам нужно. Что делать?
В подобной ситуации поможет использование управляющего символа, обратной косой черты, перед знаком доллара:
echo "I have $1 in my pocket"Теперь сценарий выведет именно то, что ожидается.

Использование управляющей последовательности для вывода знака доллара
Пользовательские переменные
В дополнение к переменным среды, bash-скрипты позволяют задавать и использовать в сценарии собственные переменные. Подобные переменные хранят значение до тех пор, пока не завершится выполнение сценария.
Как и в случае с системными переменными, к пользовательским переменным можно обращаться, используя знак доллара:
#!/bin/bash
# testing variables
grade=5
person="Adam"
echo "$person is a good boy, he is in grade $grade"Вот что получится после запуска такого сценария.

Пользовательские переменные в сценарии
Подстановка команд
Одна из самых полезных возможностей bash-скриптов — это возможность извлекать информацию из вывода команд и назначать её переменным, что позволяет использовать эту информацию где угодно в файле сценария.
Сделать это можно двумя способами.
- С помощью значка обратного апострофа «`»
- С помощью конструкции
$()
Используя первый подход, проследите за тем, чтобы вместо обратного апострофа не ввести одиночную кавычку. Команду нужно заключить в два таких значка:
mydir=`pwd`При втором подходе то же самое записывают так:
mydir=$(pwd)А скрипт, в итоге, может выглядеть так:
#!/bin/bash
mydir=$(pwd)
echo $mydir
В ходе его работы вывод команды pwdбудет сохранён в переменной mydir, содержимое которой, с помощью команды echo, попадёт в консоль.

Скрипт, сохраняющий результаты работы команды в переменной
Математические операции
Для выполнения математических операций в файле скрипта можно использовать конструкцию вида $((a+b)):
#!/bin/bash
var1=$(( 5 + 5 ))
echo $var1
var2=$(( $var1 * 2 ))
echo $var2
Математические операции в сценарии
Управляющая конструкция if-then
В некоторых сценариях требуется управлять потоком исполнения команд. Например, если некое значение больше пяти, нужно выполнить одно действие, в противном случае — другое. Подобное применимо в очень многих ситуациях, и здесь нам поможет управляющая конструкция if-then. В наиболее простом виде она выглядит так:
if команда
then
команды
fiА вот рабочий пример:
#!/bin/bash
if pwd
then
echo "It works"
fi
В данном случае, если выполнение команды pwdзавершится успешно, в консоль будет выведен текст «it works».
Воспользуемся имеющимися у нас знаниями и напишем более сложный сценарий. Скажем, надо найти некоего пользователя в /etc/passwd, и если найти его удалось, сообщить о том, что он существует.
#!/bin/bash
user=likegeeks
if grep $user /etc/passwd
then
echo "The user $user Exists"
fiВот что получается после запуска этого скрипта.
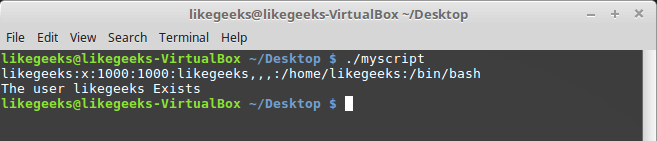
Поиск пользователя
Здесь мы воспользовались командой grepдля поиска пользователя в файле /etc/passwd. Если команда grepвам незнакома, её описание можно найти здесь.
В этом примере, если пользователь найден, скрипт выведет соответствующее сообщение. А если найти пользователя не удалось? В данном случае скрипт просто завершит выполнение, ничего нам не сообщив. Хотелось бы, чтобы он сказал нам и об этом, поэтому усовершенствуем код.
Управляющая конструкция if-then-else
Для того, чтобы программа смогла сообщить и о результатах успешного поиска, и о неудаче, воспользуемся конструкцией if-then-else. Вот как она устроена:
if команда
then
команды
else
команды
fi
Если первая команда возвратит ноль, что означает её успешное выполнение, условие окажется истинным и выполнение не пойдёт по ветке else. В противном случае, если будет возвращено что-то, отличающееся от нуля, что будет означать неудачу, или ложный результат, будут выполнены команды, расположенные после else.
Напишем такой скрипт:
#!/bin/bash
user=anotherUser
if grep $user /etc/passwd
then
echo "The user $user Exists"
else
echo "The user $user doesn’t exist"
fi
Его исполнение пошло по ветке else.

Запуск скрипта с конструкцией if-then-else
Ну что же, продолжаем двигаться дальше и зададимся вопросом о более сложных условиях. Что если надо проверить не одно условие, а несколько? Например, если нужный пользователь найден, надо вывести одно сообщение, если выполняется ещё какое-то условие — ещё одно сообщение, и так далее. В подобной ситуации нам помогут вложенные условия. Выглядит это так:
if команда1
then
команды
elif команда2
then
команды
fi
Если первая команда вернёт ноль, что говорит о её успешном выполнении, выполнятся команды в первом блоке then, иначе, если первое условие окажется ложным, и если вторая команда вернёт ноль, выполнится второй блок кода.
#!/bin/bash
user=anotherUser
if grep $user /etc/passwd
then
echo "The user $user Exists"
elif ls /home
then
echo "The user doesn’t exist but anyway there is a directory under /home"
fi
В подобном скрипте можно, например, создавать нового пользователя с помощью команды useradd, если поиск не дал результатов, или делать ещё что-нибудь полезное.
Сравнение чисел
В скриптах можно сравнивать числовые значения. Ниже приведён список соответствующих команд.
n1 -eq n2Возвращает истинное значение, еслиn1равноn2.
n1 -ge n2Возвращает истинное значение, еслиn1больше или равноn2.
n1 -gt n2Возвращает истинное значение, еслиn1большеn2.
n1 -le n2Возвращает истинное значение, еслиn1меньше или равноn2.
n1 -lt n2Возвращает истинное значение, если n1 меньшеn2.
n1 -ne n2Возвращает истинное значение, еслиn1не равноn2.
В качестве примера опробуем один из операторов сравнения. Обратите внимание на то, что выражение заключено в квадратные скобки.
#!/bin/bash
val1=6
if [ $val1 -gt 5 ]
then
echo "The test value $val1 is greater than 5"
else
echo "The test value $val1 is not greater than 5"
fiВот что выведет эта команда.

Сравнение чисел в скриптах
Значение переменной val1больше чем 5, в итоге выполняется ветвь thenоператора сравнения и в консоль выводится соответствующее сообщение.
Сравнение строк
В сценариях можно сравнивать и строковые значения. Операторы сравнения выглядят довольно просто, однако у операций сравнения строк есть определённые особенности, которых мы коснёмся ниже. Вот список операторов.
str1 = str2Проверяет строки на равенство, возвращает истину, если строки идентичны.
str1 != str2Возвращает истину, если строки не идентичны.
str1 < str2Возвращает истину, еслиstr1меньше, чемstr2.
str1 > str2Возвращает истину, еслиstr1больше, чемstr2.
-n str1Возвращает истину, если длинаstr1больше нуля.
-z str1Возвращает истину, если длинаstr1равна нулю.
Вот пример сравнения строк в сценарии:
#!/bin/bash
user ="likegeeks"
if [$user = $USER]
then
echo "The user $user is the current logged in user"
fiВ результате выполнения скрипта получим следующее.

Сравнение строк в скриптах
Вот одна особенность сравнения строк, о которой стоит упомянуть. А именно, операторы «>» и «<» необходимо экранировать с помощью обратной косой черты, иначе скрипт будет работать неправильно, хотя сообщений об ошибках и не появится. Скрипт интерпретирует знак «>» как команду перенаправления вывода.
Вот как работа с этими операторами выглядит в коде:
#!/bin/bash
val1=text
val2="another text"
if [ $val1 > $val2 ]
then
echo "$val1 is greater than $val2"
else
echo "$val1 is less than $val2"
fiВот результаты работы скрипта.

Сравнение строк, выведенное предупреждение
Обратите внимание на то, что скрипт, хотя и выполняется, выдаёт предупреждение:
./myscript: line 5: [: too many arguments
Для того, чтобы избавиться от этого предупреждения, заключим $val2 в двойные кавычки:
#!/bin/bash
val1=text
val2="another text"
if [ $val1 > "$val2" ]
then
echo "$val1 is greater than $val2"
else
echo "$val1 is less than $val2"
fiТеперь всё работает как надо.

Сравнение строк
Ещё одна особенность операторов «>» и «<» заключается в том, как они работают с символами в верхнем и нижнем регистрах. Для того, чтобы понять эту особенность, подготовим текстовый файл с таким содержимым:
Likegeeks
likegeeks
Сохраним его, дав имя myfile, после чего выполним в терминале такую команду:
sort myfileОна отсортирует строки из файла так:
likegeeks
Likegeeks
Команда sort, по умолчанию, сортирует строки по возрастанию, то есть строчная буква в нашем примере меньше прописной. Теперь подготовим скрипт, который будет сравнивать те же строки:
#!/bin/bash
val1=Likegeeks
val2=likegeeks
if [ $val1 > $val2 ]
then
echo "$val1 is greater than $val2"
else
echo "$val1 is less than $val2"
fiЕсли его запустить, окажется, что всё наоборот — строчная буква теперь больше прописной.
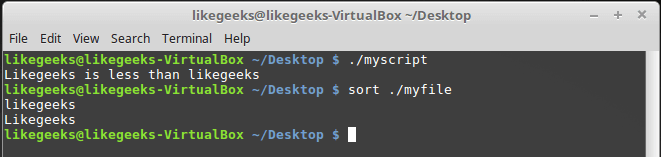
Команда sort и сравнение строк в файле сценария
В командах сравнения прописные буквы меньше строчных. Сравнение строк здесь выполняется путём сравнения ASCII-кодов символов, порядок сортировки, таким образом, зависит от кодов символов.
Команда sort, в свою очередь, использует порядок сортировки, заданный в настройках системного языка.
Проверки файлов
Пожалуй, нижеприведённые команды используются в bash-скриптах чаще всего. Они позволяют проверять различные условия, касающиеся файлов. Вот список этих команд.
-d fileПроверяет, существует ли файл, и является ли он директорией.
-e fileПроверяет, существует ли файл.
-f fileПроверяет, существует ли файл, и является ли он файлом.
-r fileПроверяет, существует ли файл, и доступен ли он для чтения.
-s file Проверяет, существует ли файл, и не является ли он пустым.
-w fileПроверяет, существует ли файл, и доступен ли он для записи.
-x fileПроверяет, существует ли файл, и является ли он исполняемым.
file1 -nt file2Проверяет, новее лиfile1, чемfile2.
file1 -ot file2Проверяет, старше лиfile1, чемfile2.
-O fileПроверяет, существует ли файл, и является ли его владельцем текущий пользователь.
-G fileПроверяет, существует ли файл, и соответствует ли его идентификатор группы идентификатору группы текущего пользователя.
Эти команды, как впрочем, и многие другие рассмотренные сегодня, несложно запомнить. Их имена, являясь сокращениями от различных слов, прямо указывают на выполняемые ими проверки.
Опробуем одну из команд на практике:
#!/bin/bash
mydir=/home/likegeeks
if [ -d $mydir ]
then
echo "The $mydir directory exists"
cd $ mydir
ls
else
echo "The $mydir directory does not exist"
fiЭтот скрипт, для существующей директории, выведет её содержимое.

Вывод содержимого директории
Полагаем, с остальными командами вы сможете поэкспериментировать самостоятельно, все они применяются по тому же принципу.
Итоги
Сегодня мы рассказали о том, как приступить к написанию bash-скриптов и рассмотрели некоторые базовые вещи. На самом деле, тема bash-программирования огромна. Эта статья является переводом первой части большой серии из 11 материалов. Если вы хотите продолжения прямо сейчас — вот список оригиналов этих материалов. Для удобства сюда включён и тот, перевод которого вы только что прочли.
- Bash Script Step By Step — здесь речь идёт о том, как начать создание bash-скриптов, рассмотрено использование переменных, описаны условные конструкции, вычисления, сравнения чисел, строк, выяснение сведений о файлах.
- Bash Scripting Part 2, Bash the awesome — тут раскрываются особенности работы с циклами for и while.
- Bash Scripting Part 3, Parameters & options — этот материал посвящён параметрам командной строки и ключам, которые можно передавать скриптам, работе с данными, которые вводит пользователь, и которые можно читать из файлов.
- Bash Scripting Part 4, Input & Output — здесь речь идёт о дескрипторах файлов и о работе с ними, о потоках ввода, вывода, ошибок, о перенаправлении вывода.
- Bash Scripting Part 5, Sighals & Jobs — этот материал посвящён сигналам Linux, их обработке в скриптах, запуску сценариев по расписанию.
- Bash Scripting Part 6, Functions — тут можно узнать о создании и использовании функций в скриптах, о разработке библиотек.
- Bash Scripting Part 7, Using sed — эта статья посвящена работе с потоковым текстовым редактором sed.
- Bash Scripting Part 8, Using awk — данный материал посвящён программированию на языке обработки данных awk.
- Bash Scripting Part 9, Regular Expressions — тут можно почитать об использовании регулярных выражений в bash-скриптах.
- Bash Scripting Part 10, Practical Examples — здесь приведены приёмы работы с сообщениями, которые можно отправлять пользователям, а так же методика мониторинга диска.
- Bash Scripting Part 11, Expect Command — этот материал посвящён средству Expect, с помощью которого можно автоматизировать взаимодействие с интерактивными утилитами. В частности, здесь идёт речь об expect-скриптах и об их взаимодействии с bash-скриптами и другими программами.
Полагаем, одно из ценных свойств этой серии статей заключается в том, что она, начинаясь с самого простого, подходящего для пользователей любого уровня, постепенно ведёт к довольно серьёзным темам, давая шанс всем желающим продвинуться в деле создания сценариев командной строки Linux.
Уважаемые читатели! Просим гуру bash-программирования рассказать о том, как они добрались до вершин мастерства, поделиться секретами, а от тех, кто только что написал свой первый скрипт, ждём впечатлений.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Переводить остальные части цикла статей?
Проголосовали 1539 пользователей.
Воздержались 124 пользователя.
Shell scripting is an important part of process automation in Linux. Scripting helps you write a sequence of commands in a file and then execute them.
This saves you time because you don’t have to write certain commands again and again. You can perform daily tasks efficiently and even schedule them for automatic execution.
You can also set certain scripts to execute on startup such as showing a particular message on launching a new session or setting certain environment variables.
The applications and uses of scripting are numerous, so let’s dive in.
In this article, you will learn:
- What is a bash shell?
- What is a bash script and how do you identify it?
- How to create your first bash script and execute it.
- The basic syntax of shell scripting.
- How to see a system’s scheduled scripts.
- How to automate scripts by scheduling via cron jobs.
The best way to learn is by practicing. I highly encourage you to follow along using Replit. You can access a running Linux shell within minutes.
Introduction to the Bash Shell
The Linux command line is provided by a program called the shell. Over the years, the shell program has evolved to cater to various options.
Different users can be configured to use different shells. But most users prefer to stick with the current default shell. The default shell for many Linux distros is the GNU Bourne-Again Shell (bash). Bash is succeeded by Bourne shell (sh).
When you first launch the shell, it uses a startup script located in the .bashrc or .bash_profile file which allows you to customize the behavior of the shell.
When a shell is used interactively, it displays a $ when it is waiting for a command from the user. This is called the shell prompt.
[username@host ~]$
If shell is running as root, the prompt is changed to #. The superuser shell prompt looks like this:
[root@host ~]#
Bash is very powerful as it can simplify certain operations that are hard to accomplish efficiently with a GUI. Remember that most servers do not have a GUI, and it is best to learn to use the powers of a command line interface (CLI).
What is a Bash Script?
A bash script is a series of commands written in a file. These are read and executed by the bash program. The program executes line by line.
For example, you can navigate to a certain path, create a folder and spawn a process inside it using the command line.
You can do the same sequence of steps by saving the commands in a bash script and running it. You can run the script any number of times.
How Do You Identify a Bash Script?
File extension of .sh.
By naming conventions, bash scripts end with a .sh. However, bash scripts can run perfectly fine without the sh extension.
Scripts start with a bash bang.
Scripts are also identified with a shebang. Shebang is a combination of bash # and bang ! followed the the bash shell path. This is the first line of the script. Shebang tells the shell to execute it via bash shell. Shebang is simply an absolute path to the bash interpreter.
Below is an example of the shebang statement.
#! /bin/bashThe path of the bash program can vary. We will see later how to identify it.
Execution rights
Scripts have execution rights for the user executing them.
An execution right is represented by x. In the example below, my user has the rwx (read, write, execute) rights for the file test_script.sh

File colour
Executable scripts appear in a different colour from rest of the files and folders.
In my case, the scripts with execution rights appear as green.
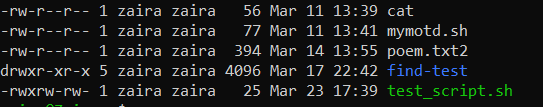
How to Create Your First Bash Script
Let’s create a simple script in bash that outputs Hello World.
Create a file named hello_world.sh
touch hello_world.shFind the path to your bash shell.
which bash
In my case, the path is /usr/bin/bash and I will include this in the shebang.
Write the command.
We will echo «hello world» to the console.
Our script will look something like this:
#! usr/bin/bash
echo "Hello World"Edit the file hello_world.sh using a text editor of your choice and add the above lines in it.
Provide execution rights to your user.
Modify the file permissions and allow execution of the script by using the command below:
chmod u+x hello_world.shchmod modifies the existing rights of a file for a particular user. We are adding +x to user u.
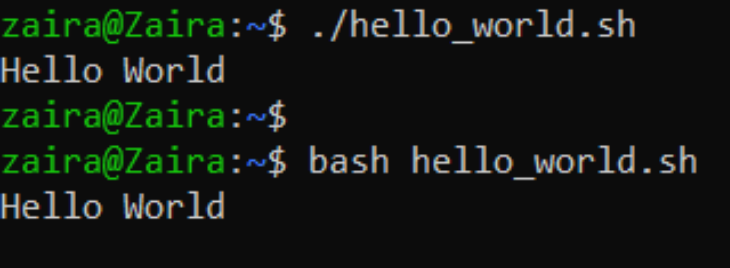
Run the script.
You can run the script in the following ways:
./hello_world.sh
bash hello_world.sh.
Here’s the output:
The Basic Syntax of Bash Scripting
Just like any other programming language, bash scripting follows a set of rules to create programs understandable by the computer. In this section, we will study the syntax of bash scripting.
How to define variables
We can define a variable by using the syntax variable_name=value. To get the value of the variable, add $ before the variable.
#!/bin/bash
# A simple variable example
greeting=Hello
name=Tux
echo $greeting $name
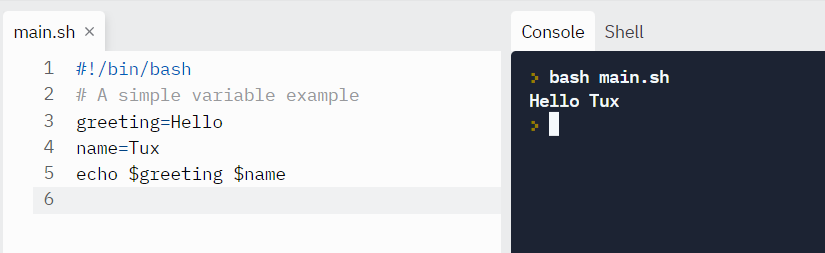
Tux is also the name of the Linux mascot, the penguin.

Arithmetic Expressions
Below are the operators supported by bash for mathematical calculations:
| Operator | Usage |
|---|---|
| + | addition |
| — | subtraction |
| * | multiplication |
| / | division |
| ** | exponentiation |
| % | modulus |
Let’s run a few examples.
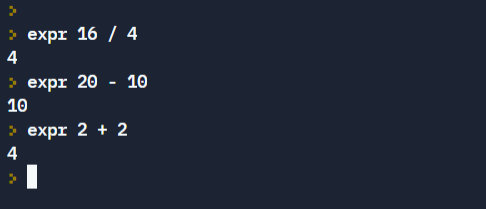
Numerical expressions can also be calculated and stored in a variable using the syntax below:
var=$((expression))
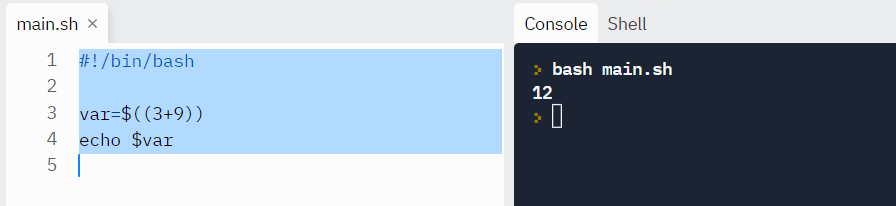
Let’s try an example.
#!/bin/bash
var=$((3+9))
echo $var
Fractions are not correctly calculated using the above methods and truncated.
For decimal calculations, we can use bc command to get the output to a particular number of decimal places. bc (Bash Calculator) is a command line calculator that supports calculation up to a certain number of decimal points.
echo "scale=2;22/7" | bc
Where scale defines the number of decimal places required in the output.

