Из песочницы, Компиляторы, Python
Рекомендация: подборка платных и бесплатных курсов Python — https://katalog-kursov.ru/

Пишем свой «Язык программирования» на Python3
1. Лексер
В этой статье мы сделаем, так сказать python2, создание переменных, вывод их в консоль
Если вам зайдёт, то сделаю 2 часть поста 

Для начала, определимся с названием языка — к примеру «xnn»
Теперь создадим файл xnn.py и запишем туда основной код:
import sys #Импортируем библиотеку sys
import os #Импортируем библиотеку os
dir = os.path.abspath(os.curdir) #Узнаём откуда запущен компилятор
p = str(dir) + '\' + str(sys.argv[1]) #sys.argv[1] - определяем 1 аргумент
print(p) # Выводим ддиректорию + файл
modules = ['if', 'else', 'while', 'for', '=', '==', '{', '}', '[', ']', '(', ')', '//'] #Создаём все зарезервированные слова
var = [] #Создаём список для лексера
vars_ = {} #Создаём список для переменных
with open(p, 'r', encoding="UTF-8") as f: #Отрываем файл из аргумента
for ex in f.read().split(): #Распределяем все слова
var.append(ex) #Записываем все слова в список var
print(var) # $ Выводим список $
Что мы делаем:
- Импортируем библиотеки os и sys
- С помощью os определяем откуда запущен компилятор, (в будущем раскажу зачем)
- Создаём путь к файлу + берём сам файл из аргумента — получаем его через sys.argv
- Дальше выводим сам путь, с файлом (в будущем это надо будет удалить)
- Создаём все зарезервированные слова — пока, нам это не надо, но в будещем понядобиться дял вывода ошибок
- Создаём списки для лексера и переменных
- Создаём сам лексер, для этого открываем файл, в режиме чтения, обязательно в
encoding=«UTF-8»
если этого не сделать, то вместо русских букв, будут иероглифы!
- С помощью for ex in read().split() распределяем весь текст на слова и помещаем каждое слово отдельно в ex
- Дальше записываем каждое слово в список var
- И выведим сам список — в будущем нужно будет удалить вывод :/
Создание файла .xnn
Теперь создадим сам файл который будем парсить, а также изменим способ открытия

Откроем его и запишем туда:
pr = Привет
rprint pr
2. Создание Компилятора
Теперь создадим компилятор!
Для этого дополним наш файл кодом, чтобы получилось вот так:
import sys #Импортируем библиотеку sys
import os #Импортируем библиотеку os
dir = os.path.abspath(os.curdir) #Узнаём откуда запущен компилятор
p = str(dir) + '\' + str(sys.argv[1]) #sys.argv[1] - определяем 1 аргумент
print(p) # Выводим ддиректорию + файл
modules = ['if', 'else', 'while', 'for', '=', '==', '{', '}', '[', ']', '(', ')', '//'] #Создаём все зарезервированные слова
var = [] #Создаём список для лексера
vars_ = {} #Создаём список для переменных
try:
with open(p, 'r', encoding="UTF-8") as f: #Отрываем файл из аргумента
for ex in f.read().split(): #Распределяем все слова
var.append(ex) #Записываем все слова в список var
print(var) # $ Выводим список $
a = -1 #Устанавливаем значение на каком сейчас var
for i in var: #Перебираем все значения
a = a + 1 #Добавляем что это значение просмотренно
if i == '=': #Если находим совпадение с "="
vars_[var[a-1]] = var[a+1] #в список vars_ добавляем занчение до и после "="
if i == 'rprint':
let = var[a+1]
for key, value in vars_.items():
if key == let:
print(value)
except FileNotFoundError:
print('Error! Файл не найден!')
Что мы делаем?
Мы перебираем все значения в var и при нахождении того или инного зарезервировонного слова, делаем определённые действия
Присваивание переменных
При совпадении i с «=» добавляем в список
vars_
значение, до «=» как key, а после «=», как value — таким образом образуя переменную
Вывод переменных
При совпадении i с «rprint» ищем в списке
vars_
совпадение для этой переменной, которое получаем через нашего друга, списка
var
После нахождение выводим значение переменной
Работа в действии
Для того чтобы скомпилировать файл, вводим данные команды в cmd:
cd path/to/files
python xnn.py prog.xnn
На выход получаем:
C:UsersHoopengoDesktopxnnprog.xnn
['pr', '=', 'Привет', 'rprint', 'pr']
Привет
3. Компиляция в .exe
Создадим копию папки с файлами и отредактируем файл xnn.py
import sys #Импортируем библиотеку sys
import os #Импортируем библиотеку os
dir = os.path.abspath(os.curdir) #Узнаём откуда запущен компилятор
p = str(dir) + '\' + str(sys.argv[1]) #sys.argv[1] - определяем 1 аргумент
modules = ['if', 'else', 'while', 'for', '=', '==', '{', '}', '[', ']', '(', ')', '//'] #Создаём все зарезервированные слова
var = [] #Создаём список для лексера
vars_ = {} #Создаём список для переменных
try:
with open(p, 'r', encoding="UTF-8") as f: #Отрываем файл из аргумента
for ex in f.read().split(): #Распределяем все слова
var.append(ex) #Записываем все слова в список var
a = -1 #Устанавливаем значение на каком сейчас var
for i in var: #Перебираем все значения
a = a + 1 #Добавляем что это значение просмотренно
if i == '=': #Если находим совпадение с "="
vars_[var[a-1]] = var[a+1] #в список vars_ добавляем занчение до и после "="
if i == 'rprint':
let = var[a+1]
for key, value in vars_.items():
if key == let:
print(value)
except FileNotFoundError:
print('Error! Файл не найден!')
Установим auto-py-to-exe
Полная информация по установке есть по этой ссылке
Введём в консоль:
auto-py-to-exe
pip install auto-py-to-exe
auto-py-to-exe
Запустится браузер. Выбираем там путь к файлу и One File
Мои Предустоновка

