Пишем регистровую машину
29 August 2019
Что-то давно я не писал в свой блог. Нужно исправлять данное недоразумение.
И сегодня в программе: регистровая виртуальную машину на языке Rust.
Введение
На написание собственной упрощенной версии меня вдохновили несколько статей с хабра, ссылки на них смотри в разделе Полезные ссылки.
Но для начала давайте определимся с терминалогией с помощью вики.
Виртуальная машина (VM, от англ. virtual machine) — программная и/или аппаратная система, эмулирующая аппаратное обеспечение некоторой платформы (target — целевая, или гостевая платформа) и исполняющая программы для target-платформы на host-платформе (host — хост-платформа, платформа-хозяин) или виртуализирующая некоторую платформу и создающая на ней среды, изолирующие друг от друга программы и даже операционные системы (см.: песочница); также спецификация некоторой вычислительной среды (например: «виртуальная машина языка программирования Си»).
В общем разработанная нами программа не является в полной мере виртуальной машиной, а скорее всего её стоит называть интерпретатором кода. Эти разбирательства в терминологии я оставляю на читателя.
Давайте теперь перейдём к определение стековой машины — в общем говоря их два вида: стековая и регистровая и исходя из названий можно понять, что стековая машина использует для расчёт стек, а регистровая регистры… Но это не совсем так, в основном стековая использует только стек, а вот регистровая может использовать регистры и стек. Но это опять же терминологические фишки.
Мы же в своей реализации будем использовать только регистровую модель.
Вроде определились со всеми важными аспектами и теперь можно перейти к примеру, на котором будем проводить тесты.
Тестовый пример
Наша задачка основана на Гипотезе Коллатца и звучит вот так:
Следующая повторяющаяся последовательность определена для множества натуральных чисел:
n → n/2 (n - чётное)
n → 3n + 1 (n - нечётное)
Используя описанное выше правило и начиная с 13, сгенерируется следующая последовательность:
13 → 40 → 20 → 10 → 5 → 16 → 8 → 4 → 2 → 1
Получившаяся последовательность (начиная с 13 и заканчивая 1) содержит 10 элементов.
Какой начальный элемент меньше миллиона генерирует самую длинную последовательность?
В нашем же примере будем делать расчёт от единицы до миллиона и для интереса реализуем её на нескольких языках:
- для языка Python
- для языка Rust
- для нашей виртуальной машин, назовём её
vm_asm
Также стоит уточнить, что реализацию будем делать наивную чтобы не мучится с оптимизацией, да и это не самоцель для данного поста.
Алгоритм нахождения длины цепочки
Входные параметры:
- start_value — начальное значение
Выходные параметры:
- seq_length — длина последовательности
Алгоритм:
- установить значение start_value в 0
- цикл пока seq_length > 1
- если остаток от деления seq_length на 2 равен нулю, то:
- поделить с округлением вниз start_value на 2
- увеличить seq_length на 1
- иначе
- умножить start_value на 3 и прибавить единицу
- поделить с округлением вниз start_value на 2
- увеличить seq_length на 2
- если остаток от деления seq_length на 2 равен нулю, то:
Вы могли заметить, что в блоке с “иначе” мы делаем сразу два шага и вы будете правы. Это небольшая оптимизация, на которую я пошёл 
Реализация на Python
На Python код будет выглядеть следующим образом:
def calc(index):
step = 0
while index > 1:
if index % 2 == 0:
index //= 2
step += 1
else:
index = (3 * index + 1) // 2
step += 2
return step
Остаётся только перебрать все значения от 1 и до 1_000_000 включительно и выбрать максимально длинную цепочку, что можно сделать вот так:
result = 0
for i in range(1, 1000001):
result = max(result, calc(i))
print(result)
Реализация на Rust
Реализация на языке Rust мало чем отличается от питоновского, лишь только синтаксис по другому выглядит и используется функция main.
fn calc(mut index: u64) -> u64 {
let mut step = 0;
while index > 1 {
if index % 2 == 0 {
index /= 2;
step += 1;
} else {
index = (3 * index + 1) / 2;
step += 2;
}
}
step
}
fn main() {
let mut result = 0;
for i in 1..1_000_001 {
result = result.max(calc(i));
}
println!("{:?}", result);
}
Реализация на виртуальной машине
Приступим к самому интересному, а именно к коду для виртуальной машины.
Я буду полагаться на Intel-подобный синтаксис ассемблера, т.к. он намного привычнее выглядит чем от AT&T.
И да, программа будет на ассемблере, так как его опкоды с операндами намного легче парсить, чем любой императивный язык программирования.
Начнём!
Сначала произведём инициализацию регистров необходимыми значениями
# r0 -- выходной результат
mov r0, 0
# r1 -- конечное значения для внешнего цикла for
mov r1, 1000001
# r2 -- внешний индекс для цикл for
mov r2, 1
Определим внешний цикл от for
# внешний цикл for
_next_step:
inc r2
cmp r2, r1
# переход к печати результата
jg _end_of_app
И последующий за ней блок с “функцией”
_calc_start:
# r3 -- текущая длина цепочки (цикл while)
mov r3, 0
# r4 -- текущий индекс (цикл while)
mov r4, r2
Внутренний цикл while выглядит немного мудрено, но это по сути прямой перенос питоновского кода на ассемблер
# внутренний цикл while
_while:
cmp r4, 1
jle _end_of_calc
# r5 временный регистр для проверки на index % 2 == 0
mov r5, r4
mod r5, 2
cmp r5, 0
jne _3n_part
# ветка при index % 2 == 0
shr r4, 1
inc r3
jmp _while
# ветка при index % 2 != 0
_3n_part:
mul r4, 3
inc r4
shr r4, 1
add r3, 2
jmp _while
Остаётся только выбрать максимальное значение цепочки и вывести на печать значение, если обход закончен
# выбора максимальной длины цепочки
_end_of_calc:
cmp r3, r0
jle _next_step
mov r0, r3
jmp _next_step
# вывод результата
_end_of_app:
print r0
Реализация интерпретатора
Так как я не очень хочу реализовывать весь функционал какого-то процессора, то ограничимся небольшим набором команд, который нужен нам для решения задачки.
Исходя ранее написанного кода можно выделить следующий набор команд:
mov #1, #2— поместить значение из #2 в #1cmp #1, #1— сравнить #1 и #2 и изменить регистровые флагиjg #1— перейти к #1 если F1 равен 0jle #1— перейти к #1 если F1 не равен 0jne #— переход к #1 если F2 равен 0jmp #1— безусловный переход к метку #1inc #1— увеличить #1 на единицуmod #1, #2— деление модулю #1 на #2add #1, #2— добавить #2 к #1mul #1, #2— умножить #1 на #2shr #1, #2— логический сдвиг вправо #1 на #2print #1— вывести значение #1 в консоль
Здесь F1 и F2 два регистровых флага, о которых поговорим позднее.
Теперь давайте определимся с работой нашего интерпретатора, то есть с шагами которые он должен выполнить:
- Загрузить файл исходного кода
- Разобрать каждую строку на инструкцию
- Выполнить код
Давайте для начала определим сущность виртуальной машины
struct VirtualMachine {
ip: u8,
reg: [u64; 8],
app: Vec<Opcode>,
label: HashMap<String, u8>,
flags: [bool; 2]
}
У нас будет:
- указатель на выполняемую инструкцию
ip, так называемый Instruction Pointer - восемь 64-х байтовых регистра
reg, так как много нам их и не надо - вектор с опкодами приложения
app, то есть наша программа - хэшмап с метками
labelдля реализации произвольного перехода к командам программы - и два флага, так называемый Регистр Флагов, но в упрощенном виде
Для упрощения написания программы регистр флагов у нас представляется только двумя значениями, хотя всегда можно реализовать весь их набор.
Установку флагов F1 и F2 будем делать вот таким образом — при сравнении двух значений с помощью опкода cmp:
- если #1 больше #2, то
F1 = 1, иначеF1 = 0 - если #1 равен #2, то
F2 = 1, иначеF2 = 0
здесь #1 — первый операнд, #2 — второй операд.
Теперь можно определить перечисление с нашим набором команд
enum Opcode {
// сложение двух регистров
ADD_r { r1: u8, r2: u8 },
// сложение регистра и значения
ADD_v { r1: u8, v1: u64 },
// инкремент регистра
INC { r1: u8 },
// деление по модулю (регистр на регистр)
MOD_r { r1: u8, r2: u8 },
// деление по модулю (регистр на значение)
MOD_v { r1: u8, v1: u64 },
// перемножение двух регистров
MUL_r { r1: u8, r2: u8 },
// умножение регистра на значение
MUL_v { r1: u8, v1: u64 },
// сдвиг регистра на значение из другого регистра
SHR_r { r1: u8, r2: u8 },
// сдвиг регистра на значение
SHR_v { r1: u8, v1: u64 },
// безусловный переход к метку
JMP { i: u8 },
// переход если #1 больше #2
JG { i: u8 },
// переход если #1 меньше, либо равно #2
JLE { i: u8 },
// переход если #1 не равно #2
JNE { i: u8 },
// поместить в регистр значение другого регистра
MOV_r { r1: u8, r2: u8 },
// поместить в регистр значение
MOV_v { r1: u8, v1: u64 },
// сравнить два регистра
CMP_r { r1: u8, r2: u8 },
// сравнить регистр и значение
CMP_v { r1: u8, v1: u64 },
// распечатать содержимое регистра
PRINT { r1: u8 }
}
Теперь остаётся только описать скелет программы
impl VirtualMachine {
// функция инициализации
fn new() -> VirtualMachine {
VirtualMachine {
ip: 0,
reg: [0_u64; 8],
app: Vec::new(),
label: HashMap::new(),
flags: [false; 2]
}
}
// функция преобразованеи кода в файле в набор инструкций
fn parse_code(&mut self, filename: &str) {}
// функция для запуска кода на выполнение
fn interp(&mut self) {}
}
fn main() {
let mut vm = VirtualMachine::new();
vm.parse_code("collatz.vm_asm");
vm.interp();
}
Остаётся только реализовать два недостающих блока по парсингу и интерпретации кода.
Начнём с самой простой функции, а именно interp. Тут всё просто вытаскиваем инструкцию по ip из app и выполняем её, попутно увеличивая значение ip. После того как значение ip будет больше чем количества инструкций в app можно закончить выполнение.
В коде это выглядит вот так:
fn interp(&mut self) {
while self.ip < self.app.len() as u8 {
match self.app[self.ip as usize] {
// здесь будут инструкции
}
self.ip += 1;
}
}
А теперь к коду инструкций, которые очень просты в реализации
Opcode::ADD_r { r1, r2 } => {
// прибавляем к первому регистру второй
self.reg[r1 as usize] += self.reg[r2 as usize];
},
Opcode::ADD_v { r1, v1 } => {
// прибавляем значение к регистру
self.reg[r1 as usize] += v1;
},
Opcode::INC { r1 } => {
// инкремент
self.reg[r1 as usize] += 1;
},
Opcode::MOD_r { r1, r2 } => {
// деление по модулю регистр на регистр
self.reg[r1 as usize] %= self.reg[r2 as usize];
},
Opcode::MOD_v { r1, v1 } => {
// деление по модулю регистр на значение
self.reg[r1 as usize] %= v1;
},
Opcode::MUL_r { r1, r2 } => {
// умножение регистров
self.reg[r1 as usize] *= self.reg[r2 as usize];
},
Opcode::MUL_v { r1, v1 } => {
// умножение на значение
self.reg[r1 as usize] *= v1;
},
Opcode::SHR_r { r1, r2 } => {
// сдвиг на значение во втором регистре
self.reg[r1 as usize] >>= self.reg[r2 as usize];
},
Opcode::SHR_v { r1, v1 } => {
// сдвиг на значение
self.reg[r1 as usize] >>= v1;
},
Opcode::JMP { i } => {
// меняем значение ip и переходим к циклу, без увеличения ip
self.ip = i;
continue;
},
Opcode::JG { i } => {
// если F1 равен true, то меняем ip
if self.flags[0] {
self.ip = i;
continue;
}
},
Opcode::JLE { i } => {
// если F1 не равен true, то меняем ip
if !self.flags[0] {
self.ip = i;
continue;
}
}
Opcode::JNE { i } => {
// если F2 равен true, то меняем ip
if self.flags[1] {
self.ip = i;
continue;
}
},
Opcode::MOV_r { r1, r2 } => {
// значение второго регистра записываем в первый
self.reg[r1 as usize] = self.reg[r2 as usize];
},
Opcode::MOV_v { r1, v1 } => {
// записываем значение в регистр
self.reg[r1 as usize] = v1;
},
Opcode::CMP_r { r1, r2 } => {
// получаем значения в регистрах
let (v1, v2) = (self.reg[r1 as usize], self.reg[r2 as usize]);
// и устанавливаем флаги в соответствии с ранее описанными условиями
self.flags[0] = if v1 > v2 { true } else { false };
self.flags[1] = if v1 != v2 { true } else { false };
},
Opcode::CMP_v { r1, v1 } => {
// тоже самое, но только второй операнд -- число
let v0 = self.reg[r1 as usize];
self.flags[0] = if v0 > v1 { true } else { false };
self.flags[1] = if v0 != v1 { true } else { false };
},
Opcode::PRINT { r1 } => {
// вывод на печать значение регистра
let v1 = self.reg[r1 as usize];
println!("{}", v1);
}
Остаётся парсинг кода, который я разбил на несколько шагов:
- чтение всего файла
- парсинг меток для реализации переходов
- парсинг основного кода
Чтение файла и разбор на отдельные блоки реализуется в пару строк
// чтения всего файла в строку
let mut f = File::open(filename).unwrap();
let mut buffer = String::new();
f.read_to_string(&mut buffer).unwrap();
// разбор на инструкции
let instr: Vec<&str> = buffer.split('n')
// разделение строк по переносам
.map(|x| x.trim())
// убираем начальные и конечные пробелы в строке
.filter(|x| !x.starts_with('#') && x.len() > 3)
// убираем строки с комментариями
.collect();
// сбор значений в вектор
Далее проходимся по списку инструкций и вычленяем из него метки
for (index, item) in instr.iter().enumerate() {
// наши метки начинаются с символа '_'
if item.starts_with('_') {
// номер строки определяем из индекса текущей строк минус количество уже определенных меток
let label_index = index as u8 - self.label.len() as u8;
// добавляем в хэшмап имя метки и номер строки для перехода
self.label.insert(item[..item.len() - 1].to_string(), label_index);
}
}
Осталось только преобразовать строковое представление инструкции в Opcode, но перед этим нужно определить пару вспомогательных функций
// функция проверяющая аргумент на принадлежность к регистру процессора
fn is_register(s: &str) -> bool {
s.starts_with('r')
}
// получение индекса регистра из строки
fn parse_register(s: &str) -> u8 {
s[1..].parse().unwrap()
}
// получение значения из строки
fn parse_value(s: &str) -> u64 {
s.parse().unwrap()
}
Ну и собственно парсинг инструкций
for item in instr {
// обрабатываем все строки, кроме меток
if !item.starts_with('_') {
// разбиваем строку по двум разделителям (' ' и ',') и отбрасываем пустые
let block: Vec<&str> = item.split(|c| c == ' ' || c == ',')
.filter(|c| c.len() > 0)
.collect();
// используем Slice pattern, чтобы разобрать список об образцу
let cmd = match &block[..] {
// инструкция сложения
&["add", arg1, arg2] => {
match (is_register(arg1), is_register(arg2)) {
// оба значения регистры
(true, true) => Opcode::ADD_r { r1: parse_register(arg1), r2: parse_register(arg2) },
// второе параметр является числом
(true, false) => Opcode::ADD_v { r1: parse_register(arg1), v1: parse_value(arg2) },
// в любых других случаях кидаем ошибку
_ => panic!("not valid arguments `{}, {}` for ADD", arg1, arg2)
}
}
// инкремент
&["inc", arg1] => {
if is_register(arg1) {
Opcode::INC { r1: parse_register(arg1) }
} else {
panic!("not valid argument `{}` for INC", arg1);
}
}
// деление по модулю
&["mod", arg1, arg2] => {
match (is_register(arg1), is_register(arg2)) {
(true, true) => Opcode::MOD_r { r1: parse_register(arg1), r2: parse_register(arg2) },
(true, false) => Opcode::MOD_v { r1: parse_register(arg1), v1: parse_value(arg2) },
_ => panic!("not valid arguments `{}, {}` for MOD", arg1, arg2)
}
}
// умножение
&["mul", arg1, arg2] => {
match (is_register(arg1), is_register(arg2)) {
(true, true) => Opcode::MUL_r { r1: parse_register(arg1), r2: parse_register(arg2) },
(true, false) => Opcode::MUL_v { r1: parse_register(arg1), v1: parse_value(arg2) },
_ => panic!("not valid arguments `{}, {}` for MUL", arg1, arg2)
}
}
// логический сдвиг вправо
&["shr", arg1, arg2] => {
match (is_register(arg1), is_register(arg2)) {
(true, true) => Opcode::SHR_r { r1: parse_register(arg1), r2: parse_register(arg2) },
(true, false) => Opcode::SHR_v { r1: parse_register(arg1), v1: parse_value(arg2) },
_ => panic!("not valid arguments `{}, {}` for SHR", arg1, arg2)
}
}
// безусловный переход
&["jmp", arg1] => {
// проверяем на существование метки
match self.label.get(arg1) {
// формируем команду перехода к метке, если она есть
Some(value) => Opcode::JMP { i: *value },
// иначе -- ошибка
None => panic!("label `{}` not found!", arg1)
}
}
// переход если больше
&["jg", arg1] => {
match self.label.get(arg1) {
Some(value) => Opcode::JG { i: *value },
None => panic!("label `{}` not found!", arg1)
}
}
// переход при меньше, либо равно
&["jle", arg1] => {
match self.label.get(arg1) {
Some(value) => Opcode::JLE { i: *value },
None => panic!("label `{}` not found!", arg1)
}
}
// переход если не равно
&["jne", arg1] => {
match self.label.get(arg1) {
Some(value) => Opcode::JNE { i: *value },
None => panic!("label `{}` not found!", arg1)
}
}
// копирование
&["mov", arg1, arg2] => {
match (is_register(arg1), is_register(arg2)) {
(true, true) => Opcode::MOV_r { r1: parse_register(arg1), r2: parse_register(arg2) },
(true, false) => Opcode::MOV_v { r1: parse_register(arg1), v1: parse_value(arg2) },
_ => panic!("not valid arguments `{}, {}` for MOV", arg1, arg2)
}
}
// сравнение
&["cmp", arg1, arg2] => {
match (is_register(arg1), is_register(arg2)) {
(true, true) => Opcode::CMP_r { r1: parse_register(arg1), r2: parse_register(arg2) },
(true, false) => Opcode::CMP_v { r1: parse_register(arg1), v1: parse_value(arg2) },
_ => panic!("not valid arguments `{}, {}` for CMP", arg1, arg2)
}
}
// печать
&["print", arg1] => {
if is_register(arg1) {
Opcode::PRINT { r1: parse_register(arg1) }
} else {
panic!("not valid argument `{}` for PRINT", arg1);
}
}
// при любых других пишем о ошибке
value => {
panic!("unknown cmd `{:?}`", value)
}
};
// добавляем распарсенную команду
self.app.push(cmd);
}
}
Вот и всё, наш интерпретатор готов, теперь можно перейти к тестам!
Тесты
На моей машине с процессором i5-8265U примеры выполняются за следующее время:
- rust: 176ms
- python: 9.83s
- vm_asm: 2.80s
В идеале нужно было произвести как минимум запусков по 10 для каждого примера и взять среднее, но это же не исследовательская работа!
Мы здесь чисто по фану собрались, а те кто хочет всегда смогут сами его провести.
Заключение
Вот так просто и незатейливо можно написать самую простой регистровый интерпретатор кода.
Весь исходный код доступен по ссылке
На этом сегодня всё, увидимся ещё через пару лет!
Полезные ссылки
- Пишем собственную виртуальную машину
- Интерпретаторы байт-кодов своими руками
- Стековые и регистровые машины
- Гипотеза Коллатца
- Регистр флагов

