Главная задача этого поста – показать один мало применяемый на языке Python архитектурный шаблон под названием «функциональное ядро — императивная оболочка», в котором функциональный код концентрируется внутри, а императивный код выносится наружу в попытке свести на нет недостатки каждого из них. Известно, что функциональные языки слабы при взаимодействии с «реальным миром», в частности с вводом данных пользователем, взаимодействием с графическим интерфейсом или другими операциями ввода-вывода. В рамках такого подхода весь код, связанный с вводом-выводом, выталкивается наружу, и внутри остается только функционально-ориентированный код.
Указанный подход задействует возможности Python по работе с функциями в рамках функциональной парадигмы, в которой функциями можно манипулировать точно так же, как и любыми другими объектами: передавать в качестве аргументов в другие функции, возвращать из функций и включать в последовательности в качестве их элементов.
Тем, кому требуется освежить свою память о функциональном программировании на языке Python, рекомендую перейти по ссылке к моему посту об основах ФП на Python.

В отличие от объектно-ориентированного стиля мышления, в котором все внимание сосредоточено на том, как нужно делать, чтобы решить задачу, функциональный стиль мышления сосредоточен на том, что нужно делать. У нас есть данные x. И требуется получить из них некий результат. С этой целью сначала надо применить к ним преобразование f , затем к полученным данным x'применить f2, затем к этим новым даннымx''применить следующее преобразование f3 и т.д. вплоть до получения нужного результата.
Такой образ мыслей отлично укладывается в то, что называется конвейером обработки данных. Конвейер обработки данных состоит из связанных между собой узлов, т.е. функций. Узел характеризуется набором входов и выходов, через которые могут передаваться объекты. Узел ожидает появления того или иного набора объектов на входе, после чего проводит вычисления и порождает объект(ы), которые он передает на выход в следующий узел конвейера.
Конвейер позволяет имплементировать архитектурный шаблон «функциональное ядро — императивная оболочка» в полной мере, выталкивая императивный код наружу. Более того, он позволяет (1) четче мониторить входы и выходы каждого шага внутри конвейера (2) легко отлаживать любой шаг и соответственно отлавливать дефекты, вставляя шаг debug, (3) но главное концентрировать всю логику в одном месте, которую легко можно улавливать одним взглядом.
В функциональных языках конвейеры находят широкое применение, и для их имплементирования даже существуют специальные синтаксические конструкции. Вот как выглядит конвейер на языке F#:
2
|> ( fun x -> x + 5)
|> ( fun x -> x * x)
|> ( fun x -> x.ToString() ) Здесь входные данные, в данном случае число 2, последовательно обрабатываются серией лямбда-функциями, и в результате будет получено строковое значение '49'. Аналогичный конвейер можно имплементировать на надмножестве языка Pyton Coconut следующим образом:
2 |> ( x -> x + 5) |> ( x -> x * x) |> ( x -> str(x)) |> printНа самом языке Python для этого нужно написать специальную функцию, и, разумеется, это будет функция более высокого порядка с использованием цикла:
# Конвейер обработки данных
def pipe(data, *fseq):
for fn in fseq:
data = fn(data)
return dataЛибо с использованием функции reduce из встроенной библиотеки functools:
# Альтернативная имплементация конвейера
from functools import reduce
def pipe(*args): return reduce(lambda x, f: f(x), args)Приведенный ниже пример демонстрирует работу конвейера на языке Python:
pipe(2,
lambda x: x + 5,
lambda x: x * x,
lambda x: str(x))или в более удобном виде:
def add(x): return lambda y: x + y
def square(x): return x * x
def tostring(x): return str(x)
pipe(2,
add(5),
square,
tostring)В обоих имплементациях конвейераpipeпоследовательность функций применяется к обновляемым данным. Функция pipe получает два аргумента: входные данные data и последовательность функций fseq. Во время первой итерации цикла for данные передаются в первую функцию из последовательности. Эта функция обрабатывает данные и возвращает результат, замещая переменную data новыми данными. Затем эти новые данные отправляются во вторую функцию и т.д. до тех пор, пока не будут выполнены все функции последовательности. По завершению своей работы функция pipe возвращает итоговые данные. Это и есть конвейер обработки данных.
Перед тем, как рассматривать конвейер обработки данных детально, сначала для сравнения приведу имплементацию конвейера в парадигме объектно-ориентированного программирования (программный код позаимствован отсюда):
class Factory:
def process(self, input):
raise NotImplementedError
class Extract(Factory):
def process(self, input):
print("Идет извлечение...")
output = {}
return output
class Parse(Factory):
def process(self, input):
print("Идет разбор...")
output = {}
return output
class Load(Factory):
def process(self, input):
print("Идет загрузка...")
output = {}
return output
pipe = {
"Извлечь" : Extract(),
"Разобрать" : Parse(),
"Загрузить" : Load(),
}
inputs = {}
# Конвейерная обработка
for name, instance in pipe.items():
inputs = instance.process(inputs)Вывод программы:
Идет извлечение...
Идет разбор...
Идет загрузка...Здесь в цикле for результат на выходе из предыдущего шага подается на вход следующего шага, как того и требует стандартный конвейер. Однако проблема с объектно-ориентированным подходом заключается в том, что он неявно привносит всю свою ОО среду, о чем емко и шутливо высказался Джо Армстронг, создатель функционально-ориентированного языка Erlang:
Вы хотели получить банан, но получили банан вместе с гориллой, которая его держит, и все джунгли в придачу.
То есть, вам приходится соблюдать всю эту церемонию с def, self, __init__, атрибутами класса и атрибутами экземпляра, инстанцированиями, методами и прочими отличительными особенностями ООП. В следующих ниже рубриках будет рассмотрено несколько примеров применения конвейера обработки данных, как функционального ядра, на основе функциональной парадигмы программирования, используя только одни функции.
Функциональное вычисление факториала числа
В приведенном ниже примере показана нерекурсивная версия алгоритма вычисления факториала (factorial) и его рекурсивной версия на основе более эффективной хвостовой рекурсии (factorial_rec). Детали имплементации обеих функций в данном случае не важны. Они приводятся в качестве примеров, на которых будет продемонстрирована работа конвейера обработки данных. Результат выполнения программы показан ниже.
Приведенная ниже версия является предварительной. Ее недостаток в том, что ее логика развернута внутри конвейера, хотя ввод-вывод данных вынесен наружу.
# Эта программа демонстрирует
# функциональную версию вычисления факториала
def datain():
return int(input('Введите неотрицательное целое число: '))
def dataout():
return lambda tup: print(f'Факториал числа {tup[0]} = {tup[1]}')
def main():
do( # Конвейер (функциональное ядро c нерекурсивным алгоритмом факториала)
datain(),
lambda n: (n, reduce(lambda x, y: x * y, range(1, n + 1))),
dataout()
)
main()Вывод программы:
Введите неотрицательное целое число: 4 (Enter)
Факториал числа 4 = 24Лямбда-функция в последнем узле конвейера (put_data()) получает кортеж, состоящий из введенного пользователем числа и полученного результата.
