Время на прочтение
13 мин
Количество просмотров 64K
Туториал
Recovery mode
Перевод
Узнайте о антипаттернах, планах выполнения, time complexity, настройке запросов и оптимизации в SQL
 Язык структурированных запросов (SQL) является незаменимым навыком в индустрии информатики, и вообще говоря, изучение этого навыка относительно просто. Однако большинство забывают, что SQL — это не только написание запросов, это всего лишь первый шаг дальше по дороге. Обеспечение производительности запросов или их соответствия контексту, в котором вы работаете, — это совсем другая вещь.
Язык структурированных запросов (SQL) является незаменимым навыком в индустрии информатики, и вообще говоря, изучение этого навыка относительно просто. Однако большинство забывают, что SQL — это не только написание запросов, это всего лишь первый шаг дальше по дороге. Обеспечение производительности запросов или их соответствия контексту, в котором вы работаете, — это совсем другая вещь.
Вот почему это руководство по SQL предоставит вам небольшой обзор некоторых шагов, которые вы можете пройти, чтобы оценить ваш запрос:
- Во-первых, вы начнете с краткого обзора важности обучения SQL для работы в области науки о данных;
- Далее вы сначала узнаете о том, как выполняется обработка и выполнение запросов SQL, чтобы понять важность создания качественных запросов. Конкретнее, вы увидите, что запрос анализируется, переписывается, оптимизируется и окончательно оценивается.
- С учетом этого, вы не только перейдете к некоторым антипаттернам запросов, которые начинающие делают при написании запросов, но и узнаете больше об альтернативах и решениях этих возможных ошибок; Кроме того, вы узнаете больше о методическом подходе к запросам на основе набора.
- Вы также увидите, что эти антипаттерны вытекают из проблем производительности и что, помимо «ручного» подхода к улучшению SQL-запросов, вы можете анализировать свои запросы также более структурированным, углубленным способом, используя некоторые другие инструменты, которые помогают увидеть план запроса; И,
- Вы вкратце узнаете о time complexity и big O notation, для получения представления о сложности плана выполнения во времени перед выполнением запроса;
- Вы кратко узнаете о том, как оптимизировать запрос.
Почему следует изучать SQL для работы с данными?
SQL далеко не мертв: это один из самых востребованных навыков, который вы находите в описаниях должностей из индустрии обработки и анализа данных, независимо от того, претендуете ли вы на аналитику данных, инженера данных, специалиста по данным или на любые другие роли. Это подтверждают 70% респондентов опроса О ‘Рейли (O’ Reilly Data Science Salary Survey) за 2016 год, которые указывают, что используют SQL в своем профессиональном контексте. Более того, в этом опросе SQL выделяется выше языков программирования R (57%) и Python (54%).
Вы получаете картину: SQL — это необходимый навык, когда вы работаете над получением работы в индустрии информатики.
Неплохо для языка, который был разработан в начале 1970-х, верно?
Но почему именно так часто используется? И почему он не умер, несмотря на то, что он существует так долго?
Есть несколько причин: одной из первых причин могло бы стать то, что компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в реляционных системах управления потоками данных (RDSMS), и для доступа к этим данным нужен SQL. SQL — это lingua franca данных: он дает возможность взаимодействовать практически с любой базой данных или даже строить свою собственную локально!
Если этого еще недостаточно, имейте в виду, что существует довольно много реализаций SQL, которые несовместимы между вендорами и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является для вас требованием найти свой путь в индустрии (информатики).
Кроме того, можно с уверенностью сказать, что к SQL также присоединились более новые технологии, такие как Hive, интерфейс языка запросов, похожий на SQL, для запросов и управления большими наборами данных, или Spark SQL, который можно использовать для выполнения запросов SQL. Опять же, SQL, который вы там найдете, будет отличаться от стандарта, который вы могли бы узнать, но кривая обучения будет значительно проще.
Если вы хотите провести сравнение, рассматривайте его как обучение линейной алгебре: приложив все эти усилия в этот один предмет, вы знаете, что вы сможете использовать его, чтобы также освоить машинное обучение!
Короче говоря, вот почему вы должны изучить этот язык запросов:
- Его довольно легко освоить, даже для новичков. Кривая обучения довольно проста и постепенна, поэтому вы будете писать запросы в кратчайшие сроки.
- Он следует принципу «учись один раз, используй везде», так что это отличное вложение твоего времени!
- Это отличное дополнение к языкам программирования; В некоторых случаях написание запроса даже предпочтительнее написания кода, потому что он более производительный!
- …
Чего вы все еще ждете? 
Обработка SQL и выполнение запросов
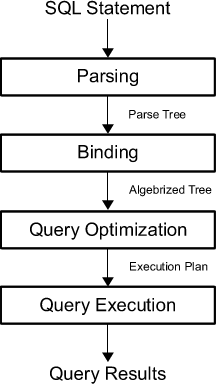
Чтобы повысить производительность вашего SQL-запроса, вы сначала должны знать, что происходит внутри, когда вы нажимаете ярлык для выполнения запроса.
Сначала запрос разбирается в «дерево разбора» (parse tree); Запрос анализируется на предмет соответствия синтаксическим и семантическим требованиям. Синтаксический анализатор создает внутреннее представление входного запроса. Затем эти выходные данные передаются в механизм перезаписи.
Затем оптимизатор должен найти оптимальное выполнение или план запроса для данного запроса. План выполнения точно определяет, какой алгоритм используется для каждой операции, и как координируется выполнение операций.
Чтобы найти наиболее оптимальный план выполнения, оптимизатор перечисляет все возможные планы выполнения, определяет качество или стоимость каждого плана, принимает информацию о текущем состоянии базы данных, а затем выбирает наилучший из них в качестве окончательного плана выполнения. Поскольку оптимизаторы запросов могут быть несовершенными, пользователям и администраторам баз данных иногда приходится вручную изучать и настраивать планы, созданные оптимизатором, чтобы повысить производительность.
Теперь вы, вероятно, задаетесь вопросом, что считается «хорошим планом запроса».
Как вы уже читали, качество стоимости плана играет немаловажную роль. Более конкретно, такие вещи, как количество дисковых операций ввода-вывода (disk I/Os), которые требуются для оценки плана, стоимость CPU плана и общее время отклика, которое может наблюдать клиент базы данных, и общее время выполнения, имеют важное значение. Вот тут-то и возникнет понятие сложности времени (time complexity). Подробнее об этом вы узнаете позже.
Затем выбранный план запроса выполняется, оценивается механизмом выполнения системы и возвращаются результаты запроса.
Написание SQL-запросов
Из предыдущего раздела, возможно, не стало ясно, что принцип Garbage In, Garbage Out (GIGO) естественным образом проявляется в процессе обработки и выполнения запроса: тот, кто формулирует запрос, также имеет ключи к производительности ваших запросов SQL. Если оптимизатор получит плохо сформулированный запрос, он сможет сделать только столько же…
Это означает, что есть некоторые вещи, которые вы можете сделать, когда пишете запрос. Как вы уже видели во введении, ответственность тут двоякая: речь идет не только о написании запросов, которые соответствуют определенному стандарту, но и о сборе идей о том, где проблемы производительности могут скрыться в вашем запросе.
Идеальная отправная точка — подумать о «местах» в ваших запросах, где могут возникнуть проблемы. И, в общем, есть четыре ключевых слова, в которых новички могут ожидать возникновения проблем с производительностью:
- Условие
WHERE; - Любые ключевые слова
INNER JOINилиLEFT JOIN; А также, - Условие
HAVING;
Конечно, этот подход прост и наивен, но, для новичка, эти пункты являются отличными указателями, и можно с уверенностью сказать, что когда вы только начинаете, именно в этих местах происходят ошибки и, как ни странно, где их также трудно заметить.
Тем не менее, вы также должны понимать, что производительность — это нечто, что должно стать значимым. Однако просто сказать, что эти предложения и ключевые слова плохи — это не то, что нужно, когда вы думаете о производительности SQL. Наличие предложения WHERE или HAVING в запросе не обязательно означает, что это плохой запрос…
Ознакомьтесь со следующим разделом, чтобы узнать больше об антипаттернах и альтернативных подходах к построению вашего запроса. Эти советы и рекомендации предназначены в качестве руководства. То, как и если вам действительно нужно переписать ваш запрос, зависит, помимо прочего, от количества данных, базы данных и количества раз, которое вам нужно для выполнения запроса. Это полностью зависит от цели вашего запроса и иметь некоторые предварительные знания о базе данных, с которой вы будете работать, имеет решающее значение!
1. Извлекайте только необходимые данные
Умозаключение «чем больше данных, тем лучше» — не обязательно должна соблюдаться при написании SQL: вы рискуете не только запутаться, получив больше данных, чем вам действительно нужно, но и производительность может пострадать от того, что ваш запрос получает слишком много данных.
Вот почему, как правило, стоит обратить внимание на оператор SELECT, предложение DISTINCT и оператор LIKE.
Оператор SELECT
Первое, что уже можно проверить, когда вы написали запрос, является ли инструкция SELECT максимально компактной. Целью здесь должно быть удаление ненужных столбцов из SELECT. Таким образом вы заставляете себя только извлекать данные, которые служат вашей цели запроса.
Если у вас есть коррелированные подзапросы с EXISTS, вы должны попытаться использовать константу в операторе SELECT этого подзапроса вместо выбора значения фактического столбца. Это особенно удобно, когда вы проверяете только существование.
Помните, что коррелированный подзапрос является подзапросом, использующим значения из внешнего запроса. И обратите внимание, что, несмотря на то, что NULL может работать в этом контексте как «константа», это очень запутанно!
Рассмотрим следующий пример, чтобы понять, что подразумевается под использованием константы:
SELECT driverslicensenr, name
FROM Drivers
WHERE EXISTS
(SELECT '1'
FROM Fines
WHERE fines.driverslicensenr = drivers.driverslicensenr); Совет: полезно знать, что наличие коррелированного подзапроса не всегда является хорошей идеей. Вы всегда можете рассмотреть возможность избавиться от них, например, переписав их с помощью INNER JOIN:
SELECT driverslicensenr, name
FROM drivers
INNER JOIN fines ON fines.driverslicensenr = drivers.driverslicensenr; Операция DISTINCT
Инструкция SELECT DISTINCT используется для возврата только различных значений. DISTINCT — это пункт, которого, безусловно, следует стараться избегать, если можно. Как и в других примерах, время выполнения увеличивается только при добавлении этого предложения в запрос. Поэтому всегда полезно рассмотреть, действительно ли вам нужна эта операция DISTINCT, чтобы получить результаты, которые вы хотите достичь.
Оператор LIKE
При использовании оператора LIKE в запросе индекс не используется, если шаблон начинается с % или _. Это не позволит базе данных использовать индекс (если он существует). Конечно, с другой точки зрения, можно также утверждать, что этот тип запроса потенциально оставляет возможность для получения слишком большого количества записей, которые не обязательно удовлетворяют цели запроса.
Опять же, знание данных, хранящихся в базе данных, может помочь вам сформулировать шаблон, который будет правильно фильтровать все данные, чтобы найти только строки, которые действительно важны для вашего запроса.
2. Ограничьте свои результаты
Если вы не можете избежать фильтрации вашего оператора SELECT, вы можете ограничить свои результаты другими способами. Вот здесь и подходят такие подходы, как предложение LIMIT и преобразования типов данных.
Операторы TOP, LIMIT и ROWNUM
Можно добавить операторы LIMIT или TOP в запросы, чтобы задать максимальное число строк для результирующего набора. Вот несколько примеров:
SELECT TOP 3 *
FROM Drivers;
Обратите внимание, что вы можете дополнительно указать PERCENT, например, если вы измените первую строку запроса с помощью SELECT TOP 50 PERCENT *.
SELECT driverslicensenr, name
FROM Drivers
LIMIT 2;
Кроме того, можно добавить предложение ROWNUM, эквивалентное использованию LIMIT в запросе:
SELECT *
FROM Drivers
WHERE driverslicensenr = 123456 AND ROWNUM <= 3;Преобразования типов данных
Всегда следует использовать наиболее эффективные, т.е. наименьшие, типы данных. Всегда есть риск, когда вы предоставляете огромный тип данных, когда меньший будет более достаточным.
