На сегодняшний день в японском языке существуют 214 ключей из которых и состоит иероглиф.
Некоторые ключи могут как записываться как самостоятельные иероглифы (水 — «вода» в качестве иероглифа), так и входить в состав других иероглифов (洗 — «вода» слева). Например, так 人 «человек» записывается как самостоятельный иероглиф. Так человек записывается в качестве ключа слева 休, а так 今 — в качестве ключа сверху.
В нашей литературе для ключей созданы номера в порядке возрастания черт, в Японии же такой нумерации нет (точней нумерация есть, но японцы ее не используют так как мы).

Пример из отечественного учебника по японскому языку

Пример из отечественного учебника по японскому языку
Сами японцы указывают название ключа и место, в котором он расположен, например, Сандзуй-хэн (氵), или как его обычно называют просто Сандзуй. Это ключ «3 Воды», который расположен слева на что указывает название Хэн.
В данный момент выделение ключа не является чем-то обязательным, как это было раньше, т.к. сейчас мало кто пользуется бумажными иероглифическими словарями. Поэтому про правила выделения ключа я говорить не буду и Вам не советую заморачиваться на этот счет.
P.S. Выражаю исключительно свое мнение на этот счет. Не могу сказать, что выделение ключа является чем-то без чего невозможно жить.
В свое время меня заставляли учить вплоть до номера ключа (и на удивление, я запомнил абсолютно все номера ключей), чтобы было «удобнее пользоваться» словарями, но на практике я это так и не дошел до этого, т.к. уже много-много лет назад были программы удобнее, чем простые бумажные словари.
Чуть позже это сможет пригодится в случае с запоминанием некоторых онных чтений, но опять же, на начальном этапе рановато.
Иероглиф состоит из радикалов, неких «кирпичиков», выучив которые запоминания иероглифа не будет таким сложным, как это кажется на первый взгляд.
Это легко достигается мнемоникой. Если не понятно, что это, посмотрите видео с мнемоникой ниже, где мы подробно разбираем данный метод.
Как мы уже знаем из предыдущего видео, иероглифы были позаимствованы японцами у китайцев, поэтому у иероглифов в японском языке обычно как минимум два чтения: японское кунное и китайское онное.
Как только вы выучите порядок штрихов радикалов и привыкните к принципу, вы обнаружите, что несложно угадать правильный порядок черт для большинства кандзи.
Чаще всего штрихи наносятся из левого верхнего угла в правый нижний. Это означает, что горизонтальные черты обычно пишут слева направо, а вертикальные — сверху вниз. В любом случае когда вы сомневаетесь в порядке штрихов, сверьтесь со словарем.
Основные правила написания иероглифов.
Порядок написания.
Есть несколько основных правил для правильного порядка написания иероглифов (кандзи):
1. Иероглифы пишутся сверху вниз, от верхних элементов к нижним; иероглифы пишутся слева направо, от левых элементов к правым;

2. Горизонтальные черты пишутся слева направо, вертикальные – сверху вниз.
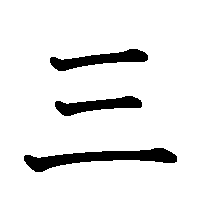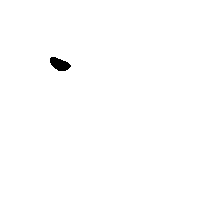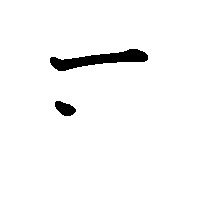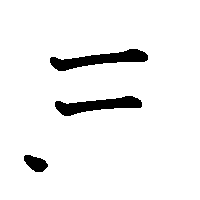
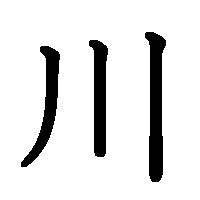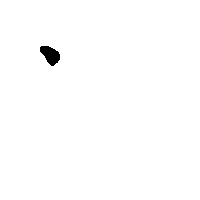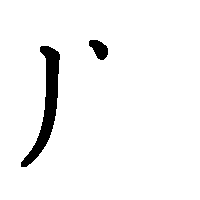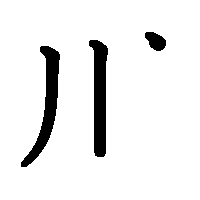
3. Сначала пишутся горизонтальные черты, потом вертикальные.

4. Ломанные черты пишем одной чертой.

5. Сначала пишется ① центральная черта, а только потом ② левая и ③ правая.

6. Сначала пишется внешняя сторона «коробки» (囗 кунигамаэ — ключ 31, не путать с ключом 口 «рот» ключ 30), потом «внутренность», а последняя черта должна дописывать «коробку» снизу.

7. Если одна черта пересекает весь иероглиф, то ее пишем последней.

8. Различные «крышечки» (тарэ — расположение элемента, который охватывает иероглиф сверху и слева) всегда пишутся первыми.

9. Элементы типо дороги 辶 (различные «Нё:» にょう — Ключи, которые находятся в нижне-левой части кандзи) пишутся последними.
И не забывайте, что и тут есть исключения, поэтому всегда сверяйте данные.
Например, исключение из правила №3. Вот в таком порядке пишутся иероглифы «правый» и «левый».

Иероглиф «левый»

Иероглиф «Правый»
Из правила №5 мы увидели, что центр пишется первым, но и тут есть исключения, например, иероглиф «Огонь».

Из правила №9 тоже есть исключения, например, иероглиф «просыпаться».

Также, не стоит забывать, что в иероглифах и в азбуках есть печатное письмо, а есть рукописное письмо. Это аналог печатных и письменных букв в русском языке. Там может встретиться достаточно отличий, поэтому проводя аналогию с русским, старайтесь придерживаться именно письменных знаков, а не печатных.

Обязательно соблюдайте правильный порядок написания черт!
Мы не будем сейчас спорить насколько это правильно, но это нужно хотя бы потому что в 90% случаев соблюдая правильный порядок черт писать будет удобнее.
В самом начале может быть немного затруднительно, но зато потом, после написания не одной сотни кандзи, Вы поймете, что затратив немного больше времени в начале Вы будете на автоматизме быстро и правильно писать кандзи, т.к. рука уже будет набита и в большинстве случаев таким образом можно быстрее запоминать как пишутся изученные иероглифы.
Также, не забудьте про баланс. Для этого распечатайте прописи. При написании Вы не должны наезжать и тем более заезжать за края.

Таким образом Вы выработаете определенный навык писать иероглифы сбалансированно.
На сегодня это все. Если Вам понравилось — рассказывайте друзьям, подписывайтесь на наш YouTube канал, а также, на наши группы в социальных сетях, с Вами был Игорь Коротков. До встречи!
This article is about the Chinese-derived characters used in Japanese writing. For other uses, see Kanji (disambiguation).
| Kanji | |
|---|---|

Kanji written in kanji with furigana |
|
| Script type |
Logographic |
|
Time period |
5th century AD – present |
| Direction | vertical right-to-left, left-to-right |
| Languages | Old Japanese, Kanbun, Japanese, Ryukyuan languages |
| Related scripts | |
|
Parent systems |
Oracle bone script
|
|
Sister systems |
Hanja, Zhuyin, traditional Chinese, simplified Chinese, Chữ Hán, Chữ Nôm, Khitan script, Jurchen script, Tangut script, Yi script |
| ISO 15924 | |
| ISO 15924 | Hani (500), Han (Hanzi, Kanji, Hanja) |
| Unicode | |
|
Unicode alias |
Han |
| This article contains phonetic transcriptions in the International Phonetic Alphabet (IPA). For an introductory guide on IPA symbols, see Help:IPA. For the distinction between [ ], / / and ⟨ ⟩, see IPA § Brackets and transcription delimiters. |
Kanji (漢字, pronounced [kaɲdʑi] (![]() listen)) are the logographic Chinese characters taken from the Chinese script, and used in the writing of Japanese.[1] They were made a major part of the Japanese writing system during the time of Old Japanese and are still used, along with the subsequently-derived syllabic scripts of hiragana and katakana.[2][3] The characters have Japanese pronunciations; most have two, with one based on the Chinese sound. A few characters were invented in Japan by constructing character components derived from other Chinese characters. After World War II, Japan made its own efforts to simplify the characters, now known as shinjitai, by a process similar to China’s simplification efforts, with the intention to increase literacy among the common folk. Since the 1920s, the Japanese government has published character lists periodically to help direct the education of its citizenry through the myriad Chinese characters that exist. There are nearly 3,000 kanji used in Japanese names and in common communication.
listen)) are the logographic Chinese characters taken from the Chinese script, and used in the writing of Japanese.[1] They were made a major part of the Japanese writing system during the time of Old Japanese and are still used, along with the subsequently-derived syllabic scripts of hiragana and katakana.[2][3] The characters have Japanese pronunciations; most have two, with one based on the Chinese sound. A few characters were invented in Japan by constructing character components derived from other Chinese characters. After World War II, Japan made its own efforts to simplify the characters, now known as shinjitai, by a process similar to China’s simplification efforts, with the intention to increase literacy among the common folk. Since the 1920s, the Japanese government has published character lists periodically to help direct the education of its citizenry through the myriad Chinese characters that exist. There are nearly 3,000 kanji used in Japanese names and in common communication.
The term kanji in Japanese literally means «Han characters».[4] It is written in Japanese by using the same characters as in traditional Chinese, and both refer to the character writing system known in Chinese as hanzi (traditional Chinese: 漢字; simplified Chinese: 汉字; pinyin: hànzì; lit. ‘Han characters’).[5] The significant use of Chinese characters in Japan first began to take hold around the 5th century AD and has since had a profound influence in shaping Japanese culture, language, literature, history, and records.[6] Inkstone artifacts at archaeological sites dating back to the earlier Yayoi period were also found to contain Chinese characters.[7]
Although some characters, as used in Japanese and Chinese, have similar meanings and pronunciations, others have meanings or pronunciations that are unique to one language or the other. For example, 誠 means ‘honest’ in both languages but is pronounced makoto or sei in Japanese, and chéng in Standard Mandarin Chinese. Individual kanji characters invented in Japan, or multi-kanji words coined in Japanese, have also influenced and been borrowed into Chinese, Korean, and Vietnamese in recent times. For example, the word for telephone, 電話 denwa in Japanese, is calqued as diànhuà in Mandarin Chinese, điện thoại in Vietnamese and 전화 jeonhwa in Korean.[8]
History[edit]

Nihon Shoki (720 AD), considered by historians and archaeologists as the most complete extant historical record of ancient Japan, was written entirely in kanji.
Chinese characters first came to Japan on official seals, letters, swords, coins, mirrors, and other decorative items imported from China.[9] The earliest known instance of such an import was the King of Na gold seal given by Emperor Guangwu of Han to a Wa emissary in 57 AD.[10] Chinese coins as well as inkstones from the first century AD have also been found in Yayoi period archaeological sites.[6][7] However, the Japanese people of that era probably had little to no comprehension of the script, and they would remain relatively illiterate until the fifth century AD, when writing in Japan became more widespread.[6] According to the Nihon Shoki and Kojiki, a semi-legendary scholar called Wani was dispatched to Japan by the Kingdom of Baekje during the reign of Emperor Ōjin in the early fifth century, bringing with him knowledge of Confucianism and Chinese characters.[11]
The earliest Japanese documents were probably written by bilingual Chinese or Korean officials employed at the Yamato court.[6] For example, the diplomatic correspondence from King Bu of Wa to Emperor Shun of Liu Song in 478 AD has been praised for its skillful use of allusion. Later, groups of people called fuhito were organized under the monarch to read and write Classical Chinese. During the reign of Empress Suiko (593–628), the Yamato court began sending full-scale diplomatic missions to China, which resulted in a large increase in Chinese literacy at the Japanese court.[11]
In ancient times, paper was so rare that people wrote kanji onto thin, rectangular strips of wood, called mokkan (木簡). These wooden boards were used for communication between government offices, tags for goods transported between various countries, and the practice of writing. The oldest written kanji in Japan discovered so far were written in ink on wood as a wooden strip dated to the 7th century, a record of trading for cloth and salt.
The Japanese language had no written form at the time Chinese characters were introduced, and texts were written and read only in Chinese. Later, during the Heian period (794–1185), a system known as kanbun emerged, which involved using Chinese text with diacritical marks to allow Japanese speakers to read Chinese sentences and restructure them into Japanese on the fly, by changing word order and adding particles and verb endings, in accordance with the rules of Japanese grammar. This was essentially a kind of codified sight translation.
Chinese characters also came to be used to write texts in the vernacular Japanese language, resulting in the modern kana syllabaries. Around 650 AD, a writing system called man’yōgana (used in the ancient poetry anthology Man’yōshū) evolved that used a number of Chinese characters for their sound, rather than for their meaning. Man’yōgana written in cursive style evolved into hiragana (literally «fluttering kana» in reference to the motion of the brush during cursive writing), or onna-de, that is, «ladies’ hand»,[12] a writing system that was accessible to women (who were denied higher education). Major works of Heian-era literature by women were written in hiragana. Katakana (literally «partial kana«, in reference to the practice of using a part of a kanji character) emerged via a parallel path: monastery students simplified man’yōgana to a single constituent element. Thus the two other writing systems, hiragana and katakana, referred to collectively as kana, are descended from kanji. In contrast with kana (仮名, literally «borrowed name», in reference to the character being «borrowed» as a label for its sound), kanji are also called mana (真名, literally «true name», in reference to the character being used as a label for its meaning).
In modern Japanese, kanji are used to write certain words or parts of words (usually content words such as nouns, adjective stems, and verb stems), while hiragana are used to write inflected verb and adjective endings, phonetic complements to disambiguate readings (okurigana), particles, and miscellaneous words which have no kanji or whose kanji are considered obscure or too difficult to read or remember. Katakana are mostly used for representing onomatopoeia, non-Japanese loanwords (except those borrowed from ancient Chinese), the names of plants and animals (with exceptions), and for emphasis on certain words.
Orthographic reform and lists of kanji[edit]

Since ancient times, there has been a strong opinion in Japan that kanji is the orthodox form of writing, but there were also people who argued against it.[13] Kamo no Mabuchi, a scholar of the Edo period, criticized the large number of characters in kanji. He also appreciated the small number of characters in kana characters and argued for the limitation of kanji.
After the Meiji Restoration and as Japan entered an era of active exchange with foreign countries, the need for script reform in Japan began to be called for. Some scholars argued for the abolition of kanji and the writing of Japanese using only kana or Latin characters. However, these views were not so widespread.
However, the need to limit the number of kanji characters was understood, and in May 1923, the Japanese government announced 1,962 kanji characters for regular use. In 1940, the Japanese Army decided on the «Table of Restricted Kanji for Weapons Names» (兵器名称用制限漢字表, heiki meishō yō seigen kanji hyō) which limited the number of kanji that could be used for weapons names to 1,235. In 1942, the National Language Council announced the «Standard Kanji Table» (標準漢字表, hyōjun kanji-hyō) with a total of 2,528 characters, showing the standard for kanji used by ministries and agencies and in general society.[14]
In 1946, after World War II and under the Allied Occupation of Japan, the Japanese government, guided by the Supreme Commander of the Allied Powers, instituted a series of orthographic reforms, to help children learn and to simplify kanji use in literature and periodicals.
The number of characters in circulation was reduced, and formal lists of characters to be learned during each grade of school were established.
Some characters were given simplified glyphs, called shinjitai (新字体). Many variant forms of characters and obscure alternatives for common characters were officially discouraged.
These are simply guidelines, so many characters outside these standards are still widely known and commonly used; these are known as hyōgaiji (表外字).
Kyōiku kanji[edit]
The kyōiku kanji (教育漢字, lit. «education kanji») are the 1,026 first kanji characters that Japanese children learn in elementary school, from first grade to sixth grade. The grade-level breakdown is known as the gakunen-betsu kanji haitōhyō (学年別漢字配当表), or the gakushū kanji (学習漢字). This list of kanji is maintained by the Japanese Ministry of Education and prescribes which kanji characters and which kanji readings students should learn for each grade.
Jōyō kanji[edit]
The jōyō kanji (常用漢字, regular-use kanji) are 2,136 characters consisting of all the Kyōiku kanji, plus 1,110 additional kanji taught in junior high and high school.[15] In publishing, characters outside this category are often given furigana. The jōyō kanji were introduced in 1981, replacing an older list of 1,850 characters known as the tōyō kanji (当用漢字, general-use kanji), introduced in 1946. Originally numbering 1,945 characters, the jōyō kanji list was expanded to 2,136 in 2010. Some of the new characters were previously Jinmeiyō kanji; some are used to write prefecture names: 阪, 熊, 奈, 岡, 鹿, 梨, 阜, 埼, 茨, 栃 and 媛.
Jinmeiyō kanji[edit]
As of September 25, 2017, the jinmeiyō kanji (人名用漢字, kanji for use in personal names) consists of 863 characters. Kanji on this list are mostly used in people’s names and some are traditional variants of jōyō kanji. There were only 92 kanji in the original list published in 1952, but new additions have been made frequently. Sometimes the term jinmeiyō kanji refers to all 2,999 kanji from both the jōyō and jinmeiyō lists combined.
Hyōgai kanji[edit]
Hyōgai kanji (表外漢字, «unlisted characters») are any kanji not contained in the jōyō kanji and jinmeiyō kanji lists. These are generally written using traditional characters, but extended shinjitai forms exist.
Japanese Industrial Standards for kanji[edit]
The Japanese Industrial Standards for kanji and kana define character code-points for each kanji and kana, as well as other forms of writing such as the Latin alphabet, Cyrillic script, Greek alphabet, Arabic numerals, etc. for use in information processing. They have had numerous revisions. The current standards are:
- JIS X 0208,[16] the most recent version of the main standard. It has 6,355 kanji.
- JIS X 0212,[17] a supplementary standard containing a further 5,801 kanji. This standard is rarely used, mainly because the common Shift JIS encoding system could not use it. This standard is effectively obsolete.
- JIS X 0213,[18] a further revision which extended the JIS X 0208 set with 3,695 additional kanji, of which 2,743 (all but 952) were in JIS X 0212. The standard is in part designed to be compatible with Shift JIS encoding.
- JIS X 0221:1995, the Japanese version of the ISO 10646/Unicode standard.
Gaiji[edit]
Gaiji (外字, literally «external characters») are kanji that are not represented in existing Japanese encoding systems. These include variant forms of common kanji that need to be represented alongside the more conventional glyph in reference works and can include non-kanji symbols as well.
Gaiji can be either user-defined characters, system-specific characters or third-party add-on products.[19] Both are a problem for information interchange, as the code point used to represent an external character will not be consistent from one computer or operating system to another.
Gaiji were nominally prohibited in JIS X 0208-1997 where the available number of code-points was reduced to only 940.[20] JIS X 0213-2000 used the entire range of code-points previously allocated to gaiji, making them completely unusable. Most desktop and mobile systems have moved to Unicode negating the need for gaiji for most users. Nevertheless, they persist today in Japan’s three major mobile phone information portals, where they are used for emoji (pictorial characters).
Unicode allows for optional encoding of gaiji in private use areas, while Adobe’s SING (Smart INdependent Glyphlets)[21][22] technology allows the creation of customized gaiji.
The Text Encoding Initiative uses a ⟨g⟩ element to encode any non-standard character or glyph, including gaiji.[23] (The g stands for gaiji.)[24]
Total number of kanji[edit]
There is no definitive count of kanji characters, just as there is none of Chinese characters generally. The Dai Kan-Wa Jiten, which is considered to be comprehensive in Japan, contains about 50,000 characters. The Zhonghua Zihai, published in 1994 in China, contains about 85,000 characters, but the majority of them are not in common use in any country, and many are obscure variants or archaic forms.[25][26][27]
A list of 2,136 jōyō kanji (常用漢字) is regarded as necessary for functional literacy in Japanese. Approximately a thousand more characters are commonly used and readily understood by the majority in Japan and a few thousand more find occasional use, particularly in specialized fields of study but those may be obscure to most out of context. A total of 13,108 characters can be encoded in various Japanese Industrial Standards for kanji.
Readings[edit]
| Borrowing typology of Han characters | ||
|---|---|---|
| Meaning | Pronunciation | |
| a) semantic on | L1 | L1 |
| b) semantic kun | L1 | L2 |
| c) phonetic on | — | L1 |
| d) phonetic kun | — | L2 |
| *With L1 representing the language borrowed from (Chinese) and L2 representing the borrowing language (Japanese).[28] |
Because of the way they have been adopted into Japanese, a single kanji may be used to write one or more different words—or, in some cases, morphemes—and thus the same character may be pronounced in different ways. From the reader’s point of view, kanji are said to have one or more different «readings». Although more than one reading may become activated in the brain,[29] deciding which reading is appropriate depends on recognizing which word it represents, which can usually be determined from context, intended meaning, whether the character occurs as part of a compound word or an independent word, and sometimes location within the sentence. For example, 今日 is usually read kyō, meaning «today», but in formal writing is instead read konnichi, meaning «nowadays»; this is understood from context. Nevertheless, some cases are ambiguous and require a furigana gloss, which are used to simplify difficult readings or to specify a non-standard reading.
Kanji readings are categorized as either on’yomi (音読み, literally «sound reading», from Chinese) or kun’yomi (訓読み, literally «meaning reading», native Japanese), and most characters have at least two readings, at least one of each.
However, some characters have only a single reading, such as kiku (菊, «chrysanthemum», an on-reading) or iwashi (鰯, «sardine», a kun-reading); kun-only are common for Japanese-coined kanji (kokuji).
Some common kanji have ten or more possible readings; the most complex common example is 生, which is read as sei, shō, nama, ki, o-u, i-kiru, i-kasu, i-keru, u-mu, u-mareru, ha-eru, and ha-yasu, totaling eight basic readings (the first two are on, while the rest are kun), or 12 if related verbs are counted as distinct; see okurigana § 生 for details.
Most often, a character will be used for both sound and meaning, and it is simply a matter of choosing the correct reading based on which word it represents.
On’yomi (Sino-Japanese reading) [edit]
The on’yomi (音読み, [oɰ̃jomi], lit. «sound(-based) reading»), the Sino-Japanese reading, is the modern descendant of the Japanese approximation of the base Chinese pronunciation of the character at the time it was introduced. It was often previously referred to as translation reading, as it was recreated readings of the Chinese pronunciation but was not the Chinese pronunciation or reading itself, similar to the English pronunciation of Latin loanwords. Old Japanese scripts often stated that on’yomi readings were also created by the Japanese during their arrival and re-borrowed by the Chinese as their own. There also exist kanji created by the Japanese and given an on’yomi reading despite not being a Chinese-derived or a Chinese-originating character. Some kanji were introduced from different parts of China at different times, and so have multiple on’yomi, and often multiple meanings. Kanji invented in Japan (kokuji) would not normally be expected to have on’yomi, but there are exceptions, such as the character 働 «to work», which has the kun’yomi «hatara(ku)» and the on’yomi «dō«, and 腺 «gland», which has only the on’yomi «sen«—in both cases these come from the on’yomi of the phonetic component, respectively 動 «dō» and 泉 «sen«.
Generally, on’yomi are classified into four types according to their region and time of origin:
- Go-on (呉音, «Wu sound») readings derive from the pronunciation used in the Northern and Southern dynasties of China during the 5th and 6th centuries, primarily from the speech of the capital Jiankang (today’s Nanjing). They are related to Wu Chinese and the Shanghainese language.
- Kan-on (漢音, «Han sound») readings come from the pronunciation utilized during the Tang dynasty of China in the 7th to 9th centuries, primarily from the standard speech of the capital, Chang’an (modern Xi’an). Here, Kan refers to Han Chinese people or China proper.
- Tō-on (唐音, «Tang sound») readings are based on the pronunciations of later dynasties of China, such as the Song and Ming. They cover all readings adopted from the Heian era to the Edo period. This is also known as Tōsō-on (唐宋音, Tang and Song sound).
- Kan’yō-on (慣用音, «customary sound») readings, which are mistaken or changed readings of the kanji that have become accepted into the Japanese language. In some cases, they are the actual readings that accompanied the character’s introduction to Japan but do not match how the character «should» (is prescribed to) be read according to the rules of character construction and pronunciation.
| Kanji | Meaning | Go-on | Kan-on | Tō-on | Kan’yō-on |
|---|---|---|---|---|---|
| 明 | bright | myō | mei | (min) | — |
| 行 | go | gyō gō |
kō kō |
(an) | — |
| 極 | extreme | goku | kyoku | — | — |
| 珠 | pearl | shu | shu | ju | (zu) |
| 度 | degree | do | (to) | — | — |
| 輸 | transport | (shu) | (shu) | — | yu |
| 雄 | masculine | — | — | — | yū |
| 熊 | bear | — | — | — | yū |
| 子 | child | shi | shi | su | — |
| 清 | clear | shō | sei | (shin) | — |
| 京 | capital | kyō | kei | (kin) | — |
| 兵 | soldier | hyō | hei | — | — |
| 強 | strong | gō | kyō | — | — |
The most common form of readings is the kan-on one, and use of a non-kan-on reading in a word where the kan-on reading is well known is a common cause of reading mistakes or difficulty, such as in ge-doku (解毒, detoxification, anti-poison) (go-on), where 解 is usually instead read as kai. The go-on readings are especially common in Buddhist terminology such as gokuraku (極楽, paradise), as well as in some of the earliest loans, such as the Sino-Japanese numbers. The tō-on readings occur in some later words, such as isu (椅子, chair), futon (布団, mattress), and andon (行灯, a kind of paper lantern). The go-on, kan-on, and tō-on readings are generally cognate (with rare exceptions of homographs; see below), having a common origin in Old Chinese, and hence form linguistic doublets or triplets, but they can differ significantly from each other and from modern Chinese pronunciation.
In Chinese, most characters are associated with a single Chinese sound, though there are distinct literary and colloquial readings. However, some homographs (多音字 pinyin: duōyīnzì) such as 行 (háng or xíng) (Japanese: an, gō, gyō) have more than one reading in Chinese representing different meanings, which is reflected in the carryover to Japanese as well. Additionally, many Chinese syllables, especially those with an entering tone, did not fit the largely consonant-vowel (CV) phonotactics of classical Japanese. Thus most on’yomi are composed of two morae (beats), the second of which is either a lengthening of the vowel in the first mora (to ei, ō, or ū), the vowel i, or one of the syllables ku, ki, tsu, chi, fu (historically, later merged into ō and ū), or moraic n, chosen for their approximation to the final consonants of Middle Chinese. It may be that palatalized consonants before vowels other than i developed in Japanese as a result of Chinese borrowings, as they are virtually unknown in words of native Japanese origin, but are common in Chinese.
On’yomi primarily occur in multi-kanji compound words (熟語, jukugo), many of which are the result of the adoption, along with the kanji themselves, of Chinese words for concepts that either did not exist in Japanese or could not be articulated as elegantly using native words. This borrowing process is often compared to the English borrowings from Latin, Greek, and Norman French, since Chinese-borrowed terms are often more specialized, or considered to sound more erudite or formal, than their native counterparts (occupying a higher linguistic register). The major exception to this rule is family names, in which the native kun’yomi are usually used (though on’yomi are found in many personal names, especially men’s names).
Kun’yomi (native reading) [edit]
The kun’yomi (訓読み, [kɯɰ̃jomi], lit. «meaning reading»), the native reading, is a reading based on the pronunciation of a native Japanese word, or yamato kotoba, that closely approximated the meaning of the Chinese character when it was introduced. As with on’yomi, there can be multiple kun’yomi for the same kanji, and some kanji have no kun’yomi at all.
For instance, the character for east, 東, has the on’yomi tō, from Middle Chinese tung. However, Japanese already had two words for «east»: higashi and azuma. Thus the kanji 東 had the latter readings added as kun’yomi. In contrast, the kanji 寸, denoting a Chinese unit of measurement (about 30 mm or 1.2 inch), has no native Japanese equivalent; it only has an on’yomi, sun, with no native kun’yomi. Most kokuji, Japanese-created Chinese characters, only have kun’yomi, although some have back-formed a pseudo-on’yomi by analogy with similar characters, such as 働 dō, from 動 dō, and there are even some, such as 腺 sen «gland», that have only an on’yomi.
Kun’yomi are characterized by the strict (C)V syllable structure of yamato kotoba. Most noun or adjective kun’yomi are two to three syllables long, while verb kun’yomi are usually between one and three syllables in length, not counting trailing hiragana called okurigana. Okurigana are not considered to be part of the internal reading of the character, although they are part of the reading of the word. A beginner in the language will rarely come across characters with long readings, but readings of three or even four syllables are not uncommon. This contrasts with on’yomi, which are monosyllabic, and is unusual in the Chinese family of scripts, which generally use one character per syllable—not only in Chinese, but also in Korean, Vietnamese, and Zhuang; polysyllabic Chinese characters are rare and considered non-standard.
承る uketamawaru, 志 kokorozashi, and 詔 mikotonori have five syllables represented by a single kanji, the longest readings in the jōyō character set. These unusually long readings are due to a single character representing a compound word:
- 承る is a single character for a compound verb, one component of which has a long reading.
- It has an alternative spelling as 受け賜る u(ke)-tamawa(ru), hence (1+1)+3=5.
- Compare common 受け付ける u(ke)-tsu(keru).
- 志 is a nominalization of the verb 志す which has a long reading kokoroza(su).
- This is due to its being derived from a noun-verb compound, 心指す kokoro-za(su).
- The nominalization removes the okurigana, hence increasing the reading by one mora, yielding 4+1=5.
- Compare common 話 hanashi 2+1=3, from 話す hana(su).
- 詔 is a triple compound.
- It has an alternative spelling 御言宣 mi-koto-nori, hence 1+2+2=5.
Further, some Jōyō characters have long non-Jōyō readings (students learn the character, but not the reading), such as omonpakaru for 慮る.
In a number of cases, multiple kanji were assigned to cover a single Japanese word. Typically when this occurs, the different kanji refer to specific shades of meaning. For instance, the word なおす, naosu, when written 治す, means «to heal an illness or sickness». When written 直す it means «to fix or correct something». Sometimes the distinction is very clear, although not always. Differences of opinion among reference works are not uncommon; one dictionary may say the kanji are equivalent, while another dictionary may draw distinctions of use. As a result, native speakers of the language may have trouble knowing which kanji to use and resort to personal preference or by writing the word in hiragana. This latter strategy is frequently employed with more complex cases such as もと moto, which has at least five different kanji: 元, 基, 本, 下, and 素, the first three of which have only very subtle differences. Another notable example is sakazuki «sake cup», which may be spelt as at least five different kanji: 杯, 盃, 巵/卮, and 坏; of these, the first two are common—formally 杯 is a small cup and 盃 a large cup.
Local dialectical readings of kanji are also classified under kun’yomi, most notably readings for words in Ryukyuan languages. Further, in rare cases gairaigo (borrowed words) have a single character associated with them, in which case this reading is formally classified as a kun’yomi, because the character is being used for meaning, not sound.
Ateji[edit]
Ateji (当て字, 宛字 or あてじ) are characters used only for their sounds. In this case, pronunciation is still based on a standard reading, or used only for meaning (broadly a form of ateji, narrowly jukujikun). Therefore, only the full compound—not the individual character—has a reading. There are also special cases where the reading is completely different, often based on a historical or traditional reading.
The analogous phenomenon occurs to a much lesser degree in Chinese varieties, where there are literary and colloquial readings of Chinese characters—borrowed readings and native readings. In Chinese these borrowed readings and native readings are etymologically related, since they are between Chinese varieties (which are related), not from Chinese to Japanese (which are not related). They thus form doublets and are generally similar, analogous to different on’yomi, reflecting different stages of Chinese borrowings into Japanese.
Gairaigo[edit]
Longer readings exist for non-Jōyō characters and non-kanji symbols, where a long gairaigo word may be the reading (this is classed as kun’yomi—see single character gairaigo, below)—the character 糎 has the seven kana reading センチメートル senchimētoru «centimeter», though it is generally written as «cm» (with two half-width characters, so occupying one space); another common example is ‘%’ (the percent sign), which has the five kana reading パーセント pāsento.
Mixed readings [edit]

