
Привет, Хабр! Недавно у меня возникла идея создать собственный алгоритм хеширования, на вход которого можно бы было подать информацию любой длины и получить хеш определенного размера. Особенность всех алгоритмов хеширование — в их необратимости. Но существует и другой, не менее важный момент — однозначность.
Для начала мы рассмотрим несколько моментов, касающихся общих принципов работы хеширующих алгоритмов.
1 Идеи
1.1 Однозначность

Действительно, обеспечить однозначность с помощью блока определенного размера невозможно. Если подумать, то можно придти к выводу, что абсолютно все существующие алгоритмы хеширования допускают неоднозначность.
Возьмем несколько кусков информации, которые после операции хеширования получают одинаковый результат. В некоторых случаях это может оказаться некритично. А что если это система авторизации? На большинстве сайтов проверка осуществляется md5 хешем, и поэтому такая неоднозначность в формировании хеша может ускорить брутфорс пароля.
Однозначность можно повысить добавлением спецсимволов (вида #,$,%,^,&) в хеш, но его удобство несколько понизится. Хотя если использовать большую длину хеша и спецсимволы можно значительно повысить стойкость алгоритма.
1.2 Необратимость
Обеспечить необратимость можно довольно простыми способами. Операциями сложения, умножения, деления и вычитания кодов символов, а также различные специализированные операции. В отличии от неоднозначности, создать необратимый алгоритм вполне возможно. Необратимость алгоритма широко используется для хранения различной чувствительной информации (например паролей).
2 Создание алгоритма
Реализовать алгоритм я решил на C++.
2.1 Функция number() или отбеливание (whitening)
Первым делом нужно написать функцию, которая будет принимать определенное число на вход и выдавать ANSI код символа 0-9, a-z, A-Z. Выбор символа будет зависеть именно от входного числа.
int number(int x) { // вспомогательная функция отбеливания
x+=256;
while (!(((x <= 57) && (x >= 48)) || ((x <= 90) && (x >= 65)) || ((x <= 122) && (x >= 97)))) {
if (x < 48) {x+=24;} else {x-=47;}
}
return x;
}
Цикл будет выполняться пока не подберется код символа, соответствующий 0-9 или a-z или A-Z. Это будет ключевая функция необратимости, так как подобрать символ в обратную сторону довольно проблематично.
2.2 Ввод данных
Хранить входную строку будет std::vector, а для ввода-вывода мы будем использовать консоль.
int main() {
std::vector<char> v;
char s;
while (std::cin>>s) {
if (s == ';') break;
v.push_back(s);
}
std::cout<<"Hash: "<<ruhash(v)<<std::endl;
return 0;
}
Объявляем последовательность и заполняем ее данными. Для остановки ввода я выбрал символ ‘;‘. Его можно легко изменить на любой другой. Функция ruhash() будем возвращать строку с нашим хешем.
2.3 Написание функции ruhash()
Функцию хеширования ruhash() и функцию отбеливания number() я решил вынести в заголовочный файл ruhash.h. Далее займемся продумыванием и написанием основного функционала.
Выходной хеш у нас должен быть всегда равен 32 символам (a-z, A-Z, 0-9). На вход должна подаваться последовательность любой длины. В процессе создания алгоритма мы будем использовать функцию отбеливания number(), которая была описана выше.
Первым делом нужно дополнить входной блок до такого количества символов, чтобы возведя 2 в n степень можно бы было его получить. В добавок к этому количество дополняемых символов должно быть больше 64. Это нужно, чтобы улучшить показатель однозначности. Рассмотрим это на примере. На вход поступило 300 символов, значит ближайший блок будет 512. Если же поступит 500 символов на вход, то он дополнится до 1024 символов.
std::string ruhash(std::vector<char> v) { // алгоритм хеширования
int len = v.size(); // определяем длину входного блока
int min = 64; // минимальный блок
while (min < len) min*=2; // блок должен быть 64, 128, 256, 512 бит и т.д.
if ((min - len) < 64) min*=2; // если количество информации, которое требуется дописать меньше 64, то будем дописывать еще
int add = min-len; // количество информации, которую нужно добавить
...
Так, теперь у нас количество символов, которые нужно дописать. Дальше нужно сгенерировать соль и дописать данные. Соль будем генерировать на основе суммы кодов всех символов, отнимем от этого числа длину исходной последовательности символов и прогоним ее через отбеливание. При дописывании информации будем добавлять к соли элементы исходной и добавляемой последовательности, а также счетчик.
...
int salt = 0; // соль на основе суммы кодов всех символов и длины
for (int i = 0; i < v.size(); ++i) salt+=v[i]; // собираем из кодов всех символов соль
salt = number(salt-len); // добавляем в соль длину
for (int i = 1; i <= add; ++i) v.push_back(number(i*salt*v[i])); // дописываем информацию на основе соли, счетчика и входной строки, отбеливаем ее
...
Теперь у нас есть целый блок размером 128, 256, 512… символов. Пришло время применить операцию сворачивания этого блока в блок размером 32 символа. Перед реализацией его на C++ я немного продемонстрирую принцип работы этой техники в упрощенном варианте.
Допустим, что дана последовательность из 8 символов. Мы ее свернем в 4 символов по схеме ниже.

На этой картинке вполне наглядно выглядит операция сворачивания. Таким образом повторяя несколько раз эту операцию можно свернуть даже 512 символов в 32.
...
std::vector<int> prev; // выходной вектор
for (int i = 0; i < v.size(); ++i) prev.push_back(v[i]); // переписываем коды символов в выходной вектор
std::vector<int> now; // промежуточный вектор
while (prev.size() != 32) { // пока размер вектора не станет 32, будем его сокращать
for (int j = 0; j < prev.size(); j+=2) {
int t = prev[j] + prev[j+1]; // складываем пары чисел в одно, тем самым уменьшая размер последовательности в 2 раза
now.push_back(t);
}
prev = now; // промежуточный блок переписываем в выходной вектор
now.clear();
}
...
На данный момент у нас есть 32-битный блок, состоящий из чисел. На последнем этапе мы прогоним их через функцию number(), то есть отбелим и посимвольно перепишем все содержимое конечного вектора в строку и затем вернем результат работы всего алгоритма.
...
std::vector<char> f; // конечный хеш
for (int i = 0; i < prev.size(); ++i) {
f.push_back(number(prev[i]+i*i)); // отбеливаем полученный вектор
}
std::string hash; // строка для результата
for (int i = 0; i < f.size(); ++i) {
hash+=f[i];
}
return hash;
}3 Итоги
Мы написали вполне хорошую функцию хеширования на C++ и рассмотрели некоторые приемы получения необратимого алгоритма. Вообще, сравнивая современные алгоритмы хеширования, лучше всего использовать 256-битные алгоритмы хеширования для более точного сравнения информации больших объемов. Для коротких 20-30 битных паролей вполне подойдет md5.
4 Взлом
Хотите попробовать взломать свежеиспеченный алгоритм RuHash? Жители Хабра могут попробовать взломать вот такой хеш, то есть получить исходную строку.
MqsvgafTwEVaGoVaziEMpkdztMNfUaLU
Исходники: https://github.com/ilyadev/RuHash
In hashing there is a hash function that maps keys to some values. But these hashing function may lead to collision that is two or more keys are mapped to same value. Chain hashing avoids collision. The idea is to make each cell of hash table point to a linked list of records that have same hash function value.
Let’s create a hash function, such that our hash table has ‘N’ number of buckets.
To insert a node into the hash table, we need to find the hash index for the given key. And it could be calculated using the hash function.
Example: hashIndex = key % noOfBuckets
Insert: Move to the bucket corresponds to the above calculated hash index and insert the new node at the end of the list.
Delete: To delete a node from hash table, calculate the hash index for the key, move to the bucket corresponds to the calculated hash index, search the list in the current bucket to find and remove the node with the given key (if found).
