В одной из статей было рассказано, как создать свой собственный виртуальный Forth-процессор, пригодный для исполнения некоторых команд, упрощающих процесс создания компиляторов/интерпретаторов стековых языков программирования. В этой же статье была продемонстрирована простейшая программа в форме шестнадцатеричных кодов, которые легко понимаются эмулятором того самого виртуального процессора, но написание более сложных программ (даже простейших нетривиальных процедур) является крайне сложным процессом.
В этот раз попробуем упростить написание программ для J1, используя предложение из той самой статьи о написании собственного ассемблера…
Создание ассемблера крайне трудоемкое дело, но только не в нашем случае: у нас слишком простой процессор — именно под такой мотивацией мы и будем создавать ассемблер, который будет транслировать некоторое подобие ассемблерных команд (они называются ассемблерным мнемониками или просто мнемониками) в их шестнадцатеричное представление, которое мы будем записывать в некоторый удобный файловый формат для последующего запуска.
Для начала создадим удобный синтаксис нашего ассемблера с учетом того, что этот синтаксис должен легко читаться, а также легко интерпретироваться транслятором. Обеспечивая минимальное множество поддерживаемых команд, которое при необходимости может быть расширено, синтаксис ассемблера будет выглядеть так:
<мнемоника_1>
<мнемоника_2>
...
tag <имя_метки_1>
<мнемоника_1>
<мнемоника_2>
...
<имя процедуры>:
<мнемоника_1>
<мнемоника_2>
...
В таком ассемблере поддерживаются базовые мнемоники, которые обеспечивают исполнение минимальных инструкций процессора J1, условные/безусловные переходы на некоторую именованную метку, создание и вызов именновых процедур и размещение литералов в стек. Данные особенности транслятора освобождают от необходимости вручную расчитывать адреса переходов и размещения процедур, поскольку именование меток/процедур обеспечивает сокрытие адресов от программиста ценой невозможности ручного указания передачи управления по адресу (хотя это не особо и проблема: при необходимости можно добавить и интерпретацию числовых адресов вместо меток).
В ассемблере будут поддерживаться следующие инструкции:
nop нет операции add сложение xor исключающее или and побитовое и or побитовое или invert побитовое инвертирование eq равенство lt меньше ult беззнаковое меньше swap обмен значений стека dup дублирование вершины стека drop удалить вершину стека over поместить на вершину предпоследнее число из стека nip удаление предпоследнего числа из стека pushr поместить вершину стека данных в стек вызовов popr поместить вершину стека вызовов в стек данных load загрузить в стек значение из ячейки памяти store сохранить в ячейку памяти значение из стека dsp глубина стека данных lsh сдвиг влево rsh сдвиг вправо decr декремент up увеличить указатель стека данных на 1 down уменьшить указатель стека данных на 1 copy копирование halt останов процессора
Теперь приступим к реализации ассемблера и для начала определим необходимые «заимствования» из стандартной библиотеки и ряд псевдонимов для описания предметной области ассемблера:
import std.algorithm; import std.conv; import std.range; import std.stdio; import std.string; alias Instruction = ushort; alias Command = Instruction[]; alias TranslationTable = Command[string]; enum TranslationTable MNEMONICS = [ "nop" : [0x6000], "add" : [0x6202], "xor" : [0x6502], "and" : [0x6302], "or": [0x6402], "invert" : [0x6600], "eq" : [0x6702], "lt" : [0x6802], "ult" : [0x6f02], "swap" : [0x6180], "dup" : [0x6081], "drop" : [0x6102], "over" : [0x6181], "nip" : [0x6002], "pushr" : [0x6146], "popr" : [0x6b89], "load" : [0x6c00], "store" : [0x6022, 0x6102], "dsp" : [0x6e81], "lsh" : [0x6d02], "rsh" : [0x6902], "decr" : [0x6a00], "up" : [0x6001], "down" : [0x6002], "copy" : [0x6100], "halt": [0xffff] ]; alias Name = string; alias Address = ushort; alias JumpTable = Address[Name];
Псевдонимы обьеспечивают удобство для обозначения таких понятий как инструкция (т.е элементарная шестнадцатеричная команда J1), команда (т.е ряд последовательных шестнадцатеричных инструкций), а также трансляционную таблицу (таблица, которая определяет в какую последовательность инструкций транслируется каждая из поддерживаемых мнемоник). Также, мы определяем три псевдонима, которые будут описывать таблицу переходов по меткам/процедурам.
Алгоритм транслятора очень прост: загружаем исходный текст программы на ассемблере в транслятор, выполняем обработку исходного текста, заменяя мнемоники ассемблера на шестнадцатеричные команды и обрабатывая инструкции условного/безусловного перехода (заменяем эти команды заранее вычисленными шестнадцатеричными значениями), выполнив все подстановки и вычисления, сохраняем результат в файл в удобном формате.
Для выполнения намеченного алгоритма на первом этапе нужно выполнить своеобразное препроцессирование файла, вычислив адреса именнованных меток и адреса именованных процедур, поскольку необходимые «теги» (так условно назовем имена процедур/меток) могут встречаться как в начале файла с исходным кодом, так и в его конце, а это может усложнить процесс трансляции файла. Препроцессирование в этом случае будет означать генерирование таблицы переходов, которая представляет собой ассоциативный массив, в котором роль ключей будут выполнять «теги», а в роли значений — адреса «тегов». Генерирование таблицы переходов выглядит так: поскольку каждая команда ассемблера расположена с новой строки (это по сути дела обязательный элемент синтаксиса ассемблера), то сначала выполняется разбиение листинга на строки и инициализация счетчика адресов нулем. Далее, идет просмотр списка строк с постепенным увеличением на 1 счетчика адресов в том случае, если встреченная строка содержит или мнемонику или элементарную инструкцию (у нас 4 таких инструкции: push/jmp/jz/call), в противном же случае — увеличение счетчика адресов не произойдет, но может произойти добавление «тега» в таблицу переходов на основании его типа (т.е добавление адресов именованной метки отличается о добавления именованной процедуры). В остальных случаях препроцессирование игнорирует увеличение счетчика адресов, считая, что строка в таких случаях не несет никакой смысловой нагрузки. Также важный момент: приращение счетчика адреса в случае наличия мнемоники в трансляционной таблице осуществляется не на единицу, а на длину (т.е на количество элементарных шестнадцатеричных команд) мнемоники в инструкциях.
Код всей процедуры выглядит так:
// подготовка таблицы переходов
auto createJumpTable(string assemblerListing, ref JumpTable table)
{
string[] preparedListing = assemblerListing.strip.splitLines;
Address address = 0;
foreach (assemblerMnemonic; preparedListing)
{
string mnemonic = assemblerMnemonic.strip.split[0].strip;
// обработка управляющих инструкций
if ((mnemonic == "push" ) || (mnemonic == "jmp" ) || (mnemonic == "jz" ) || (mnemonic == "call" ))
{
address++;
}
// обработка процедур
if (mnemonic.endsWith(":"))
{
string procedureName = mnemonic[0..$-1];
table[procedureName] = address;
}
// обработка меток
if (mnemonic == "tag")
{
string tagName = assemblerMnemonic.strip.split[1].strip;
table[tagName] = address;
}
// обработка обычных инструкций
if (mnemonic in MNEMONICS)
{
address += MNEMONICS[mnemonic].length;
}
}
}
Следующий шаг ассемблера после получения таблицы переходов — это выполнение генерации последовательности шестнадцатеричных команд на основе таблицы переходов. Разбор ассемблерного листинга осуществляется следующим образом: производится разбиение исходного листинга на массив строк, далее из каждой строки извлекается мнемоника и/или базовая команда и ее аргумент, после чего происходит поиск мнемоники в трансляционной таблице и выборка из нее нужного кода и помещение его в массив шестнадцатеричных команд (т.е в итоговый результат ассемблерования). В случае, если окажется что мнемоника представляет собой одну из элементарных инструкций, то произойдет разбор инструкции и превращение ее в одну шестнадцатеричную команду, а дальнейшие операции совпадают с описанным ранее случаем.
Выглядит трансляция в шестнадцатеричные коды вот так:
// транслировать в шестнадцатеричные коды
auto toAssemblerCodes(string assemblerListing, JumpTable table)
{
Command command;
string mnemonic, argument;
string[] preparedListing = assemblerListing.strip.splitLines;
foreach (assemblerMnemonic; preparedListing)
{
mnemonic = assemblerMnemonic.strip.split[0].strip;
if (assemblerMnemonic.strip.split.length > 1)
{
argument = assemblerMnemonic.strip.split[1].strip;
}
else
{
argument = "";
}
switch (mnemonic)
{
case "push":
command ~= 0x8000 | to!Instruction(argument);
break;
case "jmp":
command ~= 0x0000 | table[argument];
break;
case "jz":
command ~= 0x2000 | table[argument];
break;
case "call":
command ~= 0x4000 | table[argument];
break;
case "ret":
auto lastCommand = command[$-1];
command[$-1] = 0x1000 | lastCommand;
break;
default:
break;
}
if (mnemonic in MNEMONICS)
{
command ~= MNEMONICS[mnemonic];
}
}
return command;
}
Теперь самое интересное: нас интересует итоговый набор шестнадцатеричных кодов после ассемблирования необходимо преобразовать в файл удобного формата.
Помните, в статье про J1 я упоминал про то, что существуют и аппаратные его реализации в виде прпоектов для FPGA/ASIC ?
Файл удобного формата был бы очень кстати, если бы предполагалась загрузка кодов процессора прямо в плату FPGA, и тут стоит вспомнить то, что J1 работает с памятью некоторого размера и не имеет портов ввода/вывода. Это обстоятельство позволяет предположить, что тут удобнее всего был файл, который представляет собой нечто вроде слепка памяти, который можно напрямую загрузить в плату. Именно такие раздумья меня привели к поиску максимально простого формата файла, который легко бы разбирался и при этом его можно было бы напрямую загрузить в плату (хотя я таким и не занимался)…
К счастью, формат нашелся и называется он Memory Initialization File (или сокращенно MIF). Используется данный формат для инициализации модулей памяти, которые работают внутри FPGA плат фирмы Altera (кстати, уже давно эта контора является подразделением компании Intel) и он очень простой — это текстовой файл (не бинарный) с простым человекочитаемым заголовком и его очень просто разбирать.
Вот примерно так выглядит этот файл:
-- Quartus II generated Memory Initialization File (.mif) WIDTH=<ширина значений, помещаемых в память>; DEPTH=<количество значений>; ADDRESS_RADIX=HEX; DATA_RADIX=HEX; CONTENT BEGIN <первый адрес> : <значение>; ... <последний адрес> : <значение>; END;
В нашем случае, WIDTH=16 (так как у нас 16-битные значения), DEPTH=16384 (так как у нас память включает в себя именно столько значений), ADRESS_RADIX и DATA_RADIX указывают на то в каком формате будут указаны адреса и значения, в нашем случае это шестнадцатеричные коды из 4х цифр.