A jūbako (重箱), which has a mixed on-kun reading

A yutō (湯桶), which has a mixed kun-on reading
There are many kanji compounds that use a mixture of on’yomi and kun’yomi, known as jūbako yomi (重箱読み, multi-layered food box) or yutō (湯桶, hot liquid pail) words (depending on the order), which are themselves examples of this kind of compound (they are autological words): the first character of jūbako is read using on’yomi, the second kun’yomi (on-kun, 重箱読み).
It is the other way around with yu-tō (kun-on, 湯桶読み).
Formally, these are referred to as jūbako-yomi (重箱読み, jūbako reading) and yutō-yomi (湯桶読み, yutō reading). Note that in both these words, the on’yomi has a long vowel; long vowels in Japanese generally are derived from sound changes common to loans from Chinese, hence distinctive of on’yomi. These are the Japanese form of hybrid words. Other examples include basho (場所, «place», kun-on, 湯桶読み), kin’iro (金色, «golden», on-kun, 重箱読み) and aikidō (合気道, the martial art Aikido», kun-on-on, 湯桶読み).
Ateji often use mixed readings. For instance the city of Sapporo (サッポロ), whose name derives from the Ainu language and has no meaning in Japanese, is written with the on-kun compound 札幌 (which includes sokuon as if it were a purely on compound).
Special readings[edit]
Gikun (義訓) and jukujikun (熟字訓) are readings of kanji combinations that have no direct correspondence to the characters’ individual on’yomi or kun’yomi. From the point of view of the character, rather than the word, this is known as a 難訓 (nankun, «difficult reading»), and these are listed in kanji dictionaries under the entry for the character.
Gikun are other readings assigned to a character instead of its standard readings. An example is reading 寒 (meaning «cold») as fuyu («winter») rather than the standard readings samu or kan, and instead of the usual spelling for fuyu of 冬. Another example is using 煙草 (lit. «smoke grass») with the reading tabako («tobacco») rather than the otherwise-expected readings of kemuri-gusa or ensō. Some of these, such as for tabako, have become lexicalized, but in many cases this kind of use is typically non-standard and employed in specific contexts by individual writers. Aided with furigana, gikun could be used to convey complex literary or poetic effect (especially if the readings contradict the kanji), or clarification if the referent may not be obvious.
Jukujikun are when the standard kanji for a word are related to the meaning, but not the sound. The word is pronounced as a whole, not corresponding to sounds of individual kanji. For example, 今朝 («this morning») is jukujikun. This word is not read as *ima’asa, the expected kun’yomi of the characters, and only infrequently as konchō, the on’yomi of the characters. The most common reading is kesa, a native bisyllabic Japanese word that may be seen as a single morpheme, or as a compound of ke (“this”, as in kefu, the older reading for 今日, “today”), and asa, “morning”.[30] Likewise, 今日 («today») is also jukujikun, usually read with the native reading kyō; its on’yomi, konnichi, does occur in certain words and expressions, especially in the broader sense «nowadays» or «current», such as 今日的 («present-day»), although in the phrase konnichi wa («good day»), konnichi is typically spelled wholly with hiragana rather than with the kanji 今日.
Jukujikun are primarily used for some native Japanese words, such as Yamato (大和 or 倭, the name of the dominant ethnic group of Japan, a former Japanese province as well as ancient name for Japan), and for some old borrowings, such as 柳葉魚 (shishamo, literally «willow leaf fish») from Ainu, 煙草 (tabako, literally “smoke grass”) from Portuguese, or 麦酒 (bīru, literally “wheat alcohol”) from Dutch, especially if the word was borrowed before the Meiji Period. Words whose kanji are jukujikun are often usually written as hiragana (if native), or katakana (if borrowed); some old borrowed words are also written as hiragana, especially Portuguese loanwords such as かるた (karuta) from Portuguese «carta» (English “card”) or てんぷら (tempura) from Portuguese «tempora» (English “times, season”),[citation needed] as well as たばこ (tabako).
Sometimes, jukujikun can even have more kanji than there are syllables, examples being kera (啄木鳥, “woodpecker”), gumi (胡頽子, “silver berry, oleaster”),[31] and Hozumi (八月朔日, a surname).[32] This phenomenon is observed in animal names that are shortened and used as suffixes for zoological compound names, for example when 黄金虫, normally read as koganemushi, is shortened to kogane in 黒黄金虫 kurokogane, although zoological names are commonly spelled with katakana rather than with kanji. Outside zoology, this type of shortening only occurs on a handful of words, for example 大元帥 daigen(sui), or the historical male name suffix 右衛門 -emon, which was shortened from the word uemon.
Jukujikun are quite varied. Often the kanji compound for jukujikun is idiosyncratic and created for the word, and there is no corresponding Chinese word with that spelling. In other cases a kanji compound for an existing Chinese word is reused, where the Chinese word and on’yomi may or may not be used in Japanese. For example, 馴鹿 (“reindeer”) is jukujikun for tonakai, from Ainu, but the on’yomi reading of junroku is also used. In some cases, Japanese coinages have subsequently been borrowed back into Chinese, such as 鮟鱇 (ankō, “monkfish”).
The underlying word for jukujikun is a native Japanese word or foreign borrowing, which either does not have an existing kanji spelling (either kun’yomi or ateji) or for which a new kanji spelling is produced. Most often the word is a noun, which may be a simple noun (not a compound or derived from a verb), or may be a verb form or a fusional pronunciation. For example, the word 相撲 (sumō, “sumo”) is originally from the verb 争う (sumau, “to vie, to compete”), while 今日 (kyō, “today”) is fusional (from older ke, “this” + fu, “day”).
In rare cases jukujikun is also applied to inflectional words (verbs and adjectives), in which case there is frequently a corresponding Chinese word. The most common example of an inflectional jukujikun is the adjective 可愛い (kawai-i, “cute”), originally kawafayu-i; the word (可愛) is used in Chinese, but the corresponding on’yomi is not used in Japanese. By contrast, «appropriate» can be either 相応しい (fusawa-shii, as jukujikun) or 相応 (sōō, as on’yomi). Which reading to use can be discerned by the presence or absence of the -shii ending (okurigana). A common example of a verb with jukujikun is 流行る (haya-ru, “to spread, to be in vogue”), corresponding to on’yomi 流行 (ryūkō). A sample jukujikun deverbal (noun derived from a verb form) is 強請 (yusuri, “extortion”), from 強請る (yusu-ru, “to extort”), spelling from 強請 (kyōsei, “extortion”). See the 義訓 and 熟字訓 articles in the Japanese Wikipedia for many more examples. Note that there are also compound verbs and, less commonly, compound adjectives, and while these may have multiple kanji without intervening characters, they are read using the usual kun’yomi. Examples include 面白い (omo-shiro-i, “interesting”, literally “face + white”) and 狡賢い (zuru-gashiko-i, “sly”, literally “cunning, crafty + clever, smart”).
Typographically, the furigana for jukujikun are often written so they are centered across the entire word, or for inflectional words over the entire root—corresponding to the reading being related to the entire word—rather than each part of the word being centered over its corresponding character, as is often done for the usual phono-semantic readings.
Broadly speaking, jukujikun can be considered a form of ateji, though in narrow usage «ateji» refers specifically to using characters for sound and not meaning (sound-spelling), whereas «jukujikun» refers to using characters for their meaning and not sound (meaning-spelling).
Many jukujikun (established meaning-spellings) began life as gikun (improvised meaning-spellings). Occasionally a single word will have many such kanji spellings. An extreme example is hototogisu (lesser cuckoo), which may be spelt in a great many ways, including 杜鵑, 時鳥, 子規, 不如帰, 霍公鳥, 蜀魂, 沓手鳥, 杜宇,田鵑, 沓直鳥, and 郭公—many of these variant spellings are particular to haiku poems.
Single character gairaigo[edit]
In some rare cases, an individual kanji has a reading that is borrowed from a modern foreign language (gairaigo), though most often these words are written in katakana. Notable examples include pēji (頁、ページ, page), botan (釦/鈕、ボタン, button), zero (零、ゼロ, zero), and mētoru (米、メートル, meter). See list of single character gairaigo for more. These are classed as kun’yomi of a single character, because the character is being used for meaning only (without the Chinese pronunciation), rather than as ateji, which is the classification used when a gairaigo term is written as a compound (2 or more characters). However, unlike the vast majority of other kun’yomi, these readings are not native Japanese, but rather borrowed, so the «kun’yomi» label can be misleading. The readings are also written in katakana, unlike the usual hiragana for native kun’yomi. Note that most of these characters are for units, particularly SI units, in many cases using new characters (kokuji) coined during the Meiji period, such as kiromētoru (粁、キロメートル, kilometer, 米 «meter» + 千 «thousand»).
Nanori[edit]
Some kanji also have lesser-known readings called nanori (名乗り), which are mostly used for names (often given names) and, in general, are closely related to the kun’yomi. Place names sometimes also use nanori or, occasionally, unique readings not found elsewhere.
When to use which reading[edit]
Although there are general rules for when to use on’yomi and when to use kun’yomi, the language is littered with exceptions, and it is not always possible for even a native speaker to know how to read a character without prior knowledge (this is especially true for names, both of people and places); further, a given character may have multiple kun’yomi or on’yomi. When reading Japanese, one primarily recognizes words (multiple characters and okurigana) and their readings, rather than individual characters, and only guess readings of characters when trying to «sound out» an unrecognized word.
Homographs exist, however, which can sometimes be deduced from context, and sometimes cannot, requiring a glossary. For example, 今日 may be read either as kyō «today (informal)» (special fused reading for native word) or as konnichi «these days (formal)» (on’yomi); in formal writing this will generally be read as konnichi.
In some cases multiple readings are common, as in 豚汁 «pork soup», which is commonly pronounced both as ton-jiru (mixed on-kun) and buta-jiru (kun-kun), with ton somewhat more common nationally. Inconsistencies abound—for example 牛肉 gyū-niku «beef» and 羊肉 yō-niku «mutton» have on-on readings, but 豚肉 buta-niku «pork» and 鶏肉 tori-niku «poultry» have kun-on readings.
The main guideline is that a single kanji followed by okurigana (hiragana characters that are part of the word)—as used in native verbs and adjectives—always indicates kun’yomi, while kanji compounds (kango) usually use on’yomi, which is usually kan-on; however, other on’yomi are also common, and kun’yomi are also commonly used in kango.
For a kanji in isolation without okurigana, it is typically read using their kun’yomi, though there are numerous exceptions. For example, 鉄 «iron» is usually read with the on’yomi tetsu rather than the kun’yomi kurogane. Chinese on’yomi which are not the common kan-on reading are a frequent cause of difficulty or mistakes when encountering unfamiliar words or for inexperienced readers, though skilled natives will recognize the word; a good example is ge-doku (解毒, detoxification, anti-poison) (go-on), where (解) is usually instead read as kai.
Okurigana (送り仮名) are used with kun’yomi to mark the inflected ending of a native verb or adjective, or by convention. Note that Japanese verbs and adjectives are closed class, and do not generally admit new words (borrowed Chinese vocabulary, which are nouns, can form verbs by adding -suru (〜する, to do) at the end, and adjectives via 〜の -no or 〜な -na, but cannot become native Japanese vocabulary, which inflect). For example: 赤い aka-i «red», 新しい atara-shii «new», 見る mi-ru «(to) see». Okurigana can be used to indicate which kun’yomi to use, as in 食べる ta-beru versus 食う ku-u (casual), both meaning «(to) eat», but this is not always sufficient, as in 開く, which may be read as a-ku or hira-ku, both meaning «(to) open». 生 is a particularly complicated example, with multiple kun and on’yomi—see okurigana: 生 for details. Okurigana is also used for some nouns and adverbs, as in 情け nasake «sympathy», 必ず kanarazu «invariably», but not for 金 kane «money», for instance. Okurigana is an important aspect of kanji usage in Japanese; see that article for more information on kun’yomi orthography
Kanji occurring in compounds (multi-kanji words) (熟語, jukugo) are generally read using on’yomi, especially for four-character compounds (yojijukugo). Though again, exceptions abound, for example, 情報 jōhō «information», 学校 gakkō «school», and 新幹線 shinkansen «bullet train» all follow this pattern. This isolated kanji versus compound distinction gives words for similar concepts completely different pronunciations. 北 «north» and 東 «east» use the kun’yomi kita and higashi, being stand-alone characters, but 北東 «northeast», as a compound, uses the on’yomi hokutō. This is further complicated by the fact that many kanji have more than one on’yomi: 生 is read as sei in 先生 sensei «teacher» but as shō in 一生 isshō «one’s whole life». Meaning can also be an important indicator of reading; 易 is read i when it means «simple», but as eki when it means «divination», both being on’yomi for this character.
These rules of thumb have many exceptions. Kun’yomi compound words are not as numerous as those with on’yomi, but neither are they rare. Examples include 手紙 tegami «letter», 日傘 higasa «parasol», and the famous 神風 kamikaze «divine wind». Such compounds may also have okurigana, such as 空揚げ (also written 唐揚げ) karaage «Chinese-style fried chicken» and 折り紙 origami, although many of these can also be written with the okurigana omitted (for example, 空揚 or 折紙). In general, compounds coined in Japan using japanese roots will be read in kun’yomi while those imported from China will be read in on’yomi.
Similarly, some on’yomi characters can also be used as words in isolation: 愛 ai «love», 禅 Zen, 点 ten «mark, dot». Most of these cases involve kanji that have no kun’yomi, so there can be no confusion, although exceptions do occur. Alone 金 may be read as kin «gold» or as kane «money, metal»; only context can determine the writer’s intended reading and meaning.
Multiple readings have given rise to a number of homographs, in some cases having different meanings depending on how they are read. One example is 上手, which can be read in three different ways: jōzu (skilled), uwate (upper part), or kamite (stage left/house right). In addition, 上手い has the reading umai (skilled). More subtly, 明日 has three different readings, all meaning «tomorrow»: ashita (casual), asu (polite), and myōnichi (formal). Furigana (reading glosses) is often used to clarify any potential ambiguities.
Conversely, in some cases homophonous terms may be distinguished in writing by different characters, but not so distinguished in speech, and hence potentially confusing. In some cases when it is important to distinguish these in speech, the reading of a relevant character may be changed. For example, 私立 (privately established, esp. school) and 市立 (city established) are both normally pronounced shi-ritsu; in speech these may be distinguished by the alternative pronunciations watakushi-ritsu and ichi-ritsu. More informally, in legal jargon 前文 «preamble» and 全文 «full text» are both pronounced zen-bun, so 前文 may be pronounced mae-bun for clarity, as in «Have you memorized the preamble [not ‘whole text’] of the constitution?». As in these examples, this is primarily using a kun’yomi for one character in a normally on’yomi term.
As stated above, jūbako and yutō readings are also not uncommon. Indeed, all four combinations of reading are possible: on-on, kun-kun, kun-on and on-kun.
Legalese[edit]
Certain words take different readings depending on whether the context concerns legal matters or not. For example:
| Word | Common reading | Legalese reading |
|---|---|---|
| 懈怠 («negligence»)[33] | ketai | kaitai |
| 競売 («auction»)[33] | kyōbai | keibai |
| 兄弟姉妹 («siblings») | kyōdai shimai | keitei shimai |
| 境界 («metes and bounds») | kyōkai | keikai |
| 競落 («acquisition at an auction»)[33] | kyōraku | keiraku |
| 遺言 («will»)[33] | yuigon | igon |
For legal contexts where distinction must be made for homophonous words such as baishun and karyō, see Ambiguous readings below.
Ambiguous readings[edit]
In some instances where even context cannot easily provide clarity for homophones, alternative readings or mixed readings can be used instead of regular readings to avoid ambiguity. For example:
| Ambiguous reading | Disambiguated readings |
|---|---|
| baishun | baishun (売春, «selling sex», on)
kaishun (買春, «buying sex», yutō)[34] |
| itoko | jūkeitei (従兄弟, «male cousin», on)
jūshimai (従姉妹, «female cousin», on) jūkei (従兄, «older male cousin», on) jūshi (従姉, «older female cousin», on) jūtei (従弟, «younger male cousin», on) jūmai (従妹, «younger female cousin», on) |
| jiten | kotobaten (辞典, «word dictionary», yutō)[34]
kototen (事典, «encyclopedia», yutō)[34][33] mojiten (字典, «character dictionary», irregular, from moji (文字, «character»))[34] |
| kagaku | kagaku (科学, «science», on)
bakegaku (化学, «chemistry», yutō)[34][33] |
| karyō | ayamachiryō (過料, «administrative fine», yutō)[34][33]
togaryō (科料, «misdemeanor fine», yutō)[34][33] |
| Kōshin | Kinoesaru (甲申, «Greater-Wood-Monkey year», kun)
Kinoetatsu (甲辰, «Greater-Wood-Dragon year», kun) Kanoesaru (庚申, «Greater-Fire-Monkey year», kun) Kanoetatsu (庚辰, «Greater-Fire-Dragon year», kun) |
| Shin | Hatashin (秦, «Qin», irregular, from the alternative reading Hata used as a family name)[34][33]
Susumushin (晋, «Jin», irregular, from the alternative reading Susumu used as a personal name)[34][33] |
| shiritsu | ichiritsu (市立, «municipal», yutō)[34][33]
watakushiritsu (私立, «private», yutō)[34][33] |
Place names[edit]
Several famous place names, including those of Japan itself (日本 Nihon or sometimes Nippon), those of some cities such as Tokyo (東京 Tōkyō) and Kyoto (京都 Kyōto), and those of the main islands Honshu (本州 Honshū), Kyushu (九州 Kyūshū), Shikoku (四国 Shikoku), and Hokkaido (北海道 Hokkaidō) are read with on’yomi; however, the majority of Japanese place names are read with kun’yomi: 大阪 Ōsaka, 青森 Aomori, 箱根 Hakone. Names often use characters and readings that are not in common use outside of names. When characters are used as abbreviations of place names, their reading may not match that in the original. The Osaka (大阪) and Kobe (神戸) baseball team, the Hanshin (阪神) Tigers, take their name from the on’yomi of the second kanji of Ōsaka and the first of Kōbe. The name of the Keisei (京成) railway line—linking Tokyo (東京) and Narita (成田)—is formed similarly, although the reading of 京 from 東京 is kei, despite kyō already being an on’yomi in the word Tōkyō.
Japanese family names are also usually read with kun’yomi: 山田 Yamada, 田中 Tanaka, 鈴木 Suzuki. Japanese given names often have very irregular readings. Although they are not typically considered jūbako or yutō, they often contain mixtures of kun’yomi, on’yomi and nanori, such as 大助 Daisuke [on-kun], 夏美 Natsumi [kun-on]. Being chosen at the discretion of the parents, the readings of given names do not follow any set rules, and it is impossible to know with certainty how to read a person’s name without independent verification. Parents can be quite creative, and rumours abound of children called 地球 Āsu («Earth») and 天使 Enjeru («Angel»); neither are common names, and have normal readings chikyū and tenshi respectively. Some common Japanese names can be written in multiple ways, e.g. Akira can be written as 亮, 彰, 明, 顕, 章, 聴, 光, 晶, 晄, 彬, 昶, 了, 秋良, 明楽, 日日日, 亜紀良, 安喜良 and many other characters and kanji combinations not listed,[35] Satoshi can be written as 聡, 哲, 哲史, 悟, 佐登史, 暁, 訓, 哲士, 哲司, 敏, 諭, 智, 佐登司, 總, 里史, 三十四, 了, 智詞, etc.,[36] and Haruka can be written as 遥, 春香, 晴香, 遥香, 春果, 晴夏, 春賀, 春佳, and several other possibilities.[37] Common patterns do exist, however, allowing experienced readers to make a good guess for most names. To alleviate any confusion on how to pronounce the names of other Japanese people, most official Japanese documents require Japanese to write their names in both kana and kanji.[32]
Chinese place names and Chinese personal names appearing in Japanese texts, if spelled in kanji, are almost invariably read with on’yomi. Especially for older and well-known names, the resulting Japanese pronunciation may differ widely from that used by modern Chinese speakers. For example, Mao Zedong’s name is pronounced as Mō Takutō (毛沢東) in Japanese, and the name of the legendary Monkey King, Sun Wukong, is pronounced Son Gokū (孫悟空) in Japanese.
Today, Chinese names that are not well known in Japan are often spelled in katakana instead, in a form much more closely approximating the native Chinese pronunciation. Alternatively, they may be written in kanji with katakana furigana. Many such cities have names that come from non-Chinese languages like Mongolian or Manchu. Examples of such not-well-known Chinese names include:
| English name | Japanese name | ||
|---|---|---|---|
| Rōmaji | Katakana | Kanji | |
| Harbin | Harubin | ハルビン | 哈爾浜 |
| Ürümqi | Urumuchi | ウルムチ | 烏魯木斉 |
| Qiqihar | Chichiharu | チチハル | 斉斉哈爾 |
| Lhasa | Rasa | ラサ | 拉薩 |
Internationally renowned Chinese-named cities tend to imitate the older English pronunciations of their names, regardless of the kanji’s on’yomi or the Mandarin or Cantonese pronunciation, and can be written in either katakana or kanji. Examples include:
| English name | Mandarin name (Pinyin) | Hokkien name (Tâi-lô) | Cantonese name (Yale) | Japanese name | ||
|---|---|---|---|---|---|---|
| Kanji | Katakana | Rōmaji | ||||
| Hong Kong | Xianggang | Hiong-káng / Hiang-káng | Hēung Góng | 香港 | ホンコン | Honkon |
| Macao/Macau | Ao’men | ò-mn̂g / ò-bûn | Ou Mùhn | 澳門 | マカオ | Makao |
| Shanghai | Shanghai | Siōng-hái / Siāng-hái | Seuhng Hói | 上海 | シャンハイ | Shanhai |
| Beijing/Peking | Beijing | Pak-kiann | Bāk Gīng | 北京 | ペキン | Pekin |
| Nanjing/Nanking | Nanjing | Lâm-kiann | Nàahm Gīng | 南京 | ナンキン | Nankin |
| Taipei | Taibei | Tâi-pak | Tòih Bāk | 台北 | タイペイ / タイホク | Taipei / Taihoku |
| Kaohsiung | Gaoxiong / Dagou | Ko-hiông | Gōu Hùhng | 高雄 / 打狗 | カオシュン / タカオ | Kaoshun / Takao |
Notes:
- Guangzhou, the city, is pronounced Kōshū, while Guangdong, its province, is pronounced Kanton, not Kōtō (in this case, opting for a Tō-on reading rather than the usual Kan-on reading).
- Kaohsiung was originally pronounced Takao (or similar) in Hokkien and Japanese. It received this written name (kanji/Chinese) from Japanese, and later its spoken Mandarin name from the corresponding characters. The English name «Kaohsiung» derived from its Mandarin pronunciation. Today it is pronounced either カオシュン or タカオ in Japanese.
- Taipei is generally pronounced たいほく in Japanese.
In some cases the same kanji can appear in a given word with different readings. Normally this occurs when a character is duplicated and the reading of the second character has voicing (rendaku), as in 人人 hito-bito «people» (more often written with the iteration mark as 人々), but in rare cases the readings can be unrelated, as in tobi-haneru (跳び跳ねる, «hop around», more often written 飛び跳ねる).
Pronunciation assistance[edit]
Because of the ambiguities involved, kanji sometimes have their pronunciation for the given context spelled out in ruby characters known as furigana, (small kana written above or to the right of the character) or kumimoji (small kana written in-line after the character). This is especially true in texts for children or foreign learners. It is also used in newspapers and manga for rare or unusual readings, or for situations like the first time a character’s name is given, and for characters not included in the officially recognized set of essential kanji. Works of fiction sometimes use furigana to create new «words» by giving normal kanji non-standard readings, or to attach a foreign word rendered in katakana as the reading for a kanji or kanji compound of the same or similar meaning.
Spelling words[edit]
Conversely, specifying a given kanji, or spelling out a kanji word—whether the pronunciation is known or not—can be complicated, due to the fact that there is not a commonly used standard way to refer to individual kanji (one does not refer to «kanji #237»), and that a given reading does not map to a single kanji—indeed there are many homophonous words, not simply individual characters, particularly for kango (with on’yomi). Easiest is to write the word out—either on paper or tracing it in the air—or look it up (given the pronunciation) in a dictionary, particularly an electronic dictionary; when this is not possible, such as when speaking over the phone or writing implements are not available (and tracing in air is too complicated), various techniques can be used. These include giving kun’yomi for characters—these are often unique—using a well-known word with the same character (and preferably the same pronunciation and meaning), and describing the character via its components. For example, one may explain how to spell the word kōshinryō (香辛料, spice) via the words kao-ri (香り, fragrance), kara-i (辛い, spicy), and in-ryō (飲料, beverage)—the first two use the kun’yomi, the third is a well-known compound—saying «kaori, karai, ryō as in inryō.»
Dictionaries[edit]
In dictionaries, both words and individual characters have readings glossed, via various conventions. Native words and Sino-Japanese vocabulary are glossed in hiragana (for both kun and on readings), while borrowings (gairaigo)—including modern borrowings from Chinese—are glossed in katakana; this is the standard writing convention also used in furigana. By contrast, readings for individual characters are conventionally written in katakana for on readings, and hiragana for kun readings. Kun readings may further have a separator to indicate which characters are okurigana, and which are considered readings of the character itself. For example, in the entry for 食, the reading corresponding to the basic verb eat (食べる, taberu) may be written as た.べる (ta.beru), to indicate that ta is the reading of the character itself. Further, kanji dictionaries often list compounds including irregular readings of a kanji.
Local developments and divergences from Chinese[edit]
Since kanji are essentially Chinese hanzi used to write Japanese, the majority of characters used in modern Japanese still retain their Chinese meaning, physical resemblance with some of their modern traditional Chinese characters counterparts, and a degree of similarity with Classical Chinese pronunciation imported to Japan from 5th to 9th century.[38] Nevertheless, after centuries of development, there is a notable number of kanji used in modern Japanese which have different meaning from hanzi used in modern Chinese. Such differences are the result of:
- the use of characters created in Japan,
- characters that have been given different meanings in Japanese, and
- post-World War II simplifications (shinjitai) of the character.
Likewise, the process of character simplification in mainland China since the 1950s has resulted in the fact that Japanese speakers who have not studied Chinese may not recognize some simplified characters.
Kokuji [edit]
In Japanese, Kokuji (国字, «national characters») refers to Chinese characters made outside of China. Specifically, kanji made in Japan are referred to as Wasei kanji (和製漢字). They are primarily formed in the usual way of Chinese characters, namely by combining existing components, though using a combination that is not used in China. The corresponding phenomenon in Korea is called gukja (國字), a cognate name; there are however far fewer Korean-coined characters than Japanese-coined ones. Other languages using the Chinese family of scripts sometimes have far more extensive systems of native characters, most significantly Vietnamese chữ Nôm, which comprises over 20,000 characters used throughout traditional Vietnamese writing, and Zhuang sawndip, which comprises over 10,000 characters, which are still in use.
Since kokuji are generally devised for existing native words, these usually only have native kun readings. However, they occasionally have a Chinese on reading, derived from a phonetic, as in 働, dō, and in rare cases only have an on reading, as in 腺, sen, from 泉, which was derived for use in technical compounds (腺 means «gland», hence used in medical terminology).
The majority of kokuji are ideogrammatic compounds (会意字), meaning that they are composed of two (or more) characters, with the meaning associated with the combination. For example, 働 is composed of 亻 (person radical) plus 動 (action), hence «action of a person, work». This is in contrast to kanji generally, which are overwhelmingly phono-semantic compounds. This difference is because kokuji were coined to express Japanese words, so borrowing existing (Chinese) readings could not express these—combining existing characters to logically express the meaning was the simplest way to achieve this. Other illustrative examples (below) include 榊 sakaki tree, formed as 木 «tree» and 神 «god», literally «divine tree», and 辻 tsuji «crossroads, street» formed as 辶 (⻌) «road» and 十 «cross», hence «cross-road».
In terms of meanings, these are especially for natural phenomena (esp. flora and fauna species), including a very large number of fish, such as 鰯 (sardine), 鱈 (codfish), 鮴 (seaperch), and 鱚 (sillago), and trees, such as 樫 (evergreen oak), 椙 (Japanese cedar), 椛 (birch, maple) and 柾 (spindle tree).[39] In other cases they refer to specifically Japanese abstract concepts, everyday words (like 辻, «crossroads», see above), or later technical coinages (such as 腺, «gland», see above).
There are hundreds of kokuji in existence.[40] Many are rarely used, but a number have become commonly used components of the written Japanese language. These include the following:
Jōyō kanji has about nine kokuji; there is some dispute over classification, but generally includes these:
- 働 どう dō, はたら(く) hatara(ku) «work», the most commonly used kokuji, used in the fundamental verb hatara(ku) (働く, «work»), included in elementary texts and on the Proficiency Test N5.
- 込 こ(む) ko(mu), used in the fundamental verb komu (込む, «to be crowded»)
- 匂 にお(う) nio(u), used in common verb niou (匂う, «to smell, to be fragrant»)
- 畑 はたけ hatake «field of crops»
- 腺 せん sen, «gland»
- 峠 とうげ tōge «mountain pass»
- 枠 わく waku, «frame»
- 塀 へい hei, «wall»
- 搾 しぼ(る) shibo(ru), «to squeeze» (disputed; see below);
jinmeiyō kanji
- 榊 さかき sakaki «tree, genus Cleyera«
- 辻 つじ tsuji «crossroads, street»
- 匁 もんめ monme (unit of weight)
Hyōgaiji:
- 躾 しつけ shitsuke «training, rearing (an animal, a child)»
Some of these characters (for example, 腺, «gland»)[41] have been introduced to China. In some cases the Chinese reading is the inferred Chinese reading, interpreting the character as a phono-semantic compound (as in how on readings are sometimes assigned to these characters in Chinese), while in other cases (such as 働), the Japanese on reading is borrowed (in general this differs from the modern Chinese pronunciation of this phonetic). Similar coinages occurred to a more limited extent in Korea and Vietnam.
Historically, some kokuji date back to very early Japanese writing, being found in the Man’yōshū, for example—鰯 iwashi «sardine» dates to the Nara period (8th century)—while they have continued to be created as late as the late 19th century, when a number of characters were coined in the Meiji era for new scientific concepts. For example, some characters were produced as regular compounds for some (but not all) SI units, such as 粁 (米 «meter» + 千 «thousand, kilo-«) for kilometer, 竏 (立 «liter» + 千 «thousand, kilo-«) for kiloliter, and 瓩 (瓦 «gram» + «thousand, kilo-«) for kilogram. However, SI units in Japanese today are almost exclusively written using rōmaji or katakana such as キロメートル or ㌖ for km, キロリットル for kl, and キログラム or ㌕ for kg.[42]
In Japan, the kokuji category is strictly defined as characters whose earliest appearance is in Japan.[43] If a character appears earlier in the Chinese literature, it is not considered a kokuji even if the character was independently coined in Japan and unrelated to the Chinese character (meaning «not borrowed from Chinese»). In other words, kokuji are not simply characters that were made in Japan, but characters that were first made in Japan. An illustrative example is ankō (鮟鱇, monkfish). This spelling was created in Edo period Japan from the ateji (phonetic kanji spelling) 安康 for the existing word ankō by adding the 魚 radical to each character—the characters were «made in Japan». However, 鮟 is not considered kokuji, as it is found in ancient Chinese texts as a corruption of 鰋 (魚匽). 鱇 is considered kokuji, as it has not been found in any earlier Chinese text. Casual listings may be more inclusive, including characters such as 鮟.[note 1] Another example is 搾, which is sometimes not considered kokuji due to its earlier presence as a corruption of Chinese 榨.
Kokkun[edit]
In addition to kokuji, there are kanji that have been given meanings in Japanese that are different from their original Chinese meanings. These are not considered kokuji but are instead called kokkun (国訓) and include characters such as the following:
| Char. | Japanese | Chinese | ||
|---|---|---|---|---|
| Reading | Meaning | Pinyin | Meaning | |
| 藤 | fuji | wisteria | téng | rattan, cane, vine[note 2] |
| 沖 | oki | offing, offshore | chōng | rinse, minor river (Cantonese) |
| 椿 | tsubaki | Camellia japonica | chūn | Toona spp. |
| 鮎 | ayu | sweetfish | nián | catfish (rare, usually written 鯰) |
| 咲 | saki | blossom | xiào | smile (rare, usually written 笑) |
Types of kanji by category[edit]
Han-dynasty scholar Xu Shen in his 2nd-century dictionary Shuowen Jiezi classified Chinese characters into six categories (Chinese: 六書 liùshū, Japanese: 六書 rikusho). The traditional classification is still taught but is problematic and no longer the focus of modern lexicographic practice, as some categories are not clearly defined, nor are they mutually exclusive: the first four refer to structural composition, while the last two refer to usage.[44]
Shōkei moji (象形文字)[edit]
Shōkei (Mandarin: xiàngxíng) characters are pictographic sketches of the object they represent. For example, 目 is an eye, while 木 is a tree. The current forms of the characters are very different from the originals, though their representations are more clear in oracle bone script and seal script. These pictographic characters make up only a small fraction of modern characters.
Shiji moji (指事文字)[edit]
Shiji (Mandarin: zhǐshì) characters are ideographs, often called «simple ideographs» or «simple indicatives» to distinguish them and tell the difference from compound ideographs (below). They are usually simple graphically and represent an abstract concept such as 上 «up» or «above» and 下 «down» or «below». These make up a tiny fraction of modern characters.
Kaii moji (会意文字)[edit]
Kaii (Mandarin: huìyì) characters are compound ideographs, often called «compound indicatives», «associative compounds», or just «ideographs». These are usually a combination of pictographs that combine semantically to present an overall meaning. An example of this type is 休 (rest) from 亻 (person radical) and 木 (tree). Another is the kokuji 峠 (mountain pass) made from 山 (mountain), 上 (up) and 下 (down). These make up a tiny fraction of modern characters.
Keisei moji (形声文字)[edit]
Keisei (Mandarin: xíngshēng) characters are phono-semantic or radical-phonetic compounds, sometimes called «semantic-phonetic», «semasio-phonetic», or «phonetic-ideographic» characters, are by far the largest category, making up about 90% of the characters in the standard lists; however, some of the most frequently used kanji belong to one of the three groups mentioned above, so keisei moji will usually make up less than 90% of the characters in a text. Typically they are made up of two components, one of which (most commonly, but by no means always, the left or top element) suggests the general category of the meaning or semantic context, and the other (most commonly the right or bottom element) approximates the pronunciation. The pronunciation relates to the original Chinese, and may now only be distantly detectable in the modern Japanese on’yomi of the kanji; it generally has no relation at all to kun’yomi. The same is true of the semantic context, which may have changed over the centuries or in the transition from Chinese to Japanese. As a result, it is a common error in folk etymology to fail to recognize a phono-semantic compound, typically instead inventing a compound-indicative explanation.
Tenchū moji (転注文字)[edit]
Tenchū (Mandarin: zhuǎnzhù) characters have variously been called «derivative characters», «derivative cognates», or translated as «mutually explanatory» or «mutually synonymous» characters; this is the most problematic of the six categories, as it is vaguely defined. It may refer to kanji where the meaning or application has become extended. For example, 楽 is used for ‘music’ and ‘comfort, ease’, with different pronunciations in Chinese reflected in the two different on’yomi, gaku ‘music’ and raku ‘pleasure’.
Kasha moji (仮借文字)[edit]
Kasha (Mandarin: jiǎjiè) are rebuses, sometimes called «phonetic loans». The etymology of the characters follows one of the patterns above, but the present-day meaning is completely unrelated to this. A character was appropriated to represent a similar-sounding word. For example, 来 in ancient Chinese was originally a pictograph for «wheat». Its syllable was homophonous with the verb meaning «to come», and the character is used for that verb as a result, without any embellishing «meaning» element attached. The character for wheat 麦, originally meant «to come», being a keisei moji having ‘foot’ at the bottom for its meaning part and «wheat» at the top for sound. The two characters swapped meaning, so today the more common word has the simpler character. This borrowing of sounds has a very long history.
[edit]
The iteration mark (々) is used to indicate that the preceding kanji is to be repeated, functioning similarly to a ditto mark in English. It is pronounced as though the kanji were written twice in a row, for example iroiro (色々, «various») and tokidoki (時々, «sometimes»). This mark also appears in personal and place names, as in the surname Sasaki (佐々木). This symbol is a simplified version of the kanji 仝, a variant of dō (同, «same»).
Another abbreviated symbol is ヶ, in appearance a small katakana «ke», but actually a simplified version of the kanji 箇, a general counter. It is pronounced «ka» when used to indicate quantity (such as 六ヶ月, rokkagetsu «six months») or «ga» if used as a genitive (as in 関ヶ原 sekigahara «Sekigahara»).
The way how these symbols may be produced on a computer depends on the operating system. In macOS, typing じおくり will reveal the symbol 々 as well as ヽ, ゝ and ゞ. To produce 〻, type おどりじ. Under Windows, typing くりかえし will reveal some of these symbols, while in Google IME, おどりじ may be used.
Collation[edit]
Kanji, whose thousands of symbols defy ordering by conventions such as those used for the Latin script, are often collated using the traditional Chinese radical-and-stroke sorting method. In this system, common components of characters are identified; these are called radicals. Characters are grouped by their primary radical, then ordered by number of pen strokes within radicals. For example, the kanji character 桜, meaning «cherry», is sorted as a ten-stroke character under the four-stroke primary radical 木 meaning «tree». When there is no obvious radical or more than one radical, convention governs which is used for collation.
Other kanji sorting methods, such as the SKIP system, have been devised by various authors.
Modern general-purpose Japanese dictionaries (as opposed to specifically character dictionaries) generally collate all entries, including words written using kanji, according to their kana representations (reflecting the way they are pronounced). The gojūon ordering of kana is normally used for this purpose.
Kanji education[edit]

