Если вам нужно выбрать определенные данные из одного или нескольких источников, можно воспользоваться запросом на выборку. Запрос на выборку позволяет получить только необходимые сведения, а также помогает объединять информацию из нескольких источников. В качестве источников данных для запросов на выборку можно использовать таблицы и другие такие же запросы. В этом разделе вкратце рассматриваются запросы на выборку и предлагаются пошаговые инструкции по их созданию с помощью Мастера запросов либо в Конструктор.
Если вы хотите узнать больше о принципах работы запросов на примере базы данных Northwind, ознакомьтесь со статьей Общие сведения о запросах.
В этой статье
-
Overview
-
Создание запроса SELECT с помощью мастера запросов
-
Создание запроса в режиме конструктора
Общие сведения
Когда возникает потребность в каких-то данных, редко бывает необходимо все содержимое одной таблицы. Например, если вам нужна информация из таблицы контактов, как правило, речь идет о конкретной записи или только о номере телефона. Иногда бывает необходимо объединить данные сразу из нескольких таблиц, например совместить информацию о клиентах со сведениями о заказчиках. Для выбора необходимых данных используются запросы на выборку.
Запрос на выборки — это объект базы данных, в который в Режим таблицы. Запрос не хранит данные, а отображает данные, хранимые в таблицах. Запрос может показывать данные из одной или нескольких таблиц, из других запросов или из их сочетания.
Преимущества запросов
Запрос позволяет выполнять перечисленные ниже задачи.
-
Просматривать значения только из полей, которые вас интересуют. При открытии таблицы отображаются все поля. Вы можете сохранить запрос, который выдает лишь некоторые из них.
Примечание: Запрос только возвращает данные, но не сохраняет их. При сохранении запроса вы не сохраняете копию соответствующих данных.
-
Объединять данные из нескольких источников. В таблице обычно можно увидеть только те сведения, которые в ней хранятся. Запрос позволяет выбрать поля из разных источников и указать, как именно нужно объединить информацию.
-
Использовать выражения в качестве полей. Например, в роли поля может выступить функция, возвращающая дату, а с помощью функции форматирования можно управлять форматом значений из полей в результатах запроса.
-
Просматривать записи, которые отвечают указанным вами условиям. При открытии таблицы отображаются все записи. Вы можете сохранить запрос, который выдает лишь некоторые из них.
Основные этапы создания запроса на выборку
Вы можете создать запрос на выборку с помощью мастера или конструктора запросов. Некоторые элементы недоступны в мастере, однако их можно добавить позже из конструктора. Хотя это разные способы, основные этапы аналогичны.
-
Выберите таблицы или запросы, которые хотите использовать в качестве источников данных.
-
Укажите поля из источников данных, которые хотите включить в результаты.
-
Также можно задать условия, которые ограничивают набор возвращаемых запросов записей.
Создав запрос на выборку, запустите его, чтобы посмотреть результаты. Чтобы выполнить запрос на выборку, откройте его в режиме таблицы. Сохранив запрос, вы сможете использовать его позже (например, в качестве источника данных для формы, отчета или другого запроса).
Создание запроса на выборку с помощью мастера запросов
Мастер позволяет автоматически создать запрос на выборку. При использовании мастера вы не полностью контролируете все детали процесса, однако таким способом запрос обычно создается быстрее. Кроме того, мастер иногда обнаруживает в запросе простые ошибки и предлагает выбрать другое действие.
Подготовка
Если вы используете поля из источников данных, которые не связаны между собой, мастер запросов предлагает создать между ними отношения. Он откроет окно отношений, однако если вы внесете какие-то изменения, то вам потребуется перезапустить мастер. Таким образом, перед запуском мастера имеет смысл сразу создать все отношения, которые потребуются вашему запросу.
Дополнительную информацию о создании отношений между таблицами можно найти в статье Руководство по связям между таблицами.
Использование мастера запросов
-
На вкладке Создание в группе Запросы нажмите кнопку Мастер запросов.

-
В диалоговом окне Новый запрос выберите пункт Простой запрос и нажмите кнопку ОК.
-
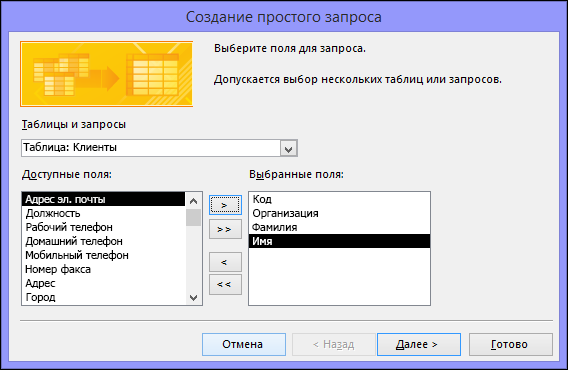
Теперь добавьте поля. Вы можете добавить до 255 полей из 32 таблиц или запросов.
Для каждого поля выполните два указанных ниже действия.
-
В разделе Таблицы и запросы щелкните таблицу или запрос, содержащие поле.
-
В разделе Доступные поля дважды щелкните поле, чтобы добавить его в список Выбранные поля. Если вы хотите добавить в запрос все поля, нажмите кнопку с двумя стрелками вправо (>>).
-
Добавив в запрос все необходимые поля, нажмите кнопку Далее.
-
-
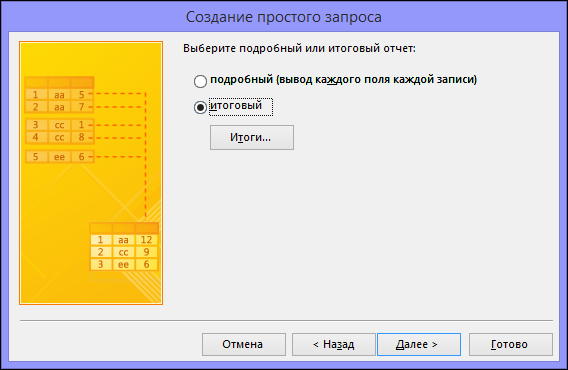
Если вы не добавили ни одного числового поля (поля, содержащего числовые данные), перейдите к действию 9. При добавлении числового поля вам потребуется выбрать, что именно вернет запрос: подробности или итоговые данные.
Выполните одно из указанных ниже действий.
-
Если вы хотите просмотреть отдельные записи, выберите пункт подробный и нажмите кнопку Далее. Перейдите к действию 9.
-
Если вам нужны итоговые числовые данные, например средние значения, выберите пункт итоговый и нажмите кнопку Итоги.
-
-
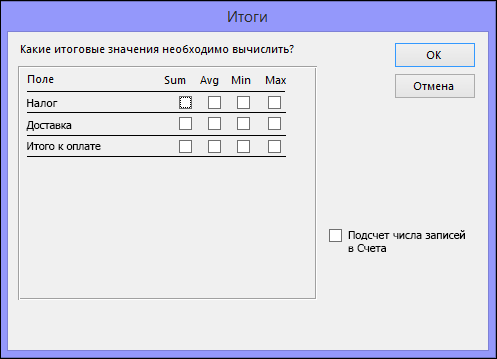
В диалоговом окне Итоги укажите необходимые поля и типы итоговых данных. В списке будут доступны только числовые поля.
Для каждого числового поля выберите одну из перечисленных ниже функций.
-
Sum — запрос вернет сумму всех значений, указанных в поле.
-
Avg — запрос вернет среднее значение поля.
-
Min — запрос вернет минимальное значение, указанное в поле.
-
Max — запрос вернет максимальное значение, указанное в поле.
-
-
Если вы хотите, чтобы в результатах запроса отобразилось число записей в источнике данных, установите соответствующий флажок Подсчет числа записей в (название источника данных).
-
Нажмите ОК, чтобы закрыть диалоговое окно Итоги.
-
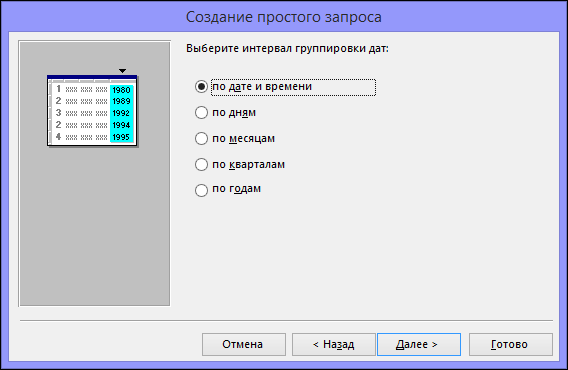
Если вы не добавили в запрос ни одного поля даты и времени, перейдите к действию 9. Если вы добавили в запрос поля даты и времени, мастер запросов предложит вам выбрать способ группировки значений даты. Предположим, вы добавили в запрос числовое поле («Цена») и поле даты и времени («Время_транзакции»), а затем в диалоговом окне Итоги указали, что хотите отобразить среднее значение по числовому полю «Цена». Поскольку вы добавили поле даты и времени, вы можете подсчитать итоговые величины для каждого уникального значения даты и времени, например для каждого месяца, квартала или года.
Выберите период, который хотите использовать для группировки значений даты и времени, а затем нажмите кнопку Далее.
Примечание: В режиме конструктора для группировки значений по периодам можно использовать выражения, однако в мастере доступны только указанные здесь варианты.
-
На последней странице мастера задайте название запроса, укажите, хотите ли вы открыть или изменить его, и нажмите кнопку Готово.
Если вы решили открыть запрос, он отобразит выбранные данные в режиме таблицы. Если вы решили изменить запрос, он откроется в режиме конструктора.