How to read user input
Sometimes you’ll need to gather user input and perform relevant operations.
In bash, we can take user input using the read command.
read variable_nameTo prompt the user with a custom message, use the -p flag.
read -p "Enter your age" variable_name
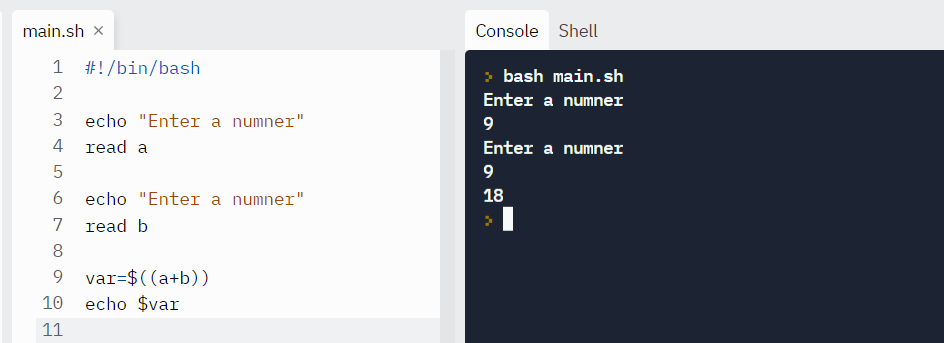
Example:
#!/bin/bash
echo "Enter a numner"
read a
echo "Enter a numner"
read b
var=$((a+b))
echo $var
Numeric Comparison logical operators
Comparison is used to check if statements evaluate to true or false. We can use the below shown operators to compare two statements:
| Operation | Syntax | Explanation |
|---|---|---|
| Equality | num1 -eq num2 | is num1 equal to num2 |
| Greater than equal to | num1 -ge num2 | is num1 greater than equal to num2 |
| Greater than | num1 -gt num2 | is num1 greater than num2 |
| Less than equal to | num1 -le num2 | is num1 less than equal to num2 |
| Less than | num1 -lt num2 | is num1 less than num2 |
| Not Equal to | num1 -ne num2 | is num1 not equal to num2 |
Syntax:
if [ conditions ]
then
commands
fiExample:
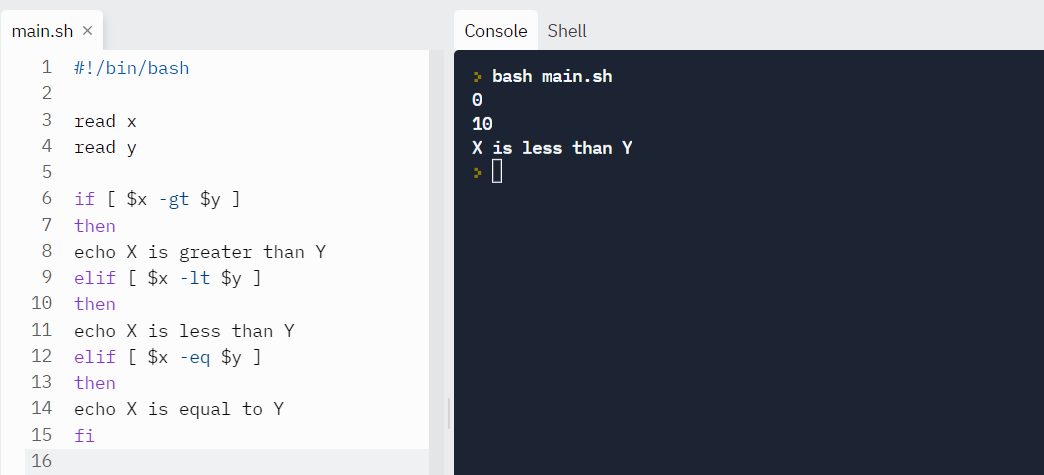
Let’s compare two numbers and find their relationship:
read x
read y
if [ $x -gt $y ]
then
echo X is greater than Y
elif [ $x -lt $y ]
then
echo X is less than Y
elif [ $x -eq $y ]
then
echo X is equal to Y
fi
Output:
Conditional Statements (Decision Making)
Conditions are expressions that evaluate to a boolean expression (true or false). To check conditions, we can use if, if-else, if-elif-else and nested conditionals.
The structure of conditional statements is as follows:
if...then...fistatementsif...then...else...fistatementsif..elif..else..fiif..then..else..if..then..fi..fi..(Nested Conditionals)
Syntax:
if [[ condition ]]
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fiTo create meaningful comparisons, we can use AND -a and OR -o as well.
The below statement translates to: If a is greater than 40 and b is less than 6.
if [ $a -gt 40 -a $b -lt 6 ]
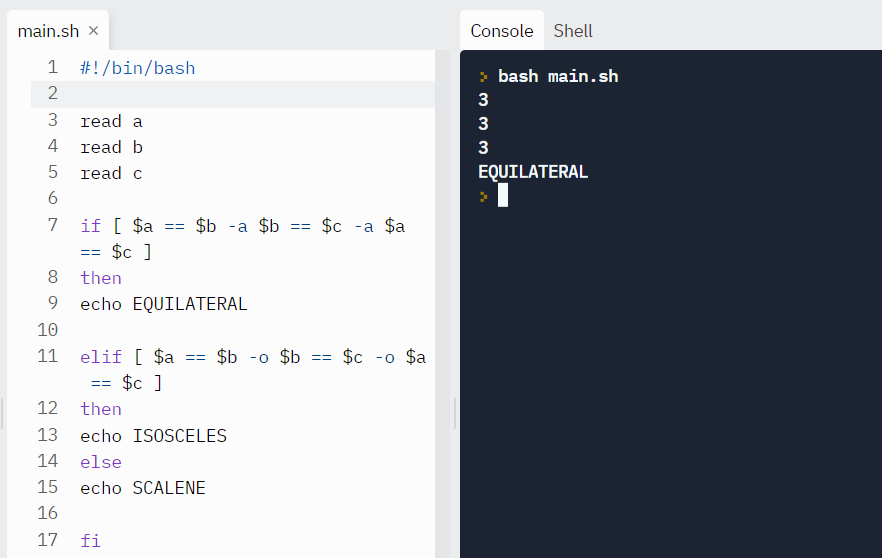
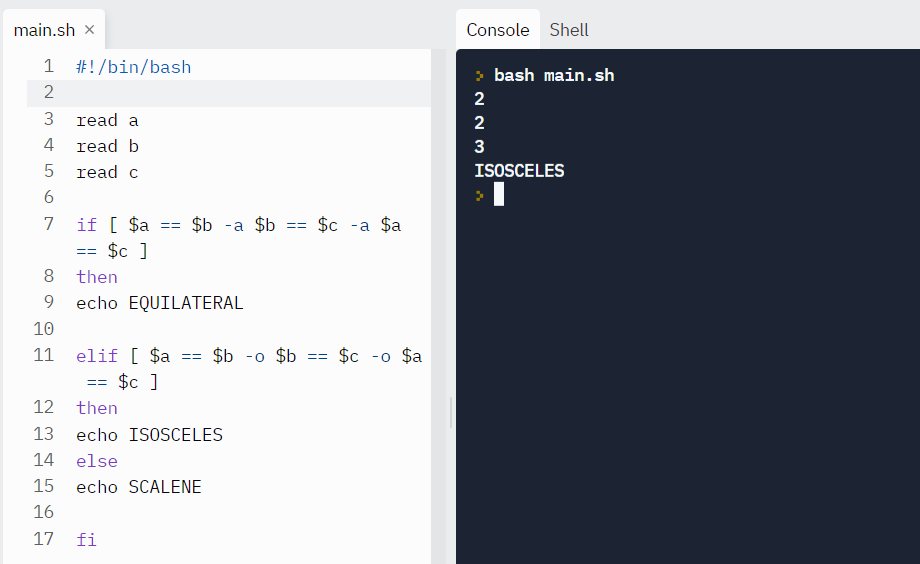
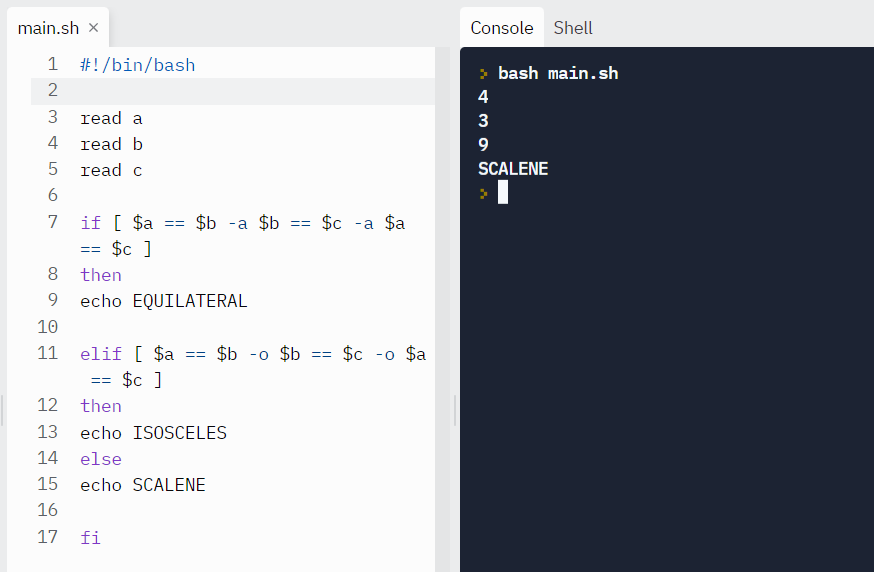
Example: Let’s find the triangle type by reading the lengths of its sides.
read a
read b
read c
if [ $a == $b -a $b == $c -a $a == $c ]
then
echo EQUILATERAL
elif [ $a == $b -o $b == $c -o $a == $c ]
then
echo ISOSCELES
else
echo SCALENE
fiOutput:
Test case #1
Test case #2
Test case #3
Looping and skipping
For loops allow you to execute statements a specific number of times.
Looping with numbers:
In the example below, the loop will iterate 5 times.
#!/bin/bash
for i in {1..5}
do
echo $i
done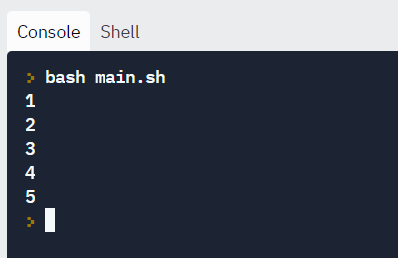
Looping with strings:
We can loop through strings as well.
#!/bin/bash
for X in cyan magenta yellow
do
echo $X
done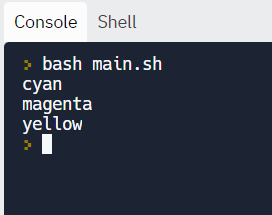
While loop
While loops check for a condition and loop until the condition remains true. We need to provide a counter statement that increments the counter to control loop execution.
In the example below, (( i += 1 )) is the counter statement that increments the value of i.
Example:
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
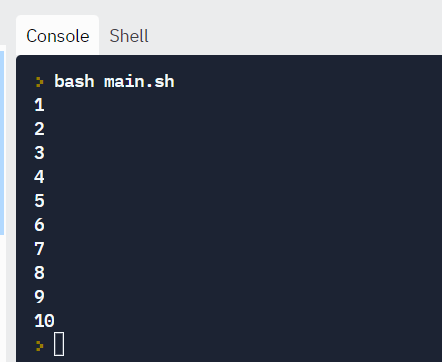
Reading files
Suppose we have a file sample_file.txt as shown below:

We can read the file line by line and print the output on the screen.
#!/bin/bash
LINE=1
while read -r CURRENT_LINE
do
echo "$LINE: $CURRENT_LINE"
((LINE++))
done < "sample_file.txt"Output:
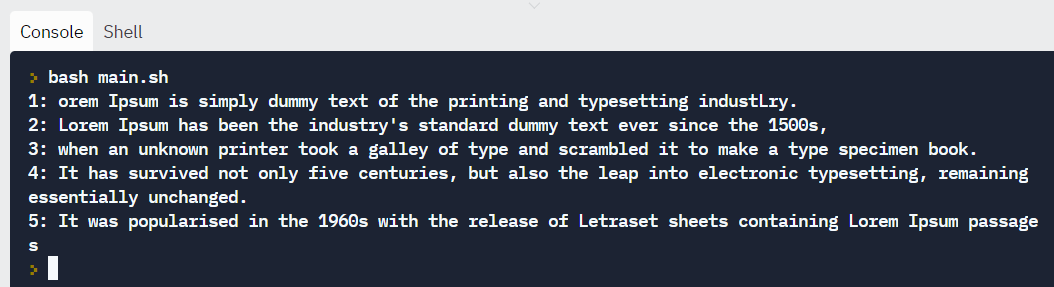
How to execute commands with back ticks
If you need to include the output of a complex command in your script, you can write the statement inside back ticks.
Syntax:
var= ` commands `
Example: Suppose we want to get the output of a list of mountpoints with tmpfs in their name. We can craft a statement like this: df -h | grep tmpfs.
To include it in the bash script, we can enclose it in back ticks.
#!/bin/bash
var=`df -h | grep tmpfs`
echo $varOutput:

How to get arguments for scripts from the command line
It is possible to give arguments to the script on execution.
$@ represents the position of the parameters, starting from one.
#!/bin/bash
for x in $@
do
echo "Entered arg is $x"
doneRun it like this:
./script arg1 arg2
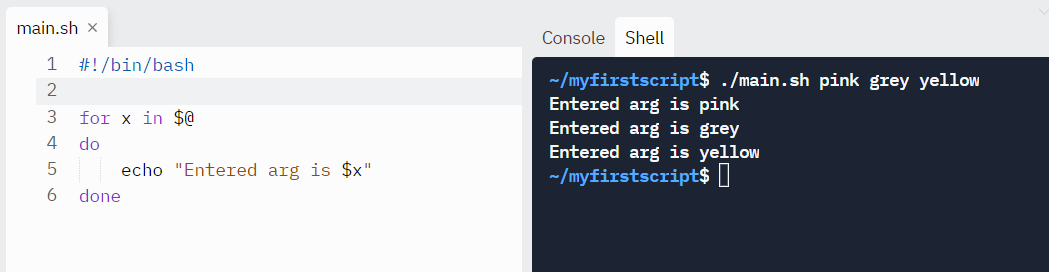
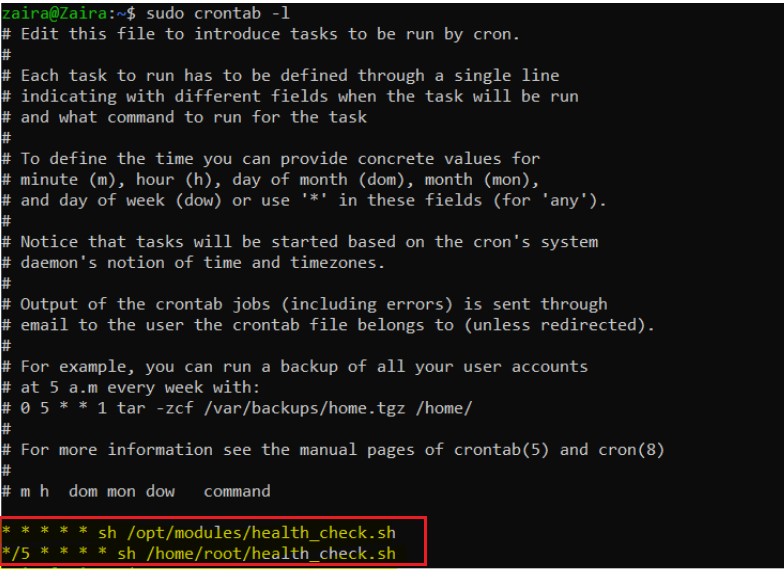
How to Automate Scripts by Scheduling via cron Jobs
Cron is a job scheduling utility present in Unix like systems. You can schedule jobs to execute daily, weekly, monthly or in a specific time of the day. Automation in Linux heavily relies on cron jobs.
Below is the syntax to schedule crons:
# Cron job example
* * * * * sh /path/to/script.shHere, * represent represents minute(s) hour(s) day(s) month(s) weekday(s), respectively.
Below are some examples of scheduling cron jobs.
| SCHEDULE | SCHEDULED VALUE |
|---|---|
| 5 0 * 8 * | At 00:05 in August. |
| 5 4 * * 6 | At 04:05 on Sunday. |
| 0 22 * * 1-5 | At 22:00 on every day-of-week from Monday through Friday. |
You can learn about cron in detail in this blog post.
How to Check Existing Scripts in a System
Using crontab
crontab -l lists the already scheduled scripts for a particular user.
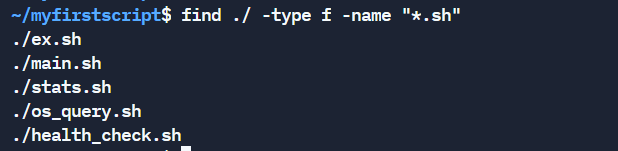
Using the find command
The find command helps to locate files based on certain patterns. As most of the scripts end with .sh, we can use the find script like this:
find . -type f -name "*.sh"Where,
.represents the current directory. You can change the path accordingly.-type findicates that the file type we are looking for is a text based file.*.shtells to match all files ending with.sh.
If you are interested to read about the find command in detail, check my other post.
Wrapping up
In this tutorial we learned the basics of shell scripting. We looked into examples and syntax which can help us write meaningful programs.
What’s your favorite thing you learned from this tutorial? Let me know on Twitter!
You can read my other posts here.
Work vector created by macrovector — www.freepik.com
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Shell scripting is an important part of process automation in Linux. Scripting helps you write a sequence of commands in a file and then execute them.
This saves you time because you don’t have to write certain commands again and again. You can perform daily tasks efficiently and even schedule them for automatic execution.
You can also set certain scripts to execute on startup such as showing a particular message on launching a new session or setting certain environment variables.
The applications and uses of scripting are numerous, so let’s dive in.
In this article, you will learn:
- What is a bash shell?
- What is a bash script and how do you identify it?
- How to create your first bash script and execute it.
- The basic syntax of shell scripting.
- How to see a system’s scheduled scripts.
- How to automate scripts by scheduling via cron jobs.
The best way to learn is by practicing. I highly encourage you to follow along using Replit. You can access a running Linux shell within minutes.
Introduction to the Bash Shell
The Linux command line is provided by a program called the shell. Over the years, the shell program has evolved to cater to various options.
Different users can be configured to use different shells. But most users prefer to stick with the current default shell. The default shell for many Linux distros is the GNU Bourne-Again Shell (bash). Bash is succeeded by Bourne shell (sh).
When you first launch the shell, it uses a startup script located in the .bashrc or .bash_profile file which allows you to customize the behavior of the shell.
When a shell is used interactively, it displays a $ when it is waiting for a command from the user. This is called the shell prompt.
[username@host ~]$
If shell is running as root, the prompt is changed to #. The superuser shell prompt looks like this:
[root@host ~]#
Bash is very powerful as it can simplify certain operations that are hard to accomplish efficiently with a GUI. Remember that most servers do not have a GUI, and it is best to learn to use the powers of a command line interface (CLI).
What is a Bash Script?
A bash script is a series of commands written in a file. These are read and executed by the bash program. The program executes line by line.
For example, you can navigate to a certain path, create a folder and spawn a process inside it using the command line.
You can do the same sequence of steps by saving the commands in a bash script and running it. You can run the script any number of times.
How Do You Identify a Bash Script?
File extension of .sh.
By naming conventions, bash scripts end with a .sh. However, bash scripts can run perfectly fine without the sh extension.
Scripts start with a bash bang.
Scripts are also identified with a shebang. Shebang is a combination of bash # and bang ! followed the the bash shell path. This is the first line of the script. Shebang tells the shell to execute it via bash shell. Shebang is simply an absolute path to the bash interpreter.
Below is an example of the shebang statement.
#! /bin/bashThe path of the bash program can vary. We will see later how to identify it.
Execution rights
Scripts have execution rights for the user executing them.
An execution right is represented by x. In the example below, my user has the rwx (read, write, execute) rights for the file test_script.sh
![]()
File colour
Executable scripts appear in a different colour from rest of the files and folders.
In my case, the scripts with execution rights appear as green.
How to Create Your First Bash Script
Let’s create a simple script in bash that outputs Hello World.
Create a file named hello_world.sh
touch hello_world.shFind the path to your bash shell.
which bash
In my case, the path is /usr/bin/bash and I will include this in the shebang.
Write the command.
We will echo «hello world» to the console.
Our script will look something like this:
#! usr/bin/bash
echo "Hello World"Edit the file hello_world.sh using a text editor of your choice and add the above lines in it.
Provide execution rights to your user.
Modify the file permissions and allow execution of the script by using the command below:
chmod u+x hello_world.shchmod modifies the existing rights of a file for a particular user. We are adding +x to user u.
Run the script.
You can run the script in the following ways:
./hello_world.sh
bash hello_world.sh.
Here’s the output:
The Basic Syntax of Bash Scripting
Just like any other programming language, bash scripting follows a set of rules to create programs understandable by the computer. In this section, we will study the syntax of bash scripting.
How to define variables
We can define a variable by using the syntax variable_name=value. To get the value of the variable, add $ before the variable.
#!/bin/bash
# A simple variable example
greeting=Hello
name=Tux
echo $greeting $name
Tux is also the name of the Linux mascot, the penguin.
Arithmetic Expressions
Below are the operators supported by bash for mathematical calculations:
| Operator | Usage |
|---|---|
| + | addition |
| — | subtraction |
| * | multiplication |
| / | division |
| ** | exponentiation |
| % | modulus |
Let’s run a few examples.
Numerical expressions can also be calculated and stored in a variable using the syntax below:
var=$((expression))
Let’s try an example.
#!/bin/bash
var=$((3+9))
echo $var
Fractions are not correctly calculated using the above methods and truncated.
For decimal calculations, we can use bc command to get the output to a particular number of decimal places. bc (Bash Calculator) is a command line calculator that supports calculation up to a certain number of decimal points.
echo "scale=2;22/7" | bc
Where scale defines the number of decimal places required in the output.
How to read user input
Sometimes you’ll need to gather user input and perform relevant operations.
In bash, we can take user input using the read command.
read variable_nameTo prompt the user with a custom message, use the -p flag.
read -p "Enter your age" variable_name
Example:
#!/bin/bash
echo "Enter a numner"
read a
echo "Enter a numner"
read b
var=$((a+b))
echo $var
Numeric Comparison logical operators
Comparison is used to check if statements evaluate to true or false. We can use the below shown operators to compare two statements:
| Operation | Syntax | Explanation |
|---|---|---|
| Equality | num1 -eq num2 | is num1 equal to num2 |
| Greater than equal to | num1 -ge num2 | is num1 greater than equal to num2 |
| Greater than | num1 -gt num2 | is num1 greater than num2 |
| Less than equal to | num1 -le num2 | is num1 less than equal to num2 |
| Less than | num1 -lt num2 | is num1 less than num2 |
| Not Equal to | num1 -ne num2 | is num1 not equal to num2 |
Syntax:
if [ conditions ]
then
commands
fiExample:
Let’s compare two numbers and find their relationship:
read x
read y
if [ $x -gt $y ]
then
echo X is greater than Y
elif [ $x -lt $y ]
then
echo X is less than Y
elif [ $x -eq $y ]
then
echo X is equal to Y
fi
Output:
Conditional Statements (Decision Making)
Conditions are expressions that evaluate to a boolean expression (true or false). To check conditions, we can use if, if-else, if-elif-else and nested conditionals.
The structure of conditional statements is as follows:
if...then...fistatementsif...then...else...fistatementsif..elif..else..fiif..then..else..if..then..fi..fi..(Nested Conditionals)
Syntax:
if [[ condition ]]
then
statement
elif [[ condition ]]; then
statement
else
do this by default
fiTo create meaningful comparisons, we can use AND -a and OR -o as well.
The below statement translates to: If a is greater than 40 and b is less than 6.
if [ $a -gt 40 -a $b -lt 6 ]
Example: Let’s find the triangle type by reading the lengths of its sides.
read a
read b
read c
if [ $a == $b -a $b == $c -a $a == $c ]
then
echo EQUILATERAL
elif [ $a == $b -o $b == $c -o $a == $c ]
then
echo ISOSCELES
else
echo SCALENE
fiOutput:
Test case #1
Test case #2
Test case #3
Looping and skipping
For loops allow you to execute statements a specific number of times.
Looping with numbers:
In the example below, the loop will iterate 5 times.
#!/bin/bash
for i in {1..5}
do
echo $i
done
Looping with strings:
We can loop through strings as well.
#!/bin/bash
for X in cyan magenta yellow
do
echo $X
done
While loop
While loops check for a condition and loop until the condition remains true. We need to provide a counter statement that increments the counter to control loop execution.
In the example below, (( i += 1 )) is the counter statement that increments the value of i.
Example:
#!/bin/bash
i=1
while [[ $i -le 10 ]] ; do
echo "$i"
(( i += 1 ))
done
Reading files
Suppose we have a file sample_file.txt as shown below:
We can read the file line by line and print the output on the screen.
#!/bin/bash
LINE=1
while read -r CURRENT_LINE
do
echo "$LINE: $CURRENT_LINE"
((LINE++))
done < "sample_file.txt"Output:
How to execute commands with back ticks
If you need to include the output of a complex command in your script, you can write the statement inside back ticks.
Syntax:
var= ` commands `
Example: Suppose we want to get the output of a list of mountpoints with tmpfs in their name. We can craft a statement like this: df -h | grep tmpfs.
To include it in the bash script, we can enclose it in back ticks.
#!/bin/bash
var=`df -h | grep tmpfs`
echo $varOutput:
How to get arguments for scripts from the command line
It is possible to give arguments to the script on execution.
$@ represents the position of the parameters, starting from one.
#!/bin/bash
for x in $@
do
echo "Entered arg is $x"
doneRun it like this:
./script arg1 arg2
How to Automate Scripts by Scheduling via cron Jobs
Cron is a job scheduling utility present in Unix like systems. You can schedule jobs to execute daily, weekly, monthly or in a specific time of the day. Automation in Linux heavily relies on cron jobs.
Below is the syntax to schedule crons:
# Cron job example
* * * * * sh /path/to/script.shHere, * represent represents minute(s) hour(s) day(s) month(s) weekday(s), respectively.
Below are some examples of scheduling cron jobs.
| SCHEDULE | SCHEDULED VALUE |
|---|---|
| 5 0 * 8 * | At 00:05 in August. |
| 5 4 * * 6 | At 04:05 on Sunday. |
| 0 22 * * 1-5 | At 22:00 on every day-of-week from Monday through Friday. |
You can learn about cron in detail in this blog post.
How to Check Existing Scripts in a System
Using crontab
crontab -l lists the already scheduled scripts for a particular user.
Using the find command
The find command helps to locate files based on certain patterns. As most of the scripts end with .sh, we can use the find script like this:
find . -type f -name "*.sh"Where,
.represents the current directory. You can change the path accordingly.-type findicates that the file type we are looking for is a text based file.*.shtells to match all files ending with.sh.
If you are interested to read about the find command in detail, check my other post.
Wrapping up
In this tutorial we learned the basics of shell scripting. We looked into examples and syntax which can help us write meaningful programs.
What’s your favorite thing you learned from this tutorial? Let me know on Twitter!
You can read my other posts here.
Work vector created by macrovector — www.freepik.com
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Бесплатная книга-сайт на русском, полный гайд
Advanced Bash-Scripting Guide
Введение
BASH — Bourne-Again SHell (что может переводится как «перерожденный шел», или «Снова шел Борна(создатель sh)»), самый популярный командный интерпретатор в юниксоподобных системах, в особенности в GNU/Linux. Ниже приведу ряд встроенных команд, которые мы будем использовать для создания своих скриптов.
breakвыход из цикла for, while или until
continueвыполнение следующей итерации цикла for, while или until
echoвывод аргументов, разделенных пробелами, на стандартное устройство вывода
exitвыход из оболочки
exportотмечает аргументы как переменные для передачи в дочерние процессы в среде
hashзапоминает полные имена путей команд, указанных в качестве аргументов, чтобы не искать их при следующем обращении
killпосылает сигнал завершения процессу
