Исходный код программы на С — это текстовая запись программы на языке программирования С. Исходный код на С пишется таким образом, чтобы любой программист, владеющий этим языком программирования, смог разобрать, что там написано.
С — это язык программирования, который проверен временем. Изначально он задумывался как заменитель Ассемблера, чтобы писать на нем операционные системы.
С — это высокоуровневый язык, который не зависит от архитектуры устройства, а это значит, что программы, написанные на нем, можно использовать на разных платформах. Таким образом, С стал идеальным языком для операционных систем, драйверов и программ системного значения.
Исходный код программы на С
Сегодня языки программирования С и С++ ставят рядом, потому что С++ — это улучшенная версия С.Таким образом, программы, которые пишутся на С, будут корректными и для языка программирования С++. Из этого получается, что для извлечения исходного кода программы на С можно использовать инструменты, предназначенные для С++, но об этом чуть позже.
Исходный код программы на С — это программный код, который еще не был скомпилирован и содержится в файлах с расширением данного языка. У этого языка имеется несколько расширений, и делятся они в зависимости от типов файлов:
заголовочный файлы используют расширение «.h», поэтому называются h-файлы;
файлы реализации используют расширение «.с» для языка С и «.срр», «.схх», «.сс» для языка программирования С++.
Любой проект, реализованный на С, будет иметь файлы обоих типов. Но нужно отметить, что:
h-файлы — это файлы, содержащие сведения о программе;
файлы реализации — это сам код программы.
Когда вам нужен исходный код программы на С, то больший интерес вам представляют файлы реализации. При этом единую функционирующую программу составляют оба вида файлов.
Как получить исходный код программы на С
Исходный код априори принадлежит своему автору. Поэтому если автор кода выставляет его в открытые источники, то пользователи получают программу с открытым исходным кодом. В этой ситуации пользователи могут воспользоваться исходным кодом программы по своему усмотрению, например:
помочь доработать программу, вплоть до того, чтобы стать соавтором;
использовать код, чтобы создать подобную программу, однако тут есть тонкости: нужно будет указать автора исходного кода или что-то еще;
чуть-чуть подправить программу для личного пользования;
и др.
Если автор скрывает исходный код программы, то получить его:
противозаконно, потому что авторы закрывают код и защищают его лицензиями;
очень сложно, а иногда практически невозможно.
Процесс получения исходного кода из закрытой программы — это реверсивная инженерия или обратное программирование. У закрытых программ пользователи не могут видеть исходный код программы, лишь ее исполняемые или скомпилированные файлы, например, файлы «.ехе» для Windows-программ. Если открыть исполняемый или скомпилированный файл, то там не будет ничего общего с языком программирования. Все, что там можно будет увидеть, — это беспорядочный набор цифр и букв или двоичный код из сочетания «1» и «0».
Исходный код программы на С: обратное программирование
Обратное программирование — это длительный и муторный процесс. Чем больше программа, для которой вы хотите получить исходный код, тем сложнее будет этот процесс. В некоторых случаях процесс «реверса» займет несколько лет, например, попробуйте воссоздать исходный код операционной системы Windows.
Реверсное программирование завязано на применении специфического программного обеспечения: декомпиляторы, дешифровщики, деобфускаторы, отладчики, оптимизаторы и т. д. В этом заключается еще одна сложность — достать качественные программы из этой категории в открытом доступе практически нереально. Все, что есть в открытом доступе, может помочь только с небольшими программами. Если вам нужен будет исходный код более серьезной программы на С, то искать специализированное ПО — это та еще затея, но поисковик, анонимные сообщества хакеров и darknet вам в помощь, при том что способы попробовать восстановить исходный код полностью или частично есть.
Способы попробовать восстановить исходный код программы на С:
IDA Pro — одна из лучших и бесплатных программ из категории «реверсивная инженерия»;
«hiew.exe» — утилита, которая не выдаст исходный код программы, но поможет править его на языке ассемблера;
нужно внимательно посмотреть имеющийся код программы: если к нему подшиты PDB-файлы (опытные программисты этого не делают, но мало ли что), тогда есть возможность прямо в IDE узнать номера строк исходников, имена переменных, функций, констант и т. д.; при помощи такого подхода добиться исходного кода не получится, но у вас будет вся информация для того, чтобы понять, как он функционирует;
необходимо проверить, не встроен ли в программу «debug info»: если встроен, то можно использовать его, как и в предыдущем способе, чтобы узнать информацию об исходном коде;
DisSharp — программа, которая способна раскрыть часть кода на С++ и С#;
Refox — данная утилита поможет, если программа на С скомпилирована в какой-либо байт-кодовый язык;
exe.scope.exe или Resourcehacker.exe — утилиты, которые не раскрывают исходный код, но помогают определить, какие библиотеки используются в программе.
Универсальных средств нет. Нет такого, чтобы вы запустили какое-то программное обеспечение, и оно вам выдало исходный код программы на С. Чтобы добиться исходного кода, нужно будет повозиться и узнавать все частями. Например:
при помощи одной утилиты вы узнаете используемые библиотеки;
при помощи другой — имена классов и функций;
третья поможет частично раскрыть код;
и т. д., пока у вас не сложится общая картина об исходниках.
Опять же, если код хорошо защищен, то сам процесс становится намного сложнее, потому что тогда нужно будет разбираться с защитой, прежде чем применять какие-то утилиты для обнаружения исходников.
Заключение
Если вам нужен исходный код программы на С, а он закрыт, то вам остается только обратное программирование. Прежде чем начать этот процесс, подумайте об ответственности, ведь реверсивная инженерия — это нарушение авторских прав и законодательства многих государств.
Термины «исходный код» и «объектный код» довольно часто встречаются в мире программирования и веб-дизайна. В этой статье мы постараемся разобраться в этих терминах, а также объясним контекст, в котором они используются.
Что такое исходный код
Исходный код — это набор инструкций или команд, который может быть прочитан человеком. Грубо говоря — это обычный текстовый файл.
После создания исходного кода он сохраняется в файле в соответствии с его расширением. Например, файл JavaScript сохраняется с расширением «.js», а файл C++ — с расширением «.cpp». Переводчик языка получает исходный код, а затем преобразует его в машинный код, который по другому называется объектным кодом.
Для эффективной разработки программы исходный код пишется либо на ассемблере, либо на высокоуровневом языке программирования.
Язык ассемблера — это машинно-ориентированный язык, который требует специальных знаний для его расшифровки. В высокоуровневых языках программирования в качестве инструкций используются английские и математические символы, а также языки — C, C++, Java, Python, JavaScript.
Как используется исходный код
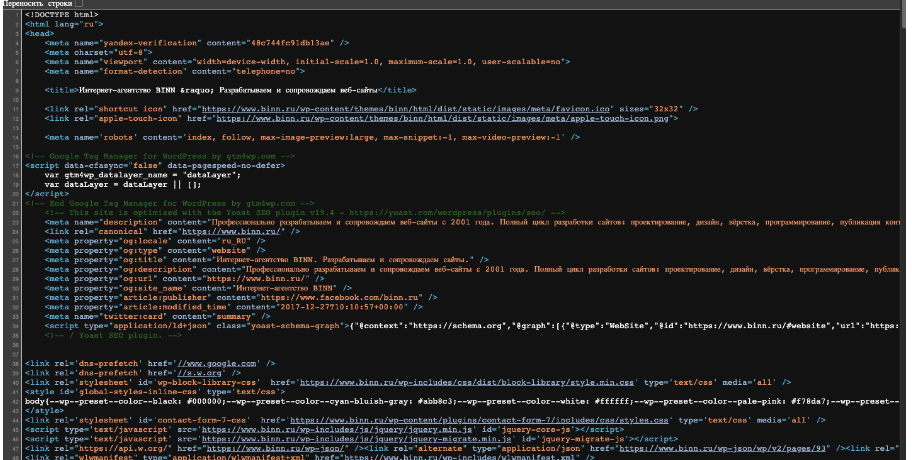
Исходный код написан простым текстом, который хорошо понятен людям. Исходный код любого веб-сайта найти несложно — достаточно щелкнуть правой кнопкой мыши на любой веб-странице и перейти к пункту «Просмотреть исходный код страницы».
Вам откроется новая вкладка с исходным кодом. Вот так выглядит исходный код главной страницы интернет-агентства Binn. Исходный код с этой веб-страницы написан в текстовом формате и может быть прочитан как обычными людьми, так и программистами.
Что такое объектный код
Объектный код представляет собой компьютерный числовой код, который состоит из двоичных чисел, таких как 0 и 1, и может быть распознан только компьютером. Грубо говоря, объектный код — это промежуточное представление кода, то есть еще не машинный, но уже не исходный.