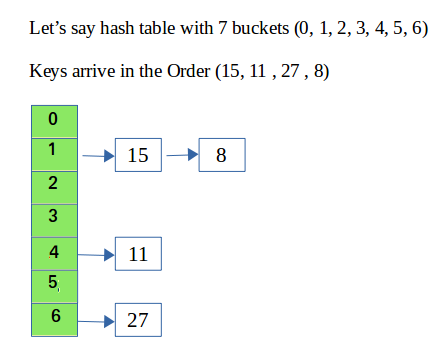
Please refer Hashing | Set 2 (Separate Chaining) for details.
Methods to implement Hashing in Java
- With help of HashTable (A synchronized implementation of hashing)
Java
import java.util.*;
class GFG {
public static void main(String args[])
{
Hashtable<Integer, String>
hm = new Hashtable<Integer, String>();
hm.put(1, "Geeks");
hm.put(12, "forGeeks");
hm.put(15, "A computer");
hm.put(3, "Portal");
System.out.println(hm);
}
}
Output
{15=A computer, 3=Portal, 12=forGeeks, 1=Geeks}
- With the help of HashMap (A non-synchronized faster implementation of hashing)
Java
import java.util.*;
class GFG {
static void createHashMap(int arr[])
{
HashMap<Integer, Integer> hmap = new HashMap<Integer, Integer>();
for (int i = 0; i < arr.length; i++) {
Integer c = hmap.get(arr[i]);
if (hmap.get(arr[i]) == null) {
hmap.put(arr[i], 1);
}
else {
hmap.put(arr[i], ++c);
}
}
System.out.println(hmap);
}
public static void main(String[] args)
{
int arr[] = { 10, 34, 5, 10, 3, 5, 10 };
createHashMap(arr);
}
}
Output
{34=1, 3=1, 5=2, 10=3}
- With the help of LinkedHashMap (Similar to HashMap, but keeps order of elements)
Java
import java.util.*;
public class BasicLinkedHashMap
{
public static void main(String a[])
{
LinkedHashMap<String, String> lhm =
new LinkedHashMap<String, String>();
lhm.put("one", "practice.geeksforgeeks.org");
lhm.put("two", "code.geeksforgeeks.org");
lhm.put("four", "www.geeksforgeeks.org");
System.out.println(lhm);
System.out.println("Getting value for key 'one': "
+ lhm.get("one"));
System.out.println("Size of the map: " + lhm.size());
System.out.println("Is map empty? " + lhm.isEmpty());
System.out.println("Contains key 'two'? "+
lhm.containsKey("two"));
System.out.println("Contains value 'practice.geeks"
+"forgeeks.org'? "+ lhm.containsValue("practice"+
".geeksforgeeks.org"));
System.out.println("delete element 'one': " +
lhm.remove("one"));
System.out.println(lhm);
}
}
Output
{one=practice.geeksforgeeks.org, two=code.geeksforgeeks.org, four=www.geeksforgeeks.org}
Getting value for key 'one': practice.geeksforgeeks.org
Size of the map: 3
Is map empty? false
Contains key 'two'? true
Contains value 'practice.geeksforgeeks.org'? true
delete element 'one': practice.geeksforgeeks.org
{two=code.geeksforgeeks.org, four=www.geeksforgeeks.org}
- With the help of ConcurretHashMap(Similar to Hashtable, Synchronized, but faster as multiple locks are used)
Java
import java.util.concurrent.*;
class ConcurrentHashMapDemo {
public static void main(String[] args)
{
ConcurrentHashMap<Integer, String> m =
new ConcurrentHashMap<Integer, String>();
m.put(100, "Hello");
m.put(101, "Geeks");
m.put(102, "Geeks");
System.out.println("ConcurrentHashMap: " + m);
m.putIfAbsent(101, "Hello");
System.out.println("nConcurrentHashMap: " + m);
m.remove(101, "Geeks");
System.out.println("nConcurrentHashMap: " + m);
m.replace(100, "Hello", "For");
System.out.println("nConcurrentHashMap: " + m);
}
}
Output
ConcurentHashMap: {100=Hello, 101=Geeks, 102=Geeks}
ConcurentHashMap: {100=Hello, 101=Geeks, 102=Geeks}
ConcurentHashMap: {100=Hello, 102=Geeks}
ConcurentHashMap: {100=For, 102=Geeks}
- With the help of HashSet (Similar to HashMap, but maintains only keys, not pair)
Java
import java.util.*;
class Test {
public static void main(String[] args)
{
HashSet<String> h = new HashSet<String>();
h.add("India");
h.add("Australia");
h.add("South Africa");
h.add("India");
System.out.println(h);
System.out.println("nHashSet contains India or not:"
+ h.contains("India"));
h.remove("Australia");
System.out.println("nList after removing Australia:" + h);
System.out.println("nIterating over list:");
Iterator<String> i = h.iterator();
while (i.hasNext())
System.out.println(i.next());
}
}
Output
[South Africa, Australia, India] HashSet contains India or not:true List after removing Australia:[South Africa, India] Iterating over list: South Africa India
With the help of LinkedHashSet (Similar to LinkedHashMap, but maintains only keys, not pair)
Java
import java.util.LinkedHashSet;
public class Demo
{
public static void main(String[] args)
{
LinkedHashSet<String> linkedset =
new LinkedHashSet<String>();
linkedset.add("A");
linkedset.add("B");
linkedset.add("C");
linkedset.add("D");
linkedset.add("A");
linkedset.add("E");
System.out.println("Size of LinkedHashSet = " +
linkedset.size());
System.out.println("Original LinkedHashSet:" + linkedset);
System.out.println("Removing D from LinkedHashSet: " +
linkedset.remove("D"));
System.out.println("Trying to Remove Z which is not "+
"present: " + linkedset.remove("Z"));
System.out.println("Checking if A is present=" +
linkedset.contains("A"));
System.out.println("Updated LinkedHashSet: " + linkedset);
}
}
Output
Size of LinkedHashSet = 5 Original LinkedHashSet:[A, B, C, D, E] Removing D from LinkedHashSet: true Trying to Remove Z which is not present: false Checking if A is present=true Updated LinkedHashSet: [A, B, C, E]
- With the help of TreeSet (Implements the SortedSet interface, Objects are stored in a sorted and ascending order).
Java
import java.util.*;
class TreeSetDemo {
public static void main(String[] args)
{
TreeSet<String> ts1 = new TreeSet<String>();
ts1.add("A");
ts1.add("B");
ts1.add("C");
ts1.add("C");
System.out.println("TreeSet: " + ts1);
System.out.println("nTreeSet contains A or not:"
+ ts1.contains("A"));
ts1.remove("A");
System.out.println("nTreeSet after removing A:" + ts1);
System.out.println("nIterating over TreeSet:");
Iterator<String> i = ts1.iterator();
while (i.hasNext())
System.out.println(i.next());
}
}
Output
TreeSet: [A, B, C] TreeSet contains A or not:true TreeSet after removing A:[B, C] Iterating over TreeSet: B C
In hashing there is a hash function that maps keys to some values. But these hashing function may lead to collision that is two or more keys are mapped to same value. Chain hashing avoids collision. The idea is to make each cell of hash table point to a linked list of records that have same hash function value.
Let’s create a hash function, such that our hash table has ‘N’ number of buckets.
To insert a node into the hash table, we need to find the hash index for the given key. And it could be calculated using the hash function.
Example: hashIndex = key % noOfBuckets
Insert: Move to the bucket corresponds to the above calculated hash index and insert the new node at the end of the list.
Delete: To delete a node from hash table, calculate the hash index for the key, move to the bucket corresponds to the calculated hash index, search the list in the current bucket to find and remove the node with the given key (if found).
Please refer Hashing | Set 2 (Separate Chaining) for details.