pwdвыводит текущий рабочий каталог
readчитает строку из ввода оболочки и использует ее для присвоения значений указанным переменным.
returnзаставляет функцию оболочки выйти с указанным значением
shiftперемещает позиционные параметры налево
testвычисляет условное выражение
timesвыводит имя пользователя и системное время, использованное оболочкой и ее потомками
trapуказывает команды, которые должны выполняться при получении оболочкой сигнала
unsetвызывает уничтожение переменных оболочки
waitждет выхода из дочернего процесса и сообщает выходное состояние.
И конечно же кроме встроенных команд мы будем использовать целую кучу внешних, отдельных команд-программ, с которыми мы познакомимся уже в процессе
Что необходимо знать с самого начала
- Любой bash-скрипт должен начинаться со строки:
#!/bin/bash
в этой строке после #! указывается путь к bash-интерпретатору, поэтому если он у вас установлен в другом месте(где, вы можете узнать набрав whereis bash) поменяйте её на ваш путь.
- Коментарии начинаются с символа # (кроме первой строки).
- В bash переменные не имеют типа(о них речь пойдет ниже)
Переменные и параметры скрипта
Приведу как пример небольшой пример, который мы разберем:
#!/bin/bash#указываем где у нас хранится bash-интерпретатор
#присваиваем переменной parametr1 значение первого параметра скрипта
parametr1=$1
#присваиваем переменной script_name значение имени скрипта
script_name=$0
# команда echo выводит определенную строку, обращение к переменным осуществляется через $имя_переменной.
echo "Вы запустили скрипт с именем $script_name и параметром $parametr1"
# здесь мы видим другие кавычки, разница в том, что в одинарных кавычках не происходит подстановки переменных.
echo 'Вы запустили скрипт с именем $script_name и параметром $parametr1'
#Выход с кодом 0 (удачное завершение работы скрипта)
exit 0
Результат выполнения скрипта:
ite@ite-desktop:~$ ./test.sh qwerty
Вы запустили скрипт с именем ./test.sh и параметром qwerty
Вы запустили скрипт с именем $script_name и параметром $parametr1
После того как мы познакомились как использовать переменные и передавать скрипту параметры, время познакомиться с зарезервированными переменными:
$DIRSTACK— содержимое вершины стека каталогов
$EDITOR— текстовый редактор по умолчанию
$EUID— Эффективный UID. Если вы использовали программу su для выполнения команд от другого пользователя, то эта переменная содержит UID этого пользователя, в то время как…
$UID— …содержит реальный идентификатор, который устанавливается только при логине.
$FUNCNAME— имя текущей функции в скрипте.
$GROUPS— массив групп к которым принадлежит текущий пользователь
$HOME— домашний каталог пользователя
$HOSTNAME— ваш hostname
$HOSTTYPE— архитектура машины.
$LC_CTYPE— внутренняя переменная, котороя определяет кодировку символов
$OLDPWD— прежний рабочий каталог
$OSTYPE— тип ОС
$PATH— путь поиска программ
$PPID— идентификатор родительского процесса
$SECONDS— время работы скрипта(в сек.)
$#— общее количество параметров переданных скрипту
$*— все аргументы переданыне скрипту(выводятся в строку)
$@— тоже самое, что и предыдущий, но параметры выводятся в столбик
$!— PID последнего запущенного в фоне процесса
$$— PID самого скрипта
Условия
Условные операторы, думаю, знакомы практически каждому, кто хоть раз пытался на чем-то писать программы. В bash условия пишутся след. образом (как обычно на примере):
#!/bin/bash
#в переменную source засовываем первый параметр скрипта
source=$1
#в переменную dest засовываем второй параметр скрипта
dest=$2# в ковычках указываем имена переменных для сравнения. -eq — логическое сравнение обозначающие «равны»
if [[ "$source" -eq "$dest" ]]
# если они действительно равны, то
then
#выводим сообщение об ошибке, т.к. $source и $dest у нас равны
echo "Применик $dest и источник $source один и тот же файл!"
# выходим с ошибкой (1 — код ошибки)
exit 1
# если же они не равны
else
# то выполняем команду cp: копируем источник в приемник
cp $source $dest
echo "Удачное копирование!"
fi#обозначаем окончание условия.
Результат выполнения скрипта:
ite@ite-desktop:~$ ./primer2.sh 1 1
Применик 1 и источник 1 один и тот же файл!
ite@ite-desktop:~$ ./primer2.sh 1 2
Удачное копирование!
Структура if-then-else используется следующим образом:
if<команда или набор команд возвращающих код возврата(0 или 1)>
then
<если выражение после if истино, то выполняется этот блок>
else
<если выражение после if ложно, тот этот>
В качестве команд возвращающих код возврата могут выступать структуры [[ , [ , test, (( )) или любая другая(или несколько) linux-команда.
test— используется для логического сравнения. после выражения, неоьбходима закрывающая скобка «]»
[— синоним команды test
[[— расширенная версия «[» (начиная с версии 2.02)(как в примере), внутри которой могут быть использованы || (или), & (и). Долна иметь закрывающуб скобку «]]»
(( ))— математическое сравнение.
для построения многоярусных условий вида:
if ...
then ....
else
if ....
then....
else ....
для краткости и читаемости кода, можно использовать структуру:
if ..
then ...
elif ...
then ...
elif ...
Условия. Множественный выбор
Если необходимо сравнивать какоую-то одну переменную с большим количеством параметров, то целесообразней использовать оператор case.
#!/bin/bash
echo "Выберите редатор для запуска:"
echo "1 Запуск программы nano"
echo "2 Запуск программы vi"
echo "3 Запуск программы emacs"
echo "4 Выход"
#здесь мы читаем в переменную $doing со стандартного ввода
read doing
case $doing in
1)
/usr/bin/nano# если $doing содержит 1, то запустить nano
;;
2)
/usr/bin/vi# если $doing содержит 2, то запустить vi
;;
3)
/usr/bin/emacs# если $doing содержит 3, то запустить emacs
;;
4)
exit 0
;;
*)#если введено с клавиатуры то, что в case не описывается, выполнять следующее:
echo "Введено неправильное действие"
esac#окончание оператора case.
Результат работы:
ite@ite-desktop:~$ ./menu2.sh
Выберите редатор для запуска:
1 Запуск программы nano
2 Запуск программы vi
3 Запуск программы emacs
4 Выход
После выбор цифры и нажатия Enter запуститься тот редактор, который вы выбрали(если конечно все пути указаны правильно, и у вас установлены эти редакторы )
Прведу список логических операторв, которые используются для конструкции if-then-else-fi:
-z# строка пуста
-n# строка не пуста
=, (==)# строки равны
!=# строки неравны
-eq# равно
-ne# неравно
-lt,(< )# меньше
-le,(<=)# меньше или равно
-gt,(>)#больше
-ge,(>=)#больше или равно
!#отрицание логического выражения
-a,(&&)#логическое «И»
-o,(||)# логическое «ИЛИ»
С основами языка и условиями мы разобрались, чтобы не перегружать статью, разобью её на несколько частей(допустим на 3). Во второй части разберем операторы цикла и выполнение математических операций.
Основы BASH. Часть 2
Циклы. Цикл for-in.
Оператор for-in предназначен для поочередного обращения к значениям перечисленным в списке. Каждое значение поочередно в списке присваивается переменной.
Синтаксис следующий:
for переменная in список_значений
do
команды
done
Рассмотрим небольшой пример:
#!/bin/bash
for i in 0 1 2 3 4 #переменной $i будем поочередно присваивать значения от 0 до 4 включительно
do
echo "Console number is $i" >> /dev/pts/$i #Пишем в файл /dev/pts/$i(файл виртуального терминала) строку "Console number is $i"
done #цикл окончен
exit 0
После выполнения примера в первых 5 виртуальных консолях(терминалах) появится строка с её номером. В переменную $i поочередно подставляются значения из списка и в цикле идет работа со значением этой переменной
Циклы. Цикл while.
Цикл while сложнее цикла for-in и используется для повторения команд, пока какое-то выражение истинно( код возврата = 0).
Синтаксис оператора следующий:
while выражение или команда возвращающая код возврата
do
команды
done
Пример работы цикла рассмотрим на следующем примере:
#!/bin/bash
again=yes #присваиваем значение "yes" переменной again
while [ "$again" = "yes" ] #Будем выполнять цикл, пока $again будет равно "yes"
do
echo "Please enter a name:"
read name
echo "The name you entered is $name"
echo "Do you wish to continue?"
read again
done
echo "Bye-Bye"
А теперь результат работы скрипта:
ite@ite-desktop:~$ ./bash2_primer1.sh
Please enter a name:
ite
The name you entered is ite
Do you wish to continue?
yes
Please enter a name:
mihail
The name you entered is mihail
Do you wish to continue?
no
Bye-Bye
Как видим цикл выполняется до тех пор, пока мы не введем что-то отличное от «yes». Между do и done можно описывать любые структуры, операторы и т.п., все они будут выполнятся в цикле.Но следует быть осторожным с этим циклом, если вы запустите на выполнение в нём какую-либо команду, без изменения переменной выражения, вы можете попасть в бесконечный цикл.
Теперь об условии истинности. После while, как и в условном операторе if-then-else можно вставлять любое выражение или команду, которая возвращает код возврата, и цикл будет исполнятся до тех пор, пока код возврата = 0! Оператор [ аналог команды test, которая проверяет истинность условия, которое ей передали.
Рассмотрим еще один пример, я взял его из книги Advanced Bash Scripting. Уж очень он мне понравился :), но я его немного упростил. В этом примере мы познакомимся с еще одним типом циклов UNTIL-DO. Эта практически полный аналог цикла WHILE-DO, только выполняется пока какое-то выражение ложно.
Вот пример:
#!/bin/bash
echo "Введите числитель: "
read dividend
echo "Введите знаменатель: "
read divisor
dnd=$dividend #мы будем изменять переменные dividend и divisor,
#сохраним их знания в других переменных, т.к. они нам
#понадобятся
dvs=$divisor
remainder=1
until [ "$remainder" -eq 0 ]
do
let "remainder = dividend % divisor"
dividend=$divisor
divisor=$remainder
done
echo "НОД чисел $dnd и $dvs = $dividend"
Результат выполнения скрипта:
ite@ite-desktop:~$ ./bash2_primer3.sh
Введите числитель:
100
Введите знаменатель:
90
НОД чисел 100 и 90 = 10
Математические операции
Команда let.
Команда let производит арифметические операции над числами и переменными.
Рассмотрим небольшой пример, в котором мы производим некоторые вычисления над введенными числами:
#!/bin/bash
echo "Введите a: "
read a
echo "Введите b: "
read b
let "c = a + b" #сложение
echo "a+b= $c"
let "c = a / b" #деление
echo "a/b= $c"
let "c <<= 2" #сдвигает c на 2 разряда влево
echo "c после сдвига на 2 разряда: $c"
let "c = a % b" # находит остаток от деления a на b
echo "$a / $b. остаток: $c "
Результат выполнения:
ite@ite-desktop:~$ ./bash2_primer2.sh
Введите a:
123
Введите b:
12
a+b= 135
a/b= 10
c после сдвига на 2 разряда: 40
123 / 12. остаток: 3
Ну вот, как видите ничего сложного, список математических операций стандартный:
+— сложение
—— вычитание
*— умножение
/— деление
**— возведение в степень
%— модуль(деление по модулю), остаток от деления
letпозволяет использовать сокращения арифметических команд, тем самым сокращая кол-во используемых переменных. Например:a = a+bэквивалентноa +=bи т.д
Для начала немного полезной теории.
Перенаправление потоков.
В bash (как и многих других оболочках) есть встроенные файловые дескрипторы: 0 (stdin), 1 (stdout), 2 (stderr).
stdout — Стандартный вывод. Сюда попадает все что выводят программы
stdin — Стандартный ввод. Это все что набирает юзер в консоли
stderr — Стандартный вывод ошибок.
Для операций с этими дескрипторами, существуют специальные символы: > (перенаправление вывода), < (перенаправление ввода). Оперировать ими не сложно. Например:
cat /dev/random > /dev/null #перенаправить вывод команды cat /dev/random в /dev/null (абсолютно бесполезная операция :)) )
или
ls -la > listing #записать в файл listing содержание текущего каталога (уже полезней)
Если есть необходимость дописывать в файл(при использовании «>» он заменятеся), необходимо вместо «>» использовать «>>«
sudo < my_password
после просьбы sudo ввести пароль, он возьмется из файла my_password, как будто вы его ввели с клавиатуры.
Если необходимо записать в файл только ошибки, которые могли возникнуть при работе программы, то можно использовать:
./program_with_error 2> error_file
цифра 2 перед «>» означает что нужно перенаправлять все что попадет в дескриптор 2(stderr).
Если необходимо заставить stderr писать в stdout, то это можно след. образом:
./program_with_error 2>&1
символ «&» означает указатель на дескриптор 1(stdout)
(Поумолчанию stderr пишет на ту консоль, в котрой работает пользователь(вренее пишет на дисплей)).
2. Конвееры.
Конвеер — очень мощный инструмент для работы с консолью Bash. Синтаксис простой:
команда1 | команда 2 — означает, что вывод команды 1 передастся на ввод команде 2
Конвееры можно группировать в цепочки и выводить с помощью перенаправления в файл, например:
ls -la | grep «hash» |sort > sortilg_list
вывод команды ls -la передается команде grep, которая отбирает все строки, в которых встретится слово hash, и передает команде сортировке sort, которая пишет результат в файл sorting_list. Все довольно понятно и просто.
Чаще всего скрипты на Bash используются в качестве автоматизации каких-то рутинных операций в консоли, отсюда иногда возникает необходимость в обработке stdout одной команды и передача на stdin другой команде, при этом результат выполнения одной команды должен быть неким образом обработан. В этом разделе я постораюсь объяснить основные принципы работы с внешними командами внутри скрипта. Думаю что примеров я привел достаточно и можно теперь писать только основные моменты.
1. Передача вывода в переменную.
Для того чтобы записать в переменную вывод какой-либо команды, достаточно заключить команду в `` ковычки, например
a = ` echo «qwerty» `
echo $a
Результат работы: qwerty
Однако если вы захотите записать в переменную список директорий, то необходимо, должным образом обработать результат для помещения данных в переменную. Рассмотрим небольшой, пример:
LIST=`find /svn/ -type d 2>/dev/null| awk '{FS="/"} {print $4}'| sort|uniq | tr 'n' ' '`
for ONE_OF_LIST in $LIST
do
svnadmin hotcopy /svn/$ONE_OF_LIST /svn/temp4backup/$ONE_OF_LIST
done
Здесь мы используем цикл for-do-done для архивирование всех директорий в папке /svn/ с помощью команды svnadmin hotcopy(что в нашем случае не имеет никого значения, просто как пример). Наибольшй интерес вызывает строка: LIST=find /svn/ -type d 2>/dev/null| awk '{FS="/"} {print $4}'| sort|uniq | tr 'n' ' ' В ней переменной LIST присваивается выполнение команды find, обработанной командами awk, sort, uniq,tr(все эти команды мы рассматривать не будем, ибо это отдельная статья). В переменной LIST будут имена всех каталогов в папке /svn/ пгомещенных в одну строку(для того чтобы её стравить циклу.