К началу страницы
Создание запроса в режиме конструктора
В режиме конструктора можно вручную создать запрос на выборку. В этом режиме вы полнее контролируете процесс создания запроса, однако здесь легче допустить ошибку и необходимо больше времени, чем в мастере.
Создание запроса
-
Действие 1. Добавьте источники данных
-
Действие 2. Соедините связанные источники данных
-
Действие 3. Добавьте выводимые поля
-
Действие 4. Укажите условия
-
Действие 5. Рассчитайте итоговые значения
-
Действие 6. Просмотрите результаты
Действие 1. Добавьте источники данных
При использовании конструктора для добавления источников данных их источники и поля добавляются в отдельных шагах. Однако вы всегда можете добавить дополнительные источники позже.
-
На вкладке Создание в группе Другое нажмите кнопку Конструктор запросов.
-
Дважды щелкните каждый источник данных, который вы хотите использовать, или выберите каждый из них, а затем нажмите кнопку «Добавить».
Автоматическое соединение
Если между добавляемыми источниками данных уже заданы отношения, они автоматически добавляются в запрос в качестве соединений. Соединения определяют, как именно следует объединять данные из связанных источников. Access также автоматически создает соединение между двумя таблицами, если они содержат поля с совместимыми типами данных и одно из них — первичный ключ.
Вы можете настроить соединения, добавленные приложением Access. Access выбирает тип создаваемого соединения на основе отношения, которое ему соответствует. Если Access создает соединение, но для него не определено отношение, Access добавляет внутреннее соединение.
Если приложение Access при добавлении источников данных автоматически создало соединения правильных типов, вы можете перейти к действию 3 (добавление выводимых полей).
Повторное использование одного источника данных
В некоторых случаях необходимо соединить две копии одной и той же таблицы или запроса, называемые запросом самосоединение, которые объединяют записи из одной таблицы при совпадении значений в соединитьые поля. Например, допустим, что у вас есть таблица «Сотрудники», в которой в поле «ОтчетЫВ» для записи каждого сотрудника вместо имени отображается его имя руководителя. Вместо этого вы можете самостоятельно отобразить имя руководителя в записях каждого сотрудника.
При добавлении источника данных во второй раз Access присвоит имени второго экземпляра окончание «_1». Например, при повторном добавлении таблицы «Сотрудники» ее второй экземпляр будет называться «Сотрудники_1».
Действие 2. Соедините связанные источники данных
Если у источников данных, которые вы добавляете в запрос, уже есть связи, Access автоматически создает внутреннее присоединение для каждой связи. Если целостность данных, access также отображает «1» над линией связи, чтобы показать, какая таблица находится на стороне «один» отношение «один-ко-многим», и символ бесконечности(∞),чтобы показать, какая таблица находится на стороне «многие».
Если вы добавили в запрос другие запросы и не создали между ними отношения, Access не создает автоматических соединений ни между ними, ни между запросами и таблицами, которые не связаны между собой. Если Access не создает соединения при добавлении источников данных, как правило, их следует создать вручную. Источники данных, которые не соединены с другими источниками, могут привести к проблемам в результатах запроса.
Кроме того, можно сменить тип соединения с внутреннего на внешнее соединение, чтобы запрос включал больше записей.
Добавление соединения
-
Чтобы создать соединение, перетащите поле из одного источника данных в соответствующее поле в другом источнике.
Access добавит линию между двумя полями, чтобы показать, что они соединены.

