
Вместо вступления
Всем привет! Сегодня хотелось бы поговорить о том, как просто и с удовольствием писать тестируемый код. Дело в том, что в нашей компании мы постоянно контролируем и очень ценим качество наших продуктов. Еще бы – ведь с ними ежедневно работают миллионы человек, и для нас просто недопустимо подвести наших пользователей. Только представьте, наступил срок сдачи отчетности, и вы тщательно и с удовольствием, используя заботливо разработанный нами пользовательский интерфейс СБИС, подготовили документы, еще раз перепроверили каждую циферку и вновь убедились, что встречи с вежливыми людьми из налоговой в ближайшее время не будет. И вот, легким нажатием мыши кликаете на заветную кнопку «Отправить» и тут БАХ! приложение вылетает, документы уничтожаются, жарким пламенем пылает монитор, и кажется, люди в погонах уже настойчиво стучат в двери, требуя сдачи отчетности. Вот как-то так все может и получиться:

Фух… Ну, согласен, с монитором, наверное, все-таки погорячился  Но все же возникшая ситуация может оставить пользователя нашего продукта не в самом благостном состоянии духа.
Но все же возникшая ситуация может оставить пользователя нашего продукта не в самом благостном состоянии духа.
Так вот, поскольку мы в Тензоре дорожим моральным состоянием наших клиентов, то для нас очень важно, чтобы разработанные нами продукты были всеобъемлюще протестированы — у нас в компании во многом это обеспечивают почти что 300 тестировщиков, контролирующих качество наших продуктов. Однако мы стараемся, чтобы качество контролировалось на всех этапах разработки. Поэтому в процессе разработки мы стараемся использовать автоматизированное юнит-тестирование, не говоря уже об интеграционных, нагрузочных и приемных тестах.
Однако на сегодняшний день из нашего опыта собеседований можно отметить, что не все владеют навыками создания тестируемого кода. Поэтому мы хотим рассказать «на пальцах» о принципах создания тестируемого кода, а также показать, как можно создавать юнит-тесты, которые легки в поддержке и модернизации.
Изложенный ниже материал во многом был представлен на конференции C++ Russia, так что вы можете его почитать, послушать и даже посмотреть.
Характеристики хороших юнит-тестов
Одной из первых задач, с которой приходится сталкиваться при написании любого автоматически выполняемого теста, является обработка внешних зависимостей. Под внешней зависимостью будем понимать сущности, с которыми взаимодействует тестируемый код, но над которыми у него нет полного контроля. К таким неподконтрольным внешним зависимостям можно отнести операции, требующие взаимодействия с жестким диском, базой данных, сетевым соединением, генератором случайных чисел и прочим.
Надо сказать, что автоматизированное тестирование можно производить на разных уровнях системы, но мы рассмотрим вопросы, связанные именно с юнит-тестами.
Для наиболее ясного понимания принципов, положенных в основу приведенных ниже примеров, код был упрощен (так, например, опущены квалификаторы const). Сами же примеры тестов реализованы с использованием библиотеки GoogleTest.
Одно из наиболее важных отличий интеграционного теста от юнит-теста в том, что юнит-тест имеет полный контроль над всеми внешними зависимостями. Это позволяет достичь того, что отдельно взятый юнит-тест обладает следующими свойствами:
- повторяем — в результате запуска тест на выходе всегда выдает одно и то же значение (всегда приводит систему в одно и то же состояние);
- стабилен — в какое бы время дня и ночи тест бы не запускался, он либо всегда проходит, либо всегда не проходит;
- изолирован — порядок запуска всех имеющихся юнит-тестов, а также действия, выполняемые внутри тестов, никак не влияют на результат выполнения отдельно взятого юнит-теста.
Все это приводит к тому, что запуск множества юнит-тестов, обладающих описанными свойствами, можно автоматизировать и осуществлять, по сути, нажатием одной кнопки.
Хороший юнит-тест выполняется быстро. Потому что если в проекте тестов много, и прогон каждого из них будет длительным, то прогон всех тестов займет уже значительное время. Это может привести к тому, что при изменениях кода прогон всех юнит-тестов будет производиться все реже, из-за этого время получения реакции системы на изменения увеличится, а значит увеличится и время обнаружения внесенной ошибки.
Говорят, что у некоторых с тестированием приложений все складывается гораздо проще, но нам, простым смертным, не обладающим такой скоростной вертушкой, приходится не так сладко. Так что будем разбираться дальше.

Юнит-тестирование. С чего все начинается
Написание любого юнит-теста начинается с выбора его имени. Один из рекомендуемых подходов к наименованию юнит-теста – формировать его имя из трех частей:
— имя тестируемой рабочей единицы
— сценарий теста
— ожидаемый результат
Таким образом, мы можем получить, например, такие имена: Sum_ByDefault_ReturnsZero, Sum_WhenCalled_CallsTheLogger. Они читаются как завершенное предложение, а это повышает простоту работы с тестами. Чтобы понять, что тестируется, достаточно, без вникания в логику работы кода, просто прочитать названия тестов.
Но в ряде случаев с логикой работы тестового кода все-таки нужно разбираться. Чтобы упростить эту работу, структуру юнит-теста можно формировать из трех частей:
— часть Arrange — здесь производится создание и инициализация требуемых для проведения теста объектов
— часть Act — собственно проведение тестируемого действия
— часть Assert — здесь производится сравнение полученного результата с эталонным
Для того чтобы повысить читабельность тестов рекомендуется эти части отделять друг от друга пустой строкой. Это сориентирует тех, кто читает ваш код, и поможет быстрее найти ту часть теста, которая их интересует больше всего.
При покрытии логики работы кода юнит-тестами каждый модуль тестируемого кода должен выполнять одно из следующих действий. Так, тестированию можно подвергать:
— возвращаемый результат
— изменение состояния системы
— взаимодействие между объектами
В первых двух случаях мы сталкиваемся с задачей разделения. Она заключается в том, чтобы не вводить в средства тестирования код, над которым мы не имеем полного контроля. В последнем случае приходится решать задачу распознавания. Она заключается в том, чтобы получить доступ к значениям, которые недоступны для тестируемого кода: например, когда нужен контроль получения логов удаленным web-сервером.
Чтобы писать тестируемый код, надо уметь реализовывать и применять по назначению поддельные объекты (fake objects).
Существует несколько подходов к классификации поддельных объектов, Мы рассмотрим одну из базовых, которая соответствует задачам, решаемым в процессе создания тестируемого кода.
Она выделяет два класса поддельных объектов: stub-объекты и mock-объекты. Они предназначены для решения разных задач: stub-объект – для решения задачи разделения, а mock-объект – для решения задачи распознавания. Наибольшая разница заключается в том, что при использовании stub-объекта assert (операция сравнения полученного результата с эталонным) производится между тестовым и тестируемым кодом, а использование mock-объекта предполагает его анализ, который и показывает пройден тест или нет.
Если логику работы можно протестировать на основе анализа возвращаемого значения или изменения состояния системы, то так и сделайте. Как показывает практика, юнит-тесты, которые используют mock-объекты сложнее создавать и поддерживать, чем тесты, использующие stub-объекты.
Рассмотрим приведенные принципы на примере работы с унаследованным (legacy) кодом. Пусть у нас есть класс EntryAnalyzer, представленный на рис. 1, и мы хотим покрыть юнит-тестами его публичный метод Analyze. Это связано с тем, что мы планируем изменять этот класс, или же хотим таким образом задокументировать его поведение.
Для покрытия кода тестами определим его внешние зависимости. В нашем случае этих зависимостей две: работа с базой данных и работа с сетевым соединением, которая проводится в классах WebService и DatabaseManager соответственно.
class EntryAnalyzer {
public:
bool Analyze( std::stringename ) {
if( ename.size() < 2 ) {
webService.LogError( "Error: "+ ename );
return false;
}
if( false== dbManager.IsValid( ename ) )
return false;
return true;
}
private:
DatabaseManager dbManager;
WebService webService;
};Рис.1. Код тестируемого класса, не пригодный для покрытия юнит-тестами
Таким образом, для класса EntryAnalyzer они и являются внешними зависимостями. Потенциально, между проверкой dbManager.IsValid и финальной инструкцией «return true» может присутствовать код, требующий тестирования. При написании тестов получить доступ к нему мы сможем только после избавления от существующих внешних зависимостей. Для упрощения дальнейшего изложения такой дополнительный код не приведен.
Теперь рассмотрим способы разрыва внешних зависимостей. Структура данных классов приведена на рис. 2.
class WebService {
public:
void LogError( std::string msg ) {
/* логика, включающая
работу с сетевым соединением*/
}
};
class DatabaseManager {
public:
bool IsValid( std::string ename ) {
/* логика, включающая
операции чтения из базы данных*/
}
};Рис.2. Структура классов для работы с сетевым соединением и базой данных
Для написания тестируемого кода очень важно уметь разрабатывать, опираясь на контракты, а не на конкретные реализации. В нашем случае контрактом исходного класса является определение, валидно или нет имя ячейки (entry).
На языке С++ данный контракт может быть задокументирован в виде абстрактного класса, который содержит виртуальный метод IsValid, тело которого определять не требуется. Теперь можно создать два класса, реализующих этот контракт: первый будет взаимодействовать с базой данных и использоваться в «боевой» (production) версии нашей программы, а второй будет изолирован от неподконтрольных зависимостей и будет использоваться непосредственно для проведения тестирования. Описанная схема приведена на рис. 3.

Рис.3. Введение интерфейса для разрыва зависимости от взаимодействия с базой данных
Пример кода, позволяющий осуществить разрыв зависимости, в нашем случае от базы данных, представлен на рис. 4.

Рис.4. Пример классов, позволяющих осуществить разрыв зависимости от базы данных
В приведенном коде следует обратить внимание на спецификатор override у методов, реализующих функционал, заданный в интерфейсе. Это повышает надежность создаваемого кода, так как он явно указывает компилятору, что сигнатуры этих двух функций должны совпадать.
Также следует обратить внимание на объявление деструктора абстрактного класса виртуальным. Если это выглядит удивительно и неожиданно, то можно сгонять за книгой С. Майерса “Эффективное использование С++” и читать ее взахлеб, причем особое внимание уделить приведенному там правилу №7;).
Спойлер для особо нетерпеливых
это необходимо, чтобы избежать утечек памяти при уничтожении объекта производного класса через указатель на базовый класс.
Разрыв зависимости с использованием stub-объектов
Рассмотрим шаги, которые нужны для тестирования нашего класса EntryAnalyzer. Как было сказано выше, реализация тестов с использованием stub-объектов несколько проще, чем с использование mock-объектов. Поэтому сначала рассмотрим способы разрыва зависимости от базы данных.
Способ 1. Параметризация конструктора
Вначале избавимся от жестко заданного использования класса DatabaseManager. Для этого перейдем к работе с указателем, типа IDatabaseManager. Для сохранения работоспособности класса нам также нужно определить конструктор «по умолчанию», в котором мы укажем необходимость использования «боевой» реализации. Внесенные изменения и полученный видоизмененный класс представлены на рис. 5.

Рис.5. Класс после рефакторинга, который позволяет осуществить разрыв зависимости от базы данных
Для внедрения зависимости следует добавить еще один конструктор класса, но теперь уже с аргументом. Этот аргумент как раз и будет определять, какую реализацию интерфейса следует использовать. Конструктор, который будет использоваться для тестирования класса, представлен на рис. 6.

Рис.6. Конструктор, используемый для внедрения зависимости
Теперь наш класс выглядит следующим образом (зеленой рамкой обведен конструктор, используемый для тестирования класса):
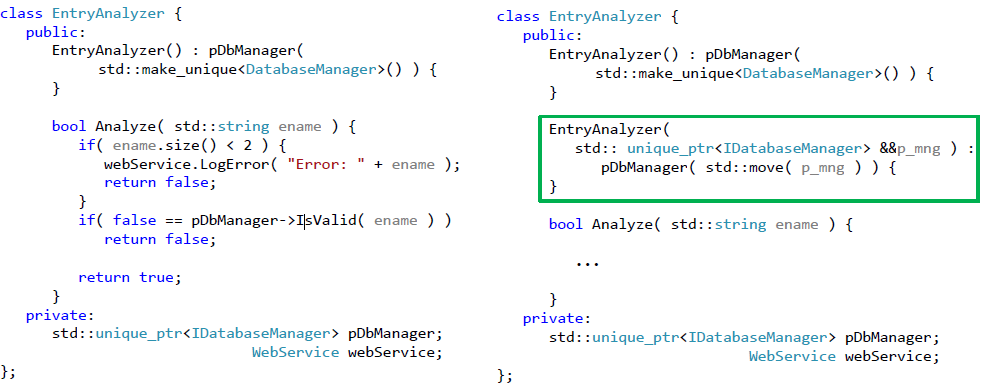
Рис.7. Рефакторинг класса, позволяющий осуществить разрыв зависимости от базы данных
Теперь мы можем написать следующий тест, демонстрирующий результат обработки валидного имени ячейки (см. рис. 8):
TEST_F( EntryAnalyzerTest, Analyze_ValidEntryName_ReturnsTrue )
{
EntryAnalyzer ea( std::make_unique<FakeDatabaseManager>( true ) );
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class FakeDatabaseManager : public IDatabaseManager {
public:
bool WillBeValid;
FakeDatabaseManager( bool will_be_valid ) :
WillBeValid( will_be_valid ) {
}
bool IsValid( std::string ename ) override {
return WillBeValid;
}
};Рис.8. Пример теста, не взаимодействующего с реальной базой данных
Изменение значения параметра конструктора fake-объекта влияет на результат выполнения функции IsValid. Кроме того, это позволяет повторно использовать fake-объект в тестах, требующих как утвердительные, так и отрицательные результаты обращения к базе данных.
Рассмотрим второй способ параметризации конструктора. В этом случае нам потребуется использование фабрик — объектов, которые являются ответственными за создание других объектов.
Вначале проделаем все те же шаги по замене жестко заданного использования класса DatabaseManager – перейдем к использованию указателя на объект, реализующий требуемый интерфейс. Но теперь в конструкторе «по умолчанию» возложим обязанности по созданию требуемых объектов на фабрику.
Получившаяся реализация приведена на рис. 9.
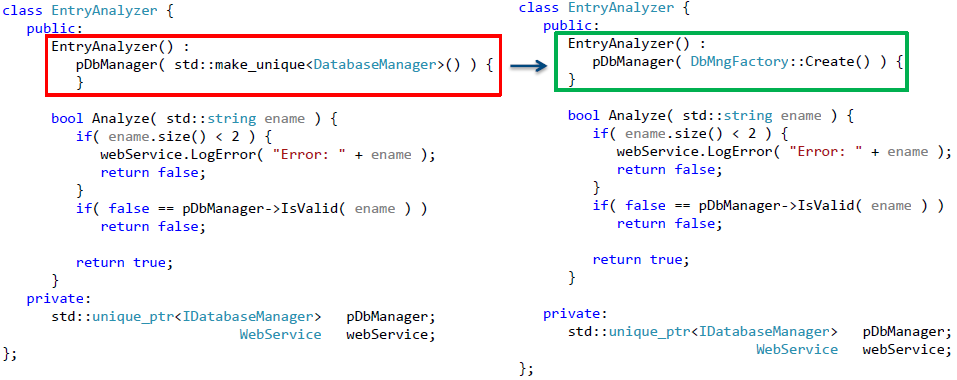
Рис. 9. Рефакторинг класса с целью использования фабрик для создания объекта, взаимодействующего с базой данных
С учетом введенного фабричного класса, сам тест теперь можно написать следующим образом:
TEST_F( EntryAnalyzerTest,
Analyze_ValidEntryName_ReturnsTrue )
{
DbMngFactory::SetManager(
std::make_unique<FakeDatabaseManager>( true ) );
EntryAnalyzer ea;
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class DbMngFactory {
public:
static std::unique_ptr<IDatabaseManager> Create() {
if( nullptr == pDbMng )
return std::make_unique<DatabaseManager>();
return std::move( pDbMng );
}
static void SetManager(
std::unique_ptr<IDatabaseManager> &&p_mng ) {
pDbMng = std::move( p_mng );
}
private:
static std::unique_ptr<IDatabaseManager> pDbMng;
};Рис.10. Еще один пример теста, не взаимодействующего с реальной базой данных
Важное отличие данного подхода от ранее рассмотренного – использование одного и того же конструктора для создания объектов как для «боевого», так и для тестового кода. Всю заботу по созданию требуемых объектов берет на себя фабрика. Это позволяет разграничить зоны ответственности классов. Конечно, человеку, который будет разбираться с вашим кодом, потребуется некоторое время для понимания взаимоотношений этих классов. Однако в перспективе этот подход позволяет добиться более гибкого кода, приспособленного для долгосрочной поддержки.
Способ 2. «Выделить и переопределить»
Рассмотрим еще один поход к разрыву зависимости от базы данных — «Выделить и переопределить» (Extract and override). Возможно, его применение покажется более простым и таких вот эмоций не вызовет:

Его основная идея в том, чтобы локализовать зависимости «боевого» класса в одной или нескольких функциях, а затем переопределить их в классе-наследнике. Рассмотрим на практике этот подход.
Начнем с локализации зависимости. В нашем случае зависимость заключается в обращении к методу IsValid класса DatabaseManager. Мы можем выделить эту зависимость в отдельную функцию. Обратите внимание, что изменения следует вносить максимально осторожно. Причина – в отсутствии тестов, с помощью которых можно удостовериться, что эти изменения не сломают существующую логику работы. Для того чтобы вносимые нами изменения были наиболее безопасными, необходимо стараться максимально сохранять сигнатуры функций. Таким образом, вынесем код, содержащий внешнюю зависимость, в отдельный метод (см. рис. 11).

Рис.11. Вынесение кода, содержащего внешнюю зависимость в отдельный метод
Каким же образом можно провести тестирование нашего класса в этом случае? Все просто – объявим выделенную функцию виртуальной, отнаследуем от исходного класса новый класс, в котором и переопределим функцию базового класса, содержащего зависимость. Так мы получили класс, свободный от внешних зависимостей – и теперь его можно смело вводить в средства тестирования для покрытия тестами. На рис. 12 представлен один из способов реализации такого тестируемого класса.
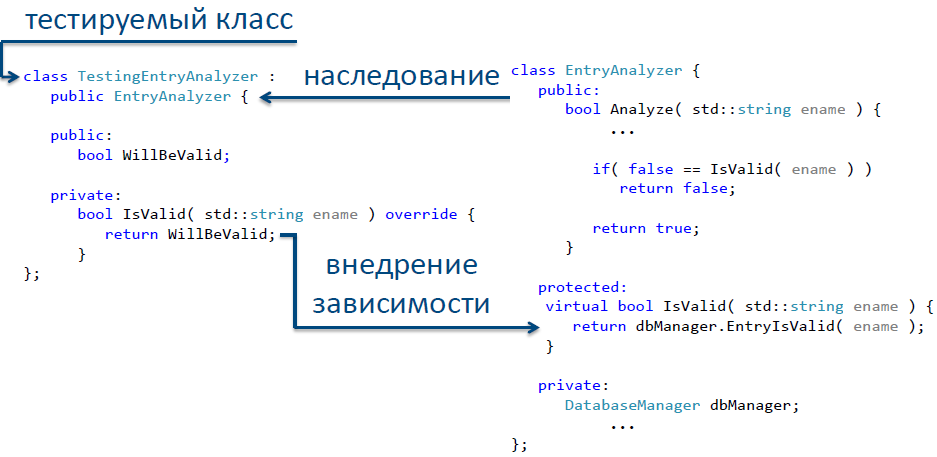
Рис.12. Реализация метода «Выделить и переопределить» для разрыва зависимости
Сам тест теперь можно написать следующим образом:
TEST_F( EntryAnalyzerTest, Analyze_ValidEntryName_ReturnsTrue)
{
TestingEntryAnalyzer ea;
ea.WillBeValid = true;
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class TestingEntryAnalyzer : public EntryAnalyzer {
public:
bool WillBeValid;
private:
bool IsValid( std::string ename ) override {
return WillBeValid;
}
};Рис.13. И еще один пример теста, не взаимодействующего с реальной базой данных
Описанный подход является одним из самых простых в реализации, и его полезно иметь в арсенале своих навыков.
Разрыв зависимости с использованием mock-объектов
Теперь мы умеем разрывать зависимости от базы данных с использованием stub-объектов. Но у нас еще осталась необработанной зависимость от удаленного web-сервера. С помощью mock-объекта мы можем разорвать эту зависимость.
Что же надо для этого сделать? Здесь нам пригодится комбинация из уже рассмотренных методов. Вначале локализуем нашу зависимость в одной из функций, которую затем объявим виртуальной. Не забываем при этом сохранять сигнатуры функций! Теперь выделим интерфейс, определяющий контракт класса WebService и вместо явного использования класса будем использовать указатель unique_ptr требуемого типа. И создадим класс-наследник, в котором эта виртуальная функция будет переопределена. Полученный после рефакторинга класс представлен на рис. 14.

