Время на прочтение
9 мин
Количество просмотров 1.3M
Вашему вниманию предлагается описание основных аспектов протокола HTTP — сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.
HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». В соответствии со спецификацией OSI, HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616.
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных — сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP — это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
Предположим, что он ввёл в адресной строке следующее:
http://alizar.habrahabr.ru/
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.habrahabr.ru.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
telnet alizar.habrahabr.ru 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод — это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) — по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко — HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок — это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Метод URI HTTP/Версия
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
GET / HTTP/1.1
Метод (в англоязычной тематической литературе используется слово method, а также иногда слово verb — «глагол») представляет собой последовательность из любых символов, кроме управляющих и разделителей, и определяет операцию, которую нужно осуществить с указанным ресурсом. Спецификация HTTP 1.1 не ограничивает количество разных методов, которые могут быть использованы, однако в целях соответствия общим стандартам и сохранения совместимости с максимально широким спектром программного обеспечения как правило используются лишь некоторые, наиболее стандартные методы, смысл которых однозначно раскрыт в спецификации протокола.
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
OPTIONS * HTTP/1.1
Версия определяет, в соответствии с какой версией стандарта HTTP составлен запрос. Указывается как два числа, разделённых точкой (например 1.1).
Для того, чтобы обратиться к веб-странице по определённому адресу (в данном случае путь к ресурсу — это «/»), нам следует отправить следующий запрос:
GET / HTTP/1.1
Host: alizar.habrahabr.ru
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Впрочем, в спецификации HTTP рекомендуется программировать HTTP-сервер таким образом, чтобы при обработке запросов в качестве межстрочного разделителя воспринимался символ LF, а предшествующий символ CR, при наличии такового, игнорировался. Соответственно, на практике бо́льшая часть серверов корректно обработает и такой запрос, где заголовки отделены символом LF, и он же дважды добавлен после объявления последнего заголовка.
Если вы хотите отправить запрос в точном соответствии со спецификацией, можете воспользоваться управляющими последовательностями r и n:
echo -en "GET / HTTP/1.1rnHost: alizar.habrahabr.rurnrn" | ncat alizar.habrahabr.ru 80
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
HTTP/Версия Код состояния Пояснение
Версия протокола здесь задаётся так же, как в запросе.
Код состояния (Status Code) — три цифры (первая из которых указывает на класс состояния), которые определяют результат совершения запроса. Например, в случае, если был использован метод GET, и сервер предоставляет ресурс с указанным идентификатором, то такое состояние задаётся с помощью кода 200. Если сервер сообщает о том, что такого ресурса не существует — 404. Если сервер сообщает о том, что не может предоставить доступ к данному ресурсу по причине отсутствия необходимых привилегий у клиента, то используется код 403. Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
HTTP/1.1 200 OK
Server: nginx/1.2.1
Date: Sat, 08 Mar 2014 22:53:46 GMT
Content-Type: application/octet-stream
Content-Length: 7
Last-Modified: Sat, 08 Mar 2014 22:53:30 GMT
Connection: keep-alive
Accept-Ranges: bytes
Wisdom
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
Смотрите сами:
HTTP/1.1 302 Moved Temporarily
Server: nginx
Date: Sat, 08 Mar 2014 22:29:53 GMT
Content-Type: text/html
Content-Length: 154
Connection: keep-alive
Keep-Alive: timeout=25
Location: http://habrahabr.ru/users/alizar/
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
В заголовке Location передан новый адрес. Теперь URI (идентификатор ресурса) изменился на /users/alizar/, а обращаться нужно на этот раз к серверу по адресу habrahabr.ru (впрочем, в данном случае это тот же самый сервер), и его же указывать в заголовке Host.
То есть:
GET /users/alizar/ HTTP/1.1
Host: habrahabr.ru
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS.
Название этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, а также, как правило, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.
На данный момент HTTPS поддерживается всеми популярными веб-браузерами.
А есть дополнительные возможности?
Протокол HTTP предполагает достаточно большое количество возможностей для расширения. В частности, спецификация HTTP 1.1 предполагает возможность использования заголовка Upgrade для переключения на обмен данными по другому протоколу. Запрос с таким заголовком отправляется клиентом. Если серверу требуется произвести переход на обмен данными по другому протоколу, то он может вернуть клиенту ответ со статусом «426 Upgrade Required», и в этом случае клиент может отправить новый запрос, уже с заголовком Upgrade.
Такая возможность используется, в частности, для организации обмена данными по протоколу WebSocket (протокол, описанный в спецификации RFC 6455, позволяющий обеим сторонам передавать данные в нужный момент, без отправки дополнительных HTTP-запросов): стандартное «рукопожатие» (handshake) сводится к отправке HTTP-запроса с заголовком Upgrade, имеющим значение «websocket», на который сервер возвращает ответ с состоянием «101 Switching Protocols», и далее любая сторона может начать передавать данные уже по протоколу WebSocket.
Что-то ещё, кстати, используют?
На данный момент существуют и другие протоколы, предназначенные для передачи веб-содержимого. В частности, протокол SPDY (произносится как английское слово speedy, не является аббревиатурой) является модификацией протокола HTTP, цель которой — уменьшить задержки при загрузке веб-страниц, а также обеспечить дополнительную безопасность.
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
Опубликованный в ноябре 2012 года черновик спецификации протокола HTTP 2.0 (следующая версия протокола HTTP после версии 1.1, окончательная спецификация для которой была опубликована в 1999) базируется на спецификации протокола SPDY.
Многие архитектурные решения, используемые в протоколе SPDY, а также в других предложенных реализациях, которые рабочая группа httpbis рассматривала в ходе подготовки черновика спецификации HTTP 2.0, уже ранее были получены в ходе разработки протокола HTTP-NG, однако работы над протоколом HTTP-NG были прекращены в 1998.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
В общем-то, да. Можно было бы описать конкретные методы и заголовки, но фактически эти знания нужны скорее в том случае, если вы пишете что-то конкретное (например, веб-сервер или какое-то клиентское программное обеспечение, которое связывается с серверами через HTTP), и для базового понимания принципа работы протокола не требуются. К тому же, всё это вы можете очень легко найти через Google — эта информация есть и в спецификациях, и в Википедии, и много где ещё.
Впрочем, если вы знаете английский и хотите углубиться в изучение не только самого HTTP, но и используемых для передачи пакетов TCP/IP, то рекомендую прочитать вот эту статью.
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Удачи и плодотворного обучения!
#статьи
- 30 сен 2022
-

0
Рассказываем об одном из самых популярных интернет-протоколов, на котором работает весь современный веб — HTTP.
Иллюстрация: Оля Ежак для Skillbox Media

Любитель научной фантастики и технологического прогресса. Хорошо сочетает в себе заумного технаря и утончённого гуманитария. Пишет про IT и радуется этому.
Каждый раз, когда вы включаете компьютер и заходите почитать статьи о программировании, браузер посылает куда-то какие-то запросы. Он делает это беспрерывно, пока вы сидите в интернете. Что это за запросы и зачем они нужны? Давайте разбираться.
HTTP означает «протокол передачи гипертекста» (или HyperText Transfer Protocol). Он представляет собой список правил, по которым компьютеры обмениваются данными в интернете. HTTP умеет передавать все возможные форматы файлов — например, видео, аудио, текст. Но при этом состоит только из текста.
Например, когда вы вписываете в строке браузера www.skillbox.ru, он составляет запрос и отправляет его на сервер, чтобы получить HTML-страницу сайта. Когда сервер обрабатывает запрос, то он отправляет ответ, в котором написано, что всё «ок» и вот вам сайт.
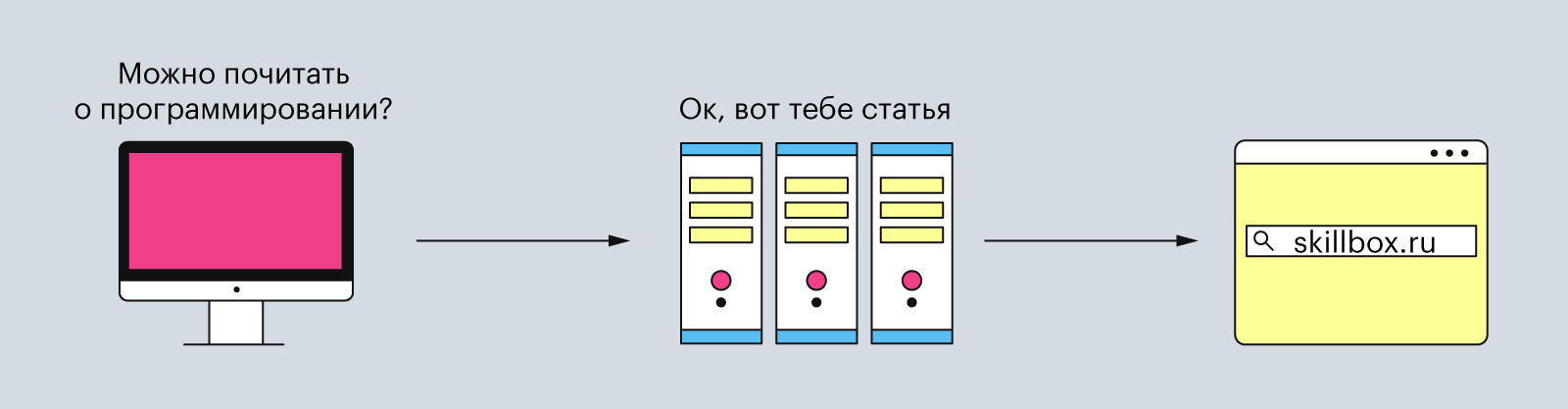
Иллюстрация: Polina Vari для Skillbox Media
Протокол HTTP используют ещё с 1992 года. Он очень простой, но при этом довольно функциональный. А ещё HTTP находится на самой вершине модели OSI (на прикладном уровне), где приложения обмениваются друг с другом данными. А работает HTTP с помощью протоколов TCP/IP и использует их, чтобы передавать данные.
Кроме HTTP в интернете работает ещё протокол HTTPS. Аббревиатура расшифровывается как «защищённый протокол передачи гипертекста» (или HyperText Transfer Protocol Secure). Он нужен для безопасной передачи данных по Сети. Всё происходит по тем же принципам, как и у HTTP, правда, перед отправкой данные дополнительно шифруются, а затем расшифровываются на сервере.
Например, HTTPS используют во время ввода данных банковской карты или паролей на сайтах — да и в целом большинство современных сайтов используют именно его.
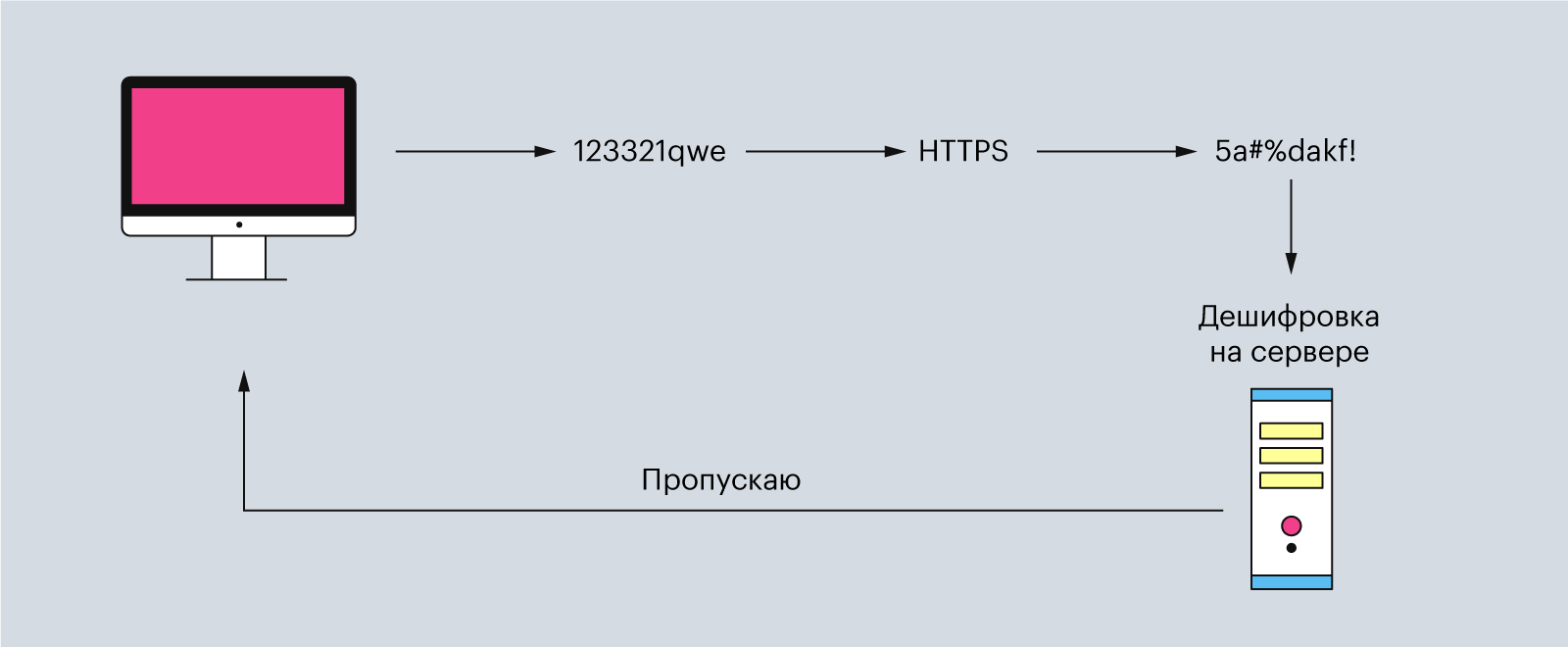
Иллюстрация: Polina Vari для Skillbox Media
HTTP состоит из двух элементов: клиента и сервера. Клиент отправляет запросы и ждёт данные от сервера. А сервер ждёт, пока ему придёт очередной запрос, обрабатывает его и возвращает ответ клиенту.
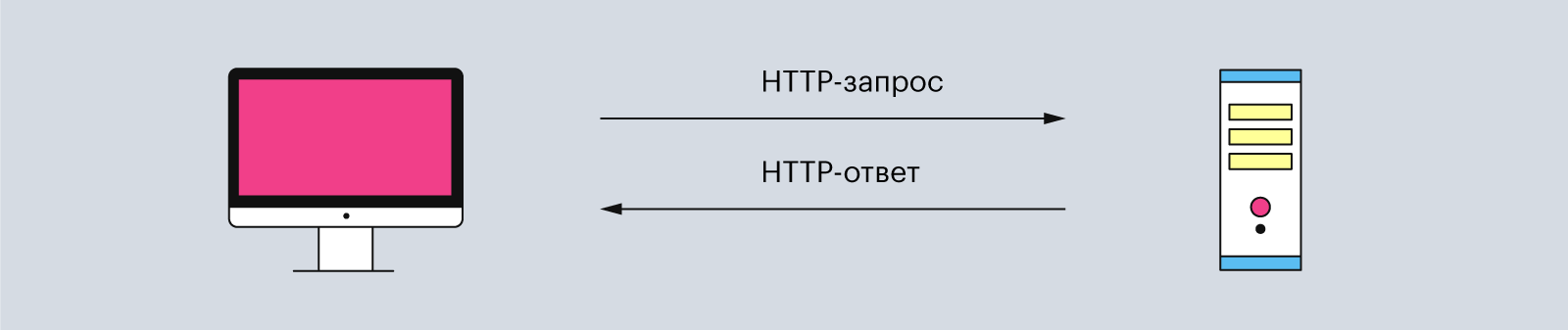
Иллюстрация: Polina Vari для Skillbox Media
Обычно эта связь между клиентом и сервером имеет посредников в виде прокси-серверов. Они нужны для разных операций — например, для безопасности и конфиденциальности, кэширования или распределения нагрузки на серверы.
Поэтому типичная процедура отправки HTTP-запроса от клиента выглядит так:
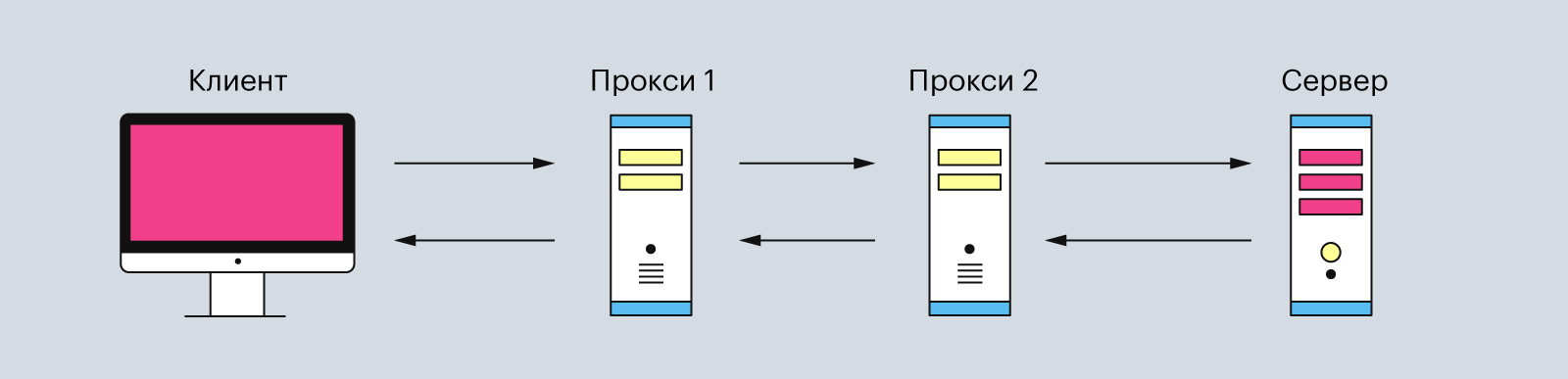
Иллюстрация: Polina Vari для Skillbox Media
Клиентом может быть любое устройство, через которое пользователь запрашивает данные. Часто в роли клиента выступает веб-браузер, программы для отладки приложений или даже командная строка. Главная особенность клиента — он всегда инициирует запрос.
Сервер — это устройство, которое обрабатывает запросы клиента. Он может состоять как из одного компьютера, так и из кластера. А ещё несколько виртуальных серверов могут находиться на одной физической машине.
Прокси-серверы — это второстепенные серверы, которые располагаются между клиентом и главным сервером. Они обрабатывают HTTP-запросы, а также ответы на них. Чаще всего прокси-серверы используют для кэширования и сжатия данных, обхода ограничений и анонимных запросов. И ещё — обычно между клиентом и основным сервером находится один или несколько таких прокси-серверов.
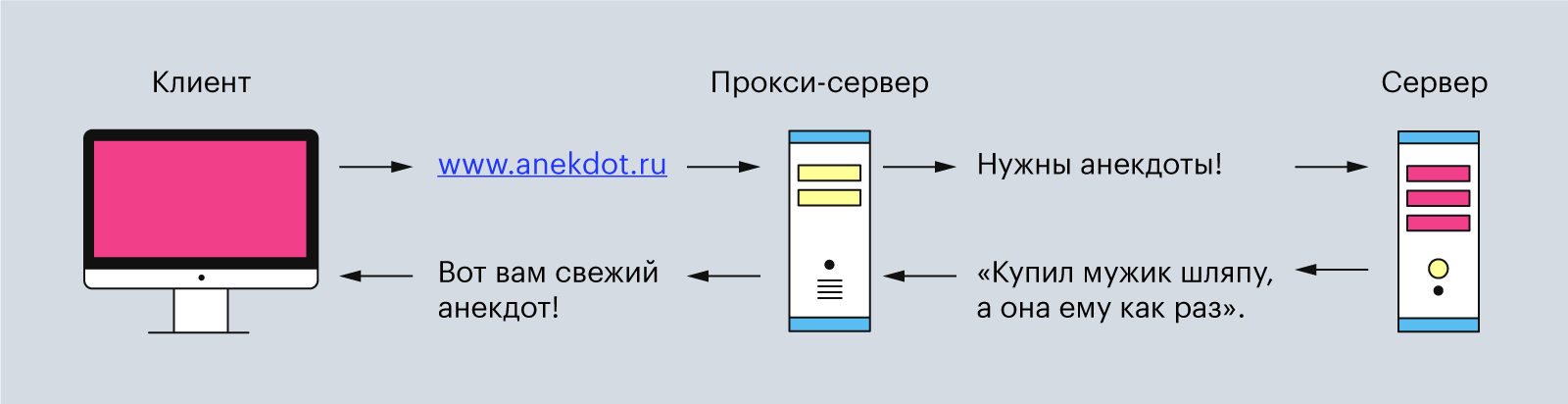
Иллюстрация: Polina Vari для Skillbox Media
Весь процесс передачи HTTP-запроса можно разбить на пять шагов. Давайте разберём их подробнее.
Чтобы отправить HTTP-запрос, нужно использовать URL-адрес — это «унифицированный указатель ресурса» (или Uniform Resource Locator). Он указывает браузеру, что нужно использовать HTTP-протокол, а затем получить файл с этого адреса обратно. Обычно URL-адреса начинаются с http:// или https:// (зависит от версии протокола).
Например, http://www.skillbox.ru — это URL-адрес. Он представляет собой главную страницу Skillbox. Но также в URL-адресе могут быть и поддомены — http://www.skillbox.ru/media. Теперь мы запросили главную страницу Skillbox Media.
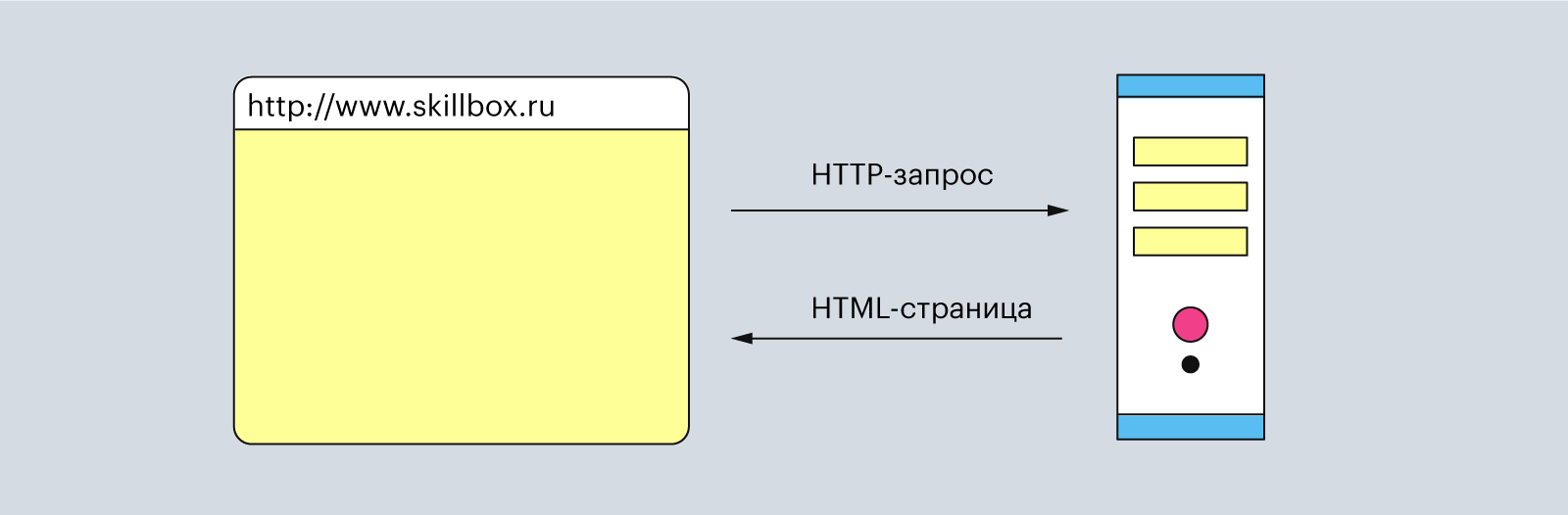
Иллюстрация: Polina Vari для Skillbox Media
Для пользователей URL-адрес — это набор понятных слов: Skillbox, Yandex, Google. Но для компьютера эти понятные нам слова — набор непонятных символов.
Поэтому браузер отправляет введённые вами слова в DNS, преобразователь URL-адресов в IP-адреса. DNS расшифровывается как «доменная система имён» (Domain Name System), и его можно представить как огромную таблицу со всеми зарегистрированными именами для сайтов и их IP-адресами.
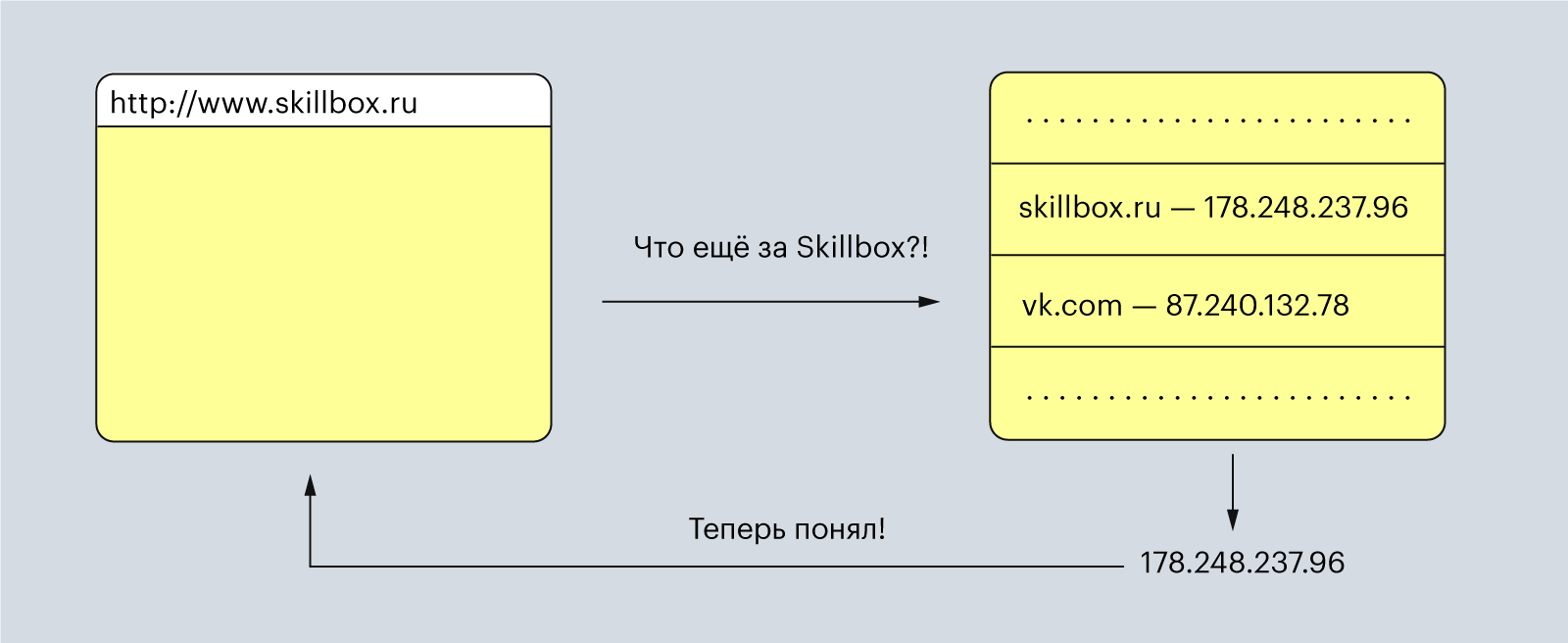
Иллюстрация: Polina Vari для Skillbox Media
DNS возвращает браузеру IP-адрес, с которым тот уже умеет работать. Теперь браузер начинает составлять HTTP-запрос с вложенным в него IP-адресом.
Сам HTTP-запрос может выглядеть так:

Здесь четыре элемента: метод — «GET», URI — «/», версия HTTP — «1.1» и адрес хоста — «www.skillbox.ru». Давайте разберём каждый из них подробнее.
Метод — это действие, которое клиент ждёт от сервера. Например, отправить ему HTML-страницу сайта или скачать документ. Протокол HTTP не ограничивает количество разных методов, но программисты договорились между собой использовать только три основных:
- GET — чтобы получить данные с сервера. Например, видео с YouTube или мем с Reddit.
- POST — чтобы отправить данные на сервер. Например, сообщение в Telegram или новый трек в SoundCloud.
- HEAD — чтобы получить только метаданные об HTML-странице сайта. Это те данные, которые находятся в <head>-теге HTML-файла.
URI расшифровывается как «унифицированный идентификатор ресурса» (или Uniform Resource Identifier) — это полный адрес сайта в Сети. Он состоит из двух частей: URL и URN. Первое — это адрес хоста. Например, www.skillbox.ru или www.vk.com. Второе — это то, что ставится после URL и символа / — например, для URI www.skillbox.ru/media URN-адресом будет /media. URN ещё можно назвать адресом до конкретного файла на сайте.
Версия HTTP указывает, какую версию HTTP браузер использует при отправке запроса. Если её не указывать, по умолчанию будет стоять версия 1.1. Она нужна, чтобы сервер вернул HTTP-ответ с той же версией HTTP-протокола и не создал ошибок с чтением у клиента.
Адрес хоста нужен, чтобы указать, с какого сайта клиент пытается получить данные. Адрес указывают в виде домена, но он сразу же меняется на IP-адрес перед отправкой запроса с помощью DNS.

Иллюстрация: Polina Vari для Skillbox Media
После получения и обработки HTTP-запроса сервер создаёт ответ и отправляет его обратно клиенту. В нём содержатся дополнительная информация (метаданные) и запрашиваемые данные.
Простой HTTP-ответ выглядит так:

Здесь три главные части: статус ответа — HTTP/1.1 200 OK, заголовки Content-Type и Content-Length и тело ответа — HTML-код. Рассмотрим их подробнее.
Статус ответа содержит версию HTTP-протокола, который клиент указал в HTTP-запросе. А после неё идёт код статуса ответа — 200, что означает успешное получение данных. Затем — словесное описание статуса ответа: «ок».
Всего статусов в спецификации HTTP 1.1 — 40. Вот самые популярные из них:
- 200 OK — данные успешно получены;
- 201 Created — значит, что запрос успешный, а данные созданы. Его используют, чтобы подтверждать успех запросов PUT или POST;
- 300 Moved Permanently — указывает, что URL-адрес изменили навсегда;
- 400 Bad Request — означает неверно сформированный запрос. Обычно это случается в связке с запросами POST и PUT, когда данные не прошли проверку или представлены в неправильном формате;
- 401 Unauthorized — нужно выполнить аутентификацию перед тем, как запрашивать доступ к ресурсу;
- 404 Not Found — значит, что не удалось найти запрашиваемый ресурс;
- 405 Forbidden — говорит, что указанный метод HTTP не поддерживается для запрашиваемого ресурса;
- 409 Conflict — произошёл конфликт. Например, когда клиент хочет создать дважды данные с помощью запроса PUT;
- 500 Internal Server Error — означает ошибку со стороны сервера.
Заголовки помогают браузеру разобраться с полученными данными и представить их в правильном виде. Например, заголовок Content-Type сообщает, какой формат файла пришёл и какие у него дополнительные параметры, а Content-Length — сколько места в байтах занимает этот файл.
Тело ответа содержит в себе сам файл. Например, сервер может вернуть код HTML-документа или отправить JPEG-картинку.

Иллюстрация: Polina Vari для Skillbox Media
Как только браузер получил ответ с веб-страницей, он отображает её с помощью внутреннего движка. И на этом весь процесс отправки и получение HTTP-запросов заканчивается, а клиент получает нужные ему данные.
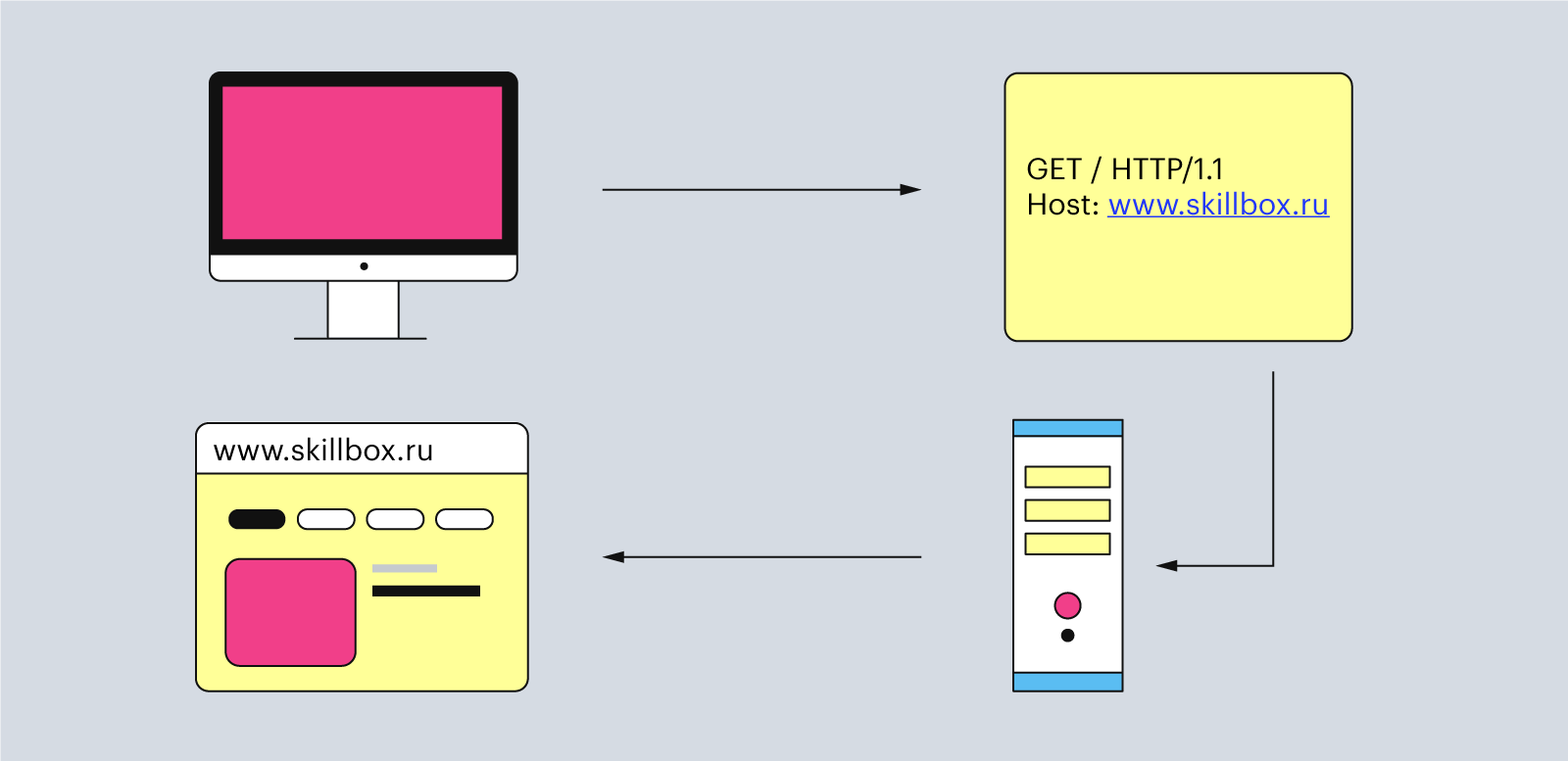
Иллюстрация: Polina Vari для Skillbox Media
- HTTP-протокол — это набор правил, по которым компьютеры обмениваются данными друг с другом. Его инициирует клиент (в данном случае — человек, заходящий в интернет с любого устройства), а обрабатывает сервер и возвращает обратно клиенту. Между ними могут находиться прокси-серверы, которые занимаются дополнительными задачами — шифрованием данных, перераспределением нагрузки или кэшированием.
- HTTP-запрос содержит четыре элемента: метод, URI, версию HTTP и адрес хоста. Метод указывает, какое действие нужно совершить. URI — это путь до конкретного файла на сайте. Версию HTTP нужно указывать, чтобы избежать ошибок, а адрес хоста помогает браузеру определить, куда отправлять HTTP-запрос.
- HTTP-ответ имеет три части: статус ответа, заголовки и тело ответа. В статусе ответа сообщается, всё ли прошло успешно и возникли ли ошибки. В заголовках указывается дополнительная информация, которая помогает браузеру корректно отобразить файл. А в тело ответа сервер кладёт запрашиваемый файл.

