
Наступил Апокалипсис.
Нет, не стоит бежать запасаться банками с консервами и крышками отечественной бай-колы! Апокалипсис произошёл только в нашей фантазии и с определённой целью — чтобы проверить, а может ли человек, обладающий только книгами по теме и стандартной библиотекой языка, воссоздать инструмент, который будет служить ему верой и правдой?
Так родился учебный проект SicQL, реляционная СУБД, чей символ — сова — это олицетворение силы знаний и мудрости. Олицетворение тех знаний и той мудрости, которые мы получим, создав с нуля то, чем мы пользуемся каждый день, может, не осознавая всей сложности таких инструментов.
Приглашаю присоединиться к увлекательному путешествию!
Содержание
-
Как создать свою СУБД с нуля и не сойти с ума. Практическое пособие некроманту. Часть первая (данная статья)
-
Предисловие
-
Глава 0. Новое начало истории
-
Глава 1. Архитектура. Noctua ex machina
-
Глава 2. Транзакции, или как остаться без копейки в кармане
-
Глава 3. Деревья. Сбалансированные. Страшно
-
Глава 4. Профессиональный переводчик на совиный — как довериться пользователю и не сломать базу
-
Глава 5. Заверитель транзакций. Виртуальный нотариус собственной персоной
-
Послесловие
-
Полезные ссылки
-
Постскриптум
-
Предисловие
Иногда мы слишком просто принимаем за должное то, что было создано кровью и потом прошлых поколений. Используем в качестве вызываемых библиотек в нашем скриптовом коде, используем в качестве хранилища бесчисленного множества заказов… И это нельзя считать за грех ровно до того момента, пока мы знаем, что мы делаем.
Но современная парадигма обучения программированию не всегда предполагает знание основополагающих принципов инструментов, с которыми мы работаем каждый день. И не было бы это проблемой, если бы не то последствие, которое вытекает из такого отношения — что бы вы думали о спортсмене-бегуне, который не знает, как работает его организм? «Ну бегаю и бегаю, что пристали-то?» — а в решающий момент, за день до соревнования, потянет ногу каким-нибудь глупым упражнением. «Кто же знал, что так получится…» — а вот мы постараемся такого не допустить.
Глава 0. Новое начало истории
Итак — мы немного отвлеклись — грянул Судный день. Его часы оттикали полночь и снова пошли по кругу. В новом мире постапокалипсиса не существует ни того количества дистрибутивов Линукса, ни новых версий Айфона каждый год — в общем, всего того разнообразия любимых (или не очень) плодов существовавшей ранее цивилизации.
Но давайте заранее условимся — мы всё-таки создаём учебный проект, а не по-настоящему симулируем (как бы это странно не звучало) новый, отчасти пугающий, мир. Поэтому, думаю, простительно, если мы всё же воспользуемся некоторыми библиотеками в тех местах, в которых мы не хотим излишне повышать сложность. У учёбы есть задача — научиться, научиться чему-то конкретному, и мы подробно разберём эти задачи в следующей главе про архитектуру базы данных. Если по пути воплощения в жизнь нашей СУБД возникнут задачи, которые не попадают в изначально установленные критерии, то будет разумно воспользоваться уже готовыми решениями.
Для начала хочу донести пару важных принципов, по которым была написана данная статья:
-
Структура статьи составлена таким образом, чтобы даже в мире постапокалипсиса по её тексту можно было воссоздать без особых других знаний эту СУБД. Пусть даже не с помощью языка Rust, а с помощью какого-нибудь новоизобретённого Rusty или C**.
-
Процесс создания SicQL продолжается и по сей день — сначала создавалась статья, а затем уже начались работы по воплощению СУБД, притом она, как и сама статья, неоднократно переписывалась в виду особенностей как меня, автора, так и Rust — прототипы за две недельки не напишешь. Так что советую заглянуть через пару месяцев в исходный код и увидеть если не бета-релиз, то хотя бы альфу, которую можно будет полноценно потыкать. И где-то там будет вторая часть статьи с ревизией положений, изложенных ниже, хе-хе.
-
Так как исследуемая тема настолько обширна, что даже отдельных статей на каждую часть архитектуры не хватит, то, во-первых, иные подходы к решению поставленных задач затрагиваются только мельком, во-вторых, многие полезные с точки зрения оптимизации вещи не реализованы даже в теории, а в-третьих, раздел используемых источников сконструирован таким образом, чтобы после прочтения данной статьи можно было бы более основательно углубиться в затронутые темы, что я и советую. В том числе, я ожидаю, что знающие люди в комментариях дополнительно расскажут про вышеперечисленные первый и второй пункты, что ещё более повысит ценность данного текста с точки зрения простора для размышлений и развития себя как разностороннего специалиста.
Ну что ж, мы зашли уже слишком далеко, чтобы останавливаться! В путь!

Глава 1. Архитектура. Noctua ex machina
Что-что делаем?
Начнём с определения абстрактного класса BasedTable… Эй, погоди! А что делаем-то?
Базы данных — это круто, системы управления базами данных — ещё круче, реляционные системы… Ну вы поняли. Нельзя сказать «а давайте сделаем projectName», а затем начать усердно писать код — с таким оголтелым подходом к разработке мы не то что наткнёмся на неведомые подводные камни, но и вообще не закончим проект. Поэтому немного угомоним свои высокие порывы инженерной души и взглянем на ситуацию со стороны.
Всякий инженерный проект — это решение конкретной задачи. В частности, поэтому так желанная серебряная пуля невозможна — не существует универсального решения. В конце концов, мы учим железку действовать определённым образом в определённом контексте. Осуществляется ли это условными конструкциями if … else или определённым датасетом, который мы скармливаем нейронке, — не так важно. Важно то, что учителя, в итоге, — это мы. Поэтому от того, насколько мы сможем увидеть решение задачи заранее, и зависит успешность проекта.
Взгляните только на простого столяра, которому требуется смастерить табуретку — явно она не получается случайно в процессе изготовления — табуретка уже существует в голове мастера как законченный проект. Вот, в голове мы её крутим-вертим, разбиваем на составные части, прикидываем необходимые инструменты… И как-то в конце концов переносим нашу воображаемую табуретку в реальный мир. Магия!
Чем же отличается наш случай от столяра с табуреткой? Высокой степенью абстракций. Мы не ощущаем прямого контакта с данным произведением человеческого труда. Из этого и растут дальнейшие проблемы — непонятно даже за что ухватиться. Так что перед тем, как обучать машину решать задачу, давайте научимся решать её сами.
Перепридумываем перепридуманное
В сущности, задача стоит так — предоставить человеку относительно ясный и понятный интерфейс для работы с долгосрочным хранилищем данных. Во как — мысль наша пошла-поехала, начинаем разбивать задачу на подзадачи!
Какой самый удобный для человека, так скажем, визуальный интерфейс? Текст. Есть предположение, что человеку удобнее всего получать информацию из пиктограмм — но, во-первых, я такое даже и представить не могу (отсылаю к предыдущему параграфу), а во-вторых, нам нужно не только информацию извлекать, но и вносить. А как уж эти пиктограммы в компьютер заносить да обучить машину их считывать — это, извините, не ко мне, а к специалистам по машинному обучению. Остались они в постапокалиптическом мире или нет — ещё один хороший вопрос.
Отлично! Значит, взаимодействовать будем с помощью текста — тем самым нужен какой-то определённый язык… И тут в игру вступают ограничения, заданные изначально, то есть вроде наступивший постапокалипсис. Давайте условимся о том, что переизобретать SQL (к его сущности мы перейдём немного позже) мы не будем. Свою NoSQL базу данных сделаем как-нибудь в следующий раз.
Но так просто мы не отделаемся. Потому что под словами «переизобретение» в абзаце выше могут скрываться две вещи: переизобретение спецификации языка и переизобретение самого языка. Что это за странная игра слов? Смотрим ниже:
Допустим, в гипотетическом языке программирования под фирменным названием Language™ существуют две конструкции:
выражение + выражение?
выражение - выражение? …где выражение — число или одна из этих синтаксических конструкций, обособленных круглыми скобками (). Тут мы вступаем на одно очень интересное поле лингвистики, но не будем торопить события, всё успеем разобрать.
Замечательно — у нас на руках правила, которые задают синтаксис этого языка. Но синтаксис на то и синтаксис, что задаёт лишь правильное расположение лексем. Но как бы мы не ставили, хоть и правильно, слова в языке, он не может являться языком, пока он не будет что-то значить. Это называется семантикой языка.
Можно написать хоть сотни стандартов, описывающих синтаксис языка, но кто-то на этом языке должен говорить — собственно сама СУБД. Точнее сказать, вталдычивать программе о нужных нам записях в базе данных будем мы, но только таким образом, чтобы это понимала программа. Следовательно мы, авторы этой программы, должны каким-то магическим образом научить её понимать некоторое подмножество языка SQL. Именно это, я считаю, тоже можно считать за изобретение языка — хоть уже и по имеющимся стандартам, и всему прочему.
Дружим запрос с процессором
«Но кто-то на этом языке должен говорить…» Интересное заявление — мы начали одушевлять миллионы транзисторов на камне с работающей операционной системой на борту. Пока что он нам не отвечает — то, что мы ему пытаемся сказать, выходит за рамки его понимания. Для него всё бренное есть наличие или отсутствие напряжения на контактах.
Довольно пессимистично для начала, особо учитывая окружающую нас реальность. Но у нас давний друг, выручавший не одно поколение человечества — разум. И у этого разума есть занимательное свойство — способность к абстракции. Не важно, что мы имеем сейчас на руках — мы всегда можем придумать что-то лучше. Что-то, чем легче оперировать. А дальше дело будет за малым — пару миллионов электронных (где-то мы это уже видели) и химических сигналов, и абстрактное видение буквально осуществится с помощью наших ручек.
Но долой эту лирику — давайте строить мост между процессором и человеком с двух концов:
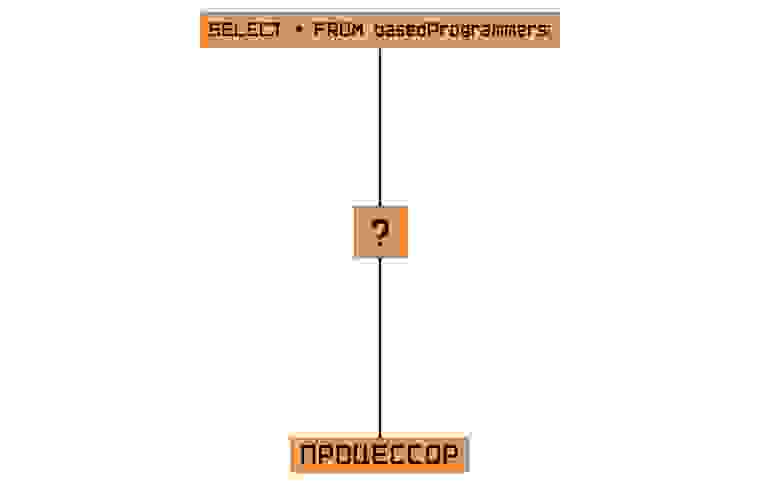
За какой конец взяться?
Конкретно разберём замеченную нами проблему: первое, мы не имеем представления, да и, желательно, не должны, о том, как процессор взаимодействует с данными, второе, мы не знаем, во что стоит переводить строку запроса.
Ответ кроется в разборе проблемы выше — чтобы знать, во что стоит перевести запрос, мы должны знать, как процессор работает с данными. Поэтому первый компонент нашей архитектуры должен быть тем, кто будет заботиться о правильном расположении данных в хранилище, то есть первым делом будем браться за бэкэнд нашей СУБД.
Что из имеющегося под рукой мы можем использовать под хранилище? Компьютер предоставляет нам две опции: храни данные либо в оперативной памяти, но до завершения своего процесса, либо в файловой системе, но надолго. Многие проблемы встанут перед нами только в случае хранения базы в файловой системе, поэтому условимся, что база будет представлять из себя одну большую последовательность записей в одном файле, который можно представить как массив в оперативной памяти, ведь мы хотим сохранить для пользователей такую возможность.
Далее — вот мы храним данные, но в каком формате? Записать белиберду — просто, а как её считать и преобразить обратно?
Сделать простое иногда во много раз сложнее, чем сложное, поэтому не будем изобретать велосипед, пока это нам напрямую не понадобится. «В лоб» задача решается следующим образом:

То есть в данный момент база представляет из себя один текстовый файл с последовательностью записей, предварённых заголовком с метаданными: какие поля есть в записях, какого они типа.
Из-за данного формата данных перед нами встали следующие проблемы:
-
Перед тем, как начинать операции с данными на диске, мы должны выгрузить их в оперативную память — иначе скорость работы будет неимоверно низкой. Но, допустим, нам нужна запись под номером 100500 — нам что, придётся загрузить все записи с 1-ой по 100500-ую? А если там хранятся гигабайты данных?
-
А как мы будем доставать 100500-ую запись? Как видно выше, каждая новая запись начинается на новой строке, то есть они разделяются символом переноса строки (в зависимости от платформы — CRLF/LF/…). Нам придётся считывать символ за символом, строку за строкой — звучит так же плохо, как и в предыдущим примере.
-
Текстовый формат данных — ну слишком жирно! Каждый символ (в том числе и пробелы, и переносы строк, и запятые) занимает 1 байт при кодировке UTF-8 или 2 байта при UTF-16. Звучит не так страшно? Представим 100000 записей всего лишь с одним знаковым целочисленным полем, хранящем максимальное число, которое можно уместить в 32 битах —
2147483647. В UTF-8 это поле занимает 10 байт, а бинарный формат, то есть запись, как есть — 4 байта,0x7f 0xff 0xff 0xffпри шестнадцатеричном формате записи. 6 байтов разницы, плёвое дело? Ну-ну — в итоге вместо ~390 килобайт данная таблица будем занимать весь мегабайт! В два с половиной раза больше!
Как мы можем решить эти проблемы?
-
Мысль первая: почему бы не разделить этот файл — но не на отдельные файлы, а на сегменты, чей размер будет известен заранее?
Размер должен быть определён заранее и желательно не должен меняться. Если размер сегментов будет зависеть от количества строк (например, 100 записей в одном сегменте), то нам так же придётся считывать строку за строкой, пока не насчитываем достаточное количество для перевода страницы. Непорядок… -
Мысль вторая: а если мы отойдём от текстового формата данных и перейдём к бинарному?
Если принять оба этих решения, то мы получим следующий формат файла:

Так как теперь у нас нет знаков CRLF/LF, которые бы указывали на начало новой записи, то нам нужно либо располагать записи на странице особым образом, либо перед началом поля данных хранить тип, некоторый байт, чьё значение бы указывало на то, сколько байтов, за ним следующих, считать, и что они значат (строка, номер записи, целое число, число с плавающей запятой…).
Здесь и далее будем рассматривать это всё достаточно концептуально — записи располагаются последовательно на странице. О том, как это на самом деле будет происходить, будем смотреть уже во второй части статьи по реализации всех наших задумок.
В СУБД такие сегменты обычно именуются страницами, но могут встречаться и другие названия. Поэтому будем называть их именно страницами.
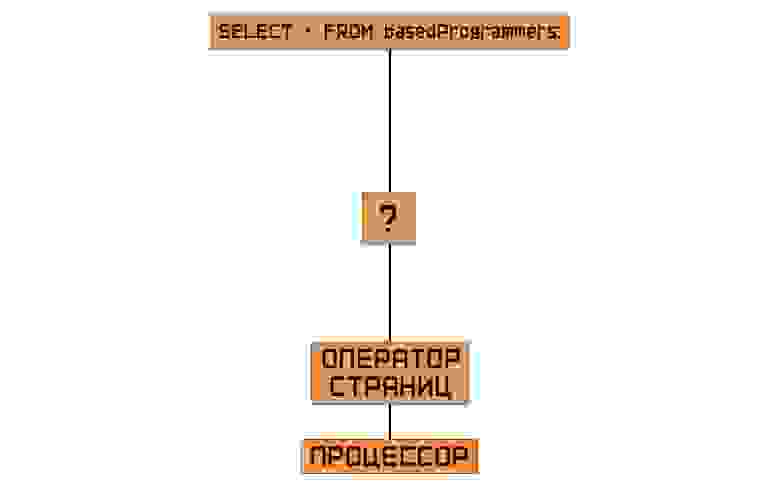
Теперь у нас есть файл базы данных, разделённый на страницы одного размера. В нашей архитектуре должен появиться герой, который сможет разобраться в этом, который сможет предоставлять вверх по цепочке структуры СУБД эти страницы.
В английской литературе его зовут просто — pager. Пейджер, то есть страничник. Диспетчер, оператор страниц. Звучит во всех случаях глупо, но ради сохранения консистентности текста будем называть его оператором страниц.
Этот оператор запрашивает данные у файла ровно по странице — и это сделано не просто ради решения тех проблем, которые мы выявили ранее, а ещё ради облегчения дискового процесса ввода-вывода. Диск, в отличие от оперативной памяти (и то оперативная память ведёт себя лучше, когда запрашиваемые данные расположены рядом друг с другом в виду внутреннего строения), считывает данные не по байтам, а по огромным сегментам — и операционная система так же хранит эти данные в страницах. Зачастую размер такой страницы равняется 4096 байтам, то есть 4 килобайтам. Так что такую особенность нужно оседлать и использовать в своих нуждах.
Вообще современные СУБД усиленно следят за количеством операций ввода-вывода, так как это повышает как скорость работы, так и время жизни накопителя, особенно, если он твердотельный. В этом участвуют многоуровневые кэши внутри структуры, строение хранящихся данных… Но современные СУБД сгинули в пучине ядерного огня, так что времени философствовать у нас не так уж и много!
Как вы заметили в примере с упрощённым бинарным представлением файла, в странице под номером 0 расположены названия таблицы вместе с номером той страницы, на которой таблица начинается; а в самой странице, в конце, указывается номер следующей страницы, на которой следуют данные, которые не поместились в странице предыдущей.
Следите за руками — если одной страницы не хватает для расположения всех данных таблицы, то мы берём любую попавшуюся под руку свободную страницу (пусть она даже не будет последующей!), вписываем указатель в последнюю страницу таблицы, продолжаем записывать данные в новую страницу.
Немного отойдём от темы. Мне трудно было уместить в голову понятие указателей в бинарном файле — поэтому объясню в том числе и для читателей: указатель на страницу — это её индекс, смещение от начала файла. В том числе и указатель на байт в бинарном файле — это его смещение от начала файла.
Если вы уже знакомы с понятием указателей в оперативной памяти, то там адрес всегда указывает на одно и то же место в этой памяти. Если представить оперативную память как один большой файл, то указатель в ней практически то же самое, что и указатель в файле. Простое смещение от начала структуры…
«Берём любую попавшуюся под руку» — хе-хе, а руки-то вот они, не уследили! Такие вещи кто-то должен делать — но точно не оператор страниц. У него цель одна — паковать данные в страницы. Что там дальше — это, извините, не его ответственность. Пусть мир перевернётся уже во второй раз — но внутрь страницы не заглянет!
Значит нам нужен ещё один оператор… Если страницы соединить в продиктованном указателями порядке, то мы получим таблицу. Значит это… оператор таблиц! Как всё легко, оказывается!
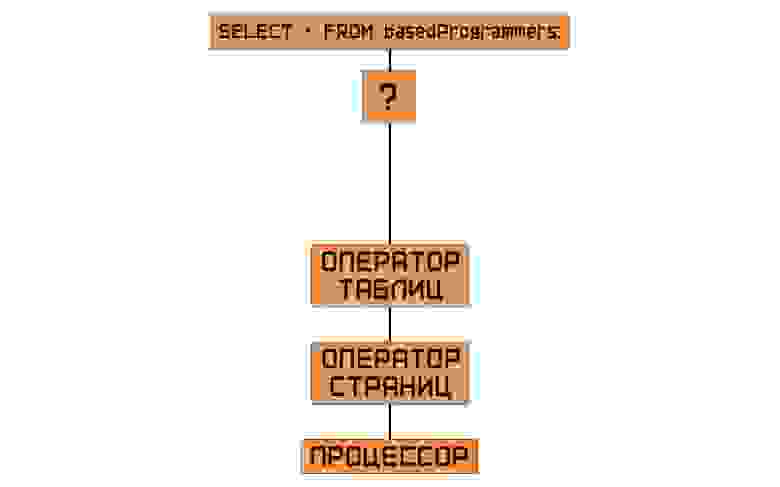
Оператор таблиц уже может заглядывать внутрь страницы — он может увидеть указатели, может увидеть, наконец, уже данные наших записей. Иными словами, оператор таблиц предоставляет вверх по структуре СУБД атомарные, то есть минимально возможные, инструкции над этими данными. Конечно, нам придётся поработать с тем, как эффективно хранить эти указатели, но, если особо не всматриваться, архитектура бэкэнда завершена. Внимательные читатели могли заметить, что мы упустили несколько важных вещей — но мы к ним вернёмся, не переживайте.
Значит, приступим к созданию нашего фронтэнда — того, что будет понимать повеления пользователя и трансформировать их во внятные для бэкэнда инструкции.
На данном уровне абстракции запрос от пользователя представляет из себя строку. Как одну целую строку переделать в набор инструкций, да так, чтобы ещё и пользователь понял, что он сделал не так?
Если вы чутка знакомы с тем, как работают компиляторы и интерпретаторы языков программирования, то вы уже знаете ответ. В общем, подход такой: создать из строки промежуточные представления, на каждом из этих представлений производить как валидацию данного уровня анализа, так и подготавливать данное представление для следующего уровня.
Какие уровни анализа текста мы знаем из школьного курса русского языка?
Лексический анализ: на данном уровне предложение представляет из себя набор лексем, то есть характеристик слова на основе его происхождения, назначения, употребления в речи… Также могут включаться и отношения данного слова с другими в предложении, но для нас это уже перебор. Строка после проведения этого анализа переводится в массив лексем, которые точно присутствуют в языке SQL. Если пользователь ввёл SELECT …, то такая лексема существует, и мы передаём её дальше. Если же, по чистой случайности, в строке находится SLECT …, то ни о каком правильном запросе не может идти и речи, мы всё-таки просматриваем всю строку, и отдаём массив ошибок обратно пользователю. Почему не остановиться на первой ошибке? Да вы только представьте адские муки того, кто допустил множество ошибок в запросе на несколько строк! Переделывать запрос и опять скармливать СУБД… User experience first, как говорится.
Синтаксический анализ: предложение есть взаимосвязанный набор слов, представляющий из себя определённую структуру. Анализ данного уровня должен выявить эту структуру, и найти ошибки, если структура не удовлетворяет языку. Чаще всего эта структура называется абстрактным синтаксическим деревом, о чём мы поговорим в отдельной главе. Мы получаем набор лексем, не заботимся о том, правильные ли это слова (практически, так как всю такую грязную работу совершили на прошлом этапе), и выстраиваем отражающую взаимоотношения слов структуру.
Семантический анализ: слова, структуры слов, это понятно — но предложение ведь должно нести какой-то смысл. Так как SQL это своего рода приказы — «возьми, обнови, вставь, создай», то и осмысливать это нужно как приказы — перед тем, как исполнить, стоит подумать о том, возможно ли вообще их исполнение. Если пользователь пытается получить несуществующее поле из таблицы, то он должен быть об этом предупреждён, а дальнейшая обработка запроса должна быть остановлена.
Дальше логика начинает расходиться, поэтому продолжим мыслить только в понятиях SQL. Этот язык в своей логике опирается на реляционную алгебру. Операции в этой алгебре представляют собой, если говорить упрощённо, навороченные логические операции. Множества, связи, перемножения, различные проекции… Что если семантически верное синтаксическое дерево (простите!) перевести в операции реляционной алгебры, раз уж в конце концов всё к ней и сводится? Таким образом мы облегчим сложность строения бэкэнда нашей СУБД, обеспечим будущую расширяемость функциональности — реляционная алгебра проще по строению, чем ветвистые и глубокие синтаксические деревья.
Произведя перевод всего запроса в реляционную алгебру, мы получили определённый план выполнения. Но кто сказал, что пользователь знает, как правильно составить план? Вдруг он не знает о существовании чего-то, что облегчило бы выполнение этого плана?
Данный этап называется оптимизацией запроса. В СУБД канувшей в лету цивилизации такая информация являлась, в большинстве своём, коммерческой тайной. Хранилась под строжайшим запретом, под семью замками и за пятиметровым забором из колючей проволоки. Возможно где-то тут кроется причина падения той цивилизации, но я, честно говоря, уже и не помню, что тогда было.
Но, в любом случае, делать оптимизацию мы не будем. Мы подготовили для себя фундамент, на котором можно будет легко, хе-хе, эту оптимизацию прикрутить. Но не сегодня — и так много чего весёлого впереди!
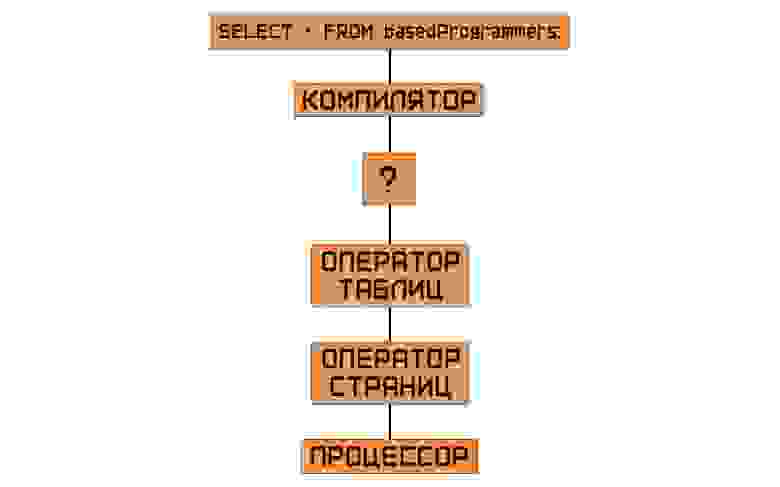
Мы оформили фронтэнд и бэкэнд. Компилятор предоставляет в бэкэнд план, записанный в формате реляционной алгебры, а оператор таблиц предоставляет, собственно, таблицы с записями в них, скрывая все страшные подробности хранения данных.
Но что-то не сходится… С одной стороны расположен план, а с другой — атомарные инструкции. Как будто здесь не хватает ещё одного компонента системы (если вы ещё не заметили это из картинки выше), который бы мог бы отработать по сгенерированному плану…
То, что мы упустили из анализа ранее, — и есть ключевой компонент СУБД, её сердце. Движок. Он-то и будет по высокоуровневым инструкциям (плану) производить вычисления над записями, которые предоставляет оператор таблиц.
Но здесь кроется ещё одна проблема — операции реляционной алгебры не так-то просты, они не всегда могут располагаться последовательно по смыслу, а, значит, движку придётся проводить предварительный анализ плана, что тоже увеличивает сложность компонента системы. Что же делать?
Решение этой проблемы кроется в ещё одном (боже мой!) анализе запроса. Теперь точно последнем. План, представляющий собой реляционную алгебру, можно перевести в последовательную цепочку инструкций, которую движок прочитает и выполнит так же последовательно.
Такой компонент уже можно называть не просто движком, а целой виртуальной машиной, со своим набором инструкций, регистрами и другими страшными вещами. Итого в строение компилятора (не просто так же он называется компилятором!) мы добавляем генератор кода для виртуальной машины, и этот код будет тем минимальным уровнем инструкций, которые может произвести ввод пользователя.
Мы смогли сохранить простоту каждого компонента нашей системы, не усложняя при этом общую цепочку взаимодействий — step by step, шаг за шагом запрос преодолевает проверки и преобразования, в конце концов добираясь до тех самых данных, ради которых и была затеяна вся эта история.
Скрываем реализацию — кто, что и кому должен?
Мы проделали долгий путь по общему анализу «подкапотной» нашей СУБД, с целью сохранения как простоты, так и концептуального содержания, чтобы не отбросить учебные (и немножко покрупнее — у нас всё-таки постапокалипсис за бортом) цели в угоду создания собственных велосипедов!
Но это не конец пути, а только начало. Поэтому сделаем привал, и посмотрим на то, что мы в итоге придумали — со всеми подробностями о том, какой компонент кому и что должен передавать по цепочке вызовов.
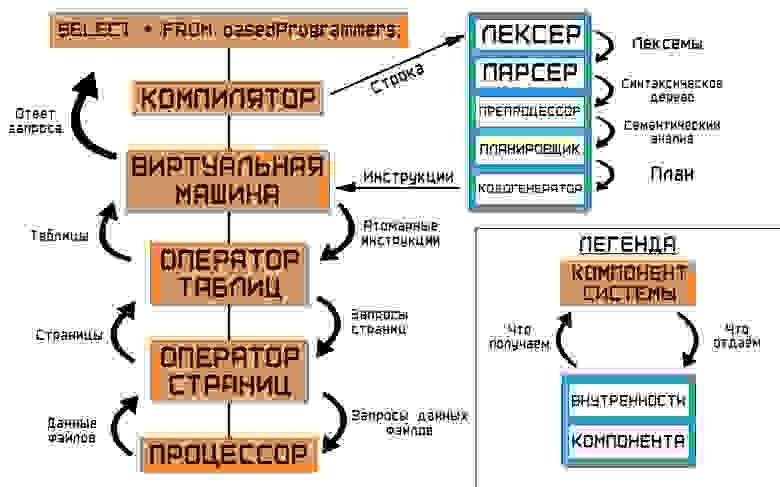
Каждый из компонентов скрывает свою часть реализации СУБД: компилятору не очень важно то, как данные хранятся на диске, как организованы соединения. У него есть своя часть работы — и он её должен выполнять, чтобы об этом не заботились нижележащие части нашей системы.
После общего анализа, разумеется, мы приступим к рассмотрению каждого компонента отдельно, рассмотрим подводные камни, которые мы не видели сверху, погрузимся в контекст — и, наконец-то, наломаем дров!
Глава 2. Транзакции, или как остаться без копейки в кармане

Кислотный ACID
СУБД должна поддерживать несколько подключений к одной и той же базе данных. Несколько процессов, приложений, или несколько потоков в одном процессе должны иметь возможность взаимодействовать с одним файлом базы данных.
И тут начинает происходить какой-то неведомый ужас. Мы еле-еле сообразили, что делать с одним подключением, а тут уже появляются несколько. Наши мозги начинают потихоньку плавиться — возможно это влияние той радиоактивной кислоты с потолка. Хм, кислота…
Нам пришла ещё одна помощь из прошлого мира — это ACID. Странная аббревиатура, с моей точки зрения, так как переводится как «кислотный». Возможно, что она так называется потому, что СУБД должна работать, даже если случится кислотный дождь — что я имею в виду под этой аналогией? Рассмотрим, собственно, сами принципы, скрывающиеся за этими словами, правда, не очень последовательно:
I, Isolation — несколько транзакций могут происходить одновременно, и должны это делать без вмешательства одна в другую.
Когда-нибудь это закончится, и страшные новые слова перестанут появляться — но, видимо, даже ядерная война этому не поспособствует. Транзакции — это что такое?
Вот одно соединение может выполнить один запрос. И точно понятно, что никто иной в этот запрос не должен вмешиваться. Ну, по крайней мере, желательно. Тогда данный запрос можно рассматривать как отдельную транзакцию — но что, если мы несколько расширим границы невмешательства с одного запроса на несколько? Мы предварительно скажем СУБД: «Вот слушай, сейчас я начну транзакцию, и я хочу, чтобы запросы внутри неё представляли нечто единое и неразделимое». Сделаем все наши грязные дела с данными, а потом завершим транзакцию. И нас вообще не беспокоит, что во время выполнения этой транзакции делают другие приложения — дай мне, наконец, уже мои данные, база!

Вот и транзакция — это несколько запросов, которые должны с точки зрения СУБД представлять нечто единое. Это понятие поможет нам в будущем.
A, Atomicity — либо да, либо нет: транзакция или произошла, или была отменена, и все изменения, которые были произведены этой транзакцией, не произошли. Довольно простое понятие с точки зрения пользователя, так как «ну а как что-то может произойти наполовину?», но разработчики СУБД уже не одно поколение ломают головы о том, как это можно поддерживать. Но кто думает о разработчиках?.. Разберутся!
На то транзакция — это набор единых запросов и команд, которые не могут произойти только на половину. Если СУБД сказала, что транзакция исполнена — значит должна быть исполнена! Ну, или отменена, об этом тоже стоит помнить.
Вот, кстати, почему СУБД называется SicQL — от латинского слова sic! — что сказано, то сказано — и сделано! А то, что оно там связано с совами да сычами, — это вы надумали, ничего такого, хе-хе.
C, Consistency — база данных должна остаться согласованной, или хотя бы целостной (и это два разных понятия, разберём чуть ниже), до и после заверения транзакции. Здесь мы вводим понятия «заверения» транзакции, от английского commit (в контексте СУБД получается именно заверение, хотя перевести можно и иначе). Мы просим базу данных заверить выполнение транзакции — и или принять её, или отклонить. Но это разговор про Atomicity, здесь же вводится требование, что база данных не только должна поддерживать атомарность, но и согласованность данных.
Примечание
По слову commit кстати есть интересная история про наименования commit messages в системе контроля версий Git. Идут споры о том, в каком времени писать сообщения – в прошедшем, допустим, Added smth, или в настоящем, Add smth. Традиционным считается второй подход, хотя более логичным звучит первый. Бытует мнение, что вот, создатель Git, Linux и просто хороший человек Линус Торвальдс плохо владел английским, и поэтому сообщения к коммитам писал с ошибкой. Но это не так. Commit есть глагол «заверь», «подтверди», и сообщение должно правильно расшифровываться как «добавь что-то», а не «добавил…».
D, Durability — устойчивость. СУБД заверила транзакцию, но, вот те на, сервер потух. И устойчивая СУБД должна гарантировать то, что заверенная транзакция не будет потеряна даже в том случае, если случится апокалипсис, или, в локальном случае, если операционная система отдаст концы.
Но всё это чистая теория. Разрыв между практикой и теорией на практике в стократ больше, чем в теории. Посмотрим же на чистую практику.
Первая встреча с монстром конкуренции
Представим следующую ситуацию: процессы A и B имеют открытое соединение с одной и той же базой данных, в которой записан баланс кошелька определённого человека.
Процесс A хочет перевести на другой кошелёк 100 рублей. Он считывает данные из записи и получает 100 рублей — отлично, значит можно перевести — организовываем соединение с другим кошельком…
Как вдруг в эту ситуацию вмешивается процесс B. Он тоже хочет перевести на другой счёт 100 рублей. Считывает текущий баланс, получает 100 рублей — начинает производить бизнес-логику, в конце концов записав обратно баланс в 0 рублей.
Но вот процесс А организовал соединение, произвёл все вычисления и даёт задание СУБД записать баланс в те же 0 рублей. «Ну что, процесс — не дурак, делаем, как сказано», — и что же мы получаем в итоге?
Было 100 рублей. Перевели 200. Получили баланс в 0 рублей. Некрасиво получилось…

Мы столкнулись с аномалией — то есть с таким поведением, при котором вроде бы верные с точки зрения одной транзакции изменения при выполнении вместе с другой транзакцией приводят к нарушению согласованности данных.
Что такое согласованные данные — вопрос хороший, так как в рамках СУБД мы определить это не можем. Целостность данных — можем (например, что данные в ячейке не должны равняться NULL), так как понятие целостности полностью лежит в поле управления СУБД. Согласованность данных же определяется приложением, пользующимся СУБД.
Оставлять это так, как сейчас, нельзя — мы переносим заботу о правильном порядке выполнения транзакций на пользователя — а что это тогда за СУБД, которая не может (или не хочет) исполнять контракт по слежению за данными? Я даю СУБД данные, а она заставляет меня ещё и следить, чтобы они случайно не перемешались?
Нужно искать решение. И оно есть — в самом SQL.
Кладём болт на аномалии в реальном времени
Стандартом SQL (SQL92) определяются некоторые из известных аномалий, которые могут происходить в рамках одной транзакции: потерянное обновление (с которым мы столкнулись выше), грязное чтение (получение данных из ещё не заверенной транзакции), неповторяющееся чтение (получение данных из заверенной транзакции), фантомное чтение (получение новых записей из заверенной транзакции). Ещё есть известные, но не описанные стандартом аномалии, и неизвестные, то есть ещё не обнаруженные, аномалии. Но мы усложнять ситуацию ещё крепче не будем, так что примем за правило, что действия СУБД при других аномалиях — это неописанное поведение (unspecified behaviour).
Далее стандарт определяет степени изоляции транзакций, каждая из которых описывает список тех аномалий, которые могут произойти:
-
Read uncommited:
-
грязное чтение,
-
-
Read commited:
-
неповторяющееся чтение,
-
-
Repeateble read:
-
фантомное чтение,
-
-
Serializable:
-
полное отсутствие аномалий!
-
Каждая изоляция как бы «наслаивается» одна над другой, допуская всё больше и больше аномалий.
А вот Serializable — это отдельная история: СУБД должна заверить приложение, что транзакции, выполненные параллельно, выполнятся и повлияют на данные так же, как если бы они выполнялись последовательно. Про это сразу забываем — это сладкие мечты параллельного вычисления. Но…
Может быть сможем?
Или нет? Вдруг самая сладкая мечта — отсутствие семантических багов и обеспечение согласованности — лежит прямо у нас под носом?
Давайте попробуем придумать такую систему параллельного вычисления, которая позволит исполнить требования Serializable.
Представим два соединения к базе данных, X и Y. База данных состоит из трёх страниц — мастер-страницы и двух страниц таблицы T.

X начинает транзакцию чтения, читает страницу 2. Y начинает транзакцию по записи новых данных в страницу 2, СУБД заверяет эту транзакцию. Для удовлетворения ограничений по изоляции транзакций новое чтение страницы 2 транзакцией в X должно выдать те же данные, что и при первом чтении.
Значит нам нужно хранить как неизменённые данные, так и изменённые, при том условии, что заверение изменённых данных не должно перезаписывать неизменённые данные до того момента, пока не будут заверены транзакции по чтению неизменённых данных.

Ох, вот это да! Вот это условие… Хотя подождите — ведь мы уже всё нужное описали! Стоит просто накинуть на неизменённые данные и изменённые данные страшные и непонятные названия, как мы получим вполне рабочее решение, которое нужно просто обличить в код.

