Предыдущие части
- Часть первая — habrahabr.ru/post/255361
- Часть вторая — habrahabr.ru/post/255523
- Часть третья — habrahabr.ru/post/255825
В данной части мы рассмотрим
Многотабличные запросы:
- Операции горизонтального соединения таблиц – JOIN
- Связь таблиц при помощи WHERE-условия
- Операции вертикального объединения результатов запросов – UNION
Работу с подзапросами:
- Подзапросы в блоках FROM, SELECT
- Подзапрос в конструкции APPLY
- Использование предложения WITH
- Подзапросы в блоке WHERE:
- Групповое сравнение — ALL, ANY
- Условие EXISTS
- Условие IN
Добавим немного новых данных
Для демонстрационных целей добавим несколько отделов и должностей:
SET IDENTITY_INSERT Departments ON
INSERT Departments(ID,Name) VALUES(4,N'Маркетинг и реклама')
INSERT Departments(ID,Name) VALUES(5,N'Логистика')
SET IDENTITY_INSERT Departments OFF
SET IDENTITY_INSERT Positions ON
INSERT Positions(ID,Name) VALUES(5,N'Маркетолог')
INSERT Positions(ID,Name) VALUES(6,N'Логист')
INSERT Positions(ID,Name) VALUES(7,N'Кладовщик')
SET IDENTITY_INSERT Positions OFF
JOIN-соединения – операции горизонтального соединения данных
Здесь нам очень пригодится знание структуры БД, т.е. какие в ней есть таблицы, какие данные хранятся в этих таблицах и по каким полям таблицы связаны между собой. Первым делом всегда досконально изучайте структуру БД, т.к. нормальный запрос можно написать только тогда, когда ты знаешь, что откуда берется. У нас структура состоит из 3-х таблиц Employees, Departments и Positions. Приведу здесь диаграмму из первой части:
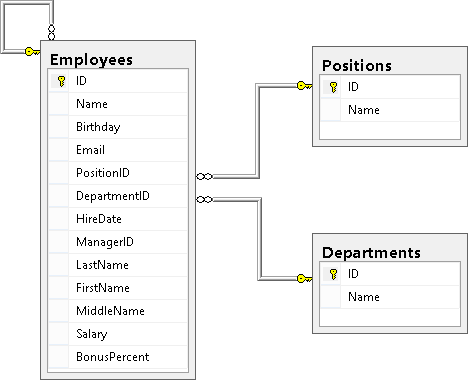
Если суть РДБ – разделяй и властвуй, то суть операций объединений снова склеить разбитые по таблицам данные, т.е. привести их обратно в человеческий вид.
Если говорить просто, то операции горизонтального соединения таблицы с другими таблицами используются для того, чтобы получить из них недостающие данные. Вспомните пример с еженедельным отчетом для директора, когда при запросе из таблицы Employees, нам для получения окончательного результата недоставало поля «Название отдела», которое находится в таблице Departments.
Начнем с теории. Есть пять типов соединения:
- JOIN – левая_таблица JOIN правая_таблица ON условия_соединения
- LEFT JOIN – левая_таблица LEFT JOIN правая_таблица ON условия_соединения
- RIGHT JOIN – левая_таблица RIGHT JOIN правая_таблица ON условия_соединения
- FULL JOIN – левая_таблица FULL JOIN правая_таблица ON условия_соединения
- CROSS JOIN – левая_таблица CROSS JOIN правая_таблица
| Краткий синтаксис | Полный синтаксис | Описание (Это не всегда всем сразу понятно. Так что, если не понятно, то просто вернитесь сюда после рассмотрения примеров.) |
|---|---|---|
| JOIN | INNER JOIN | Из строк левой_таблицы и правой_таблицы объединяются и возвращаются только те строки, по которым выполняются условия_соединения. |
| LEFT JOIN | LEFT OUTER JOIN | Возвращаются все строки левой_таблицы (ключевое слово LEFT). Данными правой_таблицы дополняются только те строки левой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк правой_таблицы вставляются NULL-значения. |
| RIGHT JOIN | RIGHT OUTER JOIN | Возвращаются все строки правой_таблицы (ключевое слово RIGHT). Данными левой_таблицы дополняются только те строки правой_таблицы, для которых выполняются условия_соединения. Для недостающих данных вместо строк левой_таблицы вставляются NULL-значения. |
| FULL JOIN | FULL OUTER JOIN | Возвращаются все строки левой_таблицы и правой_таблицы. Если для строк левой_таблицы и правой_таблицы выполняются условия_соединения, то они объединяются в одну строку. Для строк, для которых не выполняются условия_соединения, NULL-значения вставляются на место левой_таблицы, либо на место правой_таблицы, в зависимости от того данных какой таблицы в строке не имеется. |
| CROSS JOIN | — | Объединение каждой строки левой_таблицы со всеми строками правой_таблицы. Этот вид соединения иногда называют декартовым произведением. |
Как видно из таблицы полный синтаксис от краткого отличается только наличием слов INNER или OUTER.
Лично я всегда при написании запросов использую только краткий синтаксис, по той причине:
- Это короче и не засоряет запрос лишними словами;
- По словам LEFT, RIGHT, FULL и CROSS и так понятно о каком соединении идет речь, так же и в случае просто JOIN;
- Считаю слова INNER и OUTER в данном случае ненужными рудиментами, которые больше путают начинающих.
Но конечно, это мое личное предпочтение, возможно кому-то нравится писать длинно, и он видит в этом свои прелести.
Понимание каждого вида соединения очень важно, т.к. от применения того или иного вида, результат запроса может отличаться. Сравните результаты одного и того же запроса с применением разного типа соединения, попробуйте пока просто увидеть разницу и идите дальше (мы сюда еще вернемся):
-- JOIN вернет 5 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
-- LEFT JOIN вернет 6 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
-- RIGHT JOIN вернет 7 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
-- FULL JOIN вернет 8 строк
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
FULL JOIN Departments dep ON emp.DepartmentID=dep.ID
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
-- CROSS JOIN вернет 30 строк - (6 строк таблицы Employees) * (5 строк таблицы Departments)
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
CROSS JOIN Departments dep
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 1 | Администрация |
| 1003 | Андреев А.А. | 3 | 1 | Администрация |
| 1004 | Николаев Н.Н. | 3 | 1 | Администрация |
| 1005 | Александров А.А. | NULL | 1 | Администрация |
| 1000 | Иванов И.И. | 1 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 2 | Бухгалтерия |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 2 | Бухгалтерия |
| 1004 | Николаев Н.Н. | 3 | 2 | Бухгалтерия |
| 1005 | Александров А.А. | NULL | 2 | Бухгалтерия |
| 1000 | Иванов И.И. | 1 | 3 | ИТ |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | 3 | ИТ |
| 1000 | Иванов И.И. | 1 | 4 | Маркетинг и реклама |
| 1001 | Петров П.П. | 3 | 4 | Маркетинг и реклама |
| 1002 | Сидоров С.С. | 2 | 4 | Маркетинг и реклама |
| 1003 | Андреев А.А. | 3 | 4 | Маркетинг и реклама |
| 1004 | Николаев Н.Н. | 3 | 4 | Маркетинг и реклама |
| 1005 | Александров А.А. | NULL | 4 | Маркетинг и реклама |
| 1000 | Иванов И.И. | 1 | 5 | Логистика |
| 1001 | Петров П.П. | 3 | 5 | Логистика |
| 1002 | Сидоров С.С. | 2 | 5 | Логистика |
| 1003 | Андреев А.А. | 3 | 5 | Логистика |
| 1004 | Николаев Н.Н. | 3 | 5 | Логистика |
| 1005 | Александров А.А. | NULL | 5 | Логистика |
Настало время вспомнить про псевдонимы таблиц
Пришло время вспомнить про псевдонимы таблиц, о которых я рассказывал в начале второй части.
В многотабличных запросах, псевдоним помогает нам явно указать из какой именно таблицы берется поле. Посмотрим на пример:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID
В нем поля с именами ID и Name есть в обоих таблицах и в Employees, и в Departments. И чтобы их различать, мы предваряем имя поля псевдонимом и точкой, т.е. «emp.ID», «emp.Name», «dep.ID», «dep.Name».
Вспоминаем почему удобнее пользоваться именно короткими псевдонимами – потому что, без псевдонимов наш запрос бы выглядел следующим образом:
SELECT Employees.ID,Employees.Name,Employees.DepartmentID,Departments.ID,Departments.Name
FROM Employees
JOIN Departments ON Employees.DepartmentID=Departments.ID
По мне, стало очень длинно и хуже читаемо, т.к. имена полей визуально потерялись среди повторяющихся имен таблиц.
В многотабличных запросах, хоть и можно указать имя без псевдонима, в случае если имя не дублируется во второй таблице, но я бы рекомендовал всегда использовать псевдонимы в случае соединения, т.к. никто не гарантирует, что поле с таким же именем со временем не добавят во вторую таблицу, а тогда ваш запрос просто сломается, ругаясь на то что он не может понять к какой таблице относится данное поле.
Только используя псевдонимы, мы сможем осуществить соединения таблицы самой с собой. Предположим встала задача, получить для каждого сотрудника, данные сотрудника, который был принят прямо до него (табельный номер отличается на единицу меньше). Допустим, что у нас табельные номера выдаются последовательно и без дырок, тогда мы можем это сделать примерно следующим образом:
SELECT
e1.ID EmpID1,
e1.Name EmpName1,
e2.ID EmpID2,
e2.Name EmpName2
FROM Employees e1
LEFT JOIN Employees e2 ON e1.ID=e2.ID+1 -- получить данные предыдущего сотрудника
Т.е. здесь одной таблице Employees, мы дали псевдоним «e1», а второй «e2».
Разбираем каждый вид горизонтального соединения
Для этой цели рассмотрим 2 небольшие абстрактные таблицы, которые так и назовем LeftTable и RightTable:
CREATE TABLE LeftTable(
LCode int,
LDescr varchar(10)
)
GO
CREATE TABLE RightTable(
RCode int,
RDescr varchar(10)
)
GO
INSERT LeftTable(LCode,LDescr)VALUES
(1,'L-1'),
(2,'L-2'),
(3,'L-3'),
(5,'L-5')
INSERT RightTable(RCode,RDescr)VALUES
(2,'B-2'),
(3,'B-3'),
(4,'B-4')
Посмотрим, что в этих таблицах:
SELECT * FROM LeftTable
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2 |
| 3 | L-3 |
| 5 | L-5 |
SELECT * FROM RightTable
| RCode | RDescr |
|---|---|
| 2 | B-2 |
| 3 | B-3 |
| 4 | B-4 |
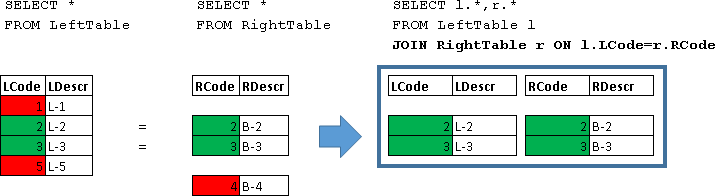
JOIN
SELECT l.*,r.*
FROM LeftTable l
JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
Здесь были возвращены объединения строк для которых выполнилось условие (l.LCode=r.RCode)
LEFT JOIN
SELECT l.*,r.*
FROM LeftTable l
LEFT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
Здесь были возвращены все строки LeftTable, которые были дополнены данными строк из RightTable, для которых выполнилось условие (l.LCode=r.RCode)

RIGHT JOIN
SELECT l.*,r.*
FROM LeftTable l
RIGHT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Здесь были возвращены все строки RightTable, которые были дополнены данными строк из LeftTable, для которых выполнилось условие (l.LCode=r.RCode)

По сути если мы переставим LeftTable и RightTable местами, то аналогичный результат мы получим при помощи левого соединения:
SELECT l.*,r.*
FROM RightTable r
LEFT JOIN LeftTable l ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Я за собой заметил, что я чаще применяю именно LEFT JOIN, т.е. я сначала думаю, данные какой таблицы мне важны, а потом думаю, какая таблица/таблицы будет играть роль дополняющей таблицы.
FULL JOIN – это по сути одновременный LEFT JOIN + RIGHT JOIN
SELECT l.*,r.*
FROM LeftTable l
FULL JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
Вернулись все строки из LeftTable и RightTable. Строки для которых выполнилось условие (l.LCode=r.RCode) были объединены в одну строку. Отсутствующие в строке данные с левой или правой стороны заполняются NULL-значениями.

CROSS JOIN
SELECT l.*,r.*
FROM LeftTable l
CROSS JOIN RightTable r
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2 |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 2 | B-2 |
| 5 | L-5 | 2 | B-2 |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2 | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2 | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Каждая строка LeftTable соединяется с данными всех строк RightTable.