Привет, друзья!
Своим появлением на свет данный пост обязан процессом обучения в Codeby.School вообще, и курсов «SQL-Injection Master» и
Ссылка скрыта от гостей
в частности…
Фигура первая. Лирическая.
При старте потока на втором приобретенном курсе, сразу бросились в глаза вопросы в чате потока, на предмет «какую же всё-таки лучше всего операционку использовать/установить при создании лаборатории для прохождения курса?». Где-то это я уже видел, подумалось мне, и решил перечитать чат потока от предыдущего курса. Ну-да! Вот же оно! Те же вопросы и проблемы, что и сейчас! Причём это самые большие по времени и объёму «войны» в чате…
Я вот лично, поражаюсь выдержке «кураторов», которые вынуждены отвечать на эти вопросы каждые три-четыре-пять месяцев (при старте потока). Причём это то, что видно в открытом доступе, а, что творится у них в личке и представить страшно! При этом подозреваю, что кроме общения с нами, они ещё и другую работу выполняют… Наши «кураторы» вынуждены, соблюдать субординацию с нами, но я то нет!!! Поэтому читая сообщения «продвинутых» пользователей (они-же «свидетели Kali Linux), хочется сделать рука-лицо! Друзья! Зачем Вам при прохождении курса Kali? Нет, ну серьёзно??? Аргумент, из серии «там всё есть», это детский лепет. Никто и никогда не использует в Kali все её возможности на 100%! Ну и нам для прохождения курсов этих возможностей не требуется. Гораздо проще, создать свою машину, без «свистелок и перделок», возможностей которой на 200% хватит для прохождения любого курса (но это не точно – за wapt не отвечаю)! Просто впоследствии читая сообщения тех кто «воткнул» Kali, из серии «а у меня не работает, то, что вы пишете в методичке!, Что мне делать???», и старания «кураторов» поправить «продвинутому» ситуацию, я испытываю некоторое «жжение в филейной части» с немым вопросом на устах «какого…!». Всё же было расписано в начале методички, в чате и плюс ко всему показано на видео. «О чём ты думал?». Хотел показать свою продвинутость? И как оно? Сработало?
На этой оптимистической ноте и предлагаю своё драгоценное мнение (которое никому не интересно, и я могу засунуть его себе «глубоко в карман, и никому не показывать…))), по выбору ОС и практику по созданию лаборатории для прохождения курсов «SQL-Injection Master», «Python для Пентестера», ну и не только!
Фигура вторая. Практическая.
Нам с Вами для всего «вот этого» достаточно, будет «Linux Mint». Причём практика показала, что версии «Mate» вполне достаточно, и даже за глаза достаточно! Немного телодвижений по навешиванию того, что отсутствуете и «вот оно счастье»!!!
Для пытливых умов, задающихся вопросом почему именно Mate? Рекомендую
Ссылка скрыта от гостей
с существующими редакциями и их отличиями. Может Вы выберите и другую версию, но
Ссылка скрыта от гостей
хватает «за глаза»!
Создавать всё будем в VMware Workstation (кто умеет создавать виртуалки в VMware Workstation, переходит сразу ко второй части)
На сайте куча инструкций как всё сделать в VirtualBox (халява сэр!), но эти инструкции написаны нашими наставниками, и они не могут официально «рекомендовать» нам приобрести продукцию VMware. А я могу)). И даже на «магазин приложений» намекаю, который РКН недавно разблокировал)). Хотя ничто не запрещает развернуть стенд в любой среде виртуализации (ProxMox, Брест и иже с ними).
Приступим’c!
Запускаем нашу VMware Workstation (в дальнейшем в мануале все описанное касается версии 15) и выбираем «Создать новую виртуальную машину»

В окне мастера создания новой виртуальной машины, отмечаем тип конфигурации «Выборочный (дополнительно) и кликаем «Далее».