Реализация записи полученных шестнадцатеричных команд в альтеровский файл инициализации памяти может быть описана следующим образом:
// превратить в файл инициализации Альтеры
auto toMIF(Command command, string filename, ushort depth = 16_384)
{
enum string HEADER =
`-- Quartus II generated Memory Initialization File (.mif)
WIDTH=16;
DEPTH=%d;
ADDRESS_RADIX=HEX;
DATA_RADIX=HEX;
CONTENT BEGIN
`;
while (command.length < depth)
{
command ~= cast(ushort) 0xFFFF;
}
File file;
file.open(filename, "w");
file.writef(HEADER, depth);
for (ushort i = 0; i < command.length; i++)
{
string index = format("%0.4x", i).toUpper;
string data = format("%0.4x", command[i]).toUpper;
file.writefln("t%s : %s;", index, data);
}
file.write("END;");
}
Объединить процедуры в единый механизм транслятора, который будет обрабатывать произвольный файл с листингом и записывать в любой иной файл можно следующим образом (не претендуя на полноту реализации, конечно):
import std.algorithm;
import std.conv;
import std.range;
import std.stdio;
import std.string;
alias Instruction = ushort;
alias Command = Instruction[];
alias TranslationTable = Command[string];
enum TranslationTable MNEMONICS = [
"nop" : [0x6000],
"add" : [0x6202],
"xor" : [0x6502],
"and" : [0x6302],
"or": [0x6402],
"invert" : [0x6600],
"eq" : [0x6702],
"lt" : [0x6802],
"ult" : [0x6f02],
"swap" : [0x6180],
"dup" : [0x6081],
"drop" : [0x6102],
"over" : [0x6181],
"nip" : [0x6002],
"pushr" : [0x6146],
"popr" : [0x6b89],
"load" : [0x6c00],
"store" : [0x6022, 0x6102],
"dsp" : [0x6e81],
"lsh" : [0x6d02],
"rsh" : [0x6902],
"decr" : [0x6a00],
"up" : [0x6001],
"down" : [0x6002],
"copy" : [0x6100],
"halt": [0xffff]
];
alias Name = string;
alias Address = ushort;
alias JumpTable = Address[Name];
// подготовка таблицы переходов
auto createJumpTable(string assemblerListing, ref JumpTable table)
{
string[] preparedListing = assemblerListing.strip.splitLines;
Address address = 0;
foreach (assemblerMnemonic; preparedListing)
{
string mnemonic = assemblerMnemonic.strip.split[0].strip;
// обработка управляющих инструкций
if ((mnemonic == "push" ) || (mnemonic == "jmp" ) || (mnemonic == "jz" ) || (mnemonic == "call" ))
{
address++;
}
// обработка процедур
if (mnemonic.endsWith(":"))
{
string procedureName = mnemonic[0..$-1];
table[procedureName] = address;
}
// обработка меток
if (mnemonic == "tag")
{
string tagName = assemblerMnemonic.strip.split[1].strip;
table[tagName] = address;
}
// обработка обычных инструкций
if (mnemonic in MNEMONICS)
{
address += MNEMONICS[mnemonic].length;
}
}
}
// транслировать в шестнадцатеричные коды
auto toAssemblerCodes(string assemblerListing, JumpTable table)
{
Command command;
string mnemonic, argument;
string[] preparedListing = assemblerListing.strip.splitLines;
foreach (assemblerMnemonic; preparedListing)
{
mnemonic = assemblerMnemonic.strip.split[0].strip;
if (assemblerMnemonic.strip.split.length > 1)
{
argument = assemblerMnemonic.strip.split[1].strip;
}
else
{
argument = "";
}
switch (mnemonic)
{
case "push":
command ~= 0x8000 | to!Instruction(argument);
break;
case "jmp":
command ~= 0x0000 | table[argument];
break;
case "jz":
command ~= 0x2000 | table[argument];
break;
case "call":
command ~= 0x4000 | table[argument];
break;
case "ret":
auto lastCommand = command[$-1];
command[$-1] = 0x1000 | lastCommand;
break;
default:
break;
}
if (mnemonic in MNEMONICS)
{
command ~= MNEMONICS[mnemonic];
}
}
return command;
}
// превратить в файл инициализации Альтеры
auto toMIF(Command command, string filename, ushort depth = 16_384)
{
enum string HEADER =
`-- Quartus II generated Memory Initialization File (.mif)
WIDTH=16;
DEPTH=%d;
ADDRESS_RADIX=HEX;
DATA_RADIX=HEX;
CONTENT BEGIN
`;
while (command.length < depth)
{
command ~= cast(ushort) 0xFFFF;
}
File file;
file.open(filename, "w");
file.writef(HEADER, depth);
for (ushort i = 0; i < command.length; i++)
{
string index = format("%0.4x", i).toUpper;
string data = format("%0.4x", command[i]).toUpper;
file.writefln("t%s : %s;", index, data);
}
file.write("END;");
}
void main(string[] args)
{
import std.file;
auto assemblerListing = cast(string) std.file.read(args[1]);
JumpTable jumps;
createJumpTable(assemblerListing, jumps);
assemblerListing.toAssemblerCodes(jumps).toMIF(args[2]);
}
Теперь для испытаний напишем простой цикл для J1 c помощью которого выполним умножение двух чисел:
push 5 push 5000 store jmp cycle multiply: add ret tag cycle push 1024 call multiply push 5000 load decr dup jz end push 5000 store jmp cycle tag end halt
Что происходит в ассемблерном листинге ?
Для начала размещаем число 5 в ячейке памяти по адресу 5000 (число 5 — это второй множитель) и осуществляем переход на метку cycle, где начинается весь основной цикл. После перехода размещаем первый множитель — число 1024 в стеке, после чего вызываем процедуру умножения (она просто осуществляет сложение двух чисел в стеке, но будет вызывана несколько раз, что и приведет к получению результата умножения), затем размещаем адрес первого множителя в стеке (это число 5000), затем используем адрес для загрузки значения из памяти в стек, выполняем уменьшение на единицу загруженного значения, выполняем дублирование уменьшенного значения, команда jz выполняет сравнение значения на стеке с 0, и если сравнение было успешным, то выполняется переход на метку end (т.е выполянется переход на условие окончания программы). Если переход не удался, то выполняется следующая за jz инструкция, т.о после этого мы помещаем в стек число 5000 (адрес ячейки памяти со вторым множителем) и выполняем переход на метку cycle. Переход на метку cycle фактически дает бесконечный цикл, единственным условием выхода из которого служит наличие нуля на вершине стека — данное условие проверяется инструкцией jz, а конечным сам цикл делает уменьшение на единицу значения ячейки памяти с последующим размещением этого значения в стеке и дублированием его. Дублирование в нашем случае нужно для того, что значение могло быть использовано для последующего выполнения перехода на условие окончание, которым является служебная команда halt.
Прежде чем проводить испытания данного кода, нам потребуется исходный код эмулятора J1, которы можно взять из статьи про виртуальный процессор. Также необходимо внести правку в один из методов класса J1_CPU, а именно в метод executeProgram:
void executeProgram()
{
// 0xffff = HALT
while (RAM[programCounter] != 0xffff)
{
writefln("{pc : %d, instruction : %0.4x}", programCounter, RAM[programCounter]);
// RAM.toMIF("dump.mif");
execute(RAM[programCounter]);
print;
}
}
правка небольшая и обеспечивает несколько иную интерпретацию команды halt, которая теперь имеет шестнадцатеричный код 0xffff (также можно раскоментировать закоментированную строку, чтобы в конце работы программы иметь дамп памяти процессора в удобном виде, правда для этого необходимо скопировать процедуру toMIF из исходных кодов ассемблера). После этого добавляем процедуру загрузки MIF-файла и модифицируем процедуру main для того, чтобы запускать программу, заключенную в MIF-файле:
auto fromMIF(string filename)
{
ushort[16_384] commands;
auto content = cast(string) std.file.read(filename);
auto begin = content.indexOf("CONTENT BEGIN") + "CONTENT BEGIN".length;
auto end = content.indexOf("END;");
content = content[begin..end].strip;
foreach (index, line; content.splitLines)
{
auto separatorIndex = line.indexOf(":") + 1;
auto dataLine = line[separatorIndex..$-1].strip.toLower;
commands[index] = parse!ushort(dataLine, 16);
}
return commands;
}
void main(string[] args)
{
J1_CPU j1 = new J1_CPU;
uint16[16_384] ram = fromMIF(args[1]);
j1.setMemory(ram);
j1.executeProgram;
}
Теперь можно запускать J1 с описанной выше ассемблерной программой, которая дает вот такой результат:
{pc : 0, instruction : 8005}
[rs] : [0, 5, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 1, instruction : 9388}
[rs] : [0, 5, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 2, instruction : 6022}
[rs] : [0, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 3, instruction : 6102}
[rs] : [0, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 4, instruction : 0006}
[rs] : [0, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [0, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [0, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [1024, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [1024, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [1024, 5, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [1024, 4, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [1024, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [1024, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 13, instruction : 9388}
[rs] : [1024, 4, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 14, instruction : 6022}
[rs] : [1024, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 15, instruction : 6102}
[rs] : [1024, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 16, instruction : 0006}
[rs] : [1024, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [1024, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [1024, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [2048, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [2048, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [2048, 4, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [2048, 3, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [2048, 3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [2048, 3, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 13, instruction : 9388}
[rs] : [2048, 3, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 14, instruction : 6022}
[rs] : [2048, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 15, instruction : 6102}
[rs] : [2048, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 16, instruction : 0006}
[rs] : [2048, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [2048, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [2048, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [3072, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [3072, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [3072, 3, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [3072, 2, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [3072, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [3072, 2, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 13, instruction : 9388}
[rs] : [3072, 2, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 14, instruction : 6022}
[rs] : [3072, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 15, instruction : 6102}
[rs] : [3072, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 16, instruction : 0006}
[rs] : [3072, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [3072, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [3072, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [4096, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [4096, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [4096, 2, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [4096, 1, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [4096, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [4096, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 13, instruction : 9388}
[rs] : [4096, 1, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 14, instruction : 6022}
[rs] : [4096, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 15, instruction : 6102}
[rs] : [4096, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 16, instruction : 0006}
[rs] : [4096, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 6, instruction : 8400}
[rs] : [4096, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 7, instruction : 4005}
[rs] : [4096, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 5, instruction : 7202}
[rs] : [5120, 1024, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 8, instruction : 9388}
[rs] : [5120, 5000, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 9, instruction : 6c00}
[rs] : [5120, 1, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 10, instruction : 6a00}
[rs] : [5120, 0, 5000, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 11, instruction : 6081}
[rs] : [5120, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
{pc : 12, instruction : 2011}
[rs] : [5120, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
[rs] : [0, 8, 8, 8, 8, 8, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Итак, в этой статье был описан простейший вариант ассемблера для виртуального процессора, который транслирует программу в файл инициализации памяти. Данный ассемблер дает код, который может быть пригоден для записи в память, которую можно сформировать внутри FPGA платы фирмы Altera. Конечно, не стоит рассчитывать на то, что описанный транслятор совершенен и что он пригоден для реальных боевых задач. Многое можно улучшить как в коде ассемблерного транслятора, так и в функционале (например можно добавить макродирективы и расширить набор команд), также многим может показаться, что мы напрямую привязаны к платам Altera, но весь приведенный код является экспериментальным и может быть именно вы, наш, читатель сможете внести свой вклад в его улучшение.