Write-ahead log — это упреждающий журнал. Страница ещё не была записана в файл базы данных, но СУБД заверяет приложение, что все соединения, начавшие транзакцию после заверения данной транзакции, получат новые данные, в то время как другие работающие транзакции этих изменений не увидят.
Но мы видим ситуацию с точки зрения транзакции записи. Как же она выглядит с точки зрения другой транзакции?
Представим, что мы совершаем транзакцию чтения. Сначала нужно посмотреть журнал — нет ли там обновлённой страницы, записанной заверенной транзакцией?
Однако здесь кроется две детали:
-
Деталь первая. А что если в журнал после открытия транзакции занесли ещё одну, ту же самую страницу?
-
Деталь вторая. Как считывать этот журнал? Он может доходить до нескольких мегабайт, что может заметно ухудшить производительность соединения.
Смотрим в определение такого простого слова как журнал: «книга, тетрадь или электронный ресурс для регулярной, периодической записи наблюдений, фактов и т. п.» Периодической записи — то есть записи наслаиваются друг на друга. Если мы запомним на время открытия транзакции определённую позицию в журнале, ниже которой данные для нас будут являться заверенными, а данные выше мы считывать не будем — то мы обеспечим ту самую Serializable изоляцию транзакций, позволив одновременное существование открытых транзакций записи и чтения. И пусть в журнале существуют несколько версий одной и той же страницы, читать мы будем только ту, которая находится ближе всего к нашей метке позиции.
Какая же красота! Как лаконично и понятно — однако стойте, а что же делать с двумя транзакциями записи?
Снова обращаемся к определению журнала — раз записи наслаиваются друг на друга, то представьте себе обычную человеческую очередь… за колбасой, к примеру. Вкусной! Я вас в этом заверяю, хе-хе.
Вот как два человека могут стоять в одном и том же месте в очереди? Да они же передерутся, глотки вырвут, но первое место в очереди займут! Если одновременно обслуживать двоих людей за колбасой, хранящейся на одном складе, то я точно уверен, что кому-то из этих двух несчастных колбасы не достанется. Что там дальше за мордобой будет — я даже не представляю.
Поэтому журнал будет доступен только одной транзакции записи — следующим придётся подождать того момента, как предыдущая транзакция разблокирует упреждающий журнал.
А чтобы посмотреть количество колбасы на складе — да ради бога, смотрите, сколько хотите — хоть один, хоть два, хоть миллион раз одновременно. Можно даже смотреть количество колбасы по тем моментам, как кто-то её купил. А там наверно ещё и хлебушек есть…
А колбасой-то придётся делиться!
Ну что ж — после таких примеров обязательно нужно подкрепиться. Да, простите, не удержался, больше такого не будет. Я вас завер… Всё-всё, закончили!
С первой деталью всё решили. Осталась вторая — как считывать журнал эффективно?
Есть давняя история о том, как хранить данные о данных — индексы.
Однако правильно создать индекс может только транзакция записи — ведь только она видит журнал в последнем состоянии, отображающем истинное состояние всей базы данных.
Но этот индекс могут считывать и транзакции чтения — неужто мы сбросим весь наш прогресс и начнём сначала?
Спокойно, товарищи, — нужно сделать всего одну простую вещь. Сделать индекс обратно совместимым. Просим индекс узнать — под каким номером в журнале хранится запрашиваемая страница, да такая, чтобы она была меньше хранимого в метке значения? Либо мы найдём значение и отправимся читать страницу из журнала, либо не найдём. Ну-с, бывает — вперёд в файл базы данных!
Так как операция чтения будет совершаться при каждом запросе страницы, то алгоритмическая сложность![]() , то есть «о-большое», должна быть минимальной. Алгоритмическая сложность вставки элементов в этот индекс, конечно, тоже должна быть поменьше, но если будет стоять выбор между меньшей сложностью считывания, но большей сложностью вставки, и большей сложностью считывания, но меньшей — вставки, то выбор должен пасть на первое.
, то есть «о-большое», должна быть минимальной. Алгоритмическая сложность вставки элементов в этот индекс, конечно, тоже должна быть поменьше, но если будет стоять выбор между меньшей сложностью считывания, но большей сложностью вставки, и большей сложностью считывания, но меньшей — вставки, то выбор должен пасть на первое.
Понятие алгоритмической сложности для тех, кто с ней не знаком, хоть и кроется под ореолом тайного и проклятого знания, но кто запрещает нам не вдаваться в подробности? Алгоритмическая сложность «о-большое» представляет из себя скорость роста времени выполнения алгоритма от увеличения количества элементов, к которому применяется этот самый алгоритм, в худшем случае (для обозначения лучшего случая есть нотация «омега-большое»). ![]() — скорость линейна: если количество элементов выросло в тысячу раз, то во столько же раз вырастет время выполнения алгоритма. Если на одном элементе скорость равняется 1 мс, то на двух элементах — 2 мс, на тысяче элементов — 1 с. И та же логика на всех других зависимостях.
— скорость линейна: если количество элементов выросло в тысячу раз, то во столько же раз вырастет время выполнения алгоритма. Если на одном элементе скорость равняется 1 мс, то на двух элементах — 2 мс, на тысяче элементов — 1 с. И та же логика на всех других зависимостях.
Но где и каким образом будет храниться этот индекс?
Нам нужно сообщаться с другими процессами — а как можно обратиться к чужой памяти? Эту вещь контролирует операционная система, и даже если мы попытаемся хоть как-нибудь продвинуться в этом направлении самостоятельно, то наш миленький процесс СУБД повесится, оставив предсмертную записку Segmentation fault (core dumped).
Нужен иной подход — и его предоставляет та же операционная система. Это отображение файла в память. Вдаваться в подробности того, как оно работает под капотом, мы не будем, условимся на том, что это доступная для чтения и записи нескольким процессам память.
Далее начинаем задавать требования для структуры данных: возможность предоставлять по двум значениям — номеру страницы и маркеру транзакции — номер страницы в упреждающем журнале. Так как в журнале может существовать несколько версий одной и той же страницы, но в разных транзакциях, то индексировать мы будем номера страниц.
Нам нужен массив — и здесь есть повод для раздумий. На данный момент предполагается наиглупейший способ хранения информации о транзакции — этот массив будет длиной в лимит страниц для упреждающего журнала. Этот массив будет содержать номера страниц так, как они содержатся в журнале — если в журнале страница 5 находится на втором месте, то и в массиве в элементе под индексом 2 будет лежать число 5.
Таким образом, поиск в таком индексе будет организован через простой алгоритм: прыгаем на элемент с индексом, равному маркеру транзакции, считываем влево, пока не найдём либо номер нужной нам страницы, либо начало массива — что значит, что в журнале нужной нам страницы нет.
Также я предполагаю, что в будущем мы сможем это оптимизировать с помощью хэш-таблиц с открытой адресацией — отдадим это на откуп будущему мне и читателю. Пока что алгоритмическая сложность поиска в таком индексе линейна и зависит от лимита страниц в журнале, что сильно лимит этот ограничивает.
Пылесос? Ещё и автоматический??? Дайте два!
Со всеми этими дополнительными файлами, журналами и индексами жить интересней и приятней, да вот возникает один вопрос — а что с ними делать-то в конце концов? Вот они у нас хранятся, собирают данные. Но СУБД данные не только сохраняет — но и удаляет. А вот о том, как от этих файлов избавиться — точнее сказать, как эти файлы очистить — мы не очень подумали.
Ведь если упреждающий журнал с его индексом не чистить, то вскоре нам понадобится уже индекс для индекса, хе-хе.
Сначала узнаем, как удаляются записи: для того, чтобы особо не нагружать ввод-вывод, мы просто будем указывать в начале записи, жива она или нет. Но и здесь встаёт та же проблема — пометили запись как удалённую, а кто за нами чистить будет?
Но и тут на амбразуру неведомой сложности кинулся ещё один герой — пылесос. Да-да, именно так переводится ключевое слово VACUUM, которое вызывает операцию по очистке файла базы данных от тех записей, которые были помечены к удалению. Операция дорогая — и требует просмотра каждой записи в базе данных. Алгоритм, в общем, простой: открыли таблицу, поехали смотреть запись за записью: запись мёртвая? — удалить, запомнить расположение, искать следующую запись. И если она живая — сдвинуть на то место, которое мы запомнили на предыдущем шаге. Делаем до упора, до конца таблицы — а затем удаляем страницы, которые оказались вовсе пусты.
Всё это дело требует некоторой сноровки и инструментов оператора таблиц, которым мы займёмся в следующей главе. Плюс желательно было бы гарантировать, что мы случайно файл не сломаем своими кривыми ручками, поэтому базу данных скопируем и все операции будем выполнять уже на ней. Операция стала ещё дороже — но мы же не будем пытаться запихнуть в эту СУБД 200 терабайт данных? Правда ведь?..

Это был наш первый пылесос, который будет заниматься очисткой файла базы данных. У второго пылесоса задача другая, но не менее важная — очистка упреждающего журнала. Здесь мы мудрить не будем — мы просто перенесём все страницы из журнала на их положенное место в основном файле. Когда это должно происходить? Зачастую пользователю об этом задумываться не стоит, поэтому поставим автоматическую очистку на отметке в 100 страниц в журнале — вспоминаем, как устроен наш индекс журнала. Если транзакция записи обнаруживает, что отметка достигнута — блокирует файл, дабы никто не смог ничего в этот момент с файлом сотворить, а затем очищает упреждающий журнал. Или это сделает последнее закрывшееся соединение.
Ну что ж, наконец перейдём к самому интересному — тому, как эти страницы организованы между собой, как устроены записи, — к оператору таблиц!
Глава 3. Деревья. Сбалансированные. Страшно

Слово дерево и слово смерть для вас означает одно и то же!
Как мы помним из первой главы, страницы скованны одной цепью связанны однонаправленным списком — каждая предыдущая страница в таблице ссылается на следующую. Но нужно внести некоторый порядок в происходящее.
Во-первых, напоминаю, в одной базе данных может существовать не одна таблица, значит и таких списков должно быть несколько — за ними придётся следить. Под это дело лучше всего подойдёт первая страница в файле, будем называть её мастер-страницей (или мастер таблицей, если информация не помещается только на первой странице) — в ней будут, как в обычной таблице, храниться названия таблиц, их колонок, типы колонок и прочая информация, которая позволит легче ориентироваться в файле (и выполнять некоторые условия по целостности данных) — но, самое главное, будут храниться номера первых страниц таблиц. Или, лучше сказать, входных страниц, корней таблиц.
У вас начинают прокрадываться мысли, к чему я веду. Когда мы разделяли файл базы данных на сегменты, мы делали это из побуждений облегчить поиск записи — но такое последствие вытекает не сразу. Чтобы знать, к какой странице обращаться за определённой записью, мы должны построить индекс таблицы.
В чём заключается сущность индекса? Мы в неструктурированную информацию вносим дополнительный смысл, который позволяет уменьшить время поиска по индексированному ключу.
Как это выглядит на практике: у нас есть 100 записей на двух страницах и дополнительная структура данных, которая сообщает нам, что записи с 1-ую по 50-ую находятся на первой странице, а с 50-ой по 100-ую — на второй странице. Если бы нам была нужна 100-ая запись, то без такой структуры нам бы пришлось прочитать каждую запись, а с ней — только половину (затратив время дополнительно только на чтение данных из такой структуры).
Конечно, пример взят с потолка, но перед нами теперь ясно вырисовывается проблема — какую структуру данных применить для индекса?
Есть такая страшная вещь как деревья. Я даже слышал, что ими пугают первокурсников непослушных детей. Но ничего они не страшные — их просто до кучи много. Но разве это не играет нам на руку?
Хрестоматийный пример — бинарные деревья поиска. Допустим, мы имеем массив чисел [1, 2, 3, 4, 5, 6, 7]. Если для поиска мы будем перебирать каждый элемент массива, то наш алгоритм поиска номера элемента в массиве будет иметь сложность![]() .Но что если мы организуем индекс с помощью бинарного дерева поиска?
.Но что если мы организуем индекс с помощью бинарного дерева поиска?

Допустим, нам нужно узнать местоположение числа 5 в массиве. Число 5 больше или меньше, чем число 4? Больше, значит идём по правой ветви. Число больше или меньше 6? Меньше, значит идём по левой ветви. Число равно 5? Равно — и его индекс в массиве равняется 4 (удивительно!).
Поиск, организованный с помощью бинарного дерева оказался быстрее — но постоянна ли его алгоритмическая сложность? Вдруг кто-то поиграется с нашей структурой, и вместо нормального дерева мы получим следующее:

Однонаправленный список! Хотя мы можем проводить те же операции сравнения, но от бинарного дерева здесь ничего не осталось. Дерево выродилось, а итоговая скорость поиска только уменьшилась, ведь мы не получаем бонусов к скорости ни от индекса, ни от самой структуры массива, которая позволяет практически бесплатно обращаться к случайному его элементу.
Вырождение дерева — это плохо. Поэтому умные люди задолго до нас придумали иные подходы к деревьям поиска, которые сводили бы к нулю возможность их вырождения. Сегодня мы ознакомимся с одним из видов сбалансированных деревьев как одним из способов хранения индексов — с![]() и
и![]() деревьями.
деревьями.
Дубы, ели, доколе?!
Заглянув в Википедию, вы увидите только много-много терминов, которые вроде бы описывают свойства и алгоритмы cбалансированных деревьев. Ох, совсем забыл, постапокалипсис… Так что надеваем противогазы и вперёд на поверхность, бороться со сложностью!
Кардинальное различие между![]() и
и![]() деревьями (для упрощения в дальнейшем будем называть их просто сбалансированными) заключается в том, что данные в последних хранятся только в листьях, а также зачастую листья связаны с помощью списка. Забегая вперёд, хочу предупредить, что зачастую для индексов используются
деревьями (для упрощения в дальнейшем будем называть их просто сбалансированными) заключается в том, что данные в последних хранятся только в листьях, а также зачастую листья связаны с помощью списка. Забегая вперёд, хочу предупредить, что зачастую для индексов используются![]() деревья, но чтобы и далее не забивать мозг информацией, мы остановимся только на создании
деревья, но чтобы и далее не забивать мозг информацией, мы остановимся только на создании![]() деревьев.
деревьев.
Если представить запись в формате ключ-значение, то ключом будет являться некоторый уникальный номер записи, а значением — все оставшиеся колонки записи.
Сущность![]() деревьев в нашем случае заключается в следующих вещах:
деревьев в нашем случае заключается в следующих вещах:
-
Два вида узлов: внутренние узлы и листья. Внутренние узлы хранят только ключи и указатели на нижележащие узлы, т. е. потомков. Каждый из потомков делегирует свой максимальный ключ, за исключением крайнего правого потомка. Листья содержат как ключи, так и значения по этим ключам.
-
Указатели и интервалы ключей. У внутреннего узла есть
 ключей и
ключей и потомков. Крайний левый указатель ссылается на потомка, который является корнем для поддерева, хранящего в себе ключи в интервале
потомков. Крайний левый указатель ссылается на потомка, который является корнем для поддерева, хранящего в себе ключи в интервале![left(-infty, K_1right]](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%2081%2022'%3E%3C/svg%3E) . Крайний правый указатель ссылается на поддерево с ключами в интервале
. Крайний правый указатель ссылается на поддерево с ключами в интервале . Иной указатель, под номером
. Иной указатель, под номером , для которого верно неравенство
, для которого верно неравенство , ссылаются на поддерево с ключами в интервале
, ссылаются на поддерево с ключами в интервале![left(K_{i-1}, K_iright]](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%2085%2022'%3E%3C/svg%3E) .
. -
Однонаправленный список из листьев. Так как ключи в листьях расположены упорядоченно, то для более лёгкого перебора всех ключей в дереве каждый лист, содержащий ключи
 , имеет ссылку на лист, содержащий ключи
, имеет ссылку на лист, содержащий ключи , либо не имеет ссылку, если этот лист конечный.
, либо не имеет ссылку, если этот лист конечный. -
Сильная ветвистость дерева и постоянная высота. Выше мы говорили про какое-то энное число. Весь смысл cбалансированных деревьев заключается в том, что в него встроены алгоритмы, которые позволяют отложить вырождение до смерти Вселенной, а также вместить большое количество ключей на одном узле. Знаете, в чём оно нам поможет? В том, что мы снизим количество обращений к диску во время обхода дерева при поиске! Но такое число
 должно быть действительно большим — и его верхняя граница будет задана всем свободным местом на странице. Для того, чтобы свободное место на странице было легко отслеживать, то при каждом добавлении записи мы будем высчитывать свободное место на странице и хранить его в заголовке страницы. Нижняя граница будет равняться двум, чтобы из дерева не получился однонаправленный список.
должно быть действительно большим — и его верхняя граница будет задана всем свободным местом на странице. Для того, чтобы свободное место на странице было легко отслеживать, то при каждом добавлении записи мы будем высчитывать свободное место на странице и хранить его в заголовке страницы. Нижняя граница будет равняться двум, чтобы из дерева не получился однонаправленный список.
Что ж…

Какой-то ужас. Пиктограммы лучше текста, говорите? Ну тогда смотрим визуализацию свойств:

Понятно, что сбалансированное дерево за просто так ничего делать не будет. Будем его учить жить и не вырождаться.
Переворачивать не придётся. Придётся дробить
И опять какая-то чужеродная сила вмешалась в наш чистый мир деревьев — все наши узлы оказались под завязку забиты, а мы захотели внести новую запись. Как мы поступим?
Для начала заходим в тот лист, в котором должна храниться новая запись. Если свободного места на странице меньше, чем размер новой записи, то мы начинаем творить магию — запрашиваем у оператора страниц новую страницу, делим записи в текущей странице пополам — раскидываем половинки записей на обе страницы. Вписываем индекс новой страницы в старую, а в новую страницу вписываем указатель старой. Теперь в листах есть свободное место, но ключи во внутренних узлах ещё не обновлены.
Здесь есть общий подход и один пограничный случай — начнём с последнего. Если же мы пытались добавить новую запись в последнего потомка узла, то нам нужно только добавить в предка ещё один ключ, взяв максимальный ключ от старого потомка, и ещё один указатель — на новую страницу. В ином случае нам придётся как добавлять ключ с указателем на новую страницу, так и обновлять старый ключ.
Но вот ещё один пограничный случай — а что если делегировать ключи и указатель некому, так как мы находимся в корне дерева, который является в том числе ещё и внутренним узлом?
Тогда придётся запрашивать у оператора страниц ещё одну новую страницу, которая станет новым корнем. Здесь как придётся обновлять указатель на корень уже в мастер-таблице, которая по сути тоже является сбалансированным деревом, так и переносить в новую страницу ключи с указателями — и эта цепная реакция может спровоцировать очень, очень долгую операцию по балансировке дерева. Но такова плата за постоянную алгоритмическую сложность по поиску…
Кстати об алгоритмической сложности — какова она в нашем случае? Так как для того, чтобы выйти на нужную запись, мы должны совершить следующее:
-
Зайти в корень, сравнить искомый ключ с первым хранящемся: если он меньше или равен ему, то идём по указателю с таким же номером, что и у ключа; если он больше, то смотрим: остались ли ещё ключи в узле? Если да, то проверяем со следующим ключом. Если нет, то идём по последнему указателю.
-
Зайти во внутренний узел, проделываем ту же самую операцию со сравнениями.
-
Как зашли в лист, начинаем прогонять искомый ключ со всеми ключами в узле.
Итого, мы имеем алгоритмическую сложность поиска нужной страницы в![]() , где
, где![]() — высота дерева от корня до листьев, а
— высота дерева от корня до листьев, а![]() — минимальное количество ветвей в каком-либо из узлов.
— минимальное количество ветвей в каком-либо из узлов.
Хоть это заняло больше времени, чем простое хранение однонаправленного списка, мы выиграли практически во всём, воспользовавшись сбалансированными деревьями. В том числе с их помощью мы сможем реализовывать ограничения на какие-либо поля, однако данная тема выходит за рамки этой части.
Как в итоге сделать просто
В итоге оператор таблиц предоставляет следующие возможности для СУБД: создать таблицу, удалить таблицу, найти значение по ключу, вставить пару ключ-значение, пометить пару к удалению (настоящее удаление пары и поддержку VACUUM мы реализуем в следующий раз), выдать все записи таблицы в порядке возрастания.
Вот я бы хотел заострить внимание на последнем — про выдачу всех записей таблицы. Как-то неудобно получится, если мы будем переносить заботу о задаче по работе с данными на вышестоящие компоненты архитектуры. Нужно снова выдумать некую абстракцию, которая облегчит работу, а затем просто её поддерживать иными, не важными для вышестоящих компонентов, способами.
Я надеюсь, что вы знакомы с понятием итератора. Если же нет, то не беда — это инструмент, который не вываливает на нас все страшные подробности хранящихся данных во всей их полноте благодаря тому, что просто предоставляет только одну запись за раз. Мы можем двигаться вперёд или назад, сбрасывать курсор, доставать запись, на которую курсор указывает.
Данный инструмент позволит облегчить следующую часть нашей архитектуры — компилятор.
Глава 4. Профессиональный переводчик на совиный — как довериться пользователю и не сломать базу