При выборе совместимого оборудования ничего не меняя, кликаем «Далее»
В следующем окне с помощью кнопки «Обзор» выбираем файл установочного образа операционной системы (в моём случае Linux Mint Mate)
Тип гостевой операционной системы указываем «Linux» и версию в выпадающем списке выбираем «Debian 10.x 64-bit»
Задаём имя нашей машины и место для её хранения.
Указываем кол-во процессоров и используемых ядер для ВМ (выбирайте два ядра).
На следующем шаге задаём кол-во оперативной памяти, которым Вы готовы пожертвовать для вашего стенда (не надо жадничать…)
Теперь необходимо настроить — как ваша виртуалка будет подключаться к сети. По умолчанию Workstation предлагает вариант NAT. Но! Если вы планируете делать лабораторки во время работы
конечно нет!, что ты несёшь!, как ты мог подумать такое!
, то после создания машины, можно в настройках изменить тип подключения на «прямое подключение к физической сети». Тогда машина будет получать свой выделенный IP от DHCP сервера вашего домашнего роутера, и настроив на роутере проброс портов, можно будет подключаться к ней напрямую, минуя подключение к хост системе.
Следующие два окна, «Выбор контроллеров…» и «Выбор типа диска» пролетаем ничего не трогая)
В окне выбора диска, благосклонно принимаем предложение Workstation «создать новый виртуальный диск»
Задаём его размер (20 Гб как правило достаточно), подтверждаем, что хотим сохранить его в виде одного файла и указываем путь где он будет храниться.
После всех этих манипуляций, нас поджидает окно, где сообщается, что всё готово для создания виртуальной машины. Но если мы вдруг, что-то вспомнили, то можем поменять что-либо в настройках до её создания. Для это необходимо кликнуть по кнопке «Настройка оборудования». Что мы и сделаем, чтобы удалить лишнее оборудования, которое нам Workstation насовала в конфигурацию. Такое как принтер и звуковая карта.
Выбираем лишнее устройство и кликаем по «Удалить».

И после всех этих манипуляций, вернувшись по нажатию кнопки «Закрыть» в окно создания виртуальной машины, кликаем «Готово».

И попадаем в окно созданной машины, где будут её описание и самая главная кнопка в виде зелёного треугольника « Включить виртуальную машину» («Фух! Полдела сделано! Можно отметить!)). Что мы незамедлительно и сделаем. (т.е. включим, а не отметим)

И сразу после включения увидим стартовый экран Linux Mint. Где можно в принципе ничего не делать, а просто подождать, и загрузка операционки стартует автоматически. Либо если не терпится нажать Enter.

Ahtung! Это не установка операционки, а просто её загрузка (достаточно быстрая) в режиме LiveBoot. А вот после её загрузки, как раз и появляется возможность именно установить ось на диск. Для чего на рабочий стол создатели оси вывели специальный ярлык «Install Linux Mint». Который мы с вами и запустим на исполнение двойным кликом мыши.

И попадём в стартовые окна выбора языка системы, раскладки клавиатуры и установки кодеков.



Добравшись до диалога разметки диска, остановим свой выбор на «Стереть…», ведь нам не за что переживать! Диск то виртуальный!

Согласимся с записью изменений на диск и выберем часовой пояс.


После всех этих манипуляций начнётся установка ОС. (пропущен экран создания учётной записи — но тут уж сами!).

По окончании которой вы увидите диалоговое окно, с предложением ребутнуться, дабы всё устаканилось!

На такое заманчивое предложение нельзя не согласиться и при появлении ниже изображенного окна, просто давим Enter, т.к. извлекать нам нечего.

И вот оно счастье!

Прежде чем обвешивать ОCь всем необходимым, сперва всё таки надо пойти путём best practice, набраться немного терпения и сделать update и upgrade.
apt update

apt upgrade

Ну вот мы и подошли к основной части. Установим web-server apache.
sudo apt install apache2

На папку где будут наши веб страницы и скрипты, навесим права и сменим владельца (при создании машины был создан пользователь student c паролем 111111).
sudo shmod -R 775 /var/www/html
sudo chown -R student:student /var/www/html
(вместо student пишете своё имя пользователя, которое было создано при установке)


И добавим apache в автозагрузку: sudo systemctl enable apache2

Проверим версию установленного php: php -v

Хм. Пусто… Незамедлительно исправим: sudo apt-get install php 7.4

И перепроверим: php -v

Установим дополнительные пакеты для связки php, mysqli и apache
sudo apt-get install php7.4-mysqli
sudo apt-get install libapache2-mod-php7.4
sudo apt install mariadb-server php-mysql



Добавим в автозагрузку mysql: sudo systemctl enable mysql.service

Установим git. Он нам понадобится для sqlmap: sudo apt-get install git

Следом клонируем sqlmap: git clone –depth 1
sqlmap-dev

Добавляем alias для sqlmap: sudo xed ~/.bashrc
и в конец файла добавляем: alias sqlmap=’python3 /home/student/sqlmap-dev/sqlmap.py’
(вместо student пишете своё имя пользователя, которое было создано при установке)

Проверяем…

Устанавливаем Burp.
Устанавливаем openjdk.
curl -O
Ссылка скрыта от гостей

Распаковываем: tar xvf openjdk-14_linux-x64_bin.tar.gz

Перемещаем папку /opt/: sudo mv jdk-14 /opt/
И выполним эти команды:
sudo update-alternatives —install /usr/bin/java java /opt/jdk-14/bin/java 1
sudo update-alternatives —install /usr/bin/javac javac /opt/jdk-14/bin/javac 1

Дальше в браузере переходим на страничку
Ссылка скрыта от гостей
и в меню Products выбираем «Burp Suite Community Edition»

Чтобы скачать Burp без регистрации (и СМС) переходим сразу по ссылке
Ссылка скрыта от гостей

И жмакаем Download (подразумевается, что всё это Вы проделываете в системе, куда устанавливается Burp, т.е. Mint. Иначе версия ОС в поле для скачивания может быть другая).

После скачивания, переходим в папку загрузки и кликнув правой кнопкой мыши по скачанному файлу, выберем пункт «Свойства»

И в открывшемся окне отметим пункт «Позволять выполнение файла как программы»

После чего, исполняем двойной клик по скачанному файлу и выбираем пункт «Запустить»

Немного подождав (секунд 10-15) увидим классическое окно инсталляции программы, где отщёлкаем все Next-ы, ничего не меняя (ну или меняя если очень хочется).

И после этого можем наблюдать его в меню, и там же вывести на рабочий стол.

И насладиться хорошо проделанной работой…)))

Для прочитавших это «истинных» линуксоидов и сказавших «Фиии…! Не кошерно! Only shell должен использоваться!», отвечу так: вы не одни, а люди сюда пришли учиться! И не все до сегодняшнего дня видели Linux. Кому то привычнее графический режим. Shell им на курсе ещё хватит)
Ну и на сладкое поставим Filezilla. Ближе к концу курса пригодится)
sudo apt install filezilla