Написание сценариев оболочки может быть довольно сложной задачей, прежде всего потому, что оболочка не является самым дружественным для использования языком. Тем не менее, я надеюсь показать вам в этом уроке, что сценарий оболочки на самом деле не такой жесткий или страшный, как вы могли ожидать.
В этом уроке мы напишем скрипт, который упростит процесс использования тестовой среды Jasmine. На самом деле, я бы не использовал этот скрипт сегодня; Я бы использовал Grunt.js или что-то подобное. Тем не менее, я написал этот скрипт до того, как появился Grunt, и я обнаружил, что это оказалось отличным способом получить более удобный интерфейс с помощью сценариев оболочки, поэтому мы его используем.
Одно замечание: этот учебник немного связан с моим предстоящим курсом Tuts + Premium «Advanced Command Line Techniques». Чтобы узнать больше о чем-либо в этом уроке, следите за обновлениями этого курса. В дальнейшем в этом уроке он будет называться «курс».
Итак, наш сценарий, который я называю jazz, будет иметь четыре основные функции:
- Он загрузит Jasmine из Интернета, распакует его и удалит код примера.
- Он создаст файлы JavaScript и связанные с ними файлы спецификаций и предварительно заполнит их небольшим количеством кода шаблона.
- Он откроет тесты в браузере.
- Он отобразит текст справки, которая описана выше.
Начнем с файла сценария.
Шаг 1 — Создание файла
Написание сценария оболочки полезно, только если вы можете использовать его с терминала; Чтобы иметь возможность использовать свои собственные сценарии на терминале, вам нужно поместить их в папку, находящуюся в переменной PATH вашего терминала (вы можете увидеть свою переменную PATH, выполнив echo $ PATH). Я создал папку ~/bin (где ~ — домашний каталог) на моем компьютере, и именно там мне нравится сохранять собственные скрипты (если вы сделаете то же самое, вам придется добавить их в свой path). Итак, просто создайте файл с названием jazz, и поместите его в свою папку.
Конечно, мы также должны сделать этот файл исполняемым; В противном случае мы не сможем его запустить. Мы можем сделать это, выполнив следующую команду:
chmod +x jazz
Теперь, когда мы можем фактически выполнить скрипт, добавим очень важную часть. Все сценарии оболочки должны начинаться с shebang). Как говорит Википедия, это должна быть первая строка сценария; Он указывает, какой интерпретатор или оболочка должен запускать этот сценарий. Мы просто собираемся использовать базовую стандартную оболочку:
#!/bin/sh
Хорошо, теперь когда у нас все настроено, мы готовы начать писать фактический код.
Шаг 2 — Обозначение потока скрипта
Раньше я указывал, какими должны быть разные функции нашего сценария оболочки. Но как скрипт узнает, какую функцию запустить? Мы будем использовать комбинацию параметра оболочки и оператора case. При запуске скрипта из командной строки мы будем использовать подкоманду, например:
jazz init
jazz create SomeFile
jazz run
jazz help
Это должно выглядеть знакомо, особенно если вы использовали Git:
git init
git status
git commit
Основываясь на этом первом параметре (init, create, run, help), наш оператор case решит, что нужно запускать. Однако нам нужен вариант по умолчанию: что произойдет, если первый параметр не задан, или мы получаем нераспознанный первый параметр? В этих случаях мы покажем текст справки. Итак, начнем!
Шаг 3 — Написание текста справки
Начнем с оператора if, который проверяет наш первый параметр:
if [ $1 ]
then
# do stuff
else
# show help
fi
Сначала вы можете быть немного смущены, потому что оператор shell if довольно отличается от инструкции if «обычного» языка программирования. Чтобы лучше понять это, просмотрите скринкаст на условных высказываниях в курсе. Этот код проверяет наличие первого параметра ($1); Если он есть, мы выполним код then; else мы покажем текст справки.
Это хорошая идея, чтобы обернуть печать текста справки в функции, потому что нам нужно называть его более одного раза. Нам нужно определить функцию до ее вызова, поэтому мы поставим ее наверху. Мне это нравится, потому что теперь, как только я открываю файл, я вижу документацию для скрипта, которая может быть полезным напоминанием при возвращении к коду, который вы не видели долгое время. Без дальнейших церемоний, вот функция help:
function help () {
echo "jazz - A simple script that makes using the Jasmine testing framework in a standalone project a little simpler."
echo "
echo " jazz init - include jasmine in the project";
echo " jazz create FunctionName - creates ./src/FunctionName.js ./spec/FunctionNameSpec.js";
echo " jazz run - runs tests in browser";
}
Теперь просто замените эту функцию # show help вызовом функции help.
else
help
fi
Шаг 4 — Пишем case выражения
Если есть первый параметр, нам нужно выяснить, что это такое. Для этого мы используем оператор case:
case "$1" in init) ;; create) ;; run) ;; *) help ;; esac
Мы передаем первый параметр в оператор case; он должен соответствовать одному из четырех вариантов: «init», «create», «run» или «wildcard», default case. Обратите внимание, что у нас нет явного случая «help»: это просто наш случай по умолчанию. Это работает, потому что ничего, кроме «init», «create» и «run», не является командами, которые мы распознаем, поэтому он должен получить текст справки.
Теперь мы готовы написать функциональный код, и мы начнем с jazz init.
Шаг 5 — Подготовка Jasmine с jazz init
Весь код, который мы пишем здесь, будет идти в нашем case init) из приведенного выше примера case. Первый шаг — фактически загрузить автономную версию Jasmine, которая входит в zip-файл:
echo "Downloading Jasmine ..."
curl -sO $JASMINE_LINK
Сначала мы выводим небольшое сообщение, а затем используем curl для загрузки zip. Флаг s делает его тихим (без вывода), а флаг O сохраняет содержимое zip в файл (в противном случае он будет выводить его). Но что такое переменная $JASMINE_LINK? Ну, вы можете поместить фактическую ссылку на zip-файл там, но я предпочитаю поместить его в переменную по двум причинам: во-первых, это не позволяет нам повторять часть пути, как вы увидите через минуту. Во-вторых, с этой переменной в верхней части файла упрощается изменение версии Jasmine, которую мы используем: просто измените эту переменную. Вот это объявление переменной (я положил ее вне оператора if вверху):
JASMIME_LINK="http://cloud.github.com/downloads/pivotal/jasmine/jasmine-standalone-1.3.1.zip"
Помните, что в этой строке нет пробелов вокруг знака равенства.
Теперь, когда у нас есть наш zip-файл, мы можем разархивировать его и подготовить содержимое:
unzip -q <code>basename $JASMINE_LINK</code>
rm -rf <code>basename $JASMINE_LINK</code> src/*.js spec/*.js
В двух из этих строк мы используем basename $JASMINE_LINK; Команда basename просто уменьшает путь до базового имени: так что path/to/file.zip становится просто file.zip. Это позволяет нам использовать переменную $JASMINE_LINK для ссылки на наш локальный zip-файл.
После того, как мы распакуем, мы удалим этот zip-файл, а также все файлы JavaScript в каталогах src и spec. Это образцы файлов, с которыми работает Jasmine, и они нам не нужны.
Затем у нас есть проблема только для Mac. По умолчанию, когда вы загружаете что-то из Интернета на Mac, когда вы пытаетесь запустить его в первый раз, вас попросят подтвердить, что вы хотите его запустить. Это связано с расширенным атрибутом com.apple.quarantine, который Apple помещает в файл. Нам нужно удалить этот атрибут.
if which xattr > /dev/null && [ "<code>xattr SpecRunner.html</code>" = "com.apple.quarantine" ]
then
xattr -d com.apple.quarantine SpecRunner.html
fi
Начнем с проверки наличия команды xattr, поскольку она не существует в некоторых Unix-системах (я не уверен, но это может быть только программа Mac). Если вы наблюдали за просмотром курсора в условных выражениях, вы узнаете, что мы можем передать любую команду в if: Если она имеет статус выхода ничего, кроме 0, то значение будет false. Если which найдет команду xattr, она выйдет с 0; В противном случае выйдет с 1. В любом случае, which отобразит некоторый вывод; Мы можем не показывать его, перенаправив в /dev/null (это специальный файл, который отбрасывает все записанные на него данные).
Этот двойной амперсанд является логическим И; Он для второго условия, которое мы хотим проверить. То есть, имеет ли SpecRunner.html этот атрибут? Мы можем просто запустить команду xattr на файле и сравнить ее вывод с строкой, которую мы ожидаем. (Мы не можем просто ожидать, что файл будет иметь этот атрибут, потому что вы можете отключить эту функцию в Mac OS X, и мы получим сообщение об ошибке при попытке удалить его, если файл не имеет атрибута).
Итак, если xattr найден и файл имеет атрибут, мы удалим его с флагом d (для удаления). Довольно просто, правда?
Последний шаг — отредактировать SpecRunner.html. В настоящее время он содержит теги скриптов для файлов примеров, которые мы удалили; Мы также должны удалить те теги скриптов. Я знаю, что те теги сценария охватывают строки от 12 до 18 в файлах. Таким образом, мы можем использовать редактор потока sed для удаления этих строк:
sed -i "" '12,18d' SpecRunner.html
echo "Jasmine initialized!"
Флаг i сообщает sed об изменении файла на месте или для сохранения вывода из команды в тот же файл, который мы проходили; Пустая строка после флага означает, что мы не хотим, чтобы sed архивировал файл для нас; Если бы вы этого хотели, вы могли бы просто поместить расширение файла в эту строку (например, .bak, чтобы получить SpecRunner.html.bak).
Наконец, мы сообщим пользователю, что Jasmine был инициализирован. И на этом наша команда jazz init готова.
Шаг 6 — Создание файлов с помощью jazz create
Затем мы позволим нашим пользователям создавать файлы JavaScript и связанные с ними файлы спецификаций. Эта часть кода войдет в раздел «create» в case, который мы писали ранее.
if [ $2 ]
then
# create files
else
echo "please include a name for the file"
fi
При использовании jazz create нам нужно включить имя файла в качестве второго параметра: jazz create View, например. Мы будем использовать его для создания src/View.js и spec/ViewSpec.js. Итак, если нет второго параметра, мы напомним пользователю добавить его.
Если есть имя файла, мы начнем с создания этих двух файлов (внутри then части):
echo "function $2 () {nn}" > src/$2.js
echo "describe('$2', function () {nn});" > spec/$2Spec.js
Конечно, вы можете поместить все, что захотите, в свой файл src. Я делаю кое что основное здесь; Поэтому jazz create View создаст src/View.js с этим содержимым:
function View () {
}
Вы можете заменить эту первую echo строку следующим:
echo "var $2 = (function () {ntvar $2Prototype = {nnt};nntreturn {nttcreate : function (attrs) {ntttvar o = Object.create($2Prototype);ntttextend(o, attrs);ntttreturn o;ntt}n t};n}());" > src/$2.js
И тогда jazz create View приведет к следующему:
var View = (function () {
var ViewPrototype = {
};
return {
create : function (attrs) {
var o = Object.create(ViewPrototype);
extend(o, attrs);
return o;
}
};
}());
Итак, ваше воображение — это предел. Конечно, вы захотите, чтобы spec-файл был стандартным кодом спецификации Jasmine, что я и выше; Но вы можете настроить это, как вам нравится.
Следующий шаг — добавить теги скриптов для этих файлов в SpecRunner.html. Сначала это может показаться сложным: как мы можем добавить строки в середину файла программно? Еще раз, это sed, который выполняет эту работу.
sed -i "" "11a
<script src='src/$2.js'></script>
<script src='spec/$2Spec.js'></script>
" SpecRunner.html
Мы начинаем так же, как и раньше: редактирование на месте без резервного копирования. Затем наша команда: в строке 11 мы хотим добавить две следующие строки. Важно избегать двух новых строк, чтобы они отображались в тексте. Как вы можете видеть, это просто вставляет те два скриптовых тега, именно то, что нам нужно для этого шага.
Мы можем закончить с небольшим выводом:
echo "Created:"
echo "t- src/$2.js"
echo "t- spec/$2Spec.js"
echo "Edited:"
echo "t- SpecRunner.html"
И это jazz create!
Шаг 7 — Выполнение спецификаций с jazz run
Последний шаг — фактически запустить тесты. Это означает открытие файла SpecRunner.html в браузере. Здесь будет небольшая оговорка. В Mac OS X мы можем использовать команду open, чтобы открыть файл в своей программе по умолчанию; Это не будет работать ни на одной другой ОС, но я так и делаю здесь. К сожалению, нет реального межплатформенного способа сделать это, о котором я знаю. Если вы используете этот скрипт под Cygwin в Windows, вы можете использовать cygstart вместо open; В противном случае попробуйте googling «[ваш ОС] shell script open browser» и посмотрите, что можно придумать. К сожалению, некоторые версии Linux (по крайней мере, Ubuntu, по моему опыту) имеют open команду для чего-то совершенно другого.
if [ "`which open`" = '/usr/bin/open' ]
then
open SpecRunner.html
else
echo "Please open SpecRunner.html in your browser"
fi
К настоящему времени вы точно знаете, что это значит: если у нас есть команда open, то мы откроем SpecRunner.html, иначе мы просто напечатаем сообщение, в котором пользователь должен открыть файл в браузере.
Первоначально, if условие выглядело так:
if which open > /dev/null
Как мы это делали с xattr, оно просто проверяло наличие open; Однако, поскольку я узнал, что в Linux существует другая команда open (даже на моем сервере Ubuntu, который даже не может открыть браузер!), Я решил, что лучше сравнить путь программы open, поскольку в Linux она находится в /bin/open (опять же, по крайней мере, на сервере Ubuntu).
Вся эта лишняя словесность об open может показаться оправданием для отсутствия у меня хорошего решения, на самом деле это указывает на что-то важное в командной строке. Не путайте понимания терминалов с пониманием конфигурации компьютера. Этот учебник и связанный с ним курс научили вас немного работе в оболочке Bash (и оболочке Z), но это не значит, что каждый компьютер, который вы используете, будет настроен одинаково; Существует множество способов установки новых команд (или разных версий команд), а также удаления команд. Предостережение разработчику.
Ну, это весь скрипт! Здесь снова, все вместе:
#! /bin/sh
function help () {
