Введение в серверную часть
- Обзор: First steps
- Далее
Добро пожаловать на курс для начинающих по программированию серверной части сайта! В этой первой статье мы рассмотрим программирование на стороне сервера с высокого уровня, отвечая на такие вопросы, как «что это»?, «как это отличается от программирования на стороне клиента»? и «почему это так полезно»? После прочтения этой статьи вы поймёте дополнительные возможности, доступные веб-сайтам посредством программирования на стороне сервера.
| Перед стартом: | Базовая компьютерная грамотность. Базовое понимание, что такое веб-сервер. |
|---|---|
| Цель: | Ознакомиться с тем, что такое программирование серверной части, на что оно способно и чем отличается от программирования клиентской части. |
Большинство крупных веб-сайтов используют программирование серверной части чтобы динамично отображать различные данные при необходимости, в основном взятые из базы данных, располагающейся на сервере и отправляемые клиенту для отображения через некоторый код (например, HTML и JavaScript).
Возможно, самая значительная польза программирования серверной части в том, что оно позволяет формировать контент веб-сайта под конкретного пользователя. Динамические сайты могут выделять контент, который более актуален в зависимости от предпочтений и привычек пользователя. Это также может упростить использование сайтов за счёт сохранения личных предпочтений и информации, например, повторного использования сохранённых данных кредитной карты для оптимизации последующих платежей.
Это также даёт возможность взаимодействовать с пользователем сайта, посылая уведомления и обновления по электронной почте или по другим каналам. Все эти возможности позволяют глубже взаимодействовать с пользователями.
В современном мире веб-разработки настоятельно рекомендуется узнать о разработке на стороне сервера.
Что такое программирование серверной части сайта?
Веб-браузеры взаимодействуют с веб-серверами при помощи гипертекстового транспортного протокола (HTTP). Когда вы нажимаете на ссылку на веб-странице, заполняете форму или запускаете поиск, HTTP-запрос отправляется из вашего браузера на целевой сервер.
Запрос включает в себя URL, определяющий затронутый ресурс, метод, определяющий требуемое действие (например, получить, удалить или опубликовать ресурс) и может включать дополнительную информацию, закодированную в параметрах URL (пары поле-значение, отправленные как строка запроса), как POST запрос (данные, отправленные методом HTTP POST) или в куки-файлах.
Веб-серверы ожидают сообщений с клиентскими запросами, обрабатывают их по прибытию и отвечают веб-браузеру при помощи ответного HTTP сообщения (HTTP-ответ). Ответ содержит строку состояния, показывающую, был ли запрос успешным или нет (например, «HTTP/1.1 200 OK» в случае успеха).
Тело успешного ответа на запрос может содержать запрашиваемые данные (например, новую HTML-страницу или изображение, и т. п.), который может отображаться через веб-браузер.
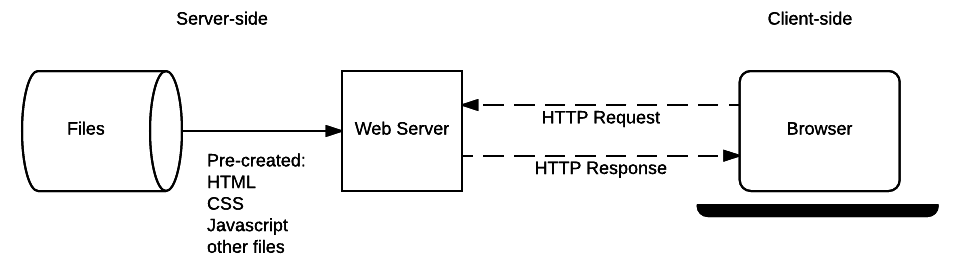
Статические сайты
Схема ниже показывает базовую архитектуру веб-сервера для статического сайта (статический сайт — это тот, который возвращает одно и то же жёстко закодированное содержимое с сервера всякий раз, когда запрашивается конкретный ресурс). Когда пользователь хочет перейти на страницу, браузер отправляет HTTP-запрос «GET» с указанием его URL.
Сервер извлекает запрошенный документ из своей файловой системы и возвращает HTTP-ответ, содержащий документ и успешный статус (обычно 200 OK). Если файл не может быть извлечён по каким-либо причинам, возвращается статус ошибки (смотри ошибки клиента и ошибки сервера).
Динамические сайты
Динамический веб-сайт — это тот, где часть содержимого ответа генерируется динамически только при необходимости. На динамическом веб-сайте HTML-страницы обычно создаются путём вставки данных из базы данных в заполнители в HTML-шаблонах (это гораздо более эффективный способ хранения большого количества контента, чем использование статических сайтов).
Динамический сайт может возвращать разные данные для URL-адреса на основе информации, предоставленной пользователем или сохранёнными настройками, и может выполнять другие операции, как часть возврата ответа (например, отправку уведомлений).
Большая часть кода для поддержки динамического веб-сайта должна выполняться на сервере. Создание этого кода известно, как «программирование серверной части» (или иногда «программирование бэкенда»).
Схема ниже показывает простую архитектуру динамического сайта. Как и на предыдущей схеме, браузеры отправляют HTTP-запросы на сервер, затем сервер обрабатывает запросы и возвращает соответствующие HTTP-ответы.
Запросы статических ресурсов обрабатываются так же, как и для статических сайтов (статические ресурсы — это любые файлы, которые не меняются, обычно это: CSS, JavaScript, изображения, предварительно созданные PDF-файлы и прочее).
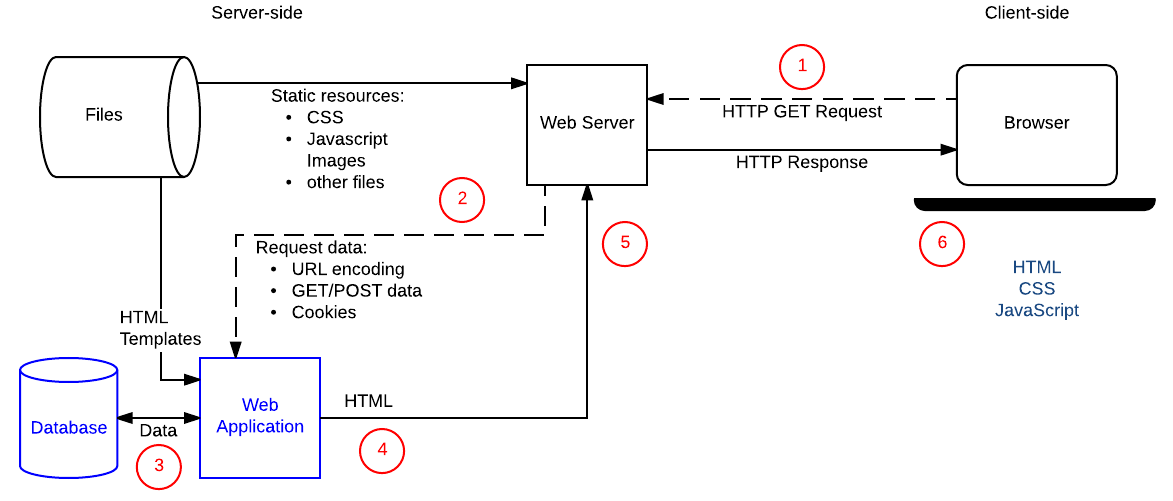
Запросы динамических данных отправляются (2) в код серверной части (показано на диаграмме как Веб-приложение). Для «динамических запросов» сервер интерпретирует запрос, читает необходимую информацию из базы данных (3), комбинирует извлечённые данные с шаблонами HTML и возвращает ответ, содержащий сгенерированный HTML (5, 6).
Одинаково ли программирование серверной части и клиентской?
Теперь обратим внимание на код, задействованный в серверной части и клиентской части. В каждом случае код существенно различается:
- Они имеют различные цели и назначение.
- Как правило, они не используют одни и те же языки программирования (исключение составляет JavaScript, который можно использовать на стороне сервера и клиента).
- Они выполняются в разных средах операционной системы.
Код, который выполняется в браузере, известный как код клиентской части, прежде всего связан с улучшением внешнего вида и поведения отображаемой веб-страницы. Это включает в себя выбор и стилизацию компонентов пользовательского интерфейса, создание макетов, навигацию, проверку форм и т. д. Напротив, программирование веб-сайта на стороне сервера в основном включает выбор содержимого, которое возвращается браузеру в ответ на запросы. Код на стороне сервера обрабатывает такие задачи, как проверка отправленных данных и запросов, использование баз данных для хранения и извлечения данных и отправка правильных данных клиенту по мере необходимости.
Код клиентской части написан с использованием HTML, CSS и JavaScript — он запускается в веб-браузере и практически не имеет доступа к базовой операционной системе (включая ограниченный доступ к файловой системе).
Веб-разработчики не могут контролировать, какой браузер может использовать каждый пользователь для просмотра веб-сайта — браузеры обеспечивают противоречивые уровни совместимости с функциями кода на стороне клиента, и одной из задач программирования на стороне клиента является изящная обработка различий в поддержке браузера.
Код серверной части может быть написан на любом количестве языков программирования — примеры популярных языков серверной части включают в себя PHP, Python, Ruby, C# и NodeJS (JavaScript). Код серверной части имеет полный доступ к операционной системе сервера, и разработчик может выбрать какой язык программирования (и какую версию) он хотел бы использовать.
Разработчики обычно пишут свой код, используя веб-фреймворки. Веб-фреймворки — это наборы функций, объектов, правил и других конструкций кода, предназначенных для решения общих проблем, ускорения разработки и упрощения различных типов задач, стоящих в конкретной области.
И снова, поскольку и клиентская и серверная части используют фреймворки, области очень разные и, следовательно, фреймворки тоже разные. Фреймворки клиентской части упрощают вёрстку и представление данных, тогда как фреймворки серверной части обеспечивают много «обычной» функциональности веб-сервера, которую вы, возможно, в противном случае, должны были осуществлять самостоятельно (например, поддержка сессий, поддержка пользователей и аутентификация, простой доступ к базе данных, шаблонам библиотек и т. д.).
Примечание: Фреймворки клиентской части часто используются для ускорения написания кода клиентской части, но вы также можете решить писать весь код руками; на самом деле, написание кода руками может быть более быстрым и эффективным, если вам нужен небольшой простой веб-сайт UI.
И, наоборот, вы практически никогда не посмотрите в сторону написания кода серверной части веб-приложения без фреймворка: осуществление жизненно важной функции, такой как HTTP сервер действительно сложно сделать с нуля, скажем, на Python, но веб-фреймворки для Python, такие как Django, обеспечивают это из коробки наряду с другими полезными инструментами.
Что можно сделать в серверной части?
Программирование серверной части очень полезно поскольку позволяет эффективно доставлять информацию, составленную для индивидуальных пользователей и, таким образом, создавать намного лучший опыт использования.
Компании, такие как Amazon, используют программирование серверной части для построения исследовательских результатов для товаров, формирования целевого предложения, основанного на предпочтениях клиента и предыдущих покупках, упрощения заказов и т. д. Банки используют программирование серверной части, чтобы хранить учётную информацию и позволять только авторизованным пользователям просматривать и совершать транзакции. Другие сервисы, такие как Facebook, Twitter, Instagram и Wikipedia используют бэкенд, чтобы выделять, распространять и контролировать доступ к интересному контенту.
Некоторые типичные применения и выгоды бэкенда перечислены ниже. Вы заметите, что есть некоторое пересечение!
Эффективное хранение и доставка информации
Представьте, сколько товаров доступно на Amazon, и представьте, сколько постов было написано на Facebook? Создание статической страницы для каждого товара или поста было бы абсолютно неэффективным.
Программирование серверной части позволяет вместо этого хранить информацию в базе данных и динамически создавать и возвращать HTML и другие типы файлов (например, PDF, изображения, и т. д.). Также есть возможность просто вернуть данные (JSON, XML, и т. д.) для отображения, используя подходящий фреймворк клиентской части (это уменьшает загрузку процессора на сервере и количество передаваемых данных).
Сервер не ограничен в отправке информации из баз данных и может вместо этого возвращать результат инструментов программного обеспечения или данные из сервисов коммуникации. Контент даже может быть целевым относительно устройства клиента, который его получает.
Из-за того, что информация находится в базе данных, её также можно легко передать и обновить через другие бизнес системы (например, отслеживание).
Примечание: вам не нужно сильно напрягать своё воображение, чтобы увидеть достоинства кода серверной части для эффективного хранения и передачи информации:
- Зайдите на Amazon или в другой интернет-магазин.
- Введите в поиск несколько ключевых слов и заметьте, как структура страницы не изменилась, тогда как результаты изменились.
- Откройте два или три разных товара. Заметьте, что они имеют схожую структуру и внешний вид, но содержимое для разных товаров было вставлено из базы данных.
Для обычного поиска (например, «рыба») вы можете увидеть буквально миллионы найденных значений. Использование базы данных позволяет им храниться и передаваться эффективно, и это позволяет контролировать представление информации всего в одном месте.
Настраиваемый пользовательский опыт взаимодействия
Серверы могут хранить и использовать информацию о клиентах чтобы поставлять удобный и сделанный индивидуально пользовательский опыт взаимодействия. Например, многие сайты хранят данные кредитных карт, чтобы не нужно было вводить их повторно. Сайты, наподобие Google Maps, могут использовать сохранённое и текущее местоположение для предоставления информации о маршруте, а также историю поиска или путешествий для выделения местных предприятий в результатах поиска.
Более глубокий анализ привычек пользователя может быть использован для прогнозирования их интересов и дальнейших настроек ответов и уведомлений, например, предоставление списка ранее посещённых популярных мест, которые вы, возможно, захотите найти на карте.