Methods to implement Hashing in Java
- With help of HashTable (A synchronized implementation of hashing)
Java
import java.util.*;
class GFG {
public static void main(String args[])
{
Hashtable<Integer, String>
hm = new Hashtable<Integer, String>();
hm.put(1, "Geeks");
hm.put(12, "forGeeks");
hm.put(15, "A computer");
hm.put(3, "Portal");
System.out.println(hm);
}
}
Output
{15=A computer, 3=Portal, 12=forGeeks, 1=Geeks}
- With the help of HashMap (A non-synchronized faster implementation of hashing)
Java
import java.util.*;
class GFG {
static void createHashMap(int arr[])
{
HashMap<Integer, Integer> hmap = new HashMap<Integer, Integer>();
for (int i = 0; i < arr.length; i++) {
Integer c = hmap.get(arr[i]);
if (hmap.get(arr[i]) == null) {
hmap.put(arr[i], 1);
}
else {
hmap.put(arr[i], ++c);
}
}
System.out.println(hmap);
}
public static void main(String[] args)
{
int arr[] = { 10, 34, 5, 10, 3, 5, 10 };
createHashMap(arr);
}
}
Output
{34=1, 3=1, 5=2, 10=3}
- With the help of LinkedHashMap (Similar to HashMap, but keeps order of elements)
Java
import java.util.*;
public class BasicLinkedHashMap
{
public static void main(String a[])
{
LinkedHashMap<String, String> lhm =
new LinkedHashMap<String, String>();
lhm.put("one", "practice.geeksforgeeks.org");
lhm.put("two", "code.geeksforgeeks.org");
lhm.put("four", "www.geeksforgeeks.org");
System.out.println(lhm);
System.out.println("Getting value for key 'one': "
+ lhm.get("one"));
System.out.println("Size of the map: " + lhm.size());
System.out.println("Is map empty? " + lhm.isEmpty());
System.out.println("Contains key 'two'? "+
lhm.containsKey("two"));
System.out.println("Contains value 'practice.geeks"
+"forgeeks.org'? "+ lhm.containsValue("practice"+
".geeksforgeeks.org"));
System.out.println("delete element 'one': " +
lhm.remove("one"));
System.out.println(lhm);
}
}
Output
{one=practice.geeksforgeeks.org, two=code.geeksforgeeks.org, four=www.geeksforgeeks.org}
Getting value for key 'one': practice.geeksforgeeks.org
Size of the map: 3
Is map empty? false
Contains key 'two'? true
Contains value 'practice.geeksforgeeks.org'? true
delete element 'one': practice.geeksforgeeks.org
{two=code.geeksforgeeks.org, four=www.geeksforgeeks.org}
- With the help of ConcurretHashMap(Similar to Hashtable, Synchronized, but faster as multiple locks are used)
Java
import java.util.concurrent.*;
class ConcurrentHashMapDemo {
public static void main(String[] args)
{
ConcurrentHashMap<Integer, String> m =
new ConcurrentHashMap<Integer, String>();
m.put(100, "Hello");
m.put(101, "Geeks");
m.put(102, "Geeks");
System.out.println("ConcurrentHashMap: " + m);
m.putIfAbsent(101, "Hello");
System.out.println("nConcurrentHashMap: " + m);
m.remove(101, "Geeks");
System.out.println("nConcurrentHashMap: " + m);
m.replace(100, "Hello", "For");
System.out.println("nConcurrentHashMap: " + m);
}
}
Output
ConcurentHashMap: {100=Hello, 101=Geeks, 102=Geeks}
ConcurentHashMap: {100=Hello, 101=Geeks, 102=Geeks}
ConcurentHashMap: {100=Hello, 102=Geeks}
ConcurentHashMap: {100=For, 102=Geeks}
- With the help of HashSet (Similar to HashMap, but maintains only keys, not pair)
Java
import java.util.*;
class Test {
public static void main(String[] args)
{
HashSet<String> h = new HashSet<String>();
h.add("India");
h.add("Australia");
h.add("South Africa");
h.add("India");
System.out.println(h);
System.out.println("nHashSet contains India or not:"
+ h.contains("India"));
h.remove("Australia");
System.out.println("nList after removing Australia:" + h);
System.out.println("nIterating over list:");
Iterator<String> i = h.iterator();
while (i.hasNext())
System.out.println(i.next());
}
}
Output
[South Africa, Australia, India] HashSet contains India or not:true List after removing Australia:[South Africa, India] Iterating over list: South Africa India
With the help of LinkedHashSet (Similar to LinkedHashMap, but maintains only keys, not pair)
Java
import java.util.LinkedHashSet;
public class Demo
{
public static void main(String[] args)
{
LinkedHashSet<String> linkedset =
new LinkedHashSet<String>();
linkedset.add("A");
linkedset.add("B");
linkedset.add("C");
linkedset.add("D");
linkedset.add("A");
linkedset.add("E");
System.out.println("Size of LinkedHashSet = " +
linkedset.size());
System.out.println("Original LinkedHashSet:" + linkedset);
System.out.println("Removing D from LinkedHashSet: " +
linkedset.remove("D"));
System.out.println("Trying to Remove Z which is not "+
"present: " + linkedset.remove("Z"));
System.out.println("Checking if A is present=" +
linkedset.contains("A"));
System.out.println("Updated LinkedHashSet: " + linkedset);
}
}
Output
Size of LinkedHashSet = 5 Original LinkedHashSet:[A, B, C, D, E] Removing D from LinkedHashSet: true Trying to Remove Z which is not present: false Checking if A is present=true Updated LinkedHashSet: [A, B, C, E]
- With the help of TreeSet (Implements the SortedSet interface, Objects are stored in a sorted and ascending order).
Java
import java.util.*;
class TreeSetDemo {
public static void main(String[] args)
{
TreeSet<String> ts1 = new TreeSet<String>();
ts1.add("A");
ts1.add("B");
ts1.add("C");
ts1.add("C");
System.out.println("TreeSet: " + ts1);
System.out.println("nTreeSet contains A or not:"
+ ts1.contains("A"));
ts1.remove("A");
System.out.println("nTreeSet after removing A:" + ts1);
System.out.println("nIterating over TreeSet:");
Iterator<String> i = ts1.iterator();
while (i.hasNext())
System.out.println(i.next());
}
}
Output
TreeSet: [A, B, C] TreeSet contains A or not:true TreeSet after removing A:[B, C] Iterating over TreeSet: B C
58
Вид занятия – лабораторная работа Цель – исследование методов хеширования
Продолжительность – 4 часа
Одна из важных задач, решаемых в программировании,— это обеспечение быстрого (желательно прямого) доступа к данным по некоему коду (индексу, адресу). Примером может стать упорядоченный по алфавиту телефонный справочник. Первая буква фамилии абонента является его хэшкодом, и при поиске мы просматриваем не все фамилии, а только нужную букву.
Хеширование (hashing) — преобразование входного массива данных произвольной длины в выходную битовую строку фиксированной длины. Такие преобразования обеспечиваются с помощью хеш-функций, а их результаты называют хеш-кодом.
Хеш-таблицы являются ближайшими родственниками обычных таблиц. Таблица превращается в хэш-таблицу, когда к заданному элементу осуществляется непоследовательный доступ с помощью хеш-функции. В хеш-функцию, в общем, передается элемент данных, который она преобразовывается в целое число, которое используется как индекс в таблице. Например, вы имеете таблицу, в которую вы намерены сохранять значения ИНН персонала фирмы, но вместо истинных значений вы разделите ИНН на какое-то число (допустим 3) и сохраните в таблице результат деления.
Взакрытой хэш-таблице, хеш-ключ — индекс элемента, в котором вы сохраняете дату и данные, связанные с этой датой. Если слот в таблице занят другой датой (это называется «коллизия»), Вы можете или генерировать другой хеш-ключ (называется «нелинейное перехеширование») или найти в таблице доступный слот (линейное перехеширование).
Воткрытой хэш-таблице (более общий случай), каждый элемент в таблице – голова связанного списка элементов данных. В этой модели, коллизия обрабатывается, при помощи добавления элемента коллизии к списку, который начинает в слоте таблицы, куда ссылаются оба ключа. Этот подход имеет преимущество, что таблица не ограничивает числом элементов, которые таблица может содержать, в то время как закрытая таблица не может содержать большее количество элементов данных, чем элементов в таблице.
Вслучае прямой адресации элемент с ключом k хранится в ячейке k. При хешировании этот элемент хранится в ячейке h(k), т.е. мы используем хеш-функцию h для вычисления ячейки для данного ключа k.
Цель хеш-функции состоит в том, чтобы уменьшить рабочий диапазон индексов массива, и вместо |U| значений мы можем обойтись всего лишь m значениями.
