Эта статья представляет собой ознакомительный материал о написании загрузчика на С и Ассемблере. Сразу скажу, что здесь я не буду вдаваться в сравнение производительности итогового кода, созданного на этих языках. В этой работе я просто вкратце изложу процесс создания загрузочного флоппи-образа путем написания собственного кода с последующим его внедрением в загрузочный сектор устройства. Все содержание будет разделено на цикл из трех статей, так как сразу сложно изложить всю нужную информацию и о компьютерах, и об устройствах загрузки, и о написании самого кода. В первой части я поясню наиболее общие аспекты компьютерной науки и суть процесса загрузки, а также обобщу значение и важность каждого этапа, чтобы упростить их понимание и запоминание.
О чем пойдет речь?
Мы рассмотрим написание кода программы и его копирование в загрузочный сектор образа флоппи-диска, после чего с помощью эмулятора bochs (x86) для Linux научимся проверять работоспособность полученной дискеты с загрузчиком.
О чем речь не пойдет
В этой статье я не рассказываю, почему загрузчик нельзя написать на других подобных ассемблеру языках, а также не говорю о недостатках его написания на одном языке по отношению к другому. Поскольку наша цель – познакомиться с написанием загрузочного кода, я не хочу нагружать вас более продвинутыми темами типа его скорости, уменьшения и т.д.
Структура статьи
Начнем мы со знакомства с основами, после чего перейдем к написанию самого кода. В целом план будет такой:
• Знакомство с загрузочными устройствами.
• Знакомсто со средой разработки.
• Знакомство с микропроцессором.
• Написание кода на ассемблере.
• Написание кода на С.
• Создание мини-программы для отображения прямоугольников.
К сведению: эта статья окажется наиболее полезной, если у вас уже есть хоть какой-то опыт программирования. Несмотря на ее ознакомительный характер, написание загрузочных программ на ассемблере и C может оказаться непростой задачей. Поэтому новичкам в программировании я рекомендую сначала ознакомиться с базовыми вводными материалами и уже потом возвращаться к этому.
Здесь я буду постепенно описывать процесс в форме вопросов и ответов, попутно приводя различную компьютерную терминологию. Вообще, я написал это руководство так, как будто обращаю его самому себе. A дискуссионный формат выбрал, потому что лично мне он помогает лучше понять важность и назначение рассматриваемого материала в повседневной жизни.
Знакомство с загрузочными устройствами
Что происходит при включении стандартного компьютера?
Обычно при нажатии кнопки включения питания от нее подается сигнал блоку питания о необходимости подачи необходимого напряжения на внутреннее и внешнее оборудование компьютера, такое как процессор, монитор, клавиатура и пр. Процессор при этом инициализирует ПЗУ-чип BIOS (базовую систему ввода/вывода) для загрузки содержащейся в нем исполняемой программы, именуемой также — BIOS.
После запуска BIOS выполняет следующие задачи:
• Тестирование оборудования при подаче питания (Power On self Test).
• Проверка частоты и доступности шин.
• Проверка системных часов и аппаратной информации в CMOS RAM.
• Проверка настроек системы, предустановок оборудования и т.д.
• Тестирование подключенного оборудования, начиная с RAM, дисководов, оптических приводов, HDD и т.д.
• В зависимости от определенной в разделе загрузочных устройств информации выполняет поиск загрузочного диска и переходит к его инициализации.
К сведению: все ЦПУ с архитектурой x86 в процессе загрузки запускаются в реальном режиме (Real Mode).
Что такое загрузочное устройство?
Загрузочным называется устройство, содержащее загрузочный сектор или блок загрузки. BIOS считывает это устройство, начиная с загрузки этого загрузочного сектора в RAM для выполнения, после чего переходит далее.
Что такое сектор?
Сектор – это особый раздел загрузочного диска, размер которого обычно составляет 512 байт. Чуть позже я подробнее поясню о том, как измеряется память компьютера и приведу сопутствующую терминологию.
Что такое загрузочный сектор?
Загрузочный сектор или блок загрузки – это область загрузочного устройства, в которой содержится загружаемый в RAM машинный код, за что отвечает встроенная в ПК прошивка на стадии инициализации. На флоппи-диске размер сектора составляет 512 байт. Чуть позже о байтах будет сказано дополнительно.
Как работает загрузочное устройство?
При его инициализации BIOS находит и загружает первый сектор (загрузочный) в RAM и начинает его выполнение. Расположенный в загрузочном секторе код является первой программой, которую можно отредактировать для определения дальнейшего функционирования компьютера после его запуска. Здесь я имею в виду, что вы можете написать собственный код и скопировать его в загрузочный сектор, чтобы система работала так, как вам нужно. Сам же этот код и будет называться тем самым начальным загрузчиком.
Что такое начальный загрузчик?
В компьютерной области загрузчиком называется программа, выполняемая при каждой инициализации загрузочного устройства во время запуска и перезагрузки ПК. Технически это выполняемый машинный код, соответствующий архитектуре типа используемого в системе ЦПУ.
Какие есть виды микропроцессоров?
Я приведу основные:
• 16 битные
• 32 битные
• 64 битные
Чем больше значение бит, тем к большему объему памяти имеют доступ программы, получая большую производительность в плане временного хранилища, обработки и пр. На сегодня микропроцессоры производят две основные компании – Intel и AMD. В этой же статьи я буду обращаться только к процессорам семейства Intel (x86).
В чем отличие процессоров Intel и AMD?
Каждый производитель использует свой уникальный способ проектирования микропроцессоров с аппаратной точки зрения и в плане используемых наборов инструкций.
Знакомство со средой разработки
Что такое реальный режим?
Я уже упоминал, что все процессоры с архитектурой x86 при загрузке с устройства запускаются в реальном режиме. Это очень важно иметь в виду при написании загрузочного кода для любого устройства. Реальный режим поддерживает только 16-битные инструкции. Поэтому создаваемый вами код для загрузки в загрузочную запись или сектор должен компилироваться в 16-битный формат. В реальном режиме инструкции могут работать только с 16 битами одновременно. Например, в 16-битном ЦПУ конкретная инструкция будет способна складывать в одном цикле два 16-битных числа. Если же для процесса будет необходимо сложить два 32-битных числа, то потребуется больше циклов, выполняющих сложение 16-битных чисел.
Что такое набор инструкций?
Это гетерогенная коллекция сущностей, ориентированных на конкретную архитектуру микропроцессора, с помощью которых пользователь может взаимодействовать с ним. Здесь я подразумеваю коллекцию сущностей, состоящую из внутренних типов данных, инструкций, регистров, режимов адресации, архитектуры памяти, обработки прерываний и исключений, а также внешнего I/O. Обычно для семейства микропроцессоров создаются общие наборы инструкций. Процессор Intel-8086 относится к семейству 8086, 80286, 80386, 80486, Pentium, Pentium I, II, III, которое также известно как семейство x86. В этой статье я будут использовать набор инструкций, относящийся именно к этому типу процессоров.
Как написать код для загрузочного сектора устройства?
Для реализации этой задачи необходимо иметь представление о:
• Операционной системе (GNU Linux).
• Ассемблере (GNU Assembler).
• Наборе инструкций (x86).
• Написании инструкций на GNU Assembler для x86 микропроцессоров.
• Компиляторе (как вариант язык C).
• Компоновщике (GNU linker ld)
• Эмуляторе x86, например bochs, используемом для тестирования.
Что такое операционная система?
Объясню очень просто. Это большой набор различных программ, написанных сотнями и даже тысячами профессионалов, которые помогают пользователям в решении их повседневных задач. К таким задам можно отнести подключение к интернету, общение в соцсетях, создание и редактирование файлов, работу с данными, игры и многое другое. Все это реализуется с помощью операционной системы. Помимо этого, ОС также регулирует функционирование аппаратных средств, обеспечивая для вас оптимальным режим работы.
Отдельно отмечу, что все современные ОС работают в защищенном режиме.
Какие виды ОС бывают?
• Windows
• Linux
• MAC
• …
Что значит защищенный режим?
В отличие от реального режима, защищенный поддерживает 32-битные инструкции. Но вам об этом задумываться не стоит, так как нас не особо волнует процесс функционирования ОС.
Что такое Ассемблер?
Ассемблер преобразует передаваемые пользователем инструкции в машинный код.
Разве компилятор делает не то же самое?
На более высоком уровне да, но, фактически, внутри компилятора этим занимается именно ассемблер.
Почему компилятор не может генерировать машинный код напрямую?
Основная задача компилятора состоит в преобразовании инструкций пользователя в их промежуточный набор, называемый инструкциями ассемблера, после чего ассемблер преобразует их в соответствующий машинный код.
Зачем нужна ОС для написания кода загрузочного сектора?
Прямо сейчас я не хочу вдаваться в подробности и ограничусь пояснением в рамках материала текущей статьи. Как я говорил, для написания инструкций, которые поймет микропроцессор, нам нужен компилятор. Он, в свою очередь, разрабатывается в качестве утилиты ОС и используется через нее, соответственно.
Какую ОС можно использовать?
Так как я писал загрузочные программы под Ubuntu, то и вам для ознакомления с данным руководством порекомендую именно эту ОС.
Какой следует использовать компилятор?
Я писал загрузчики при помощи GNU GCC и демонстрировать компиляцию кода я буду на нем же. Как протестировать рукописный код для загрузочного сектора? Я представлю вам эмулятор архитектуры x86, который помогает дорабатывать код, не требуя постоянной перезагрузки компьютера при редактировании загрузочного сектора устройства.
Знакомство с микропроцессором
Прежде чем изучать программирование микропроцессора, нам необходимо разобрать использование регистров.
Что такое регистры?
Регистры подобны утилитам микропроцессора, служащим для временного хранения данных и управления ими согласно нашим потребностям. Предположим, пользователь задает операцию сложения 2 и 3, для чего компьютер сохраняет число 3 в одном регистре, а 2 в другом, после чего складывает содержимое этих регистров. В итоге ЦПУ помещает результат в еще один регистр, который и представляет нужный пользователю вывод. Регистры разделяются на четыре основных типа:
• регистры общего назначения;
• сегментные регистры;
• индексные регистры;
• регистры стека.
Я дам краткое пояснение по каждому типу.
Регистры общего назначения используются для хранения временных данных, необходимых программе в процессе выполнения. Каждый такой регистр имеет емксоть 16 бит или 2 байта.
• AX – регистр сумматора;
• BX – регистр базового адреса;
• CX – регистр-счетчик;
• DX – регистр данных.
Сегментные регистры: служат для представления микропроцессору адреса памяти. Здесь нужно знать два термина:
• Сегмент: независимый блок памяти, поддерживаемый аппаратно. Обычно обозначается начальным адресом.
• Смещение: указывает индекс относительно начала сегмента.
Пример: у нас есть байт, представляющий значение “X” и расположенный в 10-й позиции от начала блока памяти со стартовым адресом 0x7c00. В данной ситуации мы выразим сегмент как 0x7c00, а смещение как 10.
Абсолютным адресом тогда будет 0x7c00 + 10.
Здесь я хочу выделить четыре категории:
• CS – сегмент кода;
• SS – сегмент стека;
• DS – сегмент данных;
• ES – расширенный сегмент.
При этом нужно учитывать ограничения этих регистров, а именно невозможность прямого присваивания адреса. Вместо этого нам приходится копировать адрес сначала в регистры общего назначения, после чего снова копировать его уже в сегментные. Например, для решения задачи обнаружения байта “X” мы делаем следующее:
movw $0x07c0, %ax
movw %ax , %ds
movw (0x0A) , %ax Здесь происходит:
• загрузка значения 0x07c0 * 16 в AX;
• загрузка содержимого AX в DS;
• установка 0x7c00 + 0x0a в AX.
Регистры стека:
• BP – базовый указатель;
• SP – указатель стека.
Индексные регистры:
• SI: регистр индекса источника.
• DI: регистр индекса получателя.
• AX: используется ЦПУ для арифметических операций.
• BX: может содержать адрес процедуры или переменной (это также могут SI, DI и BP) и использоваться для выполнения арифметических операций и перемещения данных.
• CX: выступает в роли счетчика цикла при повторении инструкций.
• DX: содержит старшие 16 бит произведения при умножении, а также задействуется при делении.
• CS: содержит базовый адрес всех выполняемых инструкций программы.
• SS: содержит базовый адрес стека.
• DS: содержит предустановленный адрес переменных.
• ES: содержит дополнительный базовый адрес переменных памяти.
• BP: содержит предполагаемое смещение из регистра SS. Часто используется подпрограммами для обнаружения переменных, переданных в стек вызывающей программой.
• SP: содержит смещение вершины стека.
• SI: используется в инструкциях перемещения строк. При этом на исходную строку указывает регистр SI.
• DI: выступает в роли места назначения для инструкций перемещения строк.
Что такое бит?
В вычислительных средах бит является наименьшей единицей данных, представляющей их в двоичном формате, где 1 = да, а 0 = нет.
Дополнительно о регистрах:
Ниже описано дальнейшее подразделение регистров:
• AX: первые 8 бит AX обозначаются как AL, последние 8 бит как AH.
• BX: первые 8 бит BX обозначаются как BL, последние 8 как как BH.
• CX: первые 8 бит CX обозначаются как CL, последние 8 бит как CH.
• DX: первые 8 бит DX обозначаются как DL, последние 8 бит как DH.
Как обращаться к функциям BIOS?
BIOS предоставляет ряд функций, позволяющих распределять приоритеты ЦПУ. Доступ к этим возможностям BIOS можно получить с помощью прерываний.
Что такое прерывания?
Для приостановки стандартного потока программы и обработки событий, требующих быстрой реакции, используются прерывания. Например, при перемещении мыши соответствующее аппаратное обеспечение прерывает текущую программу для обработки этого перемещения. В результате прерывания управление передается специальной программе-обработчику. При этом каждому типу прерывания присваивается целое число. В начальной области физической памяти располагается таблица векторов прерываний, в которой находятся сегментированные адреса их обработчиков. Номер прерывания, по сути, является индексом из этой таблицы.
Какое прерывание будем использовать мы?
Прерывание INT 0x10.
Написание кода на Ассемблере
Какие типы данных доступны в GNU Assembler?
Типы данных определяют их характеристики и могут быть следующими:
• байт;
• слово;
• Int;
• ASCII;
• ASCIIZ.
Байт: состоит из восьми бит и считается наименьшей единицей хранения информации при программировании.
Слово: единица данных, состоящая из 16 бит.
Int: целочисленный тип данных, состоящий из 32 бит, которые могут быть представлены четырьмя байтами или двумя словами.
Прим. Справедливости ради, стоит отметить, что размер Int зависит от архитектуры и может составлять от 16 до 64 бит (а на некоторых системах даже 8 бит). То, очем говорит автор — это тип long. Подробнее о типах С можно прочесть по ссылке.
ASCII: представляет группу байтов без нулевого символа.
ASCIIZ: выражает группу байтов, завершающуюся нулевым символом.
Как генерировать код для реального режима в Ассемблере?
В процессе запуска ЦПУ в реальном режиме (16 бит) мы можем задействовать только встроенные функции BIOS. Я имею в виду, что с помощью этих функций можно написать собственный код загрузчика, поместить его в загрузочный сектор и выполнить загрузку. Давайте рассмотрим написание на Ассемблере небольшого фрагмента программы для генерации 16-битного кода ЦПУ через GNU Assembler.
Файл-образец: test.S
.code16 #генерирует 16-битный код
.text #расположение исполняемого кода
.globl _start;
_start: #точка входа
. = _start + 510 #перемещение из позиции 0 к 510-му байту
.byte 0x55 #добавление сигнатуры загрузки
.byte 0xaa #добавление сигнатуры загрузкиПояснения:
• .code16: это директива, отдаваемая ассемблеру для генерации не 32-, а 16-битного кода. Зачем это нужно? Ассемблер вы будете использовать через операционную систему, а код загрузчика будете писать с помощью компилятора. Но вы также наверняка помните, что ОС работает в защищенном 32-битном режиме. Поэтому, по умолчанию ассемблер в такой ОС будет производить 32-битный код, что не соответствует нашей задаче. Данная же директива исправляет этот нюанс, и мы получаем 16-битный код.
• .text: этот раздел содержит фактические машинные инструкции, составляющие вашу программу.
• .globl _start: .global <символ> делает символ видимым для компоновщика. При определении символа в подпрограмме его значение становится доступным для других связанных подпрограмм. Иначе говоря, символ получает атрибуты от символа с таким же именем, находящегося в другом файле, связанном с этой программой.
• _start: точка входа в основной код, а также предустановленная точка входа для компоновщика.
• = _start + 510: переход от начальной позиции к 510-му байту.
• .byte 0x55: первый байт, определяемый как часть сигнатуры загрузки (511-й байт).
• .byte 0xaa: последний байт, определяемый как часть сигнатуры загрузки (512-й байт).
Как скомпилировать программу ассемблера?
Сохраните код в файле test.S и введите в командной строке:
• as test.S -o test.o
• ld –Ttext 0x7c00 --oformat=binary test.o –o test.bin
Что означают эти команды?
• as test.S –o test.o: преобразует заданный код в промежуточную объектную программу, которая затем преобразуется уже в машинный код.
• --oformat=binary сообщает компоновщику, что выходной двоичный файл должен быть простым двоичным образом, т.е. не иметь кода запуска, связывания адресов и пр.
• –Ttext 0x7c00 сообщает компоновщику, что для вычисления абсолютного адреса нужно загрузить адрес “text” (сегмент кода) в 0x7c00.
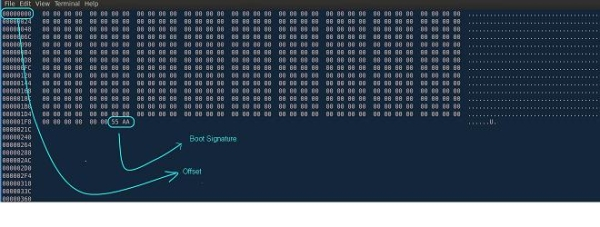
Что такое сигнатура загрузки?
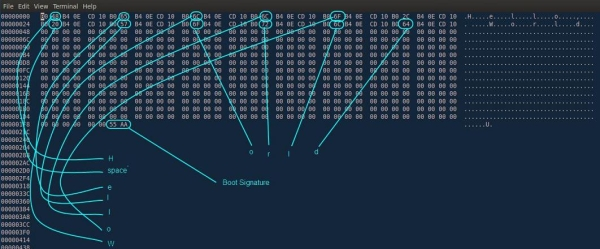
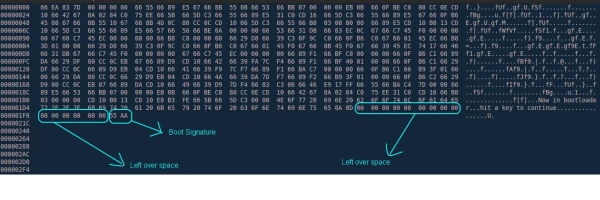
Давайте вспомним о загрузочном секторе, используемом BIOS для запуска системы, и подумаем, как BIOS узнает о наличии такого сектора на устройстве? Тут нужно пояснить, что состоит он из 512 байт, в которых для 510-го байта ожидается символ 0x55, а для 511-го символ 0xaa. Исходя из этого, BIOS проверяет соответствие двух последний байт загрузочного сектора этим значениям и либо продолжает загрузку, либо сообщает о ее невозможности. При помощи hex-редактора можно просматривать содержимое двоичного файла в более читабельном виде, и ниже в качестве примера я привел снимок этого файла.
Как скопировать исполняемый код на загрузочное устройство и протестировать его?
Чтобы создать образ для дискеты размером 1.4Мб, введите в командную строку следующее:
• dd if=/dev/zero of=floppy.img bs=512 count=2880
Чтобы скопировать этот код в загрузочный сектор файла образа, введите:
• dd if=test.bin of=floppy.img
Для проверки программы введите:
• bochs
Если bochs не установлен, тогда можно ввести следующее:
• sudo apt-get install bochs-x
Файл-образец: bochsrc.txt
megs: 32
#romimage: file=/usr/local/bochs/1.4.1/BIOS-bochs-latest, address=0xf0000
#vgaromimage: /usr/local/bochs/1.4.1/VGABIOS-elpin-2.40
floppya: 1_44=floppy.img, status=inserted
boot: a
log: bochsout.txt
mouse: enabled=0 В результате должно отобразиться стандартное окно эмуляции bochs:

Просмотр:
Если теперь заглянуть в файл test.bin через hex-редактор, то вы увидите, что сигнатура загрузки находится после 510-го байта:
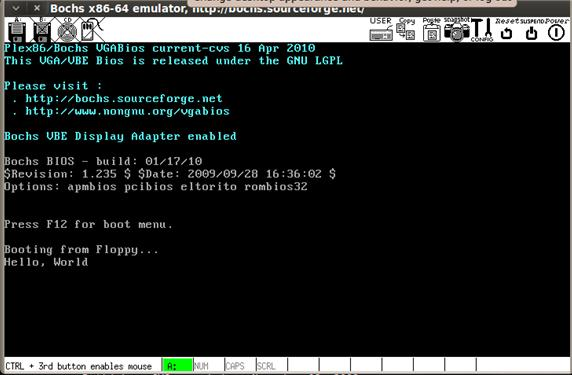
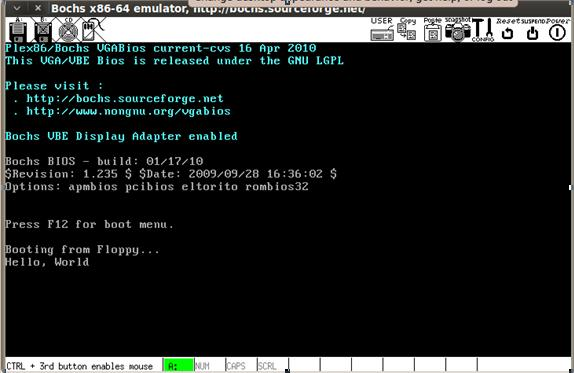
Пока что вы просто увидите сообщение “Booting from Floppy”, так как в коде мы еще ничего не прописали. Давайте рассмотрим пару других примеров создания кода на ассемблере.
Файл-образец: test2.S
.code16 #генерирует 16-битный код
.text #расположение исполняемого кода
.globl _start;
_start: #точка входа
movb $'X' , %al #выводимый символ
movb $0x0e, %ah #выводимый служебный код bios
int $0x10 #прерывание цпу
. = _start + 510 #перемещение из позиции 0 к 510-му байту
.byte 0x55 #добавление сигнатуры загрузки
.byte 0xaa #добавление сигнатуры загрузкиПосле ввода этого кода сохраните его в test2.S и выполните действия согласно прежней инструкции, изменив имя исходного файла. После компиляции, копирования кода в загрузочный сектор и выполнения bochs вы должны увидеть следующий экран, где теперь отображается прописанная нами в коде буква X.
Поздравляю, ваша первая программа в загрузочном секторе работает!
Просмотр:
В hex-редакторе вы увидите, что символ X находится во второй позиции от начального адреса.

Теперь давайте выведем на экран текст побуквенно.
Файл-образец: test3.S
.code16 #генерирует 16-битный код
.text #расположение исполняемого кода
.globl _start;
_start: #точка входа
#выводит 'H'
movb $'H' , %al
movb $0x0e, %ah
int $0x10
#выводит 'e'
movb $'e' , %al
movb $0x0e, %ah
int $0x10
#выводит 'l'
movb $'l' , %al
movb $0x0e, %ah
int $0x10
#выводит 'l'
movb $'l' , %al
movb $0x0e, %ah
int $0x10
#выводит 'o'
movb $'o' , %al
movb $0x0e, %ah
int $0x10
#выводит ','
movb $',' , %al
movb $0x0e, %ah
int $0x10
#выводит ' '
movb $' ' , %al
movb $0x0e, %ah
int $0x10
#выводит 'W'
movb $'W' , %al
movb $0x0e, %ah
int $0x10
#выводит'o'
movb $'o' , %al
movb $0x0e, %ah
int $0x10
#выводит 'r'
movb $'r' , %al
movb $0x0e, %ah
int $0x10
#выводит 'l'
movb $'l' , %al
movb $0x0e, %ah
int $0x10
#выводит 'd'
movb $'d' , %al
movb $0x0e, %ah
int $0x10
. = _start + 510 #перемещение из позиции 0 к 510-му байту
.byte 0x55 #добавление сигнатуры загрузки
.byte 0xaa #добавление сигнатуры загрузкиСохраните файл как test3.S. После компиляции и всех сопутствующих действий перед вами отобразится следующий экран:
Просмотр:
Хорошо. Теперь давайте напишем программу, выводящую на экран фразу “Hello, World”.