Ну вот и всё!
Этого достаточно для прохождения курса «SQL-Injection Master». А если надо установить более того, что здесь описано, то отошлю вас к статье одного из преподавателей и создателей курсов explorer (теперь и одного из руководителей Codeby). Руководствуясь которой вы сможете из Mint склепать Kali (ну почти) )
P.S.
Для тех, кто дочитал до конца, bonus-track.
Ссылка скрыта от гостей
можно скачать уже готовую машину, на которой уже установлено всё, что описано в этом посте.
Удачи, в прохождении курса (будет нелегко)!!
P.P.S.
Кто-то спросит, а причём здесь курс «Python для Пентестера»?
А притом, что лабораторию всё равно создавать придётся. Правда там для прохождения ДЗ нужно установить IDE самостоятельно, но вооружившись описанным выше, и внимательно читая методички, проблем не возникнет!
- Download B32 Virtual Machine source code — 30.7 KB
- Download B32 Virtual Machine complete tutorial (PDF) — 2.02 MB
Attention People
I am working on a new version of this, a B33 virtual machine. I will post it on here when its done. This one will not have a PDF and the full tutorial will be contained in the code project article. I will make sure I let everyone know when its done!
Introduction
Have you ever wondered how the Microsoft .NET Framework or how a Java virtual machine works? Have you ever wondered how to create your own emulator to target a specific computer you own? If you answered yes to any of these questions, then you will find my tutorial helpful. B32 is a complete virtual machine created in C#. This is part 1 of a 2 part series. The tutorial presented here on CodeProject is a condensed version of the complete PDF tutorial. In this part of the tutorial, I will explain the fundamentals, enough to get us started, and we will code the assembler portion of our virtual machine. Part 2 will build the actual virtual machine. The tutorial starts from scratch with a new project and solution. It will teach you how to write both, an assembler for our B32 intermediate language code, and it will teach you how to write the virtual machine itself.
Intended Audience
This tutorial assumes you are pretty familiar with C# and Visual Studio 2005 or 2008. This tutorial was written with Visual Studio 2008, targeting the .NET Framework 2.0. It should also work with Visual Studio 2005. Some of the concepts introduced in this tutorial may be a little hard for a beginner C# programmer to understand. I have tried to make it as simple to understand as possible. Keep in mind that, after reading this tutorial, no one will be able to walk away from it ready to build the next Java or something. Virtual machines are very complex tasks, and even simple ones can take many years to make. If you need help or have questions, you are welcome to post them here or email me direct at icemanind@yahoo.com. If I lose any of you, I suggest reading the PDF and using it as a reference to supplement this article. The PDF goes into more details.
Virtual Machine Fundamentals
To build a virtual machine, you first need to understand what a virtual machine is. A virtual machine is a software implementation of either a real physical machine or a fictional machine. To create a virtual machine, we first need to define an intermediate language (sometimes called an assembly language). This intermediate language will be the lowest level, human readable code, that will eventually get assembled into bytecode. Bytecode consists of one or more bytes of data that is readable only by our virtual machine (in real world machines, this would be called the «machine language»). The «assembler», which converts Intermediate Language into bytecode, will be the first tool we will develop. This will be developed in this part of the tutorial.
Planning Out our Virtual Machine
Before getting our hands dirty with any code, we need to plan out our virtual machine and how it will work. I believe in trying to stick with the KISS (Keep It Simple Stupid) principle whenever possible. B32, the virtual machine created in this tutorial, is going to be a 16-bit machine. It will have access to 64K of memory, and B32 bytecode programs will have access to any of this memory ranging from $0000 — $FFFF. 64K may not seem like a lot of memory compared to today’s modern computers; however, as you will see, 64K will be more than enough to produce some interesting B32 programs.
I said that programs would have access to 64K of memory; however, not all of this will be for storage. From $A000 — $AFA0, this 4K area of memory will be devoted to our B32 screen output. Screen output in our virtual machine will work very similar to older DOS programs. There will be 1 byte for the character and 1 byte for the attribute on an 80×25 screen. The attribute byte comes after the character byte, and it defines the foreground and background color of the character.
Our virtual machine will have two 8-bit registers called ‘A’ and ‘B’. Registers are kind of like variables in programming. We can store any number between 0 and 255 in either register ‘A’, ‘B’, or both. In addition, we are going to have two 16-bit registers called ‘X’ and ‘Y’. These registers can hold any value from 0 to 65,535. As if that’s not enough, we are going to have one more 16-bit register called ‘D’. This register is unique, as ‘D’ represents the high order bits and low order bits of registers ‘A’ and ‘B’. In other words, if we were to store a value of $12F9 in our D register, then it would automatically change register ‘A’ to have the value $12 and register ‘B’ to have the value $F9. The opposite is also true. If we store $C1 in register ‘A’ and $78 in register ‘B’, then register ‘D’ would have the value $C178.
Before diving into creating our assembler, we need to define at least three mnemonics for now to make any kind of useful program. Mnemonics, by the way, are the building blocks of our intermediate language. They are human readable characters, usually 3-5 characters long, that tell the assembler what we want to do; e.g., «The verb». Most (but not all) mnemonics have an operand. An operand is some kind of data or information for the mnemonic to act on. For now, our assembler will understand the following mnemonics:
| Mnemonic | Bytecode | Description |
LDA |
$01 | Loads an 8-bit value into our ‘A’ register |
LDX |
$02 | Loads a 16-bit value into our ‘X’ register |
STA |
$03 | Stores the byte value loaded in the ‘A’ register into the address pointed to by the ‘X’ register |
END |
$04 | Terminates execution of our program. |
If you are confused by what ‘STA‘ actually does, think of it like this. If ‘X’ register contained $1234 and ‘A’ register contained $9F, then executing ‘STA‘ would store the value $9F at memory location $1234. The rest of the mnemonics should make sense.
Here is our first B32 assembly test file, which will compile with our assembler, once it is done:
START: LDA #65 LDX #$A000 STA ,X END START
You may be wondering what the pound sign ‘#’ means? In our B32 intermediate language, the ‘#’ will always mean «use this data», or rather, use the value immediately following the pound sign. The first line in our program is called a label. A label is a human readable point of reference in our program. Labels must start with a letter and end with a colon ‘:’, followed by a new line. For simplicity, our assembler will not have any error checking, so we must play by some rules. All mnemonics must be preceded by one or more spaces. This is how our assembler knows whether the text is a label or a mnemonic. Labels, obviously, should not have a space preceding them. The second line assigns the value 65 to our ‘A’ register. The third line assigns the hexadecimal number $A000 to our ‘X’ register. The fourth line says to store the value of the ‘A’ register into the memory location pointed to by our ‘X’ register. In other words, store 65 at $A000. The final line in the program tells our program to end. The ‘START‘ preceding END tells the assembler where the execution of this program should begin. In this case, it starts at the ‘START‘ label, which is the beginning of our program.
You might be able to guess at what this will do. Remember, we said earlier that our screen will start at $A000? This program should put a capital letter ‘A’ (65 is ASCII for the letter ‘A’) in the upper left hand corner of our B32 screen. Pretty dull, I know. But it will demonstrate the workings of our assembler and virtual machine.
The last thing we need to do before we start building the assembler is to define a B32 binary file format. Our file format should start with a header with some magic numbers so that our virtual machine will know if our program is a valid B32 binary file. Our B32 binaries will start with the letters ‘B32’. That will be our magic number. After that will be the 16-bit starting address. This defines where in our 64K memory our program is to be loaded. Our assembler will default our origin to $1000, but we can change that to anything. Following that will be the 16-bit execution address. This is where the execution of our binary program will start. Finally, our bytecode will follow.
Building our Assembler
You can download the source code to both the assembler and the virtual machine from up above. Keep in mind that the source code was built using the PDF tutorial. Therefore, our assembler will have a lot more functionality and mnemonics built into it than what is explained in this section. Rather than explaining a step-by-step process for building the assembler, I will just explain the important parts. If you want a step-by-step, read the PDF file attached above.
The assembler works by first reading in the source file into a string buffer, and then by opening a BinaryWriter stream, pointing to our output B32 binary program:
private void btnAssemble_Click(object sender, EventArgs e) { AsLength = Convert.ToUInt16(this.txtOrigin.Text, 16); System.IO.BinaryWriter output; System.IO.TextReader input; System.IO.FileStream fs = new System.IO.FileStream( this.txtOutputFileName.Text, System.IO.FileMode.Create); output = new System.IO.BinaryWriter(fs); input = System.IO.File.OpenText(this.txtSourceFileName.Text); SourceProgram = input.ReadToEnd(); input.Close(); output.Write('B'); output.Write('3'); output.Write('2'); output.Write(Convert.ToUInt16(this.txtOrigin.Text, 16)); output.Write((ushort)0); Parse(output); output.Seek(5, System.IO.SeekOrigin.Begin); output.Write(ExecutionAddress); output.Close(); fs.Close(); MessageBox.Show("Done!"); }
Notice our B32 magic bytes are written followed by the origin (or start address), followed by a 16-bit zero. This zero will be replaced later by the execution address. For now, we have no way of knowing what that will be. A call to Parse() is made, which is where most of our work is done. Once it’s done, we seek back to that zero we placed earlier and replace it with the execution address. Finally, we close the streams and show a «Done!» box.
Our assembler works in two passes. The first pass simply scans the assembly file for all the labels and stores those labels in a hash table. This first pass is crucial in case there is a reference to a future label. The second pass does the hard part of converting the mnemonics into bytecode. Here is our Parse() function:
private void Parse(System.IO.BinaryWriter OutputFile) { CurrentNdx = 0; while (IsEnd == false) LabelScan(OutputFile, true); IsEnd = false; CurrentNdx = 0; AsLength = Convert.ToUInt16(this.txtOrigin.Text, 16); while (IsEnd == false) LabelScan(OutputFile, false); }
This function simply goes into a loop, calling another function called LabelScan. The first loop is the first pass. After resetting the index, it goes into a second loop. This is our second pass. All LabelScan() does is detect if the first character is a space. If it is, it assumes it is not a label, and it reads in the mnemonic. This mnemonic is passed off to another function that uses a series of ‘if‘ statements on the mnemonic, calling the appropriate function to process the mnemonic:
private void ReadMneumonic(System.IO.BinaryWriter OutputFile, bool IsLabelScan) { string Mneumonic = ""; while (!(char.IsWhiteSpace(SourceProgram[CurrentNdx]))) { Mneumonic = Mneumonic + SourceProgram[CurrentNdx]; CurrentNdx++; } if (Mneumonic.ToUpper() == "LDX") InterpretLDX(OutputFile, IsLabelScan); if (Mneumonic.ToUpper() == "LDA") InterpretLDA(OutputFile, IsLabelScan); if (Mneumonic.ToUpper() == "STA") InterpretSTA(OutputFile, IsLabelScan); if (Mneumonic.ToUpper() == "END") { IsEnd = true; DoEnd(OutputFile, IsLabelScan); EatWhiteSpaces(); ExecutionAddress = (ushort)LabelTable[(GetLabelName())]; return; } }
Each of the Interpret() functions pretty much do the same thing. They read the operand, if there is one, then writes the appropriate byte code to the output file.
If you download the assembler from the link above, go ahead and try to compile our test program. Remember to precede each mnemonic with at least one space (mnemonics only, not labels). Also, remember to end the last line with a new line. Keep those two rules in mind, and the test program should compile and produce a .B32 binary file.
If you want more details on how the compiler works, reference the PDF tutorial. It goes into a lot more depth.
History
This is my first PDF tutorial. I wanted to get my feet wet a little bit and see how people responded to my writing and tutorial skills. This is only part 1 of the virtual machine tutorial. Part 2 will go into how to build the actual virtual machine. Please leave feedback, good or bad, and let me know if this was a help to you.
This member has not yet provided a Biography. Assume it’s interesting and varied, and probably something to do with programming.
- Download B32 Virtual Machine source code — 30.7 KB
- Download B32 Virtual Machine complete tutorial (PDF) — 2.02 MB
Attention People
I am working on a new version of this, a B33 virtual machine. I will post it on here when its done. This one will not have a PDF and the full tutorial will be contained in the code project article. I will make sure I let everyone know when its done!
Introduction
Have you ever wondered how the Microsoft .NET Framework or how a Java virtual machine works? Have you ever wondered how to create your own emulator to target a specific computer you own? If you answered yes to any of these questions, then you will find my tutorial helpful. B32 is a complete virtual machine created in C#. This is part 1 of a 2 part series. The tutorial presented here on CodeProject is a condensed version of the complete PDF tutorial. In this part of the tutorial, I will explain the fundamentals, enough to get us started, and we will code the assembler portion of our virtual machine. Part 2 will build the actual virtual machine. The tutorial starts from scratch with a new project and solution. It will teach you how to write both, an assembler for our B32 intermediate language code, and it will teach you how to write the virtual machine itself.
Intended Audience
This tutorial assumes you are pretty familiar with C# and Visual Studio 2005 or 2008. This tutorial was written with Visual Studio 2008, targeting the .NET Framework 2.0. It should also work with Visual Studio 2005. Some of the concepts introduced in this tutorial may be a little hard for a beginner C# programmer to understand. I have tried to make it as simple to understand as possible. Keep in mind that, after reading this tutorial, no one will be able to walk away from it ready to build the next Java or something. Virtual machines are very complex tasks, and even simple ones can take many years to make. If you need help or have questions, you are welcome to post them here or email me direct at icemanind@yahoo.com. If I lose any of you, I suggest reading the PDF and using it as a reference to supplement this article. The PDF goes into more details.
Virtual Machine Fundamentals
To build a virtual machine, you first need to understand what a virtual machine is. A virtual machine is a software implementation of either a real physical machine or a fictional machine. To create a virtual machine, we first need to define an intermediate language (sometimes called an assembly language). This intermediate language will be the lowest level, human readable code, that will eventually get assembled into bytecode. Bytecode consists of one or more bytes of data that is readable only by our virtual machine (in real world machines, this would be called the «machine language»). The «assembler», which converts Intermediate Language into bytecode, will be the first tool we will develop. This will be developed in this part of the tutorial.
Planning Out our Virtual Machine
Before getting our hands dirty with any code, we need to plan out our virtual machine and how it will work. I believe in trying to stick with the KISS (Keep It Simple Stupid) principle whenever possible. B32, the virtual machine created in this tutorial, is going to be a 16-bit machine. It will have access to 64K of memory, and B32 bytecode programs will have access to any of this memory ranging from $0000 — $FFFF. 64K may not seem like a lot of memory compared to today’s modern computers; however, as you will see, 64K will be more than enough to produce some interesting B32 programs.
I said that programs would have access to 64K of memory; however, not all of this will be for storage. From $A000 — $AFA0, this 4K area of memory will be devoted to our B32 screen output. Screen output in our virtual machine will work very similar to older DOS programs. There will be 1 byte for the character and 1 byte for the attribute on an 80×25 screen. The attribute byte comes after the character byte, and it defines the foreground and background color of the character.
Our virtual machine will have two 8-bit registers called ‘A’ and ‘B’. Registers are kind of like variables in programming. We can store any number between 0 and 255 in either register ‘A’, ‘B’, or both. In addition, we are going to have two 16-bit registers called ‘X’ and ‘Y’. These registers can hold any value from 0 to 65,535. As if that’s not enough, we are going to have one more 16-bit register called ‘D’. This register is unique, as ‘D’ represents the high order bits and low order bits of registers ‘A’ and ‘B’. In other words, if we were to store a value of $12F9 in our D register, then it would automatically change register ‘A’ to have the value $12 and register ‘B’ to have the value $F9. The opposite is also true. If we store $C1 in register ‘A’ and $78 in register ‘B’, then register ‘D’ would have the value $C178.
Before diving into creating our assembler, we need to define at least three mnemonics for now to make any kind of useful program. Mnemonics, by the way, are the building blocks of our intermediate language. They are human readable characters, usually 3-5 characters long, that tell the assembler what we want to do; e.g., «The verb». Most (but not all) mnemonics have an operand. An operand is some kind of data or information for the mnemonic to act on. For now, our assembler will understand the following mnemonics:
| Mnemonic | Bytecode | Description |
LDA |
$01 | Loads an 8-bit value into our ‘A’ register |
LDX |
$02 | Loads a 16-bit value into our ‘X’ register |
STA |
$03 | Stores the byte value loaded in the ‘A’ register into the address pointed to by the ‘X’ register |
END |
$04 | Terminates execution of our program. |
If you are confused by what ‘STA‘ actually does, think of it like this. If ‘X’ register contained $1234 and ‘A’ register contained $9F, then executing ‘STA‘ would store the value $9F at memory location $1234. The rest of the mnemonics should make sense.
Here is our first B32 assembly test file, which will compile with our assembler, once it is done:
START: LDA #65 LDX #$A000 STA ,X END START
You may be wondering what the pound sign ‘#’ means? In our B32 intermediate language, the ‘#’ will always mean «use this data», or rather, use the value immediately following the pound sign. The first line in our program is called a label. A label is a human readable point of reference in our program. Labels must start with a letter and end with a colon ‘:’, followed by a new line. For simplicity, our assembler will not have any error checking, so we must play by some rules. All mnemonics must be preceded by one or more spaces. This is how our assembler knows whether the text is a label or a mnemonic. Labels, obviously, should not have a space preceding them. The second line assigns the value 65 to our ‘A’ register. The third line assigns the hexadecimal number $A000 to our ‘X’ register. The fourth line says to store the value of the ‘A’ register into the memory location pointed to by our ‘X’ register. In other words, store 65 at $A000. The final line in the program tells our program to end. The ‘START‘ preceding END tells the assembler where the execution of this program should begin. In this case, it starts at the ‘START‘ label, which is the beginning of our program.
You might be able to guess at what this will do. Remember, we said earlier that our screen will start at $A000? This program should put a capital letter ‘A’ (65 is ASCII for the letter ‘A’) in the upper left hand corner of our B32 screen. Pretty dull, I know. But it will demonstrate the workings of our assembler and virtual machine.
The last thing we need to do before we start building the assembler is to define a B32 binary file format. Our file format should start with a header with some magic numbers so that our virtual machine will know if our program is a valid B32 binary file. Our B32 binaries will start with the letters ‘B32’. That will be our magic number. After that will be the 16-bit starting address. This defines where in our 64K memory our program is to be loaded. Our assembler will default our origin to $1000, but we can change that to anything. Following that will be the 16-bit execution address. This is where the execution of our binary program will start. Finally, our bytecode will follow.
Building our Assembler
You can download the source code to both the assembler and the virtual machine from up above. Keep in mind that the source code was built using the PDF tutorial. Therefore, our assembler will have a lot more functionality and mnemonics built into it than what is explained in this section. Rather than explaining a step-by-step process for building the assembler, I will just explain the important parts. If you want a step-by-step, read the PDF file attached above.
The assembler works by first reading in the source file into a string buffer, and then by opening a BinaryWriter stream, pointing to our output B32 binary program:
private void btnAssemble_Click(object sender, EventArgs e) { AsLength = Convert.ToUInt16(this.txtOrigin.Text, 16); System.IO.BinaryWriter output; System.IO.TextReader input; System.IO.FileStream fs = new System.IO.FileStream( this.txtOutputFileName.Text, System.IO.FileMode.Create); output = new System.IO.BinaryWriter(fs); input = System.IO.File.OpenText(this.txtSourceFileName.Text); SourceProgram = input.ReadToEnd(); input.Close(); output.Write('B'); output.Write('3'); output.Write('2'); output.Write(Convert.ToUInt16(this.txtOrigin.Text, 16)); output.Write((ushort)0); Parse(output); output.Seek(5, System.IO.SeekOrigin.Begin); output.Write(ExecutionAddress); output.Close(); fs.Close(); MessageBox.Show("Done!"); }
Notice our B32 magic bytes are written followed by the origin (or start address), followed by a 16-bit zero. This zero will be replaced later by the execution address. For now, we have no way of knowing what that will be. A call to Parse() is made, which is where most of our work is done. Once it’s done, we seek back to that zero we placed earlier and replace it with the execution address. Finally, we close the streams and show a «Done!» box.
Our assembler works in two passes. The first pass simply scans the assembly file for all the labels and stores those labels in a hash table. This first pass is crucial in case there is a reference to a future label. The second pass does the hard part of converting the mnemonics into bytecode. Here is our Parse() function:
private void Parse(System.IO.BinaryWriter OutputFile) { CurrentNdx = 0; while (IsEnd == false) LabelScan(OutputFile, true); IsEnd = false; CurrentNdx = 0; AsLength = Convert.ToUInt16(this.txtOrigin.Text, 16); while (IsEnd == false) LabelScan(OutputFile, false); }
This function simply goes into a loop, calling another function called LabelScan. The first loop is the first pass. After resetting the index, it goes into a second loop. This is our second pass. All LabelScan() does is detect if the first character is a space. If it is, it assumes it is not a label, and it reads in the mnemonic. This mnemonic is passed off to another function that uses a series of ‘if‘ statements on the mnemonic, calling the appropriate function to process the mnemonic:
private void ReadMneumonic(System.IO.BinaryWriter OutputFile, bool IsLabelScan) { string Mneumonic = ""; while (!(char.IsWhiteSpace(SourceProgram[CurrentNdx]))) { Mneumonic = Mneumonic + SourceProgram[CurrentNdx]; CurrentNdx++; } if (Mneumonic.ToUpper() == "LDX") InterpretLDX(OutputFile, IsLabelScan); if (Mneumonic.ToUpper() == "LDA") InterpretLDA(OutputFile, IsLabelScan); if (Mneumonic.ToUpper() == "STA") InterpretSTA(OutputFile, IsLabelScan); if (Mneumonic.ToUpper() == "END") { IsEnd = true; DoEnd(OutputFile, IsLabelScan); EatWhiteSpaces(); ExecutionAddress = (ushort)LabelTable[(GetLabelName())]; return; } }
Each of the Interpret() functions pretty much do the same thing. They read the operand, if there is one, then writes the appropriate byte code to the output file.
If you download the assembler from the link above, go ahead and try to compile our test program. Remember to precede each mnemonic with at least one space (mnemonics only, not labels). Also, remember to end the last line with a new line. Keep those two rules in mind, and the test program should compile and produce a .B32 binary file.
If you want more details on how the compiler works, reference the PDF tutorial. It goes into a lot more depth.
History
This is my first PDF tutorial. I wanted to get my feet wet a little bit and see how people responded to my writing and tutorial skills. This is only part 1 of the virtual machine tutorial. Part 2 will go into how to build the actual virtual machine. Please leave feedback, good or bad, and let me know if this was a help to you.
This member has not yet provided a Biography. Assume it’s interesting and varied, and probably something to do with programming.
Что такое виртуальная машина
В статье мы расскажем, что называется виртуальной машиной и для чего она предназначена, разберём преимущества и недостатки использования виртуальных машин, кратко рассмотрим 4 виртуальные машины и установим VirtualBox.
Что такое виртуальная машина и зачем она нужна
Виртуальная машина (ВМ или VM) — это виртуальный компьютер, который использует выделенные ресурсы реального компьютера (процессор, диск, адаптер). Эти ресурсы хранятся в облаке и позволяют ВМ работать автономно. Простыми словами, виртуальная машина позволяет создать на одном компьютере ещё один компьютер, который будет использовать его ресурсы, но работать изолированно.
ВМ может работать в отдельном окне как программа или запускаться через панель управления.