Рисунок 12.1. — Пример поиска данных в реляционной таблице с помощью хеширования

59
Само собой разумеется, функция h должна быть детерминистической и для одного и того же значения и всегда давать одно и то же хеш-значение h(k). Однако поскольку |U| > т, должно существовать как минимум два ключа, которые имеют одинаковое хеш-значение.
Таким образом, полностью избежать коллизий невозможно в принципе, и хорошая хеш-функция в состоянии только минимизировать количество коллизий.
Идеальная функция хеширования должна обладать следующими свойствами:
1.Быть применимой к аргументу любого размера.
2.Выходное хеш-значение должно иметь фиксированный размер.
3.Скорость вычисления должна быть такой, чтобы опережать время затрачиваемое на обработку исходного значения.
4.Хеш-функция должна быть чувствительной к всевозможным изменениям во входных данных.
5.Хеш-функция должна быть однонаправленной, то есть обладать свойствами необратимости.
6.Вероятность того, что значения хеш-функций двух различных входных данных совпадут, должна быть ничтожно мала.
Отечественный стандарт хеширования
Отечественным стандартом генерирования хэш-функции является алгоритм ГОСТ Р 34.11-94. Этот стандарт является обязательным для применения в качестве алгоритма хеширования в государственных организациях РФ и ряде коммерческих организаций. Коротко данный алгоритм хеширования можно описать следующим образом [9].
Шаг 1. Инициализация регистра хеш-значения. Если длина сообщения не превышает 256 бит — переход к шагу 3, если превышает — переход к шагу 2.
Шаг 2. Итеративное вычисление хеш-значения блоков хешируемых данных по 256 бит с использованием хранящегося в регистре хеш-значения предыдущего блока. Вычисление включает в себя следующие действия:
—генерацию ключей шифрования на основе блока хешируемых данных;
—шифрование хранящегося в регистре хеш-значения в виде четырех блоков
—по 64 бит по алгоритму ГОСТ 28147-89 в режиме простой замены;
—перемешивание результата.
Вычисление производится до тех пор, пока длина необработанных входных данных не станет меньше или равной 256 бит. В этом случае — переход к шагу 3.
Шаг З. Дополнение битовыми нулями необработанной части сообщения до 256 бит. Вычисление хеш-значения аналогично шагу 2. В результате в регистре оказывается искомое хэш-значение.
Создание хеш-функции
Хеш-функция зависит от типа обслуживаемых значений, другими словами способ хеширования определяется типом исходных данных. При создании хеш-функции следует избегать преобразования типов, т.е. исходное значение и хеш-значение должно быть однотипным. Правда из этого правила может быть и исключения, например при хешировании строковых значений.
Наиболее распространённый метод хеширования выбор в качестве размера M хеш-таблицы простого числа и вычисление остатка от деления исходного значения k на M.
h(k) = k mod т (12.1).
Такая функция называется модульной хеш-функцией. Модульные хеш-функции хорошо подходят для хеширования целых чисел.
Хеш-функции для строковых значений, алгоритм Гонера
Как получить хеш-значение для данных больших размерностей? Допустим, что у нас есть исходное слово: “averylongkey”. Если это слово описать в виде 7-ми разрядного ASCII кода, то мы получим примерно следующую картину [2]:

60
97*12811+118*12810+101*1289+114*1288+
121*1287+108*1286+111*1285+110*1284+
103*1283+107*1282+101*1281+121*1280,
что примерно равно 7.5571538*1023.
Как вы понимаете, это абсолютно неприемлемо, но представьте себе какое значение вы получите если вам придётся обрабатывать ещё более значительные строковые типы данных.
Поэтому для обработки строковых значений часто применяется алгоритм Горнера.
(((((((((((97*128+118)*128+101)*128+114)*128+121)*128+108)*128+111)*128+110)*
128+103)*128+107)*128+101)*128+121)*128
Другими словами можно вычислить десятичное число, соответствующее коду соответствующее коду символов строки при просмотре ее слева направо, умножая полученное значение на 128, а затем добавляя кодовое значение следующего символа.
Со временем этот алгоритм создаёт число, которое вообще будет нельзя представить на компьютере. Однако полученное число нас мало интересует, поскольку при хешировании нам требуется остаток от деления исходного числа на M. Результат можно получить даже не сохраняя большое накопленное значение, т.к. в любое время можно отбросить число кратное M – при каждом выполнении сложения и умножения нужно хранить только остаток деления по модулю M.
Задание
Создайте текстовый файл input.txt содержащий 50-60 строк случайных латинских символов (от 1 до 20-ти символов в строке). Указанный файл будет служить источником данных для вашей дальнейшей работы.
1.Разработайте хеш-функцию и структуру хеш-таблицы.
2.Реализуйте операции вставки хеш-значений в хеш-таблицу.
3.Реализуйте операции поиска данных в хеш-таблице следующим образом: пользователь вводит произвольную строку латинских символов; по нажатию клавиши ввод программа преобразует запрашиваемые данные в хеш-значение; в хештаблице находим наиболее близкое хеш-значение и узнаём номер строки в файле input.txt с наиболее подходящей текстовой строкой.
4.Внесите предложения по борьбе с коллизиями.

Привет! Недавно у меня возникла идея создать собственный алгоритм хеширования, на вход которого можно бы было подать информацию любой длины и получить хеш определенного размера. Особенность всех алгоритмов хеширование — в их необратимости. Но существует и другой, не менее важный момент — однозначность.
Для начала мы рассмотрим несколько моментов, касающихся общих принципов работы хеширующих алгоритмов.
1 Идеи
1.1 Однозначность

Действительно, обеспечить однозначность с помощью блока определенного размера невозможно. Если подумать, то можно придти к выводу, что абсолютно все существующие алгоритмы хеширования допускают неоднозначность.
Возьмем несколько кусков информации, которые после операции хеширования получают одинаковый результат. В некоторых случаях это может оказаться некритично. А что если это система авторизации? На большинстве сайтов проверка осуществляется md5 хешем, и поэтому такая неоднозначность в формировании хеша может ускорить брутфорс пароля.
Однозначность можно повысить добавлением спецсимволов (вида #,$,%,^,&) в хеш, но его удобство несколько понизится. Хотя если использовать большую длину хеша и спецсимволы можно значительно повысить стойкость алгоритма.
1.2 Необратимость
Обеспечить необратимость можно довольно простыми способами. Операциями сложения, умножения, деления и вычитания кодов символов, а также различные специализированные операции. В отличии от неоднозначности, создать необратимый алгоритм вполне возможно. Необратимость алгоритма широко используется для хранения различной чувствительной информации (например паролей).
2 Создание алгоритма
Реализовать алгоритм я решил на C++.
2.1 Функция number() или отбеливание (whitening)
Первым делом нужно написать функцию, которая будет принимать определенное число на вход и выдавать ANSI код символа 0-9, a-z, A-Z. Выбор символа будет зависеть именно от входного числа.
int number(int x) { // вспомогательная функция отбеливания
x+=256;
while (!(((x <= 57) && (x >= 48)) || ((x <= 90) && (x >= 65)) || ((x <= 122) && (x >= 97)))) {
if (x < 48) {x+=24;} else {x-=47;}
}
return x;
}
Цикл будет выполняться пока не подберется код символа, соответствующий 0-9 или a-z или A-Z. Это будет ключевая функция необратимости, так как подобрать символ в обратную сторону довольно проблематично.
2.2 Ввод данных
Хранить входную строку будет std::vector, а для ввода-вывода мы будем использовать консоль.
int main() {
std::vector<char> v;
char s;
while (std::cin>>s) {
if (s == ';') break;
v.push_back(s);
}
std::cout<<"Hash: "<<ruhash(v)<<std::endl;
return 0;
}
Объявляем последовательность и заполняем ее данными. Для остановки ввода я выбрал символ ‘;‘. Его можно легко изменить на любой другой. Функция ruhash() будем возвращать строку с нашим хешем.
2.3 Написание функции ruhash()
Функцию хеширования ruhash() и функцию отбеливания number() я решил вынести в заголовочный файл ruhash.h. Далее займемся продумыванием и написанием основного функционала.