При этом мы также определим функции и макросы, с помощью которых и будем выводить эту строку.
Файл-образец: test4.S
#генерирует 16-битный код
.code16
#расположение исполняемого кода
.text
.globl _start;
#точка входа загрузочного кода
_start:
jmp _boot #переход к загрузочному коду
welcome: .asciz "Hello, Worldnr" #здесь мы определяем строку
.macro mWriteString str #макрос, вызывающий функцию вывода строки
leaw str, %si
call .writeStringIn
.endm
#функция вывода строки
.writeStringIn:
lodsb
orb %al, %al
jz .writeStringOut
movb $0x0e, %ah
int $0x10
jmp .writeStringIn
.writeStringOut:
ret
_boot:
mWriteString welcome
#перемещение от начала к 510-му байту и присоединение сигнатуры загрузки
. = _start + 510
.byte 0x55
.byte 0xaa Сохраните файл как test4.S. Теперь после компиляции и всего за ней следующего вы увидите:
Отлично! Если вы поняли все проделанные мной действия и успешно создали аналогичную программу, то я вас поздравляю еще раз!
Просмотр:
Что такое функция?
Функция – это блок кода, имеющий имя и переиспользуемое свойство.
Что такое макрос?
Макрос – это фрагмент кода с присвоенным именем, на место использования которого подставляется содержимое этого макроса.
В чем синтаксическое отличие функции от макроса?
Для вызова функции используется следующий синтаксис:
• push <аргумент>
• call <имя функции>
А для макроса такой:
• macroname <аргумент>
И поскольку синтаксис вызова и применения макроса проще, чем функции, я предпочел использовать в основном коде именно его.
Написание кода в компиляторе С
Что такое C?
С – это язык программирования общего назначения, разработанный сотрудником Bell Labs Деннисом Ритчи в 1969-1973 годах.
Почему мы используем именно этот язык? Причина в том, что создаваемые на нем программы, как правило, не велики и отличаются высокой скоростью. Помимо этого, он включает низкоуровневые возможности, которые обычно доступны только в ассемблере или машинном языке. Ко всему прочему, С также является структурированным.
Что нужно для написания кода на С?
Мы будем использовать компилятор GNU C под названием GCC и разберем написание в нем программы на примере.
Файл-образец: test.c
__asm__(".code16n");
__asm__("jmpl $0x0000, $mainn");
void main() {
} Файл: test.ld
ENTRY(main);
SECTIONS
{
. = 0x7C00;
.text : AT(0x7C00)
{
*(.text);
}
.sig : AT(0x7DFE)
{
SHORT(0xaa55);
}
} Для компиляции программы введите в командной строке:
• gcc -c -g -Os -march=i686 -ffreestanding -Wall -Werror test.c -o test.o
• ld -static -Ttest.ld -nostdlib --nmagic -o test.elf test.o
• objcopy -O binary test.elf test.bin
Что значат эти команды?
Первая преобразует код C в промежуточную объектную программу, которая в последствии преобразуется в машинный код.
• gcc -c -g -Os -march=i686 -ffreestanding -Wall -Werror test.c -o test.o:
Что значат эти команды?
• -c: используется для компиляции исходного кода без линковки.
• -g: генерирует отладочную информацию для отладчика GDB.
• -Os: оптимизация размера кода.
• -march: генерирует код для конкретной архитектуры ЦПУ (в нашем случае i686).
• -ffreestanding: в среде отдельных программ может отсутствовать стандартная библиотека, а инструкции запуска программы не обязательно располагаются в “main”.
• -Wall: активирует все предупреждающие сообщения компилятора. Рекомендуется всегда использовать эту опцию.
• -Werror: активирует трактовку предупреждений как ошибок.
• test.c: имя входного исходного файла.
• -o: генерация объектного кода.
• test.o: имя выходного файла объектного кода.
С помощью всей этой комбинации флагов мы генерируем объектный код, помогающий нам в обнаружении ошибок и предупреждений, а также создаем более эффективный код для данного типа ЦПУ. Если не указать march=i686, будет сгенерирован код для используемой вами машины. В связи с этим нужно указывать, для какого именно типа ЦПУ он создается.
• ld -static -Ttest.ld -nostdlib --nmagic test.elf -o test.o:
Эта команда вызывает компоновщик из командной строки, и ниже я поясню, как именно мы его используем.
Что значат эти флаги?
• -static: не линковать с общими библиотеками.
• -Ttest.ld: разрешить компоновщику следовать командам из его скрипта.
• -nostdlib: разрешить компоновщику генерировать код, не линкуя функции запуска стандартной библиотеки C.
• --nmagic: разрешить компоновщику генерировать код без фрагментов _start_SECTION и _stop_SECTION.
• test.elf: имя выходного файла (соответствующий платформе формат хранения исполняемых файлов. Windows: PE, Linux: ELF)
• -o: генерация объектного кода.
• test.o: имя входного файла объектного кода.
Что такое компоновщик?
Он выполняет последний этап компиляции. ld (компоновщик) получает один или более объектных файлов либо библиотек и совмещает их в один, как правило, исполняемый файл. В ходе этого процесса он обрабатывает ссылки на внешние символы, присваивает конечные адреса процедурам/функциям и переменным, а также корректирует код и данные для отражения актуальных адресов.
Не забывайте, что мы не используем в коде стандартные библиотеки и сложные функции.
• objcopy -O binary test.elf test.bin
Эта команда служит для генерации независимого от платформы кода. Обратите внимание, что в Linux исполняемые файлы хранятся не так, как в Windows. В каждой системе свой способ хранения, но мы создаем всего-навсего небольшой загрузочный код, который на данный момент не зависит от ОС.
Зачем в программе C использовать инструкции ассемблера?
В реальном режиме к функциям BIOS можно легко обратиться через прерывания при помощи именно инструкций ассемблера.
Как скопировать код на загрузочное устройство и проверить его?
Чтобы создать образ для дискеты размером 1.4Мб, введите в командную строку:
• dd if=/dev/zero of=floppy.img bs=512 count=2880
Чтобы скопировать код в загрузочный сектор файла образа, введите:
• dd if=test.bin of=floppy.img
Для проверки программы введите:
• bochs
Должно отобразиться стандартное окно эмуляции:
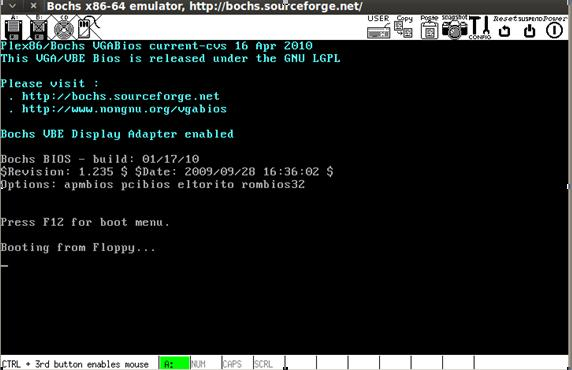
Что мы видим: как и в первом нашем примере, пока что здесь отображается только сообщение “Booting from Floppy”.
Для вложения инструкция ассемблера в программу C мы используем ключевое слово __asm__.
• Дополнительно мы задействуем __volatile__, указывая компилятору, что код нужно оставить как есть, без изменений.
Такой способ вложения называется встраивание ассемблерного кода.
Рассмотрим еще несколько примеров написания с помощью компилятора.
Пишем программу для вывода на экран ‘X’
Файл-образец: test2.c
__asm__(".code16n");
__asm__("jmpl $0x0000, $mainn");
void main() {
__asm__ __volatile__ ("movb $'X' , %aln");
__asm__ __volatile__ ("movb $0x0e, %ahn");
__asm__ __volatile__ ("int $0x10n");
}Написав код, сохраните файл как test2.c и скомпилируйте его согласно все тем же инструкциям, изменив исходное имя. После компиляции, копирования кода в загрузочный сектор и выполнения команды bochs вы снова увидите экран, где отображается буква X:
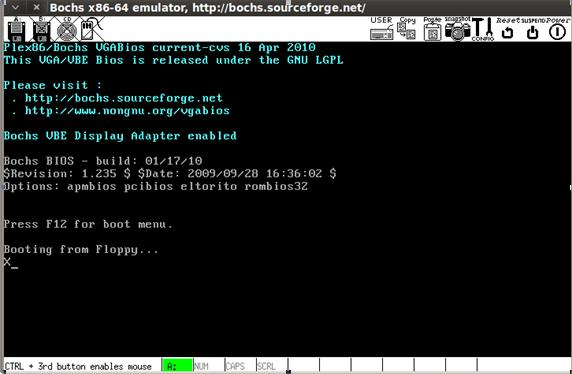
Теперь напишем код для показа фразы “Hello, World”
Для вывода данной строки мы также определим функции и макросы.
Файл-образец: test3.c
/* генерирует 16-битный код */
__asm__(".code16n");
/* переходит к точке входа загрузочного кода */
__asm__("jmpl $0x0000, $mainn");
void main() {
/* выводит 'H' */
__asm__ __volatile__("movb $'H' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'e' */
__asm__ __volatile__("movb $'e' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'l' */
__asm__ __volatile__("movb $'l' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'l' */
__asm__ __volatile__("movb $'l' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'o' */
__asm__ __volatile__("movb $'o' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит ',' */
__asm__ __volatile__("movb $',' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит ' ' */
__asm__ __volatile__("movb $' ' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'W' */
__asm__ __volatile__("movb $'W' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'o' */
__asm__ __volatile__("movb $'o' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'r' */
__asm__ __volatile__("movb $'r' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'l' */
__asm__ __volatile__("movb $'l' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
/* выводит 'd' */
__asm__ __volatile__("movb $'d' , %aln");
__asm__ __volatile__("movb $0x0e, %ahn");
__asm__ __volatile__("int $0x10n");
}
Сохраните этот код в файле test3.c и следуйте уже знакомым вам инструкциям, изменив имя исходного файла и скопировав скомпилированный код в загрузочный сектор дискеты. Теперь на этапе проверки должна отобразиться надпись «Hello, World»:
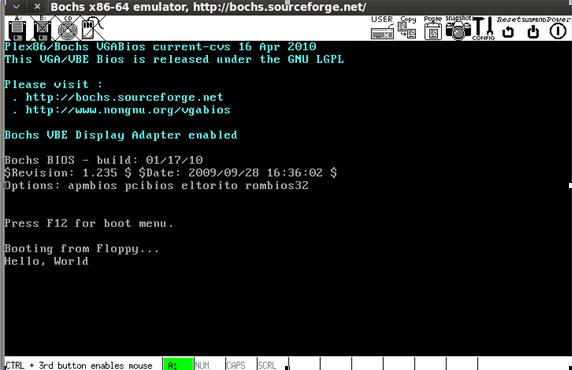
Напишем на C программу для вывода строки “Hello, World”
При этом мы определим функцию, выводящую эту строку на экран.
Файл-образец: test4.c
/*генерирует 16-битный код*/
__asm__(".code16n");
/*переход к точке входа в загрузочный код*/
__asm__("jmpl $0x0000, $mainn");
/* пользовательская функция для вывода серии знаков, завершаемых нулевым символом*/
void printString(const char* pStr) {
while(*pStr) {
__asm__ __volatile__ (
"int $0x10" : : "a"(0x0e00 | *pStr), "b"(0x0007)
);
++pStr;
}
}
void main() {
/* вызов функции <code>printString</code> со строкой в качестве аргумента*/
printString("Hello, World");
} Сохраните этот код в файле test4.c и снова проследуйте всем инструкциям компиляции и загрузки, в результате чего на экране должно отобразиться следующее:
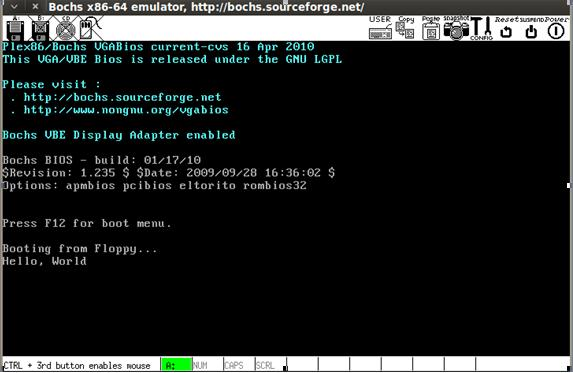
Все это время мы учились путем преобразования программ ассемблера в программы C. К настоящему моменту вы должны уже хорошо уяснить процесс их написания на обоих этих языках, а также уметь выполнять компиляцию и проверку.
Далее мы перейдем к написанию циклов и их использованию в функциях, а также познакомимся с другими службами BIOS.
Мини-проект отображения прямоугольников
Файл-образец: test5.c
/* генерирует 16-битный код */
__asm__(".code16n");
/* переход к главной функции или программному коду */
__asm__("jmpl $0x0000, $mainn");
#define MAX_COLS 320 /* количество столбцов экрана */
#define MAX_ROWS 200 /* количество строк экрана */
/* функция вывода строки*/
/* input ah = 0x0e*/
/* input al = <выводимый символ>*/
/* прерывание: 0x10*/
/* мы используем прерывание 0x10 с кодом функции 0x0e для вывода байта из al*/
/* эта функция получает в качестве аргумента строку и выводит символ за символом, пока не достигнет нуля*/
void printString(const char* pStr) {
while(*pStr) {
__asm__ __volatile__ (
"int $0x10" : : "a"(0x0e00 | *pStr), "b"(0x0007)
);
++pStr;
}
}
/* функция, получающая сигнал о нажатии клавиши на клавиатуре */
/* input ah = 0x00*/
/* input al = 0x00*/
/* прерывание: 0x10*/
/* эта функция регистрирует нажатие пользователем клавиши для продолжения выполнения */
void getch() {
__asm__ __volatile__ (
"xorw %ax, %axn"
"int $0x16n"
);
}
/* функция вывода на экран цветного пикселя в заданном столбце и строке */
/* входной ah = 0x0c*/
/* входной al = нужный цвет*/
/* входной cx = столбец*/
/* входной dx = строка*/
/* прерывание: 0x10*/
void drawPixel(unsigned char color, int col, int row) {
__asm__ __volatile__ (
"int $0x10" : : "a"(0x0c00 | color), "c"(col), "d"(row)
);
}
/* функции очистки экрана и установки видео-режима 320x200 пикселей*/
/* функция для очистки экрана */
/* входной ah = 0x00 */
/* входной al = 0x03 */
/* прерывание = 0x10 */
/* функция для установки видео режима */
/* входной ah = 0x00 */
/* входной al = 0x13 */
/* прерывание = 0x10 */
void initEnvironment() {
/* очистка экрана */
__asm__ __volatile__ (
"int $0x10" : : "a"(0x03)
);
__asm__ __volatile__ (
"int $0x10" : : "a"(0x0013)
);
}
/* функция вывода прямоугольников в порядке уменьшения их размера */
/* я выбрал следующую последовательность отрисовки: */
/* из левого верхнего угла в левый нижний, затем в правый нижний, оттуда в верхний правый и в завершении в верхний левый край */
void initGraphics() {
int i = 0, j = 0;
int m = 0;
int cnt1 = 0, cnt2 =0;
unsigned char color = 10;
for(;;) {
if(m < (MAX_ROWS - m)) {
++cnt1;
}
if(m < (MAX_COLS - m - 3)) {
++cnt2;
}
if(cnt1 != cnt2) {
cnt1 = 0;
cnt2 = 0;
m = 0;
if(++color > 255) color= 0;
}
/* верхний левый -> левый нижний */
j = 0;
for(i = m; i < MAX_ROWS - m; ++i) {
drawPixel(color, j+m, i);
}
/* левый нижний -> правый нижний */
for(j = m; j < MAX_COLS - m; ++j) {
drawPixel(color, j, i);
}
/* правый нижний -> правый верхний */
for(i = MAX_ROWS - m - 1 ; i >= m; --i) {
drawPixel(color, MAX_COLS - m - 1, i);
}
/* правый верхний -> левый верхний */
for(j = MAX_COLS - m - 1; j >= m; --j) {
drawPixel(color, j, m);
}
m += 6;
if(++color > 255) color = 0;
}
}
/* эта функция является загрузочным кодом и вызывает следующие функции: */
/* вывод на экран сообщения, предлагающего пользователю нажать любую клавишу для продолжения. После нажатия клавиши происходит отрисовка прямоугольников в порядке убывания их размера */
void main() {
printString("Now in bootloader...hit a key to continuenr");
getch();
initEnvironment();
initGraphics();
}Сохраните все это в файле test5.c и следуйте все тем же инструкциям компиляции с последующим копированием кода в загрузочный сектор дискеты.
Теперь в качестве результата вы увидите:
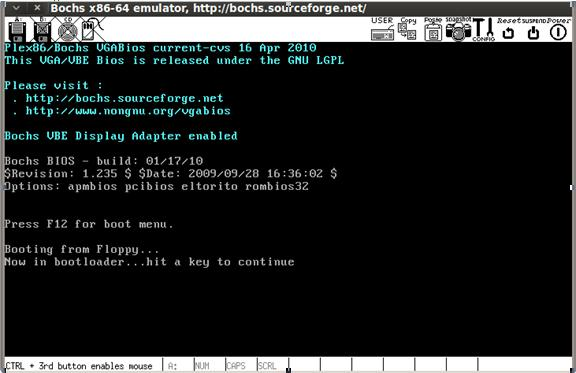
Нажмите любую клавишу.
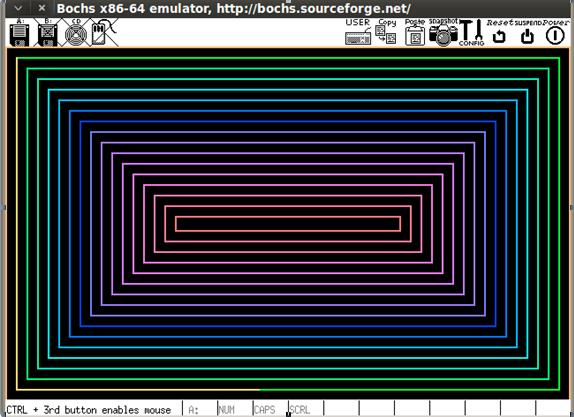
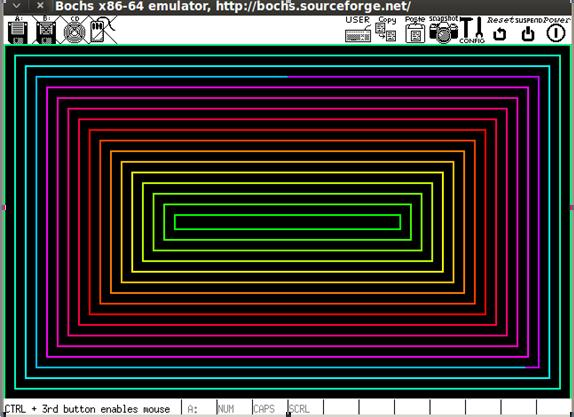
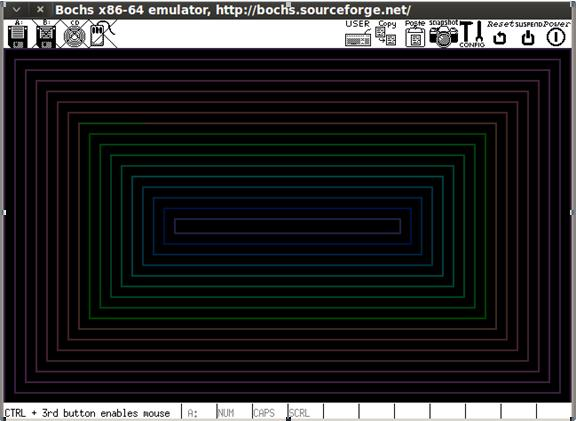
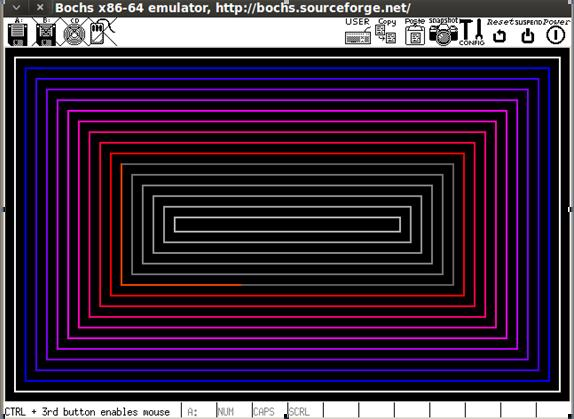
Просмотр:
Если внимательно рассмотреть содержимое исполняемого файла, то можно заметить, что в нем практически закончилось свободное пространство. Поскольку размер загрузочного сектора ограничен 512 байтами, мы смогли вместить только несколько функций, а именно выполнить инициализацию среды и вывод цветных прямоугольников. Вот снимок содержимого файла:
На этом первая часть серии статей заканчивается. В следующей части я расскажу о режимах адресации, используемых для обращения к данным и чтения дискет. Помимо этого, мы рассмотрим, почему загрузчики обычно пишутся на ассемблере, а не на C, а также затронем ограничения последнего в контексте генерации кода.
Примечание переводчика: описание автором функционирования регистров и некоторых других технических деталей, по всей видимости, требует уточнения. В связи с этим по вызывающим сомнение вопросам рекомендуется обратиться к более авторитетным литературным источникам.

Чтобы не было обвинений в плагиате предупреждаю сразу, всё нижеследующее взято на сайте asmdev.narod.ru, автор Андрей Валяев <dron@infosec.ru>, материалы были в форме рассылки, поэтому подвергнуты минимальной литобработке.
Создание операционной системы на ассемблере
- введение / основные сведения о ядре
- организация работы с памятью
- этапы загрузки различных ОС
- создание bootsector’а
- основы защищенного режима
- шлюзы / виртуальный режим процессора 8086
- исключения защищенного режима / микроядерные системы
- файловые системы
- чтение ext2fs
- форматы файлов ELF и PE
- процесс загрузки
- определение количества памяти
В этой работе будут использоваться:
- Многоплатформенный ассемблер nasm (есть версии для UNIX, DOS и Windows), поддерживающий команды практически всех современных процессоров и многообразием понимаемых форматов.
- любой ANSI C компилятор.
Глава #1
В этой главе вы не увидите исходных текстов готовых программ, это все еще только предстоит написать при вашем активном участии.
Начнем с написания ядра. Ядро будет ориентированно на UNIX-подобные операционные системы. Для простоты с самого начала будем стремиться к совместимости с существующими системами.
Задача состоит в следующем:
Сделать, по возможности, компактное, надежное и быстрое ядро, с максимальным эффектом используя возможности процессора. Писать будем в основном на Ассемблере.
Для начала разберемся, как устроены системы
.
Ядро состоит из следующих компонентов:
- «Собственно ядро»
- Драйвера устройств
- Системные вызовы
В зависимости от организации внутренних взаимодействий, ядра подразделяются на «микроядра» (microkernel) и монолитные ядра.
Системы с «микроядром» строятся по модульному принципу, имеют обособленное ядро, и механизм взаимодействия между драйверами устройств и процессами. По такому принципу строятся системы реального времени. Примерно так сделан QNX или HURD.
Монолитное ядро имеет более жесткую внутреннюю структуру. Все установленные драйвера жестко связываются между собой, обычно прямыми вызовами. По таким принципам строятся обыкновенные операционные системы типа Linux, FreeBSD.
Естественно, не все так четко, идеального монолитного или «микроядра» нет, наверное, ни в одной системе, просто системы приближаются к тому или иному типу ядра.
Очень хотелось бы, чтобы то, что делаем, больше походило на первый тип ядер.
Немного углубляемся в аппаратные возможности компьютеров
.