Возвращаемся к таблицам Employees и Departments
Надеюсь вы поняли принцип работы горизонтальных соединений. Если это так, то возвратитесь на начало раздела «JOIN-соединения – операции горизонтального соединения данных» и попробуйте самостоятельно понять примеры с объединением таблиц Employees и Departments, а потом снова возвращайтесь сюда, обсудим это вместе.
Давайте попробуем вместе подвести резюме для каждого запроса:
| Запрос | Резюме |
|---|---|
|
По сути данный запрос вернет только сотрудников, у которых указано значение DepartmentID. Т.е. мы можем использовать данное соединение, в случае, когда нам нужны данные по сотрудникам числящихся за каким-нибудь отделом (без учета внештаткиков). |
|
Вернет всех сотрудников. Для тех сотрудников у которых не указан DepartmentID, поля «dep.ID» и «dep.Name» будут содержать NULL. Вспоминайте, что NULL значения в случае необходимости можно обработать, например, при помощи ISNULL(dep.Name,’вне штата’). Этот вид соединения можно использовать, когда нам важно получить данные по всем сотрудникам, например, чтобы получить список для начисления ЗП. |
|
Здесь мы получили дырки слева, т.е. отдел есть, но сотрудников в этом отделе нет. Такое соединение можно использовать, например, когда нужно выяснить, какие отделы и кем у нас заняты, а какие еще не сформированы. Эту информацию можно использовать для поиска и приема новых работников из которых будет формироваться отдел. |
|
Этот запрос важен, когда нам нужно получить все данные по сотрудникам и все данные по имеющимся отделам. Соответственно получаем дырки (NULL-значения) либо по сотрудникам, либо по отделам (внештатники). Данный запрос, например, может использоваться в целях проверки, все ли сотрудники сидят в правильных отделах, т.к. может у некоторых сотрудников, которые числятся как внештатники, просто забыли указать отдел. |
|
В таком виде даже сложно придумать где это можно применить, поэтому пример с CROSS JOIN я покажу ниже. |
Обратите внимание, что в случае повторения значений DepartmentID в таблице Employees, произошло соединение каждой такой строки со строкой из таблицы Departments с таким же ID, то есть данные Departments объединились со всеми записями для которых выполнилось условие (emp.DepartmentID=dep.ID):

В нашем случае все получилось правильно, т.е. мы дополнили таблицу Employees, данными таблицы Departments. Я специально заострил на этом внимание, т.к. бывают случаи, когда такое поведение нам не нужно. Для демонстрации поставим задачу – для каждого отдела вывести последнего принятого сотрудника, если сотрудников нет, то просто вывести название отдела. Возможно напрашивается такое решение – просто взять предыдущий запрос и поменять условие соединение на RIGHT JOIN, плюс переставить поля местами:
SELECT dep.ID,dep.Name,emp.ID,emp.Name
FROM Employees emp
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1001 | Петров П.П. |
| 3 | ИТ | 1003 | Андреев А.А. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
Но мы для ИТ-отдела получили три строчки, когда нам нужна была только строчка с последним принятым сотрудником, т.е. Николаевым Н.Н.
Задачу такого рода, можно решить, например, при помощи использования подзапроса:
SELECT dep.ID,dep.Name,emp.ID,emp.Name
FROM Employees emp
/*
объединяем с подзапросом возвращающим последний (максимальный - MAX(ID))
идентификатор сотрудника для каждого отдела (GROUP BY DepartmentID)
*/
JOIN
(
SELECT MAX(ID) MaxEmployeeID
FROM Employees
GROUP BY DepartmentID
) lastEmp
ON emp.ID=lastEmp.MaxEmployeeID
RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID -- все данные Departments
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
При помощи предварительного объединения Employees с данными подзапроса, мы смогли оставить только нужных нам для соединения с Departments сотрудников.
Здесь мы плавно переходим к использованию подзапросов. Я думаю использование их в таком виде должно быть для вас понятно на интуитивном уровне. То есть подзапрос подставляется на место таблицы и играет ее роль, ничего сложного. К теме подзапросов мы еще вернемся отдельно.
Посмотрите отдельно, что возвращает подзапрос:
SELECT MAX(ID) MaxEmployeeID
FROM Employees
GROUP BY DepartmentID
| MaxEmployeeID |
|---|
| 1005 |
| 1000 |
| 1002 |
| 1004 |
Т.е. он вернул только идентификаторы последних принятых сотрудников, в разрезе отделов.
Соединения выполняются последовательно сверху-вниз, наращиваясь как снежный ком, который катится с горы. Сначала происходит соединение «Employees emp JOIN (Подзапрос) lastEmp», формируя новый выходной набор:
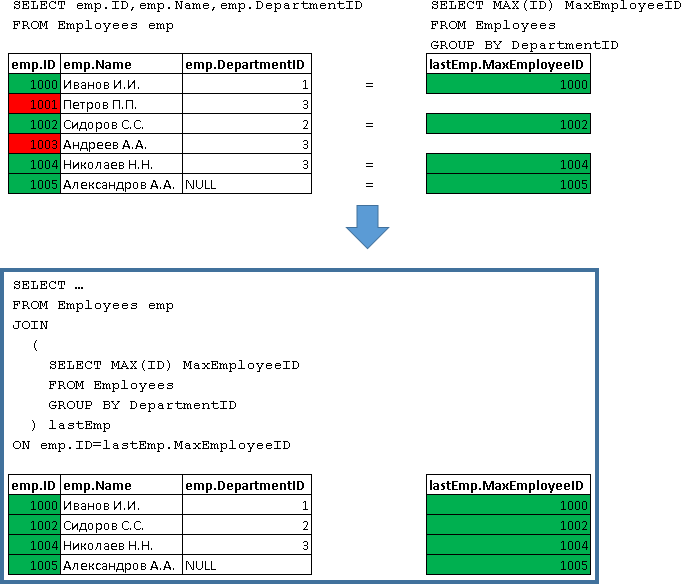
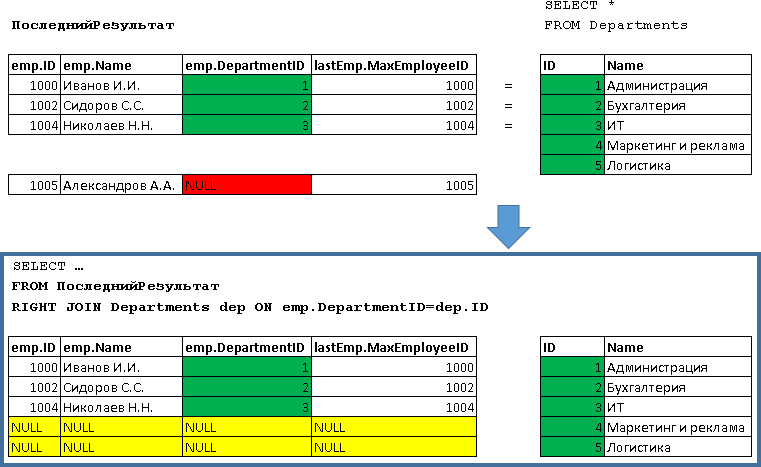
Потом идет объединение набора, полученного «Employees emp JOIN (Подзапрос) lastEmp» (назовем его условно «ПоследнийРезультат») с Departments, т.е. «ПоследнийРезультат RIGHT JOIN Departments dep»:
Самостоятельная работа для закрепления материала
Если вы новичок, то вам обязательно нужно прорабатывать каждую JOIN-конструкцию, до тех пор, пока вы на 100% не будете понимать, как работает каждый вид соединения и правильно представлять результат какого вида будет получен в итоге.
Для закрепления материала про JOIN-соединения сделаем следующее:
-- очистим таблицы LeftTable и RightTable
TRUNCATE TABLE LeftTable
TRUNCATE TABLE RightTable
GO
-- и зальем в них другие данные
INSERT LeftTable(LCode,LDescr)VALUES
(1,'L-1'),
(2,'L-2a'),
(2,'L-2b'),
(3,'L-3'),
(5,'L-5')
INSERT RightTable(RCode,RDescr)VALUES
(2,'B-2a'),
(2,'B-2b'),
(3,'B-3'),
(4,'B-4')
Посмотрим, что в таблицах:
SELECT *
FROM LeftTable
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| 5 | L-5 |
SELECT *
FROM RightTable
| RCode | RDescr |
|---|---|
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| 4 | B-4 |
А теперь попытайтесь сами разобрать, каким образом получилась каждая строчка запроса с каждым видом соединения (Excel вам в помощь):
SELECT l.*,r.*
FROM LeftTable l
JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
SELECT l.*,r.*
FROM LeftTable l
LEFT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
SELECT l.*,r.*
FROM LeftTable l
RIGHT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
SELECT l.*,r.*
FROM LeftTable l
FULL JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
SELECT l.*,r.*
FROM LeftTable l
CROSS JOIN RightTable r
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| 5 | L-5 | 2 | B-2a |
| 1 | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| 5 | L-5 | 2 | B-2b |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2a | 4 | B-4 |
| 2 | L-2b | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Еще раз про JOIN-соединения
Еще один пример с использованием нескольких последовательных операций соединении. Здесь повтор получился не специально, так получилось – не выбрасывать же материал.  Но ничего «повторение – мать учения».
Но ничего «повторение – мать учения».
Если используется несколько операций соединения, то в таком случае они применяются последовательно сверху-вниз. Грубо говоря, после каждого соединения создается новый набор и следующее соединение уже происходит с этим расширенным набором. Рассмотрим простой пример:
SELECT
e.ID,
e.Name EmployeeName,
p.Name PositionName,
d.Name DepartmentName
FROM Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
Первым делом выбрались все записи таблицы Employees:
SELECT
e.*
FROM Employees e -- 1
Дальше произошло соединение с таблицей Departments:
SELECT
e.*, -- к полям Employees
d.* -- добавились соответствующие (e.DepartmentID=d.ID) поля Departments
FROM Employees e -- 1
LEFT JOIN Departments d ON e.DepartmentID=d.ID -- 2
Дальше уже идет соединение этого набора с таблицей Positions:
SELECT
e.*, -- к полям Employees
d.*, -- добавились соответствующие (e.DepartmentID=d.ID) поля Departments
p.* -- добавились соответствующие (e.PositionID=p.ID) поля Positions
FROM Employees e -- 1
LEFT JOIN Departments d ON e.DepartmentID=d.ID -- 2
LEFT JOIN Positions p ON e.PositionID=p.ID -- 3
Т.е. это выглядит примерно так:

И в последнюю очередь идет возврат тех данных, которые мы просим вывести:
SELECT
e.ID, -- 1. идентификатор сотрудника
e.Name EmployeeName, -- 2. имя сотрудника
p.Name PositionName, -- 3. название должности
d.Name DepartmentName -- 4. название отдела
FROM Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
Соответственно, ко всему этому полученному набору можно применить фильтр WHERE и сортировку ORDER BY:
SELECT
e.ID, -- 1. идентификатор сотрудника
e.Name EmployeeName, -- 2. имя сотрудника
p.Name PositionName, -- 3. название должности
d.Name DepartmentName -- 4. название отдела
FROM Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
WHERE d.ID=3 -- используем поля из поле ID из Departments
AND p.ID=3 -- используем для фильтрации поле ID из Positions
ORDER BY e.Name -- используем для сортировки поле Name из Employees
| ID | EmployeeName | PositionName | DepartmentName |
|---|---|---|---|
| 1004 | Николаев Н.Н. | Программист | ИТ |
| 1001 | Петров П.П. | Программист | ИТ |
То есть последний полученный набор – представляет собой такую же таблицу, над которой можно выполнять базовый запрос:
SELECT [DISTINCT] список_столбцов или *
FROM источник
WHERE фильтр
ORDER BY выражение_сортировки
То есть если раньше в роли источника выступала только одна таблица, то теперь на это место мы просто подставляем наше выражение:
Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
В результате чего получаем тот же самый базовый запрос:
SELECT
e.ID,
e.Name EmployeeName,
p.Name PositionName,
d.Name DepartmentName
FROM
/* источник - начало */
Employees e
LEFT JOIN Departments d ON e.DepartmentID=d.ID
LEFT JOIN Positions p ON e.PositionID=p.ID
/* источник - конец */
WHERE d.ID=3
AND p.ID=3
ORDER BY e.Name
А теперь, применим группировку:
SELECT
ISNULL(dep.Name,'Прочие') DepName,
COUNT(DISTINCT emp.PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(emp.Salary) SalaryAmount,
AVG(emp.Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM
/* источник - начало */
Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
/* источник - конец */
GROUP BY emp.DepartmentID,dep.Name
ORDER BY DepName
Видите, мы все так же крутимся вокруг да около базовых конструкций, теперь надеюсь понятно, почему очень важно в первую очередь хорошо понять их.
И как мы увидели, в запросе на месте любой таблицы может стоять подзапрос. В свою очередь подзапросы могут быть вложены в подзапросы. И все эти подзапросы тоже представляют из себя базовые конструкции. То есть базовая конструкция, это кирпичики, из которых строится любой запрос.
Обещанный пример с CROSS JOIN
Давайте используем соединение CROSS JOIN, чтобы подсчитать сколько сотрудников, в каком отделе и на каких должностях числится. Для каждого отдела перечислим все существующие должности:
SELECT
d.Name DepartmentName,
p.Name PositionName,
e.EmplCount
FROM Departments d
CROSS JOIN Positions p
LEFT JOIN
(
/*
здесь я использовал подзапрос для подсчета сотрудников
в разрезе групп (DepartmentID,PositionID)
*/
SELECT DepartmentID,PositionID,COUNT(*) EmplCount
FROM Employees
GROUP BY DepartmentID,PositionID
) e
ON e.DepartmentID=d.ID AND e.PositionID=p.ID
ORDER BY DepartmentName,PositionName