Объектный код обычно используется на этапе сборки программы. Это вывод исходного кода после компиляции. Объектный код остается в объектном файле — COM, COFF (общий формат объектных файлов). Объектный код, машинный код и двоичный код могут использоваться взаимозаменяемо.
Как используется объектный код
Объектный код обычно включает интерпретированную или скомпилированную программируемую логику, встроенное ПО и различные библиотеки.
Объектный код генерируется компилятором, который считывает исходные инструкции компьютерного языка более высокого уровня, а затем переводит их в эквивалентные инструкции машинного языка. Визуально объектный код выглядит следующим образом:

Объектный код написан с помощью нулей и единиц, и его сложно прочитать людям, для его чтения необходим компьютер.
Компиляция исходного код в объектный
Компилятор преобразует удобочитаемый код в объектный (или машинный) код. У каждого высокоуровневого языка программирования есть свой собственный компилятор, который преобразует код в язык, понятный машине. Визуально процесс разработки ПО может выглядеть примерно так:
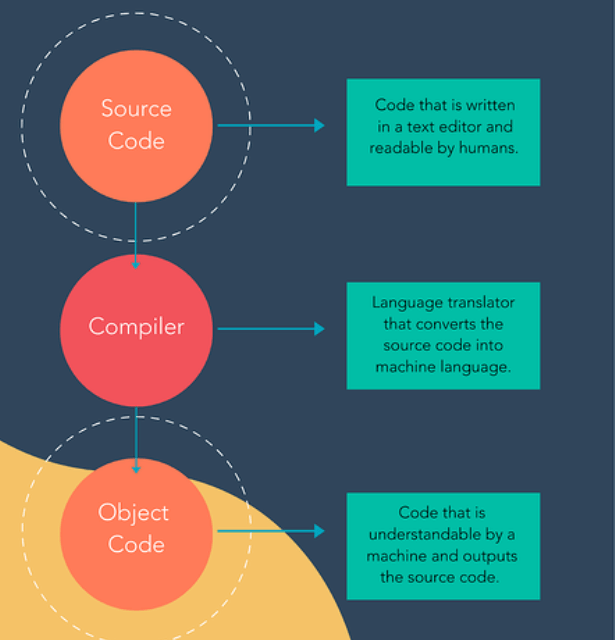
Исходный код и объектный код можно рассматривать как версии до и после компьютерного программирования. Рассмотрим этапы:
- Программист, который использует типы языка Java в нужной последовательности, сохраняет их, изменяя наименование так, чтобы оно содержало исходный код.
- После этого файл готов к компиляции и проходит через компилятор Java.
- Полученный результат (скомпилированный файл) называется объектным кодом.
- Объектный код содержит последовательность инструкций, которые понятны процессору, но трудны для понимания человеком.
Разница между исходным и объектным кодом
Теперь, когда у нас есть общее представление об исходном и объектном коде, мы можем сформулировать основное различие между этими двумя терминами.
Если коротко, то исходный код — это набор инструкций, который написан с использованием языка программирования, а объектный код — это результат исходного кода после обработки компилятором.
Исходный код против объектного кода
Исходный код создает объектный код, и чтобы создать приложение, которое в дальнейшем можно распространить, объектный код создает исполняемый файл, который доступен для любых пользователей.
Точно так же, как человек понимает родной язык, компьютеры понимают машинный язык. Иногда даже человеку нужен переводчик для понимания иностранного языка, поэтому компьютеру потребуется компилятор (переводчик), чтобы отличить исходный код от объектного кода.
Источник: hubspot.com
Как выглядит программный код
Содержание
- Содержание
- Назначение [ править | править код ]
- Организация [ править | править код ]
- Качество [ править | править код ]
- Неисполняемый исходный код [ править | править код ]
- Описание
- Качество кода
- Вредоносный программный код
- Рекомендации по написанию хорошего кода
- Имена переменных и выявление ошибок
- Заключение

Исхо́дный код (также исхо́дный текст) — текст компьютерной программы на каком-либо языке программирования или языке разметки, который может быть прочтён человеком. В обобщённом смысле — любые входные данные для транслятора. Исходный код транслируется в исполняемый код целиком до запуска программы при помощи компилятора или может исполняться сразу при помощи интерпретатора.
Содержание
Назначение [ править | править код ]
Исходный код либо используется для получения объектного кода, либо выполняется интерпретатором. Изменения выполняются только над исходным, с последующим повторным преобразованием в объектный.
Другое важное назначение исходного кода — в качестве описания программы. По тексту программы можно восстановить логику её поведения. Для облегчения понимания исходного кода используются комментарии. Существуют также инструментальные средства, позволяющие автоматически получать документацию по исходному коду — т. н. генераторы документации.
Кроме того, исходный код имеет много других применений. Он может использоваться как инструмент обучения; начинающим программистам бывает полезно исследовать существующий исходный код для изучения техники и методологии программирования. Он также используется как инструмент общения между опытными программистами благодаря своей лаконичной и недвусмысленной природе. Совместное использование кода разработчиками часто упоминается как фактор, способствующий улучшению опыта программистов.
Программисты часто переносят исходный код (в виде модулей, в имеющемся виде или с адаптацией) из одного проекта в другой, что носит название повторного использования кода.
Исходный код — важнейший компонент для процесса портирования программного обеспечения на другие платформы. Без исходного кода какой-либо части ПО портирование либо слишком сложно, либо вообще невозможно.
Организация [ править | править код ]
Исходный код некоторой части ПО (модуля, компонента) может состоять из одного или нескольких файлов. Код программы не обязательно пишется только на одном языке программирования. Например, часто программы, написанные на языке Си, из соображений оптимизации содержат вставки кода на языке ассемблера. Также возможны ситуации, когда некоторые компоненты или части программы пишутся на различных языках, с последующей сборкой в единый исполняемый модуль при помощи технологии, известной как компоновка библиотек (library linking).
Сложное программное обеспечение при сборке требует использования десятков или даже сотен файлов с исходным кодом. В таких случаях для упрощения сборки обычно используются файлы проектов, содержащие описание зависимостей между файлами с исходным кодом и описывающие процесс сборки. Эти файлы также могут содержать параметры для компилятора и среды проектирования. Для разных сред проектирования могут применяться разные файлы проекта, причём в некоторых средах эти файлы могут быть в текстовом формате, пригодном для непосредственного редактирования программистом с помощью универсальных текстовых редакторов, в других средах поддерживаются специальные форматы, а создание и изменения файлов производится с помощью специальных инструментальных программ. Файлы проектов обычно включают в понятие «исходный код». Часто под исходным кодом подразумевают и файлы ресурсов, содержащие различные данные, например графические изображения, нужные для сборки программы.
Для облегчения работы с исходным кодом и для совместной работы над кодом командой программистов используются системы управления версиями.
Качество [ править | править код ]
В отличие от человека, для компьютера нет «хорошо написанного» или «плохо написанного» кода. Но то, как написан код, может сильно влиять на процесс сопровождения ПО. О качестве исходного кода можно судить по следующим параметрам:
- читаемость кода (в том числе наличие комментариев к коду);
- лёгкость в поддержке, тестировании, отладке и устранении ошибок, модификации и портировании;
- экономное использование ресурсов: памяти, процессора, дискового пространства;
- отсутствие замечаний, выводимых компилятором;
- отсутствие «мусора» — неиспользуемых переменных, недостижимых блоков кода, ненужных устаревших комментариев и т. д.;
- адекватная обработка ошибок;
- возможность интернационализации интерфейса.
Неисполняемый исходный код [ править | править код ]
Копилефтные лицензии для свободного ПО требуют распространения исходного кода. Эти лицензии часто используются также для работ, не являющихся программами — например, документации, изображений, файлов данных для компьютерных игр.
В таких случаях исходным кодом считается форма данной работы, предпочтительная для её редактирования. В лицензиях, предназначенных не только для ПО, она также может называться версией в «прозрачном формате». Это может быть, например:
- для файла, сжатого с потерей данных — версия без потерь;
- для рендеравекторного изображения или трёхмерной модели — соответственно, векторная версия и модель;
- для изображения текста — такой же текст в текстовом формате;
- для музыки — файл во внутреннем формате музыкального редактора;
- и наконец, сам файл, если он удовлетворяет указанным условиям, либо если более удобной версии просто не существовало.