Один, отдельно взятый, процессор, в один момент времени, может исполнять только одну программу. Но к компьютерам предъявляются более широкие требования. Мало кто, в настоящее время, удовлетворился однозадачной операционной системой (к каким относился DOS, например). В связи с этим разработчики процессоров предусмотрели мультизадачные возможности.
Возможность эта заключается в том, что процессор выполняет какую-то одну программу (их еще называют процессами или задачами). Затем, по истечении некоторого времени (обычно это время меряется микросекундами), операционная система переключает процессор на другую программу. При этом все регистры текущей программы сохраняются. Это необходимо для того, чтобы через некоторое время вновь передать управление этой программе. Программа при этом не замечает каких либо изменений, для нее процесс переключения остается незаметен.
Для того чтобы программа не могла, каким либо образом, нарушить работоспособность системы или других программ, разработчики процессоров предусмотрели механизмы защиты.
Процессор предоставляет 4 «кольца защиты» (уровня привилегий), можно было бы использовать все, но это связано со сложностями взаимодействия программ разного уровня защиты. Поэтому в большинстве существующих систем используют два уровня. 0 — привилегированный уровень (ядро) и 3 — непривилегированный (пользовательские программы).
Всем этим обеспечивается надежное функционирование системы и независимость программ друг от друга.
Теперь немного поподробнее про устройство ядра.
На «Собственно ядро» возлагаются функции менеджера памяти и процессов. Переключение процессов — это основной момент нормального функционирования системы. Драйвера не должны «тормозить», а тем более блокировать работу ядра. Windows — наглядный пример того, что этого нельзя допустить!
Теперь о драйверах. Драйвера — это специальные программы, обеспечивающие работу устройств компьютера. В существующих системах (во FreeBSD это точно есть, про Linux не уверен) предусматриваются механизмы прерывания работы драйверов по истечении какого-то времени. Правда, все зависит от того, как написан драйвер. Можно написать драйвер под FreeBSD или Linux, который полностью блокирует работу системы.
Избежать этого при двухуровневой защите не представляется возможным, поэтому драйвера надо будет тщательно программировать. В нашей работе драйверам уделим очень много внимания, поскольку от этого в основном зависит общая производительность системы.
Системные вызовы — это интерфейс между процессами и ядром (читайте-железом). Никаких других методов взаимодействия процессов с устройствами компьютера быть не должно. Системных вызовов достаточно много, на Linux их 190, на FreeBSD их порядка 350, причем большей частью они совпадают, соответствуя стандарту POSIX (стандарт, описывающий системные вызовы в UNIX). Разница заключается в передаче параметров, что легко будет предусмотреть. Естественно, нельзя сделать ядро, работающее одновременно на Linux и на FreeBSD, но по отдельности совместимость вполне реализуема.
Прикладным программам абсолютно безразлично, как системные вызовы реализуются в ядре. Это облегчает для нас обеспечение совместимости с существующими системами.
В следующей главе поговорим о защищенном режиме процессора, распределении памяти, менеджере задач и рассмотрим, как это сделано в существующих системах.
Вопросы
- Какой бы вы хотели видеть СВОЮ систему?
- На какую систему она должна походить?
- Сколько места на винчестере занимать?
- Сколько памяти требовать для работы?
Глава #2
В этой главе поговорим об архитектуре современных процессоров и о предоставляемых средствах защиты. Понимание этого будет необходимо нам, когда перейдем непосредственно к программированию операционной системы.
Как процессор работает с памятью?
Для начала небольшое предисловие.
В процессорах имеются базовые регистры, которые могут задавать смещение. На 16-битной архитектуре максимальное смещение могло быть до 64 килобайт, что, в общем-то, не много и вызывало определенные трудности (разные модели памяти, разные форматы файлов). Так же, в 16-битной архитектуре присутствовали сегментные регистры, которые указывали адрес сегмента в памяти. В процессорах, начиная с i386, базовые регистры стали 32-х битными, что позволяет адресовать до 4 гигабайт. Сегментные регистры остались 16-битными, и в защищенном режиме они не содержат адреса! они содержат индекс дескриптора. В реальном режиме сегментные регистры работают так же, как и на 16-битных процессорах.
В реальном режиме сегментные регистры непосредственно указывают на адрес начала сегмента в памяти. Это позволяет нам, без каких либо преград, адресовать 1 мегабайт памяти. Но создает определенные трудности для защиты. А защищать нужно многое. Например, не можем пользовательским программам дать возможность непосредственно обращаться к коду или данным ядра. Так же нельзя давать возможность пользовательским программам обращаться к коду или данным других пользовательских программ, поскольку это может нарушить их работоспособность.
Для этого был изобретен защищенный режим работы процессора, который появился в процессорах i286.
Защищенность этого режима заключается в следующем:
Сегментный регистр больше не указывает на адрес в памяти. В этом регистре теперь задается индекс в таблице дескрипторов.
Таблица дескрипторов может быть глобальная или локальная (применяется в многозадачных системах для изоляции адресного пространства задач) и представляет собой массив записей, по 8 байт в каждой, где описываются адреса, пределы и права доступа к сегментам.
Про адрес ничего не буду говорить, и так все ясно. Что такое предел? В этом Поле описывается размер сегмента. При обращении за пределы сегмента процессор генерирует исключение (специальное прерывание защищенного режима). Так же исключение генерируется в случае нарушения прав доступа к сегменту. Поле прав доступа описывает возможность чтения/записи сегмента, возможность выполнения кода сегмента, уровень привилегий для доступа к сегменту.
При обращении к сегменту из дескриптора берется базовый адрес сегмента и складывается со смещением сегмента. Так получается линейный 32-х разрядный (в i286 — 24-х разрядный) адрес. Для i286 на этом процесс получения адреса завершается, линейный адрес там равен физическому. Для i386 или выше это справедливо не всегда.
Страничная организация памяти.
В процессорах, начиная с i386, появилась, так называемая, страничная организация памяти. Страница имеет размер 4 килобайта или 4 мегабайта. Большие страницы могут быть только в pentium или выше. Не знаю только, какой толк от таких страниц.
Если возможность страничной адресации не используется, то линейный адрес, как и на i286, равен физическому. Если используется — то линейный адрес разбивается на три части. Первая, 10-битная, часть адреса является индексом в каталоге страниц, который адресуется системным регистром CR3. Запись в каталоге страниц указывает адрес таблицы страниц. Вторая, 10-битная, часть адреса является индексом в таблице страниц. Запись в таблице страниц указывает физический адрес нахождения страницы в памяти. последние 12 бит адреса указывают смещение в этой странице.
В страничных записях, как и в дескрипторных записях, есть служебные биты, описывающие права доступа, и некоторые другие тонкости страниц. Одной из важных тонкостей является бит присутствия страницы в памяти. В случае не присутствия страницы, процессор генерирует исключение, в котором можно считать данную страницу из файла или из swap раздела. Это сильно облегчает реализацию виртуальной памяти. Более подробно про все это можно прочитать в книгах по архитектуре процессоров. Вернемся к операционным системам.
Многозадачность.
Многозадачные возможности в процессорах так же появились в процессорах, начиная с i286. Для реализации этого, процессор для каждой задачи использует, так называемый, «сегмент состояния задачи» («Task State Segment», сокращенно TSS). В этом сегменте, при переключении задач, сохраняются все базовые регистры процессора, сегменты и указатели стека для трех уровней защиты (для каждого уровня используется свой стек), сегментный адрес локальной таблицы дескрипторов («Local descriptor table», сокращенно LDT). В процессорах, начиная с i386, там еще хранится адрес каталога страниц (регистр CR3). Так же этот сегмент обеспечивает некоторые другие механизмы защиты, но о них пока не будем говорить.
Операционная система может расширить TSS, и использовать его для хранения регистров и состояния сопроцессора. Процессор при переключении задач не сохраняет этого. Так же возможны другие применения.
Что из всего этого следует?
Не будем ориентироваться на процессор i286, поскольку 16-битная архитектура и отсутствие механизма страничного преобразования сильно усложняет программирование операционной системы. К тому же, таких процессоров давно уже никто не использует. ")
Ориентируемся на i386 или более старшие модели процессоров, вплоть до последних.
Ядро системы при распределении памяти оперирует 4-х килобайтными страницами.
Страницы могут использоваться самим ядром, для нужд драйверов (кэширование, например), или для процессов.
Программа или процесс состоит из следующих частей:
- Сегмент кода. Может только выполняться, сама программа его не прочитать, не переписать не может! Использовать для этого сегмента swap не нужно, при необходимости код считывается прямо из файла;
- Сегмент данных состоит из трех частей:
- Константные данные, их тоже можно загружать из файла, так как они не меняются при работе программы;
- Инициализированные данные. Участвует в процессе свопинга;
- Не инициализированные данные. Так же участвует в свопинге;
- Сегмент стека. Так же участвует в свопинге.
Но, обычно, системы делят сегмент данных на две части: инициализированные данные и не инициализированные данные.
Все сегменты разбиваются на страницы. Сегмент кода имеет постоянный размер. Сегмент данных может увеличиваться в сторону больших адресов. Сегмент стека, поскольку растет вниз, увеличивается в сторону уменьшения адресов. Страницы памяти для дополнительных данных или стека выделяются системой по мере необходимости.
Очень интересный момент
При выполнении программы операционная система делает следующие действия:
- Готовит для программы локальную таблицу дескрипторов;
- Готовит для программы каталог страниц, все страницы помечаются как не присутствующие в памяти.
При передаче управления этой программе процессор генерирует исключение по отсутствию страницы, в котором нужная страница загружается из файла или инициализируется.
Еще один интересный момент
Когда в системе загружается две или более одинаковых программы — нет необходимости для каждой из них выделять место для кодового сегмента, они спокойно могут использовать один код на всех.
Глава #3
В этой главе поговорим, о порядке загрузки операционных систем.
Процесс загрузки, естественно, начинается с BIOS.
При старте процессор находится в реальном режиме, следовательно больше одного мегабайта памяти адресовать не может. Но это и не обязательно.
BIOS проверяет устройства, с которых может производиться загрузка. Порядок проверки в современных BIOS устанавливается. В список устройств могут входить Floppy disk, IDE disk, CDROM, SCSI disk…
Вне зависимости от типа устройства суть загрузки одна…
На устройстве обнаруживается boot sector. Для CDROM это не совсем справедливо, но про них пока не будем говорить. BootSector загружается в память по адресу 0:7с00. Дальнейшее поведение BootSector’а зависит от системы.
Загрузка Linux.
Для Linux свойственно два способа загрузки:
- Загрузка через boot sector ядра;
- Загрузка через boot manager LILO (Linux Loader);
Процесс загрузки через ядро используется обычно на Floppy дисках и происходит в следующем порядке:
- boot sector переписывает свой код по адресу 9000h:0;
- Загружает с диска Setup, который записан в нескольких последующих секторах, по адресу: 9000h:0200h;
- Загружает ядро по адресу 1000h:0. Ядро так же следует в последующих секторах за Setup. Ядро не может быть больше чем 508 килобайт, но так как оно, чаще всего, архивируется — это не страшно;
- Запускается Setup;
- Проверяется корректность Setup;
- Производится проверка оборудования средствами BIOS. Определяется размер памяти, инициализируется клавиатура и видеосистема, наличие жестких дисков, наличие шины MCA (Micro channel bus), PC/2 mouse, APM BIOS (Advanced power management);
- Производится переход в защищенный режим;
- Управление передается по адресу 1000h:0 на ядро;
- Если ядро архивировано, оно разархивируется. иначе просто переписывается по адресу 100000h (за пределы первого мегабайта);
- Управление передается по этому адресу;
- Активируется страничная адресация;
- Инициализируются idt и gdt, при этом в кодовый сегмент и в сегмент данных ядра входит вся виртуальная память;
- Инициализируются драйвера;
- Управление передается неуничтожимому процессу init;
- init запускает все остальные необходимые программы в соответствии с файлами конфигурации;
В случае загрузки через LILO:
- boot sector LILO переписывает свой код по адресу 9a00h:0;
- До адреса 9b00h:0 размещает свой стек;
- Загружает вторичный загрузчик по адресу 9b00h:0 и передает ему управление;
- Вторичный загрузчик загружает boot sector ядра по адресу 9000h:0;
- Загружает Setup по адресу 9000h:0200h;
- Загружает ядро по адресу 1000h:0;
- Управление передается программе Setup. Зачем загружает boot sector из ядра? не понятно;
В Linux есть такое понятие как «big kernel». Такой kernel сразу загружается по адресу 100000h.
Загрузка FreeBSD.
Принципиальных отличий для FreeBSD, конечно, нет. основное отличие состоит в том, что ядро, как и модули ядра являются перемещаемыми и могут быть загружены или выгружены в процессе загрузки системы.
Порядок загрузки примерно следующий:
- BootSector загружает вторичный загрузчик;
- Вторичный загрузчик переводит систему в защищенный режим и запускает loader;
- loader предоставляет пользователю возможность выбрать необходимые модули или запустить другое ядро;
- После чего управление передается ядру и начинается инициализация драйверов;
Давайте по порядку рассмотрим, как грузятся системы от Microsoft.
Загрузка DOS.
boot sector DOS загружает в память два файла: io.sys и msdos.sys. Названия этих файлов в разных версиях DOS различались, не важно. Файл io.sys содержит в себе функции прерывания int 21h, файл msdos.sys обрабатывает config.sys, и запускает командный интерпретатор command.com, который в свою очередь обрабатывает командный файл autoexec.bat.
Загрузка Windows 9x.
Отличие от DOS заключается в том, что функции msdos.sys взял на себя io.sys. msdos.sys остался ради совместимости как конфигурационный файл. После того как командный интерпретатор command.com обрабатывает autoexec.bat вызывается программа win.com, которая осуществляет перевод системы в защищенный режим, и запускает различные другие программы, обеспечивающие работу системы.
Загрузка Windows NT.
boot sector NT — зависти от формата FS, для FAT устанавливается один, для NTFS — другой, в нем содержиться код чтения FS, без обработки подкаталогов.
- boot sector загружает NTLDR из корневой директории, который запускается в real mode;
- NTLDR певодит систему в защищенный режим;
- Создаются необходимые таблицы страниц для доступа к первому мегабайту памяти;
- Активируется механизм страничного преобразования;
- Далее NTLDR читает файл boot.ini, для этого он использует встроенный read only код FS. В отличии от кода бутсектора он может читать подкаталоги;
- На экране выводится меню выбора вида загрузки;
- После выбора, или по истечении таймаута, NTLDR из файла boot.ini определяет нахождение системной директории Windows, она может находиться в другом разделе, но обязательно должна быть корневой;
- Если в boot.ini указана загрузка DOS (или Win9x), то файл bootsect.dos загружается в память и выполняется горячая перезагрузка;
- Далее обрабатывается boot.ini;
- Загружается ntdetect.com, который выводит сообщение «NTDETECT V4.0 Checking Hardware», и детектит различные устройства… Вся информация собирается во внешней структуре данных, которая в дальнейшем становиться ключем реестра «HKEY_LOCAL_MACHINEHARDWAREDESCRIPTION»;
- NTLDR выводит сообщение «OSLOADER V4.0»;
- Из директории winntsystem32 загружается ntoskrnl.exe, содержащий в себе ядро и подсистемы выполнения (менеджер памяти, кэш менеджер, менеджер объектов), и файл hal.dll, который содержит в себе интерфейс с аппаратным обеспечением;
- Далее NTLDR предоставляет возможность выбрать «последние известные хорошие» конфигурации. В зависимости от выбора выбираются копии реестра используемые для запуска;
- Загружает все драйвера и другие необходимые для загрузки файлы;
- В завершение он запускает функцию main из ntoskrnl.exe и завершает свою работу;
Не могу гарантировать полную достоверность представленной информации, NT я знаю плохо, тем более не знаю что у нее внутри. Так же не могу что-либо более конкретного сказать про распределение памяти в процессе загрузки Windows NT. некоторые неточности могут быть связаны с моим плохим знанием английского, желающие могут посмотреть на оригинал по адресу: Inside the Boot Process, Part 1
Узнали как загружаются системы? В своей системе не будем слепо следовать какому либо из представленных здесь путей. Ради совместимости обеспечим формат ядра, аналогичный Linux. В этой системе все сделано достаточно понятно и просто. Ориентируемся на Linux.
А в следующей главе поговорим о распределении памяти в системе и начнем писать свой boot sector.
Глава #4
Начнаем писать свой загрузочный сектор (boot sector). Сразу скажу, что в этом исходнике опытные люди не увидят ничего особенного, может быть даже наоборот, кому-то покажется что все можно было сделать гораздо лучше, не спорю. Я не очень старался. Про законченность говорить пока рано, это все еще неоднократно будет меняться.
boot sector загружается в память по адресу 0:7c00h и имеет длину 512 байт. Это не слишком много, поэтому возможности boot sector’a ограничиваются загрузкой какого либо вторичного загрузчика.
Наш boot sector, по образу и подобию linux, будет загружать в память два блока. Первым является тот самый вторичный загрузчик, у нас он, как и в linux, называется setup. Вторым является собственно ядро.
Этот boot sector служит для загрузки ядра с дискет, поэтому, на первых порах, он жестко привязан к диску «a:».
BIOS предоставляет возможность читать по нескольку секторов сразу, но не более чем до границы дорожки. Такая возможность, конечно, ускоряет чтение с диска, но представляет собой большие сложности в программировании, так как надо учитывать границы сегментов (в реальном режиме сегмент может быть не больше, чем 64к) и границы дорожек, получается достаточно хитрый алгоритм.
Пойдем немного другим путем. Читаем с диска по секторам. Это, конечно, медленнее, но здесь скорость не очень критична. За то это гораздо проще и компактнее реализуется.
А теперь давайте разбираться, как это все работает.
| Assembler | ||
|
Для начала описываем место и размер для каждого загружаемого блока.
Размеры пока произвольные, поскольку все остальное еще предстоит написать.
| Assembler | ||
|
boot sector загружается и запускается по адресу 0:7c00h Содержимое регистров при старте таково:
- cs содержит 0
- ip содержит 7с00h
Прерывания запрещены! Про содержание остальных регистров пока ничего не известно. Остальные регистры инициализируем самостоятельно.
| Assembler | ||
|
Стек у нас будет располагаться перед программой, до служебной области BIOS еще остается порядка 30 килобайт, для стека больше чем достаточно. Прерывания изначально запрещены, но я все равно сделаю это самостоятельно, на всякий случай. и разрешу после установки стека. Никаких проблем это вызвать, по-моему, не должно.
Так же, нулевым значением, инициализируем сегментный регистр ds.
| Assembler | ||
|
Чтобы все было красиво и радовало глаз, на время чтения отключаем курсор. Иначе он будет мелькать на экране. Чтобы его потом восстановить сохраним его форму в стеке.
| Assembler | ||
|
Загружаем первый блок (setup). Процедуру загрузки блока рассмотрим немного позже.
| Assembler | ||
|
Загружаем второй блок (kernel). Здесь все аналогично первому блоку.
| Assembler | ||
|
Восстанавливаем форму курсора.
| Assembler | ||
|
На этом работа boot sector’а заканчивается. Дальним переходом передаем управление программе setup.
Далее располагаются функции.
| Assembler | ||
|
Функция загрузки блока. Она же занимается выводом на экран процентного счетчика.
| Assembler | ||
|
В этой функции ничего сложного нет. Обыкновенный цикл.
А вот следующая функция загружает с диска отдельный сектор, при этом оперируя его линейным адресом.
Есть так называемое int13 extension, разработанное совместно фирмами MicroSoft и Intel. Это расширение BIOS работает почти аналогичным образом, Считывая сектора по их линейным адресам, но оно поддерживается не всеми BIOS, имеет несколько разновидностей и работает в основном для жестких дисков. Поэтому нам не подходит.
В своей работе ориентируемся пока только на чтение с floppy диска, размером 1,4 мегабайта. Поэтому будем использовать функцию, которой в качестве параметров задается номер дорожки, головки и сектора.
| Assembler | ||
|
Абсолютный номеp сектоpа вычисляется по фоpмуле:
AbsSectNo = (CylNo * SectPerTrack * Heads) + (HeadNo * SectPerTrack) + (SectNo — 1)
Значит обpатное спpаведливо:
CylNo = AbsSectNo / (SectPerTrack * Heads) HeadNo = остаток / SectorPerTrack SectNo = остаток + 1
| Assembler | ||
|
Поделив номер сектора на количество секторов на дорожке, в остатке получаем номер сектора на дорожке. Это значение хранится в 6 младших битах регистра cl.
| Assembler | ||
|
Номер диска храниться в dl и устанавливается в 0 (это диск a: )
| Assembler | ||
|
Младший бит частного определяет для нас номер головки. (0 или 1)
| Assembler | ||
|
Оставшиеся биты частного определяют номер цилиндра (или дорожки).
восемь младших бит номера хранятся в регистре ch, два старших бита номера хранятся в двух старших битах регистра cl.
| Assembler | ||
|
В случае ошибки чтения не будем возвращать из функции какие-либо результаты, а повторяем чтение, пока оно не окажется успешным. В случае неуспешного чтения все равно ничего не будет работать! Для верности, в случае сбоя, производим сброс устройства.
| Assembler | ||
|
Далее идет две интерфейсные функции, обеспечивающие вывод на экран строк и десятичных цифр. Ничего особенного они из себя не представляют а для вывода пользуются телетайпным прерыванием BIOS (ah = 0eh, int 10h), которое обеспечивает вывод одного символа с обработкой некоторых служебных кодов.
| Assembler | ||
|
Эта функция ограничена выводом чисел до 99 включительно, случай с большим числом обрабатывается как переполнение и отображается как ‘##’.
| Assembler | ||
|
Далее располагаются несколько служебных сообщений.
| Assembler | ||
|
Эта комбинация заполняет оставшееся место в секторе нулями. А остается у нас еще около 200 байт.
Последние два байта называются «Partition table signature», что не совсем корректно. Фактически эта сигнатура говорит BIOS’у о том, что этот сектор является загрузочным.
Этот boot sector, помимо того, что читает по секторам, отличается от линуксового еще и размещением в памяти. После загрузки он не перемещает себя в памяти, и работает по тому же адресу, по которому его загрузил BIOS. Так же setup загружается непосредственно следом за boot sector’ом, с адреса 7e00h, что в принципе не помешает ему работать в других адресах, если будем загружать наше ядро через LILO, например.
Скомпилированную версию boot sector’а вы можете найти в файловом архиве (секция «наработки»).
В следующей главе переходим к программе setup и рассматриваем порядок перехода в защищенный режим.
Глава #5
Рассмотрим немного подробнее организацию памяти в защищенном режиме и поговорим о концепциях защиты.
История организации памяти.
Ранние модели процессоров от Intel имели 16 бит шины данных и 20 бит шины адреса. Это налагало определенные ограничения на адресацию памяти, ибо 16-бинтный регистр невозможно было использовать для адресации более чем 64 килобайт памяти. Чтобы обойти это препятствие разработчики предусмотрели сегментные регистры. Сегментный регистр хранит в себе старшие 16 бит адреса и для получения полного адреса к сегментному адресу прибавляется смещение в сегменте.
| 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Сегмент | |||||||||||||||||||
| Смещение | |||||||||||||||||||
| Линейный адрес |
Таким образом, стало возможным адресовать до 1 мегабайта памяти. Это же позволило делать программы, не настолько привязанными к памяти и упростило адресацию. Сегменты могут начинаться с любого адреса, кратного 16 байтам, эти 16-байтные блоки памяти получили название параграфов. Но это и создает определенные неудобства. Первое неудобство состоит в том, что на один адрес памяти указывает 4096 различных комбинаций сегмент/смещение. Второе неудобство состоит в том, что нет возможности ограничить программам доступ к тем или иным частям памяти, что в некоторых случаях может быть существенно!
Введение защищенного режима решило эти проблемы, но ради совместимости любой из современных процессоров может работать в реальном или виртуальном режиме процессора i8086.
Защита.
Для обеспечения надежной работы операционных систем и прикладных программ разработчики процессоров предусмотрели в них механизмы защиты. В процессорах фирмы Intel предусмотрено четыре уровня привилегий для программ и данных. Нулевой уровень считается наиболее привилегированным, третий уровень — наименее.