Japanese schoolchildren are expected to learn 1,026 basic kanji characters, the kyōiku kanji, before finishing the sixth grade. The order in which these characters are learned is fixed. The kyōiku kanji list is a subset of a larger list, originally of 1,945 kanji characters and extended to 2,136 in 2010, known as the jōyō kanji—characters required for the level of fluency necessary to read newspapers and literature in Japanese. This larger list of characters is to be mastered by the end of the ninth grade.[45] Schoolchildren learn the characters by repetition and radical.
Students studying Japanese as a foreign language are often required by a curriculum to acquire kanji without having first learned the vocabulary associated with them. Strategies for these learners vary from copying-based methods to mnemonic-based methods such as those used in James Heisig’s series Remembering the Kanji. Other textbooks use methods based on the etymology of the characters, such as Mathias and Habein’s The Complete Guide to Everyday Kanji and Henshall’s A Guide to Remembering Japanese Characters. Pictorial mnemonics, as in the text Kanji Pict-o-graphix by Michael Rowley, are also seen.
The Japan Kanji Aptitude Testing Foundation provides the Kanji kentei (日本漢字能力検定試験 Nihon kanji nōryoku kentei shiken; «Test of Japanese Kanji Aptitude»), which tests the ability to read and write kanji. The highest level of the Kanji kentei tests about six thousand kanji.[46]
See also[edit]
- Chinese influence on Japanese culture
- Braille kanji
- Hanja (Korean equivalent)
- Chữ Hán (Vietnamese equivalent)
- Han unification
- Chinese family of scripts
- Japanese script reform
- Japanese typefaces (shotai)
- Japanese writing system
- Kanji of the year
- List of kanji by stroke count
- Radical (Chinese character)
- Stroke order
- Table of kanji radicals
- Rōmaji
- Cangjie
Notes[edit]
- ^ 国字 at 漢字辞典ネット demonstrates this, listing both 鮟 and 鱇 as kokuji, but starring 鮟 and stating that dictionaries do not consider it to be a kokuji.
- ^ the word for wisteria being «紫藤», with the addition of «紫», «purple»
References[edit]
Citations[edit]
- ^ Matsunaga, Sachiko (1996). «The Linguistic Nature of Kanji Reexamined: Do Kanji Represent Only Meanings?». The Journal of the Association of Teachers of Japanese. 30 (2): 1–22. doi:10.2307/489563. ISSN 0885-9884. JSTOR 489563.
- ^ Taylor, Insup; Taylor, Maurice Martin (1995). Writing and literacy in Chinese, Korean, and Japanese. Amsterdam: John Benjamins Publishing Company. p. 305. ISBN 90-272-1794-7.
- ^ McAuley, T. E.; Tranter, Nicolas (2001). Language change in East Asia. Richmond, Surrey: Curzon. pp. 180–204.
- ^ Suski, P.M. (2011). The Phonetics of Japanese Language: With Reference to Japanese Script. p. 1. ISBN 9780203841808.
- ^ Malatesha Joshi, R.; Aaron, P.G. (2006). Handbook of orthography and literacy. New Jersey: Routledge. pp. 481–2. ISBN 0-8058-4652-2.
- ^ a b c d Miyake (2003), 8.
- ^ a b Yamazaki, Kento (October 5, 2001). «Tawayama find hints kanji introduced in Yayoi Period». The Japan Times. Retrieved February 15, 2022.
- ^ Chen, Haijing (2014). «A Study of Japanese Loanwords in Chinese». University of Oslo.
- ^ Mathieu (November 19, 2017). «The History of Kanji 漢字の歴史». It’s Japan Time. Retrieved September 12, 2021.
- ^ «Gold Seal (Kin-in)». Fukuoka City Museum. Retrieved September 1, 2014.
- ^ a b Miyake (2003), 9.
- ^ Hadamitzky, Wolfgang and Spahn, Mark (2012), Kanji and Kana: A Complete Guide to the Japanese Writing System, Third Edition, Rutland, VT: Tuttle Publishing. ISBN 4805311169. p. 14.
- ^ Berger, Gordon M. (1975). «Review of Ishiwara Kanji and Japan’s Confrontation with the West». Journal of Japanese Studies. 2 (1): 156–169. doi:10.2307/132045. ISSN 0095-6848.
- ^ «人名用漢字の新字旧字 第82回 「鉄」と「鐵」». Sanseidō. Retrieved August 14, 2015.
- ^ Tamaoka, K., Makioka, S., Sanders, S. & Verdonschot, R. G. (2017). «www.kanjidatabase.com: a new interactive online database for psychological and linguistic research on Japanese kanji and their compound words». Psychological Research 81, 696-708.
- ^ JIS X 0208:1997.
- ^ JIS X 0212:1990.
- ^ JIS X 0213:2000.
- ^ Lunde, Ken (1999). CJKV Information Processing. «O’Reilly Media, Inc.». ISBN 978-1-56592-224-2.
- ^ Lunde, Ken (1999). CJKV Information Processing. «O’Reilly Media, Inc.». ISBN 978-1-56592-224-2.
- ^ Introducing the SING Gaiji architecture, Adobe.
- ^ OpenType Technology Center, Adobe.
- ^ «Representation of Non-standard Characters and Glyphs», P5: Guidelines for Electronic Text Encoding and Interchange, TEI-C.
- ^ «TEI element g (character or glyph)», P5: Guidelines for Electronic Text Encoding and Interchange, TEI-C.
- ^ Kuang-Hui Chiu, Chi-Ching Hsu (2006). Chinese Dilemmas : How Many Ideographs are Needed Archived July 17, 2011, at the Wayback Machine, National Taipei University
- ^ Shouhui Zhao, Dongbo Zhang, The Totality of Chinese Characters—A Digital Perspective
- ^ Daniel G. Peebles, SCML: A Structural Representation for Chinese Characters Archived March 10, 2016, at the Wayback Machine, May 29, 2007
- ^ Rogers, Henry (2005). Writing Systems: A Linguistic Approach. Oxford: Blackwell. ISBN 0631234640
- ^ Verdonschot, R. G.; La Heij, W.; Tamaoka, K.; Kiyama, S.; You, W. P.; Schiller, N. O. (2013). «The multiple pronunciations of Japanese kanji: A masked priming investigation». The Quarterly Journal of Experimental Psychology. 66 (10): 2023–38. doi:10.1080/17470218.2013.773050. PMID 23510000. S2CID 13845935.
- ^ «Gogen Yurai Jiten» 語源由来辞典 [Etymology Derivation Dictionary] (in Japanese). Lookvise, Inc. March 26, 2006. Retrieved February 9, 2022.
«Kefu» no «ke» wa, «kesa» to onaji «ke» de, «ko» no imi.
「けふ」の「け」は、「今朝(けさ)」と同じ「け」で、「こ(此)」の意味。 [The ke in kefu is the same ke as in kesa, meaning «this».] - ^ «How many possible phonological forms could be represented by a randomly chosen single character?». japanese.stackexchange.com. Retrieved July 15, 2017.
- ^ a b «How do Japanese names work?». www.sljfaq.org. Retrieved November 14, 2017.
- ^ a b c d e f g h i j k l Daijirin
- ^ a b c d e f g h i j k Kōjien
- ^ «ateji Archives». Tofugu. Archived from the original on December 25, 2015. Retrieved February 18, 2016.
- ^ «Satoshi». jisho.org. Retrieved March 5, 2016.
- ^ «Haruka». jisho.org. Retrieved March 5, 2016.
- ^ SHIMIZU, HIDEKO (2010). «Review of Remembering the Kanji 2: A Systematic Guide to Reading the Japanese Characters. 3rd ed.; Remembering the Kanji 3: Writing and Reading Japanese Characters for Upper-Level Proficiency. 2nd ed., JAMES W. HEISIG». The Modern Language Journal. 94 (3): 519–521. ISSN 0026-7902.
- ^ Koichi (August 21, 2012). «Kokuji: «Made In Japan,» Kanji Edition». Tofugu. Retrieved March 5, 2017.
- ^ «Kokuji list», SLJ FAQ.
- ^ Buck, James H. (October 15, 1969) «Some Observations on kokuji» in The Journal-Newsletter of the Association of Teachers of Japanese, Vol. 6, No. 2, pp. 45–9.
- ^ «A list of kokuji (国字)». www.sljfaq.org. Retrieved March 5, 2017.
- ^ Buck, James H. (1969). «Some Observations on kokuji». The Journal-Newsletter of the Association of Teachers of Japanese. 6 (2): 45–49. doi:10.2307/488823. ISSN 0004-5810.
- ^ Yamashita, Hiroko; Maru, Yukiko (2000). «Compositional Features of Kanji for Effective Instruction». The Journal of the Association of Teachers of Japanese. 34 (2): 159–178. doi:10.2307/489552. ISSN 0885-9884. JSTOR 489552.
- ^ Halpern, J. (2006) The Kodansha Kanji Learner’s Dictionary. ISBN 1568364075. p. 38a.
- ^ Rose, Heath (June 5, 2017). The Japanese Writing System: Challenges, Strategies and Self-regulation for Learning Kanji. Multilingual Matters. pp. 129–130. ISBN 978-1-78309-817-0.
Sources[edit]
- DeFrancis, John (1990). The Chinese Language: Fact and Fantasy. Honolulu: University of Hawaii Press. ISBN 0-8248-1068-6.
- Hadamitzky, W., and Spahn, M., (1981) Kanji and Kana, Boston: Tuttle.
- Hannas, William. C. (1997). Asia’s Orthographic Dilemma. Honolulu: University of Hawaii Press. ISBN 0-8248-1892-X (paperback); ISBN 0-8248-1842-3 (hardcover).
- Kaiser, Stephen (1991). «Introduction to the Japanese Writing System». In Kodansha’s Compact Kanji Guide. Tokyo: Kondansha International. ISBN 4-7700-1553-4.
- Miyake, Marc Hideo (2003). Old Japanese: A Phonetic Reconstruction. New York, NY; London, England: RoutledgeCurzon.
- Morohashi, Tetsuji. 大漢和辞典 Dai Kan-Wa Jiten (Comprehensive Chinese–Japanese Dictionary) 1984–1986. Tokyo: Taishukan.
- Mitamura, Joyce Yumi and Mitamura, Yasuko Kosaka (1997). Let’s Learn Kanji. Tokyo: Kondansha International. ISBN 4-7700-2068-6.
- Unger, J. Marshall (1996). Literacy and Script Reform in Occupation Japan: Reading Between the Lines. ISBN 0-19-510166-9.
External links[edit]
![]()
Look up kanji in Wiktionary, the free dictionary.
![]()
Wikimedia Commons has media related to Kanji.
- Jim Breen’s WWWJDIC server used to find Kanji from English or romanized Japanese
- Change in Script Usage in Japanese: A Longitudinal Study of Japanese Government White Papers on Labor, discussion paper by Takako Tomoda in the Electronic Journal of Contemporary Japanese Studies, August 19, 2005.
- Jisho—Online Japanese dictionary
Glyph conversion[edit]
- A simple Shinjitai—Kyūjitai converter
- A practical Shinjitai—Kyūjitai—Simplified Chinese character converter
- A complex Shinjitai—Kyūjitai converter
- A downloadable Shinjitai—Kyūjitai—Simplified Chinese character converter Archived February 10, 2009, at the Wayback Machine
This article is about the Chinese-derived characters used in Japanese writing. For other uses, see Kanji (disambiguation).
| Kanji | |
|---|---|
|
Kanji written in kanji with furigana |
|
| Script type |
Logographic |
|
Time period |
5th century AD – present |
| Direction | vertical right-to-left, left-to-right |
| Languages | Old Japanese, Kanbun, Japanese, Ryukyuan languages |
| Related scripts | |
|
Parent systems |
Oracle bone script
|
|
Sister systems |
Hanja, Zhuyin, traditional Chinese, simplified Chinese, Chữ Hán, Chữ Nôm, Khitan script, Jurchen script, Tangut script, Yi script |
| ISO 15924 | |
| ISO 15924 | Hani (500), Han (Hanzi, Kanji, Hanja) |
| Unicode | |
|
Unicode alias |
Han |
| This article contains phonetic transcriptions in the International Phonetic Alphabet (IPA). For an introductory guide on IPA symbols, see Help:IPA. For the distinction between [ ], / / and ⟨ ⟩, see IPA § Brackets and transcription delimiters. |
Kanji (漢字, pronounced [kaɲdʑi] (![]() listen)) are the logographic Chinese characters taken from the Chinese script, and used in the writing of Japanese.[1] They were made a major part of the Japanese writing system during the time of Old Japanese and are still used, along with the subsequently-derived syllabic scripts of hiragana and katakana.[2][3] The characters have Japanese pronunciations; most have two, with one based on the Chinese sound. A few characters were invented in Japan by constructing character components derived from other Chinese characters. After World War II, Japan made its own efforts to simplify the characters, now known as shinjitai, by a process similar to China’s simplification efforts, with the intention to increase literacy among the common folk. Since the 1920s, the Japanese government has published character lists periodically to help direct the education of its citizenry through the myriad Chinese characters that exist. There are nearly 3,000 kanji used in Japanese names and in common communication.
listen)) are the logographic Chinese characters taken from the Chinese script, and used in the writing of Japanese.[1] They were made a major part of the Japanese writing system during the time of Old Japanese and are still used, along with the subsequently-derived syllabic scripts of hiragana and katakana.[2][3] The characters have Japanese pronunciations; most have two, with one based on the Chinese sound. A few characters were invented in Japan by constructing character components derived from other Chinese characters. After World War II, Japan made its own efforts to simplify the characters, now known as shinjitai, by a process similar to China’s simplification efforts, with the intention to increase literacy among the common folk. Since the 1920s, the Japanese government has published character lists periodically to help direct the education of its citizenry through the myriad Chinese characters that exist. There are nearly 3,000 kanji used in Japanese names and in common communication.
The term kanji in Japanese literally means «Han characters».[4] It is written in Japanese by using the same characters as in traditional Chinese, and both refer to the character writing system known in Chinese as hanzi (traditional Chinese: 漢字; simplified Chinese: 汉字; pinyin: hànzì; lit. ‘Han characters’).[5] The significant use of Chinese characters in Japan first began to take hold around the 5th century AD and has since had a profound influence in shaping Japanese culture, language, literature, history, and records.[6] Inkstone artifacts at archaeological sites dating back to the earlier Yayoi period were also found to contain Chinese characters.[7]
Although some characters, as used in Japanese and Chinese, have similar meanings and pronunciations, others have meanings or pronunciations that are unique to one language or the other. For example, 誠 means ‘honest’ in both languages but is pronounced makoto or sei in Japanese, and chéng in Standard Mandarin Chinese. Individual kanji characters invented in Japan, or multi-kanji words coined in Japanese, have also influenced and been borrowed into Chinese, Korean, and Vietnamese in recent times. For example, the word for telephone, 電話 denwa in Japanese, is calqued as diànhuà in Mandarin Chinese, điện thoại in Vietnamese and 전화 jeonhwa in Korean.[8]
History[edit]
Nihon Shoki (720 AD), considered by historians and archaeologists as the most complete extant historical record of ancient Japan, was written entirely in kanji.
Chinese characters first came to Japan on official seals, letters, swords, coins, mirrors, and other decorative items imported from China.[9] The earliest known instance of such an import was the King of Na gold seal given by Emperor Guangwu of Han to a Wa emissary in 57 AD.[10] Chinese coins as well as inkstones from the first century AD have also been found in Yayoi period archaeological sites.[6][7] However, the Japanese people of that era probably had little to no comprehension of the script, and they would remain relatively illiterate until the fifth century AD, when writing in Japan became more widespread.[6] According to the Nihon Shoki and Kojiki, a semi-legendary scholar called Wani was dispatched to Japan by the Kingdom of Baekje during the reign of Emperor Ōjin in the early fifth century, bringing with him knowledge of Confucianism and Chinese characters.[11]
The earliest Japanese documents were probably written by bilingual Chinese or Korean officials employed at the Yamato court.[6] For example, the diplomatic correspondence from King Bu of Wa to Emperor Shun of Liu Song in 478 AD has been praised for its skillful use of allusion. Later, groups of people called fuhito were organized under the monarch to read and write Classical Chinese. During the reign of Empress Suiko (593–628), the Yamato court began sending full-scale diplomatic missions to China, which resulted in a large increase in Chinese literacy at the Japanese court.[11]
In ancient times, paper was so rare that people wrote kanji onto thin, rectangular strips of wood, called mokkan (木簡). These wooden boards were used for communication between government offices, tags for goods transported between various countries, and the practice of writing. The oldest written kanji in Japan discovered so far were written in ink on wood as a wooden strip dated to the 7th century, a record of trading for cloth and salt.
The Japanese language had no written form at the time Chinese characters were introduced, and texts were written and read only in Chinese. Later, during the Heian period (794–1185), a system known as kanbun emerged, which involved using Chinese text with diacritical marks to allow Japanese speakers to read Chinese sentences and restructure them into Japanese on the fly, by changing word order and adding particles and verb endings, in accordance with the rules of Japanese grammar. This was essentially a kind of codified sight translation.
Chinese characters also came to be used to write texts in the vernacular Japanese language, resulting in the modern kana syllabaries. Around 650 AD, a writing system called man’yōgana (used in the ancient poetry anthology Man’yōshū) evolved that used a number of Chinese characters for their sound, rather than for their meaning. Man’yōgana written in cursive style evolved into hiragana (literally «fluttering kana» in reference to the motion of the brush during cursive writing), or onna-de, that is, «ladies’ hand»,[12] a writing system that was accessible to women (who were denied higher education). Major works of Heian-era literature by women were written in hiragana. Katakana (literally «partial kana«, in reference to the practice of using a part of a kanji character) emerged via a parallel path: monastery students simplified man’yōgana to a single constituent element. Thus the two other writing systems, hiragana and katakana, referred to collectively as kana, are descended from kanji. In contrast with kana (仮名, literally «borrowed name», in reference to the character being «borrowed» as a label for its sound), kanji are also called mana (真名, literally «true name», in reference to the character being used as a label for its meaning).
In modern Japanese, kanji are used to write certain words or parts of words (usually content words such as nouns, adjective stems, and verb stems), while hiragana are used to write inflected verb and adjective endings, phonetic complements to disambiguate readings (okurigana), particles, and miscellaneous words which have no kanji or whose kanji are considered obscure or too difficult to read or remember. Katakana are mostly used for representing onomatopoeia, non-Japanese loanwords (except those borrowed from ancient Chinese), the names of plants and animals (with exceptions), and for emphasis on certain words.
Orthographic reform and lists of kanji[edit]
Since ancient times, there has been a strong opinion in Japan that kanji is the orthodox form of writing, but there were also people who argued against it.[13] Kamo no Mabuchi, a scholar of the Edo period, criticized the large number of characters in kanji. He also appreciated the small number of characters in kana characters and argued for the limitation of kanji.
After the Meiji Restoration and as Japan entered an era of active exchange with foreign countries, the need for script reform in Japan began to be called for. Some scholars argued for the abolition of kanji and the writing of Japanese using only kana or Latin characters. However, these views were not so widespread.
However, the need to limit the number of kanji characters was understood, and in May 1923, the Japanese government announced 1,962 kanji characters for regular use. In 1940, the Japanese Army decided on the «Table of Restricted Kanji for Weapons Names» (兵器名称用制限漢字表, heiki meishō yō seigen kanji hyō) which limited the number of kanji that could be used for weapons names to 1,235. In 1942, the National Language Council announced the «Standard Kanji Table» (標準漢字表, hyōjun kanji-hyō) with a total of 2,528 characters, showing the standard for kanji used by ministries and agencies and in general society.[14]
In 1946, after World War II and under the Allied Occupation of Japan, the Japanese government, guided by the Supreme Commander of the Allied Powers, instituted a series of orthographic reforms, to help children learn and to simplify kanji use in literature and periodicals.
The number of characters in circulation was reduced, and formal lists of characters to be learned during each grade of school were established.
Some characters were given simplified glyphs, called shinjitai (新字体). Many variant forms of characters and obscure alternatives for common characters were officially discouraged.
These are simply guidelines, so many characters outside these standards are still widely known and commonly used; these are known as hyōgaiji (表外字).
Kyōiku kanji[edit]
The kyōiku kanji (教育漢字, lit. «education kanji») are the 1,026 first kanji characters that Japanese children learn in elementary school, from first grade to sixth grade. The grade-level breakdown is known as the gakunen-betsu kanji haitōhyō (学年別漢字配当表), or the gakushū kanji (学習漢字). This list of kanji is maintained by the Japanese Ministry of Education and prescribes which kanji characters and which kanji readings students should learn for each grade.
Jōyō kanji[edit]
The jōyō kanji (常用漢字, regular-use kanji) are 2,136 characters consisting of all the Kyōiku kanji, plus 1,110 additional kanji taught in junior high and high school.[15] In publishing, characters outside this category are often given furigana. The jōyō kanji were introduced in 1981, replacing an older list of 1,850 characters known as the tōyō kanji (当用漢字, general-use kanji), introduced in 1946. Originally numbering 1,945 characters, the jōyō kanji list was expanded to 2,136 in 2010. Some of the new characters were previously Jinmeiyō kanji; some are used to write prefecture names: 阪, 熊, 奈, 岡, 鹿, 梨, 阜, 埼, 茨, 栃 and 媛.
Jinmeiyō kanji[edit]
As of September 25, 2017, the jinmeiyō kanji (人名用漢字, kanji for use in personal names) consists of 863 characters. Kanji on this list are mostly used in people’s names and some are traditional variants of jōyō kanji. There were only 92 kanji in the original list published in 1952, but new additions have been made frequently. Sometimes the term jinmeiyō kanji refers to all 2,999 kanji from both the jōyō and jinmeiyō lists combined.
Hyōgai kanji[edit]
Hyōgai kanji (表外漢字, «unlisted characters») are any kanji not contained in the jōyō kanji and jinmeiyō kanji lists. These are generally written using traditional characters, but extended shinjitai forms exist.
Japanese Industrial Standards for kanji[edit]
The Japanese Industrial Standards for kanji and kana define character code-points for each kanji and kana, as well as other forms of writing such as the Latin alphabet, Cyrillic script, Greek alphabet, Arabic numerals, etc. for use in information processing. They have had numerous revisions. The current standards are:
- JIS X 0208,[16] the most recent version of the main standard. It has 6,355 kanji.
- JIS X 0212,[17] a supplementary standard containing a further 5,801 kanji. This standard is rarely used, mainly because the common Shift JIS encoding system could not use it. This standard is effectively obsolete.
- JIS X 0213,[18] a further revision which extended the JIS X 0208 set with 3,695 additional kanji, of which 2,743 (all but 952) were in JIS X 0212. The standard is in part designed to be compatible with Shift JIS encoding.
- JIS X 0221:1995, the Japanese version of the ISO 10646/Unicode standard.
Gaiji[edit]
Gaiji (外字, literally «external characters») are kanji that are not represented in existing Japanese encoding systems. These include variant forms of common kanji that need to be represented alongside the more conventional glyph in reference works and can include non-kanji symbols as well.
Gaiji can be either user-defined characters, system-specific characters or third-party add-on products.[19] Both are a problem for information interchange, as the code point used to represent an external character will not be consistent from one computer or operating system to another.
Gaiji were nominally prohibited in JIS X 0208-1997 where the available number of code-points was reduced to only 940.[20] JIS X 0213-2000 used the entire range of code-points previously allocated to gaiji, making them completely unusable. Most desktop and mobile systems have moved to Unicode negating the need for gaiji for most users. Nevertheless, they persist today in Japan’s three major mobile phone information portals, where they are used for emoji (pictorial characters).
Unicode allows for optional encoding of gaiji in private use areas, while Adobe’s SING (Smart INdependent Glyphlets)[21][22] technology allows the creation of customized gaiji.
The Text Encoding Initiative uses a ⟨g⟩ element to encode any non-standard character or glyph, including gaiji.[23] (The g stands for gaiji.)[24]
Total number of kanji[edit]
There is no definitive count of kanji characters, just as there is none of Chinese characters generally. The Dai Kan-Wa Jiten, which is considered to be comprehensive in Japan, contains about 50,000 characters. The Zhonghua Zihai, published in 1994 in China, contains about 85,000 characters, but the majority of them are not in common use in any country, and many are obscure variants or archaic forms.[25][26][27]
A list of 2,136 jōyō kanji (常用漢字) is regarded as necessary for functional literacy in Japanese. Approximately a thousand more characters are commonly used and readily understood by the majority in Japan and a few thousand more find occasional use, particularly in specialized fields of study but those may be obscure to most out of context. A total of 13,108 characters can be encoded in various Japanese Industrial Standards for kanji.
Readings[edit]
| Borrowing typology of Han characters | ||
|---|---|---|
| Meaning | Pronunciation | |
| a) semantic on | L1 | L1 |
| b) semantic kun | L1 | L2 |
| c) phonetic on | — | L1 |
| d) phonetic kun | — | L2 |
| *With L1 representing the language borrowed from (Chinese) and L2 representing the borrowing language (Japanese).[28] |
Because of the way they have been adopted into Japanese, a single kanji may be used to write one or more different words—or, in some cases, morphemes—and thus the same character may be pronounced in different ways. From the reader’s point of view, kanji are said to have one or more different «readings». Although more than one reading may become activated in the brain,[29] deciding which reading is appropriate depends on recognizing which word it represents, which can usually be determined from context, intended meaning, whether the character occurs as part of a compound word or an independent word, and sometimes location within the sentence. For example, 今日 is usually read kyō, meaning «today», but in formal writing is instead read konnichi, meaning «nowadays»; this is understood from context. Nevertheless, some cases are ambiguous and require a furigana gloss, which are used to simplify difficult readings or to specify a non-standard reading.
Kanji readings are categorized as either on’yomi (音読み, literally «sound reading», from Chinese) or kun’yomi (訓読み, literally «meaning reading», native Japanese), and most characters have at least two readings, at least one of each.
However, some characters have only a single reading, such as kiku (菊, «chrysanthemum», an on-reading) or iwashi (鰯, «sardine», a kun-reading); kun-only are common for Japanese-coined kanji (kokuji).
Some common kanji have ten or more possible readings; the most complex common example is 生, which is read as sei, shō, nama, ki, o-u, i-kiru, i-kasu, i-keru, u-mu, u-mareru, ha-eru, and ha-yasu, totaling eight basic readings (the first two are on, while the rest are kun), or 12 if related verbs are counted as distinct; see okurigana § 生 for details.
Most often, a character will be used for both sound and meaning, and it is simply a matter of choosing the correct reading based on which word it represents.
On’yomi (Sino-Japanese reading) [edit]
The on’yomi (音読み, [oɰ̃jomi], lit. «sound(-based) reading»), the Sino-Japanese reading, is the modern descendant of the Japanese approximation of the base Chinese pronunciation of the character at the time it was introduced. It was often previously referred to as translation reading, as it was recreated readings of the Chinese pronunciation but was not the Chinese pronunciation or reading itself, similar to the English pronunciation of Latin loanwords. Old Japanese scripts often stated that on’yomi readings were also created by the Japanese during their arrival and re-borrowed by the Chinese as their own. There also exist kanji created by the Japanese and given an on’yomi reading despite not being a Chinese-derived or a Chinese-originating character. Some kanji were introduced from different parts of China at different times, and so have multiple on’yomi, and often multiple meanings. Kanji invented in Japan (kokuji) would not normally be expected to have on’yomi, but there are exceptions, such as the character 働 «to work», which has the kun’yomi «hatara(ku)» and the on’yomi «dō«, and 腺 «gland», which has only the on’yomi «sen«—in both cases these come from the on’yomi of the phonetic component, respectively 動 «dō» and 泉 «sen«.
Generally, on’yomi are classified into four types according to their region and time of origin:
- Go-on (呉音, «Wu sound») readings derive from the pronunciation used in the Northern and Southern dynasties of China during the 5th and 6th centuries, primarily from the speech of the capital Jiankang (today’s Nanjing). They are related to Wu Chinese and the Shanghainese language.
- Kan-on (漢音, «Han sound») readings come from the pronunciation utilized during the Tang dynasty of China in the 7th to 9th centuries, primarily from the standard speech of the capital, Chang’an (modern Xi’an). Here, Kan refers to Han Chinese people or China proper.
- Tō-on (唐音, «Tang sound») readings are based on the pronunciations of later dynasties of China, such as the Song and Ming. They cover all readings adopted from the Heian era to the Edo period. This is also known as Tōsō-on (唐宋音, Tang and Song sound).
- Kan’yō-on (慣用音, «customary sound») readings, which are mistaken or changed readings of the kanji that have become accepted into the Japanese language. In some cases, they are the actual readings that accompanied the character’s introduction to Japan but do not match how the character «should» (is prescribed to) be read according to the rules of character construction and pronunciation.
| Kanji | Meaning | Go-on | Kan-on | Tō-on | Kan’yō-on |
|---|---|---|---|---|---|
| 明 | bright | myō | mei | (min) | — |
| 行 | go | gyō gō |
kō kō |
(an) | — |
| 極 | extreme | goku | kyoku | — | — |
| 珠 | pearl | shu | shu | ju | (zu) |
| 度 | degree | do | (to) | — | — |
| 輸 | transport | (shu) | (shu) | — | yu |
| 雄 | masculine | — | — | — | yū |
| 熊 | bear | — | — | — | yū |
| 子 | child | shi | shi | su | — |
| 清 | clear | shō | sei | (shin) | — |
| 京 | capital | kyō | kei | (kin) | — |
| 兵 | soldier | hyō | hei | — | — |
| 強 | strong | gō | kyō | — | — |
The most common form of readings is the kan-on one, and use of a non-kan-on reading in a word where the kan-on reading is well known is a common cause of reading mistakes or difficulty, such as in ge-doku (解毒, detoxification, anti-poison) (go-on), where 解 is usually instead read as kai. The go-on readings are especially common in Buddhist terminology such as gokuraku (極楽, paradise), as well as in some of the earliest loans, such as the Sino-Japanese numbers. The tō-on readings occur in some later words, such as isu (椅子, chair), futon (布団, mattress), and andon (行灯, a kind of paper lantern). The go-on, kan-on, and tō-on readings are generally cognate (with rare exceptions of homographs; see below), having a common origin in Old Chinese, and hence form linguistic doublets or triplets, but they can differ significantly from each other and from modern Chinese pronunciation.
In Chinese, most characters are associated with a single Chinese sound, though there are distinct literary and colloquial readings. However, some homographs (多音字 pinyin: duōyīnzì) such as 行 (háng or xíng) (Japanese: an, gō, gyō) have more than one reading in Chinese representing different meanings, which is reflected in the carryover to Japanese as well. Additionally, many Chinese syllables, especially those with an entering tone, did not fit the largely consonant-vowel (CV) phonotactics of classical Japanese. Thus most on’yomi are composed of two morae (beats), the second of which is either a lengthening of the vowel in the first mora (to ei, ō, or ū), the vowel i, or one of the syllables ku, ki, tsu, chi, fu (historically, later merged into ō and ū), or moraic n, chosen for their approximation to the final consonants of Middle Chinese. It may be that palatalized consonants before vowels other than i developed in Japanese as a result of Chinese borrowings, as they are virtually unknown in words of native Japanese origin, but are common in Chinese.
On’yomi primarily occur in multi-kanji compound words (熟語, jukugo), many of which are the result of the adoption, along with the kanji themselves, of Chinese words for concepts that either did not exist in Japanese or could not be articulated as elegantly using native words. This borrowing process is often compared to the English borrowings from Latin, Greek, and Norman French, since Chinese-borrowed terms are often more specialized, or considered to sound more erudite or formal, than their native counterparts (occupying a higher linguistic register). The major exception to this rule is family names, in which the native kun’yomi are usually used (though on’yomi are found in many personal names, especially men’s names).
Kun’yomi (native reading) [edit]
The kun’yomi (訓読み, [kɯɰ̃jomi], lit. «meaning reading»), the native reading, is a reading based on the pronunciation of a native Japanese word, or yamato kotoba, that closely approximated the meaning of the Chinese character when it was introduced. As with on’yomi, there can be multiple kun’yomi for the same kanji, and some kanji have no kun’yomi at all.
For instance, the character for east, 東, has the on’yomi tō, from Middle Chinese tung. However, Japanese already had two words for «east»: higashi and azuma. Thus the kanji 東 had the latter readings added as kun’yomi. In contrast, the kanji 寸, denoting a Chinese unit of measurement (about 30 mm or 1.2 inch), has no native Japanese equivalent; it only has an on’yomi, sun, with no native kun’yomi. Most kokuji, Japanese-created Chinese characters, only have kun’yomi, although some have back-formed a pseudo-on’yomi by analogy with similar characters, such as 働 dō, from 動 dō, and there are even some, such as 腺 sen «gland», that have only an on’yomi.
Kun’yomi are characterized by the strict (C)V syllable structure of yamato kotoba. Most noun or adjective kun’yomi are two to three syllables long, while verb kun’yomi are usually between one and three syllables in length, not counting trailing hiragana called okurigana. Okurigana are not considered to be part of the internal reading of the character, although they are part of the reading of the word. A beginner in the language will rarely come across characters with long readings, but readings of three or even four syllables are not uncommon. This contrasts with on’yomi, which are monosyllabic, and is unusual in the Chinese family of scripts, which generally use one character per syllable—not only in Chinese, but also in Korean, Vietnamese, and Zhuang; polysyllabic Chinese characters are rare and considered non-standard.
承る uketamawaru, 志 kokorozashi, and 詔 mikotonori have five syllables represented by a single kanji, the longest readings in the jōyō character set. These unusually long readings are due to a single character representing a compound word:
- 承る is a single character for a compound verb, one component of which has a long reading.
- It has an alternative spelling as 受け賜る u(ke)-tamawa(ru), hence (1+1)+3=5.
- Compare common 受け付ける u(ke)-tsu(keru).
- 志 is a nominalization of the verb 志す which has a long reading kokoroza(su).
- This is due to its being derived from a noun-verb compound, 心指す kokoro-za(su).
- The nominalization removes the okurigana, hence increasing the reading by one mora, yielding 4+1=5.
- Compare common 話 hanashi 2+1=3, from 話す hana(su).
- 詔 is a triple compound.
- It has an alternative spelling 御言宣 mi-koto-nori, hence 1+2+2=5.
Further, some Jōyō characters have long non-Jōyō readings (students learn the character, but not the reading), such as omonpakaru for 慮る.
In a number of cases, multiple kanji were assigned to cover a single Japanese word. Typically when this occurs, the different kanji refer to specific shades of meaning. For instance, the word なおす, naosu, when written 治す, means «to heal an illness or sickness». When written 直す it means «to fix or correct something». Sometimes the distinction is very clear, although not always. Differences of opinion among reference works are not uncommon; one dictionary may say the kanji are equivalent, while another dictionary may draw distinctions of use. As a result, native speakers of the language may have trouble knowing which kanji to use and resort to personal preference or by writing the word in hiragana. This latter strategy is frequently employed with more complex cases such as もと moto, which has at least five different kanji: 元, 基, 本, 下, and 素, the first three of which have only very subtle differences. Another notable example is sakazuki «sake cup», which may be spelt as at least five different kanji: 杯, 盃, 巵/卮, and 坏; of these, the first two are common—formally 杯 is a small cup and 盃 a large cup.
Local dialectical readings of kanji are also classified under kun’yomi, most notably readings for words in Ryukyuan languages. Further, in rare cases gairaigo (borrowed words) have a single character associated with them, in which case this reading is formally classified as a kun’yomi, because the character is being used for meaning, not sound.
Ateji[edit]
Ateji (当て字, 宛字 or あてじ) are characters used only for their sounds. In this case, pronunciation is still based on a standard reading, or used only for meaning (broadly a form of ateji, narrowly jukujikun). Therefore, only the full compound—not the individual character—has a reading. There are also special cases where the reading is completely different, often based on a historical or traditional reading.
The analogous phenomenon occurs to a much lesser degree in Chinese varieties, where there are literary and colloquial readings of Chinese characters—borrowed readings and native readings. In Chinese these borrowed readings and native readings are etymologically related, since they are between Chinese varieties (which are related), not from Chinese to Japanese (which are not related). They thus form doublets and are generally similar, analogous to different on’yomi, reflecting different stages of Chinese borrowings into Japanese.
Gairaigo[edit]
Longer readings exist for non-Jōyō characters and non-kanji symbols, where a long gairaigo word may be the reading (this is classed as kun’yomi—see single character gairaigo, below)—the character 糎 has the seven kana reading センチメートル senchimētoru «centimeter», though it is generally written as «cm» (with two half-width characters, so occupying one space); another common example is ‘%’ (the percent sign), which has the five kana reading パーセント pāsento.
Mixed readings [edit]
A jūbako (重箱), which has a mixed on-kun reading
A yutō (湯桶), which has a mixed kun-on reading
There are many kanji compounds that use a mixture of on’yomi and kun’yomi, known as jūbako yomi (重箱読み, multi-layered food box) or yutō (湯桶, hot liquid pail) words (depending on the order), which are themselves examples of this kind of compound (they are autological words): the first character of jūbako is read using on’yomi, the second kun’yomi (on-kun, 重箱読み).
It is the other way around with yu-tō (kun-on, 湯桶読み).
Formally, these are referred to as jūbako-yomi (重箱読み, jūbako reading) and yutō-yomi (湯桶読み, yutō reading). Note that in both these words, the on’yomi has a long vowel; long vowels in Japanese generally are derived from sound changes common to loans from Chinese, hence distinctive of on’yomi. These are the Japanese form of hybrid words. Other examples include basho (場所, «place», kun-on, 湯桶読み), kin’iro (金色, «golden», on-kun, 重箱読み) and aikidō (合気道, the martial art Aikido», kun-on-on, 湯桶読み).
Ateji often use mixed readings. For instance the city of Sapporo (サッポロ), whose name derives from the Ainu language and has no meaning in Japanese, is written with the on-kun compound 札幌 (which includes sokuon as if it were a purely on compound).
Special readings[edit]
Gikun (義訓) and jukujikun (熟字訓) are readings of kanji combinations that have no direct correspondence to the characters’ individual on’yomi or kun’yomi. From the point of view of the character, rather than the word, this is known as a 難訓 (nankun, «difficult reading»), and these are listed in kanji dictionaries under the entry for the character.
Gikun are other readings assigned to a character instead of its standard readings. An example is reading 寒 (meaning «cold») as fuyu («winter») rather than the standard readings samu or kan, and instead of the usual spelling for fuyu of 冬. Another example is using 煙草 (lit. «smoke grass») with the reading tabako («tobacco») rather than the otherwise-expected readings of kemuri-gusa or ensō. Some of these, such as for tabako, have become lexicalized, but in many cases this kind of use is typically non-standard and employed in specific contexts by individual writers. Aided with furigana, gikun could be used to convey complex literary or poetic effect (especially if the readings contradict the kanji), or clarification if the referent may not be obvious.
Jukujikun are when the standard kanji for a word are related to the meaning, but not the sound. The word is pronounced as a whole, not corresponding to sounds of individual kanji. For example, 今朝 («this morning») is jukujikun. This word is not read as *ima’asa, the expected kun’yomi of the characters, and only infrequently as konchō, the on’yomi of the characters. The most common reading is kesa, a native bisyllabic Japanese word that may be seen as a single morpheme, or as a compound of ke (“this”, as in kefu, the older reading for 今日, “today”), and asa, “morning”.[30] Likewise, 今日 («today») is also jukujikun, usually read with the native reading kyō; its on’yomi, konnichi, does occur in certain words and expressions, especially in the broader sense «nowadays» or «current», such as 今日的 («present-day»), although in the phrase konnichi wa («good day»), konnichi is typically spelled wholly with hiragana rather than with the kanji 今日.
Jukujikun are primarily used for some native Japanese words, such as Yamato (大和 or 倭, the name of the dominant ethnic group of Japan, a former Japanese province as well as ancient name for Japan), and for some old borrowings, such as 柳葉魚 (shishamo, literally «willow leaf fish») from Ainu, 煙草 (tabako, literally “smoke grass”) from Portuguese, or 麦酒 (bīru, literally “wheat alcohol”) from Dutch, especially if the word was borrowed before the Meiji Period. Words whose kanji are jukujikun are often usually written as hiragana (if native), or katakana (if borrowed); some old borrowed words are also written as hiragana, especially Portuguese loanwords such as かるた (karuta) from Portuguese «carta» (English “card”) or てんぷら (tempura) from Portuguese «tempora» (English “times, season”),[citation needed] as well as たばこ (tabako).
Sometimes, jukujikun can even have more kanji than there are syllables, examples being kera (啄木鳥, “woodpecker”), gumi (胡頽子, “silver berry, oleaster”),[31] and Hozumi (八月朔日, a surname).[32] This phenomenon is observed in animal names that are shortened and used as suffixes for zoological compound names, for example when 黄金虫, normally read as koganemushi, is shortened to kogane in 黒黄金虫 kurokogane, although zoological names are commonly spelled with katakana rather than with kanji. Outside zoology, this type of shortening only occurs on a handful of words, for example 大元帥 daigen(sui), or the historical male name suffix 右衛門 -emon, which was shortened from the word uemon.
Jukujikun are quite varied. Often the kanji compound for jukujikun is idiosyncratic and created for the word, and there is no corresponding Chinese word with that spelling. In other cases a kanji compound for an existing Chinese word is reused, where the Chinese word and on’yomi may or may not be used in Japanese. For example, 馴鹿 (“reindeer”) is jukujikun for tonakai, from Ainu, but the on’yomi reading of junroku is also used. In some cases, Japanese coinages have subsequently been borrowed back into Chinese, such as 鮟鱇 (ankō, “monkfish”).
The underlying word for jukujikun is a native Japanese word or foreign borrowing, which either does not have an existing kanji spelling (either kun’yomi or ateji) or for which a new kanji spelling is produced. Most often the word is a noun, which may be a simple noun (not a compound or derived from a verb), or may be a verb form or a fusional pronunciation. For example, the word 相撲 (sumō, “sumo”) is originally from the verb 争う (sumau, “to vie, to compete”), while 今日 (kyō, “today”) is fusional (from older ke, “this” + fu, “day”).
In rare cases jukujikun is also applied to inflectional words (verbs and adjectives), in which case there is frequently a corresponding Chinese word. The most common example of an inflectional jukujikun is the adjective 可愛い (kawai-i, “cute”), originally kawafayu-i; the word (可愛) is used in Chinese, but the corresponding on’yomi is not used in Japanese. By contrast, «appropriate» can be either 相応しい (fusawa-shii, as jukujikun) or 相応 (sōō, as on’yomi). Which reading to use can be discerned by the presence or absence of the -shii ending (okurigana). A common example of a verb with jukujikun is 流行る (haya-ru, “to spread, to be in vogue”), corresponding to on’yomi 流行 (ryūkō). A sample jukujikun deverbal (noun derived from a verb form) is 強請 (yusuri, “extortion”), from 強請る (yusu-ru, “to extort”), spelling from 強請 (kyōsei, “extortion”). See the 義訓 and 熟字訓 articles in the Japanese Wikipedia for many more examples. Note that there are also compound verbs and, less commonly, compound adjectives, and while these may have multiple kanji without intervening characters, they are read using the usual kun’yomi. Examples include 面白い (omo-shiro-i, “interesting”, literally “face + white”) and 狡賢い (zuru-gashiko-i, “sly”, literally “cunning, crafty + clever, smart”).
Typographically, the furigana for jukujikun are often written so they are centered across the entire word, or for inflectional words over the entire root—corresponding to the reading being related to the entire word—rather than each part of the word being centered over its corresponding character, as is often done for the usual phono-semantic readings.
Broadly speaking, jukujikun can be considered a form of ateji, though in narrow usage «ateji» refers specifically to using characters for sound and not meaning (sound-spelling), whereas «jukujikun» refers to using characters for their meaning and not sound (meaning-spelling).
Many jukujikun (established meaning-spellings) began life as gikun (improvised meaning-spellings). Occasionally a single word will have many such kanji spellings. An extreme example is hototogisu (lesser cuckoo), which may be spelt in a great many ways, including 杜鵑, 時鳥, 子規, 不如帰, 霍公鳥, 蜀魂, 沓手鳥, 杜宇,田鵑, 沓直鳥, and 郭公—many of these variant spellings are particular to haiku poems.
Single character gairaigo[edit]
In some rare cases, an individual kanji has a reading that is borrowed from a modern foreign language (gairaigo), though most often these words are written in katakana. Notable examples include pēji (頁、ページ, page), botan (釦/鈕、ボタン, button), zero (零、ゼロ, zero), and mētoru (米、メートル, meter). See list of single character gairaigo for more. These are classed as kun’yomi of a single character, because the character is being used for meaning only (without the Chinese pronunciation), rather than as ateji, which is the classification used when a gairaigo term is written as a compound (2 or more characters). However, unlike the vast majority of other kun’yomi, these readings are not native Japanese, but rather borrowed, so the «kun’yomi» label can be misleading. The readings are also written in katakana, unlike the usual hiragana for native kun’yomi. Note that most of these characters are for units, particularly SI units, in many cases using new characters (kokuji) coined during the Meiji period, such as kiromētoru (粁、キロメートル, kilometer, 米 «meter» + 千 «thousand»).