Однако при добавлении преобразования типа данных в запрос увеличивается только время выполнения.
Альтернатива заключается в том, чтобы максимально избежать преобразования типов данных. Обратите внимание также на то, что не всегда возможно удалить или пропустить преобразование типа данных из запросов, но при этом следует обязательно стремиться к их включению и что при этом необходимо проверить эффект добавления перед выполнением запроса.
3. Не делайте запросы более сложными, чем они должны быть
Преобразования типов данных приводят вас к следующему пункту: вам не следует чрезмерно проектировать ваши запросы. Постарайтесь сделать их простыми и эффективными. Это может показаться слишком простым или глупым даже для того, чтобы быть подсказкой, главным образом потому, что запросы могут быть сложными.
Однако в примерах, упомянутых в следующих разделах, вы увидите, что вы можете легко начать делать простые запросы более сложными, чем они должны быть.
Оператор OR
Когда вы используете оператор OR в своем запросе, скорее всего, вы не используете индекс.
Помните, что индекс — это структура данных, которая повышает скорость поиска данных в таблице базы данных, но это обходится дорого: потребуются дополнительные записи и потребуется дополнительное место для хранения, чтобы поддерживать структуру данных индекса. Индексы используются для быстрого поиска или поиска данных без необходимости искать каждую строку в базе данных при каждом обращении к таблице базы данных. Индексы могут быть созданы с использованием одного или нескольких столбцов в таблице базы данных.
Если вы не используете индексы, включенные в базу данных, выполнение вашего запроса неизбежно займет больше времени. Вот почему лучше всего искать альтернативы использованию оператора OR в вашем запросе;
Рассмотрим следующий запрос:
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr = 123456
OR driverslicensenr = 678910
OR driverslicensenr = 345678;Оператор можно заменить на:
Условие с IN; или
SELECT driverslicensenr, name
FROM Drivers
WHERE driverslicensenr IN (123456, 678910, 345678);
Две инструкции SELECT с UNION.
Совет: здесь вы должны быть осторожны, чтобы не использовать ненужную операцию UNION, потому что вы просматриваете одну и ту же таблицу несколько раз. В то же время вы должны понимать, что когда вы используете UNIONв своем запросе, время выполнения увеличивается. Альтернативы операции UNION: переформулировка запроса таким образом, чтобы все условия были помещены в одну инструкцию SELECT, или использование OUTER JOIN вместо UNION.
Совет: имейте также в виду, что, хотя OR — и другие операторы, которые будут упомянуты в следующих разделах — скорее всего, не используют индекс, поиск по индексу не всегда предпочтителен!
Оператор NOT
Когда ваш запрос содержит оператор NOT, вполне вероятно, что индекс не используется, как и с оператором OR. Это неизбежно замедлит ваш запрос. Если вы не знаете, что здесь подразумевается, рассмотрите следующий запрос:
SELECT driverslicensenr, name
FROM Drivers
WHERE NOT (year > 1980);
Этот запрос, безусловно, будет выполняться медленнее, чем вы, возможно, ожидаете, в основном потому, что он сформулирован гораздо сложнее, чем может быть: в таких случаях, как этот, лучше всего искать альтернативу. Рассмотрите возможность замены NOT операторами сравнения, такими как >, <> или !>; Приведенный выше пример действительно может быть переписан и выглядеть примерно так:
SELECT driverslicensenr, name
FROM Drivers
WHERE year <= 1980;Это уже выглядит лучше, не так ли?
Оператор AND
Оператор AND — это другой оператор, который не использует индекс и который может замедлить запрос, если он используется чрезмерно сложным и неэффективным образом, как в следующем примере:
SELECT driverslicensenr, name
FROM Drivers
WHERE year >= 1960 AND year <= 1980;
Лучше переписать этот запрос, используя оператор BETWEEN:
SELECT driverslicensenr, name
FROM Drivers
WHERE year BETWEEN 1960 AND 1980;Операторы ANY и ALL
Кроме того, операторы ANY и ALL — это те операторы, с которыми вам следует быть осторожным, поскольку, если включить их в свои запросы, индекс не будет использоваться. Здесь пригодятся альтернативные функции агрегирования, такие как MIN или MAX.
Совет: в тех случаях, когда вы используете предлагаемые альтернативы, вы должны знать о том, что все функции агрегации, такие как SUM, AVG, MIN, MAX над многими строками, могут привести к длительному запросу. В таких случаях можно попытаться минимизировать количество строк для обработки или предварительно вычислить эти значения. Вы еще раз видите, что важно знать о своей среде, своей цели запроса,… Когда вы принимаете решение о том, какой запрос использовать!
Изолируйте столбцы в условиях
Также в случаях, когда столбец используется в вычислении или в скалярной функции, индекс не используется. Возможным решением было бы просто выделить конкретный столбец, чтобы он больше не был частью вычисления или функции. Рассмотрим следующий пример:
SELECT driverslicensenr, name
FROM Drivers
WHERE year + 10 = 1980;Это выглядит забавно, а? Вместо этого попробуйте пересмотреть расчет и переписать запрос примерно так:
SELECT driverslicensenr, name
FROM Drivers
WHERE year = 1970;4. Отсутствие грубой силы
Этот последний совет означает, что не следует пытаться ограничить запрос слишком сильно, так как это может повлиять на его производительность. Это особенно справедливо для соединений и для предложения HAVING.
Порядок таблиц в соединениях
При соединении двух таблиц может быть важно учитывать порядок таблиц в соединении. Если видно, что одна таблица значительно больше другой, может потребоваться переписать запрос так, чтобы самая большая таблица помещалась последней в соединении.
Избыточные условия при соединениях
При добавлении слишком большого количества условий к соединениям SQL обязан выбрать определенный путь. Однако может быть, что этот путь не всегда является более эффективным.
Условие HAVING
Условие HAVING было первоначально добавлено в SQL, так как ключевое слово WHERE не могло использоваться с агрегатными функциями. HAVING обычно используется с операцией GROUP BY, чтобы ограничить группы возвращаемых строк только теми, которые удовлетворяют определенным условиям. Однако, если это условие используется в запросе, индекс не используется, что, как вы уже знаете, может привести к тому, что запрос на самом деле не так хорошо работает.
Если вы ищете альтернативу, попробуйте использовать условие WHERE.
Рассмотрим следующие запросы:
SELECT state, COUNT(*)
FROM Drivers
WHERE state IN ('GA', 'TX')
GROUP BY state
ORDER BY stateSELECT state, COUNT(*)
FROM Drivers
GROUP BY state
HAVING state IN ('GA', 'TX')
ORDER BY state
Первый запрос использует предложение WHERE, чтобы ограничить количество строк, которые необходимо суммировать, тогда как второй запрос суммирует все строки в таблице, а затем использует HAVING, чтобы отбросить вычисленные суммы. В таких случаях вариант с предложением WHERE явно лучше, так как вы не тратите ресурсы.
Видно, что речь идет не об ограничении результирующего набора, а об ограничении промежуточного числа записей в запросе.
Следует отметить, что различие между этими двумя условиями заключается в том, что предложение WHERE вводит условие для отдельных строк, в то время как предложение HAVING вводит условие для агрегаций или результатов выбора, где один результат, такой как MIN, MAX, SUM,… был создан из нескольких строк.
Вы видите, оценка качества, написание и переписывание запросов не является простой задачей, если учесть, что они должны быть максимально производительными; Предотвращение антипаттернов и рассмотрение альтернативных вариантов также будут частью ответственности при написании запросов, которые необходимо выполнять на базах данных в профессиональной среде.
Этот список был лишь небольшим обзором некоторых антипаттернов и советов, которые, надеюсь, помогут начинающим; Если вы хотите получить представление о том, что более старшие разработчики считают наиболее частыми антиобразцами, ознакомьтесь с этим обсуждением.
Set-based против процедурных подходов к написанию запросов
В вышеприведенных антипаттернах подразумевалось то, что они фактически сводятся к разнице в основанных на наборах и процедурных подходах к построению ваших запросов.
Процедурный подход к запросам — это подход, очень похожий на программирование: вы говорите системе, что делать и как это делать.
Примером этого являются избыточные условия в соединениях или случаи, когда вы злоупотребляете условями HAVING, как в приведенных выше примерах, в которых вы запрашиваете базу данных, выполняя функцию и затем вызывая другую функцию, или вы используете логику, содержащую условия, циклы, пользовательские функции (UDF), курсоры,… чтобы получить конечный результат. При таком подходе вы часто будете запрашивать подмножество данных, затем запрашивать другое подмножество данных и так далее.
Неудивительно, что этот подход часто называют «пошаговым» или «построчным» запросом.
Другой подход — подход, основанный на наборе, где вы просто указываете, что делать. Ваша роль состоит в указании условий или требований для результирующего набора, который вы хотите получить из запроса. То, как ваши данные извлекаются, вы оставляете внутренним механизмам, которые определяют реализацию запроса: вы позволяете ядру базы данных определять лучшие алгоритмы или логику обработки для выполнения вашего запроса.
Поскольку SQL основан на наборах, неудивительно, что этот подход будет более эффективным, чем процедурный, и он также объясняет, почему в некоторых случаях SQL может работать быстрее, чем код.
Совет основанный на наборах подход к запросам — также тот, который большинство ведущих работодателей в отрасли информационных технологий попросит вас освоить! Часто необходимо переключаться между этими двумя типами подходов.
Обратите внимание, что если вам когда либо понадобится процедурный запрос, вы должны рассмотреть возможность его переписывания или рефакторинга.
В следующей части будут рассмотрены план и оптимизация запросов
👉 Система управления базами данных (СУБД) — это отдельная программа, которая работает как сервер, независимо от PHP.
Создавать свои базы данных, таблицы и наполнять их данными можно прямо из этой же программы, но для выполнения этих операций прежде придётся познакомиться с ещё одним языком программирования — SQL.
SQL или Structured Query Language (язык структурированных запросов) — язык программирования, предназначенный для управления данными в СУБД. Все современные СУБД поддерживают SQL.
На языке SQL выражаются все действия, которые можно провести с данными: от записи и чтения данных, до администрирования самого сервера СУБД. Для повседневной работы совсем не обязательно знать весь этот язык; достаточно ознакомиться лишь с основными понятиями синтаксиса и ключевыми словами.
Кроме того, SQL очень простой язык по своей структуре, поэтому его освоение не составит большого труда.
Язык SQL — это в первую очередь язык запросов, а кроме того он очень похож на естественный язык. Каждый раз, когда требуется прочитать или записать любую информацию в БД, требуется составить корректный запрос. Такой запрос должен быть выражен в терминах SQL.
Например, чтобы вывести на экран все записи из таблицы города, составим такой запрос:
ПРОЧИТАТЬ всё ИЗ ТАБЛИЦЫ 'города'Если перевести этот запрос на язык SQL, то корректным результатом будет:
SELECT * FROM 'cities'Теперь напишем запрос на добавление в таблицу города нового города:
ВСТАВЬ В ТАБЛИЦУ 'города' ЗНАЧЕНИЯ 'имя города' = 'Санкт-Петербург'Перевод на SQL:
INSERT INTO 'cities' SET 'name' = 'Санкт-Петербург'Эта команда создаст в таблице города новую запись, где полю имя города будет присвоено значение Санкт-Петербург.
С помощью SQL можно не только добавлять и читать данные, но и:
- удалять и обновлять записи в таблицах;
- создавать и редактировать сами таблицы;
- производить операции над данными: считать сумму, получать самое большое или малое значение, и так далее;
- настраивать работу сервера СУБД.
MySQL
Существует множество различных реляционных СУБД. Самая известная СУБД — это Microsoft Access, входящая в состав офисного пакета приложений Microsoft Office. Нет никаких препятствий для использования в качестве СУБД MS Access, но для задач веб-программирования гораздо лучше подходит альтернативная программа — MySQL.
В отличие от MS Access, MySQL абсолютно бесплатна, может работать на серверах с Linux, обладает гораздо большей производительностью и безопасностью, что делает её идеальным кандидатом на роль базы данных в веб-разработке.
Подавляющее большинство сайтов и приложений на PHP используют в качестве СУБД именно MySQL.