Примечание: Google Maps сохраняет вашу историю поиска и посещений. Часто посещаемые или часто вводимые в поиск локации выделяются больше, чем остальные.
Результаты поиска Google оптимизируются на основе предыдущего поиска.
- Перейдите в поиск Google.
- Произведите поиск по слову «футбол».
- Теперь попробуйте ввести «любимое» в поисковой строке и понаблюдайте, как работают подсказки автозаполнения поиска.
Стечение обстоятельств? Нет!
Контролируемый доступ к контенту
Программирование серверной части позволяет сайтам ограничивать доступ авторизованным пользователям и предоставлять только ту информацию, которую пользователю разрешено видеть.
Реальные примеры:
- Социальные сети, такие как Facebook, позволяют пользователям полностью контролировать свои данные, но только своим друзьям разрешать просматривать или комментировать их. Пользователь определяет, кто может просматривать его данные и, более того, чьи данные появляются на его стене. Авторизация — центральная часть опыта взаимодействия.
- Сайт, на котором вы находитесь прямо сейчас, контролирует доступ к контенту: статьи видны всем, но только авторизованные пользователи могут редактировать контент. Чтобы проверить это, нажмите на кнопку «Редактировать» в верхней части страницы, и, если вы авторизованы, вы увидите редакторский интерфейс, а если нет — вас перенаправит на страницу авторизации.
Примечание: Рассмотрим другие реальные примеры, где доступ к контенту контролируется. Например, что вы можете увидеть, если зайдёте на сайт вашего банка? Авторизуйтесь через вашу учётную запись, и какую дополнительную информацию вы можете просматривать и редактировать? Что за информацию вы можете увидеть, которую может редактировать только банк?
Хранение информации о сессии/состоянии
Программирование серверной части позволяет разработчикам использовать сессии – изначально это механизм, позволяющий серверу хранить информацию о текущем пользователе сайта и отправлять разные ответы, основанные на этой информации.
Это позволяет, например, сайту знать, что пользователь был предварительно авторизован и выводить ссылки на его адрес электронной почты или историю заказов или, возможно, сохранить прогресс простой игры, так чтобы пользователь мог вернуться на сайт продолжить с того места, где он закончил.
Примечание: Посетите новостной сайт, у которого есть подписка и откройте ветку тегов (например, The Age). Продолжайте посещать сайт в течение нескольких часов/дней. В итоге вас начнёт перенаправлять на страницы, объясняющие, как оформить платную подписку, а сами статьи станут вам недоступны. Эта информация является примером сессии, сохранённой в куки-файлах.
Уведомления и средства связи
Серверы могут отправлять общие или пользовательские уведомления непосредственно через сайт или по электронной почте, через смс, мгновенные сообщения, видеосвязь или другие средства связи.
Вот несколько примеров:
- Facebook или Twitter отправляет уведомления по электронной почте и смс-сообщения, чтобы уведомить вас о новых разговорах.
- Amazon регулярно отправляет письма на электронную почту, предлагающие товары, похожие на те, которые уже были куплены или просматривались вами, которые могут вас заинтересовать.
- Веб-сервер может посылать сообщения администратору сайта, предупреждая его о том, что на сервере заканчивается память или о подозрительной активности пользователя.
Примечание: Самый распространённый вид уведомлений – это «подтверждение регистрации». Возьмите почти любой интересующий вас крупный сайт (Google, Amazon, Instagram и т. п.) и создайте новую учётную запись, используя ваш адрес электронной почты. Вскоре вы получите письмо, подтверждающее факт вашей регистрации или содержащее информацию о необходимости активировать вашу учётную запись.
Анализ данных
Веб-сайт может собирать много данных о своих пользователях: что они ищут, что они покупают, что они рекомендуют, как долго они остаются на каждой странице. Программирование серверной части может быть использовано, чтобы усовершенствовать ответы, основанные на анализе этих данных.
Например, и Amazon, и Google рекламируют товары на основании предыдущих поисков (и покупок).
Примечание: Если вы пользуетесь Facebook, зайдите на вашу стену и посмотрите на ряд постов. Заметьте, что некоторые посты не идут по порядку: в частности, посты с большим количеством «лайков» часто находятся выше по списку, чем остальные. Также взгляните на рекламу, которую вам показывают, вы вероятно увидите рекламу товаров, которые искали на других сайтах. Алгоритм Facebook для выделения контента и рекламы может казаться мистикой, но очевидно, что он зависит от ваших лайков и запросов поиска!
Подведение итогов
Поздравляем, вы дошли до конца первой статьи о программировании серверной части.
Теперь вы узнали, что код серверной части выполняется на веб-сервере и его основная роль состоит в контролировании отправляемой пользователю информации (тогда как код клиентской части в основном определяет структуру и способ преподнесения информации пользователю). Вы должны также понимать, что это полезно, так как позволяет создавать веб-сайты, которые эффективно доставляют информацию, собранную для конкретных пользователей и иметь чёткое представление о некоторых вещах, которые вы сможете делать, когда станете разработчиком бэкенда.
Наконец, вы должны понимать, что код серверной части может быть написан на разных языках программирования, и что вам следует использовать веб-фреймворк для упрощения процесса написания кода.
В следующей статье мы поможем вам выбрать лучший фреймворк для вашего первого сайта; затем мы изучим несколько основных взаимодействий с клиентской частью более подробно.
- Обзор: First steps
- Далее
Время на прочтение
7 мин
Количество просмотров 30K
Большую часть своей веб-карьеры я работал исключительно на стороне клиента. Проектирование адаптивных макетов, создание визуализаций из больших объемов данных, создание инструментальных панелей приложений и т. Д. Но мне никогда не приходилось иметь дело с маршрутизацией или HTTP-запросами напрямую. До не давнего времени.
Этот пост представляет собой описание того, как я узнал больше о веб-разработке на стороне сервера с помощью Node.js, и краткое сравнение написания простого HTTP-сервера с использованием 3 разных сред, Express, Koa.js и Hapi.js.
Примечание: если вы опытный разработчик Node.js, вы, вероятно, подумаете о том, что это все элементарно/просто. ¯_(ツ)_/¯.
Некоторые основы сети
Когда я начал работать в веб-индустрии пару лет назад, я наткнулся на курс по компьютерным сетям профессора Дэвида Ветерала на Coursera. К сожалению, он больше не доступен, но лекции по-прежнему доступны на веб-сайте Pearson.
Мне очень понравился этот курс, потому что он объяснял, что происходило под капотом, в понятной форме, поэтому, если вы можете взять в руки учебник «Компьютерные сети», прочитайте все подробности о чудесах сети.

Здесь, однако, я собираюсь лишь кратко рассказать о контексте. HTTP (Hypertext Transfer Protocol) — это протокол связи, используемый в компьютерных сетях. В Интернете их много, таких как SMTP (простой протокол передачи почты), FTP (протокол передачи файлов), POP3 (протокол почтового отделения 3) и так далее.
Эти протоколы позволяют устройствам с совершенно разным аппаратным / программным обеспечением связываться друг с другом, поскольку они предоставляют четко определенные форматы сообщений, правила, синтаксис и семантику и т.д. Это означает, что, пока устройство поддерживает определенный протокол, оно может связываться с любым другим устройством. в сети.

От TCP / IP против OSI: в чем разница между двумя моделями?
Операционные системы обычно поставляются с поддержкой сетевых протоколов, таких как HTTP, из коробки, что объясняет, почему нам не нужно явно устанавливать какое-либо дополнительное программное обеспечение для доступа в Интернет. Большинство сетевых протоколов поддерживают открытое соединение между двумя устройствами, что позволяет им передавать данные туда и обратно.
HTTP, на котором работает сеть, отличается. Он известен как протокол без установления соединения, потому что он основан на режиме работы запрос / ответ. Веб-браузеры отправляют на сервер запросы на изображения, шрифты, контент и т.д., но после выполнения запроса соединение между браузером и сервером разрывается.

Servers and Clients
Термин сервер может слегка сбивать с толку людей, впервые знакомых с отраслью, поскольку он может относиться как к аппаратному обеспечению (физические компьютеры, на которых размещены все файлы и программное обеспечение, требуемое веб-сайтами), так и к программному обеспечению (программе, которая позволяет пользователям получать доступ к этим файлам в Интернете).
Сегодня мы поговорим о программной стороне вещей. Но сначала несколько определений. URL обозначает Universal Resource Locator и состоит из 3 частей: протокола, сервера и запрашиваемого файла.
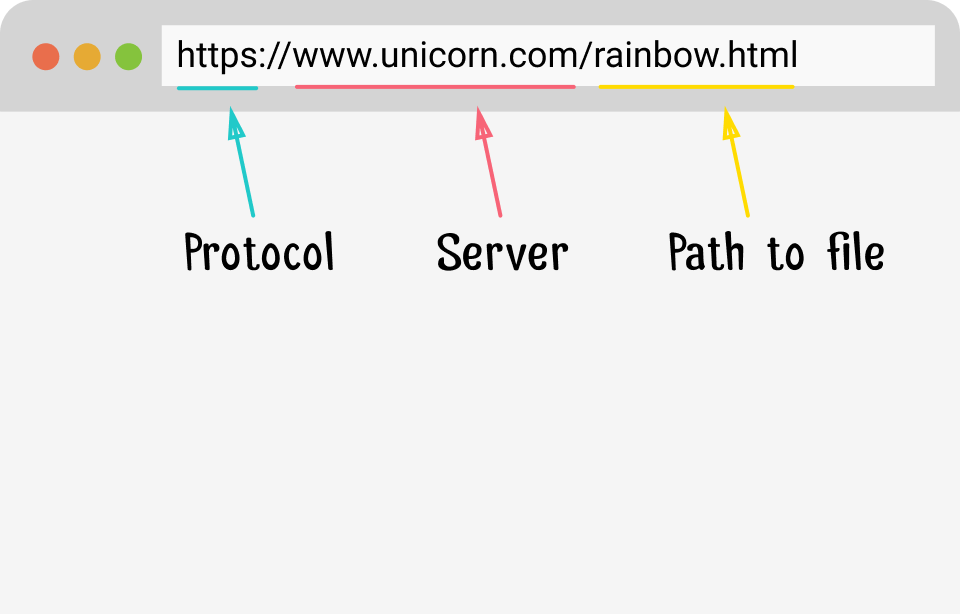
Структура URL адреса
Протокол HTTP определяет несколько методов, которые браузер может использовать, чтобы попросить сервер выполнить кучу различных действий, наиболее распространенными из которых являются GET и POST. Когда пользователь щелкает ссылку или вводит URL-адрес в адресную строку, браузер отправляет GET-запрос на сервер для получения ресурса, определенного в URL-адресе.
Сервер должен знать, как обрабатывать этот HTTP-запрос, чтобы получить правильный файл, а затем отправить его обратно браузеру, который его запросил. Наиболее популярное программное обеспечение веб-сервера, которое обрабатывает это Apache и NGINX.

Веб-серверы обрабатывают входящие запросы и отвечают на них соответственно
Оба представляют собой полнофункциональные пакеты программного обеспечения с открытым исходным кодом, которые включают в себя такие функции, как схемы аутентификации, перезапись URL-адресов, ведение журнала и проксирование, и это лишь некоторые из них. Apache и NGINX написаны на C. Технически, вы можете написать веб-сервер на любом языке. Python, golang.org/pkg/net/http, Ruby, этот список может продолжаться довольно долго. Просто некоторые языки лучше выполняют определенные вещи, чем другие.
Создание HTTP сервера с Node.js
Node.js — это среда выполнения Javascript, построенная на движке Chrome V8 Javascript. Он поставляется с модулем http, который предоставляет набор функций и классов для построения HTTP-сервера.
Для этого базового HTTP-сервера мы также будем использовать файловую систему, путь и URL-адрес, которые являются собственными модулями Node.js.
Начните с импорта необходимых модулей.
const http = require('http') // Чтобы использовать HTTP-интерфейсы в Node.js
const fs = require('fs') // Для взаимодействия с файловой системой
const path = require('path') // Для работы с путями файлов и каталогов
const url = require('url') // Для разрешения и разбора URL
Мы также создадим словарь типов MIME, чтобы мы могли назначить соответствующий тип MIME запрашиваемому ресурсу на основе его расширения. Полный список типов MIME можно найти в Internet Assigned Numbers Authority (интернет-центре назначенных номеров).
const mimeTypes = {
'.html': 'text/html',
'.js': 'text/javascript',
'.css': 'text/css',
'.ico': 'image/x-icon',
'.png': 'image/png',
'.jpg': 'image/jpeg',
'.gif': 'image/gif',
'.svg': 'image/svg+xml',
'.json': 'application/json',
'.woff': 'font/woff',
'.woff2': 'font/woff2'
}
Теперь мы можем создать HTTP-сервер с функцией http.createServer(), которая будет возвращать новый экземпляр http.Server.
const server = http.createServer()
Мы передадим функцию-обработчик запроса в createServer() с объектами запроса и ответа. Эта функция вызывается один раз каждый раз, когда к серверу поступает HTTP-запрос.
server.on('request', (req, res) => {
// здесь нужно сделать больше
})
Сервер запускается путем вызова метода listen объекта server с номером порта, который мы хотим, чтобы сервер прослушивал, например, 5000.
server.listen(5000)
Объект request является экземпляром IncomingMessage и позволяет нам получать доступ ко всей информации о запросе, такой как статус ответа, заголовки и данные.
Объект response является экземпляром ServerResponse, который является записываемым потоком и предоставляет множество методов для отправки данных обратно клиенту.