Изменение соединения
-
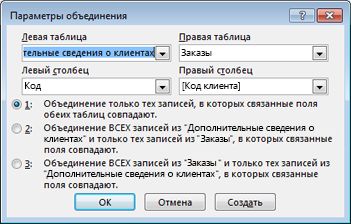
Дважды щелкните соединение, которое требуется изменить.
Откроется диалоговое окно Параметры соединения.
-
Ознакомьтесь с тремя вариантами в диалоговом окне Параметры соединения.
-
Выберите нужный вариант и нажмите кнопку ОК.
После создания соединений можно добавить выводимые поля: они будут содержать данные, которые должны отображаться в результатах.
Действие 3. Добавьте выводимые поля
Вы можете легко добавить поле из любого источника данных, добавленного в действии 1.
-
Для этого перетащите поле из источника в верхней области окна конструктора запросов вниз в строку Поле бланка запроса (в нижней части окна конструктора).
При добавлении поля таким образом Access автоматически заполняет строку Таблица в таблице конструктора в соответствии с источником данных поля.
Совет: Чтобы быстро добавить все поля в строку «Поле» бланка запроса, дважды щелкните имя таблицы или запроса в верхней области, чтобы выделить все поля в нем, а затем перетащите их все сразу вниз на бланк.
Использование выражения в качестве выводимого поля
Вы можете использовать выражение в качестве выводимого поля для вычислений или создания результатов запроса с помощью функции. В выражениях могут использоваться данные из любых источников запроса, а также функции, например Format или InStr, константы и арифметические операторы.
-
В пустом столбце таблицы запроса щелкните строку Поле правой кнопкой мыши и выберите в контекстном меню пункт Масштаб.
-
В поле Масштаб введите или вставьте необходимое выражение. Перед выражением введите имя, которое хотите использовать для результата выражения, а после него — двоеточие. Например, чтобы обозначить результат выражения как «Последнее обновление», введите перед ним фразу Последнее обновление:.
Примечание: С помощью выражений можно выполнять самые разные задачи. Их подробное рассмотрение выходит за рамки этой статьи. Дополнительные сведения о создании выражений см. в статье Создание выражений.
Действие 4. Укажите условия
Этот этап является необязательным.
С помощью условий можно ограничить количество записей, которые возвращает запрос, выбирая только те из них, значения полей в которых отвечают заданным критериям.
Определение условий для выводимого поля
-
В таблице конструктора запросов в строке Условие отбора поля, значения в котором вы хотите отфильтровать, введите выражение, которому должны удовлетворять значения в поле для включения в результат. Например, чтобы включить в запрос только записи, в которых в поле «Город» указано «Рязань», введите Рязань в строке Условие отбора под этим полем.
Различные примеры выражений условий для запросов можно найти в статье Примеры условий запроса.
-
Укажите альтернативные условия в строке или под строкой Условие отбора.
Когда указаны альтернативные условия, запись включается в результаты запроса, если значение соответствующего поля удовлетворяет любому из указанных условий.
Условия для нескольких полей
Условия можно задать для нескольких полей. В этом случае для включения записи в результаты должны выполняться все условия в соответствующей строке Условия отбора либо Или.
Настройка условий на основе поля, которое не включается в вывод
Вы можете добавить в запрос поле, но не включать его значения в выводимые результаты. Это позволяет использовать содержимое поля для ограничения результатов, но при этом не отображать его.
-
Добавьте поле в таблицу запроса.
-
Снимите для него флажок в строке Показывать.
-
Задайте условия, как для выводимого поля.
Действие 5. Рассчитайте итоговые значения
Этот этап является необязательным.
Вы также можете вычислить итоговые значения для числовых данных. Например, может потребоваться узнать среднюю цену или общий объем продаж.
Для расчета итоговых значений в запросе используется строка Итого. По умолчанию строка Итого не отображается в режиме конструктора.
-
Когда запрос открыт в конструкторе, на вкладке «Конструктор» в группе «Показать или скрыть» нажмите кнопку Итоги.
Access отобразит строку Итого на бланке запроса.
-
Для каждого необходимого поля в строке Итого выберите нужную функцию. Набор доступных функций зависит от типа данных в поле.
Дополнительные сведения о функциях строки «Итого» в запросах см. в статье Суммирование или подсчет значений в таблице с помощью строки «Итого».
Действие 6. Просмотрите результаты
Чтобы увидеть результаты запроса, на вкладке «Конструктор» нажмите кнопку Выполнить. Access отобразит результаты запроса в режиме таблицы.
Чтобы вернуться в режим конструктора и внести в запрос изменения, щелкните Главная > Вид > Конструктор.
Настраивайте поля, выражения или условия и повторно выполняйте запрос, пока он не будет возвращать нужные данные.
К началу страницы
Для
выборки информации из таблиц базы данных
используется SQL-инструкций SELECT (выбрать)
языка SQL.
Упрощенный
синтаксис SQL-инструкций SELECT
в общем случае выглядит следующим
образом:
SELECT
[DISTINCT]
<СПИСОК АТРИБУТОВ>
FROM
<список таблиц> [WHERE
<условие выборки >]
[ORDER
BY
<СПИСОК АТРИБУТОВ>]
[GROUP
BY
<список атрибутов>]
[HAVING
<условие>]
[UNION
<выражение с оператором SELECT>];
Примечание:
в квадратных скобках указаны
элементы, которые могут отсутствовать
в запросе.
Ключевое
слово SELECT
сообщает базе данных, что данное
предложение является запросом на
извлечение информации. После слова
SELECT
через запятую перечисляются наименования
полей (список атрибутов), содержимое
которых запрашивается.
Обязательным
ключевым словом в предложении-запросе
SELECT
является слово FROM
(из). За ключевым словом FROM
указывается список разделенных запятыми
имен таблиц, из которых извлекается
информация.
3. Содержание работы
Задание
№1.
Создать запрос на выборку в режиме SQL
всех значений полей ИМЯ и ФАМИЛИЯ из
таблицы СПИСОК.
Перейдите
на вкладку Запросы,
щелкнув в Окне базы данных кнопку
Запросы.
Нажмите
кнопку Создать
и
в открывшемся окне Новый
запрос
выберите
Конструктор.
Нажмите
кнопку ОК, в открывшемся окне Добавление
таблицы кнопку
Закрыть.
Щелкните
на раскрывающемся списке кнопки Вид на
панели инструментов и выберите режим
SQL.
В
открывшемся окне Запрос
1: запрос на
выборку наберите:
SELECT
ИМЯ, ФАМИЛИЯ
FROM
СПИСОК;
Для
запуска запроса нажмите кнопку Запуск
на
панели инструментов.
Задание
№2.
Создать запрос на выборку в режиме SQL
всех столбцов таблицы СПИСОК.
Вместо
перечисления имен столбцов можно
использовать символ «*» (звездочка).
SELECT
*
FROM
СПИСОК;
Результатом
выполнения запроса будет вся таблица
СПИСОК.
Задание
№3.
Создать запрос на выборку в режиме SQL
названий городов, где проживают студенты,
сведения о которых находятся в таблице
ЛИЧНЫЕ_ДАННЫЕ.
SELECT
ГОРОД
FROM
ЛИЧНЫЕ_ДАННЫЕ;
Результатом
запроса будет таблица, в которой
будут встречаться одинаковые строки.
Внимание!
Получаемые в результате SQL-запроса
таблицы не в полной мере отвечают
определению реляционного отношения. В
частности, в них могут оказаться кортежи
с одинаковыми значениями атрибутов.
Для
исключения из результата SELECT
запроса повторяющихся записей используется
ключевое слово DISTINCT
(отличный). Если запрос SELECT
извлекает множество полей, то DISTINCT
исключает дубликаты строк, в которых
значения всех выбранных полей идентичны.
Предыдущий
запрос можно записать в следующем виде.
SELECT
DISTINCT
ГОРОД
FROM
ЛИЧНЫЕ_ДАННЫЕ;
В
результате получим таблицу, в которой
дубликаты строк исключены.
Ключевое
слово ALL
(все), в отличие от DISTINCT,
оказывает противоположное действие,
то есть при его использовании повторяющиеся
строки включаются в состав выходных
данных. Режим, задаваемый ключевым
словом ALL,
действует по умолчанию, поэтому в
реальных запросах для этих целей оно
практически не используется.
Задание
№4.
Создать запрос на выборку в режиме SQL,
выполняющий выборку имен всех студентов
с фамилией Воробьёв, сведения о которых
находятся в таблице СПИСОК.
Для
задания в запросе условия отбора
используется ключевое слово
WHERE
(где), принимающее значение истина или
ложь для значении полей строк таблиц,
к которым обращается оператор
SELECT.
Предложение WHERE
определяет, какие строки указанных
таблиц должны быть выбраны. В таблицу,
являющуюся результатом запроса,
включаются только те строки, для которых
условие (предикат), указанное в
предложении WHERE
принимает значение истина.
Запрос
будет выглядеть следующим образом:
SELECT
ФАМИЛИЯ,
ИМЯ
FROM
СПИСОК
WHERE
ФАМИЛИЯ=’Воробьёв’;
Задание
№5.
Создать запрос на выборку в режиме SQL
для получения имен и фамилий студентов,
обучающихся в группе УИТ-41 и получающих
стипендию (размер стипендии больше
нуля).
В
задаваемых в предложении WHERE
условиях могут использоваться операции
сравнения, определяемые операторами
= (равно), > (больше), < (меньше), >=
(больше или равно), < = (меньше или
равно), <>
(не
равно), а также логические операторы
AND,
OR
и NOT.
SQL-запрос
будет выглядеть таким образом:
SELECT
ИМЯ,
ФАМИЛИЯ
FROM
СПИСОК
WHERE
ГРУППА
=’УИТ-41’ AND
СТИПЕНДИЯ> 0;
Задание
№6.
Создать запрос в режиме SQL.
на выборку из таблицы ЛИЧНЫЕ_ДАННЫЕ
сведении о студентах, имеющих оценки
по физике только 4 и 5.
При
задании логического условия в предложении
WHERE
могут быть использованы операторы IN,
BETWEEN,
LIKE,
IS
NULL.
Операторы
IN
(равен любому из списки) и NOT
IN
(не равен ни одному из списка) используются
для сравнения проверяемого значения
поля с заданным списком. Этот список
значений указывается в скобках справа
от оператора IN.
Построенный
с использованием IN
предикат (условие) считается истинны,
если значение поля, имя которого указано
слева от IN,
совпадает (подразумевается точное
совпадение) с одним из значений,
перечисленных в списке, указанном в
скобках справа от IN.
Предикат,
построенный с использованием NOT
IN,
считается истинным, если значение поля,
имя которого указано слева от NOT
IN,
не совпадает ни с одним из значений,
перечисленных в списке, указанном в
скобках справа от NOT
IN.
Запрос
будет выглядеть следующим образом:
SELECT
*
FROM
ЛИЧНЫЕ_ДАННЫЕ
WHERE
ФИЗИКА
IN
(4,
5);
Задание
№7.
Coздать
зanpoc
и режиме SQL
на выборку сведений о студентах, не
имеющих ни одной экзаменационной оценки
по физике и математике, равной 4 и 5.
SELECT
*
FROM
ЛИЧНЫЕ_ДАННЫЕ
WHERE
ФИЗИКА
NOT
IN
(4, 5) AND
МАТЕМАТИКА
NOT
IN
(4, 5);
Задание
№8.
Создать запрос в режиме SQL
на выборку записей о преподавателях,
часы которых находятся в пределах между
30 и 40.
Оператор
BETWEEN
используется для проверки условия
вхождении значения поля в заданный
интервал, то есть вместо списка
значений атрибута этот оператор задает
границы его изменения.
Оператор
BETWEEN
может использоваться как для числовых,
так и для символьных типов полей.
Зanpoc
будет иметь вид:
SELECT
*
FROM
ГРУППЫ
WHERE
ЧАСЫ
BETWEEN
30
AND
40;
Граничные
значения, в данном случае значения
30 и 40, входят во множество значений,
с которыми производится сравнение.
Задание
№9.
Создать запрос в режиме SQL
на выборку из таблицы СПИСОК сведений
о студентах, фамилии которых начинаются
на букву «В».
Опеpamop
LIKE
применим только к символьным полям.
Этот оператор просмаmpueaem
строковые значения полей с целью
определения, входит ли
Заданная
в операторе LIKE
подстрока (образец поиска) в символьную
строку-значение проверяемого поля.
SELECT*
FROM
СПИСОК
WHERE
ФАМИЛИЯ
LIKE
‘В*’;
Методы выборки: Типы с примерами
Опубликовано 2023-02-11 19:53 пользователем