Так же в защищенном режиме совсем иначе работает механизм преобразования адресов. в сегментном регистре теперь хранится не старшие биты адреса, а селектор. селектор представляет из себя индекс в таблице дескрипторов. И кроме этого содержит в себе несколько служебных бит. Формат селектора такой:
| 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Index | TI | RPL |
Поле Index определяет индекс в дескрипторной таблице.
В процессорах Intel одновременно в системе может существовать две дескрипторных таблицы: Глобальная (Global descriptor table или GDT) и Локальная (Local descriptor table или LDT).
GDT существует в единственном экземпляре. Адрес и предел GDT хранятся в специальном системном регистре (GDTR) в 48 бит длиной (6 байт).
LDT может быть индивидуальная для каждой задачи, или общая для системы, или же ее вообще может не быть. Адрес и размер LDT определяется в GDT, для обращения к LDT в процессоре существует специальный регистр (LDTR), но в отличии от GDTR он имеет размер 16 бит и содержит в себе селектор из GDT.
Поле TI (Table indicator) селектора определяет принадлежность селектора GDT (0) или LDT (1).
Поле RPL (Requested privilege level) определяет запрашиваемые привилегии.
Дескрипторы сегментов
Дескрипторные таблицы состоят из записей по 64 бита (8 байт) в каждой. Формат дескриптора таков:
| 7 | 6 | 5 | 4 |
| Базовый адрес 31-24 | Предел 19-16 | Права доступа | Базовый адрес 23-16 |
| 3 | 2 | 1 | 0 |
| Базовый адрес 15-0 | Предел 15-0 |
Сразу бросается в глаза очень странная организация дескриптора, но это связано с совместимостью с процессором i286, формат дескриптора в котором был таков:
| 7 | 6 | 5 | 4 |
| Зарезервировано | Права доступа | Базовый адрес 23-16 | |
| 3 | 2 | 1 | 0 |
| Базовый адрес 15-0 | Предел 15-0 |
Что же содержится в дескрипторе:
Базовый адрес — 32 бита (24 бита для i286). Определяет линейный адрес памяти, с которого начинается сегмент. В отличие от реального режима этот адрес может быть указан с точностью до байта.
Предел — 20 бит (16 бит для i286). Определяет размер сегмента (максимальный адрес, по которому может быть произведено обращение, это справедливо не всегда но об этом чуть позже). 20-битное поле может показаться не очень то большим для 32-х битного процессора, но это не так. Оно не всегда показывает размер в байтах. Но и об этом чуть позже.
Байт прав доступа:
- Бит P (present) — Указывает на присутствие сегмента в памяти. обращение к отсутствующему сегменту вызывает особый случай не присутствия сегмента в памяти.
- Двух битное поле DPL определяет уровень привилегий сегмента. Про Уровни привилегий поговорим чуть позже.
- Бит S (Segment)- Будучи установленным в 1, определяет сегмент памяти, к которому может быть получен доступ на чтение (запись) или выполнение.
- Три бита Type — в зависимости от бита S определяет либо возможности чтения/записи, выполнения сегмента или определяет тип системных данных, хранимых в селекторе. Подробнее это выглядит так:
Если бит S установлен в 1, то поле Type делится на биты:2 1 0 1 — код Подчиненный сегмент кода Допустимо считывание 0 — данные Расширяется вниз Допустима запись Если сегмент расширяется вниз (это используется для стековых сегментов) то поле предела показывает адрес, выше которого допустима запись. ниже запись недопустима и вызовет нарушение пределов сегмента.
- Бит А (Accessed) устанавливается в 1, если к сегменту производилось обращение.
Если бит S установлен в 0, то в сегменте находится служебная информация определяемая полем Typе и битом A.
| TYPE | A | Описание |
|---|---|---|
| 000 | 1 | TSS для i286 |
| 001 | 0 | LDT |
| 001 | 1 | Занятый TSS для i286 |
| 010 | 0 | Шлюз вызова i286 |
| 010 | 1 | Шлюз задачи |
| 011 | 0 | Шлюз прерывания i286 |
| 011 | 1 | Шлюз исключения i286 |
| 100 | 1 | TSS для i386 |
| 101 | 1 | Занятый TSS i386 |
| 110 | 0 | Шлюз вызова i386 |
| 111 | 0 | Шлюз прерывания i386 |
| 111 | 1 | Шлюз ловушки i386 |
Остальные комбинации либо недопустимы, либо зарезервированы.
TSS — это сегмент состояния задачи (Task state segment) о них поговорим в следующей главе.
Шестой байт дескриптора, помимо старших бит предела, содержит в себе несколько битовых полей.
- Бит G (Granularity) — определяет размер элементов, в которых измеряется предел. если 0 — предел в байтах, если 1 — размер в страницах.
- Бит D (Default size) — размер операндов в сегменте. Если 0 — 16 бит. если 1 — 32 бита.
- Бит U (User) — доступен для пользователя (вернее для программиста операционной системы)
И снова защита.
Немного терминологии:
Уровень привилегий может быть от 0(высший) до 3(низший). Следовательно повышение уровня привилегий соответствует его уменьшению в численном эквиваленте, понижение — наоборот.
В дескрипторе содержатся биты DPL, которые определяют максимальный уровень привелегий для доступа к сегменту.
В селекторе содержится RPL — то есть запрашиваемый уровень привилегий.
RPL секущего кодового сегмента (хранится в регистре cs) является уровнем привилегий данного процесса и называется текущим уровнем привилегий (CPL)
Прямые обращения к сегментам возможны при соблюдении следующих условий:
- В случае если запрашиваемый уровень привилегий больше текущего, то запрашиваемый уровень понижается до текущего.
- При обращении к сегменту данных RPL селектора должен быть не ниже DPL сегмента.
- При обращении к сегменту кода возможно только при равенстве CPL, RPL и DPL.
- Если сегмент кода помечен как подчиненный, то для обращения к нему необходимо иметь уровень привилегий не ниже уровня сегмента. При этом выполнение сегмента происходит с текущим уровнем привилегий.
Косвенные вызовы возможны только через шлюзы при соблюдении следующих условий:
- DPL шлюза должен быть не выше, чем CPL сегмента, из которого производится вызов шлюза.
- DPL сегмента, на который указывает шлюз, должно быть не ниже чем DPL шлюза.
Эпилог.
Тема конечно очень сложна для понимания. В следующих главах концентрируем внимание на таких моментах. Интересующиеся люди могут почитать дополнительную, более подробную информацию по защите в литературе по микропроцессорам фирмы Intel.
Глава #6
В этой главе продолжим разговор о защищенном режиме процессора, узнаете, что такое шлюзы. А так же вкратце поговорим о виртуальном режиме процессора 8086.
В 4-ой главе, когда я расписывал вам, как писать boot sector, я допустил одну достаточно серьезную ошибку, которую признаю и благодарю Bug Maker’а, за то, что обратил на это мое внимание. В процедуре load_sector я, первым делом, делю номер сектора на количество секторов на дорожке. Для деления используя беззнаковую команду div, предварительно расширяя ax в dx:ax знаковой командой cwd. Правда если учесть что максимальное количество секторов на гибком диске не превышает 2880, то старший, знаковый, бит ax всегда нулевой. Но, тем не менее, ошибка потенциальная. Этот фрагмент кода стоит писать так:
| Assembler | ||
|
Исправившись, я вообще убрал команду cwd, и теперь делю на байт cl. Все это, к тому же, сэкономило мне два байта.
Но это еще не все.. при написании boot sector’а я говорил, что это совсем не окончательная версия. Так оно и получается. Из бутсектора мы уберем код загрузки kernel. Этим будет заниматься программа setup. Следовательно, boot sector’у осанется только считать setup и запусить его… Даже если сделать более корректную обработку ошибок чтения, у нас остается около 250 байт на всякие развлечения…
А setup должен будет уметь достаточно многое. В него будет встроена поддержка файловой системы, поддержка выполняемых форматов файлов. Мы собираемся делать микроядро, и setup’у придется загружать помимо ядра еще несколько дополнительных программ, которые понадобятся нам для нормального старта системы.
Но об этом позже. А теперь продолжаем разбираться с защищенным режимом.
Шлюзы
В предыдущей главе, когда говорили о дескрипторах и дескрипторных таблицах ни словом не упомянули о дескрипторной таблице прерываний (Interrupt description table или IDT). Эта таблица так же состоит из дескрипторов, но в отличии от LDT и GDT в этой таблице могут размечаться только шлюзы. В защищенном режиме все прерывания происходят через IDT. Традиционная таблица векторов прерываний здесь не используется.
Формат дескрипторов шлюзов отличается от дескриптора сегмента.
Для начала рассмотрим шлюз вызова.
| 7 | 6 | 5 | 4 |
| Смещение 31-16 | Права доступа | Количество слов стека | |
| 3 | 2 | 1 | 0 |
| Селектор | Смещение 15-0 |
В поле прав доступа задается уровень привилегий, который должен быть ниже CPL текущего процесса, бит присутствия и соответствующий тип в остальных полях.
Селектор и смещение задают адрес вызываемой функции, при этом селектор должен присутствовать либо в GDT либо в активной LDT.
Параметр «Количество слов стека» служит для передачи аргументов в вызываемую функцию, при этом соответствующее количество слов копируется из стека текущего уровня привилегий в стек уровня привилегий вызываемой функции. Это поле использует только младшие 5 бит четвертого байта. Остальные биты должны быть нулевыми.
Обращаться к такому шлюзу, если дескриптор не расположен в IDT, можно только командой call far, при этом указываемое в команде смещение игнорируется. А селектор должен указывать на дескриптор шлюза вызова.
Шлюз прерывания и шлюз ловушки имеют одинаковый формат, отличаются между собой типами в байте прав доступа. В отличии от шлюза вызова эти шлюзы не содержат в себе Количества слов стека, поскольку прерывания бывают аппаратными и передача в них параметров через стек — бессмысленна. Эти шлюзы используются обычно только в IDT.
Шлюз задачи содержит в себе значительно меньше информации.
Во втором и третьем байте дескриптора записывается селектор TSS (Сегмента состояния задачи). Поле прав доступа заполняется аналогично другим шлюзам, но с соответствующим типом. Остальные поля дескриптора не используются.
При вызове такого шлюза происходит переключение контекста задачи. При этом вызывающая задача блокируется и не может быть вызвана до тех пор, пока вызванная задача не вернет ей управление командой iret.
Про правила доступа к шлюзам я говорил в прошлой главе, и в этот раз я закончу на этом. в следующей главе расскажу про прерывания более подробно.
Виртуальный режим процессора 8086.
Для возможности запуска из защищенного режима программ, предназначенных для реального, существует так называемый «Виртуальный режим процессора 8086». При этом полноценно работают механизмы преобразования адресов защищенного режима. А так же многозадачные системы, которые могут одновременно выполнять как защищенные задачи, так и виртуальные. При этом адресация в виртуальной задаче осуществляется традиционным для 8086 методом — сегмент/смещение.
Обращение к прерываниям осуществляется через IDT, но таблица прерываний реального режима может быть обработана из функций, шлюзы которых размещаются в IDT.
Обращение виртуальной задачи к портам так же может быть отслежено через прерывания защищенного режима. При обращении к запрещенным портам происходит исключение.
При желании может быть обеспечена абсолютно прозрачная работа нескольких виртуальных задач в одной мультизадачной среде. Но мы этой возможностью не будем пользоваться, и в своей работе будем рассчитывать на программы исключительно защищенного режима.
Глава #7
Исключения защищенного режима
Исключения или системные прерывания существовали еще в самых первых моделях процессоров от Intel. Вот их список:
| 0 | Division by zero (деление на ноль или переполнение при делении); |
| 1 | Single step (пошаговая отладка); |
| 3 | Breakpoint; |
| 4 | Overflow (срабатывает при команде into в случае установленного флага overflow в регистре flags); |
| 6 | Invalid opcode (i286+); |
| 7 | No math chip; |
Исключения располагаются в начале таблицы прерываний. В реальном режиме занимают 8 первых векторов прерываний.
Введение защищенного режима потребовало введения дополнительных исключений. В защищенном режиме первые 32 вектора прерываний зарезервированы для исключений. Не все они используются в существующих процессорах, в будующем возможно их будет больше. Системные прерывания в защищенном режиме делятся на три типа: нарушения (fault), ловушки (trap) и аварии (abort). Итак в защищенном режиме у нас существуют следующие исключения:
| 0 | Divide error | fault |
| 1 | Debug | fault/trap |
| 3 | Breakpoint | trap |
| 4 | Overflow | trap |
| 5 | Bounds check | fault |
| 6 | Invalid opcode | fault |
| 7 | Coprocessor not available | fault |
| 8 | Double fault | abort |
| 9 | Coprocessor segment overrun | fault |
| 10 | Invalid tss | fault |
| 11 | Segment not present | fault |
| 12 | Stack fault | fault |
| 13 | General protection fault | fault |
| 14 | Page fault | fault |
| 16 | Coprocessor error | fault |
| 17 | Alignument check | fault (i486+); |
| 18 | Hardware check | abort (Pentium+); |
| 19 | SIMD | fault (Pentium III+) |
.
Нарушения возникают вследствии несанкционированных или неправильных действий программы, предполагается, что ошибки можно исправить и продолжить выполнение программы с инструкции, которая вызвала ошибку.
Ловушки возникают после выполнения инструкции, но тоже подразумевают исправление ошибочной ситуации и дальнейшую работу программы.
Аварии возникают в случае критических нарушений, после этого программа уже не может быть перезапущена и должна быть закрыта.
Но иногда в случае ошибки или ловушки программа тем не менее не может продолжить свое выполнение. Это зависит от тяжести нарушения и от организации операционной системы, которая обрабатывает исключения. И если ошибка или ловушка не может быть исправлена, программу так же следует закрыть.
При возникновении исключения процессор иногда помещает в стек код ошибки, по которому обработчик исключения может проанализировать и, возможно, исправить возникшую ошибку.
Все исключения обрабатываются операционной системой. В случае микроядерных систем этим занимается микроядро.
Микроядерные системы
В первых главах уже касались этой темы, но тогда ограничились буквально несколькими словами. Теперь двигаемся именно в сторону микроядерности, значит стоит поподробнее рассказать, что это такое.
Принцип микроядерности заключается в том, что ядро практически не выполняет операций, связанных с обслуживанием внешних устройств. Эту функцию выполняют специальные программы-сервера. Ядро лишь предоставляет им возможность обращаться к устройствам. Помимо этого ядро обеспечивает многозадачность (параллельное выполнение программных потоков), межпроцессное взаимодействие и менеджмент памяти.
Приложения (как и сервера) у нас работают на третьем, непривилегированном кольце и не могут свободно обращаться к портам ввода/вывода или dma памяти. Тем более не могут сами устанавливать свои обработчики прерываний. Для использования ресурсов процессы обращаются к ядру с просьбой выделить необходимые ресурсы в их распоряжение. Осуществляется это следующим образом:
Для обеспечения доступа к портам ввода/вывода используются возможности процессоров, впервые появившиеся intel 80386. У каждой задачи (в сегменте состояния задачи (TSS)) существует карта доступности портов ввода/вывода. Приложение обращается к ядру с «просьбой» зарегистрировать для нее диапазон портов. Если эти порты до тех пор никем не были заняты, то ядро предоставляет их в распоряжение процесса, помечая их как доступные в карте доступности ввода/вывода этого процесса.
DMA память, опять таки после запроса у ядра, с помощью страничного преобразования подключается к адресному пространству процесса. Настройка каналов осуществляется ядром по «просьбе» процесса.
Доступ к аппаратным прерываниям (IRQ) осуществляется сложнее. Для этого процесс порождает в себе поток (thread), и сообщает ядру, что этот поток будет обрабатывать какое-то IRQ. При возникновении аппаратного прерывания, которое обрабатывает всетаки ядро, данный процесс выходит из состояния спячки, в котором он находился в ожидании прерывания, и ставится в очередь к менеджеру процессов. Такие потоки должны иметь более высокий приоритет, чем все остальные, дабы вызываться как можно скорее.
Но, как я говорил, ядро выполняет еще некоторые функции, немаловажная из которых — это межпроцессное взаимодействие. Оно представляет из себя возможность процессов обмениваться сообщениями между собой. В отличии от монолитных систем в микроядерных системах межпроцессное взаимодействие (Inter Process Communication или IPC) это едва ли не основное средство общения между процессами, и поскольку все драйвера у нас такие же процессы, микроядерное IPC должно быть очень быстрым. Быстродействие IPC достигается за счет передачи сообщений без промежуточного буферизирования в ядре. Либо непосредственным переписыванием процессу-получателю, либо с помощью маппинга страниц (если сообщения большого размера).
Менеджер памяти имеет как бы две стороны. Первая сторона — внутренняя, распределение памяти между приложениями, организация свопинга (который тоже осуществляется не ядром непосредственно, а специальной программой-сервером) никаким образом не интересует остальные программы. Но другая сторона — внешняя служит именно для них. Программы могут запросить у ядра во временное пользование некоторое количество памяти, которое ядро им обязательно предоставит (в разумных пределах… гигабайта два… не больше… . Или же программы могут запросить у ядра какой-то определенный участок памяти. Это бывает необходимо программам-серверам. И это требование ядром также вполне может быть удовлетворено при условии, что никакая другая программа до того не забронировала этот участок памяти для себя.
Глава #8
В этой главе поговорим о файловых системах.
Файловая система — это немаловажный момент в операционной системе, они бывают разные, различаются по производительности, надежности, по-разному экономно используют пространство.
Есть много файловых систем, которые нам, в принципе, подойдут (EXT2FS, FFS, NTFS, RaiserFS и много других), есть так же файловые системы, которые нам вообще не подойдут (FAT). В процессе развития нашей операционной системы мы создадим поддержку и для них, но для начала надо остановиться на чем-то одном. Этой одной файловой системой будет EXT2FS.
В этой главе подробно рассмотрим файловые системы FAT, и более подробно файловую систему Linux (ext2). Поскольку наша операционная система будет юниксоподобная, то файловые системы FAT нам никак не подходят, поскольку они не обеспечивают мер ограничения доступа, и по сути своей не являются многопользовательскими. Про остальные файловые системы я ограничусь лишь основными моментами.
Так же я не стану затрагивать тему разделов диска. Обсудим это в другой раз.
Основные принципы файловых систем
Все устройства блочного доступа (к которым относятся жесткие или гибкие диски, компакт диски) при чтении/записи информации оперируют секторами. Для жестких или гибких дисков размер сектора равен 512 байт, в компакт-дисках размер сектора равен 2048 байт. Сектора являются физической единицей информации для носителя.
Для файловых систем такое распределение часто бывает не очень удобно, и в них вводится понятие кластера. Кластеры часто бывают больше по размеру, чем сектора носителя. Кластеры являются логической единицей файловых систем. Правда, не всегда они называются кластерами. В ext2 кластеры называются просто блоками, но это не столь важно. Для организации кластеров файловые системы хранят таблицы кластеров. Таблицы кластеров, естественно, расходуют дисковое пространство. Помимо этого, дополнительное дисковое пространство расходуется под каталоги файлов. Эти неизбежные расходы в разных файловых системах имеют разную величину. Но об этом мы поговорим ниже.
Файловые системы на базе FAT (File Allocation Table)
Этот тип файловых систем разработала фирма Microsoft достаточно давно. Вместе с первыми DOS… С тех пор неоднократно натыкались на различные препятствия и дорабатывались в соответствии с требованиями времени.
Теперь пойдет небольшой экскурс в историю.
- В 1977 году Биллом Гейтсом и Марком МакДональдом была разработана первая файловая система FAT. Ради совместимости с CP/M в ней было ограничено имя файла. Максимальная длина имени составляла 8 символов, и 3 символа можно было использовать для расширения файла. Регистр букв не различался и не сохранялся. Размер кластера не превышал 4 килобайта. Размер диска не мог превышать 16 мегабайт.
- В 1981 году вышла первая версия MSDOS, которая базировалась на FAT.
- Начиная с MSDOS версии 3.0, в файловой системе появилось понятие каталога.
- Для поддержки разделов более 16 мегабайт размер элемента FAT был увеличен до 16 бит, (первая версия была 12-битная) а максимальный размер кластера увеличен до 32 килобайт. Это позволило создавать разделы до 2 гигабайт.
- В таком состоянии FAT просуществовал до появления VFAT, появившегося вместе с выходом Windows’95, в которой появилась поддержка длинных имен файлов. Теперь имя файлов могло иметь длину до 255 символов, но ради совместимости старый формат имен так же остался существовать.
- Немного позже FAT был еще расширен, размер элемента FAT стал 32 бита, при этом максимальный размер кластера вновь уменьшился до 4 килобайт, но это позволило создавать разделы до 2 терабайт. Кроме того, была расширена информация о файлах. Теперь она позволяли хранить помимо времени создания файла время модификации и время последнего обращения к файлу.
Ну а теперь подробнее рассмотрим структуру этой файловой системы.
Общий формат файловой системы на базе FAT таков:
- Boot sector (в нем так же содержится «Блок параметров FS»)
- Reserved Sectors (могут отсутствовать)
- FAT (Таблица размещения файлов)
- FAT (вторая копия таблицы размещения файлов, может отсутствовать)
- Root directory (корневая директория)
- Область файлов. (Кластеры файловой системы)
Boot sector имеет размер 512 байт, как мы уже знаем, может содержать в себе загрузчик системы, но помимо этого для FAT он содержит Блок параметров. Блок параметров размещается в boot sector’е по смещению 0x0b и содержит в себе следующую информацию:
| C | ||
|
Размер кластера можно вычислить, умножив Sector_Size на Sectors_Per_Cluster.
Общий размер диска определяется следующим образом: Если значение Total_Sectors равно 0, то раздел более 32 мегабайт и его длина в секторах храниться в Big_Total_Sectors. Иначе размер раздела показан в Total_Sectors.
Таблица FAT начинается с сектора, номер которого храниться в Reserved_Sectors и имеет длину Sectors_Per_FAT; при 16-битном FAT размер таблицы может составлять до 132 килобайт (или 256 секторов) (в FAT12 до 12 килобайт).
Вторая копия FAT служит для надежности системы… но может отсутствовать.
После таблицы FAT следует корневая директория диска. Размер этой директории ограничен Root_Entries записями. Формат записи в директории таков:
| C | ||
|
Размер записи — 32 байта, следовательно, общий размер корневой директории можно вычислить, умножив Root_Entries на 32.
Далее на диске следуют кластеры файловой системы. Из записи в директории берется первый номер кластера, с него начинается файл. В FAT под этим номером может содержаться либо код последнего кластера (0xffff или 0xfff для FAT12) либо номер кластера, следующего за этим.
При записи файла из FAT выбираются свободные кластеры по порядку от начала. В результате возникает фрагментация файловой системы, и существенно замедляется ее работа. Но это уже выходит за тему рассылки.
Все выше сказанное про FAT справедливо для FAT12 и FAT16. FAT32 более существенно отличается, но общие принципы организации для нее примерно такие же. VFAT ничем не отличается от FAT16, для хранения длинных имен там используется однеа запись в директории для хранения короткого имени файла и несколько записей для хранения длинного. Длинное имя храниться в unicode, и на запись в директории приходится 13 символов длинного имени, причем они разбросаны по некоторым полям записи, остальные поля заполняются с таким расчетом, чтобы старые программы не реагировали на такую запись.
С первого взгляда видна не высокая производительность таких файловых систем. Не буду поливать грязью Microsoft, у них и без меня достаточно проблем… К тому же и у них есть другие разработки, которые не столь плохи. Но о них мы поговорим ниже… А сейчас давайте посмотрим на ext2fs. Правда, эта файловая система несколько другого уровня, и сравнивать ее с FAT — нельзя. Но обо всем по порядку.
Ext2fs (Расширенная файловая система версия 2)
Linux разрабатывался на операционной системе Minix. В ней была (да и есть) файловая система minixfs. Система не очень гибкая и достаточно ограниченная. После появления Linux была разработана (на базе minixfs) файловая система extfs, которую в скором времени заменила ext2fs, которая и используется в большинстве Linux, по сей день.