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать

Научитесь: Профессия Веб-разработчик
Узнать больше
Большинство используемых нами веб- и мобильных приложений постоянно взаимодействуют с глобальной сетью. Почти все подобные коммуникации совершаются с помощью запросов по протоколу HTTP. Рассказываем о них подробнее.
HTTP (HyperText Transfer Protocol, дословно — «протокол передачи гипертекста») представляет собой протокол прикладного уровня, используемый для доступа к ресурсам Всемирной Паутины. Под термином гипертекст следует понимать текст, в понятном для человека представлении, при этом содержащий ссылки на другие ресурсы.
Данный протокол описывается спецификацией RFC 2616. На сегодняшний день наиболее распространенной версией протокола является версия HTTP/2, однако нередко все еще можно встретить более раннюю версию HTTP/1.1.
В обмене информацией по HTTP-протоколу принимают участие клиент и сервер. Происходит это по следующей схеме:
- Клиент запрашивает у сервера некоторый ресурс.
- Сервер обрабатывает запрос и возвращает клиенту ресурс, который был запрошен.
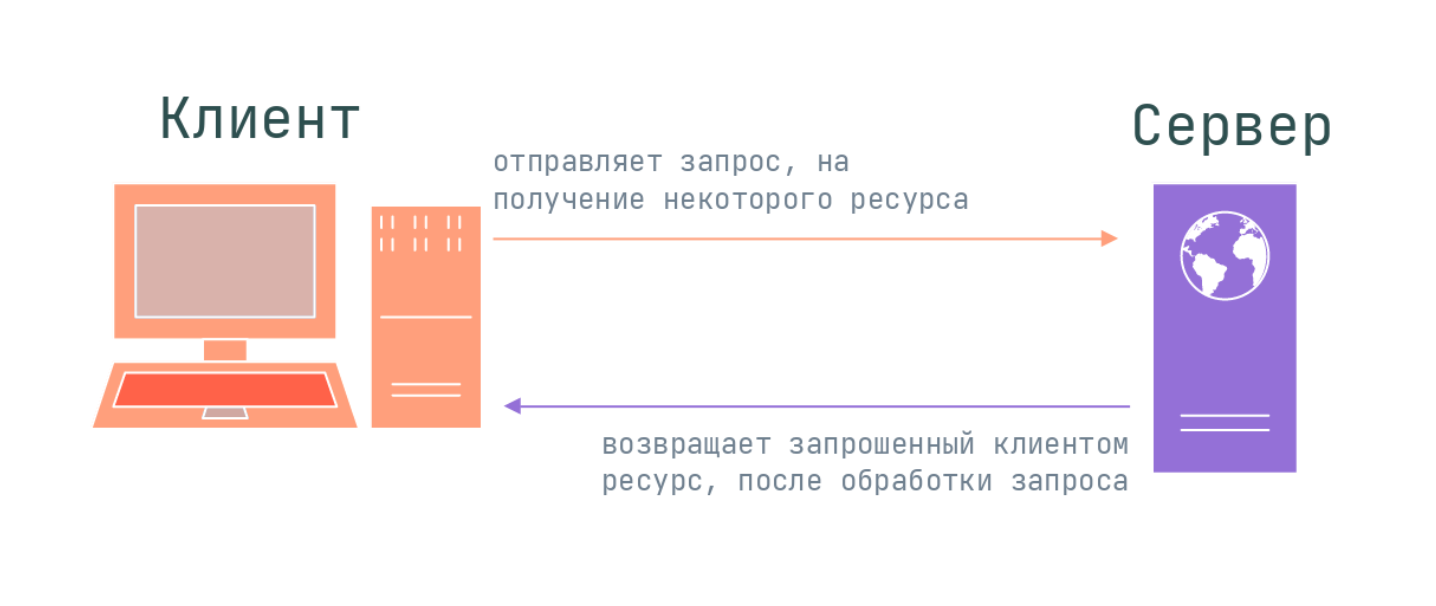
По умолчанию для коммуникации по HTTP используется порт 80, хотя вместо него может быть выбран и любой другой порт. Многое зависит от конфигурации конкретного веб-сервера.
Подробнее о протоколе HTTP читайте по ссылке →
HTTP-сообщения: запросы и ответы
Данные между клиентом и сервером в рамках работы протокола передаются с помощью HTTP-сообщений. Они бывают двух видов:
- Запросы (HTTP Requests) — сообщения, которые отправляются клиентом на сервер, чтобы вызвать выполнение некоторых действий. Зачастую для получения доступа к определенному ресурсу. Основой запроса является HTTP-заголовок.
- Ответы (HTTP Responses) — сообщения, которые сервер отправляет в ответ на клиентский запрос.
Само по себе сообщение представляет собой информацию в текстовом виде, записанную в несколько строчек.
В целом, как запросы HTTP, так и ответы имеют следующую структуру:
- Стартовая строка (start line) — используется для описания версии используемого протокола и другой информации — вроде запрашиваемого ресурса или кода ответа. Как можно понять из названия, ее содержимое занимает ровно одну строчку.
- HTTP-заголовки (HTTP Headers) — несколько строчек текста в определенном формате, которые либо уточняют запрос, либо описывают содержимое тела сообщения.
- Пустая строка, которая сообщает, что все метаданные для конкретного запроса или ответа были отправлены.
- Опциональное тело сообщения, которое содержит данные, связанные с запросом, либо документ (например HTML-страницу), передаваемый в ответе.
Рассмотрим атрибуты HTTP-запроса подробнее.
Стартовая строка
Стартовая строка HTTP-запроса состоит из трех элементов:
- Метод HTTP-запроса (method, реже используется термин verb). Обычно это короткое слово на английском, которое указывает, что конкретно нужно сделать с запрашиваемым ресурсом. Например, метод GET сообщает серверу, что пользователь хочет получить некоторые данные, а POST — что некоторые данные должны быть помещены на сервер.
- Цель запроса. Представлена указателем ресурса URL, который состоит из протокола, доменного имени (или IP-адреса), пути к конкретному ресурсу на сервере. Дополнительно может содержать указание порта, несколько параметров HTTP-запроса и еще ряд опциональных элементов.
- Версия используемого протокола (либо HTTP/1.1, либо HTTP/2), которая определяет структуру следующих за стартовой строкой данных.
В примере ниже стартовая строка указывает, что в качестве метода используется GET, обращение будет произведено к ресурсу /index.html, по версии протокола HTTP/1.1:
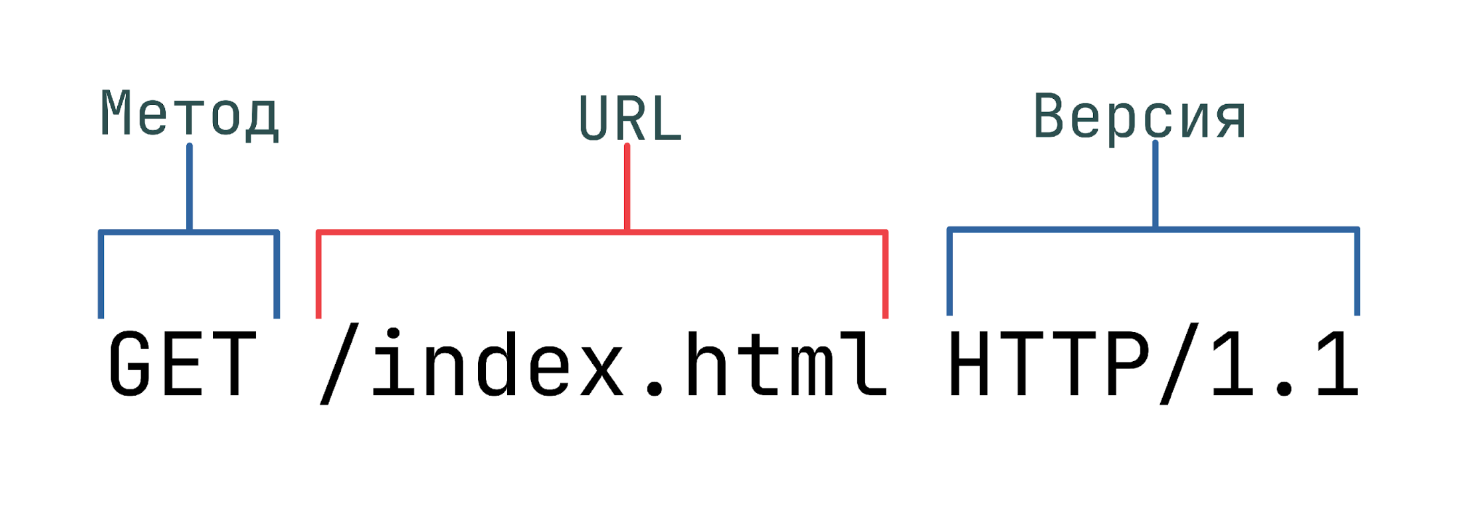
Разберемся с каждым из названных элементов подробнее.
Методы
Методы позволяют указать конкретное действие, которое мы хотим, чтобы сервер выполнил, получив наш запрос. Так, некоторые методы позволяют браузеру (который в большинстве случаев является источником запросов от клиента) отправлять дополнительную информацию в теле запроса — например, заполненную форму или документ.
Ниже приведены наиболее используемые методы и их описание:
Разберемся с каждым из названных элементов подробнее.
| Метод | Описание |
| GET | Позволяет запросить некоторый конкретный ресурс. Дополнительные данные могут быть переданы через строку запроса (Query String) в составе URL (например ?param=value).О составляющих URL мы поговорим чуть позже. |
| POST | Позволяет отправить данные на сервер. Поддерживает отправку различных типов файлов, среди которых текст, PDF-документы и другие типы данных в двоичном виде. Обычно метод POST используется при отправке информации (например, заполненной формы логина) и загрузке данных на веб-сайт, таких как изображения и документы. |
| HEAD | Здесь придется забежать немного вперед и сказать, что обычно сервер в ответ на запрос возвращает заголовок и тело, в котором содержится запрашиваемый ресурс. Данный метод при использовании его в запросе позволит получить только заголовки, которые сервер бы вернул при получении GET-запроса к тому же ресурсу. Запрос с использованием данного метода обычно производится для того, чтобы узнать размер запрашиваемого ресурса перед его загрузкой. |
| PUT | Используется для создания (размещения) новых ресурсов на сервере. Если на сервере данный метод разрешен без надлежащего контроля, то это может привести к серьезным проблемам безопасности. |
| DELETE | Позволяет удалить существующие ресурсы на сервере. Если использование данного метода настроено некорректно, то это может привести к атаке типа «Отказ в обслуживании» (Denial of Service, DoS) из-за удаления критически важных файлов сервера. |
| OPTIONS | Позволяет запросить информацию о сервере, в том числе информацию о допускаемых к использованию на сервере HTTP-методов. |
| PATCH | Позволяет внести частичные изменения в указанный ресурс по указанному расположению. |
URL
Получение доступа к ресурсам по HTTP-протоколу осуществляется с помощью указателя URL (Uniform Resource Locator). URL представляет собой строку, которая позволяет указать запрашиваемый ресурс и еще ряд параметров.
Использование URL неразрывно связано с другими элементами протокола, поэтому далее мы рассмотрим его основные компоненты и строение:
Поле Scheme используется для указания используемого протокола, всегда сопровождается двоеточием и двумя косыми чертами (://).
Host указывает местоположение ресурса, в нем может быть как доменное имя, так и IP-адрес.
Port, как можно догадаться, позволяет указать номер порта, по которому следует обратиться к серверу. Оно начинается с двоеточия (:), за которым следует номер порта. При отсутствии данного элемента номер порта будет выбран по умолчанию в соответствии с указанным значением Scheme (например, для http:// это будет порт 80).
Далее следует поле Path. Оно указывает на ресурс, к которому производится обращение. Если данное поле не указано, то сервер в большинстве случаев вернет указатель по умолчанию (например index.html).
Поле Query String начинается со знака вопроса (?), за которым следует пара «параметр-значение», между которыми расположен символ равно (=). В поле Query String могут быть переданы несколько параметров с помощью символа амперсанд (&) в качестве разделителя.
Не все компоненты необходимы для доступа к ресурсу. Обязательно следует указать только поля Scheme и Host.
Версии HTTP
Раз уж мы упомянули версию протокола как элемента стартовой строки, то стоит сказать об основных отличиях версий HTTP/1.X от HTTP/2.X.
Последняя стабильная, наиболее стандартизированная версия протокола первого поколения (версия HTTP/1.1) вышла в далеком 1997 году. Годы шли, веб-страницы становились сложнее, некоторые из них даже стали приложениями в том виде, в котором мы понимаем их сейчас. Кроме того, объем медиафайлов и скриптов, которые добавляли интерактивность страницам, рос. Это, в свою очередь, создавало перегрузки в работе протокола версии HTTP/1.1.
Стало очевидно, что у HTTP/1.1 есть ряд значительных недостатков:
- Заголовки, в отличие от тела сообщения, передавались в несжатом виде.
- Часто большая часть заголовков в сообщениях совпадала, но они продолжали передаваться по сети.
- Отсутствовала возможность так называемого мультиплексирования — механизма, позволяющего объединить несколько соединений в один поток данных. Приходилось открывать несколько соединений на сервере для обработки входящих запросов.
С выходом HTTP/2 было предложено следующее решение: HTTP/1.X-сообщения разбивались на так называемые фреймы, которые встраивались в поток данных.
Фреймы данных (тела сообщения) отделялись от фреймов заголовка, что позволило применять сжатие. Вместе с появлением потоков появился и ранее описанный механизм мультиплексирования — теперь можно было обойтись одним соединением для нескольких потоков.
Единственное о чем стоит сказать в завершение темы: HTTP/2 перестал быть текстовым протоколом, а стал работать с «сырой» двоичной формой данных. Это ограничивает чтение и создание HTTP-сообщений «вручную». Однако такова цена за возможность реализации более совершенной оптимизации и повышения производительности.
Заголовки
HTTP-заголовок представляет собой строку формата «Имя-Заголовок:Значение», с двоеточием(:) в качестве разделителя. Название заголовка не учитывает регистр, то есть между Host и host, с точки зрения HTTP, нет никакой разницы. Однако в названиях заголовков принято начинать каждое новое слово с заглавной буквы. Структура значения зависит от конкретного заголовка. Несмотря на то, что заголовок вместе со значениями может быть достаточно длинным, занимает он всего одну строчку.
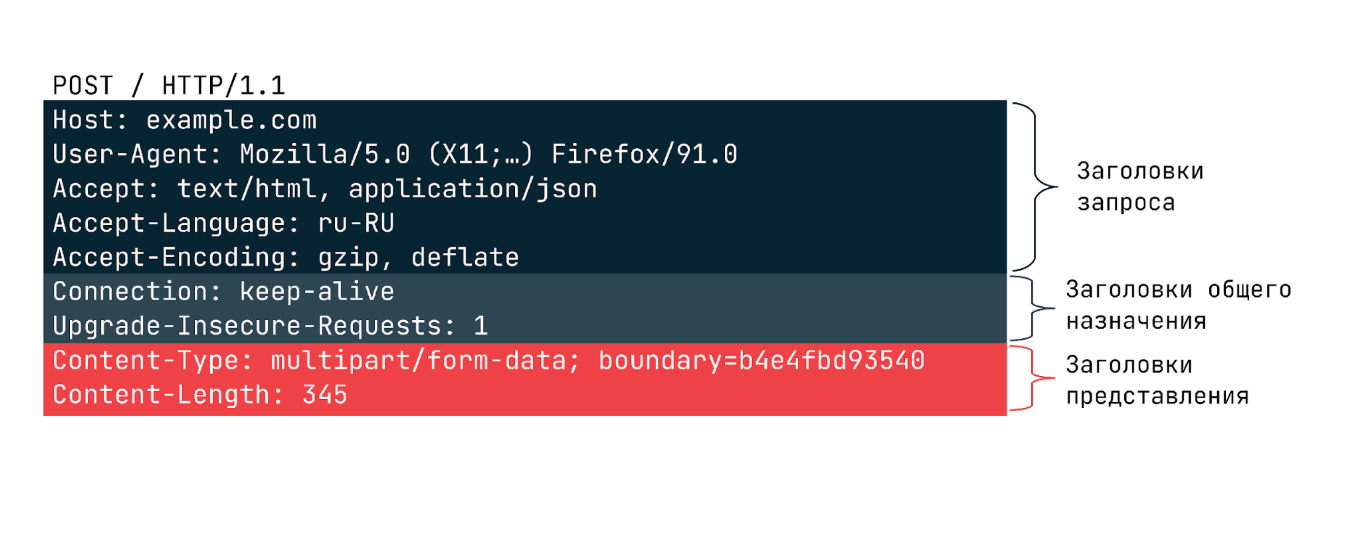
В запросах может передаваться большое число различных заголовков, но все их можно разделить на три категории:
- Общего назначения, которые применяются ко всему сообщению целиком.
- Заголовки запроса уточняют некоторую информацию о запросе, сообщая дополнительный контекст или ограничивая его некоторыми логическими условиями.
- Заголовки представления, которые описывают формат данных сообщения и используемую кодировку. Добавляются к запросу только в тех случаях, когда с ним передается некоторое тело.
Ниже можно видеть пример заголовков в запросе:
Самые частые заголовки запроса
| Заголовок | Описание |
| Host | Используется для указания того, с какого конкретно хоста запрашивается ресурс. В качестве возможных значений могут использоваться как доменные имена, так и IP-адреса. На одном HTTP-сервере может быть размещено несколько различных веб-сайтов. Для обращения к какому-то конкретному требуется данный заголовок. |
| User-Agent | Заголовок используется для описания клиента, который запрашивает ресурс. Он содержит достаточно много информации о пользовательском окружении. Например, может указать, какой браузер используется в качестве клиента, его версию, а также операционную систему, на которой этот клиент работает. |
| Refer | Используется для указания того, откуда поступил текущий запрос. Например, если вы решите перейти по какой-нибудь ссылке в этой статье, то вероятнее всего к запросу будет добавлен заголовок Refer: https://selectel.ru |
| Accept | Позволяет указать, какой тип медиафайлов принимает клиент. В данном заголовке могут быть указаны несколько типов, перечисленные через запятую (‘ , ‘). А для указания того, что клиент принимает любые типы, используется следующая последовательность — */*. |
| Cookie | Данный заголовок может содержать в себе одну или несколько пар «Куки-Значение» в формате cookie=value. Куки представляют собой небольшие фрагменты данных, которые хранятся как на стороне клиента, так и на сервере, и выступают в качестве идентификатора. Куки передаются вместе с запросом для поддержания доступа клиента к ресурсу. Помимо этого, куки могут использоваться и для других целей, таких как хранение пользовательских предпочтений на сайте и отслеживание клиентской сессии. Несколько кук в одном заголовке могут быть перечислены с помощью символа точка с запятой (‘ ; ‘), который используется как разделитель. |
| Authorization | Используется в качестве еще одного метода идентификации клиента на сервере. После успешной идентификации сервер возвращает токен, уникальный для каждого конкретного клиента. В отличие от куки, данный токен хранится исключительно на стороне клиента и отправляется клиентом только по запросу сервера. Существует несколько типов аутентификации, конкретный метод определяется тем веб-сервером или веб-приложением, к которому клиент обращается за ресурсом. |
Тело запроса
Завершающая часть HTTP-запроса — это его тело. Не у каждого HTTP-метода предполагается наличие тела. Так, например, методам вроде GET, HEAD, DELETE, OPTIONS обычно не требуется тело. Некоторые виды запросов могут отправлять данные на сервер в теле запроса: самый распространенный из таких методов — POST.
Ответы HTTP
HTTP-ответ является сообщением, которое сервер отправляет клиенту в ответ на его запрос. Его структура равна структуре HTTP-запроса: стартовая строка, заголовки и тело.
Строка статуса (Status line)
Стартовая строка HTTP-ответа называется строкой статуса (status line). На ней располагаются следующие элементы:
- Уже известная нам по стартовой строке запроса версия протокола (HTTP/2 или HTTP/1.1).
- Код состояния, который указывает, насколько успешно завершилась обработка запроса.
- Пояснение — короткое текстовое описание к коду состояния. Используется исключительно для того, чтобы упростить понимание и восприятие человека при просмотре ответа.

Коды состояния и текст статуса
Коды состояния HTTP используются для того, чтобы сообщить клиенту статус их запроса. HTTP-сервер может вернуть код, принадлежащий одной из пяти категорий кодов состояния:
| Категория | Описание |
| 1xx | Коды из данной категории носят исключительно информативный характер и никак не влияют на обработку запроса. |
| 2xx | Коды состояния из этой категории возвращаются в случае успешной обработки клиентского запроса. |
| 3xx | Эта категория содержит коды, которые возвращаются, если серверу нужно перенаправить клиента. |
| 4xx | Коды данной категории означают, что на стороне клиента был отправлен некорректный запрос. Например, клиент в запросе указал не поддерживаемый метод или обратился к ресурсу, к которому у него нет доступа. |
| 5xx | Ответ с кодами из этой категории приходит, если на стороне сервера возникла ошибка. |
Полный список кодов состояния доступен в спецификации к протоколу, ниже приведены только самые распространенные коды ответов:
| Категория | Описание |
| 200 OK | Возвращается в случае успешной обработки запроса, при этом тело ответа обычно содержит запрошенный ресурс. |
| 302 Found | Перенаправляет клиента на другой URL. Например, данный код может прийти, если клиент успешно прошел процедуру аутентификации и теперь может перейти на страницу своей учетной записи. |
| 400 Bad Request | Данный код можно увидеть, если запрос был сформирован с ошибками. Например, в нем отсутствовали символы завершения строки. |
| 403 Forbidden | Означает, что клиент не обладает достаточными правами доступа к запрошенному ресурсу. Также данный код можно встретить, если сервер обнаружил вредоносные данные, отправленные клиентом в запросе. |
| 404 Not Found | Каждый из нас, так или иначе, сталкивался с этим кодом ошибки. Данный код можно увидеть, если запросить у сервера ресурс, которого не существует на сервере. |
| 500 Internal Error | Данный код возвращается сервером, когда он не может по определенным причинам обработать запрос. |
Помимо основных кодов состояния, описанных в стандарте, существуют и коды состояния, которые объявляются крупными сетевыми провайдерами и серверными платформами. Так, коды состояния, используемые Selectel, можно посмотреть здесь.
Заголовки ответа
Response Headers, или заголовки ответа, используются для того, чтобы уточнить ответ, и никак не влияют на содержимое тела. Они существуют в том же формате, что и остальные заголовки, а именно «Имя-Значение» с двоеточием (:) в качестве разделителя.
Ниже приведены наиболее часто встречаемые в ответах заголовки:
| Категория | Пример | Описание |
| Server | Server: ngnix | Содержит информацию о сервере, который обработал запрос. |
| Set-Cookie | Set-Cookie:PHPSSID=bf42938f | Содержит куки, требуемые для идентификации клиента. Браузер парсит куки и сохраняет их в своем хранилище для дальнейших запросов. |
| WWW-Authenticate | WWW-Authenticate: BASIC realm=»localhost» | Уведомляет клиента о типе аутентификации, который необходим для доступа к запрашиваемому ресурсу. |
Тело ответа
Последней частью ответа является его тело. Несмотря на то, что у большинства ответов тело присутствует, оно не является обязательным. Например, у кодов «201 Created» или «204 No Content» тело отсутствует, так как достаточную информацию для ответа на запрос они передают в заголовке.
Безопасность HTTP-запросов, или что такое HTTPs
HTTP является расширяемым протоколом, который предоставляет огромное количество возможностей, а также поддерживает передачу всевозможных типов файлов. Однако, вне зависимости от версии, у него есть один существенный недостаток, который можно заметить если перехватить отправленный HTTP-запрос:
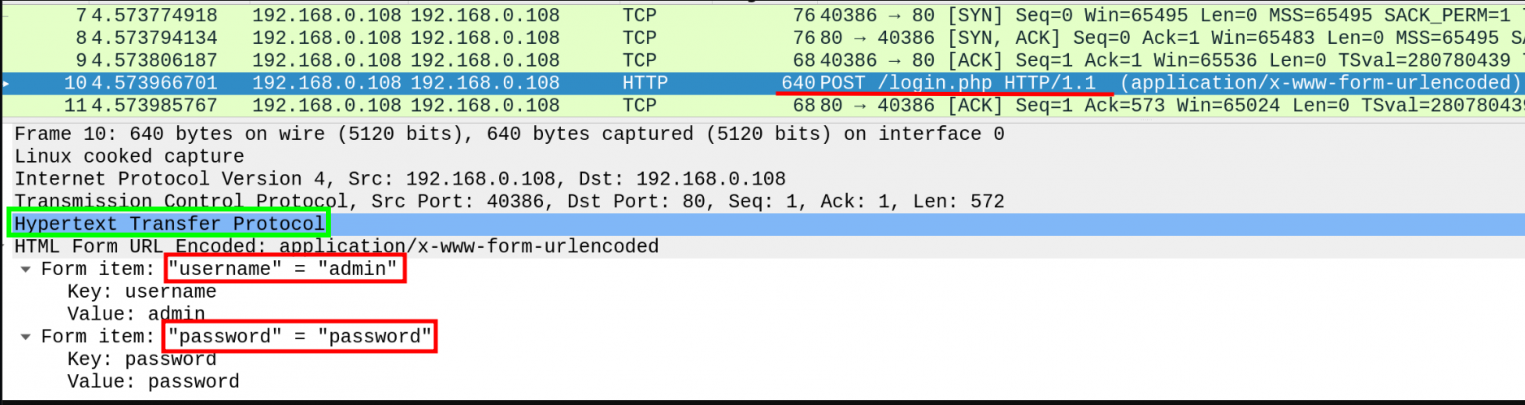
Да, все верно: данные передаются в открытом виде. HTTP сам по себе не предоставляет никаких средств шифрования.
Но как же тогда работают различные банковские приложения, интернет-магазины, сервисы оплаты услуг и прочие приложения, в которых циркулирует чувствительная информация пользователей?
Время рассказать про HTTPs!
HTTPs (HyperText Transfer Protocol, secure) является расширением HTTP-протокола, который позволяет шифровать отправляемые данные, перед тем как они попадут на транспортный уровень. Данный протокол по умолчанию использует порт 443.
Теперь если мы перехватим не HTTP , а HTTPs-запрос, то не увидим здесь ничего интересного:
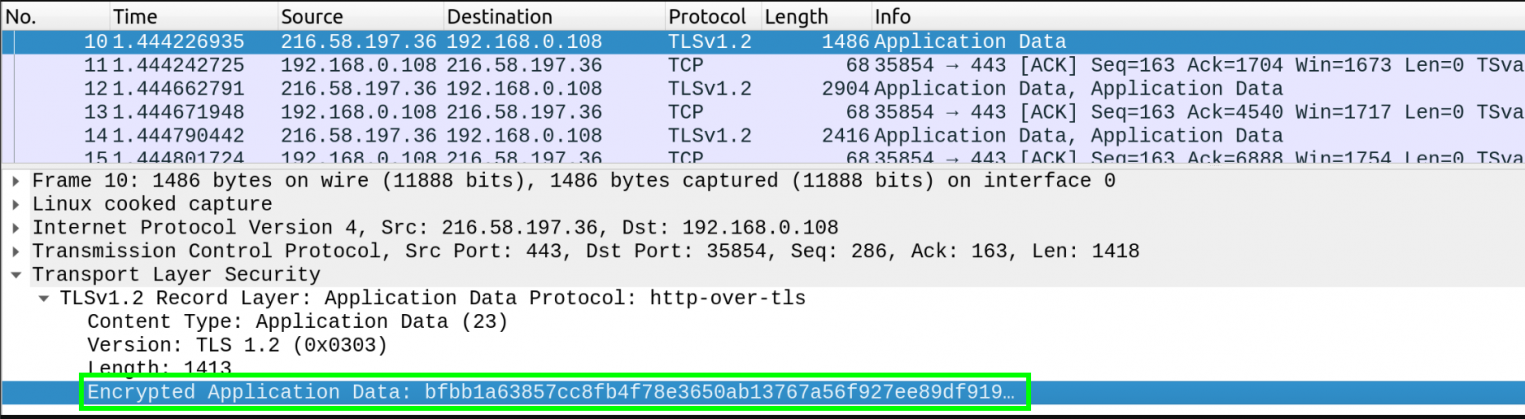
Данные передаются в едином зашифрованном потоке, что делает невозможным получение учетных данных пользователей и прочей критической информации средствами обычного перехвата.
Повысьте безопасность на сетевых портах с Selectel
Три межсетевых экрана для любых потребностей бизнеса.
Выбрать
Если хотите подробнее узнать о деталях работы протокола, читайте статью в нашем блоге →
Как отправить HTTP-запрос и прочитать его ответ
Теория это, конечно, отлично, но ничего так хорошо не закрепляет материал, как практика
Мы рассмотрим несколько способов, как написать HTTP-запрос в браузер, послать HTTP-запрос на сервер и получить ответ:
- Инструменты разработчика в браузере.
- Утилита cURL.
Инструменты разработчика
Основной программой на наших устройствах, которая работает с HTTP-протоколом, в большинстве случаев является браузер. Помимо обычных пользователей, с браузерами часто работают и разработчики веб-приложений. Именно их инструментами мы воспользуемся для работы с запросами и ответами.
По нажатию комбинации клавиш [Ctrl+Shift+I] или просто [F12] в подавляющем большинстве современных браузеров у нас откроется окно инструментов разработчика, которая представляет собой панель с несколькими вкладками. Нужная нам вкладка обычно называется Network. Перейдем в нее, а в адресной строке введем URL того сайта, на который хотим попасть. В качестве примера воспользуемся сайтом блога Selectel — https://selectel.ru/blog/.
После нажатия Enter сайт начнет загружаться, а открытая вкладка Network — заполняться различными элементами, начиная все больше напоминать приборную панель самолета.
Не спешите пугаться. Это всего лишь список ресурсов, которые нужны для правильного отображения и работы сайта.
Нажав на любой из них, мы можем увидеть детали обработки отправленного запроса:
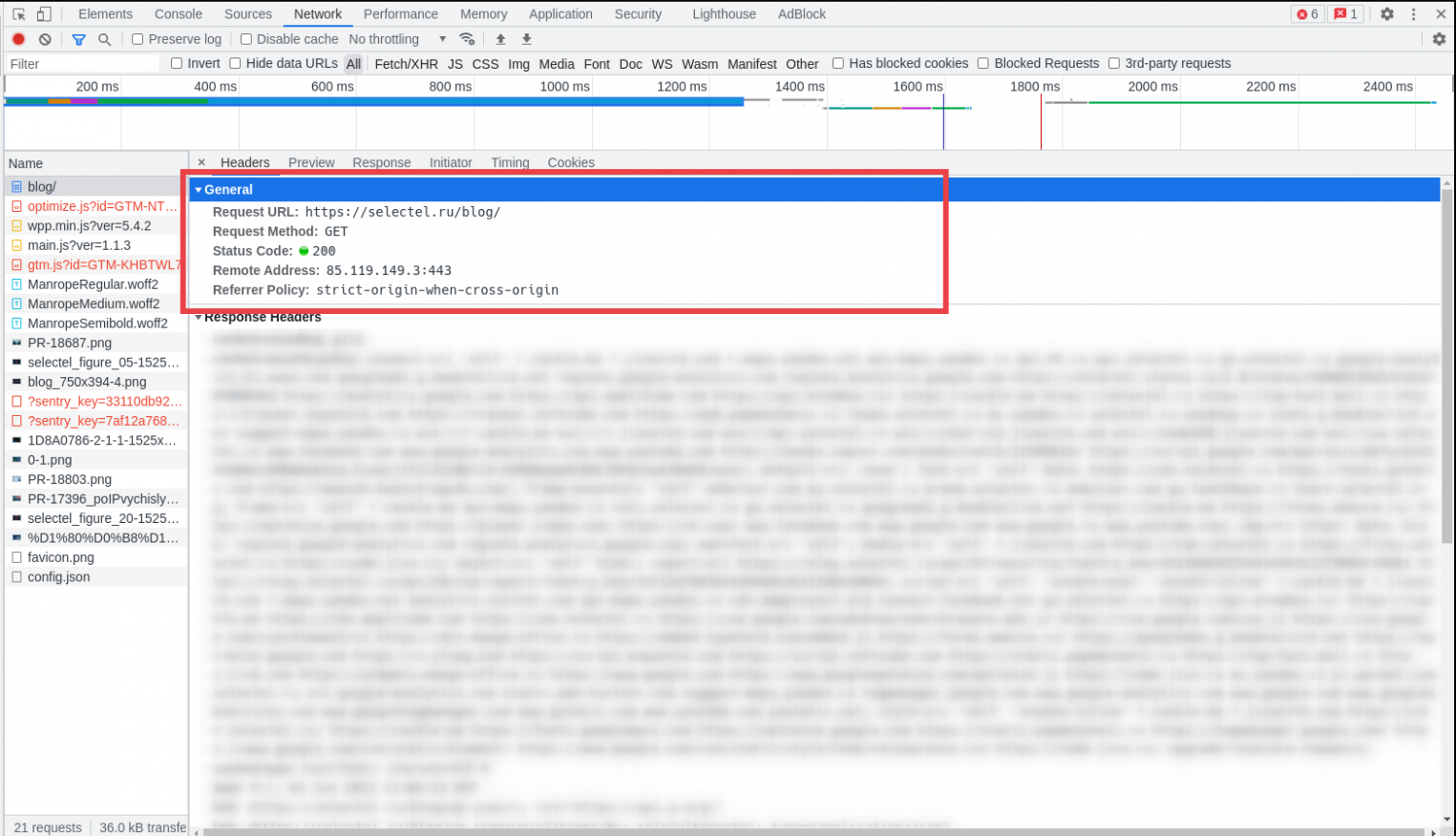
В данном запросе, например:
- URL, к которому было совершено обращение — https://selectel.ru/blog,
- Метод, который был использован в запросе — GET,
- И в качестве кода возврата сервер вернул нам страницу с кодом статуса — 200 OK
Утилита cURL
Следующий инструмент, с помощью которого мы сможем послать запрос на тот или иной сервер, это утилита cURL.
cURL (client URL) является небольшой утилитой командной строки, которая позволяет работать с HTTP и рядом других протоколов.
Для отправки запроса и получения ответа мы можем воспользоваться флагом -v и указанием URL того ресурса, который мы хотим получить. «Схему» HTTP-запроса можно увидеть на скрине ниже:

После запуска утилита выполняет:
- подключение к серверу,
- самостоятельно разрешает все вопросы, необходимые для отправки запроса по HTTPs,
- отправляет запрос, содержимое которого мы можем видеть благодаря флагу -v,
- принимая ответ от сервера, отображает его в командной строке «как-есть».
Помимо этого, у данной утилиты есть огромное количество опций, которые предоставляют возможности по детальной настройке отправляемых запросов. Все эти возможности и делают ее такой популярной у веб-разработчиков и других специалистов, которым приходится работать с протоколом HTTP.
Заключение
HTTP представляет собой расширяемый протокол прикладного уровня, на котором работает весь веб-сегмент интернета. В данной статье мы рассмотрели принцип его работы, структуру, «компоненты» HTTP-запросов. Коснулись вопросов отличия версий протокола, HTTPs — его расширения, добавляющего шифрование. Разобрали устройство запроса, поняли, как можно отправить HTTP-запрос и получить ответ от сервера.
Написание «расчет» или «рассчет» — это одна из самых распространенных ошибок. Это слово является существительным в единственном числе. Его однокоренным является словообразование «четный».
В соответствии с правилом русского языка:
- если корнем слова является «чёт», то в его приставке пишется одна буква «с»: расчёт, расчётный. Однако, есть слово-исключение: бессчётный;
- если корнем слова является «счит» через букву «и», то в его приставке пишется две буквы «с»: рассчитать.