Установка
Последняя версия MySQL доступна для загрузки по ссылке: https://dev. mysql. com/downloads/mysql/. На этой странице следует выбрать MySQL Installer for Windows и нажать на кнопку Download для загрузки.
В процессе установки запомните директорию, куда вы устанавливаете MySQL (скрывается под ссылкой Advanced options). На шаге Accounts and Roles установщик попросит придумать пароль для доступа к БД (MySQL Root Password) — обязательно запомните или запишите этот пароль — он вам ещё понадобится.
Если для своей работы вы используете программную среду OpenServer, то этот раздел можно смело пропустить, так как в состав OpenServer уже входит свежая версия MySQL.
Выполнение запросов
По умолчанию, если вы не устанавливали дополнительные программы, у MySQL нет графического интерфейса пользователя. Это значит, что единственный способ работы с ней — это использование командной строки.
- Откройте командную строку (Выполнить —
cmd.exe). - Перейдите в каталог с установленной MySQL:
cd /d <каталог установки>/bin. - Выполните:
mysql -uroot -p. - Введите пароль, заданный при установке.
Если вы всё выполнили верно, то в командной строке запустится клиент для работы с MySQL (вы поймете это по строке приглашения «mysql>»). С этого момента можно вводить любые SQL запросы, но каждый запрос обязательно должен заканчиваться точкой с запятой ;.
Оператор SQL create database: создание новой базы данных>
Приступим к практике — начнём создавать базу данных для ведения погодного дневника.
Начать следует с создания новой базы данных для нашего сайта. Новая БД в MySQL создаётся простой командой:
CREATE DATABASE <имя базы данных>После этого MySQL создаст для нас новую БД, в которой будет происходить вся дальнейшая работа. Это важно: после создания БД её невозможно будет переименовать, а только удалить и создать заново. По этой причине крайне внимательно подойдите к выбору имени для базы данных.
create table
Зачем нужен: создание таблиц
Создав новую БД, сообщим MySQL, что теперь мы собираемся работать именно с ней. Выбор активной БД выполняется командой:
USE <имя базы>;Пришло время создать первые таблицы! Для ведения дневника по всем правилам, понадобится создать три таблицы: города (cities), пользователи (users) и записи о погоде weather_log. В подразделе «Запись» этой главы описано, как должна выглядеть структура таблицы weather_log. Переведём это описание на язык SQL:
CREATE TABLE weather_log (
id INT AUTO_INCREMENT PRIMARY KEY,
city_id INT,
day DATE,
temperature INT,
cloud TINYINT DEFAULT 0
);Чтобы ввести многострочную команду в командной строке используйте символ в конце каждой строки, кроме последней.
Теперь создадим таблицу городов:
CREATE TABLE cities (
id INT AUTO_INCREMENT PRIMARY KEY,
name CHAR(128)
)MySQL может показать созданную таблицу, если попросить об этом командой:
SHOW COLUMNS FROM weather_logВ ответе будут перечислены все поля таблицы, их тип и другие характеристики.
Что такое первичный ключ
В примере с созданием новой таблицы при перечислении необходимых полей первым полем идёт id INT AUTO_INCREMENT PRIMARY KEY. Это поле называется первичным ключом. Обязательно создавать первичный ключ в каждой таблице.
👉 Первичный ключ — это особенное поле, в котором сохраняется уникальный идентификатор записи.
Первичный ключ нужен, чтобы у программиста и базы данных всегда была возможность однозначно обратиться к одной конкретной записи для её чтения, обновления или удаления. Если назначить поле первичным ключом, то БД будет следить за тем, чтобы значение в этом поле больше не повторялось в таблице.
А если ещё и добавить аттрибут AUTO_INCREMENT, то MySQL при добавлении новых записей будет заполнять это поле сама. AUTO_INCREMENT будет играть роль счётчика — каждая новая запись в таблице получит значение на единицу больше максимального существующего значения.
insert into
Зачем нужен: добавление записи в таблицу
Начнём с добавления новых данных в таблицу. Для добавления записи используется следующий синтаксис:
insert into <название таблицы> set <имя столбца1> = <значение2>, <имя столбца2> = <значение2>...В начале добавим город в таблицу городов:
insert into cities set name = 'Санкт-Петербург'При добавлении записи необязательно указывать значения для всех полей. Многие из полей имеют значения по умолчанию, которые сами заполняются при сохранении.
Теперь создадим запись о погоде за сегодня.
При определении таблицы weatherlog мы решили ссылаться на город, путём записи в поле cityid идентификатора города из таблицы cities. Так как мы только что добавили новый город, ничего не мешает использовать его идентификатор в записи о погоде.
Идентификатором города будет первичный ключ, который также был определён в качестве первого поля таблицы. Нумерация этого поля начинается с единицы, значит первая добавленная запись имеет идентификатор 1. Зная это, запрос на добавление записи о погоде в Санкт-Петербурге за третье сентября 2017 года выглядит так:
INSERT INTO weather_log SET city_id = 1, day = '2017-09-03', temperature = 5, cloud = 1;select. Чтение информации из БД
Для вывода информации из БД используются запросы типа SELECT.
В запросе нужно указать имя таблицы, необходимые поля, а также дополнительные параметры (будут рассмотрены в следующем уроке).
SELECT <перечисление полей> FROM <имя таблицы>Например, чтобы получить список всех доступных городов:
SELECT id, name FROM citiesВсе погодные записи:
SELECT id, day, city_id, temperature, cloud FROM weather_logВместо перечисления всех столбцов можно использовать знак звездочки — *.
Оператор update: обновление информации в БД
При добавлении записи очень легко совершить ошибку: сделать опечатку, не указать значение для одного из полей, и так далее. Естественно, язык SQL предлагает возможности для редактирования уже созданных записей.
Предположим, что при добавлении погодной записи пользователь ошибся и ввёл неверную дату. Чтобы исправить эту ошибку, нужно использовать оператор обновления — UPDATE. Запрос с этим оператором позволяет обновить значение одного или нескольких полей в существующей записи. Выглядит он так:
UPDATE <имя таблицы> SET <имя столбца1> = <значение2>, <имя столбца2> = <значение2>... WHERE <имя столбца> = <значение>Но чтобы правильно составить запрос, необходимо определить условие для поиска записи, которую предлагается обновить. В противном случае, если не указать это условие, то будут обновлены абсолютно все записи в таблице.
В качестве такого условия лучше всего использовать первичный идентификатор записи. Поэтому, прежде чем выполнять запрос обновления, нужно выполнить запрос на чтение информации из таблицы, чтобы узнать, под каким идентификатором сохранилась ошибочная запись. Допустим, этот идентификатор — единица, а правильная дата — седьмое декабря 2022 года.
Запрос на обновление:
UPDATE weather_log SET day = '2022-12-07' WHERE id = 1Оператор join: объединение записей из двух таблиц
В нашей таблице для хранения погодного дневника город сохраняется как идентификатор, поэтому при обычном чтении данных из этой таблицы вместо названия города стоит непонятное число. Чтобы подставить на место числа действительное значение, а конкретнее — название города, в SQL существуют операторы объединения — JOIN. Поддержка операторов объединения и позволяет базе данных называться реляционной.
Поменяем запрос на показ погодных записей, чтобы он объединял две таблицы, а в поле города показывалось его название, а не идентификатор:
SELECT day, cities.name, temperature, cloud FROM weather_log JOIN cities ON weather_log.city_id = cities.idВажно усвоить три самых главных момента:
- При чтении из объединённых таблиц, в перечислении полей после SELECT нужно явно указывать в поле имени также имя таблицы, с которой производится объединение.
- Всегда есть основная таблица (тб1), из которой читается большинство полей, и присоединяемая (тб2), имя которой определяется после оператора JOIN.
- Помимо указания имени второй таблицы, обязательно следует указать условие, по которому будет происходить объединение. В этом примере таким условием будет соответствие идентификатора города из тб1 (
weather_log.city_id) первичному ключу города из тб2 (cities.id).
Добро пожаловать на первый урок по реляционным базам данных и языку SQL.
Реляционные базы данных представляют собой набор таблиц с информацией.
Вроде такой:
| id | name | count | price |
|---|---|---|---|
| 1 | Телевизор | 3 | 43200.00 |
| 2 | Микроволновая печь | 4 | 3200.00 |
| 3 | Холодильник | 3 | 12000.00 |
| 4 | Роутер | 1 | 1340.00 |
| 5 | Компьютер | 0 | 26150.00 |
Или такой:
| id | first_name | last_name | birthday | age |
|---|---|---|---|---|
| 1 | Дмитрий | Иванов | 1996-12-11 | 20 |
| 2 | Олег | Лебедев | 2000-02-07 | 17 |
| 3 | Тимур | Шевченко | 1998-04-27 | 19 |
| 4 | Светлана | Иванова | 1993-08-06 | 23 |
| 5 | Олег | Ковалев | 2002-02-08 | 15 |
| 6 | Алексей | Иванов | 1993-08-05 | 23 |
| 7 | Алена | Процук | 1997-02-28 | 18 |
Каждая таблица состоит из столбцов и строк.
Посмотрим внимательней на таблицу products, которая хранит данные о товарах в интернет-магазине. Таблица содержит 4 столбца: id, name, count и price. Каждый из столбцов отвечает за какой-то определенный тип информации: id — это уникальный номер товара, name — его имя, count — количество, price — цена.
Строка отвечает за конкретный товар в таблице. Если мы посмотрим на третью строку, то найдем там «Холодильник» с ценой 12 000 рублей в количестве 3 штук.
Другая таблица — это users, которая хранит данные о пользователях в системе. В таблице 5 столбцов: также уникальный номер пользователя id, имя, фамилия, возраст — age и дата рождения — birthday.
Как я уже говорил, каждый столбец отвечает за какую-то информацию и эта информация относится к определенному типу данных. Столбцы first_name и last_name строковые, age и id содержат числа, а birthday — дату.
Название столбца, его тип и порядок строго задаются на этапе создания таблицы. Об этом мы поговорим в других уроках.
А вот записи таблицы (или строки) заполняются в процессе её использования. Поэтому столбцов у нас жестко 5. А строк может быть сколько угодно. Зарегистрировался пользователь на сайте — добавили строку. Привезли новые товары в магазин — таблица растет.
Добавление, удаление, изменение или получение данных из таблиц, выполняется с помощью языка SQL.
- SQL
- — это язык общения с базами данных.
Давайте попробуем получить информацию из таблицы users. Для этого надо написать и выполнить такой SQL-запрос:
SELECT * FROM usersПолучили всех пользователей из таблицы users:
| id | first_name | last_name | birthday | age |
|---|---|---|---|---|
| 1 | Дмитрий | Иванов | 1996-12-11 | 20 |
| 2 | Олег | Лебедев | 2000-02-07 | 17 |
| 3 | Тимур | Шевченко | 1998-04-27 | 19 |
| 4 | Светлана | Иванова | 1993-08-06 | 23 |
| 5 | Олег | Ковалев | 2002-02-08 | 15 |
| 6 | Алексей | Иванов | 1993-08-05 | 23 |
| 7 | Алена | Процук | 1997-02-28 | 18 |
Рассмотрим SQL запрос подробнее.
Оператор SELECT говорит, что мы будем извлекать данные. После него идет список столцов, которые мы хотим получить. Если указать звездочку (*), как у нас, то получим все столбцы в том порядке, в котором они определены в таблице: id, first_name, last_name и тд. Далее идет конструкция FROM users, которая буквально означает ИЗ users.
То есть вся SQL конструкция читается как ВЫБРАТЬ все столбцы ИЗ таблицы users.
Теперь вместо звездочки напишем: last_name, first_name, birthday, чтобы у нас получился такой SQL-запрос:
SELECT last_name, first_name, birthday FROM usersЕсли его выполнить, то мы снова получим всех пользователей из таблицы users, но на этот раз только фамилию, имя и дату рождения. То есть записи все, а столбцы нет:
| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 2 | Лебедев | Олег | 2000-02-07 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 5 | Ковалев | Олег | 2002-02-08 |
| 6 | Иванов | Алексей | 1993-08-05 |
| 7 | Процук | Алена | 1997-02-28 |
Кроме того, что мы получили не все столбцы, мы дополнительно изменили их порядок на тот, который нам удобен. В оригинальной таблице first_name стоит перед last_name, а у нас наоборот.