Любая программа или онлайн-сервисы, например, Word, Microsoft Windows, WhatsApp или же браузер, которые ежедневно запускают сотни миллионов человек, так или иначе, состоят из особых инструкций. Или специального программного кода, который понятен машине, говорит, что ей делать или, наоборот, не делать. Или как правильно реагировать на действия пользователя. Что такое программный код, будет разобрано в этой статье.
Описание
Программный код программы — это текст, выполненный на особом языке, понятном машине. Он может выполняться непосредственно по тексту с помощью интерпретатора или транслироваться в особый вид с помощью компилятора.

Исходный код программы может состоять из нескольких файлов. При этом все они должны быть одинакового формата. Текст программы, содержащейся в них, должен быть написан на одном и том же языке. Правда, могут встречаться и исключения. Например, в веб-разработке в файле страницы могут содержаться несколько различных языков программирования и стандартов. В зависимости от сложности проекта, могут присутствовать такие языки и технологии, как PHP, HTML, JavaScript, Java и другие.
Сложные программные комплексы при сборке могут потребовать большого количества файлов, которое может исчисляться целыми сотнями. Для совместной работы над такими большими проектами программисты очень часто используют системы контроля версий. Они позволяют одновременно работать с несколькими экземплярами исходного кода, который на определённом этапе разработки можно соединить в один общий.

Качество кода
Компьютер не способен понять, как написан код для него, плохо или хорошо. Если он будет работоспособен и не содержит ошибок, то машина запустит его в любом случае. Плохой код может усложнить задачи сопровождения программного обеспечения. Особенно актуально это для больших проектов. Обычно качественный код характеризуется несколькими параметрами:
- Читаемость кода. Одного взгляда на него должно хватать, чтобы обобщенно понять, что реализуется участком кода.
- Присутствие понятных и ёмких комментариев. Данный параметр очень сильно влияет на читаемость, легкость в отладке, тестирование поддержки и устранение ошибок программного кода.
- Низкая сложность.
- Оптимизация кода. Организовать его стоит таким образом, чтобы программа использовала как можно меньше системных ресурсов, таких как память, время процессора и пространство жёсткого диска.
- Отсутствие мусора. То есть не используемых переменных или блоков кода, в которой никогда не заходит управление программой.
Вредоносный программный код
Помимо полезных программ, существуют такие, которые могут нанести вред системе или даже оборудованию. Как правило, пишется такой код людьми, которые заинтересованы в какой-либо выгоде от происходящего процесса. Например, программы, которые могут похищать личные данные с компьютеров пользователей. Ими могут быть номера платёжных карт, паспортные данные, или какая-либо другая конфиденциальная информация. Другие могут просто оказывать влияние на работу системы, тем самым вызывая сбои и мешая полноценной функциональности.
Рекомендации по написанию хорошего кода
Джефф Вогел — программист с большим опытом — поделился несколькими советами для того, чтобы научить начинающих разработчиков правилам хорошего кода.
В частности, он предлагает всегда комментировать свой программный код. Что такое комментарий? Это понятное и краткое описание того, что происходит в данной строке кода или функции. Дело в том, что разработка определённой программы может затянуться на месяц или вообще приостановиться на некоторое время. Вернувшись к работе над проектом через пару месяцев, даже опытному программисту будет сложно разобраться в своей же программе. Но подробные комментарии смогут восстановить цепочку событий и поведение кода.
Далее он рекомендует использовать в программе глобальные переменные как можно чаще. Это объясняется тем, что при изменении программного кода, придётся корректировать значение переменной всего лишь в одном месте. При этом все использующие значение функции или процедуры сразу об этом узнают и будут производить операции уже с новыми данными.
Имена переменных и выявление ошибок
Правильное название переменных также поможет значительно сократить время на изучение исходного кода программы, даже если код написан собственными руками. То есть хорошим кодом считается такой текст, где переменные и функции имеют имена, по которым можно понять, что именно они делают или хранят. При этом нужно стараться не использовать длинных имён переменных.

Очень важно уделять большое внимание своевременному устранению ошибок. Что такое программный код, который исполняется идеально? Это код, в котором нет ошибок. То есть любое ветвление цикла или изменение переменной, или вовсе какие-либо непредвиденные действия пользователя, всегда приведут к ожидаемому результату. Это достигается за счёт тестирования готового программного продукта по несколько раз.
Выявление ошибок программного кода, а точнее, их предугадывание возможно на этапе проектирования программы. Присутствие в коде различных проверок условий и возможных исключений, поможет вести управление программой по определённому курсу.
Оптимизация имеет колоссальное значение для написания работоспособной программы, которая будет экономно использовать ресурсы компьютера и при этом не допускать ошибок выполнения программного кода. Что такое оптимизированная программа? Это продукт, который способен выполнять весь заявленный функционал, ведя себя при этом «тихо» и экономно.
Практически всегда оптимизации для стабильной работы программы можно добиться только в результате проведения нескольких тестов на разных платформах и в различных условиях. Если программа начинает вести себя непредсказуемо, нужно определить, что стало причиной и по возможности устранить или перехватить процесс.
Заключение
Что такое программный код? Говоря простым языком, это набор инструкций и понятий для компьютера. Он содержит текст, который компилятор или интерпретатор могут превратить в понятный машине язык. То есть, по сути, программный код — это посредник между человеком и компьютером, который упрощает их взаимоотношения.
Исходный код — это текст компьютерной программы на языке программирования или языке разметки, который состоит из цифр и букв английского языка для понимания человеком. Исходный код компьютерной программы транслируется в исполняемы код, понятный для компьютера, и запускает работу программы с помощью компилятора или выполняет код через интерпретатор. С исходным кодом работают программисты, прописывая всю логику работы программы, добавляя комментарии в наиболее сложные участки кода для понимания их работы другими программистами, генерируя автоматическими инструментами документацию исходного кода.
Комментарии и документация, да и сам по себе исходный код программы, предназначен не только для понимания принципов и логики работы программы и отдельных ее частей, но и для обучения начинающих программистов, изучения применяемых техни и методологии разработанной программы. Совместное использование программного кода позволяет улучшать общий опыт работы программистов.
Так как очень часто одни и те же участки программного кода используются в нескольких местах программы, либо задействованы в нескольких других программах, такие участки кода принято выделять в модули и компоненты, которые можно в любой момент быстро подключить и использовать в нужной программе. Такое действие назвается — повторным использованием программного кода. Это очень облегчает разработку программ и делает ее заметно быстрей, без необходимости повторно писать одни и те же участки программного кода.
В случае применения таких модулей и компонентов, да и вообще, исходного кода самого по себе, важным моментом является переносимость на другие программные платформы, их правильная работа на этих платформах.
Переносимые модули и компоненты с исходным кодом могут состоять из одного и более файлов (десятки, тысячи файлов с кодом), а также написаны на разных языках программирования. Например, часть программы на языке программирования Си, может содержать части кода на языке ассемблера.
Для удобства и облегчения работы с исходным кодом существует множество инструментов, позволяющий автоматизировать написание кода, обеспечивать командную работу над кодом, создавать и контролировать различные версии программ.
Для компьютера, нет разницы и понимания «хорошего кода» или «плохого кода». Программисту же, для понимания что происходит в программе, написанной другим программистом, поддержки и написания новых частей программы, качество исходного кода является очень важной вещью. Ведь если код будет труден для понимания, его невозможно прочитать, а если возможно, но на это уходит много времени, то разработка и поддержка программы существенно усложнит жизнь программиста. Поэтому качество кода должно соответствовать следующим требованиям:
- читаемость кода — простой и локаничный код, с понятными комментариями там, где это действительно требуется
- легкость в пониманиии, тестировании и отладке для написания новых частей программы и устранения ошибок
- экономичное использование ресурсов — памяти, процессов, пространства на диске
- отсутствие неиспользуемых переменных, неиспользуемых участков кода, устаревших комментариев
- переносимость программы на другие платформы
👉 В этом разделе мы на примерах разбираем сложные айтишные термины. Если вы хотите почитать вдохновляющие и честные истории о карьере в IT, переходите в другие разделы.
Программный код — это текст, написанный на языке программирования. Обычно его пишут программисты, и этот процесс называется «кодинг». С помощью кода создают программы: отдают компьютеру команды, которые он выполняет.
Когда человек пишет код, про него говорят, что он кодит. Чаще всего этот термин применяют по отношению к программистам, которых еще называют кодерами.
Код программы изначально воспринимается компьютером как простой текст. Чтобы он заработал, нужно передать его специальному инструменту — компилятору или интерпретатору нужного языка. Тот преобразует код в вид, понятный машине. После этого его можно будет запустить.