Напоследок прикладываю полный код процессора J1 с модификациями:
import std.conv : to;
// 16-разрядное беззнаковое целое
alias int16 = short;
// 16-разрядное беззнаковое целое
alias uint16 = ushort;
class J1_CPU
{
private
{
enum RAM_SIZE = 16_384;
// стек данных
uint16[33] dataStack;
// стек вызовов
uint16[32] returnStack;
// память
uint16[RAM_SIZE] RAM;
// указатель на вершину стека данных
int16 dataPointer;
// указатель на вершину стека вызовов
int16 returnPointer;
// счетчик инструкций
uint16 programCounter;
// маски для различения типов инструкций j1
enum J1_INSTRUCTION : uint16
{
JMP = 0x0000,
JZ = 0x2000,
CALL = 0x4000,
ALU = 0x6000,
LIT = 0x8000
};
// маски для различения аргументов инструкций j1
enum J1_DATA : uint16
{
LITERAL = 0x7fff,
TARGET = 0x1fff
};
// исполнение команд АЛУ
auto executeALU(uint16 instruction)
{
uint16 q;
uint16 t;
uint16 n;
uint16 r;
// вершина стека
if (dataPointer > 0)
{
t = dataStack[dataPointer];
}
// элемент под вершиной стека
if (dataPointer > 0)
{
n = dataStack[dataPointer - 1];
}
// предыдущий адрес возврата
if (returnPointer > 0)
{
r = returnStack[returnPointer - 1];
}
// увеличить счетчик инструкций
programCounter++;
// извлечение кода операции АЛУ
uint16 operationCode = (instruction & 0x0f00) >> 8;
// опознание операций
switch (operationCode)
{
case 0:
q = t;
break;
case 1:
q = n;
break;
case 2:
q = to!uint16(t + n);
break;
case 3:
q = t & n;
break;
case 4:
q = t | n;
break;
case 5:
q = t ^ n;
break;
case 6:
q = to!uint16(~to!int(t));
break;
case 7:
q = (t == n) ? 1u : 0u;
break;
case 8:
q = (to!int16(n) < to!int16(t)) ? 1u : 0u; break; case 9: q = n >> t;
break;
case 10:
q = to!uint16(t - 1u);
break;
case 11:
q = returnStack[returnPointer];
break;
case 12:
q = RAM[t];
break;
case 13:
q = to!uint16(n << t);
break;
case 14:
q = to!uint16(dataPointer + 1u);
break;
case 15:
q = (n < t) ? 1u : 0u; break; default: break; } // код действия с указателем на стек данных // (+1 - увеличить указатель, 0 - не трогать, -1 уменьшить (= 2 в двоичном коде)) uint16 ds = instruction & 0x0003; // код действия с указателем на стек возвратов // (+1 - увеличить указатель, 0 - не трогать, -1 уменьшить (= 2 в двоичном коде)) uint16 rs = (instruction & 0x000c) >> 2;
switch (ds)
{
case 1:
dataPointer++;
break;
case 2:
dataPointer--;
break;
default:
break;
}
switch (rs)
{
case 1:
returnPointer++;
break;
case 2:
returnPointer--;
break;
default:
break;
}
// флаг NTI
if ((instruction & 0x0020) != 0)
{
RAM[t] = n;
}
// флаг TR
if ((instruction & 0x0040) != 0)
{
returnStack[returnPointer] = t;
}
// флаг TR
if ((instruction & 0x0080) != 0)
{
dataStack[dataPointer-1] = t;
}
// флаг RPC
if ((instruction & 0x1000) != 0)
{
programCounter = returnStack[returnPointer];
}
if (dataPointer >= 0)
{
dataStack[dataPointer] = q;
}
}
}
public
{
auto execute(uint16 instruction)
{
// опознать тип инструкции
uint16 instructionType = instruction & 0xe000;
// операнд над которым осуществляется инструкция
uint16 operand = instruction & J1_DATA.TARGET;
// распознать конкретную инструкцию процессора
switch (instructionType)
{
// безусловный переход
case J1_INSTRUCTION.JMP:
programCounter = operand;
break;
// переход на адрес, если на вершине стека 0
case J1_INSTRUCTION.JZ:
if (dataStack[dataPointer] == 0)
{
programCounter = operand;
}
else
{
programCounter++;
}
dataPointer--;
break;
// передать управление на адрес
case J1_INSTRUCTION.CALL:
returnPointer++;
returnStack[returnPointer] = to!uint16(programCounter + 1);
programCounter = operand;
break;
// выполнить инструкцию АЛУ
case J1_INSTRUCTION.ALU:
executeALU(operand);
break;
// положить на стек литерал
case J1_INSTRUCTION.LIT:
operand = instruction & J1_DATA.LITERAL;
dataPointer++;
dataStack[dataPointer] = operand;
programCounter++;
break;
default:
break;
}
}
this()
{
this.RAM = new uint16[RAM_SIZE];
this.dataPointer = 0;
this.returnPointer = 0;
this.programCounter = 0;
}
void print()
{
writeln("[rs] : ", dataStack);
writeln("[rs] : ", returnStack);
}
void executeProgram()
{
// 0xffff = HALT
while (RAM[programCounter] != 0xffff)
{
writefln("{pc : %d, instruction : %0.4x}", programCounter, RAM[programCounter]);
// RAM.toMIF("dump.mif");
execute(RAM[programCounter]);
print;
}
}
void setMemory(uint16[RAM_SIZE] ram)
{
this.RAM = ram;
}
auto getMemory()
{
return RAM;
}
}
}
import std.algorithm;
import std.conv;
import std.file;
import std.range;
import std.string;
import std.stdio;
// превратить в файл инициализации Альтеры
auto toMIF(uint16[16_384] command, string filename, ushort depth = 16_384)
{
enum string HEADER =
`-- Quartus II generated Memory Initialization File (.mif)
WIDTH=16;
DEPTH=%d;
ADDRESS_RADIX=HEX;
DATA_RADIX=HEX;
CONTENT BEGIN
`;
File file;
file.open(filename, "w");
file.writef(HEADER, depth);
for (ushort i = 0; i < command.length; i++)
{
string index = format("%0.4x", i).toUpper;
string data = format("%0.4x", command[i]).toUpper;
file.writefln("t%s : %s;", index, data);
}
file.write("END;");
}
auto fromMIF(string filename)
{
ushort[16_384] commands;
auto content = cast(string) std.file.read(filename);
auto begin = content.indexOf("CONTENT BEGIN") + "CONTENT BEGIN".length;
auto end = content.indexOf("END;");
content = content[begin..end].strip;
foreach (index, line; content.splitLines)
{
auto separatorIndex = line.indexOf(":") + 1;
auto dataLine = line[separatorIndex..$-1].strip.toLower;
commands[index] = parse!ushort(dataLine, 16);
}
return commands;
}
void main(string[] args)
{
J1_CPU j1 = new J1_CPU;
uint16[16_384] ram = fromMIF(args[1]);
j1.setMemory(ram);
j1.executeProgram;
}
?
![]()
Log in
If this type of authorization does not work for you, convert your account using the link
-

-
June 22 2015, 09:08
- IT
- Cancel
Как написать свой язык программирования на ассемблере
Originally posted by  ermouth at Как написать свой язык программирования на ассемблере
ermouth at Как написать свой язык программирования на ассемблере
Очень клёвая презенташка. В середине, естественно, появляется LISP – куда ж без него )

Прекрасный подход, никакого жульничества типа сторонних библиотек и тп. При этом анонимные функции высшего порядка, GC, eval и все такие прелести.
GC, правда, родом из 1970 (оригинал публикации CJ Cheney) и его по нынешним временам никак эффективным не назовёшь – зато он очень простой.
Создание ОС, языка и софта с нуля
09.10.2016, 20:38. Показов 14621. Ответов 173

Здравствуйте уважаемые программисты!
_ У многих время от времени возникает идея создать свою операционную систему. Вот и я пришёл к такой мысли ") Я самоучка, в детстве программировал на асме в ZX-Spectrum, после армии увлёкся сайтостроением, затем форексом(писал советники). Создал большой интернет проект, но средств на раскрутку и найм персонала не было, понятно, почему полез в форекс. Далее сменив работу, постепенно забросил свои проекты. Но данный опыт мне очень сольно помогает в моих новых разработках.
Я самоучка, в детстве программировал на асме в ZX-Spectrum, после армии увлёкся сайтостроением, затем форексом(писал советники). Создал большой интернет проект, но средств на раскрутку и найм персонала не было, понятно, почему полез в форекс. Далее сменив работу, постепенно забросил свои проекты. Но данный опыт мне очень сольно помогает в моих новых разработках.
Поначалу захотелось сделать удобную программу подобно 1С, но удобнее и проще. Сделал небольшие модули, мини базу данных custodem(только запись и чтение простых типов данных), публикатор publisher(своего рода веб-сервер), bucinator(передача данных по сети и между модулями базы данных и публикатором), cerebrum(язык программирования подобный PHP для веб сайтов, но проще).
_ Всё это писал на Lazarus, так как делал разные приложения для упрощения своей работы на Delphi, привык к паскалю, а так как Lazarus c кросплатформенной компиляцией и свободно распространяемый, решил написать приложение для работы на нём, но из идеи приложения для работы переросло во что-то большее. Со временем создам сайт проекта, опишу всё более подробно, выложу модули.
Далее на основе этих модулей можно сделать простые приложения для производств(подобно 1С), торговли(подобно торговому терминалу форекс), поликлиник(для карточек пациентов) и др. Это сможет сделать даже школьник, который знает Паскаль, всё можно написать также в Lazarus. Сайты, которые будут размещаться на личных компьютерах.
_ Теперь ближе к теме. Работая над своими проектами я всегда искал единомышленников, но так и не находил, так как живу на периферии и в ближайшем кругу нет программистов которые хотят что-то сами сделать. Также время от времени, возникала мысль о более продуманной системе. Сейчас изучаю ассемблер и есть желание написать свою ОС.
Итак, если тут есть желающие написать свою удобную операционную систему, то предлагаю следующее:
- собрать команду специалистов
- обсудить структуру ОС
- распределить задачи
- приступить к реализации
Моя идея операционной системы такая:
- создать драйвера для работы с дисками, видеобуфером, звуком, мышкой и др. периферийных устройств по мере надобности
- ядро управления памятью, базу данных, передача данных по сети
- интерпретатор языка программирования, напрашивается название EMPEROR
") , так как на этом языке будут писаться все программы для нашей операционной системы
, так как на этом языке будут писаться все программы для нашей операционной системы
Язык EMPEROR будет создавать окна, вставлять нужные компоненты в приложении и тд. Это будет очень простой язык, на котором сможет писать кто угодно.
Если соберётся хорошая команда, то думаю за год, максимум два мы создадим СУПЕР операционку ") Итак, кто согласен участвовать в этом?
Итак, кто согласен участвовать в этом?
Добавлено через 6 часов 4 минуты
Наверняка у многих уже есть наработки. По себе знаю в одиночку такой грандиозный проект не реализовать. Если вы откажитесь от применения своих знаний и наработок в создании работающей ОС, то считайте, вы зря делали, то, что сделали и это окажется никому не нужным, так как чтобы это работало, надо ещё очень многое создать на что у вас не хватит и жизни, это, во-первых. А во-вторых, предлагаю написать лицензионное соглашение по созданию и распространению исходных кодов по принципу свободного распространения, а также договор долевого участия в капитализации операционной системы, то есть распределения дохода от участия разработчиков. В третьих если будет хорошая команда, то эта операционка будет очень быстро написана и доступна всем, на основе чего уже можно будет создавать полезные коммерческие приложения (платёжная система, бизнес приложения, социальные и частные приложения, подробнее о идеях могу рассказать позже).
Если вы не зарегистрированы на форуме можете написать мне на email:
del
Добавлено через 54 минуты
Кто в деле пишем о своём опыте в той или иной области, например
:
Есть опыт в создании больших проектов, создании языка программирования, базы данных, платёжной системы.
Это я о себе В ассемблере у меня на данный момент мало опыта, но думаю наверстаю, указанный опыт может применим в разработке ОС. То есть я хочу заняться созданием ядра ОС. Если вы имеете опыт в работе с дисками, видео, звуком и тд. отписывайтесь кто желает включиться в разработку.
__________________
Помощь в написании контрольных, курсовых и дипломных работ, диссертаций здесь
1
Почему мне пришла в голову идея разработать собственный компилятор? Однажды мне на глаза попалась книга, где описывались примеры проектирования в AutoCAD на встроенном в него языке AutoLISP. Я захотел c ними разобраться, но прежде меня заинтересовал сам ЛИСП. “Неплохо бы поближе познакомиться с ним”, – подумал я и начал подыскивать литературу и среду разработки. С литературой все оказалось просто – по ЛИСПу ее море в Интернете. Достаточно зайти на портал [1]. Дело оставалось за малым – найти хорошую среду программирования, и вот тут-то начались трудности. Компиляторов под ЛИСП тоже немало, но все они оказались мне малопонятны. Ни один пример из Вики, по разным причинам, не отработал нормально в скачанных мною компиляторах. Собственно, серьезно я с ними не разбирался, но, увы, во многих не нашел как скомпилировать EXE-файл. Самое интересное, что компиляторы эти были собраны разными людьми практически в домашних условиях…
Виталий Белик
by Stilet
И мне пришла в голову мысль: а почему бы не попробовать самому написать свой компилятор или, основываясь на каком-либо диалекте какого-либо языка, свой собственный язык программирования? К тому же на форумах я часто видел темы, где слезно жаловались на тиранов-преподавателей, поставивших задачу написания курсовой – компилятора или эвалюатора (программы, вычисляющей введенное в виде строки выражение). Мне стало еще интереснее: а что если простому студенту, не искушенному книгами Вирта или Страуструпа, написать такую программу? Появился мотив.
In the Beginning
Итак, начнем. Прежде всего, нужно поставить задачу хотя бы на первом этапе. Задача будет банальная: доказать самому себе, что написание компилятора не такой уж сложный и страшный процесс. И что мы, хитрые и смекалистые, способны родить в муках собственного творчества шедевр, который, возможно, полюбится массам. Да и вообще: приятно писать программы на собственном языке, не так ли?
Что ж, цель поставлена. Теперь самое время определиться со следующими пунктами:
- Под какую платформу будет компилировать код программа?
- На каком языке будет код, переводимый в машинный язык?
- На чем будем писать сам компилятор?
Первый пункт достаточно важен, ибо широкое разнообразие операционных систем (даже три монстра – Windows, Linux и MacOS) уже путают все карты. Их исполняемые файлы по-разному устроены, так что нам, простым смертным, придется выбрать из этой “кагалы” одну операционную систему и, соответственно, ее формат исполняемых файлов. Я предлагаю начать с Windows, просто потому, что мне нравится эта операционная система более других. Это не значит, что я терпеть не могу Linux, просто я его не очень хорошо знаю, а такие начинания лучше делать по максимуму, зная систему, для которой проектируешь.
Два остальных пункта уже не так важны. В конце концов, можно придумать свой собственный диалект языка. Я предлагаю взять один из старейших языков программирования – LISP. Из всех языков, что я знаю, он мне кажется более простым по синтаксису, более атомарным, ибо в нем каждая операция берется в скобочки; таким образом, к нему проще написать анализатор. С выбором, на чем писать, еще проще: писать нужно на том языке, который лучше всего знаешь. Мне ближе паскалевидные языки, я хорошо знаю Delphi, поэтому в своей разработке я избираю именно его, хотя никто не мешает сделать то же самое на Си. Оба языка прекрасно подходят для написания такого рода программ. Я не беру в расчет Ассемблер потому, что его диалект приближен к машинному языку, а не к человеческому.
To Shopping
Выяснив платформу, для которой будем писать компилятор (я имею в виду Win32), подберем все необходимое для комфортной работы. Давайте составим список, что же нам пригодится в наших изысканиях.