Для того, чтобы легче запомнить правило написания слов «расчет» и «рассчитывать», нужно руководствоваться вот такой закономерностью:
- если в корне буква «ё» (существительное), то в приставке одна «с»;
- если в корне буква «и» (глагол), то в приставке две «с».
Сделаем морфемный разбор рассматриваемого слова:
- рас — приставка;
- чёт — корень.
Таким образом, пишется «расчет» правильно с одной буквой «с».
Примеры предложений
Расчёт был закончен номером десять, таким образом участники соревнований прошли предстартовую подготовку.
Группа программистов произвела расчёт нейронной модели и подготовила алгоритм обучения нейронной сети.
Литературный пример
Каждый теперича кроток,
Ну да и нам-то расчёт:
На восемь гривен подметок…
(«Песни о свободном слове», Н. А. Некрасов)
Правильно
Пишется — единственно верный вариант написания слова, который зафиксирован во всех словарях русского языка. Глагол пишется через букву «е» во втором слоге и без мягкого знака, так как в вопросе, который ставится к слову мягкого знака нет (что делает?).
Это слово правильно пишется только так
Сегодня совсем не пишется, муза не пришла
Учитель, а как правильно пишется слово «аккумулятор»?
В этой графе пишется дата рождения
Неправильно
Пишится, пишеться
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите левый Ctrl+Enter.
Читайте также:

Рис. Как правильно пишется слово «агентство»?
КАК ПРАВИЛЬНО ПИШЕТСЯ СЛОВО «агентство» И ПОЧЕМУ? Правильное написание слова «агентство» необходимо запомнить, так как оно является словарным и к нему невозможно подобрать однокоренное проверочное слово. Слово «агентство» обязательно к запоминанию в 9, 11 классе(ах).
аге́нтство
УДАРЕНИЕ. Ударение в слове «агентство» падает на второй слог (ударная гласная «Е»).
ПРОИСХОЖДЕНИЕ/ЭТИМОЛОГИЯ СЛОВА. Слово «агентство» происходит от русского существительного «агент», а оно в свою очередь от латинского «agens» (agent) — то есть «выразительный, активный; истец; ревизор». «Agens» образовано от латинского «agere», что в переводе на русский язык означает «приводить в движение, гнать».
Слово «что-то» правильно пишется с дефисом.
Чтобы выбрать правильный вариант написания слова «что то» или «что-то», выясним часть речи, к которой оно принадлежит.
Часть речи слова «что-то»
Слово «что» только указывает на предмет, не называя его конкретно, и отвечает на вопрос: что?
По этим грамматическим признакам отнесем его к местоимениям.
Дополнительный материал
Это местоимение в зависимости от контекста бывает относительным или вопросительным.
Вопросительное местоимение участвует в создании прямого вопроса, например:
Что это дымит там, за холмом? (Б. Горбатов)
Что пророчит сей необъятный простор? (Н.В. Гоголь)
Но что это? Ветер внезапно налетел и промчался (И.С. Тургенев)
Относительное местоимение «что» связывает две части сложноподчиненного предложения, то есть является союзным словом.
Слава борцам, что за правду вставали, знамя победы высоко несли (С. Михалков).
Всех верней на белом свете путь, что ты проложишь сам (Е. Долматовский).
Дополнительный материал
Правописание слова «что-то»
Определив, что анализируемое слово является местоимением, выясним, какой вариант написания слова «что-то» или «что то» выбрать.
Слово «то» может писаться по-разному, отдельно и с дефисом, в зависимости от того, какой частью речи оно является (местоимением, частицей, союзом), с каким словом оно употребляется и в каком контексте.
От относительного местоимения «что» образуется неопределённое местоимение с помощью частицы «то»:
Словообразование
что → что-то
Оно неопределённо указывает на предмет, признак или качество.
В картинах Архипа Куинджи есть что-то отличающее его картины от работ многих современников (В. Бялик).
Посредством дефиса присоединяется частица «то» к словам, принадлежащим к разным частям речи:
- к неопределенным местоимениям — кто-то, какой-то, чей-то, сколько-то, столько-то;
- к неопределённым наречиям — когда-то, где-то, куда-то, зачем-то, почему-то.
А также в определенном контексте она употребляется с существительными, глаголами, другими частицами, о чём более подробно узнаем из статьи «Раздельное и дефисное написание «то» со словами».
Вывод
Неопределённое местоимение «что-то» пишется с дефисом.
Примеры предложений
Что-то с грохотом упало с полки.
Что-то знакомое было в чертах этого лица.
Хочется увидеть что-то интересное в этом городе.

«Поэтому» и «по этому» — как правильно пишется? На самом деле, оба варианта являются правильными. Важный нюанс — необходимо знать, в какой ситуации будет правильным использовать тот или иной вариант написания. Сейчас мы с этим разберемся.
Распространенные ошибки – варианты неправильного написания
Недопустимо писать слово через дефис – «по-этому».
Так же нередко можно встретить случаи, когда пишут через букву «е» – «поетому», что является ошибкой.
Части речи
|
Слово |
Часть речи |
|
Поэтому (слитно) |
Наречие |
|
По этому (раздельно) |
Указательное местоимение с предлогом |
В каких случаях пишем поэтому (слитно)
Пишем слитно «поэтому» в случаях, когда в предложении есть обоснование чего-то, то есть присутствует объяснение какого-то действия. В этом случае это наречие с союзным словом.
Примеры правильного слитного написания:
На улице стемнело, поэтому они включили фонарь.
Он знал ответ на этот вопрос, поэтому поднял руку.
Он был уже не молод, поэтому искал себе женщину постарше.
Где ставить запятую?
В предложении, где первая часть повествует читателю о причине, а вторая является следствием первой части, слово «поэтому» будет как раз связующим словом между причиной и следствием. Поэтому необходимо ставить запятую перед словом «поэтому».
В случаях, когда предложение начинается со слова «поэтому», выделять запятыми нет необходимости.
В каких случаях пишем по этому (раздельно)
Раздельно пишем «по этому» в случаях, когда в предложении мы указываем на конкретный предмет, явление или что-то другое. В данном случае это указательное местоимение с предлогом.
Примеры правильного раздельного написания:
Уровень воды поднялся и они решили идти по этому мосту, а не по другому.
По этому пути можно дойти в город в два раза быстрее.
По этой поверхности Марса еще не ступала нога человека.
Синонимы к слову поэтому
|
Потому |
Наречие указательное |
|
Почему |
Наречие вопросительное |
|
Затем |
Наречие указательное |
|
Отчего |
Союз |
|
Оттого |
Наречие указательное |
|
Следовательно |
Союз |
|
То-то |
Частица |
|
Потому-то |
Местоименное прилагательное |
|
Посему |
Наречие |
|
Оттого-то |
Местоименное прилагательное |
|
Следственно |
Союз |
|
Благодаря тому |
Прилагательное |
|
Благодаря чего |
Прилагательное |
|
Благодаря этому |
Местоимение-существительное |
|
В рассуждении сего |
Прилагательное |
|
В связи с этим |
Краткое прилагательное |
|
Ввиду этого |
Местоимение-существительное |
|
Вот почему |
Наречие вопросительное |
|
Вследствие того |
Прилагательное |
|
Вследствие чего |
Прилагательное |
|
Вследствие этого |
Местоимение-существительное |
|
Из-за этого |
Местоимение-существительное |
|
По этой причине |
Существительное |
| International standard |
|
|---|---|
| Developed by | initially CERN; IETF, W3C |
| Introduced | 1991; 32 years ago |
| Website | https://httpwg.org/specs/ |
The Hypertext Transfer Protocol (HTTP) is an application layer protocol in the Internet protocol suite model for distributed, collaborative, hypermedia information systems.[1] HTTP is the foundation of data communication for the World Wide Web, where hypertext documents include hyperlinks to other resources that the user can easily access, for example by a mouse click or by tapping the screen in a web browser.
Development of HTTP was initiated by Tim Berners-Lee at CERN in 1989 and summarized in a simple document describing the behavior of a client and a server using the first HTTP protocol version that was named 0.9.[2]
That first version of HTTP protocol soon evolved into a more elaborated version that was the first draft toward a far future version 1.0.[3]
Development of early HTTP Requests for Comments (RFCs) started a few years later and it was a coordinated effort by the Internet Engineering Task Force (IETF) and the World Wide Web Consortium (W3C), with work later moving to the IETF.
HTTP/1 was finalized and fully documented (as version 1.0) in 1996.[4] It evolved (as version 1.1) in 1997 and then its specifications were updated in 1999, 2014, and 2022.[5]
Its secure variant named HTTPS is used by more than 80% of websites.[6]
HTTP/2, published in 2015, provides a more efficient expression of HTTP’s semantics «on the wire». It is now used by 41% of websites[7] and supported by almost all web browsers (over 97% of users).[8] It is also supported by major web servers over Transport Layer Security (TLS) using an Application-Layer Protocol Negotiation (ALPN) extension[9] where TLS 1.2 or newer is required.[10][11]
HTTP/3, the successor to HTTP/2, was published in 2022.[12] It is now used by over 25% of websites[13] and is supported by many web browsers (over 75% of users).[14] HTTP/3 uses QUIC instead of TCP for the underlying transport protocol. Like HTTP/2, it does not obsolesce previous major versions of the protocol. Support for HTTP/3 was added to Cloudflare and Google Chrome first,[15][16] and is also enabled in Firefox.[17] HTTP/3 has lower latency for real-world web pages, if enabled on the server, load faster than with HTTP/2, and even faster than HTTP/1.1, in some cases over 3× faster than HTTP/1.1 (which is still commonly only enabled).[18]
Technical overview[edit]

URL beginning with the HTTP scheme and the WWW domain name label
HTTP functions as a request–response protocol in the client–server model. A web browser, for example, may be the client whereas a process, named web server, running on a computer hosting one or more websites may be the server. The client submits an HTTP request message to the server. The server, which provides resources such as HTML files and other content or performs other functions on behalf of the client, returns a response message to the client. The response contains completion status information about the request and may also contain requested content in its message body.
A web browser is an example of a user agent (UA). Other types of user agent include the indexing software used by search providers (web crawlers), voice browsers, mobile apps, and other software that accesses, consumes, or displays web content.
HTTP is designed to permit intermediate network elements to improve or enable communications between clients and servers. High-traffic websites often benefit from web cache servers that deliver content on behalf of upstream servers to improve response time. Web browsers cache previously accessed web resources and reuse them, whenever possible, to reduce network traffic. HTTP proxy servers at private network boundaries can facilitate communication for clients without a globally routable address, by relaying messages with external servers.
To allow intermediate HTTP nodes (proxy servers, web caches, etc.) to accomplish their functions, some of the HTTP headers (found in HTTP requests/responses) are managed hop-by-hop whereas other HTTP headers are managed end-to-end (managed only by the source client and by the target web server).
HTTP is an application layer protocol designed within the framework of the Internet protocol suite. Its definition presumes an underlying and reliable transport layer protocol,[19] thus Transmission Control Protocol (TCP) is commonly used. However, HTTP can be adapted to use unreliable protocols such as the User Datagram Protocol (UDP), for example in HTTPU and Simple Service Discovery Protocol (SSDP).
HTTP resources are identified and located on the network by Uniform Resource Locators (URLs), using the Uniform Resource Identifiers (URI’s) schemes http and https. As defined in RFC 3986, URIs are encoded as hyperlinks in HTML documents, so as to form interlinked hypertext documents.
In HTTP/1.0 a separate connection to the same server is made for every resource request.[20]
In HTTP/1.1 instead a TCP connection can be reused to make multiple resource requests (i.e. of HTML pages, frames, images, scripts, stylesheets, etc.).[21][22]
HTTP/1.1 communications therefore experience less latency as the establishment of TCP connections presents considerable overhead, specially under high traffic conditions.[23]
HTTP/2 is a revision of previous HTTP/1.1 in order to maintain the same client–server model and the same protocol methods but with these differences in order:
- to use a compressed binary representation of metadata (HTTP headers) instead of a textual one, so that headers require much less space;
- to use a single TCP/IP (usually encrypted) connection per accessed server domain instead of 2 to 8 TCP/IP connections;
- to use one or more bidirectional streams per TCP/IP connection in which HTTP requests and responses are broken down and transmitted in small packets to almost solve the problem of the HOLB (head of line blocking). [note 1]
- to add a push capability to allow server application to send data to clients whenever new data is available (without forcing clients to request periodically new data to server by using polling methods).[24]
HTTP/2 communications therefore experience much less latency and, in most cases, even more speed than HTTP/1.1 communications.
HTTP/3 is a revision of previous HTTP/2 in order to use QUIC + UDP transport protocols instead of TCP/IP connections also to slightly improve the average speed of communications and to avoid the occasional (very rare) problem of TCP/IP connection congestion that can temporarily block or slow down the data flow of all its streams (another form of «head of line blocking«).
History[edit]