Приведенная ниже расширенная версия программы вычисления факториала имеет более читабельный вид, т.к. шаги конвейера — ввод данных, алгоритм и вывод данных — выделены в отдельные функции. В нее также добавлен функционал валидации входных данных. Чуть позже будет дано пояснение.
from functools import reduce
# Эта программа демонстрирует
# функциональную версию функции вычисления факториала
def main():
# Алгоритм 1. Рекурсивная версия с хвостовой рекурсией
def factorial_rec(n):
fn = lambda n, acc=1: acc if n == 0 else fn(n - 1, acc * n)
return n, fn(n)
# Алгоритм 2. Нерекурсивная версия
def factorial(n):
return n, reduce(lambda x, y: x * y, range(1, n + 1))
# Ввод данных со своим конвейером внутри
def datain():
def get_int(msg=''): # Утилитная функция
return int(input(msg))
def validate(n): # Валидация входных данных
if not isinstance(n, int):
raise TypeError("Число должно быть целым.")
if not n >= 0:
raise ValueError("Число должно быть >= 0.")
return n
msg = 'Введите неотрицательное целое число: '
return pipe(get_int(msg), validate)
# Вывод данных
def dataout():
def fn(data):
n, fact = data
print(f'Факториал числа {n} равняется {fact}')
return fn
# Конвейер (функциональное ядро)
pipe(datain(), # вход: - выход: int
factorial, # вход: int выход: кортеж
dataout()) # вход: кортеж выход: -
main()Вывод программы:
Введите неотрицательное целое число: 4 (Enter)
Факториал числа 4 равняется 24Функциональным ядром приведенной выше программы являются строки:
pipe(datain(),
factorial,
dataout())Они представлены конвейером из трех узлов, т.е. функциями datain, factorial и dataout. Функция datain занимается получением данных от пользователя, которые затем передаются по конвейеру дальше. Функция factorial является собственно обрабатывающим алгоритмом, в данном случае нерекурсивной функцией вычисления факториала, которая получает данные, их обрабатывает и передает по конвейеру дальше. И функция dataout получает данные и показывает их пользователю. Обратите внимание, что функция datain имеет свой собственный конвейер, который состоит из получения данных от пользователя и их валидации.
Следует отметить два важных момента. Во-первых, передаваемые от узла к узлу данные должны соответствовать какому-то определенному протоколу. Во-вторых, количество узлов может быть любым.
Такая организация программного кода:
-
Позволяет менять узлы конвейера на другие с целью тестирования различных и более эффективных имплементаций алгоритмов. Например, вместо нерекурсивной функции
factorial, можно поместить рекурсивную функциюfactorial_rec.
pipe(datain(), factorial_rec, dataout())-
Облегчает проведение отладки программы, позволяя на каждом стыке вставлять отладочный код с целью проверки промежуточных результатов и тестирования производительности отдельных узлов.
Например, рассмотрим вторую возможность – отладку. В этом случае можно написать вспомогательную функцию debug:
def debug(data):
print(data)
return dataИ затем ее вставить в конвейер, чтобы проверить результаты работы отдельных узлов конвейера:
pipe(datain(), debug, factorial, debug, dataout())Если выполнить программу в таком варианте, то будут получены следующие результаты:
Вывод программы:
Введите неотрицательное целое число: 4 (Enter)
4
(4, 24)Факториал числа 4 равняется 24
Как видно из результатов, на вход в функцию factorial поступает введенное пользователем значение 4, а на выходе из нее возвращается кортеж с исходным числом и полученным результатом (4, 24). Этот результат показывает, что программа работает, как и ожидалось. Как вариант, вместо проверочной функции debug можно написать функцию-таймер, которая могла бы хронометрировать отдельные узлы конвейера.
Приведем еще пару примеров с аналогичной организацией программного кода на основе функционального ядра в виде конвейера.
Функциональное вычисление последовательности Фибоначчи
from functools import reduce
# Эта программа демонстрирует
# функциональную версию вычисления последовательности Фибоначчи
def main():
# Алгоритм
def fibonacci(n, x=0, y=1):
# Функция fib возвращает n-ое число последовательности.
fib = lambda n, x=0, y=1: x if n <= 0 else fib(n - 1, y, x + y)
# Функция reduce собирает результаты в список acc
acc = []
reduce(lambda _, y: acc.append(fib(y)), range(n + 1))
return n, acc
# Ввод данных
def datain():
def get_int(msg=''): # Утилитная функция
return int(input(msg))
def validate(n): # Валидация входных данных
if not isinstance(n, int):
raise TypeError("Число должно быть целым.")
if not n >= 0:
raise ValueError("Число должно быть ноль положительным.")
if n > 10:
raise ValueError("Число должно быть не больше 10.")
return n
msg = 'Введите неотрицательное целое число не больше 10: '
return pipe(get_int(msg), validate)
# Вывод данных
def dataout():
def fn(data):
n, seq = data
msg = f'Первые {n} чисел последовательности Фибоначчи:'
print(msg)
[print(el) for el in seq]
return fn
# Конвейер (функциональное ядро)
pipe(datain(), fibonacci, dataout())
main()
Вывод программы
Введите неотрицательное целое число не больше 10: 10 (Enter)
Первые 10 чисел последовательности Фибоначчи:
1
1
2
3
5
8
13
21
34
55Функциональное суммирование диапазона значений последовательности
# Эта программа демонстрирует
# функциональную версию суммирование
# диапазона значений последовательности
def main():
# Алгоритм
def range_sum(data):
seq, params = data
fn = lambda start, end: 0 if start > end
else seq[start] + fn(start + 1, end)
return fn(*params)
# Ввод данных
def datain():
seq = [1, 2, 3, 4, 5, 6, 7, 8, 9]
params = (2,5) # params - это параметры start, end
return seq, params
# Вывод данных
def dataout():
def f(data):
msg = 'Сумма значений со 2 по 5 позиции равняется '
print(msg, format(data), sep='')
return f
# Конвейер (функциональное ядро)
pipe(datain(), range_sum, dataout())
main()
Вывод программы
Сумма значений со 2 по 5 позиции равняется 18Выводы
Приведенный в настоящей главе материал имеет ознакомительный характер и служит для иллюстрации возможностей функциональной парадигмы программирования на Python с целью дальнейших самостоятельных исследований и чтобы побудить программистов дать функциональному стилю шанс. Помимо конвейера функциональное ядро может быть имплементировано в виде графа: дерева или ориентированного ациклического графа. Сам конвейер может быть расширен изнутри и включать ветвление. Кроме того, конвейеры могут использоваться в разных частях программы, собираться вместе, например, по условию, и пр. Как всегда, все зависит от потребности и фантазии разработчика.) Например, конвейер можно имплементировать в составе функции загрузки данных:
# Множественная диспетчеризация (мультиметод)
import pandas as pd
class Data:
uk, uk_scrbd, ru = range(3)
def load_data(identity):
'''имплементация мультиметода на Python; загружает
данные в зависимости от значения идентификатора'''
return {
Data.uk: lambda: do('ch01/UK2010.xls',
pd.read_excel
),
Data.ru: lambda: do('ch01/RU2011.xls',
pd.read_excel,
lambda o: o[o['Election Year'].notnull()]
)
}[identity]()
load_data(Data.uk)Исходный код поста находится в моем репо на Github. Материал поста использовался в качестве авторского дополнения в русском переводе книги «Strating Out with Python». В англоязычном интернете можно найти материал, в котором рассматриваются различные варианты имплементации конвейера на Python и шаблоны ветвления потока данных внутри конвейера. Например,
-
Доклад на конференции PyCon, в котором обсуждается архитектурный шаблон «функциональное ядро и императивная оболочка».