echo "jazz - A simple script that makes using the Jasmine testing framework in a standalone project a little simpler."
echo ""
echo " jazz init - include jasmine in the project";
echo " jazz create FunctionName - creates ./src/FunctionName.js ./spec/FunctionNameSpec.js";
echo " jazz run - runs tests in browser";
}
JASMIME_LINK="http://cloud.github.com/downloads/pivotal/jasmine/jasmine-standalone-1.3.1.zip"
if [ $1 ]
then
case "$1" in
init)
echo "Downloading Jasmine . . ."
curl -sO $JASMIME_LINK
unzip -q `basename $JASMIME_LINK`
rm `basename $JASMIME_LINK` src/*.js spec/*.js
if which xattr > /dev/null && [ "`xattr SpecRunner.html`" = "com.apple.quarantine" ]
then
xattr -d com.apple.quarantine SpecRunner.html
fi
sed -i "" "12,18d" SpecRunner.html
echo "Jasmine initialized!"
;;
create)
if [ $2 ]
then
echo "function $2 () {nn}" > ./src/$2.js
echo "describe('$2', function () {nit('runs');n});" > ./spec/$2Spec.js
sed -i "" "11a
<script src='src/$2.js'></script>
<script src='spec/$2Spec.js'></script>
" SpecRunner.html
echo "Created:"
echo "t- src/$2.js"
echo "t- spec/$2Spec.js"
echo "Edited:"
echo "t- SpecRunner.html"
else
echo 'please add a name for the file'
fi
;;
"run")
if [ "`which open`" = '/usr/bin/open' ]
then
open ./SpecRunner.html
else
echo "Please open SpecRunner.html in your browser"
fi
;;
*)
help;
;;
esac
else
help;
fi
Ну, продолжайте, попробуйте!
mkdir project
cd project
jazz init
jazz create Dog
# edit src/Dog.js and spec/DogSpec.js
jazz run
Кстати, если вы хотите немного поучаствовать в этом проекте, вы можете найти его на Github.
Вывод
Итак, у вас теперь есть это! Мы только что написали сценарий оболочки промежуточного уровня; Это было не так уж плохо, не так ли? Не забудьте следить за моим предстоящим курсом Tuts + Premium; Вы узнаете гораздо больше о многих методах, используемых в этой статье, а также о многих других. Получайте удовольствие от работы в терминале!
Каким бы простым ни был графический интерфейс в Linux и сколько бы там ни было функций, все равно есть задачи, которые удобнее решать через терминал. Во-первых, потому что это быстрее, во-вторых — не на всех машинах есть графический интерфейс, например, на серверах все действия выполняются через терминал, в целях экономии вычислительных ресурсов.
Если вы уже более опытный пользователь, то, наверное, часто выполняете различные задачи через терминал. Часто встречаются задачи, для которых нужно выполнять несколько команд по очереди, например, для обновления системы необходимо сначала выполнить обновление репозиториев, а уже затем скачать новые версии пакетов. Это только пример и таких действий очень много, даже взять резервное копирование и загрузку скопированных файлов на удаленный сервер. Поэтому, чтобы не набирать одни и те же команды несколько раз можно использовать скрипты. В этой статье мы рассмотрим написание скриптов на Bash, рассмотрим основные операторы, а также то как они работают, так сказать, bash скрипты с нуля.
Основы скриптов
Скрипт или как его еще называют — сценарий, это последовательность команд, которые по очереди считывает и выполняет программа-интерпретатор, в нашем случае это программа командной строки — bash.
Скрипт — это обычный текстовый файл, в котором перечислены обычные команды, которые мы привыкли вводить вручную, а также указанна программа, которая будет их выполнять. Загрузчик, который будет выполнять скрипт не умеет работать с переменными окружения, поэтому ему нужно передать точный путь к программе, которую нужно запустить. А дальше он уже передаст ваш скрипт этой программе и начнется выполнение.
Простейший пример скрипта для командной оболочки Bash:
#!/bin/bash
echo "Hello world"
Утилита echo выводит строку, переданную ей в параметре на экран. Первая строка особая, она задает программу, которая будет выполнять команды. Вообще говоря, мы можем создать скрипт на любом другом языке программирования и указать нужный интерпретатор, например, на python:
#!/usr/bin/env python
print("Hello world")
Или на PHP:
#!/usr/bin/env php
echo "Hello world";
В первом случае мы прямо указали на программу, которая будет выполнять команды, в двух следующих мы не знаем точный адрес программы, поэтому просим утилиту env найти ее по имени и запустить. Такой подход используется во многих скриптах. Но это еще не все. В системе Linux, чтобы система могла выполнить скрипт, нужно установить на файл с ним флаг исполняемый.
Этот флаг ничего не меняет в самом файле, только говорит системе, что это не просто текстовый файл, а программа и ее нужно выполнять, открыть файл, узнать интерпретатор и выполнить. Если интерпретатор не указан, будет по умолчанию использоваться интерпретатор пользователя. Но поскольку не все используют bash, нужно указывать это явно.
Чтобы сделать файл исполняемым в linux выполните:
chmod ugo+x файл_скрипта
Теперь выполняем нашу небольшую первую программу:
./файл_скрипта
Все работает. Вы уже знаете как написать маленький скрипт, скажем для обновления. Как видите, скрипты содержат те же команды, что и выполняются в терминале, их писать очень просто. Но теперь мы немного усложним задачу. Поскольку скрипт, это программа, ему нужно самому принимать некоторые решения, хранить результаты выполнения команд и выполнять циклы. Все это позволяет делать оболочка Bash. Правда, тут все намного сложнее. Начнем с простого.
Переменные в скриптах
Написание скриптов на Bash редко обходится без сохранения временных данных, а значит создания переменных. Без переменных не обходится ни один язык программирования и наш примитивный язык командной оболочки тоже.
Возможно, вы уже раньше встречались с переменными окружения. Так вот, это те же самые переменные и работают они аналогично.
Например, объявим переменную string:
string="Hello world"
Значение нашей строки в кавычках. Но на самом деле кавычки не всегда нужны. Здесь сохраняется главный принцип bash — пробел — это специальный символ, разделитель, поэтому если не использовать кавычки world уже будет считаться отдельной командой, по той же причине мы не ставим пробелов перед и после знака равно.
Чтобы вывести значение переменной используется символ $. Например:
echo $string
Модифицируем наш скрипт:
#!/bin/bash
string1="hello "
string2=world
string=$string1$string2
echo $string
И проверяем:
./script
Hello world
Bash не различает типов переменных так, как языки высокого уровня, например, С++, вы можете присвоить переменной как число, так и строку. Одинаково все это будет считаться строкой. Оболочка поддерживает только слияние строк, для этого просто запишите имена переменных подряд:
#!/bin/bash
string1="hello "
string2=world
string=$string1$string2 and me
string3=$string1$string2" and me"
echo $string3
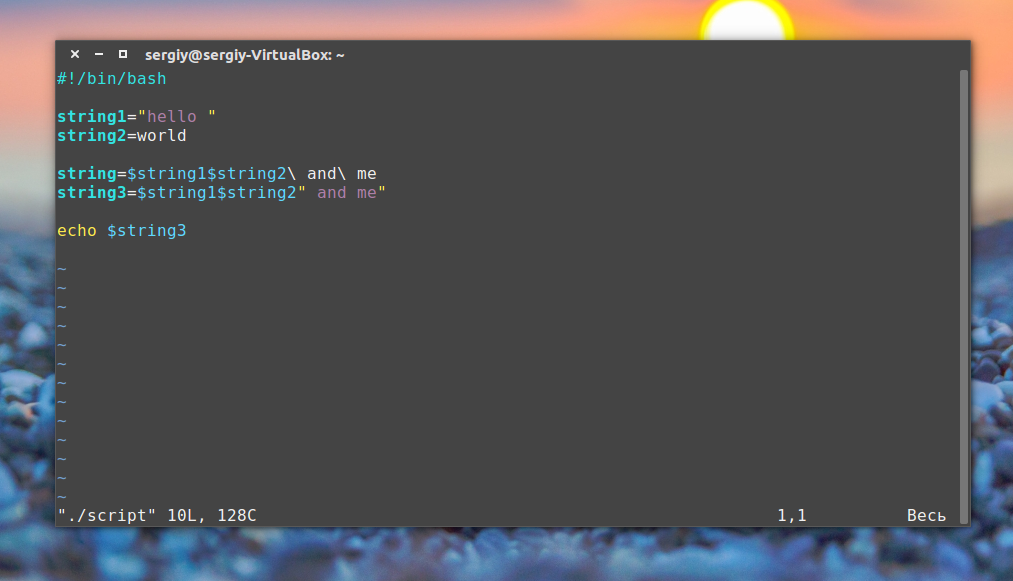
Проверяем:
./script
Обратите внимание, что как я и говорил, кавычки необязательны если в строке нет спецсимволов. Присмотритесь к обоим способам слияния строк, здесь тоже демонстрируется роль кавычек. Если же вам нужны более сложные способы обработки строк или арифметические операции, это не входит в возможности оболочки, для этого используются обычные утилиты.
Переменные и вывод команд
Переменные не были бы настолько полезны, если бы в них невозможно было записать результат выполнения утилит. Для этого используется такой синтаксис:
$(команда)
С помощью этой конструкции вывод команды будет перенаправлен прямо туда, откуда она была вызвана, а не на экран. Например, утилита date возвращает текущую дату. Эти команды эквивалентны:
date
echo $(date)
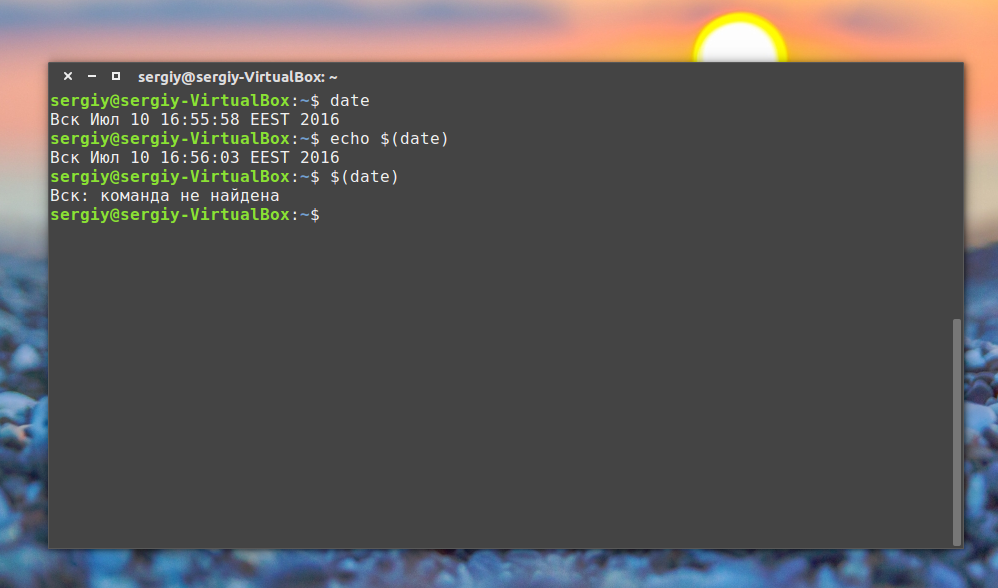
Понимаете? Напишем скрипт, где будет выводиться hello world и дата:
#!/bin/bash
string1="hello world "
string2=$(date)
string=$string1$string2
echo $string
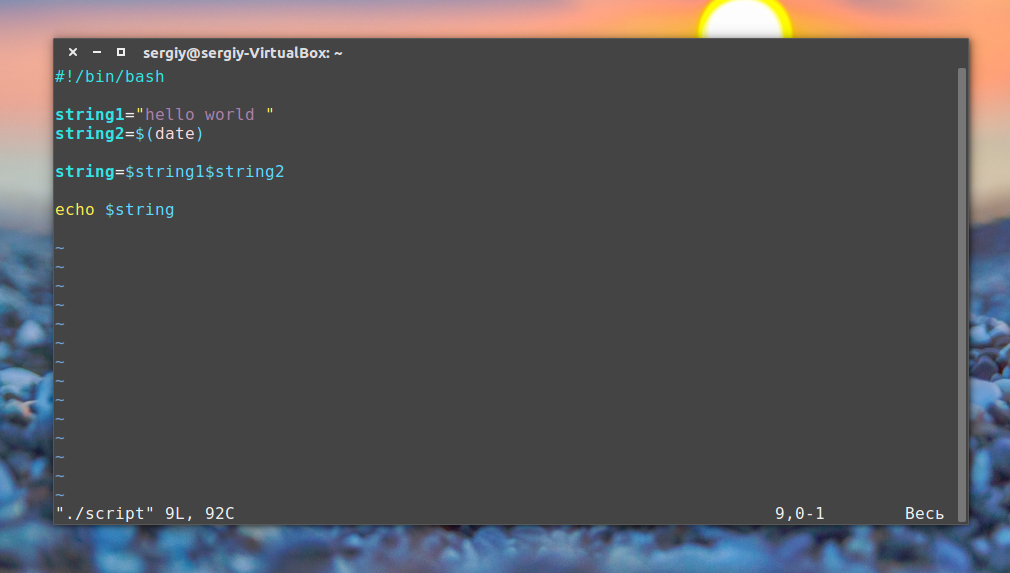
Теперь вы знаете достаточно о переменных, и готовы создать bash скрипт, но это еще далеко не все. Дальше мы рассмотрим параметры и управляющие конструкции. Напомню, что это все обычные команды bash, и вам необязательно сохранять их в файле, можно выполнять сразу же на ходу.
Параметры скрипта
Не всегда можно создать bash скрипт, который не зависит от ввода пользователя. В большинстве случаев нужно спросить у пользователя какое действие предпринять или какой файл использовать. При вызове скрипта мы можем передавать ему параметры. Все эти параметры доступны в виде переменных с именами в виде номеров.
Переменная с именем 1 содержит значение первого параметра, переменная 2, второго и так далее. Этот bash скрипт выведет значение первого параметра:
#!/bin/bash
echo $1
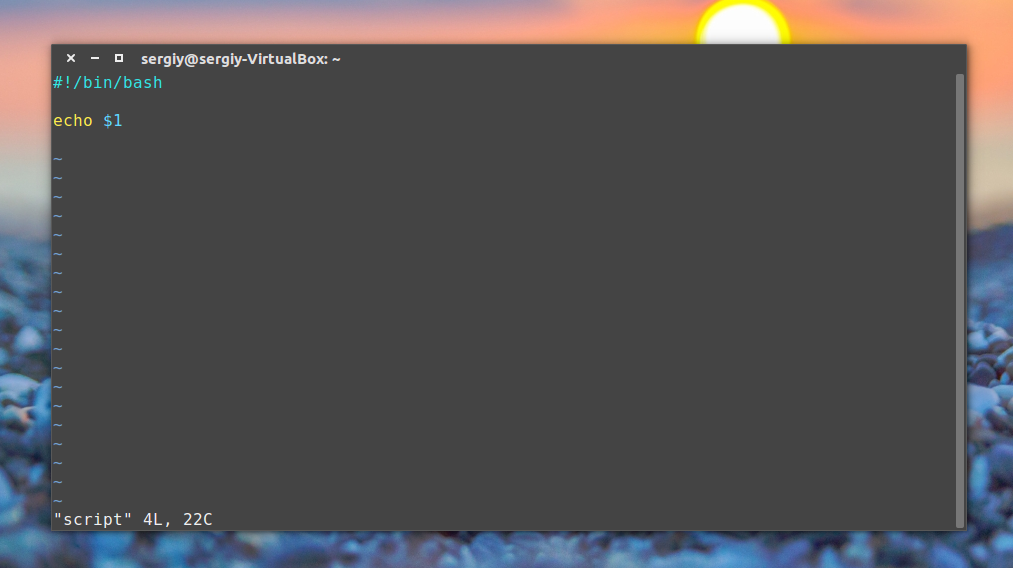
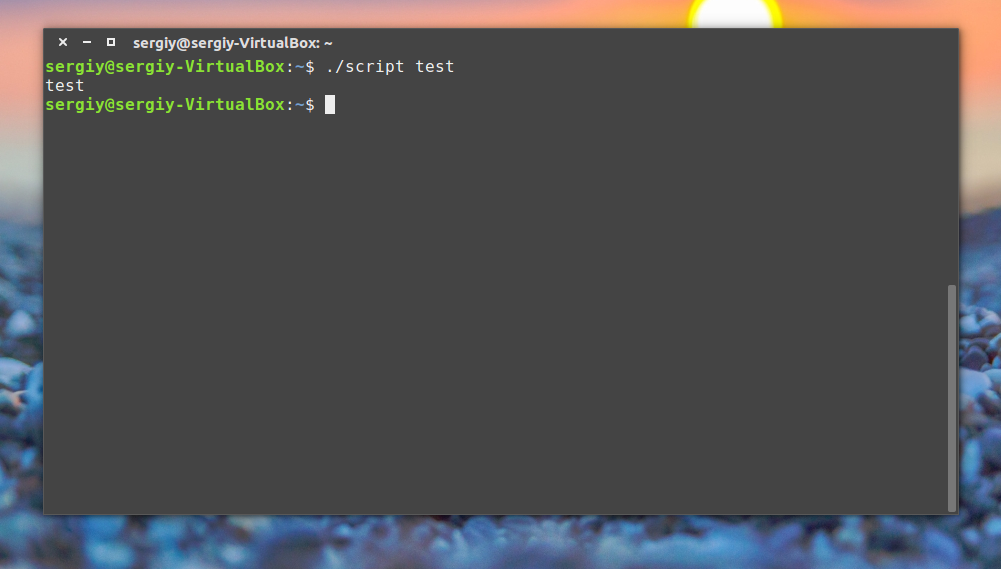
Управляющие конструкции в скриптах
Создание bash скрипта было бы не настолько полезным без возможности анализировать определенные факторы, и выполнять в ответ на них нужные действия. Это довольно-таки сложная тема, но она очень важна для того, чтобы создать bash скрипт.
В Bash для проверки условий есть команда Синтаксис ее такой:
if команда_условие
then
команда
else
команда
fi
Эта команда проверяет код завершения команды условия, и если 0 (успех) то выполняет команду или несколько команд после слова then, если код завершения 1 выполняется блок else, fi означает завершение блока команд.
Но поскольку нам чаще всего нас интересует не код возврата команды, а сравнение строк и чисел, то была введена команда [[, которая позволяет выполнять различные сравнения и выдавать код возврата зависящий от результата сравнения. Ее синтаксис:
[[ параметр1 оператор параметр2 ]]
Для сравнения используются уже привычные нам операторы <,>,=,!= и т д. Если выражение верно, команда вернет 0, если нет — 1. Вы можете немного протестировать ее поведение в терминале. Код возврата последней команды хранится в переменной $?:
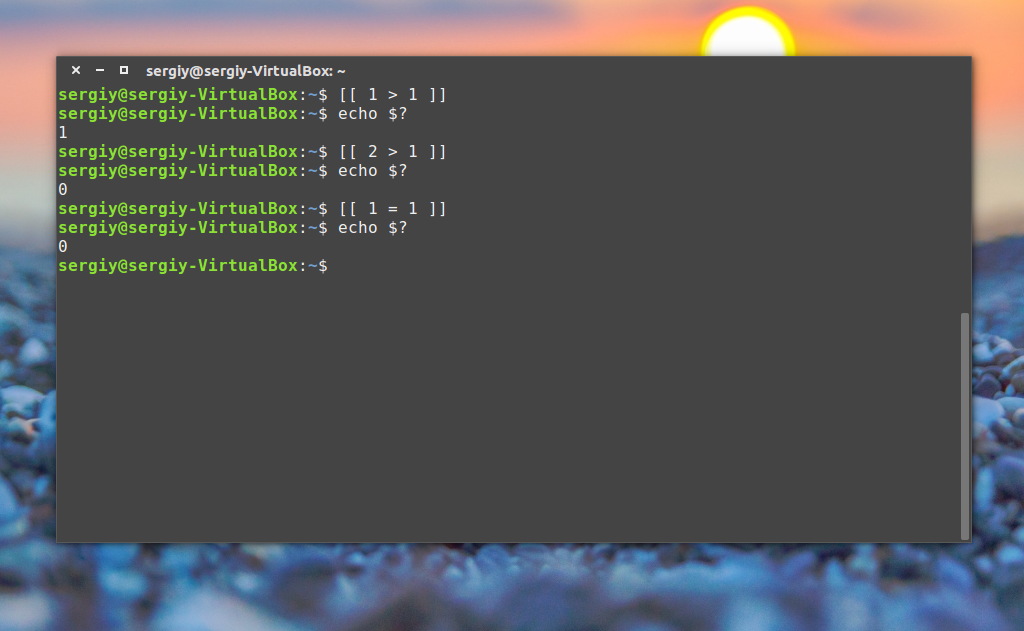
Теперь объединением все это и получим скрипт с условным выражением:
#!/bin/bash
if [[ $1 > 2 ]]
then
echo $1" больше 2"
else
echo $1" меньше 2 или 2"
fi
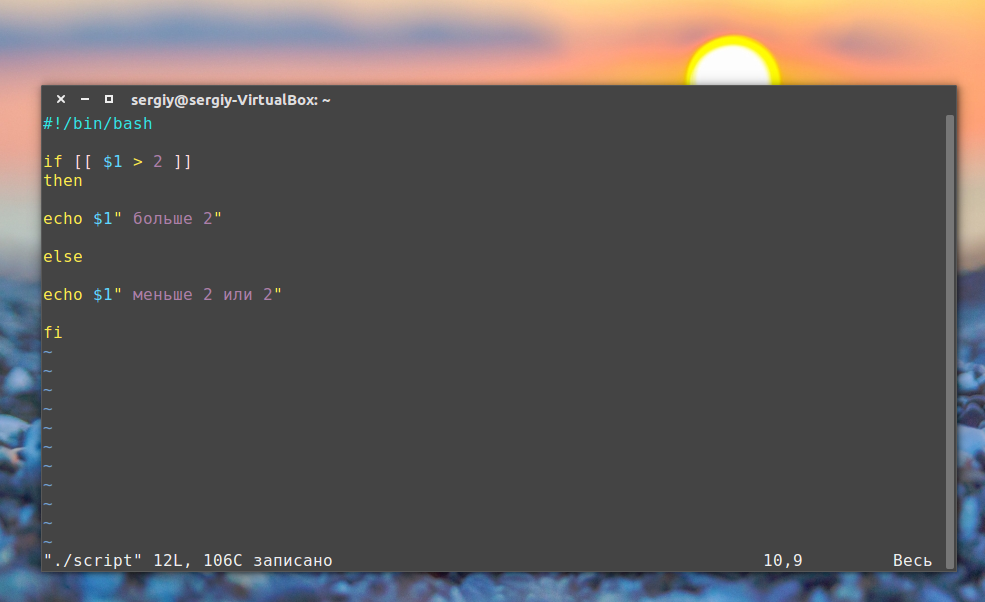
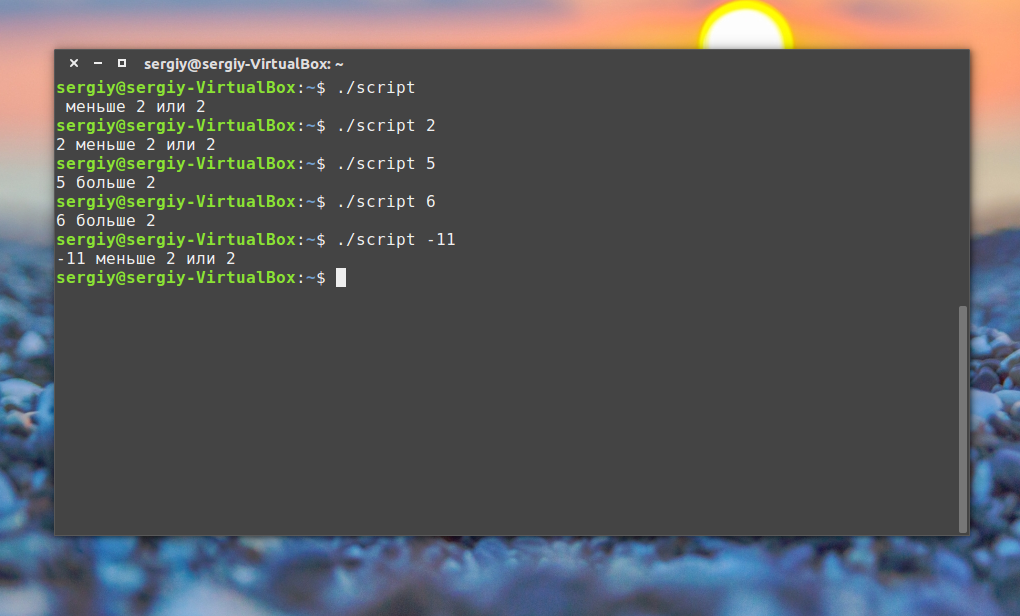
Конечно, у этой конструкции более мощные возможности, но это слишком сложно чтобы рассматривать их в этой статье. Возможно, я напишу об этом потом. А пока перейдем к циклам.
Циклы в скриптах
Преимущество программ в том, что мы можем в несколько строчек указать какие действия нужно выполнить несколько раз. Например, возможно написание скриптов на bash, которые состоят всего из нескольких строчек, а выполняются часами, анализируя параметры и выполняя нужные действия.
Первым рассмотрим цикл for. Вот его синтаксис:
for переменная in список
do
команда
done
Перебирает весь список, и присваивает по очереди переменной значение из списка, после каждого присваивания выполняет команды, расположенные между do и done.
Например, переберем пять цифр:
#!/bin/bash
for index in 1 2 3 4 5
do
echo $index
done
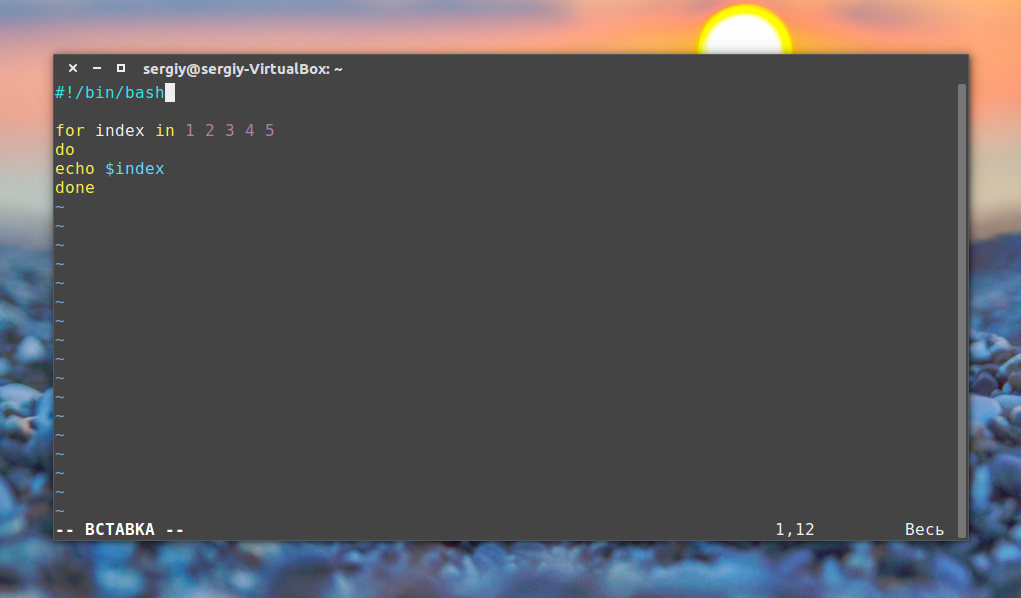
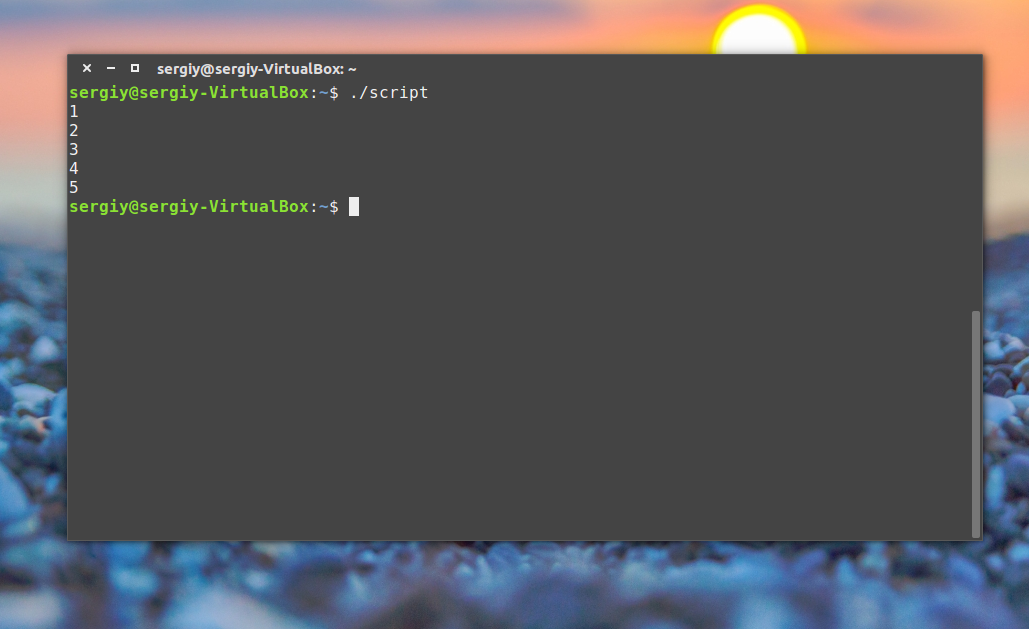
Или вы можете перечислить все файлы из текущей директории:
for file in $(ls -l); do echo "$file"; done
Как вы понимаете, можно не только выводить имена, но и выполнять нужные действия, это очень полезно когда выполняется создание bash скрипта.
Второй цикл, который мы рассмотрим — это цикл while, он выполняется пока команда условия возвращает код 0, успех. Рассмотрим синтаксис:
while команда условие
do
команда
done
Рассмотрим пример:
#!/bin/bash
index=1
while [[ $index < 5 ]]
do
echo $index
let "index=index+1"
done
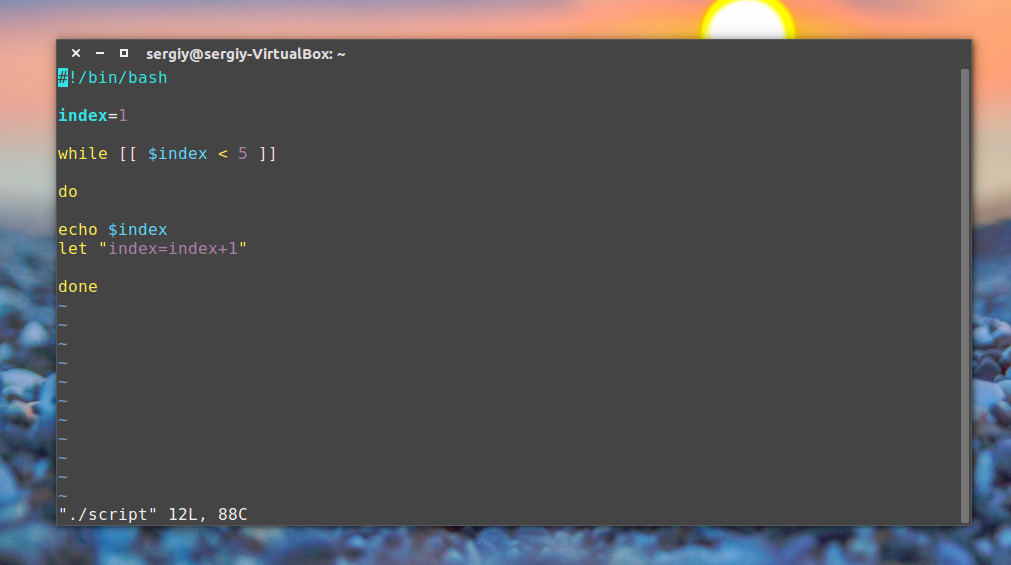
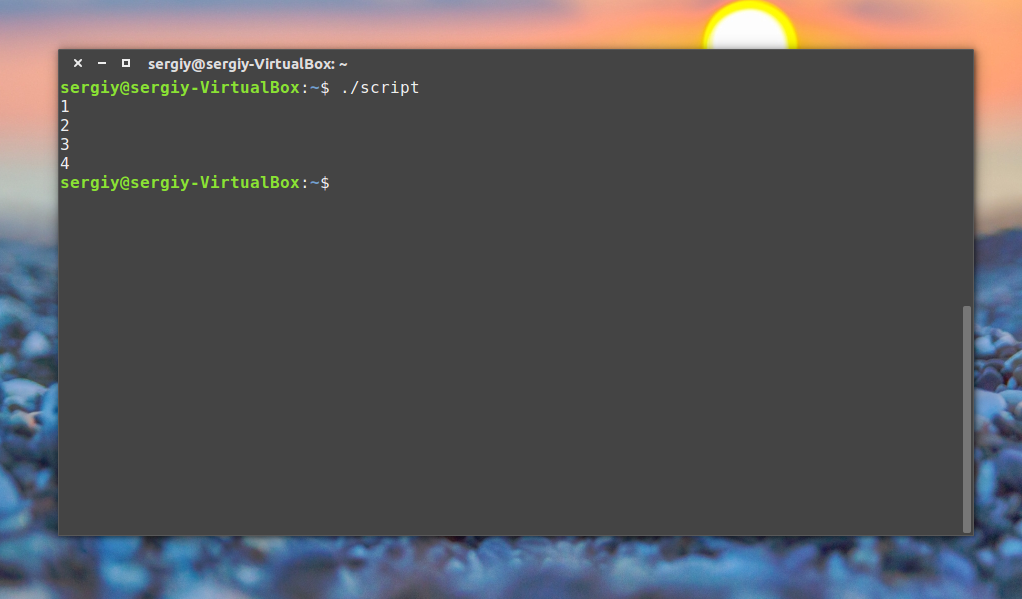
Как видите, все выполняется, команда let просто выполняет указанную математическую операцию, в нашем случае увеличивает значение переменной на единицу.
Хотелось бы отметить еще кое-что. Такие конструкции, как while, for, if рассчитаны на запись в несколько строк, и если вы попытаетесь их записать в одну строку, то получите ошибку. Но тем не менее это возможно, для этого там, где должен быть перевод строки ставьте точку с запятой «;». Например, предыдущий цикл можно было выполнить в виде одной строки:
index=1; while [[ $index < 5 ]]; do echo $index; let "index=index+1"; done;
Все очень просто я пытался не усложнять статью дополнительными терминами и возможностями bash, только самое основное. В некоторых случаях, возможно, вам понадобиться сделать gui для bash скрипта, тогда вы можете использовать такие программы как zenity или kdialog, с помощью них очень удобно выводить сообщения пользователю и даже запрашивать у него информацию.
Выводы
Теперь вы понимаете основы создания скрипта в linux и можете написать нужный вам скрипт, например, для резервного копирования. Я пытался рассматривать bash скрипты с нуля. Поэтому далеко не все аспекты были рассмотрены. Возможно, мы еще вернемся к этой теме в одной из следующих статей.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Введение
Набор встроенных команд bash (и его аналогов sh, zsh, etc) совместим с любым POSIX-совместимым приложением в Linux, что позволяет встроить в ваш bash-скрипт любое совместимое приложение. Это дает очень большой набор возможностей в сфере автоматизации рутинных задач администрирования систем Linux, деплоя и сборки приложений, различных пакетных обработок, в том числе аудио и видео.
Командная строка — самый мощный пользовательский интерфейс из существующих на данный момент. Базовый уровень знаний получить достаточно просто. Рекомендуется изучить руководство bash. Это можно сделать, выполнив команду man bash.
Суть bash-скриптов — записать все ваши действия в один файл и выполнять их по необходимости.
В этой статье расскажем про написание bash-скриптов с нуля и получим представление, какую пользу можно из них извлечь. Рекомендуем держать под рукой bash-справочник, если вы планируете заняться этим всерьез.
Развертывание среды
Для выполнения скриптов, которые мы будем учиться писать, нужна среда. Если вы используете на своем компьютере систему Linux, вы можете делать все локально. Если Windows, — можете установить WSL/WSL2. Кроме того, вы можете создать виртуальный сервер и подключиться к нему по SSH. Так вы не навредите своему компьютеру если что-то пойдет не так.
Мы выбрали вариант создать виртуальную машину. Залогинимся в личном кабинете https://my.selectel.ru/, нажав на вкладку «Облачная платформа». Там вы сможете создать виртуальный сервер.
Необходимо выбрать зону размещения сервера исходя из его близости к пользователям. Чем дальше сервер, тем выше пинг.