Рис.14. Класс после рефакторинга, подготовленный для разрыва зависимости от сетевого взаимодействия
Введем в класс-наследник указатель shared_ptr на объект, реализующий выделенный интерфейс. Все, что нам осталось — это использовать метод параметризации конструктора для внедрения зависимости. Теперь наш класс, который теперь можно протестировать, выглядит следующим образом:
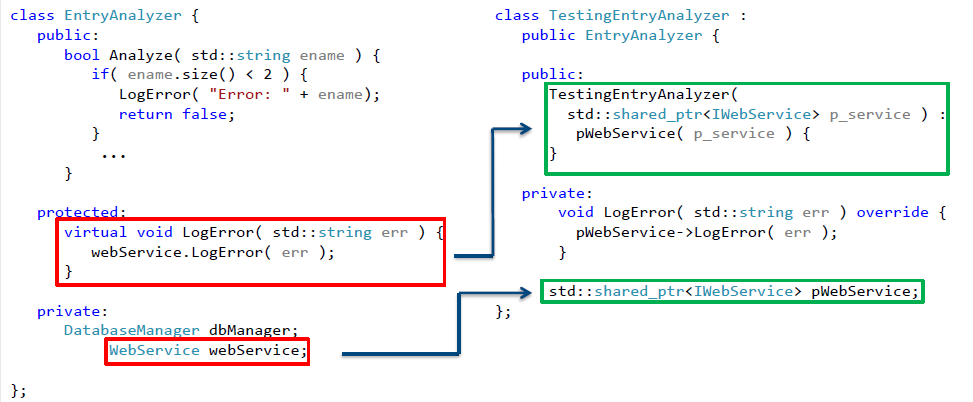
Рис.15. Тестируемый класс, позволяющий осуществить разрыв зависимости от сетевого взаимодействия
И теперь мы можем написать следующий тест:
TEST_F( EntryAnalyzerTest, Analyze_TooShortEntryName_LogsErrorToWebServer )
{
std::shared_ptr<FakeWebService> p_web_service =
std::make_shared<FakeWebService>();
TestingEntryAnalyzer ea( p_web_service );
bool result = ea.Analyze( "e" );
ASSERT_EQ( p_web_service->lastError, "Error: e" );
}
class TestingEntryAnalyzer : public EntryAnalyzer {
public:
TestingEntryAnalyzer(
std::shared_ptr<IWebService> p_service ) :
pWebService( p_service ) {
}
private:
void LogError( std::string err ) override {
pWebService->LogError( err );
}
std::shared_ptr<IWebService> pWebService;
};
class FakeWebService : public IWebService {
public:
void LogError( std::string error ) override {
lastError = error;
}
std::string lastError;
};Рис.16. Пример теста, не взаимодействующего с сетевым соединением
Таким образом, внедрив зависимость с помощью параметризации конструктора, на основе анализа состояния mock-объекта мы можем узнать, какие сообщения будет получать удаленный web-сервис.
Рекомендации для создания тестов, легких для поддержки и модернизации
Рассмотрим же теперь подходы к построению юнит-тестов, которые легки в поддержке и модернизации. Возможно, во многом это опять же связано с недоверием к самому себе.

Первая рекомендация заключается в том, что один тест должен тестировать только один результат работы. В этом случае, если тест не проходит, то можно сразу однозначно сказать, какая часть логики работы «боевого» кода не прошла проверку. Если же в одном тесте содержится несколько assert, то без повторного прогона теста и последующего дополнительного анализа тяжело однозначно сказать, где именно была нарушена логика.
Вторая рекомендация в том, что тестированию следует подвергать только публичные методы класса. Это связано с тем, что публичные методы, по сути, определяют контракт класса — то есть тот функционал, который он обязуется выполнить. Однако конкретная реализация его выполнения остается на его усмотрение. Таким образом, в ходе развития проекта может быть изменен способ выполнения того или иного действия, что может потребовать изменения логики работы приватных методов класса. В итоге это может привести к непрохождению ряда тестов, написанных для приватных методов, хотя сам публичный контракт класса при этом не нарушен. Если тестирование приватного метода все-таки требуется, рекомендуется найти публичный метод у класса, который его использует и написать тест уже относительно него.
Однако порой тесты не проходят, и приходится разбираться, что же пошло не так. При этом довольно неприятная ситуация может возникнуть, если ошибка содержится в самом тесте. Как правило, в первую очередь причины непрохождения мы начинаем искать именно в логике работы тестируемого «боевого» кода, а не самого теста. В этом случае на поиск причины непрохождения может быть потрачена куча времени. Для того чтобы этого избежать, надо стремиться к тому, чтобы сам тестовый код был максимально простым – избегайте использования в тесте каких-либо операторов ветвления (switch, if, for, while и пр.). Если же необходимо протестировать ветвление в «боевом» коде, то лучше написать два отдельных теста для каждой из веток. Таким образом, типовой юнит-тест можно представить как последовательность вызовов методов с дальнейшим assert.
Рассмотрим теперь следующую ситуацию: есть класс, для которого написано большое количество тестов, например, 100. Внутри каждого из них требуется создание тестируемого объекта, конструктору которого требуется один аргумент. Однако с ходом развития проекта, ситуация изменилась — и теперь одного аргумента недостаточно, и нужно два. Изменение количества параметров конструктора приведет к тому, что все 100 тестов не будут успешно компилироваться, и для того чтобы привести их в порядок придется внести изменения во все 100 мест.
Чтобы избежать такой ситуации, давайте следовать хорошо известному нам всем правилу: «Избегать дублирования кода». Этого можно добиться за счет использования в тестах фабричных методов для создания тестируемых объектов. В этом случае при изменении сигнатуры конструктора тестируемого объекта достаточно будет внести соответствующую правку только в одном месте тестового проекта.
Это может значительно сократить время, затрачиваемое на поддержку существующих тестов в работоспособном состоянии. А это может оказаться особенно важным в ситуации, когда в очередной раз нас будут поджимать все сроки со всех сторон.

Стало интересно? Можно погрузиться глубже.
Для дальнейшего и более подробного погружения в тему юнит-тестирования советую книгу Roy Osherove «The art of unit testing». Кроме того, довольно часто также возникает ситуация, когда требуется внести изменения в уже существующий код, который не покрыт тестами. Один из наиболее безопасных подходов заключается в том, чтобы вначале создать своеобразную «сетку безопасности» — покрыть его тестами, а затем уже внести требуемые изменения. Такой подход очень хорошо описан в книге М. Физерса «Эффективная работа с унаследованным кодом». Так что освоение описанных авторами подходов может принести нам, как разработчикам, в арсенал очень важные и полезные навыки.
Спасибо за уделенное время! Рад, если что-то из выше изложенного окажется полезным и своевременным. С удовольствием постараюсь ответить в комментариях на вопросы, если такие возникнут.
Автор: Виктор Ястребов vyastrebov
Программирование • 14 июля 2022 • 5 мин чтения
Юнит-тесты: что это такое, зачем они нужны и как их проводят
После того, как программист написал код, нужно провести тесты: вручную или автоматически проверить, что всё работает без ошибок. Одна из разновидностей таких тестов — модульные или юнит-тесты. Расскажем подробно, что такое модульное тестирование, в чём его особенности.
- Что такое юниты
- Что такое модульное тестирование
- Зачем тестировать юниты
- Особенности и преимущества юнит-тестов
- Процесс проведения и методы юнит-тестирования
- Главное о юнит-тестировании
Что такое юниты
Чтобы разобраться с понятием юнит-тестирования, надо для начала узнать определение юнитов. Любая программа состоит из юнитов, или модулей, — отдельных блоков и функций. Кнопка добавления товара в корзину, формула калькулятора стоимости, скрипт для формирования карточки товара — всё это отдельные модули.
Тестирование мобильных приложений: инструкция для начинающих
Что такое модульное тестирование
Модули взаимодействуют и обеспечивают работу программы или приложения. Чтобы проверить, правильно ли написан модуль, проводят юнит-тесты, или модульное тестирование, — проверку не всего приложения, а одного модуля. Пример юнит-теста — проверка функции подсчёта общей стоимости заказа.
Модульное тестирование проводят сразу после написания кода. Проверить работу кнопки в готовом приложении не получится, потому что на неё уже влияют другие модули.
Зачем тестировать юниты
Главная причина написания юнит-тестов — тестирование отдельных модулей. Поскольку каждый модуль пишется отдельно, тестировать его тоже можно изолированно, без связки с другими. Получается простая схема: программист написал модуль → протестировал его → продолжил разработку для связи с другими модулями и других тестов.
Если пропустить этап юнит-тестирования, в следующий раз не получится понять, что именно вызвало ошибку: какой-то из модулей или неправильно настроенная интеграция между ними. Придётся разбираться, тратить время и всё равно тестировать отдельные юниты.
Для примера представим автомобиль. Его «юниты» — это двигатель, подача бензина, зажигание. Можно проверить их по отдельности и ещё до сборки увидеть поломки и починить их. А можно собрать автомобиль, не протестировав юниты, — и он не поедет. Придётся всё разбирать и проверять каждую деталь.
Особенности и преимущества юнит-тестов
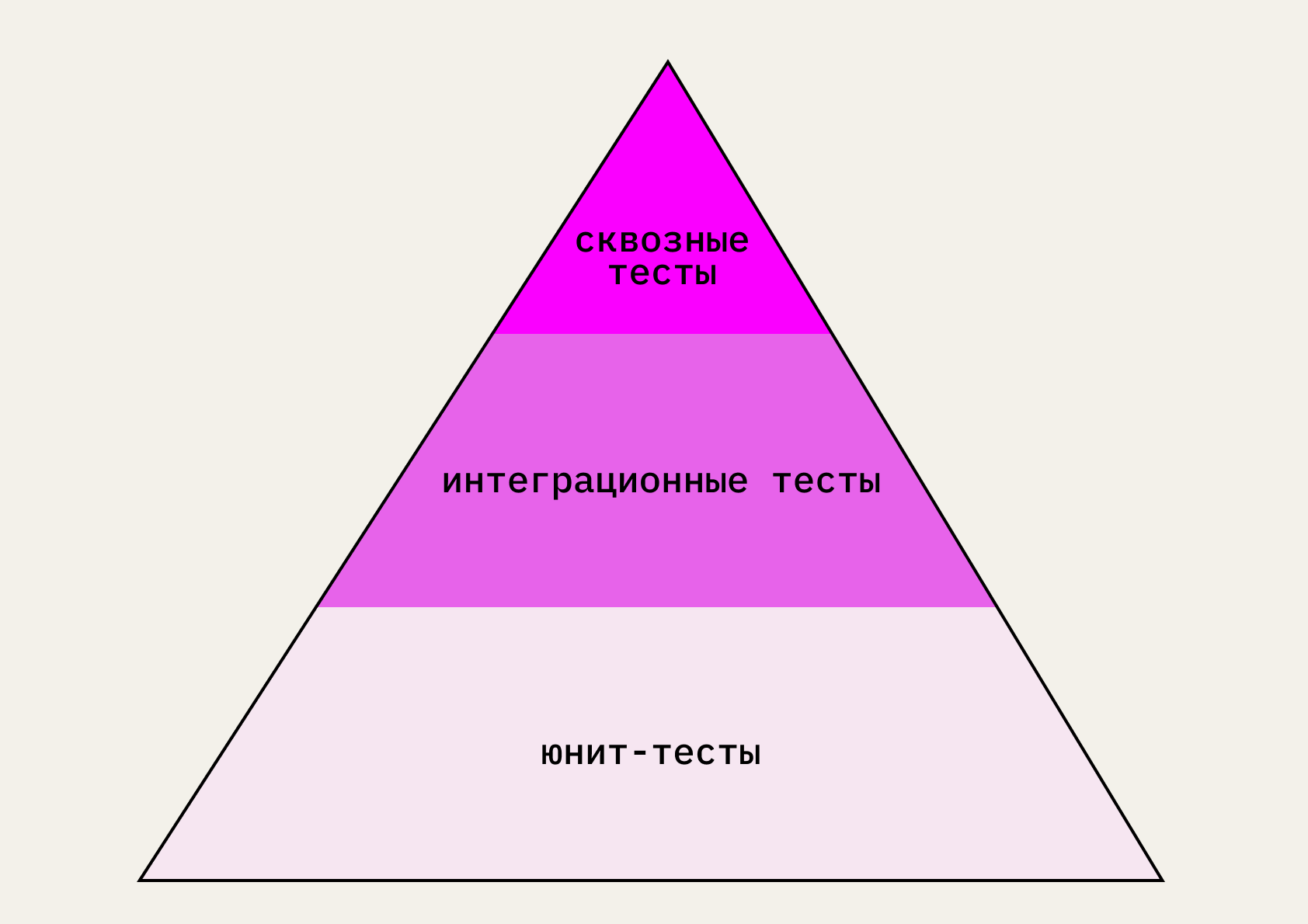
Так выглядит пирамида тестирования. Юнит-тесты в ней занимают основание — их нужно проводить чаще всего.
Интеграционные тесты — тестирование взаимодействия нескольких юнитов. Например, кнопки «Купить товар» и корзины.
Сквозные (end-to-end) тесты — тестирование работы большого количества юнитов вместе. Это может быть как всё приложение, так и конкретный сценарий, например поиск товара, его помещение в корзину, заказ и оплата.
Если сравнивать с другими тестами, у модульных есть следующие особенности:
● Можно провести сразу после написания кода. Программист пишет конкретный модуль и тут же его тестирует — не нужно ждать готовности других модулей или интеграций.
● Быстрее, чем другие тесты, так как охватывают только небольшую функцию. Часто один такой юнит-тест занимает всего пару миллисекунд.
● Не требуют серьёзной инфраструктуры, так как их выполнение не требовательно к вычислительным ресурсам.
● За счёт лёгкости и скорости юнит-тесты самые дешёвые.
● Разные юниты можно тестировать одновременно.
● Легко автоматизировать, так как при таких тестах нет имитации сценария пользователя — только проверка реакции кода на те или иные действия и данные.
● Просто посчитать, какой процент кода покрыт тестами.
Поэтому в пирамиде тестирования юнит-тесты стоят в самом низу — для экономии времени и сил их стоит проводить больше всего. В идеальном случае мы можем вообще обойтись только модульным тестированием проекта, то есть всего написанного кода — проверять только юниты, так как интеграция между ними предсказуемо работает правильно.
На курсе Практикума «Инженер по тестированию» мы разбираем разные виды тестов и отрабатываем их на реальных практических задачах. Вводный курс доступен бесплатно.
Начните карьеру в IT с профессии тестировщика
Спустя 4 месяца обучения в вашем портфолио будет 6 протестированных приложений. Пройдите бесплатную вводную часть курса, чтобы попробовать себя в роли тестировщика.

Процесс проведения и методы юнит-тестирования
В общих чертах модульное тестирование кода выглядит так:
-
Разработчик пишет код конкретной функции — юнита.
-
Проверяет, чтобы функция была изолирована, то есть не вшита намертво в другие функции. Если вшита — переписывает её, чтобы вынести.
-
Если функции нужны реакции от других модулей, разработчик создаёт моки — заглушки, которые имитируют другие модули и взаимодействие с ними. Например, передают данные, на которые тестируемый юнит должен отреагировать.
-
После этого разработчик пишет тесты и исправляет ошибки.
-
После запускает юнит-тест в режиме покрытия и смотрит, все ли строки функции покрыты, то есть протестированы.
-
В итоге через пару итераций получается хороший протестированный код.
Но есть и другой подход — Test driven development. Его суть в том, что разработчики получают задачу и сначала пишут тесты, основываясь на принципах модульного тестирования: на проверке отдельных юнитов сразу после написания кода. И уже под эти тесты пишут код, стараясь избежать предполагаемых ошибок.
Инструменты для проведения юнит-тестов. Например, если пишете на javascript, существует пакет jest. Он позволяет быстро делать заглушки, содержит инструменты для проверки покрытия, позволяет запускать тесты в разных режимах, в том числе в многопоточном.
Для других языков программирования тоже существуют свои инструменты для создания юнит-тестов — JUnit , Mockk, robolectric, пакет unittes для Python.
Главное о юнит-тестировании
- Юнит, или модульные тесты, проверяют отдельные блоки и функции написанного кода.
- Юнит-тесты нужны, чтобы быстро протестировать написанный фрагмент кода и сразу понять, где именно кроется ошибка.
- Юнит-тесты дешевле и быстрее других, их легко автоматизировать.
- Чтобы юнит-тест получился, тестируемый модуль должен быть изначально изолирован от другого кода. Если нужны какие-то зависимости, их имитируют заглушками — моками.
Что такое API и что о нём нужно знать веб-разработчику
Что разработчику нужно знать о контейнерах Docker
#статьи
- 9 сен 2021
-

0
Что такое юнит-тесты и почему они так важны
Бывает, кодишь 10 минут, а дебажишь 2 часа. Чтобы такого не случилось, пилите юнит-тесты. Михаил Фесенко рассказал, как их правильно готовить.
Oli Scarff / Staff / GettyImages

Журналист, коммерческий автор и редактор. Пишет про IT, цифровой маркетинг и бизнес.
Сайт: darovska.com.