В обработчике запросов мы хотим сделать следующее:
- Разобрать входящий запрос и обработать его без расширений
const parsedUrl = new URL(req.url, 'https://node-http.glitch.me/') let pathName = parsedUrl.pathname let ext = path.extname(pathName) // Для обработки URL с конечным символом '/', удаляем вышеупомянутый '/' // затем перенаправляем пользователя на этот URL с помощью заголовка 'Location' if (pathName !== '/' && pathName[pathName.length - 1] === '/') { res.writeHead(302, {'Location': pathName.slice(0, -1)}) res.end() return } // Если запрос для корневого каталога, вернуть index.html // В противном случае добавляем «.html» к любому другому запросу без расширения if (pathName === '/') { ext = '.html' pathName = '/index.html' } else if (!ext) { ext = '.html' pathName += ext } - Выполните некоторые элементарные проверки, чтобы определить, существует ли запрошенный ресурс, и ответить соответственно
// Создаем правильный путь к файлу, чтобы получить доступ к соответствующим ресурсам const filePath = path.join(process.cwd(), '/public', pathName) // Проверяем, существует ли запрошенный ресурс на сервере fs.exists(filePath, function (exists, err) { // Если запрошенный ресурс не существует, ответим 404 Not Found if (!exists || !mimeTypes[ext]) { console.log('Файл не найден: ' + pathName) res.writeHead(404, {'Content-Type': 'text/plain'}) res.write('404 Not Found') res.end() return } // В противном случае отправим ответ со статусом 200 OK, // и добавляем правильный заголовок типа контента res.writeHead(200, {'Content-Type': mimeTypes[ext]}) // Считать файл и передать его в ответ const fileStream = fs.createReadStream(filePath) fileStream.pipe(res) })
Весь код размещен на Glitch, и вы можете сделать ремикс на проект, если хотите.
https://glitch.com/edit/#!/node-http
Создание HTTP-сервера с фреймворками Node.js
Фреймворки Node.js, такие как Express, Koa.js и Hapi.js, поставляются с различными полезными функциями промежуточного программного обеспечения, в дополнение к множеству других удобных функций, которые избавляют разработчиков от необходимости писать самим.
Лично я чувствую, что лучше сначала изучать основы без фреймворков, просто для понимания того, что происходит под капотом, а затем после этого сходить с ума с любым фреймворком, который вам нравится.
В Express имеется собственный встроенный плагин для обслуживания статических файлов, поэтому код, необходимый для выполнения тех же действий, что и в собственном Node.js, значительно короче.
const express = require('express')
const app = express()
// Укажем директорию в которой будут лежать наши файлы
app.use(express.static('public'))
// Отправляем index.html, когда пользователи получают доступ к
// корневому каталог с использованием res.sendFile()
app.get('/', (req, res) => {
res.sendFile(__dirname + '/public/index.html')
})
app.listen(5000)
Koa.js не имеет подобного плагина внутри своего ядра, поэтому любой требуемый плагин должен быть установлен отдельно. Последняя версия Koa.js использует асинхронные функции в пользу обратных вызовов. Для обслуживания статических файлов вы можете использовать плагин koa-static.
const serve = require('koa-static')
const koa = require('koa')
const app = new koa()
// Укажем директорию в которой будут лежать наши файлы
// По умолчанию koa-static будет обслуживать файл index.html в корневом каталоге
app.use(serve(__dirname + '/public'))
app.listen(5000)Hapi.js поддерживает настройку и вращается вокруг настройки объекта server. Он использует плагины для расширения возможностей, таких как маршрутизация, аутентификация и так далее. Для обслуживания статических файлов нам понадобится плагин с именем inert.
const path = require('path')
const hapi = require('hapi')
const inert = require('inert')
// Маршруты могут быть настроены на объекте сервера
const server = new hapi.Server({
port: 5000,
routes: {
files: {
relativeTo: path.join(__dirname, 'public')
}
}
})
const init = async () => {
// server.register() команда добавляет плагин в приложение
await server.register(inert)
// inert добавляет обработчик каталога в
// указатель маршрута для обслуживания нескольких файлов
server.route({
method: 'GET',
path: '/{param*}',
handler: {
directory: {
path: '.',
redirectToSlash: true,
index: true
}
}
})
await server.start()
}
init()У каждой из этих платформ есть свои плюсы и минусы, и они будут более очевидными для более крупных приложений, а не просто для обслуживания одной HTML-страницы. Выбор структуры будет сильно зависеть от реальных требований проекта, над которым вы работаете.
Завершение
Если сетевая сторона вещей всегда была для вас черным ящиком, надеюсь, эта статья может послужить полезным введением в протокол, который обеспечивает работу сети. Я также настоятельно рекомендую прочитать документацию по API Node.js, которая очень хорошо написана и очень полезна для любого новичка в Node.js в целом.
- HTTP by MDN
- Anatomy of an HTTP Transaction
- HTTP Server: Everything you need to know to build a simple HTTP server from scratch
Концепция создания приложений довольно проста – программист пишет исходный код, который выполняется. Так работает каждая утилита, виджет или игра. Но для того, чтобы создавать уникальный софт, нужно знать немало особенностей. Пример – какой язык программирования выбрать, какие конкретно инструменты задействовать для решения поставленных перед разработчиком задач.
Есть отдельный вид контента, требующий особого внимания, особенно в 21 веке. Это – веб-утилиты. Такое программное обеспечение лучше всего пишется на веб languages (скриптовых). Отличным решением станет JavaScript. Он специализируется преимущественно на веб-разработке, легко запоминается и работает относительно быстро.
Для web-софта, особенно сложного, важна серверная работа. О ней пойдет речь в данной статье. Информация по JS, а также лучшим платформам (среди них есть Node) для программирования на этом языке окажется полезной не только новичкам, но и опытным программистам.
Основные термины – что знать о веб-разработке
Несмотря на то, что с помощью JS можно довольно легко и быстро создавать приложения, работающие в Сети, каждый должен хорошо разбираться в терминологии. Без этого нюанса невозможно освоить ни серверную, ни клиентскую части контента.
Запомнить рекомендуется следующие понятия:
- веб-утилита – client-серверная программа, в котором client (web interface) осуществляет запуск посредством браузера, а серверная часть работает на специальном веб-сервере;
- клиент – локальное устройство, находящееся на стороне юзера, которое отправляет запросы к серверам для дальнейшей работы;
- сетевой протокол – сборник принципов и правил, которые задают принципы выполнения взаимодействия между устройствами в пределах виртуальной сети;
- архитектура – элемент, отвечающий за формулирование принципов «общения» между локальными устройствами, а также за правила взаимодействий непосредственно в пределах протокола.
Все эти понятия относятся к языку программирования JS, а также к другим веб-языкам. Чтобы в процессе разработки не возникло никаких проблем, рекомендуется дополнительно изучить и запомнить основные термины в программировании. Это поможет при составлении даже самых сложных программных кодов.
Сервер – определение понятия
Введение в веб-разработку осуществляется путем изучения не только подходящего языка программирования, но и с терминов, связанных с servers. Все это относится и к JS тоже.
Сервер – программный компонент вычислительной системы (устройства), который отвечает за выполнение сервисных (обслуживающих) функций по запросу client. Он предоставляет доступ к тем или иным ресурсам, возможностям, услугам.
Сервером в JS и других языках также могут называть мощное устройство, которое используется для решения задач, связанных с программными кодами. Осуществляет сервисное обслуживание по запросам. Отвечает за сохранение данных и БД.
Серверная часть представляет собой программу, которая обеспечивает работу сайта. Разработка подобной утилиты подразумевает непосредственное создание веб-странички. Серверная часть находится на server. Пользователи в сети не могут получить к ней доступ. Работой с оной занимаются веб-программеры.
Особенности клиент-серверной модели
Стоит обратить внимание на то, что в JS и других программных языках концепция клиент-серверов обладает собственными ключевыми особенностями. Работает следующим образом:
- Client формирует запрос и отправляет его на сервер.
- Последний принимает «сигнал».
- Осуществляется системная обработка поданного запроса и выполнение соответствующих операций.
- Клиенту выводится тот или иной результат.
Важно: данная схема предусматривает одновременную работу с несколькими clients.
Если происходит одновременная отправка нескольких запросов, согласно установленным принципам производится обработка оных в порядке очереди. У посылаемых на server команд может быть совершенно разный приоритет. Некоторые обладают высоким показателем – они будут обрабатываться системой/устройством/утилитой в первую очередь.
За что отвечают клиенты и серверы
В JS и не только на стороне сервера реализовываются следующие задачи:
- обеспечение защиты информации;
- хранение разнообразных электронных материалов;
- предоставление доступа к данным;
- непосредственная обработка клиентских запросов;
- отправка ответов на ту или иную команду, посланную от clients.
А вот параметры, проходящие реализацию со стороны клиента:
- предоставление доступа к пользовательскому графическому интерфейсу;
- формирование запроса для дальнейшей обработки и выполнения той или иной команды;
- отправка запросов на server;
- получение результатов;
- направление дополнительных групп команд (добавление, обновление, удаление сведений).
Все это – лишь введение в клиент-серверную часть программирования в JS. Не зная соответствующие основы, составить веб-утилиту будет крайне проблематично.
Концепции постройки системы
Перед тем, как создавать код на JS, стоит хорошо усвоить принципы работы клиент-серверной части контента. Существуют следующие концепции постройки оной:
- Слабый клиент-мощный сервер. База данных и другая информация обрабатывается за счет серверной мощности. Пользователи здесь обладают сильно ограниченными правами. Сервер отправляет ответ, не требующий дополнительной обработки. Client будет взаимодействовать с пользователем: создаст и направит необходимую команду, примет входящие сигналы, осуществит результирующую часть.
- Сильный клиент. Тут некоторая часть обработки информации отдается clients. Server здесь будет простым местом хранения информации (база данных, таблица и так далее). Основная деятельность ведется на пользовательском устройстве. Часть электронных материалов переносится на девайс клиента.
Есть еще один вариант – когда система или софт, который обрабатывает информацию, предоставляется юзеру. Здесь server – это особое хранилище данных. Все манипуляции по обработке и предоставлению сведений переносится на клиентский компьютер.
Важно: при программировании на JS стоит заранее определиться с концепцией. В противном случае создать качественный софт не получится. Код JavaScript придется переписывать.
Архитектура
При желании код на JS можно написать в самом обычном «Блокноте» с расширением .js. Утилита заработает, но лучше всего пользоваться для реализации поставленной задачи специальными утилитами. Они называются платформами (один вариант – Node). Помогают довольно быстро создать даже сложный проект, задействовав удобный интерфейс и функциональные возможности.
Но перед этим необходимо хорошо разобраться в принципах работы клиент-сервера. Существуют следующие виды архитектур:
- Двухуровневая. Здесь есть server, который отвечает за получение входящих запросов, а также отправку ответов юзерам. Для реализации поставленной задачи задействуются собственные системные ресурсы.
- Трехуровневая. Включает в себя предоставление информации через графический пользовательский прикладной объект, представленный сервером приложений. Здесь присутствует менеджер ресурсов. Это – база данных (ее server), который предоставляет информацию.
Второй вариант может переходить во многоуровневую. В данном случае при работе с программой JS получится установить группы дополнительных servers. Такая архитектура – лучшее решение для повышения производительности.
Введение в принципы работы рассматриваемого типа приложений и игр закончено. Теперь можно остановиться на таком моменте как платформа (пример – VIM, Node). С ее помощью удается создавать веб-контент с максимальным комфортом. Это – специальный софт, предназначенный для разработки.
В случае с JS вариантов платформ очень много. Каждая имеет собственные преимущества и недостатки. Далее будут представлены самые успешные из них. Также получится определить лучший редактор для программера, решившего использовать programming language из Java семейства.
Notepad++
Первый вариант – это Notepad. Редактор, который имеет открытый исходный код. С ним разберется даже новичок.
Обладает следующими особенностями:
- синтаксис можно подсветить на нескольких языках (включая JS);
- автоформатирование;
- автодополнение;
- навигация посредством вкладок;
- файловые менеджеры;
- карты кода;
- работа с кодировками различных типов;
- возможность подключения компиляторов и плагинов.
Единственный существенный недостаток – это работа исключительно на Windows. Для других операционных систем предстоит искать иной редактор JS.
Vim – непревзойденная классика
Классическая среда программирования, поддерживающая множество languages of programming. Иногда кажется, что разобраться с Vim достаточно трудно (синтаксис остается понятным), но это не так. Новичкам в разработке нередко этот софт доставляет хлопоты, но в будущем менять его не захочется.
При помощи Vim можно:
- работать с плагинами;
- осуществлять замену тем;
- назначать горячие клавиши.
Работает на всех операционных системах, включая MS DOS и OS/2.
Visual Studio
Детище компании Microsoft. IDE, который предусматривает все необходимое для работы с JS и веб-разработки. Здесь имеется дебагер и возможность создания Unit-тестов.
Недостатков несколько:
- большой вес;
- наличие подписки до 250 долларов в месяц для полноценной разработки;
- установка на Linux через Wine.
Для новичков имеется бесплатная версия, позволяющая составлять контент с открытым исходным кодом.
Nodejs
Еще один редактор, на который можно найти специальные уроки в Сети – это Node. Представляет собой программную платформу, которая базируется на движке V8 (транслирует Javascript в машинную кодификацию). Превращает JS в язык общего назначения.
Node – кроссплатформенная среда, имеющая открытый исходный код. С ее помощью удастся создать проект серверного или сетевого типа. Node – отличное решение и для новичков, и для опытных разработчиков.
Преимущества и возможности платформы
Многие разрабы, решившие создавать уникальные сложные утилиты web-характера, отдают предпочтение именно Node. Поэтому данную платформу рекомендуется рассмотреть более детально.