The term hypertext was coined by Ted Nelson in 1965 in the Xanadu Project, which was in turn inspired by Vannevar Bush’s 1930s vision of the microfilm-based information retrieval and management «memex» system described in his 1945 essay «As We May Think». Tim Berners-Lee and his team at CERN are credited with inventing the original HTTP, along with HTML and the associated technology for a web server and a client user interface called web browser. Berners-Lee designed HTTP in order to help with the adoption of his other idea: the «WorldWideWeb» project, which was first proposed in 1989, now known as the World Wide Web.
The first web server went live in 1990.[25][26] The protocol used had only one method, namely GET, which would request a page from a server.[27] The response from the server was always an HTML page.[2]
Summary of HTTP milestone versions[edit]
| Version | Year introduced | Current status |
|---|---|---|
| HTTP/0.9 | 1991 | Obsolete |
| HTTP/1.0 | 1996 | Obsolete |
| HTTP/1.1 | 1997 | Standard |
| HTTP/2 | 2015 | Standard |
| HTTP/3 | 2022 | Standard |
- HTTP/0.9
- In 1991, the first documented official version of HTTP was written as a plain document, less than 700 words long, and this version was named HTTP/0.9. HTTP/0.9 supported only GET method, allowing clients to only retrieve HTML documents from the server, but not supporting any other file formats or information upload.[2]
- HTTP/1.0-draft
- Since 1992, a new document was written to specify the evolution of the basic protocol towards its next full version. It supported both the simple request method of the 0.9 version and the full GET request that included the client HTTP version. This was the first of the many unofficial HTTP/1.0 drafts that preceded the final work on HTTP/1.0.[3]
- W3C HTTP Working Group
- After having decided that new features of HTTP protocol were required and that they had to be fully documented as official RFCs, in early 1995 the HTTP Working Group (HTTP WG, led by Dave Raggett) was constituted with the aim to standardize and expand the protocol with extended operations, extended negotiation, richer meta-information, tied with a security protocol which became more efficient by adding additional methods and header fields.[28][29]
- The HTTP WG planned to revise and publish new versions of the protocol as HTTP/1.0 and HTTP/1.1 within 1995, but, because of the many revisions, that timeline lasted much more than one year.[30]
- The HTTP WG planned also to specify a far future version of HTTP called HTTP-NG (HTTP Next Generation) that would have solved all remaining problems, of previous versions, related to performances, low latency responses, etc. but this work started only a few years later and it was never completed.
- HTTP/1.0
- In May 1996, RFC 1945 was published as a final HTTP/1.0 revision of what had been used in previous 4 years as a pre-standard HTTP/1.0-draft which was already used by many web browsers and web servers.
- In early 1996 developers started to even include unofficial extensions of the HTTP/1.0 protocol (i.e. keep-alive connections, etc.) into their products by using drafts of the upcoming HTTP/1.1 specifications.[31]
- HTTP/1.1
- Since early 1996, major web browsers and web server developers also started to implement new features specified by pre-standard HTTP/1.1 drafts specifications. End-user adoption of the new versions of browsers and servers was rapid. In March 1996, one web hosting company reported that over 40% of browsers in use on the Internet used the new HTTP/1.1 header «Host» to enable virtual hosting. That same web hosting company reported that by June 1996, 65% of all browsers accessing their servers were pre-standard HTTP/1.1 compliant.[32]
- In January 1997, RFC 2068 was officially released as HTTP/1.1 specifications.
- In June 1999, RFC 2616 was released to include all improvements and updates based on previous (obsolete) HTTP/1.1 specifications.
- W3C HTTP-NG Working Group
- Resuming the old 1995 plan of previous HTTP Working Group, in 1997 an HTTP-NG Working Group was formed to develop a new HTTP protocol named HTTP-NG (HTTP New Generation). A few proposals / drafts were produced for the new protocol to use multiplexing of HTTP transactions inside a single TCP/IP connection, but in 1999, the group stopped its activity passing the technical problems to IETF.[33]
- IETF HTTP Working Group restarted
- In 2007, the IETF HTTP Working Group (HTTP WG bis or HTTPbis) was restarted firstly to revise and clarify previous HTTP/1.1 specifications and secondly to write and refine future HTTP/2 specifications (named httpbis).[34][35]
- SPDY: an unofficial HTTP protocol developed by Google
- In 2009, Google, a private company, announced that it had developed and tested a new HTTP binary protocol named SPDY. The implicit aim was to greatly speed up web traffic (specially between future web browsers and its servers).
- SPDY was indeed much faster than HTTP/1.1 in many tests and so it was quickly adopted by Chromium and then by other major web browsers.[36]
- Some of the ideas about multiplexing HTTP streams over a single TCP/IP connection were taken from various sources, including the work of W3C HTTP-NG Working Group.
- HTTP/2
- In January–March 2012, HTTP Working Group (HTTPbis) announced the need to start to focus on a new HTTP/2 protocol (while finishing the revision of HTTP/1.1 specifications), maybe taking in consideration ideas and work done for SPDY.[37][38]
- After a few months about what to do to develop a new version of HTTP, it was decided to derive it from SPDY.[39]
- In May 2015, HTTP/2 was published as RFC 7540 and quickly adopted by all web browsers already supporting SPDY and more slowly by web servers.
- 2014 updates to HTTP/1.1
- In June 2014, the HTTP Working Group released an updated six-part HTTP/1.1 specification obsoleting RFC 2616:
- RFC 7230, HTTP/1.1: Message Syntax and Routing
- RFC 7231, HTTP/1.1: Semantics and Content
- RFC 7232, HTTP/1.1: Conditional Requests
- RFC 7233, HTTP/1.1: Range Requests
- RFC 7234, HTTP/1.1: Caching
- RFC 7235, HTTP/1.1: Authentication
- HTTP/0.9 Deprecation
- In RFC 7230 Appendix-A, HTTP/0.9 was deprecated for servers supporting HTTP/1.1 version (and higher):[40]
Since HTTP/0.9 did not support header fields in a request, there is no mechanism for it to support name-based virtual hosts (selection of resource by inspection of the Host header field). Any server that implements name-based virtual hosts ought to disable support for HTTP/0.9. Most requests that appear to be HTTP/0.9 are, in fact, badly constructed HTTP/1.x requests caused by a client failing to properly encode the request-target.
- Since 2016 many product managers and developers of user agents (browsers, etc.) and web servers have begun planning to gradually deprecate and dismiss support for HTTP/0.9 protocol, mainly for the following reasons:[41]
- it is so simple that an RFC document was never written (there is only the original document);[2]
- it has no HTTP headers and lacks many other features that nowadays are required for minimal security reasons;
- it has not been widespread since 1999..2000 (because of HTTP/1.0 and HTTP/1.1) and is commonly used only by some very old network hardware, i.e. routers, etc.
- [note 2]
- HTTP/3
- In 2020, the first drafts HTTP/3 were published and major web browsers and web servers started to adopt it.
- On 6 June 2022, IETF standardized HTTP/3 as RFC 9114.[42]
- Updates and refactoring in 2022
- In June 2022, a batch of RFCs was published, deprecating many of the previous documents and introducing a few minor changes and a refactoring of HTTP semantics description into a separate document.
- RFC 9110, HTTP Semantics
- RFC 9111, HTTP Caching
- RFC 9112, HTTP/1.1
- RFC 9113, HTTP/2
- RFC 9114, HTTP/3 (see also the section above)
- RFC 9204, QPACK: Field Compression for HTTP/3
- RFC 9218, Extensible Prioritization Scheme for HTTP
HTTP data exchange[edit]
HTTP is a stateless application-level protocol and it requires a reliable network transport connection to exchange data between client and server.[19] In HTTP implementations, TCP/IP connections are used using well known ports (typically port 80 if the connection is unencrypted or port 443 if the connection is encrypted, see also List of TCP and UDP port numbers).[43][44] In HTTP/2, a TCP/IP connection plus multiple protocol channels are used. In HTTP/3, the application transport protocol QUIC over UDP is used.
Request and response messages through connections[edit]
Data is exchanged through a sequence of request–response messages which are exchanged by a session layer transport connection.[19] An HTTP client initially tries to connect to a server establishing a connection (real or virtual). An HTTP(S) server listening on that port accepts the connection and then waits for a client’s request message. The client sends its request to the server. Upon receiving the request, the server sends back an HTTP response message (header plus a body if it is required). The body of this message is typically the requested resource, although an error message or other information may also be returned. At any time (for many reasons) client or server can close the connection. Closing a connection is usually advertised in advance by using one or more HTTP headers in the last request/response message sent to server or client.[21]
Persistent connections[edit]
In HTTP/0.9, the TCP/IP connection is always closed after server response has been sent, so it is never persistent.
In HTTP/1.0, as stated in RFC 1945, the TCP/IP connection should always be closed by server after a response has been sent. [note 3]
In HTTP/1.1 a keep-alive-mechanism was officially introduced so that a connection could be reused for more than one request/response. Such persistent connections reduce request latency perceptibly because the client does not need to re-negotiate the TCP 3-Way-Handshake connection after the first request has been sent. Another positive side effect is that, in general, the connection becomes faster with time due to TCP’s slow-start-mechanism.
HTTP/1.1 added also HTTP pipelining in order to further reduce lag time when using persistent connections by allowing clients to send multiple requests before waiting for each response. This optimization was never considered really safe because a few web servers and many proxy servers, specially transparent proxy servers placed in Internet / Intranets between clients and servers, did not handle pipelined requests properly (they served only the first request discarding the others, they closed the connection because they saw more data after the first request or some proxies even returned responses out of order etc.). Besides this only HEAD and some GET requests (i.e. limited to real file requests and so with URLs without query string used as a command, etc.) could be pipelined in a safe and idempotent mode. After many years of struggling with the problems introduced by enabling pipelining, this feature was first disabled and then removed from most browsers also because of the announced adoption of HTTP/2.
HTTP/2 extended the usage of persistent connections by multiplexing many concurrent requests/responses through a single TCP/IP connection.
HTTP/3 does not use TCP/IP connections but QUIC + UDP (see also: technical overview).
Content retrieval optimizations[edit]
- HTTP/0.9
- a requested resource was always sent entirely.
- HTTP/1.0
- HTTP/1.0 added headers to manage resources cached by client in order to allow conditional GET requests; in practice a server has to return the entire content of the requested resource only if its last modified time is not known by client or if it changed since last full response to GET request. One of these headers, «Content-Encoding», was added to specify whether the returned content of a resource was or was not compressed.
- If the total length of the content of a resource was not known in advance (i.e. because it was dynamically generated, etc.) then the header
"Content-Length: number"was not present in HTTP headers and the client assumed that when server closed the connection, the content had been entirely sent. This mechanism could not distinguish between a resource transfer successfully completed and an interrupted one (because of a server / network error or something else). - HTTP/1.1
- HTTP/1.1 introduced:
- new headers to better manage the conditional retrieval of cached resources.
- chunked transfer encoding to allow content to be streamed in chunks in order to reliably send it even when the server does not know in advance its length (i.e. because it is dynamically generated, etc.).
- byte range serving, where a client can request only one or more portions (ranges of bytes) of a resource (i.e. the first part, a part in the middle or in the end of the entire content, etc.) and the server usually sends only the requested part(s). This is useful to resume an interrupted download (when a file is really big), when only a part of a content has to be shown or dynamically added to the already visible part by a browser (i.e. only the first or the following n comments of a web page) in order to spare time, bandwidth and system resources, etc.
- HTTP/2, HTTP/3
- Both HTTP/2 and HTTP/3 have kept the above mentioned features of HTTP/1.1.
HTTP authentication[edit]
HTTP provides multiple authentication schemes such as basic access authentication and digest access authentication which operate via a challenge–response mechanism whereby the server identifies and issues a challenge before serving the requested content.
HTTP provides a general framework for access control and authentication, via an extensible set of challenge–response authentication schemes, which can be used by a server to challenge a client request and by a client to provide authentication information.[1]
The authentication mechanisms described above belong to the HTTP protocol and are managed by client and server HTTP software (if configured to require authentication before allowing client access to one or more web resources), and not by the web applications using a web application session.
Authentication realms[edit]
The HTTP Authentication specification also provides an arbitrary, implementation-specific construct for further dividing resources common to a given root URI. The realm value string, if present, is combined with the canonical root URI to form the protection space component of the challenge. This in effect allows the server to define separate authentication scopes under one root URI.[1]
HTTP application session [edit]
HTTP is a stateless protocol. A stateless protocol does not require the web server to retain information or status about each user for the duration of multiple requests.
Some web applications need to manage user sessions, so they implement states, or server side sessions, using for instance HTTP cookies[45] or hidden variables within web forms.
To start an application user session, an interactive authentication via web application login must be performed. To stop a user session a logout operation must be requested by user. These kind of operations do not use HTTP authentication but a custom managed web application authentication.
HTTP/1.1 request messages[edit]
Request messages are sent by a client to a target server.[note 4]
Request syntax[edit]
A client sends request messages to the server, which consist of:[46]
- a request line, consisting of the case-sensitive request method, a space, the requested URL, another space, the protocol version, a carriage return, and a line feed, e.g.:
GET /images/logo.png HTTP/1.1
- zero or more request header fields (at least 1 or more headers in case of HTTP/1.1), each consisting of the case-insensitive field name, a colon, optional leading whitespace, the field value, an optional trailing whitespace and ending with a carriage return and a line feed, e.g.:
Host: www.example.com Accept-Language: en
- an empty line, consisting of a carriage return and a line feed;
- an optional message body.
In the HTTP/1.1 protocol, all header fields except Host: hostname are optional.
A request line containing only the path name is accepted by servers to maintain compatibility with HTTP clients before the HTTP/1.0 specification in RFC 1945.[47]
Request methods[edit]
An HTTP/1.1 request made using telnet. The request message, response header section, and response body are highlighted.
HTTP defines methods (sometimes referred to as verbs, but nowhere in the specification does it mention verb) to indicate the desired action to be performed on the identified resource. What this resource represents, whether pre-existing data or data that is generated dynamically, depends on the implementation of the server. Often, the resource corresponds to a file or the output of an executable residing on the server. The HTTP/1.0 specification[48] defined the GET, HEAD, and POST methods, and the HTTP/1.1 specification[49] added five new methods: PUT, DELETE, CONNECT, OPTIONS, and TRACE. Any client can use any method and the server can be configured to support any combination of methods. If a method is unknown to an intermediate, it will be treated as an unsafe and non-idempotent method. There is no limit to the number of methods that can be defined, which allows for future methods to be specified without breaking existing infrastructure. For example, WebDAV defined seven new methods and RFC 5789 specified the PATCH method.
Method names are case sensitive.[50][51] This is in contrast to HTTP header field names which are case-insensitive.[52]
- GET
- The GET method requests that the target resource transfer a representation of its state. GET requests should only retrieve data and should have no other effect. (This is also true of some other HTTP methods.)[1] For retrieving resources without making changes, GET is preferred over POST, as they can be addressed through a URL. This enables bookmarking and sharing and makes GET responses eligible for caching, which can save bandwidth. The W3C has published guidance principles on this distinction, saying, «Web application design should be informed by the above principles, but also by the relevant limitations.»[53] See safe methods below.
- HEAD
- The HEAD method requests that the target resource transfer a representation of its state, as for a GET request, but without the representation data enclosed in the response body. This is useful for retrieving the representation metadata in the response header, without having to transfer the entire representation. Uses include checking whether a page is available through the status code and quickly finding the size of a file (
Content-Length).
- POST
- The POST method requests that the target resource process the representation enclosed in the request according to the semantics of the target resource. For example, it is used for posting a message to an Internet forum, subscribing to a mailing list, or completing an online shopping transaction.[54]
- PUT
- The PUT method requests that the target resource create or update its state with the state defined by the representation enclosed in the request. A distinction from POST is that the client specifies the target location on the server.[55]
- DELETE
- The DELETE method requests that the target resource delete its state.
- CONNECT
- The CONNECT method requests that the intermediary establish a TCP/IP tunnel to the origin server identified by the request target. It is often used to secure connections through one or more HTTP proxies with TLS.[56][57] See HTTP CONNECT method.
- OPTIONS
- The OPTIONS method requests that the target resource transfer the HTTP methods that it supports. This can be used to check the functionality of a web server by requesting ‘*’ instead of a specific resource.
- TRACE
- The TRACE method requests that the target resource transfer the received request in the response body. That way a client can see what (if any) changes or additions have been made by intermediaries.
- PATCH
- The PATCH method requests that the target resource modify its state according to the partial update defined in the representation enclosed in the request. This can save bandwidth by updating a part of a file or document without having to transfer it entirely.[58]
All general-purpose web servers are required to implement at least the GET and HEAD methods, and all other methods are considered optional by the specification.[51]
| Request method | RFC | Request has payload body | Response has payload body | Safe | Idempotent | Cacheable |
|---|---|---|---|---|---|---|
| GET | RFC 9110 | Optional | Yes | Yes | Yes | Yes |
| HEAD | RFC 9110 | Optional | No | Yes | Yes | Yes |
| POST | RFC 9110 | Yes | Yes | No | No | Yes |
| PUT | RFC 9110 | Yes | Yes | No | Yes | No |
| DELETE | RFC 9110 | Optional | Yes | No | Yes | No |
| CONNECT | RFC 9110 | Optional | Yes | No | No | No |
| OPTIONS | RFC 9110 | Optional | Yes | Yes | Yes | No |
| TRACE | RFC 9110 | No | Yes | Yes | Yes | No |
| PATCH | RFC 5789 | Yes | Yes | No | No | No |
Safe methods[edit]
A request method is safe if a request with that method has no intended effect on the server. The methods GET, HEAD, OPTIONS, and TRACE are defined as safe. In other words, safe methods are intended to be read-only. They do not exclude side effects though, such as appending request information to a log file or charging an advertising account, since they are not requested by the client, by definition.
In contrast, the methods POST, PUT, DELETE, CONNECT, and PATCH are not safe. They may modify the state of the server or have other effects such as sending an email. Such methods are therefore not usually used by conforming web robots or web crawlers; some that do not conform tend to make requests without regard to context or consequences.
Despite the prescribed safety of GET requests, in practice their handling by the server is not technically limited in any way. Careless or deliberately irregular programming can allow GET requests to cause non-trivial changes on the server. This is discouraged because of the problems which can occur when web caching, search engines, and other automated agents make unintended changes on the server. For example, a website might allow deletion of a resource through a URL such as https://example.com/article/1234/delete, which, if arbitrarily fetched, even using GET, would simply delete the article.[59] A properly coded website would require a DELETE or POST method for this action, which non-malicious bots would not make.
One example of this occurring in practice was during the short-lived Google Web Accelerator beta, which prefetched arbitrary URLs on the page a user was viewing, causing records to be automatically altered or deleted en masse. The beta was suspended only weeks after its first release, following widespread criticism.[60][59]
Idempotent methods[edit]
A request method is idempotent if multiple identical requests with that method have the same effect as a single such request. The methods PUT and DELETE, and safe methods are defined as idempotent. Safe methods are trivially idempotent, since they are intended to have no effect on the server whatsoever; the PUT and DELETE methods, meanwhile, are idempotent since successive identical requests will be ignored. A website might, for instance, set up a PUT endpoint to modify a user’s recorded email address. If this endpoint is configured correctly, any requests which ask to change a user’s email address to the same email address which is already recorded—e.g. duplicate requests following a successful request—will have no effect. Similarly, a request to DELETE a certain user will have no effect if that user has already been deleted.
In contrast, the methods POST, CONNECT, and PATCH are not necessarily idempotent, and therefore sending an identical POST request multiple times may further modify the state of the server or have further effects, such as sending multiple emails. In some cases this is the desired effect, but in other cases it may occur accidentally. A user might, for example, inadvertently send multiple POST requests by clicking a button again if they were not given clear feedback that the first click was being processed. While web browsers may show alert dialog boxes to warn users in some cases where reloading a page may re-submit a POST request, it is generally up to the web application to handle cases where a POST request should not be submitted more than once.
Note that whether or not a method is idempotent is not enforced by the protocol or web server. It is perfectly possible to write a web application in which (for example) a database insert or other non-idempotent action is triggered by a GET or other request. To do so against recommendations, however, may result in undesirable consequences, if a user agent assumes that repeating the same request is safe when it is not.
Cacheable methods[edit]
A request method is cacheable if responses to requests with that method may be stored for future reuse. The methods GET, HEAD, and POST are defined as cacheable.
In contrast, the methods PUT, DELETE, CONNECT, OPTIONS, TRACE, and PATCH are not cacheable.
[edit]
Request header fields allow the client to pass additional information beyond the request line, acting as request modifiers (similarly to the parameters of a procedure). They give information about the client, about the target resource, or about the expected handling of the request.
HTTP/1.1 response messages[edit]
A response message is sent by a server to a client as a reply to its former request message.[note 4]
Response syntax[edit]
A server sends response messages to the client, which consist of:[46]
- a status line, consisting of the protocol version, a space, the response status code, another space, a possibly empty reason phrase, a carriage return and a line feed, e.g.:
HTTP/1.1 200 OK
- zero or more response header fields, each consisting of the case-insensitive field name, a colon, optional leading whitespace, the field value, an optional trailing whitespace and ending with a carriage return and a line feed, e.g.:
Content-Type: text/html
- an empty line, consisting of a carriage return and a line feed;
- an optional message body.
Response status codes[edit]
In HTTP/1.0 and since, the first line of the HTTP response is called the status line and includes a numeric status code (such as «404») and a textual reason phrase (such as «Not Found»). The response status code is a three-digit integer code representing the result of the server’s attempt to understand and satisfy the client’s corresponding request. The way the client handles the response depends primarily on the status code, and secondarily on the other response header fields. Clients may not understand all registered status codes but they must understand their class (given by the first digit of the status code) and treat an unrecognized status code as being equivalent to the x00 status code of that class.
The standard reason phrases are only recommendations, and can be replaced with «local equivalents» at the web developer’s discretion. If the status code indicated a problem, the user agent might display the reason phrase to the user to provide further information about the nature of the problem. The standard also allows the user agent to attempt to interpret the reason phrase, though this might be unwise since the standard explicitly specifies that status codes are machine-readable and reason phrases are human-readable.
The first digit of the status code defines its class:
1XX(informational)- The request was received, continuing process.
2XX(successful)- The request was successfully received, understood, and accepted.
3XX(redirection)- Further action needs to be taken in order to complete the request.
4XX(client error)- The request contains bad syntax or cannot be fulfilled.
5XX(server error)- The server failed to fulfill an apparently valid request.
[edit]
The response header fields allow the server to pass additional information beyond the status line, acting as response modifiers. They give information about the server or about further access to the target resource or related resources.
Each response header field has a defined meaning which can be further refined by the semantics of the request method or response status code.
HTTP/1.1 example of request / response transaction[edit]
Below is a sample HTTP transaction between an HTTP/1.1 client and an HTTP/1.1 server running on www.example.com, port 80.[note 5][note 6]
Client request[edit]
GET / HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: en-GB,en;q=0.5 Accept-Encoding: gzip, deflate, br Connection: keep-alive
A client request (consisting in this case of the request line and a few headers that can be reduced to only the "Host: hostname" header) is followed by a blank line, so that the request ends with a double end of line, each in the form of a carriage return followed by a line feed. The "Host: hostname" header value distinguishes between various DNS names sharing a single IP address, allowing name-based virtual hosting. While optional in HTTP/1.0, it is mandatory in HTTP/1.1. (A «/» (slash) will usually fetch a /index.html file if there is one.)
Server response[edit]
HTTP/1.1 200 OK Date: Mon, 23 May 2005 22:38:34 GMT Content-Type: text/html; charset=UTF-8 Content-Length: 155 Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux) ETag: "3f80f-1b6-3e1cb03b" Accept-Ranges: bytes Connection: close <html> <head> <title>An Example Page</title> </head> <body> <p>Hello World, this is a very simple HTML document.</p> </body> </html>
The ETag (entity tag) header field is used to determine if a cached version of the requested resource is identical to the current version of the resource on the server. "Content-Type" specifies the Internet media type of the data conveyed by the HTTP message, while "Content-Length" indicates its length in bytes. The HTTP/1.1 webserver publishes its ability to respond to requests for certain byte ranges of the document by setting the field "Accept-Ranges: bytes". This is useful, if the client needs to have only certain portions[61] of a resource sent by the server, which is called byte serving. When "Connection: close" is sent, it means that the web server will close the TCP connection immediately after the end of the transfer of this response.[21]
Most of the header lines are optional but some are mandatory. When header "Content-Length: number" is missing in a response with an entity body then this should be considered an error in HTTP/1.0 but it may not be an error in HTTP/1.1 if header "Transfer-Encoding: chunked" is present. Chunked transfer encoding uses a chunk size of 0 to mark the end of the content. Some old implementations of HTTP/1.0 omitted the header "Content-Length" when the length of the body entity was not known at the beginning of the response and so the transfer of data to client continued until server closed the socket.
A "Content-Encoding: gzip" can be used to inform the client that the body entity part of the transmitted data is compressed by gzip algorithm.
Encrypted connections[edit]
The most popular way of establishing an encrypted HTTP connection is HTTPS.[62] Two other methods for establishing an encrypted HTTP connection also exist: Secure Hypertext Transfer Protocol, and using the HTTP/1.1 Upgrade header to specify an upgrade to TLS. Browser support for these two is, however, nearly non-existent.[63][64][65]
Similar protocols[edit]
- The Gopher protocol is a content delivery protocol that was displaced by HTTP in the early 1990s.
- The SPDY protocol is an alternative to HTTP developed at Google, superseded by HTTP/2.
- The Gemini protocol is a Gopher-inspired protocol which mandates privacy-related features.
See also[edit]
- InterPlanetary File System — can replace http
- Comparison of file transfer protocols
- Constrained Application Protocol – a semantically similar protocol to HTTP but used UDP or UDP-like messages targeted for devices with limited processing capability; re-uses HTTP and other internet concepts like Internet media type and web linking (RFC 5988)[66]
- Content negotiation
- Digest access authentication
- HTTP compression
- HTTP/2 – developed by the IETF’s Hypertext Transfer Protocol (httpbis) working group[67]
- List of HTTP header fields
- List of HTTP status codes
- Representational state transfer (REST)
- Variant object
- Web cache
- WebSocket
Notes[edit]
- ^ In practice, these streams are used as multiple TCP/IP sub-connections to multiplex concurrent requests/responses, thus greatly reducing the number of real TCP/IP connections on server side, from 2..8 per client to 1, and allowing many more clients to be served at once.
- ^ In 2022, HTTP/0.9 support has not been officially completely deprecated and is still present in many web servers and browsers (for server responses only), even if usually disabled. It is unclear how long it will take to decommission HTTP/0.9.
- ^ Since late 1996, some developers of popular HTTP/1.0 browsers and servers (specially those who had planned support for HTTP/1.1 too), started to deploy (as an unofficial extension) a sort of keep-alive-mechanism (by using new HTTP headers) in order to keep the TCP/IP connection open for more than a request/response pair and so to speed up the exchange of multiple requests/responses.[31]
- ^ a b HTTP/2 and HTTP/3 have a different representation for HTTP methods and headers.
- ^ HTTP/1.0 has the same messages except for a few missing headers.
- ^ HTTP/2 and HTTP/3 use the same request / response mechanism but with different representations for HTTP headers.
References[edit]
- ^ a b c d Fielding, R.; Nottingham, M.; Reschke, J. (June 2022). HTTP Semantics. IETF. doi:10.17487/RFC9110. RFC 9110.
- ^ a b c d Tim Berner-Lee (1991-01-01). «The Original HTTP as defined in 1991». www.w3.org. World Wide Web Consortium. Retrieved 2010-07-24.
- ^ a b Tim Berner-Lee (1992). «Basic HTTP as defined in 1992». www.w3.org. World Wide Web Consortium. Retrieved 2021-10-19.
- ^ In RFC 1945. That specification was then overcome by HTTP/1.1.
- ^ RFC 2068 (1997) was obsoleted by RFC 2616 in 1999, which was obsoleted by RFC 7230 in 2014, which was obsoleted by RFC 9110 in 2022.
- ^ «Usage Statistics of Default protocol https for websites». w3techs.com. Retrieved 2022-10-16.
- ^ «Usage Statistics of HTTP/2 for websites». w3techs.com. Retrieved 2022-12-02.
- ^ «Can I use… Support tables for HTML5, CSS3, etc». caniuse.com. Retrieved 2022-10-16.
- ^ «Transport Layer Security (TLS) Application-Layer Protocol Negotiation Extension». IETF. July 2014. RFC 7301.
- ^ Belshe, M.; Peon, R.; Thomson, M. «Hypertext Transfer Protocol Version 2, Use of TLS Features». Archived from the original on 2013-07-15. Retrieved 2015-02-10.
- ^ Benjamin, David. «Using TLS 1.3 with HTTP/2». tools.ietf.org. Retrieved 2020-06-02.
This lowers the barrier for deploying TLS 1.3, a major security improvement over TLS 1.2.
- ^ «HTTP/3». Retrieved 2022-06-06.
- ^ «Usage Statistics of HTTP/3 for websites». w3techs.com. Retrieved 2022-10-16.
- ^ «Can I use… Support tables for HTML5, CSS3, etc». caniuse.com. Retrieved 2022-10-16.
- ^ Cimpanu, Catalin (26 September 2019). «Cloudflare, Google Chrome, and Firefox add HTTP/3 support». ZDNet. Retrieved 27 September 2019.
- ^ «HTTP/3: the past, the present, and the future». The Cloudflare Blog. 2019-09-26. Retrieved 2019-10-30.
- ^ «Firefox Nightly supports HTTP 3 — General — Cloudflare Community». 2019-11-19. Retrieved 2020-01-23.
- ^ «HTTP/3 is Fast». Request Metrics. Retrieved 2022-07-01.
- ^ a b c «Connections, Clients, and Servers». RFC 9110, HTTP Semantics. sec. 3.3. doi:10.17487/RFC9110. RFC 9110.
- ^ «Overall Operation». RFC 1945. pp. 6–8. sec. 1.3. doi:10.17487/RFC1945. RFC 1945.
- ^ a b c «Connection Management: Establishment». RFC 9112, HTTP/1.1. sec. 9.1. doi:10.17487/RFC9112. RFC 9112.
- ^ «Connection Management: Persistence». RFC 9112, HTTP/1.1. sec. 9.3. doi:10.17487/RFC9112. RFC 9112.
- ^ «Classic HTTP Documents». W3.org. 1998-05-14. Retrieved 2010-08-01.
- ^ «HTTP/2 Protocol Overview». RFC 9113, HTTP/2). sec. 2. doi:10.17487/RFC7540. RFC 7540.
- ^ «Invention Of The Web, Web History, Who Invented the Web, Tim Berners-Lee, Robert Cailliau, CERN, First Web Server». LivingInternet. Retrieved 2021-08-11.
- ^ Berners-Lee, Tim (1990-10-02). «daemon.c — TCP/IP based server for HyperText». www.w3.org. Retrieved 2021-08-11.
- ^ Berners-Lee, Tim. «HyperText Transfer Protocol». World Wide Web Consortium. Retrieved 31 August 2010.
- ^ Raggett, Dave. «Dave Raggett’s Bio». World Wide Web Consortium. Retrieved 11 June 2010.
- ^ Raggett, Dave; Berners-Lee, Tim. «Hypertext Transfer Protocol Working Group». World Wide Web Consortium. Retrieved 29 September 2010.
- ^ Raggett, Dave. «HTTP WG Plans». World Wide Web Consortium. Retrieved 29 September 2010.
- ^ a b David Gourley; Brian Totty; Marjorie Sayer; Anshu Aggarwal; Sailu Reddy (2002). HTTP: The Definitive Guide. (excerpt of chapter: «Persistent Connections»). O’Reilly Media, inc. ISBN 9781565925090. Retrieved 2021-10-18.
- ^ «HTTP/1.1». Webcom.com Glossary entry. Archived from the original on 2001-11-21. Retrieved 2009-05-29.
- ^ «HTTP-NG Working Group». www.w3.org. World Wide Web Consortium. 1997. Retrieved 2021-10-19.
- ^ Web Administrator (2007). «HTTP Working Group». httpwg.org. IETF. Retrieved 2021-10-19.
- ^ Web Administrator (2007). «HTTP Working Group: charter httpbis». datatracker.ietf.org. IETF. Retrieved 2021-10-19.
- ^ «SPDY: An experimental protocol for a faster web». dev.chromium.org. Google. 2009-11-01. Retrieved 2021-10-19.
- ^ «Rechartering httpbis». IETF; HTTP WG. 2012-01-24. Retrieved 2021-10-19.
- ^ IESG Secretary (2012-03-19). «WG Action: RECHARTER: Hypertext Transfer Protocol Bis (httpbis)». IETF; HTTP WG. Retrieved 2021-10-19.
- ^ Ilya Grigorik; Surma (2019-09-03). «High Performance Browser Networking: Introduction to HTTP/2». developers.google.com. Google Inc. Retrieved 2021-10-19.
- ^ «Appendix-A: HTTP Version History». RFC 7230, HTTP/1.1: Message Syntax and Routing. p. 78. sec. A. doi:10.17487/RFC7230. RFC 7230.
- ^ Matt Menke (2016-06-30). «Intent to Deprecate and Remove: HTTP/0.9 Support». groups.google.com. Retrieved 2021-10-15.
- ^ «HTTP/3». Retrieved 2022-06-06.
- ^ «http URI Scheme». RFC 9110, HTTP Semantics. sec. 4.2.1. doi:10.17487/RFC9110. RFC 9110.
- ^ «https URI Scheme». RFC 9110, HTTP Semantics. sec. 4.2.2. doi:10.17487/RFC9110. RFC 9110.
- ^ Lee, Wei-Bin; Chen, Hsing-Bai; Chang, Shun-Shyan; Chen, Tzung-Her (2019-01-25). «Secure and efficient protection for HTTP cookies with self-verification». International Journal of Communication Systems. 32 (2): e3857. doi:10.1002/dac.3857. S2CID 59524143.
- ^ a b «Message format». RFC 9112: HTTP/1.1. sec. 2.1. doi:10.17487/RFC9112. RFC 9112.
- ^ «Apache Week. HTTP/1.1». 090502 apacheweek.com
- ^ Berners-Lee, Tim; Fielding, Roy T.; Nielsen, Henrik Frystyk. «Method Definitions». Hypertext Transfer Protocol – HTTP/1.0. IETF. pp. 30–32. sec. 8. doi:10.17487/RFC1945. RFC 1945.
- ^ «Method Definitions». RFC 2616. pp. 51–57. sec. 9. doi:10.17487/RFC2616. RFC 2616.
- ^ «Request Line». RFC 9112, HTTP/1.1. sec. 3. doi:10.17487/RFC9112. RFC 9112.
- ^ a b «Methods: Overview». RFC 9110, HTTP Semantics. sec. 9.1. doi:10.17487/RFC9110. RFC 9110.
- ^ «Header Fields». RFC 9110, HTTP Semantics. sec. 6.3. doi:10.17487/RFC9110. RFC 9110.
- ^ Jacobs, Ian (2004). «URIs, Addressability, and the use of HTTP GET and POST». Technical Architecture Group finding. W3C. Retrieved 26 September 2010.
- ^ «POST». RFC 9110, HTTP Semantics. sec. 9.3.3. doi:10.17487/RFC9110. RFC 9110.
- ^ «PUT». RFC 9110, HTTP Semantics. sec. 9.3.4. doi:10.17487/RFC9110. RFC 9110.
- ^ «CONNECT». RFC 9110, HTTP Semantics. sec. 9.3.6. doi:10.17487/RFC9110. RFC 9110.
- ^ «Vulnerability Note VU#150227: HTTP proxy default configurations allow arbitrary TCP connections». US-CERT. 2002-05-17. Retrieved 2007-05-10.
- ^ Dusseault, Lisa; Snell, James M. (March 2010). PATCH Method for HTTP. IETF. doi:10.17487/RFC5789. RFC 5789.
- ^ a b Ediger, Brad (2007-12-21). Advanced Rails: Building Industrial-Strength Web Apps in Record Time. O’Reilly Media, Inc. p. 188. ISBN 978-0596519728.
A common mistake is to use GET for an action that updates a resource. […] This problem came into the Rails public eye in 2005, when the Google Web Accelerator was released.
- ^ Cantrell, Christian (2005-06-01). «What Have We Learned From the Google Web Accelerator?». Adobe Blogs. Adobe. Archived from the original on 2017-08-19. Retrieved 2018-11-19.
- ^ Luotonen, Ari; Franks, John (February 22, 1996). Byte Range Retrieval Extension to HTTP. IETF. I-D draft-ietf-http-range-retrieval-00.
- ^ Canavan, John (2001). Fundamentals of Networking Security. Norwood, MA: Artech House. pp. 82–83. ISBN 9781580531764.
- ^ Zalewski, Michal. «Browser Security Handbook». Retrieved 30 April 2015.
- ^ «Chromium Issue 4527: implement RFC 2817: Upgrading to TLS Within HTTP/1.1». Retrieved 30 April 2015.
- ^ «Mozilla Bug 276813 – [RFE] Support RFC 2817 / TLS Upgrade for HTTP 1.1». Retrieved 30 April 2015.
- ^ Nottingham, Mark (October 2010). Web Linking. IETF. doi:10.17487/RFC5988. RFC 5988.
- ^ «Hypertext Transfer Protocol Bis (httpbis) – Charter». IETF. 2012.
External links[edit]
- Official website