Еще обратите внимание, что результатом работы SQL запроса является таблица. То есть мы берем исходную таблицу, которая хранится в базе, и с помощью SQL запроса получаем другую таблицу — с теми данными, которые нам нужны.
И часто требуется получить не все данные, а только те, которые соответствуют какому-то условию. Давайте снова изменим наш SQL-запрос, чтобы он стал таким:
SELECT last_name, first_name, birthday FROM users WHERE age > 18Если его выполнить, то мы получим список пользователей которым уже исполнилось 19 лет:
| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 6 | Иванов | Алексей | 1993-08-05 |
Конструкция WHERE позволяет фильтровать исходные данные в соответствии с нашими условиями. В данном случае мы получаем данные из таблицы users ГДЕ (WHERE) в столбце age значение больше 18.
Так как age — это числовой столбец, то его уместно сравнивать с числами. Если заменить знак больше на равно и снова запустить, то получим всех 18 летних пользователей. А если поставим >= , то получим совершеннолетних пользователей:
SELECT last_name, first_name, birthday FROM users WHERE age >= 18| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 4 | Иванова | Светлана | 1993-08-06 |
| 6 | Иванов | Алексей | 1993-08-05 |
| 7 | Процук | Алена | 1997-02-28 |
Как видите SQL запросы довольно просто составлять и читать. Язык создавался для того, чтобы им могли пользоваться люди, которые не умеют программировать.
А теперь самое время потренироваться в SQL, для этого к каждому уроку привязано несколько задач, которые вы можете решать в специальном тренажере прямо на сайте.
Следующий урок
Урок 2. Составные условия
В этом уроке вы узнаете как формировать сложные условия в SQL-запросах с использованием операторов AND и OR.
Посмотреть
Тарифы
-
-
55 видео-уроков
Более 7 часов видео
-
Дополнительные материалы
Схемы, методички, исходные коды
-
Возможность скачать видео
Смотреть уроки можно даже без интернета
-
Доступ к курсу навсегда
Можете освежить знания через год или два
-
271 практическое задание
Практические занятия на тренажере
-
Поддержка преподавателя
Помощь в решении заданий в течение 24 часов
-
Сертификат о прохождении курса
Подтверждение ваших навыков
-
Эталонные решения
Решения преподавателя
-
-
-
55 видео-уроков
Более 7 часов видео
-
Дополнительные материалы
Схемы, методички, исходные коды
-
Возможность скачать видео
Смотреть уроки можно даже без интернета
-
Доступ к курсу навсегда
Условия бесплатного тарифа могут измениться
-
271 практическое задание
Практические занятия на тренажере
-
Поддержка преподавателя
Помощь в решении заданий в течение 24 часов
-
Сертификат о прохождении курса
Подтверждение ваших навыков
-
Эталонные решения
Решения преподавателя
-
Регистрация
Основы SQL
Structured Query Language (SQL) — язык структурированных запросов, с помощью него пишутся специальные запросы (SQL инструкции) к базе данных с целью получения этих данных из базы и для манипулирования этими данными.
С точки зрения реализации язык SQL представляет собой набор операторов, которые делятся на определенные группы и у каждой группы есть свое назначение. В сокращенном виде эти группы называются DDL, DML, DCL и TCL.
DDL – Data Definition Language
Data Definition Language (DDL) – это группа операторов определения данных. Другими словами, с помощью операторов, входящих в эту группы, мы определяем структуру базы данных и работаем с объектами этой базы, т.е. создаем, изменяем и удаляем их.
В эту группу входят следующие операторы:
- CREATE – используется для создания объектов базы данных;
- ALTER – используется для изменения объектов базы данных;
- DROP – используется для удаления объектов базы данных.
DML – Data Manipulation Language
Data Manipulation Language (DML) – это группа операторов для манипуляции данными. С помощью этих операторов мы можем добавлять, изменять, удалять и выгружать данные из базы, т.е. манипулировать ими.
В эту группу входят самые распространённые операторы языка SQL:
- SELECT – осуществляет выборку данных;
- INSERT – добавляет новые данные;
- UPDATE – изменяет существующие данные;
- DELETE – удаляет данные.
DCL – Data Control Language
Data Control Language (DCL) – группа операторов определения доступа к данным. Иными словами, это операторы для управления разрешениями, с помощью них мы можем разрешать или запрещать выполнение определенных операций над объектами базы данных.
TCL – Transaction Control Language
Transaction Control Language (TCL) – группа операторов для управления транзакциями. Транзакция – это команда или блок команд (инструкций), которые успешно завершаются как единое целое, при этом в базе данных все внесенные изменения фиксируются на постоянной основе или отменяются, т.е. все изменения, внесенные любой командой, входящей в транзакцию, будут отменены.
Базовый синтаксис SQL команды SELECT
Одна из основных функций SQL — получение данных из СУБД. Для построения всевозможных запросов к базе данных используется оператор SELECT. Он позволяет выполнять сложные проверки и обработку данных.
Общая структура запроса
SELECT [DISTINCT | ALL] поля_таблиц [FROM список_таблиц] [WHERE условия_на_ограничения_строк] [GROUP BY условия_группировки] [HAVING условия_на_ограничения_строк_после_группировки] [ORDER BY порядок_сортировки [ASC | DESC]] [LIMIT ограничение_количества_записей]
В описанной структуре запроса необязательные параметры указаны в квадратных скобках.
Параметры оператора
- DISTINCT используется для исключения повторяющихся строк из результата
- ALL (по умолчанию) используется для получения всех данных, в том числе и повторений
- FROM перечисляет используемые в запросе таблицы из базы данных
- WHERE — это условный оператор, который используется для ограничения строк по какому-либо условию
- GROUP BY используется для группировки строк
- HAVING применяется после группировки строк для фильтрации по значениям агрегатных функций
- ORDER BY используется для сортировки. У него есть два параметра:
- ASC (по умолчанию) используется для сортировки по возрастанию
- DESC — по убыванию
- LIMIT используется для ограничения количества строк для вывода
SQL-псевдонимы
Псевдонимы используются для представления столбцов или таблиц с именем отличным от оригинального. Это может быть полезно для улучшения читабельности имён и создания более короткого наименования столбца или таблицы.
Например, если в вашей таблице есть столбец good_type_id, вы можете переименовать его просто в id, для того, чтобы сделать его более коротким и удобным в использовании в будущем.
Для создания псевдонимов используется оператор AS:
SELECT good_type_id AS id FROM GoodTypes;
Примеры использования
Вы можете выводить любые строки и числа вместо столбцов:
Для того, чтобы вывести все данные из таблицы Company, вы можете использовать символ «*», который буквально означает «все столбцы»:
Вы можете вывести любой столбец, определённый в таблице, например, town_to из таблицы Trip:
SELECT town_to FROM Trip;
Также вы можете вывести несколько столбцов. Для этого их нужно перечислить через запятую:
SELECT member_name, status FROM FamilyMembers;
Иногда возникают ситуации, в которых нужно получить только уникальные записи. Для этого вы можете использовать DISTINCT. Например, выведем список городов без повторений, в которые летали самолеты:
SELECT DISTINCT town_to FROM Trip;
Эта конструкция используется для формирования словарей, примеры рассмотрим в главе про команду INSERT
Условный оператор WHERE
Ситуация, когда требуется сделать выборку по определенному условию, встречается очень часто. Для этого в операторе SELECT существует параметр WHERE, после которого следует условие для ограничения строк. Если запись удовлетворяет этому условию, то попадает в результат, иначе отбрасывается.
Общая структура запроса с оператором WHERE
SELECT поля_таблиц FROM список_таблиц WHERE условия_на_ограничения_строк [логический_оператор другое_условия_на_ограничения_строк];
В описанной структуре запроса необязательные параметры указаны в квадратных скобках.
В условном операторе применяются операторы сравнения, специальные и логические операторы.
Операторы сравнения
Операторы сравнения служат для сравнения 2 выражений, их результатом может являться ИСТИНА (1), ЛОЖЬ (0) и NULL.
Результат сравнения с NULL является NULL. Исключением является оператор эквивалентности.
| Оператор | Описание |
|---|---|
| = | Оператор равенство |
| <=> | Оператор эквивалентность Аналогичный оператору равенства, с одним лишь исключением: в отличие от него, оператор эквивалентности вернет ИСТИНУ при сравнении NULL <=> NULL |
| <> или != |
Оператор неравенство |
| < | Оператор меньше |
| <= | Оператор меньше или равно |
| > | Оператор больше |
| >= | Оператор больше или равно |
Специальные операторы
-
IS [NOT] NULL— позволяет узнать равно ли проверяемое значение NULL.Для примера выведем всех членов семьи, у которых статус в семье не равен NULL:
SELECT * FROM FamilyMembers WHERE status IS NOT NULL;
-
[NOT] BETWEEN min AND max— позволяет узнать расположено ли проверяемое значение столбца в интервале между min и max.Выведем все данные о покупках с ценой от 100 до 500 рублей из таблицы Payments:
SELECT * FROM Payments WHERE unit_price BETWEEN 100 AND 500;
-
[NOT] IN— позволяет узнать входит ли проверяемое значение столбца в список определённых значений.Выведем имена членов семьи, чей статус равен «father» или «mother»:
SELECT member_name FROM FamilyMembers WHERE status IN ('father', 'mother');
-
[NOT] LIKE шаблон [ESCAPE символ]— позволяет узнать соответствует ли строка определённому шаблону.Например, выведем всех людей с фамилией «Quincey»:
SELECT member_name FROM FamilyMembers WHERE member_name LIKE '% Quincey';
Трафаретные символы
В шаблоне разрешается использовать два трафаретных символа:
- символ подчеркивания (_), который можно применять вместо любого единичного символа в проверяемом значении
- символ процента (%) заменяет последовательность любых символов (число символов в последовательности может быть от 0 и более) в проверяемом значении.
| Шаблон | Описание |
|---|---|
| never% | Сопоставляется любым строкам, начинающимся на «never». |
| %ing | Сопоставляется любым строкам, заканчивающимся на «ing». |
| _ing | Сопоставляется строкам, имеющим длину 4 символа, при этом 3 последних обязательно должны быть «ing». Например, слова «sing» и «wing». |
ESCAPE-символ
ESCAPE-символ используется для экранирования трафаретных символов. В случае если вам нужно найти строки, содержащие проценты (а процент — это зарезервированный символ), вы можете использовать ESCAPE-символ.
Например, вы хотите получить идентификаторы задач, прогресс которых равен 3%:
SELECT job_id FROM Jobs WHERE progress LIKE '3!%' ESCAPE '!';
Если бы мы не экранировали трафаретный символ, то в выборку попало бы всё, что начинается на 3.
Логические операторы
Логические операторы необходимы для связывания нескольких условий ограничения строк.
- Оператор NOT — меняет значение специального оператора на противоположный
- Оператор OR — общее значение выражения истинно, если хотя бы одно из них истинно
- Оператор AND — общее значение выражения истинно, если они оба истинны
- Оператор XOR — общее значение выражения истинно, если один и только один аргумент является истинным
Выведем все полёты, которые были совершены на самолёте «Boeing», но, при этом, вылет был не из Лондона:
SELECT * FROM Trip WHERE plane = 'Boeing' AND NOT town_from = 'London';
Выборка сводных данных (из двух и более таблиц)
При формировании сводной выборки данные беруться из нескольких таблиц. В операторе FROM исходные таблицы перечисляются через запятую. Также им могут быть присвоены алиасы. Синтаксис запроса выглядит следующийм образом:
SELECT [ALIAS | TABLE].Название_поля1, [ALIAS | TABLE].Название_поля2,... FROM Table1 [ALIAS], Table2 [ALIAS] ...