4. Создание установщика
В копированной папке создадим файл bat.py:
import os
with open('path\xnn.exe', 'r', encoding='UTF-8') as f:
lean = f.read()
directory_folder = r"C:\Windows\System32\xnn.exe"
folder_path = os.path.dirname(directory_folder) # Путь к папке с файлом
if not os.path.exists(folder_path): #Если пути не существует создаем его
os.makedirs(folder_path)
with open(directory_folder, 'w', encoding='UTF-8') as file: # Открываем фаил и пишем
file.write(lean)
После этого компилируем его в .exe и бросаем в туже директорию, должно получится так:

5. Установка
Теперь установим
Для этого отроем файл bat.exe, после чего произведотся установка
Перезапустим консоль и введём:
cd path/to/file
xnn prog.xnn
И получим:
Привет
Если пишет что «xnn не является внутренней командой», то самостоятельно добавьте файл xnn.exe в папку «C:WindowsSystem32».
In this article, we are going to learn how to create your own programming language using SLY(Sly Lex Yacc) and Python. Before we dig deeper into this topic, it is to be noted that this is not a beginner’s tutorial and you need to have some knowledge of the prerequisites given below.
Prerequisites
- Rough knowledge about compiler design.
- Basic understanding of lexical analysis, parsing and other compiler design aspects.
- Understanding of regular expressions.
- Familiarity with Python programming language.
Getting Started
Install SLY for Python. SLY is a lexing and parsing tool which makes our process much easier.
pip install sly
Building a Lexer
The first phase of a compiler is to convert all the character streams(the high level program that is written) to token streams. This is done by a process called lexical analysis. However, this process is simplified by using SLY
First let’s import all the necessary modules.
Python3
Now let’s build a class BasicLexer which extends the Lexer class from SLY. Let’s make a compiler that makes simple arithmetic operations. Thus we will need some basic tokens such as NAME, NUMBER, STRING. In any programming language, there will be space between two characters. Thus we create an ignore literal. Then we also create the basic literals like ‘=’, ‘+’ etc., NAME tokens are basically names of variables, which can be defined by the regular expression [a-zA-Z_][a-zA-Z0-9_]*. STRING tokens are string values and are bounded by quotation marks(” “). This can be defined by the regular expression ”.*?”.
Whenever we find digit/s, we should allocate it to the token NUMBER and the number must be stored as an integer. We are doing a basic programmable script, so let’s just make it with integers, however, feel free to extend the same for decimals, long etc., We can also make comments. Whenever we find “//”, we ignore whatever that comes next in that line. We do the same thing with new line character. Thus, we have build a basic lexer that converts the character stream to token stream.
Python3
class BasicLexer(Lexer):
tokens = { NAME, NUMBER, STRING }
ignore = 't '
literals = { '=', '+', '-', '/',
'*', '(', ')', ',', ';'}
NAME = r'[a-zA-Z_][a-zA-Z0-9_]*'
STRING = r'".*?"'
@_(r'd+')
def NUMBER(self, t):
t.value = int(t.value)
return t
@_(r'//.*')
def COMMENT(self, t):
pass
@_(r'n+')
def newline(self, t):
self.lineno = t.value.count('n')
Building a Parser
First let’s import all the necessary modules.
Python3
Now let’s build a class BasicParser which extends the Lexer class. The token stream from the BasicLexer is passed to a variable tokens. The precedence is defined, which is the same for most programming languages. Most of the parsing written in the program below is very simple. When there is nothing, the statement passes nothing. Essentially you can press enter on your keyboard(without typing in anything) and go to the next line. Next, your language should comprehend assignments using the “=”. This is handled in line 18 of the program below. The same thing can be done when assigned to a string.
Python3
class BasicParser(Parser):
tokens = BasicLexer.tokens
precedence = (
('left', '+', '-'),
('left', '*', '/'),
('right', 'UMINUS'),
)
def __init__(self):
self.env = { }
@_('')
def statement(self, p):
pass
@_('var_assign')
def statement(self, p):
return p.var_assign
@_('NAME "=" expr')
def var_assign(self, p):
return ('var_assign', p.NAME, p.expr)
@_('NAME "=" STRING')
def var_assign(self, p):
return ('var_assign', p.NAME, p.STRING)
@_('expr')
def statement(self, p):
return (p.expr)
@_('expr "+" expr')
def expr(self, p):
return ('add', p.expr0, p.expr1)
@_('expr "-" expr')
def expr(self, p):
return ('sub', p.expr0, p.expr1)
@_('expr "*" expr')
def expr(self, p):
return ('mul', p.expr0, p.expr1)
@_('expr "/" expr')
def expr(self, p):
return ('div', p.expr0, p.expr1)
@_('"-" expr %prec UMINUS')
def expr(self, p):
return p.expr
@_('NAME')
def expr(self, p):
return ('var', p.NAME)
@_('NUMBER')
def expr(self, p):
return ('num', p.NUMBER)
The parser should also parse in arithmetic operations, this can be done by expressions. Let’s say you want something like shown below. Here all of them are made into token stream line-by-line and parsed line-by-line. Therefore, according to the program above, a = 10 resembles line 22. Same for b =20. a + b resembles line 34, which returns a parse tree (‘add’, (‘var’, ‘a’), (‘var’, ‘b’)).
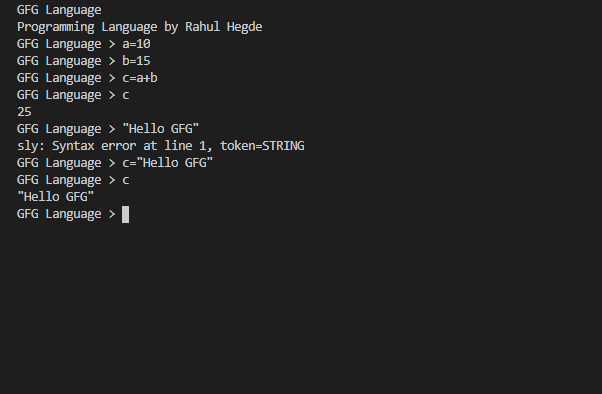
GFG Language > a = 10 GFG Language > b = 20 GFG Language > a + b 30
Now we have converted the token streams to a parse tree. Next step is to interpret it.
Execution
Interpreting is a simple procedure. The basic idea is to take the tree and walk through it to and evaluate arithmetic operations hierarchically. This process is recursively called over and over again till the entire tree is evaluated and the answer is retrieved. Let’s say, for example, 5 + 7 + 4. This character stream is first tokenized to token stream in a lexer. The token stream is then parsed to form a parse tree. The parse tree essentially returns (‘add’, (‘add’, (‘num’, 5), (‘num’, 7)), (‘num’, 4)). (see image below)
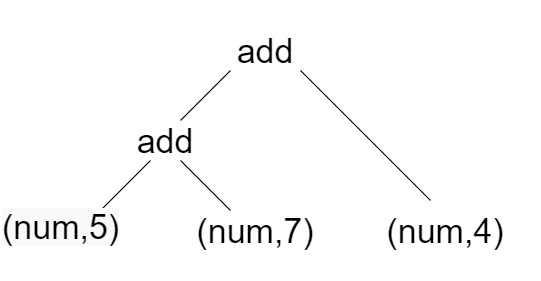
The interpreter is going to add 5 and 7 first and then recursively call walkTree and add 4 to the result of addition of 5 and 7. Thus, we are going to get 16. The below code does the same process.
Python3
class BasicExecute:
def __init__(self, tree, env):
self.env = env
result = self.walkTree(tree)
if result is not None and isinstance(result, int):
print(result)
if isinstance(result, str) and result[0] == '"':
print(result)
def walkTree(self, node):
if isinstance(node, int):
return node
if isinstance(node, str):
return node
if node is None:
return None
if node[0] == 'program':
if node[1] == None:
self.walkTree(node[2])
else:
self.walkTree(node[1])
self.walkTree(node[2])
if node[0] == 'num':
return node[1]
if node[0] == 'str':
return node[1]
if node[0] == 'add':
return self.walkTree(node[1]) + self.walkTree(node[2])
elif node[0] == 'sub':
return self.walkTree(node[1]) - self.walkTree(node[2])
elif node[0] == 'mul':
return self.walkTree(node[1]) * self.walkTree(node[2])
elif node[0] == 'div':
return self.walkTree(node[1]) / self.walkTree(node[2])
if node[0] == 'var_assign':
self.env[node[1]] = self.walkTree(node[2])
return node[1]
if node[0] == 'var':
try:
return self.env[node[1]]
except LookupError:
print("Undefined variable '"+node[1]+"' found!")
return 0
Displaying the Output
To display the output from the interpreter, we should write some codes. The code should first call the lexer, then the parser and then the interpreter and finally retrieves the output. The output in then displayed on to the shell.
Python3
if __name__ == '__main__':
lexer = BasicLexer()
parser = BasicParser()
print('GFG Language')
env = {}
while True:
try:
text = input('GFG Language > ')
except EOFError:
break
if text:
tree = parser.parse(lexer.tokenize(text))
BasicExecute(tree, env)