-
Еще один доклад на конференции PyCon, в котором на 11-ой минуте обсуждается та же тематика.
-
Очень рекомендую презентацию на Youtube «Конвейеризация на Python — конвейеры в приложениях науки о данных».
-
Несколько общих шаблонов дизайна конвейеров можно найти здесь, здесь и здесь.
Если же помимо функционала map/filter/reduce/zip и библиотеки functools вам нужны более функциональные инструменты, то существуют сторонние пакеты Python, такие как:
-
Пакет pyrsistent, который предлагает немутируемые структуры данных
-
Пакет pydash, который предлагает функциональные инструменты
-
Пакет fnc, который предлагает функциональные инструменты
-
Пакет toolz, который предлагает стандартную библиотеку ФП
Вместе с тем, следует помнить о том, что язык Python по своему дизайну не имеет полного арсенала средств для ФП и скорее служит хорошим введением в ФП. Отсутствие оптимизации стека для хвостовой рекурсии в пределе делает невозможным чистое ФП. Вместе с тем внедрение его принципов помогает четче излагать логику, избегать громоздкости ООП и смотреть на задачу под иным функциональным углом зрения, который ближе тому, как мы думаем.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Полезность материала
Проголосовали 37 пользователей.
Воздержались 12 пользователей.
-
Как написать своё ядро.
![[IMG]](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%200%200'%3E%3C/svg%3E)
Приветствую вас, вы читаете статью о том, где сумасшедший вроде меня будет объяснять вам как написать своё ядро для серверов майнкрафт. Подразумевается, что эта статья — объяснение документации простыми словами.
Начало.
Для начала, нам нужно определиться с языком и некоторыми другими вещами. В этой статье мы будем использовать Python 3, так как он более лёгкий для новичков, а ещё потому, что мне так захотелось. Так же стоит определиться где мы будем писать, а именно в каком IDE. Нет, вы конечно можете использовать удобные Nano и Vim, но не все люди любят терминалы. Я могу предложить вам несколько IDE.1. Visual Studio Code. Поделка Microsoft. Присутствует версия DEB.
2. PyCharm. Поделка JetBrains. Как по мне его минус — написан он на java. Отсутствует DEB.
3. Sublime Text. Поделка не знаю кого. Это вообще не IDE. DEB присутствует.Когда мы выбрали IDE, можно приступать к созданию проекта. Лично я буду пользоваться Visual Studio, так как он мне удобнее. Надо бы создать проект. Как делать это, показывать не буду — Вам нечего делать тут если вы не знаете как создавать проект в своей IDE. После того как у нас есть пустая папка, нам надо создать скелет проекта. Первое что мы создадим будет файлом requirements.txt. Он нужен для удобной установки зависимостей. В него мы будем писать названия всех библиотек которые используем. После создания сразу запишем туда строчки.
Это наши две зависимости. Поясню, quarry — библиотека для удобной работы с протоколом майнкрафт, а loguru это просто рай для программиста, она позволяет работать с логами очень удобно. Далее мы создадим виртуальное окружение которое нужно, чтобы не засорять систему разными библиотеками нужными для проекта. Сделать это легко и просто можно командой:
$ virtualenv venv -p python3
У нас создастся как бы «отдельная система» с установленным питоном 3-ей версии. Теперь надо войти в это окружение. Для этого используем команду:
$ source venv/bin/activate
Теперь надо бы установить все наши зависимости, сделаем это через PiP:
$ pip install -r requirements.txt
Нам осталось совсем немного. Создадим лишь файл оболочки в корневой папке для запуска проекта. В моём случае это будет start.sh. Он пока остаётся пустым, так как самой «начинки» у нас ещё нету.
Библиотека Quarry
Как было упомянуто ранее, для работы с протоколом мы будем использовать библиотеку quarry. Более 90% работы она будет выполнять за нас. Первым делом, давайте создадим главную папку, пусть она называется так же как и проект, только с маленькой буквы. В ней мы создадим файл main.py. Он будет служить стартовой точкой для программы, будет разбирать аргументы и запускать сам сервер. Давайте напишем в него примерно такой код:from loguru import logger # Логирование import argparse # Аргументы def main(): parser = argparse.ArgumentParser() parser.add_argument("-m", "--motd", default="Test!", type=str, help="Server motd") args = parser.parse_args() logger.add("latest.log", rotation="5 MB") logger.info("All works!") main()Этот короткий код-заготовка при запуске вызовет главную функцию, распарсит аргументы и положит их в args. После этого создастя файл latest.log который будет пересоздаваться каждый раз когда будет достигать 5 MB веса и выведется сообщение «All works!». Окей, давайте теперь напишем основную логику. Создадим файл с любым названием. Теперь нам нужно создать для него некоторую заготовку. Для этого импортируем некоторые классы.
from twisted.internet import reactor from quarry.net.server import ServerProtocol, ServerFactory
Далее, нам нужно создать классы наследники.
class ExampleProtocol(ServerProtocol): def player_joined(self): # Игрок зашёл ServerProtocol.player_joined(self) # Базовые действия при заходе игрока self.close("You disconnected because you {0}".format(self.display_name)) # Кикаем игрока по причине "You disconnected because you [имя игрока]" class ExampleFactory(ServerFactory): protocol = ExampleProtocol # Устанавливаем протокол motd = "My shiny test motd!" # Устанавливаем мотд для сервераНа этом и подошла к концу первая часть. Вторую я напишу, если эта часть окажется хоть кому то полезной и/или интересной. Хочу отметить, что созданный проект не дописан и не должен работать.
Последнее редактирование: 4 окт 2020 -
Это ответ тем, кто говорил, что мне стоит написать туториал о чём то оригинальном.
Последнее редактирование: 4 окт 2020 -
Как написать своё ядро. Часть II.
Приветствую вас, вы читаете продолжение статьи о том, где сумасшедший вроде меня наконец изъяснится до конца вам о том, как написать ядро для сервера майнкрафт. Если вы не видели 1-ую статью, советую прочитать сначала её. Цель данной статьи — показать, насколько легко написать своё ядро.