Для начала нам просто крайне необходимо выяснить, как же все-таки компиляторы генерируют исполняемые EXE-файлы под Windows. Для этого стоит почитать немного об устройстве этих “экзэшек”, как их часто называют, покопаться в их “кишках”. В этом могут помочь современные отладчики и дизассемблеры, способные показать, из чего состоит “экзэшка”. Я знаю два, на мой взгляд, лучших инструмента: OllyDebugger (он же “Оля”) и The Interactive Disassembler (в простонародье зовущийся IDA).
Оба инструмента можно достать на их официальных сайтах http://www.ollydbg.de/ и http://www.hex-rays.com/idapro. Они помогут нам заглянуть в святая святых – храм, почитаемый загрузчиком исполнимых файлов, – и посмотреть, каков интерьер этого храма, дабы загрузчик наших экзэшек чувствовал себя в нем так же комфортно, как “ковбой в подгузниках Хаггис”.
Также нам понадобится какая-нибудь экзэшка в качестве жертвы, которую мы будем препарировать этими скальпелями-дизассемблерами. Здесь все сложнее. Дело в том, что благородные компиляторы имеют дурную привычку пихать в экзэшник, помимо необходимого для работы кода, всякую всячину, зачастую ненужную. Это, конечно, не мусор, но без него вполне можно обойтись, а вот для нашего исследования внутренностей экзэшек он может стать серьезной помехой. Мы ведь не Ричарды Столлманы и искусством реверсинга в совершенстве не владеем. Поэтому нам лучше было бы найти такую программу, которая содержала бы в себе как можно меньше откомпилированного кода, дабы не отвлекаться на него. В этом нам может помочь компилятор Ассемблера для Windows. Я знаю два неплохих компилятора: Macro Assembler (он же MASM) и Flat Assembler (он же FASM). Я лично предпочитаю второй – у него меньше мороки при компилировании программы, есть собственный редактор, в отличие от MASM компиляция проходит нажатием одной-единственной кнопки. Для MASM разработаны среды проектирования, например MASM Builder. Это достаточно неплохой визуальный инструмент, где на форму можно кидать компоненты по типу Delphi или Visual Studio, но, увы, не лишенный багов. Поэтому воспользуемся FASM. Скачать его можно везде, это свободно распространяемый инструмент. Ну и, конечно, не забудем о среде, на которой и будет написан наш компилятор. Я уже сказал, что это будет Delphi. Если хотите конкретнее – Delphi 6.
The Theory and Researching
Прежде чем приступить к написанию компилятора, неплохо бы узнать, что это за формат “экзэшка” такой. Согласно [2], Windows использует некий PE-формат. Это расширение ранее применявшегося в MS-DOS, так называемого MZ формата [3]. Сам чистый MZ-формат простой и незатейливый – это 32 байта (в минимальном виде, если верить FASM; Турбо Паскаль может побольше запросить), где содержится описание для DOS-загрузчика. В Windows его решили оставить, видимо, для совместимости со старыми программами. Вообще, если честно, размер DOS-заголовка может варьироваться в зависимости от того, что после этих 28 байт напихает компилятор. Это может быть самая разнообразная информация, например для операционок, которые не смогли бы использовать скомпилированный DOS или Windows-экзэшник, представленная в качестве машинного кода, который прерываниями BIOS выводит на экран надпись типа “Эта программа не может быть запущена…”. Кстати, сегодняшние компиляторы поступают так же.
Давайте посмотрим на это чудо техники, воспользовавшись простенькой программой, написанной на чистом Ассемблере FASM (см. Рис. 1):

Рис. 1. Исходник для препарирования
Сохраним файл под неким именем, например Dumpy. Нажмем F9 или выберем в меню пункт RUN. В той же папке будет создан EXE-файл. Это и будет наша жертва, которую мы будем препарировать. Теперь ничто не мешает нам посмотреть: “из чего же, из чего же сделаны наши девчонки?”.
Запустим OllyDebuger. Откроем в “Оле” наш экзэшник. Поскольку фактически кода в нем нет, нас будет интересовать его устройство, его структура. В меню View есть пункт Memory, после выбора которого “Оля” любезно покажет структуру загруженного файла (см. Рис. 2):
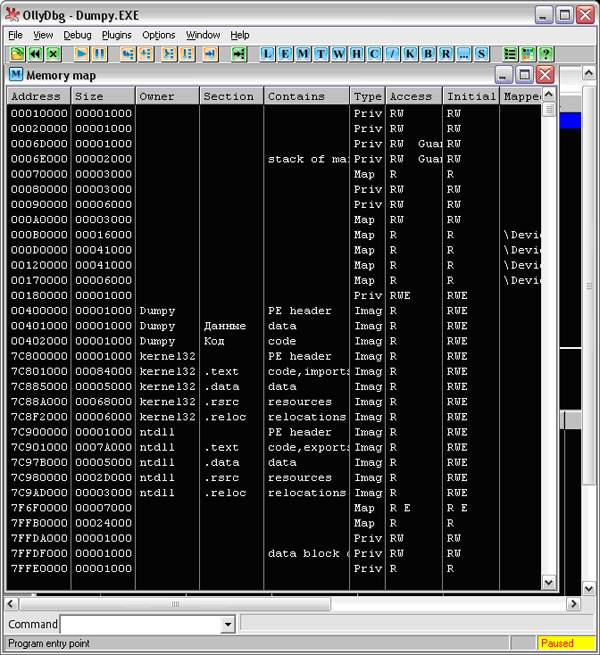
Рис. 2. Карта памяти Dumpy
Это не только сам файл, но и все, что было загружено и применено вместе с ним, библиотеки, ресурсы программы и библиотек, стек и прочее, разбитое на блоки, называемые секциями. Из всего этого нас будут интересовать три секции, владелец которых Dumpy, – это непосредственно содержимое загруженного файла.
Собственно, эти секции были описаны нами в исходнике, я не зря назвал их по-русски (ведь операционной системе все равно, как названы секции, главное – их имена должны укладываться точь-в-точь в 8 байт. Это придется учесть обязательно).
Заглянем в первую секцию PE Header. Сразу же можем увидеть (см. Рис. 3), что умная “Оля” подсказывает нам, какие поля* у этой структуры:
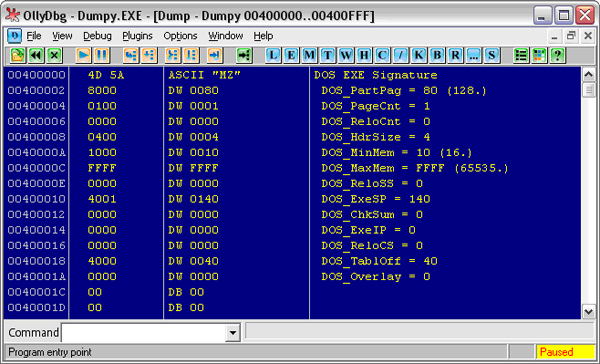
Рис. 3. MZ-заголовок
* Комментарий автора.
Сразу хочу оговориться, не все из этих полей нам важны. Тем паче что сам Windows использует из них от силы 2-3 поля. Прежде всего, это DOS EXE Signature – здесь (читайте в Википедии по ссылке выше) помещаются две буквы MZ – инициалы создателя MS-DOS, и поле DOS_PartPag. В нем указывается размер MZ-заголовка в байтах, после которых помещается уже PE-заголовок.
Последнее поле, которое для нас важно, находится по смещению 3Ch от начала файла (см. Рис. 4):
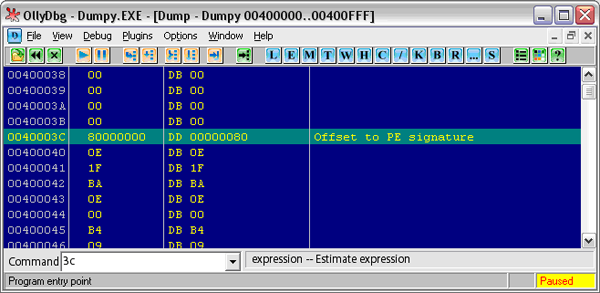
Рис. 4. Смещение на PE-заголовок
Это поле – точка начала РЕ-заголовка. В Windows, в отличие от MS-DOS, MZ-заголовок заканчивается именно на отметке 40**, что соответствует 64 байтам. При написании компилятора будем соблюдать это правило неукоснительно.
* Комментарий автора.
Обратите внимание! Далее, с 40-го смещения, “Оля” показывает какую-то белиберду. Эта белиберда есть атавизм DOS и представляет из себя оговоренную выше информацию, с сообщением о том, что данная программа может быть запущена только под DOS-Windows. Этакий перехватчик ошибок. Как показывает практика, этот мусор можно без сожаления выкинуть. Наш компилятор не будет генерировать его, сразу переходя к PE-заголовку.
Что ж, перейдем непосредственно к PE-заголовку (см. Рис. 5). Как показывает “Оля”, нам нужно перейти на 80-й байт. Да, чуть не забыл. Все числа адресации указываются в 16-тиричной системе счисления. Для этого после чисел ставится латинская буква “H”. “Оля” не показывает ее, принимая эту систему по умолчанию для адресации. Это нужно учесть, чтобы не запутаться в исследованиях. Фактически 80h – это 128-й байт.
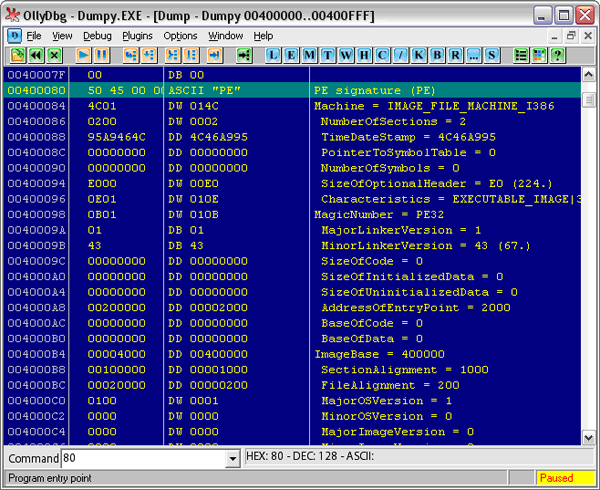
Рис. 5. Начало РЕ-заголовка
Вот она, святая обитель характеристик экзэшника. Именно этой информацией пользуется загрузчик Windows, чтобы расположить файл в памяти и выделить ему необходимую память для нужд. Вообще, считается, что этот формат хорошо описан в литературе. Достаточно выйти через Википедию по ссылкам в ее статьях [4] или банально забить в поисковик фразу вроде “ФОРМАТ ИСПОЛНЯЕМЫХ ФАЙЛОВ PortableExecutables (PE)”, как сразу же можно найти кучу описаний. Поэтому я поясню только основные его поля, которые нам понадобятся непосредственно для написания компилятора…
Прежде всего, это PE Signature – 4-хбайтовое поле. В разной литературе оно воспринимается по-разному. Иногда к нему приплюсовывают еще поле Machine, оговариваясь, чтобы выравнять до 8 байт. Мы же, как любители исследовать, доверимся “Оле” с “Идой” и будем разбирать поля непосредственно по их подсказкам. Это поле содержит две латинские буквы верхнего регистра “PE”, как бы намекая нам, что это Portable Executable-формат.
Следующее за ним поле указывает, для какого семейства процессоров пригоден данный код. Всего их, как показывает литература, 7 видов:
0000h __unknown
014Ch __80386
014Dh __80486
014Eh __80586
0162h __MIPS Mark I (R2000, R3000)
0163h __MIPS Mark II (R6000)
0166h __MIPS Mark III (R4000)
Думаю, нам стоит выбрать из всего этого второй вид – 80386. Кстати, наблюдательные личности могли заметить, что в компиляторах Ассемблера есть директива, указывающая, какое семейство процессора использовать, как, например, в MASM (см. Рис. 6):
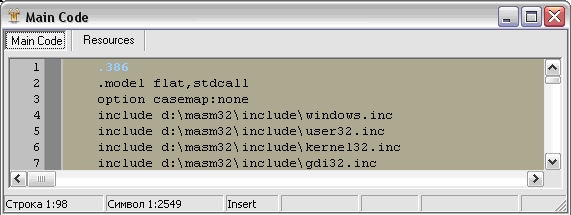
Рис. 6. Указание семейства процессоров в МАСМ
386 как раз и говорит о том, что в этом поле будет стоять значение 014Ch***.
* Комментарий автора.