Node обладает следующими особенностями:
- синтаксис подсвечивается;
- есть асинхронные скрипты, основанные на событиях;
- высокая производительность;
- работа однопоточного типа, только среда поддерживает масштабируемость;
- разнообразные библиотеки и фреймворки (express, nest и другие);
- отсутствие буферизации – информация будет выводить сведения на дисплей по частям.
Node – среда, имеющая лицензию MIT. Ей пользуются разнообразные популярные крупные компании. Пример – eBay, PayPal, Microsoft.
Для чего нужна
Среда Node отлично зарекомендовала себя. По ней есть разнообразные уроки. Они учат грамотно применять фреймворк express для веб-утилит и другим возможностям редактора. Чаще всего Node используют для создания приложений:
- где нужен ввод-вывод информации;
- с потоковой передачей электронных сведений;
- поддерживающих активное применение данных в реальном времени (поможет фреймворк express);
- базирующихся на API JSON.
Node Editor имеет относительно простой syntax и понятный interface. Легко устанавливается – достаточно скачать Node с официального сайта.
Редактор для работы с Node JS выглядит просто. При помощи этой платформы можно запрограммировать микроконтроллер. В основе заложен принцип событийно-ориентированного и асинхронного программирования с неблокирующим вводом-выводом.
А для того, чтобы не искать уроки по Node JS и серверной-части утилит стоит посетить специализированные дистанционные курсы. Длятся до года, по выпуску выдается сертификат, подтверждающий знания в соответствующей области. Есть предложения и для новичков, и для опытных разработчиков. С таким решением осваивание Node и программирования не доставит никаких хлопот.

Архитектура Web-приложений
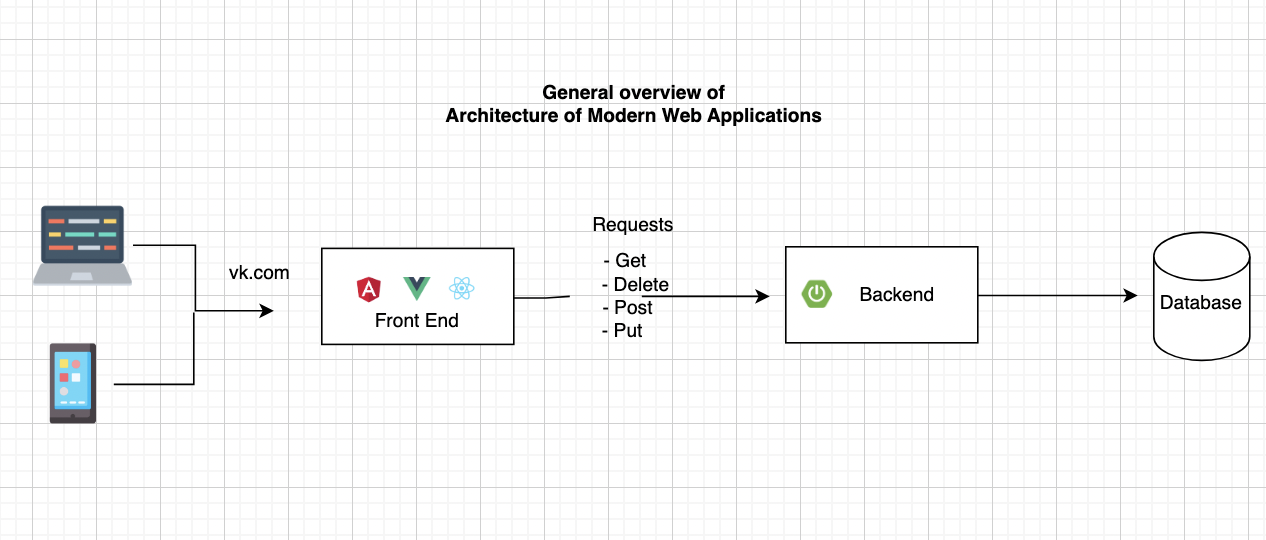
Архитектура современных приложений состоит из отдельных модулей, как показано на рисунке выше. Эти модули часто называют Frontend и Backend. Frontend – это модуль, который отвечает за юзер-интерфейс и логику, которые предоставляется приложением при использовании. Так, например когда мы заходим в соцсети через браузер, мы взаимодействуем именно с FrontEnd-модулем приложения. То, как отображаются наши посты в виде сторисов или карточек, сообщения и другие активности реализуются именно в FrontEnd-модуле. А все данные, которые мы видим, хранятся и обрабатываются в Backend или серверной части приложения. Эти модули обмениваются между собой посредством разных архитектурных стилей: REST, GRPC и форматов сообщений – JSON и XML.
В этой статье мы напишем примитивную серверную часть социальной сети с использованием Spring Boot, запустим свой сервер, рассмотрим разные типы HTTP запросов и их применение.
Необходимое требование к читателю: умение писать на Java и базовые знания Spring Framework. Данная статья познакомит вас со Spring Boot и даст базовые понятия данного фреймворка.
Инициализация проекта
Чтобы создать Spring Boot проект, перейдем на страницу https://start.spring.io/ и выберем необходимые зависимости: в нашем случае Spring Web. Чтобы запустить проект, необходима минимальная версия Java 17. Скачиваем проект и открываем в любом IDE (в моем случае – Intellij Idea)
Spring Web – зависимость, которая предоставляет контейнер сервлетов Apache Tomcat (является дефолтным веб-сервером). Проще говоря, сервлеты – это классы, которые обрабатывают все входящие запросы.
Открываем проект и запускаем.
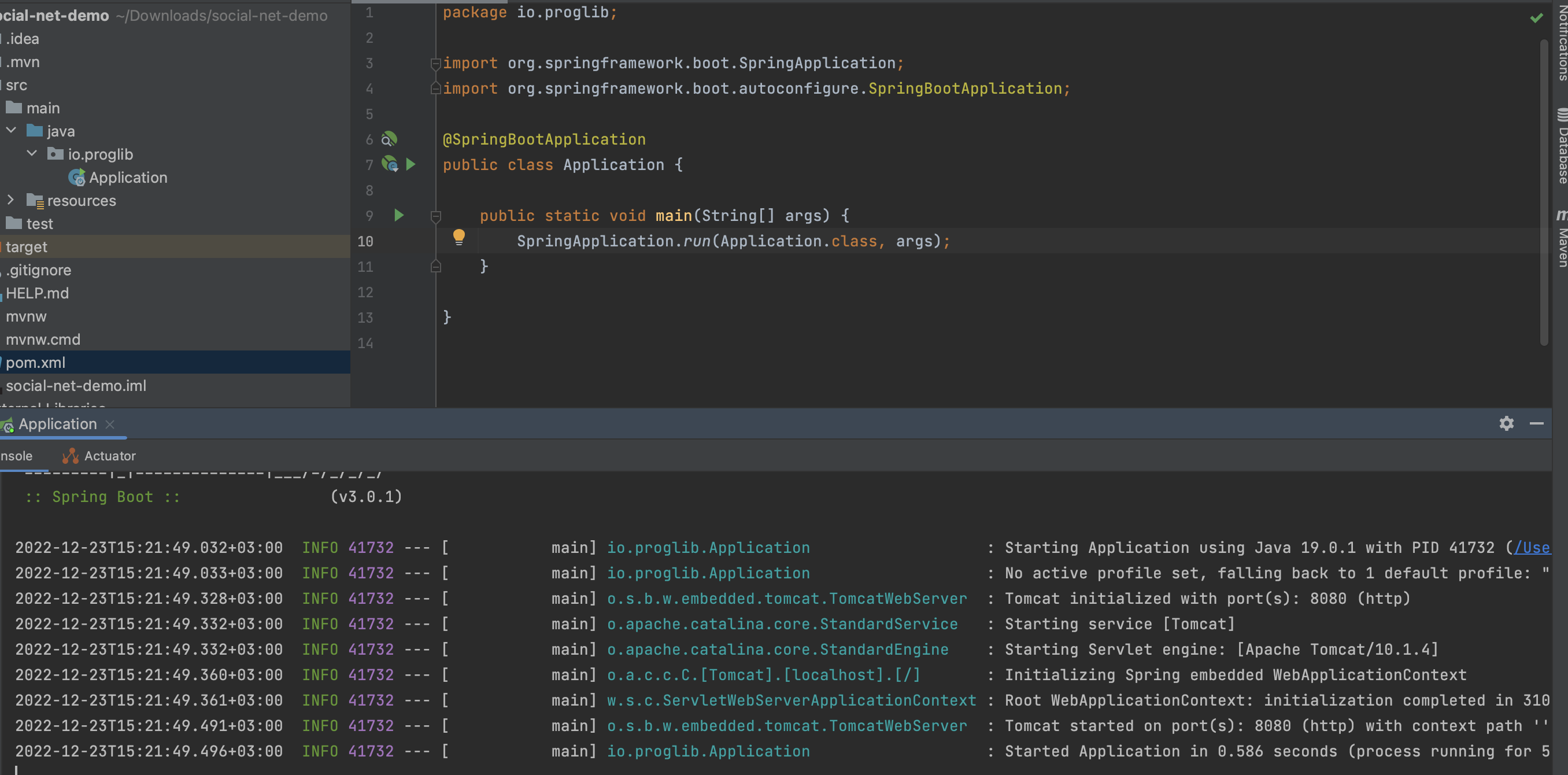
Мы видим, что проект запустился и готов обрабатывать запросы на порту 8080 – Tomcat started on port(s): 8080 (http).
Теперь создадим свой первый класс – GreetingController. Controller-классы ответственны за обработку входящих запросов и возвращают ответ.
Чтобы сделать наш класс Controller, достаточно прописать аннотацию @RestController. @RequestMapping указывает, по какому пути будет находиться определённый ресурс или выполняться логика.
package io.proglib;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/greet")
public class GreetingController {
@GetMapping
public String greet() {
return "Hello";
}
}
Перезапускаем проект, и сервер готов уже обрабатывать наши запросы.
Открываем браузер по адресу http://localhost:8080/greet и получаем следующий вывод.
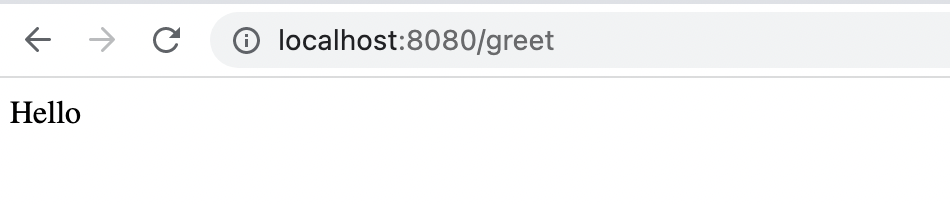
Если отправить запрос по адресу http://localhost:8080/ , мы получим ошибку, т. к. по этому пути не определены логика обработки запроса и ресурсы.
Request Params
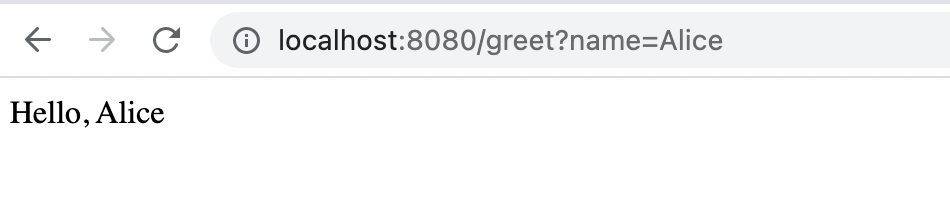
При отправке запросов мы часто используем переменные в запросе, чтобы передавать дополнительную информацию или же делать запросы гибкими. Параметр в запросе передаётся в конце адреса (=url) сервера и указывается после вопросительного знака (=?).
Например, http://localhost:8080/greet?name=Alice. Параметр запроса является = name cо значением = Alice.
Чтобы обрабатывать переменную запроса, используется аннотация @RequestParam. Параметры запроса могут быть опциональными или же обязательными. @RequestParam("name") означает следующее: взять ту переменную из запроса, название которого равно name.
@RestController
@RequestMapping("/greet")
public class GreetingController {
@GetMapping
public String greet(@RequestParam("name") String name) {
return "Hello, " + name;
}
}
Вдобавок, запрос может содержать несколько параметров.
Например, http://localhost:8080/greet/full?name=John&surname=Smith. Параметры выделяются знаком &. В этом запросе два параметра: name=John и surname=Smith.
Чтобы обработать каждый параметр запроса, нужно пометить каждую переменную @RequestParam.
package io.proglib;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/greet")
public class GreetingController {
@GetMapping
public String greet(@RequestParam("name") String name) {
return "Hello, " + name;
}
@GetMapping("/full")
public String fullGreeting(@RequestParam("name") String name,
@RequestParam("surname") String surname) {
return "Nice to meet you, " + name + " " + surname;
}
}

Path Variable
PathVariable по применению похож на @Request Param. @PathVariable также является параметром запроса, но используются внутри адреса запроса. Например,
RequestParam – http://localhost:8080/greet/full?name=John&surname=Smith PathVariable – http://localhost:8080/greet/John. В этом случае John является PathVariable.
В запросе можно указывать несколько PathVariable, как и в случае RequestParam
package io.proglib;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/greet")
public class GreetingController {
@GetMapping
public String greet(@RequestParam("name") String name) {
return "Hello, " + name;
}
@GetMapping("/full")
public String fullGreeting(@RequestParam("name") String name, @RequestParam("surname") String surname) {
return "Nice to meet you, " + name + " " + surname;
}
@GetMapping("/{name}")
public String greetWithPathVariable(@PathVariable("name") String name) {
return "Hello, " + name;
}
}
Чтобы протестировать, открываем браузер и переходим по адресам: http://localhost:8080/greet/John/Smith и http://localhost:8080/greet/John

Запрос с двумя параметризованными PathVariable.