Nanori[edit]
Some kanji also have lesser-known readings called nanori (名乗り), which are mostly used for names (often given names) and, in general, are closely related to the kun’yomi. Place names sometimes also use nanori or, occasionally, unique readings not found elsewhere.
When to use which reading[edit]
Although there are general rules for when to use on’yomi and when to use kun’yomi, the language is littered with exceptions, and it is not always possible for even a native speaker to know how to read a character without prior knowledge (this is especially true for names, both of people and places); further, a given character may have multiple kun’yomi or on’yomi. When reading Japanese, one primarily recognizes words (multiple characters and okurigana) and their readings, rather than individual characters, and only guess readings of characters when trying to «sound out» an unrecognized word.
Homographs exist, however, which can sometimes be deduced from context, and sometimes cannot, requiring a glossary. For example, 今日 may be read either as kyō «today (informal)» (special fused reading for native word) or as konnichi «these days (formal)» (on’yomi); in formal writing this will generally be read as konnichi.
In some cases multiple readings are common, as in 豚汁 «pork soup», which is commonly pronounced both as ton-jiru (mixed on-kun) and buta-jiru (kun-kun), with ton somewhat more common nationally. Inconsistencies abound—for example 牛肉 gyū-niku «beef» and 羊肉 yō-niku «mutton» have on-on readings, but 豚肉 buta-niku «pork» and 鶏肉 tori-niku «poultry» have kun-on readings.
The main guideline is that a single kanji followed by okurigana (hiragana characters that are part of the word)—as used in native verbs and adjectives—always indicates kun’yomi, while kanji compounds (kango) usually use on’yomi, which is usually kan-on; however, other on’yomi are also common, and kun’yomi are also commonly used in kango.
For a kanji in isolation without okurigana, it is typically read using their kun’yomi, though there are numerous exceptions. For example, 鉄 «iron» is usually read with the on’yomi tetsu rather than the kun’yomi kurogane. Chinese on’yomi which are not the common kan-on reading are a frequent cause of difficulty or mistakes when encountering unfamiliar words or for inexperienced readers, though skilled natives will recognize the word; a good example is ge-doku (解毒, detoxification, anti-poison) (go-on), where (解) is usually instead read as kai.
Okurigana (送り仮名) are used with kun’yomi to mark the inflected ending of a native verb or adjective, or by convention. Note that Japanese verbs and adjectives are closed class, and do not generally admit new words (borrowed Chinese vocabulary, which are nouns, can form verbs by adding -suru (〜する, to do) at the end, and adjectives via 〜の -no or 〜な -na, but cannot become native Japanese vocabulary, which inflect). For example: 赤い aka-i «red», 新しい atara-shii «new», 見る mi-ru «(to) see». Okurigana can be used to indicate which kun’yomi to use, as in 食べる ta-beru versus 食う ku-u (casual), both meaning «(to) eat», but this is not always sufficient, as in 開く, which may be read as a-ku or hira-ku, both meaning «(to) open». 生 is a particularly complicated example, with multiple kun and on’yomi—see okurigana: 生 for details. Okurigana is also used for some nouns and adverbs, as in 情け nasake «sympathy», 必ず kanarazu «invariably», but not for 金 kane «money», for instance. Okurigana is an important aspect of kanji usage in Japanese; see that article for more information on kun’yomi orthography
Kanji occurring in compounds (multi-kanji words) (熟語, jukugo) are generally read using on’yomi, especially for four-character compounds (yojijukugo). Though again, exceptions abound, for example, 情報 jōhō «information», 学校 gakkō «school», and 新幹線 shinkansen «bullet train» all follow this pattern. This isolated kanji versus compound distinction gives words for similar concepts completely different pronunciations. 北 «north» and 東 «east» use the kun’yomi kita and higashi, being stand-alone characters, but 北東 «northeast», as a compound, uses the on’yomi hokutō. This is further complicated by the fact that many kanji have more than one on’yomi: 生 is read as sei in 先生 sensei «teacher» but as shō in 一生 isshō «one’s whole life». Meaning can also be an important indicator of reading; 易 is read i when it means «simple», but as eki when it means «divination», both being on’yomi for this character.
These rules of thumb have many exceptions. Kun’yomi compound words are not as numerous as those with on’yomi, but neither are they rare. Examples include 手紙 tegami «letter», 日傘 higasa «parasol», and the famous 神風 kamikaze «divine wind». Such compounds may also have okurigana, such as 空揚げ (also written 唐揚げ) karaage «Chinese-style fried chicken» and 折り紙 origami, although many of these can also be written with the okurigana omitted (for example, 空揚 or 折紙). In general, compounds coined in Japan using japanese roots will be read in kun’yomi while those imported from China will be read in on’yomi.
Similarly, some on’yomi characters can also be used as words in isolation: 愛 ai «love», 禅 Zen, 点 ten «mark, dot». Most of these cases involve kanji that have no kun’yomi, so there can be no confusion, although exceptions do occur. Alone 金 may be read as kin «gold» or as kane «money, metal»; only context can determine the writer’s intended reading and meaning.
Multiple readings have given rise to a number of homographs, in some cases having different meanings depending on how they are read. One example is 上手, which can be read in three different ways: jōzu (skilled), uwate (upper part), or kamite (stage left/house right). In addition, 上手い has the reading umai (skilled). More subtly, 明日 has three different readings, all meaning «tomorrow»: ashita (casual), asu (polite), and myōnichi (formal). Furigana (reading glosses) is often used to clarify any potential ambiguities.
Conversely, in some cases homophonous terms may be distinguished in writing by different characters, but not so distinguished in speech, and hence potentially confusing. In some cases when it is important to distinguish these in speech, the reading of a relevant character may be changed. For example, 私立 (privately established, esp. school) and 市立 (city established) are both normally pronounced shi-ritsu; in speech these may be distinguished by the alternative pronunciations watakushi-ritsu and ichi-ritsu. More informally, in legal jargon 前文 «preamble» and 全文 «full text» are both pronounced zen-bun, so 前文 may be pronounced mae-bun for clarity, as in «Have you memorized the preamble [not ‘whole text’] of the constitution?». As in these examples, this is primarily using a kun’yomi for one character in a normally on’yomi term.
As stated above, jūbako and yutō readings are also not uncommon. Indeed, all four combinations of reading are possible: on-on, kun-kun, kun-on and on-kun.
Legalese[edit]
Certain words take different readings depending on whether the context concerns legal matters or not. For example:
| Word | Common reading | Legalese reading |
|---|---|---|
| 懈怠 («negligence»)[33] | ketai | kaitai |
| 競売 («auction»)[33] | kyōbai | keibai |
| 兄弟姉妹 («siblings») | kyōdai shimai | keitei shimai |
| 境界 («metes and bounds») | kyōkai | keikai |
| 競落 («acquisition at an auction»)[33] | kyōraku | keiraku |
| 遺言 («will»)[33] | yuigon | igon |
For legal contexts where distinction must be made for homophonous words such as baishun and karyō, see Ambiguous readings below.
Ambiguous readings[edit]
In some instances where even context cannot easily provide clarity for homophones, alternative readings or mixed readings can be used instead of regular readings to avoid ambiguity. For example:
| Ambiguous reading | Disambiguated readings |
|---|---|
| baishun | baishun (売春, «selling sex», on)
kaishun (買春, «buying sex», yutō)[34] |
| itoko | jūkeitei (従兄弟, «male cousin», on)
jūshimai (従姉妹, «female cousin», on) jūkei (従兄, «older male cousin», on) jūshi (従姉, «older female cousin», on) jūtei (従弟, «younger male cousin», on) jūmai (従妹, «younger female cousin», on) |
| jiten | kotobaten (辞典, «word dictionary», yutō)[34]
kototen (事典, «encyclopedia», yutō)[34][33] mojiten (字典, «character dictionary», irregular, from moji (文字, «character»))[34] |
| kagaku | kagaku (科学, «science», on)
bakegaku (化学, «chemistry», yutō)[34][33] |
| karyō | ayamachiryō (過料, «administrative fine», yutō)[34][33]
togaryō (科料, «misdemeanor fine», yutō)[34][33] |
| Kōshin | Kinoesaru (甲申, «Greater-Wood-Monkey year», kun)
Kinoetatsu (甲辰, «Greater-Wood-Dragon year», kun) Kanoesaru (庚申, «Greater-Fire-Monkey year», kun) Kanoetatsu (庚辰, «Greater-Fire-Dragon year», kun) |
| Shin | Hatashin (秦, «Qin», irregular, from the alternative reading Hata used as a family name)[34][33]
Susumushin (晋, «Jin», irregular, from the alternative reading Susumu used as a personal name)[34][33] |
| shiritsu | ichiritsu (市立, «municipal», yutō)[34][33]
watakushiritsu (私立, «private», yutō)[34][33] |
Place names[edit]
Several famous place names, including those of Japan itself (日本 Nihon or sometimes Nippon), those of some cities such as Tokyo (東京 Tōkyō) and Kyoto (京都 Kyōto), and those of the main islands Honshu (本州 Honshū), Kyushu (九州 Kyūshū), Shikoku (四国 Shikoku), and Hokkaido (北海道 Hokkaidō) are read with on’yomi; however, the majority of Japanese place names are read with kun’yomi: 大阪 Ōsaka, 青森 Aomori, 箱根 Hakone. Names often use characters and readings that are not in common use outside of names. When characters are used as abbreviations of place names, their reading may not match that in the original. The Osaka (大阪) and Kobe (神戸) baseball team, the Hanshin (阪神) Tigers, take their name from the on’yomi of the second kanji of Ōsaka and the first of Kōbe. The name of the Keisei (京成) railway line—linking Tokyo (東京) and Narita (成田)—is formed similarly, although the reading of 京 from 東京 is kei, despite kyō already being an on’yomi in the word Tōkyō.
Japanese family names are also usually read with kun’yomi: 山田 Yamada, 田中 Tanaka, 鈴木 Suzuki. Japanese given names often have very irregular readings. Although they are not typically considered jūbako or yutō, they often contain mixtures of kun’yomi, on’yomi and nanori, such as 大助 Daisuke [on-kun], 夏美 Natsumi [kun-on]. Being chosen at the discretion of the parents, the readings of given names do not follow any set rules, and it is impossible to know with certainty how to read a person’s name without independent verification. Parents can be quite creative, and rumours abound of children called 地球 Āsu («Earth») and 天使 Enjeru («Angel»); neither are common names, and have normal readings chikyū and tenshi respectively. Some common Japanese names can be written in multiple ways, e.g. Akira can be written as 亮, 彰, 明, 顕, 章, 聴, 光, 晶, 晄, 彬, 昶, 了, 秋良, 明楽, 日日日, 亜紀良, 安喜良 and many other characters and kanji combinations not listed,[35] Satoshi can be written as 聡, 哲, 哲史, 悟, 佐登史, 暁, 訓, 哲士, 哲司, 敏, 諭, 智, 佐登司, 總, 里史, 三十四, 了, 智詞, etc.,[36] and Haruka can be written as 遥, 春香, 晴香, 遥香, 春果, 晴夏, 春賀, 春佳, and several other possibilities.[37] Common patterns do exist, however, allowing experienced readers to make a good guess for most names. To alleviate any confusion on how to pronounce the names of other Japanese people, most official Japanese documents require Japanese to write their names in both kana and kanji.[32]
Chinese place names and Chinese personal names appearing in Japanese texts, if spelled in kanji, are almost invariably read with on’yomi. Especially for older and well-known names, the resulting Japanese pronunciation may differ widely from that used by modern Chinese speakers. For example, Mao Zedong’s name is pronounced as Mō Takutō (毛沢東) in Japanese, and the name of the legendary Monkey King, Sun Wukong, is pronounced Son Gokū (孫悟空) in Japanese.
Today, Chinese names that are not well known in Japan are often spelled in katakana instead, in a form much more closely approximating the native Chinese pronunciation. Alternatively, they may be written in kanji with katakana furigana. Many such cities have names that come from non-Chinese languages like Mongolian or Manchu. Examples of such not-well-known Chinese names include:
| English name | Japanese name | ||
|---|---|---|---|
| Rōmaji | Katakana | Kanji | |
| Harbin | Harubin | ハルビン | 哈爾浜 |
| Ürümqi | Urumuchi | ウルムチ | 烏魯木斉 |
| Qiqihar | Chichiharu | チチハル | 斉斉哈爾 |
| Lhasa | Rasa | ラサ | 拉薩 |
Internationally renowned Chinese-named cities tend to imitate the older English pronunciations of their names, regardless of the kanji’s on’yomi or the Mandarin or Cantonese pronunciation, and can be written in either katakana or kanji. Examples include:
| English name | Mandarin name (Pinyin) | Hokkien name (Tâi-lô) | Cantonese name (Yale) | Japanese name | ||
|---|---|---|---|---|---|---|
| Kanji | Katakana | Rōmaji | ||||
| Hong Kong | Xianggang | Hiong-káng / Hiang-káng | Hēung Góng | 香港 | ホンコン | Honkon |
| Macao/Macau | Ao’men | ò-mn̂g / ò-bûn | Ou Mùhn | 澳門 | マカオ | Makao |
| Shanghai | Shanghai | Siōng-hái / Siāng-hái | Seuhng Hói | 上海 | シャンハイ | Shanhai |
| Beijing/Peking | Beijing | Pak-kiann | Bāk Gīng | 北京 | ペキン | Pekin |
| Nanjing/Nanking | Nanjing | Lâm-kiann | Nàahm Gīng | 南京 | ナンキン | Nankin |
| Taipei | Taibei | Tâi-pak | Tòih Bāk | 台北 | タイペイ / タイホク | Taipei / Taihoku |
| Kaohsiung | Gaoxiong / Dagou | Ko-hiông | Gōu Hùhng | 高雄 / 打狗 | カオシュン / タカオ | Kaoshun / Takao |
Notes:
- Guangzhou, the city, is pronounced Kōshū, while Guangdong, its province, is pronounced Kanton, not Kōtō (in this case, opting for a Tō-on reading rather than the usual Kan-on reading).
- Kaohsiung was originally pronounced Takao (or similar) in Hokkien and Japanese. It received this written name (kanji/Chinese) from Japanese, and later its spoken Mandarin name from the corresponding characters. The English name «Kaohsiung» derived from its Mandarin pronunciation. Today it is pronounced either カオシュン or タカオ in Japanese.
- Taipei is generally pronounced たいほく in Japanese.
In some cases the same kanji can appear in a given word with different readings. Normally this occurs when a character is duplicated and the reading of the second character has voicing (rendaku), as in 人人 hito-bito «people» (more often written with the iteration mark as 人々), but in rare cases the readings can be unrelated, as in tobi-haneru (跳び跳ねる, «hop around», more often written 飛び跳ねる).
Pronunciation assistance[edit]
Because of the ambiguities involved, kanji sometimes have their pronunciation for the given context spelled out in ruby characters known as furigana, (small kana written above or to the right of the character) or kumimoji (small kana written in-line after the character). This is especially true in texts for children or foreign learners. It is also used in newspapers and manga for rare or unusual readings, or for situations like the first time a character’s name is given, and for characters not included in the officially recognized set of essential kanji. Works of fiction sometimes use furigana to create new «words» by giving normal kanji non-standard readings, or to attach a foreign word rendered in katakana as the reading for a kanji or kanji compound of the same or similar meaning.
Spelling words[edit]
Conversely, specifying a given kanji, or spelling out a kanji word—whether the pronunciation is known or not—can be complicated, due to the fact that there is not a commonly used standard way to refer to individual kanji (one does not refer to «kanji #237»), and that a given reading does not map to a single kanji—indeed there are many homophonous words, not simply individual characters, particularly for kango (with on’yomi). Easiest is to write the word out—either on paper or tracing it in the air—or look it up (given the pronunciation) in a dictionary, particularly an electronic dictionary; when this is not possible, such as when speaking over the phone or writing implements are not available (and tracing in air is too complicated), various techniques can be used. These include giving kun’yomi for characters—these are often unique—using a well-known word with the same character (and preferably the same pronunciation and meaning), and describing the character via its components. For example, one may explain how to spell the word kōshinryō (香辛料, spice) via the words kao-ri (香り, fragrance), kara-i (辛い, spicy), and in-ryō (飲料, beverage)—the first two use the kun’yomi, the third is a well-known compound—saying «kaori, karai, ryō as in inryō.»
Dictionaries[edit]
In dictionaries, both words and individual characters have readings glossed, via various conventions. Native words and Sino-Japanese vocabulary are glossed in hiragana (for both kun and on readings), while borrowings (gairaigo)—including modern borrowings from Chinese—are glossed in katakana; this is the standard writing convention also used in furigana. By contrast, readings for individual characters are conventionally written in katakana for on readings, and hiragana for kun readings. Kun readings may further have a separator to indicate which characters are okurigana, and which are considered readings of the character itself. For example, in the entry for 食, the reading corresponding to the basic verb eat (食べる, taberu) may be written as た.べる (ta.beru), to indicate that ta is the reading of the character itself. Further, kanji dictionaries often list compounds including irregular readings of a kanji.
Local developments and divergences from Chinese[edit]
Since kanji are essentially Chinese hanzi used to write Japanese, the majority of characters used in modern Japanese still retain their Chinese meaning, physical resemblance with some of their modern traditional Chinese characters counterparts, and a degree of similarity with Classical Chinese pronunciation imported to Japan from 5th to 9th century.[38] Nevertheless, after centuries of development, there is a notable number of kanji used in modern Japanese which have different meaning from hanzi used in modern Chinese. Such differences are the result of:
- the use of characters created in Japan,
- characters that have been given different meanings in Japanese, and
- post-World War II simplifications (shinjitai) of the character.
Likewise, the process of character simplification in mainland China since the 1950s has resulted in the fact that Japanese speakers who have not studied Chinese may not recognize some simplified characters.
Kokuji [edit]
In Japanese, Kokuji (国字, «national characters») refers to Chinese characters made outside of China. Specifically, kanji made in Japan are referred to as Wasei kanji (和製漢字). They are primarily formed in the usual way of Chinese characters, namely by combining existing components, though using a combination that is not used in China. The corresponding phenomenon in Korea is called gukja (國字), a cognate name; there are however far fewer Korean-coined characters than Japanese-coined ones. Other languages using the Chinese family of scripts sometimes have far more extensive systems of native characters, most significantly Vietnamese chữ Nôm, which comprises over 20,000 characters used throughout traditional Vietnamese writing, and Zhuang sawndip, which comprises over 10,000 characters, which are still in use.
Since kokuji are generally devised for existing native words, these usually only have native kun readings. However, they occasionally have a Chinese on reading, derived from a phonetic, as in 働, dō, and in rare cases only have an on reading, as in 腺, sen, from 泉, which was derived for use in technical compounds (腺 means «gland», hence used in medical terminology).
The majority of kokuji are ideogrammatic compounds (会意字), meaning that they are composed of two (or more) characters, with the meaning associated with the combination. For example, 働 is composed of 亻 (person radical) plus 動 (action), hence «action of a person, work». This is in contrast to kanji generally, which are overwhelmingly phono-semantic compounds. This difference is because kokuji were coined to express Japanese words, so borrowing existing (Chinese) readings could not express these—combining existing characters to logically express the meaning was the simplest way to achieve this. Other illustrative examples (below) include 榊 sakaki tree, formed as 木 «tree» and 神 «god», literally «divine tree», and 辻 tsuji «crossroads, street» formed as 辶 (⻌) «road» and 十 «cross», hence «cross-road».
In terms of meanings, these are especially for natural phenomena (esp. flora and fauna species), including a very large number of fish, such as 鰯 (sardine), 鱈 (codfish), 鮴 (seaperch), and 鱚 (sillago), and trees, such as 樫 (evergreen oak), 椙 (Japanese cedar), 椛 (birch, maple) and 柾 (spindle tree).[39] In other cases they refer to specifically Japanese abstract concepts, everyday words (like 辻, «crossroads», see above), or later technical coinages (such as 腺, «gland», see above).
There are hundreds of kokuji in existence.[40] Many are rarely used, but a number have become commonly used components of the written Japanese language. These include the following:
Jōyō kanji has about nine kokuji; there is some dispute over classification, but generally includes these:
- 働 どう dō, はたら(く) hatara(ku) «work», the most commonly used kokuji, used in the fundamental verb hatara(ku) (働く, «work»), included in elementary texts and on the Proficiency Test N5.
- 込 こ(む) ko(mu), used in the fundamental verb komu (込む, «to be crowded»)
- 匂 にお(う) nio(u), used in common verb niou (匂う, «to smell, to be fragrant»)
- 畑 はたけ hatake «field of crops»
- 腺 せん sen, «gland»
- 峠 とうげ tōge «mountain pass»
- 枠 わく waku, «frame»
- 塀 へい hei, «wall»
- 搾 しぼ(る) shibo(ru), «to squeeze» (disputed; see below);
jinmeiyō kanji
- 榊 さかき sakaki «tree, genus Cleyera«
- 辻 つじ tsuji «crossroads, street»
- 匁 もんめ monme (unit of weight)
Hyōgaiji:
- 躾 しつけ shitsuke «training, rearing (an animal, a child)»
Some of these characters (for example, 腺, «gland»)[41] have been introduced to China. In some cases the Chinese reading is the inferred Chinese reading, interpreting the character as a phono-semantic compound (as in how on readings are sometimes assigned to these characters in Chinese), while in other cases (such as 働), the Japanese on reading is borrowed (in general this differs from the modern Chinese pronunciation of this phonetic). Similar coinages occurred to a more limited extent in Korea and Vietnam.
Historically, some kokuji date back to very early Japanese writing, being found in the Man’yōshū, for example—鰯 iwashi «sardine» dates to the Nara period (8th century)—while they have continued to be created as late as the late 19th century, when a number of characters were coined in the Meiji era for new scientific concepts. For example, some characters were produced as regular compounds for some (but not all) SI units, such as 粁 (米 «meter» + 千 «thousand, kilo-«) for kilometer, 竏 (立 «liter» + 千 «thousand, kilo-«) for kiloliter, and 瓩 (瓦 «gram» + «thousand, kilo-«) for kilogram. However, SI units in Japanese today are almost exclusively written using rōmaji or katakana such as キロメートル or ㌖ for km, キロリットル for kl, and キログラム or ㌕ for kg.[42]
In Japan, the kokuji category is strictly defined as characters whose earliest appearance is in Japan.[43] If a character appears earlier in the Chinese literature, it is not considered a kokuji even if the character was independently coined in Japan and unrelated to the Chinese character (meaning «not borrowed from Chinese»). In other words, kokuji are not simply characters that were made in Japan, but characters that were first made in Japan. An illustrative example is ankō (鮟鱇, monkfish). This spelling was created in Edo period Japan from the ateji (phonetic kanji spelling) 安康 for the existing word ankō by adding the 魚 radical to each character—the characters were «made in Japan». However, 鮟 is not considered kokuji, as it is found in ancient Chinese texts as a corruption of 鰋 (魚匽). 鱇 is considered kokuji, as it has not been found in any earlier Chinese text. Casual listings may be more inclusive, including characters such as 鮟.[note 1] Another example is 搾, which is sometimes not considered kokuji due to its earlier presence as a corruption of Chinese 榨.
Kokkun[edit]
In addition to kokuji, there are kanji that have been given meanings in Japanese that are different from their original Chinese meanings. These are not considered kokuji but are instead called kokkun (国訓) and include characters such as the following:
| Char. | Japanese | Chinese | ||
|---|---|---|---|---|
| Reading | Meaning | Pinyin | Meaning | |
| 藤 | fuji | wisteria | téng | rattan, cane, vine[note 2] |
| 沖 | oki | offing, offshore | chōng | rinse, minor river (Cantonese) |
| 椿 | tsubaki | Camellia japonica | chūn | Toona spp. |
| 鮎 | ayu | sweetfish | nián | catfish (rare, usually written 鯰) |
| 咲 | saki | blossom | xiào | smile (rare, usually written 笑) |
Types of kanji by category[edit]
Han-dynasty scholar Xu Shen in his 2nd-century dictionary Shuowen Jiezi classified Chinese characters into six categories (Chinese: 六書 liùshū, Japanese: 六書 rikusho). The traditional classification is still taught but is problematic and no longer the focus of modern lexicographic practice, as some categories are not clearly defined, nor are they mutually exclusive: the first four refer to structural composition, while the last two refer to usage.[44]
Shōkei moji (象形文字)[edit]
Shōkei (Mandarin: xiàngxíng) characters are pictographic sketches of the object they represent. For example, 目 is an eye, while 木 is a tree. The current forms of the characters are very different from the originals, though their representations are more clear in oracle bone script and seal script. These pictographic characters make up only a small fraction of modern characters.
Shiji moji (指事文字)[edit]
Shiji (Mandarin: zhǐshì) characters are ideographs, often called «simple ideographs» or «simple indicatives» to distinguish them and tell the difference from compound ideographs (below). They are usually simple graphically and represent an abstract concept such as 上 «up» or «above» and 下 «down» or «below». These make up a tiny fraction of modern characters.
Kaii moji (会意文字)[edit]
Kaii (Mandarin: huìyì) characters are compound ideographs, often called «compound indicatives», «associative compounds», or just «ideographs». These are usually a combination of pictographs that combine semantically to present an overall meaning. An example of this type is 休 (rest) from 亻 (person radical) and 木 (tree). Another is the kokuji 峠 (mountain pass) made from 山 (mountain), 上 (up) and 下 (down). These make up a tiny fraction of modern characters.
Keisei moji (形声文字)[edit]
Keisei (Mandarin: xíngshēng) characters are phono-semantic or radical-phonetic compounds, sometimes called «semantic-phonetic», «semasio-phonetic», or «phonetic-ideographic» characters, are by far the largest category, making up about 90% of the characters in the standard lists; however, some of the most frequently used kanji belong to one of the three groups mentioned above, so keisei moji will usually make up less than 90% of the characters in a text. Typically they are made up of two components, one of which (most commonly, but by no means always, the left or top element) suggests the general category of the meaning or semantic context, and the other (most commonly the right or bottom element) approximates the pronunciation. The pronunciation relates to the original Chinese, and may now only be distantly detectable in the modern Japanese on’yomi of the kanji; it generally has no relation at all to kun’yomi. The same is true of the semantic context, which may have changed over the centuries or in the transition from Chinese to Japanese. As a result, it is a common error in folk etymology to fail to recognize a phono-semantic compound, typically instead inventing a compound-indicative explanation.
Tenchū moji (転注文字)[edit]
Tenchū (Mandarin: zhuǎnzhù) characters have variously been called «derivative characters», «derivative cognates», or translated as «mutually explanatory» or «mutually synonymous» characters; this is the most problematic of the six categories, as it is vaguely defined. It may refer to kanji where the meaning or application has become extended. For example, 楽 is used for ‘music’ and ‘comfort, ease’, with different pronunciations in Chinese reflected in the two different on’yomi, gaku ‘music’ and raku ‘pleasure’.
Kasha moji (仮借文字)[edit]
Kasha (Mandarin: jiǎjiè) are rebuses, sometimes called «phonetic loans». The etymology of the characters follows one of the patterns above, but the present-day meaning is completely unrelated to this. A character was appropriated to represent a similar-sounding word. For example, 来 in ancient Chinese was originally a pictograph for «wheat». Its syllable was homophonous with the verb meaning «to come», and the character is used for that verb as a result, without any embellishing «meaning» element attached. The character for wheat 麦, originally meant «to come», being a keisei moji having ‘foot’ at the bottom for its meaning part and «wheat» at the top for sound. The two characters swapped meaning, so today the more common word has the simpler character. This borrowing of sounds has a very long history.
[edit]
The iteration mark (々) is used to indicate that the preceding kanji is to be repeated, functioning similarly to a ditto mark in English. It is pronounced as though the kanji were written twice in a row, for example iroiro (色々, «various») and tokidoki (時々, «sometimes»). This mark also appears in personal and place names, as in the surname Sasaki (佐々木). This symbol is a simplified version of the kanji 仝, a variant of dō (同, «same»).
Another abbreviated symbol is ヶ, in appearance a small katakana «ke», but actually a simplified version of the kanji 箇, a general counter. It is pronounced «ka» when used to indicate quantity (such as 六ヶ月, rokkagetsu «six months») or «ga» if used as a genitive (as in 関ヶ原 sekigahara «Sekigahara»).
The way how these symbols may be produced on a computer depends on the operating system. In macOS, typing じおくり will reveal the symbol 々 as well as ヽ, ゝ and ゞ. To produce 〻, type おどりじ. Under Windows, typing くりかえし will reveal some of these symbols, while in Google IME, おどりじ may be used.
Collation[edit]
Kanji, whose thousands of symbols defy ordering by conventions such as those used for the Latin script, are often collated using the traditional Chinese radical-and-stroke sorting method. In this system, common components of characters are identified; these are called radicals. Characters are grouped by their primary radical, then ordered by number of pen strokes within radicals. For example, the kanji character 桜, meaning «cherry», is sorted as a ten-stroke character under the four-stroke primary radical 木 meaning «tree». When there is no obvious radical or more than one radical, convention governs which is used for collation.
Other kanji sorting methods, such as the SKIP system, have been devised by various authors.
Modern general-purpose Japanese dictionaries (as opposed to specifically character dictionaries) generally collate all entries, including words written using kanji, according to their kana representations (reflecting the way they are pronounced). The gojūon ordering of kana is normally used for this purpose.
Kanji education[edit]
Japanese schoolchildren are expected to learn 1,026 basic kanji characters, the kyōiku kanji, before finishing the sixth grade. The order in which these characters are learned is fixed. The kyōiku kanji list is a subset of a larger list, originally of 1,945 kanji characters and extended to 2,136 in 2010, known as the jōyō kanji—characters required for the level of fluency necessary to read newspapers and literature in Japanese. This larger list of characters is to be mastered by the end of the ninth grade.[45] Schoolchildren learn the characters by repetition and radical.
Students studying Japanese as a foreign language are often required by a curriculum to acquire kanji without having first learned the vocabulary associated with them. Strategies for these learners vary from copying-based methods to mnemonic-based methods such as those used in James Heisig’s series Remembering the Kanji. Other textbooks use methods based on the etymology of the characters, such as Mathias and Habein’s The Complete Guide to Everyday Kanji and Henshall’s A Guide to Remembering Japanese Characters. Pictorial mnemonics, as in the text Kanji Pict-o-graphix by Michael Rowley, are also seen.
The Japan Kanji Aptitude Testing Foundation provides the Kanji kentei (日本漢字能力検定試験 Nihon kanji nōryoku kentei shiken; «Test of Japanese Kanji Aptitude»), which tests the ability to read and write kanji. The highest level of the Kanji kentei tests about six thousand kanji.[46]
See also[edit]
- Chinese influence on Japanese culture
- Braille kanji
- Hanja (Korean equivalent)
- Chữ Hán (Vietnamese equivalent)
- Han unification
- Chinese family of scripts
- Japanese script reform
- Japanese typefaces (shotai)
- Japanese writing system
- Kanji of the year
- List of kanji by stroke count
- Radical (Chinese character)
- Stroke order
- Table of kanji radicals
- Rōmaji
- Cangjie
Notes[edit]
- ^ 国字 at 漢字辞典ネット demonstrates this, listing both 鮟 and 鱇 as kokuji, but starring 鮟 and stating that dictionaries do not consider it to be a kokuji.
- ^ the word for wisteria being «紫藤», with the addition of «紫», «purple»
References[edit]
Citations[edit]
- ^ Matsunaga, Sachiko (1996). «The Linguistic Nature of Kanji Reexamined: Do Kanji Represent Only Meanings?». The Journal of the Association of Teachers of Japanese. 30 (2): 1–22. doi:10.2307/489563. ISSN 0885-9884. JSTOR 489563.
- ^ Taylor, Insup; Taylor, Maurice Martin (1995). Writing and literacy in Chinese, Korean, and Japanese. Amsterdam: John Benjamins Publishing Company. p. 305. ISBN 90-272-1794-7.
- ^ McAuley, T. E.; Tranter, Nicolas (2001). Language change in East Asia. Richmond, Surrey: Curzon. pp. 180–204.
- ^ Suski, P.M. (2011). The Phonetics of Japanese Language: With Reference to Japanese Script. p. 1. ISBN 9780203841808.
- ^ Malatesha Joshi, R.; Aaron, P.G. (2006). Handbook of orthography and literacy. New Jersey: Routledge. pp. 481–2. ISBN 0-8058-4652-2.
- ^ a b c d Miyake (2003), 8.
- ^ a b Yamazaki, Kento (October 5, 2001). «Tawayama find hints kanji introduced in Yayoi Period». The Japan Times. Retrieved February 15, 2022.
- ^ Chen, Haijing (2014). «A Study of Japanese Loanwords in Chinese». University of Oslo.
- ^ Mathieu (November 19, 2017). «The History of Kanji 漢字の歴史». It’s Japan Time. Retrieved September 12, 2021.
- ^ «Gold Seal (Kin-in)». Fukuoka City Museum. Retrieved September 1, 2014.
- ^ a b Miyake (2003), 9.
- ^ Hadamitzky, Wolfgang and Spahn, Mark (2012), Kanji and Kana: A Complete Guide to the Japanese Writing System, Third Edition, Rutland, VT: Tuttle Publishing. ISBN 4805311169. p. 14.
- ^ Berger, Gordon M. (1975). «Review of Ishiwara Kanji and Japan’s Confrontation with the West». Journal of Japanese Studies. 2 (1): 156–169. doi:10.2307/132045. ISSN 0095-6848.
- ^ «人名用漢字の新字旧字 第82回 「鉄」と「鐵」». Sanseidō. Retrieved August 14, 2015.
- ^ Tamaoka, K., Makioka, S., Sanders, S. & Verdonschot, R. G. (2017). «www.kanjidatabase.com: a new interactive online database for psychological and linguistic research on Japanese kanji and their compound words». Psychological Research 81, 696-708.
- ^ JIS X 0208:1997.
- ^ JIS X 0212:1990.
- ^ JIS X 0213:2000.
- ^ Lunde, Ken (1999). CJKV Information Processing. «O’Reilly Media, Inc.». ISBN 978-1-56592-224-2.
- ^ Lunde, Ken (1999). CJKV Information Processing. «O’Reilly Media, Inc.». ISBN 978-1-56592-224-2.
- ^ Introducing the SING Gaiji architecture, Adobe.
- ^ OpenType Technology Center, Adobe.
- ^ «Representation of Non-standard Characters and Glyphs», P5: Guidelines for Electronic Text Encoding and Interchange, TEI-C.
- ^ «TEI element g (character or glyph)», P5: Guidelines for Electronic Text Encoding and Interchange, TEI-C.
- ^ Kuang-Hui Chiu, Chi-Ching Hsu (2006). Chinese Dilemmas : How Many Ideographs are Needed Archived July 17, 2011, at the Wayback Machine, National Taipei University
- ^ Shouhui Zhao, Dongbo Zhang, The Totality of Chinese Characters—A Digital Perspective
- ^ Daniel G. Peebles, SCML: A Structural Representation for Chinese Characters Archived March 10, 2016, at the Wayback Machine, May 29, 2007
- ^ Rogers, Henry (2005). Writing Systems: A Linguistic Approach. Oxford: Blackwell. ISBN 0631234640
- ^ Verdonschot, R. G.; La Heij, W.; Tamaoka, K.; Kiyama, S.; You, W. P.; Schiller, N. O. (2013). «The multiple pronunciations of Japanese kanji: A masked priming investigation». The Quarterly Journal of Experimental Psychology. 66 (10): 2023–38. doi:10.1080/17470218.2013.773050. PMID 23510000. S2CID 13845935.
- ^ «Gogen Yurai Jiten» 語源由来辞典 [Etymology Derivation Dictionary] (in Japanese). Lookvise, Inc. March 26, 2006. Retrieved February 9, 2022.
«Kefu» no «ke» wa, «kesa» to onaji «ke» de, «ko» no imi.
「けふ」の「け」は、「今朝(けさ)」と同じ「け」で、「こ(此)」の意味。 [The ke in kefu is the same ke as in kesa, meaning «this».] - ^ «How many possible phonological forms could be represented by a randomly chosen single character?». japanese.stackexchange.com. Retrieved July 15, 2017.
- ^ a b «How do Japanese names work?». www.sljfaq.org. Retrieved November 14, 2017.
- ^ a b c d e f g h i j k l Daijirin
- ^ a b c d e f g h i j k Kōjien
- ^ «ateji Archives». Tofugu. Archived from the original on December 25, 2015. Retrieved February 18, 2016.
- ^ «Satoshi». jisho.org. Retrieved March 5, 2016.
- ^ «Haruka». jisho.org. Retrieved March 5, 2016.
- ^ SHIMIZU, HIDEKO (2010). «Review of Remembering the Kanji 2: A Systematic Guide to Reading the Japanese Characters. 3rd ed.; Remembering the Kanji 3: Writing and Reading Japanese Characters for Upper-Level Proficiency. 2nd ed., JAMES W. HEISIG». The Modern Language Journal. 94 (3): 519–521. ISSN 0026-7902.
- ^ Koichi (August 21, 2012). «Kokuji: «Made In Japan,» Kanji Edition». Tofugu. Retrieved March 5, 2017.
- ^ «Kokuji list», SLJ FAQ.
- ^ Buck, James H. (October 15, 1969) «Some Observations on kokuji» in The Journal-Newsletter of the Association of Teachers of Japanese, Vol. 6, No. 2, pp. 45–9.
- ^ «A list of kokuji (国字)». www.sljfaq.org. Retrieved March 5, 2017.
- ^ Buck, James H. (1969). «Some Observations on kokuji». The Journal-Newsletter of the Association of Teachers of Japanese. 6 (2): 45–49. doi:10.2307/488823. ISSN 0004-5810.
- ^ Yamashita, Hiroko; Maru, Yukiko (2000). «Compositional Features of Kanji for Effective Instruction». The Journal of the Association of Teachers of Japanese. 34 (2): 159–178. doi:10.2307/489552. ISSN 0885-9884. JSTOR 489552.
- ^ Halpern, J. (2006) The Kodansha Kanji Learner’s Dictionary. ISBN 1568364075. p. 38a.
- ^ Rose, Heath (June 5, 2017). The Japanese Writing System: Challenges, Strategies and Self-regulation for Learning Kanji. Multilingual Matters. pp. 129–130. ISBN 978-1-78309-817-0.
Sources[edit]
- DeFrancis, John (1990). The Chinese Language: Fact and Fantasy. Honolulu: University of Hawaii Press. ISBN 0-8248-1068-6.
- Hadamitzky, W., and Spahn, M., (1981) Kanji and Kana, Boston: Tuttle.
- Hannas, William. C. (1997). Asia’s Orthographic Dilemma. Honolulu: University of Hawaii Press. ISBN 0-8248-1892-X (paperback); ISBN 0-8248-1842-3 (hardcover).
- Kaiser, Stephen (1991). «Introduction to the Japanese Writing System». In Kodansha’s Compact Kanji Guide. Tokyo: Kondansha International. ISBN 4-7700-1553-4.
- Miyake, Marc Hideo (2003). Old Japanese: A Phonetic Reconstruction. New York, NY; London, England: RoutledgeCurzon.
- Morohashi, Tetsuji. 大漢和辞典 Dai Kan-Wa Jiten (Comprehensive Chinese–Japanese Dictionary) 1984–1986. Tokyo: Taishukan.
- Mitamura, Joyce Yumi and Mitamura, Yasuko Kosaka (1997). Let’s Learn Kanji. Tokyo: Kondansha International. ISBN 4-7700-2068-6.
- Unger, J. Marshall (1996). Literacy and Script Reform in Occupation Japan: Reading Between the Lines. ISBN 0-19-510166-9.
External links[edit]
![]()
Look up kanji in Wiktionary, the free dictionary.
![]()
Wikimedia Commons has media related to Kanji.
- Jim Breen’s WWWJDIC server used to find Kanji from English or romanized Japanese
- Change in Script Usage in Japanese: A Longitudinal Study of Japanese Government White Papers on Labor, discussion paper by Takako Tomoda in the Electronic Journal of Contemporary Japanese Studies, August 19, 2005.
- Jisho—Online Japanese dictionary
Glyph conversion[edit]
- A simple Shinjitai—Kyūjitai converter
- A practical Shinjitai—Kyūjitai—Simplified Chinese character converter
- A complex Shinjitai—Kyūjitai converter
- A downloadable Shinjitai—Kyūjitai—Simplified Chinese character converter Archived February 10, 2009, at the Wayback Machine
Последняя и самая известная сторона японской письменности — кандзи.
Кандзи — китайские иероглифы, адаптированные для японского языка.
Большая часть японских слов пишется в кандзи, но звуки те же, что в хирагане и катакане.
Порядок штрихов
С самого начала изучения уделяйте внимание правильному порядку и направлению линий, чтобы избежать вредных привычек.
Часто изучающие не видят смысла в порядке штрихов, если результат тот же.
Но они упускают из виду то, что существуют тысячи символов и не всегда они пишутся так тщательно как выглядят на печати.
Правильный порядок штрихов помогает узнать иероглифы, даже если вы пишите быстро или от руки.
Простейшие символы, называемые радикалами, часто используются как компоненты сложных символов.
Как только вы выучите порядок штрихов радикалов и привыкните к принципу, вы обнаружите, что несложно угадать правильный порядок для большинства кандзи.
Чаще всего штрихи наносятся из левого верхнего угла в правый нижний.
Это означает, что горизонтальные черты обычно рисуют слева направо, а вертикальные — сверху вниз.
В любом случае когда вы сомневаетесь в порядке штрихов, сверьтесь со словарем кандзи.
Кандзи в лексиконе
В современном японском используется немногим более 2 тысяч иероглифов, и запоминание каждого по отдельности не работает так хорошо как с хираганой.
Эффективная стратегия овладения кандзи — изучение с новыми словами с большим контекстом.
Так для закрепления в памяти мы связываем символ с контекстной информацией.
Кандзи используются для представления реальных слов, поэтому сосредоточьтесь на словах и лексике, а не на самих символах.
Вы увидите, как работают кандзи, выучив несколько распространенных иероглифов и слов из данного параграфа.
Чтения кандзи
Первый кандзи, который мы изучим —「人」, иероглиф для понятия «человек».
Это простой символ из двух черт, каждая из которых наносится сверху вниз.
Возможно вы заметили, что символ из шрифта не всегда похож на рукописную версию ниже.
Это еще один важный повод сверяться с порядком штрихов.
 |
Значение: человек; личность |
| Кунъёми: ひと | |
| Онъёми: ジン |
Кандзи в японском языке имеют одно или несколько чтений, которые делят на две категории: кунъёми (или кун, или кунное чтение) и онъёми (или он, или онное чтение). Кунъёми — японское чтение иероглифа, в то время как онъёми основано на оригинальном китайском произношении.
В основном кунъёми используется для слов из одного символа. В качестве примера — слово со значением «человек»:
人 【ひと】 — человек
Кунъёми также используется для исконно японских слов, включая большинство прилагательных и глаголов.
Онъёми в большинстве случаев используется для слов, пришедших из китайского языка, часто из двух или более кандзи. По этой причине онъёми часто записывается катаканой. Больше примеров последует по мере изучения кандзи. Один очень полезный пример онъёми — присоединение 「人」 к названиям стран для описания национальности.
Примеры:
- アメリカ人 【アメリカ・じん】 — американец
- フランス人 【ふらんす・じん】 — француз
Хотя у большинства иероглифов нет множества кунъёми или онъёми, у наиболее распространенных кандзи, вроде 「人」, много чтений. Здесь я буду приводить только чтения, применимые к изучаемым словам. Изучение чтений без контекста в виде слов создает ненужную путаницу, поэтому я не рекомендую учить все чтения сразу.
Теперь, после знакомства с общей идеей, давайте изучим чуть больше слов и сопутствующие им кандзи. Красные точки на диаграммах порядка черт демонстрируют, где начинается каждый штрих.
- 日本 【に・ほん】 — Япония
- 本 【ほん】 — книга
| 日 | Значение: солнце; день |
| Онъёми: ニ |
| 本 | Значение: основа, источник; книга |
| Онъёми: ホン |
- 学生 【がく・せい】 — учащийся
- 先生 【せん・せい】 — учитель
| 学 | Значение: учение; знания; наука |
| Онъёми: ガク |
| 先 | Значение: впереди; предшествование, превосходство |
| Онъёми: セン |
| 生 | Значение: жизнь |
| Онъёми: セイ |
- 高い 【たか・い】 — высокий; дорогой
- 学校 【がっ・こう】 — школа
- 高校 【こう・こう】 — старшая школа (третья ступень обучения, эквивалентна 10–12 классам у нас)
| 高 | Значение: высокий; дорогой |
| Кунъёми: たか・い | |
| Онъёми: コウ |
| 校 | Значение: школа |
| Онъёми: コウ |
- 小さい 【ちい・さい】 — маленький
- 大きい 【おお・きい】 — большой
- 小学校 【しょう・がっ・こう】 — начальная школа (первая ступень обучения, соответствует 1–6 классам у нас)
- 中学校 【ちゅう・がっ・こう】 — средняя школа (вторая ступень обучения, 7–9 класс у нас)
- 大学 【だい・がく】 — колледж; университет
- 小学生 【しょう・がく・せい】 — учащийся начальной школы
- 中学生 【ちゅう・がく・せい】 — учащийся средней школы
- 大学生 【だい・がく・せい】 — студент
| 小 | Значение: маленький |
| Кунъёми: ちい・さい | |
| Онъёми: ショウ |
| 中 | Значение: середина; внутри |
| Онъёми: チュウ |
| 大 | Значение: большой |
| Кунъёми: おお・きい | |
| Онъёми: ダイ |
- 国 【くに】 — страна
- 中国 【ちゅう・ごく】 — Китай
- 中国人 【ちゅう・ごく・じん】 — китаец
| 国 | Значение: страна |
| Кунъёми: くに | |
| Онъёми: コク |
- 日本語 【に・ほん・ご】 — японский язык
- 中国語 【ちゅう・ごく・ご】 — китайский язык
- 英語 【えい・ご】 — английский язык
- フランス語 【フランス・ご】 — французский язык
- スペイン語 【スペイン・ご】 — испанский язык
| 英 | Значение: Англия |
| Онъёми: エイ |
| 語 | Значение: язык |
| Онъёми: ゴ |
Только с 14 символами мы изучили более 25 слов — от Китая до школьника!
Кандзи обычно воспринимаются как основное препятствие в изучении, но их легко превратить в ценный инструмент, если изучать вместе со словами.
Окуригана и изменение чтений
Вы могли заметить, что некоторые слова оканчиваются хираганой, например 「高い」 или 「大きい」.
Так как это прилагательные, сопровождающая хирагана, называемая окуриганой, нужна для различных преобразований без влияния на кандзи.
Запоминайте, где именно заканчивается кандзи и начинается хирагана.
Не надо писать 「大きい」 как 「大い」.
Вы также могли заметить, что чтения кандзи по отдельности не соответствуют чтениям в некоторых словах.
Например, 「学校」 читается как 「がっこう」, а не 「がくこう」.
Чтения часто так трансформируются для облегчения произношения.
В идеале проверяйте чтение каждого нового для вас слова.
К счастью, с помощью онлайн- и электронных словарей поиск новых кандзи не представляет трудностей.
Руководство по поиску кандзи (англ.)
Разные кандзи для похожих слов
Кандзи часто используется для создания нюансов или придания иного оттенка значению слова.
Для некоторых слов важно использовать правильный кандзи в нужной ситуации.
Например, прилагательное「あつい」 — «горячий» — при описании климата пишут как 「暑い」, а если речь о горячем объекте или человеке —「熱い」.
| 暑 | Значение: горячий (только для описания климата) |
| Кунъёми: あつ・い |
| 熱 | Значение: жар; лихорадка |
| Кунъёми: あつ・い |
В других случаях, хотя и применяются кандзи, верные для всех значений выбранного слова, автор вправе выбирать иероглифы с узким значением, соответственно стилю.
В примерах данной книги обычно используются общие и простые кандзи.
Подробности об использовании разных кандзи для одного и того же слова вас ждут в руководстве по изучению слов (англ.).
Японский язык — он красив и благозвучен, загадочен и непонятен. Воистину интересный и одновременно вызывающий страх. Русский человек — особенно не знающий других языков — найдёт в нём для себя много незнакомого и непонятного. Суффиксы-счётчики, порядок слов в предложении, ритмика и интонация… И, разумеется, японские иероглифы, или иначе — кандзи.