Продолжение
Вспомним про наш уже существующий проект и допишем его. Определимся с целью нашего ядра, давайте сплагиатим небольшую часть из моего проекта и будет генерировать для каждого игрока отдельный токен. Входим в виртуальное окружение и открываем все нужные файлы в нашем IDE.Приступим к написанию кода. Сначала напишем логику самого сервера. Импортируем библиотеку secrets(она стандартная для python3 и заносить в requirements.txt её не надо)
Данная библиотека поможет нам в генерации ключа игрока. Добавим пару строчек перед этим.
self.close("You disconnected because you {0}".format(self.display_name))Вот, что мы допишем.
token = secrets.hex(5) # 5 - Длина ключа, может быть любой
Данный код сгенерирует HEX-последовательность и положит её в переменную token. Далее нам надо немного подправить файл main.py где обрабатываются аргументы. Добавим в него несколько аргументов. Вот что у нас получится.
from loguru import logger # Логирование import argparse # Аргументы def main(): parser = argparse.ArgumentParser() parser.add_argument("-a", "--api", required=True type=str, help="HTTPS API to send requests") parser.add_argument("-A", "--api-token", required=True, type=str, help="API TOKEN for authorization.") args = parser.parse_args() logger.add("latest.log", rotation="5 MB") logger.info("All works!") main()Теперь для запуска нашего сервера, обязательно надо будет указать адрес сайта, на который будет отправляться POST запрос с данными и токен, чтобы сайт мог определить, что запрос именно от нашего сервера. В основном файле нам осталось только отправить запрос. Но сначала мы доделаем файл main.py. Допишем в наш основной файл функцию(не относящуюся к какому либо классу).
def main(args): f = ExampleFactory() f.api = args.api f.token = args.api_token f.listen('localhost', 25565) reactor.run()Она нужна для того, чтобы мы могли вызвать её из main.py передав аргументы как аргумент. Разберём её подробнее, в ней мы создаём экземпляр фабрики и устанавливаем несколько переменных у этого экземпляра. Это нужно для того, чтобы мы могли получить эти переменные в классе-протоколе. Дальше, мы заставляем фабрику слушать ‘localhost’ на порте 25565(стандартный порт майнкрафт серверов). Теперь мы можем со спокойной совестью импортировать эту функцию в main.py и вызвать её. Наш сервер уже способен запуститься и генерировать токен на каждого игрока. Давайте кстати изменим причину кика в основном файле на причину содержащую токен. Например «Your token is: [token]». Остаётся только отправить запрос, это сделаем при помощи стандартной библиотеки request. Импортируем её.Определим несколько переменных отвечающих за данные запроса и его хёдеры. Назовём их к примеру headers и data. Это всё должно находиться перед закрытием соединения. Вот что мы допишем.
headers = {"Authorization":"Bearer " + self.factory.token} data = {"token":token,"username":self.display_name,"uuid":self.uuid}Разберёмся. Начнём с хёдеров, первым и единственным у нас будет хёдер Authorization. Он служит в запросах для авторизации в чём то или где то. Мы используем его для того, чтобы сказать серверу о том что это мы. Дальше идёт переменная data — тело запроса. Оно содержит такие параметры как token — токен сгенерированный для пользователя в коде выше, username — имя пользователя(игрока), uuid — UUID игрока. Давайте отправим это всё дело на сервер при помощи данного кода.
try: request = requests.post(self.factory.api, headers=headers, data=data) except: self.logger.error("HTTP API cannot be requested.") self.close("Internal Server Error")В данном коде мы пробуем отправить POST-запрос на адрес из переменной api в фабрике с хёдерами headers и с данными data. Если возникает ошибка — печатаем в консоль повесть о том, что мы не можем достучаться до сервера и закрываем соединение с пользователем по причине «Internal Server Error».
Открываем файл оболочки(у меня start.sh) и записываем туда команду для вызова main.py файла.
Вот впринципе и всё.
-

iForgotPassword
Активный участник
Пользователь- Баллы:
- 66
- Имя в Minecraft:
- iForgotPassword
Интересно, но так бессмысленно…
Почему Python?
Это не ядро, а какой-то скрипт, который выводит motd и кикает при коннекте.
Тема интересная, развития никакого, к сожалению. -
Я дал лишь основу, чтобы из этого можно было сделать что либо ещё, по своей задумке. Python разве не легче для понимания и не занимает меньше оперативы? К тому же библиотека Quarry благодаря которой я написал статью, попалась мне на глаза первее, чем любая библиотека под яву(Они вообще такие есть под неё?).
-
iForgotPassword
Активный участник
Пользователь- Баллы:
- 66
- Имя в Minecraft:
- iForgotPassword
Я твой посыл понял, лайк бы поставил на теме. Мне не понравилось то, что как-то не до конца раскрыта тема, наверное. Не знаю.
Не уверен, что прочитав эту статью кто-то захочет написать свое ядро сервера, да и к тому же на Python, когда все вокруг Minecraft крутится на Java. Java — де-факто для мира Minecraft и никакой другой язык в ближайшее время его не заменит. К тому же, менять Java на Python плохая идея т.к Python еще менее производительнее чем Java (как минимум из-за того, что Python интерпретируемый язык). К тому же, количество выделяемой памяти под приложение Java/Python не играет роли, если итоговая производительность приложения ниже.
Я точно не знаю как создаются ядра для серверов, но, если я не ошибаюсь, есть ядро Bukkit, а все остальное — его форки в той или иной степени.
Также при написании своего ядра на Python возникнет ряд проблем с интеграцией Java плагинов.
Да и в целом Python не предназначен для высоконагруженной системы (могу ошибаться) -
Java к слову майнкрафт скорее всего выбрал не потому что им так захотелось, а потому что он просто кроссплатформенный. Но компиляция Java насколько знаю — не превращение кода в бинарник, Java кроссплатформенная из за принципа её работы. Она компилирует приложение в понятный для себя байткод, его к слову прочитать можно легко и без особых проблем, а только потом уже при запуске она превращает его в понятный для машины код(это всё не точно, я не обновлял знания по работе Java давно). А выделенная оперативка играет роль, так как чем меньше надо оперативки — тем лучше, ведь запустить прогу ты сможешь на машине с характеристиками чуть хуже. А на счёт Bukkit — необязательно, это не какой то закон.
-
iForgotPassword
Активный участник
Пользователь- Баллы:
- 66
- Имя в Minecraft:
- iForgotPassword
Java выбрал Маркус Перссон т.к он на нем изначально программировал => все последующее развитие Minecraft на Java.
Java являются JIT-компилируемыми. Для JIT-компиляции требуется промежуточный язык, позволяющий разбивать код на блоки (или фреймы). Сам по себе JIT не делает выполнение быстрее, ведь он по-прежнему выполняет те же последовательности байт-кода. Однако, он позволяет выполнять оптимизацию в рантайме. Хороший JIT-оптимизатор видит, какие части приложения выполняются чаще, и помечает их тегом "hot spot", чтобы в следующий раз выполнение прошло быстрее.
Сейчас заканчивается 2020г, а не 90-00, когда размер памяти играл большую роль.