В данном случае сначала выполнилось соединение при помощи CROSS JOIN, а затем к полученному набору сделалось соединение с данными из подзапроса при помощи LEFT JOIN. Вместо таблицы в LEFT JOIN мы использовали подзапрос.
Подзапрос заключается в скобки и ему присваивается псевдоним, в данном случае это «e». То есть в данном случае объединение происходит не с таблицей, а с результатом следующего запроса:
SELECT DepartmentID,PositionID,COUNT(*) EmplCount
FROM Employees
GROUP BY DepartmentID,PositionID
| DepartmentID | PositionID | EmplCount |
|---|---|---|
| NULL | NULL | 1 |
| 2 | 1 | 1 |
| 1 | 2 | 1 |
| 3 | 3 | 2 |
| 3 | 4 | 1 |
Вместе с псевдонимом «e» мы можем использовать имена DepartmentID, PositionID и EmplCount. По сути дальше подзапрос ведет себя так же, как если на его месте стояла таблица. Соответственно, как и у таблицы,
все имена колонок, которые возвращает подзапрос, должны быть заданы явно и не должны повторяться.
Связь при помощи WHERE-условия
Для примера перепишем следующий запрос с JOIN-соединением:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
JOIN Departments dep ON emp.DepartmentID=dep.ID -- условие соединения таблиц
WHERE emp.DepartmentID=3 -- условие фильтрации данных
Через WHERE-условие он примет следующую форму:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM
Employees emp,
Departments dep
WHERE emp.DepartmentID=dep.ID -- условие соединения таблиц
AND emp.DepartmentID=3 -- условие фильтрации данных
Здесь плохо то, что происходит смешивание условий соединения таблиц (emp.DepartmentID=dep.ID) с условием фильтрации (emp.DepartmentID=3).
Теперь посмотрим, как сделать CROSS JOIN:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM Employees emp
CROSS JOIN Departments dep -- декартово соединение (соединение без условия)
WHERE emp.DepartmentID=3 -- условие фильтрации данных
Через WHERE-условие он примет следующую форму:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name
FROM
Employees emp,
Departments dep
WHERE emp.DepartmentID=3 -- условие фильтрации данных
Т.е. в этом случае мы просто не указали условие соединения таблиц Employees и Departments. Чем плох этот запрос? Представьте, что кто-то другой смотрит на ваш запрос и думает «кажется тот, кто писал запрос забыл здесь дописать условие (emp.DepartmentID=dep.ID)» и с радостью, что обнаружил косяк, дописывает это условие. В результате чего задуманное вами может сломаться, т.к. вы подразумевали CROSS JOIN. Так что, если вы делаете декартово соединение, то лучше явно укажите, что это именно оно, используя конструкцию CROSS JOIN.
Для оптимизатора запроса может быть и без разницы как вы реализуете соединение (при помощи WHERE или JOIN), он их может выполнить абсолютно одинаково. Но из соображения понимаемости кода, я бы рекомендовал в современных СУБД стараться никогда не делать соединение таблиц при помощи WHERE-условия. Использовать WHERE-условия для соединения, в том случае, если в СУБД реализованы конструкции JOIN, я бы назвал сейчас моветоном. WHERE-условия служат для фильтрации набора, и не нужно перемешивать условия служащие для соединения, с условиями отвечающими за фильтрацию. Но если вы пришли к выводу, что без реализации соединения через WHERE не обойтись, то конечно приоритет за решеной задачей и «к черту все устои».
UNION-объединения – операции вертикального объединения результатов запросов
Я специально использую словосочетания горизонтальное соединение и вертикальное объединение, т.к. заметил, что новички часто недопонимают и путают суть этих операций.
Давайте первым делом вспомним как мы делали первую версию отчета для директора:
SELECT
'Администрация' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=1 -- данные по Администрации
SELECT
'Бухгалтерия' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=2 -- данные по Бухгалтерии
SELECT
'ИТ' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- данные по ИТ отделу
SELECT
'Прочие' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID IS NULL -- и еще не забываем данные по внештатникам
Так вот, если бы мы не знали, что существует операция группировки, но знали бы, что существует операция объединения результатов запроса при помощи UNION ALL, то мы могли бы склеить все эти запросы следующим образом:
SELECT
'Администрация' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=1 -- данные по Администрации
UNION ALL
SELECT
'Бухгалтерия' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=2 -- данные по Бухгалтерии
UNION ALL
SELECT
'ИТ' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID=3 -- данные по ИТ отделу
UNION ALL
SELECT
'Прочие' Info,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount
FROM Employees
WHERE DepartmentID IS NULL -- и еще не забываем данные по внештатникам

Т.е. UNION ALL позволяет склеить результаты, полученные разными запросами в один общий результат.
Соответственно количество колонок в каждом запросе должно быть одинаковым, а также должны быть совместимыми и типы этих колонок, т.е. строка под строкой, число под числом, дата под датой и т.п.
Немного теории
В MS SQL реализованы следующие виды вертикального объединения:
| Операция | Описание |
|---|---|
| UNION ALL | В результат включаются все строки из обоих наборов. (A+B) |
| UNION | В результат включаются только уникальные строки двух наборов. DISTINCT(A+B) |
| EXCEPT | В результат попадают уникальные строки верхнего набора, которые отсутствуют в нижнем наборе. Разница 2-х множеств. DISTINCT(A-B) |
| INTERSECT | В результат включаются только уникальные строки, присутствующие в обоих наборах. Пересечение 2-х множеств. DISTINCT(A&B) |
Все это проще понять на наглядном примере.
Создадим 2 таблицы и наполним их данными:
CREATE TABLE TopTable(
T1 int,
T2 varchar(10)
)
GO
CREATE TABLE BottomTable(
B1 int,
B2 varchar(10)
)
GO
INSERT TopTable(T1,T2)VALUES
(1,'Text 1'),
(1,'Text 1'),
(2,'Text 2'),
(3,'Text 3'),
(4,'Text 4'),
(5,'Text 5')
INSERT BottomTable(B1,B2)VALUES
(2,'Text 2'),
(3,'Text 3'),
(6,'Text 6'),
(6,'Text 6')
Посмотрим на содержимое:
SELECT *
FROM TopTable
| T1 | T2 |
|---|---|
| 1 | Text 1 |
| 1 | Text 1 |
| 2 | Text 2 |
| 3 | Text 3 |
| 4 | Text 4 |
| 5 | Text 5 |
SELECT *
FROM BottomTable
| B1 | B2 |
|---|---|
| 2 | Text 2 |
| 3 | Text 3 |
| 6 | Text 6 |
| 6 | Text 6 |
UNION ALL
SELECT T1 x,T2 y
FROM TopTable
UNION ALL
SELECT B1,B2
FROM BottomTable

UNION
SELECT T1 x,T2 y
FROM TopTable
UNION
SELECT B1,B2
FROM BottomTable
По сути UNION можно представить, как UNION ALL, к которому применена операция DISTINCT:

EXCEPT
SELECT T1 x,T2 y
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable

INTERSECT
SELECT T1 x,T2 y
FROM TopTable
INTERSECT
SELECT B1,B2
FROM BottomTable

Завершаем разговор о UNION-соединениях
Вот в принципе и все, что касается вертикальных объединений, это намного проще, чем JOIN-соединения.
Чаще всего в моей в практике находит применение UNION ALL, но и другие виды вертикальных объединений находят свое применение.
При нескольких операциях вертикально объединения, не гарантируется, что они будут выполняться последовательно сверху-вниз. Создадим еще одну таблицу и рассмотрим это на примере:
CREATE TABLE NextTable(
N1 int,
N2 varchar(10)
)
GO
INSERT NextTable(N1,N2)VALUES
(1,'Text 1'),
(4,'Text 4'),
(6,'Text 6')
Например, если мы напишем просто:
SELECT T1 x,T2 y
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
INTERSECT
SELECT N1,N2
FROM NextTable
То мы получим:
| x | y |
|---|---|
| 1 | Text 1 |
| 2 | Text 2 |
| 3 | Text 3 |
| 4 | Text 4 |
| 5 | Text 5 |
Т.е. получается сначала выполнился INTERSECT, а после EXCEPT. Хотя логически будто должно было быть наоборот, т.е. идти сверху-вниз.
Я редко использую эти операции объединений, а тем более в таком виде, поэтому, чтобы не думать не гадать, в какой очередности он выполняет объединения, можно просто при помощи скобок явно указать последовательность объединений, давайте скажем, что сначала нужно сделать EXCEPT, а потом INTERSECT:
(
SELECT T1 x,T2 y
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
)
INTERSECT
SELECT N1,N2
FROM NextTable
| x | y |
|---|---|
| 1 | Text 1 |
| 4 | Text 4 |
Вот теперь я получил то, что и хотел.
Я не знаю работает ли такой синтаксис в других СУБД, но если что используйте подзапрос:
SELECT x,y
FROM
(
SELECT T1 x,T2 y
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
) q
INTERSECT
SELECT N1,N2
FROM NextTable
При использовании ORDER BY сортировка применяется к окончательному набору:
SELECT T1 x,T2 y
FROM TopTable
UNION ALL
SELECT B1,B2
FROM BottomTable
UNION ALL
SELECT B1,B2
FROM BottomTable
ORDER BY x DESC
Для задания сортировки здесь удобней использовать псевдоним колонки, заданный в первом запросе.
Самое главное про UNION-объединения я вроде написал, если что поиграйте с UNION-объединениями самостоятельно.
Примечание. В СУБД Oracle тоже есть такие же виды соединения, разница только в операции EXCEPT, там она называется MINUS.
Использование подзапросов
Подзапросы я оставил на последнюю очередь, т.к. прежде чем их использовать нужно научиться правильно строить запросы. К тому же в некоторых случаях можно вообще избежать использования подзапросов и обойтись базовыми конструкциями.
Косвенно мы уже использовали подзапросы в блоке FROM. Там результат, возвращаемый подзапросом по сути играет роль новой таблицы. Думаю, большого смысла останавливаться здесь нет смысла. Просто рассмотрим абстрактный пример с объединением 2-х подзапросов:
SELECT q1.x1,q1.y1,q2.x2,q2.y2
FROM
(
SELECT T1 x1,T2 y1
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
) q1
JOIN
(
SELECT T1 x2,T2 y2
FROM TopTable
EXCEPT
SELECT N1,N2
FROM NextTable
) q2
ON q1.x1=q2.x2
Если не понятно, сразу, то разбирайте такие запросы по частям. Т.е. сначала посмотрите, что возвращает первый подзапрос «q1», потом, что возвращает второй подзапрос «q2», а затем выполните операцию JOIN над результатами подзапросов «q1» и «q2».
Конструкция WITH
Это достаточно полезная конструкция особенно в случае работы с большими подзапросами.
Сравним:
SELECT q1.x1,q1.y1,q2.x2,q2.y2
FROM
(
SELECT T1 x1,T2 y1
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
) q1
JOIN
(
SELECT T1 x2,T2 y2
FROM TopTable
EXCEPT
SELECT N1,N2
FROM NextTable
) q2
ON q1.x1=q2.x2
То же самое написанное при помощи WITH:
WITH q1 AS(
SELECT T1 x1,T2 y1
FROM TopTable
EXCEPT
SELECT B1,B2
FROM BottomTable
),
q2 AS(
SELECT T1 x2,T2 y2
FROM TopTable
EXCEPT
SELECT N1,N2
FROM NextTable
)
-- основной запрос становится более прозрачным
SELECT q1.x1,q1.y1,q2.x2,q2.y2
FROM q1
JOIN q2 ON q1.x1=q2.x2
Как видим большие подзапросы вынесены и поименованы в блоке WITH, что дало возможность разгрузить текст основного запроса и сделать его понятным.
Вспомним так же пример из предыдущей части, где использовалось представление ViewEmployeesInfo:
CREATE VIEW ViewEmployeesInfo
AS
SELECT
emp.*, -- вернуть все поля таблицы Employees
dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments
pos.Name PositionName -- и еще добавить поле Name из таблицы Positions
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
И запрос, который использовал данное представление:
SELECT
DepartmentName,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg
FROM ViewEmployeesInfo emp
GROUP BY DepartmentID,DepartmentName
ORDER BY DepartmentName
По сути WITH дает нам возможность разместить текст из представления непосредственно в запросе, т.е. смысл один и тот же:
WITH cteEmployeesInfo AS(
SELECT
emp.*, -- вернуть все поля таблицы Employees
dep.Name DepartmentName, -- к этим полям добавить поле Name из таблицы Departments
pos.Name PositionName -- и еще добавить поле Name из таблицы Positions
FROM Employees emp
LEFT JOIN Departments dep ON emp.DepartmentID=dep.ID
LEFT JOIN Positions pos ON emp.PositionID=pos.ID
)
SELECT
DepartmentName,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg
FROM cteEmployeesInfo emp
GROUP BY DepartmentID,DepartmentName
ORDER BY DepartmentName
Только в случае созданного представления мы можем использовать его из разных запросов, т.к. представление создается на уровне БД. Тогда как подзапрос оформленный в блоке WITH виден только в рамках этого запроса.
Использование WITH по-другому называет CTE-выражениями:
Общие табличные выражения (CTE — Common Table Expressions) позволяют существенно уменьшить объем кода, если многократно приходится обращаться к одним и тем же запросам. CTE играет роль представления, которое создается в рамках одного запроса и, не сохраняется как объект схемы.У CTE есть еще одно важное назначение, с его помощью можно написать рекурсивный запрос.
Приведу только небольшой пример рекурсивного запроса. Отобразим сотрудников с учетом их подчинения другому сотруднику (если помните, у нас в таблице Employees ключ, ссылающийся на эту же таблицу).
WITH cteEmpl AS(
SELECT ID,CAST(Name AS nvarchar(300)) Name,1 EmpLevel
FROM Employees
WHERE ManagerID IS NULL -- все сотрудники у которых нет вышестоящего
UNION ALL
SELECT emp.ID,CAST(SPACE(cte.EmpLevel*5)+emp.Name AS nvarchar(300)),cte.EmpLevel+1
FROM Employees emp
JOIN cteEmpl cte ON emp.ManagerID=cte.ID
)
SELECT *
FROM cteEmpl
| ID | Name | EmpLevel |
|---|---|---|
| 1000 | Иванов И.И. | 1 |
| 1002 | _____Сидоров С.С. | 2 |
| 1003 | _____Андреев А.А. | 2 |
| 1005 | _____Александров А.А. | 2 |
| 1001 | __________Петров П.П. | 3 |
| 1004 | __________Николаев Н.Н. | 3 |
Для наглядности пробелы заменены знаками подчеркивания.
Рассматривать, как строятся рекурсивные запросы, в рамках данного учебника я не буду. Я считаю, это достаточно специфичная тема для начинающих, и она пока совсем ни к чему им. Прежде чем приступать к изучению рекурсивных запросов нужно уверено научиться пользоваться всеми основными конструкциями, о которых я рассказал, без данной базы дальше двигаться не стоит. В большинстве случаев, знание базовых конструкций, вам будет достаточно для написания запросов любой сложности.
Продолжаем разговор про подзапросы
Давайте теперь рассмотрим, как можно использовать подзапросы еще, а также передавать в них параметры при помощи псевдонима из основного запроса.
Здесь я уже не буду сильно углубляться в разъяснение, т.к. к этому этапу вы уже должны были научиться мыслить и понимать принцип работы с данными. Обязательно практикуйтесь, выполняйте примеры и пытайтесь и понять полученный результат. Чтобы понять, нужно прочувствовать каждый пример себе.
Подзапрос можно использовать в блоке SELECT
Вернемся к нашему отчету:
SELECT
DepartmentID,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg -- плюс выполняем пожелание директора
FROM Employees
GROUP BY DepartmentID
Здесь название отдела можно так же достать при помощи подзапроса с параметром:
SELECT
/*
используем подзапрос с параметром
в данном случае подзапрос должен возвращать одну строку
и только одно значение
*/
(SELECT Name FROM Departments dep WHERE dep.ID=emp.DepartmentID) DepartmentName,
COUNT(DISTINCT PositionID) PositionCount,
COUNT(*) EmplCount,
SUM(Salary) SalaryAmount,
AVG(Salary) SalaryAvg
FROM Employees emp -- задаем псевдоним
GROUP BY DepartmentID
ORDER BY DepartmentName
В данном случае подзапрос (SELECT Name FROM Departments dep WHERE dep.ID=emp.DepartmentID) выполнится 4 раза, т.е. для каждого значения emp.DepartmentID
Подзапрос в данном случае должен возвращать только одну строку и одну колонку. Если в подзапросе получается много строк, то используйте в нем либо TOP, либо какую-нибудь агрегатную функцию, чтобы в итоге получилась одна строка. Например, получим для каждого отдела ID последнего принятого сотрудника:
SELECT
ID,
Name,
-- подзапрос 1а - получаем ID сотрудника
(SELECT MAX(ID) FROM Employees emp WHERE emp.DepartmentID=dep.ID) LastEmpID_var1,
-- подзапрос 1б - получаем ID сотрудника
(SELECT TOP 1 ID FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpID_var2,
-- подзапрос 2 - получаем имя сотрудника
(SELECT TOP 1 Name FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpName
FROM Departments dep
Не хорошо правда ведь? Т.к. каждый из трех подзапросов выполнится по 4 раза (для каждой возвращенной строки), итого выполнится 12 подзапросов.
Поэтому, я бы рекомендовал прибегать к использованию подзапросов с параметрами в самую последнюю очередь, т.к. когда вы не можете выразить запрос при помощи простых операций соединений, т.к. использование подзапросов в таких случаях может сильно понизить скорость выполнения запроса. Потому что подзапрос с параметром будет выполняться для каждого переданного ему параметра.
Подзапросы с конструкцией APPLY
В MS SQL для последнего примера:
SELECT
ID,
Name,
-- подзапрос 1 - получаем ID сотрудника
(SELECT TOP 1 ID FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpID,
-- подзапрос 2 - получаем имя сотрудника
(SELECT TOP 1 Name FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY ID DESC) LastEmpName
FROM Departments dep
можно применить конструкцию APPLY, которая имеет 2 формы – CROSS APPLY и OUTER APPLY.
Конструкция APPLY позволяет избавиться от множества подзапросов, как в данном примере, когда требуется получить и ID и Name последнего принятого сотрудника для каждого отдела:
SELECT
ID,
Name,
empInfo.LastEmpID,
empInfo.LastEmpName
FROM Departments dep
CROSS APPLY
(
SELECT TOP 1 ID LastEmpID,Name LastEmpName
FROM Employees emp
WHERE emp.DepartmentID=dep.ID
ORDER BY emp.ID DESC
) empInfo
| ID | Name | LastEmpID | LastEmpName |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
Здесь подзапрос блока CROSS APPLY выполнится для каждого значения строки из таблицы Departments. Если подзапрос строки не вернет, то данный отдел исключается из результирующего списка.
Если требуется, чтобы были возвращены все строки таблицы Departments, то используйте следующую форму этого оператора OUTER APPLY:
SELECT
ID,
Name,
empInfo.LastEmpID,
empInfo.LastEmpName
FROM Departments dep
OUTER APPLY
(
SELECT TOP 1 ID LastEmpID,Name LastEmpName
FROM Employees emp
WHERE emp.DepartmentID=dep.ID
ORDER BY emp.ID DESC
) empInfo
| ID | Name | LastEmpID | LastEmpName |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
В общем, достаточно полезный оператор, который в некоторых ситуациях сильно упрощающий запрос. Данный подзапрос так же сработает для каждой строки результирующего набора, т.е. для каждого переданного параметра, но сработает он намного эффективнее, чем в случае использования множества подзапросов. С прочими деталями в случае применения APPLY, например, для случая, когда подзапрос возвращает несколько строк, я думаю вы сможете разобраться самостоятельно. Ладно, раз уж заговорил об этом, то приведу небольшой пример для самостоятельного разбора:
SELECT dep.ID,dep.Name,pos.PositionID,pos.PositionName
FROM Departments dep
CROSS APPLY
(
SELECT ID PositionID,Name PositionName
FROM Positions
) pos
Использование подзапросов в блоке WHERE
Для примера получим отделы, в которых числится более двух сотрудников:
SELECT *
FROM Departments dep
WHERE (SELECT COUNT(*) FROM Employees emp WHERE emp.DepartmentID=dep.ID)>2
Так как здесь мы используем оператор сравнения, то соответственно подзапрос должен возвращать максимум одну строку и одно значение, т.е. так же когда подзапрос используется и в блоке SELECT.
Конструкции EXISTS и NOT EXISTS
Позволяют проверить есть ли соответствующие условию записи в подзапросе:
-- отделы в которых есть хотя бы один сотрудник
SELECT *
FROM Departments dep
WHERE EXISTS(SELECT * FROM Employees emp WHERE emp.DepartmentID=dep.ID)
-- отделы в которых нет ни одного сотрудника
SELECT *
FROM Departments dep
WHERE NOT EXISTS(SELECT * FROM Employees emp WHERE emp.DepartmentID=dep.ID)
Здесь все просто – EXISTS возвращает True, если подзапрос возвращает хотя бы одну строку, и False, если подзапрос не возвращает строк. NOT EXISTS – инверсия результата.
Конструкция IN и NOT IN с подзапросом
До этого мы рассматривали IN с перечислением значений. Так же можно использовать его с подзапросом, который возвращает перечень этих значений:
-- отделы где есть сотрудники
SELECT *
FROM Departments
WHERE ID IN(SELECT DISTINCT DepartmentID FROM Employees WHERE DepartmentID IS NOT NULL)
-- отделы где нет сотрудников
SELECT *
FROM Departments
WHERE ID NOT IN(SELECT DISTINCT DepartmentID FROM Employees WHERE DepartmentID IS NOT NULL)
Обратите внимание, что я исключил NULL значение используя условие (DepartmentID IS NOT NULL) в подзапросе. NULL значения в данном случае так же опасны – смотрите об этом в описании конструкции IN во второй части.
Операции группового сравнения ALL и ANY
Данные операторы, очень хитрые и их использовать нужно очень аккуратно. Вообще в своей практике я их применяю достаточно редко, предпочитая использовать в условиях операторы IN или EXISTS.
Операторы ALL и ANY используются в тех случаях, когда необходимо проверить условие на соответствие, с каждым значением которое вернул подзапрос. Они, как и оператор EXISTS работают только с подзапросами.
Для примера в каждом отделе выберем сотрудника, у которого ЗП больше ЗП всех сотрудников работающих в этом же отделе. Для этой цели применим ALL:
SELECT ID,Name,DepartmentID,Salary
FROM Employees e1
WHERE e1.Salary>ALL(
SELECT e2.Salary
FROM Employees e2
WHERE e2.DepartmentID=e1.DepartmentID -- учесть только сотрудников этого же отдела
AND e2.ID<>e1.ID -- чтобы исключить сравнение со своей же ЗП
AND e2.Salary IS NOT NULL -- исключить NULL значения
)
| ID | Name | DepartmentID | Salary |
|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 5000 |
| 1002 | Сидоров С.С. | 2 | 2500 |
| 1003 | Андреев А.А. | 3 | 2000 |
| 1005 | Александров А.А. | NULL | 2000 |
Здесь происходит проверка на то, что e1.Salary больше значений e2.Salary, которые вернул подзапрос.
Как думаете, почему здесь вернулись даже те сотрудники, для которых подзапрос не вернул ни одной строки? А потому что логика такая – нет записей, не с чем проверять, а значит я и так больше всех. ))) Вот такая хитрость здесь скрыта.
Для большего понимания, давайте посмотрим, как можно здесь оператор ALL заменить оператором NOT EXISTS:
SELECT ID,Name,DepartmentID,Salary
FROM Employees e1
WHERE NOT EXISTS(
SELECT *
FROM Employees e2
WHERE e2.DepartmentID=e1.DepartmentID -- учесть только сотрудников этого же отдела
AND e2.Salary>e1.Salary -- выбираем только ЗП больше ЗП этого сотрудника
)
Т.е. мы тут выразили то же самое только другими словами «Верни сотрудников для которых нет сотрудников из того же отдела с большей ЗП чем у него».
Здесь становится понятно почему ALL возвращает истинное значение в том случае если подзапрос не возвращает данных.
Так же обратите внимание, что для ALL важно исключить NULL-значения из подзапроса, иначе результат проверки на каждое значение может оказаться неопределенным. Сравнивайте в этом случае логика ALL логикой при использовании AND, т.е. выражение (Salary>1000 AND Salary>1500 AND Salary>NULL) вернет NULL.
А вот с ANY (он же SOME) будет по-другому:
SELECT ID,Name,DepartmentID,Salary
FROM Employees e1
WHERE e1.Salary>ANY( -- ANY = SOME
SELECT e2.Salary
FROM Employees e2
WHERE e2.DepartmentID=e1.DepartmentID -- учесть только сотрудников этого же отдела
AND e2.ID<>e1.ID -- чтобы исключить сравнение со своей же ЗП
)
| ID | Name | DepartmentID | Salary |
|---|---|---|---|
| 1003 | Андреев А.А. | 3 | 2000 |
C оператором ANY важно, чтобы подзапрос вернул записи, с которыми можно сравнить на любое выполнение условия. Т.к. во всех отделах сидят только по одному сотруднику, кроме ИТ-отдела, то вернулся только Андреев А.А., чью ЗП удалось сравнить с ЗП других сотрудников этого же отдела. Т.е. мы вытащили здесь тех, чья ЗП больше любой ЗП сотрудника из этого же отдела.
Давайте для большего понимания, попробуем выразить здесь ANY при помощи EXISTS:
SELECT ID,Name,DepartmentID,Salary
FROM Employees e1
WHERE EXISTS(
SELECT *
FROM Employees e2
WHERE e2.DepartmentID=e1.DepartmentID -- учесть только сотрудников этого же отдела