Выходной хеш у нас должен быть всегда равен 32 символам (a-z, A-Z, 0-9). На вход должна подаваться последовательность любой длины. В процессе создания алгоритма мы будем использовать функцию отбеливания number(), которая была описана выше.
Первым делом нужно дополнить входной блок до такого количества символов, чтобы возведя 2 в n степень можно бы было его получить. В добавок к этому количество дополняемых символов должно быть больше 64. Это нужно, чтобы улучшить показатель однозначности. Рассмотрим это на примере. На вход поступило 300 символов, значит ближайший блок будет 512. Если же поступит 500 символов на вход, то он дополнится до 1024 символов.
std::string ruhash(std::vector<char> v) { // алгоритм хеширования
int len = v.size(); // определяем длину входного блока
int min = 64; // минимальный блок
while (min < len) min*=2; // блок должен быть 64, 128, 256, 512 бит и т.д.
if ((min - len) < 64) min*=2; // если количество информации, которое требуется дописать меньше 64, то будем дописывать еще
int add = min-len; // количество информации, которую нужно добавить
...
Так, теперь у нас количество символов, которые нужно дописать. Дальше нужно сгенерировать соль и дописать данные. Соль будем генерировать на основе суммы кодов всех символов, отнимем от этого числа длину исходной последовательности символов и прогоним ее через отбеливание. При дописывании информации будем добавлять к соли элементы исходной и добавляемой последовательности, а также счетчик.
...
int salt = 0; // соль на основе суммы кодов всех символов и длины
for (int i = 0; i < v.size(); ++i) salt+=v[i]; // собираем из кодов всех символов соль
salt = number(salt-len); // добавляем в соль длину
for (int i = 1; i <= add; ++i) v.push_back(number(i*salt*v[i])); // дописываем информацию на основе соли, счетчика и входной строки, отбеливаем ее
...
Теперь у нас есть целый блок размером 128, 256, 512… символов. Пришло время применить операцию сворачивания этого блока в блок размером 32 символа. Перед реализацией его на C++ я немного продемонстрирую принцип работы этой техники в упрощенном варианте.
Допустим, что дана последовательность из 8 символов. Мы ее свернем в 4 символов по схеме ниже.

На этой картинке вполне наглядно выглядит операция сворачивания. Таким образом повторяя несколько раз эту операцию можно свернуть даже 512 символов в 32.
...
std::vector<int> prev; // выходной вектор
for (int i = 0; i < v.size(); ++i) prev.push_back(v[i]); // переписываем коды символов в выходной вектор
std::vector<int> now; // промежуточный вектор
while (prev.size() != 32) { // пока размер вектора не станет 32, будем его сокращать
for (int j = 0; j < prev.size(); j+=2) {
int t = prev[j] + prev[j+1]; // складываем пары чисел в одно, тем самым уменьшая размер последовательности в 2 раза
now.push_back(t);
}
prev = now; // промежуточный блок переписываем в выходной вектор
now.clear();
}
...
На данный момент у нас есть 32-битный блок, состоящий из чисел. На последнем этапе мы прогоним их через функцию number(), то есть отбелим и посимвольно перепишем все содержимое конечного вектора в строку и затем вернем результат работы всего алгоритма.
...
std::vector<char> f; // конечный хеш
for (int i = 0; i < prev.size(); ++i) {
f.push_back(number(prev[i]+i*i)); // отбеливаем полученный вектор
}
std::string hash; // строка для результата
for (int i = 0; i < f.size(); ++i) {
hash+=f[i];
}
return hash;
}3 Итоги
Мы написали вполне хорошую функцию хеширования на C++ и рассмотрели некоторые приемы получения необратимого алгоритма. Вообще, сравнивая современные алгоритмы хеширования, лучше всего использовать 256-битные алгоритмы хеширования для более точного сравнения информации больших объемов. Для коротких 20-30 битных паролей вполне подойдет md5.
4 Взлом
Хотите попробовать взломать свежеиспеченный алгоритм RuHash? Жители Хабра могут попробовать взломать вот такой хеш, то есть получить исходную строку.
MqsvgafTwEVaGoVaziEMpkdztMNfUaLU
Исходники: https://github.com/ilyadev/RuHash
Автор: ilyacoding
Источник
Хэширование. Хеш-функции. Хеширование с открытой адресацией.
Хэширование — структура данных, в которой можно будет осуществлять, поиск за время O(1).
Если каждый элемент находится там где ему следует быть, то поиск может использовать только сравнения для обнаружения присутствия искомого.
Хэш-таблица это коллекция элементов, которые сохраняются таким образом чтобы позже их было легко найти. Каждая позиция в хэш-таблице (часто называемая слотом) может содержать собственно элемент и целое число, начинающееся с нуля. Например, у нас есть слот 0, слот 1, слот 2 и так далее.
Первоначально хэш таблица не содержит элементов, так что каждый из слотов пуст.
Хеш-функции
Связь между элементом и слотом, в который он кладётся, называется хэш-функцией. Она принимает любой элемент из коллекции и возвращает целое число из диапазона имен слотов (от О до m-1).
Для заданной коллекции элементов хэш функция, связывающая каждый из них c уникальным слотом, называется идеальной хэш-функцией
Метод деления
Построение хеш-функции методом деления состоит в отображении ключа к в одну из m ячеек путем получения остатка от деления к на m:
h(k) = к mod m
Например, если хеш-таблица имеет размер m = 12, а значение ключа k = 100, то h(k) = 4. Поскольку для вычисления хеш-функции требуется только одна операция деления, хеширование методом деления достаточно быстрое.
Число m не должно быть степенью 2, поскольку если m = 2^Р, то h(k) представляет собой просто р младших битов числа k.
Зачастую хорошие результаты можно получить, выбирая в качестве значения m простое число, достаточно далекое от степени двойки. Например, мы хотим создать хеш-таблицу с разрешением коллизий методом цепочек для хранения порядка n = 2000 символьных строк, размер символов в которых равен 8 бит. Нас устраивает проверка в среднем трех элементов при неудачном поиске, так что мы выбираем размер таблицы равным m = 701. Число 701 выбрано как простое число, близкое к величине 2000/3 и не являющееся степенью 2. Рассматривая каждый ключ к как целое число, мы получаем искомую хеш-функцию
h(k) = к mod 701
Метод умножения
Построение хеш-функции методом умножения выполняется в два этапа. Сначала мы умножаем ключ к на константу 0 < А < 1 и выделяем дробную часть полученного произведения. Затем мы умножаем полученное значение на m и выделяем целую часть:
h(k) = ⌊m (кА mod 1)⌋
Универсальное хэширование
Если специально подбирать данные, можно попасть в такую ситуацию, когда все ключи будут соответствовать одной позиции в хеш-таблице, тогда время поиска индекса может достигать времени поиска в списке. Выход из данной ситуации — универсальное хеширование — выбор хеш-функции во время исполнения программы случайным образом из некоторого множества хеш-функций. Т.е. при повторном вызове алгоритма с теми же данными алгоритм может работать уже совсем по-другому.
Хеширование с открытой адресацией
В случае метода открытой адресации (или по-другому: закрытого хеширования) все элементы хранятся непосредственно в хеш-таблице, без использования связанных списков. В отличии от хеширования с цепочками, при использовании метода открытой адресации может возникнуть ситуация, когда хеш-таблица окажется полностью заполненной, так что будет невозможно добавлять в неё новые элементы. Так что при возникновении такой ситуации решением может быть динамическое увеличение размера хеш-таблицы, с одновременной её перестройкой.
Однако здесь есть одна проблема: два ключа могут быть хешированны в одну и ту же ячейку. Такая ситуация называется коллизией.
Для разрешения же коллизий применяются несколько подходов. Самый простой из них — это метод линейного исследования. В этом случае при возникновении коллизии следующие за текущей ячейки проверяются одна за другой, пока не найдётся пустая ячейка, куда и помещается наш элемент. Так, при достижении последнего индекса таблицы, мы перескакиваем в начало, рассматривая её как «цикличный» массив.