Обратите внимание на одну небольшую, но очень важную особенность: байты в файле непосредственно идут как бы в перевернутом виде. Вместо 14С в файл нужно писать байты в обратном порядке, начиная с младшего, т. е. получится 4С01 (0 здесь дополняет до байта. Это для человеческого глаза сделано, иначе все 16-тиричные редакторы показывали бы нестройные 4С1. (Согласитесь, трудно было понять, какие две цифры из этого числа к какому байту относятся.) Эту особенность обязательно придется учесть. Для простоты нелишним было бы написать пару функций, которые число превращают в такую вот перевернутую последовательность байт (что мы в дальнейшем и сделаем).
Следующее важное для нас поле – NumberOfSections. Это количество секций без учета PE-секции. Имеются в виду только те секции, которые принадлежат файлу (в карте памяти их владелец – Dumpy). В нашем случае это “Данные” и “код”.
Следующее поле хоть и не столь важно, но я его опишу. Это TimeDateStamp – поле, где хранится дата и время компиляции. Вообще, я его проигнорирую, не суть важно сейчас, когда был скомпилирован файл. Впрочем, если кому захочется помещать туда время, то флаг в руки.
Сразу хочу предупредить, что меня как исследователя не интересовали поля с нулевыми значениями. На данном этапе они действительно неважны, поэтому в компиляторе их и нужно будет занулить.
Следующее важное поле – SizeOfOptionalHeader. Оно содержит число, указывающее, сколько байт осталось до начала описания секций. В принципе, нас будет устраивать число 0Eh (224 байта).
Далее идет поле “характеристики экзэшника”. Мы и его будем считать константным:
Characteristics (EXECUTABLE_IMAGE|32BIT_MACHINE|LINE_NUMS_STRIPPED|LOCAL_SYMS_STRIPPED)
И равно оно 010Eh. На этом поле заканчивается так называемый “файловый заголовок” и начинается “Опциональный”.
Следующее поле – MagicNumber. Это тоже константа. Так называемое магическое число. Если честно, я не очень понял, для чего оно служит, в разных источниках это поле преподносится по-разному, но все хором ссылаются на знаменитый дизассемблер HIEW, в котором якобы впервые появилось описание этого поля именно в таком виде. Примем на веру.
Следующие два поля, хоть и не нулевые, но нам малоинтересны. Это: MajorLinkerVersion и MinorLinkerVersion. Это два байта версии компилятора. Угадайте, что я туда поставил?
Следующее важное поле – AddressOfEntryPoint. Важность этого поля в том, что оно указывает на адрес, с которого начинается первая команда, – с нее процессор начнет выполнение. Дело в том, что на этапе компиляции значение этого поля не сразу известно. Ее формула достаточно проста. Сначала указывается адрес первой секции плюс ее размер. К ней плюсуются размеры остальных секций до секции, считаемой секцией кода. Например, в нашей жертве это выглядит так (см. Рис. 7):
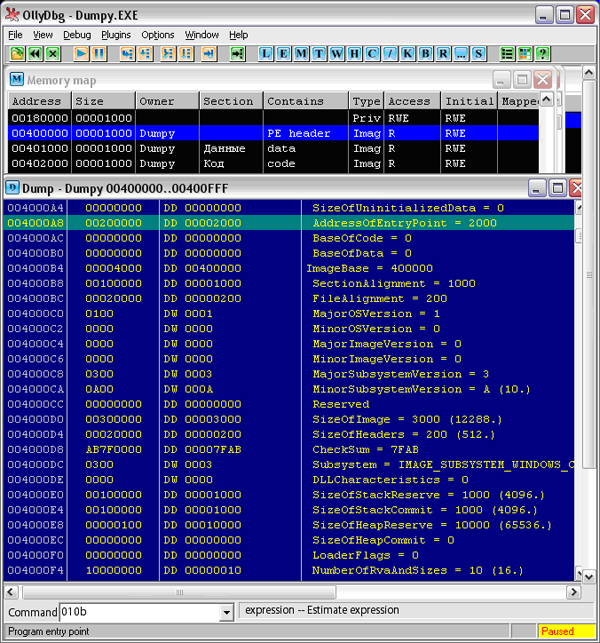
Рис. 7. Расчет точки входа
Здесь секция кода вторая по счету, значит, Адрес точки входа равен размеру секции “Данные” плюс ее начало и равен 2000. К этому еще пририсовывается базовый адрес, в который загрузчик “сажает” файл, но он в вычислении для нашего компилятора не участвует. Поэтому в жертве точка входа имеет значение 2000.
Следующее поле – ImageBase. Это поле я приму как константу, хотя и не оговаривается ее однозначное значение. Это значение указывает адрес, с которого загрузчик поместит файл в память. Оно должно нацело делиться на 64000. В общем, необязательно указывать именно 400000h, можно и другой адрес. Уже не помню, где я слышал, что загрузчик может на свое усмотрение поменять это число, если вдруг в тот участок памяти нельзя будет загружать, но не будем это проверять, а примем на веру как константу =400000h.
Следующая важная константа – SectionAlignment. Это значение говорит о размере секций после загрузки. Принцип прост: каждая секция (имеется в виду ее реализация) дополняется загрузчиком пустыми байтами до числа, указанного в этом поле. Это так называемое выравнивание секций. Тут уж хороший компилятор должен думать самостоятельно, какой размер секций ему взять, чтобы все переменные (или сам код), которые в коде используются, поместились без проблем. Согласно спецификации, это число должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). В принципе, пока что для простенького компилятора можно принять это значение как константу. Нас вполне устроит среднее значение 1000h (4096 байт – не правда ли, расточительный мусор? На этом весь Windows построен – живет на широкую ногу, память экономить не умеет).
Далее следует поле FileAlignment. Это тоже хитрое поле. Оно содержит значение, сколько байт нужно дописать в конец каждой секции в сам файл, т. е. выравнивание секции, но уже в файле. Это значение тоже должно быть степенью двойки в пределах от 200h (512 байт) до 10000h (64 000 байт). Неплохо бы рассчитывать функцией это поле в зависимости от размеров, данных в секции.
Следующие поля – MajorSubsystemVersion и MinorSubsystemVersion – примем на веру как константы. 3h и Аh соответственно. Это версия операционной системы, под которую рассчитывается данная компиляция****.
* Комментарий автора.
Я не проверял на других ОС: у меня WinXP. В принципе можно не полениться и попробовать пооткрывать “Олей” разные программы, рассчитанные на другие версии Windows.
Далее из значимых следует SizeOfImage. Это размер всего заголовка, включая размер описания всех секций. Фактически это сумма PE-заголовка плюс его выравнивание, плюс сумма всех секций, учитывая их выравнивание. Ее тоже придется рассчитывать.
Следующее поле – SizeOfHeaders (pазмеp файла минус суммарный pазмеp описания всех секций в файле). В нашем случае это 1536-512 * 2=200h (512 байт). Однако РЕ тоже выравнен! Это поле тоже нужно будет рассчитывать.
Далее следует не менее коварное поле – CheckSum. Это CRC сумма файла. Ужас… Мы еще файл не создали, а нам уже нужно ее посчитать (опять-таки вспоминается Микрософт злым громким словом). Впрочем, и тут можно вывернуться. В Win API предусмотрена функция расчета CRC для области данных в памяти, проще говоря, массива байт – CheckSumMappedFile. Можно ей скормить наш эмбрион файла. Причем веселье в том, что эта операция должна быть самой последней до непосредственной записи в файл. Однако, как показывает практика, Windows глубоко наплевать на это поле, так что мы вполне можем не морочить себе голову этим расчетом (согласитесь, держать в файле поле, которое никому не нужно, да еще и напрягать нас лишним расчетом – это глупо, но, увы, в этом изюминка политики Микрософта. Складывается впечатление, что программисты, писавшие Windows, никак не согласовывали между собой стратегию. Спонтанно писали. Импровизировали).
Следующее поле – Subsystem. Может иметь следующие значения*****:
- IMAGE_SUBSYSTEM_WINDOWS_CUI=3. Это говорит о том, что наш откомпилированный экзэшник является консольной программой.
- IMAGE_SUBSYSTEM_WINDOWS_GUI=4. Это говорит о том, что экзэшник может создавать окна и оперировать сообщениями.
* Комментарий автора.
Для справки, кто хорошо знает Delphi: директивы компилятора {$APPTYPE GUI} и {$APPTYPE CONSOLE} именно эти параметры и выставляет.
Вот, собственно, и все важные для нас параметры. Остальные можно оставить константно, как показывает “Оля”:
DLLCharacteristics = 0
SizeOfStackReserve = 1000h (4096)
SizeOfStackCommit = 1000h (4096)
SizeOfHeapReserve = 10000h (65536)
NumberOfRvaAndSizes = 10h (16)
И остаток забить нулями (посмотрите в “Оле” до начала секций, какие там еще параметры). О них можно почитать подробнее по ссылкам, которые я привел.
После идет описание секций. Каждое описание занимает 32 байта. Давайте взглянем на них (Рис. 8):
Рис. 8. Описание секций
В начале секции идет ее имя (8 байт), после этого поле – VirtualSize, описывает (я процитирую из уроков Iczeliona) “RVA-секции. PE-загpузчик использует значение в этом поле, когда мэппиpует секцию в память. То есть, если значение в этом поле pавняется 1000h и файл загpужен в 400000h, секция будет загpужена в 401000h”.
Однако “Оля” почему-то показывает для обеих секций одно и то же значение 9. Что это? Я не понял, почему так. Пока оставим это как данное. Вдруг в будущем разберемся.
Далее следует VirtualAddres, который указывает, с какого адреса плюс ImageBase будет начинаться в памяти секция – это важное поле, именно оно станет для нашего компилятора базой для расчета адреса к переменной. Собственно, адрес этот напрямую зависит от размера секции. Следующий параметр PointerToRawData – это смещение на начало секции в скомпилированном файле. Как я понял, этот параметр компиляторы любят подводить под FileAlignment. И последнее – поле Characteristics. Сюда прописывается доступ к секции. В нашем случае для секции кода оно будет равным 60000020=CODE|EXECUTE|READ, а для секции данных C0000040=INITIALIZED_DATA |READ|WRITE.
Вот и все. Закончилось описание заголовка. Далее он выравнивается нулями до 4095 байт (с этим числом связан один прикол). В файле мы его будем дополнять до FileAlignment (в нашем случае до 200h).
Hello world. Hey! Is There Anybody Out There?
Вот мы и прошлись по кишкам нашей жертвы – экзэшника. Напоследок попробуем на скорую руку закрутить простейший компилятор для DOS-системы без PE-заголовка. Для этого подойдут инструменты, которые так почему-то любят преподавать до сих пор.
Я говорю о классическом Паскале. Итак, предположим, злобный преподаватель поставил задачу: написать компилятор программы вывода на экран некой строки, которую мы опишем для компилятора, введя ее ручками (см. листинг 1):
var header,commands,s:string;
e,i:integer;
f:file;
begin
{Это MZ-заголовок}
header:=#$4D#$5A#$3E#$00#$01#$00#$
00#$00#$02#$00#$00#$01#$FF#$FF#$02#$00#$00;
header:=header+#$10#$00#$00#
$00#$00#$00#$00#$1C#$00#$00#$00#$00#$00#$00#$00;
writeln(
‘give me welcome ![]() ’);readln(s);
’);readln(s);
{Поскольку у нас все в одном сегменте, и код и данные, лежащие непосредственно в конце кода, нужно, чтобы регистр, содержащий базу данных, указывал на код. Предположим, мы будем считать, что и сам код представляет из себя данные. Для этого поместим в стек адрес сегмента кода}
{*******************************************************************************************}
Commands:=#$0E; { push cs}
{и внесем из стека этот адрес в регистр сегмента данных}
Commands:=Commands+#$1F; { pop ds}
Commands:=Commands+#$B4#$09; { mov ah, 9 – Вызовем функцию вывода строки на экран}
{Передадим в регистр DX-адрес на строку. Поскольку пока что строка у нас не определена, передадим туда нули, а позже подкорректируем это место}
Commands:=Commands+#$BA#$
00#$00; { mov dx, }
{Запомним место, которое нужно будет скорректировать. Этим приемом я буду пользоваться, чтобы расставить адреса в коде, который обращается к переменным}
e:=length(commands)-1;
{Выведем на экран строку}
Commands:=Commands+#$CD#$21;
{ int 21h ; DOS – PRINT STRING}
{подождем, пока пользователь не нажмет любую клавишу}
Commands:=Commands+#$B4#$01; { mov ah, 1}
Commands:=Commands+#$CD#$21; { int 21h ; DOS – KEYBOARD INPUT}
{После чего корректно завершим программу средствами DOS}
Commands:=Commands+#$B4#$4C; { mov ah, 4Ch}
Commands:=Commands+#$CD#$21; {int 21h ; DOS – 2+ – QUIT WITH EXIT CODE (EXIT)}
Commands:=Commands+#$C3; {retn}
{*******************************************************************************************}
{Теперь будем править адреса, обращающиеся к переменной. Поскольку само значение переменной у нас после всего кода (и переменная) одно, мы получим длину уже имеющегося кода – это и будет смещение на начало переменной}
i:=length(commands);
{В запомненное место, куда нужно править, запишем в обратном порядке это смещение}
commands[e]:=chr(lo
(i));
commands[e+1]:=chr(hi(i));
{Учтем, что в DOS есть маленький атавизм – строки там должны завершаться символом $. По крайней мере, для этой функции.}
commands:=commands+s+‘$’;
{не забудем дописать в начало заголовок}
commands:=header+commands;
{Теперь скорректируем поле DOS_PartPag. Для DOS-программ оно указывает на общий размер файла. Честно говоря, я не знаю, зачем это было нужно авторам, может быть, когда они изобретали это, еще не было возможности получать размер файла из FAT. Опять-таки запишем в обратном порядке}
i:=length(commands);
commands[3]:=chr(lo(i))
;
commands[4]:=chr(hi(i));
{Ну, и кульминация этого апофигея – запись скомпилированного массива байт в файл. Все заметили, что я воспользовался типом String, – он в паскалевских языках был изначально развит наиудобнейшим образом}
Assign(f,‘File.exe’);rewrite(f);
BlockWrite(f,commands[1],length(commands), e);
Close(f);
end.