Виртуализация, и виртуальная машина в частности, расширяет возможности IT-инфраструктуры. Она будет полезна разработчикам программных продуктов, веб-дизайнерам, а также тем, кто планирует перейти на новую ОС, но не уверен в выборе.
Для чего нужна виртуальная машина:
- чтобы разворачивать две и более независимые операционные системы на одном физическом устройстве. Например, на вашем компьютере установлена операционная система Windows 7, а на виртуальную машину вы установили Windows XP/8/10 или Linux;
- для экспериментов с программным обеспечением (например, кодом, предназначенным для запуска в различных ОС), не подвергая риску стабильность компьютера;
- чтобы устанавливать и тестировать различные программы и утилиты, не занимая место на основном ПК;
- чтобы запускать программы, которые не поддерживает основная ОС, или подключать оборудование, несовместимое с ней. Например, применять Windows-программы на Mac или Linux;
- для безопасного запуска приложения (программы), которое вызывает недоверие или подозрение на вирусы;
- чтобы эмулировать компьютерные сети и сложные среды, не настраивая виртуальную машину каждый раз. Можно сохранить настройки и продолжить с того этапа, где остановились;
- для создания резервных копий ОС.
Если сравнивать функции виртуальной машины с работой на обычном ПК, то можно выделить как преимущества, так и недостатки.
Преимущества виртуальной машины
- Можно выключить ПК или перейти к другой задаче с сохранением текущего состояния машины. Если вы решите продолжить работу, ВМ загрузится в том состоянии, в котором находилась в момент выключения.
- На VM можно делать снапшоты, которые позволяют откатываться до предыдущих конфигураций. Это удобно, если при тестировании нестабильного софта произошла критическая ошибка. По сравнению с основной системой, для ВМ выделяется меньше места на дисковом пространстве и откат до раннего состояния происходит быстрее.
- Машину можно сохранять или дублировать как изолированную среду. Её можно будет запустить позднее или скопировать на другой ПК. Заданные конфигурации сохранятся.
- ВМ вместе со всеми данными легко переносится с одного ПК на другой. Портативный софт для виртуальной машины сохраняет информацию одним файлом (в виде образа системы) на физическом компьютере. Для переноса достаточно переместить этот файл.
- ВМ не занимает место постоянной памяти, а оперирует выделенной временной памятью. Все действия фиксируются в виде лога, который очищается при завершении каждого сеанса.
- Для переподключения на другую ОС не нужно перезагружать компьютер.
- На одном устройстве можно хранить несколько виртуальных машин с несколькими ОС в разных состояниях.
Недостатки использования VM
- Чтобы одновременно запускать на ВМ несколько операционных систем, нужно иметь соответствующие аппаратные ресурсы.
- ОС в виртуальных машинах могут работать медленнее. Несмотря на то что показатели производительности виртуальных ОС стремятся к показателям физических ОС, на данный момент развития они всё-таки не равны.
- Виртуальная платформа поддерживает не весь функционал аппаратного обеспечения. VMware уже поддерживает USB 3.0, контроллеры портов COM и LPT и приводы CD-ROM, но с виртуализацией видеоадаптеров и поддержкой функций аппаратного ускорения трехмерной графики могут быть сложности.
Ниже мы расскажем про самые популярные и простые в использовании виртуальные машины и разберём их недостатки и преимущества.
Какие бывают виртуальные машины
К самым популярным виртуальным машинам относятся:
- VirtualBox,
- Microsoft Hyper-V,
- VMware Workstation Player,
- Parallels Desktop.
Microsoft Hyper-V ― это VM от Майкрософт.
| Плюсы | Минусы |
|---|---|
| Привычный интерфейс для пользователей Microsoft | Не запускается с версий ниже Windows 10 |
| Сразу установлена на Windows 10 (Pro, Enterprise, и Education) | Нельзя установить на MacOS |
| Поддерживает различные старые версии Windows | Интерфейс уступает VMWare и VirtualBox |
VMware Workstation ― платная мощная виртуальная машина для профессионального использования. Работает в основном с Windows и Linux. Имеет бесплатную версию VMware Player, но она значительно ограничена функционалом.
| Плюсы | Минусы |
|---|---|
| Установка систем по шаблону | Платная VM |
| Удобный интерфейс | Нельзя записать видео с экрана виртуальной машины |
| Высокая стабильность и надёжность | |
| Детальная настройка оборудования. Можно отдельно настроить ID процессора, количество видеопамяти и др. | |
| Поддержка 3D-графики и DirectX 10 | |
| Поддерживает EFI |
Parallels Desktop ― это ВМ, которая позволяет использовать программы разных операционных систем на Mac.
| Плюсы | Минусы |
|---|---|
| Работает без перегрузок | Платная программа |
| Поддерживает различные операционные системы (Windows, Linux, разные версии MacOS и другие ОС) | Работает только на MacOS |
VirtualBox ― cамая популярная программа виртуализации с открытым исходным кодом. С её помощью можно запускать любые операционные системы, например Windows, Linux, Mac, Android. Программа имеет русифицированный интерфейс и проста в применении.
| Плюсы | Минусы |
|---|---|
| Бесплатная VM | Нельзя выделить машине больше, чем 256 МБ видеопамяти. Для современных систем этого мало |
| Имеет русскоязычную версию | Не поддерживается DirectX для 3D-графики |
| Интуитивно понятный интерфейс, подходит новичкам | |
| Можно управлять через GUI (графический пользовательский интерфейс) и командную строку | |
| Есть комплект SDK | |
| Можно подключать USB-устройства к виртуальным компьютерам, чтобы работать с ними напрямую | |
| Поддерживает протокол RDP (протокол удалённого доступа) |
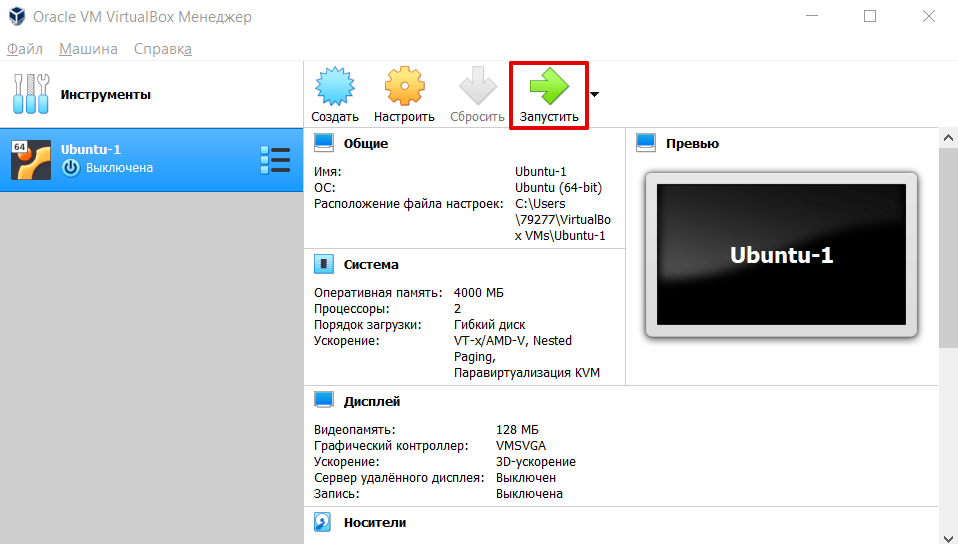
Все машины имеют свои сильные и слабые стороны. Нельзя рекомендовать только одну. Для примера мы рассмотрим, как создать виртуальную машину Oracle VirtualBox.
Как создать виртуальную машину Oracle VirtualBox
-
1.
Скачайте и установите VirtualBox на компьютер.
-
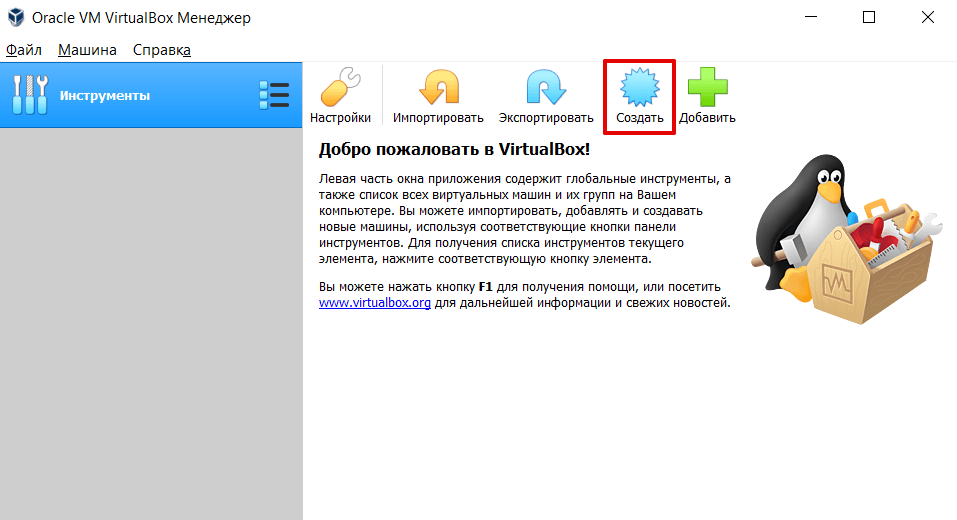
2.
Откройте панель управления Oracle и нажмите Создать:

-
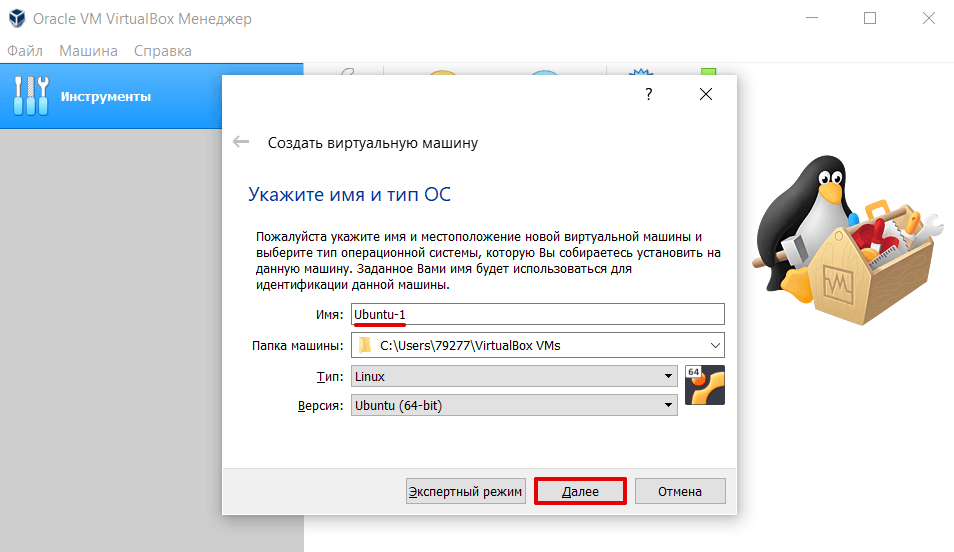
3.
Введите название виртуальной машины (например, Ubuntu-1). Кликните Далее:
-
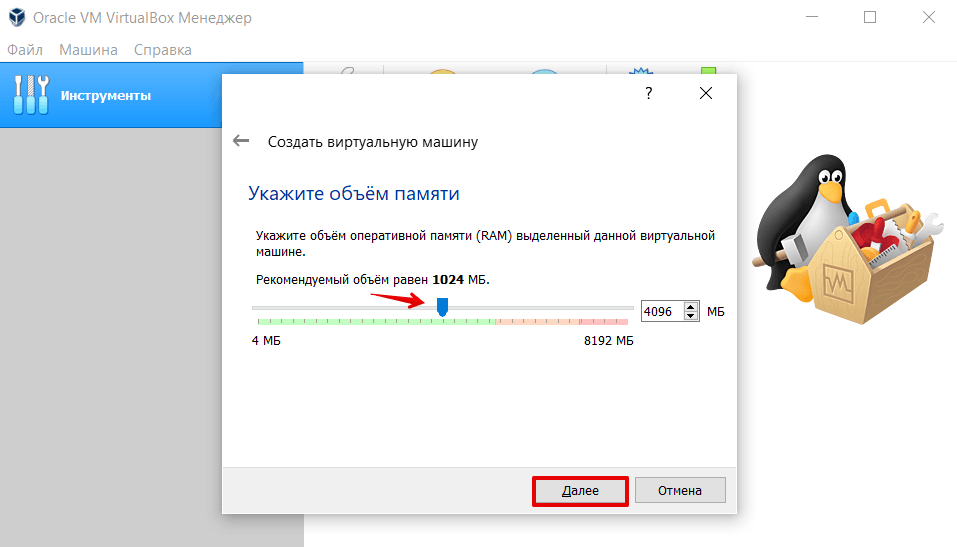
4.
Чтобы выделить объём памяти для машины, сдвиньте ползунок вправо. Мы рекомендуем указать объём 4 ГБ, но если на вашем компьютере недостаточно оперативной памяти, выбирайте максимум 2-3 ГБ. Нажмите Далее:
-
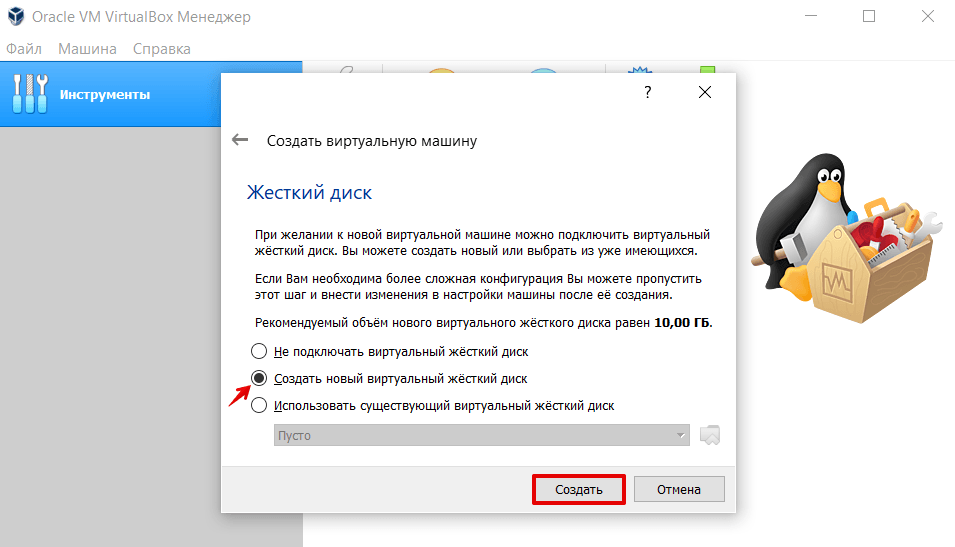
5.
Выберите пункт «Создать новый виртуальный жёсткий диск» и кликните Создать:
-
6.
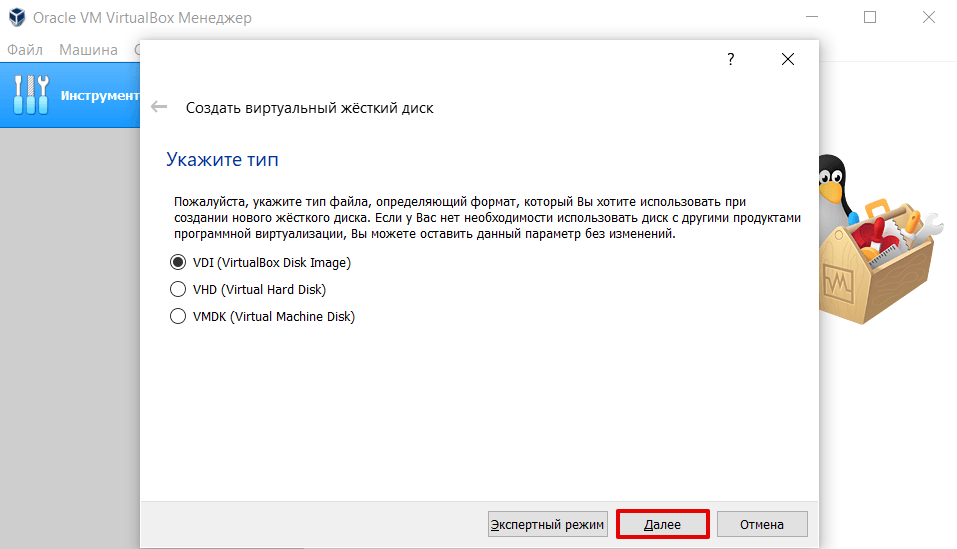
Укажите тип файла «VDI (VirtualBox Disk Image)» и нажмите Далее:
-
7.
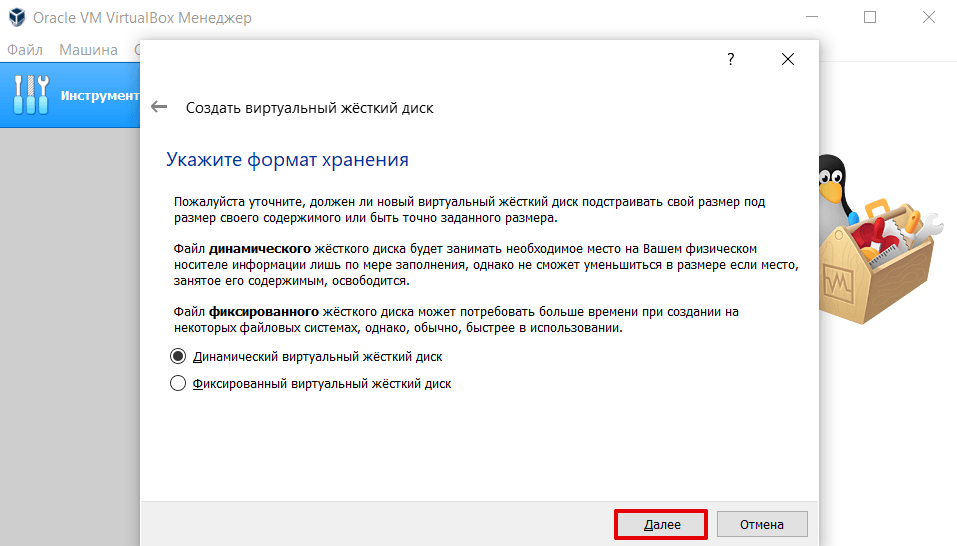
Выберите формат хранения «Динамический виртуальный жёсткий диск». Нажмите Далее:
-
8.
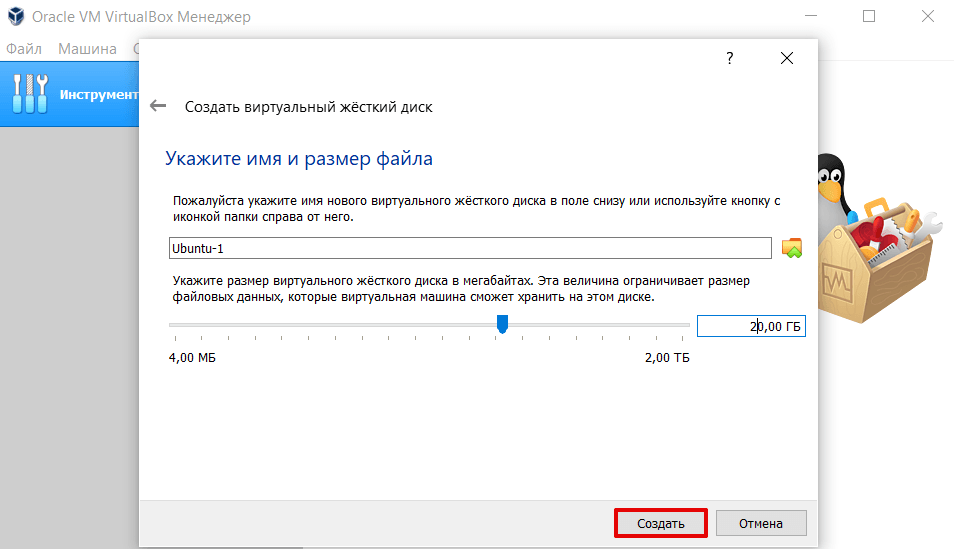
Укажите объём жёсткого диска 20 ГБ. Кликните Создать:
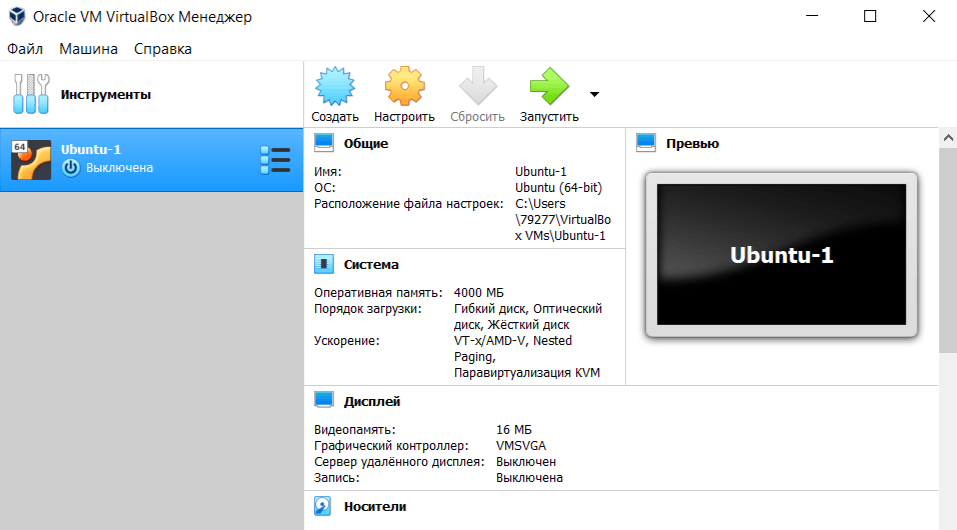
Готово, вы создали VM Oracle. Теперь переходите к установке операционной системы.
Как установить операционную систему в Oracle VirtualBox
Рассмотрим, как установить операционную систему на примере Ubuntu 20.04.
-
1.
Скачайте дистрибутив Ubuntu на компьютер.
-
2.
Откройте панель управления Oracle и нажмите Настроить:
-
3.
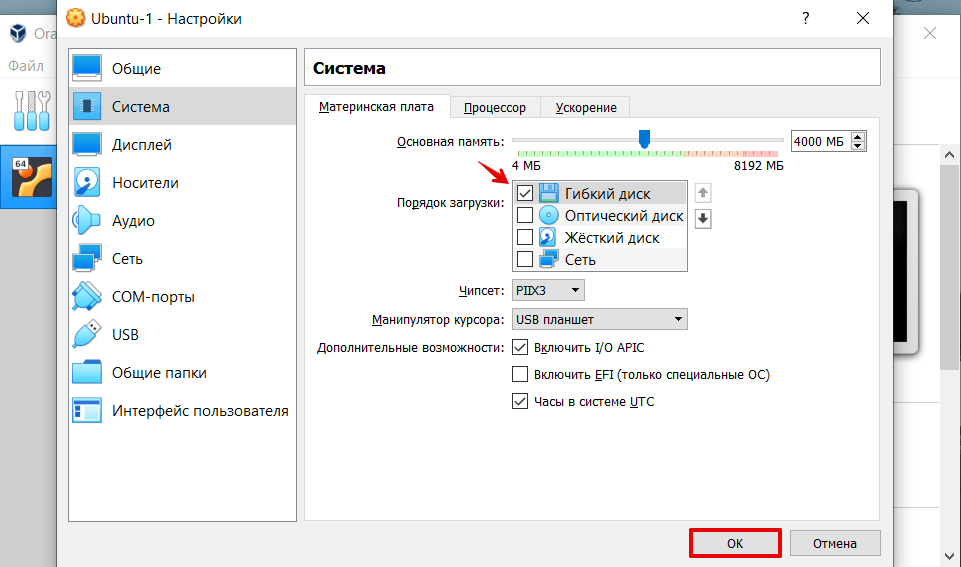
Перейдите в раздел Система. На вкладке «Материнская плата» поставьте галочку напротив пункта «Гибкий диск»:
-
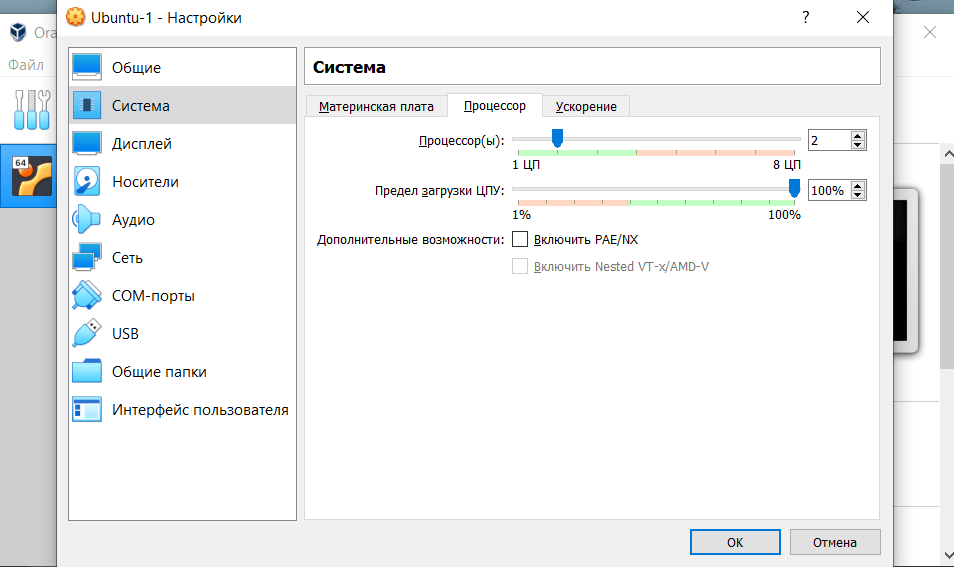
4.
На вкладке «Процессор» выберите 2 ядра:
-
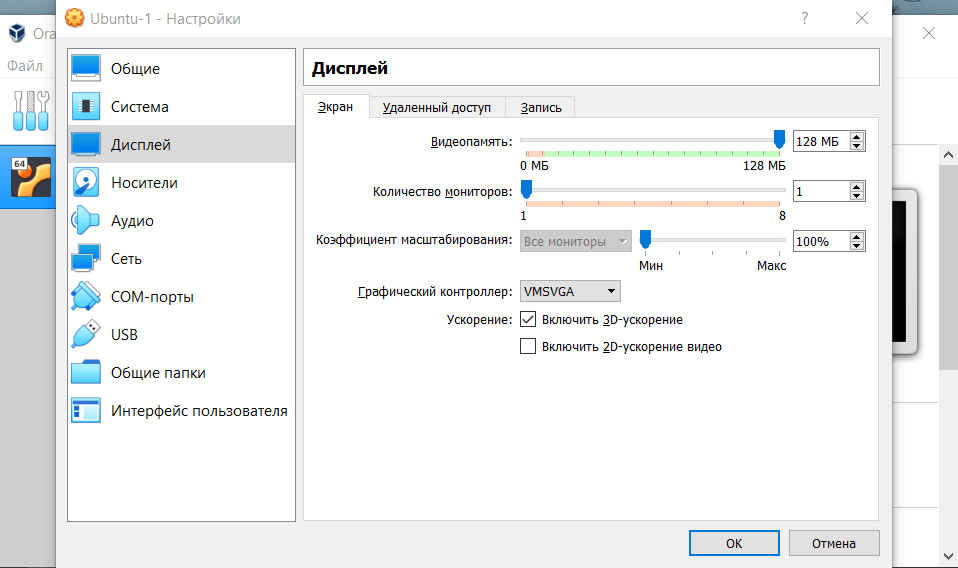
5.