Для начала давайте рассмотрим основное устройство этой файловой системы:
- Boot sector (1 сектор)
- Свободно (1 сектор, может быть использован для расширения Boot sector’а до килобайта)
- Super block (2 сектора или 1024 байта длиной)
- Group descriptors (2 сектора максимум)
- Group 1
- Group 2
- … и так далее… до Group 32 если необходимо
.Если ext2fs находится на каком ни будь разделе жесткого диска, или является не загрузочной, то boot sector’а там может вообще не быть.
Super block содержит в себе информацию о файловой системе и имеет следующий формат:
| C | ||
|
Не буду описывать значение всех полей этой структуры, ограничусь основными. Размер блока файловой системы можно вычислить так: 1024 * s_log_block_size. Размер блока может быть 1, 2 или 4 килобайта размером.
Об остальных полях чуть попозже.
А теперь рассмотрим группы дескрипторов файловой системы.
Формат дескриптора группы таков:
| C | ||
|
Содержимое группы таково:
- Block bitmap (Битовая карта занятости блоков)
- Inode bitmap (Битовая карта занятости inode)
- Inode table (Таблица inode)
- Available blocks (блоки, доступные для размещения файлов)
Блоки в файловой системе отсчитываются с начала раздела. В дескрипторе группы содержаться номер блока с битовой картой блоков группы, номер блока с битовой картой инодов, и номер блока с которого начинается таблица inode. Про inode мы поговорим чуть попозже, а сперва разберемся с битовыми картами.
В суперблоке храниться количество блоков в группе (s_blocks_per_group). Битовая карта имеет соответствующий размер в битах (занимает она не более блока). и в зависимости от размера блока может содержать информацию об использовании 8, 32 или 132 мегабайт максимум. Дисковое пространство раздела разбивается на группы в соответствии с этими значениями. А групп, как я уже упоминал, может быть до 32… что позволяет создавать разделы, в зависимости от размера блока, 256, 1024 или 4096 мегабайт соответственно.
В битовую карту блоков группы входят так же те блоки, которые используются под саму карту, под карту inode и под таблицу inode. Они сразу помечаются как занятые.
Теперь давайте разберемся, что такое inode. В отличии от FAT информация о файле здесь храниться не в директории, а в специальной структуре, которая носит название inode (информационный узел). В записи директории содержится только адрес inode и имя файла. При этом на один inode могут ссылаться несколько записей директории. Это называется hard link.
Формат inode таков:
| C | ||
|
Как видно из приведенной выше структуры в inode содержится следующая информация:
- Тип и права доступа файла (i_mode)
- идентификатор хозяина файла (i_uid)
- Размер (i_size)
- Время доступа, создания, модификации и удаления файла (после удаления inode не удаляется, а просто перестает занимать блоки файловой системы)
- Идентификатор группы
- Количество записей в директориях, указывающих на этот inode…
- Количество занимаемых блоков fs
- дополнительные флаги ext2fs
- таблица занимаемых блоков
- Ну и другая, не столь существенная в данных момент информация.
Остановимся поподробнее на таблице занимаемых блоков. Как видите там всего 14 записей. Но 14 блоков — это мало для одного файла. Дело в том, что не все записи содержат номера блоков. 13-я запись содержит косвенный блок, то есть блок, в котором содержится таблица блоков. А 14-я запись содержит номер блока в котором содержится таблица номеров блоков, в которых содержаться таблицы блоков занимаемых файлом… так что размер файла практически ничто не ограничивает.
Первые 10 inode зарезервированы для специфического использования.
Для корневой директории в этой файловой системе не отводится заранее отведенного места. Любая, в том числе и корневая директория в этой файловой системе является по сути своей обыкновенным файлом. Но для облегчения поиска корневой директории для нее зарезервирован inode номер 2.
В этой файловой системе в отличие от FAT существуют методы защиты файлов, которые обеспечиваются указанием идентификаторов пользователя и группы, а так же правами доступа, которые указываются в inode в поле i_mode.
За счет нескольких групп блоков уменьшается перемещение головки носителя при обращении к файлам, что увеличивает скорость обращения и уменьшает износ носителя. Да и сама файловая система организована так, что для чтения файлов не требуется загрузка больших объемов служебной информации, Что тоже не может не сказаться на производительности.
Примерно так же устроены файловые системы FFS, HPFS, NTFS. Но в их устройство я не буду вдаваться. И так уже глава очень большой получается.
Но в недавнее время появился еще один тип файловых систем. Эти системы унаследовали некоторые черты от баз данных и получили общее название «Журналируемые файловые системы». Особенность их заключается в том что все действия, производимые в файловой системе фиксируются в журнале, который правда съедает некоторый объем диска, но это позволяет значительно повысит надежность систем. В случае сбоя проверяется состояние файловой системы и сверяется с записями в журнале. В случае обнаружения несоответствий довести операцию до конца не составляет проблем, и отпадает необходимость в ремонте файловой системы. К таким файловым системам относятся ext3fs, RaiserFS и еще некоторые.
Глава #9
Эта глава посвящена чтению файлов с файловой системы ext2fs. Эту систему мы, скорее всего, возьмем за базовую для начала. FAT для наших целей мало подходит. Тот boot sector, который публиковался до этого — можно забыть, от него уже почти ничего не осталось. Связано это с тем, что мы отошли от linux, наша система будет совсем другой. Я, конечно, предвижу трудности связанные с переносом программного обеспечения. Возможно продумаем возможность эмуляции существующих операционных систем. Время покажет.
Так же прошу меня простить, что мы занимаемся тут всякой ерундой с бутсекторами и файловыми системами, но до сих пор так и не начали писать собственно ядро. Задача эта не столь, тривиальна и нужно многое продумать, чтобы не было потом горько и обидно за бесцельно написанный код.
Чтение ext2fs
В предыдущей главе описывалась структура этой файловой системы. В файловой системе присутствует Super Block и дескрипторы групп. Эта информация хранится в начале раздела. Super Block во 2-м килобайте, дескрипторы групп — в третьем.
Первый килобайт для нужд файловой системы не используется и может быть целиком использован для boot sector’а (правда он уже будет не сектор, а килобайт . Но для этого следует подгрузить второй сектор boot’а.
А для инициализации файловой системы нам нужно загрузить super block и дескрипторы групп, они же понадобятся нам для работы с файловой системой.
Это все можно загрузить одновременно, как мы и сделаем.
| Assembler | ||
|
Для этого мы используем уже знакомую процедуру загрузки блока, но эта процедура станет значительно короче, потому что никаких процентов мы больше не будем выводить.
В es засылается адрес, следующий за загруженным загрузочным сектором (Загружается он, как мы помним, по адресу 7c00h, и имеет длину 200h байт, следовательно свободная память начинается с адреса 7e00h, а сегмент для этого адреса равен 7e0h). В ax засылается номер сектора с которого начинается блок (в нашем случае это первый сектор, загрузочный сектор является нулевым). в cx засылается длина загружаемых данных в секторах (1 — дополнительная часть boot sector’а, 2 — Super Block ext2, 2 — дескрипторы групп. Всего 5 секторов).
Теперь вызовем процедуру инициализации файловой системы. Эта процедура достаточно проста, и проверяет только соответствие magic номера файловой системы и вычисляет размеры блока для работы.
| Assembler | ||
|
В случае несоответствия magic номера происходит вывод сообщения об ошибке и выход из подпрограммы. Чтобы сигнализировать об ошибке используется бит C регистра flags.
| Assembler | ||
|
Все эти значения нам понадобятся для работы. А теперь рассмотрим процедуру загрузки одного блока файловой системы.
| Assembler | ||
|
При входе в эту процедуру ax содержит номер блока (блоки нумеруются с нуля), es содержит адрес памяти для загрузки содержимого блока.
Номер блока нам надо преобразовать в номер сектора, для этого мы умножаем его на длину блока в секторах. А в cx у нас уже записана длина блока в секторах, то есть все готово для вызова процедуры load_block.
После считывания блока мы модифицируем регистр es, чтобы последующие блоки грузить следом за этим… в принципе модифицирование указателя можно перенести в другое место, в процедуру загрузки файла, это будет наверное даже проще и компактнее, но сразу я об этом не подумал. 
Но пошли дальше… основной структурой описывающей файл в ext2fs является inode. Inode хранятся в таблицах, по одной таблице на каждую группу. Количество inode в группе зафиксировано в супер блоке. Итак, процедура загрузки inode:
| Assembler | ||
|
Поделив номер inode на количество inode в группе, в ax мы получаем номер группы, в которой находится inode, в dx получаем номер inode в группе.
| Assembler | ||
|
ax умножаем на размер записи о группе (делается это сдвигом, но, по сути, то же самое умножение) и получаем смещение группы в таблице дескрипторов групп. gd — базовый адрес таблицы групп. Последняя операция извлекает из дескриптора группы адрес таблицы inode этой группы (адрес задается в блоках файловой системы) который у нас пока будет храниться в bx.
| Assembler | ||
|
Теперь разберемся с inode. Определим его смещение в таблице inode группы.
| Assembler | ||
|
Поделив это значение на размер блока мы получим номер блока относительно начала таблицы inode (ax), и смещение inode в блоке (dx). К номеру блока (bx) прибавим блок, в котором находится inode.
| Assembler | ||
|
Загрузим этот блок в память.
| Assembler | ||
|
Восстановим содержимое сегментного регистра es и перепишем inode из блока в отведенное для него место.
| Assembler | ||
|
Inode загружен. Теперь по нему можно загружать файл. Здесь все не столь однозначно. Процедура загрузки файла состоит из нескольких модулей. Потому что помимо прямых ссылок inode может содержать косвенные ссылки на блоки. В принципе можно ограничить возможности считывающей подпрограммы необходимым минимумом, полная поддержка обеспечивает загрузку файлов до 4 гигабайт размером. Естественно в реальном режиме мы такими файлами оперировать не сможем, да это и не нужно. Но сейчас мы рассмотрим полную поддержку:
| Assembler | ||
|
В inode хранятся прямые ссылки на 12 блоков файловой системы. Такие блоки мы загружаем с помощью процедуры dir_blocks (она будет описана ниже). Данный этап может загрузить максимум 12/24/48 килобайт файла (в зависимости от размера блока fs 1/2/4 килобайта). После окончания работы процедуры проверяем, все ли содержимое файла уже загружено или еще нет. Если нет, то загрузка продолжается по косвенной таблице блоков. Косвенная таблица — это отдельный блок в файловой системе, который содержит в себе таблицу блоков.
| Assembler | ||
|
В inode только одна косвенная таблица первого уровня (cx=1). Для загрузки блоков из такой таблицы мы используем процедуру idir_blocks. Это позволяет нам, в зависимости от размера блока загрузить 268/1048/4144 килобайта файла. Если файл еще не загружен до конца, то используется косвенная таблица второго уровня.
| Assembler | ||
|
В inode также только одна косвенная таблица второго уровня (cx=1). Для загрузки блоков из такой таблицы мы используем процедуру ddir_blocks. Это позволяет нам, в зависимости от размера блока загрузить 64.2/513/4100 мегабайт файла. Если файл опять не загружен до конца (где же столько памяти взять??), то используется косвенная таблица третьего уровня. Ради этого мы уже не будем вызывать подпрограмм, а обработаем ее в этой процедуре.
| Assembler | ||
|
В inode и эта таблица присутствует только в одном экземпляре (куда же больше?). Это, крайняя возможность, позволяет нам, в зависимости от размера блока, загрузить 16/256.5/4100 гигабайт файла. Что уже является пределом даже для размера файловой системы (4 терабайта).
| Assembler | ||
|
Конечно, такие крайности нам при старте будут не к чему, с учетом, что мы находимся в реальном режиме и не можем адресовать больше ~600к памяти.
Кратко рассмотрю вспомогательные функции:
| Assembler | ||
|
Эта функция загружает прямые блоки. Ради простоты я пока не обрабатывал блоки номер которых превышает 16 бит. Это создает ограничение на размер файловой системы в 65 мегабайт, а реально еще меньше, поскольку load_block у нас тоже не оперирует с секторами, номер которых больше 16 бит, ограничение по размеру уменьшается до 32 мегабайт. В дальнейшем эти ограничения мы конечно обойдем, а пока достаточно.
В этой функции стоит проверка количества загруженных блоков, для того чтобы вовремя выйти из процедуры считывания.
| Assembler | ||
|
Эта функция обращается в свою очередь к функции dir_blocks, предварительно загрузив в память содержимое косвенного блока. так же имеет контроль длины файла.
Функция ddir_blocks в точности аналогична этой, только для считывания вызывает не dir_blocks, а idir_blocks, поскольку адреса блоков в ней дважды косвенны.
Но мы еще не рассмотрели самого главного. Процедуры, которая по пути файла может загрузить его с диска. Начнем.
| Assembler | ||
|
Если путь файла не начинается со слэш, то это в данном случае является ошибкой. Мы не оперируем понятием текущий каталог!
| Assembler | ||
|
Загружаем корневой inode — он имеет номер 2.
| Assembler | ||
|
Уберем лидирующий слэш… или несколько слэшей, такое не является ошибкой.
| Assembler | ||
|
Загрузим содержимое файла. Директории, в том числе и корневая, являются такими же файлами, как и все остальные, только содержат в себе записи о находящихся в директории файлах.
| Assembler | ||
|
По inode установим тип файла.
Если файл не регулярный, то это может быть директорией. Это проконтролируем ниже.
| Assembler | ||
|
Если это файл, который нам надлежит скачать — то в [si] будет содержаться 0, означающий что мы обработали весь путь.
| Assembler | ||
|
А поскольку содержимое файла уже загружено, то можем со спокойной совестью вернуть управление. Битом C сообщив, что все закончилось хорошо.
| Assembler | ||
|
Если этот inode не является директорией, то это или не поддерживаемый тип файла или ошибка в пути.
| Assembler | ||
|
Если то, что мы загрузили, является директорией, то со смещения 0 (bx) в этом файле содержится список записей о файлах. Нам нужно выбрать среди них нужную. В dx сохраним длину файла, по ней будем определять коней директории.
| Assembler | ||
|
Сравниваем имена из директории с именем, на которое указывает si. Если не совпадает — перейдем на следующую запись (чуть ниже)
| Assembler | ||
|
Если совпал, то в пути после имени должно содержаться либо ‘/’ либо 0 — символ конца строки. Если это не так, значит это не подходящий файл.
| Assembler | ||
|
Загружаем очередной inode.
| Assembler | ||
|
И переходим к его обработке. Это продолжается до тех пор, пока не пройдем весь путь.
| Assembler | ||
|
Если путь не совпадает, и если в директории еще есть записи — продолжаем проверку.
| Assembler | ||
|
Иначе выводим сообщение об ошибке
| Assembler | ||
|
И прекращаем работу.
Вот и весь алгоритм. Не смотря на большой размер этого повествования, код занимает всего около 450 байт. А если убрать параноидальные функции, то и того меньше. Не стоит пытаться откомпилировать этот код, все эти модули вы сможете найти на нашем сайте, ссылка на который приведена ниже. Здесь я все это привел для того чтобы объяснить как и что. Надеюсь у меня это получается хоть как-то. Если кто-то что-то не понимает — пишите мне, мой адрес вы всегда можете найти чуть ниже.
В следующей главе рассмотрим форматы выполняемых файлов, используемые в unix. Это нам тоже потребуется на этапе загрузки.
В этой главе речь пойдет о форматах выполняемых файлов. Будут рассмотрены два формата: ELF и PE, и немного коснемся распределения памяти.
Формат ELF
В данном обзоре мы будем говорить только о 32-х битной версии этого формата, ибо 64-х битная нам пока ни к чему.
Любой файл формата ELF (в том числе и объектные модули этого формата) состоит из следующих частей:
- Заголовок ELF файла;
- Таблица программных секций (в объектных модулях может отсутствовать);
- Секции ELF файла;
- Таблица секций (в выполняемом модуле может отсутствовать);
Ради производительности в формате ELF не используются битовые поля. И все структуры обычно выравниваются на 4 байта.
Теперь рассмотрим типы, используемые в заголовках ELF файлов:
| Тип | Размер | Выравнивание | Комментарий |
| Elf32_Addr | 4 | 4 | Адрес |
| Elf32_Half | 2 | 2 | Беззнаковое короткое целое |
| Elf32_Off | 4 | 4 | Смещение |
| Elf32_SWord | 4 | 4 | Знаковое целое |
| Elf32_Word | 4 | 4 | Беззнаковое целое |
| unsigned char | 1 | 1 | Безнаковое байтовое целое |
Теперь рассмотрим заголовок файла:
| C | ||
|
Массив e_ident содержит в себе информацию о системе и состоит из нескольких подполей.
| C | ||
|
- ei_magic — постоянное значение для всех ELF файлов, равное { 0x7f, ‘E’, ‘L’, ‘F’}
- ei_class — класс ELF файла (1 — 32 бита, 2 — 64 бита который мы не рассматриваем)
- ei_data — определяет порядок следования байт для данного файла (этот порядок зависит от платформы и может быть прямым (LSB или 1) или обратным (MSB или 2)) Для процессоров Intel допустимо только значение 1.
- ei_version — достаточно бесполезное поле, и если не равно 1 (EV_CURRENT) то файл считается некорректным.
- В поле ei_pad операционные системы хранят свою идентификационную информацию. Это поле может быть пустым. Для нас оно тоже не важно.
- Поле заголовка e_type может содержать несколько значений, для выполняемых файлов оно должно быть ET_EXEC равное 2
- e_machine — определяет процессор на котором может работать данный выполняемый файл (Для нас допустимо значение EM_386 равное 3)
- Поле e_version соответствует полю ei_version из заголовка.
- Поле e_entry определяет стартовый адрес программы, который перед стартом программы размещается в eip.
- Поле e_phoff определяет смещение от начала файла, по которому располагается таблица программных секций, используемая для загрузки программ в память.
Не буду перечислять назначение всех полей, не все нужны для загрузки. Лишь еще два опишу.
- Поле e_phentsize определяет размер записи в таблице программных секций.
- И поле e_phnum определяет количество записей в таблице программных секций.
Таблица секций (не программных) используется для линковки программ. мы ее рассматривать не будем. Так же мы не будем рассматривать динамически линкуемые модули. Тема эта достаточно сложная, для первого знакомства не подходящая.
Теперь про программные секции. Формат записи таблицы программных секций таков:
| C | ||
|
Подробнее о полях.
- p_type — определяет тип программной секции. Может принимать несколько значений, но нас интересует только одно. PT_LOAD (1). Если секция именно этого типа, то она предназначена для загрузки в память.
- p_offset — определяет смещение в файле, с которого начинается данная секция.
- p_vaddr — определяет виртуальный адрес, по которому эта секция должна быть загружена в память.
- p_paddr — определяет физический адрес, по которому необходимо загружать данную секцию. Это поле не обязательно должно использоваться и имеет смысл лишь для некоторых платформ.
- p_filesz — определяет размер секции в файле.
- p_memsz — определяет размер секции в памяти. Это значение может быть больше предыдущего.
- Поле p_flag определяет тип доступа к секциям в памяти. Некоторые секции допускается выполнять, некоторые записывать. Для чтения в существующих системах доступны все.
Загрузка формата ELF
С заголовком мы немного разобрались. Теперь я приведу алгоритм загрузки бинарного файла формата ELF. Алгоритм схематический, не стоит рассматривать его как работающую программу.
int LoadELF (unsigned char *bin)
| C | ||
|
По серьезному стоит еще проанализировать поля EPH->p_flags, и расставить на соответствующие страницы права доступа, да и просто копирование здесь не подойдет, но это уже не относится к формату, а к распределению памяти. Поэтому сейчас об этом не будем говорить.
Формат PE
Во многом он аналогичен формату ELF, ну и не удивительно, там так же должны быть секции, доступные для загрузки.
Как и все в Microsoft формат PE базируется на формате EXE. Структура файла такова:
- 00h — EXE заголовок (не буду его рассматривать, он стар как Дос.
")
- 20h — OEM заголовок (ничего существенного в нем нет);
- 3сh — смещение реального PE заголовка в файле (dword).
- таблица перемещения stub;
- stub;
- PE заголовок;
- таблица объектов;
- объекты файла;
stub — это программа, выполняющаяся в реальном режиме и производящая какие-либо предварительные действия. Может и отсутствовать, но иногда может быть нужна.
Нас интересует немного другое, заголовок PE.
Структура его такая:
| C | ||
|
Много всякого там находится. Достаточно сказать, что размер этого заголовка — 248 байт.
И главное что большинство из этих полей не используется. (Кто так строит?) Нет, они, конечно, имеют назначение, вполне известное, но моя тестовая программа, например, в полях pe_code_base, pe_code_size и тд содержит нули но при этом прекрасно работает. Напрашивается вывод, что загрузка файла осуществляется на основе таблицы объектов. Вот о ней то мы и поговорим.
Таблица объектов следует непосредственно после PE заголовка. Записи в этой таблице имеют следующий формат:
| C | ||
|
- o_name — имя секции, для загрузки абсолютно безразлично;
- o_vsize — размер секции в памяти;
- o_vaddr — адрес в памяти относительно ImageBase;
- o_psize — размер секции в файле;
- o_poff — смещение секции в файле;
- o_flags — флаги секции;
Вот на флагах стоит остановиться поподробнее.
| 00000004h | используется для кода с 16 битными смещениями |
| 00000020h | секция кода |
| 00000040h | секция инициализированных данных |
| 00000080h | секция неинициализированных данных |
| 00000200h | комментарии или любой другой тип информации |
| 00000400h | оверлейная секция |
| 00000800h | не будет являться частью образа программы |
| 00001000h | общие данные |
| 00500000h | выравнивание по умолчанию, если не указано иное |
| 02000000h | может быть выгружен из памяти |
| 04000000h | не кэшируется |
| 08000000h | не подвергается страничному преобразованию |
| 10000000h | разделяемый |
| 20000000h | выполнимый |
| 40000000h | можно читать |
| 80000000h | можно писать |
Опять таки не буду с разделяемыми и оверлейными секциями, нас интересуют код, данные и права доступа.
В общем, этой информации уже достаточно для загрузки бинарного файла.
Загрузка формата PE
| C | ||
|
Это опять таки не готовая программа, а алгоритм загрузки.
И опять таки многие моменты не освещаются, так как выходят за пределы темы.
Но теперь стоит немного поговорить про существующие системные особенности.
Системные особенности
Не смотря на гибкость средств защиты, имеющихся в процессорах (защита на уровне таблиц дескрипторов, защита на уровне сегментов, защита на уровне страниц) в существующих системах (как в Windows, так и в Unix) полноценено используется только страничная защита, которая хотя и может уберечь код от записи, но не может уберечь данные от выполнения. (Может быть, с этим и связано изобилие уязвимостей систем?)
Все сегменты адресуются с нулевого линейного адреса и простираются до конца линейной памяти. Разграничение процессов производится только на уровне страничных таблиц.
В связи с этим все модули линкуются не с начальных адресов, а с достаточно большим смещением в сегменте. В Windows используется базовый адрес в сегменте — 0x400000, в юникс (Linux или FreeBSD) — 0x8048000.
Некоторые особенности так же связаны со страничной организацией памяти.
ELF файлы линкуются таким образом, что границы и размеры секций приходятся на 4-х килобайтные блоки файла.
А в PE формате, не смотря на то, что сам формат позволяет выравнивать секции на 512 байт, используется выравнивание секций на 4к, меньшее выравнивание в Windows не считается корректным.
продолжение
4
В предыдущей заметке мы успешно перешли в защищенный режим процессора Intel x86. Прежде чем нам двинуться дальше в изучении защищенного режима, нам надо решить одну проблему. Загрузочный сектор, который загружается в оперативную память при старте компьютера и в котором находится наша программа, имеет размер всего 512 байт. Скоро нам перестанет хватать этого размера. Поэтому мы должны научиться загружать в оперативную память секторы с дискеты, на которой находится наша программа. Программа, которая умеет это делать, называется bootloader. Вот его мы и напишем. Работать будем в реальном режиме, чтобы пользоваться сервисами BIOS для работы с дисками.
Процедурное прогарммирование
Исходный код загрузчика обещал быть довольно большим, поэтому, чтобы не запутаться, я написал его в стиле процедурного программирования. Подробный рассказ о функциях и о том, как они пишутся на языке ассемблера, вы найдете в книге Kip Irvine — Assembly Language for x86 Processors, 7th edition — 2014 Глава 5 — Procedures.