HTTP-методы
Когда мы говорим о запросах, мы также подразумеваем HTTP-метод, который используется при отправке этого запроса. Каждый запрос представляет собой некий HTTP-метод. Например, когда мы переходим в браузере по адресу http://localhost:8080/greet/John/Smith, наш браузер отправляет GET-запрос на сервер.
Большая часть информационных систем обмениваются данными посредством HTTP-методов. Основными HTTP-методами являются – POST, GET, PUT, DELETE. Эти четыре запроса также называют CRUD-запросами.
- POST-метод – используется при создании новых ресурсов или данных. Например, когда мы загружаем новые посты в соцсетях, чаще всего используется POST-запросы. POST-запрос может иметь тело запроса.
- GET-метод – используется при получении данных. Например, при открытии любого веб-приложения, отправляется именно GET-запрос для получения данных и отображения их на странице. GET-запрос не имеет тела запроса.
- PUT-метод – используется для обновления данных, а также может иметь тело запроса, как и POST.
- DELETE-метод – используется для удаления данных.
Реализация основных методов
Давайте создадим сущности и реализуем методы, чтобы наш сервер принимал все четыре запроса. Для этого создадим сущности User и Post, и будем проводить операции над ними.
Для простоты User имеет только два поля: username и список постов posts, а сущность Post имеет поле description и imageUrl.
Сущность User:
package io.proglib;
import java.util.ArrayList;
import java.util.List;
public class User {
private String username;
private List<Post> posts;
public User() {
posts = new ArrayList<>();
}
public User(String username, List<Post> posts) {
this.username = username;
this.posts = posts == null ? new ArrayList<>() : posts;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public List<Post> getPosts() {
return posts;
}
public void setPosts(List<Post> posts) {
this.posts = posts;
}
}
Сущность Post:
package io.proglib;
public record Post(
String description,
String imageUrl
) {
}
Создаем новый класс контроллер – UserActivityController, который будет обрабатывать наши запросы – POST, GET, PUT, DELETE.
Наш контроллер: UserActivityController.
Будем использовать список – List<User> users в качестве локальной базы данных, где будем хранить все наши данные.
package io.proglib;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/users")
public class UserActivityController {
private final static List<User> users = new ArrayList<>();
}
POST-запрос: добавление нового пользователя
Чтобы указать, что метод принимает POST-запросы используем аннотацию – @PostMapping. Так как запрос имеет тело запроса, где мы передаем пользователя, нужно пометить переменную user аннотацией @RequestBody.
@PostMapping("")
public User addUser(@RequestBody User user) {
users.add(user);
return user;
}
GET-запрос: получение пользователей
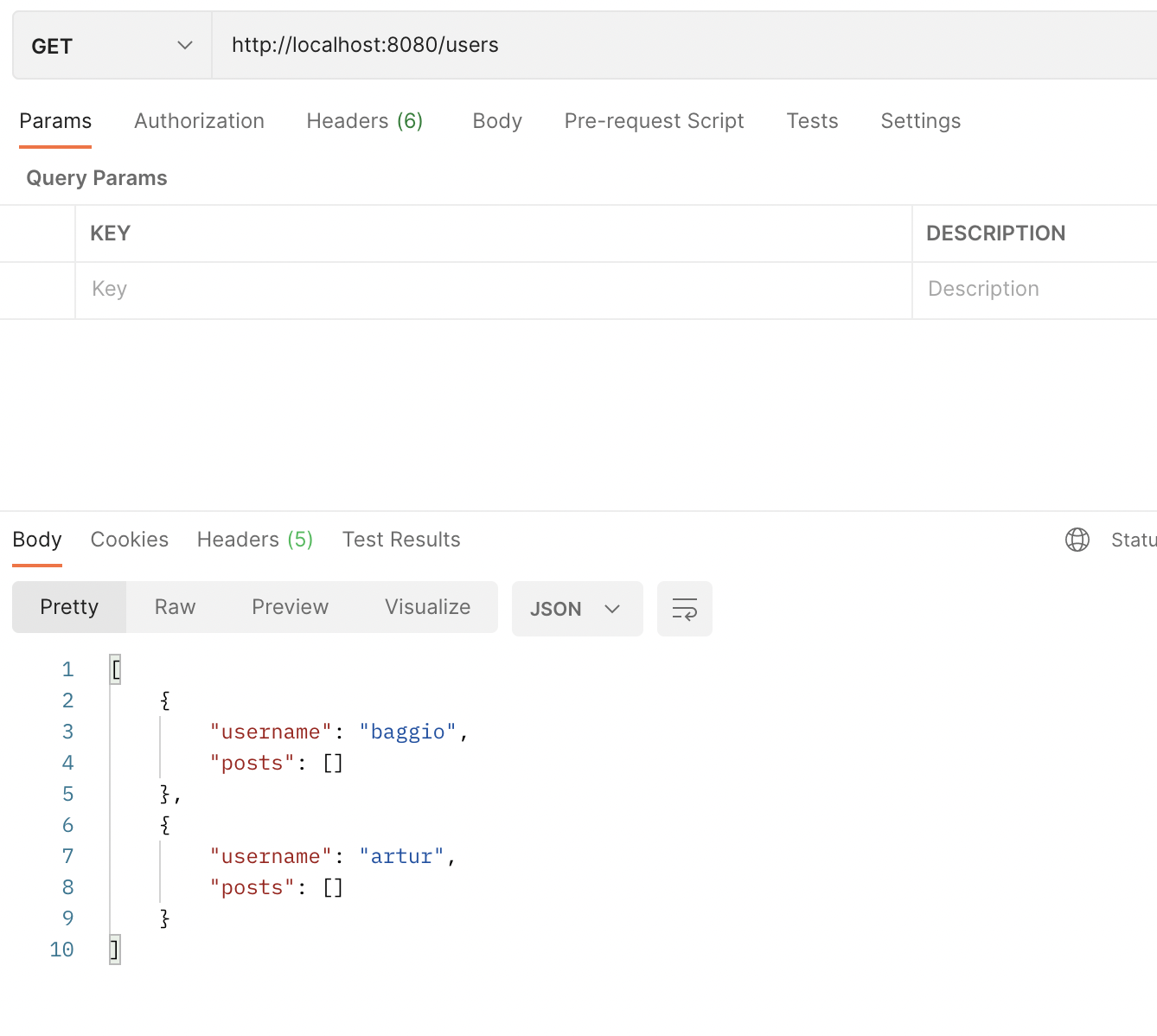
@GetMapping("")
public List<User> getUsers() {
return users;
}
@GetMapping("/{username}")
public User getUserByUsername(@PathVariable("username") String username) {
return users.stream().filter(user -> user.getUsername().equals(username))
.findFirst().get();
}
@Getmapping("") указывает, что методы обрабатывают GET-запросы. Значение, которое передаётся внутри аннотации, является частью url или адреса. Например, запрос http://localhost:8080/users/baggio обработается методом getUserByUsername(), а запрос http://localhost:8080/users/ обработается методом http://localhost:8080/users.
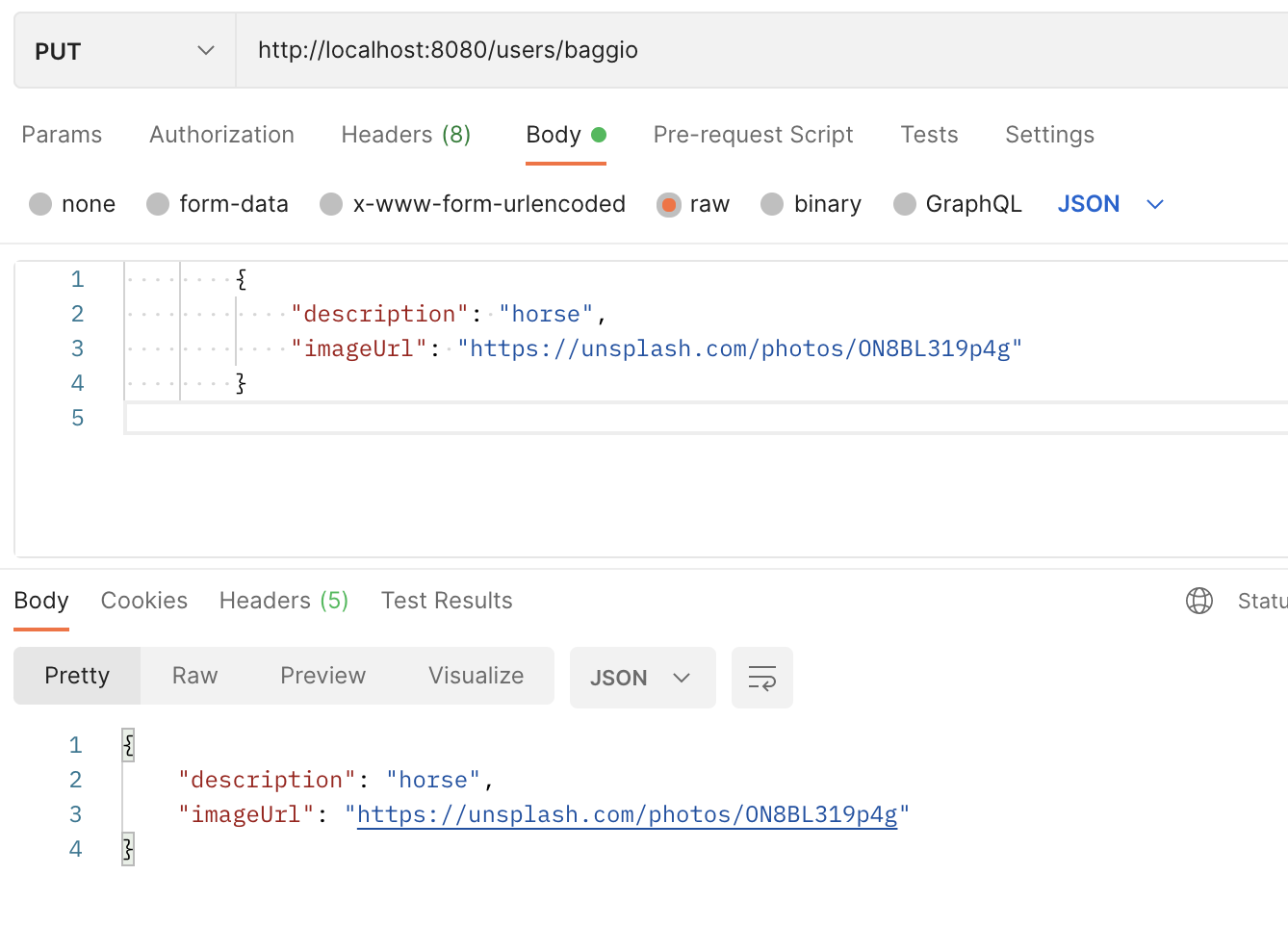
PUT-запрос: обновление данных
@PutMapping("/{username}")
public Post update(@PathVariable("username") String username, @RequestBody Post post) {
users.stream().filter(user ->
user.getUsername().equals(username))
.findAny()
.ifPresent(user -> user.getPosts().add(post));
return post;
}
@PutMapping("/{username}") указывает, что метод принимает PUT-запросы. В нашем примере в запросе мы передаем параметр запроса, а также тело запроса – post. Метод принимает – username, ищет юзера из списка с таким username и добавляем новый пост к его списку постов.