It is necessary to know that we haven’t handled any errors. So SLY is going to show it’s error messages whenever you do something that is not specified by the rules you have written.
Execute the program you have written using,
python you_program_name.py
Footnotes
The interpreter that we built is very basic. This, of course, can be extended to do a lot more. Loops and conditionals can be added. Modular or object oriented design features can be implemented. Module integration, method definitions, parameters to methods are some of the features that can be extended on to the same.
In this article, we are going to learn how to create your own programming language using SLY(Sly Lex Yacc) and Python. Before we dig deeper into this topic, it is to be noted that this is not a beginner’s tutorial and you need to have some knowledge of the prerequisites given below.
Prerequisites
- Rough knowledge about compiler design.
- Basic understanding of lexical analysis, parsing and other compiler design aspects.
- Understanding of regular expressions.
- Familiarity with Python programming language.
Getting Started
Install SLY for Python. SLY is a lexing and parsing tool which makes our process much easier.
pip install sly
Building a Lexer
The first phase of a compiler is to convert all the character streams(the high level program that is written) to token streams. This is done by a process called lexical analysis. However, this process is simplified by using SLY
First let’s import all the necessary modules.
Python3
Now let’s build a class BasicLexer which extends the Lexer class from SLY. Let’s make a compiler that makes simple arithmetic operations. Thus we will need some basic tokens such as NAME, NUMBER, STRING. In any programming language, there will be space between two characters. Thus we create an ignore literal. Then we also create the basic literals like ‘=’, ‘+’ etc., NAME tokens are basically names of variables, which can be defined by the regular expression [a-zA-Z_][a-zA-Z0-9_]*. STRING tokens are string values and are bounded by quotation marks(” “). This can be defined by the regular expression ”.*?”.
Whenever we find digit/s, we should allocate it to the token NUMBER and the number must be stored as an integer. We are doing a basic programmable script, so let’s just make it with integers, however, feel free to extend the same for decimals, long etc., We can also make comments. Whenever we find “//”, we ignore whatever that comes next in that line. We do the same thing with new line character. Thus, we have build a basic lexer that converts the character stream to token stream.
Python3
class BasicLexer(Lexer):
tokens = { NAME, NUMBER, STRING }
ignore = 't '
literals = { '=', '+', '-', '/',
'*', '(', ')', ',', ';'}
NAME = r'[a-zA-Z_][a-zA-Z0-9_]*'
STRING = r'".*?"'
@_(r'd+')
def NUMBER(self, t):
t.value = int(t.value)
return t
@_(r'//.*')
def COMMENT(self, t):
pass
@_(r'n+')
def newline(self, t):
self.lineno = t.value.count('n')
Building a Parser
First let’s import all the necessary modules.
Python3
Now let’s build a class BasicParser which extends the Lexer class. The token stream from the BasicLexer is passed to a variable tokens. The precedence is defined, which is the same for most programming languages. Most of the parsing written in the program below is very simple. When there is nothing, the statement passes nothing. Essentially you can press enter on your keyboard(without typing in anything) and go to the next line. Next, your language should comprehend assignments using the “=”. This is handled in line 18 of the program below. The same thing can be done when assigned to a string.
Python3
class BasicParser(Parser):
tokens = BasicLexer.tokens
precedence = (
('left', '+', '-'),
('left', '*', '/'),
('right', 'UMINUS'),
)
def __init__(self):
self.env = { }
@_('')
def statement(self, p):
pass
@_('var_assign')
def statement(self, p):
return p.var_assign
@_('NAME "=" expr')
def var_assign(self, p):
return ('var_assign', p.NAME, p.expr)
@_('NAME "=" STRING')
def var_assign(self, p):
return ('var_assign', p.NAME, p.STRING)
@_('expr')
def statement(self, p):
return (p.expr)
@_('expr "+" expr')
def expr(self, p):
return ('add', p.expr0, p.expr1)
@_('expr "-" expr')
def expr(self, p):
return ('sub', p.expr0, p.expr1)
@_('expr "*" expr')
def expr(self, p):
return ('mul', p.expr0, p.expr1)
@_('expr "/" expr')
def expr(self, p):
return ('div', p.expr0, p.expr1)
@_('"-" expr %prec UMINUS')
def expr(self, p):
return p.expr
@_('NAME')
def expr(self, p):
return ('var', p.NAME)
@_('NUMBER')
def expr(self, p):
return ('num', p.NUMBER)
The parser should also parse in arithmetic operations, this can be done by expressions. Let’s say you want something like shown below. Here all of them are made into token stream line-by-line and parsed line-by-line. Therefore, according to the program above, a = 10 resembles line 22. Same for b =20. a + b resembles line 34, which returns a parse tree (‘add’, (‘var’, ‘a’), (‘var’, ‘b’)).
GFG Language > a = 10 GFG Language > b = 20 GFG Language > a + b 30
Now we have converted the token streams to a parse tree. Next step is to interpret it.
Execution
Interpreting is a simple procedure. The basic idea is to take the tree and walk through it to and evaluate arithmetic operations hierarchically. This process is recursively called over and over again till the entire tree is evaluated and the answer is retrieved. Let’s say, for example, 5 + 7 + 4. This character stream is first tokenized to token stream in a lexer. The token stream is then parsed to form a parse tree. The parse tree essentially returns (‘add’, (‘add’, (‘num’, 5), (‘num’, 7)), (‘num’, 4)). (see image below)
The interpreter is going to add 5 and 7 first and then recursively call walkTree and add 4 to the result of addition of 5 and 7. Thus, we are going to get 16. The below code does the same process.
Python3
class BasicExecute:
def __init__(self, tree, env):
self.env = env
result = self.walkTree(tree)
if result is not None and isinstance(result, int):
print(result)
if isinstance(result, str) and result[0] == '"':
print(result)
def walkTree(self, node):
if isinstance(node, int):
return node
if isinstance(node, str):
return node
if node is None:
return None
if node[0] == 'program':
if node[1] == None:
self.walkTree(node[2])
else:
self.walkTree(node[1])
self.walkTree(node[2])
if node[0] == 'num':
return node[1]
if node[0] == 'str':
return node[1]
if node[0] == 'add':
return self.walkTree(node[1]) + self.walkTree(node[2])
elif node[0] == 'sub':
return self.walkTree(node[1]) - self.walkTree(node[2])
elif node[0] == 'mul':
return self.walkTree(node[1]) * self.walkTree(node[2])
elif node[0] == 'div':
return self.walkTree(node[1]) / self.walkTree(node[2])
if node[0] == 'var_assign':
self.env[node[1]] = self.walkTree(node[2])
return node[1]
if node[0] == 'var':
try:
return self.env[node[1]]
except LookupError:
print("Undefined variable '"+node[1]+"' found!")
return 0
Displaying the Output
To display the output from the interpreter, we should write some codes. The code should first call the lexer, then the parser and then the interpreter and finally retrieves the output. The output in then displayed on to the shell.
Python3
if __name__ == '__main__':
lexer = BasicLexer()
parser = BasicParser()
print('GFG Language')
env = {}
while True:
try:
text = input('GFG Language > ')
except EOFError:
break
if text:
tree = parser.parse(lexer.tokenize(text))
BasicExecute(tree, env)
It is necessary to know that we haven’t handled any errors. So SLY is going to show it’s error messages whenever you do something that is not specified by the rules you have written.
Execute the program you have written using,
python you_program_name.py
Footnotes