Структура программы
Задача представленной ниже программы — загрузить 2-й сектор с дискеты в оперативную память и передать управление находящемуся там (во 2-ом секторе) машинному коду, который всего лишь выводит на экран текстовое сообщение, чтобы показать, что 2-й сектор действительно загружен. В BIOS есть функции, которые умеют загружать информацию с диска в оперативную память, другое дело, что вызвать эти функции не так просто, как хотелось бы, в силу их заковыристого интерфейса. Поэтому я написал несколько функций-оберток над нужными мне сервисами BIOS и пометил их в отдельный заголовочный файл bios_services.inc. Функции, которые я поместил в заголовочный файл, позволяют загрузить с любого диска любые сектора в оперативную память по любому адресу (в пределах адресного пространства реального режима, разумеется). Причем функции эти принимают свои параметры привычным для меня образом — через стек (а не через регистры, как большинство функций BIOS). В основном же файле программы boot_sector.asm я директивой include подключаю файл bios_services.inc и просто вызываю из него одну из функций, которая загружает с дискеты 2-й сектор. Ниже показано содержимое файлов boot_sector.asm и bios_services.inc.
Исходный код загрузчика
; boot_sector.asm
; Real mode bootloader
; ============================================== CODE ==========================================================
use16 ; generate 16-bit code
org 7C00h ; the code starts at 0x7C00 memory address
start:
jmp far dword 0x0000:entr ; makes CS=0, IP=entr
entr:
xor ax, ax ; ax = 0
mov ds, ax ; setup data segment ds=ax=0
cli ; when we set up stack we need disable interrupts because stack is involved in interrupts handling
mov ss, ax ; setup stack segment ss=ax=0
mov sp, 0x7C00 ; stack will grow starting from 0x7C00 memory address
sti ; enable interrupts
mov byte [disk_id], dl ; save disk identifier (it appears in dl after the start of PC)
; Print message
push message
call BIOS_PrintString
; Reset disk subsystem
push [disk_id]
call BIOS_ResetDiskSubsystem
push [disk_id] ; push disk identifier
push dword 1 ; push LBA of the 1st sector to load
push 1 ; push number of sectors to load
push second_sector ; push memory address at which sectors are to be loaded
call BIOS_LoadSectorsSmart
jmp second_sector
include ‘bios_services.inc’
; =============================================== DATA =========================================================
disk_id dw 0x0000 ; disk identifier (0…3 — floppy disks; greater or equal to 0x80 — other disk types)
message db ‘Starting bootloader…’, 0x0D, 0x0A, 0
finish:
; The size of a disk sector is 512 bytes. Boot sector signature occupies the two last bytes.
; The gap between the end of the source code and the boot sector signature is filled with zeroes.
times 510—finish+start db 0
db 55h, 0AAh ; boot sector signature
; =============================================== 2nd SECTOR ===================================================
second_sector:
; Print message from the 2nd sector
push message_sector2
call BIOS_PrintString
cli ; disable maskable interrupts
hlt ; halt the processor
message_sector2 db ‘The second sector has been loaded successfully!’, 0x0D, 0x0A, 0
; bios_services.inc
use16 ; generate 16-bit code
; <—- BIOS_ClearScreen ———-
BIOS_ClearScreen:
mov ax, 0x0003 ; ah=0 means clear screen and setup video mode, al=3 means text mode, 80×25 screen, CGA/EGA adapter, etc.
int 0x10 ; call BIOS standard video service function
ret
; ———————————>
; <—- BIOS_PrintString ———-
; Prints out a string. The string must be zero-terminated.
; Parameters: word [bp + 4] — address of the string
BIOS_PrintString:
push bp
mov bp, sp
; save registers in stack
push ax
push bx
push si
mov si, [bp + 4] ; si = string address
cld ; clear direction flag (DF is a flag used for string operations)
mov ah, 0x0E ; (int 0x10) BIOS function index (write a charachter to the active video page)
mov bh, 0x00 ; (int 0x10) video page number
.puts_loop:
lodsb ; load to al the next charachter located at [si] address in memory (si is incremented automatically because the direction flag DF = 0)
test al, al ; zero in al means the end of the string
jz .puts_loop_exit
int 0x10 ; call BIOS standard video service
jmp .puts_loop
.puts_loop_exit:
; restore registers from stack
pop si
pop bx
pop ax
mov sp, bp
pop bp
ret 2
; ———————————>
; <—- BIOS_ResetDiskSubsystem —
; Resets disk subsystem.
; Parameters: word [bp + 4] — disk identifier
BIOS_ResetDiskSubsystem:
push bp
mov bp, sp
push dx ; save dx in stack
mov dl, [bp + 4]
.reset:
mov ah, 0 ; (int 0x13) Device reset. Causes controller recalibration.
int 0x13 ; call disk input/output service
jc .reset ; if CF=1 an error has happened and we try again.
pop dx ; restore dx
mov sp, bp
pop bp
ret 2
; ———————————>
; <—- BIOS_GetDiskParameters —-
; Determines parameters of a specified disk.
; Parameters: word [bp + 4] — disk identifier
; Returns: dl — overall number of disks in the system
; dh — maximum head index
; ch — maximum cylinder index
; cl — number of sectors per a track
; Remarks: floppy disk 1.44 MB has 2 heads (0 and 1), 80 tracks (0…79) and 18 sectors per a track (1…18)
BIOS_GetDiskParameters:
push bp
mov bp, sp
push es ; save es in stack
; set ES:DI to 0000h:0000h to work around some buggy BIOS
;(http://en.wikipedia.org/wiki/INT_13H)
xor ax, ax ; ax = 0
mov es, ax ; es = 0
xor di, di ; di = 0
mov dl, [bp + 4] ; drive index
mov ah, 0x08 ; read drive parameters
int 0x13 ; call disk input/output service
pop es ; restore es
mov sp, bp
pop bp
ret 2
; ———————————>
; <—- BIOS_IsExDiskServiceSupported —
; Returns 1 (true) if BIOS supports extended disk service and 0 (false) otherwise.
; Returns: ax=1 or ax=0
BIOS_IsExDiskServiceSupported:
mov ah, 0x41 ; check extensions present
mov bx, 0x55AA ; signature
int 0x13 ; call disk input/output service
jc .not_supported ; if extended disk service is not supported CF flag will be set to 1
mov ax, 1 ; ax = 1
ret
.not_supported:
xor ax, ax ; ax = 0
ret
; ———————————>
; <—- LBAtoCHS ——————
; Function accepts linear sector number (Linear Block Address — LBA) and converts it into a format CYLINDER:HEAD:SECTOR (CHS).
; Parameters: dword [bp + 10] — LBA
; word [bp + 6] — Sectors per Track (SPT)
; word [bp + 4] — Heads per Cylinder (HPC)
; Returns: ch — CYLINDER
; dh — HEAD
; cl — SECTOR
; Remarks: LBA = ((CYLINDER * HPC + HEAD) * SPT) + SECTOR — 1
; CYLINDER = LBA / ( HPC * SPT )
; temp = LBA % ( HPC * SPT )
; HEAD = temp / SPT
; SECTOR = temp % SPT + 1
LBAtoCHS:
push bp
mov bp, sp
push ax ; save ax in stack
; dx:ax = LBA
mov dx, [bp + 10]
mov ax, [bp + 8]
movzx cx, byte [ebp + 6] ; cx = SPT
div cx ; divide dx:ax (LBA) by cx (SPT) (AX = quotient, DX = remainder)
mov cl, dl ; CL = SECTOR = remainder
inc cl ; sectors are indexed starting from 1
div byte [bp + 4] ; AL = LBA % HPC; AH = remainder
mov dh, ah ; DH = HEAD = remainder
mov ch, al ; CH = CYLINDER = quotient
pop ax ; restore ax from stack
mov sp, bp
pop bp
ret 8
; ———————————>
; <—- BIOS_LoadSectors ———-
; Loads sequential sectors from disk into RAM.
; Parameters: word [bp + 12] — disk identifier
; dword [bp + 8] — Linear Block Address (LBA) of the first sector to load
; word [bp + 6] — number of sectors to load
; word [bp + 4] — memory address (in data segment) at which sectors are to be loaded
; Remarks: this function allows for loading sectors from disk within first 8 GiB
BIOS_LoadSectors:
push bp
mov bp, sp
; save necessary registers to stack
push es
push ax
push bx
push dx
mov ax, ds
mov es, ax
mov dl, [bp + 12] ; DL = disk identifier
call BIOS_GetDiskParameters
push dword [bp + 8] ; push LBA
push cx ; push Sectors Per Track
push dx ; push Heads Per Cylinder
call LBAtoCHS ; ch:dh:cl = Cylinder:Head:Sector
.read:
mov dl, [bp + 12] ; DL = disk identifier
mov bx, [bp + 4] ; ES:BX = memory address at which sectors are to be loaded
mov al, [bp + 6] ; AL = number of sectors to load
mov ah, 0x02 ; (int 0x13) Read Sectors From Drive function
int 0x13 ; call disk input/output service
jc .read ; if CF=1, an error occured and we try again
; restore registers from stack
pop dx
pop bx
pop ax
pop es
mov sp, bp
pop bp
ret 10
; ———————————>
; <—- BIOS_LoadSectorsEx ———
; Loads sequential sectors from disk into RAM (uses extended disk input/output service).
; Parameters: word [bp + 12] — disk identifier
; dword [bp + 8] — Linear Block Address (LBA) of the first sector to load
; word [bp + 6] — number of sectors to load
; word [bp + 4] — memory address (in data segment) at which sectors are to be loaded
; Remarks: this function assumes that stack segment and data segment are the same (ss == ds)
; this function allows for loading sectors from disk within first 2 TiB
BIOS_LoadSectorsEx:
push bp
mov bp, sp
sub sp, 16 ; allocate memory (16 bytes) in stack for storing a special
; structure needed for calling bios load-from-disk service
; save necessary registers to stack
push ax
push dx
push si
mov byte[bp — 16], 16 ; structure size = 16 bytes
mov byte[bp — 15], 0 ; unused, should be zero
mov ax, [bp + 6] ; number of sectors to load
mov [bp — 14], ax
mov ax, [bp + 4] ; memory address at which sectors are to be loaded
mov [bp — 12], ax
mov ax, ds ; segment to which sectors are to be loaded
mov [bp — 10], ax
mov ax, [bp + 8] ; 64-bit sector number (1st word)
mov [bp — 8], ax
mov ax, [bp + 10] ; 64-bit sector number (2nd word)
mov [bp — 6], ax
mov word[bp — 4], 0 ; 64-bit sector number (3rd word)
mov word[bp — 2], 0 ; 64-bit sector number (4th word)
mov dl, [bp + 12] ; DL = disk identifier
lea si, [bp — 16] ; si = structure’s address
mov ah, 0x42 ; (int 0x13) Extended Read Sectors From Drive function
int 0x13 ; call disk input/output service
; restore registers from stack
pop si
pop dx
pop ax
mov sp, bp
pop bp
ret 10
; ———————————>
; <—- BIOS_LoadSectorsSmart ——
; Loads sequential sectors from disk into RAM.
; Parameters: word [bp + 12] — disk identifier
; dword [bp + 8] — Linear Block Address (LBA) of the first sector to load
; word [bp + 6] — number of sectors to load
; word [bp + 4] — memory address (in data segment) at which sectors are to be loaded
; Remarks: this function assumes that stack segment and data segment are the same (ss == ds)
BIOS_LoadSectorsSmart:
call BIOS_IsExDiskServiceSupported
cmp ax, 0
je BIOS_LoadSectors
jmp BIOS_LoadSectorsEx
; ———————————>
Объяснение работы программы
Идентификатор диска
Как вам уже известно, первые 512 байт нашей программы загружаются с дискеты. Но ведь мы могли бы записать нашу программу не только на дискету, но и на CD или даже на жесткий диск. Чтобы программа могла узнать, с какого именно носителя она была скопирована в оперативную память, BIOS помещает в регистр dl целое число — так называемый идентификатор диска. Зачем программе знать, с какого носителя она была загружена? Чтобы дозагрузить свою часть, оставшуюся на этом носителе. Как мы можем использовать идентификатор диска? В BIOS есть функции, которые относятся к т. н. сервису дискового ввода-вывода (disk input/output service) — прерывание 0x13. Эти функции принимают идентификатор диска в качестве параметра. Для дискет идентификатор может принимать значения от 0 до 3, для всех остальных дисков — значения от 128 и выше.
Дисковый сервис
Чтобы скопировать сектора с диска в оперативную память, мы можем воспользоваться функцией 0x02 (ah=0x02) дискового сервиса BIOS (int 0x13). Но тут есть одна проблема: функция, которая загружает сектора в память, принимает в качестве параметра адрес 1-ого загружаемого сектора в формате Цилиндр:Головка:Сектор (Cylinder:Head:Sector — CHS). Программисту оперировать адресами секторов в таком формате неудобно, ему более привычен т. н. формат LBA (Linear Block Address), в котором сектора диска предстают в виде однородного массива. Поэтому программисту приходится преобразовывать один формат в другой (LBA to CHS).
Преобразование линейного адреса сектора (LBA) в формат Цилиндр:Головка:Сектор (CHS)
Прежде всего, вы должны понимать, как устроен диск. Например, жесткий диск — это набор круглых стеклянных пластин, покрытых ферромагнитным материалом и нанизанных на вращающийся шпиндель (ось). У каждой пластины есть две поверхности, и над каждой поверхностью расположена считывающая/записывающая головка (head). Поверхность состоит из концентрических кругов, которые называются дорожками (tracks). Совокупность дорожек одинакового радиуса, расположенных на разных пластинах, называется цилиндром (cylinder). Дорожки делятся на сектора размером 512 байт. В процессе считывания или записи головка располагается над нужной дорожкой и ждет, когда под ней проедет нужный сектор. Формат жесткого и гибкого диска одинаков. Подробнее читайте тут: Wikipedia — Cylinder-head-sector. Есть простые формулы преобразования LBA в CHS и наоборот, они приведены в исходном коде функции LBAtoCHS нашей программы.
Определение параметров диска
Определение параметров диска (количество головок, цилиндров и секторов на одну дорожку) необходимо, чтобы мы могли преобразовать адрес LBA в адрес CHS. Параметры диска можно получить при помощи функции 0x08 прерывания 0x13. Входной параметр для этой функции — идентификатор диска. Я поместил определение параметров диска в функцию BIOS_GetDiskParameters. Однако есть в BIOS функция, которая избавит нас от необходимости получать параметры диска и преобразовывать LBA в CHS — она называется «расширенный дисковый сервис».
Расширенный дисковый сервис
Расширенный дисковый сервис может поддерживаться либо не поддерживаться той или иной версией BIOS. Узнать, поддерживается ли он можно, вызвав функцию 0x41 прерывания 0x13. Если сервис поддерживается, то флаг переноса CF будет сброшен в 0, в противном случае — установлен в 1. Все это я поместил в функцию BIOS_IsExDiskServiceSupported. Загрузить секторы диска в память при помощи расширенного дискового сервиса можно, вызвав функцию 0x42 прерывания 0x13. Функция принимает в качестве параметра указатель на специальную структуру, которую мы должны создать в оперативной памяти (целесообразно делать это в стеке). Структура содержит LBA первого сектора и количество секторов для загрузки, а также адрес в памяти, по которому надо загружать сектора. Вызов функции расширенного дискового сервиса я поместил в функцию BIOS_LoadSectorsEx.
Отладчик Bochs
Программа стала достаточно сложной, поэтому при ее написании я допускал различные ошибки. О наличии ошибок программист узнает обычно, когда программа у него не работает. Как узнать, в чем конкретно состоит ошибка? Для этого надо выполнить программу пошагово (т. е. с остановкой после каждой машинной команды) и выяснить, в каком месте программа делает не то, что нужно. Этот процесс называется отладкой. Виртуальная машина Bochs позволяет программисту выполнять отладку — т. е. пошагово выполнять программу, ставить точки останова, манипулировать регистрами и оперативной памятью компьютера.
В папке установки Bochs (у меня это C:Program Files (x86)Bochs-2.6.9) находится файл bochsdbg.exe. Это версия виртуальной машины, предназначенная специально для отладки программ. После ее запуска и нажатия вами в окне Bochs Start Menu кнопки Start, машина остановится на первой же машинной инструкции BIOS, и в окне Bochs for Windows — Console вы увидите приглашение bochs:1>. Далее вы можете вводить различные команды для отладки, их полный список приведен в разделе Using Bochs internal debugger документации, которая поставляется в составе дистрибутива Bochs (у меня документация находится в папке C:Program Files (x86)Bochs-2.6.9docs). Вы можете например пошагово выполнять программу при помощи команды step, ставить точки останова при помощи команды lbreak, просматривать содержимое регистров при помощи команды registers и многое другое (обратите внимание, что у команд есть сокращенные варианты).
После старта машина останавливается на первой команде BIOS. Нас программа в BIOS вряд ли интересует, нас интересует наша собственная программа, поэтому после запуска отладчика полезно установить точку останова на машинную команду с линейным адресом 0x7c00 (адрес, по которому с диска в память копируется наша программа) и продолжить выполнение программы до тех пор, пока не встретится точка останова:
Файл листинга
Если вы отлаживаете программу в Bochs, то вам очень пригодится файл листинга — файл, который содержит в человекочитаемом виде следующую информацию:
- исходный код вашей программы на ассемблере
- машинные коды ассемблерных команд в шестнадцатеричном виде
- данные в шестнадцатеричном виде
- адреса машинных команд в памяти и адреса относительно начала двоичного файла (Relative Virtual Address — RVA)
Без этой информации отлаживать сколько-нибудь сложную программу в Bochs практически невозможно. Вы ведь должны знать, по каким адресам в памяти ставить точки останова и по каким адресам в памяти расположены ваши переменные.
Если вы программируете на FASM’е, то для того чтобы сгенерировать листинг, вам надо сначала сгенерировать так называемый файл символов — symbolic information file. Это можно сделать, указав ключ -s в командной строке компилятора fasm.exe, например:
fasm source.asm -s source.fas
Здесь source.asm — файл исходного кода, source.fas — файл символов, который генерируется компилятором из файла исходного кода.
Затем вы вызываете утилиту listing.exe, которая и генерирует файл листинга:
listing -a source.fas source.lst
Здесь source.fas — файл символов, source.lst — файл листинга, который нам и нужен.
Но тут есть небольшая проблема: утилита listing.exe поставляется в составе дистрибутива FASM, но не в виде скомпилированной программы, а в виде исходного кода на ассемблере, который вы должны сами скомпилировать. Исходный код программы listing.exe расположен в файле C:FASMTOOLSWIN32LISTING.ASM. Этот исходный код написан на ассемблере FASM. Попытка скомпилировать этот файл компилятором fasm.exe из командной строки не приводит к успеху — компилятор не может найти заголовочные файлы (с расширением .inc), на которые ссылался файл исходного кода. Оказывается, в этом файле есть директивы INCLUDE, которые ссылаются на различные заголовочные файлы, причем путь к этим заголовочным файлам не указан (поиск по папке установки FASM показал, что нужные заголовочные файлы лежат в папках TOOLS и INCLUDE). Решение проблемы нашлось в файле руководства C:FASMFASM.PDF в разделе 1.1.1 System requirements: надо либо создать переменную окружения INCLUDE и присвоить ей путь к папке C:FASMINCLUDE, либо запустить графический вариант компилятора, который называется fasmw.exe. После первого запуска fasmw.exe в той же папке появится файл FASMW.INI. В этом файле надо добавить в самое начало следующий текст:
[Environment]
Include=C:FASMINCLUDE
Затем в программе fasmw.exe мы открываем файл C:FASMTOOLSWIN32LISTING.ASM и щелкаем пункт меню Run > Compile, после чего в папке C:FASMTOOLSWIN32 появится файл LISTING.EXE.
Про генерацию листинга всё. Информация была почерпнута мной из файлов C:FASMTOOLSREADME.TXT и C:FASMFASM.PDF (раздел 1.1.1 System requirements).
Makefile
Поскольку теперь я хотел, чтобы при построении программы генерировался файл листинга, я должен был написать новый makefile, текст которого приведен ниже:
all: floppy.img boot_sector.lst
floppy.img : boot_sector.bin
dd if=«/dev/zero» of=«floppy.img» bs=1024 count=1440
dd if=boot_sector.bin of=floppy.img conv=notrunc
boot_sector.bin : boot_sector.asm bios_services.inc
fasm boot_sector.asm boot_sector.bin
boot_sector.lst: boot_sector.fas
listing —a boot_sector.fas boot_sector.lst
boot_sector.fas: boot_sector.asm bios_services.inc
fasm boot_sector.asm —s boot_sector.fas
В следующей заметке мы займемся обработкой прерываний в защищенном режиме.
Что вас здесь ждёт
Если вы так же любопытны, как я, вы наверняка задумывались о том, как работают операционные системы. Здесь я расскажу о некоторых исследованиях и экспериментах, которые я провёл, чтобы лучше понять, как работают вычислительные и операционные системы. После прочтения вы создадите свою загрузочную программу, которая будет работать в любом приложении виртуальных машин, например в Virtual Box.
Важное замечание
Эта статья не предназначена для того, чтобы объяснить работу загрузчика во всей его сложности. Этот пример — отправная точка для x86 архитектуры. Для понимания этой статьи требуется базовое знание микропроцессоров и программирования.
Что такое загрузчик?
Простыми словами загрузчик — это часть программы, загружаемая в рабочую память компьютера после загрузки.
После нажатия кнопки Пуск компьютеру предстоит многое сделать. Запускается и выполняет свою работу прошивка, называемая BIOS (базовая система ввода-вывода). После этого BIOS передаёт управление загрузчику, установленному на любом доступном носителе: USB, жёстком диске, CD и т.д. BIOS последовательно просматривает все носители, проверяя уникальную подпись, которую также называют записью загрузки. Когда она найдена и загружена в память компьютера, начинает работать процессор. Если быть более точным, эта запись располагается по адресу 0x7C00. Сохраните его, он нужен для написания загрузчика.
Работа внутри первого сектора всего с 512 байтами.
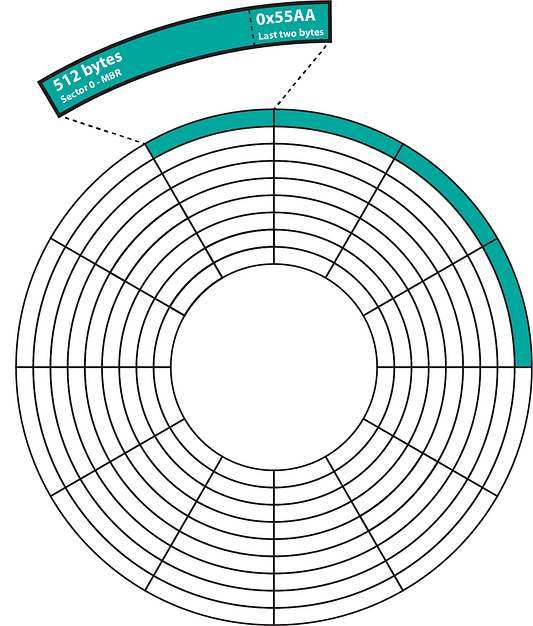
Как упоминалось выше, в процессе инициализации BIOS ищет в первом секторе загрузочного устройства уникальную подпись. Её значение равно 0xAA55 и должно находиться в последних двух байтах первого сектора. И хотя все 512 байт доступны в главной загрузочной записи, мы не можем использовать их все: мы должны вычесть схему и подпись таблицы раздела диска и подпись. Останется только 440 байт. Маловато. Но вы можете решить эту проблему, написав код для загрузки данных из других секторов в памяти.
Шаги инициализации в упрощённом виде
- BIOS загружает компьютеры и их периферийные устройства.
- BIOS ищет загрузочные устройства.
- Когда BIOS находит подпись 0xAA55 в MBR, он загружает этот сектор в память в позицию 0x7C00 и передаёт управление этой точке входа, то есть начинает выполнение инструкций с точки в памяти 0x7C00.