Для чего нужен программный код
Компьютер не понимает человеческие языки. Но и программный код на современных языках программирования ему непонятен: его нужно компилировать или интерпретировать, чтобы он заработал. Возникает вопрос: почему тогда не писать программы на человеческом языке. Но так не получится — код все-таки нужен. Попробуем объяснить простыми словами, почему.
Человеческие языки сложные. Практически невозможно создать компилятор, который переводил бы человеческие естественные языки в понятный компьютеру вид. В программировании есть область их распознавания, которая называется NLP, но она очень сложная и не способна распознать все. Поэтому человеческий язык в качестве языка программирования просто не подойдет.
Код помогает быстрее и лаконичнее отдавать команды. Представьте, что вам нужно отсортировать большое количество данных. Описать задачу обычным текстом будет сложнее, чем написать одну или две строчки кода.
Код понятен и структурирован. Современные языки программирования — высокоуровневые. Это значит, что их уровень абстракции выше, ближе к человеческому пониманию, чем к машинному. Поэтому код на них нужно компилировать или интерпретировать. Исходный «язык машины» — длинные машинные коды из нулей и единиц, и писать на них программы человеку практически невозможно. Будет совершенно непонятно. А по программному коду видно, что он делает — его синтаксис приближен к человеческому пониманию.
Языки программирования служат своеобразным компромиссом между сложными для человека машинными кодами и непонятным для компьютера человеческим языком.
Как выглядит программный код
Это набор строчек на языке программирования. Языки обычно приближены к английскому: слова из него заимствуются для обозначения команд. По структуре код состоит из команд, связей между ними, различных операторов и знаков препинания, а также переменных и значений. Большие группы команд, которые выполняют конкретное действие, собираются в блоки — функции.
В конце каждой строчки в большинстве языков ставится точка с запятой. Она помогает компилятору или интерпретатору понять, что команда закончилась. Но это не всегда так: например, в Python вместо точки с запятой используется перенос строки.
На картинках с кодом, которые вы наверняка видели в сети, он разноцветный. Это происходит, потому что специальные средства для программирования подсвечивают разные элементы его синтаксиса для наглядности.
Разбираемся с терминами: каким бывает код
Это не классификация — просто список терминов, которые часто можно услышать в контексте написания кода. Они могут быть похожи, но означают разное.
Исходный код, или сурс, source code — текст программы, который написал разработчик. Может быть открытым или закрытым. Открытый исходный код может просмотреть кто угодно. Закрытый или спрятан от пользователей, или вообще отсутствует в готовом программном продукте — вместо него используются исполняемые коды.
Исполняемый код — код, который может исполнить программа. Иногда противопоставляется исходному. Чаще всего так называют код, который получился в результате компиляции. Компилятор переводит исходный код в машинный, который сможет исполнить операционная система, — на выходе получается исполняемый код.
Чистый код — это понятие другого порядка, которое, скорее, относится к правилам хорошего тона для разработчиков. Чистым называют код, который хорошо написан, не слишком многословен, понятен и лаконичен. Такой код легко прочитать другим разработчикам, а не только автору.
В чем пишут код
Языки программирования устроены так, что код можно написать в любом редакторе, даже в «Блокноте». Компьютер в таком случае воспримет его как текст, а для запуска нужно выполнить дополнительные действия: сохранить файл в нужном формате, отправить его компилятору или интерпретатору. Если это код на JavaScript, проще всего запустить его в браузере. А если код на внутренних языках операционной системы — в консоли.
Чаще всего программисты пишут код в специальных программах: средах разработки, они же IDE, и редакторах кода. Среда — более мощный инструмент со множеством дополнительных функций. Код можно запустить прямо из нее одной кнопкой. Редактор проще, в нем легче разобраться, и он менее ресурсоемкий.
Специальные средства для написания кода умеют больше, чем текстовые редакторы. Они подсвечивают синтаксис и делают код разноцветным, чтобы разработчику было понятнее. Они помогают находить неудачные места, отлаживать программы, выводить данные и делать много других вещей. Это удобные и наглядные инструменты.
Новичкам мы рекомендуем начать с редакторов кода или IDE. Так удобнее писать и сложнее запутаться.
Из чего состоит код
Набор правил, по которым пишется код, называется синтаксисом. Синтаксис поясняет, какие команды можно использовать, какой должна быть структура кода, как правильно расставлять связи, передавать аргументы и использовать разные операторы. Его можно сравнить с правилами русского языка.
Синтаксис языка программирования ничего не говорит о смысле программы. Он отвечает только за правильность написания.
Код состоит из команд, связей между ними и других элементов синтаксиса. Вот какими они бывают.
Сначала договоримся об общих понятиях.
- Командами мы будем называть непосредственные указания для компьютера, что сделать. Например, напечатать слово: print(“слово”).
- Связями будем называть разные элементы, связывающие команды друг с другом. Чаще всего это знаки пунктуации и различные операторы.
А теперь рассмотрим компоненты более подробно.
Переменные. Когда пользователь оперирует какими-то значениями по нескольку раз, ему бывает нужно куда-то их записать. Для этого в языках программирования существуют переменные. У переменной есть имя, тип и значение.
- Имя показывает, как обращаться к переменной. Например, если мы объявили a = 5, то переменная называется a.
- Значение – это данные, которые лежат в переменной. Для названной выше переменной a это число 5.
- Тип данных показывает, какой вид информации находится в переменной: число, буква, строка или что-то более сложное. Есть простые и составные типы данных. В первых хранятся примитивные значения вроде чисел и строк, во вторых – сложные конструкции из нескольких примитивов или даже функций.
Работа с типами данных в разных языках программирования – тема для отдельной статьи. Они могут сильно различаться: где-то тип надо указывать явно, где-то нет. В некоторых языках можно сравнивать или складывать данные разных типов, в других нельзя. Вариаций много, поэтому стоит сразу смотреть, как устроены типы в выбранном вами языке.
Константы. Так называют переменные, значение которых нельзя изменить. Оно задается раз и навсегда. В некоторых языках программирования, например в функциональных, все переменные по сути являются константами.
Ключевые слова. Ключевые слова — это особые зарезервированные слова, которые используются для технических целей. Например, значения True и False, «истинно» или «ложно». Зачастую эти слова — не команды: они рассказывают компьютеру о каком-то значении или формате. Зарезервированными словами нельзя что-то назвать. Например, в программе не может быть переменной, имя которой True.
Идентификаторы. Так в информатике называются имена, которые программисты дают сущностям в коде. Например, имя переменной — это ее идентификатор. А если пользователь захочет создать какую-то функцию, то он даст ей имя. Оно тоже будет идентификатором.
Значения и литералы. Литералы еще называют безымянными константами. Это значения какого-то типа, которые используются в коде, но не привязаны к переменной. Они не меняются, ведь их никуда не записывают — это не переменные. Изменить литерал можно только одним способом: переписать исходный код.
Например, когда мы пишем print(“слово”), строка «слово» — это литерал. Нам не нужно записывать ее в переменную, но и обойтись без нее не получится. Она остается в коде как безымянная константа.
Знаки пунктуации и символы. Символы чаще всего бывают связями. Иногда — операторами. Это «знаки препинания» для языка программирования: точка, двоеточие, запятая, точка с запятой и так далее. Они помогают структурировать программу. Например, скобки () после функции обрамляют данные, которые нужно передать ей при запуске. А сами данные перечисляются через запятую, чтобы отделить одно от другого.
Правила пунктуации опять же различаются в зависимости от языка. Но чаще всего в языках программирования можно встретить круглые, квадратные и фигурные скобки, запятые и точки с запятой, а также точки и кавычки. Среди других распространенных символов — двоеточие, значок ^, вопросительный знак, вертикальная или косая черта, процент и многое другое.
Операции, операторы и операнды. Не пугайтесь. Операции — это определенные действия с данными: сложение, вычитание, сравнение и так далее. Причем речь не всегда идет о действиях в математическом смысле — это просто хороший наглядный пример.
Операции состоят из операндов и операторов.
- Операнд – это переменная или литерал, что-то, с чем мы будем работать.
- Оператор – это символ или слово для обозначения действия.
Например, в операции a + 2 переменная a и литерал 2 будут операндами, а знак + оператором.
Функции. Иногда набор команд бывает нужно объединить в один блок, чтобы потом вызывать его как одну большую команду. Это возможно. Такие блоки в программировании называются функциями.
У функции чаще всего есть имя (исключения встречаются, но редко) и список аргументов — данных, которые передаются ей при вызове. Когда программист вызывает функцию, она выполняет заложенные в ней действия.