- IETF HTTP Working Group on GitHub
- «Change History for HTTP». W3.org. Retrieved 2010-08-01. A detailed technical history of HTTP.
- «Design Issues for HTTP». W3.org. Retrieved 2010-08-01. Design Issues by Berners-Lee when he was designing the protocol.
| International standard |
|
|---|---|
| Developed by | initially CERN; IETF, W3C |
| Introduced | 1991; 32 years ago |
| Website | https://httpwg.org/specs/ |
The Hypertext Transfer Protocol (HTTP) is an application layer protocol in the Internet protocol suite model for distributed, collaborative, hypermedia information systems.[1] HTTP is the foundation of data communication for the World Wide Web, where hypertext documents include hyperlinks to other resources that the user can easily access, for example by a mouse click or by tapping the screen in a web browser.
Development of HTTP was initiated by Tim Berners-Lee at CERN in 1989 and summarized in a simple document describing the behavior of a client and a server using the first HTTP protocol version that was named 0.9.[2]
That first version of HTTP protocol soon evolved into a more elaborated version that was the first draft toward a far future version 1.0.[3]
Development of early HTTP Requests for Comments (RFCs) started a few years later and it was a coordinated effort by the Internet Engineering Task Force (IETF) and the World Wide Web Consortium (W3C), with work later moving to the IETF.
HTTP/1 was finalized and fully documented (as version 1.0) in 1996.[4] It evolved (as version 1.1) in 1997 and then its specifications were updated in 1999, 2014, and 2022.[5]
Its secure variant named HTTPS is used by more than 80% of websites.[6]
HTTP/2, published in 2015, provides a more efficient expression of HTTP’s semantics «on the wire». It is now used by 41% of websites[7] and supported by almost all web browsers (over 97% of users).[8] It is also supported by major web servers over Transport Layer Security (TLS) using an Application-Layer Protocol Negotiation (ALPN) extension[9] where TLS 1.2 or newer is required.[10][11]
HTTP/3, the successor to HTTP/2, was published in 2022.[12] It is now used by over 25% of websites[13] and is supported by many web browsers (over 75% of users).[14] HTTP/3 uses QUIC instead of TCP for the underlying transport protocol. Like HTTP/2, it does not obsolesce previous major versions of the protocol. Support for HTTP/3 was added to Cloudflare and Google Chrome first,[15][16] and is also enabled in Firefox.[17] HTTP/3 has lower latency for real-world web pages, if enabled on the server, load faster than with HTTP/2, and even faster than HTTP/1.1, in some cases over 3× faster than HTTP/1.1 (which is still commonly only enabled).[18]
Technical overview[edit]
URL beginning with the HTTP scheme and the WWW domain name label
HTTP functions as a request–response protocol in the client–server model. A web browser, for example, may be the client whereas a process, named web server, running on a computer hosting one or more websites may be the server. The client submits an HTTP request message to the server. The server, which provides resources such as HTML files and other content or performs other functions on behalf of the client, returns a response message to the client. The response contains completion status information about the request and may also contain requested content in its message body.
A web browser is an example of a user agent (UA). Other types of user agent include the indexing software used by search providers (web crawlers), voice browsers, mobile apps, and other software that accesses, consumes, or displays web content.
HTTP is designed to permit intermediate network elements to improve or enable communications between clients and servers. High-traffic websites often benefit from web cache servers that deliver content on behalf of upstream servers to improve response time. Web browsers cache previously accessed web resources and reuse them, whenever possible, to reduce network traffic. HTTP proxy servers at private network boundaries can facilitate communication for clients without a globally routable address, by relaying messages with external servers.
To allow intermediate HTTP nodes (proxy servers, web caches, etc.) to accomplish their functions, some of the HTTP headers (found in HTTP requests/responses) are managed hop-by-hop whereas other HTTP headers are managed end-to-end (managed only by the source client and by the target web server).
HTTP is an application layer protocol designed within the framework of the Internet protocol suite. Its definition presumes an underlying and reliable transport layer protocol,[19] thus Transmission Control Protocol (TCP) is commonly used. However, HTTP can be adapted to use unreliable protocols such as the User Datagram Protocol (UDP), for example in HTTPU and Simple Service Discovery Protocol (SSDP).
HTTP resources are identified and located on the network by Uniform Resource Locators (URLs), using the Uniform Resource Identifiers (URI’s) schemes http and https. As defined in RFC 3986, URIs are encoded as hyperlinks in HTML documents, so as to form interlinked hypertext documents.
In HTTP/1.0 a separate connection to the same server is made for every resource request.[20]
In HTTP/1.1 instead a TCP connection can be reused to make multiple resource requests (i.e. of HTML pages, frames, images, scripts, stylesheets, etc.).[21][22]
HTTP/1.1 communications therefore experience less latency as the establishment of TCP connections presents considerable overhead, specially under high traffic conditions.[23]
HTTP/2 is a revision of previous HTTP/1.1 in order to maintain the same client–server model and the same protocol methods but with these differences in order:
- to use a compressed binary representation of metadata (HTTP headers) instead of a textual one, so that headers require much less space;
- to use a single TCP/IP (usually encrypted) connection per accessed server domain instead of 2 to 8 TCP/IP connections;
- to use one or more bidirectional streams per TCP/IP connection in which HTTP requests and responses are broken down and transmitted in small packets to almost solve the problem of the HOLB (head of line blocking). [note 1]
- to add a push capability to allow server application to send data to clients whenever new data is available (without forcing clients to request periodically new data to server by using polling methods).[24]
HTTP/2 communications therefore experience much less latency and, in most cases, even more speed than HTTP/1.1 communications.
HTTP/3 is a revision of previous HTTP/2 in order to use QUIC + UDP transport protocols instead of TCP/IP connections also to slightly improve the average speed of communications and to avoid the occasional (very rare) problem of TCP/IP connection congestion that can temporarily block or slow down the data flow of all its streams (another form of «head of line blocking«).
History[edit]
The term hypertext was coined by Ted Nelson in 1965 in the Xanadu Project, which was in turn inspired by Vannevar Bush’s 1930s vision of the microfilm-based information retrieval and management «memex» system described in his 1945 essay «As We May Think». Tim Berners-Lee and his team at CERN are credited with inventing the original HTTP, along with HTML and the associated technology for a web server and a client user interface called web browser. Berners-Lee designed HTTP in order to help with the adoption of his other idea: the «WorldWideWeb» project, which was first proposed in 1989, now known as the World Wide Web.
The first web server went live in 1990.[25][26] The protocol used had only one method, namely GET, which would request a page from a server.[27] The response from the server was always an HTML page.[2]
Summary of HTTP milestone versions[edit]
| Version | Year introduced | Current status |
|---|---|---|
| HTTP/0.9 | 1991 | Obsolete |
| HTTP/1.0 | 1996 | Obsolete |
| HTTP/1.1 | 1997 | Standard |
| HTTP/2 | 2015 | Standard |
| HTTP/3 | 2022 | Standard |
- HTTP/0.9
- In 1991, the first documented official version of HTTP was written as a plain document, less than 700 words long, and this version was named HTTP/0.9. HTTP/0.9 supported only GET method, allowing clients to only retrieve HTML documents from the server, but not supporting any other file formats or information upload.[2]
- HTTP/1.0-draft
- Since 1992, a new document was written to specify the evolution of the basic protocol towards its next full version. It supported both the simple request method of the 0.9 version and the full GET request that included the client HTTP version. This was the first of the many unofficial HTTP/1.0 drafts that preceded the final work on HTTP/1.0.[3]
- W3C HTTP Working Group
- After having decided that new features of HTTP protocol were required and that they had to be fully documented as official RFCs, in early 1995 the HTTP Working Group (HTTP WG, led by Dave Raggett) was constituted with the aim to standardize and expand the protocol with extended operations, extended negotiation, richer meta-information, tied with a security protocol which became more efficient by adding additional methods and header fields.[28][29]
- The HTTP WG planned to revise and publish new versions of the protocol as HTTP/1.0 and HTTP/1.1 within 1995, but, because of the many revisions, that timeline lasted much more than one year.[30]
- The HTTP WG planned also to specify a far future version of HTTP called HTTP-NG (HTTP Next Generation) that would have solved all remaining problems, of previous versions, related to performances, low latency responses, etc. but this work started only a few years later and it was never completed.
- HTTP/1.0
- In May 1996, RFC 1945 was published as a final HTTP/1.0 revision of what had been used in previous 4 years as a pre-standard HTTP/1.0-draft which was already used by many web browsers and web servers.
- In early 1996 developers started to even include unofficial extensions of the HTTP/1.0 protocol (i.e. keep-alive connections, etc.) into their products by using drafts of the upcoming HTTP/1.1 specifications.[31]
- HTTP/1.1
- Since early 1996, major web browsers and web server developers also started to implement new features specified by pre-standard HTTP/1.1 drafts specifications. End-user adoption of the new versions of browsers and servers was rapid. In March 1996, one web hosting company reported that over 40% of browsers in use on the Internet used the new HTTP/1.1 header «Host» to enable virtual hosting. That same web hosting company reported that by June 1996, 65% of all browsers accessing their servers were pre-standard HTTP/1.1 compliant.[32]
- In January 1997, RFC 2068 was officially released as HTTP/1.1 specifications.
- In June 1999, RFC 2616 was released to include all improvements and updates based on previous (obsolete) HTTP/1.1 specifications.
- W3C HTTP-NG Working Group
- Resuming the old 1995 plan of previous HTTP Working Group, in 1997 an HTTP-NG Working Group was formed to develop a new HTTP protocol named HTTP-NG (HTTP New Generation). A few proposals / drafts were produced for the new protocol to use multiplexing of HTTP transactions inside a single TCP/IP connection, but in 1999, the group stopped its activity passing the technical problems to IETF.[33]
- IETF HTTP Working Group restarted
- In 2007, the IETF HTTP Working Group (HTTP WG bis or HTTPbis) was restarted firstly to revise and clarify previous HTTP/1.1 specifications and secondly to write and refine future HTTP/2 specifications (named httpbis).[34][35]
- SPDY: an unofficial HTTP protocol developed by Google
- In 2009, Google, a private company, announced that it had developed and tested a new HTTP binary protocol named SPDY. The implicit aim was to greatly speed up web traffic (specially between future web browsers and its servers).
- SPDY was indeed much faster than HTTP/1.1 in many tests and so it was quickly adopted by Chromium and then by other major web browsers.[36]
- Some of the ideas about multiplexing HTTP streams over a single TCP/IP connection were taken from various sources, including the work of W3C HTTP-NG Working Group.
- HTTP/2
- In January–March 2012, HTTP Working Group (HTTPbis) announced the need to start to focus on a new HTTP/2 protocol (while finishing the revision of HTTP/1.1 specifications), maybe taking in consideration ideas and work done for SPDY.[37][38]
- After a few months about what to do to develop a new version of HTTP, it was decided to derive it from SPDY.[39]
- In May 2015, HTTP/2 was published as RFC 7540 and quickly adopted by all web browsers already supporting SPDY and more slowly by web servers.
- 2014 updates to HTTP/1.1
- In June 2014, the HTTP Working Group released an updated six-part HTTP/1.1 specification obsoleting RFC 2616:
- RFC 7230, HTTP/1.1: Message Syntax and Routing
- RFC 7231, HTTP/1.1: Semantics and Content
- RFC 7232, HTTP/1.1: Conditional Requests
- RFC 7233, HTTP/1.1: Range Requests
- RFC 7234, HTTP/1.1: Caching
- RFC 7235, HTTP/1.1: Authentication
- HTTP/0.9 Deprecation
- In RFC 7230 Appendix-A, HTTP/0.9 was deprecated for servers supporting HTTP/1.1 version (and higher):[40]
Since HTTP/0.9 did not support header fields in a request, there is no mechanism for it to support name-based virtual hosts (selection of resource by inspection of the Host header field). Any server that implements name-based virtual hosts ought to disable support for HTTP/0.9. Most requests that appear to be HTTP/0.9 are, in fact, badly constructed HTTP/1.x requests caused by a client failing to properly encode the request-target.
- Since 2016 many product managers and developers of user agents (browsers, etc.) and web servers have begun planning to gradually deprecate and dismiss support for HTTP/0.9 protocol, mainly for the following reasons:[41]
- it is so simple that an RFC document was never written (there is only the original document);[2]
- it has no HTTP headers and lacks many other features that nowadays are required for minimal security reasons;
- it has not been widespread since 1999..2000 (because of HTTP/1.0 and HTTP/1.1) and is commonly used only by some very old network hardware, i.e. routers, etc.
- [note 2]
- HTTP/3
- In 2020, the first drafts HTTP/3 were published and major web browsers and web servers started to adopt it.
- On 6 June 2022, IETF standardized HTTP/3 as RFC 9114.[42]
- Updates and refactoring in 2022
- In June 2022, a batch of RFCs was published, deprecating many of the previous documents and introducing a few minor changes and a refactoring of HTTP semantics description into a separate document.
- RFC 9110, HTTP Semantics
- RFC 9111, HTTP Caching
- RFC 9112, HTTP/1.1
- RFC 9113, HTTP/2
- RFC 9114, HTTP/3 (see also the section above)
- RFC 9204, QPACK: Field Compression for HTTP/3
- RFC 9218, Extensible Prioritization Scheme for HTTP
HTTP data exchange[edit]
HTTP is a stateless application-level protocol and it requires a reliable network transport connection to exchange data between client and server.[19] In HTTP implementations, TCP/IP connections are used using well known ports (typically port 80 if the connection is unencrypted or port 443 if the connection is encrypted, see also List of TCP and UDP port numbers).[43][44] In HTTP/2, a TCP/IP connection plus multiple protocol channels are used. In HTTP/3, the application transport protocol QUIC over UDP is used.
Request and response messages through connections[edit]
Data is exchanged through a sequence of request–response messages which are exchanged by a session layer transport connection.[19] An HTTP client initially tries to connect to a server establishing a connection (real or virtual). An HTTP(S) server listening on that port accepts the connection and then waits for a client’s request message. The client sends its request to the server. Upon receiving the request, the server sends back an HTTP response message (header plus a body if it is required). The body of this message is typically the requested resource, although an error message or other information may also be returned. At any time (for many reasons) client or server can close the connection. Closing a connection is usually advertised in advance by using one or more HTTP headers in the last request/response message sent to server or client.[21]
Persistent connections[edit]
In HTTP/0.9, the TCP/IP connection is always closed after server response has been sent, so it is never persistent.
In HTTP/1.0, as stated in RFC 1945, the TCP/IP connection should always be closed by server after a response has been sent. [note 3]
In HTTP/1.1 a keep-alive-mechanism was officially introduced so that a connection could be reused for more than one request/response. Such persistent connections reduce request latency perceptibly because the client does not need to re-negotiate the TCP 3-Way-Handshake connection after the first request has been sent. Another positive side effect is that, in general, the connection becomes faster with time due to TCP’s slow-start-mechanism.
HTTP/1.1 added also HTTP pipelining in order to further reduce lag time when using persistent connections by allowing clients to send multiple requests before waiting for each response. This optimization was never considered really safe because a few web servers and many proxy servers, specially transparent proxy servers placed in Internet / Intranets between clients and servers, did not handle pipelined requests properly (they served only the first request discarding the others, they closed the connection because they saw more data after the first request or some proxies even returned responses out of order etc.). Besides this only HEAD and some GET requests (i.e. limited to real file requests and so with URLs without query string used as a command, etc.) could be pipelined in a safe and idempotent mode. After many years of struggling with the problems introduced by enabling pipelining, this feature was first disabled and then removed from most browsers also because of the announced adoption of HTTP/2.
HTTP/2 extended the usage of persistent connections by multiplexing many concurrent requests/responses through a single TCP/IP connection.
HTTP/3 does not use TCP/IP connections but QUIC + UDP (see also: technical overview).
Content retrieval optimizations[edit]
- HTTP/0.9
- a requested resource was always sent entirely.
- HTTP/1.0
- HTTP/1.0 added headers to manage resources cached by client in order to allow conditional GET requests; in practice a server has to return the entire content of the requested resource only if its last modified time is not known by client or if it changed since last full response to GET request. One of these headers, «Content-Encoding», was added to specify whether the returned content of a resource was or was not compressed.
- If the total length of the content of a resource was not known in advance (i.e. because it was dynamically generated, etc.) then the header
"Content-Length: number"was not present in HTTP headers and the client assumed that when server closed the connection, the content had been entirely sent. This mechanism could not distinguish between a resource transfer successfully completed and an interrupted one (because of a server / network error or something else). - HTTP/1.1
- HTTP/1.1 introduced:
- new headers to better manage the conditional retrieval of cached resources.
- chunked transfer encoding to allow content to be streamed in chunks in order to reliably send it even when the server does not know in advance its length (i.e. because it is dynamically generated, etc.).
- byte range serving, where a client can request only one or more portions (ranges of bytes) of a resource (i.e. the first part, a part in the middle or in the end of the entire content, etc.) and the server usually sends only the requested part(s). This is useful to resume an interrupted download (when a file is really big), when only a part of a content has to be shown or dynamically added to the already visible part by a browser (i.e. only the first or the following n comments of a web page) in order to spare time, bandwidth and system resources, etc.
- HTTP/2, HTTP/3
- Both HTTP/2 and HTTP/3 have kept the above mentioned features of HTTP/1.1.
HTTP authentication[edit]
HTTP provides multiple authentication schemes such as basic access authentication and digest access authentication which operate via a challenge–response mechanism whereby the server identifies and issues a challenge before serving the requested content.
HTTP provides a general framework for access control and authentication, via an extensible set of challenge–response authentication schemes, which can be used by a server to challenge a client request and by a client to provide authentication information.[1]
The authentication mechanisms described above belong to the HTTP protocol and are managed by client and server HTTP software (if configured to require authentication before allowing client access to one or more web resources), and not by the web applications using a web application session.
Authentication realms[edit]
The HTTP Authentication specification also provides an arbitrary, implementation-specific construct for further dividing resources common to a given root URI. The realm value string, if present, is combined with the canonical root URI to form the protection space component of the challenge. This in effect allows the server to define separate authentication scopes under one root URI.[1]
HTTP application session [edit]
HTTP is a stateless protocol. A stateless protocol does not require the web server to retain information or status about each user for the duration of multiple requests.
Some web applications need to manage user sessions, so they implement states, or server side sessions, using for instance HTTP cookies[45] or hidden variables within web forms.
To start an application user session, an interactive authentication via web application login must be performed. To stop a user session a logout operation must be requested by user. These kind of operations do not use HTTP authentication but a custom managed web application authentication.
HTTP/1.1 request messages[edit]
Request messages are sent by a client to a target server.[note 4]
Request syntax[edit]
A client sends request messages to the server, which consist of:[46]
- a request line, consisting of the case-sensitive request method, a space, the requested URL, another space, the protocol version, a carriage return, and a line feed, e.g.:
GET /images/logo.png HTTP/1.1
- zero or more request header fields (at least 1 or more headers in case of HTTP/1.1), each consisting of the case-insensitive field name, a colon, optional leading whitespace, the field value, an optional trailing whitespace and ending with a carriage return and a line feed, e.g.:
Host: www.example.com Accept-Language: en
- an empty line, consisting of a carriage return and a line feed;
- an optional message body.
In the HTTP/1.1 protocol, all header fields except Host: hostname are optional.
A request line containing only the path name is accepted by servers to maintain compatibility with HTTP clients before the HTTP/1.0 specification in RFC 1945.[47]
Request methods[edit]
An HTTP/1.1 request made using telnet. The request message, response header section, and response body are highlighted.
HTTP defines methods (sometimes referred to as verbs, but nowhere in the specification does it mention verb) to indicate the desired action to be performed on the identified resource. What this resource represents, whether pre-existing data or data that is generated dynamically, depends on the implementation of the server. Often, the resource corresponds to a file or the output of an executable residing on the server. The HTTP/1.0 specification[48] defined the GET, HEAD, and POST methods, and the HTTP/1.1 specification[49] added five new methods: PUT, DELETE, CONNECT, OPTIONS, and TRACE. Any client can use any method and the server can be configured to support any combination of methods. If a method is unknown to an intermediate, it will be treated as an unsafe and non-idempotent method. There is no limit to the number of methods that can be defined, which allows for future methods to be specified without breaking existing infrastructure. For example, WebDAV defined seven new methods and RFC 5789 specified the PATCH method.
Method names are case sensitive.[50][51] This is in contrast to HTTP header field names which are case-insensitive.[52]
- GET
- The GET method requests that the target resource transfer a representation of its state. GET requests should only retrieve data and should have no other effect. (This is also true of some other HTTP methods.)[1] For retrieving resources without making changes, GET is preferred over POST, as they can be addressed through a URL. This enables bookmarking and sharing and makes GET responses eligible for caching, which can save bandwidth. The W3C has published guidance principles on this distinction, saying, «Web application design should be informed by the above principles, but also by the relevant limitations.»[53] See safe methods below.
- HEAD
- The HEAD method requests that the target resource transfer a representation of its state, as for a GET request, but without the representation data enclosed in the response body. This is useful for retrieving the representation metadata in the response header, without having to transfer the entire representation. Uses include checking whether a page is available through the status code and quickly finding the size of a file (
Content-Length).
- POST
- The POST method requests that the target resource process the representation enclosed in the request according to the semantics of the target resource. For example, it is used for posting a message to an Internet forum, subscribing to a mailing list, or completing an online shopping transaction.[54]
- PUT
- The PUT method requests that the target resource create or update its state with the state defined by the representation enclosed in the request. A distinction from POST is that the client specifies the target location on the server.[55]
- DELETE
- The DELETE method requests that the target resource delete its state.
- CONNECT
- The CONNECT method requests that the intermediary establish a TCP/IP tunnel to the origin server identified by the request target. It is often used to secure connections through one or more HTTP proxies with TLS.[56][57] See HTTP CONNECT method.
- OPTIONS
- The OPTIONS method requests that the target resource transfer the HTTP methods that it supports. This can be used to check the functionality of a web server by requesting ‘*’ instead of a specific resource.
- TRACE
- The TRACE method requests that the target resource transfer the received request in the response body. That way a client can see what (if any) changes or additions have been made by intermediaries.
- PATCH
- The PATCH method requests that the target resource modify its state according to the partial update defined in the representation enclosed in the request. This can save bandwidth by updating a part of a file or document without having to transfer it entirely.[58]
All general-purpose web servers are required to implement at least the GET and HEAD methods, and all other methods are considered optional by the specification.[51]
| Request method | RFC | Request has payload body | Response has payload body | Safe | Idempotent | Cacheable |
|---|---|---|---|---|---|---|
| GET | RFC 9110 | Optional | Yes | Yes | Yes | Yes |
| HEAD | RFC 9110 | Optional | No | Yes | Yes | Yes |
| POST | RFC 9110 | Yes | Yes | No | No | Yes |
| PUT | RFC 9110 | Yes | Yes | No | Yes | No |
| DELETE | RFC 9110 | Optional | Yes | No | Yes | No |
| CONNECT | RFC 9110 | Optional | Yes | No | No | No |
| OPTIONS | RFC 9110 | Optional | Yes | Yes | Yes | No |
| TRACE | RFC 9110 | No | Yes | Yes | Yes | No |
| PATCH | RFC 5789 | Yes | Yes | No | No | No |
Safe methods[edit]
A request method is safe if a request with that method has no intended effect on the server. The methods GET, HEAD, OPTIONS, and TRACE are defined as safe. In other words, safe methods are intended to be read-only. They do not exclude side effects though, such as appending request information to a log file or charging an advertising account, since they are not requested by the client, by definition.
In contrast, the methods POST, PUT, DELETE, CONNECT, and PATCH are not safe. They may modify the state of the server or have other effects such as sending an email. Such methods are therefore not usually used by conforming web robots or web crawlers; some that do not conform tend to make requests without regard to context or consequences.
Despite the prescribed safety of GET requests, in practice their handling by the server is not technically limited in any way. Careless or deliberately irregular programming can allow GET requests to cause non-trivial changes on the server. This is discouraged because of the problems which can occur when web caching, search engines, and other automated agents make unintended changes on the server. For example, a website might allow deletion of a resource through a URL such as https://example.com/article/1234/delete, which, if arbitrarily fetched, even using GET, would simply delete the article.[59] A properly coded website would require a DELETE or POST method for this action, which non-malicious bots would not make.
One example of this occurring in practice was during the short-lived Google Web Accelerator beta, which prefetched arbitrary URLs on the page a user was viewing, causing records to be automatically altered or deleted en masse. The beta was suspended only weeks after its first release, following widespread criticism.[60][59]
Idempotent methods[edit]
A request method is idempotent if multiple identical requests with that method have the same effect as a single such request. The methods PUT and DELETE, and safe methods are defined as idempotent. Safe methods are trivially idempotent, since they are intended to have no effect on the server whatsoever; the PUT and DELETE methods, meanwhile, are idempotent since successive identical requests will be ignored. A website might, for instance, set up a PUT endpoint to modify a user’s recorded email address. If this endpoint is configured correctly, any requests which ask to change a user’s email address to the same email address which is already recorded—e.g. duplicate requests following a successful request—will have no effect. Similarly, a request to DELETE a certain user will have no effect if that user has already been deleted.
In contrast, the methods POST, CONNECT, and PATCH are not necessarily idempotent, and therefore sending an identical POST request multiple times may further modify the state of the server or have further effects, such as sending multiple emails. In some cases this is the desired effect, but in other cases it may occur accidentally. A user might, for example, inadvertently send multiple POST requests by clicking a button again if they were not given clear feedback that the first click was being processed. While web browsers may show alert dialog boxes to warn users in some cases where reloading a page may re-submit a POST request, it is generally up to the web application to handle cases where a POST request should not be submitted more than once.
Note that whether or not a method is idempotent is not enforced by the protocol or web server. It is perfectly possible to write a web application in which (for example) a database insert or other non-idempotent action is triggered by a GET or other request. To do so against recommendations, however, may result in undesirable consequences, if a user agent assumes that repeating the same request is safe when it is not.
Cacheable methods[edit]
A request method is cacheable if responses to requests with that method may be stored for future reuse. The methods GET, HEAD, and POST are defined as cacheable.
In contrast, the methods PUT, DELETE, CONNECT, OPTIONS, TRACE, and PATCH are not cacheable.
[edit]
Request header fields allow the client to pass additional information beyond the request line, acting as request modifiers (similarly to the parameters of a procedure). They give information about the client, about the target resource, or about the expected handling of the request.
HTTP/1.1 response messages[edit]
A response message is sent by a server to a client as a reply to its former request message.[note 4]
Response syntax[edit]
A server sends response messages to the client, which consist of:[46]
- a status line, consisting of the protocol version, a space, the response status code, another space, a possibly empty reason phrase, a carriage return and a line feed, e.g.:
HTTP/1.1 200 OK
- zero or more response header fields, each consisting of the case-insensitive field name, a colon, optional leading whitespace, the field value, an optional trailing whitespace and ending with a carriage return and a line feed, e.g.:
Content-Type: text/html
- an empty line, consisting of a carriage return and a line feed;
- an optional message body.
Response status codes[edit]
In HTTP/1.0 and since, the first line of the HTTP response is called the status line and includes a numeric status code (such as «404») and a textual reason phrase (such as «Not Found»). The response status code is a three-digit integer code representing the result of the server’s attempt to understand and satisfy the client’s corresponding request. The way the client handles the response depends primarily on the status code, and secondarily on the other response header fields. Clients may not understand all registered status codes but they must understand their class (given by the first digit of the status code) and treat an unrecognized status code as being equivalent to the x00 status code of that class.
The standard reason phrases are only recommendations, and can be replaced with «local equivalents» at the web developer’s discretion. If the status code indicated a problem, the user agent might display the reason phrase to the user to provide further information about the nature of the problem. The standard also allows the user agent to attempt to interpret the reason phrase, though this might be unwise since the standard explicitly specifies that status codes are machine-readable and reason phrases are human-readable.
The first digit of the status code defines its class:
1XX(informational)- The request was received, continuing process.
2XX(successful)- The request was successfully received, understood, and accepted.
3XX(redirection)- Further action needs to be taken in order to complete the request.
4XX(client error)- The request contains bad syntax or cannot be fulfilled.
5XX(server error)- The server failed to fulfill an apparently valid request.
[edit]
The response header fields allow the server to pass additional information beyond the status line, acting as response modifiers. They give information about the server or about further access to the target resource or related resources.
Each response header field has a defined meaning which can be further refined by the semantics of the request method or response status code.
HTTP/1.1 example of request / response transaction[edit]
Below is a sample HTTP transaction between an HTTP/1.1 client and an HTTP/1.1 server running on www.example.com, port 80.[note 5][note 6]
Client request[edit]
GET / HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: en-GB,en;q=0.5 Accept-Encoding: gzip, deflate, br Connection: keep-alive
A client request (consisting in this case of the request line and a few headers that can be reduced to only the "Host: hostname" header) is followed by a blank line, so that the request ends with a double end of line, each in the form of a carriage return followed by a line feed. The "Host: hostname" header value distinguishes between various DNS names sharing a single IP address, allowing name-based virtual hosting. While optional in HTTP/1.0, it is mandatory in HTTP/1.1. (A «/» (slash) will usually fetch a /index.html file if there is one.)
Server response[edit]
HTTP/1.1 200 OK Date: Mon, 23 May 2005 22:38:34 GMT Content-Type: text/html; charset=UTF-8 Content-Length: 155 Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux) ETag: "3f80f-1b6-3e1cb03b" Accept-Ranges: bytes Connection: close <html> <head> <title>An Example Page</title> </head> <body> <p>Hello World, this is a very simple HTML document.</p> </body> </html>
The ETag (entity tag) header field is used to determine if a cached version of the requested resource is identical to the current version of the resource on the server. "Content-Type" specifies the Internet media type of the data conveyed by the HTTP message, while "Content-Length" indicates its length in bytes. The HTTP/1.1 webserver publishes its ability to respond to requests for certain byte ranges of the document by setting the field "Accept-Ranges: bytes". This is useful, if the client needs to have only certain portions[61] of a resource sent by the server, which is called byte serving. When "Connection: close" is sent, it means that the web server will close the TCP connection immediately after the end of the transfer of this response.[21]
Most of the header lines are optional but some are mandatory. When header "Content-Length: number" is missing in a response with an entity body then this should be considered an error in HTTP/1.0 but it may not be an error in HTTP/1.1 if header "Transfer-Encoding: chunked" is present. Chunked transfer encoding uses a chunk size of 0 to mark the end of the content. Some old implementations of HTTP/1.0 omitted the header "Content-Length" when the length of the body entity was not known at the beginning of the response and so the transfer of data to client continued until server closed the socket.
A "Content-Encoding: gzip" can be used to inform the client that the body entity part of the transmitted data is compressed by gzip algorithm.
Encrypted connections[edit]
The most popular way of establishing an encrypted HTTP connection is HTTPS.[62] Two other methods for establishing an encrypted HTTP connection also exist: Secure Hypertext Transfer Protocol, and using the HTTP/1.1 Upgrade header to specify an upgrade to TLS. Browser support for these two is, however, nearly non-existent.[63][64][65]
Similar protocols[edit]
- The Gopher protocol is a content delivery protocol that was displaced by HTTP in the early 1990s.
- The SPDY protocol is an alternative to HTTP developed at Google, superseded by HTTP/2.
- The Gemini protocol is a Gopher-inspired protocol which mandates privacy-related features.
See also[edit]
- InterPlanetary File System — can replace http
- Comparison of file transfer protocols
- Constrained Application Protocol – a semantically similar protocol to HTTP but used UDP or UDP-like messages targeted for devices with limited processing capability; re-uses HTTP and other internet concepts like Internet media type and web linking (RFC 5988)[66]
- Content negotiation
- Digest access authentication
- HTTP compression
- HTTP/2 – developed by the IETF’s Hypertext Transfer Protocol (httpbis) working group[67]
- List of HTTP header fields
- List of HTTP status codes
- Representational state transfer (REST)
- Variant object
- Web cache
- WebSocket
Notes[edit]
- ^ In practice, these streams are used as multiple TCP/IP sub-connections to multiplex concurrent requests/responses, thus greatly reducing the number of real TCP/IP connections on server side, from 2..8 per client to 1, and allowing many more clients to be served at once.
- ^ In 2022, HTTP/0.9 support has not been officially completely deprecated and is still present in many web servers and browsers (for server responses only), even if usually disabled. It is unclear how long it will take to decommission HTTP/0.9.
- ^ Since late 1996, some developers of popular HTTP/1.0 browsers and servers (specially those who had planned support for HTTP/1.1 too), started to deploy (as an unofficial extension) a sort of keep-alive-mechanism (by using new HTTP headers) in order to keep the TCP/IP connection open for more than a request/response pair and so to speed up the exchange of multiple requests/responses.[31]
- ^ a b HTTP/2 and HTTP/3 have a different representation for HTTP methods and headers.
- ^ HTTP/1.0 has the same messages except for a few missing headers.
- ^ HTTP/2 and HTTP/3 use the same request / response mechanism but with different representations for HTTP headers.
References[edit]
- ^ a b c d Fielding, R.; Nottingham, M.; Reschke, J. (June 2022). HTTP Semantics. IETF. doi:10.17487/RFC9110. RFC 9110.
- ^ a b c d Tim Berner-Lee (1991-01-01). «The Original HTTP as defined in 1991». www.w3.org. World Wide Web Consortium. Retrieved 2010-07-24.
- ^ a b Tim Berner-Lee (1992). «Basic HTTP as defined in 1992». www.w3.org. World Wide Web Consortium. Retrieved 2021-10-19.
- ^ In RFC 1945. That specification was then overcome by HTTP/1.1.
- ^ RFC 2068 (1997) was obsoleted by RFC 2616 in 1999, which was obsoleted by RFC 7230 in 2014, which was obsoleted by RFC 9110 in 2022.
- ^ «Usage Statistics of Default protocol https for websites». w3techs.com. Retrieved 2022-10-16.
- ^ «Usage Statistics of HTTP/2 for websites». w3techs.com. Retrieved 2022-12-02.
- ^ «Can I use… Support tables for HTML5, CSS3, etc». caniuse.com. Retrieved 2022-10-16.
- ^ «Transport Layer Security (TLS) Application-Layer Protocol Negotiation Extension». IETF. July 2014. RFC 7301.
- ^ Belshe, M.; Peon, R.; Thomson, M. «Hypertext Transfer Protocol Version 2, Use of TLS Features». Archived from the original on 2013-07-15. Retrieved 2015-02-10.
- ^ Benjamin, David. «Using TLS 1.3 with HTTP/2». tools.ietf.org. Retrieved 2020-06-02.
This lowers the barrier for deploying TLS 1.3, a major security improvement over TLS 1.2.
- ^ «HTTP/3». Retrieved 2022-06-06.
- ^ «Usage Statistics of HTTP/3 for websites». w3techs.com. Retrieved 2022-10-16.
- ^ «Can I use… Support tables for HTML5, CSS3, etc». caniuse.com. Retrieved 2022-10-16.
- ^ Cimpanu, Catalin (26 September 2019). «Cloudflare, Google Chrome, and Firefox add HTTP/3 support». ZDNet. Retrieved 27 September 2019.
- ^ «HTTP/3: the past, the present, and the future». The Cloudflare Blog. 2019-09-26. Retrieved 2019-10-30.
- ^ «Firefox Nightly supports HTTP 3 — General — Cloudflare Community». 2019-11-19. Retrieved 2020-01-23.
- ^ «HTTP/3 is Fast». Request Metrics. Retrieved 2022-07-01.
- ^ a b c «Connections, Clients, and Servers». RFC 9110, HTTP Semantics. sec. 3.3. doi:10.17487/RFC9110. RFC 9110.
- ^ «Overall Operation». RFC 1945. pp. 6–8. sec. 1.3. doi:10.17487/RFC1945. RFC 1945.
- ^ a b c «Connection Management: Establishment». RFC 9112, HTTP/1.1. sec. 9.1. doi:10.17487/RFC9112. RFC 9112.
- ^ «Connection Management: Persistence». RFC 9112, HTTP/1.1. sec. 9.3. doi:10.17487/RFC9112. RFC 9112.
- ^ «Classic HTTP Documents». W3.org. 1998-05-14. Retrieved 2010-08-01.
- ^ «HTTP/2 Protocol Overview». RFC 9113, HTTP/2). sec. 2. doi:10.17487/RFC7540. RFC 7540.
- ^ «Invention Of The Web, Web History, Who Invented the Web, Tim Berners-Lee, Robert Cailliau, CERN, First Web Server». LivingInternet. Retrieved 2021-08-11.
- ^ Berners-Lee, Tim (1990-10-02). «daemon.c — TCP/IP based server for HyperText». www.w3.org. Retrieved 2021-08-11.
- ^ Berners-Lee, Tim. «HyperText Transfer Protocol». World Wide Web Consortium. Retrieved 31 August 2010.
- ^ Raggett, Dave. «Dave Raggett’s Bio». World Wide Web Consortium. Retrieved 11 June 2010.
- ^ Raggett, Dave; Berners-Lee, Tim. «Hypertext Transfer Protocol Working Group». World Wide Web Consortium. Retrieved 29 September 2010.
- ^ Raggett, Dave. «HTTP WG Plans». World Wide Web Consortium. Retrieved 29 September 2010.
- ^ a b David Gourley; Brian Totty; Marjorie Sayer; Anshu Aggarwal; Sailu Reddy (2002). HTTP: The Definitive Guide. (excerpt of chapter: «Persistent Connections»). O’Reilly Media, inc. ISBN 9781565925090. Retrieved 2021-10-18.
- ^ «HTTP/1.1». Webcom.com Glossary entry. Archived from the original on 2001-11-21. Retrieved 2009-05-29.
- ^ «HTTP-NG Working Group». www.w3.org. World Wide Web Consortium. 1997. Retrieved 2021-10-19.
- ^ Web Administrator (2007). «HTTP Working Group». httpwg.org. IETF. Retrieved 2021-10-19.
- ^ Web Administrator (2007). «HTTP Working Group: charter httpbis». datatracker.ietf.org. IETF. Retrieved 2021-10-19.
- ^ «SPDY: An experimental protocol for a faster web». dev.chromium.org. Google. 2009-11-01. Retrieved 2021-10-19.
- ^ «Rechartering httpbis». IETF; HTTP WG. 2012-01-24. Retrieved 2021-10-19.
- ^ IESG Secretary (2012-03-19). «WG Action: RECHARTER: Hypertext Transfer Protocol Bis (httpbis)». IETF; HTTP WG. Retrieved 2021-10-19.
- ^ Ilya Grigorik; Surma (2019-09-03). «High Performance Browser Networking: Introduction to HTTP/2». developers.google.com. Google Inc. Retrieved 2021-10-19.
- ^ «Appendix-A: HTTP Version History». RFC 7230, HTTP/1.1: Message Syntax and Routing. p. 78. sec. A. doi:10.17487/RFC7230. RFC 7230.
- ^ Matt Menke (2016-06-30). «Intent to Deprecate and Remove: HTTP/0.9 Support». groups.google.com. Retrieved 2021-10-15.
- ^ «HTTP/3». Retrieved 2022-06-06.
- ^ «http URI Scheme». RFC 9110, HTTP Semantics. sec. 4.2.1. doi:10.17487/RFC9110. RFC 9110.
- ^ «https URI Scheme». RFC 9110, HTTP Semantics. sec. 4.2.2. doi:10.17487/RFC9110. RFC 9110.
- ^ Lee, Wei-Bin; Chen, Hsing-Bai; Chang, Shun-Shyan; Chen, Tzung-Her (2019-01-25). «Secure and efficient protection for HTTP cookies with self-verification». International Journal of Communication Systems. 32 (2): e3857. doi:10.1002/dac.3857. S2CID 59524143.
- ^ a b «Message format». RFC 9112: HTTP/1.1. sec. 2.1. doi:10.17487/RFC9112. RFC 9112.
- ^ «Apache Week. HTTP/1.1». 090502 apacheweek.com
- ^ Berners-Lee, Tim; Fielding, Roy T.; Nielsen, Henrik Frystyk. «Method Definitions». Hypertext Transfer Protocol – HTTP/1.0. IETF. pp. 30–32. sec. 8. doi:10.17487/RFC1945. RFC 1945.
- ^ «Method Definitions». RFC 2616. pp. 51–57. sec. 9. doi:10.17487/RFC2616. RFC 2616.
- ^ «Request Line». RFC 9112, HTTP/1.1. sec. 3. doi:10.17487/RFC9112. RFC 9112.
- ^ a b «Methods: Overview». RFC 9110, HTTP Semantics. sec. 9.1. doi:10.17487/RFC9110. RFC 9110.
- ^ «Header Fields». RFC 9110, HTTP Semantics. sec. 6.3. doi:10.17487/RFC9110. RFC 9110.
- ^ Jacobs, Ian (2004). «URIs, Addressability, and the use of HTTP GET and POST». Technical Architecture Group finding. W3C. Retrieved 26 September 2010.
- ^ «POST». RFC 9110, HTTP Semantics. sec. 9.3.3. doi:10.17487/RFC9110. RFC 9110.
- ^ «PUT». RFC 9110, HTTP Semantics. sec. 9.3.4. doi:10.17487/RFC9110. RFC 9110.
- ^ «CONNECT». RFC 9110, HTTP Semantics. sec. 9.3.6. doi:10.17487/RFC9110. RFC 9110.
- ^ «Vulnerability Note VU#150227: HTTP proxy default configurations allow arbitrary TCP connections». US-CERT. 2002-05-17. Retrieved 2007-05-10.
- ^ Dusseault, Lisa; Snell, James M. (March 2010). PATCH Method for HTTP. IETF. doi:10.17487/RFC5789. RFC 5789.
- ^ a b Ediger, Brad (2007-12-21). Advanced Rails: Building Industrial-Strength Web Apps in Record Time. O’Reilly Media, Inc. p. 188. ISBN 978-0596519728.
A common mistake is to use GET for an action that updates a resource. […] This problem came into the Rails public eye in 2005, when the Google Web Accelerator was released.
- ^ Cantrell, Christian (2005-06-01). «What Have We Learned From the Google Web Accelerator?». Adobe Blogs. Adobe. Archived from the original on 2017-08-19. Retrieved 2018-11-19.
- ^ Luotonen, Ari; Franks, John (February 22, 1996). Byte Range Retrieval Extension to HTTP. IETF. I-D draft-ietf-http-range-retrieval-00.
- ^ Canavan, John (2001). Fundamentals of Networking Security. Norwood, MA: Artech House. pp. 82–83. ISBN 9781580531764.
- ^ Zalewski, Michal. «Browser Security Handbook». Retrieved 30 April 2015.
- ^ «Chromium Issue 4527: implement RFC 2817: Upgrading to TLS Within HTTP/1.1». Retrieved 30 April 2015.
- ^ «Mozilla Bug 276813 – [RFE] Support RFC 2817 / TLS Upgrade for HTTP 1.1». Retrieved 30 April 2015.
- ^ Nottingham, Mark (October 2010). Web Linking. IETF. doi:10.17487/RFC5988. RFC 5988.
- ^ «Hypertext Transfer Protocol Bis (httpbis) – Charter». IETF. 2012.
External links[edit]
- Official website
- IETF HTTP Working Group on GitHub
- «Change History for HTTP». W3.org. Retrieved 2010-08-01. A detailed technical history of HTTP.
- «Design Issues for HTTP». W3.org. Retrieved 2010-08-01. Design Issues by Berners-Lee when he was designing the protocol.
HTTP — это протокол, позволяющий получать различные ресурсы, например HTML-документы. Протокол HTTP лежит в основе обмена данными в Интернете. HTTP является протоколом клиент-серверного взаимодействия, что означает инициирование запросов к серверу самим получателем, обычно веб-браузером (web-browser). Полученный итоговый документ будет (может) состоять из различных поддокументов, являющихся частью итогового документа: например, из отдельно полученного текста, описания структуры документа, изображений, видео-файлов, скриптов и многого другого.