Не удивляет, что программа получилась небольшой? Почему-то преподаватели, дающие такое задание, уверены, что студент завалится. Думаю, такие преподаватели сами не смогли бы написать компилятор. А студенты смогут, ибо, как видим, самая большая сложность – это найти нужные машинные коды для решения задачи. А уж скомпилировать их в код, подкорректировать заголовок и расставить адреса переменных – задача второстепенной сложности. В изучении ассемблерных команд поможет любая книга по Ассемблеру. Например, книга Абеля “Ассемблер для IBM PC”. Еще неплохая книга есть у Питера Нортона, где он приводит список функций DOS и BIOS.
Впрочем, можно и банальнее. Наберите в поисковике фразу “команды ассемблера описание”. Первая же ссылка выведет нас на что-нибудь вроде [5] или [6], где описаны команды Ассемблера. Например, если преподаватель задал задачку написать компилятор сложения двух чисел, то наши действия будут следующими:
- Выясняем, какая команда складывает числа. Для этого заглянем в книгу того же Абеля, где дается такой пример:
сложение содержимого
ADD AX,25 ;Прибавить 25
ADD AX,25H ;Прибавить 37 - Значит, нам нужна команда ADD. Теперь определимся: нам же нужно сложить две переменные, а это ячейки памяти; эта команда не умеет складывать сразу из переменной в переменную, для нее нужно сначала слагаемое поместить в регистр (AX для этого лучше подходит), а уж потом суммировать в него. Для помещения из памяти в регистр (согласно тому же Абелю) нужна команда
mov [адрес], ax
- Таким образом, инструкции будут выглядеть так:
mov [Адрес первой переменной], ax
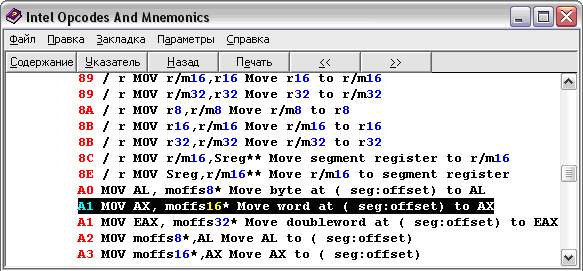
add [Адрес второй переменной], ax - Теперь нужно определиться с кодами этих команд. В комплекте с MASM идет хелп, где описаны команды и их опкоды (машинные коды, операционные коды). Вот, например, как выглядит опкод команды MOV из переменной:
Рис. 9. Опкоды MOV
Видим (см. Рис. 9), что его опкод A1 (тут тоже любят 16-тиричность). Таким образом, выяснив все коды, можно написать компилятор что-то вроде этого (см. листинг 2):
Commands:= Commands+#$A1#$00#$00; { mov [Из памяти] в AX}
aPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной a}
Commands:= Commands+#$03#$06#$00#$00;{ $03 – Это опкод команды ADD $06 – Это номер регистра AX}
bPos:= Length(Commands)-1;{Запомним позицию для корректировки переменной b}
Commands:= Commands+#$A3#$00#$00; { mov из AX в переменку b}
b2Pos:= Length(Commands)-1;
{Запомним позицию для корректировки для переменной b}А далее, в конце, скорректируем эти позиции (см. листинг 3):
commands:= commands+#$01#$00; {Это переменка a, ее значение}
i:= length(commands);
commands[aPos]:= chr(lo(i)); {Не забудем, что адреса в перевернутом виде}
commands[
aPos+1]:= chr(hi(i)); {Поэтому сначала запишем младший байт}
commands:= commands+#$02#$00; {Это переменка b, ее значение}
i:= length(commands);
commands[bPos]:= chr
(lo(i)); {Поскольку переменка b фигурирует в коде}
commands[bPos+1]:= chr(hi(i)); {дважды придется корректировать ее}
commands[b2Pos]:= chr
span style=”color: #66cc66;”>(lo(i));
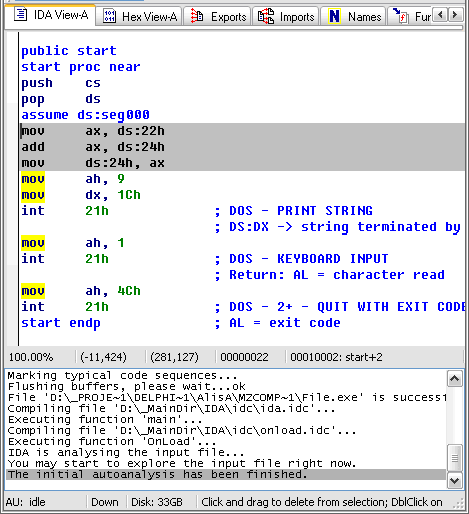
commands[b2Pos+1]:= chr(hi(i));Запустим компилятор, он скомпилирует экзэшник, который посмотрим в “Иде” (см. Рис. 10):
Рис. 10. Реверсинг нашего кода
Все верно, в регистр пошло значение одной переменной, сложилось со второй и во вторую же записалось. Это эквивалентно паскалевскому b:=b+a;
* Комментарий автора.
Обратите внимание: значения переменных мы заранее проинициализировали. При желании можно сделать, чтобы компилятор спросил их инициальное значение, и подставить в нужное место:
commands:=commands+#$01#$00; {Вот сюда вместо этих циферок}.
Post Scriptum
Ну как, студенты, воспряли духом? Теперь понятен смысл, куда двигаться в случае столкновения с такими задачами? Это вряд ли потянет на курсовую, но вполне подойдет для простенькой контрольной. А вот следующая задача – написать транслятор – уже действительно тянет даже на хороший диплом, так что пока переварим все то, что выше, а в следующий раз попробуем приготовить основное ядро компилятора, дабы потом уже делать упор на сам код программы.
Страница 1 из 2
-

programmist
New Member
- Публикаций:
-
0
- Регистрация:
- 4 июл 2007
- Сообщения:
- 29
Как думаете, реально ли написать с нуля свой ассемблер?
Компиляторы языков высокого уровня написать очень сложно, ассемблера так же сложно или нет? -
wasm_test
wasm test user
- Публикаций:
-
0
- Регистрация:
- 24 ноя 2006
- Сообщения:
- 5.582
-
programmist
New Member
- Публикаций:
-
0
- Регистрация:
- 4 июл 2007
- Сообщения:
- 29
А смысл в том, что во-первых, я хочу узнать реально ли это написать одному человеку и смогу ли в частности я (тоесть хватит ли опыта программирования), во-вторых, узнать каким образом пишутся такие вещи, ну и в-третьих, хочу изобрести велосипед
Надеюсь понятно объяснил смысл для меня создания ассемблера. -
wasm_test
wasm test user
- Публикаций:
-
0
- Регистрация:
- 24 ноя 2006
- Сообщения:
- 5.582
По большой обкурке))) А если серьезно, то это геморрой, который ни к чему хорошему не приведет — нужно будет написать кучу однообразного и неинтересного кода по формированию машинной команды. Лучше бы ты просто научился строить самостоятельно машинную команду, поможет потом.
-
programmist
New Member
- Публикаций:
-
0
- Регистрация:
- 4 июл 2007
- Сообщения:
- 29
-
programmist
Написать реально — см flat assembler (FASM) — он был написан одним человеком. -
programmist
New Member
- Публикаций:
-
0
- Регистрация:
- 4 июл 2007
- Сообщения:
- 29
Aquila
Я в курсе. Смотрел исходники: нифига не понял все так замучено там -
Veles
New Member
- Публикаций:
-
0
- Регистрация:
- 5 июл 2007
- Сообщения:
- 2
-
programmist
New Member
- Публикаций:
-
0
- Регистрация:
- 4 июл 2007
- Сообщения:
- 29
Veles
Не понял прикола.В исходниках fasm’а в файле с таблицами есть какие-то таблицы с опкодами, так вот я не пойму нафига они нужны?
Например вот часть:
-
это таблицы размещения команд для эффективной расстановке префиксов оснований и суфиксов команд, а в случае add еще и окончания. там также есть таблицы предлогов и приставок, а также способов конвертации одной инструкции в другую
-
wasm_test
wasm test user
- Публикаций:
-
0
- Регистрация:
- 24 ноя 2006
- Сообщения:
- 5.582
Чтобы их понять нужно курить то же, что курил автор
-
programmist
New Member
- Публикаций:
-
0
- Регистрация:
- 4 июл 2007
- Сообщения:
- 29
FreeManCPM
Че-то я не понял. Ну префиксы команд я еще знаю, а вот где у команды предлог, приставка, суффикс и окончание? Это же не русский язык (тогда ты забыл добавить еще корень)))Great
-
Veles
New Member
- Публикаций:
-
0
- Регистрация:
- 5 июл 2007
- Сообщения:
- 2
Кстати я где-то год назад ради прикола написал небольшой «компилятор»=)
Правда во входном языке было всего 3 команды:
ПИИСК — звук из системного динамика
ПАУЗА — остановка до нажатия клавиши
ВЫХОД — ээ… int 20h
Он создавал этакие небольшие СОМ-файлы.А насчёт прикола, «Н!» это типа int 21h в символьном виде
-
programmist
New Member
- Публикаций:
-
0
- Регистрация:
- 4 июл 2007
- Сообщения:
- 29
Надо было пойти дальше
Неее…я не хочу int 21h, я хочу WinAPI -
wasm_test
wasm test user
- Публикаций:
-
0
- Регистрация:
- 24 ноя 2006
- Сообщения:
- 5.582
Могу посмотреть как выглядит SYSENTER или INT 2E в символьном виде
-
JAPH
New Member
- Публикаций:
-
0
- Регистрация:
- 23 июн 2007
- Сообщения:
- 124
-
katrus
New Member
- Публикаций:
-
0
- Регистрация:
- 7 мар 2007
- Сообщения:
- 612
мои две копейки: я-б начал с теории. Например Ахо — «Генератор Компиляторов». В принципе написать компилятор не так уж и сложно. Оптимизирующий компилятор — это да …
-
programmist
New Member
- Публикаций:
-
0
- Регистрация:
- 4 июл 2007
- Сообщения:
- 29
Просто я думаю что те принципы, которые изложены в книге Ахо они в основном для языков высокого уровня, а ассемблер по-моему можно написать и без всяких деревьев разбора и т.п.
Вот общий алгоритм работы ассемблера как я это себе представляю:
1.Обработка препроцессора
2. 1-проход: читаем весь файл и строим таблицу меток(нужно декодировать каждую команду чтоб узнать их размер, правильно?)
2-проход: читаем файл и декодируем команды(второй раз???) и записываем их(для начала в .com файл) -
programmist
New Member
- Публикаций:
-
0
- Регистрация:
- 4 июл 2007
- Сообщения:
- 29
Че-то я вобщем заглянул в интеловский мануал и увидел сколько там разных форматов ADD, и блин как их всех обрабатывать? А там ведь еще есть MOV, AND, OR такие же большие!……..Э…а может ну его […]?
Может дизассемблер написать
-
n0name
New Member
- Публикаций:
-
0
- Регистрация:
- 5 июн 2004
- Сообщения:
- 4.336
- Адрес:
- Russia
На самом деле для некоторых мнемоник существует несколько разных байт кодов. Выбор на совести программистов асма =)
")
")
Страница 1 из 2

взята c url:
http://akps.ssau.ru/forth/tc/tj.html
( не работающий).
оригинальный url:
Как написать свой (кросс-)ассемблер
(c) Brad Rodriguez
Введение
В предыдущем выпуске журнала я описал как «загрузить» себя на новый процессор используя простой отладочный монитор. Но как вы сможете писать код для этого нового процессора, если вы не можете найти ассемблер или он вас не устраивает ? Напишите свой !