Встроенные команды языков программирования — обычно тоже функции. Просто они изначально заложены в язык. Но программист может написать и свои. Более того: разбивать код по функциям — хорошая практика, потому что это улучшает читаемость и гибкость программы.
Дополнительные наборы функций для каких-то задач называются библиотеками. Они тоже бывают встроенными, уже существующими в языке, и пользовательскими. Чтобы использовать функции из библиотеки, ее нужно подключить к программе, а если библиотеки нет на компьютере, сначала скачать.
Комментарии. В большинстве языков есть возможность писать комментарии — текстовые блоки, которые ничего не делают и нужны для удобства разработчика. Они выделяются специальными символами. Компилятор или интерпретатор игнорирует комментарии и ничего с ними не делает.
Основных назначений у комментариев два:
- документировать и объяснять. Например, разработчик может оставить комментарий около сложной функции и пояснить в нем, что она делает;
- временно скрывать участки кода. К примеру, человек превращает какую-то строку кода в комментарий, чтобы временно исключить ее из выполнения программы.
Если вы хотите профессионально заниматься программированием, записывайтесь на наши курсы. Мы будем рады помочь вам получить новую профессию.
Есть мириады способов написать плохой код. К счастью, чтобы подняться до уровня качественного кода, достаточно следовать 15 правилам. Их соблюдение не сделает из вас мастера, но позволит убедительно имитировать его.
Правило 1. Следуйте стандартам оформления кода.
У каждого языка программирования есть свой стандарт оформления кода, который говорит, как надо делать отступы, где ставить пробелы и скобки, как называть объекты, как комментировать код и т.д.
Например, в этом куске кода в соответствии со стандартом есть 12 ошибок:
for(i=0 ;i
Изучайте стандарт внимательно, учите основы наизусть, следуйте правилам как заповедям, и ваши программы станут лучше, чем большинство, написанные выпускниками вузов.
Многие организации подстраивают стандарты под свои специфические нужды. Например, Google разработал стандарты для более чем 12 языков программирования. Они хорошо продуманы, так что изучите их, если вам нужна помощь в программировании под Google. Стандарты даже включают в себя настройки редактора, которые помогут вам соблюдать стиль, и специальные инструменты, верифицирующие ваш код на соответствию этому стилю. Используйте их.
Правило 2. Давайте наглядные имена.
Ограниченные медленными, неуклюжими телетайпами, программисты в древности использовали контракты для имён переменных и процедур, чтобы сэкономить время, стуки по клавишам, чернила и бумагу. Эта культура присутствует в некоторых сообществах ради сохранения обратной совместимости. Возьмите, например, ломающую язык функцию C wcscspn (wide character string complement span). Но такой подход неприменим в современном коде.
Используйте длинные наглядные имена наподобие complementSpanLength, чтобы помочь себе и коллегам понять свой код в будущем. Исключения составляют несколько важных переменных, используемых в теле метода, наподобие итераторов циклов, параметров, временных значений или результатов исполнения.
Гораздо важнее, чтобы вы долго и хорошо думали перед тем, как что-то назвать. Является ли имя точным? Имели ли вы в виду highestPrice или bestPrice? Достаточно ли специфично имя, дабы избежать его использования в других контекстах для схожих по смыслу объектов? Не лучше ли назвать метод getBestPrice заместо getBest? Подходит ли оно лучше других схожих имён? Если у вас есть метод ReadEventLog, вам не стоит называть другой NetErrorLogRead. Если вы называете функцию, описывает ли её название возвращаемое значение?
В заключение, несколько простых правил именования. Имена классов и типов должны быть существительными. Название метода должно содержать глагол. Если метод определяет, является ли какая-то информация об объекте истинной или ложной, его имя должно начинаться с «is». Методы, которые возвращают свойства объектов, должны начинаться с «get», а устанавливающие значения свойств — «set».
Правило 3. Комментируйте и документируйте.
Начинайте каждый метод и процедуру с описания в комментарии того, что данный метод или процедура делает, параметров, возвращаемого значения и возможных ошибок и исключений. Опишите в комментариях роль каждого файла и класса, содержимое каждого поля класса и основные шаги сложного кода. Пишите комментарии по мере разработки кода. Если вы полагаете, что напишете их потом, то обманываете самого себя.
Вдобавок, убедитесь, что для вашего приложения или библиотеки есть руководство, объясняющее, что ваш код делает, определяющий его зависимости и предоставляющий инструкции для сборки, тестирования, установки и использования. Документ должен быть коротким и удобным; просто README-файла часто достаточно.
Правило 4. Не повторяйтесь.
Никогда не копируйте и не вставляйте код. Вместо этого выделите общую часть в метод или класс (или макрос, если нужно), и используйте его с соответствующими параметрами. Избегайте использования похожих данных и кусков кода. Также используйте следующие техники:
- Создание справочников API из комментариев, используя Javadoc и Doxygen.
- Автоматическая генерация Unit-тестов на основе аннотаций или соглашений об именовании.
- Генерация PDF и HTML из одного размеченного источника.
- Получение структуры классов из базы данных (или наоборот).
Правило 5. Проверяйте на ошибки и реагируйте на них.
Методы могут возвращать признаки ошибки или генерировать исключения. Обрабатывайте их. Не полагайтесь на то, что диск никогда не заполнится, ваш конфигурационный файл всегда будет на месте, ваше приложение будет запущено со всеми нужными правами, запросы на выделение памяти всегда будут успешно исполнены, или что соединение никогда не оборвётся. Да, хорошую обработку ошибок тяжело написать, и она делает код длиннее и труднее для чтения. Но игнорирование ошибок просто заметает проблему под ковёр, где ничего не подозревающий пользователь однажды её обнаружит.
Правило 6. Разделяйте код на короткие, обособленные части.
Каждый метод, функция или блок кода должн умещаться в обычном экранном окне (25-50 строк). Если получилось длиннее, разделите на более короткие куски. Даже внутри метода разделяйте длинный код на блоки, суть которых вы можете описать в комментарии в начале каждого блока.
Более того, каждый класс, модуль, файл или процесс должен выполнять определённый род задач. Если часть кода выполняет совершенно разнородные задачи, то разделите его соответственно.
Правило 7. Используйте API фреймворков и сторонние библиотеки.
Изучите, какие функции доступны с помощью API вашего фреймворка. а также что могут делать развитые сторонние библиотеки. Если библиотеки поддерживаются вашим системным менеджером пакетов, то они скорее всего окажутся хорошим выбором. Используйте код, удерживающий от желания изобретать колесо (при том бесполезной квадратной формы).
Правило 8. Не переусердствуйте с проектированием.
Проектируйте только то, что актуально сейчас. Ваш код можно делать довольно обобщённым, чтобы он поддерживал дальнейшее развитие, но только в том случае, если он не становится от этого слишком сложным. Не создавайте параметризованные классы, фабрики, глубокие иерархии и скрытые интерфейсы для решения проблем, которых даже не существует — вы не можете угадать, что случится завтра. С другой стороны, когда структура кода не подходит под задачу, не стесняйтесь рефакторить его.
Правило 9. Будьте последовательны.
Делайте одинаковые вещи одинаковым образом. Если вы разрабатываете метод, функциональность которого похожа на функциональность уже существующего, то используйте похожее имя, похожий порядок параметров и схожую структура тела. То же самое относится и к классам. Создавайте похожие поля и методы, делайте им похожие интерфейсы, и сопоставляйте новые имена уже существующим в похожих классах.
Ваш код должен соответствовать соглашениям вашего фреймворка. Например, хорошей практикой является делать диапазоны полуоткрытыми: закрытыми (включающими) слева (в начале диапазона) и открытыми (исключающими) справа (в конце). Если для конкретного случая нет соглашений, то сделайте выбор и фанатично придерживайтесь его.
Правило 10. Избегайте проблем с безопасностью.
Современный код редко работает изолированно. У него есть неизбежный риск стать мишенью атак. Они необязательно должны приходить из интернета; атака может происходить через входные данные вашего приложения. В зависимости от вашего языка программирования и предметной области, вам возможно стоит побеспокоиться о переполнении буфера, кросс-сайтовых сценариях, SQL-инъекциях и прочих подобных проблемах. Изучите эти проблемы, и избегайте их в коде. Это не сложно.
Правило 11. Используйте эффективные структуры данных и алгоритмы.
Простой код часто легче сопровождать, чем такой же, но изменённый ради эффективности. К счастью, вы можете совмещать сопровождаемость и эффективность, используя структуры данных и алгоритмы, которые даёт ваш фреймворк. Используйте map, set, vector и алгоритмы, которые работают с ними. Благодаря этому ваш код станет чище, быстрее, более масштабируемым и более экономным с памятью. Например, если вы сохраните тысячу значений в отсортированном множестве, то операция пересечения найдёт общие элементы с другим множеством за такое же число операций, а не за миллион сравнений.