AND e2.Salary<e1.Salary -- проверяем есть ли сотрудники с меньшей ЗП чем у данного сотрудника
)
Смысл здесь стал «есть ли хоть какой-то сотрудник из этого отделу у которого ЗП ниже ЗП данного сотрудника».
В таком виде становится понятно, почему ANY возвращает ложное значение, если подзапрос не возвращает данных.
Наличие NULL-значений в подзапросе здесь не так опасно, т.к. мы сравниваем на любое значение. Сравнивайте в этом случае логика ANY логикой при использовании OR, т.е. выражение (Salary>1000 OR Salary>1500 OR Salary>NULL) может вернуть истинное значение если выполнится хотя бы одно условие.
Если ANY используется для сравнения на равенство, то его можно представить при помощи IN:
SELECT *
FROM Departments
WHERE ID=ANY(SELECT DISTINCT DepartmentID FROM Employees)
Здесь мы возвращаем все отделы, в которых есть сотрудники. Соответственно это будет эквивалентно:
SELECT *
FROM Departments
WHERE ID IN(SELECT DISTINCT DepartmentID FROM Employees)
Как видите ALL и ANY можно выразить при помощи других операторов. Но в некоторых случаях их использование может сделать запрос более читабельным, поэтому для полноты картины их тоже стоит знать и применять в подходящих для этого случаях. Т.е. при написании запроса вы можете написать его так как вас попросили «выбери сотрудника у которого ЗП больше всех»:
SELECT *
FROM Employees e1
WHERE e1.Salary>ALL(SELECT e2.Salary FROM Employees e2 WHERE e2.ID<>e1.ID AND e2.Salary IS NOT NULL)
не заменяя смысл на аналогичный «выбери сотрудников для которых нет сотрудников с ЗП больше чем у него»:
SELECT *
FROM Employees e1
WHERE NOT EXISTS(SELECT * FROM Employees e2 WHERE e2.Salary>e1.Salary)
Это еще раз показывает, что язык SQL изначально задумывался как язык для обычных пользователей, чтобы они могли выражать свои мысли разными способами.
Еще пара слов про подзапросы
Подзапросы можно так же использовать во многих других блоках, например, в блоке HAVING, осуществлять проверку в конструкциях CASE. В общем, тут уже насколько хватит вашей фантазии.
Но я бы рекомендовал в первую очередь всегда пытаться решить задачу стандартными конструкциями оператора SELECT, и, если этого не получается, прибегать к помощи подзапросов.
Поэтому в данном учебнике я уделил целых три части на рассмотрение базовых конструкций и только один раздел выделил подзапросам. Я считаю, что нельзя начинать объяснение SELECT с подзапросов, т.к. зная, что есть подзапросы, но не владея базовыми конструкциями, новички могут нагородить такие трехэтажные конструкции (подзапросы в подзапросах-подзапросах), которые даже профессионалам потом бывает трудно разобрать. Но если разобраться, то в некоторых случаях, зная основы все эти трехэтажные конструкции можно было бы выразить при помощи одного запроса с использованием, например, соединений и группировок.
Я не говорю, что подзапросы – это плохо, т.к. иногда при помощи них конкретную задачу можно решить более изящно. Я говорю здесь о том, что в первую очередь нужно научится уверенно пользоваться базовыми конструкциями, ведь подзапросы тоже строятся их них. А так все конструкции хороши, когда они применяются по назначению.
Заключение
Вот мы и закончили разбираться со всеми основными конструкциями оператора SELECT. Если посчитать, то их не так много, но уверенное владение каждой из них и умение пользоваться ими сообща, дает вам огромные возможности для получения практически любой информации хранящейся в РБД.
Данный материал был создан, опираясь на свой собственный практический опыт работы с языком SQL, которому уже более 10 лет, в разных СУБД (начиная с СУБД Paradox). В данном учебнике, я постарался максимально простым образом объяснить суть всех основных конструкций языка SQL служащих для выборки данных. Я старался объяснять так, чтобы данный учебник был понятен широкому кругу людей, а не только ИТ-специалистам. Надеюсь, что это у меня получилось и что данный материал поможет вам сделать первые шаги или же поможет понять какую-нибудь отдельную конструкцию, которая возможно вам не давалась ранее. В любом случае, спасибо всем, кто уделил свое время на ознакомление с этим материалом.
В следующей части я уже в общих чертах расскажу о операторах модификации данных. В общих чертах, так как эта информация, как и знание DDL, нужна не всем (в основном ИТ-специалистам) – большинство людей изучают SQL именно в целях научиться делать выборку данных при помощи оператора SELECT. Думаю, следующая часть будет заключительной. Все знания, полученные до этого момента, нам так же пригодятся в следующей части, т.к. для правильного написания сложных конструкций по модификации данных, нужно уверено пользоваться конструкциями оператора SELECT. Например, перед тем как удалить или изменить группу строк таблицы, мы должны правильно выбрать эти данные. Поэтому следующая часть так же будет содержать конструкции SELECT и думаю будет интересна тем людям, которые изучают SQL именно из-за оператора выборки SELECT.
Для уверенного написания запросов, мало понимать теорию, нужно еще много практиковаться. Для этой цели я бы рекомендовал вам известный сайт под названием «SQL-EX.RU – Практическое владение языком SQL», который содержит несколько демонстрационных баз данных и предоставляет возможность попрактиковаться в написании самых каверзных запросов, начиная с решения самых простых задач. Там тоже есть много учебного материала по языку SQL. К тому же вы можете потягаться в решении рейтинговых задач и в итоге получить сертификат, доказывающий именно ваши практические навыки, а не только знание теории.
После того как вы уверенно научитесь использовать базовые конструкции, я бы посоветовал вам в следующую очередь самостоятельно изучить:
- Предложение OVER, которое дает возможность использовать:
- Агрегатные функции (COUNT, SUM, MIN, MAX, AVG) без использования GROUP BY;
- Ранжирующие функции: ROW_NUMBER(),RANK() и DENSE_RANK();
- Аналитические функции: LAG() и LEAD(),FIRST_VALUE() и LAST_VALUE();
- Изучить конструкции позволяющие вычислить под итоги: GROUP BY ROLLUP(…), GROUP BY GROUPING SETS(…), … А так же вспомогательные функции используемые для этих целей: GROUPING_ID() и GROUPING();
- Конструкции PIVOT, UNPIVOT.
Краткая информация по всему этому дана в пятой части в «Приложение 1 – бонус по оператору SELECT» и «Приложение 2 – OVER и аналитические функции». Дополнительную информацию по всему этому вы легко сможете найти в интернет, в той же библиотеке MSDN.
Удачи в изучении.
Часть пятая — habrahabr.ru/post/256169
Поговорим о том, как работает Join в SQL-базах данных. Для чего нужна эта директива, какие возможности она открывает и как правильно ее использовать.
Что такое SQL Join?
SQL Join – одна из наиболее часто используемых команд в SQL-синтаксисе. Она используется для поиска информации в базах данных по заранее определенным критериям. В частности, Join отвечает за объединение нескольких групп данных в единый поток информации.
И это действительно необходимо, потому что в 100% случаев контент в реляционных базах данных с поддержкой SQL-синтаксиса делится на множество таблиц, фильтровать данные в которых можно с помощью специальных команд и запросом информации из общего пула таблиц.
SQL Join помогает настроить фильтр поиска в базе данных, опираясь на взаимосвязи между различными элементами БД и их отличительные черты (теги, ID, наименования и т.п.).
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
SQL Inner Join
Этот режим объединения результатов поиска в базах данных SQL включается автоматически. Если вы не укажете намеренно тип Join, то сработает именно Inner Join. С помощью него можно указать сразу два критерия (две таблицы) и по ним отсеять контент.
Достаточно прописать SQL-запрос в духе:
SELECT * FROM table-1 JOIN table-2 ON table-1.parameter=table-2.parameter WHERE table-1.parameter IS ‘myData’
Фактически мы пытаемся выудить данные из первой таблицы и объединить их с данными из второй таблицы, при этом фильтруя только те записи, в которых совпадает значение параметра. В первой таблице оно приравнивается к myData.
На практике это может использоваться на сайте с музыкальными инструментами, например. Можно запрашивать гитары конкретного бренда, при этом еще и выбирая дополнительное условие в духе количества струн.
SELECT * FROM SevenStringGuitars JOIN Ibanez ON SevenStringGuitar.brandId=Ibanez.brandId
Таким SQL-запросом мы можем отфильтровать все инструменты бренда Ibanez в категории «Гитары» с 7 струнами.
SQL Self Join
Запросы Self Join полезны в тех случаях, когда необходимо выполнить фильтрацию контента внутри одной таблицы. Например, у вас есть список товаров в базе данных. У каждого из них указан свой бренд, но есть и те, что поставляются одним производителем. Self Join можно использовать для объединения двух стеков информации из одной таблицы.
Например, можно запросить информацию о наименовании товара и параллельно обратиться к базе с названием бренда. Результатом работы функции станет появление нового списка товаров, соответствующего критериям.
SQL-команда в этом случае может выглядеть следующим образом:
SELECT * FROM products JOIN products ON table.product=table.brand
Такой сценарий полезен практически в любом виде баз данных, так как в одной таблице нередко может храниться информация о товарах или контенте, имеющим большое количество общих параметров.
SQL Cross Join
Самый специфичный вариант фильтрации данных. Он подразумевает сбор сразу всех комбинаций элементов из нескольких таблиц, без обращения к какой-либо дополнительной информации (не требуется указывать id или любую другую строку в таблице).
Стандартный SQL-запрос с Cross Join может выглядеть следующим образом:
SELECT * FROM table-1 CROSS JOIN table-2
Этого достаточно, чтобы создать новый список элементов, в котором будут собраны все строки из базы данных, отфильтрованные только по выбранным таблицам.
Полученный набор данных называют декартовым произведением. Схематично его часто изображают как большое количество перекрестий между двумя группами элементов.
Такой вид JOIN применяется в онлайн-магазинах для вывода всех возможных пар по выбранным характеристикам одежды (цвету и размеру или другим параметрам).
SQL Outer Join
Outer Join – это своего рода противоположность Inner Join. Как понятно из названия, Outer Join предоставляет информацию не только из внутренней части поиска, но и из внешней. То есть программа ищет не только точечные совпадения по выбранным ранее критериям, а позволяет немного ослабить «хватку» и предоставить более «свободные» результаты поиска, включающие в себя элементы из таблиц, которые хоть и совпадают с критериями в SQL-запросе, но не полностью.
Когда такой подход может понадобиться? Например, для скрупулезной фильтрации товаров. Если вы готовы покупать продукцию компании «Шестерочка» и не против, если среди нее окажется молоко, но при этом вы точно не хотите покупать молоко других производителей, то вам подойдет подобный фильтр. Он позволяет дать одному из критериев поиска что-то в духе привилегий.
Разновидности Outer Join
Внешние Join-запросы существуют не в единственном виде, а сразу в трех вариациях. Каждый вариант по-своему обрабатывает информацию и в итоге выдает разные результаты.
Left
Левое объединение подразумевает как раз выше описанный сценарий. Когда мы берем одну таблицу, подключаем вторую и при этом показываем не только точные совпадения, но еще и весь список строк, полученных из левой таблицы, для которых не нашлось пары в правой таблице.
На практике это может выглядеть так:
SELECT * FROM table1 LEFT JOIN table2 ON table1.parameter=table2.parameter
Теперь мы объединяем первую и вторую таблицу, доставая информацию как о совпадениях по заданным параметрам, так и по контенту без пары в левой таблице.
При желании, надстраивая подобный фильтр, можно вовсе исключить целую категорию строк:
SELECT * FROM table1 LEFT JOIN table2 ON table1.parameter=table2.parameter WHERE table2.parameter IS NULL
На живом примере фильтрация такого рода может выглядеть так:
SELECT * FROM Russian LEFT JOIN Rap ON Russian.genreId=Rap.genreId
Представим, что мы запустили продвинутый поиск на сайте с музыкальными альбомами. Мы хотим послушать что-то на русском языке. Причем готовы даже оценить качество отечественного рэпа. При этом в целом мы рэп не любим и не хотим, чтобы он попадался на каких-то других языках.
Right
Понятно, что правое объединение будет работать в обратную сторону и покажет элементы из правой таблицы, для которых не нашлось пары в левой.
Получится следующий SQL-запрос:
SELECT * FROM table1 RIGHT JOIN table2 ON table1.parameter=table2.parameter
Если взять пример из предыдущей главы, то в реальности можно обернуть ситуацию в противоположную сторону. Искать только рэп-музыку, исключив все русское, кроме хип-хопа. Получится что-то в духе:
SELECT * FROM Russian RIGHT JOIN Rap ON Russian.genreId=Rap.genreId
Full
Это вариант для тех, кто хочет использовать сразу два разных критерия для поиска какого-либо контента. Снова вернемся к примеру с музыкальным приложением. Join Full может пригодиться, если вы хотите послушать либо что-то на русском, либо любой рэп. Вам не важны какие-либо другие параметры. Вас волнуют исключительно две характеристики. При этом вам не так важно, будут ли они пересекаться. То есть вам все равно, будет рэп на русском или же на русском будет какой-то агрессивный металл.
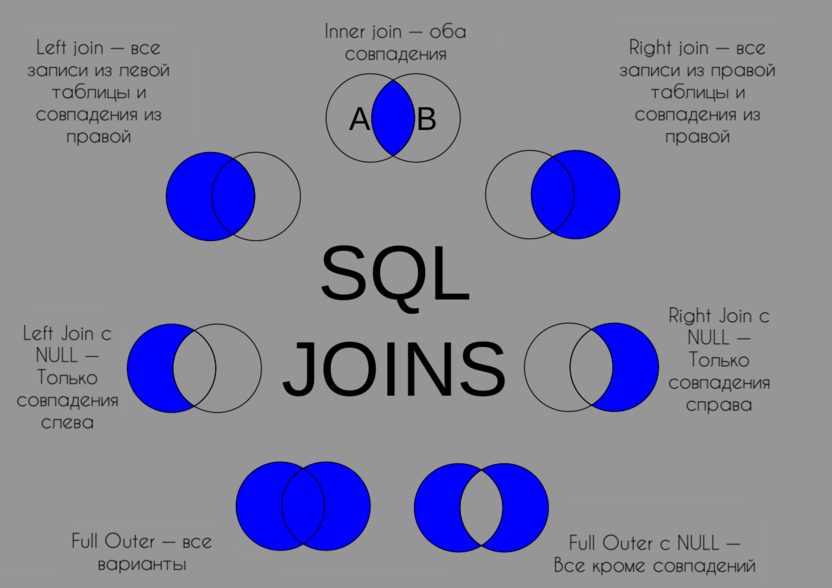
SQL-запрос с таким Join мог бы выглядеть следующим образом:
SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.parameter=table2.parameter
Можно исключить из результатов фильтрации все пары. То есть можно выбрать только рэп, но ни в коем случае не русский, и русскую музыку, но ни в коем случае не рэп (вполне могу понять такой выбор, кстати говоря).
Чтобы это сделать, необходимо написать следующий SQL-запрос.
SELECT * FROM Russian FULL OUTER JOIN Rap ON Russian.genreId=Rap.genreId WHERE Russian.genreId IS NULL OR Rap.genreId IS NULL
Теперь вы увидите в результатах поиска только непарные строки.
Вместо заключения
SQL Join – мощнейший инструмент для фильтрации строк в базах данных. Благодаря ему можно легко находить именно ту информацию, что нужна, а не возиться с недоделанными фильтрами, которые обычно предоставляют разработчики сайтов и приложений. Жаль, что такие мощные механизмы поиска доступны далеко не везде. Но, создавая собственные продукты, вы можете их реализовать. Power-пользователи точно останутся довольны.
SQL — Simple Query Language, то есть «простой язык запросов». Его создали, чтобы работать с реляционными базами данных. В таких базах данные представлены в виде таблиц. Зависимости между несколькими таблицами задают с помощью связующих — реляционных столбцов.
Когда запрашиваем данные из одной таблицы, работа со связующими столбцами не нужна. Но если нужно агрегировать данные из нескольких, стоит описать правила: как будут связаны строки на основе значений связующих столбцов. Тогда на помощь и приходит оператор join.
Что такое оператор join в SQL
Join — оператор, который используют, чтобы объединять строки из двух или более таблиц на основе связующего столбца между ними. Такой столбец еще называют ключом.
Предположим, что у нас есть таблица заказов — Orders:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
И таблица клиентов — Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Столбец CustomerID в таблице заказов соотносится со столбцом CustomerID в таблице клиентов. То есть он — связующий двух таблиц. Чтобы узнать, когда, какой клиент и какой заказ оформил, составьте запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Результат запроса будет выглядеть так:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304103 | Редиска Менеджмент | 25-07-2021 |
Общий синтаксис оператора join:
JOIN <Название таблицы для присоединения> ON <Условие присоединения на основе связующих столбцов>
Соединять можно и больше двух таблиц: к запросу добавьте еще один оператор join. Например, в дополнение к предыдущим двум таблицам у нас есть таблица продавцов — Managers:
| OrderID | ManagerName | ContactDate |
| 304101 | Артём Лапин | 05-05-2021 |
| 304102 | Егор Орлов | 15-06-2021 |
| 304103 | Евгений Соколов | 20-07-2021 |
Таблица продавцов связана с таблицей заказов столбцом OrderID. Чтобы в дополнение к предыдущему запросу узнать, какой продавец обслуживал заказ, составьте следующий запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate, Managers.ManagerName FROM Orders JOIN Customers ON Orders.CustomerID=Customers.CustomerID JOIN Managers ON Orders.OrderId=Managers.OrderId
Результат:
| OrderID | CustomerName | OrderDate | ManagerName |
| 304101 | Балалайка Сервис | 10-05-2021 | Артём Лапин |
| 304103 | Редиска Менеджмент | 25-07-2021 | Евгений Соколов |
Внутреннее соединение INNER JOIN
Если использовать оператор INNER JOIN, в результат запроса попадут только те записи, для которых выполняется условие объединения. Еще одно условие — записи должны быть в обеих таблицах. В финальный результат из примера выше не попали записи с CustomerID=23 и OrderID=304102: для них нет соответствия в таблицах.
Общий синтаксис запроса INNER JOIN:
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;