Выборка является важной частью любого исследовательского проекта. Правильный метод выборки может сделать или разрушить достоверность вашего исследования, и очень важно выбрать правильный метод для вашего конкретного вопроса. В этой статье мы подробно рассмотрим некоторые из наиболее популярных методов выборки и приведем реальные примеры того, как их можно использовать для сбора точных и надежных данных.
От простой случайной выборки до сложной стратифицированной выборки, мы рассмотрим плюсы, минусы и лучшие практики каждого метода. Итак, независимо от того, являетесь ли вы опытным исследователем или только начинаете свой путь, эта статья — обязательное чтение для всех, кто хочет освоить методы выборки. Давайте начнем!
Индекс содержания
- Что такое выборка?
- Типы выборки: методы выборки
- Типы вероятностной выборки с примерами:
- Использование вероятностной выборки
- Типы не вероятностной выборки с примерами
- Использование не вероятностной выборки
- Как вы решаете, какой тип выборки использовать?
- Разница между вероятностной и не вероятностной выборкой
- Вывод
Что такое выборка?
Выборка — это техника отбора отдельных членов или подмножества населения для того, чтобы сделать на их основе статистические выводы и оценить характеристики всего населения. Различные методы выборки широко используются исследователями в маркетинговых исследованиях, так что им не нужно изучать все население, чтобы получить действенные выводы.
Это также удобный и экономически эффективный метод, и поэтому он составляет основу любого плана исследования. Методы выборки могут быть использованы в программном обеспечении для проведения исследовательских опросов для получения оптимальных результатов.
Например, предположим, производитель лекарств хотел бы исследовать неблагоприятные побочные эффекты лекарства на население страны. В этом случае практически невозможно провести исследование, в котором участвовали бы все. В этом случае исследователь определяет выборку людей из каждой демографической группы и затем исследует их, получая ориентировочные данные о поведении препарата.
Узнайте больше об Аудитории
Типы выборки: Методы выборки
Выборка в исследованиях рыночных действий бывает двух типов — вероятностная и не вероятностная выборка. Давайте подробнее рассмотрим эти два метода выборки.
- Вероятностная выборка: Вероятностная выборка — это метод выборки, при котором исследователь выбирает несколько критериев и отбирает членов популяции случайным образом. При таком параметре отбора все члены имеют равную возможность участвовать в выборке.
- Невероятностная выборка: При невероятностной выборке исследователь случайным образом выбирает членов для исследования. Этот метод выборки не является фиксированным или заранее определенным процессом отбора. Это затрудняет для всех элементов населения равные возможности быть включенными в выборку.
В этом блоге обсуждаются различные вероятностные и не вероятностные методы выборки, которые вы можете применить в любом исследовании рынка.
Типы вероятностной выборки с примерами:
Вероятностная выборка — это метод, при котором исследователи выбирают образцы из большей совокупности на основе теории вероятности. Этот метод выборки учитывает каждого члена популяции и формирует выборки на основе фиксированного процесса.
Например, в популяции из 1000 человек каждый член имеет шанс 1/1000 быть отобранным для включения в выборку. Вероятностная выборка устраняет смещение выборки в популяции и позволяет включить в выборку всех членов.
Существует четыре типа методов вероятностной выборки:

- Простая случайная выборка: Одним из лучших методов вероятностной выборки, который помогает экономить время и ресурсы, является метод простой случайной выборки. Это надежный метод получения информации, при котором каждый отдельный член популяции выбирается случайно, чисто случайно. Например, в организации из 500 сотрудников, если команда HR решит провести мероприятия по сплочению коллектива, они, скорее всего, предпочтут выбирать фишки из миски. В этом случае каждый из 500 сотрудников имеет равную возможность быть отобранным.
- Кластерная выборка: Кластерная выборка — это метод, при котором исследователи делят всю совокупность на части или кластеры, представляющие совокупность. Кластеры определяются и включаются в выборку на основе таких демографических параметров, как возраст, пол, местоположение и т.д. Это позволяет создателю опроса сделать эффективные выводы из полученных данных.
Например, предположим, правительство Соединенных Штатов хочет оценить количество иммигрантов, проживающих на материковой части США. В этом случае они могут разделить его на кластеры, основанные на таких штатах, как Калифорния, Техас, Флорида, Массачусетс, Колорадо, Гавайи и т. д. Такой способ проведения опроса будет более эффективным, так как результаты будут распределены по штатам и предоставят глубокие данные об иммиграции. - Систематическая выборка: Исследователи используют метод систематической выборки для отбора членов выборки из популяции через регулярные промежутки времени. Он требует выбора начальной точки для выборки и размера выборки, который можно повторять через регулярные промежутки времени. Этот метод выборки имеет заранее определенный диапазон; следовательно, этот метод выборки наименее трудоемкий.
Например, исследователь намеревается собрать систематическую выборку из 500 человек в популяции численностью 5000 человек. Он/она пронумерует каждый элемент популяции от 1 до 5000 и выберет каждого 10-го человека для включения в выборку (Общая популяция/Размер выборки = 5000/500 = 10). - Стратифицированная случайная выборка: Стратифицированная случайная выборка — это метод, при котором исследователь делит популяцию на более мелкие группы, которые не пересекаются, но представляют всю популяцию. Например, исследователь, желающий проанализировать характеристики людей, принадлежащих к различным группам по годовому доходу, создает страты (группы) в соответствии с годовым доходом семьи. Например, менее $20 000, $21 000 — $30 000, $31 000 — $40 000, $41 000 — $50 000 и т. д. Таким образом, исследователь делает вывод о характеристиках людей, принадлежащих к различным группам доходов. Маркетологи могут проанализировать, на какие группы доходов ориентироваться, а какие исключить, чтобы создать дорожную карту, которая принесет плодотворные результаты.
Uses of probability sampling
Существует множество вариантов использования вероятностной выборки:
- Снижение погрешности выборки: При использовании метода вероятностной выборки погрешность выборки, полученной из совокупности, незначительна или вообще отсутствует. Выборка в основном отражает понимание и умозаключения исследователя. Вероятностная выборка приводит к более качественному сбору данных, поскольку выборка адекватно представляет население.
- Разнородное население: Когда население обширно и разнообразно, важно иметь адекватное представительство, чтобы данные не были перекошены в сторону одной демографической группы. Например, предположим, что компания Square хотела бы понять, какие люди могли бы использовать ее устройства в точках продаж. В этом случае поможет опрос, проведенный на выборке людей по всей территории США из разных отраслей промышленности и социально-экономического положения.
- Создание точной выборки: Выборка вероятностей помогает исследователям планировать и создавать точную выборку. Это помогает получить четко определенные данные.
Типы не вероятностной выборки с примерами
Не вероятностный метод — это метод выборки, который предполагает сбор обратной связи на основе возможностей исследователя или статистика по отбору выборки, а не на основе фиксированного процесса отбора. В большинстве ситуаций результаты опроса, проведенного с использованием не вероятностной выборки, приводят к искаженным результатам, которые могут не представлять желаемую целевую совокупность. Однако существуют ситуации, например, на предварительных этапах исследования или при ограничении затрат на проведение исследования, когда не вероятностная выборка будет гораздо полезнее, чем другой тип.
Четыре типа непроизводственной выборки лучше объясняют цель этого метода выборки:
- Выборка удобства: Этот метод зависит от легкости доступа к испытуемым, например, опрос покупателей в торговом центре или прохожих на оживленной улице. Обычно его называют выборкой удобства из-за того, что исследователю легко проводить его и вступать в контакт с испытуемыми. Исследователи практически не имеют полномочий для отбора элементов выборки, и он осуществляется исключительно на основе близости, а не репрезентативности. Этот метод не вероятностной выборки используется, когда существуют ограничения по времени и затратам на сбор обратной связи. В ситуациях с ограниченными ресурсами, например, на начальных этапах исследования, используется выборка по удобству.
Например, стартапы и НПО обычно проводят выборку по удобству в торговом центре для распространения листовок о предстоящих событиях или продвижения дела — они делают это, стоя у входа в торговый центр и раздавая брошюры случайным образом. - Суждение или целенаправленная выборка: Суждение или целенаправленная выборка формируется по усмотрению исследователя. Исследователи в обязательном порядке учитывают цель исследования, а также понимание целевой аудитории. Например, когда исследователи хотят понять ход мыслей людей, заинтересованных в получении степени магистра. Критерием отбора будет: «Заинтересованы ли вы в получении степени магистра в …?», а те, кто ответит «нет», будут исключены из выборки.
- Выборка снежного кома: Выборка снежного кома — это метод выборки, который исследователи применяют, когда субъектов трудно отследить. Например, опрос людей без жилья или нелегальных иммигрантов будет чрезвычайно сложным. В таких случаях, используя теорию снежного кома, исследователи могут отследить несколько категорий для опроса и получить результаты. Исследователи также применяют этот метод выборки, когда тема очень чувствительна и не обсуждается открыто — например, опросы для сбора информации о ВИЧ СПИДе. Не многие жертвы охотно ответят на вопросы. Тем не менее, исследователи могут связаться с людьми, которых они могут знать, или с волонтерами, связанными с этим делом, чтобы установить контакт с жертвами и собрать информацию.
- Квотная выборка: В квотной выборке при этом методе отбор участников происходит на основе заранее установленного стандарта. В этом случае, поскольку выборка формируется по определенным признакам, созданная выборка будет обладать теми же качествами, которые встречаются в генеральной совокупности. Это быстрый метод сбора выборки.
Uses of non-probability sampling
Невероятностная выборка используется для следующего:
- Создание гипотезы: Исследователи используют метод непропорциональной выборки для создания предположения, когда имеется ограниченная или вообще отсутствует предварительная информация. Этот метод помогает немедленно получить данные и создает базу для дальнейшего исследования.
- Исследовательские исследования: Исследователи широко используют этот метод выборки при проведении качественных исследований, пилотных исследований или исследовательских работ.
- Бюджет и временные ограничения: Невероятностный метод применяется, когда есть бюджетные и временные ограничения, и необходимо собрать некоторые предварительные данные. Поскольку схема опроса не является жесткой, проще выбрать респондентов случайным образом и попросить их пройти опрос или анкетирование.
Как вы решаете, какой тип выборки использовать?
Для любого исследования важно точно выбрать метод выборки, чтобы он соответствовал целям вашего исследования. Эффективность выборки зависит от различных факторов. Вот несколько шагов, которым следуют опытные исследователи, чтобы выбрать оптимальный метод выборки.
- Запишите цели исследования. Как правило, это должно быть сочетание стоимости, точности или аккуратности.
- Определите эффективные методы выборки, которые потенциально могут достичь целей исследования.
- Протестируйте каждый из этих методов и проверьте, помогают ли они достичь цели.
- Выберите метод, который лучше всего подходит для исследования.
Откройте силу точной выборки!
Разница между вероятностной и не вероятностной выборкой
Выше мы рассмотрели различные типы методов выборки и их подтипы. Однако, чтобы подытожить все обсуждение, ниже приведены существенные различия между вероятностными и не вероятностными методами выборки:
| Вероятностные методы выборки | Невероятностные методы выборки. | |
| Определение | Вероятностная выборка — это метод выборки, при котором выборки из большей совокупности отбираются с помощью метода, основанного на теории вероятности. | Невероятностная выборка — это метод выборки, при котором исследователь отбирает образцы на основе субъективного суждения исследователя, а не случайного отбора. |
| Альтернативно известный как | Случайный метод выборки. | Неслучайный метод выборки |
| Отбор популяции | Популяция отбирается случайным образом. | Население выбрано произвольно. |
| Натура | Исследование является окончательным. | Исследование является исследовательским. |
| Выборка | Поскольку существует метод определения выборки, демографические характеристики населения представлены убедительно. | Поскольку метод выборки произволен, демографические характеристики населения представлены почти всегда искаженно. |
| Время, затрачиваемое | На проведение исследования требуется больше времени, поскольку план исследования определяет параметры отбора до начала маркетингового исследования. | Этот тип выборочного метода является быстрым, поскольку ни выборка, ни критерии отбора выборки не определены. |
| Результаты | Данный тип выборки является полностью беспристрастным, следовательно, результаты также являются убедительными. | Данный тип выборки является полностью необъективным, следовательно, результаты также являются необъективными, что делает исследование спекулятивным. |
| Гипотеза | При вероятностной выборке существует основная гипотеза до начала исследования, и этот метод направлен на доказательство гипотезы. | При не вероятностной выборке гипотеза выводится после проведения исследования. |
Вывод
Теперь, когда мы узнали, как работают различные методы выборки, которые широко используются исследователями в маркетинговых исследованиях, чтобы им не нужно было исследовать все население для сбора действенных выводов, давайте рассмотрим инструмент, который может помочь вам управлять этими выводами.
понимает необходимость точного, своевременного и экономически эффективного метода отбора нужной выборки; именно поэтому мы предлагаем программное обеспечение Software — набор инструментов, позволяющих эффективно отбирать целевую аудиторию, управлять полученными данными в организованном, настраиваемом хранилище и управлять сообществом для обратной связи после проведения опроса.
Не упустите шанс повысить ценность исследований.
Попробуйте сегодня!
Рубрика:
- Бизнес
Ключевые слова:
- исследование рынка
Автор:
- Dan Fleetwood
Источник:
- questionpro
Перевод:
- Дмитрий Л
Выборка записей
Выбор данных выполняется командой SELECT.
Ниже приведен примерный список используемых ею конструкций и ключевых слов, полный же список зависит от реализации СУБД:
- AS — определяет временный синоним источника данных или столбца;
- FROM — указывает источники данных как таблицы, представления, другие выборки. По необходимости здесь можно указать соединение источников — каким образом запись одного источника сопоставляется с записью другого;
- WHERE — позволяет указать условия по которым нужно производить отбор данных. Если хоть одно из перечисленных условий не выполняется, запись не попадает в выборку. Здесь также можно указать соединение источников;
- ORDER BY — позволяет отсортировать выборку по указанным полям;
- ASC, DESC — задают направление сортировки;
- GROUP BY — позволяет разбить выборку на группы по указанному полю. Все записи, имеющие одно и то же значение в указанном поле, будут принадлежать одной группе;
- HAVING — позволяет задать условие включения группы в выборку. Набор возможных условий как у WHERE плюс возможность использования агрегатных функций;
- FOR UPDATE — позволяет заблокировать выбранные данные для изменения;
- DISTINCT — позволяет включить в выборку только уникальные записи. Конечно это замедляет запрос, но бывает необходимо при использовании агрегатных функций.
Это наверно самая сложная команда, поэтому ее изучение лучше разбить на несколько частей. Здесь рассмотрим эту команду в общем, а соединения, группировку данных и подобное более детально чуть позже. Пусть имеется следующая таблица с указанными данными.
-- создание таблицы create table tblname ( id integer, num double precision, constraint pk_tblname primary key (id) ); -- вставка данных insert into tblname values(1,2.0); insert into tblname values(2,3.3); insert into tblname values(3,6.6); insert into tblname values(4,2.0); insert into tblname values(5,3.3); insert into tblname values(6,6.6); commit;
выборка констант
Для выбора констант может указываться любой источник. Однако, если мы хотим просто
подсчитать значение какого-то выражения, то указывать источник имеющий сотню тысяч записей затратно по ресурсам. Поэтому многие СУБД позволяют выбрать константы без указания источника. Oracle не поддерживает синтаксис SELECT без FROM, а для выбора констант используется специальная системная таблица dual.
-- вычисляем три простых выражения SELECT 2+2, 2*2 , 2/2; SELECT 2+2, 2*2 , 2/2 FROM dual; -- для Oracle -- в выборке будет 6 одинаковых записей SELECT 2+2, 2*2 , 2/2 FROM tblname;
выборка по столбцам таблиц
Если источники данных указаны, то кроме констант можно выбирать столбцы или строить выражения с их использованием. Столбец определяется как имя_источника.имя_столбца. Если источник данных один, то его имя можно опустить. Для выбора всех столбцов всех источников используется символ *. Аналогично можно выбрать все столбцы указанного источника: имя_источника.*. Ниже приведен пример выборки всех записей нашей таблицы.
-- перечисляем столбцы SELECT tblname.id, tblname.num FROM tblname; SELECT tblname.num FROM tblname; SELECT tblname.num*2 FROM tblname; -- все столбцы указанного источника SELECT tblname.* FROM tblname; -- все столбцы всех источников SELECT * FROM tblname;
синонимы (алиасы)
При выборе данных можно назначать временные синонимы источникам данных и используемым столбцам. А в некоторых случаях необходимо. Например, когда источник подзапрос соединяется с другим источником, именование подзапроса обязательно. Другой пример, это объединение нескольких выборок, имена столбцов которых должны совпадать. Ключевое слово AS как правило необязательно, а в Oracle разрешено только для столбцов.