Правило 12. Используйте Unit-тесты.
Сложность современного ПО делает его установку дороже, а тестирование труднее. Продуктивным подходом будет сопровождение каждого куска кода тестами, которые проверяют корректность его работы. Этот подход упрощает отладку, т.к. он позволяет обнаружить ошибки раньше. Unit-тестирование необходимо, когда вы программируете на языках с динамической типизацией, как Python и JavaScript, потому что они отлавливают любые ошибки только на этапе исполнения, в то время как языки со статической типизацией наподобие Java, C# и C++ могут поймать часть из них во время компиляции. Unit-тестирование также позволяет рефакторить код уверенно. Вы можете использовать XUnit для упрощения написания тестов и автоматизации их запуска.
Правило 13. Сохраняйте код портируемым.
Если у вас нет особой причины, не используйте функциональность, доступную только на определённой платформе. Не полагайтесь на то, что определённые типы данных (как integer, указатели и временные метки) будут иметь конкретную длину (например, 32 бита), потому что этот параметр отличается на разных платформах. Храните сообщения программы отдельно от кода и на зашивайте параметры, соответствующие определённой культуре (например, разделители дробной и целой части или формат даты). Соглашения нужны для того, чтобы код мог запускаться в разных странах, так что сделайте локализацию настолько безболезненной, насколько это возможно.
Правило 14. Делайте свой код собираемым.
Простая команда должна собирать ваш код в форму, готовую к распространению. Команда должна позволять вам быстро выполнять сборку и запускать необходимые тесты. Для достижения этой цели используйте средства автоматической сборки наподобие Make, Apache Maven, или Ant. В идеале, вы должны установить интеграционную систему, которая будет проверять, собирать и тестировать ваш код при любом изменении.
Правило 15. Размещайте всё в системе контроля версий.
Все ваши элементы — код, документация, исходники инструментов, сборочные скрипты, тестовые данные — должны быть в системе контроля версий. Git и GitHub делают эту задачу дешёвой и беспроблемной. Но вам также доступны и многие другие мощные инструменты и сервисы. Вы должны быть способны собрать и протестировать вашу программу на сконфигурированной системе, просто скачав её с репозитория.
Заключение.
Сделав эти 15 правил частью вашей ежедневной практики, вы в конце концов создадите код, который легче читать, который хорошо протестирован, с большей вероятностью запустится корректно и который будет гораздо проще изменить, когда придёт время. Вы также убережёте себя и ваших пользователей от большого числа головных болей.
Перевод статьи «15 Rules for Writing Quality Code»
 Простой Пример исходного кода на языке C, язык процедурного программирования. Полученная программа выводит на экран компьютера «привет, мир». Этот первый известный фрагмент Hello world из основополагающей книги Язык программирования C происходит от Брайана Кернигана в Bell Лаборатории в 1974 году.
Простой Пример исходного кода на языке C, язык процедурного программирования. Полученная программа выводит на экран компьютера «привет, мир». Этот первый известный фрагмент Hello world из основополагающей книги Язык программирования C происходит от Брайана Кернигана в Bell Лаборатории в 1974 году.
В вычислениях, исходный код — это любой набор кода с комментариями или без него, написанный с использованием удобочитаемого язык программирования, обычно как обычный текст. Исходный код программы специально разработан для облегчения работы компьютерных программистов, которые определяют действия, которые должны выполняться компьютером, в основном путем написания исходного кода. Исходный код часто преобразуется ассемблером или компилятором в двоичный машинный код, который может выполняться компьютером. Затем машинный код может быть сохранен для выполнения в более позднее время. В качестве альтернативы исходный код может быть интерпретирован и, таким образом, немедленно выполнен.
Большая часть прикладного программного обеспечения распространяется в форме, которая включает только исполняемые файлы. Если бы исходный код был включен, он был бы полезен пользователю, программисту или системному администратору, любой из которых может пожелать изучить или изменить программу.
Содержание
- 1 Определения
- 2 История
- 3 Организация
- 4 Цели
- 5 Юридические аспекты
- 5.1 Лицензирование
- 6 Качество
- 7 См. Также
- 8 Ссылки
- 8.1 Источники
- 9 Внешние ссылки
Определения
Информационный проект Linux определяет исходный код как:
Исходный код (также называемый исходным кодом или кодом) — это версия программного обеспечения в том виде, в котором она была изначально написана (т. е. напечатана на компьютере) человеком в обычном тексте (т. е. в виде буквенно-цифровых символов, читаемых человеком).
Понятие исходного кода также может быть понято более широко, включая машинный код и нотации на графических языках, ни один из которых не является текстовым по своей природе. Пример из статьи, представленной на ежегодной конференции IEEE и по анализу исходного кода и управлению им:
Для ясности под «исходным кодом» понимается любое полностью выполнимое описание программной системы. Поэтому он так истолкован, что включает машинный код, языки очень высокого уровня и исполняемые графические представления систем.
Часто существует несколько этапов трансляции программ или минификации между исходными исходный код, набранный человеком, и исполняемая программа. В то время как некоторые, например FSF, утверждают, что промежуточный файл «не является реальным исходным кодом и не считается исходным кодом», другие считают удобным называть каждый промежуточный файл исходным кодом для следующего шаги.
История
Самые ранние программы для компьютеров с сохраненными программами вводились в двоичном формате с помощью переключателей передней панели компьютера. В этом языке программирования первого поколения не было различий между исходным кодом и машинным кодом.
. Когда IBM впервые предложила программное обеспечение для работы с его машиной, исходный код был предоставлен без дополнительной оплаты. В то время стоимость разработки и поддержки программного обеспечения была включена в стоимость оборудования. На протяжении десятилетий IBM распространяла исходный код со своими лицензиями на программные продукты, вплоть до 1983 года.
Большинство ранних компьютерных журналов публиковали исходный код как вводимые программы.
Иногда весь исходный код большой программы был опубликовано в твердом переплете, например Computers and Typesetting, vol. B: TeX, программа Дональда Кнута, исходный код PGP и внутренние компоненты Филиппа Циммерманна, PC SpeedScript Рэнди Томпсон и µC / OS, The Real -Time Kernel Жана Лабросса.
Организация
Исходный код, который составляет программу, обычно хранится в одном или нескольких текстовых файлах, хранящихся на жестком диске компьютера. ; обычно эти файлы аккуратно организованы в дерево каталогов, известное как дерево исходных текстов . Исходный код также может храниться в базе данных (как обычно для хранимых процедур ) или где-нибудь еще.
 Более сложный пример исходного кода Java. Написанный в стиле объектно-ориентированного программирования, он демонстрирует шаблонный код. С комментариями пролога, обозначенными красным, встроенными комментариями, обозначенными зеленым, и программными операторами, обозначенными синим.
Более сложный пример исходного кода Java. Написанный в стиле объектно-ориентированного программирования, он демонстрирует шаблонный код. С комментариями пролога, обозначенными красным, встроенными комментариями, обозначенными зеленым, и программными операторами, обозначенными синим.
Исходный код для конкретной части программного обеспечения может содержаться в одном файле или в нескольких файлах. Хотя такая практика встречается редко, исходный код программы может быть написан на разных языках программирования. Например, программа, написанная в основном на языке программирования C, может иметь части, написанные на языке ассемблера в целях оптимизации. Также возможно, чтобы некоторые компоненты программного обеспечения были написаны и скомпилированы отдельно на произвольном языке программирования, а затем интегрированы в программное обеспечение с использованием метода, называемого связывание библиотек. В некоторых языках, таких как Java, это можно сделать во время времени выполнения (каждый класс компилируется в отдельный файл, который связывается интерпретатором во время выполнения).
Еще один метод состоит в том, чтобы сделать основную программу интерпретатором для языка программирования, либо разработанного специально для рассматриваемого приложения, либо универсального, а затем записать большую часть фактических пользовательских функций в виде макросов или другие формы надстроек на этом языке, подход, используемый, например, в текстовом редакторе GNU Emacs.
Кодовая база проекта компьютерного программирования представляет собой большую коллекцию всего исходного кода всех компьютерных программ, составляющих проект. Стало обычной практикой поддерживать кодовые базы в системах управления версиями. Умеренно сложное программное обеспечение обычно требует компиляции или сборки нескольких, иногда десятков или даже сотен различных файлов исходного кода. В этих случаях инструкции для компиляции, такие как Makefile, включены в исходный код. Они описывают программные отношения между файлами исходного кода и содержат информацию о том, как они должны быть скомпилированы.