Delete-запрос: удаление данных
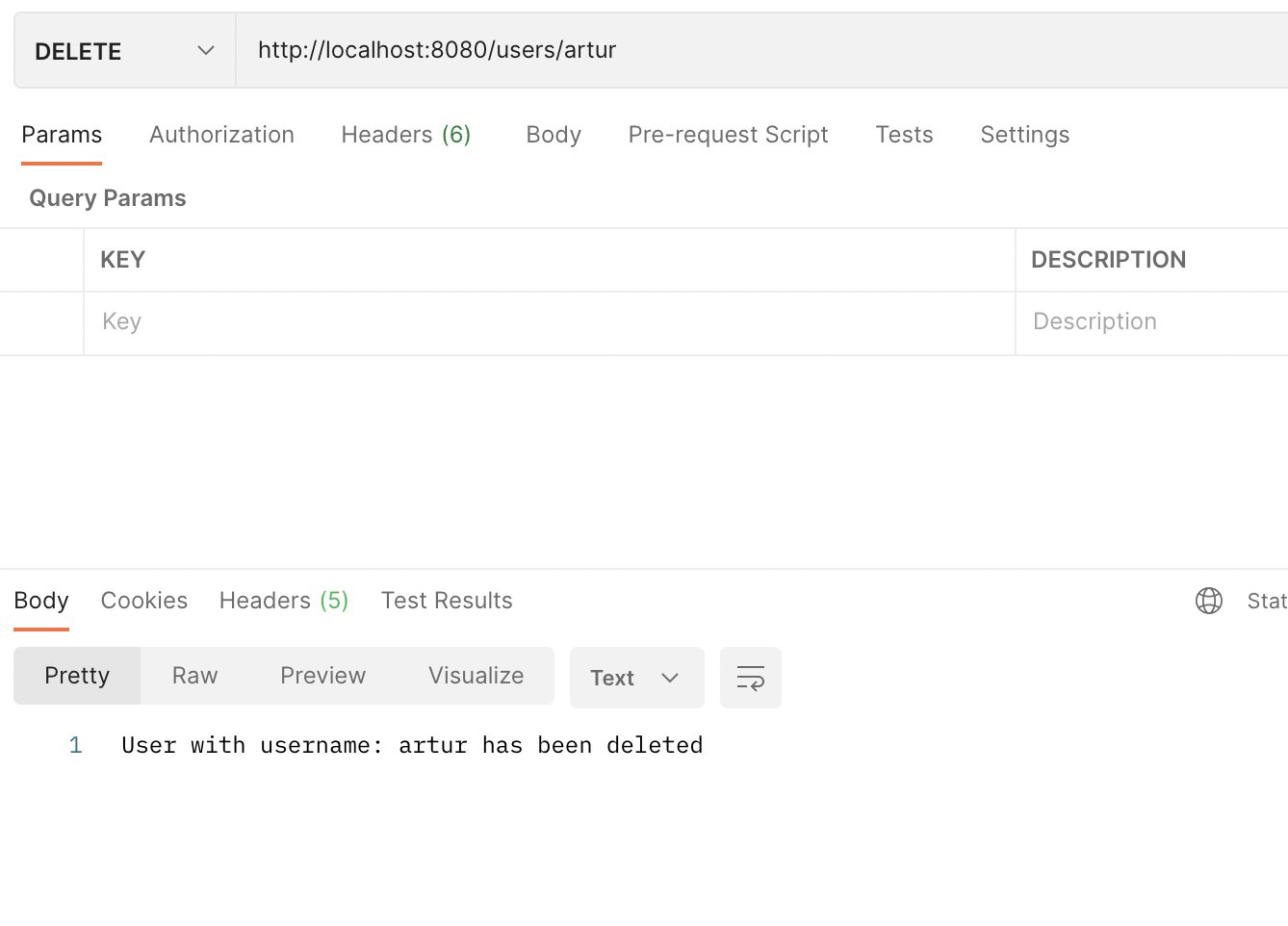
@DeleteMapping("/{username}")
public String deleteUser(@PathVariable("username") String username) {
users.stream().filter(user ->
user.getUsername().equals(username))
.findAny()
.ifPresent(users::remove);
return "User with username: " + username + " has been deleted";
}
@DeleteMapping("/{username}") – указывает, что метод принимает DELETE-запросы.
Данный метод получает параметр username из запроса и удаляет из списка пользователя с таким username.
Запуск приложения и тестирование
Чтобы убедиться, что все работает, мы можем отправить каждый вид запроса и протестировать. Для этого нам необходим API-client, который может посылать запросы. В примерах я использую POSTMAN.
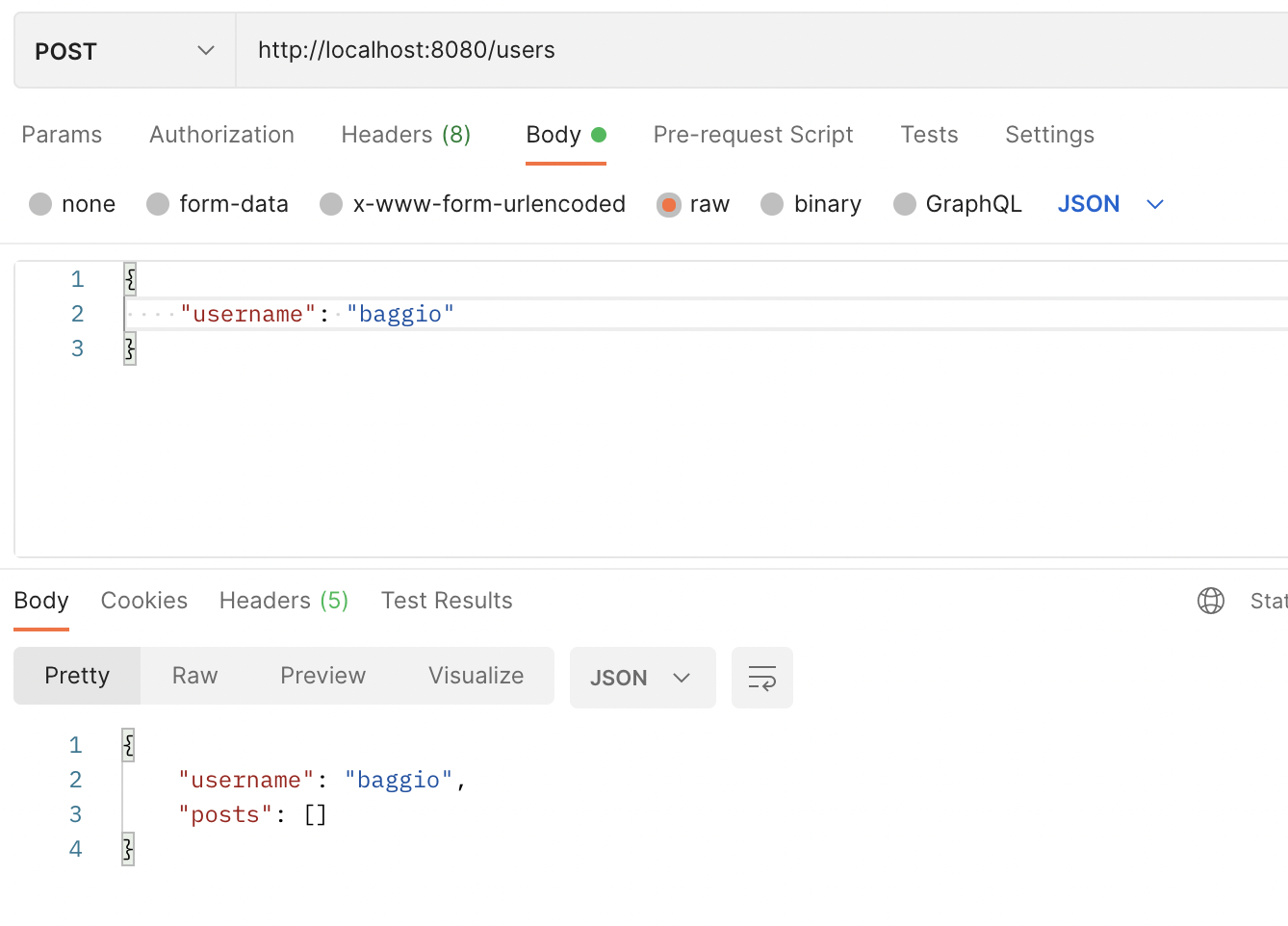
Post-запрос: создание нового пользователя.
Тело запроса отправляется в виде JSON.
GET-запрос: получение пользователей
PUT-запрос: обновление списка постов пользователя
DELETE-запрос: удаление пользователя по username
***
В этой статье мы рассмотрели архитектуру современных web-приложений, а также написали свою серверную часть приложения, получив поверхностные знания по Spring Boot, HTTP запросы и параметры запросов.
Ссылка на репозиторий
Исходный код можно найти по ссылке.
Материалы по теме
- ☕ Сертификаты и тренинги для Java-разработчика
- ☕🛣️ Дорожная карта Java-разработчика в 2023 году: путь с нуля до первой работы
Если вы хотите стать профессиональным веб-разработчиком или просто хотите понять концепции, которые имеют отношение к сети, вы находитесь в правильном месте! Многие из концепций, относящихся к серверной веб-разработке, могут быть довольно сложными. С обилием современных фреймворков и инструментов всегда есть что-то новое, чему можно научиться. Тем не менее, здорово иметь четкое понимание основ, прежде чем сосредоточиться на деталях современных фреймворков и сложных инструментах.
Далее предлагаю рассмотреть основы серверной (backend) разработки, связанной с созданием простого веб-приложения. Это даст вам представление о фундаментальных концепциях серверной веб-разработки, так что вы будете настроены на успех, если решите продолжить обучение по этим темам.
Для того чтобы стать backend-разработчиком необходимо освоить:
- основные компоненты веб-приложения;
- обязанности backend разработчика;
- что такое HTTP и какая его роль в работе веб-приложений;
- RESTful API.
Ознакомление с данными вещами позволит вам получить основу для дальнейшего изучения серверной разработки. Часть из них я рассмотрю далее в этой статье.
Если вас интересует продвижение сайтов, то этот вопрос никак не раскрыт в данной статье, но неоднократно рассматривался в других статьях этого блога. Отмечу, что при разработке веб-приложений необходимо учитывать тот факт, что продвижение будет необходимо после запуска проекта. Тем самым, необходимый функционал необходимо будет реализовать как раз на этапе разработки.
Введение в Back-End разработку (основные понятия)
Давайте посмотрим, что же такое бэкэнд и какую роль он играет в веб-приложении.
Веб-приложение – это клиент-серверное приложение, в котором клиент (веб-интерфейс) запускается в веб-браузере, а серверная часть запускается на веб-сервере.
Вероятно, вы уже слышали что такое frontend разработка. Frontend представляет собой интерфейс веб-приложения который выводится в веб-браузере и облегчает взаимодействие пользователя с веб-приложением.
Back-end веб-разработка включает в себя создание «мозга» приложения, который берет на себя весь функционал веб-приложения. Эта функциональность зависит от необходимой логики и данных, которые веб-приложение должно обеспечивать. Frontend часто называют клиентской стороной (client-side), а backend – серверной стороной (server-side) веб-приложения.
Когда пользовательскому интерфейсу приложения требуется доступ к данным, он отправляет запрос на сервер. При этом, серверная часть веб-приложения обычно должна иметь возможность:
- получать запросы от клиентов и интерпретировать их назначение;
- выполнять обработку операций согласно логике запроса;
- взаимодействовать с базами данных для хранения информации и обеспечения доступа к ней;
- отправлять ответ клиенту на его запрос с указанием статуса и результата запроса.
Backend разработчики ответственны за написание кода для серверной стороны веб-приложения, обеспечивающего перечисленный выше функционал.
Исследуем Backend
Теперь, когда мы представили роль бэкэнда веб-приложения, давайте более подробно рассмотрим компоненты серверной части. Серверная часть веб-приложения состоит из нескольких компонентов, обычно называемых уровнями или слоями приложения.
Наиболее распространенные слои веб-приложения:
- Уровень представления. Этот уровень относится к пользовательскому интерфейсу приложения. Пользовательский интерфейс веб-приложения включает код HTML, CSS и JavaScript, который запускается в браузере для отображения веб-страниц, составляющих интерфейс приложения, и управления их динамическим поведением при взаимодействии пользователя со страницей.
- Прикладной уровень. Этот слой обрабатывает логику, которая обеспечивает функционирование веб-приложения. Тут выполняются любые операции и алгоритмы, обеспечивающие работу бизнес-функций приложения. Например, если пользователь пытается запланировать возврат товара в приложении для покупок, бизнес-логика, скорее всего, проверит, что крайний срок возврата не прошел, запросит у пользователя желаемый метод возврата и обновит статус заказ. Этот тип бизнес-логики может обрабатываться на стороне клиента и на стороне сервера, но обычно обрабатывается на стороне сервера, поскольку он тесно связан с динамическими данными приложения.
- Уровень данных. Этот уровень хранит, организует и управляет доступом к данным приложения с использованием базы данных. Реализуется в коде на стороне сервера.
Архитектура приложения и подходы в её реализации
Существует несколько способов создания веб-приложения. Например, одно решение, которое должны принять разработчики и архитекторы программного обеспечения – это рендеринг на стороне клиента или рендеринг на стороне сервера.
При рендеринге на стороне клиента код JavaScript, выполняемый в веб-браузере пользователя, отвечает за запрос данных с сервера и манипулирование веб-страницей по мере необходимости. Например, если пользователь вводит в форму недопустимое значение, код на стороне клиента обновит страницу сообщением об ошибке, не обращаясь к серверу и не перезагружая страницу.
При рендеринге на стороне сервера клиент запрашивает новую веб-страницу с сервера для каждого обновления и отображает страницу такой, какой она была получена. Например, если пользователь вводит в форму недопустимое значение, код на стороне клиента запросит новую страницу с сообщением об ошибке.
Часто используются комбинация этих подходов, когда для начальной страницы используется серверный рендеринг, а затем она обновляется по мере необходимости при помощи рендеринга на стороне клиента.
В последнее время все чаще применяется разработка приложений с рендерингом на стороне клиента, а обмен данными с сервером происходит при помощи API-запросов. Таким образом важно разобраться с тем, что такое RESTful web API, как работает и взаимодействует с БД.
Компоненты и их взаимодействие
Теперь, когда мы изучили логические уровни приложения, давайте посмотрим, где они находятся в реальности.

Серверная часть веб-приложения называется серверной, поскольку этот код выполняется на веб-сервере.
Веб-сервер – это физический компьютер, на котором размещается ваше приложение и который доступен для пользователей по всему миру через Интернет. Как разработчик, вы можете выбрать операционную систему (Windows, Linux и т. д.), программное обеспечение веб-сервера (Apache, Nginx, IIS) и аппаратные возможности, соответствующие потребностям.
На базовом уровне веб-сервер обрабатывает запросы на получение веб-контента и передает его клиентам. Происходит это путем идентификации ресурсов, которые запрашивает клиент на основе URL, затем HTML-файл страницы и таблица стилей CSS передается клиенту и отображается браузером.
Для динамических сайтов и веб-приложений работает сервер приложений запущенный на веб-сервере, который обрабатывает бизнес-логику приложения. Эта бизнес-логика и есть тот серверный код, написанием которого занимается backend-разработчик. Код должен обеспечивать обработку запросов от клиента, обмен данными с базой данных, выполнение любых необходимых изменений или модификаций, а затем возврат результата клиенту. Код может быть написан на таких серверных языках как Python, JavaScript/Node.js, Ruby, PHP и многих других.