об авторе
Фесенко Михаил, можно просто Фес. Разработчик, раньше работал системным администратором, пишет на чём скажут, но пока писал на PHP, Go, Python, Bash. Сейчас работает в «Яндекс.Облаке», до этого работал во «ВКонтакте». Любит жену, кино и снимать видео =)
Юнит-тест (unit test), или модульный тест, — это программа, которая проверяет работу небольшой части кода. Разработчики регулярно обновляют сайты и приложения, добавляют фичи, рефакторят код и вносят правки, а затем проверяют, как всё работает.
Тестировать систему целиком после каждого обновления — довольно муторно и неэффективно. Поэтому обновлённые или исправленные части кода прогоняют через юнит-тесты.
На практике используют разные тесты — их разделяют по уровню абстракции с помощью пирамиды Майка Кона:
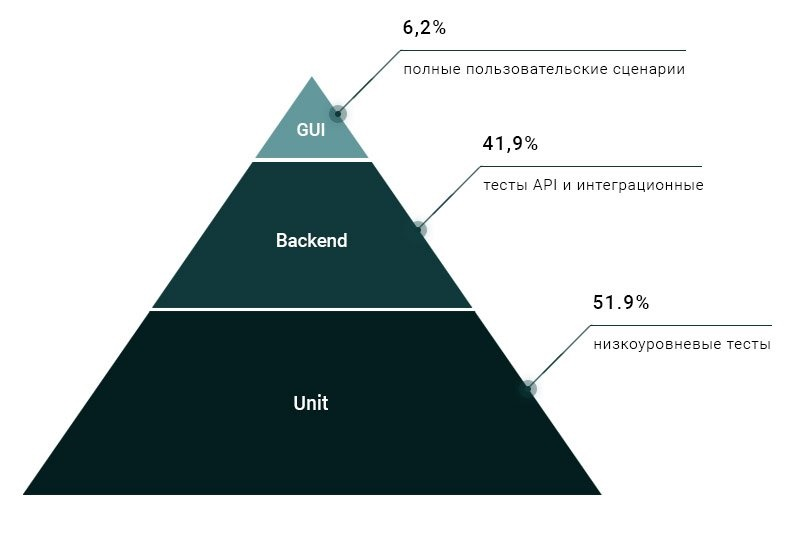
Чем выше тест в пирамиде, тем больше частей программы он затрагивает. Высокоуровневые тесты «ближе к бизнесу»: они проверяют бизнес-логику и пользовательские процессы. А те, что внизу пирамиды, помогают найти проблемы в отдельных частях кода. Например, какую-нибудь функцию, которая генерирует имя файла.
Большая часть тестов работает на верхних уровнях и не позволяет точечно отлавливать баги. Те же интеграционные тесты проверяют, как взаимодействуют между собой разные системы. А Е2Е-тесты исследуют процессы со стороны пользователя: например, когда он регистрируется и логинится на сайте.
В отличие от них, юнит-тесты нужны в следующих случаях:
- если код непонятен — на ревью возникли вопросы по его работе;
- если код часто меняется — чтобы не проверять его вручную;
- если обновления в одной части кода могут сломать что-то в другой части.
Некоторые программисты пишут только юнит-тесты, а на интеграционные или E2E-тесты жалеют времени. На самом деле нужно покрывать систему всеми видами тестов, чтобы знать, как взаимодействуют друг с другом разные части программы, какие промежуточные результаты они выдают. Но в то же время, если юнит-тесты показывают ошибку, её покажет и интеграционный, и E2E-тест.
Для юнит-тестирования подключают тестовые фреймворки — они позволяют «мокать», то есть имитировать функции. В коде больших проектов много зависимостей: одна функция вызывает другую и влияет на разные части программы. Но, как правило, достаточно проверить функции «в вакууме», отдельно от остального кода. Для этого и нужен тестовый фреймворк — он моделирует условия, в которых функция А вызывает функцию Б изолированно от других функций.
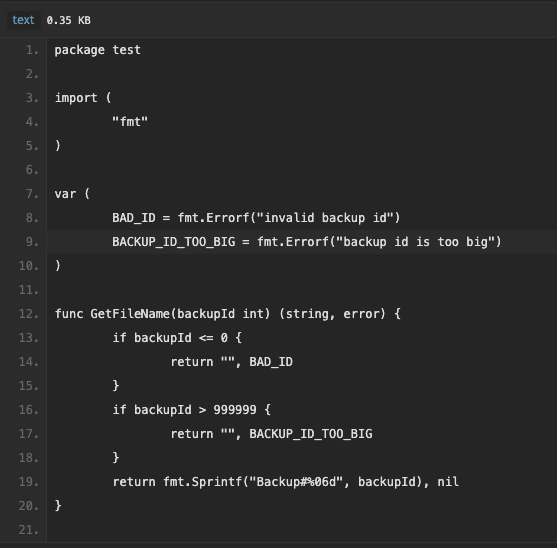
Простой пример: у нас есть функция на Go, которая получает id бэкапа и возвращает имя бэкап-файла:
Протестируем её с помощью набора входных и выходных данных. Они должны учитывать все ситуации, поэтому не забываем про негативные кейсы — когда программа возвращает ошибку. Вот набор тестовых данных:
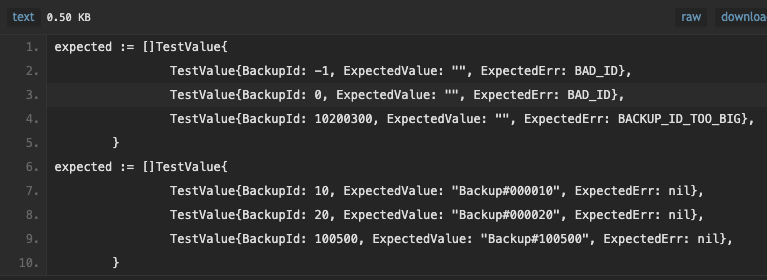
В первую очередь я прописал запрещённые данные (-1 и 0) и слишком большое значение (10200300). Когда пользователь их вводит, функция не должна возвращать результат. Вместо этого мы ждём сообщения об ошибке: BAD_ID или BACKUP_ID_TOO_BIG. Когда же функция получает валидный id, она выводит отформатированное имя файла, например Backup#000010.
А вот и код самого теста:
Порой код для тестирования даже больше основного — и это норма. Но иногда всё-таки стоит задуматься, на самом ли деле тест должен быть таким объёмным. Я бы посоветовал покрывать тестами только те фрагменты кода, которые вы планируете менять. Или сложные части, которые, скорее всего, придётся чинить или поддерживать.
Некоторые разработчики мокают всё подряд. Из-за этого тесты становятся хрупкими, а код — сложным и непонятным. На самом деле для юнит-тестирования достаточно лишь немного переписать код, а огромные функции лучше разбить на более мелкие.
В старой хорошей книге «Экстремальное программирование» есть классная мысль: сначала пишите тест, а только потом программу. Это клёвый подход, но не все могут так делать (а кто-то просто не хочет тратить время).
Есть разработчики, которые не проводят модульное тестирование: «Ой, у нас большой проект, и переписать 1000 строк под тесты или замокать их — слишком запарно». На самом деле покрыть код тестами несложно. Вот несколько советов.
Написали код — напишите тест. Я видел много проектов, в которых юнит-тесты писали по принципу «новый код — новый тест». Думаю, это правильный подход, ведь, когда добавляешь в программу что-то новое, она часто ломается. К тому же, если писать тесты сразу, не придётся переворачивать весь код, когда он разрастётся.
Есть более жёсткий принцип: новый код без тестов на ревью не принимается. Конечно, он работает, если сроки не горят, — иначе программист рефакторит или покрывает его тестами позже.
Используйте тестовый фреймворк. В тестировании не нужно изобретать велосипед. Для популярных языков уже есть готовые решения, поэтому достаточно вбить в поиске test frameworks, и вы получите целый список. Вот, например, результат для Python:
Пишите простые тесты. Надо понимать, что происходит с входными данными и какой результат должна вернуть функция. Если непонятно — меняем нейминг и разбиваем функции на более мелкие, избавляемся от зависимостей. Пусть одна функция принимает результат, а другая возвращает. Так проще тестировать.
Допустим, у нас есть такая функция:
Func processdata() {
result_a = process_a()
result_b = process_b(result_a)
return prepare_output(result_b)
}
Её не нужно прогонять через юнит-тест, потому что тогда придётся мокать process_a, process_b и prepare_output. Тут нужен интеграционный тест, который проверит, как эти компоненты взаимодействуют между собой. Вообще, если код сложно покрывать юнит-тестами, используйте интеграционные — они проверяют общую работу системы, модуля или библиотеки.
Не забывайте про негативные тесты. Это the best practice. Что произойдёт, если передать в программу неправильные данные? Какую ошибку она выведет и выведет ли?
Покрывайте тестами все циклы и if-else. Этот совет касается кода, который нужно поддерживать. Если ему не следовать, на одной из итераций правок вы или ваш коллега просто всё сломаете.
Проверяйте качество тестов. Сделать это поможет мутационное тестирование. Мутационный фреймворк случайно меняет константы и значения в условных операторах и циклах, создаёт копию кода, в которой поочерёдно меняет условия. Например, было <=, а стало >= или было COUNT=3, а стало COUNT=10. Каждая замена тестируется: если код поменялся, а тесты не упали, значит, код не покрыт тестами.
На мутационное тестирование уходит много времени. Можно подключить плагин, который считает code coverage по тесту и выдаёт отчёт. Например, у нас покрыто тестами 43 тысячи строк кода, а 10 тысяч — нет. Значит, code coverage 81%. Но тут важен не только сам процент, но и качество — какие именно фрагменты кода и какими именно тестами покрыты. Например, не всё может быть под юнит-тестами — часть может перекрываться интеграционными.
Обеспечьте достаточный процент покрытия кода. Года три-четыре назад я был фанатиком стопроцентного покрытия. Конечно, безумно круто, когда ты всегда знаешь, что именно сломалось. Но в продакшне этого добиться сложно — да и не нужно. Исключение — маленькие проекты или «жёсткие» команды, для которых полное покрытие в приоритете.
На самом деле, code coverage в 70–90% — уже крутой показатель, но и меньше 70% — тоже плохо. И ещё важный момент: новый код не должен понижать уровень code coverage.
Проверить code coverage можно с помощью coveralls.io:

Coveralls принимает результаты тестов и выдаёт отчёт: показывает процент покрытия и как он изменился с последнего теста.

Не делайте хрупкие тесты. Если тест нестабильный и регулярно падает, его называют хрупким. Его результат может зависеть от дня недели, времени суток, чётности или нечётности запуска. Бывает, две функции работают параллельно и на итоговый результат влияет то, какая из них закончит выполняться первой. Такие функции лучше разбивать на несколько простых и тестировать по отдельности. Мокайте всё что нужно, чтобы сделать тест управляемым, но не переборщите — иначе код будет сложно поддерживать.
Если в коде есть глобалки или стейты, в них между вызовами функции сохраняется стейт/кэш и другая информация. Очищайте их перед каждым тестом и убедитесь, что тесты не зависят друг от друга.
Допустим, мы написали юнит-тесты для двух функций. Но не учли, что первая функция сохраняет данные в глобалке, а вторая из-за этого меняет своё поведение. В результате первый тест проходит нормально, а второй падает или ведёт себя странно. А всё потому, что мы не сбросили состояние глобальной переменной.
Следите за скоростью тестов. Тесты должны работать быстро. Если они проверяют кусок кода 10–15 минут — разработчики устанут ждать и отключат их нафиг. Поэтому регулярно проверяйте скорость, ищите узкие места и оптимизируйте тесты. Если есть проблемы, подключитесь через дебаггер — возможно, основной код плохо оптимизирован и искать проблему нужно в продакшне.
Если у вас ещё остались сомнения, писать юнит-тесты или нет, вот несколько аргументов за. Итак, чем полезны юнит-тесты.
Упрощают работу — находят ошибки, которые вы можете не заметить (меня это много раз спасало). Например, меняешь одну строчку, чтобы поправить логи, а ломается весь код. Благодаря тестам я узнавал об этом ещё до продакшна.
Понятно документируют код. Если вам неочевидно, как работает та или иная функция, можно пройти дальше по коду или открыть юнит-тест. По нему сразу видно, какие параметры принимает функция и что отдаёт после выполнения. Это упрощает жизнь тем, кто работает с чужим кодом.
Помогают ничего не сломать при рефакторинге. Бывает, что код написан непонятно и ты не можешь его отрефакторить, потому что наверняка что-то сломаешь в продакшне. А с тестами код можно смело рефакторить.
Упрощают разработку. Кажется, что юнит-тесты всё усложняют, ведь нужно написать в два раз больше кода — не только функцию, но и тест к ней. Но я много раз убеждался: когда пишешь код без тестов, потом тратишь гораздо больше времени на поиск и исправление ошибок.
Бывает, бац-бац — и в продакшн, а потом понеслось: исправляешь код первый, второй, третий раз. И постоянно вспоминаешь, как тестировать его вручную. У меня даже были файлики с входными данными для таких проверок. Тогда я тестировал программы вручную, по бумажке, и тратил на это уйму времени. А если бы написал юнит-тест, нашёл бы эти баги сразу и не переписывал код по несколько раз.
Сейчас в коммерческой разработке без тестов почти не работают — а в большинстве компаний от разработчиков даже требуют покрывать код юнит-тестами. Везде, где я работал в последние несколько лет, тоже было такое правило. Ведь если в команде кто-то факапит, то может развалиться вся работа — а тестирование как раз защищает от краха.
Современные компании подписывают SLA — гарантируют работоспособность сервиса. Если продукт упадёт, бизнесу придётся заплатить деньги. Поэтому лучше подождать тестов и не катить код, который положит весь продакшн. Даже если сайт или приложение пролежат всего две минуты, это ударит по репутации и дорого обойдётся компании.
Чтобы лучше понять юнит-тесты, изучите тестовые фреймворки вашего языка. А потом найдите крупные open-source-проекты, которые их используют, и посмотрите, как они работают. Можно даже скачать проект и поиграть с тестами, чтобы глубже погрузиться в тему.
У фреймворков разный подход к написанию тестов, вызову методов, мокам и неймингу. Плюс у каждого из них есть сторонники и хейтеры, поэтому пробуйте и выбирайте. Главное — чтобы фреймворк хорошо мокал ваш код. Например, если у вас специфичный ORM, убедитесь, что фреймворк умеет с ним работать.
Чтобы познать тонкости разработки и тестирования приложений, лучше сразу учиться у практикующих профессионалов. Приходите в университет Skillbox, выбирайте курс и осваивайте программирование под присмотром экспертов.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать

Научитесь: Профессия Инженер по тестированию
Узнать больше
содержание
Unit тестирование. Mockito. Test Driven Development
Основано на этой лекции.
В этой лекции мы поговорим о Unit-тестировании. Узнаем, как тестировать андроид-приложения, как работать с библиотекой Mokito, как измерить уровень покрытия тестами в вашем проекте. Отдельно рассмотрим такой подход к рахзработке, как Test Driven Development.
Содержание:
- Введение
- Unit-тестирование
- JUnit
- Mockito
- Unit-тестирование с классами Android
- Unit-тестирование с серверными запросами
- Dependency Injection
- Измерение покрытия кода тестами
- Дополнительно– Test Driven Development (TDD)
Введение
На сегодняшний день тестирование систем является неотъемлемой частью процесса их разработки, и, разумеется, приложения под Android не стали исключением. Тестирование систем позволяет приобрести определенную уверенность в корректности и качестве их работы. Кроме того, тестирование позволяет проще вносить изменения (после внесения изменений систему можно протестировать и убедиться, что она работает корректно).
Существует немало видов тестирования, но для начала нас интересует разделение тестирования по степени автоматизации. Здесь можно очень грубо разделить тестирование на автоматизированное и ручное. Ручное тестирование подразумевает проверку системы человеком, сверку с техническим заданием и требованиями и поиск несоответствий и багов. Автоматическое тестирование позволяет выполнять тестирование системы программно.
Разумеется, у обоих этих способов есть свои преимущества и свои недостатки. Ручное тестирование позволяет лучше выявить недостатки, в том числе и такие проблемы, которые сложно найти с помощью автоматизированного тестирования (к примеру, с помощью автоматизированного тестирования будет тяжело заметить неправильный шрифт или неправильное расположение элементов).
С другой стороны, ручное тестирование в тысячи раз медленнее автоматического. В среднем, за рабочий день тестировщик может полностью проверить работу достаточно небольшого приложения за один день на одном устройстве, в то время как автоматическое тестирование позволяет буквально за несколько минут проверить корректность работы приложения на большом количестве устройств (или мгновенно выполнить тесты для бизнес-логики на JUnit).
Поскольку каждый вид тестирования имеет свои преимущества, правильным решением, будет их совместное использование.
Но нас, разумеется, будет интересовать только автоматическое тестирование, которое позволяет разработчику самостоятельно протестировать свое приложение. Кроме того, написание тестов при разработке имеет еще несколько очень важных преимуществ:
- Если вы хотите писать тесты, то вам придется придерживаться определенного архитектурного стиля. Мы обсуждали это уже не раз, и именно возможность тестирования была одной из основных причин, из-за которой мы занимались изучением архитектуры приложений.
- Написание тестов позволяет еще на этапе разработки выявить некоторые проблемы и случайные ошибки в вашем коде.
- Если в вашем проекте есть автоматические тесты, вы можете с меньшим риском вносить изменения в различные участки кода, поскольку с помощью тестов вы можете быстро проверить, что новыми изменениями вы не сломали старое поведение (конечно, тесты дают не гарантию корректности кода, а только лишь некоторую уверенность в этом, что тоже хорошо).
- Наличие тестов позволяет контролировать процесс разработки: тесты можно поставить на CI-сервер, чтобы отслеживать текущее состояние кода или проверять рабочие ветки, что очень удобно и дает гарантию того, что в production (релиз) попадет только код с выполняющимися тестами.
- Автоматические тесты могут служить документацией к вашему коду.
Кроме того, существует немало других разделений по видам тестирования. Один из наиболее употребляемых и важных разделений тестирования – это разделение тестирования по степени их модульности. Здесь в общем случае выделяется 3 вида тестирования:
- Модульное тестирование – это тестирование отдельных модулей системы в независимом от других модулей окружении. Это, вероятно, наиболее популярный и известный вид тестирования, и это логично. Чем более детальное тестирование мы выполняем, тем легче найти потенциальные ошибки, так как в тестировании одного модуля мы проверяем корректность работы только этого модуля, а он, конечно, имеет намного меньшую сложность, чем вся система в целом. Именно для реализации модульного тестирования мы и создавали гибкую и удобную архитектуру с разбиением приложения на слои и отдельные модули.
- Интеграционное тестирование – после проверки корректности работы отдельных модулей нужно проверить, как эти модули взаимодействуют между собой. Потому что система – это не только набор отдельных модулей, но и правила и средства их взаимодействия. Каждый модуль в отдельности может работать правильно, но при этом объединение нескольких модулей может содержать ошибки. Это тестирование выполняется уже на более высоком уровне.
- Системное тестирование – после объединения всех модулей приложения в единую систему и проведения интеграционного тестирования для различных групп модулей нужно провести тестирование того, как система работает в целом и насколько она соответствует изначальным требованиям. Это тестирование на глобальном уровне, поэтому детали реализации отдельных модулей уже не играют роли – система проверяется больше с точки зрения пользователя, или по методу черного ящика.
В рамках системы Android можно выполнять автоматизированное тестирование всех видов, изложенных выше. Но есть и особенности. Во-первых, в рамках нашей архитектуры основным компонентом, который содержит бизнес-логику и который должен быть протестирован в первую очередь, является делегат или Presenter. Presenter – это обычный Java-класс (с возможными зависимостями от Android), поэтому тесты для него пишутся в рамках модульного тестирования и с помощью стандартного фреймворка JUnit. Также в рамках модульного тестирования нужно протестировать работу слоя данных.
В случае модульного тестирования все достаточно очевидно. Но что же насчет интеграционного и системного тестирования? Что является интеграцией нескольких модулей в случае Android-приложения? Обычно под интеграцией нескольких модулей понимается конкретный экран приложения, на котором объединяются модули, содержащие бизнес-логику, и модули из слоя данных. Конкретный экран уже должен быть протестирован с точки зрения пользователя, хоть и с небольшими знаниями о том, как устроена система внутри.
И насчет системного тестирования также все очевидно – это тестирование всего приложения и всех его экранов. Оно также выполняется с точки зрения пользователя.
Тестирование слоя данных, а также интеграционное и системное тестирование в Android реализуются с помощью специальных средств, которые будут рассмотрены в рамках следующей лекции. А сейчас мы перейдем к тестированию бизнес-логики приложения, а именно к тестированию Presenter-ов.
JUnit
Мы много раз сказали о тестировании, а также о разных средствах для написания тестов. Но что же такое тесты? Интуитивно мы понимаем, что это означает. Тесты – это некоторые проверки или утверждения, которые позволяют в определенной степени убедиться в корректности работы системы.
Для модульного тестирования Java-кода используется фреймворк JUnit. Этот фреймворк позволяет конфигурировать окружение для тестов, исполнять код, который будет проверять работу некоторых классов, и выводить результаты тестов (сколько успешных тестов, сколько ошибок, и где именно произошли ошибки).
Разберем простейший пример написания тестов. Допустим, у нас есть класс, в котором определен только один метод для сложения двух чисел:
class MyCalc { fun Sum(a: Int, b: Int): Int = a+b }
И напишем для него тестовый класс:
@RunWith(JUnit4.class) class MyCalcTest { lateinit val calc: MyCalc @Before fun setUp(){ // создаем экземпляр класса calc = MyCalc() } @Test fun sum() { // тестируем результат функции Assert.assertEquals(calc.Sum(2,2), 4) } @After fun tearDown(){ // } }
Какие основные элементы есть в этом тесте? Во-первых, в аннотации @RunWith указывается так называемый Runner, который и отвечает за запуск тестов, корректный вызов и обработку всех методов (но вроде работает и без него).
Во-вторых, мы указываем тестовые методы. Тестовые методы – это методы с аннотацией @Test, в которых выполняется непосредственная проверка тестируемого кода. Большинство проверок выполняется с помощью методов, начинающихся с assert: assertTrue, assertEquals и другие. Эти методы проверяют, соответствует ли результат работы (в нашем примере сложение чисел 2 и 2) ожидаемому значению (в нашем примере это число 4). В случае ошибки выбрасывается исключение, и JUnit информирует нас о том, что какой-то тест не выполняется.
И еще два важных метода – это методы, помеченные аннотациями @Before и @After. Код метода с аннотацией @Before будет выполняться перед выполнением каждого тестового метода. Соответственно, код с аннотацией @After будет выполняться после каждого тестового метода. Эти методы нужны для того, чтобы подготовить какие-то параметры или объекты к тестам (например, вынести тестируемый объект в поле класса и инициализировать его в методе setUp вместо того, чтобы выполнять инициализацию в каждом тестовом методе) или же очистить ресурсы после окончания тестового метода.
Фреймворк JUnit очень простой, и писать тесты на нем легко. По сути, все, что есть в этом примере, и есть основные возможности JUnit. Поэтому мы сразу перейдем к тестированию Presenter-а, который мы создавали в рамках прошлой лекции.
Начнем с простого, проверим, что Presenter корректно создается и инициализируется. Напомним, какие поля определены в этом Presenter-е:
class AuthPresenter(private val authView: AuthView){ ...
Получается, что нам нужно создать экземпляр объекта, который реализует интерфейс AuthView. Создадим этот объект, реализовав все его методы и ничего в них не выполняя:
var mPresenter = object : AuthView { override fun successLogin() {} override fun showLoginError(error: String) {} override fun showPasswordError(error: String) {} override fun showLoading() {} override fun hideLoading() {} override fun getToken(): String = "" override fun setToken(token: String) {} }
И мы наконец-то можем проверить, что наш Presenter корректно создается и инициализируется:
@Test fun testCreated(){ val presenter = AuthPresenter(mPresenter) assertNotNull(presenter) }
При запуске теста может возникнуть ошибка:
java.lang.RuntimeException: Method isEmpty in android.text.TextUtils not mocked.Это происходит из-за того, что класс TextUtils входит в библиотеку Андроид, про которую JVM пока не знает. Пока можно в build.graddle в секцию android добавить заглушку, подробнее эта тема будет затронута ниже:testOptions { unitTests.returnDefaultValues = true }
Казалось бы, это самый простой тест, но для его написания мы потратили очень много кода. Можно надеяться, что дальше все пойдет проще. Теперь протестируем метод, который вызывается при старте приложения (напомним, этот метод проверяет текущее состояние авторизации и, если пользователь уже авторизован, то открывает главный экран). Этот метод выглядит следующим образом:
init { val token = authView.getToken() if(token.trim()!="") authView.successLogin() }
Для этого метода возможно в общем случае два сценария, которые нужно протестировать: когда отсутствует сохраненный токен – тогда Presenter не должен вызывать никакие методы у View, и когда в приложении есть сохраненный токен, тогда Presenter должен вызвать метод successLogin у View.
И вот здесь серьезная проблема. В первом примере мы показывали, как проверить работу метода, который возвращает какой-то результат. Но как проверить void метод? Или еще хуже, как проверить то, что у какого-то объекта не был вызван ни один метод? Конечно, мы можем для каждого тестового метода писать свою реализацию AuthView, которая проверяла бы то, что был вызван определенный метод. Поэтому можно было бы написать примерно такой код (мне его лениво переводить на котлин, в принципе и так понятно):
public class TestAuthView implements AuthView { private final boolean mExpectRepositories; private final boolean mExpectLoginError; public TestAuthView(boolean expectRepositories, boolean expectLoginError) { mExpectRepositories = expectRepositories; mExpectLoginError = expectLoginError; } @Override public void successLogin() { assertTrue(mExpectRepositories); } @Override public void showLoginError() { assertTrue(mExpectLoginError); } }
Тогда эту реализацию можно было бы использовать следующим образом:
@Test public void testEmptyLogin() throws Exception { AuthView authView = new TestAuthView(false, true); AuthPresenter presenter = new AuthPresenter(mLifecycleHandler, authView); presenter.tryLogIn("", "123456"); }
При создании TestAuthView мы ожидаем, что для данного теста не будет вызван метод successLogin, зато будет вызван метод showLoginError. И такой подход может работать.
Но теперь мы можем усложнить пример. Допустим, нам нужно проверить, что какой-то метод был вызван несколько раз. Да, мы можем ввести специальные счетчики для каждого метода и вспомогательные классы для проверки этих счетчиков, но это становится уже слишком сложно. А ведь мы так же хотели бы проверять, правильные ли параметры были переданы вызванному методу.
Есть и другой пример, который наверняка отобьет желание реализовывать предложенный подход. Предположим, что для каких-то целей нам потребовалось передать объект Context в Presenter. И, если мы попробуем создать таким способом экземпляр класса Context, то мы получим порядка 150 методов, которые нужно переопределить, что уже совсем нетривиально.
Разумеется, мы не единственные разработчики, которые столкнулись с такой проблемой, и для нее уже давно известны способы решения. Самый простой и известный из этих способов – это библиотека Mockito.
Mockito
Mockito – это библиотека для создания mock-объектов на Java. Mock-объекты – это обычные объекты, все методы которого возвращают значения по умолчанию. Казалось бы, что в этом хорошего? Использование mock-объектов имеет три огромных преимущества:
- Позволяет в одну строчку создать экземпляр любого класса или интерфейса, при этом нет необходимости реализовывать или переопределять методы. Здесь есть только одно исключение – final классы. Поэтому простой совет – не используйте final классы (хотя есть инструменты, позволяющие замокать и их).
- Mock-объект позволяет узнать, был ли вызван какой-либо метод у этого объекта, а также сколько раз он был вызван и с какими параметрами.
- Mock-объект можно настроить таким образом, чтобы он реагировал на вызов какого-то метода нужным образом (возвращал определенный результат, выбрасывал исключение).
У котлина все классы по-умолчанию являются final, но к нашему счастью есть библиотека и для котлина, где это ограничение снято. В зависимости проекта добавьте:
testImplementation 'com.nhaarman.mockitokotlin2:mockito-kotlin:2.2.0'
Первые два преимущества – это как раз то, что нам нужно! Мы можем создать mock-объект для AuthView, а также узнать, какие методы у него были вызваны. Создать mock-объект с помощью Mockito очень просто – для этого служит статический метод mock:
val authView = Mockito.mock(AuthView::class.java)
И теперь мы можем вызывать все методы интерфейса AuthView, Mockito зарегистрирует все вызовы, которые мы сможем дальше проверить. Тогда мы можем написать тесты для проверки входа при существующем логине следующим образом:
@Test fun testNextScreenOpened(){ //создаем mock-объект для интерфейса AuthView val authView = Mockito.mock(AuthView::class.java) //создаем заглушку для метода getToken, всегда возвращаем "token" Mockito.`when`(authView.getToken()).thenReturn("token") // создаем экземпляр класса AuthPresenter val presenter = AuthPresenter(authView) // проверка токена происходит в конструкторе, поэтому мы сразу можем проверить вызывался ли метод successLogin Mockito.verify(authView).successLogin() }
Такая форма записи позволяет проверить, действительно ли у экземпляра AuthView был вызван метод successLogin. Мы также можем проверить, что у AuthView, например, не был вызван метод showLoading во время процесса инициализации:
Mockito.verify(authView, never()).showLoading()
^^^^^^^
Как видно, для этого используется еще одна форма метода verify, где вторым параметром указывается функция, возвращающая VerificationMode.
Кроме самого факта был вызов функции или нет можно узнать и количество вызовов. Например, предыдущий пример можно переписать так:
Mockito.verify(authView, Mockito.times(0)).showLoading()
Кроме этого, Mockito позволяет в удобной форме проверить, что у mock-объекта не был вызван ни один метод. Для этого служит метод verifyNoMoreInteractions. К примеру, так может выглядеть тест, проверяющий, что Presenter не вызывает у View никакие методы после создания (у нас этот тест не пройдет, т.к. метод getToken вызывается сразу из конструктора):
@Test fun testNextScreenNotOpened(){ val authView = Mockito.mock(AuthView::class.java) Mockito.`when`(authView.getToken()).thenReturn("") val presenter = AuthPresenter(authView) Mockito.verifyNoMoreInteractions(authView) }
На самом деле, мощь Mockito не ограничивается только этими методами. Как уже было сказано, Mockito позволяет подменять реализацию методов, чтобы они возвращали определенное значение и выбрасывали исключение. Но для нас будет достаточно рассмотренных средств.
Справедливости ради нужно сказать, что существуют и другие библиотеки для создания mock-объектов, но признается, что Mockito является наиболее удобной из них (к тому же она постоянно развивается).
А пока мы продолжаем писать тесты для конструктора AuthPresenter (казалось бы, что метод состоит из 3 строчек, но в нем собраны почти все проблемы тестирования модулей Android-приложений на JUnit). Напомним еще раз, как выглядит конструктор:
init { val token = authView.getToken() if(token.trim()!="") authView.successLogin() }
Мы уже говорили, что для этого метода есть два сценария: когда токен пустой и когда он не пустой.
Тут пропущен кусок оригинальной статьи, где рассматиривается создание класса для работы с токеном. Но у нас этот функционал отдан на откуп вызывающему классу, так что для тестирования сценариев с токеном нам достаточно заглушки на метод getToken
И теперь мы можем написать тесты для всех рассмотренных случаев:
lateinit var mAuthView: AuthView @Before fun startUp(){ mAuthView = Mockito.mock(AuthView::class.java) } @Test fun testNextScreenOpened(){ Mockito.`when`(mAuthView.getToken()).thenReturn("token") AuthPresenter(mAuthView) Mockito.verify(mAuthView).successLogin() } @Test fun testEmptyToken(){ Mockito.`when`(mAuthView.getToken()).thenReturn("") AuthPresenter(mAuthView) Mockito.verify(mAuthView, never()).showLoading() Mockito.verify(mAuthView, never()).successLogin() }
Теперь мы можем достаточно простым способом подменять значение токена и тестировать Presenter в зависимости от значения токена.
Unit-тестирование с классами Android
К сожалению, это еще не все проблемы, с которыми мы сталкиваемся при написании тестов. Использование Mockito – это весьма стандартный подход и в Java, который позволяет подменить реализацию или замокать некоторые вызовы, например, обращение к БД. Android добавляет и свои проблемы. Попробуем сейчас запустить тесты и получим ошибку:
java.lang.RuntimeException: Method isEmpty in android.text.TextUtils not mocked.
И сейчас пришла пора узнать, почему в таких делегатах как Presenter, которые тестируются на JUnit, не рекомендуется использовать зависимости от Android-классов. Это происходит потому, что тестирование на JUnit выполняется на JVM (виртуальной машине Java), которая ничего не знает о классах Android (а TextUtils определен в пакете android.text). Это фактически означает, что тесты на JUnit не смогут скомпилироваться, если в тестируемых классах есть зависимости от классов Android. Чтобы избежать этого, все классы Android поставляются в виде файла android.jar, в котором есть все классы и методы из Android. Но все методы во всех классах из этого jar-файла не содержат реализацию, а только выбрасывают исключение. Это позволяет тестам компилироваться, но не позволяет использовать эти методы напрямую.
Мы уже можем предположить, как решить такую проблему, когда мы используем экземпляры классов Android – тут нам поможет Mockito. Мы можем создавать экземпляры классов Android и мокать нужные методы.
К сожалению, в этом небольшом, но очень проблемном методе есть еще одна деталь – он использует статические методы из классов Android, а именно TextUtils. Мы уже знаем, как бороться с проблемой статических методов. Но здесь есть своя специфика.
В случае PreferenceUtils мы изменили доступ к простым данным, добавив новый класс в слое данных. В случае TextUtils мы можем поступить также, но это может быть слишком сложно – для каждого такого метода делать специальный класс, в таком случае мы получим слишком много разных делегатов. Переносить TextUtils в слой данных также не слишком хороший вариант, так как он не имеет к этому слою никакого отношения. Есть 3 разных способа решения этой проблемы, которые мы сейчас и рассмотрим.
Первым способом является библиотека PowerMock. PowerMock по принципу работы очень похож на Mockito, только в отличие от Mockito он позволяет замокать не только объекты и их методы, но в том числе и конструкторы объектов, и статические методы. Логичный вопрос – почему не использовать всегда PowerMock вместо Mockito? PowerMock должен использоваться в старых проектах, где вы не можете легко изменить реализацию какого-то метода, или же в случаях, когда вам нужно замокать какую-то библиотеку. PowerMock делает ваши тесты зависимыми от реализации, то есть вы в тестах уже указываете, как должен работать ваш код, а не тестируете его работу. Mockito должно быть достаточно для того, чтобы протестировать ваш код. Если Mockito недостаточно, значит, вам стоит пересмотреть архитектуру.
Про PowerMock нужно знать, так как бывают ситуации, когда без него не обойтись. Поэтому рассмотрим пример его использования. Во-первых, нужно подготовить Runner для JUnit и указать классы, в которых будут замоканы статические методы:
TODO: PowerMock не взлетел
Здесь мы указываем, что хотим замокать класс TextUtils (это позволяет PowerMock перехватывать вызовы методов этого класса), и после этого мокаем сам метод isEmpty.
Этот способ нужно знать, но применять его нужно очень и очень аккуратно, иначе PowerMock может быстро стать “золотым молотком” в ваших тестах.
Вторым и наиболее популярным способом работы с классами Android в рамках JUnit является библиотека Robolectric. Эта библиотека позволяет эмулировать работу Android-приложения на JVM. Разумеется, это будет только эмуляция и только для основных функций системы, но для тестирования это очень удобно. Использовать Robolectric очень легко, нужно только добавить зависимости:
testImplementation 'org.robolectric:robolectric:4.2.1'
И указать в качестве Runner класс RobolectricTestRunner:
@RunWith(RobolectricTestRunner::class) @Config(sdk=[21], manifest = Config.NONE) class AuthPresenterTest { ...
И это все! Правда, время запуска тестов может увеличиться, так как Robolectriс выполняет загрузку всех своих классов, чтобы вы могли использовать их в тестах.
Robolectric использует концепцию shadow классов. Когда вы обращаетесь к какому-либо классу, Robolectric проверяет наличие такого Shadow класса, и, если он существует, вызов метода идет к этому классу, а не к исходному классу. При этом вам не нужно явно указывать, реализацию каких классов вам нужно заменить. В состав библиотеки Robolectric изначально входит большое количество shadow классов, которые нужны для замены самых популярных классов из Android. Но вы также можете добавить и свои shadow классы, если вам не хватает стандартных.
Нужно также сказать, что Robolectric позволяет выполнять базовое тестирование UI-элементов, но для этого не нужно его использовать. Для тестирования UI следует использовать настоящие устройства и другие фреймворки, например, Espresso.
И есть еще один способ, который является очень простым и в то же время действенным. В подавляющем большинстве случаев с проблемой того, как замокать статический метод, вы столкнетесь как раз при использовании методов TextUtils.isEmpty или TextUtils.equals. И тогда, если нельзя использовать стандартные классы из Android, то можно создать собственный класс с этими методами (скопировав их в свой класс):
// автоматическая трансляция кода - не проверял object TextUtils { fun isEmpty(text: CharSequence?): Boolean { return text == null || text.length == 0 } }
И теперь во всех классах можно использовать собственный класс TextUtils вместо классов Android. Этот способ достаточно простой, но позволяет решить возникшую проблему.
Unit-тестирование с серверными запросами
Мы наконец-то разобрались со всеми возникшими проблемами, и теперь наши тесты для конструктора наконец работают как нужно! Мы знаем, как замокать различные объекты, как работать со статическими методами и даже как простейшим образом подменять реализацию нужных классов из слоя данных. И теперь нам осталось разобрать еще один важный вопрос, о котором мы говорили изначально – как изменять окружение для эмулирования различных ответов сервера. В данном примере это нужно для того, чтобы проверить различные варианты для ответов авторизации. Напомним код для авторизации в Presenter:
fun tryLogIn(login: String, password: String) { if (login.trim()=="") { authView.showLoginError( ERROR_EMPTY_LOGIN ) } else if (password.trim()=="") { authView.showPasswordError( ERROR_EMPTY_PASSWORD ) } else { // показ прогресс-бара authView.showLoading() try { // в оригинальной статье опущен момент с сохранением токена - это нужно делать тут val jsonResp = JSONObject(Factory.repository!!.login("qq", "ww")) if(jsonResp.has("status") && jsonResp.getString("status")=="OK") { authView.setToken("some token") authView.successLogin() } else { authView.showLoginError(ERROR_AUTH) } } catch (e: Exception){ authView.showLoginError(ERROR_NETWORK) } authView.hideLoading() } }
Какие варианты нам нужно протестировать для этого метода? Разумеется, это случаи, когда логин или пароль пустые, написание для них тестовых методов является тривиальной задачей:
@Test fun testEmptyLogin(){ Mockito.`when`(mAuthView.getToken()).thenReturn("") val mPresenter = AuthPresenter(mAuthView) mPresenter.tryLogIn("", "password") Mockito.verify(mAuthView).showLoginError(AuthPresenter.ERROR_EMPTY_LOGIN) } @Test fun testEmptyPassword(){ Mockito.`when`(mAuthView.getToken()).thenReturn("") val mPresenter = AuthPresenter(mAuthView) mPresenter.tryLogIn("login", "") Mockito.verify(mAuthView).showPasswordError(AuthPresenter.ERROR_EMPTY_PASSWORD) }
Теперь у нас осталось еще два случая: успешная авторизация на сервере и неудача при попытке авторизации (все возможные ошибки обрабатываются одинаково, поэтому других важных вариантов здесь нет).
Как мы могли бы проверить корректность обработки этих двух вариантов? Самый простой способ – выполнить реальные запросы на сервер, используя в первом случае существующие данные для авторизации, а для проверки ошибки – любые случайные данные. На самом деле, это не самый плохой вариант из возможных. Тестирование на реальном сервере, а не на измененном для теста окружении будет ближе к реальной работе системы. Однако здесь есть несколько минусов:
- Для проверки стандартных корректных сценариев будет необходимо использовать в коде реальные данные существующих пользователей. Конечно, это не настолько критично, так как можно использовать специальных тестовых пользователей.
- Серверные запросы могут выполняться не быстро. В случае, когда у вас несколько тысяч тестов, это может оказать ощутимый эффект на скорости выполнения тестов, что нежелательно. Кроме того, такое количество запросов может ощутимо нагружать работу сервера.
- Тестовые методы попадают в зависимость от окружения. Допустим, вы проверяете сценарий корректного входа и ожидаете успешный вход при вводе реальных данных. А в этот момент на сервере, к которому вы обращаетесь в тесте, случился сбой, и поэтому вы получите ошибку, а тест не пройдет, хотя он написан верно.
По комплексу описанных причин лучше использовать различные методы для подмены окружения при тестировании. Под окружением в данном случае имеется в виду слой данных. И здесь есть большое количество различных вариантов.
Самый простой из этих вариантов мы уже рассмотрели в процессе избавления от проблемы при работе с настройками – это статическое поле для Repository и метод для установки этого поля. Этот способ тривиальный, но вполне эффективный.
Мы этот вариант не рассматривали и дальше будем использовать штатные средства библиотеки Fuel для тестирования.
Этот код устарел — не использовать!!!
Библиотека Fuel позволяет задать своего клиента, который симулирует ответы на запросы:
FuelManager.instance.client = object : Client { // переопределяем метод executeRequest и формуруем нужный нам ответ - в данном случае ошибка сервера override fun executeRequest(request: Request): Response { return Response( request.url, statusCode = 500 ) } }
Проверим сценарии авторизации.
// тест на ошибку связи/сервера @Test fun testNetworkError(){ FuelManager.instance.client = object : Client { override fun executeRequest(request: Request): Response { return Response( request.url, statusCode = 500 ) } } Mockito.`when`(mAuthView.getToken()).thenReturn("") val mPresenter = AuthPresenter(mAuthView) // логин/пароль условно валидные mPresenter.tryLogIn("login", "password") // в результате должен вызваться метод showLoginError Mockito.verify(mAuthView).showLoginError(AuthPresenter.ERROR_NETWORK) } // тест на успешную авторизацию @Test fun testSuccessLogin(){ FuelManager.instance.client = object : Client { override fun executeRequest(request: Request): Response { // подсовываем валидный ответ val resp = """{"status":"OK"}""".toByteArray() return Response( request.url, body = DefaultBody.from( {ByteArrayInputStream(resp)}, {-1} ) ) } } Mockito.`when`(mAuthView.getToken()).thenReturn("") val mPresenter = AuthPresenter(mAuthView) mPresenter.tryLogIn("login", "password") // при валидном ответе должен быть вызван метод successLogin Mockito.verify(mAuthView).successLogin() }
Проверим сценарии авторизации. Для этого создадим тестовый класс для реализации объекта Repository, который в зависимости от логина/пароля будет возвращать валидный/не валидный ответ:
class DummyAPI(): API() {
override fun login(name: String, password: String): String {
return if(name=="alice" && password=="qwerty") """{"status":"OK","token":"123"}"""
else """{"status":"error","error":"user $name not found"}"""
}
}
И теперь напишем оставшиеся тесты для проверки сценариев авторизации:
@Test fun testSuccessAuth() { Factory.repository = DummyAPI() Mockito.`when`(mAuthView.getToken()).thenReturn("") val mPresenter = AuthPresenter(mAuthView) mPresenter.tryLogIn("alice", "qwerty") Mockito.verify(mAuthView).successLogin() } @Test fun testErrorAuth() { Factory.repository = DummyAPI() Mockito.`when`(mAuthView.getToken()).thenReturn("") val mPresenter = AuthPresenter(mAuthView) mPresenter.tryLogIn("bob", "12345") Mockito.verify(mAuthView).showLoginError(AuthPresenter.ERROR_AUTH) }
Таким образом, мы можем протестировать все возможные сценарии работы Presenter-а исключительно с помощью Unit-тестов и обрести определенную уверенность в том, что этот класс работает корректно.
Кроме того, с помощью Unit-тестов мы можем проверить и комплексную работу Presenter-а, к примеру, типичные сценарии взаимодействия пользователя с экраном авторизации. Какие это могут быть сценарии? Например, этот экран может открыть неавторизованный пользователь, который вначале введет неправильные данные, а после исправит ошибку и войдет в приложение. Мы можем протестировать полностью весь этот сценарий с точки зрения логики:
@Test fun testScreenScenario(){ Mockito.`when`(mAuthView.getToken()).thenReturn("") Factory.repository = DummyAPI() val mPresenter = AuthPresenter(mAuthView) // проверяется, что ни один метод еще не вызфывлся, // но в нашей реализации этого делать нельзя - getToken вызывается из конструктора // Mockito.verifyNoMoreInteractions(mAuthView) mPresenter.tryLogIn("login", "password") Mockito.verify(mAuthView).showLoading() Mockito.verify(mAuthView).hideLoading() Mockito.verify(mAuthView).showLoginError(AuthPresenter.ERROR_AUTH) mPresenter.tryLogIn("alice", "qwerty") Mockito.verify(mAuthView, times(2)).showLoading() Mockito.verify(mAuthView, times(2)).hideLoading() Mockito.verify(mAuthView).successLogin() }
Для улучшения понимания и закрепления материала еще раз проговорим, что происходит в этом тесте. Во-первых, мы мокаем поставщик локальных данных так, чтобы он возвращал пустой токен (это ситуация, когда пользователь не авторизован). В таком случае Presenter не должен ничего отдавать View.
Далее, мы подменяем репозиторий, чтобы корректно проверять сценарии авторизации. После этого пользователь вводит неправильные данные, и ему возвращается ошибка. Мы проверяем, что эта ошибка обрабатывается. Также мы проверяем, что во время выполнения запроса на авторизацию показывается и скрывается прогресс. И, наконец, мы проверяем корректный вход, чтобы убедиться, что Presenter корректно обрабатывает и такую ситуацию даже после первого ошибочного входа.
Такие тесты также весьма полезны, но лучше отдавать предпочтение небольшим тестам, которые легко понять и читать. И чем больше таких тестов будет в приложении, тем лучше для вашего приложения.
Рассмотренных примеров и средств при построении корректной архитектуры будет достаточно для большинства возникающих ситуаций. Но также существует еще несколько важных моментов, которые нужно рассмотреть подробнее. И в первую очередь это различные средства обеспечения замены репозитория и других объектов. Статический метод для установки значения работает хорошо, но существует немало альтернатив такому подходу, которые имеют свои преимущества и их нужно рассмотреть. Для реализации такой возможности используются принципы Inversion of Control (IoC) и Dependency Injection (DI).
Дальше идет текст из оригинальной статьи, на котлин не переведено
Dependency Injection
Если говорить совсем общими словами, то эти принципы IoC и DI позволяют уменьшить связность кода, не думать о том, как инициализировать объекты и подменять объекты во время работы приложения. Нас интересует в первую очередь последнее свойство, так как мы хотим подменить ответ сервера или же реализацию классов, выполняющих серверные запросы.
Существует много путей реализации IoC и DI в Android для описанной ситуации, более того, есть даже принципиальное различие в способах подмены результата:
- Подмена ответа сервера: использование тестового окружения или подстановка своего ответа через OkHttp (собственно в предыдущем разделе мы это и делали).
- Подмена моделей ответа: static setter, который мы уже рассмотрели, библиотеки для реализации DI и productFlavors в gradle (а это как раз пропустили).
Чтобы не усложнять и без того не очень простой материал текущей лекции, способы реализации DI и IoC будут подробно рассмотрены в рамках следующей лекции, а пока мы дадим их небольшое описание и обзор.
Первый из предложенных способов более актуален для проведения интеграционного и системного тестирования, когда мы хотим проверить работу приложения в целом и сделать так, чтобы изменение ответов выполнялось как можно “дальше” от самого приложения. Потому что при таком подходе мы можем проверить, как будет работать приложение для конечного пользователя, а не только в рамках тестового окружения.
Существует немало библиотек для Android, которые позволяют использовать принципы Dependency Injection. Это Guice, Dagger 2, недавно появившийся tiger и другие. Но на самом деле у них всех есть свои недостатки. Во-первых, некоторые из них, к примеру, Guice, замедляют работу приложения. Во-вторых, вспомните, что нам нужно только менять ответы сервера и почти для любой части приложения все элементы жестко зафиксированы. Поэтому использовать лишнюю библиотеку только для того, чтобы подменить ответы в нескольких местах – это не всегда разумно. Поэтому Dagger 2 будет рассмотрен только в рамках дополнительной лекции.
Но, вероятно, одним из самых удобных и мощных решений для реализации принципов IoC является использование product flavors из gradle плагина для Android, которые полностью поддерживаются в Android Studio.
Product flavors позволяют использовать разный код и разные ресурсы в зависимости от типа сборки. Мы можем сделать два различных product flavors (например, mock и prod). Во флаворе mock мы будем использовать тестовые ответы сервера или другие моки, и будем писать тесты с использованием этого флавора. Флавор prod может использовать реальный сервер, и мы будем проверять в нем работу приложения в рамках ручного тестирования.
Все средства для реализации DI мы обсудим во время изучения UI-тестирования, а пока нам достаточно простейшего способа с использованием статического метода для установки значения.
Измерение покрытия кода тестами
Также очень важно знать и уметь измерять, насколько полно и качественно вы тестируете свой код. Для этого существуют инструменты проверки процента покрытия кода тестами. Во-первых, это стандартный запуск тестов из Android Studio с измерения покрытия. Такой способ позволяет посмотреть, какой код был выполнен в ходе тестов, а какой остался нетронутым. Это позволяет очень удобно найти участки кода, которые не были протестированы, и написать тесты для них.
Во-вторых, есть более совершенные инструменты, такие как JaCoCo (Java Code Coverage), которые позволяют проверять процент покрытия кода тестами более детально. JaCoCo позволяет отслеживать покрытие различных веток развития программы, а не только обычное выполнение кода по строками.
Например, у нас есть следующий метод:
public int someMethod(boolean first, boolean second) { if (first || second) { return 1; } return 2; }
И тесты для него:
@Test public void testSomeMethodCondition() throws Exception { int result = someMethod(false, true); assertEquals(1, result); } @Test public void testSomeMethodDefault() throws Exception { int result = someMethod(false, false); assertEquals(2, result); }
Для таких тестов при измерении покрытия из Android Studio вы получите результат в 100% (так как в ходе тестов были выполнены хотя бы раз все строчки метода), а при измерении покрытия с помощью JaCoCo вы получите результат, что есть еще случаи, которые вы не протестировали (различные варианты использования булевских переменных). К сожалению, JaCoCo не указывает, какой именно участок вашего кода не протестирован, так как он работает на уровне байт-кода и не знает о вашем исходном коде. Но JaCoCo все равно является мощным инструментом, который нужно использовать в своих проектах.
Test Driven Development (TDD)
Test driven development – это методология разработки, в ходе которой разработчик вначале пишет тест, а уже после пишет код, который будет соответствовать этому тесту. У такого подхода есть свои преимущества:
- Поскольку вы сначала пишете тесты, вы не сможете оказаться в ситуации, когда код уже написан, а на написания тестов нет времени или возможностей (разумеется, если будете следовать методологии TDD).
- Мы обсуждали, что хорошая архитектура нужна для того, чтобы можно было писать тесты. Когда вы в первую очередь пишете тесты, вы вынуждены создавать архитектуру, которая позволит этим тестам выполняться.
- Очень часто разработчики пишут тесты таким образом, чтобы они соответствовали написанному коду, а не наоборот. Из-за этого тесты часто бывают бесполезны. Когда вы пишете код так, чтобы он соответствовал вашим тестам, вы более уверены в том, что тесты действительно проверяют корректность работы системы. Конечно, если вы умеете писать хорошие и полные тесты для ваших классов.
Процесс разработки через тестирование является полностью противоположным тому, как мы привыкли писать программы. Обычно мы пишем код и после уже тестируем его. С разработкой через тестирования все полностью наоборот.
Процесс разработки через тестирование состоит из следующих шагов:
- Создать тест, который не выполняется.
- Написать самый простой и примитивный код, который позволит тесту выполниться.
- Поскольку на втором шаге был написан, возможно, неудачный код, то теперь мы должны отрефакторить его. При этом во время рефакторинга нужно постоянно запускать тест, чтобы проверить, что мы ничего не сломали в ходе рефакторинга.
- После завершения такого процесса мы возвращаемся к пункту 1 и пишем новый тест.
Тогда структурную схему такого подхода можно представить в виде следующей диаграммы:

Когда вы следуете методологии TDD, ваши тесты являются спецификацией того, как должна вести себя система в итоговом варианте. Если вы можете написать тесты для всех пунктов вашей спецификации, то вы получите хорошую уверенность в том, что система работает как нужно.
Конечно, поначалу такая схема работы может занимать много лишнего времени, но ее стоит попробовать, так как в будущем это может помочь вам добиться высоких результатов, особенно если вы заботитесь о качестве своих программных продуктов.
содержание
What is a software product? The business code itself, right? Actually, that’s only a part of it. A software product consists of different elements:
- Business code
- Documentation
- CI/CD pipeline
- Communication rules
- Automation tests
Pure code is not enough anymore. Only if these parts are integrated into a solid system, can it be called a software product.
Tests are crucial in software development. Moreover, there is no separation between “application” and “tests” anymore. Not because the absence of the latter will result in an unmaintainable and non-functional product (though it’s definitely the case), rather due to the fact that tests guide architecture design and assure code testability.
Unit tests are only a fraction of the huge testing philosophy. There are dozens of different kinds of tests. Tests are the foundation of development these days. You can read my article about integration tests on Semaphore’s blog. But now it is time to deep dive into unit testing.
The code examples for this article are in Java, but the given rules are common for any programming language.
Table of contents
- What is unit testing
- Test-driven development
- Unit tests requirements
- The unit testing mindset
- Best practices
- Unit testing tools
What is unit testing
Every developer has experience in writing unit tests. We all know their purpose and what they look like. It can be hard, however, to give a strict definition for a unit test. The problem lies within the understanding of what a unit is. Let’s try to clarify that first.
A unit is an isolated piece of functionality.
Sounds reasonable. According to this definition, every unit test in the suite should cover a single unit.
Take a look at the schema below. The application consists of many modules, and each module has a number of units.

In this case, there are 6 units:
- UserService
- RoleService
- PostService
- CommentService
- UserRepo
- RoleRepo
According to the given schema, the unit can be defined in this way:
A unit is a class that can be tested in isolation from the whole system.
So, we can write tests for each specific unit, right? Well, this statement is both correct and incorrect, because units do not exist independently of one another. They have to interact with each other, or the application won’t work.
Then how can we write unit tests for something that cannot practically be isolated? We’ll get to this soon, but let’s make another point clear first.
Test Driven Development
Test Driven Development is the technical practice of writing tests before the business code. When I heard about it for the first time, I was confused. How can one write tests when there is nothing to test? Let’s see how it works.
TDD declares three steps:
- Write a test for the new functionality. It’s going to fail because you haven’t written the required business code yet.
- Add the minimum code to implement the feature.
- If the test passes, refactor the result and go back to the first step.
This lifecycle is called Red-Green-Refactor.
Some authors have proposed enhancements for the formula. You can find examples with 4 or even 5 steps, but the idea remains the same.
The problem of unit definition
Suppose we’re creating a blog where authors can write posts and users can leave comments. We want to build functionality for adding new comments. The required behaviour consists of the following points:
- User provides post id and comment content.
- If the post is absent, an exception is thrown.
- If comment content is longer than 300 characters, an exception is thrown.
- If all validations pass, the comment should be saved successfully.
Here is the possible Java implementation:
public class CommentService {
private final PostRepository postRepository;
private final CommentRepository commentRepository;
// constructor is omitted for brevity
public void addComment(long postId, String content) {
if (!postRepository.existsByid(postId)) {
throw new CommentAddingException("No post with id = " + postId);
}
if (content.length() > 300) {
throw new CommentAddingException("Too long comment: " + content.length());
}
commentRepository.save(new Comment(postId, content));
}
}It’s not hard to test the content’s length. The problem is that CommentService relies on dependencies passed through the constructor. How should we test the class in this case? I cannot give you a single answer, because there are two schools of TDD. The Detroit School (classicist) and the London School (mockist). Each one declares the unit in a different way.
The Detroit School of TDD
If a classicist wanted to test the addComment method we described earlier, the service instantiation might look like this:
class CommentServiceTest {
@Test
void testWithStubs() {
CommentService service = new CommentService(
new StubPostRepository(),
new StubCommentRepository()
);
}
}In this case, StubPostRepository and StubCommentRepository are implementations of the corresponding interfaces used for test cases. By the way, the Detroit School does not restrict applying to real business classes.
To summarize the idea, take a look at the schema below. The Detroit School declares the unit not as a separate class but a combination of ones. Different units can overlap.

There are many test suites that depend on the same implementations — StubPostRepository и StubCommentRepository.
So, the Detroit school followers would declare the unit in this way:
A unit is a class that can be tested in isolation from the whole system. Any external dependencies should be either replaced with stubs or real business objects.
The London School of TDD
A mockist, on the other hand, would test addComment differently.
class CommentServiceTest {
@Test
void testWithStubs() {
PostRepository postRepository = mock(PostRepository.class);
CommentRepository commentRepository = mock(CommentRepository.class);
CommentService service = new CommentService(
postRepository,
commentRepository
);
}
}The London School defines a unit as a strongly isolated piece of code. Each mock is an implementation of the class’s dependency. Mocks should be unique for every test case.
A unit is a class that can be tested in isolation from the whole system. Any external dependencies should be mocked. No stubs are allowed to be reused. Applying real business objects is prohibited.
Take a look at the schema below to clarify the point.