Словодробилка
На вход мы получаем строку и только. Значит мы должны пройтись по всей строке, символ за символом, и на выходе отдать массив лексем, или токенов.
У нас есть определённые зарезервированные слова, по типу SELECT или UPDATE, или зарезервированные символы (например, оператор неравенства !=), которые нельзя будет использовать в качестве идентификаторов, то есть названий колонок и таблиц. Поэтому, если мы встретим такие слова, то сможем без раздумий скушать их и превратить в токены ключевых слов.
Также мы можем предугадывать токены — если слово начинается на SELEC, то это либо SELECT, либо идентификатор — для такого поведения нам потребуется заглядывать за символ дальше, но не поглощать, т. е. удалять из обрабатываемой строки.
Определив список всех операций, ключевых слов, мы должны определить токены для чисел и для всех остальных слов. Числа мы будем поддерживать целые и с плавающей запятой, а для всех остальных слов определим возможные символы, которые они могут содержать — и если в слове встретится символ {, то мы выкинем ошибку — но, повторюсь, только после окончания обработки всей строки.
Нас, в конце концов, не заботит расположения слов — лишь бы символы в словах были нормальные, да ключевые слова, операторы и символы заранее определялись, чтобы мы не занимались той же самой работой на этапе обработки токенов парсером, на который мы сейчас и переключимся.
Посылаем слова на три буквы
Какие три буквы, спросите вы? Как в том анекдоте — НБ… Ой, не то — БНФ! Форма Бэкуса — Наура. Мы уже встречались с ней в самом начале статьи, когда обсуждали гипотетический язык Language™:
вычисление
::= выражения '?'
;
выражения
::= выражение
| '(' выражения ')' операция '(' выражения ')'
;
выражение
::= цифра операция цифра
;
цифра
::= '1' | '2' | '3'
| '4' | '5' | '6'
| '7' | '8' | '9'
| '0'
;
операция
::= '+'
| '-'
;Только что-то схема заметно выросла. Мы записали синтаксис языка с помощью БНФ, и весь смысл этой схемы заключается в том, что существует определённое количество нетерминалов и терминалов. Терминалы — это то, что записано в кавычках — они сводятся к определённым символам. Нетерминалы — это, в общем, всё остальное: комбинации терминалов и нетерминалов (последовательность или выбор с помощью оператора |).
Такой формат описания синтаксиса языка является очень мощным инструментом — с его помощью автоматические генераторы парсеров даже способны выдать рабочий… парсер?
Но в нашем случае генератором парсера побудем мы. Чтобы было легче понять, что происходит, мы опишем наше, своё собственное подмножество SQL.
SQL очень выразителен — и поэтому описывать его полностью не будем. Вот вы сколько уже статью читайте? Себя пощадите, или меня хотя бы. Но заглядывайте в исходный код SicQL, вдруг там появилось что-нибудь ещё!
Начнём с самого верха: что представляет собой запрос? Это либо транзакция чтения/записи, с несколькими выражениями внутри, либо одно выражение. Так и пишем!
query
::= 'BEGIN WRITE TRANSACTION;'
(statement ';')+
'COMMIT' ';'?
| 'BEGIN READ TRANSACTION;'
(select ';')+
'COMMIT' ';'?
| statement ';'
;Тут появились некоторые новые символы — и они являются ни терминалами, ни нетерминалами (что?). Элементы можно группировать в группы с помощью скобок, а затем указывать, что элемент может не появиться или появиться только один раз (символ ?), появиться один раз и больше (символ +), не появиться или появиться несколько раз (символ *). Такой формат записи не был задуман изначально в БНФ, но зато появился в расширенной версии БНФ (extended BNF, EBNF) — но она не позволяет выдумать что-то иное — просто запись выглядит почище.
Дальше нам нужно определить из чего может состоять само выражение:
statement
::= select
| create
| drop
| insert
| update
| delete
;Ну как-то не очень показательно… Давайте возьмём описание выражения по созданию таблицы в базе — нетерминалаcreate— рассмотрим его поподробней.
create
::= 'CREATE' 'TABLE' table_existence?
'(' column_definition (',' column_definition)* ')'
;Вот уже что-то поинтереснее. Идут терминалыCREATEиTABLE— это понятно. Затем нетерминалtable_existence, который хранит в себе терминалыIF NOT EXISTSи которого вообще может в запросе не быть. Затем скобки — здесь будут указываться декларации колонок: название колонки и её тип.
column_definition
::= column_name type
;
column_name
::= identifier
;
type
::= 'VARCHAR' '(' integer ')'
| 'FLOAT'
| 'INTEGER'
| 'BOOLEAN'
;
identifier
::= word
;А что это за нетерминалыintegerиword? Целое число и слово — но мы их определять в БНФ не будем; и так понятно.
Понятен теперь и возможный синтаксис нашего подмножества SQL. Но как же мы будем создавать из массива токенов ветвистое абстрактное синтаксическое дерево?
Воспользуемся машинами состояния, конечными автоматами — мы находимся в том или ином состоянии, и чётко определены всевозможные состояния, в которые мы можем перейти из текущего — мы не можем прыгнуть в любое другое состояние, если этот переход не определён заранее. Это очень занимательная тема, так что настоятельно рекомендую освоить её в свободное время.
Вот, допустим, мы парсим column_definition — и у нас есть только одно возможное состояние, которое включает в себя сочетание нетерминалов column_name и type. Значит, если мы не сможем войти в это состояние, то переданное сочетание токенов не верно, и мы выбросим ошибку — но сначала не пользователю, а тому, кто пользуется текущим парсером. И он уже решит — либо все его возможные переходы состояния оказались неверны, а значит и весь массив токенов в принципе, либо надо опробовать следующее состояние. Ведь все нетерминалы, в конечном счёте, стремятся стать терминалами.
По такому же принципу действуют парсеры column_name и type. Пробуем всевозможные состояния, пока не получим… короткое замыкание!

Ведь электроны, образно, путешествуют везде, постоянно ищут возможность замкнуть цепь. Гифка выше очень хорошо показывает работу нашего парсера.
И, таким образом, мы создаём для каждого нетерминала, сводящегося к определённому набору токенов, терминалов, парсер, и комбинируем их для вышестоящих нетерминалов. Но только нам необходимо, чтобы из одного и того же набора токенов всегда получалось одно и то же синтаксическое дерево. Ведь мы же не хотим повышать напряжение для той же работы, хе-хе.
Примечание
Парсер языка Language™, кстати, мог использовать в том числе и обратную польскую нотацию, Reverse Polish Notation (RPL), когда выражение (5 + 6) - 2 будет преобразовано не в абстрактное синтаксическое дерево, а в такое состояние: 56+2-. Довольно красиво, не так ли? Знак операции стоит после всех операндов, что позволяет избавиться от структуры дерева с предками и детьми. Но такой трюк можно провернуть только в тех языках, в которых количество операндов строго ограничено (хоть и не всегда), чего не скажешь о нашем выразительном SQL.
Так как в нашей схеме синтаксиса отдельно указаны места, где могут находиться названия колонок и таблиц, в дереве мы будем хранить не собственно токены, образующие идентификатор, а указатели на них, индексы идентификаторов в отдельном массиве, который мы будем именовать символьной таблицей. Ведь мы, опять же, не хотим, чтобы препроцессор, осуществляющий семантический анализ, проходился снова по одному и тому же дереву в поисках идентификаторов?
А в чём смысл?

Извините…
Вот мы и добрались до одного из самых простых компонентов нашей системы — препроцессора. Ему на вход, из-за наших предыдущих инженерных решений, необходима только символьная таблица, простой массив простых элементов. Ну и, конечно, доступ к самой базе данных, у которой он сможет спросить метаданные — какие таблицы существуют, и какие колонки в них находятся, с какими типами. Отвечать на этот вопрос, разумеется, будет оператор таблиц — ведь мы же не хотим прыгать через голову и работать со страницами напрямую.
Тут особо и расписывать нечего — поэтому не будем лить воду посмотрели на котика, расслабились, переходим дальше.
Алгебра пригодилась! Правда не та…
И да, это совсем не та алгебра, о которой вы могли подумать. Это реляционная алгебра. Здесь нет привычных операций вычитания, сложения… Здесь они круче, и на порядок.
Данные представлены здесь в виде отношений — множеств упорядоченных кортежей. То, что для нас является таблицей с именами и возрастами, для реляционной алгебры это отношение с кортежами (Имя, Возраст). Упорядоченных кортежей потому, чтобы атрибуты (= колонки) внутри кортежей не перемешались, хе-хе.
Над этими кортежами мы можем совершать множество различных операций — притом результат такой операции, в конечном счёте, вернёт отношение, или множество кортежей, над которым снова можно провести какую-либо операцию. Это один из фундаментов нашей будущей поддержки как вложенных операций, так и оптимизаций.
Разберём несколько основных операций реляционной алгебры:
-
Выборка отношения по определённому условию
 : такая операция выберет все кортежи, которые удовлетворяют условию.
: такая операция выберет все кортежи, которые удовлетворяют условию. -
Проекция отношения на его атрибуты
 : название говорит само за себя — мы просто возьмём из кортежей данные только по определённым колонкам, атрибутам.
: название говорит само за себя — мы просто возьмём из кортежей данные только по определённым колонкам, атрибутам. -
Декартово произведение отношений
 : мы получим всевозможные сочетания кортежей в двух отношениях — декартово произведение отношений Буквы( (А), (Б) ) и Цифры( (0), (1) ) выдаст отношение из кортежей (А, 0), (А, 1), (Б, 0), (Б, 1).
: мы получим всевозможные сочетания кортежей в двух отношениях — декартово произведение отношений Буквы( (А), (Б) ) и Цифры( (0), (1) ) выдаст отношение из кортежей (А, 0), (А, 1), (Б, 0), (Б, 1). -
Объединение отношений с одинаковыми атрибутами
 : мы «приплюсуем» к кортежам первого отношения все те кортежи второго отношения, которых нет в первом.
: мы «приплюсуем» к кортежам первого отношения все те кортежи второго отношения, которых нет в первом. -
Пересечение отношений с одинаковыми атрибутами
мы возьмём в итоговое отношения только те кортежи, которые присутствуют и в первом, и во втором отношении. -
Разница отношений с одинаковыми атрибутами
 : в итоговом отношении окажутся те кортежи, которые присутствуют только в первом отношении.
: в итоговом отношении окажутся те кортежи, которые присутствуют только в первом отношении.
Ну, это замечательно — но как преобразовать имеющееся абстрактное синтаксическое дерево в операции над отношениями?
Так как возможные операции SQL, слава богу, ограничены, то мы просто можем сопоставить одну операцию SQL с другой операцией реляционной алгебры, на пути сделав некоторые преобразования.
SELECT * FROM bP — это проекция![]() .
.
SELECT name FROM basedProgrammers WHERE age > 30 — ![]() .
.
Название отношения, конечно, сокращено — вводить операцию переименования будем с помощью символьной таблицы на уровне парсера, а не планировщика.
Наделав шаблоны для основных синтаксических конструкций SQL, мы создали план, который можно без дополнительных преобразований оптимизировать — но план так и останется планом, пока мы не превратим его в конкретные действия, инструкции для нашей виртуальной машины…
Котогенератор
Эх если бы у меня был такой котогенератор, я и не мучался бы никогда. Но имеем, что имеем — только суровый кодогенератор для нашей виртуальной машины.
Описывать кодогенератор, не представляя, для кого создаётся этот код — достаточно сложно, но возможно благодаря заранее продуманной системе. Нам нужно ветвистую структуру данных сделать плоской, превратить в последовательный набор инструкций.
Началом последовательности инструкции будет инструкция по открытию транзакции — или чтения, или записи. Взаимодействие с выводом пользователю будет осуществляться с помощью только одной инструкции, которая выдаст массив записей по запросу, а также завершит выполнение кода.
Но каким образом мы будем взаимодействовать с оператором таблиц? Да легко — ведь он же нам предоставил курсор, который мы можем двигать туда-сюда по записям. Значит вводим инструкцию по открытию курсора на определённой таблице, и этот курсор будет указывать на одну запись, из которой мы можем доставать данные.
Выразить условия выборки нам помогут циклы. Кто имел опыт с ассемблером, тот знает про инструкции «прыжков» — допустим, в человекочитаемом формате смысл такой: ПЕРЕЙТИ НА ИНСТРУКЦИЮ 5 ЕСЛИ 2 > 1. И если инструкции с первой по пятую не имеют других прыжков, то мы получим бесконечный цикл.
На каждую операцию сравнения будет своя инструкция: прыгнуть, если равно, прыгнуть, если больше, если меньше, если не равно… А то, что с чем сравниваем, будем указывать как операнды в этих инструкциях.
Операндами могут являться как какие-то конкретные значения, либо значения определённой колонки из открытого курсора.
Простые инструкции, но в итоге с помощью них мы можем выразить, например, декартово произведение:
ТРАНЗАКЦИЯ ЧТЕНИЯ
ОТКРЫТЬ КУРСОР 'БУКВЫ' ; Курсор 0 на таблице с буквами русского алфавита
ОТКРЫТЬ КУРСОР 'ЦИФРЫ' ; Курсор 1 на таблице со всеми цифрами
КОЛОНКА 0 1 ; Берём из курсора 0 колонку с буквой алфавита, записываем
КОЛОНКА 1 1 ; Уже колонка из курсора 1 с цифрой
ЗАПИСЬ В РЕЗУЛЬТАТ ; Складываем получившуюся запись в массив
ВПЕРЁД 1 3 ; Если запись, следующая за курсором 1, существует,
; то прыгаем на инструкцию с индексом 3 (считаем с 0)
; и двигаем курсор на одну запись,
; иначе выполняем инструкции дальше
СБРОС 1 ; Делаем так, чтобы курсор 1 снова указывал на первую запись в таблице
ВПЕРЁД 0 3
ВЫВОД ; Останавливаем выполнение и отдаём массив с записями, которые мы получили
ЗАВЕРЬ ; Заверяем транзакцию
СТОП ; Останавливаем виртуальную машинуПредлагаю вам самим побыть в качестве виртуальной машины и провести данную операцию на простенькой таблице с двумя буквами и двумя цифрами — а затем сравнить с результатом такой операции в параграфе выше.
Для перевода реляционной алгебры в инструкции для виртуальной машины нам понадобится та же самая техника, которой мы сумели воспользоваться на уровне планировщика — для каждой операции мы создадим свой «шаблон» кода с возможными местами, в которые мы можем подставить другой код в зависимости от наличия потомков в узле дерева реляционной алгебры.
Самое главное требования к шаблонам кода — это отсутствие «побочных эффектов». Шаблоны должны делать только те действия, которые необходимы для выполнения операции, иначе мы рискуем сделать только хуже по скорости выполнения запроса — или у нас откроется сотня курсоров над одной и той же таблице, или один шаблон может поломаться от того, что над его курсором случайно поработал другой код.
Глава 5. Заверитель транзакций. Виртуальный нотариус собственной персоной

Вошли и вышли, виртуальная машина за 20 минут
И восстали машины из пепла ядерного огня, и пошла война на уничтожение человечества. И шла она десятилетия, но последнее сражение состоится не в будущем, оно состоится здесь, в наше время, сегодня ночью.
А мне вообще нужно указывать источник?
Вроде слово страшное, но на самом деле ничего страшного в виртуальных машинах нет — поэтому не сопротивляйтесь разберёмся с тем, из чего они состоят:
-
Во-первых, мы имеем встроенную в виртуальную машину память. Их может быть несколько, каждая для своей задачи или общего назначения, — такие ячейки памяти называются регистрами. Например, нам обязательно понадобится регистр, указывающий на следующую инструкцию, которую следует исполнить.
-
Во-вторых, есть «оперативная память» — для нас это будет простым массивом, в который мы сможем складывать результаты вычислений по инструкции записи в результат.
-
В-третьих, так как код последователен, то мы не должны создавать ветвистые процедуры выполнения — для каждой инструкции напишем свою функцию и закинем её в одну большую функцию «процессор», которая выбирает, какую функцию исполнить, исходя из инструкции, на которую указывает регистр, о котором мы говорили выше. Сама функция-процессор — это просто бесконечный цикл, который крутится, пока не напорется на ошибку или не встретит инструкцию остановки.
Вот и вся сложность — и всё благодаря тому, что мы чётко распределили обязанности по всем компонентам системы. Разделили сложность — и как вдруг она исчезла.
Нам нужно добавить в схему выше только пару вещей — и это виды регистров. Регистров специального назначения у нас будет всего два: это регистр-указатель и регистр, в котором будет храниться запись, получаемая от операций над записями в курсорах. По вызову операции записи в результат мы будем переносить этот регистр в «оперативную память», а затем очистим его.
Регистры общего назначения — это наши любимые курсоры. Плохая получается встроенная память, которая может расти, хе-хе, ведь мы будем эмулировать такие регистры с помощью простого динамического массива.
Виртуальная машина готова — она настолько виртуальная, что находится только в нашей голове, по крайней мере пока — но мы забыли одну вещь…
Восстанавливаемся от ошибок — почти как взрослые
На этапе создания компилятора мы всё-таки продолжали обработку ошибок, чтобы пользователю было легче разобраться со своей писаниной. Но если наша виртуальная машина вдруг столкнётся с таким, что курсор открыть невозможно, так как таблицы не существует — ну-с, это капут, товарищи. Мы столько анализов не для этого проводили, чтобы такие ошибки встречать.
Поэтому если ошибки и случаются, что абсолютно возможно, то процесс обработки запроса следует закончить. Но просто повесить процесс с сообщением «страшно, очень страшно, мы не знаем, что это такое» нельзя — у нас вообще-то транзакция открыта. Другие соединения надеются на нас, что мы не будем устраивать суматоху на пустом (или не очень) месте, надеются, что мы не будем перекидывать свою ответственность на них.
Поэтому, словив ошибку, мы начнём не копить их, а откатывать все изменения, которые мы произвели для совершения транзакции — если же это была транзакция записи, то мы запишем в журнал, что или мы дураки, или пользователь слишком хитрый, что данную транзакцию следует рассматривать как не случившуюся и заносить её в файл нельзя. Можно, конечно, начать вычищать журнал, но это будет продлением жизни ошибочного состояния! Индекс журнала обновлять не будем, чтобы на нашу ошибку не напоролись заново, а затем снимем все блокировки записи с файлов. Ещё было бы хорошо завести отдельный журнал ошибок, который будут читать только администраторы базы данных, для того, чтобы они узнали, что же произошло, и решили вопрос в случае необходимости.
Если же мы были в транзакции чтения, то нам будет необходимо только снять блокировки чтения на журнале и на базе данных.
После восстановления от ошибки мы «выключаем» виртуальную машину, выдаём пользователю сообщение о внутренней ошибке. Try again later, хе-хе.
Послесловие
Что дальше?
Так как время оказалось не резиновым, то у нас всё ещё остался огромный простор для развития дальнейшей функциональности. В том числе, пока нам не хватает даже в теории:
-
Поддержки foreign keys, «синтаксического сахара» над JOIN’ами и ограничителями,
-
Императивного подмножества SQL со своими функциями,
-
Большего множества типов хранящихся значений, например, BLOB, TEXT, JSON, DATE…
-
Индексов на основе B-деревьев, способных индексировать значения по нескольким полям, необходимых для обеспечения требований целостности данных,
-
Поддержки операции VACUUM на уровне оператора таблиц,
-
Сложной системы оптимизаций запросов,
-
Сервера, способного отправлять запросы «по проводу»,
-
Возможности выбора необходимой пользователю степени изоляции,
-
Вложенных запросов.
И прочее, и прочее. В одну статью всё вышеперечисленное уж точно не поместится — так что либо задача остаётся на вас, либо… Ждите продолжения — с блэкджеком и живыми совами!
А зачем всё это?
Всё это, конечно, детский сад — реальные СУБД, настоящие production-ready инженерные решения, в которые вложены сотни человеко-лет, устроены сложнее, страшнее и далее по списку.
Но кто запрещает нам экспериментировать, создавать свои любительские проекты? Ведь и Linux, и Postgres, и Rust, как и многие другие важные вещи (не только в сфере IT), изначально создавались как простые, ни на что не рассчитывающие, студенческие поделки…
Как говорится — это редиска, но это наша редиска!
Поэтому творите, друзья, — вдруг именно ваше решение проложит путь в светлое будущее. И без всяких постапокалипсисов. Хотя почему вдруг — я в этом уверен.
Спасибо за составление компании на этом пути — не переключайтесь, впереди ещё вторая часть!
Полезные ссылки
-
Исходный код SicQL
-
Архитектура SQLite и документация к ней
-
К. Дейт, Введение в системы баз данных
-
Р. Нистрем, Crafting Interpreters
-
БиблияКомпиляторы: принципы, технологии и инструменты -
К. Дейт, SQL и реляционная теория
-
Системы базы данных: полное собрание
Постскриптум
Хочется выразить отдельные благодарности:
-
Мише, автору канала МиКаст в Telegram, за его полезные советы на до сих пор продолжающемся пути становления программистом,
-
коллективу историко-философского журнала «Русская Пустошь» за помощь во вычитке статьи.
А также я буду очень рад, если данная часть статьи заинтересовала хотя бы одного человека испытать себя на поле создания системных инструментов с нуля — в таком случае статья выполнила свою цель: представить сложные вещи интересным приключением, ведь тогда они и вовсе перестанут быть сложными. Хотя бы будет потом с чем сравнить через пару месяцев, хе-хе.
Время на прочтение
13 мин
Количество просмотров 31K
Своя СУБД за 3 недели. Нужно всего-лишь каждый день немного времени уделять архитектуре; и всё остальное время вкалывать на результат, печатая и перепечатывая сотни строк кода.
По закону Мерфи, если есть более одного проекта на выбор — я возьмусь за самый сложный из предложенных. Так случилось и с последним заданием курса о системах управления базами данных (СУБД).