Пишем код
Код загрузчика на ассемблере:
bits 16
org 0x7c00
boot:
mov si, message
mov ah,0x0e
.loop:
lodsb
or al,al
jz halt
int 0x10
jmp .loop
halt:
cli
hlt
message: db "Hey! This code is my boot loader operating.",0
times 510 - ($-$$) db 0
dw 0xaa55
Ассемблер необходимо скомпилировать в машинный код. Обратите внимание, что 512 в шестнадцатеричной системе — это 0x200, а последние два байта — 0x55 и 0xAA. Он инвертирован по сравнению с кодом ассемблера выше, что связано с системой порядка хранения, называемой порядком следования байтов. Например, в big-endian системе два байта, требуемых для шестнадцатеричного числа 0x55AA, будут храниться как 0x55AA (если 55 хранится по адресу 0x1FE, AA будет храниться 0x1FF). В little-endian системе это число будет храниться как 0xAA55 (AA по адресу 0x1FE, 55 в 0x1FF).
0000000 be 10 7c b4 0e ac 08 c0 74 04 cd 10 eb f7 fa f4
0000010 48 65 79 21 20 54 68 69 73 20 63 6f 64 65 20 69
0000020 73 20 6d 79 20 62 6f 6f 74 20 6c 6f 61 64 65 72
0000030 20 6f 70 65 72 61 74 69 6e 67 2e 00 00 00 00 00
0000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
*
00001f0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 55 aa
0000200Машинный код после компиляции NASM
Как работает этот код
Я объясню этот код построчно в случае если вам не знаком ассемблер:
1. Если укажем целевой режим процессора, директива BITS укажет, где NASM следует сгенерировать код, предназначенный для работы на процессоре, поддерживающем 16-битный, 32-битный или 64-битный режим. Синтаксис — BITS XX, где XX это 16, 32 или 64.
2. Если укажем адрес начала программы в бинарном файла, директива ORG укажет начальный адрес, по которому NASM будет считать начало программы при её загрузке в память. Когда этот код переводится в машинный, компилятор и компоновщик определяют и организуют все структуры данных, необходимые программе. Для этой цели будет использован начальный адрес.
3. Это просто ярлык. Когда он определён в коде, то ссылается на позицию в памяти, которую вы можете указать. Он используется вместе с командами условного перехода для контроля потока приложения.
После разбора четвёртой строки нам необходимо описать концепцию регистров:
Регистр процессора — блок ячеек памяти, образующий сверхбыструю оперативную память (СОЗУ) внутри процессора. Используется самим процессором и большей частью недоступен программисту: например, при выборке из памяти очередной команды она помещается в регистр команд, к которому программист обратиться не может. Википедия
4. Назначение данных с помощью инструкции MOV, которая используется для перемещения данных. В данном случае мы перемещаем значение адреса в памяти ярлыка сообщения в регистр SI, который укажет на текст “Hey! This code is my boot loader operating”. На картинке ниже видим, что при переводе в машинный код этот текст хранится в позиции 0x7C10.

5. Мы будем использовать видеосервисы BIOS для отображения текста на экране, поэтому сейчас мы настраиваем отображение по своему желанию. Сервис перемещает байт 0x0E в регистр AH.
6. Ещё одна ссылка на метку, позволяющая управлять потоком выполнения. Позднее мы используем её для создания цикла.
7. Эта инструкция загружает байт из операнда-источника в регистр AL. Вспомните четвёртую строку, где регистру SI была задана позиция текстового адреса. Теперь эта инструкция получает символ, хранящийся в ячейке памяти 0x7C10. Важно заметить, что она ведёт себя как массив, и мы указываем на первую позицию, содержащую символ ‘H’, как видно на рисунке ниже. Этот текст будет представлен итеративно по вертикали, и каждый символ будет задаваться каждый раз. Кроме того, второй символ не был представлен снимком, извлечённым из программы IDA. 0x65 в ASCII отображает символ ‘e’:
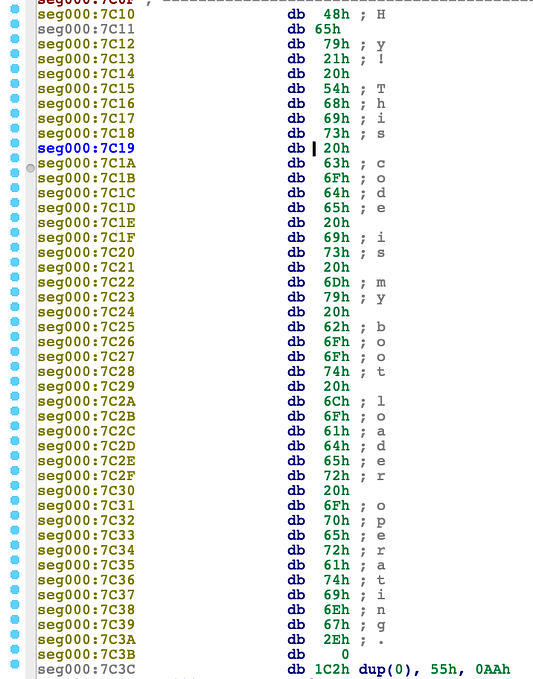
8. Выполнение логической операции OR между (AL | AL) на первый взгляд кажется бессмысленным, однако это не так. Нам нужно проверить, равен ли результат этой операции нулю, основываясь на логическом булевом значении. После этой операции результат будет, например, [1 | 1 = 1] или [0 | 0 = 0].
9. Переход к метке остановки (строка 12), если результат последней операции OR равен нулю. В первый момент значение AL равно [0x48 = ‘H’] , основываясь на последней инструкции LODSB, помните строку 7? Значит, код не перейдёт к метке остановки в первый раз. Почему так? (0x48 OR 0x48) = 0x48, следовательно он переходит к следующей инструкции на следующей строке. Важно заметить, что инструкция JZ связана не только с инструкцией OR. Существует другой регистр, FLAGS, который наблюдается в процессе операций перехода, то есть результат операции OR хранится в этом регистре FLAG и наблюдается инструкцией JZ.
10. Вызывая прерывание BIOS, инструкция INT 0x10 отображает значение AL на экране. Вспомните строку 5, мы задали значение AH байтом 0x0E. Это комбинация для представления значения AL на экране.
11. Переход к метке loop, которая без всяких условий похожа на инструкцию GOTO в языках высокого уровня.
12. Мы снова на строке 7, LODSB перехватывает контроль. После того, как байт будет перемещён из адреса в памяти в регистр AL, регистр SI инкрементируется. Во второй раз он указывает на адрес 0x7C11 = [0x65 ‘e’], затем на экране отображается символ ‘e’. Этот цикл будет выполняться до тех пор, пока не достигнет адреса 0x7C3B = [0x00 0], и, когда JZ снова выполнится в строке 9, поток будет доведён до метки остановки.
13. Здесь мы заканчиваем наше путешествие. Выполнение останавливают инструкции CLI и HLT.
14. На строке 17 вы видите инструкцию, которая заполняет оставшиеся 510 байтов нулями после чего добавляет подпись загрузочной записи 0xAA55.
Компилируем и запускаем
Убедитесь, что компилятор NASM и эмулятор виртуальной машины QEMU установлены на ваш компьютер. Воспользуйтесь предпочтительным менеджер зависимостей или скачайте их из интернета.
Для Linux наберите в терминале:
sudo apt-get install nasm qemu
На Mac OS можно использовать homebrew:
brew install nasm qemu
После этого вам нужно создать файл с кодом сборки, представленным в коде загрузчика выше. Давайте назовём этот файл boot.asm и затем запустим команду NASM:
nasm -f bin boot.asm -o boot.bin
Будет создан двоичный файл, который нужно запустить на виртуальной машине. Давайте запустим на QEMU:
qemu-system-x86_64 -fda boot.bin
Вы увидите следующий экран:
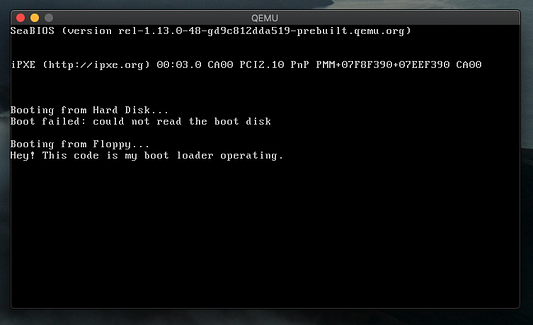
Запуск из Virtual box
Сначала вам нужно создать виртуальный пустой флоппи диск:
dd if=/dev/zero bs=1024 count=0 > floppy.img
Затем добавить внутрь него двоичное содержимое:
cat boot.bin >> floppy.img
Теперь вы можете создать машину Virtual Box и запустить её, используя файл загрузки:
Многие вещи я не стал здесь рассматривать, чтобы не быть слишком многословным. Если вы новичок в этой непростой теме, у вас наверняка возникло множество вопросов, и это прекрасная отправная точка для исследований. Для лучшего понимания многих принципов вычислительных и операционных систем я рекомендую книгу Эндрю С. Таненбаума “Операционные системы. Разработка и реализация”.
Создание загрузочного сектора
21.08.2011
При загрузке компьютера BIOS считывает первый сектор дискового накопителя (жесткий/гибкий диск/DVD/CDROM)
(MBR) в оперативную память по адресу 0000:7С00h и передает туда управление. Затем уже загрузчик передает управление операционной системе.
Чтобы BIOS мог идентифицировать программу начальной загрузки, она в конце должна содержать ключ 55h 0aah.
Начальный загрузчик может выглядеть примерно так (для создания исполняемого файла воспользуемся MASMом и скомпилируем com-файл)
;===================== Загрузочный сектор. Евгений Попов, 2011=====================
;==================================================================================
.model tiny ;для того чтобы masm скомпилировал односегментную программу не более 512 байт
CSEG segment
assume CS:CSEG
org 7c00h ;BIOS производит чтение 512 байт первого сектора MBR в ОЗУ по адресу 0x00007C00
;(0x07C0:0x0000 в формате реального режима), затем прочитанному коду передаётся управление
start:
cli ;запрещаем прерывания
xor ax,ax ;обнуляем регистр ах
mov ds,ax ;настраиваем сегмент данных на нулевой адрес
mov es,ax ;настраиваем сегмент es на нулевой адрес
mov ss,ax ;настраиваем сегмент стека на нулевой адрес
mov sp,07C00h ;сегмент sp указывает на текущую вершину стека
sti ;разрешаем прерывания
;очищаем экран
mov al, 02h
mov ah, 00h
int 10h
call GetCursorPos ;получаем позицию курсора
mov bp, offset msg ; Загрузка
mov cx, 15
call print ;Вывод на экран строки msg
add dh,1 ;переходим на одну строку ниже
call SetCursorPos
mov bp, offset Con ; Загрузка
mov cx, 23
call print
mov dx,1701h
call SetCursorPos
mov bp,offset Off
mov cx,30
call print
mov bp, offset Copyright
mov cx,30
add dh,01h
call SetCursorPos
call print
call Char_in
cmp al,'o'
jz Turn_Off
cmp al,'r'
jz Restart
;cmp al, 0Dh ;Если нажимаем на Enter, то переходим к загрузке ядра
;jz Kernel ;поскольку ядра нет, код оставлен на будущее
jmp $
;===================== Подпрограммы ===================================
print: ;в регистре bp - строка, в регистре cx - длина этой строки
mov bl,04h ;в регистре bl- атрибут
mov ax,1301h
int 10h
ret
;----------------------------------
GetCursorPos: ;получаем текущее значение курсора функиция 3h прерывания 10h
; в bh страница
mov ah,3h
xor bh,bh
int 10h
ret
;----------------------------------
SetCursorPos: ;установка курсора : функция 02h прерывания 10h
mov ah,2h
xor bh,bh
int 10h
ret
;----------------------------------
Char_in: ;ожидание нажатой клавиши : функция 10h прерывания 16h
mov ah,10h
int 16h
ret
;----------------------------------
Turn_Off: ;выключение компа
mov ax,5301h
sub bx,bx
int 15h
jb stop
mov ax,530eh
sub bx,bx
int 15h
jb stop
mov ax,5307h
mov bx,0001h
mov cx,0003h
int 15h
stop:
ret
Restart:
jmp dword ptr reboot
;===================== выводимые сообщения=====================
msg db Hello Eugene...',0
Off db 'r --restart o --turn off',0
Copyright db 'Copyright ',1,' Eugene Popov, 2011',0
Con db 'Press Enter to Continue',0
reboot dd 0ffff0000h ;переход по этому адресу будет вызывать перезагрузку
;----------------------------------
codeend:
db 510-(codeend-start) dup (0) ;заполняем оставшуюся часть нулями
db 055h,0AAh ;сигнатура, символизирующая о завершении загрузочного сектора
CSEG ends
end start
Теперь выведем результат программы. Для этого воспользуемся эмулятором Bochs.
Сначала нам надо создать конфигурационный файл для программы — в моем случае он выглядит так
# configuration file generated by Bochs plugin_ctrl: unmapped=1, biosdev=1, speaker=1, extfpuirq=1, gameport=1, pci_ide=1, acpi=1, ioapic=1 config_interface: win32config display_library: win32 memory: host=32, guest=10 romimage: file="C:Program FilesBochs-2.4.6/BIOS-bochs-latest" vgaromimage: file="C:Program FilesBochs-2.4.6/VGABIOS-lgpl-latest" boot: disk floppy_bootsig_check: disabled=0 # no floppya # no floppyb ata0: enabled=1, ioaddr1=0x1f0, ioaddr2=0x3f0, irq=14 ata0-master: type=disk, mode=flat, translation=auto, path="C:UsersEugeneNBOOT1.COM", cylinders=1, heads=1, spt=1, biosdetect=auto, model="Generic 1234" ata0-slave: type=disk, mode=flat, translation=auto, path="C:UsersEugeneASMBOOT12.BIN", cylinders=20, heads=16, spt=63, biosdetect=auto, model="Generic 1234" ata1: enabled=1, ioaddr1=0x170, ioaddr2=0x370, irq=15 ata2: enabled=0 ata3: enabled=0 parport1: enabled=1, file="" parport2: enabled=0 com1: enabled=1, mode=null, dev="" com2: enabled=0 com3: enabled=0 com4: enabled=0 usb_uhci: enabled=0 usb_ohci: enabled=0 i440fxsupport: enabled=1 vga_update_interval: 50000 vga: extension=vbe cpu: count=1, ips=4000000, reset_on_triple_fault=1, ignore_bad_msrs=1 cpuid: cpuid_limit_winnt=0, mmx=1, sse=sse2, xapic=1, sep=1, aes=0, xsave=0, movbe=0, 1g_pages=0, pcid=0 fsgsbase=0 cpuid: stepping=3, vendor_string="GenuineIntel", brand_string=" Intel(R) Pentium(R) 4 CPU " print_timestamps: enabled=0 port_e9_hack: enabled=0 text_snapshot_check: enabled=0 private_colormap: enabled=0 clock: sync=none, time0=local # no cmosimage ne2k: enabled=0 pnic: enabled=0 sb16: enabled=0 # no loader log: - logprefix: %t%e%d panic: action=ask error: action=report info: action=report debug: action=ignore pass: action=fatal keyboard_type: mf keyboard_serial_delay: 250 keyboard_paste_delay: 100000 keyboard_mapping: enabled=0, map= user_shortcut: keys=none mouse: enabled=0, type=ps2, toggle=ctrl+mbutton
В данном случае у меня файл программы загрузки — C:UsersEugeneNBOOT1.COM
В итоге получим следующую картинку
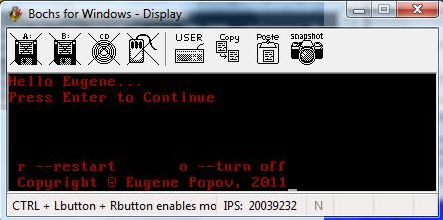
Written on 20 Января 2007. Posted in Assembler
Наш загрузочный сектор будет искать в корневом каталоге некоторый файл — загрузчик, загрузит его в память и передаст ему управление на его начало. А загрузчик уже сам разберется, что ему делать дальше. Я использую NASM, т.к. считаю, что он больше подходит для наших целей.
И так, приступим. Как я уже говорил, в начале нашего загрузочного сектора располагается заголовок FAT, опишем его:
; Общая часть для всех типов FAT
BS_jmpBoot:
jmp short BootStart ; Переходим на код загрузчика
nop
BS_OEMName db '*-v4VIHC' ; 8 байт, что было на моей дискете, то и написал
BPB_BytsPerSec dw 0x200 ; Байт на сектор
BPB_SecPerClus db 1 ; Секторов на кластер
BPB_RsvdSecCnt dw 1 ; Число резервных секторов
BPB_NumFATs db 2 ; Количектво копий FAT
BPB_RootEntCnt dw 224 ; Элементов в корневом катологе (max)
BPB_TotSec16 dw 2880 ; Всего секторов или 0
BPB_Media db 0xF0 ; код типа устройства
BPB_FATsz16 dw 9 ; Секторов на элемент таблицы FAT
BPB_SecPerTrk dw 18 ; Секторов на дорожку
BPB_NumHeads dw 2 ; Число головок
BPB_HiddSec dd 0 ; Скрытых секторов
BPB_TotSec32 dd 0 ; Всего секторов или 0
; Заголовок для FAT12 и FAT16
BS_DrvNum db 0 ; Номер дика для прерывания int 0x13
BS_ResNT db 0 ; Зарезервировано для Windows NT
BS_BootSig db 29h ; Сигнатура расширения
BS_VolID dd 2a876CE1h ; Серийный номер тома
BS_VolLab db 'X boot disk' ; 11 байт, метка тома
BS_FilSysType db 'FAT12 ' ; 8 байт, тип ФС
; Структура элемента каталога
struc DirItem
DIR_Name: resb 11
DIR_Attr: resb 1
DIR_ResNT: resb 1
DIR_CrtTimeTenth resb 1
DIR_CrtTime: resw 1
DIR_CrtDate: resw 1
DIR_LstAccDate: resw 1
DIR_FstClusHi: resw 1
DIR_WrtTime: resw 1
DIR_WrtDate: resw 1
DIR_FstClusLow: resw 1
DIR_FileSize: resd 1
endstruc ;DirItem
Большинство полей мы использовать не будем, и так мало места для полета. Загрузчик BIOS передает нам управление на начало загрузочного сектора, т.е. на BS_jmpBoot, поэтому в начале заголовка FAT на отводится 3 байта для короткой или длинной инструкции jmp. Мы в данном случае использовали короткую, указав модификатор short, и в третьем байте просто разместили однобайтовую инструкцию nop.
По инструкции jmp short BootStart мы переходим на наш код. Проведем небольшую инициализацию:
; Наши не инициализированные переменные
; При инициализации они затрут не нужные нам
; поля заголовка FAT: BS_jmpBoot и BS_OEMName
struc NotInitData
SysSize: resd 1 ; Размер системной области FAT
fails: resd 1 ; Число неудачных попыток при чтении
fat: resd 1 ; Номер загруженного сектора с элементами FAT
endstruc ;NotInitData
; По этому адресу мы будем загружать загрузчик
%define SETUP_ADDR 0x1000
; А по этому адресу нас должны были загрузить
%define BOOT_ADDR 0x7C00
%define BUF 0x500
BootStart:
cld
xor cx, cx
mov ss, cx
mov es, cx
mov ds, cx
mov sp, BOOT_ADDR
mov bp, sp
; Сообщим о том что мы загружаемся
mov si, BOOT_ADDR + mLoading
call print
Все сегментные регистры настраиваем на начало физической памяти. Вершину стека настраиваем на начало нашего сектора, стек растет вниз (т.е. в сторону младших адресов), так что проблем быть не должно. Туда же указывает регистр bp — нам нужно обращаться к полям заголовка FAT и паре наших переменных. Мы используем базовую адресацию со смещением, для чего используем регистр bp т.к. в этом случае можно использовать однобайтовые смещения, вместо двухбайтовых адресов, что позволяет сократить код. Процедуру print, выводящую сообщение на экран, рассмотрим позже.
Теперь нам нужно вычислить номера первых секторов корневого каталога и данных файлов.
mov al, [byte bp+BPB_NumFATs]
cbw
mul word [byte bp+BPB_FATsz16]
add ax, [byte bp+BPB_HiddSec]
adc dx, [byte bp+BPB_HiddSec+2]
add ax, [byte bp+BPB_RsvdSecCnt]
adc dx, cx
mov si, [byte bp+BPB_RootEntCnt]
; dx:ax - Номер первого сектора корневого каталога
; si - Количество элементов в корневом каталоге
pusha
; Вычислим размер системной области FAT = резервные сектора +
; все копии FAT + корневой каталог
mov [bp+SysSize], ax ; осталось добавить размер каталога
mov [bp+SysSize+2], dx
; Вычислим размер корневого каталога
mov ax, 32
mul si
; dx:ax - размер корневого каталога в байтах, а надо в секторах
mov bx, [byte bp+BPB_BytsPerSec]
add ax, bx
dec ax
div bx
; ax - размер корневого каталога в секторах
add [bp+SysSize], ax ; Теперь мы знаем размер системной
adc [bp+SysSize+2], cx ; области FAT, и начало области данных
popa
; В dx:ax - снова номер первого сектора корневого каталога
; si - количество элементов в корневом каталоге
Теперь мы будем просматривать корневой каталог в поисках нужного нам файла
NextDirSector:
; Загрузим очередной сектор каталога во временный буфер
mov bx, 700h ; es:bx - буфер для считываемого сектора
mov di, bx ; указатель текущего элемента каталога
mov cx, 1 ; количество секторов для чтения
call ReadSectors
jc near DiskError ; ошибка при чтении
RootDirLoop:
; Ищем наш файл
; cx = 0 после функции ReadSectors
cmp [di], ch ; byte ptr [di] = 0?
jz near NotFound ; Да, это последний элемент в каталоге
; Нет, не последний, сравним имя файла
pusha
mov cl, 11 ; длина имени файла с расширением
mov si, BOOT_ADDR + LoaderName ; указатель на имя искомого файла
rep cmpsb ; сравниваем
popa
jz short Found ; Нашли, выходим из цикла
; Нет, ищем дальше
dec si ; RootEntCnt
jz near NotFound ; Это был последний элемент каталога
add di, 32 ; Переходим к следующему элементу каталога
; bx указывает на конец прочтенного сектора после call ReadSectors
cmp di, bx ; Последний элемент в буфере?
jb short RootDirLoop ; Нет, проверим следующий элемент
jmp short NextDirSector ; Да последний, загрузим следующий сектор
Из этого кода мы можем выйти одну из трех точек: ошибка при чтении DiskError, файл наден Found или файл не найден NotFound.
Загрузка файла в память
Если файл найден, то загрузим его в память и передадим управление на его начало.
Found:
; Загрузка загрузчика (извените, калабур)
mov bx, SETUP_ADDR
mov ax, [byte di+DIR_FstClusLow] ; Номер первого кластера файла
; Загружаем сектор с элемнтами FAT, среди которых есть FAT[ax]
; LoadFAT сохраняет значения всех регистров
call LoadFAT
ReadCluster:
; ax - Номер очередного кластера
; Загрузим его в память
push ax
; Первые два элемента FAT служебные
dec ax
dec ax
; Число секторов для чтения
; cx = 0 после ReadSectors
mov cl, [byte bp+BPB_SecPerClus] ; Секторов на кластер
mul cx
; dx:ax - Смещение кластера относительно области данных
add ax, [byte bp+SysSize]
adc dx, [byte bp+SysSize+2]
; dx:ax - Номер первого сектора требуемого кластера
; cx еще хранит количество секторов на кластер
; es:bx - конец прошлого кластера и начало нового
call ReadSectors ; читаем кластер
jc near DiskError ; Увы, ошибка чтения
pop ax ; Номер кластера
; Это конец файла?