При выборке сводных таблиц нужно учитывать, что исходные таблицы перемножаются. Т.е. если на входе у нас были таблицы:
| id | Name |
|---|---|
| 1 | Иванов |
| 2 | Петров |
| id | Name | Phone |
|---|---|---|
| 1 | Иванов | 322223 |
| 2 | Петров | 111111 |
То при простом запросе без условий
SELECT a.*, b.* FROM Table1 a, Table2 b
Получим примерно следующее:
| id | Name | id2 | Name2 | Phone |
|---|---|---|---|---|
| 1 | Иванов | 1 | Иванов | 322223 |
| 1 | Иванов | 2 | Петров | 111111 |
| 2 | Петров | 1 | Иванов | 322223 |
| 2 | Петров | 2 | Петров | 111111 |
Чтобы выбрать уникальные значения, нам нужно использовать оператор WHERE для связи этих таблиц
SELECT a.*, b.Phone FROM Table1 a, Table2 b WHERE a.Name=b.Name
| id | Name | Phone |
|---|---|---|
| 1 | Иванов | 322223 |
| 2 | Петров | 111111 |
Сводные выборки нужны при импорте данных в базу. Сначала вы выделяете из таблиц импорта словари. А потом из таблиц импорта и словарей формируете запрос INSERT ... SELECT для записи данных в основную таблицу.
Вложенные SQL запросы
Вложенный запрос — это запрос на выборку, который используется внутри инструкции SELECT, INSERT, UPDATE или DELETE или внутри другого вложенного запроса. Подзапрос может быть использован везде, где разрешены выражения.
Пример структуры вложенного запроса
SELECT поля_таблиц FROM список_таблиц WHERE конкретное_поле IN ( SELECT поле_таблицы FROM таблица )
Здесь, SELECT поля_таблиц FROM список_таблиц WHERE конкретное_поле IN (...) — внешний запрос, а SELECT поле_таблицы FROM таблица — вложенный (внутренний) запрос.
Каждый вложенный запрос, в свою очередь, может содержать один или несколько вложенных запросов. Количество вложенных запросов в инструкции не ограничено.
Подзапрос может содержать все стандартные инструкции, разрешённые для использования в обычном SQL-запросе: DISTINCT, GROUP BY, LIMIT, ORDER BY, объединения таблиц, запросов и т.д.
Подзапрос может возвращать скаляр (одно значение), одну строку, один столбец или таблицу (одну или несколько строк из одного или нескольких столбцов). Они называются скалярными, столбцовыми, строковыми и табличными подзапросами.
Подзапрос как скалярный операнд
Скалярный подзапрос — запрос, возвращающий единственное скалярное значение (строку, число и т.д.).
Следующий простейший запрос демонстрирует вывод единственного значения (названия компании). В таком виде он не имеет большого смысла, однако ваши запросы могут быть намного сложнее.
SELECT ( SELECT name FROM company LIMIT 1 );
Таким же образом можно использовать скалярные подзапросы для фильтрации строк с помощью WHERE, используя операторы сравнения.
SELECT * FROM FamilyMembers WHERE birthday = ( SELECT MAX(birthday) FROM FamilyMembers );
С помощью данного запроса возможно получить самого младшего члена семьи. Здесь используется подзапрос для получения максимальной даты рождения, которая затем используется для фильтрации строк.
Подзапросы с ANY, IN, ALL
ANY — ключевое слово, которое должно следовать за операцией сравнения (>, <, <>, = и т.д.), возвращающее TRUE, если хотя бы одно из значений столбца подзапроса удовлетворяет обозначенному условию.
SELECT поля_таблицы_1 FROM таблица_1 WHERE поле_таблицы_1 <= ANY (SELECT поле_таблицы_2 FROM таблица_2);
ALL — ключевое слово, которое должно следовать за операцией сравнения, возвращающее TRUE, если все значения столбца подзапроса удовлетворяет обозначенному условию.
SELECT поля_таблицы_1 FROM таблица_1 WHERE поле_таблицы_1 > ALL (SELECT поле_таблицы_2 FROM таблица_2);
IN — ключевое слово, являющееся псевдонимом ключевому слову ANY с оператором сравнения = (эквивалентность), либо <> ALL для NOT IN. Например, следующие запросы равнозначны:
... WHERE поле_таблицы_1 = ANY (SELECT поле_таблицы_2 FROM таблица_2);
... WHERE поле_таблицы_1 IN (SELECT поле_таблицы_2 FROM таблица_2);
Строковые подзапросы
Строковый подзапрос — это подзапрос, возвращающий единственную строку с более чем одной колонкой. Например, следующий запрос получает в подзапросе единственную строку, после чего по порядку попарно сравнивает полученные значения со значениями во внешнем запросе.
SELECT поля_таблицы_1 FROM таблица_1 WHERE (первое_поле_таблицы_1, второе_поле_таблицы_1) = ( SELECT первое_поле_таблицы_2, второе_поле_таблицы_2 FROM таблица_2 WHERE id = 10 );
Данную конструкцию удобно использовать для замены логических операторов. Так, следующие два запроса полностью эквивалентны:
SELECT поля_таблицы_1 FROM таблица_1 WHERE (первое_поле_таблицы_1, второе_поле_таблицы_1) = (1, 1); SELECT поля_таблицы_1 FROM таблица_1 WHERE первое_поле_таблицы_1 = 1 AND второе_поле_таблицы_1 = 1;
Связанные подзапросы
Связанным подзапросом является подзапрос, который содержит ссылку на таблицу, которая была объявлена во внешнем запросе. Здесь вложенный запрос ссылается на внешюю таблицу «таблица_1»:
SELECT поля_таблицы_1 FROM таблица_1 WHERE поле_таблицы_1 IN ( SELECT поле_таблицы_2 FROM таблица_2 WHERE таблица_2.поле_таблицы_2 = таблица_1.поле_таблицы_1 );
Подзапросы как производные таблицы
Производная таблица — выражение, которое генерирует временную таблицу в предложении FROM, которая работает так же, как и обычные таблицы, которые вы указываете через запятую. Так выглядит общий синтаксис запроса с использованием производных таблиц:
SELECT поля_таблицы_1 FROM (подзапрос) [AS] псевдоним_производной_таблицы
Обратите внимание на то, что для производной таблицы обязательно должен указываться её псевдоним, для того, чтобы имелась возможность обратиться к ней в других частях запроса.
Обработка вложенных запросов
Вложенные подзапросы обрабатываются «снизу вверх». То есть сначала обрабатывается вложенный запрос самого нижнего уровня. Далее значения, полученные по результату его выполнения, передаются и используются при реализации подзапроса более высокого уровня и т.д.
Добавление данных, оператор INSERT
Для добавления новых записей в таблицу предназначен оператор INSERT.
Общая структура запроса с оператором INSERT
INSERT INTO имя_таблицы [(поле_таблицы, ...)] VALUES (значение_поля_таблицы, ...) | SELECT поле_таблицы, ... FROM имя_таблицы ...
В описанной структуре запроса необязательные параметры указаны в квадратных скобках. Вертикальной чертой обозначен альтернативный синтаксис.
Значения можно вставлять перечислением с помощью слова values, перечислив их в круглых скобках через запятую или c помощью оператора select. Таким образом, добавить новые записей можно следующими способами:
INSERT INTO Goods (good_id, good_name, type) VALUES (5, 'Table', 2);
INSERT INTO Goods VALUES (5, 'Table', 2);
INSERT INTO Goods SELECT good_id, good_name, type FROM Goods where good_name = 2;
Первичный ключ при добавлении новой записи
Следует помнить, что первичный ключ таблицы является уникальным значением и добавление уже существующего значения приведет к ошибке.
При добавлении новой записи с уникальными индексами выбор такого уникального значения может оказаться непростой задачей. Решением может быть дополнительный запрос, направленный на выявление максимального значения первичного ключа для генерации нового уникального значения.
INSERT INTO Goods SELECT COUNT(*) + 1, 'Table', 2 FROM Goods;
В SQL введен механизм его автоматической генерации. Для этого достаточно снабдить первичный ключ good_id атрибутом AUTO_INCREMENT. Тогда при создании новой записи в качестве значения good_id достаточно передать NULL или 0 — поле автоматически получит значение, равное максимальному значению столбца good_id, плюс единица.
CREATE TABLE Goods ( good_id INT NOT NULL AUTO_INCREMENT ... );
INSERT INTO Goods VALUES (NULL, 'Table', 2);
Пример
Теперь, зная синткасис команд INSERT и SELECT, можем разобраться как создать из исходного набора данных словари и загрузить данные в БД с учетом внешних ключей
Допустим есть список агентов (данные полученные от заказчика в виде CSV-файла), у которых есть поля название, тип и т.д. (далее по тексту я её называю таблица импорта)

В структуре БД поле «тип агента» создано как внешний ключ на таблицу типов


Заполнение словарей
Для добавления «типов агентов» в таблицу AgentType мы будем использовать альтернативный синтаксис INSERT ... SELECT
-
Пишем инструкцию SELECT, которая выбирает уникальные записи из таблицы импорта:
SELECT DISTINCT Тип_агента FROM agents_import
- Ключевое слово DISTINCT относится только к топу полю, перед которым написано. В нашем случае выбирает уникальные названия типов агентов.
- Откуда брать поле Image в предметной области не написано и в исходных данных его нет. Но т.к. в целевой таблице это поле не обязательное, то можно его пропустить
Этот запрос можно выполнить отдельно, чтобы проверить что получится
-
После отладки запроса SELECT перед ним допишем запрос INSERT:
INSERT INTO AgentType (Title) SELECT DISTINCT Тип_агента FROM agents_import
- Поле ID можно пропустить, оно автоинкрементное и создастся само (по крайней мере в MsSQL)
- Количество вставляемых полей (Title) должно быть равным количеству выбираемых полей (Тип_агента)
Если в таблице есть обязательные поля, а нем неоткуда взять для них данные, то мы можем в SELECT вставить фиксированные значения (в примере пустая строка):
```sql INSERT INTO AgentType (Title, Image) SELECT DISTINCT Тип_агента, '' -- ^^ FROM agents_import ```
Заполнение основной таблицы
-
Тоже сначала пишем SELECT запрос, чтобы проверить те ли данные получаются
-
напоминаю, что порядок и количество выбираемых и вставляемых полей должны быть одинаковыми
-
в поле AgentTypeID мы должны вставить ID соответсвующей записи из таблицы AgentType, поэтому выборка у нас из двух таблиц и чтобы не писать перед каждым полем полные названия таблиц мы присваиваем им алиасы
SELECT asi.Наименование_агента, att.ID, asi.Юридический_адрес, asi.ИНН, asi.КПП, asi.Директор, asi.Телефон_агента, asi.Электронная_почта_агента, asi.Логотип_агента, asi.Приоритет FROM agents_import asi, AgentType att WHERE asi.Тип_агента=att.Title
Т.е. мы выбираем перечисленные поля из таблицы agents_import и добавляем к ним ID агента у которого совпадает название.
При выборке из нескольких таблиц исходные данные перемножаются. Т.е. если мы не заполним перед этой выборкой словарь, то
100 * 0 = пустая выборка.Если же мы не укажем условие WHERE, то выберутся, к примеру,
100 * 10 = 1000записей (каждый агент будет в каждой категории). Поэтому важно, чтобы условие WHERE выбирало уникальные значения.Естественно, количество внешних ключей в таблице может быть больше одного, в таком случае в секции FROM перечисляем все используемые словари и в секции WHERE перечисляем условия для всех таблиц объединив их логическим выражением AND
```sql ... WHERE a.Name=b.Name AND a.Title=c.Title AND a.Price=d.Price ... ```где алиасы b, c, d — словарные таблицы, а алиас «а» — таблица импорта
-
-
Написав и проверив работу выборки (она должна возвращать чтолько же записей, сколько в таблице импорта) дописываем команду вставки данных:
INSERT INTO Agent (Title, AgentTypeID, Address, INN, KPP, DirectorName, Phone, Email, Logo, Priority) SELECT asi.Наименование_агента, att.ID, asi.Юридический_адрес, asi.ИНН, asi.КПП, asi.Директор, asi.Телефон_агента, asi.Электронная_почта_агента, asi.Логотип_агента, asi.Приоритет FROM agents_import asi, AgentType att WHERE asi.Тип_агента=att.Title
Практическое задание
В каталоге data этого репозитория находится структура БД (ms.sql) и файлы для импорта: products_k_import.csv, materials_short_k_import.txt, productmaterial_k_import.xlsx.