База данных – это место, где хранятся данные для приложения. База данных хранит, организует и предоставляет доступ к данным приложения. Существует несколько типов баз данных и систем управления базами данных, которые можно использовать для серверной веб-разработки.
Краткое резюме
Таким образом, веб-сервер предоставляет доступ к ресурсам в Интернете, обрабатывая веб-запросы от клиентов. Он может содержать сервер приложений, который обрабатывает динамическую бизнес-логику приложения, а также подключаться к базе данных, которая соответствует уровню данных приложения. Эти два компонента, которые необходимо программировать в качестве backend-разработчика. Существует множество языков и технологий, которые вы можете использовать для каждого слоя (представление, приложение, данные) и для веб-сервера. Комбинация технологий, используемых для приложения, составляет «стек» разработки программного обеспечения. В следующих статьях я планирую рассмотреть эти компоненты более подробно.
 Что такое веб-сервер? С точки зрения обывателя — это некий черный ящик, который обрабатывает запросы браузера и выдает в ответ веб-страницы. Технический специалист засыплет вас массой малопонятных терминов. В итоге начинающим администраторам веб-серверов бывает порой трудно разобраться во всем многообразии терминов и технологий. Действительно, область веб-разработки динамично развивается, но в основе многих современных решений лежат базовые технологии и принципы, о которых мы сегодня и поговорим.
Что такое веб-сервер? С точки зрения обывателя — это некий черный ящик, который обрабатывает запросы браузера и выдает в ответ веб-страницы. Технический специалист засыплет вас массой малопонятных терминов. В итоге начинающим администраторам веб-серверов бывает порой трудно разобраться во всем многообразии терминов и технологий. Действительно, область веб-разработки динамично развивается, но в основе многих современных решений лежат базовые технологии и принципы, о которых мы сегодня и поговорим.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Если не знаешь с чего начать, то начинать надо сначала. Чтобы не запутаться во всем многообразии современных веб-технологий нужно обратиться к истории, чтобы понять, с чего начинался современный интернет и как развивались и совершенствовались технологии.
HTTP-сервер
На заре развития интернета сайты представляли собой простое хранилище специальным образом размеченных документов и некоторых связанных с ними данных: файлов, изображений и т.п. Для того, чтобы документы могли ссылаться друг на друга и связанные данные был предложен специальный язык гипертекстовой разметки HTML, а для доступа к таким документам посредством сети интернет протокол HTTP. И язык, и протокол, развиваясь и совершенствуясь, дожили до наших дней без существенных изменений. И только начавший приходить на смену принятому в 1999 году протоколу HTTP/1.1 протокол HTTP/2 несет кардинальные изменения с учетом требований современной сети.
Протокол HTTP реализован по клиент-серверной технологии и работает по принципу запрос-ответ без сохранения состояния. Целью запроса служит некий ресурс, который определяется единым идентификатором ресурса — URI (Uniform Resource Identifier), HTTP использует одну из разновидностей URI — URL (Uniform Resource Locator) — универсальный указатель ресурса, который помимо сведений о ресурсе определяет также его физическое местоположение.
Задача HTTP-сервера обработать запрос клиента и либо выдать ему требуемый ресурс, либо сообщить о невозможности это сделать. Рассмотрим следующую схему:
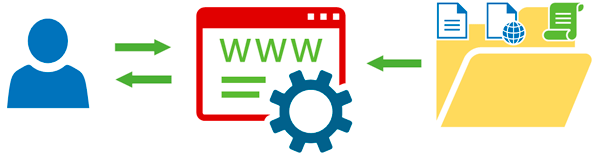
Пользователь посредством HTTP-клиента, чаще всего это браузер, запрашивает у HTTP-сервера некий URL, сервер проверяет и отдает соответствующий этому URL-файл, обычно это HTML-страница. Полученный документ может содержать ссылки на связанные ресурсы, например, изображения. Если их нужно отображать на странице, то клиент последовательно запрашивает их у сервера, кроме изображений также могут быть запрошены таблицы стилей, скрипты, исполняемые на стороне клиента и т.д. Получив все необходимые ресурсы браузер обработает их согласно кода HTML-документа и выдаст пользователю готовую страницу.
Как уже многие догадались, под именем HTTP-сервера в данной схеме находится сущность, которая более известна сегодня под названием веб-сервер. Основная цель и задача веб-сервера — обработка HTTP-запросов и возврат пользователю их результатов. Веб-сервер не умеет самостоятельно генерировать контент и работает только со статическим содержимым. Это актуально и для современных веб-серверов, несмотря на все богатство их возможностей.
Долгое время одного веб-сервера было достаточно для реализации полноценного сайта. Но по мере роста сети интернет возможностей статического HTML стало остро не хватать. Простой пример: каждая статическая страница самодостаточна и должна содержать ссылки на все связанные с ней ресурсы, при добавлении новых страниц ссылки на них потребуется добавить на уже существующие страницы, иначе пользователь никогда не сможет попасть на них.
Сайты того времени вообще мало походили на современные, например, ниже показан вид одного из пионеров русскоязычного интернета, сайт компании Rambler:
 А переход по любой из ссылок вообще может привести современного пользователя в недоумение, вернуться назад с такой страницы не представляется возможным, кроме как через нажатие одноименной кнопки в браузере.
А переход по любой из ссылок вообще может привести современного пользователя в недоумение, вернуться назад с такой страницы не представляется возможным, кроме как через нажатие одноименной кнопки в браузере.
 Попытка создать что-то более-менее похожее на современный сайт очень скоро превращалась в нарастающий объем работ по внесению изменений в уже существующие страницы. Ведь если мы что-то поменяли в общей части сайта, например, логотип в шапке, то нам нужно внести это изменение на все существующие страницы. А если мы изменили путь к одной из страниц или удалили ее, то нам надо будет найти все ссылки на нее и изменить или удалить их.
Попытка создать что-то более-менее похожее на современный сайт очень скоро превращалась в нарастающий объем работ по внесению изменений в уже существующие страницы. Ведь если мы что-то поменяли в общей части сайта, например, логотип в шапке, то нам нужно внести это изменение на все существующие страницы. А если мы изменили путь к одной из страниц или удалили ее, то нам надо будет найти все ссылки на нее и изменить или удалить их.
Поэтому следующим шагом в развитии веб-серверов стала поддержка технологии включения на стороне сервера — SSI (Server Side Includes). Она позволяла включать в код страницы содержимое иных файлов, что давало возможность вынести повторяющиеся элементы, такие как шапка, подвал, меню и т.п. в отдельные файлы и просто подключать при окончательной сборке страницы.
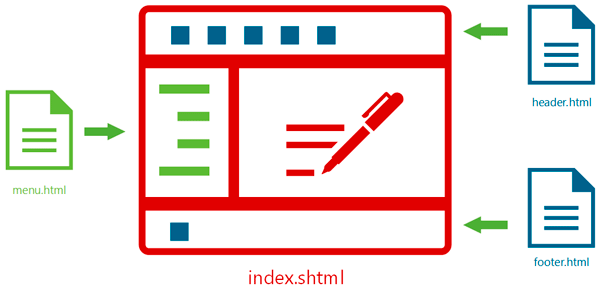 Теперь, чтобы изменить логотип или пункт меню изменения надо будет внести всего лишь в один файл, вместо правки всех существующих страниц. Кроме того, SSI позволял выводить на страницы некоторое динамическое содержимое, например, актуальную дату и выполнять несложные условия и работать с переменными. Это был значительный шаг вперед, облегчавший труд вебмастеров и повышавший удобство пользователей. Однако реализовать по-настоящему динамический сайт данные технологии все еще не позволяли.
Теперь, чтобы изменить логотип или пункт меню изменения надо будет внести всего лишь в один файл, вместо правки всех существующих страниц. Кроме того, SSI позволял выводить на страницы некоторое динамическое содержимое, например, актуальную дату и выполнять несложные условия и работать с переменными. Это был значительный шаг вперед, облегчавший труд вебмастеров и повышавший удобство пользователей. Однако реализовать по-настоящему динамический сайт данные технологии все еще не позволяли.
Стоит отметить, что SSI активно применяется и сегодня, там, где в код страницы нужно вставить некий статический контент, прежде всего благодаря простоте и нетребовательности к ресурсам.
CGI
Следующим шагом в развитии веб-технологии стало появление специальных программ (скриптов) выполняющих обработку запроса пользователей на стороне сервера. Чаще всего они пишутся на скриптовых языках, первоначально это был Perl, сегодня пальму лидерства удерживает PHP. Постепенно возник целый класс программ — системы управления контентом — CMS (Content management system), которые представляют полноценные веб-приложения способные обеспечить динамическую обработку запросов пользователя.
Теперь важный момент: веб-сервера не умели и не умеют выполнять скрипты, их задача — отдача статического содержимого. Здесь на сцену выходит новая сущность — сервер приложений, который представляет собой интерпретатор скриптовых языков и с помощью которого работают написанные на них веб-приложения. Для хранения данных обычно используются СУБД, что обусловлено необходимостью доступа к большому количеству взаимосвязанной информации.
Однако сервер приложений не умеет работать с протоколом HTTP и обрабатывать пользовательские запросы, так как это задача веб-сервера. Чтобы обеспечить их взаимодействие был разработан общий интерфейс шлюза — CGI (Common Gateway Interface).
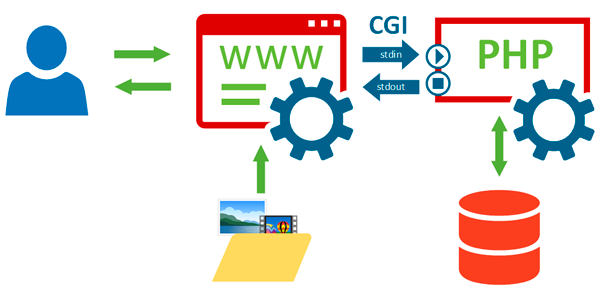 Следует четко понимать, CGI — это не программа и не протокол, это именно интерфейс, т.е. совокупность способов взаимодействия между приложениями. Также не следует путать термин CGI с понятием CGI-приложения или CGI-скрипта, которыми обозначают программу (скрипт) поддерживающую работу через интерфейс CGI.
Следует четко понимать, CGI — это не программа и не протокол, это именно интерфейс, т.е. совокупность способов взаимодействия между приложениями. Также не следует путать термин CGI с понятием CGI-приложения или CGI-скрипта, которыми обозначают программу (скрипт) поддерживающую работу через интерфейс CGI.
Для передачи данных используются стандартные потоки ввода-вывода, от веб-сервера к СGI-приложению данные передаются через stdin, принимаются назад через stdout, для передачи сообщений об ошибках используется stderr.
Рассмотрим процесс работы такой системы подробнее. Получив запрос от браузера пользователя веб-сервер определяет, что запрошено динамическое содержимое и формирует специальный запрос, которой через интерфейс CGI направляет веб-приложению. При его получении приложение запускается и выполняет запрос, результатом которого служит HTML-код динамически сформированной страницы, который передается назад веб-серверу, после чего приложение завершает свою работу.
Еще одно важное отличие динамического сайта — его страницы физически не существуют в том виде, который отдается пользователю. Фактически имеется веб-приложение, т.е. набор скриптов и шаблонов, и база данных, которая хранит материалы сайта и служебную информацию, отдельно располагается статическое содержимое: картинки, java-скрипты, файлы.
Получив запрос веб-приложение извлекает данные из БД и заполняет ими указанный в запросе шаблон. Результат отдается веб-серверу, который дополняет сформированную таким образом страницу статическим содержимым (изображения, скрипты, стили) и отдает ее браузеру пользователя. Сама страница при этом нигде не сохраняется, разве что в кэше, и при получении нового запроса произойдет повторная генерация страницы.
К достоинствам CGI можно отнести языковую и архитектурную независимость: CGI-приложение может быть написано на любом языке и одинаково хорошо работать с любым веб-сервером. Учитывая простоту и открытость стандарта это привело к бурному развитию веб-приложений.
Однако, кроме достоинств, CGI обладает и существенными недостатками. Основной из них — высокие накладные расходы на запуск и остановку процесса, что влечет за собой повышенные требования к аппаратным ресурсам и невысокую производительность. А использование стандартных потоков ввода-вывода ограничивает возможности масштабирования и обеспечения высокой доступности, так как требует, чтобы веб-сервер и сервер приложений находились в пределах одной системы.
На текущий момент CGI практически не применяется, так как ему на смену пришли более совершенные технологии.
FastCGI
Как следует из названия, основной целью разработки данной технологии было повышение производительности CGI. Являясь ее дальнейшим развитием FastCGI представляет собой клиент-серверный протокол для взаимодействия веб-сервера и сервера приложений, обеспечивающий высокую производительность и безопасность.
FastCGI устраняет основную проблему CGI — повторный запуск процесса веб-приложения на каждый запрос, FastCGI процессы запущены постоянно, что позволяет существенно экономить время и ресурсы. Для передачи данных вместо стандартных потоков используются UNIX-сокеты или TCP/IP, что позволяет размещать веб-сервер и сервера приложений на разных хостах, таким образом обеспечивая масштабирование и/или высокую доступность системы.
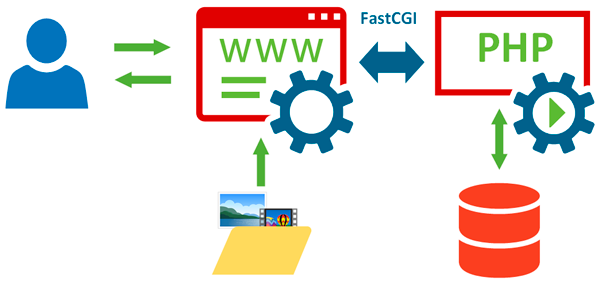 Также мы можем запустить на одном компьютере несколько FastCGI процессов, которые могут обрабатывать запросы параллельно, либо иметь различные настройки или версии скриптового языка. Например, можно одновременно иметь несколько версий PHP для разных сайтов, направляя их запросы разным FastCGI процессам.