Клиенты и серверы взаимодействуют, обмениваясь одиночными сообщениями (а не потоком данных). Сообщения, отправленные клиентом, обычно веб-браузером, называются запросами, а сообщения, отправленные сервером, называются ответами.
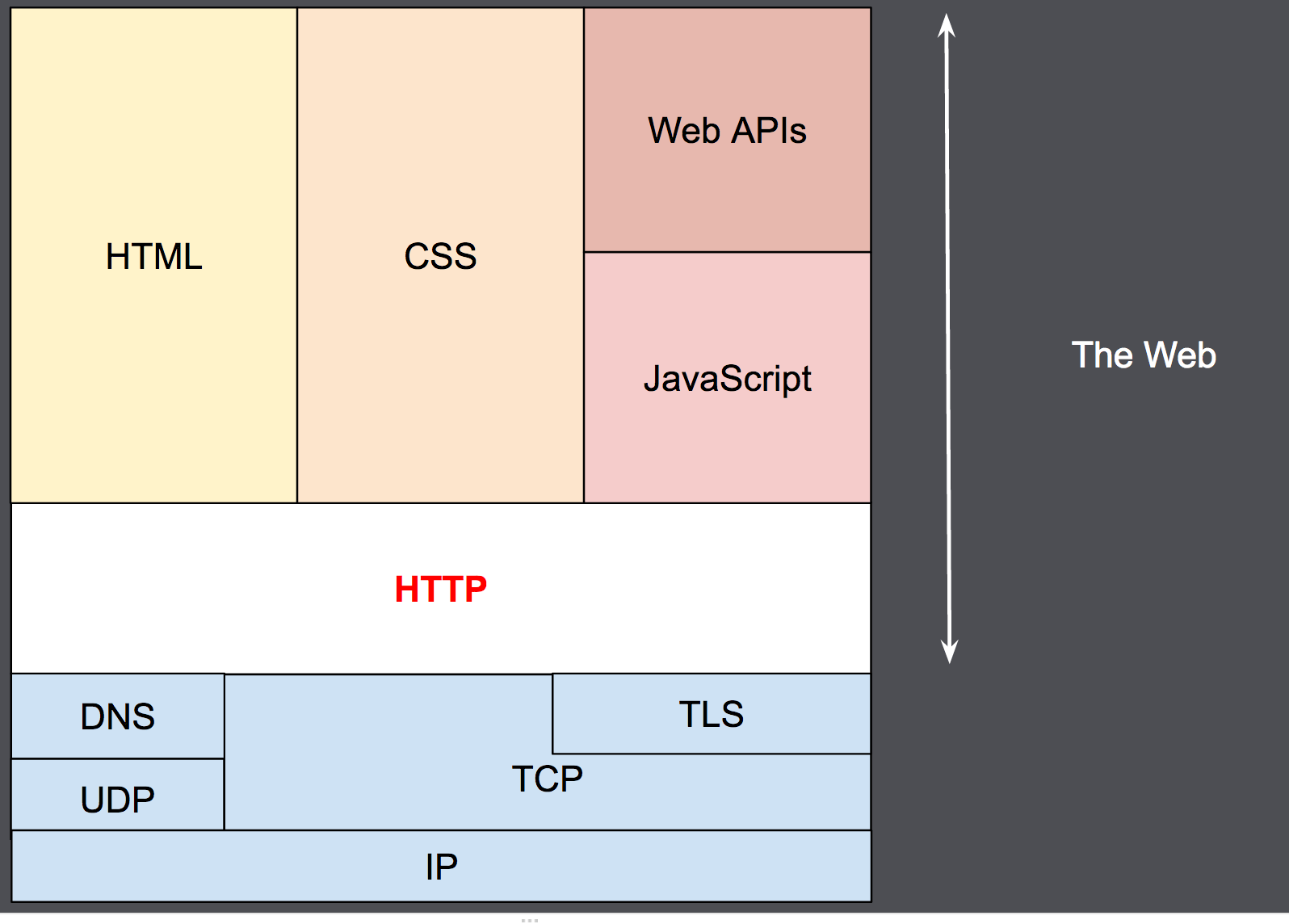 Хотя HTTP был разработан ещё в начале 1990-х годов, за счёт своей расширяемости в дальнейшем он все время совершенствовался. HTTP является протоколом прикладного уровня, который чаще всего использует возможности другого протокола — TCP (или TLS — защищённый TCP) — для пересылки своих сообщений, однако любой другой надёжный транспортный протокол теоретически может быть использован для доставки таких сообщений. Благодаря своей расширяемости, он используется не только для получения клиентом гипертекстовых документов, изображений и видео, но и для передачи содержимого серверам, например, с помощью HTML-форм. HTTP также может быть использован для получения только частей документа с целью обновления веб-страницы по запросу (например, посредством AJAX запроса).
Хотя HTTP был разработан ещё в начале 1990-х годов, за счёт своей расширяемости в дальнейшем он все время совершенствовался. HTTP является протоколом прикладного уровня, который чаще всего использует возможности другого протокола — TCP (или TLS — защищённый TCP) — для пересылки своих сообщений, однако любой другой надёжный транспортный протокол теоретически может быть использован для доставки таких сообщений. Благодаря своей расширяемости, он используется не только для получения клиентом гипертекстовых документов, изображений и видео, но и для передачи содержимого серверам, например, с помощью HTML-форм. HTTP также может быть использован для получения только частей документа с целью обновления веб-страницы по запросу (например, посредством AJAX запроса).
Составляющие систем, основанных на HTTP
HTTP — это клиент-серверный протокол, то есть запросы отправляются какой-то одной стороной — участником обмена (user-agent) (либо прокси вместо него). Чаще всего в качестве участника выступает веб-браузер, но им может быть кто угодно, например, робот, путешествующий по Сети для пополнения и обновления данных индексации веб-страниц для поисковых систем.
Каждый запрос (англ. request) отправляется серверу, который обрабатывает его и возвращает ответ (англ. response). Между этими запросами и ответами как правило существуют многочисленные посредники, называемые прокси, которые выполняют различные операции и работают как шлюзы или кэш, например.