Иллюстрация работы INNER JOIN
Слово INNER в запросе можно опускать, тогда общий синтаксис запроса будет выглядеть так:
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
Внешние соединения OUTER JOIN
Если использовать внешнее соединение, то в результат запроса попадут не только записи с совпадениями в обеих таблицах, но и записи одной из таблиц целиком. Этим внешнее соединение отличается от внутреннего.
Указание таблицы, из которой нужно выбрать все записи без фильтрации, называется направлением соединения.
LEFT OUTER JOIN / LEFT JOIN
В финальный результат такого соединения попадут все записи из левой, первой таблицы. Даже если не будет ни одного совпадения с правой. И записи из второй таблицы, для которых выполняется условие объединения.

Иллюстрация работы LEFT JOIN
Синтаксис:
SELECT column_name(s) FROM table1 LEFT JOIN table2 ON table1.column_name = table2.column_name;
Пример:
Таблица Orders:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
Таблица Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders LEFT JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Результат:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304102 | null | 20-06-2021 |
| 304103 | Редиска Менеджмент | 25-07-2021 |
RIGHT OUTER JOIN / RIGHT JOIN
В финальный результат этого соединения попадут все записи из правой, второй таблицы. Даже если не будет ни одного совпадения с левой. И записи из первой таблицы, для которых выполняется условие объединения.

Иллюстрация работы RIGHT JOIN
Синтаксис:
SELECT column_name(s) FROM table1 RIGHT JOIN table2 ON table1.column_name = table2.column_name;
Пример:
Таблица Orders:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
Таблица Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders RIGHT JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Результат:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| null | Рога и копыта | null |
| 304103 | Редиска Менеджмент | 25-07-2021 |
FULL OUTER JOIN / FULL JOIN
В финальный результат такого соединения попадут все записи из обеих таблиц. Независимо от того, выполняется условие объединения или нет.

Иллюстрация работы FULL JOIN
Синтаксис:
SELECT column_name(s) FROM table1 FULL JOIN table2 ON table1.column_name = table2.column_name;
Пример:
Таблица Orders
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
Таблица Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Запрос:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders FULL JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
Результат:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304102 | null | 20-06-2021 |
| 304103 | Редиска Менеджмент | 25-07-2021 |
| null | Рога и копыта | null |
Перекрестное соединение CROSS JOIN
Этот оператор отличается от предыдущих операторов соединения: ему не нужно задавать условие объединения (ON table1.column_name = table2.column_name). Записи в таблице с результатами — это результат объединения каждой записи из левой таблицы с записями из правой. Такое действие называют декартовым произведением.

Иллюстрация работы CROSS JOIN
Синтаксис:
SELECT column_name(s) FROM table1 CROSS JOIN table2;
Пример:
Таблица Orders:
| OrderID | CustomerID | OrderDate |
| 304101 | 21 | 10-05-2021 |
| 304102 | 34 | 20-06-2021 |
| 304103 | 22 | 25-07-2021 |
Таблица Customers:
| CustomerID | CustomerName | ContactName |
| 21 | Балалайка Сервис | Иван Иванов |
| 22 | Рога и копыта | Семён Семёнов |
| 23 | Редиска Менеджмент | Пётр Петров |
Запрос:
</p> SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate FROM Orders CROSS JOIN Customers;
Результат:
| OrderID | CustomerName | OrderDate |
| 304101 | Балалайка Сервис | 10-05-2021 |
| 304101 | Рога и копыта | 10-05-2021 |
| 304101 | Редиска Менеджмент | 10-05-2021 |
| 304102 | Балалайка Сервис | 20-06-2021 |
| 304102 | Рога и копыта | 20-06-2021 |
| 304102 | Редиска Менеджмент | 20-06-2021 |
| 304103 | Балалайка Сервис | 25-07-2021 |
| 304103 | Рога и копыта | 25-07-2021 |
| 304103 | Редиска Менеджмент | 25-07-2021 |
Соединение SELF JOIN
Его используют, когда в запросе нужно соединить несколько записей из одной и той же таблицы.
В SQL нет отдельного оператора, чтобы описать SELF JOIN соединения. Поэтому, чтобы описать соединения данных из одной и той же таблицы, воспользуйтесь операторами JOIN или WHERE.
Учтите, что в одном запросе нельзя дважды использовать имя одной и той же таблицы: иначе запрос вернет ошибку. Поэтому, чтобы выполнить соединение таблицы SQL с самой собой, в запросе ей присваивают два разных временных имени — алиаса.
Синтаксис соединения SELF JOIN при использовании оператора JOIN:
SELECT column_name(s) FROM table1 a1 JOIN table1 a2 ON a1.column_name = a2.column_name;
Оператор JOIN может быть любым: используйте LEFT JOIN, RIGHT JOIN. Результат будет таким же, как когда объединяли две разные таблицы.
Синтаксис соединения SELF JOIN при использовании оператора WHERE:
SELECT column_name(s) FROM table1 a1, table1 a2 WHERE a1.common_col_name = a2.common_col_name;
Пример:
Талица Students:
| StudentID | Name | CourseID | Duration |
| 1 | Артём | 1 | 3 |
| 2 | Пётр | 2 | 4 |
| 1 | Артём | 2 | 4 |
| 3 | Борис | 3 | 2 |
| 2 | Ирина | 3 | 5 |
Запрос с оператором WHERE:
SELECT s1.StudentID, s1.Name FROM Students AS s1, Students s2 WHERE s1.StudentID = s2.StudentID AND s1.CourseID <> s2.CourseID;
Результат:
| StudentID | Name |
| 1 | Артём |
| 2 | Ирина |
| 1 | Артём |
| 2 | Пётр |
Запрос с оператором JOIN:
SELECT s1.StudentID, s1.Name FROM Students s1 JOIN Students s2 ON s1.StudentID = s2.StudentID AND s1.CourseID <> s2.CourseID GROUP BY StudentID;
Результат:
| StudentID | Name |
| 1 | Артём |
| 2 | Ирина |
Главное о join в SQL
- В SQL используют операторы соединения join, чтобы объединять данные из нескольких таблиц. Когда результат должен содержать только данные двух таблиц с общим ключом, применяют INNER JOIN или просто JOIN.
- Если нужен полный список записей одной из таблиц, объединенных с данными из другой, используют операторы LEFT и RIGHT JOIN.
- Если результат должен содержать полный список записей обеих таблиц, где некоторые записи объединены, применяют оператор FULL JOIN.
- Если нужно декартово произведение двух таблиц, используют оператор CROSS JOIN. Хотите соединить данные из одной и той же таблицы между собой — нужен SELF JOIN.
Научитесь писать SQL-запросы на курсе «Аналитик данных» Skypro. Изучите агрегатные функции, подзапросы и WITH, JOIN, оконные функции и многое другое, а еще — решите бизнес-задачу с помощью SQL.
Еще в программе: базовые формулы Excel, работа в Power Pivot и Power Query, Python для анализа данных. Справитесь и без опыта в IT: учим с азов, ведем до диплома и помогаем найти работу.
#статьи
- 15 мар 2021
-