Цели
Исходный код в основном используется в качестве входных данных для процесса, создающего исполняемую программу (т.е. он скомпилирован или интерпретируется ). Он также используется как метод передачи алгоритмов между людьми (например, фрагменты кода в книгах).
Компьютерные программисты часто считают полезным просмотреть существующий исходный код узнать о методах программирования. Совместное использование исходного кода между разработчиками часто упоминается как фактор, способствующий развитию их навыков программирования. Некоторые люди считают исходный код выразительной художественной средой.
Перенос программного обеспечения на другие компьютерные платформы обычно непомерно сложно без исходного кода. Без исходного кода для конкретной части программного обеспечения переносимость обычно требует больших вычислительных затрат. Возможные варианты переноса включают двоичную трансляцию и эмуляцию исходной платформы.
Декомпиляция исполняемой программы может использоваться для генерации исходного кода либо на ассемблерном коде, либо на языке высокого уровня.
Программисты часто адаптируют исходный код из одного куска программного обеспечения для использования в других проектах, концепция, известная как повторное использование программного обеспечения.
Правовые аспекты
Ситуация варьируется во всем мире, но в Соединенных Штатах до 1974 года программное обеспечение и его исходный код не были охраняемое авторским правом и, следовательно, всегда программное обеспечение, являющееся общественным достоянием.
В 1974 году Комиссия США по новому технологическому использованию произведений, охраняемых авторским правом (CONTU), решила, что «компьютерные программы в той степени, в которой они воплощают оригинальное творение автора, являются надлежащим объектом авторского права «.
В 1983 году в судебном деле США Apple против Франклина было решено, что то же самое применимо к объектному коду ; и что Закон об авторском праве предоставил компьютерным программам статус авторских прав на литературные произведения.
В 1999 году в судебном деле Соединенных Штатов Бернштейн против Соединенных Штатов было далее постановлено, что исходный код может считаться конституционно защищенной формой свободы слова. Сторонники свободы слова утверждали, что, поскольку исходный код передает информацию программистам, написан на каком-то языке и может использоваться для обмена юмором и других художественных занятий, это защищенная форма общения.
Лицензирование
Пример уведомления об авторских правах:
Авторские права [гггг] [имя владельца авторских прав]
Лицензировано в соответствии с лицензией Apache, версия 2.0 («Лицензия»); вы не можете использовать этот файл, кроме как в соответствии с Лицензией. Вы можете получить копию Лицензии по адресу
- http://www.apache.org/licenses/LICENSE-2.0
Если это не требуется применимым законодательством или не согласовано в письменной форме, программное обеспечение, распространяемое по Лицензии, распространяется на ОСНОВАНИЕ «КАК ЕСТЬ», БЕЗ ГАРАНТИЙ ИЛИ УСЛОВИЙ ЛЮБОГО РОДА, явных или подразумеваемых. См. Лицензию, чтобы узнать о конкретных языках, регулирующих разрешения и ограничения в соответствии с Лицензией.
Автор нетривиального произведения, например программного обеспечения, имеет несколько исключительных прав, среди которых авторские права на исходный код и объектный код. Автор имеет право и возможность предоставить клиентам и пользователям своего программного обеспечения некоторые из своих исключительных прав в форме лицензирования программного обеспечения. Программное обеспечение и сопровождающий его исходный код могут быть связаны с несколькими парадигмами лицензирования; наиболее важным отличием является открытый исходный код и проприетарное программное обеспечение. Это делается путем включения уведомления об авторских правах, в котором объявляются условия лицензирования. Если уведомление не найдено, то подразумевается значение по умолчанию Все права защищены.
В целом программное обеспечение является открытым исходным кодом, если исходный код можно свободно использовать, распространять, изменять и изучать, и является собственностью, если исходный код хранится в секрете или находится в частной собственности и ограничен. Одной из первых опубликованных лицензий на программное обеспечение, прямо предоставляющих эти свободы, была Стандартная общественная лицензия GNU в 1989 г.; лицензия BSD — еще один ранний пример из 1990 года.
Для проприетарного программного обеспечения — положения различных законов об авторском праве, коммерческая тайна и патенты используются для закрытия исходного кода. Кроме того, многие части розничного программного обеспечения поставляются с лицензионным соглашением с конечным пользователем (EULA), которое обычно запрещает декомпиляцию, обратное проектирование, анализ, изменение или обход защиты от копирования. Типы защиты исходного кода — помимо традиционной компиляции в объектный код — включают шифрование кода, обфускацию кода или преобразование кода.
Качество
То, как написана программа, может иметь важные последствия для ее сопровождающих. Соглашения о кодировании, которые подчеркивают удобочитаемость и некоторые языковые соглашения, нацелены на поддержку исходного кода программного обеспечения, что включает отладку и обновление. Другие приоритеты, такие как скорость выполнения программы или возможность компилировать программу для нескольких архитектур, часто делают читаемость кода менее важным фактором, поскольку качество кода обычно зависит от его цели.
См. Также
- Байт-код
- Код как данные
- Соглашения о кодировании
- Компьютерный код
- Устаревший код
- Машинный код
- Язык разметки
- Скрытый код
- Код объекта
- Программное обеспечение с открытым исходным кодом
- Пакет (система управления пакетами)
- Язык программирования
- Репозиторий исходного кода
- Подсветка синтаксиса
- Язык визуального программирования
Ссылки
Источники
- (VEW04) «Использование декомпилятора для восстановления исходного кода в реальном мире», М. Ван Эммерик и Т. Ваддингтон, Рабочая конференция по обратному проектированию, Делфт, Нидерланды, 9–12 ноября 2004 г. Расширенная версия статьи.
Внешние ссылки
- Определением исходного кода Информационным проектом Linux (LINFO)
- «Обязательно система аккредитации продуктов ИТ-безопасности ». MetaFilter.com. 22 сентября 2008 г.
введет правила, обязывающие иностранные фирмы раскрывать секретную информацию о цифровой бытовой технике и других продуктах с мая следующего года, Йомиури Симбун сообщил со ссылкой на неназванные источники. Если компания отказывается раскрывать информацию, Китай запретит ей экспортировать продукт на китайский рынок или производить или продавать его в Китае, говорится в документе.
- Та же программа, написанная на нескольких языках
- Обфускатор Javascript
Simple C-language source code example, a procedural programming language. The resulting program prints «hello, world» on the computer screen. This first known «Hello world» snippet from the seminal book The C Programming Language originates from Brian Kernighan in the Bell Laboratories in 1974.[1]
| Program execution |
|---|
| General concepts |
|
| Types of code |
|
| Compilation strategies |
|
| Notable runtimes |
|
| Notable compilers & toolchains |
|
<templatestyles src=»Module:Navbar/styles.css»></templatestyles>
|
In computing, source code is any collection of code, possibly with comments, written using[1] a human-readable programming language, usually as plain text. The source code of a program is specially designed to facilitate the work of computer programmers, who specify the actions to be performed by a computer mostly by writing source code. The source code is often transformed by an assembler or compiler into binary machine code understood by the computer. The machine code might then be stored for execution at a later time. Alternatively, source code may be interpreted and thus immediately executed.
Most application software is distributed in a form that includes only executable files. If the source code were included it would be useful to a user, programmer or a system administrator, any of whom might wish to study or modify the program.
Definitions
The Linux Information Project defines source code as:[2]
Source code (also referred to as source or code) is the version of software as it is originally written (i.e., typed into a computer) by a human in plain text (i.e., human readable alphanumeric characters).
The notion of source code may also be taken more broadly, to include machine code and notations in graphical languages, neither of which are textual in nature. An example from an article presented on the annual IEEE conference and on Source Code Analysis and Manipulation:[3]
For the purpose of clarity «source code» is taken to mean any fully executable description of a software system. It is therefore so construed as to include machine code, very high level languages and executable graphical representations of systems.[4]
Often there are several steps of program translation or minification between the original source code typed by a human and an executable program. While some, like the FSF, argue that an intermediate file «is not real source code and does not count as source code»,[5] others find it convenient to refer to each intermediate file as the source code for the next steps.
History
The earliest programs for stored-program computers were entered in binary through the front panel switches of the computer. This first-generation programming language had no distinction between source code and machine code.
When IBM first offered software to work with its machine, the source code was provided at no additional charge. At that time, the cost of developing and supporting software was included in the price of the hardware. For decades, IBM distributed source code with its software product licenses, until 1983.[6]
Most early computer magazines published source code as type-in programs.