The interpreter that we built is very basic. This, of course, can be extended to do a lot more. Loops and conditionals can be added. Modular or object oriented design features can be implemented. Module integration, method definitions, parameters to methods are some of the features that can be extended on to the same.
Как все началось
Дело было утром. Я захотел создать что-то на питоне, сложное, но посильное для меня. И тут я понял, что хочу создать язык программирования…
Как я создавал его…
Lexer
Куда же без него! Он требуется для «разделения» всего на токены. Если объяснить зачем он тогда представим: у нас есть код (CoffeScript).
a = true
if a
console.log('Hello, lexer')И лексер превращает этот код в это(сокращенная запись):
[IDENTIFIER:"a"]
[ASSIGN:"="]
[BOOLEAN:"true"]
[NEWLINE:"n"]
[NEWLINE:"n"]
[KEYWORD:"if"]
[IDENTIFIER:"a"]
[NEWLINE:"n"]
[INDENT:" "]
[IDENTIFIER:"console"]
[DOT:"."]
[IDENTIFIER:"log"]
[ROUND_BRAKET_START:"("]
[STRING:"'Hello, lexer'"]
[ROUND_BRAKET_END:")"]
[NEWLINE:"n"]
[OUTDENT:""]
[EOF:"EOF"]Но в моем случае я делаю все проще, т.к. это будет излишком трудности, а также язык программирования у меня простой. У меня все просто:
def lexer(code):
code = code.split(";") # Токенезация
code = code[0:-1] # Т.к. есть баг, что последний элемент пустой
return parse(code, number=0) # "Отсылаем" это все парсеруИ код (моего «ЯП»):
printf Test; exit;Он превратит в читабельное (!):
["printf Test", "exit"]Парсер
Самое сложное только начинается… Сделать токенезацию легко, а обработать это сложно. В теории мы должны проверять команду, потом ее аргументы. Кажется это легко, но нет! По началу все было примерно так:
number = 0
if code[number].startswith("printf"):
print(code[number][7:-0]
number += 1Но ничего не работало, точнее не печатало текст, потом я попробовал так:
number = 0
if code[number].startswith("printf"):
print(code[number][7:-1]
number += 1Но приходилось писать в конце любой символ. Потом я понял, что, если узнать длину строки и обрезать с 7-го символа по последний все должно работать.
number = 0
if code[number].startswith("printf"):
l = len(code[number])
print(code[number][7:l]
number += 1Вроде работает, но если выводить текст боле два и более раз то в начале идет лишний пробел… Но даже с помощью переменной проверяющей печатался ли раньше текст, ничего не работало правильно. После нескольких десятков минут и кружки кофе я придумал, что и как.
if code[number][7] == " ":
l = len(code[number])
print(code[number][8:l]
else:
l = len(code[number])
print(code[number][7:l]
Но все равно ничего не работало  и с таким лицом я пытался что-то сделать… Целый час. И спустя около полутора часа я сделал это!
и с таким лицом я пытался что-то сделать… Целый час. И спустя около полутора часа я сделал это!
l = len(code[number]) # Получаем длину
if code[number][6] == " ": # Если 6-ой символ это пробел
print(code[number][7:l]) # Печатаем все с 7-го символа
else: # Иначе
print(code[number][8:l]) #Потом полчаса шаманства и… Все работает на ура!
P.S.
- Не весь код с комментариями, т.к. он ориентирован на продвинутых программистов.
- Код в спойлере, т.к. он длинный и в «главный» текст статьи не входит.
- Прошу не ругаться насчет кода, мне 11 лет.
- Это моя первая статья на Хабре и вообще.
- Код в начале был взят из одной статьи на Хабре.
Код
def parse(code, number=0):
try:
# Print function #
if code[number].startswith("printf") or code[number].startswith(" printf"):
# Get len
l = len(code[number])
# If text starts with space
if code[number][6] == " ":
print(code[number][7:l])
# Else
else:
print(code[number][8:l])
number += 1
parse(code, number)
# Input function #
if code[number].startswith("input") or code[number].startswith(" input"):
# Get len
l = len(code[number])
# If text starts with space
if code[number][6] == " ":
input(code[number][7:l])
# Else
else:
input(code[number][8:l])
number += 1
parse(code, number)
# Exit function #
elif code[number].startswith("exit") or code[number].startswith(" exit"):
input("nPress "Enter" to exit.")
exit()
else:
cl = len(code[number])
command = code[number]
command = command[1:cl]
print("n", "=" * 10)
print("Error!")
print("Undefined command " + '"' + command + '"' + ".")
print("=" * 10)
input("Press "Enter" to exit...")
exit()
except IndexError:
input("n[!] Press "Enter" to exit.")
exit()
def lexer(code):
code = code.split(";")
code = code[0:-1]
return parse(code, number=0)
code = input()
lexer(code)
Пишем свой язык программирования без мам, пап и бизонов. Часть 0: теория
Тема написания своего ЯПа не дает мне покоя уже около полугода. Я не ставил перед собой цель «убить» CoffeeScript, TypeScript, ELM, тысячи их, я просто хотел понять кухню и как они вообще пишутся.
К моему неприятному удивлению, большинство из этих языков используют Jison (Bison для JavaScript), а это не совсем попадало под мою задачу — «понять», так как по сути дела Jison делает все за вас, собирает AST по заданным вами правилам (Jison как таковой отличный инструмент, который делает за вас львиную долю работы, но сейчас не о нем).
В конечном итоге я методом проб и ошибок (а если сказать точнее, чтения статей и реверс инжиниринга) научился писать свои полноценные языки программирования от разбития исходного текста на лексемы до его трансляции в JS код.
Стоит заметить, что данное руководство не привязано к JavaScript, он выбран исключительно из соображений скорости разработки и читаемости, так что вы можете написать свой «лисп»/»питон»/»ваш абсолютно новый синтаксис» на любом знакомом вам языке.
Также до момента написании компилятора (в нашем случае транслятора), процесс написания языка не отличается от процессов создания языков компилируемых в ASM/JVM bitcode/LLVM bitcode/etc, а это значит, что данное руководство не ограничивается созданием языка трансляцируемого в JavaScript.
Весь код, который будет написан в данной (и последующих статьях), лежит на Github’е. Тегами обозначены начало и концы статей для удобства.
Немного теории
Не углубляясь в википедийность, процесс трансляции исходного кода в конечный JS код протекает следующим образом:
Что тут происходит:
1) Lexer
Исходный код нашей программы разбивается на лексемы. По-простому это нахождение в исходном тексте ключевых слов, литералов, символов, идентификаторов и т.д.
Т.е. на выходе из этого (CoffeeScript):
Мы получаем это (сокращенная запись):
Так-как CoffeeScript отступо-чувствительный и не имеет явного выделения блока скобками < и >, блоки отделяются отступами ( INDENT ом и OUTDENT ом), которые по сути заменяет скобки.
2) Parser
Парсер составляет AST из токенов (лексем). Он обходит весь массив и рекурсивно подбирает подходящие паттерны, основываясь на типи токена или их последовательности.
Из полученных токенов в пункте 1, parser составит, примерно такое дерево (сокращенная запись):
Не стоит пугаться объема дерева, на деле он генерируется рекурсивно и его создание не вызывает трудностей.
3) Compiler
Построение конечного кода по AST. Этот пункт можно заменить на компиляцию в байткод, или даже рантайм, но в рамках данной серии статей мы рассмотрим реализацию транслятора в другой язык программирования.
Компилятор (читай транслятор) преобразует Абстрактно-Синтаксическое Дерево в JavaScript код:
Вот и все. Большинство компиляторов работают именно по такому принципу (с незначительными изменениями. Иногда добавляют процесс стримминга исходного текста в поток символов, иногда напротив объединяют парсинг и компиляцию в один этап, но не нам их судить).
Habrlang
Итак, разобравшись с теорией, нам предстоит собрать свой язык программирования, у которого будет примерно следующий синтаксис (что-бы не особо париться, мы будем делать смесь из Ruby, Python и CoffeeScript):
В следующей главе вы реализуем все основные классы нашего транслятора, и научим его транслировать комментарии Habrlang‘а в JavaScript.
Источник
Создаем свой язык программирования с блэкджеком и компилятором
В этом пособии с соответствующими примерами кода рассказываем о том, как написать при помощи Python свой язык программирования и компилятор к нему.