15
Выбираем, какие фильмы посмотреть, с помощью соединения данных в SQL.
скриншот из игры team fortress 2 / valve

Фулстек-разработчик. Любимый стек: Java + Angular, но в хорошей компании готова писать хоть на языке Ада.
Опять эта проблема — выбрать кино на вечер. Благодаря стриминговым сервисам доступны едва ли не все фильмы мира: это бесконечное полотно с постерами и фильтры, фильтры, фильтры…

МОЗГ: Поставлю-ка я фильтр по стране: пусть будет Дания, и добавлю ограничение по жанру — триллер… Ну вот — другое дело, относительно небольшой список.
— Мозг, а знаешь почему? Да потому что здесь только фильмы, которые сняты в Дании И помечены как триллеры.
— Но если мне нужно не И, а ИЛИ? Или я хочу выбирать из датских фильмов, но только НЕ триллеры? Как выставить такой фильтр?
— Да не знаю я, как задать такие критерии в этом сервисе. Вот если бы можно было писать на SQL — тут бы решение нашлось для любой комбинации признаков.
— Пруфы будут?
— Легко! Ещё и картинки будут. У меня и база фильмов уже спарсена — тренируйся не хочу.
Назовём множество датских фильмов — D, а множество триллеров — T. У каждого фильма будет уникальный номер, он же ключ. Раз ключ — пусть зовётся Key.
Заодно вспомним, как на SQL пишется простой запрос для связывания данных из двух таблиц:
SELECT * (или список полей)
FROM D
JOIN T ON D.Key=T.Key
WHERE условие отбора
Если не уточнить тип соединения (JOIN), то по умолчанию применяется INNER JOIN — как раз тот вариант, который сработал в нашем кинофильтре. Это он выбирает и триллеры, и датские фильмы одновременно.
А вот и обещанная картинка:
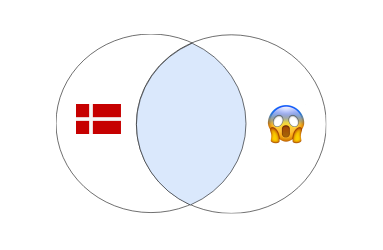
При INNER JOIN (внешнее соединение) выбираются только совпадающие по условию объединения данные из обеих таблиц. Порядок таблиц в запросе не важен.
Подойдёт, если:
- я хочу выбрать датские фильмы;
- и согласна, что среди них могут быть триллеры;
- но мне не интересны триллеры производства других стран, только датские.
Вот так будет выглядеть SQL-запрос:
SELECT *
FROM D
LEFT JOIN T ON D.Key=T.Key
И подобающая случаю диаграмма:
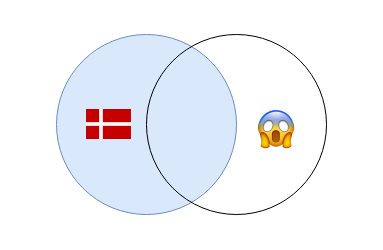
LEFT JOIN (левое внешнее объединение) — то же самое, что LEFT OUTER JOIN.
В результат попадают совпадающие по ключу данные обеих таблиц и все записи из левой таблицы, для которых не нашлось пары в правой.
— А что, если я вообще не фанат триллеров, но датские фильмы мне интересны?
— Тогда к скрипту выше нужно дописать одно условие:
SELECT *
FROM D
LEFT JOIN T ON D.Key=T.Key
WHERE T.Key IS NULL
Дословно T.Key IS NULL означает, что нужно включить в результат только записи, в которых значение ключа для записей из множества триллеров пусто.
— Как это пусто? Ведь у фильма не может быть пустой номер!
— Верно. Думай об этом не как о едином множестве фильмов, а как о парах фильмов из двух групп. Мы берём один фильм из первой группы (датские) и ищем во второй группе (триллеров) для него пару — фильм с таким же номером.
Если пара найдётся (значит, попался датский триллер) — считаем, что T.Key не пустой, иначе он как раз и будет IS NULL.
Диаграмма теперь выглядит так:
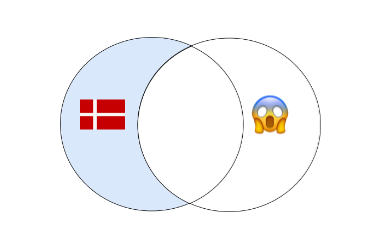
Если день не задался и смотреть что-то доброе и вечное настроения нет, можно установить фильтр для отбора только триллеров. И пусть даже среди них будут датские, но вот другие категории датских фильмов рассматривать не будем.
SELECT *
FROM D
RIGHT JOIN T ON D.Key=T.Key
Вот как это выглядит на диаграмме:
— Подожди, ну не настолько же всё плохо — давай хотя бы датские триллеры исключим. Мне кажется, я даже догадываюсь, как это сделать:
SELECT *
FROM D
RIGHT JOIN T ON D.Key=T.Key
WHERE D.Key IS NULL
— Совершенно верно! Наверняка и диаграмма для этого случая тебя не удивит:
RIGHT JOIN (правое внешнее соединение) — то же самое, что RIGHT OUTER JOIN.
В результат объединения попадают совпадающие по ключу записи обеих таблиц и все данные из правой таблицы, для которых не нашлось пары в левой.
— Что, если фильм нам подойдёт, когда он ИЛИ датский, ИЛИ триллер?
— Тогда и пригодился бы новый тип JOIN:
SELECT *
FROM D
FULL OUTER JOIN T ON D.Key=T.Key
И вот такая «цельная» у него диаграмма:
FULL JOIN (полное внешнее соединение) — то же самое, что FULL OUTER JOIN.
В результат объединения попадают совпадающие по ключу записи обеих таблиц и все строки из этих двух таблиц, для которых пар не нашлось. Порядок таблиц в запросе не важен.
— А если я хочу ИЛИ датский, ИЛИ триллер, но не одновременно эти два признака, так можно?
— Да, можно и так. Здесь снова пригодится проверка на NULL.
SELECT *
FROM D
FULL OUTER JOIN T ON D.Key=T.Key
WHERE D.Key IS NULL OR T.Key IS NULL
И общий для триллеров и датских фильмов сектор на диаграмме останется незакрашенным:
— Что ж, похоже, мы перебрали все возможные комбинации для связывания двух множеств.
— А вот и нет. Есть ещё один, особенный джойн.
У него и персональное название есть — декартово произведение. Для двух множеств в результате CROSS JOIN получаются все возможные пары, в каждой из которых будет представитель одного и второго множества.
SELECT *
FROM D
CROSS JOIN T
— Стоп! А где же тут соединение по ключу: ON D.Key=T.Key?
— В том-то и дело, что мы составляем пары, не обращая внимания на ключи, просто каждый элемент первой группы сопоставляем с каждым из второй.
— Звучит как-то сложно. Зачем вообще могут понадобиться такие пары? Для фильмов это бессмыслица какая-то получится.
— Пожалуй. Давай возьмём пример ближе к жизни. Предположим, есть магазин одежды, и мы хотим составить для него таблицу размеров одежды, но с учётом её цвета. То есть нужны все возможные комбинации размер + цвет. Это и достигается с помощью CROSS JOIN.
А схематично изобразить это можно вот так:
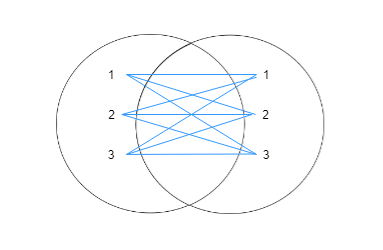
CROSS JOIN (перекрёстное объединение) возвращает декартово произведение: все возможные комбинации соединения записей из первой и второй таблиц.
— Ок, с джойнами теперь всё ясно. Остался только один вопрос.
— И какой же?
— Смотреть-то что будем? 😜

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать

Научитесь: SQL-разработчик
Узнать больше
👉 В этом разделе мы на примерах разбираем сложные айтишные термины. Если вы хотите почитать вдохновляющие и честные истории о карьере в IT, переходите в другие разделы.
JOIN — это команда в языке запросов SQL, необходимом для работы с базами данных. Объединяет данные из двух разных таблиц в базе. Цель использования команды — получить нужное подмножество данных.
Командой JOIN в SQL пользуются очень часто, она одна из наиболее важных. В реляционных базах данных информация распределена по таблицам, а большая часть работы с базами подразумевает поиск в них нужных сведений. Для этого используются разные команды, и JOIN — одна из них.
Применение команды можно сравнить с использованием фильтра по товарам в интернет-магазине: разработчик выбирает определенное подмножество с помощью настроенных запросов. Обычно JOIN используется в блоках SELECT, которые «выбирают» из базы таблицы и записи, отвечающие нужным критериям.
В основном SQL-запросы используют администраторы баз данных и бэкенд-разработчики — люди, работа которых подразумевает получение сведений из базы. Но понимание работы JOIN важно и представителям других профессий, так как базовые знания SQL необходимы в любом проекте, — например, сотрудникам технической поддержки, контент-менеджерам, SEO-специалистам и другим.
Читайте также: Как стать backend-разработчиком с нуля?
- Для «умного» поиска по таблицам в рамках одной базы данных. Использование разных режимов работы оператора помогает отфильтровать сведения по определенным критериям.
- Для быстрого отсечения информации, которая не нужна в рамках конкретного запроса.
- Для соединения двух таблиц в одну, например, чтобы отправить полученную информацию единым блоком.
Изначально JOIN — бинарный оператор, то есть он работает с двумя переданными объектами. На практике современные реализации могут воспринимать и больше двух таблиц, просто операция в таком случае выполняется несколько раз.
Оператору передаются таблицы, которые нужно объединить, и критерий для объединения — логическое выражение, которое называется ключом. В процессе работы JOIN таблицы проверяются на соответствие этому критерию. Например, значение поля ID в одной таблице должно соответствовать полю ID в другом. Оператор проверит строки обеих таблиц и выберет пары строк, где ID совпадают.
Найденные результаты объединяются в одну таблицу. Две соответствующие друг другу разные строки преобразуются в одну — это важнейшее условие работы JOIN. Строки чаще всего из разных таблиц, но это не обязательно. Главная особенность JOIN — объединение двух объектов в один.
Варианты работы команды JOIN
Выше мы написали, что у JOIN есть разные режимы работы. Они дают разные результаты; различаются и ситуации, в которых они могут пригодиться. Чаще всего выделяют четыре режима SQL JOIN: Inner, Outer, Self и Cross.
Особенности работы легче всего объяснить с помощью диаграмм Венна, которые также называют кругами Эйлера. На них множества представляются как круги, а объекты, которые относятся к обоим множествам, — как пересечения этих кругов.
Это самый простой и часто используемый вариант команды — внутреннее объединение. Если режим работы операции не указан вручную, то SQL автоматически воспримет любой JOIN как внутренний.
Оператору передаются две таблицы, и он возвращает их внутреннее пересечение по какому-либо критерию. Результатом будут записи, которые соответствуют обеим таблицам, — их перед отправкой объединят.

Например, если в одной таблице будут перечислены черные животные, а в другой — собаки, то Inner Join вернет одну таблицу с перечислением черных собак. Столбцы будут «склеены» друг с другом, несмотря на то что в базе данные хранятся в разных таблицах. Это похоже на бинарное «и» из алгебры логики.
Внутреннее соединение используется чаще всего.
Второй распространенный вариант — внешнее соединение. Если внутреннее объединение имеет сходство с бинарным «и», то внешнее — несколько вариаций бинарного «или». Такой JOIN более гибкий, он возвращает не только строгое пересечение между двумя таблицами, но и отдельные элементы, которые принадлежат только одному из множеств. Какому — зависит от типа.
Left Join. Возвращает пересечение множеств и все элементы из левой таблицы. Например, человек хочет посмотреть кино, но на русский фильм согласен, только если это боевик. Фильтр вернет ему все фильмы из множества «боевики», фильмы из подмножества «русские боевики», но других фильмов из множества «русские» там не будет.