Именно злосчастные иероглифы, в большинстве случаев, отбивают энтузиазм погрузиться в язык страны восходящего солнца. С наскока очень тяжело разобраться в целых словарях незнакомых символов и пиктограмм, тем более — запомнить их значения и начать употреблять их в письменной речи. Но, если углубиться в тему, можно найти протоптанную тысячами энтузиастов дорожку, взять курс и смело идти к цели.
Мы расскажем, как формировался японский язык, как в него попали китайские иероглифы и как начать в них разбираться и по пути не потерять рассудок.
Японские иероглифы и их значение
Кандзи (漢字, буквально — китайская письменность) — один из трёх видов письма, которые использует японский язык, совместно со слоговой азбукой — каной. Хирагана, с округлёнными и плавными символами, используется повсеместно. Катакана, с более прямыми линиями, в основном используется для заимствований из других языков.

При копировании из китайского иероглифы сохранили принципы словообразования. Кандзи являются идеограммами — у большей части составляющих их символов есть свой собственный смысл. За этот счёт, из пары простых иероглифов можно составить один сложный, или, поставив их рядом, можно получить слово с новым значением, совместив их смысловую нагрузку. К примеру, иероглиф 水означает «вода». Поставьте его рядом с 着 (одежда; надевать), получится слово 水着 — купальник. Или, 木 — дерево — можно превратить в 林 (пролесок; буквально — несколько деревьев) или даже в 森 (лес)
По сути, любую необходимую информацию можно записать, пользуясь слоговой азбукой. Тем не менее, красивые японские и китайские иероглифы — со всеми их особенностями и трудностями в изучении — упрощают понимание языка в обиходе, сжимая крупные слова в несколько пиктограмм.
История
Хоть и территории восточной Азии огромны и необъятны, с культурной точки зрения страны этого региона тесно друг с другом переплетены, и империи Поднебесной оказывали постоянное влияние на развитие всех своих соседей. В своё время, китайская идеология даосизма смешалась с пришедшим из Индии буддизмом. Так появился чань-буддизм (禪), который попал в Корею и стал сон-буддизмом (선). Оттуда он перекочевал на японский архипелаг, закрепился, слегка видоизменился и стал известен на весь мир как дзен-буддизм (禅). Наряду с китайским же конфуцианством и родным для Японии синтоизмом, он является основной государственной религией .