Линейное хеширование достаточно просто реализуется, однако с ним связана существенная проблема — кластеризация. Это явление создания длинных последовательностей занятых ячеек, которое увеличивает среднее время поиска в таблице. Для снижения эффекта кластеризации используется другая стратегия разрешения коллизий — двойное хеширование. Основная идея заключается в том, что для определения шага смещения исследований при коллизии в ячейке используется другая хеш-функция, вместо линейного смещения на одну позицию.
Одной из сложных вопросов реализации хеширования с открытой адресацией — это операция удаления элемента. Дело в том, что если мы просто удалим некий элемент их хеш-таблицы, то сделаем невозможным поиск ключа, в процессе вставки которого текущая ячейка оказалась заполненной. Так, мы можем помечать очищенные ячейки какой-то меткой, чтобы впоследствии это учитывать.
Применение — словари, текстовые редакторы, списки
Хэширование¶
В предыдущих разделах мы смогли усовершенствовать наши алгоритмы поиска,
используя преимущества информации о том, где элементы хранятся относительно
друг друга. Например, зная, что список упорядочен, мы можем осуществлять поиск
за логарифмическое время, используя бинарный алгоритм. В этом разделе мы
попытаемся пойти ещё на шаг дальше: построить такую структуру данных, в которой
можно будет осуществлять поиск за время (O(1)).
Эту концепцию называют хэшированием.
Теперь нам надо знать больше, чем просто расположение элемента, когда мы ищем
его в коллекции. Если каждый элемент находится там, где ему следует быть, то
поиск может использовать только сравнения для обнаружения присутствия искомого.
Однако, дальше мы увидим, что это, как правило, не единственный выход.
Хэш-таблица — это коллекция элементов, которые сохраняются таким образом,
чтобы позже их было легко найти. Каждая позиция в хэш-таблице (часто называемая
слотом) может содержать собственно элемент и целое число, начинающееся с нуля.
Например, у нас есть слот 0, слот 1, слот 2 и так далее. Первоначально хэш-таблица
не содержит элементов, так что каждый из них пуст. Мы можем сделать реализацию
хэш-таблицы, используя список, в котором каждый элемент инициализирован
специальным значением Python None. Рисунок 4
демонстрирует хэш-таблицу размером (m=11). Другими словами, в ней есть
(m) слотов, пронумерованных от 0 до 10.

Рисунок 4: Хэш-таблица с 11-ю пустыми слотами
Связь между элементом и слотом, в который он кладётся, называется
хэш-функцией. Она принимает любой элемент из коллекции и возвращает целое
число из диапазона имён слотов (от 0 до (m-1)). Предположим, что у нас
есть набор целых чисел 54, 26, 93, 17, 77 и 31. Наша первая хэш-функция, иногда
называемая “методом остатков”, просто берёт элемент и делит его на размер таблицы,
возвращая остаток в качестве хэш-значения ((h(item)=item % 11)).
В таблице 4 представлены все хэш-значения чисел из
нашего примера. Обратите внимание: метод остатков (модульная арифметика) обычно
присутствует в той или иной форме во всех хэш-функциях, поскольку результат
должен лежать в диапазоне имён слотов.
| Элемент | Хэш-значение |
|---|---|
| 54 | 10 |
| 26 | 4 |
| 93 | 5 |
| 17 | 6 |
| 77 | 0 |
| 31 | 9 |
Поскольку хэш-значения могут быть посчитаны, мы можем вставить каждый элемент в
хэш-таблицу на определённое место, как это показано на
рисунке 5. Обратите внимание, что теперь заняты 6 из 11
слотов. Это называется фактором загрузки и обычно обозначается
(lambda = frac {numberofitems}{tablesize}).
В этом примере (lambda = frac {6}{11}).

Рисунок 5: Хэш-таблица с шестью элементами
Теперь, когда мы хотим найти элемент, мы просто используем хэш-функцию, чтобы
вычислить имя слота элемента и затем проверить по таблице его наличие. Эта
операция поиска имеет (O(1)), поскольку на вычисление хэш-значения
требуется константное время, как и на переход по найденному индексу. Если всё
находится там, где ему положено, то мы получаем алгоритм поиска за константное
время.
Возможно, вы уже заметили, что такая техника работает только если каждый элемент
отображается на уникальную позицию в хэш-таблице. Например, если следующим в
нашей коллекции будет элемент 44, то он будет иметь хэш-значение 0
((44 % 11 == 0)). А так как 77 тоже имеет хэш-значение 0, то у нас
проблемы. В соответствии с хэш-функцией два или более элементов должны иметь
один слот. Это называется коллизией (иногда “столкновением”). Очевидно, что
коллизии создают проблемы для техники хэширования. Позднее мы обсудим их в деталях.
Хэш-функции¶
Для заданной коллекции элементов хэш-функция, связывающая каждый из них с
уникальным слотом, называется идеальной хэш-функцией. Если мы знаем, что ни
один элемент коллекции никогда не изменится, то возможно создать идеальную
хэш-функцию (см. упражнения, чтобы узнать об этом больше). К сожалению, для
произвольного набора элементов не существует систематического способа
сконструировать идеальную хэш-функцию. К счастью, для эффективной работы она
нам и не нужна.
Один из способов всегда иметь идеальную хэш-функцию состоит в увеличении размера
хэш-таблицы таким образом, чтобы в ней могло быть размещено каждое из возможных
значений элементов. Таким образом гарантируется уникальность слотов. Хотя такой
подход практичен для малого числа элементов, при возрастании их количества он
перестаёт быть осуществимым. Например, для девятизначных индексов социального
страхования потребуется порядка миллиарда слотов. Даже если мы захотим всего
лишь хранить данные для класса из 25 студентов, то потратим на это чудовищное
количество памяти.
Наша цель: создать хэш-функцию, которая минимизировала бы количество коллизий,
легко считалась и равномерно распределяла элементы в хэш-таблице. Существует
несколько распространённых способов расширить простой метод остатков.
Рассмотрим некоторые из них.
Метод свёртки для создания хэш-функций начинает с деления элемента на
составляющие одинаковой величины (кроме последнего, который может иметь
отличающийся размер). Эти кусочки складываются вместе и дают результирующее
хэш-значение. Например, если наш элемент — телефонный номер 436-555-4601, то мы
можем взять цифры и рабить их на группы по два (43, 65, 55, 46, 01). После
сложения (43+65+55+46+01) мы получим 210. Если предположить, что
хэш-таблица имеет 11 слотов, то нужно выполнить дополнительный шаг, поделив это
число на 11 и взяв остаток. В данном случае (210 % 11) равно 1, так что
телефонный номер 436-555-4601 хэшируется в слот 1. Некоторые методы свёртки идут
на шаг дальше и перед сложением переворачивают каждый из кусочков разбиения.
Для примера выше мы бы получили (43+56+55+64+01 = 219),
что даёт (219 % 11 = 10).
Другая числовая техника для создания хэш-функций называется
методом средних квадратов. Сначала значение элемента возводится в квадрат,
а затем из получившихся в результате цифр выделяется некоторая порция. Например,
если элемент равен 44, то мы прежде вычислим (44 ^{2} = 1,936). Выделив
две средние цифры (93) и выполнив шаг получения остатка, мы получим 5
((93 % 11)). Таблица 5 показывает элементы, к
которым применили оба метода: остатков и средних квадратов. Убедитесь, что
понимаете, как эти значения были получены.
| Элемент | Остаток | Средний квадрат |
|---|---|---|
| 54 | 10 | 3 |
| 26 | 4 | 7 |
| 93 | 5 | 9 |
| 17 | 6 | 8 |
| 77 | 0 | 4 |
| 31 | 9 | 6 |
Мы также можем создать хэш-функцию для символьных элементов (например, строк).
Слово “cat” можно рассматривать, как последовательность кодов его букв.
>>> ord('c') 99 >>> ord('a') 97 >>> ord('t') 116
Затем можно взять эти три кода, сложить их и спользовать метод остатков, чтобы
получить хэш-значение (см. рисунок 6).
Листинг 1 демонстрирует функцию hash, принимающую
строку и размер таблицы и возвращающую хэш-значение из диапазона от 0 до tablesize-1.