ФОРТ — идеальный язык для этого. Для TSM320 например я написал кросс-ассемблер всего за два часа, включая длинный обеденный перерыв. Обычно это занимает около двух дней, но для одного из процессоров (Zilog Super8) потребовалось пять дней. Но когда у вас больше времен чем денег, это не важно.
В части 1 этой статьи я опишу основные принципы ФОРТ-ассемблеров — структурированные, однопроходные, постфиксные. Многое из этого применимо для любого процессора, и это концепции почти любого ФОРТ-ассемблера.
В части 2 я покажу как писать ассемблер для специфичного процессора Motorola 6809. Этот ассемблер прост но не тривиален, занимает 15 страниц исходного кода. Кроме всего прочего, этот пример покажет как реализовывать инструкции с множественными режимами адресации. Изучив этот пример, вы сможете понять как использовать особенности вашего процессора.
Зачем использовать ФОРТ?
Мне кажется что ФОРТ — простейший язык для написания ассемблера.
Прежде всего ФОРТ имеет текстовый интерпретатор для разбора текстовых строк и выполнения соответствующих команд. Преобразование текстовых строк в байты кода — как раз и есть задача ассемблера. Операнды и режимы адресации также реализуются через ФОРТ-слова.
ФОРТ также включает определяющие слова, которые позволяют легко описать большие наборы слов с общим действием. Эта возможность очень полезна при определении мнемоник ассемблера.
Так как при работе ассемблера доступны все слова ФОРТ а, они могут быть использованы при использовании ассемблера не только для вычисления адресов и операндов, и и для выполнения более сложных действий.
В общем так как ассемблер полностью реализуется через слова ФОРТ а, определения ФОРТ а аналогичны макро-определениям.
Простейший пример: ассемблирование NOP
Для понимания того как ФОРТ транслирует мнемоники в машинный код, рассмотрим простейший случай: инструкцию NOP (0x12 для 6809, 0x90 для 80×86).
Обычный ассемблер при нахождении строки «NOP» должен добавить соответствующий байт в выходной файл и увеличить указатель на 1. Операнды и комментарии игнорируются. Я также пока буду игнорировать метки.
В ФОРТ е выходным файлом обычно является словарь в памяти или при кросс-ассемблировании блок памяти: образ памяти целевой системы. Так, определим слово NOP соответствующим образом: «скомпилировать опкод NOP и увеличить указатель».
Код:
: NOP, 0x12 C, ;
Обратите внимание что в этом примере используется возможность SP-FORTH воспринимать числа с префиксом 0x (шестнадцатеричные числа) независимо от текущей системы счисления, заданной в переменной BASE. Если ваша ФОРТ-система не имеет такой возможности, для удобства в начале кода ассемблера можно использовать слово HEX.
Также следует обратить внимание на то, что при использовании целевого компилятора для кросс-разработки слово C, должно быть переопределено так, чтобы оно компилировало байт в образ памяти целевой системы.
Для ассемблерных опкодов часто задаются имена ФОРТ-слов имеющие в конце символ «,», как это сделано выше. Это делается из-за того что многие ФОРТ-слова (например AND, XOR, OR) конфликтуют с мнемониками ассемблера. Простейшее решение — слегка изменить мнемоники (символ «,» в ФОРТ е обозначает что что-то компилируется (добавляется) в словарь).
Класс наследуемых опкодов
Большинство процессором имеют много инструкций подобных NOP, которые не требуют операндов. Все они могут быть определены в ФОРТ е через двоеточие, но это значительно увеличивает объем исходного кода. Намного более эффективным является использование механизма определяющих слов для того, чтобы задать для всех таких слов общее поведение. В терминах ООП это значит создание экземпляров единственног класса.Это далется с использованием слов CREATE и DOES>.
В приведенном примере параметр (разный для каждого созданного слова) обычный опкод, который должен быть скомпилирован для каждой инструкции.
Код:
: cmd0ops определение имени класса команды без опреандов
CREATE этот код выполняется при создании слов
C, ( byte — ) сохранить байт для нового определяющего слова
DOES> ( — addr ) этот код определяющего слова (общее действие)
C@ ( addr — byte) получить сохраненный при создании слова опкод
C, ( byte — ) скомпилировать опкод
;
Примеры использования определяющего слова cmd0ops:
Код:
0x12 cmd0ops NOP,
0x3A cmd0ops ABX,
0x3D cmd0ops MUL,
Обратие особое внимание на то, что этот пример дан для обычного ФОРТ -ассемблера, а не кросс-ассемблера, то есть генерируемый код компилируется в основной словарь ФОРТ-системы. При кросс-компиляции (использовании целевого компилятора) нужно сделать несколько финтов ушами — например нужно использовать разные варианты слова C, в блоках CREATE и DOES> слова cmd0ops, которые должны компилировать опкод соответственно в словарь ФОРТ-системы и в область памяти целевой системы.
Эта техника дает некоторую экономию памяти почти без потери скорости, но реальное удобство будет видно при определении сложных инструкций, которые требуют параметры и модификаторы режимов адресации.
Обработка операднов инструкций
Большинство команд ассемблера требуют один или более операндов. Для этих команд ассемблер должен быть способен разбирать текст из входного потока и интерпретировать его как операнды. Для постфиксного ФОРТ-ассемблера используется более простой способ, использующий готовый механизм интерпретации ФОРТ-системы.
Итак ФОРТ будет использоваться для разбора операндов. Числа обрабатываются как обычно (в любой системе счисления), для EQU выражений могут использоваться обучные константы ФОРТ CONSTANT. Так как операнды определяют формат ассемблируемой команды, они должны быть обработаны до команды ассемблера. Результаты разбора операндов обычно оставляются на стеке данных и используются командами ассемблера для определения формата команды и используемого оп-кода. Для ФОРТ-ассемблера используется уникальный ( ну не совсем уникальный — GNU assembler тоже постфиксный) постфиксный формат команд: операнды, за которыми следует команда ассемблера.
Для примера рассмотрим инструкцию ORCC процессора 6809, которая использует простой числовой параметр:
Код:
: ORCC, 0x1A C, C, ;
пример использования: 0x34 ORCC,
Выполнение этой команды состоит из двух этапов:
1 компилируется опкод инструкции ORCC 0x1A;
2 компилируется параметр инструкции 0x34, взятый со словаря.
Эта команда предполагает что на стеке уже лежит числовой параметр, полученный в результате разбора операндов, которые в нашем случае имеют вид простого hex числа 0x34 в исходном коде.
Достоинство такого ассемблера — доступна вся мощь ФОРТ а, которая может быть использована для формирования операндов, например:
Код:
0x01 CONSTANT CY-FLAG используем константы ФОРТа для задания операндов
0x02 CONSTANT OV-FLAG
0x04 CONSTANT Z-FLAG
CY-FLAG Z-FLAG + ORCC, команда ORCC проверит флаги CY и Z
Из примера видно что расширение разбора операндов для определяющих слов ассемблера достаточн просто.
Обработка режимов адресации
Для современных процессоров для одной команды используется несколько форматов и различные оп-коды в зависимости от режима адресации. ФОРТ-ассемблеры решают эту проблему несколькими способами в зависимости от типа процессора. Все эти способы используют методологию ФОРТ а: операторы определения режима адресации являются ФОРТ-словами. Когда эти слова исполняются, они изменяют формат ассемблируемой инструкции.
1 помещение дополнительных параметров на стек.
Это наиболее удобно если всегда должен указываться режим адресации. Слова режима адресации оставляют на стеке некоторые константы, которые обрабатываются словами ассемблера. Иногда эти значения могут быть «магическим числом», добавляемым к опкоду для изменения режима адресации команды. Кодга это неприменимо, используется выбор формата команды в блоке CASE. В общем случае скомпилированные инструкции могут иметь разнуб длину в зависимости от режима адресации.
2 установка флагов или значений в фиксированных переменных.
Это наиболее удобно если режим адресации опционален. Не зная что был указан режим адресации, вы не можете знать что значение на стеке «магическое число» или просто значение операнда. Решение этой пролемы: режим адресации указывать помещая соответствующую ему константу в определенную переменную (часто называемую MODE). После выполнения каждой команды ассемблера эта переменная инийиализируется значением по умолчанию. Если используется команда ассемблера, у которой может быть несколько режимов адресации, то она определяет содержимое этой переменной.
3 модификация значений параметров непосредственно на стеке.
Это иногда возможно для реализации слов указывающих режим адресации, которые работают модифицируя значения операндов. Этот метод используется редко.
Все эти три метода я использовал с некоторыми расширениями для реализации ассемблера 6809.
Для большинства процессоров имена регистров задаются обычными константами ФОРТ а, и оставляют на стеке свои значения. Для некоторых процессоров также удобно иметь имена регистров, определяющие режим «регистровой адресации». Это легко сделать определяя имена регистров как определяющие слова, которые создают слова, устанавливающие режим адресации (а стеке или в переменной MODE).
Некоторые процессоры позволяют использовать несколько режимов адресации в одной инструкции. Если чисто режимов адресации фиксировано, они могут оставляться на стеке. Если чисто переменное, необходимо знать сколько их был указано, и нужно использовать несколько переменных MODE$_{n}$. Для процессора Super8 я должен был отслеживать не только сколько режимов адресации указано, но и сколько операндов. Я сделал это сохраняя позицию стека отдельно для каждого режима адресации.
Рассмотрим инструкцию 6809 ADD. Для упрощения игнорируем индексированные режимы адресации, и реализуем только три режима: непосредственный (immediate), прямой (direct) и расширенный (extended):
Код:
исходный код ассемблируется как
————————————————
immediate <число> # ADD, 8B nn
direct <адрес> <> ADD, 9B nn
extended <адрес> ADD, BB aa aa
Так как режим extended не имеет оператора режима адресации, режим адресации оказывается уже определенным. Слова ФОРТ а # и <> устанавливают режим адресации.
Рассмотрим систему команд 6809. Если опкод immediate является основным значением, то опкод в direct режиме равен базовому +0x10, в indexed режиме +0x20 и в extended режиме +0x30. Это справедливо для почти всех инструкций, использующих эти режимы адресации. Исключение составляют те опкод, для которых опкоды в режиме direct имяют форму 0x0?.
Такие особенности системы команд нужно использовать. Это общее правило при написании ассемблеров: найдите или сделайте сами таблицу опкодов, и найдите закономерности — особенно те, которые применимы для режимов адресации или других модификаторов инструкций (таких как коды условий).
В нашем случае нужно использовать следующие значения переменной MODE:
Код:
VARIABLE MODE
: # 0x00 MODE ! ;
: <> 0x10 MODE ! ;
: RESET 0x30 MODE ! ; значение по умолчанию
Значение по умолчанию 0x30 (extended режим) устанавливается словом RESET. Это слово будет использоваться после того как будет ассемблирована каждая инструкция.
Теперь может быть написана команда ассемблера ADD,. Давайте посмотрим ее старую версию и напишем определяющие слова для создания команд ассемблера.
Код:
: GENERAL-OP ( <базовый опкод> — )
CREATE C,
DOES> ( <операнд> — )
C@ получить базовый опкод
MODE @ + добавляем «магическое число»
C, ассемблируем опкод
MODE @ CASE
0x00 OF C, ENDOF операнд байт
0x10 OF C, ENDOF операнд байт
0x30 OF , ENDOF операнд слово (2 байта)
ENDCASE
RESET выбор режима адресации по умолчанию
;
8B GENERAL-OP ADD,
Каждый экземпляр GENERAL-OP будет иметь различный базовый опкод. Когда ADD, выполняется, он будет получать этот базовый опкод, добавлять к нему значение MODE, и комплировать полученный байт. Дале он будет брать операнд, находящийся на стеке, и компилировать его в зависимости от выбранного режима адресации как байт или слово. В конце MODE будет сброшен в значение по умолчанию.
Отметим что уже определен весь код, который нужно использовать для определения инструкций того же семейства что и ADD:
Код:
0x89 GENERAL-OP ADC,
0x84 GENERAL-OP AND,
0x85 GENERAL-OP BIT,
Сохранение памяти при использовании определяющих слов по сравнению с обучными словами определенными через двоеточие очевидно. Все команды ассемблера, приведенные выше, используют единственный блок кода после DOES>, вызов которого из этих слов занимает всего несколько байт.
На самом деле это не мой код реального ассемблера 6809 — существуют дополнительные особые случаи, которые необходимо реализовать. Но он показывает что сохраняя что достаточно сделать чтобы сохранить информацию о режиме и как свободно использовать конструкцию CASE чтобы реализовать наиболее простые наборы команд.