Также мы можем запустить на одном компьютере несколько FastCGI процессов, которые могут обрабатывать запросы параллельно, либо иметь различные настройки или версии скриптового языка. Например, можно одновременно иметь несколько версий PHP для разных сайтов, направляя их запросы разным FastCGI процессам.
Для управления FastCGI процессами и распределением нагрузки служат менеджеры процессов, они могут быть как частью веб-сервера, так и отдельными приложениями. Популярные веб-сервера Apache и Lighttpd имеют встроенные менеджеры FastCGI процессов, в то время как Nginx требует для своей работы c FastCGI внешний менеджер.
PHP-FPM и spawn-fcgi
Из внешних менеджеров для FastCGI процессов применяются PHP-FPM и spawn-fcgi. PHP-FPM первоначально был набором патчей к PHP от Андрея Нигматулина, решавший ряд вопросов управления FastCGI процессами, начиная с версии 5.3 является частью проекта и входит в поставку PHP. PHP-FPM умеет динамически управлять количеством процессов PHP в зависимости от нагрузки, перезагружать пулы без потери запросов, аварийный перезапуск сбойных процессов и представляет собой достаточно продвинутый менеджер.
Spawn-fcgi является частью проекта Lighttpd, но в состав одноименного веб-сервера не входит, по умолчанию Lighttpd использует собственный, более простой, менеджер процессов. Разработчики рекомендуют использовать его в случаях, когда вам нужно управлять FastCGI процессами расположенными на другом хосте, либо требуются расширенные настройки безопасности.
Внешние менеджеры позволяют изолировать каждый FastCGI процесс в своем chroot (смена корневого каталога приложения без возможности доступа за его пределы), отличном как от chroot иных процессов, так и от chroot веб-сервера. И, как мы уже говорили, позволяют работать с FastCGI приложениями расположенными на других серверах через TCP/IP, в случае локального доступа следует выбирать доступ через UNIX-сокет, как быстрый тип соединения.
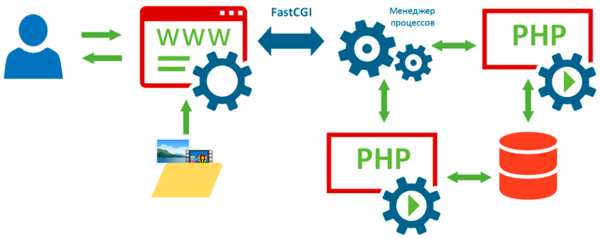 Если снова посмотреть на схему, то мы увидим, что у нас появился новый элемент — менеджер процессов, который является посредником между веб-сервером и серверами приложений. Это несколько усложняет схему, так как настраивать и сопровождать приходится большее количество служб, но в тоже время открывает более широкие возможности, позволяя настроить каждый элемент сервера четко под свои задачи.
Если снова посмотреть на схему, то мы увидим, что у нас появился новый элемент — менеджер процессов, который является посредником между веб-сервером и серверами приложений. Это несколько усложняет схему, так как настраивать и сопровождать приходится большее количество служб, но в тоже время открывает более широкие возможности, позволяя настроить каждый элемент сервера четко под свои задачи.
На практике, выбирая между встроенным менеджером и внешним здраво оцените ситуацию и выбирайте именно тот инструмент, который наиболее подходит вашим запросам. Например, создавая простой сервер для нескольких сайтов на типовых движках применение внешнего менеджера будет явно излишним. Хотя никто не навязывает вам своей точки зрения. Linux тем и хорош, что каждый может, как из конструктора, собрать именно то, что ему надо.
SCGI, PCGI, PSGI, WSGI и прочие
Погружаясь в тему веб-разработки, вы непременно будете встречаться с упоминанием различных CGI-технологий, наиболее популярные из которых мы перечислили в заголовке. От такого многообразия можно и растеряться, но если вы внимательно прочитали начало нашей статьи, то знаете, как работает CGI и FastCGI, а, следовательно, разобраться с любой из этих технологий не составит для вас труда.
Несмотря на различия в реализациях того или иного решения базовые принципы остаются общими. Все эти технологии предоставляют интерфейс шлюза (Gateway Interface) для взаимодействия веб-сервера с сервером приложений. Шлюзы позволяют развязать между собой среды веб-сервера и веб-приложения, позволяя использовать любые сочетания без оглядки на возможную несовместимость. Проще говоря, неважно, поддерживает ли ваш веб-сервер конкретную технологию или скриптовый язык, главное, чтобы он умел работать с нужным типом шлюза.
И раз уж мы перечислили в заголовке целую пачку аббревиатур, то пройдем по ним более подробно.
SCGI (Simple Common Gateway Interface) — простой общий интерфейс шлюза — разработан как альтернатива CGI и во многом аналогичен FastCGI, но более прост в реализации. Все, о чем мы рассказывали применительно к FastGCI справедливо и для SCGI.
PCGI (Perl Common Gateway Interface) — библиотека Perl для работы с интерфейсом CGI, долгое время являлась основным вариантом работы с Perl-приложениями через CGI, отличается хорошей производительностью (насколько это применимо к CGI) при скромных потребностях в ресурсах и неплохой защиты от перегрузки.
PSGI (Perl Web Server Gateway Interface) — технология взаимодействия веб-сервера и сервера приложений для Perl. Если PCGI представляет собой инструмент для работы с классическим CGI интерфейсом, то PSGI более напоминает FastCGI. PSGI-сервер представляет среду для выполнения Perl-приложений которая постоянно запущена в качестве службы и может взаимодействовать с веб-сервером через TCP/IP или UNIХ-сокеты и предоставляет Perl-приложениям те же преимущества, что и FastCGI.
WSGI (Web Server Gateway Interface) — еще один специфичный интерфейс шлюза, предназначенный для взаимодействия веб-сервера с сервером приложений для программ, написанных на языке Phyton.
Как несложно заметить, все перечисленные нами технологии являются в той или иной степени аналогами CGI/FastCGI, но для специфичных областей применения. Приведенных нами данных будет вполне достаточно для общего понимания принципа и механизмов их работы, а более глубокое их изучение имеет смысл только при серьезной работе с указанными технологиями и языками.
Сервер приложений как модуль Apache
Если раньше мы говорили о неком абстрактном веб-сервере, то теперь речь пойдет о конкретном решении и дело здесь не в наших предпочтениях. Среди веб-серверов Apache занимает особое место, в большинстве случаев, когда говорят о веб-сервере на платформе Linux, да и о веб-сервере вообще, то подразумеваться будет именно Apache.
Можно сказать, что это своего рода веб-сервер «по умолчанию». Возьмите любой массовый хостинг — там окажется Apache, возьмите любое веб-приложение — настройки по умолчанию выполнены под Apache.
Да, с технологической точки зрения Apache не является венцом технологий, но именно он представляет золотую середину, прост, понятен, гибок в настройках, универсален. Если вы делаете первые шаги в сайтостроении — то Apache ваш выбор.
Здесь нас могут упрекнуть, что Apache уже давно неактуален, все «реальные пацаны» уже поставили Nginx и т.д. и т.п., поэтому поясним данный момент более подробно. Все популярные CMS из коробки сконфигурированы для использования совместно с Apache, это позволяет сосредоточить все внимание на работу именно с веб-приложением, исключив из возможного источника проблем веб-сервер.
Все популярные среди новичков форумы тоже подразумевают в качестве веб-сервера Apache и большинство советов и рекомендаций будут относиться именно к нему. В тоже время альтернативные веб-сервера как правило требуют более тонкой и тщательной настройки, как со стороны веб-сервера, так и со стороны веб-приложения. При этом пользователи данных продуктов обычно гораздо более опытны и типовые проблемы новичков в их среде не обсуждаются. В итоге может сложиться ситуация, когда ничего не работает и спросить не у кого. С Apache такого гарантированно не произойдет.
Собственно, что такого сделали разработчики Apache, что позволило их детищу занять особое место? Ответ достаточно прост: они пошли своим путем. В то время как CGI предлагал абстрагироваться от конкретных решений, сосредоточившись на универсальном шлюзе, в Apache поступили по-другому — максимально интегрировали веб-сервер и сервер приложений.
Действительно, если запустить сервер приложений как модуль веб-сервера в общем адресном пространстве, то мы получим гораздо более простую схему:
 Какие преимущества это дает? Чем проще схема и меньше в ней элементов, тем проще и дешевле сопровождать ее и обслуживать, тем меньше в ней точек отказа. Если для единичного сервера это может быть не так важно, то в рамках хостинга это весьма значительный фактор.
Какие преимущества это дает? Чем проще схема и меньше в ней элементов, тем проще и дешевле сопровождать ее и обслуживать, тем меньше в ней точек отказа. Если для единичного сервера это может быть не так важно, то в рамках хостинга это весьма значительный фактор.
Второе преимущество — производительность. Снова огорчим поклонников Nginx, благодаря работе в едином адресном пространстве, по производительности сервера приложений Apache + mod_php всегда будет на 10-20% быстрее любого иного веб-сервера + FastCGI (или иное CGI решение). Но также следует помнить, что скорость работы сайта обусловлена не только производительностью сервера приложений, но и рядом иных условий, в которых альтернативные веб-сервера могут показывать значительно лучший результат.
Но есть еще одно, достаточно серьезное преимущество, это возможность настройки сервера приложений на уровне отдельного сайта или пользователя. Давайте вернемся немного назад: в FastCGI/CGI схемах сервер приложений — это отдельная служба, со своими, отдельными, настройками, которая даже может работать от имени другого пользователя или на другом хосте. С точки зрения администратора одиночного сервера или какого-нибудь крупного проекта — это отлично, но для пользователей и администраторов хостинга — не очень.
Развитие интернета привело к тому, что количество возможных веб-приложений (CMS, скриптов, фреймворков и т.п.) стало очень велико, а низкий порог вхождения привлек к сайтостроению большое количество людей без специальных технических знаний. В тоже время разные веб-приложения могли требовать различной настройки сервера приложений. Как быть? Каждый раз обращаться в поддержку?
Решение нашлось довольно просто. Так как сервер-приложений теперь часть веб-сервера, то можно поручить последнему управлять его настройками. Традиционно для управления настройками Apache помимо конфигурационных файлов применялись файлы httaccess, которые позволяли пользователям писать туда свои директивы и применять их к той директории, где расположен данный файл и ниже, если там настройки не перекрываются своим файлом httaccess. В режиме mod_php данные файлы позволяют также изменять многие опции PHP для отдельного сайта или директории.
Для принятия изменений не требуется перезапуск веб-сервера и в случае ошибки перестанет работать только этот сайт (или его часть). Кроме того, внести изменения в простой текстовый файл и положить его в папку на сайте под силу даже неподготовленным пользователям и безопасно для сервера в целом.
Сочетание всех этих преимуществ и обеспечило Apache столь широкое применение и статус универсального веб-сервера. Другие решения могут быть быстрее, экономичнее, лучше, но они всегда требуют настройки под задачу, поэтому применяются в основном в целевых проектах, в массовом сегменте безальтернативно доминирует Apache.
Поговорив о достоинствах, перейдем к недостаткам. Некоторые из них просто являются обратной стороной медали. Тот факт, что сервер приложений является частью веб-сервера дает плюсы в производительности и простоте настройки, но в тоже время ограничивает нас как с точки зрения безопасности — сервер приложений всегда работает от имени веб-сервера, так и в гибкости системы, мы не можем разнести веб-сервер и сервер приложений на разные хосты, не можем использовать сервера с разными версиями скриптового языка или разными настройками.
Второй минус — более высокое потребление ресурсов. В схеме с CGI сервер приложений генерирует страницу и отдает ее веб-серверу, освобождая ресурсы, связка Apache + mod_php держит ресурсы сервера приложений занятыми до тех пор, пока веб-сервер не отдаст содержимое страницы клиенту. Если клиент медленный, то ресурсы будут заняты на все время его обслуживания. Именно поэтому перед Apache часто ставят Nginx, который играет роль быстрого клиента, это позволяет Apache быстро отдать страницу и освободить ресурсы, переложив взаимодействие с клиентом на более экономичный Nginx.
Заключение
Охватить в одной статье весь спектр современных технологий невозможно, поэтому мы сосредоточились только на основных из них, некоторые вещи умышленно оставив за кадром, а также прибегли к существенным упрощениям. Несомненно, начав работать в этой области вам потребуется более глубокое изучение темы, но для того, чтобы воспринимать новые знания нужен определенный теоретический фундамент, который мы постарались заложить данным материалом.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Платформа сайта и серверная часть
Из чего состоит серверная часть сайтов, которые я делаю. Если вкратце, используются популярные и проверенные временем серверные технологии — операционная система Linux, вебсервер nginx, СУБД MySQL и mongoDB, интерпретатор языка PHP. Серверный код сайтов пишется на языке PHP и языке шаблонов Smarty. В качестве основного программного обеспечения сайтов («движка») используется платформа EMPS.
git, GitLab, GitHub, Bitbucket
Вся правка кода сайта на сервере осуществляется только через git, что облегчает работу с кодом как одному человеку, так и целой команде разработчиков. Не надо никаких копирований файлов и синхронизаций. Написал на домашнем компьютере что нужно — нажал commit, push — всё, изменения уже на сайте.