Обычно между браузером и сервером гораздо больше различных устройств-посредников, которые играют какую-либо роль в обработке запроса: маршрутизаторы, модемы и так далее. Благодаря тому, что Сеть построена на основе системы уровней (слоёв) взаимодействия, эти посредники «спрятаны» на сетевом и транспортном уровнях. В этой системе уровней HTTP занимает самый верхний уровень, который называется «прикладным» (или «уровнем приложений»). Знания об уровнях сети, таких как представительский, сеансовый, транспортный, сетевой, канальный и физический, имеют важное значение для понимания работы сети и диагностики возможных проблем, но не требуются для описания и понимания HTTP.
Клиент: участник обмена
Участник обмена (user agent) — это любой инструмент или устройство, действующие от лица пользователя. Эту задачу преимущественно выполняет веб-браузер; в некоторых случаях участниками выступают программы, которые используются инженерами и веб-разработчиками для отладки своих приложений.
Браузер всегда является той сущностью, которая создаёт запрос. Сервер обычно этого не делает, хотя за многие годы существования сети были придуманы способы, которые могут позволить выполнить запросы со стороны сервера.
Чтобы отобразить веб страницу, браузер отправляет начальный запрос для получения HTML-документа этой страницы. После этого браузер изучает этот документ и запрашивает дополнительные файлы, необходимые для отображения содержания веб-страницы (исполняемые скрипты, информацию о макете страницы — CSS таблицы стилей, дополнительные ресурсы в виде изображений и видео-файлов), которые непосредственно являются частью исходного документа, но расположены в других местах сети. Далее браузер соединяет все эти ресурсы для отображения их пользователю в виде единого документа — веб-страницы. Скрипты, выполняемые самим браузером, могут получать по сети дополнительные ресурсы на последующих этапах обработки веб-страницы, и браузер соответствующим образом обновляет отображение этой страницы для пользователя.
Веб-страница является гипертекстовым документом. Это означает, что некоторые части отображаемого текста являются ссылками, которые могут быть активированы (обычно нажатием кнопки мыши) с целью получения и соответственно отображения новой веб-страницы (переход по ссылке). Это позволяет пользователю «перемещаться» по страницам сети (Internet). Браузер преобразует эти гиперссылки в HTTP-запросы и в дальнейшем полученные HTTP-ответы отображает в понятном для пользователя виде.
Веб-сервер
На другой стороне коммуникационного канала расположен сервер, который обслуживает (англ. serve) пользователя, предоставляя ему документы по запросу. С точки зрения конечного пользователя, сервер всегда является некой одной виртуальной машиной, полностью или частично генерирующей документ, хотя фактически он может быть группой серверов, между которыми балансируется нагрузка, то есть перераспределяются запросы различных пользователей, либо сложным программным обеспечением, опрашивающим другие компьютеры (такие как кеширующие серверы, серверы баз данных, серверы приложений электронной коммерции и другие).
Сервер не обязательно расположен на одной машине, и наоборот — несколько серверов могут быть расположены (хоститься) на одной и той же машине. В соответствии с версией HTTP/1.1 и имея Host заголовок, они даже могут делить тот же самый IP-адрес.
Прокси
Между веб-браузером и сервером находятся большое количество сетевых узлов, передающих HTTP сообщения. Из-за слоистой структуры большинство из них оперируют также на транспортном сетевом или физическом уровнях, становясь прозрачным на HTTP слое и потенциально снижая производительность. Эти операции на уровне приложений называются прокси. Они могут быть прозрачными или нет, (изменяющие запросы не пройдут через них), и способны исполнять множество функций:
- caching (кеш может быть публичным или приватными, как кеш браузера)
- фильтрация (как сканирование антивируса, родительский контроль, …)
- выравнивание нагрузки (позволить нескольким серверам обслуживать разные запросы)
- аутентификация (контролировать доступом к разным ресурсам)
- протоколирование (разрешение на хранение истории операций)
Основные аспекты HTTP
HTTP — прост
Даже с большей сложностью, введённой в HTTP/2 путём инкапсуляции HTTP-сообщений в фреймы, HTTP, как правило, прост и удобен для восприятия человеком. HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более лёгкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
HTTP — расширяемый
Введённые в HTTP/1.0 HTTP-заголовки сделали этот протокол лёгким для расширения и экспериментирования. Новая функциональность может быть даже введена простым соглашением между клиентом и сервером о семантике нового заголовка.
HTTP не имеет состояния, но имеет сессию
HTTP не имеет состояния: не существует связи между двумя запросами, которые последовательно выполняются по одному соединению. Из этого немедленно следует возможность проблем для пользователя, пытающегося взаимодействовать с определённой страницей последовательно, например, при использовании корзины в электронном магазине. Но хотя ядро HTTP не имеет состояния, куки позволяют использовать сессии с сохранением состояния. Используя расширяемость заголовков, куки добавляются к рабочему потоку, позволяя сессии на каждом HTTP-запросе делиться некоторым контекстом или состоянием.
HTTP и соединения
Соединение управляется на транспортном уровне, и потому принципиально выходит за границы HTTP. Хотя HTTP не требует, чтобы базовый транспортный протокол был основан на соединениях, требуя только надёжность, или отсутствие потерянных сообщений (т.е. как минимум представление ошибки). Среди двух наиболее распространённых транспортных протоколов Интернета, TCP надёжен, а UDP — нет. HTTP впоследствии полагается на стандарт TCP, являющийся основанным на соединениях, несмотря на то, что соединение не всегда требуется.
HTTP/1.0 открывал TCP-соединение для каждого обмена запросом/ответом, имея два важных недостатка: открытие соединения требует нескольких обменов сообщениями, и потому медленно, хотя становится более эффективным при отправке нескольких сообщений, или при регулярной отправке сообщений: тёплые соединения более эффективны, чем холодные.
Для смягчения этих недостатков, HTTP/1.1 предоставил конвейерную обработку (которую оказалось трудно реализовать) и устойчивые соединения: лежащее в основе TCP соединение можно частично контролировать через заголовок Connection. HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение тёплым и более эффективным.
Проводятся эксперименты по разработке лучшего транспортного протокола, более подходящего для HTTP. Например, Google экспериментирует с QUIC (которая основана на UDP) для предоставления более надёжного и эффективного транспортного протокола.
Чем можно управлять через HTTP
Естественная расширяемость HTTP со временем позволила большее управление и функциональность Сети. Кеш и методы аутентификации были ранними функциями в истории HTTP. Способность ослабить первоначальные ограничения, напротив, была добавлена в 2010-е.
Ниже перечислены общие функции, управляемые с HTTP.
-
Кеш
Сервер может инструктировать прокси и клиенты, указывая что и как долго кешировать. Клиент может инструктировать прокси промежуточных кешей игнорировать хранимые документы. -
Ослабление ограничений источника
Для предотвращения шпионских и других нарушающих приватность вторжений, веб-браузер обеспечивает строгое разделение между веб-сайтами. Только страницы из того же источника могут получить доступ к информации на веб-странице. Хотя такие ограничение нагружают сервер, заголовки HTTP могут ослабить строгое разделение на стороне сервера, позволяя документу стать частью информации с различных доменов (по причинам безопасности). -
Аутентификация
Некоторые страницы доступны только специальным пользователям. Базовая аутентификация может предоставляться через HTTP, либо через использование заголовкаWWW-Authenticate(en-US) и подобных ему, либо с помощью настройки спецсессии, используя куки. -
Прокси и туннелирование (en-US)
Серверы и/или клиенты часто располагаются в интернете и скрывают свои истинные IP-адреса от других. HTTP запросы идут через прокси для пересечения этого сетевого барьера. Не все прокси — HTTP прокси. SOCKS-протокол, например, оперирует на более низком уровне. Другие, как, например, ftp, могут быть обработаны этими прокси. -
Сессии
Использование HTTP кук позволяет связать запрос с состоянием на сервере. Это создаёт сессию, хотя ядро HTTP — протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.
HTTP поток
Когда клиент хочет взаимодействовать с сервером, являющимся конечным сервером или промежуточным прокси, он выполняет следующие шаги:
- Открытие TCP соединения: TCP-соединение будет использоваться для отправки запроса (или запросов) и получения ответа. Клиент может открыть новое соединение, переиспользовать существующее или открыть несколько TCP-соединений к серверу.
- Отправка HTTP-сообщения: HTTP-сообщения (до HTTP/2) являются человекочитаемыми. Начиная с HTTP/2, простые сообщения инкапсулируются во фреймы, делая невозможным их чтение напрямую, но принципиально остаются такими же.
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr - Читает ответ от сервера:
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html <!DOCTYPE html... (here comes the 29769 bytes of the requested web page) - Закрывает или переиспользует соединение для дальнейших запросов.
Если активирован HTTP-конвейер, несколько запросов могут быть отправлены без ожидания получения первого ответа целиком. HTTP-конвейер тяжело внедряется в существующие сети, где старые куски ПО сосуществуют с современными версиями. HTTP-конвейер был заменён в HTTP/2 на более надёжные мультиплексные запросы во фрейме.
HTTP сообщения
Подробнее в отдельной статье «Сообщения HTTP»
HTTP/1.1 и более ранние HTTP сообщения человекочитаемые. В версии HTTP/2 эти сообщения встроены в новую бинарную структуру, фрейм, позволяющий оптимизации, такие как компрессия заголовков и мультиплексирование. Даже если часть оригинального HTTP сообщения отправлена в этой версии HTTP, семантика каждого сообщения не изменяется и клиент воссоздаёт (виртуально) оригинальный HTTP-запрос. Это также полезно для понимания HTTP/2 сообщений в формате HTTP/1.1.
Существует два типа HTTP сообщений, запросы и ответы, каждый в своём формате.
Запросы
Примеры HTTP запросов:
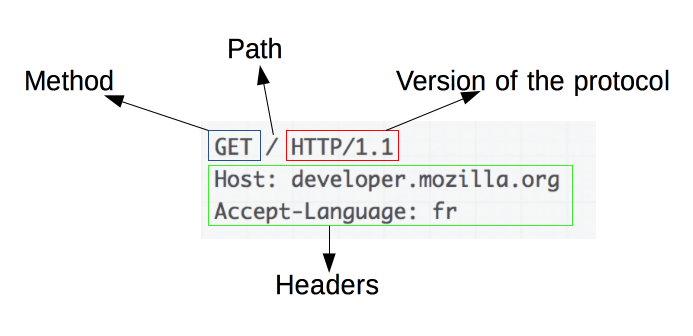
Запросы содержат следующие элементы:
- HTTP-метод, обычно глагол подобно
GET,POSTили существительное, какOPTIONSилиHEAD, определяющее операцию, которую клиент хочет выполнить. Обычно, клиент хочет получить ресурс (используяGET) или передать значения HTML-формы (используяPOST), хотя другие операции могут быть необходимы в других случаях. - Путь к ресурсу: URL ресурсы лишены элементов, которые очевидны из контекста, например без протокола (
http://), домена (здесьdeveloper.mozilla.org), или TCP порта (здесь80). - Версию HTTP-протокола.
- Заголовки (опционально), предоставляющие дополнительную информацию для сервера.
- Или тело, для некоторых методов, таких как
POST, которое содержит отправленный ресурс.
Ответы
Примеры ответов:
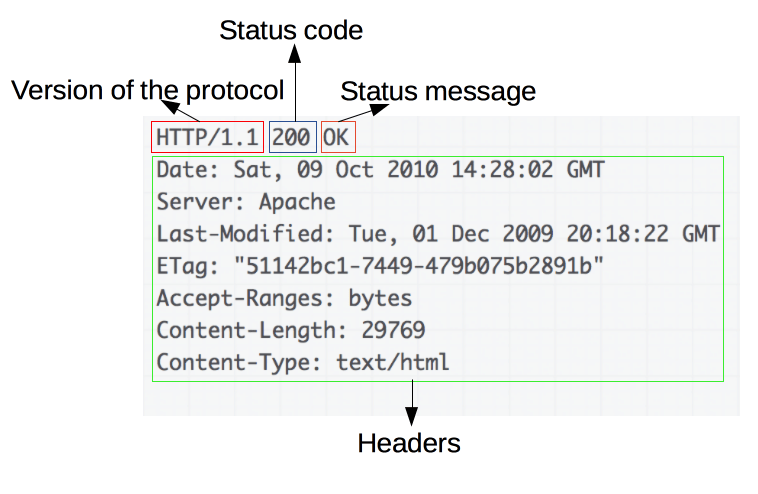
Ответы содержат следующие элементы:
- Версию HTTP-протокола.
- HTTP код состояния, сообщающий об успешности запроса или причине неудачи.
- Сообщение состояния — краткое описание кода состояния.
- HTTP заголовки, подобно заголовкам в запросах.
- Опционально: тело, содержащее пересылаемый ресурс.
Вывод
HTTP — лёгкий в использовании расширяемый протокол. Структура клиент-сервера, вместе со способностью к простому добавлению заголовков, позволяет HTTP продвигаться вместе с расширяющимися возможностями Сети.
Хотя HTTP/2 добавляет некоторую сложность, встраивая HTTP сообщения во фреймы для улучшения производительности, базовая структура сообщений осталась с HTTP/1.0. Сессионный поток остаётся простым, позволяя исследовать и отлаживать с простым монитором HTTP-сообщений.