Нажмем «Создать сервер».
В разделе «Источник» убеждаемся, что выбран образ Ubuntu 20.04.

Конфигурацию можно настроить по своим потребностям.

В разделе «Сеть» стоит выбрать «Подсеть — Плавающий IP-адрес».
В разделе «Доступ» загрузите SSH-ключ и не забудьте сохранить root-пароль. Подробнее об этом рассказано в этой статье
Теперь можно создать сервер кнопкой «Создать» в самом низу.
Будет отображена страница статуса сервера, надо дождаться индикации ACTIVE вверху справа.

Теперь на вкладке «Порты» можно посмотреть IP-адрес, присвоенный серверу.

Не копируйте чужой код
Копирование чужого кода на свой компьютер/сервер опасно. Ранее существовал «патч Бармина», представляющий из себя команду rm -rf /*. Ее очень любили давать новичкам Linux на некоторых конференциях в качестве универсального средства от всех проблем. Суть команды — рекурсивное удаление всех каталогов внутри корневого каталога, т. е. всех системных и пользовательских файлов. Сейчас эта команда не сработает во всех актуальных версиях Linux, но раньше она служила злой шуткой и наказанием тем, кто копировал чужие скрипты на свои серверы и выполнял их. Способов навредить серверу/компьютеру все еще достаточно, но они не столь очевидны.
Выбор редактора
Вам потребуется удобный текстовый редактор. Если вы подключаетесь по SSH, то лучшим выбором будут 3 варианта:
- * vim (если умеете из него выходить)
- * nano (прост, удобен и надежен)
- * mcedit (входит в пакет mc, классический двухпанельный консольный файловый менеджер)
Если вы делаете все локально, выбор полностью на вас. Обычный выбор под Linux — gedit. В этой инструкции мы пользовались nano через SSH на удаленном сервере.
Запуск “Hello, World!”
Первая программа, которую обычно пишут программисты это «Hello, World!» — простой вывод этой строки. Мы тоже с этого начнем. За вывод строки в консоль отвечает команда echo. Прямо в консоли вы можете напечатать echo «Hello, World!» и получить соответствующий вывод:
root@geneviev:~ # echo "Hello, World!"
Hello, World!
Сделаем это программой. Команда touch helloworld.sh создаст файл helloworld.sh. Команда nano helloworld.sh откроет этот файл для редактирования. Заполним файл нашей программой:
#!/bin/bash
echo "Hello, World!"
Для выхода с сохранением из nano надо нажать CTRL + O для сохранения (после чего нажать enter для перезаписи текущего открытого файла), а потом CTRL + X для выхода. Можно выходить без сохранения, при этом он спросит, точно ли вы хотите выйти без сохранения. Если да, надо нажать N для выхода без сохранения. Если вы нажмете Y, он спросит куда сохранить измененный файл, можно нажать enter для перезаписи редактируемого файла.
Разберем, что мы написали.
Первой строкой идет #!/bin/bash — фактически это указание на местоположение интерпретатора. Чтобы при запуске скрипта не требовалось указывать отдельно интерпретатор. Убедиться, что ваш bash интерпретатор лежит по этому пути можно через команду which bash:
root@geneviev:~ # which bash
/usr/bin/bash
Второй строкой идет непосредственно вся наша программа. Как она работает, мы разобрали выше, перейдем к выполнению.
Запустить ваш скрипт/команду можно двумя способами.
Способ №1: bash helloworld.sh. Вы вызываете интерпретатор и в аргументе передаете ему имя файла для исполнения.
root@geneviev:~ # bash helloworld.sh
Hello, World!
Способ №2: Сначала надо разрешить системе исполнять скрипт: chmod +x helloworld.sh. Эта команда сделает файл исполняемым. Теперь вы можете запустить его как любой бинарный файл в linux: ./helloworld.sh.
root@geneviev:~ # ./helloworld.sh
Hello, World!
Первая программа готова, она просто выводит строку в консоль.
Аргументы
Это параметры, которые вы можете передать программе при ее вызове. Например, программа ping принимает в качестве обязательного аргумента IP-адрес или DNS-имя, которое требуется пропинговать: ping selectel.ru. Это простой и удобный способ общения пользователя с программой.
Давайте научим нашу программу принимать аргументы и работать с ними. Доступ к аргументам осуществляется через служебную команду $X где X это число. $0 — всегда имя исполняемого скрипта. $1 — первый аргумент, $2 — второй и так далее. Конечно, если вы планируете передавать пару десятков аргументов вашему приложению, это может быть несколько утомительно, так что вам понадобится что-то вроде этого цикла, чтобы перебрать все поступившие аргументы:
for var in "$@"; do
echo "$var"
done
Подробнее про циклы будет рассказано в следующих разделах.
Пример, создадим новый файл: touch hellousername.sh. Выдаем права на исполнение chmod +x hellousername.sh.
Открываем nano hellousername.sh
Код примера следующий:
#!/bin/bash
echo "Hello, $1!"
Сохраняем, закрываем. Смотрим, что получилось.
root@geneviev:~ # ./hellousername.sh Vasya
Hello, Vasya!
Программа получилась маленькая, но она учит пользоваться (на самом базовом уровне) аргументами, которые мы в нее можем передать. В данном случае аргумент передается один, Vasya, мы сразу его используем, не делая никаких проверок.
root@geneviev:~ # ./hellousername.sh
Hello, !
При таком сценарии в нашей программе баг: она ни с кем не поздоровается. Чтобы исправить ситуацию, есть 2 способа: проверить число аргументов или проверить содержимое аргумента.
Способ №1
#!/bin/bash
if [ "$#" -lt 1 ]; then
echo "Недостаточно аргументов. Пожалуйста, передайте в качестве аргумента имя. Пример: $0 Vasya"
exit 1
fi
echo "Hello, $1!"
Более подробно конструкцию if then [else] fi мы рассмотрим далее, пока не будем на ней останавливаться. Важно понимать, что тут проверяется. $# Это число аргументов без учета имени скрипта, который всегда $0.
Способ №2
#!/bin/bash
if [ -z "$1" ]; then
echo "Имя пустое или не передано. Пожалуйста, передайте в качестве аргумента имя. Пример: $0 Vasya"
exit 1
fi
echo "Hello, $1!"
Здесь тоже используется конструкция if then [else] fi. Ключ -z в if используется для проверки переменной на пустую строку. Есть противоположный ключ -n, он проверяет что строка не пустая. Конечно, этот способ некорректно использовать для проверки входящих аргументов, но в теле самой программы он будет полезен. Например, чтобы проверить что выполненное в самой программе приложение что-то вернуло.
Управляющие конструкции
if-else
Написание программ на любом из языков длиннее нескольких строчек сложно представить без ветвления. В разных языках бывают разные варианты ветвления, но в большинстве случаев используется синтаксис if else. В bash это также присутствует.
Возьмем один из примеров выше.
#!/bin/bash
if [ "$#" -lt 1 ]; then
echo "Недостаточно аргументов. Пожалуйста, передайте в качестве аргумента имя. Пример: $0 Vasya"
exit 1
fi
echo "Hello, $1!"
Происходит проверка системной переменной $# на то, что она меньше, чем (lower than, -lt) 1. Если это выражение истинно, мы переходим в блок команд, открывающийся ключевым словом then. Весь блок, начинающийся с if, должен завершаться ключевым словом fi. Более сложная структура ветвления может выглядеть примерно так:
if TEST-COMMAND1
then
STATEMENTS1
elif TEST-COMMAND2
then
STATEMENTS2
else
STATEMENTS3
fi
Реальный пример:
#!/bin/bash
if [ "$#" -lt 1 ];
then
echo "Недостаточно аргументов. Пожалуйста, передайте в качестве аргумента имя. Пример: $0 Vasya"
exit 1
fi
if [ "$1" = "Vasya" ]; then
echo "Whatsupp, Vasiliy?"
elif [ "$1" = "Masha" ];
then
echo "Hey, Masha"
elif [ "$1" = "Michael" ];
then
echo "Shalom, Michael"
else
echo "Hi, $1"
fi
Вывод программы:
root@geneviev:~ # ./hellousername.sh Vasya
Whatsupp, Vasiliy?
root@geneviev:~ # ./hellousername.sh Masha
Hey, Masha
root@geneviev:~ # ./hellousername.sh Michael
Shalom, Michael
root@geneviev:~ # ./hellousername.sh Andrew
Hi, Andrew
root@geneviev:~ # ./hellousername.sh
Недостаточно аргументов. Пожалуйста, передайте в качестве аргумента имя. Пример: ./hellousername.sh Vasya
Выражение «$1» = «Vasya» проверяет строки на идентичность. Блок после else выполняется только если выше не найден более подходящий блок.
&& и ||
В предыдущей главе вы могли заметить, что я использовал exit 1 для завершения работы программы в случае неуспешной проверки аргумента. Это означает, что программа завершилась с ошибкой. В bash есть операторы && и ||, которые используются для создания цепочек команд. Каждая цепочка зависит от результата выполнения предыдущей программы.
Пример 1: command1 && command2. В этом случае command2 выполнится, только если command1 завершится с кодом 0 (exit 0, по умолчанию).
Пример 2: command1 || command2. В этом случае command2 выполнится, только если command1 завершится с кодом отличным от 0.
Пример 3: command1 && command2 || command3. Если command1 завершится с кодом 0, то будет выполнен command2, иначе command3.
Переменные
Как гласит один из основных принципов программирования — Do Not Repeat Yourself (DRY). Вот и мы не будем повторять себя и перепишем предыдущий пример с использованием переменных, чтобы не вызывать echo каждый раз.
Переменные в bash создаются присваиванием: x=»foo bar» или z=$1. Переменной x мы присвоили строку @foo bar«, а переменной z мы присвоили значение первого аргумента. Использовать именованные переменные гораздо удобнее, чем использовать $1, особенно когда надо использовать его значение во многих местах.
К тому же, аргументы могут идти в разном порядке. Осмысленные названия переменных очень важны, при разрастании программы это снизит неизбежную путаницу. Избегайте имен переменных (и функций) вроде «a», «b», «zzzz», etc.
Чтобы не вызывать echo в каждом варианте с разными строками, разобьем строку на части. Первая часть будет приветствием. Вторая — именем. Третья — завершающим знаком препинания. Его можно не выносить в переменную.
#!/bin/bash
greetString="Hello"
nameString="stranger"
if [ "$#" -lt 1 ];
then
echo "Недостаточно аргументов. Пожалуйста, передайте в качестве аргумента имя. Пример: $0 Vasya"
exit 1
fi
if [ "$1" = "Vasya" ];
then
nameString="Vasiliy"
greetString="Whatsup"
elif [ "$1" = "Masha" ];
then
nameString="Maria"
elif [ "$1" = "Michael" ];
then
greetString="Shalom"
nameString="Michael"
fi
echo "$greetString, $nameString!"
В этом примере мы создаем переменные greetString и nameString, которым присваиваем значения по умолчанию. В конце программа выводит значения этих двух переменных с помощью echo и форматированной строки (в двойных кавычках переменные раскрываются). Между этими действиями программа определяет, надо ли присваивать переменным другие значения.
Switch case
Использование if-else конструкции в нашем примере не является оптимальным вариантом. Мы всего лишь сверяем значение переменной с определенным набором значений. В такой ситуации лучшим выбором будет switch-case-конструкция.
case "$variable" in
"$condition1" )
command...
;;
"$condition2" )
command...
;;
esac
Перепишем нашу программу приветствий с использованием switch-case:
#!/bin/bash
name=$1
case "$name" in
"Vasya" )
nameString="Vasiliy"
greetString="Whatsup"
;;
"Masha" )
greetString="Hey"
nameString="Maria"
;;
* )
greetString="Hello"
nameString="stranger"
;;
esac
echo "$greetString, $nameString!"
Циклы
Как и любой полноценный язык программирования, bash поддерживает циклы. Цикл for и цикл while. Циклы нужны, чтобы выполнять какой-то код заданное число раз. Например, при парсинге CSV перебирать построчно и каждую строку рассматривать отдельно.
Цикл for
Вот пример структуры цикла for:
for var in list
do
команды
done
Простой реальный пример:
#!/bin/bash
for name in Maria Vasya Michael stranger
do
echo "Hello, $name!"
done
Вывод:
root@geneviev:~ # ./cycle.sh
Hello, Maria!
Hello, Vasya!
Hello, Michael!
Hello, stranger!
Программа просто перебирает все имена, разделенные пробелом, и выводит их с помощью echo.
Попробуем немного усложнить пример:
#!/bin/bash
file=$1
for name in $(cat $file)
do
echo "Hello, $name!"
done
Создадим файл с именами touch names и запишем в него список имен для приветствия:
Maria
Vasiliy
Ivan
Nikolai
Innokentiy
Вывод:
root@geneviev:~ # ./cycle.sh
^C
root@geneviev:~ # ./cycle.sh names
Hello, Maria!
Hello, Vasiliy!
Hello, Ivan!
Hello, Nikolai!
Hello, Innokentiy!
Обратите внимание на ^C. Это символ прерывания выполнения программы. В нашем случае мы вызвали программу без аргумента, и она вошла в вечный цикл. Можно сказать, зависла. Пришлось завершить ее принудительно. Не забывайте делать проверки входных данных в реальных программах. Как это делать, можете посмотреть в главах if-else и switch case, например.
В нашей программе есть небольшой баг. Модифицируем файл имен:
Erich Maria Remarque
Vasiliy
Ivan
Nikolai
Innokentiy
Запустим программу, получим вывод:
root@geneviev:~ # ./cycle.sh names
Hello, Erich!
Hello, Maria!
Hello, Remarque!
Hello, Vasiliy!
Hello, Ivan!
Hello, Nikolai!
Hello, Innokentiy!
Как говорится, «Кто все эти люди?». Так получается, потому что у нас не задана переменная окружения IFS (Internal Field Separator), указывающая на разделители полей. Наш цикл использует пробелы и переносы строки как разделители. В начале скрипта (после #!/bin/bash) укажите использовать перенос строки как разделитель полей: IFS=$’n’.
root@geneviev:~ # ./cycle.sh names
Hello, Erich Maria Remarque!
Hello, Vasiliy!
Hello, Ivan!
Hello, Nikolai!
Hello, Innokentiy!
В итоге мы получим возможность работать со строками целиком. Это пригодится для парсинга CSV.
Обычно цикл for используется со счетчиком. В C-like стиле. Что-то вроде for (i=0;i<10;i++){}. В bash тоже так можно.
#!/bin/bash
for (( i=1; i <= 10; i++ ))
do
echo "number is $i"
done
Вывод:
root@geneviev:~ # ./cycle.sh
number is 1
number is 2
number is 3
number is 4
number is 5
number is 6
number is 7
number is 8
number is 9
number is 10
Цикл while
Схема организации цикла while:
while команда проверки условия
do
другие команды
done
Простой способ сделать бесконечную петлю (бесконечный цикл):
while true
do
echo "this is infinity loop"
done
Это может пригодится, например, когда вам нужно вызывать что-то чаще, чем позволяет cron (например, раз в минуту). Или когда вам просто надо проверять какое-то значение постоянно. Областей применения у бесконечных циклов много.
Здесь используются те же самые выражения, что и в if:
#!/bin/bash
count=0
while [ $count -lt 10 ]
do
(( count++ ))
echo "count: $count"
done
Вывод:
root@geneviev:~ # ./cycle.sh
count: 1
count: 2
count: 3
count: 4
count: 5
count: 6
count: 7
count: 8
count: 9
count: 10
Из цикла можно выйти с помощью команды break (работает также и для for):
#!/bin/bash
count=0
while [ $count -lt 10 ]
do
(( count++ ))
echo "count: $count"
if [ "$count" -gt 5 ]
then
break
fi
done
Вывод:
root@geneviev:~ # ./cycle.sh
count: 1
count: 2
count: 3
count: 4
count: 5
count: 6
Заключение
Несмотря на огромную конкуренцию в сфере автоматизации рутины со стороны python, ruby, perl bash не сдает позиции. Он прост в освоении и использовании, гибок и так или иначе присутствует в абсолютном большинстве дистрибутивов Linux.
В этой статье были приведены только основы написания программ на bash. Надеемся, вы нашли их полезными для себя.
In this tutorial, we use Visual Studio 2019 and C++ to generate independent x64 machine code that can be used as shellcode, This operation needs extreme skills, but with this tutorial, you can generate your shellcode very easily…
Introduction
Shellcode is one of the most popular things in attacking and hacking, it’s described in many different ways, but let’s see what Wikipedia says:
Wikipedia:
In hacking, a shellcode is a small piece of code used as the payload in the exploitation of a software vulnerability.
It is called «shellcode» because it typically starts a command shell from which the attacker can control the compromised machine, but any piece of code that performs a similar task can be called shellcode.
Yep. It’s very correct but I describe shellcode as a piece of code that can be allocated and executed dynamically at runtime and it has no dependency on any static API of operating system or programming runtimes.
It may be wrong but this is the best name I could find for what we are going to do in this article, so…
Let’s start!
Background
The reasons I ended up doing this kind of stuff are:
- Improving my programming skills and my understanding of how a computer works
- Improving security of my applications and games
- It’s damn fun!
Yes of course! it can be used for bad and malicious purposes but you know… It’s a sword! Protect or harm… it’s up to you!
By using this technique, you can convert critical parts of your code like license checking to shellcode and encrypt it in your application. When you need to approve a license, you just decrypt the code to a heap-based space and execute it, after you finished, you dispose and release the code from memory… this makes the code harder to debug and prevent static program analysis.
Preparing Project and Environment
1. Required Tools & Software
- Visual Studio 2019
- VC++ Build Tools
- CFF Explorer ( PE Viewer/Editor )
- HxD (Hex Editor)
2. Creating Empty Projects
- Open Visual Studio 2019
- Create two empty C++ projects.
- Name one
code_genand other onecode_tester - Set
code_genConfiguration Type to «Dynamic Library (.dll)» - Set
code_testerConfiguration Type to «Application (.exe)» - Set projects to x64 and Release mode.
3. Configuring Dynamic-Library to API Independent PE File
Currently, our code_gen is depended on CRT (C Runtime) and Windows Kernel. Follow the steps to make it fully independent.
- Add a .cpp (not .c) file to
code_genand write this basic code in it:extern "C" bool _code() { return true; }
- Go to
code_genproject settings and configure the following options:- Advanced > Use Debug Libraries: No
- Advanced > Whole Program Optimization: No Whole Program Optimization
- C/C++ > General > Debug Information Format: None
- C/C++ > General > SDL checks: No (/sdl-)
- C/C++ > Code Generation > Enable C++ Exceptions: No
- C/C++ > Code Generation > Runtime Library: Multi-threaded (/MT)
- C/C++ > Code Generation > Security Check: Disable Security Check (/GS-)
- C/C++ > Language > Conformance mode: No
- C/C++ > Language > C++ Language Standard: ISO C++17 Standard (/std:c++17)
- Linker > Input > Additional Dependencies: Empty
- Linker > Input > Additional Dependencies > Uncheck Inherit parent or project defaults
- Linker > Input > Ignore All Default Libraries: Yes (/NODEFAULTLIB)
- Linker > Debugging > Generate Debug Info: No
- Linker > Debugging > Generate Map File: Yes (/MAP)
- Linker > Debugging > SubSystem: Native (/SUBSYSTEM:NATIVE)
- Linker > Optimization > References: No (/OPT:NOREF)
- Linker > Advanced > Entry Point: _code
- Linker > Advanced > No Entry Point: Yes (/NOENTRY)
NOTE:
By changing entry point property to _code, we prevent resource only DLL generation, also we tell the compiler not to use CRT entrypoint.
4. Configuring Tester Application
Tester doesn’t need any special configs, currently, we will focus only on code generation, manipulation and execution.
Add a main.cpp file to code_tester and write this basic code in it:
#include <windows.h> #include <iostream> using namespace std; int main() { return EXIT_SUCCESS; }
In the next part of this article, I will teach you how to create applications with your own custom structure.
Alright, now we’re all set and ready! Also, you can download the basic setup source here if you’re a lazy genius kind of person. 
- Download StarterKit source — 3.1 KB
Basic Approach
Let’s start from something small and basic using only math, change the _code function to this:
extern "C" int _code(int x, int y) { return x * y + (x + y); }
Now compile and you should get the DLL, if not… check all the steps again and make sure your configuration is all correct.
)
We only need .dll and .map file, our DLL file contains the assembled x64 machine code and our map file contains information about the addresses used by the linker, but the most important thing inside the map file is the address and offset of our code inside the virtual memory space that our code gets mapped.
- Open code_gen.dll with CFF Explorer.

As you can see, our DLL has no import/export address table (IAT/EAT) and we have only three sections, we don’t need the last two of them, one contains debug directory data and one contains default resources like file version. The code we are looking for is inside .text section which contains machine codes.
The only information we need from section area (PE Viewer) is .text section Virtual Address and Raw Address.
- Open code_gen.dll inside HxD or any other hex editor, Press Ctrl+G or select Search->Goto… and enter the raw address… That’s the code we’re looking for! Pretty easy, right?
C3 opcode means RETURN which shows it’s the end of our function, we don’t need the zero bytes at all.
- Select the bytes and select Edit -> Copy as -> C from menu bar and then paste it inside main.cpp.
The code should look like this:
#include <windows.h> #include <iostream> using namespace std; unsigned char _code_raw[9] = { 0x8D, 0x42, 0x01, 0x0F, 0xAF, 0xC1, 0x03, 0xC2, 0xC3 }; int main() { return EXIT_SUCCESS; }
- Now we should create our function type definition, add this code in global scope:
typedef int(*_code_t)(int, int);
- It’s time to set our raw code access flag to executable so CPU can execute it, add this code in main:
DWORD old_flag; VirtualProtect(_code_raw, sizeof _code_raw, PAGE_EXECUTE_READWRITE, &old_flag); - And the last step is execution which is pretty simple, add this code before return:
_code_t fn_code = (_code_t)(void*)_code_raw; int x = 500; int y = 1200; printf("Result of function : %dn", fn_code(x, y));
- Build
code_testerand run it, Bam! It’s working! Result should look like:
Result of code_tester.exe:
Result of function : 601700

Well, this was a very basic approach without any allocation, encryption/decryption, compression/decompression, etc., but good enough to give you an understanding of what’s happening here.
- Download Basic Approach source — 9.4 KB
Now… let’s go to the next level!
Advanced Approach
In the basic approach, we had the actual code because it was very basic but when it comes to more complex codes like compression, encryption, license checking, etc., it’s not easy like this anymore, code can get its offset at any address in the binary and that’s why we need .map file.
Also in basic approach, we didn’t use any c runtime or Windows API but in the real world, we need them a lot… so we have to solve this issue as well. (Explained in Part 2)
Alright, in this part of the article, we create two shellcodes, one for encrypting buffer and one for decrypting buffer.
- Clone tiny-aes-c repo to your computer, copy only aes.c and aes.h in
code_genproject. - Change the code.cpp to this:
extern "C" { #include "aes.h" bool _encrypt(void* data, size_t size) { return true; } }
NOTE:
You can avoid using extern «C» if you change code.cpp to code.c but you can’t use any C++ feature in future, anyway most of the C++ libraries are based on C and they are all compatible with this method.
tiny-aes-c is based on C language and there’s only some C runtime functions that the compiler will optimize to pure machine codes, this means our shellcode is already heavily optimized by compiler and this is a good thing!
- Write the encryption code like this and don’t use any data on stack, you must not have a .data section in your DLL file after compile, If you do check all the codes and put stack-based data inside the functions.
Here’s the code for encryption:
extern "C" { #include "aes.h" bool _encrypt(void* data, size_t size) { struct AES_ctx ctx; unsigned char key[32] = { 0xBB, 0x17, 0xCA, 0x8C, 0x69, 0x7F, 0xA1, 0x89, 0x3B, 0xCF, 0xA8, 0x12, 0x34, 0x6F, 0xB6, 0xE8, 0x79, 0x89, 0xDA, 0xD0, 0x0B, 0xA9, 0xA1, 0x1B, 0x5B, 0x38, 0xD0, 0x4A, 0x20, 0x4D, 0xB8, 0x0E}; unsigned char iv[16] = { 0xA3, 0xF3, 0xD4, 0xC5, 0x5E, 0xCD, 0x41, 0xA6, 0x22, 0xC9, 0x8D, 0xE5, 0xA3, 0xBB, 0x29, 0xF1}; AES_init_ctx_iv(&ctx, key, iv); AES_CBC_encrypt_buffer(&ctx, (uint8_t*)data, size); return true; } }
- Compile and open code_gen.dll with CFF Explorer:
As you see, there’s a .rdata section added to the DLL, this section is generated by
tiny-aes-cforsboxandrsboxlookup tables and it’s not possible to make the machine code work without these data.Manually merging two sections data and re-addressing every value in the machine code is pretty much hard and needs a lots of time but…
There’s a one-line of magical compiler directive that helps us here! Add the following code at the top of code.cpp:
#pragma comment(linker, "/merge:.rdata=.text") - Compile again and open code_gen.dll with CFF Explorer:
Boom! It’s fixed, now our code directly gets feed from allocated data in lower addresses above itself.
- Open code_gen.dll inside HxD or any other hex editor, Press Ctrl+G or select Search->Goto… and enter the .text section raw address. Press Ctrl+E or select Edit->Select Block… and enter the .text section raw size, then copy the buffer as c array and paste it inside a header file and add it to
code_testerproject like shellcode_encrypter_raw.h and name the array same as file.
NOTE:
For ease of code extraction you can directly right click on the section in CFF Explorer and click on dump section, sometimes it produce extra size so I stick to the manual way.
- Change
code_testermain.cpp file to this:#include <windows.h> #include <stdio.h> #include <fstream> #include <vector> #include "shellcode_encrypter_raw.h" using namespace std; typedef bool(*_encrypt)(void*, size_t); #define ENC_SC_RAW shellcode_encrypter_raw #define FUNCTION_OFFSET 0 int main(int argc, char* argv[]) { if (argc != 4) return EXIT_FAILURE; char* input_file = argv[1]; char* process_mode = argv[2]; char* output_file = argv[3]; DWORD old_flag; VirtualProtect(ENC_SC_RAW, sizeof ENC_SC_RAW, PAGE_EXECUTE_READWRITE, &old_flag); _encrypt encrypt = (_encrypt)(void*)&ENC_SC_RAW[FUNCTION_OFFSET]; ifstream input_file_reader(argv[1], ios::binary); vector<uint8_t> input_file_buffer(istreambuf_iterator<char>(input_file_reader), {}); for (size_t i = 0; i < 16; i++) input_file_buffer.insert(input_file_buffer.begin(), 0x0); for (size_t i = 0; i < 16; i++) input_file_buffer.push_back(0x0); if (strcmp(process_mode, "-e") == 0) encrypt(input_file_buffer.data(), input_file_buffer.size()); fstream file_writter; file_writter.open(output_file, ios::binary | ios::out); file_writter.write((char*)input_file_buffer.data(), input_file_buffer.size()); file_writter.close(); printf("OK"); return EXIT_SUCCESS; }
- Ok, the next step is finding the address offset of
_encryptfunction in the shellcode, open code_gen.map with a text editor. (I use Notepad++.) - Search for
_encryptand you must find this line:0001:000012c0 _encrypt 00000001800022C0 f code.objNow we know our function offset in virtual offset but we need its actual offset, our virtual offset is 0x22C0.
- Head back to the CFF Explorer and check for .text section virtual address which is 0x1000, Now the only thing we need to do is subtract them which gives us 0x12C0 and this is our offset, replace the value inside the code:
#define FUNCTION_OFFSET 0x12C0 - Compile and test it using command line:
code_tester.exe some_image.jpg -e some_image_encrypted.jpg
[ NUCLEAR EXPLOSION ! ]
The result of EXE is OK and the generated file is completely encrypted using AES-256!
- Download Advanced Approach (Encrypter Only) source — 32.7 KB
- Alright, to generate decrypter shellcode, follow the exact steps except:
- Use
AES_CBC_decrypt_bufferinstead ofAES_CBC_encrypt_buffer - Change type definition to this:
typedef bool(*_crypt)(void*, size_t);
Here’s how the main.cpp code should look:
#include <windows.h> #include <stdio.h> #include <fstream> #include <vector> #include "shellcode_encrypter_raw.h" #include "shellcode_decrypter_raw.h" using namespace std; typedef bool(*_crypt)(void*, size_t); #define ENC_SC_RAW shellcode_encrypter_raw #define DEC_SC_RAW shellcode_decrypter_raw #define FUNCTION_OFFSET 0x12C0 int main(int argc, char* argv[]) { if (argc != 4) return EXIT_FAILURE; char* input_file = argv[1]; char* process_mode = argv[2]; char* output_file = argv[3]; if (strcmp(process_mode, "-e") != 0 && strcmp(process_mode, "-d") != 0) return EXIT_FAILURE; DWORD old_flag; VirtualProtect(ENC_SC_RAW, sizeof ENC_SC_RAW, PAGE_EXECUTE_READWRITE, &old_flag); VirtualProtect(DEC_SC_RAW, sizeof DEC_SC_RAW, PAGE_EXECUTE_READWRITE, &old_flag); _crypt encrypt = (_crypt)(void*)&ENC_SC_RAW[FUNCTION_OFFSET]; _crypt decrypt = (_crypt)(void*)&DEC_SC_RAW[FUNCTION_OFFSET]; ifstream input_file_reader(argv[1], ios::binary); vector<uint8_t> input_file_buffer(istreambuf_iterator<char>(input_file_reader), {}); if(strcmp(process_mode, "-d") == 0) goto SKIP_PADDING; for (size_t i = 0; i < 16; i++) input_file_buffer.insert(input_file_buffer.begin(), 0x0); for (size_t i = 0; i < 16; i++) input_file_buffer.push_back(0x0); SKIP_PADDING: if (strcmp(process_mode, "-e") == 0) encrypt(input_file_buffer.data(), input_file_buffer.size()); if (strcmp(process_mode, "-d") == 0) decrypt(input_file_buffer.data(), input_file_buffer.size()); fstream file_writter; file_writter.open(output_file, ios::binary | ios::out); if (strcmp(process_mode, "-e") == 0) file_writter.write((char*)input_file_buffer.data(), input_file_buffer.size()); if (strcmp(process_mode, "-d") == 0) file_writter.write((char*)&input_file_buffer[16], input_file_buffer.size() - 32); file_writter.close(); printf("OK"); return EXIT_SUCCESS; }
- Use
- Compile and test it using command line:
code_tester.exe some_image_encrypted.jpg -d some_image_decrypted.jpg