К тому же, зачем тебе много оперативки, если у тебя стоит никчемный процессор? Оперативная память нужна для того, чтобы хранить в ней какие-то данные и быстро ими манипулировать. А т.к у нас не текстовый редактор а сервер, то нам нужна многопоточность и быстрота процессора => оперативная память на втором месте. Если у тебя будет все тупить в следствие того, что процессор не может обработать такое кол-во операций, то пиши пропало, оператос не спасет. -
Так поэтому и хорошо делать программы с мелким потреблением оперативы, чтобы ты мог вбухать больше денег в процессор и при этом программа всё равно запустилась. Да и вообще, всегда будет лучше, если программа требует меньше ресурсов.
-
iForgotPassword
Активный участник
Пользователь- Баллы:
- 66
- Имя в Minecraft:
- iForgotPassword
Разница в количестве потребляемой оперативной памяти не такая большая, чтобы пренебрегать скоростью работы
-
Ну и в конце концов, этоn конечно скорее всего не будет применяться для написания таких вещей где важна скорость работы буквально RealTime.
-
iForgotPassword
Активный участник
Пользователь- Баллы:
- 66
- Имя в Minecraft:
- iForgotPassword
-
Этот quarry в любом случае нигде не будет применятся да. Ибо это не ядро, а пустой протокол майна. Внутри него ничего нет. И таких протоколов много на гитхабе, даже на node js есть
-
Бред.
Сейчас все еще смотрят на бенчи. Все что быстрее эквивалентно тому что это лучше.
Большую роль играет удобство, но если у тебя всё хавает тонну озу и нагружает процессор до предела — люди будут перестраиваться под другой продукт.
Ну есть майн на плюсах который намного производительнее оригинала т.к не содержит тонны абстракций на абстракциях, глупые реализации простейших вещей, и прочее.ладно…….
ТС’у:
Тема полнейший бред, это не ядро.
Это больше похоже на какую-то проксю для обработки запросов с клиента. -
SimMiMo
Активный участник
ПользовательСейчас обычный недорогой дедик имеет 32-64 гб памяти и это все будет дешеветь с каждым годом.
Майн на мобилу.. покет едишн. Если честно, под него вообще нормальных ядер нет, одно говно.
Да и любителей телефончиков не настолько чтобы дофига. Не представляю, как там пэхаться.
Но опять же, это не вина самого майна пе.Последнее редактирование: 20 окт 2020 -
iForgotPassword
Активный участник
Пользователь- Баллы:
- 66
- Имя в Minecraft:
- iForgotPassword
майнна плюсах это же Bedrock edition, то бишь PE, PS4 и пр. что != Java edition
-
Дак бедрок есть не только на телефоны o_0
Что ****ь за бред ты несешь? Причём тут то что он не Java Edition? Мы говорим то что он в разы производительнее чем оригинал (даже если убрать тот факт что он нативный), т.к в нём нету сотни тысяч абстракций, глупых реализаций, и просто врапперов над врапперами.
Каждый прыжок по сегментам занимает кучу времени, особенно если забить на то что твой код нужно оптимизировать т.к ты работаешь через виртуалку.
Инфляция это who -
Так потому он и прекрасен, он уже убирает мороку с подключением и даёт какой никакой API для работы с пакетами. При этом над пакетами play у тебя есть полный контроль. К тому же там есть примеры, из который вполне будет понятно как реализовать определённую вещь.
-
Ну дает и что? А серверлогики то нет. Портировать весь кубач на питон? Ну такое.
![[IMG]](https://xakep.ru/wp-content/uploads/2018/06/174506/boromir-text.jpg)

![[IMG]](https://indicator.ru/thumb/2250x0/filters:quality(75):no_upscale()/imgs/2019/08/13/13/3514908/8fa0db23446feec0b65e0de1c9a18e315230c800.jpg)

Поделиться этой страницей
Главная задача этого поста – показать один мало применяемый в Python подход к работе функциями в рамках более общей функциональной парадигмы, в которой функциями можно манипулировать точно так же, как и любыми другими объектами: присваивать переменным, передавать в качестве аргументов в другие функции, возвращать из функций и включать в последовательности в качестве их элементов.

Функциональный стиль программирования очень близок к тому, как размышляет человек во время решения задачи. «Пусть дано x. В целях решения задачи с этими данными необходимо выполнить серию преобразований. Сначала применить к ним f и получить результирующие данные x'. Затем к новым данным применить f2 и получить новые результирующие данные x'' и т.д.
Как оказалось, такой образ мыслей отлично укладывается в то, что называется конвейером обработки данных. Конвейер обработки данных состоит из связанных между собой узлов, т.е. функций. Узел характеризуется набором входных и выходных каналов, по которым могут передаваться объекты. Узел ожидает появления определенного набора объектов на своем входном канале, после чего проводит вычисления и порождает объект(ы) на своем выходном канале, которые передаются в следующий узел в конвейере.
В функциональных языках конвейеры находят широкое применение, и для их имплементирования даже существуют специальные синтаксические конструкции. Вот как выглядит конвейер в языке F#:
2
|> ( fun x -> x + 5)
|> ( fun x -> x * x)
|> ( fun x -> x.ToString() )
Здесь входные данные, в данном случае число 2, последовательно обрабатываются серией лямбда-функций. Аналогичный конвейер можно имплементировать на языке Python, но для этого нужно написать специальную функцию, и, разумеется, это будет функция более высокого порядка:
# Конвейер обработки данных
def pipe(data, *fseq):
for fn in fseq:
data = fn(data)
return data
Приведенный ниже пример демонстрирует работу конвейера:
pipe(2,
lambda x: x + 5,
lambda x: x * x,
lambda x: str(x))
Число 2 проходит серию преобразований, и в результате будет получено строковое значение '49'. По сравнению с функцией reduce, в которой переданная в качестве аргумента одна единственная редуцирующая функция по очереди применяется к последовательности данных, в функции pipe наоборот последовательность функций применяется к обновляемым данным.
Функция pipe получает два аргумента: входные данные data и последовательность функций fseq. Во время первой итерации цикла for данные передаются в первую функцию из последовательности. Эта функция обрабатывает данные и возвращает результат, замещая переменную data новыми данными. Затем эти новые данные отправляются во вторую функцию и т.д. до тех пор, пока не будут выполнены все функции последовательности. По завершению своей работы функция pipe возвращает итоговые данные. Это и есть конвейер обработки данных.
Примечание. В приведенном выше примере функции pipe использован оператор упаковки *. В зависимости от контекста оператор * служит для упаковки получаемых нескольких аргументов в одну параметрическую переменную либо распаковки списка передаваемых в функцию аргументов.
Когда он используется в параметре функции, как в приведенном выше примере, он служит для упаковки всех аргументов в одну параметрическую переменную. Например,
def my_sum(*args): # Упаковка в список
return sum(args)
my_sum(1, 2, 3, 4, 5)
Когда он используется при вызове функции он служит для разложения передаваемого списка на отдельные аргументы. Например,
def fun(a, b, c, d):
print(a, b, c, d)
my_list = [1, 2, 3, 4]
fun(*my_list) # Разложение на четыре аргумента
В следующих ниже рубриках будут рассмотрены примеры применения конвейера обработки данных на основе функциональной парадигмы программирования.