Введение
Изучение компиляторов и устройства языков программирования по видеоурокам и руководствам – дело для новичков тяжелое. В этих материалах нередко отсутствуют важные составляющие. Цель публикации – помочь людям, ищущим способ создать свой язык программирования и компилятор. Пример игрушечный, но позволит понять, с чего начать и в каком направлении двигаться.
Системные требования
Если вы незнакомы с нижеприведенными понятиями, не беспокойтесь – мы проясним необходимость этих компонентов далее, по ходу создания компилятора. В качестве лексера и парсера используется PLY. В роли низкоуровневого языка-посредника для генерации оптимизированного кода выступает LLVMlite.
Таким образом, к системе предъявляются следующие требования:
Свой язык программирования: с чего начать?
Начнем с того, что назовем свой язык программирования. В качестве примера он будет называться TOY. Пусть пример программы на языке TOY выглядит следующим образом:
Любой язык программирования включает множество составляющих его компонентов. Чтобы не застрять в мелочах, возьмем в качестве микропрограммы вызов одной функции нашего языка:
Как для этой однострочной программы формально описать грамматику языка? Чтобы это сделать, необходимо использовать расширенную Бэкус – Наурову форму (РБНФ) (англ. Extended Backus–Naur Form ( EBNF )). Это формальная система определения синтаксиса языка. Воплощается она при помощи метаязыка, определяющего в одном документе всевозможные грамматические конструкции. Чтобы в деталях разобраться с тем, как работает РБНФ, прочтите эту публикацию.
Создаем РБНФ (EBNF)
Создадим РБНФ, которая опишет минимальный функционал нашей микропрограммы. Начнем с операции суммирования:
Соответствующая РБНФ будет выглядеть следующим образом:
Дополним язык операцией вычитания:
В соответствующем РБНФ изменится первая строка:
Наконец, опишем функцию print:
В этом случае в РБНФ появится новая строка, описывающая работу с выражениями:
В таком ключе развивается описание грамматики языка. Как же научить компьютер транслироваться эту грамматику в бинарный исполняемый код? Для этого нужен компилятор.
Компилятор
Компилятор – это программа, переводящая текст ЯП на машинный или другие языки. Программы на TOY в этом руководстве будут компилироваться в промежуточное представление LLVM IR (IR – сокращение от Intermediate Representation) и затем в машинный язык.