; Получим значение следующего элемента FAT
pusha
; Вычислим адрес элемента FAT
mov bx, ax
shl ax, 1
add ax, bx
shr ax, 1
; Получим номер сектора, в котором находится текущий элемент FAT
cwd
div word [byte bp+BPB_BytsPerSec]
cmp ax, [bp+fat] ; Мы уже читали этот сектор?
popa
je Checked ; Да, читали
; Нет, надо загрузить этот сектор
call LoadFAT
Checked:
; Вычислим адрес элемента FAT в буфере
push bx
mov bx, ax
shl bx, 1
add bx, ax
shr bx, 1
and bx, 511 ; остаток от деления на 512
mov bx, [bx+0x700] ; а вот и адрес
; Извлечем следующий элемент FAT
; В FAT16 и FAT32 все немного проще :(
test al, 1
jnz odd
and bx, 0xFFF
jmp short done
odd:
shr bx, 4
done:
mov ax, bx
pop bx
; bx - новый элемент FAT
cmp ax, 0xFF8 ; EOF - конец файла?
jb ReadCluster ; Нет, читаем следующий кластер
; Наконец-то загрузили
mov ax, SETUP_ADDR>>4 ; SETUP_SEG
mov es, ax
mov ds, ax
; Передаем управление, наше дело сделано :)
jmp SETUP_ADDR>>4:0LoadFAT ;proc
; Процедура для загрузки сектора с элементами FAT
; Элемент ax должен находится в этом секторе
; Процедура не должна менять никаких регистров
pusha
; Вычисляем адрес слова содержащего нужный элемент
mov bx, ax
shl ax, 1
add ax, bx
shr ax, 1
cwd
div word [byte bp+BPB_BytsPerSec]
; ax - смещение сектора относительно начала таблицы FAT
mov [bp+fat], ax ; Запомним это смещение, dx = 0
cwd ; dx:ax - номер сектора, содержащего FAT[?]
; Добавим смещение к первой копии таблицы FAT
add ax, [byte bp+BPB_RsvdSecCnt]
adc dx, 0
add ax, [byte bp+BPB_HiddSec]
adc dx, [byte bp+BPB_HiddSec+2]
mov cx, 1 ; Читаем один сектор. Можно было бы и больше, но не быстрее
mov bx, 700h ; Адрес буфера
call ReadSectors
jc DiskError ; Ошибочка вышла
popa
ret
;LoadFAT endp
В FAT12 на каждый элемент FAT отводится по 12 бит, что несколько усложняет нашу работу, в FAT16 и FAT32 на каждый элемент отводится по 16 и 32 бита соответственно и можно просто прочесть слово или двойное слово, а в FAT12 необходимо прочесть слово содержащее элемент FAT и правильно извлечь из него 12 бит.
Процедура загрузки секторов
Теперь разберем процедуру загрузки секторов. Процедура получает номер сектора в dx:ax (нумерация с нуля) и преобразует его к формату CSH (цилиндр, сектор, сторона), используемому прерыванием BIOS int 0x13.
<>; *************************************************
; * Чтение секторов с диска *
; *************************************************
; * Входные параметры: *
; * dx:ax - (LBA) номер сектора *
; * cx - количество секторов для чтения *
; * es:bx - адрес буфера *
; *************************************************
; * Выходные параметры: *
; * cx - Количество не прочтенных секторов *
; * es:bx - Указывает на конец буфера *
; * cf = 1 - Произошла ошибка при чтении *
; *************************************************
ReadSectors ;proc
next_sector:
; Читаем очередной сектор
mov byte [bp+fails], 3 ; Количество попыток прочесть сектор
try:
; Очередная попытка
pusha
; Преобразуем линейный адрес в CSH
; dx:ax = a1:a0
xchg ax, cx ; cx = a0
mov ax, [byte bp+BPB_SecPerTrk]
xchg ax, si ; si = Scnt
xchg ax, dx ; ax = a1
xor dx, dx
; dx:ax = 0:a1
div si ; ax = q1, dx = c1
xchg ax, cx ; cx = q1, ax = a0
; dx:ax = c1:a0
div si ; ax = q2, dx = c2 = c
inc dx ; dx = Sector?
xchg cx, dx ; cx = c, dx = q1
; dx:ax = q1:q2
div word [byte bp+BPB_NumHeads] ; ax = C (track), dx = H
mov dh, dl ; dh = H
mov ch, al
ror ah, 2
or cl, ah
mov ax, 0201h ; ah=2 - номер функции, al = 1 сектор
mov dl, [byte bp+BS_DrvNum]
int 13h
popa
jc Failure ; Ошибка при чтении
; Номер следующего сектора
inc ax
jnz next
inc dx
next:
add bx, [byte bp+BPB_BytsPerSec]
dec cx ; Все сектора прочтены?
jnz next_sector ; Нет, читаем дальше
return:
ret
Failure:
dec byte [bp+fails] ; Последняя попытка?
jnz try ; Нет, еще раз
; Последняя, выходим с ошибкой
stc
ret
;ReadSectors endp
>
Осталось всего ничего:
; Сообщения об ошибках
NotFound: ; Файл не найден
mov si, BOOT_ADDR + mLoaderNotFound
call print
jmp short die
DiskError: ; Ошибка чтения
mov si, BOOT_ADDR + mDiskError
call print
;jmp short die
die: ; Просто ошибка
mov si, BOOT_ADDR + mReboot
call print
_die: ; Бесконечный цикл, пользователь сам нажмет Reset
jmp short _die
; Процедура вывода ASCIIZ строки на экран
; ds:si - адрес строки
print: ; proc
pusha
print_char:
lodsb ; Читаем очередной символ
test al, al ; 0 - конец?
jz short pr_exit ; Да конец
; Нет, выводим этот символ
mov ah, 0eh
mov bl, 7
int 10h
jmp short print_char ; Следующий
pr_exit:
popa
ret
;print endp
; Перевод строки
%define endl 10,13,0
; Строковые сообщения
mLoading db 'Loading...',endl
mDiskError db 'Disk I/O error',endl
mLoaderNotFound db 'Loader not found',endl
mReboot db 'Reboot system',endl
; Выравнивание размера образа на 512 байт
times 499-($-$$) db 0
LoaderName db 'BOOTOR ' ; Имя файла загрузчика
BootMagic dw 0xAA55 ; Сигнатура загрузочного сектора
Компиляция
Ну вот вроде бы и все. Компилируется все это до безобразия просто:
> nasm -f bin boot.asm -lboot.lst -oboot.bin
Осталось только как-то записать этот образ в загрузочный сектор вашей дискеты и разместить в корне этой дискеты файл загрузчика BOOTOR. Загрузочный сектор можно записать с помощью такой вот простой программы на Turbo (Borland) Pascal. Эта программа будет работать как в DOS, так и в Windows — пробовал на WinXP — работает как ни странно, но только с floopy. Но все же я рекомендую запускать эту утилиту из-под чистого DOS’а, т.к. WinXP обновляет не все поля в заголовке FAT и загрузочный сектор может работать некорректно.
var
fn:string;
f:file;
buf:array[0..511] of byte;
ok:boolean;
begin
fn:=ParamStr(1);
if fn=» then writeln(‘makeboot bootsect.bin’)
else
begin
writeln(‘Making boot floppy’);
{$I-}
assign(f,fn);
reset(f,sizeof(buf));
BlockRead(f,buf,1);
close(f);
{$I+}
if IOResult<>0 then
begin
Writeln(‘Failed to read file «‘,fn,‘»‘);
Halt(1);
end;
ok:=false;
asm
mov ax, 0301h
mov cx, 1
mov dx, 0
mov bx, seg buf
mov es, bx
mov bx, offset buf
int 13h
jc @error
mov ok, true
@error:
end;
if ok then writeln(‘Done :)’)
else begin
writeln(‘Makeboot failed :(‘);
Halt(1);
end;
end;
end.
Introduction
In the previous article, I tried to brief about booting, how to write a bootable code in C and assembly, and how to embed assembly statements inside a
C program as well.
We also tried to write a few programs to examine if our code injected into the boot sector of a device works or not. In this article, I will try to explain about segmentation
and reading data from a floppy disk during booting and displaying it onto the screen. We will try writing
a few programs
and examine if we can read the data and try displaying it onto the screen.
What is the scope of the article?
I will limit the scope of the article onto how to write a program code in assembly, and how to copy it to the boot sector of a 3.5 inches floppy disk image,
and then how to test the floppy disk to boot it with the code we have written using an x86 emulator like bochs. I will take the help of BIOS services to achieve the task
of reading data from a floppy disk. By doing so we can explore more about BIOS routines and feel comfortable playing around in Real Mode.
Breakdown of topics
- Introduction to segmentation
- Programming environment
- Reading data from RAM-Memory
- Introduction to storage devices
- Architecture of a floppy disk
- Interaction with a floppy disk
Introduction to Segmentation
Before I proceed writing some examples on how to read a floppy disk, I wanted to refresh the topic of segmentation and its need as below.
What is
Segmentation?
The main memory is divided into segments that are indexed by few special registers called as segment registers (CS, DS, SS and ES).
What is the use of
Segmentation?
When we specify a 16-bit address, the CPU automatically calculates the start address of the respective segment. However, it is the duty of the programmer
to specify the start address of each segment especially when writing a program like boot loader.
What are the different types of segments?
I will mention only four types for now, as they are important for us to understand.
- Code Segment
- Data Segment
- Stack Segment
- Extended Segment
Code Segment
It is one of the sections of a program in memory that contains the executable instructions.
If you refer to my previous article, you will see the label .text where under which we intend to place the instructions to execute. When the program is loaded into memory,
the instructions under section .text are placed into code segment.
In CPU, we use CS register to refer to the code segment in memory.
Data Segment
It is one of the sections of a program in memory that contains variables both static and global by the programmer. We use DS register to refer to the data segment in memory.
Stack Segment
A programmer can use registers to store, modify and retrieve data during the scope of the program
that he has written. As there are only a few registers available for a programmer to use during the run time of the program, there is always a chance that the program logic
might get complicated, as there are only a few registers available for temporary use. Due to this, the programmer might always feel the need for a bigger place, which is more flexible
in terms of storing, processing and retrieving data. The CPU designers have come up with a special segment called the stack segment.
In order to store and retrieve data on stack segment, the programmer uses push and pop instructions. We use push instructions to pass arguments to functions as well.
We use SS register to refer to the stack segment in memory. Also remember that stack grows downwards.
Extended Segment:
The extended segment is normally used to load data that is much bigger than the size of the data that is stored in data segment. You will further see that I will try to load the data
from the floppy on Extended segment. We use ES register to refer to the Extended Segment in memory.
How to set Segment registers?
The programmer does not have the freedom to directly set any of the segment registers but instead we follow this way.
movw $0x07c0, %ax movw %ax, %ds
What does the above step means?
- Copy the data to a general purpose register.
- Then assign it to the segment register.
We are setting AX register to 0x07c0
And when we are copying the contents of AX to DS. The absolute address is calculated as below.
DS = 16 * AX So DS = 0x7c00
We further use offset to traverse from here on. To reach to a location in Data segment, we use offsets.
Programming environment
- Operating system (GNU Linux)
- Assembler (GNU Assembler)
- Compiler (GNU GCC)
- Linker (GNU linker ld)
- An x86 emulator used for our testing purposes(bochs).
Reading data from RAM
Note
Now, if you observe BIOS loads our program at 0x7c00 and starts executing it and then our program starts printing values one by one. We access the data on RAM by directly specifying
the offset and setting the data segment to 0x7c00.
Example1
Once our program is loaded by BIOS at 0x7c00, let us try to read data from offset 3 and 4 and then print them onto the screen.
Program: test.S
.code16 #generate 16-bit code
.text #executable code location
.globl _start
_start: #code entry point
jmp _boot #jump to boot code
data : .byte 'X' #variable
data1: .byte 'Z' #variable
_boot:
movw $0x07c0, %ax #set ax = 0x07c0
movw %ax , %ds #set ds = 16 * 0x07c0 = 0x7c00
#Now we will copy the data at position 3 from 0x7c00:0x0000
# and then print it onto the screen
movb 0x02 , %al #copy the data at 2nd position to %al
movb $0x0e , %ah
int $0x10
#Now we will copy the data at position 4 from 0x7c00:0x0000
# and then print it onto the screen
movb 0x03 , %al #copy the data at 3rd position to %al
movb $0x0e , %ah
int $0x10
#infinite loop
_freeze:
jmp _freeze
. = _start + 510 #mov to 510th byte from 0 pos
.byte 0x55 #append boot signature
.byte 0xaa #append boot signature
Now on the command line, to generate binary and to copy the code to boot sector of a floppy disk, type as below and then hit return.
- as test.S –o test.o
- ld –Ttext=0x7c00 –oformat=binary boot.o –o boot.bin
- dd if=/dev/zero of=floppy.img bs=512 count=2880
- dd if=boot.bin of=floppy.img
Note
If you open the boot.bin file in hexadecimal editor, you will see something similar as below.

You will see that X and Y are in the third and fourth position from 0th offset of 0x7c00.
To test the code, type the following commands as below.
- bochs
Example:
Once our program is loaded by BIOS at 0x7c00, let us read a null terminated string from offset 2 and then print it.
Program: test2.S
.code16 #generate 16-bit code
.text #executable code location
.globl _start
_start: #code entry point
jmp _boot #jump to boot code
data : .asciz "This is boot loader" #variable
#calls the printString function which
#starts printing string from the position
.macro mprintString start_pos #macro to print string
pushw %si
movw start_pos, %si
call printString
popw %si
.endm
printString: #function to print string
printStringIn:
lodsb
orb %al , %al
jz printStringOut
movb $0x0e, %ah
int $0x10
jmp printStringIn
printStringOut:
ret
_boot:
movw $0x07c0, %ax #set ax = 0x07c0
movw %ax , %ds #set ds = 16 * 0x07c0 = 0x7c00
mprintString $0x02
_freeze:
jmp _freeze
. = _start + 510 #mov to 510th byte from 0 pos
.byte 0x55 #append boot signature
.byte 0xaa #append boot signature
If you compile the program and open the binary in hexadecimal editor, you may see the string as “This is boot loader” onto output.
Introduction to storage devices
What is a storage device?
It is a device used for information storage, retrieval. It can also be used as a bootable media.
Why does a computer require storage devices?
We use computers mainly to store information, retrieve the information and process it so as part of storing and retrieval
of information, the manufactures came up with a new device called a storage device with various types.
What are the various types of storage devices available?
Depending on the size of the data, I will try to list them as below.
- Floppy disk
- Hard disk
- USB Disk
And more…
What is a floppy disk?
It is a device used for information storage, retrieval. It is also used as a bootable media.
A floppy disk is designed to store small amounts of data whose maximum size
could be limited to few Mega Bytes.
What is a Mega Byte?
In computing, the size of the data is measured in one of the following ways:
- Bit: It can store
a value of either a 1 or 0 - Nibble: 4 bits
- Byte(B): 8 bits
- Kilo Byte(KB): 1024 bytes
- Mega Byte(MB): 1 Kilo Byte * 1 Kilo Byte = 1,048,576 Bytes = 1024 Kilo Bytes = 1024 * 1024 Bytes
- Giga Byte(GB): 1,073,741,824 Bytes= 2^30 Bytes = 1024 Mega Bytes = 1,048,576 Kilo Bytes = 1024 * 1024 * 1024 Bytes
- Tera Byte(TB): 1,099,511,627,776 Bytes= 2^40 Bytes = 1024 Giga Bytes = 1,048,576 Megabytes = 1024 * 1024 * 1024 * 1024 Bytes
And more…but we will limit our selves to the above.
How does a floppy disk look like?
How much data can I store on a floppy disk?
It all depends upon various types of floppy disks available from manufactures and their respective sizes.
I will simply try to list the details of 3.5 inches floppy disk which I have used earlier in my life.
Name Description Size(mm) Volume(mm2) Capicity(MB) 3.5 inches 3.5 inch Floppy Disk 93.7 x 90.0 x 3.3 27,828.9 1.44 MB
Architecture of a typical floppy disk
The above diagram shows you the architecture of a typical floppy disk and let us be concerned about
3.5 inches floppy disk and I will explain more about it as below.
How to describe a 3.5 inches floppy disk?
- It has 2 sides
- It side is called as a head.
- Each Side contains 80 tracks on it.
- Each track contains 18 sectors in it.
- Each sector contains 512 bytes in it.
How to calculate the size of a floppy disk?
- Total Size in Bytes: Total sides * Total tracks * Total Sectors Per Track * Total Bytes Per Sector.
Total Size(Bytes) = 2 * 80 * 18 * 512 = 1474560 Bytes.
- Total Size in Kilo Bytes: (Total sides * Total tracks * Total Sectors Per Track * Total Bytes)/1024.
Total Size(KB) = (2 * 80 * 18 * 512)/1024 = 1474560/1024 = 1440 KB.
- Total Size in Mega Bytes: ((Total sides * Total tracks * Total Sectors Per Track * Total Bytes)/1024)/1024
Total Size(MB) = ((2 * 80 * 18 * 512)/1024)/1024 = (1474560/1024)/1024 = 1440/1024 = 1.4 MB
Where is boot sector located on a floppy disk?
It is located on the first sector of the disk.
Interaction with a floppy disk
How to read data from a floppy disk?
As our mission in this article is to read data from a floppy disk, the only choice left to us as of now is to use BIOS Services in our program as during the boot time we are in Real Mode to interact with the floppy disk. We need to use BIOS Interrupts to achieve our task.
Which interrupts are we going to use?
Interrupt 0x13 Service code 0x02
How to access a floppy disk using the interrupt 0x13?
- To request BIOS to read a sector on a floppy we use below.
AH = 0x02
- To request BIOS to read from the ‘N’th cylinder we use below.
CH = ‘N’
- To request BIOS to read from the ‘N’th head we use below.
DH = ‘N’
- To request BIOS to read ‘N’th sector we use below.
CL = ‘N’
- To request BIOS to read ‘N’ number of sectors we use below.
AL = N
- To interrupt the CPU to perform this activity we use below.
Int 0x13
Reading data from Floppy Disk
Let us write a program to display the labels of few sectors.
Program: test.S
.code16 #generate 16-bit code
.text #executable code location
.globl _start
_start:
jmp _boot #jump to the boot code to start execution
msgFail: .asciz "something has gone wrong..." #message about erroneous operation
#macro to print null terminated string
#this macro calls function PrintString
.macro mPrintString str
leaw str, %si
call PrintString
.endm
#function to print null terminated string
PrintString:
lodsb
orb %al , %al
jz PrintStringOut
movb $0x0e, %ah
int $0x10
jmp PrintString
PrintStringOut:
ret
#macro to read a sector from a floppy disk
#and load it at extended segment
.macro mReadSectorFromFloppy num
movb $0x02, %ah #read disk function
movb $0x01, %al #total sectors to read
movb $0x00, %ch #select cylinder zero
movb $0x00, %dh #select head zero
movb num, %cl #start reading from this sector
movb $0x00, %dl #drive number
int $0x13 #interrupt cpu to get this job done now
jc _failure #if fails then throw error
cmpb $0x01, %al #if total sectors read != 1
jne _failure #then throw error
.endm
#display the string that we have inserted as the
#identifier of the sector
DisplayData:
DisplayDataIn:
movb %es:(%bx), %al
orb %al , %al
jz DisplayDataOut
movb $0x0e , %ah
int $0x10
incw %bx
jmp DisplayDataIn
DisplayDataOut:
ret
_boot:
movw $0x07c0, %ax #initialize the data segment
movw %ax , %ds #to 0x7c00 location
movw $0x9000, %ax #set ax = 0x9000
movw %ax , %es #set es = 0x9000 = ax
xorw %bx , %bx #set bx = 0
mReadSectorFromFloppy $2 #read a sector from floppy disk
call DisplayData #display the label of the sector
mReadSectorFromFloppy $3 #read 3rd sector from floppy disk
call DisplayData #display the label of the sector
_freeze: #infinite loop
jmp _freeze #
_failure: #
mPrintString msgFail #write error message and then
jmp _freeze #jump to the freezing point
. = _start + 510 #mov to 510th byte from 0 pos
.byte 0x55 #append first part of the boot signature
.byte 0xAA #append last part of the boot signature
_sector2: #second sector of the floppy disk
.asciz "Sector: 2nr" #write data to the begining of the sector
. = _sector2 + 512 #move to the end of the second sector
_sector3: #third sector of the floppy disk
.asciz "Sector: 3nr" #write data to the begining of the sector
. = _sector3 + 512 #move to the end of the third sector
Now compile the code as below
- as test.S -o test.o
- ld -Ttext=0x0000 —oformat=binary test.o -o test.bin
- dd if=test.bin of=floppy.img
If you open the test.bin in an hexadecimal editor you will find that I have embedded a label to sector 2 and 3. I have highlighted them in the below snapshot.

If you run the program by typing bochs on command prompt you will see as below.
What is the functionality of the above program?
In the above program we define macros and functions to read and display the contents of the strings that are embedded in each sector.
Let me brief you about each macro and function.
#macro to print null terminated string
#this macro calls function PrintString
.macro mPrintString str
leaw str, %si
call PrintString
.endm
This macro is defined to take a string as an argument and internally it calls another function called
PrintString which does the job of displaying character by character onto the screen.
#function to print null terminated string PrintString: lodsb orb %al , %al jz PrintStringOut movb $0x0e, %ah int $0x10 jmp PrintString PrintStringOut: Ret
This is the function called by the macro mPrintString to display each byte of the null terminated string onto the screen.
#macro to read a sector from a floppy disk
#and load it at extended segment
.macro mReadSectorFromFloppy num
movb $0x02, %ah #read disk function
movb $0x01, %al #total sectors to read
movb $0x00, %ch #select cylinder zero
movb $0x00, %dh #select head zero
movb num, %cl #start reading from this sector
movb $0x00, %dl #drive number
int $0x13 #interrupt cpu to get this job done now
jc _failure #if fails then throw error
cmpb $0x01, %al #if total sectors read != 1
jne _failure #then throw error
.endm
This macro mReadSectorFromFloppy reads a sector into the extended segment and places there for further processing. This macro takes a sector number to read as an argument.
#display the string that we have inserted as the #identifier of the sector DisplayData: DisplayDataIn: movb %es:(%bx), %al orb %al , %al jz DisplayDataOut movb $0x0e , %ah int $0x10 incw %bx jmp DisplayDataIn DisplayDataOut: Ret
This function displays each byte of the data from beginning until a null terminated character is encountered.
_boot:
movw $0x07c0, %ax #initialize the data segment
movw %ax , %ds #to 0x7c00 location
movw $0x9000, %ax #set ax = 0x9000
movw %ax , %es #set es = 0x9000 = ax
xorw %bx , %bx #set bx = 0
This is the main boot code for execution. Before we begin with printing the contents of the disk, we set the data segment to 0x7c00 and also set the extended segment to 0x9000.
What is the purpose of setting the extended segment?
First we read a sector into our program memory at 0x9000 and then start displaying the content of the sector.
That is why we set the Extended segment to 0x9000.
mReadSectorFromFloppy $2 #read a sector from floppy disk call DisplayData #display the label of the sector mReadSectorFromFloppy $3 #read 3rd sector from floppy disk call DisplayData #display the label of the sector
We call the macro to read sector2 and then display its content and then again we call the macro to read sector 3 and then display its content.
_freeze: #infinite loop jmp _freeze #
After displaying the contents of the sectors, we go into one infinite loop to hang our program.
_failure: # mPrintString msgFail #write error message and then jmp _freeze #jump to the freezing point
We defined this section to jump to this label incase of any erroneous situations and then hang the program again.
. = _start + 510 #mov to 510th byte from 0 pos .byte 0x55 #append first part of the boot signature .byte 0xAA #append last part of the boot signature
We move to the 510th byte of the sector and then append the boot signature which is a mandatory for a floppy disk to be identified as a bootable device,
else the system throws an error as invalid disk.
_sector2: #second sector of the floppy disk
.asciz "Sector: 2nr" #write data to the begining of the sector
. = _sector2 + 512 #move to the end of the second sector
_sector3: #third sector of the floppy disk
.asciz "Sector: 3nr" #write data to the begining of the sector
. = _sector3 + 512 #move to the end of the third sector
The above step performs appending a string at the beginning of the sector 2 and 3.
That’s all for this article 
Have fun and try to explore reading floppy disk in real mode and embed the functionality into your bootloader.
In the following articles I will try to brief about File systems and their importance. We will also write a minimal bootloader to parse a fat12 formatted floppy disk,
how to read and write to it and also write a second stage bootloader and its importance.
Bye for now
Ashakiran is from Hyderabad, India and currently working as a Software Engineer in USA. He is a hobbyist programmer and enjoys writing code.