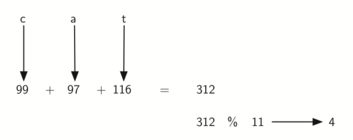
Рисунок 6: Хэширование строки с использованием кодов символов
Листинг 1
def hash(astring, tablesize): sum = 0 for pos in range(len(astring)): sum = sum + ord(astring[pos]) return sum%tablesize
Интересное наблюдение: когда мы используем эту хэш-функцию, анаграммы всегда
будут иметь одинаковое хэш-значение. Чтобы исправить это, следует использовать
позицию символа в качестве веса. Рисунок 7 показывает
один из вариантов использования позиционного значения в качестве весового фактора.
Модификацию функции hash мы оставляем в качестве упражнения.
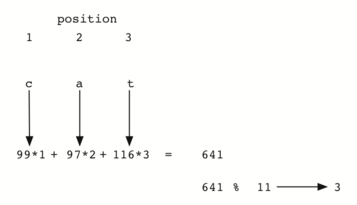
Рисунок 7: Хэширование строки с использованием кодов символов и весов
Вы можете придумать другие числовые способы вычисления хэш-значений для элементов
коллекции. Важно только помнить, что эффекитвная хэш-функция не должна являться
доминирующей частью процессов хранения и поиска. Если она слишком сложна, то
требует много работы на вычисление имени слота. В этом случае проще было бы
использовать последовательный или бинарный поиск, описанные выше. Таким образом,
сама идея хэширования терпит поражение.
Разрешение коллизий¶
Вернёмся к проблеме коллизий. Когда два элемента хэшируются в один слот, нам
требуется систематический метод для размещения в хэш-таблице второго элемента.
Этот процесс называется разрешением коллизии. Как мы утверждали ранее, если
хэш-функция идеальна, то коллизии никогда не произойдёт. Однако, поскольку часто
такое положение дел невозможно, разрешение коллизий становится важной частью
хэширования.
Одним из методов разрешения коллизий является просмотр хэш-таблицы и поиск
другого свободного слота для размещения в нём элемента, создавшего проблему.
Простой способ сделать это — начать с оригинальной позиции хэш-значения и
перемещаться по слотам определённым образом до тех пор, пока не будет найден
пустой. Заметьте: нам может понадобиться вернуться обратно к первому слоту
(циклически), чтобы охватить хэш-таблицу целиком. Этот процесс разрешения
коллизий называется открытой адресацией, поскольку пытается найти следующий
свободный слот (или адрес) в хэш-таблице. Систематически посещая каждый слот по
одному разу, мы действуем в соответствии с техникой открытой адресации,
называемой линейным пробированием.
Рисунок 8 показывает расширенный набор целых элементов
после применения простой хэш-функции метода остатков (54,26,93,17,77,31,44,55,20).
В таблице 4 выше собраны хэш-значения оригинальных
элементов, а на рисунке 5 представлено первоначальное
содержимое хэш-таблицы. Когда мы пытаемся поместить 44 в слот 0, возникает
коллизия. При линейном пробировании мы последовательно — слот за слотом —
просматриваем таблицу, до тех пор, пока не найдём открытую позицию. В данном
случае это оказался слот 1.
В следующий раз 55, которое должно разместиться в слоте 0, будет положено в слот
2 — следующую незанятую позицию. Последнее значение 20 хэшируется в слот 9. Но
поскольку он занят, мы делаем линейное пробирование. Мы посещаем слоты
10, 0, 1, 2 и наконец находим пустой слот на позиции 3.

Рисунок 8: Разрешение коллизий путём линейного пробирования
Поскольку мы построили хэш-таблицу с помощью открытой адресации
(или линейного пробирования), важно использовать тот же метод при поиске элемента.
Предположим, мы хотим найти число 93. Вчисление его хэш-значения даст 5. Обнаружив
в пятом слоте 93, мы вернём True. Но что если мы ищем 20? Теперь хэш-значение
равно 9, а слот 9 содержит 31. Нельзя просто вернуть False, поскольку здесь
могла быть коллизия. Так что мы вынуждены провести последвательный поиск, начиная
с десятой позиции, который закончится, когда найдётся число 20 или пустой слот.
Недостатком линейного пробирования является его склонность к кластеризации:
элементы в таблице группируются. Это означает, что если возникает много коллизий
с одним хэш-значением, то окружающие его слоты при линейном пробировании будут
заполнены. Это начнёт оказывать влияние на вставку других элементов, как мы
наблюдали выше при попытке вставить в таблицу число 20. В итоге, кластер
значений, хэшируемых в 0, должен быть пропущен, чтобы найти вакантное место.
Этот кластер показан на рисунке 9.

Рисунок 9: Кластер элементов для слота 0
Одним из способов иметь дело с кластеризацией является расширение линейного
пробирования таким образом, чтобы вместо последовательного поиска следующего
свободного места мы пропускали слоты, получая таким образом более равномерное
распределение элементов, вызвавших коллизии. Потенциально это уменьшит
возникающую кластеризацию. Рисунок 10 показывает
элементы после разрешения коллизий с использованием пробирования “плюс 3”.
Это означает, что при возникновении коллизии, мы рассматриваем каждый третий
слот до тех пор, пока не найдём пустой.

Рисунок 10: Разрешение коллизий с использованием методики “плюс 3”
Общее название для такого процесса поиска другого слота после коллизии
— повторное хэширование. С помощью простого линейного пробирования повторная
хэш-функция выглядит как (newhashvalue = rehash(oldhashvalue)), где
(rehash(pos) = (pos + 1) % sizeoftable). Повторное хэширование “плюс 3”
может быть определёно как (rehash(pos) = (pos+3) % sizeoftable).
В общем случае: (rehash(pos) = (pos + skip) % sizeoftable). Важно
отметить, что величина “пропуска” должна быть такой, чтобы в конце концов
пройти по всем слотам. В противном случае часть таблицы окажется
неиспользованной. Для обеспечения этого условия часто предполагается,
что размер таблицы является простым числом. Вот почему в примере мы
использовали 11.
Ещё одним вариантом линейного пробирования является квадратичное пробирование.
Вместо использования константного значения “пропуска”, мы используем повторную
хэш-функцию, которая инкрементирует хэш-значение на 1, 3, 5, 7, 9 и так далее.
Это означает, что если первое хэш-значение равно (h), то последующими
будут (h+1), (h+4), (h+9), (h+16) и так далее.
Другими словами, квадратичное пробирование использует пропуск, состоящий из
следующих один за другим полных квадратов. Рисунок 11
демонстрирует значения из нашего примера после использования этой методики.

Рисунок 11: Разрешение коллизий с помощью квадратичного пробирования
Альтернативным методом решения проблемы коллизий является разрешение каждому
слоту содержать ссылку на коллекцию (или цепочку) значений. Цепочки
позволяют множеству элементов занимать одну и ту же позицию в хэш-таблице.
Чем больше элементов хэшируются в одно место, тем сложнее найти элемент в
коллекции. Рисунок 12 показывает, как элементы добавляются
в хэш-таблицу с использованием цепочек для разрешения коллизий.
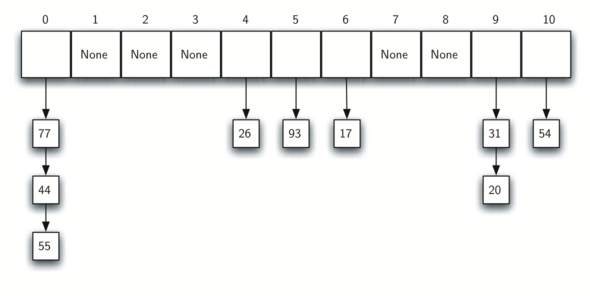
Рисунок 12: Разрешение коллизий с помощью цепочек
Когда мы хотим найти элемент, мы используем хэш-функцию для генерации номера
слота, в котором он должен размещаться. Поскольку каждый слот содержит коллекцию,
мы используем различные техники поиска, чтобы определить, представлен ли он в
ней. Преимуществом данного подхода является вероятность получить гораздо меньше
элементов в каждом слоте, так что поиск будет более эффективным. Более подробный
анализ мы проведём в конце этой главы.
Самопроверка
Q-50: В хэш-таблице размером 13 какой индекс будет связан со следующими двумя
ключами 27, 130?