Необходимо во-первых, восстановить структуру БД из скрипта, во-вторых, импортировать исходные данные в Excel, в-третьих исправить данные (смотрите на структуру таблиц в БД, где-то надо явно указать тип данных, где-то вырезать лишние данные…) и в-четвёртых загрузить исправленные данные в БД (сначала просто импорт во временные таблицы, потом разнести SQL-запросами по нужным таблицам)
В этой статье мы рассмотрим некоторые базовые запросы SQL, с изучения которых стоит начинать новичкам в этом языке. Вы научитесь создавать базу данных и таблицы, вносить в них данные и делать выборки нужных сведений.

Аббревиатура SQL расшифровывается как «Structured Query Language» — язык структурированных запросов. С помощью этого языка вы можете работать с записями в базах данных.
SQL состоит из команд и декларативных ключевых слов, которые являются как бы инструкциями для базы данных.
При помощи команд SQL можно создавать и удалять таблицы в базах данных, добавлять в них данные или вносить изменения, искать и быстро находить нужные сведения.
В этой статье мы рассмотрим основные ключевые слова и операторы SQL и разберем, как с их помощью запрашивать конкретную информацию из базы данных.
Структура базы данных
Прежде чем мы начнем разбирать запросы, нужно, чтобы вы поняли иерархию базы данных.
База данных SQL — это набор взаимосвязанных сведений, хранящихся в таблицах. В каждой таблице есть столбцы, описывающие хранящиеся в них данные, и строки, в которых эти данные хранятся. Поле — это отдельный кусочек данных в строке. Чтобы найти нужные данные, мы должны написать, что именно мы хотим получить.
Возьмем для примера некую компанию, штат которой разбросан по всему миру. Допустим, у этой компании есть много баз данных. Чтобы увидеть их полный список, нужно набрать SHOW DATABASES;
Результат может выглядеть как-то так:
+--------------------+ | Databases | +--------------------+ | mysql | | information_schema | | employees | | test | | sys | +--------------------+
В каждой отдельной базе данных может быть много таблиц. Чтобы увидеть, какие таблицы есть в базе данных employees из нашего примера, нужно набрать SHOW TABLES in employees;. В таблицах могут содержаться данные по разным командам, что отражается в названиях: engineering, product, marketing, sales.
+----------------------+ | Tables_in_employees | +----------------------+ | engineering | | product | | marketing | | sales | +----------------------+
Все таблицы состоят из различных столбцов, описывающих данные.
Чтобы просмотреть столбцы таблицы Engineering, используйте Describe Engineering;. Каждый столбец этой таблицы может описывать какой-то один атрибут сотрудника, например: employee_id, first_name, last_name, email, country и salary.
Вывод:
+-----------+-------------------+--------------+ | Name | Null | Type | +-----------+-------------------+--------------+ |EMPLOYEE_ID| NOT NULL | INT(6) | |FIRST_NAME | NOT NULL |VARCHAR2(20) | |LAST_NAME | NOT NULL |VARCHAR2(25) | |EMAIL | NOT NULL |VARCHAR2(255) | |COUNTRY | NOT NULL |VARCHAR2(30) | |SALARY | NOT NULL |DECIMAL(10,2) | +-----------+-------------------+--------------+
Таблицы также состоят из строк — отдельных записей. В нашем примере в строках будут указаны id, имена, фамилии, email, зарплата и страны проживания сотрудников. Каждая строка будет касаться одного сотрудника, допустим, из команды Engineering.
Базовые запросы SQL
Все операции, которые можно осуществлять с данными, входят в понятие «CRUD».
CRUD расшифровывается как Create, Read, Update и Delete (создать, прочесть, обновить, удалить). Это четыре основных операции, которые мы осуществляем, делая запросы к базе данных.
Мы создаем информацию в базе (CREATE), мы читаем, получаем информацию из базы (READ), мы обновляем данные или осуществляем какие-то манипуляции с ними (UPDATE) и, при желании, можем удалять данные (DELETE).
Для осуществления различных операций с данными в SQL есть специальные ключевые слова (операторы). Ниже мы рассмотрим некоторые простые запросы SQL и их синтаксис.
Ключевые слова в SQL
CREATE DATABASE
Для создания базы данных с именем engineering мы используем следующий код:
CREATE DATABASE engineering;
CREATE TABLE
Синтаксис:
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype
);
Этот запрос создает новую таблицу в базе данных.
В нем задается имя таблицы, а также имена столбцов, которые нам нужны.
Что касается типов данных (datatype), они могут быть разными. Самые распространенные — INT, DECIMAL, DATETIME, VARCHAR, NVARCHAR, FLOAT и BIT.
В нашем примере запрос может быть таким:
CREATE TABLE engineering ( employee_id int(6) NOT NULL, first_name varchar(20) NOT NULL, last_name varchar(25) NOT NULL, email varchar(255) NOT NULL, country varchar(30), salary decimal(10,2) NOT NULL );
Таблица, созданная по этому запросу, будет выглядеть так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| |
ALTER TABLE
После создания таблицы мы можем изменять ее путем добавления столбцов.
Синтаксис:
ALTER TABLE table_name ADD column_name datatype;
Допустим, мы хотим добавить в только что созданную таблицу столбец с днями рождения сотрудников. Это можно сделать так:
ALTER TABLE engineering ADD birthday date;
Теперь таблица выглядит немного иначе:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | BIRTHDAY | |
| |
INSERT
Это ключевое слово служит для вставки данных в таблицы и создания новых строк. В аббревиатуре CRUD это соответствует букве C.
Синтаксис:
INSERT INTO table_name(column1, column2, column3,..) VALUES(value1, 'value2', value3,..);
Этот запрос создает новую запись в таблице, т. е. новую строку.
В части INSERT INTO мы указываем столбцы, которые хотим заполнить информацией. В VALUES указана информация, которую нужно сохранить.
При вставке строковых значений их нужно брать в одинарные кавычки.
Например:
INSERT INTO table_name(employee_id,first_name,last_name,email,country,salary) VALUES (1,'Timmy','Jones','timmy@gmail.com','USA',2500.00); (2,'Kelly','Smith','ksmith@gmail.com','UK',1300.00);
Теперь таблица будет выглядеть так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
SELECT
Это ключевое слово служит для выборки данных из базы. В CRUD эта операция соответствует букве R.
Синтаксис:
SELECT column1,column2 FROM table_name;
В нашем примере этот запрос будет выглядеть следующим образом:
SELECT first_name,last_name FROM engineering;
Результат:
+-----------+----------+ |FirstName | LastName | +-----------+----------+ | Timmy | Jones | | Kelly | Smith | +-----------+----------+
Ключевое слово SELECT указывает на конкретный столбец, из которого мы хотим выбрать данные.
В части FROM определяется сама таблица.
Вот еще один пример запроса SELECT:
SELECT * FROM table_name;
Астериск (звездочка) означает, что нам нужна вся информация из указанной таблицы (а не отдельный столбец).
WHERE
WHERE позволяет составлять более специфичные (конкретные) запросы.
Например, мы можем использовать WHERE, чтобы выбрать из нашей таблицы Engineering сотрудников с определенным уровнем зарплаты.
SELECT employee_id,first_name,last_name,email,country FROM engineering WHERE salary > 1500
Таблица из предыдущего примера:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
Теперь вывод будет такой:
+-----------+----------+----------+----------------+------------+ |employee_id|first_name|last_name |email |country | +-----------+----------+----------+----------------+------------+ | 1| Timmy |Jones |timmy@gmail.com | USA | +-----------+----------+----------+----------------+------------+
Данные отфильтрованы, и нам показывается только то, что отвечает условию. То есть в выводе мы получаем только строки, где зарплата больше 1500.
Операторы AND, OR, BETWEEN в SQL
Эти операторы позволяют еще больше уточнить запрос. С их помощью можно добавить больше критериев в блоке WHERE.
Оператор AND принимает два условия, причем, чтобы строка попала в результат, оба условия должны быть истинными.
SELECT column_name
FROM table_name
WHERE column1 =value1
AND column2 = value2;
OR тоже принимает два условия, но чтобы строка попала в результат, достаточно истинности хотя бы одного.
SELECT column_name
FROM table_name
WHERE column_name = value1
OR column_name = value2;
Оператор BETWEEN отфильтровывает результаты в определенном диапазоне чисел или текста.
SELECT column1,column2 FROM table_name WHERE column_name BETWEEN value1 AND value2;
Все эти операторы можно комбинировать друг с другом.
Допустим, наша таблица выглядит так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Если мы напишем такой запрос:
SELECT * FROM engineering
WHERE employee_id BETWEEN 3 AND 7
AND
country = 'Germany';
Мы получим следующий результат:
+------------+-----------+-----------+----------------+--------+--------+ |employee_id | first_name| last_name | email |country |salary | +------------+-----------+-----------+----------------+--------+--------+ |5 |Emilia |Fischer |emfis@gmail.com | Germany| 2365.90| |7 |Louis |Meyer |lmey@gmail.com | Germany| 2145.70| +------------+-----------+-----------+----------------+--------+--------+
Были выбраны все столбцы, где employee_id от 3 до 7, а страна проживания — Германия.
ORDER BY
Ключевое слово ORDER BY позволяет отсортировать выдачу по столбцам, указанным в SELECT.
Отсортированные результаты выводятся в порядке возрастания или убывания.
По умолчанию сортировка идет по возрастанию. Но мы можем указать желаемый порядок явно — при помощи команды ORDER BY column_name DESC | ASC .
SELECT employee_id, first_name, last_name,salary FROM engineering ORDER BY salary DESC;
В этом примере мы отсортировали зарплату сотрудников в команде engineering и представили вывод в порядке убывания числовых значений (DESC — от англ. descending — «нисходящий»).
GROUP BY
Ключевое слово GROUP BY в SQL позволяет комбинировать строки с идентичными и похожими данными.
Это полезно для приведения в порядок дублирующихся данных и записей, которые повторяются в таблице многократно.
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;
Здесь COUNT(*) подсчитывает все строки и возвращает число строк в указанной таблице, группируя строки-дубликаты.
От редакции Techrocks: о COUNT и других агрегатных функциях можно почитать в статье «Агрегатные функции в SQL: объяснение с примерами запросов».
LIMIT
При помощи LIMIT можно указать максимальное число строк, которые должны попасть в результат.
Это бывает полезно при работе с большими наборами данных. Если данных много, запрос может обрабатываться слишком долго. Но когда будет достигнут лимит результатов, обработка прекратится.
Синтаксис:
SELECT column1,column2 FROM table_name LIMIT number;
UPDATE
Ключевое слово UPDATE позволяет обновлять записи в таблице. В CRUD этой операции соответствует буква U.
Синтаксис:
UPDATE table_name
SET column1 = value1,
column2 = value2
WHERE condition;
В условии WHERE указывается запись, которую нужно отредактировать.
UPDATE engineering SET country = 'Spain' WHERE employee_id = 1
Прежде наша таблица выглядела так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Теперь, после выполнения запроса, она выглядит так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | Spain | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Обновилась страна проживания сотрудника с id 1.
Обновить информацию можно и с помощью значений из другой таблицы. Для этого применяется ключевое слово JOIN.
UPDATE table_name
SET table_name1.column_name1 = table_name2.column_name1
table_name1.column_name2 = table_name2.column2
FROM table_name1
JOIN table_name2
ON table_name1.column_name = table_2.column_name;
DELETE
Ключевое слово DELETE служит для удаления записей из таблицы. В CRUD операция удаления представлена буквой D.
Синтаксис:
DELETE FROM table_name WHERE condition;
Пример с нашей таблицей:
DELETE FROM engineering WHERE employee_id = 2;
При выполнении запроса будет удалена запись о сотруднике с id 2 из команды engineering.
DROP COLUMN
Чтобы удалить из таблицы столбец, можно воспользоваться следующим кодом:
ALTER TABLE table_name DROP COLUMN column_name;
DROP TABLE
Для удаления всей таблицы выполните следующий запрос:
DROP TABLE table_name;
Итоги
В этой статье мы пробежались по самым базовым запросам, с которых начинают все новички в SQL.
Мы научились создавать таблицы и строки, группировать и обновлять данные и, наконец, удалять их. Попутно мы также разобрали SQL-запросы в привязке к операциям CRUD.
Перевод статьи «Learn SQL Queries – Database Query Tutorial for Beginners».