-- t синоним таблицы tblname
SELECT t.id, t.num
FROM tblname AS t; -- не для Oracle
SELECT t.id, t.num
FROM tblname t; -- для всех
-- именование подзапроса, используемого
-- как источник данных
SELECT * FROM (select num from tblname ) t
-- источник подзапрос соединяется
-- с другим источником
SELECT t.tid, t2.num
FROM (
select id as tid, num as tnum
from tblname
) t,
tblname t2
WHERE t.tid=t2.id
-- синоним для столбца
SELECT t.num*2 AS num2 FROM tblname t;
-- "двойное число" русский синоним для столбца
SELECT t.num*2 AS "двойное число"
FROM tblname t;
SELECT t.id "ид", t.num*2 AS "двойное число"
FROM tblname t;
-- `` расширение MySQL
SELECT t.num*2 AS `двойное число` FROM tblname t;
уникальные записи
Записи выборки считаются одинаковыми, если значения соответствующих полей одинаковы. Поэтому для демонстрации distinct на нашей таблице нужно исключить первичный ключ (поле id) из выборки.
-- есть одинаковые записи SELECT t.num FROM tblname t; -- только уникальные записи SELECT DISTINCT t.num FROM tblname t;
Конструкция ORDER BY позволяет последовательно отсортировать сразу по нескольким столбцам. Столбцы, по которым происходит сортировка, желательно проиндексировать.
-- сортировка записей по полю num SELECT * FROM tblname ORDER BY num -- восходящая сортировка SELECT * FROM tblname t ORDER BY t.num ASC -- нисходящая сортировка SELECT * FROM tblname ORDER BY t.num DESC
выборка по условию
Конструкция WHERE позволяет ограничить множество выбираемых записей. Ниже приведено несколько примеров.
SELECT * FROM tblname t WHERE t.id > 3
-- следующие примеры возвращают одни и те же записи
SELECT * FROM tblname t WHERE t.id=2 or t.id=4;
SELECT * FROM tblname t WHERE t.id in (2,4);
SELECT * FROM tblname t
WHERE t.id in(
-- для Oracle: select 2 as c from dual
select 2 as c
union
-- для Oracle: select 4 as c from dual
select 4 as c
); -- для Oracle
SELECT t.* FROM
tblname t,
(
-- для Oracle: select 2 as c from dual
select 2 as c
union
-- для Oracle: select 4 as c from dual
select 4 as c
) t2
WHERE t.id=t2.c;
выборка по группам
И напоследок пару примеров группировки данных.
-- группировка по полям num и id SELECT t.num, t.id FROM tblname t GROUP BY num, id; -- первый столбец будет отсортирован по возрастанию -- второй столбец каждой группы по убыванию SELECT t.num, t.id FROM tblname t GROUP BY num, id ORDER BY num ASC, id DESC -- исключаем из выборки группу 3.3 SELECT t.num, t.id FROM tblname t GROUP BY num, id HAVING num!=3.3 ORDER BY num ASC, id DESC
Соединения (Join)
Этот раздел написан на основе материалов сайта Javenue.
Ключевое слово join в SQL используется при построении select выражений. Инструкция Join позволяет объединить колонки из нескольких таблиц в одну. Объединение происходит временное и целостность таблиц не нарушается. Существует три типа join-выражений:
- inner join;
- outer join;
- cross join;
В свою очередь, outer join может быть left, right и full (слово outer обычно опускается).
В качестве примера (DBMS Oracle) создадим две простые таблицы и сконструируем для них SQL-выражения с использованием join.
В первой таблице будет хранится ID пользователя и его nick-name, а во второй — ID ресурса, имя ресурса и ID пользователя, который может этот ресурс администрировать.
create table t_users ( t_id number(11, 0), t_nick varchar(16), primary key (t_id) ) create table t_resources ( t_id number(11, 0), t_name varchar(16), t_userid number (11, 0), primary key (t_id) )
Содержимое таблиц пусть будет таким:
T_ID T_NICK 1 user1 3 user3 4 user4 T_ID T_NAME T_USERID 1 res1 3 2 res2 1 3 res3 2 5 res5 3
Конструкция join выглядит так:
... join_type join table_name on condition ...
Где join_type — тип join-выражения, table_name — имя таблицы, которая присоединяется к результату, condition — условие объединения таблиц.
Кострукция join располагается сразу после select-выражения. Можно использовать несколько таких конструкций подряд для объединения соответствующего кол-ва таблиц. Логичнее всего использовать join в том случае, когда таблица имеет внешний ключ (foreign key).
Inner join необходим для получения только тех строк, для которых существует соответствие записей главной таблицы и присоединяемой. Иными словами условие condition должно выполняться всегда. Пример:
select t_resources.t_name, t_users.t_nick from t_resources inner join t_users on t_users.t_id = t_resources.t_userid
Результат будет таким:
T_NAME T_NICK res2 user1 res1 user3 res5 user3
В случае с left join из главной таблицы будут выбраны все записи, даже если в присоединяемой таблице нет совпадений, то есть условие condition не учитывает присоединяемую (правую) таблицу. Пример:
select t_resources.t_name, t_users.t_nick from t_resources left join t_users on t_users.t_id = t_resources.t_userid
Результат выполнения запроса:
T_NAME T_NICK res1 user3 res2 user1 res3 (null) res5 user3
Результат показывает все ресурсы и их администраторов, вне зависимотсти от того есть они или нет.
Right join отображает все строки удовлетворяющие правой части условия condition, даже если они не имеют соответствия в главной (левой) таблице:
select t_resources.t_name, t_users.t_nick from t_resources right join t_users on t_users.t_id = t_resources.t_userid
А результат будет следующим:
T_NAME T_NICK res2 user1 res1 user3 res5 user3 (null) user4
Результирующая таблица показывает ресурсы и их администраторов. Если адмнистратор не задействован, эта запись тоже будет отображена. Такое может случиться, например, если ресурс был удален.
Full outer join (ключевое слово outer можно опустить) необходим для отображения всех возможных комбинаций строк из нескольких таблиц. Иными словами, это объединение результатов left и right join.
select t_resources.t_name, t_users.t_nick from t_resources full join t_users on t_users.t_id = t_resources.t_userid
А результат будет таким:
T_NAME T_NICK res1 user3 res2 user1 res3 (null) res5 user3 (null) user4
Некоторые СУБД не поддерживают такую функциональность (например, MySQL), в таких случаях обычно используют объединение двух запросов:
select t_resources.t_name, t_users.t_nick from t_resources left join t_users on t_users.t_id = t_resources.t_userid union select t_resources.t_name, t_users.t_nick from t_resources right join t_users on t_users.t_id = t_resources.t_userid
Наконец, cross join. Этот тип join еще называют декартовым произведением (на английском — cartesian product). Настоятельно рекомендую использовать его с умом, так как время выполнения запроса с увеличением числа таблиц и строк в них растет нелинейно. Вот пример запроса, который аналогичен cross join:
select t_resources.t_name, t_users.t_nick from t_resources, t_users
Агрегатные функции, группировка данных
Для группировки данных в запросе select используется конструкция group by,
в которой должны быть перечислены те же столбцы, что и после select. Ниже приведен
пример вывода данных по группам для таблицы bills.
-- таблица счетов
create table bills(
id integer,
d date, -- дата счета
summ double precision ,-- сумма счета
constraint pk_bills primary key (id)
);
-- вставка данных
insert into bills
values(1, date '2008-01-01', 5.5);
insert into bills
values(2, date '2008-02-01', 3.14);
insert into bills
values(3, date '2008-03-01', 10.14);
insert into bills
values(4, date '2008-01-01', 7.2);
insert into bills
values(5, date '2008-02-01', 6.4);
insert into bills
values(6, date '2008-03-01', 2.5);
commit;
-- вывод данных по группам
select t.d, t.summ from bills t
group by t.d, t.summ
Сами по себе группы редко используются, и предыдущий пример выборки можно заменить
сортировкой. Другое дело, если необходимо воспользоваться одной из групповых функций,
называемых агрегатными:
- avg([DISTINCT|ALL] column) — среднее значение по указанному столбцу;
- count(*|[DISTINCT|ALL] соlumn) — количество элементов в выборке
или в группе определяемой указанным столбцом; - sum([DISTINCT | ALL] соlumn) — сумма значений указанного столбца;
- max(соlumn) — максимальное значение в столбце;
- min(соlumn) — минимальное значение в столбце.
Ключевое слово DISTINCT позволяет игнорировать повторные значения в столбце, ALL
обрабатывает все значения в столбце (по умолчанию), * позволяет включить в обработку поля с null значением.
В MySQL между именем функции и скобкой не должно быть пробелов.
Ниже приведен пример использования агрегатных функций в качестве выбираемых данных. Если
агрегатная функция используется в выборке без group by, то она применяется ко всем записям
выборки, иначе для каждой группы в отдельности. И в любом случае в перечислении select нельзя
смешивать групповые столбцы с не групповыми.
-- статистические данные по всем месяцам
select count(*) as "число записей",
max(t.summ) as "макс. сумма",
min(t.summ) as "мин. сумма",
avg(t.summ) as "средняя сумма",
sum(t.summ) as "общая сумма"
from bills t;
-- статистические данные по каждому месяцу
select t.d as "месяц", count(1) as "число записей",
max(t.summ) as "макс. сумма",
min(t.summ) as "мин. сумма",
avg(t.summ) as "средняя сумма",
sum(t.summ) as "общая сумма"
from bills t
group by t.d
Агрегатные функции можно использовать в выражениях условия в конструкции having для
отбора группы.
-- отбираем группы у которых общая сумма больше 12
select t.d as "месяц", count(*) as "число записей",
max(t.summ) as "макс. сумма",
min(t.summ) as "мин. сумма",
avg(t.summ) as "средняя сумма",
sum(t.summ) as "общая сумма"
from bills t
group by t.d
having sum(t.summ)>12
Операции над выборками
Так как выборка по сути является множеством, то и доступные операции над ними
соответствующие:
- UNION — объединение, в конечной выборке записи из обоих запросов;
- INTERSECT — пересечение, в конечной выборке записи входящие в оба запроса;
- EXCEPT — исключение, в конечной выборке записи входящие только в первый запрос.
Запросы участвующие в таких операциях должны следовать нескольким условиям.
Иметь одинаковое число столбцов, соответствующие столбцы должны быть одного типа.
Тип данных столбца должен быть простым, т.е. не разрешаются типы подобные blob.
MySQL 5 поддерживает только UNION, в Oracle EXCEPT для других целей,
а для исключения используется MINUS.
-- from dual только для Oracle -- в MySQL нельзя заключить -- запросы в круглые скобки select 1 as i from dual UNION select 2 as i from dual UNION -- попробуйте также INTERSECT и EXCEPT select 2 as i from dual UNION select 3 as i from dual;
По умолчанию в результирующую выборку попадают только уникальные записи.
Для включения всех записей используется ключевое слово ALL после имени операции.
Например, в следующем примере будет две записи со значением 2.
select 1 as i from dual UNION select 2 as i from dual UNION ALL select 2 as i from dual UNION select 3 as i from dual;
Добавление итогов в SQL
Еще раз рассмотрим таблицу bills созданную в пункте об агрегатных функциях.
Предположим мы хотим вывести все суммы, а в конце выборки добавить итоговую сумму.
Наиболее универсальным способом является объединение двух запросов.
-- в MySQL между cast и ( не должно быть пробелов select cast(t.d as char(12)) as d, t.summ from bills t union select 'ИТОГ', sum(t.summ) from bills t;
Для решения подобных задач в стандарте введена конструкция ROLLUP генерирующая
дополнительную строку. Если в определении столбца агрегатная функция не используется,
то соответствующее поле в этой строке заполняется значением null. В противном случае
заполняется значением выражения столбца, причем агрегатная функция выполняется ко
всем записям основной выборки.
-- для Oracle, столбцы группировки перешли в ROLLUP select coalesce(cast(t.d as char(12)),'ИТОГ') as d, sum(t.summ) as summ from bills t group by ROLLUP(t.d, t.summ) -- для MySQL select coalesce(cast(t.d as char(12)),'ИТОГ') as d, sum(t.summ) as summ from bills t group by t.d, t.summ WITH ROLLUP;
А теперь предположим мы хотим вывести все суммы с итогами по каждой группе и в конце выборки
общий итог. Ниже приведен пример с использованием объединений. Чтобы общий итог был точно в
конце выборки, задаем в поле d максимальню дату. В Oracle и Postgre можно оставить значение
null.
select t.d1, t.summ from (
select
cast(t.d as char(12)) as d1,
t.d,
t.summ
from bills t
union
select -- выборка итогов по группам
'итого' as d1,
t.d,
sum(t.summ) as summ
from bills t
group by t.d
union
select -- выборка общего итога
'ИТОГО' as d1,
DATE '9999-01-01' as d,
sum(t.summ) as summ
from bills t
) t
order by d,summ
Подобную задачу можно решить с помощью стандартной конструкции CUBE, если она уже
реализована в СУБД. Куб генерирует не только общий итог, но и все возможные под итоги.
Ниже приведен пример использования куба. Для упрощения кода пустые значения не заменяются.
select * from (
select
t.d,
t.summ,
sum(t.summ) as itog
from bills t
-- для MySQL: group by t.d, t.summ WITH CUBE
group by cube(t.d, t.summ) -- для Oracle
order by d
) t
where -- убираем не нужные под итоги
not(t.summ=itog and d is null) or
(d is null and summ is null)
Нумерация записей
В стандарт SQL2003 уже добавлена функция row_number(), если она еще не реализована
в вашей версии БД, используйте следующие методы.
Oracle
В Oracle для нумерации записей введен псевдостолбец rownum.
select rownum, t.*
from tblname t
order by id desc
-- rownum можно использовать в условиях
-- попробуйте операции <> и >
select rownum, t.*
from tb t
where rownum < 4
order by id desc;
MySQL
В MySQL для этого надо воспользоваться переменной. Чтобы увидеть результат следующего
примера в MySQLQueryBrowser, необходимо начать транзакцию (на панели кнопка после слова
Transaction). Далее выполняем приведенные в примере команды и затем завершаем транзакцию
(соседняя кнопка с галочкой).
-- устанавливаем значение локальной переменной в 0
-- ее можете назвать как хотите
set @rownum:=0;
-- выборка с нумерацией
select @rownum:=@rownum+1, t.*
from tblname t
order by id desc;
PostgreSQL
В PostgreSQL для этих целей можно выделить последовательность и сбрасывать ее перед новой
выборкой.
-- создаем временную (для текущей сессии)
-- последовательность seqrownum для нумерации записей
create temp sequence seqrownum;
-- сбрасываем последовательность
select setval('seqrownum',1);
-- выборка с нумерацией
select nextval('seqrownum')-1, t.*
from tblseq t
order by id desc;
На уроке будет рассмотрен язык запросов: оператор SELECT sql — на выборку данных
SQL-запрос Select предназначен для обычной выборки из базы данных. Т.е. если нам необходимо просто получить данные, не делая с ними никакой обработки и не внося изменений в базу данных, то можно смело использовать данный запмагарос.
Синтаксис оператора SELECT
SELECT * FROM имя_таблицы;Это самый простой вариант работы с оператором, когда мы выбираем все записи из таблицы БД.
Символ
*обозначает выборку всех записей из таблицы. При этом столбцы и строки результирующего набора не упорядочены.
Рассмотрим примеры sql запросов select:
Пример БД «Институт»: если вы создали локальную базу данных и заполнили таблицы, как в рассмотренном ранее уроке (или же воспользовались сервисом sqlFiddle), то выполним следующий пример.
Необходимо выбрать все записи из таблицы teachers