And that’s it! Now you have two small shellcodes that do the encryption/decryption for you!
You can dispose the code after you used them. Also, you can compress and encrypt them using different keys and decrypt them just on the fly when you need them.
- Download Finished Advanced Approach source — 39.2 KB
Conclusion
This is the end of Part 1. In Part 2, we will create an EXE/DLL packer/protector from scratch using only C++ by the same technique but we get involved in much much complex stuff like resolving, obfuscation, call redirections and etc.
I hope you enjoyed the article. Feel free to ask your questions in the comments.
Stay tuned!
History
- 7th June, 2021: Initial version
In this tutorial, we use Visual Studio 2019 and C++ to generate independent x64 machine code that can be used as shellcode, This operation needs extreme skills, but with this tutorial, you can generate your shellcode very easily…
Introduction
Shellcode is one of the most popular things in attacking and hacking, it’s described in many different ways, but let’s see what Wikipedia says:
Wikipedia:
In hacking, a shellcode is a small piece of code used as the payload in the exploitation of a software vulnerability.
It is called «shellcode» because it typically starts a command shell from which the attacker can control the compromised machine, but any piece of code that performs a similar task can be called shellcode.
Yep. It’s very correct but I describe shellcode as a piece of code that can be allocated and executed dynamically at runtime and it has no dependency on any static API of operating system or programming runtimes.
It may be wrong but this is the best name I could find for what we are going to do in this article, so…
Let’s start!
Background
The reasons I ended up doing this kind of stuff are:
- Improving my programming skills and my understanding of how a computer works
- Improving security of my applications and games
- It’s damn fun!
Yes of course! it can be used for bad and malicious purposes but you know… It’s a sword! Protect or harm… it’s up to you!
By using this technique, you can convert critical parts of your code like license checking to shellcode and encrypt it in your application. When you need to approve a license, you just decrypt the code to a heap-based space and execute it, after you finished, you dispose and release the code from memory… this makes the code harder to debug and prevent static program analysis.
Preparing Project and Environment
1. Required Tools & Software
- Visual Studio 2019
- VC++ Build Tools
- CFF Explorer ( PE Viewer/Editor )
- HxD (Hex Editor)
2. Creating Empty Projects
- Open Visual Studio 2019
- Create two empty C++ projects.
- Name one
code_genand other onecode_tester - Set
code_genConfiguration Type to «Dynamic Library (.dll)» - Set
code_testerConfiguration Type to «Application (.exe)» - Set projects to x64 and Release mode.
3. Configuring Dynamic-Library to API Independent PE File
Currently, our code_gen is depended on CRT (C Runtime) and Windows Kernel. Follow the steps to make it fully independent.
- Add a .cpp (not .c) file to
code_genand write this basic code in it:extern "C" bool _code() { return true; }
- Go to
code_genproject settings and configure the following options:- Advanced > Use Debug Libraries: No
- Advanced > Whole Program Optimization: No Whole Program Optimization
- C/C++ > General > Debug Information Format: None
- C/C++ > General > SDL checks: No (/sdl-)
- C/C++ > Code Generation > Enable C++ Exceptions: No
- C/C++ > Code Generation > Runtime Library: Multi-threaded (/MT)
- C/C++ > Code Generation > Security Check: Disable Security Check (/GS-)
- C/C++ > Language > Conformance mode: No
- C/C++ > Language > C++ Language Standard: ISO C++17 Standard (/std:c++17)
- Linker > Input > Additional Dependencies: Empty
- Linker > Input > Additional Dependencies > Uncheck Inherit parent or project defaults
- Linker > Input > Ignore All Default Libraries: Yes (/NODEFAULTLIB)
- Linker > Debugging > Generate Debug Info: No
- Linker > Debugging > Generate Map File: Yes (/MAP)
- Linker > Debugging > SubSystem: Native (/SUBSYSTEM:NATIVE)
- Linker > Optimization > References: No (/OPT:NOREF)
- Linker > Advanced > Entry Point: _code
- Linker > Advanced > No Entry Point: Yes (/NOENTRY)
NOTE:
By changing entry point property to _code, we prevent resource only DLL generation, also we tell the compiler not to use CRT entrypoint.
4. Configuring Tester Application
Tester doesn’t need any special configs, currently, we will focus only on code generation, manipulation and execution.
Add a main.cpp file to code_tester and write this basic code in it:
#include <windows.h> #include <iostream> using namespace std; int main() { return EXIT_SUCCESS; }
In the next part of this article, I will teach you how to create applications with your own custom structure.
Alright, now we’re all set and ready! Also, you can download the basic setup source here if you’re a lazy genius kind of person.
- Download StarterKit source — 3.1 KB
Basic Approach
Let’s start from something small and basic using only math, change the _code function to this:
extern "C" int _code(int x, int y) { return x * y + (x + y); }
Now compile and you should get the DLL, if not… check all the steps again and make sure your configuration is all correct.
We only need .dll and .map file, our DLL file contains the assembled x64 machine code and our map file contains information about the addresses used by the linker, but the most important thing inside the map file is the address and offset of our code inside the virtual memory space that our code gets mapped.
- Open code_gen.dll with CFF Explorer.
As you can see, our DLL has no import/export address table (IAT/EAT) and we have only three sections, we don’t need the last two of them, one contains debug directory data and one contains default resources like file version. The code we are looking for is inside .text section which contains machine codes.
The only information we need from section area (PE Viewer) is .text section Virtual Address and Raw Address.
- Open code_gen.dll inside HxD or any other hex editor, Press Ctrl+G or select Search->Goto… and enter the raw address… That’s the code we’re looking for! Pretty easy, right?
C3 opcode means RETURN which shows it’s the end of our function, we don’t need the zero bytes at all.
- Select the bytes and select Edit -> Copy as -> C from menu bar and then paste it inside main.cpp.
The code should look like this:
#include <windows.h> #include <iostream> using namespace std; unsigned char _code_raw[9] = { 0x8D, 0x42, 0x01, 0x0F, 0xAF, 0xC1, 0x03, 0xC2, 0xC3 }; int main() { return EXIT_SUCCESS; }
- Now we should create our function type definition, add this code in global scope:
typedef int(*_code_t)(int, int);
- It’s time to set our raw code access flag to executable so CPU can execute it, add this code in main:
DWORD old_flag; VirtualProtect(_code_raw, sizeof _code_raw, PAGE_EXECUTE_READWRITE, &old_flag); - And the last step is execution which is pretty simple, add this code before return:
_code_t fn_code = (_code_t)(void*)_code_raw; int x = 500; int y = 1200; printf("Result of function : %dn", fn_code(x, y));
- Build
code_testerand run it, Bam! It’s working! Result should look like:
Result of code_tester.exe:
Result of function : 601700
Well, this was a very basic approach without any allocation, encryption/decryption, compression/decompression, etc., but good enough to give you an understanding of what’s happening here.
- Download Basic Approach source — 9.4 KB
Now… let’s go to the next level!
Advanced Approach
In the basic approach, we had the actual code because it was very basic but when it comes to more complex codes like compression, encryption, license checking, etc., it’s not easy like this anymore, code can get its offset at any address in the binary and that’s why we need .map file.
Also in basic approach, we didn’t use any c runtime or Windows API but in the real world, we need them a lot… so we have to solve this issue as well. (Explained in Part 2)
Alright, in this part of the article, we create two shellcodes, one for encrypting buffer and one for decrypting buffer.
- Clone tiny-aes-c repo to your computer, copy only aes.c and aes.h in
code_genproject. - Change the code.cpp to this:
extern "C" { #include "aes.h" bool _encrypt(void* data, size_t size) { return true; } }
NOTE:
You can avoid using extern «C» if you change code.cpp to code.c but you can’t use any C++ feature in future, anyway most of the C++ libraries are based on C and they are all compatible with this method.
tiny-aes-c is based on C language and there’s only some C runtime functions that the compiler will optimize to pure machine codes, this means our shellcode is already heavily optimized by compiler and this is a good thing!
- Write the encryption code like this and don’t use any data on stack, you must not have a .data section in your DLL file after compile, If you do check all the codes and put stack-based data inside the functions.
Here’s the code for encryption:
extern "C" { #include "aes.h" bool _encrypt(void* data, size_t size) { struct AES_ctx ctx; unsigned char key[32] = { 0xBB, 0x17, 0xCA, 0x8C, 0x69, 0x7F, 0xA1, 0x89, 0x3B, 0xCF, 0xA8, 0x12, 0x34, 0x6F, 0xB6, 0xE8, 0x79, 0x89, 0xDA, 0xD0, 0x0B, 0xA9, 0xA1, 0x1B, 0x5B, 0x38, 0xD0, 0x4A, 0x20, 0x4D, 0xB8, 0x0E}; unsigned char iv[16] = { 0xA3, 0xF3, 0xD4, 0xC5, 0x5E, 0xCD, 0x41, 0xA6, 0x22, 0xC9, 0x8D, 0xE5, 0xA3, 0xBB, 0x29, 0xF1}; AES_init_ctx_iv(&ctx, key, iv); AES_CBC_encrypt_buffer(&ctx, (uint8_t*)data, size); return true; } }
- Compile and open code_gen.dll with CFF Explorer:
As you see, there’s a .rdata section added to the DLL, this section is generated by
tiny-aes-cforsboxandrsboxlookup tables and it’s not possible to make the machine code work without these data.Manually merging two sections data and re-addressing every value in the machine code is pretty much hard and needs a lots of time but…
There’s a one-line of magical compiler directive that helps us here! Add the following code at the top of code.cpp:
#pragma comment(linker, "/merge:.rdata=.text") - Compile again and open code_gen.dll with CFF Explorer:
Boom! It’s fixed, now our code directly gets feed from allocated data in lower addresses above itself.
- Open code_gen.dll inside HxD or any other hex editor, Press Ctrl+G or select Search->Goto… and enter the .text section raw address. Press Ctrl+E or select Edit->Select Block… and enter the .text section raw size, then copy the buffer as c array and paste it inside a header file and add it to
code_testerproject like shellcode_encrypter_raw.h and name the array same as file.
NOTE:
For ease of code extraction you can directly right click on the section in CFF Explorer and click on dump section, sometimes it produce extra size so I stick to the manual way.
- Change
code_testermain.cpp file to this:#include <windows.h> #include <stdio.h> #include <fstream> #include <vector> #include "shellcode_encrypter_raw.h" using namespace std; typedef bool(*_encrypt)(void*, size_t); #define ENC_SC_RAW shellcode_encrypter_raw #define FUNCTION_OFFSET 0 int main(int argc, char* argv[]) { if (argc != 4) return EXIT_FAILURE; char* input_file = argv[1]; char* process_mode = argv[2]; char* output_file = argv[3]; DWORD old_flag; VirtualProtect(ENC_SC_RAW, sizeof ENC_SC_RAW, PAGE_EXECUTE_READWRITE, &old_flag); _encrypt encrypt = (_encrypt)(void*)&ENC_SC_RAW[FUNCTION_OFFSET]; ifstream input_file_reader(argv[1], ios::binary); vector<uint8_t> input_file_buffer(istreambuf_iterator<char>(input_file_reader), {}); for (size_t i = 0; i < 16; i++) input_file_buffer.insert(input_file_buffer.begin(), 0x0); for (size_t i = 0; i < 16; i++) input_file_buffer.push_back(0x0); if (strcmp(process_mode, "-e") == 0) encrypt(input_file_buffer.data(), input_file_buffer.size()); fstream file_writter; file_writter.open(output_file, ios::binary | ios::out); file_writter.write((char*)input_file_buffer.data(), input_file_buffer.size()); file_writter.close(); printf("OK"); return EXIT_SUCCESS; }
- Ok, the next step is finding the address offset of
_encryptfunction in the shellcode, open code_gen.map with a text editor. (I use Notepad++.) - Search for
_encryptand you must find this line:0001:000012c0 _encrypt 00000001800022C0 f code.objNow we know our function offset in virtual offset but we need its actual offset, our virtual offset is 0x22C0.
- Head back to the CFF Explorer and check for .text section virtual address which is 0x1000, Now the only thing we need to do is subtract them which gives us 0x12C0 and this is our offset, replace the value inside the code:
#define FUNCTION_OFFSET 0x12C0 - Compile and test it using command line:
code_tester.exe some_image.jpg -e some_image_encrypted.jpg
[ NUCLEAR EXPLOSION ! ]
The result of EXE is OK and the generated file is completely encrypted using AES-256!
- Download Advanced Approach (Encrypter Only) source — 32.7 KB
- Alright, to generate decrypter shellcode, follow the exact steps except:
- Use
AES_CBC_decrypt_bufferinstead ofAES_CBC_encrypt_buffer - Change type definition to this:
typedef bool(*_crypt)(void*, size_t);
Here’s how the main.cpp code should look:
#include <windows.h> #include <stdio.h> #include <fstream> #include <vector> #include "shellcode_encrypter_raw.h" #include "shellcode_decrypter_raw.h" using namespace std; typedef bool(*_crypt)(void*, size_t); #define ENC_SC_RAW shellcode_encrypter_raw #define DEC_SC_RAW shellcode_decrypter_raw #define FUNCTION_OFFSET 0x12C0 int main(int argc, char* argv[]) { if (argc != 4) return EXIT_FAILURE; char* input_file = argv[1]; char* process_mode = argv[2]; char* output_file = argv[3]; if (strcmp(process_mode, "-e") != 0 && strcmp(process_mode, "-d") != 0) return EXIT_FAILURE; DWORD old_flag; VirtualProtect(ENC_SC_RAW, sizeof ENC_SC_RAW, PAGE_EXECUTE_READWRITE, &old_flag); VirtualProtect(DEC_SC_RAW, sizeof DEC_SC_RAW, PAGE_EXECUTE_READWRITE, &old_flag); _crypt encrypt = (_crypt)(void*)&ENC_SC_RAW[FUNCTION_OFFSET]; _crypt decrypt = (_crypt)(void*)&DEC_SC_RAW[FUNCTION_OFFSET]; ifstream input_file_reader(argv[1], ios::binary); vector<uint8_t> input_file_buffer(istreambuf_iterator<char>(input_file_reader), {}); if(strcmp(process_mode, "-d") == 0) goto SKIP_PADDING; for (size_t i = 0; i < 16; i++) input_file_buffer.insert(input_file_buffer.begin(), 0x0); for (size_t i = 0; i < 16; i++) input_file_buffer.push_back(0x0); SKIP_PADDING: if (strcmp(process_mode, "-e") == 0) encrypt(input_file_buffer.data(), input_file_buffer.size()); if (strcmp(process_mode, "-d") == 0) decrypt(input_file_buffer.data(), input_file_buffer.size()); fstream file_writter; file_writter.open(output_file, ios::binary | ios::out); if (strcmp(process_mode, "-e") == 0) file_writter.write((char*)input_file_buffer.data(), input_file_buffer.size()); if (strcmp(process_mode, "-d") == 0) file_writter.write((char*)&input_file_buffer[16], input_file_buffer.size() - 32); file_writter.close(); printf("OK"); return EXIT_SUCCESS; }
- Use
- Compile and test it using command line:
code_tester.exe some_image_encrypted.jpg -d some_image_decrypted.jpg
And that’s it! Now you have two small shellcodes that do the encryption/decryption for you!
You can dispose the code after you used them. Also, you can compress and encrypt them using different keys and decrypt them just on the fly when you need them.
- Download Finished Advanced Approach source — 39.2 KB
Conclusion
This is the end of Part 1. In Part 2, we will create an EXE/DLL packer/protector from scratch using only C++ by the same technique but we get involved in much much complex stuff like resolving, obfuscation, call redirections and etc.
I hope you enjoyed the article. Feel free to ask your questions in the comments.
Stay tuned!
History
- 7th June, 2021: Initial version
![]()
Сообщение от Волосатый

вызвать програму которая написана в команде и…и…и вот тут я стопарюсь-как это сделать?
У вас команда состоит из вызова двух программ. Тут задача шелла в том, чтобы разбить команду на вызовы отдельных программ и выполнить их, перенаправив потоки ввода/вывода.
Например, символ ‘|’ обозначает, что весь вывод программы, вызов которой расположен слева, должен быть перенаправлен на ввод программы, вызов которой расположен справа. А символ ‘>’ обозначает, что весь вывод программы, вызов которой расположен слева, направляется в файл, имя которого расположено справа (с перезаписью при запуске).
Но имейте в виду, что этот синтаксис не является обязательным. Он стандартен и ожидаем, да, но тем не менее, никто не запретит вам реализовать шелл со своим собственным синтаксисом перенаправления потоков.
![]()
Сообщение от Волосатый
я не знаю как мой сшел должен вызывать программы
Спарсить команду, вычленить из нее командные строки каждой из вызываемых программ (у вас это две строки «find tmp/ -mindepth 1 -a -print0» и «xargs -n 100 -0 rm -rf»), запустить эти программы, связав соответствующим образом их потоки ввода/вывода (у вас это перенаправление вывода первой программы на ввод второй), дождаться завершения работы программ и вывести новое приглашение.
![]()
Сообщение от Волосатый
например командой «cd home» переходить по каталогу
Тут просто. Получив команду «cd /path/to/directory» нужно просто сменить текущий каталог на «/path/to/directory», не забыв при этом обработать спецсимвол «~» и переменные окружения, если таковые имеются.