От редакции Techrocks. Вам также могут быть интересны другие статьи по теме SQL:
- Топ-30 вопросов по SQL на технических собеседованиях
- ТОП-10 сайтов, на которых можно потренировать SQL-запросы
- Порядок выполнения SQL-операций
- Выражение CASE в SQL: объяснение на примерах
The knowledge of SQL has always been in demand. Even if you don’t have a job as a data analyst or any other relevant position, knowing how to write basic SQL queries can be a useful addition to your resume.
There are plenty of resources to learn about SQL, including our informative Essential SQL blog. However, such an abundance of information often confuses learners, especially beginners, because it’s quite scattered.
So, today, we’ve collected all the essential information about writing SQL queries into one ultimate guide to help you gain and practice this knowledge more effectively.
A Brief Look at SQL and Its Main Components
Structured Query Language (SQL) is a programming language specific to a domain, designed to help maintain structured data held in a database. Basically, this language is what helps us communicate with a database, update it, and retrieve data from it.
From this definition, we can conclude that you can use SQL to perform a variety of tasks, like:
- creating a database
- launching tables and writing queries in a database
- requesting information from a database
- update or delete specific records or an entire database
To better understand how this language functions, you also need to have a basic knowledge of its main components or dialects.
- Data Definition Language – the SQL dialect used to create a database, update the data inside of it, or delete the database entirely.
- Data Manipulation Language – the SQL dialect used to maintain the database and specify what you want to do with it (enter, change, or extract).
- Data Control Language – the SQL dialect used to secure the database.
Some experts also single out the Transaction Control Language dialect that is used to manage and control transactions in order to maintain data integrity (the assurance of accuracy and consistency) in the SQL statement.
What Do You Need to Write an SQL Query?
To write an SQL query, you will first need to create a relational database.
In SQL, we call a database relational because it is divided into tables that are related to each other. These tables break down the data into smaller and more manageable units, which allows better maintenance and overall performance.
Where can you create an SQL database?
To do it, you need to have a Database Management System (DBMS) installed. A DBMS is a software that helps you create and manage the database. If you don’t have one installed on your system already, here are a few most popular options:
- MySQL (open-source)
- SQL Server Express (open-source)
- Oracle (paid)
Regardless of the DBMS you choose, all of them provide security and protection for all the databases you create. It also helps maintain consistency if there are several users working on the DBMS at once.
The Guide to Writing an SQL Query
Now, let’s take a closer look at what you need to know to write an SQL query as well as some common mistakes to avoid.
Step #1: Understand the Process behind the SQL Query
Before you start writing an SQL query, you need to understand how it works, when performing commands.
When you enter a query, it is immediately parsed into a tree. A parser, which is a computer program that translates SQL statements into a parse tree, helps identify whether the query fits the syntactical as well as semantic requirements, i.e., that it is recognizable.
Then, if everything is correct, the parser creates an internal query, which is then passed to the rewrite engine.
After that, the task optimizer, which analyzes how many execution plans a query has, finds the optimal execution plan for your given query. This plan represents the algorithm, which will be used to perform the command.
If the query is written correctly, you will get the results you expect.
Now, let’s take a look at what it takes to write a proper SQL query.
Step #2: Get a Database Ready
So, as we already mentioned, to write an SQL query, you need to create an environment for it by launching a database.
If you already have your DBMS software installed, you can proceed right to creating a database by using a ‘CREATE DATABASE’ statement. The basic syntax of this command will look like this:
CREATE DATABASE database_name;
For instance, if you want to create a database for client reviews, the result will look like this:
CREATE DATABASE client_reviews;
To move on to using your database, you need to continue your SQL query with the ‘USE’ statement:
USE client_reviews;
This will make this database a target for all your future commands.
Keep in mind: if the database with this name already exists, you will get an error message. However, to avoid this, you can use the ‘IF NOT EXISTS’ statement. Here’s how it looks like in MySQL:
mysql> CREATE DATABASE IF NO EXISTS client_reviews;
If your query is correct, you will get an OK message.
Step #3: Create a Table to Organize Information
If the database is ready, you can now proceed to creating a table. As we already mentioned, tables help you structure your queries and make the data more manageable.
To create a table, you need to input the ‘CREATE TABLE’ statement. The syntax for this statement will look similar to this:
CREATE TABLE table_name ( column1_name_constraint, … )
It is clear what we should insert in the table name and column name, but let’s take a closer look at the types of constraints.
A constraint is a declaration of data type, which indicates what kind of data the column will include. There are several kinds of constraints that you can include in a column:
- CHAR – fixed-length data strings (max. size of 255 characters)
- DATE – dates in the YYYY-MM-DD format
- DATETIME – dates in the YYYY-MM-DD format and time in the HH:MM:SS format
- DECIMAL – precise decimal data
- INT – numbers within the range of 2147483648 to 2147483647
- TEXT – textual data (max. size of 65,500 characters)
- TIMESTAMP – timestamp data with the precise number of seconds
- VARCHAR – variable-length data strings (max. size of 65,500 characters)
- Modifiers – UNIQUE constraint ensures unique value for each row in a column; PRIMARY-KEY constraint marks a relevant field in the table; DEFAULT constraint represents the default value of the columns; AUTO_INCREMENT automatically assigns value to a field if it has not been specified; CHECK constraint puts a restriction on the values that can be included in one column; NOT NULL constraint excludes the null value from a field.
If we create a table for each of the people who have given their customer reviews, the final result will look like this:
CREATE TABLE customer profiles ( id INT NOT NULL AUTO_INCREMENT name VARCHAR NOT NULL birth_date DATE review TEXT ) ;
When creating a table, you can encounter the same problem as with a database if the table does not exist. To avoid it, to the ‘CREATE TABLE’ statement, you should also add the ‘IF NOT EXISTS’ statement.
Step #4: Start with the Basic SQL Statements
When the table is ready and operational, you can now continue writing SQL queries by inserting data inside the table.
Here are all basic statements to input and manage the data inside the table:
1) ‘INSERT INTO’ statement
This statement is used to include new rows into a table. Here’s how the syntax will look like in this case:
INSERT INTO table_name (column1, column2, column 3);
You can also include values – the data that you want to include in each column.
Here’s how the final query would look like for our customer reviews table after inserting data into it:
INSERT INTO customer profiles (name, birth_date, review) VALUES (‘Jennifer Dickinson’, ‘1987-07-07’, ‘good service’)
The final result will give you a numbered list of the names, birth dates, and reviews in the form of a table.
2) ‘SELECT’ clause
This clause is used to select and extract data from one or different tables. The syntax for this clause will follow this pattern:
SELECT column1_name, column2_name FROM table_name -_name
The combination of the ‘SELECT’ and ‘FROM’ clauses allows you to fetch information from one or several columns within one or different tables. If you want to select all columns in one table, you can simply use the combination of ‘SELECT’, ‘FROM’ clauses, and the name of the table.
3) ‘WHERE’ clause
By inserting this clause in a table, you can select data based on a certain condition. It is helpful if you want to select for an update or entirely delete one of the records in a row or a column based on a condition like a name, birth date, etc. Here’s the basic syntax using this clause:
SELECT column1_name FROM table_name WHERE condition -_name
As you can see, the WHERE clause is used together with the ‘SELECT’ and ‘FROM’ clauses to help you fetch the right data from the right column or row.
You can also use the ‘WHERE’ clause to filter different records based on a certain condition.
To make sure that you select the right data, this clause allows you to use several basic comparison operators:
- = (equal)
- > (greater than)
- < (less than)
- >= (greater than or equal)
- <= (less than or equal)
- LIKE (to find similar patterns)
- IN (finding matches according to a certain value)
- BETWEEN (defining the range of values)
To make these operators work, include them right after the ‘WHERE’ clause.
4) ‘AND’ and ‘OR’ operators
To write a basic SQL query and effectively select the data from a certain column in a table, you also need to use ‘AND’ and ‘OR’ operators used together with the ‘WHERE’ clause.
The AND operator is used to combine two different conditions and gives you the results only if there is data that matches both these conditions. Here’s how the syntax with the ‘AND’ operator looks like:
SELECT column1_name, column2_name…FROM table_name WHERE condition1 AND condition2
Respectively, the OR operator combines two different conditions and gives you the results if there is data that matches one of these conditions. The syntax, in this case, looks like this:
SELECT column1_name, column2_name…FROM table_name WHERE condition1 OR condition2
To write a more complex SQL query, you can also combine the ‘AND’ and ‘OR’ operators, which will allow you to retrieve data that matches many different conditions.
5) ‘IN’ and ‘BETWEEN’ Operators
These operators help you select an exclusive variety of values based on certain conditions.
The IN operator allows you to select all the data that falls under a certain criterion. The syntax of the query, including the ‘IN’ operator, should look like this:
SELECT column1_name…FROM table_name WHERE condition1 IN (value1, value2, value3…)
For instance, you can retrieve information about customers coming from the same country using this operator. Similarly, you can add ‘NOT’ to the ‘IN’ operator, if you want to exclude some results.
If you want to get results within a certain range of values, you can use the BETWEEN operator. In this case, the syntax will look as follows:
SELECT column1_name…FROM table_name WHERE condition1 BETWEEN value1 AND value 2
As you can see, the ‘AND’ operator is also used to compare the values and fetch the results.
6) ‘ORDER BY’ clause
This clause is used when you want to put the fetched results in a certain order. The ORDER BY clause tells the server how to organize the data, and the syntax looks like this:
SELECT column_list…FROM table_name ORDER BY column_name
preferred order of the fetched data.
7) ‘LIMIT’ clause
If you want to limit the number of results, you can include the ‘LIMIT’ clause in MySQL or Top clause in SQL Server. The basic syntax using this clause looks like this:
SELECT column_list…FROM table_name ORDER BY value LIMIT number
As you can see, the ‘ORDER BY’ clause is also used in this case, because it helps identify the values to be limited.
 ‘UPDATE’ statement
‘UPDATE’ statement
 ‘UPDATE’ statement
‘UPDATE’ statementOnce you’ve inserted and selected data, you can now proceed to writing an SQL query to update this data. To do it, you will need to use the UPDATE statement, for which the syntax looks similar to this:
UPDATE table_name SET column1_name = value 1… WHERE condition1, condition2…
The ‘SET’ clause allows you to identify a specific column or row that needs to be updated. You can also use all the above-mentioned operators, like ‘AND’ and ‘OR’ to update the table.
9) ‘DELETE’ statement
This statement allows you to remove one or several rows. The syntax for this query is simple and looks like this:
DELETE FROM table_name WHERE condition
The ‘WHERE’ clause specifies the record that should be deleted according to the condition assigned to it. Don’t omit it, otherwise, you will delete all the records from the table.
10) ‘TRUNCATE TABLE’ statement
However, if you do want to remove all the rows at once, the TRUNCATE TABLE statement will help you do it quicker than a ‘DELETE’ statement. The syntax for this query looks like this:
TRUNCATE TABLE table_name
While removing the rows from the table, this statement doesn’t actually delete the structure of the table. You can use this statement if you want to rework the entire table.
Step #5: Proofread Your SQL Query
If you’ve finished writing an SQL query and it still doesn’t work, you might have made a mistake along the way.
So, watch out for these most common SQL query mistakes and make sure you proofread your query to avoid them:
- Misspelled commands. This is the most common SQL query mistake. To solve this problem, you can use an SQL editor to fix the broken SQL statements and clauses. If your query contains text under the TEXT constraint, you also need to proofread it. You can do it quickly using different thesis sites containing automated proofreaders.
- The omission of punctuation signs. A proper SQL query also needs to have brackets and quotation marks to operate properly. So check your query for single quotes and double quotes and make sure everything displays properly.
- Improper order of the statement. If your query doesn’t work, the statements in it might be in an improper order. Having syntax templates at hand might help if you don’t have enough experience writing SQL queries.
To make your SQL queries work, you need to write them while keeping in mind where performance problems might appear within your query. Then, if you get an error message, you might already have an understanding, where to look for an issue and how to solve it.
Don’t Get Discouraged!
Learning SQL is a lot like learning a foreign language – practice makes perfect.
When it comes to writing SQL queries, it is important to follow the syntax patterns to complete them while keeping in mind the process behind the queries.
Other than that, writing SQL queries is very much straightforward, starting from the creation of the database and the table as the foundation for your query, and ending with proofreading your query to eliminate mistakes.