Использование LLVM позволяет оптимизировать процесс компиляции без изучения самого процесса оптимизации. У LLVM действительно хорошая библиотека для работы с компиляторами.
Наш компилятор можно разделить на три составляющие:
Для лексического анализатора и парсера мы будем использовать RPLY, очень близкий к PLY. Это библиотека Python с теми же лексическими и парсинговыми инструментами, но с более качественным API. Для генератора кода будем использовать LLVMLite – библиотеку Python для связывания компонентов LLVM.
1. Лексический анализатор
Итак, первый компонент компилятора – лексический анализатор. Роль этого компонента заключается в том, чтобы разделять текст программы на токены.

Воспользуемся последней структурой из примера для РБНФ и найдем токены. Рассмотрим команду:
Наш лексический анализатор должен разделить эту строку на следующий список токенов:
Напишем код компилятора. Для начала создадим файл lexer.py, в программном коде которого будут определяться токены. Для создания лексического анализатора воспользуемся классом LexerGenerator библиотеки RPLY.
Создадим основной файл программы main.py. В этом файле мы впоследствии объединим функционал трех компонентов компилятора. Для начала импортируем созданный нами класс Lexer и определим токены для нашей однострочной программы:
При запуске main.py мы увидим на выходе вышеописанные токены. Вы можете изменить названия своих токенов, но для простоты согласования с функциями парсера их лучше оставить как есть.
2. Синтаксический анализатор
Второй компонент компилятора – синтаксический анализатор (он же парсер). Его роль – синтаксический анализ текста программы. Данный компонент принимает список токенов на входе и создает на выходе абстрактное синтаксическое дерево (АСД). Эта концепция более трудна, чем идея списка токенов, поэтому мы настоятельно рекомендуем хотя бы по приведенным выше ссылкам изучить принципы работы парсеров и синтаксических деревьев.

Чтобы воплотить в жизнь синтаксический анализатор, будем использовать структуру, созданную на этапе РБНФ. К счастью, анализатор RPLY использует формат, схожий с РБНФ. Самое сложное – присоединить синтаксический анализатор к АСД, но когда вы поймете идею, это действие станет действительно механическим.
Во-первых, создадим файл ast.py. Он будет содержать все классы, которые могут быть вызваны парсером, и создавать АСД.
Во-вторых, нам необходимо создать сам анализатор. Для этого в новом файле parser.py аналогично лексеру используем класс ParserGenerator из библиотеки RPLY:
Наконец, обновляем файл main.py, чтобы объединить возможности синтаксического и лексического анализаторов:
Теперь при запуске main.py мы получим значение 6. и оно действительно соответствует нашей однострочной программе «print(4 + 4 – 2);».
Таким образом, при помощи двух этих компонентов мы создали работающий компилятор, интерпретирующий язык TOY. Однако компилятор по-прежнему не создает исполняемый машинный код и не оптимизирован. Для этого мы перейдем к самой сложной части руководства – генерации кода с помощью LLVM.
3. Генератор кода
Третья и последняя часть компилятора – это генератор кода. Его роль заключается в том, чтобы преобразовывать АСД в машинный код или промежуточное представление. В нашем случае будет происходить преобразование АСД в промежуточное представление LLVM (LLVM IR).
LLVM может оказаться действительно сложным для понимания инструментом, поэтому обратите внимание на документацию LLVMlite. LLVMlite не имеет реализации для функции печати, поэтому вы должны определить собственную функцию.
Чтобы начать, создадим файл codegen.py, содержащий класс CodeGen. Этот класс отвечает за настройку LLVM и создание/сохранение IR-кода. В нем мы также объявим функцию печати.
Теперь обновим основной файл main.py, чтобы вызывать методы CodeGen:
Как вы можете видеть, для того, чтобы обработка происходила классическим образом, входная программа была вынесена в отдельный файл input.toy. Это уже больше похоже на классический компилятор. Файл input.toy содержит все ту же однострочную программу:
Еще одно изменение – передача парсеру методов module, builder и printf. Это сделано, чтобы мы могли отправить эти объекты АСД. Таким образом, для получения объектов и передачи их АСД необходимо изменить parser.py:
Наконец, самое важное. Мы должны изменить файл ast.py, чтобы получать эти объекты и создавать LLMV АСД, используя методы из библиотеки LLVMlite:
После изменений компилятор готов к преобразованию программы на языке TOY в файл промежуточного представления LLVM output.ll. Далее используем LLC для создания файла объекта output.o и GCC для получения конечного исполняемого файла:
Теперь вы можете запустить исполняем файл, для создания которого вами использовался свой язык программирования:
Следующие шаги
Мы надеемся, что после прохождения этого руководства вы разобрались в общих чертах в концепции РБНФ и трех основных составляющих компилятора. Благодаря этим знаниям вы можете создать свой язык программирования и написать оптимизированный компилятор при помощи Python. Мы призываем вас не останавливаться на достигнутом и добавить в свой язык и компилятор другие важные составляющие:
Итоговый программный код вы также найдете на GitHub.
Другие материалы по теме языков программирования
Источник
В этом разделе мы обсудим основной синтаксис и разберем пример Python – запустим простую программу для печати Hello World на консоли.
Python предоставляет нам два способа запуска программы:
Давайте подробно обсудим каждый из них.
Интерактивная подсказка помощника
Python предоставляет нам возможность выполнять инструкции интерактивного помощника. Это предпочтительнее в том случае, когда нас беспокоит вывод каждой строки программы Python.
Чтобы использовать интерактивный режим, откройте терминал(или командную строку) и введите python(python3 в случае, если в вашей системе установлены Python2 и Python3).
Откроется следующее приглашение, в котором мы можем выполнить оператор Python и проверить влияние на консоль.