Реализация структур управления
Структурное программирование наделало очень много шума, и было написано множество макропакетов «структурного ассемблирования» для распространенных ассемблеров. Но ФОРТ-ассемблерам изначально присущи такие свойства как отсутствие меток, структурный ассемблерный код, что объяснятся той причиной что на ФОРТ е проще реализовать структурный ассемблер чем метки.
Структуры, обычно включаемые в ФОРТ-ассемблеры, аналогичны структурам высокоуровневого ФОРТ а. Для их отличия к ним добавляется запятая, как это было сделано для ассемблерных команд.
BEGIN, UNTIL,
Эта самая простая для понимания ассемблерная структура. Ассемблерный код должен защиклиться до метки BEGIN до того как будет удовлетворено некоторое условие. Синтаксис для ФОРТ-ассемблера:
BEGIN, <код> <условие> UNTIL,
Код условия предположительно определен как операнд или режим адресации для интсрукции перехода.
Очевидно что UNTIL должен комплировать условный переход. Условия перехода должны быть инвертированы так что если условие удовлетворяется, то переход игнорируется, в отличие от перехода когда условие ложно. Ассемблерный код для обычного ассемблера должен иметь вид:
Код:
xxx: …
…
…
JR ~cc,xxx ~cc то же что и NOT(cc)
Существует два свойства, помогающие реализовать эту струткуру. Слово THERE ( аналог HERE) при целевой компиляции возвращает текущий указатель компиляции. Числа могут храниться на стеке не влияя на реботу ФОРТ а, и доставаться по необходимости.
Итак BEGIN, должен запоминать позицию указателя компиляции помещая ее в стек, а UNTIL, будет ассемблировать условный переход по запомненному на стеке адресу.
Код:
: BEGIN, ( — a ) HERE ;
: UNTIL, ( a cc — ) NOTCC JR, ; флаг перехода инвертируется
Как видно по стековой нотации BEGIN, оставляет на стеке текущий адрес, и UNTIL, использует запомненный адрес и код условия для компиляции условного перехода. Слово NOTCC предварительно инвертирует код условия. Слово JR, использует адрес перехода и (инвертированный) код условия для формирования соответствущего кода условного перехода 6809.
Такая реализация позволяет использовать вложенные условные циклы:
Код:
BEGIN,
…
BEGIN,
…
cc UNTIL,
…
cc UNTIL,
Вложенный UNTIL, ссылается на вложенный BEGIN,, формируая код цикла внутри кода охватывающего цикла.
BEGIN, AGAIN,
ФОРТ также поддерживает конструкцию бесконечного цикла BEGIN AGAIN. Определение этой конструкции для ассемблера аналогично, за тем исключением что код условия не используется, и компилируется безуслоный переход на начало цикла.
DO, LOOP,
Многие процессоры предоставляют некоторые инструкции цикла. Так как их нет у 6809, расмотрим Zilog Super8. Он имеет инструкцию DJNZ (декремент и переход если не ноль), которая может использовать любой из 16 регистров как счетчик цикла. Для процессора 80×86 эта инструкция работает только с регистром (E)CX. Цикл на структурном ассемблере будет иметь вид:
Код:
DO, … r LOOP,
где r регистр используемый как счетчик цикла.
Код:
: DO, ( — a) HERE ;
: LOOP, ( a r — ) DJNZ, ;
В некоторых ФОРТ-ассемблерах DO, также ассемблирует код инициализации счетчика цикла, но это уменьшает гибкость.
IF, THEN,
Эта конструкция — простейшая конструкция, использующая ссылки вперед. Если условие истинно, она должна выполняться, иначе управление передается на первую инструкцию после THEN,.
Ассемблерный код для ФОРТ-синтаксиса
Код:
cc IF, … … … THEN,
будет иметь вид
Код:
JP ~cc,xxx
…
…
…
xxx:
Обратите внимание что код условия должен быть инвертирован аналогично UNTIL,.
В однопроходном ассемблере необходимый переход вперед не может быть скомпилирован сразу, так как адрес перехода еще неизвестен. Эта проблема решается путем ассемблирования пустого перехода типа JMP 0 и помещения на стек адреса операнда команды JMP. Позже слово THEN, сможет взять этот адрес и пропатчить скомплирированный JMP, соответствующм образом модифицировав его операнд.
Код:
: IF, (cc — a)
NOT 0 SWAP JP, условный переход
HERE 2 — помещаем на стек HERE-<размер операнда>
;
: THEN, (a —)
HERE SWAP ! запоминаем по адресу операнда JP текущий HERE
;
IF, инвертирует код условия и компилирует условный переход на нулевой адрес, кладя адрес операнда на стек. После компиляции условного перехода HERE указывает на байт после него, поэтом нужно вычесть размер операнда условного перехода. THEN, затем модифицирует команду условного перехода, изменяя адрес перехода на реальный.
Приведенный вариант THEN, — самый простой вариант для процессоров, использующих условный переход по абсолютному 16-битному адресу. У многих процессоров есть только команда условного перехода по относительному адресу $127 байт от адреса команды перехода. В этом случае размер операнда равен одному байту, а THEN, должен предварительно вычесть из HERE адрес на стеке.
IF, ELSE, THEN,
Улучшенный вариант IF, THEN, дополняется блоком кода, выполняемом если условие не выполняется:
Код:
cc IF, … … ELSE, … … THEN,
Ассемблерный код этой конструкции имеет вид:
Код:
JP ~cc,xxx
… ; код «если»
…
JP yyy
xxx: … ; код «иначе»
…
yyy:
ELSE, должен модифицировать действия IF, и THEN, следующим образом:
1 переход вперед в IF, долен быть модифицирован чтобы выполнялся переход на начало блока ELSE, («xxx»);
2 адрес, положенный на стек THEN, должен быть записан в операнд безусловного перехода в конце блока IF, («JP yyy»).
ELSE, также должен компилировать безусловный переход.
Код:
: ELSE (a — a)
0 T JP, безусловный переход
HERE 2 — поместить в стек адрес операнда перехода для THEN,
SWAP получить адрес перехода IF,
HERE SWAP ! заменить его на текущий адрес
;
Условие перехода T обозначает TRUE, то есть безусловный переход. При определении ELSE, может быть использован код IF, и THEN, если таже определено условие F FALSE:
Код:
: ELSE (a — a) F IF, SWAP THEN, ;
SWAP адресов в стеке инвертирует последовательность модификации инструкций перехода так, что THEN, модифицирует переход внутри кода ELSE,:
Код:
IF,(1) … IF,(2) THEN,(1) … THEN,(2)
______________/
внутри ELSE,
BEGIN, WHILE, REPEAT,
Наиболее сложной ассемблернй структурой является цикл ПОКА, в котором условие проверяется в начале цикла, а не в конце.
Код:
BEGIN, <код> cc WHILE, <код цикла> REPEAT,
На практике между BEGIN, и WHILE, может быть вставлен любой код, а не только задание условия.
WHILE, должен скомпилировать условный переход по инверсному условию на код за REPEAT,. Если код условия cc удовлетворяется, этот переход должен игнорироваться и выполняться код цикла.
REPEAT, должен компилировать безусловный переход на BEGIN,.
Код:
BEGIN,(1) … cc IF,(2) … AGAIN,(1) THEN,(2)
Это может быть сделано с использованием существующих слов:
Код:
: WHILE, (a cc — a a) IF, SWAP ;
: REPEAT, (a a — ) AGAIN, THEN, ;
Заголовок ФОРТ-определения
В большинстве приложений машинный код, созданный ФОРТ-ассемблером, помещается в словарь с помощью CODE <имя>, который создает словарную статью с именем <имя> и связывает ее со словарным списком.
Слово CODE получает имя слова из входного потока, создает определение в словаре с этим именем, и настраивает указатель словаря на начало поля кода этого имени.
Стандартный ФОРТ использует слово CODE не только для выделения начала ассемблерного определения в словаре, но и дополнительной инициализации ассемблера (установке переменных типа MODE).
Кросс-компиляция
До сих пор мы предполагали что в словарь компилируется машинный код системы, на которой и исполняется.
Для кросс-компиляции обычно выполняется компиляция в отдельную область памяти. Эта область может иметь или не иметь словарной структуры, но она отделена от словаря хост-машины, и скомплированный код не может быть исполнен.
Чаще всего для этого используется набор слов для доступа к целевому пространству памяти по аналогии с обычным долступом к памяти в ФОРТ е. Для этого могут быть использованы обычные слова с префиксом «T»:
TDP (указатель компиляции DP целевой системы) THERE (аналог HERE для целевой системы) если VALUE-переменная, TDP не нужен)
Иногда вместо использования префиска «T» эти слова определяются в отдельном словаре целевого компилятора. Словарная структура ФОРТ а позволяет иметь несколько наборов совпадающих по имени слов с различным действием.
Компиляция на диск
Целевая компиляция также может выполняться сразу на диск (в файл) без использования буфера памяти целевой системы, но из-за использования прямого побайтного доступа к файлу это может значительно замедлить работу компилятора. Особенно это заметно если не используется кеширование дисковых операций.
Безопасная компиляция
Некоторые реализации ФОРТ а используют безопасную компиляцию, которая пытяется отловить ошибки типа несбалансированных структур управления типа
Код:
IF, … cc UNTIL,
В этом примере UNTIL, некорректно использует адрес, помещенный на стек IF,.
Обычный метод проверки сбалансированности структур управления — помещение на стек данных или на отдельный стек констант, уникальных для каждого управляющего слова, которые проверяются другими словами:
Код:
IF, помещает 1;
THEN, проверяет на 1;
ELSE, проверяет на 1 и оставляет 1;
BEGIN, оставляет 2;
UNTIL, проверяет 2;
AGAIN, проверяет 2;
WHILE, проверяет 2 и оставляет 3;
REPEAT, оставляет 3
DO, оставляет 4;
LOOP, проверяет 4.
Стоимость такой безопасности — увеличение сложности манипуляций со стеком в таких словах как ELSE, и WHILE,. Ткже программист может захотеть последовательность в которой управляющие структуры are resolved вручную манипулируя стеком. Безопасность делает это более сложным.
Метки
Даже в эру структурного программирования некоторые программисты используют метки в ассемблерном коде.
Принципиальная проблема с именоваными метками в ФОРТ-ассемблере — так как метки это ФОРТ-слова, они должны быть скомпилированы в словарь во время незавершенной компиляции другого слова в машинном коде, например:
Код:
CODE TEST … <машиннный код> …
HERE CONSTANT LABEL1
… <машинный код> …
LABEL1 NZ JP,
Как видно из примера определение метки LABEL1 должно создавать словарную статью внутри серидины CODE. Вот несколько решений 1 метки определяются только вне машинного кода. 2 используются некие предопределенные переменные для временного хранения меток. 3 для меток используется отдельное словарное пространство, например как это сделано по схеме TRANSIENT . 4 для машинного кода используется отдельное пространство словаря. Это наиболее часто используемый метод при мета-компиляции. Большинство мета-компиляторов ФОРТ а поддерживают метки с некоторыми сложностями.
Табличный ассемблер
Большинство ФОРТ-ассемблеров могут отрабатывать режимы адресации и инструкции используя структуры типа CASE. Их можно назвать процедурными ассемблерами.
Некоторые процессоры типа 68000 имеют настолько сложные наборы инструкций и режимов адресации, что становится сложным строить деревья выбора при ассемблеировании их команд. В таких случаях более подходящим является использование таблиц, что уменьшает используемую память и процессорное время.
Я не буду описывать такие процессоры — табличные ассемблеры писать намного сложнее.
Префиксные ассемблеры
Иногда использование префиксных ассемблеров необходимо. Например мне однажды пришлось переводить многие килобайты ассемблерного кода для Super8 для обычного Zilogовского ассемблера для ФОРТ-ассемблера. Существует трюк позволяющий имитировать префиксный ассемблер при использовании методов, описанных в этой статье.
В основном этот трюк можно определить как отложенное выполнение ассемблирования после того как были обработаны операнды. Это делается следующим словом ассемблера.
Так каждое слово ассемблера модифицируется так что оно 1 сохраняет свой код или адрес кода, компилирующего команду; 2 выполняет компилирующий команду код для предыдущего слова ассемблера.
Код:
… JP operand ADD operands …
JP сохраняет указатель на свой код в какой-либо переменной. Далее обрабатываются операнды. ADD берет информацию, запомненную JP и выполняет действие JP, которое использует операнды на стеке. Когда код JP завершается, ADD сохраняет свой адрес, и процесс продолжается.
Особо должны отрабатываться первые и последние команды в ассемблерном блоке. Если используются переменные режима, то их сохранение и восстановление станоится кошмаром.
Вывод
Я рассмотрел наиболее простые методики используемые в ФОРТ-ассемблерах. Изучение готового ассемблера может дать вам информацию как писать собственный ассемблер, но лучший способ изучения — действие.