Функциональная имплементация вычисления факториала числа
В приведенном ниже примере показана нерекурсивная версия алгоритма вычисления факториала (factorial) и его рекурсивной версия на основе более эффективной хвостовой рекурсии (factorial_rec). Детали имплементации обеих функций в данном случае не важны. Они приводятся в качестве примеров, на которых будет продемонстрирована работа конвейера обработки данных. Результат выполнения программы показан ниже.
1 # Эта программа демонстрирует
2 # функциональную версию функции factorial из главы 12
3
4 def main():
5 # Конвейер (ядро c нерекурсивным алгоритмом факториала)
6 pipe(int(input('Введите неотрицательное целое число: ')),
7 lambda n: (n, reduce(lambda x, y: x * y, range(1, n + 1))),
8 lambda tup:
9 print(f'Факториал числа {tup[0]} равняется {tup[1]}'))
# Вызвать главную функцию
main()
Вывод программы:
Введите неотрицательное целое число: 4 (Enter)
Факториал числа 4 равняется 24
В строке 8 лямбда-функция в последнем узле конвейера получает кортеж, состоящий из введенного пользователем числа и полученного результата.
В приведенную ниже расширенную версию программы вычисления факториала добавлена валидация входных данных, и алгоритмы выделены в отдельные функции. Чуть позже будет дано пояснение.
1 # Эта программа демонстрирует
2 # функциональную версию функции factorial из главы 12
3
4 def get_int(msg=''):
5 return int(input(msg))
6
7 def main():
8 # Алгоритм 1. Рекурсивная версия с хвостовой рекурсией
9 def factorial_rec(n):
10 fn = lambda n, acc=1: acc if n == 0 else fn(n - 1, acc * n)
11 return n, fn(n)
12
13 # Алгоритм 2. Нерекурсивная версия
14 def factorial(n):
15 return n, reduce(lambda x, y: x * y, range(1, n + 1))
16
17 # Ввод данных
18 def indata():
19 def validate(n): # Валидация входных данных
20 if not isinstance(n, int):
21 raise TypeError("Число должно быть целым.")
22 if not n >= 0:
23 raise ValueError("Число должно быть >= 0.")
24 return n
25 msg = 'Введите неотрицательное целое число: '
26 return pipe(get_int(msg), validate)
27
28 # Вывод данных
29 def outdata():
30 def fn(data):
31 n, fact = data
32 print(f'Факториал числа {n} равняется {fact}')
33 return fn
34
35 # Конвейер (функциональное ядро)
36 pipe(indata(), # вход: - выход: int
37 factorial, # вход: int выход: кортеж
38 outdata()) # вход: кортеж выход: -
39
40 # Вызвать главную функцию
41 main()
Вывод программы:
Введите неотрицательное целое число: 4 (Enter)
Факториал числа 4 равняется 24
Функциональным ядром программы являются строки 36-38:
pipe(indata(),
factorial,
outdata())
Они представлены конвейером из трех узлов, т.е. функциями indata, factorial и outdata. Функция indata занимается получением данных от пользователя, которые затем передаются по конвейеру дальше. Функция factorial является собственно обрабатывающим алгоритмом, в данном случае нерекурсивной функцией вычисления факториала, которая получает данные, их обрабатывает и передает по конвейеру дальше. И функция outdata получает данные и показывает их пользователю. Обратите внимание, что функция indata имеет свой собственный конвейер, который состоит из получения данных от пользователя и их валидации.
Следует отметить два важных момента. Во-первых, передаваемые от узла к узлу данные должны соответствовать какому-то определенному протоколу. Во-вторых, количество узлов может быть любым.
Такая организация программного кода:
-
Позволяет менять узлы конвейера на другие с целью тестирования различных и более эффективных имплементаций алгоритмов. Например, вместо нерекурсивной функции factorial, можно поместить рекурсивную функцию factorial_rec.
pipe(indata(), factorial_rec, outdata())
-
Облегчает проведение отладки программы, позволяя на каждом стыке вставлять отладочный код с целью проверки промежуточных результатов и тестирования производительности отдельных узлов.
Например, рассмотрим вторую возможность – отладку. В этом случае можно написать вспомогательную функцию check:
def check(data):
print(data)
return data
И затем ее вставить в конвейер, чтобы проверить результаты работы отдельных узлов конвейера:
pipe(indata(), check, factorial, check, outdata())
Если выполнить программу в таком варианте, то будут получены следующие результаты:
Вывод программы:
Введите неотрицательное целое число: 4 (Enter)
4
(4, 24)
Факториал числа 4 равняется 24
Как видно из результатов, на вход в функцию factorial поступает введенное пользователем значение 4, а на выходе из нее возвращается кортеж с исходным числом и полученным результатом (4, 24). Этот результат показывает, что программа работает, как и ожидалось. Как вариант, вместо проверочной функции можно написать функцию-таймер, которая могла бы хронометрировать отдельные узлы конвейера.
Приведем еще пару примеров с аналогичной организацией программного кода на основе функционального ядра в виде конвейера.
Функциональная имплементация вычисления последовательности Фибоначчи
# Эта программа демонстрирует
# функциональную версию функции fibonacci из главы 12
def main():
# Алгоритм
def fibonacci(n, x=0, y=1):
# Функция fib возвращает n-ое число последовательности.
fib = lambda n, x=0, y=1: x if n <= 0 else fib(n - 1, y, x + y)
# Функция reduce собирает результаты в список acc
acc = []
reduce(lambda _, y: acc.append(fib(y)), range(n + 1))
return n, acc
# Валидация входных данных
def validate(n):
if not isinstance(n, int):
raise TypeError("Число должно быть целым.")
if not n >= 0:
raise ValueError("Число должно быть ноль положительным.")
if n > 10:
raise ValueError("Число должно быть не больше 10.")
return n
# Ввод данных
def indata():
msg = 'Введите неотрицательное целое число не больше 10: '
return pipe(get_int(msg), validate)
# Вывод данных
def outdata():
def fn(data):
n, seq = data
msg = f'Первые {n} чисел последовательности Фибоначчи:'
print(msg)
[print(el) for el in seq]
return fn
# Конвейер (функциональное ядро)
pipe(indata(), fibonacci, outdata())
# Вызвать главную функцию.
main()
Вывод программы
Введите неотрицательное целое число не больше 10: 10 (Enter)
Первые 10 чисел последовательности Фибоначчи:
1
1
2
3
5
8
13
21
34
55
Функциональная имплементация суммирования диапазона значений последовательности
# Эта программа демонстрирует
# функциональную версию функции range_sum из главы 12
def main():
# Алгоритм
def range_sum(data):
seq, params = data
fn = lambda start, end: 0 if start > end
else seq[start] + fn(start + 1, end)
return fn(*params)
# Ввод данных
def indata():
seq = [1, 2, 3, 4, 5, 6, 7, 8, 9]
params = (2,5) # params - это параметры start, end
return seq, params
# Вывод данных
def outdata():
def f(data):
msg = 'Сумма значений со 2 по 5 позиции равняется '
print(msg, format(data), sep='')
return f
# Конвейер (функциональное ядро)
pipe(indata(), range_sum, outdata())
# Вызвать главную функцию.
main()
Вывод программы
Сумма значений со 2 по 5 позиции равняется 18
Приведенный в настоящей главе материал имеет ознакомительный характер и предназначен для того, чтобы продемонстрировать возможности функционального парадигмы программирования на Python с целью дальнейших самостоятельных исследований и побудить программистов дать функциональному стилю шанс.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
os-project
Пишем свою собственную операционную систему с нуля!