Постановка задачи
Согласно ТЗ, требовалось создать СУБД с нуля на Vanilla Python 3.6 (без сторонних библиотек). Конечный продукт должен обладать следующими свойствами:
- хранит базу в бинарном формате в едином файле
- DDL: поддерживает три типа данных: Integer, Float и Varchar(N). Для упрощения, все они фиксированной длины.
- DML: поддерживает базовые SQL операции:
- INSERT
- UPDATE
- DELETE
- SELECT с WHERE и JOIN. С каким именно JOIN — указано не было, поэтому на всякий случай мы сделали и CROSS, и INNER
- выдерживает 100’000 записей
Подход к проектированию
Разработать СУБД с нуля казалось нетривиальной задачей (как ни странно, так оно и оказалось). Поэтому мы — ecat3 и @ratijas — подошли к этому делу научно. В команде нас только двое (не считая себя и мою персону), а значит распиливать задачи и координировать их выполнение в разы легче, чем, собственно, их выполнять. По окончании распила вышло следующе:
| Задача | Исполнитель(-и) |
|---|---|
| Парсер + AST + REPL | ratijas, написавший не один калькулятор на всяких lex/yacc |
| Структура файла базы | ecat3, съевший собаку на файловых системах |
| Движок (низкоуровневые операции над базой) |
ecat3 |
| Интерфейс (высокоуровневая склейка) |
Вместе |
Изначально времени было выделено две недели, поэтому предполагалось выполнить индивидуальные задачи за неделю, а оставшееся время совместно уделить склейке и тестированию.
С формальной частью закончили, перейдем к практической. СУБД должна быть современной и актуальной. В современном Иннополисе актуальным является месседжер Телеграм, чат-боты и общение в группах с помощью «/слештегов» (это как #хештеги, только начинаются со /слеша). Поэтому язык запросов, близко напоминающий SQL, мало того что не чувствителен к регистру, так ещё и не чувствителен к /слешу непосредственно перед любым идентификатором: ‘SELECT’ и ‘/select’ это абсолютно одно и то же. Кроме того, подобно всякому студенту университета, каждая команда (statement) языка должна завершаться ‘/drop’. (Конечно же, тоже независимо от регистра. Кого вообще в такой ситуации волнует какой-то там регистр?)
Типичнейшая /днюха в /чате

Так родилась идея названия: dropSQL. Собственно /drop‘ом называется отчисление студента из университета; по некоторым причинам, это слово получило широкое распространение у нас в Иннополисе. (Ещё один местный феномен: аутизм, или, более корректно, /autism. Но мы приберегли его на особый случай.)
Первым делом разложили грамматику dropSQL на BNF (и зря — левые рекурсии не подходят нисходящим парсерам).
BNF грамматика dropSQL
Полная версия по ссылке
/stmt
: /create_stmt
| /drop_stmt
| /insert_stmt
| /update_stmt
| /delete_stmt
| /select_stmt
;
/create_stmt
: "/create" "table" existence /table_name "(" /columns_def ")" "/drop"
;
existence
: /* empty */
| "if" "not" "exists"
;
/table_name
: /identifier
;
/columns_def
: /column_def
| /columns_def "," /column_def
;
/column_def
: /column_name type /primary_key
;
...
Примеры валидных dropSQL команд, из онлайн справки продукта
/create table t(a integer, b float, c varchar(42)) /drop
/insert into t (a, c, b) values (42, 'morty', 13.37), (?1, ?2, ?3) /drop
/select *, a, 2 * b, c /as d from t Alias /where (a < 100) /and (c /= '') /drop
/update t set c = 'rick', a = a + 1 /drop
/delete from t where c > 'r' /drop
/drop table if exists t /drop
Работаем на результат! Никаких исключений!
После нескольких месяцев с Rust в качестве основного языка, крайне не хотелось снова погрязнуть в обработке исключений. Очевидным аргументом против исключений является то, что разбрасываться ими дорого, а ловить — громоздко. Ситуация ухудшается тем, что Python даже в версии 3.6 с Type Annotations, в отличие от той же Java, не позволяет указать типы исключений, которые могут вылететь из метода. Иначе говоря: глядя на сигнатуру метода, должно стать ясно, чего от него ожидать. Так почему бы не объеденить эти типы под одной крышей, которая называется «enum Error»? А над этим создать ещё одну «крышу» под названием Result; о нём пойдёт речь чуть ниже. Конечно, в стандартной библиотеке есть места, которые могут «взорваться»; но такие вызовы в нашем коде надежно обложены try’ями со всех сторон, которые сводят любое исключение к возврату ошибки, минимизируя возникновение внештатных ситуаций во время исполнения.
Итак, было решено навелосипедить алгебраический тип результата (привет, Rust). В питоне с алгебраическими типами всё плохо; а модуль стандартной библиотеки enum больше напоминает чистую сишечку.
В худших традициях ООП, используем наследование для определения конструкторов результата: Ok и Err. И не забываем про статическую типизацию (Ну мааам, у меня уже третья версия! Можно у меня будет наконец статическая типизация в Python, ну пожаалуйста?):
result.py
import abc
from typing import *
class Result(Generic[T, E], metaclass=abc.ABCMeta):
"""
enum Result< T > {
Ok(T),
Err(E),
}
"""
# Сборище абстрактных методов и просто дефолтных значений
def is_ok(self) -> bool:
return False
def is_err(self) -> bool:
return False
def ok(self) -> T:
raise NotImplementedError
def err(self) -> E:
raise NotImplementedError
...
class Ok(Generic[T, E], Result[T, E]):
def __init__(self, ok: T) -> None:
self._ok = ok
def is_ok(self) -> bool:
return True
def ok(self) -> T:
return self._ok
...
class Err(Generic[T, E], Result[T, E]):
def __init__(self, error: E) -> None:
self._err = error
def is_err(self) -> bool:
return True
def err(self) -> E:
return self._err
...
Отлично! Приправим немного соусом из функциональных преобразований. Далеко не все понадобятся, так что возьмем необходимый минимум.
result.py (продолжение)
class Result(Generic[T, E], metaclass=abc.ABCMeta):
...
def ok_or(self, default: T) -> T:
...
def err_or(self, default: E) -> E:
...
def map(self, f: Callable[[T], U]) -> 'Result[U, E]':
# Ух-ты! Что это за одинарные кавычки тут у нас в типе возврата?
# Оказывается, так в Python делается своего рода "forward declaration".
# Даже называется немного по-другому. Почитать можно в PEP 484:
# https://www.python.org/dev/peps/pep-0484/#forward-references
...
def and_then(self, f: Callable[[T], 'Result[U, E]']) -> 'Result[U, E]':
...
def __bool__(self) -> bool:
# упрощает проверку через `if`
return self.is_ok()
И сразу пример использования:
Пример использования Result
def try_int(x: str) -> Result[int, str]:
try:
return Ok(int(x))
except ValueError as e:
return Err(str(e))
def fn(arg: str) -> None:
r = try_int(arg) # 'r' for 'Result'
if not r: return print(r.err()) # one-liner, shortcut for `if r.is_err()`
index = r.ok()
print(index) # do something with index
Писанина в таком стиле всё ещё занимает по 3 строчки на каждый вызов. Но зато приходит четкое понимание, где какие ошибки могли возникнуть, и что с ними произойдет. Плюс, код продолжается на том же уровне вложенности; это весьма важное качество, если метод содержит полдюжины однородных вызовов.
Парсер, IResult, Error::{Empty, Incomplete, Syntax}, REPL, 9600 бод и все-все-все
Парсер занял значительную часть времени разработки. Грамотно составленный парсер должен обеспечить пользователю удобство использования фронтэнда продукта. Важнейшими задачами парсера являются:
- Внятные репорты об ошибках
- Интерактивный инкрементальный построчный ввод, или, проще говоря, REPL
Располагая «не только лишь всей» стандартной библиотекой питона, но и своими скромными познаниями в написании парсеров, мы понимали, что придется закатать рукава, и наваять ручной рекурсивный нисходящий парсер (англ. Recursive descent parser). Дело это долгое, муторное, зато даёт высокий градус контроля над ситуацией.
Один из первых вопросов, требовавших ответа: как быть с ошибками? Как быть — выше уже разобрались. Но что вообще представляет собой ошибка? Например, после «/create table» может находиться «if not exists», а может и не находиться — ошибка ли это? Если да, то какого рода? где должна быть обработана? («Поставьте на паузу», и предложите свои варианты в комментариях.)
Первая версия парсера различала два вида ошибок: Expected (ожидали одно, а получили что-то другое) и EOF (конец файла) как подкласс предыдущего. Всё бы ничего, пока дело не дошло до REPL. Такой парсер не различает между частиным вводом (началом команды) и отсутствием чего-либо (EOF, если так можно сказать про интерактивный ввод с терминала). Только неделю спустя, методом проб и ошибок удалось найти схему, удовлетворяющую нашей доменной области.
Схема состоит в том, что всё есть поток, а парсер — лишь скромный метод next() у потока. А также в том, что класс ошибки должен быть переписан на алгебраический (подобно Result), и вместо EOF введены варианты Empty и Incomplete.

Новый тип ошибки
class Error(metaclass=abc.ABCMeta):
"""
enum Error {
Empty,
Incomplete,
Syntax { expected: str, got: str },
}
"""
def empty_to_incomplete(self) -> 'Error':
if isinstance(self, Empty):
return Incomplete()
else:
return self
class Empty(Error): ...
class Incomplete(Error): ...
class Syntax(Error):
def __init__(self, expected: str, got: str) -> None: ...
# stream-specific result type alias
IResult = Result[T, Error]
IOk = Ok[T, Error]
IErr = Err[T, Error]
Интерфейс потока
class Stream(Generic[T], metaclass=abc.ABCMeta):
def current(self) -> IResult[T]: ...
def next(self) -> IResult[T]: ...
def collect(self) -> IResult[List[T]]: ...
def peek(self) -> IResult[T]: ...
def back(self, n: int = 1) -> None: ...
@abc.abstractmethod
def next_impl(self) -> IResult[T]: ...
Поток — это абстракция. Потоку всё-равно, какие элементы производить. Поток знает, когда остановиться. Всё, что требуется для реализации своего потока — переписать единственный абстрактный метод next_impl() -> IResult[T]. Что должен вернуть этот метод? Рассмотрим на примере потока токенов:
| Что там дальше | Пример (ввод) | Тип результата | Пример (результат) |
|---|---|---|---|
| Всё нормально, очередной элемент |
/delete from t ... |
IOk(token) | IOk(Delete()) |
| Остались одни пробелы и комментарии |
n -- wubba -- lubba -- dub dub! |
IErr(Empty()) | IErr(Empty()) |
| Начало чего-то большего |
'string... (нет закрывающей кавычки) |
IErr(Incomplete()) | IErr(Incomplete()) |
| Ты втираешь мне какую-то дичь |
#$% |
IErr(Syntax(…)) | IErr(Syntax(expected=’token’, got=’#’)) |
Потоки организованы в иерархию. Каждый уровень содержит свой буфер, что позволяет заглядывать вперёд (peek() -> IResult[T]) и откатываться назад (back(n: int = 1) -> None) при необходимости.
А самое приятное, что поток можно «собрать» в один большой список всех IOk(элементов), что выдает next() — до первой IErr(), разумеется. При чем список вернется лишь когда IErr содержала Empty; в противном случае, ошибка пробросится выше. Эта конструкция позволяет легко и элегантно построить REPL.
Основа REPL
class Repl:
def reset(self):
self.buffer = ''
self.PS = self.PS1
def start(self):
self.reset()
while True:
self.buffer += input(self.PS)
self.buffer += 'n'
stmts = Statements.from_str(self.buffer).collect()
if stmts.is_ok():
... # execute one-by-one
self.reset()
elif stmts.err().is_incomplete():
self.PS = self.PS2 # read more
elif stmts.err().is_syntax():
print(stmts.err())
self.reset()
else: pass # ignore Err(Empty())
Characters
Этот поток проходит по символам строки. Единственный тип ошибки: Empty в конце строки.
Tokens
Поток токенов. Его второе имя — Лексер. Тут встречаются и ошибки, и строки без закрывающих кавычек, и всякое…
Каждый тип токенов, включая каждое ключевое слово по отдельности, представлен отдельным классом-вариантом абстрактного класса Token (или лучше думать про него как про enum Token?) Это для того, чтобы парсеру команд (statements) было удобно кастовать токены к конкретным типам.
Типичная часть лексера
def next_impl(self, ...) -> IResult[Token]:
...
char = self.characters.current().ok()
if char == ',':
self.characters.next()
return IOk(Comma())
elif char == '(':
self.characters.next()
return IOk(LParen())
elif ...
Statements
Кульминация, парсер собственной персоной. Вместо тысячи слов, пару сниппетов:
streams/statements.py
class Statements(Stream[AstStmt]):
def __init__(self, tokens: Stream[Token]) -> None:
super().__init__()
self.tokens = tokens
@classmethod
def from_str(cls, source: str) -> 'Statements':
return Statements(Tokens.from_str(source))
def next_impl(self) -> IResult[AstStmt]:
t = self.tokens.peek()
if not t: return Err(t.err())
tok = t.ok()
if isinstance(tok, Create):
return CreateTable.from_sql(self.tokens)
if isinstance(tok, Drop):
return DropTable.from_sql(self.tokens)
if isinstance(tok, Insert):
return InsertInto.from_sql(self.tokens)
if isinstance(tok, Delete):
return DeleteFrom.from_sql(self.tokens)
if isinstance(tok, Update):
return UpdateSet.from_sql(self.tokens)
if isinstance(tok, Select):
return SelectFrom.from_sql(self.tokens)
return Err(Syntax('/create, /drop, /insert, /delete, /update or /select', str(tok)))
ast/delete_from.py
class DeleteFrom(AstStmt):
def __init__(self, table: Identifier, where: Optional[Expression]) -> None:
super().__init__()
self.table = table
self.where = where
@classmethod
def from_sql(cls, tokens: Stream[Token]) -> IResult['DeleteFrom']:
"""
/delete_stmt
: "/delete" "from" /table_name /where_clause /drop
;
"""
# next item must be the "/delete" token
t = tokens.next().and_then(Cast(Delete))
if not t: return IErr(t.err())
t = tokens.next().and_then(Cast(From))
if not t: return IErr(t.err().empty_to_incomplete())
t = tokens.next().and_then(Cast(Identifier))
if not t: return IErr(t.err().empty_to_incomplete())
table = t.ok()
t = WhereFromSQL.from_sql(tokens)
if not t: return IErr(t.err().empty_to_incomplete())
where = t.ok()
t = tokens.next().and_then(Cast(Drop))
if not t: return IErr(t.err().empty_to_incomplete())
return IOk(DeleteFrom(table, where))
Важно отметить, что любые ошибки типа Empty, кроме самого первого, парсеры должны преобразовывать в Incomplete, для корректной работы REPL. Для этого есть вспомагательная функция empty_to_incomplete() -> Error. Чего нет, и никогда не будет, так это макросов: строка if not t: return IErr(t.err().empty_to_incomplete()) встречается в кодовой базе по меньшей мере 50 раз, и тут ничего не попишешь. Серъёзно, в какой-то момент захотелось юзать Сишный препроцессор.
Про бинарный формат
Глобально файл базы поделен на блоки, и размер файла кратен размеру блока. Размер блока по умолчанию равен 12 КиБ, но опционально может быть увеличен до 18, 24 или 36 КиБ. Если Вы дата сатанист на магистратуре, и у вас очень большие данные — можно поднять даже до 42 КиБ.
Блоки пронумерованы с нуля. Нулевой блок содержит метаданные обо всей базе. За ним 16 блоков под метаданные таблиц. С блока #17 начинаются блоки с данными. Указателем на блок называется порядковый номер блока

Метаданных базы на текущий момент не так много: название длиной до 256 байт и кол-во блоков с данными.

Мета-блок таблицы самый непростой. Тут хранится название таблицы, список всех колонок с их типами, количество записей и указатели на блоки данных.
Количество таблиц фиксировано в коде. Хотя это относительно легко может быть исправлено, если хранить указатели на мета-блоки таблиц в мета-блоке базы.

Указатели на блоки работают по принципу указателей в inode. Об этом прекрасно писал Таненбаум и дюжины других уважаемых людей. Таким образом, таблицы видят свои блоки с данными как «страницы». Разница в том, что страницы, идущие с точки зрения таблицы по порядку, физически располагаются в файле как бог на душу положит. Проводя аналогии с virtual memory в операционках, страница: virtual page number, блок: physical page number.
Блоки данных не имеют конкретной структуры сами по себе. Но когда их объеденить в порядке, продиктованном указателями, они предстанут непрерывным потоком записей (record / tuple) фиксированной длины. Таким образом, зная порядковый номер записи, извлечь или записать её — операция практически константного времени, O(1*), с амортизацией на выделение новых блоков при необходимости.
Первый байт записи содержит информацию о том, жива ли эта запись, или была удалена. Остальные работу по упаковке и распаковке данных берет на себя стандартный модуль struct.
Операция /update всегда делает перезапись «in-place», а /delete только подменяет первый байт. Операция VACUUM не поддерживается.