Summary of unit definition
The Detroit School and the London school have arguments behind approaches they propose. These arguments are, however, beyond the scope of this article. For our purposes, I will apply both mocks and stubs.
So, it’s time to settle on our final unit definition. Take a look at the statement below.
A unit is a class that can be tested in isolation from the whole system. All external dependencies should be either mocked or replaced with stubs. No business objects should be involved in the process of testing.
We’re not involving external business objects in the single unit. Though the Detroit School of TDD allows for it, I consider this approach unstable. This is because business objects’ behaviour can evolve as the system grows. As they change, they might affect other parts of the code. There is, however, one exception from the rule: Value objects. These are data structures that encapsulate isolated pieces. For example, the Money value object consists of the amount and the currency. The FullName object can have the first name, the last name, and the patronymic. Those classes are plain data holders with no specific behaviour, so it’s OK to apply them directly in tests.
Now that we have a working definition of a unit, let’s move on to establishing how a unit test should be constructed. Each unit test has to follow a set of defined requirements. Take a look at the list below:
- Classes should not break the DI (dependency inversion) principle.
- Unit tests should not affect each other.
- Unit tests should be deterministic.
- Unit tests should not depend on any external state.
- Unit tests should run fast.
- All Tests Should Run in the CI Environment
Let’s clarify each point step by step.
Unit test requirements
Classes should not break the DI Principle
This one is the most obvious, but it’s worth mentioning because breaking this rule renders unit testing meaningless.
Take a look at the code snippet below:
public class CommentService {
private final PostRepository postRepository = new PostRepositoryImpl();
private final CommentRepository commentRepository = new CommentRepositoryImpl();
...
}Even though CommentService declares external dependencies, they are bonded to PostRepositoryImpl and CommentRepositoryImpl. This makes it impossible to pass stubs/doubles/mocks to verify the class’s behaviour in isolation. This is why you should pass all dependencies through the constructor.
Unit tests should not affect each other
The philosophy of unit testing can be summed up in the following statement:
A user can run all unit tests either sequentially or in parallel. This should not affect the result of their execution. Why is that important? Suppose that you ran tests A and B and everything worked just fine. But the CI node ran test B and then test A. If the result of test B influences test A, it can lead to false negative behaviour. Such cases are tough to track and fix.
Suppose that we have the StubCommentRepository for testing purposes.
public class StubCommentRepository implements CommentRepository {
private final List<Comment> comments = new ArrayList<>();
@Override
public void save(Comment comment) {
comments.add(comment);
}
public List<Comment> getSaved() {
return comments;
}
public void deleteSaved() {
comments.clear();
}
}If we passed the same instance of StubCommentRepository, would it guarantee that unit tests are not affecting each other? The answer is no. You see, StubCommentRepository is not thread-safe. It is probable that parallel tests won’t give the same results as sequential ones.
There are two ways to solve this issue:
- Make sure that each stub is thread-safe.
- Create a new stub/mock for every test case.
Unit tests should be deterministic
A unit test should depend only on input parameters but not on outer states (system time, number of CPUs, default encoding, etc.). Because there is no guarantee that every developer in the team has the same hardware setup. Suppose that you have 8 CPUs on your machine and a test makes an assumption regarding this. Your colleague with 16 CPUs will probably be irritated that the test is failing on their machine every time.
Let’s take a look at an example. Imagine that we want to test a util method that tells whether a provided date-time is morning or not. This is how our test might look:
class DateUtilTest {
@Test
void shouldBeMorning() {
OffsetDateTime now = OffsetDateTime.now();
assertTrue(DateUtil.isMorning(now));
}
}This test is not deterministic by design. It will succeed only if the current system time is classified as morning.
The best practice here is to avoid declaring test data by calling non-pure functions. These include:
- Current date time.
- System timezone.
- Hardware parameters.
- Random numbers.
It should be mentioned that property-based testing provides similar data generation, although it works a bit differently. We’ll discuss it at the end of the article.
Unit tests should not depend on any external state
This means that every test run guarantees the same result within any environment. Trivial? Perhaps it is. Though the reality might be trickier. Let’s see what happens if your test relies on an external HTTP service always being available and returns the expected result each time.
Suppose we’re creating a service that provides a weather status. It accepts a URL where HTTP API calls are transmitted. Take a look at the code snippet below. It’s a simple test that checks that current weather status is always present.
class WeatherTest {
@Test
void shouldGetCurrentWeatherStatus() {
String apiRoot = "https://api.openweathermap.org";
Weather weather = new Weather(apiRoot);
WeatherStatus weatherStatus = weather.getCurrentStatus();
assertNotNull(weatherStatus);
}
}The problem is that the external API might be unstable. We cannot guarantee that the outer service will always respond. Even if we did, there is still the possibility that the CI server running the build forbids HTTP requests. For example, there could be some firewall restrictions.
It is important that a unit test is a solid piece of code that doesn’t require any external services to run successfully.
All tests should run in the CI environment
Tests act preventatively. They should reject any code that does not pass the stated specifications. This means that code that does not pass its unit test should not be merged to the main branch.
Why is this important? Suppose that we merge branches with broken code. When release time comes we need to compile the main branch, build the artefacts, and proceed with the deployment pipeline, right? But remember that code is potentially broken. The production might go down. We could run tests manually before the release, but what if they fail? We would have to fix those bugs on the fly. This could result in a delayed release and customer dissatisfaction. Being sure that the main branch has been thoroughly tested means that we can deploy without fear.
The best way to achieve this is to integrate tests run in the CI environment. Semaphore does it brilliantly. The tool can also show each failed test run, so you don’t have to crawl into CI build logs to track down problems.
It should be stated here that all kinds of tests should be run in the CI environment, i.e. integration and E2E tests also.
Summary of unit test requirements
As you can see, unit tests are not as straightforward as they seem to be. This is because unit testing is not about assertions and error messages. Unit tests validate behaviour, not the fact that the mocks have been invoked with particular parameters.
How much effort should you put into tests? There is no universal answer, but when you write tests you should remember these points:
- A test is excellent code documentation. If you’re unaware of the system’s behaviour, the test can help you to understand the class’s purpose and API.
- There is a high chance that you’ll come back to the test later. If it’s poorly written, you’ll have to spend too much time figuring out what it actually does.
There is an even simpler formula for the stated points. Every time you’re writing a test, keep this quote in mind:
Tests are parts of code that do not have tests.
The unit testing mindset
What is the philosophy behind unit testing? I’ve mentioned the word behaviour several times throughout the article. In a nutshell, that is the answer. A unit test checks behaviour, but not direct function calls. This may sound a bit complicated, so let’s deconstruct the statement.
Refactoring stability
Imagine that you have done some minor code refactoring, and a bunch of your tests suddenly start failing. This is a maddening scenario. If there are no business logic changes, we don’t want to break our tests. Let’s clarify the point with a concrete example.
Let’s assume that a user can delete all the posts they have archived. Here is the possible Java implementation.
public class PostDeleteService {
private final UserService userService;
private final PostRepository postRepository;
public void deleteAllArchivedPosts() {
User currentUser = userService.getCurrentUser();
List<Post> posts = postRepository.findByPredicate(
PostPredicate.create()
.archived(true).and()
.createdBy(oneOf(currentUser))
);
postRepository.deleteAll(posts);
}
}PostRepository is an interface that represents external storage. For example, it could be PostgreSQL or MySQL. PostPredicate is a custom predicate builder.
How can we test the method’s correctness? We could provide mocks for UserService and PostRepository and check the input parameters’ equity. Take a look at the example below:
public class PostDeleteServiceTest {
// initialization
@Test
void shouldDeletePostsSuccessfully() {
User mockUser = mock(User.class);
List<Post> mockPosts = mock(List.class);
when(userService.getCurrentUser()).thenReturn(mockUser);
when(postRepository.findByPredicate(
eq(PostPredicate.create()
.archived(true).and()
.createdBy(oneOf(mockUser)))
)).thenReturn(mockPosts);
postDeleteService.deleteAllArchivedPosts();
verify(postRepository, times(1)).deleteAll(mockPosts);
}
}The when, thenReturn, and eq methods are part of the Mockito Java library. We’ll talk more about various testing libraries at the end of the article.
Do we test behaviour here? Actually, we don’t. There is no testing, rather we are verifying the order of methods called. The problem is that the unit test does not tolerate refactoring of the code it is testing.
Imagine that we decided to replace oneOf(user) with is(user) predicate usage. An example could look like this:
public class PostDeleteService {
private final UserService userService;
private final PostRepository postRepository;
public void deleteAllArchivedPosts() {
User currentUser = userService.getCurrentUser();
List<Post> posts = postRepository.findByPredicate(
PostPredicate.create()
.archived(true).and()
// replaced 'oneOf' with 'is'
.createdBy(is(currentUser))
);
postRepository.deleteAll(posts);
}
}This should not make any difference, right? The refactoring hasn’t changed the business logic at all. But the test is going to fail now, because of this mocking setup.
public class PostDeleteServiceTest {
// initialization
@Test
void shouldDeletePostsSuccessfully() {
// setup
when(postRepository.findByPredicate(
eq(PostPredicate.create()
.archived(true).and()
// 'oneOf' but not 'is'
.createdBy(oneOf(mockUser)))
)).thenReturn(mockPosts);
// action
}
}Every time we do even a slight refactoring, the test fails. That makes maintenance a big burden. Imagine what might go wrong if we made major changes. For example, if we added the postRepository.deleteAllByPredicate method, it would break the whole test setup.
This is happening because the previous examples are focusing on the wrong thing. We want to test behaviour. Let’s see how we can make a new test that will do that. First, we need to declare a custom PostRepository implementation for test purposes. It’s OK to store data in RAM, what’s important is PostPredicate recognition. Therefore, the calling method relies on the fact that predicates are treated correctly.
Here’s the refactored version of the test:
public class PostDeleteServiceTest {
// initialization
@Test
void shouldDeletePostsSuccessfully() {
User currentUser = aUser().name("n1");
User anotherUser = aUser().name("n2");
when(userService.getCurrentUser()).thenReturn(currentUser);
testPostRepository.store(
aPost().withUser(currentUser).archived(true),
aPost().withUser(currentUser).archived(true),
aPost().withUser(anotherUser).archived(true)
);
postDeleteService.deleteAllArchivedPosts();
assertEquals(1, testPostRepository.count());
}
}Here is what changed:
- There is no PostRepository mocking. We introduced a custom implementation: TestPostRepository. It encapsulates the stored posts and guarantees the correct PostPredicate processing.
- Instead of declaring PostRepository returning a list of posts, we put the real objects within TestPostRepository.
- We don’t care about which functions have been called. We want to validate the delete operation itself. We know that the storage consists of 2 archived posts of the current user and 1 post of another user. The successful operation process should leave 1 post. That’s why we put assertEquals on posts count.
Now the test is isolated from the specific method invocations checks. We care only about the correctness of the TestPostRepository implementation itself. It doesn’t matter exactly how PostDeleteService implements the business case. It’s not about “how”, it’s about “what” a unit does. Furthermore, this refactoring won’t break the test.
You might also notice that UserService is still a regular mock. That’s fine because the probability of the getCurrentUser() method substitution is not significant. Besides, the method has no parameters. This means that we don’t have to deal with a possible input parameter mismatch. Mocks aren’t good or bad, just keep in mind that different tasks require different tools.
A few words about MVC frameworks
The vast majority of applications and services are developed using an MVC framework. Spring Boot is the most popular one for Java. Even though many authors claim that your design architecture should not depend on a framework (e.g. Robert Martin), the reality is not so simple. Nowadays, many projects are “framework-oriented”. It’s hard or even impossible to replace one framework with another. This, of course, influences test design as well.
I do not fully agree with the notion that your code should be “totally isolated from frameworks”. In my opinion, depending on a framework’s features to reduce boilerplate and focus on business logic is not a big deal. But that is an extensive debate that is outside of the scope of this article.
What is important to remember is that your business code should be abstracted from the framework’s architecture. This means that any class should be unaware of the environment in which the developer has installed it. Otherwise, your tests become too coupled in unnecessary details. If you decide to switch from one framework to another at some point, it would be a Herculean task. The required time and effort to do it would be unacceptable for any company.
Let’s move on to an example. Assume we have an XML generator. Each element has a unique integer ID and we have a service that generates those IDs. But what if the number of generated XMLs is huge? If every element in every XML document had a unique integer id, it could lead to integer overflow. Let’s imagine that we are using Spring in our project. To overcome this issue we decided to declare IDService with the prototype scope. So, XMLService should receive a new instance of IDService every time a generator is triggered. Take a look at the example below:
@Service
public class XMLGenerator {
@Autowired
private IDService idService;
public XML generateXML(String rawData) {
// split raw data and traverse each element
for (Element element : splittedElements) {
element.setId(idService.generateId());
}
// processing
return xml;
}
}The problem here is that XMLGenerator is a singleton (the default Spring bean scope). Therefore, it instantiated 1s and IDService is not refreshed.
We could fix that by injecting ApplicationContext and requesting the bean directly.
@Service
public class XMLGenerator {
@Autowired
private ApplicationContext context;
public XML generateXML(String rawData) {
// Creates new IDService instance
IDService idService = context.getBean(IDService.class);
// split raw data and traverse each element
for (Element element : splittedElements) {
element.setId(idService.generateId());
}
// processing
return xml;
}
}But here is the thing: now the class is bound to the Spring ecosystem. XMLGenerator understands that there is a DI-container, and it’s possible to retrieve a class instance from it. In this case, unit testing becomes harder. Because you cannot test XMLGenerator outside of the Spring context.
The better approach is to declare an IDServiceFactory, as shown below:
@Service
public class XMLGenerator {
@Autowired
private IDServiceFactory factory;
public XML generateXML(String rawData) {
IDService idService = factory.getInstance();
// split raw data and traverse each element
for (Element element : splittedElements) {
element.setId(idService.generateId());
}
// processing
return xml;
}
}That’s better. IDServiceFactory encapsulates the logic of retrieving the IDService instance. IDServiceFactory is injected into the class field directly. Spring can do it. But what if there is no Spring? Could you do this with the plain unit test? Well, technically it’s possible. The Java Reflection API allows you to modify private fields’ values. I’m not going to discuss this at length, but I’ll just say: never use Reflection API in your tests! It’s an absolute anti-pattern.
There is one exception. If your business code does work with Reflection API, then it’s OK to apply reflection in tests as well.
Let’s get back to DI. There are 3 approaches to implement dependency injection:
- Field injection
- Setter injection
- Constructor injection
The second and the third approach do not share the problems of the first one. We can apply either of them. Both will work. Take a look at the code example below:
@Service
public class XMLGenerator {
private final IDServiceFactory factory;
public XMLGenerator(IDServiceFactory factory) {
this.factory = factory;
}
public XML generateXML(String rawData) {
IDService idService = factory.getInstance();
// split raw data and traverse each element
for (Element element : splittedElements) {
element.setId(idService.generateId());
}
// processing
return xml;
}
}Now the XMLGenerator is completely isolated from the framework details.
Unit testing mindset summary
- Test what the code does but not how it does it.
- Code refactoring should not break tests.
- Isolate the code from the frameworks’ details.
Best practices
Now we can discuss some best practices to help you increase the quality of your unit tests.
Naming
Most IDEs generate a test suite name by adding the Test suffix to the class name. PostServiceTest, WeatherTest, CommentControllerTest, etc. Sometimes this might be sufficient, but I think that there are some issues with this approach:
- The type of test is not self-describing (unit, integration, e2e).
- You cannot tell which methods are tested.
In my opinion, the better way is to enhance the simple Test suffix:
- Specify the particular type of test. This will help us to clarify the test borders. For example, you might have multiple test suites for the same class (PostServiceUnitTest , PostServiceIntegrationTest , PostServiceE2ETest).
- Add the name of the method that is being tested. For example, WeatherUnitTest_getCurrentStatus. Or CommentControllerE2ETest_createComment.
The second point is debatable. Some developers claim that every class should be as solid as possible, and distinguishing tests by the method name can lead to treating classes as dummy data structures.
These arguments do make sense, but I think that putting the method name also provides advantages:
- Not all classes are solid. Even if you’re the biggest fan of Domain-Driven Design, it is impossible to build every class this way.
- Some methods are more complicated than others. You might have 10 test methods just to verify the behaviour of a single class method. If you put all tests inside one test suite, you will make it huge and difficult to maintain.
You could also apply different naming strategies according to specific context. There is no single right way to go about this, but remember that naming is an important maintainability feature. It’s a good practice to choose one strategy to share within your team.
Assertions
I’ve heard it stated that each test should have a single assertion. If you have more, then it’s better to split it into multiple suites.
I’m not generally fond of edge opinions. This one does make sense, but I would rephrase it a bit.
Each test case should assert a single business case.
It’s OK to have multiple assertions, but make sure that they clarify a solid operation. For example, look at the code example below:
public class PersonServiceTest {
// initialization
@Test
void shouldCreatePersonSuccessfully() {
Person person = personService.createNew("firstName", "lastName");
assertEquals("firstName", person.getFirstName());
assertEquals("lastName", person.getLastName());
}
}Even though there are two assertions, they are bound to the same business context (i.e. creating a new Person).
Now check out this code snippet:
class WeatherTest {
// initialization
@Test
void shouldGetCurrentWeatherStatus() {
LocalDate date = LocalDate.of(2012, 5, 25);
WeatherStatus testWeatherStatus = generateStatus();
tuneWeather(date, testWeatherStatus);
WeatherStatus result = weather.getStatusForDate(date);
assertEquals(
testWeatherStatus,
result,
"Unexpected weather status for date " + date
);
assertEquals(
result,
weather.getStatusForDate(date),
"Weather service is not idempotent for date " + date
);
}
}These two assertions do not build a solid piece of code. We’re testing the result of getStatusForDate and the fact that the function call is idempotent. It’s better to split this suite into two tests because the two things being tested aren’t directly linked.
Error messages
Tests can fail. That’s the whole idea of testing. If your suite is red, what should you do? Fix the code? But how should you do it? What’s the source of the problem? If an assertion fails, we get an error log that tells us what went wrong, right? Indeed, it’s true. Sadly, those messages aren’t always useful. How you write your tests can determine what kind of feedback you get in the error log.
Take a look at the code example below:
class WeatherTest {
// initialization
@ParameterizedTest
@MethodSource("weatherDates")
void shouldGetCurrentWeatherStatus(LocalDate date) {
WeatherStatus testWeatherStatus = generateStatus();
tuneWeather(date, testWeatherStatus);
WeatherStatus result = weather.getStatusForDate(date);
assertEquals(testWeatherStatus, result);
}
}Suppose that weatherDates provide 20 different date values. As a matter of fact, there are 20 tests. One test failed and here is what you got as the error message.
expected: <SHINY> but was: <CLOUDY>
Expected :SHINY
Actual :CLOUDYNot so descriptive, is it? 19/20 tests have succeeded. There must be some problem with a date, but the error message didn’t give much detail. Can we rewrite the test so that we get more feedback on failure? Of course! Take a look at the code snippet below:
class WeatherTest {
// initialization
@ParameterizedTest
@MethodSource("weatherDates")
void shouldGetCurrentWeatherStatus(LocalDate date) {
WeatherStatus testWeatherStatus = generateStatus();
tuneWeather(date, testWeatherStatus);
WeatherStatus result = weather.getStatusForDate(date);
assertEquals(
testWeatherStatus,
result,
"Unexpected weather status for date " + date
);
}
}Now the error message is much clearer.
Unexpected weather status for date 2022-03-12 ==> expected: <SHINY> but was: <CLOUDY>
Expected :SHINY
Actual :CLOUDYIt’s obvious that something is wrong with the date: 2022-03-12. This error log gives us a clue as to where we should start our investigation.
Also, pay attention to the toString implementation. When you pass an object to assertEquals, the library transforms it into a string using this method.
Test data initialization
When we test anything, we probably need some data to test against it (e.g. rows in the database, objects, variables, etc.). There are 3 known ways to initialise data in a test:
- Direct Declaration.
- Object Mother Pattern.
- Test Data Builder Pattern .
Direct Declaration
Suppose that we have the Post class. Take a look at the code snippet below:
public class Post {
private Long id;
private String name;
private User userWhoCreated;
private List<Comment> comments;
// constructor, getters, setters
}We can create new instances with constructors:
public class PostTest {
@Test
void someTest() {
Post post = new Post(
1,
"Java for beginners",
new User("Jack", "Brown"),
List.of(new Comment(1, "Some comment"))
);
// action...
}
}There are, however, some problems with this approach:
- Parameter names are not descriptive. You have to check the constructor’s declaration to tell the meaning of each provided value.
- Class attributes are not static. What if another field were added? You would have to fix every constructor invocation in every test.
What about setters? Let’s see how that would look:
public class PostTest {
@Test
void someTest() {
Post post = new Post();
post.setId(1);
post.setName("Java for beginners");
User user = new User();
user.setFirstName("Jack");
user.setLastName("Brown");
post.setUser(user);
Comment comment = new Comment();
comment.setId(1);
comment.setTitle("Some comment");
post.setComments(List.of(comment));
// action...
}
}Now the parameter names are transparent, but other issues have appeared.
- The declaration is too verbose. At first glance, it’s hard to tell what’s going on.
- Some parameters might be obligatory. If we added another field to the Post class, it could lead to runtime exceptions due to the object’s inconsistency.
We need a different approach to solve these problems.
Object Mother Pattern
In reality, it’s just a simple static factory that hides the instantiation complexity behind a nice facade. Take a look at the code example below:
public class PostFactory {
public static Post createSimplePost() {
// simple post logic
}
public static Post createPostWithUser(User user) {
// simple post logic
}
}This works for simple cases. But the Post class has many invariants (e.g. post with comment, post with comment and user, post with user, post with user and multiple comments, etc.). If we tried to declare a separate method for every possible situation, it would quickly turn into a mess. Enter Test Data Builder.
Test Data Builder Pattern
The name defines its purpose. It’s a builder created specifically to test data declarations. Let’s see what it looks like in the form of a test:
public class PostTest {
@Test
void someTest() {
Post post = aPost()
.id(1)
.name("Java for beginners")
.user(aUser().firstName("Jack").lastName("Brown"))
.comments(List.of(
aComment().id(1).title("Some comment")
))
.build();
// action...
}
}aPost(), aUser(), and aComment() are static methods that create builders for the corresponding classes. They encapsulate the default values for all attributes. Calling id, name, and other methods overrides the values. You can also enhance the default builder-pattern approach and make them immutable, making every attribute change return a new builder instance. It’s also helpful to declare templates to reduce boilerplate.
public class PostTest {
private PostBuilder defaultPost =
aPost().name("post1").comments(List.of(aComment()));
@Test
void someTest() {
Post postWithNoComments = defaultPost.comments(emptyList()).build();
Post postWithDifferentName = defaultPost.name("another name").build();
// action...
}
}If you want to really dive into this, I wrote a whole article about declaring test data in a clean way. You can read it here.
Best practices summary
- Naming is important. Test suite names should be declarative enough to understand their purpose.
- Do not group assertions that have nothing in common.
- Specific error messages are the key to quick bug spotting.
- Test data initialization is important. Do not neglect this.
But the main thing you should remember about testing is:
Tests should help to write code, but not increase the burden of maintenance.
There are dozens of testing libraries and frameworks on the market. I’m going to list the most popular ones for the Java language.
JUnit
The de facto standard for Java. Used in most projects. It provides a test running engine and assertion library combined in one artefact.
Mockito
The most popular mocking library for Java. It provides a friendly fluent API to set testing mocks. Take a look at the example below:
public class SomeSuite {
@Test
void someTest() {
// creates a mock for CommentService
CommentService mockService = mock(CommentService.class);
// when mockService.getCommentById(1) is called, new Comment instance is returned
when(mockService.getCommentById(eq(1)))
.thenReturn(new Comment());
// when mockService.getCommentById(2) is called, NoSuchElementException is thrown
when(mockService.getCommentById(eq(2)))
.thenThrow(new NoSuchElementException());
}
}Spock
As the documentation says, this is an enterprise-ready specification framework. In a nutshell, it has a test runner, and assertion and mocking utils. You write Spock tests in Groovy instead of Java. Here is a simple case validating that 2 + 2 = 4:
def "two plus two should equal four"() {
given:
int left = 2
int right = 2
when:
int result = left + right
then:
result == 4
}Vavr Test
Vavr Test requires special attention. This one is a property testing library. It differs from regular assertion-based tools. Vavr Test provides an input value generator. For each generated value it checks the invariant result. If this is false, the amount of test data is reduced until only the failures remain. Take a look at the example below that checks that whether the isEven function is working correctly:
public class SomeSuite {
@Test
void someTest() {
Arbitrary<Integer> evenNumbers = Arbitrary.integer()
.filter(i -> i > 0)
.filter(i -> i % 2 == 0);
CheckedFunction1<Integer, Boolean> alwaysEven =
i -> isEven(i);
CheckResult result = Property
.def("All numbers must be treated as even ones")
.forAll(evenNumbers)
.suchThat(alwaysEven)
.check();
result.assertIsSatisfied();
}
}Conclusion
Testing is a significant part of software development, and unit tests are fundamental. They represent the basis for all kinds of automation tests, so it’s crucial to write unit tests to the highest standard of quality.
The biggest advantage of tests is that they can run without manual interactions. Be sure that you run tests in the CI environment on each change in a pull request. If you don’t do this, the quality of your project will suffer. Semaphore CI is a brilliant CI/CD tool for automating and running tests and deployments, so give it a try.
That’s that! If you have any questions or suggestions, you can text me or leave your comments here. Thanks for reading!
Юнит-тесты. Быстрый старт – эффективный результат (с примерами на C++) +23
Программирование, C++, Управление разработкой, Тестирование IT-систем, Блог компании Тензор
Рекомендация: подборка платных и бесплатных курсов создания сайтов — https://katalog-kursov.ru/