Чтобы ограничить количество выбранных записей используется служебное слово
LIMIT:SELECT * FROM имя_таблицы LIMIT 2,3;В примере происходит выборка 3 записей из таблицы, начиная со 2 записи.
Этот запрос особо необходим при создании блока страниц навигации.
Чтобы упорядочить поля результирующего набора, их следует перечислить через запятую в нужном порядке после слова
SELECT:
SELECT name, zarplata FROM teachers;
Выберет все значения полей name и zarplata в том же порядке (сначала name, затем zarplata)

Сортировка в SQL
Чтобы выполнить сортировку по любому из полей, указанных в предложении
SELECT, используется предложениеORDER BY:
SELECT name, zarplata, premia FROM teachers ORDER BY name;
Выберет значения полей name, zarplata, premia и отсортирует по полю name (по алфавиту)

Пример: БД «Компьютерный магазин». Выбрать данные о скорости и памяти компьютеров. Требуется упорядочить результирующий набор по скорости процессора в порядке возрастания.
SELECT `Скорость`,`Память` FROM `pc` ORDER BY `Скорость` ASC
Или
SELECT `Скорость`,`Память` FROM `pc` ORDER BY 1 ASC
Результат:

Сортировку можно выполнять по двум полям:
SELECT `Скорость`,`Память` FROM `pc` ORDER BY `Скорость` ASC, `Память` ASC
Задание sql select 1_1. База данных Компьютерный магазин: Получить информацию только о скорости процессора и объеме оперативной памяти компьютеров.
Задание sql select 1_2. База данных Компьютерный магазин: Требуется упорядочить результирующий набор по объему оперативной памяти в порядке убывания.
Сортировку можно производить по возрастанию, тогда добавляется параметр
ASC(он же применяется по умолчанию) или по убыванию (в таком случае добавляется параметрDESC):
SELECT name, zarplata, premia FROM teachers ORDER BY name DESC;
Выберет значения полей name, zarplata, premia и отсортирует по полю name по убыванию

Задание 1_3. БД «Компьютерные курсы». Вывести информацию о фамилиях и годах рождения. Упорядочить результирующий набор по году рождения в порядке убывания.
Удаление повторяющихся значений в SQL
В случае когда необходимо получить уникальные строки, можно использовать ключевое слово
DISTINCT.DISTINCT (в переводе с английского ОТЛИЧИЕ) — аргумент, который устраняет двойные значения:
Пример БД «Институт»: требуется узнать возможные варианты размера премий. Если не использовать Distinct, в результате будет выдаваться два одинаковых значения. Удалить в sql повторяющиеся значения можно при введении Distinct — в результате дублирующиеся значения не повторяются.
SELECT premia FROM teachers;
SELECT DISTINCT premia FROM teachers;


Рассмотрим другой пример из базы данных «Компьютерный магазин»:
Пример: База данных «Компьютерный магазин»: требуется получить информацию только о скорости процессора и объеме оперативной памяти компьютеров
SELECT Скорость, Память FROM PC;
Результат:

В таблице PC первичным ключом является поле code. Поскольку это поле отсутствует в запросе, в приведенном выше результирующем наборе имеются дубликаты строк.
Когда требуется получить уникальные строки (например, нас интересуют только различные комбинации скорости процессора и объема памяти, а не характеристики всех имеющихся компьютеров), то нужно использовать Distinct:
SELECT DISTINCT Скорость, Память FROM PC;
Результат:

Задание sql select 1_3. База данных Компьютерный магазин: Из таблицы Продукты выбрать различные страны-производители.
Задание sql select 1_1. БД «Институт» Выполните запрос на выборку id и name из таблицы учителей. Отсортируйте фамилии учителей по убыванию
Задание sql select 1_2. БД «Институт» Выведите возможные варианты длины курсов (length) из таблицы курсов (courses), удалив повторяющиеся значения
Задание 1_4. БД «Компьютерные курсы». Из таблицы личные данные вывести поля Word и Excell. Получить уникальные строки
Язык sql: where условие
Условие выполняется предложением
WHERE <предикат>
которое записывается после предложенияFROM.При этом в результирующий набор попадут только те записи, для которых значение предиката равно
TRUE(истина).
Пример БД «Институт»: Выводить данные преподавателя из таблицы teachers, фамилия которого Иванов
SELECT * FROM `teachers` WHERE `name` = 'Иванов'