Про операции над таблицами, RowSet и джойны
Пришло время прочно скрепить лучшее из двух миров несколькими мотками скотча.
MC слева — AST узлы верхнего уровня (подклассы AstStmt). Их выполнение происходит в контексте соединения с базой. Также поддерживаются позиционные аргументы — «?N» токены в выражениях в теле запроса, например: «/delete from student /where name = ?1 /drop». Сами выражения рекурсивны, а их вычисление не представляет собой научного прорыва.
MC справа — драйвер БД, оперирующий над записями по одной за раз, используя порядковый номер внутри таблицы как идентификатор. Только он знает, какие таблицы существуют, и как с ними работать.
Поехали!
Их первый совместный сингл про креативность. Создать новую таблицу не сложнее, чем взять первый попавшийся пустой дескриптор из 16, и вписать туда название и список колонок.
Затем, трек с символическим названием /drop. В домашней версии демо-записи происходит следующее: 1) найти дескриптор таблицы по имени; 2) обнулить. Кого волнуют неосвобожденные блоки со страницами данных?
Insert снисходителен к нарушению порядка колонок, поэтому перед отправкой кортежа на запись, его пропускают через специальный фильтр transition_vector.
Далее речь пойдет про работу с записями таблиц, поэтому позвольте сразу представить нашего рефери: RowSet.
Сферический RowSet в вакууме
class RowSet(metaclass=abc.ABCMeta):
@abc.abstractmethod
def columns(self) -> List[Column]:
"""
Describe columns in this row set.
"""
@abc.abstractmethod
def iter(self) -> Iterator['Row']:
"""
Return a generator which yields rows from the underlying row stream or a table.
"""
Главный конкретный подвид этого зверя — TableRowSet — занимается выборкой всех живых (не удаленных) записей по порядку. Прочие разновидности RowSet в dropSQL реализуют необходимый минимум реляционной алгебры.
| Оператор реляционной алгебры | Обозначение | Класс |
|---|---|---|
| Проекция | π(ID, NAME) expr |
ProjectionRowSet |
| Переименование | ρa/b expr |
ProjectionRowSet + RenameTableRowSet |
| Выборка | σ(PRICE>90) expr |
FilteredRowSet |
| Декартово произведение | PRODUCTS × SELLERS |
CrossJoinRowSet |
| Inner Join (назовём это расширением) |
σ(cond)( A x B ) |
InnerJoinRowSet =
FilteredRowSet(
CrossJoinRowSet(...))
|
Кроме того ещё есть программируемый MockRowSet. Он хорош для тестирования. Также, с его помощью возможен доступ к мастер-таблице под названием «
/autism
«.
Прелесть в том, что различные RowSet’ы можно комбинировать как угодно: выбрать таблицу «student», указать алиас «S», отфильтровать «/where scholarship > ’12k’», выбрать другую таблицу «courses», соединить «/on (course/sid = S/id) /and (course/grade < ‘B’)», проецировать на «S/id, S/first_name/as/name» — это представляется следующей иерархией:
ProjectionRowSet([S/id, S/first_name/as/name])
FilteredRowSet((course/sid = S/id) /and (course/grade < 'B'))
CrossJoinRowSet
FilteredRowSet(scholarship > '12k')
RenameTableRowSet('S')
TableRowSet('student')
TableRowSet('courses')
Итак, вооружившись столь мощным инструментом, возвращаемся к лютневой музыке XVI века…
Про четвертый трек, /select, тут больше нечего добавить. Симфония из RowSet’ов такая, что душу завораживает. Благодаря этому, реализация получилась крайне лаконичной.
Реализация /select … from
class SelectFrom(AstStmt):
...
def execute(self, db: 'fs.DBFile', args: ARGS_TYPE = ()) -> Result['RowSet', str]:
r = self.table.row_set(db)
if not r: return Err(r.err())
rs = r.ok()
for join in self.joins:
r = join.join(rs, db, args)
if not r: return Err(r.err())
rs = r.ok()
if self.where is not None:
rs = FilteredRowSet(rs, self.where, args)
rs = ProjectionRowSet(rs, self.columns, args)
return Ok(rs)
Два последних: /update и /delete используют наработки предшественника. При чем /update применяет технику, похожую на описанный выше «transition_vector».
Такой вот концерт! Спасибо за внимание! Занавес!..
Хотелки
Пока что не сбывшиеся мечты:
- Поддержка /primary key не только в парсере
- Унарные операторы
- Вложенные запросы
- Вывод типов для выражений
- Удобный API для Python
Так как это был учебный проект, мы не получили за него ни копейки. Хотя, судя по статистике sloc, могли бы сейчас кушать красную икорку.
Отчет sloccount
Have a non-directory at the top, so creating directory top_dir
Creating filelist for dropSQL
Creating filelist for tests
Creating filelist for util
Categorizing files.
Finding a working MD5 command....
Found a working MD5 command.
Computing results.
SLOC Directory SLOC-by-Language (Sorted)
2764 dropSQL python=2764
675 tests python=675
28 util python=28
Totals grouped by language (dominant language first):
python: 3467 (100.00%)
Total Physical Source Lines of Code (SLOC) = 3,467
Development Effort Estimate, Person-Years (Person-Months) = 0.74 (8.85)
(Basic COCOMO model, Person-Months = 2.4 * (KSLOC**1.05))
Schedule Estimate, Years (Months) = 0.48 (5.73)
(Basic COCOMO model, Months = 2.5 * (person-months**0.38))
Estimated Average Number of Developers (Effort/Schedule) = 1.55
Total Estimated Cost to Develop = $ 99,677
(average salary = $56,286/year, overhead = 2.40).
SLOCCount, Copyright (C) 2001-2004 David A. Wheeler
SLOCCount is Open Source Software/Free Software, licensed under the GNU GPL.
SLOCCount comes with ABSOLUTELY NO WARRANTY, and you are welcome to
redistribute it under certain conditions as specified by the GNU GPL license;
see the documentation for details.
Please credit this data as "generated using David A. Wheeler's 'SLOCCount'."
Благодарности
- Университету Иннополис за уютное окружение и крутые знакомства.
- Профессору Евгению Зуеву за курс по компиляторам вообще, и за лекцию о парсерах в частности
- Профессору Manuel Mazzara и TA Руслану за курс по СУБД. /GodBlessMazzara
А в следующий раз мы заимплементим свою не-реляционку, с агрегейшн пайплайнами и транзакциями; и назовём её — /noDropSQL!
В прошлой статье мы рассказали про SQLite — простую базу данных, которая может работать почти на любой платформе. Теперь проверим теорию на практике: напишем простой код на Python, который сделает нам простую базу и наполнит её данными и связями.
Предыстория
Если это первая статья про базы данных, которую вы читаете, то лучше сделать так, а потом вернуться сюда:
- Почитать про виды баз данных и посмотреть на схему связей в реляционной базе данных. Там простая схема про магазин — в ней связаны товары, клиенты и покупки.
- Посмотреть, как работают SQL-запросы: что это такое, как база на них реагирует и что получается в итоге. В статье мы с помощью SQL-запросов сделали базу данных по магазинной схеме.

Что будем делать
Сегодня мы сделаем то же самое, что и в SQL-запросах, но на Python, используя стандартную библиотеку sqlite3:
- создадим базу и таблицы в ней;
- наполним их данными;
- создадим связи;
- проверим, как это работает.
После этого мы сможем использовать такой же подход в других проектах и хранить все данные не в текстовых файлах, а в полноценной базе данных.
Подключаем и создаём базу данных
За работу с SQLite в Python отвечает стандартная библиотека sqlite3:
# подключаем SQLite
import sqlite3 as sl
Теперь нам нужно указать файл базы данных, с которым мы будем дальше работать. Удобство библиотеки в том, что нам достаточно указать имя файла, а дальше будет такое:
- если этого файла нет, то программа создаст пустую базу данных с таким именем;
- если указанный файл есть, то программа подключится к нему и будет с ним работать.
Получается, нам неважно, есть файл с базой или нет — мы в любом случае после запуска получим то, что нам нужно. Для этого пишем команду:
# открываем файл с базой данных
con = sl.connect('thecode.db')
Мы указали, что файл называется thecode.db, без указания папок и дисков. Это значит, что файл с базой появится в той же папке, что и наш скрипт — можно в этом убедиться после запуска программы.
Создаём таблицу с товарами
У нас есть база, в которой можно создавать таблицы для хранения данных. Создадим первую таблицу для товаров:
with con:
con.execute("""
CREATE TABLE goods (
product VARCHAR(20) PRIMARY KEY,
count INTEGER,
price INTEGER
);
""")Если посмотреть внимательно на код, можно заметить, что текст внутри кавычек полностью повторяет обычный SQL-запрос, который мы уже использовали в прошлой статье. Единственное отличие — в SQLite используется INTEGER вместо INT:
CREATE TABLE goods (
product VARCHAR(20) PRIMARY KEY,
count INT,
price INT
);Теперь соберём код вместе и запустим его ещё раз:
# подключаем SQLite
import sqlite3 as sl
# открываем файл с базой данных
con = sl.connect('thecode.db')
# создаём таблицу для товаров
with con:
con.execute("""
CREATE TABLE goods (
product VARCHAR(20) PRIMARY KEY,
count INTEGER,
price INTEGER
);
""")Но после второго запуска компьютер почему-то выдаёт ошибку:
❌ sqlite3.OperationalError: table goods already exists
Дело в том, что при повторном запуске программа пытается создать таблицу с товарами, которая уже есть в базе. Так как имена таблиц совпадают, а двух одинаковых имён быть не может, отсюда и возникает ошибка.
Чтобы не попадать в такую ситуацию, добавим проверку: посмотрим, есть ли в базе нужная нам таблица или нет. Если нет — создаём, если есть — двигаемся дальше:
# открываем базу
with con:
# получаем количество таблиц с нужным нам именем
data = con.execute("select count(*) from sqlite_master where type='table' and name='goods'")
for row in data:
# если таких таблиц нет
if row[0] == 0:
# создаём таблицу для товаров
with con:
con.execute("""
CREATE TABLE goods (
product VARCHAR(20) PRIMARY KEY,
count INTEGER,
price INTEGER
);
""")Точно так же мы потом сделаем и с остальными таблицами — сразу встроим проверку, и если нужных таблиц не будет, то программа создаст их автоматически.
Теперь наполняем нашу таблицу товарами, используя стандартный SQL-запрос. Например, можно добавить два стола, которые стоят по 3000 ₽:
INSERT INTO goods SET
product = 'стол',
count = 2,
price = 3000;
Но добавлять записи по одному товару за раз — это долго и неэффективно. Проще сразу в одном запросе добавить все нужные товары: стол, стул и табурет:
# подготавливаем множественный запрос
sql = 'INSERT INTO goods (product, count, price) values(?, ?, ?)'
# указываем данные для запроса
data = [
('стол', 2, 3000),
('стул', 5, 1000),
('табурет', 1, 500)
]
# добавляем с помощью множественного запроса все данные сразу
with con:
con.executemany(sql, data)
# выводим содержимое таблицы на экран
with con:
data = con.execute("SELECT * FROM goods")
for row in data:
print(row)В конце мы добавили вывод таблицы — так можно убедиться, что запрос сработал и данные отправились в базу в нужное место.

Создаём и заполняем таблицу с товарами
Заведём таблицу clients для клиентов и заполним её точно так же, как мы это сделали с клиентской таблицей. Для этого просто копируем предыдущий код, меняем название таблицы и указываем правильные названия полей.Ещё посмотрите на отличие от обычного SQL в последней строке объявления полей таблицы: вместо id INT AUTO_INCREMENT PRIMARY KEY надо указать id INTEGER PRIMARY KEY. Без этого не будет работать автоувеличение счётчика.
# --- создаём таблицу с клиентами ---
# открываем базу
with con:
# получаем количество таблиц с нужным нам именем — clients
data = con.execute("select count(*) from sqlite_master where type='table' and name='clients'")
for row in data:
# если таких таблиц нет
if row[0] == 0:
# создаём таблицу для клиентов
with con:
con.execute("""
CREATE TABLE clients (
name VARCHAR(40),
phone VARCHAR(10) UNIQUE,
id INTEGER PRIMARY KEY
);
""")
# подготавливаем множественный запрос
sql = 'INSERT INTO clients (name, phone) values(?, ?)'
# указываем данные для запроса
data = [
('Миша', 9208381096),
('Наташа', 9307265198),
('Саша', 9307281096)
]
# добавляем с помощью множественного запроса все данные сразу
with con:
con.executemany(sql, data)
# выводим содержимое таблицы с клиентами на экран
with con:
data = con.execute("SELECT * FROM clients")
for row in data:
print(row)Cоздаём таблицу с покупками и связываем всё вместе
У нас всё готово для того, чтобы на основе первых двух таблиц создать третью — в ней будут данные сразу и о покупках, и о том, кто это купил. Если интересно, как это работает в деталях, — почитайте статью про связи в базе данных.
# --- создаём таблицу с покупками ---
# открываем базу
with con:
# получаем количество таблиц с нужным нам именем — orders
data = con.execute("select count(*) from sqlite_master where type='table' and name='orders'")
for row in data:
# если таких таблиц нет
if row[0] == 0:
# создаём таблицу для покупок
with con:
con.execute("""
CREATE TABLE orders (
order_id INTEGER PRIMARY KEY,
product VARCHAR,
amount INTEGER,
client_id INTEGER,
FOREIGN KEY (product) REFERENCES goods(product),
FOREIGN KEY (client_id) REFERENCES clients(id)
);
""")Проверим, что связь работает: добавим в таблицу с заказами запись о том, что Миша купил 2 табурета:
# подготавливаем запрос
sql = 'INSERT INTO orders (product, amount, client_id) values(?, ?, ?)'
# указываем данные для запроса
data = [
('табурет', 2, 1)
]
# добавляем запись в таблицу
with con:
con.executemany(sql, data)
# выводим содержимое таблицы с покупками на экран
with con:
data = con.execute("SELECT * FROM orders")
for row in data:
print(row)Компьютер выдал строку (1, ‘табурет’, 2, 1), значит, таблицы связались правильно.
Что дальше
Теперь, когда мы знаем, как работать с SQLite в Python, можно использовать эту базу данных в более серьёзных проектах:
- хранить результаты парсинга;
- запоминать отсортированные датасеты;
- вести учёт пользователей и их действий в системе.
Подпишитесь, чтобы не пропустить продолжение про SQLite. А если вам интересна аналитика и работа с данными, приходите на курс «SQL для работы с данными и аналитики».
Вёрстка:
Кирилл Климентьев
Введение
В этой статье я хотел бы дать полезную информацию для тех, кто решил создать свою собственную базу данных, но не знает с чего начать.
Работаю с данными более 20 лет, участвовал во множестве проектов, связанных с созданием баз данных, приложений сбора и обработки больших массивов данных. За это время я пробовал много инструментов работы с данными и в результате получил представление о том, что и как нужно использовать для решения разного типа задач. Надеюсь, что мой опыт пригодится и вам.