Вместо вступления
Всем привет! Сегодня хотелось бы поговорить о том, как просто и с удовольствием писать тестируемый код. Дело в том, что в нашей компании мы постоянно контролируем и очень ценим качество наших продуктов. Еще бы – ведь с ними ежедневно работают миллионы человек, и для нас просто недопустимо подвести наших пользователей. Только представьте, наступил срок сдачи отчетности, и вы тщательно и с удовольствием, используя заботливо разработанный нами пользовательский интерфейс СБИС, подготовили документы, еще раз перепроверили каждую циферку и вновь убедились, что встречи с вежливыми людьми из налоговой в ближайшее время не будет. И вот, легким нажатием мыши кликаете на заветную кнопку «Отправить» и тут БАХ! приложение вылетает, документы уничтожаются, жарким пламенем пылает монитор, и кажется, люди в погонах уже настойчиво стучат в двери, требуя сдачи отчетности. Вот как-то так все может и получиться:

Фух… Ну, согласен, с монитором, наверное, все-таки погорячился Но все же возникшая ситуация может оставить пользователя нашего продукта не в самом благостном состоянии духа.
Так вот, поскольку мы в Тензоре дорожим моральным состоянием наших клиентов, то для нас очень важно, чтобы разработанные нами продукты были всеобъемлюще протестированы — у нас в компании во многом это обеспечивают почти что 300 тестировщиков, контролирующих качество наших продуктов. Однако мы стараемся, чтобы качество контролировалось на всех этапах разработки. Поэтому в процессе разработки мы стараемся использовать автоматизированное юнит-тестирование, не говоря уже об интеграционных, нагрузочных и приемных тестах.
Однако на сегодняшний день из нашего опыта собеседований можно отметить, что не все владеют навыками создания тестируемого кода. Поэтому мы хотим рассказать «на пальцах» о принципах создания тестируемого кода, а также показать, как можно создавать юнит-тесты, которые легки в поддержке и модернизации.
Изложенный ниже материал во многом был представлен на конференции C++ Russia, так что вы можете его почитать, послушать и даже посмотреть.
Характеристики хороших юнит-тестов
Одной из первых задач, с которой приходится сталкиваться при написании любого автоматически выполняемого теста, является обработка внешних зависимостей. Под внешней зависимостью будем понимать сущности, с которыми взаимодействует тестируемый код, но над которыми у него нет полного контроля. К таким неподконтрольным внешним зависимостям можно отнести операции, требующие взаимодействия с жестким диском, базой данных, сетевым соединением, генератором случайных чисел и прочим.
Надо сказать, что автоматизированное тестирование можно производить на разных уровнях системы, но мы рассмотрим вопросы, связанные именно с юнит-тестами.
Для наиболее ясного понимания принципов, положенных в основу приведенных ниже примеров, код был упрощен (так, например, опущены квалификаторы const). Сами же примеры тестов реализованы с использованием библиотеки GoogleTest.
Одно из наиболее важных отличий интеграционного теста от юнит-теста в том, что юнит-тест имеет полный контроль над всеми внешними зависимостями. Это позволяет достичь того, что отдельно взятый юнит-тест обладает следующими свойствами:
- повторяем — в результате запуска тест на выходе всегда выдает одно и то же значение (всегда приводит систему в одно и то же состояние);
- стабилен — в какое бы время дня и ночи тест бы не запускался, он либо всегда проходит, либо всегда не проходит;
- изолирован — порядок запуска всех имеющихся юнит-тестов, а также действия, выполняемые внутри тестов, никак не влияют на результат выполнения отдельно взятого юнит-теста.
Все это приводит к тому, что запуск множества юнит-тестов, обладающих описанными свойствами, можно автоматизировать и осуществлять, по сути, нажатием одной кнопки.
Хороший юнит-тест выполняется быстро. Потому что если в проекте тестов много, и прогон каждого из них будет длительным, то прогон всех тестов займет уже значительное время. Это может привести к тому, что при изменениях кода прогон всех юнит-тестов будет производиться все реже, из-за этого время получения реакции системы на изменения увеличится, а значит увеличится и время обнаружения внесенной ошибки.
Говорят, что у некоторых с тестированием приложений все складывается гораздо проще, но нам, простым смертным, не обладающим такой скоростной вертушкой, приходится не так сладко. Так что будем разбираться дальше.

Юнит-тестирование. С чего все начинается
Написание любого юнит-теста начинается с выбора его имени. Один из рекомендуемых подходов к наименованию юнит-теста – формировать его имя из трех частей:
— имя тестируемой рабочей единицы
— сценарий теста
— ожидаемый результат
Таким образом, мы можем получить, например, такие имена: Sum_ByDefault_ReturnsZero, Sum_WhenCalled_CallsTheLogger. Они читаются как завершенное предложение, а это повышает простоту работы с тестами. Чтобы понять, что тестируется, достаточно, без вникания в логику работы кода, просто прочитать названия тестов.
Но в ряде случаев с логикой работы тестового кода все-таки нужно разбираться. Чтобы упростить эту работу, структуру юнит-теста можно формировать из трех частей:
— часть Arrange — здесь производится создание и инициализация требуемых для проведения теста объектов
— часть Act — собственно проведение тестируемого действия
— часть Assert — здесь производится сравнение полученного результата с эталонным
Для того чтобы повысить читабельность тестов рекомендуется эти части отделять друг от друга пустой строкой. Это сориентирует тех, кто читает ваш код, и поможет быстрее найти ту часть теста, которая их интересует больше всего.
При покрытии логики работы кода юнит-тестами каждый модуль тестируемого кода должен выполнять одно из следующих действий. Так, тестированию можно подвергать:
— возвращаемый результат
— изменение состояния системы
— взаимодействие между объектами
В первых двух случаях мы сталкиваемся с задачей разделения. Она заключается в том, чтобы не вводить в средства тестирования код, над которым мы не имеем полного контроля. В последнем случае приходится решать задачу распознавания. Она заключается в том, чтобы получить доступ к значениям, которые недоступны для тестируемого кода: например, когда нужен контроль получения логов удаленным web-сервером.
Чтобы писать тестируемый код, надо уметь реализовывать и применять по назначению поддельные объекты (fake objects).
Существует несколько подходов к классификации поддельных объектов, Мы рассмотрим одну из базовых, которая соответствует задачам, решаемым в процессе создания тестируемого кода.
Она выделяет два класса поддельных объектов: stub-объекты и mock-объекты. Они предназначены для решения разных задач: stub-объект – для решения задачи разделения, а mock-объект – для решения задачи распознавания. Наибольшая разница заключается в том, что при использовании stub-объекта assert (операция сравнения полученного результата с эталонным) производится между тестовым и тестируемым кодом, а использование mock-объекта предполагает его анализ, который и показывает пройден тест или нет.
Если логику работы можно протестировать на основе анализа возвращаемого значения или изменения состояния системы, то так и сделайте. Как показывает практика, юнит-тесты, которые используют mock-объекты сложнее создавать и поддерживать, чем тесты, использующие stub-объекты.
Рассмотрим приведенные принципы на примере работы с унаследованным (legacy) кодом. Пусть у нас есть класс EntryAnalyzer, представленный на рис. 1, и мы хотим покрыть юнит-тестами его публичный метод Analyze. Это связано с тем, что мы планируем изменять этот класс, или же хотим таким образом задокументировать его поведение.
Для покрытия кода тестами определим его внешние зависимости. В нашем случае этих зависимостей две: работа с базой данных и работа с сетевым соединением, которая проводится в классах WebService и DatabaseManager соответственно.
class EntryAnalyzer {
public:
bool Analyze( std::stringename ) {
if( ename.size() < 2 ) {
webService.LogError( "Error: "+ ename );
return false;
}
if( false== dbManager.IsValid( ename ) )
return false;
return true;
}
private:
DatabaseManager dbManager;
WebService webService;
};Рис.1. Код тестируемого класса, не пригодный для покрытия юнит-тестами
Таким образом, для класса EntryAnalyzer они и являются внешними зависимостями. Потенциально, между проверкой dbManager.IsValid и финальной инструкцией «return true» может присутствовать код, требующий тестирования. При написании тестов получить доступ к нему мы сможем только после избавления от существующих внешних зависимостей. Для упрощения дальнейшего изложения такой дополнительный код не приведен.
Теперь рассмотрим способы разрыва внешних зависимостей. Структура данных классов приведена на рис. 2.
class WebService {
public:
void LogError( std::string msg ) {
/* логика, включающая
работу с сетевым соединением*/
}
};
class DatabaseManager {
public:
bool IsValid( std::string ename ) {
/* логика, включающая
операции чтения из базы данных*/
}
};Рис.2. Структура классов для работы с сетевым соединением и базой данных
Для написания тестируемого кода очень важно уметь разрабатывать, опираясь на контракты, а не на конкретные реализации. В нашем случае контрактом исходного класса является определение, валидно или нет имя ячейки (entry).
На языке С++ данный контракт может быть задокументирован в виде абстрактного класса, который содержит виртуальный метод IsValid, тело которого определять не требуется. Теперь можно создать два класса, реализующих этот контракт: первый будет взаимодействовать с базой данных и использоваться в «боевой» (production) версии нашей программы, а второй будет изолирован от неподконтрольных зависимостей и будет использоваться непосредственно для проведения тестирования. Описанная схема приведена на рис. 3.
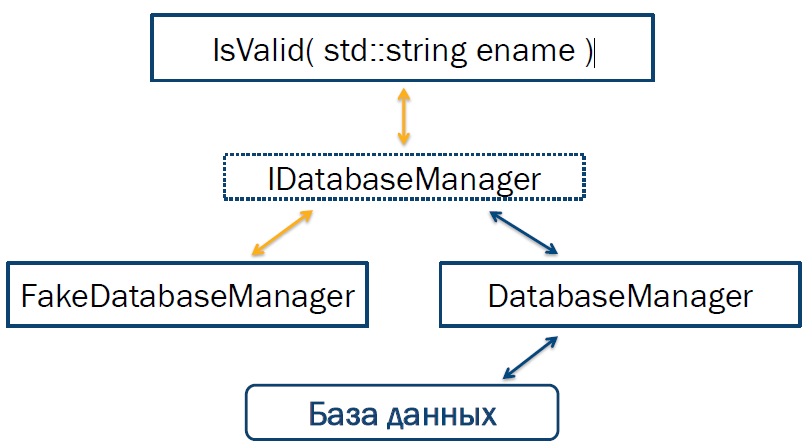
Рис.3. Введение интерфейса для разрыва зависимости от взаимодействия с базой данных
Пример кода, позволяющий осуществить разрыв зависимости, в нашем случае от базы данных, представлен на рис. 4.

Рис.4. Пример классов, позволяющих осуществить разрыв зависимости от базы данных
В приведенном коде следует обратить внимание на спецификатор override у методов, реализующих функционал, заданный в интерфейсе. Это повышает надежность создаваемого кода, так как он явно указывает компилятору, что сигнатуры этих двух функций должны совпадать.
Также следует обратить внимание на объявление деструктора абстрактного класса виртуальным. Если это выглядит удивительно и неожиданно, то можно сгонять за книгой С. Майерса “Эффективное использование С++” и читать ее взахлеб, причем особое внимание уделить приведенному там правилу №7;).
Спойлер для особо нетерпеливых
это необходимо, чтобы избежать утечек памяти при уничтожении объекта производного класса через указатель на базовый класс.
Разрыв зависимости с использованием stub-объектов
Рассмотрим шаги, которые нужны для тестирования нашего класса EntryAnalyzer. Как было сказано выше, реализация тестов с использованием stub-объектов несколько проще, чем с использование mock-объектов. Поэтому сначала рассмотрим способы разрыва зависимости от базы данных.
Способ 1. Параметризация конструктора
Вначале избавимся от жестко заданного использования класса DatabaseManager. Для этого перейдем к работе с указателем, типа IDatabaseManager. Для сохранения работоспособности класса нам также нужно определить конструктор «по умолчанию», в котором мы укажем необходимость использования «боевой» реализации. Внесенные изменения и полученный видоизмененный класс представлены на рис. 5.

Рис.5. Класс после рефакторинга, который позволяет осуществить разрыв зависимости от базы данных
Для внедрения зависимости следует добавить еще один конструктор класса, но теперь уже с аргументом. Этот аргумент как раз и будет определять, какую реализацию интерфейса следует использовать. Конструктор, который будет использоваться для тестирования класса, представлен на рис. 6.