Hopefully, our guide will help you become more skilled at writing SQL queries, as you now have the essential knowledge and the tools to do this.
The knowledge of SQL has always been in demand. Even if you don’t have a job as a data analyst or any other relevant position, knowing how to write basic SQL queries can be a useful addition to your resume.
There are plenty of resources to learn about SQL, including our informative Essential SQL blog. However, such an abundance of information often confuses learners, especially beginners, because it’s quite scattered.
So, today, we’ve collected all the essential information about writing SQL queries into one ultimate guide to help you gain and practice this knowledge more effectively.
A Brief Look at SQL and Its Main Components
Structured Query Language (SQL) is a programming language specific to a domain, designed to help maintain structured data held in a database. Basically, this language is what helps us communicate with a database, update it, and retrieve data from it.
From this definition, we can conclude that you can use SQL to perform a variety of tasks, like:
- creating a database
- launching tables and writing queries in a database
- requesting information from a database
- update or delete specific records or an entire database
To better understand how this language functions, you also need to have a basic knowledge of its main components or dialects.
- Data Definition Language – the SQL dialect used to create a database, update the data inside of it, or delete the database entirely.
- Data Manipulation Language – the SQL dialect used to maintain the database and specify what you want to do with it (enter, change, or extract).
- Data Control Language – the SQL dialect used to secure the database.
Some experts also single out the Transaction Control Language dialect that is used to manage and control transactions in order to maintain data integrity (the assurance of accuracy and consistency) in the SQL statement.
What Do You Need to Write an SQL Query?
To write an SQL query, you will first need to create a relational database.
In SQL, we call a database relational because it is divided into tables that are related to each other. These tables break down the data into smaller and more manageable units, which allows better maintenance and overall performance.
Where can you create an SQL database?
To do it, you need to have a Database Management System (DBMS) installed. A DBMS is a software that helps you create and manage the database. If you don’t have one installed on your system already, here are a few most popular options:
- MySQL (open-source)
- SQL Server Express (open-source)
- Oracle (paid)
Regardless of the DBMS you choose, all of them provide security and protection for all the databases you create. It also helps maintain consistency if there are several users working on the DBMS at once.
The Guide to Writing an SQL Query
Now, let’s take a closer look at what you need to know to write an SQL query as well as some common mistakes to avoid.
Step #1: Understand the Process behind the SQL Query
Before you start writing an SQL query, you need to understand how it works, when performing commands.
When you enter a query, it is immediately parsed into a tree. A parser, which is a computer program that translates SQL statements into a parse tree, helps identify whether the query fits the syntactical as well as semantic requirements, i.e., that it is recognizable.
Then, if everything is correct, the parser creates an internal query, which is then passed to the rewrite engine.
After that, the task optimizer, which analyzes how many execution plans a query has, finds the optimal execution plan for your given query. This plan represents the algorithm, which will be used to perform the command.
If the query is written correctly, you will get the results you expect.
Now, let’s take a look at what it takes to write a proper SQL query.
Step #2: Get a Database Ready
So, as we already mentioned, to write an SQL query, you need to create an environment for it by launching a database.
If you already have your DBMS software installed, you can proceed right to creating a database by using a ‘CREATE DATABASE’ statement. The basic syntax of this command will look like this:
CREATE DATABASE database_name;
For instance, if you want to create a database for client reviews, the result will look like this:
CREATE DATABASE client_reviews;
To move on to using your database, you need to continue your SQL query with the ‘USE’ statement:
USE client_reviews;
This will make this database a target for all your future commands.
Keep in mind: if the database with this name already exists, you will get an error message. However, to avoid this, you can use the ‘IF NOT EXISTS’ statement. Here’s how it looks like in MySQL:
mysql> CREATE DATABASE IF NO EXISTS client_reviews;
If your query is correct, you will get an OK message.
Step #3: Create a Table to Organize Information
If the database is ready, you can now proceed to creating a table. As we already mentioned, tables help you structure your queries and make the data more manageable.
To create a table, you need to input the ‘CREATE TABLE’ statement. The syntax for this statement will look similar to this:
CREATE TABLE table_name ( column1_name_constraint, … )
It is clear what we should insert in the table name and column name, but let’s take a closer look at the types of constraints.
A constraint is a declaration of data type, which indicates what kind of data the column will include. There are several kinds of constraints that you can include in a column:
- CHAR – fixed-length data strings (max. size of 255 characters)
- DATE – dates in the YYYY-MM-DD format
- DATETIME – dates in the YYYY-MM-DD format and time in the HH:MM:SS format
- DECIMAL – precise decimal data
- INT – numbers within the range of 2147483648 to 2147483647
- TEXT – textual data (max. size of 65,500 characters)
- TIMESTAMP – timestamp data with the precise number of seconds
- VARCHAR – variable-length data strings (max. size of 65,500 characters)
- Modifiers – UNIQUE constraint ensures unique value for each row in a column; PRIMARY-KEY constraint marks a relevant field in the table; DEFAULT constraint represents the default value of the columns; AUTO_INCREMENT automatically assigns value to a field if it has not been specified; CHECK constraint puts a restriction on the values that can be included in one column; NOT NULL constraint excludes the null value from a field.
If we create a table for each of the people who have given their customer reviews, the final result will look like this:
CREATE TABLE customer profiles ( id INT NOT NULL AUTO_INCREMENT name VARCHAR NOT NULL birth_date DATE review TEXT ) ;
When creating a table, you can encounter the same problem as with a database if the table does not exist. To avoid it, to the ‘CREATE TABLE’ statement, you should also add the ‘IF NOT EXISTS’ statement.
Step #4: Start with the Basic SQL Statements
When the table is ready and operational, you can now continue writing SQL queries by inserting data inside the table.
Here are all basic statements to input and manage the data inside the table:
1) ‘INSERT INTO’ statement
This statement is used to include new rows into a table. Here’s how the syntax will look like in this case:
INSERT INTO table_name (column1, column2, column 3);
You can also include values – the data that you want to include in each column.
Here’s how the final query would look like for our customer reviews table after inserting data into it:
INSERT INTO customer profiles (name, birth_date, review) VALUES (‘Jennifer Dickinson’, ‘1987-07-07’, ‘good service’)
The final result will give you a numbered list of the names, birth dates, and reviews in the form of a table.
2) ‘SELECT’ clause
This clause is used to select and extract data from one or different tables. The syntax for this clause will follow this pattern:
SELECT column1_name, column2_name FROM table_name -_name
The combination of the ‘SELECT’ and ‘FROM’ clauses allows you to fetch information from one or several columns within one or different tables. If you want to select all columns in one table, you can simply use the combination of ‘SELECT’, ‘FROM’ clauses, and the name of the table.
3) ‘WHERE’ clause
By inserting this clause in a table, you can select data based on a certain condition. It is helpful if you want to select for an update or entirely delete one of the records in a row or a column based on a condition like a name, birth date, etc. Here’s the basic syntax using this clause:
SELECT column1_name FROM table_name WHERE condition -_name
As you can see, the WHERE clause is used together with the ‘SELECT’ and ‘FROM’ clauses to help you fetch the right data from the right column or row.
You can also use the ‘WHERE’ clause to filter different records based on a certain condition.
To make sure that you select the right data, this clause allows you to use several basic comparison operators:
- = (equal)
- > (greater than)
- < (less than)
- >= (greater than or equal)
- <= (less than or equal)
- LIKE (to find similar patterns)
- IN (finding matches according to a certain value)
- BETWEEN (defining the range of values)
To make these operators work, include them right after the ‘WHERE’ clause.
4) ‘AND’ and ‘OR’ operators
To write a basic SQL query and effectively select the data from a certain column in a table, you also need to use ‘AND’ and ‘OR’ operators used together with the ‘WHERE’ clause.
The AND operator is used to combine two different conditions and gives you the results only if there is data that matches both these conditions. Here’s how the syntax with the ‘AND’ operator looks like:
SELECT column1_name, column2_name…FROM table_name WHERE condition1 AND condition2
Respectively, the OR operator combines two different conditions and gives you the results if there is data that matches one of these conditions. The syntax, in this case, looks like this:
SELECT column1_name, column2_name…FROM table_name WHERE condition1 OR condition2
To write a more complex SQL query, you can also combine the ‘AND’ and ‘OR’ operators, which will allow you to retrieve data that matches many different conditions.
5) ‘IN’ and ‘BETWEEN’ Operators
These operators help you select an exclusive variety of values based on certain conditions.
The IN operator allows you to select all the data that falls under a certain criterion. The syntax of the query, including the ‘IN’ operator, should look like this:
SELECT column1_name…FROM table_name WHERE condition1 IN (value1, value2, value3…)
For instance, you can retrieve information about customers coming from the same country using this operator. Similarly, you can add ‘NOT’ to the ‘IN’ operator, if you want to exclude some results.
If you want to get results within a certain range of values, you can use the BETWEEN operator. In this case, the syntax will look as follows:
SELECT column1_name…FROM table_name WHERE condition1 BETWEEN value1 AND value 2
As you can see, the ‘AND’ operator is also used to compare the values and fetch the results.
6) ‘ORDER BY’ clause
This clause is used when you want to put the fetched results in a certain order. The ORDER BY clause tells the server how to organize the data, and the syntax looks like this:
SELECT column_list…FROM table_name ORDER BY column_name
preferred order of the fetched data.
7) ‘LIMIT’ clause
If you want to limit the number of results, you can include the ‘LIMIT’ clause in MySQL or Top clause in SQL Server. The basic syntax using this clause looks like this:
SELECT column_list…FROM table_name ORDER BY value LIMIT number
As you can see, the ‘ORDER BY’ clause is also used in this case, because it helps identify the values to be limited.
‘UPDATE’ statement
Once you’ve inserted and selected data, you can now proceed to writing an SQL query to update this data. To do it, you will need to use the UPDATE statement, for which the syntax looks similar to this:
UPDATE table_name SET column1_name = value 1… WHERE condition1, condition2…
The ‘SET’ clause allows you to identify a specific column or row that needs to be updated. You can also use all the above-mentioned operators, like ‘AND’ and ‘OR’ to update the table.
9) ‘DELETE’ statement
This statement allows you to remove one or several rows. The syntax for this query is simple and looks like this:
DELETE FROM table_name WHERE condition
The ‘WHERE’ clause specifies the record that should be deleted according to the condition assigned to it. Don’t omit it, otherwise, you will delete all the records from the table.
10) ‘TRUNCATE TABLE’ statement
However, if you do want to remove all the rows at once, the TRUNCATE TABLE statement will help you do it quicker than a ‘DELETE’ statement. The syntax for this query looks like this:
TRUNCATE TABLE table_name
While removing the rows from the table, this statement doesn’t actually delete the structure of the table. You can use this statement if you want to rework the entire table.
Step #5: Proofread Your SQL Query
If you’ve finished writing an SQL query and it still doesn’t work, you might have made a mistake along the way.
So, watch out for these most common SQL query mistakes and make sure you proofread your query to avoid them:
- Misspelled commands. This is the most common SQL query mistake. To solve this problem, you can use an SQL editor to fix the broken SQL statements and clauses. If your query contains text under the TEXT constraint, you also need to proofread it. You can do it quickly using different thesis sites containing automated proofreaders.
- The omission of punctuation signs. A proper SQL query also needs to have brackets and quotation marks to operate properly. So check your query for single quotes and double quotes and make sure everything displays properly.
- Improper order of the statement. If your query doesn’t work, the statements in it might be in an improper order. Having syntax templates at hand might help if you don’t have enough experience writing SQL queries.
To make your SQL queries work, you need to write them while keeping in mind where performance problems might appear within your query. Then, if you get an error message, you might already have an understanding, where to look for an issue and how to solve it.
Don’t Get Discouraged!
Learning SQL is a lot like learning a foreign language – practice makes perfect.
When it comes to writing SQL queries, it is important to follow the syntax patterns to complete them while keeping in mind the process behind the queries.
Other than that, writing SQL queries is very much straightforward, starting from the creation of the database and the table as the foundation for your query, and ending with proofreading your query to eliminate mistakes.
Hopefully, our guide will help you become more skilled at writing SQL queries, as you now have the essential knowledge and the tools to do this.