Зачем создавать собственную базу данных
Если вы читаете эту статью, то вы уже стоите перед задачей создания собственной базы данных. Вот основные причины, по которым люди создают их.
1. Данных становится очень много
Это, наверное, одна из основных причин. Какой бы деятельностью вы не занимались, у вас будет накапливаться информация, и вам надо её собирать и хранить. Информация может быть представлена на бумажных документах, в электронных письмах, бланках и таблицах. И если вначале бумажные документы могут уместиться на рабочем столе, а электронные — в одной папке на жестком диске вашего компьютера, то довольно скоро вы станете замечать, что начинаете тонуть в накапливающейся информации.
2. Становится трудно находить нужную информацию
Уверен, что у каждого из вас были такие моменты, когда вам срочно нужна определенная информация, и вы никак не можете ее найти. Начинаете вспоминать, где эта информация находится, рыться в сообщениях электронной почты, сообщениях разных мессенджеров, в папках с документами на вашем столе. Если бы люди подсчитали, сколько времени они тратят на эти поиски за год, то ужаснулись бы.
Кроме потери времени, эти поиски постоянно мешают вам в решении важных задач.
3. Необходимо делиться информацией или работать с ней совместно
Предположим, у вас отличная память, и вы очень организованный человек. Вы знаете точно, где и что у вас находится и можете найти нужную информацию за несколько минут. Но как только появляется необходимость поделиться вашей информацией и работать с ней совместно, начинаются большие проблемы.
Часто другие люди либо не хотят, либо не могут понять, как у вас организовано хранение информации и какие правила действуют. Начав делиться своей информацией, вы через некоторое время приходите к выводу, что теряете контроль над вашими данными и не можете им доверять, как раньше.
Этапы создания собственной базы данных
Весь процесс создания базы данных можно разбить на 4 этапа.
1. Анализ и выработка требований к базе данных
На этом этапе нужно проанализировать данные, которые вы собираетесь хранить в базе, определить их состав и объем. Стоит определиться, будет ли ваша база данных многопользовательской, и если да, то сколько будет пользователей. Также нужно составить список всех функций по управлению данными. Чем более точно вы проработаете требования на этом этапе, тем меньше риск ошибиться на следующих.
2. Выбор инструментов создания базы данных
На основе требований к вашей базе данных нужно выбрать один из имеющихся инструментов создания баз. Таких инструментов много. Информации о них в Интернете также очень много. Большинство из них вы можете попробовать бесплатно и выяснить, подходят ли они для вас. Также на этом этапе может понадобиться помощь профессиональных консультантов.
3. Создание структуры базы данных
Выбрав инструмент, нужно создать в нём структуру базы. Это очень важный этап, так как неверная структура не позволит вам организовать правильный поиск и может затруднить масштабирование и доработку базы данных. Надо понимать, что по мере наполнения вашей базы данными вносить изменения в её структуру станет всё труднее и труднее.
4. Наполнение базы данных
После того как структура создана, можно приступать к наполнению базы данных. На этом этапе при вводе реальных данных может оказаться, что структура базы данных не оптимальна, и нужно внести в нее изменения или даже полностью переработать. Или выясниться, что выбранный для создания базы данных инструмент не подходит для решения ваших задач. Поэтому тут не стоит спешить и сразу пытаться загружать все данные, а имеет смысл начать с небольших порций и убедиться, что всё сделано правильно и у вас не возникнет проблем впоследствии.
Инструменты для создания базы данных
Можно выделить 4 основных типа инструментов для создания собственной базы данных:
- табличные редакторы;
- файловое хранилище;
- классические СУБД;
- онлайн-базы данных.
Постараемся разобраться в сфере применения, в плюсах и минусах этих инструментов.
Табличные редакторы
Сейчас практически любой человек пользуется табличными редакторами. Когда нам нужно собрать какие-нибудь данные и придать им некоторую структуру, первым делом мы вспоминаем об электронных таблицах.
Это очень мощный инструмент для работы с данными, и многие его используют для создания своих баз данных.
Современный табличный редактор, такой как MS Excel, имеет удобный интерфейс, огромное количество функций, возможность создавать простые интерфейсы, специализированный язык программирования.
Я видел множество систем, автоматизирующих бизнес-процессы компаний, построенных на базе Excel и VBA, которые использовали широкий набор функций, предоставляемый этим продуктом. Но большинство из них со временем пришлось заменить на более специализированные решения из-за ограничений, имеющихся у табличных редакторов.
Также стоит отметить, что в последнее время всё более популярными становятся онлайн-табличные редакторы, такие как Google Sheets, Smartsheet и т. д. Их функциональность пока уступает классическим табличным редакторам, но по удобству и доступности они уже во многом их превосходят.
Ограничения
- В табличных редакторах очень трудно создать жесткую структуру данных. В таблицах четыре основных структурных элемента — листы, строки, столбцы и ячейки. Когда вы начинаете создавать документ, то наделяете эти элементы определенным смыслом и тем самым создаете структуру данных, связи и ограничения. Но вы это создаете у себя в мозгу. Сама программа не знает, что ячейки одной строки связаны между собой и описывают один конкретный объект, что в некоторых ячейках находятся данные, а в других — названия столбцов.
И такая вариативность, и гибкость хороша, когда у вас небольшой объем несложных по структуре данных и вы не работаете над данными совместно.
- Табличные редакторы не предназначены для работы с большим количеством данных. Когда у вас несколько тысяч записей, проблем, как правило, не возникает, но с ростом количества записей с такой таблицей становится трудно работать. Кроме того, значительно повышается риск случайной порчи или удаления данных. Достаточно один раз неудачно отсортировать их, и вы можете полностью потерять целостность данных.
- Трудно связывать данные. Если у вас есть несколько таблиц и данные в них логически связаны, то нужно их объединять и в самом редакторе. Это можно сделать, но потребуются определенные усилия и жесткий контроль за содержимым всех участвующих в связях ячейках и листах. Ибо достаточно сделать несколько неправильных изменений, и вы можете потерять важную информацию.
- Совместная работа. Изначально таблицы предназначались в основном для однопользовательского применения. Сейчас современные онлайн-редакторы позволяют работать совместно. Но дав доступ на изменение данных, вы со временем можете обнаружить, что важные данные были искажены или удалены и это опять может быть связано с тем, что другие люди неправильно поняли их структуру и как данные связаны.
Файловое хранилище
Если ваша задача — структурированно хранить файлы и их описание с целью быстрого поиска нужного файла, то вы можете создать базу данных файлов в виде структурированного файлового хранилища. Его можно организовать на вашем жестком диске, корпоративном файловом сервере или в облачном файловом хранилище.
Практически у каждого из нас уже есть подобная база данных на собственном компьютере или ноутбуке. Вы структурируете свои рабочие документы, свои фотографии, видео и другие файлы, раскладывая их по папкам с соответствующим названием.
При этом структура хранения информации создается с помощью иерархии папок и стандартизированных имен файлов, например: тип документа, номер документа, дата документа или дата съемки, место съемки.
Плюсом такого решения является простота реализации и понятность. Но и у файлового хранилища есть ряд ограничений.
Ограничения
- Поиск. Как правило, поиск вы можете проводить только по имени файлов, по тем фразам, которые находятся в нём. И тут возникает 2 проблемы.
Первая проблема — ограничение длины имени файлов в файловой системе. Вы просто не сможете создать длинное описание файлов.
Вторая проблема — вы сможете проводить только очень простой поиск файлов по фразам, находящимся в их названии, и не сможете проводить сложные выборки на основе нескольких параметров поиска. И если при персональном использовании и небольшом количестве файлов можно попытаться это сделать простым просмотром содержимого папок, то в базах данных уровня компании это будет просто физически невозможно. - Доступность. Если вы используете файлы только внутри организации, то проблем с доступностью не должно быть. А если нужно получить доступ к информации по сети «Интернет», например, из дома, или нужно дать доступ к вашей информации сторонней организации, то в случае внутрисетевого хранилища, это будет очень затруднительно. При использовании облачного хранилища проблем не должно быть.
- Совместная работа и настройка прав доступа. Просто выкладывать все файлы на файловый сервер и предоставлять к ним доступ всем не совсем правильно и рискованно. Нужно обязательно администрировать доступ к информации как на уровне папок, так и доступных пользователям действий. И тут необходимо привлекать IT-специалистов. Кроме того, контролировать изменения в структуре и файлах тоже сложно.
- Бэкап. Нельзя забывать и о резервировании информации, так как, к сожалению, срок службы жестких дисков на вашем компьютере или сервере не бесконечен. И эта задача ложится полностью на вас или ваших IT-специалистов.
Классические СУБД
Классические СУБД — это самое мощное и гибкое решения для создания баз данных.
С помощью них вы можете создать совершенно любую базу данных, любого масштаба и интерфейса. Практически все корпоративные системы сделаны на основе той или иной СУБД. Как правило, это Microsoft SQL Server или Oracle. В большинстве онлайн-платформ и веб-сайтов применяется СУБД MySQL.
У классических СУБД почти нет ограничений и есть огромное количество инструментов администрирования, интеграции и управления.
Но, как вы понимаете, идеальных решений не бывает, и у такого подхода есть свои недостатки.
Ограничения
Интерфейс. К сожалению, пользователи вашей БД не смогут напрямую работать с СУБД, нужно разрабатывать отдельный интерфейс. И как раз разработка этого интерфейса является самой трудоемкой частью создания решения. Вам придется поручить эту задачу программисту-разработчику или фирме, специализированной на разработке приложений. Кроме поиска разработчиков, вам понадобится самим сначала создать техническое задание на разработку, а потом постоянно контролировать процесс разработки и тестировать полученный интерфейс. Эти задачи трудоемки и требуют соответствующих знаний.
Сопровождение и развитие. Надо понимать, что созданный для вашей базы данных интерфейс будет нетиповым, уникальным, созданным под вас. И естественно, в нём будут появляться баги, его нужно будет дорабатывать и тратить значительные ресурсы на сопровождение. Также трудности могут возникнуть, когда вам захочется существенно изменить ваш продукт. Как правило, разработчики при создании интерфейса и структуры базы данных исходят из вашего ТЗ и не закладывают в систему большие возможности ее дальнейшего развития. И когда вам захочется модернизировать вашу базу данных, это может оказаться невозможным из-за существенных ограничений выбранной платформы или заложенных в коде, созданном разработчиками. Иногда из-за этих ограничений приходится разрабатывать полностью новое решение.
Время. На разработку интерфейса потребуется время. И как часто бывает, времени потребуется существенно больше, чем будет изначально запланировано.
Риски. А что, если ваш разработчик интерфейса через некоторое время откажется сопровождать ваше решение или технологию, на которой оно реализовано? Вы не можете безболезненно сменить разработчика и попадаете в определенную зависимость.
Стоимость. Это существенный недостаток, так как разработка приложения с нуля стоит очень больших денег. Кроме того, потребуются затраты на сопровождение получившегося решения. И если затраты на разработку и сопровождение типовых тиражируемых и облачных решений равномерно распределяются среди всех клиентов разработчика таких решений, то в вашем случае все затраты на сопровождение вашего уникального решения лягут полностью на ваши плечи.
Конструкторы онлайн-баз данных
Конструкторы онлайн-баз данных появились значительно недавно и стали возможны благодаря появлению современной и недорогой облачной инфраструктуры (amazon aws, google cloud, ms azure) и развитию технологий построения многофункциональных web-интерфейсов.
Современные конструкторы онлайн-баз данных стремятся соединить возможности корпоративных СУБД с простотой использования современных веб-приложений.
Основная их цель — дать возможность создавать полноценные онлайн-базы данных и веб-приложения с минимальными затратами на их создание и сопровождение. В отличие от классических СУБД, конструкторы, как правило, содержат как саму базу данных, так и инструменты создания интерфейса к ней, приспособив его к решению конкретных задач пользователя.
При этом в конструкторах есть все средства для эффективной совместной работы с данными, включая средства разграничения доступа и мониторинга.
Для создания базы данных и интерфейса вам не потребуется навыков программирования или их разработки. Уже сейчас практически любой человек со среднем уровнем компьютерных знаний за несколько часов может создать приложение с базой данных, ничем не уступающее решениям корпоративного класса.
Основными преимуществами конструкторов баз данных являются:
- доступность;
- простота настройки и администрирования;
- быстрота создания баз данных;
- небольшие затраты на сопровождение.
Но и тут, конечно, есть свои ограничения.
Ограничения
Функционал. Несмотря на то, что функционал данных решений с каждым годом становится всё более широким, он всё-таки ограничен. Например, вы не сможете добавить свою кнопку, изменить цвет элементов или добавить обработчик нестандартных событий. Вам придется подстраивать свои процессы под имеющийся функционал.
Только онлайн. Для того чтобы сократить стоимость решения и добавлять функционал как можно быстрее, разработчикам конструкторов баз данных приходится отказаться от вариантов установки системы на сервера клиентов. Соответственно у клиентов возникают опасения о безопасности своих данных или потери контроля над ними. По мере развития рынка облачных решений надежность и безопасность хранения данных в облаке повышается.
По своему опыту могу сказать, что риск потери или несанкционированного доступа к данным, хранящимся на собственных серверах наших заказчиков, зачастую выше, чем риск потери облачных данных, которые они хранят у нас. Это связано с тем, что уровень администрирования IT-систем в большинстве компаний не соответствуют современному уровню угроз.
От чего зависит выбор решения
Сразу хочу сказать, что универсального алгоритма выбора того или иного решения нет. Надо пробовать различные варианты или переходить с одного на другой по мере необходимости. Выбор того или иного решения зависит:
- от объема создаваемой базы данных;
- количества пользователей;
- сложности структуры базы данных;
- состава функций по управлению данными;
- имеющегося бюджета;
- требуемого срока реализации.
Но я бы дал следующие советы:
- Если вы собираетесь хранить структурированные данные небольшого объема и в основном для личного использования, то, я думаю, стоит выбрать табличный редактор.
- Если вам нужно хранить исключительно файлы и использовать их совместно с небольшим количеством людей, понимающих и соблюдающих структуру и правила наименования файлов и папок, то стоит выбрать файловое хранилище.
- Если вам нужна специализированная база данных и сделанный под вас интерфейс со множеством уникальных функций, тесно увязанная с вашими бизнес-процессами и другими используемыми системами, то вам необходима классическая база данных и заказная разработка интерфейса.
- Если вам нужна, с одной стороны, понятная и простая многопользовательская база данных, а с другой, — обладающая основными функциями и возможностями классических баз данных, то стоит посмотреть в сторону конструкторов онлайн-баз данных.
Также конструктор подойдёт в том случае, если вы не определились с выбором инструмента создания базы данных. Начав её делать в конструкторе, вы легко сможете впоследствии мигрировать на другое решение.
На что также стоит обратить внимание при создании собственной базы данных
Хочу еще выделить пару важных моментов, о которых стоить помнить при создании базы данных.
Неправильные требования
В основе всех неудач в проектах создания баз данных в компаниях, как правило, лежат неправильные требования к создаваемой базе — структуре данных и функциям интерфейса. И это понятно. Для того чтобы правильно их сформулировать, нужен опыт создания БД и глубокие знания процессов внутри компании. И, к сожалению, если вы нанимаете сторонних разработчиков, то у них, возможно, будет опыт создания БД, но не будет экспертизы в сфере деятельности вашей компании. И, наоборот, вы можете досконально знать устройство всех процессов в организации, но не разбираетесь в тонкостях баз данных.
Кроме того, в независимости от того, насколько будет правильно спроектирована база данных, реальная её эксплуатация порой вносит очень серьезные коррективы.
Поэтому мой совет будет следующим. Постарайтесь идти от простого к сложному: попробуйте создать прототип вашей базы данных в Excel, а лучше в конструкторе онлайн-баз данных. Попытайтесь начать работать с этой базой данных, поработать совместно. Попробуйте использовать имеющиеся функции для решения ваших задач. И уже по итогам вы сможете сформировать более точные требования. В любом случае данные, которые вы будет использовать в базе, никуда не пропадут — вы всегда их сможете выгрузить и использовать в конечном продукте.
Может так оказаться, что те же недорогие конструкторы баз данных готовы покрыть 80-90% ваших требований и оставшиеся 10-20% не стоят тех денег и усилий, которые потребуются для их реализации. Также не стоить забывать, что сейчас так всё быстро меняется, что к тому времени, как вы реализуете 100% нужного вам функционала, сама задача может уже коренным образом измениться.
Плохое юзабилити
При разработке требований к базе данных и создании интерфейса часто допускается одна и таже ошибка — игнорирование вопросов, связанных с юзабилити интерфейса.
А именно от правильного юзабилити во многом зависит эффективность работы с создаваемой базой данных.
Плохо проработанный интерфейс приводит к дополнительным потерям времени на обучение сотрудников и работу с самой базой данных.
Также надо учитывать, что порой больше всего затрат времени и денег уходит не на покупку или разработку базы данных, а на наполнение её информацией. Часто затраты на наполнение базы данных могут быть в разы больше затрат, чем на создание её структуры и интерфейса.
И тут могут возникнуть проблемы с удобством интерфейса и производительностью ввода данных.
Чем меньше времени вы будете тратить на ввод данных, поиск, изменение, тем больше эффекта вы получите от использования своей базы данных.
К сожалению, мне часто приходится видеть базы данных со сложной, непонятной структурой и ужасно запутанным интерфейсом ввода информации. Так, например, ввод одних и тех же данных может занимать десятки секунд в правильно спроектированном интерфейсе и несколько минут в интерфейсе, в котором не уделяли внимание юзабилити.
Тратя лишнее время на ввод данных, вы теряете его, а значит, упускаете и свои деньги.
Заключение
Надеюсь, данная статья поможет вам в создании своей собственной базы данных. Если вы сделаете правильный выбор инструмента и не допустите основных ошибок, то получите эффективное решение ваших задач.
Установка
Когда вы изучаете новый язык, самым важным аспектом является практика. Одно дело – прочитать статью и совсем другое – применить полученную информацию. Давайте начнем с установки базы данных на компьютер.
Первый шаг – установить SQL
Мы будем использовать PostgreSQL (Postgres) – достаточно распространенный SQL диалект. Для этого откроем страницу загрузки, выберем операционную систему (в моем случае Windows), и запустим установку. Если вы установите пароль для вашей базы данных, постарайтесь сразу не забыть его, он нам дальше понадобится. Поскольку наша база будет локальной, можете использовать простой пароль, например: admin.
Следующий шаг – установка pgAdmin
pgAdmin – это графический интерфейс пользователя (GUI – graphical user interface), который упрощает взаимодействие с базой данных PostgreSQL. Перейдите на страницу загрузки, выберите вашу операционную систему и следуйте указаниям (в статье используется Postgres 14 и pgAdmin 4 v6.3.).
После установки обоих компонентов открываем pgAdmin и нажимаем Add new server. На этом шаге установится соединение с существующим сервером, именно поэтому необходимо сначала установить Postgres. Я назвал свой сервер home и использовал пароль, указанный при установке.
Теперь всё готово к созданию таблиц. Давайте создадим набор таблиц, которые моделируют школу. Нам необходимы таблицы: ученики, классы, оценки. При создании модели данных необходимо учитывать, что в одном классе может быть много учеников, а у ученика может быть много оценок (такое отношение называется «один ко многим»).
Мы можем создать таблицы напрямую в pgAdmin, но вместо этого мы напишем код, который можно будет использовать в дальнейшем, например, для пересоздания таблиц. Для создания запроса, который создаст наши таблицы, нажимаем правой кнопкой мыши на postgres (пункт расположен в меню слева home → Databases (1) → postgres и далее выбираем Query Tool.
Начнем с создания таблицы классов (classrooms). Таблица будет простой: она будет содержать идентификатор id и имя учителя – teacher. Напишите следующий код в окне запроса (query tool) и запустите (run или F5).
DROP TABLE IF EXISTS classrooms CASCADE;
CREATE TABLE classrooms (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
teacher VARCHAR(100)
);
В первой строке фрагмент DROP TABLE IF EXISTS classrooms удалит таблицу classrooms, если она уже существует. Важно учитывать, что Postgres, не позволит нам удалить таблицу, если она имеет связи с другими таблицами, поэтому, чтобы обойти это ограничение (constraint) в конце строки добавлен оператор CASCADE. CASCADE – автоматически удалит или изменит строки из зависимой таблицы, при внесении изменений в главную. В нашем случае нет ничего страшного в удалении таблицы, поскольку, если мы на это пошли, значит мы будем пересоздавать всё с нуля, и остальные таблицы тоже удалятся.
Добавление DROP TABLE IF EXISTS перед CREATE TABLE позволит нам систематизировать схему нашей базы данных и создать скрипты, которые будут очень удобны, если мы захотим внести изменения – например, добавить таблицу, изменить тип данных поля и т. д. Для этого нам просто нужно будет внести изменения в уже готовый скрипт и перезапустить его.
Ничего нам не мешает добавить наш код в систему контроля версий. Весь код для создания базы данных из этой статьи вы можете посмотреть по ссылке.
Также вы могли обратить внимание на четвертую строчку. Здесь мы определили, что колонка id является первичным ключом (primary key), что означает следующее: в каждой записи в таблице это поле должно быть заполнено и каждое значение должно быть уникальным. Чтобы не пришлось постоянно держать в голове, какое значение id уже было использовано, а какое – нет, мы написали GENERATED ALWAYS AS IDENTITY, этот приём является альтернативой синтаксису последовательности (CREATE SEQUENCE). В результате при добавлении записей в эту таблицу нам нужно будет просто добавить имя учителя.
И в пятой строке мы определили, что поле teacher имеет тип данных VARCHAR (строка) с максимальной длиной 100 символов. Если в будущем нам понадобится добавить в таблицу учителя с более длинным именем, нам придется либо использовать инициалы, либо изменять таблицу (alter table).
Теперь давайте создадим таблицу учеников (students). Новая таблица будет содержать: уникальный идентификатор (id), имя ученика (name), и внешний ключ (foreign key), который будет указывать (references) на таблицу классов.
DROP TABLE IF EXISTS students CASCADE;
CREATE TABLE students (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
name VARCHAR(100),
classroom_id INT,
CONSTRAINT fk_classrooms
FOREIGN KEY(classroom_id)
REFERENCES classrooms(id)
);
И снова мы перед созданием новой таблицы удаляем старую, если она существует, добавляем поле id, которое автоматически увеличивает своё значение и имя с типом данных VARCHAR (строка) и максимальной длиной 100 символов. Также в эту таблицу мы добавили колонку с идентификатором класса (classroom_id), и с седьмой по девятую строку установили, что ее значение указывает на колонку id в таблице классов (classrooms).
Мы определили, что classroom_id является внешним ключом. Это означает, что мы задали правила, по которым данные будут записываться в таблицу учеников (students). То есть Postgres на данном этапе не позволит нам вставить строку с данными в таблицу учеников (students), в которой указан идентификатор класса (classroom_id), не существующий в таблице classrooms. Например: у нас в таблице классов 10 записей (id с 1 до 10), система не даст нам вставить данные в таблицу учеников, у которых указан идентификатор класса 11 и больше.
INSERT INTO students
(name, classroom_id)
VALUES
('Matt', 1);
/*
ERROR: insert or update on table "students" violates foreign
key constraint "fk_classrooms"
DETAIL: Key (classroom_id)=(1) is not present in table
"classrooms".
SQL state: 23503
*/
Теперь давайте добавим немного данных в таблицу классов (classrooms). Так как мы определили, что значение в поле id будет увеличиваться автоматически, нам нужно только добавить имена учителей.
INSERT INTO classrooms
(teacher)
VALUES
('Mary'),
('Jonah');
SELECT * FROM classrooms;
/*
id | teacher
-- | -------
1 | Mary
2 | Jonah
*/
Прекрасно! Теперь у нас есть записи в таблице классов, и мы можем добавить данные в таблицу учеников, а также установить нужные связи (с таблицей классов).
INSERT INTO students
(name, classroom_id)
VALUES
('Adam', 1),
('Betty', 1),
('Caroline', 2);
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
*/
Но что же случится, если у нас появится новый ученик, которому ещё не назначили класс? Неужели нам придется ждать, пока станет известно в каком он классе, и только после этого добавить его запись в базу данных?
Конечно же, нет. Мы установили внешний ключ, и он будет блокировать запись, поскольку ссылка на несуществующий id класса невозможна, но мы можем в качестве идентификатора класса (classroom_id) передать null. Это можно сделать двумя способами: указанием null при записи значений, либо просто передачей только имени.
-- явно определим значение NULL
INSERT INTO students
(name, classroom_id)
VALUES
('Dina', NULL);
-- неявно определим значение NULL
INSERT INTO students
(name)
VALUES
('Evan');
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
4 | Dina | [null]
5 | Evan | [null]
*/
И наконец, давайте заполним таблицу успеваемости. Этот параметр, как правило, формируется из нескольких составляющих – домашние задания, участие в проектах, посещаемость и экзамены. Мы будем использовать две таблицы. Таблица заданий (assignments), как понятно из названия, будет содержать данные о самих заданиях, и таблица оценок (grades), в которой мы будем хранить данные о том, как ученик выполнил эти задания.
DROP TABLE IF EXISTS assignments CASCADE;
DROP TABLE IF EXISTS grades CASCADE;
CREATE TABLE assignments (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
category VARCHAR(20),
name VARCHAR(200),
due_date DATE,
weight FLOAT
);
CREATE TABLE grades (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
assignment_id INT,
score INT,
student_id INT,
CONSTRAINT fk_assignments
FOREIGN KEY(assignment_id)
REFERENCES assignments(id),
CONSTRAINT fk_students
FOREIGN KEY(student_id)
REFERENCES students(id)
);
Вместо того чтобы вставлять данные вручную, давайте загрузим их с помощью CSV-файла. Вы можете скачать файл из этого репозитория или создать его самостоятельно. Имейте в виду, чтобы разрешить pgAdmin доступ к данным, вам может понадобиться расширить права доступа к папке (в моем случае – это папка db_data).
COPY assignments(category, name, due_date, weight)
FROM 'C:/Users/mgsosna/Desktop/db_data/assignments.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 5
Query returned successfully in 118 msec.
*/
COPY grades(assignment_id, score, student_id)
FROM 'C:/Users/mgsosna/Desktop/db_data/grades.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 25
Query returned successfully in 64 msec.
*/
Теперь давайте проверим, что мы всё сделали верно. Напишем запрос, который покажет среднюю оценку, по каждому виду заданий с группировкой по учителям.
SELECT
c.teacher,
a.category,
ROUND(AVG(g.score), 1) AS avg_score
FROM
students AS s
INNER JOIN classrooms AS c
ON c.id = s.classroom_id
INNER JOIN grades AS g
ON s.id = g.student_id
INNER JOIN assignments AS a
ON a.id = g.assignment_id
GROUP BY
1,
2
ORDER BY
3 DESC;
/*
teacher | category | avg_score
------- | --------- | ---------
Jonah | project | 100.0
Jonah | homework | 94.0
Jonah | exam | 92.5
Mary | homework | 78.3
Mary | exam | 76.0
Mary | project | 69.5
*/
Отлично! Мы установили, настроили и наполнили базу данных.
***
Итак, в этой статье мы научились:
- создавать базу данных;
- создавать таблицы;
- наполнять таблицы данными;
- устанавливать связи между таблицами;
Теперь у нас всё готово, чтобы пробовать более сложные возможности SQL. Мы начнем с возможностей синтаксиса, которые, вероятно, вам еще не знакомы и которые откроют перед вами новые границы в написании SQL-запросов. Также мы разберем некоторый виды соединений таблиц (JOIN) и способы организации запросов в тех случаях, когда они занимают десятки или даже сотни строк.
В следующей части мы разберем:
- виды фильтраций в запросах;
- запросы с условиями типа if-else;
- новые виды соединений таблиц;
- функции для работы с массивами;
Материалы по теме
- 🐘 8 лучших GUI клиентов PostgreSQL в 2021 году
- 🐍🐬 Python и MySQL: практическое введение
- 🐍🗄️ Управление данными с помощью Python, SQLite и SQLAlchemy