После написания отчета о печати нажмите клавишу Enter.

Здесь мы получаем сообщение “Hello World!” на консоли.
Использование файла сценария(Программирование в режиме сценария)
Подсказка интерпретатора лучше всего подходит для выполнения однострочных операторов кода. Однако мы не можем писать код каждый раз на терминале. Не рекомендуется писать несколько строк кода.
Чтобы запустить этот файл с именем first.py, нам нужно запустить следующую команду на терминале.

Шаг – 1: Откройте интерактивную оболочку Python и нажмите «Файл», затем выберите «Создать», откроется новый пустой скрипт, в котором мы можем написать наш код.

Шаг 2: Теперь напишите код и нажмите «Ctrl + S», чтобы сохранить файл.

Шаг – 3: После сохранения кода мы можем запустить его, нажав «Выполнить» или «Выполнить модуль». Он отобразит вывод в оболочку.

Результат будет показан следующим образом.

Шаг – 4: Кроме того, мы также можем запустить файл с помощью терминала операционной системы. Но мы должны знать путь к каталогу, в котором мы сохранили наш файл.


Многострочные операторы


Плюсы и минусы режима сценария
Режим сценария также имеет несколько преимуществ и недостатков. Давайте разберемся в следующих преимуществах запуска кода в режиме скрипта:
Посмотрим на недостатки скриптового режима:
Начало работы с PyCharm
В нашей первой программе мы использовали gedit в CentOS в качестве редактора. В Windows у нас есть альтернатива, например блокнот или блокнот ++, для редактирования кода. Однако эти редакторы не используются в качестве IDE для Python, поскольку они не могут отображать предложения, связанные с синтаксисом.
JetBrains предоставляет самую популярную и широко используемую кроссплатформенную IDE PyCharm для запуска программ Python.
Установка PyCharm
Как мы уже говорили, PyCharm – это кроссплатформенная IDE, поэтому ее можно установить в различных операционных системах. В этом разделе руководства мы рассмотрим процесс установки PyCharm в Windows, MacOS, CentOS и Ubuntu.
Windows
Установить PyCharm в Windows очень просто. Чтобы установить PyCharm в операционной системе Windows, перейдите по ссылке https://www.jetbrains.com/pycharm/download/download-thanks.html?platform=windows, чтобы загрузить установщика. Дважды щелкните файл установки(.exe) и установите PyCharm, нажимая «Далее» на каждом шаге.
Чтобы создать первую программу для Pycharm, выполните следующий шаг.
Шаг – 1. Откройте редактор Pycharm. Нажмите на «Создать новый проект», чтобы создать новый проект.

Шаг – 2. Выберите место для сохранения проекта.

Шаг – 3. Щелкните меню «Файл» и выберите «Новый». При нажатии на опцию «Новый» он покажет различные форматы файлов. Выберите «Файл Python».

Шаг – 4. Теперь введите имя файла Python и нажмите «ОК». Мы написали «Первую программу».

Шаг – 5. Теперь введите первую программу – print(«Hello World»), затем нажмите меню «Выполнить», чтобы запустить программу.

Шаг – 6. Результат появится внизу экрана.

Базовый синтаксис Python
Отступы в Python
Отступы – наиболее важная концепция языка программирования Python. Неправильное использование отступов приведет к ошибке “IndentationError” в нашем коде.
Отступы – это не что иное, как добавление пробелов перед оператором, когда это необходимо. Без отступа Python не знает, какой оператор выполнять следующим. Отступ также определяет, какие операторы принадлежат какому блоку. Если нет отступа или отступ неправильный, отобразится «IndentationError» и прервет наш код.