В самом Китае иероглифическая письменность зародилась ещё при первых династиях — Шан-Инь (商殷) и Чжоу (周). Основные археологические доказательства письменности, оставшиеся с тех времен — так называемые кости-оракулы. На лопатки крупного рогатого скота и на панцири черепах наносились письмена. Затем их обжигали в огне. От температуры на костях проступали трещины, по которым потом гадали — искали предсказания или волеизъявления духов предков.

По ранним изображениям на таких костях видна эволюция иероглифов — человек видел какой-то предмет или существо и создавал рисунок. Постепенно эти рисунки закреплялись в обиходе, и с их помощью люди делали записи на бамбуковых и деревянных дощечках, до наших времен, к сожалению, не доживших. Во времена династий Шань и, особенно, Цинь символы унифицировались, а затем упрощались. Уже при династии Хань (漢朝), распавшейся в 220 году н.э., использовалась система письменности, идентичная современной китайской.

К слову, именно иероглиф 漢 интерпретируется как Китай. Все дальнейшие китайские династии искали легитимность именно через обращение к Хань, и этническая принадлежность современных китайцев — Ханьцы. Японское слово Кандзи буквально переводится как «Письменность Хань».
В Японии же своей письменности ещё не было. Но сформировалось устное наречие, которым передавались из поколения в поколение истории и легенды, а также распространялась родная религия японцев — синтоизм.
Первое государство на архипелаге — Ямато (大和 — мир, великая гармония) — сформировалось примерно одновременно с распадом Хань. Где-то в начале V века нашей эры корейские монахи принесли на острова конфуцианство, а с ним — и письменность. Китайские иероглифы начали использоваться для ведения государственных дел, для записи истории, для бизнеса. Правители страны во многих вопросах равнялись именно на Поднебесную, как и её другие соседи, а признаком образованности для человека было знание китайской письменности.
Сформировалась так называемая манъёгана — практика записи японских слов схожими по звучанию китайскими иероглифами.
Для основной массы — и в первую очередь, для женщин -образование было недоступно. Поэтому китайская письменность упрощалась, и постепенно превратилась в слоговую азбуку. Катакана — вид скорописи, которой пользовались монахи, а хирагана — упрощённые китайские иероглифы, для записи которых использовался стиль каллиграфии Цаошу.

Несколько прочтений у японских иероглифов
Именно в истории языка и лежит одна из главных трудностей кандзи.
Манъёгана долгое время была основным видом письменности, и произношение китайских иероглифов «с японским акцентом» закрепилось. Но японский язык в устной форме существовал задолго до их проникновения в японский обиход. Поэтому, на них начали накладывать и коренные прочтения. Создалась ситуация, в которой у одного символа было два и больше вариантов прочтения.
Изначальное, «китайское» прочтение иероглифа называется онным, или онъёми (от 音 — おん — он — звук). Обычно, онное прочтение записывается катаканой.
Наложенный на него японский перевод — кунное прочтение, или кунъёми (訓 — くん — кун — урок). Оно, в свою очередь, обычно записывается хираганой.

К примеру, уже знакомый иероглиф 水 имеет два прочтения. Онное — スイ, или «суй», от китайского «шуэ». Кунное — みず, или «мидзу». Оба прочтения переводятся как «вода». Но кунъёми будет употребляться с более частыми в обиходе выражениями (飲み水 [のみみず] — номи мидзу — пить воду), а онъёми — с более возвышенными и абстрактными понятиями, или же техническими терминами и заимствованиями (水- スイ — суй — вода (как один из элементов); или 浄水 — ジョウスイ — джо:суй — очищенная вода)
Сколько всего иероглифов
В японском языке насчитываются десятки тысяч иероглифов. Но наиболее часто в обиходе используется около 2 тысяч. Японское Министерство образования рекомендует список из 2136 кандзи, называя их иероглифами «для ежедневного пользования», или 常用漢字 (джо:йо: кандзи).

К слову, всего 893 из них содержат лишь одно прочтение. А в 138 — три и более варианта!
Почему японцы не откажутся от иероглифов
С первого взгляда, 3 системы письма могут показаться бессмысленным усложнением. Зачем учить более 2 тысяч кандзи, если любое их прочтение можно переписать с помощью слоговой азбуки?
Безусловно, отказ от иероглифов упростит процесс переноса информации в текст. Но его прочтение сильно усложнится.
К примеру, возьмём одну фразу и запишем её дважды — один раз, используя только хирагану, и второй — с необходимыми кандзи.
きょう,今日、 すし,寿司を た,食べに い,行きますか?
«къё:, суши о табе ни имас ка?»
,きょう、すしをたべにいきますか?
Перевод — Ты собираешься есть суши сегодня?
Разница в скорости прочтения между двумя фразами очевидна. Но понять, о чем идет речь, проще, прочитав именно первую.
В японском языке нет пробелов, и, чтобы отделить слова друг от друга, может потребоваться время. И это предложение — не самое длинное.
А ведь у иероглифов может быть несколько прочтений. Или же, одно прочтение может быть у разных иероглифов. К примеру, слово Кандзи в хирагане выглядит так — . Но это прочтение равнозначно между несколькими составными словами:
かんじ,漢字 → かん,感じ → かんじ,幹事 → 監事
Сидеть и перебирать контекст в сложных документах может быть проблематично.
Также, обратите внимание на этот иероглиф — じ. Символы хираганы рядом с кандзи называются «окуригана». Они склоняют и спрягают слова, создают новые формы и части речи. Ещё один плюс иероглифов в том, что они делят слова на составные части. Если в предложении из исключительно каны придётся искать границы между словами, с кандзи достаточно найти, где кончается окуригана. Обычно, ориентируются на так называемый «послелог» — предлог, идущий после слова.
В ближайшее время Япония не собирается отказываться от кандзи. Возможно, это замедляет процесс обучения языку и отбивает энтузиазм. Но понимание языка со знанием иероглифов — гораздо быстрее и удобнее. Необходимо лишь запомнить несколько принципов, которые ускорят их разучивание.
Как быстро запоминать иероглифы
История о том, как кто-то сделал себе тату из японских символов, не зная перевода, и на всю жизнь остался с глупейшей надписью на теле, не нова. Возможно, у вас есть и свои примеры из жизни.
Если вам необходимо подтянуть знания в иероглифах — не важно, для новой тату или для будущей поездки в страну восходящего солнца — прежде чем броситься в словари и учить все 2 тысячи символов, необходимо систематизировать знания. В первую очередь, нужно понять, из чего кандзи состоят.
Радикалы, или ключи
Список радикалов — ближайшая к понятию «алфавит кандзи» вещь в японском языке. Это — основные пиктограммы, из которых составляются иероглифы. Знание радикалов поможет с быстрым распознанием значения слова или с поиском его прочтения. Радикалы можно воспринимать как отдельные буквы алфавита. Потому и важно начинать учить кандзи, начиная с них. Представьте, если бы вас попросили понять слово «глупость», но вы не знали бы кириллицы. Вы бы запомнили значение этой комбинации букв, но в других словах, увидев их же, вы бы не поняли их значения.