Occasionally the entire source code to a large program is published as a hardback book, such as Computers and Typesetting, vol. B: TeX, The Program by Donald Knuth, PGP Source Code and Internals by Philip Zimmermann, PC SpeedScript by Randy Thompson, and µC/OS, The Real-Time Kernel by Jean Labrosse.
Organization
The source code which constitutes a program is usually held in one or more text files stored on a computer’s hard disk; usually these files are carefully arranged into a directory tree, known as a source tree. Source code can also be stored in a database (as is common for stored procedures) or elsewhere.
File:CodeCmmt002.svg A more complex Java source code example. Written in object-oriented programming style, it demonstrates boilerplate code. With prologue comments indicated in red, inline comments indicated in green, and program statements indicated in blue.
The source code for a particular piece of software may be contained in a single file or many files. Though the practice is uncommon, a program’s source code can be written in different programming languages.[7] For example, a program written primarily in the C programming language, might have portions written in assembly language for optimization purposes. It is also possible for some components of a piece of software to be written and compiled separately, in an arbitrary programming language, and later integrated into the software using a technique called library linking. In some languages, such as Java, this can be done at run time (each class is compiled into a separate file that is linked by the interpreter at runtime).
Yet another method is to make the main program an interpreter for a programming language,[citation needed]
either designed specifically for the application in question or general-purpose, and then write the bulk of the actual user functionality as macros or other forms of add-ins in this language, an approach taken for example by the GNU Emacs text editor.
The code base of a computer programming project is the larger collection of all the source code of all the computer programs which make up the project. It has become common practice to maintain code bases in version control systems. Moderately complex software customarily requires the compilation or assembly of several, sometimes dozens or maybe even hundreds, of different source code files. In these cases, instructions for compilations, such as a Makefile, are included with the source code. These describe the programming relationships among the source code files, and contain information about how they are to be compiled.
Purposes
Source code is primarily used as input to the process that produces an executable program (i.e., it is compiled or interpreted). It is also used as a method of communicating algorithms between people (e.g., code snippets in books).[8]
Computer programmers often find it helpful to review existing source code to learn about programming techniques.[8] The sharing of source code between developers is frequently cited as a contributing factor to the maturation of their programming skills.[8] Some people consider source code an expressive artistic medium.[9]
Porting software to other computer platforms is usually prohibitively difficult without source code. Without the source code for a particular piece of software, portability is generally computationally expensive.[citation needed]
Possible porting options include binary translation and emulation of the original platform.
Decompilation of an executable program can be used to generate source code, either in assembly code or in a high-level language.
Programmers frequently adapt source code from one piece of software to use in other projects, a concept known as software reusability.
Legal aspects
See also: History of free and open-source software
The situation varies worldwide, but in the United States before 1974, software and its source code was not copyrightable and therefore always public domain software.[10]
In 1974, the US Commission on New Technological Uses of Copyrighted Works (CONTU) decided that «computer programs, to the extent that they embody an author’s original creation, are proper subject matter of copyright».[11][12]
In 1983 in the United States court case Apple v. Franklin it was ruled that the same applied to object code; and that the Copyright Act gave computer programs the copyright status of literary works.
In 1999, in the United States court case Bernstein v. United States it was further ruled that source code could be considered a constitutionally protected form of free speech. Proponents of free speech argued that because source code conveys information to programmers, is written in a language, and can be used to share humor and other artistic pursuits, it is a protected form of communication.[13][14][15]
Licensing
<templatestyles src=»Template:Quote_box/styles.css» />
Copyright notice example:[16]
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the «License»);
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
- http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an «AS IS» BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
An author of a non-trivial work like software,[12] has several exclusive rights, among them the copyright for the source code and object code.[17] The author has the right and possibility to grant customers and users of his software some of his exclusive rights in form of software licensing. Software, and its accompanying source code, can be associated with several licensing paradigms; the most important distinction is open source vs proprietary software. This is done by including a copyright notice that declares licensing terms. If no notice is found, then the default of All rights reserved is implied.
Generally speaking, software is open source if the source code is free to use, distribute, modify and study, and proprietary if the source code is kept secret, or is privately owned and restricted. One of the first software licenses to be published and to explicitly grant these freedoms was the GNU General Public License in 1989; the BSD license is another early example from 1990.
For proprietary software, the provisions of the various copyright laws, trade secrecy and patents are used to keep the source code closed. Additionally, many pieces of retail software come with an end-user license agreement (EULA) which typically prohibits decompilation, reverse engineering, analysis, modification, or circumventing of copy protection. Types of source code protection—beyond traditional compilation to object code—include code encryption, code obfuscation or code morphing.
Quality
Main article: Software quality
The way a program is written can have important consequences for its maintainers. Coding conventions, which stress readability and some language-specific conventions, are aimed at the maintenance of the software source code, which involves debugging and updating. Other priorities, such as the speed of the program’s execution, or the ability to compile the program for multiple architectures, often make code readability a less important consideration, since code quality generally depends on its purpose.
See also
- Bytecode
- Code as data
- Coding conventions
- Computer code
- Legacy code
- Machine code
- Markup language
- Obfuscated code
- Object code
- Open-source software
- Package (package management system)
- Programming language
- Source code repository
- Syntax highlighting
- Visual programming language
References
- ↑ 1.0 1.1 «Programming in C: A Tutorial». Archived from the original on 23 February 2015. https://web.archive.org/web/20150223025837/http://cm.bell-labs.com/cm/cs/who/dmr/ctut.pdf.
- ↑ The Linux Information Project. «Source Code Definition».
- ↑ SCAM Working Conference, 2001–2010.
- ↑ Why Source Code Analysis and Manipulation Will Always Be Important by Mark Harman, 10th IEEE International Working Conference on Source Code Analysis and Manipulation (SCAM 2010). Timişoara, Romania, 12–13 September 2010.
- ↑ «gnu.org». https://www.gnu.org/philosophy/free-sw.en.html.
- ↑ Martin Goetz (February 8, 1988). «Object-code only: Is IBM playing fair?». Computerworld 22 (6): 59. https://books.google.com/books?id=hSBrPSYgjI4C&printsec=frontcover#v=onepage&q&f=false. «It was in 1983 that IBM reversed its 20-year-old policy of distributing source code with its software product licenses.»
- ↑ «Extending and Embedding the Python Interpreter». docs.python.org. https://docs.python.org/extending/.
- ↑ 8.0 8.1 8.2 Spinellis, D: Code Reading: The Open Source Perspective. Addison-Wesley Professional, 2003. ISBN 0-201-79940-5
- ↑ «Art and Computer Programming» ONLamp.com, (2005)
- ↑ P., Liu, Joseph; L., Dogan, Stacey (2005). «Copyright Law and Subject Matter Specificity: The Case of Computer Software» (in en). New York University Annual Survey of American Law 61 (2). https://lawdigitalcommons.bc.edu/lsfp/536/.
- ↑ Apple Computer, Inc. v. Franklin Computer Corporation Puts the Byte Back into Copyright Protection for Computer Programs in Golden Gate University Law Review Volume 14, Issue 2, Article 3 by Jan L. Nussbaum (January 1984)
- ↑ 12.0 12.1 Lemley, Menell, Merges and Samuelson. Software and Internet Law, p. 34.
- ↑ http://cr.yp.to/export/2002/08.02-bernstein-subst.pdf
- ↑ Bernstein v. US Department of Justice on eff.org
- ↑ EFF at 25: Remembering the Case that established Code as Speech on EFF.org by Alison Dame-Boyle (16 April 2015)
- ↑ https://www.apache.org/licenses/LICENSE-2.0
- ↑ Hancock, Terry (2008-08-29). «What if copyright didn’t apply to binary executables?». Free Software Magazine. http://www.freesoftwaremagazine.com/articles/what_if_copyright_didnt_apply_binary_executables. Retrieved 2016-01-25.
- (VEW04) «Using a Decompiler for Real-World Source Recovery», M. Van Emmerik and T. Waddington, the Working Conference on Reverse Engineering, Delft, Netherlands, 9–12 November 2004. Extended version of the paper.
External links
- Source Code Definition by The Linux Information Project (LINFO)
- «Obligatory accreditation system for IT security products». MetaFilter.com. 22 September 2008. http://www.metafilter.com/75061/Obligatory-accreditation-system-for-IT-security-products. «will introduce rules requiring foreign firms to disclose secret information about digital household appliances and other products from May next year, the Yomiuri Shimbun said, citing unnamed sources. If a company refuses to disclose information, China would ban it from exporting the product to the Chinese market or producing or selling it in China, the paper said.»
- Same program written in multiple languages
- Javascript Obfuscator