Идея написать ОС возникла у меня в процессе поиска идеи для сайд-проекта. Это исключительно хобби-проект, не рассчитанный на серьезность и достоверность, и хотя я пытался объяснить многие новые и неочевидные концепты, с которыми я столкнулся в процессе разработки, я мог что-то упустить, так как я сам только учусь — именно поэтому я настоятельно рекомендую пользоваться гуглом и любыми другими источниками информации когда вы познакомитесь с чем-то новым в гайде. Гуглите абсолютно всё. Я серьезно.
**Prerequisites: **Для комфортного прохождения гайда нужно уметь программировать на языке Си на базовом уровне (одно из обязательных требований: понимать принципы работы с указателями), иметь опыт разработки на высокоуровневых ЯП. С синтаксисом ассемблера можно ознакомиться по ссылке ниже, но все же рекомендую побольше почитать или посмотреть по нему туториалов.
Навигация по репозиторию
guide/ — гайд с последовательными уроками, теорией и задокументированным кодом
- Гайд разделен на главы, например
00-BOOT-SECTOR - Главы разделены на упражнения, например
ex00 - Упражнения содержат в себе код и теорию. Выглядят как
main.asm
src/ — исходный код ОС
Установка и запуск
- Установить эмулятор QEMU (подробнее: https://www.qemu.org/download/)
sudo apt install qemu-kvm qemu
- Собрать кросс-компилятор gcc для i386 архитектуры процессора. Удобнее использовать готовый отсюда: https://wiki.osdev.org/GCC_Cross-Compiler#Prebuilt_Toolchains. Для компьютеров на Linux с x86_64 архитектурой:
wget http://newos.org/toolchains/i386-elf-4.9.1-Linux-x86_64.tar.xz
mkdir /usr/local/i386elfgcc
tar -xf i386-elf-4.9.1-Linux-x86_64.tar.xz -C /usr/local/i386elfgcc --strip-components=1
export PATH=$PATH:/usr/local/i386elfgcc/bin
- Клонировать и собрать проект
git clone https://github.com/thedenisnikulin/os-project
cd os-project/src/build
make
- Запустить образ ОС с помощью эмулятора
qemu-system-i386 -fda os-image.bin
Справочник по синтаксису ассемблера NASM
https://www.opennet.ru/docs/RUS/nasm/nasm_ru3.html
Дополнительная информация
Ссылки на полезный материал которым я пользовался в качестве теории.
На русском языке:
- Серия статей о ядре Linux и его внутреннем устройстве: https://github.com/proninyaroslav/linux-insides-ru
- Статья «Давай напишем ядро!»: https://xakep.ru/2018/06/18/lets-write-a-kernel/
На английском языке:
- Небольшая книга по разработке собственной ОС (70 страниц): https://www.cs.bham.ac.uk/~exr/lectures/opsys/10_11/lectures/os-dev.pdf
- Общее введене в разработку операционных систем: https://wiki.osdev.org/Getting_Started
- Туториал по разработке ядра операционной системы для 32-bit x86 архитектуры. Первые шаги в создании собсвтенной ОС: https://wiki.osdev.org/Bare_Bones
- Продолжение предыдущего туториала: https://wiki.osdev.org/Meaty_Skeleton
- Про загрузку ОС (booting): https://wiki.osdev.org/Boot_Sequence
- Список туториалов по написанию ядра и модулей к ОС: https://wiki.osdev.org/Tutorials
- Внушительных размеров гайд по разработке ОС с нуля: http://www.brokenthorn.com/Resources/OSDevIndex.html
- Книга, описывающая ОС xv6 (не особо вникал, но должно быть что-то годное): https://github.com/mit-pdos/xv6-riscv-book, сама ОС: https://github.com/mit-pdos/xv6-public
- «Небольшая книга о разработке операционных систем» https://littleosbook.github.io/
- Операционная система от 0 до 1 (книга): https://github.com/tuhdo/os01
- ОС, написанная как пример для предыдущей книги: https://github.com/tuhdo/sample-os
- Интересная статья про программирование модулей для Линукса и про системное программирование https://jvns.ca/blog/2014/09/18/you-can-be-a-kernel-hacker/
- Еще одна статья от автора предыдущей https://jvns.ca/blog/2014/01/04/4-paths-to-being-a-kernel-hacker/
- Пример простого модуля к ядру линукса: https://github.com/jvns/kernel-module-fun/blob/master/hello.c
- Еще один туториал о том, как написать ОС с нуля: https://github.com/cfenollosa/os-tutorial
- Статья «Давайте напишем ядро»: https://arjunsreedharan.org/post/82710718100/kernels-101-lets-write-a-kernel
- Сабреддит по разработке ОС: https://www.reddit.com/r/osdev/
- Большой список идей для проектов для разных ЯП, включая C/C++: https://github.com/tuvtran/project-based-learning/blob/master/README.md
- Еще один список идей для проектов https://github.com/danistefanovic/build-your-own-x
- «Давайте напишем ядро с поддержкой ввода с клавиатуры и экрана»: https://arjunsreedharan.org/post/99370248137/kernel-201-lets-write-a-kernel-with-keyboard-and
Чтобы было проще понимать, скажу, что виртуальное окружение — это “коробка”, в которую мы складываем все необходимые для проекта инструменты, например, python библиотеки. Если мы хотим, чтобы кто-то смог повторить или продолжить нашу работу, мы просто отдаем нашу “коробку” со всеми необходимыми настройками. Хочу заметить, некоторые инструменты мы можем использовать один раз, что делает нецелесообразным его хранение в локальном интерпретаторе python и мы его храним отдельно в виртуальном окружении, не засоряя локальный интерпретатор.
Давайте начнем настройку. Чтобы создать виртуальное окружение необходимо в терминале использовать следующую команду: python –m venv my_env
“my_env” это название виртуального окружения, можно назвать его, как угодно.
После выполнения команды можно заметить, что в директории создалась папка “my_env”, это и есть наше виртуальное окружение
Далее для работы с виртуальным окружением исполняем команду: my_envScriptsactivate
Слева от пути появилось название нашего окружения, что говорит нам о том, что виртуальное окружение активировано. Запустив команду pip list, видим, что в нашем окружении сейчас стоит две библиотеки pip (пакетный менеджер python) и setuptools (библиотека для создания пакетов).
Добавить дополнительные модули можно командой pip install *название пакета*. Установим в наше окружение библиотеки numpy, pandas, scipy.(Вы можете добавить нужные библиотеки через пробел, либо отдельно для каждой вызвать команду pip install)
Проверим наличие установленных библиотек уже известной командой pip list
Таким образом, при наличии разных версий библиотек в локальном интерпретаторе и виртуальном окружении, будет импортирована версия из виртуального окружения (при условии активации на момент импорта).