Рис.6. Конструктор, используемый для внедрения зависимости
Теперь наш класс выглядит следующим образом (зеленой рамкой обведен конструктор, используемый для тестирования класса):
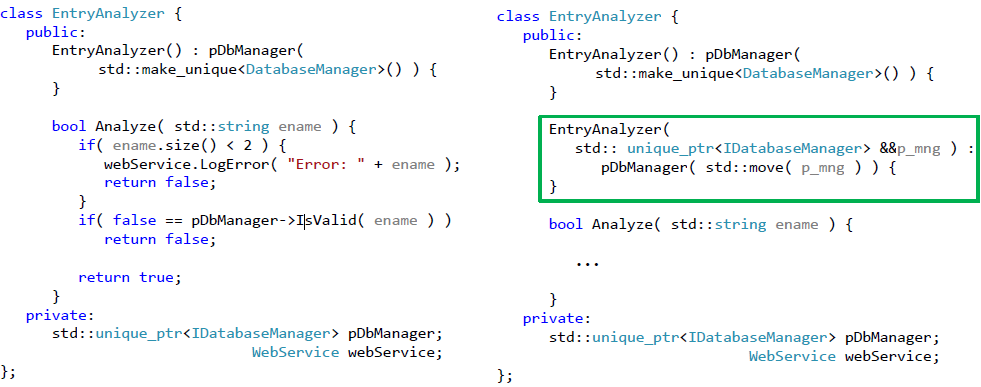
Рис.7. Рефакторинг класса, позволяющий осуществить разрыв зависимости от базы данных
Теперь мы можем написать следующий тест, демонстрирующий результат обработки валидного имени ячейки (см. рис. 8):
TEST_F( EntryAnalyzerTest, Analyze_ValidEntryName_ReturnsTrue )
{
EntryAnalyzer ea( std::make_unique<FakeDatabaseManager>( true ) );
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class FakeDatabaseManager : public IDatabaseManager {
public:
bool WillBeValid;
FakeDatabaseManager( bool will_be_valid ) :
WillBeValid( will_be_valid ) {
}
bool IsValid( std::string ename ) override {
return WillBeValid;
}
};Рис.8. Пример теста, не взаимодействующего с реальной базой данных
Изменение значения параметра конструктора fake-объекта влияет на результат выполнения функции IsValid. Кроме того, это позволяет повторно использовать fake-объект в тестах, требующих как утвердительные, так и отрицательные результаты обращения к базе данных.
Рассмотрим второй способ параметризации конструктора. В этом случае нам потребуется использование фабрик — объектов, которые являются ответственными за создание других объектов.
Вначале проделаем все те же шаги по замене жестко заданного использования класса DatabaseManager – перейдем к использованию указателя на объект, реализующий требуемый интерфейс. Но теперь в конструкторе «по умолчанию» возложим обязанности по созданию требуемых объектов на фабрику.
Получившаяся реализация приведена на рис. 9.
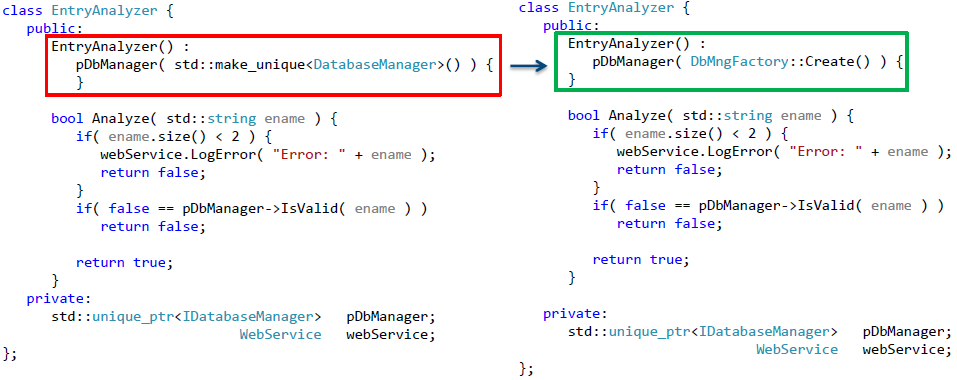
Рис. 9. Рефакторинг класса с целью использования фабрик для создания объекта, взаимодействующего с базой данных
С учетом введенного фабричного класса, сам тест теперь можно написать следующим образом:
TEST_F( EntryAnalyzerTest,
Analyze_ValidEntryName_ReturnsTrue )
{
DbMngFactory::SetManager(
std::make_unique<FakeDatabaseManager>( true ) );
EntryAnalyzer ea;
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class DbMngFactory {
public:
static std::unique_ptr<IDatabaseManager> Create() {
if( nullptr == pDbMng )
return std::make_unique<DatabaseManager>();
return std::move( pDbMng );
}
static void SetManager(
std::unique_ptr<IDatabaseManager> &&p_mng ) {
pDbMng = std::move( p_mng );
}
private:
static std::unique_ptr<IDatabaseManager> pDbMng;
};Рис.10. Еще один пример теста, не взаимодействующего с реальной базой данных
Важное отличие данного подхода от ранее рассмотренного – использование одного и того же конструктора для создания объектов как для «боевого», так и для тестового кода. Всю заботу по созданию требуемых объектов берет на себя фабрика. Это позволяет разграничить зоны ответственности классов. Конечно, человеку, который будет разбираться с вашим кодом, потребуется некоторое время для понимания взаимоотношений этих классов. Однако в перспективе этот подход позволяет добиться более гибкого кода, приспособленного для долгосрочной поддержки.
Способ 2. «Выделить и переопределить»
Рассмотрим еще один поход к разрыву зависимости от базы данных — «Выделить и переопределить» (Extract and override). Возможно, его применение покажется более простым и таких вот эмоций не вызовет:

Его основная идея в том, чтобы локализовать зависимости «боевого» класса в одной или нескольких функциях, а затем переопределить их в классе-наследнике. Рассмотрим на практике этот подход.
Начнем с локализации зависимости. В нашем случае зависимость заключается в обращении к методу IsValid класса DatabaseManager. Мы можем выделить эту зависимость в отдельную функцию. Обратите внимание, что изменения следует вносить максимально осторожно. Причина – в отсутствии тестов, с помощью которых можно удостовериться, что эти изменения не сломают существующую логику работы. Для того чтобы вносимые нами изменения были наиболее безопасными, необходимо стараться максимально сохранять сигнатуры функций. Таким образом, вынесем код, содержащий внешнюю зависимость, в отдельный метод (см. рис. 11).

Рис.11. Вынесение кода, содержащего внешнюю зависимость в отдельный метод
Каким же образом можно провести тестирование нашего класса в этом случае? Все просто – объявим выделенную функцию виртуальной, отнаследуем от исходного класса новый класс, в котором и переопределим функцию базового класса, содержащего зависимость. Так мы получили класс, свободный от внешних зависимостей – и теперь его можно смело вводить в средства тестирования для покрытия тестами. На рис. 12 представлен один из способов реализации такого тестируемого класса.
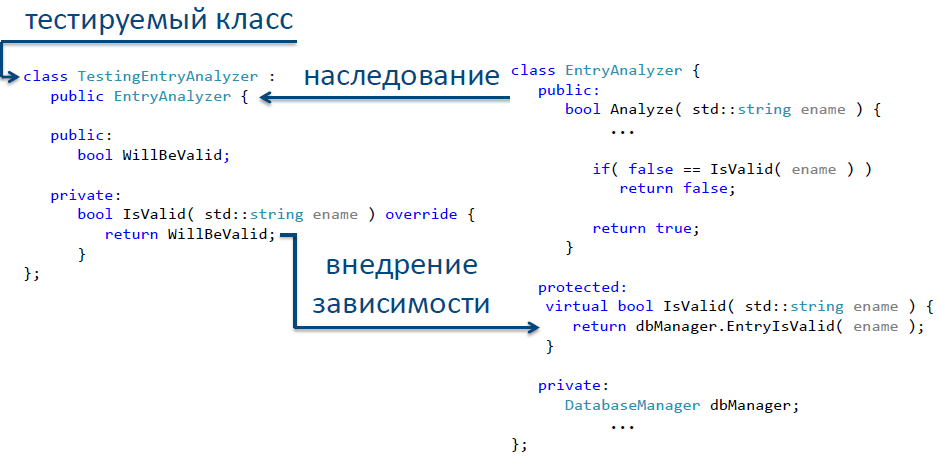
Рис.12. Реализация метода «Выделить и переопределить» для разрыва зависимости
Сам тест теперь можно написать следующим образом:
TEST_F( EntryAnalyzerTest, Analyze_ValidEntryName_ReturnsTrue)
{
TestingEntryAnalyzer ea;
ea.WillBeValid = true;
bool result = ea.Analyze( "valid_entry_name" );
ASSERT_EQ( result, true );
}
class TestingEntryAnalyzer : public EntryAnalyzer {
public:
bool WillBeValid;
private:
bool IsValid( std::string ename ) override {
return WillBeValid;
}
};Рис.13. И еще один пример теста, не взаимодействующего с реальной базой данных
Описанный подход является одним из самых простых в реализации, и его полезно иметь в арсенале своих навыков.
Разрыв зависимости с использованием mock-объектов
Теперь мы умеем разрывать зависимости от базы данных с использованием stub-объектов. Но у нас еще осталась необработанной зависимость от удаленного web-сервера. С помощью mock-объекта мы можем разорвать эту зависимость.
Что же надо для этого сделать? Здесь нам пригодится комбинация из уже рассмотренных методов. Вначале локализуем нашу зависимость в одной из функций, которую затем объявим виртуальной. Не забываем при этом сохранять сигнатуры функций! Теперь выделим интерфейс, определяющий контракт класса WebService и вместо явного использования класса будем использовать указатель unique_ptr требуемого типа. И создадим класс-наследник, в котором эта виртуальная функция будет переопределена. Полученный после рефакторинга класс представлен на рис. 14.

Рис.14. Класс после рефакторинга, подготовленный для разрыва зависимости от сетевого взаимодействия
Введем в класс-наследник указатель shared_ptr на объект, реализующий выделенный интерфейс. Все, что нам осталось — это использовать метод параметризации конструктора для внедрения зависимости. Теперь наш класс, который теперь можно протестировать, выглядит следующим образом:
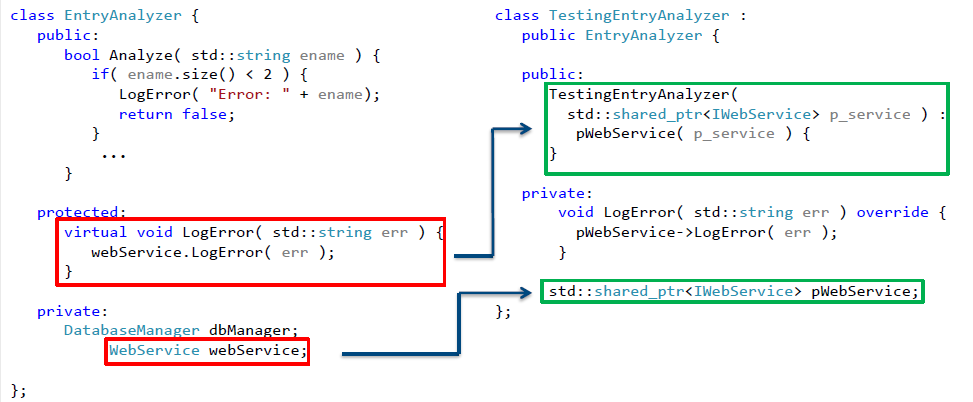
Рис.15. Тестируемый класс, позволяющий осуществить разрыв зависимости от сетевого взаимодействия
И теперь мы можем написать следующий тест:
TEST_F( EntryAnalyzerTest, Analyze_TooShortEntryName_LogsErrorToWebServer )
{
std::shared_ptr<FakeWebService> p_web_service =
std::make_shared<FakeWebService>();
TestingEntryAnalyzer ea( p_web_service );
bool result = ea.Analyze( "e" );
ASSERT_EQ( p_web_service->lastError, "Error: e" );
}
class TestingEntryAnalyzer : public EntryAnalyzer {
public:
TestingEntryAnalyzer(
std::shared_ptr<IWebService> p_service ) :
pWebService( p_service ) {
}
private:
void LogError( std::string err ) override {
pWebService->LogError( err );
}
std::shared_ptr<IWebService> pWebService;
};
class FakeWebService : public IWebService {
public:
void LogError( std::string error ) override {
lastError = error;
}
std::string lastError;
};Рис.16. Пример теста, не взаимодействующего с сетевым соединением
Таким образом, внедрив зависимость с помощью параметризации конструктора, на основе анализа состояния mock-объекта мы можем узнать, какие сообщения будет получать удаленный web-сервис.
Рекомендации для создания тестов, легких для поддержки и модернизации
Рассмотрим же теперь подходы к построению юнит-тестов, которые легки в поддержке и модернизации. Возможно, во многом это опять же связано с недоверием к самому себе.

Первая рекомендация заключается в том, что один тест должен тестировать только один результат работы. В этом случае, если тест не проходит, то можно сразу однозначно сказать, какая часть логики работы «боевого» кода не прошла проверку. Если же в одном тесте содержится несколько assert, то без повторного прогона теста и последующего дополнительного анализа тяжело однозначно сказать, где именно была нарушена логика.
Вторая рекомендация в том, что тестированию следует подвергать только публичные методы класса. Это связано с тем, что публичные методы, по сути, определяют контракт класса — то есть тот функционал, который он обязуется выполнить. Однако конкретная реализация его выполнения остается на его усмотрение. Таким образом, в ходе развития проекта может быть изменен способ выполнения того или иного действия, что может потребовать изменения логики работы приватных методов класса. В итоге это может привести к непрохождению ряда тестов, написанных для приватных методов, хотя сам публичный контракт класса при этом не нарушен. Если тестирование приватного метода все-таки требуется, рекомендуется найти публичный метод у класса, который его использует и написать тест уже относительно него.
Однако порой тесты не проходят, и приходится разбираться, что же пошло не так. При этом довольно неприятная ситуация может возникнуть, если ошибка содержится в самом тесте. Как правило, в первую очередь причины непрохождения мы начинаем искать именно в логике работы тестируемого «боевого» кода, а не самого теста. В этом случае на поиск причины непрохождения может быть потрачена куча времени. Для того чтобы этого избежать, надо стремиться к тому, чтобы сам тестовый код был максимально простым – избегайте использования в тесте каких-либо операторов ветвления (switch, if, for, while и пр.). Если же необходимо протестировать ветвление в «боевом» коде, то лучше написать два отдельных теста для каждой из веток. Таким образом, типовой юнит-тест можно представить как последовательность вызовов методов с дальнейшим assert.
Рассмотрим теперь следующую ситуацию: есть класс, для которого написано большое количество тестов, например, 100. Внутри каждого из них требуется создание тестируемого объекта, конструктору которого требуется один аргумент. Однако с ходом развития проекта, ситуация изменилась — и теперь одного аргумента недостаточно, и нужно два. Изменение количества параметров конструктора приведет к тому, что все 100 тестов не будут успешно компилироваться, и для того чтобы привести их в порядок придется внести изменения во все 100 мест.
Чтобы избежать такой ситуации, давайте следовать хорошо известному нам всем правилу: «Избегать дублирования кода». Этого можно добиться за счет использования в тестах фабричных методов для создания тестируемых объектов. В этом случае при изменении сигнатуры конструктора тестируемого объекта достаточно будет внести соответствующую правку только в одном месте тестового проекта.
Это может значительно сократить время, затрачиваемое на поддержку существующих тестов в работоспособном состоянии. А это может оказаться особенно важным в ситуации, когда в очередной раз нас будут поджимать все сроки со всех сторон.

Стало интересно? Можно погрузиться глубже.
Для дальнейшего и более подробного погружения в тему юнит-тестирования советую книгу Roy Osherove «The art of unit testing». Кроме того, довольно часто также возникает ситуация, когда требуется внести изменения в уже существующий код, который не покрыт тестами. Один из наиболее безопасных подходов заключается в том, чтобы вначале создать своеобразную «сетку безопасности» — покрыть его тестами, а затем уже внести требуемые изменения. Такой подход очень хорошо описан в книге М. Физерса «Эффективная работа с унаследованным кодом». Так что освоение описанных авторами подходов может принести нам, как разработчикам, в арсенал очень важные и полезные навыки.
Спасибо за уделенное время! Рад, если что-то из выше изложенного окажется полезным и своевременным. С удовольствием постараюсь ответить в комментариях на вопросы, если такие возникнут.
Автор: Виктор Ястребов vyastrebov
Рано или поздно перед вами как перед программистом встанет вопрос:«Как писать юнит—тесты?». Это связано с простой целью — удостовериться, что множество компонентов вашего сложного приложения работают как единое целое и самое главное — правильно.
Unit—тесты — это первый этап при выявлении багов в приложении, за ними идут более «тонкие» тесты:
интеграционные;
приемочные;
тесты «руками».
Поэтому к написанию unit-тестов нужно подойти со всей ответственностью.
Как писать юнит—тесты
Прежде чем писать unit—тесты, нужно для начала определиться, а нужны ли они вашей разработке? Потому что не всем проектам необходимо подобное тестирование. К примеру, не нужно знать, как писать unit—тесты, если:
Ваш проект — это небольшой html-сайт из 2-5 страниц и с 1-2-мя формами отправки заявки или письма с обратной связью. В таком проекте не присутствует сложная логика, для которой нужно писать юнит—тесты. Все проверяется «руками» и очень быстро.
Ваш проект — это проект «представления», когда, опять же, отсутствует сложная логика: лендинг, рекламный сайт, флеш-игра, несложная верста или анимация и др.
Вы делаете презентационный софт для выставки и очень сильно ограничены во времени.
Вы создаете идеальный код и всегда вообще без ошибок. А сам код может мгновенно изменяться под требования заказчика, и более того, код способен объяснить заказчику, что его требования — это полная нелепость и непонимание сути заказываемой разработки.
В общем, первые 3 пункта подсказывают, что когда у вас сжаты сроки, сжат бюджет, простая разработка и просто нет смысла тратить время на дополнительное тестирование, потому что софт будет жить 1-3 дня, — в таких случаях проводить юнит—тестирование необязательно.
Последний пункт — это шутка, потому что программистов, пишущих идеальный код, пока нет, но, возможно, вы будете первым. А пока даже разработчики с большим стажем допускают ошибки и постоянно оптимизируют свой код, поэтому в итоге они проводят свои разработки через все этапы тестирования, через юнит—тесты в том числе. Потому что любой сложный и долгосрочный проект в отсутствии качественного тестирования рано или поздно обречен на провал и, скорее всего, будет переписан с нуля.
Написание unit—тестов
Написание unit—тестов — дело ответственное, поэтому перед написанием теста нужно знать несколько правил:
Тест должен быть достоверным.
Он не должен зависеть от окружения.
Написанный тест должен легко обслуживаться.
Тест должен быть максимально простым и понятным.
Должен присутствовать автоматический режим запуска тестов.
Тест пишется для того кода, в котором нет уверенности.
Когда пишется тест для классов, то писать его нужно, двигаясь от простого метода к сложному.
Если стоит выбор, что проверять: результат или поведение, то всегда сначала нужно проверять результат.
Если к коду невозможно написать тест, то это, скорее всего, «говнокод», и его нужно переписывать.
У любого теста должна быть возможна фальсификация, то есть должно быть такое входное значение, чтобы тест провалился.
Тест должен провалиться только тогда, когда тестируемый код меняется. И никогда не должен проваливаться просто так.
Плохой тест всегда лучше, чем полное отсутствие юнит—теста.
Итак, чтобы реализовать все вышеперечисленные правила и знать наверняка, как писать эффективные юнит—тесты, нужно:
Правильно выбирать логическое размещение unit-тестов в вашей VCS. К примеру, если ваша разработка монолитная, то тесты расположить в папку Tests. Если приложение состоит из нескольких элементов, то имеет смысл хранить тесты в папке каждого элемента.
Правильно выбирать способ называть проект с тестом. Лучше всего добавлять к отдельному проекту его личный тестовый проект, например: когда у вас проект называется <Имя_проекта>.Core, то имеет смысл просто добавить <Имя_проекта>.Core.tests.
При тестировании классов использовать такой же способ называть тест. Должен быть такой же подход, как описано выше, например: когда у вас есть класс FindProblem, то его тестовый проект должен быть FindProblemTests.
Выбирать фреймворк для теста, который лучше всего подойдет. Не нужно изобретать колесо, когда уже придумали велосипед. Можно воспользоваться некоторыми популярными фреймворками для теста: MsTest, NUnit, xUnit и др.
Писать тело теста в едином стиле, чтобы было проще читать и поддерживать код.
Тестировать одну вещь за раз. Нужно упрощать процесс тестирования. Если вам нужно протестировать сложный процесс (например, процесс покупки в интернет-магазине), то разбивайте его на более мелкие части и тестируйте их отдельно.
Не относиться к юнит-тестам как к второстепенному коду. Все принципы и технологии при разработке основного кода должны использоваться и при написании тестов.
Несколько книг, которые отлично раскрывают ответ на вопрос о том, как писать юнит—тесты:
«The Art of Unit Testing» от Roy Osherove;
«xUnit Test Patterns: Refactoring Test Code» от Gerard Meszaros;
«Working Effectively with Legacy Code» от Michael Feathers;
«Pragmatic Unit Testing in C# with NUnit, 2nd Edition» от Andy Hunt и Dave Thomas.
Заключение
Прежде чем искать, как написать юнит—тест, нужно определиться, а нужен ли он вашему приложению? Ведь написание unit—тестов — это дополнительные работа и время, поэтому это не всегда эффективно в небольших разработках.
С другой стороны, есть мнение, что сложные разработки лучше начинать с написания тестов, а не с самой программы. И в этом есть свои преимущества, к примеру, в таком случае у вас будет уже готовая структура будущего приложения и вы точно не сделаете спагетти-код в своей будущей разработке.
Если вы определили, что вам необходимо написание unit—тестов, то относитесь к этому процессу так же серьезно, как и к самой разработке — это сэкономит вам в дальнейшем кучу времени.