Отступы Python определяют, какая группа операторов принадлежит конкретному блоку. В языках программирования, таких как C, C ++, java, для определения блоков кода используются фигурные скобки <>.
В Python операторы, находящиеся на одном уровне справа, принадлежат одному блоку. Мы можем использовать четыре пробела для определения отступа. Давайте посмотрим на следующие строки кода.
В приведенном выше коде цикл for имеет блоки кода, если оператор имеет блок кода внутри цикла for. Оба с четырьмя пробелами с отступом. Последний оператор print() без отступа; это означает, что он не принадлежит циклу for.
Комментарии в Python
Комментарии необходимы для определения кода и помогают нам и другим людям понять код. Просматривая комментарий, мы можем легко понять назначение каждой строки, написанной нами в коде. Мы также можем очень легко найти ошибки, исправить их и использовать в других приложениях.
В Python мы можем применять комментарии, используя символ решетки #. Интерпретатор Python полностью игнорирует строки, за которыми следует символ решетки. Хороший программист всегда использует комментарии, чтобы сделать код стабильным. Давайте посмотрим на следующий пример комментария.
Мы можем добавить комментарий в каждую строку кода Python.
Хорошая идея – добавить код в любую строку раздела кода, цель которого неочевидна. Это лучший способ изучить при написании кода.
Типы комментариев
Python предоставляет возможность писать комментарии двумя способами – однострочный комментарий и многострочный комментарий.
Однострочный комментарий начинается с символа решетки #, за которым следует текст для дальнейшего объяснения.
Мы также можем написать комментарий рядом с оператором кода. Рассмотрим следующий пример.
Многострочные комментарии – Python не имеет явной поддержки многострочных комментариев, но мы можем использовать символ решетки # для нескольких строк. Например –
Мы также можем использовать другой способ.
Это основное введение в комментарии. Просмотрите наш урок по комментариям Python, чтобы изучить его подробно.
Идентификаторы Python
Идентификаторы Python относятся к имени, используемому для идентификации переменной, функции, модуля, класса, модуля или других объектов. Есть несколько правил, которым нужно следовать при присвоении имени переменной Python.
Мы определили базовый синтаксис языка программирования Python. Мы должны ознакомиться с основной концепцией любого языка программирования. Как только мы запомним концепции, упомянутые выше, изучение Python станет проще.
Источник
Как объединить 5 языков программирования в одном Python проекте?
На сегодняшний день существует несколько тысяч языков программирования, каждый из которых создавался с определенной целью, пытаясь изменить и улучшить недостатки своих предшественников. Так, например, появился язык Kotlin, который был нацелен на замену Java в мобильной разработке. В 2010 году увидел свет язык Rust, разработчики которого пытались создать быстрый и безопасный язык, который закрывал бы многие недостатки C/C++.
Сейчас практически никто не ставит цели создать универсальный язык для всех задач и всех платформ, так как в каждой области есть свои потребности и нюансы для языка. Например, если в системной разработке требуется следить за памятью, то в местах, где нужно написать простой рабочий продукт, можно пренебречь тем, сколько памяти использует язык для своей работы.
Но что делать, если необходимо использовать несколько языков программирования в одном проекте?
Зачастую бывает так, что один язык не очень хорошо может справляться с теми задачами, которые нужно решить. Для этого программист может без проблем пересесть на другой язык. Но что делать, если уже имеется какая-то часть кода, которая написана на одном языке программирования, а другая часть кода на другом? Например, есть приложение, написанное на Python и есть какие-то структуры, модули или методы, которые написаны на Java (C/C#/JS) и уже оптимизированы с учетом этого языка, а переписывание этого кода на Python может занять много времени, да и код на Python будет выполняться намного медленнее и использовать больше памяти.
Можно попробовать объединить все эти наработки в одно приложение. Благо на сегодняшний день уже реализовано много библиотек, которые позволят без лишних проблем это сделать.
Цель статьи: попробовать написать одно приложение, где будет использоваться код, написанный на 5 разных языках программирования.
В качестве примера языки будут реализовать следующее: Cи будет проверять число на простоту методом квадратного корня, C# проверит число на простоту методом Милера-Рабина, Java проверит число на простоту методом Ферма, Python будет раскладывать число на множители, а JS будет высчитывать сумму числового ряда для полученных множителей.
Для того, чтобы запустить код Java из Python необходимо создать maven java проект (я пользуюсь IntellIJ). В нем создать модуль (я назвал его pkg_java) и в нем создать класс (название: JavaPrime) с логикой проверки числа на простоту методом Ферма:
 Создание jar-артефакта
Создание jar-артефакта
Модуль Java был успешно загружен, теперь можно пользоваться тестом Ферма.
Для того, чтоб запустить C# код в Python, нужно для начала создать библиотеку классов C# (я использовал VS2019):

Назовем проект is_prime_csharp (данный проект в будущем будет импортироваться в Python с таким же названием). Реализуем логику алгоритма Милера-Рабин:
Теперь модуль C# готов к работе, методом Милера-Рабина для проверки числа на простоту можно пользоваться.
Для связи С с Python сначала реализуем алгоритм квадратного корня для проверки числа на простоту:
Модуль C успешно загружен.
JavaScript
В main.py пропишем логику запуска программы:
С такой структурой программы:
 структура Python проекта
структура Python проекта
И вызовем метод JS из Python:
Python
Для начала реализуем метод факторизации чисел:
Результат
Программа имеет простой графический интерфейс:
 интерфейс итоговой программы
интерфейс итоговой программы
Необходимо ввести число в поле “Число” и нажать кнопку “выполнить”. После чего через JS обработать нажатие данной кнопки и вызвать метод из Python:
Теперь можно запустить программу и проверить, будет ли всё вместе работать:
 Тест программы простым число 12421
Тест программы простым число 12421  Тест программы составным числом 12879
Тест программы составным числом 12879
Вывод
Связать несколько языков программирования вместе в одной программе возможно, но это не совсем хорошая идея, так как при запуске программы на стороннем ПК надо быть уверенным, что у пользователя установлены нужные сервисы/зависимости/ПО, например, стоит ли JVM. Для быстрой проверки работоспособности каких-то идей, модулей, логики можно попробовать использовать подход, описанный в статье. Данный способ позволяет экономить кучу времени, вместо того, чтобы мучаться и переписывать код на другой язык в надежде, что всё будет работать как надо. Этот способ может подойти в тех случаях, когда нет возможности разработать адекватную микросервисную архитектуру приложения, а нужно использовать несколько разных кусков кода/модулей.
Как итог, получилось связать Python + JS + Java + C + C# (+ HTML + CSS) в одной программе, сделав при этом полноценное десктопное приложение, которое работает быстро без лишних задержек при обращении к методам, написанным на другом языке. В таком подходе есть плюсы: можно использовать фишки других языков (например, использовать преимущества скорости в C, Java, C# с (или без) использованием многопоточности, задействующей несколько ядер процессора, а также можно реализовывать структуры, которые будут использовать меньше памяти нежели Python).
Источник