Задание sql select 1_4. База данных Компьютерный магазин: Получить информацию о частоте процессора и объеме оперативной памяти для компьютеров с ценой ниже 6000
Задание sql select 1_5. База данных Компьютерный магазин: Вывести производителей принтеров
Задание 1_5. БД «Компьютерные курсы». Получить информацию по полям Фамилия, Имя, Отчество из таблицы Список, о студентках, имя которых Ольга
Несколько условий в SQL
Предикаты (условия) могут состоять как из одного выражения, так и из любой комбинации выражений, построенных с помощью булевых операторов:
AND,ORили NOT
Пример БД «Институт»: вывести код преподавателя, зарплата которого составляет 10000, а премия 500
SELECT * FROM `teachers` WHERE `zarplata`=10000 AND `premia`=500
Задание sql select 1_2. БД «Институт» Из таблицы courses вывести длину курса (length), название которого — «Программирование SQL»
Реляционные операторы, встречающиеся в условиях:
=Равный
>Больше чем
<Меньше чем
>=Больше чем или равно
<=Меньше чем или равно
<>Не равно
Задание sql select 1_6. База данных «Компьютерный магазин»: Получить информацию о компьютерах, имеющих частоту процессора не менее 500 Мгц и цену ниже 25000
Задание sql select 1_7. База данных «Компьютерный магазин»: Получить информацию обо всех принтерах, которые не являются струйными и стоят меньше 5000
Задание 1_6. БД «Компьютерные курсы». Получить информацию о студентах:
— год рождения которых выше 1983 и обучающихся на первом курсе;
— год рождения которых не 1980 или обучающихся на курсе старше второго.
Between в SQL (между)
Предикат
BETWEENпроверяет, попадают ли значения проверяемого выражения в диапазон, задаваемый пограничными выражениями, соединяемыми служебным словомAND.Синтаксис:
<Проверяемое выражение> [NOT] BETWEEN <Начальное выражение> AND <Конечное выражение>
Пример БД «Институт»: Вывести фамилию и зарплату преподавателя, зарплата которого между 5000 и 10000.
SELECT name, zarplata FROM teachers WHERE (zarplata BETWEEN 5000 AND 10000);

Пример БД «Институт»: Вывести фамилию и зарплату преподавателя, зарплата которого не находится в диапазоне от 5000 до 10000.
SELECT name, zarplata FROM teachers WHERE (zarplata NOT BETWEEN 5000 AND 10000);

Задание sql select 1_8. База данных «Компьютерный магазин»: Требуется найти номер и частоту процессора компьютеров стоимостью от 25000 до 35000
Предикат IN
Предикат
INопределяет, будет ли значение проверяемого выражения обнаружено в наборе значений, который явно определен.Синтаксис:
<Проверяемое выражение> [NOT] IN (<набор значений>)
Пример БД «Институт»: вывести имена преподавателей, зарплата которых составляет 5000, 10000 или 11000
SELECT name, zarplata FROM teachers WHERE (zarplata IN (5000,10000,11000));

Пример БД «Институт»: вывести имена преподавателей, зарплата которых не находится среди значений: 5000, 10000 или 11000
SELECT name, zarplata FROM teachers WHERE (zarplata NOT IN (5000,10000,11000));

Задание sql select 1_3. БД «Институт» Вывести фамилию, зарплату и премию учителей, премия которых от 2000 до 5000 рублей.
Задание sql select 1_9. База данных «Компьютерный магазин»: Требуется найти номер, частоту процессора и объем жесткого диска тех компьютеров, которые комплектуются жесткими дисками 500 или 1000Гб.
Предикат IN с подзапросом
Предикат
INопределяет, будет ли значение проверяемого выражения обнаружено в наборе значений, который получен с помощью табличного подзапроса.Синтаксис:
<Проверяемое выражение> [NOT] IN (<подзапрос>)
Пример: БД «Компьютерный магазин». Найти номер, частоту процессора и объем жесткого диска тех компьютеров, которые имеют частоту процессора 1000, 2000 и 3000 МГц и выпускаются производителем Америка
SELECT `Номер`,`Скорость`,`HD` FROM `pc` WHERE `Скорость` IN (1000,2000,3000) AND `Номер` IN (SELECT `Номер` FROM product WHERE Производитель = "Америка")
Результат:

Задание sql select 10. База данных «Компьютерный магазин»: Найти производителей компьютеров, с частотой процессора не менее 2000 МГц
Задание sql select. База данных Институт: Вывести зарплату тех преподавателей, у которых уже стоят уроки (есть записи в таблице lessons)
Язык SQL запрос LIKE
Предикат
LIKEсравнивает проверяемое значение с шаблоном в выражении.Синтаксис:
<Проверяемое значение>[NOT] LIKE <Выражение>
Пример: Вывести все данные о преподавателях, фамилии которых заканчиваются на "а"
SELECT * FROM teachers WHERE (name LIKE "%а");
Символ % заменяет любую последовательность символов.
Важно: При работе с СУБД Access символ % заменяется на символ *

Задание sql select 14. База данных «Компьютерные курсы». Вывести данные о преподавателях, фамилия которых начинается с м. Упорядочить значения по возрастанию зарплаты
Задание sql select 11. База данных «Компьютерный магазин»: Найти все номера компьютеров, производитель которых начинается на букву «Я»
Задание sql select 12. База данных «Компьютерный магазин»: Найти все номера компьютеров, производитель которых заканчивается на букву «Я» и не начинается с буквы «Р»
Задание 1_10. БД «Компьютерные курсы». Из таблицы Личные данные вывести Адрес студента, номер телефона которого заканчивается цифрами 33
Задание 1_11. БД «Компьютерные курсы». Вывести сведения по студентам из таблицы Список, фамилия которых не заканчивается на «ин»
|
14 / 10 / 6 Регистрация: 27.07.2019 Сообщений: 252 |
|
|
1 |
|
Написать выборку из БЗ23.07.2021, 19:40. Показов 1134. Ответов 5
Здравствуйте. Подскажите как можно написать выборку из базы узнать Ценность дня. По какому условию нужно вытаскивать товары за Ценность дня. Что-то вроде популярные товары за день. Товары которые люди больше всех интересовались за сутки. Какие будут идеи) И 100 лучших предложений как можно реализовать?
__________________
0 |

|
Модератор 8291 / 5511 / 2255 Регистрация: 21.01.2014 Сообщений: 23,707 Записей в блоге: 3 |
|
|
23.07.2021, 21:06 |
2 |
|
Какие будут идеи Идея одна — показать структуру базы и связи между таблицами.
0 |

|
14 / 10 / 6 Регистрация: 27.07.2019 Сообщений: 252 |
|
|
24.07.2021, 13:46 [ТС] |
3 |
|
Идея одна — показать структуру базы Не понял про связи между таблицами. В моем случай связь, идет по двум таблицам. Таблица categories и products. Миниатюры
0 |
|
Невнимательный 2340 / 701 / 254 Регистрация: 08.02.2013 Сообщений: 4,824 Записей в блоге: 2 |
|
|
24.07.2021, 14:06 |
4 |
|
Товары которые люди больше всех интересовались за сутки В products же нет поля с колличеством интересовавшихся. …Если где-то записывается каждое действие интересующегося, Не по теме: Если к полям таблиц, при создании добавляются ещё и комментарии,
0 |

|
Stranger 14 / 10 / 6 Регистрация: 27.07.2019 Сообщений: 252 |
||||||||||||||||
|
24.07.2021, 15:23 [ТС] |
5 |
|||||||||||||||
|
В products же нет поля с количеством интересовавшихся. Да тоже думаю будет правильно хранить количество за сутки.
Но это нужно знать сколько было и сколько стало за тутки. Как-то пока не не ясно. Вот только как продумать последованность. Или как продумать выполнение кода. Создать куку на сутки. По окончании сутки обнулять данное поле в базе.
Что-то на подобии этого сделать. Изначально у меня было поле
Но решил попробовать сделать просто вытаскивать так.
Вроде работает но если не ошибаюсь то идет выборка за 6 дней. Хотя планировалась чтобы выборка шла за неделю(7 дней)
0 |
|
Stranger 14 / 10 / 6 Регистрация: 27.07.2019 Сообщений: 252 |
||||
|
06.11.2021, 14:00 [ТС] |
6 |
|||
|
Здравствуйте. Есть задача изменять поля по дате. Написал такие строки.
Изменяется столбец только `products`.`date_today`, а `products`.`popular_today` не меняется почему? Миниатюры
0 |
|
IT_Exp Эксперт 87844 / 49110 / 22898 Регистрация: 17.06.2006 Сообщений: 92,604 |
06.11.2021, 14:00 |
|
6 |