Перейдите в раздел Дисплей. Поставьте галочку напротив пункта «Включить 3D-ускорение» и перетяните ползунок вправо, чтобы выделить максимально возможный объём видеопамяти:
-
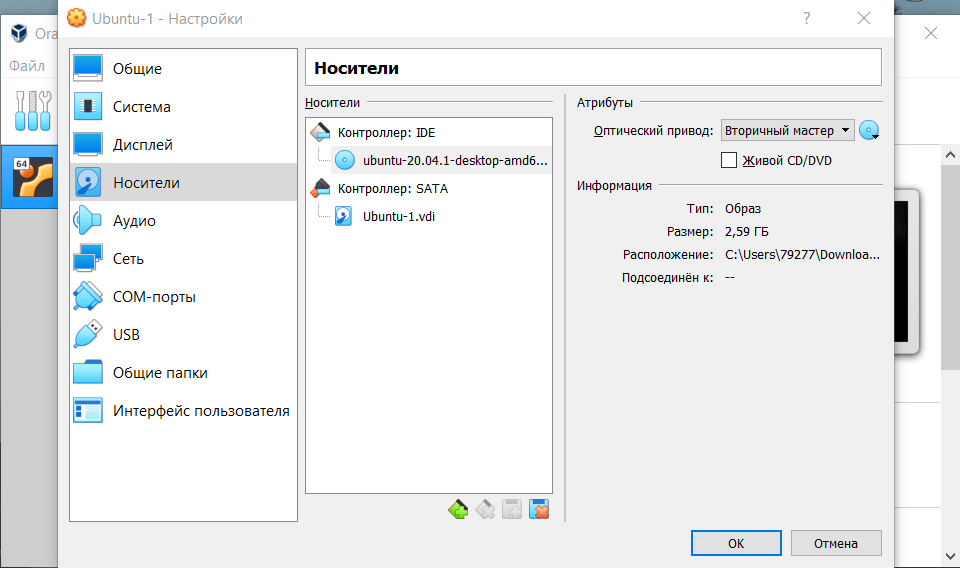
6.
Перейдите в раздел Носители и выберите «Пусто». Затем нажмите на иконку Диск — Выбрать образ оптического диска. Загрузите дистрибутив Ubuntu, который вы скачали на первом шаге.
-
7.
После загрузки кликните Ок:
-
8.
На главной странице нажмите Запустить:
-
9.
Подождите, пока загрузится машина:
-
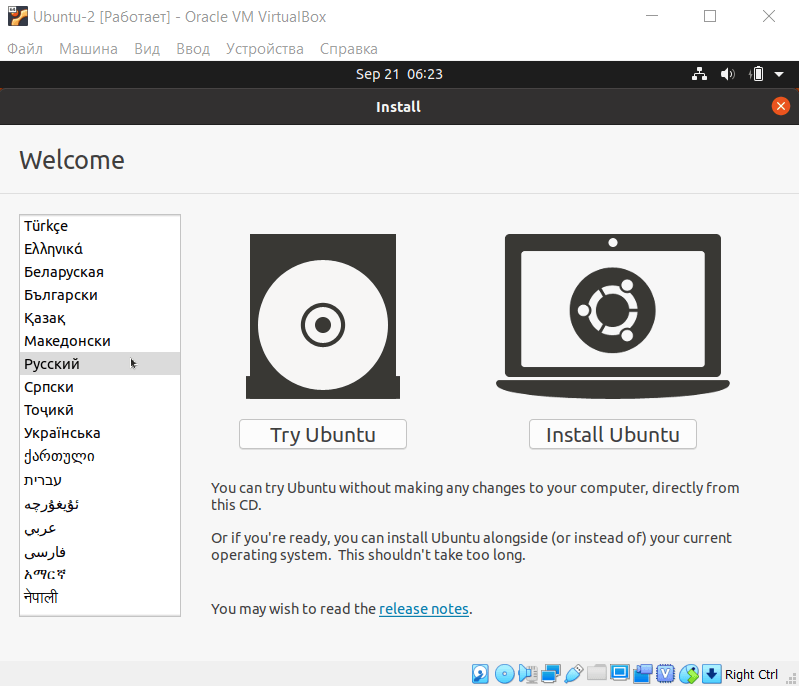
10.
В приветственном окне выберите нужный язык:
-
11.
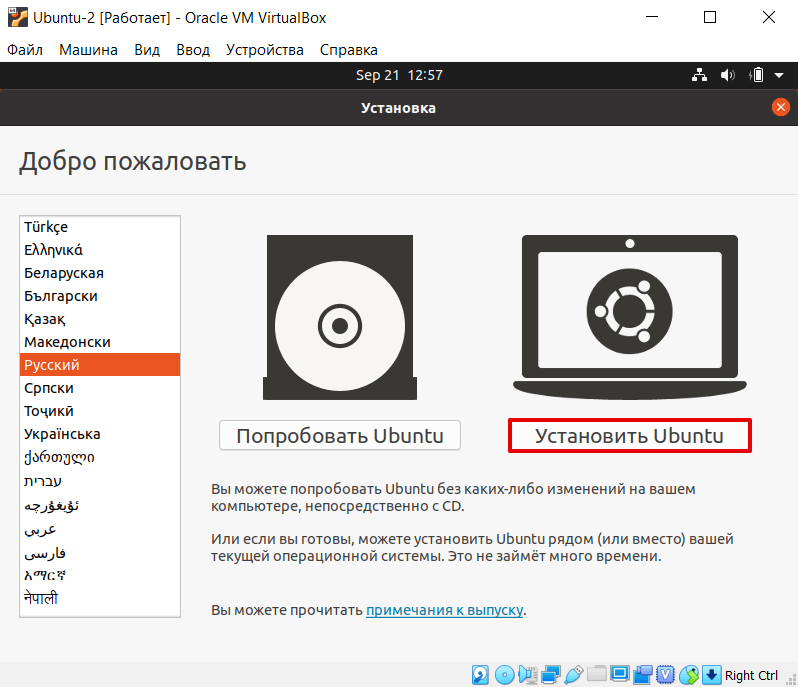
Нажмите установить Ubuntu:
-
12.
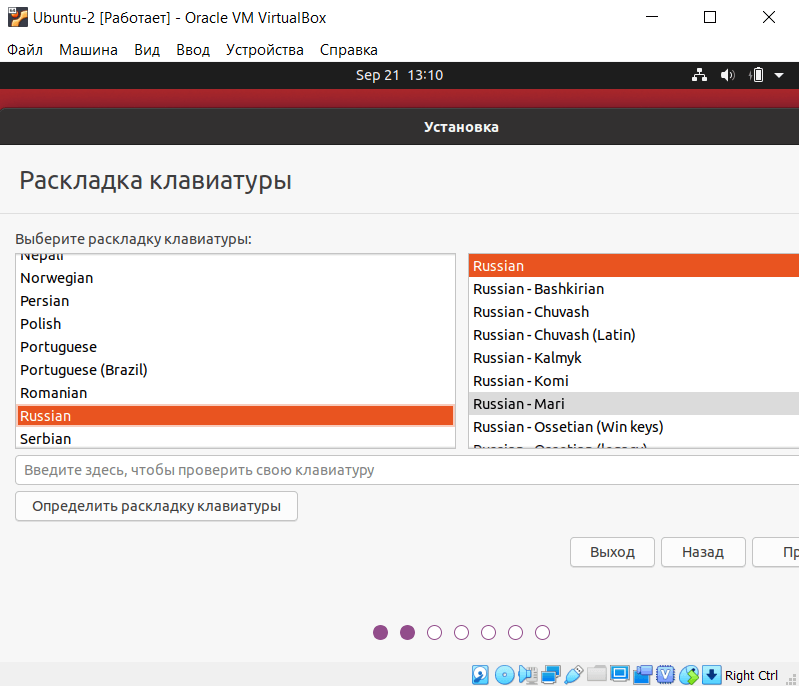
Выберите раскладку клавиатуры «Russian». Нажмите Продолжить:
-
13.
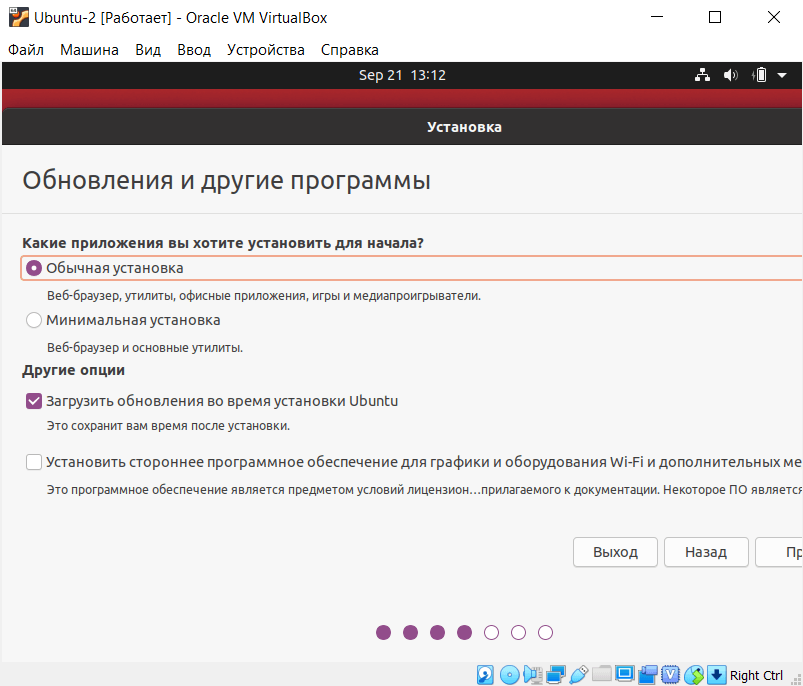
Выберите пункты «Обычная установка» и «Загрузить обновления во время установки Ubuntu». Затем кликните Продолжить:
-
14.
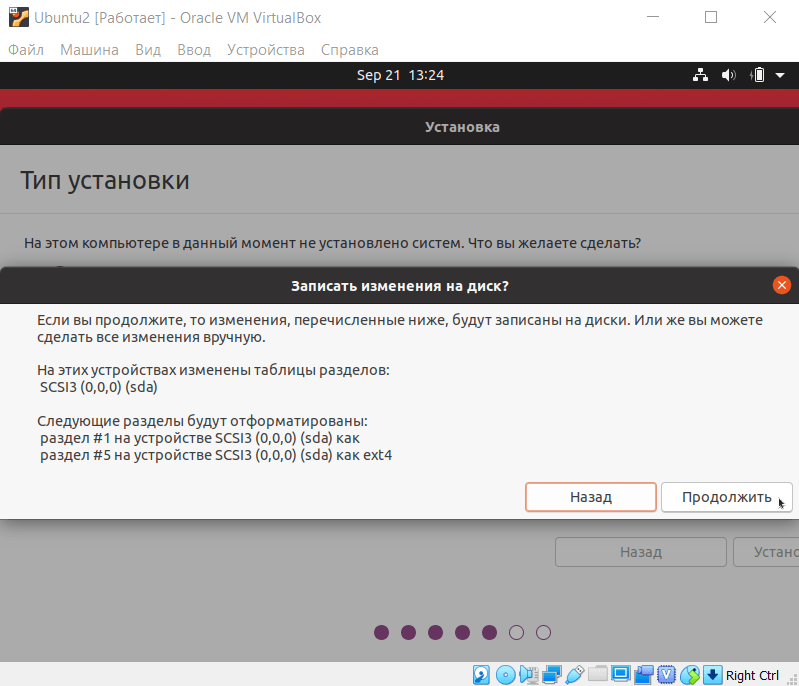
Выберите тип установки «Стереть диск и установить Ubuntu» и нажмите Установить:
Затем кликните Продолжить:
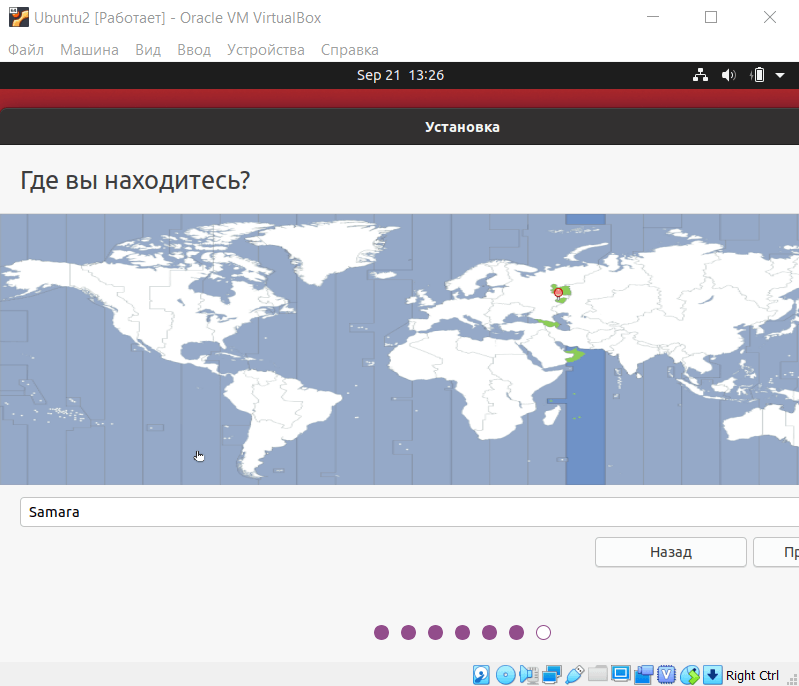
-
15.
Назначьте нужный регион и нажмите Продолжить:
-
16.
Зарегистрируйтесь. Задайте имя и пароль, остальные поля будут заполнены автоматически. Нажмите Продолжить:
-
17.
Дождитесь окончания установки и кликните Перезагрузить:
-
18.
Дождитесь перезагрузки и нажмите Enter:
-
19.
Выберите учётную запись, которую вы создали на шаге 15:
-
20.
Введите пароль, который вы задали при создании учётной записи:
-
21.
Примите предлагаемые настройки или нажмите Далее в правом верхнем углу экрана:

Готово, вы установили ОС Ubuntu 20.04 и можете приступать к работе:
Теперь вы знаете, зачем нужна виртуальная машина и как запустить её с помощью программы VirtualBox.
Виртуальный дата-центр VMware
Кроме VM, есть более крупные решения ― виртуальные дата-центры. Например, виртуальный дата-центр VMware, который можно заказать в REG.RU.
Для чего используют виртуальный дата-центр?
Эта услуга подходит для применения как частными лицами, так и крупными организациями и корпорациями. Возможности виртуализации в совокупности с облачными вычислениями обладают такими преимуществами как масштабируемость, экономичность и доступность ресурсов в любое время. Можно создавать и развёртывать несколько ВМ одновременно. К примеру, вы можете создать один виртуальный контейнер vApp с машинами для тестовой среды, а другой — для продуктивной. При этом у вас будет возможность изолировать их с помощью разных сетей. Подробнее об услуге читайте в статье: Как начать работу с VMware.
Теперь вы знаете, что собой представляет ВМ, что делает виртуальная машина и какими ресурсами виртуальной машины можно управлять, и при необходимости можете заказать Виртуальный дата-центр VMware в REG.RU.
|
0 / 0 / 0 Регистрация: 07.05.2013 Сообщений: 38 |
|
|
1 |
|
Написание виртуальной машины27.03.2015, 08:20. Показов 6091. Ответов 3
Доброго времени суток! Стоит задача: написать простенькую виртуальную машину, эмулирующую работу компьютера. Ограничений на язык нет, но предпочтительней C++. Подскажите исходники, литературу и т.п. Не представляю с чего начать и какую задачу можно реализовать.
__________________
0 |

|
Ушел с форума
16456 / 7420 / 1186 Регистрация: 02.05.2013 Сообщений: 11,617 Записей в блоге: 1 |
|
|
27.03.2015, 08:34 |
2 |
|
Исходники VirtualBox в открытом доступе, бери и пользуйся, как говорится.
0 |
|
0 / 0 / 0 Регистрация: 07.05.2013 Сообщений: 38 |
|
|
27.03.2015, 08:38 [ТС] |
3 |
|
«эмулирующую работу компьютера» — имеется ввиду не полноценная работа компьютера, а обработка пары команд, записанных в оперативной памяти.
0 |