С радикалами проще — напомню, кандзи являются идеограммами. То есть, значение иероглифа, скорее всего, будет лежать именно в идеограммах и радикалах, из которых он составлен.
К примеру, возьмём иероглиф «город» — 町. Он состоит из двух более простых иероглифов-радикалов:
- 田 (рисовое поле)
- 丁(улица)
Ещё один пример. 電 — сложный и пугающий кандзи с единственным прочтением — «электричество». Он состоит из 3 радикалов:
- 雨 (дождь)
- 田 (рисовое поле)
- 乚 (зонт)
По некоторым радикалам можно примерно понять значение иероглифа
- Кандзи с ключом 魚 (сакана) — «Рыба» — в большинстве случаев означают один из видов рыбы: 鮪 (магуро) — тунец; 鰻 (унаги) — угорь
- Иероглиф 火 (хи) — «Огонь» — передаст слову смысл света или разрушения:灯火 — (томосиби) — фонарь, факел; 炸 (каку) — взрыв; 災 (вазаваи) — катастрофа, неудача, бедствие, зло

Большинство кандзи состоит из нескольких радикалов, обычно от 1 до 3. А черт в них может быть больше десяти. Наиболее сложные, придуманные в Японии иероглифы — или кокудзи — требуют несколько десятков линий. Хороший пример — 龘. Этот кандзи обозначает «изображение дракона, крадущегося или взлетающего в бой» и состоит из 48 линий. На деле, он состоит из заимствованного иероглифа 龍 (рю) — «дракон», изображённого трижды.
Именно поэтому и важно начинать изучение с ключей. Запоминать каждую мелкую линию, которая, на первый взгляд, не имеет связи или смысловой нагрузки — бессмысленный труд.
Всего существует 214 основных радикалов, из которых часть используется крайне редко. Их список всегда можно найти в словарях и учебниках японского языка. Также, для англоговорящих читателей будет полезен онлайн сервис jisho.org, который помогает в поисках необходимых ключей.

Как учить японские иероглифы и их обозначения
Хорошим стартом изучения кандзи будет список из 100 самых популярных японских иероглифов — sng.ac.jp. Проблема в том, что у наиболее часто используемых кандзи зачастую больше двух значений. Поэтому для начала, старайтесь запоминать не прочтения символов, а их значения. 水, в первую очередь — вода.
Постепенно наполняя свой словарный запас, вы будете наблюдать этот иероглиф в качестве радикала или как составную часть слова, и разные произношения быстрее запомнятся именно в контексте.
Также, не стоит пренебрегать мнемоникой. Все иероглифы изначально произошли из рисунков. Ищите мнемоническое обозначение для кандзи и радикалов, запоминайте их, отталкиваясь от найденного вами смысла в линиях и символах.
Попробуем создать историю для иероглифа 電. Напомню, он состоит из 3 частей:
- 雨 (дождь)
- 田 (рисовое поле)
- 乚 (зонт)
«Стоя под дождём на рисовом поле, держа в руках зонт, Бенджамин Франклин изобрёл электричество!»
По тому же принципу, можно собирать небольшие предложения, которые хорошо запоминаются и демонстрируют, из чего состоит иероглиф.
日 (солнце) + 月 (луна) = 明 (ярко): «Солнце отражается от Луны, и становится ярко»
目 (глаз) + 亡 (смерть) =盲 (слепота): «Смерть глаза ведёт к слепоте»
禾 (зерно) + 口 (рот) = 和 (мир, время без войны): «Зёрна кладутся в рот. Все сыты — значит, настало мирное время»
Порядок написания черт в иероглифах
Для правильной записи иероглифов полезно помнить, сколько всего линий требуется для его начертания. Это не критично, но в будущем позволяет избежать ошибок. В целом, для линий кандзи есть подробный список правил, которые распространяются на все фрагменты и радикалы:


- Если в иероглифе 2 линии заканчиваются в одной точке, начните с той, которая ведёт в левый нижний угол, а закончите в правом нижнем.
- У правила есть исключения — линии, которые перечёркивают весь иероглиф, а также малые линии.




Где искать иероглифы
Для желающих изучать кандзи существует множество полезных сервисов.
Тот же jisho.org будет полезен для изучения и радикалов, и прочтений, и использований в контексте.
sng.ac.jp — здесь вы найдете 100 наиболее используемых кандзи в японском языке
shounen.ru — список из 881 основных японских иероглифов
japanese-words.org — полезный сайт, дающий ежедневные задания для заучивания кандзи, а также мнемонические тренировки.
Видео
На этом канале вы можете познакомиться подробнее с японской каллиграфией. У большинства видео есть русский перевод!
В японском языке используется более 2000 иероглифов. Многих это пугает — они не знают, реально ли их выучить, сколько времени это займёт, с чего вообще начать и как именно их учить. Эта инструкция расскажет о кандзи (японских иероглифах, заимствованных с Китая) и ответит на все эти вопросы.
Эта статья подойдёт как людям с нулевым знанием японского языка, так и с хорошим (в этом случае Вы можете пропустить введение).
Оглавление:
- Введение:
- Что такое кандзи и для чего они используются?
- Когда нужно учить кандзи?
- Нужно ли вообще учить кандзи?
- Сколько используется кандзи в японском языке?
- Реально ли выучить кандзи?
- Сколько времени займёт изучение кандзи?
- Перед началом:
- Когда используется онъёми, а когда кунъёми?
- Суть:
- Как учить кандзи:
- Начало изучения
- Что нужно учить в кандзи
- Нужно ли учить слова с иероглифом?
- Как именно учить кандзи
- Как запомнить картинку иероглифа
- Как запомнить чтения иероглифа
- Почему важен порядок черт
- Сайт для изучения кандзи — akanji.ru
- Как учить кандзи:
Когда нужно учить кандзи?
Если Вы только начали изучать японский язык, учить иероглифы Вам пока ещё совсем не надо. Самое первое, что нужно сделать — выучить хирагану и катакану (о них будет упомянуто ниже). Но и после этого изучать иероглифы ещё рано — перед этим Вы должны хоть немного поизучать сам японский язык. Более подробно написано в статье «Как выучить японский язык». Там же написано, когда начать учить иероглифы.
Что такое кандзи и для чего они используются?
В японском языке используется отличная от китайского система письменности. В китайском весь текст и все слова записываются иероглифами. В японском для записи используются сразу три вида письменности одновременно — хирагана, катакана и иероглифы. При этом знаки хираганы и катаканы иероглифами не являются и относятся ближе к буквам, чем к иероглифам.
К счастью, выучить хирагану и катакану не представляет особого труда — в каждой из них всего лишь по 46 уникальных знаков. Прописывая их по памяти в тетради можно выучить их за 1–2 дня.
Каждая из трёх систем письменности используется для своей цели:
- Для начала иероглифы — самая главная часть, именно ими записываются корни почти всех слов. Впрочем, хоть иероглифы и являются главной частью, если сложить все символы текста, знаки каны (хираганы и катаканы) будут встречаться в 2.9 раза чаще, чем иероглифы. Таким образом, иероглифы составляют в среднем всего лишь примерно 26% символов в тексте, но это самые главные 26% символов. В т. ч. отчасти так происходит, потому что нередко один иероглиф заменяет сразу несколько знаков каны (но это только одна из причин).
- Далее, знаки хираганы — используются для записи:
- Изменяющихся частей слов (т. е. начало слова может писаться иероглифами, а конец хираганой).
- Всех частиц.
- Некоторых слов.
Также используется для записи:
- Слов, состоящих из слишком редких иероглифов.
- Звуков, например, произнесённых человеком или обычных.
- Вне текста, когда нужно передать именно звучание, например, чтение иероглифов может быть подписано хираганой сверху над ними (это называется фуригана).
Знаки хираганы — самые частые символы в тексте.
- Ну и наконец, знаки катаканы — используются для записи всех заимствованных слов. В т. ч. заимствованными словами считаются географические названия и имена людей. Например, Ваше имя будет писаться именно знаками катаканы (по крайней мере, если у Вас не японское имя, которое обычно пишется иероглифами, хотя изредка родители дают имена, которые решают писать хираганой или даже катаканой).
Также иногда, как и знаки хираганы, используются для:
- Некоторых слов, например, マジ、ラーメン、ゴミ、バラ、ガキ、アホ (но в отличие от знаков хираганы, таких слов мало).
- Слов, состоящих из слишком редких иероглифов (но хираганой чаще).
- Звуков.
Также иногда используются специально в качестве художественного приёма.
В итоге, кандзи — это иероглифы, заимствованные с Китая, использующиеся вместе с двумя канами, и служат для записи корней слов, и таким образом являются самой важной (хоть и не самой частой) составляющей текста, т. к. именно корни слов — самая важная часть текста. Впрочем, и другие части текста тоже очень важны.
Нужно ли вообще учить кандзи?
Да, как мы выяснили в предыдущем разделе, кандзи — главная составляющая текста, и без их знания у Вас не получится ничего прочитать (и написать тоже).
Сколько используется кандзи в японском языке?
Список кандзи стандартизирован — ровно 2136 иероглифов (называются «дзёё кандзи», их список можно найти здесь, и именно его проходят дети в японских школах) + ещё около 850 иероглифов, которые не включены в стандартные иероглифы, но всё же иногда используются.
При этом чтобы понимать 96% иероглифов в тексте, нужно знать 2136 + 54 = 2190 кандзи.
Чтобы понимать 98% — 2136 + 396 = 2532 кандзи.
Чтобы понимать 99% — 2136 + 855 = 2991 кандзи.
Чтобы понимать 99.5% — 2136 + 1333 = 3469 кандзи.
Чтобы понимать 99.8% — 2136 + 1932 = 4068 кандзи.
Чтобы понимать 99.9% — 2136 + 2336 = 4472 кандзи.
Конечно же, понимать 100% кандзи не нужно, вполне хватит и 99%, т. е. хватит 3000 кандзи. Кроме того, если в тексте использован кандзи, не входящий в стандартные 2136 кандзи, то:
- Зачастую это просто кандзи из имени, и знать Вам этот кандзи не нужно.
- Либо на нём может стоять подпись его чтения фуриганой, особенно если это редкий кандзи.
Благодаря этому, даже если Вы выучите только 2500 кандзи, Вы вряд ли будете часто сталкиваться с проблемами при чтении текстов.
Сами японцы в основном тоже не изучают много иероглифов сверх 2136, но могут запоминать их без изучения в процессе жизни. Обычно такие неизученные иероглифы не получится написать самостоятельно от руки, но они будут узнаваться в тексте.
Если отвечать на вопрос раздела, в японском используется от 3000 (99% охват) до 4500 (99.9% охват) иероглифов, но при этом самые популярные 2000 иероглифов составляют 96% всех иероглифов в тексте. Для хорошего знания японского нужно владеть примерно 2500–3500 кандзи. В школе проходят 2136 кандзи.
Реально ли выучить кандзи?
Конечно, иначе бы их не использовали! Ну а если серьёзно, 1 кандзи требует около 6 минут на изучение и ещё где-то столько же на повторение в будущем. Изучение 2136 стандартных иероглифов займёт около 430 часов. Если регулярно изучать по 1 часу в день, то в итоге все 2136 кандзи выучатся где-то через 1 год и 2 месяца. Для более полного изучения нужно выучить 2500 кандзи — это займёт где-то 1 год и 4.5 месяца. А если Вы пошли дальше, и решили выучить 3000 кандзи, то все их Вы выучите примерно через 1 год и 8 месяцев.
Также нужно сказать про сами иероглифы: это не беспорядочные картинки, как можно было бы подумать. Все иероглифы состоят либо из одинаковых частей, количество которых достаточно мало, либо из других более простых иероглифов. Таким образом, знакомясь с каждым новым иероглифом, на самом деле Вы уже неплохо его знаете.
Также необязательно ставить цель выучить сразу все иероглифы. Даже если Вы выучите только 200 популярных (за месяц и 10 дней), Вы уже будете узнавать 49% кандзи в тексте. После 500 (3 месяца) Вы будете узнавать 71% кандзи, а после 1000 (6.5 мес) — 86%. В прочем, есть и плохие новости: если допустим, Вы узнаёте 71% кандзи, а какое-то слово состоит из двух кандзи (а таких большинство), то вероятность, что Вы сможете его прочитать всего лишь 50%.
Итог: да, выучить кандзи реально, и в зависимости от изучаемого количества и темпа изучения это займёт от 1 до 2 лет. Если у Вас много свободного времени, то можно изучить и быстрее, например, тратя по 4 часа в день можно изучить 2500 кандзи за 4 месяца.
Сколько времени займёт изучение кандзи?
Около 1 года и 4.5 месяца по часу в день. Более подробный ответ читайте в предыдущем разделе «Реально ли выучить кандзи?».
Когда используется онъёми, а когда кунъёми?
- Иероглиф читается по кунъёми (японское чтение иероглифа):
- Практически всегда, когда к иероглифу дописана хирагана. Пример: 見る.
- Порядка в 90% случаев, если иероглиф использован один, без других иероглифов. Пример: 目.
- Практически всегда, если это фамилия или топоним, даже несмотря на то, что там стоят несколько иероглифов вместе. Пример: 田中.
- Иероглиф читается по онъёми (китайское чтение иероглифа):
- Порядка в 99% случаев, если слово состоит из нескольких иероглифов подряд без хираганы. Пример: 電車.
Тем не менее есть небольшое количество исключений, читающихся в таких случаях по кунъёми. Эти исключения нужно просто знать.
- Порядка в 10% случаев, если иероглиф использован один, без других иероглифов. Пример: 本.
- Порядка в 99% случаев, если слово состоит из нескольких иероглифов подряд без хираганы. Пример: 電車.
Таким образом, алгоритм выбора чтения следующий:
- Если к слову дописана кана, читаем по кунъёми.
- Если слово состоит из одного иероглифа, пытаемся читать по кунъёми. В 90% случаев Вы будете правы, но в 10% случаев всё-таки нужно будет читать по онъёми.
- В остальных случаях, когда слово состоит из 2+ иероглифов, читаем по онъёми.
- Если это фамилия или топоним, читаем по кунъёми вне зависимости от других условий.
Как видно самое сложное — второй вариант, когда иероглиф один. Но в реальной жизни это почти не доставляет никаких проблем:
- Если Вы не знаете это слово, не так страшно прочитать его неправильно, т. к. Вы в любом случае не поймёте его смысл, пока не посмотрите в словарь. А когда посмотрите в словарь, то увидите правильное чтение.
- В японском языке используется около 3000 иероглифов, а всего слов 30 тыс. Это значит, что слов, состоящих только из одного иероглифа не больше 10% от всех слов.
- При изучении иероглифа практически всегда приводится его чтение, когда он стоит один. Причём само чтение Вы уже итак знаете (т. к. чтения Вы обязаны выучить). Как итог Вы, скорее всего, будете знать правильно чтение.
PS. Также встречаются и другие варианты чтений:
- В именах (не путать с фамилиями) иероглифы читаются вообще фиг пойми как. С этим нужно смириться.
- Существует небольшое количество слов:
- Которые читаются ни по ону, ни по куну, а имеют уникальное чтение, использующееся только в этом слове. Их нужно просто знать. Такие необычные чтения называются 熟字訓 (дзюкудзикун). Таких слов мало (менее 1% от всех слов).
- Со смешанным чтением: часть кандзи по онам, часть по кунам. Их тоже нужно просто знать, и их тоже мало.
Как учить кандзи
Начало изучения
Первое что Вам нужно сделать, чтобы начать учить кандзи — найти пособие для изучения. Это может быть сайт, приложение или специальная таблица с информацией об иероглифах. Лучшим пособием для русскоговорящей аудитории является сайт (и одновременно веб-приложение) akanji.ru. Про него ещё будет сказано ниже.
При этом бумажные пособия проигрывают электронным из-за отсутствия интерактивности. Интерактивность нужна, т. к. при изучении Вам понадобится называть по значению иероглифа остальную информацию о нём. Впрочем, если Вы найдёте двухсторонние карточки, то их вполне можно использовать — на одной стороне должно быть написано только значение, а на другой вся остальная информация (какая именно, будет описано ниже). Двусторонние карточки вполне обладают интерактивностью. Тем не менее электронные пособия обычно удобнее по следующим причинам:
- Можно исследовать состав иероглифа. Например, иероглиф 見 (смотреть) состоит из 目 (глаз) и 儿. Просмотр состава помогает в запоминании и изучении иероглифов.
- Можно учить иероглифы в порядке популярности.
- Можно вести свои списки иероглифов. При использовании карточек это делать сложнее.
- Может быть тяжело найти качественные карточки. Например, часть инфы может быть не указана. Также зачастую чтения пишутся не каной, а латиницей — это большая ошибка.
- Пользоваться чуть удобнее — например, для «переворота» достаточно нажать клавишу.
- Если сравнивать с akanji.ru, то на нём может быть указана дополнительная информация, например, частота в тексте или ссылка на Яркси. Также сайт представляет очень мощный поиск по незнакомым иероглифам.
К сожалению, у сайта akanji.ru в данный момент нет адаптированной мобильной версии, но если Вы с компьютера, то это будет лучший выбор (его преимущества по сравнению с другими сайтами описаны ниже).
Что нужно учить в кандзи
Следующий вопрос, который возникает — что именно учить в иероглифах. При изучении Вы должны обязательно выучить следующие вещи:
- Значения иероглифа.
- Написание иероглифа + порядок черт при написании. Вы должны уметь написать иероглиф от руки на бумаге по памяти (если будет криво — нестрашно).
- Китайские чтения иероглифа (онъёми). Такие чтения обычно используются в словах, состоящих из двух и более иероглифов без использования каны, например 電車 (электропоезд) читается как でんしゃ. Первый иероглиф 電 был прочитан как でん, а второй 車 как しゃ — это всё онъёми.
- Японские чтения иероглифа (кунъёми). Такие чтения обычно используются в словах из одного иероглифа, либо из одного иероглифа + каны. Например, 車 (машина) читается как くるま.
- Окуригану. Окуригана — это кана, которая дописывается к иероглифу для получения полноценного слова. Например, есть иероглифы, которые сами по себе могут образовать слово, например, 車 (くるま) — «машина», а есть, которые могут образовать слово после добавления каны, например, 行 — такого слова нет, но зато есть слово 行く (いく) — «идти». В данном случае иероглиф 行 читается い. Но поскольку само по себе чтение い никогда не используется, в чтении Вы увидите что-то типа い⬝く, где い — чтение иероглифа, а く — окуригана. Окуригана обычно отделяется точкой или выделена цветом. При изучении Вы должны знать, какая часть относится к чтению, а какая к окуригане.
- Некоторые слова. Подробнее в следующем разделе.
У многих иероглифов есть несколько онъёми или кунъёми — в этом случае нужно учить их все, по крайней мере если они не относятся к редким. На сайте akanji.ru все чтения, не выделенные серым цветом, к редким не относятся, поэтому учить нужно их все. Учить нужно как онъёми, так и кунъёми, не пытайтесь выучить только что-то одно из этого.
Нужно ли учить слова с иероглифом?
Если отвечать кратко — желательно выучить по 1 слову на каждое онъёми и обязательно на каждое кунъёми.
Там где изучение желательно — это значит, что есть как плюсы, так и минусы. Плюс в том, что выученные слова помогут строить ассоциации при запоминании чтения иероглифа. Например, Вы встретили какой-то иероглиф в тексте, но не помните его чтение, но тут же вспоминаете, что этот иероглиф, допустим, был в слове 電車 (でんしゃ), а значит он читается «でん». Минус же в том, что это значительно замедлит темп изучения иероглифов.
Если отвечать подробно, то:
-
Для онъёми:
- Если Вы не знаете ни одного слова с определённым онъёми, то желательно выучить одно самое популярное слово с ним. Это поможет запомнить чтение.
Тем не менее, изучение этих слов снижает темп изучения иероглифов. Поэтому конечное решение должно оставаться за Вами.
- Если Вы уже знаете слова с этим онъёми, то дополнительные слова можно не учить, т. к. прочитать кандзи Вы уже итак можете. Но хотя бы 1 раз прочитать несколько самых популярных слов с этим кандзи всё-таки стоит (они будут выводиться на akanji.ru в будущем, сейчас пока там выводятся не самые популярные и мало).
- Если Вы не знаете ни одного слова с определённым онъёми, то желательно выучить одно самое популярное слово с ним. Это поможет запомнить чтение.
-
Для кунъёми:
- Для каждого кунъёми нужно выучить как минимум одно главное слово с этим кунъёми (чаще всего одно слово и будет). Но много усилий для этого потратить не придётся: в предыдущем разделе мы уже итак сказали, что нужно выучить как чтения, так и окуригану, соответственно, всё, что Вам остаётся — доучить значение слова.
Причины изучения: 1) Потому что это очень легко. Приложив минимум усилий Вы сможете пополнить словарный запас. 2) Это позволит Вам лучше понять и запомнить кандзи.
- Также у некоторых кунъёми могут быть сразу несколько слов, отличающихся окуриганой. Минимум одно главное слово с каждым кунъёми надо выучить (как было сказано выше), а остальные нужно учить в зависимости от условий:
- Если суммарно у слова только один кунъёми, то выучить остальные слова очень желательно, чтобы: 1) Лучше уметь читать эти слова в тексте. Раз Вы их знаете, будете максимально уверены при их чтении. 2) Чтобы пополнить словарный запас, ведь слова, читающиеся по кунъёми — это чисто японские слова, а значит велика вероятность, что это популярное слово.
Но если Вы на данном этапе хотите сэкономить время, чтобы выучить больше иероглифов, можно отложить эти слова на потом. Я бы не сказал, что Вы что-то потеряете, т. к. каждый выученный кандзи, думаю, даст Вам как минимум не меньше пользы.
- Если же у слова более одного кунъёми, то желательность изучения слов повышается ещё сильнее. Причина: в противном случае Вы просто не будете знать, какое чтение выбрать. Например, у иероглифа есть 2 кунъёми. Но как понять, какое из них нужно выбрать в данный момент? Единственный ответ — знать это слово.
Учить их сразу или отложить на потом, также остаётся Вашим решением, мы не будем давать конкретных советов.
Есть и хорошая новость: к счастью, таких иероглифов очень мало, чтобы было более одного кунъёми, и при этом были кунъёми с несколькими словами.
- Если суммарно у слова только один кунъёми, то выучить остальные слова очень желательно, чтобы: 1) Лучше уметь читать эти слова в тексте. Раз Вы их знаете, будете максимально уверены при их чтении. 2) Чтобы пополнить словарный запас, ведь слова, читающиеся по кунъёми — это чисто японские слова, а значит велика вероятность, что это популярное слово.
- Для каждого кунъёми нужно выучить как минимум одно главное слово с этим кунъёми (чаще всего одно слово и будет). Но много усилий для этого потратить не придётся: в предыдущем разделе мы уже итак сказали, что нужно выучить как чтения, так и окуригану, соответственно, всё, что Вам остаётся — доучить значение слова.
Как именно учить кандзи
Убедиться, что Вы знаете иероглиф, можно, если Вы назовёте всю требуемую информацию о нём по памяти. Поэтому обычно в качестве базового принципа при изучении используется сокрытие все инфы, кроме значения, и попытки назвать эту информацию по памяти (сюда включается и пропись иероглифа в тетради с верным порядком черт).
Конечно же, назвать информацию, не зная ничего не получится. Поэтому в самом начале этот иероглиф в открытую прописываются в тетради + в добавок к этому прописываются его чтения (1 раз) для лучшего запоминания. Далее инфа скрывается, и то же самое нужно уже повторить и написать по памяти (кроме прописи чтений, их достаточно просто проговорить). Поскольку Вы только что видели иероглиф, у Вас это получится. А если не получится, то нужно попробовать ещё раз, и так до тех пор, пока не получится.
Итак, базовый принцип, который может использоваться для изучения, понятен. Мы описали общую стратегию для одного иероглифа, но поскольку иероглифов много, способ нужно немного усложнить. Первое усложнение — лучше брать сразу 5 кандзи, а не один. Если взять только один, то может показаться, что Вы «выучили» его, но на самом деле через минуту забудете. Если взять 5, то между ними будет проходить хоть небольшой, но всё-таки определённый интервал, и таким образом Вы не подумаете по ошибке, что уже хорошо знаете его.
Первый раз Вы прописываете эти 5 иероглифов в открытую, от первого до пятого. Потом закрываете все 5 иероглифов и пытаетесь их также назвать от первого до пятого, но уже вслепую. Естественно, с первого раза это не получится, но на самом деле именно на это и делается расчёт. Если у Вас получается без проблем назвать всю требуемую информацию об определённом кандзи, то Вы убираете его из этого списка. А если не получается (или получается с трудом), то перемещаете его в конец списка. По началу, в списке всегда будет 5 кандзи, а каждый следующий будет перемещаться в конец, но после определённого количества итераций повторения какой-то из них запомнится так хорошо, что Вы сможете его назвать по памяти, и после этого его можно будет удалить из списка, и останется 4 кандзи. Далее останется 3, потом 2, потом 1, и потом будут выучены все 5 кандзи.
Следующее усложнение, которое нужно ввести, связано с тем, что выученные 5 кандзи тоже забудутся через какое время, хоть оно и больше, чем время для одного кандзи. В связи с этим важно повторение последних выученных кандзи. Поэтому, прежде чем приступать к изучение новых 5 кандзи, нужно взять список из старых 20–30 кандзи, и по такому же принципу назвать его вслепую от первого до последнего. Более старые кандзи из этого списка будет назвать проще, а более новые затруднительнее. Но опять же — именно на это и расчёт. Если назвать хорошо у Вас не получилось, Вы также перемещаете этот кандзи в конец списка. Разница только в том, что как только Вы дойдёте до последнего иероглифа (не считая перемещённых), то перед тем, как начать повторять перемещённые кандзи, Вам нужно взять новые 5 кандзи, прописать их в открытую, и добавить их в конец к перемещённым. Далее нужно начать повторять перемещённые по принципу, описанному ранее.
Пример: Вы взяли 30 последних кандзи. Когда дошли до 30-го, оказалось, что хорошо назвать Вы смогли только 17, а 13 добавлены в конец списка. Далее Вы изучаете ещё 5 кандзи (в открытую) и добавляете их в конец оставшегося списка. Суммарно в оставшемся списке окажется 13 + 5 = 18 кандзи. Вы начинаете повторять их по кругу, удаляя из списка хорошо названные кандзи, и рано или поздно в списке останется 0 кандзи. В этот момент Вы сможете сказать, что: 1) Повторили старые кандзи и теперь знаете их лучше, 2) Выучили 5 новых кандзи. После этого можно учить новые 5.
Реализовать такую схему обучения позволяет сайт akanji.ru, для этого нужно поставить галочку «Режим обучения» (над списком кандзи). Наведя указатель мыши на подсказку справа от галочки, можно узнать, какими клавишами можно добавлять кандзи в конец списка и какими клавишами открывать информацию об иероглифе, чтобы проверить себя. Перед началом изучения можно пройти туториал, для этого нужно нажать «Начать учить кандзи» на списком кандзи (НЕ в режиме обучения). Также вместо 5 кандзи можно добавлять 4–6 кандзи. 4 удобно, если в списке уже итак много сложных кандзи, а 6, если, наоборот, список идёт очень хорошо.
Иногда нужно устраивать большое повторение. Например, раз в неделю можно повторять последние 100 иероглифов, раз в 2 недели — 200, раз в месяц — 400, раз в 2 месяца — 800 и раз в 4 месяца — 1600. Распределить план повторений можно в ежедневнике, календаре или блокноте. Иероглифы, с которыми возникли проблемы, добавляются к повторению, которое будет через неделю.
Как запомнить картинку иероглифа
Если Вы воспользуетесь способом, описанном в предыдущем разделе, то уже итак, скорее всего, сможете без проблем запоминать картинку иероглифа. Если у Вас всё-таки возникли с этим проблемы, помочь могут следующие вещи:
- Главный помощник в запоминании картинки иероглифа — его пропись в тетради. Если Вы не будете его прописывать, он никогда не запомнится. Мы рекомендуем прописывать кандзи в клетчатой тетради, 1 кандзи при этом должен занимать 4 клетки. Чтения можно писать в одну клетку (достаточно 1 раза). Пробелы между иероглифами или чтениями не нужны.
- Иероглифы состоят не из случайных черт, а из более простых иероглифов и ограниченного набора повторяющихся составных частей, которые тоже имеют своё значение. Соответственно, когда Вы знакомитесь с новым иероглифом, на самом деле его изображение Вы уже неплохо знаете, по крайней мере это далеко не то же самое, что учить абсолютно новый элемент письма, который Вы никогда не видели. Запомнить картинку иероглифа намного проще, чем знак каны или букву какого-нибудь алфавита.
Поэтому совет, который можно дать — изучайте, из каких частей состоит иероглиф, и смотрите их значение. Это позволит Вам составить ассоциации к картинке иероглифа, что поможет легче его запомнить. Смотреть состав иероглифа можно на сайте akanji.ru, нажав на кнопку «Состав» справа от иероглифа.
- Стройте ассоциации к картинке иероглифа. В т. ч., как было сказано выше, в этом может помочь исследование состава иероглифа. Ассоциации можно придумывать самому. Например 休 (отдых) можно запомнить как человек (亻), лежащий под деревом (木), и отдыхающий.
- Попробуйте выучить популярные составные части иероглифов.
- Зачастую, чтобы вспомнить картинку иероглифа, достаточно вспомнить первую черту. Поэтому соблюдение правильного порядка черт (что Вы обязаны делать) поможет в запоминании иероглифов.
Кроме того, соблюдение порядка само по себе очень сильно облегчает запоминание иероглифа: если бы порядка не было, то непонятно, какую черту рисовать следующей, и в итоге можно примерно знать все черты, но не мочь нарисовать иероглиф точно, а сама картинка в памяти бы, возможно, откладывалась как беспорядочный набор черт. Благодаря наличию порядка такого не происходит. В случае порядка есть 1 способ написать кандзи, а без порядка таких способов могло бы быть миллионы, что мешало бы запоминанию.
Как запомнить чтения иероглифа
- Самый простой способ запомнить чтение — знать какое-то слово с этим иероглифом. Поэтому при изучении посмотрите список слов с иероглифов и проверьте, нет ли среди них Вам знакомых. Если вдруг ни одного слова не оказалось, возможно, Вы захотите выучить новое. Если чтения даются Вам плохо, можно даже попытаться учить именно те иероглифы, которые попадаются в изучаемых Вами словах. Если Вы не хотите учить слова, можно хотя бы просто смотреть одно самое популярное слово каждый раз при повторении иероглифа.
- Иногда одна из составных частей иероглифа обозначает его чтение (онъёми). Это называется «фонетик» иероглифа. Например, 供 читается «きょう», т. к. 共 тоже читается «きょう», и если Вы знаете чтение 共, то запомнить чтение 供 не составит труда. Смотреть фонетики иероглифов (у которых они есть) можно на сайте akanji.ru, наводя указатель на кандзи, либо с помощью функции «Состав».
- Попытайтесь строить ассоциации к чтению. Когда у Вас будет определённый набор выученных иероглифов, Вы можете строить ассоциации к чтениям этих других иероглифов, даже если они не являются фонетиками. Можно строить ассоциации к словам, вещам, типам и т. д.
Почему важен порядок черт
- Как говорилось выше, это упрощает изучение и запоминание иероглифа. С определённым порядком есть только 1 вариант написания, а с произвольным их может быть миллионы, что усложняет запоминание. Также благодаря порядку иногда можно вспомнить иероглиф, если вспомнить его первую черту.
- При ручном письме иероглифы не всегда пишутся также тщательно, как при печати, поэтому без правильного порядка может быть сложнее прочитать или написать иероглиф.
- Из-за неверного порядка Ваш вид иероглифа может отличаться от правильного.
- Без правильного порядка Вы не сможете воспользоваться системами рукописного ввода.
- Когда Вы рисуете кистью, при пересечении черт видно какая черта была раньше, а какая позже, и другие люди увидят, если Вы пишете иероглиф неправильно.
- С правильным порядком черт иероглиф получается красивее.
Сайт для изучения кандзи akanji.ru
Сайт (и одновременно веб-приложение) akanji.ru — лучший вариант для изучения кандзи. Обладает перед конкурентами следующими преимуществами (скопировано прямо с сайта):
- Бесплатное. Есть вся необходимая для изучения информация (на русском), в т. ч.:
- Написание, чтения (с выделением окуриганы), значения
- Порядок черт
- Дополнительная полезная информация:
- Состав: На всех иероглифах есть кнопка «Состав», которая показывает, из каких частей иероглиф. При наведении указателя на часть пишется её значение и прочая информация. В итоге, когда все части известны, запомнить иероглиф намного проще.
- Ключи и фонетики: В составе ключи и фонетики выделяются цветом — так проще запомнить чтение. Также они выводятся при наведении указателя на иероглиф.
- Частота в тексте: На всех иероглифах пишется их частота в тексте.
- Популярные слова: На всех иероглифах указаны популярные слова с ними.
- Мощный поиск:
- Поиск по чтениям, значениям, количеству черт, радикалу и даже выражения.
- По любым составным частям — позволяет найти почти любой иероглиф несколькими кликами мыши. При знании 300–500 кандзи можно найти около 97% оставшихся кандзи.
- Списки для изучения:
- Как в порядке популярности кандзи, так и в школьном или JLPT.
- Можно создавать свои (до 10).
- Очень удобный режим обучения (нажмите «Начать учить кандзи», чтобы узнать подробнее).
- Отличие от Яркси: Яркси — это именно словарь с полной информацией об определённом иероглифе, и он не подходит для изучения иероглифов. Приложение akanji же изначально создавалось для изучения и имеет все функции для этого.
Для начала пользования нужно зайти на сайт и нажать «Начать учить кандзи» — приложение само расскажет Вам, как им пользоваться. Главный недостаток — нет адаптированной мобильной версии, а также нет возможности прописи кандзи пальцем с экрана мобильного телефона. Если Вы с компьютера, это нестрашно, т. к. в этом случае лучше прописывать кандзи в тетради, и данный сайт будет лучшим выбором.
Нужно отметить, что сайт ещё в процессе улучшения. В блоге разработчики пообещали следующие вещи:
- Заполнить информацию об оставшихся иероглифах (сейчас заполнено только 1000).
- Улучшить информацию о текущих иероглифах до совершенства.
- С помощью анализа японских текстов, интернета и прочего указать самые популярные слова с каждым иероглифом и номер их популярности. Сейчас указаны просто популярные слова, не все из них самые популярные, а также их не так много.
- Улучшить систему чтений, а также отображения популярных слов с чтениями.
Заключение
Мы описали всё, что только может понадобиться по изучению кандзи. Надеемся, статья была Вам полезна  Но если мы что-то упустили или у Вас остались вопросы, пожалуйста, обращайтесь во ВКонтакте либо на
Но если мы что-то упустили или у Вас остались вопросы, пожалуйста, обращайтесь во ВКонтакте либо на 