Из статьи вы узнаете, как за несколько шагов в LibreOffice создать простую базу данных на примере словаря терминов.
Статья написана для пользователей, которые ничего не знают о базах данных. Поэтому в тексте нет сложных терминов и определений, а в базе данных всего две таблицы и одна простая форма для ввода данных.
Базы данных разрабатываются не только программистами и не только для больших приложений. Например, в университетах создают базы данных для хранения научной и учебной информации, а затем регистрируют их в Роспатенте.
Свидетельства о госрегистрации баз данных приравниваются к научным публикациям (Постановление Правительства РФ от 24.09.2013 N 842 (ред. от 01.10.2018, с изм. от 26.05.2020) «О порядке присуждения ученых степеней»), поэтому на них ссылаются в диссертациях, отчётах, статьях, указывают в резюме и портфолио. Кроме того, свидетельство служит подтверждением квалификации сотрудника при проведении аттестации.
База данных: что это такое?
Когда информации много, то работать с ней трудно. Данные могут быть разбросаны по разным файлам и папкам, их легко потерять и сложно найти.
В базе данных весь материал систематизирован, структурирован и хранится в одном месте. С ним легко и удобно взаимодействовать. Вы можете искать и фильтровать информацию так, как это делается в интернет-магазинах и поисковых системах.
База данных — это одна или несколько таблиц, в которые заносится информация. Количество столбцов в таблицах и их тип определяется пользователем — автором базы данных.
Как можно создавать базы данных
Базы данных создаются в специальных программах, которые называются системами управления базами данных.
Систем управления базами данных много. Среди них: Microsoft SQL Server, Oracle Database, PostgreSQL, MySQL, SQLite. Для простых и небольших баз данных уровня лаборатории/кафедры/школы подойдут бесплатные OpenOffice.org Base или LibreOffice Base.
Как создать базу данных в LibreOffice Base
LibreOffice — бесплатный пакет офисных программ. Является альтернативой коммерческому Microsoft Office.
Мы создавали эту инструкцию для LibreOffice 6.4. Чтобы не было расхождений при создании базы данных по этому руководству, рекомендуем работать с LibreOffice версии 6.1 и выше.
Итак, давайте создадим простую базу данных «Словарь терминов», в которой будут храниться термины, их определения, а также разделы учебной дисциплины, к которым они относятся. В качестве примера мы взяли дисциплину «Базы данных».
Шаг 1. Запуск программы и подготовка
Запустите программу для создания баз данных LibreOffice Base.
В появившемся окне Мастера баз данных выберите Создать новую базу данных, укажите формат Firebird встроенная, нажмите Далее.
На втором шаге Мастера установите флажок в Открыть базу для редактирования, нажмите Готово.
В появившемся окне выберите папку, в которой нужно сохранить базу данных, введите имя файла. Нажмите Сохранить.
Шаг 2. Создание таблиц
В базах данных принято хранить один вид информации в одной таблице. Например, информация о сотрудниках, информация о подразделениях, информация о проектах организации — всё это должно быть в разных таблицах. Чтобы база данных и пользователь понимали, в каком подразделении работает сотрудник, и какие проекты разрабатываются в подразделениях, создаются дополнительные столбцы или таблицы для хранения связей между записями. Так устраняется избыточность информации в базе данных.
Каждая строка в таблице должна быть уникальна, чтобы база данных понимала, какую запись следует удалить или отредактировать. Для этого создаётся первичный ключ в таблице — столбец, в котором значения встречаются ровно по одному разу. Это похоже на ситуацию, когда фамилия, имя, отчество и даже дата рождения у двух людей могут совпадать, но данные их паспортов обязательно будут отличаться. В случае с базой данных аналогом паспорта выступает столбец с первичным ключом.
В нашем примере два вида информации: термин и раздел дисциплины, для которой создаётся словарь. Каждый термин относится к определённому разделу дисциплины, поэтому надо установить связь между будущими таблицами.
В окне редактора базы данных кликните на Создать таблицу в режиме дизайна…
В появившемся окне добавьте характеристики столбцов таблицы для разделов дисциплины:
- Имя поля — Номер. Тип поля — Целое [INTEGER]. Автозначение — Да (будет автоматически наращивать значение поля при добавлении новой записи в таблицу: 1, 2, 3 и т.д.). Этот столбец будет первичным ключом таблицы, и база данных сама добавит этот признак (будет отображаться изображение ключика с левой стороны поля).
- Имя поля — Раздел. Тип поля — Текст [VARCHAR], длина 100. В этом столбце будут находиться названия разделов дисциплины.
Для сохранения таблицы выберите пункт меню Файл — Сохранить. В диалоговом окне укажите название таблицы — Разделы, нажмите ОК.
Закройте окно со структурой таблицы Разделы.
Сохраните базу данных (Файл — Сохранить).
Для создания второй таблицы с терминами опять кликните на Создать таблицу в режиме дизайна… и введите параметры столбцов таблицы:
- Имя поля — Номер. Тип поля — Целое [INTEGER]. Автозначение — Да. Столбец будет первичным ключом таблицы по аналогии с таблицей Разделы.
- Имя поля — Раздел. Тип поля — Целое [INTEGER]. Автозначение — Нет. Обязательное — Да. В данном столбце будут указываться значения первичного ключа таблицы Разделы для того, чтобы связать термины и разделы, к которым они относятся.
- Имя поля — Термин. Тип поля — Текст [VARCHAR], длина 100. Обязательное — Да. В этом столбце будут находиться термины.
- Имя поля — Определение. Тип поля — Текст [VARCHAR], длина 255. В этом столбце будут находиться определения терминов.
- Имя поля — Источник. Тип поля — Текст [VARCHAR], длина 255. В этом столбце будет указываться информация об источнике, из которого взята информация о термине. Например, ссылка на страницу сайта, библиографическая ссылка.
Проверьте указанную структуру с изображением ниже.
Сохраните таблицу под именем Термины, закройте окно структуры таблицы.
Сохраните базу данных.
Шаг 3. Создание связи между таблицами
В главном меню программы выберите пункт Сервис — Связи..
Далее с помощью окна добавьте обе таблицы для установления связей между ними.
Так как столбец Раздел в таблице Термины создан для хранения ключа соответствующего термину раздела, то нам надо его связать со столбцом Номер таблицы Разделы.
Для этого левой кнопкой мыши установите курсор на столбце Номер таблицы Разделы и, не отпуская кнопки, ведите курсор к столбцу Раздел таблицы Термины. Отпустите кнопку мыши. В результате таблицы будут соединены ломаной линией. На одном конце линии будет 1, а на другом — n. Это указывает на тип связи один-ко-многим, что означает, что к одному разделу может относиться много терминов.
Сохраните образованную связь (Файл — Сохранить) и закройте окно.
Сохраните базу данных.
Шаг 4. Ввод данных в таблицы
Для добавления информации о разделах откройте одноимённую таблицу. Установите курсор мыши в первой строке в столбце Раздел и введите название. Нажмите клавишу Enter на клавиатуре и введите ещё одно название раздела в новой строке и опять нажмите на клавишу Enter. Обратите внимание, что столбец Номер заполняется автоматически, потому что мы указали в его настройках Автозначение.
Теперь чтобы заполнить данные о терминах, откройте таблицу Термины. Введите данные, как показано на рисунке ниже. Обратите внимание: для указания раздела, к которому относится термин, нам надо знать его номер в таблице Разделы. Если разделов и терминов много, то вводить такую информацию становится неудобным, так как придётся подглядывать в таблицу Разделы.
На этом шаге, в принципе, уже можно завершить работу с базой данных, заполнив всею необходимую информацию о разделах и терминах.
Поздравляем — ваша первая база данных создана!
Чтобы вводить информацию о разделах и терминах с использованием удобного графического интерфейса и привычных пользователям элементов ввода (флажки, текстовые поля, выпадающие списки и пр.), в LibreOffice Base предусмотрены Формы.
Обратите внимание: не все системы управления базами данных поддерживают создание форм. Для большинства придётся программировать приложения, чтобы получить удобный пользовательский интерфейс.
Шаг 5. Создание формы для добавления и просмотра данных
Форма — это набор элементов для ввода информации в таблицы базы данных (текстовые поля, выпадающие списки, переключатели, навигатор по строкам и пр.).
В одной форме может быть сколько угодно главных и подчинённых форм. В нашем случае главной формой выступает форма с разделами, а подчинённой — форма с терминами. Перемещаясь по строкам таблицы главной формы, мы сможем видеть термины, которые относятся к текущему разделу. Теперь знать номер раздела для ввода термина нам не придётся: мы будем выбирать его из выпадающего списка.
Чтобы начать создание формы, в левой части окна базы данных выберите раздел Формы. Кликните на Создать форму в режиме дизайна…
Выберите пункт меню Форма — Навигатор форм… В результате появится маленькое окно со списком форм.
Создание главной формы для работы с разделами
Создайте главную форму для работы с разделами. Для этого правой кнопкой мыши щёлкните на пункте Формы и в контекстном меню выберите Создать — Форма.
Правой кнопкой мыши кликните на созданной форме в Навигаторе форм. Далее в контекстном меню выберите Свойства.
В окне свойств формы на вкладке Общие введите название формы «Форма Разделы». На вкладке Данные укажите Тип содержимого —Таблица, в поле Содержимое введите имя таблицы — Разделы, отключите Панель навигации. Остальные настройки не меняйте.
Сохраните форму базы данных (Файл — Сохранить), введите название формы.
Проверьте активность Мастера элементов управления в меню Форма. Кликните на этом пункте, если он не активен.
В главную форму добавим таблицу для просмотра и редактирования разделов. Для этого установите курсор мыши на элементе Форма разделы в Навигаторе форм.
Выберите пункт главного меню Форма — Таблица. В левой части окна формы курсором мыши нарисуйте таблицу. В появившемся окне с помощью кнопки =>> добавьте все поля таблицы в созданный элемент управления.
Поменяйте Привязку у таблицы с Как символ на К странице, чтобы можно было перемещать её в любое место формы.
Столбец Раздел сделайте шире. На названии столбца Номер кликните правой кнопкой мыши и в контекстном меню выберите Столбец….
В появившемся окне настроек укажите 0 в пункте Точность, затем закройте окно.
С помощью Вставка — Текстовое поле добавьте на форму подпись с текстом РАЗДЕЛЫ и отформатируйте на свой вкус.
Чтобы посмотреть, как работает созданная форма, отключите Режим разработки в меню Форма.
Чтобы вернуться к редактированию формы выберите пункт Режим разработки повторно.
Создание подчинённой формы для работы с терминами
Чтобы создать форму, подчинённую главной форме с разделами, кликните правой кнопкой мыши на Форма Разделы в Навигаторе форм, и выберите пункт Создать — Форма.
Кликните правой кнопкой мыши на появившейся в Навигаторе форм форме и в контекстном меню выберите Свойства. В окне свойств формы на вкладке Общие введите название Форма Термины. На вкладке Данные укажите Тип содержимого — Таблица, Содержимое — Термины. Отключите Панель навигации.
Нажмите на кнопку с тремя точками напротив пункта Связь с главным полем. В появившемся окне выберите поле Раздел для таблицы Термины и Номер для таблицы Разделы.
Напротив свойства Сортировка кликните на кнопке с тремя точками и в появившемся окне укажите Имя поля — Термин, а Порядок сортировки — по возрастанию.
С помощью Форма — Текстовое поле добавьте три новых элемента в подчинённую форму. Далее указаны свойства для каждого из них.
В свойствах первого текстового поля укажите Поле Термин в Имя. Во вкладке Данные выберите Термин в свойстве Поле данных. Укажите Нет в свойстве Пустая строка — NULL, чтобы программа не разрешала сохранять термины с пустыми названиями.
Выберите второе текстовое поле. Укажите Поле Определение в свойстве Имя. В свойстве Тип текста укажите Многострочный. Поле данных — Определение. Остальное не меняйте.
В свойстве Имя третьего текстового поля укажите Поле Источник. Поле данных — Источник. Остальное не меняйте.
Выберите пункт меню Форма — Список и разместите на форме новый элемент управления. В появившемся диалоговом окне укажите таблицу Разделы в качестве источника данных для построения списка. Кликните Далее.
На следующем шаге укажите Раздел в качестве Отображаемого поля. Кликните Далее.
На последнем шаге Мастера укажите Раздел для Поле из таблицы значений и Номер для Поле из таблицы списка. Кликните Готово.
С помощью Форма — Панель навигации разместите на форме элемент, позволяющий перемещаться по записям таблицы с терминами.
Для всех элементов подчинённой формы добавьте подписи с использованием Вставка — Текстовое поле. Оформите на свой вкус.
Ваша форма должна выглядеть примерно так:
Сохраните форму с использованием Файл — Сохранить. Закройте окно редактирования формы.
Два раза кликните на созданной Форма добавление в разделе Формы базы данных. Так созданная форма откроется для работы с таблицами базы данных. Перемещаясь по строкам таблицы с разделами, вы делаете активным один из них.
Чтобы изменить форму, кликните правой кнопкой мыши на её названии и в контекстном меню выберите Правка…
Итоги
Мы рассмотрели, что такое базы данных и зачем они нужны.
Мы научились создавать простую базу данных в бесплатной программе LibreOffice Base. Создали две таблицы, установили между ними связь. Для наполнения базы данных и просмотра её содержимого мы создали форму.
Эту базу данных можно использовать в качестве основы для создания других баз данных с похожей структурой.
Прим. перев. Предполагается, что вы уже имеете начальные знания по SQL. Если вы плохо понимаете, что такое таблицы, строки, индексы, первичные ключи и ссылочная целостность, то лучше сначала изучить их, например по этим видео:
А если вы знакомы с SQL и вас не остановили предыдущие термины, на всякий случай напомним, что:
- атомарность предполагает, что значение нельзя разделить на несколько атрибутов;
- под кортежем понимается запись (строка) в таблице базы данных;
- атрибут — это колонка таблицы;
- неключевой атрибут — это атрибут, не входящий в состав никакого потенциального ключа.
***
Есть минимум два требования, которые должны быть соблюдены при проектировании структуры БД:
- Сохранить всю информацию после разделения её на таблицы.
- Минимизировать избыточность того, как эта информация хранится.
Примечание Второй пункт важен не только из-за того, что избыточность влияет на размер БД. Чаще всего при обновлении данных нужно обработать много строк. В таком случае вы рискуете просто забыть обновить некоторые из них, что приведёт к коллизиям внутри БД.
Ниже перечислены некоторые рекомендации, которые помогут добиться эффективной структуры:
- используйте хотя бы третью нормальную форму;
- создавайте ограничения для входных данных;
- не храните ФИО в одном поле, также как и полный адрес;
- установите для себя правила именования таблиц и полей.
Используйте хотя бы третью нормальную форму
Нормальные формы — это требования, которые должны соблюдаться при правильной проектировке базы данных.
Нормальных форм существует целых 6 штук, однако обычно соблюдают всего лишь 3 и для начала этого более чем достаточно.
Первая нормальная форма
Для примера будем использовать отношение сотрудники_отделы_проекты. В нём есть информация о номере сотрудника, его фамилии, номере отдела, в котором он работает, номере телефона отдела и так далее.

Это отношение, как и любое другое, автоматически находится в первой нормальной форме:
- в отношении нет одинаковых кортежей;
- кортежи не упорядочены;
- атрибуты не упорядочены и различаются по наименованию;
- все значения атрибутов атомарны.
Вторая нормальная форма
В нашем случае у таблицы выше имеется сложный (составной) ключ {Н_СОТР, Н_ПРО}. От части ключа Н_СОТР зависят неключевые атрибуты ФАМ, Н_ОТД, ТЕЛ. От части ключа Н_ПРО зависит неключевой атрибут ПРОЕКТ. А вот атрибут Н_ЗАДАН зависит от всего составного ключа, так как сотрудник может выполнять одно задание в одном проекте.
Поэтому для приведения отношения ко второй нормальной форме из отношения сотрудники_отделы_проекты нужно выделить два отношения сотрудники_отделы и проекты, а исходное отношение оставим отношением задания.
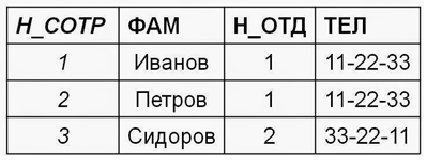

Наконец, третья нормальная форма
Отношение находится в третьей нормальной форме, когда отношение находится во второй нормальной форме и все неключевые атрибуты взаимно независимы.
Для того, чтобы устранить зависимость неключевых атрибутов, нужно произвести декомпозицию отношения ещё на несколько отношений. При этом те неключевые атрибуты, которые являются зависимыми, выносятся в отдельное отношение.
Отношение сотрудники_отделы не находится в третьей нормальной форме, так как имеется зависимость неключевых атрибутов, таких как зависимость номера телефона от номера отдела. Поэтому декомпозируем отношение сотрудники_отделы на два отношения — сотрудники и отделы:
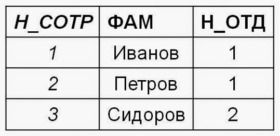
Используйте проверочные ограничения
База данных — это не просто набор таблиц. В неё встроено много инструментов, которые помогут с сохранностью и качеством данных.
В первую очередь БД поможет с ограничением значений, которые принимают поля.
Внешние ключи регламентируют отношения между таблицами. Благодаря им сильно упрощается контроль за структурой базы, уменьшается и упрощается код приложения. Правильно настроенные внешние ключи — это гарант того, что увеличится целостность данных за счёт уменьшения избыточности. Поэтому обязательно применяйте ограничение внешнего ключа при определении связей между таблицами.
Выражения ON DELETE и ON UPDATE внешних ключей используются для указания действий, которые будут выполняться при удалении строк родительской таблицы (ON DELETE) или изменении родительского ключа (ON UPDATE). Не пренебрегайте ими.
Стоит убедиться, что обязательность заполнения (NOT NULL) проверяется для полей, которые строго не должны оставаться пустыми.
Используйте CHECK, чтобы убедиться, что значения входят в диапазон (например чтобы цена не была отрицательной).
Не храните ФИО в одном поле, также как и полный адрес
Представим ситуацию, когда вам понадобится узнать, в каком городе продукт более популярен. В таком случае, если полный адрес хранится в виде цельной строки, сделать это будет очень тяжело, ведь вам нужно будет каким-то образом выделить из этой строки город. Учитывая все возможные форматы и варианты адресов, эта задача становится практически невыполнимой. Похожая ситуация и с ФИО. Даже если кажется, что это ни к чему, храните эти данные в разных полях, и в будущем вы поблагодарите себя.
Установите для себя правила именования таблиц и полей
Сложно работать с данными, которые выглядят как-то так: user.firstName, user.last_name, user.birthDate. Конечно, каждый программист в праве сам выбирать для себя стиль наименования, но для SQL рекомендуется выбрать наименование с подчёркиванием. Потому что не все SQL-движки одинаково работают с заглавными буквами, а помещать всё в кавычки бывает утомительно.
Ещё нужно определиться как будут называться таблицы — во множественном числе (users) или в единственном (user). Каждая базовая структура в БД обычно настроена на множественное число, поэтому и именовать таблицы стоит соответственно.
Не упускайте возможность сложить побольше обязанностей на базу данных, чтобы облегчить себе работу над приложением и думать о его структуре, а не о контроле табличных связей.
Всё приходит с опытом. Спроектируйте две-три схемы, и картинка сама сложится у вас в голове. Отталкивайтесь от задачи —некоторыми рекомендациями иногда можно пренебречь.
Перевод статьи «A humble guide to database schema design»