Q-51: Предположим, у вас есть следующий набор ключей для вставки в хэш-таблицу,
содержащую ровно 11 значений: 113 , 117 , 97 , 100 , 114 , 108 , 116 ,
105 , 99. Что из следующего лучше всего демонстрирует содержимое таблицы
после вставки всех ключей с использованием линейного пробирования?
a) 100, __, __, 113, 114, 105, 116, 117, 97, 108, 99
b) 99, 100, __, 113, 114, __, 116, 117, 105, 97, 108
c) 100, 113, 117, 97, 14, 108, 116, 105, 99, __, __
d) 117, 114, 108, 116, 105, 99, __, __, 97, 100, 113
Реализация абстрактного типа данных Map¶
Одной из наиболее используемых коллекций Python являются словари. Напомним, что
словарь — ассоциативный тип данных, в котором можно хранить пары ключ-значение.
Ключи используются для поиска ассоциативных значений данных. Мы часто называем
эту идею отображением.
Абстрактный тип данных Map можно определить следующим образом.
Его структура — неупорядоченная коллекция ассоциаций между ключами и значениями.
Все ключи уникальны, таким образом поддерживаются отношения “один к одному”
между ключами и значениями. Операции для такого типа данных представлены ниже:
- Map() Создаёт новый пустой экземпляр типа. Возвращает пустую коллекцию
отображений. - put(key, val) Добавляет новую пару ключ-значение в отображение. Если
такой ключ уже имеется, то заменяет старое значение новым. - get(key) Принимает ключ, возвращает соответствующее ему значение из
коллекции или None. - del Удаляет пару ключ-значение из отображения, используя оператор вида
del map[key]. - len() Возвращает количество пар ключ-значение, хранящихся в коллекции.
- in Возвращает True для оператора вида key in map, если данный ключ
присутствует в коллекции, или False в противном случае.
Одним из больших преимуществ словарей является то, что, имея ключ, мы можем
найти ассоциированное с ним значение очень быстро. Для обеспечения надлежащей
скорости требуется реализация, поддерживающая эффективный поиск. Мы можем
использовать список с последовательным или бинарным поиском, но правильнее
будет воспользоваться хэш-таблицей, описанной выше, поскольку поиск элемента в
ней может приближаться к производительности (O(1)).
В листинге 2 мы используем два списка,
чтобы создать класс HashTable, воплощающий абстрактный тип данных Map.
Один список, называемый slots, будет содержать ключи элементов, а
параллельный ему список data — значения данных. Когда мы находим ключ, на
соответствующей позиции в списке с данными будет находиться связанное с ним
значение. Мы будем работать со списком ключей, как с хэш-таблицей, используя
идеи, представленные ранее. Обратите внимание, что первоначальный размер
хэш-таблицы выбран равным 11. Хотя это число произвольно, важно, чтобы оно было
простым. Это сделает алгоритм разрешения коллизий максимально эффективным.
Листинг 2
class HashTable: def __init__(self): self.size = 11 self.slots = [None] * self.size self.data = [None] * self.size
hashfunction реализует простой метод остатков. В качестве техники разрешения
коллизий используется линейное пробирование с функцией повторного хэширования
“плюс 1”. Функция put (см. листинг 3)
предполагает, что в конце-концов найдётся пустой слот, или такой ключ уже
присутствует в self.slots. Она вычисляет оригинальное хэш-значение и, если
слот не пуст, применяет функцию rehash до тех пор, пока не найдёт свободное
место. Если непустой слот уже содержит ключ, старое значение данных будет
заменено на новое.
Листинг 3
def put(self,key,data): hashvalue = self.hashfunction(key,len(self.slots)) if self.slots[hashvalue] == None: self.slots[hashvalue] = key self.data[hashvalue] = data else: if self.slots[hashvalue] == key: self.data[hashvalue] = data #replace else: nextslot = self.rehash(hashvalue,len(self.slots)) while self.slots[nextslot] != None and self.slots[nextslot] != key: nextslot = self.rehash(nextslot,len(self.slots)) if self.slots[nextslot] == None: self.slots[nextslot]=key self.data[nextslot]=data else: self.data[nextslot] = data #replace def hashfunction(self,key,size): return key%size def rehash(self,oldhash,size): return (oldhash+1)%size
Аналогично функция get (см. листинг 4)
начинает с вычисления начального хэш-значения. Если искомая величина не
содержится в этом слоте, то используется rehash для определения следующей
позиции. Обратите внимание: строка 15 гарантирует, что поиск закончится,
проверяя, не вернулись ли мы в начальный слот. Если такое происходит, значит
все возможные слоты исчерпаны, и элемент в коллекции не представлен.
Кончный метод класса HashTable предоставляет для словарей дополнительный
функционал. Мы перегружаем методы __getitem__ и __setitem__, чтобы
получать доступ к элементам с помощью []. Это подразумевает, что созданному
экземпляру HashTable будет доступен знакомый оператор индекса. Оставшиеся
методы мы оставляем в качестве упражнения.
Листинг 4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
def get(self,key): startslot = self.hashfunction(key,len(self.slots)) data = None stop = False found = False position = startslot while self.slots[position] != None and not found and not stop: if self.slots[position] == key: found = True data = self.data[position] else: position=self.rehash(position,len(self.slots)) if position == startslot: stop = True return data def __getitem__(self,key): return self.get(key) def __setitem__(self,key,data): self.put(key,data) |
Следующая сессия демонстрирует класс HashTable в действии. Сначала мы
создаём хэш-таблицу и сохраняем в неё несколько элементов с целочисленными
ключами и строковыми значениями данных.
>>> H=HashTable() >>> H[54]="cat" >>> H[26]="dog" >>> H[93]="lion" >>> H[17]="tiger" >>> H[77]="bird" >>> H[31]="cow" >>> H[44]="goat" >>> H[55]="pig" >>> H[20]="chicken" >>> H.slots [77, 44, 55, 20, 26, 93, 17, None, None, 31, 54] >>> H.data ['bird', 'goat', 'pig', 'chicken', 'dog', 'lion', 'tiger', None, None, 'cow', 'cat']
Далее мы получаем доступ и изменяем некоторые из элементов в хэш-таблице.
Обратите внимание, что значение с ключом 20 заменяется.
>>> H[20] 'chicken' >>> H[17] 'tiger' >>> H[20]='duck' >>> H[20] 'duck' >>> H.data ['bird', 'goat', 'pig', 'duck', 'dog', 'lion', 'tiger', None, None, 'cow', 'cat'] >> print(H[99]) None
Целиком пример хэш-таблицы можно увидеть в ActiveCode 1.
Пример хэш-таблицы целиком (hashtablecomplete)
Анализ хэширования¶
Как мы заключили выше, в лучшем случае хэширование предоставляет технику поиска
за константное время: (O(1)). Однако, из-за некоторого числа коллизий с
количеством сравнений всё не так просто. Несмотря на то, что полный анализ
хэширования выходит за рамки этого текста, мы можем определить несколько
общеизвестных результатов, аппроксимирующих количество сравнений, необходимое
для поиска элемента.
Наиболее важной частью информации, которую нам надо проанализировать при
использовании хэш-таблицы, является фактор загрузки (lambda).
Концептуально, если (lambda) мало, то вероятность столкновений низкая.
Т.е. элементы вероятнее всего будут находиться в слотах, соответствующих их
хэш-значениям. Если же (lambda) велико, то это означает близость таблицы
к заполнению, т.е. будет возникать всё больше и больше коллизий. Следовательно,
их разрешение будет более сложным, требовать больше сравнений для поиска
свободного слота. В случае цепочек увеличение коллизий означает возрастание
количества элементов в каждой из них.
Как и раньше, мы будем рассматривать результаты удачного и неудачного поиска.
В первом случае, при использовании открытой адресации с линейным пробированием
среднее число сравнений приблизительно равно
(frac{1}{2}left(1+frac{1}{1-lambda}right)).
Во втором — (frac{1}{2}left(1+left(frac{1}{1-lambda}right)^2right)).
Если мы используем цепочки, то среднее количество сравнений будет
(1 + frac {lambda}{2}) для удачного поиска и (lambda) для неудачного.