Если вы уже научились читать основную японскую азбуку хирагану, то вам можно переходить к изучению письма. А если вы еще не освоили эту базу, то советуем прочитать нашу статью про хирагану, где подробно объясняется, как она образована, и описываются эффективные способы запоминания.
Умение писать не только закрепляет уже полученные знания, но и помогает в дальнейшем освоении иностранного языка. Особенно это важно при изучении японского, так как его буквы сильно отличаются от привычных нам алфавитов.
Начать изучать японское письмо стоит именно с двух слоговых азбук: хираганы и катаканы. Они обе состоят из одинаковых звуков, но по написанию совершенно разные. Единственная вещь, которая объединяет их на письме — это четкая последовательность черт, в которой записываются знаки. Все они пишутся в одно касание и в определенном направлении. В противном случае значение буквы может исказиться.
Согласно американскому лингвисту, Тимоти Стауту, типы черт, которыми записывают японские символы можно разделить на:
- «Остановку» (томэ). Пишущий останавливает карандаш, заканчивая линию, до того, как поднять его кончик от бумаги.
- «Скачок» (ханэ). Во время написания карандаш отрывается от бумаги, «перепрыгивая» на следующую черту. Из-за этого в конце линии получается небольшой хвостик.
- «Мазок» (харай). В самом конце черты карандаш медленно отрывается от бумаги, оставляя угловатый хвостик или завитушку.
Буква «ке» (в азбуке хирагане) является хорошим примером всех трех типов. Первая черта — это «скачок», вторая — «остановка», третья — «мазок».
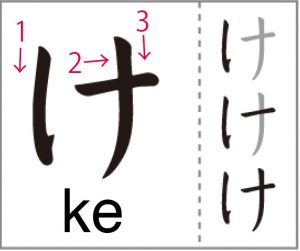
Помимо соблюдения последовательности черт, важно обращать внимание на пропорции символов. Ведь при письме на русском или английском никто не записывает одну букву уже или выше другой. Так и с японскими знаками — нужно стараться делать их одинаковыми. Это актуально для всех языков, ведь иначе письмо будет не просто смотреться некрасиво, но и трудно читаться.
Как пишется хирагана
Давайте подробнее рассмотрим правила написания именно этой азбуки, ведь она является ключевой и основополагающей для изучения.
Хирагана ассоциируется с плавными линиями и округлыми формами. Поэтому при изучении письма обратите внимание на то, что в ней практически нет прямых линий, все они немного наклонены или изогнуты.
Японский язык и его алфавит: Ряд «А»
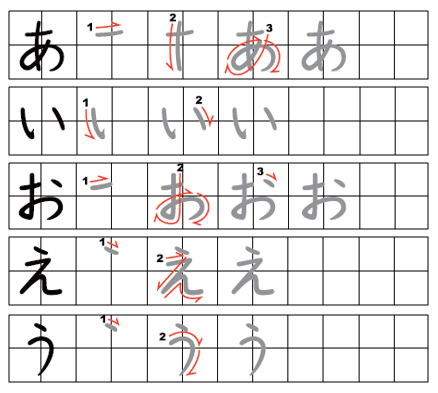
あ — пишется в 3 черты. Обратите внимание, что вторая немного искривлена влево. Писать нижнюю часть знака надо начинать справа. Она похожа на небольшой крендель. Этот элемент часто встречается в хирагане.
Некоторые буквы похожи между собой, поэтому так важно писать их правильно, чтобы не запутаться. Например, при некорректном написании «А» можно перепутать с «МЭ».

い — 2 черты. Первая относится к типу «скачок», из-за чего в конце линии получается небольшой крючок. Она немного похожа на клюшку. Вторая черта короче первой. Если сделать ее длиннее, то получится «РИ». Обе линии немного изогнуты.

お — состоит из 3-х черт. Первая пишется в левой части квадратика. Вторая черта — это вертикальная линия, переходящая в округлую завитушку, напоминающую нижнюю часть буквы «А». Последняя линия — это короткий штрих в правой верхней части.
え — в этой букве всего 2 черты. Первая— простая и прямая сверху, а вторая — линия, похожая на цифру 1 с волнообразной линией в конце. Нужно следить, чтобы эта волна не была слишком длинной и не уходила бы слишком высоко.
う — 2 черты. Маленькая черта сверху (такая же, как в «Э»). А внизу — кривая линия, похожая на ухо. И не спутайте эту букву с «РА».

Японские буквы, алфавит хирагана: Ряд «КА»
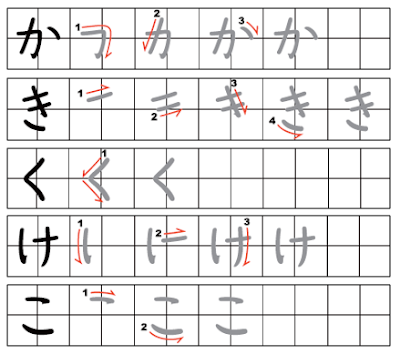
か — 3 черты. Обратите внимание, что первая черта — это «уголок»: изогнутая линия, которая идет слева направо, уходя вниз. Вторая линия вертикальная. Она ставится в левой части квадрата и пишется с небольшим наклоном. Последняя черта — маленькая линия в правой верхней части.
き — 4 черты. Сначала ставятся две параллельные линии. Затем — наклонная прямая. Последний штрих немного выгнутый и ставится он внизу. В отличие от печатного варианта, на письме третья и четвертая линии не пересекаются.
く — 1 черта, напоминающая угол. Главное следить за тем, чтобы верхняя и нижняя половины были одинаковой длины.
け — 3 черты. Первая изогнутая линия в левой части квадратика. В правой части пишется маленькая горизонтальная черта, которую пересекает длинная линия, закругленная снизу. Эта часть немного напоминает крест.
こ — 2 черты. Они ставятся одна над другой и обе немного изогнуты. При этом первая черта короче второй.
Знаки нигори ставятся справа. Это должны быть две одинаковые по длине линии. Не ставьте их слишком близко к основному слогу.

Японский алфавит и его символы: Ряд «СА»
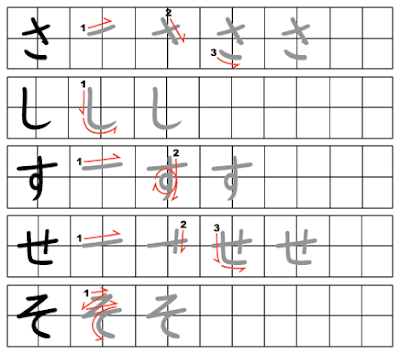
さ — 3 черты. В японском есть буквы похожие между собой. Этот знак, например, напоминает «КИ», только вместо двух горизонтальных линий — одна. На письме вторая и третья линии также не соединяются.
し — 1 вертикальная черта, плавно закругленная на конце.
す — 2 черты. Горизонтальную линию пересекает одна вертикальная, которая в середине закручивается в узелок и заканчивает свой путь легким изгибом в левую сторону.
せ — 3 черты. Первая — горизонтальная, она немного направлена вверх. Следующая линия вертикальная и короткая. На ее конце образуется небольшой хвостик, так как она относится к типу «скачок». Последняя — тоже вертикальная, однако внизу она плавно загибается вправо.
そ — 1 черта. Эта буква пишется в одно касание. Верхняя ее часть напоминает английскую «Z», а снизу к ней добавляется изогнутая влево линия.
Японская азбука: Ряд «ТА»

た — 4 черты. В левой части квадрата линии образуют крест: короткая горизонтальная черта пересекается длинной вертикальной линией. Справа под первой чертой ставится две параллельные линии, похожие на небольшую букву こ (КО).
ち — 2 черты. Первая — короткая и горизонтальная. Вторая вертикальная линия начинается с легкого наклона влево и заканчивается полуовальным изгибом вправо. Немного напоминает цифру 5.
つ — 1 черта изогнутая вправо. Ее верхняя часть длиннее нижней.
て — 1 черта. От конца длинной горизонтальной черты, идущей немного вверх, отходит изогнутая влево линия. Важно помнить, что эта буква пишется в одно касание.
と — 2 черты. Короткая наклонная соприкасается с небольшим полуовалом.
Японский алфавит, как писать: Ряд «НА»
Множественные завитушки делают этот ряд самым сложным для запоминание во всей хирагане.
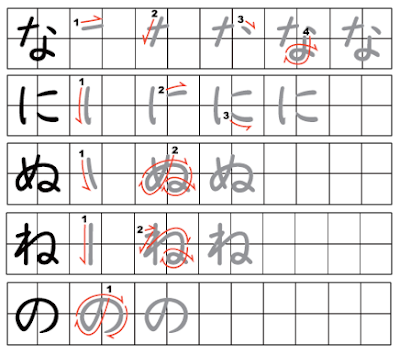
な — 4 черты. Слева пишется такой же «крест», как в букве た (ТА), только короче. Обратите внимание, что третья линия — это маленькая наклонная, а та, которая пишется под ней, — это четвертая, а не наоборот. Эта последняя черта на конце закручена в «узелок». Запомните этот элемент, он ключевой в этом ряду.
に — 3 черты. В левой части ставится большая вертикальная черта, а справа — две параллельные черты, похожие на こ (КО). Проследите, чтобы между ними было достаточно места.
ぬ — 2 черты. Первый вертикальный штрих пишется под наклоном. Вторая линия похожа на нижнюю часть буквы あ (А), только с тем отличием, что в конце она закручивается в «узелок».
ね — 2 черты. Первая линия — вертикальная прямая. Следующий штрих — одно целое, он пишется в одно касание. Начинается он в левом верхнем углу. Пишем небольшой зигзаг, который в конце превращается в округлую дуру и снова закручивается «узелком».
の — 1 черта. Изогнутая линия идет из середины в нижний левый угол, плавно поднимаясь наверх и образуя полуокружность в правой части квадратика.
Японская слоговая азбука хирагана: Ряд «ХА»

は — 3 черты. Первая длинная линия такая же, как в に (НИ). Вторая — горизонтальная, ее пересекает вертикальная, закручивающаяся в «петельку» на конце. Эта последняя черта похожа на 4-ую линию в букве な (НА).
へ — 1 черта. Начинается в левой части в середине клеточки, идет наверх и на середине уходит в правый нижний угол. Вторая ее часть длиннее первой, поэтому будьте аккуратнее.
ふ — 4 черты. В середине сверху ставится маленький вертикальный штрих. Затем пишется небольшая изогнутая вправо дуга, а по бокам ставятся две линии, похожие на запятые. Они смотрят в разные стороны.
ひ — 1 черта. В верхнем левом углу чертится короткая линия вверх, которая уходит вниз, образуя полуокружность, которая завершается такой же чертой в правом верхнем углу. Учитывайте то, что эта полуокружность немного наклонена в левую сторону.
ほ — 4 черты. Эта буква очень похожа на は (ХА), но в правой части наверху ставятся две черты, а не одна. Соблюдайте аккуратность при написании четвертой черты, ведь одна не заходит за пределы второй.
Как вы помните, из этого ряда образуются ряды «БА», который пишется со знаком нигори, и ряд «ПА», носящий символ ханнигори. Он, так же, как и его брат, ставится в правом верхнем углу:
Японские буквы: Ряд «МА»
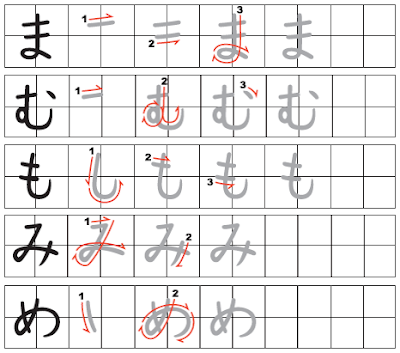
ま — 3 черты. Сначала ставятся две одинаковые горизонтальные линии, которые пересекает вертикальная, завивающаяся в «петлю» в конце. Эта буква похожа на правый элемент в ほ (ХО), но в ней последняя вертикальная черта заходит за пределы первой линии.
む — 3 черты. Первый штрих — это обычная маленькая черта. Вторая линия в начале очень похожа на す (СУ), но она не заканчивается внизу, а уходит вправо и наверх. В правом верхнем углу пишется маленькая «запятая».
も — 3 черты. Эта буква похожа на し (СИ), которую пересекают две параллельные линии. Надо соблюдать осторожность в порядке написания штрихов. В отличие от き (КИ) и ま (МА), горизонтальные черты этой буквы ставятся после того, как будет написан «крючок».
み — 2 черты. Первая линия начинается в левом верхнем углу, поднимается немного вверх и тут же уходит вниз, закручивая маленькую «петлю». В конце первой линии ставится небольшая вертикальная черта, параллельная левой части.
め — 2 черты. Эта буква очень похожа на ぬ (НУ), но у нее нет «узла» в конце.
Хирагана для детей: Ряд «Я»
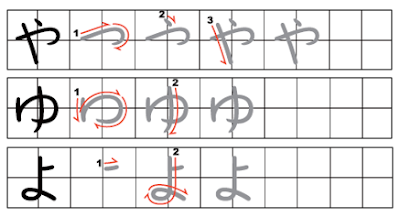
や — 3 черты. «Я» начинается с маленькой дуги в верхней половине квадрата. Над ней в середине ставится штрих в виде запятой. Затем чертится вертикальная линия, идущая из левого верхнего угла к середине.
ゆ — 2 черты. Первая линия начинается в левой половине. Небольшой вертикальный штрих переходит в полуокружность. Во второй половине квадрата ее пересекает вертикальная изогнутая черта.
よ — 2 черты. Сначала ставится очень короткая черта в правой части квадрата. Далее ровно в середине чертится уже знакомая вертикальная линия с «петлей» на конце. Такая же, как в ま, は и ほ.
Хирагана учить: Ряд «РА»

ら — 2 черты. В середине квадрата сверху ставится небольшая наклонная черточка. Затем — вертикальная линия, переходящая в полуовал.
り — 2 черты. Слева чертится вертикальная немного изогнутая линия. Вторая линия длиннее первой, она загибается немного влево в конце. В печатном варианте эти две черты пересекаются.
る — 1 черта. Начинается с зигзага, который переходит в полукруг, заканчивающейся «узелком» на конце. Однако обратите внимание, что, в отличии от других подобных «петелек» (в な, ま, ほ), у этой отсутвует хвостик.
れ — 2 черты. Эта буква похожа на ね (НЭ), но тут конец второй линии не образует «петлю», а загибается вправо.
ろ — 1 черта. Тут все довольно просто, ведь эта буква пишется так же, как る (РУ), но без «узелка» в конце. Главное, теперь их не спутать! Обратите внимание на то, что линия заканчивается в середине клеточки.
Полный японский алфавит: Ряд «ВА»

わ — 2 черты. Эта буква ничего вам не напоминает? Она пишется так же, как ね (НЭ) и れ (РЭ), но здесь конец второй линии образует полуовал.
を — 3 черты. Первая — горизонтальная. Следующая — вертикальная. Она идет из середины и наклонена влево, затем от нее отводится дуга право. Этот элемент похож на английскую букву «h». Последняя черта — это изогнутый влево полуовал, похожий на перевернутую つ (ЦУ).
ん — 1 черта. От наклонной влево вертикальной черты отходит небольшая «волна». Этот символ также похож на букву «h», написанную курсивом.
Японские прописи: Хирагана
Самый простой способ научиться писать — начать использовать японские прописи.
Хирагана запоминается достаточно легко благодаря частому использованию и витиеватым буквам, которые сильно различаются между собой и остаются в памяти.

Азбуку хирагану можно изучать по простым прописям для практики всех основных слогов. В них четко показан порядок написания черт. Прописи с дополнительными слогами (нигори, ханнигори и маленькими буквами) отсутствуют. Однако, зная 46 базовых сочетаний, остальные вы сможете написать без проблем.
Освоив правила проставления черт, следует переходить к чистой практике. Эти прописи помогут развить моторную память. Благодаря тому, что в них нужно несколько раз обводить слоги по контуру, хирагана быстро запомнится.
Материалы для детей также окажут помощь в закреплении знаний. Прописи с картинками и простыми словами — хороший способ усовершенствовать письмо и выучить названия животных, растений и других предметов.

Более продвинутый тип прописей по хирагане можно скачать в pdf тут. Для каждого символа есть три ряда клеточек:
- В первом нужно обвести буквы по линиям.
- Во втором ряду надо попытаться повторить образец самостоятельно.
- Третий ряд нужно заполнить, не смотря на образец, а затем сравнить то, что получилось с оригиналом.
Хирагана — это основная азбука в японском. Именно с нее стоит начинать обучение не только письма, но и чтения и произношения.
Японские прописи: Катакана
Считается, что, в отличие от хираганы, эта азбука запоминается тяжелее. Это может быть связано с тем, что она используется реже. Также в ней много похожих между собой, почти одинаковых, букв: ソ (со), ン (н), シ (си) и ツ (цу). Поэтому нужно уделять особое внимание направлению и порядку нанесения штрихов.
Как и в первой азбуке, сначала надо разобраться в последовательности черт. Для этого лучше использовать простые прописи. В закреплении полученных знаний помогут практические листы с обведением линий. Затем можно перейти к детским прописям со словами.
Как только основы будут выучены, надо начать практику по более серьезным прописям на катакане.
Дополнительные тетради для прописи по катакане для печати вы найдете тут.

С прописями придется сталкиваться часто на всем пути обучения. В японском языке есть целых три вида письменности — хирагана, катакана, кандзи — и каждый символ в них пишется в определенной последовательности. Как только с двумя слоговыми азбуками будет покончено, можно приступать к изучению иероглифов.
Скачайте себе специальную тетрадь для японского языка с пустыми клеточками, представленную ниже. Так по ходу знакомства с новыми словами и грамматикой вы сможете сразу отрабатывать правописание.

Японские иероглифы, каллиграфия
В отличие от азбук научиться писать кандзи гораздо сложнее. В Японии существует целый вид искусства, посвященный начертанию иероглифов — каллиграфия. Так что, говоря о письме, мы просто не можем не упомянуть ее.
Сёдо: (書道), или дословно «путь письма» — традиционное восточное искусство, как и сами иероглифы, пришедшее в Японию из Китая. В то время как европейские алфавиты выполняют преимущественно функциональную роль, иероглифы еще с древних времен являются отдельными художественными объектами.
Японская каллиграфия для начинающих
Если вы самостоятельно решили овладеть этим искусством, то нужно знать, что это непростой процесс. Ведь каллиграфия это не просто красивое написание символов, а целая наука, включающая в себя особые правила, историю и философию.
Как и каждое дело, за которое берутся японцы, весь процесс работы — отдельный ритуал. Техника и любое действие, начиная от выбора кистей и подготовки туши, имеет смысл и должно быть отточено до предела.
«Путь письма» по своему концепту близок к буддизму. Считается, что это дорога совершенствования себя с помощью туши, кисти и бумаги. Если человек не придет к гармонии внутри себя, то он не сможет изобразить красиво иероглиф. Именно поэтому истинная красота каллиграфического символа в гармонии и душевном спокойствии, достигнутом мастером.
Для начала важно знать, какие инструменты используют каллиграфические мастера:
- кисть (筆 — фудэ);
- чернильница для растворения твердой туши (硯 — судзури);
- черная или красная тушь (墨 — суми);
- специальная японская бумага (和紙 — васи);
- держатели (文鎮 — бунсин) и подложки (下敷き — ситадзики) для бумаги.
Начинающим можно приобрести все необходимое в художественном магазине: простую гуашь, мягкую заостренную кисть, бумагу и баночку для воды. И лишь потом надо будет расширять свой арсенал более профессиональными инструментами.
Наверное, каждый из учащихся сталкивался с необходимостью искать кандзи в словаре, не зная его чтения. В этом случае можно нарисовать японский иероглиф и перевести онлайн в переводчике. Но, даже для этого нужно знать, в какой последовательности пишутся кандзи. Иначе символ может распознаться неправильно.
А изучение каллиграфии без этого знания и вовсе не возможно. Посмотрите видео о том, как научиться писать японские иероглифы.

Каждый иероглиф имеет собственную четкую структуру. Вспомните про 3 вида линий, о которых говорилось выше: остановка, скачок и мазок. При написании кандзи важно помнить о них.

Кисть мастер держит только большим, указательным и средним пальцами за середину или выше, наклоняя ее на 45 градусов. Важно научиться плавно вести каждую черту, надавливая и ослабляя нажим в нужные моменты.
Как нарисовать японские иероглифы
После подготовления основных инструментов, вам нужно будет выбрать иероглиф. Начинать стоит с самых простых, например, с «человека» (人).
Разделите лист на 4 квадрата, чтобы понимать, в какой части должна находится каждая черта. Далее, держа кисть под углом 45 градусов, сделайте первый мазок и ведите линию наискось влево. Вторую линию начертите вправо, остановитесь и с нажимом уведите ее еще немного вправо. Вот и готов кандзи «человек»!

Также во время обучения рекомендуется смотреть как можно больше видео про каллиграфию, чтобы вы могли эти увиденные японские иероглифы скопировать и больше тренироваться. И помните: в любом деле главное — это практика!
А какой вид письменности вам нравится больше — хирагана, катакана или кандзи — и почему? Напишите в комментариях!
Каллиграфия японского языка. Тетрадь для иероглифов, хираганы, катаканы. Статья о том, как рисовать японские иероглифы для начинающих. Прописи японских азбук.