Создадим файл зависимостей от внешних библиотек, чтобы члены команды могли пользоваться инструментами из проекта. Это можно сделать вручную, а можно автоматически командой из pip – pip freeze>> requirements.txt.
Если посмотреть содержимое файла requirements, то увидим, связку – название библиотеки и версия, необходимая для работы скрипта. Наш коллега создает и активирует виртуальное окружение (как это делать написано в начале статьи), и командой pip install –r “requirements.txt” устанавливает все библиотеки из файла, (в кавычках указываем путь до файла requirements).
Для работы с jupyter notebook устанавливаем в наше виртуальное окружение pip модуль notebook командой pip install notebook, вместе с ним устанавливается модуль настройки kernel (ядра) — ipykernel. Для создания kernel используем команду python -m ipykernel install —name=env_kernel (env_kernel это название нашего нового ядра).
Запускаем jupyter notebook командой jupyter notebook, теперь создавая новый ноутбук в окне new (новый) мы видим все доступные kernels.
Если новое ядро не создавать (использовать ядро по умолчанию), библиотеки в jupyter notebook будут ставиться из корневого интерпретатора.
Давайте посмотрим как это работает: на локальном интерпретаторе стоит библиотека SVA_PM, а на виртуальном окружении ее нет (при импорте библиотеки SVA_PM на виртуальном окружении должна быть ошибка, т.к. ее нет). Проверим работу каждого ядра с данной библиотекой.
Пример с ядром, которое установлено по умолчанию.
Пример с ядром, которое мы создали для виртуального окружения.
В случае если нужно удалить kernel можно воспользоваться командой jupyter kernelspec remove *название kernel.
Для того, чтобы деактивировать наше виртуальное окружение используем команду deactivate.
Скидывая файл скрипта и файл зависимостей, у коллеги не должно возникнуть проблем с запуском.
Данный инструмент языка python, позволяет специалистам IT-профиля, вести свои проекты, не засоряя память громоздкими модулями, и проблемами разных версий библиотек.
Improve Article
Save Article
Improve Article
Save Article
Prerequisite: SVM
Let’s create a Linear Kernel SVM using the sklearn library of Python and the Iris Dataset that can be found in the dataset library of Python.
Linear Kernel is used when the data is Linearly separable, that is, it can be separated using a single Line. It is one of the most common kernels to be used. It is mostly used when there are a Large number of Features in a particular Data Set. One of the examples where there are a lot of features, is Text Classification, as each alphabet is a new feature. So we mostly use Linear Kernel in Text Classification.
Note: Internet Connection must be stable while running the below code because it involves downloading data.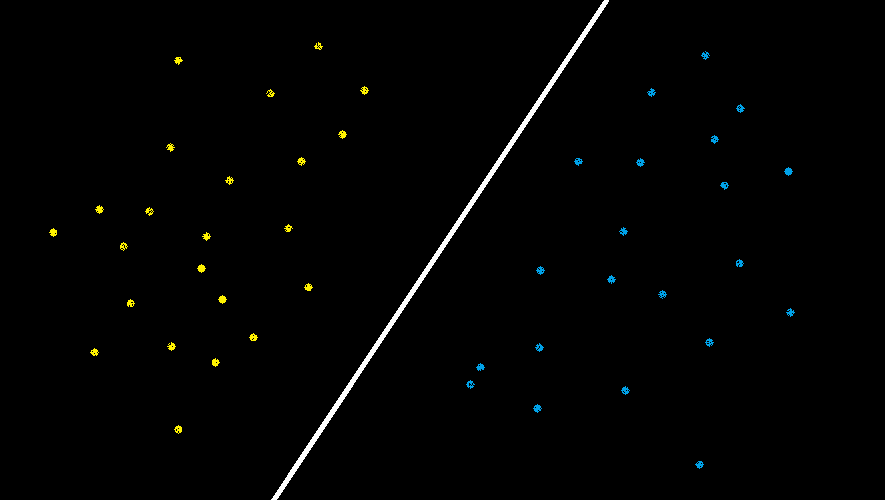
In the above image, there are two set of features “Blue” features and the “Yellow” Features. Since these can be easily separated or in other words, they are linearly separable, so the Linear Kernel can be used here.
Advantages of using Linear Kernel:
1. Training a SVM with a Linear Kernel is Faster than with any other Kernel.
2. When training a SVM with a Linear Kernel, only the optimisation of the C Regularisation parameter is required. On the other hand, when training with other kernels, there is a need to optimise the γ parameter which means that performing a grid search will usually take more time.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
iris = datasets.load_iris()
X = iris.data[:, :2]
y = iris.target
C = 1.0
svc = svm.SVC(kernel ='linear', C = 1).fit(X, y)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.subplot(1, 1, 1)
Z = svc.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap = plt.cm.Paired, alpha = 0.8)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
plt.show()
Output: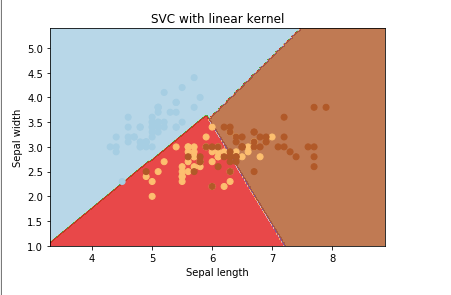
Here all the features are separated using simple lines, thus representing the Linear Kernel.
Improve Article
Save Article
Improve Article
Save Article
Prerequisite: SVM
Let’s create a Linear Kernel SVM using the sklearn library of Python and the Iris Dataset that can be found in the dataset library of Python.
Linear Kernel is used when the data is Linearly separable, that is, it can be separated using a single Line. It is one of the most common kernels to be used. It is mostly used when there are a Large number of Features in a particular Data Set. One of the examples where there are a lot of features, is Text Classification, as each alphabet is a new feature. So we mostly use Linear Kernel in Text Classification.
Note: Internet Connection must be stable while running the below code because it involves downloading data.
In the above image, there are two set of features “Blue” features and the “Yellow” Features. Since these can be easily separated or in other words, they are linearly separable, so the Linear Kernel can be used here.
Advantages of using Linear Kernel:
1. Training a SVM with a Linear Kernel is Faster than with any other Kernel.
2. When training a SVM with a Linear Kernel, only the optimisation of the C Regularisation parameter is required. On the other hand, when training with other kernels, there is a need to optimise the γ parameter which means that performing a grid search will usually take more time.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, datasets
iris = datasets.load_iris()
X = iris.data[:, :2]
y = iris.target
C = 1.0
svc = svm.SVC(kernel ='linear', C = 1).fit(X, y)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
plt.subplot(1, 1, 1)
Z = svc.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap = plt.cm.Paired, alpha = 0.8)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')
plt.show()
Output:
Here all the features are separated using simple lines, thus representing the Linear Kernel.