Right Join. Работает по тому же принципу, но вместо левой таблицы — правая. То есть человек получит в результатах боевики, только если они русские.

Join Full. Возвращает обе таблицы, объединенные в одну. Например, человек хочет увидеть список из всех боевиков и всех русских фильмов, без исключений.

Это не отдельный метод, мы описали его отдельно от остальных только для наглядности. Это тот же самый Outer Join, но с дополнительным параметром, который убирает из результатов поиска пересечение категорий. Это противоположность Inner Join.
Left Join с NULL. Возвращает данные из левой таблицы, но без пересечений с правой. Человеку покажутся все боевики, но русского кино и в частности русских боевиков среди них не будет.

Right Join с NULL. Соответственно, работает так же, но по отношению к «правой», второй таблице.

Join Full с NULL. Работает как исключающее «или». Он тоже возвращает результат из обеих таблиц, кроме пересечений. Покажутся все русские фильмы и все боевики, а вот кино из подмножества «русские боевики» в результате не будет.

Как и с любым JOIN, результаты перед отправкой объединяются в одну таблицу.
Его еще называют перекрестным. Это своеобразный вариант соединения, который нужен не так часто, но важен для понимания. Он возвращает декартово произведение — собираются все возможные пары из обеих таблиц. В отличие от остальных режимов, Cross Join не требует указания дополнительной информации.
Стандартное обращение к двум таблицам тоже покажет декартово произведение. Cross Join отличается от простого вызова двух таблиц тем, что они объединяются в одну.
В виде диаграммы Венна это соединение представить невозможно. Скорее можно объяснить его на примере математики. Например, в одном наборе десять чисел, в другом — пять. Cross Join между этими наборами — это все возможные комбинации сумм двух чисел из разных наборов. Результат будет выглядеть как таблица 11×5, где в каждой ячейке лежит своя сумма.

В разработке Cross Join может использоваться при создании тех же фильтров в интернет-магазине. Например, человек ищет обувь по характеристикам «тип» и «размер» — должны быть выведены все возможные комбинации типа с размером.
Это «самосоединение», объединение внутри одной таблицы. Оно используется тогда, когда у разных полей одной таблицы могут быть одинаковые значения. Например, один и тот же участник музыкальной группы может быть и вокалистом, и, например, клавишником. Если из базы музыкальных групп понадобится извлечь те, где вокалист и клавишник — одно лицо, потребуется Self Join.
Эта вариация может быть и внутренней, и внешней. Ее отличие в том, что таблица при таком режиме присоединяется сама к себе. Без практики это может быть непривычно, но в процессе использования логику работы легко понять.
Чтобы Self Join работал правильно, могут потребоваться псевдонимы таблиц: они помогают называть одну и ту же таблицу разными именами. В результате оператор «воспринимает» переданные сущности как разные.
Для начала работы с SQL-запросами требуется СУБД — система для управления базами данных. Начинающие обычно выбирают MySQL: она простая в освоении, мало весит и распространяется бесплатно.
С помощью СУБД можно создать базу и управлять ей, модифицировать данные и пр. Можно работать с разными операциями, включая JOIN. Удаленный сервер не обязателен: есть программные решения, позволяющие «поднять» серверную часть на том же устройстве. На «сервере» находится хранилище данных, а запросы поступают от «клиента».
Многотабличные запросы
В предыдущих статьях описывалась работа только с одной таблицей базы данных.
В реальности же очень часто приходится делать выборку из нескольких таблиц, каким-то образом объединяя их.
В данной статье вы узнаете основные способы соединения таблиц.
Например, если мы хотим получить информацию о тратах на покупки, мы можем ее получить следующим образом:
SELECT family_member, amount * unit_price AS price FROM PaymentsВ поле family_member полученной выборки отображаются идентификаторы записей из таблицы FamilyMembers, но для нас они мало что значат.
Вместо этих идентификаторов было бы гораздо нагляднее выводить имена тех, кто покупал (поле member_name из таблицы FamilyMember).
Ровно для этого и существует объединение таблиц и оператор JOIN.
Общая структура многотабличного запроса
SELECT поля_таблиц FROM таблица_1 [INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_2 ON условие_соединения [INNER] | [[LEFT | RIGHT | FULL][OUTER]] JOIN таблица_n ON условие_соединения]Как можно увидеть по структуре, соединение бывает:

- внутренним INNER (по-умолчанию)
- внешним OUTER, при этом внешнее соединение делится на левое LEFT, правое RIGHT и полное FULL
С более подробными деталями, чем отличается внутреннее соединение от внешнего и как они работают, мы познакомимся в следующих статьях.
Пока нам достаточно лишь знать, что для вышеописанного примера с запросом на покупки нам понадобится именно запрос с внутренним соединением,
который будет выглядять следующим образом:
SELECT family_member, member_name, amount * unit_price AS price FROM Payments INNER JOIN FamilyMembers ON Payments.family_member = FamilyMembers.member_idВ данном запросе мы сопоставляем записи из таблицы Payments и записи из таблицы FamilyMembers.
Чтобы сопоставление работало, мы указываем как именно
записи из двух разных таблиц должны находить друг друга. Это условие указывается после ON:ON Payments.family_member = FamilyMembers.member_idВ нашем случае поле family_member указывает на идентификатор в таблице FamilyMembers и таким образом помогает однозначному сопоставлению.
В большинстве случаев условием соединения является равенство столбцов таблиц (таблица_1.поле = таблица_2.поле),
однако точно так же можно использовать и другие операторы сравнения.
Присоединение таблиц в запросах — это базовый инструмент в работе с базами данных. Давайте рассмотрим какие присоединения (JOIN) бывают, и что от этого меняется в результатах запроса.
Для начала создадим две таблицы, над которыми будем проводить опыты. Это таблица с именами сотрудников и словарь с перечнем должностей.
Persons (Сотрудники)
Столбец position_ref (от «position reference») это ссылка на следующую таблицу, где перечислены должности сотрудников.
Positions (должности)
Т.е. чтобы узнать должность сотрудника в таблице Persons, нужно присоединить соответствующие данные из таблицы Positions, связывая их по значениям position_ref и id_pos.
Далее мы рассмотрим все варианты присоединений. Данные специально подобраны так, чтобы продемонстрировать отличия в результатах разных запросов.
INNER JOIN
Внутреннее присоединение. Равносильно просто JOIN или CROSS JOIN (верно для MYSQL, в стандарте SQL INNER JOIN не эквивалентен синтаксически CROSS JOIN, т.к. используется с выражением ON).
|
SELECT id_person, name, id_pos, title FROM `persons` INNER JOIN `positions` ON id_pos = position_ref |
Такое присоединение покажет нам данные из таблиц, только если условие связывания соблюдается — т.е. для сотрудника указан существующий в словаре идентификатор должности.
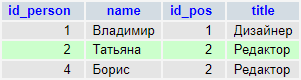
Если поменять порядок соединения таблиц — получим тот же результат.
Условно представим себе эти таблицы, как пересекающиеся множества, где пересечение — это наличие связи между таблицами. Получим картинку:
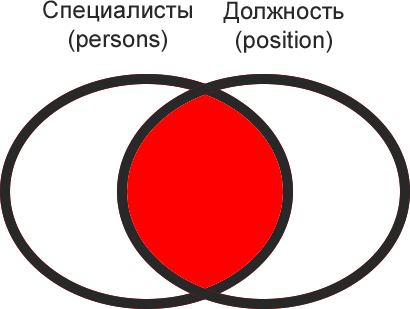
Далее проследим как получить разные части (подмножества) данного множества.
OUTER JOIN
Внешнее присоединение. Различают LEFT OUTER JOIN и RIGHT OUTER JOIN, и обычно опускают слово «OUTER».
Внешнее присоединение включает в себя результаты запроса INNER и добавляются «неиспользованные» строки из одной из таблиц. Какую таблицу использовать в качестве «добавки» — указывает токен LEFT или RIGHT.
LEFT JOIN
Внешнее присоединение «слева».
|
SELECT id_person, name, id_pos, title FROM `persons` LEFT OUTER JOIN `positions` ON id_pos = position_ref |
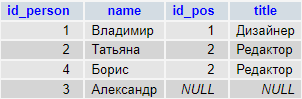
«Левая» таблица persons, содержит строку id_person#3 — «Александр», где указан идентификатор должности, отсутствующей в словаре. Мы увидим все записи из «левой» таблицы, тогда как правая будет присоединена по возможности.
На картинке это можно показать вот так:

RIGHT JOIN
Присоединение «справа».
|
SELECT id_person, name, id_pos, title FROM persons RIGHT OUTER JOIN positions ON id_pos = position_ref |
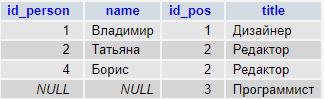
Тут данные из «левой» таблицы присоединяются к «правой».
Словарь должностей (правая таблица) содержит неиспользуемую запись с id_pos#3 — «программист». Теперь она попала в результат запроса.
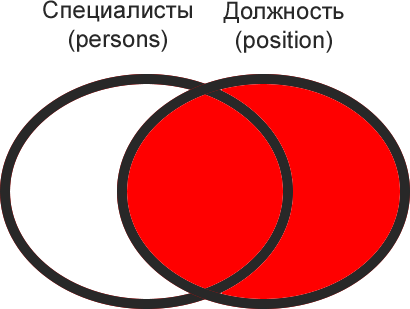
Полное множество
MySQL не знает соединения FULL OUTER JOIN. Что если нужно получить полное множество?
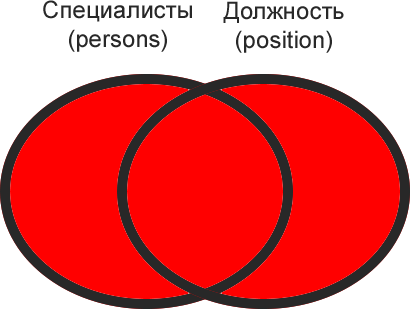
Первый способ — объединение запросов LEFT и RIGHT.
|
(SELECT id_person, name, id_pos, title FROM persons LEFT OUTER JOIN positions ON id_pos = position_ref) UNION (SELECT id_person, name, id_pos, title FROM persons RIGHT OUTER JOIN positions ON id_pos = position_ref) |
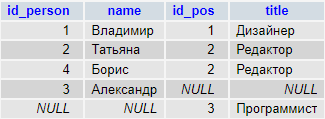
При таком вызове UNION, после слияния результатов, SQL отсечет дубли (как DISTINCT). Для отсечения дублей SQL прибегает к сортировке. Это может сказываться на быстродействии.
Второй способ — объединение LEFT и RIGHT, но в одном из запросов мы исключаем часть, соответствующую INNER. А объединение задаём как UNION ALL, что позволяет движку SQL обойтись без сортировки.
|
(SELECT id_person, name, id_pos, title FROM persons LEFT OUTER JOIN positions ON id_pos = position_ref) UNION ALL (SELECT id_person, name, id_pos, title FROM persons RIGHT OUTER JOIN positions ON id_pos = position_ref WHERE id_person is NULL) |
Этот пример показывает нам как исключить пересечение и получить только левую или правую часть множества.
Левое подмножество
LEFT JOIN ограничиваем проверкой, что данных из второй таблицы нет.
|
SELECT id_person, name, id_pos, title FROM persons LEFT OUTER JOIN positions ON id_pos = position_ref WHERE id_pos is NULL |

В нашем примере — это специалисты, у которых не задана должность или нет должности с указанным ключом.
![]()
Правое подмножество
Аналогично выделяем правую часть.
|
SELECT id_person, name, id_pos, title FROM persons RIGHT OUTER JOIN positions ON id_pos = position_ref WHERE id_person is NULL |

![]()
В нашем случае получим должности, которые никому не назначены.
Всё кроме пересечения
Остался один вариант, тот когда исключено пересечение множеств. Его можно сложить из двух предыдущих запросов через UNION ALL (т.к. подмножества не пересекаются).
|
(SELECT id_person, name, id_pos, title FROM persons LEFT OUTER JOIN positions ON id_pos = position_ref WHERE id_pos is NULL) UNION ALL (SELECT id_person, name, id_pos, title FROM persons RIGHT OUTER JOIN positions ON id_pos = position_ref WHERE id_person is NULL) |
Это запрос соберет все случаи, когда по какой то причине данные из таблиц не связаны.
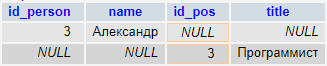
А графически такое объединение выглядит следующим образом:

Данная запись опубликована в 19.09.2017 20:19 и размещена в mySQL.
Вы можете перейти в конец страницы и оставить ваш комментарий.